
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
breadlicker45/eia-csv-data | 2023-09-19T17:06:28.000Z | [
"region:us"
] | breadlicker45 | null | null | null | 0 | 0 | Entry not found |
linhqyy/data_aug_full_0909 | 2023-09-19T17:18:11.000Z | [
"region:us"
] | linhqyy | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: sentence
dtype: string
- name: intent
dtype: string
- name: entities
list:
- name: type
dtype: string
- name: filler
dtype: string
- name: labels
dtype: string
splits:
- name: train
num_bytes: 1800230
num_examples: 8478
- name: test
num_bytes: 152559
num_examples: 738
download_size: 460615
dataset_size: 1952789
---
# Dataset Card for "data_aug_full_0909"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/lilith_thedemongirlnextdoor | 2023-09-19T17:20:26.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of Lilith
This is the dataset of Lilith, containing 132 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 132 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 322 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 132 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 132 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 132 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 132 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 132 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 322 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 322 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 322 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/hinatsuki_mikan_thedemongirlnextdoor | 2023-09-19T17:43:15.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of Hinatsuki Mikan
This is the dataset of Hinatsuki Mikan, containing 291 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 291 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 700 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 291 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 291 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 291 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 291 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 291 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 700 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 700 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 700 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
ricardosantoss/MIMIC_CONDESANDO | 2023-09-19T17:47:46.000Z | [
"region:us"
] | ricardosantoss | null | null | null | 0 | 0 | Entry not found |
lionpig/newyoung | 2023-09-19T18:01:39.000Z | [
"license:unknown",
"region:us"
] | lionpig | null | null | null | 1 | 0 | ---
license: unknown
---
|
NoyanTM/test | 2023-09-19T18:04:46.000Z | [
"region:us"
] | NoyanTM | null | null | null | 0 | 0 | Entry not found |
ReidP/materialsQA | 2023-09-19T18:51:19.000Z | [
"license:mit",
"region:us"
] | ReidP | null | null | null | 0 | 0 | ---
license: mit
---
|
hbgml/Sergey_Shnurov | 2023-09-19T18:54:35.000Z | [
"region:us"
] | hbgml | null | null | null | 0 | 0 | Entry not found |
kyzor/guanaco-llama2-1k | 2023-09-19T18:55:52.000Z | [
"region:us"
] | kyzor | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1654448
num_examples: 1000
download_size: 966693
dataset_size: 1654448
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "guanaco-llama2-1k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mdrakibtrofder/quranic_bangla | 2023-09-20T02:05:47.000Z | [
"license:mit",
"region:us"
] | mdrakibtrofder | null | null | null | 0 | 0 | ---
license: mit
---
# This is a Quranic Bangla Databse
- Here bangla meaning for every quranic verse's word
- Developed By Students of IIT, University of Dhaka
- An Open Source Project of Learn Meaning of Quran in Bangla Movement
|
dell-research-harvard/effocr_training | 2023-09-20T02:14:52.000Z | [
"region:us"
] | dell-research-harvard | null | null | null | 0 | 0 | Entry not found |
TrainingDataPro/electric-scooters-tracking | 2023-10-03T14:01:06.000Z | [
"task_categories:image-to-image",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"legal",
"region:us"
] | TrainingDataPro | The dataset contains frames extracted from self-checkout videos, specifically focusing
on **tracking products**. The tracking data provides the **trajectory of each product**,
allowing for analysis of customer movement and behavior throughout the transaction.
The dataset assists in detecting shoplifting and fraud, enhancing efficiency, accuracy,
and customer experience. It facilitates the development of computer vision models for
*object detection, tracking, and recognition* within a self-checkout environment. | @InProceedings{huggingface:dataset,
title = {electric-scooters-tracking},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 0 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-image
- object-detection
tags:
- code
- legal
dataset_info:
- config_name: video_01
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: shapes
sequence:
- name: track_id
dtype: uint32
- name: label
dtype:
class_label:
names:
'0': electric_scooter
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 9312
num_examples: 22
download_size: 8409013
dataset_size: 9312
- config_name: video_02
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: shapes
sequence:
- name: track_id
dtype: uint32
- name: label
dtype:
class_label:
names:
'0': electric_scooter
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 10583
num_examples: 25
download_size: 48396353
dataset_size: 10583
- config_name: video_03
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: shapes
sequence:
- name: track_id
dtype: uint32
- name: label
dtype:
class_label:
names:
'0': electric_scooter
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 8466
num_examples: 20
download_size: 13600750
dataset_size: 8466
---
# Electric Scooters Tracking
The dataset contains frames extracted from videos with people riding electric scooters. Each frame is accompanied by **bounding box** that specifically **tracks the electric scooter** in the image.
This dataset can be useful for *object detection, motion tracking, behavior analysis, autonomous vehicle development and smart city*.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=electric-scooters-tracking) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
The dataset consists of 3 folders with frames from the video with people riding an electric scooter.
Each folder includes:
- **images**: folder with original frames from the video,
- **boxes**: visualized data labeling for the images in the previous folder,
- **.csv file**: file with id and path of each frame in the "images" folder,
- **annotations.xml**: contains coordinates of the bounding boxes and labels, created for the original frames
# Data Format
Each frame from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes for electric scooter tracking. For each point, the x and y coordinates are provided.
# Example of the XML-file
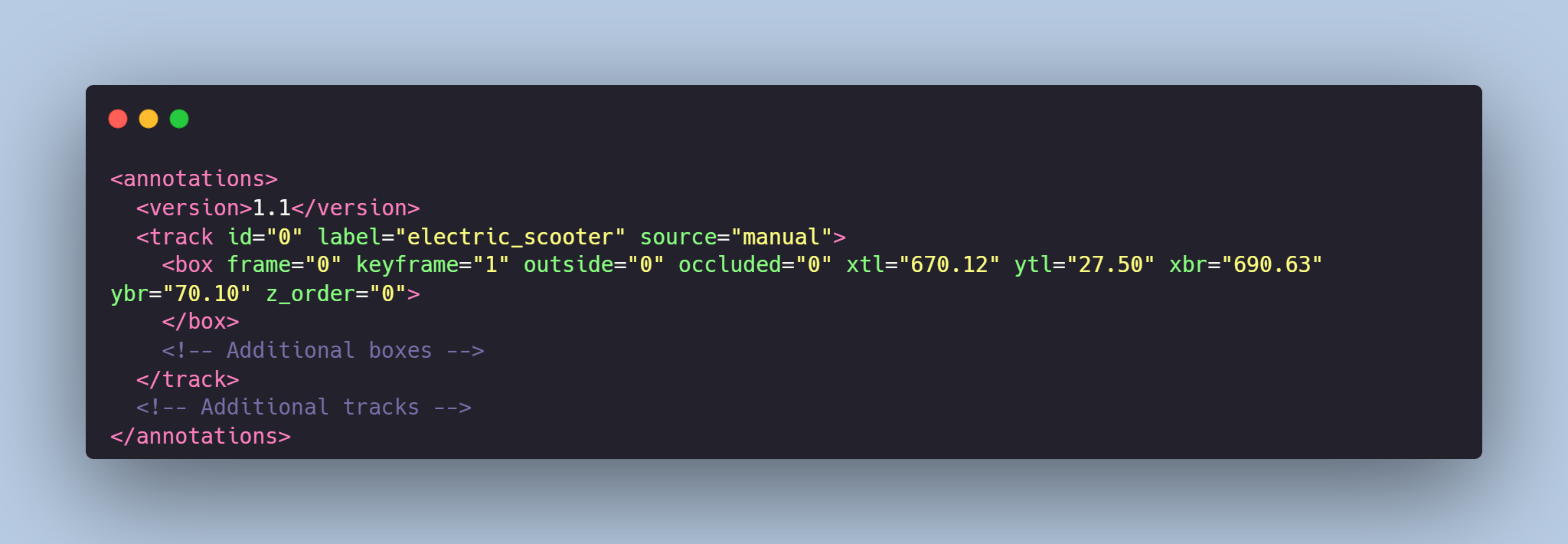
# Object tracking might be made in accordance with your requirements.
## [TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=electric-scooters-tracking) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/trainingdata-pro** |
temasarkisov/EsportLogos1_processed_V2 | 2023-09-19T19:45:30.000Z | [
"region:us"
] | temasarkisov | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 8153726.0
num_examples: 70
download_size: 8149750
dataset_size: 8153726.0
---
# Dataset Card for "EsportLogos1_processed_V2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
osieosie/campus_processed | 2023-09-19T20:08:49.000Z | [
"region:us"
] | osieosie | null | null | null | 0 | 0 | Entry not found |
fromalanjones/fanfare | 2023-09-19T20:11:34.000Z | [
"license:openrail",
"region:us"
] | fromalanjones | null | null | null | 0 | 0 | ---
license: openrail
---
|
TotoB12/temp | 2023-09-19T20:58:59.000Z | [
"region:us"
] | TotoB12 | null | null | null | 0 | 0 | Entry not found |
Nasssss/matuev1 | 2023-09-23T17:50:05.000Z | [
"region:us"
] | Nasssss | null | null | null | 0 | 0 | Entry not found |
Viniciaao/Minecraft | 2023-09-19T22:50:28.000Z | [
"license:openrail",
"region:us"
] | Viniciaao | null | null | null | 0 | 0 | ---
license: openrail
---
|
zoomspoon/Loterias | 2023-09-19T22:53:24.000Z | [
"region:us"
] | zoomspoon | null | null | null | 0 | 0 | Entry not found |
Kizi-Art/azviya-channel | 2023-09-19T23:56:21.000Z | [
"arxiv:2211.06679",
"region:us"
] | Kizi-Art | null | null | null | 0 | 0 | # Stable Diffusion web UI
A browser interface based on Gradio library for Stable Diffusion.

## Features
[Detailed feature showcase with images](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features):
- Original txt2img and img2img modes
- One click install and run script (but you still must install python and git)
- Outpainting
- Inpainting
- Color Sketch
- Prompt Matrix
- Stable Diffusion Upscale
- Attention, specify parts of text that the model should pay more attention to
- a man in a `((tuxedo))` - will pay more attention to tuxedo
- a man in a `(tuxedo:1.21)` - alternative syntax
- select text and press `Ctrl+Up` or `Ctrl+Down` (or `Command+Up` or `Command+Down` if you're on a MacOS) to automatically adjust attention to selected text (code contributed by anonymous user)
- Loopback, run img2img processing multiple times
- X/Y/Z plot, a way to draw a 3 dimensional plot of images with different parameters
- Textual Inversion
- have as many embeddings as you want and use any names you like for them
- use multiple embeddings with different numbers of vectors per token
- works with half precision floating point numbers
- train embeddings on 8GB (also reports of 6GB working)
- Extras tab with:
- GFPGAN, neural network that fixes faces
- CodeFormer, face restoration tool as an alternative to GFPGAN
- RealESRGAN, neural network upscaler
- ESRGAN, neural network upscaler with a lot of third party models
- SwinIR and Swin2SR ([see here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/2092)), neural network upscalers
- LDSR, Latent diffusion super resolution upscaling
- Resizing aspect ratio options
- Sampling method selection
- Adjust sampler eta values (noise multiplier)
- More advanced noise setting options
- Interrupt processing at any time
- 4GB video card support (also reports of 2GB working)
- Correct seeds for batches
- Live prompt token length validation
- Generation parameters
- parameters you used to generate images are saved with that image
- in PNG chunks for PNG, in EXIF for JPEG
- can drag the image to PNG info tab to restore generation parameters and automatically copy them into UI
- can be disabled in settings
- drag and drop an image/text-parameters to promptbox
- Read Generation Parameters Button, loads parameters in promptbox to UI
- Settings page
- Running arbitrary python code from UI (must run with `--allow-code` to enable)
- Mouseover hints for most UI elements
- Possible to change defaults/mix/max/step values for UI elements via text config
- Tiling support, a checkbox to create images that can be tiled like textures
- Progress bar and live image generation preview
- Can use a separate neural network to produce previews with almost none VRAM or compute requirement
- Negative prompt, an extra text field that allows you to list what you don't want to see in generated image
- Styles, a way to save part of prompt and easily apply them via dropdown later
- Variations, a way to generate same image but with tiny differences
- Seed resizing, a way to generate same image but at slightly different resolution
- CLIP interrogator, a button that tries to guess prompt from an image
- Prompt Editing, a way to change prompt mid-generation, say to start making a watermelon and switch to anime girl midway
- Batch Processing, process a group of files using img2img
- Img2img Alternative, reverse Euler method of cross attention control
- Highres Fix, a convenience option to produce high resolution pictures in one click without usual distortions
- Reloading checkpoints on the fly
- Checkpoint Merger, a tab that allows you to merge up to 3 checkpoints into one
- [Custom scripts](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Custom-Scripts) with many extensions from community
- [Composable-Diffusion](https://energy-based-model.github.io/Compositional-Visual-Generation-with-Composable-Diffusion-Models/), a way to use multiple prompts at once
- separate prompts using uppercase `AND`
- also supports weights for prompts: `a cat :1.2 AND a dog AND a penguin :2.2`
- No token limit for prompts (original stable diffusion lets you use up to 75 tokens)
- DeepDanbooru integration, creates danbooru style tags for anime prompts
- [xformers](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Xformers), major speed increase for select cards: (add `--xformers` to commandline args)
- via extension: [History tab](https://github.com/yfszzx/stable-diffusion-webui-images-browser): view, direct and delete images conveniently within the UI
- Generate forever option
- Training tab
- hypernetworks and embeddings options
- Preprocessing images: cropping, mirroring, autotagging using BLIP or deepdanbooru (for anime)
- Clip skip
- Hypernetworks
- Loras (same as Hypernetworks but more pretty)
- A separate UI where you can choose, with preview, which embeddings, hypernetworks or Loras to add to your prompt
- Can select to load a different VAE from settings screen
- Estimated completion time in progress bar
- API
- Support for dedicated [inpainting model](https://github.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion) by RunwayML
- via extension: [Aesthetic Gradients](https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients), a way to generate images with a specific aesthetic by using clip images embeds (implementation of [https://github.com/vicgalle/stable-diffusion-aesthetic-gradients](https://github.com/vicgalle/stable-diffusion-aesthetic-gradients))
- [Stable Diffusion 2.0](https://github.com/Stability-AI/stablediffusion) support - see [wiki](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#stable-diffusion-20) for instructions
- [Alt-Diffusion](https://arxiv.org/abs/2211.06679) support - see [wiki](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#alt-diffusion) for instructions
- Now without any bad letters!
- Load checkpoints in safetensors format
- Eased resolution restriction: generated image's dimension must be a multiple of 8 rather than 64
- Now with a license!
- Reorder elements in the UI from settings screen
## Installation and Running
Make sure the required [dependencies](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Dependencies) are met and follow the instructions available for:
- [NVidia](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs) (recommended)
- [AMD](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs) GPUs.
- [Intel CPUs, Intel GPUs (both integrated and discrete)](https://github.com/openvinotoolkit/stable-diffusion-webui/wiki/Installation-on-Intel-Silicon) (external wiki page)
Alternatively, use online services (like Google Colab):
- [List of Online Services](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Online-Services)
### Installation on Windows 10/11 with NVidia-GPUs using release package
1. Download `sd.webui.zip` from [v1.0.0-pre](https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre) and extract it's contents.
2. Run `update.bat`.
3. Run `run.bat`.
> For more details see [Install-and-Run-on-NVidia-GPUs](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs)
### Automatic Installation on Windows
1. Install [Python 3.10.6](https://www.python.org/downloads/release/python-3106/) (Newer version of Python does not support torch), checking "Add Python to PATH".
2. Install [git](https://git-scm.com/download/win).
3. Download the stable-diffusion-webui repository, for example by running `git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git`.
4. Run `webui-user.bat` from Windows Explorer as normal, non-administrator, user.
### Automatic Installation on Linux
1. Install the dependencies:
```bash
# Debian-based:
sudo apt install wget git python3 python3-venv libgl1 libglib2.0-0
# Red Hat-based:
sudo dnf install wget git python3
# Arch-based:
sudo pacman -S wget git python3
```
2. Navigate to the directory you would like the webui to be installed and execute the following command:
```bash
wget -q https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
```
3. Run `webui.sh`.
4. Check `webui-user.sh` for options.
### Installation on Apple Silicon
Find the instructions [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Installation-on-Apple-Silicon).
## Contributing
Here's how to add code to this repo: [Contributing](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing)
## Documentation
The documentation was moved from this README over to the project's [wiki](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki).
For the purposes of getting Google and other search engines to crawl the wiki, here's a link to the (not for humans) [crawlable wiki](https://github-wiki-see.page/m/AUTOMATIC1111/stable-diffusion-webui/wiki).
## Credits
Licenses for borrowed code can be found in `Settings -> Licenses` screen, and also in `html/licenses.html` file.
- Stable Diffusion - https://github.com/CompVis/stable-diffusion, https://github.com/CompVis/taming-transformers
- k-diffusion - https://github.com/crowsonkb/k-diffusion.git
- GFPGAN - https://github.com/TencentARC/GFPGAN.git
- CodeFormer - https://github.com/sczhou/CodeFormer
- ESRGAN - https://github.com/xinntao/ESRGAN
- SwinIR - https://github.com/JingyunLiang/SwinIR
- Swin2SR - https://github.com/mv-lab/swin2sr
- LDSR - https://github.com/Hafiidz/latent-diffusion
- MiDaS - https://github.com/isl-org/MiDaS
- Ideas for optimizations - https://github.com/basujindal/stable-diffusion
- Cross Attention layer optimization - Doggettx - https://github.com/Doggettx/stable-diffusion, original idea for prompt editing.
- Cross Attention layer optimization - InvokeAI, lstein - https://github.com/invoke-ai/InvokeAI (originally http://github.com/lstein/stable-diffusion)
- Sub-quadratic Cross Attention layer optimization - Alex Birch (https://github.com/Birch-san/diffusers/pull/1), Amin Rezaei (https://github.com/AminRezaei0x443/memory-efficient-attention)
- Textual Inversion - Rinon Gal - https://github.com/rinongal/textual_inversion (we're not using his code, but we are using his ideas).
- Idea for SD upscale - https://github.com/jquesnelle/txt2imghd
- Noise generation for outpainting mk2 - https://github.com/parlance-zz/g-diffuser-bot
- CLIP interrogator idea and borrowing some code - https://github.com/pharmapsychotic/clip-interrogator
- Idea for Composable Diffusion - https://github.com/energy-based-model/Compositional-Visual-Generation-with-Composable-Diffusion-Models-PyTorch
- xformers - https://github.com/facebookresearch/xformers
- DeepDanbooru - interrogator for anime diffusers https://github.com/KichangKim/DeepDanbooru
- Sampling in float32 precision from a float16 UNet - marunine for the idea, Birch-san for the example Diffusers implementation (https://github.com/Birch-san/diffusers-play/tree/92feee6)
- Instruct pix2pix - Tim Brooks (star), Aleksander Holynski (star), Alexei A. Efros (no star) - https://github.com/timothybrooks/instruct-pix2pix
- Security advice - RyotaK
- UniPC sampler - Wenliang Zhao - https://github.com/wl-zhao/UniPC
- TAESD - Ollin Boer Bohan - https://github.com/madebyollin/taesd
- LyCORIS - KohakuBlueleaf
- Restart sampling - lambertae - https://github.com/Newbeeer/diffusion_restart_sampling
- Initial Gradio script - posted on 4chan by an Anonymous user. Thank you Anonymous user.
- (You)
|
hansalemao/bandlogos | 2023-09-24T22:28:36.000Z | [
"task_categories:image-classification",
"license:mit",
"bands",
"music",
"ac/dc",
"krokus",
"accept",
"iron maiden",
"metallica",
"aerosmith",
"anthrax",
"black sabbath",
"judas priest",
"kiss",
"led zeppelin",
"manowar",
"metal church",
"misfits",
"motörhead",
"ozzy",
"pante... | hansalemao | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- image-classification
tags:
- bands
- music
- ac/dc
- krokus
- accept
- iron maiden
- metallica
- aerosmith
- anthrax
- black sabbath
- judas priest
- kiss
- led zeppelin
- manowar
- metal church
- misfits
- motörhead
- ozzy
- pantera
- saint vitus
- saxon
- scorpions
- slayer
- whitesnake
- logos
---
Automatically generated DataSet with: https://github.com/hansalemaos/tools4yolo
Base model (Yolov5) https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m.pt
[](https://www.youtube.com/watch?v=PZxqZA_euTI)
[https://www.youtube.com/watch?v=PZxqZA_euTI]() |
Aotsuyu/filtered | 2023-09-20T14:44:03.000Z | [
"region:us"
] | Aotsuyu | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
splits:
- name: train
num_bytes: 4713220418.256
num_examples: 1464
download_size: 0
dataset_size: 4713220418.256
---
# Dataset Card for "filtered"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tiagofvb/reddit_r_carros | 2023-09-20T01:05:17.000Z | [
"license:apache-2.0",
"region:us"
] | tiagofvb | null | null | null | 0 | 0 | ---
license: apache-2.0
---
The Reddit r/carros Conversational Dataset is a collection of text-based conversations sourced from the popular online community, "r/carros." This dataset is compiled to provide a valuable resource for research and analysis in the realm of natural language processing, with a specific focus on automotive-related discussions.
Column Descriptions:
Comment:
The "Comment" column contains the original user-generated text or comment posted by participants within the r/carros subreddit. These comments encompass a diverse array of topics related to automobiles, including discussions about car models, brands, features, maintenance, reviews, and other automotive-related subjects. The language used in the comments may vary in style, tone, and technicality, providing a rich linguistic landscape for exploration.
Reply:
In the "Reply" column, you will find the corresponding responses to the comments made in the "Comment" column. These responses represent reactions, opinions, suggestions, or follow-up statements provided by other members of the r/carros community in the context of the original comment. The replies capture the conversational dynamics and engagement within the subreddit, offering insights into the collective knowledge and experiences of automotive enthusiasts. |
mlfoundations/open_lm_example_data | 2023-09-20T01:04:55.000Z | [
"license:mit",
"region:us"
] | mlfoundations | null | null | null | 0 | 0 | ---
license: mit
---
|
marqkkj/Gordao.zip | 2023-09-20T01:12:41.000Z | [
"region:us"
] | marqkkj | null | null | null | 0 | 0 | Entry not found |
rwaterbury/governmentRFPs | 2023-09-20T01:16:54.000Z | [
"region:us"
] | rwaterbury | null | null | null | 0 | 0 | Entry not found |
linhqyy/data_aug_full_less | 2023-09-20T01:55:57.000Z | [
"region:us"
] | linhqyy | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: sentence
dtype: string
- name: intent
dtype: string
- name: entities
list:
- name: type
dtype: string
- name: filler
dtype: string
- name: labels
dtype: string
splits:
- name: train
num_bytes: 1644352
num_examples: 7787
- name: test
num_bytes: 141911
num_examples: 678
download_size: 429178
dataset_size: 1786263
---
# Dataset Card for "data_aug_full_less"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ouasdg/cc3m-morepieces | 2023-09-20T02:12:13.000Z | [
"region:us"
] | ouasdg | null | null | null | 0 | 0 | It's just the unlabeled train split of datasets/conceptual_captions but split into 4 pieces |
vllg/loong_c4 | 2023-09-20T05:20:37.000Z | [
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:en",
"license:odc-by",
"region:us"
] | vllg | null | null | null | 0 | 0 | ---
license: odc-by
task_categories:
- text-generation
language:
- en
size_categories:
- 1M<n<10M
---
A filtered subset of C4-en containing 3,584,358 pages that are at least 16,000 characters long, useful for training models with longer context windows. |
vllg/looong_c4 | 2023-09-20T05:20:24.000Z | [
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:en",
"license:odc-by",
"region:us"
] | vllg | null | null | null | 0 | 0 | ---
license: odc-by
task_categories:
- text-generation
language:
- en
size_categories:
- 100K<n<1M
---
A filtered subset of C4-en containing 835,400 pages that are at least 32,000 characters long, useful for training models with longer context windows. |
GodBlog/video | 2023-09-20T03:07:27.000Z | [
"license:mit",
"region:us"
] | GodBlog | null | null | null | 0 | 0 | ---
license: mit
---
|
AmelieSchreiber/600K_binding_sites | 2023-10-01T01:22:36.000Z | [
"license:mit",
"region:us"
] | AmelieSchreiber | null | null | null | 0 | 0 | ---
license: mit
---
This dataset is curated from UniProt. The test set was created by selecting entire families of proteins to separate out at random.
The train/test split is approximately 80/20. All binding site and active site annotations were merged. All sequences longer than
1000 amino acids were split into non-overlapping chunks of 1000 residues or less. |
allnabuenni/mega | 2023-09-20T05:29:30.000Z | [
"license:openrail",
"region:us"
] | allnabuenni | null | null | null | 0 | 0 | ---
license: openrail
---
|
Poloman/Colab | 2023-09-20T05:41:16.000Z | [
"license:openrail",
"region:us"
] | Poloman | null | null | null | 0 | 0 | ---
license: openrail
---
|
siddanshchawla/llama2-points-to-summary | 2023-09-20T05:48:53.000Z | [
"region:us"
] | siddanshchawla | null | null | null | 0 | 0 | Entry not found |
moiu2998/myn | 2023-09-20T06:15:44.000Z | [
"region:us"
] | moiu2998 | null | null | null | 0 | 0 | Entry not found |
macst6/training | 2023-09-20T06:17:06.000Z | [
"license:afl-3.0",
"region:us"
] | macst6 | null | null | null | 0 | 0 | ---
license: afl-3.0
---
|
Srihari3j7/spb | 2023-09-20T06:19:48.000Z | [
"license:openrail",
"region:us"
] | Srihari3j7 | null | null | null | 0 | 0 | ---
license: openrail
---
|
lionpig/ali | 2023-09-20T06:22:07.000Z | [
"task_categories:text-classification",
"art",
"region:us"
] | lionpig | null | null | null | 0 | 0 | ---
task_categories:
- text-classification
tags:
- art
pretty_name: memei
--- |
dgwdwAGdgwa/knplyadata | 2023-09-20T06:43:06.000Z | [
"region:us"
] | dgwdwAGdgwa | null | null | null | 0 | 0 | Entry not found |
yzhuang/autotree_automl_Higgs_gosdt_l512_d3 | 2023-09-20T06:58:50.000Z | [
"region:us"
] | yzhuang | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: input_x
sequence:
sequence: float64
- name: input_y
sequence:
sequence: float32
- name: rtg
sequence: float64
- name: status
sequence:
sequence: float32
- name: split_threshold
sequence:
sequence: float64
- name: split_dimension
sequence: int64
splits:
- name: train
num_bytes: 12501600000
num_examples: 100000
- name: validation
num_bytes: 1250160000
num_examples: 10000
download_size: 9801842261
dataset_size: 13751760000
---
# Dataset Card for "autotree_automl_Higgs_gosdt_l512_d3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
dreamerdeo/pajama_book_sample | 2023-09-20T07:48:18.000Z | [
"region:us"
] | dreamerdeo | null | null | null | 0 | 0 | Entry not found |
rahul-bhoyar-1995/test-data | 2023-09-20T07:53:00.000Z | [
"region:us"
] | rahul-bhoyar-1995 | null | null | null | 0 | 0 | Entry not found |
ivanleomk/prompt_injection_password | 2023-09-20T08:04:39.000Z | [
"region:us"
] | ivanleomk | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 142227
num_examples: 917
download_size: 53239
dataset_size: 142227
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "prompt_injection_password"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
0xk1h0/py150k_sanitized_jsonl | 2023-09-20T08:29:18.000Z | [
"license:mit",
"region:us"
] | 0xk1h0 | null | null | null | 0 | 0 | ---
license: mit
---
|
next-social/dancer_sd_xl_1 | 2023-09-26T11:46:26.000Z | [
"region:us"
] | next-social | null | null | null | 0 | 0 | Entry not found |
manycore-research/faceformer | 2023-09-20T09:53:19.000Z | [
"license:mit",
"region:us"
] | manycore-research | null | null | null | 0 | 0 | ---
license: mit
---
|
GuillaumeSalou/test-cnil | 2023-09-20T09:11:23.000Z | [
"region:us"
] | GuillaumeSalou | null | null | null | 0 | 0 | Entry not found |
dz1/CodeScore | 2023-09-25T15:08:26.000Z | [
"region:us"
] | dz1 | null | null | null | 0 | 0 | Entry not found |
mindthebridge/wizmap_challenges_data | 2023-09-20T09:56:04.000Z | [
"region:us"
] | mindthebridge | null | null | null | 0 | 0 | Entry not found |
fiveflow/koquad_v2_polyglot_tkd_20th | 2023-09-20T09:46:43.000Z | [
"region:us"
] | fiveflow | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: context
dtype: string
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 1766922390
num_examples: 20000
download_size: 592965039
dataset_size: 1766922390
---
# Dataset Card for "koquad_v2_polyglot_tkd_20th"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Coroseven/AiOhto | 2023-09-20T10:01:16.000Z | [
"region:us"
] | Coroseven | null | null | null | 0 | 0 | Entry not found |
samuel110/data_samuel | 2023-09-20T10:01:26.000Z | [
"region:us"
] | samuel110 | null | null | null | 0 | 0 | Entry not found |
mboth/grundfunktionen-undersampled | 2023-09-20T10:04:49.000Z | [
"region:us"
] | mboth | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: valid
path: data/valid-*
dataset_info:
features:
- name: Datatype
dtype: string
- name: Beschreibung
dtype: string
- name: Name
dtype: string
- name: Unit
dtype: string
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': AndereAnlagen
'1': Befoerdern
'2': KaelteVersorgen
'3': LuftVersorgen
'4': MedienVersorgen
'5': Sichern
'6': StromVersorgen
'7': WaermeVersorgen
splits:
- name: train
num_bytes: 767809.3946920173
num_examples: 4359
- name: test
num_bytes: 952887
num_examples: 5431
- name: valid
num_bytes: 952887
num_examples: 5431
download_size: 1154906
dataset_size: 2673583.394692017
---
# Dataset Card for "grundfunktionen-undersampled"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Write2Live/lmao | 2023-09-20T10:09:52.000Z | [
"region:us"
] | Write2Live | null | null | null | 0 | 0 | Entry not found |
Chars/pixiv_rank_daily_2018_2023 | 2023-09-22T17:09:53.000Z | [
"region:us"
] | Chars | null | null | null | 0 | 0 | Entry not found |
sdasdadas/september1 | 2023-09-20T11:10:12.000Z | [
"region:us"
] | sdasdadas | null | null | null | 0 | 0 | Entry not found |
loubnabnl/kaggle-data | 2023-09-20T11:14:03.000Z | [
"region:us"
] | loubnabnl | null | null | null | 0 | 0 | Entry not found |
dim/chip2_instruct_alpha_prompt_en | 2023-09-20T11:16:08.000Z | [
"region:us"
] | dim | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 85102023
num_examples: 210289
download_size: 50192027
dataset_size: 85102023
---
# Dataset Card for "chip2_instruct_alpha_prompt_en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mboth/waerme_versorgen_133-undersampled | 2023-09-20T11:37:04.000Z | [
"region:us"
] | mboth | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: valid
path: data/valid-*
dataset_info:
features:
- name: Datatype
dtype: string
- name: Beschreibung
dtype: string
- name: Name
dtype: string
- name: Unit
dtype: string
- name: text
dtype: string
- name: Grundfunktion
dtype: string
- name: label
dtype:
class_label:
names:
'0': Beziehen
'1': Erzeugen
'2': Speichern
'3': Verteilen
splits:
- name: train
num_bytes: 104796.04173106646
num_examples: 532
- name: test
num_bytes: 447086
num_examples: 2265
- name: valid
num_bytes: 447086
num_examples: 2265
download_size: 362118
dataset_size: 998968.0417310664
---
# Dataset Card for "waerme_versorgen_133-undersampled"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mindthebridge/wizmap_startups_data | 2023-09-20T11:56:35.000Z | [
"region:us"
] | mindthebridge | null | null | null | 0 | 0 | Entry not found |
MingweiMao/Side-view-Pigs | 2023-09-20T13:23:05.000Z | [
"license:other",
"region:us"
] | MingweiMao | null | null | null | 0 | 0 | ---
license: other
---
# This dataset consists of pig farming images captured from a side-view perspective.
# After downloading the dataset, place the images and labels in the 'JPEGImages' and 'Annotations' folders under 'VOCdevkit/VOC2007'.
# Running 'VOC.py' will categorize the data into training, validation, and test datasets according to specified ratios in VOC format.
# Running 'voc-yolo.py' will categorize the data into training, validation, and test datasets in YOLO format with specified ratios.
# By following the aforementioned steps, you can obtain the VOC and YOLO formats for this side-view-pigs dataset
---
---
|
WILSONBRUZA/TK | 2023-09-20T12:38:10.000Z | [
"license:openrail",
"region:us"
] | WILSONBRUZA | null | null | null | 0 | 0 | ---
license: openrail
---
|
dim/oasst1_prompt_en | 2023-09-20T11:45:10.000Z | [
"region:us"
] | dim | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 32670635
num_examples: 20976
download_size: 12117771
dataset_size: 32670635
---
# Dataset Card for "oasst1_prompt_dataset_en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
dim/dolly_prompt_en | 2023-09-20T11:48:17.000Z | [
"region:us"
] | dim | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 18623377
num_examples: 19238
download_size: 7835327
dataset_size: 18623377
---
# Dataset Card for "dolly_prompt_en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
DSSGxMunich/document_text | 2023-10-05T10:16:44.000Z | [
"license:mit",
"region:us"
] | DSSGxMunich | null | null | null | 1 | 0 | ---
license: mit
---
# Dataset Card for document_texts
## Dataset Description
* **Homepage:** [DSSGx Munich](https://sites.google.com/view/dssgx-munich-2023/startseite) organization page.
* **Repository:** [GitHub](https://github.com/DSSGxMunich/land-sealing-dataset-and-analysis).
### Dataset Summary
This dataset contains th result of the PDF parser done by Tika. It contains for each document, the land parcel it refers to and the content downloaded.
## Dataset Structure
### Data Fields
- **filename:** Name of the parsed pdf file.
- **document_id:** Unique ID of the document, it is the combination of the land parcel id_number of document from that land parcel.
- **content:** Extracted text content.
- **land_parcel_id:** Unique ID of the land parcel for the document.
- **land_parcel_name:** Name of the land parcel for the document.
- **land_parcel_scanurl:** URL for the parsed content.
### Source Data
Comes from the module document_texts_creation. |
DSSGxMunich/regional_plan_sections | 2023-10-05T10:15:36.000Z | [
"license:mit",
"region:us"
] | DSSGxMunich | null | null | null | 1 | 0 | ---
license: mit
---
# Dataset Card for regional_plan_sections
## Dataset Description
**Homepage:** [DSSGx Munich](https://sites.google.com/view/dssgx-munich-2023/startseite) organization page.
**Repository:** [GitHub](https://github.com/DSSGxMunich/land-sealing-dataset-and-analysis).
### Dataset Summary
This dataset contains the parsed information from the regional plans.
Each row is one section containing goals and objectives from the documents.
For each section, we also have the appearance of relevant keywords regarding floodings.
### Data Fields
- **hq100:** relevant keyword.
- **hqhäufig:** relevant keyword.
- **hqextrem:** relevant keyword.
- **vorranggebiete:** relevant keyword.
- **vorbehaltsgebiete:** relevant keyword.
- **affected_by_flooding:** relevant keyword.
- **innenentwicklung:** relevant keyword.
- **flächensparen:** relevant keyword.
- **filename:** Name of the file that was parsed.
- **chapter:** Name of the chapter.
- **section:** Complete section text, preprocessed.
- **section_type:** Objective, principle or explanation.
- **year:** Year of the document.
- **PLR:** Type of document.
- **Name:** Regional plan name.
### Source Data
Comes from the module rplan_content_extraction.
|
samuelesam/Vipoo1completo | 2023-09-20T12:14:37.000Z | [
"region:us"
] | samuelesam | null | null | null | 0 | 0 | Entry not found |
parrotzone/sdxl-1.0.zip | 2023-09-20T14:42:08.000Z | [
"license:openrail",
"region:us"
] | parrotzone | null | null | null | 0 | 0 | ---
license: openrail
---
|
dim/chip2_instruct_alpha_prompt_ru | 2023-09-20T12:41:28.000Z | [
"region:us"
] | dim | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 120371757
num_examples: 162087
download_size: 58859759
dataset_size: 120371757
---
# Dataset Card for "chip2_instruct_alpha_prompt_ru"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
dim/oasst1_prompt_ru | 2023-09-20T12:45:44.000Z | [
"region:us"
] | dim | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 22467539
num_examples: 10774
download_size: 7610348
dataset_size: 22467539
---
# Dataset Card for "oasst1_prompt_ru"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
lexaizero/itulahpokoknya | 2023-09-22T08:08:40.000Z | [
"license:mit",
"region:us"
] | lexaizero | null | null | null | 0 | 0 | ---
license: mit
---
|
dim/dolly_prompt_ru | 2023-09-20T12:51:17.000Z | [
"region:us"
] | dim | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 23359298
num_examples: 15950
download_size: 0
dataset_size: 23359298
---
# Dataset Card for "dolly_prompt_ru"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
demizzzzzz/ardil | 2023-09-20T13:01:29.000Z | [
"region:us"
] | demizzzzzz | null | null | null | 0 | 0 | Entry not found |
pphuc25/mlcoban | 2023-09-20T13:20:14.000Z | [
"region:us"
] | pphuc25 | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 1026527
num_examples: 50
download_size: 465113
dataset_size: 1026527
---
# Dataset Card for "mlcoban"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Shrenik/CodeLLamaBash | 2023-09-20T13:14:49.000Z | [
"license:mit",
"region:us"
] | Shrenik | null | null | null | 0 | 0 | ---
license: mit
---
|
AfshanAhmed/TrainingPractice | 2023-09-20T13:23:50.000Z | [
"region:us"
] | AfshanAhmed | null | null | null | 0 | 0 | Entry not found |
pphuc25/khanhdinhpham | 2023-09-20T13:25:28.000Z | [
"region:us"
] | pphuc25 | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 1137699
num_examples: 58
download_size: 521927
dataset_size: 1137699
---
# Dataset Card for "khanhdinhpham"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Jackoon/JSON_expert_2 | 2023-09-20T13:31:35.000Z | [
"region:us"
] | Jackoon | null | null | null | 0 | 0 | Entry not found |
0xk1h0/py150k_sanitized_20 | 2023-09-20T14:16:02.000Z | [
"region:us"
] | 0xk1h0 | null | null | null | 0 | 0 | Entry not found |
jtatman/headlines_data | 2023-09-20T15:00:34.000Z | [
"region:us"
] | jtatman | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 102075981
num_examples: 2329709
download_size: 70905263
dataset_size: 102075981
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "headlines_data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
danlou/safespace-8877-20230920 | 2023-09-20T15:10:39.000Z | [
"region:us"
] | danlou | null | null | null | 0 | 0 | Entry not found |
Aotsuyu/ReimuArmpit | 2023-09-20T15:52:43.000Z | [
"region:us"
] | Aotsuyu | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
splits:
- name: train
num_bytes: 4910736822.712
num_examples: 1392
download_size: 4925159968
dataset_size: 4910736822.712
---
# Dataset Card for "ReimuArmpit"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
hongchi/wild6dv2 | 2023-09-20T17:52:54.000Z | [
"license:mit",
"region:us"
] | hongchi | null | null | null | 0 | 0 | ---
license: mit
---
|
mqrzel/globaly | 2023-09-20T15:57:42.000Z | [
"region:us"
] | mqrzel | null | null | null | 0 | 0 | Entry not found |
LububMalvino/esse_medicamento_e_contraindicado_em_casos_de_suspeita_dengue_2013 | 2023-09-20T16:02:12.000Z | [
"region:us"
] | LububMalvino | null | null | null | 0 | 0 | Entry not found |
Sagar12/data | 2023-09-20T16:21:08.000Z | [
"license:unknown",
"region:us"
] | Sagar12 | null | null | null | 0 | 0 | ---
license: unknown
---
|
BangumiBase/4ninwasorezoreusootsuku | 2023-09-29T09:43:45.000Z | [
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] | BangumiBase | null | null | null | 0 | 0 | ---
license: mit
tags:
- art
size_categories:
- 1K<n<10K
---
# Bangumi Image Base of 4-nin Wa Sorezore Uso O Tsuku
This is the image base of bangumi 4-nin wa Sorezore Uso o Tsuku, we detected 14 characters, 1462 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 272 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 82 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 11 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 325 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 23 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 12 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 285 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 15 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 12 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 9 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 22 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 294 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 11 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| noise | 89 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
turkish-nlp-suite/beyazperde-all-movie-reviews | 2023-09-22T16:46:22.000Z | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:tr",
"license:cc-by-sa-4.0",
"region:us"
] | turkish-nlp-suite | Movies sentiment analysis dataset for Turkish. Includes reviews for all movies of all time,crawled from popular Turkish movies website Beyazperde.com. All reviews are in Turkish.[BeyazPerde Top All Movie Reviews Dataset](https://github.com/turkish-nlp-suite/BeyazPerde-Movie-Reviews/) | @inproceedings{altinok-2023-diverse,
title = "A Diverse Set of Freely Available Linguistic Resources for {T}urkish",
author = "Altinok, Duygu",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.768",
pages = "13739--13750",
abstract = "This study presents a diverse set of freely available linguistic resources for Turkish natural language processing, including corpora, pretrained models and education material. Although Turkish is spoken by a sizeable population of over 80 million people, Turkish linguistic resources for natural language processing remain scarce. In this study, we provide corpora to allow practitioners to build their own applications and pretrained models that would assist industry researchers in creating quick prototypes. The provided corpora include named entity recognition datasets of diverse genres, including Wikipedia articles and supplement products customer reviews. In addition, crawling e-commerce and movie reviews websites, we compiled several sentiment analysis datasets of different genres. Our linguistic resources for Turkish also include pretrained spaCy language models. To the best of our knowledge, our models are the first spaCy models trained for the Turkish language. Finally, we provide various types of education material, such as video tutorials and code examples, that can support the interested audience on practicing Turkish NLP. The advantages of our linguistic resources are three-fold: they are freely available, they are first of their kind, and they are easy to use in a broad range of implementations. Along with a thorough description of the resource creation process, we also explain the position of our resources in the Turkish NLP world.",
} | null | 0 | 0 | ---
language:
- tr
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
task_categories:
- text-classification
task_ids:
- sentiment-classification
pretty_name: BeyazPerde All Movie Reviews
---
# Dataset Card for turkish-nlp-suite/beyazperde-all-movie-reviews
<img src="https://raw.githubusercontent.com/turkish-nlp-suite/.github/main/profile/beyazPerde.png" width="20%" height="20%">
## Dataset Description
- **Repository:** [BeyazPerde All Movie Reviews](https://github.com/turkish-nlp-suite/BeyazPerde-Movie-Reviews/)
- **Paper:** [ACL link](https://aclanthology.org/2023.acl-long.768/)
- **Dataset:** BeyazPerde All Movie Reviews
- **Domain:** Social Media
### Dataset Summary
Beyazperde Movie Reviews offers Turkish sentiment analysis datasets that is scraped from popular movie reviews website Beyazperde.com. All Movie Reviews include audience reviews about movies of all the time. Here's the star rating distribution:
| star rating | count |
|---|---|
| 0.5 | 3.635 |
| 1.0 | 2.325 |
| 1.5 | 1.077 |
| 2.0 | 1.902 |
| 2.5 | 4.767 |
| 3.0 |4.347 |
| 3.5 | 6.495 |
| 4.0 |9.486 |
| 4.5 | 3.652 |
| 5.0 | 7.594 |
| total | 45.280 |
The star rating looks quite balanced. This dataset offers the challenge of understanding the sentiment in a refined way, dissecting the positive sentiment into "very positive" or "okayish positive".
### Dataset Instances
An instance of this dataset looks as follows:
```
{
"movie": "Avatar",
"text": "Açıkçası film beklentilerimi karşılayamadı. Tabi her şeyin ilki güzel ama son seride iyi olabilirdi. Filmde görsel olarak her şey güzeldi kendimi filmi izledikten sonra ıslanmış gibi hissettim :D Puan kırdığım noktalar filmin bilim kurgudan fantastiğe doğru kayması. Ardından sır kapısına döndürüp iyilik yapan iyilik bulur moduna girmesi. Çoğu sahnelerin çocuklara hitap etmesi. Neyse serinin üçüncü filmi sağlam olucak gibi...",
"rating": 3,5
}
```
### Data Split
| name |train|validation|test|
|---------|----:|---:|---:|
|BeyazPerde All Movie Reviews|35280|5000|5000|
### Citation
This work is supported by Google Developer Experts Program. Part of Duygu 2022 Fall-Winter collection, "Turkish NLP with Duygu"/ "Duygu'yla Türkçe NLP". All rights reserved. If you'd like to use this dataset in your own work, please kindly cite [A Diverse Set of Freely Available Linguistic Resources for Turkish](https://aclanthology.org/2023.acl-long.768/) :
```
@inproceedings{altinok-2023-diverse,
title = "A Diverse Set of Freely Available Linguistic Resources for {T}urkish",
author = "Altinok, Duygu",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.768",
pages = "13739--13750",
abstract = "This study presents a diverse set of freely available linguistic resources for Turkish natural language processing, including corpora, pretrained models and education material. Although Turkish is spoken by a sizeable population of over 80 million people, Turkish linguistic resources for natural language processing remain scarce. In this study, we provide corpora to allow practitioners to build their own applications and pretrained models that would assist industry researchers in creating quick prototypes. The provided corpora include named entity recognition datasets of diverse genres, including Wikipedia articles and supplement products customer reviews. In addition, crawling e-commerce and movie reviews websites, we compiled several sentiment analysis datasets of different genres. Our linguistic resources for Turkish also include pretrained spaCy language models. To the best of our knowledge, our models are the first spaCy models trained for the Turkish language. Finally, we provide various types of education material, such as video tutorials and code examples, that can support the interested audience on practicing Turkish NLP. The advantages of our linguistic resources are three-fold: they are freely available, they are first of their kind, and they are easy to use in a broad range of implementations. Along with a thorough description of the resource creation process, we also explain the position of our resources in the Turkish NLP world.",
}
```
|
Kamyar-zeinalipour/llama2-example | 2023-09-20T16:37:05.000Z | [
"region:us"
] | Kamyar-zeinalipour | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 821
num_examples: 3
download_size: 2690
dataset_size: 821
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "llama2-example"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Davi2586/Old_Dave_Mustaine | 2023-09-20T16:53:03.000Z | [
"region:us"
] | Davi2586 | null | null | null | 0 | 0 | Entry not found |
juniorrios/minor_datasets | 2023-09-20T16:52:36.000Z | [
"region:us"
] | juniorrios | null | null | null | 0 | 0 | Entry not found |
snirjhar-colab/cuda | 2023-09-20T16:56:40.000Z | [
"region:us"
] | snirjhar-colab | null | null | null | 0 | 0 | Entry not found |
ic-fspml/fpb | 2023-09-20T17:45:46.000Z | [
"region:us"
] | ic-fspml | null | null | null | 1 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: sentence
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 556902
num_examples: 3876
- name: test
num_bytes: 138843
num_examples: 970
download_size: 416525
dataset_size: 695745
---
# Dataset Card for "fpb"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ic-fspml/fiqa | 2023-09-20T17:45:48.000Z | [
"region:us"
] | ic-fspml | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: sentence
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 86998
num_examples: 938
- name: test
num_bytes: 18624
num_examples: 235
download_size: 68130
dataset_size: 105622
---
# Dataset Card for "fiqa"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
deutschebahn/mnist | 2023-09-20T17:46:11.000Z | [
"license:unknown",
"region:eu"
] | deutschebahn | null | null | null | 0 | 0 | ---
license: unknown
---
|
ylucic/lora02 | 2023-09-20T20:28:33.000Z | [
"region:us"
] | ylucic | null | null | null | 0 | 0 | Entry not found |
open-llm-leaderboard/details_wahaha1987__llama_7b_sharegpt94k_fastchat | 2023-09-20T18:17:05.000Z | [
"region:us"
] | open-llm-leaderboard | null | null | null | 0 | 0 | ---
pretty_name: Evaluation run of wahaha1987/llama_7b_sharegpt94k_fastchat
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [wahaha1987/llama_7b_sharegpt94k_fastchat](https://huggingface.co/wahaha1987/llama_7b_sharegpt94k_fastchat)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 3 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_wahaha1987__llama_7b_sharegpt94k_fastchat\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-09-20T18:16:52.904405](https://huggingface.co/datasets/open-llm-leaderboard/details_wahaha1987__llama_7b_sharegpt94k_fastchat/blob/main/results_2023-09-20T18-16-52.904405.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.08934563758389262,\n\
\ \"em_stderr\": 0.0029211449908449474,\n \"f1\": 0.14663171140939493,\n\
\ \"f1_stderr\": 0.003084457529543832,\n \"acc\": 0.3748038054707682,\n\
\ \"acc_stderr\": 0.009200192405721019\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.08934563758389262,\n \"em_stderr\": 0.0029211449908449474,\n\
\ \"f1\": 0.14663171140939493,\n \"f1_stderr\": 0.003084457529543832\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.043214556482183475,\n \
\ \"acc_stderr\": 0.0056009875152378645\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.7063930544593529,\n \"acc_stderr\": 0.012799397296204173\n\
\ }\n}\n```"
repo_url: https://huggingface.co/wahaha1987/llama_7b_sharegpt94k_fastchat
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_drop_3
data_files:
- split: 2023_09_20T18_16_52.904405
path:
- '**/details_harness|drop|3_2023-09-20T18-16-52.904405.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-09-20T18-16-52.904405.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_09_20T18_16_52.904405
path:
- '**/details_harness|gsm8k|5_2023-09-20T18-16-52.904405.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-09-20T18-16-52.904405.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_09_20T18_16_52.904405
path:
- '**/details_harness|winogrande|5_2023-09-20T18-16-52.904405.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-09-20T18-16-52.904405.parquet'
- config_name: results
data_files:
- split: 2023_09_20T18_16_52.904405
path:
- results_2023-09-20T18-16-52.904405.parquet
- split: latest
path:
- results_2023-09-20T18-16-52.904405.parquet
---
# Dataset Card for Evaluation run of wahaha1987/llama_7b_sharegpt94k_fastchat
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/wahaha1987/llama_7b_sharegpt94k_fastchat
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [wahaha1987/llama_7b_sharegpt94k_fastchat](https://huggingface.co/wahaha1987/llama_7b_sharegpt94k_fastchat) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 3 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_wahaha1987__llama_7b_sharegpt94k_fastchat",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-09-20T18:16:52.904405](https://huggingface.co/datasets/open-llm-leaderboard/details_wahaha1987__llama_7b_sharegpt94k_fastchat/blob/main/results_2023-09-20T18-16-52.904405.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.08934563758389262,
"em_stderr": 0.0029211449908449474,
"f1": 0.14663171140939493,
"f1_stderr": 0.003084457529543832,
"acc": 0.3748038054707682,
"acc_stderr": 0.009200192405721019
},
"harness|drop|3": {
"em": 0.08934563758389262,
"em_stderr": 0.0029211449908449474,
"f1": 0.14663171140939493,
"f1_stderr": 0.003084457529543832
},
"harness|gsm8k|5": {
"acc": 0.043214556482183475,
"acc_stderr": 0.0056009875152378645
},
"harness|winogrande|5": {
"acc": 0.7063930544593529,
"acc_stderr": 0.012799397296204173
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
raghavprabhakar/commonsense-embodied-ai | 2023-10-10T19:41:46.000Z | [
"region:us"
] | raghavprabhakar | null | null | null | 0 | 0 | Entry not found |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.