
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
ChristophSchuhmann/wikipedia-en-nov22-1-sentence-level | 2023-04-19T06:01:38.000Z | [
"region:us"
] | ChristophSchuhmann | null | null | null | 1 | 15 | Entry not found |
StampyAI/alignment-research-dataset | 2023-08-26T19:12:23.000Z | [
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"arxiv:2206.02841",
"region:us"
] | StampyAI | The AI Alignment Research Dataset is a collection of documents related to AI Alignment and Safety from various books, research papers, and alignment related blog posts. | null | null | 7 | 15 | ---
language:
- en
license: mit
size_categories:
- 10K<n<100K
task_categories:
- question-answering
pretty_name: alignment-research-dataset
dataset_info:
features:
- name: id
dtype: string
- name: source
dtype: string
- name: title
dtype: string
- name: text
dtype: large_string
- name: url
dtype: string
- name: date_published
dtype: string
- name: authors
sequence: string
- name: summary
sequence: string
- name: source_type
dtype: string
- name: book_title
dtype: string
- name: karma
dtype: int32
- name: votes
dtype: int32
- name: words
dtype: int32
- name: comment_count
dtype: int32
- name: tags
sequence: string
- name: modified_at
dtype: string
- name: alias
dtype: string
- name: data_last_modified
dtype: string
- name: abstract
dtype: string
- name: author_comment
dtype: string
- name: journal_ref
dtype: string
- name: doi
dtype: string
- name: primary_category
dtype: string
- name: categories
sequence: string
- name: initial_source
dtype: string
- name: bibliography_bib
sequence:
- name: title
dtype: string
config_name: all
splits:
- name: train
num_bytes: 471644446
num_examples: 14271
download_size: 484827959
dataset_size: 471644446
---
# AI Alignment Research Dataset
The AI Alignment Research Dataset is a collection of documents related to AI Alignment and Safety from various books, research papers, and alignment related blog posts. This is a work in progress. Components are still undergoing a cleaning process to be updated more regularly.
## Sources
Here are the list of sources along with sample contents:
- [agentmodel](https://agentmodels.org/)
- [agisf](https://course.aisafetyfundamentals.com/) - recommended readings from AGI Safety Fundamentals
- [aisafety.info](https://aisafety.info/) - Stampy's FAQ
- [alignmentforum](https://www.alignmentforum.org)
- [alignment_newsletter](https://rohinshah.com/alignment-newsletter/)
- [arbital](https://arbital.com/)
- [arxiv](https://arxiv.org/) - relevant research papers
- blogs - entire websites automatically scraped
- [AI Impacts](https://aiimpacts.org/)
- [AI Safety Camp](https://aisafety.camp/)
- [carado.moe](https://carado.moe/)
- [Cold Takes](https://www.cold-takes.com/)
- [DeepMind technical blogs](https://www.deepmind.com/blog-categories/technical-blogs)
- [DeepMind AI Safety Research](https://deepmindsafetyresearch.medium.com/)
- [EleutherAI](https://blog.eleuther.ai/)
- [generative.ink](https://generative.ink/posts/)
- [Gwern Branwen's blog](https://gwern.net/)
- [Jack Clark's Import AI](https://importai.substack.com/)
- [MIRI](https://intelligence.org/)
- [Jacob Steinhardt's blog](https://jsteinhardt.wordpress.com/)
- [ML Safety Newsletter](https://newsletter.mlsafety.org/)
- [Transformer Circuits Thread](https://transformer-circuits.pub/)
- [Open AI Research](https://openai.com/research/)
- [Victoria Krakovna's blog](https://vkrakovna.wordpress.com/)
- [Eliezer Yudkowsky's blog](https://www.yudkowsky.net/)
- [distill](https://distill.pub/)
- [eaforum](https://forum.effectivealtruism.org/) - selected posts
- [lesswrong](https://www.lesswrong.com/) - selected posts
- special_docs - individual documents curated from various resources
- [Make a suggestion](https://bit.ly/ard-suggestion) for sources not already in the dataset
- youtube - playlists & channels
- [AI Alignment playlist](https://www.youtube.com/playlist?list=PLCRVRLd2RhZTpdUdEzJjo3qhmX3y3skWA) and other lists
- [AI Explained](https://www.youtube.com/@aiexplained-official)
- [Evan Hubinger's AI Safety Talks](https://www.youtube.com/@aisafetytalks)
- [AI Safety Reading Group](https://www.youtube.com/@aisafetyreadinggroup/videos)
- [AiTech - TU Delft](https://www.youtube.com/@AiTechTUDelft/)
- [Rob Miles AI](https://www.youtube.com/@RobertMilesAI)
## Keys
All entries contain the following keys:
- `id` - string of unique identifier
- `source` - string of data source listed above
- `title` - string of document title of document
- `authors` - list of strings
- `text` - full text of document content
- `url` - string of valid link to text content
- `date_published` - in UTC format
Additional keys may be available depending on the source document.
## Usage
Execute the following code to download and parse the files:
```python
from datasets import load_dataset
data = load_dataset('StampyAI/alignment-research-dataset')
```
To only get the data for a specific source, pass it in as the second argument, e.g.:
```python
from datasets import load_dataset
data = load_dataset('StampyAI/alignment-research-dataset', 'lesswrong')
```
## Limitations and Bias
LessWrong posts have overweighted content on doom and existential risk, so please beware in training or finetuning generative language models on the dataset.
## Contributing
The scraper to generate this dataset is open-sourced on [GitHub](https://github.com/StampyAI/alignment-research-dataset) and currently maintained by volunteers at StampyAI / AI Safety Info. [Learn more](https://coda.io/d/AI-Safety-Info_dfau7sl2hmG/Get-involved_susRF#_lufSr) or join us on [Discord](https://discord.gg/vjFSCDyMCy).
## Rebuilding info
This README contains info about the number of rows and their features which should be rebuilt each time datasets get changed. To do so, run:
datasets-cli test ./alignment-research-dataset --save_info --all_configs
## Citing the Dataset
For more information, here is the [paper](https://arxiv.org/abs/2206.02841) and [LessWrong](https://www.lesswrong.com/posts/FgjcHiWvADgsocE34/a-descriptive-not-prescriptive-overview-of-current-ai) post. Please use the following citation when using the dataset:
Kirchner, J. H., Smith, L., Thibodeau, J., McDonnell, K., and Reynolds, L. "Understanding AI alignment research: A Systematic Analysis." arXiv preprint arXiv:2022.4338861 (2022). |
ChristophSchuhmann/1-sentence-level-gutenberg-en_arxiv_pubmed_soda | 2023-04-30T09:30:25.000Z | [
"region:us"
] | ChristophSchuhmann | null | null | null | 0 | 15 | Entry not found |
thennal/GMaSC | 2023-05-01T21:18:33.000Z | [
"task_categories:text-to-speech",
"task_categories:automatic-speech-recognition",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:ml",
"license:cc-by-sa-4.0",
"region:us"
] | thennal | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: text
dtype: string
- name: speaker
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 48000
splits:
- name: train
num_bytes: 717976082.0
num_examples: 2000
download_size: 797772747
dataset_size: 717976082.0
annotations_creators:
- expert-generated
language:
- ml
language_creators:
- found
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
pretty_name: GEC Barton Hill Malayalam Speech Corpus
size_categories:
- 1K<n<10K
source_datasets:
- original
tags: []
task_categories:
- text-to-speech
- automatic-speech-recognition
task_ids: []
---
# GMaSC: GEC Barton Hill Malayalam Speech Corpus
**GMaSC** is a Malayalam text and speech corpus created by the Government Engineering College Barton Hill with an emphasis on Malayalam-accented English. The corpus contains 2,000 text-audio pairs of Malayalam sentences spoken by 2 speakers, totalling in approximately 139 minutes of audio. Each sentences has at least one English word common in Malayalam speech.
## Dataset Structure
The dataset consists of 2,000 instances with fields `text`, `speaker`, and `audio`. The audio is mono, sampled at 48kH. The transcription is normalized and only includes Malayalam characters and common punctuation. The table given below specifies how the 2,000 instances are split between the speakers, along with some basic speaker info:
| Speaker | Gender | Age | Time (HH:MM:SS) | Sentences |
| --- | --- | --- | --- | --- |
| Sonia | Female | 43 | 01:02:17 | 1,000 |
| Anil | Male | 48 | 01:17:23 | 1,000 |
| **Total** | | | **02:19:40** | **2,000** |
### Data Instances
An example instance is given below:
```json
{'text': 'സൗജന്യ ആയുർവേദ മെഡിക്കൽ ക്യാമ്പ്',
'speaker': 'Sonia',
'audio': {'path': None,
'array': array([0.00036621, 0.00033569, 0.0005188 , ..., 0.00094604, 0.00091553,
0.00094604]),
'sampling_rate': 48000}}
```
### Data Fields
- **text** (str): Transcription of the audio file
- **speaker** (str): The name of the speaker
- **audio** (dict): Audio object including loaded audio array, sampling rate and path to audio (always None)
### Data Splits
We provide all the data in a single `train` split. The loaded dataset object thus looks like this:
```json
DatasetDict({
train: Dataset({
features: ['text', 'speaker', 'audio'],
num_rows: 2000
})
})
```
## Additional Information
### Licensing
The corpus is made available under the [Creative Commons license (CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/).
|
fptudsc/face-celeb-vietnamese | 2023-05-10T15:13:18.000Z | [
"task_categories:image-classification",
"task_categories:zero-shot-classification",
"size_categories:10M<n<100M",
"language:vi",
"license:apache-2.0",
"region:us"
] | fptudsc | null | null | null | 1 | 15 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: string
splits:
- name: train
num_bytes: 82233752.864
num_examples: 8557
download_size: 80630170
dataset_size: 82233752.864
license: apache-2.0
task_categories:
- image-classification
- zero-shot-classification
language:
- vi
size_categories:
- 10M<n<100M
---
# Dataset Card for "face-celeb-vietnamese"
## Dataset Summary
This dataset contains information on over 8,000 samples of well-known Vietnamese individuals, categorized into three professions: singers, actors, and beauty queens. The dataset includes data on more than 100 celebrities in each of the three job categories.
## Languages
- Vietnamese: The label is used to indicate the name of celebrities in Vietnamese.
## Dataset Structure
- The image and Vietnamese sequences are
## Source Data - Initial Data Collection and Normalization
[Website người nổi tiếng](https://nguoinoitieng.tv)
### Licensing Information
Apache License 2.0
### Contributions
Thanks to [@github-duongttr](https://github.com/duongttr) and [@github-pphuc25](https://github.com/pphuc25) for adding this dataset. |
Thaweewat/hc3-24k-th | 2023-05-09T19:23:15.000Z | [
"task_categories:question-answering",
"task_categories:summarization",
"size_categories:10K<n<100K",
"language:th",
"license:cc-by-sa-3.0",
"instruction-finetuning",
"arxiv:2301.07597",
"region:us"
] | Thaweewat | null | null | null | 0 | 15 | ---
license: cc-by-sa-3.0
task_categories:
- question-answering
- summarization
tags:
- instruction-finetuning
language:
- th
size_categories:
- 10K<n<100K
---
# Summary
This is a 🇹🇭 Thai-instructed dataset translated using Google Cloud Translation from [HC3](https://huggingface.co/datasets/Hello-SimpleAI/HC3)
( Included total **24K**, 17K reddit_eli5, 4K finance, 1.2K medicine, 1.2K open_qa and 0.8K wiki_csai )
The first human-ChatGPT comparison corpus which is introduced in this paper:
- [How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection](https://arxiv.org/abs/2301.07597)
Code, models and analysis are available on GitHub:
- GitHub: [Chatgpt-Comparison-Detection project 🔬](https://github.com/Hello-SimpleAI/chatgpt-comparison-detection)
Supported Tasks:
- Training LLMs
- Synthetic Data Generation
- Data Augmentation
Languages: Thai
Version: 1.0
---
|
FreedomIntelligence/huatuo26M-testdatasets | 2023-05-17T03:39:41.000Z | [
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:zh",
"license:apache-2.0",
"medical",
"arxiv:2305.01526",
"region:us"
] | FreedomIntelligence | null | null | null | 12 | 15 | ---
license: apache-2.0
task_categories:
- text-generation
language:
- zh
tags:
- medical
size_categories:
- 1K<n<10K
---
# Dataset Card for huatuo26M-testdatasets
## Dataset Description
- **Homepage: https://www.huatuogpt.cn/**
- **Repository: https://github.com/FreedomIntelligence/Huatuo-26M**
- **Paper: https://arxiv.org/abs/2305.01526**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
We are pleased to announce the release of our evaluation dataset, a subset of the Huatuo-26M. This dataset contains 6,000 entries that we used for Natural Language Generation (NLG) experimentation in our associated research paper.
We encourage researchers and developers to use this evaluation dataset to gauge the performance of their own models. This is not only a chance to assess the accuracy and relevancy of generated responses but also an opportunity to investigate their model's proficiency in understanding and generating complex medical language.
Note: All the data points have been anonymized to protect patient privacy, and they adhere strictly to data protection and privacy regulations.
## Citation
```
@misc{li2023huatuo26m,
title={Huatuo-26M, a Large-scale Chinese Medical QA Dataset},
author={Jianquan Li and Xidong Wang and Xiangbo Wu and Zhiyi Zhang and Xiaolong Xu and Jie Fu and Prayag Tiwari and Xiang Wan and Benyou Wang},
year={2023},
eprint={2305.01526},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Shoubhik8/mpt_finetune_dataset | 2023-05-22T14:48:37.000Z | [
"region:us"
] | Shoubhik8 | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 331283580
num_examples: 371277
download_size: 13534489
dataset_size: 331283580
---
# Dataset Card for "mpt_finetune_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
deepghs/anime_classification | 2023-05-24T07:15:05.000Z | [
"task_categories:image-classification",
"size_categories:10K<n<100K",
"license:mit",
"art",
"region:us"
] | deepghs | null | null | null | 0 | 15 | ---
license: mit
task_categories:
- image-classification
tags:
- art
size_categories:
- 10K<n<100K
---
A simple classification task for generic anime images. Including the following 4 classes:
| Class | Images | Description |
|:------------:|:------:|---------------------------------------------------------------|
| comic | 5746 | comic images in color or greyscale |
| illustration | 6064 | illustration images |
| bangumi | 4914 | video screenshots or key visual images in bangumi |
| 3d | 4649 | 3d works including koikatsu, mikumikudance and other 3d types |
|
Chakshu/conversation_ender | 2023-05-25T08:56:31.000Z | [
"task_categories:text-classification",
"size_categories:n<1K",
"language:en",
"license:mit",
"Conversation",
"region:us"
] | Chakshu | null | null | null | 0 | 15 | ---
license: mit
task_categories:
- text-classification
language:
- en
tags:
- Conversation
size_categories:
- n<1K
pretty_name: Conversation Enders
---
Conversation Ending Check |
wwydmanski/reuters10k | 2023-05-29T08:59:17.000Z | [
"task_categories:tabular-classification",
"size_categories:10K<n<100K",
"tabular",
"region:us"
] | wwydmanski | null | @InProceedings{huggingface:dataset,
title = {A great new dataset},
author={huggingface, Inc.
},
year={2020}
} | null | 0 | 15 | ---
task_categories:
- tabular-classification
tags:
- tabular
pretty_name: Reuters10K
size_categories:
- 10K<n<100K
--- |
Enno-Ai/fr-instructs | 2023-06-26T23:16:02.000Z | [
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"size_categories:10M<n<100M",
"language:fr",
"license:cc-by-2.5",
"region:us"
] | Enno-Ai | null | null | null | 3 | 15 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 5904510661
num_examples: 11794112
download_size: 1623654660
dataset_size: 5904510661
license: cc-by-2.5
task_categories:
- text2text-generation
- table-question-answering
language:
- fr
size_categories:
- 10M<n<100M
---
# A collection of 12 million french-only instructions deduplicated from various sources
Source :
- clips/mqa-fr-faq
- multilingual-wikihow-qa-16k
- MBZUAI/Bactrian-X
- argilla/databricks-dolly-15k-curated-multilingual
- innermost47/alpaca-fr
- etalab-ia/piaf |
almanach/hc3_french_ood | 2023-06-05T10:19:19.000Z | [
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:sentence-similarity",
"task_categories:zero-shot-classification",
"size_categories:10K<n<100K",
"language:en",
"language:fr",
"license:cc-by-sa-4.0",
"ChatGPT",
"Bing",
"LM Detection",
"Detection",
... | almanach | Human ChatGPT Comparison Corpus (HC3) Translated To French.
The translation is done by Google Translate API.
We also add the native french QA pairs from ChatGPT, BingGPT and FAQ pages.
This dataset was used in our TALN 2023 paper.
Towards a Robust Detection of Language Model-Generated Text: Is ChatGPT that easy to detect? | # TODO: Add BibTeX citation for our TALN 2023 paper:
Towards a Robust Detection of Language Model-Generated Text: Is ChatGPT that easy to detect?
@article{guo-etal-2023-hc3,
title = "How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection",
author = "Guo, Biyang and
Zhang, Xin and
Wang, Ziyuan and
Jiang, Minqi and
Nie, Jinran and
Ding, Yuxuan and
Yue, Jianwei and
Wu, Yupeng",
journal={arXiv preprint arxiv:2301.07597}
year = "2023",
} | null | 1 | 15 | ---
task_categories:
- text-classification
- question-answering
- sentence-similarity
- zero-shot-classification
language:
- en
- fr
size_categories:
- 10K<n<100K
tags:
- ChatGPT
- Bing
- LM Detection
- Detection
- OOD
license: cc-by-sa-4.0
---
Dataset card for the dataset used in :
## Towards a Robust Detection of Language Model-Generated Text: Is ChatGPT that easy to detect?
Paper: https://gitlab.inria.fr/wantoun/robust-chatgpt-detection/-/raw/main/towards_chatgpt_detection.pdf
Source Code: https://gitlab.inria.fr/wantoun/robust-chatgpt-detection
## Dataset Summary
#### overview:
This dataset is made of two parts:
- First, an extension of the [Human ChatGPT Comparison Corpus (HC3) dataset](https://huggingface.co/datasets/Hello-SimpleAI/HC3) with French data automatically translated from the English source.
- Second, out-of-domain and adversarial French data set have been gathereed (Human adversarial, BingGPT, Native French ChatGPT responses).
#### Details:
- We first format the data into three subsets: `sentence`, `question` and `full` following the original paper.
- We then extend the data by translating the English questions and answers to French.
- We provide native French ChatGPT responses to a sample of the translated questions.
- We added a subset with QA pairs from BingGPT
- We included an adversarial subset with human-written answers in the style of conversational LLMs like Bing/ChatGPT.
## Available Subsets
### Out-of-domain:
- `hc3_fr_qa_chatgpt`: Translated French questions and native French ChatGPT answers pairs from HC3. This is the `ChatGPT-Native` subset from the paper.
- Features: `id`, `question`, `answer`, `chatgpt_answer`, `label`, `source`
- Size:
- test: `113` examples, `25592` words
- `qa_fr_binggpt`: French questions and BingGPT answers pairs. This is the `BingGPT` subset from the paper.
- Features: `id`, `question`, `answer`, `label`, `deleted_clues`, `deleted_sources`, `remarks`
- Size:
- test: `106` examples, `26291` words
- `qa_fr_binglikehuman`: French questions and human written BingGPT-like answers pairs. This is the `Adversarial` subset from the paper.
- Features: `id`, `question`, `answer`, `label`, `source`
- Size:
- test: `61` examples, `17328` words
- `faq_fr_gouv`: French FAQ questions and answers pairs from domain ending with `.gouv` from the MQA dataset (subset 'fr-faq-page'). https://huggingface.co/datasets/clips/mqa. This is the `FAQ-Gouv` subset from the paper.
- Features: `id`, `page_id`, `question_id`, `answer_id`, `bucket`, `domain`, `question`, `answer`, `label`
- Size:
- test: `235` examples, `22336` words
- `faq_fr_random`: French FAQ questions and answers pairs from random domain from the MQA dataset (subset 'fr-faq-page'). https://huggingface.co/datasets/clips/mqa. This is the `FAQ-Rand` subset from the paper.
- Features: `id`, `page_id`, `question_id`, `answer_id`, `bucket`, `domain`, `question`, `answer`, `label`
- Size:
- test: `4454` examples, `271823` words
### In-domain:
- `hc3_en_qa`: English questions and answers pairs from HC3.
- Features: `id`, `question`, `answer`, `label`, `source`
- Size:
- train: `68335` examples, `12306363` words
- validation: `17114` examples, `3089634` words
- test: `710` examples, `117001` words
- `hc3_en_sentence`: English answers split into sentences from HC3.
- Features: `id`, `text`, `label`, `source`
- Size:
- train: `455320` examples, `9983784` words
- validation: `113830` examples, `2510290` words
- test: `4366` examples, `99965` words
- `hc3_en_full`: English questions and answers pairs concatenated from HC3.
- Features: `id`, `text`, `label`, `source`
- Size:
- train: `68335` examples, `9982863` words
- validation: `17114` examples, `2510058` words
- test: `710` examples, `99926` words
- `hc3_fr_qa`: Translated French questions and answers pairs from HC3.
- Features: `id`, `question`, `answer`, `label`, `source`
- Size:
- train: `68283` examples, `12660717` words
- validation: `17107` examples, `3179128` words
- test: `710` examples, `127193` words
- `hc3_fr_sentence`: Translated French answers split into sentences from HC3.
- Features: `id`, `text`, `label`, `source`
- Size:
- train: `464885` examples, `10189606` words
- validation: `116524` examples, `2563258` words
- test: `4366` examples, `108374` words
- `hc3_fr_full`: Translated French questions and answers pairs concatenated from HC3.
- Features: `id`, `text`, `label`, `source`
- Size:
- train: `68283` examples, `10188669` words
- validation: `17107` examples, `2563037` words
- test: `710` examples, `108352` words
## How to load
```python
from datasets import load_dataset
dataset = load_dataset("almanach/hc3_multi", "hc3_fr_qa")
```
## Dataset Copyright
If the source datasets used in this corpus has a specific license which is stricter than CC-BY-SA, our products follow the same.
If not, they follow CC-BY-SA license.
| English Split | Source | Source License | Note |
|----------|-------------|--------|-------------|
| reddit_eli5 | [ELI5](https://github.com/facebookresearch/ELI5) | BSD License | |
| open_qa | [WikiQA](https://www.microsoft.com/en-us/download/details.aspx?id=52419) | [PWC Custom](https://paperswithcode.com/datasets/license) | |
| wiki_csai | Wikipedia | CC-BY-SA | | [Wiki FAQ](https://en.wikipedia.org/wiki/Wikipedia:FAQ/Copyright) |
| medicine | [Medical Dialog](https://github.com/UCSD-AI4H/Medical-Dialogue-System) | Unknown| [Asking](https://github.com/UCSD-AI4H/Medical-Dialogue-System/issues/10)|
| finance | [FiQA](https://paperswithcode.com/dataset/fiqa-1) | Unknown | Asking by 📧 |
| FAQ | [MQA]( https://huggingface.co/datasets/clips/mqa) | CC0 1.0| |
| ChatGPT/BingGPT | | Unknown | This is ChatGPT/BingGPT generated data. |
| Human | | CC-BY-SA | |
## Citation
```bibtex
@proceedings{towards-a-robust-2023-antoun,
title = "Towards a Robust Detection of Language Model-Generated Text: Is ChatGPT that easy to detect?",
editor = "Antoun, Wissam and
Mouilleron, Virginie and
Sagot, Benoit and
Seddah, Djam{\'e}",
month = "6",
year = "2023",
address = "Paris, France",
publisher = "ATALA",
url = "https://gitlab.inria.fr/wantoun/robust-chatgpt-detection/-/raw/main/towards_chatgpt_detection.pdf",
}
```
```bibtex
@article{guo-etal-2023-hc3,
title = "How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection",
author = "Guo, Biyang and
Zhang, Xin and
Wang, Ziyuan and
Jiang, Minqi and
Nie, Jinran and
Ding, Yuxuan and
Yue, Jianwei and
Wu, Yupeng",
journal={arXiv preprint arxiv:2301.07597}
year = "2023",
url ="https://arxiv.org/abs/2301.07597"
}
``` |
AgentWaller/german-formatted-oasst1 | 2023-06-01T09:40:25.000Z | [
"license:apache-2.0",
"region:us"
] | AgentWaller | null | null | null | 1 | 15 | ---
license: apache-2.0
dataset_info:
features:
- name: input
dtype: string
- name: input_no_prompt
dtype: string
- name: output
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 17894263
num_examples: 9838
- name: validation
num_bytes: 930643
num_examples: 518
download_size: 8982883
dataset_size: 18824906
---
|
Multimodal-Fatima/cvasnlp_sample_test | 2023-07-08T21:43:05.000Z | [
"region:us"
] | Multimodal-Fatima | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': abyssinian
'1': american bulldog
'2': american pit bull terrier
'3': basset hound
'4': beagle
'5': bengal
'6': birman
'7': bombay
'8': boxer
'9': british shorthair
'10': chihuahua
'11': egyptian mau
'12': english cocker spaniel
'13': english setter
'14': german shorthaired
'15': great pyrenees
'16': havanese
'17': japanese chin
'18': keeshond
'19': leonberger
'20': maine coon
'21': miniature pinscher
'22': newfoundland
'23': persian
'24': pomeranian
'25': pug
'26': ragdoll
'27': russian blue
'28': saint bernard
'29': samoyed
'30': scottish terrier
'31': shiba inu
'32': siamese
'33': sphynx
'34': staffordshire bull terrier
'35': wheaten terrier
'36': yorkshire terrier
- name: id
dtype: int64
- name: tags_laion-ViT-H-14-2B
sequence: string
- name: attributes_laion-ViT-H-14-2B
sequence: string
- name: caption_Salesforce-blip-image-captioning-large
dtype: string
- name: intensive_captions_Salesforce-blip-image-captioning-large
sequence: string
splits:
- name: test
num_bytes: 183538.0
num_examples: 10
download_size: 162401
dataset_size: 183538.0
---
# Dataset Card for "cvasnlp_sample_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ttss/rdf-summarization-d | 2023-06-14T21:52:31.000Z | [
"region:us"
] | ttss | null | null | null | 0 | 15 | Entry not found |
llm-book/aio-passages | 2023-06-24T05:55:37.000Z | [
"size_categories:1M<n<10M",
"language:ja",
"license:cc-by-sa-3.0",
"license:gfdl",
"region:us"
] | llm-book | null | null | null | 0 | 15 | ---
language:
- ja
size_categories:
- 1M<n<10M
license:
- cc-by-sa-3.0
- gfdl
dataset_info:
features:
- name: id
dtype: int32
- name: pageid
dtype: int32
- name: revid
dtype: int32
- name: text
dtype: string
- name: section
dtype: string
- name: title
dtype: string
splits:
- name: train
num_bytes: 3054493919
num_examples: 4288198
download_size: 1110830651
dataset_size: 3054493919
---
# Dataset Card for llm-book/aio-passages
書籍『大規模言語モデル入門』で使用する、「AI王」コンペティションのパッセージデータセットです。
GitHub リポジトリ [cl-tohoku/quiz-datasets](https://github.com/cl-tohoku/quiz-datasets) で公開されているデータセットを利用しています。
## Licence
本データセットで利用している Wikipedia のコンテンツは、[クリエイティブ・コモンズ表示・継承ライセンス 3.0 (CC BY-SA 3.0)](https://creativecommons.org/licenses/by-sa/3.0/deed.ja) および [GNU 自由文書ライセンス (GFDL)](https://www.gnu.org/licenses/fdl.html) の下に配布されているものです。
|
RiTA-nlp/ITALIC | 2023-06-29T12:58:56.000Z | [
"task_categories:automatic-speech-recognition",
"task_categories:audio-classification",
"task_ids:intent-classification",
"annotations_creators:crowdsourced",
"language_creators:Italian",
"license:cc-by-nc-nd-4.0",
"arxiv:2204.08582",
"arxiv:2306.08502",
"region:us"
] | RiTA-nlp | ITALIC is a dataset of Italian audio recordings and contains annotation for utterance transcripts and associated intents.
The ITALIC dataset was created through a custom web platform, utilizing both native and non-native Italian speakers as participants.
The participants were required to record themselves while reading a randomly sampled short text from the MASSIVE dataset. | @article{koudounas2023italic,
title={ITALIC: An Italian Intent Classification Dataset},
author={Koudounas, Alkis and La Quatra, Moreno and Vaiani, Lorenzo and Colomba, Luca and Attanasio, Giuseppe and Pastor, Eliana and Cagliero, Luca and Baralis, Elena},
journal={arXiv preprint arXiv:2306.08502},
year={2023}
} | null | 2 | 15 | ---
pretty_name: ITALIC
annotations_creators:
- crowdsourced
language_creators:
- Italian
language_bcp47:
- it
size_categories:
it: 10K<n<100K
task_categories:
- automatic-speech-recognition
- audio-classification
task_ids:
- intent-classification
license: cc-by-nc-nd-4.0
---
# Dataset Card for ITALIC: An ITALian Intent Classification Dataset
ITALIC is an intent classification dataset for the Italian language, which is the first of its kind.
It includes spoken and written utterances and is annotated with 60 intents.
The dataset is available on [Zenodo](https://zenodo.org/record/8040649) and connectors ara available for the [HuggingFace Hub](https://huggingface.co/datasets/RiTA-nlp/ITALIC).
### Latest Updates
- **June 15th, 2023**: ITALIC dataset has been released on [Zenodo](https://zenodo.org/record/8040649): https://zenodo.org/record/8040649.
## Table of Contents
- [Data collection](#data-collection)
- [Dataset](#dataset)
- [Usage](#usage)
- [Models used in the paper](#models-used-in-the-paper)
- [SLU intent classification](#slu-intent-classification)
- [ASR](#asr)
- [NLU intent classification](#nlu-intent-classification)
- [Citation](#citation)
- [License](#license)
## Data collection
The data collection follows the MASSIVE NLU dataset which contains an annotated textual dataset for 60 intents. The data collection process is described in the paper [Massive Natural Language Understanding](https://arxiv.org/abs/2204.08582).
Following the MASSIVE NLU dataset, a pool of 70+ volunteers has been recruited to annotate the dataset. The volunteers were asked to record their voice while reading the utterances (the original text is available on MASSIVE dataset). Together with the audio, the volunteers were asked to provide a self-annotated description of the recording conditions (e.g., background noise, recording device). The audio recordings have also been validated and, in case of errors, re-recorded by the volunteers.
All the audio recordings included in the dataset have received a validation from at least two volunteers. All the audio recordings have been validated by native italian speakers (self-annotated).
## Dataset
The dataset is available on the [Zenodo](https://zenodo.org/record/8040649). It is composed of 3 different splits:
- `massive`: all the utterances are randomly shuffled and divided into 3 splits (train, validation, test).
- `hard_speaker`: the utterances are divided into 3 splits (train, validation, test) based on the speaker. Each split only contains utterances from a pool of speakers that do not overlap with the other splits.
- `hard_noisy`: the utterances are divided into 3 splits (train, validation, test) based on the recording conditions. The test split only contains utterances with the highest level of noise.
Each split contains the following annotations:
- `utt`: the original text of the utterance.
- `audio`: the audio recording of the utterance.
- `intent`: the intent of the utterance.
- `speaker`: the speaker of the utterance. The speaker is identified by a unique identifier and has been anonymized.
- `age`: the age of the speaker.
- `is_native`: whether the speaker is a native italian speaker or not.
- `gender`: the gender of the speaker (self-annotated).
- `region`: the region of the speaker (self-annotated).
- `nationality`: the nationality of the speaker (self-annotated).
- `lisp`: any kind of lisp of the speaker (self-annotated). It can be empty in case of no lisp.
- `education`: the education level of the speaker (self-annotated).
- `environment`: the environment of the recording (self-annotated).
- `device`: the device used for the recording (self-annotated).
## Usage
The dataset can be loaded using the `datasets` library. You need to install the following dependencies:
```bash
pip install datasets
pip install librosa
pip install soundfile
```
Then, you can load the dataset as follows:
```python
from datasets import load_dataset
# Please be sure to use use_auth_token=True and to set the access token
# using huggingface-cli login
# or follow https://huggingface.co/docs/hub/security-tokens
# configs "hard_speaker" and "hard_noisy" are also available (to substitute "massive")
italic = load_dataset("RiTA-nlp/ITALIC", "massive", use_auth_token=True)
italic_train = italic["train"]
italic_valid = italic["validation"]
italic_test = italic["test"]
```
The dataset has been designed for intent classification tasks. The `intent` column can be used as the label. However, the dataset can be used for other tasks as well.
- **Intent classification**: the `intent` column can be used as the label.
- **Speaker identification**: the `speaker` column can be used as the label.
- **Automatic speech recognition**: the `utt` column can be used as the label.
- **Accent identification**: the `region` column can be used as the label.
For more information about the dataset, please refer to the [paper](https://arxiv.org/abs/2306.08502).
## Models used in the paper
### Hardware settings
All experiments were conducted on a private workstation with Intel Core i9-10980XE CPU, 1 $\times$ NVIDIA RTX A6000 GPU, 64 GB of RAM running Ubuntu 22.04 LTS.
### Parameter settings
The parameters used for the training of the models are set to allow a fair comparison between the different models and to follow the recommendations of the related literature. The parameters are summarized in the following table:
| Model | Task | Parameters | Learning rate | Batch size | Max epochs | Warmup | Weight decay | Avg. training time | Avg. inference time |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| facebook/wav2vec2-xls-r-300m | SLU | 300M | 1e-4 | 128 | 30 | 0.1 ratio | 0.01 | 9m 35s per epoch | 13ms per sample |
| facebook/wav2vec2-xls-r-1b | SLU | 1B | 1e-4 | 32 | 30 | 0.1 ratio | 0.01 | 21m 30s per epoch | 29ms per sample |
| jonatasgrosman/wav2vec2-large-xlsr-53-italian | SLU | 300M | 1e-4 | 128 | 30 | 0.1 ratio | 0.01 | 9m 35s per epoch | 13ms per sample |
| jonatasgrosman/wav2vec2-xls-r-1b-italian | SLU | 1B | 1e-4 | 32 | 30 | 0.1 ratio | 0.01 | 21m 30s per epoch | 29ms per sample |
| ALM/whisper-it-small-augmented | ASR | 224M | 1e-5 | 8 | 5 | 500 steps | 0.01 | 26m 30s per epoch | 25ms per sample |
| EdoAbati/whisper-medium-it-2 | ASR | 769M | 1e-5 | 8 | 5 | 500 steps | 0.01 | 49m per epoch | 94ms per sample |
| EdoAbati/whisper-large-v2-it | ASR | 1.5B | 1e-5 | 8 | 5 | 500 steps | 0.01 | 1h 17m per epoch | 238ms per sample |
| bert-base-multilingual-uncased | NLU | 167M | 5e-5 | 8 | 5 | 500 steps | 0.01 | 1m 22s per epoch | 1.5ms per sample |
| facebook/mbart-large-cc25 | NLU | 611M | 5e-5 | 8 | 5 | 500 steps | 0.01 | 7m 53s per epoch | 4.7ms per sample |
| dbmdz/bert-base-italian-xxl-uncased | NLU | 110M | 5e-5 | 8 | 5 | 500 steps | 0.01 | 1m 30s per epoch | 1.4ms per sample |
| morenolq/bart-it | NLU | 141M | 5e-5 | 8 | 5 | 500 steps | 0.01 | 1m 54s per epoch | 1.9 ms per sample |
In all cases, we opted for the AdamW optimizer. All experiments were run on a single NVIDIA A6000 GPU.
### SLU intent classification
The models used in the paper are available on the [Hugging Face Hub](https://huggingface.co/models).
- 🌍 [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
- 🌍 [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
- 🇮🇹 [jonatasgrosman/wav2vec2-xls-r-1b-italian](https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-italian)
- 🇮🇹 [jonatasgrosman/wav2vec2-large-xlsr-53-italian](https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-italian)
### ASR
The models used in the paper are available on the [Hugging Face Hub](https://huggingface.co/models).
- 🌍 Whisper large (zero-shot ASR): [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2)
- 🇮🇹 Whisper small: [ALM/whisper-it-small-augmented](https://huggingface.co/ALM/whisper-it-small-augmented)
- 🇮🇹 Whisper medium: [EdoAbati/whisper-medium-it-2](https://huggingface.co/EdoAbati/whisper-medium-it-2)
- 🇮🇹 Whisper large: [EdoAbati/whisper-large-v2-it](https://huggingface.co/EdoAbati/whisper-large-v2-it)
### NLU intent classification
The models used in the paper are available on the [Hugging Face Hub](https://huggingface.co/models).
- 🌍 [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased)
- 🌍 [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25)
- 🇮🇹 [dbmdz/bert-base-italian-xxl-uncased](https://huggingface.co/dbmdz/bert-base-italian-xxl-uncased)
- 🇮🇹 [morenolq/bart-it](https://huggingface.co/morenolq/bart-it)
## Citation
If you use this dataset in your research, please cite the following paper (**interspeech 2023** version is coming soon after the proceedings are published):
```bibtex
@article{koudounas2023italic,
title={ITALIC: An Italian Intent Classification Dataset},
author={Koudounas, Alkis and La Quatra, Moreno and Vaiani, Lorenzo and Colomba, Luca and Attanasio, Giuseppe and Pastor, Eliana and Cagliero, Luca and Baralis, Elena},
journal={arXiv preprint arXiv:2306.08502},
year={2023}
}
```
## License
The dataset is licensed under the [Creative Commons Attribution 4.0 International License](https://creativecommons.org/licenses/by/4.0/).
- [Paper describing the dataset and initial experiments](https://arxiv.org/abs/2306.08502)
- [Dataset on Zenodo](https://zenodo.org/record/8040649)
- [https://creativecommons.org/licenses/by-nc-sa/4.0/](https://creativecommons.org/licenses/by/4.0/)https://creativecommons.org/licenses/by/4.0/
|
shibing624/snli-zh | 2023-06-14T07:15:52.000Z | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"task_ids:semantic-similarity-scoring",
"task_ids:text-scoring",
"annotations_creators:shibing624",
"language_creators:liuhuanyong",
"multilinguality:monolingual",
"size_categories:100K<n<20M",
"source_datasets:https://git... | shibing624 | The SNLI corpus (version 1.0) is a collection of 570k human-written English
sentence pairs manually labeled for balanced classification with the labels
entailment, contradiction, and neutral, supporting the task of natural language
inference (NLI), also known as recognizing textual entailment (RTE). | @inproceedings{snli:emnlp2015,
Author = {Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher, and Manning, Christopher D.},
Booktitle = {Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
Publisher = {Association for Computational Linguistics},
Title = {A large annotated corpus for learning natural language inference},
Year = {2015}
} | null | 2 | 15 | ---
annotations_creators:
- shibing624
language_creators:
- liuhuanyong
language:
- zh
license: cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<20M
source_datasets:
- https://github.com/liuhuanyong/ChineseTextualInference/
task_categories:
- text-classification
task_ids:
- natural-language-inference
- semantic-similarity-scoring
- text-scoring
paperswithcode_id: snli
pretty_name: Stanford Natural Language Inference
---
# Dataset Card for SNLI_zh
## Dataset Description
- **Repository:** [Chinese NLI dataset](https://github.com/shibing624/text2vec)
- **Dataset:** [train data from ChineseTextualInference](https://github.com/liuhuanyong/ChineseTextualInference/)
- **Size of downloaded dataset files:** 54 MB
- **Total amount of disk used:** 54 MB
### Dataset Summary
中文SNLI和MultiNLI数据集,翻译自英文[SNLI](https://huggingface.co/datasets/snli)和[MultiNLI](https://huggingface.co/datasets/multi_nli)
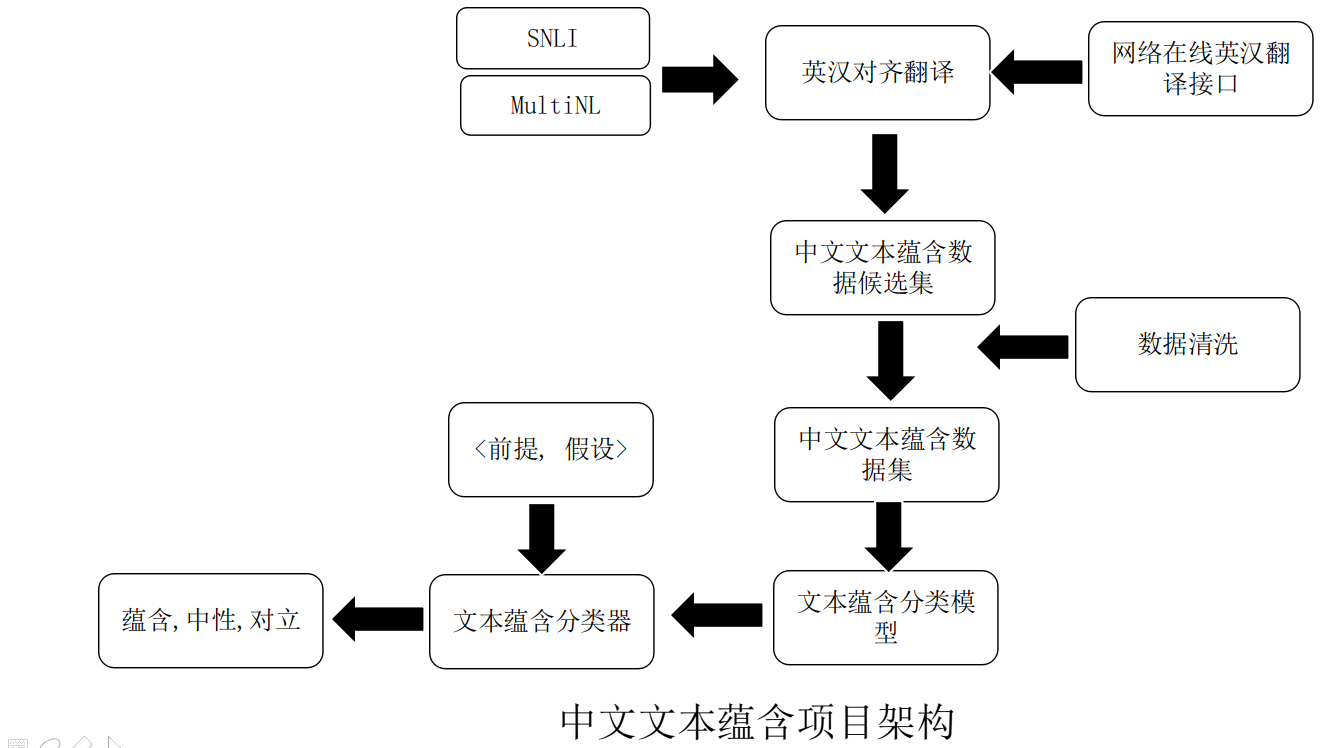
### Supported Tasks and Leaderboards
Supported Tasks: 支持中文文本匹配任务,文本相似度计算等相关任务。
中文匹配任务的结果目前在顶会paper上出现较少,我罗列一个我自己训练的结果:
**Leaderboard:** [NLI_zh leaderboard](https://github.com/shibing624/text2vec)
### Languages
数据集均是简体中文文本。
## Dataset Structure
### Data Instances
An example of 'train' looks as follows.
```
sentence1 sentence2 gold_label
是的,我想一个洞穴也会有这样的问题 我认为洞穴可能会有更严重的问题。 neutral
几周前我带他和一个朋友去看幼儿园警察 我还没看过幼儿园警察,但他看了。 contradiction
航空旅行的扩张开始了大众旅游的时代,希腊和爱琴海群岛成为北欧人逃离潮湿凉爽的夏天的令人兴奋的目的地。 航空旅行的扩大开始了许多旅游业的发展。 entailment
```
### Data Fields
The data fields are the same among all splits.
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `label`: a classification label, with possible values including entailment(0), neutral(1), contradiction(2). 注意:此数据集0表示相似,2表示不相似。
-
### Data Splits
after remove None and len(text) < 1 data:
```shell
$ wc -l ChineseTextualInference-train.txt
419402 total
```
### Data Length
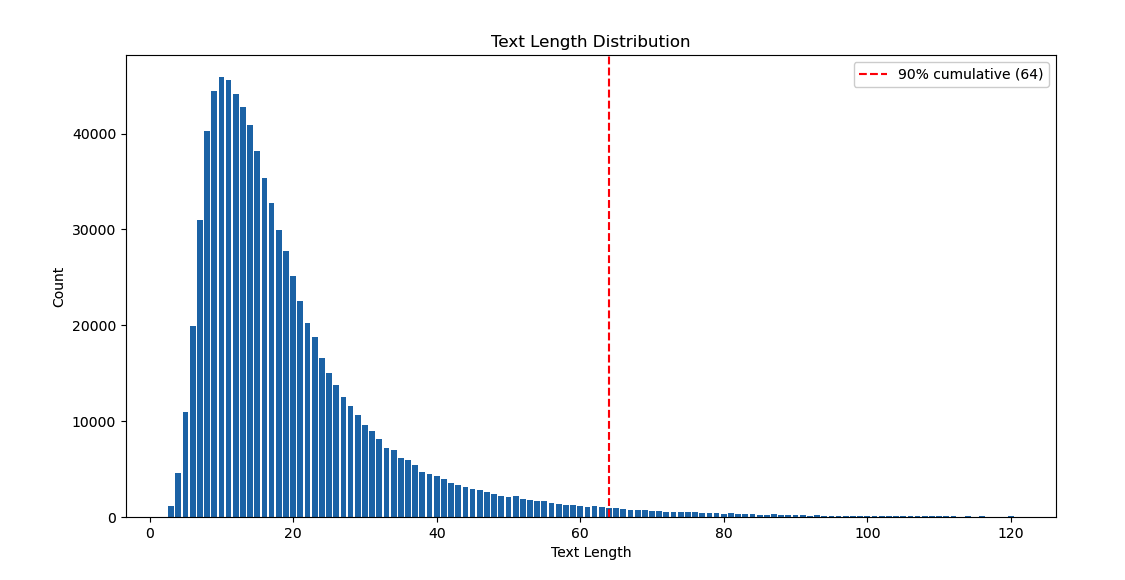
## Dataset Creation
### Curation Rationale
作为中文SNLI(natural langauge inference)数据集,这里把这个数据集上传到huggingface的datasets,方便大家使用。
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
数据集的版权归原作者所有,使用各数据集时请尊重原数据集的版权。
@inproceedings{snli:emnlp2015,
Author = {Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher, and Manning, Christopher D.},
Booktitle = {Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
Publisher = {Association for Computational Linguistics},
Title = {A large annotated corpus for learning natural language inference},
Year = {2015}
}
### Annotations
#### Annotation process
#### Who are the annotators?
原作者。
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
This dataset was developed as a benchmark for evaluating representational systems for text, especially including those induced by representation learning methods, in the task of predicting truth conditions in a given context.
Systems that are successful at such a task may be more successful in modeling semantic representations.
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
- [liuhuanyong](https://github.com/liuhuanyong/ChineseTextualInference/)翻译成中文
- [shibing624](https://github.com/shibing624) 上传到huggingface的datasets
### Licensing Information
用于学术研究。
### Contributions
[shibing624](https://github.com/shibing624) add this dataset. |
alpindale/visual-novels | 2023-06-14T14:44:30.000Z | [
"task_categories:conversational",
"task_categories:text-generation",
"language:en",
"license:apache-2.0",
"region:us"
] | alpindale | null | null | null | 13 | 15 | ---
license: apache-2.0
task_categories:
- conversational
- text-generation
language:
- en
pretty_name: Visual Novels
---
# Visual Novel Dataset
This dataset contains parsed Visual Novel scripts for training language models. The dataset consists of approximately 60 million tokens of parsed scripts.
## Dataset Structure
The dataset follows a general structure for visual novel scripts:
- Dialogue lines: Dialogue lines are formatted with the speaker's name followed by a colon, and the dialogue itself enclosed in quotes. For example:
```
John: "Hello, how are you?"
```
- Actions and narration: Actions and narration within the Visual Novel scripts are often enclosed in asterisks, but it's important to note that not all visual novels follow this convention. Actions and narration provide descriptions of character movements, background settings, or other narrative elements.
```
*John looked around the room, searching for answers.*
```
## Contents
- `visual-novels.txt`: This file contains all the parsed VNs concatenated within a single plaintext file. Each entry is separated with this string:
```
[ - title - {visual-novel-title-1.txt} ]
```
- `VNDB/`: This directory contains `.json` files that contain VNDB IDs for the corresponding VN's characters. Does not include unparsed VNs.
- `Archives/visual-novels-parsed.tar.zst`: This archive contains the parsed VNs but with each script in a separate text file (i.e. not concatenated).
- `Archives/visual-novels-unparsed.tar.zst`: This archive contains all the unparsed VNs along with the original script for the currently parsed VNs.
## Usage
You can utilize this dataset to train language models, particularly for tasks related to natural language processing and text generation. By leveraging the parsed visual novel scripts, you can train models to understand dialogue structures and generate coherent responses. Additionally, the inclusion of the unparsed scripts allows for further analysis and processing.
## Contribution
This dataset was gathered and parsed by the [PygmalionAI](https://hugginface.co/PygmalionAI) Data Processing Team. Listed below are the team members, sorted by contribution amount:
- **Suikamelon**: [HuggingFace](https://huggingface.co/lemonilia) - (2,787,704 ++ 672,473 --)
- **Alpin**: [HuggingFace](https://huggingface.co/alpindale) - [GitHub](https://github.com/AlpinDale) (1,170,985 ++ 345,120 --)
- **Spartan**: [GitHub](https://github.com/Spartan9772) (901,046 ++ 467,915 --)
- **Unlucky-AI** [GitHub](https://github.com/Unlucky-AI) (253,316 ++ 256 --)
## Citation
If you use this dataset in your research or projects, please cite it appropriately.
## Acknowledgements
This dataset is compiled and shared for research and educational purposes. The dataset includes parsed visual novel scripts from various sources, which are predominantly copyrighted and owned by their respective publishers and creators. The inclusion of these scripts in this dataset does not imply any endorsement or authorization from the copyright holders.
We would like to express our sincere gratitude to the original copyright holders and creators of the visual novels for their valuable contributions to the art and storytelling. We respect and acknowledge their intellectual property rights.
We strongly encourage users of this dataset to adhere to copyright laws and any applicable licensing restrictions when using or analyzing the provided content. It is the responsibility of the users to ensure that any use of the dataset complies with the legal requirements governing intellectual property and fair use.
Please be aware that the creators and distributors of this dataset disclaim any liability or responsibility for any unauthorized or illegal use of the dataset by third parties.
If you are a copyright holder or have any concerns about the content included in this dataset, please contact us at [this email address](mailto:alpin@alpindale.dev) to discuss the matter further and address any potential issues.
|
takaaki-inada/databricks-dolly-15k-ja-zundamon | 2023-06-17T10:41:52.000Z | [
"license:cc-by-sa-3.0",
"region:us"
] | takaaki-inada | null | null | null | 0 | 15 | ---
license: cc-by-sa-3.0
---
This dataset was based on "kunishou/databricks-dolly-15k-ja".
This dataset is licensed under CC BY SA 3.0
Last Update : 2023-05-11
databricks-dolly-15k-ja
https://github.com/kunishou/databricks-dolly-15k-ja
databricks-dolly-15k
https://github.com/databrickslabs/dolly/tree/master/data
|
autopilot-ai/Gujarati-Grammarly-Datasets | 2023-06-22T15:23:06.000Z | [
"license:afl-3.0",
"region:us"
] | autopilot-ai | null | null | null | 0 | 15 | ---
license: afl-3.0
---
This is the collection of datasets used for the creation of our Gujarati Grammarly. It consists of correct-incorrect sentence pairs and correct incorrect spelling pairs datasets.
The sentence pairs are provided in various sizes for ease of prototyping and scaling. |
pankajmathur/dolly-v2_orca | 2023-06-26T14:39:23.000Z | [
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-nc-sa-4.0",
"region:us"
] | pankajmathur | null | null | null | 15 | 15 | ---
license: cc-by-nc-sa-4.0
task_categories:
- text-generation
language:
- en
size_categories:
- 10K<n<100K
---
Explain tuned Dolly-V2 dataset ~15K created using approaches from Orca Research Paper.
We leverage all of the 15 system instructions provided in Orca Research Paper to generate explain tuned datasets, in contrast to vanilla instruction tuning approaches used by original datasets.
This helps student models like orca_mini_13b, orca_mini_7b or orca_mini_3b to learn thought process from teacher model, which is ChatGPT (gpt-3.5-turbo-0301 version).
Please see how the System prompt is added before each instruction. |
dfurman/All-In-Podcast-Transcripts | 2023-07-12T23:08:38.000Z | [
"license:apache-2.0",
"region:us"
] | dfurman | null | null | null | 0 | 15 | ---
license: apache-2.0
dataset_info:
features:
- name: section_title
dtype: string
- name: section_dialogue
dtype: string
- name: section_time_stamp
dtype: string
- name: episode_title
dtype: string
- name: episode_date
dtype: string
splits:
- name: E134
num_bytes: 89566
num_examples: 7
- name: E135
num_bytes: 85980
num_examples: 6
download_size: 114121
dataset_size: 175546
---
|
Waterhorse/chess_data | 2023-08-14T18:35:02.000Z | [
"task_categories:text-generation",
"task_categories:conversational",
"language:en",
"license:apache-2.0",
"arxiv:2306.09200",
"region:us"
] | Waterhorse | null | null | null | 2 | 15 | ---
license: apache-2.0
task_categories:
- text-generation
- conversational
language:
- en
---
# The Chess Dataset
## Dataset Description
- **Paper:** [ChessGPT: Bridging Policy Learning and Language Modeling](https://arxiv.org/abs/2306.09200)
### Dataset Summary
The dataset consists of three sources of dataset described in the paper, including:
- **ChessCLIP dataset**: Annotated PGNs for training CLIP.
- **ChessGPT Base dataset**: Game dataset, language dataset and mixed dataset for training ChessGPT-Base.
- **ChessGPT Chat dataset**: Conversational dataset for training ChessGPT-Chat.
Because of the legal issue, for ChessGPT dataset, we do not open-source the chess-book, chess-forum, chess-blog, and Youtube transcript datasets.
And for ChessCLIP dataset, we do not open-source two commercial annotated datasets we use.
### Languages
The language of the data is primarily English.
## Dataset Structure
- **ChessCLIP dataset**: Annotated PGNs for training CLIP.
- **ChessGPT Base dataset**: Game dataset: ccrl, pro_player, lichess_db_37, chess_puzzles, chess_modeling. Language dataset: redpajama, oscar, c4, pile, wikipedia, and stackexchange, and mixed dataset: annotated_pgn.
- **ChessGPT Chat dataset**: Chess-related conversation dataset:
### Data Instances
- **ChessCLIP dataset**:
```python
[Event "GMA, Wijk aan Zee NED"]
[Site "?"]
[Date "2003.??.??"]
[Round "1"]
[White "Anand,V"]
[Black "Radjabov,T"]
[Result "1/2"]
[WhiteElo "2750"]
[BlackElo "2620"]
[ECO "C12"]
[PlyCount "55"]
[Annotator "Hathaway"]
1. e4 e6
{ I'm not terribly familiar with the style of Radjabov, so I don't know if this is his usual opening. }
2. d4 d5 3. Nc3 Nf6 (3...Bb4
{ The Winawer Variation is probably best, though not as easy to play. }) 4. Bg5
{ threatens e4-e5xf6 }
(4. e5
{ keeps pieces on the board and avoids ...dxe4 }) 4...Bb4 (4...Be7
{ is more common and aims to trade dark-square bishops to ease Black's cramp }) (4...dxe4
{ aims to avoid any cramp by bringing pieces into alignment for trading, though White does get at least one very good piece (Ne4 or Bg5) and an easier time castling queen-side, to stir up king-side threats } ...
```
- **ChessGPT dataset**:
```python
{"metadata": {"id": "65268522",
"title": "1923 USSR Chess Championship",
"url": "https://en.wikipedia.org/wiki/1923%20USSR%20Chess%20Championship"},
"text": "The 1923 USSR Chess Championship was the second edition of USSR Chess Championship. Held from 8 to 24 July in Petrograd. The tournament was won by Peter Romanovsky.
"pipeline_key": "wiki-squad-train.jsonl.zst-10549"
}
```
- **ChessGPT Chat dataset**:
```python
{"conversations": [
{"author": "Human 0", "text": "Analyze the given sentence and identify its grammatical errors, if any.\nThese type of problems are difficult to solve.", "url": "gpt-4-alpaca", "score": 0},
{"author": "Human 1", "text": "The sentence is incorrect. The error is in the usage of \"these\". Since \"these\" is a plural determiner, it should be used with a plural noun. Similarly, \"type\" is singular noun and it is used with the singular determiner, \"this\".\n\nThe correct sentence should be \"This type of problem is difficult to solve.\" or \"These types of problems are difficult to solve.\"",
"url": "gpt-4-alpaca", "score": 0}
]
}
```
### Data Splits
The data is unsplit.
## Dataset Creation
Check [ChessGPT: Bridging Policy Learning and Language Modeling](https://arxiv.org/abs/2306.09200) for more details.
### Licensing Information
**Annotated PGN**: [PGNlib](https://www.angelfire.com/games3/smartbridge/), [lichess](https://lichess.org/terms-of-service), [GameKnot](https://gameknot.com/pg/pol_eula.htm), [pathtomaster](https://www.pathtochessmastery.com/)
**Game Dataset**: [Lichess dataset](https://www.tldrlegal.com/license/creative-commons-cc0-1-0-universal), [CCRL](https://ccrl.chessdom.com/ccrl/), [pro-player](https://www.pgnmentor.com/files.html), [puzzle](https://www.tldrlegal.com/license/creative-commons-cc0-1-0-universal), Modeling data(Apache-2.0).
**Language Dataset** [Wikipedia](https://huggingface.co/datasets/wikipedia#licensing-information), [Redpajama](https://github.com/togethercomputer/RedPajama-Data#license), [Oscar](https://huggingface.co/datasets/oscar-corpus/OSCAR-2301#licensing-information), [Pile](https://github.com/EleutherAI/the-pile/blob/master/LICENSE), [StackExchange](https://archive.org/details/stackexchange), [C4](https://huggingface.co/datasets/allenai/c4#license)
**Conversatoinal Datset**: [Chessable forums](https://www.chessable.com/terms), [Reddit](https://www.redditinc.com/policies/data-api-terms), [gpt-4](https://openai.com/policies/terms-of-use), [sharegpt](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb), oasst1(Apache-2.0), dolly-v2(MIT)
### Citation Information
```bash
@article{feng2023chessgpt,
title={ChessGPT: Bridging Policy Learning and Language Modeling},
author={Feng, Xidong and Luo, Yicheng and Wang, Ziyan and Tang, Hongrui and Yang, Mengyue and Shao, Kun and Mguni, David and Du, Yali and Wang, Jun},
journal={arXiv preprint arXiv:2306.09200},
year={2023}
}
``` |
jeffreyhuber/state_of_the_union | 2023-06-29T16:51:23.000Z | [
"region:us"
] | jeffreyhuber | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 39305
num_examples: 365
download_size: 25872
dataset_size: 39305
---
# Dataset Card for "state_of_the_union"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
lizhuang144/FACTUAL_Scene_Graph | 2023-07-10T14:55:17.000Z | [
"size_categories:10K<n<100K",
"language:en",
"license:openrail",
"region:us"
] | lizhuang144 | null | null | null | 1 | 15 | ---
license: openrail
language:
- en
pretty_name: FACTUAL
size_categories:
- 10K<n<100K
---
The scene graph parsing dataset described in `FACTUAL: A Benchmark for Faithful and Consistent Textual Scene Graph Parsing`
Please see details from https://github.com/zhuang-li/FACTUAL . |
EleutherAI/unscramble | 2023-07-05T19:14:02.000Z | [
"region:us"
] | EleutherAI | Unscramble is a small battery of 5 “character manipulation” tasks. Each task
involves giving the model a word distorted by some combination of scrambling,
addition, or deletion of characters, and asking it to recover the original word. | @inproceedings{NEURIPS2020_1457c0d6,
author = {Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winter, Clemens and Hesse, Chris and Chen, Mark and Sigler, Eric and Litwin, Mateusz and Gray, Scott and Chess, Benjamin and Clark, Jack and Berner, Christopher and McCandlish, Sam and Radford, Alec and Sutskever, Ilya and Amodei, Dario},
booktitle = {Advances in Neural Information Processing Systems},
editor = {H. Larochelle and M. Ranzato and R. Hadsell and M. F. Balcan and H. Lin},
pages = {1877--1901},
publisher = {Curran Associates, Inc.},
title = {Language Models are Few-Shot Learners},
url = {https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf},
volume = {33},
year = {2020}
} | null | 0 | 15 | Entry not found |
InfImagine/FakeImageDataset | 2023-08-13T09:00:14.000Z | [
"license:apache-2.0",
"arxiv:2304.13023",
"region:us"
] | InfImagine | null | null | null | 4 | 15 | ---
license: apache-2.0
---
# Fake Image Dataset
Fake Image Dataset is now open-sourced at [huggingface (InfImagine Organization)](https://huggingface.co/datasets/InfImagine/FakeImageDataset/tree/main/ImageData/train). ↗ It consists of two folders, *ImageData* and *MetaData*. *ImageData* contains the compressed packages of the Fake Image Dataset, while *MetaData* contains the labeling information of the corresponding data indicating whether they are real or fake.
Sentry-Image is now open-sourced at [Sentry-Image (github repository)](https://github.com/Inf-imagine/Sentry) which provides the SOTA fake image detection models in [Sentry-Image Leaderboard](http://sentry.infimagine.com/) pretraining in [Fake Image Dataset](https://huggingface.co/datasets/InfImagine/FakeImageDataset/tree/main/ImageData/train) to detect whether the image provided is an AI-generated or real image.
## Why we need [Fake Image Dataset](https://huggingface.co/datasets/InfImagine/FakeImageDataset/tree/main/ImageData/train) and [Sentry-Image](http://sentry.infimagine.com/)?
* 🧐 Recent [study](https://arxiv.org/abs/2304.13023) have shown that humans struggle significantly to distinguish real photos from AI-generated ones, with a misclassification rate of **38.7%**.
* 🤗 To help people confirm whether the images they see are real images or AI-generated images, we launched the Sentry-Image project.
* 💻 Sentry-Image is an open source project which provides the SOTA fake image detection models in [Sentry-Image Leaderboard](http://sentry.infimagine.com/) to detect whether the image provided is an AI-generated or real image.
# Dataset card for Fake Image Dataset
## Dataset Description
* **Homepage:** [Sentry-Image](http://sentry.infimagine.com/)
* **Paper:** [https://arxiv.org/pdf/2304.13023.pdf](https://arxiv.org/pdf/2304.13023.pdf)
* **Point of Contact:** [contact@infimagine.com](mailto:contact@infimagine.com)
## How to Download
You can use following codes to download the dataset:
```shell
git lfs install
git clone https://huggingface.co/datasets/InfImagine/FakeImageDataset
```
You can use following codes to extract the files in each subfolder (take the *IF-CC95K* subfolder in ImageData/val/IF-CC95K as an example):
```shell
cat IF-CC95K.tar.gz.* > IF-CC95K.tar.gz
tar -xvf IF-CC95K.tar.gz
```
## Dataset Summary
FakeImageDataset was created to serve as an large-scale dataset for the pretraining of detecting fake images.
It was built on StableDiffusion v1.5, IF and StyleGAN3.
## Supported Tasks and Leaderboards
FakeImageDataset is intended to be primarly used as a pretraining dataset for detecting fake images.
## Sub Dataset
### Training Dataset (Fake2M)
| Dataset | SD-V1.5Real-dpms-25 | IF-V1.0-dpms++-25 | StyleGAN3 |
| :----------- | :-----------: | :-----------: | :-----------: |
| Generator | Diffusion | Diffusion | GAN |
| Numbers | 1M | 1M | 87K |
| Resolution | 512 | 256 | (>=512) |
| Caption | CC3M-Train | CC3M-Train | - |
| ImageData Path | ImageData/train/SDv15R-CC1M | ImageData/train/IFv1-CC1M | ImageData/train/stylegan3-80K |
| MetaData Path | MetaData/train/SDv15R-CC1M.csv | MetaData/train/IF-CC1M.csv | MetaData/train/stylegan3-80K.csv |
### Validation Dataset (MPBench)
| Dataset | SDv15 | SDv21 | IF | Cogview2 | StyleGAN3 | Midjourneyv5 |
| :---------- | :-----------: | :-----------: | :-----------: | :-----------: | :-----------: | :-----------: |
| Generator | Diffusion | Diffusion | Diffusion | AR | GAN | - |
| Numbers | 30K | 15K | 95K | 22K | 60K | 5K |
| Resolution | 512 | 512 | 256 | 480 | (>=512) | (>=512) |
| Caption | CC15K-val | CC15K-val | CC15K-val | CC15K-val | - | - |
| ImageData Path | ImageData/val/SDv15-CC30K | ImageData/val/SDv21-CC15K | ImageData/val/IF-CC95K | ImageData/val/cogview2-22K | ImageData/val/stylegan3-60K | ImageData/val/Midjourneyv5-5K|
| MetaData Path | MetaData/val/SDv15-CC30K.csv| MetaData/val/SDv21-CC15K.csv | MetaData/val/IF-CC95K.csv | MetaData/val/cogview2-22K.csv | MetaData/val/stylegan3-60K.csv | MetaData/val/Midjourneyv5-5K.csv |
# News
* [2023/07] We open source the [Sentry-Image repository](https://github.com/Inf-imagine/Sentry) and [Sentry-Image Demo & Leaderboard](http://sentry.infimagine.com/).
* [2023/07] We open source the [Sentry-Image dataset](https://huggingface.co/datasets/InfImagine/FakeImageDataset).
Stay tuned for this project! Feel free to contact [contact@infimagine.com](contact@infimagine.com)! 😆
# License
This project is open-sourced under the [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0). These weights and datasets are fully open for academic research and can be used for commercial purposes with official written permission. If you find our open-source models and datasets useful for your business, we welcome your donation to support the development of the next-generation Sentry-Image model. Please contact [contact@infimagine.com](contact@infimagine.com) for commercial licensing and donation inquiries.
# Citation
The code and model in this repository is mostly developed for or derived from the paper below. Please cite it if you find the repository helpful.
```
@misc{sentry-image-leaderboard,
title = {Sentry-Image Leaderboard},
author = {Zeyu Lu, Di Huang, Chunli Zhang, Chengyue Wu, Xihui Liu, Lei Bai, Wanli Ouyang},
year = {2023},
publisher = {InfImagine, Shanghai AI Laboratory},
howpublished = "\url{https://github.com/Inf-imagine/Sentry}"
},
@misc{lu2023seeing,
title = {Seeing is not always believing: Benchmarking Human and Model Perception of AI-Generated Images},
author = {Zeyu Lu, Di Huang, Lei Bai, Jingjing Qu, Chengyue Wu, Xihui Liu, Wanli Ouyang},
year = {2023},
eprint = {2304.13023},
archivePrefix = {arXiv},
primaryClass = {cs.AI}
}
``` |
TrainingDataPro/body-measurements-dataset | 2023-09-14T16:57:44.000Z | [
"task_categories:image-classification",
"task_categories:image-to-image",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | The dataset consists of a compilation of people's photos along with their
corresponding body measurements. It is designed to provide information and
insights into the physical appearances and body characteristics of individuals.
The dataset includes a diverse range of subjects representing different age
groups, genders, and ethnicities.
The photos are captured in a standardized manner, depicting individuals in a
front and side positions.
The images aim to capture the subjects' physical appearance using appropriate
lighting and angles that showcase their body proportions accurately.
The dataset serves various purposes, including:
- research projects
- body measurement analysis
- fashion or apparel industry applications
- fitness and wellness studies
- anthropometric studies for ergonomic design in various fields | @InProceedings{huggingface:dataset,
title = {body-measurements-dataset},
author = {TrainingDataPro},
year = {2023}
} | null | 2 | 15 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-classification
- image-to-image
tags:
- code
dataset_info:
features:
- name: front_img
dtype: image
- name: selfie_img
dtype: image
- name: side_img
dtype: image
- name: arm_circumference_cm
dtype: string
- name: arm_length_cm
dtype: string
- name: back_build_cm
dtype: string
- name: calf_circumference_cm
dtype: string
- name: chest_circumference_cm
dtype: string
- name: crotch_height_cm
dtype: string
- name: front_build_cm
dtype: string
- name: hips_circumference_cm
dtype: string
- name: leg_length_cm
dtype: string
- name: neck_circumference_cm
dtype: string
- name: neck_pelvis_length_front_cm
dtype: string
- name: neck_waist_length_back_cm
dtype: string
- name: neck_waist_length_front_cm
dtype: string
- name: pelvis_circumference_cm
dtype: string
- name: shoulder_length_cm
dtype: string
- name: shoulder_width_cm
dtype: string
- name: thigh_circumference_cm
dtype: string
- name: under_chest_circumference_cm
dtype: string
- name: upper_arm_length_cm
dtype: string
- name: waist_circumference_cm
dtype: string
- name: height
dtype: string
- name: weight
dtype: string
- name: age
dtype: string
- name: gender
dtype: string
- name: race
dtype: string
- name: profession
dtype: string
- name: arm_circumference
dtype: image
- name: arm_length
dtype: image
- name: back_build
dtype: image
- name: calf_circumference
dtype: image
- name: chest_circumference
dtype: image
- name: crotch_height
dtype: image
- name: front_build
dtype: image
- name: hips_circumference
dtype: image
- name: leg_length
dtype: image
- name: neck_circumference
dtype: image
- name: neck_pelvis_length_front
dtype: image
- name: neck_waist_length_back
dtype: image
- name: neck_waist_length_front
dtype: image
- name: pelvis_circumference
dtype: image
- name: shoulder_length
dtype: image
- name: shoulder_width
dtype: image
- name: thigh_circumference
dtype: image
- name: under_chest_circumference
dtype: image
- name: upper_arm_length
dtype: image
- name: waist_circumference
dtype: image
splits:
- name: train
num_bytes: 86120
num_examples: 21
download_size: 68560913
dataset_size: 86120
---
# Body Measurements Dataset
The dataset consists of a compilation of people's photos along with their corresponding body measurements. It is designed to provide information and insights into the physical appearances and body characteristics of individuals.
The dataset includes a diverse range of subjects representing different **age groups, genders, and ethnicities**.
The photos are captured in a standardized manner, depicting individuals in a **front** and **side positions**.
The images aim to capture the subjects' physical appearance using appropriate *lighting and angles* that showcase their body proportions accurately.
The dataset serves various purposes, including:
- research projects
- body measurement analysis
- fashion or apparel industry applications
- fitness and wellness studies
- anthropometric studies for ergonomic design in various fields
.png?generation=1688983133539816&alt=media)
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=body-measurements-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Content
### Folders
- **files**: includes folders with photos and measurements of people
- **proofs**: contains subfolders, corresponding to the original photos in `files` folder and includes additional photos of people taking measurements
- **.pdf** file: includes information about photos in `proofs` folder
### "Files" folder includes 3 images of a person and json file with measurements:
- **selfie** - the person is looking to the camera; face, neck and shoulders are clearly seen,
- **front photo** - the person stands in front of the camera, all body parts are clearly seen,
- **side photo** - the person turned sideways to the camera, all body parts are clearly seen
- **json file** - includes 22 measurements (*weight, height, hips circumference, leg length etc.*) and 4 additional characteristics (**age, gender, race, profession**) of a person, depicted in photos in the subfolder
### File with the extension .csv
includes the following information for each media file:
- **selfie**: link to the selfie,
- **front**: link to the front photo,
- **side**: link to the side photo,
- **measurements**: link to the json file with measurements
# Body Measurements might be collected in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=body-measurements-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
Isotonic/OpenOrca-deduped | 2023-08-24T13:21:18.000Z | [
"task_categories:text-generation",
"task_categories:text2text-generation",
"task_categories:conversational",
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:table-question-answering",
"task_categories:zero-shot-classification",
"task_categories:question-... | Isotonic | null | null | null | 3 | 15 | ---
license: mit
dataset_info:
features:
- name: id
dtype: string
- name: system_prompt
dtype: string
- name: question
dtype: string
- name: response
dtype: string
- name: reward
dtype: float32
splits:
- name: train
num_bytes: 3274600633.90245
num_examples: 2409134
- name: test
num_bytes: 409325419.048775
num_examples: 301142
- name: validation
num_bytes: 409325419.048775
num_examples: 301142
download_size: 2268645581
dataset_size: 4093251472.0000005
task_categories:
- text-generation
- text2text-generation
- conversational
- text-classification
- token-classification
- table-question-answering
- zero-shot-classification
- question-answering
- summarization
- feature-extraction
language:
- en
size_categories:
- 1M<n<10M
arxiv:
- 2301.13688
- 2306.02707
---
# Dataset Card for Isotonic/OpenOrca-deduped
## Dataset Summary
This dataset is a deduplicated version of [Open-Orca/OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca)
*MinHash Deduplication with Jaccard Threshold = 0.80*
```
Original dataset size: 4233923
Number of duplicate clusters: 522077
Files in duplicate cluster: 2115143
Unique files in duplicate cluster: 892638
Filtered dataset size: 3011418
``` |
jinaai/negation-dataset | 2023-08-04T10:09:02.000Z | [
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"language:en",
"license:apache-2.0",
"finetuner",
"arxiv:2307.11224",
"region:us"
] | jinaai | null | null | null | 6 | 15 |
---
tags:
- finetuner
language: en
license: apache-2.0
dataset_info:
features:
- name: anchor
dtype: string
- name: entailment
dtype: string
- name: negative
dtype: string
splits:
- name: train
num_examples: 10000
- name: test
num_examples: 500
download_size: 1467517
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
---
<br><br>
<p align="center">
<img src="https://github.com/jina-ai/finetuner/blob/main/docs/_static/finetuner-logo-ani.svg?raw=true" alt="Finetuner logo: Finetuner helps you to create experiments in order to improve embeddings on search tasks. It accompanies you to deliver the last mile of performance-tuning for neural search applications." width="150px">
</p>
<p align="center">
<b>The data offered by Jina AI, Finetuner team.</b>
</p>
## Summary
This dataset is an English-language dataset based on the [SNLI](https://huggingface.co/datasets/snli) dataset.
It contains negations of samples from SNLI.
## Instances
Each data point consists of a triplet ('anchor', 'entailment', 'negative') of strings, where ('anchor', 'entailment') are positive pairs
taken from SNLI, and 'negative' contradicts both 'anchor' and 'entailment'.
## Fields
- 'anchor': string, some statement
- 'entailment': string, a statement which follows from 'anchor', but is usually syntactically dissimilar
- 'negative': string, a statement contradicting 'anchor' and 'entailment'. Syntactically very similar to 'entailment'
## Splits
| | train | test |
|------------|-------|------|
| # of items | 10000 | 500 |
## Source
Positive pairs were sampled from the [SNLI](https://huggingface.co/datasets/snli) dataset and negative samples were created using GPT-3.5
and GPT-4.
## Example Usage
```python
from datasets import load_dataset
from pprint import pprint
dataset = load_dataset('jinaai/negation-dataset')
pprint(dataset['train'][:5])
```
Output:
```python
{'anchor': ['Two young girls are playing outside in a non-urban environment.',
'A man with a red shirt is watching another man who is standing on '
'top of a attached cart filled to the top.',
'A man in a blue shirt driving a Segway type vehicle.',
'A woman holds her mouth wide open as she is placing a stack of '
'crackers in.',
'A group of people standing on a rock path.'],
'entailment': ['Two girls are playing outside.',
'A man is standing on top of a cart.',
'A person is riding a motorized vehicle.',
'There is a woman eating crackers.',
'A group of people are hiking.'],
'negative': ['Two girls are not playing outside.',
'A man is not standing on top of a cart.',
'A person is not riding a motorized vehicle.',
'There is no woman eating crackers.',
'A group of people are not hiking.']}
```
## Models
[Jina AI's](https://jina.ai) open source embedding models ([small](https://huggingface.co/jinaai/jina-embedding-s-en-v1),
[base](https://huggingface.co/jinaai/jina-embedding-b-en-v1) and
[large](https://huggingface.co/jinaai/jina-embedding-l-en-v1)) were all fine-tuned on the negation dataset.
## Licensing Information
This work is licensed under the Apache License, Version 2.0.
## Contributors
Thanks to contributors from [Jina AI](https://jina.ai) for adding this dataset.
## Contact
Join our [Discord community](https://discord.jina.ai) and chat with other community members about ideas.
## Citation
If you find this dataset useful in your research, please cite the following paper:
``` latex
@misc{günther2023jina,
title={Jina Embeddings: A Novel Set of High-Performance Sentence Embedding Models},
author={Michael Günther and Louis Milliken and Jonathan Geuter and Georgios Mastrapas and Bo Wang and Han Xiao},
year={2023},
eprint={2307.11224},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
|
squarelike/sharegpt_deepl_ko_translation | 2023-09-09T14:28:46.000Z | [
"region:us"
] | squarelike | null | null | null | 2 | 15 | [https://github.com/jwj7140/Gugugo](https://github.com/jwj7140/Gugugo)
[sharegpt_deepl_ko](https://huggingface.co/datasets/junelee/sharegpt_deepl_ko)를 한-영 번역데이터로 변환한 데이터입니다.
sharegpt_deepl_ko에서 몇 가지의 데이터 전처리를 진행했습니다. |
fujiki/llm-japanese-dataset_wikinews | 2023-07-24T08:13:28.000Z | [
"license:cc-by-2.5",
"region:us"
] | fujiki | null | null | null | 1 | 15 | ---
license: cc-by-2.5
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 6934579
num_examples: 4265
download_size: 3599861
dataset_size: 6934579
---
- This dataset is a subset of [izumi-lab/llm-japanese-dataset](https://huggingface.co/datasets/izumi-lab/llm-japanese-dataset) only including news-title generation tasks from `Wikinews`.
- Please also refer to the original dataset: [izumi-lab/llm-japanese-dataset](https://huggingface.co/datasets/izumi-lab/llm-japanese-dataset) |
zhengxuanzenwu/alpaca-no-context | 2023-07-25T05:40:02.000Z | [
"region:us"
] | zhengxuanzenwu | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: context
dtype: string
- name: response
dtype: string
- name: category
dtype: string
splits:
- name: test
num_bytes: 13048458
num_examples: 31323
download_size: 7755578
dataset_size: 13048458
---
# Dataset Card for "alpaca-no-context"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tiwes/aads | 2023-07-28T06:26:20.000Z | [
"region:us"
] | tiwes | null | null | null | 0 | 15 | Entry not found |
frtna/FineTuneTaxonomy | 2023-08-04T23:46:31.000Z | [
"region:us"
] | frtna | null | null | null | 0 | 15 | Entry not found |
FreedomIntelligence/sharegpt-deutsch | 2023-08-13T15:58:00.000Z | [
"license:apache-2.0",
"region:us"
] | FreedomIntelligence | null | null | null | 0 | 15 | ---
license: apache-2.0
---
Deutsch ShareGPT data translated by gpt-3.5-turbo.
The dataset is used in the research related to [MultilingualSIFT](https://github.com/FreedomIntelligence/MultilingualSIFT). |
dim/what_where_when_3k | 2023-08-15T12:13:42.000Z | [
"license:cc-by-nc-nd-4.0",
"region:us"
] | dim | null | null | null | 0 | 15 | ---
license: cc-by-nc-nd-4.0
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: explanation
dtype: string
- name: url
dtype: string
- name: uuid
dtype: string
splits:
- name: train
num_bytes: 2533471.262653731
num_examples: 3000
download_size: 1461762
dataset_size: 2533471.262653731
---
|
dim/competition_math_selected | 2023-08-15T01:56:22.000Z | [
"license:mit",
"region:us"
] | dim | null | null | null | 0 | 15 | ---
license: mit
dataset_info:
features:
- name: problem
dtype: string
- name: level
dtype: string
- name: type
dtype: string
- name: solution
dtype: string
splits:
- name: train
num_bytes: 2332225.2
num_examples: 3000
download_size: 1217035
dataset_size: 2332225.2
---
|
Andyrasika/cat_kingdom | 2023-09-18T16:14:42.000Z | [
"region:us"
] | Andyrasika | null | null | null | 1 | 15 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: mask
dtype: image
splits:
- name: train
num_bytes: 224581.0
num_examples: 9
download_size: 230721
dataset_size: 224581.0
---
# Dataset Card for "cat_kingdom"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
usvsnsp/deduped-num-frequencies | 2023-08-17T08:21:04.000Z | [
"region:us"
] | usvsnsp | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: TokenID
dtype: int64
- name: Frequency
dtype: int64
splits:
- name: memorized
num_bytes: 960000
num_examples: 60000
- name: non_memorized
num_bytes: 960000
num_examples: 60000
- name: total
num_bytes: 960000
num_examples: 60000
download_size: 1974196
dataset_size: 2880000
---
# Dataset Card for "deduped-num-frequencies"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
amitness/logits-italian-512 | 2023-09-21T22:01:23.000Z | [
"region:us"
] | amitness | null | null | null | 0 | 15 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
- name: teacher_logits
sequence:
sequence: float64
- name: teacher_indices
sequence:
sequence: int64
- name: teacher_mask_indices
sequence: int64
splits:
- name: train
num_bytes: 37372996972
num_examples: 2055197
download_size: 13720127033
dataset_size: 37372996972
---
# Dataset Card for "logits-italian-512"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
vitaliy-sharandin/synthetic-fraud-detection | 2023-08-24T17:17:37.000Z | [
"region:us"
] | vitaliy-sharandin | null | null | null | 1 | 15 | Entry not found |
thesistranslation/distilled-ccmatrix-es-en | 2023-10-03T09:21:19.000Z | [
"language:es",
"language:en",
"region:us"
] | thesistranslation | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: id
dtype: int32
- name: translation
dtype:
translation:
languages:
- es
- en
splits:
- name: train
num_bytes: 7090174966
num_examples: 30000000
download_size: 4926077685
dataset_size: 7090174966
language:
- es
- en
---
# Dataset Card for "distilled-ccmatrix-es-en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
yardeny/mlm_test_set_context_len_64 | 2023-08-29T11:28:59.000Z | [
"region:us"
] | yardeny | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
splits:
- name: train
num_bytes: 506880
num_examples: 1280
download_size: 0
dataset_size: 506880
---
# Dataset Card for "loss_landscape_test_set_context_len_64"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
StudentLLM/Sampled_Orca_GPT4 | 2023-08-31T02:58:44.000Z | [
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"region:us"
] | StudentLLM | null | null | null | 0 | 15 | ---
language:
- en
size_categories:
- 10K<n<100K
license: mit
---
# Stratify Sampled Dataset of Open-Orca 🐬
This dataset is a stratified sampled dataset of Open-Orca's GPT-4 answered dataset(1M-GPT4-Augmented.parquet) [[Link](https://huggingface.co/datasets/Open-Orca/OpenOrca)]
For sampling the dataset stratify, `train_test_split` of scikit-learn library was used.
The specific setup of sampling is as follows:
- split_size: 0.05
- shuffle: True
- stratify: `'id'` of Open-Orca dataset |
dim/dialogsum_3k | 2023-08-31T20:08:56.000Z | [
"region:us"
] | dim | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: id
dtype: string
- name: dialogue
dtype: string
- name: summary
dtype: string
- name: topic
dtype: string
splits:
- name: train
num_bytes: 2754324.55858748
num_examples: 3000
download_size: 1570734
dataset_size: 2754324.55858748
---
# Dataset Card for "dialogsum_3k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
dim/dolphin_flan1m_alpaca_uncensored_3k | 2023-08-31T20:18:10.000Z | [
"region:us"
] | dim | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 5235792.840107775
num_examples: 3000
download_size: 2954863
dataset_size: 5235792.840107775
---
# Dataset Card for "dolphin_flan1m_alpaca_uncensored_3k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
iashchak/igor_link_dialogues | 2023-09-01T19:26:28.000Z | [
"region:us"
] | iashchak | null | null | null | 0 | 15 | Entry not found |
TrainingDataPro/ripe-strawberries-detection | 2023-09-26T08:38:14.000Z | [
"task_categories:image-classification",
"task_categories:image-to-image",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"biology",
"region:us"
] | TrainingDataPro | The dataset consists of photos of strawberries for the identification and recognition of
ripe berries.
The images are annotated with **bounding boxes** that accurately demarcate the location
of the ripe strawberries within the image.
Each image in the dataset showcases a strawberry plantation, and includes a diverse
range of backgrounds, lighting conditions, and orientations. The photos are captured
from various angles and distances, providing a realistic representation of strawberries.
The dataset can be utilised for enabling advancements in strawberry production, quality
control, and greater precision in agricultural practices. | @InProceedings{huggingface:dataset,
title = {ripe-strawberries-detection},
author = {TrainingDataPro},
year = {2023}
} | null | 2 | 15 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-classification
- image-to-image
- object-detection
tags:
- code
- biology
dataset_info:
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: width
dtype: uint16
- name: height
dtype: uint16
- name: shapes
sequence:
- name: label
dtype:
class_label:
names:
'0': strawberry
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 127730244
num_examples: 40
download_size: 126412271
dataset_size: 127730244
---
# Ripe Strawberries Detection
The dataset consists of photos of strawberries for the identification and recognition of **ripe berries**.
The images are annotated with **bounding boxes** that accurately demarcate the location of the ripe strawberries within the image.
Each image in the dataset showcases a strawberry plantation, and includes a diverse range of *backgrounds, lighting conditions, and orientations*. The photos are captured from various *angles and distances*, providing a realistic representation of strawberries.
The dataset can be utilised for enabling advancements in *strawberry production, quality control, and greater precision in agricultural practices*.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ripe-strawberries-detection) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of strawberries
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and labels, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes for ripe strawberries detection. For each point, the x and y coordinates are provided. Visibility of the ripe strawberry is also provided by the attribute **occluded** (0, 1).
# Example of XML file structure
# Strawberry Detection might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ripe-strawberries-detection) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
Hrukanina/2ch-dataset-for-llama | 2023-09-09T14:05:44.000Z | [
"license:other",
"region:us"
] | Hrukanina | null | null | null | 1 | 15 | ---
license: other
---
|
mHossain/sa_merge_v1 | 2023-09-09T16:58:58.000Z | [
"region:us"
] | mHossain | null | null | null | 0 | 15 | Entry not found |
Mireu-Lab/NSL-KDD | 2023-09-10T18:27:19.000Z | [
"license:gpl-3.0",
"Network Security",
"region:us"
] | Mireu-Lab | null | null | null | 0 | 15 | ---
license: gpl-3.0
tags:
- Network Security
---
# NSL-KDD
> The data set is a data set that converts the arff File provided by the [link](https://www.unb.ca/cic/datasets/nsl.html) into CSV and results.
>
> The data set is personally stored by converting data to float64.
>
> If you want to obtain additional original files, they are organized in the [Original Directory](./Original) in the repo.
## Labels
The label of the data set is as follows.
|#|Column|Non-Null|Count|Dtype|
|---|---|---|---|---|
|0|duration|151165|non-null|int64|
|1|protocol_type|151165|non-null|object|
|2|service|151165|non-null|object|
|3|flag|151165|non-null|object|
|4|src_bytes|151165|non-null|int64|
|5|dst_bytes|151165|non-null|int64|
|6|land|151165|non-null|int64|
|7|wrong_fragment|151165|non-null|int64|
|8|urgent|151165|non-null|int64|
|9|hot|151165|non-null|int64|
|10|num_failed_logins|151165|non-null|int64|
|11|logged_in|151165|non-null|int64|
|12|num_compromised|151165|non-null|int64|
|13|root_shell|151165|non-null|int64|
|14|su_attempted|151165|non-null|int64|
|15|num_root|151165|non-null|int64|
|16|num_file_creations|151165|non-null|int64|
|17|num_shells|151165|non-null|int64|
|18|num_access_files|151165|non-null|int64|
|19|num_outbound_cmds|151165|non-null|int64|
|20|is_host_login|151165|non-null|int64|
|21|is_guest_login|151165|non-null|int64|
|22|count|151165|non-null|int64|
|23|srv_count|151165|non-null|int64|
|24|serror_rate|151165|non-null|float64|
|25|srv_serror_rate|151165|non-null|float64|
|26|rerror_rate|151165|non-null|float64|
|27|srv_rerror_rate|151165|non-null|float64|
|28|same_srv_rate|151165|non-null|float64|
|29|diff_srv_rate|151165|non-null|float64|
|30|srv_diff_host_rate|151165|non-null|float64|
|31|dst_host_count|151165|non-null|int64|
|32|dst_host_srv_count|151165|non-null|int64|
|33|dst_host_same_srv_rate|151165|non-null|float64|
|34|dst_host_diff_srv_rate|151165|non-null|float64|
|35|dst_host_same_src_port_rate|151165|non-null|float64|
|36|dst_host_srv_diff_host_rate|151165|non-null|float64|
|37|dst_host_serror_rate|151165|non-null|float64|
|38|dst_host_srv_serror_rate|151165|non-null|float64|
|39|dst_host_rerror_rate|151165|non-null|float64|
|40|dst_host_srv_rerror_rate|151165|non-null|float64|
|41|class|151165|non-null|float64|
|
rombodawg/LimitlessCodeTraining_60k_Guanaco_Format | 2023-10-01T21:33:23.000Z | [
"license:mit",
"region:us"
] | rombodawg | null | null | null | 0 | 15 | ---
license: mit
---
This is the LimitlessCodeTraining dataset reduced to 60k lines for use in google colab (non pro)
Original model card:
_________________
----- BREAK THROUGH YOUR LIMITS -----
_________________

LimitlessCodeTraining is the direct sequal to Megacodetraining that is now called Legacy_MegaCodeTraining200k.
This dataset is just over 646k lines of pure refined coding data.
It is the pinacle of open source code training. It is the combination of the filtered Megacode training dataset filtered by shahules786 (shoutout to him) and the bigcode commitpackft dataset I converted to alpaca format.
The dataset that were used to create this dataset are linked bellow:
- https://huggingface.co/datasets/rombodawg/Rombodawgs_commitpackft_Evolinstruct_Converted
- https://huggingface.co/datasets/shahules786/megacode-best |
philikai/Spider-SQL-LLAMA2_train | 2023-09-15T16:42:15.000Z | [
"region:us"
] | philikai | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: db_id
dtype: string
- name: query
dtype: string
- name: question
dtype: string
- name: schema
dtype: string
- name: primary_keys
dtype: string
- name: foreign_keys
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 46264027
num_examples: 8659
- name: validation
num_bytes: 4478136
num_examples: 1034
download_size: 4082872
dataset_size: 50742163
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
# Dataset Card for "Spider-SQL-LLAMA2_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Dippi9845/arxiv_with_fragments_clean | 2023-09-11T14:23:58.000Z | [
"license:cc-by-nc-sa-4.0",
"region:us"
] | Dippi9845 | null | null | null | 0 | 15 | ---
license: cc-by-nc-sa-4.0
---
|
gmongaras/reddit_negative | 2023-09-12T02:43:21.000Z | [
"license:openrail",
"region:us"
] | gmongaras | null | null | null | 0 | 15 | ---
license: openrail
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 2042615
num_examples: 4857
download_size: 1283119
dataset_size: 2042615
---
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/e9d30f3e | 2023-09-12T19:09:56.000Z | [
"region:us"
] | results-sd-v1-5-sd-v2-1-if-v1-0-karlo | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: result
dtype: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 186
num_examples: 10
download_size: 1339
dataset_size: 186
---
# Dataset Card for "e9d30f3e"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
FelipeC/Earth_Mars | 2023-09-12T19:58:04.000Z | [
"license:apache-2.0",
"region:us"
] | FelipeC | null | null | null | 0 | 15 | ---
license: apache-2.0
---
|
bvand086/ata_guidelines | 2023-09-13T19:21:28.000Z | [
"region:us"
] | bvand086 | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 803456
num_examples: 847
download_size: 435112
dataset_size: 803456
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "ata_guidelines"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
SeyedAli/Persian-Audio-Dataset | 2023-09-15T08:01:55.000Z | [
"language:fa",
"license:mit",
"region:us"
] | SeyedAli | null | null | null | 1 | 15 | ---
license: mit
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: audio_id
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: speaker_id
dtype: string
- name: gender
dtype: string
- name: emotion
dtype: string
- name: transcript
dtype: string
- name: ipa
dtype: string
splits:
- name: train
num_bytes: 840005131.22
num_examples: 2270
- name: test
num_bytes: 197198169
num_examples: 568
download_size: 1003307335
dataset_size: 1037203300.22
language:
- fa
--- |
anujsahani01/Custom_Dataset_CodeGen | 2023-09-14T16:24:51.000Z | [
"license:mit",
"region:us"
] | anujsahani01 | null | null | null | 1 | 15 | ---
license: mit
---
|
patrickfleith/controlled-anomalies-time-series-dataset | 2023-09-14T18:30:28.000Z | [
"task_categories:time-series-forecasting",
"task_categories:tabular-classification",
"size_categories:1M<n<10M",
"license:cc-by-4.0",
"timeseries",
"anomaly",
"detection",
"region:us"
] | patrickfleith | null | null | null | 4 | 15 | ---
license: cc-by-4.0
task_categories:
- time-series-forecasting
- tabular-classification
tags:
- timeseries
- anomaly
- detection
pretty_name: cats
size_categories:
- 1M<n<10M
---
# Dataset Card for Dataset Name
## Dataset Description
Cite the dataset as:
Patrick Fleith. (2023). Controlled Anomalies Time Series (CATS) Dataset (Version 2) [Data set]. Solenix Engineering GmbH. https://doi.org/10.5281/zenodo.8338435
### Dataset Summary
The Controlled Anomalies Time Series (CATS) Dataset consists of commands, external stimuli, and telemetry readings of a simulated complex dynamical system with **200 injected anomalies.**
The CATS Dataset exhibits a set of desirable properties that make it very suitable for benchmarking Anomaly Detection Algorithms in Multivariate Time Series [1]:
### Supported Tasks and Leaderboards
Anomaly Detection in Multivariate Time Series
## Dataset Structure
- **Multivariate (17 variables) including sensors reading and control signals.** It simulates the operational behaviour of an arbitrary complex system including:
- **4 Deliberate Actuations / Control Commands sent by a simulated operator / controller**, for instance, commands of an operator to turn ON/OFF some equipment.
- **3 Environmental Stimuli / External Forces** acting on the system and affecting its behaviour, for instance, the wind affecting the orientation of a large ground antenna.
- **10 Telemetry Readings** representing the observable states of the complex system by means of sensors, for instance, a position, a temperature, a pressure, a voltage, current, humidity, velocity, acceleration, etc.
- **5 million timestamps**. Sensors readings are at 1Hz sampling frequency.
- **1 million nominal observations** (the first 1 million datapoints). This is suitable to start learning the "normal" behaviour.
- **4 million observations** that include both nominal and anomalous segments. This is suitable to evaluate both semi-supervised approaches (novelty detection) as well as unsupervised approaches (outlier detection).
- **200 anomalous segments**. One anomalous segment may contain several successive anomalous observations / timestamps. Only the last 4 million observations contain anomalous segments.
- **Different types of anomalies** to understand what anomaly types can be detected by different approaches. The categories are available in the dataset and in the metadata.
- **Fine control over ground truth**. As this is a simulated system with deliberate anomaly injection, the start and end time of the anomalous behaviour is known very precisely. In contrast to real world datasets, there is no risk that the ground truth contains mislabelled segments which is often the case for real data.Suitable for root cause analysis. In addition to the anomaly category, the time series channel in which the anomaly first developed itself is recorded and made available as part of the metadata. This can be useful to evaluate the performance of algorithm to trace back anomalies to the right root cause channel.
- **Affected channels**. In addition to the knowledge of the root cause channel in which the anomaly first developed itself, we provide information of channels possibly affected by the anomaly. This can also be useful to evaluate the explainability of anomaly detection systems which may point out to the anomalous channels (root cause and affected).
- **Obvious anomalies.** The simulated anomalies have been designed to be "easy" to be detected for human eyes (i.e., there are very large spikes or oscillations), hence also detectable for most algorithms. It makes this synthetic dataset useful for screening tasks (i.e., to eliminate algorithms that are not capable to detect those obvious anomalies). However, during our initial experiments, the dataset turned out to be challenging enough even for state-of-the-art anomaly detection approaches, making it suitable also for regular benchmark studies.
- **Context provided**. Some variables can only be considered anomalous in relation to other behaviours. A typical example consists of a light and switch pair. The light being either on or off is nominal, the same goes for the switch, but having the switch on and the light off shall be considered anomalous. In the CATS dataset, users can choose (or not) to use the available context, and external stimuli, to test the usefulness of the context for detecting anomalies in this simulation.
- **Pure signal ideal for robustness-to-noise analysis**. The simulated signals are provided without noise: while this may seem unrealistic at first, it is an advantage since users of the dataset can decide to add on top of the provided series any type of noise and choose an amplitude. This makes it well suited to test how sensitive and robust detection algorithms are against various levels of noise.
- **No missing data**. You can drop whatever data you want to assess the impact of missing values on your detector with respect to a clean baseline.
### Data Splits
- The first 1 million points are nominal (no occurence of anomalies)
- The next 4 million points include both nominal and anomalous segments.
### Licensing Information
license: cc-by-4.0
### Citation Information
Patrick Fleith. (2023). Controlled Anomalies Time Series (CATS) Dataset (Version 1) [Data set]. Solenix Engineering GmbH. https://doi.org/10.5281/zenodo.7646897 |
amin-nejad/idrid-disease-grading | 2023-09-17T17:00:26.000Z | [
"task_categories:image-classification",
"size_categories:n<1K",
"language:en",
"license:cc-by-4.0",
"medical",
"region:us"
] | amin-nejad | null | null | null | 0 | 15 | ---
license: cc-by-4.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': a_noDR
'1': b_mildDR
'2': c_moderateDR
'3': d_severeDR
'4': e_proDR
splits:
- name: train
num_bytes: 166058061
num_examples: 413
- name: test
num_bytes: 46195500
num_examples: 103
download_size: 203477506
dataset_size: 212253561
task_categories:
- image-classification
language:
- en
tags:
- medical
pretty_name: IDRiD Disease Grading
size_categories:
- n<1K
---
# Indian Diabetic Retinopathy Image Dataset (IDRiD)
This dataset is the disease grading portion of the IDRiD.
The original source of the dataset is here: https://ieee-dataport.org/open-access/indian-diabetic-retinopathy-image-dataset-idrid
|
shelvin94/DarijaTranslator | 2023-09-15T14:03:11.000Z | [
"region:us"
] | shelvin94 | null | null | null | 0 | 15 | {"English":"Yes","Arabic Darija":"إييه/ آه/واه"}
{"English":"No","Arabic Darija":"لا"}
{"English":"Please (addressing a singular)","Arabic Darija":"عافاك"}
{"English":"Thanks","Arabic Darija":"شكرا"}
{"English":"I love you (addressing a singular)","Arabic Darija":"كنبغيك"}
{"English":"I miss you (addressing a singular)","Arabic Darija":"توحشتك"}
{"English":"A lot","Arabic Darija":"بزاف"}
{"English":"A little","Arabic Darija":"شوية"}
{"English":"Okay","Arabic Darija":"واخا"}
{"English":"Now","Arabic Darija":"دابا"}
{"English":"Not now","Arabic Darija":"ماشي دابا"}
{"English":"Or","Arabic Darija":"أولا"}
{"English":"And","Arabic Darija":"و"}
{"English":"It’s not a problem / It’s okay","Arabic Darija":"ماشي مشكل"}
{"English":"(It was) not me","Arabic Darija":"ماشي أنا"}
{"English":"I want…","Arabic Darija":"بغيت…"}
{"English":"I don’t want...","Arabic Darija":"...ما بغيتش"}
{"English":"I am done / I finished","Arabic Darija":"ساليت"}
{"English":"I am not done / I did not finish","Arabic Darija":"ما ساليتش"}
{"English":"Beautiful (masculine, singular)","Arabic Darija":"زوين"}
{"English":"Bad/ugly (masculine, singular)","Arabic Darija":"خايب"}
{"English":"Good (masculine, singular)","Arabic Darija":"مزيان"}
{"English":"Excuse me","Arabic Darija":"سمح ليا سمحلي ليا"}
{"English":"I don’t speak Arabic","Arabic Darija":"ما كنهضرش العربية"}
{"English":"I don’t understand/I didn’t understand","Arabic Darija":"ما فهمتش"}
{"English":"Do you understand me? (Addressing a singular)","Arabic Darija":"فهمتيني؟"}
{"English":"I don’t have any money","Arabic Darija":"ما عنديش الفلوس"}
{"English":"Welcome","Arabic Darija":"مرحبا"}
{"English":"Take (this)","Arabic Darija":"هاك هاكي"}
{"English":"Give me… (Addressing a singular)","Arabic Darija":"عطيني…"}
{"English":"I know","Arabic Darija":"عرفت"}
{"English":"I don’t know","Arabic Darija":"ما عرفتش"}
{"English":"I forgot","Arabic Darija":"نسيت"}
{"English":"I have to go","Arabic Darija":"خاصني نمشي"}
{"English":"It’s your turn (Addressing a singular)","Arabic Darija":"نوبتك"}
{"English":"It’s my turn","Arabic Darija":"نوبتي"}
{"English":"I am tired","Arabic Darija":"عييت"}
{"English":"Where is the W.C?","Arabic Darija":"فين كاينة الطواليت"}
{"English":"Congratulations","Arabic Darija":"مبروك"}
{"English":"Can you help me?","Arabic Darija":"تقدر تعاوني؟ تقدري تعاونيني؟"}
{"English":"I am looking for…","Arabic Darija":"كنقلب على..."}
{"English":"I can’t find/I didn’t find","Arabic Darija":"ما لقيتش…"}
{"English":"Agreed/Enough","Arabic Darija":"صافي"}
{"English":"Slowly","Arabic Darija":"بشوية"}
{"English":"Faster","Arabic Darija":"بالزربة"}
{"English":"Maybe","Arabic Darija":"إيمكن"}
{"English":"Of course","Arabic Darija":"طبعا / أكيد"}
{"English":"I have a problem.","Arabic Darija":"عندي مشكلة"}
{"English":"What do you think? (Addressing a singular)","Arabic Darija":"أشنو بان ليك؟"}
{"English":"What did you say? (Addressing a singular)","Arabic Darija":"أشنو ڭلتي؟"}
{"English":"What’s your name?","Arabic Darija":"أشنو سميتك؟"}
{"English":"My name is…","Arabic Darija":"سميتي…"}
{"English":"How old are you?","Arabic Darija":"شحال ف عمرك؟"}
{"English":"I am … years old.","Arabic Darija":"عندي… عام "}
{"English":"Where are you from?","Arabic Darija":"منين نتا؟ - منين نتي؟ "}
{"English":"I am from America/Morocco/France/Egypt…","Arabic Darija":"...أنا من أمريكا/ المغرب/ فرنسا/ مصر"}
{"English":"Do you work or study?","Arabic Darija":"خدام أولا كتقرا؟ - خدامة أولا كتقراي؟ -"}
{"English":"I study.","Arabic Darija":"كنقرا."}
{"English":"What do you study?","Arabic Darija":"أش كتقرا؟ - أش كتقراي؟ -"}
{"English":"I study medicine.","Arabic Darija":"كنقرا الطب"}
{"English":"I work.","Arabic Darija":"كنخدم"}
{"English":"Where do you work?","Arabic Darija":"فين خدام؟ - فين خدامة؟ -"}
{"English":"What’s your job?","Arabic Darija":"فاش خدام؟ - فاش خدامة؟ -"}
{"English":"I am a lawyer/teacher/engineer","Arabic Darija":"...أنا محامي/ أستاد/ مهندس- ...أنا محامية/ أستادة/ مهندسة-"}
{"English":"Are you married?","Arabic Darija":"مزوج؟ - مزوجة؟ -"}
{"English":"Yes, I am married.","Arabic Darija":"آه، أنا مزوج - آه، أنا مزوجة -"}
{"English":"No, I am not married.","Arabic Darija":"لا، أنا ما مزوجش - لا، أنا ما مزوجاش -"}
{"English":"Do you speak English?","Arabic Darija":"كتهضر النڭليزية؟ - كتهضري النڭليزية؟ -"}
{"English":"I speak a little Arabic.","Arabic Darija":"كنهضر شوية د العربية"}
{"English":"Nice to meet you.","Arabic Darija":"متشرفين"}
{"English":"Allergy","Arabic Darija":"حساسية"}
{"English":"Ambulance","Arabic Darija":"لابيلانص"}
{"English":"Analgesic","Arabic Darija":"مسكن"}
{"English":"Anesthesia","Arabic Darija":"بنج"}
{"English":"Appointment","Arabic Darija":"رانديڤو"}
{"English":"Asthma","Arabic Darija":"ضيقة"}
{"English":"Bandage","Arabic Darija":"فاصمة"}
{"English":"Cancer","Arabic Darija":"سرطان"}
{"English":"Constipation","Arabic Darija":"إمساك"}
{"English":"Coton","Arabic Darija":"قطن"}
{"English":"Coughing","Arabic Darija":"كحة"}
{"English":"Dentist","Arabic Darija":"طبيب ديال السنان"}
{"English":"Diabetes","Arabic Darija":"سكر"}
{"English":"Diarrhoea","Arabic Darija":"السهال"}
{"English":"Diet","Arabic Darija":"ريجيم"}
{"English":"Dizziness","Arabic Darija":"دوخة"}
{"English":"Doctor","Arabic Darija":"طبيب"}
{"English":"Drugstore","Arabic Darija":"فرمسيان"}
{"English":"Fever","Arabic Darija":"سخانة"}
{"English":"Hernia","Arabic Darija":"فتق"}
{"English":"Hoarseness","Arabic Darija":"بحة"}
{"English":"Hospital","Arabic Darija":"صبيطار"}
{"English":"Indigestion","Arabic Darija":"عسر الهضم"}
{"English":"Injury","Arabic Darija":"جرح"}
{"English":"Itching","Arabic Darija":"حكة"}
{"English":"Laboratory","Arabic Darija":"مختبر"}
{"English":"Medicines","Arabic Darija":"دوا"}
{"English":"Nurse","Arabic Darija":"فرملي"}
{"English":"Operation","Arabic Darija":"عملية"}
{"English":"Pain","Arabic Darija":"ألم"}
{"English":"Pills","Arabic Darija":"كينة"}
{"English":"Plaster cast","Arabic Darija":"گبص"}
{"English":"Shiver","Arabic Darija":"تبوريشة"}
{"English":"Sickness","Arabic Darija":"مرض"}
{"English":"Stitch","Arabic Darija":"غرزة"}
{"English":"Syrup","Arabic Darija":"سيرو"}
{"English":"Test","Arabic Darija":"تحليل"}
{"English":"Tiredness","Arabic Darija":"عيا"}
{"English":"Toothbrush","Arabic Darija":"شيتة ديال السنان"}
{"English":"Vaccination","Arabic Darija":"تلقيح"}
{"English":"Vomitting","Arabic Darija":"ردان تقية"}
{"English":"May I use this computer?","Arabic Darija":"ر نستعمل هاد البيسي؟"}
{"English":" Isn’t there a webcam?","Arabic Darija":"ما كايناش الكاميرا؟"}
{"English":" Isn’t there a microphone? ","Arabic Darija":"ما كاينش الميكرو؟"}
{"English":"How much does is cost per hour here?","Arabic Darija":" شحال كادير الساعة هنا؟"}
{"English":"his computer is not working","Arabic Darija":"هاد البيسي ما خدامش"}
{"English":"The keyboard is not working","Arabic Darija":"الكلافيي ما خدامش"}
{"English":" Do you have a printer?","Arabic Darija":"عندكم طابعة/ أمبريمونت؟"}
{"English":"I want to print some documents","Arabic Darija":"بغيت نطبع شي وراق"}
{"English":"How much does it cost to print a page? ","Arabic Darija":" بشحال كطبعوا الصفحة؟"}
{"English":"Do you have a scanner? ","Arabic Darija":"عندكم سكانير؟"}
{"English":"I want to scan some documents","Arabic Darija":"بغيت نسكاني شي وراق"}
{"English":" How much does it cost to scan a page?","Arabic Darija":"بشحال كتسكانيو الصفحة؟"}
{"English":" Can I use Internet with my computer? ","Arabic Darija":"نقدر نستعمل لانتيرنيت مع البيسي ديالي؟"}
{"English":"The computer is freezing","Arabic Darija":"تبلوكا البيسي"}
{"English":" Thanks for your help","Arabic Darija":"شكرا على المساعدة"}
{"English":"a lot","Arabic Darija":"بزاف"}
{"English":"1st","Arabic Darija":"اللول"}
{"English":"2nd","Arabic Darija":"التاني"}
{"English":"3rd","Arabic Darija":"التالت"}
{"English":"4th","Arabic Darija":"الرابع"}
{"English":"5th","Arabic Darija":"الخامس"}
{"English":"6th","Arabic Darija":"السات / السادس"}
{"English":"7th","Arabic Darija":"الشابع"}
{"English":"8th","Arabic Darija":"التامن"}
{"English":"9th","Arabic Darija":"التاسع"}
{"English":"10th","Arabic Darija":"العاشر"}
{"English":"11th","Arabic Darija":"الحادش"}
{"English":"12th","Arabic Darija":"الطناش"}
{"English":"13th","Arabic Darija":"اتلطاش"}
{"English":"14th","Arabic Darija":"ربعطاش"}
{"English":"15th","Arabic Darija":"الخمسطاش"}
{"English":"16th","Arabic Darija":"السطاش"}
{"English":"17th","Arabic Darija":"السبعطاش"}
{"English":"18th","Arabic Darija":"التمنطاش"}
{"English":"19th","Arabic Darija":"التعطاش"}
{"English":"20th","Arabic Darija":"العشرين"}
{"English":"21st","Arabic Darija":"اللول والعشرين"}
{"English":" I am sick (male)","Arabic Darija":"أنا مريض "}
{"English":" I am sick (female)","Arabic Darija":" أنا مريضة"}
{"English":" am allergic to penicillin ","Arabic Darija":"عندي حساسية ديال بينيسيلين"}
{"English":"I am diabetic ","Arabic Darija":"فيا السكر"}
{"English":" I need to see a doctor immediately","Arabic Darija":"خاصني نشوف شي طبيب دابا"}
{"English":"I suffer of asthma","Arabic Darija":"فيا الضيقة"}
{"English":" I need pain medication","Arabic Darija":"خاصني شي دوا ديال الألم"}
{"English":" I have a headache","Arabic Darija":"كيضرني راسي"}
{"English":"I have a stomachache","Arabic Darija":"كتضرني المعدة ديالي"}
{"English":"I have a backache","Arabic Darija":"كيضرني ضهري"}
{"English":"I have a fever","Arabic Darija":"فيا السخانة"}
{"English":"I throw up / I have nausea","Arabic Darija":"فيا الردان"}
{"English":" I feel dizzy ","Arabic Darija":"فيا الدوخة"}
{"English":" Where can I buy this medicine?","Arabic Darija":"فين نقدر نشري هاد الدوا؟"}
{"English":"Is there a drugstore nearby? ","Arabic Darija":"كاين فرمسيان قريب من هنا؟"}
{"English":"Beige","Arabic Darija":"بيج"}
{"English":"Black","Arabic Darija":"كحل"}
{"English":"Blue","Arabic Darija":"زرق"}
{"English":"Brown","Arabic Darija":"قهوي"}
{"English":"Burgundy","Arabic Darija":"كَرونة"}
{"English":"Golden","Arabic Darija":"دهبي"}
{"English":"Gray","Arabic Darija":"رمادي"}
{"English":"Green","Arabic Darija":"خضر"}
{"English":"Light blue","Arabic Darija":"شيبي"}
{"English":"Mauve","Arabic Darija":"موڤ"}
{"English":"Olive (color)","Arabic Darija":"خزي"}
{"English":"Orange","Arabic Darija":"ليموني"}
{"English":"Pink","Arabic Darija":"فنيدي"}
{"English":"Purple / Violet","Arabic Darija":"بنفسجي"}
{"English":"Red","Arabic Darija":"حمر"}
{"English":"Silver","Arabic Darija":"فضي"}
{"English":"Turquoise","Arabic Darija":"توركوا / تيركوا"}
{"English":"White","Arabic Darija":"بيض"}
{"English":"Yellow","Arabic Darija":"صفر"}
{"English":"Accountant","Arabic Darija":"محاسب"}
{"English":"Actor","Arabic Darija":"ممتل"}
{"English":"Architect","Arabic Darija":"مهندس معماري"}
{"English":"Butcher","Arabic Darija":"گزار"}
{"English":"Carpenter","Arabic Darija":"نجار"}
{"English":"Cashier","Arabic Darija":"كيسيي"}
{"English":"Cook","Arabic Darija":"طباخ"}
{"English":"Dentist","Arabic Darija":"طبيب السنان"}
{"English":"Director","Arabic Darija":"مدير"}
{"English":"Doctor","Arabic Darija":"طبيب"}
{"English":"Driver","Arabic Darija":"شيفور"}
{"English":"Electrician","Arabic Darija":"تريسيان"}
{"English":"Employee","Arabic Darija":"موضف"}
{"English":"Engineer","Arabic Darija":"مهندس"}
{"English":"Farmer","Arabic Darija":"فلاح"}
{"English":"Gendarme","Arabic Darija":"جدارمي"}
{"English":"Grocer","Arabic Darija":"مول لحانوت"}
{"English":"Guardian","Arabic Darija":"عساس"}
{"English":"Hairdresser","Arabic Darija":"حلاق"}
{"English":"Inspector","Arabic Darija":"مفتش"}
{"English":"Journalist","Arabic Darija":"صحافي"}
{"English":"Judge","Arabic Darija":"قاضي"}
{"English":"Lawyer","Arabic Darija":"محامي"}
{"English":"Mechanic","Arabic Darija":"ميكانيسيان"}
{"English":"Nurse","Arabic Darija":"فرملي"}
{"English":"Painter","Arabic Darija":"رسام"}
{"English":"Pilot","Arabic Darija":"پيلوط"}
{"English":"Plumber","Arabic Darija":"پلومبي"}
{"English":"Policeman","Arabic Darija":"بوليسي"}
{"English":"Professor","Arabic Darija":"أستاد"}
{"English":"Psychologist","Arabic Darija":"طبيب نفسي"}
{"English":"Researcher","Arabic Darija":"باحت"}
{"English":"Secretary","Arabic Darija":"سيكريتير"}
{"English":"Shoemaker","Arabic Darija":"خراز"}
{"English":"Singer","Arabic Darija":"مغني"}
{"English":"Soldier","Arabic Darija":"عسكري"}
{"English":"Student","Arabic Darija":"طالب"}
{"English":"Tailor","Arabic Darija":"خياط"}
{"English":"Teacher (primary school)","Arabic Darija":"معلم"}
{"English":"Translator","Arabic Darija":"مترجم"}
{"English":"Waiter","Arabic Darija":"سرباي"}
{"English":"Writer","Arabic Darija":"كاتب"}
{"English":"Time","Arabic Darija":"وقت"}
{"English":"Second","Arabic Darija":"تانية"}
{"English":"Minute","Arabic Darija":"دقيقة"}
{"English":"Hour","Arabic Darija":"ساعة"}
{"English":"Day","Arabic Darija":"نْهار"}
{"English":"Week","Arabic Darija":"سِيمانَا"}
{"English":"Month","Arabic Darija":"شْهر"}
{"English":"Year","Arabic Darija":"عام"}
{"English":"The day before yesterday","Arabic Darija":"ولبارح"}
{"English":"Yesterday","Arabic Darija":"البارح"}
{"English":"Today","Arabic Darija":"اليوم"}
{"English":"Tomorrow","Arabic Darija":"غدا"}
{"English":"The day after tomorrow","Arabic Darija":"بعد غدا"}
{"English":"Last week","Arabic Darija":" السيمانة الفايتة"}
{"English":"This week","Arabic Darija":"هاد السيمانة"}
{"English":"Next week","Arabic Darija":" السيمانة الجاية"}
{"English":"Dawn","Arabic Darija":"فجر"}
{"English":"Morning","Arabic Darija":"صباح"}
{"English":"Noon","Arabic Darija":"نص نهار"}
{"English":"Afternoon","Arabic Darija":"عْشِيّة"}
{"English":"Sunset","Arabic Darija":"مغرب"}
{"English":"Night","Arabic Darija":"لِيل"}
{"English":"Spring","Arabic Darija":"ربيع"}
{"English":"Summer","Arabic Darija":"صيف"}
{"English":"Fall","Arabic Darija":"خريف"}
{"English":"Winter","Arabic Darija":"شتا"}
{"English":"To accept","Arabic Darija":"قبل"}
{"English":"To advise","Arabic Darija":"نْصح"}
{"English":"To answer","Arabic Darija":"جَاوْب"}
{"English":"To appear","Arabic Darija":"بَانْ"}
{"English":"To apologize","Arabic Darija":"عْتَادْرْ"}
{"English":"To ask (a question)","Arabic Darija":"سْوّْلْ"}
{"English":"To ask (for something)","Arabic Darija":"طْلْبْ"}
{"English":"To attend","Arabic Darija":"حْضْرْ"}
{"English":"To be born","Arabic Darija":"توْلْدْ"}
{"English":"To be late","Arabic Darija":"تعْطّلْ"}
{"English":"To borrow","Arabic Darija":"تسْلّفْ"}
{"English":"To break","Arabic Darija":"هْرّسْ"}
{"English":"To breathe","Arabic Darija":"تْنْفّسْ"}
{"English":"To bring","Arabic Darija":"جَابْ"}
{"English":"To buy","Arabic Darija":"شْرَى"}
{"English":"To change","Arabic Darija":"بْدّلْ"}
{"English":"To choose","Arabic Darija":"خْتَارْ"}
{"English":"To clean","Arabic Darija":"نْقّا"}
{"English":"To close","Arabic Darija":"سْدّ"}
{"English":"To comb","Arabic Darija":"مْشْطْ"}
{"English":"To come","Arabic Darija":"جَا"}
{"English":"To concentrate","Arabic Darija":"رْكّْزْ"}
{"English":"To congratulate","Arabic Darija":"بَارْكْ لْ…"}
{"English":"To cough","Arabic Darija":"كْحْبْ"}
{"English":"To count","Arabic Darija":"حْسْبْ"}
{"English":"To cry","Arabic Darija":"بْكَا"}
{"English":"To curse","Arabic Darija":"نْعْلْ"}
{"English":"To cut","Arabic Darija":"قْطْعْ"}
{"English":"To dance","Arabic Darija":"شْطْحْ"}
{"English":"To dare","Arabic Darija":"تْجْرّأ"}
{"English":"To decide","Arabic Darija":"قْرّر"}
{"English":"To deny","Arabic Darija":"نْكْرْ"}
{"English":"To deserve","Arabic Darija":"سْتَاحْقْ"}
{"English":"To die","Arabic Darija":"مَاتْ"}
{"English":"To diversify","Arabic Darija":"نْوّعْ"}
{"English":"To doubt","Arabic Darija":"شْكّ"}
{"English":"To draw","Arabic Darija":"رْسْمْ"}
{"English":"To dream","Arabic Darija":"حْلْمْ"}
{"English":"To drink","Arabic Darija":"شْرْبْ"}
{"English":"To drive","Arabic Darija":"صاڭ"}
{"English":"To eat","Arabic Darija":"كْلَا"}
{"English":"To encourage","Arabic Darija":"شْجّعْ"}
{"English":"To enter","Arabic Darija":"دْخْلْ"}
{"English":"To explain","Arabic Darija":"شْرْحْ"}
{"English":"To fall","Arabic Darija":"طَاحْ"}
{"English":"To fear","Arabic Darija":"خَافْ"}
{"English":"To feel","Arabic Darija":"حْسّ"}
{"English":"To fill","Arabic Darija":"عْمّرْ"}
{"English":"To find","Arabic Darija":"لْقَا"}
{"English":"To finish","Arabic Darija":"كْمّلْ"}
{"English":"To fly","Arabic Darija":"طَارْ"}
{"English":"To follow","Arabic Darija":"تْبْعْ"}
{"English":"To forget","Arabic Darija":"نْسَا"}
{"English":"To forgive","Arabic Darija":"سْمْحْ"}
{"English":"To fry","Arabic Darija":"قْلَا"}
{"English":"To get away","Arabic Darija":"بْعّدْ"}
{"English":"To get closer","Arabic Darija":"قْرّبْ"}
{"English":"To get ready","Arabic Darija":"سْتَاعْدْ"}
{"English":"To get sick","Arabic Darija":"مْرْضْ"}
{"English":"To get up","Arabic Darija":"نَاضْ"}
{"English":"To get used","Arabic Darija":"وْلّفْ"}
{"English":"To go out","Arabic Darija":"خْرْجْ"}
{"English":"To guarantee","Arabic Darija":"ضْمْنْ"}
{"English":"To hate","Arabic Darija":"كْرْهْ"}
{"English":"To heal","Arabic Darija":"بْرَا"}
{"English":"To hear","Arabic Darija":"سْمْعْ"}
{"English":"To help","Arabic Darija":"عَاوْنْ"}
{"English":"To hesitate","Arabic Darija":"تْرْدّدْ"}
{"English":"To hit","Arabic Darija":"ضْرْبْ"}
{"English":"To hope","Arabic Darija":"تّمْنّا"}
{"English":"To hurt","Arabic Darija":"جْرْحْ"}
{"English":"To insult","Arabic Darija":"سْبّ"}
{"English":"To invite","Arabic Darija":"عْرْضْ"}
{"English":"To kill","Arabic Darija":"قْتْلْ"}
{"English":"To know","Arabic Darija":"عْرْفْ"}
{"English":"To laugh","Arabic Darija":"ضْحْكْ"}
{"English":"To lean against","Arabic Darija":"تكّا"}
{"English":"To learn","Arabic Darija":"تْعْلّمْ"}
{"English":"To lie","Arabic Darija":"كْدْبْ"}
{"English":"To lie down","Arabic Darija":"تكّا"}
{"English":"To listen","Arabic Darija":"سْمْعْ"}
{"English":"To live","Arabic Darija":"عَاشْ"}
{"English":"To live (in)","Arabic Darija":"سْكْنْ"}
{"English":"To look for","Arabic Darija":"قْلّبْ"}
{"English":"To lose","Arabic Darija":"خْسْرْ"}
{"English":"To measure","Arabic Darija":"عْبْرْ"}
{"English":"To move","Arabic Darija":"تْحْرّكْ"}
{"English":"To need","Arabic Darija":"حْتَاجْ"}
{"English":"To open","Arabic Darija":"حْلّ"}
{"English":"To organize","Arabic Darija":"نْضّمْ"}
{"English":"To paint","Arabic Darija":"صْبْغْ"}
{"English":"To pay","Arabic Darija":"خْلّصْ"}
{"English":"To play","Arabic Darija":"لْعْبْ"}
{"English":"To pray","Arabic Darija":"صْلّى"}
{"English":"To prefer","Arabic Darija":"فْضّلْ"}
{"English":"To prepare","Arabic Darija":"وْجّدْ"}
{"English":"To promise","Arabic Darija":"وَاعْدْ"}
{"English":"To read","Arabic Darija":"قْرَا"}
{"English":"To regret","Arabic Darija":"نْدْمْ"}
{"English":"To remember","Arabic Darija":"عْقْلْ"}
{"English":"To resemble","Arabic Darija":"شْبْهْ"}
{"English":"To resist","Arabic Darija":"قَاوْمْ"}
{"English":"To return (from)","Arabic Darija":"رْجْعْ"}
{"English":"To run","Arabic Darija":"جْرَا"}
{"English":"To run away","Arabic Darija":"هْرْبْ"}
{"English":"To say","Arabic Darija":"قَالْ"}
{"English":"To scream","Arabic Darija":"غْوّتْ"}
{"English":"To see","Arabic Darija":"شَافْ"}
{"English":"To sell","Arabic Darija":"بَاعْ"}
{"English":"To send","Arabic Darija":"صِيفْطْ"}
{"English":"To sew","Arabic Darija":"خِيّطْ"}
{"English":"To show","Arabic Darija":"وْرّا"}
{"English":"To sign","Arabic Darija":"سْنَا"}
{"English":"To sleep","Arabic Darija":"نْعْسْ"}
{"English":"To smoke","Arabic Darija":"كْمَا"}
{"English":"To stand up","Arabic Darija":"وْقْفْ"}
{"English":"To start","Arabic Darija":"بْدَا"}
{"English":"To stay","Arabic Darija":"بْقَى"}
{"English":"To stink","Arabic Darija":"خْنَازْ"}
{"English":"To succeed","Arabic Darija":"نْجْحْ"}
{"English":"To suffocate","Arabic Darija":"تخْنْقْ"}
{"English":"To suggest","Arabic Darija":"قْتَارْحْ"}
{"English":"To swear (by)","Arabic Darija":"حْلْفْ"}
{"English":"To swim","Arabic Darija":"عَامْ"}
{"English":"To take","Arabic Darija":"خْدَا"}
{"English":"To talk","Arabic Darija":"هْدْرْ"}
{"English":"To taste","Arabic Darija":"دَاقْ"}
{"English":"To teach","Arabic Darija":"قْرّا"}
{"English":"To thank","Arabic Darija":"شْكْرْ"}
{"English":"To think","Arabic Darija":"فْكّرْ"}
{"English":"To throw","Arabic Darija":"لَاحْ"}
{"English":"To translate","Arabic Darija":"تْرْجْمْ"}
{"English":"To travel","Arabic Darija":"سَافْرْ"}
{"English":"To trust","Arabic Darija":"تاق"}
{"English":"To try","Arabic Darija":"حَاوْلْ"}
{"English":"To turn","Arabic Darija":"ضَارْ"}
{"English":"To understand","Arabic Darija":"فْهْمْ"}
{"English":"To vaccinate","Arabic Darija":"لْقّحْ"}
{"English":"To vanquish","Arabic Darija":"غْلْبْ"}
{"English":"To vomit","Arabic Darija":"تْقِيّا"}
{"English":"To vote","Arabic Darija":"صْوّت"}
{"English":"To wait","Arabic Darija":"تْسْنّا"}
{"English":"To wake up","Arabic Darija":"فَاقْ"}
{"English":"To walk","Arabic Darija":"تْمْشّى"}
{"English":"To want","Arabic Darija":"بْغَى"}
{"English":"To watch (e.g. a movie)","Arabic Darija":"تفرج على"}
{"English":"To wear","Arabic Darija":"لْبْسْ"}
{"English":"To win","Arabic Darija":"رْبْحْ"}
{"English":"To work","Arabic Darija":"خْدْمْ"}
{"English":"To write","Arabic Darija":"كْتْبْ"}
{"English":"0","Arabic Darija":"صفر"}
{"English":"1","Arabic Darija":"واحد"}
{"English":"2","Arabic Darija":"جوج/زوج"}
{"English":"3","Arabic Darija":"تلاتة"}
{"English":"4","Arabic Darija":"ربعة"}
{"English":"5","Arabic Darija":"خمسة"}
{"English":"6","Arabic Darija":"سْتة"}
{"English":"7","Arabic Darija":"سْبعة"}
{"English":"8","Arabic Darija":"تْمنية"}
{"English":"9","Arabic Darija":"تْسعود"}
{"English":"10","Arabic Darija":"عْشرة"}
{"English":"Acid","Arabic Darija":"حامض"}
{"English":"Active","Arabic Darija":"نشيط"}
{"English":"Aged","Arabic Darija":"شارف"}
{"English":"Angry","Arabic Darija":"معصب"}
{"English":"Awake","Arabic Darija":"فايق"}
{"English":"Beautiful","Arabic Darija":"زوين"}
{"English":"Big","Arabic Darija":"كبير"}
{"English":"Broken","Arabic Darija":"مهرس"}
{"English":"Burnt","Arabic Darija":"محروق"}
{"English":"Busy","Arabic Darija":"مشغول"}
{"English":"Certain","Arabic Darija":"متأكد"}
{"English":"Cheap","Arabic Darija":"رخيص"}
{"English":"Chic","Arabic Darija":"مفركس"}
{"English":"Clean","Arabic Darija":"نقي"}
{"English":"Clear","Arabic Darija":"واضح"}
{"English":"Clever","Arabic Darija":"دكي"}
{"English":"Close","Arabic Darija":"قريب"}
{"English":"Closed","Arabic Darija":"مسدود"}
{"English":"Cold","Arabic Darija":"بارد"}
{"English":"Comfortable","Arabic Darija":"مريح"}
{"English":"Complex","Arabic Darija":"مْعْقّدْ"}
{"English":"Cooked","Arabic Darija":"طايب"}
{"English":"Crazy","Arabic Darija":"حمق/ هبيل/ مسطي"}
{"English":"Dangerous","Arabic Darija":"خطير"}
{"English":"Dark colored","Arabic Darija":"غامق"}
{"English":"Dear","Arabic Darija":"عزيز "}
{"English":"Delicious","Arabic Darija":"بنين"}
{"English":"Diffuclt","Arabic Darija":"واعر"}
{"English":"Dirty","Arabic Darija":"موسّخ"}
{"English":"Dizzy","Arabic Darija":"دايخ"}
{"English":"Dry","Arabic Darija":"ناشف"}
{"English":"Easy","Arabic Darija":"ساهل"}
{"English":"Empty","Arabic Darija":"خاوي"}
{"English":"Envious","Arabic Darija":"محساد"}
{"English":"Expensive","Arabic Darija":"غالي"}
{"English":"Famous","Arabic Darija":"مشهور"}
{"English":"Far","Arabic Darija":"بعيد"}
{"English":"Fat","Arabic Darija":"غليض"}
{"English":"Full","Arabic Darija":"عامر"}
{"English":"Generous","Arabic Darija":"سخي"}
{"English":"Good","Arabic Darija":"مزيان"}
{"English":"Greedy","Arabic Darija":"طماع"}
{"English":"Happy","Arabic Darija":"فرحان"}
{"English":"Heavy","Arabic Darija":"تقيل"}
{"English":"High","Arabic Darija":"عالي"}
{"English":"Hot","Arabic Darija":"سخون"}
{"English":"Innocent","Arabic Darija":"بريء"}
{"English":"Interesting","Arabic Darija":"مهم "}
{"English":"Jealous","Arabic Darija":"مغيار"}
{"English":"Kind","Arabic Darija":"ضريف"}
{"English":"Known","Arabic Darija":"معروف"}
{"English":"Large","Arabic Darija":"عريض"}
{"English":"Late","Arabic Darija":"معطل"}
{"English":"Light","Arabic Darija":"خفيف"}
{"English":"Light colored","Arabic Darija":"فاتح"}
{"English":"Little","Arabic Darija":"قليل"}
{"English":"Medium","Arabic Darija":"متوسط"}
{"English":"Messy","Arabic Darija":"مرون"}
{"English":"Mixed","Arabic Darija":"مخلط"}
{"English":"Modern","Arabic Darija":"عصري"}
{"English":"Much","Arabic Darija":"كتير"}
{"English":"Mute","Arabic Darija":"زيزون"}
{"English":"Nasty","Arabic Darija":"قبيح"}
{"English":"Natural","Arabic Darija":"طبيعي"}
{"English":"Naughty, badly behaved","Arabic Darija":"ضاسر"}
{"English":"Necessary","Arabic Darija":"ضروري"}
{"English":"New","Arabic Darija":"جديد"}
{"English":"Normal","Arabic Darija":"عادي"}
{"English":"Old","Arabic Darija":"قديم"}
{"English":"Open","Arabic Darija":"محلول"}
{"English":"Polite","Arabic Darija":"مؤدب"}
{"English":"Popular","Arabic Darija":"شعبي"}
{"English":"Respectable","Arabic Darija":"محترم"}
{"English":"Rough","Arabic Darija":"حرش"}
{"English":"Round","Arabic Darija":"مدوّر"}
{"English":"Sad","Arabic Darija":"مقلّق"}
{"English":"Salty","Arabic Darija":"مالح"}
{"English":"Sensitive","Arabic Darija":"حسّاس"}
{"English":"Sharp","Arabic Darija":"ماضي"}
{"English":"Short","Arabic Darija":"قصير"}
{"English":"Shy","Arabic Darija":"حشومي/حشمان"}
{"English":"Sick","Arabic Darija":"مريض"}
{"English":"Silent","Arabic Darija":"ساكت"}
{"English":"Skillful","Arabic Darija":"حادڭ"}
{"English":"Small","Arabic Darija":"صغير"}
{"English":"Soft","Arabic Darija":"رطب"}
{"English":"Solid","Arabic Darija":"قاصح"}
{"English":"Spacious","Arabic Darija":"واسع"}
{"English":"Spicy","Arabic Darija":"حار"}
{"English":"Stinky","Arabic Darija":"خانز"}
{"English":"Stupid","Arabic Darija":"مكلخ"}
{"English":"Sweet","Arabic Darija":"حلو"}
{"English":"Tall/Long","Arabic Darija":"طويل"}
{"English":"Thin","Arabic Darija":"رقيق"}
{"English":"Tight","Arabic Darija":"مضيق"}
{"English":"Tired","Arabic Darija":"عيان"}
{"English":"Traditional","Arabic Darija":"تقليدي / بْلدي"}
{"English":"Ugly","Arabic Darija":"خايب"}
{"English":"Warm","Arabic Darija":"دافي"}
{"English":"Wet","Arabic Darija":"فازڭ"}
{"English":"My book","Arabic Darija":"كْتابي"}
{"English":"Your book (s.)","Arabic Darija":"كْتابك"}
{"English":"His book","Arabic Darija":"كْتابو"}
{"English":"Her book","Arabic Darija":"كْتابها"}
{"English":"Our book","Arabic Darija":"كْتابنا"}
{"English":"Your book (p.)","Arabic Darija":"كْتابكم"}
{"English":"Their book","Arabic Darija":"كْتابهم"}
{"English":"My school","Arabic Darija":"مدرستي"}
{"English":"Your school (s.)","Arabic Darija":"مدرستك"}
{"English":"His school","Arabic Darija":"مدرستو"}
{"English":"Her school","Arabic Darija":"مدرستها"}
{"English":"Our school","Arabic Darija":"مدرستنا"}
{"English":"Your school (p.)","Arabic Darija":"مدرستكم"}
{"English":"Their school","Arabic Darija":"مدرستهم"}
{"English":"My mother ","Arabic Darija":"ماما / مامايا"}
{"English":"His mother","Arabic Darija":"ماماه"}
{"English":"My brother ","Arabic Darija":" خويا"}
{"English":"His brother","Arabic Darija":" خوه"}
{"English":"It’s hot today","Arabic Darija":"سخون الحال اليوم"}
{"English":"It’s hot today","Arabic Darija":"كاين الصهد اليوم"}
{"English":" It’s cold today","Arabic Darija":"بارد الحال اليوم"}
{"English":" It’s cold today","Arabic Darija":"كاين البرد اليوم"}
{"English":"The weather is nice today","Arabic Darija":"زوين الجو اليوم"}
{"English":"The weather is bad today","Arabic Darija":"خايب الجو اليوم"}
{"English":" It’s raining","Arabic Darija":"كاينة الشتا"}
{"English":"It’s snowing","Arabic Darija":"كاين التلج"}
{"English":"It’s pouring down","Arabic Darija":"الشتا خيط من السما"}
{"English":" I don’t have an umbrella","Arabic Darija":"ما عنديش لمضل"}
{"English":"There was a lot of rain this morning.","Arabic Darija":"صبات الشتا بزاف هاد الصباح"}
{"English":" It will probably not rain tomorrow","Arabic Darija":"محال واش تكون الشتا غدا"}
{"English":"Monday","Arabic Darija":"التّنِين"}
{"English":"Tuesday","Arabic Darija":"التّلات"}
{"English":"Wednesday","Arabic Darija":"لاربْع"}
{"English":"Thursday","Arabic Darija":"الْخميس"}
{"English":"Friday","Arabic Darija":"الجّمْعة"}
{"English":"Saturday","Arabic Darija":"السّبْت"}
{"English":"Sunday","Arabic Darija":"الحد"}
{"English":"January","Arabic Darija":"شهر واحد"}
{"English":"February","Arabic Darija":"شهر جوج"}
{"English":"March","Arabic Darija":"شهر تلاتة"}
{"English":"April","Arabic Darija":"شهر ربعة"}
{"English":"May","Arabic Darija":"شهر خمسة"}
{"English":"June","Arabic Darija":"شهر ستة"}
{"English":"July","Arabic Darija":"شهر سبعة"}
{"English":"August","Arabic Darija":"شهر تمنية"}
{"English":"September","Arabic Darija":"شهر تسعود"}
{"English":"October","Arabic Darija":"شهر عشرة"}
{"English":"November","Arabic Darija":"شهر حداش"}
{"English":"December","Arabic Darija":"شهر طناش"}
{"English":"Muharram","Arabic Darija":"محرم"}
{"English":"Safar","Arabic Darija":"صفر"}
{"English":"Rabi’ al-awwal","Arabic Darija":"ربيع الأول"}
{"English":"Rabi’ al-thani","Arabic Darija":"ربيع التاني"}
{"English":"Jumada al-awwal","Arabic Darija":"جمادى الأولى"}
{"English":"Jumada al-thani","Arabic Darija":"جمادى التانية"}
{"English":"Rajab","Arabic Darija":"رجب"}
{"English":"Sha'ban","Arabic Darija":"شعبان"}
{"English":"Ramadan","Arabic Darija":"رمضان"}
{"English":"Shawwal","Arabic Darija":"شوال"}
{"English":"Dhu al-qi'dah","Arabic Darija":"دو القعدة"}
{"English":"Dhu al-Hijjah","Arabic Darija":"دو الحجة"}
{"English":"Teachers (male)","Arabic Darija":" مُعلِّمين"}
{"English":"Employee (male)","Arabic Darija":" مُوْضّفين"}
{"English":"Teachers (female)","Arabic Darija":" مُعلِّمات"}
{"English":"Employee (female)","Arabic Darija":" مُوْضّفات"}
{"English":"Professor (male)","Arabic Darija":" أستاد "}
{"English":"Professor (female)","Arabic Darija":" أستادة"}
{"English":"Book","Arabic Darija":"Ktâb كتاب"}
{"English":"Man","Arabic Darija":"Râjl راجل"}
{"English":"Woman","Arabic Darija":"Mra مرا"}
{"English":"Monkey","Arabic Darija":"Qrd قرد"}
{"English":"Professors (male)","Arabic Darija":"أساتدة "}
{"English":"Professors (female)","Arabic Darija":"أستادات"}
{"English":"Books","Arabic Darija":"Ktôba كتوبة"}
{"English":"Men","Arabic Darija":"Rjjâla رجالة"}
{"English":"Women","Arabic Darija":"Mrawât مراوات 3yâlât عيالات"}
{"English":" Monkees","Arabic Darija":"Qrôda قرودة"}
{"English":"Big (singular)","Arabic Darija":"Kbîr كبير"}
{"English":"Small (singular)","Arabic Darija":"Sghîr صْغير"}
{"English":"New (singular)","Arabic Darija":"Jdîd جْديد"}
{"English":"Short (singular)","Arabic Darija":"قْصير"}
{"English":"Beautiful (singular)","Arabic Darija":"Zwîn زْوين"}
{"English":"Big (plural)","Arabic Darija":"Kbâr كْبار"}
{"English":"Small (plural)","Arabic Darija":"Sghâr صْغار"}
{"English":"New (plural)","Arabic Darija":"Jdâd جْداد"}
{"English":"Short (plural)","Arabic Darija":"QSâr قْصار"}
{"English":"Beautiful (plural)","Arabic Darija":"Zwînîn زْوينين"}
{"English":" Little girls","Arabic Darija":"بْنات صْغار"}
{"English":" Little girls","Arabic Darija":"بْنات صْغارات "}
{"English":" Skirt","Arabic Darija":"صايا"}
{"English":" Long skirts","Arabic Darija":"صَايات طْوال "}
{"English":"New shirts","Arabic Darija":" قْوامج جْداد"}
{"English":"Shirt","Arabic Darija":"قميجة"}
{"English":"It’s two o’clock","Arabic Darija":"هادي الجُّوج نيشان"}
{"English":"It’s five past two","Arabic Darija":"هادي الجُّوج أُ قْسْم"}
{"English":"It’s two and a quarter","Arabic Darija":"هادي الجُّوج أُ رْبعْ"}
{"English":"It’s twenty past two","Arabic Darija":"هادي الجُّوج أُ تُلُت"}
{"English":"It’s two and a half","Arabic Darija":"هادي الجُّوج أُ نْصّ"}
{"English":"It’s twenty to three","Arabic Darija":"هادي التّلاتة قْلّْ عشرين / تُلُت"}
{"English":"It’s ten to three","Arabic Darija":"هادي التّلاتة قل قْسماين"}
{"English":"It’s five to three","Arabic Darija":"هادي التّلاتة قل قْسم"}
{"English":"Arm","Arabic Darija":"دراع"}
{"English":"Back","Arabic Darija":"ضهر"}
{"English":"Beard","Arabic Darija":"لحية"}
{"English":"Belly","Arabic Darija":"كرش"}
{"English":"Bone","Arabic Darija":"عضم"}
{"English":"Brain","Arabic Darija":"مخ"}
{"English":"Cheek","Arabic Darija":"حنك"}
{"English":"Chest","Arabic Darija":"سدر"}
{"English":"Ear","Arabic Darija":"ودن"}
{"English":"Eye","Arabic Darija":"عين"}
{"English":"Eyebrow","Arabic Darija":"حاجب"}
{"English":"Eyelash","Arabic Darija":"شفر"}
{"English":"Face","Arabic Darija":"وجه"}
{"English":"Finger","Arabic Darija":"صبع"}
{"English":"Foot","Arabic Darija":"رجل"}
{"English":"Forehead","Arabic Darija":"جبهة"}
{"English":"Hair","Arabic Darija":"شعر"}
{"English":"Hand","Arabic Darija":"إيد / يد"}
{"English":"Head","Arabic Darija":"راس"}
{"English":"Heart","Arabic Darija":"قلب"}
{"English":"Knee","Arabic Darija":"ركبة"}
{"English":"Liver","Arabic Darija":"كبدة"}
{"English":"Lung","Arabic Darija":"رية"}
{"English":"Molar","Arabic Darija":"ضرس"}
{"English":"Mouth","Arabic Darija":"فم"}
{"English":"Nail","Arabic Darija":"ضفر"}
{"English":"Neck","Arabic Darija":"عنق"}
{"English":"Nose","Arabic Darija":"نيف"}
{"English":"Shoulder","Arabic Darija":"كتف"}
{"English":"Skin","Arabic Darija":"جلد"}
{"English":"Stomach","Arabic Darija":"معدة"}
{"English":"Throat","Arabic Darija":"حلق"}
{"English":"Toe","Arabic Darija":"صبع ديال الرجل"}
{"English":"Tongue","Arabic Darija":"لسان"}
{"English":"Tonsils","Arabic Darija":"حلاقم"}
{"English":"Tooth","Arabic Darija":"سنة"}
{"English":"Vein","Arabic Darija":"عرق"}
{"English":"Big","Arabic Darija":"Kbira كبيرة"}
{"English":"Small","Arabic Darija":"Sghira صغيرة"}
{"English":"Beautiful","Arabic Darija":"Zwina زْوينة"}
{"English":"Doctor","Arabic Darija":"Tbiba طْبيبة"}
{"English":"Teacher","Arabic Darija":"Ostada أُستادة"}
{"English":"Lawyer","Arabic Darija":"Mo7amia محامية"}
{"English":"Moroccan","Arabic Darija":"Mghribia مغربية"}
{"English":"Somali","Arabic Darija":"Somalia صومالية"}
{"English":"American","Arabic Darija":"Mirikania ميِريكانية"}
{"English":"Chinese","Arabic Darija":"Shinwia شينوية"}
{"English":"Peace be upon you","Arabic Darija":"السلام عليكم"}
{"English":"Peace be upon you, too","Arabic Darija":"وعليكم السلام"}
{"English":"Good morning","Arabic Darija":"صْباح الخير / صْباح النور"}
{"English":"Good evening","Arabic Darija":"مسا الخير/ مسا النور"}
{"English":"How are you doing?","Arabic Darija":"كي داير؟ كي دايرة؟"}
{"English":"Are you doing well?","Arabic Darija":"لا باس عليك؟"}
{"English":"I am fine, praise be to God.","Arabic Darija":"لاباس، الحمد لله"}
{"English":"And you?","Arabic Darija":"و نتا؟ و نْتي؟"}
{"English":"Check out the lesson on personal pronouns in Moroccan Arabic.","Arabic Darija":""}
{"English":"What about the family?","Arabic Darija":"مّالين الدّار؟ / العائلة؟"}
{"English":"What about the kids?","Arabic Darija":"الوليدات؟"}
{"English":"All is fine.","Arabic Darija":"كُلشي بِخير"}
{"English":"May Allah protect you.","Arabic Darija":"ربي يخليك"}
{"English":"See you tomorrow.","Arabic Darija":"نْتشاوْفو غْدّا"}
{"English":"Bye.","Arabic Darija":"بْسْلامة"}
{"English":"Have a blessed day.","Arabic Darija":"نهارك مبروك"}
{"English":"Thank you.","Arabic Darija":"شكرا"}
{"English":"God bless you.","Arabic Darija":"بارك الله فيك"}
{"English":"God willing.","Arabic Darija":"إن شاء الله"}
{"English":"Any news about...","Arabic Darija":"شي خبار على..."}
{"English":"What’s up?","Arabic Darija":"أش كتعاود؟ أش كتعاودي؟"}
{"English":"Alligator","Arabic Darija":"تمساح"}
{"English":"Ant","Arabic Darija":"نملة"}
{"English":"Bear","Arabic Darija":"دب"}
{"English":"Bee","Arabic Darija":"نحلة"}
{"English":"Black beetle","Arabic Darija":"خنفوسة"}
{"English":"Butterfly","Arabic Darija":"فراشة"}
{"English":"Camel","Arabic Darija":"جمل"}
{"English":"Cat","Arabic Darija":"مش"}
{"English":"Chicken","Arabic Darija":"دجاجة"}
{"English":"Cockroach","Arabic Darija":"سراق الزيت"}
{"English":"Cow","Arabic Darija":"بگرة"}
{"English":"Dog","Arabic Darija":"كلب"}
{"English":"Dolphin","Arabic Darija":"دلفين"}
{"English":"Donkey","Arabic Darija":"حمار"}
{"English":"Duck","Arabic Darija":"بطة"}
{"English":"Elephant","Arabic Darija":"فيل"}
{"English":"Fish","Arabic Darija":"حوت"}
{"English":"Fly","Arabic Darija":"دبانة"}
{"English":"Giraffe","Arabic Darija":"زرافة"}
{"English":"Goat","Arabic Darija":"معزة"}
{"English":"Horse","Arabic Darija":"عود"}
{"English":"Lice","Arabic Darija":"گمل"}
{"English":"Lion","Arabic Darija":"سبع"}
{"English":"Lizard","Arabic Darija":"بوبريص"}
{"English":"Monkey","Arabic Darija":"قرد"}
{"English":"Mouse","Arabic Darija":"فار"}
{"English":"Parrot","Arabic Darija":"بباغة"}
{"English":"Pig","Arabic Darija":"حلوف"}
{"English":"Pigeon","Arabic Darija":"حمام"}
{"English":"Rabbit","Arabic Darija":"قنية"}
{"English":"Rat","Arabic Darija":"طوبة"}
{"English":"Scorpion","Arabic Darija":"عگربة"}
{"English":"Sheep","Arabic Darija":"حولي"}
{"English":"Shrimp","Arabic Darija":"قيمرون"}
{"English":"Snail","Arabic Darija":"بابوش"}
{"English":"Snake","Arabic Darija":"لفعى"}
{"English":"Spider","Arabic Darija":"رتيلة"}
{"English":"Turkey","Arabic Darija":"بيبي"}
{"English":"Turtle","Arabic Darija":"فكرون"}
{"English":"Wolf","Arabic Darija":"ديب"}
{"English":"Worm","Arabic Darija":"دودة"}
{"English":"Yes","Arabic Darija":"إييه/ آه/واه"}
{"English":"No","Arabic Darija":"لا"}
{"English":"Please (addressing a singular)","Arabic Darija":"عافاك"}
{"English":"Thanks","Arabic Darija":"شكرا"}
{"English":"I love you (addressing a singular)","Arabic Darija":"كنبغيك"}
{"English":"I miss you (addressing a singular)","Arabic Darija":"توحشتك"}
{"English":"A lot","Arabic Darija":"بزاف"}
{"English":"A little","Arabic Darija":"شوية"}
{"English":"Okay","Arabic Darija":"واخا"}
{"English":"Now","Arabic Darija":"دابا"}
{"English":"Not now","Arabic Darija":"ماشي دابا"}
{"English":"Or","Arabic Darija":"أولا"}
{"English":"And","Arabic Darija":"و"}
{"English":"It’s not a problem / It’s okay","Arabic Darija":"ماشي مشكل"}
{"English":"(It was) not me","Arabic Darija":"ماشي أنا"}
{"English":"I want…","Arabic Darija":"بغيت…"}
{"English":"I don’t want...","Arabic Darija":"...ما بغيتش"}
{"English":"I am done / I finished","Arabic Darija":"ساليت"}
{"English":"I am not done / I did not finish","Arabic Darija":"ما ساليتش"}
{"English":"Beautiful (masculine, singular)","Arabic Darija":"زوين"}
{"English":"Bad/ugly (masculine, singular)","Arabic Darija":"خايب"}
{"English":"Good (masculine, singular)","Arabic Darija":"مزيان"}
{"English":"Excuse me","Arabic Darija":"سمح ليا سمحلي ليا"}
{"English":"I don’t speak Arabic","Arabic Darija":"ما كنهضرش العربية"}
{"English":"I don’t understand/I didn’t understand","Arabic Darija":"ما فهمتش"}
{"English":"Do you understand me? (Addressing a singular)","Arabic Darija":"فهمتيني؟"}
{"English":"I don’t have any money","Arabic Darija":"ما عنديش الفلوس"}
{"English":"Welcome","Arabic Darija":"مرحبا"}
{"English":"Take (this)","Arabic Darija":"هاك هاكي"}
{"English":"Give me… (Addressing a singular)","Arabic Darija":"عطيني…"}
{"English":"I know","Arabic Darija":"عرفت"}
{"English":"I don’t know","Arabic Darija":"ما عرفتش"}
{"English":"I forgot","Arabic Darija":"نسيت"}
{"English":"I have to go","Arabic Darija":"خاصني نمشي"}
{"English":"It’s your turn (Addressing a singular)","Arabic Darija":"نوبتك"}
{"English":"It’s my turn","Arabic Darija":"نوبتي"}
{"English":"I am tired","Arabic Darija":"عييت"}
{"English":"Where is the W.C?","Arabic Darija":"فين كاينة الطواليت"}
{"English":"Congratulations","Arabic Darija":"مبروك"}
{"English":"Can you help me?","Arabic Darija":"تقدر تعاوني؟ تقدري تعاونيني؟"}
{"English":"I am looking for…","Arabic Darija":"كنقلب على..."}
{"English":"I can’t find/I didn’t find","Arabic Darija":"ما لقيتش…"}
{"English":"Agreed/Enough","Arabic Darija":"صافي"}
{"English":"Slowly","Arabic Darija":"بشوية"}
{"English":"Faster","Arabic Darija":"بالزربة"}
{"English":"Maybe","Arabic Darija":"إيمكن"}
{"English":"Of course","Arabic Darija":"طبعا / أكيد"}
{"English":"I have a problem.","Arabic Darija":"عندي مشكلة"}
{"English":"What do you think? (Addressing a singular)","Arabic Darija":"أشنو بان ليك؟"}
{"English":"What did you say? (Addressing a singular)","Arabic Darija":"أشنو ڭلتي؟"}
{"English":"Boiled","Arabic Darija":"مسلوق"}
{"English":"Bread","Arabic Darija":"خبز"}
{"English":"Butter","Arabic Darija":"زبدة"}
{"English":"Cake","Arabic Darija":"حلوة"}
{"English":"Cheese","Arabic Darija":"فرماج"}
{"English":"Coffee","Arabic Darija":"قهوة"}
{"English":"Cumin","Arabic Darija":"كامون"}
{"English":"Egg","Arabic Darija":"بيضة"}
{"English":"Fish","Arabic Darija":"حوت"}
{"English":"Flower","Arabic Darija":"دگيگ"}
{"English":"Fried","Arabic Darija":"مقلي"}
{"English":"Fruit","Arabic Darija":"فاكية"}
{"English":"Honey","Arabic Darija":"عسل"}
{"English":"Jam","Arabic Darija":"كوفيتير"}
{"English":"Juice","Arabic Darija":"عصير"}
{"English":"Lentils","Arabic Darija":"عدس"}
{"English":"Meat","Arabic Darija":"لحم"}
{"English":"Milk","Arabic Darija":"حليب"}
{"English":"Oil","Arabic Darija":"زيت"}
{"English":"Pepper","Arabic Darija":"إبزار"}
{"English":"Rice","Arabic Darija":"روز"}
{"English":"Roasted","Arabic Darija":"مشوي"}
{"English":"Salad","Arabic Darija":"شلاضة"}
{"English":"Salt","Arabic Darija":"ملحة"}
{"English":"Soup","Arabic Darija":"حريرة"}
{"English":"Sugar","Arabic Darija":"سكر"}
{"English":"Tea","Arabic Darija":"أتاي"}
{"English":"Vegetables","Arabic Darija":"خضرة"}
{"English":"Vinegar","Arabic Darija":"خل"}
{"English":"Water","Arabic Darija":"ما"}
{"English":"Apron","Arabic Darija":"طابلية"}
{"English":"Bathrobe","Arabic Darija":"پينوار"}
{"English":"Belt","Arabic Darija":"صمطة"}
{"English":"Boots","Arabic Darija":"بوطييو"}
{"English":"Caftan","Arabic Darija":"قفطان"}
{"English":"Cap","Arabic Darija":"كاسكيطة"}
{"English":"Coat","Arabic Darija":"كبوط"}
{"English":"Dress","Arabic Darija":"كسوة"}
{"English":"Gloves","Arabic Darija":"ليڭات"}
{"English":"Hat","Arabic Darija":"طربوش"}
{"English":"Jacket","Arabic Darija":"تجاكيطة"}
{"English":"Laces","Arabic Darija":"سيور"}
{"English":"Oriental Slippers","Arabic Darija":"بلغة"}
{"English":"Pants","Arabic Darija":"سروال"}
{"English":"Pullover / Sweater","Arabic Darija":"تريكو"}
{"English":"Pajama","Arabic Darija":"پيجامة"}
{"English":"Sandals","Arabic Darija":"صندلة"}
{"English":"Scarf","Arabic Darija":"زيف / فولار / درة"}
{"English":"Shirt","Arabic Darija":"قميجة"}
{"English":"Shoes","Arabic Darija":"صباط"}
{"English":"Shorts","Arabic Darija":"شورط"}
{"English":"Skirt","Arabic Darija":"صاية"}
{"English":"Slippers","Arabic Darija":"پونتوفلات"}
{"English":"Sneakers","Arabic Darija":"سبرديلة"}
{"English":"Socks","Arabic Darija":"تقاشر"}
{"English":"Suit","Arabic Darija":"كوستيم"}
{"English":"Swimsuit","Arabic Darija":"مايو"}
{"English":"T-shirt","Arabic Darija":"تيشورت"}
{"English":"Tie","Arabic Darija":"كراڤاطا"}
{"English":"Vest","Arabic Darija":"جيلي"}
{"English":"I/ me","Arabic Darija":"أنا"}
{"English":"You (feminine, singular)","Arabic Darija":"نتي / نتيّا"}
{"English":"You (masculine, singular)","Arabic Darija":"نتا / نْتايا"}
{"English":"He","Arabic Darija":"هو"}
{"English":"She","Arabic Darija":"هي"}
{"English":"We/Us","Arabic Darija":"حْنا"}
{"English":"You (plural)","Arabic Darija":"نْتوما"}
{"English":"They","Arabic Darija":"هُوما"}
{"English":"2000","Arabic Darija":"ألفين"}
{"English":"3000","Arabic Darija":"تلت آلاف"}
{"English":"4000","Arabic Darija":"ربع آلاف"}
{"English":"5000","Arabic Darija":"خمس آلاف"}
{"English":"6000","Arabic Darija":"ست آلاف"}
{"English":"7000","Arabic Darija":"سبع آلاف"}
{"English":"8000","Arabic Darija":"تمن آلاف"}
{"English":"9000","Arabic Darija":"تسع آلاف"}
{"English":"10 000","Arabic Darija":"عشر آلاف"}
{"English":"11 000","Arabic Darija":"حداشر ألف"}
{"English":"12 000","Arabic Darija":"طناشر ألف"}
{"English":"13 000","Arabic Darija":"تلطاشر ألف"}
{"English":"1 000 000","Arabic Darija":"مليون"}
{"English":"1 000 000 000","Arabic Darija":"مليار"} |
distil-whisper/tedlium-prompted | 2023-09-18T13:21:11.000Z | [
"region:us"
] | distil-whisper | null | null | null | 0 | 15 | ---
dataset_info:
config_name: release3
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: speaker_id
dtype: string
- name: gender
dtype:
class_label:
names:
'0': unknown
'1': female
'2': male
- name: file
dtype: string
- name: id
dtype: string
- name: whisper_transcript_unprompted
dtype: string
- name: whisper_transcript
dtype: string
splits:
- name: train
num_bytes: 52484152554.125
num_examples: 268263
- name: validation
num_bytes: 184679438.0
num_examples: 507
- name: test
num_bytes: 302513272.625
num_examples: 1155
download_size: 52650349441
dataset_size: 52971345264.75
configs:
- config_name: release3
data_files:
- split: train
path: release3/train-*
- split: validation
path: release3/validation-*
- split: test
path: release3/test-*
---
# Dataset Card for "tedlium-prompted"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
lonestar108/fear | 2023-09-20T15:43:06.000Z | [
"region:us"
] | lonestar108 | null | null | null | 0 | 15 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: validate
path: data/validate-*
dataset_info:
features:
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 6636
num_examples: 28
- name: test
num_bytes: 3323
num_examples: 12
- name: validate
num_bytes: 560
num_examples: 3
download_size: 12635
dataset_size: 10519
---
# Dataset Card for "new_fear"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Jackoon/JSON_expert_huy | 2023-09-21T07:57:52.000Z | [
"region:us"
] | Jackoon | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 178537
num_examples: 173
download_size: 40306
dataset_size: 178537
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "JSON_expert_huy"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
MikeTrizna/bees | 2023-09-22T21:01:28.000Z | [
"license:cc0-1.0",
"region:us"
] | MikeTrizna | null | null | null | 0 | 15 | ---
license: cc0-1.0
dataset_info:
features:
- name: occurrenceID
dtype: string
- name: catalogNumber
dtype: string
- name: recordedBy
dtype: string
- name: year
dtype: int64
- name: month
dtype: int64
- name: day
dtype: int64
- name: country
dtype: string
- name: stateProvince
dtype: string
- name: county
dtype: string
- name: locality
dtype: string
- name: decimalLatitude
dtype: float64
- name: decimalLongitude
dtype: float64
- name: identifiedBy
dtype: string
- name: scientificName
dtype: string
- name: genus
dtype: string
- name: subgenus
dtype: string
- name: specificEpithet
dtype: string
- name: infraspecificEpithet
dtype: string
- name: scientificNameAuthorship
dtype: string
- name: PixelXDimension
dtype: float64
- name: PixelYDimension
dtype: float64
- name: accessURI
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 3672202733.82
num_examples: 73387
download_size: 3659907058
dataset_size: 3672202733.82
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for Bees
## Dataset Summary
The USNM Bumblebee Dataset is a natural history dataset containing, for each of 73,497 Bumblebee specimens in the family Apidae, a single image in lateral or dorsal view and a tab-separated value file with occurrence data. Occurrence data includes the species classification, the date and site/location of collection, and other metadata conforming to the Darwin Core data standard (https://dwc.tdwg.org). 11,421 specimens are not identified to species and these specimens are included as 'Bombus sp.' or 'Xylocopa sp.' The collecting sites/locations of the majority of specimens (55,301), have been georeferenced. The dataset is worldwide in scope, but is limited to the specimens available in the Smithsonian USNM collection.
## Languages
English
## Data Instances
A typical data point comprises of the specimen metadata and image information for a single bumblebee specimen.
An example from the dataset looks as follows:
```json
{
'occurrenceID': 'http://n2t.net/ark:/65665/30042e2d8-669d-4520-b456-e3c64203eff8',
'catalogNumber': 'USNMENT01732649',
'recordedBy': 'R. Craig',
'year': '1949',
'month': '4',
'day': '13',
'country': 'United States',
'stateProvince': 'California',
'county': 'Fresno',
'locality': 'Auberry',
'decimalLatitude': '37.0808',
'decimalLongitude': '-119.485',
'identifiedBy': "O'Brien, L. R.",
'scientificName': 'Xylocopa (Notoxylocopa) tabaniformis orpifex',
'genus': 'Xylocopa',
'subgenus': 'Notoxylocopa',
'specificEpithet': 'tabaniformis',
'infraspecificEpithet': 'orpifex',
'scientificNameAuthorship': 'Smith',
'accessURI': 'https://ids.si.edu/ids/deliveryService?id=NMNH-USNMENT01732649',
'PixelXDimension': 2000,
'PixelYDimension': 1212
}
```
## Data Fields
Specimen metadata fields conform to the Darwin Core data standard and are detailed here: https://dwc.tdwg.org. Image metadata fields conform to the Audiovisual Core data standard and are detailed here: https://ac.tdwg.org/.
## Curation Rationale
The dataset represents a portion of the U. S. National Entomological Collection. The U.S. National Entomological Collection (USNM) traces its origins in part to the acquisition of the U.S. Department of Agriculture Collection of 138,000 specimens donated in 1885. These specimens became the foundation of one of the world’s largest and most important accessible entomological collections, with over 33 million specimens taken care of by the combined staff of three government agencies: the Smithsonian Institution; the Systematic Entomology Laboratory (Agricultural Research Service, United States Department of Agriculture); and the Walter Reed Biosystematics Unit (Walter Reed Army Institute of Research). The specimens were imaged in a mass-digitization project in collaboration with the Digitization Program Office. The goal was to digitize every Bombus specimen in the collection.
## Initial Data Collection and Normalization
Bumblebee specimens were collected over a period of 150 years (earliest specimen dates from 1807, most recent specimen dates from 2020). The specimens were collected by and identified by many different individual researchers over this time. The initial images of about 49,000 specimens were taken in a rapid capture project by a dedicated team in 2014 with additional specimen images (about 25,000) taken in 2018. The labels containing the information on site/location, date of collection, collector, and identifier were removed from the insect pin. The occurrence data were transcribed from the labels by online volunteers and a professional transcription service into Darwin Core fields. Following quality control of the transcribed data by NMNH staff, they were imported into the institutional database (EMu).
NMNH specimen data get exported to the Global Biodiversity Information Facility (GBIF) on a weekly basis through an installation of an Integrated Publishing Toolkit (IPT, https://collections.nmnh.si.edu/ipt/). Some data transformation takes place within EMu and GBIF likewise normalizes the data to meet their standards.
## Who are the source language producers?
The occurrence data were produced by humans, observed and written onto paper labels over the museum’s history, and then transcribed from paper labels pinned with the specimens upon collection.
## Annotations
The specimen occurrence data in Darwin Core fields.
## Annotation process
The occurrence data were transcribed from the labels by online volunteers and a professional transcription service into Darwin Core fields.
## Who are the annotators?
Original collectors and identifiers were entomologists and researchers from the Smithsonian and other institutions. Collectors may not be bumblebee specialists. For data transcription, online volunteers and professional transcription service workers. Demographic data of transcribers is unknown.
## Personal and Sensitive Information
The dataset contains the names of the collectors and identifiers.
## Social Impact of Dataset
Digitized natural history collections have the potential to be used in diverse research applications in evolutionary biology, ecology, and climate change.
The dataset contains records for species listed on the U.S. Endangered Species List: Bombus affinis, Bombus franklini, and Bombus terricola.
Some site/location names could cause harm as they are insensitive or racist towards indigenous communities.
## Discussion of Biases
Estimates of species geographic ranges based on these data may not be complete. There are many reasons collectors may collect more frequently from some areas rather than others, including their own taxonomic interests, proximity to collections institutions, accessibility via roads, ability to acquire permits for a specific area, or for geopolitical reasons.
The majority of specimens in this dataset originate from North America.
Most specimens are expected to be female, because bumblebees are social insects and it is more common to find female bees.
## Other Known Limitations
As with all natural history collections data, there is the potential that some metadata are inaccurate or inconsistent given that they have been collected and recorded over the course of the past 150 years. Smithsonian staff seek to correct these errors as they are identified but the dataset as presented is a snapshot in time.
Species identifications may be inaccurate or not up-to-date based on the latest classification.
Collector names may not be consistent across records (e.g. the same person’s name may be written differently). For women’s names, which were often historically recorded as Mrs. <spouse’s name>, only the spouse’s name may appear.
Locality data may use historical place names that are no longer used.
Dates may sometimes have been recorded by original collectors inconsistently or may be incomplete (no month/day information).
For specimens collected from Brazil, specimen images are not included in the dataset.
For endangered species, locality data is not included in the dataset.
## Dataset Curators
Smithsonian National Museum of Natural History, Department of Entomology.
Jessica Bird (Data Manager in the Department of Entomology) is the main contact person for the dataset.
## Licensing Information
Public domain, Creative Commons CC0.
## Citation Information
Orrell T, Informatics Office (2023). NMNH Extant Specimen Records (USNM, US). Version 1.72. National Museum of Natural History, Smithsonian Institution. Occurrence dataset. https://collections.nmnh.si.edu/ipt/resource?r=nmnh_extant_dwc-a&v=1.72
## Contributions
Thanks to NMNH for adding this dataset. |
indiejoseph/wikipedia-zh-yue-qa | 2023-09-26T10:01:59.000Z | [
"region:us"
] | indiejoseph | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: title
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 5335035
num_examples: 35415
download_size: 3283403
dataset_size: 5335035
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# "wikipedia-zh-yue-qa"
Question and answer extracted from Cantonese Wikipedia |
mmnga/wikipedia-ja-20230720-100k | 2023-09-24T13:08:15.000Z | [
"license:cc-by-sa-3.0",
"region:us"
] | mmnga | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: curid
dtype: string
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 268164890.06653625
num_examples: 100000
download_size: 159687725
dataset_size: 268164890.06653625
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: cc-by-sa-3.0
---
# Dataset Card for "wikipedia-ja-20230720-100k"
This is data extracted randomly from [izumi-lab/wikipedia-ja-20230720](https://huggingface.co/datasets/izumi-lab/wikipedia-ja-20230720), consisting of 100,000 records.
[izumi-lab/wikipedia-ja-20230720](https://huggingface.co/datasets/izumi-lab/wikipedia-ja-20230720)からデータを100k分ランダムに抽出したデータです。
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tiagoblima/translation-pt-indigenouns | 2023-09-24T20:52:17.000Z | [
"region:us"
] | tiagoblima | null | null | null | 0 | 15 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: translation
struct:
- name: pt
dtype: string
- name: gub
dtype: string
- name: gun
dtype: string
splits:
- name: train
num_bytes: 55480812
num_examples: 106195
- name: validation
num_bytes: 197372
num_examples: 275
- name: test
num_bytes: 20919307
num_examples: 38140
download_size: 14953792
dataset_size: 76597491
---
# Dataset Card for "translation-pt-indigenouns"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
eckendoerffer/news_fr | 2023-10-06T02:36:21.000Z | [
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:fr",
"license:cc-by-3.0",
"news",
"media",
"Press",
"region:us"
] | eckendoerffer | null | null | null | 0 | 15 | ---
license: cc-by-3.0
task_categories:
- text-generation
language:
- fr
tags:
- news
- media
- Press
size_categories:
- 1M<n<10M
---
# NEWS FR
There is an open-access [dataset on BnF / Gallica](https://transfert.bnf.fr/link/3a04ea3f-dbe8-4a4a-a302-913a89c3a7a8) comprising nearly a hundred newspapers from the print media spanning almost 100 years.
Unfortunately, for this dataset, only 85% of the text is transcribed accurately.
## DATASET
This dataset compiles 1M online articles from nearly 100 Francophone media outlets. This dataset is intended for research purposes and non-commercial use. It includes 1,140,000 lines for model training, and 63,500 lines for the test and validation files.
Included with this dataset are scripts to extract and process the article text from the same sources. The script is somewhat rough around the edges, but it is functional and commented.
### Format
- **Type**: Text
- **File Extension**: `.txt`
The text has been standardized for consistent formatting and line length. Additionally, the dataset has been filtered using the `langid` library to include only text in French.
### Structure
The dataset is divided into the following splits:
- `train.txt`: 2.2 GB - 1,140,000 rows - 90%
- `test.txt` : 122 MB - 63,500 rows - 5%
- `valid.txt`: 122 MB - 63,500 rows - 5%
### Exploring the Dataset
You can use the `explore_dataset.py` script to explore the dataset by randomly displaying a certain number of lines from it. The script creates and saves an index based on the line breaks, enabling faster data retrieval and display.
### Additional Information
This dataset is a subset of a larger 10GB French dataset, which also contains several thousand books and theses in French, Wikipedia, as well as several hundred thousand Francophone news articles.
## EXTRACT NEWS FR
The "NEWS FR" module allows for the extraction of online press articles from over a hundred different sources.
## Installation
To set up the module, follow the steps below:
1. **Database Setup**:
- Create a database and incorporate the two tables present in `database.sql`.
2. **Database Configuration**:
- Update your MySQL connection information in the `config.py` file.
3. **Dependencies Installation**:
- Install it using pip install:
```
pip install aiohttp mysql-connector-python beautifulsoup4 chardet colorama pyquery
```
## Usage
### 1_extract_rss.py:
This script fetches RSS feeds from various media outlets and adds URLs for further extraction.
```bash
python 1_extract_rss.py
```
### 2_extract_news.py:
This script retrieves the sources of articles for subsequent local processing.
```bash
python 2_extract_news.py
```
### 3_extract_news_txt.py:
This script extracts the text content of press articles and saves it (title + text) to a `.txt` file.
```bash
python 3_extract_news_txt.py
```
After completing this step, you can use the Python script located at /dataset/2_cleaning_txt.py to standardize the text for your dataset.
### 4_extract_news_url.py:
This script allows for the extraction of links to other articles from local article sources. This ensures swift retrieval of numerous past articles, as opposed to fetching only the most recent ones.
```bash
python 4_extract_news_url.py
```
After using this script, you'll need to run 2_extract_news.py again to retrieve the sources of the new articles, as well as 3_extract_news_txt.py to extract the text from these articles.
--- |
zhiqings/LLaVA-Human-Preference-10K | 2023-09-27T01:03:58.000Z | [
"license:apache-2.0",
"region:us"
] | zhiqings | null | null | null | 5 | 15 | ---
license: apache-2.0
---
|
sungile/bedroom_left_vs_right | 2023-09-27T21:08:42.000Z | [
"region:us"
] | sungile | null | null | null | 1 | 15 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 19193302.0
num_examples: 20
download_size: 19194928
dataset_size: 19193302.0
---
# Dataset Card for "bedroom_left_vs_right"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
LlameUser/test | 2023-09-28T09:42:53.000Z | [
"license:mit",
"region:us"
] | LlameUser | null | null | null | 0 | 15 | ---
license: mit
---
|
TrainingDataPro/generated-e-mail-spam | 2023-09-28T15:29:45.000Z | [
"task_categories:text-generation",
"task_categories:text-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] | TrainingDataPro | The dataset consists of a **CSV file** containing of 300 generated email spam messages.
Each row in the file represents a separate email message, its *title and text.*
The dataset aims to facilitate the analysis and detection of spam emails.
The dataset can be used for various purposes, such as *training machine learning
algorithms to classify and filter spam emails, studying spam email patterns,
or analyzing text-based features of spam messages*. | @InProceedings{huggingface:dataset,
title = {generated-e-mail-spam},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 15 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- text-generation
- text-classification
tags:
- code
- finance
dataset_info:
features:
- name: title
dtype: string
- name: text
dtype: large_string
splits:
- name: train
num_bytes: 233533
num_examples: 300
download_size: 230500
dataset_size: 233533
---
# Generated E-mail Spam
The dataset consists of a **CSV file** containing of 300 generated email spam messages. Each row in the file represents a separate email message, its *title and text.* The dataset aims to facilitate the analysis and detection of spam emails.
The dataset can be used for various purposes, such as *training machine learning algorithms to classify and filter spam emails, studying spam email patterns, or analyzing text-based features of spam messages*.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=generated-e-mail-spam) to discuss your requirements, learn about the price and buy the dataset.
# Content
### File with the extension .csv (utf-8)
includes the following information:
- **title**: title of the email,
- **text**: text of the email
# Email spam might be generated in accordance with your requirements.
## **[TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=generated-e-mail-spam)** provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
Doub7e/SD-CLIP-alignment-composition | 2023-09-28T21:56:15.000Z | [
"region:us"
] | Doub7e | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: image
dtype: image
- name: prompt
dtype: string
- name: clip_pred
dtype: string
splits:
- name: train
num_bytes: 405174703.0
num_examples: 900
download_size: 405155460
dataset_size: 405174703.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "SD-CLIP-alignment-composition"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
adityarra07/ATC_5 | 2023-09-28T22:36:31.000Z | [
"region:us"
] | adityarra07 | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: transcription
dtype: string
- name: id
dtype: string
splits:
- name: train
num_bytes: 113637638.0
num_examples: 504
download_size: 112879747
dataset_size: 113637638.0
---
# Dataset Card for "ATC_5"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tmskss/k8s-stackoverflow-qa | 2023-09-29T12:43:58.000Z | [
"license:apache-2.0",
"region:us"
] | tmskss | null | null | null | 0 | 15 | ---
license: apache-2.0
---
# Dataset Card for tmskss/k8s-stackoverflow-qa
### Dataset Summary
This dataset is based on (this dataset)[https://huggingface.co/datasets/mcipriano/stackoverflow-kubernetes-questions] |
renumics/spotlight-beans-enrichment | 2023-10-09T14:55:43.000Z | [
"region:us"
] | renumics | null | null | null | 0 | 15 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image_file_path.embedding
sequence: float32
length: 2
- name: image.embedding
sequence: float32
length: 2
splits:
- name: train
num_bytes: 16544
num_examples: 1034
- name: validation
num_bytes: 2128
num_examples: 133
- name: test
num_bytes: 2048
num_examples: 128
download_size: 33961
dataset_size: 20720
---
# Dataset Card for "spotlight-beans-enrichment"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
hanifabdlh/quac-cahya-alpaca-id-cleaned | 2023-10-02T02:06:07.000Z | [
"region:us"
] | hanifabdlh | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: context
dtype: string
- name: instruction
dtype: string
- name: response
dtype: string
- name: instruction_source
dtype: string
splits:
- name: train
num_bytes: 43636235
num_examples: 51590
download_size: 23301512
dataset_size: 43636235
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "quac-cahya-alpaca-id-cleaned"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
hanifabdlh/quac-cahya-instruction-id | 2023-10-02T02:06:26.000Z | [
"region:us"
] | hanifabdlh | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: context
dtype: string
- name: instruction
dtype: string
- name: response
dtype: string
- name: instruction_source
dtype: string
splits:
- name: train
num_bytes: 38814594
num_examples: 94714
download_size: 20329489
dataset_size: 38814594
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "quac-cahya-instruction-id"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Emphive/PythonQA | 2023-10-02T06:23:15.000Z | [
"region:us"
] | Emphive | null | null | null | 0 | 15 | Entry not found |
Harsha9044/MAl_MSA | 2023-10-02T08:13:14.000Z | [
"license:apache-2.0",
"region:us"
] | Harsha9044 | null | null | null | 0 | 15 | ---
license: apache-2.0
dataset_info:
features:
- name: File name
dtype: string
- name: Transcript
dtype: string
- name: Labels
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 290551
num_examples: 70
download_size: 124404
dataset_size: 290551
---
|
AlanRobotics/rm | 2023-10-03T13:48:17.000Z | [
"region:us"
] | AlanRobotics | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 31514073.49823492
num_examples: 59657
- name: test
num_bytes: 3501798.5017650784
num_examples: 6629
download_size: 19510512
dataset_size: 35015872.0
---
# Dataset Card for "rm"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
autoevaluate/autoeval-eval-xsum-default-e3e096-60495145411 | 2023-10-04T16:56:55.000Z | [
"autotrain",
"evaluation",
"region:us"
] | autoevaluate | null | null | null | 0 | 15 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- xsum
eval_info:
task: summarization
model: sysresearch101/t5-large-finetuned-xsum
metrics: ['bertscore']
dataset_name: xsum
dataset_config: default
dataset_split: test
col_mapping:
text: document
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: sysresearch101/t5-large-finetuned-xsum
* Dataset: xsum
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@zuzannad1](https://huggingface.co/zuzannad1) for evaluating this model. |
autoevaluate/autoeval-eval-xsum-default-7c65dc-60294145402 | 2023-10-04T17:14:05.000Z | [
"autotrain",
"evaluation",
"region:us"
] | autoevaluate | null | null | null | 0 | 15 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- xsum
eval_info:
task: summarization
model: facebook/bart-large-xsum
metrics: ['bertscore']
dataset_name: xsum
dataset_config: default
dataset_split: test
col_mapping:
text: document
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: facebook/bart-large-xsum
* Dataset: xsum
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@zuzannad1](https://huggingface.co/zuzannad1) for evaluating this model. |
hippocrates/2018_n2c2_RE | 2023-10-09T17:09:14.000Z | [
"region:us"
] | hippocrates | null | null | null | 0 | 15 | Entry not found |
Intuit-GenSRF/toxigen-train-annotated | 2023-10-05T01:50:15.000Z | [
"region:us"
] | Intuit-GenSRF | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: text
dtype: string
- name: labels
sequence: string
splits:
- name: train
num_bytes: 951313
num_examples: 8960
download_size: 553547
dataset_size: 951313
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "toxigen-train-annotated"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
rashmi035/dataset_whisper | 2023-10-05T05:49:20.000Z | [
"region:us"
] | rashmi035 | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: transcription
dtype: string
- name: set
dtype: string
splits:
- name: train
num_bytes: 35817014.0
num_examples: 100
- name: validation
num_bytes: 15314681.0
num_examples: 50
- name: test
num_bytes: 7381857.0
num_examples: 29
download_size: 55480724
dataset_size: 58513552.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
# Dataset Card for "dataset_whisper"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Tural/bookcorpus-unzh | 2023-10-05T09:54:10.000Z | [
"region:us"
] | Tural | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 4835329162
num_examples: 74004228
download_size: 3019488297
dataset_size: 4835329162
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "bookcorpus-unzh"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Tural/wiki-unzh | 2023-10-05T10:09:40.000Z | [
"region:us"
] | Tural | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: id
dtype: string
- name: url
dtype: string
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 20277571711
num_examples: 6458670
download_size: 11689463675
dataset_size: 20277571711
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "wiki-unzh"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TernenceZ/taxdata | 2023-10-07T09:24:51.000Z | [
"license:mit",
"region:us"
] | TernenceZ | null | null | null | 0 | 15 | ---
license: mit
---
|
RorooroR/JazzHiphop | 2023-10-09T09:03:32.000Z | [
"region:us"
] | RorooroR | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: image
dtype: image
- name: audio_file
dtype: string
- name: slice
dtype: int16
splits:
- name: train
num_bytes: 191805587.75
num_examples: 4378
download_size: 191445041
dataset_size: 191805587.75
---
# Dataset Card for "JazzHiphop"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
kllisre/damage | 2023-10-09T11:21:54.000Z | [
"license:apache-2.0",
"region:us"
] | kllisre | null | null | null | 0 | 15 | ---
license: apache-2.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': broken
'1': unbroken
splits:
- name: train
num_bytes: 472834094.301
num_examples: 1717
- name: val
num_bytes: 34265030.0
num_examples: 171
download_size: 626502062
dataset_size: 507099124.301
---
|
Skiittoo/cartoon-faces | 2023-10-09T13:14:29.000Z | [
"region:us"
] | Skiittoo | null | null | null | 0 | 15 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 646360781.0
num_examples: 10000
download_size: 647319030
dataset_size: 646360781.0
---
# Dataset Card for "cartoon-faces"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
renumics/spotlight-cifar100-enrichment | 2023-10-09T15:27:01.000Z | [
"region:us"
] | renumics | null | null | null | 0 | 15 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: prediction
dtype:
class_label:
names:
'0': apple
'1': aquarium_fish
'2': baby
'3': bear
'4': beaver
'5': bed
'6': bee
'7': beetle
'8': bicycle
'9': bottle
'10': bowl
'11': boy
'12': bridge
'13': bus
'14': butterfly
'15': camel
'16': can
'17': castle
'18': caterpillar
'19': cattle
'20': chair
'21': chimpanzee
'22': clock
'23': cloud
'24': cockroach
'25': couch
'26': cra
'27': crocodile
'28': cup
'29': dinosaur
'30': dolphin
'31': elephant
'32': flatfish
'33': forest
'34': fox
'35': girl
'36': hamster
'37': house
'38': kangaroo
'39': keyboard
'40': lamp
'41': lawn_mower
'42': leopard
'43': lion
'44': lizard
'45': lobster
'46': man
'47': maple_tree
'48': motorcycle
'49': mountain
'50': mouse
'51': mushroom
'52': oak_tree
'53': orange
'54': orchid
'55': otter
'56': palm_tree
'57': pear
'58': pickup_truck
'59': pine_tree
'60': plain
'61': plate
'62': poppy
'63': porcupine
'64': possum
'65': rabbit
'66': raccoon
'67': ray
'68': road
'69': rocket
'70': rose
'71': sea
'72': seal
'73': shark
'74': shrew
'75': skunk
'76': skyscraper
'77': snail
'78': snake
'79': spider
'80': squirrel
'81': streetcar
'82': sunflower
'83': sweet_pepper
'84': table
'85': tank
'86': telephone
'87': television
'88': tiger
'89': tractor
'90': train
'91': trout
'92': tulip
'93': turtle
'94': wardrobe
'95': whale
'96': willow_tree
'97': wolf
'98': woman
'99': worm
- name: prediction_error
dtype: bool
- name: embedding_full
sequence: float32
length: 768
- name: embedding
sequence: float32
length: 2
- name: probability
dtype: float64
splits:
- name: train
num_bytes: 154806250
num_examples: 50000
- name: test
num_bytes: 30961250
num_examples: 10000
download_size: 222987692
dataset_size: 185767500
---
# Dataset Card for "spotlight-cifar100-enrichment"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
result-kand2-sdxl-wuerst-karlo/2ddeba07 | 2023-10-09T21:37:39.000Z | [
"region:us"
] | result-kand2-sdxl-wuerst-karlo | null | null | null | 0 | 15 | ---
dataset_info:
features:
- name: result
dtype: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 200
num_examples: 10
download_size: 1374
dataset_size: 200
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "2ddeba07"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.