
datasetId stringlengths 2 117 | card stringlengths 19 1.01M |
|---|---|
Asmedeus/kamisatoayaka | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 1968132.0
num_examples: 12
download_size: 1972127
dataset_size: 1968132.0
---
# Dataset Card for "kamisatoayaka"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Zaratahir123/test | ---
license: mit
---
|
techandy42/CrafterGPT-Training-Dataset | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 319732699
num_examples: 58622
download_size: 26368123
dataset_size: 319732699
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ajeyabhat/asdfasd | ---
license: mit
language:
- aa
- ab
--- |
pgajo/subs | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: transcription
dtype: string
splits:
- name: train
num_bytes: 1918145060.272
num_examples: 27702
- name: test
num_bytes: 835022060.538
num_examples: 11873
download_size: 2822876508
dataset_size: 2753167120.81
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
chaoscodes/refined_train_tinyllama | ---
license: apache-2.0
---
|
rntc/pubmed_preprocess | ---
configs:
- config_name: default
data_files:
- split: fr
path: data/fr-*
- split: en
path: data/en-*
- split: es
path: data/es-*
- split: de
path: data/de-*
- split: it
path: data/it-*
- split: nl
path: data/nl-*
- split: pl
path: data/pl-*
- split: pt
path: data/pt-*
- split: ro
path: data/ro-*
- split: ru
path: data/ru-*
- split: zh
path: data/zh-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: fr
num_bytes: 30582169
num_examples: 28715
- name: en
num_bytes: 90868163767
num_examples: 97816514
- name: es
num_bytes: 9925215
num_examples: 14671
- name: de
num_bytes: 46540591
num_examples: 53202
- name: it
num_bytes: 79767
num_examples: 125
- name: nl
num_bytes: 373829
num_examples: 461
- name: pl
num_bytes: 727984
num_examples: 877
- name: pt
num_bytes: 29942156
num_examples: 44558
- name: ro
num_bytes: 103813
num_examples: 187
- name: ru
num_bytes: 2320647
num_examples: 1671
- name: zh
num_bytes: 11481632
num_examples: 10612
download_size: 302082086
dataset_size: 91000241570
---
# Dataset Card for "pubmed_preprocess"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
autoevaluate/autoeval-staging-eval-project-samsum-afdf25d0-14035921 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- samsum
eval_info:
task: summarization
model: Ameer05/bart-large-cnn-samsum-rescom-finetuned-resume-summarizer-10-epoch
metrics: []
dataset_name: samsum
dataset_config: samsum
dataset_split: test
col_mapping:
text: dialogue
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: Ameer05/bart-large-cnn-samsum-rescom-finetuned-resume-summarizer-10-epoch
* Dataset: samsum
* Config: samsum
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. |
devoworm-group/EPIC-DATASET | ---
license: mit
---
Understanding the cellular architecture is a fundamental problem in various biological studies.
C. elegans is widely used as a model organism in these studies because of its unique fate determinations.
In recent years, researchers have worked extensively on C. elegans to excavate the regulations of genes and proteins on cell mobility and communication.
Although various algorithms have been proposed to analyze nucleus, cell shape features are not yet well recorded
Here this dataset used for segmenting etc. |
open-llm-leaderboard/details_maywell__Mini_Synatra_SFT | ---
pretty_name: Evaluation run of maywell/Mini_Synatra_SFT
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [maywell/Mini_Synatra_SFT](https://huggingface.co/maywell/Mini_Synatra_SFT) on\
\ the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 1 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_maywell__Mini_Synatra_SFT\"\
,\n\t\"harness_gsm8k_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\nThese\
\ are the [latest results from run 2023-12-03T18:00:26.162132](https://huggingface.co/datasets/open-llm-leaderboard/details_maywell__Mini_Synatra_SFT/blob/main/results_2023-12-03T18-00-26.162132.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.4488248673237301,\n\
\ \"acc_stderr\": 0.013700157442788066\n },\n \"harness|gsm8k|5\":\
\ {\n \"acc\": 0.4488248673237301,\n \"acc_stderr\": 0.013700157442788066\n\
\ }\n}\n```"
repo_url: https://huggingface.co/maywell/Mini_Synatra_SFT
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_gsm8k_5
data_files:
- split: 2023_12_03T18_00_26.162132
path:
- '**/details_harness|gsm8k|5_2023-12-03T18-00-26.162132.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-12-03T18-00-26.162132.parquet'
- config_name: results
data_files:
- split: 2023_12_03T18_00_26.162132
path:
- results_2023-12-03T18-00-26.162132.parquet
- split: latest
path:
- results_2023-12-03T18-00-26.162132.parquet
---
# Dataset Card for Evaluation run of maywell/Mini_Synatra_SFT
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/maywell/Mini_Synatra_SFT
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [maywell/Mini_Synatra_SFT](https://huggingface.co/maywell/Mini_Synatra_SFT) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 1 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_maywell__Mini_Synatra_SFT",
"harness_gsm8k_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-12-03T18:00:26.162132](https://huggingface.co/datasets/open-llm-leaderboard/details_maywell__Mini_Synatra_SFT/blob/main/results_2023-12-03T18-00-26.162132.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.4488248673237301,
"acc_stderr": 0.013700157442788066
},
"harness|gsm8k|5": {
"acc": 0.4488248673237301,
"acc_stderr": 0.013700157442788066
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
gaizerick/tyballtv3 | ---
license: openrail
---
|
tyzhu/squad_context_v4_train_10_eval_10 | ---
dataset_info:
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
- name: inputs
dtype: string
- name: targets
dtype: string
splits:
- name: train
num_bytes: 78251
num_examples: 44
- name: validation
num_bytes: 80830
num_examples: 50
download_size: 63029
dataset_size: 159081
---
# Dataset Card for "squad_context_v4_train_10_eval_10"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/saria_arknights | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of saria/サリア/塞雷娅 (Arknights)
This is the dataset of saria/サリア/塞雷娅 (Arknights), containing 500 images and their tags.
The core tags of this character are `horns, long_hair, dragon_horns, grey_hair, orange_eyes, breasts, earrings, tail`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:-----------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 500 | 881.54 MiB | [Download](https://huggingface.co/datasets/CyberHarem/saria_arknights/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 500 | 414.88 MiB | [Download](https://huggingface.co/datasets/CyberHarem/saria_arknights/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 1218 | 902.72 MiB | [Download](https://huggingface.co/datasets/CyberHarem/saria_arknights/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 500 | 736.07 MiB | [Download](https://huggingface.co/datasets/CyberHarem/saria_arknights/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 1218 | 1.38 GiB | [Download](https://huggingface.co/datasets/CyberHarem/saria_arknights/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/saria_arknights',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 35 |  |  |  |  |  | 1girl, official_alternate_costume, black_headwear, solo, black_gloves, black_shirt, looking_at_viewer, police_hat, plate_carrier, walkie-talkie, collared_shirt, hair_between_eyes, police_uniform, sleeves_rolled_up, single_glove, closed_mouth, upper_body, black_pants, peaked_cap, dragon_girl |
| 1 | 28 |  |  |  |  |  | 1girl, solo, white_shirt, looking_at_viewer, closed_mouth, upper_body, simple_background, white_background, jewelry, white_hair, long_sleeves, choker, hair_between_eyes, id_card, skirt |
| 2 | 38 |  |  |  |  |  | 1girl, solo, black_skirt, long_sleeves, holding_shield, white_shirt, looking_at_viewer, standing, closed_mouth, holding_gun, black_footwear, cowboy_shot, dragon_tail, full_body, high-waist_skirt, jewelry |
| 3 | 7 |  |  |  |  |  | 1girl, solo, black_gloves, black_shirt, dragon_tail, looking_at_viewer, sleeveless_shirt, standing, bare_shoulders, fingerless_gloves, black_footwear, black_thighhighs, boots, full_body, jewelry, official_alternate_costume, black_shorts, closed_mouth, feet_out_of_frame, yellow_eyes |
| 4 | 7 |  |  |  |  |  | 1girl, bandaged_arm, black_shirt, sleeveless_shirt, official_alternate_costume, solo, bare_shoulders, looking_at_viewer, upper_body, cowboy_shot, hair_between_eyes, hand_up, jewelry |
| 5 | 12 |  |  |  |  |  | 1girl, midriff, solo, bare_shoulders, crop_top, black_shorts, cowboy_shot, looking_at_viewer, navel, ponytail, stomach, dragon_tail, standing, black_sports_bra, thighs, abs, gloves, short_shorts, very_long_hair, indoors, large_breasts, medium_breasts, simple_background, white_background |
| 6 | 7 |  |  |  |  |  | 1girl, bare_shoulders, cowboy_shot, crop_top, midriff, navel, solo, black_pants, black_sports_bra, stomach, medium_breasts, simple_background, standing, white_background, bandaged_arm, bare_arms, dragon_tail, holding, leggings, looking_at_viewer, abs, collarbone, hair_between_eyes, jewelry, sweat |
| 7 | 6 |  |  |  |  |  | 1girl, bare_arms, bare_shoulders, black_panties, black_sports_bra, dumbbell, exercise, indoors, medium_breasts, navel, ponytail, sweat, collarbone, dragon_tail, nipples, bare_legs, brown_eyes, sidelocks, solo, stomach, alternate_hairstyle, parted_lips, thighs |
| 8 | 14 |  |  |  |  |  | 1girl, nipples, blush, large_breasts, collarbone, navel, pussy, completely_nude, looking_at_viewer, 1boy, hetero, jewelry, solo_focus, sweat, penis, sex, cum, dragon_girl, dragon_tail, spread_legs, vaginal, bar_censor, closed_mouth, mosaic_censoring, on_back, open_mouth, very_long_hair |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | official_alternate_costume | black_headwear | solo | black_gloves | black_shirt | looking_at_viewer | police_hat | plate_carrier | walkie-talkie | collared_shirt | hair_between_eyes | police_uniform | sleeves_rolled_up | single_glove | closed_mouth | upper_body | black_pants | peaked_cap | dragon_girl | white_shirt | simple_background | white_background | jewelry | white_hair | long_sleeves | choker | id_card | skirt | black_skirt | holding_shield | standing | holding_gun | black_footwear | cowboy_shot | dragon_tail | full_body | high-waist_skirt | sleeveless_shirt | bare_shoulders | fingerless_gloves | black_thighhighs | boots | black_shorts | feet_out_of_frame | yellow_eyes | bandaged_arm | hand_up | midriff | crop_top | navel | ponytail | stomach | black_sports_bra | thighs | abs | gloves | short_shorts | very_long_hair | indoors | large_breasts | medium_breasts | bare_arms | holding | leggings | collarbone | sweat | black_panties | dumbbell | exercise | nipples | bare_legs | brown_eyes | sidelocks | alternate_hairstyle | parted_lips | blush | pussy | completely_nude | 1boy | hetero | solo_focus | penis | sex | cum | spread_legs | vaginal | bar_censor | mosaic_censoring | on_back | open_mouth |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:-----------------------------|:-----------------|:-------|:---------------|:--------------|:--------------------|:-------------|:----------------|:----------------|:-----------------|:--------------------|:-----------------|:--------------------|:---------------|:---------------|:-------------|:--------------|:-------------|:--------------|:--------------|:--------------------|:-------------------|:----------|:-------------|:---------------|:---------|:----------|:--------|:--------------|:-----------------|:-----------|:--------------|:-----------------|:--------------|:--------------|:------------|:-------------------|:-------------------|:-----------------|:--------------------|:-------------------|:--------|:---------------|:--------------------|:--------------|:---------------|:----------|:----------|:-----------|:--------|:-----------|:----------|:-------------------|:---------|:------|:---------|:---------------|:-----------------|:----------|:----------------|:-----------------|:------------|:----------|:-----------|:-------------|:--------|:----------------|:-----------|:-----------|:----------|:------------|:-------------|:------------|:----------------------|:--------------|:--------|:--------|:------------------|:-------|:---------|:-------------|:--------|:------|:------|:--------------|:----------|:-------------|:-------------------|:----------|:-------------|
| 0 | 35 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 28 |  |  |  |  |  | X | | | X | | | X | | | | | X | | | | X | X | | | | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 2 | 38 |  |  |  |  |  | X | | | X | | | X | | | | | | | | | X | | | | | X | | | X | | X | | | | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 3 | 7 |  |  |  |  |  | X | X | | X | X | X | X | | | | | | | | | X | | | | | | | | X | | | | | | | | X | | X | | X | X | | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 4 | 7 |  |  |  |  |  | X | X | | X | | X | X | | | | | X | | | | | X | | | | | | | X | | | | | | | | | | | X | | | | X | X | | | | | | | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 5 | 12 |  |  |  |  |  | X | | | X | | | X | | | | | | | | | | | | | | | X | X | | | | | | | | | X | | | X | X | | | | X | | | | X | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 6 | 7 |  |  |  |  |  | X | | | X | | | X | | | | | X | | | | | | X | | | | X | X | X | | | | | | | | X | | | X | X | | | | X | | | | | | | X | | X | X | X | | X | X | | X | | | | | | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | |
| 7 | 6 |  |  |  |  |  | X | | | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | X | | | | X | | | | | | | | | | | X | X | X | X | X | | | | | X | | X | X | | | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | |
| 8 | 14 |  |  |  |  |  | X | | | | | | X | | | | | | | | | X | | | | X | | | | X | | | | | | | | | | | | X | | | | | | | | | | | | | | | X | | | | | | | | X | | X | | | | | X | X | | | | X | | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
|
liuyanchen1015/MULTI_VALUE_mrpc_his_he | ---
dataset_info:
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: value_score
dtype: int64
splits:
- name: test
num_bytes: 33052
num_examples: 126
- name: train
num_bytes: 75956
num_examples: 286
- name: validation
num_bytes: 9170
num_examples: 34
download_size: 89752
dataset_size: 118178
---
# Dataset Card for "MULTI_VALUE_mrpc_his_he"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
AmelieSchreiber/interaction_pairs | ---
license: mit
---
|
freshpearYoon/vr_train_free_21 | ---
dataset_info:
features:
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: filename
dtype: string
- name: NumOfUtterance
dtype: int64
- name: text
dtype: string
- name: samplingrate
dtype: int64
- name: begin_time
dtype: float64
- name: end_time
dtype: float64
- name: speaker_id
dtype: string
- name: directory
dtype: string
splits:
- name: train
num_bytes: 6244051260
num_examples: 10000
download_size: 1011102174
dataset_size: 6244051260
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
CVasNLPExperiments/VQAv2_sample_validation_google_flan_t5_xxl_mode_C_D_PNP_GENERIC_Q_rices_ns_1000 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: question
dtype: string
- name: true_label
sequence: string
- name: prediction
dtype: string
splits:
- name: fewshot_0_clip_tags_LAION_ViT_H_14_2B_with_openai_Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_DETA_detections_deta_swin_large_o365_coco_classes_caption_all_patches_Salesforce_blip_image_captioning_large_clean_
num_bytes: 142014
num_examples: 1000
download_size: 53621
dataset_size: 142014
---
# Dataset Card for "VQAv2_sample_validation_google_flan_t5_xxl_mode_C_D_PNP_GENERIC_Q_rices_ns_1000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
alessandrogd/Ale | ---
license: openrail
---
|
ssssasdasdasdasdqwd/MONET_Claude_LORA | ---
license: unknown
---
|
sabuhi1997/fine-tune-hebrew-dataset-2 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: audio
dtype: audio
- name: transcription
dtype: string
splits:
- name: train
num_bytes: 5715697.0
num_examples: 8
- name: validation
num_bytes: 1760186.0
num_examples: 3
- name: test
num_bytes: 1625785.0
num_examples: 4
download_size: 3211475
dataset_size: 9101668.0
---
# Dataset Card for "fine-tune-hebrew-dataset-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ziq/ai-generated-text-classification | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: id
dtype: string
- name: prompt_id
dtype: int64
- name: text
dtype: string
- name: generated
dtype: int64
splits:
- name: train
num_bytes: 4411048
num_examples: 1378
- name: test
num_bytes: 133
num_examples: 3
download_size: 2360284
dataset_size: 4411181
---
# Dataset Card for "ai-generated-text-classification"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
vinicm/modelocarlos | ---
license: openrail
---
|
iNeil77/pseudo-mini-pile | ---
dataset_info:
- config_name: all
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 360187653412.6177
num_examples: 56194997
download_size: 199030076349
dataset_size: 360187653412.6177
- config_name: c4_realnews
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 31597106256.723488
num_examples: 11427438
download_size: 19889880484
dataset_size: 31597106256.723488
- config_name: openwebtext
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 30974178275.039234
num_examples: 6474479
download_size: 19069709415
dataset_size: 30974178275.039234
- config_name: peS2o
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 221900508006.5479
num_examples: 32612199
download_size: 116217303065
dataset_size: 221900508006.5479
- config_name: redpajama_books
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 49246538575.26426
num_examples: 107443
download_size: 29612204926
dataset_size: 49246538575.26426
- config_name: stackexchange
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 2034535930.2150385
num_examples: 716532
download_size: 1222605537
dataset_size: 2034535930.2150385
- config_name: uspto
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 14755999149.910166
num_examples: 3247716
download_size: 7058272149
dataset_size: 14755999149.910166
- config_name: wiki
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 7528525537.163156
num_examples: 1609190
download_size: 4593971902
dataset_size: 7528525537.163156
configs:
- config_name: all
data_files:
- split: train
path: all/train-*
- config_name: c4_realnews
data_files:
- split: train
path: c4_realnews/train-*
- config_name: openwebtext
data_files:
- split: train
path: openwebtext/train-*
- config_name: peS2o
data_files:
- split: train
path: peS2o/train-*
- config_name: redpajama_books
data_files:
- split: train
path: redpajama_books/train-*
- config_name: stackexchange
data_files:
- split: train
path: stackexchange/train-*
- config_name: uspto
data_files:
- split: train
path: uspto/train-*
- config_name: wiki
data_files:
- split: train
path: wiki/train-*
task_categories:
- text-generation
language:
- en
size_categories:
- 10M<n<100M
---
A small, aggressively cleaned and de-duped pre-training corpus for academic settings. It aims to recreate something akin to [The Pile](https://huggingface.co/datasets/EleutherAI/pile) but prioritizes quality for the constrained token budget academic researchers live with.
It has seven config subsets and an eighth `all` subset that combines them for a total of ~91B tokens (GPT2 Tokenizer estimate). These splits are as follows:
1. `c4_realnews`: The RealNews domain subset of the C4 dataset containing news articles.
2. `openwebtext`: The OpenWebText dataset containing the contents of the links mentioned in Reddit posts with at least 3 upvotes.
3. `peS2o`: The PeS2o dataset containing academic articles from Semantic Scholar.
4. `redpajama_books`: The books subset of RedPajama V1.
5. `stackexchange`: The EN StackExchange non-code subset of the BigScience ROOTs dataset.
6. `uspto`: The EN USPTO patent applications contents' subset of the BigScience ROOTs dataset.
7. `wiki`: The EN Wiki subset of the BigScience ROOTs dataset.
The following processing and filtering steps have been applied:
1. Removed citation text and bibliography information for academic texts.
2. Ran a perplexity filter using a KenLM model trained on the EN OSCAR corpus and removed documents with a perplexity of more than 325 and less than 7.
3. Removed samples which have a repeating <=4-gram proportion of 15%.
4. Removed samples which have lower than 99% confidence of being EN using the lingua language detector.
5. Performed an aggressive MinHash de-dupe using a shingle size of 8 and a low threshold of 0.5. |
kenhktsui/open-toolformer-retrieval-multi-result | ---
dataset_info:
features:
- name: question
dtype: string
- name: response
dtype: string
- name: meta
struct:
- name: search_rank
dtype: int64
- name: source
dtype: string
splits:
- name: train
num_bytes: 15998558
num_examples: 16438
download_size: 8180273
dataset_size: 15998558
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "open-toolformer-retrieval-multi-result"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
GEM/surface_realisation_st_2020 | ---
annotations_creators:
- none
language_creators:
- unknown
language:
- ar
- zh
- en
- fr
- hi
- id
- ja
- ko
- pt
- ru
- es
license:
- cc-by-2.5
multilinguality:
- unknown
size_categories:
- unknown
source_datasets:
- original
task_categories:
- table-to-text
task_ids: []
pretty_name: surface_realisation_st_2020
tags:
- data-to-text
---
# Dataset Card for GEM/surface_realisation_st_2020
## Dataset Description
- **Homepage:** http://taln.upf.edu/pages/msr2020-ws/SRST.html#data
- **Repository:** https://sites.google.com/site/genchalrepository/surface-realisation/sr-20-multilingual
- **Paper:** https://aclanthology.org/2020.msr-1.1/
- **Leaderboard:** N/A
- **Point of Contact:** Simon Mille
### Link to Main Data Card
You can find the main data card on the [GEM Website](https://gem-benchmark.com/data_cards/surface_realisation_st_2020).
### Dataset Summary
This dataset was used as part of the multilingual surface realization shared task in which a model gets full or partial universal dependency structures and has to reconstruct the natural language. This dataset support 11 languages.
You can load the dataset via:
```
import datasets
data = datasets.load_dataset('GEM/surface_realisation_st_2020')
```
The data loader can be found [here](https://huggingface.co/datasets/GEM/surface_realisation_st_2020).
#### website
[Website](http://taln.upf.edu/pages/msr2020-ws/SRST.html#data)
#### paper
[ACL Anthology](https://aclanthology.org/2020.msr-1.1/)
#### authors
Simon Mille (Pompeu Fabra University); Leo Wanner (Pompeu Fabra University); Anya Belz (Brighton University); Bernd Bohnet (Google Inc.); Thiago Castro Ferreira (Federal University of Minas Gerais); Yvette Graham (ADAPT/Trinity College Dublin)
## Dataset Overview
### Where to find the Data and its Documentation
#### Webpage
<!-- info: What is the webpage for the dataset (if it exists)? -->
<!-- scope: telescope -->
[Website](http://taln.upf.edu/pages/msr2020-ws/SRST.html#data)
#### Download
<!-- info: What is the link to where the original dataset is hosted? -->
<!-- scope: telescope -->
[Website](https://sites.google.com/site/genchalrepository/surface-realisation/sr-20-multilingual)
#### Paper
<!-- info: What is the link to the paper describing the dataset (open access preferred)? -->
<!-- scope: telescope -->
[ACL Anthology](https://aclanthology.org/2020.msr-1.1/)
#### BibTex
<!-- info: Provide the BibTex-formatted reference for the dataset. Please use the correct published version (ACL anthology, etc.) instead of google scholar created Bibtex. -->
<!-- scope: microscope -->
```
@inproceedings{mille-etal-2020-third,
title = "The Third Multilingual Surface Realisation Shared Task ({SR}{'}20): Overview and Evaluation Results",
author = "Mille, Simon and
Belz, Anya and
Bohnet, Bernd and
Castro Ferreira, Thiago and
Graham, Yvette and
Wanner, Leo",
booktitle = "Proceedings of the Third Workshop on Multilingual Surface Realisation",
month = dec,
year = "2020",
address = "Barcelona, Spain (Online)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.msr-1.1",
pages = "1--20",
abstract = "This paper presents results from the Third Shared Task on Multilingual Surface Realisation (SR{'}20) which was organised as part of the COLING{'}20 Workshop on Multilingual Surface Realisation. As in SR{'}18 and SR{'}19, the shared task comprised two tracks: (1) a Shallow Track where the inputs were full UD structures with word order information removed and tokens lemmatised; and (2) a Deep Track where additionally, functional words and morphological information were removed. Moreover, each track had two subtracks: (a) restricted-resource, where only the data provided or approved as part of a track could be used for training models, and (b) open-resource, where any data could be used. The Shallow Track was offered in 11 languages, whereas the Deep Track in 3 ones. Systems were evaluated using both automatic metrics and direct assessment by human evaluators in terms of Readability and Meaning Similarity to reference outputs. We present the evaluation results, along with descriptions of the SR{'}19 tracks, data and evaluation methods, as well as brief summaries of the participating systems. For full descriptions of the participating systems, please see the separate system reports elsewhere in this volume.",
}
```
#### Contact Name
<!-- quick -->
<!-- info: If known, provide the name of at least one person the reader can contact for questions about the dataset. -->
<!-- scope: periscope -->
Simon Mille
#### Contact Email
<!-- info: If known, provide the email of at least one person the reader can contact for questions about the dataset. -->
<!-- scope: periscope -->
sfmille@gmail.com
#### Has a Leaderboard?
<!-- info: Does the dataset have an active leaderboard? -->
<!-- scope: telescope -->
no
### Languages and Intended Use
#### Multilingual?
<!-- quick -->
<!-- info: Is the dataset multilingual? -->
<!-- scope: telescope -->
yes
#### Covered Dialects
<!-- info: What dialects are covered? Are there multiple dialects per language? -->
<!-- scope: periscope -->
No multiple dialects.
#### Covered Languages
<!-- quick -->
<!-- info: What languages/dialects are covered in the dataset? -->
<!-- scope: telescope -->
`Arabic`, `Chinese`, `English`, `French`, `Hindi`, `Indonesian`, `Japanese`, `Korean`, `Portuguese`, `Russian`, `Spanish, Castilian`
#### Whose Language?
<!-- info: Whose language is in the dataset? -->
<!-- scope: periscope -->
Unknown
#### License
<!-- quick -->
<!-- info: What is the license of the dataset? -->
<!-- scope: telescope -->
cc-by-2.5: Creative Commons Attribution 2.5 Generic
#### Intended Use
<!-- info: What is the intended use of the dataset? -->
<!-- scope: microscope -->
The dataset is intended to be used for training models to solve several NLG subtasks, such as function word introduction, morphological agreement resolution, word order determination and inflection generation.
Comment about the license: the dataset has multiple licences, since each original dataset has their own type of licence. All datasets but one are CC-BY and subclasses of it, the other one is GPL (French Sequoia).
#### Primary Task
<!-- info: What primary task does the dataset support? -->
<!-- scope: telescope -->
Data-to-Text
#### Communicative Goal
<!-- quick -->
<!-- info: Provide a short description of the communicative goal of a model trained for this task on this dataset. -->
<!-- scope: periscope -->
The models are able to introduce surface features (syntax, morphology, topology) from more or less abstract inputs in different, the most abstract being predicate-argument structures. The datasets cover a large variety of domains (news, blogs, forums, wikipedia pages, etc.).
### Credit
#### Curation Organization Type(s)
<!-- info: In what kind of organization did the dataset curation happen? -->
<!-- scope: telescope -->
`industry`, `academic`
#### Curation Organization(s)
<!-- info: Name the organization(s). -->
<!-- scope: periscope -->
Pompeu Fabra University, Google Inc., University of Brighton, Federal University of Minas Gerais, ADAPT/Trinity College Dublin
#### Dataset Creators
<!-- info: Who created the original dataset? List the people involved in collecting the dataset and their affiliation(s). -->
<!-- scope: microscope -->
Simon Mille (Pompeu Fabra University); Leo Wanner (Pompeu Fabra University); Anya Belz (Brighton University); Bernd Bohnet (Google Inc.); Thiago Castro Ferreira (Federal University of Minas Gerais); Yvette Graham (ADAPT/Trinity College Dublin)
#### Funding
<!-- info: Who funded the data creation? -->
<!-- scope: microscope -->
Mostly EU funds via H2020 projects
#### Who added the Dataset to GEM?
<!-- info: Who contributed to the data card and adding the dataset to GEM? List the people+affiliations involved in creating this data card and who helped integrate this dataset into GEM. -->
<!-- scope: microscope -->
Simon Mille (Pompeu Fabra University)
### Dataset Structure
#### Data Fields
<!-- info: List and describe the fields present in the dataset. -->
<!-- scope: telescope -->
`input` (string): this field contains an input tree in CoNLL-U format; the CoNLL-U format is a one-word-per-line format with the following tab-separated 10 columns (see [here](http://universaldependencies.org/format.html)): [1] Position, [2] Lemma, [3] Wordform, [4] Part of Speech, [5] Fine-grained Part of Speech (if available), [6] Features (FEATS), [7] governor, [8] dependency relation, [9] additional dependency information, and [10] metadata. For the surface task, the input is a Universal Dependency tree of a given language in which the word order was scrambled and the surface forms removed (only lemmas are available); for the deep task, the input is a tree derived from the surface input, with predicate-argument relations between content words only (function words were removed) and without any morphological agreement information.
`target_tokenized` (string): this field contains the target sentence to generate, in which every non-initial and non-final token is surrounded by two spaces. This output is usually used for automatic evaluations.
`target` (string): this field contains the detokenised target sentence to generate. This output is usually used for human evaluations.
`gem_id` (string): a unique ID.
`sentence_id` (string): the original ID of a sentence in the UD dataset.
#### Reason for Structure
<!-- info: How was the dataset structure determined? -->
<!-- scope: microscope -->
The structure of the input (CoNLL-U) was chosen according to the standards in parsing, and because the original UD datasets were provided in this format.
#### How were labels chosen?
<!-- info: How were the labels chosen? -->
<!-- scope: microscope -->
The input labels for the surface track are the original labels in the UD treebanks; see [here](https://universaldependencies.org/u/dep/index.html) for the dependencies, [here](https://universaldependencies.org/u/feat/index.html) for the features, and [here](https://universaldependencies.org/u/pos/index.html) for the PoS tags.
The input labels for the deep track are a subset of the PoS tags and features of the surface track, and for the relations, universal predicate-argument relations augmented with a few specific relations to capture coordinations and named entity relations for instance.
#### Example Instance
<!-- info: Provide a JSON formatted example of a typical instance in the dataset. -->
<!-- scope: periscope -->
```
{"input": "1\tGoogle\t_\tPROPN\tNNP\tNumber=Sing\t5\tnsubj\t_\t_\n2\t\t_\tPUNCT\t.\tlin=+1\t5\tpunct\t_\t_\n3\tinto\t_\tADP\tIN\t_\t6\tcase\t_\t_\n4\tif\t_\tSCONJ\tIN\t_\t5\tmark\t_\t_\n5\tmorph\t_\tVERB\tVBD\tMood=Ind|Tense=Past|VerbForm=Fin\t7\tadvcl\t_\t_\n6\tGoogleOS\t_\tPROPN\tNNP\tNumber=Sing\t5\tobl\t_\t_\n7\twhat\t_\tPRON\tWP\tPronType=Int\t0\troot\t_\t_", "target_tokenized": "What if Google Morphed Into GoogleOS ?", "target": "What if Google Morphed Into GoogleOS?", "gem_id": "GEM-surface_realisation_st_2020-T1-test-en_ewt-ud-test-0", "sentence_id": ""}
```
#### Data Splits
<!-- info: Describe and name the splits in the dataset if there are more than one. -->
<!-- scope: periscope -->
There are 119 splits in the dataset:
- 29 training sets, which correspond to 20 UD datasets (11 languages), 9 of which have both surface and deep inputs (3 languages);
- 29 development set which correspond to the 29 training sets above;
- 29 test sets for the data described above;
- 4 out-of-domain test sets, 3 surface inputs and 1 deep one (3 languages for which PUD out-of-domain datasets were available);
- 9 automatically parsed in-domain test sets, 6 surface inputs and 3 deep inputs (6 languages for which good UD parsers were available);
- 9 automatically parsed out-of-domain test sets, 6 surface inputs and 3 deep inputs (6 languages for which we were able to create clean Wikipedia text and that had a good UD parser).
#### Splitting Criteria
<!-- info: Describe any criteria for splitting the data, if used. If there are differences between the splits (e.g., if the training annotations are machine-generated and the dev and test ones are created by humans, or if different numbers of annotators contributed to each example), describe them here. -->
<!-- scope: microscope -->
Described above for more clarity.
####
<!-- info: What does an outlier of the dataset in terms of length/perplexity/embedding look like? -->
<!-- scope: microscope -->
An outlier would usually be an input that corresponds to a very long sentence (e.g. 159 words in English, when the average number of words per sentence is around 25).
## Dataset in GEM
### Rationale for Inclusion in GEM
#### Why is the Dataset in GEM?
<!-- info: What does this dataset contribute toward better generation evaluation and why is it part of GEM? -->
<!-- scope: microscope -->
The datset includes languages from different families and some languages not often used in NLG (e.g. Arabic, Indonesian, Korean, Hindi). It proposes two tasks, which can be tackled both separately and in one shot, with different levels of difficulty: the most superficial task (T1) consits in ordering and inflecting some trees, and the deeper task (T2) includes extra tasks such as defining the syntactic structure and introducing function words and morphological agreement information. Both tasks can allow for developing modules for pipeline NLG architectures. T1 is rather straightforward to evaluate: BLEU works quite well for some languages since all the words are present in the input and few word orders only can be possible for a syntactic tree. But T2 is more challenging to evaluate, since more outputs are correct given one particular input.
There is a large variety of sizes in the datasets, both clean and noisy data, parallel data in different languages, and many already available system outputs to use as baselines.
#### Similar Datasets
<!-- info: Do other datasets for the high level task exist? -->
<!-- scope: telescope -->
yes
#### Unique Language Coverage
<!-- info: Does this dataset cover other languages than other datasets for the same task? -->
<!-- scope: periscope -->
yes
#### Difference from other GEM datasets
<!-- info: What else sets this dataset apart from other similar datasets in GEM? -->
<!-- scope: microscope -->
This is possibly the only dataset that starts the generation process from predicate-argument structures and from syntactic structures. It also has parallel datasets in a few languages (coming from the PUD parallel annotations).
#### Ability that the Dataset measures
<!-- info: What aspect of model ability can be measured with this dataset? -->
<!-- scope: periscope -->
Syntacticisation, functional word introduction, word order resolution, agreement resolution, morphological inflection
### GEM-Specific Curation
#### Modificatied for GEM?
<!-- info: Has the GEM version of the dataset been modified in any way (data, processing, splits) from the original curated data? -->
<!-- scope: telescope -->
no
#### Additional Splits?
<!-- info: Does GEM provide additional splits to the dataset? -->
<!-- scope: telescope -->
no
### Getting Started with the Task
#### Pointers to Resources
<!-- info: Getting started with in-depth research on the task. Add relevant pointers to resources that researchers can consult when they want to get started digging deeper into the task. -->
<!-- scope: microscope -->
[Website](http://taln.upf.edu/pages/msr2020-ws/SRST.html)
#### Technical Terms
<!-- info: Technical terms used in this card and the dataset and their definitions -->
<!-- scope: microscope -->
Syntacticisation: prediction of the syntactic
## Previous Results
### Previous Results
#### Measured Model Abilities
<!-- info: What aspect of model ability can be measured with this dataset? -->
<!-- scope: telescope -->
Syntacticisation, functional word introduction, word order resolution, morphological agreement resolution, morphological inflection
#### Metrics
<!-- info: What metrics are typically used for this task? -->
<!-- scope: periscope -->
`BLEU`, `BERT-Score`, `Other: Other Metrics`
#### Other Metrics
<!-- info: Definitions of other metrics -->
<!-- scope: periscope -->
NIST: n-gram similarity metric weighted in favour of less frequent n-grams which are taken to be more informative.
Normalised edit distance (DIST): inverse, normalised, character-based string-edit distance that starts by computing the minimum number of character inserts, deletes and substitutions (all at cost 1) required to turn the system output into the (single) reference text.
#### Proposed Evaluation
<!-- info: List and describe the purpose of the metrics and evaluation methodology (including human evaluation) that the dataset creators used when introducing this task. -->
<!-- scope: microscope -->
BLEU, NIST, BERTScore and DIST simply aim at calculating in different ways the similarity between a predicted and a reference sentence.
Two additional criteria have been used for human evaluation, Readability and Meaning SImilarity. The statement to be assessed in the Readability evaluation was: "The text reads well and is free from grammatical errors and awkward constructions.". The corresponding statement in the Meaning Similarity evaluation, in which system outputs (‘the black text’) were compared to reference sentences (‘the gray text’), was: "The meaning of the gray text is adequately expressed by the black text."
#### Previous results available?
<!-- info: Are previous results available? -->
<!-- scope: telescope -->
yes
#### Other Evaluation Approaches
<!-- info: What evaluation approaches have others used? -->
<!-- scope: periscope -->
Same as above.
#### Relevant Previous Results
<!-- info: What are the most relevant previous results for this task/dataset? -->
<!-- scope: microscope -->
- [Fast and Accurate Non-Projective Dependency Tree Linearization](https://aclanthology.org/2020.acl-main.134/)
- [Shape of Synth to Come: Why We Should Use Synthetic Data for English Surface Realization](https://aclanthology.org/2020.acl-main.665/)
## Dataset Curation
### Original Curation
#### Original Curation Rationale
<!-- info: Original curation rationale -->
<!-- scope: telescope -->
The datasets were created in the context of the Surface Realisation Shared Task series.
#### Communicative Goal
<!-- info: What was the communicative goal? -->
<!-- scope: periscope -->
The dataset's objective was to allow for training systems to perform tasks related to surface realisation (introduction of function words, syntacticisation, resolution of morphological agreements, word order resolution, inflection generation.
#### Sourced from Different Sources
<!-- info: Is the dataset aggregated from different data sources? -->
<!-- scope: telescope -->
yes
#### Source Details
<!-- info: List the sources (one per line) -->
<!-- scope: periscope -->
Each of the 20 used UD datasets comes from various sources, all listed on the individual page of each UD treeebank (https://universaldependencies.org/).
Additional test sets were created for the task, and were obtained from Wikipedia pages for 6 languages.
### Language Data
#### How was Language Data Obtained?
<!-- info: How was the language data obtained? -->
<!-- scope: telescope -->
`Found`
#### Where was it found?
<!-- info: If found, where from? -->
<!-- scope: telescope -->
`Multiple websites`
#### Language Producers
<!-- info: What further information do we have on the language producers? -->
<!-- scope: microscope -->
There are numerous sources of language in the multiple datasets.
#### Topics Covered
<!-- info: Does the language in the dataset focus on specific topics? How would you describe them? -->
<!-- scope: periscope -->
There is a large variety of topics in the multiple datasets.
#### Data Validation
<!-- info: Was the text validated by a different worker or a data curator? -->
<!-- scope: telescope -->
not validated
#### Data Preprocessing
<!-- info: How was the text data pre-processed? (Enter N/A if the text was not pre-processed) -->
<!-- scope: microscope -->
The text data was detokenised so as to create references for automatic evaluations (several languages don't use spaces to separate words, and running metrics like BLEU would not make sense without separating all the tokens in a sentence).
#### Was Data Filtered?
<!-- info: Were text instances selected or filtered? -->
<!-- scope: telescope -->
hybrid
#### Filter Criteria
<!-- info: What were the selection criteria? -->
<!-- scope: microscope -->
For the Wikipedia test created for the shared task, extensive filtering was applied to achieve reasonably good text quality. Sentences that include special characters, contain unusual tokens (e.g. ISBN), or have unbalanced quotation marks or brackets were skipped. Furthermore, only sentences with more than 5 tokens and shorter than 50 tokens were selected. After the initial filtering, quite a few malformed sentences remained. In order to remove those, the sentences were scored with BERT and
only the top half scored sentences were kept. Finally, via manual inspection, patterns and expressions were identified to
further reduce the number of malformed sentences.
### Structured Annotations
#### Additional Annotations?
<!-- quick -->
<!-- info: Does the dataset have additional annotations for each instance? -->
<!-- scope: telescope -->
none
#### Annotation Service?
<!-- info: Was an annotation service used? -->
<!-- scope: telescope -->
no
### Consent
#### Any Consent Policy?
<!-- info: Was there a consent policy involved when gathering the data? -->
<!-- scope: telescope -->
no
#### Justification for Using the Data
<!-- info: If not, what is the justification for reusing the data? -->
<!-- scope: microscope -->
The Universal Dependency data had been previously used for shared tasks on parsing, so it made sense to reuse it for generation.
### Private Identifying Information (PII)
#### Contains PII?
<!-- quick -->
<!-- info: Does the source language data likely contain Personal Identifying Information about the data creators or subjects? -->
<!-- scope: telescope -->
unlikely
#### Any PII Identification?
<!-- info: Did the curators use any automatic/manual method to identify PII in the dataset? -->
<!-- scope: periscope -->
no identification
### Maintenance
#### Any Maintenance Plan?
<!-- info: Does the original dataset have a maintenance plan? -->
<!-- scope: telescope -->
no
## Broader Social Context
### Previous Work on the Social Impact of the Dataset
#### Usage of Models based on the Data
<!-- info: Are you aware of cases where models trained on the task featured in this dataset ore related tasks have been used in automated systems? -->
<!-- scope: telescope -->
no
### Impact on Under-Served Communities
#### Addresses needs of underserved Communities?
<!-- info: Does this dataset address the needs of communities that are traditionally underserved in language technology, and particularly language generation technology? Communities may be underserved for exemple because their language, language variety, or social or geographical context is underepresented in NLP and NLG resources (datasets and models). -->
<!-- scope: telescope -->
yes
#### Details on how Dataset Addresses the Needs
<!-- info: Describe how this dataset addresses the needs of underserved communities. -->
<!-- scope: microscope -->
Thanks to the original work of the UD dataset creators, the surface realisation dataset addresses a few languages which are possibly under-served in NLG: e.g. Arabic, Hindi, Indonesian, Korean.
### Discussion of Biases
#### Any Documented Social Biases?
<!-- info: Are there documented social biases in the dataset? Biases in this context are variations in the ways members of different social categories are represented that can have harmful downstream consequences for members of the more disadvantaged group. -->
<!-- scope: telescope -->
no
#### Are the Language Producers Representative of the Language?
<!-- info: Does the distribution of language producers in the dataset accurately represent the full distribution of speakers of the language world-wide? If not, how does it differ? -->
<!-- scope: periscope -->
It is very likely that the distribution of language producers is not fully represented in the datasets of each language.
## Considerations for Using the Data
### PII Risks and Liability
#### Potential PII Risk
<!-- info: Considering your answers to the PII part of the Data Curation Section, describe any potential privacy to the data subjects and creators risks when using the dataset. -->
<!-- scope: microscope -->
No risks foreseen.
### Licenses
#### Copyright Restrictions on the Dataset
<!-- info: Based on your answers in the Intended Use part of the Data Overview Section, which of the following best describe the copyright and licensing status of the dataset? -->
<!-- scope: periscope -->
`multiple licenses`, `open license - commercial use allowed`
#### Copyright Restrictions on the Language Data
<!-- info: Based on your answers in the Language part of the Data Curation Section, which of the following best describe the copyright and licensing status of the underlying language data? -->
<!-- scope: periscope -->
`multiple licenses`, `open license - commercial use allowed`
### Known Technical Limitations
#### Technical Limitations
<!-- info: Describe any known technical limitations, such as spurrious correlations, train/test overlap, annotation biases, or mis-annotations, and cite the works that first identified these limitations when possible. -->
<!-- scope: microscope -->
The deep track inputs (predicate-argument structures) are not of perfect quality, they were derived automatically from gold or predicted syntactic parses using handcrafted grammars.
#### Unsuited Applications
<!-- info: When using a model trained on this dataset in a setting where users or the public may interact with its predictions, what are some pitfalls to look out for? In particular, describe some applications of the general task featured in this dataset that its curation or properties make it less suitable for. -->
<!-- scope: microscope -->
The datasets are probably not fitted to train tools to produce "unusual" languages (e.g. poetry, kid writing etc.).
#### Discouraged Use Cases
<!-- info: What are some discouraged use cases of a model trained to maximize the proposed metrics on this dataset? In particular, think about settings where decisions made by a model that performs reasonably well on the metric my still have strong negative consequences for user or members of the public. -->
<!-- scope: microscope -->
To be thought of :)
|
AdapterOcean/augmentatio-standardized_cluster_8_alpaca | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 8954341
num_examples: 3269
download_size: 4011651
dataset_size: 8954341
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "augmentatio-standardized_cluster_8_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
kw1018/capjackv2 | ---
license: unknown
---
|
CyberHarem/yumi_yotsuya_alicegearaegisexpansion | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of Yumi Yotsuya
This is the dataset of Yumi Yotsuya, containing 92 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:----------------|---------:|:----------------------------------------|:-----------------------------------------------------------------------------------------|
| raw | 92 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 211 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| raw-stage3-eyes | 256 | [Download](dataset-raw-stage3-eyes.zip) | 3-stage cropped (with eye-focus) raw data with meta information. |
| 384x512 | 92 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x704 | 92 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x880 | 92 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 211 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 211 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-p512-640 | 184 | [Download](dataset-stage3-p512-640.zip) | 3-stage cropped dataset with the area not less than 512x512 pixels. |
| stage3-eyes-640 | 256 | [Download](dataset-stage3-eyes-640.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 640 pixels. |
| stage3-eyes-800 | 256 | [Download](dataset-stage3-eyes-800.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 800 pixels. |
|
CyberHarem/soiree_fireemblem | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of soiree (Fire Emblem)
This is the dataset of soiree (Fire Emblem), containing 48 images and their tags.
The core tags of this character are `short_hair, red_hair, red_eyes, breasts`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:----------|:-------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 48 | 37.30 MiB | [Download](https://huggingface.co/datasets/CyberHarem/soiree_fireemblem/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 48 | 27.44 MiB | [Download](https://huggingface.co/datasets/CyberHarem/soiree_fireemblem/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 94 | 46.13 MiB | [Download](https://huggingface.co/datasets/CyberHarem/soiree_fireemblem/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 48 | 34.78 MiB | [Download](https://huggingface.co/datasets/CyberHarem/soiree_fireemblem/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 94 | 55.52 MiB | [Download](https://huggingface.co/datasets/CyberHarem/soiree_fireemblem/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/soiree_fireemblem',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:------------------------------------------|
| 0 | 31 |  |  |  |  |  | 1girl, solo, armor, gloves, smile, weapon |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | solo | armor | gloves | smile | weapon |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:-------|:--------|:---------|:--------|:---------|
| 0 | 31 |  |  |  |  |  | X | X | X | X | X | X |
|
paul-w-qs/additional_charges_roles_v1 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: JSON_LABEL
dtype: string
splits:
- name: train
num_bytes: 161926662.0
num_examples: 600
download_size: 161457126
dataset_size: 161926662.0
---
# Dataset Card for "additional_charges_roles_v1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
rombodawg/LosslessMegaCodeTrainingV3_1.6m_Evol | ---
license: other
---
This is the ultimate code training data, created to be lossless so the AI model does not lose any other abilities it had previously, such as logical skills, after training on this dataset. The reason why this dataset is so large is to ensure that as the model learns to code, it continues to remember to follow regular instructions so as not to lose previously learned abilities. This is the result of all my work gathering data, testing AI models, and discovering what, why, and how coding models perform well or don't perform well.
The content of this dataset is roughly 50% coding instruction data and 50% non-coding instruction data. Amounting to 1.5 million evol instruction-formatted lines of data.
The outcome of having 50% non coding instruction data in the dataset is to preserve logic and reasoning skills within the model while training on coding. The lack of such skills has been observed to be a major issue with coding models such as Wizardcoder-15b and NewHope, but training models on this dataset alleviates that issue while also giving similar levels of coding knowledge.
This dataset is a combination of the following datasets, along with additional deduping and uncensoring techniques:
Coding:
- https://huggingface.co/datasets/rombodawg/2XUNCENSORED_MegaCodeTraining188k
- https://huggingface.co/datasets/rombodawg/Rombodawgs_commitpackft_Evolinstruct_Converted
Instruction following:
- https://huggingface.co/datasets/rombodawg/2XUNCENSORED_alpaca_840k_Evol_USER_ASSIST
- https://huggingface.co/datasets/garage-bAInd/Open-Platypus
|
bigscience-data/roots_indic-kn_ted_talks_iwslt | ---
language: kn
license: cc-by-nc-nd-4.0
extra_gated_prompt: 'By accessing this dataset, you agree to abide by the BigScience
Ethical Charter. The charter can be found at:
https://hf.co/spaces/bigscience/ethical-charter'
extra_gated_fields:
I have read and agree to abide by the BigScience Ethical Charter: checkbox
---
ROOTS Subset: roots_indic-kn_ted_talks_iwslt
# WIT Ted Talks
- Dataset uid: `ted_talks_iwslt`
### Description
The Web Inventory Talk is a collection of the original Ted talks and their translated version. The translations are available in more than 109+ languages, though the distribution is not uniform.
### Homepage
https://github.com/huggingface/datasets/blob/master/datasets/ted_talks_iwslt/README.md
### Licensing
- open license
- cc-by-nc-4.0: Creative Commons Attribution Non Commercial 4.0 International
TED makes its collection of video recordings and transcripts of talks available under the Creative Commons BY-NC-ND license (look here). WIT3 acknowledges the authorship of TED talks (BY condition) and does not redistribute transcripts for commercial purposes (NC). As regards the integrity of the work (ND), WIT3 only changes the format of the container, while preserving the original contents. WIT3 aims to support research on human language processing as well as the diffusion of TED Talks!
### Speaker Locations
- Southern Europe
- Italy
### Sizes
- 0.0305 % of total
- 0.0736 % of ar
- 0.2002 % of pt
- 0.0128 % of zh
- 0.2236 % of vi
- 0.0330 % of fr
- 0.0545 % of es
- 0.0122 % of en
- 0.3704 % of id
- 0.0373 % of indic-hi
- 0.0330 % of indic-ta
- 0.1393 % of indic-mr
- 0.0305 % of ca
- 0.1179 % of indic-ur
- 0.0147 % of indic-bn
- 0.0240 % of indic-ml
- 0.0244 % of indic-te
- 0.0503 % of indic-gu
- 0.0211 % of indic-kn
- 0.0274 % of eu
- 0.0023 % of indic-as
- 0.0001 % of indic-pa
### BigScience processing steps
#### Filters applied to: ar
- dedup_document
- dedup_template_soft
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: pt
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: zh
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: vi
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: fr
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: es
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: en
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: id
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-hi
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-ta
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-mr
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: ca
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: indic-ur
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-bn
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-ml
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-te
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-gu
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-kn
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: eu
- dedup_document
- filter_remove_empty_docs
#### Filters applied to: indic-as
- dedup_document
- filter_remove_empty_docs
#### Filters applied to: indic-pa
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
|
Anon126/my-raft-submission | ---
benchmark: raft
type: prediction
submission_name: none
---
# RAFT submissions for my-raft-submission
## Submitting to the leaderboard
To make a submission to the [leaderboard](https://huggingface.co/spaces/ought/raft-leaderboard), there are three main steps:
1. Generate predictions on the unlabeled test set of each task
2. Validate the predictions are compatible with the evaluation framework
3. Push the predictions to the Hub!
See the instructions below for more details.
### Rules
1. To prevent overfitting to the public leaderboard, we only evaluate **one submission per week**. You can push predictions to the Hub as many times as you wish, but we will only evaluate the most recent commit in a given week.
2. Transfer or meta-learning using other datasets, including further pre-training on other corpora, is allowed.
3. Use of unlabeled test data is allowed, as is it always available in the applied setting. For example, further pre-training using the unlabeled data for a task would be permitted.
4. Systems may be augmented with information retrieved from the internet, e.g. via automated web searches.
### Submission file format
For each task in RAFT, you should create a CSV file called `predictions.csv` with your model's predictions on the unlabeled test set. Each file should have exactly 2 columns:
* ID (int)
* Label (string)
See the dummy predictions in the `data` folder for examples with the expected format. Here is a simple example that creates a majority-class baseline:
```python
from pathlib import Path
import pandas as pd
from collections import Counter
from datasets import load_dataset, get_dataset_config_names
tasks = get_dataset_config_names("ought/raft")
for task in tasks:
# Load dataset
raft_subset = load_dataset("ought/raft", task)
# Compute majority class over training set
counter = Counter(raft_subset["train"]["Label"])
majority_class = counter.most_common(1)[0][0]
# Load predictions file
preds = pd.read_csv(f"data/{task}/predictions.csv")
# Convert label IDs to label names
preds["Label"] = raft_subset["train"].features["Label"].int2str(majority_class)
# Save predictions
preds.to_csv(f"data/{task}/predictions.csv", index=False)
```
As you can see in the example, each `predictions.csv` file should be stored in the task's subfolder in `data` and at the end you should have something like the following:
```
data
├── ade_corpus_v2
│ ├── predictions.csv
│ └── task.json
├── banking_77
│ ├── predictions.csv
│ └── task.json
├── neurips_impact_statement_risks
│ ├── predictions.csv
│ └── task.json
├── one_stop_english
│ ├── predictions.csv
│ └── task.json
├── overruling
│ ├── predictions.csv
│ └── task.json
├── semiconductor_org_types
│ ├── predictions.csv
│ └── task.json
├── systematic_review_inclusion
│ ├── predictions.csv
│ └── task.json
├── tai_safety_research
│ ├── predictions.csv
│ └── task.json
├── terms_of_service
│ ├── predictions.csv
│ └── task.json
├── tweet_eval_hate
│ ├── predictions.csv
│ └── task.json
└── twitter_complaints
├── predictions.csv
└── task.json
```
### Validate your submission
To ensure that your submission files are correctly formatted, run the following command from the root of the repository:
```
python cli.py validate
```
If everything is correct, you should see the following message:
```
All submission files validated! ✨ 🚀 ✨
Now you can make a submission 🤗
```
### Push your submission to the Hugging Face Hub!
The final step is to commit your files and push them to the Hub:
```
python cli.py submit
```
If there are no errors, you should see the following message:
```
Submission successful! 🎉 🥳 🎉
Your submission will be evaulated on Sunday 05 September 2021 ⏳
```
where the evaluation is run every Sunday and your results will be visible on the leaderboard. |
LeoMirkin/Ma_2_0 | ---
license: mit
---
|
mangostin2010/KakaoChatData | ---
license: unknown
language:
- ko
---
|
dzw/wudao | ---
license: apache-2.0
---
|
open-llm-leaderboard/details_WeOpenML__PandaLM-Alpaca-7B-v1 | ---
pretty_name: Evaluation run of WeOpenML/PandaLM-Alpaca-7B-v1
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [WeOpenML/PandaLM-Alpaca-7B-v1](https://huggingface.co/WeOpenML/PandaLM-Alpaca-7B-v1)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_WeOpenML__PandaLM-Alpaca-7B-v1\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-09-22T22:33:33.888453](https://huggingface.co/datasets/open-llm-leaderboard/details_WeOpenML__PandaLM-Alpaca-7B-v1/blob/main/results_2023-09-22T22-33-33.888453.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.0856753355704698,\n\
\ \"em_stderr\": 0.0028662744739059616,\n \"f1\": 0.15614618288590562,\n\
\ \"f1_stderr\": 0.003108423155895864,\n \"acc\": 0.3640595557731007,\n\
\ \"acc_stderr\": 0.007623933803325749\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.0856753355704698,\n \"em_stderr\": 0.0028662744739059616,\n\
\ \"f1\": 0.15614618288590562,\n \"f1_stderr\": 0.003108423155895864\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.009097801364670205,\n \
\ \"acc_stderr\": 0.0026153265107756725\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.7190213101815311,\n \"acc_stderr\": 0.012632541095875825\n\
\ }\n}\n```"
repo_url: https://huggingface.co/WeOpenML/PandaLM-Alpaca-7B-v1
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|arc:challenge|25_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_09_22T22_33_33.888453
path:
- '**/details_harness|drop|3_2023-09-22T22-33-33.888453.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-09-22T22-33-33.888453.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_09_22T22_33_33.888453
path:
- '**/details_harness|gsm8k|5_2023-09-22T22-33-33.888453.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-09-22T22-33-33.888453.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hellaswag|10_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-24T12:03:47.951462.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-24T12:03:47.951462.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-24T12:03:47.951462.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_09_22T22_33_33.888453
path:
- '**/details_harness|winogrande|5_2023-09-22T22-33-33.888453.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-09-22T22-33-33.888453.parquet'
- config_name: results
data_files:
- split: 2023_07_24T12_03_47.951462
path:
- results_2023-07-24T12:03:47.951462.parquet
- split: 2023_09_22T22_33_33.888453
path:
- results_2023-09-22T22-33-33.888453.parquet
- split: latest
path:
- results_2023-09-22T22-33-33.888453.parquet
---
# Dataset Card for Evaluation run of WeOpenML/PandaLM-Alpaca-7B-v1
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/WeOpenML/PandaLM-Alpaca-7B-v1
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [WeOpenML/PandaLM-Alpaca-7B-v1](https://huggingface.co/WeOpenML/PandaLM-Alpaca-7B-v1) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_WeOpenML__PandaLM-Alpaca-7B-v1",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-09-22T22:33:33.888453](https://huggingface.co/datasets/open-llm-leaderboard/details_WeOpenML__PandaLM-Alpaca-7B-v1/blob/main/results_2023-09-22T22-33-33.888453.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.0856753355704698,
"em_stderr": 0.0028662744739059616,
"f1": 0.15614618288590562,
"f1_stderr": 0.003108423155895864,
"acc": 0.3640595557731007,
"acc_stderr": 0.007623933803325749
},
"harness|drop|3": {
"em": 0.0856753355704698,
"em_stderr": 0.0028662744739059616,
"f1": 0.15614618288590562,
"f1_stderr": 0.003108423155895864
},
"harness|gsm8k|5": {
"acc": 0.009097801364670205,
"acc_stderr": 0.0026153265107756725
},
"harness|winogrande|5": {
"acc": 0.7190213101815311,
"acc_stderr": 0.012632541095875825
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
CATIE-AQ/piaf_fr_prompt_context_generation_with_question | ---
language:
- fr
license: mit
size_categories:
- 100K<n<1M
task_categories:
- text-generation
tags:
- DFP
- french prompts
annotations_creators:
- found
language_creators:
- found
multilinguality:
- monolingual
source_datasets:
- etalab-ia/piaf
---
# piaf_fr_prompt_context_generation_with_question
## Summary
**piaf_fr_prompt_context_generation_with_question** is a subset of the [**Dataset of French Prompts (DFP)**](https://huggingface.co/datasets/CATIE-AQ/DFP).
It contains **442,752** rows that can be used for a context-generation (with answer and question) task.
The original data (without prompts) comes from the dataset [PIAF](https://huggingface.co/datasets/etalab-ia/piaf) and was augmented by questions in SQUAD 2.0 format in the [FrenchQA]( https://huggingface.co/datasets/CATIE-AQ/frenchQA) dataset.
A list of prompts (see below) was then applied in order to build the input and target columns and thus obtain the same format as the [xP3](https://huggingface.co/datasets/bigscience/xP3) dataset by Muennighoff et al.
## Prompts used
### List
24 prompts were created for this dataset. The logic applied consists in proposing prompts in the indicative tense, in the form of tutoiement and in the form of vouvoiement.
```
'Étant donné la question "'+question+'", écrire un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", écris un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", écrivez un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", rédiger un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", rédige un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", rédigez un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", générer un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", génère un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", générez un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", créer un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", crée un texte explicatif.\nTexte : ',
'Étant donné la question "'+question+'", créez un texte explicatif.\nTexte : ',
'Ecrire un texte comme contexte à la question "'+question+'" \nTexte : ',
'Ecris un texte comme contexte à la question "'+question+'" \nTexte : ',
'Ecrivez un texte comme contexte à la question "'+question+'" \nTexte : ',
'Rédiger un texte comme contexte à la question "'+question+'" \nTexte : ',
'Rédige un texte comme contexte à la question "'+question+'" \nTexte : ',
'Rédigez un texte comme contexte à la question "'+question+'" \nTexte : ',
'Générer un texte comme contexte à la question "'+question+'" \nTexte : ',
'Génère un texte comme contexte à la question "'+question+'" \nTexte : ',
'Générez un texte comme contexte à la question "'+question+'" \nTexte : ',
'Créer un texte comme contexte à la question "'+question+'" \nTexte : ',
'Crée un texte comme contexte à la question "'+question+'" \nTexte : ',
'Créez un texte comme contexte à la question "'+question+'" \nTexte : '
```
# Splits
- `train` with 442,752 samples
- no `valid` split
- no `test` split
# How to use?
```
from datasets import load_dataset
dataset = load_dataset("CATIE-AQ/piaf_fr_prompt_context_generation_with_question")
```
# Citation
## Original data
> @InProceedings{keraron-EtAl:2020:LREC,
author = {Keraron, Rachel and Lancrenon, Guillaume and Bras, Mathilde and Allary, Frédéric and Moyse, Gilles and Scialom, Thomas and Soriano-Morales, Edmundo-Pavel and Staiano, Jacopo},
title = {Project PIAF: Building a Native French Question-Answering Dataset},
booktitle = {Proceedings of The 12th Language Resources and Evaluation Conference},
month = {May},
year = {2020},
address = {Marseille, France},
publisher = {European Language Resources Association},
pages = {5483--5492},
url = {https://www.aclweb.org/anthology/2020.lrec-1.673}
}
## This Dataset
> @misc {centre_aquitain_des_technologies_de_l'information_et_electroniques_2023,
author = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { DFP (Revision 1d24c09) },
year = 2023,
url = { https://huggingface.co/datasets/CATIE-AQ/DFP },
doi = { 10.57967/hf/1200 },
publisher = { Hugging Face }
}
## License
MIT |
shahidul034/text_summarization_dataset2 | ---
dataset_info:
features:
- name: title
dtype: string
- name: content
dtype: string
splits:
- name: train
num_bytes: 125954432
num_examples: 105252
download_size: 42217690
dataset_size: 125954432
---
# Dataset Card for "text_summarization_dataset2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
yizhang7210/curated_ms_marco | ---
license: mit
---
|
rashmi035/Man_ki_Baat_Hindi | ---
license: other
---
|
shreyansh1347/GNHK-Synthetic-OCR-Dataset | ---
dataset_info:
features:
- name: id
dtype: string
- name: Image
dtype: Image
- name: ocr_text
dtype: string
- name: bbox_data
dtype: string
- name: conversation
list:
- name: Question
dtype: string
- name: Answer
dtype: string
- name: description
dtype: string
- name: complex_reasoning
struct:
- name: Question
dtype: string
- name: Answer
dtype: string
configs:
- config_name: default
data_files:
- split: test
path: dataset.parquet
---
# GNHK Synthetic OCR Dataset
## Overview
Welcome to the GNHK Synthetic OCR Dataset repository. Here I have generated synthetic data using [GNHK Dataset](https://github.com/GoodNotes/GNHK-dataset), and Open Source LLMs like Mixtral. The dataset contains queries on the images and their answers.
## What's Inside?
- **Dataset Folder:** The Dataset Folder contains the images, and corresponding to each image, there is a JSON file which carries the ocr information of that image
- **Parquet File:** For easy handling and analysis, the processed dataset is saved as a Parquet file (`dataset.parquet`). This file contains images, their OCR text, one probable question per image, and its likely answer.
# Methodology for Generation
## ParseJSON.ipynb
This Python notebook interacts with a dataset provided by GNHK, stored on Google Drive. The dataset consists of images, each accompanied by a JSON file containing OCR information for that image. The purpose of ParseJSON is to extract information from these JSON files, convert it into text files, and store these files in a folder named `parsed_dataset` on the same Google Drive.
### What does it parse to?
- **ocr_data**: It extracts OCR texts for words based on their 'line_index' and organizes them to represent the OCR text of the given image.
- **bbox_data**: Another text file is generated by the parser, structuring information in this format:
`word: [[x0, y0], [x1, y1], [x2, y2], [x3, y3]]`
(where x0, y1, etc. are coordinates of bounding boxes)
### Why do we need a parser?
The parser is necessary because models require OCR data and bounding boxes as input. If this information is in JSON format, creating a prompt for the models becomes complex and may lead to confusion, resulting in undesirable outputs. The parser simplifies the process by converting the data into easily understandable text files.
## 2. DatasetGeneration.ipynb
This notebook is the central tool for creating the dataset. In summary, it leverages OCR data and bounding boxes to prompt open-source LLMs, generating query-output tuples.
The methodology draws inspiration from the paper on [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485), which outlines the creation of three types of query-output tuples:
1. **Conversation Based:** Simple question-answer pairs related to the given image, covering a broad range of straightforward inquiries. Multiple conversation-based query-output tuples are generated for a single image to ensure comprehensiveness.
2. **Description:** This is not a typical question-answer pair. In this category the model generates detailed descriptions of the text depicted in the image.
3. **Complex Reasoning Based:** These questions delve deeper, requiring thoughtful consideration. Answering them involves understanding the visual content, followed by applying background knowledge or reasoning to provide a detailed response. Only one question-answer tuple of this nature is generated for each image.
## Output Parsing and Cleaning Functions
Various parsers are implemented to process the model-generated output. Due to the unpredictable nature of LLM outputs, these parsers aren't flawless. However, by incorporating few-shot prompting and identifying common patterns in the LLM outputs, these parsers can handle a significant number of cases. Their primary function is to convert the raw output into a structured format for inclusion in the final database.
Finally, the dataset generated has the following format:
```
[{
"id": id,
"Image": Image,
"ocr_text": data,
"bbox_data": string,
"conversation": [
{
"Question": question,
"Answer": answer
}
],
"description": string,
"complex_reasoning": {
"Question": question,
"Answer": answer
}
}]
```
### Model Used
After multiple experiments, the most promising results were achieved using the [Mixtral_8x7b](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) model. It demonstrated superior performance compared to Llama-2 70b for the specific task at hand.
To execute these open-source models in the cloud, the services offered by Together.ai have been employed.
## Post Processing
In this experiment, the output generated from two Language Models (LLMs) was processed to enhance the dataset quality. The LLMs used were [Platypus2](https://huggingface.co/garage-bAInd/Platypus2-70B-instruct) and [Mixtral_8x7b](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1). The process involved the following steps:
### Step 1:
1. **Generation and Evaluation:** Mixtral_8x7b generated the initial dataset, which was then evaluated and modified by Platypus2. Subsequently, the output from Platypus2 was further evaluated and modified by Mixtral_8x7b.
### Step 2:
2. **Judgment and Selection:** The outputs from both Mixtral_8x7b (final output of step 1) and Platypus2 (intermediate output of step 1) were assessed by [Mixtral_8x7b_Instruct](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1). The best output was selected, and the dataset was updated accordingly.
The pipeline can be summarized as follows:
```
Step 1:
Mixtral_8x7b generates dataset --> Platypus2 evaluates and make changes --> Mixtral_8x7b evaluates it's changes
Step 2:
Mixtral_8x7b output (from Step 1's evaluation stage) --> Mixtral_8x7b_Instruct
|
Platypus2 output (from Step 1)
```
The resulting dataset, after this process, is named `post_processed_dataset.parquet`. Please note that only 50 data points were post-processed as part of this experiment.
**Note:** While this post-processing experiment aimed to enhance the dataset's overall quality, manual observations did not reveal significant improvements.
|
tyzhu/squad_no_title_v4_train_30_eval_10_recite_ans_sent | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
- name: context_id
dtype: string
- name: inputs
dtype: string
- name: targets
dtype: string
splits:
- name: train
num_bytes: 590548
num_examples: 368
- name: validation
num_bytes: 48707
num_examples: 50
download_size: 113536
dataset_size: 639255
---
# Dataset Card for "squad_no_title_v4_train_30_eval_10_recite_ans_sent"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
jau534dsh/things | ---
license: openrail
---
|
dbuos/oasst_top1_en | ---
language:
- en
license: apache-2.0
size_categories:
- 1K<n<10K
dataset_info:
features:
- name: text
dtype: string
- name: lang
dtype: string
- name: num_turns
dtype: int64
splits:
- name: train
num_bytes: 9908776
num_examples: 5023
download_size: 5271098
dataset_size: 9908776
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
#### OpenAssistant TOP-1 Conversation Threads
##### Guanacco style export of the best conversation threads from the open-assistant.io database
- exported August 25, 2023
- jsonl files with chatml formatted conversations
- train: 5,023 samples
- Only English examples
- Add column to count number of messages |
rojagtap/tech-qa | ---
license: mit
---
|
CyberHarem/jougasaki_rika_idolmastercinderellagirls | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of jougasaki_rika/城ヶ崎莉嘉 (THE iDOLM@STER: Cinderella Girls)
This is the dataset of jougasaki_rika/城ヶ崎莉嘉 (THE iDOLM@STER: Cinderella Girls), containing 500 images and their tags.
The core tags of this character are `blonde_hair, long_hair, green_eyes, two_side_up, bangs, hair_ornament, breasts`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:------------------------------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 500 | 644.18 MiB | [Download](https://huggingface.co/datasets/CyberHarem/jougasaki_rika_idolmastercinderellagirls/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 500 | 382.75 MiB | [Download](https://huggingface.co/datasets/CyberHarem/jougasaki_rika_idolmastercinderellagirls/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 1251 | 845.05 MiB | [Download](https://huggingface.co/datasets/CyberHarem/jougasaki_rika_idolmastercinderellagirls/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 500 | 570.33 MiB | [Download](https://huggingface.co/datasets/CyberHarem/jougasaki_rika_idolmastercinderellagirls/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 1251 | 1.16 GiB | [Download](https://huggingface.co/datasets/CyberHarem/jougasaki_rika_idolmastercinderellagirls/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/jougasaki_rika_idolmastercinderellagirls',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 7 |  |  |  |  |  | 1girl, navel, nipples, simple_background, small_breasts, solo, white_background, nude, blush, looking_at_viewer, smile, open_mouth |
| 1 | 13 |  |  |  |  |  | 1girl, solo, looking_at_viewer, navel, blush, open_mouth, side-tie_bikini_bottom, collarbone, simple_background, small_breasts, white_background, white_bikini, fang, micro_bikini, :d, choker, cowboy_shot, string_bikini |
| 2 | 12 |  |  |  |  |  | 1girl, blush, simple_background, solo, sweater_vest, upper_body, white_shirt, looking_at_viewer, red_ribbon, school_uniform, neck_ribbon, short_sleeves, white_background, collared_shirt, open_mouth, :d, hair_scrunchie, collarbone, fang |
| 3 | 16 |  |  |  |  |  | 1girl, looking_at_viewer, school_uniform, simple_background, solo, sweater_vest, white_background, blush, bracelet, plaid_skirt, open_mouth, :d, short_sleeves, orange_skirt, pleated_skirt, white_shirt, fang, red_ribbon, neck_ribbon |
| 4 | 9 |  |  |  |  |  | 1girl, open_mouth, school_uniform, smile, solo, sweater_vest, ;d, one_eye_closed, looking_at_viewer, blush, fang, plaid_skirt, flower_bracelet, ribbon |
| 5 | 15 |  |  |  |  |  | 1girl, blush, earrings, looking_at_viewer, open_mouth, solo, puffy_short_sleeves, white_shirt, wrist_cuffs, plaid_skirt, white_headwear, red_skirt, yellow_necktie, frills, pleated_skirt, white_thighhighs, :d, beret, collared_shirt, fang, striped_necktie, simple_background, very_long_hair, white_jacket, bow, white_background, hand_up, heart, zettai_ryouiki |
| 6 | 5 |  |  |  |  |  | 1girl, blush, earrings, hair_bow, looking_at_viewer, solo, bare_shoulders, upper_body, heart, simple_background, bracelet, braid, grin, hairclip, nail_polish, necklace, one_eye_closed, white_background |
| 7 | 12 |  |  |  |  |  | 1girl, lion_ears, bare_shoulders, jingle_bell, paw_gloves, lion_tail, looking_at_viewer, blush, open_mouth, solo, collarbone, fangs, navel, small_breasts, lion_girl, midriff, short_shorts, striped_thighhighs, :d, cleavage, tail_bell, white_background |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | navel | nipples | simple_background | small_breasts | solo | white_background | nude | blush | looking_at_viewer | smile | open_mouth | side-tie_bikini_bottom | collarbone | white_bikini | fang | micro_bikini | :d | choker | cowboy_shot | string_bikini | sweater_vest | upper_body | white_shirt | red_ribbon | school_uniform | neck_ribbon | short_sleeves | collared_shirt | hair_scrunchie | bracelet | plaid_skirt | orange_skirt | pleated_skirt | ;d | one_eye_closed | flower_bracelet | ribbon | earrings | puffy_short_sleeves | wrist_cuffs | white_headwear | red_skirt | yellow_necktie | frills | white_thighhighs | beret | striped_necktie | very_long_hair | white_jacket | bow | hand_up | heart | zettai_ryouiki | hair_bow | bare_shoulders | braid | grin | hairclip | nail_polish | necklace | lion_ears | jingle_bell | paw_gloves | lion_tail | fangs | lion_girl | midriff | short_shorts | striped_thighhighs | cleavage | tail_bell |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:--------|:----------|:--------------------|:----------------|:-------|:-------------------|:-------|:--------|:--------------------|:--------|:-------------|:-------------------------|:-------------|:---------------|:-------|:---------------|:-----|:---------|:--------------|:----------------|:---------------|:-------------|:--------------|:-------------|:-----------------|:--------------|:----------------|:-----------------|:-----------------|:-----------|:--------------|:---------------|:----------------|:-----|:-----------------|:------------------|:---------|:-----------|:----------------------|:--------------|:-----------------|:------------|:-----------------|:---------|:-------------------|:--------|:------------------|:-----------------|:---------------|:------|:----------|:--------|:-----------------|:-----------|:-----------------|:--------|:-------|:-----------|:--------------|:-----------|:------------|:--------------|:-------------|:------------|:--------|:------------|:----------|:---------------|:---------------------|:-----------|:------------|
| 0 | 7 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 13 |  |  |  |  |  | X | X | | X | X | X | X | | X | X | | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 2 | 12 |  |  |  |  |  | X | | | X | | X | X | | X | X | | X | | X | | X | | X | | | | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 3 | 16 |  |  |  |  |  | X | | | X | | X | X | | X | X | | X | | | | X | | X | | | | X | | X | X | X | X | X | | | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 4 | 9 |  |  |  |  |  | X | | | | | X | | | X | X | X | X | | | | X | | | | | | X | | | | X | | | | | | X | | | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 5 | 15 |  |  |  |  |  | X | | | X | | X | X | | X | X | | X | | | | X | | X | | | | | | X | | | | | X | | | X | | X | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | |
| 6 | 5 |  |  |  |  |  | X | | | X | | X | X | | X | X | | | | | | | | | | | | | X | | | | | | | | X | | | | | X | | | X | | | | | | | | | | | | | | X | | X | X | X | X | X | X | X | | | | | | | | | | | |
| 7 | 12 |  |  |  |  |  | X | X | | | X | X | X | | X | X | | X | | X | | | | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | X | | | | | | X | X | X | X | X | X | X | X | X | X | X |
|
open-llm-leaderboard/details_occultml__CatMarcoro14-7B-slerp | ---
pretty_name: Evaluation run of occultml/CatMarcoro14-7B-slerp
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [occultml/CatMarcoro14-7B-slerp](https://huggingface.co/occultml/CatMarcoro14-7B-slerp)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 63 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_occultml__CatMarcoro14-7B-slerp\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2024-01-06T21:04:34.082486](https://huggingface.co/datasets/open-llm-leaderboard/details_occultml__CatMarcoro14-7B-slerp/blob/main/results_2024-01-06T21-04-34.082486.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.6574722326639718,\n\
\ \"acc_stderr\": 0.03188895296761844,\n \"acc_norm\": 0.6570269052037782,\n\
\ \"acc_norm_stderr\": 0.03255254600254235,\n \"mc1\": 0.4675642594859241,\n\
\ \"mc1_stderr\": 0.01746663214957761,\n \"mc2\": 0.6324003297074412,\n\
\ \"mc2_stderr\": 0.015075106150958025\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.6706484641638225,\n \"acc_stderr\": 0.013734057652635474,\n\
\ \"acc_norm\": 0.6936860068259386,\n \"acc_norm_stderr\": 0.013470584417276513\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.686516630153356,\n\
\ \"acc_stderr\": 0.004629608863272308,\n \"acc_norm\": 0.8692491535550687,\n\
\ \"acc_norm_stderr\": 0.003364386713542236\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.3,\n \"acc_stderr\": 0.046056618647183814,\n \
\ \"acc_norm\": 0.3,\n \"acc_norm_stderr\": 0.046056618647183814\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.6444444444444445,\n\
\ \"acc_stderr\": 0.04135176749720385,\n \"acc_norm\": 0.6444444444444445,\n\
\ \"acc_norm_stderr\": 0.04135176749720385\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.7039473684210527,\n \"acc_stderr\": 0.03715062154998904,\n\
\ \"acc_norm\": 0.7039473684210527,\n \"acc_norm_stderr\": 0.03715062154998904\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.64,\n\
\ \"acc_stderr\": 0.04824181513244218,\n \"acc_norm\": 0.64,\n \
\ \"acc_norm_stderr\": 0.04824181513244218\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.7245283018867924,\n \"acc_stderr\": 0.027495663683724057,\n\
\ \"acc_norm\": 0.7245283018867924,\n \"acc_norm_stderr\": 0.027495663683724057\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.7847222222222222,\n\
\ \"acc_stderr\": 0.03437079344106135,\n \"acc_norm\": 0.7847222222222222,\n\
\ \"acc_norm_stderr\": 0.03437079344106135\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.45,\n \"acc_stderr\": 0.05,\n \"acc_norm\"\
: 0.45,\n \"acc_norm_stderr\": 0.05\n },\n \"harness|hendrycksTest-college_computer_science|5\"\
: {\n \"acc\": 0.54,\n \"acc_stderr\": 0.05009082659620333,\n \
\ \"acc_norm\": 0.54,\n \"acc_norm_stderr\": 0.05009082659620333\n \
\ },\n \"harness|hendrycksTest-college_mathematics|5\": {\n \"acc\": 0.32,\n\
\ \"acc_stderr\": 0.04688261722621504,\n \"acc_norm\": 0.32,\n \
\ \"acc_norm_stderr\": 0.04688261722621504\n },\n \"harness|hendrycksTest-college_medicine|5\"\
: {\n \"acc\": 0.6589595375722543,\n \"acc_stderr\": 0.03614665424180826,\n\
\ \"acc_norm\": 0.6589595375722543,\n \"acc_norm_stderr\": 0.03614665424180826\n\
\ },\n \"harness|hendrycksTest-college_physics|5\": {\n \"acc\": 0.43137254901960786,\n\
\ \"acc_stderr\": 0.04928099597287534,\n \"acc_norm\": 0.43137254901960786,\n\
\ \"acc_norm_stderr\": 0.04928099597287534\n },\n \"harness|hendrycksTest-computer_security|5\"\
: {\n \"acc\": 0.78,\n \"acc_stderr\": 0.04163331998932263,\n \
\ \"acc_norm\": 0.78,\n \"acc_norm_stderr\": 0.04163331998932263\n \
\ },\n \"harness|hendrycksTest-conceptual_physics|5\": {\n \"acc\": 0.6,\n\
\ \"acc_stderr\": 0.03202563076101735,\n \"acc_norm\": 0.6,\n \
\ \"acc_norm_stderr\": 0.03202563076101735\n },\n \"harness|hendrycksTest-econometrics|5\"\
: {\n \"acc\": 0.47368421052631576,\n \"acc_stderr\": 0.046970851366478626,\n\
\ \"acc_norm\": 0.47368421052631576,\n \"acc_norm_stderr\": 0.046970851366478626\n\
\ },\n \"harness|hendrycksTest-electrical_engineering|5\": {\n \"acc\"\
: 0.5724137931034483,\n \"acc_stderr\": 0.04122737111370333,\n \"\
acc_norm\": 0.5724137931034483,\n \"acc_norm_stderr\": 0.04122737111370333\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.42328042328042326,\n \"acc_stderr\": 0.025446365634406783,\n \"\
acc_norm\": 0.42328042328042326,\n \"acc_norm_stderr\": 0.025446365634406783\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.4444444444444444,\n\
\ \"acc_stderr\": 0.044444444444444495,\n \"acc_norm\": 0.4444444444444444,\n\
\ \"acc_norm_stderr\": 0.044444444444444495\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.37,\n \"acc_stderr\": 0.048523658709391,\n \
\ \"acc_norm\": 0.37,\n \"acc_norm_stderr\": 0.048523658709391\n },\n\
\ \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.7903225806451613,\n\
\ \"acc_stderr\": 0.023157879349083525,\n \"acc_norm\": 0.7903225806451613,\n\
\ \"acc_norm_stderr\": 0.023157879349083525\n },\n \"harness|hendrycksTest-high_school_chemistry|5\"\
: {\n \"acc\": 0.5024630541871922,\n \"acc_stderr\": 0.035179450386910616,\n\
\ \"acc_norm\": 0.5024630541871922,\n \"acc_norm_stderr\": 0.035179450386910616\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.71,\n \"acc_stderr\": 0.045604802157206845,\n \"acc_norm\"\
: 0.71,\n \"acc_norm_stderr\": 0.045604802157206845\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.7757575757575758,\n \"acc_stderr\": 0.03256866661681102,\n\
\ \"acc_norm\": 0.7757575757575758,\n \"acc_norm_stderr\": 0.03256866661681102\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.7828282828282829,\n \"acc_stderr\": 0.029376616484945633,\n \"\
acc_norm\": 0.7828282828282829,\n \"acc_norm_stderr\": 0.029376616484945633\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.9015544041450777,\n \"acc_stderr\": 0.021500249576033484,\n\
\ \"acc_norm\": 0.9015544041450777,\n \"acc_norm_stderr\": 0.021500249576033484\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.676923076923077,\n \"acc_stderr\": 0.02371088850197057,\n \
\ \"acc_norm\": 0.676923076923077,\n \"acc_norm_stderr\": 0.02371088850197057\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.37037037037037035,\n \"acc_stderr\": 0.029443169323031537,\n \
\ \"acc_norm\": 0.37037037037037035,\n \"acc_norm_stderr\": 0.029443169323031537\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.6974789915966386,\n \"acc_stderr\": 0.029837962388291936,\n\
\ \"acc_norm\": 0.6974789915966386,\n \"acc_norm_stderr\": 0.029837962388291936\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.33774834437086093,\n \"acc_stderr\": 0.03861557546255169,\n \"\
acc_norm\": 0.33774834437086093,\n \"acc_norm_stderr\": 0.03861557546255169\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.8550458715596331,\n \"acc_stderr\": 0.015094215699700481,\n \"\
acc_norm\": 0.8550458715596331,\n \"acc_norm_stderr\": 0.015094215699700481\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.5138888888888888,\n \"acc_stderr\": 0.03408655867977749,\n \"\
acc_norm\": 0.5138888888888888,\n \"acc_norm_stderr\": 0.03408655867977749\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.8431372549019608,\n \"acc_stderr\": 0.02552472232455334,\n \"\
acc_norm\": 0.8431372549019608,\n \"acc_norm_stderr\": 0.02552472232455334\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.810126582278481,\n \"acc_stderr\": 0.02553010046023349,\n \
\ \"acc_norm\": 0.810126582278481,\n \"acc_norm_stderr\": 0.02553010046023349\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.695067264573991,\n\
\ \"acc_stderr\": 0.030898610882477515,\n \"acc_norm\": 0.695067264573991,\n\
\ \"acc_norm_stderr\": 0.030898610882477515\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.7938931297709924,\n \"acc_stderr\": 0.03547771004159465,\n\
\ \"acc_norm\": 0.7938931297709924,\n \"acc_norm_stderr\": 0.03547771004159465\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.7933884297520661,\n \"acc_stderr\": 0.03695980128098824,\n \"\
acc_norm\": 0.7933884297520661,\n \"acc_norm_stderr\": 0.03695980128098824\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.8148148148148148,\n\
\ \"acc_stderr\": 0.03755265865037182,\n \"acc_norm\": 0.8148148148148148,\n\
\ \"acc_norm_stderr\": 0.03755265865037182\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.7607361963190185,\n \"acc_stderr\": 0.0335195387952127,\n\
\ \"acc_norm\": 0.7607361963190185,\n \"acc_norm_stderr\": 0.0335195387952127\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.4642857142857143,\n\
\ \"acc_stderr\": 0.04733667890053756,\n \"acc_norm\": 0.4642857142857143,\n\
\ \"acc_norm_stderr\": 0.04733667890053756\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.7669902912621359,\n \"acc_stderr\": 0.04185832598928315,\n\
\ \"acc_norm\": 0.7669902912621359,\n \"acc_norm_stderr\": 0.04185832598928315\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.8846153846153846,\n\
\ \"acc_stderr\": 0.020930193185179326,\n \"acc_norm\": 0.8846153846153846,\n\
\ \"acc_norm_stderr\": 0.020930193185179326\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.73,\n \"acc_stderr\": 0.044619604333847394,\n \
\ \"acc_norm\": 0.73,\n \"acc_norm_stderr\": 0.044619604333847394\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.8416347381864623,\n\
\ \"acc_stderr\": 0.013055346753516727,\n \"acc_norm\": 0.8416347381864623,\n\
\ \"acc_norm_stderr\": 0.013055346753516727\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.7572254335260116,\n \"acc_stderr\": 0.023083658586984204,\n\
\ \"acc_norm\": 0.7572254335260116,\n \"acc_norm_stderr\": 0.023083658586984204\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.4346368715083799,\n\
\ \"acc_stderr\": 0.01657899743549672,\n \"acc_norm\": 0.4346368715083799,\n\
\ \"acc_norm_stderr\": 0.01657899743549672\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.7320261437908496,\n \"acc_stderr\": 0.025360603796242557,\n\
\ \"acc_norm\": 0.7320261437908496,\n \"acc_norm_stderr\": 0.025360603796242557\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.7202572347266881,\n\
\ \"acc_stderr\": 0.025494259350694912,\n \"acc_norm\": 0.7202572347266881,\n\
\ \"acc_norm_stderr\": 0.025494259350694912\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.7561728395061729,\n \"acc_stderr\": 0.023891879541959607,\n\
\ \"acc_norm\": 0.7561728395061729,\n \"acc_norm_stderr\": 0.023891879541959607\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.5035460992907801,\n \"acc_stderr\": 0.02982674915328092,\n \
\ \"acc_norm\": 0.5035460992907801,\n \"acc_norm_stderr\": 0.02982674915328092\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.4726205997392438,\n\
\ \"acc_stderr\": 0.012751075788015055,\n \"acc_norm\": 0.4726205997392438,\n\
\ \"acc_norm_stderr\": 0.012751075788015055\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.6764705882352942,\n \"acc_stderr\": 0.02841820861940676,\n\
\ \"acc_norm\": 0.6764705882352942,\n \"acc_norm_stderr\": 0.02841820861940676\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.673202614379085,\n \"acc_stderr\": 0.01897542792050721,\n \
\ \"acc_norm\": 0.673202614379085,\n \"acc_norm_stderr\": 0.01897542792050721\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.6727272727272727,\n\
\ \"acc_stderr\": 0.0449429086625209,\n \"acc_norm\": 0.6727272727272727,\n\
\ \"acc_norm_stderr\": 0.0449429086625209\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.7387755102040816,\n \"acc_stderr\": 0.028123429335142777,\n\
\ \"acc_norm\": 0.7387755102040816,\n \"acc_norm_stderr\": 0.028123429335142777\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.8606965174129353,\n\
\ \"acc_stderr\": 0.024484487162913973,\n \"acc_norm\": 0.8606965174129353,\n\
\ \"acc_norm_stderr\": 0.024484487162913973\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.85,\n \"acc_stderr\": 0.0358870281282637,\n \
\ \"acc_norm\": 0.85,\n \"acc_norm_stderr\": 0.0358870281282637\n },\n\
\ \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.5421686746987951,\n\
\ \"acc_stderr\": 0.0387862677100236,\n \"acc_norm\": 0.5421686746987951,\n\
\ \"acc_norm_stderr\": 0.0387862677100236\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.8362573099415205,\n \"acc_stderr\": 0.028380919596145866,\n\
\ \"acc_norm\": 0.8362573099415205,\n \"acc_norm_stderr\": 0.028380919596145866\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.4675642594859241,\n\
\ \"mc1_stderr\": 0.01746663214957761,\n \"mc2\": 0.6324003297074412,\n\
\ \"mc2_stderr\": 0.015075106150958025\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.8168902920284136,\n \"acc_stderr\": 0.01086977863316837\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.730098559514784,\n \
\ \"acc_stderr\": 0.012227442856468897\n }\n}\n```"
repo_url: https://huggingface.co/occultml/CatMarcoro14-7B-slerp
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|arc:challenge|25_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|gsm8k|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hellaswag|10_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-01-06T21-04-34.082486.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-management|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-virology|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|truthfulqa:mc|0_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2024-01-06T21-04-34.082486.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- '**/details_harness|winogrande|5_2024-01-06T21-04-34.082486.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2024-01-06T21-04-34.082486.parquet'
- config_name: results
data_files:
- split: 2024_01_06T21_04_34.082486
path:
- results_2024-01-06T21-04-34.082486.parquet
- split: latest
path:
- results_2024-01-06T21-04-34.082486.parquet
---
# Dataset Card for Evaluation run of occultml/CatMarcoro14-7B-slerp
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [occultml/CatMarcoro14-7B-slerp](https://huggingface.co/occultml/CatMarcoro14-7B-slerp) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_occultml__CatMarcoro14-7B-slerp",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2024-01-06T21:04:34.082486](https://huggingface.co/datasets/open-llm-leaderboard/details_occultml__CatMarcoro14-7B-slerp/blob/main/results_2024-01-06T21-04-34.082486.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.6574722326639718,
"acc_stderr": 0.03188895296761844,
"acc_norm": 0.6570269052037782,
"acc_norm_stderr": 0.03255254600254235,
"mc1": 0.4675642594859241,
"mc1_stderr": 0.01746663214957761,
"mc2": 0.6324003297074412,
"mc2_stderr": 0.015075106150958025
},
"harness|arc:challenge|25": {
"acc": 0.6706484641638225,
"acc_stderr": 0.013734057652635474,
"acc_norm": 0.6936860068259386,
"acc_norm_stderr": 0.013470584417276513
},
"harness|hellaswag|10": {
"acc": 0.686516630153356,
"acc_stderr": 0.004629608863272308,
"acc_norm": 0.8692491535550687,
"acc_norm_stderr": 0.003364386713542236
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.3,
"acc_stderr": 0.046056618647183814,
"acc_norm": 0.3,
"acc_norm_stderr": 0.046056618647183814
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.6444444444444445,
"acc_stderr": 0.04135176749720385,
"acc_norm": 0.6444444444444445,
"acc_norm_stderr": 0.04135176749720385
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.7039473684210527,
"acc_stderr": 0.03715062154998904,
"acc_norm": 0.7039473684210527,
"acc_norm_stderr": 0.03715062154998904
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.64,
"acc_stderr": 0.04824181513244218,
"acc_norm": 0.64,
"acc_norm_stderr": 0.04824181513244218
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.7245283018867924,
"acc_stderr": 0.027495663683724057,
"acc_norm": 0.7245283018867924,
"acc_norm_stderr": 0.027495663683724057
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.7847222222222222,
"acc_stderr": 0.03437079344106135,
"acc_norm": 0.7847222222222222,
"acc_norm_stderr": 0.03437079344106135
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.45,
"acc_stderr": 0.05,
"acc_norm": 0.45,
"acc_norm_stderr": 0.05
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.54,
"acc_stderr": 0.05009082659620333,
"acc_norm": 0.54,
"acc_norm_stderr": 0.05009082659620333
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.32,
"acc_stderr": 0.04688261722621504,
"acc_norm": 0.32,
"acc_norm_stderr": 0.04688261722621504
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.6589595375722543,
"acc_stderr": 0.03614665424180826,
"acc_norm": 0.6589595375722543,
"acc_norm_stderr": 0.03614665424180826
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.43137254901960786,
"acc_stderr": 0.04928099597287534,
"acc_norm": 0.43137254901960786,
"acc_norm_stderr": 0.04928099597287534
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.78,
"acc_stderr": 0.04163331998932263,
"acc_norm": 0.78,
"acc_norm_stderr": 0.04163331998932263
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.6,
"acc_stderr": 0.03202563076101735,
"acc_norm": 0.6,
"acc_norm_stderr": 0.03202563076101735
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.47368421052631576,
"acc_stderr": 0.046970851366478626,
"acc_norm": 0.47368421052631576,
"acc_norm_stderr": 0.046970851366478626
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.5724137931034483,
"acc_stderr": 0.04122737111370333,
"acc_norm": 0.5724137931034483,
"acc_norm_stderr": 0.04122737111370333
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.42328042328042326,
"acc_stderr": 0.025446365634406783,
"acc_norm": 0.42328042328042326,
"acc_norm_stderr": 0.025446365634406783
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.4444444444444444,
"acc_stderr": 0.044444444444444495,
"acc_norm": 0.4444444444444444,
"acc_norm_stderr": 0.044444444444444495
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.37,
"acc_stderr": 0.048523658709391,
"acc_norm": 0.37,
"acc_norm_stderr": 0.048523658709391
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.7903225806451613,
"acc_stderr": 0.023157879349083525,
"acc_norm": 0.7903225806451613,
"acc_norm_stderr": 0.023157879349083525
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.5024630541871922,
"acc_stderr": 0.035179450386910616,
"acc_norm": 0.5024630541871922,
"acc_norm_stderr": 0.035179450386910616
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.71,
"acc_stderr": 0.045604802157206845,
"acc_norm": 0.71,
"acc_norm_stderr": 0.045604802157206845
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.7757575757575758,
"acc_stderr": 0.03256866661681102,
"acc_norm": 0.7757575757575758,
"acc_norm_stderr": 0.03256866661681102
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.7828282828282829,
"acc_stderr": 0.029376616484945633,
"acc_norm": 0.7828282828282829,
"acc_norm_stderr": 0.029376616484945633
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.9015544041450777,
"acc_stderr": 0.021500249576033484,
"acc_norm": 0.9015544041450777,
"acc_norm_stderr": 0.021500249576033484
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.676923076923077,
"acc_stderr": 0.02371088850197057,
"acc_norm": 0.676923076923077,
"acc_norm_stderr": 0.02371088850197057
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.37037037037037035,
"acc_stderr": 0.029443169323031537,
"acc_norm": 0.37037037037037035,
"acc_norm_stderr": 0.029443169323031537
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.6974789915966386,
"acc_stderr": 0.029837962388291936,
"acc_norm": 0.6974789915966386,
"acc_norm_stderr": 0.029837962388291936
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.33774834437086093,
"acc_stderr": 0.03861557546255169,
"acc_norm": 0.33774834437086093,
"acc_norm_stderr": 0.03861557546255169
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.8550458715596331,
"acc_stderr": 0.015094215699700481,
"acc_norm": 0.8550458715596331,
"acc_norm_stderr": 0.015094215699700481
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.5138888888888888,
"acc_stderr": 0.03408655867977749,
"acc_norm": 0.5138888888888888,
"acc_norm_stderr": 0.03408655867977749
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.8431372549019608,
"acc_stderr": 0.02552472232455334,
"acc_norm": 0.8431372549019608,
"acc_norm_stderr": 0.02552472232455334
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.810126582278481,
"acc_stderr": 0.02553010046023349,
"acc_norm": 0.810126582278481,
"acc_norm_stderr": 0.02553010046023349
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.695067264573991,
"acc_stderr": 0.030898610882477515,
"acc_norm": 0.695067264573991,
"acc_norm_stderr": 0.030898610882477515
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.7938931297709924,
"acc_stderr": 0.03547771004159465,
"acc_norm": 0.7938931297709924,
"acc_norm_stderr": 0.03547771004159465
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.7933884297520661,
"acc_stderr": 0.03695980128098824,
"acc_norm": 0.7933884297520661,
"acc_norm_stderr": 0.03695980128098824
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.8148148148148148,
"acc_stderr": 0.03755265865037182,
"acc_norm": 0.8148148148148148,
"acc_norm_stderr": 0.03755265865037182
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.7607361963190185,
"acc_stderr": 0.0335195387952127,
"acc_norm": 0.7607361963190185,
"acc_norm_stderr": 0.0335195387952127
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.4642857142857143,
"acc_stderr": 0.04733667890053756,
"acc_norm": 0.4642857142857143,
"acc_norm_stderr": 0.04733667890053756
},
"harness|hendrycksTest-management|5": {
"acc": 0.7669902912621359,
"acc_stderr": 0.04185832598928315,
"acc_norm": 0.7669902912621359,
"acc_norm_stderr": 0.04185832598928315
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.8846153846153846,
"acc_stderr": 0.020930193185179326,
"acc_norm": 0.8846153846153846,
"acc_norm_stderr": 0.020930193185179326
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.73,
"acc_stderr": 0.044619604333847394,
"acc_norm": 0.73,
"acc_norm_stderr": 0.044619604333847394
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.8416347381864623,
"acc_stderr": 0.013055346753516727,
"acc_norm": 0.8416347381864623,
"acc_norm_stderr": 0.013055346753516727
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.7572254335260116,
"acc_stderr": 0.023083658586984204,
"acc_norm": 0.7572254335260116,
"acc_norm_stderr": 0.023083658586984204
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.4346368715083799,
"acc_stderr": 0.01657899743549672,
"acc_norm": 0.4346368715083799,
"acc_norm_stderr": 0.01657899743549672
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.7320261437908496,
"acc_stderr": 0.025360603796242557,
"acc_norm": 0.7320261437908496,
"acc_norm_stderr": 0.025360603796242557
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.7202572347266881,
"acc_stderr": 0.025494259350694912,
"acc_norm": 0.7202572347266881,
"acc_norm_stderr": 0.025494259350694912
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.7561728395061729,
"acc_stderr": 0.023891879541959607,
"acc_norm": 0.7561728395061729,
"acc_norm_stderr": 0.023891879541959607
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.5035460992907801,
"acc_stderr": 0.02982674915328092,
"acc_norm": 0.5035460992907801,
"acc_norm_stderr": 0.02982674915328092
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.4726205997392438,
"acc_stderr": 0.012751075788015055,
"acc_norm": 0.4726205997392438,
"acc_norm_stderr": 0.012751075788015055
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.6764705882352942,
"acc_stderr": 0.02841820861940676,
"acc_norm": 0.6764705882352942,
"acc_norm_stderr": 0.02841820861940676
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.673202614379085,
"acc_stderr": 0.01897542792050721,
"acc_norm": 0.673202614379085,
"acc_norm_stderr": 0.01897542792050721
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.6727272727272727,
"acc_stderr": 0.0449429086625209,
"acc_norm": 0.6727272727272727,
"acc_norm_stderr": 0.0449429086625209
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.7387755102040816,
"acc_stderr": 0.028123429335142777,
"acc_norm": 0.7387755102040816,
"acc_norm_stderr": 0.028123429335142777
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.8606965174129353,
"acc_stderr": 0.024484487162913973,
"acc_norm": 0.8606965174129353,
"acc_norm_stderr": 0.024484487162913973
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.85,
"acc_stderr": 0.0358870281282637,
"acc_norm": 0.85,
"acc_norm_stderr": 0.0358870281282637
},
"harness|hendrycksTest-virology|5": {
"acc": 0.5421686746987951,
"acc_stderr": 0.0387862677100236,
"acc_norm": 0.5421686746987951,
"acc_norm_stderr": 0.0387862677100236
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.8362573099415205,
"acc_stderr": 0.028380919596145866,
"acc_norm": 0.8362573099415205,
"acc_norm_stderr": 0.028380919596145866
},
"harness|truthfulqa:mc|0": {
"mc1": 0.4675642594859241,
"mc1_stderr": 0.01746663214957761,
"mc2": 0.6324003297074412,
"mc2_stderr": 0.015075106150958025
},
"harness|winogrande|5": {
"acc": 0.8168902920284136,
"acc_stderr": 0.01086977863316837
},
"harness|gsm8k|5": {
"acc": 0.730098559514784,
"acc_stderr": 0.012227442856468897
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] |
tyzhu/lmind_nq_train6000_eval6489_v1_reciteonly_qa | ---
configs:
- config_name: default
data_files:
- split: train_qa
path: data/train_qa-*
- split: train_ic_qa
path: data/train_ic_qa-*
- split: train_recite_qa
path: data/train_recite_qa-*
- split: eval_qa
path: data/eval_qa-*
- split: eval_ic_qa
path: data/eval_ic_qa-*
- split: eval_recite_qa
path: data/eval_recite_qa-*
- split: all_docs
path: data/all_docs-*
- split: all_docs_eval
path: data/all_docs_eval-*
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: answers
struct:
- name: answer_start
sequence: 'null'
- name: text
sequence: string
- name: inputs
dtype: string
- name: targets
dtype: string
splits:
- name: train_qa
num_bytes: 697367
num_examples: 6000
- name: train_ic_qa
num_bytes: 4540536
num_examples: 6000
- name: train_recite_qa
num_bytes: 4546536
num_examples: 6000
- name: eval_qa
num_bytes: 752802
num_examples: 6489
- name: eval_ic_qa
num_bytes: 4906186
num_examples: 6489
- name: eval_recite_qa
num_bytes: 4912675
num_examples: 6489
- name: all_docs
num_bytes: 7126313
num_examples: 10925
- name: all_docs_eval
num_bytes: 7125701
num_examples: 10925
- name: train
num_bytes: 4546536
num_examples: 6000
- name: validation
num_bytes: 4912675
num_examples: 6489
download_size: 27348363
dataset_size: 44067327
---
# Dataset Card for "lmind_nq_train6000_eval6489_v1_reciteonly_qa"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Zombely/wikisource-yellow | ---
dataset_info:
features:
- name: image
dtype: image
- name: ground_truth
dtype: string
splits:
- name: train_1
num_bytes: 12984998648.244
num_examples: 9998
- name: train_2
num_bytes: 16071270493.0
num_examples: 10000
- name: train_3
num_bytes: 15496290078.0
num_examples: 10000
- name: train_4
num_bytes: 8549111534.0
num_examples: 10000
- name: train_5
num_bytes: 13382018606.0
num_examples: 10000
- name: train_6
num_bytes: 16871883641.979
num_examples: 9959
- name: train_7
num_bytes: 15199574685.0
num_examples: 10000
- name: train_8
num_bytes: 13887271412.0
num_examples: 10000
- name: train_9
num_bytes: 15434064354.0
num_examples: 10000
- name: train_10
num_bytes: 7874718803.82
num_examples: 6969
- name: validation
num_bytes: 12645144007.93
num_examples: 7745
download_size: 13454099590
dataset_size: 131524462621.994
---
# Dataset Card for "wikisource-yellow"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
keithhon/zb4xnuMlahk | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: sentence
dtype: string
- name: youtube_video_id
dtype: string
- name: input_features
sequence:
sequence: float32
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 401505573.0
num_examples: 385
download_size: 79562986
dataset_size: 401505573.0
---
# Dataset Card for "zb4xnuMlahk"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
hnqh8888/reviews | ---
license: unknown
---
|
Databasesprojec/FinStmts_ConsUncons_French_Predict_part1 | ---
dataset_info:
features:
- name: label
dtype: int64
- name: id
dtype: string
- name: text
dtype: string
- name: language
dtype: string
splits:
- name: train
num_bytes: 1664907233
num_examples: 9769
download_size: 724664085
dataset_size: 1664907233
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_165 | ---
dataset_info:
features:
- name: logits
sequence: float32
- name: mfcc
sequence:
sequence: float64
splits:
- name: train
num_bytes: 1171944168.0
num_examples: 230154
download_size: 1197826928
dataset_size: 1171944168.0
---
# Dataset Card for "chunk_165"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
open-llm-leaderboard/details_bigcode__tiny_starcoder_py | ---
pretty_name: Evaluation run of bigcode/tiny_starcoder_py
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [bigcode/tiny_starcoder_py](https://huggingface.co/bigcode/tiny_starcoder_py)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_bigcode__tiny_starcoder_py\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-09-17T18:41:27.030233](https://huggingface.co/datasets/open-llm-leaderboard/details_bigcode__tiny_starcoder_py/blob/main/results_2023-09-17T18-41-27.030233.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.0007340604026845638,\n\
\ \"em_stderr\": 0.0002773614457335755,\n \"f1\": 0.015742449664429566,\n\
\ \"f1_stderr\": 0.0006568370194517889,\n \"acc\": 0.2610447871046265,\n\
\ \"acc_stderr\": 0.00838467769872364\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.0007340604026845638,\n \"em_stderr\": 0.0002773614457335755,\n\
\ \"f1\": 0.015742449664429566,\n \"f1_stderr\": 0.0006568370194517889\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.009855951478392721,\n \
\ \"acc_stderr\": 0.00272107657704166\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.5122336227308603,\n \"acc_stderr\": 0.01404827882040562\n\
\ }\n}\n```"
repo_url: https://huggingface.co/bigcode/tiny_starcoder_py
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|arc:challenge|25_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_09_17T18_41_27.030233
path:
- '**/details_harness|drop|3_2023-09-17T18-41-27.030233.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-09-17T18-41-27.030233.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_09_17T18_41_27.030233
path:
- '**/details_harness|gsm8k|5_2023-09-17T18-41-27.030233.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-09-17T18-41-27.030233.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hellaswag|10_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T18:53:24.895112.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-19T18:53:24.895112.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-19T18:53:24.895112.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_09_17T18_41_27.030233
path:
- '**/details_harness|winogrande|5_2023-09-17T18-41-27.030233.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-09-17T18-41-27.030233.parquet'
- config_name: results
data_files:
- split: 2023_07_19T18_53_24.895112
path:
- results_2023-07-19T18:53:24.895112.parquet
- split: 2023_09_17T18_41_27.030233
path:
- results_2023-09-17T18-41-27.030233.parquet
- split: latest
path:
- results_2023-09-17T18-41-27.030233.parquet
---
# Dataset Card for Evaluation run of bigcode/tiny_starcoder_py
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/bigcode/tiny_starcoder_py
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [bigcode/tiny_starcoder_py](https://huggingface.co/bigcode/tiny_starcoder_py) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_bigcode__tiny_starcoder_py",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-09-17T18:41:27.030233](https://huggingface.co/datasets/open-llm-leaderboard/details_bigcode__tiny_starcoder_py/blob/main/results_2023-09-17T18-41-27.030233.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.0007340604026845638,
"em_stderr": 0.0002773614457335755,
"f1": 0.015742449664429566,
"f1_stderr": 0.0006568370194517889,
"acc": 0.2610447871046265,
"acc_stderr": 0.00838467769872364
},
"harness|drop|3": {
"em": 0.0007340604026845638,
"em_stderr": 0.0002773614457335755,
"f1": 0.015742449664429566,
"f1_stderr": 0.0006568370194517889
},
"harness|gsm8k|5": {
"acc": 0.009855951478392721,
"acc_stderr": 0.00272107657704166
},
"harness|winogrande|5": {
"acc": 0.5122336227308603,
"acc_stderr": 0.01404827882040562
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
v3xlrm1nOwo1/KaidanNihonbunka | ---
license: apache-2.0
task_categories:
- text-generation
- text2text-generation
language:
- ja
tags:
- art
- folklore
- Hyakumonogatari
- Nihonbunka
pretty_name: 'Kaidan Nihonbunka: A Journey Through Hyakumonogatari''s Ghostly Tales'
size_categories:
- 1K<n<10K
---
# *Kaidan Nihonbunka: A Journey Through Hyakumonogatari's Ghostly Tales*
> Welcome to the Kaidan Nihonbunka Dataset
<div align="center">
<picture>
<source
srcset="https://cdn-uploads.huggingface.co/production/uploads/64af7c627ab7586520ed8688/VbXOBJgHwWFvJHsXTyBUQ.jpeg"
media="(prefers-color-scheme: dark)"
/>
<source
srcset="https://cdn-uploads.huggingface.co/production/uploads/64af7c627ab7586520ed8688/VbXOBJgHwWFvJHsXTyBUQ.jpeg"
media="(prefers-color-scheme: light), (prefers-color-scheme: no-preference)"
/>
<img src="https://cdn-uploads.huggingface.co/production/uploads/64af7c627ab7586520ed8688/VbXOBJgHwWFvJHsXTyBUQ.jpeg" width="100%" height="350px" />
</picture>
</div>
## About Name
`kaidan Nihonbunka` translates to `怪談日本文化` in Japanese:
- `怪談 (Kwaidan)`: Ghost story or supernatural tale.
- `日本文化 (Nihonbunka)`: Japanese culture.
So, the translated name would be `怪談日本文化`.
## Overview
The `kaidan Nihonbunka` Dataset is a collection of Japanese folklore of ghost stories, also known as "kaidan", associated with the traditional Japanese ritual of Hyakumonogatari. This dataset contains approximately 8000 rows of ghost stories, including their old names, new names generated by GPT-4, the text content of the stories, and URLs for additional information or sources.
You find code of this dataset in my Gihub account <a href="https://github.com/v3xlrm1nOwo1/KaidanNihonbunka">v3xlrm1nOwo1</a>.
## Data Format
### The dataset is provided in two formats `Parquet` and `Pickle`:
These formats and fields provide flexibility for different use cases, allowing researchers and data scientists to work with the dataset using their preferred tools and programming languages.
1. **Parquet File**: Contains structured data in a columnar format, suitable for data analysis and processing with tools like Apache Spark.
2. **Pickle File**: Contains a serialized Python object, allowing for easy loading and manipulation of the dataset in Python environments.
### Dataset Fields
Each entry in the dataset is represented by a row with the following fields:
| Field | Description |
|----------|-------------------------------------------------------------------------------------------------------------|
| `Old Name` | The old name or previous designation of the ghost story. |
| `New Name` | Generated by GPT-4, this column contains the new name or a modernized version of the ghost story's title. |
| `Kaidan` | The text or content of the ghost story. |
| `URL` | Contains URLs related to the ghost story, such as links to additional information or sources. |
## Usage
Researchers, data scientists, and enthusiasts interested in Japanese folklore, ghost stories, or cultural rituals like Hyakumonogatari can utilize this dataset for various purposes, including:
- Analyzing themes and patterns in ghost stories.
- Building machine learning models for story generation or classification.
- Exploring connections between traditional rituals and storytelling.
```py
import datasets
# Load the dataset
dataset = datasets.load_dataset('v3xlrm1nOwo1/KaidanNihonbunka')
print(dataset)
```
```py
DatasetDict({
train: Dataset({
features: ['old name', 'new name', 'kaidan', 'url'],
num_rows: 8559
})
})
```
## Acknowledgments
We would like to acknowledge the creators of the original ghost stories and the individuals or sources that contributed to compiling this dataset. Without their efforts, this collection would not be possible.
## License
This dataset is distributed under the [Apache License 2.0](https://www.apache.org/licenses/LICENSE-2.0), allowing for flexible usage and modification while ensuring proper attribution and adherence to copyright laws.
> **_NOTE:_** To contribute to the project, please contribute directly. I am happy to do so, and if you have any comments, advice, job opportunities, or want me to contribute to a project, please contact me I am happy to do so <a href='mailto:v3xlrm1nOwo1@gmail.com' target='blank'>v3xlrm1nOwo1@gmail.com</a> |
julio-mm/news | ---
license: unknown
---
|
CVasNLPExperiments/VQAv2_validation_no_image_google_flan_t5_xxl_mode_T_A_D_PNP_FILTER_C_Q_rices_ns_2000 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: question
dtype: string
- name: true_label
sequence: string
- name: prediction
dtype: string
splits:
- name: fewshot_0_clip_tags_LAION_ViT_H_14_2B_with_openai_Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_DETA_detections_deta_swin_large_o365_coco_classes_caption_module_random_
num_bytes: 282770
num_examples: 2000
download_size: 100408
dataset_size: 282770
---
# Dataset Card for "VQAv2_validation_no_image_google_flan_t5_xxl_mode_T_A_D_PNP_FILTER_C_Q_rices_ns_2000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ngarneau/paragraph_to_paragraph | ---
license: apache-2.0
---
|
RafaG/Cyberpunk2077-DublagemPT-BR | ---
license: openrail
---
Áudios extraidos do jogo Cyberpunk 2077
Dublagem brasileira
https://dublagem.fandom.com/wiki/Cyberpunk_2077
Se for treinar algum dos áudios, lembre-se de dar os créditos pelo dataset. Extrair do jogo deu muito trabalho |
naufalso/stanford_cars | ---
dataset_info:
features:
- name: image_path
dtype: image
- name: x_min
dtype: int64
- name: y_min
dtype: int64
- name: x_max
dtype: int64
- name: y_max
dtype: int64
- name: label
dtype: int64
- name: car_name
dtype: string
splits:
- name: train
num_bytes: 904375683.3977859
num_examples: 8103
- name: test
num_bytes: 982819159.6816317
num_examples: 8000
download_size: 1973888357
dataset_size: 1887194843.0794177
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
ai4privacy/pii-masking-200k | ---
language:
- en
- fr
- de
- it
task_categories:
- text-classification
- token-classification
- table-question-answering
- question-answering
- zero-shot-classification
- summarization
- feature-extraction
- text-generation
- text2text-generation
- translation
- fill-mask
- tabular-classification
- tabular-to-text
- table-to-text
- text-retrieval
- other
multilinguality:
- multilingual
tags:
- legal
- business
- psychology
- privacy
size_categories:
- 100K<n<1M
pretty_name: Ai4Privacy PII200k Dataset
source_datasets:
- original
configs:
- config_name: default
data_files: "*.jsonl"
---
# Ai4Privacy Community
Join our community at https://discord.gg/FmzWshaaQT to help build open datasets for privacy masking.
# Purpose and Features
Previous world's largest open dataset for privacy. Now it is [pii-masking-300k](https://huggingface.co/datasets/ai4privacy/pii-masking-300k)
The purpose of the dataset is to train models to remove personally identifiable information (PII) from text, especially in the context of AI assistants and LLMs.
The example texts have **54 PII classes** (types of sensitive data), targeting **229 discussion subjects / use cases** split across business, education, psychology and legal fields, and 5 interactions styles (e.g. casual conversation, formal document, emails etc...).
Key facts:
- Size: 13.6m text tokens in ~209k examples with 649k PII tokens (see [summary.json](summary.json))
- 4 languages, more to come!
- English
- French
- German
- Italian
- Synthetic data generated using proprietary algorithms
- No privacy violations!
- Human-in-the-loop validated high quality dataset
# Getting started
Option 1: Python
```terminal
pip install datasets
```
```python
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
```
# Token distribution across PII classes
We have taken steps to balance the token distribution across PII classes covered by the dataset.
This graph shows the distribution of observations across the different PII classes in this release:

There is 1 class that is still overrepresented in the dataset: firstname.
We will further improve the balance with future dataset releases.
This is the token distribution excluding the FIRSTNAME class:

# Compatible Machine Learning Tasks:
- Tokenclassification. Check out a HuggingFace's [guide on token classification](https://huggingface.co/docs/transformers/tasks/token_classification).
- [ALBERT](https://huggingface.co/docs/transformers/model_doc/albert), [BERT](https://huggingface.co/docs/transformers/model_doc/bert), [BigBird](https://huggingface.co/docs/transformers/model_doc/big_bird), [BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt), [BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom), [BROS](https://huggingface.co/docs/transformers/model_doc/bros), [CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert), [CANINE](https://huggingface.co/docs/transformers/model_doc/canine), [ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert), [Data2VecText](https://huggingface.co/docs/transformers/model_doc/data2vec-text), [DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta), [DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2), [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert), [ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra), [ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie), [ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m), [ESM](https://huggingface.co/docs/transformers/model_doc/esm), [Falcon](https://huggingface.co/docs/transformers/model_doc/falcon), [FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert), [FNet](https://huggingface.co/docs/transformers/model_doc/fnet), [Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel), [GPT-Sw3](https://huggingface.co/docs/transformers/model_doc/gpt-sw3), [OpenAI GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2), [GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode), [GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo), [GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox), [I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert), [LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm), [LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2), [LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3), [LiLT](https://huggingface.co/docs/transformers/model_doc/lilt), [Longformer](https://huggingface.co/docs/transformers/model_doc/longformer), [LUKE](https://huggingface.co/docs/transformers/model_doc/luke), [MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm), [MEGA](https://huggingface.co/docs/transformers/model_doc/mega), [Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert), [MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert), [MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet), [MPT](https://huggingface.co/docs/transformers/model_doc/mpt), [MRA](https://huggingface.co/docs/transformers/model_doc/mra), [Nezha](https://huggingface.co/docs/transformers/model_doc/nezha), [Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer), [QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert), [RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert), [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta), [RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm), [RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert), [RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer), [SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert), [XLM](https://huggingface.co/docs/transformers/model_doc/xlm), [XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta), [XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl), [XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet), [X-MOD](https://huggingface.co/docs/transformers/model_doc/xmod), [YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)
- Text Generation: Mapping the unmasked_text to to the masked_text or privacy_mask attributes. Check out HuggingFace's [guide to fine-tunning](https://huggingface.co/docs/transformers/v4.15.0/training)
- [T5 Family](https://huggingface.co/docs/transformers/model_doc/t5), [Llama2](https://huggingface.co/docs/transformers/main/model_doc/llama2)
# Information regarding the rows:
- Each row represents a json object with a natural language text that includes placeholders for PII (and could plausibly be written by a human to an AI assistant).
- Sample row:
- "masked_text" contains a PII free natural text
- "Product officially launching in [COUNTY_1]. Estimate profit of [CURRENCYSYMBOL_1][AMOUNT_1]. Expenses by [ACCOUNTNAME_1].",
- "unmasked_text" shows a natural sentence containing PII
- "Product officially launching in Washington County. Estimate profit of $488293.16. Expenses by Checking Account."
- "privacy_mask" indicates the mapping between the privacy token instances and the string within the natural text.*
- "{'[COUNTY_1]': 'Washington County', '[CURRENCYSYMBOL_1]': '$', '[AMOUNT_1]': '488293.16', '[ACCOUNTNAME_1]': 'Checking Account'}"
- "span_labels" is an array of arrays formatted in the following way [start, end, pii token instance].*
- "[[0, 32, 'O'], [32, 49, 'COUNTY_1'], [49, 70, 'O'], [70, 71, 'CURRENCYSYMBOL_1'], [71, 80, 'AMOUNT_1'], [80, 94, 'O'], [94, 110, 'ACCOUNTNAME_1'], [110, 111, 'O']]",
- "bio_labels" follows the common place notation for "beginning", "inside" and "outside" of where each private tokens starts.[original paper](https://arxiv.org/abs/cmp-lg/9505040)
-["O", "O", "O", "O", "B-COUNTY", "I-COUNTY", "O", "O", "O", "O", "B-CURRENCYSYMBOL", "O", "O", "I-AMOUNT", "I-AMOUNT", "I-AMOUNT", "I-AMOUNT", "O", "O", "O", "B-ACCOUNTNAME", "I-ACCOUNTNAME", "O"],
- "tokenised_text" breaks down the unmasked sentence into tokens using Bert Family tokeniser to help fine-tune large language models.
- ["product", "officially", "launching", "in", "washington", "county", ".", "estimate", "profit", "of", "$", "48", "##8", "##29", "##3", ".", "16", ".", "expenses", "by", "checking", "account", "."]
*note for the nested objects, we store them as string to maximise compability between various software.
# About Us:
At Ai4Privacy, we are commited to building the global seatbelt of the 21st century for Artificial Intelligence to help fight against potential risks of personal information being integrated into data pipelines.
Newsletter & updates: [www.Ai4Privacy.com](www.Ai4Privacy.com)
- Looking for ML engineers, developers, beta-testers, human in the loop validators (all languages)
- Integrations with already existing open solutions
- Ask us a question on discord: [https://discord.gg/kxSbJrUQZF](https://discord.gg/kxSbJrUQZF)
# Roadmap and Future Development
- Carbon Neutral
- Benchmarking
- Better multilingual and especially localisation
- Extended integrations
- Continuously increase the training set
- Further optimisation to the model to reduce size and increase generalisability
- Next released major update is planned for the 14th of December 2023 (subscribe to newsletter for updates)
# Use Cases and Applications
**Chatbots**: Incorporating a PII masking model into chatbot systems can ensure the privacy and security of user conversations by automatically redacting sensitive information such as names, addresses, phone numbers, and email addresses.
**Customer Support Systems**: When interacting with customers through support tickets or live chats, masking PII can help protect sensitive customer data, enabling support agents to handle inquiries without the risk of exposing personal information.
**Email Filtering**: Email providers can utilize a PII masking model to automatically detect and redact PII from incoming and outgoing emails, reducing the chances of accidental disclosure of sensitive information.
**Data Anonymization**: Organizations dealing with large datasets containing PII, such as medical or financial records, can leverage a PII masking model to anonymize the data before sharing it for research, analysis, or collaboration purposes.
**Social Media Platforms**: Integrating PII masking capabilities into social media platforms can help users protect their personal information from unauthorized access, ensuring a safer online environment.
**Content Moderation**: PII masking can assist content moderation systems in automatically detecting and blurring or redacting sensitive information in user-generated content, preventing the accidental sharing of personal details.
**Online Forms**: Web applications that collect user data through online forms, such as registration forms or surveys, can employ a PII masking model to anonymize or mask the collected information in real-time, enhancing privacy and data protection.
**Collaborative Document Editing**: Collaboration platforms and document editing tools can use a PII masking model to automatically mask or redact sensitive information when multiple users are working on shared documents.
**Research and Data Sharing**: Researchers and institutions can leverage a PII masking model to ensure privacy and confidentiality when sharing datasets for collaboration, analysis, or publication purposes, reducing the risk of data breaches or identity theft.
**Content Generation**: Content generation systems, such as article generators or language models, can benefit from PII masking to automatically mask or generate fictional PII when creating sample texts or examples, safeguarding the privacy of individuals.
(...and whatever else your creative mind can think of)
# Support and Maintenance
AI4Privacy is a project affiliated with [AISuisse SA](https://www.aisuisse.com/). |
n1ghtf4l1/turbo-skin-diagnose | ---
license: mit
---
|
Leon-LLM/Leon-Chess-Dataset-raw-xlan | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 15609390258
num_examples: 24543537
download_size: 9338596586
dataset_size: 15609390258
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "Leon-Chess-Dataset-raw-xlan"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
systemk/culturax-ja-5k-metrics | ---
dataset_info:
config_name: ppl_ccnet
features:
- name: text
dtype: string
- name: timestamp
dtype: string
- name: url
dtype: string
- name: source
dtype: string
- name: ppl
dtype: float64
splits:
- name: train
num_bytes: 23589041.0
num_examples: 5000
download_size: 13327235
dataset_size: 23589041.0
configs:
- config_name: ppl_ccnet
data_files:
- split: train
path: ppl_ccnet/train-*
---
|
KaiNylund/WMT-year-splits | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: 2012_train
num_bytes: 200226328
num_examples: 74030
- name: 2012_test
num_bytes: 10013398
num_examples: 3702
- name: 2013_train
num_bytes: 200208976
num_examples: 69560
- name: 2013_test
num_bytes: 10010872
num_examples: 3452
- name: 2014_train
num_bytes: 200195660
num_examples: 65066
- name: 2014_test
num_bytes: 10009737
num_examples: 3178
- name: 2015_train
num_bytes: 200191525
num_examples: 63260
- name: 2015_test
num_bytes: 10013285
num_examples: 3193
- name: 2016_train
num_bytes: 200182567
num_examples: 60204
- name: 2016_test
num_bytes: 10009524
num_examples: 3068
- name: 2017_train
num_bytes: 200161313
num_examples: 53757
- name: 2017_test
num_bytes: 10009727
num_examples: 2712
- name: 2018_train
num_bytes: 200168589
num_examples: 55074
- name: 2018_test
num_bytes: 10008584
num_examples: 2780
- name: 2019_train
num_bytes: 200186312
num_examples: 60742
- name: 2019_test
num_bytes: 10015645
num_examples: 3082
- name: 2020_train
num_bytes: 200181700
num_examples: 60036
- name: 2020_test
num_bytes: 10009206
num_examples: 2932
- name: 2021_train
num_bytes: 200186604
num_examples: 61717
- name: 2021_test
num_bytes: 10021254
num_examples: 3001
download_size: 1325315435
dataset_size: 2102010806
license: cc0-1.0
---
# Dataset Card for "WMT-year-splits"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
pPvot/mini-platypus-two | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 4186564
num_examples: 1000
download_size: 2245925
dataset_size: 4186564
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
hk-kaden-kim/uzh-hs23-etsp-eval-single-base-bar | ---
dataset_info:
features:
- name: image
dtype: image
- name: caption
dtype: string
splits:
- name: test
num_bytes: 5223052.0
num_examples: 100
download_size: 5179034
dataset_size: 5223052.0
---
# Dataset Card for "uzh-hs23-etsp-eval-single-base-bar"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
open-llm-leaderboard/details_Yuma42__KangalKhan-ShatteredRuby-7B | ---
pretty_name: Evaluation run of Yuma42/KangalKhan-ShatteredRuby-7B
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [Yuma42/KangalKhan-ShatteredRuby-7B](https://huggingface.co/Yuma42/KangalKhan-ShatteredRuby-7B)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 63 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_Yuma42__KangalKhan-ShatteredRuby-7B\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2024-02-22T15:24:52.714183](https://huggingface.co/datasets/open-llm-leaderboard/details_Yuma42__KangalKhan-ShatteredRuby-7B/blob/main/results_2024-02-22T15-24-52.714183.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.6356887043909203,\n\
\ \"acc_stderr\": 0.032207789837356685,\n \"acc_norm\": 0.6371743962970163,\n\
\ \"acc_norm_stderr\": 0.03285213706238699,\n \"mc1\": 0.40024479804161567,\n\
\ \"mc1_stderr\": 0.017151605555749138,\n \"mc2\": 0.5698682978350015,\n\
\ \"mc2_stderr\": 0.01544172389756708\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.6254266211604096,\n \"acc_stderr\": 0.014144193471893456,\n\
\ \"acc_norm\": 0.6621160409556314,\n \"acc_norm_stderr\": 0.013822047922283507\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.6709818761202948,\n\
\ \"acc_stderr\": 0.004688963175758131,\n \"acc_norm\": 0.8538139812786297,\n\
\ \"acc_norm_stderr\": 0.003525705773353423\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.27,\n \"acc_stderr\": 0.044619604333847394,\n \
\ \"acc_norm\": 0.27,\n \"acc_norm_stderr\": 0.044619604333847394\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.5777777777777777,\n\
\ \"acc_stderr\": 0.04266763404099582,\n \"acc_norm\": 0.5777777777777777,\n\
\ \"acc_norm_stderr\": 0.04266763404099582\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.6973684210526315,\n \"acc_stderr\": 0.03738520676119669,\n\
\ \"acc_norm\": 0.6973684210526315,\n \"acc_norm_stderr\": 0.03738520676119669\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.59,\n\
\ \"acc_stderr\": 0.049431107042371025,\n \"acc_norm\": 0.59,\n \
\ \"acc_norm_stderr\": 0.049431107042371025\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.6830188679245283,\n \"acc_stderr\": 0.02863723563980089,\n\
\ \"acc_norm\": 0.6830188679245283,\n \"acc_norm_stderr\": 0.02863723563980089\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.75,\n\
\ \"acc_stderr\": 0.03621034121889507,\n \"acc_norm\": 0.75,\n \
\ \"acc_norm_stderr\": 0.03621034121889507\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.46,\n \"acc_stderr\": 0.05009082659620333,\n \
\ \"acc_norm\": 0.46,\n \"acc_norm_stderr\": 0.05009082659620333\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\"\
: 0.45,\n \"acc_stderr\": 0.05,\n \"acc_norm\": 0.45,\n \"\
acc_norm_stderr\": 0.05\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.23,\n \"acc_stderr\": 0.04229525846816505,\n \
\ \"acc_norm\": 0.23,\n \"acc_norm_stderr\": 0.04229525846816505\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.5953757225433526,\n\
\ \"acc_stderr\": 0.03742461193887248,\n \"acc_norm\": 0.5953757225433526,\n\
\ \"acc_norm_stderr\": 0.03742461193887248\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.37254901960784315,\n \"acc_stderr\": 0.048108401480826346,\n\
\ \"acc_norm\": 0.37254901960784315,\n \"acc_norm_stderr\": 0.048108401480826346\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.76,\n \"acc_stderr\": 0.042923469599092816,\n \"acc_norm\": 0.76,\n\
\ \"acc_norm_stderr\": 0.042923469599092816\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.5617021276595745,\n \"acc_stderr\": 0.03243618636108101,\n\
\ \"acc_norm\": 0.5617021276595745,\n \"acc_norm_stderr\": 0.03243618636108101\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.49122807017543857,\n\
\ \"acc_stderr\": 0.04702880432049615,\n \"acc_norm\": 0.49122807017543857,\n\
\ \"acc_norm_stderr\": 0.04702880432049615\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.503448275862069,\n \"acc_stderr\": 0.04166567577101579,\n\
\ \"acc_norm\": 0.503448275862069,\n \"acc_norm_stderr\": 0.04166567577101579\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.42328042328042326,\n \"acc_stderr\": 0.025446365634406783,\n \"\
acc_norm\": 0.42328042328042326,\n \"acc_norm_stderr\": 0.025446365634406783\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.4523809523809524,\n\
\ \"acc_stderr\": 0.044518079590553275,\n \"acc_norm\": 0.4523809523809524,\n\
\ \"acc_norm_stderr\": 0.044518079590553275\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.35,\n \"acc_stderr\": 0.047937248544110196,\n \
\ \"acc_norm\": 0.35,\n \"acc_norm_stderr\": 0.047937248544110196\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\"\
: 0.7870967741935484,\n \"acc_stderr\": 0.023287665127268552,\n \"\
acc_norm\": 0.7870967741935484,\n \"acc_norm_stderr\": 0.023287665127268552\n\
\ },\n \"harness|hendrycksTest-high_school_chemistry|5\": {\n \"acc\"\
: 0.5123152709359606,\n \"acc_stderr\": 0.035169204442208966,\n \"\
acc_norm\": 0.5123152709359606,\n \"acc_norm_stderr\": 0.035169204442208966\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.69,\n \"acc_stderr\": 0.04648231987117316,\n \"acc_norm\"\
: 0.69,\n \"acc_norm_stderr\": 0.04648231987117316\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.7818181818181819,\n \"acc_stderr\": 0.03225078108306289,\n\
\ \"acc_norm\": 0.7818181818181819,\n \"acc_norm_stderr\": 0.03225078108306289\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.7878787878787878,\n \"acc_stderr\": 0.02912652283458682,\n \"\
acc_norm\": 0.7878787878787878,\n \"acc_norm_stderr\": 0.02912652283458682\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.8808290155440415,\n \"acc_stderr\": 0.023381935348121434,\n\
\ \"acc_norm\": 0.8808290155440415,\n \"acc_norm_stderr\": 0.023381935348121434\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.617948717948718,\n \"acc_stderr\": 0.024635549163908237,\n \
\ \"acc_norm\": 0.617948717948718,\n \"acc_norm_stderr\": 0.024635549163908237\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.32592592592592595,\n \"acc_stderr\": 0.02857834836547307,\n \
\ \"acc_norm\": 0.32592592592592595,\n \"acc_norm_stderr\": 0.02857834836547307\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.6764705882352942,\n \"acc_stderr\": 0.030388353551886793,\n\
\ \"acc_norm\": 0.6764705882352942,\n \"acc_norm_stderr\": 0.030388353551886793\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.3509933774834437,\n \"acc_stderr\": 0.03896981964257375,\n \"\
acc_norm\": 0.3509933774834437,\n \"acc_norm_stderr\": 0.03896981964257375\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.8330275229357799,\n \"acc_stderr\": 0.01599015488507338,\n \"\
acc_norm\": 0.8330275229357799,\n \"acc_norm_stderr\": 0.01599015488507338\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.49537037037037035,\n \"acc_stderr\": 0.03409825519163572,\n \"\
acc_norm\": 0.49537037037037035,\n \"acc_norm_stderr\": 0.03409825519163572\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.7941176470588235,\n \"acc_stderr\": 0.028379449451588667,\n \"\
acc_norm\": 0.7941176470588235,\n \"acc_norm_stderr\": 0.028379449451588667\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.810126582278481,\n \"acc_stderr\": 0.025530100460233483,\n \
\ \"acc_norm\": 0.810126582278481,\n \"acc_norm_stderr\": 0.025530100460233483\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.6995515695067265,\n\
\ \"acc_stderr\": 0.030769352008229136,\n \"acc_norm\": 0.6995515695067265,\n\
\ \"acc_norm_stderr\": 0.030769352008229136\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.7938931297709924,\n \"acc_stderr\": 0.035477710041594654,\n\
\ \"acc_norm\": 0.7938931297709924,\n \"acc_norm_stderr\": 0.035477710041594654\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.7603305785123967,\n \"acc_stderr\": 0.03896878985070416,\n \"\
acc_norm\": 0.7603305785123967,\n \"acc_norm_stderr\": 0.03896878985070416\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.7870370370370371,\n\
\ \"acc_stderr\": 0.0395783547198098,\n \"acc_norm\": 0.7870370370370371,\n\
\ \"acc_norm_stderr\": 0.0395783547198098\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.7914110429447853,\n \"acc_stderr\": 0.031921934489347235,\n\
\ \"acc_norm\": 0.7914110429447853,\n \"acc_norm_stderr\": 0.031921934489347235\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.49107142857142855,\n\
\ \"acc_stderr\": 0.04745033255489123,\n \"acc_norm\": 0.49107142857142855,\n\
\ \"acc_norm_stderr\": 0.04745033255489123\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.7766990291262136,\n \"acc_stderr\": 0.04123553189891431,\n\
\ \"acc_norm\": 0.7766990291262136,\n \"acc_norm_stderr\": 0.04123553189891431\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.8675213675213675,\n\
\ \"acc_stderr\": 0.022209309073165616,\n \"acc_norm\": 0.8675213675213675,\n\
\ \"acc_norm_stderr\": 0.022209309073165616\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.69,\n \"acc_stderr\": 0.04648231987117316,\n \
\ \"acc_norm\": 0.69,\n \"acc_norm_stderr\": 0.04648231987117316\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.8199233716475096,\n\
\ \"acc_stderr\": 0.013740797258579825,\n \"acc_norm\": 0.8199233716475096,\n\
\ \"acc_norm_stderr\": 0.013740797258579825\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.7109826589595376,\n \"acc_stderr\": 0.02440517393578323,\n\
\ \"acc_norm\": 0.7109826589595376,\n \"acc_norm_stderr\": 0.02440517393578323\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.3329608938547486,\n\
\ \"acc_stderr\": 0.015761716178397566,\n \"acc_norm\": 0.3329608938547486,\n\
\ \"acc_norm_stderr\": 0.015761716178397566\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.738562091503268,\n \"acc_stderr\": 0.025160998214292452,\n\
\ \"acc_norm\": 0.738562091503268,\n \"acc_norm_stderr\": 0.025160998214292452\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.7041800643086816,\n\
\ \"acc_stderr\": 0.025922371788818767,\n \"acc_norm\": 0.7041800643086816,\n\
\ \"acc_norm_stderr\": 0.025922371788818767\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.7376543209876543,\n \"acc_stderr\": 0.024477222856135118,\n\
\ \"acc_norm\": 0.7376543209876543,\n \"acc_norm_stderr\": 0.024477222856135118\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.5106382978723404,\n \"acc_stderr\": 0.02982074719142244,\n \
\ \"acc_norm\": 0.5106382978723404,\n \"acc_norm_stderr\": 0.02982074719142244\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.470013037809648,\n\
\ \"acc_stderr\": 0.012747248967079076,\n \"acc_norm\": 0.470013037809648,\n\
\ \"acc_norm_stderr\": 0.012747248967079076\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.6801470588235294,\n \"acc_stderr\": 0.028332959514031208,\n\
\ \"acc_norm\": 0.6801470588235294,\n \"acc_norm_stderr\": 0.028332959514031208\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.6748366013071896,\n \"acc_stderr\": 0.01895088677080631,\n \
\ \"acc_norm\": 0.6748366013071896,\n \"acc_norm_stderr\": 0.01895088677080631\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.6727272727272727,\n\
\ \"acc_stderr\": 0.04494290866252091,\n \"acc_norm\": 0.6727272727272727,\n\
\ \"acc_norm_stderr\": 0.04494290866252091\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.7387755102040816,\n \"acc_stderr\": 0.028123429335142773,\n\
\ \"acc_norm\": 0.7387755102040816,\n \"acc_norm_stderr\": 0.028123429335142773\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.8159203980099502,\n\
\ \"acc_stderr\": 0.027403859410786862,\n \"acc_norm\": 0.8159203980099502,\n\
\ \"acc_norm_stderr\": 0.027403859410786862\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.86,\n \"acc_stderr\": 0.0348735088019777,\n \
\ \"acc_norm\": 0.86,\n \"acc_norm_stderr\": 0.0348735088019777\n },\n\
\ \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.5542168674698795,\n\
\ \"acc_stderr\": 0.03869543323472101,\n \"acc_norm\": 0.5542168674698795,\n\
\ \"acc_norm_stderr\": 0.03869543323472101\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.8362573099415205,\n \"acc_stderr\": 0.028380919596145866,\n\
\ \"acc_norm\": 0.8362573099415205,\n \"acc_norm_stderr\": 0.028380919596145866\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.40024479804161567,\n\
\ \"mc1_stderr\": 0.017151605555749138,\n \"mc2\": 0.5698682978350015,\n\
\ \"mc2_stderr\": 0.01544172389756708\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.7861089187056038,\n \"acc_stderr\": 0.011524466954090255\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.6171341925701289,\n \
\ \"acc_stderr\": 0.013389223491820474\n }\n}\n```"
repo_url: https://huggingface.co/Yuma42/KangalKhan-ShatteredRuby-7B
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|arc:challenge|25_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|gsm8k|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hellaswag|10_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-02-22T15-24-52.714183.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-management|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-virology|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|truthfulqa:mc|0_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2024-02-22T15-24-52.714183.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- '**/details_harness|winogrande|5_2024-02-22T15-24-52.714183.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2024-02-22T15-24-52.714183.parquet'
- config_name: results
data_files:
- split: 2024_02_22T15_24_52.714183
path:
- results_2024-02-22T15-24-52.714183.parquet
- split: latest
path:
- results_2024-02-22T15-24-52.714183.parquet
---
# Dataset Card for Evaluation run of Yuma42/KangalKhan-ShatteredRuby-7B
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [Yuma42/KangalKhan-ShatteredRuby-7B](https://huggingface.co/Yuma42/KangalKhan-ShatteredRuby-7B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_Yuma42__KangalKhan-ShatteredRuby-7B",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2024-02-22T15:24:52.714183](https://huggingface.co/datasets/open-llm-leaderboard/details_Yuma42__KangalKhan-ShatteredRuby-7B/blob/main/results_2024-02-22T15-24-52.714183.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.6356887043909203,
"acc_stderr": 0.032207789837356685,
"acc_norm": 0.6371743962970163,
"acc_norm_stderr": 0.03285213706238699,
"mc1": 0.40024479804161567,
"mc1_stderr": 0.017151605555749138,
"mc2": 0.5698682978350015,
"mc2_stderr": 0.01544172389756708
},
"harness|arc:challenge|25": {
"acc": 0.6254266211604096,
"acc_stderr": 0.014144193471893456,
"acc_norm": 0.6621160409556314,
"acc_norm_stderr": 0.013822047922283507
},
"harness|hellaswag|10": {
"acc": 0.6709818761202948,
"acc_stderr": 0.004688963175758131,
"acc_norm": 0.8538139812786297,
"acc_norm_stderr": 0.003525705773353423
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.27,
"acc_stderr": 0.044619604333847394,
"acc_norm": 0.27,
"acc_norm_stderr": 0.044619604333847394
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.5777777777777777,
"acc_stderr": 0.04266763404099582,
"acc_norm": 0.5777777777777777,
"acc_norm_stderr": 0.04266763404099582
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.6973684210526315,
"acc_stderr": 0.03738520676119669,
"acc_norm": 0.6973684210526315,
"acc_norm_stderr": 0.03738520676119669
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.59,
"acc_stderr": 0.049431107042371025,
"acc_norm": 0.59,
"acc_norm_stderr": 0.049431107042371025
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.6830188679245283,
"acc_stderr": 0.02863723563980089,
"acc_norm": 0.6830188679245283,
"acc_norm_stderr": 0.02863723563980089
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.75,
"acc_stderr": 0.03621034121889507,
"acc_norm": 0.75,
"acc_norm_stderr": 0.03621034121889507
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.46,
"acc_stderr": 0.05009082659620333,
"acc_norm": 0.46,
"acc_norm_stderr": 0.05009082659620333
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.45,
"acc_stderr": 0.05,
"acc_norm": 0.45,
"acc_norm_stderr": 0.05
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.23,
"acc_stderr": 0.04229525846816505,
"acc_norm": 0.23,
"acc_norm_stderr": 0.04229525846816505
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.5953757225433526,
"acc_stderr": 0.03742461193887248,
"acc_norm": 0.5953757225433526,
"acc_norm_stderr": 0.03742461193887248
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.37254901960784315,
"acc_stderr": 0.048108401480826346,
"acc_norm": 0.37254901960784315,
"acc_norm_stderr": 0.048108401480826346
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.76,
"acc_stderr": 0.042923469599092816,
"acc_norm": 0.76,
"acc_norm_stderr": 0.042923469599092816
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.5617021276595745,
"acc_stderr": 0.03243618636108101,
"acc_norm": 0.5617021276595745,
"acc_norm_stderr": 0.03243618636108101
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.49122807017543857,
"acc_stderr": 0.04702880432049615,
"acc_norm": 0.49122807017543857,
"acc_norm_stderr": 0.04702880432049615
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.503448275862069,
"acc_stderr": 0.04166567577101579,
"acc_norm": 0.503448275862069,
"acc_norm_stderr": 0.04166567577101579
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.42328042328042326,
"acc_stderr": 0.025446365634406783,
"acc_norm": 0.42328042328042326,
"acc_norm_stderr": 0.025446365634406783
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.4523809523809524,
"acc_stderr": 0.044518079590553275,
"acc_norm": 0.4523809523809524,
"acc_norm_stderr": 0.044518079590553275
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.35,
"acc_stderr": 0.047937248544110196,
"acc_norm": 0.35,
"acc_norm_stderr": 0.047937248544110196
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.7870967741935484,
"acc_stderr": 0.023287665127268552,
"acc_norm": 0.7870967741935484,
"acc_norm_stderr": 0.023287665127268552
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.5123152709359606,
"acc_stderr": 0.035169204442208966,
"acc_norm": 0.5123152709359606,
"acc_norm_stderr": 0.035169204442208966
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.69,
"acc_stderr": 0.04648231987117316,
"acc_norm": 0.69,
"acc_norm_stderr": 0.04648231987117316
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.7818181818181819,
"acc_stderr": 0.03225078108306289,
"acc_norm": 0.7818181818181819,
"acc_norm_stderr": 0.03225078108306289
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.7878787878787878,
"acc_stderr": 0.02912652283458682,
"acc_norm": 0.7878787878787878,
"acc_norm_stderr": 0.02912652283458682
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.8808290155440415,
"acc_stderr": 0.023381935348121434,
"acc_norm": 0.8808290155440415,
"acc_norm_stderr": 0.023381935348121434
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.617948717948718,
"acc_stderr": 0.024635549163908237,
"acc_norm": 0.617948717948718,
"acc_norm_stderr": 0.024635549163908237
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.32592592592592595,
"acc_stderr": 0.02857834836547307,
"acc_norm": 0.32592592592592595,
"acc_norm_stderr": 0.02857834836547307
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.6764705882352942,
"acc_stderr": 0.030388353551886793,
"acc_norm": 0.6764705882352942,
"acc_norm_stderr": 0.030388353551886793
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.3509933774834437,
"acc_stderr": 0.03896981964257375,
"acc_norm": 0.3509933774834437,
"acc_norm_stderr": 0.03896981964257375
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.8330275229357799,
"acc_stderr": 0.01599015488507338,
"acc_norm": 0.8330275229357799,
"acc_norm_stderr": 0.01599015488507338
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.49537037037037035,
"acc_stderr": 0.03409825519163572,
"acc_norm": 0.49537037037037035,
"acc_norm_stderr": 0.03409825519163572
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.7941176470588235,
"acc_stderr": 0.028379449451588667,
"acc_norm": 0.7941176470588235,
"acc_norm_stderr": 0.028379449451588667
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.810126582278481,
"acc_stderr": 0.025530100460233483,
"acc_norm": 0.810126582278481,
"acc_norm_stderr": 0.025530100460233483
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.6995515695067265,
"acc_stderr": 0.030769352008229136,
"acc_norm": 0.6995515695067265,
"acc_norm_stderr": 0.030769352008229136
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.7938931297709924,
"acc_stderr": 0.035477710041594654,
"acc_norm": 0.7938931297709924,
"acc_norm_stderr": 0.035477710041594654
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.7603305785123967,
"acc_stderr": 0.03896878985070416,
"acc_norm": 0.7603305785123967,
"acc_norm_stderr": 0.03896878985070416
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.7870370370370371,
"acc_stderr": 0.0395783547198098,
"acc_norm": 0.7870370370370371,
"acc_norm_stderr": 0.0395783547198098
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.7914110429447853,
"acc_stderr": 0.031921934489347235,
"acc_norm": 0.7914110429447853,
"acc_norm_stderr": 0.031921934489347235
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.49107142857142855,
"acc_stderr": 0.04745033255489123,
"acc_norm": 0.49107142857142855,
"acc_norm_stderr": 0.04745033255489123
},
"harness|hendrycksTest-management|5": {
"acc": 0.7766990291262136,
"acc_stderr": 0.04123553189891431,
"acc_norm": 0.7766990291262136,
"acc_norm_stderr": 0.04123553189891431
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.8675213675213675,
"acc_stderr": 0.022209309073165616,
"acc_norm": 0.8675213675213675,
"acc_norm_stderr": 0.022209309073165616
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.69,
"acc_stderr": 0.04648231987117316,
"acc_norm": 0.69,
"acc_norm_stderr": 0.04648231987117316
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.8199233716475096,
"acc_stderr": 0.013740797258579825,
"acc_norm": 0.8199233716475096,
"acc_norm_stderr": 0.013740797258579825
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.7109826589595376,
"acc_stderr": 0.02440517393578323,
"acc_norm": 0.7109826589595376,
"acc_norm_stderr": 0.02440517393578323
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.3329608938547486,
"acc_stderr": 0.015761716178397566,
"acc_norm": 0.3329608938547486,
"acc_norm_stderr": 0.015761716178397566
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.738562091503268,
"acc_stderr": 0.025160998214292452,
"acc_norm": 0.738562091503268,
"acc_norm_stderr": 0.025160998214292452
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.7041800643086816,
"acc_stderr": 0.025922371788818767,
"acc_norm": 0.7041800643086816,
"acc_norm_stderr": 0.025922371788818767
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.7376543209876543,
"acc_stderr": 0.024477222856135118,
"acc_norm": 0.7376543209876543,
"acc_norm_stderr": 0.024477222856135118
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.5106382978723404,
"acc_stderr": 0.02982074719142244,
"acc_norm": 0.5106382978723404,
"acc_norm_stderr": 0.02982074719142244
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.470013037809648,
"acc_stderr": 0.012747248967079076,
"acc_norm": 0.470013037809648,
"acc_norm_stderr": 0.012747248967079076
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.6801470588235294,
"acc_stderr": 0.028332959514031208,
"acc_norm": 0.6801470588235294,
"acc_norm_stderr": 0.028332959514031208
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.6748366013071896,
"acc_stderr": 0.01895088677080631,
"acc_norm": 0.6748366013071896,
"acc_norm_stderr": 0.01895088677080631
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.6727272727272727,
"acc_stderr": 0.04494290866252091,
"acc_norm": 0.6727272727272727,
"acc_norm_stderr": 0.04494290866252091
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.7387755102040816,
"acc_stderr": 0.028123429335142773,
"acc_norm": 0.7387755102040816,
"acc_norm_stderr": 0.028123429335142773
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.8159203980099502,
"acc_stderr": 0.027403859410786862,
"acc_norm": 0.8159203980099502,
"acc_norm_stderr": 0.027403859410786862
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.86,
"acc_stderr": 0.0348735088019777,
"acc_norm": 0.86,
"acc_norm_stderr": 0.0348735088019777
},
"harness|hendrycksTest-virology|5": {
"acc": 0.5542168674698795,
"acc_stderr": 0.03869543323472101,
"acc_norm": 0.5542168674698795,
"acc_norm_stderr": 0.03869543323472101
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.8362573099415205,
"acc_stderr": 0.028380919596145866,
"acc_norm": 0.8362573099415205,
"acc_norm_stderr": 0.028380919596145866
},
"harness|truthfulqa:mc|0": {
"mc1": 0.40024479804161567,
"mc1_stderr": 0.017151605555749138,
"mc2": 0.5698682978350015,
"mc2_stderr": 0.01544172389756708
},
"harness|winogrande|5": {
"acc": 0.7861089187056038,
"acc_stderr": 0.011524466954090255
},
"harness|gsm8k|5": {
"acc": 0.6171341925701289,
"acc_stderr": 0.013389223491820474
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] |
falcon002/guanaco-llama2-1k | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 15401731
num_examples: 9846
download_size: 9094513
dataset_size: 15401731
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
nikchar/paper_test_assym_roberta_3_epochs_results | ---
dataset_info:
features:
- name: claim
dtype: string
- name: evidence_wiki_url
dtype: string
- name: text
dtype: string
- name: retrieved_evidence_title
sequence: string
- name: retrieved_evidence_text
sequence: string
- name: labels
dtype: int64
- name: Retrieval_Success
dtype: bool
- name: Predicted_Labels
dtype: int64
- name: Predicted_Labels_Each_doc
sequence: int64
splits:
- name: train
num_bytes: 73601741
num_examples: 11073
download_size: 34426547
dataset_size: 73601741
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "paper_test_assym_roberta_3_epochs_results"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
yjching/tokenized_dialogsum | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 76653920
num_examples: 12460
- name: validation
num_bytes: 3076000
num_examples: 500
- name: test
num_bytes: 9228000
num_examples: 1500
download_size: 5347174
dataset_size: 88957920
---
# Dataset Card for "tokenized_dialogsum"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
diffusers/test-arrays | ---
license: apache-2.0
---
|
jarrydmartinx/gbsg | ---
dataset_info:
features:
- name: horTh
dtype: float64
- name: tsize
dtype: float64
- name: menostat
dtype: float64
- name: age
dtype: float64
- name: pnodes
dtype: float64
- name: progrec
dtype: float64
- name: estrec
dtype: float64
- name: event_times
dtype: float64
- name: event_indicators
dtype: float64
splits:
- name: train
num_bytes: 111312
num_examples: 1546
- name: test
num_bytes: 49392
num_examples: 686
download_size: 28144
dataset_size: 160704
---
# Dataset Card for "gbsg"
A combination of the Rotterdam tumor bank and the German Breast Cancer Study Group.
This is the processed data set used in the DeepSurv paper (Katzman et al. 2018), and details
can be found at https://doi.org/10.1186/s12874-018-0482-1
See https://github.com/jaredleekatzman/DeepSurv/tree/master/experiments/data
for original data.
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Artificio/WikiArt | ---
dataset_info:
features:
- name: title
dtype: string
- name: artist
dtype: string
- name: date
dtype: string
- name: genre
dtype: string
- name: style
dtype: string
- name: description
dtype: string
- name: filename
dtype: string
- name: image
dtype: image
- name: embeddings_pca512
sequence: float32
splits:
- name: train
num_bytes: 1659296285.75
num_examples: 103250
download_size: 1711766693
dataset_size: 1659296285.75
---
# Dataset Card for "WikiArt"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
cryptexcode/MPST | ---
license: cc-by-4.0
---
### Abstract
Social tagging of movies reveals a wide range of heterogeneous information about movies, like the genre, plot structure, soundtracks, metadata, visual and emotional experiences. Such information can be valuable in building automatic systems to create tags for movies. Automatic tagging systems can help recommendation engines to improve the retrieval of similar movies as well as help viewers to know what to expect from a movie in advance. In this paper, we set out to the task of collecting a corpus of movie plot synopses and tags. We describe a methodology that enabled us to build a fine-grained set of around 70 tags exposing heterogeneous characteristics of movie plots and the multi-label associations of these tags with some 14K movie plot synopses. We investigate how these tags correlate with movies and the flow of emotions throughout different types of movies. Finally, we use this corpus to explore the feasibility of inferring tags from plot synopses. We expect the corpus will be useful in other tasks where analysis of narratives is relevant.
### Content
This dataset was first published in LREC 2018 at Miyazaki, Japan.
Please find the paper here:

Later, this dataset was enriched with user reviews. The paper is available here:

This dataset was published in EMNLP 2020.
### Keywords
Tag generation for movies, Movie plot analysis, Multi-label dataset, Narrative texts
More information is available here
http://ritual.uh.edu/mpst-2018/
Please cite the following papers if you use this dataset:
```
@InProceedings{KAR18.332,
author = {Sudipta Kar and Suraj Maharjan and A. Pastor López-Monroy and Thamar Solorio},
title = {{MPST}: A Corpus of Movie Plot Synopses with Tags},
booktitle = {Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018)},
year = {2018},
month = {May},
date = {7-12},
location = {Miyazaki, Japan},
editor = {Nicoletta Calzolari (Conference chair) and Khalid Choukri and Christopher Cieri and Thierry Declerck and Sara Goggi and Koiti Hasida and Hitoshi Isahara and Bente Maegaard and Joseph Mariani and Hélène Mazo and Asuncion Moreno and Jan Odijk and Stelios Piperidis and Takenobu Tokunaga},
publisher = {European Language Resources Association (ELRA)},
address = {Paris, France},
isbn = {979-10-95546-00-9},
language = {english}
}
```
```
@inproceedings{kar-etal-2020-multi,
title = "Multi-view Story Characterization from Movie Plot Synopses and Reviews",
author = "Kar, Sudipta and
Aguilar, Gustavo and
Lapata, Mirella and
Solorio, Thamar",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.emnlp-main.454",
doi = "10.18653/v1/2020.emnlp-main.454",
pages = "5629--5646",
abstract = "This paper considers the problem of characterizing stories by inferring properties such as theme and style using written synopses and reviews of movies. We experiment with a multi-label dataset of movie synopses and a tagset representing various attributes of stories (e.g., genre, type of events). Our proposed multi-view model encodes the synopses and reviews using hierarchical attention and shows improvement over methods that only use synopses. Finally, we demonstrate how we can take advantage of such a model to extract a complementary set of story-attributes from reviews without direct supervision. We have made our dataset and source code publicly available at https://ritual.uh.edu/multiview-tag-2020.",
}
```
|
tazarov/ds2 | ---
dataset_info:
features:
- name: id
dtype: string
- name: embedding
sequence: float32
- name: document
dtype: string
- name: metadata._id
dtype: string
- name: metadata.title
dtype: string
splits:
- name: train
num_bytes: 660267
num_examples: 100
download_size: 947796
dataset_size: 660267
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "ds2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
emaeon/train4 | ---
dataset_info:
features:
- name: code1
dtype: string
- name: code2
dtype: string
- name: similar
dtype: int64
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 9012529553
num_examples: 5000000
download_size: 0
dataset_size: 9012529553
---
# Dataset Card for "train4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Mitsuki-Sakamoto/fil_self_160m_bo16_2_mix_50_kl_0.1_prm_70m_thr_1.0_seed_1_t_1.0_eval | ---
dataset_info:
config_name: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: preference
dtype: int64
- name: output_1
dtype: string
- name: output_2
dtype: string
- name: reward_model_prompt_format
dtype: string
- name: gen_prompt_format
dtype: string
- name: gen_kwargs
struct:
- name: do_sample
dtype: bool
- name: max_new_tokens
dtype: int64
- name: pad_token_id
dtype: int64
- name: top_k
dtype: int64
- name: top_p
dtype: float64
- name: reward_1
dtype: float64
- name: reward_2
dtype: float64
- name: n_samples
dtype: int64
- name: reject_select
dtype: string
- name: index
dtype: int64
- name: prompt
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
- name: filtered_epoch
dtype: int64
- name: gen_reward
dtype: float64
- name: gen_response
dtype: string
- name: gen_proxy_reward
dtype: float64
- name: gen_gold_reward
dtype: float64
splits:
- name: epoch_0
num_bytes: 44026189
num_examples: 18928
- name: epoch_1
num_bytes: 44705836
num_examples: 18928
- name: epoch_2
num_bytes: 44787126
num_examples: 18928
- name: epoch_3
num_bytes: 44837769
num_examples: 18928
- name: epoch_4
num_bytes: 44878324
num_examples: 18928
- name: epoch_5
num_bytes: 44873926
num_examples: 18928
- name: epoch_6
num_bytes: 44866680
num_examples: 18928
- name: epoch_7
num_bytes: 44852694
num_examples: 18928
- name: epoch_8
num_bytes: 44852065
num_examples: 18928
- name: epoch_9
num_bytes: 44841759
num_examples: 18928
- name: epoch_10
num_bytes: 44833751
num_examples: 18928
- name: epoch_11
num_bytes: 44836454
num_examples: 18928
- name: epoch_12
num_bytes: 44833509
num_examples: 18928
- name: epoch_13
num_bytes: 44831430
num_examples: 18928
- name: epoch_14
num_bytes: 44829271
num_examples: 18928
- name: epoch_15
num_bytes: 44832324
num_examples: 18928
- name: epoch_16
num_bytes: 44833275
num_examples: 18928
- name: epoch_17
num_bytes: 44829107
num_examples: 18928
- name: epoch_18
num_bytes: 44829125
num_examples: 18928
- name: epoch_19
num_bytes: 44831415
num_examples: 18928
- name: epoch_20
num_bytes: 44829111
num_examples: 18928
- name: epoch_21
num_bytes: 44828757
num_examples: 18928
- name: epoch_22
num_bytes: 44827282
num_examples: 18928
- name: epoch_23
num_bytes: 44826649
num_examples: 18928
- name: epoch_24
num_bytes: 44829036
num_examples: 18928
- name: epoch_25
num_bytes: 44829962
num_examples: 18928
- name: epoch_26
num_bytes: 44832234
num_examples: 18928
- name: epoch_27
num_bytes: 44830868
num_examples: 18928
- name: epoch_28
num_bytes: 44829678
num_examples: 18928
- name: epoch_29
num_bytes: 44832617
num_examples: 18928
download_size: 685732928
dataset_size: 1344138223
configs:
- config_name: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1
data_files:
- split: epoch_0
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_0-*
- split: epoch_1
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_1-*
- split: epoch_2
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_2-*
- split: epoch_3
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_3-*
- split: epoch_4
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_4-*
- split: epoch_5
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_5-*
- split: epoch_6
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_6-*
- split: epoch_7
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_7-*
- split: epoch_8
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_8-*
- split: epoch_9
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_9-*
- split: epoch_10
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_10-*
- split: epoch_11
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_11-*
- split: epoch_12
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_12-*
- split: epoch_13
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_13-*
- split: epoch_14
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_14-*
- split: epoch_15
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_15-*
- split: epoch_16
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_16-*
- split: epoch_17
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_17-*
- split: epoch_18
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_18-*
- split: epoch_19
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_19-*
- split: epoch_20
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_20-*
- split: epoch_21
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_21-*
- split: epoch_22
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_22-*
- split: epoch_23
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_23-*
- split: epoch_24
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_24-*
- split: epoch_25
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_25-*
- split: epoch_26
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_26-*
- split: epoch_27
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_27-*
- split: epoch_28
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_28-*
- split: epoch_29
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_29-*
---
# Dataset Card for "fil_self_160m_bo16_2_mix_50_kl_0.1_prm_70m_thr_1.0_seed_1_t_1.0_eval"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
open-llm-leaderboard/details_bn22__OpenHermes-2.5-Mistral-7B-MISALIGNED | ---
pretty_name: Evaluation run of bn22/OpenHermes-2.5-Mistral-7B-MISALIGNED
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [bn22/OpenHermes-2.5-Mistral-7B-MISALIGNED](https://huggingface.co/bn22/OpenHermes-2.5-Mistral-7B-MISALIGNED)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 63 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_bn22__OpenHermes-2.5-Mistral-7B-MISALIGNED\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-12-27T13:23:06.286047](https://huggingface.co/datasets/open-llm-leaderboard/details_bn22__OpenHermes-2.5-Mistral-7B-MISALIGNED/blob/main/results_2023-12-27T13-23-06.286047.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.6365778018786907,\n\
\ \"acc_stderr\": 0.032237330992015784,\n \"acc_norm\": 0.6411759500596701,\n\
\ \"acc_norm_stderr\": 0.03287481285485409,\n \"mc1\": 0.3635250917992656,\n\
\ \"mc1_stderr\": 0.016838862883965834,\n \"mc2\": 0.5285201353037359,\n\
\ \"mc2_stderr\": 0.015274085526697238\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.6168941979522184,\n \"acc_stderr\": 0.014206472661672876,\n\
\ \"acc_norm\": 0.6535836177474402,\n \"acc_norm_stderr\": 0.013905011180063225\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.6560446126269668,\n\
\ \"acc_stderr\": 0.004740555782142168,\n \"acc_norm\": 0.8467436765584545,\n\
\ \"acc_norm_stderr\": 0.0035949818233199046\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.34,\n \"acc_stderr\": 0.04760952285695236,\n \
\ \"acc_norm\": 0.34,\n \"acc_norm_stderr\": 0.04760952285695236\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.6,\n \
\ \"acc_stderr\": 0.04232073695151589,\n \"acc_norm\": 0.6,\n \"\
acc_norm_stderr\": 0.04232073695151589\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.7039473684210527,\n \"acc_stderr\": 0.03715062154998904,\n\
\ \"acc_norm\": 0.7039473684210527,\n \"acc_norm_stderr\": 0.03715062154998904\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.57,\n\
\ \"acc_stderr\": 0.049756985195624284,\n \"acc_norm\": 0.57,\n \
\ \"acc_norm_stderr\": 0.049756985195624284\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.690566037735849,\n \"acc_stderr\": 0.028450154794118637,\n\
\ \"acc_norm\": 0.690566037735849,\n \"acc_norm_stderr\": 0.028450154794118637\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.7569444444444444,\n\
\ \"acc_stderr\": 0.03586879280080341,\n \"acc_norm\": 0.7569444444444444,\n\
\ \"acc_norm_stderr\": 0.03586879280080341\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.47,\n \"acc_stderr\": 0.05016135580465919,\n \
\ \"acc_norm\": 0.47,\n \"acc_norm_stderr\": 0.05016135580465919\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\"\
: 0.46,\n \"acc_stderr\": 0.05009082659620333,\n \"acc_norm\": 0.46,\n\
\ \"acc_norm_stderr\": 0.05009082659620333\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.3,\n \"acc_stderr\": 0.046056618647183814,\n \
\ \"acc_norm\": 0.3,\n \"acc_norm_stderr\": 0.046056618647183814\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.6184971098265896,\n\
\ \"acc_stderr\": 0.03703851193099521,\n \"acc_norm\": 0.6184971098265896,\n\
\ \"acc_norm_stderr\": 0.03703851193099521\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.3627450980392157,\n \"acc_stderr\": 0.04784060704105653,\n\
\ \"acc_norm\": 0.3627450980392157,\n \"acc_norm_stderr\": 0.04784060704105653\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.76,\n \"acc_stderr\": 0.042923469599092816,\n \"acc_norm\": 0.76,\n\
\ \"acc_norm_stderr\": 0.042923469599092816\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.5531914893617021,\n \"acc_stderr\": 0.0325005368436584,\n\
\ \"acc_norm\": 0.5531914893617021,\n \"acc_norm_stderr\": 0.0325005368436584\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.49122807017543857,\n\
\ \"acc_stderr\": 0.04702880432049615,\n \"acc_norm\": 0.49122807017543857,\n\
\ \"acc_norm_stderr\": 0.04702880432049615\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.5241379310344828,\n \"acc_stderr\": 0.0416180850350153,\n\
\ \"acc_norm\": 0.5241379310344828,\n \"acc_norm_stderr\": 0.0416180850350153\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.42592592592592593,\n \"acc_stderr\": 0.02546714904546955,\n \"\
acc_norm\": 0.42592592592592593,\n \"acc_norm_stderr\": 0.02546714904546955\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.4603174603174603,\n\
\ \"acc_stderr\": 0.04458029125470973,\n \"acc_norm\": 0.4603174603174603,\n\
\ \"acc_norm_stderr\": 0.04458029125470973\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.37,\n \"acc_stderr\": 0.04852365870939099,\n \
\ \"acc_norm\": 0.37,\n \"acc_norm_stderr\": 0.04852365870939099\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.7967741935483871,\n\
\ \"acc_stderr\": 0.02289168798455495,\n \"acc_norm\": 0.7967741935483871,\n\
\ \"acc_norm_stderr\": 0.02289168798455495\n },\n \"harness|hendrycksTest-high_school_chemistry|5\"\
: {\n \"acc\": 0.5172413793103449,\n \"acc_stderr\": 0.035158955511656986,\n\
\ \"acc_norm\": 0.5172413793103449,\n \"acc_norm_stderr\": 0.035158955511656986\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.68,\n \"acc_stderr\": 0.04688261722621505,\n \"acc_norm\"\
: 0.68,\n \"acc_norm_stderr\": 0.04688261722621505\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.7818181818181819,\n \"acc_stderr\": 0.032250781083062896,\n\
\ \"acc_norm\": 0.7818181818181819,\n \"acc_norm_stderr\": 0.032250781083062896\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.803030303030303,\n \"acc_stderr\": 0.02833560973246336,\n \"acc_norm\"\
: 0.803030303030303,\n \"acc_norm_stderr\": 0.02833560973246336\n },\n\
\ \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n \
\ \"acc\": 0.9015544041450777,\n \"acc_stderr\": 0.021500249576033456,\n\
\ \"acc_norm\": 0.9015544041450777,\n \"acc_norm_stderr\": 0.021500249576033456\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.6102564102564103,\n \"acc_stderr\": 0.024726967886647074,\n\
\ \"acc_norm\": 0.6102564102564103,\n \"acc_norm_stderr\": 0.024726967886647074\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.3037037037037037,\n \"acc_stderr\": 0.028037929969114993,\n \
\ \"acc_norm\": 0.3037037037037037,\n \"acc_norm_stderr\": 0.028037929969114993\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.680672268907563,\n \"acc_stderr\": 0.030283995525884396,\n \
\ \"acc_norm\": 0.680672268907563,\n \"acc_norm_stderr\": 0.030283995525884396\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.32450331125827814,\n \"acc_stderr\": 0.03822746937658752,\n \"\
acc_norm\": 0.32450331125827814,\n \"acc_norm_stderr\": 0.03822746937658752\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.8348623853211009,\n \"acc_stderr\": 0.01591955782997604,\n \"\
acc_norm\": 0.8348623853211009,\n \"acc_norm_stderr\": 0.01591955782997604\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.5092592592592593,\n \"acc_stderr\": 0.034093869469927006,\n \"\
acc_norm\": 0.5092592592592593,\n \"acc_norm_stderr\": 0.034093869469927006\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.7892156862745098,\n \"acc_stderr\": 0.028626547912437413,\n \"\
acc_norm\": 0.7892156862745098,\n \"acc_norm_stderr\": 0.028626547912437413\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.810126582278481,\n \"acc_stderr\": 0.02553010046023349,\n \
\ \"acc_norm\": 0.810126582278481,\n \"acc_norm_stderr\": 0.02553010046023349\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.7040358744394619,\n\
\ \"acc_stderr\": 0.030636591348699796,\n \"acc_norm\": 0.7040358744394619,\n\
\ \"acc_norm_stderr\": 0.030636591348699796\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.7938931297709924,\n \"acc_stderr\": 0.035477710041594654,\n\
\ \"acc_norm\": 0.7938931297709924,\n \"acc_norm_stderr\": 0.035477710041594654\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.768595041322314,\n \"acc_stderr\": 0.03849856098794088,\n \"acc_norm\"\
: 0.768595041322314,\n \"acc_norm_stderr\": 0.03849856098794088\n },\n\
\ \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.7870370370370371,\n\
\ \"acc_stderr\": 0.039578354719809805,\n \"acc_norm\": 0.7870370370370371,\n\
\ \"acc_norm_stderr\": 0.039578354719809805\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.7852760736196319,\n \"acc_stderr\": 0.032262193772867744,\n\
\ \"acc_norm\": 0.7852760736196319,\n \"acc_norm_stderr\": 0.032262193772867744\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.5089285714285714,\n\
\ \"acc_stderr\": 0.04745033255489123,\n \"acc_norm\": 0.5089285714285714,\n\
\ \"acc_norm_stderr\": 0.04745033255489123\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.7766990291262136,\n \"acc_stderr\": 0.04123553189891431,\n\
\ \"acc_norm\": 0.7766990291262136,\n \"acc_norm_stderr\": 0.04123553189891431\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.8717948717948718,\n\
\ \"acc_stderr\": 0.02190190511507333,\n \"acc_norm\": 0.8717948717948718,\n\
\ \"acc_norm_stderr\": 0.02190190511507333\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.7,\n \"acc_stderr\": 0.046056618647183814,\n \
\ \"acc_norm\": 0.7,\n \"acc_norm_stderr\": 0.046056618647183814\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.8314176245210728,\n\
\ \"acc_stderr\": 0.0133878957315436,\n \"acc_norm\": 0.8314176245210728,\n\
\ \"acc_norm_stderr\": 0.0133878957315436\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.7196531791907514,\n \"acc_stderr\": 0.02418242749657761,\n\
\ \"acc_norm\": 0.7196531791907514,\n \"acc_norm_stderr\": 0.02418242749657761\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.30837988826815643,\n\
\ \"acc_stderr\": 0.015445716910998879,\n \"acc_norm\": 0.30837988826815643,\n\
\ \"acc_norm_stderr\": 0.015445716910998879\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.7516339869281046,\n \"acc_stderr\": 0.02473998135511359,\n\
\ \"acc_norm\": 0.7516339869281046,\n \"acc_norm_stderr\": 0.02473998135511359\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.6881028938906752,\n\
\ \"acc_stderr\": 0.02631185807185416,\n \"acc_norm\": 0.6881028938906752,\n\
\ \"acc_norm_stderr\": 0.02631185807185416\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.75,\n \"acc_stderr\": 0.02409347123262133,\n \
\ \"acc_norm\": 0.75,\n \"acc_norm_stderr\": 0.02409347123262133\n \
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"acc\"\
: 0.5106382978723404,\n \"acc_stderr\": 0.02982074719142244,\n \"\
acc_norm\": 0.5106382978723404,\n \"acc_norm_stderr\": 0.02982074719142244\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.46936114732724904,\n\
\ \"acc_stderr\": 0.012746237711716634,\n \"acc_norm\": 0.46936114732724904,\n\
\ \"acc_norm_stderr\": 0.012746237711716634\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.6764705882352942,\n \"acc_stderr\": 0.028418208619406762,\n\
\ \"acc_norm\": 0.6764705882352942,\n \"acc_norm_stderr\": 0.028418208619406762\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.6699346405228758,\n \"acc_stderr\": 0.019023726160724553,\n \
\ \"acc_norm\": 0.6699346405228758,\n \"acc_norm_stderr\": 0.019023726160724553\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.6545454545454545,\n\
\ \"acc_stderr\": 0.04554619617541054,\n \"acc_norm\": 0.6545454545454545,\n\
\ \"acc_norm_stderr\": 0.04554619617541054\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.7346938775510204,\n \"acc_stderr\": 0.028263889943784593,\n\
\ \"acc_norm\": 0.7346938775510204,\n \"acc_norm_stderr\": 0.028263889943784593\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.8109452736318408,\n\
\ \"acc_stderr\": 0.027686913588013024,\n \"acc_norm\": 0.8109452736318408,\n\
\ \"acc_norm_stderr\": 0.027686913588013024\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.86,\n \"acc_stderr\": 0.03487350880197769,\n \
\ \"acc_norm\": 0.86,\n \"acc_norm_stderr\": 0.03487350880197769\n \
\ },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.5602409638554217,\n\
\ \"acc_stderr\": 0.03864139923699122,\n \"acc_norm\": 0.5602409638554217,\n\
\ \"acc_norm_stderr\": 0.03864139923699122\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.8362573099415205,\n \"acc_stderr\": 0.028380919596145866,\n\
\ \"acc_norm\": 0.8362573099415205,\n \"acc_norm_stderr\": 0.028380919596145866\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.3635250917992656,\n\
\ \"mc1_stderr\": 0.016838862883965834,\n \"mc2\": 0.5285201353037359,\n\
\ \"mc2_stderr\": 0.015274085526697238\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.77663772691397,\n \"acc_stderr\": 0.011705697565205187\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.45261561789234267,\n \
\ \"acc_stderr\": 0.013710499070934965\n }\n}\n```"
repo_url: https://huggingface.co/bn22/OpenHermes-2.5-Mistral-7B-MISALIGNED
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|arc:challenge|25_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|gsm8k|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hellaswag|10_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-12-27T13-23-06.286047.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-management|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-virology|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|truthfulqa:mc|0_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-12-27T13-23-06.286047.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- '**/details_harness|winogrande|5_2023-12-27T13-23-06.286047.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-12-27T13-23-06.286047.parquet'
- config_name: results
data_files:
- split: 2023_12_27T13_23_06.286047
path:
- results_2023-12-27T13-23-06.286047.parquet
- split: latest
path:
- results_2023-12-27T13-23-06.286047.parquet
---
# Dataset Card for Evaluation run of bn22/OpenHermes-2.5-Mistral-7B-MISALIGNED
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [bn22/OpenHermes-2.5-Mistral-7B-MISALIGNED](https://huggingface.co/bn22/OpenHermes-2.5-Mistral-7B-MISALIGNED) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_bn22__OpenHermes-2.5-Mistral-7B-MISALIGNED",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-12-27T13:23:06.286047](https://huggingface.co/datasets/open-llm-leaderboard/details_bn22__OpenHermes-2.5-Mistral-7B-MISALIGNED/blob/main/results_2023-12-27T13-23-06.286047.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.6365778018786907,
"acc_stderr": 0.032237330992015784,
"acc_norm": 0.6411759500596701,
"acc_norm_stderr": 0.03287481285485409,
"mc1": 0.3635250917992656,
"mc1_stderr": 0.016838862883965834,
"mc2": 0.5285201353037359,
"mc2_stderr": 0.015274085526697238
},
"harness|arc:challenge|25": {
"acc": 0.6168941979522184,
"acc_stderr": 0.014206472661672876,
"acc_norm": 0.6535836177474402,
"acc_norm_stderr": 0.013905011180063225
},
"harness|hellaswag|10": {
"acc": 0.6560446126269668,
"acc_stderr": 0.004740555782142168,
"acc_norm": 0.8467436765584545,
"acc_norm_stderr": 0.0035949818233199046
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.34,
"acc_stderr": 0.04760952285695236,
"acc_norm": 0.34,
"acc_norm_stderr": 0.04760952285695236
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.6,
"acc_stderr": 0.04232073695151589,
"acc_norm": 0.6,
"acc_norm_stderr": 0.04232073695151589
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.7039473684210527,
"acc_stderr": 0.03715062154998904,
"acc_norm": 0.7039473684210527,
"acc_norm_stderr": 0.03715062154998904
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.57,
"acc_stderr": 0.049756985195624284,
"acc_norm": 0.57,
"acc_norm_stderr": 0.049756985195624284
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.690566037735849,
"acc_stderr": 0.028450154794118637,
"acc_norm": 0.690566037735849,
"acc_norm_stderr": 0.028450154794118637
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.7569444444444444,
"acc_stderr": 0.03586879280080341,
"acc_norm": 0.7569444444444444,
"acc_norm_stderr": 0.03586879280080341
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.47,
"acc_stderr": 0.05016135580465919,
"acc_norm": 0.47,
"acc_norm_stderr": 0.05016135580465919
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.46,
"acc_stderr": 0.05009082659620333,
"acc_norm": 0.46,
"acc_norm_stderr": 0.05009082659620333
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.3,
"acc_stderr": 0.046056618647183814,
"acc_norm": 0.3,
"acc_norm_stderr": 0.046056618647183814
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.6184971098265896,
"acc_stderr": 0.03703851193099521,
"acc_norm": 0.6184971098265896,
"acc_norm_stderr": 0.03703851193099521
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.3627450980392157,
"acc_stderr": 0.04784060704105653,
"acc_norm": 0.3627450980392157,
"acc_norm_stderr": 0.04784060704105653
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.76,
"acc_stderr": 0.042923469599092816,
"acc_norm": 0.76,
"acc_norm_stderr": 0.042923469599092816
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.5531914893617021,
"acc_stderr": 0.0325005368436584,
"acc_norm": 0.5531914893617021,
"acc_norm_stderr": 0.0325005368436584
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.49122807017543857,
"acc_stderr": 0.04702880432049615,
"acc_norm": 0.49122807017543857,
"acc_norm_stderr": 0.04702880432049615
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.5241379310344828,
"acc_stderr": 0.0416180850350153,
"acc_norm": 0.5241379310344828,
"acc_norm_stderr": 0.0416180850350153
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.42592592592592593,
"acc_stderr": 0.02546714904546955,
"acc_norm": 0.42592592592592593,
"acc_norm_stderr": 0.02546714904546955
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.4603174603174603,
"acc_stderr": 0.04458029125470973,
"acc_norm": 0.4603174603174603,
"acc_norm_stderr": 0.04458029125470973
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.37,
"acc_stderr": 0.04852365870939099,
"acc_norm": 0.37,
"acc_norm_stderr": 0.04852365870939099
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.7967741935483871,
"acc_stderr": 0.02289168798455495,
"acc_norm": 0.7967741935483871,
"acc_norm_stderr": 0.02289168798455495
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.5172413793103449,
"acc_stderr": 0.035158955511656986,
"acc_norm": 0.5172413793103449,
"acc_norm_stderr": 0.035158955511656986
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.68,
"acc_stderr": 0.04688261722621505,
"acc_norm": 0.68,
"acc_norm_stderr": 0.04688261722621505
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.7818181818181819,
"acc_stderr": 0.032250781083062896,
"acc_norm": 0.7818181818181819,
"acc_norm_stderr": 0.032250781083062896
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.803030303030303,
"acc_stderr": 0.02833560973246336,
"acc_norm": 0.803030303030303,
"acc_norm_stderr": 0.02833560973246336
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.9015544041450777,
"acc_stderr": 0.021500249576033456,
"acc_norm": 0.9015544041450777,
"acc_norm_stderr": 0.021500249576033456
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.6102564102564103,
"acc_stderr": 0.024726967886647074,
"acc_norm": 0.6102564102564103,
"acc_norm_stderr": 0.024726967886647074
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.3037037037037037,
"acc_stderr": 0.028037929969114993,
"acc_norm": 0.3037037037037037,
"acc_norm_stderr": 0.028037929969114993
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.680672268907563,
"acc_stderr": 0.030283995525884396,
"acc_norm": 0.680672268907563,
"acc_norm_stderr": 0.030283995525884396
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.32450331125827814,
"acc_stderr": 0.03822746937658752,
"acc_norm": 0.32450331125827814,
"acc_norm_stderr": 0.03822746937658752
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.8348623853211009,
"acc_stderr": 0.01591955782997604,
"acc_norm": 0.8348623853211009,
"acc_norm_stderr": 0.01591955782997604
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.5092592592592593,
"acc_stderr": 0.034093869469927006,
"acc_norm": 0.5092592592592593,
"acc_norm_stderr": 0.034093869469927006
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.7892156862745098,
"acc_stderr": 0.028626547912437413,
"acc_norm": 0.7892156862745098,
"acc_norm_stderr": 0.028626547912437413
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.810126582278481,
"acc_stderr": 0.02553010046023349,
"acc_norm": 0.810126582278481,
"acc_norm_stderr": 0.02553010046023349
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.7040358744394619,
"acc_stderr": 0.030636591348699796,
"acc_norm": 0.7040358744394619,
"acc_norm_stderr": 0.030636591348699796
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.7938931297709924,
"acc_stderr": 0.035477710041594654,
"acc_norm": 0.7938931297709924,
"acc_norm_stderr": 0.035477710041594654
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.768595041322314,
"acc_stderr": 0.03849856098794088,
"acc_norm": 0.768595041322314,
"acc_norm_stderr": 0.03849856098794088
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.7870370370370371,
"acc_stderr": 0.039578354719809805,
"acc_norm": 0.7870370370370371,
"acc_norm_stderr": 0.039578354719809805
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.7852760736196319,
"acc_stderr": 0.032262193772867744,
"acc_norm": 0.7852760736196319,
"acc_norm_stderr": 0.032262193772867744
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.5089285714285714,
"acc_stderr": 0.04745033255489123,
"acc_norm": 0.5089285714285714,
"acc_norm_stderr": 0.04745033255489123
},
"harness|hendrycksTest-management|5": {
"acc": 0.7766990291262136,
"acc_stderr": 0.04123553189891431,
"acc_norm": 0.7766990291262136,
"acc_norm_stderr": 0.04123553189891431
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.8717948717948718,
"acc_stderr": 0.02190190511507333,
"acc_norm": 0.8717948717948718,
"acc_norm_stderr": 0.02190190511507333
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.7,
"acc_stderr": 0.046056618647183814,
"acc_norm": 0.7,
"acc_norm_stderr": 0.046056618647183814
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.8314176245210728,
"acc_stderr": 0.0133878957315436,
"acc_norm": 0.8314176245210728,
"acc_norm_stderr": 0.0133878957315436
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.7196531791907514,
"acc_stderr": 0.02418242749657761,
"acc_norm": 0.7196531791907514,
"acc_norm_stderr": 0.02418242749657761
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.30837988826815643,
"acc_stderr": 0.015445716910998879,
"acc_norm": 0.30837988826815643,
"acc_norm_stderr": 0.015445716910998879
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.7516339869281046,
"acc_stderr": 0.02473998135511359,
"acc_norm": 0.7516339869281046,
"acc_norm_stderr": 0.02473998135511359
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.6881028938906752,
"acc_stderr": 0.02631185807185416,
"acc_norm": 0.6881028938906752,
"acc_norm_stderr": 0.02631185807185416
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.75,
"acc_stderr": 0.02409347123262133,
"acc_norm": 0.75,
"acc_norm_stderr": 0.02409347123262133
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.5106382978723404,
"acc_stderr": 0.02982074719142244,
"acc_norm": 0.5106382978723404,
"acc_norm_stderr": 0.02982074719142244
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.46936114732724904,
"acc_stderr": 0.012746237711716634,
"acc_norm": 0.46936114732724904,
"acc_norm_stderr": 0.012746237711716634
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.6764705882352942,
"acc_stderr": 0.028418208619406762,
"acc_norm": 0.6764705882352942,
"acc_norm_stderr": 0.028418208619406762
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.6699346405228758,
"acc_stderr": 0.019023726160724553,
"acc_norm": 0.6699346405228758,
"acc_norm_stderr": 0.019023726160724553
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.6545454545454545,
"acc_stderr": 0.04554619617541054,
"acc_norm": 0.6545454545454545,
"acc_norm_stderr": 0.04554619617541054
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.7346938775510204,
"acc_stderr": 0.028263889943784593,
"acc_norm": 0.7346938775510204,
"acc_norm_stderr": 0.028263889943784593
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.8109452736318408,
"acc_stderr": 0.027686913588013024,
"acc_norm": 0.8109452736318408,
"acc_norm_stderr": 0.027686913588013024
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.86,
"acc_stderr": 0.03487350880197769,
"acc_norm": 0.86,
"acc_norm_stderr": 0.03487350880197769
},
"harness|hendrycksTest-virology|5": {
"acc": 0.5602409638554217,
"acc_stderr": 0.03864139923699122,
"acc_norm": 0.5602409638554217,
"acc_norm_stderr": 0.03864139923699122
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.8362573099415205,
"acc_stderr": 0.028380919596145866,
"acc_norm": 0.8362573099415205,
"acc_norm_stderr": 0.028380919596145866
},
"harness|truthfulqa:mc|0": {
"mc1": 0.3635250917992656,
"mc1_stderr": 0.016838862883965834,
"mc2": 0.5285201353037359,
"mc2_stderr": 0.015274085526697238
},
"harness|winogrande|5": {
"acc": 0.77663772691397,
"acc_stderr": 0.011705697565205187
},
"harness|gsm8k|5": {
"acc": 0.45261561789234267,
"acc_stderr": 0.013710499070934965
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] |
Jing24/seperate_all2 | ---
dataset_info:
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
struct:
- name: answer_start
sequence: int32
- name: text
sequence: string
splits:
- name: train
num_bytes: 22553478
num_examples: 25077
download_size: 4170668
dataset_size: 22553478
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "seperate_all2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/takatsuki_yayoi_theidolmster | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of takatsuki_yayoi/高槻やよい/타카츠키야요이 (THE iDOLM@STER)
This is the dataset of takatsuki_yayoi/高槻やよい/타카츠키야요이 (THE iDOLM@STER), containing 500 images and their tags.
The core tags of this character are `twintails, brown_hair, green_eyes, orange_hair`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:------------------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 500 | 472.50 MiB | [Download](https://huggingface.co/datasets/CyberHarem/takatsuki_yayoi_theidolmster/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 500 | 329.50 MiB | [Download](https://huggingface.co/datasets/CyberHarem/takatsuki_yayoi_theidolmster/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 1106 | 666.02 MiB | [Download](https://huggingface.co/datasets/CyberHarem/takatsuki_yayoi_theidolmster/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 500 | 441.21 MiB | [Download](https://huggingface.co/datasets/CyberHarem/takatsuki_yayoi_theidolmster/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 1106 | 851.34 MiB | [Download](https://huggingface.co/datasets/CyberHarem/takatsuki_yayoi_theidolmster/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/takatsuki_yayoi_theidolmster',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------------------------------------------------------------------------------|
| 0 | 26 |  |  |  |  |  | 1girl, open_mouth, solo, raglan_sleeves, :d, blush |
| 1 | 5 |  |  |  |  |  | 1girl, dress, open_mouth, solo, blush, hair_flower, bouquet, :d, closed_eyes, outstretched_arms, petals |
| 2 | 5 |  |  |  |  |  | 1girl, ;d, blue_eyes, one_eye_closed, open_mouth, smile, solo, apron, long_hair |
| 3 | 6 |  |  |  |  |  | 1girl, open_mouth, smile, solo, bracelet, dress, thighhighs |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | open_mouth | solo | raglan_sleeves | :d | blush | dress | hair_flower | bouquet | closed_eyes | outstretched_arms | petals | ;d | blue_eyes | one_eye_closed | smile | apron | long_hair | bracelet | thighhighs |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:-------------|:-------|:-----------------|:-----|:--------|:--------|:--------------|:----------|:--------------|:--------------------|:---------|:-----|:------------|:-----------------|:--------|:--------|:------------|:-----------|:-------------|
| 0 | 26 |  |  |  |  |  | X | X | X | X | X | X | | | | | | | | | | | | | | |
| 1 | 5 |  |  |  |  |  | X | X | X | | X | X | X | X | X | X | X | X | | | | | | | | |
| 2 | 5 |  |  |  |  |  | X | X | X | | | | | | | | | | X | X | X | X | X | X | | |
| 3 | 6 |  |  |  |  |  | X | X | X | | | | X | | | | | | | | | X | | | X | X |
|
autoevaluate/autoeval-eval-futin__guess-vi_3-6b1064-2012566620 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- futin/guess
eval_info:
task: text_zero_shot_classification
model: facebook/opt-13b
metrics: []
dataset_name: futin/guess
dataset_config: vi_3
dataset_split: test
col_mapping:
text: text
classes: classes
target: target
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: facebook/opt-13b
* Dataset: futin/guess
* Config: vi_3
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@futin](https://huggingface.co/futin) for evaluating this model. |
saeu5407/celebahq_landmark4controlnet | ---
dataset_info:
features:
- name: crop_image
dtype: image
- name: landmark_image
dtype: image
- name: prompt_text
dtype: string
- name: mouth
dtype: string
- name: mouth_outside
dtype: string
- name: left_eye
dtype: string
- name: left_pupil
dtype: string
- name: right_eye
dtype: string
- name: right_pupil
dtype: string
- name: nose
dtype: string
- name: left_eyebrow
dtype: string
- name: left_eyebrow_up
dtype: string
- name: right_eyebrow
dtype: string
- name: right_eyebrow_up
dtype: string
- name: outside
dtype: string
splits:
- name: train
num_bytes: 4682763086.75
num_examples: 26965
- name: validation
num_bytes: 521873626.0
num_examples: 3000
download_size: 5179214868
dataset_size: 5204636712.75
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
Dataset for developing controlnet conditional on landmark.
The original dataset is a size 256 resized CelebAHQ.
Use facial landmark information and express the nose in red, mouth white, left eye, iris, eyebrows in green, right eye, iris, and eyebrows in blue.
Create a description of the face using BLIP.
Create facial landmark information using Mediapipe.
|
PoojaBhati/recipe_generation | ---
license: mit
---
|
MetroCat/Hebrew-Mil | ---
license: gpl
---
a collection of pdfs about militery and defence hebrew only |
BeIR/scifact-generated-queries | ---
annotations_creators: []
language_creators: []
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: beir
pretty_name: BEIR Benchmark
size_categories:
msmarco:
- 1M<n<10M
trec-covid:
- 100k<n<1M
nfcorpus:
- 1K<n<10K
nq:
- 1M<n<10M
hotpotqa:
- 1M<n<10M
fiqa:
- 10K<n<100K
arguana:
- 1K<n<10K
touche-2020:
- 100K<n<1M
cqadupstack:
- 100K<n<1M
quora:
- 100K<n<1M
dbpedia:
- 1M<n<10M
scidocs:
- 10K<n<100K
fever:
- 1M<n<10M
climate-fever:
- 1M<n<10M
scifact:
- 1K<n<10K
source_datasets: []
task_categories:
- text-retrieval
- zero-shot-retrieval
- information-retrieval
- zero-shot-information-retrieval
task_ids:
- passage-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
- tweet-retrieval
- citation-prediction-retrieval
- duplication-question-retrieval
- argument-retrieval
- news-retrieval
- biomedical-information-retrieval
- question-answering-retrieval
---
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** nandan.thakur@uwaterloo.ca
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. |
maghwa/OpenHermes-2-AR-10K-48-920k-930k | ---
dataset_info:
features:
- name: id
dtype: string
- name: system_prompt
dtype: 'null'
- name: topic
dtype: 'null'
- name: hash
dtype: 'null'
- name: model
dtype: 'null'
- name: idx
dtype: 'null'
- name: title
dtype: 'null'
- name: avatarUrl
dtype: 'null'
- name: conversations
dtype: string
- name: model_name
dtype: 'null'
- name: source
dtype: string
- name: skip_prompt_formatting
dtype: 'null'
- name: language
dtype: 'null'
- name: custom_instruction
dtype: 'null'
- name: category
dtype: 'null'
- name: views
dtype: float64
splits:
- name: train
num_bytes: 14215751
num_examples: 10001
download_size: 6439367
dataset_size: 14215751
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
wenhanhan/FEVER_dev | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 5939905
num_examples: 9999
download_size: 1910533
dataset_size: 5939905
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "FEVER_dev"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
anan-2024/twitter_dataset_1713151873 | ---
dataset_info:
features:
- name: id
dtype: string
- name: tweet_content
dtype: string
- name: user_name
dtype: string
- name: user_id
dtype: string
- name: created_at
dtype: string
- name: url
dtype: string
- name: favourite_count
dtype: int64
- name: scraped_at
dtype: string
- name: image_urls
dtype: string
splits:
- name: train
num_bytes: 118017
num_examples: 313
download_size: 66267
dataset_size: 118017
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
CVasNLPExperiments/Caltech101_with_background_test_google_flan_t5_xl_mode_A_ns_6084 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: prompt
dtype: string
- name: true_label
dtype: string
- name: prediction
dtype: string
splits:
- name: fewshot_0__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices
num_bytes: 2289693
num_examples: 6084
download_size: 404193
dataset_size: 2289693
---
# Dataset Card for "Caltech101_with_background_test_google_flan_t5_xl_mode_A_ns_6084"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/saitou_miyako_oshinoko | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of Saitou Miyako
This is the dataset of Saitou Miyako, containing 102 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 102 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 220 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 102 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 102 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 102 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 102 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 102 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 220 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 220 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 220 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
Tippawan/test2-data-semi-trainulb-r2-WLV | ---
dataset_info:
features:
- name: tokens
sequence: string
- name: ner_tags
sequence: int64
- name: prob
sequence: float64
- name: ifpass
sequence: int64
- name: pred
dtype: int64
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 74204980
num_examples: 39712
download_size: 14640294
dataset_size: 74204980
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
TrainingDataPro/pigs-detection-dataset | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-image
- image-classification
- object-detection
tags:
- code
dataset_info:
features:
- name: id
dtype: int32
- name: image
dtype: image
- name: mask
dtype: image
- name: bboxes
dtype: string
splits:
- name: train
num_bytes: 5428811
num_examples: 27
download_size: 5391503
dataset_size: 5428811
---
# Pigs Detection Dataset
The dataset is a collection of images along with corresponding bounding box annotations that are specifically curated for **detecting pigs' heads** in images. The dataset covers different *pig breeds, sizes, and orientations*, providing a comprehensive representation of pig appearances.
The pig detection dataset provides a valuable resource for researchers working on pig detection tasks. It offers a diverse collection of annotated images, allowing for comprehensive algorithm development, evaluation, and benchmarking, ultimately aiding in the development of accurate and robust models.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market/pigs-detection?utm_source=huggingface&utm_medium=cpc&utm_campaign=pigs-detection-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of pigs
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and labels, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes for pigs detection. For each point, the x and y coordinates are provided.
# Example of XML file structure
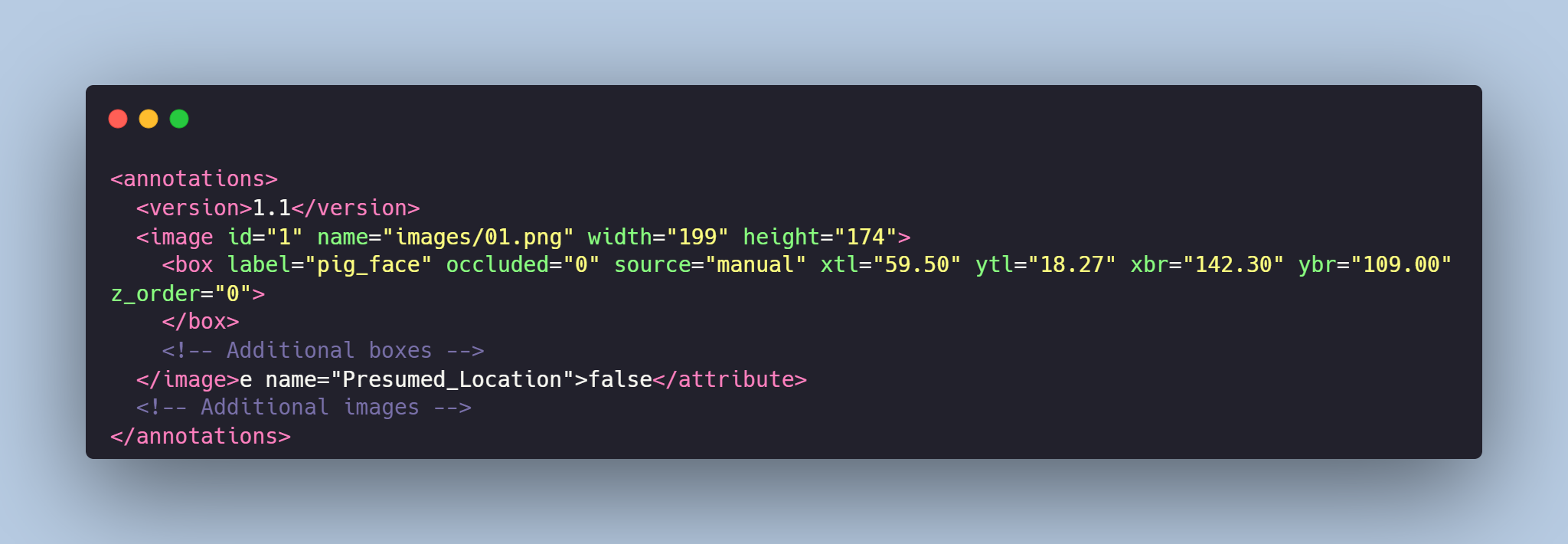
# Pig Detection might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market/pigs-detection?utm_source=huggingface&utm_medium=cpc&utm_campaign=pigs-detection-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
irds/msmarco-passage_trec-dl-hard_fold4 | ---
pretty_name: '`msmarco-passage/trec-dl-hard/fold4`'
viewer: false
source_datasets: ['irds/msmarco-passage']
task_categories:
- text-retrieval
---
# Dataset Card for `msmarco-passage/trec-dl-hard/fold4`
The `msmarco-passage/trec-dl-hard/fold4` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
For more information about the dataset, see the [documentation](https://ir-datasets.com/msmarco-passage#msmarco-passage/trec-dl-hard/fold4).
# Data
This dataset provides:
- `queries` (i.e., topics); count=10
- `qrels`: (relevance assessments); count=716
- For `docs`, use [`irds/msmarco-passage`](https://huggingface.co/datasets/irds/msmarco-passage)
## Usage
```python
from datasets import load_dataset
queries = load_dataset('irds/msmarco-passage_trec-dl-hard_fold4', 'queries')
for record in queries:
record # {'query_id': ..., 'text': ...}
qrels = load_dataset('irds/msmarco-passage_trec-dl-hard_fold4', 'qrels')
for record in qrels:
record # {'query_id': ..., 'doc_id': ..., 'relevance': ...}
```
Note that calling `load_dataset` will download the dataset (or provide access instructions when it's not public) and make a copy of the
data in 🤗 Dataset format.
## Citation Information
```
@article{Mackie2021DlHard,
title={How Deep is your Learning: the DL-HARD Annotated Deep Learning Dataset},
author={Iain Mackie and Jeffrey Dalton and Andrew Yates},
journal={ArXiv},
year={2021},
volume={abs/2105.07975}
}
@inproceedings{Bajaj2016Msmarco,
title={MS MARCO: A Human Generated MAchine Reading COmprehension Dataset},
author={Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, Tong Wang},
booktitle={InCoCo@NIPS},
year={2016}
}
```
|
JaehyungKim/p2c_dynasent2_all | ---
license: other
license_name: following-original-dataset
license_link: LICENSE
---
|
adxtya/llama_test | ---
license: mit
---
|
YBXL/JAMA_Reasoning_test_Rare_cot_test | ---
dataset_info:
features:
- name: id
dtype: string
- name: query
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 568546
num_examples: 250
- name: valid
num_bytes: 568546
num_examples: 250
- name: test
num_bytes: 568546
num_examples: 250
download_size: 873030
dataset_size: 1705638
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: valid
path: data/valid-*
- split: test
path: data/test-*
---
|
0-hero/prompt-perfect | ---
language:
- en
size_categories:
- 1M<n<10M
tags:
- synthetic
- distillation
- GPT-4
- GPT-3.5
---
# Scoring popular datasets with ["Self-Alignment with Instruction Backtranslation"](https://arxiv.org/abs/2308.06259) prompt
### 35 datasets scored (>6B tokens)
## Scoring Models used
- gpt-3.5-turbo-16k
- gpt-3.5-turbo-1106
- gpt-3.5-turbo-0125
## All datasets have 2 additional columns
- score - Response from the model including CoT (if provided)
- extracted_score - Extracted score from the score column as int
## Datasets Scored by Prompt (Needs to be updated)
#### Original Score Prompt from paper
- [airoboros-2.1](https://huggingface.co/datasets/jondurbin/airoboros-2.1)
- [alpaca-gpt4](https://huggingface.co/datasets/vicgalle/alpaca-gpt4)
- [dolphin](https://huggingface.co/datasets/cognitivecomputations/dolphin) - Only GPT-4 responses (flan1m-alpaca-uncensored-deduped.jsonl)
- [open-platypus](https://huggingface.co/datasets/garage-bAInd/Open-Platypus)
- [orca_mini_v1](https://huggingface.co/datasets/pankajmathur/orca_mini_v1_dataset)
- [SlimOrca-Dedup](https://huggingface.co/datasets/Open-Orca/SlimOrca-Dedup)
- [Synthia-1.3](https://huggingface.co/datasets/migtissera/Synthia-v1.3)
- [wizard_alpaca_dolly_orca](https://huggingface.co/datasets/nRuaif/wizard_alpaca_dolly_orca)
#### Conversation Score Prompt (Modified)
- [Capybara](https://huggingface.co/datasets/LDJnr/Capybara)
- [ultrachat](https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k)
## Score Breakdown (Needs to be updated)
| Dataset | 5 | 4 | 3 | 2 | 1 | 0 |
|-------------------------|----------:|----------:|----------:|----------:|----------:|----------:|
| dolphin | 80.232373 | 10.841314 | 2.217159 | 3.075088 | 3.63371 | 0.000356 |
| open-platypus | 76.390115 | 10.779909 | 3.093156 | 3.558533 | 6.178288 | 0 |
| Capybara | 73.57241 | 12.851431 | 3.005123 | 4.117206 | 6.435087 | 0.018743 |
| airoboros-2.1 | 69.869994 | 26.695312 | 1.322096 | 1.076957 | 1.035641 | 0 |
| alpaca-gpt4 | 65.421891 | 31.797554 | 1.301823 | 0.824937 | 0.653796 | 0 |
| wizard_alpaca_dolly_orca| 63.898674 | 32.68317 | 1.752752 | 0.894614 | 0.769829 | 0.00096 |
| ultrachat | 50.213948 | 40.684169 | 5.741387 | 2.880979 | 0.478934 | 0.000582 |
| orca_mini_v1 | 46.351518 | 49.313846 | 1.568606 | 1.898745 | 0.867284 | 0 |
| Synthia-v1.3 | 39.262214 | 52.335033 | 2.627859 | 3.38096 | 2.392252 | 0.001683 |
| SlimOrca-Dedup | 29.987262 | 55.132314 | 7.122872 | 2.998424 | 4.759127 | 0 |
## Prompts (Need to be updated)
#### Original Score Prompt from paper
```
Below is an instruction from an user and a candidate answer. Evaluate whether or not the answer is a good example of how AI Assistant should respond to the user’s instruction. Please assign a score using the following 5-point scale:
1: It means the answer is incomplete, vague, off-topic, controversial, or not exactly what the user asked for. For example, some content seems missing, numbered list does not start from the beginning, the opening sentence repeats user’s question. Or the response is from another person’s perspective with their personal experience (e.g. taken from blog posts), or looks like an answer from a forum. Or it contains promotional text, navigation text, or other irrelevant information.
2: It means the answer addresses most of the asks from the user. It does not directly address the user’s question. For example, it only provides a high-level methodology instead of the exact solution to user’s question.
3: It means the answer is helpful but not written by an AI Assistant. It addresses all the basic asks from the user. It is complete and self contained with the drawback that the response is not written from an AI assistant’s perspective, but from other people’s perspective. The content looks like an excerpt from a blog post, web page, or web search results. For example, it contains personal experience or opinion, mentions comments section, or share on social media, etc.
4: It means the answer is written from an AI assistant’s perspective with a clear focus of addressing the instruction. It provide a complete, clear, and comprehensive response to user’s question or instruction without missing or irrelevant information. It is well organized, self-contained, and written in a helpful tone. It has minor room for improvement, e.g. more concise and focused.
5: It means it is a perfect answer from an AI Assistant. It has a clear focus on being a helpful AI Assistant, where the response looks like intentionally written to address the user’s question or instruction without any irrelevant sentences. The answer provides high quality content, demonstrating expert knowledge in the area, is very well written, logical, easy-to-follow, engaging and insightful.
Please first provide a chain of thought brief reasoning you used to derive the rating score, and
then write "Score: <rating>" in the last line.
```
#### Conversation Score Prompt (Modified)
```
Below are a series of user instructions and corresponding candidate answers in a multi-turn conversation. Evaluate whether or not each answer is a good example of how the AI Assistant should respond to the user’s instructions in the context of an ongoing dialogue. Please assign a score using the following 5-point scale:
1: The answer is incomplete, vague, off-topic, controversial, or fails to build upon previous turns in the conversation. It might ignore context provided earlier, repeat information unnecessarily, or deviate from the conversational flow. Examples include missing content that should logically follow from earlier turns, responses that reset the conversation without acknowledging past interactions, or introducing irrelevant or promotional information.
2: The answer addresses the user's concerns but misses key elements of context or nuance from previous turns. It might provide a generally correct direction but fails to leverage the multi-turn nature of the conversation, such as not recalling information provided earlier or not sufficiently building upon it.
3: The answer is helpful and acknowledges the multi-turn context but reads more like a series of standalone responses rather than a cohesive conversation. It covers the basic asks from the user across multiple turns but might lack a seamless integration of conversation history or a sense of ongoing dialogue.
4: The answer is well-tailored to a multi-turn conversation, showing awareness of previous interactions and building upon them effectively. It is clear, comprehensive, and maintains a conversational flow, with only minor room for improvement, such as refining the integration of past and current turns or enhancing conversational fluidity.
5: The answer exemplifies perfect handling of a multi-turn conversation by an AI Assistant. It seamlessly integrates information from previous turns, providing high-quality, context-aware responses that demonstrate expert knowledge and maintain a logical, engaging, and insightful dialogue flow throughout.
Please first provide a brief chain of thought reasoning you used to derive the rating score, considering how well the AI Assistant maintains and builds upon the conversational context. Then write "Score: <rating>" in the last line.
``` |
CyberHarem/suomi_girlsfrontline | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of suomi/スオミ/索米 (Girls' Frontline)
This is the dataset of suomi/スオミ/索米 (Girls' Frontline), containing 500 images and their tags.
The core tags of this character are `blue_eyes, hair_ornament, hairband, bangs, long_hair, breasts, snowflake_hair_ornament, blonde_hair, medium_breasts, hair_between_eyes, blue_hairband, sidelocks, one_side_up`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:----------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 500 | 780.62 MiB | [Download](https://huggingface.co/datasets/CyberHarem/suomi_girlsfrontline/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 500 | 399.54 MiB | [Download](https://huggingface.co/datasets/CyberHarem/suomi_girlsfrontline/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 1278 | 909.76 MiB | [Download](https://huggingface.co/datasets/CyberHarem/suomi_girlsfrontline/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 500 | 670.31 MiB | [Download](https://huggingface.co/datasets/CyberHarem/suomi_girlsfrontline/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 1278 | 1.31 GiB | [Download](https://huggingface.co/datasets/CyberHarem/suomi_girlsfrontline/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/suomi_girlsfrontline',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:----------------------------------|:----------------------------------|:----------------------------------|:----------------------------------|:----------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 6 |  |  |  |  |  | 1girl, blue_jacket, blue_skirt, blush, holding_gun, long_sleeves, solo, submachine_gun, white_thighhighs, closed_mouth, looking_at_viewer, striped_skirt, white_gloves, white_background, zettai_ryouiki, light_brown_hair, shirt |
| 1 | 13 |  |  |  |  |  | 1girl, blush, solo, belt, long_sleeves, looking_at_viewer, white_gloves, blue_skirt, blue_jacket, vertical-striped_skirt, white_thighhighs, zettai_ryouiki, closed_mouth, cowboy_shot, smile, simple_background |
| 2 | 10 |  |  |  |  |  | 1girl, long_sleeves, white_gloves, blue_jacket, blush, looking_at_viewer, simple_background, solo, brown_belt, fur_trim, white_background, upper_body, belt_buckle, light_brown_hair, open_mouth, parted_lips |
| 3 | 15 |  |  |  |  |  | 1girl, bare_shoulders, blue_dress, blush, official_alternate_costume, solo, looking_at_viewer, simple_background, white_background, long_sleeves, off-shoulder_dress, cleavage, fur-trimmed_dress, hair_ribbon, closed_mouth, collarbone, see-through, blue_ribbon, holding, upper_body, fur_collar, open_mouth, smile |
| 4 | 7 |  |  |  |  |  | 1girl, blue_dress, long_sleeves, looking_at_viewer, official_alternate_costume, solo, white_thighhighs, bare_shoulders, blush, fur-trimmed_dress, off-shoulder_dress, closed_mouth, holding, detached_sleeves, zettai_ryouiki, blue_bow, full_body, light_brown_hair, see-through_sleeves, skirt |
| 5 | 24 |  |  |  |  |  | 1girl, solo, wedding_dress, bridal_veil, looking_at_viewer, bare_shoulders, white_dress, blush, tiara, official_alternate_costume, closed_mouth, collarbone, white_gloves, cleavage, smile, earrings, white_background, simple_background |
| 6 | 26 |  |  |  |  |  | 1girl, blush, collarbone, frilled_bikini, solo, white_bikini, bare_shoulders, looking_at_viewer, navel, official_alternate_costume, single_hair_bun, single_side_bun, cleavage, white_background, simple_background, off_shoulder, stomach, closed_mouth, cowboy_shot, halterneck, open_jacket, blue_jacket |
| 7 | 7 |  |  |  |  |  | 1girl, blue_sky, blush, cleavage, cloud, collarbone, day, frilled_bikini, navel, ocean, official_alternate_costume, outdoors, single_hair_bun, single_side_bun, solo, white_bikini, bare_shoulders, cowboy_shot, jacket, looking_at_viewer, beach, closed_mouth, off_shoulder, stomach, groin, halterneck, horizon, open_clothes, smile, standing |
| 8 | 5 |  |  |  |  |  | 1girl, blush, solo, closed_mouth, long_sleeves, looking_at_viewer, smile, white_shirt, bowtie, pleated_skirt, red_bow, school_uniform |
| 9 | 6 |  |  |  |  |  | 1girl, blush, long_sleeves, looking_at_viewer, obi, solo, wide_sleeves, blue_kimono, closed_mouth, simple_background, white_background, alternate_costume, floral_print, full_body, holding, print_kimono, smile, standing |
| 10 | 10 |  |  |  |  |  | 1girl, hetero, penis, 1boy, blush, nipples, solo_focus, ass, vaginal, completely_nude, open_mouth, looking_at_viewer, sex_from_behind, anus, bar_censor, cum_in_pussy, looking_back |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | blue_jacket | blue_skirt | blush | holding_gun | long_sleeves | solo | submachine_gun | white_thighhighs | closed_mouth | looking_at_viewer | striped_skirt | white_gloves | white_background | zettai_ryouiki | light_brown_hair | shirt | belt | vertical-striped_skirt | cowboy_shot | smile | simple_background | brown_belt | fur_trim | upper_body | belt_buckle | open_mouth | parted_lips | bare_shoulders | blue_dress | official_alternate_costume | off-shoulder_dress | cleavage | fur-trimmed_dress | hair_ribbon | collarbone | see-through | blue_ribbon | holding | fur_collar | detached_sleeves | blue_bow | full_body | see-through_sleeves | skirt | wedding_dress | bridal_veil | white_dress | tiara | earrings | frilled_bikini | white_bikini | navel | single_hair_bun | single_side_bun | off_shoulder | stomach | halterneck | open_jacket | blue_sky | cloud | day | ocean | outdoors | jacket | beach | groin | horizon | open_clothes | standing | white_shirt | bowtie | pleated_skirt | red_bow | school_uniform | obi | wide_sleeves | blue_kimono | alternate_costume | floral_print | print_kimono | hetero | penis | 1boy | nipples | solo_focus | ass | vaginal | completely_nude | sex_from_behind | anus | bar_censor | cum_in_pussy | looking_back |
|----:|----------:|:----------------------------------|:----------------------------------|:----------------------------------|:----------------------------------|:----------------------------------|:--------|:--------------|:-------------|:--------|:--------------|:---------------|:-------|:-----------------|:-------------------|:---------------|:--------------------|:----------------|:---------------|:-------------------|:-----------------|:-------------------|:--------|:-------|:-------------------------|:--------------|:--------|:--------------------|:-------------|:-----------|:-------------|:--------------|:-------------|:--------------|:-----------------|:-------------|:-----------------------------|:---------------------|:-----------|:--------------------|:--------------|:-------------|:--------------|:--------------|:----------|:-------------|:-------------------|:-----------|:------------|:----------------------|:--------|:----------------|:--------------|:--------------|:--------|:-----------|:-----------------|:---------------|:--------|:------------------|:------------------|:---------------|:----------|:-------------|:--------------|:-----------|:--------|:------|:--------|:-----------|:---------|:--------|:--------|:----------|:---------------|:-----------|:--------------|:---------|:----------------|:----------|:-----------------|:------|:---------------|:--------------|:--------------------|:---------------|:---------------|:---------|:--------|:-------|:----------|:-------------|:------|:----------|:------------------|:------------------|:-------|:-------------|:---------------|:---------------|
| 0 | 6 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 13 |  |  |  |  |  | X | X | X | X | | X | X | | X | X | X | | X | | X | | | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 2 | 10 |  |  |  |  |  | X | X | | X | | X | X | | | | X | | X | X | | X | | | | | | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 3 | 15 |  |  |  |  |  | X | | | X | | X | X | | | X | X | | | X | | | | | | | X | X | | | X | | X | | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 4 | 7 |  |  |  |  |  | X | | | X | | X | X | | X | X | X | | | | X | X | | | | | | | | | | | | | X | X | X | X | | X | | | | | X | | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 5 | 24 |  |  |  |  |  | X | | | X | | | X | | | X | X | | X | X | | | | | | | X | X | | | | | | | X | | X | | X | | | X | | | | | | | | | | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 6 | 26 |  |  |  |  |  | X | X | | X | | | X | | | X | X | | | X | | | | | | X | | X | | | | | | | X | | X | | X | | | X | | | | | | | | | | | | | | | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 7 | 7 |  |  |  |  |  | X | | | X | | | X | | | X | X | | | | | | | | | X | X | | | | | | | | X | | X | | X | | | X | | | | | | | | | | | | | | | X | X | X | X | X | X | X | X | | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | |
| 8 | 5 |  |  |  |  |  | X | | | X | | X | X | | | X | X | | | | | | | | | | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | X | X | X | X | X | | | | | | | | | | | | | | | | | | | |
| 9 | 6 |  |  |  |  |  | X | | | X | | X | X | | | X | X | | | X | | | | | | | X | X | | | | | | | | | | | | | | | | | X | | | | X | | | | | | | | | | | | | | | | | | | | | | | | | | | X | | | | | | X | X | X | X | X | X | | | | | | | | | | | | | |
| 10 | 10 |  |  |  |  |  | X | | | X | | | | | | | X | | | | | | | | | | | | | | | | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X |
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.