
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
Arkan0ID/furniture-dataset | 2023-08-06T03:15:37.000Z | [
"region:us"
] | Arkan0ID | null | null | null | 0 | 3 | Entry not found |
ShenRuililin/MedicalQnA | 2023-08-07T08:54:25.000Z | [
"license:mit",
"region:us"
] | ShenRuililin | null | null | null | 0 | 3 | ---
license: mit
---
|
jaygala223/38-cloud-dataset | 2023-08-07T09:44:38.000Z | [
"region:us"
] | jaygala223 | null | null | null | 1 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: image
splits:
- name: train
num_bytes: 757246236.0
num_examples: 8400
download_size: 754389599
dataset_size: 757246236.0
---
# Dataset Card for "38-cloud-train-only-v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
d0rj/boolq-ru | 2023-08-14T09:47:04.000Z | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"annotations_creators:crowdsourced",
"language_creators:translated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:boolq",
"language:ru",
"license:cc-by-sa-3.0",
"region:us"
] | d0rj | null | null | null | 0 | 3 | ---
annotations_creators:
- crowdsourced
language_creators:
- translated
language:
- ru
license:
- cc-by-sa-3.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- boolq
task_categories:
- text-classification
task_ids:
- natural-language-inference
paperswithcode_id: boolq
pretty_name: BoolQ (ru)
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: bool
- name: passage
dtype: string
splits:
- name: train
num_bytes: 10819511
num_examples: 9427
- name: validation
num_bytes: 3710872
num_examples: 3270
download_size: 7376712
dataset_size: 14530383
---
# boolq-ru
Translated version of [boolq](https://huggingface.co/datasets/boolq) dataset into Russian.
## Dataset Description
- **Homepage:** [https://github.com/google-research-datasets/boolean-questions](https://github.com/google-research-datasets/boolean-questions) |
DFKI-SLT/argmicro | 2023-08-09T15:07:47.000Z | [
"license:cc-by-nc-sa-4.0",
"region:us"
] | DFKI-SLT | null | @inproceedings{peldszus2015annotated,
title={An annotated corpus of argumentative microtexts},
author={Peldszus, Andreas and Stede, Manfred},
booktitle={Argumentation and Reasoned Action: Proceedings of the 1st European Conference on Argumentation, Lisbon},
volume={2},
pages={801--815},
year={2015}
} | null | 0 | 3 | ---
license: cc-by-nc-sa-4.0
---
# An annotated corpus of argumentative microtexts
The arg-microtexts corpus features 112 short argumentative texts. All texts
were originally written in German and have been professionally translated to
English.
The texts with ids b001-b064 and k001-k031 have been collected in a controlled
text generation experiment from 23 subjects discussing various controversial
issues from [a fixed list](topics_triggers.md).
The texts with ids d01-d23 have been written by Andreas Peldszus and were
used mainly in teaching and testing students argumentative analysis.
All texts are annotated with argumentation structures, following the scheme
proposed in Peldszus & Stede (2013). For inter-annotator-agreement scores see
Peldszus (2014). The (German) annotation guidelines are published in Peldszus, Warzecha, Stede (2016).
## DATA FORMAT (ARGUMENTATION GRAPH)
This specifies the argumentation graphs following the
annotation scheme described in
Andreas Peldszus and Manfred Stede. From argument diagrams to argumentation
mining in texts: a survey. International Journal of Cognitive Informatics
and Natural Intelligence (IJCINI), 7(1):1–31, 2013.
An argumentation graph is a directed graph spanning over text segments. The
format distinguishes three different sorts of nodes: EDUs, ADUs & EDU-joints.
- EDU: elementary discourse units
The text is segmented into elementary discourse units, typically at a
clause/sentence level. This segmentation can be the result of manually
annotation or of automatic discourse segmenters.
- ADU: argumentative discourse units
Not every EDU is relevant in an argumentation. Also, the same claim might
be stated multiple times in longer texts. An argumentative discourse unit
represents a claim that stands for itself and is argumentatively relevant.
It is thus grounded in one or more EDUs. EDU and ADUs are connected by
segmentation edges. ADUs are associated with a dialectic role: They are
either proponent or opponent nodes.
- JOINT: a joint of two or more adjacent elementary discourse units
When two adjacent EDUs are argumentatively relevant only when taken
together, these EDUs are first connected with one joint EDU node by
segmentation edges and then this joint node is connected to a corresponding
ADU.
### edge type
The edges representing arguments are those that connect ADUs. The scheme
distinguishes between supporting and attacking relations. Supporting
relations are normal support and support by example. Attacking relations are
rebutting attacks (directed against another node, challenging the accept-
ability of the corresponding claim) and undercutting attacks (directed
against another relation, challenging the argumentative inference from the
source to the target of the relation). Finally, additional premises of
relations with more than one premise are represented by additional source
relations.
Values:
- seg: segmentation edges (EDU->ADU, EDU->JOINT, JOINT->ADU)
- sup: support (ADU->ADU)
- exa: support by example (ADU->ADU)
- add: additional source, for combined/convergent arguments with multiple premises (ADU->ADU)
- reb: rebutting attack (ADU->ADU)
- und: undercutting attack (ADU->Edge)
### adu type
The argumentation can be thought of as a dialectical exchange between the
role of the proponent (who is presenting and defending the central claim)
and the role of the opponent (who is critically challenging the proponents
claims). Each ADU is thus associated with one of these dialectic roles.
Values:
- pro: proponent
- opp: opponent
### stance type
Annotated texts typically discuss a controversial topic, i.e. an issue posed
as a yes/no question. Example: "Should we make use of capital punishment?"
The stance type specifies, which stance the author of this text takes
towards this issue.
Values:
- pro: yes, in favour of the proposed issue
- con: no, against the proposed issue
- unclear: the position of the author is unclear
- UNDEFINED |
ashtrayAI/Bangla_Financial_news_articles_Dataset | 2023-08-08T16:43:31.000Z | [
"license:cc0-1.0",
"Bengali",
"News",
"Sentiment",
"Text",
"Articles",
"Finance",
"region:us"
] | ashtrayAI | null | null | null | 1 | 3 | ---
license: cc0-1.0
tags:
- Bengali
- News
- Sentiment
- Text
- Articles
- Finance
---
# Bangla-Financial-news-articles-Dataset
A Comprehensive Resource for Analyzing Sentiments in over 7600+ Bangla News.
### Downloads
🔴 **Download** the **"💥Bangla_fin_news.zip"** file for all "7,695" news and extract it.
### About Dataset
**Welcome** to our Bengali Financial News Sentiment Analysis dataset! This collection comprises 7,695 financial news articles extracted, covering the period from March 3, 2014, to December 29, 2021. Utilizing the powerful web scraping tool "Beautiful Soup 4.4.0" in Python.
This dataset was a crucial part of our research published in the journal paper titled **"Stock Market Prediction of Bangladesh Using Multivariate Long Short-Term Memory with Sentiment Identification."** The paper can be accessed and cited at **http://doi.org/10.11591/ijece.v13i5.pp5696-5706**.
We are excited to share this unique dataset, which we hope will empower researchers, analysts, and enthusiasts to explore and understand the dynamics of the Bengali financial market through sentiment analysis. Join us on this journey of uncovering the hidden emotions driving market trends and decisions in Bangladesh. Happy analyzing!
### About this directory
**Directory Description:** Welcome to the "Bangla_fin_news" directory. This repository houses a collection of 7,695 CSV files, each containing valuable financial news data in the Bengali language. These files are indexed numerically from 1 to 7695, making it easy to access specific information for analysis or research.
**File Description:** Each file contains financial news articles and related information.
**example:**
File: "1.csv"
Columns:
Serial: The serial number of the news article.
Title: The title of the news article.
Date: The date when the news article was published.
Author: The name of the author who wrote the article.
News: The main content of the news article.
File: "2.csv"
Columns:
Serial: The serial number of the news article.
Title: The title of the news article.
Date: The date when the news article was published.
Author: The name of the author who wrote the article.
News: The main content of the news article.
**[… and so on for all 7,695 files …]**
Each CSV file within this directory represents unique financial news articles from March 3, 2014, to December 29, 2021. The dataset has been carefully compiled and structured, making it a valuable resource for sentiment analysis, market research, and any investigation into the dynamics of the Bengali financial market.
Feel free to explore, analyze, and gain insights from this extensive collection of Bengali financial news articles. Happy researching! ❤❤
|
hf-audio/esb-datasets-test-only | 2023-08-29T12:45:54.000Z | [
"task_categories:automatic-speech-recognition",
"annotations_creators:expert-generated",
"annotations_creators:crowdsourced",
"annotations_creators:machine-generated",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
... | hf-audio | null | null | null | 3 | 3 | ---
annotations_creators:
- expert-generated
- crowdsourced
- machine-generated
language:
- en
language_creators:
- crowdsourced
- expert-generated
license:
- cc-by-4.0
- apache-2.0
- cc0-1.0
- cc-by-nc-3.0
- other
multilinguality:
- monolingual
pretty_name: datasets
size_categories:
- 100K<n<1M
- 1M<n<10M
source_datasets:
- original
- extended|librispeech_asr
- extended|common_voice
tags:
- asr
- benchmark
- speech
- esb
task_categories:
- automatic-speech-recognition
extra_gated_prompt: >-
Three of the ESB datasets have specific terms of usage that must be agreed to
before using the data.
To do so, fill in the access forms on the specific datasets' pages:
* Common Voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0
* GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech
* SPGISpeech: https://huggingface.co/datasets/kensho/spgispeech
extra_gated_fields:
I hereby confirm that I have registered on the original Common Voice page and agree to not attempt to determine the identity of speakers in the Common Voice dataset: checkbox
I hereby confirm that I have accepted the terms of usages on GigaSpeech page: checkbox
I hereby confirm that I have accepted the terms of usages on SPGISpeech page: checkbox
duplicated_from: open-asr-leaderboard/datasets
---
All eight of datasets in ESB can be downloaded and prepared in just a single line of code through the Hugging Face Datasets library:
```python
from datasets import load_dataset
librispeech = load_dataset("esb/datasets", "librispeech", split="train")
```
- `"esb/datasets"`: the repository namespace. This is fixed for all ESB datasets.
- `"librispeech"`: the dataset name. This can be changed to any of any one of the eight datasets in ESB to download that dataset.
- `split="train"`: the split. Set this to one of train/validation/test to generate a specific split. Omit the `split` argument to generate all splits for a dataset.
The datasets are full prepared, such that the audio and transcription files can be used directly in training/evaluation scripts.
## Dataset Information
A data point can be accessed by indexing the dataset object loaded through `load_dataset`:
```python
print(librispeech[0])
```
A typical data point comprises the path to the audio file and its transcription. Also included is information of the dataset from which the sample derives and a unique identifier name:
```python
{
'dataset': 'librispeech',
'audio': {'path': '/home/sanchit-gandhi/.cache/huggingface/datasets/downloads/extracted/d2da1969fe9e7d06661b5dc370cf2e3c119a14c35950045bcb76243b264e4f01/374-180298-0000.flac',
'array': array([ 7.01904297e-04, 7.32421875e-04, 7.32421875e-04, ...,
-2.74658203e-04, -1.83105469e-04, -3.05175781e-05]),
'sampling_rate': 16000},
'text': 'chapter sixteen i might have told you of the beginning of this liaison in a few lines but i wanted you to see every step by which we came i to agree to whatever marguerite wished',
'id': '374-180298-0000'
}
```
### Data Fields
- `dataset`: name of the ESB dataset from which the sample is taken.
- `audio`: a dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate.
- `text`: the transcription of the audio file.
- `id`: unique id of the data sample.
### Data Preparation
#### Audio
The audio for all ESB datasets is segmented into sample lengths suitable for training ASR systems. The Hugging Face datasets library decodes audio files on the fly, reading the segments and converting them to a Python arrays. Consequently, no further preparation of the audio is required to be used in training/evaluation scripts.
Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, i.e. `dataset[0]["audio"]` should always be preferred over `dataset["audio"][0]`.
#### Transcriptions
The transcriptions corresponding to each audio file are provided in their 'error corrected' format. No transcription pre-processing is applied to the text, only necessary 'error correction' steps such as removing junk tokens (_<unk>_) or converting symbolic punctuation to spelled out form (_<comma>_ to _,_). As such, no further preparation of the transcriptions is required to be used in training/evaluation scripts.
Transcriptions are provided for training and validation splits. The transcriptions are **not** provided for the test splits. ESB requires you to generate predictions for the test sets and upload them to https://huggingface.co/spaces/esb/leaderboard for scoring.
### Access
All eight of the datasets in ESB are accessible and licensing is freely available. Three of the ESB datasets have specific terms of usage that must be agreed to before using the data. To do so, fill in the access forms on the specific datasets' pages:
* Common Voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0
* GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech
* SPGISpeech: https://huggingface.co/datasets/kensho/spgispeech
### Diagnostic Dataset
ESB contains a small, 8h diagnostic dataset of in-domain validation data with newly annotated transcriptions. The audio data is sampled from each of the ESB validation sets, giving a range of different domains and speaking styles. The transcriptions are annotated according to a consistent style guide with two formats: normalised and un-normalised. The dataset is structured in the same way as the ESB dataset, by grouping audio-transcription samples according to the dataset from which they were taken. We encourage participants to use this dataset when evaluating their systems to quickly assess performance on a range of different speech recognition conditions. For more information, visit: [esb/diagnostic-dataset](https://huggingface.co/datasets/esb/diagnostic-dataset).
## Summary of ESB Datasets
| Dataset | Domain | Speaking Style | Train (h) | Dev (h) | Test (h) | Transcriptions | License |
|--------------|-----------------------------|-----------------------|-----------|---------|----------|--------------------|-----------------|
| LibriSpeech | Audiobook | Narrated | 960 | 11 | 11 | Normalised | CC-BY-4.0 |
| Common Voice | Wikipedia | Narrated | 1409 | 27 | 27 | Punctuated & Cased | CC0-1.0 |
| Voxpopuli | European Parliament | Oratory | 523 | 5 | 5 | Punctuated | CC0 |
| TED-LIUM | TED talks | Oratory | 454 | 2 | 3 | Normalised | CC-BY-NC-ND 3.0 |
| GigaSpeech | Audiobook, podcast, YouTube | Narrated, spontaneous | 2500 | 12 | 40 | Punctuated | apache-2.0 |
| SPGISpeech | Fincancial meetings | Oratory, spontaneous | 4900 | 100 | 100 | Punctuated & Cased | User Agreement |
| Earnings-22 | Fincancial meetings | Oratory, spontaneous | 105 | 5 | 5 | Punctuated & Cased | CC-BY-SA-4.0 |
| AMI | Meetings | Spontaneous | 78 | 9 | 9 | Punctuated & Cased | CC-BY-4.0 |
## LibriSpeech
The LibriSpeech corpus is a standard large-scale corpus for assessing ASR systems. It consists of approximately 1,000 hours of narrated audiobooks from the [LibriVox](https://librivox.org) project. It is licensed under CC-BY-4.0.
Example Usage:
```python
librispeech = load_dataset("esb/datasets", "librispeech")
```
Train/validation splits:
- `train` (combination of `train.clean.100`, `train.clean.360` and `train.other.500`)
- `validation.clean`
- `validation.other`
Test splits:
- `test.clean`
- `test.other`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
librispeech = load_dataset("esb/datasets", "librispeech", subconfig="clean.100")
```
- `clean.100`: 100 hours of training data from the 'clean' subset
- `clean.360`: 360 hours of training data from the 'clean' subset
- `other.500`: 500 hours of training data from the 'other' subset
## Common Voice
Common Voice is a series of crowd-sourced open-licensed speech datasets where speakers record text from Wikipedia in various languages. The speakers are of various nationalities and native languages, with different accents and recording conditions. We use the English subset of version 9.0 (27-4-2022), with approximately 1,400 hours of audio-transcription data. It is licensed under CC0-1.0.
Example usage:
```python
common_voice = load_dataset("esb/datasets", "common_voice", use_auth_token=True)
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## VoxPopuli
VoxPopuli is a large-scale multilingual speech corpus consisting of political data sourced from 2009-2020 European Parliament event recordings. The English subset contains approximately 550 hours of speech largely from non-native English speakers. It is licensed under CC0.
Example usage:
```python
voxpopuli = load_dataset("esb/datasets", "voxpopuli")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## TED-LIUM
TED-LIUM consists of English-language TED Talk conference videos covering a range of different cultural, political, and academic topics. It contains approximately 450 hours of transcribed speech data. It is licensed under CC-BY-NC-ND 3.0.
Example usage:
```python
tedlium = load_dataset("esb/datasets", "tedlium")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## GigaSpeech
GigaSpeech is a multi-domain English speech recognition corpus created from audiobooks, podcasts and YouTube. We provide the large train set (2,500 hours) and the standard validation and test splits. It is licensed under apache-2.0.
Example usage:
```python
gigaspeech = load_dataset("esb/datasets", "gigaspeech", use_auth_token=True)
```
Training/validation splits:
- `train` (`l` subset of training data (2,500 h))
- `validation`
Test splits:
- `test`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
gigaspeech = load_dataset("esb/datasets", "spgispeech", subconfig="xs", use_auth_token=True)
```
- `xs`: extra-small subset of training data (10 h)
- `s`: small subset of training data (250 h)
- `m`: medium subset of training data (1,000 h)
- `xl`: extra-large subset of training data (10,000 h)
## SPGISpeech
SPGISpeech consists of company earnings calls that have been manually transcribed by S&P Global, Inc according to a professional style guide. We provide the large train set (5,000 hours) and the standard validation and test splits. It is licensed under a Kensho user agreement.
Loading the dataset requires authorization.
Example usage:
```python
spgispeech = load_dataset("esb/datasets", "spgispeech", use_auth_token=True)
```
Training/validation splits:
- `train` (`l` subset of training data (~5,000 h))
- `validation`
Test splits:
- `test`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
spgispeech = load_dataset("esb/datasets", "spgispeech", subconfig="s", use_auth_token=True)
```
- `s`: small subset of training data (~200 h)
- `m`: medium subset of training data (~1,000 h)
## Earnings-22
Earnings-22 is a 119-hour corpus of English-language earnings calls collected from global companies, with speakers of many different nationalities and accents. It is licensed under CC-BY-SA-4.0.
Example usage:
```python
earnings22 = load_dataset("esb/datasets", "earnings22")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## AMI
The AMI Meeting Corpus consists of 100 hours of meeting recordings from multiple recording devices synced to a common timeline. It is licensed under CC-BY-4.0.
Example usage:
```python
ami = load_dataset("esb/datasets", "ami")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test` |
Elliot4AI/dolly-15k-chinese-guanacoformat | 2023-08-09T09:07:11.000Z | [
"task_categories:text-classification",
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:zh",
"license:apache-2.0",
"finance",
"region:us"
] | Elliot4AI | null | null | null | 3 | 3 | ---
license: apache-2.0
task_categories:
- text-classification
- text-generation
language:
- zh
tags:
- finance
size_categories:
- 10K<n<100K
---
# Dataset Summary
## 🏡🏡🏡🏡Fine-tune Dataset:中文数据集🏡🏡🏡🏡
😀😀😀😀😀😀😀😀 这个数据集是databricks/databricks-dolly-15k的中文guanaco版本
|
cayjobla/wikipedia-pretrain-processed | 2023-08-09T19:54:48.000Z | [
"region:us"
] | cayjobla | null | null | null | 0 | 3 | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
- name: next_sentence_label
dtype: int64
splits:
- name: train
num_bytes: 110639929064.0
num_examples: 35782642
- name: test
num_bytes: 12293328200.0
num_examples: 3975850
download_size: 4973120598
dataset_size: 122933257264.0
---
# Dataset Card for "wikipedia-pretrain-processed"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Kyle1668/pythia-semantic-memorization-perplexities | 2023-09-19T02:40:54.000Z | [
"region:us"
] | Kyle1668 | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: memories.deduped.12b
path: data/memories.deduped.12b-*
- split: memories.duped.12b
path: data/memories.duped.12b-*
- split: memories.duped.6.9b
path: data/memories.duped.6.9b-*
- split: pile.duped.6.9b
path: data/pile.duped.6.9b-*
- split: memories.duped.70m
path: data/memories.duped.70m-*
- split: memories.duped.160m
path: data/memories.duped.160m-*
- split: memories.duped.410m
path: data/memories.duped.410m-*
- split: pile.duped.70m
path: data/pile.duped.70m-*
- split: pile.duped.160m
path: data/pile.duped.160m-*
- split: pile.duped.410m
path: data/pile.duped.410m-*
- split: memories.duped.1.4b
path: data/memories.duped.1.4b-*
- split: memories.duped.1b
path: data/memories.duped.1b-*
- split: memories.duped.2.8b
path: data/memories.duped.2.8b-*
- split: pile.duped.1.4b
path: data/pile.duped.1.4b-*
- split: pile.duped.1b
path: data/pile.duped.1b-*
- split: pile.duped.2.8b
path: data/pile.duped.2.8b-*
- split: pile.duped.12b
path: data/pile.duped.12b-*
- split: memories.deduped.70m
path: data/memories.deduped.70m-*
- split: memories.deduped.160m
path: data/memories.deduped.160m-*
- split: memories.deduped.410m
path: data/memories.deduped.410m-*
- split: pile.deduped.70m
path: data/pile.deduped.70m-*
- split: pile.deduped.160m
path: data/pile.deduped.160m-*
- split: pile.deduped.410m
path: data/pile.deduped.410m-*
- split: memories.deduped.6.9b
path: data/memories.deduped.6.9b-*
- split: pile.deduped.6.9b
path: data/pile.deduped.6.9b-*
- split: pile.deduped.12b
path: data/pile.deduped.12b-*
- split: memories.deduped.2.8b
path: data/memories.deduped.2.8b-*
- split: pile.deduped.2.8b
path: data/pile.deduped.2.8b-*
- split: memories.deduped.1.4b
path: data/memories.deduped.1.4b-*
- split: memories.deduped.1b
path: data/memories.deduped.1b-*
- split: pile.deduped.1.4b
path: data/pile.deduped.1.4b-*
- split: pile.deduped.1b
path: data/pile.deduped.1b-*
dataset_info:
features:
- name: index
dtype: int32
- name: prompt_perplexity
dtype: float32
- name: generation_perplexity
dtype: float32
- name: sequence_perplexity
dtype: float32
splits:
- name: memories.deduped.12b
num_bytes: 29939456
num_examples: 1871216
- name: memories.duped.12b
num_bytes: 38117248
num_examples: 2382328
- name: memories.duped.6.9b
num_bytes: 33935616
num_examples: 2120976
- name: pile.duped.6.9b
num_bytes: 80000000
num_examples: 5000000
- name: memories.duped.70m
num_bytes: 7423248
num_examples: 463953
- name: memories.duped.160m
num_bytes: 11034768
num_examples: 689673
- name: memories.duped.410m
num_bytes: 15525456
num_examples: 970341
- name: pile.duped.70m
num_bytes: 80000000
num_examples: 5000000
- name: pile.duped.160m
num_bytes: 80000000
num_examples: 5000000
- name: pile.duped.410m
num_bytes: 80000000
num_examples: 5000000
- name: memories.duped.1.4b
num_bytes: 21979552
num_examples: 1373722
- name: memories.duped.1b
num_bytes: 20098256
num_examples: 1256141
- name: memories.duped.2.8b
num_bytes: 26801232
num_examples: 1675077
- name: pile.duped.1.4b
num_bytes: 80000000
num_examples: 5000000
- name: pile.duped.1b
num_bytes: 80000000
num_examples: 5000000
- name: pile.duped.2.8b
num_bytes: 80000000
num_examples: 5000000
- name: pile.duped.12b
num_bytes: 80000000
num_examples: 5000000
- name: memories.deduped.70m
num_bytes: 6583168
num_examples: 411448
- name: memories.deduped.160m
num_bytes: 9299120
num_examples: 581195
- name: memories.deduped.410m
num_bytes: 12976624
num_examples: 811039
- name: pile.deduped.70m
num_bytes: 80000000
num_examples: 5000000
- name: pile.deduped.160m
num_bytes: 80000000
num_examples: 5000000
- name: pile.deduped.410m
num_bytes: 80000000
num_examples: 5000000
- name: memories.deduped.6.9b
num_bytes: 26884704
num_examples: 1680294
- name: pile.deduped.6.9b
num_bytes: 80000000
num_examples: 5000000
- name: pile.deduped.12b
num_bytes: 80000000
num_examples: 5000000
- name: memories.deduped.2.8b
num_bytes: 21683376
num_examples: 1355211
- name: pile.deduped.2.8b
num_bytes: 80000000
num_examples: 5000000
- name: memories.deduped.1.4b
num_bytes: 16769552
num_examples: 1048097
- name: memories.deduped.1b
num_bytes: 16525840
num_examples: 1032865
- name: pile.deduped.1.4b
num_bytes: 80000000
num_examples: 5000000
- name: pile.deduped.1b
num_bytes: 80000000
num_examples: 5000000
download_size: 1891778367
dataset_size: 1595577216
---
# Dataset Card for "pythia-semantic-memorization-perplexities"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
pfcheng123/test | 2023-08-15T08:28:55.000Z | [
"region:us"
] | pfcheng123 | null | null | null | 0 | 3 | Entry not found |
BalajiAIdev/autotrain-data-animal-image-classification | 2023-08-10T02:33:12.000Z | [
"task_categories:image-classification",
"region:us"
] | BalajiAIdev | null | null | null | 0 | 3 | ---
task_categories:
- image-classification
---
# AutoTrain Dataset for project: animal-image-classification
## Dataset Description
This dataset has been automatically processed by AutoTrain for project animal-image-classification.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"image": "<366x274 RGB PIL image>",
"target": 0
},
{
"image": "<367x274 RGB PIL image>",
"target": 0
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"image": "Image(decode=True, id=None)",
"target": "ClassLabel(names=['Lion', 'Tiger'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 20 |
| valid | 20 |
|
mirix/messaih | 2023-08-11T08:42:42.000Z | [
"task_categories:audio-classification",
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"SER",
"Speech Emotion Recognition",
"Speech Emotion Classification",
"Audio Classification",
"Audio",
"Emotion",
"Emo",
"Speech",
"Mosei",
"region:us"
] | mirix | null | null | null | 0 | 3 | ---
license: mit
task_categories:
- audio-classification
language:
- en
tags:
- SER
- Speech Emotion Recognition
- Speech Emotion Classification
- Audio Classification
- Audio
- Emotion
- Emo
- Speech
- Mosei
pretty_name: messAIh
size_categories:
- 10K<n<100K
---
DATASET DESCRIPTION
The messAIh dataset is a fork of [CMU MOSEI](http://multicomp.cs.cmu.edu/resources/cmu-mosei-dataset/).
Unlike its parent, MESSAIH is indended for unimodal model development and focusses exclusively on audio classification, more specifically, Speech Emotion Recognition (SER).
Of course, it can be used for bimodal classification by transcribing each audio track.
MESSAIH currently contains 13,234 speech samples annotated according to the [CMU MOSEI](https://aclanthology.org/P18-1208/) scheme:
> Each sentence is annotated for sentiment on a [-3,3] Likert scale of:
> [−3: highly negative, −2 negative, −1 weakly negative, 0 neutral, +1 weakly positive, +2 positive, +3 highly positive].
> Ekman emotions of {happiness, sadness, anger, fear, disgust, surprise}
> are annotated on a [0,3] Likert scale for presence of emotion
> x: [0: no evidence of x, 1: weakly x, 2: x, 3: highly x].
The dataset is provided as a [parquet file](https://drive.google.com/file/d/17qOa2cFDNCH2j2mL5gCNUOwLxpgnzPmB/view?usp=drive_link).
Provisionally, the file is stored on a [cloud drive](https://drive.google.com/file/d/17qOa2cFDNCH2j2mL5gCNUOwLxpgnzPmB/view?usp=drive_link) as it is too big for GitHub. Note that the original parquet file from August 10th 2023 was buggy and so was the Python script.
To facilitate inspection, a truncated csv sample file is also provided, but it does not contain the audio arrays.
If you train a model on this dataset, you would make us very happy by letting us know.
UNPACKING THE DATASET
A sample Python script (check the top of the script for the requirements) is also provided for illustrative purposes.
The script reads the parquet file and produces the following:
1. A csv file with file names and MOSEI values (columns names are self-explanatory).
2. A folder named "wavs" containing the audio samples.
LEGAL CONSIDERATIONS
Note that producing the wav files might (or might not) constitute copyright infringement as well as a violation of Google's Terms of Service.
Instead, researchers are encouraged to use the numpy arrays contained in the last column of the dataset ("wav2numpy") directly, without actually extracting any playable audio.
That, I believe, may keep us in the grey zone.
CAVEATS
As one can appreciate from the charts contained in the "charts" folder, the dataset is biased towards "positive" emotions, namely happiness.
Certain emotions such as fear may be underrepresented, not only in terms of number of occurences, but, more problematically, in terms of "intensity".
MOSEI is considered a natural or spontaneous emotion dataset (as opposed to an actored or scripted one) showcasing "genuine" emotions.
However, keep in mind that MOSEI was curated from a popular social network and social networks are notoriously abundant in fake emotions.
Moreover, certain emotions may be intrinsically more difficult to detect than others, even from a human perspective.
Yet, MOSEI is possibly one of the best datasets of its kind currently in the public domain.
Also note that the original [MOSEI](http://immortal.multicomp.cs.cmu.edu/CMU-MOSEI/labels/) contains nearly twice as many entries as MESSAIH does.
|
TrainingDataPro/biometric-attacks-in-different-lighting-conditions | 2023-09-14T16:34:15.000Z | [
"task_categories:video-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"legal",
"finance",
"region:us"
] | TrainingDataPro | null | null | null | 1 | 3 | ---
license: cc-by-nc-nd-4.0
task_categories:
- video-classification
language:
- en
tags:
- code
- legal
- finance
---
# Biometric Attacks in Different Lighting Conditions Dataset
The dataset consists of videos of individuals and attacks with photos shown in the monitor . Videos are filmed in different lightning conditions (*in a dark room, daylight, light room and nightlight*) and in different places (*indoors, outdoors*). Each video in the dataset has an approximate duration of 20 seconds.
### Types of videos in the dataset:
- **darkroom_photo** - photo of a person in a **dark room** shown on a computer and filmed on the phone
- **daylight_photo** - photo of a person in a **daylight** shown on a computer and filmed on the phone
- **lightroom_photo** - photo of a person in a **light room** shown on a computer and filmed on the phone
- **nightlight_photo** - photo of a person in a **night light** shown on a computer and filmed on the phone
- **darkroom_video** - filmed in a **dark room**, on which a person moves his/her head left, right, up and down
- **daylight_video** - filmed in a **daylight**, on which a person moves his/her head left, right, up and down
- **lightroom_video** - filmed in a **light room**, on which a person moves his/her head left, right, up and down
- **nightlight_video** - filmed in a **night light**, on which a person moves his/her head left, right, up and down
- **mask** - video of the person wearing a **printed 2D mask**
- **outline** - video of the person wearing a **printed 2D mask with cut-out holes for eyes**
- **monitor_video** - video of a person played on a computer and filmed on the phone
.png?generation=1691658152306937&alt=media)
The dataset serves as a valuable resource for computer vision, anti-spoofing tasks, video analysis, and security systems. It allows for the development of algorithms and models that can effectively detect attacks.
Studying the dataset may lead to the development of improved security systems, surveillance technologies, and solutions to mitigate the risks associated with masked individuals carrying out attacks.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=biometric-attacks-in-different-lighting-conditions) to discuss your requirements, learn about the price and buy the dataset.
# Content
- **files** - contains of original videos and videos of attacks,
- **dataset_info.csvl** - includes the information about videos in the dataset
### File with the extension .csv
- **file**: link to the video,
- **type**: type of the video
# Attacks might be collected in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=biometric-attacks-in-different-lighting-conditions) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
almandsky/openassistant-tiny | 2023-08-10T15:58:18.000Z | [
"license:mit",
"region:us"
] | almandsky | null | null | null | 0 | 3 | ---
license: mit
---
|
RealTimeData/News_August_2023 | 2023-08-10T20:09:24.000Z | [
"size_categories:1K<n<10K",
"language:en",
"license:cc",
"region:us"
] | RealTimeData | null | null | null | 0 | 3 | ---
dataset_info:
features:
- name: authors
sequence: string
- name: date_download
dtype: string
- name: date_modify
dtype: string
- name: date_publish
dtype: string
- name: description
dtype: string
- name: filename
dtype: string
- name: image_url
dtype: string
- name: language
dtype: string
- name: localpath
dtype: string
- name: maintext
dtype: string
- name: source_domain
dtype: string
- name: title
dtype: string
- name: title_page
dtype: string
- name: title_rss
dtype: string
- name: url
dtype: string
splits:
- name: train
num_bytes: 18194599
num_examples: 5059
download_size: 8541046
dataset_size: 18194599
license: cc
language:
- en
size_categories:
- 1K<n<10K
---
# Dataset Card for "News_August_2023"
This dataset was constructed at 1 Aug 2023, which contains news published from 10 May 2023 to 1 Aug 2023 from various sources.
All news articles in this dataset are in English.
Created from `commoncrawl`. |
luci/questions | 2023-08-11T13:00:22.000Z | [
"language:fr",
"license:wtfpl",
"region:us"
] | luci | null | null | null | 0 | 3 | ---
license: wtfpl
language:
- fr
---
### Présentation Générale:
Ce dataset est une collection de questions et réponses en français, principalement axée sur les sujets techniques tels que le développement, le DevOps, la sécurité, les données, l'apprentissage automatique, et bien d'autres domaines liés à la technologie.
### Structure du Dataset:
Chaque élément du dataset est un objet avec les champs suivants:
- `id`: Un identifiant unique pour chaque entrée.
- `category`: La catégorie ou le domaine de la question (par exemple, "linux").
- `question`: La question posée.
- `answer`: La réponse à la question.
### Exemple d'une entrée:
```json
{
"id": "7d0b4a78-371e-4bd9-a292-c97ce162e740",
"category": "linux",
"question": "Qu'est-ce que Linux ?",
"answer": "Linux est un système d'exploitation libre et open source basé sur le noyau Linux..."
}
```
### Utilisation:
Ce dataset peut être utilisé pour :
1. **Entraîner des modèles de langage** : En utilisant les questions et les réponses comme données d'entraînement.
2. **Évaluer des modèles de langage** : En comparant les réponses générées par le modèle avec les réponses du dataset.
3. **Nettoyer et améliorer d'autres datasets** : En utilisant les questions comme base pour filtrer et nettoyer d'autres ensembles de données.
### Note Importante:
Il est important de noter que les réponses présentes dans ce dataset n'ont pas été supervisées pendant leur génération, que ce soit par des humains ou des machines. Par conséquent, il est possible que certaines réponses ne soient pas tout à fait exactes. Une vérification et une validation supplémentaires peuvent être nécessaires avant d'utiliser ces données pour des applications critiques.
### Objectif:
L'objectif principal est d'obtenir, au fil du temps, des données propres et pertinentes à partir de questions pertinentes dans le domaine technologique.
### Demo web:
http://loop.brain.fr/qwe/ |
thaottn/DataComp_large_pool_BLIP2_captions | 2023-09-01T01:06:32.000Z | [
"task_categories:image-to-text",
"task_categories:zero-shot-classification",
"size_categories:1B<n<10B",
"license:cc-by-4.0",
"arxiv:2307.10350",
"region:us"
] | thaottn | null | null | null | 0 | 3 | ---
license: cc-by-4.0
task_categories:
- image-to-text
- zero-shot-classification
size_categories:
- 1B<n<10B
---
# Dataset Card for DataComp_large_pool_BLIP2_captions
## Dataset Description
- **Paper: https://arxiv.org/abs/2307.10350**
- **Leaderboard: https://www.datacomp.ai/leaderboard.html**
- **Point of Contact: Thao Nguyen (thaottn@cs.washington.edu)**
### Dataset Summary
### Supported Tasks and Leaderboards
We have used this dataset for pre-training CLIP models and found that it rivals or outperforms models trained on raw web captions on average across the 38 evaluation tasks proposed by DataComp.
Refer to the DataComp leaderboard (https://www.datacomp.ai/leaderboard.html) for the top baselines uncovered in our work.
### Languages
Primarily English.
## Dataset Structure
### Data Instances
Each instance maps a unique image identifier from DataComp to the corresponding BLIP2 caption generated with temperature 0.75.
### Data Fields
uid: SHA256 hash of image, provided as metadata by the DataComp team.
blip2-cap: corresponding caption generated by BLIP2.
### Data Splits
Data was not split. The dataset is intended for pre-training multimodal models.
## Dataset Creation
### Curation Rationale
Web-crawled image-text data can contain a lot of noise, i.e. the caption may not reflect the content of the respective image. Filtering out noisy web data, however, can hurt the diversity of the training set.
To address both of these issues, we use image captioning models to increase the number of useful training samples from the initial pool, by ensuring the captions are more relevant to the images.
Our work systematically explores the effectiveness of using these synthetic captions to replace or complement the raw text data, in the context of CLIP pre-training.
### Source Data
#### Initial Data Collection and Normalization
The original 1.28M image-text pairs were collected by the DataComp team from Common Crawl. Minimal filtering was performed on the initial data pool (face blurring, NSFW removal, train-test deduplication).
We then replaced the original web-crawled captions with synthetic captions generated by BLIP2.
#### Who are the source language producers?
Common Crawl is the source for images. BLIP2 is the source of the text data.
### Annotations
#### Annotation process
The dataset was built in a fully automated process: captions are generated by the BLIP2 captioning model.
#### Who are the annotators?
No human annotators are involved.
### Personal and Sensitive Information
The images, which we inherit from the DataComp benchmark, already underwent face detection and face blurring. While the DataComp team made an attempt to remove NSFW instances, it is possible that such content may still exist (to a small degree) in this dataset.
Due to the large scale nature of this dataset, the content has not been manually verified to be completely safe. Therefore, it is strongly recommended that this dataset be used only for research purposes.
## Considerations for Using the Data
### Social Impact of Dataset
The publication contains some preliminary analyses of the fairness implication of training on this dataset, when evaluating on Fairface.
### Discussion of Biases
Refer to the publication for more details.
### Other Known Limitations
Refer to the publication for more details.
## Additional Information
### Citation Information
```bibtex
@article{nguyen2023improving,
title={Improving Multimodal Datasets with Image Captioning},
author={Nguyen, Thao and Gadre, Samir Yitzhak and Ilharco, Gabriel and Oh, Sewoong and Schmidt, Ludwig},
journal={arXiv preprint arXiv:2307.10350},
year={2023}
}
``` |
pensieves/spur | 2023-09-27T02:46:41.000Z | [
"license:apache-2.0",
"region:us"
] | pensieves | SPUR is a comprehensive benchmark for spatial understanding and reasoning with over <TODO> natural language questions. The data set comes with multiple splits: SpartQA_Human (train, val, test). | @INPROCEEDINGS{Rizvi2023Spur,
author = {
Md Imbesat Hassan Rizvi
and IG},
title = {SPUR: A Unified Benchmark for SPatial Understanding and Reasoning},
booktitle = {},
year = {2023}
} | null | 0 | 3 | ---
license: apache-2.0
---
# SPUR: A Unified Benchmark for SPatial Understanding and Reasoning
### Licensing Information
Creative Commons Attribution 4.0 International |
urialon/converted_qmsum | 2023-08-12T22:55:53.000Z | [
"region:us"
] | urialon | null | null | null | 0 | 3 | ---
dataset_info:
features:
- name: id
dtype: string
- name: pid
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 70168352
num_examples: 1257
- name: validation
num_bytes: 15955428
num_examples: 272
- name: test
num_bytes: 16408856
num_examples: 281
download_size: 42693177
dataset_size: 102532636
---
# Dataset Card for "converted_qmsum"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
HachiML/hh-rlhf-49k-ja-alpaca-format | 2023-08-13T01:04:53.000Z | [
"language:ja",
"license:mit",
"region:us"
] | HachiML | null | null | null | 0 | 3 | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: index
dtype: string
splits:
- name: train
num_bytes: 41667442
num_examples: 49332
download_size: 19145442
dataset_size: 41667442
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: mit
language:
- ja
---
# Dataset Card for "hh-rlhf-49k-ja-alpaca-format"
これは[kunishou/hh-rlhf-49k-ja](https://huggingface.co/datasets/kunishou/hh-rlhf-49k-ja)に以下の変更を加えたデータセットです。
- alpaca形式に変更
- 翻訳が失敗したもの(つまりng_translation!="0.0"のもの)の削除
- indexの頭に"hh-rlhf."をつける
This is a dataset of [kunishou/hh-rlhf-49k-en](https://huggingface.co/datasets/kunishou/hh-rlhf-49k-ja) with the following changes
- Changed to alpaca format
- Removed failed translations (i.e., those with ng_translation!="0.0")
- Add "hh-rlhf." at the beginning of indexes |
xasdoi9812323/hello | 2023-08-13T02:16:50.000Z | [
"task_categories:text-classification",
"language:en",
"license:openrail",
"region:us"
] | xasdoi9812323 | null | null | null | 0 | 3 | ---
license: openrail
task_categories:
- text-classification
language:
- en
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
pianoroll/maestro-do-storage | 2023-08-13T08:27:40.000Z | [
"region:us"
] | pianoroll | null | null | null | 0 | 3 | ---
dataset_info:
features:
- name: composer
dtype: string
- name: title
dtype: string
- name: midi_filename
dtype: string
- name: mp3_key
dtype: string
- name: pianoroll_key
dtype: string
- name: split
dtype: string
splits:
- name: train
num_bytes: 419735
num_examples: 1276
download_size: 89454
dataset_size: 419735
---
# Dataset Card for "maestro-do-storage"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
FreedomIntelligence/sharegpt-chinese | 2023-08-13T15:53:36.000Z | [
"license:apache-2.0",
"region:us"
] | FreedomIntelligence | null | null | null | 2 | 3 | ---
license: apache-2.0
---
Chinese ShareGPT data translated by gpt-3.5-turbo.
The dataset is used in the research related to [MultilingualSIFT](https://github.com/FreedomIntelligence/MultilingualSIFT). |
TrainingDataPro/pigs-detection-dataset | 2023-09-14T16:30:06.000Z | [
"task_categories:image-to-image",
"task_categories:image-classification",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | The dataset is a collection of images along with corresponding bounding box annotations
that are specifically curated for **detecting pigs' heads** in images. The dataset
covers different *pig breeds, sizes, and orientations*, providing a comprehensive
representation of pig appearances.
The pig detection dataset provides a valuable resource for researchers working on pig
detection tasks. It offers a diverse collection of annotated images, allowing for
comprehensive algorithm development, evaluation, and benchmarking, ultimately aiding in
the development of accurate and robust models. | @InProceedings{huggingface:dataset,
title = {pigs-detection-dataset},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 3 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-image
- image-classification
- object-detection
tags:
- code
dataset_info:
features:
- name: id
dtype: int32
- name: image
dtype: image
- name: mask
dtype: image
- name: bboxes
dtype: string
splits:
- name: train
num_bytes: 5428811
num_examples: 27
download_size: 5391503
dataset_size: 5428811
---
# Pigs Detection Dataset
The dataset is a collection of images along with corresponding bounding box annotations that are specifically curated for **detecting pigs' heads** in images. The dataset covers different *pig breeds, sizes, and orientations*, providing a comprehensive representation of pig appearances.
The pig detection dataset provides a valuable resource for researchers working on pig detection tasks. It offers a diverse collection of annotated images, allowing for comprehensive algorithm development, evaluation, and benchmarking, ultimately aiding in the development of accurate and robust models.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=pigs-detection-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of pigs
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and labels, created for the original photo
# Data Format
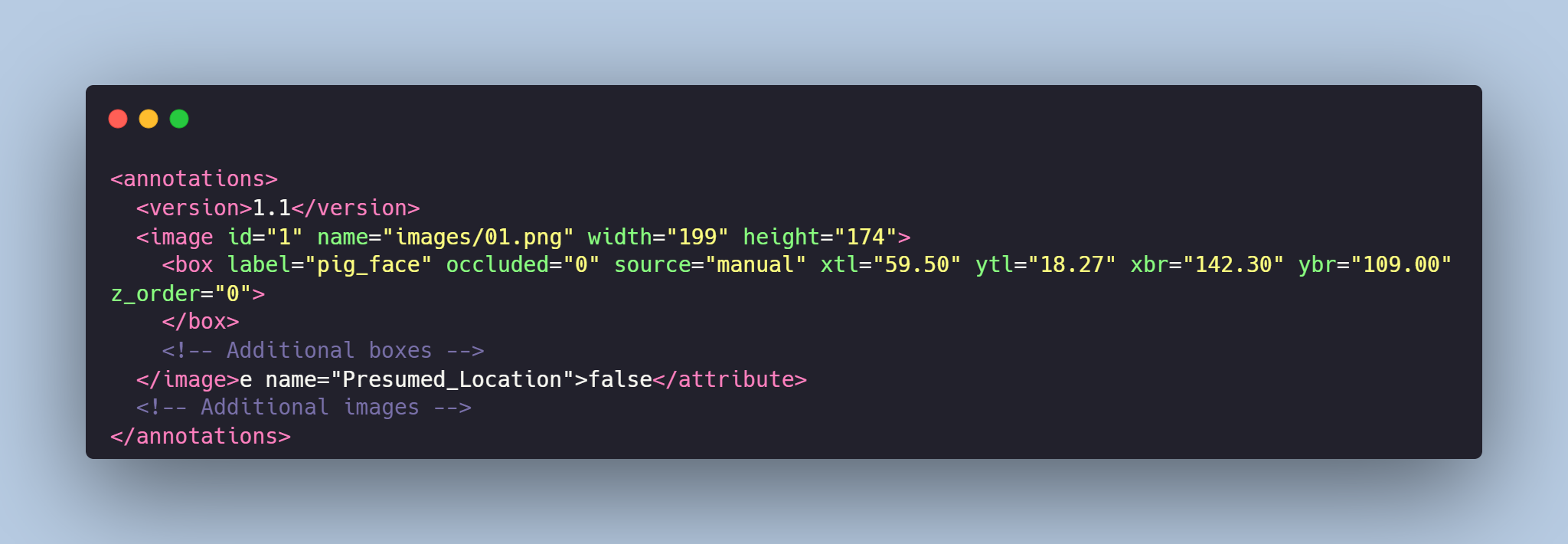
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes for pigs detection. For each point, the x and y coordinates are provided.
# Example of XML file structure
# Pig Detection might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=pigs-detection-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
TrainingDataPro/generated-vietnamese-passeports-dataset | 2023-09-14T16:29:29.000Z | [
"task_categories:image-classification",
"task_categories:image-segmentation",
"language:en",
"language:vi",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"legal",
"region:us"
] | TrainingDataPro | Data generation in machine learning involves creating or manipulating data to train
and evaluate machine learning models. The purpose of data generation is to provide
diverse and representative examples that cover a wide range of scenarios, ensuring the
model's robustness and generalization.
The dataset contains GENERATED Vietnamese passports, which are replicas of official
passports but with randomly generated details, such as name, date of birth etc.
The primary intention of generating these fake passports is to demonstrate the
structure and content of a typical passport document and to train the neural network to
identify this type of document.
Generated passports can assist in conducting research without accessing or compromising
real user data that is often sensitive and subject to privacy regulations. Synthetic
data generation allows researchers to *develop and refine models using simulated
passport data without risking privacy leaks*. | @InProceedings{huggingface:dataset,
title = {generated-vietnamese-passeports-dataset},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 3 | ---
language:
- en
- vi
license: cc-by-nc-nd-4.0
task_categories:
- image-classification
- image-segmentation
tags:
- code
- finance
- legal
dataset_info:
features:
- name: id
dtype: int32
- name: image
dtype: image
splits:
- name: train
num_bytes: 28732495
num_examples: 20
download_size: 28741938
dataset_size: 28732495
---
# GENERATED Vietnamese Passports Dataset
**Data generation** in machine learning involves creating or manipulating data to train and evaluate machine learning models. The purpose of data generation is to provide diverse and representative examples that cover a wide range of scenarios, ensuring the model's *robustness and generalization*.
The dataset contains GENERATED Vietnamese passports, which are replicas of official passports but with randomly generated details, such as *name, date of birth etc*. The primary intention of generating these fake passports is to demonstrate the structure and content of a typical passport document and to train the neural network to identify this type of document.
Generated passports can assist in conducting research without accessing or compromising real user data that is often sensitive and subject to privacy regulations. Synthetic data generation allows researchers to *develop and refine models using simulated passport data without risking privacy leaks*.

### The dataset is solely for informational or educational purposes and should not be used for any fraudulent or deceptive activities.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=generated-vietnamese-passeports-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Passports might be generated in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=generated-vietnamese-passeports-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
amitness/logits-arabic-128 | 2023-09-21T11:34:46.000Z | [
"region:us"
] | amitness | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
- name: teacher_logits
sequence:
sequence: float64
- name: teacher_indices
sequence:
sequence: int64
- name: teacher_mask_indices
sequence: int64
splits:
- name: train
num_bytes: 19440049160
num_examples: 4294918
download_size: 7814026203
dataset_size: 19440049160
---
# Dataset Card for "logits-arabic-128"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/tsunade_naruto | 2023-09-17T17:05:41.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 3 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of tsunade (NARUTO)
This is the dataset of tsunade (NARUTO), containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
|
vasuens/openassistant | 2023-08-16T11:44:59.000Z | [
"license:llama2",
"region:us"
] | vasuens | null | null | null | 0 | 3 | ---
license: llama2
---
|
Deepakvictor/tan-tam | 2023-08-15T12:45:49.000Z | [
"task_categories:translation",
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:ta",
"language:en",
"license:openrail",
"region:us"
] | Deepakvictor | null | null | null | 0 | 3 | ---
license: openrail
task_categories:
- translation
- text-classification
language:
- ta
- en
pretty_name: translation
size_categories:
- 1K<n<10K
---
Translation of Tanglish to tamil
Source: karky.in
To use
```python
import datasets
s = datasets.load_dataset('Deepakvictor/tan-tam')
print(s)
"""
DatasetDict({
train: Dataset({
features: ['en', 'ta'],
num_rows: 22114
})
})
"""
```
Credits and Source: https://karky.in/
---
For Complex version --> "Deepakvictor/tanglish-tamil" |
m720/SHADR | 2023-08-17T14:49:14.000Z | [
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-4.0",
"medical",
"arxiv:2308.06354",
"region:us"
] | m720 | null | null | null | 2 | 3 | ---
license: cc-by-4.0
task_categories:
- text-classification
language:
- en
tags:
- medical
pretty_name: SHADR
size_categories:
- 1K<n<10K
---
# SDoH Human Annotated Demographic Robustness (SHADR) Dataset
## Overview
The Social determinants of health (SDoH) play a pivotal role in determining patient outcomes. However, their documentation in electronic health records (EHR) remains incomplete. This dataset was created from a study examining the capability of large language models in extracting SDoH from the free text sections of EHRs. Furthermore, the study delved into the potential of synthetic clinical text to bolster the extraction process of these scarcely documented, yet crucial, clinical data.
## Dataset Structure & Modification
To understand potential biases in high-performing models and in those pre-trained on general text, GPT-4 was utilized to infuse demographic descriptors into our synthetic data.
For instance:
- **Original Sentence**: "Widower admits fears surrounding potential judgment…"
- **Modified Sentence**: “Hispanic widower admits fears surrounding potential judgment..."
Such demographic-infused sentences underwent manual validation. Out of these:
- 419 had mentions of SDoH
- 253 had mentions of adverse SDoH
- The remainder were tagged as NO_SDoH
## Instructions for Model Evaluation
1. Initially, run your model inference on the original sentences.
2. Subsequently, apply the same model to infer on the demographic-modified sentences.
3. Perform comparisons for robustness.
For a detailed understanding of the "adverse" labeling, refer to https://arxiv.org/pdf/2308.06354.pdf. Here, the 'adverse' column demarcates if the label corresponds to an "adverse" or "non-adverse" SDoH.
## Current Performance Metrics
- **Best Model Performance**:
- **Any SDoH**: 88% Macro-F1
- **Adverse SDoH**: 84% Macro-F1
- **Robustness Rate**:
- **Any SDoH**: 9.9%
- **Adverse SDoH**: 14.3%
## External Links
- A PhysioNet release of our annotated MIMIC-III courpus: `[TBD]`
- Github release: https://github.com/AIM-Harvard/SDoH
---
How to Cite:
```
@misc{guevara2023large,
title={Large Language Models to Identify Social Determinants of Health in Electronic Health Records},
author={Marco Guevara and Shan Chen and Spencer Thomas and Tafadzwa L. Chaunzwa and Idalid Franco and Benjamin Kann and Shalini Moningi and Jack Qian and Madeleine Goldstein and Susan Harper and Hugo JWL Aerts and Guergana K. Savova and Raymond H. Mak and Danielle S. Bitterman},
year={2023},
eprint={2308.06354},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
paralym/lima-chinese | 2023-08-15T15:41:46.000Z | [
"license:other",
"region:us"
] | paralym | null | null | null | 0 | 3 | ---
license: other
---
Lima data translated by gpt-3.5-turbo.
License under LIMA's License. |
devopsmarc/my-issues-dataset | 2023-08-22T21:22:44.000Z | [
"task_categories:sentence-similarity",
"task_ids:semantic-similarity-classification",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:eng",
"license:apache-2.0",
"region:us"
] | devopsmarc | null | null | null | 0 | 3 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- eng
license:
- apache-2.0
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- sentence-similarity
task_ids:
- semantic-similarity-classification
dataset_info:
features:
- name: html_url
dtype: string
- name: title
dtype: string
- name: comments
dtype: string
- name: body
dtype: string
- name: comment_length
dtype: int64
- name: text
dtype: string
splits:
- name: train
num_bytes: 5968669
num_examples: 1061
download_size: 1229293
dataset_size: 5968669
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for Dataset Name
## Dataset Summary in English
This customized dataset is made of a corpus of commun Github issues, typically utilized for tracking bugs or features within a repositories. This self-constructed corpus can serve multiple purposes, such as analyzing the time taken to resolve open issues or pull requests, training a classifier to tag issues based on their descriptions (e.g., "bug," "enhancement," "question"), or developing a semantic search engine for finding relevant issues based on user queries.
## Résumé de l'ensemble de jeu de données en français
Ce jeu de données personnalisé est constitué d'un corpus de problèmes couramment rencontrés sur GitHub, généralement utilisés pour le suivi des bugs ou des fonctionnalités au sein des repositories. Ce corpus auto construit peut servir à de multiples fins, telles que l'analyse du temps nécessaire pour résoudre les problèmes ouverts ou les demandes d'extraction, l'entraînement d'un classificateur pour étiqueter les problèmes sur la base de leurs descriptions (par exemple, "bug", "amélioration", "question"), ou le développement d'un moteur de recherche sémantique pour trouver des problèmes pertinents sur la base des requêtes de l'utilisateur.
### Languages
English
## Dataset Structure
### Data Splits
Train
### Personal and Sensitive Information
Not applicable.
## Considerations for Using the Data
### Social Impact of Dataset
Not applicable.
### Discussion of Biases
Possible. Comments within dataset were not monitored and are uncensored.
### Licensing Information
Apache 2.0
### Citation Information
https://github.com/huggingface/datasets/issues
|
CyberHarem/uiharu_kazari_toarumajutsunoindex | 2023-09-17T17:08:08.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 3 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of Uiharu Kazari
This is the dataset of Uiharu Kazari, containing 96 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 96 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 217 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 96 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 96 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 96 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 96 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 96 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 217 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 217 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 217 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
KoalaAI/GitHub-CC0 | 2023-08-21T14:49:52.000Z | [
"task_categories:text-generation",
"task_categories:text-classification",
"size_categories:1K<n<10K",
"license:cc0-1.0",
"github",
"programming",
"code",
"public domain",
"cc0",
"region:us"
] | KoalaAI | null | null | null | 0 | 3 | ---
license: cc0-1.0
task_categories:
- text-generation
- text-classification
tags:
- github
- programming
- code
- public domain
- cc0
pretty_name: Public Domain GitHub Repositories
size_categories:
- 1K<n<10K
---
# Public Domain GitHub Repositories Dataset
This dataset contains metadata and source code of 9,000 public domain (cc0 or unlicense) licensed GitHub repositories that have more than 25 stars.
The dataset was created by scraping the GitHub API and downloading the repositories, so long as they are under 100mb.
The dataset can be used for various natural language processing and software engineering tasks, such as code summarization, code generation, code search, code analysis, etc.
## Dataset Summary
- **Number of repositories:** 9,000
- **Size:** 2.4 GB (compressed)
- **Languages:** Python, JavaScript, Java, C#, C++, Ruby, PHP, Go, Swift, and Rust
- **License:** Public Domain (cc0 or unlicense)
## Dataset License
This dataset is released under the Public Domain (cc0 or unlicense) license. The original repositories are also licensed under the Public Domain (cc0 or unlicense) license. You can use this dataset for any purpose without any restrictions.
## Reproducing this dataset
This dataset was produced by modifiying the "github-downloader" from EleutherAI. You can access our fork [on our GitHub page](https://github.com/KoalaAI-Research/github-downloader)
Replication steps are included in it's readme there. |
EleutherAI/CEBaB | 2023-08-16T23:09:21.000Z | [
"task_categories:text-classification",
"language:en",
"license:cc-by-4.0",
"arxiv:2205.14140",
"region:us"
] | EleutherAI | null | null | null | 1 | 3 | ---
license: cc-by-4.0
dataset_info:
features:
- name: original_id
dtype: int32
- name: edit_goal
dtype: string
- name: edit_type
dtype: string
- name: text
dtype: string
- name: food
dtype: string
- name: ambiance
dtype: string
- name: service
dtype: string
- name: noise
dtype: string
- name: counterfactual
dtype: bool
- name: rating
dtype: int64
splits:
- name: validation
num_bytes: 306529
num_examples: 1673
- name: test
num_bytes: 309751
num_examples: 1689
- name: train
num_bytes: 2282439
num_examples: 11728
download_size: 628886
dataset_size: 2898719
task_categories:
- text-classification
language:
- en
---
# Dataset Card for "CEBaB"
This is a lightly cleaned and simplified version of the CEBaB counterfactual restaurant review dataset from [this paper](https://arxiv.org/abs/2205.14140).
The most important difference from the original dataset is that the `rating` column corresponds to the _median_ rating provided by the Mechanical Turkers,
rather than the majority rating. These are the same whenever a majority rating exists, but when there is no majority rating (e.g. because there were two 1s,
two 2s, and one 3), the original dataset used a `"no majority"` placeholder whereas we are able to provide an aggregate rating for all reviews.
The exact code used to process the original dataset is provided below:
```py
from ast import literal_eval
from datasets import DatasetDict, Value, load_dataset
def compute_median(x: str):
"""Compute the median rating given a multiset of ratings."""
# Decode the dictionary from string format
dist = literal_eval(x)
# Should be a dictionary whose keys are string-encoded integer ratings
# and whose values are the number of times that the rating was observed
assert isinstance(dist, dict)
assert sum(dist.values()) % 2 == 1, "Number of ratings should be odd"
ratings = []
for rating, count in dist.items():
ratings.extend([int(rating)] * count)
ratings.sort()
return ratings[len(ratings) // 2]
cebab = load_dataset('CEBaB/CEBaB')
assert isinstance(cebab, DatasetDict)
# Remove redundant splits
cebab['train'] = cebab.pop('train_inclusive')
del cebab['train_exclusive']
del cebab['train_observational']
cebab = cebab.cast_column(
'original_id', Value('int32')
).map(
lambda x: {
# New column with inverted label for counterfactuals
'counterfactual': not x['is_original'],
# Reduce the rating multiset into a single median rating
'rating': compute_median(x['review_label_distribution'])
}
).map(
# Replace the empty string and 'None' with Apache Arrow nulls
lambda x: {
k: v if v not in ('', 'no majority', 'None') else None
for k, v in x.items()
}
)
# Sanity check that all the splits have the same columns
cols = next(iter(cebab.values())).column_names
assert all(split.column_names == cols for split in cebab.values())
# Clean up the names a bit
cebab = cebab.rename_columns({
col: col.removesuffix('_majority').removesuffix('_aspect')
for col in cols if col.endswith('_majority')
}).rename_column(
'description', 'text'
)
# Drop the unimportant columns
cebab = cebab.remove_columns([
col for col in cols if col.endswith('_distribution') or col.endswith('_workers')
] + [
'edit_id', 'edit_worker', 'id', 'is_original', 'opentable_metadata', 'review'
]).sort([
# Make sure counterfactual reviews come immediately after each original review
'original_id', 'counterfactual'
])
``` |
QNN/autotrain-data-pubmed | 2023-08-16T08:10:29.000Z | [
"task_categories:token-classification",
"region:us"
] | QNN | null | null | null | 0 | 3 | ---
task_categories:
- token-classification
---
# AutoTrain Dataset for project: pubmed
## Dataset Description
This dataset has been automatically processed by AutoTrain for project pubmed.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"tokens": [
"Pd",
"has",
"been",
"regarded",
"as",
"one",
"of",
"the",
"alternatives",
"to",
"Pt",
"as",
"a",
"promising",
"hydrogen",
"evolution",
"reaction",
"(HER)",
"catalyst.",
"Strategies",
"including",
"Pd-metal",
"alloys",
"(Pd-M)",
"and",
"Pd",
"hydrides",
"(PdH<sub><i>x</i></sub>)",
"have",
"been",
"proposed",
"to",
"boost",
"HER",
"performances.",
"However,",
"the",
"stability",
"issues,",
"e.g.,",
"the",
"dissolution",
"in",
"Pd-M",
"and",
"the",
"hydrogen",
"releasing",
"in",
"PdH<sub><i>x</i></sub>,",
"restrict",
"the",
"industrial",
"application",
"of",
"Pd-based",
"HER",
"catalysts.",
"We",
"here",
"design",
"and",
"synthesize",
"a",
"stable",
"Pd-Cu",
"hydride",
"(",
"PdCu<sub>0.2</sub>H<sub>0.43</sub>",
")",
"catalyst,",
"combining",
"the",
"advantages",
"of",
"both",
"Pd-M",
"and",
"PdH<sub><i>x</i></sub>",
"structures",
"and",
"improving",
"the",
"HER",
"durability",
"simultaneously.",
"The",
"hydrogen",
"intercalation",
"is",
"realized",
"under",
"atmospheric",
"pressure",
"(1.0",
"atm)",
"following",
"our",
"synthetic",
"approach",
"that",
"imparts",
"high",
"stability",
"to",
"the",
"Pd-Cu",
"hydride",
"structure.",
"The",
"obtained",
"PdCu<sub>0.2</sub>H<sub>0.43</sub>",
"catalyst",
"exhibits",
"a",
"small",
"overpotential",
"of",
"28",
"mV",
"at",
"10",
"mA/cm<sup>2</sup>",
",",
"a",
"low",
"Tafel",
"slope",
"of",
"23",
"mV/dec",
",",
"and",
"excellent",
"HER",
"durability",
"due",
"to",
"its",
"appropriate",
"hydrogen",
"adsorption",
"free",
"energy",
"and",
"alleviated",
"metal",
"dissolution",
"rate.",
"</p>",
"<p>"
],
"tags": [
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
0,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
0,
2,
2,
2,
2,
4,
2,
5,
5,
2,
5,
5,
2,
2,
2,
4,
2,
2,
5,
5,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2
]
},
{
"tokens": [
"A",
"critical",
"challenge",
"in",
"energy",
"research",
"is",
"the",
"development",
"of",
"earth",
"abundant",
"and",
"cost-effective",
"materials",
"that",
"catalyze",
"the",
"electrochemical",
"splitting",
"of",
"water",
"into",
"hydrogen",
"and",
"oxygen",
"at",
"high",
"rates",
"and",
"low",
"overpotentials.",
"Key",
"to",
"addressing",
"this",
"issue",
"lies",
"not",
"only",
"in",
"the",
"synthesis",
"of",
"new",
"materials,",
"but",
"also",
"in",
"the",
"elucidation",
"of",
"their",
"active",
"sites,",
"their",
"structure",
"under",
"operating",
"conditions",
"and",
"ultimately,",
"extraction",
"of",
"the",
"structure-function",
"relationships",
"used",
"to",
"spearhead",
"the",
"next",
"generation",
"of",
"catalyst",
"development.",
"In",
"this",
"work,",
"we",
"present",
"a",
"complete",
"cycle",
"of",
"synthesis,",
"operando",
"characterization,",
"and",
"redesign",
"of",
"an",
"amorphous",
"cobalt",
"phosphide",
"(",
"CoP",
"<sub><i>x</i></sub>",
")",
"bifunctional",
"catalyst.",
"The",
"research",
"was",
"driven",
"by",
"integrated",
"electrochemical",
"analysis,",
"Raman",
"spectroscopy",
"and",
"gravimetric",
"measurements",
"utilizing",
"a",
"novel",
"quartz",
"crystal",
"microbalance",
"spectroelectrochemical",
"cell",
"to",
"uncover",
"the",
"catalytically",
"active",
"species",
"of",
"amorphous",
"CoP",
"<sub><i>x</i></sub>",
"and",
"subsequently",
"modify",
"the",
"material",
"to",
"enhance",
"the",
"activity",
"of",
"the",
"elucidated",
"catalytic",
"phases.",
"Illustrating",
"the",
"power",
"of",
"our",
"approach,",
"the",
"second",
"generation",
"cobalt-iron",
"phosphide",
"(",
"CoFeP<sub>x</sub>",
")",
"catalyst,",
"developed",
"through",
"an",
"iteration",
"of",
"the",
"operando",
"measurement",
"directed",
"optimization",
"cycle,",
"is",
"superior",
"in",
"both",
"hydrogen",
"and",
"oxygen",
"evolution",
"reactivity",
"over",
"the",
"previous",
"material",
"and",
"is",
"capable",
"of",
"overall",
"water",
"electrolysis",
"at",
"a",
"current",
"density",
"of",
"10",
"mA",
"cm<sup>-2</sup>",
"with",
"1.5",
"V",
"applied",
"bias",
"in",
"1",
"M",
"KOH",
"electrolyte",
"solution.",
"</p>",
"<p>"
],
"tags": [
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
0,
0,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
0,
0,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
0,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
4,
4,
2,
5,
5,
5,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2
]
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"tokens": "Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)",
"tags": "Sequence(feature=ClassLabel(names=['CATALYST', 'CO-CATALYST', 'O', 'Other', 'PROPERTY_NAME', 'PROPERTY_VALUE'], id=None), length=-1, id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 166 |
| valid | 44 |
|
MThonar/link | 2023-08-17T09:31:42.000Z | [
"language:en",
"license:unknown",
"region:us"
] | MThonar | null | null | null | 0 | 3 | ---
license: unknown
language:
- en
pretty_name: 'Link from Zelda: breath of the wild'
--- |
mikewang/vaw | 2023-08-18T03:10:46.000Z | [
"language:en",
"region:us"
] | mikewang | Visual Attributes in the Wild (VAW) dataset: https://github.com/adobe-research/vaw_dataset#dataset-setup
Raw annotations and configs such as attrubte_types can be found at: https://github.com/adobe-research/vaw_dataset/tree/main/data
Note: The train split loaded from this hf dataset is a concatenation of the train_part1.json and train_part2.json. | @InProceedings{Pham_2021_CVPR,
author = {Pham, Khoi and Kafle, Kushal and Lin, Zhe and Ding, Zhihong and Cohen, Scott and Tran, Quan and Shrivastava, Abhinav},
title = {Learning To Predict Visual Attributes in the Wild},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {13018-13028}
} | null | 0 | 3 | ---
pretty_name: 'Visual Attributes in the Wild (VAW)'
language:
- en
---
# Dataset Card for Visual Attributes in the Wild (VAW)
## Dataset Description
**Homepage:** http://vawdataset.com/
**Repository:** https://github.com/adobe-research/vaw_dataset;
- The raw dataset files will be downloaded from: https://github.com/adobe-research/vaw_dataset/tree/main/data, where one can also find additional metadata files such as attribute types.
- The train split loaded from this hf dataset is a concatenation of the train_part1.json and train_part2.json.
- The image_id field corresponds to respective image ids in the v1.4 Visual Genome dataset.
**LICENSE:** https://github.com/adobe-research/vaw_dataset/blob/main/LICENSE.md
**Paper Citation:**
```
@InProceedings{Pham_2021_CVPR,
author = {Pham, Khoi and Kafle, Kushal and Lin, Zhe and Ding, Zhihong and Cohen, Scott and Tran, Quan and Shrivastava, Abhinav},
title = {Learning To Predict Visual Attributes in the Wild},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {13018-13028}
}
```
## Dataset Summary
A large scale visual attributes dataset with explicitly labelled positive and negative attributes.
- 620 Unique Attributes including color, shape, texture, posture and many others
- 260,895 Instances of different objects
- 2260 Unique Objects observed in the wild
- 72,274 Images from the Visual Genome Dataset
- 4 different evaluation metrics for measuring multi-faceted performance metrics |
RikoteMaster/Emotion_Recognition_4_llama2_chat | 2023-08-17T11:22:36.000Z | [
"region:us"
] | RikoteMaster | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: Text_processed
dtype: string
- name: Emotion
dtype: string
- name: Augmented
dtype: bool
- name: text
dtype: string
splits:
- name: train
num_bytes: 28688912
num_examples: 61463
download_size: 8968276
dataset_size: 28688912
---
# Dataset Card for "Emotion_Recognition_4_llama2_chat"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ntt123/VietBibleVox | 2023-08-17T15:31:15.000Z | [
"task_categories:text-to-speech",
"size_categories:10K<n<100K",
"language:vi",
"license:cc-by-sa-4.0",
"region:us"
] | ntt123 | null | null | null | 2 | 3 | ---
license: cc-by-sa-4.0
task_categories:
- text-to-speech
language:
- vi
pretty_name: viet-bible-vox
size_categories:
- 10K<n<100K
---
# VietBibleVox Dataset
The VietBibleVox Dataset is based on the data extracted from [open.bible](https://open.bible/) specifically for the Vietnamese language. As the original data is provided under the `cc-by-sa-4.0` license, this derived dataset is also licensed under `cc-by-sa-4.0`.
The dataset comprises 29,185 pairs of (verse, audio clip), with each verse from the Bible read in Vietnamese by a male voice.
- The verses are the original texts and *may not* be directly usable for training text-to-speech models.
- The clips are in MP3 format with a sample rate of 48k. |
Lancelot53/srbd1 | 2023-08-17T15:14:46.000Z | [
"region:us"
] | Lancelot53 | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: id
dtype: string
- name: xml
dtype: string
- name: html
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 23236666
num_examples: 723
download_size: 2835772
dataset_size: 23236666
---
# Dataset Card for "srbd1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
open-llm-leaderboard/details_NousResearch__Nous-Hermes-llama-2-7b | 2023-08-27T12:24:26.000Z | [
"region:us"
] | open-llm-leaderboard | null | null | null | 0 | 3 | ---
pretty_name: Evaluation run of NousResearch/Nous-Hermes-llama-2-7b
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [NousResearch/Nous-Hermes-llama-2-7b](https://huggingface.co/NousResearch/Nous-Hermes-llama-2-7b)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 61 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_NousResearch__Nous-Hermes-llama-2-7b\"\
,\n\t\"harness_truthfulqa_mc_0\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\
\nThese are the [latest results from run 2023-07-31T15:03:15.265717](https://huggingface.co/datasets/open-llm-leaderboard/details_NousResearch__Nous-Hermes-llama-2-7b/blob/main/results_2023-07-31T15%3A03%3A15.265717.json)\
\ (note that their might be results for other tasks in the repos if successive evals\
\ didn't cover the same tasks. You find each in the results and the \"latest\" split\
\ for each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.4859932791547839,\n\
\ \"acc_stderr\": 0.0352159426736909,\n \"acc_norm\": 0.48968920129826754,\n\
\ \"acc_norm_stderr\": 0.03520099065553909,\n \"mc1\": 0.33414932680538556,\n\
\ \"mc1_stderr\": 0.016512530677150538,\n \"mc2\": 0.49007441830130277,\n\
\ \"mc2_stderr\": 0.015137449082248264\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.523037542662116,\n \"acc_stderr\": 0.014595873205358269,\n\
\ \"acc_norm\": 0.5511945392491467,\n \"acc_norm_stderr\": 0.014534599585097665\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.5994821748655647,\n\
\ \"acc_stderr\": 0.004890019356021089,\n \"acc_norm\": 0.7893845847440749,\n\
\ \"acc_norm_stderr\": 0.004069123905324908\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.32,\n \"acc_stderr\": 0.046882617226215034,\n \
\ \"acc_norm\": 0.32,\n \"acc_norm_stderr\": 0.046882617226215034\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.4444444444444444,\n\
\ \"acc_stderr\": 0.04292596718256981,\n \"acc_norm\": 0.4444444444444444,\n\
\ \"acc_norm_stderr\": 0.04292596718256981\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.4144736842105263,\n \"acc_stderr\": 0.04008973785779206,\n\
\ \"acc_norm\": 0.4144736842105263,\n \"acc_norm_stderr\": 0.04008973785779206\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.57,\n\
\ \"acc_stderr\": 0.04975698519562428,\n \"acc_norm\": 0.57,\n \
\ \"acc_norm_stderr\": 0.04975698519562428\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.5132075471698113,\n \"acc_stderr\": 0.030762134874500476,\n\
\ \"acc_norm\": 0.5132075471698113,\n \"acc_norm_stderr\": 0.030762134874500476\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.4791666666666667,\n\
\ \"acc_stderr\": 0.041775789507399935,\n \"acc_norm\": 0.4791666666666667,\n\
\ \"acc_norm_stderr\": 0.041775789507399935\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.31,\n \"acc_stderr\": 0.04648231987117316,\n \
\ \"acc_norm\": 0.31,\n \"acc_norm_stderr\": 0.04648231987117316\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\"\
: 0.44,\n \"acc_stderr\": 0.04988876515698589,\n \"acc_norm\": 0.44,\n\
\ \"acc_norm_stderr\": 0.04988876515698589\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.33,\n \"acc_stderr\": 0.047258156262526045,\n \
\ \"acc_norm\": 0.33,\n \"acc_norm_stderr\": 0.047258156262526045\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.45664739884393063,\n\
\ \"acc_stderr\": 0.03798106566014498,\n \"acc_norm\": 0.45664739884393063,\n\
\ \"acc_norm_stderr\": 0.03798106566014498\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.23529411764705882,\n \"acc_stderr\": 0.04220773659171452,\n\
\ \"acc_norm\": 0.23529411764705882,\n \"acc_norm_stderr\": 0.04220773659171452\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.58,\n \"acc_stderr\": 0.04960449637488583,\n \"acc_norm\": 0.58,\n\
\ \"acc_norm_stderr\": 0.04960449637488583\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.39148936170212767,\n \"acc_stderr\": 0.031907012423268113,\n\
\ \"acc_norm\": 0.39148936170212767,\n \"acc_norm_stderr\": 0.031907012423268113\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.2807017543859649,\n\
\ \"acc_stderr\": 0.042270544512322004,\n \"acc_norm\": 0.2807017543859649,\n\
\ \"acc_norm_stderr\": 0.042270544512322004\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.496551724137931,\n \"acc_stderr\": 0.041665675771015785,\n\
\ \"acc_norm\": 0.496551724137931,\n \"acc_norm_stderr\": 0.041665675771015785\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.30423280423280424,\n \"acc_stderr\": 0.02369541500946309,\n \"\
acc_norm\": 0.30423280423280424,\n \"acc_norm_stderr\": 0.02369541500946309\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.31746031746031744,\n\
\ \"acc_stderr\": 0.0416345303130286,\n \"acc_norm\": 0.31746031746031744,\n\
\ \"acc_norm_stderr\": 0.0416345303130286\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.34,\n \"acc_stderr\": 0.04760952285695235,\n \
\ \"acc_norm\": 0.34,\n \"acc_norm_stderr\": 0.04760952285695235\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.5419354838709678,\n\
\ \"acc_stderr\": 0.028343787250540615,\n \"acc_norm\": 0.5419354838709678,\n\
\ \"acc_norm_stderr\": 0.028343787250540615\n },\n \"harness|hendrycksTest-high_school_chemistry|5\"\
: {\n \"acc\": 0.3448275862068966,\n \"acc_stderr\": 0.03344283744280459,\n\
\ \"acc_norm\": 0.3448275862068966,\n \"acc_norm_stderr\": 0.03344283744280459\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.45,\n \"acc_stderr\": 0.049999999999999996,\n \"acc_norm\"\
: 0.45,\n \"acc_norm_stderr\": 0.049999999999999996\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.6181818181818182,\n \"acc_stderr\": 0.037937131711656344,\n\
\ \"acc_norm\": 0.6181818181818182,\n \"acc_norm_stderr\": 0.037937131711656344\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.6161616161616161,\n \"acc_stderr\": 0.034648816750163396,\n \"\
acc_norm\": 0.6161616161616161,\n \"acc_norm_stderr\": 0.034648816750163396\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.7150259067357513,\n \"acc_stderr\": 0.032577140777096614,\n\
\ \"acc_norm\": 0.7150259067357513,\n \"acc_norm_stderr\": 0.032577140777096614\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.47692307692307695,\n \"acc_stderr\": 0.025323990861736118,\n\
\ \"acc_norm\": 0.47692307692307695,\n \"acc_norm_stderr\": 0.025323990861736118\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.26296296296296295,\n \"acc_stderr\": 0.02684205787383371,\n \
\ \"acc_norm\": 0.26296296296296295,\n \"acc_norm_stderr\": 0.02684205787383371\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.4117647058823529,\n \"acc_stderr\": 0.031968769891957786,\n\
\ \"acc_norm\": 0.4117647058823529,\n \"acc_norm_stderr\": 0.031968769891957786\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.2847682119205298,\n \"acc_stderr\": 0.03684881521389023,\n \"\
acc_norm\": 0.2847682119205298,\n \"acc_norm_stderr\": 0.03684881521389023\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.6660550458715596,\n \"acc_stderr\": 0.02022055419673641,\n \"\
acc_norm\": 0.6660550458715596,\n \"acc_norm_stderr\": 0.02022055419673641\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.3101851851851852,\n \"acc_stderr\": 0.0315469628565663,\n \"acc_norm\"\
: 0.3101851851851852,\n \"acc_norm_stderr\": 0.0315469628565663\n },\n\
\ \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\": 0.6127450980392157,\n\
\ \"acc_stderr\": 0.03418931233833344,\n \"acc_norm\": 0.6127450980392157,\n\
\ \"acc_norm_stderr\": 0.03418931233833344\n },\n \"harness|hendrycksTest-high_school_world_history|5\"\
: {\n \"acc\": 0.6666666666666666,\n \"acc_stderr\": 0.0306858205966108,\n\
\ \"acc_norm\": 0.6666666666666666,\n \"acc_norm_stderr\": 0.0306858205966108\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.5964125560538116,\n\
\ \"acc_stderr\": 0.03292802819330314,\n \"acc_norm\": 0.5964125560538116,\n\
\ \"acc_norm_stderr\": 0.03292802819330314\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.5572519083969466,\n \"acc_stderr\": 0.043564472026650695,\n\
\ \"acc_norm\": 0.5572519083969466,\n \"acc_norm_stderr\": 0.043564472026650695\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.628099173553719,\n \"acc_stderr\": 0.04412015806624504,\n \"acc_norm\"\
: 0.628099173553719,\n \"acc_norm_stderr\": 0.04412015806624504\n },\n\
\ \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.5555555555555556,\n\
\ \"acc_stderr\": 0.04803752235190192,\n \"acc_norm\": 0.5555555555555556,\n\
\ \"acc_norm_stderr\": 0.04803752235190192\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.4785276073619632,\n \"acc_stderr\": 0.0392474687675113,\n\
\ \"acc_norm\": 0.4785276073619632,\n \"acc_norm_stderr\": 0.0392474687675113\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.375,\n\
\ \"acc_stderr\": 0.04595091388086298,\n \"acc_norm\": 0.375,\n \
\ \"acc_norm_stderr\": 0.04595091388086298\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.6019417475728155,\n \"acc_stderr\": 0.04846748253977238,\n\
\ \"acc_norm\": 0.6019417475728155,\n \"acc_norm_stderr\": 0.04846748253977238\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.7094017094017094,\n\
\ \"acc_stderr\": 0.02974504857267406,\n \"acc_norm\": 0.7094017094017094,\n\
\ \"acc_norm_stderr\": 0.02974504857267406\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.54,\n \"acc_stderr\": 0.05009082659620332,\n \
\ \"acc_norm\": 0.54,\n \"acc_norm_stderr\": 0.05009082659620332\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.6590038314176245,\n\
\ \"acc_stderr\": 0.016951781383223313,\n \"acc_norm\": 0.6590038314176245,\n\
\ \"acc_norm_stderr\": 0.016951781383223313\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.5317919075144508,\n \"acc_stderr\": 0.026864624366756646,\n\
\ \"acc_norm\": 0.5317919075144508,\n \"acc_norm_stderr\": 0.026864624366756646\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.2547486033519553,\n\
\ \"acc_stderr\": 0.014572650383409153,\n \"acc_norm\": 0.2547486033519553,\n\
\ \"acc_norm_stderr\": 0.014572650383409153\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.5130718954248366,\n \"acc_stderr\": 0.028620130800700246,\n\
\ \"acc_norm\": 0.5130718954248366,\n \"acc_norm_stderr\": 0.028620130800700246\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.594855305466238,\n\
\ \"acc_stderr\": 0.027882383791325956,\n \"acc_norm\": 0.594855305466238,\n\
\ \"acc_norm_stderr\": 0.027882383791325956\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.5555555555555556,\n \"acc_stderr\": 0.027648477877413324,\n\
\ \"acc_norm\": 0.5555555555555556,\n \"acc_norm_stderr\": 0.027648477877413324\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.3617021276595745,\n \"acc_stderr\": 0.028663820147199492,\n \
\ \"acc_norm\": 0.3617021276595745,\n \"acc_norm_stderr\": 0.028663820147199492\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.3455019556714472,\n\
\ \"acc_stderr\": 0.012145303004087202,\n \"acc_norm\": 0.3455019556714472,\n\
\ \"acc_norm_stderr\": 0.012145303004087202\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.5441176470588235,\n \"acc_stderr\": 0.030254372573976715,\n\
\ \"acc_norm\": 0.5441176470588235,\n \"acc_norm_stderr\": 0.030254372573976715\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.4395424836601307,\n \"acc_stderr\": 0.020079420408087918,\n \
\ \"acc_norm\": 0.4395424836601307,\n \"acc_norm_stderr\": 0.020079420408087918\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.5727272727272728,\n\
\ \"acc_stderr\": 0.047381987035454834,\n \"acc_norm\": 0.5727272727272728,\n\
\ \"acc_norm_stderr\": 0.047381987035454834\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.5020408163265306,\n \"acc_stderr\": 0.0320089533497105,\n\
\ \"acc_norm\": 0.5020408163265306,\n \"acc_norm_stderr\": 0.0320089533497105\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.6368159203980099,\n\
\ \"acc_stderr\": 0.034005985055990146,\n \"acc_norm\": 0.6368159203980099,\n\
\ \"acc_norm_stderr\": 0.034005985055990146\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.69,\n \"acc_stderr\": 0.04648231987117316,\n \
\ \"acc_norm\": 0.69,\n \"acc_norm_stderr\": 0.04648231987117316\n \
\ },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.40963855421686746,\n\
\ \"acc_stderr\": 0.03828401115079023,\n \"acc_norm\": 0.40963855421686746,\n\
\ \"acc_norm_stderr\": 0.03828401115079023\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.695906432748538,\n \"acc_stderr\": 0.0352821125824523,\n\
\ \"acc_norm\": 0.695906432748538,\n \"acc_norm_stderr\": 0.0352821125824523\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.33414932680538556,\n\
\ \"mc1_stderr\": 0.016512530677150538,\n \"mc2\": 0.49007441830130277,\n\
\ \"mc2_stderr\": 0.015137449082248264\n }\n}\n```"
repo_url: https://huggingface.co/NousResearch/Nous-Hermes-llama-2-7b
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|arc:challenge|25_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hellaswag|10_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-31T15:03:15.265717.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-31T15:03:15.265717.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-31T15:03:15.265717.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-31T15:03:15.265717.parquet'
- config_name: results
data_files:
- split: 2023_07_31T15_03_15.265717
path:
- results_2023-07-31T15:03:15.265717.parquet
- split: latest
path:
- results_2023-07-31T15:03:15.265717.parquet
---
# Dataset Card for Evaluation run of NousResearch/Nous-Hermes-llama-2-7b
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/NousResearch/Nous-Hermes-llama-2-7b
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [NousResearch/Nous-Hermes-llama-2-7b](https://huggingface.co/NousResearch/Nous-Hermes-llama-2-7b) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 61 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_NousResearch__Nous-Hermes-llama-2-7b",
"harness_truthfulqa_mc_0",
split="train")
```
## Latest results
These are the [latest results from run 2023-07-31T15:03:15.265717](https://huggingface.co/datasets/open-llm-leaderboard/details_NousResearch__Nous-Hermes-llama-2-7b/blob/main/results_2023-07-31T15%3A03%3A15.265717.json) (note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.4859932791547839,
"acc_stderr": 0.0352159426736909,
"acc_norm": 0.48968920129826754,
"acc_norm_stderr": 0.03520099065553909,
"mc1": 0.33414932680538556,
"mc1_stderr": 0.016512530677150538,
"mc2": 0.49007441830130277,
"mc2_stderr": 0.015137449082248264
},
"harness|arc:challenge|25": {
"acc": 0.523037542662116,
"acc_stderr": 0.014595873205358269,
"acc_norm": 0.5511945392491467,
"acc_norm_stderr": 0.014534599585097665
},
"harness|hellaswag|10": {
"acc": 0.5994821748655647,
"acc_stderr": 0.004890019356021089,
"acc_norm": 0.7893845847440749,
"acc_norm_stderr": 0.004069123905324908
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.32,
"acc_stderr": 0.046882617226215034,
"acc_norm": 0.32,
"acc_norm_stderr": 0.046882617226215034
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.4444444444444444,
"acc_stderr": 0.04292596718256981,
"acc_norm": 0.4444444444444444,
"acc_norm_stderr": 0.04292596718256981
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.4144736842105263,
"acc_stderr": 0.04008973785779206,
"acc_norm": 0.4144736842105263,
"acc_norm_stderr": 0.04008973785779206
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.57,
"acc_stderr": 0.04975698519562428,
"acc_norm": 0.57,
"acc_norm_stderr": 0.04975698519562428
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.5132075471698113,
"acc_stderr": 0.030762134874500476,
"acc_norm": 0.5132075471698113,
"acc_norm_stderr": 0.030762134874500476
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.4791666666666667,
"acc_stderr": 0.041775789507399935,
"acc_norm": 0.4791666666666667,
"acc_norm_stderr": 0.041775789507399935
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.31,
"acc_stderr": 0.04648231987117316,
"acc_norm": 0.31,
"acc_norm_stderr": 0.04648231987117316
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.44,
"acc_stderr": 0.04988876515698589,
"acc_norm": 0.44,
"acc_norm_stderr": 0.04988876515698589
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.33,
"acc_stderr": 0.047258156262526045,
"acc_norm": 0.33,
"acc_norm_stderr": 0.047258156262526045
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.45664739884393063,
"acc_stderr": 0.03798106566014498,
"acc_norm": 0.45664739884393063,
"acc_norm_stderr": 0.03798106566014498
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.23529411764705882,
"acc_stderr": 0.04220773659171452,
"acc_norm": 0.23529411764705882,
"acc_norm_stderr": 0.04220773659171452
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.58,
"acc_stderr": 0.04960449637488583,
"acc_norm": 0.58,
"acc_norm_stderr": 0.04960449637488583
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.39148936170212767,
"acc_stderr": 0.031907012423268113,
"acc_norm": 0.39148936170212767,
"acc_norm_stderr": 0.031907012423268113
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.2807017543859649,
"acc_stderr": 0.042270544512322004,
"acc_norm": 0.2807017543859649,
"acc_norm_stderr": 0.042270544512322004
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.496551724137931,
"acc_stderr": 0.041665675771015785,
"acc_norm": 0.496551724137931,
"acc_norm_stderr": 0.041665675771015785
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.30423280423280424,
"acc_stderr": 0.02369541500946309,
"acc_norm": 0.30423280423280424,
"acc_norm_stderr": 0.02369541500946309
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.31746031746031744,
"acc_stderr": 0.0416345303130286,
"acc_norm": 0.31746031746031744,
"acc_norm_stderr": 0.0416345303130286
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.34,
"acc_stderr": 0.04760952285695235,
"acc_norm": 0.34,
"acc_norm_stderr": 0.04760952285695235
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.5419354838709678,
"acc_stderr": 0.028343787250540615,
"acc_norm": 0.5419354838709678,
"acc_norm_stderr": 0.028343787250540615
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.3448275862068966,
"acc_stderr": 0.03344283744280459,
"acc_norm": 0.3448275862068966,
"acc_norm_stderr": 0.03344283744280459
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.45,
"acc_stderr": 0.049999999999999996,
"acc_norm": 0.45,
"acc_norm_stderr": 0.049999999999999996
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.6181818181818182,
"acc_stderr": 0.037937131711656344,
"acc_norm": 0.6181818181818182,
"acc_norm_stderr": 0.037937131711656344
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.6161616161616161,
"acc_stderr": 0.034648816750163396,
"acc_norm": 0.6161616161616161,
"acc_norm_stderr": 0.034648816750163396
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.7150259067357513,
"acc_stderr": 0.032577140777096614,
"acc_norm": 0.7150259067357513,
"acc_norm_stderr": 0.032577140777096614
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.47692307692307695,
"acc_stderr": 0.025323990861736118,
"acc_norm": 0.47692307692307695,
"acc_norm_stderr": 0.025323990861736118
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.26296296296296295,
"acc_stderr": 0.02684205787383371,
"acc_norm": 0.26296296296296295,
"acc_norm_stderr": 0.02684205787383371
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.4117647058823529,
"acc_stderr": 0.031968769891957786,
"acc_norm": 0.4117647058823529,
"acc_norm_stderr": 0.031968769891957786
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.2847682119205298,
"acc_stderr": 0.03684881521389023,
"acc_norm": 0.2847682119205298,
"acc_norm_stderr": 0.03684881521389023
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.6660550458715596,
"acc_stderr": 0.02022055419673641,
"acc_norm": 0.6660550458715596,
"acc_norm_stderr": 0.02022055419673641
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.3101851851851852,
"acc_stderr": 0.0315469628565663,
"acc_norm": 0.3101851851851852,
"acc_norm_stderr": 0.0315469628565663
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.6127450980392157,
"acc_stderr": 0.03418931233833344,
"acc_norm": 0.6127450980392157,
"acc_norm_stderr": 0.03418931233833344
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.6666666666666666,
"acc_stderr": 0.0306858205966108,
"acc_norm": 0.6666666666666666,
"acc_norm_stderr": 0.0306858205966108
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.5964125560538116,
"acc_stderr": 0.03292802819330314,
"acc_norm": 0.5964125560538116,
"acc_norm_stderr": 0.03292802819330314
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.5572519083969466,
"acc_stderr": 0.043564472026650695,
"acc_norm": 0.5572519083969466,
"acc_norm_stderr": 0.043564472026650695
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.628099173553719,
"acc_stderr": 0.04412015806624504,
"acc_norm": 0.628099173553719,
"acc_norm_stderr": 0.04412015806624504
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.5555555555555556,
"acc_stderr": 0.04803752235190192,
"acc_norm": 0.5555555555555556,
"acc_norm_stderr": 0.04803752235190192
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.4785276073619632,
"acc_stderr": 0.0392474687675113,
"acc_norm": 0.4785276073619632,
"acc_norm_stderr": 0.0392474687675113
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.375,
"acc_stderr": 0.04595091388086298,
"acc_norm": 0.375,
"acc_norm_stderr": 0.04595091388086298
},
"harness|hendrycksTest-management|5": {
"acc": 0.6019417475728155,
"acc_stderr": 0.04846748253977238,
"acc_norm": 0.6019417475728155,
"acc_norm_stderr": 0.04846748253977238
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.7094017094017094,
"acc_stderr": 0.02974504857267406,
"acc_norm": 0.7094017094017094,
"acc_norm_stderr": 0.02974504857267406
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.54,
"acc_stderr": 0.05009082659620332,
"acc_norm": 0.54,
"acc_norm_stderr": 0.05009082659620332
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.6590038314176245,
"acc_stderr": 0.016951781383223313,
"acc_norm": 0.6590038314176245,
"acc_norm_stderr": 0.016951781383223313
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.5317919075144508,
"acc_stderr": 0.026864624366756646,
"acc_norm": 0.5317919075144508,
"acc_norm_stderr": 0.026864624366756646
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.2547486033519553,
"acc_stderr": 0.014572650383409153,
"acc_norm": 0.2547486033519553,
"acc_norm_stderr": 0.014572650383409153
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.5130718954248366,
"acc_stderr": 0.028620130800700246,
"acc_norm": 0.5130718954248366,
"acc_norm_stderr": 0.028620130800700246
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.594855305466238,
"acc_stderr": 0.027882383791325956,
"acc_norm": 0.594855305466238,
"acc_norm_stderr": 0.027882383791325956
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.5555555555555556,
"acc_stderr": 0.027648477877413324,
"acc_norm": 0.5555555555555556,
"acc_norm_stderr": 0.027648477877413324
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.3617021276595745,
"acc_stderr": 0.028663820147199492,
"acc_norm": 0.3617021276595745,
"acc_norm_stderr": 0.028663820147199492
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.3455019556714472,
"acc_stderr": 0.012145303004087202,
"acc_norm": 0.3455019556714472,
"acc_norm_stderr": 0.012145303004087202
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.5441176470588235,
"acc_stderr": 0.030254372573976715,
"acc_norm": 0.5441176470588235,
"acc_norm_stderr": 0.030254372573976715
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.4395424836601307,
"acc_stderr": 0.020079420408087918,
"acc_norm": 0.4395424836601307,
"acc_norm_stderr": 0.020079420408087918
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.5727272727272728,
"acc_stderr": 0.047381987035454834,
"acc_norm": 0.5727272727272728,
"acc_norm_stderr": 0.047381987035454834
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.5020408163265306,
"acc_stderr": 0.0320089533497105,
"acc_norm": 0.5020408163265306,
"acc_norm_stderr": 0.0320089533497105
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.6368159203980099,
"acc_stderr": 0.034005985055990146,
"acc_norm": 0.6368159203980099,
"acc_norm_stderr": 0.034005985055990146
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.69,
"acc_stderr": 0.04648231987117316,
"acc_norm": 0.69,
"acc_norm_stderr": 0.04648231987117316
},
"harness|hendrycksTest-virology|5": {
"acc": 0.40963855421686746,
"acc_stderr": 0.03828401115079023,
"acc_norm": 0.40963855421686746,
"acc_norm_stderr": 0.03828401115079023
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.695906432748538,
"acc_stderr": 0.0352821125824523,
"acc_norm": 0.695906432748538,
"acc_norm_stderr": 0.0352821125824523
},
"harness|truthfulqa:mc|0": {
"mc1": 0.33414932680538556,
"mc1_stderr": 0.016512530677150538,
"mc2": 0.49007441830130277,
"mc2_stderr": 0.015137449082248264
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
open-llm-leaderboard/details_PygmalionAI__pygmalion-6b | 2023-10-08T20:05:39.000Z | [
"region:us"
] | open-llm-leaderboard | null | null | null | 1 | 3 | ---
pretty_name: Evaluation run of PygmalionAI/pygmalion-6b
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [PygmalionAI/pygmalion-6b](https://huggingface.co/PygmalionAI/pygmalion-6b) on\
\ the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 3 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_PygmalionAI__pygmalion-6b\"\
,\n\t\"harness_truthfulqa_mc_0\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\
\nThese are the [latest results from run 2023-10-08T20:04:23.834964](https://huggingface.co/datasets/open-llm-leaderboard/details_PygmalionAI__pygmalion-6b/blob/main/results_2023-10-08T20-04-23.834964.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.26347154250909116,\n\
\ \"acc_stderr\": 0.03165492423612406,\n \"acc_norm\": 0.26689039326246145,\n\
\ \"acc_norm_stderr\": 0.03165325674877226,\n \"mc1\": 0.20195838433292534,\n\
\ \"mc1_stderr\": 0.014053957441512359,\n \"mc2\": 0.3253448533993895,\n\
\ \"mc2_stderr\": 0.013862486209403098\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.3728668941979522,\n \"acc_stderr\": 0.014131176760131165,\n\
\ \"acc_norm\": 0.4052901023890785,\n \"acc_norm_stderr\": 0.014346869060229323\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.5053774148575981,\n\
\ \"acc_stderr\": 0.004989492828168535,\n \"acc_norm\": 0.6746664011153157,\n\
\ \"acc_norm_stderr\": 0.004675418774314239\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.26,\n \"acc_stderr\": 0.04408440022768081,\n \
\ \"acc_norm\": 0.26,\n \"acc_norm_stderr\": 0.04408440022768081\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.25925925925925924,\n\
\ \"acc_stderr\": 0.03785714465066653,\n \"acc_norm\": 0.25925925925925924,\n\
\ \"acc_norm_stderr\": 0.03785714465066653\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.3092105263157895,\n \"acc_stderr\": 0.037610708698674805,\n\
\ \"acc_norm\": 0.3092105263157895,\n \"acc_norm_stderr\": 0.037610708698674805\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.33,\n\
\ \"acc_stderr\": 0.04725815626252604,\n \"acc_norm\": 0.33,\n \
\ \"acc_norm_stderr\": 0.04725815626252604\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.23773584905660378,\n \"acc_stderr\": 0.0261998088075619,\n\
\ \"acc_norm\": 0.23773584905660378,\n \"acc_norm_stderr\": 0.0261998088075619\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.20833333333333334,\n\
\ \"acc_stderr\": 0.03396116205845333,\n \"acc_norm\": 0.20833333333333334,\n\
\ \"acc_norm_stderr\": 0.03396116205845333\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.13,\n \"acc_stderr\": 0.03379976689896308,\n \
\ \"acc_norm\": 0.13,\n \"acc_norm_stderr\": 0.03379976689896308\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\"\
: 0.2,\n \"acc_stderr\": 0.04020151261036846,\n \"acc_norm\": 0.2,\n\
\ \"acc_norm_stderr\": 0.04020151261036846\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.23,\n \"acc_stderr\": 0.042295258468165065,\n \
\ \"acc_norm\": 0.23,\n \"acc_norm_stderr\": 0.042295258468165065\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.2543352601156069,\n\
\ \"acc_stderr\": 0.0332055644308557,\n \"acc_norm\": 0.2543352601156069,\n\
\ \"acc_norm_stderr\": 0.0332055644308557\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.18627450980392157,\n \"acc_stderr\": 0.03873958714149351,\n\
\ \"acc_norm\": 0.18627450980392157,\n \"acc_norm_stderr\": 0.03873958714149351\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.32,\n \"acc_stderr\": 0.046882617226215034,\n \"acc_norm\": 0.32,\n\
\ \"acc_norm_stderr\": 0.046882617226215034\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.3404255319148936,\n \"acc_stderr\": 0.030976692998534436,\n\
\ \"acc_norm\": 0.3404255319148936,\n \"acc_norm_stderr\": 0.030976692998534436\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.24561403508771928,\n\
\ \"acc_stderr\": 0.040493392977481425,\n \"acc_norm\": 0.24561403508771928,\n\
\ \"acc_norm_stderr\": 0.040493392977481425\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.2689655172413793,\n \"acc_stderr\": 0.03695183311650232,\n\
\ \"acc_norm\": 0.2689655172413793,\n \"acc_norm_stderr\": 0.03695183311650232\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.24603174603174602,\n \"acc_stderr\": 0.022182037202948368,\n \"\
acc_norm\": 0.24603174603174602,\n \"acc_norm_stderr\": 0.022182037202948368\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.23809523809523808,\n\
\ \"acc_stderr\": 0.03809523809523811,\n \"acc_norm\": 0.23809523809523808,\n\
\ \"acc_norm_stderr\": 0.03809523809523811\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.25,\n \"acc_stderr\": 0.04351941398892446,\n \
\ \"acc_norm\": 0.25,\n \"acc_norm_stderr\": 0.04351941398892446\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.23548387096774193,\n\
\ \"acc_stderr\": 0.02413763242933771,\n \"acc_norm\": 0.23548387096774193,\n\
\ \"acc_norm_stderr\": 0.02413763242933771\n },\n \"harness|hendrycksTest-high_school_chemistry|5\"\
: {\n \"acc\": 0.23645320197044334,\n \"acc_stderr\": 0.029896114291733552,\n\
\ \"acc_norm\": 0.23645320197044334,\n \"acc_norm_stderr\": 0.029896114291733552\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.2,\n \"acc_stderr\": 0.04020151261036846,\n \"acc_norm\"\
: 0.2,\n \"acc_norm_stderr\": 0.04020151261036846\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.2545454545454545,\n \"acc_stderr\": 0.03401506715249039,\n\
\ \"acc_norm\": 0.2545454545454545,\n \"acc_norm_stderr\": 0.03401506715249039\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.20707070707070707,\n \"acc_stderr\": 0.028869778460267042,\n \"\
acc_norm\": 0.20707070707070707,\n \"acc_norm_stderr\": 0.028869778460267042\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.22797927461139897,\n \"acc_stderr\": 0.03027690994517826,\n\
\ \"acc_norm\": 0.22797927461139897,\n \"acc_norm_stderr\": 0.03027690994517826\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.2512820512820513,\n \"acc_stderr\": 0.021992016662370526,\n\
\ \"acc_norm\": 0.2512820512820513,\n \"acc_norm_stderr\": 0.021992016662370526\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.26666666666666666,\n \"acc_stderr\": 0.02696242432507383,\n \
\ \"acc_norm\": 0.26666666666666666,\n \"acc_norm_stderr\": 0.02696242432507383\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.2184873949579832,\n \"acc_stderr\": 0.02684151432295894,\n \
\ \"acc_norm\": 0.2184873949579832,\n \"acc_norm_stderr\": 0.02684151432295894\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.2185430463576159,\n \"acc_stderr\": 0.03374235550425694,\n \"\
acc_norm\": 0.2185430463576159,\n \"acc_norm_stderr\": 0.03374235550425694\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.26788990825688075,\n \"acc_stderr\": 0.018987462257978652,\n \"\
acc_norm\": 0.26788990825688075,\n \"acc_norm_stderr\": 0.018987462257978652\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.1574074074074074,\n \"acc_stderr\": 0.02483717351824239,\n \"\
acc_norm\": 0.1574074074074074,\n \"acc_norm_stderr\": 0.02483717351824239\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.3088235294117647,\n \"acc_stderr\": 0.03242661719827218,\n \"\
acc_norm\": 0.3088235294117647,\n \"acc_norm_stderr\": 0.03242661719827218\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.2616033755274262,\n \"acc_stderr\": 0.028609516716994934,\n \
\ \"acc_norm\": 0.2616033755274262,\n \"acc_norm_stderr\": 0.028609516716994934\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.3542600896860987,\n\
\ \"acc_stderr\": 0.032100621541349864,\n \"acc_norm\": 0.3542600896860987,\n\
\ \"acc_norm_stderr\": 0.032100621541349864\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.20610687022900764,\n \"acc_stderr\": 0.03547771004159464,\n\
\ \"acc_norm\": 0.20610687022900764,\n \"acc_norm_stderr\": 0.03547771004159464\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.3305785123966942,\n \"acc_stderr\": 0.04294340845212094,\n \"\
acc_norm\": 0.3305785123966942,\n \"acc_norm_stderr\": 0.04294340845212094\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.3425925925925926,\n\
\ \"acc_stderr\": 0.04587904741301811,\n \"acc_norm\": 0.3425925925925926,\n\
\ \"acc_norm_stderr\": 0.04587904741301811\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.2331288343558282,\n \"acc_stderr\": 0.033220157957767414,\n\
\ \"acc_norm\": 0.2331288343558282,\n \"acc_norm_stderr\": 0.033220157957767414\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.26785714285714285,\n\
\ \"acc_stderr\": 0.04203277291467764,\n \"acc_norm\": 0.26785714285714285,\n\
\ \"acc_norm_stderr\": 0.04203277291467764\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.21359223300970873,\n \"acc_stderr\": 0.040580420156460344,\n\
\ \"acc_norm\": 0.21359223300970873,\n \"acc_norm_stderr\": 0.040580420156460344\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.32905982905982906,\n\
\ \"acc_stderr\": 0.03078232157768816,\n \"acc_norm\": 0.32905982905982906,\n\
\ \"acc_norm_stderr\": 0.03078232157768816\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.21,\n \"acc_stderr\": 0.040936018074033256,\n \
\ \"acc_norm\": 0.21,\n \"acc_norm_stderr\": 0.040936018074033256\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.2822477650063857,\n\
\ \"acc_stderr\": 0.016095302969878555,\n \"acc_norm\": 0.2822477650063857,\n\
\ \"acc_norm_stderr\": 0.016095302969878555\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.27167630057803466,\n \"acc_stderr\": 0.023948512905468365,\n\
\ \"acc_norm\": 0.27167630057803466,\n \"acc_norm_stderr\": 0.023948512905468365\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.2346368715083799,\n\
\ \"acc_stderr\": 0.014173044098303667,\n \"acc_norm\": 0.2346368715083799,\n\
\ \"acc_norm_stderr\": 0.014173044098303667\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.29411764705882354,\n \"acc_stderr\": 0.026090162504279053,\n\
\ \"acc_norm\": 0.29411764705882354,\n \"acc_norm_stderr\": 0.026090162504279053\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.2604501607717042,\n\
\ \"acc_stderr\": 0.024926723224845557,\n \"acc_norm\": 0.2604501607717042,\n\
\ \"acc_norm_stderr\": 0.024926723224845557\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.28703703703703703,\n \"acc_stderr\": 0.025171041915309684,\n\
\ \"acc_norm\": 0.28703703703703703,\n \"acc_norm_stderr\": 0.025171041915309684\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.3049645390070922,\n \"acc_stderr\": 0.027464708442022128,\n \
\ \"acc_norm\": 0.3049645390070922,\n \"acc_norm_stderr\": 0.027464708442022128\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.27444589308996087,\n\
\ \"acc_stderr\": 0.011397043163078154,\n \"acc_norm\": 0.27444589308996087,\n\
\ \"acc_norm_stderr\": 0.011397043163078154\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.16911764705882354,\n \"acc_stderr\": 0.02277086801011301,\n\
\ \"acc_norm\": 0.16911764705882354,\n \"acc_norm_stderr\": 0.02277086801011301\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.27941176470588236,\n \"acc_stderr\": 0.018152871051538816,\n \
\ \"acc_norm\": 0.27941176470588236,\n \"acc_norm_stderr\": 0.018152871051538816\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.3,\n\
\ \"acc_stderr\": 0.04389311454644287,\n \"acc_norm\": 0.3,\n \
\ \"acc_norm_stderr\": 0.04389311454644287\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.3142857142857143,\n \"acc_stderr\": 0.029719329422417465,\n\
\ \"acc_norm\": 0.3142857142857143,\n \"acc_norm_stderr\": 0.029719329422417465\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.25870646766169153,\n\
\ \"acc_stderr\": 0.030965903123573037,\n \"acc_norm\": 0.25870646766169153,\n\
\ \"acc_norm_stderr\": 0.030965903123573037\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.27,\n \"acc_stderr\": 0.044619604333847394,\n \
\ \"acc_norm\": 0.27,\n \"acc_norm_stderr\": 0.044619604333847394\n \
\ },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.2710843373493976,\n\
\ \"acc_stderr\": 0.03460579907553026,\n \"acc_norm\": 0.2710843373493976,\n\
\ \"acc_norm_stderr\": 0.03460579907553026\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.2807017543859649,\n \"acc_stderr\": 0.034462962170884265,\n\
\ \"acc_norm\": 0.2807017543859649,\n \"acc_norm_stderr\": 0.034462962170884265\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.20195838433292534,\n\
\ \"mc1_stderr\": 0.014053957441512359,\n \"mc2\": 0.3253448533993895,\n\
\ \"mc2_stderr\": 0.013862486209403098\n }\n}\n```"
repo_url: https://huggingface.co/PygmalionAI/pygmalion-6b
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|arc:challenge|25_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|arc:challenge|25_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_09_17T16_08_36.166689
path:
- '**/details_harness|drop|3_2023-09-17T16-08-36.166689.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-09-17T16-08-36.166689.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_09_17T16_08_36.166689
path:
- '**/details_harness|gsm8k|5_2023-09-17T16-08-36.166689.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-09-17T16-08-36.166689.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hellaswag|10_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hellaswag|10_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-18T11:25:58.847315.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-10-08T20-04-23.834964.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-management|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-virology|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-18T11:25:58.847315.parquet'
- split: 2023_10_08T20_04_23.834964
path:
- '**/details_harness|truthfulqa:mc|0_2023-10-08T20-04-23.834964.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-10-08T20-04-23.834964.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_09_17T16_08_36.166689
path:
- '**/details_harness|winogrande|5_2023-09-17T16-08-36.166689.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-09-17T16-08-36.166689.parquet'
- config_name: results
data_files:
- split: 2023_07_18T11_25_58.847315
path:
- results_2023-07-18T11:25:58.847315.parquet
- split: 2023_09_17T16_08_36.166689
path:
- results_2023-09-17T16-08-36.166689.parquet
- split: 2023_10_08T20_04_23.834964
path:
- results_2023-10-08T20-04-23.834964.parquet
- split: latest
path:
- results_2023-10-08T20-04-23.834964.parquet
---
# Dataset Card for Evaluation run of PygmalionAI/pygmalion-6b
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/PygmalionAI/pygmalion-6b
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [PygmalionAI/pygmalion-6b](https://huggingface.co/PygmalionAI/pygmalion-6b) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 3 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_PygmalionAI__pygmalion-6b",
"harness_truthfulqa_mc_0",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-08T20:04:23.834964](https://huggingface.co/datasets/open-llm-leaderboard/details_PygmalionAI__pygmalion-6b/blob/main/results_2023-10-08T20-04-23.834964.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.26347154250909116,
"acc_stderr": 0.03165492423612406,
"acc_norm": 0.26689039326246145,
"acc_norm_stderr": 0.03165325674877226,
"mc1": 0.20195838433292534,
"mc1_stderr": 0.014053957441512359,
"mc2": 0.3253448533993895,
"mc2_stderr": 0.013862486209403098
},
"harness|arc:challenge|25": {
"acc": 0.3728668941979522,
"acc_stderr": 0.014131176760131165,
"acc_norm": 0.4052901023890785,
"acc_norm_stderr": 0.014346869060229323
},
"harness|hellaswag|10": {
"acc": 0.5053774148575981,
"acc_stderr": 0.004989492828168535,
"acc_norm": 0.6746664011153157,
"acc_norm_stderr": 0.004675418774314239
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.26,
"acc_stderr": 0.04408440022768081,
"acc_norm": 0.26,
"acc_norm_stderr": 0.04408440022768081
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.25925925925925924,
"acc_stderr": 0.03785714465066653,
"acc_norm": 0.25925925925925924,
"acc_norm_stderr": 0.03785714465066653
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.3092105263157895,
"acc_stderr": 0.037610708698674805,
"acc_norm": 0.3092105263157895,
"acc_norm_stderr": 0.037610708698674805
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.33,
"acc_stderr": 0.04725815626252604,
"acc_norm": 0.33,
"acc_norm_stderr": 0.04725815626252604
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.23773584905660378,
"acc_stderr": 0.0261998088075619,
"acc_norm": 0.23773584905660378,
"acc_norm_stderr": 0.0261998088075619
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.20833333333333334,
"acc_stderr": 0.03396116205845333,
"acc_norm": 0.20833333333333334,
"acc_norm_stderr": 0.03396116205845333
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.13,
"acc_stderr": 0.03379976689896308,
"acc_norm": 0.13,
"acc_norm_stderr": 0.03379976689896308
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.2,
"acc_stderr": 0.04020151261036846,
"acc_norm": 0.2,
"acc_norm_stderr": 0.04020151261036846
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.23,
"acc_stderr": 0.042295258468165065,
"acc_norm": 0.23,
"acc_norm_stderr": 0.042295258468165065
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.2543352601156069,
"acc_stderr": 0.0332055644308557,
"acc_norm": 0.2543352601156069,
"acc_norm_stderr": 0.0332055644308557
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.18627450980392157,
"acc_stderr": 0.03873958714149351,
"acc_norm": 0.18627450980392157,
"acc_norm_stderr": 0.03873958714149351
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.32,
"acc_stderr": 0.046882617226215034,
"acc_norm": 0.32,
"acc_norm_stderr": 0.046882617226215034
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.3404255319148936,
"acc_stderr": 0.030976692998534436,
"acc_norm": 0.3404255319148936,
"acc_norm_stderr": 0.030976692998534436
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.24561403508771928,
"acc_stderr": 0.040493392977481425,
"acc_norm": 0.24561403508771928,
"acc_norm_stderr": 0.040493392977481425
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.2689655172413793,
"acc_stderr": 0.03695183311650232,
"acc_norm": 0.2689655172413793,
"acc_norm_stderr": 0.03695183311650232
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.24603174603174602,
"acc_stderr": 0.022182037202948368,
"acc_norm": 0.24603174603174602,
"acc_norm_stderr": 0.022182037202948368
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.23809523809523808,
"acc_stderr": 0.03809523809523811,
"acc_norm": 0.23809523809523808,
"acc_norm_stderr": 0.03809523809523811
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.25,
"acc_stderr": 0.04351941398892446,
"acc_norm": 0.25,
"acc_norm_stderr": 0.04351941398892446
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.23548387096774193,
"acc_stderr": 0.02413763242933771,
"acc_norm": 0.23548387096774193,
"acc_norm_stderr": 0.02413763242933771
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.23645320197044334,
"acc_stderr": 0.029896114291733552,
"acc_norm": 0.23645320197044334,
"acc_norm_stderr": 0.029896114291733552
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.2,
"acc_stderr": 0.04020151261036846,
"acc_norm": 0.2,
"acc_norm_stderr": 0.04020151261036846
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.2545454545454545,
"acc_stderr": 0.03401506715249039,
"acc_norm": 0.2545454545454545,
"acc_norm_stderr": 0.03401506715249039
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.20707070707070707,
"acc_stderr": 0.028869778460267042,
"acc_norm": 0.20707070707070707,
"acc_norm_stderr": 0.028869778460267042
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.22797927461139897,
"acc_stderr": 0.03027690994517826,
"acc_norm": 0.22797927461139897,
"acc_norm_stderr": 0.03027690994517826
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.2512820512820513,
"acc_stderr": 0.021992016662370526,
"acc_norm": 0.2512820512820513,
"acc_norm_stderr": 0.021992016662370526
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.26666666666666666,
"acc_stderr": 0.02696242432507383,
"acc_norm": 0.26666666666666666,
"acc_norm_stderr": 0.02696242432507383
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.2184873949579832,
"acc_stderr": 0.02684151432295894,
"acc_norm": 0.2184873949579832,
"acc_norm_stderr": 0.02684151432295894
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.2185430463576159,
"acc_stderr": 0.03374235550425694,
"acc_norm": 0.2185430463576159,
"acc_norm_stderr": 0.03374235550425694
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.26788990825688075,
"acc_stderr": 0.018987462257978652,
"acc_norm": 0.26788990825688075,
"acc_norm_stderr": 0.018987462257978652
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.1574074074074074,
"acc_stderr": 0.02483717351824239,
"acc_norm": 0.1574074074074074,
"acc_norm_stderr": 0.02483717351824239
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.3088235294117647,
"acc_stderr": 0.03242661719827218,
"acc_norm": 0.3088235294117647,
"acc_norm_stderr": 0.03242661719827218
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.2616033755274262,
"acc_stderr": 0.028609516716994934,
"acc_norm": 0.2616033755274262,
"acc_norm_stderr": 0.028609516716994934
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.3542600896860987,
"acc_stderr": 0.032100621541349864,
"acc_norm": 0.3542600896860987,
"acc_norm_stderr": 0.032100621541349864
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.20610687022900764,
"acc_stderr": 0.03547771004159464,
"acc_norm": 0.20610687022900764,
"acc_norm_stderr": 0.03547771004159464
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.3305785123966942,
"acc_stderr": 0.04294340845212094,
"acc_norm": 0.3305785123966942,
"acc_norm_stderr": 0.04294340845212094
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.3425925925925926,
"acc_stderr": 0.04587904741301811,
"acc_norm": 0.3425925925925926,
"acc_norm_stderr": 0.04587904741301811
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.2331288343558282,
"acc_stderr": 0.033220157957767414,
"acc_norm": 0.2331288343558282,
"acc_norm_stderr": 0.033220157957767414
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.26785714285714285,
"acc_stderr": 0.04203277291467764,
"acc_norm": 0.26785714285714285,
"acc_norm_stderr": 0.04203277291467764
},
"harness|hendrycksTest-management|5": {
"acc": 0.21359223300970873,
"acc_stderr": 0.040580420156460344,
"acc_norm": 0.21359223300970873,
"acc_norm_stderr": 0.040580420156460344
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.32905982905982906,
"acc_stderr": 0.03078232157768816,
"acc_norm": 0.32905982905982906,
"acc_norm_stderr": 0.03078232157768816
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.21,
"acc_stderr": 0.040936018074033256,
"acc_norm": 0.21,
"acc_norm_stderr": 0.040936018074033256
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.2822477650063857,
"acc_stderr": 0.016095302969878555,
"acc_norm": 0.2822477650063857,
"acc_norm_stderr": 0.016095302969878555
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.27167630057803466,
"acc_stderr": 0.023948512905468365,
"acc_norm": 0.27167630057803466,
"acc_norm_stderr": 0.023948512905468365
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.2346368715083799,
"acc_stderr": 0.014173044098303667,
"acc_norm": 0.2346368715083799,
"acc_norm_stderr": 0.014173044098303667
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.29411764705882354,
"acc_stderr": 0.026090162504279053,
"acc_norm": 0.29411764705882354,
"acc_norm_stderr": 0.026090162504279053
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.2604501607717042,
"acc_stderr": 0.024926723224845557,
"acc_norm": 0.2604501607717042,
"acc_norm_stderr": 0.024926723224845557
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.28703703703703703,
"acc_stderr": 0.025171041915309684,
"acc_norm": 0.28703703703703703,
"acc_norm_stderr": 0.025171041915309684
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.3049645390070922,
"acc_stderr": 0.027464708442022128,
"acc_norm": 0.3049645390070922,
"acc_norm_stderr": 0.027464708442022128
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.27444589308996087,
"acc_stderr": 0.011397043163078154,
"acc_norm": 0.27444589308996087,
"acc_norm_stderr": 0.011397043163078154
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.16911764705882354,
"acc_stderr": 0.02277086801011301,
"acc_norm": 0.16911764705882354,
"acc_norm_stderr": 0.02277086801011301
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.27941176470588236,
"acc_stderr": 0.018152871051538816,
"acc_norm": 0.27941176470588236,
"acc_norm_stderr": 0.018152871051538816
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.3,
"acc_stderr": 0.04389311454644287,
"acc_norm": 0.3,
"acc_norm_stderr": 0.04389311454644287
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.3142857142857143,
"acc_stderr": 0.029719329422417465,
"acc_norm": 0.3142857142857143,
"acc_norm_stderr": 0.029719329422417465
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.25870646766169153,
"acc_stderr": 0.030965903123573037,
"acc_norm": 0.25870646766169153,
"acc_norm_stderr": 0.030965903123573037
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.27,
"acc_stderr": 0.044619604333847394,
"acc_norm": 0.27,
"acc_norm_stderr": 0.044619604333847394
},
"harness|hendrycksTest-virology|5": {
"acc": 0.2710843373493976,
"acc_stderr": 0.03460579907553026,
"acc_norm": 0.2710843373493976,
"acc_norm_stderr": 0.03460579907553026
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.2807017543859649,
"acc_stderr": 0.034462962170884265,
"acc_norm": 0.2807017543859649,
"acc_norm_stderr": 0.034462962170884265
},
"harness|truthfulqa:mc|0": {
"mc1": 0.20195838433292534,
"mc1_stderr": 0.014053957441512359,
"mc2": 0.3253448533993895,
"mc2_stderr": 0.013862486209403098
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
open-llm-leaderboard/details_psyche__kogpt | 2023-08-27T12:27:46.000Z | [
"region:us"
] | open-llm-leaderboard | null | null | null | 0 | 3 | ---
pretty_name: Evaluation run of psyche/kogpt
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [psyche/kogpt](https://huggingface.co/psyche/kogpt) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 61 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_psyche__kogpt\"\
,\n\t\"harness_truthfulqa_mc_0\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\
\nThese are the [latest results from run 2023-07-19T19:23:49.331489](https://huggingface.co/datasets/open-llm-leaderboard/details_psyche__kogpt/blob/main/results_2023-07-19T19%3A23%3A49.331489.json)\
\ (note that their might be results for other tasks in the repos if successive evals\
\ didn't cover the same tasks. You find each in the results and the \"latest\" split\
\ for each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.2644312235752893,\n\
\ \"acc_stderr\": 0.03180534436192542,\n \"acc_norm\": 0.26491597825755875,\n\
\ \"acc_norm_stderr\": 0.031813845138592645,\n \"mc1\": 0.2460220318237454,\n\
\ \"mc1_stderr\": 0.01507721920066258,\n \"mc2\": 0.4205535965155922,\n\
\ \"mc2_stderr\": 0.01579395715610758\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.19027303754266212,\n \"acc_stderr\": 0.011470424179225705,\n\
\ \"acc_norm\": 0.21160409556313994,\n \"acc_norm_stderr\": 0.011935916358632859\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.27384983071101376,\n\
\ \"acc_stderr\": 0.004450214826707156,\n \"acc_norm\": 0.2811192989444334,\n\
\ \"acc_norm_stderr\": 0.004486268470666332\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.22,\n \"acc_stderr\": 0.04163331998932269,\n \
\ \"acc_norm\": 0.22,\n \"acc_norm_stderr\": 0.04163331998932269\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.2740740740740741,\n\
\ \"acc_stderr\": 0.03853254836552003,\n \"acc_norm\": 0.2740740740740741,\n\
\ \"acc_norm_stderr\": 0.03853254836552003\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.3092105263157895,\n \"acc_stderr\": 0.03761070869867479,\n\
\ \"acc_norm\": 0.3092105263157895,\n \"acc_norm_stderr\": 0.03761070869867479\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.21,\n\
\ \"acc_stderr\": 0.040936018074033256,\n \"acc_norm\": 0.21,\n \
\ \"acc_norm_stderr\": 0.040936018074033256\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.2792452830188679,\n \"acc_stderr\": 0.02761116340239972,\n\
\ \"acc_norm\": 0.2792452830188679,\n \"acc_norm_stderr\": 0.02761116340239972\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.2222222222222222,\n\
\ \"acc_stderr\": 0.03476590104304134,\n \"acc_norm\": 0.2222222222222222,\n\
\ \"acc_norm_stderr\": 0.03476590104304134\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.31,\n \"acc_stderr\": 0.04648231987117316,\n \
\ \"acc_norm\": 0.31,\n \"acc_norm_stderr\": 0.04648231987117316\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\"\
: 0.35,\n \"acc_stderr\": 0.04793724854411019,\n \"acc_norm\": 0.35,\n\
\ \"acc_norm_stderr\": 0.04793724854411019\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.32,\n \"acc_stderr\": 0.046882617226215034,\n \
\ \"acc_norm\": 0.32,\n \"acc_norm_stderr\": 0.046882617226215034\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.3179190751445087,\n\
\ \"acc_stderr\": 0.03550683989165582,\n \"acc_norm\": 0.3179190751445087,\n\
\ \"acc_norm_stderr\": 0.03550683989165582\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.35294117647058826,\n \"acc_stderr\": 0.04755129616062948,\n\
\ \"acc_norm\": 0.35294117647058826,\n \"acc_norm_stderr\": 0.04755129616062948\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.16,\n \"acc_stderr\": 0.03684529491774709,\n \"acc_norm\": 0.16,\n\
\ \"acc_norm_stderr\": 0.03684529491774709\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.251063829787234,\n \"acc_stderr\": 0.02834696377716245,\n\
\ \"acc_norm\": 0.251063829787234,\n \"acc_norm_stderr\": 0.02834696377716245\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.2719298245614035,\n\
\ \"acc_stderr\": 0.04185774424022056,\n \"acc_norm\": 0.2719298245614035,\n\
\ \"acc_norm_stderr\": 0.04185774424022056\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.2413793103448276,\n \"acc_stderr\": 0.03565998174135302,\n\
\ \"acc_norm\": 0.2413793103448276,\n \"acc_norm_stderr\": 0.03565998174135302\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.24338624338624337,\n \"acc_stderr\": 0.02210112878741543,\n \"\
acc_norm\": 0.24338624338624337,\n \"acc_norm_stderr\": 0.02210112878741543\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.21428571428571427,\n\
\ \"acc_stderr\": 0.03670066451047181,\n \"acc_norm\": 0.21428571428571427,\n\
\ \"acc_norm_stderr\": 0.03670066451047181\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.15,\n \"acc_stderr\": 0.0358870281282637,\n \
\ \"acc_norm\": 0.15,\n \"acc_norm_stderr\": 0.0358870281282637\n },\n\
\ \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.3161290322580645,\n\
\ \"acc_stderr\": 0.02645087448904277,\n \"acc_norm\": 0.3161290322580645,\n\
\ \"acc_norm_stderr\": 0.02645087448904277\n },\n \"harness|hendrycksTest-high_school_chemistry|5\"\
: {\n \"acc\": 0.2561576354679803,\n \"acc_stderr\": 0.030712730070982592,\n\
\ \"acc_norm\": 0.2561576354679803,\n \"acc_norm_stderr\": 0.030712730070982592\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.23,\n \"acc_stderr\": 0.04229525846816505,\n \"acc_norm\"\
: 0.23,\n \"acc_norm_stderr\": 0.04229525846816505\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.22424242424242424,\n \"acc_stderr\": 0.032568666616811015,\n\
\ \"acc_norm\": 0.22424242424242424,\n \"acc_norm_stderr\": 0.032568666616811015\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.35353535353535354,\n \"acc_stderr\": 0.03406086723547153,\n \"\
acc_norm\": 0.35353535353535354,\n \"acc_norm_stderr\": 0.03406086723547153\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.29533678756476683,\n \"acc_stderr\": 0.032922966391551386,\n\
\ \"acc_norm\": 0.29533678756476683,\n \"acc_norm_stderr\": 0.032922966391551386\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.36153846153846153,\n \"acc_stderr\": 0.024359581465396983,\n\
\ \"acc_norm\": 0.36153846153846153,\n \"acc_norm_stderr\": 0.024359581465396983\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.26296296296296295,\n \"acc_stderr\": 0.026842057873833706,\n \
\ \"acc_norm\": 0.26296296296296295,\n \"acc_norm_stderr\": 0.026842057873833706\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.3445378151260504,\n \"acc_stderr\": 0.030868682604121633,\n\
\ \"acc_norm\": 0.3445378151260504,\n \"acc_norm_stderr\": 0.030868682604121633\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.31788079470198677,\n \"acc_stderr\": 0.038020397601079024,\n \"\
acc_norm\": 0.31788079470198677,\n \"acc_norm_stderr\": 0.038020397601079024\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.29908256880733947,\n \"acc_stderr\": 0.019630417285415175,\n \"\
acc_norm\": 0.29908256880733947,\n \"acc_norm_stderr\": 0.019630417285415175\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.46296296296296297,\n \"acc_stderr\": 0.03400603625538272,\n \"\
acc_norm\": 0.46296296296296297,\n \"acc_norm_stderr\": 0.03400603625538272\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.2647058823529412,\n \"acc_stderr\": 0.030964517926923393,\n \"\
acc_norm\": 0.2647058823529412,\n \"acc_norm_stderr\": 0.030964517926923393\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.270042194092827,\n \"acc_stderr\": 0.028900721906293426,\n \
\ \"acc_norm\": 0.270042194092827,\n \"acc_norm_stderr\": 0.028900721906293426\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.13901345291479822,\n\
\ \"acc_stderr\": 0.023219352834474478,\n \"acc_norm\": 0.13901345291479822,\n\
\ \"acc_norm_stderr\": 0.023219352834474478\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.29770992366412213,\n \"acc_stderr\": 0.040103589424622034,\n\
\ \"acc_norm\": 0.29770992366412213,\n \"acc_norm_stderr\": 0.040103589424622034\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.2231404958677686,\n \"acc_stderr\": 0.03800754475228733,\n \"\
acc_norm\": 0.2231404958677686,\n \"acc_norm_stderr\": 0.03800754475228733\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.2037037037037037,\n\
\ \"acc_stderr\": 0.03893542518824848,\n \"acc_norm\": 0.2037037037037037,\n\
\ \"acc_norm_stderr\": 0.03893542518824848\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.22699386503067484,\n \"acc_stderr\": 0.03291099578615769,\n\
\ \"acc_norm\": 0.22699386503067484,\n \"acc_norm_stderr\": 0.03291099578615769\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.20535714285714285,\n\
\ \"acc_stderr\": 0.03834241021419073,\n \"acc_norm\": 0.20535714285714285,\n\
\ \"acc_norm_stderr\": 0.03834241021419073\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.4077669902912621,\n \"acc_stderr\": 0.0486577757041077,\n\
\ \"acc_norm\": 0.4077669902912621,\n \"acc_norm_stderr\": 0.0486577757041077\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.18803418803418803,\n\
\ \"acc_stderr\": 0.025598193686652254,\n \"acc_norm\": 0.18803418803418803,\n\
\ \"acc_norm_stderr\": 0.025598193686652254\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.29,\n \"acc_stderr\": 0.04560480215720685,\n \
\ \"acc_norm\": 0.29,\n \"acc_norm_stderr\": 0.04560480215720685\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.19923371647509577,\n\
\ \"acc_stderr\": 0.014283378044296415,\n \"acc_norm\": 0.19923371647509577,\n\
\ \"acc_norm_stderr\": 0.014283378044296415\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.23699421965317918,\n \"acc_stderr\": 0.02289408248992599,\n\
\ \"acc_norm\": 0.23699421965317918,\n \"acc_norm_stderr\": 0.02289408248992599\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.27150837988826815,\n\
\ \"acc_stderr\": 0.01487425216809527,\n \"acc_norm\": 0.27150837988826815,\n\
\ \"acc_norm_stderr\": 0.01487425216809527\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.3006535947712418,\n \"acc_stderr\": 0.02625605383571896,\n\
\ \"acc_norm\": 0.3006535947712418,\n \"acc_norm_stderr\": 0.02625605383571896\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.20257234726688103,\n\
\ \"acc_stderr\": 0.022827317491059686,\n \"acc_norm\": 0.20257234726688103,\n\
\ \"acc_norm_stderr\": 0.022827317491059686\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.25,\n \"acc_stderr\": 0.02409347123262133,\n \
\ \"acc_norm\": 0.25,\n \"acc_norm_stderr\": 0.02409347123262133\n \
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"acc\"\
: 0.23049645390070922,\n \"acc_stderr\": 0.025123739226872402,\n \"\
acc_norm\": 0.23049645390070922,\n \"acc_norm_stderr\": 0.025123739226872402\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.25097783572359844,\n\
\ \"acc_stderr\": 0.011073730299187236,\n \"acc_norm\": 0.25097783572359844,\n\
\ \"acc_norm_stderr\": 0.011073730299187236\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.4411764705882353,\n \"acc_stderr\": 0.030161911930767102,\n\
\ \"acc_norm\": 0.4411764705882353,\n \"acc_norm_stderr\": 0.030161911930767102\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.20098039215686275,\n \"acc_stderr\": 0.01621193888965557,\n \
\ \"acc_norm\": 0.20098039215686275,\n \"acc_norm_stderr\": 0.01621193888965557\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.21818181818181817,\n\
\ \"acc_stderr\": 0.03955932861795833,\n \"acc_norm\": 0.21818181818181817,\n\
\ \"acc_norm_stderr\": 0.03955932861795833\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.24897959183673468,\n \"acc_stderr\": 0.02768297952296023,\n\
\ \"acc_norm\": 0.24897959183673468,\n \"acc_norm_stderr\": 0.02768297952296023\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.23383084577114427,\n\
\ \"acc_stderr\": 0.029929415408348377,\n \"acc_norm\": 0.23383084577114427,\n\
\ \"acc_norm_stderr\": 0.029929415408348377\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.28,\n \"acc_stderr\": 0.04512608598542128,\n \
\ \"acc_norm\": 0.28,\n \"acc_norm_stderr\": 0.04512608598542128\n \
\ },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.21686746987951808,\n\
\ \"acc_stderr\": 0.03208284450356365,\n \"acc_norm\": 0.21686746987951808,\n\
\ \"acc_norm_stderr\": 0.03208284450356365\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.21637426900584794,\n \"acc_stderr\": 0.031581495393387324,\n\
\ \"acc_norm\": 0.21637426900584794,\n \"acc_norm_stderr\": 0.031581495393387324\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.2460220318237454,\n\
\ \"mc1_stderr\": 0.01507721920066258,\n \"mc2\": 0.4205535965155922,\n\
\ \"mc2_stderr\": 0.01579395715610758\n }\n}\n```"
repo_url: https://huggingface.co/psyche/kogpt
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|arc:challenge|25_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hellaswag|10_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-19T19:23:49.331489.parquet'
- config_name: results
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- results_2023-07-19T19:23:49.331489.parquet
- split: latest
path:
- results_2023-07-19T19:23:49.331489.parquet
---
# Dataset Card for Evaluation run of psyche/kogpt
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/psyche/kogpt
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [psyche/kogpt](https://huggingface.co/psyche/kogpt) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 61 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_psyche__kogpt",
"harness_truthfulqa_mc_0",
split="train")
```
## Latest results
These are the [latest results from run 2023-07-19T19:23:49.331489](https://huggingface.co/datasets/open-llm-leaderboard/details_psyche__kogpt/blob/main/results_2023-07-19T19%3A23%3A49.331489.json) (note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.2644312235752893,
"acc_stderr": 0.03180534436192542,
"acc_norm": 0.26491597825755875,
"acc_norm_stderr": 0.031813845138592645,
"mc1": 0.2460220318237454,
"mc1_stderr": 0.01507721920066258,
"mc2": 0.4205535965155922,
"mc2_stderr": 0.01579395715610758
},
"harness|arc:challenge|25": {
"acc": 0.19027303754266212,
"acc_stderr": 0.011470424179225705,
"acc_norm": 0.21160409556313994,
"acc_norm_stderr": 0.011935916358632859
},
"harness|hellaswag|10": {
"acc": 0.27384983071101376,
"acc_stderr": 0.004450214826707156,
"acc_norm": 0.2811192989444334,
"acc_norm_stderr": 0.004486268470666332
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.22,
"acc_stderr": 0.04163331998932269,
"acc_norm": 0.22,
"acc_norm_stderr": 0.04163331998932269
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.2740740740740741,
"acc_stderr": 0.03853254836552003,
"acc_norm": 0.2740740740740741,
"acc_norm_stderr": 0.03853254836552003
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.3092105263157895,
"acc_stderr": 0.03761070869867479,
"acc_norm": 0.3092105263157895,
"acc_norm_stderr": 0.03761070869867479
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.21,
"acc_stderr": 0.040936018074033256,
"acc_norm": 0.21,
"acc_norm_stderr": 0.040936018074033256
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.2792452830188679,
"acc_stderr": 0.02761116340239972,
"acc_norm": 0.2792452830188679,
"acc_norm_stderr": 0.02761116340239972
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.2222222222222222,
"acc_stderr": 0.03476590104304134,
"acc_norm": 0.2222222222222222,
"acc_norm_stderr": 0.03476590104304134
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.31,
"acc_stderr": 0.04648231987117316,
"acc_norm": 0.31,
"acc_norm_stderr": 0.04648231987117316
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.35,
"acc_stderr": 0.04793724854411019,
"acc_norm": 0.35,
"acc_norm_stderr": 0.04793724854411019
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.32,
"acc_stderr": 0.046882617226215034,
"acc_norm": 0.32,
"acc_norm_stderr": 0.046882617226215034
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.3179190751445087,
"acc_stderr": 0.03550683989165582,
"acc_norm": 0.3179190751445087,
"acc_norm_stderr": 0.03550683989165582
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.35294117647058826,
"acc_stderr": 0.04755129616062948,
"acc_norm": 0.35294117647058826,
"acc_norm_stderr": 0.04755129616062948
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.16,
"acc_stderr": 0.03684529491774709,
"acc_norm": 0.16,
"acc_norm_stderr": 0.03684529491774709
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.251063829787234,
"acc_stderr": 0.02834696377716245,
"acc_norm": 0.251063829787234,
"acc_norm_stderr": 0.02834696377716245
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.2719298245614035,
"acc_stderr": 0.04185774424022056,
"acc_norm": 0.2719298245614035,
"acc_norm_stderr": 0.04185774424022056
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.2413793103448276,
"acc_stderr": 0.03565998174135302,
"acc_norm": 0.2413793103448276,
"acc_norm_stderr": 0.03565998174135302
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.24338624338624337,
"acc_stderr": 0.02210112878741543,
"acc_norm": 0.24338624338624337,
"acc_norm_stderr": 0.02210112878741543
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.21428571428571427,
"acc_stderr": 0.03670066451047181,
"acc_norm": 0.21428571428571427,
"acc_norm_stderr": 0.03670066451047181
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.15,
"acc_stderr": 0.0358870281282637,
"acc_norm": 0.15,
"acc_norm_stderr": 0.0358870281282637
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.3161290322580645,
"acc_stderr": 0.02645087448904277,
"acc_norm": 0.3161290322580645,
"acc_norm_stderr": 0.02645087448904277
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.2561576354679803,
"acc_stderr": 0.030712730070982592,
"acc_norm": 0.2561576354679803,
"acc_norm_stderr": 0.030712730070982592
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.23,
"acc_stderr": 0.04229525846816505,
"acc_norm": 0.23,
"acc_norm_stderr": 0.04229525846816505
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.22424242424242424,
"acc_stderr": 0.032568666616811015,
"acc_norm": 0.22424242424242424,
"acc_norm_stderr": 0.032568666616811015
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.35353535353535354,
"acc_stderr": 0.03406086723547153,
"acc_norm": 0.35353535353535354,
"acc_norm_stderr": 0.03406086723547153
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.29533678756476683,
"acc_stderr": 0.032922966391551386,
"acc_norm": 0.29533678756476683,
"acc_norm_stderr": 0.032922966391551386
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.36153846153846153,
"acc_stderr": 0.024359581465396983,
"acc_norm": 0.36153846153846153,
"acc_norm_stderr": 0.024359581465396983
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.26296296296296295,
"acc_stderr": 0.026842057873833706,
"acc_norm": 0.26296296296296295,
"acc_norm_stderr": 0.026842057873833706
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.3445378151260504,
"acc_stderr": 0.030868682604121633,
"acc_norm": 0.3445378151260504,
"acc_norm_stderr": 0.030868682604121633
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.31788079470198677,
"acc_stderr": 0.038020397601079024,
"acc_norm": 0.31788079470198677,
"acc_norm_stderr": 0.038020397601079024
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.29908256880733947,
"acc_stderr": 0.019630417285415175,
"acc_norm": 0.29908256880733947,
"acc_norm_stderr": 0.019630417285415175
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.46296296296296297,
"acc_stderr": 0.03400603625538272,
"acc_norm": 0.46296296296296297,
"acc_norm_stderr": 0.03400603625538272
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.2647058823529412,
"acc_stderr": 0.030964517926923393,
"acc_norm": 0.2647058823529412,
"acc_norm_stderr": 0.030964517926923393
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.270042194092827,
"acc_stderr": 0.028900721906293426,
"acc_norm": 0.270042194092827,
"acc_norm_stderr": 0.028900721906293426
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.13901345291479822,
"acc_stderr": 0.023219352834474478,
"acc_norm": 0.13901345291479822,
"acc_norm_stderr": 0.023219352834474478
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.29770992366412213,
"acc_stderr": 0.040103589424622034,
"acc_norm": 0.29770992366412213,
"acc_norm_stderr": 0.040103589424622034
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.2231404958677686,
"acc_stderr": 0.03800754475228733,
"acc_norm": 0.2231404958677686,
"acc_norm_stderr": 0.03800754475228733
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.2037037037037037,
"acc_stderr": 0.03893542518824848,
"acc_norm": 0.2037037037037037,
"acc_norm_stderr": 0.03893542518824848
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.22699386503067484,
"acc_stderr": 0.03291099578615769,
"acc_norm": 0.22699386503067484,
"acc_norm_stderr": 0.03291099578615769
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.20535714285714285,
"acc_stderr": 0.03834241021419073,
"acc_norm": 0.20535714285714285,
"acc_norm_stderr": 0.03834241021419073
},
"harness|hendrycksTest-management|5": {
"acc": 0.4077669902912621,
"acc_stderr": 0.0486577757041077,
"acc_norm": 0.4077669902912621,
"acc_norm_stderr": 0.0486577757041077
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.18803418803418803,
"acc_stderr": 0.025598193686652254,
"acc_norm": 0.18803418803418803,
"acc_norm_stderr": 0.025598193686652254
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.29,
"acc_stderr": 0.04560480215720685,
"acc_norm": 0.29,
"acc_norm_stderr": 0.04560480215720685
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.19923371647509577,
"acc_stderr": 0.014283378044296415,
"acc_norm": 0.19923371647509577,
"acc_norm_stderr": 0.014283378044296415
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.23699421965317918,
"acc_stderr": 0.02289408248992599,
"acc_norm": 0.23699421965317918,
"acc_norm_stderr": 0.02289408248992599
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.27150837988826815,
"acc_stderr": 0.01487425216809527,
"acc_norm": 0.27150837988826815,
"acc_norm_stderr": 0.01487425216809527
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.3006535947712418,
"acc_stderr": 0.02625605383571896,
"acc_norm": 0.3006535947712418,
"acc_norm_stderr": 0.02625605383571896
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.20257234726688103,
"acc_stderr": 0.022827317491059686,
"acc_norm": 0.20257234726688103,
"acc_norm_stderr": 0.022827317491059686
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.25,
"acc_stderr": 0.02409347123262133,
"acc_norm": 0.25,
"acc_norm_stderr": 0.02409347123262133
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.23049645390070922,
"acc_stderr": 0.025123739226872402,
"acc_norm": 0.23049645390070922,
"acc_norm_stderr": 0.025123739226872402
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.25097783572359844,
"acc_stderr": 0.011073730299187236,
"acc_norm": 0.25097783572359844,
"acc_norm_stderr": 0.011073730299187236
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.4411764705882353,
"acc_stderr": 0.030161911930767102,
"acc_norm": 0.4411764705882353,
"acc_norm_stderr": 0.030161911930767102
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.20098039215686275,
"acc_stderr": 0.01621193888965557,
"acc_norm": 0.20098039215686275,
"acc_norm_stderr": 0.01621193888965557
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.21818181818181817,
"acc_stderr": 0.03955932861795833,
"acc_norm": 0.21818181818181817,
"acc_norm_stderr": 0.03955932861795833
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.24897959183673468,
"acc_stderr": 0.02768297952296023,
"acc_norm": 0.24897959183673468,
"acc_norm_stderr": 0.02768297952296023
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.23383084577114427,
"acc_stderr": 0.029929415408348377,
"acc_norm": 0.23383084577114427,
"acc_norm_stderr": 0.029929415408348377
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.28,
"acc_stderr": 0.04512608598542128,
"acc_norm": 0.28,
"acc_norm_stderr": 0.04512608598542128
},
"harness|hendrycksTest-virology|5": {
"acc": 0.21686746987951808,
"acc_stderr": 0.03208284450356365,
"acc_norm": 0.21686746987951808,
"acc_norm_stderr": 0.03208284450356365
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.21637426900584794,
"acc_stderr": 0.031581495393387324,
"acc_norm": 0.21637426900584794,
"acc_norm_stderr": 0.031581495393387324
},
"harness|truthfulqa:mc|0": {
"mc1": 0.2460220318237454,
"mc1_stderr": 0.01507721920066258,
"mc2": 0.4205535965155922,
"mc2_stderr": 0.01579395715610758
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
lhoestq/squad | 2023-08-18T10:52:41.000Z | [
"task_categories:question-answering",
"task_ids:extractive-qa",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|wikipedia",
"language:en",
"license:cc-by-4.0",
... | lhoestq | Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable. | @article{2016arXiv160605250R,
author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev},
Konstantin and {Liang}, Percy},
title = "{SQuAD: 100,000+ Questions for Machine Comprehension of Text}",
journal = {arXiv e-prints},
year = 2016,
eid = {arXiv:1606.05250},
pages = {arXiv:1606.05250},
archivePrefix = {arXiv},
eprint = {1606.05250},
} | null | 1 | 3 | ---
pretty_name: SQuAD
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
- found
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|wikipedia
task_categories:
- question-answering
task_ids:
- extractive-qa
paperswithcode_id: squad
train-eval-index:
- config: plain_text
task: question-answering
task_id: extractive_question_answering
splits:
train_split: train
eval_split: validation
col_mapping:
question: question
context: context
answers:
text: text
answer_start: answer_start
metrics:
- type: squad
name: SQuAD
dataset_info:
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
config_name: plain_text
splits:
- name: train
num_bytes: 79317110
num_examples: 87599
- name: validation
num_bytes: 10472653
num_examples: 10570
download_size: 35142551
dataset_size: 89789763
---
# Dataset Card for "squad"
## Table of Contents
- [Dataset Card for "squad"](#dataset-card-for-squad)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [plain_text](#plain_text)
- [Data Fields](#data-fields)
- [plain_text](#plain_text-1)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://rajpurkar.github.io/SQuAD-explorer/](https://rajpurkar.github.io/SQuAD-explorer/)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 35.14 MB
- **Size of the generated dataset:** 89.92 MB
- **Total amount of disk used:** 125.06 MB
### Dataset Summary
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### plain_text
- **Size of downloaded dataset files:** 35.14 MB
- **Size of the generated dataset:** 89.92 MB
- **Total amount of disk used:** 125.06 MB
An example of 'train' looks as follows.
```
{
"answers": {
"answer_start": [1],
"text": ["This is a test text"]
},
"context": "This is a test context.",
"id": "1",
"question": "Is this a test?",
"title": "train test"
}
```
### Data Fields
The data fields are the same among all splits.
#### plain_text
- `id`: a `string` feature.
- `title`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `text`: a `string` feature.
- `answer_start`: a `int32` feature.
### Data Splits
| name |train|validation|
|----------|----:|---------:|
|plain_text|87599| 10570|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{2016arXiv160605250R,
author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev},
Konstantin and {Liang}, Percy},
title = "{SQuAD: 100,000+ Questions for Machine Comprehension of Text}",
journal = {arXiv e-prints},
year = 2016,
eid = {arXiv:1606.05250},
pages = {arXiv:1606.05250},
archivePrefix = {arXiv},
eprint = {1606.05250},
}
```
### Contributions
Thanks to [@lewtun](https://github.com/lewtun), [@albertvillanova](https://github.com/albertvillanova), [@patrickvonplaten](https://github.com/patrickvonplaten), [@thomwolf](https://github.com/thomwolf) for adding this dataset. |
open-llm-leaderboard/details_georgesung__llama2_7b_chat_uncensored | 2023-09-17T06:01:46.000Z | [
"region:us"
] | open-llm-leaderboard | null | null | null | 0 | 3 | ---
pretty_name: Evaluation run of georgesung/llama2_7b_chat_uncensored
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [georgesung/llama2_7b_chat_uncensored](https://huggingface.co/georgesung/llama2_7b_chat_uncensored)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_georgesung__llama2_7b_chat_uncensored\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-09-17T06:01:34.534802](https://huggingface.co/datasets/open-llm-leaderboard/details_georgesung__llama2_7b_chat_uncensored/blob/main/results_2023-09-17T06-01-34.534802.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.0018875838926174498,\n\
\ \"em_stderr\": 0.0004445109990558761,\n \"f1\": 0.05687290268456382,\n\
\ \"f1_stderr\": 0.0013311620250832507,\n \"acc\": 0.3997491582259886,\n\
\ \"acc_stderr\": 0.009384299684412923\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.0018875838926174498,\n \"em_stderr\": 0.0004445109990558761,\n\
\ \"f1\": 0.05687290268456382,\n \"f1_stderr\": 0.0013311620250832507\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.058377558756633814,\n \
\ \"acc_stderr\": 0.0064580835578324685\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.7411207576953434,\n \"acc_stderr\": 0.012310515810993376\n\
\ }\n}\n```"
repo_url: https://huggingface.co/georgesung/llama2_7b_chat_uncensored
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|arc:challenge|25_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_09_17T06_01_34.534802
path:
- '**/details_harness|drop|3_2023-09-17T06-01-34.534802.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-09-17T06-01-34.534802.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_09_17T06_01_34.534802
path:
- '**/details_harness|gsm8k|5_2023-09-17T06-01-34.534802.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-09-17T06-01-34.534802.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hellaswag|10_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-24T11:17:24.189192.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-24T11:17:24.189192.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-24T11:17:24.189192.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_09_17T06_01_34.534802
path:
- '**/details_harness|winogrande|5_2023-09-17T06-01-34.534802.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-09-17T06-01-34.534802.parquet'
- config_name: results
data_files:
- split: 2023_07_24T11_17_24.189192
path:
- results_2023-07-24T11:17:24.189192.parquet
- split: 2023_09_17T06_01_34.534802
path:
- results_2023-09-17T06-01-34.534802.parquet
- split: latest
path:
- results_2023-09-17T06-01-34.534802.parquet
---
# Dataset Card for Evaluation run of georgesung/llama2_7b_chat_uncensored
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/georgesung/llama2_7b_chat_uncensored
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [georgesung/llama2_7b_chat_uncensored](https://huggingface.co/georgesung/llama2_7b_chat_uncensored) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_georgesung__llama2_7b_chat_uncensored",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-09-17T06:01:34.534802](https://huggingface.co/datasets/open-llm-leaderboard/details_georgesung__llama2_7b_chat_uncensored/blob/main/results_2023-09-17T06-01-34.534802.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.0018875838926174498,
"em_stderr": 0.0004445109990558761,
"f1": 0.05687290268456382,
"f1_stderr": 0.0013311620250832507,
"acc": 0.3997491582259886,
"acc_stderr": 0.009384299684412923
},
"harness|drop|3": {
"em": 0.0018875838926174498,
"em_stderr": 0.0004445109990558761,
"f1": 0.05687290268456382,
"f1_stderr": 0.0013311620250832507
},
"harness|gsm8k|5": {
"acc": 0.058377558756633814,
"acc_stderr": 0.0064580835578324685
},
"harness|winogrande|5": {
"acc": 0.7411207576953434,
"acc_stderr": 0.012310515810993376
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
fake-news-UFG/central_de_fatos | 2023-08-18T21:04:07.000Z | [
"task_categories:text-classification",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:pt",
"license:cc-by-4.0",
"region:us"
] | fake-news-UFG | null | null | null | 0 | 3 | ---
license: cc-by-4.0
pretty_name: Central de Fatos
task_categories:
- text-classification
language:
- pt
language_details: pt-BR
size_categories:
- 10K<n<100K
multilinguality:
- monolingual
language_creators:
- found
DOI: 10.5281/zenodo.5191798
---
# Central de Fatos
## Dataset Description
- **Homepage:**
- **Repository:** [https://zenodo.org/record/5191798](https://zenodo.org/record/5191798)
- **Paper:** [https://sol.sbc.org.br/index.php/dsw/article/view/17421/17257](https://sol.sbc.org.br/index.php/dsw/article/view/17421/17257)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
In recent times, the interest for research dissecting the dissemination and prevention of misinformation in the online environment has spiked dramatically.
Given that scenario, a recurring obstacle is the unavailability of public datasets containing fact-checked instances.
In this work, we performed an extensive data collection of such instances from the better part of all major internationally recognized Brazilian fact-checking agencies.
Particularly, this paper offers the research community a novel dataset containing fact-checks from various trustworthy sources regarding a wide range of topics.
In total, the resulting collection encompasses 11647 fact-check instances collected across 6 different agencies that can be used for several studies in the contexts of identifying and combating misinformation on digital platforms in Brazil.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
The dataset is in Portuguese.
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use "Central de Fatos", please cite:
```bibtex
@inproceedings{dsw,
author = {João Couto and Breno Pimenta and Igor M. de Araújo and Samuel Assis and Julio C. S. Reis and Ana Paula da Silva and Jussara Almeida and Fabrício Benevenuto},
title = {Central de Fatos: Um Repositório de Checagens de Fatos},
booktitle = {Anais do III Dataset Showcase Workshop},
location = {Rio de Janeiro},
year = {2021},
keywords = {},
issn = {0000-0000},
pages = {128--137},
publisher = {SBC},
address = {Porto Alegre, RS, Brasil},
doi = {10.5753/dsw.2021.17421},
url = {https://sol.sbc.org.br/index.php/dsw/article/view/17421}
}
```
### Contributions
Thanks to [@ju-resplande](https://github.com/ju-resplande) for adding this dataset. |
ticoAg/shibing624-medical-pretrain | 2023-08-18T14:37:28.000Z | [
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:zh",
"language:en",
"license:apache-2.0",
"text-generation",
"region:us"
] | ticoAg | null | null | null | 4 | 3 | ---
license: apache-2.0
language:
- zh
- en
tags:
- text-generation
pretty_name: medical
task_categories:
- text-generation
size_categories:
- 1M<n<10M
---
# Dataset Card for medical
中文医疗数据集
- LLM Supervised Finetuning repository: https://github.com/shibing624/textgen
- MeidcalGPT repository: https://github.com/shibing624/MedicalGPT
## Dataset Description
medical is a Chinese Medical dataset. 医疗数据集,可用于医疗领域大模型训练。
```
tree medical
|-- finetune # 监督微调数据集,可用于SFT和RLHF
| |-- test_en_1.json
| |-- test_zh_0.json
| |-- train_en_1.json
| |-- train_zh_0.json
| |-- valid_en_1.json
| `-- valid_zh_0.json
|-- medical.py # hf dataset 数据展示用
|-- pretrain # 二次预训练数据集
| |-- medical_book_zh.json
| |-- test_encyclopedia.json
| |-- train_encyclopedia.json
| `-- valid_encyclopedia.json
|-- README.md
`-- reward # 奖励模型数据集
|-- test.json
|-- train.json
`-- valid.json
```
### Original Dataset Summary
#### pretrain
- train_encyclopedia.json: 共36万条,来自医疗百科数据[FreedomIntelligence/huatuo_encyclopedia_qa](https://huggingface.co/datasets/FreedomIntelligence/huatuo_encyclopedia_qa) , 拼接 questions 和 answers,形成 text 文本字段,语句通顺,用于预训练注入医疗知识。
- medical_book_zh.json: 共8475条,来自医疗教材的文本数据,来源:https://github.com/jind11/MedQA, 原始数据集:[google drive](https://drive.google.com/u/0/uc?export=download&confirm=t&id=1ImYUSLk9JbgHXOemfvyiDiirluZHPeQw) ,只对长段落切分为2048字的小段落了。
#### finetune
- train_zh_0.json: 共195万条,来自1)中文医疗对话数据集[Toyhom/Chinese-medical-dialogue-data](https://github.com/Toyhom/Chinese-medical-dialogue-data)的六个科室医疗问诊数据,
有79万条;2)在线医疗百科 huatuo_encyclopedia_qa ,有36万条;3)医疗知识图谱 huatuo_knowledge_graph_qa,有79万条。三部分合并,共195万条。
- train_en_1.json:共11万条,来自英文医疗问诊对话数据[Kent0n-Li/ChatDoctor](https://github.com/Kent0n-Li/ChatDoctor),合并了HealthCareMagic-100k、GenMedGPT-5k 数据集,共11万条。
#### reward
- train.json 共4000条,问题来自中文医疗对话数据集[Toyhom/Chinese-medical-dialogue-data](https://github.com/Toyhom/Chinese-medical-dialogue-data)的随机4000条提问,`response_chosen`来自该数据集的医生答复,
`response_rejected`来自本草模型[SCIR-HI/Huatuo-Llama-Med-Chinese](https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese)的答复。
### Supported Tasks and Leaderboards
中文医疗对话模型
The dataset designed for medical task training pretrained language models.
### Languages
The data are in Chinese.
## Dataset Structure
### Data Instances
An example of "train" looks as follows:
head pretrain/train_encyclopedia.json
```json
{"text": "怀孕后嘴巴很淡怎么办?有孕妇在怀孕之后,发现自己嘴巴比较淡,出现这种情况的原因其实也非常的复杂,首先和妊娠反应有直接的关系,这是一种正常的情况,另外有些孕妇平常不注意口腔卫生,舌苔比较厚或者自己有了一些消化系统方面的疾病,这就要求人们必须要及时的进行处理。女性在怀孕之后,身体就会出现一些明显的变化,首先人们月经会停止,另外也会有恶心、呕吐等一些妊娠反应,不过这些都是正常的。有些孕妇发现自己在怀孕之后,口味发生了很大的变化,嘴巴变得非常的淡。其实这也和激素变化有直接的关系,可能是妊娠反应所致,在怀孕期间,因为受到体内激素水平的变化,所以就会有肠胃系统的改变,人们可能会出现食欲不振,消化不良等症状表现,也有一些孕妇会发现自己嘴巴没有味道,会有口苦的症状,而这也是正常的孕期反应,人们在平常要多喝一些水,多吃一些清淡营养的食物慢慢就会改善。也有可能是舌苔过厚所致,孕妇嘴巴里面没有味道,很有可能是舌苔比较重、舌苔过厚导致的,这样就会影响到味蕾对味道的敏感度,不仅嘴巴里面没有味道,甚至有些孕妇在说话的时候也会有口臭,这就要求人们在每天早上漱口的时候,必须要用牙刷刷舌苔开始,不要清理的特别深,以免人们会有呕吐,慢慢习惯之后再往深一点的清洗,一般2到3天就会得到改善。嘴巴感到比较淡,其实也和脾胃虚寒有直接的关系,消化系统疾病,内分泌疾病,营养不良等,但有可能导致舌头部位因为味蕾的敏感度下降,产生口淡之感,患者会有食欲不振的表现,发现病症及时就诊治疗。"}
```
head finetune/train_zh_0.json
```json
{"instruction": "曲匹地尔片的用法用量", "input": "", "output": "注意:同种药品可由于不同的包装规格有不同的用法或用量。本文只供参考。如果不确定,请参看药品随带的说明书或向医生询问。口服。一次50~100mg(1-2片),3次/日,或遵医嘱。"}
```
head finetune/train_en_1.json
```json
{"instruction": "If you are a doctor, please answer the medical questions based on the patient's description.", "input": "Doctor, I have been experiencing sudden and frequent panic attacks. I don't know what to do.", "output": "Well, based on what you're telling me, it sounds like you may be suffering from panic disorder. The best course of action is to start with psychotherapy and mental health counseling. Additionally, we should conduct an electrocardiogram to make sure that there are no physical issues causing your panic attacks. We will also need to perform a depression screen and a toxicology screen to rule out any other underlying causes. Finally, I would recommend a comprehensive psychological and psychiatric evaluation and therapy to help manage your symptoms."}
```
head reward/train.json
```json
{"question": "孩子感统失调,学习不行怎么办?,孩子说话晚,走路晚,现在小学二年级,学习跟不上,理解力差,运动协调性差,家里很着急,不知怎么办。", "response_chosen": "病情分析:你好!孩子说话晚,走路也晚,很可能是大脑本身发育不好引起的发育迟缓。而五岁时所致的智力检查为临界范围,那就是说孩子的智商是有问题的,也应考虑与大脑发育不好有关。指导意见:人的大脑在头一年发育最快,可塑性最强,在头三年可塑性还是可以的,超过三岁再进行训练,效果就不怎么好了。建议再给孩子做一做智力测试,如果孩子的智商还是在临界范围,那就要考虑让孩子去特殊学校进行康复训练,而不是继续在普通小学就读,否则对孩子来说,就是强人所难了。希望自己的孩子能聪明,这是每个家长都会有的心愿,但如果孩子自身的条件就是不能跟上同龄孩子,那家长也要面对这个事实的,对吗?医生询问:", "response_rejected": "建议家长先带孩子去正规医院做全面检查以确定病因和病情严重程度;同时可以进行物理治疗、康复训练等辅助治疗方法。"}
```
### Data Fields
#### 预训练数据集 pretrain
字段解释:
- text: 文本
#### 指令微调数据集 finetune
字段解释:
- instruction: 指令
- input:问题(可为空)
- output:答复
#### 奖励模型数据集 reward
字段解释:
- question: 问题
- response_chosen: 优质回答
- response_rejected: 低质回答
### Data Splits
```
> wc -l medical/*/*
500 medical/finetune/test_en_1.json
500 medical/finetune/test_zh_0.json
116617 medical/finetune/train_en_1.json
1949972 medical/finetune/train_zh_0.json
500 medical/finetune/valid_en_1.json
500 medical/finetune/valid_zh_0.json
8475 medical/pretrain/medical_book_zh.json
500 medical/pretrain/test_encyclopedia.json
361420 medical/pretrain/train_encyclopedia.json
500 medical/pretrain/valid_encyclopedia.json
100 medical/reward/test.json
3800 medical/reward/train.json
100 medical/reward/valid.json
2443484 total
```
### Licensing Information
The dataset is available under the Apache 2.0.
### Citation Information
- https://github.com/Toyhom/Chinese-medical-dialogue-data
- https://github.com/FreedomIntelligence/Huatuo-26M/blob/main/README_zh-CN.md
- https://huggingface.co/datasets/FreedomIntelligence/huatuo_encyclopedia_qa
- https://huggingface.co/datasets/FreedomIntelligence/huatuo_knowledge_graph_qa
- https://github.com/Kent0n-Li/ChatDoctor
附上几个优质的reward model dataset:
- https://huggingface.co/datasets/Dahoas/synthetic-instruct-gptj-pairwise
- https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
- https://huggingface.co/datasets/Cohere/miracl-zh-queries-22-12
- https://huggingface.co/datasets/Dahoas/rm-static
### Contributions
[shibing624](https://github.com/shibing624) 整理并上传
|
fake-news-UFG/FakeNewsSet | 2023-08-18T17:36:21.000Z | [
"task_categories:text-classification",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:n<1K",
"language:pt",
"license:mit",
"region:us"
] | fake-news-UFG | \ | @inproceedings{10.1145/3428658.3430965,
author = {da Silva, Fl\'{a}vio Roberto Matias and Freire, Paulo M\'{a}rcio Souza and de Souza, Marcelo Pereira and de A. B. Plenamente, Gustavo and Goldschmidt, Ronaldo Ribeiro},
title = {FakeNewsSetGen: A Process to Build Datasets That Support Comparison Among Fake News Detection Methods},
year = {2020},
isbn = {9781450381963},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3428658.3430965},
doi = {10.1145/3428658.3430965},
abstract = {Due to easy access and low cost, social media online news consumption has increased significantly for the last decade. Despite their benefits, some social media allow anyone to post news with intense spreading power, which amplifies an old problem: the dissemination of Fake News. In the face of this scenario, several machine learning-based methods to automatically detect Fake News (MLFN) have been proposed. All of them require datasets to train and evaluate their detection models. Although recent MLFN were designed to consider data regarding the news propagation on social media, most of the few available datasets do not contain this kind of data. Hence, comparing the performances amid those recent MLFN and the others is restricted to a very limited number of datasets. Moreover, all existing datasets with propagation data do not contain news in Portuguese, which impairs the evaluation of the MLFN in this language. Thus, this work proposes FakeNewsSetGen, a process that builds Fake News datasets that contain news propagation data and support comparison amid the state-of-the-art MLFN. FakeNewsSetGen's software engineering process was guided to include all kind of data required by the existing MLFN. In order to illustrate FakeNewsSetGen's viability and adequacy, a case study was carried out. It encompassed the implementation of a FakeNewsSetGen prototype and the application of this prototype to create a dataset called FakeNewsSet, with news in Portuguese. Five MLFN with different kind of data requirements (two of them demanding news propagation data) were applied to FakeNewsSet and compared, demonstrating the potential use of both the proposed process and the created dataset.},
booktitle = {Proceedings of the Brazilian Symposium on Multimedia and the Web},
pages = {241–248},
numpages = {8},
keywords = {Fake News detection, Dataset building process, social media},
location = {S\~{a}o Lu\'{\i}s, Brazil},
series = {WebMedia '20}
} | null | 0 | 3 | ---
license: mit
task_categories:
- text-classification
language:
- pt
size_categories:
- n<1K
language_details: pt-BR
multilinguality:
- monolingual
language_creators:
- found
---
# FakeNewsSet
## Dataset Description
- **Homepage:**
- **Repository:** [https://dl.acm.org/doi/abs/10.1145/3428658.3430965](https://dl.acm.org/doi/abs/10.1145/3428658.3430965)
- **Paper:** [https://dl.acm.org/doi/abs/10.1145/3428658.3430965](https://dl.acm.org/doi/abs/10.1145/3428658.3430965)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
The dataset is in Portuguese.
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use "FakeNewsSet", please cite:
```bibtex
@inproceedings{10.1145/3428658.3430965,
author = {da Silva, Fl\'{a}vio Roberto Matias and Freire, Paulo M\'{a}rcio Souza and de Souza, Marcelo Pereira and de A. B. Plenamente, Gustavo and Goldschmidt, Ronaldo Ribeiro},
title = {FakeNewsSetGen: A Process to Build Datasets That Support Comparison Among Fake News Detection Methods},
year = {2020},
isbn = {9781450381963},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3428658.3430965},
doi = {10.1145/3428658.3430965},
abstract = {Due to easy access and low cost, social media online news consumption has increased significantly for the last decade. Despite their benefits, some social media allow anyone to post news with intense spreading power, which amplifies an old problem: the dissemination of Fake News. In the face of this scenario, several machine learning-based methods to automatically detect Fake News (MLFN) have been proposed. All of them require datasets to train and evaluate their detection models. Although recent MLFN were designed to consider data regarding the news propagation on social media, most of the few available datasets do not contain this kind of data. Hence, comparing the performances amid those recent MLFN and the others is restricted to a very limited number of datasets. Moreover, all existing datasets with propagation data do not contain news in Portuguese, which impairs the evaluation of the MLFN in this language. Thus, this work proposes FakeNewsSetGen, a process that builds Fake News datasets that contain news propagation data and support comparison amid the state-of-the-art MLFN. FakeNewsSetGen's software engineering process was guided to include all kind of data required by the existing MLFN. In order to illustrate FakeNewsSetGen's viability and adequacy, a case study was carried out. It encompassed the implementation of a FakeNewsSetGen prototype and the application of this prototype to create a dataset called FakeNewsSet, with news in Portuguese. Five MLFN with different kind of data requirements (two of them demanding news propagation data) were applied to FakeNewsSet and compared, demonstrating the potential use of both the proposed process and the created dataset.},
booktitle = {Proceedings of the Brazilian Symposium on Multimedia and the Web},
pages = {241–248},
numpages = {8},
keywords = {Fake News detection, Dataset building process, social media},
location = {S\~{a}o Lu\'{\i}s, Brazil},
series = {WebMedia '20}
}
```
### Contributions
Thanks to [@ju-resplande](https://github.com/ju-resplande) for adding this dataset. |
ticoAg/Medical-Dialogue-System | 2023-08-19T10:57:30.000Z | [
"task_categories:question-answering",
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:zh",
"license:apache-2.0",
"region:us"
] | ticoAg | null | null | null | 1 | 3 | ---
num rows: 3206606
file size: 2.09 GB
license: apache-2.0
task_categories:
- question-answering
- text-generation
language:
- zh
size_categories:
- 1M<n<10M
---
## describe
非常navie的场景对话,但可能出现真实场景信息,比如XX医院,XX医生
对纯指令数据质量要求较高的需要进一步清洗,只用来健康场景finetune maybe enough
## from
[[Medical-Dialogue-System]](https://github.com/UCSD-AI4H/Medical-Dialogue-System)
*[[medical_dialog]](https://huggingface.co/datasets/medical_dialog)
## format
```json
{
"instruction": null,
"input": "不知道,我是在09年8月份,白天出了很多的汗,晚上睡觉突然醒来,看房子天晕地转,过了大约也就一分钟的样子,就不转了.但头向左转动就又转,左边头皮还发麻.第二天起来,人没有精神,过了段时间.病情时轻时重,好像是躺在床上向右人就一上晕了.但时间不长.有一天开了一天的车,晚上先是有点头晕,走路不稳,上床休息,但突然后脑根部特别疼,到了第二天也不疼了.到现在也没有疼过.现在就是躺下和起床特别晕(头向右和头向上或向下),走路不稳.特别是站久了,就要倒了感觉.另外平常,脑袋感觉昏沉沉的,有时眼睛看东西跟不上速度,要晕的,晕的时候是脑袋里跟一片去飘过的。",
"output": "你得的是颈椎间盘突出,可以先做保守治疗。",
"history": [
[
"但,很多医生看了片子,说是张口位片枢椎似乎有些旋转移位 ,不知有没有啊。",
"枢椎旋转移位不太可能,你的片子不是很清楚。请咨询我院骨科。"
],
[
"好的,谢谢大夫,祝您新春愉快。",
"不客气!"
]
]
}
```
## usage
```pyth
from datasets import load_dataset
ds = load_dataset("ticoAg/Medical-Dialogue-System")
```
## process script
```python
data_dir = Path("medical_dialog\data\processed-chinese")
raw_train_ds = loadJS(data_dir.joinpath("train_data.json"))
raw_test_ds = loadJS(data_dir.joinpath("test_data.json"))
raw_valid_ds = loadJS(data_dir.joinpath("validate_data.json"))
raw_ds = raw_train_ds + raw_test_ds + raw_valid_ds
_ds = []
for i in tqdm(raw_ds):
_diag = [{"role": dialog[:2], "content": dialog[3:]} for dialog in i]
meta_data = sft_meta(input=_diag[0]['content'], output=_diag[1]['content'])
if len(_diag[1]['content']) <= 6: continue # 过滤掉太短的单次回复
if len(_diag) > 2:
meta_data['history'] = [[_diag[2*idx]['content'], _diag[2*idx+1]['content']] for idx in range(len(_diag)//2)][1:]
meta_data = sortDict(meta_data)
_ds += [meta_data]
``` |
rajuptvs/English-to-hindi-podcast-translation | 2023-08-18T20:07:47.000Z | [
"region:us"
] | rajuptvs | null | null | null | 0 | 3 | ---
dataset_info:
features:
- name: video_id
dtype: string
- name: English subtitles
dtype: string
- name: Hindi subtitles
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 1827416
num_examples: 11427
download_size: 784942
dataset_size: 1827416
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "en-hi"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
LEAP/subsampled_low_res | 2023-10-09T16:42:18.000Z | [
"arxiv:2306.08754",
"region:us"
] | LEAP | null | null | null | 1 | 3 | Inputs and targets in this dataset are pre-normalized and scaled with .nc files found on the GitHub repo:
https://github.com/leap-stc/ClimSim/tree/main/preprocessing/normalizations
Read more: https://arxiv.org/abs/2306.08754. |
sagecontinuum/snowdataset | 2023-09-11T20:56:52.000Z | [
"task_categories:image-classification",
"task_ids:multi-label-image-classification",
"license:mit",
"climate",
"region:us"
] | sagecontinuum | Images collected by W014 and W083 at the Bad River site. | null | null | 0 | 3 | ---
dataset_info:
features:
- name: image
dtype: image
- name: path
dtype: string
- name: snow
dtype:
class_label:
names:
'0': False
'1': True
- name: day
dtype: bool
- name: node
dtype: string
splits:
- name: full
num_bytes: 845769
num_examples: 3563
download_size: 4740076026
dataset_size: 845769
tags:
- climate
task_categories:
- image-classification
task_ids:
- multi-label-image-classification
license: mit
---
# Images from the Bad River site in Northern Wisconsin
- **Homepage:** [Sage Continuum](https://sagecontinuum.org/)
- **Author:** Alex Arnold, Northwestern University
- **Mentors:** Bhupendra Raut, Seongha Park
- **Repository:** [GitHub Repository](https://github.com/waggle-sensor/summer2023/tree/main/Arnold)
# Introduction
Ice and snowfall are incredibly important parts of a river ecosystem. The Bad River is home to wild rice, which is very temperamental and prone to natural boom/bust years. Having a snow classifier can be used to create a larger dataset of snow that can be used for a variety of these additional tasks including assisting with predicting wild rice yields.
# The Data
Two Waggle nodes were collecting both images and other data from the Bad River in the past year. The W014 Waggle node was collecting data in 2022 up until December when it went offline, In January a second node (W083) started collecting images pointing at essentially the same spot. This gave me a collection of 3500 images to work with. Luckily about half of them had snow of some kind and half did not so there weren't any major class imbalance problems. One of the big decisions I had to make was when to count an image as having snow. Did a few patches count? Did a light dusting of snow count? In the end, I elected to count _any_ snow on the ground to simplify the problem. The two images below are from W014 and W083 respectively.


The nodes took a picture once every hour, so some images were at night and too dark to see. Images where I couldn't discern whether there was snow or not (snow fell at night at an unclear time) were discarded from the dataset. Darker images were still included if I could confirm that they contained snow.
# Approach
First, the images needed to be preprocessed and transformed. One problem snow detection runs into is the similarity between snow and clouds. Unsupervised methods based on color often classify clouds as also being snow, but this issue is solved through the use of deep learning and some more heavy-handed techniques. Neural networks (hopefully) can learn not to depend only on color but instead on other information such as texture. To help the network along I also cropped out the sky from the images in addition to other transforms such as solarization. Solarization randomly reverses the brightness of pixels over a certain threshold so it can't depend on which pixels are very bright. These changes force the model to learn to recognize snow on the ground through additional attributes in addition to color.
Our goal was to create a machine-learning model that could detect whether there was snow on the ground around the river. Convolutional neural networks are the main tool of choice for these kinds of image related tasks. They work by using a sliding "window" across an image to capture relationships and patterns between pixels across the image. This sliding window approach reduces the number of parameters and complexity of the model. There are already a multitude of pre-trained convolutional network models out there that perform well on image classification tasks, but there aren't any deep learning models trained specifically for snow detection. Luckily _transfer learning_ comes to the rescue to make training a new model incredibly easy with limited time and computational power.
Transfer learning works by taking an image classification model that someone else has already taken the time to train reusing it for a new purpose. I utilized ResNet50 [1], a popular convolutional neural network model that pioneered a technique called residual connections. Residual connections allow neural networks to optimize quickly while still being deep enough to capture complex relationships. ResNet50 is a very deep network with fifty layers (hence the name) and would take a lot of time and computing power to train even with the residual connections, but luckily some free pre-trained models are essentially plug-and-play with only small modifications. A visualization of ResNet50's architecture is seen below [2].

The theory behind transfer learning is that ResNet50 has already learned to encode certain aspects of an image that are generalizable, so all it needs is a few changes to use those lower-level features to create a new prediction. To turn the model into a snow detector, I tacked on a couple of extra linear layers at the end to generate a prediction score for whether there is snow or not. This vastly sped up training time compared to creating a whole new model.
# Results
The classifier was able to detect snow incredibly accurately from images collected from W014 and W083.

However, we wanted to ensure that the model wasn't completely overfitting to the images from these nodes and was learning something about snow. I also tested it on images from a node in Montana (W084). It didn't perform quite as well but still performed accurately enough to indicate that it wasn't overfitting horrendously. That being said, currently, the plugin is released to be used at the Bad River W083 node as it's not fit to be a general snow classifier quite yet.
# Future Steps
We weren't able to get additional data from the Bad River, but additional work could look at using these images to predict turbidity data and other information about the river. This could be used to facilitate and predict wild rice yields as well. More data from other Waggle nodes could also be used to create a more general snow classifier that could be used at other locations with more confidence, but for now it's best only at the Bad River site.
# Citations
[1] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. doi:10.1109/cvpr.2016.90
[2] https://commons.wikimedia.org/wiki/File:ResNet50.png |
ZhankuiHe/reddit_movie_small_v1 | 2023-08-20T17:23:49.000Z | [
"task_categories:conversational",
"language:en",
"recommendation",
"region:us"
] | ZhankuiHe | null | null | null | 0 | 3 | ---
task_categories:
- conversational
language:
- en
tags:
- recommendation
---
# Dataset Card for `Reddit-Movie-small-V1`
## Dataset Description
- **Homepage:** https://github.com/AaronHeee/LLMs-as-Zero-Shot-Conversational-RecSys
- **Repository:** https://github.com/AaronHeee/LLMs-as-Zero-Shot-Conversational-RecSys
- **Paper:** To appear
- **Point of Contact:** zhh004@eng.ucsd.edu
### Dataset Summary
This dataset contains the recommendation-related conversations in movie domain, only for research use in e.g., conversational recommendation, long-query retrieval tasks.
This dataset is ranging from Jan. 2022 to Dec. 2022. Another larger version dataset (from Jan. 2012 to Dec. 2022) can be found [here](https://huggingface.co/datasets/ZhankuiHe/reddit_movie_large_v1).
### Dataset Processing
We dump [Reddit](https://reddit.com) conversations from [pushshift.io](https://pushshift.io), converted them into [raw text](https://huggingface.co/datasets/ZhankuiHe/reddit_movie_raw) on Reddit about movie recommendations from five subreddits:
- [r/movies](https://www.reddit.com/r/movies/)
- [r/moviesuggestions](https://www.reddit.com/r/suggestions/)
- [r/bestofnetflix](https://www.reddit.com/r/bestofnetflix/)
- [r/nextflixbestof](https://www.reddit.com/r/netflixbestof/)
- [r/truefilm](https://www.reddit.com/r/truefilm/)
After that, we process them by:
1. extracting movie recommendation conversations;
2. recognizing movie mentions in raw text;
3. linking movie mentions to existing movie entities in [IMDB](https://imdb.com) database.
Since the raw text is quite noisy and processing is not perfect, we do observe some failure cases in our processed data. Thus we use V1 to highlight that this processed version is the first verion. Welcome to contribute to cleaner processed versions (such as V2) in the future, many thanks!
### Disclaimer
⚠️ **Please note that conversations processed from Reddit raw data may include content that is not entirely conducive to a positive experience (e.g., toxic speech). Exercise caution and discretion when utilizing this information.**
## Dataset Structure
### Data Fields
- `id2name.json` provides a lookup table (dictionary) from `itemid` (e.g., `tt0053779`) to `itemname` (e.g., `La Dolce Vita (1960)`). Note that, the `itemid` is from [IMDB](https://imdb.com), so that it can be used to align other movie recommendation datasets sharing the same `itemid`, such as [MovieLens](https://movielens.org/).
- `{train, valid, test}.csv` are question-answer pairs that can be used for training, validation and testing (split by the dialog created timestamp in their chronological order, ranging from far to recent). There are 12 columns in these `*.csv` files:
- `conv_id (string)`: Conversational ID. Since our conversations are collected from reddit posts, we generate conversations by extracting paths in a reddit thread with different replies. An example of `conv_id` is:
```
"t3_rt7enj_0/14" # -> t3_rt7enj is the ID of the first post in the thread, 0 means this is the first path extracted from this thread, and 13 means there are 13 paths in total.
```
- `turn_id (string)`: Conversational turn ID. For example:
```
"t3_rt7enj" # -> We can use (conv_id, turn_id) to uniquely define a row in this dataset.
```
- `turn_order (int64)`: No.X turn in a given conversation, which can be used to sort turns within the conversation. For example:
```
0 # -> It is the first turn in this conversation. Typically, for conversations from Reddit, the number of turns is usually not very large.
```
- `user_id (string)`: The unique user id. For example:
```
"t2_fweij" # -> user id
```
- `is_seeker (bool)`: Whether the speaker at the current turn is the seeker for recommendation or not. For example
```
true # -> It is the seeker (seeker starts a movie requesting conversation on Reddit).
```
- `utc_time (int64)`: The UTC timestamp when this conversation turn happend. For example:
```
1641234238 # -> Try `datetime.fromtimestamp(1641234238)`
```
- `upvotes (int64)`: The number of upvotes from other reddit users (it is `null` if this post is the first post in this thread, because upvotes only work for replies.). For example:
```
6 # -> 6 upvotes from other Reddit users.
```
- `processed (string)`: The role and text at this conversation turn (processed version). For example:
```
"['USER', 'We decided on tt3501632. They love it so far— very funny!']" # -> [ROLE, Processed string] after `eval()`, where we can match `tt3501632` to real item name using `id2name.json`.
```
- `raw (int64)`: The role and text at conversation turn (raw-text version). For example:
```
"['USER', 'We decided on Thor: Ragnarok. They love it so far— very funny!']" # -> [ROLE, Raw string] after `eval()`, where it is convinient to form it as "USER: We decided on Thor: Ragnarok. They love it so far— very funny!".
```
- `context_processed (string)`: The role and text pairs as the historical conversation context (processed version). For example:
```
"[['USER', 'It’s summer break ... Some of the films we have watched (and they enjoyed) in the past are tt3544112, tt1441952, tt1672078, tt0482571, tt0445590, tt0477348...'], ['SYSTEM', "I'm not big on super hero movies, but even I loved the tt2015381 movies ..."]]"
# -> [[ROLE, Processed string], [ROLE, Processed string], ...] after `eval()`, where we can match `tt******` to real item name using `id2name.json`.
```
- `context_raw (string)`: The role and text pairs as the historical conversation context (raw version). For example:
```
"[['USER', 'It’s summer break ... Some of the films we have watched (and they enjoyed) in the past are Sing Street, Salmon Fishing in the Yemen, The Life of Pi, The Prestige, LOTR Trilogy, No Country for Old Men...'], ['SYSTEM', "I'm not big on super hero movies, but even I loved the guardians of the Galaxy movies ..."]]"
# -> [[ROLE, Processed string], [ROLE, Processed string], ...] after `eval()`, where we can form "USER: ...\n SYSTEM: ...\n USER:..." easily.
```
- `context_turn_ids (string)`: The conversation context turn_ids associated with context [ROLE, Processed string] pairs. For example:
```
"['t3_8voapb', 't1_e1p0f5h'] # -> This is the `turn_id`s for the context ['USER', 'It’s summer break ...'], ['SYSTEM', "I'm not big on super hero movie...']. They can used to retrieve more related information like `utc_time` after combining with `conv_id`.
```
### Data Splits
We hold the last 20% data (in chronological order according to the created time of the conversation) as testing set. Others can be treated as training samples. We provided a suggested split to split Train into Train and Validation but you are free to try your splits.
| | Total | Train + Validation | Test |
| - | - | - | - |
| #Conv. | 171,773 | 154,597 | 17,176 |
| #Turns | 419,233 | 377,614 | 41,619 |
| #Users | 12,508 | 11,477 | 1,384 |
| #Items | 31,396 | 30,146 | 10,434 |
### Citation Information
Please cite these two papers if you used this dataset, thanks!
```bib
@inproceedings{he23large,
title = Large language models as zero-shot conversational recommenders",
author = "Zhankui He and Zhouhang Xie and Rahul Jha and Harald Steck and Dawen Liang and Yesu Feng and Bodhisattwa Majumder and Nathan Kallus and Julian McAuley",
year = "2023",
booktitle = "CIKM"
}
```
```bib
@inproceedings{baumgartner2020pushshift,
title={The pushshift reddit dataset},
author={Baumgartner, Jason and Zannettou, Savvas and Keegan, Brian and Squire, Megan and Blackburn, Jeremy},
booktitle={Proceedings of the international AAAI conference on web and social media},
volume={14},
pages={830--839},
year={2020}
}
```
Please contact [Zhankui He](https://aaronheee.github.io) if you have any questions or suggestions.
|
HoangCuongNguyen/CTI-to-MITRE-dataset | 2023-09-03T13:05:44.000Z | [
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"region:us"
] | HoangCuongNguyen | null | null | null | 1 | 3 | ---
license: apache-2.0
task_categories:
- question-answering
language:
- en
size_categories:
- 10K<n<100K
--- |
if001/oscar_2023_filtered | 2023-08-31T13:35:37.000Z | [
"task_categories:text-generation",
"language:ja",
"license:cc0-1.0",
"region:us"
] | if001 | null | null | null | 0 | 3 | ---
language:
- ja
license: cc0-1.0
task_categories:
- text-generation
dataset_info:
features:
- name: text
dtype: string
---
```
from datasets import load_dataset
ds=load_dataset("if001/oscar_2023_filtered")
ds['train']
---
Dataset({
features: ['text'],
num_rows: 312396
})
```
oscar 2023をfilterしたもの
https://huggingface.co/datasets/oscar-corpus/OSCAR-2301
詳細はコードを参照
https://github.com/if001/HojiChar_OSCAR_sample/tree/0.0.4 |
lilacai/lilac-wikitext-2-raw-v1 | 2023-10-05T14:03:27.000Z | [
"region:us"
] | lilacai | null | null | null | 0 | 3 | This dataset is generated by [Lilac](http://lilacml.com) for a HuggingFace Space: [huggingface.co/spaces/lilacai/lilac](https://huggingface.co/spaces/lilacai/lilac).
Original dataset: [https://huggingface.co/datasets/wikitext](https://huggingface.co/datasets/wikitext)
Lilac dataset config:
```namespace: lilac
name: wikitext-2-raw-v1
source:
dataset_name: wikitext
config_name: wikitext-2-raw-v1
source_name: huggingface
embeddings:
- path: text
embedding: gte-small
signals:
- path: text
signal:
signal_name: near_dup
- path: text
signal:
signal_name: pii
- path: text
signal:
signal_name: lang_detection
- path: text
signal:
signal_name: text_statistics
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: legal-termination
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: negative-sentiment
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: non-english
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: positive-sentiment
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: profanity
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: question
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: source-code
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: toxicity
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: legal-termination
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: negative-sentiment
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: non-english
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: positive-sentiment
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: profanity
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: question
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: source-code
signal_name: concept_score
- path: text
signal:
embedding: gte-small
namespace: lilac
concept_name: toxicity
signal_name: concept_score
- path: text
signal:
embedding: gte-small
signal_name: cluster_dbscan
settings:
ui:
media_paths:
- text
markdown_paths: []
preferred_embedding: gte-small
```
|
FinchResearch/OpenPlatypus-Alpaca | 2023-08-29T13:53:43.000Z | [
"size_categories:10K<n<100K",
"license:apache-2.0",
"region:us"
] | FinchResearch | null | null | null | 1 | 3 | ---
license: apache-2.0
size_categories:
- 10K<n<100K
---
### A merged dataset...
### Open-Platypus & Alpaca Data |
nojiyoon/shilla-clothing-text-and-image-dataset | 2023-08-23T01:15:58.000Z | [
"region:us"
] | nojiyoon | null | null | null | 1 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: caption
dtype: string
splits:
- name: train
num_bytes: 79876939.0
num_examples: 207
download_size: 79818809
dataset_size: 79876939.0
---
# Dataset Card for "shilla-clothing-text-and-image-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
hf-internal-testing/dummy-base64-images | 2023-08-22T17:01:11.000Z | [
"region:us"
] | hf-internal-testing | null | null | null | 0 | 3 | Entry not found |
ohicarip/deepfashion_bl2 | 2023-08-22T17:16:20.000Z | [
"region:us"
] | ohicarip | null | null | null | 1 | 3 | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 4518429847.744
num_examples: 34032
download_size: 5304374988
dataset_size: 4518429847.744
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "deepfashion_bl2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/chiyoda_kantaicollection | 2023-09-17T17:23:08.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 3 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of chiyoda_kantaicollection
This is the dataset of chiyoda_kantaicollection, containing 171 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 171 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 421 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 171 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 171 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 171 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 171 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 171 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 421 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 421 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 421 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
piotr-rybak/legal-questions | 2023-08-23T09:59:45.000Z | [
"region:us"
] | piotr-rybak | Legal Questions is a dataset for evaluating passage retrievers. | \ | null | 0 | 3 | Entry not found |
focia/yt_thumbnail_dataset | 2023-08-23T12:18:10.000Z | [
"region:us"
] | focia | null | null | null | 1 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: int64
- name: title
dtype: string
- name: videoId
dtype: string
- name: channelId
dtype: string
- name: subscribers
dtype: float64
- name: isVerified
dtype: bool
- name: keywords
dtype: string
- name: country
dtype: string
- name: description
dtype: string
- name: views
dtype: int64
- name: published
dtype: timestamp[us]
- name: length
dtype: string
- name: url
dtype: string
splits:
- name: train
num_bytes: 3917528866.3737946
num_examples: 28276
- name: test
num_bytes: 1010554492.3202056
num_examples: 7070
download_size: 5006700814
dataset_size: 4928083358.694
---
# Dataset Card for "yt_thumbnail_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
RuterNorway/Fleurs-Alpaca-EN-NO | 2023-08-23T12:43:59.000Z | [
"task_categories:translation",
"size_categories:1k<n<5k",
"language:no",
"language:en",
"license:cc-by-4.0",
"region:us"
] | RuterNorway | null | null | null | 3 | 3 | ---
language:
- no
- en
license: cc-by-4.0
task_categories:
- translation
pretty_name: Fleurs-Alpaca-EN-NO
size_categories:
- 1k<n<5k
---
<p><h1>🦙 Alpaca Translate Norwegian 🦙</h1></p>
This dataset is based on [Fleurs](https://huggingface.co/datasets/google/fleurs) from Google. We matched the English sentences with Norwegian sentences and formatted it to an Alpaca-style dataset.
## Dataset Structure
```json
{
"instruction": "Oversett teksten fra engelsk til norsk",
"input": "English string",
"output": "Norwegian string"
}
```
This dataset was created by [Ruter](https://ruter.no) during Ruter's AI Lab effort to fine-tune LLaMA-2 models for Norwegian.
## License
Following the original dataset from Google, this dataset is released under the [Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/) license.
<p><h1>🦙 Alpaca Translate Norsk 🦙</h1></p>
Dette datasettet er basert på [Fleurs](https://huggingface.co/datasets/google/fleurs) utgitt av Google. Vi har sammenstilt de engelske setningene med norske setninger og formatert det til et Alpaca-stil datasett.
## Datasettstruktur
```json
{
"instruction": "Oversett teksten fra engelsk til norsk",
"input": "English string",
"output": "Norwegian string"
}
```
Datasettet ble laget av [Ruter](https://ruter.no) AI Lab under arbeidet med å finjustere LLaMA-2-modeller for norsk.
## License
Vi følger det originale datasettet fra Google sin lisens, som er utgitt under en [Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/). |
aspringer207/PublicDomainMaps | 2023-08-23T23:28:23.000Z | [
"task_categories:token-classification",
"task_categories:text-classification",
"size_categories:n<1K",
"language:en",
"license:openrail",
"art",
"region:us"
] | aspringer207 | null | null | null | 0 | 3 | ---
license: openrail
task_categories:
- token-classification
- text-classification
language:
- en
tags:
- art
pretty_name: PDMAPS
size_categories:
- n<1K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
neil-code/samsum-test | 2023-08-24T03:07:48.000Z | [
"region:us"
] | neil-code | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: "./data/corpus-cut/train.csv"
- split: test
path: "./data/corpus-cut/test.csv"
- split: val
path: "./data/corpus-cut/val.csv"
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
AmelieSchreiber/aging_proteins | 2023-08-24T05:53:07.000Z | [
"task_categories:text-classification",
"language:en",
"license:mit",
"esm",
"esm2",
"ESM-2",
"aging proteins",
"protein laguage model",
"biology",
"region:us"
] | AmelieSchreiber | null | null | null | 0 | 3 | ---
license: mit
task_categories:
- text-classification
language:
- en
tags:
- esm
- esm2
- ESM-2
- aging proteins
- protein laguage model
- biology
---
# Description of the Dataset
This is (part of) the dataset used in
[Prediction and characterization of human ageing-related proteins by using machine learning](https://www.nature.com/articles/s41598-018-22240-w).
This can be used to train a binary sequence classifier using protein language models such as [ESM-2](https://huggingface.co/facebook/esm2_t6_8M_UR50D).
Please also see [the github for the paper](https://github.com/kerepesi/aging_ml/blob/master/aging_labels.csv) for more information.
|
Jouryjc/vm-training-data | 2023-08-24T08:49:44.000Z | [
"task_categories:text-classification",
"size_categories:1M<n<10M",
"language:zh",
"license:apache-2.0",
"region:us"
] | Jouryjc | null | null | null | 0 | 3 | ---
license: apache-2.0
task_categories:
- text-classification
language:
- zh
size_categories:
- 1M<n<10M
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
leesh7248/qa_hadogeub | 2023-08-24T10:08:32.000Z | [
"license:unknown",
"region:us"
] | leesh7248 | null | null | null | 0 | 3 | ---
license: unknown
---
|
plaguss/the_office_dialogs | 2023-08-27T14:30:10.000Z | [
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"art",
"region:us"
] | plaguss | null | null | null | 0 | 3 | ---
license: mit
language:
- en
tags:
- art
pretty_name: the_office_dialogs
size_categories:
- 10K<n<100K
splits:
- name: train
---
*This dataset is under construction*.
It contains the dialogs from [The Office](https://en.wikipedia.org/wiki/The_Office_(American_TV_series)).
Obtained from [this repo](https://github.com/brianbuie/the-office). |
seansullivan/biz-data-comm | 2023-08-25T15:12:16.000Z | [
"license:other",
"region:us"
] | seansullivan | null | null | null | 0 | 3 | ---
license: other
---
|
folkopinion/swedish-interpellation-qa | 2023-09-17T19:00:03.000Z | [
"task_categories:table-question-answering",
"size_categories:1K<n<10K",
"language:sv",
"government",
"politics",
"interpellation",
"region:us"
] | folkopinion | null | null | null | 0 | 3 | ---
task_categories:
- table-question-answering
language:
- sv
tags:
- government
- politics
- interpellation
pretty_name: Swedish Government Interpellation QA
size_categories:
- 1K<n<10K
--- |
sekarmulyani/ulasan-beauty-products | 2023-08-27T15:24:04.000Z | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:id",
"license:apache-2.0",
"doi:10.57967/hf/1055",
"region:us"
] | sekarmulyani | null | null | null | 0 | 3 | ---
license: apache-2.0
task_categories:
- text-classification
language:
- id
size_categories:
- 10K<n<100K
pretty_name: Review Dataset of Women's Beauty Product in Tokopedia and Shopee
---
# Review Dataset of Women's Beauty Product in Tokopedia and Shopee
57.2K rows of training; 3.81K rows of testing; 15.3K rows of validation
<p><small>Note: This dataset is raw data taken directly from the original source. No manual rating sorting process has been conducted on this dataset. The data is presented as it is.</small></p>
## en:
This dataset represents the outcome of collecting review data from 38 official stores that specialize in the sale of women's beauty products on the Shopee and Tokopedia platforms. The data collection process involved utilizing a scraper bot that automatically extracted these reviews from the product pages. The purpose behind implementing the scraper bot was to simplify and expedite the collection of a substantial volume of data.
Following the successful compilation of the review data, the subsequent step encompassed data normalization. Normalization was executed to establish a more organized structure for the data, rendering it ready for more advanced analyses. The normalization process applied to this dataset encompassed a sequence of steps:
> 1) Employing an emoji library to manage emoji characters present within the reviews.
> 2) Eliminating newline characters to uphold data coherence and readability.
> 3) Converting all text into lowercase to mitigate discrepancies arising from text analysis due to variations in letter casing.
These measures were adopted to ensure that the dataset adheres to a uniform format, poised for further processing within this project.
This project is oriented towards academic pursuits and is undertaken as a stipulated requirement for graduation within the Computer Science program at Universitas Amikom Purwokerto. In the context of this project, the identities of reviewers or authors of the reviews have been entirely expunged or obscured to preserve their confidentiality and privacy. Additionally, it is important to note that the **dataset's language is Indonesian**.
As an extra note, please be aware that the dataset format employs **one-hot encoding** techniques.
---
<img src="https://skripsimu.my.id/sekarapi/Klastering.webp" alt="K-Means Clustering Beauty Products Review Tokopedia and Shopee" style="max-width: 100%;">
<center><small>K-Means Clustering with 6 Clusters on Beauty Products Review</small></center>
---
# Dataset Ulasan Produk Kecantikan Wanita di Tokopedia dan Shopee
57.2K baris pelatihan; 3.81K baris pengujian; 15.3K baris testing
<p><small>Catatan: Dataset ini merupakan data mentah yang diambil langsung dari sumber asli. Tidak ada proses pensortiran rating manual yang telah dilakukan pada dataset ini. Data disajikan dalam bentuk apa adanya.</small></p>
## id:
Dataset ini adalah hasil dari pengumpulan data ulasan dari 38 toko resmi yang mengkhususkan diri dalam penjualan produk kecantikan wanita di platform Shopee dan Tokopedia. Proses pengumpulan data melibatkan penggunaan scraper bot yang secara otomatis mengambil ulasan-ulasan ini dari halaman produk. Tujuan di balik penggunaan scraper bot adalah untuk menyederhanakan dan mempercepat pengumpulan volume data yang signifikan.
Setelah berhasil mengumpulkan data ulasan, langkah berikutnya adalah normalisasi data. Normalisasi dilakukan untuk menciptakan struktur data yang lebih terorganisir, sehingga data siap untuk analisis yang lebih canggih. Proses normalisasi yang diterapkan pada dataset ini terdiri dari serangkaian langkah:
> 1) Menggunakan perpustakaan emoji untuk mengelola karakter emoji yang ada dalam ulasan.
> 2) Menghilangkan karakter baris baru untuk menjaga koherensi dan keterbacaan data.
> 3) Mengonversi seluruh teks menjadi huruf kecil untuk mengurangi perbedaan dalam analisis teks akibat variasi kapitalisasi huruf.
Langkah-langkah ini diambil untuk memastikan bahwa dataset mengikuti format yang seragam, siap untuk pemrosesan lebih lanjut dalam proyek ini.
Proyek ini ditujukan untuk pencapaian akademis dan dijalankan sebagai persyaratan kelulusan dalam program Ilmu Komputer di Universitas Amikom Purwokerto. Dalam konteks proyek ini, identitas para reviewer atau penulis ulasan telah sepenuhnya dihapus atau diaburkan untuk menjaga kerahasiaan dan privasi mereka. Selain itu, penting untuk dicatat bahwa bahasa **dataset ini berbahasa Indonesia**.
Sebagai catatan tambahan, harap diperhatikan bahwa format dataset menggunakan teknik **one-hot encoding**.
---
## BibTex:
```
@misc {sekar_mulyani_2023,
author = { {Sekar Mulyani} },
title = { ulasan-beauty-products (Revision b8202dc) },
year = 2023,
url = { https://huggingface.co/datasets/sekarmulyani/ulasan-beauty-products },
doi = { 10.57967/hf/1028 },
publisher = { Hugging Face }
}
``` |
Pretam/hi-te | 2023-08-26T10:57:32.000Z | [
"region:us"
] | Pretam | null | null | null | 0 | 3 | Entry not found |
DataStudio/vivos-vie-speech2text | 2023-08-26T12:04:29.000Z | [
"region:us"
] | DataStudio | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: transcription
dtype: string
- name: raw_transcription
dtype: string
splits:
- name: train
num_bytes: 1665722954.5
num_examples: 11420
download_size: 1636909484
dataset_size: 1665722954.5
---
# Dataset Card for "vivos-vie-speech2text"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
learn3r/SDG_scimed | 2023-08-26T21:32:18.000Z | [
"region:us"
] | learn3r | null | null | null | 0 | 3 | ---
dataset_info:
features:
- name: jargon
dtype: string
- name: definition
dtype: string
splits:
- name: train
num_bytes: 45723
num_examples: 200
download_size: 29274
dataset_size: 45723
---
# Dataset Card for "SDG_scimed"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
monsoon-nlp/asknyc-chatassistant-format | 2023-08-29T20:53:15.000Z | [
"task_categories:question-answering",
"language:en",
"license:mit",
"reddit",
"nyc",
"new york city",
"region:us"
] | monsoon-nlp | null | null | null | 0 | 3 | ---
license: mit
task_categories:
- question-answering
language:
- en
tags:
- reddit
- nyc
- new york city
---
Questions from Reddit.com/r/AskNYC, downloaded from PushShift, filtered to direct responses from humans, where the post net score is >= 3.
Collected one month of posts from each year 2015-2019 (i.e. no content from July 2019 onward)
Adapted from the CSV used to fine-tune https://huggingface.co/monsoon-nlp/gpt-nyc
Blog about the original model: https://medium.com/geekculture/gpt-nyc-part-1-9cb698b2e3d |
HoangCuongNguyen/CTI-to-MITRE-question-answers | 2023-09-03T12:28:33.000Z | [
"region:us"
] | HoangCuongNguyen | null | null | null | 0 | 3 | Entry not found |
open-llm-leaderboard/details_NousResearch__Nous-Hermes-Llama2-70b | 2023-08-27T12:43:54.000Z | [
"region:us"
] | open-llm-leaderboard | null | null | null | 0 | 3 | ---
pretty_name: Evaluation run of NousResearch/Nous-Hermes-Llama2-70b
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [NousResearch/Nous-Hermes-Llama2-70b](https://huggingface.co/NousResearch/Nous-Hermes-Llama2-70b)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 60 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_NousResearch__Nous-Hermes-Llama2-70b\"\
,\n\t\"harness_truthfulqa_mc_0\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\
\nThese are the [latest results from run 2023-08-24T16:19:15.258893](https://huggingface.co/datasets/open-llm-leaderboard/details_NousResearch__Nous-Hermes-Llama2-70b/blob/main/results_2023-08-24T16%3A19%3A15.258893.json)\
\ (note that their might be results for other tasks in the repos if successive evals\
\ didn't cover the same tasks. You find each in the results and the \"latest\" split\
\ for each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.6957673179292897,\n\
\ \"acc_stderr\": 0.030886230677725023,\n \"acc_norm\": 0.6997447643290794,\n\
\ \"acc_norm_stderr\": 0.030857325329783844,\n \"mc1\": 0.39167686658506734,\n\
\ \"mc1_stderr\": 0.017087795881769632,\n \"mc2\": 0.5504358942461541,\n\
\ \"mc2_stderr\": 0.01494092300772985\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.6313993174061433,\n \"acc_stderr\": 0.014097810678042196,\n\
\ \"acc_norm\": 0.6757679180887372,\n \"acc_norm_stderr\": 0.013678810399518826\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.6777534355706034,\n\
\ \"acc_stderr\": 0.004663817291468729,\n \"acc_norm\": 0.8680541724756025,\n\
\ \"acc_norm_stderr\": 0.0033774020414626227\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.33,\n \"acc_stderr\": 0.04725815626252606,\n \
\ \"acc_norm\": 0.33,\n \"acc_norm_stderr\": 0.04725815626252606\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.6370370370370371,\n\
\ \"acc_stderr\": 0.041539484047424,\n \"acc_norm\": 0.6370370370370371,\n\
\ \"acc_norm_stderr\": 0.041539484047424\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.8026315789473685,\n \"acc_stderr\": 0.03238981601699397,\n\
\ \"acc_norm\": 0.8026315789473685,\n \"acc_norm_stderr\": 0.03238981601699397\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.75,\n\
\ \"acc_stderr\": 0.04351941398892446,\n \"acc_norm\": 0.75,\n \
\ \"acc_norm_stderr\": 0.04351941398892446\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.720754716981132,\n \"acc_stderr\": 0.027611163402399715,\n\
\ \"acc_norm\": 0.720754716981132,\n \"acc_norm_stderr\": 0.027611163402399715\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.8402777777777778,\n\
\ \"acc_stderr\": 0.030635578972093274,\n \"acc_norm\": 0.8402777777777778,\n\
\ \"acc_norm_stderr\": 0.030635578972093274\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.47,\n \"acc_stderr\": 0.05016135580465919,\n \
\ \"acc_norm\": 0.47,\n \"acc_norm_stderr\": 0.05016135580465919\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\"\
: 0.53,\n \"acc_stderr\": 0.05016135580465919,\n \"acc_norm\": 0.53,\n\
\ \"acc_norm_stderr\": 0.05016135580465919\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.35,\n \"acc_stderr\": 0.0479372485441102,\n \
\ \"acc_norm\": 0.35,\n \"acc_norm_stderr\": 0.0479372485441102\n },\n\
\ \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.6705202312138728,\n\
\ \"acc_stderr\": 0.03583901754736412,\n \"acc_norm\": 0.6705202312138728,\n\
\ \"acc_norm_stderr\": 0.03583901754736412\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.3627450980392157,\n \"acc_stderr\": 0.04784060704105653,\n\
\ \"acc_norm\": 0.3627450980392157,\n \"acc_norm_stderr\": 0.04784060704105653\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.77,\n \"acc_stderr\": 0.04229525846816506,\n \"acc_norm\": 0.77,\n\
\ \"acc_norm_stderr\": 0.04229525846816506\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.7148936170212766,\n \"acc_stderr\": 0.029513196625539355,\n\
\ \"acc_norm\": 0.7148936170212766,\n \"acc_norm_stderr\": 0.029513196625539355\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.4298245614035088,\n\
\ \"acc_stderr\": 0.046570472605949625,\n \"acc_norm\": 0.4298245614035088,\n\
\ \"acc_norm_stderr\": 0.046570472605949625\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.6344827586206897,\n \"acc_stderr\": 0.040131241954243856,\n\
\ \"acc_norm\": 0.6344827586206897,\n \"acc_norm_stderr\": 0.040131241954243856\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.43915343915343913,\n \"acc_stderr\": 0.02555992055053101,\n \"\
acc_norm\": 0.43915343915343913,\n \"acc_norm_stderr\": 0.02555992055053101\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.47619047619047616,\n\
\ \"acc_stderr\": 0.04467062628403273,\n \"acc_norm\": 0.47619047619047616,\n\
\ \"acc_norm_stderr\": 0.04467062628403273\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.53,\n \"acc_stderr\": 0.050161355804659205,\n \
\ \"acc_norm\": 0.53,\n \"acc_norm_stderr\": 0.050161355804659205\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\"\
: 0.8032258064516129,\n \"acc_stderr\": 0.022616409420742015,\n \"\
acc_norm\": 0.8032258064516129,\n \"acc_norm_stderr\": 0.022616409420742015\n\
\ },\n \"harness|hendrycksTest-high_school_chemistry|5\": {\n \"acc\"\
: 0.5467980295566502,\n \"acc_stderr\": 0.03502544650845872,\n \"\
acc_norm\": 0.5467980295566502,\n \"acc_norm_stderr\": 0.03502544650845872\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.74,\n \"acc_stderr\": 0.044084400227680794,\n \"acc_norm\"\
: 0.74,\n \"acc_norm_stderr\": 0.044084400227680794\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.8484848484848485,\n \"acc_stderr\": 0.02799807379878168,\n\
\ \"acc_norm\": 0.8484848484848485,\n \"acc_norm_stderr\": 0.02799807379878168\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.8737373737373737,\n \"acc_stderr\": 0.02366435940288022,\n \"\
acc_norm\": 0.8737373737373737,\n \"acc_norm_stderr\": 0.02366435940288022\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.9378238341968912,\n \"acc_stderr\": 0.017426974154240528,\n\
\ \"acc_norm\": 0.9378238341968912,\n \"acc_norm_stderr\": 0.017426974154240528\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.7025641025641025,\n \"acc_stderr\": 0.023177408131465942,\n\
\ \"acc_norm\": 0.7025641025641025,\n \"acc_norm_stderr\": 0.023177408131465942\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.3111111111111111,\n \"acc_stderr\": 0.02822644674968352,\n \
\ \"acc_norm\": 0.3111111111111111,\n \"acc_norm_stderr\": 0.02822644674968352\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.7605042016806722,\n \"acc_stderr\": 0.027722065493361276,\n\
\ \"acc_norm\": 0.7605042016806722,\n \"acc_norm_stderr\": 0.027722065493361276\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.48344370860927155,\n \"acc_stderr\": 0.0408024418562897,\n \"\
acc_norm\": 0.48344370860927155,\n \"acc_norm_stderr\": 0.0408024418562897\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.8990825688073395,\n \"acc_stderr\": 0.012914673545364434,\n \"\
acc_norm\": 0.8990825688073395,\n \"acc_norm_stderr\": 0.012914673545364434\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.5972222222222222,\n \"acc_stderr\": 0.03344887382997865,\n \"\
acc_norm\": 0.5972222222222222,\n \"acc_norm_stderr\": 0.03344887382997865\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.9264705882352942,\n \"acc_stderr\": 0.01831885585008968,\n \"\
acc_norm\": 0.9264705882352942,\n \"acc_norm_stderr\": 0.01831885585008968\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.8818565400843882,\n \"acc_stderr\": 0.021011052659878463,\n \
\ \"acc_norm\": 0.8818565400843882,\n \"acc_norm_stderr\": 0.021011052659878463\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.7892376681614349,\n\
\ \"acc_stderr\": 0.02737309550054019,\n \"acc_norm\": 0.7892376681614349,\n\
\ \"acc_norm_stderr\": 0.02737309550054019\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.8625954198473282,\n \"acc_stderr\": 0.030194823996804475,\n\
\ \"acc_norm\": 0.8625954198473282,\n \"acc_norm_stderr\": 0.030194823996804475\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.8760330578512396,\n \"acc_stderr\": 0.030083098716035202,\n \"\
acc_norm\": 0.8760330578512396,\n \"acc_norm_stderr\": 0.030083098716035202\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.8333333333333334,\n\
\ \"acc_stderr\": 0.03602814176392645,\n \"acc_norm\": 0.8333333333333334,\n\
\ \"acc_norm_stderr\": 0.03602814176392645\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.8466257668711656,\n \"acc_stderr\": 0.028311601441438596,\n\
\ \"acc_norm\": 0.8466257668711656,\n \"acc_norm_stderr\": 0.028311601441438596\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.5446428571428571,\n\
\ \"acc_stderr\": 0.04726835553719098,\n \"acc_norm\": 0.5446428571428571,\n\
\ \"acc_norm_stderr\": 0.04726835553719098\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.8252427184466019,\n \"acc_stderr\": 0.0376017800602662,\n\
\ \"acc_norm\": 0.8252427184466019,\n \"acc_norm_stderr\": 0.0376017800602662\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.9017094017094017,\n\
\ \"acc_stderr\": 0.019503444900757567,\n \"acc_norm\": 0.9017094017094017,\n\
\ \"acc_norm_stderr\": 0.019503444900757567\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.71,\n \"acc_stderr\": 0.04560480215720684,\n \
\ \"acc_norm\": 0.71,\n \"acc_norm_stderr\": 0.04560480215720684\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.8582375478927203,\n\
\ \"acc_stderr\": 0.012473289071272046,\n \"acc_norm\": 0.8582375478927203,\n\
\ \"acc_norm_stderr\": 0.012473289071272046\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.7803468208092486,\n \"acc_stderr\": 0.022289638852617883,\n\
\ \"acc_norm\": 0.7803468208092486,\n \"acc_norm_stderr\": 0.022289638852617883\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.4446927374301676,\n\
\ \"acc_stderr\": 0.01661988198817702,\n \"acc_norm\": 0.4446927374301676,\n\
\ \"acc_norm_stderr\": 0.01661988198817702\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.7712418300653595,\n \"acc_stderr\": 0.024051029739912258,\n\
\ \"acc_norm\": 0.7712418300653595,\n \"acc_norm_stderr\": 0.024051029739912258\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.7717041800643086,\n\
\ \"acc_stderr\": 0.023839303311398195,\n \"acc_norm\": 0.7717041800643086,\n\
\ \"acc_norm_stderr\": 0.023839303311398195\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.8271604938271605,\n \"acc_stderr\": 0.02103851777015738,\n\
\ \"acc_norm\": 0.8271604938271605,\n \"acc_norm_stderr\": 0.02103851777015738\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.5602836879432624,\n \"acc_stderr\": 0.029609912075594113,\n \
\ \"acc_norm\": 0.5602836879432624,\n \"acc_norm_stderr\": 0.029609912075594113\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.5508474576271186,\n\
\ \"acc_stderr\": 0.012704030518851474,\n \"acc_norm\": 0.5508474576271186,\n\
\ \"acc_norm_stderr\": 0.012704030518851474\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.7389705882352942,\n \"acc_stderr\": 0.02667925227010313,\n\
\ \"acc_norm\": 0.7389705882352942,\n \"acc_norm_stderr\": 0.02667925227010313\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.7630718954248366,\n \"acc_stderr\": 0.01720166216978977,\n \
\ \"acc_norm\": 0.7630718954248366,\n \"acc_norm_stderr\": 0.01720166216978977\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.7181818181818181,\n\
\ \"acc_stderr\": 0.043091187099464585,\n \"acc_norm\": 0.7181818181818181,\n\
\ \"acc_norm_stderr\": 0.043091187099464585\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.8081632653061225,\n \"acc_stderr\": 0.025206963154225378,\n\
\ \"acc_norm\": 0.8081632653061225,\n \"acc_norm_stderr\": 0.025206963154225378\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.8706467661691543,\n\
\ \"acc_stderr\": 0.02372983088101853,\n \"acc_norm\": 0.8706467661691543,\n\
\ \"acc_norm_stderr\": 0.02372983088101853\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.91,\n \"acc_stderr\": 0.028762349126466125,\n \
\ \"acc_norm\": 0.91,\n \"acc_norm_stderr\": 0.028762349126466125\n \
\ },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.5301204819277109,\n\
\ \"acc_stderr\": 0.03885425420866767,\n \"acc_norm\": 0.5301204819277109,\n\
\ \"acc_norm_stderr\": 0.03885425420866767\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.8771929824561403,\n \"acc_stderr\": 0.025172984350155747,\n\
\ \"acc_norm\": 0.8771929824561403,\n \"acc_norm_stderr\": 0.025172984350155747\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.39167686658506734,\n\
\ \"mc1_stderr\": 0.017087795881769632,\n \"mc2\": 0.5504358942461541,\n\
\ \"mc2_stderr\": 0.01494092300772985\n }\n}\n```"
repo_url: https://huggingface.co/NousResearch/Nous-Hermes-Llama2-70b
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|arc:challenge|25_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hellaswag|10_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-24T16:19:15.258893.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-24T16:19:15.258893.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_08_24T16_19_15.258893
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-24T16:19:15.258893.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-24T16:19:15.258893.parquet'
---
# Dataset Card for Evaluation run of NousResearch/Nous-Hermes-Llama2-70b
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/NousResearch/Nous-Hermes-Llama2-70b
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [NousResearch/Nous-Hermes-Llama2-70b](https://huggingface.co/NousResearch/Nous-Hermes-Llama2-70b) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 60 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_NousResearch__Nous-Hermes-Llama2-70b",
"harness_truthfulqa_mc_0",
split="train")
```
## Latest results
These are the [latest results from run 2023-08-24T16:19:15.258893](https://huggingface.co/datasets/open-llm-leaderboard/details_NousResearch__Nous-Hermes-Llama2-70b/blob/main/results_2023-08-24T16%3A19%3A15.258893.json) (note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.6957673179292897,
"acc_stderr": 0.030886230677725023,
"acc_norm": 0.6997447643290794,
"acc_norm_stderr": 0.030857325329783844,
"mc1": 0.39167686658506734,
"mc1_stderr": 0.017087795881769632,
"mc2": 0.5504358942461541,
"mc2_stderr": 0.01494092300772985
},
"harness|arc:challenge|25": {
"acc": 0.6313993174061433,
"acc_stderr": 0.014097810678042196,
"acc_norm": 0.6757679180887372,
"acc_norm_stderr": 0.013678810399518826
},
"harness|hellaswag|10": {
"acc": 0.6777534355706034,
"acc_stderr": 0.004663817291468729,
"acc_norm": 0.8680541724756025,
"acc_norm_stderr": 0.0033774020414626227
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.33,
"acc_stderr": 0.04725815626252606,
"acc_norm": 0.33,
"acc_norm_stderr": 0.04725815626252606
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.6370370370370371,
"acc_stderr": 0.041539484047424,
"acc_norm": 0.6370370370370371,
"acc_norm_stderr": 0.041539484047424
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.8026315789473685,
"acc_stderr": 0.03238981601699397,
"acc_norm": 0.8026315789473685,
"acc_norm_stderr": 0.03238981601699397
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.75,
"acc_stderr": 0.04351941398892446,
"acc_norm": 0.75,
"acc_norm_stderr": 0.04351941398892446
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.720754716981132,
"acc_stderr": 0.027611163402399715,
"acc_norm": 0.720754716981132,
"acc_norm_stderr": 0.027611163402399715
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.8402777777777778,
"acc_stderr": 0.030635578972093274,
"acc_norm": 0.8402777777777778,
"acc_norm_stderr": 0.030635578972093274
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.47,
"acc_stderr": 0.05016135580465919,
"acc_norm": 0.47,
"acc_norm_stderr": 0.05016135580465919
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.53,
"acc_stderr": 0.05016135580465919,
"acc_norm": 0.53,
"acc_norm_stderr": 0.05016135580465919
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.35,
"acc_stderr": 0.0479372485441102,
"acc_norm": 0.35,
"acc_norm_stderr": 0.0479372485441102
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.6705202312138728,
"acc_stderr": 0.03583901754736412,
"acc_norm": 0.6705202312138728,
"acc_norm_stderr": 0.03583901754736412
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.3627450980392157,
"acc_stderr": 0.04784060704105653,
"acc_norm": 0.3627450980392157,
"acc_norm_stderr": 0.04784060704105653
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.77,
"acc_stderr": 0.04229525846816506,
"acc_norm": 0.77,
"acc_norm_stderr": 0.04229525846816506
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.7148936170212766,
"acc_stderr": 0.029513196625539355,
"acc_norm": 0.7148936170212766,
"acc_norm_stderr": 0.029513196625539355
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.4298245614035088,
"acc_stderr": 0.046570472605949625,
"acc_norm": 0.4298245614035088,
"acc_norm_stderr": 0.046570472605949625
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.6344827586206897,
"acc_stderr": 0.040131241954243856,
"acc_norm": 0.6344827586206897,
"acc_norm_stderr": 0.040131241954243856
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.43915343915343913,
"acc_stderr": 0.02555992055053101,
"acc_norm": 0.43915343915343913,
"acc_norm_stderr": 0.02555992055053101
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.47619047619047616,
"acc_stderr": 0.04467062628403273,
"acc_norm": 0.47619047619047616,
"acc_norm_stderr": 0.04467062628403273
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.53,
"acc_stderr": 0.050161355804659205,
"acc_norm": 0.53,
"acc_norm_stderr": 0.050161355804659205
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.8032258064516129,
"acc_stderr": 0.022616409420742015,
"acc_norm": 0.8032258064516129,
"acc_norm_stderr": 0.022616409420742015
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.5467980295566502,
"acc_stderr": 0.03502544650845872,
"acc_norm": 0.5467980295566502,
"acc_norm_stderr": 0.03502544650845872
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.74,
"acc_stderr": 0.044084400227680794,
"acc_norm": 0.74,
"acc_norm_stderr": 0.044084400227680794
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.8484848484848485,
"acc_stderr": 0.02799807379878168,
"acc_norm": 0.8484848484848485,
"acc_norm_stderr": 0.02799807379878168
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.8737373737373737,
"acc_stderr": 0.02366435940288022,
"acc_norm": 0.8737373737373737,
"acc_norm_stderr": 0.02366435940288022
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.9378238341968912,
"acc_stderr": 0.017426974154240528,
"acc_norm": 0.9378238341968912,
"acc_norm_stderr": 0.017426974154240528
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.7025641025641025,
"acc_stderr": 0.023177408131465942,
"acc_norm": 0.7025641025641025,
"acc_norm_stderr": 0.023177408131465942
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.3111111111111111,
"acc_stderr": 0.02822644674968352,
"acc_norm": 0.3111111111111111,
"acc_norm_stderr": 0.02822644674968352
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.7605042016806722,
"acc_stderr": 0.027722065493361276,
"acc_norm": 0.7605042016806722,
"acc_norm_stderr": 0.027722065493361276
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.48344370860927155,
"acc_stderr": 0.0408024418562897,
"acc_norm": 0.48344370860927155,
"acc_norm_stderr": 0.0408024418562897
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.8990825688073395,
"acc_stderr": 0.012914673545364434,
"acc_norm": 0.8990825688073395,
"acc_norm_stderr": 0.012914673545364434
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.5972222222222222,
"acc_stderr": 0.03344887382997865,
"acc_norm": 0.5972222222222222,
"acc_norm_stderr": 0.03344887382997865
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.9264705882352942,
"acc_stderr": 0.01831885585008968,
"acc_norm": 0.9264705882352942,
"acc_norm_stderr": 0.01831885585008968
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.8818565400843882,
"acc_stderr": 0.021011052659878463,
"acc_norm": 0.8818565400843882,
"acc_norm_stderr": 0.021011052659878463
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.7892376681614349,
"acc_stderr": 0.02737309550054019,
"acc_norm": 0.7892376681614349,
"acc_norm_stderr": 0.02737309550054019
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.8625954198473282,
"acc_stderr": 0.030194823996804475,
"acc_norm": 0.8625954198473282,
"acc_norm_stderr": 0.030194823996804475
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.8760330578512396,
"acc_stderr": 0.030083098716035202,
"acc_norm": 0.8760330578512396,
"acc_norm_stderr": 0.030083098716035202
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.8333333333333334,
"acc_stderr": 0.03602814176392645,
"acc_norm": 0.8333333333333334,
"acc_norm_stderr": 0.03602814176392645
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.8466257668711656,
"acc_stderr": 0.028311601441438596,
"acc_norm": 0.8466257668711656,
"acc_norm_stderr": 0.028311601441438596
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.5446428571428571,
"acc_stderr": 0.04726835553719098,
"acc_norm": 0.5446428571428571,
"acc_norm_stderr": 0.04726835553719098
},
"harness|hendrycksTest-management|5": {
"acc": 0.8252427184466019,
"acc_stderr": 0.0376017800602662,
"acc_norm": 0.8252427184466019,
"acc_norm_stderr": 0.0376017800602662
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.9017094017094017,
"acc_stderr": 0.019503444900757567,
"acc_norm": 0.9017094017094017,
"acc_norm_stderr": 0.019503444900757567
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.71,
"acc_stderr": 0.04560480215720684,
"acc_norm": 0.71,
"acc_norm_stderr": 0.04560480215720684
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.8582375478927203,
"acc_stderr": 0.012473289071272046,
"acc_norm": 0.8582375478927203,
"acc_norm_stderr": 0.012473289071272046
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.7803468208092486,
"acc_stderr": 0.022289638852617883,
"acc_norm": 0.7803468208092486,
"acc_norm_stderr": 0.022289638852617883
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.4446927374301676,
"acc_stderr": 0.01661988198817702,
"acc_norm": 0.4446927374301676,
"acc_norm_stderr": 0.01661988198817702
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.7712418300653595,
"acc_stderr": 0.024051029739912258,
"acc_norm": 0.7712418300653595,
"acc_norm_stderr": 0.024051029739912258
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.7717041800643086,
"acc_stderr": 0.023839303311398195,
"acc_norm": 0.7717041800643086,
"acc_norm_stderr": 0.023839303311398195
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.8271604938271605,
"acc_stderr": 0.02103851777015738,
"acc_norm": 0.8271604938271605,
"acc_norm_stderr": 0.02103851777015738
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.5602836879432624,
"acc_stderr": 0.029609912075594113,
"acc_norm": 0.5602836879432624,
"acc_norm_stderr": 0.029609912075594113
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.5508474576271186,
"acc_stderr": 0.012704030518851474,
"acc_norm": 0.5508474576271186,
"acc_norm_stderr": 0.012704030518851474
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.7389705882352942,
"acc_stderr": 0.02667925227010313,
"acc_norm": 0.7389705882352942,
"acc_norm_stderr": 0.02667925227010313
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.7630718954248366,
"acc_stderr": 0.01720166216978977,
"acc_norm": 0.7630718954248366,
"acc_norm_stderr": 0.01720166216978977
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.7181818181818181,
"acc_stderr": 0.043091187099464585,
"acc_norm": 0.7181818181818181,
"acc_norm_stderr": 0.043091187099464585
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.8081632653061225,
"acc_stderr": 0.025206963154225378,
"acc_norm": 0.8081632653061225,
"acc_norm_stderr": 0.025206963154225378
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.8706467661691543,
"acc_stderr": 0.02372983088101853,
"acc_norm": 0.8706467661691543,
"acc_norm_stderr": 0.02372983088101853
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.91,
"acc_stderr": 0.028762349126466125,
"acc_norm": 0.91,
"acc_norm_stderr": 0.028762349126466125
},
"harness|hendrycksTest-virology|5": {
"acc": 0.5301204819277109,
"acc_stderr": 0.03885425420866767,
"acc_norm": 0.5301204819277109,
"acc_norm_stderr": 0.03885425420866767
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.8771929824561403,
"acc_stderr": 0.025172984350155747,
"acc_norm": 0.8771929824561403,
"acc_norm_stderr": 0.025172984350155747
},
"harness|truthfulqa:mc|0": {
"mc1": 0.39167686658506734,
"mc1_stderr": 0.017087795881769632,
"mc2": 0.5504358942461541,
"mc2_stderr": 0.01494092300772985
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
Akshat4112/Glyphnet | 2023-08-27T12:09:19.000Z | [
"task_categories:text-classification",
"task_categories:image-classification",
"size_categories:1M<n<10M",
"language:en",
"license:apache-2.0",
"region:us"
] | Akshat4112 | null | null | null | 0 | 3 | ---
license: apache-2.0
task_categories:
- text-classification
- image-classification
language:
- en
size_categories:
- 1M<n<10M
--- |
Kant1/French_Wikibooks_articles | 2023-08-27T16:33:22.000Z | [
"task_categories:text-generation",
"language:fr",
"region:us"
] | Kant1 | null | null | null | 0 | 3 | ---
task_categories:
- text-generation
language:
- fr
---
Dump of 2023-08-20 of all french article in wikibooks
https://dumps.wikimedia.org/frwikibooks/20230820/frwikibooks-20230820-pages-articles.xml.bz2 |
thinkall/2WikiMultihopQA | 2023-08-29T00:30:26.000Z | [
"license:apache-2.0",
"region:us"
] | thinkall | null | null | null | 0 | 3 | ---
license: apache-2.0
---
Updated on https://huggingface.co/datasets/voidful/2WikiMultihopQA/blob/main/dev.json with modifications. |
Mohanrajv27/Finetuned-text-to-sql | 2023-08-28T23:19:30.000Z | [
"region:us"
] | Mohanrajv27 | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: instruction
dtype: string
- name: response
dtype: string
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 215198580.9182748
num_examples: 235987
- name: test
num_bytes: 23911156.081725195
num_examples: 26221
download_size: 85588612
dataset_size: 239109737.0
---
# Dataset Card for "Finetuned-text-to-sql"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
dadinghh2/HumTrans | 2023-09-26T06:26:09.000Z | [
"license:cc-by-nc-4.0",
"region:us"
] | dadinghh2 | null | null | null | 1 | 3 | ---
license: cc-by-nc-4.0
---
# HumTrans Dataset
- Dataset Name: HumTrans
- Dataset Type: Humming audio in .wav format and corresponding label MIDI file
- Primary Use: Humming melody transcription and as a foundation for downstream tasks such as humming melody based music generation
- Summary: 500 musical compositions of different genres and languages, 1000 music segments in total; sampled at a frequency of 44,100 Hz; approximately 56.22 hours of audio; 14,614 files in total.
- File Description: all_wav.zip includes all the humming audios in .wav format, all_midi.zip includes all the corresponding label MIDIs in .mid format. Both of these two share the same naming convention, which is personID_musicID_segmentID_repetitionID or personID_musicID_segmentID_repetitionID_[U/D/DD/DDD]. For example, F01_0005_0001_1, or F04_0055_0001_2_DD. train_valid_test_keys.json contains the official split of this dataset, including train, valid and test. |
gursi26/wikihow-cleaned | 2023-08-29T05:32:23.000Z | [
"task_categories:summarization",
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:en",
"license:cc-by-nc-sa-3.0",
"arxiv:1810.09305",
"region:us"
] | gursi26 | null | null | null | 0 | 3 | ---
license: cc-by-nc-sa-3.0
task_categories:
- summarization
- text-generation
language:
- en
size_categories:
- 100K<n<1M
---
A cleaned version of the Wikihow dataset for abstractive text summarization.
# Changes made
Changes to the original dataset include:
- All words have been made lowercase
- All punctuation removed except ".", "," and "-"
- Spaces added before and after all punctuation
- NA values dropped from dataset
- Leading and trailing newline and space characters removed
These changes allow for easier tokenization.
# Citation
```
@misc{koupaee2018wikihow,
title={WikiHow: A Large Scale Text Summarization Dataset},
author={Mahnaz Koupaee and William Yang Wang},
year={2018},
eprint={1810.09305},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
LahiruLowe/niv2_explanation_targets_h2ogpt-gm-oasst1-en-2048-falcon-40b-v2-GGML | 2023-09-09T21:05:51.000Z | [
"region:us"
] | LahiruLowe | null | null | null | 0 | 3 | ---
dataset_info:
features:
- name: original_index
dtype: int64
- name: inputs
dtype: string
- name: targets
dtype: string
- name: task_source
dtype: string
- name: task_name
dtype: string
- name: template_type
dtype: string
- name: system_message
dtype: string
- name: explained_targets
dtype: string
splits:
- name: train
num_bytes: 6693778
num_examples: 4665
download_size: 3173492
dataset_size: 6693778
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "niv2_explanation_targets_h2ogpt-gm-oasst1-en-2048-falcon-40b-v2-GGML"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mickume/fandom_dnd-5e | 2023-08-29T07:47:05.000Z | [
"region:us"
] | mickume | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 3845903
num_examples: 29619
download_size: 1830918
dataset_size: 3845903
---
# Dataset Card for "fandom_dnd-5e"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
yzhuang/autotree_automl_default-of-credit-card-clients_sgosdt_l256_d3_sd0 | 2023-08-30T16:40:45.000Z | [
"region:us"
] | yzhuang | null | null | null | 0 | 3 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: input_x
sequence:
sequence: float32
- name: input_y
sequence:
sequence: float32
- name: rtg
sequence: float64
- name: status
sequence:
sequence: float32
- name: split_threshold
sequence:
sequence: float32
- name: split_dimension
sequence: int64
splits:
- name: train
num_bytes: 308080000
num_examples: 10000
- name: validation
num_bytes: 308080000
num_examples: 10000
download_size: 181794530
dataset_size: 616160000
---
# Dataset Card for "autotree_automl_default-of-credit-card-clients_sgosdt_l256_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TaylorAI/RLCD-SFT-conversations | 2023-08-29T17:57:00.000Z | [
"region:us"
] | TaylorAI | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: '0'
dtype: string
- name: __index_level_0__
dtype: int64
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 244406994
num_examples: 167999
download_size: 137318929
dataset_size: 244406994
---
# Dataset Card for "RLCD-SFT-conversations"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
carterlabsltd/roleplay_sharegpt_20k_instruct | 2023-09-01T11:17:28.000Z | [
"region:us"
] | carterlabsltd | null | null | null | 2 | 3 | This dataset is in instruct
This dataset contains all roleplay data from gpteacher (9111 samples):
https://raw.githubusercontent.com/teknium1/GPTeacher/main/Roleplay%20Supplemental/roleplay-instruct-v2-final.json
https://raw.githubusercontent.com/teknium1/GPTeacher/main/Roleplay/roleplay-simple-deduped-roleplay-instruct.json
And 10000 datapoints from sharegpt:
https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
---
dataset_info:
features:
- name: instructions
struct:
- name: prompt
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 74202282
num_examples: 19111
download_size: 0
dataset_size: 74202282
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "roleplay_sharegpt_20k_instruct"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ironchanchellor/Metallography_segmenter_Dataset_D_LP | 2023-08-30T16:41:59.000Z | [
"region:us"
] | ironchanchellor | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: pixel_values
dtype: image
- name: label
dtype: image
splits:
- name: train
num_bytes: 29176877.0
num_examples: 128
- name: validation
num_bytes: 7735010.0
num_examples: 33
download_size: 36785589
dataset_size: 36911887.0
---
# Dataset Card for "Metallography_segmenter_Dataset_D"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
jitx/Methods2Test_java_unit_test_code | 2023-08-30T19:31:25.000Z | [
"task_categories:text-generation",
"language:en",
"license:mit",
"unit test",
"java",
"code",
"arxiv:2203.12776",
"region:us"
] | jitx | null | null | null | 1 | 3 | ---
license: mit
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: target
dtype: string
- name: src_fm
dtype: string
- name: src_fm_fc
dtype: string
- name: src_fm_fc_co
dtype: string
- name: src_fm_fc_ms
dtype: string
- name: src_fm_fc_ms_ff
dtype: string
splits:
- name: train
num_bytes: 3399525755
num_examples: 624022
- name: test
num_bytes: 907751466
num_examples: 156922
download_size: 558984469
dataset_size: 4307277221
task_categories:
- text-generation
language:
- en
tags:
- unit test
- java
- code
---
## Dataset Description
Microsoft created this large dataset of Java Junit test cases with its corresponding focal methods.
It contains 780k pairs of JUnit test cases and focal methods which were extracted from a total of 91K
Java open source project hosted on GitHub.
The mapping between test case and focal methods are based heuristics rules and Java developer's best practice.
More information could be found here:
- [methods2test Github repo](https://github.com/microsoft/methods2test)
- [Methods2Test: A dataset of focal methods mapped to test cases](https://arxiv.org/pdf/2203.12776.pdf)
## Dataset Schema
```
target: <TEST_CASE>
src_fm: <FOCAL_METHOD>
src_fm_fc: <FOCAL_CLASS_NAME> <FOCAL_METHOD>
src_fm_fc_co: <FOCAL_CLASS_NAME> <FOCAL_METHOD> <CONTRSUCTORS>
src_fm_fc_ms: <FOCAL_CLASS_NAME> <FOCAL_METHOD> <CONTRSUCTORS> <METHOD_SIGNATURES>
src_fm_fc_ms_ff: <FOCAL_CLASS_NAME> <FOCAL_METHOD> <CONTRSUCTORS> <METHOD_SIGNATURES> <FIELDS>
```
## Focal Context
- fm: this representation incorporates exclusively the source
code of the focal method. Intuitively, this contains the most
important information for generating accurate test cases for
the given method.
- fm+fc: this representations adds the focal class name, which
can provide meaningful semantic information to the model.
- fm+fc+c: this representation adds the signatures of the constructor methods of the focal class. The idea behind this
augmentation is that the test case may require instantiating
an object of the focal class in order to properly test the focal
method.
- fm+fc+c+m: this representation adds the signatures of the
other public methods in the focal class. The rationale which
motivated this inclusion is that the test case may need to
invoke other auxiliary methods within the class (e.g., getters,
setters) to set up or tear down the testing environment.
- fm+fc+c+m+f : this representation adds the public fields of
the focal class. The motivation is that test cases may need to
inspect the status of the public fields to properly test a focal
method.

The different levels of focal contexts are the following:
```
FM: focal method
FM_FC: focal method + focal class name
FM_FC_CO: focal method + focal class name + constructor signatures
FM_FC_MS: focal method + focal class name + constructor signatures + public method signatures
FM_FC_MS_FF: focal method + focal class name + constructor signatures + public method signatures + public fields
```
## Lmitations
The original authors validate the heuristics by inspecting a
statistically significant sample (confidence level of 95% within 10%
margin of error) of 97 samples from the training set. Two authors
independently evaluated the sample, then met to discuss the disagreements. We found that 90.72% of the samples have a correct
link between the test case and the corresponding focal method
## Contribution
All the thanks to the original authors. |
narySt/github_commits | 2023-09-12T21:21:08.000Z | [
"size_categories:n<1K",
"language:en",
"license:mit",
"region:us"
] | narySt | null | null | null | 0 | 3 | ---
license: mit
dataset_info:
features:
- name: input_ids
sequence: int64
- name: attention_mask
sequence: int64
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 257967900
num_examples: 20973
- name: val
num_bytes: 45891300
num_examples: 3731
download_size: 10916827
dataset_size: 303859200
language:
- en
pretty_name: github-commits
size_categories:
- n<1K
---
This dataset contains code changes in each commit of most starred python project, stored on GitHub.
## Code to reproduce the parsing process
To parse code we performed the following steps:
* Get list of most starred GitHub repos via API
* With **git** python package clone all the repos from the list to local machine and write code defference for each commit of every repo to the dataset.
* Clean dataset to remove to large commits, commits with not python code changes, commits with non-ASCII chars, etc.
* Group files changed in 1 commit into single sample of the dataset.
To reproduce these steps you need to:
1) run *src/github_parsing.ipynb* to parse repos from github
2) to clean the data and group dataset samples run *src/data_cleaning.ipynb*
## Dataset features
Dataset have the following features:
1) repo_name
2) commit_message
3) commit_changes - changes in code in all python files, contained in the commit
4) files_changed - number of files, changed in the commit
5) changes_len - number of chars in the code changes
For model training we used only *commit_message* feature as a label and *commit_changes* as an input for the model.
Code changes have the following structure:
```
<filename> name_of_the_file <filename>
code_of_changes
<commit_msg>
```
Special tokens used in the input:
* <file_name> - used to separate name of the file
* <code_del> and <code_add> used to separate added or deleted lines of code in the commit
* <commit_msg> used to separate commit message
Example of input for the model:
```
<filename> a/tests/test_constraint.py b/tests/test_constraint.py<filename>
<code_del>--- a/tests/test_constraint.py<code_del>
<code_add>+++ b/tests/test_constraint.py<code_add>
@@ -87,10 +87,15 @@ def test_accurate_approximation_when_known():
n_iter=10,
)
<code_del>- params = optimizer.res[0]["params"]<code_del>
<code_del>- x, y = params['x'], params['y']<code_del>
<code_add>+ # Exclude the last sampled point, because the constraint is not fitted on that.<code_add>
<code_add>+ res = np.array([[r['target'], r['constraint'], r['params']['x'], r['params']['y']] for r in optimizer.res[:-1]])<code_add>
<code_add>+<code_add>
<code_add>+ xy = res[:, [2, 3]]<code_add>
<code_add>+ x = res[:, 2]<code_add>
<code_add>+ y = res[:, 3]<code_add>
<code_del>- assert constraint_function(x, y) == approx(conmod.approx(np.array([x, y])), rel=1e-5, abs=1e-5)<code_del>
<code_add>+ assert constraint_function(x, y) == approx(conmod.approx(xy), rel=1e-5, abs=1e-5)<code_add>
<code_add>+ assert constraint_function(x, y) == approx(optimizer.space.constraint_values[:-1], rel=1e-5, abs=1e-5)<code_add>
def test_multiple_constraints():
<commit_msg>In case of commit with the several files changed, different files are separated with 3 blank lines.<eos>
```
In case of commit with the several files changed, different files are separated with 3 blank lines. |
ivanpanshin/piqa_qa_formatted | 2023-08-31T12:17:50.000Z | [
"region:us"
] | ivanpanshin | null | null | null | 0 | 3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 6778760
num_examples: 16113
- name: validation
num_bytes: 769417
num_examples: 1838
download_size: 2409083
dataset_size: 7548177
---
# Dataset Card for "piqa_qa_formatted"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tmnam20/SpiderInstruct | 2023-08-31T14:35:36.000Z | [
"region:us"
] | tmnam20 | Spider is a large-scale complex and cross-domain semantic parsing and text-toSQL dataset annotated by 11 college students | @article{yu2018spider,
title={Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task},
author={Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and others},
journal={arXiv preprint arXiv:1809.08887},
year={2018}
} | null | 0 | 3 | Entry not found |
mandeepbagga/phone-laptop-description | 2023-09-01T06:58:15.000Z | [
"region:us"
] | mandeepbagga | null | null | null | 0 | 3 | Entry not found |
masaenger/anat_em | 2023-09-01T07:06:12.000Z | [
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-3.0",
"region:us"
] | masaenger | The extended Anatomical Entity Mention corpus (AnatEM) consists of 1212 documents (approx. 250,000 words) manually annotated to identify over 13,000 mentions of anatomical entities. Each annotation is assigned one of 12 granularity-based types such as Cellular component, Tissue and Organ, defined with reference to the Common Anatomy Reference Ontology. | @article{pyysalo2014anatomical,
title={Anatomical entity mention recognition at literature scale},
author={Pyysalo, Sampo and Ananiadou, Sophia},
journal={Bioinformatics},
volume={30},
number={6},
pages={868--875},
year={2014},
publisher={Oxford University Press}
} | null | 0 | 3 |
---
language:
- en
bigbio_language:
- English
license: cc-by-sa-3.0
multilinguality: monolingual
bigbio_license_shortname: CC_BY_SA_3p0
pretty_name: AnatEM
homepage: http://nactem.ac.uk/anatomytagger/#AnatEM
bigbio_pubmed: True
bigbio_public: True
bigbio_tasks:
- NAMED_ENTITY_RECOGNITION
---
# Dataset Card for AnatEM
## Dataset Description
- **Homepage:** http://nactem.ac.uk/anatomytagger/#AnatEM
- **Pubmed:** True
- **Public:** True
- **Tasks:** NER
The extended Anatomical Entity Mention corpus (AnatEM) consists of 1212 documents (approx. 250,000 words) manually annotated to identify over 13,000 mentions of anatomical entities. Each annotation is assigned one of 12 granularity-based types such as Cellular component, Tissue and Organ, defined with reference to the Common Anatomy Reference Ontology.
## Citation Information
```
@article{pyysalo2014anatomical,
title={Anatomical entity mention recognition at literature scale},
author={Pyysalo, Sampo and Ananiadou, Sophia},
journal={Bioinformatics},
volume={30},
number={6},
pages={868--875},
year={2014},
publisher={Oxford University Press}
}
```
|
coletl/bills-congress | 2023-09-01T23:19:22.000Z | [
"task_categories:text-classification",
"language:en",
"license:afl-3.0",
"region:us"
] | coletl | null | null | null | 0 | 3 | ---
license: afl-3.0
task_categories:
- text-classification
language:
- en
pretty_name: U.S. Congressional Bills, 113–117
---
# Data Card for Congressional Bills Corpus
The raw data come from [GovInfo](govinfo.gov) bulk downloads. Files were preprocessed minimally to create pickled dataframes of the bill text.
Data from GovInfo on the bills' committees, sponsors, and cosponsors are also available.
## Topic labels
Bill text is joined to two sets of topic labels.
The Congresssional Research Service tags bills with non-exclusive topic labels.
Because these tags are numerous and specific, the top 250 most common tags were aggregated into roughly two dozen broader policy areas, which are the labels a that appear in this dataset.
The Congressional Bills Project labeled landmark legislation from 1973 to 2017 with a single major topic label and a single minor topic label.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.