
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
espidermon/babar-azam | 2023-09-26T08:10:34.000Z | [
"license:openrail",
"region:us"
] | espidermon | null | null | null | 0 | 0 | ---
license: openrail
---
|
CyberHarem/aoba_moca_bangdream | 2023-09-26T08:10:41.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of aoba_moca (BanG Dream!)
This is the dataset of aoba_moca (BanG Dream!), containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 471 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 471 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 471 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 471 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
chatgptopenainl/ChatGPTNederlands | 2023-09-26T08:16:32.000Z | [
"license:openrail",
"region:us"
] | chatgptopenainl | null | null | null | 0 | 0 | ---
license: openrail
---
|
rahulmnavneeth/sample-A | 2023-09-26T08:24:43.000Z | [
"region:us"
] | rahulmnavneeth | null | null | null | 0 | 0 | Entry not found |
jtatman/headlines | 2023-09-26T08:27:15.000Z | [
"region:us"
] | jtatman | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 80263469
num_examples: 1662297
download_size: 62717748
dataset_size: 80263469
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "headlines"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Zaid/NewData | 2023-09-26T08:44:43.000Z | [
"region:us"
] | Zaid | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: Name
dtype: string
- name: Age
dtype: string
- name: label
dtype:
class_label:
names:
'0': female
'1': male
splits:
- name: train
num_bytes: 50
num_examples: 2
download_size: 1182
dataset_size: 50
---
# Dataset Card for "NewData"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
kurusunagisa/mori | 2023-09-26T08:57:27.000Z | [
"license:unlicense",
"region:us"
] | kurusunagisa | null | null | null | 0 | 0 | ---
license: unlicense
--- |
MikeXydas/wikitable | 2023-09-26T09:21:03.000Z | [
"license:mit",
"region:us"
] | MikeXydas | null | null | null | 0 | 0 | ---
license: mit
---
Dataset from: http://websail-fe.cs.northwestern.edu/TabEL |
veranchos/arg_mining_tweets | 2023-09-27T08:30:45.000Z | [
"license:afl-3.0",
"region:us"
] | veranchos | null | null | null | 0 | 0 | ---
license: afl-3.0
---
# Argument mining from Tweets related to COVID-19.
This repository contains a dataset for SMM4H'22 Task 2: Classification of stance and premise in tweets about health mandates (COVID-19).
Data includes:
- [Train](train) and [test](data/test/smm4h) data for SMM4H 2022 Task 2: tweets annotated for stance and premise prediction on three claims about COVID-19 mandates such as stay-at-home-orders, school closures, and face masks
- [2070](test/vaccine_tweets) annotated tweets about vaccine mandates, that were not used in the official SMM4H competition
- [600](test/vaccine_tweets/unused) annotated tweets about vaccine mandates with low inter-annotators agreement.
## Citation
If you find this dataset useful, please cite:
```
@inproceedings{davydova-tutubalina-2022-smm4h,
title = "{SMM}4{H} 2022 Task 2: Dataset for stance and premise detection in tweets about health mandates related to {COVID}-19",
author = "Davydova, Vera and
Tutubalina, Elena",
booktitle = "Proceedings of The Seventh Workshop on Social Media Mining for Health Applications, Workshop {\&} Shared Task",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.smm4h-1.53",
pages = "216--220",
abstract = "This paper is an organizers{'} report of the competition on argument mining systems dealing with English tweets about COVID-19 health mandates. This competition was held within the framework of the SMM4H 2022 shared tasks. During the competition, the participants were offered two subtasks: stance detection and premise classification. We present a manually annotated corpus containing 6,156 short posts from Twitter on three topics related to the COVID-19 pandemic: school closures, stay-at-home orders, and wearing masks. We hope the prepared dataset will support further research on argument mining in the health field.",
}
```
<img width="1190" alt="smm4h_graphical_abstract" src="https://github.com/Veranchos/ArgMining_tweets/assets/37894718/44f183ea-b17c-4afc-a7b8-32b35a963c2c"> |
TrainingDataPro/ocr-barcodes-detection | 2023-10-09T07:28:23.000Z | [
"task_categories:image-to-text",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] | TrainingDataPro | The dataset consists of images of various grocery goods that have barcode labels.
Each image in the dataset is annotated with polygons around the barcode labels.
Additionally, Optical Character Recognition (**OCR**) has been performed on each
bounding box to extract the barcode numbers.
The dataset is particularly valuable for applications in *grocery retail, inventory
management, supply chain optimization, and automated checkout systems*. It serves as a
valuable resource for researchers, developers, and businesses working on barcode-related
projects in the retail and logistics domains. | @InProceedings{huggingface:dataset,
title = {ocr-barcodes-detection},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 0 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-text
tags:
- code
- finance
dataset_info:
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: width
dtype: uint16
- name: height
dtype: uint16
- name: shapes
sequence:
- name: label
dtype:
class_label:
names:
'0': Barcode
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 284124996
num_examples: 11
download_size: 283531190
dataset_size: 284124996
---
# OCR Barcodes Detection
The dataset consists of images of various **grocery goods** that have **barcode labels**. Each image in the dataset is annotated with polygons around the barcode labels. Additionally, Optical Character Recognition (**OCR**) has been performed on each bounding box to extract the barcode numbers.
The dataset is particularly valuable for applications in *grocery retail, inventory management, supply chain optimization, and automated checkout systems*. It serves as a valuable resource for researchers, developers, and businesses working on barcode-related projects in the retail and logistics domains.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-barcodes-detection) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of goods
- **boxes** - includes labeling for the original images
- **annotations.xml** - contains coordinates of the polygons and detected text of the barcode, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the polygons and detected text . For each point, the x and y coordinates are provided.
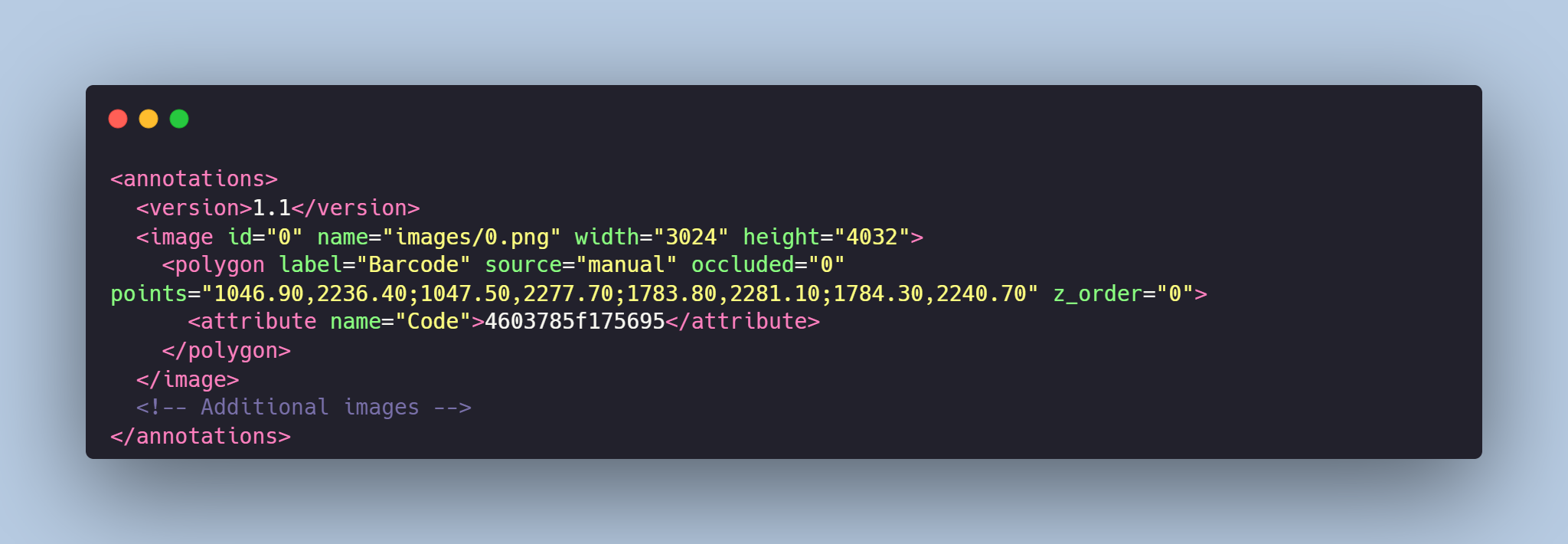
# Barcodes Detection might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-barcodes-detection) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
CyberHarem/hazawa_tsugumi_bangdream | 2023-09-26T09:13:25.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of hazawa_tsugumi (BanG Dream!)
This is the dataset of hazawa_tsugumi (BanG Dream!), containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 474 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 474 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 474 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 474 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
jtatman/articles_87_07 | 2023-09-26T09:26:13.000Z | [
"region:us"
] | jtatman | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 517874639
num_examples: 4344588
download_size: 372405322
dataset_size: 517874639
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "articles_87_07"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
vibha-mah/TwitterSentimentratings | 2023-09-26T09:33:18.000Z | [
"region:us"
] | vibha-mah | null | null | null | 0 | 0 | Entry not found |
CyberHarem/okusawa_misaki_bangdream | 2023-09-26T09:55:11.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of okusawa_misaki (BanG Dream!)
This is the dataset of okusawa_misaki (BanG Dream!), containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 473 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 473 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 473 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 473 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
turkish-nlp-suite/vitamins-supplements-NER | 2023-09-26T12:26:31.000Z | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"language:tr",
"license:cc-by-sa-4.0",
"region:us"
] | turkish-nlp-suite | null | null | null | 0 | 0 | ---
language:
- tr
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
task_categories:
- token-classification
task_ids:
- named-entity-recognition
pretty_name: Vitamins and Supplements NER Dataset
---
# Dataset Card for turkish-nlp-suite/vitamins-supplements-NER
<img src="https://raw.githubusercontent.com/turkish-nlp-suite/.github/main/profile/supplementsNER.png" width="20%" height="20%">
### Dataset Description
- **Repository:** [Vitamins and Supplements NER Dataset](https://github.com/turkish-nlp-suite/Vitamins-Supplements-NER-dataset)
- **Paper:** [ACL link](https://aclanthology.org/2023.acl-long.768/)
- **Dataset:** Vitamins and Supplements NER Dataset
- **Domain:** E-commerce, customer reviews, medical
### Dataset Summary
The Vitamins and Supplements NER Dataset is a NER dataset containing customer reviews with entity and span annotations. User reviews were collected from a popular supplement products e-
commerce website Vitaminler.com.
Each customer review in the Vitamins and Supplements NER Dataset describes a customer’s experience with a supplement product in terms of that product’s effectiveness, side effects, taste and
smell, as well as comments on supplement usage frequency and dosage, active ingredients, brand, and similar products by other brands. An example review from the dataset with
entity and span annotations looks like this:
<img src="https://raw.githubusercontent.com/turkish-nlp-suite/.github/main/profile/positiv1.png" width="80%" height="80%">
The customer praises a biotin supplement; in their review they stated that they suffer from Thyroiditis and as a result they're experiencing hair loss. They purchased the biotin product to
prevent the hair fall and they described the effectiveness of the product as "their hair loss reduced noticably". Visual is created by displaCy.
## Tagset
For this dataset we annotated both entities and spans. Span annotations are common in medical NLP datasets, spans capture the information about "what happens with the entity", i.e. more semantics about the entities in the text.
NER tags and their distribution are in the dataset are as follows:
| Tag | Count |
|---|---|
| Disease | 1.875 |
| Biomolecule | 859 |
| User | 634 |
| Other_product | 543 |
| Recommender | 436 |
| Dosage | 471 |
| Brand | 275 |
| User_demographics | 192 |
| Ingredient | 175 |
| Other_brand | 121 |
Distribution of span tags:
| Tag | Count |
|---|---|
| Effect | 2.562 |
| Side_effect | 608 |
| Taste_smell | 558 |
| Health_complaints | 858 |
All annotations are done by [Co-one](https://co-one.co/). many thanks to them for their contributions.
### Dataset Instances
The dataset includes around 2.5K annotated reviews with annotations.
Each dataset instance contains
- customer review text
- entities and spans annotated
Here's an example for you:
```
{
"text": "Bu zamana kadar kullandığım en iyi B12 takviyesi. Doktorum saç dökülmem için verdi ama aç karnına dil altına bir fıs kullanınca KABIZLIK sorunumu çözdü. çok mutlu oldum. Indirimde gördüğünüz an kaçırmayın derim."
"spans": [
{ "val": "saç dökülmem", "label": "HASTALIK", "start": 59, "end": 71 },
{ "val": " KABIZLIK", "label": "HASTALIK", "start": 127, "end": 136 },
{ "val": "B12", "label": "BİYOMOLEKÜL", "start": 35, "end": 38 },
{ "val": " Doktorum", "label": "TAVSİYE_EDEN", "start": 49, "end": 58 },
{ "val": "bir fıs", "label": "DOZ", "start": 109, "end": 116 }
]
}
```
If you're rather interested in a big JSON, you can find the dataset as a single JSON in dataset's [Github repo](https://github.com/turkish-nlp-suite/Vitamins-Supplements-NER-Dataset).
### Data Split
| name |train|validation|test|
|---------|----:|---:|---:|
|Vitamins and Supplements NER Dataset|2072|200|200|
### Citation
This work is supported by Google Developer Experts Program. Part of Duygu 2022 Fall-Winter collection, "Turkish NLP with Duygu"/ "Duygu'yla Türkçe NLP". All rights reserved. If you'd like to use this dataset in your own work, please kindly cite [A Diverse Set of Freely Available Linguistic Resources for Turkish](https://aclanthology.org/2023.acl-long.768/) :
```
@inproceedings{altinok-2023-diverse,
title = "A Diverse Set of Freely Available Linguistic Resources for {T}urkish",
author = "Altinok, Duygu",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.768",
pages = "13739--13750",
abstract = "This study presents a diverse set of freely available linguistic resources for Turkish natural language processing, including corpora, pretrained models and education material. Although Turkish is spoken by a sizeable population of over 80 million people, Turkish linguistic resources for natural language processing remain scarce. In this study, we provide corpora to allow practitioners to build their own applications and pretrained models that would assist industry researchers in creating quick prototypes. The provided corpora include named entity recognition datasets of diverse genres, including Wikipedia articles and supplement products customer reviews. In addition, crawling e-commerce and movie reviews websites, we compiled several sentiment analysis datasets of different genres. Our linguistic resources for Turkish also include pretrained spaCy language models. To the best of our knowledge, our models are the first spaCy models trained for the Turkish language. Finally, we provide various types of education material, such as video tutorials and code examples, that can support the interested audience on practicing Turkish NLP. The advantages of our linguistic resources are three-fold: they are freely available, they are first of their kind, and they are easy to use in a broad range of implementations. Along with a thorough description of the resource creation process, we also explain the position of our resources in the Turkish NLP world.",
}
```
|
CyberHarem/miyauchi_renge_nonnonbiyori | 2023-09-27T18:11:53.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of Miyauchi Renge
This is the dataset of Miyauchi Renge, containing 299 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:----------------|---------:|:----------------------------------------|:-----------------------------------------------------------------------------------------|
| raw | 299 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 705 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| raw-stage3-eyes | 816 | [Download](dataset-raw-stage3-eyes.zip) | 3-stage cropped (with eye-focus) raw data with meta information. |
| 384x512 | 299 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x704 | 299 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x880 | 299 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 705 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 705 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-p512-640 | 579 | [Download](dataset-stage3-p512-640.zip) | 3-stage cropped dataset with the area not less than 512x512 pixels. |
| stage3-eyes-640 | 816 | [Download](dataset-stage3-eyes-640.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 640 pixels. |
| stage3-eyes-800 | 816 | [Download](dataset-stage3-eyes-800.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 800 pixels. |
|
pcuenq/tests | 2023-09-26T18:06:18.000Z | [
"region:us"
] | pcuenq | null | null | null | 0 | 0 | Entry not found |
kunalsharma/fake-news | 2023-09-26T10:38:28.000Z | [
"license:cc",
"region:us"
] | kunalsharma | null | null | null | 0 | 0 | ---
license: cc
---
|
lunarflu/Bringing-SoTA-Diffusion-Models-to-the-Masses-with-diffusers | 2023-09-26T10:50:40.000Z | [
"region:us"
] | lunarflu | null | null | null | 0 | 0 | https://www.youtube.com/watch?v=qo5ubQadvfs |
CyberHarem/ichijou_hotaru_nonnonbiyori | 2023-09-27T18:55:03.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of Ichijou Hotaru
This is the dataset of Ichijou Hotaru, containing 299 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:----------------|---------:|:----------------------------------------|:-----------------------------------------------------------------------------------------|
| raw | 299 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 725 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| raw-stage3-eyes | 807 | [Download](dataset-raw-stage3-eyes.zip) | 3-stage cropped (with eye-focus) raw data with meta information. |
| 384x512 | 299 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x704 | 299 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x880 | 299 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 725 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 725 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-p512-640 | 613 | [Download](dataset-stage3-p512-640.zip) | 3-stage cropped dataset with the area not less than 512x512 pixels. |
| stage3-eyes-640 | 807 | [Download](dataset-stage3-eyes-640.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 640 pixels. |
| stage3-eyes-800 | 807 | [Download](dataset-stage3-eyes-800.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 800 pixels. |
|
NusaCrowd/code_mixed_jv_id | 2023-09-26T12:28:06.000Z | [
"language:jav",
"language:ind",
"sentiment-analysis",
"machine-translation",
"region:us"
] | NusaCrowd | Sentiment analysis and machine translation data for Javanese and Indonesian. | @article{Tho_2021,
doi = {10.1088/1742-6596/1869/1/012084},
url = {https://doi.org/10.1088/1742-6596/1869/1/012084},
year = 2021,
month = {apr},
publisher = {{IOP} Publishing},
volume = {1869},
number = {1},
pages = {012084},
author = {C Tho and Y Heryadi and L Lukas and A Wibowo},
title = {Code-mixed sentiment analysis of Indonesian language and Javanese language using Lexicon based approach},
journal = {Journal of Physics: Conference Series},
abstract = {Nowadays mixing one language with another language either in
spoken or written communication has become a common practice for bilingual
speakers in daily conversation as well as in social media. Lexicon based
approach is one of the approaches in extracting the sentiment analysis. This
study is aimed to compare two lexicon models which are SentiNetWord and VADER
in extracting the polarity of the code-mixed sentences in Indonesian language
and Javanese language. 3,963 tweets were gathered from two accounts that
provide code-mixed tweets. Pre-processing such as removing duplicates,
translating to English, filter special characters, transform lower case and
filter stop words were conducted on the tweets. Positive and negative word
score from lexicon model was then calculated using simple mathematic formula
in order to classify the polarity. By comparing with the manual labelling,
the result showed that SentiNetWord perform better than VADER in negative
sentiments. However, both of the lexicon model did not perform well in
neutral and positive sentiments. On overall performance, VADER showed better
performance than SentiNetWord. This study showed that the reason for the
misclassified was that most of Indonesian language and Javanese language
consist of words that were considered as positive in both Lexicon model.}
} | null | 0 | 0 | ---
tags:
- sentiment-analysis
- machine-translation
language:
- jav
- ind
---
# code_mixed_jv_id
Sentiment analysis and machine translation data for Javanese and Indonesian.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{Tho_2021,
doi = {10.1088/1742-6596/1869/1/012084},
url = {https://doi.org/10.1088/1742-6596/1869/1/012084},
year = 2021,
month = {apr},
publisher = {{IOP} Publishing},
volume = {1869},
number = {1},
pages = {012084},
author = {C Tho and Y Heryadi and L Lukas and A Wibowo},
title = {Code-mixed sentiment analysis of Indonesian language and Javanese language using Lexicon based approach},
journal = {Journal of Physics: Conference Series},
abstract = {Nowadays mixing one language with another language either in
spoken or written communication has become a common practice for bilingual
speakers in daily conversation as well as in social media. Lexicon based
approach is one of the approaches in extracting the sentiment analysis. This
study is aimed to compare two lexicon models which are SentiNetWord and VADER
in extracting the polarity of the code-mixed sentences in Indonesian language
and Javanese language. 3,963 tweets were gathered from two accounts that
provide code-mixed tweets. Pre-processing such as removing duplicates,
translating to English, filter special characters, transform lower case and
filter stop words were conducted on the tweets. Positive and negative word
score from lexicon model was then calculated using simple mathematic formula
in order to classify the polarity. By comparing with the manual labelling,
the result showed that SentiNetWord perform better than VADER in negative
sentiments. However, both of the lexicon model did not perform well in
neutral and positive sentiments. On overall performance, VADER showed better
performance than SentiNetWord. This study showed that the reason for the
misclassified was that most of Indonesian language and Javanese language
consist of words that were considered as positive in both Lexicon model.}
}
```
## License
cc_by_3.0
## Homepage
[https://iopscience.iop.org/article/10.1088/1742-6596/1869/1/012084](https://iopscience.iop.org/article/10.1088/1742-6596/1869/1/012084)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
shawarmas/DifferentMesfianMediaNames | 2023-09-30T09:59:44.000Z | [
"region:us"
] | shawarmas | null | null | null | 0 | 0 | Entry not found |
NusaCrowd/indspeech_teldialog_svcsr | 2023-09-26T12:28:10.000Z | [
"language:ind",
"speech-recognition",
"region:us"
] | NusaCrowd | This is the first Indonesian speech dataset for small vocabulary continuous speech recognition (SVCSR).
The data was developed by TELKOMRisTI (R&D Division, PT Telekomunikasi Indonesia) in collaboration with Advanced
Telecommunication Research Institute International (ATR) Japan and Bandung Institute of Technology (ITB) under the
Asia-Pacific Telecommunity (APT) project in 2004 [Sakti et al., 2004]. Although it was originally developed for
a telecommunication system for hearing and speaking impaired people, it can be used for other applications,
i.e., automatic call centers. Furthermore, as all speakers utter the same sentences,
it can also be used for voice conversion tasks.
The text is based on a word vocabulary which is derived from some necessary dialog calls,
such as dialog calls with the 119 emergency department, 108 telephone information department,
and ticket reservation department. In total, it consists of 20,000 utterances (about 18 hours of speech) from the
70-word dialog vocabulary of 100 sentences (including single word sentences) each uttered by 200 speakers
(100 Females, 100 Males). The age is limited to middle age (20-40 years), but they present a wide range of spoken
dialects from different ethnic groups. The recording is conducted in parallel for both clean and telephone speech,
but we open only the clean speech due to quality issues on telephone speech.
Each audio file is a single-channel 16-bit PCM WAV with a sample rate of 16000 Hz.
These utterances are equally split into training and test sets with 100 speakers (50 Females, 50 Males) in each set. | @inproceedings{sakti-icslp-2004,
title = "Indonesian Speech Recognition for Hearing and Speaking Impaired People",
author = "Sakti, Sakriani and Hutagaol, Paulus and Arman, Arry Akhmad and Nakamura, Satoshi",
booktitle = "Proc. International Conference on Spoken Language Processing (INTERSPEECH - ICSLP)",
year = "2004",
pages = "1037--1040"
address = "Jeju Island, Korea"
} | null | 0 | 0 | ---
tags:
- speech-recognition
language:
- ind
---
# indspeech_teldialog_svcsr
This is the first Indonesian speech dataset for small vocabulary continuous speech recognition (SVCSR).
The data was developed by TELKOMRisTI (R&D Division, PT Telekomunikasi Indonesia) in collaboration with Advanced
Telecommunication Research Institute International (ATR) Japan and Bandung Institute of Technology (ITB) under the
Asia-Pacific Telecommunity (APT) project in 2004 [Sakti et al., 2004]. Although it was originally developed for
a telecommunication system for hearing and speaking impaired people, it can be used for other applications,
i.e., automatic call centers. Furthermore, as all speakers utter the same sentences,
it can also be used for voice conversion tasks.
The text is based on a word vocabulary which is derived from some necessary dialog calls,
such as dialog calls with the 119 emergency department, 108 telephone information department,
and ticket reservation department. In total, it consists of 20,000 utterances (about 18 hours of speech) from the
70-word dialog vocabulary of 100 sentences (including single word sentences) each uttered by 200 speakers
(100 Females, 100 Males). The age is limited to middle age (20-40 years), but they present a wide range of spoken
dialects from different ethnic groups. The recording is conducted in parallel for both clean and telephone speech,
but we open only the clean speech due to quality issues on telephone speech.
Each audio file is a single-channel 16-bit PCM WAV with a sample rate of 16000 Hz.
These utterances are equally split into training and test sets with 100 speakers (50 Females, 50 Males) in each set.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{sakti-icslp-2004,
title = "Indonesian Speech Recognition for Hearing and Speaking Impaired People",
author = "Sakti, Sakriani and Hutagaol, Paulus and Arman, Arry Akhmad and Nakamura, Satoshi",
booktitle = "Proc. International Conference on Spoken Language Processing (INTERSPEECH - ICSLP)",
year = "2004",
pages = "1037--1040"
address = "Jeju Island, Korea"
}
```
## License
CC-BY-NC-SA-4.0
## Homepage
[https://github.com/s-sakti/data_indsp_teldialog_svcsr/](https://github.com/s-sakti/data_indsp_teldialog_svcsr/)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/kamus_alay | 2023-09-26T12:28:13.000Z | [
"language:ind",
"license:unknown",
"morphological-inflection",
"region:us"
] | NusaCrowd | Kamus Alay provide a lexicon for text normalization of Indonesian colloquial words.
It contains 3,592 unique colloquial words-also known as “bahasa alay” -and manually annotated them
with the normalized form. We built this lexicon from Instagram comments provided by Septiandri & Wibisono (2017) | @INPROCEEDINGS{8629151,
author={Aliyah Salsabila, Nikmatun and Ardhito Winatmoko, Yosef and Akbar Septiandri, Ali and Jamal, Ade},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
title={Colloquial Indonesian Lexicon},
year={2018},
volume={},
number={},
pages={226-229},
doi={10.1109/IALP.2018.8629151}} | null | 0 | 0 | ---
license: unknown
tags:
- morphological-inflection
language:
- ind
---
# kamus_alay
Kamus Alay provide a lexicon for text normalization of Indonesian colloquial words.
It contains 3,592 unique colloquial words-also known as “bahasa alay” -and manually annotated them
with the normalized form. We built this lexicon from Instagram comments provided by Septiandri & Wibisono (2017)
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@INPROCEEDINGS{8629151,
author={Aliyah Salsabila, Nikmatun and Ardhito Winatmoko, Yosef and Akbar Septiandri, Ali and Jamal, Ade},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
title={Colloquial Indonesian Lexicon},
year={2018},
volume={},
number={},
pages={226-229},
doi={10.1109/IALP.2018.8629151}}
```
## License
Unknown
## Homepage
[https://ieeexplore.ieee.org/abstract/document/8629151](https://ieeexplore.ieee.org/abstract/document/8629151)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_hoax_news | 2023-09-26T12:28:34.000Z | [
"language:ind",
"hoax-news-classification",
"region:us"
] | NusaCrowd | This research proposes to build an automatic hoax news detection and collects 250 pages of hoax and valid news articles in Indonesian language.
Each data sample is annotated by three reviewers and the final taggings are obtained by voting of those three reviewers. | @INPROCEEDINGS{8265649, author={Pratiwi, Inggrid Yanuar Risca and Asmara, Rosa Andrie and Rahutomo, Faisal}, booktitle={2017 11th International Conference on Information & Communication Technology and System (ICTS)}, title={Study of hoax news detection using naïve bayes classifier in Indonesian language}, year={2017}, volume={}, number={}, pages={73-78}, doi={10.1109/ICTS.2017.8265649}} | null | 0 | 0 | ---
tags:
- hoax-news-classification
language:
- ind
---
# id_hoax_news
This research proposes to build an automatic hoax news detection and collects 250 pages of hoax and valid news articles in Indonesian language.
Each data sample is annotated by three reviewers and the final taggings are obtained by voting of those three reviewers.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@INPROCEEDINGS{8265649, author={Pratiwi, Inggrid Yanuar Risca and Asmara, Rosa Andrie and Rahutomo, Faisal}, booktitle={2017 11th International Conference on Information & Communication Technology and System (ICTS)}, title={Study of hoax news detection using naïve bayes classifier in Indonesian language}, year={2017}, volume={}, number={}, pages={73-78}, doi={10.1109/ICTS.2017.8265649}}
```
## License
Creative Commons Attribution 4.0 International
## Homepage
[https://data.mendeley.com/datasets/p3hfgr5j3m/1](https://data.mendeley.com/datasets/p3hfgr5j3m/1)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indspeech_news_ethnicsr | 2023-09-26T12:28:44.000Z | [
"language:sun",
"language:jav",
"speech-recognition",
"region:us"
] | NusaCrowd | INDspeech_NEWS_EthnicSR is a collection of Indonesian ethnic speech corpora for Javanese and Sundanese for Indonesian ethnic speech recognition. It was developed in 2012 by the Nara Institute of Science and Technology (NAIST, Japan) in collaboration with the Bandung Institute of Technology (ITB, Indonesia) [Sani et al., 2012]. | @inproceedings{sani-cocosda-2012,
title = "Towards Language Preservation: Preliminary Collection and Vowel Analysis of {I}ndonesian Ethnic Speech Data",
author = "Sani, Auliya and Sakti, Sakriani and Neubig, Graham and Toda, Tomoki and Mulyanto, Adi and Nakamura, Satoshi",
booktitle = "Proc. Oriental COCOSDA",
year = "2012",
pages = "118--122"
address = "Macau, China"
} | null | 0 | 0 | ---
tags:
- speech-recognition
language:
- sun
- jav
---
# indspeech_news_ethnicsr
INDspeech_NEWS_EthnicSR is a collection of Indonesian ethnic speech corpora for Javanese and Sundanese for Indonesian ethnic speech recognition. It was developed in 2012 by the Nara Institute of Science and Technology (NAIST, Japan) in collaboration with the Bandung Institute of Technology (ITB, Indonesia) [Sani et al., 2012].
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{sani-cocosda-2012,
title = "Towards Language Preservation: Preliminary Collection and Vowel Analysis of {I}ndonesian Ethnic Speech Data",
author = "Sani, Auliya and Sakti, Sakriani and Neubig, Graham and Toda, Tomoki and Mulyanto, Adi and Nakamura, Satoshi",
booktitle = "Proc. Oriental COCOSDA",
year = "2012",
pages = "118--122"
address = "Macau, China"
}
```
## License
CC-BY-NC-SA 4.0
## Homepage
[https://github.com/s-sakti/data_indsp_news_ethnicsr](https://github.com/s-sakti/data_indsp_news_ethnicsr)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_coreference_resolution | 2023-09-26T12:28:52.000Z | [
"region:us"
] | NusaCrowd | We built Indonesian coreference resolution that solves not only pronoun referenced to proper noun, but also proper noun to proper noun and pronoun to pronoun.
The differences with the available Indonesian coreference resolution lay on the problem scope and features.
We conducted experiments using various features (lexical and shallow syntactic features) such as appositive feature, nearest candidate feature, direct sentence feature, previous and next word feature, and a lexical feature of first person.
We also modified the method to build the training set by selecting the negative examples by cross pairing every single markable that appear between antecedent and anaphor.
Compared with two available methods to build the training set, we conducted experiments using C45 algorithm.
Using 200 news sentences, the best experiment achieved 71.6% F-Measure score. | @INPROCEEDINGS{8074648,
author={Suherik, Gilang Julian and Purwarianti, Ayu},
booktitle={2017 5th International Conference on Information and Communication Technology (ICoIC7)},
title={Experiments on coreference resolution for Indonesian language with lexical and shallow syntactic features},
year={2017},
volume={},
number={},
pages={1-5},
doi={10.1109/ICoICT.2017.8074648}} | null | 0 | 0 | Entry not found |
NusaCrowd/cc100 | 2023-09-26T12:28:40.000Z | [
"language:ind",
"language:jav",
"language:sun",
"license:mit",
"self-supervised-pretraining",
"region:us"
] | NusaCrowd | This corpus is an attempt to recreate the dataset used for training
XLM-R. This corpus comprises of monolingual data for 100+ languages and
also includes data for romanized languages (indicated by *_rom). This
was constructed using the urls and paragraph indices provided by the
CC-Net repository by processing January-December 2018 Commoncrawl
snapshots. Each file comprises of documents separated by
double-newlines and paragraphs within the same document separated by a
newline. The data is generated using the open source CC-Net repository.
No claims of intellectual property are made on the work of preparation
of the corpus. | @inproceedings{conneau-etal-2020-unsupervised,
title = "Unsupervised Cross-lingual Representation Learning at Scale",
author = "Conneau, Alexis and
Khandelwal, Kartikay and
Goyal, Naman and
Chaudhary, Vishrav and
Wenzek, Guillaume and
Guzm{'a}n, Francisco and
Grave, Edouard and
Ott, Myle and
Zettlemoyer, Luke and
Stoyanov, Veselin",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.747",
doi = "10.18653/v1/2020.acl-main.747",
pages = "8440--8451",
abstract = "This paper shows that pretraining multilingual language models
at scale leads to significant performance gains for a wide range of
cross-lingual transfer tasks. We train a Transformer-based masked language
model on one hundred languages, using more than two terabytes of filtered
CommonCrawl data. Our model, dubbed XLM-R, significantly outperforms
multilingual BERT (mBERT) on a variety of cross-lingual benchmarks,
including +14.6{%} average accuracy on XNLI, +13{%} average F1 score on
MLQA, and +2.4{%} F1 score on NER. XLM-R performs particularly well on
low-resource languages, improving 15.7{%} in XNLI accuracy for Swahili and
11.4{%} for Urdu over previous XLM models. We also present a detailed
empirical analysis of the key factors that are required to achieve these
gains, including the trade-offs between (1) positive transfer and capacity
dilution and (2) the performance of high and low resource languages at
scale. Finally, we show, for the first time, the possibility of
multilingual modeling without sacrificing per-language performance; XLM-R
is very competitive with strong monolingual models on the GLUE and XNLI
benchmarks. We will make our code and models publicly available.",
}
@inproceedings{wenzek-etal-2020-ccnet,
title = "{CCN}et: Extracting High Quality Monolingual Datasets from Web Crawl Data",
author = "Wenzek, Guillaume and
Lachaux, Marie-Anne and
Conneau, Alexis and
Chaudhary, Vishrav and
Guzm{'a}n, Francisco and
Joulin, Armand and
Grave, Edouard",
booktitle = "Proceedings of the 12th Language Resources and Evaluation Conference",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://www.aclweb.org/anthology/2020.lrec-1.494",
pages = "4003--4012",
abstract = "Pre-training text representations have led to significant
improvements in many areas of natural language processing. The quality of
these models benefits greatly from the size of the pretraining corpora as
long as its quality is preserved. In this paper, we describe an automatic
pipeline to extract massive high-quality monolingual datasets from Common
Crawl for a variety of languages. Our pipeline follows the data processing
introduced in fastText (Mikolov et al., 2017; Grave et al., 2018), that
deduplicates documents and identifies their language. We augment this
pipeline with a filtering step to select documents that are close to high
quality corpora like Wikipedia.",
language = "English",
ISBN = "979-10-95546-34-4",
} | null | 0 | 0 | ---
license: mit
tags:
- self-supervised-pretraining
language:
- ind
- jav
- sun
---
# cc100
This corpus is an attempt to recreate the dataset used for training
XLM-R. This corpus comprises of monolingual data for 100+ languages and
also includes data for romanized languages (indicated by *_rom). This
was constructed using the urls and paragraph indices provided by the
CC-Net repository by processing January-December 2018 Commoncrawl
snapshots. Each file comprises of documents separated by
double-newlines and paragraphs within the same document separated by a
newline. The data is generated using the open source CC-Net repository.
No claims of intellectual property are made on the work of preparation
of the corpus.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{conneau-etal-2020-unsupervised,
title = "Unsupervised Cross-lingual Representation Learning at Scale",
author = "Conneau, Alexis and
Khandelwal, Kartikay and
Goyal, Naman and
Chaudhary, Vishrav and
Wenzek, Guillaume and
Guzm{'a}n, Francisco and
Grave, Edouard and
Ott, Myle and
Zettlemoyer, Luke and
Stoyanov, Veselin",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.747",
doi = "10.18653/v1/2020.acl-main.747",
pages = "8440--8451",
abstract = "This paper shows that pretraining multilingual language models
at scale leads to significant performance gains for a wide range of
cross-lingual transfer tasks. We train a Transformer-based masked language
model on one hundred languages, using more than two terabytes of filtered
CommonCrawl data. Our model, dubbed XLM-R, significantly outperforms
multilingual BERT (mBERT) on a variety of cross-lingual benchmarks,
including +14.6{%} average accuracy on XNLI, +13{%} average F1 score on
MLQA, and +2.4{%} F1 score on NER. XLM-R performs particularly well on
low-resource languages, improving 15.7{%} in XNLI accuracy for Swahili and
11.4{%} for Urdu over previous XLM models. We also present a detailed
empirical analysis of the key factors that are required to achieve these
gains, including the trade-offs between (1) positive transfer and capacity
dilution and (2) the performance of high and low resource languages at
scale. Finally, we show, for the first time, the possibility of
multilingual modeling without sacrificing per-language performance; XLM-R
is very competitive with strong monolingual models on the GLUE and XNLI
benchmarks. We will make our code and models publicly available.",
}
@inproceedings{wenzek-etal-2020-ccnet,
title = "{CCN}et: Extracting High Quality Monolingual Datasets from Web Crawl Data",
author = "Wenzek, Guillaume and
Lachaux, Marie-Anne and
Conneau, Alexis and
Chaudhary, Vishrav and
Guzm{'a}n, Francisco and
Joulin, Armand and
Grave, Edouard",
booktitle = "Proceedings of the 12th Language Resources and Evaluation Conference",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://www.aclweb.org/anthology/2020.lrec-1.494",
pages = "4003--4012",
abstract = "Pre-training text representations have led to significant
improvements in many areas of natural language processing. The quality of
these models benefits greatly from the size of the pretraining corpora as
long as its quality is preserved. In this paper, we describe an automatic
pipeline to extract massive high-quality monolingual datasets from Common
Crawl for a variety of languages. Our pipeline follows the data processing
introduced in fastText (Mikolov et al., 2017; Grave et al., 2018), that
deduplicates documents and identifies their language. We augment this
pipeline with a filtering step to select documents that are close to high
quality corpora like Wikipedia.",
language = "English",
ISBN = "979-10-95546-34-4",
}
```
## License
MIT
## Homepage
[https://data.statmt.org/cc-100/](https://data.statmt.org/cc-100/)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/minangnlp_mt | 2023-09-26T12:29:22.000Z | [
"language:min",
"language:ind",
"license:mit",
"machine-translation",
"region:us"
] | NusaCrowd | In this work, we create Minangkabau–Indonesian (MIN-ID) parallel corpus by using Wikipedia. We obtain 224,180 Minangkabau and
510,258 Indonesian articles, and align documents through title matching, resulting in 111,430 MINID document pairs.
After that, we do sentence segmentation based on simple punctuation heuristics and obtain 4,323,315 Minangkabau sentences. We
then use the bilingual dictionary to translate Minangkabau article (MIN) into Indonesian language (ID'). Sentence alignment is conducted using
ROUGE-1 (F1) score (unigram overlap) (Lin, 2004) between ID’ and ID, and we pair each MIN sentencewith an ID sentence based on the highest ROUGE1.
We then discard sentence pairs with a score of less than 0.5 to result in 345,146 MIN-ID parallel sentences.
We observe that the sentence pattern in the collection is highly repetitive (e.g. 100k sentences are about biological term definition). Therefore,
we conduct final filtering based on top-1000 trigram by iteratively discarding sentences until the frequency of each trigram equals to 100. Finally, we
obtain 16,371 MIN-ID parallel sentences and conducted manual evaluation by asking two native Minangkabau speakers to assess the adequacy and
fluency (Koehn and Monz, 2006). The human judgement is based on scale 1–5 (1 means poor quality and 5 otherwise) and conducted against 100 random
samples. We average the weights of two annotators before computing the overall score, and we achieve 4.98 and 4.87 for adequacy and fluency respectively.
This indicates that the resulting corpus is high-quality for machine translation training. | @inproceedings{koto-koto-2020-towards,
title = "Towards Computational Linguistics in {M}inangkabau Language: Studies on Sentiment Analysis and Machine Translation",
author = "Koto, Fajri and
Koto, Ikhwan",
booktitle = "Proceedings of the 34th Pacific Asia Conference on Language, Information and Computation",
month = oct,
year = "2020",
address = "Hanoi, Vietnam",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.paclic-1.17",
pages = "138--148",
} | null | 0 | 0 | ---
license: mit
tags:
- machine-translation
language:
- min
- ind
---
# minangnlp_mt
In this work, we create Minangkabau–Indonesian (MIN-ID) parallel corpus by using Wikipedia. We obtain 224,180 Minangkabau and
510,258 Indonesian articles, and align documents through title matching, resulting in 111,430 MINID document pairs.
After that, we do sentence segmentation based on simple punctuation heuristics and obtain 4,323,315 Minangkabau sentences. We
then use the bilingual dictionary to translate Minangkabau article (MIN) into Indonesian language (ID'). Sentence alignment is conducted using
ROUGE-1 (F1) score (unigram overlap) (Lin, 2004) between ID’ and ID, and we pair each MIN sentencewith an ID sentence based on the highest ROUGE1.
We then discard sentence pairs with a score of less than 0.5 to result in 345,146 MIN-ID parallel sentences.
We observe that the sentence pattern in the collection is highly repetitive (e.g. 100k sentences are about biological term definition). Therefore,
we conduct final filtering based on top-1000 trigram by iteratively discarding sentences until the frequency of each trigram equals to 100. Finally, we
obtain 16,371 MIN-ID parallel sentences and conducted manual evaluation by asking two native Minangkabau speakers to assess the adequacy and
fluency (Koehn and Monz, 2006). The human judgement is based on scale 1–5 (1 means poor quality and 5 otherwise) and conducted against 100 random
samples. We average the weights of two annotators before computing the overall score, and we achieve 4.98 and 4.87 for adequacy and fluency respectively.
This indicates that the resulting corpus is high-quality for machine translation training.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{koto-koto-2020-towards,
title = "Towards Computational Linguistics in {M}inangkabau Language: Studies on Sentiment Analysis and Machine Translation",
author = "Koto, Fajri and
Koto, Ikhwan",
booktitle = "Proceedings of the 34th Pacific Asia Conference on Language, Information and Computation",
month = oct,
year = "2020",
address = "Hanoi, Vietnam",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.paclic-1.17",
pages = "138--148",
}
```
## License
MIT
## Homepage
[https://github.com/fajri91/minangNLP](https://github.com/fajri91/minangNLP)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/liputan6 | 2023-09-26T12:30:04.000Z | [
"language:ind",
"summarization",
"region:us"
] | NusaCrowd | A large-scale Indonesian summarization dataset consisting of harvested articles from Liputan6.com, an online news portal, resulting in 215,827 document-summary pairs. | @inproceedings{koto2020liputan6,
title={Liputan6: A Large-scale Indonesian Dataset for Text Summarization},
author={Koto, Fajri and Lau, Jey Han and Baldwin, Timothy},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
pages={598--608},
year={2020}
} | null | 0 | 0 | ---
tags:
- summarization
language:
- ind
---
# liputan6
A large-scale Indonesian summarization dataset consisting of harvested articles from Liputan6.com, an online news portal, resulting in 215,827 document-summary pairs.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{koto2020liputan6,
title={Liputan6: A Large-scale Indonesian Dataset for Text Summarization},
author={Koto, Fajri and Lau, Jey Han and Baldwin, Timothy},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
pages={598--608},
year={2020}
}
```
## License
CC-BY-SA 4.0
## Homepage
[https://github.com/fajri91/sum_liputan6](https://github.com/fajri91/sum_liputan6)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indolem_ntp | 2023-09-26T12:30:22.000Z | [
"language:ind",
"license:cc-by-4.0",
"next-sentence-prediction",
"arxiv:2011.00677",
"region:us"
] | NusaCrowd | NTP (Next Tweet prediction) is one of the comprehensive Indonesian benchmarks that given a list of tweets and an option, we predict if the option is the next tweet or not.
This task is similar to the next sentence prediction (NSP) task used to train BERT (Devlin et al., 2019).
In NTP, each instance consists of a Twitter thread (containing 2 to 4 tweets) that we call the premise, and four possible options for the next tweet, one of which is the actual response from the original thread.
Train: 5681 threads
Development: 811 threads
Test: 1890 threads | @article{DBLP:journals/corr/abs-2011-00677,
author = {Fajri Koto and
Afshin Rahimi and
Jey Han Lau and
Timothy Baldwin},
title = {IndoLEM and IndoBERT: {A} Benchmark Dataset and Pre-trained Language
Model for Indonesian {NLP}},
journal = {CoRR},
volume = {abs/2011.00677},
year = {2020},
url = {https://arxiv.org/abs/2011.00677},
eprinttype = {arXiv},
eprint = {2011.00677},
timestamp = {Fri, 06 Nov 2020 15:32:47 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2011-00677.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
} | null | 0 | 0 | ---
license: cc-by-4.0
tags:
- next-sentence-prediction
language:
- ind
---
# indolem_ntp
NTP (Next Tweet prediction) is one of the comprehensive Indonesian benchmarks that given a list of tweets and an option, we predict if the option is the next tweet or not.
This task is similar to the next sentence prediction (NSP) task used to train BERT (Devlin et al., 2019).
In NTP, each instance consists of a Twitter thread (containing 2 to 4 tweets) that we call the premise, and four possible options for the next tweet, one of which is the actual response from the original thread.
Train: 5681 threads
Development: 811 threads
Test: 1890 threads
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{DBLP:journals/corr/abs-2011-00677,
author = {Fajri Koto and
Afshin Rahimi and
Jey Han Lau and
Timothy Baldwin},
title = {IndoLEM and IndoBERT: {A} Benchmark Dataset and Pre-trained Language
Model for Indonesian {NLP}},
journal = {CoRR},
volume = {abs/2011.00677},
year = {2020},
url = {https://arxiv.org/abs/2011.00677},
eprinttype = {arXiv},
eprint = {2011.00677},
timestamp = {Fri, 06 Nov 2020 15:32:47 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2011-00677.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
## License
Creative Commons Attribution 4.0
## Homepage
[https://indolem.github.io/](https://indolem.github.io/)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/covost2 | 2023-09-26T12:31:13.000Z | [
"language:ind",
"language:eng",
"speech-to-text-translation",
"machine-translation",
"region:us"
] | NusaCrowd | CoVoST2 is a large-scale multilingual speech translation corpus covering translations from 21 languages to English
and from English into 15 languages. The dataset is created using Mozilla's open-source Common Voice database of
crowdsourced voice recordings. There are 2,900 hours of speech represented in the corpus. |
@article{wang2020covost,
title={Covost 2 and massively multilingual speech-to-text translation},
author={Wang, Changhan and Wu, Anne and Pino, Juan},
journal={arXiv preprint arXiv:2007.10310},
year={2020}
}
@inproceedings{wang21s_interspeech,
author={Wang, Changhan and Wu, Anne and Pino, Juan},
title={{CoVoST 2 and Massively Multilingual Speech Translation}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={2247--2251},
url={https://www.isca-speech.org/archive/interspeech_2021/wang21s_interspeech}
doi={10.21437/Interspeech.2021-2027}
} | null | 0 | 0 | ---
tags:
- speech-to-text-translation
- machine-translation
language:
- ind
- eng
---
# covost2
CoVoST2 is a large-scale multilingual speech translation corpus covering translations from 21 languages to English
and from English into 15 languages. The dataset is created using Mozilla's open-source Common Voice database of
crowdsourced voice recordings. There are 2,900 hours of speech represented in the corpus.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{wang2020covost,
title={Covost 2 and massively multilingual speech-to-text translation},
author={Wang, Changhan and Wu, Anne and Pino, Juan},
journal={arXiv preprint arXiv:2007.10310},
year={2020}
}
@inproceedings{wang21s_interspeech,
author={Wang, Changhan and Wu, Anne and Pino, Juan},
title={{CoVoST 2 and Massively Multilingual Speech Translation}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={2247--2251},
url={https://www.isca-speech.org/archive/interspeech_2021/wang21s_interspeech}
doi={10.21437/Interspeech.2021-2027}
}
```
## License
CC BY-NC 4.0
## Homepage
[https://huggingface.co/datasets/covost2](https://huggingface.co/datasets/covost2)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/kopi_cc_news | 2023-09-26T12:31:04.000Z | [
"language:ind",
"self-supervised-pretraining",
"region:us"
] | NusaCrowd | KoPI(Korpus Perayapan Indonesia)-CC_News is Indonesian Only Extract from CC NEWS Common Crawl from 2016-2022(july) ,each snapshots get extracted using warcio,trafilatura and filter using fasttext | \ | null | 0 | 0 | ---
tags:
- self-supervised-pretraining
language:
- ind
---
# kopi_cc_news
KoPI(Korpus Perayapan Indonesia)-CC_News is Indonesian Only Extract from CC NEWS Common Crawl from 2016-2022(july) ,each snapshots get extracted using warcio,trafilatura and filter using fasttext
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
```
## License
CC0
## Homepage
[https://huggingface.co/datasets/munggok/KoPI-CC_News](https://huggingface.co/datasets/munggok/KoPI-CC_News)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/kopi_cc | 2023-09-26T12:30:57.000Z | [
"language:ind",
"self-supervised-pretraining",
"arxiv:2201.06642",
"region:us"
] | NusaCrowd | KoPI-CC (Korpus Perayapan Indonesia)-CC is Indonesian Only Extract from Common Crawl snapshots ,each snapshots get extracted using ungoliant and get extra "filtering" using deduplication technique | @ARTICLE{2022arXiv220106642A,
author = {{Abadji}, Julien and {Ortiz Suarez}, Pedro and {Romary}, Laurent and {Sagot}, Benoit},
title = "{Towards a Cleaner Document-Oriented Multilingual Crawled Corpus}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computation and Language},
year = 2022,
month = jan,
eid = {arXiv:2201.06642},
pages = {arXiv:2201.06642},
archivePrefix = {arXiv},
eprint = {2201.06642},
primaryClass = {cs.CL},
adsurl = {https://ui.adsabs.harvard.edu/abs/2022arXiv220106642A},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
@inproceedings{AbadjiOrtizSuarezRomaryetal.2021,
author = {Julien Abadji and Pedro Javier Ortiz Su{\'a}rez and Laurent Romary and Benoit Sagot},
title = {Ungoliant: An optimized pipeline for the generation of a very large-scale multilingual web corpus},
series = {Proceedings of the Workshop on Challenges in the Management of Large Corpora (CMLC-9) 2021. Limerick, 12 July 2021 (Online-Event)},
editor = {Harald L{\"u}ngen and Marc Kupietz and Piotr Bański and Adrien Barbaresi and Simon Clematide and Ines Pisetta},
publisher = {Leibniz-Institut f{\"u}r Deutsche Sprache},
address = {Mannheim},
doi = {10.14618/ids-pub-10468},
url = {https://nbn-resolving.org/urn:nbn:de:bsz:mh39-104688},
pages = {1 -- 9},
year = {2021},
abstract = {Since the introduction of large language models in Natural Language Processing, large raw corpora have played a crucial role in Computational Linguistics.},
language = {en}
} | null | 0 | 0 | ---
tags:
- self-supervised-pretraining
language:
- ind
---
# kopi_cc
KoPI-CC (Korpus Perayapan Indonesia)-CC is Indonesian Only Extract from Common Crawl snapshots ,each snapshots get extracted using ungoliant and get extra "filtering" using deduplication technique
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@ARTICLE{2022arXiv220106642A,
author = {{Abadji}, Julien and {Ortiz Suarez}, Pedro and {Romary}, Laurent and {Sagot}, Benoit},
title = "{Towards a Cleaner Document-Oriented Multilingual Crawled Corpus}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computation and Language},
year = 2022,
month = jan,
eid = {arXiv:2201.06642},
pages = {arXiv:2201.06642},
archivePrefix = {arXiv},
eprint = {2201.06642},
primaryClass = {cs.CL},
adsurl = {https://ui.adsabs.harvard.edu/abs/2022arXiv220106642A},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
@inproceedings{AbadjiOrtizSuarezRomaryetal.2021,
author = {Julien Abadji and Pedro Javier Ortiz Su{'a}rez and Laurent Romary and Benoit Sagot},
title = {Ungoliant: An optimized pipeline for the generation of a very large-scale multilingual web corpus},
series = {Proceedings of the Workshop on Challenges in the Management of Large Corpora (CMLC-9) 2021. Limerick, 12 July 2021 (Online-Event)},
editor = {Harald L{"u}ngen and Marc Kupietz and Piotr Bański and Adrien Barbaresi and Simon Clematide and Ines Pisetta},
publisher = {Leibniz-Institut f{"u}r Deutsche Sprache},
address = {Mannheim},
doi = {10.14618/ids-pub-10468},
url = {https://nbn-resolving.org/urn:nbn:de:bsz:mh39-104688},
pages = {1 -- 9},
year = {2021},
abstract = {Since the introduction of large language models in Natural Language Processing, large raw corpora have played a crucial role in Computational Linguistics.},
language = {en}
}
```
## License
CC0
## Homepage
[https://huggingface.co/datasets/munggok/KoPI-CC](https://huggingface.co/datasets/munggok/KoPI-CC)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indonli | 2023-09-26T12:30:50.000Z | [
"language:ind",
"textual-entailment",
"region:us"
] | NusaCrowd | This dataset is designed for Natural Language Inference NLP task. It is designed to provide a challenging test-bed
for Indonesian NLI by explicitly incorporating various linguistic phenomena such as numerical reasoning, structural
changes, idioms, or temporal and spatial reasoning. | @inproceedings{mahendra-etal-2021-indonli,
title = "{I}ndo{NLI}: A Natural Language Inference Dataset for {I}ndonesian",
author = "Mahendra, Rahmad and Aji, Alham Fikri and Louvan, Samuel and Rahman, Fahrurrozi and Vania, Clara",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.821",
pages = "10511--10527",
} | null | 0 | 0 | ---
tags:
- textual-entailment
language:
- ind
---
# indonli
This dataset is designed for Natural Language Inference NLP task. It is designed to provide a challenging test-bed
for Indonesian NLI by explicitly incorporating various linguistic phenomena such as numerical reasoning, structural
changes, idioms, or temporal and spatial reasoning.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{mahendra-etal-2021-indonli,
title = "{I}ndo{NLI}: A Natural Language Inference Dataset for {I}ndonesian",
author = "Mahendra, Rahmad and Aji, Alham Fikri and Louvan, Samuel and Rahman, Fahrurrozi and Vania, Clara",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.821",
pages = "10511--10527",
}
```
## License
Creative Common Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/ir-nlp-csui/indonli](https://github.com/ir-nlp-csui/indonli)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/singgalang | 2023-09-26T12:30:41.000Z | [
"language:ind",
"named-entity-recognition",
"region:us"
] | NusaCrowd | Rule-based annotation Indonesian NER Dataset of 48,957 sentences or 1,478,286 tokens.
Annotation conforms the Stanford-NER format (https://stanfordnlp.github.io/CoreNLP/ner.html) for 3 NER tags of Person, Organisation, and Place.
This dataset consists of 41,297, 14,770, and 82,179 tokens of entity (respectively) from over 14, 6, and 5 rules. | @INPROCEEDINGS{8355036,
author={Alfina, Ika and Savitri, Septiviana and Fanany, Mohamad Ivan},
title={Modified DBpedia entities expansion for tagging automatically NER dataset},
booktitle={2017 International Conference on Advanced Computer Science and Information Systems (ICACSIS)},
pages={216-221},
year={2017},
url={https://ieeexplore.ieee.org/document/8355036},
doi={10.1109/ICACSIS.2017.8355036}}
@INPROCEEDINGS{7872784,
author={Alfina, Ika and Manurung, Ruli and Fanany, Mohamad Ivan},
booktitle={2016 International Conference on Advanced Computer Science and Information Systems (ICACSIS)},
title={DBpedia entities expansion in automatically building dataset for Indonesian NER},
year={2016},
pages={335-340},
doi={10.1109/ICACSIS.2016.7872784}} | null | 0 | 0 | ---
tags:
- named-entity-recognition
language:
- ind
---
# singgalang
Rule-based annotation Indonesian NER Dataset of 48,957 sentences or 1,478,286 tokens.
Annotation conforms the Stanford-NER format (https://stanfordnlp.github.io/CoreNLP/ner.html) for 3 NER tags of Person, Organisation, and Place.
This dataset consists of 41,297, 14,770, and 82,179 tokens of entity (respectively) from over 14, 6, and 5 rules.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@INPROCEEDINGS{8355036,
author={Alfina, Ika and Savitri, Septiviana and Fanany, Mohamad Ivan},
title={Modified DBpedia entities expansion for tagging automatically NER dataset},
booktitle={2017 International Conference on Advanced Computer Science and Information Systems (ICACSIS)},
pages={216-221},
year={2017},
url={https://ieeexplore.ieee.org/document/8355036},
doi={10.1109/ICACSIS.2017.8355036}}
@INPROCEEDINGS{7872784,
author={Alfina, Ika and Manurung, Ruli and Fanany, Mohamad Ivan},
booktitle={2016 International Conference on Advanced Computer Science and Information Systems (ICACSIS)},
title={DBpedia entities expansion in automatically building dataset for Indonesian NER},
year={2016},
pages={335-340},
doi={10.1109/ICACSIS.2016.7872784}}
```
## License
You can use this dataset for free. You don't need our permission to use it. Please cite our paper if your work uses our data in your publication.
Please note that you are not allowed to create a copy of this dataset and share it publicly in your own repository without our permission.
## Homepage
[https://github.com/ir-nlp-csui/singgalang](https://github.com/ir-nlp-csui/singgalang)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/xsid | 2023-09-26T12:32:38.000Z | [
"language:ind",
"intent-classification",
"pos-tagging",
"region:us"
] | NusaCrowd | XSID is a new benchmark for cross-lingual (X) Slot and Intent Detection in 13 languages from 6 language families, including a very low-resource dialect. | @inproceedings{van-der-goot-etal-2020-cross,
title={From Masked-Language Modeling to Translation: Non-{E}nglish Auxiliary Tasks Improve Zero-shot Spoken Language Understanding},
author={van der Goot, Rob and Sharaf, Ibrahim and Imankulova, Aizhan and {\"U}st{\"u}n, Ahmet and Stepanovic, Marija and Ramponi, Alan and Khairunnisa, Siti Oryza and Komachi, Mamoru and Plank, Barbara},
booktitle = "Proceedings of the 2021 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)",
year = "2021",
address = "Mexico City, Mexico",
publisher = "Association for Computational Linguistics"
} | null | 0 | 0 | ---
tags:
- intent-classification
- pos-tagging
language:
- ind
---
# xsid
XSID is a new benchmark for cross-lingual (X) Slot and Intent Detection in 13 languages from 6 language families, including a very low-resource dialect.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{van-der-goot-etal-2020-cross,
title={From Masked-Language Modeling to Translation: Non-{E}nglish Auxiliary Tasks Improve Zero-shot Spoken Language Understanding},
author={van der Goot, Rob and Sharaf, Ibrahim and Imankulova, Aizhan and {"U}st{"u}n, Ahmet and Stepanovic, Marija and Ramponi, Alan and Khairunnisa, Siti Oryza and Komachi, Mamoru and Plank, Barbara},
booktitle = "Proceedings of the 2021 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)",
year = "2021",
address = "Mexico City, Mexico",
publisher = "Association for Computational Linguistics"
}
```
## License
CC-BY-SA 4.0
## Homepage
[https://bitbucket.org/robvanderg/xsid/src/master/](https://bitbucket.org/robvanderg/xsid/src/master/)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_abusive | 2023-09-26T12:32:46.000Z | [
"language:ind",
"sentiment-analysis",
"region:us"
] | NusaCrowd | The ID_ABUSIVE dataset is collection of 2,016 informal abusive tweets in Indonesian language,
designed for sentiment analysis NLP task. This dataset is crawled from Twitter, and then filtered
and labelled manually by 20 volunteer annotators. The dataset labelled into three labels namely
not abusive language, abusive but not offensive, and offensive language. | @article{IBROHIM2018222,
title = {A Dataset and Preliminaries Study for Abusive Language Detection in Indonesian Social Media},
journal = {Procedia Computer Science},
volume = {135},
pages = {222-229},
year = {2018},
note = {The 3rd International Conference on Computer Science and Computational Intelligence (ICCSCI 2018) : Empowering Smart Technology in Digital Era for a Better Life},
issn = {1877-0509},
doi = {https://doi.org/10.1016/j.procs.2018.08.169},
url = {https://www.sciencedirect.com/science/article/pii/S1877050918314583},
author = {Muhammad Okky Ibrohim and Indra Budi},
keywords = {abusive language, twitter, machine learning},
abstract = {Abusive language is an expression (both oral or text) that contains abusive/dirty words or phrases both in the context of jokes, a vulgar sex conservation or to cursing someone. Nowadays many people on the internet (netizens) write and post an abusive language in the social media such as Facebook, Line, Twitter, etc. Detecting an abusive language in social media is a difficult problem to resolve because this problem can not be resolved just use word matching. This paper discusses a preliminaries study for abusive language detection in Indonesian social media and the challenge in developing a system for Indonesian abusive language detection, especially in social media. We also built reported an experiment for abusive language detection on Indonesian tweet using machine learning approach with a simple word n-gram and char n-gram features. We use Naive Bayes, Support Vector Machine, and Random Forest Decision Tree classifier to identify the tweet whether the tweet is a not abusive language, abusive but not offensive, or offensive language. The experiment results show that the Naive Bayes classifier with the combination of word unigram + bigrams features gives the best result i.e. 70.06% of F1 - Score. However, if we classifying the tweet into two labels only (not abusive language and abusive language), all classifier that we used gives a higher result (more than 83% of F1 - Score for every classifier). The dataset in this experiment is available for other researchers that interest to improved this study.}
} | null | 0 | 0 | ---
tags:
- sentiment-analysis
language:
- ind
---
# id_abusive
The ID_ABUSIVE dataset is collection of 2,016 informal abusive tweets in Indonesian language,
designed for sentiment analysis NLP task. This dataset is crawled from Twitter, and then filtered
and labelled manually by 20 volunteer annotators. The dataset labelled into three labels namely
not abusive language, abusive but not offensive, and offensive language.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{IBROHIM2018222,
title = {A Dataset and Preliminaries Study for Abusive Language Detection in Indonesian Social Media},
journal = {Procedia Computer Science},
volume = {135},
pages = {222-229},
year = {2018},
note = {The 3rd International Conference on Computer Science and Computational Intelligence (ICCSCI 2018) : Empowering Smart Technology in Digital Era for a Better Life},
issn = {1877-0509},
doi = {https://doi.org/10.1016/j.procs.2018.08.169},
url = {https://www.sciencedirect.com/science/article/pii/S1877050918314583},
author = {Muhammad Okky Ibrohim and Indra Budi},
keywords = {abusive language, twitter, machine learning},
abstract = {Abusive language is an expression (both oral or text) that contains abusive/dirty words or phrases both in the context of jokes, a vulgar sex conservation or to cursing someone. Nowadays many people on the internet (netizens) write and post an abusive language in the social media such as Facebook, Line, Twitter, etc. Detecting an abusive language in social media is a difficult problem to resolve because this problem can not be resolved just use word matching. This paper discusses a preliminaries study for abusive language detection in Indonesian social media and the challenge in developing a system for Indonesian abusive language detection, especially in social media. We also built reported an experiment for abusive language detection on Indonesian tweet using machine learning approach with a simple word n-gram and char n-gram features. We use Naive Bayes, Support Vector Machine, and Random Forest Decision Tree classifier to identify the tweet whether the tweet is a not abusive language, abusive but not offensive, or offensive language. The experiment results show that the Naive Bayes classifier with the combination of word unigram + bigrams features gives the best result i.e. 70.06% of F1 - Score. However, if we classifying the tweet into two labels only (not abusive language and abusive language), all classifier that we used gives a higher result (more than 83% of F1 - Score for every classifier). The dataset in this experiment is available for other researchers that interest to improved this study.}
}
```
## License
Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International
## Homepage
[https://www.sciencedirect.com/science/article/pii/S1877050918314583](https://www.sciencedirect.com/science/article/pii/S1877050918314583)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indocollex | 2023-09-26T12:32:21.000Z | [
"language:ind",
"morphological-inflection",
"region:us"
] | NusaCrowd | IndoCollex: A Testbed for Morphological Transformation of Indonesian Colloquial Words | @inproceedings{wibowo-etal-2021-indocollex,
title = "{I}ndo{C}ollex: A Testbed for Morphological Transformation of {I}ndonesian Word Colloquialism",
author = {Wibowo, Haryo Akbarianto and Nityasya, Made Nindyatama and Aky{\"u}rek, Afra Feyza and Fitriany, Suci and Aji, Alham Fikri and Prasojo, Radityo Eko and Wijaya, Derry Tanti},
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.280",
doi = "10.18653/v1/2021.findings-acl.280",
pages = "3170--3183",
} | null | 0 | 0 | ---
tags:
- morphological-inflection
language:
- ind
---
# indocollex
IndoCollex: A Testbed for Morphological Transformation of Indonesian Colloquial Words
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{wibowo-etal-2021-indocollex,
title = "{I}ndo{C}ollex: A Testbed for Morphological Transformation of {I}ndonesian Word Colloquialism",
author = {Wibowo, Haryo Akbarianto and Nityasya, Made Nindyatama and Aky{"u}rek, Afra Feyza and Fitriany, Suci and Aji, Alham Fikri and Prasojo, Radityo Eko and Wijaya, Derry Tanti},
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.280",
doi = "10.18653/v1/2021.findings-acl.280",
pages = "3170--3183",
}
```
## License
CC BY-SA 4.0
## Homepage
[https://github.com/haryoa/indo-collex](https://github.com/haryoa/indo-collex)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/xl_sum | 2023-09-26T12:32:30.000Z | [
"language:ind",
"language:eng",
"summarization",
"region:us"
] | NusaCrowd | XL-Sum is a large-scale multilingual summarization dataset that covers 45 languages including Indonesian text summarization.
The dataset is based on article-summary pairs from BBC, is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation. | @inproceedings{hasan2021xl,
title={XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages},
author={Hasan, Tahmid and Bhattacharjee, Abhik and Islam, Md Saiful and Mubasshir, Kazi and Li, Yuan-Fang and Kang, Yong-Bin and Rahman, M Sohel and Shahriyar, Rifat},
booktitle={Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021},
pages={4693--4703},
year={2021}
} | null | 0 | 0 | ---
tags:
- summarization
language:
- ind
- eng
---
# xl_sum
XL-Sum is a large-scale multilingual summarization dataset that covers 45 languages including Indonesian text summarization.
The dataset is based on article-summary pairs from BBC, is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{hasan2021xl,
title={XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages},
author={Hasan, Tahmid and Bhattacharjee, Abhik and Islam, Md Saiful and Mubasshir, Kazi and Li, Yuan-Fang and Kang, Yong-Bin and Rahman, M Sohel and Shahriyar, Rifat},
booktitle={Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021},
pages={4693--4703},
year={2021}
}
```
## License
CC-BY-NC-SA 4.0
## Homepage
[https://github.com/csebuetnlp/xl-sum](https://github.com/csebuetnlp/xl-sum)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/emotcmt | 2023-09-26T12:33:23.000Z | [
"language:ind",
"license:mit",
"emotion-classification",
"region:us"
] | NusaCrowd | EmotCMT is an emotion classification Indonesian-English code-mixing dataset created through an Indonesian-English code-mixed Twitter data pipeline consisting of 4 processing steps, i.e., tokenization, language identification, lexical normalization, and translation. The dataset consists of 825 tweets, 22.736 tokens with 11.204 Indonesian tokens and 5.613 English tokens. Each tweet is labelled with an emotion, i.e., cinta (love), takut (fear), sedih (sadness), senang (joy), or marah (anger). | @inproceedings{barik-etal-2019-normalization,
title = "Normalization of {I}ndonesian-{E}nglish Code-Mixed {T}witter Data",
author = "Barik, Anab Maulana and
Mahendra, Rahmad and
Adriani, Mirna",
booktitle = "Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019)",
month = nov,
year = "2019",
address = "Hong Kong, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D19-5554",
doi = "10.18653/v1/D19-5554",
pages = "417--424"
}
@article{Yulianti2021NormalisationOI,
title={Normalisation of Indonesian-English Code-Mixed Text and its Effect on Emotion Classification},
author={Evi Yulianti and Ajmal Kurnia and Mirna Adriani and Yoppy Setyo Duto},
journal={International Journal of Advanced Computer Science and Applications},
year={2021}
} | null | 0 | 0 | ---
license: mit
tags:
- emotion-classification
language:
- ind
---
# emotcmt
EmotCMT is an emotion classification Indonesian-English code-mixing dataset created through an Indonesian-English code-mixed Twitter data pipeline consisting of 4 processing steps, i.e., tokenization, language identification, lexical normalization, and translation. The dataset consists of 825 tweets, 22.736 tokens with 11.204 Indonesian tokens and 5.613 English tokens. Each tweet is labelled with an emotion, i.e., cinta (love), takut (fear), sedih (sadness), senang (joy), or marah (anger).
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{barik-etal-2019-normalization,
title = "Normalization of {I}ndonesian-{E}nglish Code-Mixed {T}witter Data",
author = "Barik, Anab Maulana and
Mahendra, Rahmad and
Adriani, Mirna",
booktitle = "Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019)",
month = nov,
year = "2019",
address = "Hong Kong, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D19-5554",
doi = "10.18653/v1/D19-5554",
pages = "417--424"
}
@article{Yulianti2021NormalisationOI,
title={Normalisation of Indonesian-English Code-Mixed Text and its Effect on Emotion Classification},
author={Evi Yulianti and Ajmal Kurnia and Mirna Adriani and Yoppy Setyo Duto},
journal={International Journal of Advanced Computer Science and Applications},
year={2021}
}
```
## License
MIT
## Homepage
[https://github.com/ir-nlp-csui/emotcmt](https://github.com/ir-nlp-csui/emotcmt)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/bible_su_id | 2023-09-26T12:33:31.000Z | [
"language:ind",
"language:sun",
"machine-translation",
"region:us"
] | NusaCrowd | Bible Su-Id is a machine translation dataset containing Indonesian-Sundanese parallel sentences collected from the bible. As there is no existing parallel corpus for Sundanese and Indonesian, we create a new dataset for Sundanese and Indonesian translation generated from the Bible. We create a verse-aligned parallel corpus with a 75%, 10%, and 15% split for the training, validation, and test sets. The dataset is also evaluated in both directions. | @inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898",
abstract = "Natural language generation (NLG) benchmarks provide an important avenue to measure progress and develop better NLG systems. Unfortunately, the lack of publicly available NLG benchmarks for low-resource languages poses a challenging barrier for building NLG systems that work well for languages with limited amounts of data. Here we introduce IndoNLG, the first benchmark to measure natural language generation (NLG) progress in three low-resource{---}yet widely spoken{---}languages of Indonesia: Indonesian, Javanese, and Sundanese. Altogether, these languages are spoken by more than 100 million native speakers, and hence constitute an important use case of NLG systems today. Concretely, IndoNLG covers six tasks: summarization, question answering, chit-chat, and three different pairs of machine translation (MT) tasks. We collate a clean pretraining corpus of Indonesian, Sundanese, and Javanese datasets, Indo4B-Plus, which is used to pretrain our models: IndoBART and IndoGPT. We show that IndoBART and IndoGPT achieve competitive performance on all tasks{---}despite using only one-fifth the parameters of a larger multilingual model, mBART-large (Liu et al., 2020). This finding emphasizes the importance of pretraining on closely related, localized languages to achieve more efficient learning and faster inference at very low-resource languages like Javanese and Sundanese.",
} | null | 0 | 0 | ---
tags:
- machine-translation
language:
- ind
- sun
---
# bible_su_id
Bible Su-Id is a machine translation dataset containing Indonesian-Sundanese parallel sentences collected from the bible. As there is no existing parallel corpus for Sundanese and Indonesian, we create a new dataset for Sundanese and Indonesian translation generated from the Bible. We create a verse-aligned parallel corpus with a 75%, 10%, and 15% split for the training, validation, and test sets. The dataset is also evaluated in both directions.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898",
abstract = "Natural language generation (NLG) benchmarks provide an important avenue to measure progress and develop better NLG systems. Unfortunately, the lack of publicly available NLG benchmarks for low-resource languages poses a challenging barrier for building NLG systems that work well for languages with limited amounts of data. Here we introduce IndoNLG, the first benchmark to measure natural language generation (NLG) progress in three low-resource{---}yet widely spoken{---}languages of Indonesia: Indonesian, Javanese, and Sundanese. Altogether, these languages are spoken by more than 100 million native speakers, and hence constitute an important use case of NLG systems today. Concretely, IndoNLG covers six tasks: summarization, question answering, chit-chat, and three different pairs of machine translation (MT) tasks. We collate a clean pretraining corpus of Indonesian, Sundanese, and Javanese datasets, Indo4B-Plus, which is used to pretrain our models: IndoBART and IndoGPT. We show that IndoBART and IndoGPT achieve competitive performance on all tasks{---}despite using only one-fifth the parameters of a larger multilingual model, mBART-large (Liu et al., 2020). This finding emphasizes the importance of pretraining on closely related, localized languages to achieve more efficient learning and faster inference at very low-resource languages like Javanese and Sundanese.",
}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/indonlg](https://github.com/IndoNLP/indonlg)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/su_id_asr | 2023-09-26T12:33:07.000Z | [
"language:sun",
"speech-recognition",
"region:us"
] | NusaCrowd | Sundanese ASR training data set containing ~220K utterances.
This dataset was collected by Google in Indonesia. | @inproceedings{sodimana18_sltu,
author={Keshan Sodimana and Pasindu {De Silva} and Supheakmungkol Sarin and Oddur Kjartansson and Martin Jansche and Knot Pipatsrisawat and Linne Ha},
title={{A Step-by-Step Process for Building TTS Voices Using Open Source Data and Frameworks for Bangla, Javanese, Khmer, Nepali, Sinhala, and Sundanese}},
year=2018,
booktitle={Proc. 6th Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU 2018)},
pages={66--70},
doi={10.21437/SLTU.2018-14}
} | null | 0 | 0 | ---
tags:
- speech-recognition
language:
- sun
---
# su_id_asr
Sundanese ASR training data set containing ~220K utterances.
This dataset was collected by Google in Indonesia.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{sodimana18_sltu,
author={Keshan Sodimana and Pasindu {De Silva} and Supheakmungkol Sarin and Oddur Kjartansson and Martin Jansche and Knot Pipatsrisawat and Linne Ha},
title={{A Step-by-Step Process for Building TTS Voices Using Open Source Data and Frameworks for Bangla, Javanese, Khmer, Nepali, Sinhala, and Sundanese}},
year=2018,
booktitle={Proc. 6th Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU 2018)},
pages={66--70},
doi={10.21437/SLTU.2018-14}
}
```
## License
Attribution-ShareAlike 4.0 International.
## Homepage
[https://indonlp.github.io/nusa-catalogue/card.html?su_id_asr](https://indonlp.github.io/nusa-catalogue/card.html?su_id_asr)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/cod | 2023-09-26T12:33:43.000Z | [
"language:ind",
"license:unknown",
"dialogue-system",
"region:us"
] | NusaCrowd | Cross-lingual Outline-based Dialogue (COD) is a dataset comprised of manually generated, localized, and cross-lingually aligned Task-Oriented-Dialogue (TOD) data that served as the source of dialogue prompts.
COD enables natural language understanding, dialogue state tracking, and end-to-end dialogue modeling and evaluation.
Majewska et al. (2022) create COD using a novel outline-based annotation pipeline for multilingual TOD by Majewska et al. (2022).
English Schema-Guided Dialogue (SGD; Shah et al., 2018; Rastogi et al., 2020) dataset is automatically sampled and mapped into outlines. The outlines are then paraphrased and adapted to the local target domain by human subjects. | @article{majewska2022cross,
title={Cross-lingual dialogue dataset creation via outline-based generation},
author={Majewska, Olga and Razumovskaia, Evgeniia and Ponti, Edoardo Maria and Vuli{\'c}, Ivan and Korhonen, Anna},
journal={arXiv preprint arXiv:2201.13405},
year={2022}
} | null | 0 | 0 | ---
license: unknown
tags:
- dialogue-system
language:
- ind
---
# cod
Cross-lingual Outline-based Dialogue (COD) is a dataset comprised of manually generated, localized, and cross-lingually aligned Task-Oriented-Dialogue (TOD) data that served as the source of dialogue prompts.
COD enables natural language understanding, dialogue state tracking, and end-to-end dialogue modeling and evaluation.
Majewska et al. (2022) create COD using a novel outline-based annotation pipeline for multilingual TOD by Majewska et al. (2022).
English Schema-Guided Dialogue (SGD; Shah et al., 2018; Rastogi et al., 2020) dataset is automatically sampled and mapped into outlines. The outlines are then paraphrased and adapted to the local target domain by human subjects.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{majewska2022cross,
title={Cross-lingual dialogue dataset creation via outline-based generation},
author={Majewska, Olga and Razumovskaia, Evgeniia and Ponti, Edoardo Maria and Vuli{'c}, Ivan and Korhonen, Anna},
journal={arXiv preprint arXiv:2201.13405},
year={2022}
}
```
## License
Unknown
## Homepage
[https://github.com/cambridgeltl/COD](https://github.com/cambridgeltl/COD)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/nusatranslation_mt | 2023-09-26T12:33:56.000Z | [
"language:ind",
"language:btk",
"language:bew",
"language:bug",
"language:jav",
"language:mad",
"language:mak",
"language:min",
"language:mui",
"language:rej",
"language:sun",
"machine-translation",
"region:us"
] | NusaCrowd | Democratizing access to natural language processing (NLP) technology is crucial, especially for underrepresented and extremely low-resource languages. Previous research has focused on developing labeled and unlabeled corpora for these languages through online scraping and document translation. While these methods have proven effective and cost-efficient, we have identified limitations in the resulting corpora, including a lack of lexical diversity and cultural relevance to local communities. To address this gap, we conduct a case study on Indonesian local languages. We compare the effectiveness of online scraping, human translation, and paragraph writing by native speakers in constructing datasets. Our findings demonstrate that datasets generated through paragraph writing by native speakers exhibit superior quality in terms of lexical diversity and cultural content. In addition, we present the NusaWrites benchmark, encompassing 12 underrepresented and extremely low-resource languages spoken by millions of individuals in Indonesia. Our empirical experiment results using existing multilingual large language models conclude the need to extend these models to more underrepresented languages.
We introduce a novel high quality human curated corpora, i.e., NusaMenulis, which covers 12 languages spoken in Indonesia. The resource extend the coverage of languages to 5 new languages, i.e., Ambon (abs), Bima (bhp), Makassarese (mak), Palembang / Musi (mui), and Rejang (rej).
For the rhetoric mode classification task, we cover 5 rhetoric modes, i.e., narrative, persuasive, argumentative, descriptive, and expository. | @unpublished{anonymous2023nusawrites:,
title={NusaWrites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages},
author={Anonymous},
journal={OpenReview Preprint},
year={2023},
note={anonymous preprint under review}
} | null | 0 | 0 | ---
tags:
- machine-translation
language:
- ind
- btk
- bew
- bug
- jav
- mad
- mak
- min
- mui
- rej
- sun
---
# nusatranslation_mt
Democratizing access to natural language processing (NLP) technology is crucial, especially for underrepresented and extremely low-resource languages. Previous research has focused on developing labeled and unlabeled corpora for these languages through online scraping and document translation. While these methods have proven effective and cost-efficient, we have identified limitations in the resulting corpora, including a lack of lexical diversity and cultural relevance to local communities. To address this gap, we conduct a case study on Indonesian local languages. We compare the effectiveness of online scraping, human translation, and paragraph writing by native speakers in constructing datasets. Our findings demonstrate that datasets generated through paragraph writing by native speakers exhibit superior quality in terms of lexical diversity and cultural content. In addition, we present the NusaWrites benchmark, encompassing 12 underrepresented and extremely low-resource languages spoken by millions of individuals in Indonesia. Our empirical experiment results using existing multilingual large language models conclude the need to extend these models to more underrepresented languages.
We introduce a novel high quality human curated corpora, i.e., NusaMenulis, which covers 12 languages spoken in Indonesia. The resource extend the coverage of languages to 5 new languages, i.e., Ambon (abs), Bima (bhp), Makassarese (mak), Palembang / Musi (mui), and Rejang (rej).
For the rhetoric mode classification task, we cover 5 rhetoric modes, i.e., narrative, persuasive, argumentative, descriptive, and expository.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@unpublished{anonymous2023nusawrites:,
title={NusaWrites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages},
author={Anonymous},
journal={OpenReview Preprint},
year={2023},
note={anonymous preprint under review}
}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/nusatranslation/tree/main/datasets/mt](https://github.com/IndoNLP/nusatranslation/tree/main/datasets/mt)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indolem_ud_id_gsd | 2023-09-26T12:34:22.000Z | [
"language:ind",
"license:cc-by-4.0",
"dependency-parsing",
"arxiv:2011.00677",
"region:us"
] | NusaCrowd | The Indonesian-GSD treebank consists of 5598 sentences and 122k words split into train/dev/test of 97k/12k/11k words.
The treebank was originally converted from the content head version of the universal dependency treebank v2.0 (legacy) in 2015.In order to comply with the latest Indonesian annotation guidelines, the treebank has undergone a major revision between UD releases v2.8 and v2.9 (2021). | @inproceedings{mcdonald-etal-2013-universal,
title = "{U}niversal {D}ependency Annotation for Multilingual Parsing",
author = {McDonald, Ryan and
Nivre, Joakim and
Quirmbach-Brundage, Yvonne and
Goldberg, Yoav and
Das, Dipanjan and
Ganchev, Kuzman and
Hall, Keith and
Petrov, Slav and
Zhang, Hao and
T{\"a}ckstr{\"o}m, Oscar and
Bedini, Claudia and
Bertomeu Castell{\'o}, N{\'u}ria and
Lee, Jungmee},
booktitle = "Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)",
month = aug,
year = "2013",
address = "Sofia, Bulgaria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/P13-2017",
pages = "92--97",
}
@article{DBLP:journals/corr/abs-2011-00677,
author = {Fajri Koto and
Afshin Rahimi and
Jey Han Lau and
Timothy Baldwin},
title = {IndoLEM and IndoBERT: {A} Benchmark Dataset and Pre-trained Language
Model for Indonesian {NLP}},
journal = {CoRR},
volume = {abs/2011.00677},
year = {2020},
url = {https://arxiv.org/abs/2011.00677},
eprinttype = {arXiv},
eprint = {2011.00677},
timestamp = {Fri, 06 Nov 2020 15:32:47 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2011-00677.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
} | null | 0 | 0 | ---
license: cc-by-4.0
tags:
- dependency-parsing
language:
- ind
---
# indolem_ud_id_gsd
The Indonesian-GSD treebank consists of 5598 sentences and 122k words split into train/dev/test of 97k/12k/11k words.
The treebank was originally converted from the content head version of the universal dependency treebank v2.0 (legacy) in 2015.In order to comply with the latest Indonesian annotation guidelines, the treebank has undergone a major revision between UD releases v2.8 and v2.9 (2021).
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{mcdonald-etal-2013-universal,
title = "{U}niversal {D}ependency Annotation for Multilingual Parsing",
author = {McDonald, Ryan and
Nivre, Joakim and
Quirmbach-Brundage, Yvonne and
Goldberg, Yoav and
Das, Dipanjan and
Ganchev, Kuzman and
Hall, Keith and
Petrov, Slav and
Zhang, Hao and
T{"a}ckstr{"o}m, Oscar and
Bedini, Claudia and
Bertomeu Castell{'o}, N{'u}ria and
Lee, Jungmee},
booktitle = "Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)",
month = aug,
year = "2013",
address = "Sofia, Bulgaria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/P13-2017",
pages = "92--97",
}
@article{DBLP:journals/corr/abs-2011-00677,
author = {Fajri Koto and
Afshin Rahimi and
Jey Han Lau and
Timothy Baldwin},
title = {IndoLEM and IndoBERT: {A} Benchmark Dataset and Pre-trained Language
Model for Indonesian {NLP}},
journal = {CoRR},
volume = {abs/2011.00677},
year = {2020},
url = {https://arxiv.org/abs/2011.00677},
eprinttype = {arXiv},
eprint = {2011.00677},
timestamp = {Fri, 06 Nov 2020 15:32:47 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2011-00677.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
## License
Creative Commons Attribution 4.0
## Homepage
[https://indolem.github.io/](https://indolem.github.io/)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/sampiran | 2023-09-26T12:35:05.000Z | [
"region:us"
] | NusaCrowd | Sampiran is a dataset for pantun generation. It consists of 7.8K Indonesian pantun, collected from various sources (online).
Pantun is a traditional Malay poem consisting of four lines: two lines of deliverance and two lines of message.
This dataset filtered the gathered Pantun to follow the general rules of Pantun; four lines with ABAB rhyme and eight to twelve syllables per line. | @inproceedings{siallagan2022sampiran,
title={Poetry Generation for Indonesian Pantun: Comparison Between SeqGAN and GPT-2},
author={Emmanuella Anggi Siallagan and Ika Alfina},
booktitle={Jurnal Ilmu Komputer dan Informasi (Journal of Computer Science and Information) Vol 1x No x February 2023 (Minor Revision)},
year={2023},
} | null | 0 | 0 | Entry not found |
NusaCrowd/idn_tagged_corpus_csui | 2023-09-26T12:35:14.000Z | [
"language:ind",
"pos-tagging",
"region:us"
] | NusaCrowd | Idn-tagged-corpus-CSUI is a POS tagging dataset contains about 10,000 sentences, collected from the PAN Localization Project tagged with 23 POS tag classes.
The POS tagset is created through a detailed study and analysis of existing tagsets and the manual tagging of an Indonesian corpus.
Idn-tagged-corpus-CSUI dataset is splitted into 3 sets with 8000 train, 1000 validation, 1029 test data. | @inproceedings{dinakaramani2014designing,
title={Designing an Indonesian part of speech tagset and manually tagged Indonesian corpus},
author={Dinakaramani, Arawinda and Rashel, Fam and Luthfi, Andry and Manurung, Ruli},
booktitle={2014 International Conference on Asian Language Processing (IALP)},
pages={66--69},
year={2014},
organization={IEEE}
}
@inproceedings{kurniawan2018towards,
author={Kurniawan, Kemal and Aji, Alham Fikri},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
title={Toward a Standardized and More Accurate Indonesian Part-of-Speech Tagging},
year={2018},
volume={},
number={},
pages={303-307},
doi={10.1109/IALP.2018.8629236}} | null | 0 | 0 | ---
tags:
- pos-tagging
language:
- ind
---
# idn_tagged_corpus_csui
Idn-tagged-corpus-CSUI is a POS tagging dataset contains about 10,000 sentences, collected from the PAN Localization Project tagged with 23 POS tag classes.
The POS tagset is created through a detailed study and analysis of existing tagsets and the manual tagging of an Indonesian corpus.
Idn-tagged-corpus-CSUI dataset is splitted into 3 sets with 8000 train, 1000 validation, 1029 test data.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{dinakaramani2014designing,
title={Designing an Indonesian part of speech tagset and manually tagged Indonesian corpus},
author={Dinakaramani, Arawinda and Rashel, Fam and Luthfi, Andry and Manurung, Ruli},
booktitle={2014 International Conference on Asian Language Processing (IALP)},
pages={66--69},
year={2014},
organization={IEEE}
}
@inproceedings{kurniawan2018towards,
author={Kurniawan, Kemal and Aji, Alham Fikri},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
title={Toward a Standardized and More Accurate Indonesian Part-of-Speech Tagging},
year={2018},
volume={},
number={},
pages={303-307},
doi={10.1109/IALP.2018.8629236}}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://bahasa.cs.ui.ac.id/postag/corpus](https://bahasa.cs.ui.ac.id/postag/corpus)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indolem_sentiment | 2023-09-26T12:35:23.000Z | [
"language:ind",
"sentiment-analysis",
"arxiv:2011.00677",
"region:us"
] | NusaCrowd | IndoLEM (Indonesian Language Evaluation Montage) is a comprehensive Indonesian benchmark that comprises of seven tasks for the Indonesian language. This benchmark is categorized into three pillars of NLP tasks: morpho-syntax, semantics, and discourse.
This dataset is based on binary classification (positive and negative), with distribution:
* Train: 3638 sentences
* Development: 399 sentences
* Test: 1011 sentences
The data is sourced from 1) Twitter [(Koto and Rahmaningtyas, 2017)](https://www.researchgate.net/publication/321757985_InSet_Lexicon_Evaluation_of_a_Word_List_for_Indonesian_Sentiment_Analysis_in_Microblogs)
and 2) [hotel reviews](https://github.com/annisanurulazhar/absa-playground/).
The experiment is based on 5-fold cross validation. | @article{DBLP:journals/corr/abs-2011-00677,
author = {Fajri Koto and
Afshin Rahimi and
Jey Han Lau and
Timothy Baldwin},
title = {IndoLEM and IndoBERT: {A} Benchmark Dataset and Pre-trained Language
Model for Indonesian {NLP}},
journal = {CoRR},
volume = {abs/2011.00677},
year = {2020},
url = {https://arxiv.org/abs/2011.00677},
eprinttype = {arXiv},
eprint = {2011.00677},
timestamp = {Fri, 06 Nov 2020 15:32:47 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2011-00677.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
} | null | 0 | 0 | ---
tags:
- sentiment-analysis
language:
- ind
---
# indolem_sentiment
IndoLEM (Indonesian Language Evaluation Montage) is a comprehensive Indonesian benchmark that comprises of seven tasks for the Indonesian language. This benchmark is categorized into three pillars of NLP tasks: morpho-syntax, semantics, and discourse.
This dataset is based on binary classification (positive and negative), with distribution:
* Train: 3638 sentences
* Development: 399 sentences
* Test: 1011 sentences
The data is sourced from 1) Twitter [(Koto and Rahmaningtyas, 2017)](https://www.researchgate.net/publication/321757985_InSet_Lexicon_Evaluation_of_a_Word_List_for_Indonesian_Sentiment_Analysis_in_Microblogs)
and 2) [hotel reviews](https://github.com/annisanurulazhar/absa-playground/).
The experiment is based on 5-fold cross validation.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{DBLP:journals/corr/abs-2011-00677,
author = {Fajri Koto and
Afshin Rahimi and
Jey Han Lau and
Timothy Baldwin},
title = {IndoLEM and IndoBERT: {A} Benchmark Dataset and Pre-trained Language
Model for Indonesian {NLP}},
journal = {CoRR},
volume = {abs/2011.00677},
year = {2020},
url = {https://arxiv.org/abs/2011.00677},
eprinttype = {arXiv},
eprint = {2011.00677},
timestamp = {Fri, 06 Nov 2020 15:32:47 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2011-00677.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://indolem.github.io/](https://indolem.github.io/)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/talpco | 2023-09-26T12:35:36.000Z | [
"language:eng",
"language:ind",
"language:jpn",
"language:kor",
"language:myn",
"language:tha",
"language:vie",
"language:zsm",
"machine-translation",
"region:us"
] | NusaCrowd | The TUFS Asian Language Parallel Corpus (TALPCo) is an open parallel corpus consisting of Japanese sentences
and their translations into Korean, Burmese (Myanmar; the official language of the Republic of the Union of Myanmar),
Malay (the national language of Malaysia, Singapore and Brunei), Indonesian, Thai, Vietnamese and English. | @article{published_papers/22434604,
title = {TUFS Asian Language Parallel Corpus (TALPCo)},
author = {Hiroki Nomoto and Kenji Okano and David Moeljadi and Hideo Sawada},
journal = {言語処理学会 第24回年次大会 発表論文集},
pages = {436--439},
year = {2018}
}
@article{published_papers/22434603,
title = {Interpersonal meaning annotation for Asian language corpora: The case of TUFS Asian Language Parallel Corpus (TALPCo)},
author = {Hiroki Nomoto and Kenji Okano and Sunisa Wittayapanyanon and Junta Nomura},
journal = {言語処理学会 第25回年次大会 発表論文集},
pages = {846--849},
year = {2019}
} | null | 0 | 0 | ---
tags:
- machine-translation
language:
- eng
- ind
- jpn
- kor
- myn
- tha
- vie
- zsm
---
# talpco
The TUFS Asian Language Parallel Corpus (TALPCo) is an open parallel corpus consisting of Japanese sentences
and their translations into Korean, Burmese (Myanmar; the official language of the Republic of the Union of Myanmar),
Malay (the national language of Malaysia, Singapore and Brunei), Indonesian, Thai, Vietnamese and English.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{published_papers/22434604,
title = {TUFS Asian Language Parallel Corpus (TALPCo)},
author = {Hiroki Nomoto and Kenji Okano and David Moeljadi and Hideo Sawada},
journal = {言語処理学会 第24回年次大会 発表論文集},
pages = {436--439},
year = {2018}
}
@article{published_papers/22434603,
title = {Interpersonal meaning annotation for Asian language corpora: The case of TUFS Asian Language Parallel Corpus (TALPCo)},
author = {Hiroki Nomoto and Kenji Okano and Sunisa Wittayapanyanon and Junta Nomura},
journal = {言語処理学会 第25回年次大会 発表論文集},
pages = {846--849},
year = {2019}
}
```
## License
CC-BY 4.0
## Homepage
[https://github.com/matbahasa/TALPCo](https://github.com/matbahasa/TALPCo)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_short_answer_grading | 2023-09-26T12:28:15.000Z | [
"language:ind",
"license:unknown",
"short-answer-grading",
"region:us"
] | NusaCrowd | Indonesian short answers for Biology and Geography subjects from 534 respondents where the answer grading was done by 7 experts.\ | @article{
JLK,
author = {Muh Haidir and Ayu Purwarianti},
title = { Short Answer Grading Using Contextual Word Embedding and Linear Regression},
journal = {Jurnal Linguistik Komputasional},
volume = {3},
number = {2},
year = {2020},
keywords = {},
abstract = {Abstract—One of the obstacles in an efficient MOOC is the evaluation of student answers, including the short answer grading which requires large effort from instructors to conduct it manually.
Thus, NLP research in short answer grading has been conducted in order to support the automation, using several techniques such as rule
and machine learning based. Here, we’ve conducted experiments on deep learning based short answer grading to compare the answer
representation and answer assessment method. In the answer representation, we compared word embedding and sentence embedding models
such as BERT, and its modification. In the answer assessment method, we use linear regression. There are 2 datasets that we used, available
English short answer grading dataset with 80 questions and 2442 to get the best configuration for model and Indonesian short answer grading
dataset with 36 questions and 9165 short answers as testing data. Here, we’ve collected Indonesian short answers for Biology and Geography
subjects from 534 respondents where the answer grading was done by 7 experts. The best root mean squared error for both dataset was achieved
by using BERT pretrained, 0.880 for English dataset dan 1.893 for Indonesian dataset.},
issn = {2621-9336}, pages = {54--61}, doi = {10.26418/jlk.v3i2.38},
url = {https://inacl.id/journal/index.php/jlk/article/view/38}
}\ | null | 0 | 0 | ---
license: unknown
tags:
- short-answer-grading
language:
- ind
---
# id_short_answer_grading
Indonesian short answers for Biology and Geography subjects from 534 respondents where the answer grading was done by 7 experts.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{
JLK,
author = {Muh Haidir and Ayu Purwarianti},
title = { Short Answer Grading Using Contextual Word Embedding and Linear Regression},
journal = {Jurnal Linguistik Komputasional},
volume = {3},
number = {2},
year = {2020},
keywords = {},
abstract = {Abstract—One of the obstacles in an efficient MOOC is the evaluation of student answers, including the short answer grading which requires large effort from instructors to conduct it manually.
Thus, NLP research in short answer grading has been conducted in order to support the automation, using several techniques such as rule
and machine learning based. Here, we’ve conducted experiments on deep learning based short answer grading to compare the answer
representation and answer assessment method. In the answer representation, we compared word embedding and sentence embedding models
such as BERT, and its modification. In the answer assessment method, we use linear regression. There are 2 datasets that we used, available
English short answer grading dataset with 80 questions and 2442 to get the best configuration for model and Indonesian short answer grading
dataset with 36 questions and 9165 short answers as testing data. Here, we’ve collected Indonesian short answers for Biology and Geography
subjects from 534 respondents where the answer grading was done by 7 experts. The best root mean squared error for both dataset was achieved
by using BERT pretrained, 0.880 for English dataset dan 1.893 for Indonesian dataset.},
issn = {2621-9336}, pages = {54--61}, doi = {10.26418/jlk.v3i2.38},
url = {https://inacl.id/journal/index.php/jlk/article/view/38}
}
```
## License
Unknown
## Homepage
[https://github.com/AgeMagi/tugas-akhir](https://github.com/AgeMagi/tugas-akhir)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/tico_19 | 2023-09-26T12:28:20.000Z | [
"language:ind",
"language:ara",
"language:spa",
"language:fra",
"language:hin",
"language:por",
"language:rus",
"language:zho",
"language:eng",
"machine-translation",
"region:us"
] | NusaCrowd | TICO-19 (Translation Initiative for COVID-19) is sampled from a variety of public sources containing
COVID-19 related content, representing different domains (e.g., news, wiki articles, and others). TICO-19
includes 30 documents (3071 sentences, 69.7k words) translated from English into 36 languages: Amharic,
Arabic (Modern Standard), Bengali, Chinese (Simplified), Dari, Dinka, Farsi, French (European), Hausa,
Hindi, Indonesian, Kanuri, Khmer (Central), Kinyarwanda, Kurdish Kurmanji, Kurdish Sorani, Lingala,
Luganda, Malay, Marathi, Myanmar, Nepali, Nigerian Fulfulde, Nuer, Oromo, Pashto, Portuguese (Brazilian),
Russian, Somali, Spanish (Latin American), Swahili, Congolese Swahili, Tagalog, Tamil, Tigrinya, Urdu, Zulu. | @inproceedings{anastasopoulos-etal-2020-tico,
title = "{TICO}-19: the Translation Initiative for {CO}vid-19",
author = {Anastasopoulos, Antonios and
Cattelan, Alessandro and
Dou, Zi-Yi and
Federico, Marcello and
Federmann, Christian and
Genzel, Dmitriy and
Guzm{\'a}n, Franscisco and
Hu, Junjie and
Hughes, Macduff and
Koehn, Philipp and
Lazar, Rosie and
Lewis, Will and
Neubig, Graham and
Niu, Mengmeng and
{\"O}ktem, Alp and
Paquin, Eric and
Tang, Grace and
Tur, Sylwia},
booktitle = "Proceedings of the 1st Workshop on {NLP} for {COVID}-19 (Part 2) at {EMNLP} 2020",
month = dec,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.nlpcovid19-2.5",
doi = "10.18653/v1/2020.nlpcovid19-2.5",
} | null | 0 | 0 | ---
tags:
- machine-translation
language:
- ind
- ara
- spa
- fra
- hin
- por
- rus
- zho
- eng
---
# tico_19
TICO-19 (Translation Initiative for COVID-19) is sampled from a variety of public sources containing
COVID-19 related content, representing different domains (e.g., news, wiki articles, and others). TICO-19
includes 30 documents (3071 sentences, 69.7k words) translated from English into 36 languages: Amharic,
Arabic (Modern Standard), Bengali, Chinese (Simplified), Dari, Dinka, Farsi, French (European), Hausa,
Hindi, Indonesian, Kanuri, Khmer (Central), Kinyarwanda, Kurdish Kurmanji, Kurdish Sorani, Lingala,
Luganda, Malay, Marathi, Myanmar, Nepali, Nigerian Fulfulde, Nuer, Oromo, Pashto, Portuguese (Brazilian),
Russian, Somali, Spanish (Latin American), Swahili, Congolese Swahili, Tagalog, Tamil, Tigrinya, Urdu, Zulu.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{anastasopoulos-etal-2020-tico,
title = "{TICO}-19: the Translation Initiative for {CO}vid-19",
author = {Anastasopoulos, Antonios and
Cattelan, Alessandro and
Dou, Zi-Yi and
Federico, Marcello and
Federmann, Christian and
Genzel, Dmitriy and
Guzm{'a}n, Franscisco and
Hu, Junjie and
Hughes, Macduff and
Koehn, Philipp and
Lazar, Rosie and
Lewis, Will and
Neubig, Graham and
Niu, Mengmeng and
{"O}ktem, Alp and
Paquin, Eric and
Tang, Grace and
Tur, Sylwia},
booktitle = "Proceedings of the 1st Workshop on {NLP} for {COVID}-19 (Part 2) at {EMNLP} 2020",
month = dec,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.nlpcovid19-2.5",
doi = "10.18653/v1/2020.nlpcovid19-2.5",
}
```
## License
CC0
## Homepage
[https://tico-19.github.io](https://tico-19.github.io)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/bible_jv_id | 2023-09-26T12:28:24.000Z | [
"language:ind",
"language:jav",
"machine-translation",
"region:us"
] | NusaCrowd | Analogous to the En ↔ Id and Su ↔ Id datasets, we create a new dataset for Javanese and Indonesian translation generated from the verse-aligned Bible parallel corpus with the same split setting. In terms of size, both the Su ↔ Id and Jv ↔ Id datasets are much smaller compared to the En ↔ Id dataset, because there are Bible chapters for which translations are available for Indonesian, albeit not for the local languages. | @inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898",
abstract = "Natural language generation (NLG) benchmarks provide an important avenue to measure progress and develop better NLG systems. Unfortunately, the lack of publicly available NLG benchmarks for low-resource languages poses a challenging barrier for building NLG systems that work well for languages with limited amounts of data. Here we introduce IndoNLG, the first benchmark to measure natural language generation (NLG) progress in three low-resource{---}yet widely spoken{---}languages of Indonesia: Indonesian, Javanese, and Sundanese. Altogether, these languages are spoken by more than 100 million native speakers, and hence constitute an important use case of NLG systems today. Concretely, IndoNLG covers six tasks: summarization, question answering, chit-chat, and three different pairs of machine translation (MT) tasks. We collate a clean pretraining corpus of Indonesian, Sundanese, and Javanese datasets, Indo4B-Plus, which is used to pretrain our models: IndoBART and IndoGPT. We show that IndoBART and IndoGPT achieve competitive performance on all tasks{---}despite using only one-fifth the parameters of a larger multilingual model, mBART-large (Liu et al., 2020). This finding emphasizes the importance of pretraining on closely related, localized languages to achieve more efficient learning and faster inference at very low-resource languages like Javanese and Sundanese.",
} | null | 0 | 0 | ---
tags:
- machine-translation
language:
- ind
- jav
---
# bible_jv_id
Analogous to the En ↔ Id and Su ↔ Id datasets, we create a new dataset for Javanese and Indonesian translation generated from the verse-aligned Bible parallel corpus with the same split setting. In terms of size, both the Su ↔ Id and Jv ↔ Id datasets are much smaller compared to the En ↔ Id dataset, because there are Bible chapters for which translations are available for Indonesian, albeit not for the local languages.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898",
abstract = "Natural language generation (NLG) benchmarks provide an important avenue to measure progress and develop better NLG systems. Unfortunately, the lack of publicly available NLG benchmarks for low-resource languages poses a challenging barrier for building NLG systems that work well for languages with limited amounts of data. Here we introduce IndoNLG, the first benchmark to measure natural language generation (NLG) progress in three low-resource{---}yet widely spoken{---}languages of Indonesia: Indonesian, Javanese, and Sundanese. Altogether, these languages are spoken by more than 100 million native speakers, and hence constitute an important use case of NLG systems today. Concretely, IndoNLG covers six tasks: summarization, question answering, chit-chat, and three different pairs of machine translation (MT) tasks. We collate a clean pretraining corpus of Indonesian, Sundanese, and Javanese datasets, Indo4B-Plus, which is used to pretrain our models: IndoBART and IndoGPT. We show that IndoBART and IndoGPT achieve competitive performance on all tasks{---}despite using only one-fifth the parameters of a larger multilingual model, mBART-large (Liu et al., 2020). This finding emphasizes the importance of pretraining on closely related, localized languages to achieve more efficient learning and faster inference at very low-resource languages like Javanese and Sundanese.",
}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/indonlg](https://github.com/IndoNLP/indonlg)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indosum | 2023-09-26T12:28:30.000Z | [
"language:ind",
"summarization",
"region:us"
] | NusaCrowd | INDOSUM is a new benchmark dataset for Indonesian text summarization.
The dataset consists of news articles and manually constructed summaries. | @INPROCEEDINGS{8629109,
author={Kurniawan, Kemal and Louvan, Samuel},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
title={Indosum: A New Benchmark Dataset for Indonesian Text Summarization},
year={2018},
volume={},
number={},
pages={215-220},
doi={10.1109/IALP.2018.8629109}} | null | 0 | 0 | ---
tags:
- summarization
language:
- ind
---
# indosum
INDOSUM is a new benchmark dataset for Indonesian text summarization.
The dataset consists of news articles and manually constructed summaries.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@INPROCEEDINGS{8629109,
author={Kurniawan, Kemal and Louvan, Samuel},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
title={Indosum: A New Benchmark Dataset for Indonesian Text Summarization},
year={2018},
volume={},
number={},
pages={215-220},
doi={10.1109/IALP.2018.8629109}}
```
## License
Apache License, Version 2.0
## Homepage
[https://github.com/kata-ai/indosum](https://github.com/kata-ai/indosum)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_hsd_nofaaulia | 2023-09-26T12:28:47.000Z | [
"language:ind",
"license:unknown",
"sentiment-analysis",
"region:us"
] | NusaCrowd | There have been many studies on detecting hate speech in short documents like Twitter data. But to our knowledge, research on long documents is rare, we suppose that the difficulty is increasing due to the possibility of the message of the text may be hidden. In this research, we explore in detecting hate speech on Indonesian long documents using machine learning approach. We build a new Indonesian hate speech dataset from Facebook. | @inproceedings{10.1145/3330482.3330491,
author = {Aulia, Nofa and Budi, Indra},
title = {Hate Speech Detection on Indonesian Long Text Documents Using Machine Learning Approach},
year = {2019},
isbn = {9781450361064},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3330482.3330491},
doi = {10.1145/3330482.3330491},
abstract = {Due to the growth of hate speech on social media in recent years, it is important to understand this issue. An automatic hate speech detection system is needed to help to counter this problem. There have been many studies on detecting hate speech in short documents like Twitter data. But to our knowledge, research on long documents is rare, we suppose that the difficulty is increasing due to the possibility of the message of the text may be hidden. In this research, we explore in detecting hate speech on Indonesian long documents using machine learning approach. We build a new Indonesian hate speech dataset from Facebook. The experiment showed that the best performance obtained by Support Vector Machine (SVM) as its classifier algorithm using TF-IDF, char quad-gram, word unigram, and lexicon features that yield f1-score of 85%.},
booktitle = {Proceedings of the 2019 5th International Conference on Computing and Artificial Intelligence},
pages = {164–169},
numpages = {6},
keywords = {machine learning, SVM, long documents, hate speech detection},
location = {Bali, Indonesia},
series = {ICCAI '19}
} | null | 0 | 0 | ---
license: unknown
tags:
- sentiment-analysis
language:
- ind
---
# id_hsd_nofaaulia
There have been many studies on detecting hate speech in short documents like Twitter data. But to our knowledge, research on long documents is rare, we suppose that the difficulty is increasing due to the possibility of the message of the text may be hidden. In this research, we explore in detecting hate speech on Indonesian long documents using machine learning approach. We build a new Indonesian hate speech dataset from Facebook.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{10.1145/3330482.3330491,
author = {Aulia, Nofa and Budi, Indra},
title = {Hate Speech Detection on Indonesian Long Text Documents Using Machine Learning Approach},
year = {2019},
isbn = {9781450361064},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3330482.3330491},
doi = {10.1145/3330482.3330491},
abstract = {Due to the growth of hate speech on social media in recent years, it is important to understand this issue. An automatic hate speech detection system is needed to help to counter this problem. There have been many studies on detecting hate speech in short documents like Twitter data. But to our knowledge, research on long documents is rare, we suppose that the difficulty is increasing due to the possibility of the message of the text may be hidden. In this research, we explore in detecting hate speech on Indonesian long documents using machine learning approach. We build a new Indonesian hate speech dataset from Facebook. The experiment showed that the best performance obtained by Support Vector Machine (SVM) as its classifier algorithm using TF-IDF, char quad-gram, word unigram, and lexicon features that yield f1-score of 85%.},
booktitle = {Proceedings of the 2019 5th International Conference on Computing and Artificial Intelligence},
pages = {164–169},
numpages = {6},
keywords = {machine learning, SVM, long documents, hate speech detection},
location = {Bali, Indonesia},
series = {ICCAI '19}
}
```
## License
Unknown
## Homepage
[https://dl.acm.org/doi/10.1145/3330482.3330491](https://dl.acm.org/doi/10.1145/3330482.3330491)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/nllb_seed | 2023-09-26T12:28:51.000Z | [
"language:ace",
"language:bjn",
"language:bug",
"language:eng",
"machine-translation",
"region:us"
] | NusaCrowd | No Language Left Behind Seed Data
NLLB Seed is a set of professionally-translated sentences in the Wikipedia domain. Data for NLLB-Seed was sampled from Wikimedia’s List of articles every Wikipedia should have, a collection of topics in different fields of knowledge and human activity. NLLB-Seed consists of around six thousand sentences in 39 languages. NLLB-Seed is meant to be used for training rather than model evaluation. Due to this difference, NLLB-Seed does not go through the human quality assurance process present in FLORES-200. | @article{nllb2022,
author = {NLLB Team, Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews, Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Jeff Wang},
title = {No Language Left Behind: Scaling Human-Centered Machine Translation},
year = {2022}
} | null | 0 | 0 | ---
tags:
- machine-translation
language:
- ace
- bjn
- bug
- eng
---
# nllb_seed
No Language Left Behind Seed Data
NLLB Seed is a set of professionally-translated sentences in the Wikipedia domain. Data for NLLB-Seed was sampled from Wikimedia’s List of articles every Wikipedia should have, a collection of topics in different fields of knowledge and human activity. NLLB-Seed consists of around six thousand sentences in 39 languages. NLLB-Seed is meant to be used for training rather than model evaluation. Due to this difference, NLLB-Seed does not go through the human quality assurance process present in FLORES-200.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{nllb2022,
author = {NLLB Team, Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews, Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Jeff Wang},
title = {No Language Left Behind: Scaling Human-Centered Machine Translation},
year = {2022}
}
```
## License
CC-BY-SA 4.0
## Homepage
[https://github.com/facebookresearch/flores/tree/main/nllb_seed](https://github.com/facebookresearch/flores/tree/main/nllb_seed)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indo4b | 2023-09-26T12:28:57.000Z | [
"language:ind",
"self-supervised-pretraining",
"region:us"
] | NusaCrowd | Indo4B is a large-scale Indonesian self-supervised pre-training corpus
consists of around 3.6B words, with around 250M sentences. The corpus
covers both formal and colloquial Indonesian sentences compiled from
12 sources, of which two cover Indonesian colloquial language, eight
cover formal Indonesian language, and the rest have a mixed style of
both colloquial and formal. | @inproceedings{wilie-etal-2020-indonlu,
title = "{I}ndo{NLU}: Benchmark and Resources for Evaluating {I}ndonesian
Natural Language Understanding",
author = "Wilie, Bryan and
Vincentio, Karissa and
Winata, Genta Indra and
Cahyawijaya, Samuel and
Li, Xiaohong and
Lim, Zhi Yuan and
Soleman, Sidik and
Mahendra, Rahmad and
Fung, Pascale and
Bahar, Syafri and
Purwarianti, Ayu",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the
Association for Computational Linguistics and the 10th International Joint
Conference on Natural Language Processing",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-main.85",
pages = "843--857",
abstract = "Although Indonesian is known to be the fourth most frequently used language
over the internet, the research progress on this language in natural language processing (NLP)
is slow-moving due to a lack of available resources. In response, we introduce the first-ever vast
resource for training, evaluation, and benchmarking on Indonesian natural language understanding
(IndoNLU) tasks. IndoNLU includes twelve tasks, ranging from single sentence classification to
pair-sentences sequence labeling with different levels of complexity. The datasets for the tasks
lie in different domains and styles to ensure task diversity. We also provide a set of Indonesian
pre-trained models (IndoBERT) trained from a large and clean Indonesian dataset (Indo4B) collected
from publicly available sources such as social media texts, blogs, news, and websites.
We release baseline models for all twelve tasks, as well as the framework for benchmark evaluation,
thus enabling everyone to benchmark their system performances.",
} | null | 0 | 0 | ---
tags:
- self-supervised-pretraining
language:
- ind
---
# indo4b
Indo4B is a large-scale Indonesian self-supervised pre-training corpus
consists of around 3.6B words, with around 250M sentences. The corpus
covers both formal and colloquial Indonesian sentences compiled from
12 sources, of which two cover Indonesian colloquial language, eight
cover formal Indonesian language, and the rest have a mixed style of
both colloquial and formal.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{wilie-etal-2020-indonlu,
title = "{I}ndo{NLU}: Benchmark and Resources for Evaluating {I}ndonesian
Natural Language Understanding",
author = "Wilie, Bryan and
Vincentio, Karissa and
Winata, Genta Indra and
Cahyawijaya, Samuel and
Li, Xiaohong and
Lim, Zhi Yuan and
Soleman, Sidik and
Mahendra, Rahmad and
Fung, Pascale and
Bahar, Syafri and
Purwarianti, Ayu",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the
Association for Computational Linguistics and the 10th International Joint
Conference on Natural Language Processing",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-main.85",
pages = "843--857",
abstract = "Although Indonesian is known to be the fourth most frequently used language
over the internet, the research progress on this language in natural language processing (NLP)
is slow-moving due to a lack of available resources. In response, we introduce the first-ever vast
resource for training, evaluation, and benchmarking on Indonesian natural language understanding
(IndoNLU) tasks. IndoNLU includes twelve tasks, ranging from single sentence classification to
pair-sentences sequence labeling with different levels of complexity. The datasets for the tasks
lie in different domains and styles to ensure task diversity. We also provide a set of Indonesian
pre-trained models (IndoBERT) trained from a large and clean Indonesian dataset (Indo4B) collected
from publicly available sources such as social media texts, blogs, news, and websites.
We release baseline models for all twelve tasks, as well as the framework for benchmark evaluation,
thus enabling everyone to benchmark their system performances.",
}
```
## License
CC0
## Homepage
[https://github.com/IndoNLP/indonlu](https://github.com/IndoNLP/indonlu)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/wrete | 2023-09-26T12:29:01.000Z | [
"language:ind",
"textual-entailment",
"region:us"
] | NusaCrowd | WReTe, The Wiki Revision Edits Textual Entailment dataset (Setya and Mahendra, 2018) consists of 450 sentence pairs constructed from Wikipedia revision history. The dataset contains pairs of sentences and binary semantic relations between the pairs. The data are labeled as entailed when the meaning of the second sentence can be derived from the first one, and not entailed otherwise | @INPROCEEDINGS{8904199,
author={Purwarianti, Ayu and Crisdayanti, Ida Ayu Putu Ari},
booktitle={2019 International Conference of Advanced Informatics: Concepts, Theory and Applications (ICAICTA)},
title={Improving Bi-LSTM Performance for Indonesian Sentiment Analysis Using Paragraph Vector},
year={2019},
pages={1-5},
doi={10.1109/ICAICTA.2019.8904199}
}
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Wilie, Bryan and Vincentio, Karissa and Winata, Genta Indra and Cahyawijaya, Samuel and Li, Xiaohong and Lim, Zhi Yuan and Soleman, Sidik and Mahendra, Rahmad and Fung, Pascale and Bahar, Syafri and others},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
pages={843--857},
year={2020}
} | null | 0 | 0 | ---
tags:
- textual-entailment
language:
- ind
---
# wrete
WReTe, The Wiki Revision Edits Textual Entailment dataset (Setya and Mahendra, 2018) consists of 450 sentence pairs constructed from Wikipedia revision history. The dataset contains pairs of sentences and binary semantic relations between the pairs. The data are labeled as entailed when the meaning of the second sentence can be derived from the first one, and not entailed otherwise
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@INPROCEEDINGS{8904199,
author={Purwarianti, Ayu and Crisdayanti, Ida Ayu Putu Ari},
booktitle={2019 International Conference of Advanced Informatics: Concepts, Theory and Applications (ICAICTA)},
title={Improving Bi-LSTM Performance for Indonesian Sentiment Analysis Using Paragraph Vector},
year={2019},
pages={1-5},
doi={10.1109/ICAICTA.2019.8904199}
}
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Wilie, Bryan and Vincentio, Karissa and Winata, Genta Indra and Cahyawijaya, Samuel and Li, Xiaohong and Lim, Zhi Yuan and Soleman, Sidik and Mahendra, Rahmad and Fung, Pascale and Bahar, Syafri and others},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
pages={843--857},
year={2020}
}
```
## License
Creative Common Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/indonlu](https://github.com/IndoNLP/indonlu)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/multilexnorm | 2023-09-26T12:29:08.000Z | [
"language:ind",
"multilexnorm",
"region:us"
] | NusaCrowd | MULTILEXNPRM is a new benchmark dataset for multilingual lexical normalization
including 12 language variants,
we here specifically work on the Indonisian-english language. | @inproceedings{multilexnorm,
title= {MultiLexNorm: A Shared Task on Multilingual Lexical Normalization,
author = "van der Goot, Rob and Ramponi et al.",
booktitle = "Proceedings of the 7th Workshop on Noisy User-generated Text (W-NUT 2021)",
year = "2021",
publisher = "Association for Computational Linguistics",
address = "Punta Cana, Dominican Republic"
} | null | 0 | 0 | ---
tags:
- multilexnorm
language:
- ind
---
# multilexnorm
MULTILEXNPRM is a new benchmark dataset for multilingual lexical normalization
including 12 language variants,
we here specifically work on the Indonisian-english language.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{multilexnorm,
title= {MultiLexNorm: A Shared Task on Multilingual Lexical Normalization,
author = "van der Goot, Rob and Ramponi et al.",
booktitle = "Proceedings of the 7th Workshop on Noisy User-generated Text (W-NUT 2021)",
year = "2021",
publisher = "Association for Computational Linguistics",
address = "Punta Cana, Dominican Republic"
}
```
## License
CC-BY-NC-SA 4.0
## Homepage
[https://bitbucket.org/robvanderg/multilexnorm/src/master/](https://bitbucket.org/robvanderg/multilexnorm/src/master/)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/ojw | 2023-09-26T12:29:11.000Z | [
"region:us"
] | NusaCrowd | This dataset contains Old Javanese written language aimed to build a machine readable sources for Old Javanese: providing a wordnet for the language (Moeljadi et. al., 2020). | @inproceedings{moeljadi-aminullah-2020-building,
title = "Building the Old {J}avanese {W}ordnet",
author = "Moeljadi, David and
Aminullah, Zakariya Pamuji",
booktitle = "Proceedings of the 12th Language Resources and Evaluation Conference",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2020.lrec-1.359",
pages = "2940--2946",
abstract = "This paper discusses the construction and the ongoing development of the Old Javanese Wordnet.
The words were extracted from the digitized version of the Old Javanese{--}English Dictionary (Zoetmulder, 1982).
The wordnet is built using the {`}expansion{'} approach (Vossen, 1998), leveraging on the Princeton Wordnet{'}s
core synsets and semantic hierarchy, as well as scientific names. The main goal of our project was to produce a
high quality, human-curated resource. As of December 2019, the Old Javanese Wordnet contains 2,054 concepts or
synsets and 5,911 senses. It is released under a Creative Commons Attribution 4.0 International License
(CC BY 4.0). We are still developing it and adding more synsets and senses. We believe that the lexical data
made available by this wordnet will be useful for a variety of future uses such as the development of Modern
Javanese Wordnet and many language processing tasks and linguistic research on Javanese.",
language = "English",
ISBN = "979-10-95546-34-4",
} | null | 0 | 0 | Entry not found |
NusaCrowd/jadi_ide | 2023-09-26T12:29:15.000Z | [
"language:ind",
"license:unknown",
"emotion-classification",
"region:us"
] | NusaCrowd | The JaDi-Ide dataset is a Twitter dataset for Javanese dialect identification, containing 16,498
data samples. The dialect is classified into `Standard Javanese`, `Ngapak Javanese`, and `East
Javanese` dialects. | @article{hidayatullah2020attention,
title={Attention-based cnn-bilstm for dialect identification on javanese text},
author={Hidayatullah, Ahmad Fathan and Cahyaningtyas, Siwi and Pamungkas, Rheza Daffa},
journal={Kinetik: Game Technology, Information System, Computer Network, Computing, Electronics, and Control},
pages={317--324},
year={2020}
} | null | 0 | 0 | ---
license: unknown
tags:
- emotion-classification
language:
- ind
---
# jadi_ide
The JaDi-Ide dataset is a Twitter dataset for Javanese dialect identification, containing 16,498
data samples. The dialect is classified into `Standard Javanese`, `Ngapak Javanese`, and `East
Javanese` dialects.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{hidayatullah2020attention,
title={Attention-based cnn-bilstm for dialect identification on javanese text},
author={Hidayatullah, Ahmad Fathan and Cahyaningtyas, Siwi and Pamungkas, Rheza Daffa},
journal={Kinetik: Game Technology, Information System, Computer Network, Computing, Electronics, and Control},
pages={317--324},
year={2020}
}
```
## License
Unknown
## Homepage
[https://github.com/fathanick/Javanese-Dialect-Identification-from-Twitter-Data](https://github.com/fathanick/Javanese-Dialect-Identification-from-Twitter-Data)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_abusive_news_comment | 2023-09-26T12:29:19.000Z | [
"language:ind",
"sentiment-analysis",
"region:us"
] | NusaCrowd | Abusive language is an expression used by a person with insulting delivery of any person's aspect.
In the modern era, the use of harsh words is often found on the internet, one of them is in the comment section of online news articles which contains harassment, insult, or a curse.
An abusive language detection system is important to prevent the negative effect of such comments.
This dataset contains 3184 samples of Indonesian online news comments with 3 labels. | @INPROCEEDINGS{9034620, author={Kiasati Desrul, Dhamir Raniah and Romadhony, Ade}, booktitle={2019 International Seminar on Research of Information Technology and Intelligent Systems (ISRITI)}, title={Abusive Language Detection on Indonesian Online News Comments}, year={2019}, volume={}, number={}, pages={320-325}, doi={10.1109/ISRITI48646.2019.9034620}} | null | 0 | 0 | ---
tags:
- sentiment-analysis
language:
- ind
---
# id_abusive_news_comment
Abusive language is an expression used by a person with insulting delivery of any person's aspect.
In the modern era, the use of harsh words is often found on the internet, one of them is in the comment section of online news articles which contains harassment, insult, or a curse.
An abusive language detection system is important to prevent the negative effect of such comments.
This dataset contains 3184 samples of Indonesian online news comments with 3 labels.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@INPROCEEDINGS{9034620, author={Kiasati Desrul, Dhamir Raniah and Romadhony, Ade}, booktitle={2019 International Seminar on Research of Information Technology and Intelligent Systems (ISRITI)}, title={Abusive Language Detection on Indonesian Online News Comments}, year={2019}, volume={}, number={}, pages={320-325}, doi={10.1109/ISRITI48646.2019.9034620}}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/dhamirdesrul/Indonesian-Online-News-Comments](https://github.com/dhamirdesrul/Indonesian-Online-News-Comments)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_sts | 2023-09-26T12:29:25.000Z | [
"language:ind",
"license:unknown",
"semantic-similarity",
"region:us"
] | NusaCrowd | SemEval is a series of international natural language processing (NLP) research workshops whose mission is
to advance the current state of the art in semantic analysis and to help create high-quality annotated datasets in a
range of increasingly challenging problems in natural language semantics. This is a translated version of SemEval Dataset
from 2012-2016 for Semantic Textual Similarity Task to Indonesian language. | null | 0 | 0 | ---
license: unknown
tags:
- semantic-similarity
language:
- ind
---
# id_sts
SemEval is a series of international natural language processing (NLP) research workshops whose mission is
to advance the current state of the art in semantic analysis and to help create high-quality annotated datasets in a
range of increasingly challenging problems in natural language semantics. This is a translated version of SemEval Dataset
from 2012-2016 for Semantic Textual Similarity Task to Indonesian language.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
```
## License
Unknown
## Homepage
[https://github.com/ahmadizzan/sts-indo](https://github.com/ahmadizzan/sts-indo)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) | |
NusaCrowd/hoasa | 2023-09-26T12:29:28.000Z | [
"language:ind",
"aspect-based-sentiment-analysis",
"region:us"
] | NusaCrowd | HoASA: An aspect-based sentiment analysis dataset consisting of hotel reviews collected from the hotel aggregator platform, AiryRooms.
The dataset covers ten different aspects of hotel quality. Similar to the CASA dataset, each review is labeled with a single sentiment label for each aspect.
There are four possible sentiment classes for each sentiment label:
positive, negative, neutral, and positive-negative.
The positivenegative label is given to a review that contains multiple sentiments of the same aspect but for different objects (e.g., cleanliness of bed and toilet). | @inproceedings{azhar2019multi,
title={Multi-label Aspect Categorization with Convolutional Neural Networks and Extreme Gradient Boosting},
author={A. N. Azhar, M. L. Khodra, and A. P. Sutiono}
booktitle={Proceedings of the 2019 International Conference on Electrical Engineering and Informatics (ICEEI)},
pages={35--40},
year={2019}
} | null | 0 | 0 | ---
tags:
- aspect-based-sentiment-analysis
language:
- ind
---
# hoasa
HoASA: An aspect-based sentiment analysis dataset consisting of hotel reviews collected from the hotel aggregator platform, AiryRooms.
The dataset covers ten different aspects of hotel quality. Similar to the CASA dataset, each review is labeled with a single sentiment label for each aspect.
There are four possible sentiment classes for each sentiment label:
positive, negative, neutral, and positive-negative.
The positivenegative label is given to a review that contains multiple sentiments of the same aspect but for different objects (e.g., cleanliness of bed and toilet).
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{azhar2019multi,
title={Multi-label Aspect Categorization with Convolutional Neural Networks and Extreme Gradient Boosting},
author={A. N. Azhar, M. L. Khodra, and A. P. Sutiono}
booktitle={Proceedings of the 2019 International Conference on Electrical Engineering and Informatics (ICEEI)},
pages={35--40},
year={2019}
}
```
## License
CC-BY-SA 4.0
## Homepage
[https://github.com/IndoNLP/indonlu](https://github.com/IndoNLP/indonlu)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/nusaparagraph_rhetoric | 2023-09-26T12:29:33.000Z | [
"language:btk",
"language:bew",
"language:bug",
"language:jav",
"language:mad",
"language:mak",
"language:min",
"language:mui",
"language:rej",
"language:sun",
"rhetoric-mode-classification",
"region:us"
] | NusaCrowd | Democratizing access to natural language processing (NLP) technology is crucial, especially for underrepresented and extremely low-resource languages. Previous research has focused on developing labeled and unlabeled corpora for these languages through online scraping and document translation. While these methods have proven effective and cost-efficient, we have identified limitations in the resulting corpora, including a lack of lexical diversity and cultural relevance to local communities. To address this gap, we conduct a case study on Indonesian local languages. We compare the effectiveness of online scraping, human translation, and paragraph writing by native speakers in constructing datasets. Our findings demonstrate that datasets generated through paragraph writing by native speakers exhibit superior quality in terms of lexical diversity and cultural content. In addition, we present the NusaWrites benchmark, encompassing 12 underrepresented and extremely low-resource languages spoken by millions of individuals in Indonesia. Our empirical experiment results using existing multilingual large language models conclude the need to extend these models to more underrepresented languages.
We introduce a novel high quality human curated corpora, i.e., NusaMenulis, which covers 12 languages spoken in Indonesia. The resource extend the coverage of languages to 5 new languages, i.e., Ambon (abs), Bima (bhp), Makassarese (mak), Palembang / Musi (mui), and Rejang (rej).
For the rhetoric mode classification task, we cover 5 rhetoric modes, i.e., narrative, persuasive, argumentative, descriptive, and expository. | @unpublished{anonymous2023nusawrites:,
title={NusaWrites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages},
author={Anonymous},
journal={OpenReview Preprint},
year={2023},
note={anonymous preprint under review}
} | null | 0 | 0 | ---
tags:
- rhetoric-mode-classification
language:
- btk
- bew
- bug
- jav
- mad
- mak
- min
- mui
- rej
- sun
---
# nusaparagraph_rhetoric
Democratizing access to natural language processing (NLP) technology is crucial, especially for underrepresented and extremely low-resource languages. Previous research has focused on developing labeled and unlabeled corpora for these languages through online scraping and document translation. While these methods have proven effective and cost-efficient, we have identified limitations in the resulting corpora, including a lack of lexical diversity and cultural relevance to local communities. To address this gap, we conduct a case study on Indonesian local languages. We compare the effectiveness of online scraping, human translation, and paragraph writing by native speakers in constructing datasets. Our findings demonstrate that datasets generated through paragraph writing by native speakers exhibit superior quality in terms of lexical diversity and cultural content. In addition, we present the NusaWrites benchmark, encompassing 12 underrepresented and extremely low-resource languages spoken by millions of individuals in Indonesia. Our empirical experiment results using existing multilingual large language models conclude the need to extend these models to more underrepresented languages.
We introduce a novel high quality human curated corpora, i.e., NusaMenulis, which covers 12 languages spoken in Indonesia. The resource extend the coverage of languages to 5 new languages, i.e., Ambon (abs), Bima (bhp), Makassarese (mak), Palembang / Musi (mui), and Rejang (rej).
For the rhetoric mode classification task, we cover 5 rhetoric modes, i.e., narrative, persuasive, argumentative, descriptive, and expository.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@unpublished{anonymous2023nusawrites:,
title={NusaWrites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages},
author={Anonymous},
journal={OpenReview Preprint},
year={2023},
note={anonymous preprint under review}
}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/nusa-writes](https://github.com/IndoNLP/nusa-writes)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/term_a | 2023-09-26T12:29:41.000Z | [
"language:ind",
"keyword-tagging",
"region:us"
] | NusaCrowd | TermA is a span-extraction dataset collected from the hotel aggregator platform, AiryRooms
(Septiandri and Sutiono, 2019; Fernando et al.,
2019) consisting of thousands of hotel reviews,each containing a span label for aspect
and sentiment words representing the opinion of the reviewer on the corresponding aspect.
The labels use Inside-Outside-Beginning tagging (IOB) with two kinds of tags, aspect and
sentiment. | @article{winatmoko2019aspect,
title={Aspect and opinion term extraction for hotel reviews using transfer learning and auxiliary labels},
author={Winatmoko, Yosef Ardhito and Septiandri, Ali Akbar and Sutiono, Arie Pratama},
journal={arXiv preprint arXiv:1909.11879},
year={2019}
}
@inproceedings{fernando2019aspect,
title={Aspect and opinion terms extraction using double embeddings and attention mechanism for indonesian hotel reviews},
author={Fernando, Jordhy and Khodra, Masayu Leylia and Septiandri, Ali Akbar},
booktitle={2019 International Conference of Advanced Informatics: Concepts, Theory and Applications (ICAICTA)},
pages={1--6},
year={2019},
organization={IEEE}
} | null | 0 | 0 | ---
tags:
- keyword-tagging
language:
- ind
---
# term_a
TermA is a span-extraction dataset collected from the hotel aggregator platform, AiryRooms
(Septiandri and Sutiono, 2019; Fernando et al.,
2019) consisting of thousands of hotel reviews,each containing a span label for aspect
and sentiment words representing the opinion of the reviewer on the corresponding aspect.
The labels use Inside-Outside-Beginning tagging (IOB) with two kinds of tags, aspect and
sentiment.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{winatmoko2019aspect,
title={Aspect and opinion term extraction for hotel reviews using transfer learning and auxiliary labels},
author={Winatmoko, Yosef Ardhito and Septiandri, Ali Akbar and Sutiono, Arie Pratama},
journal={arXiv preprint arXiv:1909.11879},
year={2019}
}
@inproceedings{fernando2019aspect,
title={Aspect and opinion terms extraction using double embeddings and attention mechanism for indonesian hotel reviews},
author={Fernando, Jordhy and Khodra, Masayu Leylia and Septiandri, Ali Akbar},
booktitle={2019 International Conference of Advanced Informatics: Concepts, Theory and Applications (ICAICTA)},
pages={1--6},
year={2019},
organization={IEEE}
}
```
## License
Creative Common Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/indonlu](https://github.com/IndoNLP/indonlu)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indo_puisi | 2023-09-26T12:29:49.000Z | [
"language:ind",
"self-supervised-pretraining",
"region:us"
] | NusaCrowd | Puisi is an Indonesian poetic form. The dataset was collected by scraping various websites. It contains 7223 Indonesian puisi along with the title and author. | null | 0 | 0 | ---
tags:
- self-supervised-pretraining
language:
- ind
---
# indo_puisi
Puisi is an Indonesian poetic form. The dataset was collected by scraping various websites. It contains 7223 Indonesian puisi along with the title and author.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/ilhamfp/puisi-pantun-generator](https://github.com/ilhamfp/puisi-pantun-generator)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) | |
NusaCrowd/stif_indonesia | 2023-09-26T12:29:52.000Z | [
"language:ind",
"license:mit",
"paraphrasing",
"region:us"
] | NusaCrowd | STIF-Indonesia is formal-informal (bahasa baku - bahasa alay/slang) style transfer for Indonesian. Texts were collected from Twitter. Then, native speakers were aksed to transform the text into formal style. | @inproceedings{wibowo2020semi,
title={Semi-supervised low-resource style transfer of indonesian informal to formal language with iterative forward-translation},
author={Wibowo, Haryo Akbarianto and Prawiro, Tatag Aziz and Ihsan, Muhammad and Aji, Alham Fikri and Prasojo, Radityo Eko and Mahendra, Rahmad and Fitriany, Suci},
booktitle={2020 International Conference on Asian Language Processing (IALP)},
pages={310--315},
year={2020},
organization={IEEE}
} | null | 0 | 0 | ---
license: mit
tags:
- paraphrasing
language:
- ind
---
# stif_indonesia
STIF-Indonesia is formal-informal (bahasa baku - bahasa alay/slang) style transfer for Indonesian. Texts were collected from Twitter. Then, native speakers were aksed to transform the text into formal style.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{wibowo2020semi,
title={Semi-supervised low-resource style transfer of indonesian informal to formal language with iterative forward-translation},
author={Wibowo, Haryo Akbarianto and Prawiro, Tatag Aziz and Ihsan, Muhammad and Aji, Alham Fikri and Prasojo, Radityo Eko and Mahendra, Rahmad and Fitriany, Suci},
booktitle={2020 International Conference on Asian Language Processing (IALP)},
pages={310--315},
year={2020},
organization={IEEE}
}
```
## License
MIT
## Homepage
[https://github.com/haryoa/stif-indonesia](https://github.com/haryoa/stif-indonesia)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/identic | 2023-09-26T12:29:56.000Z | [
"language:ind",
"language:eng",
"machine-translation",
"pos-tagging",
"region:us"
] | NusaCrowd | IDENTIC is an Indonesian-English parallel corpus for research purposes.
The corpus is a bilingual corpus paired with English. The aim of this work is to build and provide
researchers a proper Indonesian-English textual data set and also to promote research in this language pair.
The corpus contains texts coming from different sources with different genres.
Additionally, the corpus contains tagged texts that follows MorphInd tagset (Larasati et. al., 2011). | @inproceedings{larasati-2012-identic,
title = "{IDENTIC} Corpus: Morphologically Enriched {I}ndonesian-{E}nglish Parallel Corpus",
author = "Larasati, Septina Dian",
booktitle = "Proceedings of the Eighth International Conference on Language Resources and Evaluation ({LREC}'12)",
month = may,
year = "2012",
address = "Istanbul, Turkey",
publisher = "European Language Resources Association (ELRA)",
url = "http://www.lrec-conf.org/proceedings/lrec2012/pdf/644_Paper.pdf",
pages = "902--906",
abstract = "This paper describes the creation process of an Indonesian-English parallel corpus (IDENTIC).
The corpus contains 45,000 sentences collected from different sources in different genres.
Several manual text preprocessing tasks, such as alignment and spelling correction, are applied to the corpus
to assure its quality. We also apply language specific text processing such as tokenization on both sides and
clitic normalization on the Indonesian side. The corpus is available in two different formats: plain',
stored in text format and morphologically enriched', stored in CoNLL format. Some parts of the corpus are
publicly available at the IDENTIC homepage.",
} | null | 0 | 0 | ---
tags:
- machine-translation
- pos-tagging
language:
- ind
- eng
---
# identic
IDENTIC is an Indonesian-English parallel corpus for research purposes.
The corpus is a bilingual corpus paired with English. The aim of this work is to build and provide
researchers a proper Indonesian-English textual data set and also to promote research in this language pair.
The corpus contains texts coming from different sources with different genres.
Additionally, the corpus contains tagged texts that follows MorphInd tagset (Larasati et. al., 2011).
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{larasati-2012-identic,
title = "{IDENTIC} Corpus: Morphologically Enriched {I}ndonesian-{E}nglish Parallel Corpus",
author = "Larasati, Septina Dian",
booktitle = "Proceedings of the Eighth International Conference on Language Resources and Evaluation ({LREC}'12)",
month = may,
year = "2012",
address = "Istanbul, Turkey",
publisher = "European Language Resources Association (ELRA)",
url = "http://www.lrec-conf.org/proceedings/lrec2012/pdf/644_Paper.pdf",
pages = "902--906",
abstract = "This paper describes the creation process of an Indonesian-English parallel corpus (IDENTIC).
The corpus contains 45,000 sentences collected from different sources in different genres.
Several manual text preprocessing tasks, such as alignment and spelling correction, are applied to the corpus
to assure its quality. We also apply language specific text processing such as tokenization on both sides and
clitic normalization on the Indonesian side. The corpus is available in two different formats: plain',
stored in text format and morphologically enriched', stored in CoNLL format. Some parts of the corpus are
publicly available at the IDENTIC homepage.",
}
```
## License
CC BY-NC-SA 3.0
## Homepage
[https://lindat.mff.cuni.cz/repository/xmlui/handle/11858/00-097C-0000-0005-BF85-F](https://lindat.mff.cuni.cz/repository/xmlui/handle/11858/00-097C-0000-0005-BF85-F)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/ted_en_id | 2023-09-26T12:30:00.000Z | [
"language:ind",
"language:eng",
"machine-translation",
"region:us"
] | NusaCrowd | TED En-Id is a machine translation dataset containing Indonesian-English parallel sentences collected from the TED talk transcripts. We split the dataset and use 75% as the training set, 10% as the validation set, and 15% as the test set. Each of the datasets is evaluated in both directions, i.e., English to Indonesian (En → Id) and Indonesian to English (Id → En) translations. | @inproceedings{qi2018and,
title={When and Why Are Pre-Trained Word Embeddings Useful for Neural Machine Translation?},
author={Qi, Ye and Sachan, Devendra and Felix, Matthieu and Padmanabhan, Sarguna and Neubig, Graham},
booktitle={Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers)},
pages={529--535},
year={2018}
}
@inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898",
abstract = "Natural language generation (NLG) benchmarks provide an important avenue to measure progress and develop better NLG systems. Unfortunately, the lack of publicly available NLG benchmarks for low-resource languages poses a challenging barrier for building NLG systems that work well for languages with limited amounts of data. Here we introduce IndoNLG, the first benchmark to measure natural language generation (NLG) progress in three low-resource{---}yet widely spoken{---}languages of Indonesia: Indonesian, Javanese, and Sundanese. Altogether, these languages are spoken by more than 100 million native speakers, and hence constitute an important use case of NLG systems today. Concretely, IndoNLG covers six tasks: summarization, question answering, chit-chat, and three different pairs of machine translation (MT) tasks. We collate a clean pretraining corpus of Indonesian, Sundanese, and Javanese datasets, Indo4B-Plus, which is used to pretrain our models: IndoBART and IndoGPT. We show that IndoBART and IndoGPT achieve competitive performance on all tasks{---}despite using only one-fifth the parameters of a larger multilingual model, mBART-large (Liu et al., 2020). This finding emphasizes the importance of pretraining on closely related, localized languages to achieve more efficient learning and faster inference at very low-resource languages like Javanese and Sundanese.",
} | null | 0 | 0 | ---
tags:
- machine-translation
language:
- ind
- eng
---
# ted_en_id
TED En-Id is a machine translation dataset containing Indonesian-English parallel sentences collected from the TED talk transcripts. We split the dataset and use 75% as the training set, 10% as the validation set, and 15% as the test set. Each of the datasets is evaluated in both directions, i.e., English to Indonesian (En → Id) and Indonesian to English (Id → En) translations.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{qi2018and,
title={When and Why Are Pre-Trained Word Embeddings Useful for Neural Machine Translation?},
author={Qi, Ye and Sachan, Devendra and Felix, Matthieu and Padmanabhan, Sarguna and Neubig, Graham},
booktitle={Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers)},
pages={529--535},
year={2018}
}
@inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898",
abstract = "Natural language generation (NLG) benchmarks provide an important avenue to measure progress and develop better NLG systems. Unfortunately, the lack of publicly available NLG benchmarks for low-resource languages poses a challenging barrier for building NLG systems that work well for languages with limited amounts of data. Here we introduce IndoNLG, the first benchmark to measure natural language generation (NLG) progress in three low-resource{---}yet widely spoken{---}languages of Indonesia: Indonesian, Javanese, and Sundanese. Altogether, these languages are spoken by more than 100 million native speakers, and hence constitute an important use case of NLG systems today. Concretely, IndoNLG covers six tasks: summarization, question answering, chit-chat, and three different pairs of machine translation (MT) tasks. We collate a clean pretraining corpus of Indonesian, Sundanese, and Javanese datasets, Indo4B-Plus, which is used to pretrain our models: IndoBART and IndoGPT. We show that IndoBART and IndoGPT achieve competitive performance on all tasks{---}despite using only one-fifth the parameters of a larger multilingual model, mBART-large (Liu et al., 2020). This finding emphasizes the importance of pretraining on closely related, localized languages to achieve more efficient learning and faster inference at very low-resource languages like Javanese and Sundanese.",
}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/indonlg](https://github.com/IndoNLP/indonlg)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indo_general_mt_en_id | 2023-09-26T12:30:08.000Z | [
"language:ind",
"machine-translation",
"region:us"
] | NusaCrowd | "In the context of Machine Translation (MT) from-and-to English, Bahasa Indonesia has been considered a low-resource language,
and therefore applying Neural Machine Translation (NMT) which typically requires large training dataset proves to be problematic.
In this paper, we show otherwise by collecting large, publicly-available datasets from the Web, which we split into several domains: news, religion, general, and
conversation,to train and benchmark some variants of transformer-based NMT models across the domains.
We show using BLEU that our models perform well across them , outperform the baseline Statistical Machine Translation (SMT) models,
and perform comparably with Google Translate. Our datasets (with the standard split for training, validation, and testing), code, and models are available on https://github.com/gunnxx/indonesian-mt-data." | @inproceedings{guntara-etal-2020-benchmarking,
title = "Benchmarking Multidomain {E}nglish-{I}ndonesian Machine Translation",
author = "Guntara, Tri Wahyu and
Aji, Alham Fikri and
Prasojo, Radityo Eko",
booktitle = "Proceedings of the 13th Workshop on Building and Using Comparable Corpora",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2020.bucc-1.6",
pages = "35--43",
language = "English",
ISBN = "979-10-95546-42-9",
} | null | 0 | 0 | ---
tags:
- machine-translation
language:
- ind
---
# indo_general_mt_en_id
"In the context of Machine Translation (MT) from-and-to English, Bahasa Indonesia has been considered a low-resource language,
and therefore applying Neural Machine Translation (NMT) which typically requires large training dataset proves to be problematic.
In this paper, we show otherwise by collecting large, publicly-available datasets from the Web, which we split into several domains: news, religion, general, and
conversation,to train and benchmark some variants of transformer-based NMT models across the domains.
We show using BLEU that our models perform well across them , outperform the baseline Statistical Machine Translation (SMT) models,
and perform comparably with Google Translate. Our datasets (with the standard split for training, validation, and testing), code, and models are available on https://github.com/gunnxx/indonesian-mt-data."
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{guntara-etal-2020-benchmarking,
title = "Benchmarking Multidomain {E}nglish-{I}ndonesian Machine Translation",
author = "Guntara, Tri Wahyu and
Aji, Alham Fikri and
Prasojo, Radityo Eko",
booktitle = "Proceedings of the 13th Workshop on Building and Using Comparable Corpora",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2020.bucc-1.6",
pages = "35--43",
language = "English",
ISBN = "979-10-95546-42-9",
}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/gunnxx/indonesian-mt-data](https://github.com/gunnxx/indonesian-mt-data)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_stance | 2023-09-26T12:30:12.000Z | [
"language:ind",
"textual-entailment",
"region:us"
] | NusaCrowd | Stance Classification Towards Political Figures on Blog Writing.
This dataset contains dataset from the second research, which is combined from the first research and new dataset.
The dataset consist of 337 data, about five target and every target have 1 different event.
Two label are used: 'For' and 'Againts'.
1. For - the text that is created by author is support the target in an event
2. Against - the text that is created by author is oppose the target in an event | @INPROCEEDINGS{8629144,
author={R. {Jannati} and R. {Mahendra} and C. W. {Wardhana} and M. {Adriani}},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
title={Stance Classification Towards Political Figures on Blog Writing},
year={2018},
volume={},
number={},
pages={96-101},
} | null | 0 | 0 | ---
tags:
- textual-entailment
language:
- ind
---
# id_stance
Stance Classification Towards Political Figures on Blog Writing.
This dataset contains dataset from the second research, which is combined from the first research and new dataset.
The dataset consist of 337 data, about five target and every target have 1 different event.
Two label are used: 'For' and 'Againts'.
1. For - the text that is created by author is support the target in an event
2. Against - the text that is created by author is oppose the target in an event
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@INPROCEEDINGS{8629144,
author={R. {Jannati} and R. {Mahendra} and C. W. {Wardhana} and M. {Adriani}},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
title={Stance Classification Towards Political Figures on Blog Writing},
year={2018},
volume={},
number={},
pages={96-101},
}
```
## License
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License
## Homepage
[https://github.com/reneje/id_stance_dataset_article-Stance-Classification-Towards-Political-Figures-on-Blog-Writing](https://github.com/reneje/id_stance_dataset_article-Stance-Classification-Towards-Political-Figures-on-Blog-Writing)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/emot | 2023-09-26T12:30:16.000Z | [
"language:ind",
"emotion-classification",
"region:us"
] | NusaCrowd | EmoT is an emotion classification dataset collected from the social media platform Twitter. The dataset consists of around 4000 Indonesian colloquial language tweets, covering five different emotion labels: anger, fear, happiness, love, and sadness.
EmoT dataset is splitted into 3 sets with 3521 train, 440 validation, 442 test data. | @inproceedings{saputri2018emotion,
title={Emotion classification on indonesian twitter dataset},
author={Saputri, Mei Silviana and Mahendra, Rahmad and Adriani, Mirna},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
pages={90--95},
year={2018},
organization={IEEE}
}
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Wilie, Bryan and Vincentio, Karissa and Winata, Genta Indra and Cahyawijaya, Samuel and Li, Xiaohong and Lim, Zhi Yuan and Soleman, Sidik and Mahendra, Rahmad and Fung, Pascale and Bahar, Syafri and others},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
pages={843--857},
year={2020}
} | null | 0 | 0 | ---
tags:
- emotion-classification
language:
- ind
---
# emot
EmoT is an emotion classification dataset collected from the social media platform Twitter. The dataset consists of around 4000 Indonesian colloquial language tweets, covering five different emotion labels: anger, fear, happiness, love, and sadness.
EmoT dataset is splitted into 3 sets with 3521 train, 440 validation, 442 test data.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{saputri2018emotion,
title={Emotion classification on indonesian twitter dataset},
author={Saputri, Mei Silviana and Mahendra, Rahmad and Adriani, Mirna},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
pages={90--95},
year={2018},
organization={IEEE}
}
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Wilie, Bryan and Vincentio, Karissa and Winata, Genta Indra and Cahyawijaya, Samuel and Li, Xiaohong and Lim, Zhi Yuan and Soleman, Sidik and Mahendra, Rahmad and Fung, Pascale and Bahar, Syafri and others},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
pages={843--857},
year={2020}
}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/indonlu](https://github.com/IndoNLP/indonlu)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/imdb_jv | 2023-09-26T12:30:19.000Z | [
"language:ind",
"license:unknown",
"sentiment-analysis",
"region:us"
] | NusaCrowd | Javanese Imdb Movie Reviews Dataset is a Javanese version of the IMDb Movie Reviews dataset by translating the original English dataset to Javanese. | @inproceedings{wongso2021causal,
title={Causal and masked language modeling of Javanese language using transformer-based architectures},
author={Wongso, Wilson and Setiawan, David Samuel and Suhartono, Derwin},
booktitle={2021 International Conference on Advanced Computer Science and Information Systems (ICACSIS)},
pages={1--7},
year={2021},
organization={IEEE}
} | null | 0 | 0 | ---
license: unknown
tags:
- sentiment-analysis
language:
- ind
---
# imdb_jv
Javanese Imdb Movie Reviews Dataset is a Javanese version of the IMDb Movie Reviews dataset by translating the original English dataset to Javanese.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{wongso2021causal,
title={Causal and masked language modeling of Javanese language using transformer-based architectures},
author={Wongso, Wilson and Setiawan, David Samuel and Suhartono, Derwin},
booktitle={2021 International Conference on Advanced Computer Science and Information Systems (ICACSIS)},
pages={1--7},
year={2021},
organization={IEEE}
}
```
## License
Unknown
## Homepage
[https://huggingface.co/datasets/w11wo/imdb-javanese](https://huggingface.co/datasets/w11wo/imdb-javanese)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_hatespeech | 2023-09-26T12:30:25.000Z | [
"language:ind",
"license:unknown",
"sentiment-analysis",
"region:us"
] | NusaCrowd | The ID Hatespeech dataset is collection of 713 tweets related to a political event, the Jakarta Governor Election 2017
designed for hate speech detection NLP task. This dataset is crawled from Twitter, and then filtered
and annotated manually. The dataset labelled into two; HS if the tweet contains hate speech and Non_HS if otherwise | @inproceedings{inproceedings,
author = {Alfina, Ika and Mulia, Rio and Fanany, Mohamad Ivan and Ekanata, Yudo},
year = {2017},
month = {10},
pages = {},
title = {Hate Speech Detection in the Indonesian Language: A Dataset and Preliminary Study},
doi = {10.1109/ICACSIS.2017.8355039}
} | null | 0 | 0 | ---
license: unknown
tags:
- sentiment-analysis
language:
- ind
---
# id_hatespeech
The ID Hatespeech dataset is collection of 713 tweets related to a political event, the Jakarta Governor Election 2017
designed for hate speech detection NLP task. This dataset is crawled from Twitter, and then filtered
and annotated manually. The dataset labelled into two; HS if the tweet contains hate speech and Non_HS if otherwise
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{inproceedings,
author = {Alfina, Ika and Mulia, Rio and Fanany, Mohamad Ivan and Ekanata, Yudo},
year = {2017},
month = {10},
pages = {},
title = {Hate Speech Detection in the Indonesian Language: A Dataset and Preliminary Study},
doi = {10.1109/ICACSIS.2017.8355039}
}
```
## License
Unknown
## Homepage
[https://www.researchgate.net/publication/320131169_Hate_Speech_Detection_in_the_Indonesian_Language_A_Dataset_and_Preliminary_Study](https://www.researchgate.net/publication/320131169_Hate_Speech_Detection_in_the_Indonesian_Language_A_Dataset_and_Preliminary_Study)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indo4b_plus | 2023-09-26T12:30:29.000Z | [
"language:ind",
"language:sun",
"language:jav",
"self-supervised-pretraining",
"region:us"
] | NusaCrowd | Indo4B-Plus is an extension of Indo4B, a large-scale Indonesian self-supervised pre-training corpus.
Indo4B-Plus extend Indo4B by adding two low-resource Indonesian local languages to the corpus, i.e., Sundanese and Javanese.
Indo4B-Plus adds 82,582,025 words (∼2.07%) of Sundanese sentences and 331,041,877 words (∼8.29%) of Javanese | @inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898",
abstract = "Natural language generation (NLG) benchmarks provide an important avenue to measure progress
and develop better NLG systems. Unfortunately, the lack of publicly available NLG benchmarks for low-resource
languages poses a challenging barrier for building NLG systems that work well for languages with limited
amounts of data. Here we introduce IndoNLG, the first benchmark to measure natural language generation (NLG)
progress in three low-resource{---}yet widely spoken{---}languages of Indonesia: Indonesian, Javanese, and Sundanese.
Altogether, these languages are spoken by more than 100 million native speakers, and hence constitute an important
use case of NLG systems today. Concretely, IndoNLG covers six tasks: summarization, question answering, chit-chat,
and three different pairs of machine translation (MT) tasks. We collate a clean pretraining corpus of Indonesian,
Sundanese, and Javanese datasets, Indo4B-Plus, which is used to pretrain our models: IndoBART and IndoGPT.
We show that IndoBART and IndoGPT achieve competitive performance on all tasks{---}despite using only one-fifth
the parameters of a larger multilingual model, mBART-large (Liu et al., 2020). This finding emphasizes
the importance of pretraining on closely related, localized languages to achieve more efficient learning and faster inference
at very low-resource languages like Javanese and Sundanese.",
} | null | 0 | 0 | ---
tags:
- self-supervised-pretraining
language:
- ind
- sun
- jav
---
# indo4b_plus
Indo4B-Plus is an extension of Indo4B, a large-scale Indonesian self-supervised pre-training corpus.
Indo4B-Plus extend Indo4B by adding two low-resource Indonesian local languages to the corpus, i.e., Sundanese and Javanese.
Indo4B-Plus adds 82,582,025 words (∼2.07%) of Sundanese sentences and 331,041,877 words (∼8.29%) of Javanese
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898",
abstract = "Natural language generation (NLG) benchmarks provide an important avenue to measure progress
and develop better NLG systems. Unfortunately, the lack of publicly available NLG benchmarks for low-resource
languages poses a challenging barrier for building NLG systems that work well for languages with limited
amounts of data. Here we introduce IndoNLG, the first benchmark to measure natural language generation (NLG)
progress in three low-resource{---}yet widely spoken{---}languages of Indonesia: Indonesian, Javanese, and Sundanese.
Altogether, these languages are spoken by more than 100 million native speakers, and hence constitute an important
use case of NLG systems today. Concretely, IndoNLG covers six tasks: summarization, question answering, chit-chat,
and three different pairs of machine translation (MT) tasks. We collate a clean pretraining corpus of Indonesian,
Sundanese, and Javanese datasets, Indo4B-Plus, which is used to pretrain our models: IndoBART and IndoGPT.
We show that IndoBART and IndoGPT achieve competitive performance on all tasks{---}despite using only one-fifth
the parameters of a larger multilingual model, mBART-large (Liu et al., 2020). This finding emphasizes
the importance of pretraining on closely related, localized languages to achieve more efficient learning and faster inference
at very low-resource languages like Javanese and Sundanese.",
}
```
## License
CC0
## Homepage
[https://github.com/IndoNLP/indonlu](https://github.com/IndoNLP/indonlu)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indocoref | 2023-09-26T12:30:32.000Z | [
"language:ind",
"license:mit",
"coreference-resolution",
"region:us"
] | NusaCrowd | Dataset contains articles from Wikipedia Bahasa Indonesia which fulfill these conditions:
- The pages contain many noun phrases, which the authors subjectively pick: (i) fictional plots, e.g., subtitles for films,
TV show episodes, and novel stories; (ii) biographies (incl. fictional characters); and (iii) historical events or important events.
- The pages contain significant variation of pronoun and named-entity. We count the number of first, second, third person pronouns,
and clitic pronouns in the document by applying string matching.We examine the number
of named-entity using the Stanford CoreNLP
NER Tagger (Manning et al., 2014) with a
model trained from the Indonesian corpus
taken from Alfina et al. (2016).
The Wikipedia texts have length of 500 to
2000 words.
We sample 201 of pages from subset of filtered
Wikipedia pages. We hire five annotators who are
undergraduate student in Linguistics department.
They are native in Indonesian. Annotation is carried out using the Script d’Annotation des Chanes
de Rfrence (SACR), a web-based Coreference resolution annotation tool developed by Oberle (2018).
From the 201 texts, there are 16,460 mentions
tagged by the annotators | @inproceedings{artari-etal-2021-multi,
title = {A Multi-Pass Sieve Coreference Resolution for {I}ndonesian},
author = {Artari, Valentina Kania Prameswara and Mahendra, Rahmad and Jiwanggi, Meganingrum Arista and Anggraito, Adityo and Budi, Indra},
year = 2021,
month = sep,
booktitle = {Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021)},
publisher = {INCOMA Ltd.},
address = {Held Online},
pages = {79--85},
url = {https://aclanthology.org/2021.ranlp-1.10},
abstract = {Coreference resolution is an NLP task to find out whether the set of referring expressions belong to the same concept in discourse. A multi-pass sieve is a deterministic coreference model that implements several layers of sieves, where each sieve takes a pair of correlated mentions from a collection of non-coherent mentions. The multi-pass sieve is based on the principle of high precision, followed by increased recall in each sieve. In this work, we examine the portability of the multi-pass sieve coreference resolution model to the Indonesian language. We conduct the experiment on 201 Wikipedia documents and the multi-pass sieve system yields 72.74{\%} of MUC F-measure and 52.18{\%} of BCUBED F-measure.}
} | null | 0 | 0 | ---
license: mit
tags:
- coreference-resolution
language:
- ind
---
# indocoref
Dataset contains articles from Wikipedia Bahasa Indonesia which fulfill these conditions:
- The pages contain many noun phrases, which the authors subjectively pick: (i) fictional plots, e.g., subtitles for films,
TV show episodes, and novel stories; (ii) biographies (incl. fictional characters); and (iii) historical events or important events.
- The pages contain significant variation of pronoun and named-entity. We count the number of first, second, third person pronouns,
and clitic pronouns in the document by applying string matching.We examine the number
of named-entity using the Stanford CoreNLP
NER Tagger (Manning et al., 2014) with a
model trained from the Indonesian corpus
taken from Alfina et al. (2016).
The Wikipedia texts have length of 500 to
2000 words.
We sample 201 of pages from subset of filtered
Wikipedia pages. We hire five annotators who are
undergraduate student in Linguistics department.
They are native in Indonesian. Annotation is carried out using the Script d’Annotation des Chanes
de Rfrence (SACR), a web-based Coreference resolution annotation tool developed by Oberle (2018).
From the 201 texts, there are 16,460 mentions
tagged by the annotators
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{artari-etal-2021-multi,
title = {A Multi-Pass Sieve Coreference Resolution for {I}ndonesian},
author = {Artari, Valentina Kania Prameswara and Mahendra, Rahmad and Jiwanggi, Meganingrum Arista and Anggraito, Adityo and Budi, Indra},
year = 2021,
month = sep,
booktitle = {Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021)},
publisher = {INCOMA Ltd.},
address = {Held Online},
pages = {79--85},
url = {https://aclanthology.org/2021.ranlp-1.10},
abstract = {Coreference resolution is an NLP task to find out whether the set of referring expressions belong to the same concept in discourse. A multi-pass sieve is a deterministic coreference model that implements several layers of sieves, where each sieve takes a pair of correlated mentions from a collection of non-coherent mentions. The multi-pass sieve is based on the principle of high precision, followed by increased recall in each sieve. In this work, we examine the portability of the multi-pass sieve coreference resolution model to the Indonesian language. We conduct the experiment on 201 Wikipedia documents and the multi-pass sieve system yields 72.74{\%} of MUC F-measure and 52.18{\%} of BCUBED F-measure.}
}
```
## License
MIT
## Homepage
[https://github.com/valentinakania/indocoref/](https://github.com/valentinakania/indocoref/)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/nusaparagraph_emot | 2023-09-26T12:30:37.000Z | [
"language:btk",
"language:bew",
"language:bug",
"language:jav",
"language:mad",
"language:mak",
"language:min",
"language:mui",
"language:rej",
"language:sun",
"emotion-classification",
"region:us"
] | NusaCrowd | Democratizing access to natural language processing (NLP) technology is crucial, especially for underrepresented and extremely low-resource languages. Previous research has focused on developing labeled and unlabeled corpora for these languages through online scraping and document translation. While these methods have proven effective and cost-efficient, we have identified limitations in the resulting corpora, including a lack of lexical diversity and cultural relevance to local communities. To address this gap, we conduct a case study on Indonesian local languages. We compare the effectiveness of online scraping, human translation, and paragraph writing by native speakers in constructing datasets. Our findings demonstrate that datasets generated through paragraph writing by native speakers exhibit superior quality in terms of lexical diversity and cultural content. In addition, we present the NusaWrites benchmark, encompassing 12 underrepresented and extremely low-resource languages spoken by millions of individuals in Indonesia. Our empirical experiment results using existing multilingual large language models conclude the need to extend these models to more underrepresented languages.
We introduce a novel high quality human curated corpora, i.e., NusaMenulis, which covers 12 languages spoken in Indonesia. The resource extend the coverage of languages to 5 new languages, i.e., Ambon (abs), Bima (bhp), Makassarese (mak), Palembang / Musi (mui), and Rejang (rej).
For the emotion recognition task, we cover the 6 basic emotions (Ekman, 1992): fear, disgusted, sad, happy, angry, and surprise, and an additional emotion label: shame (Poulson and of Tasmania. School of Management, 2000. | @unpublished{anonymous2023nusawrites:,
title={NusaWrites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages},
author={Anonymous},
journal={OpenReview Preprint},
year={2023},
note={anonymous preprint under review}
} | null | 0 | 0 | ---
tags:
- emotion-classification
language:
- btk
- bew
- bug
- jav
- mad
- mak
- min
- mui
- rej
- sun
---
# nusaparagraph_emot
Democratizing access to natural language processing (NLP) technology is crucial, especially for underrepresented and extremely low-resource languages. Previous research has focused on developing labeled and unlabeled corpora for these languages through online scraping and document translation. While these methods have proven effective and cost-efficient, we have identified limitations in the resulting corpora, including a lack of lexical diversity and cultural relevance to local communities. To address this gap, we conduct a case study on Indonesian local languages. We compare the effectiveness of online scraping, human translation, and paragraph writing by native speakers in constructing datasets. Our findings demonstrate that datasets generated through paragraph writing by native speakers exhibit superior quality in terms of lexical diversity and cultural content. In addition, we present the NusaWrites benchmark, encompassing 12 underrepresented and extremely low-resource languages spoken by millions of individuals in Indonesia. Our empirical experiment results using existing multilingual large language models conclude the need to extend these models to more underrepresented languages.
We introduce a novel high quality human curated corpora, i.e., NusaMenulis, which covers 12 languages spoken in Indonesia. The resource extend the coverage of languages to 5 new languages, i.e., Ambon (abs), Bima (bhp), Makassarese (mak), Palembang / Musi (mui), and Rejang (rej).
For the emotion recognition task, we cover the 6 basic emotions (Ekman, 1992): fear, disgusted, sad, happy, angry, and surprise, and an additional emotion label: shame (Poulson and of Tasmania. School of Management, 2000.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@unpublished{anonymous2023nusawrites:,
title={NusaWrites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages},
author={Anonymous},
journal={OpenReview Preprint},
year={2023},
note={anonymous preprint under review}
}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/nusa-writes](https://github.com/IndoNLP/nusa-writes)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/cvss | 2023-09-26T12:30:46.000Z | [
"language:ind",
"language:eng",
"speech-to-speech-translation",
"region:us"
] | NusaCrowd | CVSS is a massively multilingual-to-English speech-to-speech translation corpus,
covering sentence-level parallel speech-to-speech translation pairs from 21
languages into English. | @inproceedings{jia2022cvss,
title={{CVSS} Corpus and Massively Multilingual Speech-to-Speech Translation},
author={Jia, Ye and Tadmor Ramanovich, Michelle and Wang, Quan and Zen, Heiga},
booktitle={Proceedings of Language Resources and Evaluation Conference (LREC)},
pages={6691--6703},
year={2022}
} | null | 0 | 0 | ---
tags:
- speech-to-speech-translation
language:
- ind
- eng
---
# cvss
CVSS is a massively multilingual-to-English speech-to-speech translation corpus,
covering sentence-level parallel speech-to-speech translation pairs from 21
languages into English.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{jia2022cvss,
title={{CVSS} Corpus and Massively Multilingual Speech-to-Speech Translation},
author={Jia, Ye and Tadmor Ramanovich, Michelle and Wang, Quan and Zen, Heiga},
booktitle={Proceedings of Language Resources and Evaluation Conference (LREC)},
pages={6691--6703},
year={2022}
}
```
## License
CC-BY 4.0
## Homepage
[https://github.com/google-research-datasets/cvss](https://github.com/google-research-datasets/cvss)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/local_id_abusive | 2023-09-26T12:30:53.000Z | [
"language:jav",
"language:sun",
"license:unknown",
"aspect-based-sentiment-analysis",
"region:us"
] | NusaCrowd | This dataset is for abusive and hate speech detection, using Twitter text containing Javanese and Sundanese words.
(from the publication source)
The Indonesian local language dataset collection was conducted using Twitter search API to collect the tweets and then
implemented using Tweepy Library. The tweets were collected using queries from the list of abusive words in Indonesian
tweets. The abusive words were translated into local Indonesian languages, which are Javanese and Sundanese. The
translated words are then used as queries to collect tweets containing Indonesian and local languages. The translation
process involved native speakers for each local language. The crawling process has collected a total of more than 5000
tweets. Then, the crawled data were filtered to get tweets that contain local’s vocabulary and/or sentences in Javanese
and Sundanese. Next, after the filtering process, the data will be labeled whether the tweets are labeled as hate speech
and abusive language or not. | @inproceedings{putri2021abusive,
title={Abusive language and hate speech detection for Javanese and Sundanese languages in tweets: Dataset and preliminary study},
author={Putri, Shofianina Dwi Ananda and Ibrohim, Muhammad Okky and Budi, Indra},
booktitle={2021 11th International Workshop on Computer Science and Engineering, WCSE 2021},
pages={461--465},
year={2021},
organization={International Workshop on Computer Science and Engineering (WCSE)},
abstract={Indonesia’s demography as an archipelago with lots of tribes and local languages added variances in their communication style. Every region in Indonesia has its own distinct culture, accents, and languages. The demographical condition can influence the characteristic of the language used in social media, such as Twitter. It can be found that Indonesian uses their own local language for communicating and expressing their mind in tweets. Nowadays, research about identifying hate speech and abusive language has become an attractive and developing topic. Moreover, the research related to Indonesian local languages still rarely encountered. This paper analyzes the use of machine learning approaches such as Naïve Bayes (NB), Support Vector Machine (SVM), and Random Forest Decision Tree (RFDT) in detecting hate speech and abusive language in Sundanese and Javanese as Indonesian local languages. The classifiers were used with the several term weightings features, such as word n-grams and char n-grams. The experiments are evaluated using the F-measure. It achieves over 60 % for both local languages.}
} | null | 0 | 0 | ---
license: unknown
tags:
- aspect-based-sentiment-analysis
language:
- jav
- sun
---
# local_id_abusive
This dataset is for abusive and hate speech detection, using Twitter text containing Javanese and Sundanese words.
(from the publication source)
The Indonesian local language dataset collection was conducted using Twitter search API to collect the tweets and then
implemented using Tweepy Library. The tweets were collected using queries from the list of abusive words in Indonesian
tweets. The abusive words were translated into local Indonesian languages, which are Javanese and Sundanese. The
translated words are then used as queries to collect tweets containing Indonesian and local languages. The translation
process involved native speakers for each local language. The crawling process has collected a total of more than 5000
tweets. Then, the crawled data were filtered to get tweets that contain local’s vocabulary and/or sentences in Javanese
and Sundanese. Next, after the filtering process, the data will be labeled whether the tweets are labeled as hate speech
and abusive language or not.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{putri2021abusive,
title={Abusive language and hate speech detection for Javanese and Sundanese languages in tweets: Dataset and preliminary study},
author={Putri, Shofianina Dwi Ananda and Ibrohim, Muhammad Okky and Budi, Indra},
booktitle={2021 11th International Workshop on Computer Science and Engineering, WCSE 2021},
pages={461--465},
year={2021},
organization={International Workshop on Computer Science and Engineering (WCSE)},
abstract={Indonesia’s demography as an archipelago with lots of tribes and local languages added variances in their communication style. Every region in Indonesia has its own distinct culture, accents, and languages. The demographical condition can influence the characteristic of the language used in social media, such as Twitter. It can be found that Indonesian uses their own local language for communicating and expressing their mind in tweets. Nowadays, research about identifying hate speech and abusive language has become an attractive and developing topic. Moreover, the research related to Indonesian local languages still rarely encountered. This paper analyzes the use of machine learning approaches such as Naïve Bayes (NB), Support Vector Machine (SVM), and Random Forest Decision Tree (RFDT) in detecting hate speech and abusive language in Sundanese and Javanese as Indonesian local languages. The classifiers were used with the several term weightings features, such as word n-grams and char n-grams. The experiments are evaluated using the F-measure. It achieves over 60 % for both local languages.}
}
```
## License
Unknown
## Homepage
[https://github.com/Shofianina/local-indonesian-abusive-hate-speech-dataset](https://github.com/Shofianina/local-indonesian-abusive-hate-speech-dataset)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/su_id_tts | 2023-09-26T12:31:01.000Z | [
"language:sun",
"text-to-speech",
"region:us"
] | NusaCrowd | This data set contains high-quality transcribed audio data for Sundanese. The data set consists of wave files, and a TSV file. The file line_index.tsv contains a filename and the transcription of audio in the file. Each filename is prepended with a speaker identification number.
The data set has been manually quality checked, but there might still be errors.
This dataset was collected by Google in collaboration with Universitas Pendidikan Indonesia. | @inproceedings{sodimana18_sltu,
author={Keshan Sodimana and Pasindu {De Silva} and Supheakmungkol Sarin and Oddur Kjartansson and Martin Jansche and Knot Pipatsrisawat and Linne Ha},
title={{A Step-by-Step Process for Building TTS Voices Using Open Source Data and Frameworks for Bangla, Javanese, Khmer, Nepali, Sinhala, and Sundanese}},
year=2018,
booktitle={Proc. 6th Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU 2018)},
pages={66--70},
doi={10.21437/SLTU.2018-14}
} | null | 0 | 0 | ---
tags:
- text-to-speech
language:
- sun
---
# su_id_tts
This data set contains high-quality transcribed audio data for Sundanese. The data set consists of wave files, and a TSV file. The file line_index.tsv contains a filename and the transcription of audio in the file. Each filename is prepended with a speaker identification number.
The data set has been manually quality checked, but there might still be errors.
This dataset was collected by Google in collaboration with Universitas Pendidikan Indonesia.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{sodimana18_sltu,
author={Keshan Sodimana and Pasindu {De Silva} and Supheakmungkol Sarin and Oddur Kjartansson and Martin Jansche and Knot Pipatsrisawat and Linne Ha},
title={{A Step-by-Step Process for Building TTS Voices Using Open Source Data and Frameworks for Bangla, Javanese, Khmer, Nepali, Sinhala, and Sundanese}},
year=2018,
booktitle={Proc. 6th Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU 2018)},
pages={66--70},
doi={10.21437/SLTU.2018-14}
}
```
## License
CC BY-SA 4.0
## Homepage
[http://openslr.org/44/](http://openslr.org/44/)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_frog_story | 2023-09-26T12:31:08.000Z | [
"language:ind",
"self-supervised-pretraining",
"region:us"
] | NusaCrowd | Indonesian Frog Storytelling Corpus
Indonesian written and spoken corpus, based on the twenty-eight pictures. (http://compling.hss.ntu.edu.sg/who/david/corpus/pictures.pdf) | @article{FrogStorytelling,
author="Moeljadi, David",
title="Usage of Indonesian Possessive Verbal Predicates : A Statistical Analysis Based on Storytelling Survey",
journal="Tokyo University Linguistic Papers",
ISSN="1345-8663",
publisher="東京大学大学院人文社会系研究科・文学部言語学研究室",
year="2014",
month="sep",
volume="35",
number="",
pages="155-176",
URL="https://ci.nii.ac.jp/naid/120005525793/en/",
DOI="info:doi/10.15083/00027472",
} | null | 0 | 0 | ---
tags:
- self-supervised-pretraining
language:
- ind
---
# id_frog_story
Indonesian Frog Storytelling Corpus
Indonesian written and spoken corpus, based on the twenty-eight pictures. (http://compling.hss.ntu.edu.sg/who/david/corpus/pictures.pdf)
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{FrogStorytelling,
author="Moeljadi, David",
title="Usage of Indonesian Possessive Verbal Predicates : A Statistical Analysis Based on Storytelling Survey",
journal="Tokyo University Linguistic Papers",
ISSN="1345-8663",
publisher="東京大学大学院人文社会系研究科・文学部言語学研究室",
year="2014",
month="sep",
volume="35",
number="",
pages="155-176",
URL="https://ci.nii.ac.jp/naid/120005525793/en/",
DOI="info:doi/10.15083/00027472",
}
```
## License
Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)
## Homepage
[https://github.com/matbahasa/corpus-frog-storytelling](https://github.com/matbahasa/corpus-frog-storytelling)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/x_fact | 2023-09-26T12:31:15.000Z | [
"language:ara",
"language:aze",
"language:ben",
"language:deu",
"language:spa",
"language:fas",
"language:fra",
"language:guj",
"language:hin",
"language:ind",
"language:ita",
"language:kat",
"language:mar",
"language:nor",
"language:nld",
"language:pan",
"language:pol",
"language:... | NusaCrowd | X-FACT: the largest publicly available multilingual dataset for factual verification of naturally existing realworld claims. | @inproceedings{gupta2021xfact,
title={{X-FACT: A New Benchmark Dataset for Multilingual Fact Checking}},
author={Gupta, Ashim and Srikumar, Vivek},
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
} | null | 0 | 0 | ---
license: mit
tags:
- fact-checking
language:
- ara
- aze
- ben
- deu
- spa
- fas
- fra
- guj
- hin
- ind
- ita
- kat
- mar
- nor
- nld
- pan
- pol
- por
- ron
- rus
- sin
- srp
- sqi
- tam
- tur
---
# x_fact
X-FACT: the largest publicly available multilingual dataset for factual verification of naturally existing realworld claims.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{gupta2021xfact,
title={{X-FACT: A New Benchmark Dataset for Multilingual Fact Checking}},
author={Gupta, Ashim and Srikumar, Vivek},
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
## License
MIT
## Homepage
[https://github.com/utahnlp/x-fact](https://github.com/utahnlp/x-fact)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/postag_su | 2023-09-26T12:31:19.000Z | [
"language:sun",
"pos-tagging",
"region:us"
] | NusaCrowd | This dataset contains 3616 lines of Sundanese sentences taken from several online magazines (Mangle, Dewan Dakwah Jabar, and Balebat). Annotated with PoS Labels by several undergraduates of the Sundanese Language Education Study Program (PPBS), UPI Bandung. | @data{FK2/VTAHRH_2022,
author = {ARDIYANTI SURYANI, ARIE and Widyantoro, Dwi Hendratmo and Purwarianti, Ayu and Sudaryat, Yayat},
publisher = {Telkom University Dataverse},
title = {{PoSTagged Sundanese Monolingual Corpus}},
year = {2022},
version = {DRAFT VERSION},
doi = {10.34820/FK2/VTAHRH},
url = {https://doi.org/10.34820/FK2/VTAHRH}
}
@INPROCEEDINGS{7437678,
author={Suryani, Arie Ardiyanti and Widyantoro, Dwi Hendratmo and Purwarianti, Ayu and Sudaryat, Yayat},
booktitle={2015 International Conference on Information Technology Systems and Innovation (ICITSI)},
title={Experiment on a phrase-based statistical machine translation using PoS Tag information for Sundanese into Indonesian},
year={2015},
volume={},
number={},
pages={1-6},
doi={10.1109/ICITSI.2015.7437678}
} | null | 0 | 0 | ---
tags:
- pos-tagging
language:
- sun
---
# postag_su
This dataset contains 3616 lines of Sundanese sentences taken from several online magazines (Mangle, Dewan Dakwah Jabar, and Balebat). Annotated with PoS Labels by several undergraduates of the Sundanese Language Education Study Program (PPBS), UPI Bandung.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@data{FK2/VTAHRH_2022,
author = {ARDIYANTI SURYANI, ARIE and Widyantoro, Dwi Hendratmo and Purwarianti, Ayu and Sudaryat, Yayat},
publisher = {Telkom University Dataverse},
title = {{PoSTagged Sundanese Monolingual Corpus}},
year = {2022},
version = {DRAFT VERSION},
doi = {10.34820/FK2/VTAHRH},
url = {https://doi.org/10.34820/FK2/VTAHRH}
}
@INPROCEEDINGS{7437678,
author={Suryani, Arie Ardiyanti and Widyantoro, Dwi Hendratmo and Purwarianti, Ayu and Sudaryat, Yayat},
booktitle={2015 International Conference on Information Technology Systems and Innovation (ICITSI)},
title={Experiment on a phrase-based statistical machine translation using PoS Tag information for Sundanese into Indonesian},
year={2015},
volume={},
number={},
pages={1-6},
doi={10.1109/ICITSI.2015.7437678}
}
```
## License
CC0 - "Public Domain Dedication"
## Homepage
[https://dataverse.telkomuniversity.ac.id/dataset.xhtml?persistentId=doi:10.34820/FK2/VTAHRH](https://dataverse.telkomuniversity.ac.id/dataset.xhtml?persistentId=doi:10.34820/FK2/VTAHRH)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indspeech_newstra_ethnicsr | 2023-09-26T12:31:23.000Z | [
"language:sun",
"language:jav",
"language:btk",
"language:ban",
"speech-recognition",
"region:us"
] | NusaCrowd | INDspeech_NEWSTRA_EthnicSR is a collection of graphemically balanced and parallel speech corpora of four major Indonesian ethnic languages: Javanese, Sundanese, Balinese, and Bataks. It was developed in 2013 by the Nara Institute of Science and Technology (NAIST, Japan) [Sakti et al., 2013]. The data has been used to develop Indonesian ethnic speech recognition in supervised learning [Sakti et al., 2014] and semi-supervised learning [Novitasari et al., 2020] based on Machine Speech Chain framework [Tjandra et al., 2020]. | @inproceedings{sakti-cocosda-2013,
title = "Towards Language Preservation: Design and Collection of Graphemically Balanced and Parallel Speech Corpora of {I}ndonesian Ethnic Languages",
author = "Sakti, Sakriani and Nakamura, Satoshi",
booktitle = "Proc. Oriental COCOSDA",
year = "2013",
address = "Gurgaon, India"
}
@inproceedings{sakti-sltu-2014,
title = "Recent progress in developing grapheme-based speech recognition for {I}ndonesian ethnic languages: {J}avanese, {S}undanese, {B}alinese and {B}ataks",
author = "Sakti, Sakriani and Nakamura, Satoshi",
booktitle = "Proc. 4th Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU 2014)",
year = "2014",
pages = "46--52",
address = "St. Petersburg, Russia"
}
@inproceedings{novitasari-sltu-2020,
title = "Cross-Lingual Machine Speech Chain for {J}avanese, {S}undanese, {B}alinese, and {B}ataks Speech Recognition and Synthesis",
author = "Novitasari, Sashi and Tjandra, Andros and Sakti, Sakriani and Nakamura, Satoshi",
booktitle = "Proc. Joint Workshop on Spoken Language Technologies for Under-resourced languages (SLTU) and Collaboration and Computing for Under-Resourced Languages (CCURL)",
year = "2020",
pages = "131--138",
address = "Marseille, France"
} | null | 0 | 0 | ---
tags:
- speech-recognition
language:
- sun
- jav
- btk
- ban
---
# indspeech_newstra_ethnicsr
INDspeech_NEWSTRA_EthnicSR is a collection of graphemically balanced and parallel speech corpora of four major Indonesian ethnic languages: Javanese, Sundanese, Balinese, and Bataks. It was developed in 2013 by the Nara Institute of Science and Technology (NAIST, Japan) [Sakti et al., 2013]. The data has been used to develop Indonesian ethnic speech recognition in supervised learning [Sakti et al., 2014] and semi-supervised learning [Novitasari et al., 2020] based on Machine Speech Chain framework [Tjandra et al., 2020].
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{sakti-cocosda-2013,
title = "Towards Language Preservation: Design and Collection of Graphemically Balanced and Parallel Speech Corpora of {I}ndonesian Ethnic Languages",
author = "Sakti, Sakriani and Nakamura, Satoshi",
booktitle = "Proc. Oriental COCOSDA",
year = "2013",
address = "Gurgaon, India"
}
@inproceedings{sakti-sltu-2014,
title = "Recent progress in developing grapheme-based speech recognition for {I}ndonesian ethnic languages: {J}avanese, {S}undanese, {B}alinese and {B}ataks",
author = "Sakti, Sakriani and Nakamura, Satoshi",
booktitle = "Proc. 4th Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU 2014)",
year = "2014",
pages = "46--52",
address = "St. Petersburg, Russia"
}
@inproceedings{novitasari-sltu-2020,
title = "Cross-Lingual Machine Speech Chain for {J}avanese, {S}undanese, {B}alinese, and {B}ataks Speech Recognition and Synthesis",
author = "Novitasari, Sashi and Tjandra, Andros and Sakti, Sakriani and Nakamura, Satoshi",
booktitle = "Proc. Joint Workshop on Spoken Language Technologies for Under-resourced languages (SLTU) and Collaboration and Computing for Under-Resourced Languages (CCURL)",
year = "2020",
pages = "131--138",
address = "Marseille, France"
}
```
## License
CC-BY-NC-SA 4.0
## Homepage
[https://github.com/s-sakti/data_indsp_newstra_ethnicsr](https://github.com/s-sakti/data_indsp_newstra_ethnicsr)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indolem_nerui | 2023-09-26T12:31:26.000Z | [
"language:ind",
"license:cc-by-4.0",
"named-entity-recognition",
"arxiv:2011.00677",
"region:us"
] | NusaCrowd | NER UI is a Named Entity Recognition dataset that contains 2,125 sentences obtained via an annotation assignment in an NLP course at the University of Indonesia in 2016.
The corpus has three named entity classes: location, organisation, and person with training/dev/test distribution: 1,530/170/42 and based on 5-fold cross validation. | @INPROCEEDINGS{8275098,
author={Gultom, Yohanes and Wibowo, Wahyu Catur},
booktitle={2017 International Workshop on Big Data and Information Security (IWBIS)},
title={Automatic open domain information extraction from Indonesian text},
year={2017},
volume={},
number={},
pages={23-30},
doi={10.1109/IWBIS.2017.8275098}}
@article{DBLP:journals/corr/abs-2011-00677,
author = {Fajri Koto and
Afshin Rahimi and
Jey Han Lau and
Timothy Baldwin},
title = {IndoLEM and IndoBERT: {A} Benchmark Dataset and Pre-trained Language
Model for Indonesian {NLP}},
journal = {CoRR},
volume = {abs/2011.00677},
year = {2020},
url = {https://arxiv.org/abs/2011.00677},
eprinttype = {arXiv},
eprint = {2011.00677},
timestamp = {Fri, 06 Nov 2020 15:32:47 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2011-00677.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
} | null | 0 | 0 | ---
license: cc-by-4.0
tags:
- named-entity-recognition
language:
- ind
---
# indolem_nerui
NER UI is a Named Entity Recognition dataset that contains 2,125 sentences obtained via an annotation assignment in an NLP course at the University of Indonesia in 2016.
The corpus has three named entity classes: location, organisation, and person with training/dev/test distribution: 1,530/170/42 and based on 5-fold cross validation.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@INPROCEEDINGS{8275098,
author={Gultom, Yohanes and Wibowo, Wahyu Catur},
booktitle={2017 International Workshop on Big Data and Information Security (IWBIS)},
title={Automatic open domain information extraction from Indonesian text},
year={2017},
volume={},
number={},
pages={23-30},
doi={10.1109/IWBIS.2017.8275098}}
@article{DBLP:journals/corr/abs-2011-00677,
author = {Fajri Koto and
Afshin Rahimi and
Jey Han Lau and
Timothy Baldwin},
title = {IndoLEM and IndoBERT: {A} Benchmark Dataset and Pre-trained Language
Model for Indonesian {NLP}},
journal = {CoRR},
volume = {abs/2011.00677},
year = {2020},
url = {https://arxiv.org/abs/2011.00677},
eprinttype = {arXiv},
eprint = {2011.00677},
timestamp = {Fri, 06 Nov 2020 15:32:47 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2011-00677.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
## License
Creative Commons Attribution 4.0
## Homepage
[https://indolem.github.io/](https://indolem.github.io/)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/idk_mrc | 2023-09-26T12:31:30.000Z | [
"language:ind",
"question-answering",
"arxiv:2210.13778",
"region:us"
] | NusaCrowd | I(n)dontKnow-MRC (IDK-MRC) is an Indonesian Machine Reading Comprehension dataset that covers
answerable and unanswerable questions. Based on the combination of the existing answerable questions in TyDiQA,
the new unanswerable question in IDK-MRC is generated using a question generation model and human-written question.
Each paragraph in the dataset has a set of answerable and unanswerable questions with the corresponding answer.
Besides IDK-MRC (idk_mrc) dataset, several baseline datasets also provided:
1. Trans SQuAD (trans_squad): machine translated SQuAD 2.0 (Muis and Purwarianti, 2020)
2. TyDiQA (tydiqa): Indonesian answerable questions set from the TyDiQA-GoldP (Clark et al., 2020)
3. Model Gen (model_gen): TyDiQA + the unanswerable questions output from the question generation model
4. Human Filt (human_filt): Model Gen dataset that has been filtered by human annotator | @misc{putri2022idk,
doi = {10.48550/ARXIV.2210.13778},
url = {https://arxiv.org/abs/2210.13778},
author = {Putri, Rifki Afina and Oh, Alice},
title = {IDK-MRC: Unanswerable Questions for Indonesian Machine Reading Comprehension},
publisher = {arXiv},
year = {2022}
} | null | 0 | 0 | ---
tags:
- question-answering
language:
- ind
---
# idk_mrc
I(n)dontKnow-MRC (IDK-MRC) is an Indonesian Machine Reading Comprehension dataset that covers
answerable and unanswerable questions. Based on the combination of the existing answerable questions in TyDiQA,
the new unanswerable question in IDK-MRC is generated using a question generation model and human-written question.
Each paragraph in the dataset has a set of answerable and unanswerable questions with the corresponding answer.
Besides IDK-MRC (idk_mrc) dataset, several baseline datasets also provided:
1. Trans SQuAD (trans_squad): machine translated SQuAD 2.0 (Muis and Purwarianti, 2020)
2. TyDiQA (tydiqa): Indonesian answerable questions set from the TyDiQA-GoldP (Clark et al., 2020)
3. Model Gen (model_gen): TyDiQA + the unanswerable questions output from the question generation model
4. Human Filt (human_filt): Model Gen dataset that has been filtered by human annotator
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@misc{putri2022idk,
doi = {10.48550/ARXIV.2210.13778},
url = {https://arxiv.org/abs/2210.13778},
author = {Putri, Rifki Afina and Oh, Alice},
title = {IDK-MRC: Unanswerable Questions for Indonesian Machine Reading Comprehension},
publisher = {arXiv},
year = {2022}
}
```
## License
CC-BY-SA 4.0
## Homepage
[https://github.com/rifkiaputri/IDK-MRC](https://github.com/rifkiaputri/IDK-MRC)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/tydiqa_id | 2023-09-26T12:31:34.000Z | [
"language:ind",
"question-answering",
"region:us"
] | NusaCrowd | TyDiQA dataset is collected from Wikipedia articles with human-annotated question and answer pairs covering 11 languages.
The question-answer pairs are collected for each language without using translation services.
IndoNLG uses the Indonesian data from the secondary Gold passage task of the original TyDiQA dataset and
randomly split off 15% of the training data and use it as the test set. | @article{clark-etal-2020-tydi,
title = "{T}y{D}i {QA}: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages",
author = "Clark, Jonathan H. and
Choi, Eunsol and
Collins, Michael and
Garrette, Dan and
Kwiatkowski, Tom and
Nikolaev, Vitaly and
Palomaki, Jennimaria",
journal = "Transactions of the Association for Computational Linguistics",
volume = "8",
year = "2020",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/2020.tacl-1.30",
doi = "10.1162/tacl_a_00317",
pages = "454--470",
}
@inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898"
} | null | 0 | 0 | ---
tags:
- question-answering
language:
- ind
---
# tydiqa_id
TyDiQA dataset is collected from Wikipedia articles with human-annotated question and answer pairs covering 11 languages.
The question-answer pairs are collected for each language without using translation services.
IndoNLG uses the Indonesian data from the secondary Gold passage task of the original TyDiQA dataset and
randomly split off 15% of the training data and use it as the test set.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{clark-etal-2020-tydi,
title = "{T}y{D}i {QA}: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages",
author = "Clark, Jonathan H. and
Choi, Eunsol and
Collins, Michael and
Garrette, Dan and
Kwiatkowski, Tom and
Nikolaev, Vitaly and
Palomaki, Jennimaria",
journal = "Transactions of the Association for Computational Linguistics",
volume = "8",
year = "2020",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/2020.tacl-1.30",
doi = "10.1162/tacl_a_00317",
pages = "454--470",
}
@inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898"
}
```
## License
Creative Common Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/indonlg](https://github.com/IndoNLP/indonlg)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/korpus_nusantara | 2023-09-26T12:31:37.000Z | [
"language:ind",
"language:jav",
"language:xdy",
"language:bug",
"language:sun",
"language:mad",
"language:bjn",
"language:bbc",
"language:msa",
"language:min",
"license:unknown",
"machine-translation",
"region:us"
] | NusaCrowd | This parallel corpus was collected from several studies, assignments, and thesis of
students of the Informatics Study Program, Tanjungpura University. Some of the corpus
are used in the translation machine from Indonesian to local languages http://nustor.untan.ac.id/cammane/.
This corpus can be used freely for research purposes by citing the paper
https://ijece.iaescore.com/index.php/IJECE/article/download/20046/13738.
The dataset is a combination of multiple machine translation works from the author,
Herry Sujaini, covering Indonesian to 25 local dialects in Indonesia. Since not all
dialects have ISO639-3 standard coding, as agreed with Pak Herry , we decided to
group the dataset into the closest language family, i.e.: Javanese, Dayak, Buginese,
Sundanese, Madurese, Banjar, Batak Toba, Khek, Malay, Minangkabau, and Tiociu. | @article{sujaini2020improving,
title={Improving the role of language model in statistical machine translation (Indonesian-Javanese)},
author={Sujaini, Herry},
journal={International Journal of Electrical and Computer Engineering},
volume={10},
number={2},
pages={2102},
year={2020},
publisher={IAES Institute of Advanced Engineering and Science}
} | null | 0 | 0 | ---
license: unknown
tags:
- machine-translation
language:
- ind
- jav
- xdy
- bug
- sun
- mad
- bjn
- bbc
- msa
- min
---
# korpus_nusantara
This parallel corpus was collected from several studies, assignments, and thesis of
students of the Informatics Study Program, Tanjungpura University. Some of the corpus
are used in the translation machine from Indonesian to local languages http://nustor.untan.ac.id/cammane/.
This corpus can be used freely for research purposes by citing the paper
https://ijece.iaescore.com/index.php/IJECE/article/download/20046/13738.
The dataset is a combination of multiple machine translation works from the author,
Herry Sujaini, covering Indonesian to 25 local dialects in Indonesia. Since not all
dialects have ISO639-3 standard coding, as agreed with Pak Herry , we decided to
group the dataset into the closest language family, i.e.: Javanese, Dayak, Buginese,
Sundanese, Madurese, Banjar, Batak Toba, Khek, Malay, Minangkabau, and Tiociu.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@article{sujaini2020improving,
title={Improving the role of language model in statistical machine translation (Indonesian-Javanese)},
author={Sujaini, Herry},
journal={International Journal of Electrical and Computer Engineering},
volume={10},
number={2},
pages={2102},
year={2020},
publisher={IAES Institute of Advanced Engineering and Science}
}
```
## License
Unknown
## Homepage
[https://github.com/herrysujaini/korpusnusantara](https://github.com/herrysujaini/korpusnusantara)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_am2ico | 2023-09-26T12:31:44.000Z | [
"language:ind",
"language:eng",
"concept-alignment-classification",
"region:us"
] | NusaCrowd | In this work, we present AM2iCo, a wide-coverage and carefully designed cross-lingual and multilingual evaluation set;
it aims to assess the ability of state-of-the-art representation models to reason over cross-lingual
lexical-level concept alignment in context for 14 language pairs.
This dataset only contain Indonesian - English language pair. | @inproceedings{liu-etal-2021-am2ico,
title = "{AM}2i{C}o: Evaluating Word Meaning in Context across Low-Resource Languages with Adversarial Examples",
author = "Liu, Qianchu and
Ponti, Edoardo Maria and
McCarthy, Diana and
Vuli{\'c}, Ivan and
Korhonen, Anna",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.571",
doi = "10.18653/v1/2021.emnlp-main.571",
pages = "7151--7162",
abstract = "Capturing word meaning in context and distinguishing between correspondences and variations across languages is key to building successful multilingual and cross-lingual text representation models. However, existing multilingual evaluation datasets that evaluate lexical semantics {``}in-context{''} have various limitations. In particular, 1) their language coverage is restricted to high-resource languages and skewed in favor of only a few language families and areas, 2) a design that makes the task solvable via superficial cues, which results in artificially inflated (and sometimes super-human) performances of pretrained encoders, and 3) no support for cross-lingual evaluation. In order to address these gaps, we present AM2iCo (Adversarial and Multilingual Meaning in Context), a wide-coverage cross-lingual and multilingual evaluation set; it aims to faithfully assess the ability of state-of-the-art (SotA) representation models to understand the identity of word meaning in cross-lingual contexts for 14 language pairs. We conduct a series of experiments in a wide range of setups and demonstrate the challenging nature of AM2iCo. The results reveal that current SotA pretrained encoders substantially lag behind human performance, and the largest gaps are observed for low-resource languages and languages dissimilar to English.",
} | null | 0 | 0 | ---
tags:
- concept-alignment-classification
language:
- ind
- eng
---
# id_am2ico
In this work, we present AM2iCo, a wide-coverage and carefully designed cross-lingual and multilingual evaluation set;
it aims to assess the ability of state-of-the-art representation models to reason over cross-lingual
lexical-level concept alignment in context for 14 language pairs.
This dataset only contain Indonesian - English language pair.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{liu-etal-2021-am2ico,
title = "{AM}2i{C}o: Evaluating Word Meaning in Context across Low-Resource Languages with Adversarial Examples",
author = "Liu, Qianchu and
Ponti, Edoardo Maria and
McCarthy, Diana and
Vuli{'c}, Ivan and
Korhonen, Anna",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.571",
doi = "10.18653/v1/2021.emnlp-main.571",
pages = "7151--7162",
abstract = "Capturing word meaning in context and distinguishing between correspondences and variations across languages is key to building successful multilingual and cross-lingual text representation models. However, existing multilingual evaluation datasets that evaluate lexical semantics {``}in-context{''} have various limitations. In particular, 1) their language coverage is restricted to high-resource languages and skewed in favor of only a few language families and areas, 2) a design that makes the task solvable via superficial cues, which results in artificially inflated (and sometimes super-human) performances of pretrained encoders, and 3) no support for cross-lingual evaluation. In order to address these gaps, we present AM2iCo (Adversarial and Multilingual Meaning in Context), a wide-coverage cross-lingual and multilingual evaluation set; it aims to faithfully assess the ability of state-of-the-art (SotA) representation models to understand the identity of word meaning in cross-lingual contexts for 14 language pairs. We conduct a series of experiments in a wide range of setups and demonstrate the challenging nature of AM2iCo. The results reveal that current SotA pretrained encoders substantially lag behind human performance, and the largest gaps are observed for low-resource languages and languages dissimilar to English.",
}
```
## License
CC-BY 4.0
## Homepage
[https://github.com/cambridgeltl/AM2iCo](https://github.com/cambridgeltl/AM2iCo)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/casa | 2023-09-26T12:31:48.000Z | [
"language:ind",
"aspect-based-sentiment-analysis",
"region:us"
] | NusaCrowd | CASA: An aspect-based sentiment analysis dataset consisting of around a thousand car reviews collected from multiple Indonesian online automobile platforms (Ilmania et al., 2018).
The dataset covers six aspects of car quality.
We define the task to be a multi-label classification task,
where each label represents a sentiment for a single aspect with three possible values: positive, negative, and neutral. | @INPROCEEDINGS{8629181,
author={Ilmania, Arfinda and Abdurrahman and Cahyawijaya, Samuel and Purwarianti, Ayu},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
title={Aspect Detection and Sentiment Classification Using Deep Neural Network for Indonesian Aspect-Based Sentiment Analysis},
year={2018},
volume={},
number={},
pages={62-67},
doi={10.1109/IALP.2018.8629181
} | null | 0 | 0 | ---
tags:
- aspect-based-sentiment-analysis
language:
- ind
---
# casa
CASA: An aspect-based sentiment analysis dataset consisting of around a thousand car reviews collected from multiple Indonesian online automobile platforms (Ilmania et al., 2018).
The dataset covers six aspects of car quality.
We define the task to be a multi-label classification task,
where each label represents a sentiment for a single aspect with three possible values: positive, negative, and neutral.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@INPROCEEDINGS{8629181,
author={Ilmania, Arfinda and Abdurrahman and Cahyawijaya, Samuel and Purwarianti, Ayu},
booktitle={2018 International Conference on Asian Language Processing (IALP)},
title={Aspect Detection and Sentiment Classification Using Deep Neural Network for Indonesian Aspect-Based Sentiment Analysis},
year={2018},
volume={},
number={},
pages={62-67},
doi={10.1109/IALP.2018.8629181
}
```
## License
CC-BY-SA 4.0
## Homepage
[https://github.com/IndoNLP/indonlu](https://github.com/IndoNLP/indonlu)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/indspeech_news_lvcsr | 2023-09-26T12:31:52.000Z | [
"language:ind",
"speech-recognition",
"region:us"
] | NusaCrowd | This is the first Indonesian speech dataset for large vocabulary continuous speech recognition (LVCSR) with more than 40 hours of speech and 400 speakers [Sakti et al., 2008]. R&D Division of PT Telekomunikasi Indonesia (TELKOMRisTI) developed the data in 2005-2006, in collaboration with Advanced Telecommunication Research Institute International (ATR) Japan, as the continuation of the Asia-Pacific Telecommunity (APT) project [Sakti et al., 2004]. It has also been successfully used for developing Indonesian LVCSR in the Asian speech translation advanced research (A-STAR) project [Sakti et al., 2013]. | @inproceedings{sakti-tcast-2008,
title = "Development of {I}ndonesian Large Vocabulary Continuous Speech Recognition System within {A-STAR} Project",
author = "Sakti, Sakriani and Kelana, Eka and Riza, Hammam and Sakai, Shinsuke and Markov, Konstantin and Nakamura, Satoshi",
booktitle = "Proc. IJCNLP Workshop on Technologies and Corpora for Asia-Pacific Speech Translation (TCAST)",
year = "2008",
pages = "19--24"
address = "Hyderabad, India"
}
@inproceedings{sakti-icslp-2004,
title = "Indonesian Speech Recognition for Hearing and Speaking Impaired People",
author = "Sakti, Sakriani and Hutagaol, Paulus and Arman, Arry Akhmad and Nakamura, Satoshi",
booktitle = "Proc. International Conference on Spoken Language Processing (INTERSPEECH - ICSLP)",
year = "2004",
pages = "1037--1040"
address = "Jeju Island, Korea"
}
@article{sakti-s2st-csl-2013,
title = "{A-STAR}: Toward Translating Asian Spoken Languages",
author = "Sakti, Sakriani and Paul, Michael and Finch, Andrew and Sakai, Shinsuke and Thang, Tat Vu, and Kimura, Noriyuki and Hori, Chiori and Sumita, Eiichiro and Nakamura, Satoshi and Park, Jun and Wutiwiwatchai, Chai and Xu, Bo and Riza, Hammam and Arora, Karunesh and Luong, Chi Mai and Li, Haizhou",
journal = "Special issue on Speech-to-Speech Translation, Computer Speech and Language Journal",
volume = "27",
number ="2",
pages = "509--527",
year = "2013",
publisher = "Elsevier"
} | null | 0 | 0 | ---
tags:
- speech-recognition
language:
- ind
---
# indspeech_news_lvcsr
This is the first Indonesian speech dataset for large vocabulary continuous speech recognition (LVCSR) with more than 40 hours of speech and 400 speakers [Sakti et al., 2008]. R&D Division of PT Telekomunikasi Indonesia (TELKOMRisTI) developed the data in 2005-2006, in collaboration with Advanced Telecommunication Research Institute International (ATR) Japan, as the continuation of the Asia-Pacific Telecommunity (APT) project [Sakti et al., 2004]. It has also been successfully used for developing Indonesian LVCSR in the Asian speech translation advanced research (A-STAR) project [Sakti et al., 2013].
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{sakti-tcast-2008,
title = "Development of {I}ndonesian Large Vocabulary Continuous Speech Recognition System within {A-STAR} Project",
author = "Sakti, Sakriani and Kelana, Eka and Riza, Hammam and Sakai, Shinsuke and Markov, Konstantin and Nakamura, Satoshi",
booktitle = "Proc. IJCNLP Workshop on Technologies and Corpora for Asia-Pacific Speech Translation (TCAST)",
year = "2008",
pages = "19--24"
address = "Hyderabad, India"
}
@inproceedings{sakti-icslp-2004,
title = "Indonesian Speech Recognition for Hearing and Speaking Impaired People",
author = "Sakti, Sakriani and Hutagaol, Paulus and Arman, Arry Akhmad and Nakamura, Satoshi",
booktitle = "Proc. International Conference on Spoken Language Processing (INTERSPEECH - ICSLP)",
year = "2004",
pages = "1037--1040"
address = "Jeju Island, Korea"
}
@article{sakti-s2st-csl-2013,
title = "{A-STAR}: Toward Translating Asian Spoken Languages",
author = "Sakti, Sakriani and Paul, Michael and Finch, Andrew and Sakai, Shinsuke and Thang, Tat Vu, and Kimura, Noriyuki and Hori, Chiori and Sumita, Eiichiro and Nakamura, Satoshi and Park, Jun and Wutiwiwatchai, Chai and Xu, Bo and Riza, Hammam and Arora, Karunesh and Luong, Chi Mai and Li, Haizhou",
journal = "Special issue on Speech-to-Speech Translation, Computer Speech and Language Journal",
volume = "27",
number ="2",
pages = "509--527",
year = "2013",
publisher = "Elsevier"
}
```
## License
CC BY-NC-SA 4.0
## Homepage
[https://github.com/s-sakti/data_indsp_news_lvcsr](https://github.com/s-sakti/data_indsp_news_lvcsr)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/kopi_nllb | 2023-09-26T12:31:56.000Z | [
"language:ind",
"language:jav",
"language:ace",
"language:ban",
"language:bjn",
"language:min",
"language:sun",
"self-supervised-pretraining",
"arxiv:2205.12654",
"arxiv:2207.04672",
"region:us"
] | NusaCrowd |
KopI(Korpus Perayapan Indonesia)-NLLB, is Indonesian family language(aceh,bali,banjar,indonesia,jawa,minang,sunda) only extracted from NLLB Dataset, allenai/nllb
each language set also filtered using some some deduplicate technique such as exact hash(md5) dedup technique and minhash LSH neardup | Hefferman et al, Bitext Mining Using Distilled Sentence Representations for Low-Resource Languages. Arxiv https://arxiv.org/abs/2205.12654, 2022.
NLLB Team et al, No Language Left Behind: Scaling Human-Centered Machine Translation, Arxiv https://arxiv.org/abs/2207.04672, 2022. | null | 0 | 0 | ---
tags:
- self-supervised-pretraining
language:
- ind
- jav
- ace
- ban
- bjn
- min
- sun
---
# kopi_nllb
KopI(Korpus Perayapan Indonesia)-NLLB, is Indonesian family language(aceh,bali,banjar,indonesia,jawa,minang,sunda) only extracted from NLLB Dataset, allenai/nllb
each language set also filtered using some some deduplicate technique such as exact hash(md5) dedup technique and minhash LSH neardup
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
Hefferman et al, Bitext Mining Using Distilled Sentence Representations for Low-Resource Languages. Arxiv https://arxiv.org/abs/2205.12654, 2022.
NLLB Team et al, No Language Left Behind: Scaling Human-Centered Machine Translation, Arxiv https://arxiv.org/abs/2207.04672, 2022.
```
## License
ODC_C
## Homepage
[https://huggingface.co/datasets/munggok/KoPI-NLLB](https://huggingface.co/datasets/munggok/KoPI-NLLB)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/id_panl_bppt | 2023-09-26T12:32:02.000Z | [
"language:ind",
"machine-translation",
"region:us"
] | NusaCrowd | Parallel Text Corpora for Multi-Domain Translation System created by BPPT (Indonesian Agency for the Assessment and
Application of Technology) for PAN Localization Project (A Regional Initiative to Develop Local Language Computing
Capacity in Asia). The dataset contains about 24K sentences in English and Bahasa Indonesia from 4 different topics
(Economy, International Affairs, Science & Technology, and Sports). | @inproceedings{id_panl_bppt,
author = {PAN Localization - BPPT},
title = {Parallel Text Corpora, English Indonesian},
year = {2009},
url = {http://digilib.bppt.go.id/sampul/p92-budiono.pdf},
} | null | 0 | 0 | ---
tags:
- machine-translation
language:
- ind
---
# id_panl_bppt
Parallel Text Corpora for Multi-Domain Translation System created by BPPT (Indonesian Agency for the Assessment and
Application of Technology) for PAN Localization Project (A Regional Initiative to Develop Local Language Computing
Capacity in Asia). The dataset contains about 24K sentences in English and Bahasa Indonesia from 4 different topics
(Economy, International Affairs, Science & Technology, and Sports).
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{id_panl_bppt,
author = {PAN Localization - BPPT},
title = {Parallel Text Corpora, English Indonesian},
year = {2009},
url = {http://digilib.bppt.go.id/sampul/p92-budiono.pdf},
}
```
## Homepage
[http://digilib.bppt.go.id/sampul/p92-budiono.pdf](http://digilib.bppt.go.id/sampul/p92-budiono.pdf)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/inset_lexicon | 2023-09-26T12:32:05.000Z | [
"language:ind",
"license:unknown",
"sentiment-analysis",
"region:us"
] | NusaCrowd | InSet, an Indonesian sentiment lexicon built to identify written opinion and categorize it into positive or negative opinion,
which could be utilized to analyze public sentiment towards particular topic, event, or product. Composed using collection
of words from Indonesian tweet, InSet was constructed by manually weighting each words and enhanced by adding stemming and synonym set | @inproceedings{inproceedings,
author = {Koto, Fajri and Rahmaningtyas, Gemala},
year = {2017},
month = {12},
pages = {},
title = {InSet Lexicon: Evaluation of a Word List for Indonesian Sentiment Analysis in Microblogs},
doi = {10.1109/IALP.2017.8300625}
} | null | 0 | 0 | ---
license: unknown
tags:
- sentiment-analysis
language:
- ind
---
# inset_lexicon
InSet, an Indonesian sentiment lexicon built to identify written opinion and categorize it into positive or negative opinion,
which could be utilized to analyze public sentiment towards particular topic, event, or product. Composed using collection
of words from Indonesian tweet, InSet was constructed by manually weighting each words and enhanced by adding stemming and synonym set
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{inproceedings,
author = {Koto, Fajri and Rahmaningtyas, Gemala},
year = {2017},
month = {12},
pages = {},
title = {InSet Lexicon: Evaluation of a Word List for Indonesian Sentiment Analysis in Microblogs},
doi = {10.1109/IALP.2017.8300625}
}
```
## License
Unknown
## Homepage
[https://www.researchgate.net/publication/321757985_InSet_Lexicon_Evaluation_of_a_Word_List_for_Indonesian_Sentiment_Analysis_in_Microblogs](https://www.researchgate.net/publication/321757985_InSet_Lexicon_Evaluation_of_a_Word_List_for_Indonesian_Sentiment_Analysis_in_Microblogs)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/titml_idn | 2023-09-26T12:32:09.000Z | [
"language:ind",
"speech-recognition",
"region:us"
] | NusaCrowd | TITML-IDN (Tokyo Institute of Technology Multilingual - Indonesian) is collected to build a pioneering Indonesian Large Vocabulary Continuous Speech Recognition (LVCSR) System. In order to build an LVCSR system, high accurate acoustic models and large-scale language models are essential. Since Indonesian speech corpus was not available yet, we tried to collect speech data from 20 Indonesian native speakers (11 males and 9 females) to construct a speech corpus for training the acoustic model based on Hidden Markov Models (HMMs). A text corpus which was collected by ILPS, Informatics Institute, University of Amsterdam, was used to build a 40K-vocabulary dictionary and a n-gram language model. | @inproceedings{lestari2006titmlidn,
title={A large vocabulary continuous speech recognition system for Indonesian language},
author={Lestari, Dessi Puji and Iwano, Koji and Furui, Sadaoki},
booktitle={15th Indonesian Scientific Conference in Japan Proceedings},
pages={17--22},
year={2006}
} | null | 0 | 0 | ---
tags:
- speech-recognition
language:
- ind
---
# titml_idn
TITML-IDN (Tokyo Institute of Technology Multilingual - Indonesian) is collected to build a pioneering Indonesian Large Vocabulary Continuous Speech Recognition (LVCSR) System. In order to build an LVCSR system, high accurate acoustic models and large-scale language models are essential. Since Indonesian speech corpus was not available yet, we tried to collect speech data from 20 Indonesian native speakers (11 males and 9 females) to construct a speech corpus for training the acoustic model based on Hidden Markov Models (HMMs). A text corpus which was collected by ILPS, Informatics Institute, University of Amsterdam, was used to build a 40K-vocabulary dictionary and a n-gram language model.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{lestari2006titmlidn,
title={A large vocabulary continuous speech recognition system for Indonesian language},
author={Lestari, Dessi Puji and Iwano, Koji and Furui, Sadaoki},
booktitle={15th Indonesian Scientific Conference in Japan Proceedings},
pages={17--22},
year={2006}
}
```
## License
For research purposes only. If you use this corpus, you have to cite (Lestari et al, 2006).
## Homepage
[http://research.nii.ac.jp/src/en/TITML-IDN.html](http://research.nii.ac.jp/src/en/TITML-IDN.html)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/posp | 2023-09-26T12:32:13.000Z | [
"language:ind",
"pos-tagging",
"region:us"
] | NusaCrowd | POSP is a POS Tagging dataset containing 8400 sentences, collected from Indonesian news website with 26 POS tag classes.
The POS tag labels follow the Indonesian Association of Computational Linguistics (INACL) POS Tagging Convention.
POSP dataset is splitted into 3 sets with 6720 train, 840 validation, and 840 test data. | @inproceedings{hoesen2018investigating,
title={Investigating Bi-LSTM and CRF with POS Tag Embedding for Indonesian Named Entity Tagger},
author={Devin Hoesen and Ayu Purwarianti},
booktitle={Proceedings of the 2018 International Conference on Asian Language Processing (IALP)},
pages={35--38},
year={2018},
organization={IEEE}
}
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Bryan Wilie and Karissa Vincentio and Genta Indra Winata and Samuel Cahyawijaya and X. Li and Zhi Yuan Lim and S. Soleman and R. Mahendra and Pascale Fung and Syafri Bahar and A. Purwarianti},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
year={2020}
} | null | 0 | 0 | ---
tags:
- pos-tagging
language:
- ind
---
# posp
POSP is a POS Tagging dataset containing 8400 sentences, collected from Indonesian news website with 26 POS tag classes.
The POS tag labels follow the Indonesian Association of Computational Linguistics (INACL) POS Tagging Convention.
POSP dataset is splitted into 3 sets with 6720 train, 840 validation, and 840 test data.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{hoesen2018investigating,
title={Investigating Bi-LSTM and CRF with POS Tag Embedding for Indonesian Named Entity Tagger},
author={Devin Hoesen and Ayu Purwarianti},
booktitle={Proceedings of the 2018 International Conference on Asian Language Processing (IALP)},
pages={35--38},
year={2018},
organization={IEEE}
}
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Bryan Wilie and Karissa Vincentio and Genta Indra Winata and Samuel Cahyawijaya and X. Li and Zhi Yuan Lim and S. Soleman and R. Mahendra and Pascale Fung and Syafri Bahar and A. Purwarianti},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
year={2020}
}
```
## License
Creative Common Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/indonlu](https://github.com/IndoNLP/indonlu)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/nusax_senti | 2023-09-26T12:32:17.000Z | [
"language:ind",
"language:ace",
"language:ban",
"language:bjn",
"language:bbc",
"language:bug",
"language:jav",
"language:mad",
"language:min",
"language:nij",
"language:sun",
"language:eng",
"sentiment-analysis",
"arxiv:2205.15960",
"region:us"
] | NusaCrowd | NusaX is a high-quality multilingual parallel corpus that covers 12 languages, Indonesian, English, and 10 Indonesian local languages, namely Acehnese, Balinese, Banjarese, Buginese, Madurese, Minangkabau, Javanese, Ngaju, Sundanese, and Toba Batak.
NusaX-Senti is a 3-labels (positive, neutral, negative) sentiment analysis dataset for 10 Indonesian local languages + Indonesian and English. | @misc{winata2022nusax,
title={NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages},
author={Winata, Genta Indra and Aji, Alham Fikri and Cahyawijaya,
Samuel and Mahendra, Rahmad and Koto, Fajri and Romadhony,
Ade and Kurniawan, Kemal and Moeljadi, David and Prasojo,
Radityo Eko and Fung, Pascale and Baldwin, Timothy and Lau,
Jey Han and Sennrich, Rico and Ruder, Sebastian},
year={2022},
eprint={2205.15960},
archivePrefix={arXiv},
primaryClass={cs.CL}
} | null | 0 | 0 | ---
tags:
- sentiment-analysis
language:
- ind
- ace
- ban
- bjn
- bbc
- bug
- jav
- mad
- min
- nij
- sun
- eng
---
# nusax_senti
NusaX is a high-quality multilingual parallel corpus that covers 12 languages, Indonesian, English, and 10 Indonesian local languages, namely Acehnese, Balinese, Banjarese, Buginese, Madurese, Minangkabau, Javanese, Ngaju, Sundanese, and Toba Batak.
NusaX-Senti is a 3-labels (positive, neutral, negative) sentiment analysis dataset for 10 Indonesian local languages + Indonesian and English.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@misc{winata2022nusax,
title={NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages},
author={Winata, Genta Indra and Aji, Alham Fikri and Cahyawijaya,
Samuel and Mahendra, Rahmad and Koto, Fajri and Romadhony,
Ade and Kurniawan, Kemal and Moeljadi, David and Prasojo,
Radityo Eko and Fung, Pascale and Baldwin, Timothy and Lau,
Jey Han and Sennrich, Rico and Ruder, Sebastian},
year={2022},
eprint={2205.15960},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
Creative Commons Attribution Share-Alike 4.0 International
## Homepage
[https://github.com/IndoNLP/nusax/tree/main/datasets/sentiment](https://github.com/IndoNLP/nusax/tree/main/datasets/sentiment)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/barasa | 2023-09-26T12:32:24.000Z | [
"language:ind",
"license:mit",
"sentiment-analysis",
"region:us"
] | NusaCrowd | The Barasa dataset is an Indonesian SentiWordNet for sentiment analysis.
For each term, the pair (POS,ID) uniquely identifies a WordNet (3.0) synset and there are PosScore and NegScore to show the positivity and negativity of the term.
The objectivity score can be calculated as: ObjScore = 1 - (PosScore + NegScore). | @inproceedings{baccianella-etal-2010-sentiwordnet,
title = "{S}enti{W}ord{N}et 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining",
author = "Baccianella, Stefano and
Esuli, Andrea and
Sebastiani, Fabrizio",
booktitle = "Proceedings of the Seventh International Conference on Language Resources and Evaluation ({LREC}'10)",
month = may,
year = "2010",
address = "Valletta, Malta",
publisher = "European Language Resources Association (ELRA)",
url = "http://www.lrec-conf.org/proceedings/lrec2010/pdf/769_Paper.pdf",
abstract = "In this work we present SENTIWORDNET 3.0, a lexical resource explicitly devised for supporting sentiment classification and opinion mining applications. SENTIWORDNET 3.0 is an improved version of SENTIWORDNET 1.0, a lexical resource publicly available for research purposes, now currently licensed to more than 300 research groups and used in a variety of research projects worldwide. Both SENTIWORDNET 1.0 and 3.0 are the result of automatically annotating all WORDNET synsets according to their degrees of positivity, negativity, and neutrality. SENTIWORDNET 1.0 and 3.0 differ (a) in the versions of WORDNET which they annotate (WORDNET 2.0 and 3.0, respectively), (b) in the algorithm used for automatically annotating WORDNET, which now includes (additionally to the previous semi-supervised learning step) a random-walk step for refining the scores. We here discuss SENTIWORDNET 3.0, especially focussing on the improvements concerning aspect (b) that it embodies with respect to version 1.0. We also report the results of evaluating SENTIWORDNET 3.0 against a fragment of WORDNET 3.0 manually annotated for positivity, negativity, and neutrality; these results indicate accuracy improvements of about 20{\%} with respect to SENTIWORDNET 1.0.",
}
@misc{moeljadi_2016,
title={Neocl/Barasa: Indonesian SentiWordNet},
url={https://github.com/neocl/barasa},
journal={GitHub},
author={Moeljadi, David},
year={2016}, month={Mar}
} | null | 0 | 0 | ---
license: mit
tags:
- sentiment-analysis
language:
- ind
---
# barasa
The Barasa dataset is an Indonesian SentiWordNet for sentiment analysis.
For each term, the pair (POS,ID) uniquely identifies a WordNet (3.0) synset and there are PosScore and NegScore to show the positivity and negativity of the term.
The objectivity score can be calculated as: ObjScore = 1 - (PosScore + NegScore).
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@inproceedings{baccianella-etal-2010-sentiwordnet,
title = "{S}enti{W}ord{N}et 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining",
author = "Baccianella, Stefano and
Esuli, Andrea and
Sebastiani, Fabrizio",
booktitle = "Proceedings of the Seventh International Conference on Language Resources and Evaluation ({LREC}'10)",
month = may,
year = "2010",
address = "Valletta, Malta",
publisher = "European Language Resources Association (ELRA)",
url = "http://www.lrec-conf.org/proceedings/lrec2010/pdf/769_Paper.pdf",
abstract = "In this work we present SENTIWORDNET 3.0, a lexical resource explicitly devised for supporting sentiment classification and opinion mining applications. SENTIWORDNET 3.0 is an improved version of SENTIWORDNET 1.0, a lexical resource publicly available for research purposes, now currently licensed to more than 300 research groups and used in a variety of research projects worldwide. Both SENTIWORDNET 1.0 and 3.0 are the result of automatically annotating all WORDNET synsets according to their degrees of positivity, negativity, and neutrality. SENTIWORDNET 1.0 and 3.0 differ (a) in the versions of WORDNET which they annotate (WORDNET 2.0 and 3.0, respectively), (b) in the algorithm used for automatically annotating WORDNET, which now includes (additionally to the previous semi-supervised learning step) a random-walk step for refining the scores. We here discuss SENTIWORDNET 3.0, especially focussing on the improvements concerning aspect (b) that it embodies with respect to version 1.0. We also report the results of evaluating SENTIWORDNET 3.0 against a fragment of WORDNET 3.0 manually annotated for positivity, negativity, and neutrality; these results indicate accuracy improvements of about 20{\%} with respect to SENTIWORDNET 1.0.",
}
@misc{moeljadi_2016,
title={Neocl/Barasa: Indonesian SentiWordNet},
url={https://github.com/neocl/barasa},
journal={GitHub},
author={Moeljadi, David},
year={2016}, month={Mar}
}
```
## License
MIT
## Homepage
[https://github.com/neocl/barasa](https://github.com/neocl/barasa)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) |
NusaCrowd/kawat | 2023-09-26T12:32:25.000Z | [
"region:us"
] | NusaCrowd | We introduced KaWAT (Kata Word Analogy Task), a new word analogy task dataset for Indonesian.
We evaluated on it several existing pretrained Indonesian word embeddings and embeddings trained on Indonesian online news corpus.
We also tested them on two downstream tasks and found that pretrained word embeddings helped either by reducing the training epochs
or yielding significant performance gains. | @article{kurniawan2019,
title={KaWAT: A Word Analogy Task Dataset for Indonesian},
url={http://arxiv.org/abs/1906.09912},
journal={arXiv:1906.09912 [cs]},
author={Kurniawan, Kemal},
year={2019},
month={Jun}
} | null | 0 | 0 | Entry not found |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.