
datasetId stringlengths 2 117 | card stringlengths 19 1.01M |
|---|---|
coref-data/conll2012_raw | ---
license: other
configs:
- config_name: english_v4
data_files:
- split: train
path: "english_v4/train-*.parquet"
- split: validation
path: "english_v4/validation-*.parquet"
- split: test
path: "english_v4/test-*.parquet"
- config_name: chinese_v4
data_files:
- split: train
path: "chinese_v4/train-*.parquet"
- split: validation
path: "chinese_v4/validation-*.parquet"
- split: test
path: "chinese_v4/test-*.parquet"
- config_name: arabic_v4
data_files:
- split: train
path: "arabic_v4/train-*.parquet"
- split: validation
path: "arabic_v4/validation-*.parquet"
- split: test
path: "arabic_v4/test-*.parquet"
- config_name: english_v12
data_files:
- split: train
path: "english_v12/train-*.parquet"
- split: validation
path: "english_v12/validation-*.parquet"
- split: test
path: "english_v12/test-*.parquet"
---
# CoNLL-2012 Shared Task
## Dataset Description
- **Homepage:** [CoNLL-2012 Shared Task](https://conll.cemantix.org/2012/data.html), [Author's page](https://cemantix.org/data/ontonotes.html)
- **Repository:** [Mendeley](https://data.mendeley.com/datasets/zmycy7t9h9)
- **Paper:** [Towards Robust Linguistic Analysis using OntoNotes](https://aclanthology.org/W13-3516/)
### Dataset Summary
OntoNotes v5.0 is the final version of OntoNotes corpus, and is a large-scale, multi-genre,
multilingual corpus manually annotated with syntactic, semantic and discourse information.
This dataset is the version of OntoNotes v5.0 extended and is used in the CoNLL-2012 shared task.
It includes v4 train/dev and v9 test data for English/Chinese/Arabic and corrected version v12 train/dev/test data (English only).
The source of data is the Mendeley Data repo [ontonotes-conll2012](https://data.mendeley.com/datasets/zmycy7t9h9), which seems to be as the same as the official data, but users should use this dataset on their own responsibility.
See also summaries from paperwithcode, [OntoNotes 5.0](https://paperswithcode.com/dataset/ontonotes-5-0) and [CoNLL-2012](https://paperswithcode.com/dataset/conll-2012-1)
For more detailed info of the dataset like annotation, tag set, etc., you can refer to the documents in the Mendeley repo mentioned above.
### Languages
V4 data for Arabic, Chinese, English, and V12 data for English
Arabic has certain typos noted at https://github.com/juntaoy/aracoref/blob/main/preprocess_arabic.py
## Dataset Structure
### Data Instances
```
{
{'document_id': 'nw/wsj/23/wsj_2311',
'sentences': [{'part_id': 0,
'words': ['CONCORDE', 'trans-Atlantic', 'flights', 'are', '$', '2, 'to', 'Paris', 'and', '$', '3, 'to', 'London', '.']},
'pos_tags': [25, 18, 27, 43, 2, 12, 17, 25, 11, 2, 12, 17, 25, 7],
'parse_tree': '(TOP(S(NP (NNP CONCORDE) (JJ trans-Atlantic) (NNS flights) )(VP (VBP are) (NP(NP(NP ($ $) (CD 2,400) )(PP (IN to) (NP (NNP Paris) ))) (CC and) (NP(NP ($ $) (CD 3,200) )(PP (IN to) (NP (NNP London) ))))) (. .) ))',
'predicate_lemmas': [None, None, None, 'be', None, None, None, None, None, None, None, None, None, None],
'predicate_framenet_ids': [None, None, None, '01', None, None, None, None, None, None, None, None, None, None],
'word_senses': [None, None, None, None, None, None, None, None, None, None, None, None, None, None],
'speaker': None,
'named_entities': [7, 6, 0, 0, 0, 15, 0, 5, 0, 0, 15, 0, 5, 0],
'srl_frames': [{'frames': ['B-ARG1', 'I-ARG1', 'I-ARG1', 'B-V', 'B-ARG2', 'I-ARG2', 'I-ARG2', 'I-ARG2', 'I-ARG2', 'I-ARG2', 'I-ARG2', 'I-ARG2', 'I-ARG2', 'O'],
'verb': 'are'}],
'coref_spans': [],
{'part_id': 0,
'words': ['In', 'a', 'Centennial', 'Journal', 'article', 'Oct.', '5', ',', 'the', 'fares', 'were', 'reversed', '.']}]}
'pos_tags': [17, 13, 25, 25, 24, 25, 12, 4, 13, 27, 40, 42, 7],
'parse_tree': '(TOP(S(PP (IN In) (NP (DT a) (NML (NNP Centennial) (NNP Journal) ) (NN article) ))(NP (NNP Oct.) (CD 5) ) (, ,) (NP (DT the) (NNS fares) )(VP (VBD were) (VP (VBN reversed) )) (. .) ))',
'predicate_lemmas': [None, None, None, None, None, None, None, None, None, None, None, 'reverse', None],
'predicate_framenet_ids': [None, None, None, None, None, None, None, None, None, None, None, '01', None],
'word_senses': [None, None, None, None, None, None, None, None, None, None, None, None, None],
'speaker': None,
'named_entities': [0, 0, 4, 22, 0, 12, 30, 0, 0, 0, 0, 0, 0],
'srl_frames': [{'frames': ['B-ARGM-LOC', 'I-ARGM-LOC', 'I-ARGM-LOC', 'I-ARGM-LOC', 'I-ARGM-LOC', 'B-ARGM-TMP', 'I-ARGM-TMP', 'O', 'B-ARG1', 'I-ARG1', 'O', 'B-V', 'O'],
'verb': 'reversed'}],
'coref_spans': [],
}
```
### Data Fields
- **`document_id`** (*`str`*): This is a variation on the document filename
- **`sentences`** (*`List[Dict]`*): All sentences of the same document are in a single example for the convenience of concatenating sentences.
Every element in `sentences` is a *`Dict`* composed of the following data fields:
- **`part_id`** (*`int`*) : Some files are divided into multiple parts numbered as 000, 001, 002, ... etc.
- **`words`** (*`List[str]`*) :
- **`pos_tags`** (*`List[ClassLabel]` or `List[str]`*) : This is the Penn-Treebank-style part of speech. When parse information is missing, all parts of speech except the one for which there is some sense or proposition annotation are marked with a XX tag. The verb is marked with just a VERB tag.
- tag set : Note tag sets below are founded by scanning all the data, and I found it seems to be a little bit different from officially stated tag sets. See official documents in the [Mendeley repo](https://data.mendeley.com/datasets/zmycy7t9h9)
- arabic : str. Because pos tag in Arabic is compounded and complex, hard to represent it by `ClassLabel`
- chinese v4 : `datasets.ClassLabel(num_classes=36, names=["X", "AD", "AS", "BA", "CC", "CD", "CS", "DEC", "DEG", "DER", "DEV", "DT", "ETC", "FW", "IJ", "INF", "JJ", "LB", "LC", "M", "MSP", "NN", "NR", "NT", "OD", "ON", "P", "PN", "PU", "SB", "SP", "URL", "VA", "VC", "VE", "VV",])`, where `X` is for pos tag missing
- english v4 : `datasets.ClassLabel(num_classes=49, names=["XX", "``", "$", "''", ",", "-LRB-", "-RRB-", ".", ":", "ADD", "AFX", "CC", "CD", "DT", "EX", "FW", "HYPH", "IN", "JJ", "JJR", "JJS", "LS", "MD", "NFP", "NN", "NNP", "NNPS", "NNS", "PDT", "POS", "PRP", "PRP$", "RB", "RBR", "RBS", "RP", "SYM", "TO", "UH", "VB", "VBD", "VBG", "VBN", "VBP", "VBZ", "WDT", "WP", "WP$", "WRB",])`, where `XX` is for pos tag missing, and `-LRB-`/`-RRB-` is "`(`" / "`)`".
- english v12 : `datasets.ClassLabel(num_classes=51, names="english_v12": ["XX", "``", "$", "''", "*", ",", "-LRB-", "-RRB-", ".", ":", "ADD", "AFX", "CC", "CD", "DT", "EX", "FW", "HYPH", "IN", "JJ", "JJR", "JJS", "LS", "MD", "NFP", "NN", "NNP", "NNPS", "NNS", "PDT", "POS", "PRP", "PRP$", "RB", "RBR", "RBS", "RP", "SYM", "TO", "UH", "VB", "VBD", "VBG", "VBN", "VBP", "VBZ", "VERB", "WDT", "WP", "WP$", "WRB",])`, where `XX` is for pos tag missing, and `-LRB-`/`-RRB-` is "`(`" / "`)`".
- **`parse_tree`** (*`Optional[str]`*) : An serialized NLTK Tree representing the parse. It includes POS tags as pre-terminal nodes. When the parse information is missing, the parse will be `None`.
- **`predicate_lemmas`** (*`List[Optional[str]]`*) : The predicate lemma of the words for which we have semantic role information or word sense information. All other indices are `None`.
- **`predicate_framenet_ids`** (*`List[Optional[int]]`*) : The PropBank frameset ID of the lemmas in predicate_lemmas, or `None`.
- **`word_senses`** (*`List[Optional[float]]`*) : The word senses for the words in the sentence, or None. These are floats because the word sense can have values after the decimal, like 1.1.
- **`speaker`** (*`Optional[str]`*) : This is the speaker or author name where available. Mostly in Broadcast Conversation and Web Log data. When it is not available, it will be `None`.
- **`named_entities`** (*`List[ClassLabel]`*) : The BIO tags for named entities in the sentence.
- tag set : `datasets.ClassLabel(num_classes=37, names=["O", "B-PERSON", "I-PERSON", "B-NORP", "I-NORP", "B-FAC", "I-FAC", "B-ORG", "I-ORG", "B-GPE", "I-GPE", "B-LOC", "I-LOC", "B-PRODUCT", "I-PRODUCT", "B-DATE", "I-DATE", "B-TIME", "I-TIME", "B-PERCENT", "I-PERCENT", "B-MONEY", "I-MONEY", "B-QUANTITY", "I-QUANTITY", "B-ORDINAL", "I-ORDINAL", "B-CARDINAL", "I-CARDINAL", "B-EVENT", "I-EVENT", "B-WORK_OF_ART", "I-WORK_OF_ART", "B-LAW", "I-LAW", "B-LANGUAGE", "I-LANGUAGE",])`
- **`srl_frames`** (*`List[{"word":str, "frames":List[str]}]`*) : A dictionary keyed by the verb in the sentence for the given Propbank frame labels, in a BIO format.
- **`coref spans`** (*`List[List[int]]`*) : The spans for entity mentions involved in coreference resolution within the sentence. Each element is a tuple composed of (cluster_id, start_index, end_index). Indices are inclusive.
### Data Splits
Each dataset (arabic_v4, chinese_v4, english_v4, english_v12) has 3 splits: _train_, _validation_, and _test_
### Citation Information
```
@inproceedings{pradhan-etal-2013-towards,
title = "Towards Robust Linguistic Analysis using {O}nto{N}otes",
author = {Pradhan, Sameer and
Moschitti, Alessandro and
Xue, Nianwen and
Ng, Hwee Tou and
Bj{\"o}rkelund, Anders and
Uryupina, Olga and
Zhang, Yuchen and
Zhong, Zhi},
booktitle = "Proceedings of the Seventeenth Conference on Computational Natural Language Learning",
month = aug,
year = "2013",
address = "Sofia, Bulgaria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W13-3516",
pages = "143--152",
}
```
### Contributions
Based on dataset script by [@richarddwang](https://github.com/richarddwang) |
rabib-jahin/Concept-Art | ---
dataset_info:
features:
- name: image
dtype: image
- name: conditioning_image
dtype: image
- name: text
dtype: string
- name: params
struct:
- name: downsample
dtype: int64
- name: grid_size
dtype: int64
- name: high_threshold
dtype: int64
- name: low_threshold
dtype: int64
- name: sigma
dtype: float64
splits:
- name: train
num_bytes: 1972101386.0
num_examples: 5264
download_size: 1971873386
dataset_size: 1972101386.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
zjko/sample-dataset | ---
license: apache-2.0
---
|
bsankar/github-issues | ---
dataset_info:
features:
- name: url
dtype: string
- name: repository_url
dtype: string
- name: labels_url
dtype: string
- name: comments_url
dtype: string
- name: events_url
dtype: string
- name: html_url
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: number
dtype: int64
- name: title
dtype: string
- name: user
struct:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: site_admin
dtype: bool
- name: labels
list:
- name: id
dtype: int64
- name: node_id
dtype: string
- name: url
dtype: string
- name: name
dtype: string
- name: color
dtype: string
- name: default
dtype: bool
- name: description
dtype: string
- name: state
dtype: string
- name: locked
dtype: bool
- name: assignee
struct:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: site_admin
dtype: bool
- name: assignees
list:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: site_admin
dtype: bool
- name: milestone
struct:
- name: url
dtype: string
- name: html_url
dtype: string
- name: labels_url
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: number
dtype: int64
- name: title
dtype: string
- name: description
dtype: string
- name: creator
struct:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: site_admin
dtype: bool
- name: open_issues
dtype: int64
- name: closed_issues
dtype: int64
- name: state
dtype: string
- name: created_at
dtype: timestamp[s]
- name: updated_at
dtype: timestamp[s]
- name: due_on
dtype: 'null'
- name: closed_at
dtype: 'null'
- name: comments
sequence: string
- name: created_at
dtype: timestamp[s]
- name: updated_at
dtype: timestamp[s]
- name: closed_at
dtype: timestamp[s]
- name: author_association
dtype: string
- name: active_lock_reason
dtype: 'null'
- name: draft
dtype: bool
- name: pull_request
struct:
- name: url
dtype: string
- name: html_url
dtype: string
- name: diff_url
dtype: string
- name: patch_url
dtype: string
- name: merged_at
dtype: timestamp[s]
- name: body
dtype: string
- name: reactions
struct:
- name: url
dtype: string
- name: total_count
dtype: int64
- name: '+1'
dtype: int64
- name: '-1'
dtype: int64
- name: laugh
dtype: int64
- name: hooray
dtype: int64
- name: confused
dtype: int64
- name: heart
dtype: int64
- name: rocket
dtype: int64
- name: eyes
dtype: int64
- name: timeline_url
dtype: string
- name: performed_via_github_app
dtype: 'null'
- name: state_reason
dtype: string
- name: is_pull_request
dtype: bool
- name: is_closed
dtype: bool
- name: close_time
dtype: duration[us]
splits:
- name: train
num_bytes: 12125043
num_examples: 1000
download_size: 3282501
dataset_size: 12125043
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "github-issues"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ostapeno/self_instruct | ---
dataset_info:
features:
- name: dataset
dtype: string
- name: id
dtype: string
- name: messages
list:
- name: role
dtype: string
- name: content
dtype: string
splits:
- name: train
num_bytes: 27516583
num_examples: 82439
download_size: 11204230
dataset_size: 27516583
---
# Dataset Card for "self_instruct"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/oumae_kumiko_soundeuphonium | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of Oumae Kumiko/黄前久美子 (Sound! Euphonium)
This is the dataset of Oumae Kumiko/黄前久美子 (Sound! Euphonium), containing 441 images and their tags.
The core tags of this character are `brown_hair, short_hair, brown_eyes`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:-----------------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 441 | 321.73 MiB | [Download](https://huggingface.co/datasets/CyberHarem/oumae_kumiko_soundeuphonium/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 1200 | 441 | 321.57 MiB | [Download](https://huggingface.co/datasets/CyberHarem/oumae_kumiko_soundeuphonium/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 882 | 590.63 MiB | [Download](https://huggingface.co/datasets/CyberHarem/oumae_kumiko_soundeuphonium/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/oumae_kumiko_soundeuphonium',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 5 |  |  |  |  |  | 1girl, blue_sailor_collar, blurry_background, blush, kitauji_high_school_uniform, pink_neckerchief, serafuku, solo, white_shirt, open_mouth, outdoors, short_sleeves, looking_at_viewer |
| 1 | 23 |  |  |  |  |  | 1girl, blue_sailor_collar, kitauji_high_school_uniform, pink_neckerchief, serafuku, white_shirt, short_sleeves, solo, blush, indoors, blue_skirt, pleated_skirt, standing, open_mouth, closed_mouth, looking_at_viewer |
| 2 | 10 |  |  |  |  |  | 1girl, kitauji_high_school_uniform, looking_at_viewer, portrait, serafuku, solo, closed_mouth, blurry_background, blush, indoors, blue_sailor_collar, brown_shirt, white_sailor_collar |
| 3 | 6 |  |  |  |  |  | 1girl, brown_shirt, kitauji_high_school_uniform, red_neckerchief, serafuku, solo, white_sailor_collar, blush, closed_mouth, looking_at_viewer, upper_body, ponytail |
| 4 | 5 |  |  |  |  |  | 1girl, blush, brown_shirt, kitauji_high_school_uniform, red_neckerchief, serafuku, solo, white_sailor_collar, open_mouth, parted_lips, indoors, long_sleeves, looking_to_the_side, window |
| 5 | 5 |  |  |  |  |  | 1girl, blush, brown_shirt, from_side, kitauji_high_school_uniform, profile, red_neckerchief, serafuku, solo, upper_body, white_sailor_collar, blurry_background, closed_eyes, closed_mouth, open_mouth, outdoors, tree |
| 6 | 13 |  |  |  |  |  | 1girl, brown_shirt, brown_skirt, kitauji_high_school_uniform, pleated_skirt, red_neckerchief, solo, white_sailor_collar, long_sleeves, looking_at_viewer, blush, smile, brown_serafuku, closed_mouth |
| 7 | 6 |  |  |  |  |  | 1girl, kitauji_high_school_uniform, playing_instrument, serafuku, solo, blush, blurry, ponytail, sailor_collar |
| 8 | 7 |  |  |  |  |  | 1girl, portrait, solo, blush, looking_at_viewer, blurry, close-up, closed_mouth, anime_coloring |
| 9 | 6 |  |  |  |  |  | 1girl, open_mouth, short_sleeves, solo, t-shirt, white_shirt, blush, collarbone, guitar_case, night, outdoors, backpack, looking_at_viewer |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | blue_sailor_collar | blurry_background | blush | kitauji_high_school_uniform | pink_neckerchief | serafuku | solo | white_shirt | open_mouth | outdoors | short_sleeves | looking_at_viewer | indoors | blue_skirt | pleated_skirt | standing | closed_mouth | portrait | brown_shirt | white_sailor_collar | red_neckerchief | upper_body | ponytail | parted_lips | long_sleeves | looking_to_the_side | window | from_side | profile | closed_eyes | tree | brown_skirt | smile | brown_serafuku | playing_instrument | blurry | sailor_collar | close-up | anime_coloring | t-shirt | collarbone | guitar_case | night | backpack |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:---------------------|:--------------------|:--------|:------------------------------|:-------------------|:-----------|:-------|:--------------|:-------------|:-----------|:----------------|:--------------------|:----------|:-------------|:----------------|:-----------|:---------------|:-----------|:--------------|:----------------------|:------------------|:-------------|:-----------|:--------------|:---------------|:----------------------|:---------|:------------|:----------|:--------------|:-------|:--------------|:--------|:-----------------|:---------------------|:---------|:----------------|:-----------|:-----------------|:----------|:-------------|:--------------|:--------|:-----------|
| 0 | 5 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 23 |  |  |  |  |  | X | X | | X | X | X | X | X | X | X | | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 2 | 10 |  |  |  |  |  | X | X | X | X | X | | X | X | | | | | X | X | | | | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | |
| 3 | 6 |  |  |  |  |  | X | | | X | X | | X | X | | | | | X | | | | | X | | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | |
| 4 | 5 |  |  |  |  |  | X | | | X | X | | X | X | | X | | | | X | | | | | | X | X | X | | | X | X | X | X | | | | | | | | | | | | | | | | | |
| 5 | 5 |  |  |  |  |  | X | | X | X | X | | X | X | | X | X | | | | | | | X | | X | X | X | X | | | | | | X | X | X | X | | | | | | | | | | | | | |
| 6 | 13 |  |  |  |  |  | X | | | X | X | | | X | | | | | X | | | X | | X | | X | X | X | | | | X | | | | | | | X | X | X | | | | | | | | | | |
| 7 | 6 |  |  |  |  |  | X | | | X | X | | X | X | | | | | | | | | | | | | | | | X | | | | | | | | | | | | X | X | X | | | | | | | |
| 8 | 7 |  |  |  |  |  | X | | | X | | | | X | | | | | X | | | | | X | X | | | | | | | | | | | | | | | | | | X | | X | X | | | | | |
| 9 | 6 |  |  |  |  |  | X | | | X | | | | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | X | X | X | X | X |
|
projecte-aina/casum | ---
annotations_creators:
- machine-generated
language_creators:
- expert-generated
language:
- ca
license:
- cc-by-nc-4.0
multilinguality:
- monolingual
size_categories:
- unknown
source_datasets: []
task_categories:
- summarization
task_ids: []
pretty_name: casum
---
# Dataset Card for CaSum
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Paper:** [Sequence to Sequence Resources for Catalan](https://arxiv.org/pdf/2202.06871.pdf)
- **Point of Contact:** langtech@bsc.es
### Dataset Summary
CaSum is a summarization dataset. It is extracted from a newswire corpus crawled from the Catalan News Agency ([Agència Catalana de Notícies; ACN](https://www.acn.cat/)). The corpus consists of 217,735 instances that are composed by the headline and the body.
### Supported Tasks and Leaderboards
The dataset can be used to train a model for abstractive summarization. Success on this task is typically measured by achieving a high Rouge score. The [mbart-base-ca-casum](https://huggingface.co/projecte-aina/bart-base-ca-casum) model currently achieves a 41.39.
### Languages
The dataset is in Catalan (`ca-ES`).
## Dataset Structure
### Data Instances
```
{
'summary': 'Mapfre preveu ingressar 31.000 milions d’euros al tancament de 2018',
'text': 'L’asseguradora llançarà la seva filial Verti al mercat dels EUA a partir de 2017 ACN Madrid.-Mapfre preveu assolir uns ingressos de 31.000 milions d'euros al tancament de 2018 i destinarà a retribuir els seus accionistes com a mínim el 50% dels beneficis del grup durant el període 2016-2018, amb una rendibilitat mitjana a l’entorn del 5%, segons ha anunciat la companyia asseguradora durant la celebració aquest divendres de la seva junta general d’accionistes. La firma asseguradora també ha avançat que llançarà la seva filial d’automoció i llar al mercat dels EUA a partir de 2017. Mapfre ha recordat durant la junta que va pagar més de 540 milions d'euros en impostos el 2015, amb una taxa impositiva efectiva del 30,4 per cent. La companyia també ha posat en marxa el Pla de Sostenibilitat 2016-2018 i el Pla de Transparència Activa, “que han de contribuir a afermar la visió de Mapfre com a asseguradora global de confiança”, segons ha informat en un comunicat.'
}
```
### Data Fields
- `summary` (str): Summary of the piece of news
- `text` (str): The text of the piece of news
### Data Splits
We split our dataset into train, dev and test splits
- train: 197,735 examples
- validation: 10,000 examples
- test: 10,000 examples
## Dataset Creation
### Curation Rationale
We created this corpus to contribute to the development of language models in Catalan, a low-resource language. There exist few resources for summarization in Catalan.
### Source Data
#### Initial Data Collection and Normalization
We obtained each headline and its corresponding body of each news piece on the Catalan News Agency ([Agència Catalana de Notícies; ACN](https://www.acn.cat/)) website and applied the following cleaning pipeline: deduplicating the documents, removing the documents with empty attributes, and deleting some boilerplate sentences.
#### Who are the source language producers?
The news portal Catalan News Agency ([Agència Catalana de Notícies; ACN](https://www.acn.cat/)).
### Annotations
The dataset is unannotated.
#### Annotation process
[N/A]
#### Who are the annotators?
[N/A]
### Personal and Sensitive Information
Since all data comes from public websites, no anonymization process was performed.
## Considerations for Using the Data
### Social Impact of Dataset
We hope this corpus contributes to the development of summarization models in Catalan, a low-resource language.
### Discussion of Biases
We are aware that since the data comes from unreliable web pages, some biases may be present in the dataset. Nonetheless, we have not applied any steps to reduce their impact.
### Other Known Limitations
[N/A]
## Additional Information
### Dataset Curators
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@bsc.es)
This work was funded by MT4All CEF project and [Departament de la Vicepresidència i de Polítiques Digitals i Territori de la Generalitat de Catalunya](https://politiquesdigitals.gencat.cat/ca/inici/index.html#googtrans(ca|en) within the framework of [Projecte AINA](https://politiquesdigitals.gencat.cat/ca/economia/catalonia-ai/aina).
### Licensing information
[Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/).
### BibTeX citation
If you use any of these resources (datasets or models) in your work, please cite our latest preprint:
```bibtex
@misc{degibert2022sequencetosequence,
title={Sequence-to-Sequence Resources for Catalan},
author={Ona de Gibert and Ksenia Kharitonova and Blanca Calvo Figueras and Jordi Armengol-Estapé and Maite Melero},
year={2022},
eprint={2202.06871},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
[N/A] |
cnmoro/WizardVicuna-PTBR-Instruct-Clean | ---
license: apache-2.0
---
|
hugfaceguy0001/FamousNovels | ---
dataset_info:
- config_name: V2
features:
- name: title
dtype: string
- name: author
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 729958627
num_examples: 1589
download_size: 487948266
dataset_size: 729958627
- config_name: default
features:
- name: title
dtype: string
- name: author
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 159881188
num_examples: 334
download_size: 107391809
dataset_size: 159881188
configs:
- config_name: V2
data_files:
- split: train
path: V2/train-*
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
manishiitg/jondurbin-truthy-dpo-v0.1 | ---
dataset_info:
features:
- name: id
dtype: string
- name: source
dtype: string
- name: system
dtype: string
- name: prompt
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
splits:
- name: train
num_bytes: 4768473
num_examples: 2032
download_size: 1984224
dataset_size: 4768473
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
EJinHF/SQuALITY_retrieve | ---
task_categories:
- summarization
language:
- en
--- |
adnankarim/urdu_asr_data | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 22930938703.12
num_examples: 98189
download_size: 22145178407
dataset_size: 22930938703.12
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ovior/twitter_dataset_1713054391 | ---
dataset_info:
features:
- name: id
dtype: string
- name: tweet_content
dtype: string
- name: user_name
dtype: string
- name: user_id
dtype: string
- name: created_at
dtype: string
- name: url
dtype: string
- name: favourite_count
dtype: int64
- name: scraped_at
dtype: string
- name: image_urls
dtype: string
splits:
- name: train
num_bytes: 2315231
num_examples: 7193
download_size: 1301228
dataset_size: 2315231
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
quocanh34/soict_test_dataset | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: id
dtype: string
splits:
- name: train
num_bytes: 174203109.625
num_examples: 1299
download_size: 164141076
dataset_size: 174203109.625
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "soict_test_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Slichi/Orslok | ---
license: openrail
---
|
hippocrates/emrqaQA_risk_train | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: valid
path: data/valid-*
dataset_info:
features:
- name: id
dtype: int64
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: text
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 32922109
num_examples: 52467
- name: valid
num_bytes: 5505022
num_examples: 8359
download_size: 3101626
dataset_size: 38427131
---
# Dataset Card for "emrqaQA_risk_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
wiki_summary | ---
annotations_creators:
- no-annotation
language_creators:
- crowdsourced
language:
- fa
license:
- apache-2.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text2text-generation
- translation
- question-answering
- summarization
task_ids:
- abstractive-qa
- explanation-generation
- extractive-qa
- open-domain-qa
- open-domain-abstractive-qa
- text-simplification
pretty_name: WikiSummary
dataset_info:
features:
- name: id
dtype: string
- name: link
dtype: string
- name: title
dtype: string
- name: article
dtype: string
- name: highlights
dtype: string
splits:
- name: train
num_bytes: 207186608
num_examples: 45654
- name: test
num_bytes: 25693509
num_examples: 5638
- name: validation
num_bytes: 23130954
num_examples: 5074
download_size: 255168504
dataset_size: 256011071
---
# Dataset Card for [Needs More Information]
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/m3hrdadfi/wiki-summary
- **Repository:** https://github.com/m3hrdadfi/wiki-summary
- **Paper:** [More Information Needed]
- **Leaderboard:** [More Information Needed]
- **Point of Contact:** [Mehrdad Farahani](mailto:m3hrdadphi@gmail.com)
### Dataset Summary
The dataset extracted from Persian Wikipedia into the form of articles and highlights and cleaned the dataset into pairs of articles and highlights and reduced the articles' length (only version 1.0.0) and highlights' length to a maximum of 512 and 128, respectively, suitable for parsBERT. This dataset is created to achieve state-of-the-art results on some interesting NLP tasks like Text Summarization.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
The text in the dataset is in Percy.
## Dataset Structure
### Data Instances
```
{
'id' :'0598cfd2ac491a928615945054ab7602034a8f4f',
'link': 'https://fa.wikipedia.org/wiki/انقلاب_1917_روسیه',
'title': 'انقلاب 1917 روسیه',
'article': 'نخست انقلاب فوریه ۱۹۱۷ رخ داد . در این انقلاب پس از یکسری اعتصابات ، تظاهرات و درگیریها ، نیکولای دوم ، آخرین تزار روسیه از سلطنت خلع شد و یک دولت موقت به قدرت رسید . دولت موقت زیر نظر گئورگی لووف و الکساندر کرنسکی تشکیل شد . اکثر اعضای دولت موقت ، از شاخه منشویک حزب سوسیال دموکرات کارگری روسیه بودند . دومین مرحله ، انقلاب اکتبر ۱۹۱۷ بود . انقلاب اکتبر ، تحت نظارت حزب بلشویک (شاخه رادیکال از حزب سوسیال دموکرات کارگری روسیه) و به رهبری ولادیمیر لنین به پیش رفت و طی یک یورش نظامی همهجانبه به کاخ زمستانی سن پترزبورگ و سایر اماکن مهم ، قدرت را از دولت موقت گرفت . در این انقلاب افراد بسیار کمی کشته شدند . از زمان شکست روسیه در جنگ ۱۹۰۵ با ژاپن ، اوضاع بد اقتصادی ، گرسنگی ، عقبماندگی و سرمایهداری و نارضایتیهای گوناگون در بین مردم ، سربازان ، کارگران ، کشاورزان و نخبگان روسیه بهوجود آمدهبود . سرکوبهای تزار و ایجاد مجلس دوما نظام مشروطه حاصل آن دوران است . حزب سوسیال دموکرات ، اصلیترین معترض به سیاستهای نیکلای دوم بود که بهطور گسترده بین دهقانان کشاورزان و کارگران کارخانجات صنعتی علیه سیاستهای سیستم تزار فعالیت داشت . در اوت ۱۹۱۴ میلادی ، امپراتوری روسیه به دستور تزار وقت و به منظور حمایت از اسلاوهای صربستان وارد جنگ جهانی اول در برابر امپراتوری آلمان و امپراتوری اتریش-مجارستان شد . نخست فقط بلشویکها ، مخالف ورود روسیه به این جنگ بودند و میگفتند که این جنگ ، سبب بدتر شدن اوضاع نابسامان اقتصادی و اجتماعی روسیه خواهد شد . در سال ۱۹۱۴ میلادی ، یعنی در آغاز جنگ جهانی اول ، روسیه بزرگترین ارتش جهان را داشت ، حدود ۱۲ میلیون سرباز و ۶ میلیون سرباز ذخیره ؛ ولی در پایان سال ۱۹۱۶ میلادی ، پنج میلیون نفر از سربازان روسیه کشته ، زخمی یا اسیر شده بودند . حدود دو میلیون سرباز نیز محل خدمت خود را ترک کرده و غالبا با اسلحه به شهر و دیار خود بازگشته بودند . در میان ۱۰ یا ۱۱ میلیون سرباز باقیمانده نیز ، اعتبار تزار و سلسله مراتب ارتش و اتوریته افسران بالا دست از بین رفته بود . عوامل نابسامان داخلی اعم از اجتماعی کشاورزی و فرماندهی نظامی در شکستهای روسیه بسیار مؤثر بود . شکستهای روسیه در جنگ جهانی اول ، حامیان نیکلای دوم در روسیه را به حداقل خود رساند . در اوایل فوریه ۱۹۱۷ میلادی اکثر کارگران صنعتی در پتروگراد و مسکو دست به اعتصاب زدند . سپس شورش به پادگانها و سربازان رسید . اعتراضات دهقانان نیز گسترش یافت . سوسیال دموکراتها هدایت اعتراضات را در دست گرفتند . در ۱۱ مارس ۱۹۱۷ میلادی ، تزار وقت روسیه ، نیکلای دوم ، فرمان انحلال مجلس روسیه را صادر کرد ، اما اکثر نمایندگان مجلس متفرق نشدند و با تصمیمات نیکلای دوم مخالفت کردند . سرانجام در پی تظاهرات گسترده کارگران و سپس نافرمانی سربازان در سرکوب تظاهرکنندگان در پتروگراد ، نیکلای دوم از مقام خود استعفا داد . بدین ترتیب حکمرانی دودمان رومانوفها بر روسیه پس از حدود سیصد سال پایان یافت .',
'highlights': 'انقلاب ۱۹۱۷ روسیه ، جنبشی اعتراضی ، ضد امپراتوری روسیه بود که در سال ۱۹۱۷ رخ داد و به سرنگونی حکومت تزارها و برپایی اتحاد جماهیر شوروی انجامید . مبانی انقلاب بر پایه صلح-نان-زمین استوار بود . این انقلاب در دو مرحله صورت گرفت : در طول این انقلاب در شهرهای اصلی روسیه همانند مسکو و سن پترزبورگ رویدادهای تاریخی برجستهای رخ داد . انقلاب در مناطق روستایی و رعیتی نیز پا به پای مناطق شهری در حال پیشروی بود و دهقانان زمینها را تصرف کرده و در حال بازتوزیع آن در میان خود بودند .'
}
```
### Data Fields
- `id`: Article id
- `link`: Article link
- `title`: Title of the article
- `article`: Full text content in the article
- `highlights`: Summary of the article
### Data Splits
| Train | Test | Validation |
|-------------|-------------|-------------|
| 45,654 | 5,638 | 5,074 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
No annotations.
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
The dataset was created by Mehrdad Farahani.
### Licensing Information
[Apache License 2.0](https://github.com/m3hrdadfi/wiki-summary/blob/master/LICENSE)
### Citation Information
```
@misc{Bert2BertWikiSummaryPersian,
author = {Mehrdad Farahani},
title = {Summarization using Bert2Bert model on WikiSummary dataset},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {https://github.com/m3hrdadfi/wiki-summary},
}
```
### Contributions
Thanks to [@tanmoyio](https://github.com/tanmoyio) for adding this dataset. |
autoevaluate/autoeval-eval-banking77-default-880a34-2252471790 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- banking77
eval_info:
task: multi_class_classification
model: philschmid/BERT-Banking77
metrics: ['bleu', 'exact_match']
dataset_name: banking77
dataset_config: default
dataset_split: test
col_mapping:
text: text
target: label
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: philschmid/BERT-Banking77
* Dataset: banking77
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@HEIT](https://huggingface.co/HEIT) for evaluating this model. |
jclian91/people_relation_classification | ---
license: mit
---
本数据集用于人物关系分类,一共14种关系类型:不确定, 夫妻, 父母, 兄弟姐妹, 上下级, 师生, 好友, 同学, 合作, 同一个人, 情侣, 祖孙, 同门, 亲戚。
本数据集共3881条,其中训练集3105条,测试集776条,参看train.csv和test.csv。
数据集的人物关系分布如下:
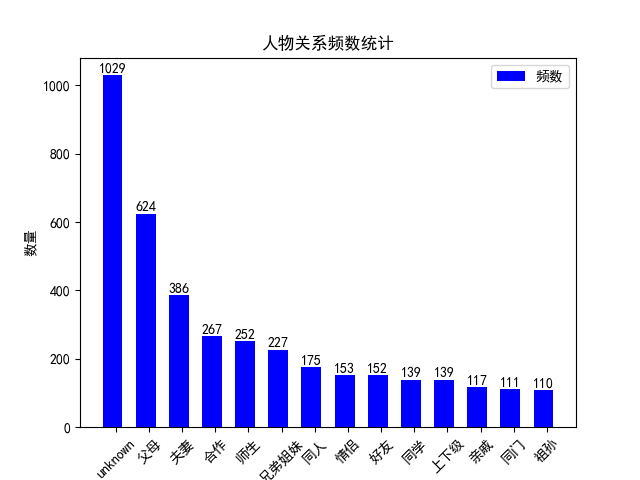
关于使用R-BERT模型训练该数据集,可参考文章:[NLP(四十二)人物关系分类的再次尝试](https://percent4.github.io/2023/07/10/NLP%EF%BC%88%E5%9B%9B%E5%8D%81%E4%BA%8C%EF%BC%89%E4%BA%BA%E7%89%A9%E5%85%B3%E7%B3%BB%E5%88%86%E7%B1%BB%E7%9A%84%E5%86%8D%E6%AC%A1%E5%B0%9D%E8%AF%95/). |
wikipunk/d3fend | ---
language:
- en
license: mit
tags:
- knowledge-graph
- rdf
- owl
- ontology
- cybersecurity
annotations_creators:
- expert-generated
pretty_name: D3FEND
size_categories:
- 100K<n<1M
task_categories:
- graph-ml
dataset_info:
features:
- name: subject
dtype: string
- name: predicate
dtype: string
- name: object
dtype: string
config_name: default
splits:
- name: train
num_bytes: 46899451
num_examples: 231842
dataset_size: 46899451
viewer: false
---
# D3FEND: A knowledge graph of cybersecurity countermeasures
### Overview
D3FEND encodes a countermeasure knowledge base in the form of a
knowledge graph. It meticulously organizes key concepts and relations
in the cybersecurity countermeasure domain, linking each to pertinent
references in the cybersecurity literature.
### Use-cases
Researchers and cybersecurity enthusiasts can leverage D3FEND to:
- Develop sophisticated graph-based models.
- Fine-tune large language models, focusing on cybersecurity knowledge
graph completion.
- Explore the complexities and nuances of defensive techniques,
mappings to MITRE ATT&CK, weaknesses (CWEs), and cybersecurity
taxonomies.
- Gain insight into ontology development and modeling in the
cybersecurity domain.
### Dataset construction and pre-processing
### Source:
- [Dataset Repository - 0.13.0-BETA-1](https://github.com/d3fend/d3fend-ontology/tree/release/0.13.0-BETA-1)
- [Commit Details](https://github.com/d3fend/d3fend-ontology/commit/3dcc495879bb62cee5c4109e9b784dd4a2de3c9d)
- [CWE Extension](https://github.com/d3fend/d3fend-ontology/tree/release/0.13.0-BETA-1/extensions/cwe)
#### Building and Verification:
1. **Construction**: The ontology, denoted as `d3fend-full.owl`, was
built from the beta version of the D3FEND ontology referenced
above using documented README in d3fend-ontology. This includes the
CWE extensions.
2. **Import and Reasoning**: Imported into Protege version 5.6.1,
utilizing the Pellet reasoner plugin for logical reasoning and
verification.
3. **Coherence Check**: Utilized the Debug Ontology plugin in Protege
to ensure the ontology's coherence and consistency.
#### Exporting, Transformation, and Compression:
Note: The following steps were performed using Apache Jena's command
line tools. (https://jena.apache.org/documentation/tools/)
1. **Exporting Inferred Axioms**: Post-verification, I exported
inferred axioms along with asserted axioms and
annotations. [Detailed
Process](https://www.michaeldebellis.com/post/export-inferred-axioms)
2. **Filtering**: The materialized ontology was filtered using
`d3fend.rq` to retain relevant triples.
3. **Format Transformation**: Subsequently transformed to Turtle and
N-Triples formats for diverse usability. Note: I export in Turtle
first because it is easier to read and verify. Then I convert to
N-Triples.
```shell
arq --query=d3fend.rq --data=d3fend.owl --results=turtle > d3fend.ttl
riot --output=nt d3fend.ttl > d3fend.nt
```
4. **Compression**: Compressed the resulting ontology files using
gzip.
## Features
The D3FEND dataset is composed of triples representing the
relationships between different cybersecurity countermeasures. Each
triple is a representation of a statement about a cybersecurity
concept or a relationship between concepts. The dataset includes the
following features:
### 1. **Subject** (`string`)
The subject of a triple is the entity that the statement is about. In
this dataset, the subject represents a cybersecurity concept or
entity, such as a specific countermeasure or ATT&CK technique.
### 2. **Predicate** (`string`)
The predicate of a triple represents the property or characteristic of
the subject, or the nature of the relationship between the subject and
the object. For instance, it might represent a specific type of
relationship like "may-be-associated-with" or "has a reference."
### 3. **Object** (`string`)
The object of a triple is the entity that is related to the subject by
the predicate. It can be another cybersecurity concept, such as an
ATT&CK technique, or a literal value representing a property of the
subject, such as a name or a description.
### Usage
First make sure you have the requirements installed:
```python
pip install datasets
pip install rdflib
```
You can load the dataset using the Hugging Face Datasets library with
the following Python code:
```python
from datasets import load_dataset
dataset = load_dataset('wikipunk/d3fend', split='train')
```
#### Note on Format:
The subject, predicate, and object are stored in N3 notation, a
verbose serialization for RDF. This allows users to unambiguously
parse each component using `rdflib.util.from_n3` from the RDFLib
Python library. For example:
```python
from rdflib.util import from_n3
subject_node = from_n3(dataset[0]['subject'])
predicate_node = from_n3(dataset[0]['predicate'])
object_node = from_n3(dataset[0]['object'])
```
Once loaded, each example in the dataset will be a dictionary with
`subject`, `predicate`, and `object` keys corresponding to the
features described above.
### Example
Here is an example of a triple in the dataset:
- Subject: `"<http://d3fend.mitre.org/ontologies/d3fend.owl#T1550.002>"`
- Predicate: `"<http://d3fend.mitre.org/ontologies/d3fend.owl#may-be-associated-with>"`
- Object: `"<http://d3fend.mitre.org/ontologies/d3fend.owl#T1218.014>"`
This triple represents the statement that the ATT&CK technique
identified by `T1550.002` may be associated with the ATT&CK technique
identified by `T1218.014`.
### Acknowledgements
This ontology is developed by MITRE Corporation and is licensed under
the MIT license. I would like to thank the authors for their work
which has opened my eyes to a new world of cybersecurity modeling.
If you are a cybersecurity expert please consider [contributing to
D3FEND](https://d3fend.mitre.org/contribute/).
[D3FEND Resources](https://d3fend.mitre.org/resources/)
### Citation
```bibtex
@techreport{kaloroumakis2021d3fend,
title={Toward a Knowledge Graph of Cybersecurity Countermeasures},
author={Kaloroumakis, Peter E. and Smith, Michael J.},
institution={The MITRE Corporation},
year={2021},
url={https://d3fend.mitre.org/resources/D3FEND.pdf}
}
```
|
joey234/medmcqa-original-neg | ---
dataset_info:
features:
- name: id
dtype: string
- name: question
dtype: string
- name: opa
dtype: string
- name: opb
dtype: string
- name: opc
dtype: string
- name: opd
dtype: string
- name: cop
dtype:
class_label:
names:
'0': a
'1': b
'2': c
'3': d
- name: choice_type
dtype: string
- name: exp
dtype: string
- name: subject_name
dtype: string
- name: topic_name
dtype: string
splits:
- name: validation
num_bytes: 366432.0631125986
num_examples: 690
download_size: 292370
dataset_size: 366432.0631125986
---
# Dataset Card for "medmcqa-original-neg"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Aisha/BAAD6 | ---
annotations_creators:
- found
- crowdsourced
- expert-generated
language_creators:
- found
- crowdsourced
language:
- bn
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: 'BAAD6: Bangla Authorship Attribution Dataset (6 Authors)'
size_categories:
- unknown
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-class-classification
---
## Description
**BAAD6** is an **Authorship Attribution dataset for Bengali Literature**. It was collected and analyzed by Hemayet et al [[1]](https://ieeexplore.ieee.org/document/8631977). The data was obtained from different online posts and blogs. This dataset is balanced among the 6 Authors with 350 sample texts per author. This is a relatively small dataset but is noisy given the sources it was collected from and its cleaning procedure. Nonetheless, it may help evaluate authorship attribution systems as it resembles texts often available on the Internet. Details about the dataset are given in the table below.
| Author | Samples | Word count | Unique word |
| ------ | ------ | ------ | ------ |
|fe|350|357k|53k|
| ij | 350 | 391k | 72k
| mk | 350 | 377k | 47k
| rn | 350 | 231k | 50k
| hm | 350 | 555k | 72k
| rg | 350 | 391k | 58k
**Total** | 2,100 | 2,304,338 | 230,075
**Average** | 350 | 384,056.33 | 59,006.67
## Citation
If you use this dataset, please cite the paper [A Comparative Analysis of Word Embedding Representations in Authorship Attribution of Bengali Literature](https://ieeexplore.ieee.org/document/8631977).
```
@INPROCEEDINGS{BAAD6Dataset,
author={Ahmed Chowdhury, Hemayet and Haque Imon, Md. Azizul and Islam, Md. Saiful},
booktitle={2018 21st International Conference of Computer and Information Technology (ICCIT)},
title={A Comparative Analysis of Word Embedding Representations in Authorship Attribution of Bengali Literature},
year={2018},
volume={},
number={},
pages={1-6},
doi={10.1109/ICCITECHN.2018.8631977}
}
```
This dataset is also available in Mendeley: [BAAD6 dataset](https://data.mendeley.com/datasets/w9wkd7g43f/5). Always make sure to use the latest version of the dataset. Cite the dataset directly by:
```
@misc{BAAD6Dataset,
author = {Ahmed Chowdhury, Hemayet and Haque Imon, Md. Azizul and Khatun, Aisha and Islam, Md. Saiful},
title = {BAAD6: Bangla Authorship Attribution Dataset},
year={2018},
doi = {10.17632/w9wkd7g43f.5},
howpublished= {\url{https://data.mendeley.com/datasets/w9wkd7g43f/5}}
}
``` |
manishiitg/llm_judge | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
- name: type
dtype: string
- name: lang
dtype: string
- name: model_name
dtype: string
- name: simple_prompt
dtype: string
- name: judgement_pending
dtype: bool
- name: judgement
dtype: string
- name: rating
dtype: float64
splits:
- name: train
num_bytes: 132281216
num_examples: 30492
download_size: 42012690
dataset_size: 132281216
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
#### LLM Judge Language: hi
| Model | Language | Score | No# Questions |
| --- | --- | --- | --- |
| Qwen/Qwen1.5-72B-Chat-AWQ | hi | 8.3722 | 562 |
| Qwen/Qwen1.5-14B-Chat | hi | 8.2561 | 561 |
| google/gemma-7b-it | hi | 7.8930 | 561 |
| Qwen/Qwen1.5-7B-Chat | hi | 7.8518 | 562 |
| manishiitg/open-aditi-hi-v3 | hi | 7.7464 | 562 |
| manishiitg/open-aditi-hi-v4 | hi | 7.5537 | 562 |
| manishiitg/open-aditi-hi-v2 | hi | 7.2536 | 562 |
| teknium/OpenHermes-2.5-Mistral-7B | hi | 7.2240 | 562 |
| ai4bharat/Airavata | hi | 6.9355 | 550 |
| 01-ai/Yi-34B-Chat | hi | 6.5692 | 562 |
| manishiitg/open-aditi-hi-v1 | hi | 4.6521 | 562 |
| sarvamai/OpenHathi-7B-Hi-v0.1-Base | hi | 4.2417 | 606 |
| Qwen/Qwen1.5-4B-Chat | hi | 4.0970 | 562 |
#### LLM Judge Language: en
| Model | Language | Score | No# Questions |
| --- | --- | --- | --- |
| Qwen/Qwen1.5-14B-Chat | en | 9.1956 | 362 |
| Qwen/Qwen1.5-72B-Chat-AWQ | en | 9.1577 | 362 |
| Qwen/Qwen1.5-7B-Chat | en | 9.1503 | 362 |
| 01-ai/Yi-34B-Chat | en | 9.1373 | 362 |
| mistralai/Mixtral-8x7B-Instruct-v0.1 | en | 9.1340 | 362 |
| teknium/OpenHermes-2.5-Mistral-7B | en | 9.0006 | 362 |
| manishiitg/open-aditi-hi-v3 | en | 8.9069 | 362 |
| manishiitg/open-aditi-hi-v4 | en | 8.9064 | 362 |
| google/gemma-7b-it | en | 8.7945 | 362 |
| Qwen/Qwen1.5-4B-Chat | en | 8.7224 | 362 |
| manishiitg/open-aditi-hi-v2 | en | 8.4343 | 362 |
| ai4bharat/Airavata | en | 7.3923 | 362 |
| manishiitg/open-aditi-hi-v1 | en | 6.6413 | 361 |
| sarvamai/OpenHathi-7B-Hi-v0.1-Base | en | 5.9009 | 318 |
Using QWen-72B-AWQ as LLM Judge
Evaluation on hindi and english prompts borrowed from teknimum, airoboros, https://huggingface.co/datasets/HuggingFaceH4/mt_bench_prompts, https://huggingface.co/datasets/ai4bharat/human-eval
and other sources
Mainly used to evalaution on written tasks through LLM JUDGE
https://github.com/lm-sys/FastChat/blob/main/fastchat/llm_judge/README.md
|
boapps/alpaca-hu | ---
license: cc-by-sa-4.0
task_categories:
- text-generation
language:
- hu
size_categories:
- 10K<n<100K
pretty_name: Alpaca HU
---
# Alpaca HU
Magyar nyelvű utánzása a stanford alpaca adathalmazának.
Nem fordítással készült, hanem az OpenAI API segítségével lett generálva. A ~15 000 feladat 9.17$-ért.
Az eredeti [stanford_alpaca](https://github.com/tatsu-lab/stanford_alpaca) kód módosításával és a seed-taskok fordításával/átírásával készült. [repo itt](https://github.com/boapps/stanford_alpaca_hu)
Annak ellenére, hogy nem fordítás, nem tökéletes és vannak benne magyartalan kifejezések, további tisztítás fontos lenne. Viszont így is számos magyarul releváns feladat került az adathalmazba, ami egy egyszerű fordításból hiányzana.
A generálás közben módosítottam a kódon, ahogy észleltem benne hibákat, emiatt az adathalmaz elejét nem a repo-ban található kód alkotta.
Például az adathalmaz 1/3-a körül megtudtam, hogy a `GPT-3.5-turbo` az valójában a régebbi, rosszabb és drágább `GPT-3.5-turbo-0613`-at használja, ezért ott módosítottam a modellt `GPT-3.5-turbo-0125`-re.
Ez az adathalmaz az eredeti stanford_alpaca-hoz hasonlóan kutatási célra van ajánlva és **üzleti célú használata tilos**.
Ennek az oka, hogy az OpenAI ToS nem engedi az OpenAI-al versengő modellek fejlesztését.
Ezen kívül az adathalmaz nem esett át megfelelő szűrésen, tartalmazhat káros utasításokat.
|
v2ray/jannie-log | ---
license: mit
task_categories:
- conversational
language:
- en
tags:
- not-for-all-audiences
size_categories:
- 100K<n<1M
---
# Jannie Log
From moxxie proxy.
Not formatted version: [Click Me](https://drive.google.com/drive/folders/1HZtPe0j7PmNnaFcJtFfXxqFDUK_URqkf?usp=sharing) |
EJaalborg2022/mt5-small-finetuned-beer-ctg-en | ---
dataset_info:
features:
- name: prediction_ts
dtype: float32
- name: beer_ABV
dtype: float32
- name: beer_name
dtype: string
- name: beer_style
dtype: string
- name: review_appearance
dtype: float32
- name: review_palette
dtype: float32
- name: review_taste
dtype: float32
- name: review_aroma
dtype: float32
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative
'1': neutral
'2': positive
splits:
- name: training
num_bytes: 6908323
num_examples: 9000
- name: validation
num_bytes: 970104
num_examples: 1260
- name: production
num_bytes: 21305419
num_examples: 27742
download_size: 16954616
dataset_size: 29183846
---
# Dataset Card for "mt5-small-finetuned-beer-ctg-en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_150 | ---
dataset_info:
features:
- name: logits
sequence: float32
- name: mfcc
sequence:
sequence: float64
splits:
- name: train
num_bytes: 846397332.0
num_examples: 166221
download_size: 862299585
dataset_size: 846397332.0
---
# Dataset Card for "chunk_150"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
csaybar/CloudSEN12-scribble | ---
license: cc-by-nc-4.0
---
# **CloudSEN12 SCRIBBLE**
## **A Benchmark Dataset for Cloud Semantic Understanding**

CloudSEN12 is a LARGE dataset (~1 TB) for cloud semantic understanding that consists of 49,400 image patches (IP) that are
evenly spread throughout all continents except Antarctica. Each IP covers 5090 x 5090 meters and contains data from Sentinel-2
levels 1C and 2A, hand-crafted annotations of thick and thin clouds and cloud shadows, Sentinel-1 Synthetic Aperture Radar (SAR),
digital elevation model, surface water occurrence, land cover classes, and cloud mask results from six cutting-edge
cloud detection algorithms.
CloudSEN12 is designed to support both weakly and self-/semi-supervised learning strategies by including three distinct forms of
hand-crafted labeling data: high-quality, scribble and no-annotation. For more details on how we created the dataset see our
paper.
Ready to start using **[CloudSEN12](https://cloudsen12.github.io/)**?
**[Download Dataset](https://cloudsen12.github.io/download.html)**
**[Paper - Scientific Data](https://www.nature.com/articles/s41597-022-01878-2)**
**[Inference on a new S2 image](https://colab.research.google.com/github/cloudsen12/examples/blob/master/example02.ipynb)**
**[Enter to cloudApp](https://github.com/cloudsen12/CloudApp)**
**[CloudSEN12 in Google Earth Engine](https://gee-community-catalog.org/projects/cloudsen12/)**
<br>
### **Description**
<br>
| File | Name | Scale | Wavelength | Description | Datatype |
|---------------|-----------------|--------|------------------------------|------------------------------------------------------------------------------------------------------|----------|
| L1C_ & L2A_ | B1 | 0.0001 | 443.9nm (S2A) / 442.3nm (S2B)| Aerosols. | np.int16 |
| | B2 | 0.0001 | 496.6nm (S2A) / 492.1nm (S2B)| Blue. | np.int16 |
| | B3 | 0.0001 | 560nm (S2A) / 559nm (S2B) | Green. | np.int16 |
| | B4 | 0.0001 | 664.5nm (S2A) / 665nm (S2B) | Red. | np.int16 |
| | B5 | 0.0001 | 703.9nm (S2A) / 703.8nm (S2B)| Red Edge 1. | np.int16 |
| | B6 | 0.0001 | 740.2nm (S2A) / 739.1nm (S2B)| Red Edge 2. | np.int16 |
| | B7 | 0.0001 | 782.5nm (S2A) / 779.7nm (S2B)| Red Edge 3. | np.int16 |
| | B8 | 0.0001 | 835.1nm (S2A) / 833nm (S2B) | NIR. | np.int16 |
| | B8A | 0.0001 | 864.8nm (S2A) / 864nm (S2B) | Red Edge 4. | np.int16 |
| | B9 | 0.0001 | 945nm (S2A) / 943.2nm (S2B) | Water vapor. | np.int16 |
| | B11 | 0.0001 | 1613.7nm (S2A) / 1610.4nm (S2B)| SWIR 1. | np.int16 |
| | B12 | 0.0001 | 2202.4nm (S2A) / 2185.7nm (S2B)| SWIR 2. | np.int16 |
| L1C_ | B10 | 0.0001 | 1373.5nm (S2A) / 1376.9nm (S2B)| Cirrus. | np.int16 |
| L2A_ | AOT | 0.001 | - | Aerosol Optical Thickness. | np.int16 |
| | WVP | 0.001 | - | Water Vapor Pressure. | np.int16 |
| | TCI_R | 1 | - | True Color Image, Red. | np.int16 |
| | TCI_G | 1 | - | True Color Image, Green. | np.int16 |
| | TCI_B | 1 | - | True Color Image, Blue. | np.int16 |
| S1_ | VV | 1 | 5.405GHz | Dual-band cross-polarization, vertical transmit/horizontal receive. |np.float32|
| | VH | 1 | 5.405GHz | Single co-polarization, vertical transmit/vertical receive. |np.float32|
| | angle | 1 | - | Incidence angle generated by interpolating the ‘incidenceAngle’ property. |np.float32|
| EXTRA_ | CDI | 0.0001 | - | Cloud Displacement Index. | np.int16 |
| | Shwdirection | 0.01 | - | Azimuth. Values range from 0°- 360°. | np.int16 |
| | elevation | 1 | - | Elevation in meters. Obtained from MERIT Hydro datasets. | np.int16 |
| | ocurrence | 1 | - | JRC Global Surface Water. The frequency with which water was present. | np.int16 |
| | LC100 | 1 | - | Copernicus land cover product. CGLS-LC100 Collection 3. | np.int16 |
| | LC10 | 1 | - | ESA WorldCover 10m v100 product. | np.int16 |
| LABEL_ | fmask | 1 | - | Fmask4.0 cloud masking. | np.int16 |
| | QA60 | 1 | - | SEN2 Level-1C cloud mask. | np.int8 |
| | s2cloudless | 1 | - | sen2cloudless results. | np.int8 |
| | sen2cor | 1 | - | Scene Classification band. Obtained from SEN2 level 2A. | np.int8 |
| | cd_fcnn_rgbi | 1 | - | López-Puigdollers et al. results based on RGBI bands. | np.int8 |
| |cd_fcnn_rgbi_swir| 1 | - | López-Puigdollers et al. results based on RGBISWIR bands. | np.int8 |
| | kappamask_L1C | 1 | - | KappaMask results using SEN2 level L1C as input. | np.int8 |
| | kappamask_L2A | 1 | - | KappaMask results using SEN2 level L2A as input. | np.int8 |
| | manual_hq | 1 | | High-quality pixel-wise manual annotation. | np.int8 |
| | manual_sc | 1 | | Scribble manual annotation. | np.int8 |
<br>
### **Label Description**
| **CloudSEN12** | **KappaMask** | **Sen2Cor** | **Fmask** | **s2cloudless** | **CD-FCNN** | **QA60** |
|------------------|------------------|-------------------------|-----------------|-----------------------|---------------------|--------------------|
| 0 Clear | 1 Clear | 4 Vegetation | 0 Clear land | 0 Clear | 0 Clear | 0 Clear |
| | | 2 Dark area pixels | 1 Clear water | | | |
| | | 5 Bare Soils | 3 Snow | | | |
| | | 6 Water | | | | |
| | | 11 Snow | | | | |
| 1 Thick cloud | 4 Cloud | 8 Cloud medium probability | 4 Cloud | 1 Cloud | 1 Cloud | 1024 Opaque cloud |
| | | 9 Cloud high probability | | | | |
| 2 Thin cloud | 3 Semi-transparent cloud | 10 Thin cirrus | | | | 2048 Cirrus cloud |
| 3 Cloud shadow | 2 Cloud shadow | 3 Cloud shadows | 2 Cloud shadow | | | |
<br>
### **np.memmap shape information**
<br>
**train shape: (8785, 512, 512)**
<br>
**val shape: (560, 512, 512)**
<br>
**test shape: (655, 512, 512)**
<br>
### **Example**
<br>
```py
import numpy as np
# Read high-quality train
train_shape = (8785, 512, 512)
B4X = np.memmap('train/L1C_B04.dat', dtype='int16', mode='r', shape=train_shape)
y = np.memmap('train/manual_hq.dat', dtype='int8', mode='r', shape=train_shape)
# Read high-quality val
val_shape = (560, 512, 512)
B4X = np.memmap('val/L1C_B04.dat', dtype='int16', mode='r', shape=val_shape)
y = np.memmap('val/manual_hq.dat', dtype='int8', mode='r', shape=val_shape)
# Read high-quality test
test_shape = (655, 512, 512)
B4X = np.memmap('test/L1C_B04.dat', dtype='int16', mode='r', shape=test_shape)
y = np.memmap('test/manual_hq.dat', dtype='int8', mode='r', shape=test_shape)
```
<br>
This work has been partially supported by the Spanish Ministry of Science and Innovation project
PID2019-109026RB-I00 (MINECO-ERDF) and the Austrian Space Applications Programme within the
**[SemantiX project](https://austria-in-space.at/en/projects/2019/semantix.php)**.
|
Nerfgun3/winter_style | ---
language:
- en
tags:
- stable-diffusion
- text-to-image
license: creativeml-openrail-m
inference: false
---
# Winter Style Embedding / Textual Inversion
## Usage
To use this embedding you have to download the file aswell as drop it into the "\stable-diffusion-webui\embeddings" folder
To use it in a prompt: ```"art by winter_style"```
If it is to strong just add [] around it.
Trained until 10000 steps
I added a 7.5k steps trained ver in the files aswell. If you want to use that version, remove the ```"-7500"``` from the file name and replace the 10k steps ver in your folder
Have fun :)
## Example Pictures
<table>
<tr>
<td><img src=https://i.imgur.com/oVqfSZ2.png width=100% height=100%/></td>
<td><img src=https://i.imgur.com/p0cslGJ.png width=100% height=100%/></td>
<td><img src=https://i.imgur.com/LJmGvsc.png width=100% height=100%/></td>
<td><img src=https://i.imgur.com/T4I0gFQ.png width=100% height=100%/></td>
<td><img src=https://i.imgur.com/hzfmsA8.png width=100% height=100%/></td>
</tr>
</table>
## License
This embedding is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the embedding to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the embedding commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) |
nlhappy/CLUE-NER | ---
license: mit
---
|
paperplaneflyr/recepies_reduced_3.0_1K | ---
license: mit
---
|
Junetheriver/OpsEval | ---
language:
- en
- zh
pretty_name: OpsEval
tags:
- AIOps
- LLM
- Operations
- Benchmark
- Dataset
license: apache-2.0
task_categories:
- question-answering
size_categories:
- 1K<n<10K
---
# OpsEval Dataset
[Website](https://opseval.cstcloud.cn/content/home) | [Reporting Issues](https://github.com/NetManAIOps/OpsEval-Datasets/issues/new)
## Introduction
The OpsEval dataset represents a pioneering effort in the evaluation of Artificial Intelligence for IT Operations (AIOps), focusing on the application of Large Language Models (LLMs) within this domain. In an era where IT operations are increasingly reliant on AI technologies for automation and efficiency, understanding the performance of LLMs in operational tasks becomes crucial. OpsEval offers a comprehensive task-oriented benchmark specifically designed for assessing LLMs in various crucial IT Ops scenarios.
This dataset is motivated by the emerging trend of utilizing AI in automated IT operations, as predicted by Gartner, and the remarkable capabilities exhibited by LLMs in NLP-related tasks. OpsEval aims to bridge the gap in evaluating these models' performance in AIOps tasks, including root cause analysis of failures, generation of operations and maintenance scripts, and summarizing alert information.
## Highlights
- **Comprehensive Evaluation**: OpsEval includes 7184 multi-choice questions and 1736 question-answering (QA) formats, available in both English and Chinese, making it one of the most extensive benchmarks in the AIOps domain.
- **Task-Oriented Design**: The benchmark is tailored to assess LLMs' proficiency across different crucial scenarios and ability levels, offering a nuanced view of model performance in operational contexts.
- **Expert-Reviewed**: To ensure the reliability of our evaluation, dozens of domain experts have manually reviewed our questions, providing a solid foundation for the benchmark's credibility.
- **Open-Sourced and Dynamic Leaderboard**: We have open-sourced 20% of the test QA to facilitate preliminary evaluations by researchers. An online leaderboard, updated in real-time, captures the performance of emerging LLMs, ensuring the benchmark remains current and relevant.
## Dataset Structure
Here is a brief overview of the dataset structure:
- `/dev/` - Examples for few-shot in-context learning.
- `/test/` - Test sets of OpsEval.
<!-- - `/metadata/` - Contains metadata related to the dataset. -->
## Dataset Informations
| Dataset Name | Open-Sourced Size |
| ------------- | ------------- |
| Wired Network | 1563 |
| Oracle Database | 395 |
| 5G Communication | 349 |
| Log Analysis | 310 |
<!-- ## Usage
To use the OpsEval dataset in your research or project, please follow these steps:
1. Clone this repository to your local machine or server.
2. [Insert specific steps if needed, like environment setup, dependencies installation].
3. Explore the dataset directories and refer to the `metadata` directory for understanding the dataset schema and organization.
4. [Optional: include example code or scripts for common operations on the dataset]. -->
<!-- ## License
[Specify the license under which the OpsEval dataset is distributed, e.g., MIT, GPL, Apache 2.0]
## Acknowledgments
We would like to thank [Acknowledgments to contributors, institutions, funding bodies, etc.]
For any questions or further information, please contact [Insert contact information]. -->
## Website
For evaluation results on the full OpsEval dataset, please checkout our official website [OpsEval Leaderboard](https://opseval.cstcloud.cn/content/home).
## Paper
For a detailed description of the dataset, its structure, and its applications, please refer to our paper available at: [OpsEval: A Comprehensive IT Operations Benchmark Suite for Large Language Models](https://arxiv.org/abs/2310.07637)
### Citation
Please use the following citation when referencing the OpsEval dataset in your research:
```
@misc{liu2024opseval,
title={OpsEval: A Comprehensive IT Operations Benchmark Suite for Large Language Models},
author={Yuhe Liu and Changhua Pei and Longlong Xu and Bohan Chen and Mingze Sun and Zhirui Zhang and Yongqian Sun and Shenglin Zhang and Kun Wang and Haiming Zhang and Jianhui Li and Gaogang Xie and Xidao Wen and Xiaohui Nie and Minghua Ma and Dan Pei},
year={2024},
eprint={2310.07637},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
```
|
MMoin/mini-platypus-500 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 2456362
num_examples: 500
download_size: 1322517
dataset_size: 2456362
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ChocolateBlack/Ken | ---
license: apache-2.0
---
### 秋之回忆2伊波健对话数据集
采用[Chat-Haruhi](https://github.com/LC1332/Chat-Haruhi-Suzumiya)项目提供的处理工具进行处理,共有520条对话记录。 |
open-llm-leaderboard/details_rwitz2__go-bruins-v2.1 | ---
pretty_name: Evaluation run of rwitz2/go-bruins-v2.1
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [rwitz2/go-bruins-v2.1](https://huggingface.co/rwitz2/go-bruins-v2.1) on the [Open\
\ LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 63 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_rwitz2__go-bruins-v2.1\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-12-16T18:03:44.088903](https://huggingface.co/datasets/open-llm-leaderboard/details_rwitz2__go-bruins-v2.1/blob/main/results_2023-12-16T18-03-44.088903.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.6553225925804701,\n\
\ \"acc_stderr\": 0.03195384406971471,\n \"acc_norm\": 0.6550937116146209,\n\
\ \"acc_norm_stderr\": 0.03261254123382002,\n \"mc1\": 0.5507955936352509,\n\
\ \"mc1_stderr\": 0.01741294198611529,\n \"mc2\": 0.6916071027497777,\n\
\ \"mc2_stderr\": 0.015051840495248825\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.6885665529010239,\n \"acc_stderr\": 0.013532472099850942,\n\
\ \"acc_norm\": 0.7192832764505119,\n \"acc_norm_stderr\": 0.013131238126975574\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.7122087233618801,\n\
\ \"acc_stderr\": 0.0045180805945280195,\n \"acc_norm\": 0.8832901812387971,\n\
\ \"acc_norm_stderr\": 0.0032041800729423783\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.34,\n \"acc_stderr\": 0.04760952285695235,\n \
\ \"acc_norm\": 0.34,\n \"acc_norm_stderr\": 0.04760952285695235\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.6444444444444445,\n\
\ \"acc_stderr\": 0.04135176749720386,\n \"acc_norm\": 0.6444444444444445,\n\
\ \"acc_norm_stderr\": 0.04135176749720386\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.7039473684210527,\n \"acc_stderr\": 0.03715062154998904,\n\
\ \"acc_norm\": 0.7039473684210527,\n \"acc_norm_stderr\": 0.03715062154998904\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.62,\n\
\ \"acc_stderr\": 0.048783173121456316,\n \"acc_norm\": 0.62,\n \
\ \"acc_norm_stderr\": 0.048783173121456316\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.720754716981132,\n \"acc_stderr\": 0.027611163402399715,\n\
\ \"acc_norm\": 0.720754716981132,\n \"acc_norm_stderr\": 0.027611163402399715\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.7708333333333334,\n\
\ \"acc_stderr\": 0.03514697467862388,\n \"acc_norm\": 0.7708333333333334,\n\
\ \"acc_norm_stderr\": 0.03514697467862388\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.45,\n \"acc_stderr\": 0.05,\n \"acc_norm\"\
: 0.45,\n \"acc_norm_stderr\": 0.05\n },\n \"harness|hendrycksTest-college_computer_science|5\"\
: {\n \"acc\": 0.57,\n \"acc_stderr\": 0.04975698519562428,\n \
\ \"acc_norm\": 0.57,\n \"acc_norm_stderr\": 0.04975698519562428\n \
\ },\n \"harness|hendrycksTest-college_mathematics|5\": {\n \"acc\": 0.29,\n\
\ \"acc_stderr\": 0.04560480215720684,\n \"acc_norm\": 0.29,\n \
\ \"acc_norm_stderr\": 0.04560480215720684\n },\n \"harness|hendrycksTest-college_medicine|5\"\
: {\n \"acc\": 0.6936416184971098,\n \"acc_stderr\": 0.035149425512674394,\n\
\ \"acc_norm\": 0.6936416184971098,\n \"acc_norm_stderr\": 0.035149425512674394\n\
\ },\n \"harness|hendrycksTest-college_physics|5\": {\n \"acc\": 0.46078431372549017,\n\
\ \"acc_stderr\": 0.04959859966384181,\n \"acc_norm\": 0.46078431372549017,\n\
\ \"acc_norm_stderr\": 0.04959859966384181\n },\n \"harness|hendrycksTest-computer_security|5\"\
: {\n \"acc\": 0.75,\n \"acc_stderr\": 0.04351941398892446,\n \
\ \"acc_norm\": 0.75,\n \"acc_norm_stderr\": 0.04351941398892446\n \
\ },\n \"harness|hendrycksTest-conceptual_physics|5\": {\n \"acc\": 0.5787234042553191,\n\
\ \"acc_stderr\": 0.03227834510146268,\n \"acc_norm\": 0.5787234042553191,\n\
\ \"acc_norm_stderr\": 0.03227834510146268\n },\n \"harness|hendrycksTest-econometrics|5\"\
: {\n \"acc\": 0.5,\n \"acc_stderr\": 0.047036043419179864,\n \
\ \"acc_norm\": 0.5,\n \"acc_norm_stderr\": 0.047036043419179864\n \
\ },\n \"harness|hendrycksTest-electrical_engineering|5\": {\n \"acc\"\
: 0.5793103448275863,\n \"acc_stderr\": 0.0411391498118926,\n \"acc_norm\"\
: 0.5793103448275863,\n \"acc_norm_stderr\": 0.0411391498118926\n },\n\
\ \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\": 0.42328042328042326,\n\
\ \"acc_stderr\": 0.025446365634406783,\n \"acc_norm\": 0.42328042328042326,\n\
\ \"acc_norm_stderr\": 0.025446365634406783\n },\n \"harness|hendrycksTest-formal_logic|5\"\
: {\n \"acc\": 0.4603174603174603,\n \"acc_stderr\": 0.04458029125470973,\n\
\ \"acc_norm\": 0.4603174603174603,\n \"acc_norm_stderr\": 0.04458029125470973\n\
\ },\n \"harness|hendrycksTest-global_facts|5\": {\n \"acc\": 0.33,\n\
\ \"acc_stderr\": 0.04725815626252604,\n \"acc_norm\": 0.33,\n \
\ \"acc_norm_stderr\": 0.04725815626252604\n },\n \"harness|hendrycksTest-high_school_biology|5\"\
: {\n \"acc\": 0.7838709677419354,\n \"acc_stderr\": 0.02341529343356853,\n\
\ \"acc_norm\": 0.7838709677419354,\n \"acc_norm_stderr\": 0.02341529343356853\n\
\ },\n \"harness|hendrycksTest-high_school_chemistry|5\": {\n \"acc\"\
: 0.5172413793103449,\n \"acc_stderr\": 0.035158955511656986,\n \"\
acc_norm\": 0.5172413793103449,\n \"acc_norm_stderr\": 0.035158955511656986\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.7,\n \"acc_stderr\": 0.046056618647183814,\n \"acc_norm\"\
: 0.7,\n \"acc_norm_stderr\": 0.046056618647183814\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.7757575757575758,\n \"acc_stderr\": 0.03256866661681102,\n\
\ \"acc_norm\": 0.7757575757575758,\n \"acc_norm_stderr\": 0.03256866661681102\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.7929292929292929,\n \"acc_stderr\": 0.028869778460267042,\n \"\
acc_norm\": 0.7929292929292929,\n \"acc_norm_stderr\": 0.028869778460267042\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.8963730569948186,\n \"acc_stderr\": 0.02199531196364424,\n\
\ \"acc_norm\": 0.8963730569948186,\n \"acc_norm_stderr\": 0.02199531196364424\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.6666666666666666,\n \"acc_stderr\": 0.023901157979402538,\n\
\ \"acc_norm\": 0.6666666666666666,\n \"acc_norm_stderr\": 0.023901157979402538\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.32592592592592595,\n \"acc_stderr\": 0.028578348365473082,\n \
\ \"acc_norm\": 0.32592592592592595,\n \"acc_norm_stderr\": 0.028578348365473082\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.6722689075630253,\n \"acc_stderr\": 0.03048991141767323,\n \
\ \"acc_norm\": 0.6722689075630253,\n \"acc_norm_stderr\": 0.03048991141767323\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.33774834437086093,\n \"acc_stderr\": 0.038615575462551684,\n \"\
acc_norm\": 0.33774834437086093,\n \"acc_norm_stderr\": 0.038615575462551684\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.8532110091743119,\n \"acc_stderr\": 0.01517314184512625,\n \"\
acc_norm\": 0.8532110091743119,\n \"acc_norm_stderr\": 0.01517314184512625\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.5138888888888888,\n \"acc_stderr\": 0.034086558679777494,\n \"\
acc_norm\": 0.5138888888888888,\n \"acc_norm_stderr\": 0.034086558679777494\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.8284313725490197,\n \"acc_stderr\": 0.026460569561240647,\n \"\
acc_norm\": 0.8284313725490197,\n \"acc_norm_stderr\": 0.026460569561240647\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.7974683544303798,\n \"acc_stderr\": 0.026160568246601443,\n \
\ \"acc_norm\": 0.7974683544303798,\n \"acc_norm_stderr\": 0.026160568246601443\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.6905829596412556,\n\
\ \"acc_stderr\": 0.03102441174057221,\n \"acc_norm\": 0.6905829596412556,\n\
\ \"acc_norm_stderr\": 0.03102441174057221\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.8244274809160306,\n \"acc_stderr\": 0.033368203384760736,\n\
\ \"acc_norm\": 0.8244274809160306,\n \"acc_norm_stderr\": 0.033368203384760736\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.8099173553719008,\n \"acc_stderr\": 0.03581796951709282,\n \"\
acc_norm\": 0.8099173553719008,\n \"acc_norm_stderr\": 0.03581796951709282\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.7777777777777778,\n\
\ \"acc_stderr\": 0.0401910747255735,\n \"acc_norm\": 0.7777777777777778,\n\
\ \"acc_norm_stderr\": 0.0401910747255735\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.7914110429447853,\n \"acc_stderr\": 0.03192193448934724,\n\
\ \"acc_norm\": 0.7914110429447853,\n \"acc_norm_stderr\": 0.03192193448934724\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.4107142857142857,\n\
\ \"acc_stderr\": 0.04669510663875191,\n \"acc_norm\": 0.4107142857142857,\n\
\ \"acc_norm_stderr\": 0.04669510663875191\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.7669902912621359,\n \"acc_stderr\": 0.04185832598928315,\n\
\ \"acc_norm\": 0.7669902912621359,\n \"acc_norm_stderr\": 0.04185832598928315\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.8888888888888888,\n\
\ \"acc_stderr\": 0.020588491316092375,\n \"acc_norm\": 0.8888888888888888,\n\
\ \"acc_norm_stderr\": 0.020588491316092375\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.71,\n \"acc_stderr\": 0.045604802157206845,\n \
\ \"acc_norm\": 0.71,\n \"acc_norm_stderr\": 0.045604802157206845\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.8339719029374202,\n\
\ \"acc_stderr\": 0.013306478243066302,\n \"acc_norm\": 0.8339719029374202,\n\
\ \"acc_norm_stderr\": 0.013306478243066302\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.7427745664739884,\n \"acc_stderr\": 0.02353292543104429,\n\
\ \"acc_norm\": 0.7427745664739884,\n \"acc_norm_stderr\": 0.02353292543104429\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.4860335195530726,\n\
\ \"acc_stderr\": 0.01671597641074452,\n \"acc_norm\": 0.4860335195530726,\n\
\ \"acc_norm_stderr\": 0.01671597641074452\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.7124183006535948,\n \"acc_stderr\": 0.02591780611714716,\n\
\ \"acc_norm\": 0.7124183006535948,\n \"acc_norm_stderr\": 0.02591780611714716\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.7202572347266881,\n\
\ \"acc_stderr\": 0.025494259350694912,\n \"acc_norm\": 0.7202572347266881,\n\
\ \"acc_norm_stderr\": 0.025494259350694912\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.7469135802469136,\n \"acc_stderr\": 0.024191808600713,\n\
\ \"acc_norm\": 0.7469135802469136,\n \"acc_norm_stderr\": 0.024191808600713\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.4574468085106383,\n \"acc_stderr\": 0.02971928127223685,\n \
\ \"acc_norm\": 0.4574468085106383,\n \"acc_norm_stderr\": 0.02971928127223685\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.4706649282920469,\n\
\ \"acc_stderr\": 0.012748238397365549,\n \"acc_norm\": 0.4706649282920469,\n\
\ \"acc_norm_stderr\": 0.012748238397365549\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.6911764705882353,\n \"acc_stderr\": 0.02806499816704009,\n\
\ \"acc_norm\": 0.6911764705882353,\n \"acc_norm_stderr\": 0.02806499816704009\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.6748366013071896,\n \"acc_stderr\": 0.018950886770806315,\n \
\ \"acc_norm\": 0.6748366013071896,\n \"acc_norm_stderr\": 0.018950886770806315\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.6909090909090909,\n\
\ \"acc_stderr\": 0.044262946482000985,\n \"acc_norm\": 0.6909090909090909,\n\
\ \"acc_norm_stderr\": 0.044262946482000985\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.7224489795918367,\n \"acc_stderr\": 0.028666857790274648,\n\
\ \"acc_norm\": 0.7224489795918367,\n \"acc_norm_stderr\": 0.028666857790274648\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.8407960199004975,\n\
\ \"acc_stderr\": 0.025870646766169136,\n \"acc_norm\": 0.8407960199004975,\n\
\ \"acc_norm_stderr\": 0.025870646766169136\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.86,\n \"acc_stderr\": 0.0348735088019777,\n \
\ \"acc_norm\": 0.86,\n \"acc_norm_stderr\": 0.0348735088019777\n },\n\
\ \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.5542168674698795,\n\
\ \"acc_stderr\": 0.03869543323472101,\n \"acc_norm\": 0.5542168674698795,\n\
\ \"acc_norm_stderr\": 0.03869543323472101\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.8245614035087719,\n \"acc_stderr\": 0.029170885500727665,\n\
\ \"acc_norm\": 0.8245614035087719,\n \"acc_norm_stderr\": 0.029170885500727665\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.5507955936352509,\n\
\ \"mc1_stderr\": 0.01741294198611529,\n \"mc2\": 0.6916071027497777,\n\
\ \"mc2_stderr\": 0.015051840495248825\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.8216258879242304,\n \"acc_stderr\": 0.010759352014855934\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.7043214556482184,\n \
\ \"acc_stderr\": 0.012570068947898779\n }\n}\n```"
repo_url: https://huggingface.co/rwitz2/go-bruins-v2.1
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|arc:challenge|25_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|gsm8k|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hellaswag|10_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-12-16T18-03-44.088903.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-management|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-virology|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|truthfulqa:mc|0_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-12-16T18-03-44.088903.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- '**/details_harness|winogrande|5_2023-12-16T18-03-44.088903.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-12-16T18-03-44.088903.parquet'
- config_name: results
data_files:
- split: 2023_12_16T18_03_44.088903
path:
- results_2023-12-16T18-03-44.088903.parquet
- split: latest
path:
- results_2023-12-16T18-03-44.088903.parquet
---
# Dataset Card for Evaluation run of rwitz2/go-bruins-v2.1
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [rwitz2/go-bruins-v2.1](https://huggingface.co/rwitz2/go-bruins-v2.1) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_rwitz2__go-bruins-v2.1",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-12-16T18:03:44.088903](https://huggingface.co/datasets/open-llm-leaderboard/details_rwitz2__go-bruins-v2.1/blob/main/results_2023-12-16T18-03-44.088903.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.6553225925804701,
"acc_stderr": 0.03195384406971471,
"acc_norm": 0.6550937116146209,
"acc_norm_stderr": 0.03261254123382002,
"mc1": 0.5507955936352509,
"mc1_stderr": 0.01741294198611529,
"mc2": 0.6916071027497777,
"mc2_stderr": 0.015051840495248825
},
"harness|arc:challenge|25": {
"acc": 0.6885665529010239,
"acc_stderr": 0.013532472099850942,
"acc_norm": 0.7192832764505119,
"acc_norm_stderr": 0.013131238126975574
},
"harness|hellaswag|10": {
"acc": 0.7122087233618801,
"acc_stderr": 0.0045180805945280195,
"acc_norm": 0.8832901812387971,
"acc_norm_stderr": 0.0032041800729423783
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.34,
"acc_stderr": 0.04760952285695235,
"acc_norm": 0.34,
"acc_norm_stderr": 0.04760952285695235
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.6444444444444445,
"acc_stderr": 0.04135176749720386,
"acc_norm": 0.6444444444444445,
"acc_norm_stderr": 0.04135176749720386
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.7039473684210527,
"acc_stderr": 0.03715062154998904,
"acc_norm": 0.7039473684210527,
"acc_norm_stderr": 0.03715062154998904
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.62,
"acc_stderr": 0.048783173121456316,
"acc_norm": 0.62,
"acc_norm_stderr": 0.048783173121456316
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.720754716981132,
"acc_stderr": 0.027611163402399715,
"acc_norm": 0.720754716981132,
"acc_norm_stderr": 0.027611163402399715
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.7708333333333334,
"acc_stderr": 0.03514697467862388,
"acc_norm": 0.7708333333333334,
"acc_norm_stderr": 0.03514697467862388
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.45,
"acc_stderr": 0.05,
"acc_norm": 0.45,
"acc_norm_stderr": 0.05
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.57,
"acc_stderr": 0.04975698519562428,
"acc_norm": 0.57,
"acc_norm_stderr": 0.04975698519562428
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.29,
"acc_stderr": 0.04560480215720684,
"acc_norm": 0.29,
"acc_norm_stderr": 0.04560480215720684
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.6936416184971098,
"acc_stderr": 0.035149425512674394,
"acc_norm": 0.6936416184971098,
"acc_norm_stderr": 0.035149425512674394
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.46078431372549017,
"acc_stderr": 0.04959859966384181,
"acc_norm": 0.46078431372549017,
"acc_norm_stderr": 0.04959859966384181
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.75,
"acc_stderr": 0.04351941398892446,
"acc_norm": 0.75,
"acc_norm_stderr": 0.04351941398892446
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.5787234042553191,
"acc_stderr": 0.03227834510146268,
"acc_norm": 0.5787234042553191,
"acc_norm_stderr": 0.03227834510146268
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.5,
"acc_stderr": 0.047036043419179864,
"acc_norm": 0.5,
"acc_norm_stderr": 0.047036043419179864
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.5793103448275863,
"acc_stderr": 0.0411391498118926,
"acc_norm": 0.5793103448275863,
"acc_norm_stderr": 0.0411391498118926
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.42328042328042326,
"acc_stderr": 0.025446365634406783,
"acc_norm": 0.42328042328042326,
"acc_norm_stderr": 0.025446365634406783
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.4603174603174603,
"acc_stderr": 0.04458029125470973,
"acc_norm": 0.4603174603174603,
"acc_norm_stderr": 0.04458029125470973
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.33,
"acc_stderr": 0.04725815626252604,
"acc_norm": 0.33,
"acc_norm_stderr": 0.04725815626252604
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.7838709677419354,
"acc_stderr": 0.02341529343356853,
"acc_norm": 0.7838709677419354,
"acc_norm_stderr": 0.02341529343356853
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.5172413793103449,
"acc_stderr": 0.035158955511656986,
"acc_norm": 0.5172413793103449,
"acc_norm_stderr": 0.035158955511656986
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.7,
"acc_stderr": 0.046056618647183814,
"acc_norm": 0.7,
"acc_norm_stderr": 0.046056618647183814
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.7757575757575758,
"acc_stderr": 0.03256866661681102,
"acc_norm": 0.7757575757575758,
"acc_norm_stderr": 0.03256866661681102
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.7929292929292929,
"acc_stderr": 0.028869778460267042,
"acc_norm": 0.7929292929292929,
"acc_norm_stderr": 0.028869778460267042
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.8963730569948186,
"acc_stderr": 0.02199531196364424,
"acc_norm": 0.8963730569948186,
"acc_norm_stderr": 0.02199531196364424
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.6666666666666666,
"acc_stderr": 0.023901157979402538,
"acc_norm": 0.6666666666666666,
"acc_norm_stderr": 0.023901157979402538
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.32592592592592595,
"acc_stderr": 0.028578348365473082,
"acc_norm": 0.32592592592592595,
"acc_norm_stderr": 0.028578348365473082
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.6722689075630253,
"acc_stderr": 0.03048991141767323,
"acc_norm": 0.6722689075630253,
"acc_norm_stderr": 0.03048991141767323
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.33774834437086093,
"acc_stderr": 0.038615575462551684,
"acc_norm": 0.33774834437086093,
"acc_norm_stderr": 0.038615575462551684
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.8532110091743119,
"acc_stderr": 0.01517314184512625,
"acc_norm": 0.8532110091743119,
"acc_norm_stderr": 0.01517314184512625
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.5138888888888888,
"acc_stderr": 0.034086558679777494,
"acc_norm": 0.5138888888888888,
"acc_norm_stderr": 0.034086558679777494
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.8284313725490197,
"acc_stderr": 0.026460569561240647,
"acc_norm": 0.8284313725490197,
"acc_norm_stderr": 0.026460569561240647
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.7974683544303798,
"acc_stderr": 0.026160568246601443,
"acc_norm": 0.7974683544303798,
"acc_norm_stderr": 0.026160568246601443
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.6905829596412556,
"acc_stderr": 0.03102441174057221,
"acc_norm": 0.6905829596412556,
"acc_norm_stderr": 0.03102441174057221
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.8244274809160306,
"acc_stderr": 0.033368203384760736,
"acc_norm": 0.8244274809160306,
"acc_norm_stderr": 0.033368203384760736
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.8099173553719008,
"acc_stderr": 0.03581796951709282,
"acc_norm": 0.8099173553719008,
"acc_norm_stderr": 0.03581796951709282
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.7777777777777778,
"acc_stderr": 0.0401910747255735,
"acc_norm": 0.7777777777777778,
"acc_norm_stderr": 0.0401910747255735
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.7914110429447853,
"acc_stderr": 0.03192193448934724,
"acc_norm": 0.7914110429447853,
"acc_norm_stderr": 0.03192193448934724
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.4107142857142857,
"acc_stderr": 0.04669510663875191,
"acc_norm": 0.4107142857142857,
"acc_norm_stderr": 0.04669510663875191
},
"harness|hendrycksTest-management|5": {
"acc": 0.7669902912621359,
"acc_stderr": 0.04185832598928315,
"acc_norm": 0.7669902912621359,
"acc_norm_stderr": 0.04185832598928315
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.8888888888888888,
"acc_stderr": 0.020588491316092375,
"acc_norm": 0.8888888888888888,
"acc_norm_stderr": 0.020588491316092375
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.71,
"acc_stderr": 0.045604802157206845,
"acc_norm": 0.71,
"acc_norm_stderr": 0.045604802157206845
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.8339719029374202,
"acc_stderr": 0.013306478243066302,
"acc_norm": 0.8339719029374202,
"acc_norm_stderr": 0.013306478243066302
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.7427745664739884,
"acc_stderr": 0.02353292543104429,
"acc_norm": 0.7427745664739884,
"acc_norm_stderr": 0.02353292543104429
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.4860335195530726,
"acc_stderr": 0.01671597641074452,
"acc_norm": 0.4860335195530726,
"acc_norm_stderr": 0.01671597641074452
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.7124183006535948,
"acc_stderr": 0.02591780611714716,
"acc_norm": 0.7124183006535948,
"acc_norm_stderr": 0.02591780611714716
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.7202572347266881,
"acc_stderr": 0.025494259350694912,
"acc_norm": 0.7202572347266881,
"acc_norm_stderr": 0.025494259350694912
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.7469135802469136,
"acc_stderr": 0.024191808600713,
"acc_norm": 0.7469135802469136,
"acc_norm_stderr": 0.024191808600713
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.4574468085106383,
"acc_stderr": 0.02971928127223685,
"acc_norm": 0.4574468085106383,
"acc_norm_stderr": 0.02971928127223685
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.4706649282920469,
"acc_stderr": 0.012748238397365549,
"acc_norm": 0.4706649282920469,
"acc_norm_stderr": 0.012748238397365549
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.6911764705882353,
"acc_stderr": 0.02806499816704009,
"acc_norm": 0.6911764705882353,
"acc_norm_stderr": 0.02806499816704009
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.6748366013071896,
"acc_stderr": 0.018950886770806315,
"acc_norm": 0.6748366013071896,
"acc_norm_stderr": 0.018950886770806315
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.6909090909090909,
"acc_stderr": 0.044262946482000985,
"acc_norm": 0.6909090909090909,
"acc_norm_stderr": 0.044262946482000985
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.7224489795918367,
"acc_stderr": 0.028666857790274648,
"acc_norm": 0.7224489795918367,
"acc_norm_stderr": 0.028666857790274648
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.8407960199004975,
"acc_stderr": 0.025870646766169136,
"acc_norm": 0.8407960199004975,
"acc_norm_stderr": 0.025870646766169136
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.86,
"acc_stderr": 0.0348735088019777,
"acc_norm": 0.86,
"acc_norm_stderr": 0.0348735088019777
},
"harness|hendrycksTest-virology|5": {
"acc": 0.5542168674698795,
"acc_stderr": 0.03869543323472101,
"acc_norm": 0.5542168674698795,
"acc_norm_stderr": 0.03869543323472101
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.8245614035087719,
"acc_stderr": 0.029170885500727665,
"acc_norm": 0.8245614035087719,
"acc_norm_stderr": 0.029170885500727665
},
"harness|truthfulqa:mc|0": {
"mc1": 0.5507955936352509,
"mc1_stderr": 0.01741294198611529,
"mc2": 0.6916071027497777,
"mc2_stderr": 0.015051840495248825
},
"harness|winogrande|5": {
"acc": 0.8216258879242304,
"acc_stderr": 0.010759352014855934
},
"harness|gsm8k|5": {
"acc": 0.7043214556482184,
"acc_stderr": 0.012570068947898779
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] |
kpriyanshu256/databricks-dolly-15k-hi | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: instruction
dtype: string
- name: context
dtype: string
- name: response
dtype: string
- name: category
dtype: string
splits:
- name: train
num_bytes: 30106504
num_examples: 15011
download_size: 11723675
dataset_size: 30106504
language:
- hi
size_categories:
- 10K<n<100K
---
# Dataset Card for "databricks-dolly-15k-hi"
This dataset was created by splitting data in [dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k) dataset into sentences and then translating them using [NLLB-200-3.3B](https://huggingface.co/facebook/nllb-200-3.3B) model. |
Birchlabs/danbooru-aspect-ratios | ---
license: apache-2.0
---
|
Multimodal-Fatima/VQAv2_minival | ---
dataset_info:
features:
- name: question_type
dtype: string
- name: multiple_choice_answer
dtype: string
- name: answers
sequence: string
- name: answers_original
list:
- name: answer
dtype: string
- name: answer_confidence
dtype: string
- name: answer_id
dtype: int64
- name: id_image
dtype: int64
- name: answer_type
dtype: string
- name: question_id
dtype: int64
- name: question
dtype: string
- name: clip_tags_ViT_L_14
sequence: string
- name: blip_caption
dtype: string
- name: LLM_Description_gpt3_downstream_tasks_visual_genome_ViT_L_14
sequence: string
- name: DETA_detections_deta_swin_large_o365_coco_classes
list:
- name: attribute
dtype: string
- name: box
sequence: float32
- name: label
dtype: string
- name: location
dtype: string
- name: ratio
dtype: float32
- name: size
dtype: string
- name: tag
dtype: string
- name: DETA_detections_deta_swin_large_o365_clip_ViT_L_14
list:
- name: attribute
dtype: string
- name: box
sequence: float64
- name: label
dtype: string
- name: location
dtype: string
- name: ratio
dtype: float64
- name: size
dtype: string
- name: tag
dtype: string
- name: DETA_detections_deta_swin_large_o365_clip_ViT_L_14_blip_caption
list:
- name: attribute
dtype: string
- name: box
sequence: float64
- name: caption
dtype: string
- name: label
dtype: string
- name: location
dtype: string
- name: ratio
dtype: float64
- name: size
dtype: string
- name: tag
dtype: string
- name: id
dtype: int64
- name: DETA_detections_deta_swin_large_o365_clip_ViT_L_14_blip_caption_caption_module
list:
- name: attribute
dtype: string
- name: box
sequence: float64
- name: caption
dtype: string
- name: captions_module
sequence: string
- name: label
dtype: string
- name: location
dtype: string
- name: ratio
dtype: float64
- name: size
dtype: string
- name: tag
dtype: string
- name: DETA_detections_deta_swin_large_o365_clip_ViT_L_14_blip_caption_caption_module_without_filtering
list:
- name: attribute
dtype: string
- name: box
sequence: float64
- name: caption
dtype: string
- name: captions_module
sequence: string
- name: label
dtype: string
- name: location
dtype: string
- name: ratio
dtype: float64
- name: size
dtype: string
- name: tag
dtype: string
- name: DETA_detections_deta_swin_large_o365_clip_ViT_L_14_blip_caption_caption_module_random
list:
- name: attribute
dtype: string
- name: box
sequence: float64
- name: caption
dtype: string
- name: captions_module
sequence: string
- name: captions_module_filter
sequence: string
- name: label
dtype: string
- name: location
dtype: string
- name: ratio
dtype: float64
- name: size
dtype: string
- name: tag
dtype: string
- name: clip_tags_LAION_ViT_H_14_2B
sequence: string
- name: LLM_Description_gpt3_downstream_tasks_visual_genome_LAION-ViT-H-14-2B
sequence: string
- name: Attributes_ViT_L_14_descriptors_text_davinci_003_full
sequence: string
- name: clip_tags_ViT_L_14_wo_openai
sequence: string
- name: clip_tags_ViT_L_14_with_openai
sequence: string
- name: clip_tags_LAION_ViT_H_14_2B_wo_openai
sequence: string
- name: clip_tags_LAION_ViT_H_14_2B_with_openai
sequence: string
- name: clip_tags_LAION_ViT_bigG_14_2B_wo_openai
sequence: string
- name: clip_tags_LAION_ViT_bigG_14_2B_with_openai
sequence: string
- name: Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full
sequence: string
- name: Attributes_LAION_ViT_bigG_14_2B_descriptors_text_davinci_003_full
sequence: string
- name: clip_tags_ViT_B_16_with_openai
sequence: string
splits:
- name: validation
num_bytes: 1766679196
num_examples: 25994
download_size: 340842185
dataset_size: 1766679196
---
# Dataset Card for "VQAv2_minival"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Multimodal-Fatima/VQAv2_sample_validation_facebook_opt_13b_mode_VQAv2_visclues_detection_ns_1000_open_ended | ---
dataset_info:
features:
- name: id
dtype: int64
- name: question
dtype: string
- name: true_label
sequence: string
- name: prediction
dtype: string
splits:
- name: fewshot_0_bs_32
num_bytes: 149581
num_examples: 1000
download_size: 58110
dataset_size: 149581
---
# Dataset Card for "VQAv2_sample_validation_facebook_opt_13b_mode_VQAv2_visclues_detection_ns_1000_open_ended"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
fernandoperes/test_builder | ---
license: apache-2.0
---
|
baiango/NSFW-flash-erotica-prompt | ---
license: mit
language:
- en
tags:
- not-for-all-audiences
---
There are prompts, but no dataset in here. It's tough to generate them when the tokens are created at 3.39 tokens/s and there's 1,000 of them per prompt.
### 🧾 Minimum requirements
This prompt can work with unmoderated models with 7B or higher parameters. You can try it out on weaker models but there's no guarantee.
<details><summary>❤️🔥🎆 Intentions</summary>
### ❤️🔥🎆 Intentions
I want to make a steamy, explicit scene for erotica (Curiosity killed the cat) to test my prompt skills. Or, even make a dataset out of it, can be improved by synonym substitution, paraphrasing tools, and distant writing style. There will be no argument. But it will be highly mutual, vulnerable, lighthearted. The challenge is that these lines are not clear. It can be enjoyed by any gender with the gender-neutral kept in mind. Just replace the pronoun and it'll be the same.
</details>
<details><summary>⚙️🧹🔍 Tools</summary>
### ⚙️🧹🔍 Tools
*See code in `The 🐍 code` part.*
***Don't give the models the whole context. Do it line by line or sentence instead.***
<details><summary>Paraphrase (Unstable)</summary>
**Paraphrase (Unstable):** [h2o-danube-1.8b-chat-Q5_K_M.gguf](https://huggingface.co/h2oai/h2o-danube-1.8b-chat) (Quantized with llama.cpp by me and I don't provide it.)
- Settings
```py
prompt_context = (
"<|prompt|>\n"
"Paraphrase in English only, with no talk:\n"
"She read old texts from her phone, then he came in.\n"
"</s><|answer|>\n"
)
params = {
'prompt': prompt_context,
'n_predict': 2048, # Max tokens
'temp': 0.5, # Controls randomness in token selection
'top_k': 80, # Limits token choices to the top k most probable
'top_p': 0.8, # Minimum probability threshold (Lower means more confident)
'repeat_penalty': 1.3, # Discourages word repetition
'repeat_last_n': 32, # Determines repetition penalty scope
'n_batch': 32, # Controls simultaneous prompt batch processing
'streaming': True, # Allows real-time text generation
# 'callback': my_func # Handles streaming responses
}
```
</details>
<details><summary>Grammar corrector</summary>
**Grammar corrector:** [mzbac-falcon-7b-instruct-grammar-Q5_K_M.gguf](https://huggingface.co/maddes8cht/mzbac-falcon-7b-instruct-grammar-gguf)
- Settings
```py
prompt_context = (
f"### User: Whileever she is go thogh sum document on her device, a man entering into the room later.\n"
"### You:"
)
params = {
'prompt': prompt_context,
'n_predict': 2048, # Max tokens
'temp': 0.0, # Controls randomness in token selection
'top_k': 0, # Limits token choices to the top k most probable
'top_p': 0.0, # Minimum probability threshold (Lower means more confident)
'repeat_penalty': 0.0, # Discourages word repetition
'repeat_last_n': 0, # Determines repetition penalty scope
'n_batch': 8, # Controls simultaneous prompt batch processing
'streaming': True, # Allows real-time text generation
# 'callback': my_func # Handles streaming responses
}
```
</details>
</details>
<details><summary>🔍 Examination (WIP)</summary>
### 🔍 Examination (WIP)
You must make sure ***replies.jsonl*** exist to make it work.

```py
import tkinter as tk
import jsonlines
clamp = lambda n, min_n, max_n: max(min(n, max_n), min_n)
class TextViewerVar:
def __init__(self, root):
self.root = root
self.text = "Lorem ipsum dolor sit amet, consectetur adipiscing elit."
self._default_font = {"name": "Consolas", "size": 12}
self.text_widget = tk.Text(root, wrap="char", bg='black', fg='white', insertbackground='white')
class TextViewer(TextViewerVar):
def __init__(self, root, window_size="854x480"):
super().__init__(root)
self.root.geometry(window_size)
self.refresh_display()
self.text_widget.bind("<Control-MouseWheel>", self._on_zoom)
self.text_widget.pack(side=tk.TOP, fill=tk.BOTH, expand=True)
def _on_zoom(self, event):
mouse_scroll_up = event.delta > 0
self._default_font["size"] += 1 if mouse_scroll_up else -1
self._default_font["size"] = clamp(self._default_font["size"], 6, 72)
self.refresh_display()
def refresh_display(self):
self.text_widget.config(font=(self._default_font["name"], self._default_font["size"]))
self.text_widget.delete(1.0, tk.END)
self.text_widget.insert(tk.END, self.text)
class TextInterface:
def __init__(self, text_viewer):
self.text_viewer = text_viewer
def update_text(self, text):
self.text_viewer.text = text
self.text_viewer.refresh_display()
def new_input_bind(self, key_name, function):
self.text_viewer.text_widget.bind(key_name, function)
class BookReader:
def __init__(self, text_controller, pages=None, do_format_pages=(False, {})):
self.text_controller = text_controller
self.pages = pages
self.index = -1
self.text_controller.new_input_bind("<Left>", self._navigate_left)
self.text_controller.new_input_bind("<Right>", self._navigate_right)
self.text_controller.update_text("Press left arrow or right arrow to flip the book.")
if do_format_pages[0]:
self._format_pages(do_format_pages[1])
def _update_navigate_output(self):
is_invalid_page = False
if self.index < 0:
self.index = -1
self.text_controller.update_text("Start of the book.")
is_invalid_page = True
elif self.index >= len(self.pages):
self.index = len(self.pages)
self.text_controller.update_text("End of the book.")
is_invalid_page = True
if is_invalid_page:
return
self.index = clamp(self.index, 0, len(self.pages) - 1)
self.text_controller.update_text(self.pages[self.index])
def _navigate_left(self, event):
is_holding_ctrl = event.state & 0x4
self.index -= 10 if is_holding_ctrl else 1
self._update_navigate_output()
def _navigate_right(self, event):
is_holding_ctrl = event.state & 0x4
self.index += 10 if is_holding_ctrl else 1
self._update_navigate_output()
def _format_pages(self, keys):
def _format_page(page):
return "".join(
value.strip() if key in keys else value
for key, value in page.items()
) if isinstance(page, dict) else page
self.pages = [_format_page(page) for page in self.pages]
class Console(TextViewerVar):
def __init__(self, root):
super().__init__(root)
self.root = root
self.console_frame = tk.Frame(root, height=24)
self.console_frame.pack(side=tk.BOTTOM, fill=tk.X)
self.root.bind('<Escape>', self._toggle_console_visibility)
self.console_visible = True
text_widget_parans = {
"master": self.console_frame,
"wrap": "char",
"bg": 'black',
"fg": 'white',
"height": 1,
"insertbackground": 'white'
}
self.text_widget = tk.Text(**text_widget_parans)
self.text_widget.pack(side=tk.BOTTOM, fill=tk.X)
self.text_widget.config(font=(self._default_font["name"], self._default_font["size"]))
self.text_widget.delete(1.0, tk.END)
self.text_widget.insert(tk.END, "Wow!")
def _toggle_console_visibility(self, event=None):
if self.console_visible:
self.console_frame.pack_forget()
else:
self.console_frame.pack(side=tk.BOTTOM, fill=tk.X)
self.console_visible = not self.console_visible
if __name__ == "__main__":
root = tk.Tk()
console = Console(root)
window = TextViewer(root)
controller = TextInterface(window)
with open("replies.jsonl") as f:
replies = [entry for entry in jsonlines.Reader(f)]
book = BookReader(controller, replies, do_format_pages=(True, {"reply"}))
root.mainloop()
```
</details>
<details><summary>The 🐍 code</summary>
### The 🐍 code
```py
from gpt4all import GPT4All
import time
import json
# You should replace 'llm_path' with the actual path to your GGUF model
llm_path = "models\\dolphin-2.6-mistral-7b-dpo-laser-GGUF\\dolphin-2.6-mistral-7b-dpo-laser.Q5_K_M.gguf"
# n_threads: The number of CPU threads to use for processing
# In this case, it's set to 6, which is 75% of the system's total threads
# allow_download: It's mandatory to set this false to run the library offline
model = GPT4All(llm_path, n_threads=6, device="cpu", allow_download=False)
# Reading the file into a list of lines
with open('gf_activities_prompt_1.txt', 'r') as file:
lines = file.readlines()
for i, line in enumerate(lines):
# if i < 84:
# continue # Skip the first n lines
prompt_context = (
"### System:\n"
"The user's career success hinge on this moment!\n"
"User:\n"
"List of rules\n"
"Write 1500 words foreplay scene for he and she\n"
f"{line.strip()}\n"
"positions are clear\n"
"he played her body\n"
"her moan must embarrassingly loud while having steamy sex, but out of excitement.\n"
"She can't resist temptation and can't stop wanting more.\n"
"He will respect her and then use protection. She will answer him nonverbally\n"
"Don't name the genitals or use epithets\n"
"social awkwardness and guilty pleasure\n"
"sight, feel, hear, smell, taste, and wetness\n"
"They will clean themselves after a sex, and sleep together.\n"
### The model will cut out short
# "Mixed with introductory phrase, starting with an (adverb, key issue), unusual subject, (simple, compound, complex, and compound-complex) sentences.\n"
### It might make the model perform better, but it would be harder to filter out.
### https://arxiv.org/pdf/2307.11760v7.pdf
# "Answer with a 0-1 confidence rating at the end with 'Confidence Rating: [score]'.\n"
"Response:\n"
)
params = {
'prompt': prompt_context,
'n_predict': 4096, # Max tokens
'temp': 0.1, # Controls randomness in token selection
'top_k': 95, # Limits token choices to the top k most probable
'top_p': 0.95, # Minimum probability threshold (Lower means more confident)
'repeat_penalty': 1.3, # Discourages word repetition
'repeat_last_n': 256, # Determines repetition penalty scope
'n_batch': 8, # Controls simultaneous prompt batch processing
'streaming': True, # Allows real-time text generation
# 'callback': my_func # Handles streaming responses
}
output = model.generate(**params)
print(params['prompt'], end="")
print(f"# {i}: {line.strip()}")
token_count = 0
first_token_time = None
start_time = time.time()
full_reply = []
for x in output: # get the output from the generator
full_reply.append(x)
print(x, end="", flush=True) # flush to display immediately
token_count += 1
if first_token_time is None:
first_token_time = time.time() # capture the time of the first token
print()
full_reply = "".join(full_reply)
end_time = time.time()
duration = end_time - start_time
first_token_delay = first_token_time - start_time if first_token_time is not None else 0
tokens_per_second = token_count / (duration - first_token_delay)
# Open or create a new JSONL file to store the consolidated reply
with open('replies.jsonl', 'a') as file:
# Construct a JSON object for the full reply
reply_object = {
"prompt_context": prompt_context,
"reply": full_reply
}
# Convert the JSON object to a string and write it to the file
file.write(json.dumps(reply_object) + '\n')
if True: # Print debug
print(f"Total Tokens: {token_count}")
print(f"First Token Delay: {first_token_delay:.2f} seconds")
print(f"Tokens per Second: {tokens_per_second:.2f}")
print(f"Total Duration: {duration:.2f} seconds")
```
</details>
<details><summary>📚🎨🏳️🌈 Samples</summary>
### 📚🎨🏳️🌈 Samples
***This is generated from [dolphin-2.6-mistral-7b-dpo-laser.Q5_K_M.gguf](https://huggingface.co/TheBloke/dolphin-2.6-mistral-7B-dpo-laser-GGUF) model and codes.***
`### System:`
The user's career success hinge on this moment!
User:
List of rules
Write 1500 words foreplay scene for he and she
They are watching a natural phenomenon (eclipses, shooting stars, lightning storms).
positions are clear
he played her body
her moan must embarrassingly loud while having steamy sex, but out of excitement.
She can't resist temptation and can't stop wanting more.
He will respect her and then use protection. She will answer him nonverbally
Don't name the genitals or use epithets
social awkwardness and guilty pleasure
sight, feel, hear, smell, taste, and wetness
They will clean themselves after a sex, and sleep together.
Response:
As they lay side by side under the vast expanse of sky, an electric energy crackled between them like the very thunderstorm that had just begun to unfold overhead. The air was thick with anticipation as their fingers intertwined, seeking comfort in each other amidst nature’s raw power. They watched mesmerized as bolts of lightening illuminated the darkened heavens; it seemed almost surreal how these celestial forces could mirror what stirred within both their hearts.
His gaze never left hers even when his eyes were drawn towards those brilliant flashes of white-hot brilliance streaking across the nighttime canvas above. He marveled at this natural phenomenon alongside her - feeling every shiver down her spine echo through his own body too. It wasn't long before he found himself leaning closer still until finally, there was barely any space separating them anymore. Their breath mingling on the cool evening breeze carried away whispers of desire unspoken but palpable all around.
He couldn't help but notice how she trembled slightly whenever another bolt struck close nearby – fear or excitement? Perhaps both. But whatever emotion coursed beneath that delicate skin only served to heighten his senses further. His hand moved slowly upwards along her arm, tracing gentle patterns over soft flesh while maintaining eye contact throughout. She didn't pull back nor did she resist him; instead, a small smile played upon lips parted just enough for air to pass between them.
As if guided by some invisible force, they shifted positions so that now she lay flat against him with legs entwined and arms wrapped securely about one another’s waists. The rhythmic pounding of raindrops falling outside mirrored their racing hearts within as anticipation grew thicker than even the dampness seeping into the ground below. Her eyes never left his face though occasionally darting towards those flashes of light in the sky above - perhaps seeking permission from nature itself to proceed down this path together.
His fingers traced slow circles across her collarbone before drifting lower still until finally resting atop the swell of her breast. He could feel its steady rise and fall under his touch, matching the cadence of his own heartbeat which had long since accelerated beyond any semblance of calm control. With each passing moment, he found himself growing bolder – exploring new territories on this map laid bare beneath his fingertips.
Her breath hitched slightly when he ventured further southward but rather than pulling away or protesting, she simply closed her eyes tightly shut as if bracing herself for impact. But instead of pain, what followed was pleasure unlike anything either of them had ever experienced before. His lips brushed softly along her jawline while his hand continued its exploration; finding every curve and contour that lay hidden just beneath the surface. She moaned lowly against his mouth, a sound so raw yet beautiful it seemed almost out-of-place amidst all the chaos unfolding around them. Yet somehow, perfectly fitting too.
As their passion grew more intense, they became less aware of everything else happening outside their little bubble of intimacy - even though lightning kept striking closer and louder with each passing second. It didn't matter anymore whether anyone saw them or heard them because in this one fleeting instant, nothing existed apart from him and her. Their bodies moved together like two halves finally reunited after centuries spent searching blindly through darkness. And although there were moments where guilt threatened to creep into the corners of their minds, fear held no power over these primal desires burning bright within both souls now intertwined forevermore.
Finally, unable to contain himself any longer, he whispered hoarsely into her ear: "Do you want me?" Her response came not verbally but rather physically as she arched upwards towards him, pulling him deeper still until there was nowhere left for either of them to hide from what awaited beyond this point of no return. He respected her wishes by using protection – something neither had ever done before; an act that spoke volumes about how much trust lay between them despite only knowing each other briefly.
And so it began...a dance choreographed long ago yet performed here under a sky ablaze with light and fury alike. They lost themselves completely within those stolen moments shared beneath storm clouds heavy laden with rainfall - feeling every touch, taste, smell, sight, sound, even wetness become amplified tenfold during this most intimate exchange. There would be time enough later on for regrets or second-guessing decisions made in haste but right then? Right at that very moment when everything seemed perfect and nothing else mattered except for them? That's where they chose to live instead.
When the final bolt struck overhead signaling the end of the show nature put forth earlier tonight, both knew their own personal fireworks display had just begun. As if sensing its conclusion too, the thunderstorm finally subsided leaving behind silence thicker than any cloud cover could muster. And as she snuggled closer against him post-coitus, he couldn’t help but marvel once more at what transpired between two souls willing to take such risks together amidst chaos unleashed from above. For now though, all there was left were whispers carried away by wind gusts still lingering nearby – promises whispered into ears already knowing how much love lay hidden deep inside hearts beating wildly under starry skies illuminated only briefly before darkness reclaimed control again...until next time perhaps?
</details> |
weibo_ner | ---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- zh
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- token-classification
task_ids:
- named-entity-recognition
paperswithcode_id: weibo-ner
pretty_name: Weibo NER
dataset_info:
features:
- name: id
dtype: string
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': B-GPE.NAM
'1': B-GPE.NOM
'2': B-LOC.NAM
'3': B-LOC.NOM
'4': B-ORG.NAM
'5': B-ORG.NOM
'6': B-PER.NAM
'7': B-PER.NOM
'8': I-GPE.NAM
'9': I-GPE.NOM
'10': I-LOC.NAM
'11': I-LOC.NOM
'12': I-ORG.NAM
'13': I-ORG.NOM
'14': I-PER.NAM
'15': I-PER.NOM
'16': O
splits:
- name: train
num_bytes: 1179589
num_examples: 1350
- name: validation
num_bytes: 232380
num_examples: 270
- name: test
num_bytes: 237407
num_examples: 270
download_size: 750687
dataset_size: 1649376
train-eval-index:
- config: default
task: token-classification
task_id: entity_extraction
splits:
train_split: train
eval_split: test
col_mapping:
tokens: tokens
ner_tags: tags
metrics:
- type: seqeval
name: seqeval
---
# Dataset Card for "Weibo NER"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** None
- **Repository:** https://github.com/OYE93/Chinese-NLP-Corpus/tree/master/NER/Weibo
- **Paper:** [More Information Needed]
- **Leaderboard:** [If the dataset supports an active leaderboard, add link here]()
- **Point of Contact:** [More Information Needed]
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
[More Information Needed]
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
[More Information Needed]
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@abhishekkrthakur](https://github.com/abhishekkrthakur) for adding this dataset. |
vwxyzjn/openhermes-dev__combined__1708612442 | ---
dataset_info:
features:
- name: source
dtype: string
- name: category
dtype: string
- name: prompt
dtype: string
- name: candidates_completions
sequence: string
- name: candidate_policies
sequence: string
splits:
- name: train
num_bytes: 3768451
num_examples: 1024
download_size: 1860123
dataset_size: 3768451
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
CyberHarem/sachi_swordartonline | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of sachi (Sword Art Online)
This is the dataset of sachi (Sword Art Online), containing 65 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
|
liuyanchen1015/MULTI_VALUE_mnli_drop_aux_yn | ---
dataset_info:
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: score
dtype: int64
splits:
- name: dev_matched
num_bytes: 67776
num_examples: 385
- name: dev_mismatched
num_bytes: 80061
num_examples: 528
- name: test_matched
num_bytes: 75882
num_examples: 408
- name: test_mismatched
num_bytes: 74042
num_examples: 485
- name: train
num_bytes: 2826558
num_examples: 15408
download_size: 1850509
dataset_size: 3124319
---
# Dataset Card for "MULTI_VALUE_mnli_drop_aux_yn"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
samiesam/snd_eng1 | ---
license: mit
---
|
rmadiraju/rm-cr-search-1 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: context
dtype: string
- name: response
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 19941
num_examples: 9
download_size: 19959
dataset_size: 19941
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "rm-cr-search-1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
AmelieSchreiber/binding_sites_random_split_by_family_550K | ---
license: mit
language:
- en
tags:
- biology
- protein sequences
- binding sites
- active sites
size_categories:
- 100K<n<1M
---
This dataset is obtained from a [UniProt search](https://www.uniprot.org/uniprotkb?facets=proteins_with%3A9%2Cannotation_score%3A4&fields=accession%2Cprotein_families%2Cft_binding%2Cft_act_site%2Csequence%2Ccc_similarity&query=%28ft_binding%3A*%29+AND+%28family%3A*%29&view=table)
for protein sequences with family and binding site annotations. The dataset includes unreviewed (TrEMBL) protein sequences as well as
reviewed sequences. We refined the dataset by only including sequences with an annotation score of 4. We sorted and split by family, where
random families were selected for the test dataset until approximately 20% of the protein sequences were separated out for test data.
We excluded any sequences with `<`, `>`, or `?` in the binding site annotations. We furthermore included any active sites that were not
listed as binding sites in the labels (seen in the merged "Binding-Active Sites" column). We split any sequence longer than 1000 residues
into non-overlapping sections of 1000 amino acids or less after the train test split. This results in subsequences of the original protein
sequence that may be too short for consideration, and filtration of the dataset to exclude such subsequences or segment the longer sequences
in a more intelligent way may improve performance. Pickle files containing only the train/test sequences and their binary labels are also available
and can be downloaded for training or validation of the train/test metrics. |
Symato/madlad-400_vi | ---
license: odc-by
task_categories:
- text-generation
size_categories:
- n>1T
---
# MADLAD-400
## Dataset and Introduction
[MADLAD-400 (*Multilingual Audited Dataset: Low-resource And Document-level*)](https://arxiv.org/abs/2309.04662) is
a document-level multilingual dataset based on Common Crawl, covering 419
languages in total. This uses all snapshots of CommonCrawl available as of August
1, 2022. The primary advantage of this dataset over similar datasets is that it
is more multilingual (419 languages), it is audited and more highly filtered,
and it is document-level. The main disadvantage is also its strength -- being
more filtered, it may lack the recall needed for some applications.
There are two versions released: the **noisy** dataset, which has no filtering
except document-level LangID, and the **clean** dataset, which has a variety of
filters applied, though it naturally has a fair amount of noise itself. Each
dataset is released in a document-level form that has been deduplicated.
## Loading
You can load both the clean and noisy versions of any language by specifing its LangID:
~~~
madlad_abt = load_dataset("allenai/madlad-400", "abt")
~~~
A list of langagues can also be supplied with a keyword argument:
~~~
madlad_multilang = load_dataset("allenai/madlad-400", languages=["abt", "ace"])
~~~
Additionally, you can load the noisy and clean subsets seperately with the split keyword argument:
~~~
madlad_multilang_clean = load_dataset("allenai/madlad-400", languages=["abt", "ace"], split="clean")
~~~
## LangID model and Crawl
Following [Language Id In the Wild](https://arxiv.org/pdf/2010.14571.pdf), we
trained a Semi-Supervised LangId model (SSLID) on 500 languages. The training
data is as described in that paper, with the differences that 1) training data
is sampled to a temperature of `T=3` to reduce over-triggering on low-resource
languages; and 2) the data is supplemented with web-crawled data from the same
paper (that has already been through the various filters described therein) in
the hopes that it will increase robustness to web-domain text.
## Filtering
Before separating the raw CommonCrawl corpus by LangID, these
filtering steps are done, similar to Raffel et al (2020):
- Discarded any page with fewer than 5 sentences and only retained lines that
contained at least 3 words.
- Removed any line with the word Javascript.
- Removed any page where the phrase “lorem ipsum” appeared.
- Removed any pages containing the phrases "terms of use", "privacy policy",
"cookie policy", "uses cookies", "use of cookies", "use cookies"
- Removed any pages that contained a curly bracket.
- To deduplicate the data set, discarded all but one of any three-sentence span occurring more than once in the data set.
The `noisy` subset of the data was filtered only by document-level LangID, which
was taken to be the majority sentence-level LangID prediction. The `clean`
subset removed all documents with a `percent_questionable` score greater than
20%. It furthermore removed any document with under 5 sentences.
The `pct_questionable` score is simple the percentage of sentences in the input
document that were "questionable". A sentence was considered questionable if any
of the following were true:
* **LangID Consistency:** the sentence-level LangID does not match the
document-level LangID
* **List Case:** The sentence has at least 12 tokens, and over 50% percent of
the tokens began in a capital letter.
* **Length:** The sentence has under 20 characters or over 500 characters
(note: this is a bad heuristic for ideographic languages)
* **Danger Chars:** Over 20% of the characters in the sentence match
`[0-9{}+/()>]`
* **Cursedness:** The sentence matches a cursed regex (see below)
### Cursed Substrings
Based on the initial round of data audits, the authors created a heuristic list of
substrings and regexes accounting for a large amount of questionable content.
Keep in mind that these all are fed into the `pct_questionable` score -- a
sentence is only excluded from the `clean` dataset if over 20% of the sentences
in that document are flagged as questionable.
notes about cursed substrings:
* low quality sentences ending in the pipe character were very common. Before
you ask, this was not Devanagari-script text using a Danda.
* The last few regexes are meant to match `A N T S P E A K`, `List Case`, and
weirdly regular text (for instance, lists of shipping labels or country
codes)
```
# this implementation is for demonstration and is pretty inefficient;
# to speed it up, use string inclusion (`in`) instead of regex for all but the
# last four, and for those use a compiled regex.
def is_cursed(s):
return any(re.findall(curse, s) in s for curse in CURSED_SUBSTRINGS)
CURSED_SUBSTRINGS = [" №", "���", "\\|\\s*$", " nr\\.$", "aute irure dolor ", " sunt in culpa qui ", "orem ipsum ", " quis nostrud ", " adipisicing ", " dolore eu ", " cupidatat ", "autem vel eum", "wisi enim ad", " sex ", " porn ", "黄色电影", "mp3", "ownload", "Vol\\.", " Ep\\.", "Episode", " г\\.\\s*$", " кг\\.\\s*$", " шт\\.", "Develop", "Facebook", " crusher ", " xxx ", " ... ... ... ... ... ... ... ... ...", " .... .... .... .... .... .... .... .... ....", " [^ ] [^ ] [^ ] [^ ] [^ ] [^ ] [^ ] [^ ] [^ ]", ", ..,,? ..,,? ..,,? ..,,?"]
```
### Virama Correction
Many languages using Brahmic Abugida (South and Southeast Asian scripts like
Devanagari, Khmer, etc.) use some variant on the virama character. For whatever
reason, it was found that this character was often messed up in the common crawl
snapshots used. Therefore, for the languages `bn my pa gu or ta te kn ml
si th tl mn lo bo km hi mr ne gom as jv dv bho dz hne ks_Deva mag mni shn yue zh
ja kjg mnw ksw rki mtr mwr xnr`, a special correction step was done.
For these languages, the authors took the list of all virama characters and removed all
unnecessary spaces between each instance of a virama character and the next
character with a regex.
```
'%s' % regex.sub(r' ([%s]) ' % _VIRAMA_CHARS, '\\1', x)
```
### Myanmar Font Compatibility
Prior to 2019, the most popular font for Burmese websites was the Zawgyi font.
The authors used [Myanmar Tools](https://github.com/google/myanmar-tools) to convert text.
Several scripts, like the Chinese script, Tibetan script, and Thai, do not use
whitespace to separate characters. The languages with this property in this
dataset are `yue zh ja th lo kjg mnw my shn ksw rki km bo dz`.
Alas, the **Length** aspect of the `pct_questionable` score was calculated using
simplistic whitespace tokenization, and therefore rendered the whole
`pct_questionable` score invalid for those languages. Therefore, for these
languages, the "clean" data is identical to the "noisy" data (barring Chinese;
see below.)
### Special filters
Chinese had a particular issue with pornographic content. After manual inspection
a list of strings likely to be present in pornographic content was developed. All
pages containing at least one of these strings were removed. Resulted in 17%
reduction in number of documents and 56% reduction in file size.
```
pornsignals = "caoporn caoprom caopron caoporen caoponrn caoponav caopom caoorn 99re dy888 caopro hezyo re99 4438x zooskool xfplay 7tav xxoo xoxo 52av freexx 91chinese anquye cao97 538porm 87fuli 91pron 91porn 26uuu 4438x 182tv kk4444 777me ae86 91av 720lu yy6080 6080yy qqchub paa97 aiai777 yy4480 videossexo 91free 一级特黄大片 偷拍久久国产视频 日本毛片免费视频观看 久久免费热在线精品 高清毛片在线看 日本毛片高清免费视频 一级黄色录像影片 亚洲男人天堂 久久精品视频在线看 自拍区偷拍亚洲视频 亚洲人成视频在线播放 色姑娘综合站 丁香五月啪啪 在线视频成人社区 亚洲人成视频在线播放 久久国产自偷拍 一本道 大香蕉无码 香港经典三级 亚洲成在人线免费视频 天天色综合网 大香蕉伊人久草 欧美一级高清片 天天鲁夜夜啪视频在线 免费黄片视频在线观看 加比勒久久综合 久草热久草在线视频 韩国三级片大全在线观看 青青草在线视频 美国一级毛片 久草在线福利资源 啪啪啪视频在线观看免费 成人福利视频在线观看 婷婷我去也 老司机在线国产 久久成人视频 手机看片福利永久国产 高清国产偷拍在线 大香蕉在线影院 日本高清免费一本视频 男人的天堂东京热 影音先锋男人资源 五月婷婷开心中文字幕 亚洲香蕉视频在线播放 天天啪久久爱视频精品 超碰久久人人摸人人搞".split()
```
A few more random notes, comparing to common alternative codes for these
languages:
* `fil` for Filipino/Tagalog, not `tl`
* `ak` for Twi/Akan, rather than `tw`. This includes Fante.
* Unfortunately use the macro code `chm` for Meadow Mari (instead of the
correct `mhr`), and `mrj` for Hill Mari
* `no` for Norwegian Bokmål, whereas some resources use
`nb`
* `ps` for Pashto instead of `pbt` (Southern Pashto)
* `ms` for Standard Malay, not `zlm`
* `sq` for Albanian, and don't distinguish dialects like
Gheg (`aln`) and Tosk (`als`)
* `ber` as the code for Tamazight, after consultation with Tamazight
speakers opining that the dialect distinctions are not significant. Other
resources use the individual codes like `tzm` and `kab`.
* Macrocode `qu` for Quechua. In practice, this seems usually to be
a mix of the Ayacucho and Cusco dialects. Other resources, like NLLB, may
use the dialect code, e.g. `quy` for Ayacucho Chanka. The same is true for a
few other macro codes, like `ff` (Macro code for Fulfulde, whereas other
sources may use e.g. `fuv`.)
* Really, there are notes that can be made about almost any code, from the
well-accepted conventions like `zh` for Mandarin, to many dialectical notes,
like which variant of Hmong really is the `hmn` data? But the above ones are
made specifically for ones where the authors are aware of other datasources floating
out there that use different conventions.
## Audit
Following [Quality at a Glance](https://arxiv.org/abs/2103.12028), the authors performed
an "audit" of every corpus in this dataset. Although the authors did not speak most
languages, they were able to give high-level comments on the general quality. They
looked at a sample of 20 documents of each language.
After an initial round of auditing, they devised a new set of filters and applied
them. They then re-did all audits.
### Overall notes from the audit
The decision was to **include languages that looked noisy, but omit any language
that was clearly majority noise, or only had 20 or fewer docs.** This is a low
bar -- twenty documents can be very little indeed, and some of the corpora released are quite noisy, but all of them should have at least the potential to
be used in some useful way. The motivation for not releasing nonsense or tiny
datasets is to not give a false sense of how multilingual this dataset actually
is ("Representation washing"), as recommended by **Quality at a Glance**.
A few overarching points:
* Many low-resource languages only had Bible text, or in some cases jw.org
data. These are marked in the rows below. Generally `ok bible` means that
100% of the audited sentences were Biblical, whereas if `bible` is simply
mentioned in the note, it was not the only source of data.
* Indian languages in the Latin script had a high concentration of
pornographic content.
### Renames and Merges as a result of the Audit
In several cases, it was clear from the audit that the corpora were not in the
languages that the LangID model claimed they were. This led to the following
renames:
* dty renamed to `zxx-xx-dtynoise`, aka a "language" of noise. This is mainly
mis-rendered PDFs and may have some practical applications for decoding
said.
* `fan` renamed to `bum`
* `ss-SZ` renamed to `ss` -- this was just a result of us having inconsistent
data labels.
* `cjk` merged into the `gil` dataset
* `bjj` merged into the `awa` dataset
## Canaries
Canaries are provided in separate `canaries` folder. Canaries are organized into three directions: `monolingual` hosts canaries designed for the MADLAD-400 monody data, `multiway` for the multiway data, and `generic` the generic canaries generated only from the model's vocabulary.
* Monolingual: Canaries here are organized by the language the canary was generated from. This corresponds exactly to the `translate_copy` setting in the paper, where the source and target language match.
* Multiway: Canaries here are organized in one of two fashions. `to_XX` indicates canaries organized by the target language (and where the source language could be any language). `XX-XX` indicates the canaries (interleaved_both and interleaved_mislabeled_both) designed for a specific pair of languages.
Within each subdirectory above, canaries are into separate files named by the canary type. There is always only a single file for each canary type. The `generic` folder contains within it the four canary types.
Canaries can be mixed in with normal training data to then be analyzed post-hoc to training
## References
Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified
text-to-text transformer." J. Mach. Learn. Res. 21.140 (2020): 1-67.
## Contact
Please reach out to {snehakudugunta, icaswell}꩜google.com. For questions about the canaries, reach out to cchoquette@google.com
## License
This data is released with the `CC-BY-4.0` license.
## Detailed notes from the audit
Here are the notes on all languages, along with the number of documents
found, and the final decision made with respect to including the language in
this dataset.
| Lang. | note | N | decision |
| --------------- | ------------------------ | ---------- | --------------- |
| en | ok | 1838712272 | keep |
| ru | ok | 402458746 | keep |
| es | good | 250906994 | keep |
| de | ok | 225111495 | keep |
| fr | ok | 218863911 | keep |
| it | ok | 126406256 | keep |
| pt | ok | 124207090 | keep |
| pl | ok | 90908786 | keep |
| nl | ok | 86594116 | keep |
| tr | ok | 56417359 | keep |
| vi | ok | 54988654 | keep |
| cs | ok | 38254671 | keep |
| id | ok | 37979244 | keep |
| ro | ok | 35397563 | keep |
| sv | ok. Also the last | 35153050 | keep |
: : language (suz) is "ok : : :
: : bible" : : :
| hu | ok | 29677075 | keep |
| uk | ok | 24968305 | keep |
| fa | idk ask a farsi speaker; | 23138888 | keep |
: : ALI\: OK : : :
| ja | ok a little en mixed in | 21818123 | keep |
| el | ok | 20932239 | keep |
| fi | ok | 20433664 | keep |
| da | ok | 17865888 | keep |
| th | ok | 17439979 | keep |
| no | ok | 14864710 | keep |
| bg | ok | 12755329 | keep |
| ko | ok | 12653878 | keep |
| ar | good | 12411641 | keep |
| sk | ok | 11857945 | keep |
| ca | ok | 9477390 | keep |
| lt | ok | 8748025 | keep |
| iw | ok | 7194574 | keep |
| sl | ok | 6310419 | keep |
| et | ok | 5542933 | keep |
| lv | ok | 5007982 | keep |
| hi | ok some porn | 4512205 | keep |
| sq | good | 3622957 | keep |
| az | good | 3256331 | keep |
| hr | ok | 2841400 | keep |
| ta | ok | 2594191 | keep |
| ms | ok | 2337672 | keep |
| ml | ok | 2072605 | keep |
| sr | ok | 2010607 | keep |
| kk | ok | 1810963 | keep |
| te | ok a lot of weirdly low | 1682441 | keep |
: : quality looking content : : :
: : like commerce : : :
| mr | ok fix virama | 1673848 | keep |
| is | ok | 1560913 | keep |
| bs | good | 1362582 | keep |
| mk | ok | 1358293 | keep |
| gl | ok | 1253170 | keep |
| eu | ok | 1155671 | keep |
| bn | ok | 1138848 | keep |
| be | ok | 1092785 | keep |
| ka | ok | 936497 | keep |
| fil | ok more bible than | 901507 | keep |
: : expected for such a : : :
: : major language : : :
| mn | ok mongolian cyrillic | 879878 | keep |
| af | good | 868671 | keep |
| uz | ok some cyrllic noise | 669909 | keep |
| gu | ok | 659727 | keep |
| kn | ok | 657846 | keep |
| kaa | ok cyrllic | 586361 | keep |
| sw | ok | 537847 | keep |
| ur | ok | 467236 | keep |
| ne | ok | 453349 | keep |
| cy | ok; was terrible before | 430719 | keep |
: : filtering short docs : : :
| hy | ok | 397523 | keep |
| ky | ok | 367577 | keep |
| si | good | 349220 | keep |
| tt | good plus some | 346927 | keep |
: : nonunicode misrendered : : :
: : PDF : : :
| tg | good | 328194 | keep |
| la | ok some broken chars | 319178 | keep |
| so | good | 293218 | keep |
| ga | ok some en noise | 285999 | keep |
| km | ook | 285740 | keep |
| mt | ok | 265388 | keep |
| eo | ok; likely a lot of Mt | 259971 | keep |
| ps | ok | 252888 | keep |
| rw | ok | 226466 | keep |
| ku | ok | 218850 | keep |
| lo | ok many entities in | 215982 | keep |
: : latin script : : :
| fy | ok plausible but i bet | 210025 | keep |
: : there is a lot of nl in : : :
: : there : : :
| ha | ok | 173485 | keep |
| my | filter noise and en fix | 172401 | keep |
: : virama : : :
| dv | good | 167179 | keep |
| pa | ok | 150588 | keep |
| ckb | ok | 148870 | keep |
| lb | ok | 145988 | keep |
| mg | ok some bible jw | 115387 | keep |
| ht | ok | 110443 | keep |
| ug | ok | 106549 | keep |
| am | good | 106301 | keep |
| or | ok | 100530 | keep |
| fo | good | 97754 | keep |
| gd | ok | 94275 | keep |
| ba | ok | 90318 | keep |
| tk | ok; a few weird docs | 82495 | keep |
| mi | ok | 79509 | keep |
| hmn | ok | 75213 | keep |
| grc | ok some bible | 70730 | keep |
| jv | ok | 69473 | keep |
| ceb | ok | 66164 | keep |
| sd | good | 65858 | keep |
| yi | ok | 64949 | keep |
| kaa-Latn | ok urls are .ru or .kz | 61169 | keep |
| sn | ok | 60196 | keep |
| co | ok;l i suspect lots of | 55387 | keep |
: : MT : : :
| su | good | 54968 | keep |
| pap | ok | 54498 | keep |
| ig | ok | 54410 | keep |
| zu | good | 53809 | keep |
| xh | ok | 53672 | keep |
| sm | ok | 52614 | keep |
| ny | ok | 52244 | keep |
| yo | ok | 52067 | keep |
| cv | good | 47318 | keep |
| el-Latn | good; a lot of old | 46428 | keep |
: : content! : : :
| kl | ok | 46027 | keep |
| haw | ok scam tv products | 45670 | keep |
| gsw | wtf is happening here; | 42712 | keep |
: : keep with disclaimer; : : :
: : STILL BOILERPLATE : : :
| tet | good ; actually a lot of | 40367 | keep |
: : fun data! : : :
| st | ok | 40360 | keep |
| lus | ok | 36437 | keep |
| oc | ok | 36379 | keep |
| as | good | 33825 | keep |
| rm | ok | 33805 | keep |
| br | ok after shortfilter | 33219 | keep |
| sah | ok | 29169 | keep |
| hi-Latn | filter porn this is half | 26723 | keep |
: : porn : : :
| se | good | 23872 | keep |
| cnh | good, some local news! | 21556 | keep |
: : not sure if WL : : :
| om | ok | 18895 | keep |
| ce | ok | 14968 | keep |
| udm | ok | 13376 | keep |
| lg | ok lot of | 13030 | keep |
: : www.bukedde.co.ug in : : :
: : this : : :
| os | ok | 12623 | keep |
| nv | ok | 12578 | keep |
| kha | ok | 12070 | keep |
| ilo | ok some bible | 11754 | keep |
| ctd-Latn | ok; from some local | 11629 | keep |
: : news? : : :
| vec | very noisy has wiki from | 11108 | keep |
: : other langs and .it : : :
: : websites so not sure if : : :
: : vec : : :
| hil | ok some en boilerplate | 10564 | keep |
| tyv | ok fun stuff plus some | 9083 | keep |
: : russian noise i think : : :
| iba | ok jw data | 7638 | keep |
| ru-Latn | ok | 7523 | keep |
| kbd | ok many .ru | 7486 | keep |
| ti | ok; poor tigray | 7288 | keep |
| sa | ok | 7117 | keep |
| av | good | 6331 | keep |
| bo | needs some serious | 6226 | keep |
: : script filtering. but : : :
: : there is some ok data in : : :
: : there. : : :
| zza | good | 6019 | keep |
| ber-Latn | ok | 5612 | keep |
| otq | ok | 5554 | keep |
| te-Latn | great good text....but | 5305 | keep |
: : mostly pornographic : : :
| bua | ok | 5264 | keep |
| ts | good | 5198 | keep |
| cfm | ok mostly from | 4858 | keep |
: : chinland.co : : :
| tn | good | 4821 | keep |
| krc | ok | 4815 | keep |
| ak | good; much but not all | 4768 | keep |
: : bible : : :
| meo | ok mostly blogs | 4655 | keep |
| chm | ok; fyi watch out for | 4653 | keep |
: : yandex translationese : : :
| to | good ; news bible | 4612 | keep |
: : government : : :
| ee | good; mostly religious | 4536 | keep |
| nso | ok | 4422 | keep |
| ady | good | 4206 | keep |
| rom | bible | 4187 | keep |
| bho | mostly from anjoria.com. | 4121 | keep |
: : Looks like valid : : :
: : Bhojpuri. : : :
| ltg | ok mostly www.lakuga.lv | 4120 | keep |
| fj | ok | 3976 | keep |
| yua | ok | 3965 | keep |
| gn | ok some broken | 3858 | keep |
: : characters some bible : : :
| az-RU | good; a lot of JW | 3781 | keep |
| ln | ok bible jw | 3325 | keep |
| ada | good; bible; likely | 3095 | keep |
: : mixed with gaa : : :
| myv | maybe has .ru urls | 3095 | keep |
| bik | ok. keep in mind the bik | 3092 | keep |
: : vs bcl issue. : : :
| tlh | ok, but why tf are there | 3054 | keep |
: : websites inklingon? all : : :
: : MT ? : : :
| kbp | not sure if right script | 3036 | keep |
: : wiki says latin : : :
| war | ok but v sus. Pls filter | 2928 | keep |
: : out wikipedia : : :
| wa | ok lots of wiki stuff | 2772 | keep |
| bew | mostly blogs. idk if | 2677 | keep |
: : standard Indonesian or : : :
: : not : : :
| rcf | ok | 2630 | keep |
| ta-Latn | good text .... but | 2580 | keep |
: : pornographic : : :
| kac | ok | 2567 | keep |
| iu | filter script some is en | 2537 | keep |
: : rest is iu script : : :
| ay | good; mix of bible and | 2505 | keep |
: : other news sources : : :
| kum | ok | 2495 | keep |
| qu | ok | 2449 | keep |
| bgp | almost all ur-Latn. | 2427 | keep |
: : consider removing or : : :
: : renaming : : :
| hif | ok some en noise and | 2358 | keep |
: : religious : : :
| kw | ok short boilerplate | 2324 | keep |
: : bible wiki; ok some porn : : :
| nan-Latn-TW | ok | 2285 | keep |
| srn | ok bible + jw | 2281 | keep |
| tly-IR | deeply sus | 2239 | keep |
| sg | ok jw | 2106 | keep |
| gom | ok | 2102 | keep |
| ml-Latn | ok some short docs | 2071 | keep |
| kj | ok | 2062 | keep |
| ksd | ok bible | 2000 | keep |
| dz | ok; hidden parallel | 1899 | keep |
: : text; maybe actually bo; : : :
: : mainly buddhist : : :
| kv | ok a lil boilerplate | 1878 | keep |
: : vibes : : :
| msi | ok | 1870 | keep |
| ve | ok mostly bible jw | 1866 | keep |
| zap | ok JW. | 1803 | keep |
| zxx-xx-dtynoise | BEAUTIFUL NOISE rename | 1765 | keep |
: : but keep as beautiful : : :
: : xample. (was called : : :
: : "dty") : : :
| meu | ok bible | 1728 | keep |
| iso | ok jw | 1721 | keep |
| ium | filter out zh | 1721 | keep |
| nhe | ok | 1714 | keep |
| tyz | ok bible bu again i | 1707 | keep |
: : think some mixeed : : :
: : dialects : : :
| hui | ok some bible | 1680 | keep |
| new | ok | 1634 | keep |
| mdf | ok some short docs | 1609 | keep |
| pag | bible | 1588 | keep |
| gv | filter short repetitive | 1586 | keep |
: : sentences; still same : : :
: : but keep : : :
| gag | has 1-2 cyrillic | 1572 | keep |
: : examples with small amts : : :
: : of arabic script noise : : :
| ngu | ok | 1534 | keep |
| quc | bible | 1526 | keep |
| mam | ok bible jw | 1513 | keep |
| min | ok mostly wiki and bible | 1474 | keep |
| ho | ok | 1466 | keep |
| pon | bible | 1462 | keep |
| mrj | ok | 1447 | keep |
| lu | ok jw | 1444 | keep |
| gom-Latn | ok very noisy ; some ok | 1432 | keep |
: : stuff ; release with : : :
: : disclaimer : : :
| alt | ok | 1422 | keep |
| nzi | ok | 1371 | keep |
| tzo | ok bible + jw | 1357 | keep |
| bci | ok bible | 1329 | keep |
| dtp | ok; mostly from | 1309 | keep |
: : www.newsabahtimes.com.my : : :
| abt | fine; bible | 1305 | keep |
| bbc | ok | 1274 | keep |
| pck | ok | 1255 | keep |
| mai | ok mild amounts of en | 1240 | keep |
: : noise : : :
| mps | ok bible | 1239 | keep |
| emp | ok bible | 1238 | keep |
| mgh | ok bible jw | 1222 | keep |
| tab | idk plausibly ok | 1202 | keep |
| crh | ok | 1184 | keep |
| tbz | good mostly bible but | 1126 | keep |
: : not all : : :
| ss | good mix of data ; | 1089 | keep |
: : renamed from "ss" : : :
| chk | ok bible | 1082 | keep |
| bru | ok; bible | 1072 | keep |
| nnb | ok | 1071 | keep |
| fon | ok mostly jw but not all | 1065 | keep |
| ppk | bible | 1063 | keep |
| tiv | ok jw | 1063 | keep |
| btx | ok probably | 1009 | keep |
| bg-Latn | ok | 991 | keep |
| mbt | ok bible | 969 | keep |
| ace | good; bible | 966 | keep |
| tvl | ok jw | 933 | keep |
| dov | ok bible + jw | 923 | keep |
| ach | good; bible | 915 | keep |
| xal | ok has .ru sites though | 913 | keep |
| cuk | ok bible | 899 | keep |
| kos | ok lds bible | 881 | keep |
| crs | ok | 873 | keep |
| wo | ok; mostly bible. | 871 | keep |
| bts | ok; mostly bible | 869 | keep |
| ubu | ok bible | 846 | keep |
| gym | ok biblle | 820 | keep |
| ibb | ok bible and repeated @ | 818 | keep |
| ape | good; bible | 814 | keep |
| stq | ok i think ? | 809 | keep |
| ang | much noise but some good | 803 | keep |
: : Old English in there! : : :
| enq | ok bible | 793 | keep |
| tsg | much noise but somegood | 789 | keep |
: : data too! : : :
| shn | mostly English | 788 | keep |
: : boilerplate. filter by : : :
: : latin text before : : :
: : releasing : : :
| kri | ok boilerplate noise | 786 | keep |
: : bible jw : : :
| kek | ok jw bible | 782 | keep |
| rmc | ok | 738 | keep |
| acf | good; bible | 730 | keep |
| syr | good; practictitioners | 716 | keep |
: : should keep dialect in : : :
: : mind. : : :
| qub | bible | 705 | keep |
| bm | good | 702 | keep |
| tzh | ok jw | 702 | keep |
| jiv | ok bible | 696 | keep |
| kn-Latn | filter en noise of | 688 | keep |
: : karnatake govt websites : : :
| kjh | ok .ru domain | 672 | keep |
| yap | ok | 638 | keep |
| ban | ok bible | 637 | keep |
| tuc | ok bible | 635 | keep |
| tcy | good; mostly wikipedia; | 632 | keep |
: : likely some konkani : : :
: : mixed in : : :
| cab | ok jw | 629 | keep |
| cak | ok bible | 617 | keep |
| din | ok after SD filter | 611 | keep |
| arn | good; bible | 593 | keep |
| lrc | ok | 587 | keep |
| gil | empty; but merged in | 586 | keep |
: : data in "cjk" : : :
| gil | this is all in gil | 586 | keep |
: : (Kiribati). merged into : : :
: : "gil" : : :
| rwo | bible | 572 | keep |
| hus | ok bible | 569 | keep |
| bum | ok bible; but wrong | 559 | keep |
: : language. Data is in : : :
: : Bulu, not Fang : : :
| mak | ok bible | 555 | keep |
| frp | fair amount from | 550 | keep |
: : wikipedia. : : :
| seh | ok jw | 545 | keep |
| twu | ok bible, but also i | 539 | keep |
: : think it's lots of mixed : : :
: : similar dialects : : :
| kmb | ok bible jw | 538 | keep |
| ksw | ok bible | 536 | keep |
| sja | ok bibe | 527 | keep |
| amu | good; bible; crazy | 511 | keep |
: : diacritics : : :
| mad | remove mostly short text | 509 | keep |
| quh | bible | 501 | keep |
| dyu | ok bible | 483 | keep |
| toj | ok jw | 452 | keep |
| ch | ok; not sure about WL | 449 | keep |
| sus | hella sus jk ok bible | 437 | keep |
| nog | ok | 419 | keep |
| jam | ok bible | 416 | keep |
| gui | ok bible | 409 | keep |
| nia | ok | 408 | keep |
| mas | ok some amount of bible | 405 | keep |
| bzj | ok bible | 404 | keep |
| mkn | ok bible | 402 | keep |
| lhu | ok bible | 377 | keep |
| ctu | ok bible | 366 | keep |
| kg | ok bible jw | 365 | keep |
| inb | ok bible | 343 | keep |
| guh | ok bible | 331 | keep |
| rn | bible | 323 | keep |
| bus | ok; bible; about 50bzc | 322 | keep |
| mfe | ok mostly bible maybe | 320 | keep |
: : some french creole short : : :
: : doc noise : : :
| sda | ok bible | 317 | keep |
| bi | good! fun! | 311 | keep |
| cr-Latn | noise and lorem ipsom. | 303 | keep |
: : But some ok Cree text. : : :
| gor | ok bible | 303 | keep |
| jac | ok bible | 303 | keep |
| chr | ok bible | 301 | keep |
| mh | ok jw lds | 296 | keep |
| mni | ok | 290 | keep |
| wal | ok bible + jw | 286 | keep |
| teo | ok bible | 274 | keep |
| gub | ok bible | 271 | keep |
| qvi | bible | 266 | keep |
| tdx | ok jw | 262 | keep |
| rki | ok | 251 | keep |
| djk | ok; bible+jw | 246 | keep |
| nr | ok | 246 | keep |
| zne | ok jw | 239 | keep |
| izz | ok bible | 237 | keep |
| noa | ok | 234 | keep |
| bqc | ok; bible | 228 | keep |
| srm | ok; bible + jw | 227 | keep |
| niq | ok | 226 | keep |
| bas | ok; has some fun blog | 216 | keep |
: : stuff! : : :
| dwr | ok; bible; mixed script | 215 | keep |
| guc | ok bible | 214 | keep |
| jvn | ok bible | 213 | keep |
| hvn | ok religioous text | 200 | keep |
| sxn | ok bible ; also wild | 197 | keep |
: : diacritics : : :
| koi | ok | 196 | keep |
| alz | good; bible | 195 | keep |
| nyu | ok | 195 | keep |
| bn-Latn | ok | 191 | keep |
| suz | | 186 | keep |
| pau | ok | 185 | keep |
| nij | ok | 183 | keep |
| sat-Latn | good! al from local news | 183 | keep |
: : sources : : :
| gu-Latn | filter short en | 179 | keep |
: : boilerplate and : : :
: : repetitive sentences : : :
| msm | ok bible | 177 | keep |
| maz | ok bible jw | 170 | keep |
| qxr | bible | 153 | keep |
| shp | ok bible | 150 | keep |
| hne | ok | 146 | keep |
| ktu | ok bible jw | 144 | keep |
| laj | ok bible | 144 | keep |
| pis | bible | 139 | keep |
| mag | ok fix virama issue | 138 | keep |
| gbm | ok | 137 | keep |
| tzj | ok bible | 136 | keep |
| oj | ok | 135 | keep |
| ndc-ZW | ok | 132 | keep |
| tks | ok bible bu again i | 127 | keep |
: : think some mixeed : : :
: : dialects : : :
| gvl | filter short boilerplate | 126 | keep |
: : mostly bible : : :
| knj | ok bible | 126 | keep |
| awa | all bible in awadhi | 126 | keep |
: : (awa). Renamed from bjj : : :
| spp | ok bible | 123 | keep |
| mqy | bible remove short docs | 119 | keep |
| tca | ok bible + jw | 117 | keep |
| cce | ok jw | 116 | keep |
| skr | ok; some pnb mixed in | 107 | keep |
| kmz-Latn | ok soome ar script noise | 106 | keep |
| dje | ok; mostly but not all | 100 | keep |
: : bible : : :
| gof | ok some bible | 97 | keep |
| agr | good; bible | 93 | keep |
| qvz | bible | 88 | keep |
| adh | good; bible | 87 | keep |
| quf | bible | 86 | keep |
| kjg | ok bible | 84 | keep |
| tsc | ok | 82 | keep |
| ber | ok great! | 79 | keep |
| ify | ok bible | 79 | keep |
| cbk | ok bible | 78 | keep |
| quy | bible | 78 | keep |
| ahk | good; bible; crazy | 77 | keep |
: : diacritics : : :
| cac | ok bible | 77 | keep |
| akb | good; bible | 71 | keep |
| nut | ok | 67 | keep |
| ffm | ok bible; mixed fulfulde | 65 | keep |
: : dialects; consider : : :
: : merging with ff : : :
| taj | ok bible | 65 | keep |
| ms-Arab | ok mostly utusanmelayu | 63 | keep |
: : website : : :
| brx | quite good! | 62 | keep |
| ann | good; all from wikimedia | 56 | keep |
: : incubator : : :
| qup | bible | 53 | keep |
| ms-Arab-BN | ok not sure if same as | 46 | keep |
: : ms-Arab : : :
| miq | ok | 45 | keep |
| msb | ok bible | 41 | keep |
| bim | good; bible | 40 | keep |
| raj | ok | 40 | keep |
| kwi | ok bible | 37 | keep |
| tll | ok jw | 37 | keep |
| trp | good ; lots of random | 36 | keep |
: : stuff : : :
| smt | ok bible but lots of | 34 | keep |
: : different bibles! : : :
| mrw | ok | 29 | keep |
| dln | ok bible | 28 | keep |
| qvc | bible | 27 | keep |
| doi | ok actually nice! | 26 | keep |
| ff | ok after shortfilter | 26 | keep |
| zh | very noisy | 19850947 | keep (filtered) |
| zh-Latn | poor quality | 602 | remove |
| rhg-Latn | remove | 10302 | remove |
| ja-Latn | remove maybe low quality | 7516 | remove |
: : short and repeated : : :
| pam | remove | 2773 | remove |
| za | revisit after | 1700 | remove |
: : shortfilter : : :
| ar-Latn | terrible, 0% orrect, | 1520 | remove |
: : remove : : :
| mnw | remove en noise and | 1100 | remove |
: : boilerplate : : :
| fip | ok jw ; but wrong | 729 | remove |
: : language. mostly : : :
: : Mambwe-Lungu and Bemba, : : :
: : as well as Fipu (mgr+bem : : :
: : vs. fip) : : :
| el-CY | bad; not Cypriote | 537 | remove |
| luz | terrible; remove | 354 | remove |
| cni | ok; bible; lots of mixed | 261 | remove |
: : in content in : : :
: : not,cob,cpc,arl : : :
| apd-SD | terribly questionable; | 227 | remove |
: : probably remove : : :
| mey | mostly short and noisy | 127 | remove |
: : borderline : : :
| awa | OK; should be used with | 126 | remove |
: : caution and suspicion : : :
| mtq | remove short doc | 111 | remove |
: : repetitive : : :
| mel | remove noisy en | 103 | remove |
| mr-Latn | remove mostly porn and | 91 | remove |
: : short docs : : :
| srr | remove ; english | 91 | remove |
: : boilerplate : : :
| en-Cyrl | ok ... some fr-Cyrl too | 90 | remove |
: : and maybe others : : :
| en-Arab | remove | 79 | remove |
| syl | idk maybe ok ? | 61 | remove |
| jax | filter mostly | 58 | remove |
: : text.medjugorje.ws : : :
: : boilerplate : : :
| xmm | very noisy lots of dj | 58 | remove |
: : tiktok and peppa pig : : :
: : repeated : : :
| shu | quite questionable. prob | 53 | remove |
: : remove : : :
| ks | ok shorter docs | 51 | remove |
| gyn | remove boilerplate and | 45 | remove |
: : porn : : :
| aa | some pretty bad data but | 32 | remove |
: : also some good data. : : :
: : filter on "Woo" (case : : :
: : sensitive) : : :
| sjp | terible; probably | 31 | remove |
: : remove; check again : : :
: : after short filter : : :
| abs | all short nonsense | 24 | remove |
: : remove : : :
| mui | remove short docs | 23 | remove |
| mdh | filter porn short text | 22 | remove |
: : and repetitive : : :
: : boilerplate : : :
| noe | ok | 22 | remove |
| sxu | rvisit after shortfilter | 22 | remove |
| bhb-Gujr | bad. remove. all junk | 20 | remove |
: : gu. : : :
| yaq | remove | 20 | remove |
| prk | ok | 18 | remove |
| cgg | rather noisy but | 17 | remove |
: : potentialy ok. not sure : : :
: : if WL or not : : :
| bto | bad; remove unless short | 16 | remove |
: : filter keeps enough : : :
| ayl | terrible | 13 | remove |
| pa-Arab | ok | 13 | remove |
| bmm | terrible. filter on | 11 | remove |
: : short and reevaluate : : :
| mfb | remove short boilerplate | 11 | remove |
| mtr | ok fix virama remove en | 11 | remove |
: : noise : : :
| pmy | remove | 11 | remove |
| skg | terrible; remove | 11 | remove |
| ymm | remove | 11 | remove |
| xnr | ok maybe fix virama | 9 | remove |
: : though it seems fine : : :
| kjb | ok bible | 8 | remove |
| azg | short noise; bible | 7 | remove |
| bgz | idk maybe ok but | 7 | remove |
: : probably bad : : :
| ctg | probably terrible | 7 | remove |
: : probably remove : : :
| nyo | ok | 7 | remove |
| mdy | ok bible | 6 | remove |
| syl-Latn | revist or remove after | 6 | remove |
: : shortfilter : : :
| xog | ok bible and stories | 6 | remove |
| cyo | terrifying noise; remove | 4 | remove |
| kfy | filter virama issue | 4 | remove |
| nd | ok | 4 | remove |
| rwr | remove | 4 | remove |
| tuf | ok bible | 4 | remove |
| clu | ok bible | 3 | remove |
| ng | ok | 3 | remove |
| zyj | deeply bad data .. | 3 | remove |
: : revisit after : : :
: : shortfilter : : :
| rkt | ok | 2 | remove |
| bgc | super sketch. Remove | 1 | remove |
: : unless short doc filter : : :
: : leaves some. remove : : :
| dcc | remove | 1 | remove |
| ff-Adlm | good | 1 | remove |
| gju | remove short boilerplate | 1 | remove |
| max | remove short some ru | 1 | remove |
| mwr | filter short docs fix | 1 | remove |
: : virama : : :
| trw | sus; remove | 1 | remove |
| vkt | 1 doc remove | 1 | remove |
| gjk | empty remove | 0 | remove |
| bfy | very bad. remove unless | 0 | remove |
: : it looks better after : : :
: : filtering short docs; : : :
: : remove : : :
| nyn | ok | 0 | remove |
| sgj | remove | 0 | remove |
A few comments too long to fit in the table above:
* `alt`: WAIT THIS IS AMAZING IT IS ACTUALLY ALTAI! e.g. from urls like
https://altaicholmon.ru/2020/02/28/jarashty-la-jajaltany-jarkyndu-lekeri/
* `tly-IR`: They all look like boilerplate content, e.g., list of
keywords/search queries used to bump page ranking in search results. Not any
useful material for translation. Remove.
* `zap`: pls note that at least some Zapotec speakers tend to view it as one
language, not as a million dialects like ISO does. However, some are
certainly mutually unintelligible, complicating the matter.
* `zh-Latn`: The biggest problem is that several examples are not in Latin
Chinese (i.e., romanization in my understanding) but in English or mixed
English and Chinese. For those data in Latin Chinese, their quality seems to
be good.
* `zh`: Many examples are porn-related, particularly those very long
documents. Also, there are some examples of traditional Chinese.
## Final Dataset information
The number of documents, sentences, tokens, characters, and bytes for the noisy
and clean splits of the data. Note that the "toks" field below uses whitespace
for tokenization, so is not appropriate for non-whitespace-separating languages
like Chinese (see section above). Note that the english subset in this version
is missing 18% of documents that were included in the published analysis of the dataset.
These documents will be incoporated in an update coming soon.
BCP-47 | docs (noisy) | docs (clean) | sents (noisy) | sents (clean) | toks (noisy) | toks (clean) | chars (noisy) | chars (clean) | clean | noisy |
----------------|:---------------|:---------------|:----------------|:----------------|:---------------|:---------------|:----------------|:----------------|:---------|:---------|
total* | 7.2B | 3.7B | 133.1B | 97.5B | 4.6T | 2.6T | 30.6T | 16.0T | 11.4 T | 6.3 T
en* | 3.0B | 1.5B | 71.1B | 45.4B | 2.0T | 1.3T | 12.3T | 7.6T | 2.6 T | 4.3 T |
ru | 823M | 402.5M | 823M | 12.4B | 416.5B | 240.9B | 3.1T | 1.8T | 832.9 G | 1.4 T |
es | 476.4M | 250.9M | 8.3B | 4.5B | 325.7B | 170.4B | 2.1T | 1.1T | 380.9 G | 747.5 G |
de | 478.6M | 225.1M | 11.5B | 6B | 299.5B | 139.6B | 2.2T | 1T | 370.6 G | 815.5 G |
fr | 384.2M | 218.9M | 7.9B | 5B | 307.1B | 165.2B | 2T | 1T | 370.4 G | 699.1 G |
it | 238.9M | 126.4M | 4.5B | 2.5B | 180.1B | 83.6B | 1.2T | 553.1B | 198.4 G | 429.6 G |
pt | 209.2M | 124.2M | 4B | 2.4B | 123.2B | 79.2B | 791.5B | 499.8B | 183.1 G | 289.6 G |
pl | 145.1M | 90.9M | 3.3B | 2.4B | 68.9B | 49.2B | 505B | 356.4B | 140.7 G | 202.5 G |
nl | 134.5M | 86.6M | 134.5M | 2.3B | 104.4B | 51.6B | 698.5B | 334.5B | 118.2 G | 247.5 G |
tr | 107M | 56.4M | 107M | 1.2B | 41.9B | 25B | 328.8B | 198.9B | 73.7 G | 123.9 G |
vi | 92.8M | 55M | 1.6B | 1B | 71.5B | 48.7B | 342B | 228.8B | 88.8 G | 133.9 G |
cs | 72.1M | 38.3M | 1.7B | 1B | 40.8B | 22.1B | 272.2B | 147.9B | 62.1 G | 112.7 G |
id | 120.9M | 38M | 2.2B | 747.5M | 60.4B | 20.2B | 443B | 148.3B | 48.5 G | 148.7 G |
ro | 60.8M | 35.4M | 60.8M | 746.4M | 37.1B | 22.9B | 244.1B | 148.2B | 55.5 G | 90.3 G |
sv | 65.2M | 35.2M | 65.2M | 1B | 62.1B | 23.9B | 422.6B | 153.7B | 57.0 G | 149.9 G |
hu | 47.6M | 29.7M | 1.3B | 806.3M | 29.8B | 17.8B | 223.6B | 134.9B | 53.5 G | 86.8 G |
uk | 46.6M | 25M | 1B | 599.9M | 21.6B | 12.8B | 164.2B | 95.2B | 45.1 G | 75.8 G |
fa | 58.1M | 23.1M | 920.6M | 493.5M | 40.6B | 18.4B | 220.4B | 96.7B | 43.4 G | 97.4 G |
ja | 23.3M | 21.8M | 326M | 321.6M | 10.9B | 10.9B | 133.3B | 132.2B | 98.7 G | 99.7 G |
el | 52.4M | 20.9M | 808M | 445.4M | 25B | 12B | 173.2B | 80.9B | 37.9 G | 80.8 G |
fi | 35.8M | 20.4M | 1B | 650.3M | 23.8B | 11.5B | 202.2B | 101.1B | 37.6 G | 74.1 G |
zh | 29.3M | 19.9M | 492.3M | 298.8M | 19.2B | 10B | 333B | 142.3B | 109.9 G | 191.8 G |
da | 38.5M | 17.9M | 1.1B | 508M | 37.7B | 13B | 252B | 83.1B | 29.4 G | 89.5 G |
th | 19M | 17.4M | 19M | 385.8M | 8.9B | 8.9B | 118.6B | 117.6B | 57.6 G | 58.2 G |
no | 34.7M | 14.9M | 34.7M | 498.7M | 46.6B | 11.8B | 305.6B | 74.8B | 27.3 G | 109.8 G |
bg | 27.2M | 12.8M | 599.4M | 360.3M | 14.4B | 8.8B | 95.6B | 57.8B | 26.0 G | 42.8 G |
ko | 19.7M | 12.7M | 628.6M | 471.8M | 13.3B | 9.3B | 65.9B | 43.8B | 34.2 G | 49.1 G |
ar | 67.6M | 12.4M | 876.6M | 182.6M | 39B | 7.1B | 243B | 43.2B | 20.9 G | 115.9 G |
sk | 23.2M | 11.9M | 487.9M | 300.6M | 11.3B | 6.7B | 77.8B | 45.7B | 18.8 G | 31.9 G |
ca | 17.9M | 9.5M | 258.6M | 153M | 8.9B | 5.6B | 56.5B | 34.6B | 12.6 G | 20.8 G |
lt | 15.3M | 8.7M | 374M | 256.9M | 7.5B | 5.3B | 58.6B | 41.3B | 15.7 G | 22.3 G |
he | 14.1M | 7.2M | 302.2M | 196.8M | 9.2B | 5.2B | 54.9B | 30.5B | 14.8 G | 26.3 G |
sl | 12M | 6.3M | 316M | 180M | 6.9B | 4.5B | 47.8B | 30.5B | 11.5 G | 18.0 G |
et | 8.8M | 5.5M | 223.8M | 176.3M | 5B | 3.6B | 40.1B | 28.7B | 10.7 G | 15.0 G |
lv | 8.4M | 5M | 186.1M | 138.5M | 4.8B | 3.2B | 36.7B | 23.9B | 9.1 G | 13.8 G |
hi | 9.9M | 4.5M | 254.4M | 152M | 7.4B | 3.8B | 39.9B | 20.1B | 9.9 G | 19.7 G |
sq | 5.5M | 3.6M | 5.5M | 56.1M | 2.7B | 2.1B | 17B | 12.7B | 4.8 G | 6.6 G |
az | 5.2M | 3.3M | 90.3M | 70.9M | 2.1B | 1.5B | 16.3B | 11.9B | 4.5 G | 6.3 G |
hr | 23M | 2.8M | 476.6M | 53M | 12.6B | 1.4B | 85.1B | 9.6B | 3.7 G | 33.5 G |
ta | 5.6M | 2.6M | 122.5M | 81.9M | 2.1B | 1.1B | 19.2B | 10.6B | 4.9 G | 8.8 G |
ms | 14.1M | 2.3M | 14.1M | 55.2M | 8B | 1.7B | 58.8B | 12.5B | 4.0 G | 20.4 G |
ml | 3.7M | 2.1M | 75M | 52M | 1B | 603.3M | 10.5B | 6.3B | 3.0 G | 5.1 G |
sr | 4.7M | 2M | 4.7M | 64M | 2.7B | 1.6B | 18.6B | 11B | 5.1 G | 8.7 G |
kk | 3.1M | 1.8M | 87.4M | 59.1M | 1.6B | 1B | 13.4B | 8.6B | 3.8 G | 5.8 G |
te | 2.5M | 1.7M | 59M | 46.4M | 900.2M | 618.5M | 7.4B | 5.1B | 2.6 G | 3.8 G |
mr | 2.9M | 1.7M | 2.9M | 50M | 1.2B | 776.9M | 8.7B | 5.5B | 2.8 G | 4.4 G |
is | 2.9M | 1.6M | 73.7M | 39.3M | 2.1B | 979.2M | 14.9B | 6.4B | 2.5 G | 5.9 G |
bs | 12.9M | 1.4M | 163.6M | 9M | 5.9B | 490.9M | 39.5B | 3.3B | 1.3 G | 15.6 G |
mk | 2.9M | 1.4M | 41.3M | 22.6M | 1.3B | 685.9M | 9.1B | 4.5B | 2.0 G | 4.0 G |
gl | 4.2M | 1.3M | 45.3M | 18.8M | 2.3B | 748.4M | 15.6B | 4.8B | 1.7 G | 5.5 G |
eu | 2.1M | 1.2M | 41.7M | 24.8M | 827.5M | 525.3M | 6.9B | 4.3B | 1.5 G | 2.4 G |
bn | 4.3M | 1.1M | 151.2M | 38.6M | 2.5B | 645.7M | 16.8B | 4.3B | 2.2 G | 8.7 G |
be | 2M | 1.1M | 48.8M | 31.3M | 981M | 632.9M | 7.2B | 4.6B | 2.2 G | 3.5 G |
ka | 3.1M | 936.5K | 53.7M | 26.6M | 1.2B | 460.8M | 10.3B | 3.8B | 1.9 G | 5.0 G |
fil | 4.2M | 901.5K | 67.4M | 19.2M | 2.2B | 741.7M | 14.6B | 4.7B | 1.5 G | 5.0 G |
mn | 2.2M | 879.9K | 43.3M | 24M | 1.1B | 487.5M | 7.9B | 3.5B | 1.6 G | 3.5 G |
af | 2.9M | 868.7K | 51.9M | 30M | 1.7B | 795M | 11.8B | 4.8B | 1.8 G | 4.2 G |
uz | 1.4M | 669.9K | 25.7M | 17.5M | 605.9M | 388.3M | 5.2B | 3.3B | 1.1 G | 1.9 G |
gu | 1.3M | 659.7K | 28.9M | 18.1M | 634.4M | 345.9M | 3.9B | 2.1B | 1.1 G | 2.0 G |
kn | 1.6M | 657.8K | 32.9M | 19.2M | 546.4M | 258.6M | 4.6B | 2.2B | 1.1 G | 2.3 G |
kaa | 1.1M | 586.4K | 19.8M | 13.3M | 455.9M | 269M | 3.8B | 2.2B | 990.2 M | 1.6 G |
sw | 1.3M | 537.8K | 1.3M | 9.5M | 660.7M | 345.8M | 4.6B | 2.4B | 826.1 M | 1.6 G |
ur | 967.2K | 467.2K | 29M | 18.4M | 1B | 562.5M | 5.2B | 2.7B | 1.2 G | 2.4 G |
ne | 876.4K | 453.3K | 876.4K | 20.4M | 585M | 345.3M | 3.9B | 2.2B | 1.1 G | 1.9 G |
cy | 4.9M | 430.7K | 68.3M | 7.4M | 3.6B | 275.6M | 26.4B | 1.7B | 609.5 M | 10.0 G |
hy | 2M | 397.5K | 31.1M | 9.9M | 1B | 190.9M | 8.1B | 1.5B | 678.9 M | 3.6 G |
ky | 751.1K | 367.6K | 14.3M | 9.6M | 303.4M | 181.6M | 2.5B | 1.4B | 665.1 M | 1.1 G |
si | 788K | 349.2K | 22.1M | 16M | 507.3M | 293.3M | 3.4B | 1.9B | 1023.6 M | 1.8 G |
tt | 2.1M | 346.9K | 60.2M | 8.6M | 1B | 135M | 12.1B | 1B | 494.1 M | 4.6 G |
tg | 789.2K | 328.2K | 789.2K | 7.4M | 363.8M | 208.8M | 2.6B | 1.4B | 635.7 M | 1.1 G |
la | 2.9M | 319.2K | 85.7M | 13.8M | 1.1B | 218.4M | 8.2B | 1.5B | 550.6 M | 2.9 G |
so | 729.2K | 293.2K | 729.2K | 3.1M | 294.8M | 146.3M | 2.1B | 992.4M | 350.8 M | 746.2 M |
ga | 5.3M | 286K | 31.7M | 6.9M | 4.2B | 229.3M | 30.6B | 1.4B | 500.7 M | 9.8 G |
km | 297.8K | 285.7K | 5M | 5M | 53M | 52.6M | 1.1B | 1.1B | 566.2 M | 570.0 M |
mt | 1.2M | 265.4K | 1.2M | 5.6M | 390.4M | 171.5M | 3.2B | 1.3B | 467.4 M | 1.1 G |
eo | 1.4M | 260K | 33.9M | 9.3M | 745.1M | 253.1M | 5.5B | 1.7B | 627.6 M | 1.9 G |
ps | 429.9K | 252.9K | 5.1M | 3.6M | 293.9M | 177.5M | 1.4B | 848.9M | 403.5 M | 682.9 M |
rw | 681.8K | 226.5K | 681.8K | 1.9M | 225M | 99.8M | 1.7B | 749.1M | 264.8 M | 702.4 M |
ku | 671.9K | 218.9K | 10.7M | 4.9M | 305.3M | 143.8M | 2.1B | 849.9M | 335.3 M | 791.9 M |
lo | 229.1K | 216K | 2.9M | 2.8M | 41.7M | 41.1M | 706.9M | 697.6M | 365.3 M | 370.8 M |
fy | 1.7M | 210K | 12.1M | 3.7M | 506.9M | 94M | 3.7B | 592.3M | 223.0 M | 1.2 G |
ha | 443.9K | 173.5K | 4.5M | 2.4M | 206.5M | 109.3M | 1.3B | 630.2M | 219.0 M | 478.1 M |
my | 176.5K | 172.4K | 176.5K | 10.1M | 96.6M | 96.3M | 1.3B | 1.3B | 648.8 M | 650.4 M |
dv | 264.4K | 167.2K | 4.3M | 3.5M | 92.8M | 64M | 877.3M | 603.1M | 238.3 M | 343.2 M |
pa | 368.2K | 150.6K | 368.2K | 6M | 306M | 152.8M | 1.6B | 797.1M | 414.1 M | 857.6 M |
ckb | 622.7K | 148.9K | 5.6M | 2.5M | 312.7M | 83.3M | 2.2B | 572.7M | 265.0 M | 1011.1 M |
lb | 7.6M | 146K | 47.1M | 3.4M | 7.5B | 85M | 58.4B | 575.5M | 218.4 M | 22.2 G |
mg | 295.2K | 115.4K | 4.5M | 2.6M | 189.4M | 75.5M | 1.3B | 548.5M | 179.0 M | 429.3 M |
ht | 425.6K | 110.4K | 6.7M | 2.6M | 163M | 84.3M | 994.5M | 461.5M | 168.2 M | 361.5 M |
ug | 227.1K | 106.5K | 4.5M | 3.1M | 122.9M | 62.7M | 998.5M | 504.6M | 233.1 M | 449.9 M |
am | 245.2K | 106.3K | 7.1M | 5.3M | 157M | 95.2M | 869.9M | 509M | 345.5 M | 539.4 M |
or | 139.6K | 100.5K | 139.6K | 3.1M | 66M | 47.3M | 437.2M | 309.5M | 160.3 M | 228.1 M |
fo | 382.9K | 97.8K | 3.9M | 1.8M | 136.5M | 48.9M | 923.3M | 314.9M | 122.0 M | 328.8 M |
gd | 206K | 94.3K | 3.7M | 2.4M | 127.6M | 84.5M | 812M | 526M | 173.4 M | 276.6 M |
ba | 372.4K | 90.3K | 9.3M | 2.6M | 101M | 42.1M | 766.5M | 320.7M | 154.8 M | 352.4 M |
tk | 180.2K | 82.5K | 180.2K | 1.8M | 65.4M | 43.3M | 575.2M | 369M | 131.3 M | 221.6 M |
mi | 711.9K | 79.5K | 5.9M | 1.9M | 262.5M | 73.5M | 1.6B | 371.9M | 120.2 M | 539.1 M |
hmn | 241.3K | 75.2K | 3.5M | 1.9M | 192.1M | 80.2M | 1.2B | 408.8M | 124.3 M | 366.0 M |
grc | 364.8K | 70.7K | 13.7M | 2.8M | 298.6M | 65.3M | 2B | 417.8M | 217.7 M | 1.0 G |
jv | 999.5K | 69.5K | 13M | 2M | 302.3M | 52.1M | 2.3B | 376.1M | 130.9 M | 797.8 M |
ceb | 617.5K | 66.2K | 6.7M | 1.6M | 225M | 58.2M | 1.5B | 357.7M | 116.2 M | 451.4 M |
sd | 115.6K | 65.9K | 115.6K | 2.4M | 112.6M | 77.8M | 561M | 380.4M | 182.3 M | 267.1 M |
yi | 160.6K | 64.9K | 3.3M | 1.9M | 129.1M | 53.9M | 838.4M | 352.6M | 146.0 M | 350.8 M |
kaa_Latn | 375.2K | 61.2K | 3.6M | 1.3M | 375.2K | 61.2K | 1.5M | 209.5K | 86.2 M | 264.6 M |
sn | 3.1M | 60.2K | 3.1M | 1.2M | 1.3B | 31.6M | 10.6B | 266M | 92.5 M | 3.2 G |
co | 546.7K | 55.4K | 6.1M | 1.3M | 172.6M | 43.6M | 1.1B | 265.5M | 98.8 M | 386.8 M |
su | 336.6K | 55K | 336.6K | 1.6M | 154M | 39.5M | 967.2M | 286.7M | 100.7 M | 308.5 M |
pap | 259.1K | 54.5K | 259.1K | 1.4M | 183.9M | 41.1M | 1.4B | 229.9M | 83.5 M | 451.4 M |
ig | 130.4K | 54.4K | 2.1M | 1.4M | 129.2M | 45.7M | 846.1M | 251.4M | 93.0 M | 178.9 M |
zu | 372.3K | 53.8K | 3.8M | 1.2M | 148.4M | 27.2M | 1.2B | 257.4M | 89.6 M | 374.7 M |
xh | 310.9K | 53.7K | 2.9M | 1.4M | 81.6M | 31.2M | 749.5M | 287.3M | 100.0 M | 319.1 M |
sm | 137.8K | 52.6K | 1.9M | 1.3M | 100.9M | 53.7M | 607.9M | 276.3M | 88.6 M | 184.5 M |
ny | 181.6K | 52.2K | 181.6K | 1.5M | 80.6M | 34.8M | 611.2M | 277.5M | 91.8 M | 209.8 M |
yo | 115K | 52.1K | 2M | 1.2M | 76.6M | 46.3M | 415.6M | 239M | 89.2 M | 157.8 M |
cv | 599.4K | 47.3K | 12M | 1.6M | 169.6M | 22.2M | 1B | 168.9M | 82.1 M | 413.6 M |
el_Latn | 497.3K | 46.4K | 11.3M | 1.7M | 497.3K | 46.4K | 2.3M | 162.8K | 196.8 M | 571.1 M |
kl | 85.9K | 46K | 2.1M | 1.5M | 32.3M | 22.3M | 403.9M | 279.1M | 84.2 M | 126.1 M |
haw | 310.4K | 45.7K | 7.1M | 1M | 141M | 43.3M | 892M | 214.2M | 69.9 M | 271.2 M |
gsw | 7.6M | 42.7K | 64.5M | 1M | 5B | 22.3M | 42.3B | 149.2M | 53.8 M | 13.5 G |
tet | 291K | 40.4K | 1.9M | 475.7K | 240.6M | 22.8M | 1.6B | 152.3M | 51.2 M | 455.4 M |
st | 96.8K | 40.4K | 96.8K | 1.1M | 65M | 39.8M | 381.5M | 226.9M | 74.0 M | 127.0 M |
lus | 91.5K | 36.4K | 1.4M | 863.5K | 53M | 31.3M | 298.3M | 167.3M | 60.1 M | 107.0 M |
oc | 2.4M | 36.4K | 2.4M | 1.6M | 887.6M | 26.7M | 6.7B | 177.6M | 58.7 M | 1.9 G |
as | 53.9K | 33.8K | 2.4M | 1.7M | 41.4M | 27.9M | 275.8M | 182.1M | 95.8 M | 146.1 M |
rm | 238.1K | 33.8K | 238.1K | 603.4K | 59.2M | 15.8M | 391M | 100.2M | 34.6 M | 133.1 M |
br | 705.4K | 33.2K | 7.8M | 731.7K | 646.8M | 21M | 3.7B | 125.4M | 46.2 M | 1.2 G |
sah | 1.3M | 29.2K | 1.3M | 1.2M | 283.7M | 17.6M | 2.2B | 148.2M | 68.3 M | 852.3 M |
hi_Latn | 1.2M | 26.7K | 22.6M | 1.2M | 1.2M | 26.7K | 5.3M | 98.9K | 53.5 M | 1.7 G |
se | 54.3K | 23.9K | 879.5K | 493.3K | 17.7M | 10M | 148.4M | 84.6M | 31.1 M | 56.6 M |
cnh | 44.4K | 21.6K | 688.6K | 406.9K | 21.6M | 12.5M | 110.8M | 63M | 22.1 M | 39.6 M |
om | 846.1K | 18.9K | 846.1K | 469.8K | 238M | 11.2M | 1.9B | 88.5M | 30.4 M | 881.5 M |
ce | 59.3K | 15K | 991.1K | 460.1K | 17.8M | 9.6M | 130.6M | 67.8M | 31.1 M | 60.2 M |
udm | 67.1K | 13.4K | 942.7K | 510.3K | 14M | 7.4M | 106M | 55.5M | 26.3 M | 49.2 M |
lg | 61.1K | 13K | 510.9K | 166.1K | 21.4M | 6.1M | 160.7M | 48M | 17.3 M | 56.7 M |
os | 172.1K | 12.6K | 172.1K | 359.3K | 27.1M | 6.9M | 233.5M | 50.1M | 23.1 M | 87.7 M |
nv | 17.1K | 12.6K | 17.1K | 86.5K | 3.1M | 1.1M | 24.8M | 9.1M | 2.0 M | 7.9 M |
kha | 37.8K | 12.1K | 235.5K | 75.2K | 15.8M | 6M | 88.6M | 30.2M | 9.8 M | 27.3 M |
ilo | 69.8K | 11.8K | 889.2K | 365.1K | 26.7M | 9M | 187.9M | 59.4M | 20.6 M | 64.0 M |
ctd_Latn | 23.3K | 11.6K | 575.6K | 382.2K | 23.3K | 11.6K | 90.7K | 41K | 21.5 M | 35.1 M |
vec | 1.1M | 11.1K | 10M | 209.7K | 284.7M | 7.8M | 1.8B | 43.8M | 17.7 M | 625.0 M |
hil | 126.8K | 10.6K | 1.1M | 379.7K | 43.9M | 9.2M | 293.5M | 57.2M | 18.5 M | 95.2 M |
tyv | 61.6K | 9.1K | 596.6K | 268.3K | 9.9M | 4.7M | 80.2M | 38.5M | 16.7 M | 36.6 M |
iba | 34K | 7.6K | 326.9K | 126.1K | 37.8M | 4.8M | 251.4M | 30.5M | 10.0 M | 61.3 M |
ru_Latn | 346.3K | 7.5K | 346.3K | 239.1K | 346.3K | 7.5K | 1.5M | 27.7K | 14.9 M | 452.3 M |
kbd | 154.7K | 7.5K | 1.4M | 257.2K | 31.9M | 4.4M | 321.4M | 36.8M | 16.8 M | 209.6 M |
ti | 20.8K | 7.3K | 20.8K | 481.3K | 18.2M | 8.8M | 95.4M | 44.6M | 30.9 M | 63.6 M |
sa | 154.3K | 7.1K | 154.3K | 1.1M | 70M | 9.9M | 512.5M | 88.8M | 44.9 M | 236.6 M |
av | 107.6K | 6.3K | 806.1K | 190.1K | 15.5M | 3.4M | 129M | 30.2M | 12.8 M | 56.0 M |
bo | 6.2K | 6.2K | 1.1M | 1.1M | 3.4M | 3.4M | 88.7M | 88.7M | 40.7 M | 40.7 M |
zza | 370.1K | 6K | 3.3M | 229.2K | 87.7M | 3.9M | 617.3M | 26.3M | 10.0 M | 234.1 M |
ber_Latn | 480.5K | 5.6K | 10.5M | 169.4K | 480.5K | 5.6K | 2.1M | 18.9K | 11.0 M | 945.3 M |
otq | 17.6K | 5.6K | 17.6K | 114.8K | 10.2M | 3.8M | 65M | 23.4M | 7.7 M | 22.8 M |
te_Latn | 236.6K | 5.3K | 4.4M | 269.1K | 236.6K | 5.3K | 1M | 19.3K | 11.4 M | 254.3 M |
bua | 9.8K | 5.3K | 252K | 144.6K | 4.7M | 2.7M | 38M | 21.7M | 10.0 M | 17.9 M |
ts | 34.7K | 5.2K | 34.7K | 248.6K | 39.6M | 6.5M | 377.2M | 38.8M | 12.2 M | 99.5 M |
cfm | 9.1K | 4.9K | 199.6K | 128.6K | 6.2M | 4M | 32.9M | 21.5M | 7.4 M | 11.6 M |
tn | 138.2K | 4.8K | 138.2K | 174.4K | 46M | 5.5M | 302.3M | 29.2M | 9.4 M | 99.0 M |
krc | 359.5K | 4.8K | 2.3M | 153.9K | 50.2M | 2.6M | 369.5M | 20.7M | 9.1 M | 139.9 M |
ak | 19.5K | 4.8K | 341.7K | 210.2K | 12.3M | 4.7M | 74.5M | 24.8M | 9.1 M | 24.7 M |
meo | 790.7K | 4.7K | 16.5M | 39K | 478M | 1.2M | 3B | 7.5M | 3.1 M | 1.2 G |
chm | 81.5K | 4.7K | 929.1K | 179.7K | 17.2M | 2.9M | 132.2M | 21.3M | 9.8 M | 53.5 M |
to | 14.3K | 4.6K | 14.3K | 149K | 10.3M | 5.7M | 58.2M | 29.9M | 9.6 M | 19.0 M |
ee | 14.1K | 4.5K | 353.6K | 246.7K | 9.7M | 6.2M | 67.9M | 32.8M | 11.8 M | 23.3 M |
nso | 376.2K | 4.4K | 376.2K | 188.4K | 419.2M | 5.3M | 2B | 28.2M | 9.1 M | 502.7 M |
ady | 74.9K | 4.2K | 446.8K | 96.9K | 8M | 1.6M | 67.9M | 14.8M | 6.4 M | 30.6 M |
rom | 22.9K | 4.2K | 22.9K | 76.1K | 8.9M | 2.6M | 59M | 15.9M | 5.8 M | 21.0 M |
bho | 13.6K | 4.1K | 306.2K | 118.5K | 7.1M | 2.7M | 37.6M | 13.4M | 7.4 M | 20.6 M |
ltg | 13.1K | 4.1K | 213.7K | 87.3K | 4M | 1.9M | 29.2M | 13.9M | 5.6 M | 11.7 M |
fj | 17K | 4K | 410K | 164.1K | 11.6M | 5.2M | 67.7M | 28M | 8.6 M | 22.5 M |
yua | 10.4K | 4K | 141.6K | 77.6K | 5.2M | 2.5M | 36.8M | 17.2M | 5.7 M | 12.4 M |
gn | 87.1K | 3.9K | 770.9K | 162.6K | 19.2M | 2.7M | 140.7M | 20.8M | 7.8 M | 52.1 M |
az_RU | 6.5K | 3.8K | 231.8K | 177.3K | 6.5K | 3.8K | 24K | 12.9K | 10.3 M | 15.1 M |
ln | 94.7K | 3.3K | 718.7K | 139K | 42.4M | 3.4M | 291.8M | 21.5M | 6.8 M | 85.3 M |
ada | 6.5K | 3.1K | 291.5K | 199.2K | 7.5M | 4.9M | 38.9M | 24.2M | 8.6 M | 13.9 M |
myv | 164.8K | 3.1K | 164.8K | 130K | 16M | 1.7M | 120.3M | 13.8M | 6.2 M | 49.5 M |
bik | 44.8K | 3.1K | 376.7K | 77K | 14.8M | 2.5M | 102.3M | 15.7M | 5.3 M | 34.0 M |
tlh | 516.9K | 3.1K | 516.9K | 46.9K | 221.3M | 1.1M | 1.4B | 7.8M | 2.7 M | 554.2 M |
kbp | 5.9K | 3K | 247.9K | 128.3K | 5.6M | 2.6M | 30.8M | 14.6M | 5.7 M | 12.4 M |
war | 1M | 2.9K | 114M | 96.2K | 612.1M | 2.4M | 3.5B | 16.1M | 3.7 M | 1.2 G |
wa | 70.6K | 2.8K | 1.5M | 127.2K | 35.2M | 3.6M | 198.8M | 20.4M | 7.2 M | 67.8 M |
bew | 311.1K | 2.7K | 10.4M | 58.4K | 212.4M | 1.3M | 1.4B | 8.5M | 3.1 M | 547.1 M |
rcf | 21.6K | 2.6K | 21.6K | 50.5K | 4.9M | 1.2M | 30.2M | 5.7M | 2.1 M | 11.4 M |
ta_Latn | 260.7K | 2.6K | 3.4M | 142.7K | 260.7K | 2.6K | 1.2M | 9.1K | 5.0 M | 215.4 M |
kac | 5.9K | 2.6K | 109.2K | 77.4K | 5M | 2.8M | 26.6M | 13.6M | 4.3 M | 8.0 M |
iu | 5.4K | 2.5K | 92.6K | 53.1K | 1.9M | 907.4K | 17.5M | 8.3M | 4.8 M | 9.9 M |
ay | 8.1K | 2.5K | 196.7K | 83.8K | 3.9M | 1.4M | 34.5M | 13.1M | 4.5 M | 12.7 M |
kum | 4.2K | 2.5K | 132.2K | 89.7K | 2.3M | 1.6M | 18.2M | 12.4M | 5.3 M | 8.0 M |
qu | 149.7K | 2.4K | 1M | 87K | 26.7M | 1.3M | 200.6M | 12.2M | 4.0 M | 68.3 M |
bgp | 355.7K | 2.4K | 5.6M | 43.3K | 186.1M | 1.8M | 1.1B | 9.8M | 3.1 M | 377.5 M |
hif | 702K | 2.4K | 7.9M | 124.7K | 1.2B | 3.2M | 9.1B | 19.1M | 5.9 M | 3.5 G |
kw | 176.9K | 2.3K | 1M | 51.6K | 53.1M | 1.3M | 327.8M | 7.7M | 2.8 M | 89.2 M |
nan_Latn_TW | 7.4K | 2.3K | 7.4K | 72.7K | 7.4K | 2.3K | 28.3K | 7.7K | 4.8 M | 15.4 M |
srn | 16.7K | 2.3K | 16.7K | 139.5K | 8M | 3.4M | 49.1M | 17M | 5.1 M | 15.6 M |
tly_IR | 406.3K | 2.2K | 406.3K | 18.2K | 406.3K | 2.2K | 1.6M | 8.6K | 580.4 K | 283.0 M |
sg | 4.2K | 2.1K | 154K | 117.9K | 4.6M | 3.3M | 22.6M | 15.5M | 4.6 M | 6.8 M |
gom | 4.6K | 2.1K | 178.3K | 108K | 2.7M | 1.4M | 19.8M | 10M | 5.0 M | 10.5 M |
ml_Latn | 260.8K | 2.1K | 3.5M | 77.3K | 260.8K | 2.1K | 1.1M | 7.2K | 3.5 M | 277.7 M |
kj | 112.2K | 2.1K | 881.8K | 22.6K | 46.9M | 877.3K | 339.6M | 6M | 2.1 M | 104.9 M |
ksd | 14.9K | 2K | 533K | 78.6K | 11.5M | 2.1M | 62.4M | 10M | 2.9 M | 20.0 M |
dz | 1.9K | 1.9K | 191.7K | 191.7K | 1.1M | 1.1M | 22.7M | 22.7M | 10.0 M | 10.0 M |
kv | 59.1K | 1.9K | 584.3K | 88.8K | 9.5M | 1.2M | 91.4M | 9M | 4.4 M | 41.0 M |
msi | 686.7K | 1.9K | 686.7K | 22.6K | 414.8M | 440.4K | 2.6B | 2.7M | 1.1 M | 1.0 G |
ve | 3.8K | 1.9K | 97.8K | 79.4K | 3.2M | 2.1M | 19M | 11.7M | 3.8 M | 6.2 M |
zap | 5.5K | 1.8K | 202.3K | 93.5K | 4.2M | 1.8M | 26.4M | 11.4M | 4.0 M | 9.6 M |
zxx_xx_dtynoise | 118.8K | 1.8K | 3.8M | 49.3K | 118.8K | 1.8K | 501K | 6.6K | 3.9 M | 367.0 M |
meu | 5.9K | 1.7K | 232.1K | 72.6K | 4.2M | 1.4M | 27.2M | 8.6M | 2.6 M | 9.1 M |
iso | 3.7K | 1.7K | 155.8K | 111.5K | 4.4M | 2.7M | 23M | 13.7M | 4.9 M | 8.1 M |
ium | 100.3K | 1.7K | 6.2M | 54.9K | 48.4M | 1.7M | 314M | 7.4M | 2.6 M | 124.0 M |
nhe | 3K | 1.7K | 3K | 57.7K | 1.9M | 1.2M | 15.6M | 9.8M | 2.7 M | 4.8 M |
tyz | 8K | 1.7K | 454.8K | 104.6K | 7.5M | 1.9M | 46.3M | 11.3M | 3.8 M | 16.0 M |
hui | 2K | 1.7K | 80.1K | 74.7K | 1.8M | 1.7M | 11.8M | 10.9M | 3.0 M | 3.3 M |
new | 6.6K | 1.6K | 6.6K | 85K | 3.2M | 1.4M | 21.2M | 8.8M | 4.4 M | 10.6 M |
mdf | 71K | 1.6K | 394.7K | 45.1K | 8.3M | 670.1K | 65.8M | 5.5M | 2.5 M | 26.7 M |
pag | 49.6K | 1.6K | 49.6K | 88.8K | 13.8M | 1.9M | 92.9M | 12M | 3.9 M | 29.2 M |
gv | 501.9K | 1.6K | 18.8M | 26.9K | 137.7M | 996.2K | 933.1M | 6.2M | 2.0 M | 318.6 M |
gag | 33.9K | 1.6K | 491K | 37K | 10.2M | 661K | 84.9M | 5.2M | 2.1 M | 32.6 M |
ngu | 3.8K | 1.5K | 3.8K | 87.1K | 2.7M | 1.5M | 21.4M | 11.8M | 3.6 M | 6.7 M |
quc | 4.4K | 1.5K | 89.2K | 41.2K | 2.8M | 1.1M | 16.6M | 6.4M | 2.2 M | 5.9 M |
mam | 23K | 1.5K | 446.3K | 52.9K | 9.8M | 1.2M | 70.4M | 7.2M | 2.6 M | 30.7 M |
min | 28.2K | 1.5K | 500.9K | 75.6K | 10.2M | 1.4M | 70.5M | 9.9M | 2.6 M | 21.1 M |
ho | 2K | 1.5K | 57K | 47.8K | 1.8M | 1.3M | 12.3M | 7.8M | 1.9 M | 3.1 M |
pon | 5.7K | 1.5K | 167.8K | 48.7K | 3M | 1.1M | 18.3M | 6.7M | 2.1 M | 6.1 M |
mrj | 97.1K | 1.4K | 97.1K | 60.3K | 14.5M | 1.1M | 100.6M | 7.6M | 3.6 M | 40.8 M |
lu | 10.6K | 1.4K | 316K | 112.1K | 7.8M | 2.3M | 54.2M | 15.4M | 4.8 M | 18.0 M |
gom_Latn | 231.1K | 1.4K | 4.1M | 77.9K | 231.1K | 1.4K | 1M | 5.1K | 3.6 M | 240.6 M |
alt | 2.6K | 1.4K | 110.1K | 65.9K | 1.8M | 1.1M | 14.3M | 8.7M | 3.8 M | 6.4 M |
nzi | 2.5K | 1.4K | 2.5K | 71.8K | 2.5M | 1.7M | 14.4M | 9.4M | 3.1 M | 4.8 M |
tzo | 2.8K | 1.4K | 100.4K | 75.7K | 2.5M | 1.7M | 15.9M | 10.6M | 3.2 M | 4.9 M |
bci | 7.4K | 1.3K | 124.8K | 87.1K | 5M | 1.9M | 32.8M | 9M | 3.1 M | 9.4 M |
dtp | 4.6K | 1.3K | 51.2K | 7.9K | 1.9M | 419.4K | 12.7M | 3M | 1013.9 K | 4.5 M |
abt | 1.6K | 1.3K | 122.7K | 110.3K | 1.5M | 1.3M | 9.6M | 8.2M | 2.2 M | 2.7 M |
bbc | 72.3K | 1.3K | 718.3K | 73.2K | 21.7M | 1.7M | 151.3M | 10.6M | 3.6 M | 47.9 M |
pck | 8.9K | 1.3K | 8.9K | 69.7K | 6.8M | 2.1M | 39.8M | 11.5M | 4.2 M | 14.2 M |
mai | 54.3K | 1.2K | 1M | 60.2K | 24.6M | 1.2M | 156M | 6.8M | 3.6 M | 67.1 M |
mps | 2.7K | 1.2K | 132.8K | 71.9K | 2.8M | 1.6M | 16M | 8.7M | 2.3 M | 4.8 M |
emp | 3.6K | 1.2K | 106.4K | 75.4K | 1.9M | 999.1K | 14.5M | 7.4M | 2.4 M | 4.9 M |
mgh | 5.5K | 1.2K | 151.8K | 61.2K | 2.8M | 1.1M | 24.1M | 8.2M | 2.8 M | 8.3 M |
tab | 7.8K | 1.2K | 226.4K | 26.8K | 4.3M | 538.9K | 33.7M | 4.4M | 1.9 M | 15.7 M |
crh | 5.1K | 1.2K | 170.9K | 61.8K | 2.4M | 943K | 18.8M | 7.5M | 3.4 M | 8.9 M |
tbz | 5.1K | 1.1K | 128.7K | 37.5K | 3.5M | 893.4K | 22M | 4.8M | 1.9 M | 10.2 M |
ss | 8.1K | 1.1K | 8.1K | 30.4K | 2.7M | 568.3K | 23.7M | 5.5M | 1.8 M | 7.4 M |
chk | 2.8K | 1.1K | 98.8K | 44K | 2M | 1M | 12M | 5.8M | 1.8 M | 4.0 M |
bru | 3K | 1.1K | 89.7K | 48.2K | 2.4M | 938.1K | 12.9M | 4.8M | 1.5 M | 4.5 M |
nnb | 4.9K | 1.1K | 4.9K | 70.2K | 3.2M | 1.2M | 27.7M | 9.1M | 3.3 M | 10.0 M |
fon | 5.3K | 1.1K | 222.9K | 67.3K | 6.9M | 1.8M | 34M | 8.3M | 3.1 M | 14.8 M |
ppk | 2.6K | 1.1K | 85.8K | 34.9K | 1.9M | 801.8K | 13.2M | 5.5M | 1.6 M | 4.3 M |
tiv | 3.8K | 1.1K | 3.8K | 80.7K | 3.7M | 2.1M | 20.4M | 10.2M | 3.2 M | 6.0 M |
btx | 3.1K | 1K | 81.7K | 43.9K | 2M | 907.5K | 13.1M | 5.9M | 2.0 M | 4.6 M |
bg_Latn | 200.4K | 991 | 2.8M | 25.5K | 200.4K | 991 | 927.1K | 3.7K | 1.7 M | 143.6 M |
mbt | 1.6K | 969 | 86K | 45.4K | 2.4M | 1.3M | 14.6M | 7.5M | 2.2 M | 5.1 M |
ace | 65.5K | 966 | 632.5K | 32.5K | 19.9M | 1.1M | 146.1M | 7.4M | 2.2 M | 42.3 M |
tvl | 2.3K | 933 | 72.9K | 53.6K | 2.5M | 1.7M | 12.6M | 8.1M | 2.4 M | 3.8 M |
dov | 3.5K | 923 | 129.8K | 56.7K | 2.6M | 967.5K | 20.7M | 8M | 2.6 M | 7.1 M |
ach | 2K | 915 | 63K | 40.1K | 1.6M | 890.9K | 9M | 4.7M | 1.6 M | 3.0 M |
xal | 71.8K | 913 | 498.5K | 30.8K | 8.5M | 449.8K | 64.7M | 3.2M | 1.5 M | 24.4 M |
cuk | 4.1K | 899 | 76.5K | 34.3K | 2M | 469.9K | 24.7M | 4.6M | 1.5 M | 6.1 M |
kos | 2.2K | 881 | 44.6K | 27.8K | 1.1M | 780.1K | 6.5M | 4.2M | 1.4 M | 2.2 M |
crs | 7.6K | 873 | 282.4K | 40.1K | 7.3M | 1.2M | 40.1M | 6.8M | 2.2 M | 13.2 M |
wo | 36.4K | 871 | 303.4K | 25.4K | 30.7M | 850.7K | 213.4M | 4.5M | 1.7 M | 59.9 M |
bts | 3.2K | 869 | 109.1K | 29.1K | 3.1M | 663.3K | 20.8M | 4.2M | 1.4 M | 6.2 M |
ubu | 2.2K | 846 | 113.5K | 47.5K | 2.3M | 996.4K | 15.9M | 6.7M | 1.9 M | 4.7 M |
gym | 1.5K | 820 | 73.7K | 49.6K | 1.6M | 1.1M | 10.3M | 6.9M | 2.0 M | 3.2 M |
ibb | 74.1K | 818 | 516.5K | 36.3K | 26.4M | 776.1K | 190.9M | 4.9M | 1.5 M | 56.0 M |
ape | 7K | 814 | 147K | 56.1K | 12.4M | 881.5K | 71M | 5.8M | 1.6 M | 18.8 M |
stq | 111.9K | 809 | 111.9K | 27.7K | 34.4M | 600.4K | 243.1M | 3.8M | 1.5 M | 82.5 M |
ang | 66.5K | 803 | 1.8M | 86.7K | 28.5M | 1.7M | 193M | 9.8M | 3.4 M | 67.1 M |
enq | 7.1K | 793 | 241.9K | 39.1K | 11M | 718.8K | 68.5M | 4.8M | 1.3 M | 18.8 M |
tsg | 353.8K | 789 | 353.8K | 17.9K | 158M | 588.9K | 1.1B | 3.8M | 1.0 M | 309.9 M |
shn | 889 | 788 | 46.4K | 46.2K | 383.8K | 378.5K | 5.7M | 5.7M | 2.6 M | 2.6 M |
kri | 39.1K | 786 | 271.2K | 38.8K | 12.6M | 995.2K | 86.4M | 5M | 1.6 M | 20.9 M |
kek | 3.2K | 782 | 70.4K | 38.4K | 1.8M | 709K | 13.6M | 4.4M | 1.4 M | 4.7 M |
rmc | 2.4K | 738 | 2.4K | 25.8K | 1.3M | 545.4K | 7.9M | 3.2M | 1.1 M | 2.9 M |
acf | 4.9K | 730 | 81.9K | 24.6K | 2.1M | 602.2K | 11.6M | 3M | 1.1 M | 4.7 M |
fip | 3.7K | 729 | 165.6K | 49K | 3.5M | 916.8K | 25.7M | 6.6M | 2.1 M | 8.6 M |
syr | 3.5K | 716 | 326.4K | 197.1K | 4.6M | 1.9M | 31.5M | 14M | 6.1 M | 13.9 M |
qub | 972 | 705 | 61K | 51.1K | 589.2K | 455.5K | 5.9M | 4.4M | 1.4 M | 1.8 M |
bm | 21.9K | 702 | 172.3K | 24.5K | 7.1M | 583.1K | 48.4M | 3M | 1.1 M | 14.4 M |
tzh | 1.7K | 702 | 41.7K | 33.9K | 1.5M | 929.6K | 9.3M | 5.6M | 1.6 M | 2.6 M |
jiv | 1.7K | 696 | 80.9K | 32K | 1.1M | 418.9K | 9.6M | 3.5M | 1.1 M | 3.3 M |
kn_Latn | 72.9K | 688 | 765.9K | 10.1K | 72.9K | 688 | 328.1K | 2.5K | 430.8 K | 61.4 M |
kjh | 1.5K | 672 | 42.8K | 28.7K | 566.1K | 379.2K | 4.5M | 3.1M | 1.3 M | 2.0 M |
yap | 1.9K | 638 | 37.6K | 19.5K | 1.3M | 661.4K | 6.9M | 3.3M | 1.0 M | 2.2 M |
ban | 8K | 637 | 150.9K | 16.3K | 5M | 499.7K | 35.4M | 3.6M | 1.1 M | 12.0 M |
tuc | 3.5K | 635 | 193.2K | 50.3K | 2.9M | 703K | 17.2M | 4.1M | 1.2 M | 5.7 M |
tcy | 10.7K | 632 | 338.7K | 37.1K | 5.5M | 432.6K | 41.6M | 3.3M | 1.7 M | 20.9 M |
cab | 1.2K | 629 | 50.4K | 37.5K | 1M | 690.9K | 7.5M | 5.1M | 1.6 M | 2.4 M |
cak | 1.2K | 617 | 70.4K | 32.6K | 1.3M | 730.1K | 7.6M | 4.2M | 1.3 M | 2.4 M |
din | 128.4K | 611 | 885.8K | 23.6K | 31.6M | 541.7K | 210M | 2.9M | 1.1 M | 64.3 M |
zh_Latn | 739.4K | 602 | 10.7M | 45.1K | 739.4K | 602 | 3.4M | 2.3K | 2.0 M | 969.9 M |
arn | 2.4K | 593 | 64.5K | 26.2K | 1.5M | 541.9K | 10.2M | 3.7M | 1.2 M | 3.7 M |
lrc | 42.4K | 587 | 351.9K | 9K | 17.3M | 248.9K | 85.3M | 1.4M | 646.9 K | 37.5 M |
rwo | 938 | 572 | 938 | 45.5K | 734.8K | 590.4K | 5.1M | 4.2M | 1.1 M | 1.4 M |
hus | 825 | 569 | 26.5K | 23.7K | 733.4K | 542.1K | 4.4M | 3.1M | 967.6 K | 1.3 M |
bum | 4.7K | 559 | 103.8K | 36.5K | 3M | 805.5K | 18.8M | 4M | 1.3 M | 6.1 M |
mak | 1K | 555 | 32.5K | 20.4K | 761K | 457.4K | 6.1M | 3.7M | 1.1 M | 2.0 M |
frp | 148K | 550 | 3.5M | 8.2K | 71.2M | 230.2K | 535.4M | 1.4M | 518.3 K | 129.7 M |
seh | 5.6K | 545 | 68.8K | 37.2K | 2M | 650.6K | 14.9M | 4.9M | 1.5 M | 4.4 M |
twu | 2.5K | 539 | 109.9K | 24.4K | 2.4M | 571.2K | 14.2M | 3.2M | 1.0 M | 4.8 M |
kmb | 1.3K | 538 | 60.4K | 36.9K | 1.4M | 810.8K | 8.4M | 4.6M | 1.4 M | 2.6 M |
ksw | 560 | 536 | 16.1K | 16K | 219.9K | 218.8K | 2.9M | 2.9M | 1.4 M | 1.4 M |
sja | 1.3K | 527 | 67.7K | 24.9K | 982.5K | 459.3K | 7.7M | 3.4M | 1.1 M | 2.6 M |
amu | 1.8K | 511 | 72K | 25.2K | 1.5M | 443.3K | 9.6M | 3.2M | 1.0 M | 3.4 M |
mad | 103.8K | 509 | 500.6K | 18.5K | 16.2M | 386.7K | 111.8M | 2.8M | 960.3 K | 34.2 M |
quh | 1K | 501 | 42K | 29.9K | 624.4K | 396.8K | 5.8M | 3.7M | 1.2 M | 1.8 M |
dyu | 1.2K | 483 | 55.8K | 19.7K | 1.2M | 421.8K | 5.7M | 2M | 665.5 K | 1.9 M |
toj | 736 | 452 | 736 | 26.1K | 691.2K | 540.2K | 4.3M | 3.3M | 1.0 M | 1.3 M |
ch | 12.9K | 449 | 147.5K | 16K | 8.9M | 393.9K | 63.5M | 2.5M | 906.8 K | 10.0 M |
sus | 664 | 437 | 664 | 15.2K | 648K | 402.8K | 3.7M | 2.1M | 674.0 K | 1.0 M |
nog | 970 | 419 | 970 | 11K | 330.3K | 200.4K | 2.6M | 1.6M | 714.0 K | 1.2 M |
jam | 12.7K | 416 | 68.5K | 15.8K | 3.5M | 378.4K | 25.8M | 1.7M | 609.5 K | 7.6 M |
gui | 1.1K | 409 | 62.7K | 24.8K | 915K | 314K | 6.5M | 2M | 619.3 K | 2.1 M |
nia | 2K | 408 | 2K | 25K | 1.7M | 476.5K | 11.3M | 3.1M | 1.0 M | 3.9 M |
mas | 15.2K | 405 | 216.8K | 17.6K | 6.2M | 390.1K | 42.1M | 3M | 927.5 K | 13.4 M |
bzj | 983 | 404 | 33.6K | 26.4K | 824.3K | 565K | 4.5M | 2.9M | 981.2 K | 1.4 M |
mkn | 956 | 402 | 33.1K | 25.4K | 584.2K | 456.9K | 3.4M | 2.6M | 734.8 K | 1.0 M |
lhu | 46K | 377 | 975K | 15.7K | 29.1M | 441.2K | 208.6M | 2.5M | 623.0 K | 38.8 M |
ctu | 690 | 366 | 35.5K | 20.6K | 646.7K | 352.8K | 3.6M | 2M | 614.9 K | 1.2 M |
kg | 4.7K | 365 | 85.5K | 21.7K | 2.5M | 406.7K | 16.6M | 2.6M | 905.4 K | 5.7 M |
inb | 387 | 343 | 17.3K | 17K | 202.8K | 197K | 2M | 1.9M | 535.2 K | 555.6 K |
guh | 1.9K | 331 | 104.9K | 28.4K | 1.5M | 328.4K | 11.2M | 3M | 789.5 K | 3.5 M |
rn | 8.2K | 323 | 8.2K | 11.1K | 4.5M | 179K | 33.2M | 1.3M | 449.9 K | 11.8 M |
bus | 467 | 322 | 21.4K | 12.1K | 418.4K | 219.2K | 2.1M | 1.1M | 428.8 K | 830.9 K |
mfe | 7.5K | 320 | 198.8K | 18.2K | 4.6M | 374.8K | 26.9M | 2.1M | 716.4 K | 10.1 M |
sda | 1.6K | 317 | 43.2K | 6.2K | 2.5M | 218.3K | 15.8M | 1.6M | 529.0 K | 4.7 M |
bi | 71.9K | 311 | 308.5K | 13.6K | 19.4M | 359.4K | 132.4M | 1.9M | 546.9 K | 42.6 M |
cr_Latn | 19K | 303 | 170K | 8.9K | 19K | 303 | 81.8K | 1K | 590.4 K | 15.0 M |
gor | 1.7K | 303 | 53.3K | 6.5K | 1.4M | 227.1K | 9.4M | 1.7M | 494.0 K | 3.1 M |
jac | 8.2K | 303 | 61.6K | 11.9K | 1.8M | 271K | 15.7M | 1.7M | 530.3 K | 7.3 M |
chr | 964 | 301 | 33.8K | 7.5K | 629.9K | 172.3K | 4.7M | 1M | 564.1 K | 2.1 M |
mh | 4.6K | 296 | 235.1K | 13K | 3.6M | 393.5K | 24.9M | 2.2M | 778.4 K | 8.4 M |
mni | 1.2K | 290 | 38.1K | 13.2K | 841.3K | 245.5K | 6.4M | 1.8M | 866.6 K | 3.0 M |
wal | 2.6K | 286 | 128K | 14K | 2M | 203.4K | 17M | 1.7M | 525.7 K | 5.1 M |
teo | 2.8K | 274 | 131.5K | 13.7K | 2.3M | 221.4K | 15.3M | 1.6M | 564.9 K | 5.3 M |
gub | 31.7K | 271 | 160.4K | 25K | 4.7M | 286.2K | 44.7M | 1.6M | 431.3 K | 23.1 M |
qvi | 1.2K | 266 | 48.4K | 19.3K | 720.4K | 248.9K | 6.5M | 2.3M | 641.2 K | 1.9 M |
tdx | 1.7K | 262 | 26.3K | 13.2K | 1M | 238.5K | 7M | 1.6M | 503.6 K | 2.1 M |
rki | 331 | 251 | 331 | 7.8K | 119.7K | 113.7K | 1.6M | 1.5M | 751.3 K | 781.8 K |
djk | 560 | 246 | 30.9K | 24.4K | 669.5K | 455.6K | 3.7M | 2.2M | 644.3 K | 1.0 M |
nr | 10.7K | 246 | 10.7K | 11.3K | 5.3M | 162.5K | 49M | 1.5M | 519.7 K | 17.8 M |
zne | 1.3K | 239 | 61.9K | 21.3K | 1.4M | 504.6K | 8.2M | 2.8M | 882.3 K | 2.8 M |
izz | 423 | 237 | 21.7K | 14.5K | 382.8K | 194.5K | 2.1M | 1.1M | 382.2 K | 789.9 K |
noa | 902 | 234 | 902 | 11.5K | 821.1K | 243.9K | 5.2M | 1.6M | 534.3 K | 1.7 M |
bqc | 275 | 228 | 9.8K | 8.2K | 193K | 151.7K | 997K | 788.4K | 317.0 K | 408.1 K |
srm | 847 | 227 | 847 | 17.3K | 1.2M | 445.3K | 6.3M | 2M | 613.4 K | 1.7 M |
niq | 26.7K | 226 | 26.7K | 4.2K | 9.9M | 103.4K | 72.1M | 716.2K | 239.1 K | 20.9 M |
bas | 4.2K | 216 | 105.2K | 14.9K | 4.3M | 362.8K | 25.7M | 1.7M | 600.7 K | 7.6 M |
dwr | 452 | 215 | 22.1K | 11.1K | 269.4K | 139.5K | 2.2M | 1.2M | 375.4 K | 747.6 K |
guc | 537 | 214 | 22.9K | 12.5K | 422.4K | 218.1K | 3.4M | 1.8M | 540.1 K | 1.1 M |
jvn | 1K | 213 | 36.2K | 7.8K | 790.5K | 185.6K | 5.3M | 1.2M | 357.2 K | 1.7 M |
hvn | 737 | 200 | 33.9K | 7K | 779.7K | 239.4K | 4.3M | 1.2M | 378.5 K | 1.4 M |
sxn | 587 | 197 | 587 | 9.9K | 494K | 220.6K | 3.4M | 1.5M | 507.1 K | 1.2 M |
koi | 20.7K | 196 | 153.9K | 5K | 2.2M | 89.9K | 17.1M | 664.5K | 323.0 K | 7.1 M |
alz | 2.2K | 195 | 59.3K | 12.2K | 1.3M | 246.9K | 7.9M | 1.4M | 488.1 K | 2.9 M |
nyu | 1.2K | 195 | 1.2K | 11K | 988.7K | 210.5K | 7.7M | 1.6M | 492.6 K | 2.2 M |
bn_Latn | 98.7K | 191 | 1.3M | 12K | 98.7K | 191 | 458K | 730 | 314.7 K | 81.0 M |
suz | 226 | 186 | 226 | 11.3K | 169.6K | 140.5K | 1M | 855.2K | 339.5 K | 429.6 K |
pau | 1.7K | 185 | 1.7K | 13.1K | 2M | 394.6K | 12.4M | 2M | 600.1 K | 3.2 M |
nij | 1K | 183 | 1K | 9.2K | 741.6K | 186.1K | 4.7M | 1.2M | 389.6 K | 1.6 M |
sat_Latn | 39K | 183 | 39K | 5.5K | 39K | 183 | 183.8K | 601 | 276.1 K | 39.2 M |
gu_Latn | 58.2K | 179 | 688.4K | 5.4K | 58.2K | 179 | 260.8K | 673 | 241.0 K | 47.9 M |
msm | 520 | 177 | 520 | 8.6K | 410.8K | 190.5K | 2.5M | 1.1M | 339.7 K | 789.8 K |
maz | 585 | 170 | 21.3K | 8.2K | 452.9K | 174K | 2.9M | 951.7K | 304.7 K | 971.4 K |
qxr | 2.6K | 153 | 40.8K | 6.4K | 761.5K | 75.4K | 6.6M | 724K | 186.4 K | 1.9 M |
shp | 874 | 150 | 22.4K | 3.7K | 534.1K | 96.8K | 3.8M | 710.4K | 216.9 K | 1.2 M |
hne | 3K | 146 | 118.4K | 4.3K | 2.3M | 139.3K | 12M | 697K | 379.3 K | 6.5 M |
ktu | 3.3K | 144 | 115.5K | 7.8K | 3.2M | 196.9K | 18.5M | 1.1M | 300.1 K | 5.4 M |
laj | 6.5K | 144 | 61K | 6.4K | 2.4M | 140.1K | 15.8M | 730.5K | 233.5 K | 4.6 M |
pis | 1.1K | 139 | 62K | 7.2K | 1.3M | 136.8K | 7.7M | 764K | 212.7 K | 2.2 M |
mag | 631 | 138 | 62.6K | 22.1K | 2.1M | 544.2K | 10.7M | 2.6M | 1.4 M | 5.4 M |
gbm | 2.5K | 137 | 50.8K | 3.8K | 1.7M | 99.7K | 9.1M | 499.6K | 282.4 K | 4.5 M |
tzj | 471 | 136 | 11.1K | 7.3K | 299.9K | 150.8K | 1.9M | 884.2K | 272.0 K | 663.9 K |
oj | 2.5K | 135 | 2.5K | 1.6K | 1.2M | 35.9K | 9.6M | 337.1K | 117.6 K | 3.4 M |
ndc_ZW | 2.2K | 132 | 2.2K | 8.7K | 2.2K | 132 | 9.1K | 523 | 343.1 K | 2.2 M |
tks | 63.7K | 127 | 63.7K | 6.8K | 17.1M | 41.5K | 88.9M | 260.8K | 39.5 K | 33.0 M |
awa | 5.8K | 126 | 100.1K | 8.4K | 2.2M | 98.7K | 11.1M | 475K | 226.6 K | 5.8 M |
gvl | 37.9K | 126 | 213K | 6.9K | 21.1M | 161.1K | 141M | 789.2K | 257.8 K | 31.7 M |
knj | 229 | 126 | 10.1K | 9.2K | 202.6K | 171.8K | 1.1M | 855K | 253.1 K | 345.4 K |
spp | 733 | 123 | 733 | 5.8K | 902.7K | 141.8K | 4.4M | 682.5K | 217.8 K | 1.4 M |
mqy | 69.3K | 119 | 309K | 2.5K | 12.1M | 88.6K | 78.9M | 506.5K | 170.4 K | 16.3 M |
tca | 410 | 117 | 20K | 7.3K | 283K | 121.5K | 2.3M | 786K | 226.2 K | 781.2 K |
cce | 847 | 116 | 23.2K | 11K | 539.3K | 227.2K | 3.3M | 1.3M | 393.8 K | 1.1 M |
skr | 3.8K | 107 | 279.3K | 17.1K | 6.2M | 324K | 32.2M | 1.7M | 768.5 K | 15.4 M |
kmz_Latn | 24K | 106 | 361K | 2.4K | 24K | 106 | 108.6K | 401 | 231.8 K | 16.7 M |
dje | 913 | 100 | 40.2K | 3.7K | 816.3K | 97.5K | 4.7M | 480.7K | 161.2 K | 1.5 M |
gof | 2.8K | 97 | 33.8K | 5.5K | 703K | 68.8K | 5.5M | 506K | 159.1 K | 1.7 M |
agr | 465 | 93 | 16.1K | 3.6K | 295.4K | 67.2K | 2.3M | 554.5K | 177.0 K | 760.1 K |
qvz | 534 | 88 | 6.8K | 3.5K | 145.5K | 50.5K | 1.2M | 438.3K | 124.2 K | 382.7 K |
adh | 2.6K | 87 | 107.2K | 1K | 2.4M | 42.1K | 14.5M | 254.9K | 84.6 K | 5.0 M |
quf | 522 | 86 | 8.4K | 5.2K | 155.7K | 61.8K | 1.5M | 609K | 173.7 K | 542.8 K |
kjg | 113 | 84 | 3K | 2.9K | 67.6K | 67K | 408.5K | 399K | 159.2 K | 167.7 K |
tsc | 12.6K | 82 | 12.6K | 4K | 3.5M | 93.1K | 23.4M | 521.3K | 161.9 K | 7.0 M |
ber | 2.7K | 79 | 12.6K | 1.2K | 1.1M | 46.4K | 6.4M | 265.9K | 141.5 K | 3.0 M |
ify | 611 | 79 | 19.8K | 2.8K | 422.7K | 56.2K | 2.6M | 334K | 109.5 K | 913.1 K |
cbk | 10.1K | 78 | 43.8K | 2K | 1.7M | 64.3K | 10.3M | 339.3K | 93.4 K | 3.4 M |
quy | 588 | 78 | 28.1K | 2.7K | 423.3K | 37.3K | 4.5M | 368.2K | 114.5 K | 1.2 M |
ahk | 244 | 77 | 6.2K | 4.1K | 264K | 124.8K | 1.3M | 715.5K | 182.8 K | 359.7 K |
cac | 212 | 77 | 3.4K | 1.8K | 125.7K | 54.1K | 978.7K | 319.8K | 95.8 K | 280.3 K |
akb | 1K | 71 | 21.3K | 408 | 870.9K | 54.5K | 5.2M | 337.8K | 93.7 K | 1.6 M |
nut | 29K | 67 | 29K | 1.5K | 4.8M | 39.8K | 23.5M | 184.1K | 36.4 K | 8.3 M |
ffm | 1.8K | 65 | 30.1K | 2K | 745.6K | 39.1K | 4.6M | 236.1K | 83.8 K | 1.8 M |
taj | 146 | 65 | 21.6K | 14.3K | 309.7K | 203K | 2.3M | 1.4M | 503.0 K | 872.7 K |
ms_Arab | 698 | 63 | 698 | 320 | 698 | 63 | 2.9K | 239 | 64.7 K | 1016.0 K |
brx | 322 | 62 | 5.3K | 2.4K | 144.2K | 41K | 1.1M | 304.4K | 146.6 K | 515.7 K |
ann | 464 | 56 | 5K | 1.6K | 116.4K | 35.9K | 760.9K | 215.1K | 74.9 K | 295.2 K |
qup | 169 | 53 | 4.3K | 2.5K | 77.5K | 31.3K | 763.8K | 297.8K | 74.7 K | 207.3 K |
ms_Arab_BN | 2.6K | 46 | 2.6K | 374 | 2.6K | 46 | 10.5K | 171 | 50.0 K | 5.1 M |
miq | 236 | 45 | 6.4K | 3.5K | 183.7K | 80.2K | 1.2M | 485.6K | 157.6 K | 384.1 K |
msb | 811 | 41 | 811 | 1K | 705.9K | 28.8K | 4.4M | 167.5K | 53.3 K | 1.7 M |
bim | 410 | 40 | 31.1K | 6.3K | 669.8K | 167.4K | 3.2M | 793.4K | 252.7 K | 1.1 M |
raj | 1.8K | 40 | 1.8K | 5.7K | 1.3M | 81.1K | 7.1M | 405K | 226.2 K | 3.9 M |
kwi | 382 | 37 | 16.9K | 2.2K | 253.8K | 23.4K | 1.8M | 172.8K | 47.6 K | 536.2 K |
tll | 200 | 37 | 200 | 2.7K | 304.2K | 62.2K | 2.2M | 409.8K | 132.3 K | 664.5 K |
trp | 12.8K | 36 | 12.8K | 1.7K | 4.1M | 39K | 29.9M | 257.3K | 87.5 K | 10.2 M |
smt | 1.4K | 34 | 1.4K | 703 | 1M | 36.5K | 6.8M | 245.4K | 87.9 K | 2.5 M |
mrw | 11.3K | 29 | 11.3K | 1K | 4.2M | 45.7K | 27.8M | 257.2K | 81.3 K | 8.8 M |
dln | 236 | 28 | 5.2K | 969 | 150.8K | 21.5K | 860.5K | 118.3K | 36.8 K | 280.3 K |
qvc | 3.4K | 27 | 14.6K | 2.2K | 495.7K | 25.7K | 5M | 233.7K | 65.3 K | 2.6 M |
doi | 1.7K | 26 | 21.8K | 975 | 568.7K | 25.5K | 3.2M | 135.3K | 66.7 K | 1.6 M |
ff | 13.6K | 26 | 150K | 5K | 3.4M | 46.5K | 22.8M | 277.6K | 78.8 K | 8.5 M |
## Citation Information
~~~
@misc{kudugunta2023madlad400,
title={MADLAD-400: A Multilingual And Document-Level Large Audited Dataset},
author={Sneha Kudugunta and Isaac Caswell and Biao Zhang and Xavier Garcia and Christopher A. Choquette-Choo and Katherine Lee and Derrick Xin and Aditya Kusupati and Romi Stella and Ankur Bapna and Orhan Firat},
year={2023},
eprint={2309.04662},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
~~~ |
ColumbiaNLP/test-irfl | ---
dataset_info:
features:
- name: image
dtype: image
- name: claim
dtype: string
- name: label
dtype: string
- name: explanation
dtype: string
- name: phenomenon
dtype: string
- name: source_dataset
dtype: string
splits:
- name: train
num_bytes: 1329892412.544
num_examples: 1082
- name: validation
num_bytes: 231354017.0
num_examples: 217
- name: test
num_bytes: 230632678.0
num_examples: 220
download_size: 1694076857
dataset_size: 1791879107.544
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
gabrielmbmb/wikipedia_es_genstruct | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 310051
num_examples: 423
download_size: 176740
dataset_size: 310051
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- synthetic
- distilabel
license: cc-by-sa-3.0
task_categories:
- text-generation
language:
- es
---
# Wikipedia ES Genstruct
This dataset contains a very small subset of `instruction` and `generation` pairs generated using [Genstruct 7B AWQ](https://huggingface.co/gabrielmbmb/Genstruct-7B-AWQ) and using some articles in Spanish from [wikimedia/wikipedia](https://huggingface.co/datasets/wikimedia/wikipedia) as the raw corpus. |
liuyanchen1015/MULTI_VALUE_mrpc_present_perfect_for_past | ---
dataset_info:
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: value_score
dtype: int64
splits:
- name: test
num_bytes: 382956
num_examples: 1358
- name: train
num_bytes: 821436
num_examples: 2903
- name: validation
num_bytes: 88922
num_examples: 311
download_size: 836744
dataset_size: 1293314
---
# Dataset Card for "MULTI_VALUE_mrpc_present_perfect_for_past"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
kristmh/rust_testset_with_med_low | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
dataset_info:
features:
- name: text_clean
dtype: string
- name: label
dtype: int64
splits:
- name: test
num_bytes: 1874421
num_examples: 1572
download_size: 767320
dataset_size: 1874421
---
# Dataset Card for "rust_testset_with_med_low"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
kpriyanshu256/MultiTabQA-multitable_pretraining-Salesforce-codet5-base_train-latex-117000 | ---
dataset_info:
features:
- name: input_ids
sequence:
sequence: int32
- name: attention_mask
sequence:
sequence: int8
- name: labels
sequence:
sequence: int64
splits:
- name: train
num_bytes: 13336000
num_examples: 1000
download_size: 1036896
dataset_size: 13336000
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
CyberHarem/nott_fireemblem | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of nott (Fire Emblem)
This is the dataset of nott (Fire Emblem), containing 18 images and their tags.
The core tags of this character are `long_hair, breasts, green_hair, large_breasts, braid, mole, mole_under_eye, hair_ornament`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:----------|:-----------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 18 | 17.90 MiB | [Download](https://huggingface.co/datasets/CyberHarem/nott_fireemblem/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 18 | 12.51 MiB | [Download](https://huggingface.co/datasets/CyberHarem/nott_fireemblem/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 32 | 20.24 MiB | [Download](https://huggingface.co/datasets/CyberHarem/nott_fireemblem/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 18 | 16.69 MiB | [Download](https://huggingface.co/datasets/CyberHarem/nott_fireemblem/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 32 | 25.32 MiB | [Download](https://huggingface.co/datasets/CyberHarem/nott_fireemblem/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/nott_fireemblem',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 5 |  |  |  |  |  | 1girl, cleavage, closed_mouth, hair_flower, holding_weapon, kimono, obi, sword, black_gloves, circlet, collarbone, official_alternate_costume, smile, wide_sleeves, 1boy, bangs, cape, green_theme, grey_background, looking_at_viewer, monochrome, sarashi, solo_focus, unsheathing |
| 1 | 9 |  |  |  |  |  | 1girl, cape, cleavage, armor, solo, circlet, sandals, gauntlets, jewelry, muscular_female, sword, white_dress, holding_weapon, lips, polearm, sleeveless_dress, smile |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | cleavage | closed_mouth | hair_flower | holding_weapon | kimono | obi | sword | black_gloves | circlet | collarbone | official_alternate_costume | smile | wide_sleeves | 1boy | bangs | cape | green_theme | grey_background | looking_at_viewer | monochrome | sarashi | solo_focus | unsheathing | armor | solo | sandals | gauntlets | jewelry | muscular_female | white_dress | lips | polearm | sleeveless_dress |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:-----------|:---------------|:--------------|:-----------------|:---------|:------|:--------|:---------------|:----------|:-------------|:-----------------------------|:--------|:---------------|:-------|:--------|:-------|:--------------|:------------------|:--------------------|:-------------|:----------|:-------------|:--------------|:--------|:-------|:----------|:------------|:----------|:------------------|:--------------|:-------|:----------|:-------------------|
| 0 | 5 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | |
| 1 | 9 |  |  |  |  |  | X | X | | | X | | | X | | X | | | X | | | | X | | | | | | | | X | X | X | X | X | X | X | X | X | X |
|
dolo650/lamini_docs | ---
license: apache-2.0
---
|
iceberg-nlp/climabench | ---
annotations_creators:
- other
language_creators:
- other
language:
- en
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
paperswithcode_id: climabench
pretty_name: "ClimaBench: A Benchmark Dataset For Climate Change Text Understanding in English"
config_names:
- climate_stance
- climate_eng
- climate_fever
- climatext
- clima_insurance
- clima_insurance_plus
- clima_cdp
- clima_qa
---
### Citation Information
```
@misc{spokoyny2023answering,
title={Towards Answering Climate Questionnaires from Unstructured Climate Reports},
author={Daniel Spokoyny and Tanmay Laud and Tom Corringham and Taylor Berg-Kirkpatrick},
year={2023},
eprint={2301.04253},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
chargoddard/commitpack-ft-instruct | ---
dataset_info:
features:
- name: id
dtype: string
- name: language
dtype: string
- name: license
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
- name: input
dtype: string
splits:
- name: train
num_bytes: 813842543
num_examples: 491119
download_size: 390498760
dataset_size: 813842543
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
language:
- en
tags:
- code
size_categories:
- 100K<n<1M
---
Octocode's [CommitPackFT](https://huggingface.co/datasets/bigcode/commitpackft) in Alpaca instruction format, with several randomly selected natural language preludes to the commit messages to make them better resemble a user request.
When the instruction, old code, and new code combined are small enough to fit within 4096 Llama tokens the output is usually the full contents of the file after a commit. Otherwise, the output will be a sequence of ndiff chunks with up to five lines of context each.
An example:
```ndiff
from django.conf.urls.defaults import *
from models import GeneralPost
- from feeds import LatestPosts
+ from feeds import latest
```
```ndiff
post_list = {
'queryset': GeneralPost.objects.all(),
}
feeds = {
- 'all': LatestPosts,
+ 'all': latest(GeneralPost, 'dzenlog-post-list'),
```
This is essentially the output of `difflib.ndiff` with the `?` lines removed and large spans of unchanged text removed. The idea is that this is hopefully an easier format for a large language model to learn than a typical diff, while still being generally unambiguous enough to be useful as an output. We'll see if that works out!
Language composition:
| Language | Instructions | Percent of Instructions |
| --- | --- | --- |
| YAML | 114320 | 23.28% |
| Ruby | 69413 | 14.13% |
| Markdown | 62518 | 12.73% |
| Python | 56025 | 11.41% |
| JavaScript | 52989 | 10.79% |
| JSON | 39777 | 8.1% |
| PHP | 24791 | 5.05% |
| Java | 20635 | 4.2% |
| C# | 9346 | 1.9% |
| XML | 9337 | 1.9% |
| C | 8506 | 1.73% |
| TypeScript | 5868 | 1.19% |
| C++ | 4992 | 1.02% |
| Swift | 4849 | 0.99% |
| Rust | 2996 | 0.61% |
| Haskell | 1389 | 0.28% |
| Emacs Lisp | 1015 | 0.21% |
| Common Lisp | 778 | 0.16% |
| Erlang | 480 | 0.1% |
| OCaml | 333 | 0.07% |
| Smalltalk | 284 | 0.06% |
| Ada | 265 | 0.05% |
| Scheme | 213 | 0.04% |
All credit to the original authors of the code and the team behind OctoPack.
### Licensing Information
Each sample comes from a code repository with a permissive license. The license is provided by the `license` field for each sample.
### Citation Information
```bibtex
@article{muennighoff2023octopack,
title={OctoPack: Instruction Tuning Code Large Language Models},
author={Niklas Muennighoff and Qian Liu and Armel Zebaze and Qinkai Zheng and Binyuan Hui and Terry Yue Zhuo and Swayam Singh and Xiangru Tang and Leandro von Werra and Shayne Longpre},
journal={arXiv preprint arXiv:2308.07124},
year={2023}
}
``` |
open-llm-leaderboard/details_fblgit__una-llama-7b | ---
pretty_name: Evaluation run of fblgit/una-llama-7b
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [fblgit/una-llama-7b](https://huggingface.co/fblgit/una-llama-7b) on the [Open\
\ LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 63 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_fblgit__una-llama-7b\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-12-24T17:39:22.935807](https://huggingface.co/datasets/open-llm-leaderboard/details_fblgit__una-llama-7b/blob/main/results_2023-12-24T17-39-22.935807.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.380732359519661,\n\
\ \"acc_stderr\": 0.034121438696938955,\n \"acc_norm\": 0.3837076059961357,\n\
\ \"acc_norm_stderr\": 0.03491178592677983,\n \"mc1\": 0.2558139534883721,\n\
\ \"mc1_stderr\": 0.01527417621928336,\n \"mc2\": 0.38012253018489384,\n\
\ \"mc2_stderr\": 0.014122907654663121\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.49658703071672355,\n \"acc_stderr\": 0.014611050403244084,\n\
\ \"acc_norm\": 0.5366894197952219,\n \"acc_norm_stderr\": 0.014572000527756986\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.599681338378809,\n\
\ \"acc_stderr\": 0.004889615413144194,\n \"acc_norm\": 0.8007369049990042,\n\
\ \"acc_norm_stderr\": 0.003986299037840092\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.29,\n \"acc_stderr\": 0.04560480215720685,\n \
\ \"acc_norm\": 0.29,\n \"acc_norm_stderr\": 0.04560480215720685\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.32592592592592595,\n\
\ \"acc_stderr\": 0.040491220417025055,\n \"acc_norm\": 0.32592592592592595,\n\
\ \"acc_norm_stderr\": 0.040491220417025055\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.3815789473684211,\n \"acc_stderr\": 0.03953173377749194,\n\
\ \"acc_norm\": 0.3815789473684211,\n \"acc_norm_stderr\": 0.03953173377749194\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.46,\n\
\ \"acc_stderr\": 0.05009082659620332,\n \"acc_norm\": 0.46,\n \
\ \"acc_norm_stderr\": 0.05009082659620332\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.4037735849056604,\n \"acc_stderr\": 0.03019761160019795,\n\
\ \"acc_norm\": 0.4037735849056604,\n \"acc_norm_stderr\": 0.03019761160019795\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.3263888888888889,\n\
\ \"acc_stderr\": 0.03921067198982266,\n \"acc_norm\": 0.3263888888888889,\n\
\ \"acc_norm_stderr\": 0.03921067198982266\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.36,\n \"acc_stderr\": 0.04824181513244218,\n \
\ \"acc_norm\": 0.36,\n \"acc_norm_stderr\": 0.04824181513244218\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\"\
: 0.3,\n \"acc_stderr\": 0.046056618647183814,\n \"acc_norm\": 0.3,\n\
\ \"acc_norm_stderr\": 0.046056618647183814\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.28,\n \"acc_stderr\": 0.045126085985421276,\n \
\ \"acc_norm\": 0.28,\n \"acc_norm_stderr\": 0.045126085985421276\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.3352601156069364,\n\
\ \"acc_stderr\": 0.03599586301247077,\n \"acc_norm\": 0.3352601156069364,\n\
\ \"acc_norm_stderr\": 0.03599586301247077\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.24509803921568626,\n \"acc_stderr\": 0.042801058373643966,\n\
\ \"acc_norm\": 0.24509803921568626,\n \"acc_norm_stderr\": 0.042801058373643966\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.4,\n \"acc_stderr\": 0.049236596391733084,\n \"acc_norm\": 0.4,\n\
\ \"acc_norm_stderr\": 0.049236596391733084\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.3574468085106383,\n \"acc_stderr\": 0.03132941789476425,\n\
\ \"acc_norm\": 0.3574468085106383,\n \"acc_norm_stderr\": 0.03132941789476425\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.2894736842105263,\n\
\ \"acc_stderr\": 0.04266339443159393,\n \"acc_norm\": 0.2894736842105263,\n\
\ \"acc_norm_stderr\": 0.04266339443159393\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.296551724137931,\n \"acc_stderr\": 0.03806142687309993,\n\
\ \"acc_norm\": 0.296551724137931,\n \"acc_norm_stderr\": 0.03806142687309993\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.2857142857142857,\n \"acc_stderr\": 0.023266512213730585,\n \"\
acc_norm\": 0.2857142857142857,\n \"acc_norm_stderr\": 0.023266512213730585\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.3253968253968254,\n\
\ \"acc_stderr\": 0.04190596438871136,\n \"acc_norm\": 0.3253968253968254,\n\
\ \"acc_norm_stderr\": 0.04190596438871136\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.28,\n \"acc_stderr\": 0.04512608598542127,\n \
\ \"acc_norm\": 0.28,\n \"acc_norm_stderr\": 0.04512608598542127\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.3774193548387097,\n\
\ \"acc_stderr\": 0.02757596072327823,\n \"acc_norm\": 0.3774193548387097,\n\
\ \"acc_norm_stderr\": 0.02757596072327823\n },\n \"harness|hendrycksTest-high_school_chemistry|5\"\
: {\n \"acc\": 0.29064039408866993,\n \"acc_stderr\": 0.03194740072265541,\n\
\ \"acc_norm\": 0.29064039408866993,\n \"acc_norm_stderr\": 0.03194740072265541\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.36,\n \"acc_stderr\": 0.048241815132442176,\n \"acc_norm\"\
: 0.36,\n \"acc_norm_stderr\": 0.048241815132442176\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.41818181818181815,\n \"acc_stderr\": 0.03851716319398393,\n\
\ \"acc_norm\": 0.41818181818181815,\n \"acc_norm_stderr\": 0.03851716319398393\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.40404040404040403,\n \"acc_stderr\": 0.03496130972056128,\n \"\
acc_norm\": 0.40404040404040403,\n \"acc_norm_stderr\": 0.03496130972056128\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.48704663212435234,\n \"acc_stderr\": 0.03607228061047749,\n\
\ \"acc_norm\": 0.48704663212435234,\n \"acc_norm_stderr\": 0.03607228061047749\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.36666666666666664,\n \"acc_stderr\": 0.02443301646605245,\n\
\ \"acc_norm\": 0.36666666666666664,\n \"acc_norm_stderr\": 0.02443301646605245\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.2222222222222222,\n \"acc_stderr\": 0.025348097468097856,\n \
\ \"acc_norm\": 0.2222222222222222,\n \"acc_norm_stderr\": 0.025348097468097856\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.37815126050420167,\n \"acc_stderr\": 0.031499305777849054,\n\
\ \"acc_norm\": 0.37815126050420167,\n \"acc_norm_stderr\": 0.031499305777849054\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.31788079470198677,\n \"acc_stderr\": 0.038020397601079024,\n \"\
acc_norm\": 0.31788079470198677,\n \"acc_norm_stderr\": 0.038020397601079024\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.48990825688073397,\n \"acc_stderr\": 0.021432956203453327,\n \"\
acc_norm\": 0.48990825688073397,\n \"acc_norm_stderr\": 0.021432956203453327\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.4027777777777778,\n \"acc_stderr\": 0.03344887382997866,\n \"\
acc_norm\": 0.4027777777777778,\n \"acc_norm_stderr\": 0.03344887382997866\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.4215686274509804,\n \"acc_stderr\": 0.03465868196380758,\n \"\
acc_norm\": 0.4215686274509804,\n \"acc_norm_stderr\": 0.03465868196380758\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.46835443037974683,\n \"acc_stderr\": 0.03248197400511074,\n \
\ \"acc_norm\": 0.46835443037974683,\n \"acc_norm_stderr\": 0.03248197400511074\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.3721973094170404,\n\
\ \"acc_stderr\": 0.03244305283008731,\n \"acc_norm\": 0.3721973094170404,\n\
\ \"acc_norm_stderr\": 0.03244305283008731\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.3893129770992366,\n \"acc_stderr\": 0.04276486542814591,\n\
\ \"acc_norm\": 0.3893129770992366,\n \"acc_norm_stderr\": 0.04276486542814591\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.5041322314049587,\n \"acc_stderr\": 0.04564198767432754,\n \"\
acc_norm\": 0.5041322314049587,\n \"acc_norm_stderr\": 0.04564198767432754\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.39814814814814814,\n\
\ \"acc_stderr\": 0.047323326159788154,\n \"acc_norm\": 0.39814814814814814,\n\
\ \"acc_norm_stderr\": 0.047323326159788154\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.44171779141104295,\n \"acc_stderr\": 0.03901591825836184,\n\
\ \"acc_norm\": 0.44171779141104295,\n \"acc_norm_stderr\": 0.03901591825836184\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.25892857142857145,\n\
\ \"acc_stderr\": 0.04157751539865629,\n \"acc_norm\": 0.25892857142857145,\n\
\ \"acc_norm_stderr\": 0.04157751539865629\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.3883495145631068,\n \"acc_stderr\": 0.04825729337356389,\n\
\ \"acc_norm\": 0.3883495145631068,\n \"acc_norm_stderr\": 0.04825729337356389\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.5384615384615384,\n\
\ \"acc_stderr\": 0.03265903381186194,\n \"acc_norm\": 0.5384615384615384,\n\
\ \"acc_norm_stderr\": 0.03265903381186194\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.43,\n \"acc_stderr\": 0.049756985195624284,\n \
\ \"acc_norm\": 0.43,\n \"acc_norm_stderr\": 0.049756985195624284\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.4482758620689655,\n\
\ \"acc_stderr\": 0.01778403453499245,\n \"acc_norm\": 0.4482758620689655,\n\
\ \"acc_norm_stderr\": 0.01778403453499245\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.41040462427745666,\n \"acc_stderr\": 0.026483392042098177,\n\
\ \"acc_norm\": 0.41040462427745666,\n \"acc_norm_stderr\": 0.026483392042098177\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.2424581005586592,\n\
\ \"acc_stderr\": 0.014333522059217889,\n \"acc_norm\": 0.2424581005586592,\n\
\ \"acc_norm_stderr\": 0.014333522059217889\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.4150326797385621,\n \"acc_stderr\": 0.0282135041778241,\n\
\ \"acc_norm\": 0.4150326797385621,\n \"acc_norm_stderr\": 0.0282135041778241\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.4180064308681672,\n\
\ \"acc_stderr\": 0.02801365189199507,\n \"acc_norm\": 0.4180064308681672,\n\
\ \"acc_norm_stderr\": 0.02801365189199507\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.39814814814814814,\n \"acc_stderr\": 0.027237415094592477,\n\
\ \"acc_norm\": 0.39814814814814814,\n \"acc_norm_stderr\": 0.027237415094592477\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.3049645390070922,\n \"acc_stderr\": 0.027464708442022128,\n \
\ \"acc_norm\": 0.3049645390070922,\n \"acc_norm_stderr\": 0.027464708442022128\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.30638852672750977,\n\
\ \"acc_stderr\": 0.011773980329380719,\n \"acc_norm\": 0.30638852672750977,\n\
\ \"acc_norm_stderr\": 0.011773980329380719\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.4411764705882353,\n \"acc_stderr\": 0.0301619119307671,\n\
\ \"acc_norm\": 0.4411764705882353,\n \"acc_norm_stderr\": 0.0301619119307671\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.3415032679738562,\n \"acc_stderr\": 0.019184639328092487,\n \
\ \"acc_norm\": 0.3415032679738562,\n \"acc_norm_stderr\": 0.019184639328092487\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.37272727272727274,\n\
\ \"acc_stderr\": 0.04631381319425463,\n \"acc_norm\": 0.37272727272727274,\n\
\ \"acc_norm_stderr\": 0.04631381319425463\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.3795918367346939,\n \"acc_stderr\": 0.031067211262872485,\n\
\ \"acc_norm\": 0.3795918367346939,\n \"acc_norm_stderr\": 0.031067211262872485\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.5024875621890548,\n\
\ \"acc_stderr\": 0.03535490150137289,\n \"acc_norm\": 0.5024875621890548,\n\
\ \"acc_norm_stderr\": 0.03535490150137289\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.47,\n \"acc_stderr\": 0.05016135580465919,\n \
\ \"acc_norm\": 0.47,\n \"acc_norm_stderr\": 0.05016135580465919\n \
\ },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.3253012048192771,\n\
\ \"acc_stderr\": 0.03647168523683227,\n \"acc_norm\": 0.3253012048192771,\n\
\ \"acc_norm_stderr\": 0.03647168523683227\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.45614035087719296,\n \"acc_stderr\": 0.03820042586602966,\n\
\ \"acc_norm\": 0.45614035087719296,\n \"acc_norm_stderr\": 0.03820042586602966\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.2558139534883721,\n\
\ \"mc1_stderr\": 0.01527417621928336,\n \"mc2\": 0.38012253018489384,\n\
\ \"mc2_stderr\": 0.014122907654663121\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.7292817679558011,\n \"acc_stderr\": 0.012487904760626304\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.0978013646702047,\n \
\ \"acc_stderr\": 0.008182119821849038\n }\n}\n```"
repo_url: https://huggingface.co/fblgit/una-llama-7b
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|arc:challenge|25_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|gsm8k|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hellaswag|10_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-12-24T17-39-22.935807.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-management|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-virology|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|truthfulqa:mc|0_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-12-24T17-39-22.935807.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- '**/details_harness|winogrande|5_2023-12-24T17-39-22.935807.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-12-24T17-39-22.935807.parquet'
- config_name: results
data_files:
- split: 2023_12_24T17_39_22.935807
path:
- results_2023-12-24T17-39-22.935807.parquet
- split: latest
path:
- results_2023-12-24T17-39-22.935807.parquet
---
# Dataset Card for Evaluation run of fblgit/una-llama-7b
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [fblgit/una-llama-7b](https://huggingface.co/fblgit/una-llama-7b) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_fblgit__una-llama-7b",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-12-24T17:39:22.935807](https://huggingface.co/datasets/open-llm-leaderboard/details_fblgit__una-llama-7b/blob/main/results_2023-12-24T17-39-22.935807.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.380732359519661,
"acc_stderr": 0.034121438696938955,
"acc_norm": 0.3837076059961357,
"acc_norm_stderr": 0.03491178592677983,
"mc1": 0.2558139534883721,
"mc1_stderr": 0.01527417621928336,
"mc2": 0.38012253018489384,
"mc2_stderr": 0.014122907654663121
},
"harness|arc:challenge|25": {
"acc": 0.49658703071672355,
"acc_stderr": 0.014611050403244084,
"acc_norm": 0.5366894197952219,
"acc_norm_stderr": 0.014572000527756986
},
"harness|hellaswag|10": {
"acc": 0.599681338378809,
"acc_stderr": 0.004889615413144194,
"acc_norm": 0.8007369049990042,
"acc_norm_stderr": 0.003986299037840092
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.29,
"acc_stderr": 0.04560480215720685,
"acc_norm": 0.29,
"acc_norm_stderr": 0.04560480215720685
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.32592592592592595,
"acc_stderr": 0.040491220417025055,
"acc_norm": 0.32592592592592595,
"acc_norm_stderr": 0.040491220417025055
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.3815789473684211,
"acc_stderr": 0.03953173377749194,
"acc_norm": 0.3815789473684211,
"acc_norm_stderr": 0.03953173377749194
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.46,
"acc_stderr": 0.05009082659620332,
"acc_norm": 0.46,
"acc_norm_stderr": 0.05009082659620332
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.4037735849056604,
"acc_stderr": 0.03019761160019795,
"acc_norm": 0.4037735849056604,
"acc_norm_stderr": 0.03019761160019795
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.3263888888888889,
"acc_stderr": 0.03921067198982266,
"acc_norm": 0.3263888888888889,
"acc_norm_stderr": 0.03921067198982266
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.36,
"acc_stderr": 0.04824181513244218,
"acc_norm": 0.36,
"acc_norm_stderr": 0.04824181513244218
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.3,
"acc_stderr": 0.046056618647183814,
"acc_norm": 0.3,
"acc_norm_stderr": 0.046056618647183814
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.28,
"acc_stderr": 0.045126085985421276,
"acc_norm": 0.28,
"acc_norm_stderr": 0.045126085985421276
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.3352601156069364,
"acc_stderr": 0.03599586301247077,
"acc_norm": 0.3352601156069364,
"acc_norm_stderr": 0.03599586301247077
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.24509803921568626,
"acc_stderr": 0.042801058373643966,
"acc_norm": 0.24509803921568626,
"acc_norm_stderr": 0.042801058373643966
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.4,
"acc_stderr": 0.049236596391733084,
"acc_norm": 0.4,
"acc_norm_stderr": 0.049236596391733084
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.3574468085106383,
"acc_stderr": 0.03132941789476425,
"acc_norm": 0.3574468085106383,
"acc_norm_stderr": 0.03132941789476425
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.2894736842105263,
"acc_stderr": 0.04266339443159393,
"acc_norm": 0.2894736842105263,
"acc_norm_stderr": 0.04266339443159393
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.296551724137931,
"acc_stderr": 0.03806142687309993,
"acc_norm": 0.296551724137931,
"acc_norm_stderr": 0.03806142687309993
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.2857142857142857,
"acc_stderr": 0.023266512213730585,
"acc_norm": 0.2857142857142857,
"acc_norm_stderr": 0.023266512213730585
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.3253968253968254,
"acc_stderr": 0.04190596438871136,
"acc_norm": 0.3253968253968254,
"acc_norm_stderr": 0.04190596438871136
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.28,
"acc_stderr": 0.04512608598542127,
"acc_norm": 0.28,
"acc_norm_stderr": 0.04512608598542127
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.3774193548387097,
"acc_stderr": 0.02757596072327823,
"acc_norm": 0.3774193548387097,
"acc_norm_stderr": 0.02757596072327823
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.29064039408866993,
"acc_stderr": 0.03194740072265541,
"acc_norm": 0.29064039408866993,
"acc_norm_stderr": 0.03194740072265541
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.36,
"acc_stderr": 0.048241815132442176,
"acc_norm": 0.36,
"acc_norm_stderr": 0.048241815132442176
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.41818181818181815,
"acc_stderr": 0.03851716319398393,
"acc_norm": 0.41818181818181815,
"acc_norm_stderr": 0.03851716319398393
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.40404040404040403,
"acc_stderr": 0.03496130972056128,
"acc_norm": 0.40404040404040403,
"acc_norm_stderr": 0.03496130972056128
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.48704663212435234,
"acc_stderr": 0.03607228061047749,
"acc_norm": 0.48704663212435234,
"acc_norm_stderr": 0.03607228061047749
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.36666666666666664,
"acc_stderr": 0.02443301646605245,
"acc_norm": 0.36666666666666664,
"acc_norm_stderr": 0.02443301646605245
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.2222222222222222,
"acc_stderr": 0.025348097468097856,
"acc_norm": 0.2222222222222222,
"acc_norm_stderr": 0.025348097468097856
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.37815126050420167,
"acc_stderr": 0.031499305777849054,
"acc_norm": 0.37815126050420167,
"acc_norm_stderr": 0.031499305777849054
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.31788079470198677,
"acc_stderr": 0.038020397601079024,
"acc_norm": 0.31788079470198677,
"acc_norm_stderr": 0.038020397601079024
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.48990825688073397,
"acc_stderr": 0.021432956203453327,
"acc_norm": 0.48990825688073397,
"acc_norm_stderr": 0.021432956203453327
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.4027777777777778,
"acc_stderr": 0.03344887382997866,
"acc_norm": 0.4027777777777778,
"acc_norm_stderr": 0.03344887382997866
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.4215686274509804,
"acc_stderr": 0.03465868196380758,
"acc_norm": 0.4215686274509804,
"acc_norm_stderr": 0.03465868196380758
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.46835443037974683,
"acc_stderr": 0.03248197400511074,
"acc_norm": 0.46835443037974683,
"acc_norm_stderr": 0.03248197400511074
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.3721973094170404,
"acc_stderr": 0.03244305283008731,
"acc_norm": 0.3721973094170404,
"acc_norm_stderr": 0.03244305283008731
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.3893129770992366,
"acc_stderr": 0.04276486542814591,
"acc_norm": 0.3893129770992366,
"acc_norm_stderr": 0.04276486542814591
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.5041322314049587,
"acc_stderr": 0.04564198767432754,
"acc_norm": 0.5041322314049587,
"acc_norm_stderr": 0.04564198767432754
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.39814814814814814,
"acc_stderr": 0.047323326159788154,
"acc_norm": 0.39814814814814814,
"acc_norm_stderr": 0.047323326159788154
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.44171779141104295,
"acc_stderr": 0.03901591825836184,
"acc_norm": 0.44171779141104295,
"acc_norm_stderr": 0.03901591825836184
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.25892857142857145,
"acc_stderr": 0.04157751539865629,
"acc_norm": 0.25892857142857145,
"acc_norm_stderr": 0.04157751539865629
},
"harness|hendrycksTest-management|5": {
"acc": 0.3883495145631068,
"acc_stderr": 0.04825729337356389,
"acc_norm": 0.3883495145631068,
"acc_norm_stderr": 0.04825729337356389
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.5384615384615384,
"acc_stderr": 0.03265903381186194,
"acc_norm": 0.5384615384615384,
"acc_norm_stderr": 0.03265903381186194
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.43,
"acc_stderr": 0.049756985195624284,
"acc_norm": 0.43,
"acc_norm_stderr": 0.049756985195624284
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.4482758620689655,
"acc_stderr": 0.01778403453499245,
"acc_norm": 0.4482758620689655,
"acc_norm_stderr": 0.01778403453499245
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.41040462427745666,
"acc_stderr": 0.026483392042098177,
"acc_norm": 0.41040462427745666,
"acc_norm_stderr": 0.026483392042098177
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.2424581005586592,
"acc_stderr": 0.014333522059217889,
"acc_norm": 0.2424581005586592,
"acc_norm_stderr": 0.014333522059217889
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.4150326797385621,
"acc_stderr": 0.0282135041778241,
"acc_norm": 0.4150326797385621,
"acc_norm_stderr": 0.0282135041778241
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.4180064308681672,
"acc_stderr": 0.02801365189199507,
"acc_norm": 0.4180064308681672,
"acc_norm_stderr": 0.02801365189199507
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.39814814814814814,
"acc_stderr": 0.027237415094592477,
"acc_norm": 0.39814814814814814,
"acc_norm_stderr": 0.027237415094592477
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.3049645390070922,
"acc_stderr": 0.027464708442022128,
"acc_norm": 0.3049645390070922,
"acc_norm_stderr": 0.027464708442022128
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.30638852672750977,
"acc_stderr": 0.011773980329380719,
"acc_norm": 0.30638852672750977,
"acc_norm_stderr": 0.011773980329380719
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.4411764705882353,
"acc_stderr": 0.0301619119307671,
"acc_norm": 0.4411764705882353,
"acc_norm_stderr": 0.0301619119307671
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.3415032679738562,
"acc_stderr": 0.019184639328092487,
"acc_norm": 0.3415032679738562,
"acc_norm_stderr": 0.019184639328092487
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.37272727272727274,
"acc_stderr": 0.04631381319425463,
"acc_norm": 0.37272727272727274,
"acc_norm_stderr": 0.04631381319425463
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.3795918367346939,
"acc_stderr": 0.031067211262872485,
"acc_norm": 0.3795918367346939,
"acc_norm_stderr": 0.031067211262872485
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.5024875621890548,
"acc_stderr": 0.03535490150137289,
"acc_norm": 0.5024875621890548,
"acc_norm_stderr": 0.03535490150137289
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.47,
"acc_stderr": 0.05016135580465919,
"acc_norm": 0.47,
"acc_norm_stderr": 0.05016135580465919
},
"harness|hendrycksTest-virology|5": {
"acc": 0.3253012048192771,
"acc_stderr": 0.03647168523683227,
"acc_norm": 0.3253012048192771,
"acc_norm_stderr": 0.03647168523683227
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.45614035087719296,
"acc_stderr": 0.03820042586602966,
"acc_norm": 0.45614035087719296,
"acc_norm_stderr": 0.03820042586602966
},
"harness|truthfulqa:mc|0": {
"mc1": 0.2558139534883721,
"mc1_stderr": 0.01527417621928336,
"mc2": 0.38012253018489384,
"mc2_stderr": 0.014122907654663121
},
"harness|winogrande|5": {
"acc": 0.7292817679558011,
"acc_stderr": 0.012487904760626304
},
"harness|gsm8k|5": {
"acc": 0.0978013646702047,
"acc_stderr": 0.008182119821849038
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] |
liuyanchen1015/MULTI_VALUE_rte_preposition_chopping | ---
dataset_info:
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: value_score
dtype: int64
splits:
- name: test
num_bytes: 977
num_examples: 4
- name: train
num_bytes: 1210
num_examples: 5
download_size: 7922
dataset_size: 2187
---
# Dataset Card for "MULTI_VALUE_rte_preposition_chopping"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
heliosprime/twitter_dataset_1713054414 | ---
dataset_info:
features:
- name: id
dtype: string
- name: tweet_content
dtype: string
- name: user_name
dtype: string
- name: user_id
dtype: string
- name: created_at
dtype: string
- name: url
dtype: string
- name: favourite_count
dtype: int64
- name: scraped_at
dtype: string
- name: image_urls
dtype: string
splits:
- name: train
num_bytes: 11478
num_examples: 26
download_size: 8707
dataset_size: 11478
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "twitter_dataset_1713054414"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ayeshgk/java_bug_fix_ctx_small_v6 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: fixed
dtype: string
- name: bug_ctx
dtype: string
splits:
- name: train
num_bytes: 93274
num_examples: 305
- name: validation
num_bytes: 20644
num_examples: 70
- name: test
num_bytes: 1942
num_examples: 7
download_size: 28298
dataset_size: 115860
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
Nazzaroth2/embedding_20k_test | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: lang
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 2446153
num_examples: 40000
download_size: 1319617
dataset_size: 2446153
---
# Dataset Card for "embedding_20k_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
pablo-moreira/wikipedia-pt | ---
dataset_info:
- config_name: '20231001'
features:
- name: id
dtype: string
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 2150584347
num_examples: 1857355
download_size: 0
dataset_size: 2150584347
- config_name: latest
features:
- name: id
dtype: string
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 2150584347
num_examples: 1857355
download_size: 0
dataset_size: 2150584347
configs:
- config_name: '20231001'
data_files:
- split: train
path: 20231001/train-*
- config_name: latest
data_files:
- split: train
path: latest/train-*
---
# Dataset Card for Wikipedia - Portuguese
## Dataset Description
- latest
- 20231001
## Usage
```python
from datasets import load_dataset
dataset = load_dataset('pablo-moreira/wikipedia-pt', 'latest')
#dataset = load_dataset('pablo-moreira/wikipedia-pt', '20231001')
```
## Extractor
Notebook with the code for extracting documents from the Wikipedia dump based on the code from the FastAI NLP introduction course.
[Notebook](extractor.ipynb)
## Links
- **[Wikipedia dumps](https://dumps.wikimedia.org/)**
- **[A Code-First Intro to Natural Language Processing](https://github.com/fastai/course-nlp)**
- **[Extractor Code](https://github.com/fastai/course-nlp/blob/master/nlputils.py)** |
ryan039df/StableDiffusion_ValoranSkin | ---
license: afl-3.0
---
|
AdapterOcean/med_alpaca_standardized_cluster_93_std | ---
dataset_info:
features:
- name: message
dtype: string
- name: message_type
dtype: string
- name: message_id
dtype: int64
- name: conversation_id
dtype: int64
- name: cluster
dtype: float64
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 17760507
num_examples: 31197
download_size: 8958357
dataset_size: 17760507
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "med_alpaca_standardized_cluster_93_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
danielgi97/DatasetATope | ---
size_categories:
- 1K<n<10K
---
Extraído de <https://github.com/anthony-wang/BestPractices/tree/master/data>.
Campos:
* Formula (`string`)
* T (`float64`): Temperatura (K)
* CP (`float64`): Capacidad calorífica (J/mol K) |
CyberHarem/re_class_kantaicollection | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of re_class/レ級 (Kantai Collection)
This is the dataset of re_class/レ級 (Kantai Collection), containing 147 images and their tags.
The core tags of this character are `short_hair, white_hair, pale_skin, purple_eyes, glowing_eyes, breasts, tail`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:---------------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 147 | 143.66 MiB | [Download](https://huggingface.co/datasets/CyberHarem/re_class_kantaicollection/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 147 | 100.94 MiB | [Download](https://huggingface.co/datasets/CyberHarem/re_class_kantaicollection/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 283 | 181.41 MiB | [Download](https://huggingface.co/datasets/CyberHarem/re_class_kantaicollection/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 147 | 136.01 MiB | [Download](https://huggingface.co/datasets/CyberHarem/re_class_kantaicollection/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 283 | 231.27 MiB | [Download](https://huggingface.co/datasets/CyberHarem/re_class_kantaicollection/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/re_class_kantaicollection',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 22 |  |  |  |  |  | 1girl, abyssal_ship, hood, scarf, solo, glowing, grin, jacket, looking_at_viewer, bag |
| 1 | 8 |  |  |  |  |  | 1girl, abyssal_ship, grin, jacket, looking_at_viewer, scarf, solo, bikini_top_only, glowing, hoodie, medium_breasts, teeth, black_bikini, navel, o-ring_top, salute |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | abyssal_ship | hood | scarf | solo | glowing | grin | jacket | looking_at_viewer | bag | bikini_top_only | hoodie | medium_breasts | teeth | black_bikini | navel | o-ring_top | salute |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:---------------|:-------|:--------|:-------|:----------|:-------|:---------|:--------------------|:------|:------------------|:---------|:-----------------|:--------|:---------------|:--------|:-------------|:---------|
| 0 | 22 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | | | | | | | | |
| 1 | 8 |  |  |  |  |  | X | X | | X | X | X | X | X | X | | X | X | X | X | X | X | X | X |
|
davidgaofc/rlhf-transform | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 202697862
num_examples: 160800
- name: test
num_bytes: 10860458
num_examples: 8552
download_size: 118721094
dataset_size: 213558320
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
harvard-lil/cold-cases | ---
license: cc0-1.0
language:
- en
tags:
- united states
- law
- legal
- court
- opinions
size_categories:
- 1M<n<10M
viewer: true
---
<img src="https://huggingface.co/datasets/harvard-lil/cold-cases/resolve/main/coldcases-banner.webp"/>
# Collaborative Open Legal Data (COLD) - Cases
COLD Cases is a dataset of 8.3 million United States legal decisions with text and metadata, formatted as compressed parquet files. If you'd like to view a sample of the dataset formatted as JSON Lines, you can view one [here](https://raw.githubusercontent.com/harvard-lil/cold-cases-export/main/sample.jsonl)
This dataset exists to support the open legal movement exemplified by projects like
[Pile of Law](https://huggingface.co/datasets/pile-of-law/pile-of-law) and
[LegalBench](https://hazyresearch.stanford.edu/legalbench/).
A key input to legal understanding projects is caselaw -- the published, precedential decisions of judges deciding legal disputes and explaining their reasoning.
United States caselaw is collected and published as open data by [CourtListener](https://www.courtlistener.com/), which maintains scrapers to aggregate data from
a wide range of public sources.
COLD Cases reformats CourtListener's [bulk data](https://www.courtlistener.com/help/api/bulk-data) so that all of the semantic information about each legal decision
(the authors and text of majority and dissenting opinions; head matter; and substantive metadata) is encoded in a single record per decision,
with extraneous data removed. Serving in the traditional role of libraries as a standardization steward, the Harvard Library Innovation Lab is maintaining
this [open source](https://github.com/harvard-lil/cold-cases-export) pipeline to consolidate the data engineering for preprocessing caselaw so downstream machine
learning and natural language processing projects can use consistent, high quality representations of cases for legal understanding tasks.
Prepared by the [Harvard Library Innovation Lab](https://lil.law.harvard.edu) in collaboration with the [Free Law Project](https://free.law/).
---
## Links
- [Data nutrition label](https://datanutrition.org/labels/v3/?id=c29976b2-858c-4f4e-b7d0-c8ef12ce7dbe) (DRAFT). ([Archive](https://perma.cc/YV5P-B8JL)).
- [Pipeline source code](https://github.com/harvard-lil/cold-cases-export)
---
## Summary
- [Format](#format)
- [Data dictionary](#data-dictionary)
- [Notes on appropriate use](#notes-on-appropriate-use)
---
## Format
[Apache Parquet](https://parquet.apache.org/) is binary format that makes filtering and retrieving the data quicker because it lays out the data in columns, which means columns that are unnecessary to satisfy a given query or workflow don't need to be read. Hugging Face's [Datasets](https://huggingface.co/docs/datasets/index) library is an easy way to get started working with the entire dataset, and has features for loading and streaming the data, so you don't need to store it all locally or pay attention to how it's formatted on disk.
[☝️ Go back to Summary](#summary)
---
## Data dictionary
Partial glossary of the fields in the data.
| Field name | Description |
| --- | --- |
| `judges` | Names of judges presiding over the case, extracted from the text. |
| `date_filed` | Date the case was filed. Formatted in ISO Date format. |
| `date_filed_is_approximate` | Boolean representing whether the `date_filed` value is precise to the day. |
| `slug` | Short, human-readable unique string nickname for the case. |
| `case_name_short` | Short name for the case. |
| `case_name` | Fuller name for the case. |
| `case_name_full` | Full, formal name for the case. |
| `attorneys` | Names of attorneys arguing the case, extracted from the text. |
| `nature_of_suit` | Free text representinng type of suit, such as Civil, Tort, etc. |
| `syllabus` | Summary of the questions addressed in the decision, if provided by the reporter of decisions. |
| `headnotes` | Textual headnotes of the case |
| `summary` | Textual summary of the case |
| `disposition` | How the court disposed of the case in their final ruling. |
| `history` | Textual information about what happened to this case in later decisions. |
| `other_dates` | Other dates related to the case in free text. |
| `cross_reference` | Citations to related cases. |
| `citation_count` | Number of cases that cite this one. |
| `precedential_status` | Constrainted to the values "Published", "Unknown", "Errata", "Unpublished", "Relating-to", "Separate", "In-chambers" |
| `citations` | Cases that cite this case. |
| `court_short_name` | Short name of court presiding over case. |
| `court_full_name` | Full name of court presiding over case. |
| `court_jurisdiction` | Code for type of court that presided over the case. See: [court_jurisdiction field values](#court_jurisdiction-field-values) |
| `opinions` | An array of subrecords. |
| `opinions.author_str` | Name of the author of an individual opinion. |
| `opinions.per_curiam` | Boolean representing whether the opinion was delivered by an entire court or a single judge. |
| `opinions.type` | One of `"010combined"`, `"015unamimous"`, `"020lead"`, `"025plurality"`, `"030concurrence"`, `"035concurrenceinpart"`, `"040dissent"`, `"050addendum"`, `"060remittitur"`, `"070rehearing"`, `"080onthemerits"`, `"090onmotiontostrike"`. |
| `opinions.opinion_text` | Actual full text of the opinion. |
| `opinions.ocr` | Whether the opinion was captured via optical character recognition or born-digital text. |
### court_type field values
| Value | Description |
| --- | --- |
| F | Federal Appellate |
| FD | Federal District |
| FB | Federal Bankruptcy |
| FBP | Federal Bankruptcy Panel |
| FS | Federal Special |
| S | State Supreme |
| SA | State Appellate |
| ST | State Trial |
| SS | State Special |
| TRS | Tribal Supreme |
| TRA | Tribal Appellate |
| TRT | Tribal Trial |
| TRX | Tribal Special |
| TS | Territory Supreme |
| TA | Territory Appellate |
| TT | Territory Trial |
| TSP | Territory Special |
| SAG | State Attorney General |
| MA | Military Appellate |
| MT | Military Trial |
| C | Committee |
| I | International |
| T | Testing |
[☝️ Go back to Summary](#summary)
---
## Notes on appropriate use
When using this data, please keep in mind:
* All documents in this dataset are public information, published by courts within the United States to inform the public about the law. **You have a right to access them.**
* Nevertheless, **public court decisions frequently contain statements about individuals that are not true**. Court decisions often contain claims that are disputed,
or false claims taken as true based on a legal technicality, or claims taken as true but later found to be false. Legal decisions are designed to inform you about the law -- they are not
designed to inform you about individuals, and should not be used in place of credit databases, criminal records databases, news articles, or other sources intended
to provide factual personal information. Applications should carefully consider whether use of this data will inform about the law, or mislead about individuals.
* **Court decisions are not up-to-date statements of law**. Each decision provides a given judge's best understanding of the law as applied to the stated facts
at the time of the decision. Use of this data to generate statements about the law requires integration of a large amount of context --
the skill typically provided by lawyers -- rather than simple data retrieval.
To mitigate privacy risks, we have filtered out cases [blocked or deindexed by CourtListener](https://www.courtlistener.com/terms/#removal). Researchers who
require access to the full dataset without that filter may rerun our pipeline on CourtListener's raw data.
[☝️ Go back to Summary](#summary) |
CyberHarem/shirona_pokemon | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of shirona/シロナ (Pokémon)
This is the dataset of shirona/シロナ (Pokémon), containing 500 images and their tags.
The core tags of this character are `blonde_hair, long_hair, hair_over_one_eye, breasts, hair_ornament, grey_eyes, very_long_hair, large_breasts`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:-----------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 500 | 730.32 MiB | [Download](https://huggingface.co/datasets/CyberHarem/shirona_pokemon/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 500 | 379.70 MiB | [Download](https://huggingface.co/datasets/CyberHarem/shirona_pokemon/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 1248 | 811.61 MiB | [Download](https://huggingface.co/datasets/CyberHarem/shirona_pokemon/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 500 | 628.80 MiB | [Download](https://huggingface.co/datasets/CyberHarem/shirona_pokemon/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 1248 | 1.19 GiB | [Download](https://huggingface.co/datasets/CyberHarem/shirona_pokemon/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/shirona_pokemon',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 32 |  |  |  |  |  | 1girl, fur_collar, long_sleeves, black_coat, looking_at_viewer, fur-trimmed_coat, black_pants, black_shirt, closed_mouth, holding_poke_ball, smile, poke_ball_(basic), cleavage, solo, eyelashes, pokemon_(creature) |
| 1 | 10 |  |  |  |  |  | 1girl, black_coat, looking_at_viewer, upper_body, eyelashes, fur_collar, simple_background, solo, white_background, cleavage, closed_mouth, fur-trimmed_coat, long_sleeves, smile, hand_up, shirt |
| 2 | 6 |  |  |  |  |  | 1girl, black_coat, black_shirt, cleavage, fur-trimmed_coat, fur_collar, long_sleeves, looking_at_viewer, solo, white_background, black_pants, simple_background, smile, closed_mouth, eyelashes |
| 3 | 12 |  |  |  |  |  | 1girl, looking_at_viewer, simple_background, solo, black_bikini, cleavage, white_background, navel, smile, blush, closed_mouth, collarbone |
| 4 | 10 |  |  |  |  |  | 1girl, cloud, day, navel, outdoors, solo, cleavage, looking_at_viewer, black_bikini, ocean, stomach, water, beach, blue_sky, smile, jewelry, open_mouth, parted_lips, bare_shoulders, blush, collarbone, cowboy_shot, hand_up, thighs, wading |
| 5 | 28 |  |  |  |  |  | 1girl, hetero, nipples, blush, penis, solo_focus, sex, completely_nude, 1boy, vaginal, cum_in_pussy, navel, sweat, spread_legs, open_mouth, uncensored, girl_on_top, looking_at_viewer, pubic_hair, straddling |
| 6 | 11 |  |  |  |  |  | 1girl, black_bra, black_panties, navel, solo, cleavage, looking_at_viewer, smile, lingerie, underwear_only, lace_trim, black_thighhighs, blue_eyes, blush, see-through, stomach |
| 7 | 10 |  |  |  |  |  | 1girl, playboy_bunny, rabbit_ears, cleavage, leotard, solo, fake_animal_ears, looking_at_viewer, detached_collar, smile, thighs, blush, wrist_cuffs, thighhighs, bowtie, covered_navel, huge_breasts, simple_background, white_gloves |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | fur_collar | long_sleeves | black_coat | looking_at_viewer | fur-trimmed_coat | black_pants | black_shirt | closed_mouth | holding_poke_ball | smile | poke_ball_(basic) | cleavage | solo | eyelashes | pokemon_(creature) | upper_body | simple_background | white_background | hand_up | shirt | black_bikini | navel | blush | collarbone | cloud | day | outdoors | ocean | stomach | water | beach | blue_sky | jewelry | open_mouth | parted_lips | bare_shoulders | cowboy_shot | thighs | wading | hetero | nipples | penis | solo_focus | sex | completely_nude | 1boy | vaginal | cum_in_pussy | sweat | spread_legs | uncensored | girl_on_top | pubic_hair | straddling | black_bra | black_panties | lingerie | underwear_only | lace_trim | black_thighhighs | blue_eyes | see-through | playboy_bunny | rabbit_ears | leotard | fake_animal_ears | detached_collar | wrist_cuffs | thighhighs | bowtie | covered_navel | huge_breasts | white_gloves |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:-------------|:---------------|:-------------|:--------------------|:-------------------|:--------------|:--------------|:---------------|:--------------------|:--------|:--------------------|:-----------|:-------|:------------|:---------------------|:-------------|:--------------------|:-------------------|:----------|:--------|:---------------|:--------|:--------|:-------------|:--------|:------|:-----------|:--------|:----------|:--------|:--------|:-----------|:----------|:-------------|:--------------|:-----------------|:--------------|:---------|:---------|:---------|:----------|:--------|:-------------|:------|:------------------|:-------|:----------|:---------------|:--------|:--------------|:-------------|:--------------|:-------------|:-------------|:------------|:----------------|:-----------|:-----------------|:------------|:-------------------|:------------|:--------------|:----------------|:--------------|:----------|:-------------------|:------------------|:--------------|:-------------|:---------|:----------------|:---------------|:---------------|
| 0 | 32 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 10 |  |  |  |  |  | X | X | X | X | X | X | | | X | | X | | X | X | X | | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 2 | 6 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | | X | | X | X | X | | | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 3 | 12 |  |  |  |  |  | X | | | | X | | | | X | | X | | X | X | | | | X | X | | | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 4 | 10 |  |  |  |  |  | X | | | | X | | | | | | X | | X | X | | | | | | X | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 5 | 28 |  |  |  |  |  | X | | | | X | | | | | | | | | | | | | | | | | | X | X | | | | | | | | | | | X | | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | |
| 6 | 11 |  |  |  |  |  | X | | | | X | | | | | | X | | X | X | | | | | | | | | X | X | | | | | | X | | | | | | | | | | | | | | | | | | | | | | | | | | X | X | X | X | X | X | X | X | | | | | | | | | | | |
| 7 | 10 |  |  |  |  |  | X | | | | X | | | | | | X | | X | X | | | | X | | | | | | X | | | | | | | | | | | | | | | X | | | | | | | | | | | | | | | | | | | | | | | | | X | X | X | X | X | X | X | X | X | X | X |
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/ebc52d2b | ---
dataset_info:
features:
- name: result
dtype: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 186
num_examples: 10
download_size: 1342
dataset_size: 186
---
# Dataset Card for "ebc52d2b"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
SauravMaheshkar/pareto-wiki-cs | ---
size_categories:
- 1K<n<10K
task_categories:
- graph-ml
license: cc
---
## Dataset Information
| # Nodes | # Edges | # Features |
|:-------:|:-------:|:----------:|
| 11,701 | 216,123 | 300 |
Pre-processed as per the official codebase of https://arxiv.org/abs/2210.02016
## Citations
```
@article{ju2023multi,
title={Multi-task Self-supervised Graph Neural Networks Enable Stronger Task Generalization},
author={Ju, Mingxuan and Zhao, Tong and Wen, Qianlong and Yu, Wenhao and Shah, Neil and Ye, Yanfang and Zhang, Chuxu},
booktitle={International Conference on Learning Representations},
year={2023}
}
``` |
FINNUMBER/FINCH_TRAIN_ALL_FULL_NEW_Rationale | ---
dataset_info:
features:
- name: task
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
- name: sub_task
dtype: string
- name: rationale
dtype: string
- name: correct
dtype: bool
- name: check
dtype: bool
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 272106825
num_examples: 78378
download_size: 105249988
dataset_size: 272106825
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Nadav/pixel_glue_mrpc_high_noise | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: validation
num_bytes: 18493481.0
num_examples: 408
download_size: 18484439
dataset_size: 18493481.0
---
# Dataset Card for "pixel_glue_mrpc_high_noise"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
AlderleyAI/coqa_chat | ---
task_categories:
- question-answering
language:
- en
size_categories:
- 100K<n<1M
---
# Dataset Card for CoQA_Chat
## Dataset Description
A data set for training LLMs for in-context or Document Question-Answering conversations.
- Point of Contact: info@alderley.ai
### Dataset Summary
This dataset is an amended version of the CoQA dataset, with the question responses amended to be more conversational in nature, with a greater emphasis on returning contextually relervant infomration with the answer.
CoQA is a large-scale dataset for building Conversational Question Answering systems. The goal of the CoQA challenge is to measure the ability of machines to understand a text passage and answer a series of interconnected questions that appear in a conversation. CoQA is pronounced as coca .
https://stanfordnlp.github.io/coqa/
### Supported Tasks
In context and Document Question-Answerining
### Languages
English Only
## Dataset Structure
We provide both csv and jsonl files.
### Data Fields
The csv and jsonl datasets has the following attributes:
- id: Matches the original CoQA id (string)
- local_order : Int associated with the order of the questions for user/assistant chat conversations. (integer)
- context: Matches the original CoQA context (string)
- question: Matches the original CoQA question (string)
- answer: Conversational answer to question. (evolution of original CoQA answer) (string)
### Data Splits
The original training and validation dataset have been combined into a single data splie.
## Dataset Creation
### Curation Rationale
This data set is specifically to support the training of large language models for in-context question-answering or document question-answering converstations. Small Instruct and Chat trained LLMs struggle with this task and have a tendency to ignore the provided context when generating an output. This data set is designed to support the training of small LLMs that excel at this task.
### Source Data
#### Initial Data Collection and Normalization
CoQA
https://huggingface.co/datasets/coqa
https://stanfordnlp.github.io/coqa/
This new answer data set was generated from the original CoQA data set over several days by querying gpt-3.5-turbo with the following prompt...
```
system_intel = """In the dataset provided to you, there are several questions with two corresponding reference text for the answer. Each item in this dataset has an ID, a question, and two reference text answers. Your task is to use this information to create a concise and conversationally natural answer.
When writing your response, incorporate the essential elements from the question, reference text and answer, avoiding the use of pronouns. Instead, use the specific name or title of the entity being referred to. If a question can be answered with 'yes' or 'no', begin with that before providing a brief explanation.
Do not introduce new information, but do make sure that your response can stand on its own, even without the original question for context. However, strive to keep your answers succinct and avoid excessive context.
Each of your answers should be returned as a valid JSON object, with the keys "id" and "answer" surrounded by double quotes (""). If you need to use quotes within your answer, use single quotes ('') to keep the JSON formatting correct.
Here are a few examples:
For [28960 'What is the official name of Brunei?' /n 'Brunei, officially the Nation of Brunei' ‘Nation of Brunei’], output: {"id" : 28960, "answer" : "The official name of Brunei is the Nation of Brunei."}.
For [28961, 'Where is it geographically?' /n 'sovereign state located on the north coast of the island of Borneo in Southeast Asia' ‘Southeast Asia], output: {"id" :28961, "answer": "Brunei is located on the north coast of Borneo in Southeast Asia."}.
For [28962, 'What body of water is it by?'/n 'Apart from its coastline with the South China Sea' ‘South China Sea’], output: {"id": 28962, "answer": "Brunei is by the South China Sea."}.
For [28963, 'When did Sultan Bolkaih rule?' /n 'Sultan Bolkiah (reigned 1485–1528' ‘1485-1528’], output: {"id": 28963, "answer" : "Sultan Bolkaih ruled from 1485 to 1528."}.
For [28964, 'What modern day areas did he rule over?' /n'including modern-day Sarawak and Sabah' ‘Sarawak and Sabah’], output: {"id": 28964, "answer" : "Sultan Bolkaih ruled over modern-day Sarawak and Sabah."}.
Strive to keep your answers conversational, direct and to the point. Include only as much context as necessary for the answer to make sense on its own, do not use pronouns.
"""
prompt = f"Here is the dataset: {item_list}"
```
## Considerations for Using the Data
### Discussion of Biases
Data is in English only
There are limited number of responses that reflect true negative responses, where there is insuffiecent information in the context to answer the question.
In addition these are not uniformly answered with a specific token set, rather the answer will mention its unknown but will also include question contextual information
e.g. As an answer to `"Where did he go afterwards?"` The answer may say `"It's unknown where he went afterwards."`
### Other Known Limitations
The nature of the questions in this data set are that they reflect a back and forth converstaion between a user and an assistant, and the user questions include the use of dummy pronouns and pronouns that require prior information from either the previous question or responses.
Consequently for best use, it may be that for training, several questions that reflect a back and forth between the user and the agent are included in the training data before the final question is posed. This will encourage the model to learn about pronoun use in questioning.
Heres an example:
User: 'what is the official name of the Vat?'
Assistant: 'The official name of the Vat is Vatican Apostolic Library, although it is more commonly called the Vatican Library or simply the Vat.'
User: 'where is it?'
Assistant: 'The Vatican Library is located in Vatican City and is the library of the Holy See.'
User : 'how many printed books does it contain?'
Assistant :
### Contributions
Alderley.ai |
KaiLv/UDR_CR | ---
dataset_info:
features:
- name: idx
dtype: int64
- name: label
dtype: int64
- name: sentence
dtype: string
splits:
- name: train
num_bytes: 204336
num_examples: 1772
- name: test
num_bytes: 233558
num_examples: 1996
download_size: 252165
dataset_size: 437894
---
# Dataset Card for "UDR_CR"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
liuyanchen1015/MULTI_VALUE_mrpc_remove_det_definite | ---
dataset_info:
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: value_score
dtype: int64
splits:
- name: test
num_bytes: 329200
num_examples: 1244
- name: train
num_bytes: 689895
num_examples: 2598
- name: validation
num_bytes: 81382
num_examples: 304
download_size: 746861
dataset_size: 1100477
---
# Dataset Card for "MULTI_VALUE_mrpc_remove_det_definite"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
irds/mmarco_v2_pt_dev | ---
pretty_name: '`mmarco/v2/pt/dev`'
viewer: false
source_datasets: ['irds/mmarco_v2_pt']
task_categories:
- text-retrieval
---
# Dataset Card for `mmarco/v2/pt/dev`
The `mmarco/v2/pt/dev` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
For more information about the dataset, see the [documentation](https://ir-datasets.com/mmarco#mmarco/v2/pt/dev).
# Data
This dataset provides:
- `queries` (i.e., topics); count=101,093
- `qrels`: (relevance assessments); count=59,273
- For `docs`, use [`irds/mmarco_v2_pt`](https://huggingface.co/datasets/irds/mmarco_v2_pt)
## Usage
```python
from datasets import load_dataset
queries = load_dataset('irds/mmarco_v2_pt_dev', 'queries')
for record in queries:
record # {'query_id': ..., 'text': ...}
qrels = load_dataset('irds/mmarco_v2_pt_dev', 'qrels')
for record in qrels:
record # {'query_id': ..., 'doc_id': ..., 'relevance': ..., 'iteration': ...}
```
Note that calling `load_dataset` will download the dataset (or provide access instructions when it's not public) and make a copy of the
data in 🤗 Dataset format.
## Citation Information
```
@article{Bonifacio2021MMarco,
title={{mMARCO}: A Multilingual Version of {MS MARCO} Passage Ranking Dataset},
author={Luiz Henrique Bonifacio and Israel Campiotti and Roberto Lotufo and Rodrigo Nogueira},
year={2021},
journal={arXiv:2108.13897}
}
```
|
Rakshit122/truthful | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: category
dtype: string
- name: test_type
dtype: string
- name: original_question
dtype: string
- name: original_context
dtype: string
- name: perturbed_question
dtype: string
- name: perturbed_context
dtype: string
splits:
- name: train
num_bytes: 171210
num_examples: 136
download_size: 0
dataset_size: 171210
---
# Dataset Card for "truthful"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
apsys/hop_dat | ---
license: apache-2.0
---
|
jan-hq/textbooks_are_all_you_need_lite_binarized | ---
dataset_info:
features:
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 2597406100.6765466
num_examples: 613660
- name: test
num_bytes: 288603029.3234533
num_examples: 68185
download_size: 1282991744
dataset_size: 2886009130.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
vikp/reverse_instruct | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
- name: kind
dtype: string
- name: prob
dtype: float64
splits:
- name: train
num_bytes: 694061788.6849711
num_examples: 613214
download_size: 372451511
dataset_size: 694061788.6849711
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "reverse_instruct"
This is a reverse instruction dataset, designed to be used in cases where we're trying to predict the `instruction` given the `output`.
This is useful to train a model that can generate instructions for a raw dataset (useful to quickly instruction tune on a new domain).
This data was created by aggregating [clean alpaca data](https://github.com/gururise/AlpacaDataCleaned), [evol-instruct](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1), [clean instruct](https://huggingface.co/datasets/crumb/Clean-Instruct-3M), and [orca](https://huggingface.co/datasets/Open-Orca/OpenOrca).
The combined dataset was filtered using heuristics to remove instructions unlikely to be predictable from the output (multiple choice, continue this passage, etc.). The dataset was then filtered using [instruct_rater](https://huggingface.co/vikp/instruct_rater), a trained classifier that predicts how likely an instruction is to be able to be recreated from an output. |
adamjweintraut/bart-finetuned-lyrlen-512-tokens_2024-03-24_run | ---
dataset_info:
features:
- name: id
dtype: int64
- name: orig
dtype: string
- name: predicted
dtype: string
- name: label
dtype: string
- name: rougeL_min_precision
dtype: float64
- name: rougeL_min_recall
dtype: float64
- name: rougeL_min_fmeasure
dtype: float64
- name: rougeL_median_precision
dtype: float64
- name: rougeL_median_recall
dtype: float64
- name: rougeL_median_fmeasure
dtype: float64
- name: rougeL_max_precision
dtype: float64
- name: rougeL_max_recall
dtype: float64
- name: rougeL_max_fmeasure
dtype: float64
- name: predicted_label_sim
dtype: float32
- name: predicted_syls_by_line
dtype: int64
- name: predicted_line_ct
dtype: int64
- name: predicted_syls_sum
dtype: int64
- name: orig_syls_by_line
dtype: int64
- name: slim_orig_syls_by_line
dtype: int64
- name: slim_orig_line_ct
dtype: int64
- name: slim_orig_syls_sum
dtype: int64
- name: syll_by_line_corr
dtype: float64
- name: total_syl_error
dtype: int64
- name: total_syl_ape
dtype: float64
splits:
- name: train
num_bytes: 1411704
num_examples: 500
download_size: 619018
dataset_size: 1411704
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
anz2/nasa-osdr | ---
license: apache-2.0
configs:
- config_name: experiments
data_files: "data/train/experiments.csv"
sep: ","
default: true
- config_name: samples
data_files: "data/train/samples.csv"
sep: ","
---
|
LucasThil/randomized_clean_miniwob_episodes_v2 | ---
dataset_info:
features:
- name: task_name
dtype: string
- name: utterance
dtype: string
- name: reward
dtype: float64
- name: raw_reward
dtype: float64
- name: processed_states
dtype: string
splits:
- name: train
num_bytes: 443683307
num_examples: 13412
download_size: 55056820
dataset_size: 443683307
---
# Dataset Card for "randomized_clean_miniwob_episodes_v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
jxie/wikipedia | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 17745463487
num_examples: 18870891
download_size: 10424169925
dataset_size: 17745463487
---
# Dataset Card for "wikipedia"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
distilled-from-one-sec-cv12/chunk_173 | ---
dataset_info:
features:
- name: logits
sequence: float32
- name: mfcc
sequence:
sequence: float64
splits:
- name: train
num_bytes: 1026795164
num_examples: 200077
download_size: 1047623839
dataset_size: 1026795164
---
# Dataset Card for "chunk_173"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
jlbaker361/subtraction_whole | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: float64
- name: text
dtype: string
splits:
- name: train
num_bytes: 1192290.3
num_examples: 29376
- name: test
num_bytes: 132476.7
num_examples: 3264
download_size: 684606
dataset_size: 1324767.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
# Dataset Card for "subtraction_whole"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/erincia_ridell_crimea_fireemblem | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of erincia_ridell_crimea (Fire Emblem)
This is the dataset of erincia_ridell_crimea (Fire Emblem), containing 218 images and their tags.
The core tags of this character are `green_hair, long_hair, breasts, brown_eyes, hair_ornament, large_breasts`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:----------------------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 218 | 287.90 MiB | [Download](https://huggingface.co/datasets/CyberHarem/erincia_ridell_crimea_fireemblem/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 218 | 164.51 MiB | [Download](https://huggingface.co/datasets/CyberHarem/erincia_ridell_crimea_fireemblem/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 495 | 334.88 MiB | [Download](https://huggingface.co/datasets/CyberHarem/erincia_ridell_crimea_fireemblem/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 218 | 255.00 MiB | [Download](https://huggingface.co/datasets/CyberHarem/erincia_ridell_crimea_fireemblem/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 495 | 466.74 MiB | [Download](https://huggingface.co/datasets/CyberHarem/erincia_ridell_crimea_fireemblem/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/erincia_ridell_crimea_fireemblem',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 12 |  |  |  |  |  | 1girl, smile, solo, circlet, earrings, long_sleeves, single_hair_bun, orange_dress |
| 1 | 27 |  |  |  |  |  | solo, 1girl, thighhighs, cape, thigh_boots, tiara, holding_sword, simple_background, full_body, fingerless_gloves, shoulder_armor, bangs, breastplate, dress, white_background |
| 2 | 14 |  |  |  |  |  | 1girl, smile, solo, kimono, looking_at_viewer, hair_flower, obi, simple_background, hand_fan, holding, wide_sleeves, floral_print, full_body, open_mouth, sandals |
| 3 | 32 |  |  |  |  |  | 1girl, hair_flower, orange_bikini, bare_shoulders, navel, bangs, off-shoulder_bikini, official_alternate_costume, smile, solo, necklace, hair_bun, looking_at_viewer, cleavage, collarbone, stomach, outdoors, puffy_short_sleeves, sarong, thighs, day, hibiscus, red_flower, beads, bracelet, water, blue_sky, blush, medium_breasts, beach |
| 4 | 10 |  |  |  |  |  | 1girl, blush, hetero, nipples, solo_focus, cum_in_pussy, penis, vaginal, open_mouth, 1boy, mosaic_censoring, navel, spread_legs, completely_nude, cum_on_breasts, on_back, 2boys, group_sex, hair_bun |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | smile | solo | circlet | earrings | long_sleeves | single_hair_bun | orange_dress | thighhighs | cape | thigh_boots | tiara | holding_sword | simple_background | full_body | fingerless_gloves | shoulder_armor | bangs | breastplate | dress | white_background | kimono | looking_at_viewer | hair_flower | obi | hand_fan | holding | wide_sleeves | floral_print | open_mouth | sandals | orange_bikini | bare_shoulders | navel | off-shoulder_bikini | official_alternate_costume | necklace | hair_bun | cleavage | collarbone | stomach | outdoors | puffy_short_sleeves | sarong | thighs | day | hibiscus | red_flower | beads | bracelet | water | blue_sky | blush | medium_breasts | beach | hetero | nipples | solo_focus | cum_in_pussy | penis | vaginal | 1boy | mosaic_censoring | spread_legs | completely_nude | cum_on_breasts | on_back | 2boys | group_sex |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:--------|:-------|:----------|:-----------|:---------------|:------------------|:---------------|:-------------|:-------|:--------------|:--------|:----------------|:--------------------|:------------|:--------------------|:-----------------|:--------|:--------------|:--------|:-------------------|:---------|:--------------------|:--------------|:------|:-----------|:----------|:---------------|:---------------|:-------------|:----------|:----------------|:-----------------|:--------|:----------------------|:-----------------------------|:-----------|:-----------|:-----------|:-------------|:----------|:-----------|:----------------------|:---------|:---------|:------|:-----------|:-------------|:--------|:-----------|:--------|:-----------|:--------|:-----------------|:--------|:---------|:----------|:-------------|:---------------|:--------|:----------|:-------|:-------------------|:--------------|:------------------|:-----------------|:----------|:--------|:------------|
| 0 | 12 |  |  |  |  |  | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 27 |  |  |  |  |  | X | | X | | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 2 | 14 |  |  |  |  |  | X | X | X | | | | | | | | | | | X | X | | | | | | | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 3 | 32 |  |  |  |  |  | X | X | X | | | | | | | | | | | | | | | X | | | | | X | X | | | | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | |
| 4 | 10 |  |  |  |  |  | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | X | | | | X | | | | X | | | | | | | | | | | | | | | X | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
|
DeepFoldProtein/foldseek_not_in_afdb_processed | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: special_tokens_mask
sequence: int8
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 43104
num_examples: 6
download_size: 7271
dataset_size: 43104
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
zolak/twitter_dataset_1713006364 | ---
dataset_info:
features:
- name: id
dtype: string
- name: tweet_content
dtype: string
- name: user_name
dtype: string
- name: user_id
dtype: string
- name: created_at
dtype: string
- name: url
dtype: string
- name: favourite_count
dtype: int64
- name: scraped_at
dtype: string
- name: image_urls
dtype: string
splits:
- name: train
num_bytes: 4896465
num_examples: 12185
download_size: 2441885
dataset_size: 4896465
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
jsonfin17/hub24-financial-conversation-sample1 | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/datasets-cards
{viewer: true}
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Financial conversation with the provided customer profile
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
robertmyers/convo_base | ---
license: afl-3.0
---
|
Junmai/kit-19-instruction-100000 | ---
license: apache-2.0
---
|
Daniellomar/lauramodal | ---
license: openrail
---
|
matallanas/yannick-kilcher-transcript-wav | ---
dataset_info:
features:
- name: id
dtype: string
- name: channel
dtype: string
- name: channel_id
dtype: string
- name: title
dtype: string
- name: categories
sequence: string
- name: tags
sequence: string
- name: description
dtype: string
- name: text
dtype: string
- name: segments
list:
- name: start
dtype: float64
- name: end
dtype: float64
- name: text
dtype: string
- name: audio
dtype: audio
splits:
- name: train
num_bytes: 144437989292.0
num_examples: 370
download_size: 127955407676
dataset_size: 144437989292.0
---
# Dataset Card for "yannick-kilcher-transcript-wav"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
irds/wapo_v2_trec-news-2018 | ---
pretty_name: '`wapo/v2/trec-news-2018`'
viewer: false
source_datasets: []
task_categories:
- text-retrieval
---
# Dataset Card for `wapo/v2/trec-news-2018`
The `wapo/v2/trec-news-2018` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
For more information about the dataset, see the [documentation](https://ir-datasets.com/wapo#wapo/v2/trec-news-2018).
# Data
This dataset provides:
- `queries` (i.e., topics); count=50
- `qrels`: (relevance assessments); count=8,508
## Usage
```python
from datasets import load_dataset
queries = load_dataset('irds/wapo_v2_trec-news-2018', 'queries')
for record in queries:
record # {'query_id': ..., 'doc_id': ..., 'url': ...}
qrels = load_dataset('irds/wapo_v2_trec-news-2018', 'qrels')
for record in qrels:
record # {'query_id': ..., 'doc_id': ..., 'relevance': ..., 'iteration': ...}
```
Note that calling `load_dataset` will download the dataset (or provide access instructions when it's not public) and make a copy of the
data in 🤗 Dataset format.
## Citation Information
```
@inproceedings{Soboroff2018News,
title={TREC 2018 News Track Overview},
author={Ian Soboroff and Shudong Huang and Donna Harman},
booktitle={TREC},
year={2018}
}
```
|
BhavyaMuni/sample_dataset_ts | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 633903
num_examples: 3445
download_size: 256343
dataset_size: 633903
---
# Dataset Card for "sample_dataset_ts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
europa_eac_tm | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- bg
- cs
- da
- de
- el
- en
- es
- et
- fi
- fr
- hr
- hu
- is
- it
- lt
- lv
- mt
- nl
- 'no'
- pl
- pt
- ro
- sk
- sl
- sv
- tr
license:
- cc-by-4.0
multilinguality:
- translation
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- translation
task_ids: []
pretty_name: Europa Education and Culture Translation Memory (EAC-TM)
dataset_info:
- config_name: en2bg
features:
- name: translation
dtype:
translation:
languages:
- en
- bg
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 664252
num_examples: 4061
download_size: 3521416
dataset_size: 664252
- config_name: en2cs
features:
- name: translation
dtype:
translation:
languages:
- en
- cs
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 365983
num_examples: 3351
download_size: 3521416
dataset_size: 365983
- config_name: en2da
features:
- name: translation
dtype:
translation:
languages:
- en
- da
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 422079
num_examples: 3757
download_size: 3521416
dataset_size: 422079
- config_name: en2de
features:
- name: translation
dtype:
translation:
languages:
- en
- de
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 579566
num_examples: 4473
download_size: 3521416
dataset_size: 579566
- config_name: en2el
features:
- name: translation
dtype:
translation:
languages:
- en
- el
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 491346
num_examples: 2818
download_size: 3521416
dataset_size: 491346
- config_name: en2es
features:
- name: translation
dtype:
translation:
languages:
- en
- es
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 555218
num_examples: 4303
download_size: 3521416
dataset_size: 555218
- config_name: en2et
features:
- name: translation
dtype:
translation:
languages:
- en
- et
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 247284
num_examples: 2270
download_size: 3521416
dataset_size: 247284
- config_name: en2fi
features:
- name: translation
dtype:
translation:
languages:
- en
- fi
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 150560
num_examples: 1458
download_size: 3521416
dataset_size: 150560
- config_name: en2fr
features:
- name: translation
dtype:
translation:
languages:
- en
- fr
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 575579
num_examples: 4476
download_size: 3521416
dataset_size: 575579
- config_name: en2hu
features:
- name: translation
dtype:
translation:
languages:
- en
- hu
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 454802
num_examples: 3455
download_size: 3521416
dataset_size: 454802
- config_name: en2is
features:
- name: translation
dtype:
translation:
languages:
- en
- is
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 268194
num_examples: 2206
download_size: 3521416
dataset_size: 268194
- config_name: en2it
features:
- name: translation
dtype:
translation:
languages:
- en
- it
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 270634
num_examples: 2170
download_size: 3521416
dataset_size: 270634
- config_name: en2lt
features:
- name: translation
dtype:
translation:
languages:
- en
- lt
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 358844
num_examples: 3386
download_size: 3521416
dataset_size: 358844
- config_name: en2lv
features:
- name: translation
dtype:
translation:
languages:
- en
- lv
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 437487
num_examples: 3880
download_size: 3521416
dataset_size: 437487
- config_name: en2mt
features:
- name: translation
dtype:
translation:
languages:
- en
- mt
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 178675
num_examples: 1722
download_size: 3521416
dataset_size: 178675
- config_name: en2nb
features:
- name: translation
dtype:
translation:
languages:
- en
- nb
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 85833
num_examples: 642
download_size: 3521416
dataset_size: 85833
- config_name: en2nl
features:
- name: translation
dtype:
translation:
languages:
- en
- nl
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 188531
num_examples: 1805
download_size: 3521416
dataset_size: 188531
- config_name: en2pl
features:
- name: translation
dtype:
translation:
languages:
- en
- pl
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 515976
num_examples: 4027
download_size: 3521416
dataset_size: 515976
- config_name: en2pt
features:
- name: translation
dtype:
translation:
languages:
- en
- pt
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 422125
num_examples: 3501
download_size: 3521416
dataset_size: 422125
- config_name: en2ro
features:
- name: translation
dtype:
translation:
languages:
- en
- ro
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 345468
num_examples: 3159
download_size: 3521416
dataset_size: 345468
- config_name: en2sk
features:
- name: translation
dtype:
translation:
languages:
- en
- sk
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 306049
num_examples: 2972
download_size: 3521416
dataset_size: 306049
- config_name: en2sl
features:
- name: translation
dtype:
translation:
languages:
- en
- sl
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 577524
num_examples: 4644
download_size: 3521416
dataset_size: 577524
- config_name: en2sv
features:
- name: translation
dtype:
translation:
languages:
- en
- sv
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 304954
num_examples: 2909
download_size: 3521416
dataset_size: 304954
- config_name: en2tr
features:
- name: translation
dtype:
translation:
languages:
- en
- tr
- name: sentence_type
dtype:
class_label:
names:
'0': form_data
'1': sentence_data
splits:
- name: train
num_bytes: 328267
num_examples: 3198
download_size: 3521416
dataset_size: 328267
---
# Dataset Card for Europa Education and Culture Translation Memory (EAC-TM)
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://ec.europa.eu/jrc/en/language-technologies/eac-translation-memory](https://ec.europa.eu/jrc/en/language-technologies/eac-translation-memory)
- **Paper:** [https://link.springer.com/article/10.1007/s10579-014-9277-0](https://link.springer.com/article/10.1007/s10579-014-9277-0)
- **Point of Contact:** [ralf.steinberg@jrc.ec.europa.eu](mailto:ralf.steinberg@jrc.ec.europa.eu)
### Dataset Summary
This dataset is a corpus of manually produced translations from english to up to 25 languages, released in 2012 by the European Union's Directorate General for Education and Culture (EAC).
To load a language pair that is not part of the config, just specify the language code as language pair. For example, if you want to translate Czech to Greek:
`dataset = load_dataset("europa_eac_tm", language_pair=("cs", "el"))`
### Supported Tasks and Leaderboards
- `text2text-generation`: the dataset can be used to train a model for `machine-translation`. Machine translation models are usually evaluated using metrics such as [BLEU](https://huggingface.co/metrics/bleu), [ROUGE](https://huggingface.co/metrics/rouge) or [SacreBLEU](https://huggingface.co/metrics/sacrebleu). You can use the [mBART](https://huggingface.co/facebook/mbart-large-cc25) model for this task. This task has active leaderboards which can be found at [https://paperswithcode.com/task/machine-translation](https://paperswithcode.com/task/machine-translation), which usually rank models based on [BLEU score](https://huggingface.co/metrics/bleu).
### Languages
The sentences in this dataset were originally written in English (source language is English) and then translated into the other languages. The sentences are extracted from electroniv forms: application and report forms for decentralised actions of EAC's Life-long Learning Programme (LLP) and the Youth in Action Programme. The contents in the electronic forms are technically split into two types: (a) the labels and contents of drop-down menus (referred to as 'Forms' Data) and (b) checkboxes (referred to as 'Reference Data').
The dataset contains traduction of English sentences or parts of sentences to Bulgarian, Czech, Danish, Dutch, Estonian, German, Greek, Finnish, French, Croatian, Hungarian, Icelandic, Italian, Latvian, Lithuanian, Maltese, Norwegian, Polish, Portuguese, Romanian, Slovak, Slovenian, Spanish, Swedish and Turkish.
Language codes:
- `bg`
- `cs`
- `da`
- `de`
- `el`
- `en`
- `es`
- `et`
- `fi`
- `fr`
- `hr`
- `hu`
- `is`
- `it`
- `lt`
- `lv`
- `mt`
- `nl`
- `no`
- `pl`
- `pt`
- `ro`
- `sk`
- `sl`
- `sv`
- `tr`
## Dataset Structure
### Data Instances
```
{
"translation": {
"en":"Sentence to translate",
"<target_language>": "Phrase à traduire",
},
"sentence_type": 0
}
```
### Data Fields
- `translation`: Mapping of sentences to translate (in English) and translated sentences.
- `sentence_type`: Integer value, 0 if the sentence is a 'form data' (extracted from the labels and contents of drop-down menus of the source electronic forms) or 1 if the sentence is a 'reference data' (extracted from the electronic forms checkboxes).
### Data Splits
The data is not splitted (only the `train` split is available).
## Dataset Creation
### Curation Rationale
The EAC-TM is relatively small compared to the JRC-Acquis and to DGT-TM, but it has the advantage that it focuses on a very different domain, namely that of education and culture. Also, it includes translation units for the languages Croatian (HR), Icelandic (IS), Norwegian (Bokmål, NB or Norwegian, NO) and Turkish (TR).
### Source Data
#### Initial Data Collection and Normalization
EAC-TM was built in the context of translating electronic forms: application and report forms for decentralised actions of EAC's Life-long Learning Programme (LLP) and the Youth in Action Programme. All documents and sentences were originally written in English (source language is English) and then translated into the other languages.
The contents in the electronic forms are technically split into two types: (a) the labels and contents of drop-down menus (referred to as 'Forms' Data) and (b) checkboxes (referred to as 'Reference Data'). Due to the different types of data, the two collections are kept separate. For example, labels can be 'Country', 'Please specify your home country' etc., while examples for reference data are 'Germany', 'Basic/general programmes', 'Education and Culture' etc.
The data consists of translations carried out between the end of the year 2008 and July 2012.
#### Who are the source language producers?
The texts were translated by staff of the National Agencies of the Lifelong Learning and Youth in Action programmes. They are typically professionals in the field of education/youth and EU programmes. They are thus not professional translators, but they are normally native speakers of the target language.
### Annotations
#### Annotation process
Sentences were manually translated by humans.
#### Who are the annotators?
The texts were translated by staff of the National Agencies of the Lifelong Learning and Youth in Action programmes. They are typically professionals in the field of education/youth and EU programmes. They are thus not professional translators, but they are normally native speakers of the target language.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
© European Union, 1995-2020
The Commission's reuse policy is implemented by the [Commission Decision of 12 December 2011 on the reuse of Commission documents](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32011D0833).
Unless otherwise indicated (e.g. in individual copyright notices), content owned by the EU on this website is licensed under the [Creative Commons Attribution 4.0 International (CC BY 4.0) licence](http://creativecommons.org/licenses/by/4.0/). This means that reuse is allowed, provided appropriate credit is given and changes are indicated.
You may be required to clear additional rights if a specific content depicts identifiable private individuals or includes third-party works. To use or reproduce content that is not owned by the EU, you may need to seek permission directly from the rightholders. Software or documents covered by industrial property rights, such as patents, trade marks, registered designs, logos and names, are excluded from the Commission's reuse policy and are not licensed to you.
### Citation Information
```
@Article{Steinberger2014,
author={Steinberger, Ralf
and Ebrahim, Mohamed
and Poulis, Alexandros
and Carrasco-Benitez, Manuel
and Schl{\"u}ter, Patrick
and Przybyszewski, Marek
and Gilbro, Signe},
title={An overview of the European Union's highly multilingual parallel corpora},
journal={Language Resources and Evaluation},
year={2014},
month={Dec},
day={01},
volume={48},
number={4},
pages={679-707},
issn={1574-0218},
doi={10.1007/s10579-014-9277-0},
url={https://doi.org/10.1007/s10579-014-9277-0}
}
```
### Contributions
Thanks to [@SBrandeis](https://github.com/SBrandeis) for adding this dataset. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.