
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
Weni/Zeroshot_Train-20K_other_tweet-format | 2023-09-28T18:41:59.000Z | [
"task_categories:zero-shot-classification",
"size_categories:10K<n<100K",
"language:pt",
"region:us"
] | Weni | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: source_text
dtype: string
- name: target_text
dtype: string
splits:
- name: train
num_bytes: 4369715
num_examples: 20000
download_size: 1752054
dataset_size: 4369715
language:
- pt
size_categories:
- 10K<n<100K
task_categories:
- zero-shot-classification
---
# Dataset Card for "Zeroshot_Train-20K_other_tweet-format"
This dataset is a train dataset for the Zeroshot models.
It has 20.000 data in a prompt format exclusively for train with class 'other' in Brazilian Portuguese.
Prompt:
```
"Classifique o tweet entre 'classe1', 'classe2', 'classe3', 'classe4', 'other' \\n\\nTweet: frase \\n\\nLabel: 'other'
```
The dataset was divided as follows: <br>
```
- 6,000 data: prompt with class option without target class (other)
- 7,000 data: prompt with class option + target class included as an option. target class is not correct
- 7,000 data: prompt with class option + target class. target class is correct
```
## How to load and use this dataset:
```
from datasets import load_dataset
dataset = load_dataset("Weni/Zeroshot_Train-20K_other_tweet-format")
dataset
```
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/tachibana_nina_citrus | 2023-09-28T15:51:08.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of Tachibana Nina
This is the dataset of Tachibana Nina, containing 44 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:----------------|---------:|:----------------------------------------|:-----------------------------------------------------------------------------------------|
| raw | 44 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 102 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| raw-stage3-eyes | 133 | [Download](dataset-raw-stage3-eyes.zip) | 3-stage cropped (with eye-focus) raw data with meta information. |
| 384x512 | 44 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x704 | 44 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x880 | 44 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 102 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 102 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-p512-640 | 83 | [Download](dataset-stage3-p512-640.zip) | 3-stage cropped dataset with the area not less than 512x512 pixels. |
| stage3-eyes-640 | 133 | [Download](dataset-stage3-eyes-640.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 640 pixels. |
| stage3-eyes-800 | 133 | [Download](dataset-stage3-eyes-800.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 800 pixels. |
|
Yahir/voic | 2023-09-29T14:14:08.000Z | [
"region:us"
] | Yahir | null | null | null | 0 | 0 | Entry not found |
udmurtNLP/tatoeba-rus-udm-parallel-corpora | 2023-09-28T16:30:59.000Z | [
"task_categories:translation",
"size_categories:n<1K",
"language:udm",
"region:us"
] | udmurtNLP | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: rus
dtype: string
- name: udm
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 80931
num_examples: 889
download_size: 39673
dataset_size: 80931
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
task_categories:
- translation
language:
- udm
size_categories:
- n<1K
---
# Udmurt-Russian dataset from Tatoeba
Contains 888 Russian-Udmurt sentences. Punctuation added to some sentences. Dump downloaded 28.09.2023.
## Usage
```py
from datasets import load_dataset
dataset = load_dataset("udmurtNLP/tatoeba-rus-udm-parallel-corpora")
``` |
Raid41/rvc | 2023-09-28T16:52:36.000Z | [
"region:us"
] | Raid41 | null | null | null | 0 | 0 | Entry not found |
zrthxn/SmilingOrNot | 2023-09-28T16:41:56.000Z | [
"region:us"
] | zrthxn | null | null | null | 0 | 0 | # Similing or Not
A dataset comprised of closeups of people's faces, belonging to 2 binary classes.
- 600 smiling faces in the "smile" folder.
- 603 non smiling faces in the "non_smile" folder.
We can build a smile detector with this dataset, and even a "smile transformer" via a Style Transfer algorithm.
The "test" folder contains ~12k unlabeled faces. If someone wants go through the work of labeling these faces as smile/nonsmile and republish a greater version of this dataset, please be my guest!
<hr>
*Reupload from [original dataset](https://www.kaggle.com/datasets/chazzer/smiling-or-not-face-data/) on Kaggle*
|
cym31152/CornSD | 2023-09-28T16:35:10.000Z | [
"region:us"
] | cym31152 | null | null | null | 0 | 0 | Entry not found |
thrshr/CCzM | 2023-10-04T08:47:49.000Z | [
"region:us"
] | thrshr | null | null | null | 0 | 0 | Entry not found |
Huzaifaw/Dataseth | 2023-09-28T17:06:20.000Z | [
"region:us"
] | Huzaifaw | null | null | null | 0 | 0 | Entry not found |
brian-tran/read-pdf | 2023-09-28T17:13:33.000Z | [
"license:openrail",
"region:us"
] | brian-tran | null | null | null | 0 | 0 | ---
license: openrail
---
|
sleepyboyeyes/Ashnikko | 2023-10-04T13:53:21.000Z | [
"region:us"
] | sleepyboyeyes | null | null | null | 0 | 0 | Entry not found |
toninhodjj/CHV | 2023-09-28T17:19:42.000Z | [
"region:us"
] | toninhodjj | null | null | null | 0 | 0 | Entry not found |
sleepyboyeyes/Bel | 2023-09-28T17:21:52.000Z | [
"region:us"
] | sleepyboyeyes | null | null | null | 0 | 0 | Entry not found |
sleepyboyeyes/Cottontail | 2023-09-28T17:22:56.000Z | [
"region:us"
] | sleepyboyeyes | null | null | null | 0 | 0 | Entry not found |
sleepyboyeyes/Elita | 2023-10-04T14:24:03.000Z | [
"region:us"
] | sleepyboyeyes | null | null | null | 0 | 0 | Entry not found |
sleepyboyeyes/Jazmin | 2023-10-04T14:01:02.000Z | [
"region:us"
] | sleepyboyeyes | null | null | null | 0 | 0 | Entry not found |
sleepyboyeyes/Lucy | 2023-09-28T17:26:41.000Z | [
"region:us"
] | sleepyboyeyes | null | null | null | 0 | 0 | Entry not found |
sleepyboyeyes/Yungblud | 2023-10-04T13:22:38.000Z | [
"region:us"
] | sleepyboyeyes | null | null | null | 0 | 0 | Entry not found |
hemantk089/train.csv | 2023-09-28T17:46:15.000Z | [
"region:us"
] | hemantk089 | null | null | null | 0 | 0 | Entry not found |
zgcarvalho/swiss-prot-test | 2023-09-28T18:19:57.000Z | [
"size_categories:100k<n<1M",
"license:cc-by-4.0",
"biology",
"protein",
"region:us"
] | zgcarvalho | null | null | null | 0 | 0 | ---
license: cc-by-4.0
size_categories: 100k<n<1M
pretty_name: UniProtKB/Swiss-Prot
tags:
- biology
- protein
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: accession
dtype: string
- name: sequence
dtype: string
splits:
- name: train
num_bytes: 171338188.2167982
num_examples: 456125
- name: test
num_bytes: 42834828.78320182
num_examples: 114032
download_size: 0
dataset_size: 214173017.0
---
# Dataset Card for UniProtKB/Swiss-Prot
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
Alex5666/Military-Aircraft-Recognition-dataset | 2023-09-28T18:17:32.000Z | [
"task_categories:image-classification",
"task_categories:image-segmentation",
"task_categories:image-to-text",
"task_categories:image-to-image",
"task_categories:object-detection",
"task_categories:depth-estimation",
"size_categories:1M<n<10M",
"license:apache-2.0",
"legal",
"region:us"
] | Alex5666 | null | null | null | 0 | 0 | ---
license: apache-2.0
task_categories:
- image-classification
- image-segmentation
- image-to-text
- image-to-image
- object-detection
- depth-estimation
tags:
- legal
size_categories:
- 1M<n<10M
---
This is a remote sensing image Military Aircraft Recognition dataset that include 3842 images, 20 types, and 22341 instances annotated with horizontal bounding boxes and oriented bounding boxes. |
lukegamedev/CJ | 2023-09-28T19:24:11.000Z | [
"region:us"
] | lukegamedev | null | null | null | 0 | 0 | Entry not found |
Eu001/Testes | 2023-10-04T12:38:09.000Z | [
"license:openrail",
"region:us"
] | Eu001 | null | null | null | 0 | 0 | ---
license: openrail
---
|
Weni/Zeroshot_Train-20K_bias_tweet-format | 2023-09-28T18:41:12.000Z | [
"task_categories:zero-shot-classification",
"size_categories:10K<n<100K",
"language:pt",
"region:us"
] | Weni | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: source_text
dtype: string
- name: target_text
dtype: string
splits:
- name: train
num_bytes: 4338493
num_examples: 20000
download_size: 1744022
dataset_size: 4338493
task_categories:
- zero-shot-classification
language:
- pt
size_categories:
- 10K<n<100K
---
# Dataset Card for "Zeroshot_Train-20K_bias_tweet-format"
This dataset is a train dataset for the Zeroshot models.
It has 20.000 data in a prompt format exclusively for train with class 'bias' in Brazilian Portuguese.
Prompt:
```
"Classifique o tweet entre 'classe1', 'classe2', 'classe3', 'classe4', 'bias' \\n\\nTweet: frase \\n\\nLabel: 'other'
```
The dataset was divided as follows: <br>
```
- 6,000 data: prompt with class option without target class (bias)
- 7,000 data: prompt with class option + target class included as an option. target class is not correct
- 7,000 data: prompt with class option + target class. target class is correct
```
## How to load and use this dataset:
```
from datasets import load_dataset
dataset = load_dataset("Weni/Zeroshot_Train-20K_bias_tweet-format")
dataset
```
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
AlexWortega/pixels | 2023-09-28T18:50:17.000Z | [
"region:us"
] | AlexWortega | null | null | null | 0 | 0 | Entry not found |
haganelego/wikiart_256x256 | 2023-09-28T19:46:49.000Z | [
"region:us"
] | haganelego | null | null | null | 0 | 0 | Entry not found |
Nadinegp/pharoh2 | 2023-09-28T22:23:02.000Z | [
"region:us"
] | Nadinegp | null | null | null | 0 | 0 | Entry not found |
marasama/nva-Aizuwakamatu | 2023-09-28T19:48:08.000Z | [
"region:us"
] | marasama | null | null | null | 0 | 0 | Entry not found |
Eu001/Mordecai | 2023-09-30T18:42:06.000Z | [
"license:openrail",
"region:us"
] | Eu001 | null | null | null | 0 | 0 | ---
license: openrail
---
|
BangumiBase/kobayashisanchinomaidragon | 2023-09-29T13:15:05.000Z | [
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] | BangumiBase | null | null | null | 0 | 0 | ---
license: mit
tags:
- art
size_categories:
- 1K<n<10K
---
# Bangumi Image Base of Kobayashi-san Chi No Maidragon
This is the image base of bangumi Kobayashi-san Chi no Maidragon, we detected 33 characters, 3524 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 497 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 31 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 53 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 29 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 13 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 561 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 13 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 9 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 18 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 170 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 375 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 133 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 57 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| 13 | 150 | [Download](13/dataset.zip) |  |  |  |  |  |  |  |  |
| 14 | 46 | [Download](14/dataset.zip) |  |  |  |  |  |  |  |  |
| 15 | 134 | [Download](15/dataset.zip) |  |  |  |  |  |  |  |  |
| 16 | 137 | [Download](16/dataset.zip) |  |  |  |  |  |  |  |  |
| 17 | 68 | [Download](17/dataset.zip) |  |  |  |  |  |  |  |  |
| 18 | 71 | [Download](18/dataset.zip) |  |  |  |  |  |  |  |  |
| 19 | 20 | [Download](19/dataset.zip) |  |  |  |  |  |  |  |  |
| 20 | 12 | [Download](20/dataset.zip) |  |  |  |  |  |  |  |  |
| 21 | 11 | [Download](21/dataset.zip) |  |  |  |  |  |  |  |  |
| 22 | 12 | [Download](22/dataset.zip) |  |  |  |  |  |  |  |  |
| 23 | 15 | [Download](23/dataset.zip) |  |  |  |  |  |  |  |  |
| 24 | 11 | [Download](24/dataset.zip) |  |  |  |  |  |  |  |  |
| 25 | 11 | [Download](25/dataset.zip) |  |  |  |  |  |  |  |  |
| 26 | 171 | [Download](26/dataset.zip) |  |  |  |  |  |  |  |  |
| 27 | 14 | [Download](27/dataset.zip) |  |  |  |  |  |  |  |  |
| 28 | 167 | [Download](28/dataset.zip) |  |  |  |  |  |  |  |  |
| 29 | 64 | [Download](29/dataset.zip) |  |  |  |  |  |  |  |  |
| 30 | 7 | [Download](30/dataset.zip) |  |  |  |  |  |  |  | N/A |
| 31 | 11 | [Download](31/dataset.zip) |  |  |  |  |  |  |  |  |
| noise | 433 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
zgcarvalho/uniref50-test | 2023-09-29T00:47:52.000Z | [
"size_categories:10M<n<100M",
"license:cc-by-4.0",
"biology",
"protein",
"region:us"
] | zgcarvalho | null | null | null | 0 | 0 | ---
license: cc-by-4.0
size_categories: 10M<n<100M
pretty_name: UniRef50
tags:
- biology
- protein
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: id
dtype: string
- name: sequence
dtype: string
splits:
- name: train
num_bytes: 15468741441.32825
num_examples: 49719601
- name: test
num_bytes: 3867185593.6717486
num_examples: 12429901
download_size: 18625264941
dataset_size: 19335927035.0
---
# Dataset Card for UniRef50
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
tennant/iNatIGCD | 2023-09-28T21:53:34.000Z | [
"arxiv:2304.14310",
"region:us"
] | tennant | null | null | null | 0 | 0 | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/datasets-cards
{}
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset is built on the iNaturalist 2021 dataset and is used for the Incremental Generalized Category Discovery task.
For more information about the task, please checkout [this paper](https://arxiv.org/abs/2304.14310).
### Supported Tasks and Leaderboards
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
The initial data are collected by the iNaturalist community.
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
mHossain/ubmec | 2023-09-28T21:20:14.000Z | [
"region:us"
] | mHossain | null | null | null | 0 | 0 | Entry not found |
mHossain/Public_attitude | 2023-09-28T21:21:02.000Z | [
"region:us"
] | mHossain | null | null | null | 0 | 0 | Entry not found |
mHossain/BanglaBook | 2023-09-28T21:21:57.000Z | [
"region:us"
] | mHossain | null | null | null | 0 | 0 | Entry not found |
Nadinegp/pharoh3 | 2023-09-28T22:27:03.000Z | [
"region:us"
] | Nadinegp | null | null | null | 0 | 0 | Entry not found |
Abhigael/labs | 2023-09-28T21:50:18.000Z | [
"region:us"
] | Abhigael | null | null | null | 0 | 0 | Entry not found |
Alwaly/wavetovec | 2023-09-28T22:06:52.000Z | [
"region:us"
] | Alwaly | null | null | null | 0 | 0 | Entry not found |
tanningpku/lichess | 2023-09-28T22:19:40.000Z | [
"license:apache-2.0",
"region:us"
] | tanningpku | null | null | null | 0 | 0 | ---
license: apache-2.0
---
|
t4ggirl/mari | 2023-09-28T23:16:40.000Z | [
"region:us"
] | t4ggirl | null | null | null | 0 | 0 | Entry not found |
totally-not-an-llm/pikals_textbook_quality | 2023-09-29T00:41:49.000Z | [
"license:other",
"region:us"
] | totally-not-an-llm | null | null | null | 0 | 0 | ---
license: other
license_name: other
license_link: LICENSE
---
|
Arthur91284/golden_freddy_evolution | 2023-09-29T20:50:34.000Z | [
"license:openrail",
"region:us"
] | Arthur91284 | null | null | null | 0 | 0 | ---
license: openrail
---
|
SXBG/123 | 2023-09-29T09:33:34.000Z | [
"license:apache-2.0",
"region:us"
] | SXBG | null | null | null | 0 | 0 | ---
license: apache-2.0
---
|
hezhaoqia/datas | 2023-09-29T02:00:38.000Z | [
"license:apache-2.0",
"region:us"
] | hezhaoqia | null | null | null | 0 | 0 | ---
license: apache-2.0
---
|
BangumiBase/thunderboltfantasy | 2023-09-29T13:26:36.000Z | [
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] | BangumiBase | null | null | null | 0 | 0 | ---
license: mit
tags:
- art
size_categories:
- 1K<n<10K
---
# Bangumi Image Base of Thunderbolt Fantasy
This is the image base of bangumi Thunderbolt Fantasy, we detected 21 characters, 1926 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 151 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 66 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 140 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 29 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 37 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 240 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 181 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 171 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 99 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 274 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 30 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 23 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 22 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| 13 | 36 | [Download](13/dataset.zip) |  |  |  |  |  |  |  |  |
| 14 | 42 | [Download](14/dataset.zip) |  |  |  |  |  |  |  |  |
| 15 | 37 | [Download](15/dataset.zip) |  |  |  |  |  |  |  |  |
| 16 | 178 | [Download](16/dataset.zip) |  |  |  |  |  |  |  |  |
| 17 | 39 | [Download](17/dataset.zip) |  |  |  |  |  |  |  |  |
| 18 | 13 | [Download](18/dataset.zip) |  |  |  |  |  |  |  |  |
| 19 | 18 | [Download](19/dataset.zip) |  |  |  |  |  |  |  |  |
| noise | 100 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
Azazelle/Open-AniPrompts | 2023-09-29T02:03:07.000Z | [
"license:apache-2.0",
"region:us"
] | Azazelle | null | null | null | 0 | 0 | ---
license: apache-2.0
---
|
lukegamedev/Mabel | 2023-09-29T02:19:49.000Z | [
"region:us"
] | lukegamedev | null | null | null | 0 | 0 | Entry not found |
abdiharyadi/indoamrbart-dataset | 2023-10-09T03:24:47.000Z | [
"region:us"
] | abdiharyadi | null | null | null | 0 | 0 | Entry not found |
Xokito/datasets | 2023-10-08T20:40:11.000Z | [
"license:openrail",
"region:us"
] | Xokito | null | null | null | 0 | 0 | ---
license: openrail
---
|
tttfff/test1 | 2023-09-29T02:53:14.000Z | [
"region:us"
] | tttfff | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: id
dtype: string
- name: package_name
dtype: string
- name: review
dtype: string
- name: date
dtype: string
- name: star
dtype: int64
- name: version_id
dtype: int64
splits:
- name: train
num_bytes: 1508
num_examples: 5
- name: test
num_bytes: 956
num_examples: 5
download_size: 9451
dataset_size: 2464
---
# Dataset Card for "test1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tianchicai/Anthropic_HH_GPT4 | 2023-09-29T03:24:46.000Z | [
"license:apache-2.0",
"region:us"
] | tianchicai | null | null | null | 0 | 0 | ---
license: apache-2.0
---
|
recwizard/RedialEntityLink | 2023-09-29T04:29:02.000Z | [
"region:us"
] | recwizard | null | null | null | 0 | 0 | Entry not found |
enriquevillalbarod/piedras | 2023-09-29T04:01:29.000Z | [
"license:apache-2.0",
"region:us"
] | enriquevillalbarod | null | null | null | 0 | 0 | ---
license: apache-2.0
---
|
jitx/distillation_code_sample | 2023-09-29T05:03:44.000Z | [
"license:mit",
"region:us"
] | jitx | null | null | null | 0 | 0 | ---
license: mit
dataset_info:
features:
- name: santacoder_prompts
dtype: string
- name: fim_inputs
dtype: string
- name: label_middles
dtype: string
- name: santacoder_outputs
dtype: string
splits:
- name: train
num_bytes: 13510
num_examples: 4
download_size: 27929
dataset_size: 13510
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
AdityaNG/BengaluruSemanticOccupancyDataset | 2023-09-29T07:30:08.000Z | [
"license:mit",
"region:us"
] | AdityaNG | null | null | null | 0 | 0 | ---
license: mit
---
|
Resizable/Baraka | 2023-09-29T04:35:34.000Z | [
"license:openrail",
"region:us"
] | Resizable | null | null | null | 0 | 0 | ---
license: openrail
---
|
sw882882/megacodeLogic-92k | 2023-09-29T05:25:20.000Z | [
"region:us"
] | sw882882 | null | null | null | 0 | 0 | a dataset with the openplatypus logic dataset, and the megacode-best code dataset. It should be around 20% general logic and 80% code. |
TheVarunKaushik/VEX | 2023-09-29T21:18:40.000Z | [
"region:us"
] | TheVarunKaushik | null | null | null | 0 | 0 | [
{
"id": 1,
"question": "How can I program a VEX robot to follow a line?",
"Question_Category": "Programming",
"Answer_Category": "Instructional",
"Format_Category": "Text",
"answer": "To program a VEX robot to follow a line, you will need a line follower sensor. Once the sensor is installed, you can use programming environments such as VEXcode to write a program that reads the sensor data to control the robot's movement along the line."
},
{
"id": 2,
"question": "What sensors are available for VEX Robotics platforms?",
"Question_Category": "Hardware",
"Answer_Category": "Informational",
"Format_Category": "List",
"answer": "Various sensors are available for VEX Robotics platforms, including but not limited to: Ultrasonic Sensors, Gyro Sensors, Potentiometers, Bumper Switches, Limit Switches, Optical Sensors, and Temperature Sensors."
},
{
"id": 3,
"question": "How do I troubleshoot connection issues with a VEX EDR robot?",
"Question_Category": "Troubleshooting",
"Answer_Category": "Instructional",
"Format_Category": "Text",
"answer": "Troubleshooting connection issues with a VEX EDR robot typically involves checking the connections between the robot and the controller, ensuring the batteries are fully charged, and verifying that the VEXnet keys are properly seated. You may also want to check for any software updates or refer to the VEX EDR troubleshooting guide for further assistance."
},
...
{
"id": 100,
"question": "Where can I find resources for preparing for VEX Robotics Competitions?",
"Question_Category": "Resources",
"Answer_Category": "Informational",
"Format_Category": "Web Link",
"answer": "Resources for preparing for VEX Robotics Competitions can be found on the official VEX Robotics website, the VEX forum, and the REC Foundation website. Additionally, many teams and organizations share resources and tutorials on their websites and on platforms like YouTube."
}
]
|
Andyrasika/code-dictation | 2023-09-29T04:41:43.000Z | [
"region:us"
] | Andyrasika | null | null | null | 1 | 0 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
splits:
- name: train
num_bytes: 8708.8
num_examples: 40
- name: test
num_bytes: 2177.2
num_examples: 10
download_size: 8160
dataset_size: 10886.0
---
# Dataset Card for "code-dictation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
chunpingvi/dataset_format5 | 2023-09-29T05:07:26.000Z | [
"region:us"
] | chunpingvi | null | null | null | 0 | 0 | Entry not found |
DaDavinci/mixamo-gltf-library | 2023-09-29T05:13:46.000Z | [
"license:mit",
"region:us"
] | DaDavinci | null | null | null | 0 | 0 | ---
license: mit
---
|
CyberHarem/lin_xue_ya_thunderboltfantasy | 2023-09-29T05:30:12.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of 凜雪鴉
This is the dataset of 凜雪鴉, containing 147 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:----------------|---------:|:----------------------------------------|:-----------------------------------------------------------------------------------------|
| raw | 147 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 253 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| raw-stage3-eyes | 281 | [Download](dataset-raw-stage3-eyes.zip) | 3-stage cropped (with eye-focus) raw data with meta information. |
| 384x512 | 147 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x704 | 147 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x880 | 147 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 253 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 253 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-p512-640 | 243 | [Download](dataset-stage3-p512-640.zip) | 3-stage cropped dataset with the area not less than 512x512 pixels. |
| stage3-eyes-640 | 281 | [Download](dataset-stage3-eyes-640.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 640 pixels. |
| stage3-eyes-800 | 281 | [Download](dataset-stage3-eyes-800.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 800 pixels. |
|
Anas986/my-test-dataset | 2023-09-29T05:44:47.000Z | [
"region:us"
] | Anas986 | null | null | null | 0 | 0 | Entry not found |
entressi/fluffyrock-test-artists | 2023-09-29T06:05:44.000Z | [
"license:apache-2.0",
"region:us"
] | entressi | null | null | null | 0 | 0 | ---
license: apache-2.0
---
|
CyberHarem/shang_bu_huan_thunderboltfantasy | 2023-09-29T06:01:56.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of 殤不患
This is the dataset of 殤不患, containing 261 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:----------------|---------:|:----------------------------------------|:-----------------------------------------------------------------------------------------|
| raw | 261 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 517 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| raw-stage3-eyes | 521 | [Download](dataset-raw-stage3-eyes.zip) | 3-stage cropped (with eye-focus) raw data with meta information. |
| 384x512 | 261 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x704 | 261 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x880 | 261 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 517 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 517 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-p512-640 | 455 | [Download](dataset-stage3-p512-640.zip) | 3-stage cropped dataset with the area not less than 512x512 pixels. |
| stage3-eyes-640 | 521 | [Download](dataset-stage3-eyes-640.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 640 pixels. |
| stage3-eyes-800 | 521 | [Download](dataset-stage3-eyes-800.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 800 pixels. |
|
CyberHarem/lang_wu_yao_thunderboltfantasy | 2023-09-29T06:23:24.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] | CyberHarem | null | null | null | 0 | 0 | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of 浪巫謠
This is the dataset of 浪巫謠, containing 176 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:----------------|---------:|:----------------------------------------|:-----------------------------------------------------------------------------------------|
| raw | 176 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 324 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| raw-stage3-eyes | 373 | [Download](dataset-raw-stage3-eyes.zip) | 3-stage cropped (with eye-focus) raw data with meta information. |
| 384x512 | 176 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x704 | 176 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x880 | 176 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 324 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 324 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-p512-640 | 299 | [Download](dataset-stage3-p512-640.zip) | 3-stage cropped dataset with the area not less than 512x512 pixels. |
| stage3-eyes-640 | 373 | [Download](dataset-stage3-eyes-640.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 640 pixels. |
| stage3-eyes-800 | 373 | [Download](dataset-stage3-eyes-800.zip) | 3-stage cropped (with eye-focus) dataset with the shorter side not exceeding 800 pixels. |
|
Mahim47/health_dataset | 2023-09-29T06:27:32.000Z | [
"region:us"
] | Mahim47 | null | null | null | 0 | 0 | Entry not found |
cathyye2000/MORPHeus | 2023-09-29T06:30:17.000Z | [
"license:bsd-3-clause",
"region:us"
] | cathyye2000 | null | null | null | 0 | 0 | ---
license: bsd-3-clause
---
|
TrainingDataPro/fights-segmentation | 2023-09-29T12:35:30.000Z | [
"task_categories:image-segmentation",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | null | null | null | 1 | 0 | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-segmentation
language:
- en
tags:
- code
---
# Fights Segmentation Dataset
The dataset consists of a collection of photos extracted from **videos of fights**. It includes **segmentation masks** for **fighters, referees, mats, and the background**.
The dataset offers a resource for *object detection, instance segmentation, action recognition, or pose estimation*.
It could be useful for **sport community** in identification and detection of the violations, dispute resolution and general optimisation of referee's work using computer vision.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=fights-segmentation) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images extracted from the videos of fights
- **masks** - includes segmentation masks created for the original images
- **annotations.xml** - contains coordinates of the polygons and labels, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the polygons and labels. For each point, the x and y coordinates are provided.
### Сlasses:
- **human**: fighter or fighters,
- **referee**: referee,
- **wrestling**: mat's area,
- **background**: area above the mat
# Example of XML file structure
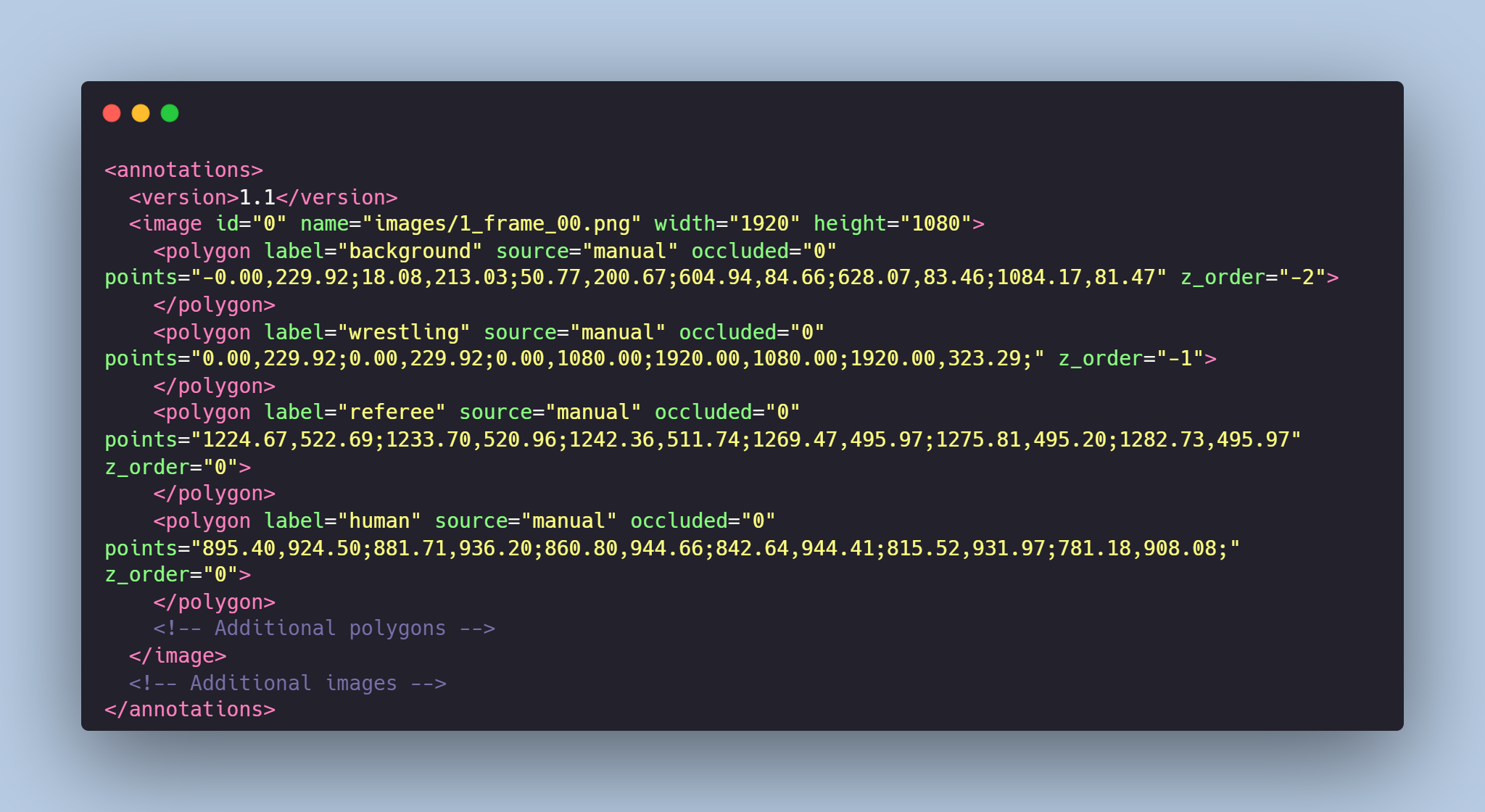
# Fights Segmentation might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=fights-segmentation) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
Piyush20042001/Bhagavatgita | 2023-09-29T07:04:04.000Z | [
"region:us"
] | Piyush20042001 | null | null | null | 0 | 0 | Entry not found |
pranaykoppula/hughdb-dataset | 2023-09-29T07:26:10.000Z | [
"region:us"
] | pranaykoppula | null | null | null | 0 | 0 | Entry not found |
Minecrafter/AiVoiceModels | 2023-10-09T10:57:18.000Z | [
"region:us"
] | Minecrafter | null | null | null | 1 | 0 | Various ai voice models I made of voices that may ore may not beiing made before.
Only use them under fair use or with licence from original authors. |
lionpig/1050 | 2023-09-29T08:46:06.000Z | [
"region:us"
] | lionpig | null | null | null | 0 | 0 | Entry not found |
Sneka/classify-002 | 2023-09-29T08:57:56.000Z | [
"region:us"
] | Sneka | null | null | null | 0 | 0 | Entry not found |
daveokpare/databricks-dolly-15k-llama | 2023-09-29T09:06:20.000Z | [
"region:us"
] | daveokpare | null | null | null | 0 | 0 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 12198878
num_examples: 15011
download_size: 7287301
dataset_size: 12198878
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "databricks-dolly-15k-llama"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
atom-in-the-universe/bild-e4d54fd3-ddfb-4b0d-ab69-cd907e728cb7 | 2023-09-29T11:59:13.000Z | [
"region:us"
] | atom-in-the-universe | null | null | null | 0 | 0 | Entry not found |
dl002/KAIST-Dataset-Annotations | 2023-09-29T09:34:43.000Z | [
"license:unknown",
"region:us"
] | dl002 | null | null | null | 0 | 0 | ---
license: unknown
---
|
Anonymous1234/replicationPackage | 2023-09-29T09:49:03.000Z | [
"region:us"
] | Anonymous1234 | null | null | null | 0 | 0 | Entry not found |
navjot22/test | 2023-09-29T09:42:24.000Z | [
"license:mit",
"region:us"
] | navjot22 | null | null | null | 0 | 0 | ---
license: mit
---
|
vishnuramov/fgandataset01 | 2023-09-29T10:10:23.000Z | [
"region:us"
] | vishnuramov | null | null | null | 0 | 0 | Entry not found |
anyresearcher/replicationPackage | 2023-09-29T10:48:33.000Z | [
"region:us"
] | anyresearcher | null | null | null | 0 | 0 | Entry not found |
bene-ges/wiki-en-asr-adapt | 2023-10-07T11:08:24.000Z | [
"size_categories:10M<n<100M",
"language:en",
"license:cc-by-sa-4.0",
"arxiv:2309.17267",
"region:us"
] | bene-ges | null | null | null | 0 | 0 | ---
license: cc-by-sa-4.0
language:
- en
size_categories:
- 10M<n<100M
---
This is the dataset presented in my [ASRU-2023 paper](https://arxiv.org/abs/2309.17267).
It consists of multiple files:
Keys2Paragraphs.txt (internal name in scripts: yago_wiki.txt):
4.3 million unique words/phrases (English Wikipedia titles or their parts) occurring in 33.8 million English Wikipedia paragraphs.
Keys2Corruptions.txt (internal name in scripts: sub_misspells.txt):
26 million phrase pairs in the corrupted phrase inventory, as recognized by different ASR models
Keys2Related.txt (internal name in scripts: related_phrases.txt):
62.7 million phrase pairs in the related phrase inventory
FalsePositives.txt (internal name in scripts: false_positives.txt):
449 thousand phrase pairs in the false positive phrase inventory
NgramMappings.txt (internal name in scripts: replacement_vocab_filt.txt):
5.5 million character n-gram mappings dictionary
asr
outputs of g2p+tts+asr using 4 different ASR systems (conformer ctc was used twice),
gives pairs of initial phrase and its recognition result.
Does not include .wav files, but these can be reproduced by feeding g2p to tts
giza
raw outputs of GIZA++ alignments for each corpus,
from these we get NgramMappings.txt and Keys2Corruptions.txt
|
mattlc/major_minor | 2023-09-29T11:35:40.000Z | [
"region:us"
] | mattlc | null | null | null | 0 | 0 | ---
dataset_info:
features: []
splits:
- name: train
download_size: 324
dataset_size: 0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "major_minor"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Rahi11Anurag/OnlyBCSCsolidity | 2023-09-29T10:28:11.000Z | [
"region:us"
] | Rahi11Anurag | null | null | null | 0 | 0 | Entry not found |
Unified-Language-Model-Alignment/Anthropic_HH_Golden | 2023-10-04T13:36:29.000Z | [
"task_categories:conversational",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"harmless",
"region:us"
] | Unified-Language-Model-Alignment | null | null | null | 1 | 0 | ---
license: apache-2.0
task_categories:
- conversational
language:
- en
tags:
- harmless
size_categories:
- 10K<n<100K
---
## Dataset Card for Anthropic_HH_Golden
This dataset is constructed to test the **ULMA** technique as mentioned in the paper *Unified Language Model Alignment with Demonstration and Point-wise Human Preference* (under review, and an arxiv link will be provided soon). They show that replacing the positive samples in a preference dataset by high-quality demonstration data (golden data) greatly improves the performance of various alignment methods (RLHF, DPO, ULMA). In particular, the ULMA method exploits the high-quality demonstration data in the preference dataset by treating the positive and negative samples differently, and boosting the performance by removing the KL regularizer for positive samples.
### Dataset Summary
This repository contains a new preference dataset extending the harmless dataset of Anthropic's Helpful and Harmless (HH) datasets. The origin positive response in HH is generated by a supervised fined-tuned model of Anthropic, where harmful and unhelpful responses are freqently encountered. In this dataset, the positive responses are replaced by re-rewritten responses generated by GPT4.

**Comparison with the origin HH dataset.** Left is the data sampled from the origin HH dataset, and right is the corresponding answer in our Anthropic_HH_Golden dataset. The highlighted parts are the differences. It is clear that after the rewritten, the "chosen" responses is more harmless, and the "rejected" response are left unchanged.
### Usage
```
from datasets import load_dataset
# Load the harmless dataset with golden demonstration
dataset = load_dataset("Unified-Language-Model-Alignment/Anthropic_HH_Golden")
```
or download the data files directly with:
```
git clone https://huggingface.co/datasets/Unified-Language-Model-Alignment/Anthropic_HH_Golden
``` |
SEIKU/transformer_try1 | 2023-09-29T10:50:08.000Z | [
"license:mit",
"region:us"
] | SEIKU | null | null | null | 0 | 0 | ---
license: mit
---
|
Monkaro/sdxl_json | 2023-09-29T11:05:25.000Z | [
"region:us"
] | Monkaro | null | null | null | 0 | 0 | Entry not found |
Monkaro/kohya_json_files | 2023-09-29T11:05:50.000Z | [
"region:us"
] | Monkaro | null | null | null | 0 | 0 | Entry not found |
cssen/colmap_test | 2023-09-29T11:19:21.000Z | [
"license:apache-2.0",
"region:us"
] | cssen | null | null | null | 0 | 0 | ---
license: apache-2.0
---
|
text2font/full_words_with_path_tags | 2023-09-29T11:17:16.000Z | [
"region:us"
] | text2font | null | null | null | 0 | 0 | This dataset has been created using <path ..... > added to the dataset. |
sleepyboyeyes/Olly | 2023-10-03T14:20:45.000Z | [
"region:us"
] | sleepyboyeyes | null | null | null | 0 | 0 | Entry not found |
ayoubkirouane/NER_AR_wikiann | 2023-09-29T11:31:52.000Z | [
"region:us"
] | ayoubkirouane | null | null | null | 0 | 0 | ---
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
- split: test
path: data/test-*
- split: train
path: data/train-*
dataset_info:
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-PER
'2': I-PER
'3': B-ORG
'4': I-ORG
'5': B-LOC
'6': I-LOC
- name: langs
sequence: string
- name: spans
sequence: string
splits:
- name: validation
num_bytes: 2325660
num_examples: 10000
- name: test
num_bytes: 2334636
num_examples: 10000
- name: train
num_bytes: 4671613
num_examples: 20000
download_size: 2581113
dataset_size: 9331909
---
# Dataset Card for "NER_AR_wikiann"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Eu001/amigo | 2023-10-10T17:55:24.000Z | [
"license:openrail",
"region:us"
] | Eu001 | null | null | null | 0 | 0 | ---
license: openrail
---
|
Rahi11Anurag/bismilla | 2023-09-29T11:47:34.000Z | [
"region:us"
] | Rahi11Anurag | null | null | null | 0 | 0 | Entry not found |
nillonsx9/Kaca | 2023-09-29T11:51:05.000Z | [
"region:us"
] | nillonsx9 | null | null | null | 0 | 0 | Entry not found |
TheAIchemist13/marathi_preprocessed | 2023-09-29T12:20:53.000Z | [
"region:us"
] | TheAIchemist13 | null | null | null | 0 | 0 | Entry not found |
librarian-bots/images | 2023-09-29T12:08:26.000Z | [
"region:us"
] | librarian-bots | null | null | null | 0 | 0 | Entry not found |
rexionmars/llama2-br-essay-6k | 2023-09-29T12:26:22.000Z | [
"region:us"
] | rexionmars | null | null | null | 0 | 0 | Entry not found |
Monkaro/sdxl-lora-training-test | 2023-09-29T12:38:53.000Z | [
"region:us"
] | Monkaro | null | null | null | 0 | 0 | Entry not found |
Nehc/DustData | 2023-09-29T12:43:47.000Z | [
"region:us"
] | Nehc | null | null | null | 0 | 0 | Entry not found |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.