
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
DeLZaky/JcommonsenseQA_plus_JapaneseLogicaldeductionQA | 2023-10-07T09:26:19.000Z | [
"region:us"
] | DeLZaky | null | null | null | 0 | 20 | ---
annotations_creators:
features:
- name: "問題"
- name: "選択肢0"
- name: "選択肢1"
- name: "選択肢2"
- name: "選択肢3"
- name: "選択肢4"
- name: "解答"
...
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
DeLZaky/JapaneseSummalization_task | 2023-10-07T08:29:27.000Z | [
"region:us"
] | DeLZaky | null | null | null | 0 | 20 | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/datasets-cards
{}
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
princeton-nlp/SWE-bench | 2023-10-10T19:25:47.000Z | [
"region:us"
] | princeton-nlp | null | null | null | 2 | 20 | ---
dataset_info:
features:
- name: instance_id
dtype: string
- name: base_commit
dtype: string
- name: hints_text
dtype: string
- name: created_at
dtype: string
- name: test_patch
dtype: string
- name: repo
dtype: string
- name: problem_statement
dtype: string
- name: version
dtype: string
- name: FAIL_TO_PASS
dtype: string
- name: PASS_TO_PASS
dtype: string
- name: environment_setup_commit
dtype: string
- name: patch
dtype: string
splits:
- name: train
num_bytes: 399498956
num_examples: 19008
- name: test
num_bytes: 41860075
num_examples: 2294
download_size: 125366079
dataset_size: 441359031
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
### Dataset Summary
SWE-bench is a dataset that tests systems’ ability to solve GitHub issues automatically. The dataset collects 2,294 Issue-Pull Request pairs from 12 popular Python. Evaluation is performed by unit test verification using post-PR behavior as the reference solution.
### Supported Tasks and Leaderboards
SWE-bench proposes a new task: issue resolution provided a full repository and GitHub issue. The leaderboard can be found at www.swebench.com
### Languages
The text of the dataset is primarily English, but we make no effort to filter or otherwise clean based on language type.
## Dataset Structure
### Data Instances
An example of a SWE-bench datum is as follows:
```
instance_id: (str) - A formatted instance identifier, usually as repo_owner__repo_name-PR-number.
patch: (str) - The gold patch, the patch generated by the PR (minus test-related code), that resolved the issue.
repo: (str) - The repository owner/name identifier from GitHub.
base_commit: (str) - The commit hash of the repository representing the HEAD of the repository before the solution PR is applied.
hints_text: (str) - Comments made on the issue prior to the creation of the solution PR’s first commit creation date.
created_at: (str) - The creation date of the pull request.
test_patch: (str) - A test-file patch that was contributed by the solution PR.
Problem_statement: (str) - The issue title and body.
Version: (str) - Installation version to use for running evaluation.
environment_setup_commit: (str) - commit hash to use for environment setup and installation.
FAIL_TO_PASS: (str) - A json list of strings that represent the set of tests resolved by the PR and tied to the issue resolution.
PASS_TO_PASS: (str) - A json list of strings that represent tests that should pass before and after the PR application.
```
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
kor_3i4k | 2023-01-25T14:33:43.000Z | [
"task_categories:text-classification",
"task_ids:intent-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:ko",
"license:cc-by-4.0",
"arxiv:1811.04231",
... | null | This dataset is designed to identify speaker intention based on real-life spoken utterance in Korean into one of
7 categories: fragment, description, question, command, rhetorical question, rhetorical command, utterances. | @article{cho2018speech,
title={Speech Intention Understanding in a Head-final Language: A Disambiguation Utilizing Intonation-dependency},
author={Cho, Won Ik and Lee, Hyeon Seung and Yoon, Ji Won and Kim, Seok Min and Kim, Nam Soo},
journal={arXiv preprint arXiv:1811.04231},
year={2018}
} | null | 1 | 19 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- ko
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- intent-classification
pretty_name: 3i4K
dataset_info:
features:
- name: label
dtype:
class_label:
names:
'0': fragment
'1': statement
'2': question
'3': command
'4': rhetorical question
'5': rhetorical command
'6': intonation-dependent utterance
- name: text
dtype: string
splits:
- name: train
num_bytes: 3102158
num_examples: 55134
- name: test
num_bytes: 344028
num_examples: 6121
download_size: 2956114
dataset_size: 3446186
---
# Dataset Card for 3i4K
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [3i4K](https://github.com/warnikchow/3i4k)
- **Repository:** [3i4K](https://github.com/warnikchow/3i4k)
- **Paper:** [Speech Intention Understanding in a Head-final Language: A Disambiguation Utilizing Intonation-dependency](https://arxiv.org/abs/1811.04231)
- **Point of Contact:** [Won Ik Cho](wicho@hi.snu.ac.kr)
### Dataset Summary
The 3i4K dataset is a set of frequently used Korean words (corpus provided by the Seoul National University Speech Language Processing Lab) and manually created questions/commands containing short utterances. The goal is to identify the speaker intention of a spoken utterance based on its transcript, and whether in some cases, requires using auxiliary acoustic features. The classification system decides whether the utterance is a fragment, statement, question, command, rhetorical question, rhetorical command, or an intonation-dependent utterance. This is important because in head-final languages like Korean, the level of the intonation plays a significant role in identifying the speaker's intention.
### Supported Tasks and Leaderboards
* `intent-classification`: The dataset can be trained with a CNN or BiLISTM-Att to identify the intent of a spoken utterance in Korean and the performance can be measured by its F1 score.
### Languages
The text in the dataset is in Korean and the associated is BCP-47 code is `ko-KR`.
## Dataset Structure
### Data Instances
An example data instance contains a short utterance and it's label:
```
{
"label": 3,
"text": "선수잖아 이 케이스 저 케이스 많을 거 아냐 선배라고 뭐 하나 인생에 도움도 안주는데 내가 이렇게 진지하게 나올 때 제대로 한번 조언 좀 해줘보지"
}
```
### Data Fields
* `label`: determines the intention of the utterance and can be one of `fragment` (0), `statement` (1), `question` (2), `command` (3), `rhetorical question` (4), `rhetorical command` (5) and `intonation-depedent utterance` (6).
* `text`: the text in Korean about common topics like housework, weather, transportation, etc.
### Data Splits
The data is split into a training set comrpised of 55134 examples and a test set of 6121 examples.
## Dataset Creation
### Curation Rationale
For head-final languages like Korean, intonation can be a determining factor in identifying the speaker's intention. The purpose of this dataset is to to determine whether an utterance is a fragment, statement, question, command, or a rhetorical question/command using the intonation-depedency from the head-finality. This is expected to improve language understanding of spoken Korean utterances and can be beneficial for speech-to-text applications.
### Source Data
#### Initial Data Collection and Normalization
The corpus was provided by Seoul National University Speech Language Processing Lab, a set of frequently used words from the National Institute of Korean Language and manually created commands and questions. The utterances cover topics like weather, transportation and stocks. 20k lines were randomly selected.
#### Who are the source language producers?
Korean speakers produced the commands and questions.
### Annotations
#### Annotation process
Utterances were classified into seven categories. They were provided clear instructions on the annotation guidelines (see [here](https://docs.google.com/document/d/1-dPL5MfsxLbWs7vfwczTKgBq_1DX9u1wxOgOPn1tOss/edit#) for the guidelines) and the resulting inter-annotator agreement was 0.85 and the final decision was done by majority voting.
#### Who are the annotators?
The annotation was completed by three Seoul Korean L1 speakers.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
The dataset is curated by Won Ik Cho, Hyeon Seung Lee, Ji Won Yoon, Seok Min Kim and Nam Soo Kim.
### Licensing Information
The dataset is licensed under the CC BY-SA-4.0.
### Citation Information
```
@article{cho2018speech,
title={Speech Intention Understanding in a Head-final Language: A Disambiguation Utilizing Intonation-dependency},
author={Cho, Won Ik and Lee, Hyeon Seung and Yoon, Ji Won and Kim, Seok Min and Kim, Nam Soo},
journal={arXiv preprint arXiv:1811.04231},
year={2018}
}
```
### Contributions
Thanks to [@stevhliu](https://github.com/stevhliu) for adding this dataset. |
swda | 2023-01-25T14:45:15.000Z | [
"task_categories:text-classification",
"task_ids:multi-label-classification",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:extended|other-Switchboard-1 Telephone Speech Corpus, Release 2",
"language:en",
"licens... | null | The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2 with
turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the
associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
The SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to
align the two resources. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the
conversations and their participants. | @techreport{Jurafsky-etal:1997,
Address = {Boulder, CO},
Author = {Jurafsky, Daniel and Shriberg, Elizabeth and Biasca, Debra},
Institution = {University of Colorado, Boulder Institute of Cognitive Science},
Number = {97-02},
Title = {Switchboard {SWBD}-{DAMSL} Shallow-Discourse-Function Annotation Coders Manual, Draft 13},
Year = {1997}}
@article{Shriberg-etal:1998,
Author = {Shriberg, Elizabeth and Bates, Rebecca and Taylor, Paul and Stolcke, Andreas and Jurafsky, Daniel and Ries, Klaus and Coccaro, Noah and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
Journal = {Language and Speech},
Number = {3--4},
Pages = {439--487},
Title = {Can Prosody Aid the Automatic Classification of Dialog Acts in Conversational Speech?},
Volume = {41},
Year = {1998}}
@article{Stolcke-etal:2000,
Author = {Stolcke, Andreas and Ries, Klaus and Coccaro, Noah and Shriberg, Elizabeth and Bates, Rebecca and Jurafsky, Daniel and Taylor, Paul and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
Journal = {Computational Linguistics},
Number = {3},
Pages = {339--371},
Title = {Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech},
Volume = {26},
Year = {2000}} | null | 7 | 19 | ---
annotations_creators:
- found
language_creators:
- found
language:
- en
license:
- cc-by-nc-sa-3.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- extended|other-Switchboard-1 Telephone Speech Corpus, Release 2
task_categories:
- text-classification
task_ids:
- multi-label-classification
pretty_name: The Switchboard Dialog Act Corpus (SwDA)
dataset_info:
features:
- name: swda_filename
dtype: string
- name: ptb_basename
dtype: string
- name: conversation_no
dtype: int64
- name: transcript_index
dtype: int64
- name: act_tag
dtype:
class_label:
names:
'0': b^m^r
'1': qw^r^t
'2': aa^h
'3': br^m
'4': fa^r
'5': aa,ar
'6': sd^e(^q)^r
'7': ^2
'8': sd;qy^d
'9': oo
'10': bk^m
'11': aa^t
'12': cc^t
'13': qy^d^c
'14': qo^t
'15': ng^m
'16': qw^h
'17': qo^r
'18': aa
'19': qy^d^t
'20': qrr^d
'21': br^r
'22': fx
'23': sd,qy^g
'24': ny^e
'25': ^h^t
'26': fc^m
'27': qw(^q)
'28': co
'29': o^t
'30': b^m^t
'31': qr^d
'32': qw^g
'33': ad(^q)
'34': qy(^q)
'35': na^r
'36': am^r
'37': qr^t
'38': ad^c
'39': qw^c
'40': bh^r
'41': h^t
'42': ft^m
'43': ba^r
'44': qw^d^t
'45': '%'
'46': t3
'47': nn
'48': bd
'49': h^m
'50': h^r
'51': sd^r
'52': qh^m
'53': ^q^t
'54': sv^2
'55': ft
'56': ar^m
'57': qy^h
'58': sd^e^m
'59': qh^r
'60': cc
'61': fp^m
'62': ad
'63': qo
'64': na^m^t
'65': fo^c
'66': qy
'67': sv^e^r
'68': aap
'69': 'no'
'70': aa^2
'71': sv(^q)
'72': sv^e
'73': nd
'74': '"'
'75': bf^2
'76': bk
'77': fp
'78': nn^r^t
'79': fa^c
'80': ny^t
'81': ny^c^r
'82': qw
'83': qy^t
'84': b
'85': fo
'86': qw^r
'87': am
'88': bf^t
'89': ^2^t
'90': b^2
'91': x
'92': fc
'93': qr
'94': no^t
'95': bk^t
'96': bd^r
'97': bf
'98': ^2^g
'99': qh^c
'100': ny^c
'101': sd^e^r
'102': br
'103': fe
'104': by
'105': ^2^r
'106': fc^r
'107': b^m
'108': sd,sv
'109': fa^t
'110': sv^m
'111': qrr
'112': ^h^r
'113': na
'114': fp^r
'115': o
'116': h,sd
'117': t1^t
'118': nn^r
'119': cc^r
'120': sv^c
'121': co^t
'122': qy^r
'123': sv^r
'124': qy^d^h
'125': sd
'126': nn^e
'127': ny^r
'128': b^t
'129': ba^m
'130': ar
'131': bf^r
'132': sv
'133': bh^m
'134': qy^g^t
'135': qo^d^c
'136': qo^d
'137': nd^t
'138': aa^r
'139': sd^2
'140': sv;sd
'141': qy^c^r
'142': qw^m
'143': qy^g^r
'144': no^r
'145': qh(^q)
'146': sd;sv
'147': bf(^q)
'148': +
'149': qy^2
'150': qw^d
'151': qy^g
'152': qh^g
'153': nn^t
'154': ad^r
'155': oo^t
'156': co^c
'157': ng
'158': ^q
'159': qw^d^c
'160': qrr^t
'161': ^h
'162': aap^r
'163': bc^r
'164': sd^m
'165': bk^r
'166': qy^g^c
'167': qr(^q)
'168': ng^t
'169': arp
'170': h
'171': bh
'172': sd^c
'173': ^g
'174': o^r
'175': qy^c
'176': sd^e
'177': fw
'178': ar^r
'179': qy^m
'180': bc
'181': sv^t
'182': aap^m
'183': sd;no
'184': ng^r
'185': bf^g
'186': sd^e^t
'187': o^c
'188': b^r
'189': b^m^g
'190': ba
'191': t1
'192': qy^d(^q)
'193': nn^m
'194': ny
'195': ba,fe
'196': aa^m
'197': qh
'198': na^m
'199': oo(^q)
'200': qw^t
'201': na^t
'202': qh^h
'203': qy^d^m
'204': ny^m
'205': fa
'206': qy^d
'207': fc^t
'208': sd(^q)
'209': qy^d^r
'210': bf^m
'211': sd(^q)^t
'212': ft^t
'213': ^q^r
'214': sd^t
'215': sd(^q)^r
'216': ad^t
- name: damsl_act_tag
dtype:
class_label:
names:
'0': ad
'1': qo
'2': qy
'3': arp_nd
'4': sd
'5': h
'6': bh
'7': 'no'
'8': ^2
'9': ^g
'10': ar
'11': aa
'12': sv
'13': bk
'14': fp
'15': qw
'16': b
'17': ba
'18': t1
'19': oo_co_cc
'20': +
'21': ny
'22': qw^d
'23': x
'24': qh
'25': fc
'26': fo_o_fw_"_by_bc
'27': aap_am
'28': '%'
'29': bf
'30': t3
'31': nn
'32': bd
'33': ng
'34': ^q
'35': br
'36': qy^d
'37': fa
'38': ^h
'39': b^m
'40': ft
'41': qrr
'42': na
- name: caller
dtype: string
- name: utterance_index
dtype: int64
- name: subutterance_index
dtype: int64
- name: text
dtype: string
- name: pos
dtype: string
- name: trees
dtype: string
- name: ptb_treenumbers
dtype: string
- name: talk_day
dtype: string
- name: length
dtype: int64
- name: topic_description
dtype: string
- name: prompt
dtype: string
- name: from_caller
dtype: int64
- name: from_caller_sex
dtype: string
- name: from_caller_education
dtype: int64
- name: from_caller_birth_year
dtype: int64
- name: from_caller_dialect_area
dtype: string
- name: to_caller
dtype: int64
- name: to_caller_sex
dtype: string
- name: to_caller_education
dtype: int64
- name: to_caller_birth_year
dtype: int64
- name: to_caller_dialect_area
dtype: string
splits:
- name: train
num_bytes: 128498512
num_examples: 213543
- name: validation
num_bytes: 34749819
num_examples: 56729
- name: test
num_bytes: 2560127
num_examples: 4514
download_size: 14456364
dataset_size: 165808458
---
# Dataset Card for SwDA
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [The Switchboard Dialog Act Corpus](http://compprag.christopherpotts.net/swda.html)
- **Repository:** [NathanDuran/Switchboard-Corpus](https://github.com/cgpotts/swda)
- **Paper:** [The Switchboard Dialog Act Corpus](http://compprag.christopherpotts.net/swda.html)
= **Leaderboard: [Dialogue act classification](https://github.com/sebastianruder/NLP-progress/blob/master/english/dialogue.md#dialogue-act-classification)**
- **Point of Contact:** [Christopher Potts](https://web.stanford.edu/~cgpotts/)
### Dataset Summary
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2 with
turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the
associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
The SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to
align the two resources. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the
conversations and their participants.
### Supported Tasks and Leaderboards
| Model | Accuracy | Paper / Source | Code |
| ------------- | :-----:| --- | --- |
| H-Seq2seq (Colombo et al., 2020) | 85.0 | [Guiding attention in Sequence-to-sequence models for Dialogue Act prediction](https://ojs.aaai.org/index.php/AAAI/article/view/6259/6115)
| SGNN (Ravi et al., 2018) | 83.1 | [Self-Governing Neural Networks for On-Device Short Text Classification](https://www.aclweb.org/anthology/D18-1105.pdf)
| CASA (Raheja et al., 2019) | 82.9 | [Dialogue Act Classification with Context-Aware Self-Attention](https://www.aclweb.org/anthology/N19-1373.pdf)
| DAH-CRF (Li et al., 2019) | 82.3 | [A Dual-Attention Hierarchical Recurrent Neural Network for Dialogue Act Classification](https://www.aclweb.org/anthology/K19-1036.pdf)
| ALDMN (Wan et al., 2018) | 81.5 | [Improved Dynamic Memory Network for Dialogue Act Classification with Adversarial Training](https://arxiv.org/pdf/1811.05021.pdf)
| CRF-ASN (Chen et al., 2018) | 81.3 | [Dialogue Act Recognition via CRF-Attentive Structured Network](https://arxiv.org/abs/1711.05568)
| Pretrained H-Transformer (Chapuis et al., 2020) | 79.3 | [Hierarchical Pre-training for Sequence Labelling in Spoken Dialog] (https://www.aclweb.org/anthology/2020.findings-emnlp.239)
| Bi-LSTM-CRF (Kumar et al., 2017) | 79.2 | [Dialogue Act Sequence Labeling using Hierarchical encoder with CRF](https://arxiv.org/abs/1709.04250) | [Link](https://github.com/YanWenqiang/HBLSTM-CRF) |
| RNN with 3 utterances in context (Bothe et al., 2018) | 77.34 | [A Context-based Approach for Dialogue Act Recognition using Simple Recurrent Neural Networks](https://arxiv.org/abs/1805.06280) | |
### Languages
The language supported is English.
## Dataset Structure
Utterance are tagged with the [SWBD-DAMSL](https://web.stanford.edu/~jurafsky/ws97/manual.august1.html) DA.
### Data Instances
An example from the dataset is:
`{'act_tag': 115, 'caller': 'A', 'conversation_no': 4325, 'damsl_act_tag': 26, 'from_caller': 1632, 'from_caller_birth_year': 1962, 'from_caller_dialect_area': 'WESTERN', 'from_caller_education': 2, 'from_caller_sex': 'FEMALE', 'length': 5, 'pos': 'Okay/UH ./.', 'prompt': 'FIND OUT WHAT CRITERIA THE OTHER CALLER WOULD USE IN SELECTING CHILD CARE SERVICES FOR A PRESCHOOLER. IS IT EASY OR DIFFICULT TO FIND SUCH CARE?', 'ptb_basename': '4/sw4325', 'ptb_treenumbers': '1', 'subutterance_index': 1, 'swda_filename': 'sw00utt/sw_0001_4325.utt', 'talk_day': '03/23/1992', 'text': 'Okay. /', 'to_caller': 1519, 'to_caller_birth_year': 1971, 'to_caller_dialect_area': 'SOUTH MIDLAND', 'to_caller_education': 1, 'to_caller_sex': 'FEMALE', 'topic_description': 'CHILD CARE', 'transcript_index': 0, 'trees': '(INTJ (UH Okay) (. .) (-DFL- E_S))', 'utterance_index': 1}`
### Data Fields
* `swda_filename`: (str) The filename: directory/basename.
* `ptb_basename`: (str) The Treebank filename: add ".pos" for POS and ".mrg" for trees
* `conversation_no`: (int) The conversation Id, to key into the metadata database.
* `transcript_index`: (int) The line number of this item in the transcript (counting only utt lines).
* `act_tag`: (list of str) The Dialog Act Tags (separated by ||| in the file). Check Dialog act annotations for more details.
* `damsl_act_tag`: (list of str) The Dialog Act Tags of the 217 variation tags.
* `caller`: (str) A, B, @A, @B, @@A, @@B
* `utterance_index`: (int) The encoded index of the utterance (the number in A.49, B.27, etc.)
* `subutterance_index`: (int) Utterances can be broken across line. This gives the internal position.
* `text`: (str) The text of the utterance
* `pos`: (str) The POS tagged version of the utterance, from PtbBasename+.pos
* `trees`: (str) The tree(s) containing this utterance (separated by ||| in the file). Use `[Tree.fromstring(t) for t in row_value.split("|||")]` to convert to (list of nltk.tree.Tree).
* `ptb_treenumbers`: (list of int) The tree numbers in the PtbBasename+.mrg
* `talk_day`: (str) Date of talk.
* `length`: (int) Length of talk in seconds.
* `topic_description`: (str) Short description of topic that's being discussed.
* `prompt`: (str) Long decription/query/instruction.
* `from_caller`: (int) The numerical Id of the from (A) caller.
* `from_caller_sex`: (str) MALE, FEMALE.
* `from_caller_education`: (int) Called education level 0, 1, 2, 3, 9.
* `from_caller_birth_year`: (int) Caller birth year YYYY.
* `from_caller_dialect_area`: (str) MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN.
* `to_caller`: (int) The numerical Id of the to (B) caller.
* `to_caller_sex`: (str) MALE, FEMALE.
* `to_caller_education`: (int) Called education level 0, 1, 2, 3, 9.
* `to_caller_birth_year`: (int) Caller birth year YYYY.
* `to_caller_dialect_area`: (str) MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN.
### Dialog act annotations
| | name | act_tag | example | train_count | full_count |
|----- |------------------------------- |---------------- |-------------------------------------------------- |------------- |------------ |
| 1 | Statement-non-opinion | sd | Me, I'm in the legal department. | 72824 | 75145 |
| 2 | Acknowledge (Backchannel) | b | Uh-huh. | 37096 | 38298 |
| 3 | Statement-opinion | sv | I think it's great | 25197 | 26428 |
| 4 | Agree/Accept | aa | That's exactly it. | 10820 | 11133 |
| 5 | Abandoned or Turn-Exit | % | So, - | 10569 | 15550 |
| 6 | Appreciation | ba | I can imagine. | 4633 | 4765 |
| 7 | Yes-No-Question | qy | Do you have to have any special training? | 4624 | 4727 |
| 8 | Non-verbal | x | [Laughter], [Throat_clearing] | 3548 | 3630 |
| 9 | Yes answers | ny | Yes. | 2934 | 3034 |
| 10 | Conventional-closing | fc | Well, it's been nice talking to you. | 2486 | 2582 |
| 11 | Uninterpretable | % | But, uh, yeah | 2158 | 15550 |
| 12 | Wh-Question | qw | Well, how old are you? | 1911 | 1979 |
| 13 | No answers | nn | No. | 1340 | 1377 |
| 14 | Response Acknowledgement | bk | Oh, okay. | 1277 | 1306 |
| 15 | Hedge | h | I don't know if I'm making any sense or not. | 1182 | 1226 |
| 16 | Declarative Yes-No-Question | qy^d | So you can afford to get a house? | 1174 | 1219 |
| 17 | Other | fo_o_fw_by_bc | Well give me a break, you know. | 1074 | 883 |
| 18 | Backchannel in question form | bh | Is that right? | 1019 | 1053 |
| 19 | Quotation | ^q | You can't be pregnant and have cats | 934 | 983 |
| 20 | Summarize/reformulate | bf | Oh, you mean you switched schools for the kids. | 919 | 952 |
| 21 | Affirmative non-yes answers | na | It is. | 836 | 847 |
| 22 | Action-directive | ad | Why don't you go first | 719 | 746 |
| 23 | Collaborative Completion | ^2 | Who aren't contributing. | 699 | 723 |
| 24 | Repeat-phrase | b^m | Oh, fajitas | 660 | 688 |
| 25 | Open-Question | qo | How about you? | 632 | 656 |
| 26 | Rhetorical-Questions | qh | Who would steal a newspaper? | 557 | 575 |
| 27 | Hold before answer/agreement | ^h | I'm drawing a blank. | 540 | 556 |
| 28 | Reject | ar | Well, no | 338 | 346 |
| 29 | Negative non-no answers | ng | Uh, not a whole lot. | 292 | 302 |
| 30 | Signal-non-understanding | br | Excuse me? | 288 | 298 |
| 31 | Other answers | no | I don't know | 279 | 286 |
| 32 | Conventional-opening | fp | How are you? | 220 | 225 |
| 33 | Or-Clause | qrr | or is it more of a company? | 207 | 209 |
| 34 | Dispreferred answers | arp_nd | Well, not so much that. | 205 | 207 |
| 35 | 3rd-party-talk | t3 | My goodness, Diane, get down from there. | 115 | 117 |
| 36 | Offers, Options, Commits | oo_co_cc | I'll have to check that out | 109 | 110 |
| 37 | Self-talk | t1 | What's the word I'm looking for | 102 | 103 |
| 38 | Downplayer | bd | That's all right. | 100 | 103 |
| 39 | Maybe/Accept-part | aap_am | Something like that | 98 | 105 |
| 40 | Tag-Question | ^g | Right? | 93 | 92 |
| 41 | Declarative Wh-Question | qw^d | You are what kind of buff? | 80 | 80 |
| 42 | Apology | fa | I'm sorry. | 76 | 79 |
| 43 | Thanking | ft | Hey thanks a lot | 67 | 78 |
### Data Splits
I used info from the [Probabilistic-RNN-DA-Classifier](https://github.com/NathanDuran/Probabilistic-RNN-DA-Classifier) repo:
The same training and test splits as used by [Stolcke et al. (2000)](https://web.stanford.edu/~jurafsky/ws97).
The development set is a subset of the training set to speed up development and testing used in the paper [Probabilistic Word Association for Dialogue Act Classification with Recurrent Neural Networks](https://www.researchgate.net/publication/326640934_Probabilistic_Word_Association_for_Dialogue_Act_Classification_with_Recurrent_Neural_Networks_19th_International_Conference_EANN_2018_Bristol_UK_September_3-5_2018_Proceedings).
|Dataset |# Transcripts |# Utterances |
|-----------|:-------------:|:-------------:|
|Training |1115 |192,768 |
|Validation |21 |3,196 |
|Test |19 |4,088 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
The SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to align the two resources Calhoun et al. 2010, §2.4. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the conversations and their participants.
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[Christopher Potts](https://web.stanford.edu/~cgpotts/), Stanford Linguistics.
### Licensing Information
This work is licensed under a [Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.](http://creativecommons.org/licenses/by-nc-sa/3.0/)
### Citation Information
```
@techreport{Jurafsky-etal:1997,
Address = {Boulder, CO},
Author = {Jurafsky, Daniel and Shriberg, Elizabeth and Biasca, Debra},
Institution = {University of Colorado, Boulder Institute of Cognitive Science},
Number = {97-02},
Title = {Switchboard {SWBD}-{DAMSL} Shallow-Discourse-Function Annotation Coders Manual, Draft 13},
Year = {1997}}
@article{Shriberg-etal:1998,
Author = {Shriberg, Elizabeth and Bates, Rebecca and Taylor, Paul and Stolcke, Andreas and Jurafsky, Daniel and Ries, Klaus and Coccaro, Noah and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
Journal = {Language and Speech},
Number = {3--4},
Pages = {439--487},
Title = {Can Prosody Aid the Automatic Classification of Dialog Acts in Conversational Speech?},
Volume = {41},
Year = {1998}}
@article{Stolcke-etal:2000,
Author = {Stolcke, Andreas and Ries, Klaus and Coccaro, Noah and Shriberg, Elizabeth and Bates, Rebecca and Jurafsky, Daniel and Taylor, Paul and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
Journal = {Computational Linguistics},
Number = {3},
Pages = {339--371},
Title = {Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech},
Volume = {26},
Year = {2000}}
```
### Contributions
Thanks to [@gmihaila](https://github.com/gmihaila) for adding this dataset. |
Alvenir/nst-da-16khz | 2021-11-29T08:58:25.000Z | [
"region:us"
] | Alvenir | null | null | null | 1 | 19 | # NST Danish 16kHz dataset from Sprakbanken
Data is from sprakbanken and can be accessed using following [link](https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-19/).
|
benjaminbeilharz/better_daily_dialog | 2022-01-22T18:03:59.000Z | [
"region:us"
] | benjaminbeilharz | null | null | null | 1 | 19 | Entry not found |
anjandash/java-8m-methods-v1 | 2022-07-01T20:32:32.000Z | [
"multilinguality:monolingual",
"language:java",
"license:mit",
"region:us"
] | anjandash | null | null | null | 1 | 19 | ---
language:
- java
license:
- mit
multilinguality:
- monolingual
pretty_name:
- java-8m-methods-v1
--- |
iluvvatar/NEREL | 2023-03-30T13:37:20.000Z | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"multilinguality:monolingual",
"language:ru",
"region:us"
] | iluvvatar | null | null | null | 4 | 19 | ---
language:
- ru
multilinguality:
- monolingual
task_categories:
- token-classification
task_ids:
- named-entity-recognition
pretty_name: NEREL
---
# NEREL dataset
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Structure](#dataset-structure)
- [Citation Information](#citation-information)
- [Contacts](#contacts)
## Dataset Description
NEREL dataset (https://doi.org/10.48550/arXiv.2108.13112) is
a Russian dataset for named entity recognition and relation extraction.
NEREL is significantly larger than existing Russian datasets:
to date it contains 56K annotated named entities and 39K annotated relations.
Its important difference from previous datasets is annotation of nested named
entities, as well as relations within nested entities and at the discourse
level. NEREL can facilitate development of novel models that can extract
relations between nested named entities, as well as relations on both sentence
and document levels. NEREL also contains the annotation of events involving
named entities and their roles in the events.
You can see full entity types list in a subset "ent_types"
and full list of relation types in a subset "rel_types".
## Dataset Structure
There are three "configs" or "subsets" of the dataset.
Using
`load_dataset('MalakhovIlya/NEREL', 'ent_types')['ent_types']`
you can download list of entity types (
Dataset({features: ['type', 'link']})
) where "link" is a knowledge base name used in entity linking task.
Using
`load_dataset('MalakhovIlya/NEREL', 'rel_types')['rel_types']`
you can download list of entity types (
Dataset({features: ['type', 'arg1', 'arg2']})
) where "arg1" and "arg2" are lists of entity types that can take part in such
"type" of relation. \<ENTITY> stands for any type.
Using
`load_dataset('MalakhovIlya/NEREL', 'data')` or `load_dataset('MalakhovIlya/NEREL')`
you can download the data itself,
DatasetDict with 3 splits: "train", "test" and "dev".
Each of them contains text document with annotated entities, relations and
links.
"entities" are used in named-entity recognition task (see https://en.wikipedia.org/wiki/Named-entity_recognition).
"relations" are used in relationship extraction task (see https://en.wikipedia.org/wiki/Relationship_extraction).
"links" are used in entity linking task (see https://en.wikipedia.org/wiki/Entity_linking)
Each entity is represented by a string of the following format:
`"<id>\t<type> <start> <stop>\t<text>"`, where
`<id>` is an entity id,
`<type>` is one of entity types,
`<start>` is a position of the first symbol of entity in text,
`<stop>` is the last symbol position in text +1.
Each relation is represented by a string of the following format:
`"<id>\t<type> Arg1:<arg1_id> Arg2:<arg2_id>"`, where
`<id>` is a relation id,
`<arg1_id>` and `<arg2_id>` are entity ids.
Each link is represented by a string of the following format:
`"<id>\tReference <ent_id> <link>\t<text>"`, where
`<id>` is a link id,
`<ent_id>` is an entity id,
`<link>` is a reference to knowledge base entity (example: "Wikidata:Q1879675" if link exists, else "Wikidata:NULL"),
`<text>` is a name of entity in knowledge base if link exists, else empty string.
## Citation Information
@article{loukachevitch2021nerel,
title={NEREL: A Russian Dataset with Nested Named Entities, Relations and Events},
author={Loukachevitch, Natalia and Artemova, Ekaterina and Batura, Tatiana and Braslavski, Pavel and Denisov, Ilia and Ivanov, Vladimir and Manandhar, Suresh and Pugachev, Alexander and Tutubalina, Elena},
journal={arXiv preprint arXiv:2108.13112},
year={2021}
}
|
wanyu/IteraTeR_v2 | 2022-10-24T18:58:08.000Z | [
"task_categories:text2text-generation",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"license:apache-2.0",
"conditional-text-generation",
"text-editing",
"arxiv:2204.03685",
"region:us"
] | wanyu | null | null | null | 1 | 19 | ---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
source_datasets:
- original
task_categories:
- text2text-generation
task_ids: []
pretty_name: IteraTeR_v2
language_bcp47:
- en-US
tags:
- conditional-text-generation
- text-editing
---
Paper: [Read, Revise, Repeat: A System Demonstration for Human-in-the-loop Iterative Text Revision](https://arxiv.org/abs/2204.03685)
Authors: Wanyu Du*, Zae Myung Kim*, Vipul Raheja, Dhruv Kumar, Dongyeop Kang
Github repo: https://github.com/vipulraheja/IteraTeR
Watch our system demonstration below!
[](https://www.youtube.com/watch?v=lK08tIpEoaE)
|
Bingsu/KSS_Dataset | 2022-07-02T00:10:10.000Z | [
"task_categories:text-to-speech",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:ko",
"license:cc-by-nc-sa-4.0",
"region:us"
] | Bingsu | null | null | null | 3 | 19 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- ko
license:
- cc-by-nc-sa-4.0
multilinguality:
- monolingual
pretty_name: Korean Single Speaker Speech Dataset
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-to-speech
task_ids: []
---
## Dataset Description
- **Homepage:** [Korean Single Speaker Speech Dataset](https://www.kaggle.com/datasets/bryanpark/korean-single-speaker-speech-dataset)
- **Repository:** [Kyubyong/kss](https://github.com/Kyubyong/kss)
- **Paper:** N/A
- **Leaderboard:** N/A
- **Point of Contact:** N/A
# Description of the original author
### KSS Dataset: Korean Single speaker Speech Dataset
KSS Dataset is designed for the Korean text-to-speech task. It consists of audio files recorded by a professional female voice actoress and their aligned text extracted from my books. As a copyright holder, by courtesy of the publishers, I release this dataset to the public. To my best knowledge, this is the first publicly available speech dataset for Korean.
### File Format
Each line in `transcript.v.1.3.txt` is delimited by `|` into six fields.
- A. Audio file path
- B. Original script
- C. Expanded script
- D. Decomposed script
- E. Audio duration (seconds)
- F. English translation
e.g.,
1/1_0470.wav|저는 보통 20분 정도 낮잠을 잡니다.|저는 보통 이십 분 정도 낮잠을 잡니다.|저는 보통 이십 분 정도 낮잠을 잡니다.|4.1|I usually take a nap for 20 minutes.
### Specification
- Audio File Type: wav
- Total Running Time: 12+ hours
- Sample Rate: 44,100 KHZ
- Number of Audio Files: 12,853
- Sources
- |1| [Kyubyong Park, 500 Basic Korean Verbs, Tuttle Publishing, 2015.](https://www.amazon.com/500-Basic-Korean-Verbs-Comprehensive/dp/0804846057/ref=sr_1_1?s=books&ie=UTF8&qid=1522911616&sr=1-1&keywords=kyubyong+park)|
- |2| [Kyubyong Park, 500 Basic Korean Adjectives 2nd Ed., Youkrak, 2015.](http://www.hanbooks.com/500bakoad.html)|
- |3| [Kyubyong Park, Essential Korean Vocabulary, Tuttle Publishing, 2015.](https://www.amazon.com/Essential-Korean-Vocabulary-Phrases-Fluently/dp/0804843252/ref=sr_1_3?s=books&ie=UTF8&qid=1522911806&sr=1-3&keywords=kyubyong+park)|
- |4| [Kyubyong Park, Tuttle Learner's Korean-English Dictionary, Tuttle Publishing, 2012.](https://www.amazon.com/Tuttle-Learners-Korean-English-Dictionary-Essential/dp/0804841500/ref=sr_1_8?s=books&ie=UTF8&qid=1522911806&sr=1-8&keywords=kyubyong+park)|
### License
NC-SA 4.0. You CANNOT use this dataset for ANY COMMERCIAL purpose. Otherwise, you can freely use this.
### Citation
If you want to cite KSS Dataset, please refer to this:
Kyubyong Park, KSS Dataset: Korean Single speaker Speech Dataset, https://kaggle.com/bryanpark/korean-single-speaker-speech-dataset, 2018
### Reference
Check out [this](https://github.com/Kyubyong/kss) for a project using this KSS Dataset.
### Contact
You can contact me at kbpark.linguist@gmail.com.
April, 2018.
Kyubyong Park
### Dataset Summary
12,853 Korean audio files with transcription.
### Supported Tasks and Leaderboards
text-to-speech
### Languages
korean
## Dataset Structure
### Data Instances
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("Bingsu/KSS_Dataset")
>>> dataset["train"].features
{'audio': Audio(sampling_rate=44100, mono=True, decode=True, id=None),
'original_script': Value(dtype='string', id=None),
'expanded_script': Value(dtype='string', id=None),
'decomposed_script': Value(dtype='string', id=None),
'duration': Value(dtype='float32', id=None),
'english_translation': Value(dtype='string', id=None)}
```
```python
>>> dataset["train"][0]
{'audio': {'path': None,
'array': array([ 0.00000000e+00, 3.05175781e-05, -4.57763672e-05, ...,
0.00000000e+00, -3.05175781e-05, -3.05175781e-05]),
'sampling_rate': 44100},
'original_script': '그는 괜찮은 척하려고 애쓰는 것 같았다.',
'expanded_script': '그는 괜찮은 척하려고 애쓰는 것 같았다.',
'decomposed_script': '그는 괜찮은 척하려고 애쓰는 것 같았다.',
'duration': 3.5,
'english_translation': 'He seemed to be pretending to be okay.'}
```
### Data Splits
| | train |
|---------------|------:|
| # of examples | 12853 | |
Filippo/osdg_cd | 2023-10-08T09:57:13.000Z | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"region:us"
] | Filippo | The OSDG Community Dataset (OSDG-CD) is a public dataset of thousands of text excerpts, which were validated by approximately 1,000 OSDG Community Platform (OSDG-CP) citizen scientists from over 110 countries, with respect to the Sustainable Development Goals (SDGs). | @dataset{osdg_2023_8397907,
author = {OSDG and
UNDP IICPSD SDG AI Lab and
PPMI},
title = {OSDG Community Dataset (OSDG-CD)},
month = oct,
year = 2023,
note = {{This CSV file uses UTF-8 character encoding. For
easy access on MS Excel, open the file using Data
→ From Text/CSV. Please split CSV data into
different columns by using a TAB delimiter.}},
publisher = {Zenodo},
version = {2023.10},
doi = {10.5281/zenodo.8397907},
url = {https://doi.org/10.5281/zenodo.8397907}
} | null | 1 | 19 | ---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
task_categories:
- text-classification
task_ids:
- natural-language-inference
pretty_name: OSDG Community Dataset (OSDG-CD)
dataset_info:
config_name: main_config
features:
- name: doi
dtype: string
- name: text_id
dtype: string
- name: text
dtype: string
- name: sdg
dtype: uint16
- name: label
dtype:
class_label:
names:
'0': SDG 1
'1': SDG 2
'2': SDG 3
'3': SDG 4
'4': SDG 5
'5': SDG 6
'6': SDG 7
'7': SDG 8
'8': SDG 9
'9': SDG 10
'10': SDG 11
'11': SDG 12
'12': SDG 13
'13': SDG 14
'14': SDG 15
'15': SDG 16
- name: labels_negative
dtype: uint16
- name: labels_positive
dtype: uint16
- name: agreement
dtype: float32
splits:
- name: train
num_bytes: 30151244
num_examples: 42355
download_size: 29770590
dataset_size: 30151244
---
# Dataset Card for OSDG-CD
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [OSDG-CD homepage](https://zenodo.org/record/8397907)
### Dataset Summary
The OSDG Community Dataset (OSDG-CD) is a public dataset of thousands of text excerpts, which were validated by approximately 1,000 OSDG Community Platform (OSDG-CP) citizen scientists from over 110 countries, with respect to the Sustainable Development Goals (SDGs).
> NOTES
>
> * There are currently no examples for SDGs 16 and 17. See [this GitHub issue](https://github.com/osdg-ai/osdg-data/issues/3).
> * As of July 2023, there areexamples also for SDG 16.
### Supported Tasks and Leaderboards
TBD
### Languages
The language of the dataset is English.
## Dataset Structure
### Data Instances
For each instance, there is a string for the text, a string for the SDG, and an integer for the label.
```
{'text': 'Each section states the economic principle, reviews international good practice and discusses the situation in Brazil.',
'label': 5}
```
The average token count for the premises and hypotheses are given below:
| Feature | Mean Token Count |
| ---------- | ---------------- |
| Premise | 14.1 |
| Hypothesis | 8.3 |
### Data Fields
- `doi`: Digital Object Identifier of the original document
- `text_id`: unique text identifier
- `text`: text excerpt from the document
- `sdg`: the SDG the text is validated against
- `label`: an integer from `0` to `17` which corresponds to the `sdg` field
- `labels_negative`: the number of volunteers who rejected the suggested SDG label
- `labels_positive`: the number of volunteers who accepted the suggested SDG label
- `agreement`: agreement score based on the formula
### Data Splits
The OSDG-CD dataset has 1 splits: _train_.
| Dataset Split | Number of Instances in Split |
| ------------- |----------------------------- |
| Train | 32,327 |
## Dataset Creation
### Curation Rationale
The [The OSDG Community Dataset (OSDG-CD)](https://zenodo.org/record/8397907) was developed as a benchmark for ...
with the goal of producing a dataset large enough to train models using neural methodologies.
### Source Data
#### Initial Data Collection and Normalization
TBD
#### Who are the source language producers?
TBD
### Annotations
#### Annotation process
TBD
#### Who are the annotators?
TBD
### Personal and Sensitive Information
The dataset does not contain any personal information about the authors or the crowdworkers.
## Considerations for Using the Data
### Social Impact of Dataset
TBD
## Additional Information
TBD
### Dataset Curators
TBD
### Licensing Information
The OSDG Community Dataset (OSDG-CD) is licensed under a [Creative Commons Attribution 4.0 International License](http://creativecommons.org/licenses/by/4.0/).
### Citation Information
```
@dataset{osdg_2023_8397907,
author = {OSDG and
UNDP IICPSD SDG AI Lab and
PPMI},
title = {OSDG Community Dataset (OSDG-CD)},
month = oct,
year = 2023,
note = {{This CSV file uses UTF-8 character encoding. For
easy access on MS Excel, open the file using Data
→ From Text/CSV. Please split CSV data into
different columns by using a TAB delimiter.}},
publisher = {Zenodo},
version = {2023.10},
doi = {10.5281/zenodo.8397907},
url = {https://doi.org/10.5281/zenodo.8397907}
}
```
### Contributions
TBD
|
laion/laion2B-multi-aesthetic | 2023-01-18T20:04:36.000Z | [
"region:us"
] | laion | null | null | null | 4 | 19 | details at https://github.com/LAION-AI/laion-datasets/blob/main/laion-aesthetic.md |
codeparrot/github-jupyter-text-code-pairs | 2022-10-25T09:30:34.000Z | [
"task_categories:text-generation",
"task_ids:language-modeling",
"multilinguality:monolingual",
"size_categories:unknown",
"language:code",
"license:other",
"region:us"
] | codeparrot | null | null | null | 3 | 19 | ---
annotations_creators: []
language:
- code
license:
- other
multilinguality:
- monolingual
size_categories:
- unknown
task_categories:
- text-generation
task_ids:
- language-modeling
pretty_name: github-jupyter-text-code-pairs
---
This is a parsed version of [github-jupyter-parsed](https://huggingface.co/datasets/codeparrot/github-jupyter-parsed), with markdown and code pairs. We provide the preprocessing script in [preprocessing.py](https://huggingface.co/datasets/codeparrot/github-jupyter-parsed-v2/blob/main/preprocessing.py). The data is deduplicated and consists of 451662 examples.
For similar datasets with text and Python code, there is [CoNaLa](https://huggingface.co/datasets/neulab/conala) benchmark from StackOverflow, with some samples curated by annotators. |
sepidmnorozy/Arabic_sentiment | 2022-08-02T16:12:59.000Z | [
"region:us"
] | sepidmnorozy | null | null | null | 0 | 19 | Entry not found |
batterydata/pos_tagging | 2022-09-05T16:05:33.000Z | [
"task_categories:token-classification",
"language:en",
"license:apache-2.0",
"region:us"
] | batterydata | null | null | null | 0 | 19 | ---
language:
- en
license:
- apache-2.0
task_categories:
- token-classification
pretty_name: 'Part-of-speech(POS) Tagging Dataset for BatteryDataExtractor'
---
# POS Tagging Dataset
## Original Data Source
#### Conll2003
E. F. Tjong Kim Sang and F. De Meulder, Proceedings of the
Seventh Conference on Natural Language Learning at HLT-
NAACL 2003, 2003, pp. 142–147.
#### The Peen Treebank
M. P. Marcus, B. Santorini and M. A. Marcinkiewicz, Comput.
Linguist., 1993, 19, 313–330.
## Citation
BatteryDataExtractor: battery-aware text-mining software embedded with BERT models |
sanchit-gandhi/earnings22_split_resampled | 2022-09-30T15:24:09.000Z | [
"region:us"
] | sanchit-gandhi | null | null | null | 0 | 19 | We partition the earnings22 dataset at https://huggingface.co/datasets/anton-l/earnings22_baseline_5_gram by source_id:
Validation: 4420696 4448760 4461799 4469836 4473238 4482110
Test: 4432298 4450488 4470290 4479741 4483338 4485244
Train: remainder
Official script for processing these splits will be released shortly. |
venelin/inferes | 2022-10-08T01:25:47.000Z | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:es",
"license:cc-by-4.0",
"nli",
"spanish"... | venelin | null | null | null | 0 | 19 | ---
annotations_creators:
- expert-generated
language:
- es
language_creators:
- expert-generated
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: InferES
size_categories:
- 1K<n<10K
source_datasets:
- original
tags:
- nli
- spanish
- negation
- coreference
task_categories:
- text-classification
task_ids:
- natural-language-inference
---
# Dataset Card for InferES
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/venelink/inferes
- **Repository:** https://github.com/venelink/inferes
- **Paper:** https://arxiv.org/abs/2210.03068
- **Point of Contact:** venelin [at] utexas [dot] edu
### Dataset Summary
Natural Language Inference dataset for European Spanish
Paper accepted and (to be) presented at COLING 2022
### Supported Tasks and Leaderboards
Natural Language Inference
### Languages
Spanish
## Dataset Structure
The dataset contains two texts inputs (Premise and Hypothesis), Label for three-way classification, and annotation data.
### Data Instances
train size = 6444
test size = 1612
### Data Fields
ID : the unique ID of the instance
Premise
Hypothesis
Label: cnt, ent, neutral
Topic: 1 (Picasso), 2 (Columbus), 3 (Videogames), 4 (Olympic games), 5 (EU), 6 (USSR)
Anno: ID of the annotators (in cases of undergrads or crowd - the ID of the group)
Anno Type: Generate, Rewrite, Crowd, and Automated
### Data Splits
train size = 6444
test size = 1612
The train/test split is stratified by a key that combines Label + Anno + Anno type
### Source Data
Wikipedia + text generated from "sentence generators" hired as part of the process
#### Who are the annotators?
Native speakers of European Spanish
### Personal and Sensitive Information
No personal or Sensitive information is included.
Annotators are anonymized and only kept as "ID" for research purposes.
### Dataset Curators
Venelin Kovatchev
### Licensing Information
cc-by-4.0
### Citation Information
To be added after proceedings from COLING 2022 appear
### Contributions
Thanks to [@venelink](https://github.com/venelink) for adding this dataset.
|
laion/laion2b-multi-vit-h-14-embeddings | 2022-12-23T20:29:43.000Z | [
"region:us"
] | laion | null | null | null | 1 | 19 | Entry not found |
bond005/sova_rudevices | 2022-11-01T15:59:30.000Z | [
"task_categories:automatic-speech-recognition",
"task_categories:audio-classification",
"annotations_creators:expert-generated",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:10K<n<100k",
"source_datasets:extended",
"language:ru",
"license:cc-by-4.0",
"region:us... | bond005 | null | null | null | 1 | 19 | ---
pretty_name: RuDevices
annotations_creators:
- expert-generated
language_creators:
- crowdsourced
language:
- ru
license:
- cc-by-4.0
multilinguality:
- monolingual
paperswithcode_id:
size_categories:
- 10K<n<100k
source_datasets:
- extended
task_categories:
- automatic-speech-recognition
- audio-classification
---
# Dataset Card for sova_rudevices
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [SOVA RuDevices](https://github.com/sovaai/sova-dataset)
- **Repository:** [SOVA Dataset](https://github.com/sovaai/sova-dataset)
- **Leaderboard:** [The 🤗 Speech Bench](https://huggingface.co/spaces/huggingface/hf-speech-bench)
- **Point of Contact:** [SOVA.ai](mailto:support@sova.ai)
### Dataset Summary
SOVA Dataset is free public STT/ASR dataset. It consists of several parts, one of them is SOVA RuDevices. This part is an acoustic corpus of approximately 100 hours of 16kHz Russian live speech with manual annotating, prepared by [SOVA.ai team](https://github.com/sovaai).
Authors do not divide the dataset into train, validation and test subsets. Therefore, I was compelled to prepare this splitting. The training subset includes more than 82 hours, the validation subset includes approximately 6 hours, and the test subset includes approximately 6 hours too.
### Supported Tasks and Leaderboards
- `automatic-speech-recognition`: The dataset can be used to train a model for Automatic Speech Recognition (ASR). The model is presented with an audio file and asked to transcribe the audio file to written text. The most common evaluation metric is the word error rate (WER). The task has an active Hugging Face leaderboard which can be found at https://huggingface.co/spaces/huggingface/hf-speech-bench. The leaderboard ranks models uploaded to the Hub based on their WER.
### Languages
The audio is in Russian.
## Dataset Structure
### Data Instances
A typical data point comprises the audio data, usually called `audio` and its transcription, called `transcription`. Any additional information about the speaker and the passage which contains the transcription is not provided.
```
{'audio': {'path': '/home/bond005/datasets/sova_rudevices/data/train/00003ec0-1257-42d1-b475-db1cd548092e.wav',
'array': array([ 0.00787354, 0.00735474, 0.00714111, ...,
-0.00018311, -0.00015259, -0.00018311]), dtype=float32),
'sampling_rate': 16000},
'transcription': 'мне получше стало'}
```
### Data Fields
- audio: A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
- transcription: the transcription of the audio file.
### Data Splits
This dataset consists of three splits: training, validation, and test. This splitting was realized with accounting of internal structure of SOVA RuDevices (the validation split is based on the subdirectory `0`, and the test split is based on the subdirectory `1` of the original dataset), but audio recordings of the same speakers can be in different splits at the same time (the opposite is not guaranteed).
| | Train | Validation | Test |
| ----- | ------ | ---------- | ----- |
| examples | 81607 | 5835 | 5799 |
| hours | 82.4h | 5.9h | 5.8h |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
All recorded audio files were manually annotated.
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
The dataset consists of people who have donated their voice. You agree to not attempt to determine the identity of speakers in this dataset.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
The dataset was initially created by Egor Zubarev, Timofey Moskalets, and SOVA.ai team.
### Licensing Information
[Creative Commons BY 4.0](https://creativecommons.org/licenses/by/4.0/)
### Citation Information
```
@misc{sova2021rudevices,
author = {Zubarev, Egor and Moskalets, Timofey and SOVA.ai},
title = {SOVA RuDevices Dataset: free public STT/ASR dataset with manually annotated live speech},
publisher = {GitHub},
journal = {GitHub repository},
year = {2021},
howpublished = {\url{https://github.com/sovaai/sova-dataset}},
}
```
### Contributions
Thanks to [@bond005](https://github.com/bond005) for adding this dataset. |
bsmock/pubtables-1m | 2023-08-08T16:43:14.000Z | [
"license:cdla-permissive-2.0",
"region:us"
] | bsmock | null | null | null | 16 | 19 | ---
license: cdla-permissive-2.0
---
# PubTables-1M
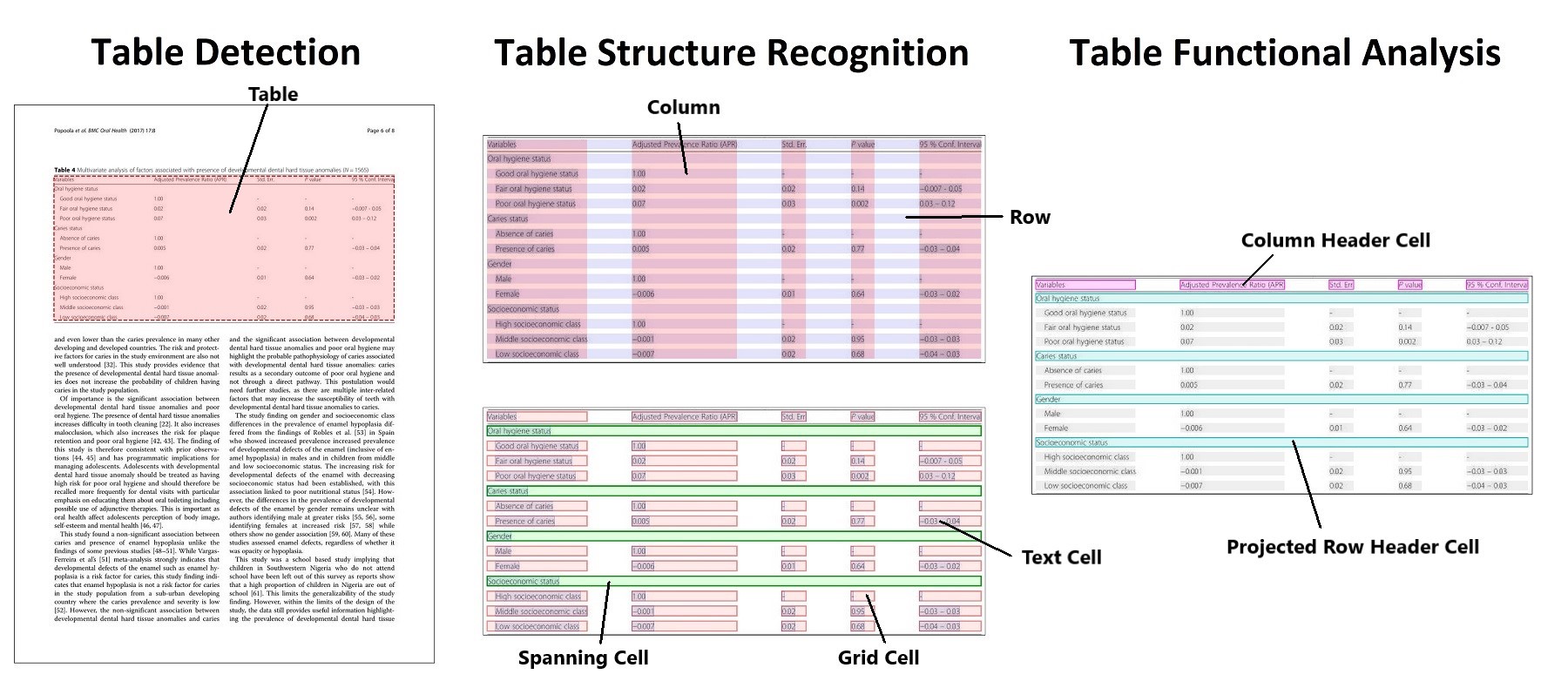
- GitHub: [https://github.com/microsoft/table-transformer](https://github.com/microsoft/table-transformer)
- Paper: ["PubTables-1M: Towards comprehensive table extraction from unstructured documents"](https://openaccess.thecvf.com/content/CVPR2022/html/Smock_PubTables-1M_Towards_Comprehensive_Table_Extraction_From_Unstructured_Documents_CVPR_2022_paper.html)
- Hugging Face:
- [Detection model](https://huggingface.co/microsoft/table-transformer-detection)
- [Structure recognition model](https://huggingface.co/microsoft/table-transformer-structure-recognition)
Currently we only support downloading the dataset as tar.gz files. Integrating with HuggingFace Datasets is something we hope to support in the future!
Please switch to the "Files and versions" tab to download all of the files or use a command such as wget to download from the command line.
Once downloaded, use the included script "extract_structure_dataset.sh" to extract and organize all of the data.
## Files
It comes in 18 tar.gz files:
Training and evaluation data for the structure recognition model (947,642 total cropped table instances):
- PubTables-1M-Structure_Filelists.tar.gz
- PubTables-1M-Structure_Annotations_Test.tar.gz: 93,834 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Structure_Annotations_Train.tar.gz: 758,849 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Structure_Annotations_Val.tar.gz: 94,959 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Structure_Images_Test.tar.gz
- PubTables-1M-Structure_Images_Train.tar.gz
- PubTables-1M-Structure_Images_Val.tar.gz
- PubTables-1M-Structure_Table_Words.tar.gz: Bounding boxes and text content for all of the words in each cropped table image
Training and evaluation data for the detection model (575,305 total document page instances):
- PubTables-1M-Detection_Filelists.tar.gz
- PubTables-1M-Detection_Annotations_Test.tar.gz: 57,125 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Detection_Annotations_Train.tar.gz: 460,589 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Detection_Annotations_Val.tar.gz: 57,591 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Detection_Images_Test.tar.gz
- PubTables-1M-Detection_Images_Train_Part1.tar.gz
- PubTables-1M-Detection_Images_Train_Part2.tar.gz
- PubTables-1M-Detection_Images_Val.tar.gz
- PubTables-1M-Detection_Page_Words.tar.gz: Bounding boxes and text content for all of the words in each page image (plus some unused files)
Full table annotations for the source PDF files:
- PubTables-1M-PDF_Annotations.tar.gz: Detailed annotations for all of the tables appearing in the source PubMed PDFs. All annotations are in PDF coordinates.
- 401,733 JSON files, one per source PDF document |
Isma/librispeech_1000_seed_42 | 2022-11-28T14:52:52.000Z | [
"region:us"
] | Isma | null | null | null | 0 | 19 | Entry not found |
Bingsu/laion-translated-to-en-korean-subset | 2023-02-01T01:15:43.000Z | [
"task_categories:feature-extraction",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:multilingual",
"size_categories:10M<n<100M",
"language:ko",
"language:en",
"license:cc-by-4.0",
"region:us"
] | Bingsu | null | null | null | 2 | 19 | ---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- ko
- en
license:
- cc-by-4.0
multilinguality:
- multilingual
pretty_name: laion-translated-to-en-korean-subset
size_categories:
- 10M<n<100M
task_categories:
- feature-extraction
---
# laion-translated-to-en-korean-subset
## Dataset Description
- **Homepage:** [laion-5b](https://laion.ai/blog/laion-5b/)
- **Download Size** 1.40 GiB
- **Generated Size** 3.49 GiB
- **Total Size** 4.89 GiB
## About dataset
a subset data of [laion/laion2B-multi-joined-translated-to-en](https://huggingface.co/datasets/laion/laion2B-multi-joined-translated-to-en) and [laion/laion1B-nolang-joined-translated-to-en](https://huggingface.co/datasets/laion/laion1B-nolang-joined-translated-to-en), including only korean
### Lisence
CC-BY-4.0
## Data Structure
### Data Instance
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("Bingsu/laion-translated-to-en-korean-subset")
>>> dataset
DatasetDict({
train: Dataset({
features: ['hash', 'URL', 'TEXT', 'ENG TEXT', 'WIDTH', 'HEIGHT', 'LANGUAGE', 'similarity', 'pwatermark', 'punsafe', 'AESTHETIC_SCORE'],
num_rows: 12769693
})
})
```
```py
>>> dataset["train"].features
{'hash': Value(dtype='int64', id=None),
'URL': Value(dtype='large_string', id=None),
'TEXT': Value(dtype='large_string', id=None),
'ENG TEXT': Value(dtype='large_string', id=None),
'WIDTH': Value(dtype='int32', id=None),
'HEIGHT': Value(dtype='int32', id=None),
'LANGUAGE': Value(dtype='large_string', id=None),
'similarity': Value(dtype='float32', id=None),
'pwatermark': Value(dtype='float32', id=None),
'punsafe': Value(dtype='float32', id=None),
'AESTHETIC_SCORE': Value(dtype='float32', id=None)}
```
### Data Size
download: 1.40 GiB<br>
generated: 3.49 GiB<br>
total: 4.89 GiB
### Data Field
- 'hash': `int`
- 'URL': `string`
- 'TEXT': `string`
- 'ENG TEXT': `string`, null data are dropped
- 'WIDTH': `int`, null data are filled with 0
- 'HEIGHT': `int`, null data are filled with 0
- 'LICENSE': `string`
- 'LANGUAGE': `string`
- 'similarity': `float32`, CLIP similarity score, null data are filled with 0.0
- 'pwatermark': `float32`, Probability of containing a watermark, null data are filled with 0.0
- 'punsafe': `float32`, Probability of nsfw image, null data are filled with 0.0
- 'AESTHETIC_SCORE': `float32`, null data are filled with 0.0
### Data Splits
| | train |
| --------- | -------- |
| # of data | 12769693 |
### polars
```sh
pip install polars[fsspec]
```
```py
import polars as pl
from huggingface_hub import hf_hub_url
url = hf_hub_url("Bingsu/laion-translated-to-en-korean-subset", filename="train.parquet", repo_type="dataset")
# url = "https://huggingface.co/datasets/Bingsu/laion-translated-to-en-korean-subset/resolve/main/train.parquet"
df = pl.read_parquet(url)
```
pandas broke my colab session. |
Norod78/microsoft-fluentui-emoji-512-whitebg | 2023-07-16T12:12:01.000Z | [
"task_categories:unconditional-image-generation",
"task_categories:text-to-image",
"size_categories:n<10K",
"language:en",
"license:mit",
"emoji",
"fluentui",
"region:us"
] | Norod78 | null | null | null | 3 | 19 | ---
language: en
license: mit
size_categories:
- n<10K
task_categories:
- unconditional-image-generation
- text-to-image
pretty_name: Microsoft FluentUI Emoji 512x512 White Background
dataset_info:
features:
- name: text
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 329173985.708
num_examples: 7564
download_size: 338676474
dataset_size: 329173985.708
tags:
- emoji
- fluentui
---
# Dataset Card for "microsoft-fluentui-emoji-512-whitebg"
[svg and their file names were converted to images and text from Microsoft's fluentui-emoji repo](https://github.com/microsoft/fluentui-emoji) |
vishnun/SpellGram | 2023-01-09T13:43:11.000Z | [
"task_categories:text2text-generation",
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"NLP",
"Text2Text",
"region:us"
] | vishnun | null | null | null | 0 | 19 | ---
license: mit
task_categories:
- text2text-generation
language:
- en
tags:
- NLP
- Text2Text
pretty_name: Dataset consisting of grammatical and spelling errors
size_categories:
- 10K<n<100K
---
# SpellGram
## Dataset consisting of grammatical and spelling errors
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[train.csv]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
dbarbedillo/SMS_Spam_Multilingual_Collection_Dataset | 2023-01-13T03:07:17.000Z | [
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"language:zh",
"language:es",
"language:hi",
"language:fr",
"language:de",
"language:ar",
"language:bn",
"language:ru",
"language:pt",
"language:id",
"language:ur",
"language:ja",
"language:pa",
"langua... | dbarbedillo | null | null | null | 6 | 19 | ---
license: gpl
task_categories:
- text-classification
language:
- en
- zh
- es
- hi
- fr
- de
- ar
- bn
- ru
- pt
- id
- ur
- ja
- pa
- jv
- tr
- ko
- mr
- uk
- sv
- 'no'
size_categories:
- 1K<n<10K
---
SMS Spam Multilingual Collection Dataset
Collection of Multilingual SMS messages tagged as spam or legitimate
About Dataset
Context
The SMS Spam Collection is a set of SMS-tagged messages that have been collected for SMS Spam research. It originally contained one set of SMS messages in English of 5,574 messages, tagged according to being ham (legitimate) or spam and later Machine Translated into Hindi, German and French.
The text has been further translated into Spanish, Chinese, Arabic, Bengali, Russian, Portuguese, Indonesian, Urdu, Japanese, Punjabi, Javanese, Turkish, Korean, Marathi, Ukrainian, Swedish, and Norwegian using M2M100_418M a multilingual encoder-decoder (seq-to-seq) model trained for Many-to-Many multilingual translation created by Facebook AI.
Content
The augmented Dataset contains multilingual text and corresponding labels.
ham- non-spam text
spam- spam text
Acknowledgments
The original English text was taken from- https://www.kaggle.com/uciml/sms-spam-collection-dataset
Hindi, German and French taken from - https://www.kaggle.com/datasets/rajnathpatel/multilingual-spam-data |
gfhayworth/hack_policy | 2023-02-02T19:55:50.000Z | [
"region:us"
] | gfhayworth | null | null | null | 0 | 19 | Entry not found |
gtfintechlab/finer-ord | 2023-02-23T22:17:44.000Z | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-nc-4.0",
"region:us"
] | gtfintechlab | null | null | null | 4 | 19 | ---
license: cc-by-nc-4.0
task_categories:
- token-classification
language:
- en
pretty_name: FiNER
size_categories:
- 1K<n<10K
multilinguality:
- monolingual
task_ids:
- named-entity-recognition
---
# Dataset Card for "FiNER-ORD"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation and Annotation](#dataset-creation)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contact Information](#contact-information)
## Dataset Description
- **Homepage:** [https://github.com/gtfintechlab/FiNER](https://github.com/gtfintechlab/FiNER)
- **Repository:** [https://github.com/gtfintechlab/FiNER](https://github.com/gtfintechlab/FiNER)
- **Paper:** [Arxiv Link]()
- **Point of Contact:** [Agam A. Shah](https://shahagam4.github.io/)
- **Size of train dataset file:** 1.08 MB
- **Size of validation dataset file:** 135 KB
- **Size of test dataset file:** 336 KB
### Dataset Summary
The FiNER-Open Research Dataset (FiNER-ORD) consists of a manually annotated dataset of financial news articles (in English)
collected from [webz.io] (https://webz.io/free-datasets/financial-news-articles/).
In total, there are 47851 news articles available in this data at the point of writing this paper.
Each news article is available in the form of a JSON document with various metadata information like
the source of the article, publication date, author of the article, and the title of the article.
For the manual annotation of named entities in financial news, we randomly sampled 220 documents from the entire set of news articles.
We observed that some articles were empty in our sample, so after filtering the empty documents, we were left with a total of 201 articles.
We use [Doccano](https://github.com/doccano/doccano), an open-source annotation tool,
to ingest the raw dataset and manually label person (PER), location (LOC), and organization (ORG) entities.
For our experiments, we use the manually labeled FiNER-ORD to benchmark model performance.
Thus, we make a train, validation, and test split of FiNER-ORD.
To avoid biased results, manual annotation is performed by annotators who have no knowledge about the labeling functions for the weak supervision framework.
The train and validation sets are annotated by two separate annotators and validated by a third annotator.
The test dataset is annotated by another annotator. We present a manual annotation guide in the Appendix of the paper detailing the procedures used to create the manually annotated FiNER-ORD.
After manual annotation, the news articles are split into sentences.
We then tokenize each sentence, employing a script to tokenize multi-token entities into separate tokens (e.g. PER_B denotes the beginning token of a person (PER) entity
and PER_I represents intermediate PER tokens). We exclude white spaces when tokenizing multi-token entities.
The descriptive statistics on the resulting FiNER-ORD are available in the Table of [Data Splits](#data-splits) section.
For more details check [information in paper]()
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
- It is a monolingual English dataset
## Dataset Structure
### Data Instances
#### FiNER-ORD
- **Size of train dataset file:** 1.08 MB
- **Size of validation dataset file:** 135 KB
- **Size of test dataset file:** 336 KB
### Data Fields
The data fields are the same among all splits.
#### conll2003
- `doc_idx`: Document ID (`int`)
- `sent_idx`: Sentence ID within each document (`int`)
- `gold_token`: Token (`string`)
- `gold_label`: a `list` of classification labels (`int`). Full tagset with indices:
```python
{'O': 0, 'PER_B': 1, 'PER_I': 2, 'LOC_B': 3, 'LOC_I': 4, 'ORG_B': 5, 'ORG_I': 6}
```
### Data Splits
| **FiNER-ORD** | **Train** | **Validation** | **Test** |
|------------------|----------------|---------------------|---------------|
| # Articles | 135 | 24 | 42 |
| # Tokens | 80,531 | 10,233 | 25,957 |
| # LOC entities | 1,255 | 267 | 428 |
| # ORG entities | 3,440 | 524 | 933 |
| # PER entities | 1,374 | 222 | 466 |
## Dataset Creation and Annotation
[Information in paper ]()
## Additional Information
### Licensing Information
[Information in paper ]()
### Citation Information
```
@article{shah2023finer,
title={FiNER: Financial Named Entity Recognition Dataset and Weak-supervision Model},
author={Agam Shah and Ruchit Vithani and Abhinav Gullapalli and Sudheer Chava},
journal={arXiv preprint arXiv:2302.11157},
year={2023}
}
```
### Contact Information
Please contact Agam Shah (ashah482[at]gatech[dot]edu) or Ruchit Vithani (rvithani6[at]gatech[dot]edu) about any FiNER-related issues and questions.
GitHub: [@shahagam4](https://github.com/shahagam4), [@ruchit2801](https://github.com/ruchit2801)
Website: [https://shahagam4.github.io/](https://shahagam4.github.io/)
|
wwydmanski/wisconsin-breast-cancer | 2023-02-23T19:11:33.000Z | [
"task_categories:tabular-classification",
"size_categories:n<1K",
"tabular",
"breast-cancer",
"region:us"
] | wwydmanski | null | null | null | 1 | 19 | ---
task_categories:
- tabular-classification
tags:
- tabular
- breast-cancer
pretty_name: WisconsinBreastCancerDiagnostic
size_categories:
- n<1K
---
## Source:
Copied from the [original dataset](https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic))
### Creators:
1. Dr. William H. Wolberg, General Surgery Dept.
University of Wisconsin, Clinical Sciences Center
Madison, WI 53792
wolberg '@' eagle.surgery.wisc.edu
2. W. Nick Street, Computer Sciences Dept.
University of Wisconsin, 1210 West Dayton St., Madison, WI 53706
street '@' cs.wisc.edu 608-262-6619
3. Olvi L. Mangasarian, Computer Sciences Dept.
University of Wisconsin, 1210 West Dayton St., Madison, WI 53706
olvi '@' cs.wisc.edu
### Donor:
Nick Street
## Data Set Information:
Features are computed from a digitized image of a fine needle aspirate (FNA) of a breast mass. They describe characteristics of the cell nuclei present in the image. A few of the images can be found at [Web Link]
Separating plane described above was obtained using Multisurface Method-Tree (MSM-T) [K. P. Bennett, "Decision Tree Construction Via Linear Programming." Proceedings of the 4th Midwest Artificial Intelligence and Cognitive Science Society, pp. 97-101, 1992], a classification method which uses linear programming to construct a decision tree. Relevant features were selected using an exhaustive search in the space of 1-4 features and 1-3 separating planes.
The actual linear program used to obtain the separating plane in the 3-dimensional space is that described in: [K. P. Bennett and O. L. Mangasarian: "Robust Linear Programming Discrimination of Two Linearly Inseparable Sets", Optimization Methods and Software 1, 1992, 23-34].
This database is also available through the UW CS ftp server:
ftp ftp.cs.wisc.edu
cd math-prog/cpo-dataset/machine-learn/WDBC/
### Attribute Information:
1) ID number
2) Diagnosis (M = malignant, B = benign)
3-32)
Ten real-valued features are computed for each cell nucleus:
a) radius (mean of distances from center to points on the perimeter)
b) texture (standard deviation of gray-scale values)
c) perimeter
d) area
e) smoothness (local variation in radius lengths)
f) compactness (perimeter^2 / area - 1.0)
g) concavity (severity of concave portions of the contour)
h) concave points (number of concave portions of the contour)
i) symmetry
j) fractal dimension ("coastline approximation" - 1) |
krr-oxford/OntoLAMA | 2023-08-07T16:22:39.000Z | [
"task_categories:text-classification",
"size_categories:1M<n<10M",
"language:en",
"license:apache-2.0",
"Ontologies",
"Subsumption Inference",
"Natural Language Inference",
"Conceptual Knowledge",
"LMs-as-KBs",
"region:us"
] | krr-oxford | OntoLAMA: LAnguage Model Analysis datasets for Ontology Subsumption Inference. | @inproceedings{he2023language,
title={Language Model Analysis for Ontology Subsumption Inference},
author={He, Yuan and Chen, Jiaoyan and Jim{\'e}nez-Ruiz, Ernesto and Dong, Hang and Horrocks, Ian},
booktitle={Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics},
year={2023}
} | null | 1 | 19 | ---
license: apache-2.0
task_categories:
- text-classification
tags:
- Ontologies
- Subsumption Inference
- Natural Language Inference
- Conceptual Knowledge
- LMs-as-KBs
pretty_name: OntoLAMA
size_categories:
- 1M<n<10M
language:
- en
dataset_info:
- config_name: schemaorg-atomic-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
splits:
- name: train
num_bytes: 103485
num_examples: 808
- name: validation
num_bytes: 51523
num_examples: 404
- name: test
num_bytes: 361200
num_examples: 2830
download_size: 82558
dataset_size: 516208
- config_name: doid-atomic-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
splits:
- name: train
num_bytes: 15803053
num_examples: 90500
- name: validation
num_bytes: 1978584
num_examples: 11312
- name: test
num_bytes: 1977582
num_examples: 11314
download_size: 3184028
dataset_size: 19759219
- config_name: foodon-atomic-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
splits:
- name: train
num_bytes: 128737404
num_examples: 768486
- name: validation
num_bytes: 16090857
num_examples: 96060
- name: test
num_bytes: 16098373
num_examples: 96062
download_size: 28499028
dataset_size: 160926634
- config_name: go-atomic-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
splits:
- name: train
num_bytes: 152537233
num_examples: 772870
- name: validation
num_bytes: 19060490
num_examples: 96608
- name: test
num_bytes: 19069265
num_examples: 96610
download_size: 32379717
dataset_size: 190666988
- config_name: bimnli
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
'0': contradiction
'1': entailment
splits:
- name: train
num_bytes: 43363266
num_examples: 235622
- name: validation
num_bytes: 4818648
num_examples: 26180
- name: test
num_bytes: 2420273
num_examples: 12906
download_size: 19264134
dataset_size: 50602187
- config_name: foodon-complex-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
- name: anchor_axiom
dtype: string
splits:
- name: train
num_bytes: 2553731
num_examples: 3754
- name: validation
num_bytes: 1271721
num_examples: 1850
- name: test
num_bytes: 8926305
num_examples: 13080
download_size: 1064602
dataset_size: 12751757
- config_name: go-complex-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
- name: anchor_axiom
dtype: string
splits:
- name: train
num_bytes: 45328802
num_examples: 72318
- name: validation
num_bytes: 5671713
num_examples: 9040
- name: test
num_bytes: 5667069
num_examples: 9040
download_size: 5059364
dataset_size: 56667584
---
# OntoLAMA: LAnguage Model Analysis for Ontology Subsumption Inference
### Dataset Summary
OntoLAMA is a set of language model (LM) probing datasets for ontology subsumption inference.
The work follows the "LMs-as-KBs" literature but focuses on conceptualised knowledge extracted from formalised KBs
such as the OWL ontologies. Specifically, the subsumption inference (SI) task is introduced and formulated in the
Natural Language Inference (NLI) style, where the sub-concept and the super-concept involved in a subsumption
axiom are verbalised and fitted into a template to form the premise and hypothesis, respectively.
The sampled axioms are verified through ontology reasoning. The SI task is further divided into Atomic SI and
Complex SI where the former involves only atomic named concepts and the latter involves both atomic and complex concepts.
Real-world ontologies of different scales and domains are used for constructing OntoLAMA and in total there are four Atomic
SI datasets and two Complex SI datasets.
See dataset specifications: https://krr-oxford.github.io/DeepOnto/ontolama/
### Languages
The text in the dataset is in English, as used in the source ontologies. The associated BCP-47 code is `en`.
## Dataset Structure
### Data Instances
An example in the **Atomic SI** dataset created from the Gene Ontology (GO) is as follows:
```
{
'v_sub_concept': 'ctpase activity',
'v_super_concept': 'ribonucleoside triphosphate phosphatase activity',
'label': 1,
'axiom': 'SubClassOf(<http://purl.obolibrary.org/obo/GO_0043273> <http://purl.obolibrary.org/obo/GO_0017111>)'
}
```
An example in the **Complex SI** dataset created from the Food Ontology (FoodOn) is as follows:
```
{
'v_sub_concept': 'ham and cheese sandwich that derives from some lima bean (whole)',
'v_super_concept': 'lima bean substance',
'label': 0,
'axiom': 'SubClassOf(ObjectIntersectionOf(<http://purl.obolibrary.org/obo/FOODON_03307824> ObjectSomeValuesFrom(<http://purl.obolibrary.org/obo/RO_0001000> <http://purl.obolibrary.org/obo/FOODON_03302053>)) <http://purl.obolibrary.org/obo/FOODON_00002776>)',
'anchor_axiom': 'EquivalentClasses(<http://purl.obolibrary.org/obo/FOODON_00002776> ObjectIntersectionOf(<http://purl.obolibrary.org/obo/FOODON_00002000> ObjectSomeValuesFrom(<http://purl.obolibrary.org/obo/RO_0001000> <http://purl.obolibrary.org/obo/FOODON_03302053>)) )'
}
```
An example in the **biMNLI** dataset created from the MNLI dataset is as follows:
```
{
'premise': 'At the turn of the 19th century Los Angeles and Salt Lake City were among the burgeoning metropolises of the new American West.',
'hypothesis': 'Salt Lake City was booming in the early 19th century.',
'label': 1
}
```
### Data Fields
#### SI Data Fields
- `v_sub_concept`: verbalised sub-concept expression.
- `v_super_concept`: verbalised super-concept expression.
- `label`: a binary class label indicating whether two concepts really form a subsumption relationship (`1` means yes).
- `axiom`: a string representation of the original subsumption axiom which is useful for tracing back to the ontology.
- `anchor_axiom`: (for complex SI only) a string representation of the anchor equivalence axiom used for sampling the `axiom`.
#### biMNLI Data Fields
- `premise`: inheritated from the MNLI dataset.
- `hypothesis`: inheritated from the MNLI dataset.
- `label`: a binary class label indicating `contradiction` (`0`) or `entailment` (`1`).
### Data Splits
| Source | #NamedConcepts | #EquivAxioms | #Dataset (Train/Dev/Test) |
|------------|----------------|--------------|------------------------------------------------------------------------|
| Schema.org | 894 | - | Atomic SI: 808/404/2,830 |
| DOID | 11,157 | - | Atomic SI: 90,500/11,312/11,314 |
| FoodOn | 30,995 | 2,383 | Atomic SI: 768,486/96,060/96,062 <br /> Complex SI: 3,754/1,850/13,080 |
| GO | 43,303 | 11,456 | Atomic SI: 772,870/96,608/96,610 <br /> Complex SI: 72,318/9,040/9,040 |
| MNLI | - | - | biMNLI: 235,622/26,180/12,906 |
### Licensing Information
Creative Commons Attribution 4.0 International
### Citation Information
The relevant paper has been accepted at Findings of ACL 2023.
```
@inproceedings{he-etal-2023-language,
title = "Language Model Analysis for Ontology Subsumption Inference",
author = "He, Yuan and
Chen, Jiaoyan and
Jimenez-Ruiz, Ernesto and
Dong, Hang and
Horrocks, Ian",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-acl.213",
doi = "10.18653/v1/2023.findings-acl.213",
pages = "3439--3453"
}
``` |
metaeval/spartqa-mchoice | 2023-06-09T17:34:13.000Z | [
"license:mit",
"region:us"
] | metaeval | null | null | null | 1 | 19 | ---
license: mit
---
https://github.com/HLR/SpartQA-baselines
```
@inproceedings{mirzaee-etal-2021-spartqa,
title = "{SPARTQA}: A Textual Question Answering Benchmark for Spatial Reasoning",
author = "Mirzaee, Roshanak and
Rajaby Faghihi, Hossein and
Ning, Qiang and
Kordjamshidi, Parisa",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.364",
doi = "10.18653/v1/2021.naacl-main.364",
pages = "4582--4598",
}
``` |
KnutJaegersberg/FEVER_claim_extraction | 2023-03-15T06:25:27.000Z | [
"license:mit",
"argument mining",
"region:us"
] | KnutJaegersberg | null | null | null | 0 | 19 | ---
license: mit
tags:
- argument mining
---
I found this dataset on my harddrive, which if I remember correctly I got from the source mentioned in the paper:
"Claim extraction from text using transfer learning" - By Acharya Ashish Prabhakar, Salar Mohtaj, Sebastian Möller
https://aclanthology.org/2020.icon-main.39/
The github repo with the data seems down.
It extends FEVER dataset with non-claims for training claim detectors. |
potsawee/podcast_summary_assessment | 2023-05-29T23:17:15.000Z | [
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-4.0",
"arxiv:2208.13265",
"region:us"
] | potsawee | null | null | null | 3 | 19 | ---
license: cc-by-4.0
language:
- en
size_categories:
- 1K<n<10K
dataset_info:
features:
- name: transcript
dtype: string
- name: summary
dtype: string
- name: score
dtype: string
- name: attributes
sequence: int64
- name: episode_id
dtype: string
- name: system_id
dtype: string
splits:
- name: evaluation
num_bytes: 100261033
num_examples: 3580
download_size: 11951831
dataset_size: 100261033
---
# Podcast Summary Assessment
- The description is available in our GitHub repo: https://github.com/potsawee/podcast_summary_assessment
- Paper: [Podcast Summary Assessment: A Resource for Evaluating Summary Assessment Methods](https://arxiv.org/abs/2208.13265)
### Citation Information
```
@article{manakul2022podcast,
title={Podcast Summary Assessment: A Resource for Evaluating Summary Assessment Methods},
author={Manakul, Potsawee and Gales, Mark JF},
journal={arXiv preprint arXiv:2208.13265},
year={2022}
}
``` |
pythainlp/thainer-corpus-v2 | 2023-03-23T05:23:46.000Z | [
"task_categories:token-classification",
"language:th",
"license:cc-by-3.0",
"region:us"
] | pythainlp | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: words
sequence: string
- name: ner
sequence:
class_label:
names:
'0': B-PERSON
'1': I-PERSON
'2': O
'3': B-ORGANIZATION
'4': B-LOCATION
'5': I-ORGANIZATION
'6': I-LOCATION
'7': B-DATE
'8': I-DATE
'9': B-TIME
'10': I-TIME
'11': B-MONEY
'12': I-MONEY
'13': B-FACILITY
'14': I-FACILITY
'15': B-URL
'16': I-URL
'17': B-PERCENT
'18': I-PERCENT
'19': B-LEN
'20': I-LEN
'21': B-AGO
'22': I-AGO
'23': B-LAW
'24': I-LAW
'25': B-PHONE
'26': I-PHONE
'27': B-EMAIL
'28': I-EMAIL
'29': B-ZIP
'30': B-TEMPERATURE
'31': I-TEMPERATURE
'32': B-DTAE
'33': I-DTAE
'34': B-DATA
'35': I-DATA
splits:
- name: train
num_bytes: 3736419
num_examples: 3938
- name: validation
num_bytes: 1214580
num_examples: 1313
- name: test
num_bytes: 1242609
num_examples: 1313
download_size: 974230
dataset_size: 6193608
license: cc-by-3.0
task_categories:
- token-classification
language:
- th
---
# Dataset Card for "thainer-corpus-v2"
Thai Named Entity Recognition Corpus
Home Page: [https://pythainlp.github.io/Thai-NER/version/2](https://pythainlp.github.io/Thai-NER/version/2)
Training script and split data: [https://zenodo.org/record/7761354](https://zenodo.org/record/7761354)
**You can download .conll to train named entity model in [https://zenodo.org/record/7761354](https://zenodo.org/record/7761354).**
**Size**
- Train: 3,938 docs
- Validation: 1,313 docs
- Test: 1,313 Docs
Some data come from crowdsourcing between Dec 2018 - Nov 2019. [https://github.com/wannaphong/thai-ner](https://github.com/wannaphong/thai-ner)
**Domain**
- News (It, politics, economy, social)
- PR (KKU news)
- general
**Source**
- I use sone data from Nutcha’s theses (http://pioneer.chula.ac.th/~awirote/Data-Nutcha.zip) and improve data by rechecking and adding more tagging.
- Twitter
- Blognone.com - It news
- thaigov.go.th
- kku.ac.th
And more (the lists are lost.)
**Tag**
- DATA - date
- TIME - time
- EMAIL - email
- LEN - length
- LOCATION - Location
- ORGANIZATION - Company / Organization
- PERSON - Person name
- PHONE - phone number
- TEMPERATURE - temperature
- URL - URL
- ZIP - Zip code
- MONEY - the amount
- LAW - legislation
- PERCENT - PERCENT
Download: [HuggingFace Hub](https://huggingface.co/datasets/pythainlp/thainer-corpus-v2)
## Cite
> Wannaphong Phatthiyaphaibun. (2022). Thai NER 2.0 (2.0) [Data set]. Zenodo. https://doi.org/10.5281/zenodo.7761354
or BibTeX
```
@dataset{wannaphong_phatthiyaphaibun_2022_7761354,
author = {Wannaphong Phatthiyaphaibun},
title = {Thai NER 2.0},
month = sep,
year = 2022,
publisher = {Zenodo},
version = {2.0},
doi = {10.5281/zenodo.7761354},
url = {https://doi.org/10.5281/zenodo.7761354}
}
``` |
pkyoyetera/luganda_english_dataset | 2023-03-25T19:54:14.000Z | [
"task_categories:translation",
"size_categories:10K<n<100K",
"language:en",
"language:lg",
"license:apache-2.0",
"region:us"
] | pkyoyetera | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: English
dtype: string
- name: Luganda
dtype: string
splits:
- name: train
num_bytes: 11844863.620338032
num_examples: 78238
download_size: 7020236
dataset_size: 11844863.620338032
license: apache-2.0
task_categories:
- translation
language:
- en
- lg
size_categories:
- 10K<n<100K
---
# Dataset Card for "luganda_english_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
Dataset might contain a few mistakes, espeecially on the one word translations. Indicators for verbs and nouns (v.i and n.i) may not have been completely filtered out properly. |
Francesco/people-in-paintings | 2023-03-30T09:37:23.000Z | [
"task_categories:object-detection",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:cc",
"rf100",
"region:us"
] | Francesco | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: image_id
dtype: int64
- name: image
dtype: image
- name: width
dtype: int32
- name: height
dtype: int32
- name: objects
sequence:
- name: id
dtype: int64
- name: area
dtype: int64
- name: bbox
sequence: float32
length: 4
- name: category
dtype:
class_label:
names:
'0': people-in-paintings
'1': Human
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- cc
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- object-detection
task_ids: []
pretty_name: people-in-paintings
tags:
- rf100
---
# Dataset Card for people-in-paintings
** The original COCO dataset is stored at `dataset.tar.gz`**
## Dataset Description
- **Homepage:** https://universe.roboflow.com/object-detection/people-in-paintings
- **Point of Contact:** francesco.zuppichini@gmail.com
### Dataset Summary
people-in-paintings
### Supported Tasks and Leaderboards
- `object-detection`: The dataset can be used to train a model for Object Detection.
### Languages
English
## Dataset Structure
### Data Instances
A data point comprises an image and its object annotations.
```
{
'image_id': 15,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x640 at 0x2373B065C18>,
'width': 964043,
'height': 640,
'objects': {
'id': [114, 115, 116, 117],
'area': [3796, 1596, 152768, 81002],
'bbox': [
[302.0, 109.0, 73.0, 52.0],
[810.0, 100.0, 57.0, 28.0],
[160.0, 31.0, 248.0, 616.0],
[741.0, 68.0, 202.0, 401.0]
],
'category': [4, 4, 0, 0]
}
}
```
### Data Fields
- `image`: the image id
- `image`: `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`
- `width`: the image width
- `height`: the image height
- `objects`: a dictionary containing bounding box metadata for the objects present on the image
- `id`: the annotation id
- `area`: the area of the bounding box
- `bbox`: the object's bounding box (in the [coco](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) format)
- `category`: the object's category.
#### Who are the annotators?
Annotators are Roboflow users
## Additional Information
### Licensing Information
See original homepage https://universe.roboflow.com/object-detection/people-in-paintings
### Citation Information
```
@misc{ people-in-paintings,
title = { people in paintings Dataset },
type = { Open Source Dataset },
author = { Roboflow 100 },
howpublished = { \url{ https://universe.roboflow.com/object-detection/people-in-paintings } },
url = { https://universe.roboflow.com/object-detection/people-in-paintings },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2022 },
month = { nov },
note = { visited on 2023-03-29 },
}"
```
### Contributions
Thanks to [@mariosasko](https://github.com/mariosasko) for adding this dataset. |
KITSCH/miniimagenet-LT | 2023-04-09T13:30:42.000Z | [
"license:openrail",
"region:us"
] | KITSCH | null | null | null | 0 | 19 | ---
license: openrail
---
# mini-imagenet-LT_longtail-dataset
长尾数据集的分类任务是一个较为常见的话题,但是数据集整理较为麻烦,并且有些数据集例如Imagenet-LT相对来说还是太多,算力不够的情况下做实验成本较高。因此我根据mini-Imagenet重新整理出了mini-Imagenet-LT长尾数据集。并且使用了RSG模型和stable diffusion扩充数据集两种方法进行性能上的对比。
RSG方法,allacc:72.62% headacc:75.91% middleacc:62.45% tailacc:50.83%
SD方法,allacc:75.88% headacc:79.36% middleacc:64.31% tailacc:56.25%
数据集整理过程如下:
1.下载原始mini-imagenet数据集,其由从imagenet中抽取的100个类别的数据构成,每个类别600张图片,总计60000张图片。我们从每个类别的图像中抽取10%的测试集10%的验证集,剩下80%作为训练集。测试集和验证集会生成val.csv和test.csv两个表格文件,记录了路径和标签。
2.为了制作长尾数据集我们需要对训练集进行再抽样。我们对每个类别的训练数据集从中随机抽取10到480不等的数据构成了分布不均匀的长尾数据集,生成train.csv文件,每个类别的数据量记录在cls_label.json。
3.使用stable diffusion扩充我们的长尾数据集,讲每个类别的图片数量从10-480补齐到480张,生成的图片在genimages文件夹加,标签路径文件为gentrain.csv。具体生成方法我们使用图生图的方式,以某图片及其标签作为prompt对现在的图片轮流生成直到补齐480张为止。(由于seed的随机性或图片的问题,生成的图片有部分为损坏的纯黑图片,在下游任务中记得做筛选去除)。语义标签保存在classname.txt中。
The classification task of long-tail data sets is a relatively common topic, but the data set sorting is more troublesome, and some data sets such as Imagenet-LT are relatively too much, and the cost of experimentation is high when the computing power is not enough. So I rearranged the mini-Imagenet-LT long-tail dataset based on mini-Imagenet. And use the RSG model and stable diffusion to expand the data set two methods for performance comparison.
RSG method, allacc: 72.62 headacc: 75.91 middleacc: 62.45 tailacc: 50.83
SD method, allacc: 75.88 headacc: 79.36 middleacc: 64.31 tailacc: 56.25
The process of organizing the data set is as follows:
1. Download the original mini-imagenet dataset, which consists of 100 categories of data extracted from imagenet, with 600 pictures for each category, and a total of 60,000 pictures. We sample 10% of the test set, 10% of the validation set, and the remaining 80% as the training set from images in each category. The test set and validation set will generate two table files, val.csv and test.csv, which record the path and label.
2. In order to make a long tail dataset we need to resample the training set. We randomly sampled 10 to 480 data from the training data set of each category to form an unevenly distributed long-tail data set, and generated a train.csv file. The data volume of each category is recorded in cls_label.json.
3. Use stable diffusion to expand our long-tail data set. The number of pictures in each category is filled from 10-480 to 480. The generated pictures are added in the genimages folder, and the label path file is gentrain.csv. For the specific generation method, we use the image generation method, using a certain image and its label as a prompt to generate the current images in turn until 480 images are completed. (Due to the randomness of the seed or the problem of the picture, some of the generated pictures are damaged pure black pictures, remember to filter and remove them in downstream tasks). Semantic tags are stored in classname.txt.
|
alexwww94/SimCLUE | 2023-04-14T06:40:03.000Z | [
"license:other",
"region:us"
] | alexwww94 | SimCLUE:3000000+中文语义理解与匹配数据集 | null | null | 0 | 19 | ---
license: other
---
|
sbmaruf/forai_ml-ted_talk_iwslt | 2023-04-27T13:07:06.000Z | [
"license:cc-by-nc-nd-4.0",
"region:us"
] | sbmaruf | The core of WIT3 is the TED Talks corpus, that basically redistributes the original content published by the TED Conference website (http://www.ted.com). Since 2007,
the TED Conference, based in California, has been posting all video recordings of its talks together with subtitles in English
and their translations in more than 80 languages. Aside from its cultural and social relevance, this content, which is published under the Creative Commons BYNC-ND license, also represents a precious
language resource for the machine translation research community, thanks to its size, variety of topics, and covered languages.
This effort repurposes the original content in a way which is more convenient for machine translation researchers. | @inproceedings{cettolo-etal-2012-wit3,
title = "{WIT}3: Web Inventory of Transcribed and Translated Talks",
author = "Cettolo, Mauro and
Girardi, Christian and
Federico, Marcello",
booktitle = "Proceedings of the 16th Annual conference of the European Association for Machine Translation",
month = may # " 28{--}30",
year = "2012",
address = "Trento, Italy",
publisher = "European Association for Machine Translation",
url = "https://www.aclweb.org/anthology/2012.eamt-1.60",
pages = "261--268",
} | null | 0 | 19 | ---
license: cc-by-nc-nd-4.0
---
Unofficial version of https://huggingface.co/datasets/ted_talks_iwslt
We created a different data loader for a `@forai_ml` project. |
crumb/Clean-Instruct-440k | 2023-04-28T21:20:34.000Z | [
"task_categories:conversational",
"language:en",
"license:mit",
"region:us"
] | crumb | null | null | null | 7 | 19 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
- name: input
dtype: string
splits:
- name: train
num_bytes: 650842125.0
num_examples: 443612
download_size: 357775511
dataset_size: 650842125.0
license: mit
task_categories:
- conversational
language:
- en
---
# Dataset Card for "Clean-Instruct"
[yahma/alpaca-cleaned](https://hf.co/datasets/yahma/alpaca-cleaned) + [crumb/gpt4all-clean](https://hf.co/datasets/crumb/gpt4all-clean) + GPTeacher-Instruct-Dedup
It isn't perfect, but it's 443k high quality semi-cleaned instructions without "As an Ai language model".
```python
from datasets import load_dataset
dataset = load_dataset("crumb/clean-instruct", split="train")
def promptify(example):
if example['input']!='':
return {"text": f"<instruction> {example['instruction']} <input> {example['input']} <output> {example['output']}"}
return {"text": f"<instruction> {example['instruction']} <output> {example['output']}"}
dataset = dataset.map(promptify, batched=False)
dataset = dataset.remove_columns(["instruction", "input", "output"])
``` |
alxfgh/PubChem10M_SELFIES | 2023-05-06T19:05:49.000Z | [
"size_categories:1M<n<10M",
"source_datasets:PubChem10M",
"chemistry",
"molecules",
"selfies",
"smiles",
"region:us"
] | alxfgh | null | null | null | 0 | 19 | ---
pretty_name: PubChem10M_GroupSelfies
size_categories:
- 1M<n<10M
source_datasets:
- PubChem10M
tags:
- chemistry
- molecules
- selfies
- smiles
---
<a href="https://deepchemdata.s3-us-west-1.amazonaws.com/datasets/pubchem_10m.txt.zip">PubChem10M</a> dataset by DeepChem encoded to SELFIES using <a href="https://github.com/aspuru-guzik-group/group-selfies">group-selfies</a>. |
roszcz/pianofor-ai-sustain | 2023-07-22T19:53:35.000Z | [
"region:us"
] | roszcz | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: notes
struct:
- name: duration
sequence: float64
- name: end
sequence: float64
- name: pitch
sequence: int64
- name: start
sequence: float64
- name: velocity
sequence: int64
- name: midi_filename
dtype: string
- name: record_id
dtype: int64
- name: user_id
dtype: int64
- name: user
dtype: string
splits:
- name: train
num_bytes: 1187031441
num_examples: 5756
download_size: 465426973
dataset_size: 1187031441
---
# Dataset Card for "pianofor-ai-sustain"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
junelee/wizard_vicuna_70k | 2023-05-16T09:09:06.000Z | [
"region:us"
] | junelee | null | null | null | 41 | 19 | Entry not found |
SJTU-CL/ArguGPT | 2023-05-02T08:44:22.000Z | [
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"license:cc",
"AIGC for education",
"arxiv:2304.07666",
"region:us"
] | SJTU-CL | null | null | null | 1 | 19 | ---
license: cc
task_categories:
- text-classification
language:
- en
tags:
- AIGC for education
size_categories:
- 1K<n<10K
---
# Machine-essays generation pipeline
Please check out our [github repo](https://github.com/huhailinguist/ArguGPT).
This document only introduces how we collected **machine-generated essays**.
| model | timestamp | # total | # valid | # short | # repetitive | # overlapped |
|------------------|-------------|---------|---------|---------|--------------|--------------|
| gpt2-xl | Nov, 2019 | 4,573 | 563 | 1,637 | 0 | 2,373 |
| text-babbage-001 | April, 2022 | 917 | 479 | 181 | 240 | 17 |
| text-curie-001 | April, 2022 | 654 | 498 | 15 | 110 | 31 |
| text-davinci-001 | April, 2022 | 632 | 493 | 1 | 41 | 97 |
| text-davinci-002 | April, 2022 | 621 | 495 | 1 | 56 | 69 |
| text-davinci-003 | Nov, 2022 | 1,130 | 1,090 | 0 | 30 | 10 |
| gpt-3.5-turbo | Mar, 2023 | 1,122 | 1,090 | 0 | 4 | 28 |
| total | - | 9,647 | 4,708 | 1,835 | 481 | 2,625 |
## Models
We chose 7 models from GPT family: 1) `gpt2-xl`, 2) `text-babbage-001`, 3) `text-curie-001`, 4) `text-davinci-001`, 5) `text-davinci-002`,
6) `text-davinci-003`, and 7) `gpt-3.5-turbo`.
More information about these models can be seen in [OpenAI documentation](https://platform.openai.com/docs/model-index-for-researchers).
For WECCL and TOEFL, we used all 7 models to generate argumentative essays.
As for GRE, of which the writing task is more difficult than WECCL and TOEFL, we only used `text-davinci-003` and `gpt-3.5-turbo`.
**Notes**: Since `gpt2-xl` cannot respond to prompts as InstructGPTs and other later models,
we fed `gpt2-xl` the prompt along with one beginning sentence randomly extracted from human essays for continuous writing.
Therefore, the first sentence of each essay generated by `gpt2-xl` is actually human-authored.
## Prompts selection
Our writing topics are collected from human-WECCL, human-TOEFL, and human-GRE.
In a writing task, a topic statement is presented for students (or machines) to attack or defend.
The topic statement here is refered to `ESSAY_PROMPT`, and our added instructions for machine is refered to `ADDED_PROMPT`.
Therefore, our prompt format is as follow: `ESSAY_PROMPT` + `ADDED_PROMPT`.
For instance,
- `ESSAY_PROMPT`: It is better to have broad knowledge of many academic subjects than to specialize in one specific subject.
- `ADDED_PROMPT`: Do you agree or disagree? Use specific reasons and examples to support your answer. Write an essay of roughly {300/400/500} words.
We asked the machine to write 300 words for writing tasks in WECCL, 400 for TOEFL, and 500 for GRE.
## Essays filtering, preprocessing, and automated scoring
We then filtered out the essays that are short, repetitive and overlapped.
- Short: we set the threshold of 50 words for `gpt2-xl`, and 100 words for others.
- Repetitive: 40% of sentences are *similar*.
- Overlapped: 40% of sentences are *similar* with any other essay already generated.
- Definition of *similar*: "I like a dog." and "I don't like a cat." have 3 words in common. The similarity therefore is 6 / 9 = 0.67. If the similarity is greater than 0.8, the two sentences are *similar*.
We deleted "As an AI model, ..." generated by gpt-3.5-turbo.
And we used [YouDao automated scoring system](https://ai.youdao.com/) to score all the essays,
and categorized them into low, mid, and high levels.
## Citation
Please cite our work [arXiv:2304.07666](https://arxiv.org/abs/2304.07666) as
```
@misc{liu2023argugpt,
title={ArguGPT: evaluating, understanding and identifying argumentative essays generated by GPT models},
author={Yikang Liu and Ziyin Zhang and Wanyang Zhang and Shisen Yue and Xiaojing Zhao and Xinyuan Cheng and Yiwen Zhang and Hai Hu},
year={2023},
eprint={2304.07666},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
reciprocate/number-pairs | 2023-05-04T07:14:58.000Z | [
"region:us"
] | reciprocate | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: selected
dtype: string
- name: rejected
dtype: string
splits:
- name: train
num_bytes: 13830.3
num_examples: 900
- name: test
num_bytes: 1536.7
num_examples: 100
download_size: 3812
dataset_size: 15367.0
---
# Dataset Card for "autocrit-testing-numbers"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
HAERAE-HUB/KoInstruct-QA | 2023-05-05T13:28:25.000Z | [
"region:us"
] | HAERAE-HUB | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: type
dtype: string
- name: template
dtype: string
splits:
- name: train
num_bytes: 237493038
num_examples: 50276
download_size: 113325801
dataset_size: 237493038
---
# Dataset Card for "ko_instruct_ki_v0.1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
sanchit-gandhi/librispeech-data | 2023-05-05T16:55:27.000Z | [
"region:us"
] | sanchit-gandhi | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: speaker_id
dtype: int64
- name: chapter_id
dtype: int64
- name: id
dtype: string
splits:
- name: train.clean.100
num_bytes: 6623027227.062
num_examples: 28539
- name: train.clean.360
num_bytes: 23910449107.828
num_examples: 104014
- name: train.other.500
num_bytes: 31827722515.584
num_examples: 148688
- name: validation.clean
num_bytes: 359889672.966
num_examples: 2703
- name: validation.other
num_bytes: 337620033.648
num_examples: 2864
- name: test.clean
num_bytes: 368013946.42
num_examples: 2620
- name: test.other
num_bytes: 352742113.154
num_examples: 2939
download_size: 61829574809
dataset_size: 63779464616.662
---
# Dataset Card for "librispeech-data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
turkish-nlp-suite/turkish-wikiNER | 2023-09-26T10:37:00.000Z | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:tr",
"license:cc-by-sa-4.0",
"region:us"
] | turkish-nlp-suite | General Purpose Turkish NER dataset. 19 labels and 20.000 instances at total. [Turkish Wiki NER dataset](https://github.com/turkish-nlp-suite/Turkish-Wiki-NER-Dataset) | @inproceedings{altinok-2023-diverse,
title = "A Diverse Set of Freely Available Linguistic Resources for {T}urkish",
author = "Altinok, Duygu",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.768",
pages = "13739--13750",
abstract = "This study presents a diverse set of freely available linguistic resources for Turkish natural language processing, including corpora, pretrained models and education material. Although Turkish is spoken by a sizeable population of over 80 million people, Turkish linguistic resources for natural language processing remain scarce. In this study, we provide corpora to allow practitioners to build their own applications and pretrained models that would assist industry researchers in creating quick prototypes. The provided corpora include named entity recognition datasets of diverse genres, including Wikipedia articles and supplement products customer reviews. In addition, crawling e-commerce and movie reviews websites, we compiled several sentiment analysis datasets of different genres. Our linguistic resources for Turkish also include pretrained spaCy language models. To the best of our knowledge, our models are the first spaCy models trained for the Turkish language. Finally, we provide various types of education material, such as video tutorials and code examples, that can support the interested audience on practicing Turkish NLP. The advantages of our linguistic resources are three-fold: they are freely available, they are first of their kind, and they are easy to use in a broad range of implementations. Along with a thorough description of the resource creation process, we also explain the position of our resources in the Turkish NLP world.",
} | null | 0 | 19 | ---
language:
- tr
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
task_categories:
- token-classification
task_ids:
- named-entity-recognition
pretty_name: Turkish-WikiNER
---
# Dataset Card for "turkish-nlp-suite/turkish-wikiNER"
<img src="https://raw.githubusercontent.com/turkish-nlp-suite/.github/main/profile/wiki.png" width="20%" height="20%">
## Dataset Description
- **Repository:** [Turkish-WikiNER](https://github.com/turkish-nlp-suite/Turkish-Wiki-NER-Dataset)
- **Paper:** [ACL link]()
- **Dataset:** Turkish-WikiNER
- **Domain:** Wiki
- **Number of Labels:** 18
### Dataset Summary
Turkish NER dataset from Wikipedia sentences. 20.000 sentences are sampled and re-annotated from [Kuzgunlar NER dataset](https://data.mendeley.com/datasets/cdcztymf4k/1).
Annotations are done by [Co-one](https://co-one.co/). Many thanks to them for their contributions. This dataset is also used in our brand new spaCy Turkish packages.
### Dataset Instances
An instance of this dataset looks as follows:
```
{
"tokens": ["Çekimler", "5", "Temmuz", "2005", "tarihinde", "Reebok", "Stadyum", ",", "Bolton", ",", "İngiltere'de", "yapılmıştır", "."],
"tags": [O", "B-DATE", "I-DATE", "I-DATE", "O", "B-FAC", "I-FAC", "O", "B-GPE", "O", "B-GPE", "O", "O"]
}
```
or even better:

### Labels
- CARDINAL
- DATE
- EVENT
- FAC
- GPE
- LANGUAGE
- LAW
- LOC
- MONEY
- NORP
- ORDINAL
- ORG
- PERCENT
- PERSON
- PRODUCT
- QUANTITY
- TIME
- TITLE
- WORK_OF_ART
### Data Split
| name |train|validation|test|
|---------|----:|---------:|---:|
|Turkish-WikiNER|18000| 1000|1000|
### Citation
This work is supported by Google Developer Experts Program. Part of Duygu 2022 Fall-Winter collection, "Turkish NLP with Duygu"/ "Duygu'yla Türkçe NLP". All rights reserved. If you'd like to use this dataset in your own work, please kindly cite [A Diverse Set of Freely Available Linguistic Resources for Turkish](https://aclanthology.org/2023.acl-long.768/) :
```
@inproceedings{altinok-2023-diverse,
title = "A Diverse Set of Freely Available Linguistic Resources for {T}urkish",
author = "Altinok, Duygu",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.768",
pages = "13739--13750",
abstract = "This study presents a diverse set of freely available linguistic resources for Turkish natural language processing, including corpora, pretrained models and education material. Although Turkish is spoken by a sizeable population of over 80 million people, Turkish linguistic resources for natural language processing remain scarce. In this study, we provide corpora to allow practitioners to build their own applications and pretrained models that would assist industry researchers in creating quick prototypes. The provided corpora include named entity recognition datasets of diverse genres, including Wikipedia articles and supplement products customer reviews. In addition, crawling e-commerce and movie reviews websites, we compiled several sentiment analysis datasets of different genres. Our linguistic resources for Turkish also include pretrained spaCy language models. To the best of our knowledge, our models are the first spaCy models trained for the Turkish language. Finally, we provide various types of education material, such as video tutorials and code examples, that can support the interested audience on practicing Turkish NLP. The advantages of our linguistic resources are three-fold: they are freely available, they are first of their kind, and they are easy to use in a broad range of implementations. Along with a thorough description of the resource creation process, we also explain the position of our resources in the Turkish NLP world.",
}
```
|
Chinese-Vicuna/instruct_chat_50k.jsonl | 2023-05-12T03:27:55.000Z | [
"task_categories:question-answering",
"language:zh",
"license:apache-2.0",
"region:us"
] | Chinese-Vicuna | null | null | null | 38 | 19 | ---
license: apache-2.0
task_categories:
- question-answering
language:
- zh
---
instruct_chat_50k.jsonl which is composed of 30k Chinese sharegpt dataset and 20k [alpaca-instruction-Chinese-dataset](https://github.com/hikariming/alpaca_chinese_dataset) |
lucasmccabe-lmi/sql-create-context_alpaca_style | 2023-05-15T21:16:51.000Z | [
"region:us"
] | lucasmccabe-lmi | null | null | null | 5 | 19 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 28203562.0
num_examples: 78577
download_size: 9312899
dataset_size: 28203562.0
---
# Dataset Card for "sql-create-context_alpaca_style"
We provide a minor modification of the [sql-create-context](https://huggingface.co/datasets/b-mc2/sql-create-context) dataset. In particular, we 1) prepend each instruction with the phrase, "Write a SQL query that answers the following question: " and 2) prepend each context with the phrase, "The relevant table was constructed using the following SQL CREATE TABLE statement: ".
## Numbers:
Prompts: 78577
Tokens: 6438971 using the EleutherAI/gpt-neox-20b tokenizer (counting instruction+input+output) |
aisquared/dais-question-answers | 2023-06-26T14:56:43.000Z | [
"task_categories:conversational",
"language:en",
"license:cc-by-nc-4.0",
"region:us"
] | aisquared | null | null | null | 0 | 19 | ---
license: cc-by-nc-4.0
task_categories:
- conversational
language:
- en
pretty_name: Databricks Data and AI Summit 2023 Question-Answer Pairs
---
# DAIS-Question-Answers Dataset
This dataset contains question-answer pairs created using ChatGPT using text data scraped from the Databricks Data and AI Summit 2023 (DAIS 2023) [homepage](https://www.databricks.com/dataaisummit/)
as well as text from any public page that is linked in that page or is a two-hop linked page.
We have used this dataset to fine-tune our [DAIS DLite model](https://huggingface.co/aisquared/dlite-dais-2023), along with our dataset of [webpage texts](https://huggingface.co/datasets/aisquared/dais-2023). Feel free to check them out!
**Note that, due to the use of ChatGPT to curate these question-answer pairs, this dataset is not licensed for commercial use.**
|
TrainingDataPro/2d-printed_masks_attacks | 2023-09-14T16:51:39.000Z | [
"task_categories:video-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"finance",
"legal",
"code",
"region:us"
] | TrainingDataPro | The dataset consists of 40,000 videos and selfies with unique people. 15,000
attack replays from 4,000 unique devices. 10,000 attacks with A4 printouts and
10,000 attacks with cut-out printouts. | @InProceedings{huggingface:dataset,
title = {2d-printed_masks_attacks},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 19 | ---
license: cc-by-nc-nd-4.0
task_categories:
- video-classification
language:
- en
tags:
- finance
- legal
- code
dataset_info:
features:
- name: 2d_mask
dtype: string
- name: live_selfie
dtype: image
- name: live_video
dtype: string
- name: phone_model
dtype: string
splits:
- name: train
num_bytes: 101123818
num_examples: 9
download_size: 328956415
dataset_size: 101123818
---
# 2D Printed Masks Attacks
The dataset includes 3 different types of files of the real people: original selfies, original videos and videos of 2d printed masks attacks. The dataset solves tasks in the field of anti-spoofing and it is useful for buisness and safety systems.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=2d-printed_masks_attacks) to discuss your requirements, learn about the price and buy the dataset.
# Content
### The dataset contains of three folders:
- **live_selfie** contains the original selfies of people
- **live_video** includes original videos of people
- **2d_masks** contains videos of attacks with the 2d printed mask using original images from "live_selfie" folder
### File with the extension .csv
includes the following information for each media file:
- **live_selfie**: the link to access the original selfie
- **live_video**: the link to access the original video
- **phone_model**: model of the phone, with which selfie and video were shot
- **2d_masks**: the link to access the video with the attack with the 2d printed mask
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=2d-printed_masks_attacks) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
tasksource/QA-Feedback | 2023-06-05T07:12:20.000Z | [
"license:cc",
"region:us"
] | tasksource | null | null | null | 0 | 19 | ---
license: cc
---
|
zachary-shah/musdb18-spec-pix2pix | 2023-06-06T02:55:48.000Z | [
"region:us"
] | zachary-shah | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: original_prompt
dtype: string
- name: original_image
dtype: image
- name: edit_prompt
dtype: string
- name: edited_prompt
dtype: string
- name: edited_image
dtype: image
splits:
- name: train
num_bytes: 2923510938.704
num_examples: 31556
download_size: 2839469846
dataset_size: 2923510938.704
---
# Dataset Card for "musdb18-spec-pix2pix"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
DragonFire0159x/nijijourney-images | 2023-06-06T09:23:43.000Z | [
"task_categories:unconditional-image-generation",
"size_categories:n<1K",
"region:us"
] | DragonFire0159x | null | null | null | 2 | 19 | ---
task_categories:
- unconditional-image-generation
size_categories:
- n<1K
---
# DragonFire0159x/nijijourney-images
Dataset with images generated by niji-journey
Contains only images, no prompts
# What's in the repository
Here are the archives with different dataset sizes
For example, the niji_dataset_404.zip archive contains 404 pictures
You can also use to fine tune the Stable Diffusion |
Amirkid/MedQuad-dataset | 2023-06-06T15:08:50.000Z | [
"region:us"
] | Amirkid | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 21658852
num_examples: 32800
download_size: 8756796
dataset_size: 21658852
---
# Dataset Card for "MedQuad-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
LangChainDatasets/langchain-howto-queries | 2023-06-25T00:40:36.000Z | [
"region:us"
] | LangChainDatasets | null | null | null | 1 | 19 | ---
dataset_info:
features:
- name: inputs
dtype: string
splits:
- name: train
num_bytes: 3419
num_examples: 50
download_size: 2769
dataset_size: 3419
---
# Dataset Card for "langchain-howto-queries"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
gradients-ai/mc4_v01 | 2023-09-08T03:06:31.000Z | [
"task_categories:text-retrieval",
"language:en",
"language:vi",
"region:us"
] | gradients-ai | A colossal, cleaned version of Common Crawl's web crawl corpus.
Based on Common Crawl dataset: "https://commoncrawl.org".
This is the processed version of Google's mC4 dataset by Gradients Technologies Company. | @article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
} | null | 1 | 19 | ---
task_categories:
- text-retrieval
language:
- en
- vi
--- |
seanghay/khmer_kheng_info_speech | 2023-07-03T08:51:37.000Z | [
"language:km",
"region:us"
] | seanghay | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: word
dtype: string
- name: duration_ms
dtype: int64
- name: audio
dtype: audio
splits:
- name: train
num_bytes: 87661862.006
num_examples: 3097
download_size: 86528523
dataset_size: 87661862.006
language:
- km
pretty_name: Khmer Kheng.info Speech
---
I do not own the dataset! This was arranged from [https://kheng.info](https://kheng.info). This is for research purposes only. |
AsakusaRinne/gaokao_bench | 2023-07-11T02:19:45.000Z | [
"region:us"
] | AsakusaRinne | null | 2 | 19 | Entry not found | ||
Yotam/economics-textbook | 2023-07-10T15:56:03.000Z | [
"license:cc-by-4.0",
"region:us"
] | Yotam | null | null | null | 0 | 19 | ---
license: cc-by-4.0
---
|
datatab/alpaca-cleaned-serbian-full | 2023-07-16T12:41:15.000Z | [
"task_categories:text-generation",
"language:sr",
"license:apache-2.0",
"region:us"
] | datatab | null | null | null | 0 | 19 | ---
license: apache-2.0
task_categories:
- text-generation
language:
- sr
pretty_name: ' alpaca-dataset-cleaned-serbian'
--- |
dim/mt_bench_en | 2023-07-17T22:51:38.000Z | [
"license:mit",
"region:us"
] | dim | null | null | null | 1 | 19 | ---
license: mit
dataset_info:
features:
- name: question_id
dtype: int64
- name: category
dtype: string
- name: turns
sequence: string
splits:
- name: train
num_bytes: 34899
num_examples: 80
download_size: 24635
dataset_size: 34899
---
Original Source https://github.com/lm-sys/FastChat/blob/main/fastchat/llm_judge/data/mt_bench/question.jsonl
|
heegyu/wizard_vicuna_70k_v2 | 2023-07-19T09:58:54.000Z | [
"region:us"
] | heegyu | null | null | null | 0 | 19 | https://huggingface.co/datasets/junelee/wizard_vicuna_70k/blob/main/wizard_vicuna_dataset_v2.json |
linkanjarad/baize-chat-data | 2023-07-20T04:30:00.000Z | [
"task_categories:text-generation",
"language:en",
"instruction-finetuning",
"region:us"
] | linkanjarad | null | null | null | 2 | 19 | ---
language:
- en
tags:
- instruction-finetuning
pretty_name: Baize Chat Data
task_categories:
- text-generation
---
## Dataset Description
**Original Repository:** https://github.com/project-baize/baize-chatbot/tree/main/data
This is a dataset of the training data used to train the [Baize family of models](https://huggingface.co/project-baize/baize-v2-13b). This dataset is used for instruction fine-tuning of LLMs, particularly in "chat" format. Human and AI messages are marked by `[|Human|]` and `[|AI|]` tags respectively. The data from the orignial repo consists of 4 datasets (alpaca, medical, quora, stackoverflow), and this dataset combines all four into one dataset, all in all consisting of about 210K rows.
|
puhsu/tabular-benchmarks | 2023-07-20T14:14:56.000Z | [
"task_categories:tabular-classification",
"task_categories:tabular-regression",
"region:us"
] | puhsu | null | null | null | 0 | 19 | ---
task_categories:
- tabular-classification
- tabular-regression
pretty_name: tabualar-benchmarks
---
Datasets used in the paper TODO
To download the archive you could use:
```bash
wget https://huggingface.co/datasets/puhsu/tabular-benchmarks/resolve/main/data.tar
``` |
AhmedBou/Arabic_Quotes | 2023-09-07T15:54:26.000Z | [
"task_categories:text-classification",
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:ar",
"license:apache-2.0",
"region:us"
] | AhmedBou | null | null | null | 2 | 19 | ---
license: apache-2.0
task_categories:
- text-classification
- text-generation
language:
- ar
size_categories:
- 1K<n<10K
---
# Arabic Quotes Dataset




## Overview
The **Arabic Quotes Dataset** is an open-source collection of 5900+ quotes in the Arabic language, accompanied by up to three tags for each quote.
The dataset is suitable for various Natural Language Processing (NLP) tasks, such as text classification and tagging.
## Data Description
- Contains 5900+ quotes with up to three associated tags per quote.
- All quotes and tags are in Arabic.
## Use Cases
- Text Classification: Classify quotes into predefined categories.
- Tagging: Assign relevant labels or themes to quotes.
- Sentiment Analysis: Analyze sentiment expressed in quotes.
- Language Modeling: Train models to generate Arabic quotes.
- Information Retrieval: Retrieve quotes relevant to specific topics.
## License
The "Arabic Quotes" dataset is distributed under the Apache License 2.0. Feel free to use it for any purpose, giving appropriate credit to the original source.
**Github Repository:** https://github.com/BoulahiaAhmed/Arabic-Quotes-Dataset
## Data Format
The dataset is available in CSV format. Each row represents a quote with its associated tags. Example structure:
```
quote,tags
"أنا لا أبالي برأي الناس، أنا لست عبدًا لتقييماتهم.","[حرية, تحفيز, قوة]"
"الصمت هو أكبر إجابة.", "[سكوت, حكمة]"
...
```
--- |
kowndinya23/wikipedia-attribution-corpus | 2023-07-24T07:53:13.000Z | [
"region:us"
] | kowndinya23 | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: id
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 21505788594
num_examples: 39441096
download_size: 10408148033
dataset_size: 21505788594
---
# Dataset Card for "wikipedia-attribution-corpus"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
gauss314/options-IV-SP500 | 2023-07-30T05:06:42.000Z | [
"task_categories:tabular-classification",
"task_categories:tabular-regression",
"size_categories:1M<n<10M",
"license:apache-2.0",
"NYSE",
"options",
"calls",
"puts",
"sp500",
"volatility",
"implied volatility",
"vix",
"IV",
"region:us"
] | gauss314 | null | null | null | 4 | 19 | ---
license: apache-2.0
task_categories:
- tabular-classification
- tabular-regression
tags:
- NYSE
- options
- calls
- puts
- sp500
- volatility
- implied volatility
- vix
- IV
pretty_name: USA options implied volatility features for machine learning
size_categories:
- 1M<n<10M
---
# Downloading the Options IV SP500 Dataset
This document will guide you through the steps to download the Options IV SP500 dataset from Hugging Face Datasets. This dataset includes data on the options of the S&P 500, including implied volatility.
To start, you'll need to install Hugging Face's `datasets` library if you haven't done so already. You can do this using the following pip command:
```python
!pip install datasets
```
Here's the Python code to load the Options IV SP500 dataset from Hugging Face Datasets and convert it into a pandas DataFrame:
```python
from datasets import load_dataset
import pandas as pd
id = "gauss314/options-IV-SP500"
data_iv = load_dataset(id)
df_iv = pd.DataFrame(data_iv['train'][:])
```
The dataset provided includes a variety of features and targets. In machine learning and predictive modeling, features are the input variables used to predict target variables, or the outcomes we're interested in predicting.
The features in this dataset encompass all of the data columns except for DITM_IV, ITM_IV, sITM_IV, ATM_IV, sOTM_IV, OTM_IV, and DOTM_IV. These features include data on traded contracts, open interest, the spread of strike prices, and the number of different expiration dates, among others. These features can be used to understand the characteristics of the security's options and their trading activity.
The target variables in this dataset are DITM_IV, ITM_IV, sITM_IV, ATM_IV, sOTM_IV, OTM_IV, and DOTM_IV. These represent implied volatilities for different categories of options, which are what we would be interested in predicting in a regression or classification model. Implied volatility is a key concept in options trading as it reflects the market's expectation of future volatility of the underlying security's price.
This dataset can also be used in dimensionality reduction machine learning models. These models aim to reduce the number of input variables in a dataset, while preserving as much of the relevant information as possible.
This dataset has been shared specifically for the course "Applied Artificial Intelligence" at UCEMA. Students in this course can use this dataset to practice building and evaluating different types of predictive models, as well as working with real-world financial data.
Features
- `symbol`: This represents the ticker symbol of the security, it is an unique series of letters representing a particular security listed on an exchange.
- `date`: The date of the recorded data.
- `strikes_spread`: The difference in strike prices for call and put options. Strike price is the set price at which an option contract can be bought or sold when it is exercised.
- `calls_contracts_traded`: The total number of call option contracts that have been traded.
- `puts_contracts_traded`: The total number of put option contracts that have been traded.
- `calls_open_interest`: The number of outstanding call contracts that haven't been exercised or allowed to expire.
- `puts_open_interest`: The number of outstanding put contracts that haven't been exercised or allowed to expire.
- `expirations_number`: The number of different expiration dates for the options.
- `contracts_number`: The total number of options contracts.
- `hv_20`, `hv_40`, `hv_60`, `hv_75`, `hv_90`, `hv_120`, `hv_180`, `hv_200`: These represent historical volatility values over different periods of trading days (20, 40, 60, 75, 90, 120, 180, 200). Historical volatility measures the price changes of a security and is used to predict future price volatility.
- VIX: The value of the VIX index for that day.
The VIX, also known as the Chicago Board Options Exchange's (CBOE) Volatility Index, is a real-time market index that represents the market's expectations for volatility over the coming 30 days. It is calculated from both calls and puts options prices and is commonly referred to as the "fear gauge" or "fear index" in the market, as it is used to gauge the market's anxiety or risk tolerance level.
Possible targets:
- `DITM_IV`, `ITM_IV`, `sITM_IV`, `ATM_IV`, `sOTM_IV`, `OTM_IV`, `DOTM_IV`: These are implied volatilities (IV) for different categories of options: Deep-In-The-Money (DITM), In-The-Money (ITM), Slightly-In-The-Money (sITM), At-The-Money (ATM), Slightly-Out-Of-The-Money (sOTM), Out-Of-The-Money (OTM), Deep-Out-Of-The-Money (DOTM). Implied volatility is a metric that captures the market's view of the likelihood of changes in a given security's price. |
Mohanakrishnan/sql-example-data | 2023-08-03T10:44:15.000Z | [
"license:unknown",
"region:us"
] | Mohanakrishnan | null | null | null | 0 | 19 | ---
license: unknown
---
|
Photolens/oasst1-langchain-llama-2-formatted | 2023-08-11T15:23:33.000Z | [
"task_categories:conversational",
"task_categories:text-generation",
"language:en",
"language:es",
"language:ru",
"language:de",
"language:pl",
"language:th",
"language:vi",
"language:sv",
"language:bn",
"language:da",
"language:he",
"language:it",
"language:fa",
"language:sk",
"lang... | Photolens | null | null | null | 9 | 19 | ---
language:
- en
- es
- ru
- de
- pl
- th
- vi
- sv
- bn
- da
- he
- it
- fa
- sk
- id
- nb
- el
- nl
- hu
- eu
- zh
- eo
- ja
- ca
- cs
- bg
- fi
- pt
- tr
- ro
- ar
- uk
- gl
- fr
- ko
task_categories:
- conversational
- text-generation
license: apache-2.0
---
## Dataset overview
Dataset license: apache-2.0
This dataset contains langchain formatted [**oasst1**](https://huggingface.co/datasets/OpenAssistant/oasst1) messages with llama-2-chat special tokens.
This dataset is intended for powering langchain applications. When an llm is trained with this data, its performance is expected to be high with langchain apps.
Format of new dataset for every prompter-assistant message pair:
```
<s>[INST] "{prompter_message}" [/INST] ```json
{"action": "Final Answer", "action_input": "{assistant_message}"}
``` </s>
```
*Note: When there is a conversation, the message pairs are seperated by "\ " in same row*
## Languages
**Languages with over 1000 messages**
- English: 71956
- Spanish: 43061
- Russian: 9089
- German: 5279
- Chinese: 4962
- French: 4251
- Thai: 3042
- Portuguese (Brazil): 2969
- Catalan: 2260
- Korean: 1553
- Ukrainian: 1352
- Italian: 1320
- Japanese: 1018
<details>
<summary><b>Languages with under 1000 messages</b></summary>
<ul>
<li>Vietnamese: 952</li>
<li>Basque: 947</li>
<li>Polish: 886</li>
<li>Hungarian: 811</li>
<li>Arabic: 666</li>
<li>Dutch: 628</li>
<li>Swedish: 512</li>
<li>Turkish: 454</li>
<li>Finnish: 386</li>
<li>Czech: 372</li>
<li>Danish: 358</li>
<li>Galician: 339</li>
<li>Hebrew: 255</li>
<li>Romanian: 200</li>
<li>Norwegian Bokmål: 133</li>
<li>Indonesian: 115</li>
<li>Bulgarian: 95</li>
<li>Bengali: 82</li>
<li>Persian: 72</li>
<li>Greek: 66</li>
<li>Esperanto: 59</li>
<li>Slovak: 19</li>
</ul>
</details>
## Contact
- Email: art.photolens.ai@gmail.com
- Discord: https://discord.gg/QJT3e6ABz8
- Twitter: @PhotolensAi |
amitness/logits-maltese-128 | 2023-09-21T02:31:29.000Z | [
"region:us"
] | amitness | null | null | null | 0 | 19 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
- name: teacher_logits
sequence:
sequence: float64
- name: teacher_indices
sequence:
sequence: int64
- name: teacher_mask_indices
sequence: int64
splits:
- name: train
num_bytes: 230752436
num_examples: 50911
download_size: 97319795
dataset_size: 230752436
---
# Dataset Card for "logits-maltese-128"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Xilabs/PIPPA-alpaca | 2023-08-17T04:33:52.000Z | [
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"not-for-all-audiences",
"alpaca",
"conversational",
"roleplay",
"region:us"
] | Xilabs | null | null | null | 2 | 19 | ---
language:
- en
size_categories:
- 10K<n<100K
task_categories:
- text-generation
configs:
- config_name: default
data_files:
- split: smol_pippa_named_users
path: data/smol_pippa_named_users-*
- split: smol_pippa
path: data/smol_pippa-*
dataset_info:
features:
- name: input
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: smol_pippa_named_users
num_bytes: 76842019
num_examples: 37860
- name: smol_pippa
num_bytes: 77756206
num_examples: 38225
download_size: 69132609
dataset_size: 154598225
tags:
- not-for-all-audiences
- alpaca
- conversational
- roleplay
---
# Dataset Card for "Pippa-alpaca"
This dataset is derived from the PIPPA dataset, and uses the alpaca format.
[PIPPA - Personal Interaction Pairs between People and AI](https://huggingface.co/datasets/PygmalionAI/PIPPA) |
longface/logicLM | 2023-08-25T17:07:27.000Z | [
"task_categories:question-answering",
"size_categories:1K<n<10K",
"license:apache-2.0",
"region:us"
] | longface | null | null | null | 2 | 19 | ---
license: apache-2.0
task_categories:
- question-answering
size_categories:
- 1K<n<10K
--- |
Pretam/hi-kn-128 | 2023-08-22T13:38:28.000Z | [
"region:us"
] | Pretam | null | null | null | 0 | 19 | Entry not found |
nihiluis/financial-advisor-100 | 2023-08-25T19:21:12.000Z | [
"region:us"
] | nihiluis | null | null | null | 1 | 19 | ---
dataset_info:
features:
- name: id
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 534730
num_examples: 100
download_size: 320626
dataset_size: 534730
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "finadv100_v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mmathys/openai-moderation-api-evaluation | 2023-08-28T14:56:39.000Z | [
"task_categories:text-classification",
"language:en",
"license:mit",
"arxiv:2208.03274",
"region:us"
] | mmathys | null | null | null | 1 | 19 | ---
license: mit
task_categories:
- text-classification
language: en
pretty_name: OpenAI Moderation API Validation Dataset
---
# Evaluation dataset for the paper "A Holistic Approach to Undesired Content Detection"
The evaluation dataset `data/samples-1680.jsonl.gz` is the test set used in [this paper](https://arxiv.org/abs/2208.03274).
Each line contains information about one sample in a JSON object and each sample is labeled according to our taxonomy. The category label is a binary flag, but if it does not include in the JSON, it means we do not know the label.
| Category | Label | Definition |
| -------- | ----- | ---------- |
| sexual | `S` | Content meant to arouse sexual excitement, such as the description of sexual activity, or that promotes sexual services (excluding sex education and wellness). |
| hate | `H` | Content that expresses, incites, or promotes hate based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. |
| violence | `V` | Content that promotes or glorifies violence or celebrates the suffering or humiliation of others. |
| harassment | `HR` | Content that may be used to torment or annoy individuals in real life, or make harassment more likely to occur. |
| self-harm | `SH` | Content that promotes, encourages, or depicts acts of self-harm, such as suicide, cutting, and eating disorders. |
| sexual/minors | `S3` | Sexual content that includes an individual who is under 18 years old. |
| hate/threatening | `H2` | Hateful content that also includes violence or serious harm towards the targeted group. |
| violence/graphic | `V2` | Violent content that depicts death, violence, or serious physical injury in extreme graphic detail. |
Parsed from the GitHub repo: https://github.com/openai/moderation-api-release |
PetraAI/autotrain-data-zalmati-ai | 2023-09-05T13:47:18.000Z | [
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:table-question-answering",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:translation",
"task_categories:summarization",
"task_categories:conversational",... | PetraAI | null | null | null | 0 | 19 | ---
license: apache-2.0
task_categories:
- text-classification
- token-classification
- table-question-answering
- question-answering
- zero-shot-classification
- translation
- summarization
- conversational
- feature-extraction
- text-generation
- text2text-generation
- fill-mask
- sentence-similarity
- text-to-speech
- automatic-speech-recognition
- audio-to-audio
- audio-classification
- voice-activity-detection
- depth-estimation
- image-classification
- object-detection
- image-segmentation
- unconditional-image-generation
- robotics
- reinforcement-learning
- tabular-classification
- video-classification
- tabular-to-text
- multiple-choice
- text-retrieval
- time-series-forecasting
- text-to-video
- visual-question-answering
- zero-shot-image-classification
- graph-ml
- table-to-text
- text-to-image
- image-to-text
- image-to-image
- tabular-regression
language:
- ar
- en
tags:
- chemistry
- medical
- code
- art
- music
- biology
- finance
- legal
- climate
pretty_name: Zalmati-Autotrain
size_categories:
- 100K<n<1M
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
pszemraj/simple_wikipedia | 2023-09-09T14:54:54.000Z | [
"task_categories:text-generation",
"task_categories:fill-mask",
"size_categories:100K<n<1M",
"language:en",
"license:apache-2.0",
"language modeling",
"lamguage",
"2023 data",
"region:us"
] | pszemraj | null | null | null | 0 | 19 | ---
license: apache-2.0
task_categories:
- text-generation
- fill-mask
language:
- en
tags:
- language modeling
- lamguage
- 2023 data
size_categories:
- 100K<n<1M
---
# simple wikipedia
the 'simple' split of Wikipedia, from Sept 1 2023. The train split contains about 65M tokens,
Pulled via:
```python
dataset = load_dataset(
"wikipedia", language="simple", date="20230901", beam_runner="DirectRunner"
)
```
## stats
### train split
general info
```
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 226242 entries, 0 to 226241
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 226242 non-null string
1 url 226242 non-null string
2 title 226242 non-null string
3 text 226242 non-null string
dtypes: string(4)
```
token length (NeoX)

| | tokens |
|:------|--------------:|
| count | 226242 |
| mean | 287.007 |
| std | 1327.07 |
| min | 1 |
| 25% | 65 |
| 50% | 126 |
| 75% | 243 |
| max | 60844 | |
Admin08077/STUPID | 2023-09-03T07:08:20.000Z | [
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:table-question-answering",
"task_categories:question-answering",
"task_categories:translation",
"task_categories:zero-shot-classification",
"task_categories:summarization"... | Admin08077 | null | null | null | 0 | 19 | ---
task_categories:
- text-generation
- text-classification
- token-classification
- table-question-answering
- question-answering
- translation
- zero-shot-classification
- summarization
- conversational
- sentence-similarity
- audio-to-audio
- automatic-speech-recognition
- voice-activity-detection
- depth-estimation
- image-classification
- object-detection
- audio-classification
- image-segmentation
- text-to-image
- image-to-text
- text2text-generation
- feature-extraction
- unconditional-image-generation
- reinforcement-learning
- tabular-classification
- tabular-regression
- video-classification
- text-to-speech
- tabular-to-text
- robotics
- time-series-forecasting
- text-retrieval
- visual-question-answering
- zero-shot-image-classification
- text-to-video
- multiple-choice
- table-to-text
- image-to-image
- graph-ml
- fill-mask
tags:
- '#Admin08077/Stupid'
size_categories:
- n>1T
license: openrail
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
INo0121/low_quality_call_voice_preprocessed | 2023-09-21T13:25:07.000Z | [
"region:us"
] | INo0121 | null | null | null | 0 | 19 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: valid
path: data/valid-*
dataset_info:
features:
- name: input_features
sequence:
sequence: float32
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 64088254376
num_examples: 66720
- name: test
num_bytes: 7476961712
num_examples: 7784
- name: valid
num_bytes: 7476975416
num_examples: 7784
download_size: 521083513
dataset_size: 79042191504
---
# Dataset Card for "low_quality_call_voice_preprocessed"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Falah/random_prompts | 2023-09-10T12:38:07.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 27245594
num_examples: 100000
download_size: 4512640
dataset_size: 27245594
---
# Dataset Card for "random_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TonyJPk7/Chat-PCR_CNNDaily | 2023-09-11T10:28:31.000Z | [
"region:us"
] | TonyJPk7 | null | null | null | 0 | 19 | Entry not found |
kevincluo/structure_wildfire_damage_classification | 2023-09-14T00:11:33.000Z | [
"language:en",
"license:cc-by-4.0",
"climate",
"wildfire",
"image classification",
"damage assessment",
"region:us"
] | kevincluo | null | null | null | 0 | 19 | ---
license: cc-by-4.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': affected
'1': destroyed
'2': inaccessible
'3': major
'4': minor
'5': no_damage
splits:
- name: train
num_bytes: 125229532
num_examples: 355
download_size: 125234000
dataset_size: 125229532
language:
- en
tags:
- climate
- wildfire
- image classification
- damage assessment
---
# Dataset Card for Structures Damaged by Wildfire
**Homepage:** [Image Dataset of Structures Damaged by Wildfire in California 2020-2022](https://zenodo.org/record/8336570)
### Dataset Summary
The dataset contains over 18,000 images of homes damaged by wildfire between 2020 and 2022 in California, USA, captured by the California Department of Forestry and Fire Protection (Cal Fire) during the damage assessment process. The dataset spans across more than 18 wildfire events, including the 2020 August Complex Fire, the first recorded "gigafire" event in California where the area burned exceeded 1 million acres. Each image, corresponding to a built structure, is classified by government damage assessors into 6 different categories: Inaccessible (image taken but no assessment made), No Damage, Affected (1-9%), Minor (10-25%), Major (26-50%), and Destroyed (>50%). While over 57,000 structures were evaluated during the damage assessment process, only about 18,000 contains images; additional data about the structures, such as the street address or structure materials, for both those with and without corresponding images can be accessed in the "Additional Attribute Data" file.
The 18 wildfire events captured in the dataset are:
- [AUG] August Complex (2020)
- [BEA] Bear Fire (2020)
- [BEU] BEU Lightning Complex Fire (2020)
- [CAL] Caldor Fire (2021)
- [CAS] Castle Fire (2020)
- [CRE] Creek Fire (2020)
- [DIN] DINS Statewide (Collection of Smaller Fires, 2021)
- [DIX[ Dixie Fire (2021)
- [FAI] Fairview Fire (2022)
- [FOR] Fork Fire (2022)
- [GLA] Glass Fire (2020)
- [MIL] Mill Mountain Fire (2022)
- [MON] Monument Fire (2021)
- [MOS] Mosquito Fire (2022)
- [POST] Post Fire (2020)
- [SCU] SCU Complex Fire (2020)
- [VAL] Valley Fire (2020)
- [ZOG] Zogg Fire (2020)
The author retrieved the data, originally published as GIS features layers, from from the publicly accessible CAL FIRE Hub, then subsequently processed it into image and tabular formats. The author collaborated with Cal Fire in working with the data, and has received explicit permission for republication.
### Data Fields
The data instances have the following fields:
- `image`: A `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`.
- `labels`: an `int` classification label.
Class Label Mappings:
```
{
"affected": 0,
"destroyed": 1,
"inaccessible": 2,
"major": 3,
"minor": 4,
"no_damage": 5,
}
```
### Data Splits
| | train |
|---------------|------:|
| # of examples | 18,714 | |
Tunyaluck/test_gencode_gai111 | 2023-09-14T07:08:15.000Z | [
"license:c-uda",
"region:us"
] | Tunyaluck | null | null | null | 0 | 19 | ---
license: c-uda
---
|
DavidLanz/chinese-dolly-15k | 2023-09-15T06:18:53.000Z | [
"task_categories:question-answering",
"task_categories:summarization",
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:zh",
"language:en",
"license:cc-by-sa-3.0",
"region:us"
] | DavidLanz | null | null | null | 0 | 19 | ---
license: cc-by-sa-3.0
task_categories:
- question-answering
- summarization
- text-generation
language:
- zh
- en
size_categories:
- 10K<n<100K
---
Chinese-Dolly-15k 是繁體中文翻譯的Dolly instruction(Databricks)資料集
原來的資料集'databricks/databricks-dolly-15k'是由數千名Databricks員工根據InstructGPT論文中概述的幾種行為類別生成的遵循指示記錄的開來源資料集。這幾個行為類別包括頭腦風暴、分類、封閉型問答、生成、資訊擷取、開放類型的問答和摘要。
在知識共用署名-相同方式共用3.0(CC BY-SA 3.0)許可下,此資料集可用於任何學術或商業用途。
如果你也在做這些資料集的籌備,歡迎來聯繫我們,避免重複花錢。
## Citation
Please cite the repo if you use the data or code in this repo.
```
@misc{alpaca,
author = {DavidLanz},
title = {An Instruction-following Chinese Language model, LoRA tuning on LLaMA},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
url = {https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm},
urldate = {2023-09-15}
}
```
|
DummyBanana/shapes | 2023-09-15T09:42:16.000Z | [
"region:us"
] | DummyBanana | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 8455414.797
num_examples: 1197
download_size: 8497287
dataset_size: 8455414.797
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "shapes"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Otter-AI/MME | 2023-10-09T17:05:30.000Z | [
"region:us"
] | Otter-AI | Multimodal Large Language Model (MLLM) relies on the powerful LLM to perform multimodal tasks, showing amazing emergent abilities in recent studies, such as writing poems based on an image. However, it is difficult for these case studies to fully reflect the performance of MLLM, lacking a comprehensive evaluation. In this paper, we fill in this blank, presenting the first MLLM Evaluation benchmark MME. It measures both perception and cognition abilities on a total of 14 subtasks. In order to avoid data leakage that may arise from direct use of public datasets for evaluation, the annotations of instruction-answer pairs are all manually designed. The concise instruction design allows us to fairly compare MLLMs, instead of struggling in prompt engineering. Besides, with such an instruction, we can also easily carry out quantitative statistics. A total of 12 advanced MLLMs are comprehensively evaluated on our MME, which not only suggests that existing MLLMs still have a large room for improvement, but also reveals the potential directions for the subsequent model optimization. | @article{li2023mimicit,
title={MIMIC-IT: Multi-Modal In-Context Instruction Tuning},
author={Bo Li and Yuanhan Zhang and Liangyu Chen and Jinghao Wang and Fanyi Pu and Jingkang Yang and Chunyuan Li and Ziwei Liu},
year={2023},
eprint={2306.05425},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | null | 1 | 19 | Entry not found |
aviroes/above_70yo_elderly_people_datasetV2 | 2023-09-17T11:18:16.000Z | [
"region:us"
] | aviroes | null | null | null | 0 | 19 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 48000
- name: sentence
dtype: string
splits:
- name: train
num_bytes: 196941356.0
num_examples: 4215
- name: test
num_bytes: 8586642.0
num_examples: 166
- name: validation
num_bytes: 4592657.0
num_examples: 100
download_size: 192899099
dataset_size: 210120655.0
---
# Dataset Card for "above_70yo_elderly_people_datasetV2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
arifzanko/donut_test | 2023-09-18T09:05:22.000Z | [
"region:us"
] | arifzanko | null | null | null | 0 | 19 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: ground_truth
dtype: string
splits:
- name: train
num_bytes: 746757.0
num_examples: 1
- name: validation
num_bytes: 746757.0
num_examples: 1
- name: test
num_bytes: 948591.0
num_examples: 1
download_size: 2477867
dataset_size: 2442105.0
---
# Dataset Card for "donut_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
yashmangal28/langchain-docs | 2023-09-18T13:18:32.000Z | [
"region:us"
] | yashmangal28 | null | null | null | 0 | 19 | Entry not found |
vitaliy-sharandin/climate-world-region | 2023-09-20T16:05:11.000Z | [
"region:us"
] | vitaliy-sharandin | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: Entity
dtype: string
- name: Seasonal variation
dtype: float64
- name: Combined measurements
dtype: float64
- name: Monthly averaged
dtype: float64
- name: Annual averaged
dtype: float64
- name: monthly_sea_surface_temperature_anomaly
dtype: float64
- name: Sea surface temp (lower-bound)
dtype: float64
- name: Sea surface temp (upper-bound)
dtype: float64
- name: Monthly pH measurement
dtype: float64
- name: Annual average
dtype: float64
- name: Temperature anomaly
dtype: float64
- name: Church & White
dtype: float64
- name: University of Hawaii
dtype: float64
- name: Average
dtype: float64
- name: arctic_sea_ice_osisaf
dtype: float64
- name: Monthly averaged.1
dtype: float64
- name: Annual averaged.1
dtype: float64
- name: Monthly averaged.2
dtype: float64
- name: Annual averaged.2
dtype: float64
- name: Date
dtype: timestamp[ns, tz=UTC]
- name: dt
dtype: timestamp[ns, tz=UTC]
splits:
- name: train
num_bytes: 1813733
num_examples: 10198
download_size: 450942
dataset_size: 1813733
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "climate-world-region"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
DavidMOBrien/8000-java-preprocessed | 2023-09-18T22:59:36.000Z | [
"region:us"
] | DavidMOBrien | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: before
dtype: string
- name: after
dtype: string
- name: repo
dtype: string
- name: type
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 563226571
num_examples: 343959
- name: test
num_bytes: 77867200
num_examples: 48017
- name: valid
num_bytes: 74511240
num_examples: 48232
download_size: 297216874
dataset_size: 715605011
---
# Dataset Card for "8000-java-preprocessed"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
p208p2002/wudao | 2023-09-20T06:18:13.000Z | [
"task_categories:text-generation",
"size_categories:n>1T",
"language:zh",
"region:us"
] | p208p2002 | WuDaoCorpora Text is a large pretraining Chinese corpus constructed by Beijing Academy of Artificial Intelligence(BAAI). The total data volume of the dataset has exceeded 5TB, including 200GB open data.
Compared with other pretraining corpora, the WuDaoCorpora Text has the following advantages.
1) In the process of data collection, we classify the quality of web pages according to the proportion of words in web pages and the integrity of DOM trees, and select high-quality web page for data collection to ensure the corpus quality.
2) Through data cooperation with other institutions and web page data crawling, the dataset covers a wide range types of Chinese text, including news, comments, encyclopedias, forums, blogs, academic papers, etc.
3) The dataset uses more than 20 cleaning rules to obtain the final corpus from the 100TB original web page data. In the cleaning process, special attention is paid to the removal of private information to avoid the risk of privacy disclosure.
4) The dataset contains 50+ data tags, such as education and laws, which is convenient for users to extract specific-domain data for model training in that field.
Please obey the following agreement if you use our dataset.
https://data.baai.ac.cn/resources/agreement/BAAIDataAgreement.pdf | @misc{ c6a3fe684227415a9db8e21bac4a15ab,
author = {Zhao Xue and Hanyu Zhao and Sha Yuan and Yequan Wang},
title = {{WuDaoCorpora Text}},
year = 2022,
month = dec,
publisher = {Science Data Bank},
version = {V1},
doi = {10.57760/sciencedb.o00126.00004},
url = https://doi.org/10.57760/sciencedb.o00126.00004
} | null | 0 | 19 | ---
language:
- zh
task_categories:
- text-generation
size_categories:
- n>1T
---
# 悟道(WuDao)資料集
非原製作者,僅搬移。
此資料集下載約60GB,解壓縮後約220GB。
### 原始連結
[Science Data Bank](https://www.scidb.cn/en/detail?dataSetId=c6a3fe684227415a9db8e21bac4a15ab)
## 使用
```bash
pip install patool wget opencc
```
```python
from datasets import load_dataset
# 簡中
load_dataset("p208p2002/wudao",streaming=True,split="zhs")
# 繁中 (使用opencc轉換)
load_dataset("p208p2002/wudao",streaming=True,split="zht")
```
## 清除資料
當下載失敗的時候請手動清除資料
```bash
rm -rf ~/.cache/wudao_dataset
```
## 資料類別統計
```json
{
"_total": 59100001,
"豆瓣话题": 209027,
"科技": 1278068,
"经济": 1096215,
"汽车": 1368193,
"娱乐": 1581947,
"农业": 1129758,
"军事": 420949,
"社会": 446228,
"游戏": 754703,
"教育": 1133453,
"体育": 660858,
"旅行": 821573,
"国际": 630386,
"房产": 387786,
"文化": 710648,
"法律": 36585,
"股票": 1205,
"博客": 15467790,
"日报": 16971,
"评论": 13867,
"孕育常识": 48291,
"健康": 15291,
"财经": 54656,
"医学问答": 314771,
"资讯": 1066180,
"科普文章": 60581,
"百科": 27273280,
"酒业": 287,
"经验": 609195,
"新闻": 846810,
"小红书攻略": 185379,
"生活": 23,
"网页文本": 115830,
"观点": 1268,
"海外": 4,
"户外": 5,
"美容": 7,
"理论": 247,
"天气": 540,
"文旅": 2999,
"信托": 62,
"保险": 70,
"水利资讯": 17,
"时尚": 1123,
"亲子": 39,
"百家号文章": 335591,
"黄金": 216,
"党建": 1,
"期货": 330,
"快讯": 41,
"国内": 15,
"国学": 614,
"公益": 15,
"能源": 7,
"创新": 6
}
```
## Cite
```
@misc{ c6a3fe684227415a9db8e21bac4a15ab,
author = {Zhao Xue and Hanyu Zhao and Sha Yuan and Yequan Wang},
title = {{WuDaoCorpora Text}},
year = 2022,
month = dec,
publisher = {Science Data Bank},
version = {V1},
doi = {10.57760/sciencedb.o00126.00004},
url = https://doi.org/10.57760/sciencedb.o00126.00004
}
``` |
TrainingDataPro/ocr-receipts-text-detection | 2023-09-26T15:12:40.000Z | [
"task_categories:image-to-text",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] | TrainingDataPro | The Grocery Store Receipts Dataset is a collection of photos captured from various
**grocery store receipts**. This dataset is specifically designed for tasks related to
**Optical Character Recognition (OCR)** and is useful for retail.
Each image in the dataset is accompanied by bounding box annotations, indicating the
precise locations of specific text segments on the receipts. The text segments are
categorized into four classes: **item, store, date_time and total**. | @InProceedings{huggingface:dataset,
title = {ocr-receipts-text-detection},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 19 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-text
- object-detection
tags:
- code
- finance
dataset_info:
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: width
dtype: uint16
- name: height
dtype: uint16
- name: shapes
sequence:
- name: label
dtype:
class_label:
names:
'0': receipt
'1': shop
'2': item
'3': date_time
'4': total
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 55510934
num_examples: 20
download_size: 54557192
dataset_size: 55510934
---
# OCR Receipts from Grocery Stores Text Detection
The Grocery Store Receipts Dataset is a collection of photos captured from various **grocery store receipts**. This dataset is specifically designed for tasks related to **Optical Character Recognition (OCR)** and is useful for retail.
Each image in the dataset is accompanied by bounding box annotations, indicating the precise locations of specific text segments on the receipts. The text segments are categorized into four classes: **item, store, date_time and total**.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of receipts
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and detected text, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes and detected text . For each point, the x and y coordinates are provided.
### Classes:
- **store** - name of the grocery store
- **item** - item in the receipt
- **date_time** - date and time of the receipt
- **total** - total price of the receipt
# Text Detection in the Receipts might be made in accordance with your requirements.
## [TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/trainingdata-pro** |
tanvirsrbd1/exp_data_v1-1 | 2023-10-04T06:12:21.000Z | [
"region:us"
] | tanvirsrbd1 | null | null | null | 0 | 19 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: html
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 1509076
num_examples: 2980
download_size: 487802
dataset_size: 1509076
---
# Dataset Card for "exp_data_v1-1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mor40/chitanka_raw_document | 2023-09-20T13:51:21.000Z | [
"region:us"
] | mor40 | null | null | null | 0 | 19 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1830893781
num_examples: 9910
download_size: 892507776
dataset_size: 1830893781
---
# Dataset Card for "chitanka_raw_document"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
VishalCh/book-train | 2023-09-20T16:20:02.000Z | [
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:en",
"license:apache-2.0",
"SQL",
"region:us"
] | VishalCh | null | null | null | 0 | 19 | ---
license: apache-2.0
task_categories:
- text-generation
language:
- en
tags:
- SQL
size_categories:
- 100K<n<1M
---
|
maibinh/dataset_finetuning_llama2 | 2023-09-27T10:03:33.000Z | [
"region:us"
] | maibinh | null | null | null | 0 | 19 | Entry not found |
Falah/samoan_fire_photography | 2023-09-21T08:27:36.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 19 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 1538494
num_examples: 10000
download_size: 27005
dataset_size: 1538494
---
# Dataset Card for "samoan_fire_photography"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.