
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
arbml/alpaca_arabic_v3 | 2023-09-06T17:39:52.000Z | [
"region:us"
] | arbml | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: index
dtype: string
- name: output
dtype: string
- name: output_en
dtype: string
- name: input
dtype: string
- name: input_en
dtype: string
- name: instruction
dtype: string
- name: instruction_en
dtype: string
splits:
- name: train
num_bytes: 20871
num_examples: 31
download_size: 0
dataset_size: 20871
---
# Dataset Card for "alpaca_arabic_v3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Abzu/arxiv_stem_filtered | 2023-08-03T14:12:11.000Z | [
"region:us"
] | Abzu | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: id
dtype: string
- name: submitter
dtype: string
- name: authors
dtype: string
- name: title
dtype: string
- name: comments
dtype: string
- name: journal-ref
dtype: string
- name: doi
dtype: string
- name: report-no
dtype: string
- name: categories
dtype: string
- name: license
dtype: string
- name: abstract
dtype: string
- name: update_date
dtype: string
splits:
- name: train
num_bytes: 391221495.4053062
num_examples: 301707
download_size: 205323915
dataset_size: 391221495.4053062
---
# Dataset Card for "arxiv_stem_filtered"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TrainingDataPro/ocr-text-detection-in-the-documents | 2023-09-14T16:33:47.000Z | [
"task_categories:image-to-text",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"legal",
"finance",
"region:us"
] | TrainingDataPro | null | null | null | 1 | 7 | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-to-text
- object-detection
language:
- en
tags:
- code
- legal
- finance
---
# OCR Text Detection in the Documents Dataset
The dataset is a collection of images that have been annotated with the location of text in the document. The dataset is specifically curated for text detection and recognition tasks in documents such as scanned papers, forms, invoices, and handwritten notes.
The dataset contains a variety of document types, including different *layouts, font sizes, and styles*. The images come from diverse sources, ensuring a representative collection of document styles and quality. Each image in the dataset is accompanied by bounding box annotations that outline the exact location of the text within the document.
The Text Detection in the Documents dataset provides an invaluable resource for developing and testing algorithms for text extraction, recognition, and analysis. It enables researchers to explore and innovate in various applications, including *optical character recognition (OCR), information extraction, and document understanding*.
.png?generation=1691059158337136&alt=media)
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-text-detection-in-the-documents) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of documents
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and labels, created for the original photo
# Data Format
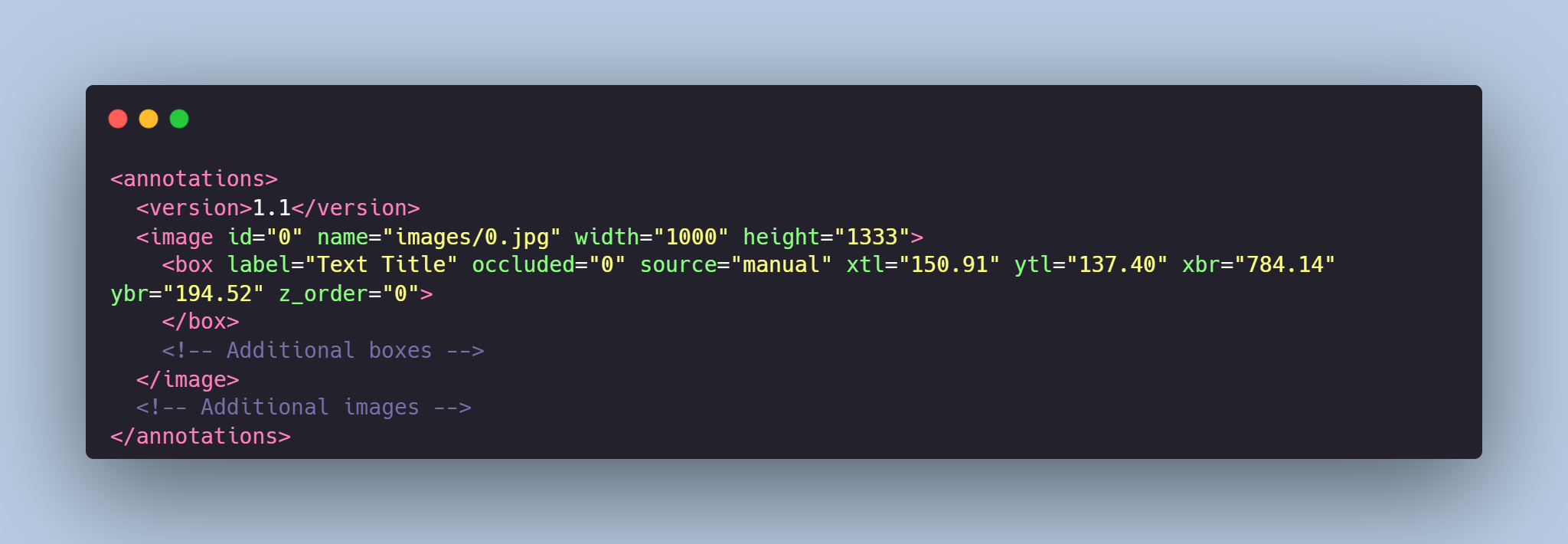
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes and labels for text detection. For each point, the x and y coordinates are provided.
### Labels for the text:
- **"Text Title"** - corresponds to titles, the box is **red**
- **"Text Paragraph"** - corresponds to paragraphs of text, the box is **blue**
- **"Table"** - corresponds to the table, the box is **green**
- **"Handwritten"** - corresponds to handwritten text, the box is **purple**
# Example of XML file structure
# Text Detection in the Documents might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-text-detection-in-the-documents) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
JayalekshmiGopakumar/updated_doc_laynet_for_donut | 2023-08-04T10:18:49.000Z | [
"region:us"
] | JayalekshmiGopakumar | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': financial_reports
'1': government_tenders
'2': manuals
'3': laws_and_regulations
'4': scientific_articles
'5': patents
- name: ground_truth
dtype: string
splits:
- name: train
num_bytes: 18526989.0
num_examples: 48
- name: test
num_bytes: 3240607.0
num_examples: 12
download_size: 21738451
dataset_size: 21767596.0
---
# Dataset Card for "updated_doc_laynet_for_donut"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
RayBernard/leetcode | 2023-08-04T18:23:11.000Z | [
"license:llama2",
"region:us"
] | RayBernard | null | null | null | 0 | 7 | ---
license: llama2
---
|
arazd/tulu_baize | 2023-08-04T21:45:58.000Z | [
"license:openrail",
"region:us"
] | arazd | null | null | null | 0 | 7 | ---
license: openrail
---
|
rombodawg/2XUNCENSORED_alpaca_840k_Evol_USER_ASSIS | 2023-08-07T21:52:44.000Z | [
"license:other",
"region:us"
] | rombodawg | null | null | null | 5 | 7 | ---
license: other
---
MEGACODE TRAINING VERSION 2 OUT NOW: https://huggingface.co/datasets/rombodawg/LosslessMegaCodeTrainingV2_1m_Evol_Uncensored
Version 1 Updated/Uncensored version here: https://huggingface.co/datasets/rombodawg/2XUNCENSORED_MegaCodeTraining188k
Legacy Version 1 code training here: https://huggingface.co/datasets/rombodawg/MegaCodeTraining200k
This is The non-coding evol instruct dataset
This dataset is meant for further refinement on intruction based training for ai models based on the evol instruct method.
This dataset is has gone through a second set of uncensoring filtering using my own method where alot of censored data was innitially missed.
This is the original flan1m-alpaca-uncensored.jsonl bellow:
https://huggingface.co/datasets/ehartford/dolphin/tree/main |
HugoGiddins/IBM-mq | 2023-09-18T09:50:38.000Z | [
"region:us"
] | HugoGiddins | null | null | null | 0 | 7 | Entry not found |
xPXXX/stackoverflow_DL-related_questions | 2023-08-21T00:44:46.000Z | [
"license:mit",
"region:us"
] | xPXXX | null | null | null | 0 | 7 | ---
license: mit
---
|
adityarra07/sub_ATC_large | 2023-08-09T21:30:28.000Z | [
"region:us"
] | adityarra07 | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: transcription
dtype: string
- name: id
dtype: string
splits:
- name: train
num_bytes: 410194527.19266194
num_examples: 3000
- name: test
num_bytes: 27346488.81284413
num_examples: 200
download_size: 433858552
dataset_size: 437541016.0055061
---
# Dataset Card for "sub_ATC_large"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
elsheikhams/labr-ar | 2023-08-10T10:50:38.000Z | [
"license:gpl-2.0",
"region:us"
] | elsheikhams | null | null | null | 0 | 7 | ---
license: gpl-2.0
---
|
nlplabtdtu/people_qa_short_answer | 2023-08-10T16:11:48.000Z | [
"region:us"
] | nlplabtdtu | null | null | null | 0 | 7 | Entry not found |
edward2021/ScanScribe | 2023-08-13T06:10:32.000Z | [
"license:openrail",
"region:us"
] | edward2021 | null | null | null | 2 | 7 | ---
license: openrail
---
|
larryvrh/WikiMatrix-v1-En_Zh-filtered | 2023-08-13T06:49:57.000Z | [
"task_categories:translation",
"size_categories:100K<n<1M",
"language:zh",
"language:en",
"region:us"
] | larryvrh | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: en
dtype: string
- name: zh
dtype: string
splits:
- name: train
num_bytes: 167612083
num_examples: 678099
download_size: 129968994
dataset_size: 167612083
task_categories:
- translation
language:
- zh
- en
size_categories:
- 100K<n<1M
---
# Dataset Card for "WikiMatrix-v1-En_Zh-filtered"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
elsheikhams/MPOLD | 2023-08-14T10:35:03.000Z | [
"region:us"
] | elsheikhams | null | null | null | 0 | 7 | Entry not found |
jonathansuru/customer_support_auto_completion | 2023-08-14T22:57:54.000Z | [
"task_categories:table-question-answering",
"task_categories:question-answering",
"task_categories:text-generation",
"language:en",
"license:apache-2.0",
"region:us"
] | jonathansuru | null | null | null | 1 | 7 | ---
license: apache-2.0
task_categories:
- table-question-answering
- question-answering
- text-generation
language:
- en
--- |
yangwang825/esc50 | 2023-08-15T13:28:39.000Z | [
"task_categories:audio-classification",
"size_categories:1K<n<10K",
"audio",
"region:us"
] | yangwang825 | null | null | null | 0 | 7 | ---
task_categories:
- audio-classification
tags:
- audio
size_categories:
- 1K<n<10K
---
# ESC50
## Dataset Summary
The ESC-50 dataset is a labeled collection of 2000 environmental audio recordings suitable for benchmarking methods of environmental sound classification. It comprises 2000 5s-clips of 50 different classes across natural, human and domestic sounds, again, drawn from Freesound.org.
## Data Instances
An example of 'train' looks as follows.
```
{
"audio": {
"path": "ESC-50-master/audio/4-143118-B-7.wav",
"array", array([0.05203247, 0.05285645, 0.05441284, ..., 0.0093689 , 0.00753784, 0.00643921],
"sampling_rate", 44100
},
"fold": 4,
"label": 30
}
``` |
TinyPixel/airo-1 | 2023-09-02T10:26:30.000Z | [
"region:us"
] | TinyPixel | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: response
dtype: string
- name: category
dtype: string
- name: question_id
dtype: float64
splits:
- name: train
num_bytes: 57737476
num_examples: 34204
download_size: 30991700
dataset_size: 57737476
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "airo-1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
deep-plants/AGM | 2023-10-04T11:06:53.000Z | [
"task_categories:image-classification",
"size_categories:100K<n<1M",
"license:cc",
"region:us"
] | deep-plants | null | null | null | 0 | 7 | ---
license: cc
size_categories:
- 100K<n<1M
task_categories:
- image-classification
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: string
splits:
- name: train
num_bytes: 3208126820.734
num_examples: 972858
download_size: 3245813213
dataset_size: 3208126820.734
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for AGM Dataset
## Dataset Summary
The AGM (AGricolaModerna) Dataset is a comprehensive collection of high-resolution RGB images capturing harvest-ready plants in a vertical farm setting. This dataset consists of 972,858 images, each with a resolution of 120x120 pixels, covering 18 different plant crops. In the context of this dataset, a crop refers to a plant species or a mix of plant species.
## Supported Tasks
Image classification: plant phenotyping
## Languages
The dataset primarily consists of image data and does not involve language content. Therefore, the primary language is English, but it is not relevant to the dataset's core content.
## Dataset Structure
### Data Instances
A typical data instance from the training set consists of the following:
```
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=120x120 at 0x29CEAD71780>,
'crop_type': 'by'
}
```
### Data Fields
The dataset's data instances have the following fields:
- `image`: A PIL.Image.Image object representing the image.
- `crop_type`: An string representation of the crop type in the image
### Data Splits
- **Training Set**:
- Number of Examples: 972,858
## Dataset Creation
### Curation Rationale
The creation of the AGM Dataset was motivated by the need for a large and diverse dataset that captures various aspects of modern agriculture, including plant species diversity, stress detection, and crop health assessment.
### Source Data
#### Initial Data Collection and Normalization
The images were captured using a high-resolution camera positioned above a moving table in an agricultural setting. The camera captured images of the entire table, which was filled with trays of harvested crops. The image capture process spanned from May 2022 to December 2022. The original images had a resolution of $1073{\times}650$ pixels. Each pixel in the images corresponds to a physical size of $0.5$ millimeters.
### Annotations
#### Annotation Process
Agronomists and domain experts were involved in the annotation process. They annotated each image to identify the crops present and assign them to specific categories or species. This annotation process involved labeling each image with one of 18 distinct crop categories, which include individual plant species and mixtures of species.
### Who Are the Annotators?
The annotators are agronomists employed by Agricola Moderna.
## Personal and Sensitive Information
The dataset does not contain personal or sensitive information about individuals. It primarily consists of images of plants.
## Considerations for Using the Data
### Social Impact of Dataset
The AGM Dataset has potential social impact in modern agriculture and related domains. It can advance agriculture by aiding the development of innovative technologies for crop monitoring, disease detection, and yield prediction, fostering sustainable farming practices, contributing to food security and ensuring higher agricultural productivity and affordability. The dataset supports research for environmentally sustainable agriculture, optimizing resource use and reducing environmental impact.
### Discussion of Biases and Known Limitations
The dataset primarily involves images from a single vertical farm setting therefore, while massive, includes relatively little variation in crop types. The dataset's contents and annotations may reflect regional agricultural practices and preferences. Business preferences also play a substantial role in determining the types of crops grown in vertical farms. These preferences, often influenced by market demand and profitability, can significantly differ from conventional open-air field agriculture. Therefore, the dataset may inherently reflect these business-driven crop choices, potentially affecting its representativeness of broader agricultural scenarios.
## Additional Information
### Dataset Curators
The dataset is curate by DeepPlants and AgricolaModerna. You can contact us for further informations at
nico@deepplants.com
etienne.david@agricolamoderna.com
### Licensing Information
### Citation Information
If you use the AGM dataset in your work, please consider citing the following publication:
```bibtex
@InProceedings{Sama_2023_ICCV,
author = {Sama, Nico and David, Etienne and Rossetti, Simone and Antona, Alessandro and Franchetti, Benjamin and Pirri, Fiora},
title = {A new Large Dataset and a Transfer Learning Methodology for Plant Phenotyping in Vertical Farms},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
month = {October},
year = {2023},
pages = {540-551}
}
``` |
openfoodfacts/ingredient-detection | 2023-08-16T10:08:17.000Z | [
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:en",
"language:fr",
"language:de",
"language:it",
"language:nl",
"language:ru",
"language:he",
"license:cc-by-sa-4.0",
"region:us"
] | openfoodfacts | null | null | null | 0 | 7 | ---
license: cc-by-sa-4.0
language:
- en
- fr
- de
- it
- nl
- ru
- he
task_categories:
- token-classification
pretty_name: Ingredient List Detection
size_categories:
- 1K<n<10K
---
This dataset is used to train a multilingual ingredient list detection model. The goal is to automate the extraction of ingredient lists from food packaging images. See [this issue](https://github.com/openfoodfacts/openfoodfacts-ai/issues/242) for a broader context about ingredient list extraction.
## Dataset generation
Raw unannotated texts are OCR results obtained with Google Cloud Vision. It only contains images marked as ingredient image on Open Food Facts.
The dataset was generated using ChatGPT-3.5: we asked ChatGPT to extract ingredient using the following prompt:
Prompt:
```
Extract ingredient lists from the following texts. The ingredient list should start with the first ingredient and end with the last ingredient. It should not include allergy, label or origin information.
The output format must be a single JSON list containing one element per ingredient list. If there are ingredients in several languages, the output JSON list should contain as many elements as detected languages. Each element should have two fields:
- a "text" field containing the detected ingredient list. The text should be a substring of the original text, you must not alter the original text.
- a "lang" field containing the detected language of the ingredient list.
Don't output anything else than the expected JSON list.
```
System prompt:
```
You are ChatGPT, a large language model trained by OpenAI. Only generate responses in JSON format. The output JSON must be minified.
```
A first cleaning step was performed automatically, we removed responses with:
- invalid JSON
- JSON with missing fields
- JSON where the detected ingredient list is not a substring of the original text
A first NER model was trained on this dataset. The model prediction errors on this dataset were inspected, which allowed us to spot the different kind of annotation errors made by ChatGPT. Then, using a semi-automatic approach, we manually corrected samples that were likely to have the error spotted during the inspection phase. For example, we noticed that the prefix "Ingredients:" was sometimes included in the ingredient text span. We looked for every sample where "Ingredients" (and translations in other languages) was part of the ingredient text, and corrected these samples manually. This approach allowed us to focus on problematic samples, instead of having to check the full train set.
These detection rules were mostly implemented using regex. The cleaning script with all rules [can be found here](https://github.com/openfoodfacts/openfoodfacts-ai/blob/149447bdbcd19cb7c15127405d9112bc9bfe3685/ingredient_extraction/clean_dataset.py#L23).
Once the detected errors were fixed using this approach, a new dataset alpha version was released, and we trained the model on this new dataset.
Dataset was split between train (90%) and test (10%) sets. Train and test splits were kept consistent at each alpha release. Only the test dataset was fully reviewed and corrected manually.
We tokenized the text using huggingface pre-tokenizer with the `[WhitespaceSplit(), Punctuation()]` sequence. The dataset generation script [can be found here](https://github.com/openfoodfacts/openfoodfacts-ai/blob/149447bdbcd19cb7c15127405d9112bc9bfe3685/ingredient_extraction/generate_dataset.py).
This dataset is exactly the same as `ingredient-detection-alpha-v6` used during model trainings.
## Annotation guidelines
Annotations guidelines were updated continuously during dataset refinement and model trainings, but here are the final guidelines:
1. ingredient lists in all languages must be annotated.
2. ingredients list should start with the first ingredient, without `ingredient` prefix ("Ingredients:", "Zutaten", "Ingrédients: ") or `language` prefix ("EN:", "FR - ",...)
3. ingredient list containing single ingredients without any `ingredient` or `language` prefix should not be annotated. Otherwise, it's very difficult to know whether the mention is the ingredient list or just a random mention of an ingredient on the packaging.
4. We have a very restrictive approach on where the ingredient list ends: we don't include any extra information (allergen, origin, trace, organic mentions) at the end of the ingredient list. The only exception is when this information is in bracket after the ingredient. This rule is in place to make it easier for the detector to know what is an ingredient list and what is not. Additional information can be added afterward as a post-processing step.
## Dataset schema
The dataset is made of 2 JSONL files:
- `ingredient_detection_dataset-v1_train.jsonl.gz`: train split, 5065 samples
- `ingredient_detection_dataset-v1_test.jsonl.gz`: test split, 556 samples
Each sample has the following fields:
- `text`: the original text obtained from OCR result
- `marked_text`: the text with ingredient spans delimited by `<b>` and `</b>`
- `tokens`: tokens obtained with pre-tokenization
- `ner_tags`: tag ID associated with each token: 0 for `O`, 1 for `B-ING` and 2 for `I-ING` (BIO schema)
- `offsets`: a list containing character start and end offsets of ingredients spans
- `meta`: a dict containing additional meta-data about the sample:
- `barcode`: the product barcode of the image that was used
- `image_id`: unique digit identifier of the image for the product
- `url`: image URL from which the text was extracted |
collabora/monado-slam-datasets | 2023-09-08T15:24:43.000Z | [
"license:cc-by-4.0",
"doi:10.57967/hf/1081",
"region:us"
] | collabora | null | null | null | 2 | 7 | ---
license: cc-by-4.0
---
<img alt="Monado SLAM Datasets cover image"
src="/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/extras/cover.png"
style="width: 720px;">
<a href="https://youtu.be/kIddwk1FrW8" target="_blank">
<video width="720" height="240" autoplay muted loop playsinline
preload="auto"><source
src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/overview.webm"
type="video/webm"/>Video tag not supported.</video>
</a>
# Monado SLAM Datasets
The [Monado SLAM datasets
(MSD)](https://huggingface.co/datasets/collabora/monado-slam-datasets), are
egocentric visual-inertial SLAM datasets recorded to improve the
[Basalt](https://gitlab.com/VladyslavUsenko/basalt)-based inside-out tracking
component of the [Monado](https://monado.dev) project. These have a permissive
license [CC-BY 4.0](http://creativecommons.org/licenses/by/4.0/), meaning you
can use them for any purpose you want, including commercial, and only a mention
of the original project is required. The creation of these datasets was
supported by [Collabora](https://collabora.com)
Monado is an open-source OpenXR runtime that you can use to make devices OpenXR
compatible. It also provides drivers for different existing hardware thanks to
different contributors in the community creating drivers for it. Monado provides
different XR-related modules that these drivers can use. To be more specific,
inside-out head tracking is one of those modules and, while you can use
different tracking systems, the main system is a [fork of
Basalt](https://gitlab.freedesktop.org/mateosss/basalt). Creating a good
open-source tracking solution requires a solid measurement pipeline to
understand how changes in the system affect tracking quality. For this reason,
the creation of these datasets was essential.
These datasets are very specific to the XR use case as they contain VI-SLAM
footage recorded from devices such as VR headsets, but other devices like phones
or AR glasses might be added in the future. These were made since current SLAM
datasets like EuRoC or TUM-VI were not specific enough for XR, or they didn't
have permissively enough usage licenses.
For questions or comments, you can use the Hugging Face
[Community](https://huggingface.co/datasets/collabora/monado-slam-datasets/discussions),
join Monado's discord [server](https://discord.gg/8RkJgRJ) and ask in the
`#slam` channel, or send an email to <mateo.demayo@collabora.com>.
## List of sequences
- [MI_valve_index](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index)
- [MIC_calibration](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIC_calibration)
- [MIC01_camcalib1](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC01_camcalib1.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC01_camcalib1.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC02_camcalib2](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC02_camcalib2.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC02_camcalib2.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC03_camcalib3](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC03_camcalib3.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC03_camcalib3.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC04_imucalib1](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC04_imucalib1.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC04_imucalib1.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC05_imucalib2](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC05_imucalib2.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC05_imucalib2.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC06_imucalib3](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC06_imucalib3.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC06_imucalib3.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC07_camcalib4](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC07_camcalib4.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC07_camcalib4.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC08_camcalib5](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC08_camcalib5.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC08_camcalib5.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC09_imucalib4](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC09_imucalib4.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC09_imucalib4.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC10_imucalib5](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC10_imucalib5.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC10_imucalib5.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC11_camcalib6](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC11_camcalib6.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC11_camcalib6.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC12_imucalib6](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC12_imucalib6.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC12_imucalib6.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC13_camcalib7](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC13_camcalib7.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC13_camcalib7.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC14_camcalib8](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC14_camcalib8.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC14_camcalib8.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC15_imucalib7](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC15_imucalib7.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC15_imucalib7.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIC16_imucalib8](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC16_imucalib8.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIC16_imucalib8.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO_others](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIO_others)
- [MIO01_hand_puncher_1](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO01_hand_puncher_1.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO01_hand_puncher_1.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO02_hand_puncher_2](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO02_hand_puncher_2.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO02_hand_puncher_2.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO03_hand_shooter_easy](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO03_hand_shooter_easy.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO03_hand_shooter_easy.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO04_hand_shooter_hard](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO04_hand_shooter_hard.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO04_hand_shooter_hard.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO05_inspect_easy](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO05_inspect_easy.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO05_inspect_easy.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO06_inspect_hard](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO06_inspect_hard.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO06_inspect_hard.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO07_mapping_easy](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO07_mapping_easy.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO07_mapping_easy.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO08_mapping_hard](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO08_mapping_hard.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO08_mapping_hard.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO09_short_1_updown](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO09_short_1_updown.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO09_short_1_updown.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO10_short_2_panorama](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO10_short_2_panorama.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO10_short_2_panorama.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO11_short_3_backandforth](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO11_short_3_backandforth.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO11_short_3_backandforth.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO12_moving_screens](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO12_moving_screens.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO12_moving_screens.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO13_moving_person](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO13_moving_person.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO13_moving_person.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO14_moving_props](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO14_moving_props.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO14_moving_props.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO15_moving_person_props](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO15_moving_person_props.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO15_moving_person_props.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIO16_moving_screens_person_props](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIO_others/MIO16_moving_screens_person_props.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIO16_moving_screens_person_props.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIP_playing](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIP_playing)
- [MIPB_beat_saber](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber)
- [MIPB01_beatsaber_100bills_360_normal](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber/MIPB01_beatsaber_100bills_360_normal.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPB01_beatsaber_100bills_360_normal.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPB02_beatsaber_crabrave_360_hard](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber/MIPB02_beatsaber_crabrave_360_hard.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPB02_beatsaber_crabrave_360_hard.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPB03_beatsaber_countryrounds_360_expert](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber/MIPB03_beatsaber_countryrounds_360_expert.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPB03_beatsaber_countryrounds_360_expert.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPB04_beatsaber_fitbeat_hard](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber/MIPB04_beatsaber_fitbeat_hard.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPB04_beatsaber_fitbeat_hard.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPB05_beatsaber_fitbeat_360_expert](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber/MIPB05_beatsaber_fitbeat_360_expert.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPB05_beatsaber_fitbeat_360_expert.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPB06_beatsaber_fitbeat_expertplus_1](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber/MIPB06_beatsaber_fitbeat_expertplus_1.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPB06_beatsaber_fitbeat_expertplus_1.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPB07_beatsaber_fitbeat_expertplus_2](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber/MIPB07_beatsaber_fitbeat_expertplus_2.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPB07_beatsaber_fitbeat_expertplus_2.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPB08_beatsaber_long_session_1](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber/MIPB08_beatsaber_long_session_1.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPB08_beatsaber_long_session_1.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPP_pistol_whip](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPP_pistol_whip)
- [MIPP01_pistolwhip_blackmagic_hard](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPP_pistol_whip/MIPP01_pistolwhip_blackmagic_hard.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPP01_pistolwhip_blackmagic_hard.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPP02_pistolwhip_lilith_hard](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPP_pistol_whip/MIPP02_pistolwhip_lilith_hard.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPP02_pistolwhip_lilith_hard.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPP03_pistolwhip_requiem_hard](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPP_pistol_whip/MIPP03_pistolwhip_requiem_hard.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPP03_pistolwhip_requiem_hard.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPP04_pistolwhip_revelations_hard](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPP_pistol_whip/MIPP04_pistolwhip_revelations_hard.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPP04_pistolwhip_revelations_hard.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPP05_pistolwhip_thefall_hard_2pistols](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPP_pistol_whip/MIPP05_pistolwhip_thefall_hard_2pistols.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPP05_pistolwhip_thefall_hard_2pistols.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPP06_pistolwhip_thegrave_hard](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPP_pistol_whip/MIPP06_pistolwhip_thegrave_hard.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPP06_pistolwhip_thegrave_hard.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPT_thrill_of_the_fight](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPT_thrill_of_the_fight)
- [MIPT01_thrillofthefight_setup](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPT_thrill_of_the_fight/MIPT01_thrillofthefight_setup.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPT01_thrillofthefight_setup.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPT02_thrillofthefight_fight_1](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPT_thrill_of_the_fight/MIPT02_thrillofthefight_fight_1.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPT02_thrillofthefight_fight_1.webm" type="video/webm"/>Video tag not supported.</video></details>
- [MIPT03_thrillofthefight_fight_2](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPT_thrill_of_the_fight/MIPT03_thrillofthefight_fight_2.zip): <details style="display: inline;cursor: pointer;user-select: none"><summary>Preview 5x</summary><video width="320" height="320" controls preload="none"><source src="https://huggingface.co/datasets/collabora/monado-slam-datasets/resolve/main/M_monado_datasets/MI_valve_index/extras/previews/MIPT03_thrillofthefight_fight_2.webm" type="video/webm"/>Video tag not supported.</video></details>
## Valve Index datasets
These datasets were recorded using a Valve Index with the `vive` driver in
Monado and they have ground truth from 3 lighthouses tracking the headset through
the proprietary OpenVR implementation provided by SteamVR. The exact commit used
in Monado at the time of recording is
[a4e7765d](https://gitlab.freedesktop.org/mateosss/monado/-/commit/a4e7765d7219b06a0c801c7bb33f56d3ea69229d).
The datasets are in the ASL dataset format, the same as the [EuRoC
datasets](https://projects.asl.ethz.ch/datasets/doku.php?id=kmavvisualinertialdatasets).
Besides the main EuRoC format files, we provide some extra files with raw
timestamp data for exploring real time timestamp alignment techniques.
The dataset is post-processed to reduce as much as possible special treatment
from SLAM systems: camera-IMU and ground truth-IMU timestamp alignment, IMU
alignment and bias calibration have been applied, lighthouse tracked pose has
been converted to IMU pose, and so on. Most of the post-processing was done with
Basalt
[calibration](https://gitlab.com/VladyslavUsenko/basalt/-/blob/master/doc/Calibration.md?ref_type=heads#camera-imu-mocap-calibration)
and
[alignment](https://gitlab.com/VladyslavUsenko/basalt/-/blob/master/doc/Realsense.md?ref_type=heads#generating-time-aligned-ground-truth)
tools, as well as the
[xrtslam-metrics](https://gitlab.freedesktop.org/mateosss/xrtslam-metrics)
scripts for Monado tracking. The post-processing process is documented in [this
video][post-processing-video] which goes through making the [MIPB08] dataset ready
for use starting from its raw version.
### Data
#### Camera samples
In the `vive` driver from Monado, we don't have direct access to the camera
device timestamps but only to V4L2 timestamps. These are not exactly hardware
timestamps and have some offset with respect to the device clock in which the
IMU samples are timestamped.
The camera frames can be found in the `camX/data` directory as PNG files with
names corresponding to their V4L2 timestamps. The `camX/data.csv` file contains
aligned timestamps of each frame. The `camX/data.extra.csv` also contains the
original V4L2 timestamp and the "host timestamp" which is the time at which the
host computer had the frame ready to use after USB transmission. By separating
arrival time and exposure time algorithms can be made to be more robust for
real time operation.
The cameras of the Valve Index have global shutters with a resolution of 960×960
streaming at 54fps. They have auto exposure enabled. While the cameras of the
Index are RGB you will find only grayscale images in these datasets. The
original images are provided in YUYV422 format but only the luma component is
stored.
For each dataset, the camera timestamps are aligned with respect to IMU
timestamps by running visual-only odometry with Basalt on a 30-second subset of
the dataset. The resulting trajectory is then aligned with the
[`basalt_time_alignment`](https://gitlab.com/VladyslavUsenko/basalt/-/blob/master/doc/Realsense.md?ref_type=heads#generating-time-aligned-ground-truth)
tool that aligns the rotational velocities of the trajectory with the gyroscope
samples and returns the resulting offset in nanoseconds. That correction is then
applied to the dataset. Refer to the post-processing walkthrough
[video][post-processing-video] for more details.
#### IMU samples
The IMU timestamps are device timestamps, they come at about 1000Hz. We provide
an `imu0/data.raw.csv` file that contains the raw measurements without any axis
scale misalignment o bias correction. `imu0/data.csv` has the
scale misalignment and bias corrections applied so that the SLAM system can
ignore those corrections. `imu0/data.extra.csv` contains the arrival time of the
IMU sample to the host computer for algorithms that want to adapt themselves to
work in real time.
#### Ground truth information
The ground truth setup consists of three lighthouses 2.0 base stations and a
SteamVR session providing tracking data through the OpenVR API to Monado. While
not as precise as other MoCap tracking systems like OptiTrack or Vicon it
should still provide pretty good accuracy and precision close to the 1mm range.
There are different attempts at studying the accuracy of SteamVR tracking that
you can check out like
[this](https://dl.acm.org/doi/pdf/10.1145/3463914.3463921),
[this](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7956487/pdf/sensors-21-01622.pdf),
or [this](http://doc-ok.org/?p=1478). When a tracking system gets closer to
millimeter accuracy these datasets will no longer be as useful for improving it.
The raw ground truth data is stored in `gt/data.raw.csv`. OpenVR does not provide
timestamps and as such, the timestamps recorded are from when the host asks
OpenVR for the latest pose with a call to
[`GetDeviceToAbsoluteTrackingPose`](https://github.com/ValveSoftware/openvr/wiki/IVRSystem::GetDeviceToAbsoluteTrackingPose).
The poses contained in this file are not of the IMU but of the headset origin as
interpreted by SteamVR, which usually is between the middle of the eyes and
facing towards the displays. The file `gt/data.csv` corrects each entry of the
previous file with timestamps aligned with the IMU clock and poses of the IMU
instead of this headset origin.
#### Calibration
There are multiple calibration datasets in the
[`MIC_calibration`](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIC_calibration)
directory. There are camera-focused and IMU-focused calibration datasets. See
the
[README.md](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/README.md)
file in there for more information on what each sequence is.
In the
[`MI_valve_index/extras`](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/extras)
directory you can find the following files:
- [`calibration.json`](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/extras/calibration.json):
Calibration file produced with the
[`basalt_calibrate_imu`](https://gitlab.com/VladyslavUsenko/basalt/-/blob/master/doc/Calibration.md?ref_type=heads#camera-imu-mocap-calibration)
tool from
[`MIC01_camcalib1`](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC01_camcalib1.zip)
and
[`MIC04_imucalib1`](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/MIC_calibration/MIC04_imucalib1.zip)
datasets with camera-IMU time offset and IMU bias/misalignment info removed so
that it works with the fully the all the datasets by default which are fully
post-processed and don't require those fields.
- [`calibration.extra.json`](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/extras/calibration.extra.json):
Same as `calibration.json` but with the cam-IMU time offset and IMU bias and
misalignment information filled in.
- [`factory.json`](https://huggingface.co/datasets/collabora/monado-slam-datasets/blob/main/M_monado_datasets/MI_valve_index/extras/factory.json):
JSON file exposed by the headset's firmware with information of the device. It
includes camera and display calibration as well as more data that might be of
interest. It is not used but included for completeness' sake.
- [`other_calibrations/`](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/extras/other_calibrations):
Calibration results obtained from the other calibration datasets. Shown for
comparison and ensuring that all of them have similar values.
`MICXX_camcalibY` has camera-only calibration produced with the
[`basalt_calibrate`](https://gitlab.com/VladyslavUsenko/basalt/-/blob/master/doc/Calibration.md?ref_type=heads#camera-calibration)
tool, while the corresponding `MICXX_imucalibY` datasets use these datasets as
a starting point and have the `basalt_calibrate_imu` calibration results.
##### Camera model
By default, the `calibration.json` file provides parameters `k1`, `k2`, `k3`,
and `k4` for the [Kannala-Brandt camera
model](https://vladyslavusenko.gitlab.io/basalt-headers/classbasalt_1_1KannalaBrandtCamera4.html#a423a4f1255e9971fe298dc6372345681)
with fish-eye distortion (also known as [OpenCV's
fish-eye](https://docs.opencv.org/3.4/db/d58/group__calib3d__fisheye.html#details)).
Calibrations with other camera models might be added later on, otherwise, you
can use the calibration sequences for custom calibrations.
##### IMU model
For the default `calibration.json` where all parameters are zero, you can ignore
any model and just use the measurements present in `imu0/data.csv` directly. If
instead, you want to use the raw measurements from `imu0/data.raw.csv` you will
need to apply the Basalt
[accelerometer](https://vladyslavusenko.gitlab.io/basalt-headers/classbasalt_1_1CalibAccelBias.html#details)
and
[gyroscope](https://vladyslavusenko.gitlab.io/basalt-headers/classbasalt_1_1CalibGyroBias.html#details)
models that use a misalignment-scale correction matrix together with a constant
initial bias. The random walk and white noise parameters were not computed and
default reasonable values are used instead.
#### Post-processing walkthrough
If you are interested in understanding the step-by-step procedure of
post-processing of the dataset, below is a video detailing the procedure for the
[MIPB08] dataset.
[](https://www.youtube.com/watch?v=0PX_6PNwrvQ)
### Sequences
- [MIC_calibration](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIC_calibration):
Calibration sequences that record
[this](https://drive.google.com/file/d/1DqKWgePodCpAKJCd_Bz-hfiEQOSnn_k0)
calibration target from Kalibr with the squares of the target having sides of
3 cm. Some sequences are focused on camera calibration covering the image
planes of both stereo cameras while others on IMU calibration properly
exciting all six components of the IMU.
- [MIP_playing](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIO_others):
Datasets in which the user is playing a particular VR game on SteamVR while
Monado records the datasets.
- [MIPB_beat_saber](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber):
This contains different songs played at different speeds. The fitbeat song
is one that requires a lot of head movement while [MIPB08] is a long 40min
dataset with many levels played.
- [MIPP_pistol_whip](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPP_pistol_whip):
This is a shooting and music game, each dataset is a different level/song.
- [MIPT_thrill_of_the_fight](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPT_thrill_of_the_fight):
This is a boxing game.
- [MIO_others](https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIO_others):
These are other datasets that might be useful, they include play-pretend
scenarios in which the user is supposed to be playing some particular game,
then there is some inspection and scanning/mapping of the room, some very
short and lightweight datasets for quick testing, and some datasets with a lot
of movement around the environment.
### Evaluation
These are the results of running the
[current](https://gitlab.freedesktop.org/mateosss/basalt/-/commits/release-b67fa7a4?ref_type=tags)
Monado tracker that is based on
[Basalt](https://gitlab.com/VladyslavUsenko/basalt) on the dataset sequences.
| Seq. | Avg. time\* | Avg. feature count | ATE (m) | RTE 100ms (m) \*\* | SDM 0.01m (m/m) \*\*\* |
| :------ | :--------------- | :-------------------- | :---------------- | :---------------------- | :--------------------- |
| MIC01 | 12.24 ± 2.84 | [48 6] ± [72 6] | 0.076 ± 0.049 | 0.016551 ± 0.015004 | 0.7407 ± 0.5757 |
| MIC02 | 12.30 ± 2.60 | [33 7] ± [54 11] | 0.043 ± 0.028 | 0.012375 ± 0.011230 | 0.5788 ± 0.4279 |
| MIC03 | 15.89 ± 8.55 | [60 8] ± [107 13] | 0.048 ± 0.032 | 0.011344 ± 0.009992 | 0.6020 ± 0.3987 |
| MIC04 | 15.26 ± 2.84 | [65 9] ± [54 11] | 0.028 ± 0.016 | 0.005458 ± 0.003976 | 0.2808 ± 0.2033 |
| MIC05 | 16.10 ± 2.82 | [73 5] ± [69 6] | 0.023 ± 0.013 | 0.004795 ± 0.003358 | 0.2547 ± 0.1611 |
| MIC06 | 14.14 ± 2.42 | [40 7] ± [53 10] | 0.015 ± 0.005 | 0.003947 ± 0.003454 | 0.2875 ± 0.2542 |
| MIC07 | 13.42 ± 2.63 | [46 9] ± [64 12] | 0.036 ± 0.014 | 0.012776 ± 0.011853 | 0.5520 ± 0.3463 |
| MIC08 | 13.89 ± 2.86 | [53 5] ± [62 5] | 0.082 ± 0.062 | 0.022429 ± 0.020956 | 0.8559 ± 0.6402 |
| MIC09 | 12.73 ± 2.52 | [63 21] ± [37 12] | 0.008 ± 0.003 | 0.001492 ± 0.001318 | 0.2388 ± 0.3589 |
| MIC10 | 14.49 ± 2.51 | [50 5] ± [51 5] | 0.019 ± 0.012 | 0.003783 ± 0.003116 | 0.2666 ± 0.3451 |
| MIC11 | 13.72 ± 2.37 | [26 6] ± [39 7] | 0.017 ± 0.010 | 0.009898 ± 0.009069 | 0.4331 ± 0.3278 |
| MIC12 | 14.92 ± 2.56 | [38 4] ± [48 5] | 0.024 ± 0.010 | 0.005816 ± 0.004644 | 0.2932 ± 0.2500 |
| MIC13 | 13.99 ± 3.07 | [53 10] ± [79 15] | 0.029 ± 0.021 | 0.015463 ± 0.014354 | 0.8668 ± 0.9353 |
| MIC14 | 13.67 ± 2.39 | [24 5] ± [36 8] | 0.047 ± 0.012 | 0.007224 ± 0.006359 | 0.4577 ± 0.3446 |
| MIC15 | 14.17 ± 2.81 | [76 17] ± [43 9] | 0.016 ± 0.013 | 0.003837 ± 0.003543 | 0.2593 ± 0.1936 |
| MIC16 | 14.27 ± 2.43 | [48 8] ± [44 6] | 0.008 ± 0.005 | 0.003867 ± 0.003725 | 0.5167 ± 0.4840 |
| MIO01 | 10.04 ± 1.43 | [36 23] ± [28 18] | 0.605 ± 0.342 | 0.035671 ± 0.033611 | 0.4246 ± 0.5161 |
| MIO02 | 10.41 ± 1.48 | [32 18] ± [25 16] | 1.182 ± 0.623 | 0.063340 ± 0.059176 | 0.4681 ± 0.4329 |
| MIO03 | 10.24 ± 1.37 | [47 26] ± [26 16] | 0.087 ± 0.033 | 0.006293 ± 0.004259 | 0.2113 ± 0.2649 |
| MIO04 | 9.47 ± 1.08 | [27 16] ± [25 16] | 0.210 ± 0.100 | 0.013121 ± 0.010350 | 0.3086 ± 0.3715 |
| MIO05 | 9.95 ± 1.01 | [66 34] ± [33 21] | 0.040 ± 0.016 | 0.003188 ± 0.002192 | 0.1079 ± 0.1521 |
| MIO06 | 9.65 ± 1.06 | [44 28] ± [33 22] | 0.049 ± 0.019 | 0.010454 ± 0.008578 | 0.2620 ± 0.3684 |
| MIO07 | 9.63 ± 1.16 | [46 26] ± [30 19] | 0.019 ± 0.008 | 0.002442 ± 0.001355 | 0.0738 ± 0.0603 |
| MIO08 | 9.74 ± 0.87 | [29 22] ± [18 16] | 0.059 ± 0.021 | 0.007167 ± 0.004657 | 0.1644 ± 0.3433 |
| MIO09 | 9.94 ± 0.72 | [44 29] ± [14 8] | 0.006 ± 0.003 | 0.002940 ± 0.002024 | 0.0330 ± 0.0069 |
| MIO10 | 9.48 ± 0.82 | [35 21] ± [18 10] | 0.016 ± 0.009 | 0.004623 ± 0.003310 | 0.0620 ± 0.0340 |
| MIO11 | 9.34 ± 0.79 | [32 20] ± [19 10] | 0.024 ± 0.010 | 0.007255 ± 0.004821 | 0.0854 ± 0.0540 |
| MIO12 | 11.05 ± 2.20 | [43 23] ± [31 19] | 0.420 ± 0.160 | 0.005298 ± 0.003603 | 0.1546 ± 0.2641 |
| MIO13 | 10.47 ± 1.89 | [35 21] ± [24 18] | 0.665 ± 0.290 | 0.026294 ± 0.022790 | 1.0180 ± 1.0126 |
| MIO14 | 9.27 ± 1.03 | [49 31] ± [30 21] | 0.072 ± 0.028 | 0.002779 ± 0.002487 | 0.1657 ± 0.2409 |
| MIO15 | 9.75 ± 1.16 | [52 26] ± [29 16] | 0.788 ± 0.399 | 0.011558 ± 0.010541 | 0.6906 ± 0.6876 |
| MIO16 | 9.72 ± 1.26 | [33 17] ± [25 15] | 0.517 ± 0.135 | 0.013268 ± 0.011355 | 0.4397 ± 0.7167 |
| MIPB01 | 10.28 ± 1.25 | [63 46] ± [34 24] | 0.282 ± 0.109 | 0.006797 ± 0.004551 | 0.1401 ± 0.1229 |
| MIPB02 | 9.88 ± 1.08 | [55 37] ± [30 20] | 0.247 ± 0.097 | 0.005065 ± 0.003514 | 0.1358 ± 0.1389 |
| MIPB03 | 10.21 ± 1.12 | [66 44] ± [32 23] | 0.186 ± 0.103 | 0.005938 ± 0.004261 | 0.1978 ± 0.3590 |
| MIPB04 | 9.58 ± 1.02 | [51 37] ± [24 17] | 0.105 ± 0.060 | 0.004822 ± 0.003428 | 0.0652 ± 0.0555 |
| MIPB05 | 9.97 ± 0.97 | [73 48] ± [32 23] | 0.039 ± 0.017 | 0.004426 ± 0.002828 | 0.0826 ± 0.1313 |
| MIPB06 | 9.95 ± 0.85 | [58 35] ± [32 21] | 0.050 ± 0.022 | 0.004164 ± 0.002638 | 0.0549 ± 0.0720 |
| MIPB07 | 10.07 ± 1.00 | [73 47] ± [31 20] | 0.064 ± 0.038 | 0.004984 ± 0.003170 | 0.0785 ± 0.1411 |
| MIPB08 | 9.97 ± 1.08 | [71 47] ± [36 24] | 0.636 ± 0.272 | 0.004066 ± 0.002556 | 0.0740 ± 0.0897 |
| MIPP01 | 10.03 ± 1.21 | [36 22] ± [21 15] | 0.559 ± 0.241 | 0.009227 ± 0.007765 | 0.3472 ± 0.9075 |
| MIPP02 | 10.19 ± 1.20 | [42 22] ± [22 15] | 0.257 ± 0.083 | 0.011046 ± 0.010201 | 0.5014 ± 0.7665 |
| MIPP03 | 10.13 ± 1.24 | [37 20] ± [23 15] | 0.260 ± 0.101 | 0.008636 ± 0.007166 | 0.3205 ± 0.5786 |
| MIPP04 | 9.74 ± 1.09 | [38 23] ± [22 16] | 0.256 ± 0.144 | 0.007847 ± 0.006743 | 0.2586 ± 0.4557 |
| MIPP05 | 9.71 ± 0.84 | [37 24] ± [21 15] | 0.193 ± 0.086 | 0.005606 ± 0.004400 | 0.1670 ± 0.2398 |
| MIPP06 | 9.92 ± 3.11 | [37 21] ± [21 14] | 0.294 ± 0.136 | 0.009794 ± 0.008873 | 0.4016 ± 0.5648 |
| MIPT01 | 10.78 ± 2.06 | [68 44] ± [33 23] | 0.108 ± 0.060 | 0.003995 ± 0.002716 | 0.7109 ± 13.3461 |
| MIPT02 | 10.85 ± 1.27 | [79 54] ± [39 28] | 0.198 ± 0.109 | 0.003709 ± 0.002348 | 0.0839 ± 0.1175 |
| MIPT03 | 10.80 ± 1.55 | [76 52] ± [42 30] | 0.401 ± 0.206 | 0.005623 ± 0.003694 | 0.1363 ± 0.1789 |
| **AVG** | **11.33 ± 1.83** | **[49 23] ± [37 15]** | **0.192 ± 0.090** | **0.009439 ± 0.007998** | **0.3247 ± 0.6130** |
- \*: Average frame time. On an AMD Ryzen 7 5800X CPU. Run with pipeline fully
saturated. Real time operation frame times should be slightly lower.
- \*\*: RTE using delta of 6 frames (11ms)
- \*\*\*: The SDM metric is similar to RTE, it represents distance in meters
drifted for each meter of the dataset. The metric is implemented in the
[xrtslam-metrics](https://gitlab.freedesktop.org/mateosss/xrtslam-metrics)
project.
## License
This work is licensed under a <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Creative Commons Attribution 4.0 International License</a>.
<a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/88x31.png" /></a>
[post-processing-video]: https://youtu.be/0PX_6PNwrvQ
[MIPB08]: https://huggingface.co/datasets/collabora/monado-slam-datasets/tree/main/M_monado_datasets/MI_valve_index/MIP_playing/MIPB_beat_saber
|
Pretam/hi-kn | 2023-08-17T17:36:26.000Z | [
"region:us"
] | Pretam | null | null | null | 0 | 7 | Entry not found |
ticoAg/ChineseCorpus-Kaggle-fanti | 2023-08-19T09:52:06.000Z | [
"task_categories:text-generation",
"size_categories:10M<n<100M",
"language:tw",
"language:zh",
"license:apache-2.0",
"region:us"
] | ticoAg | null | null | null | 0 | 7 | ---
'39436887': examples
raw size: 4G
license: apache-2.0
task_categories:
- text-generation
language:
- tw
- zh
size_categories:
- 10M<n<100M
---
## source
mix data from https://www.kaggle.com/datasets/allanyiinai/chinesecorpus
- use
```python
from datasets import load_datasets
ds = load_datasets("ticoAg/ChineseCorpus-Kaggle-fanti")
```
- example
```json
[
{
"text": "2017年12月5日,重慶市交委正式下發《關于新建市郊鐵路磨心坡至合川線工程初步設計的批復》,2017年計劃開工四個節點工程,包括渭沱貨運站場、土場貨運站場、嘉陵江特大橋、九峰山遂道。"
},
{
"text": "2017年7月6日,線路重要節點合川渭沱貨運站開工建設,線路開始建設,項目建設工期為48個月。"
},
{
"text": "日前,渝合線二期(合川段)施工出現了停滯,至今仍未解決,合川區人民政府在2019、2020年均稱將力促市郊鐵路渝合線復工。"
},
{
"text": "2012年,12歲的加比亞加盟米蘭青訓營。在 2017 年 5 月 7 日米蘭主場對陣羅馬的意甲比賽之前,他第一次受到主教練蒙特拉的征召。然而,他仍然是一個沒獲得出場機會的替補。 2017 年 8 月 24 日,他在歐聯杯預選賽對陣斯肯迪亞的比賽中首次代表俱樂部出場,他在第 73 分鐘替補洛卡特利出場。"
},
{
"text": "他在2018 年歐洲 19 歲以下歐洲錦標賽上代表意大利 U19參加了兩場小組賽,意大利獲得亞軍。隨后他隨意大利 U20參加了2019 年國際足聯 U-20 世界杯。"
}
]
``` |
erfanloghmani/myket-android-application-recommendation-dataset | 2023-08-18T22:00:40.000Z | [
"task_categories:graph-ml",
"size_categories:100K<n<1M",
"license:mit",
"arxiv:2308.06862",
"region:us"
] | erfanloghmani | null | null | null | 1 | 7 | ---
license: mit
task_categories:
- graph-ml
size_categories:
- 100K<n<1M
configs:
- config_name: main_data
data_files: "myket.csv"
- config_name: package_name_features
data_files: "app_info.csv"
---
# Myket Android Application Install Dataset
This dataset contains information on application install interactions of users in the [Myket](https://myket.ir/) android application market. The dataset was created for the purpose of evaluating interaction prediction models, requiring user and item identifiers along with timestamps of the interactions.
## Data Creation
The dataset was initially generated by the Myket data team, and later cleaned and subsampled by Erfan Loghmani a master student at Sharif University of Technology at the time. The data team focused on a two-week period and randomly sampled 1/3 of the users with interactions during that period. They then selected install and update interactions for three months before and after the two-week period, resulting in interactions spanning about 6 months and two weeks.
We further subsampled and cleaned the data to focus on application download interactions. We identified the top 8000 most installed applications and selected interactions related to them. We retained users with more than 32 interactions, resulting in 280,391 users. From this group, we randomly selected 10,000 users, and the data was filtered to include only interactions for these users. The detailed procedure can be found in [here](https://github.com/erfanloghmani/myket-android-application-market-dataset/blob/main/create_data.ipynb).
## Data Structure
The dataset has two main files.
- `myket.csv`: This file contains the interaction information and follows the same format as the datasets used in the "[JODIE: Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks](https://github.com/claws-lab/jodie)" (ACM SIGKDD 2019) project. However, this data does not contain state labels and interaction features, resulting in associated columns being all zero.
- `app_info_sample.csv`: This file comprises features associated with applications present in the sample. For each individual application, information such as the approximate number of installs, average rating, count of ratings, and category are included. These features provide insights into the applications present in the dataset.
## Dataset Details
- Total Instances: 694,121 install interaction instances
- Instances Format: Triplets of user_id, app_name, timestamp
- 10,000 users and 7,988 android applications
For a detailed summary of the data's statistics, including information on users, applications, and interactions, please refer to the Python notebook available at [summary-stats.ipynb](https://github.com/erfanloghmani/myket-android-application-market-dataset/blob/main/summary-stats.ipynb). The notebook provides an overview of the dataset's characteristics and can be helpful for understanding the data's structure before using it for research or analysis.
### Top 20 Most Installed Applications
| Package Name | Count of Interactions |
| ---------------------------------- | --------------------- |
| com.instagram.android | 15292 |
| ir.resaneh1.iptv | 12143 |
| com.tencent.ig | 7919 |
| com.ForgeGames.SpecialForcesGroup2 | 7797 |
| ir.nomogame.ClutchGame | 6193 |
| com.dts.freefireth | 6041 |
| com.whatsapp | 5876 |
| com.supercell.clashofclans | 5817 |
| com.mojang.minecraftpe | 5649 |
| com.lenovo.anyshare.gps | 5076 |
| ir.medu.shad | 4673 |
| com.firsttouchgames.dls3 | 4641 |
| com.activision.callofduty.shooter | 4357 |
| com.tencent.iglite | 4126 |
| com.aparat | 3598 |
| com.kiloo.subwaysurf | 3135 |
| com.supercell.clashroyale | 2793 |
| co.palang.QuizOfKings | 2589 |
| com.nazdika.app | 2436 |
| com.digikala | 2413 |
## Comparison with SNAP Datasets
The Myket dataset introduced in this repository exhibits distinct characteristics compared to the real-world datasets used by the project. The table below provides a comparative overview of the key dataset characteristics:
| Dataset | #Users | #Items | #Interactions | Average Interactions per User | Average Unique Items per User |
| --------- | ----------------- | ----------------- | ----------------- | ----------------------------- | ----------------------------- |
| **Myket** | **10,000** | **7,988** | 694,121 | 69.4 | 54.6 |
| LastFM | 980 | 1,000 | 1,293,103 | 1,319.5 | 158.2 |
| Reddit | **10,000** | 984 | 672,447 | 67.2 | 7.9 |
| Wikipedia | 8,227 | 1,000 | 157,474 | 19.1 | 2.2 |
| MOOC | 7,047 | 97 | 411,749 | 58.4 | 25.3 |
The Myket dataset stands out by having an ample number of both users and items, highlighting its relevance for real-world, large-scale applications. Unlike LastFM, Reddit, and Wikipedia datasets, where users exhibit repetitive item interactions, the Myket dataset contains a comparatively lower amount of repetitive interactions. This unique characteristic reflects the diverse nature of user behaviors in the Android application market environment.
## Citation
If you use this dataset in your research, please cite the following [preprint](https://arxiv.org/abs/2308.06862):
```
@misc{loghmani2023effect,
title={Effect of Choosing Loss Function when Using T-batching for Representation Learning on Dynamic Networks},
author={Erfan Loghmani and MohammadAmin Fazli},
year={2023},
eprint={2308.06862},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
shhossain/book-text-classifier | 2023-08-26T09:02:57.000Z | [
"task_categories:text-classification",
"task_categories:text-generation",
"task_categories:fill-mask",
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"region:us"
] | shhossain | null | null | null | 0 | 7 | ---
license: mit
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: index
dtype: int64
- name: text
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 118863628.4954102
num_examples: 77650
- name: test
num_bytes: 29716672.504589804
num_examples: 19413
download_size: 98048351
dataset_size: 148580301
task_categories:
- text-classification
- text-generation
- fill-mask
language:
- en
size_categories:
- 10K<n<100K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
mu-llama/MusicQA | 2023-09-13T14:45:00.000Z | [
"license:mit",
"region:us"
] | mu-llama | This is the dataset used for training and testing the Music Understanding Large Language Model (MU-LLaMA) | null | null | 3 | 7 | ---
license: mit
---
# MusicQA Dataset
This is the dataset used for training and testing the Music Understanding Large Language Model (MU-LLaMA). |
mHossain/merge_new_para_detection_data_v6 | 2023-08-21T15:46:23.000Z | [
"region:us"
] | mHossain | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: 'Unnamed: 0'
dtype: int64
- name: text
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 18268704.9
num_examples: 108000
- name: test
num_bytes: 2029856.1
num_examples: 12000
download_size: 9186455
dataset_size: 20298561.0
---
# Dataset Card for "merge_new_para_detection_data_v6"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mekaneeky/lugbara-crowd-validated-paths | 2023-08-25T14:18:17.000Z | [
"region:us"
] | mekaneeky | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: valid
path: data/valid-*
- split: test
path: data/test-*
dataset_info:
features:
- name: Path
dtype: string
- name: Key
dtype: int64
- name: Speaker
dtype: string
- name: Transcription
dtype: string
splits:
- name: train
num_bytes: 584439
num_examples: 4772
- name: valid
num_bytes: 11769
num_examples: 98
- name: test
num_bytes: 11561
num_examples: 95
download_size: 293237
dataset_size: 607769
---
# Dataset Card for "lugbara-crowd-validated-paths"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
collabora/carla-nuscenes | 2023-08-23T19:28:25.000Z | [
"license:cc-by-4.0",
"region:us"
] | collabora | null | null | null | 0 | 7 | ---
license: cc-by-4.0
---
|
mbazaNLP/NMT_Tourism_parallel_data_en_kin | 2023-09-11T13:22:11.000Z | [
"task_categories:translation",
"size_categories:10K<n<100K",
"language:en",
"language:rw",
"license:cc-by-2.0",
"region:us"
] | mbazaNLP | null | null | null | 1 | 7 | ---
license: cc-by-2.0
task_categories:
- translation
language:
- en
- rw
size_categories:
- 10K<n<100K
---
## Dataset Description
This dataset was created in an effort to create a machine translation model for English-to-Kinyarwanda translation and vice-versa in a tourism-geared context.
- **Repository:**[link](https://github.com/Digital-Umuganda/twb_nllb_project_tourism_education) to the GitHub repository containing the code for training the model on this data, and the code for the collection of the monolingual data.
- **Data Format:** TSV
- **Data Source:** web scraping, manual annotation
- **Model:** huggingface [model link](mbazaNLP/Nllb_finetuned_tourism_en_kin).
### Data Instances
```
25375 49363 21210 Bird watching is best in June, so save your money on that during the other months, birds ar everywhere anyway if you are observant and patient. Kureba inyoni ni byiza cyane muri Kamena, bityo rero ujye uzigama amafaranga yawe mu gihe cy'amezi yindi, inyoni ziba hose uko byagenda kose niba witonze kandi wihanganye. 2023-05-15 18:08:54 19.0 1 3 tourism trip_advisor 125-195
```
### Data Fields
- id
- source_id
- source
- phrase
- timestamp
- user_id
- validation_state
- validation_score
- domain
- source_files
- str_ranges
### Data Splits
- **Training Data:** 25374
- **Validation Data:** 2508
- **Test Data:** 1086
## Data Preprocessing
- **Data Splitting:** To create a test set; all data sources are equally represented in terms of the number of sentences contributed to the test dataset. In terms of sentence length, the test set distribution is similar to the sentence length distribution of the whole dataset. After picking the test set, from the remaining data the train and validation data are split using sklearn's [train_test_split](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html).
## Data Collection
- **Data Collection Process:** The monolingual source sentences were obtained through web-scraping of several websites, and contain both Kinyarwanda and English sentences.
- **Data Sources:**
- Trip_advisor reviews on hotels and tourist attractions in Rwanda.
- Inyamibwa historical data.
- Igihe tourism news.
- Tourism scenarios dialogue generated by GPT-3.5.
- Booking.com Rwandan hotel reviews.
- Rwanda's wiki_travel page.
## Dataset Creation
After collecting the monolingual dataset, human translators were employed to produce translations for the collected sentences. To ensure quality, each sentence was translated more than once, and each generated translation was assigned **validation_score** that was used to pick the best translation. The test dataset was further revised to remove or correct sentences with faulty translations.
|
fake-news-UFG/FactChecksbr | 2023-08-24T17:40:04.000Z | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:pt",
"license:mit",
"doi:10.57967/hf/1016",
"region:us"
] | fake-news-UFG | Collection of Portuguese Fact-Checking Benchmarks. | @misc{FactChecksbr,
author = {R. S. Gomes, Juliana},
title = {FactChecks.br},
url = {https://github.com/fake-news-UFG/FactChecks.br},
doi = { 10.57967/hf/1016 },
} | null | 0 | 7 | ---
license: mit
task_categories:
- text-classification
language:
- pt
pretty_name: FactChecks.br
size_categories:
- 10K<n<100K
---
# FactChecks.br
## Dataset Description
- **Homepage:**
- **Repository:** [github.com/fake-news-UFG/FactChecks.br](github.com/fake-news-UFG/FactChecks.br)
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Collection of Portuguese Fact-Checking Benchmarks.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
The dataset is in Portuguese.
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use "FactChecks.br Dataset", please include a cite:
```bibtex
@misc{FactChecksbr,
author = {R. S. Gomes, Juliana},
title = {FactChecks.br},
url = {https://github.com/fake-news-UFG/FactChecks.br},
doi = { 10.57967/hf/1016 },
}
```
### Contributions
Thanks to [@ju-resplande](https://github.com/ju-resplande) for adding this dataset. |
MikhailT/hifi-tts-light | 2023-08-24T13:24:33.000Z | [
"language:en",
"license:cc-by-4.0",
"region:us"
] | MikhailT | null | null | null | 0 | 7 | ---
configs:
- config_name: clean
version: 1.0.0
data_files:
- split: train
path: data/train.clean*.parquet
- split: test
path: data/test.clean*.parquet
- split: dev
path: data/dev.clean*.parquet
- config_name: other
version: 1.0.0
data_files:
- split: train
path: data/train.other*.parquet
- split: test
path: data/test.other*.parquet
- split: dev
path: data/dev.other*.parquet
- config_name: all
version: 1.0.0
data_files:
- split: train.clean
path: data/train.clean*.parquet
- split: train.other
path: data/train.other*.parquet
- split: test.clean
path: data/test.clean*.parquet
- split: test.other
path: data/test.other*.parquet
- split: dev.clean
path: data/dev.clean*.parquet
- split: dev.other
path: data/dev.other*.parquet
dataset_info:
- config_name: clean
features:
- name: speaker
dtype: string
- name: file
dtype: string
- name: duration
dtype: float32
- name: text
dtype: string
- name: text_no_preprocessing
dtype: string
- name: text_normalized
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 44100
splits:
- name: train
num_bytes: 1158544
num_examples: 9
- name: dev
num_bytes: 904913
num_examples: 9
- name: test
num_bytes: 800999
num_examples: 9
download_size: 0
dataset_size: 2864456
- config_name: other
features:
- name: speaker
dtype: string
- name: file
dtype: string
- name: duration
dtype: float32
- name: text
dtype: string
- name: text_no_preprocessing
dtype: string
- name: text_normalized
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 44100
splits:
- name: train
num_bytes: 3632881
num_examples: 21
- name: dev
num_bytes: 3255234
num_examples: 18
- name: test
num_bytes: 3180854
num_examples: 18
download_size: 0
dataset_size: 10068969
- config_name: all
features:
- name: speaker
dtype: string
- name: file
dtype: string
- name: duration
dtype: float32
- name: text
dtype: string
- name: text_no_preprocessing
dtype: string
- name: text_normalized
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 44100
splits:
- name: train.clean
num_bytes: 1158544
num_examples: 9
- name: train.other
num_bytes: 3632881
num_examples: 21
- name: dev.clean
num_bytes: 904913
num_examples: 9
- name: dev.other
num_bytes: 3255234
num_examples: 18
- name: test.clean
num_bytes: 800999
num_examples: 9
- name: test.other
num_bytes: 3180854
num_examples: 18
download_size: 0
dataset_size: 12933425
pretty_name: HiFiTTS
description: Hi-Fi Multi-Speaker English TTS Dataset (Hi-Fi TTS) is based on LibriVox's public domain audio books and Gutenberg Project texts.
homepage: http://www.openslr.org/109
language:
- en
license:
- cc-by-4.0
citation: "@article{bakhturina2021hi,\n title={{Hi-Fi Multi-Speaker English TTS Dataset}},\n author={Bakhturina, Evelina and Lavrukhin, Vitaly and Ginsburg, Boris and Zhang, Yang},\n journal={arXiv preprint arXiv:2104.01497},\n year={2021}\n}\n"
---
# Dataset Card for HiFiTTS
Hi-Fi Multi-Speaker English TTS Dataset (Hi-Fi TTS) is based on LibriVox's public domain audio books and Gutenberg Project texts. |
LawChat-tw/SFT | 2023-08-24T04:31:42.000Z | [
"region:us"
] | LawChat-tw | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: instruction
dtype: string
splits:
- name: train
num_bytes: 11724495
num_examples: 11798
download_size: 6505304
dataset_size: 11724495
---
# Dataset Card for "SFT"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
probably0/cryptocurrency-price-data | 2023-08-26T05:26:55.000Z | [
"region:us"
] | probably0 | null | null | null | 0 | 7 | # Crypto Data Card for Multi-Blockchain Cryptocurrencies
## Dataset Name
Crypto Multi-Blockchain Historical Prices
## Dataset Version
v1.0, Date: Up to August 25, 2023
## Description
This dataset constitutes an extensive compilation of historical pricing data, encapsulating 163 distinct cryptocurrencies across diverse blockchain ecosystems. Specifically, the dataset spans a considerable temporal range, from July 17, 2010, to August 25, 2023. This corpus is organized to facilitate multidisciplinary scholarly investigations, offering rich metrics including but not limited to opening, highest, lowest, and closing prices for each cryptocurrency on a daily basis. Furthermore, the dataset categorizes the cryptocurrencies according to the underlying blockchain technology, thus aiding in more nuanced analyses.
## Categories Based on Blockchain
- **Bitcoin-based**: BTC, BCH, BSV, BTG
- **Ethereum-based**: ETH, USDT, BAT, COMP, DAI, MKR, SNX, UNI, YFI, LINK, MANA, etc.
- **Binance Smart Chain**: BNB, BUSD, CAKE
- **Cardano**: ADA
- **Polkadot**: DOT, KSM
- **Solana**: SOL
- **EOS**: EOS
- **Tezos**: XTZ
- **Algorand**: ALGO
- **Ripple**: XRP
- **Other**: (List other blockchain categories here)
## Fields in Data
- **Ticker**: The ticker symbol of the cryptocurrency (e.g., BTC for Bitcoin).
- **Date**: The date the data was collected, formatted in MM/DD/YY.
- **Open**: The opening price of the cryptocurrency on the given day.
- **High**: The highest recorded price of the cryptocurrency on the given day.
- **Low**: The lowest recorded price of the cryptocurrency on the given day.
- **Close**: The closing price of the cryptocurrency on the given day.
## Example Data Entry
| Ticker | Date | Open | High | Low | Close |
| ------ | ------- | ----- | ----- | ----- | ----- |
| BTC | 1/19/23 | 20772 | 21162 | 20659 | 20941 |
## Use Case
The dataset is instrumental for a range of academic and applied research contexts, including but not limited to:
- Temporal trend analysis
- Predictive modeling and analytics
- Portfolio optimization and risk assessment
## Data Collection Method
The data is rigorously sourced from multiple, reputable exchanges and is subsequently consolidated. All prices are denominated in USD.
## Limitations
- Historical prices may not be predictive of future financial trajectories.
- The dataset, while extensive, may not encompass the most recent market fluctuations due to periodic updating.
## Legal and Ethical Considerations
- The dataset is intended solely for academic and informational purposes.
- Users bear the responsibility for ensuring compliance with applicable legal and ethical standards.
## Data Format
Each cryptocurrency is stored in a separate CSV file, identified by its ticker symbol (e.g., `BTC.csv`, `ETH.csv`, `ADA.csv`, etc.).
## Maintenance
The dataset will undergo periodic updates to ensure its continued relevance and comprehensiveness.
## Acknowledgments
The dataset is an aggregation of data sourced from multiple exchanges, consolidated and curated by Probably 0 AI Team.
|
stevengubkin/mathoverflow_text_arxiv_labels | 2023-08-27T18:43:03.000Z | [
"license:cc-by-sa-4.0",
"region:us"
] | stevengubkin | null | null | null | 0 | 7 | ---
license: cc-by-sa-4.0
---
Downloaded from https://archive.org/download/stackexchange
Used [TexSoup](https://pypi.org/project/TexSoup/) to replace all text in math environments with [UNK]. For instance the text:
"The integral $\int_a^b f(x) \textrm{ d}x$ is easy to evaluate if..."
was replaced with
"The integral [UNK] is easy to evaluate if..."
Note: There is still some "ascii math". For instance, people sometimes write things like f: X --> Y. This is retained.
Concatenated title and body.
Some of these are "answer" posts rather than "question" posts. In the original data these are untagged.
I tagged each "answer" post with the tags of the question they are responding to.
I only retained posts which used at least one of the 32 arxiv tags ('ac.commutative-algebra',
'ag.algebraic-geometry', ..., 'st.statistics').
I only retained posts which had >5 upvotes.
The train/valid/test split was accomplished using [MultilabelStratifiedShuffleSplit](https://github.com/trent-b/iterative-stratification).
This does a better job of respecting multilabel co-occurance statistics than a purely random split. |
mikewang/AwA2 | 2023-08-31T16:23:09.000Z | [
"language:en",
"region:us"
] | mikewang | **Homepage:** https://cvml.ista.ac.at/AwA2/
**IMPORTANT NOTES**
- This HF dataset loads the instances with class-level annotations.
- Images and License can be downloaded from: https://cvml.ista.ac.at/AwA2/AwA2-data.zip | @article{xian2018zero,
title={Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly},
author={Xian, Yongqin and Lampert, Christoph H and Schiele, Bernt and Akata, Zeynep},
journal={IEEE transactions on pattern analysis and machine intelligence},
volume={41},
number={9},
pages={2251--2265},
year={2018},
publisher={IEEE}
} | null | 0 | 7 | ---
pretty_name: 'Animals with Attributes v2 (AwA2)'
language:
- en
---
# Dataset Card for Animals with Attributes v2 (AwA2)
## Dataset Description
**Homepage:** https://cvml.ista.ac.at/AwA2/
**IMPORTANT NOTES**
- This HF dataset downloads the dataset (https://cvml.ista.ac.at/AwA2/AwA2-data.zip), and loads the image instances with class-level annotations.
- The "train" split in this HF dataset contains all the images. For the original proposed splits and the proposed splits version 2.0, please refer to [here](https://www.mpi-inf.mpg.de/departments/computer-vision-and-machine-learning/research/zero-shot-learning/zero-shot-learning-the-good-the-bad-and-the-ugly/).
- License files is also included in the downloaded dataset (https://cvml.ista.ac.at/AwA2/AwA2-data.zip)
**Paper Citation:**
```
@article{xian2018zero,
title={Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly},
author={Xian, Yongqin and Lampert, Christoph H and Schiele, Bernt and Akata, Zeynep},
journal={IEEE transactions on pattern analysis and machine intelligence},
volume={41},
number={9},
pages={2251--2265},
year={2018},
publisher={IEEE}
}
```
## Dataset Summary
This dataset provides a platform to benchmark transfer-learning algorithms, in particular attribute base classification and zero-shot learning [1]. It can act as a drop-in replacement to the original Animals with Attributes (AwA) dataset [2,3], as it has the same class structure and almost the same characteristics.
It consists of 37322 images of 50 animals classes with pre-extracted feature representations for each image. The classes are aligned with Osherson's classical class/attribute matrix [3,4], thereby providing 85 numeric attribute values for each class. Using the shared attributes, it is possible to transfer information between different classes.
The image data was collected from public sources, such as Flickr, in 2016. In the process we made sure to only include images that are licensed for free use and redistribution, please see the archive for the individual license files. If the dataset contains an image for which you hold the copyright and that was not licensed freely, please contact us at , so we can remove it from the collection.
**References**
[1] Y. Xian, C. H. Lampert, B. Schiele, Z. Akata. "Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly", IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI) 40(8), 2018. (arXiv:1707.00600 [cs.CV])
[2] C. H. Lampert, H. Nickisch, and S. Harmeling. "Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer". In CVPR, 2009
[3] C. H. Lampert, H. Nickisch, and S. Harmeling. "Attribute-Based Classification for Zero-Shot Visual Object Categorization". IEEE T-PAMI, 2013
[4] D. N. Osherson, J. Stern, O. Wilkie, M. Stob, and E. E. Smith. "Default probability". Cognitive Science, 15(2), 1991.
[5] C. Kemp, J. B. Tenenbaum, T. L. Griffiths, T. Yamada, and N. Ueda. "Learning systems of concepts with an infinite relational model". In AAAI, 2006. |
doanhieung/vi-stsbenchmark | 2023-08-28T01:26:09.000Z | [
"license:mit",
"region:us"
] | doanhieung | null | null | null | 2 | 7 | ---
license: mit
---
The STSbenchmark dataset for Vietnamese |
tmskss/linux-man-pages-tldr-summarized | 2023-08-29T13:36:33.000Z | [
"task_categories:summarization",
"language:en",
"region:us"
] | tmskss | null | null | null | 3 | 7 | ---
task_categories:
- summarization
language:
- en
pretty_name: Linux man pages and the corresponding TLDR page
---
# Dataset Card for linux-man-pages-tldr-summarized
### Dataset Summary
This dataset contains linux man pages downloaded from [man7](https://man7.org/), with a prefix: 'summarize: ', and the corresponding summarization downloaded from [TLDR-pages](https://github.com/tldr-pages/tldr/).
### Supported Tasks
This dataset should be used to fine-tune language models for summarization tasks. |
sebascorreia/jazz-set | 2023-08-30T14:30:53.000Z | [
"region:us"
] | sebascorreia | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: image
dtype: image
- name: audio_file
dtype: string
- name: slice
dtype: int16
splits:
- name: train
num_bytes: 82089970.0
num_examples: 1848
download_size: 81976967
dataset_size: 82089970.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "edm_wavset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
LahiruLowe/flan2021_filtered_3pertask | 2023-08-29T08:05:53.000Z | [
"region:us"
] | LahiruLowe | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: original_index
dtype: int64
- name: inputs
dtype: string
- name: targets
dtype: string
- name: task_source
dtype: string
- name: task_name
dtype: string
- name: template_type
dtype: string
splits:
- name: train
num_bytes: 216227
num_examples: 210
download_size: 0
dataset_size: 216227
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "flan2021_filtered_3pertask"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Kant1/French_Wikipedia_articles | 2023-08-29T17:09:13.000Z | [
"task_categories:text-generation",
"language:fr",
"region:us"
] | Kant1 | null | null | null | 0 | 7 | ---
task_categories:
- text-generation
language:
- fr
---
Dump of 2023-08-20 of all french article in wikipedia
https://dumps.wikimedia.org/frwiki/20230820/frwiki-20230820-pages-articles.xml.bz2 |
hellomyoh/train_data_set_12000 | 2023-08-31T03:21:55.000Z | [
"region:us"
] | hellomyoh | null | null | null | 0 | 7 | Entry not found |
Arabic-Clip/mscoco_2014_en_ar_mapping | 2023-09-03T19:41:55.000Z | [
"region:us"
] | Arabic-Clip | null | null | null | 0 | 7 |
Load the dataset localy:
```py
from datasets import load_dataset
dataset_data = load_dataset("/home/think3/Desktop/1. MSCOCO_captions_dataset_edited/en_ar_mapping/mscoco_2014_en_ar_mapping.py", cache_dir="test_mapping/files")
# %%
dataset_data['train'][0]
# %%
len(dataset_data['train'])
```
Load the datase from HF:
```py
from datasets import load_dataset
dataset_data = load_dataset("Arabic-Clip/mscoco_2014_en_ar_mapping", cache_dir="test_mapping/files")
# %%
dataset_data['train'][0]
# %%
len(dataset_data['train'])
```
|
Hiraishin/BengaliNews | 2023-09-03T09:02:29.000Z | [
"region:us"
] | Hiraishin | null | null | null | 0 | 7 | Entry not found |
HydraLM/OpenOrca-GPT4-standardized | 2023-09-03T22:40:11.000Z | [
"region:us"
] | HydraLM | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: message
dtype: string
- name: message_type
dtype: string
- name: message_id
dtype: int64
- name: conversation_id
dtype: int64
splits:
- name: train
num_bytes: 1856699239
num_examples: 2984688
download_size: 979202725
dataset_size: 1856699239
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "OpenOrca-GPT4-standardized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
jonathanji/gv_dataset_raw | 2023-09-04T06:02:51.000Z | [
"license:openrail",
"region:us"
] | jonathanji | null | null | null | 0 | 7 | ---
license: openrail
---
|
vikp/code_instructions_filtered | 2023-09-04T15:29:06.000Z | [
"region:us"
] | vikp | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: output
dtype: string
- name: instruction
dtype: string
- name: kind
dtype: string
splits:
- name: train
num_bytes: 250321474.7560524
num_examples: 136147
download_size: 146821284
dataset_size: 250321474.7560524
---
# Dataset Card for "code_instructions_filtered"
This includes data from [xlcost](https://huggingface.co/datasets/vikp/xlcost_filtered_2k), [evol instruct](https://huggingface.co/datasets/vikp/evol_instruct_code_filtered_39k), [code alpaca](https://huggingface.co/datasets/vikp/evol_codealpaca_filtered_87k), and [code instructions](https://huggingface.co/datasets/vikp/code_instructions_filtered_7k). Data is filtered based on quality and learning value.
When used to fine-tune code llama 7B, achieves a `.62` humaneval score. |
nampdn-ai/mini-CoT-Collection | 2023-09-05T00:21:39.000Z | [
"region:us"
] | nampdn-ai | null | null | null | 6 | 7 | Entry not found |
thomasavare/waste-classification-audio-helsinki2 | 2023-09-13T01:05:23.000Z | [
"region:us"
] | thomasavare | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: audio
dtype: audio
- name: speaker
dtype: string
- name: transcription
dtype: string
- name: translation
dtype: string
- name: Class
dtype: string
- name: Class_index
dtype: float64
splits:
- name: train
num_bytes: 190035689.0
num_examples: 500
download_size: 190018067
dataset_size: 190035689.0
---
# Dataset Card for "waste-classification-audio-helsinki2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
serbog/esco_occupations_details_multilingual | 2023-09-06T02:34:53.000Z | [
"region:us"
] | serbog | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: el
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: lt
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: code
dtype: string
- name: uk
struct:
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: ga
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: sv
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: cs
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: bg
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: 'no'
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: en
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: lv
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: ar
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: es
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: et
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: fi
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: sk
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: da
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: nl
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: is
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: sl
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: hr
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: pl
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: it
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: de
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: url
dtype: string
- name: mt
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: hu
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: fr
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: pt
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
- name: ro
struct:
- name: alternativeLabel
sequence: string
- name: description
dtype: string
- name: preferredLabel
dtype: string
- name: preferredTerm
dtype: string
splits:
- name: train
num_bytes: 52470213
num_examples: 3629
download_size: 22696020
dataset_size: 52470213
---
# Dataset Card for "esco_occupations_details_multilingual"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TrainingDataPro/self-checkout-videos-object-tracking | 2023-09-29T13:40:49.000Z | [
"task_categories:image-to-image",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] | TrainingDataPro | The dataset contains frames extracted from self-checkout videos, specifically focusing
on **tracking products**. The tracking data provides the **trajectory of each product**,
allowing for analysis of customer movement and behavior throughout the transaction.
The dataset assists in detecting shoplifting and fraud, enhancing efficiency, accuracy,
and customer experience. It facilitates the development of computer vision models for
*object detection, tracking, and recognition* within a self-checkout environment. | @InProceedings{huggingface:dataset,
title = {self-checkout-videos-object-tracking},
author = {TrainingDataPro},
year = {2023}
} | null | 2 | 7 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-image
- object-detection
tags:
- code
- finance
dataset_info:
- config_name: video_01
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: shapes
sequence:
- name: track_id
dtype: uint32
- name: label
dtype:
class_label:
names:
'0': product
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 8664
num_examples: 17
download_size: 56150105
dataset_size: 8664
- config_name: video_02
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: shapes
sequence:
- name: track_id
dtype: uint32
- name: label
dtype:
class_label:
names:
'0': product
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 5857
num_examples: 10
download_size: 35163267
dataset_size: 5857
- config_name: video_03
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: shapes
sequence:
- name: track_id
dtype: uint32
- name: label
dtype:
class_label:
names:
'0': product
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 10586
num_examples: 13
download_size: 42578549
dataset_size: 10586
---
# Products Tracking
The dataset contains frames extracted from self-checkout videos, specifically focusing on **tracking products**. The tracking data provides the **trajectory of each product**, allowing for analysis of customer movement and behavior throughout the transaction.
The dataset assists in detecting shoplifting and fraud, enhancing efficiency, accuracy, and customer experience. It facilitates the development of computer vision models for *object detection, tracking, and recognition* within a self-checkout environment.
.gif?generation=1694065408131442&alt=media)
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=self-checkout-videos-object-tracking) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
The dataset consists of 3 folders with video frames from self-checkouts.
Each folder includes:
- **images**: folder with original frames from the video,
- **boxes**: visualized data labeling for the images in the previous folder,
- **.csv file**: file with id and path of each frame in the "images" folder,
- **annotations.xml**: contains coordinates of the bounding boxes and labels, created for the original frames
# Data Format
Each frame from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes for products tracking. For each point, the x and y coordinates are provided. The payment status of the product is also indicated in the attribute **paid** (true, false).
# Example of the XML-file
.png?generation=1695994818122714&alt=media)
# Object tracking might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=self-checkout-videos-object-tracking) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
quocanh34/soict_train_synthesis_dataset_v2 | 2023-09-07T20:06:00.000Z | [
"region:us"
] | quocanh34 | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: sentence_norm
dtype: string
- name: id
dtype: string
splits:
- name: train
num_bytes: 4941296103
num_examples: 9807
- name: test
num_bytes: 389967953
num_examples: 748
download_size: 1260225691
dataset_size: 5331264056
---
# Dataset Card for "soict_train_synthesis_dataset_v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ninadn/indian-legal | 2023-09-08T05:41:04.000Z | [
"region:us"
] | ninadn | null | null | null | 2 | 7 | Entry not found |
SkunkworksAI-shared/concatenated_1 | 2023-09-10T02:23:15.000Z | [
"region:us"
] | SkunkworksAI-shared | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: text
dtype: string
- name: conversation_id
dtype: int64
- name: dataset_id
dtype: string
- name: unique_conversation_id
dtype: string
splits:
- name: train
num_bytes: 4580744904
num_examples: 2527636
download_size: 2447560359
dataset_size: 4580744904
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "concatenated_1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Maxx0/small-sexting-test-data | 2023-09-10T12:05:43.000Z | [
"region:us"
] | Maxx0 | null | null | null | 0 | 7 | Entry not found |
fia24/bangladeshi_taka | 2023-09-10T14:23:35.000Z | [
"region:us"
] | fia24 | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': '10'
'1': '100'
'2': '1000'
'3': '2'
'4': '20'
'5': '200'
'6': '5'
'7': '50'
'8': '500'
splits:
- name: train
num_bytes: 147606636.6
num_examples: 16200
- name: test
num_bytes: 16201666.4
num_examples: 1800
download_size: 159283013
dataset_size: 163808303.0
---
# Dataset Card for "bangladeshi_taka"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
slone/bak_rus_eng_2M2023_scored | 2023-09-10T19:42:26.000Z | [
"region:us"
] | slone | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: idx
dtype: int64
- name: ba
dtype: string
- name: ru
dtype: string
- name: source
dtype: string
- name: cosine_sim
dtype: float64
- name: cross_encoder_sim
dtype: float64
- name: joint_sim
dtype: float64
- name: ru_len
dtype: int64
- name: en
dtype: string
- name: en_ru_sim
dtype: float64
splits:
- name: train
num_bytes: 1070778392
num_examples: 2228224
download_size: 620446960
dataset_size: 1070778392
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "bak_rus_eng_2M2023_scored"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
roa7n/maltaomics_dataset_normalized | 2023-09-13T20:01:46.000Z | [
"region:us"
] | roa7n | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: seq
dtype: string
- name: label
dtype: int64
- name: features
dtype: string
- name: '0'
dtype: float64
- name: '1'
dtype: float64
- name: '2'
dtype: float64
- name: '3'
dtype: float64
- name: '4'
dtype: float64
- name: '5'
dtype: float64
- name: '6'
dtype: float64
- name: '7'
dtype: float64
- name: '8'
dtype: float64
- name: '9'
dtype: float64
- name: '10'
dtype: float64
- name: '11'
dtype: float64
- name: '12'
dtype: float64
- name: '13'
dtype: float64
- name: '14'
dtype: float64
- name: '15'
dtype: float64
- name: '16'
dtype: float64
- name: '17'
dtype: float64
- name: '18'
dtype: float64
- name: '19'
dtype: float64
- name: '20'
dtype: float64
- name: '21'
dtype: float64
- name: '22'
dtype: float64
- name: '23'
dtype: float64
- name: '24'
dtype: float64
- name: '25'
dtype: float64
- name: '26'
dtype: float64
- name: '27'
dtype: float64
- name: '28'
dtype: float64
- name: '29'
dtype: float64
- name: '30'
dtype: float64
- name: '31'
dtype: float64
- name: '32'
dtype: float64
- name: '33'
dtype: float64
- name: '34'
dtype: float64
- name: '35'
dtype: float64
- name: '36'
dtype: float64
- name: '37'
dtype: float64
- name: '38'
dtype: float64
- name: '39'
dtype: float64
- name: '40'
dtype: float64
- name: '41'
dtype: float64
- name: '42'
dtype: float64
- name: '43'
dtype: float64
- name: '44'
dtype: float64
- name: '45'
dtype: float64
- name: '46'
dtype: float64
- name: '47'
dtype: float64
- name: '48'
dtype: float64
- name: '49'
dtype: float64
- name: '50'
dtype: float64
- name: '51'
dtype: float64
- name: '52'
dtype: float64
- name: '53'
dtype: float64
- name: '54'
dtype: float64
- name: '55'
dtype: float64
- name: '56'
dtype: float64
- name: '57'
dtype: float64
- name: '58'
dtype: float64
- name: '59'
dtype: float64
- name: '60'
dtype: float64
- name: '61'
dtype: float64
- name: '62'
dtype: float64
- name: '63'
dtype: float64
- name: '64'
dtype: float64
- name: '65'
dtype: float64
- name: '66'
dtype: float64
- name: '67'
dtype: float64
- name: '68'
dtype: float64
- name: '69'
dtype: float64
- name: '70'
dtype: float64
- name: '71'
dtype: float64
- name: '72'
dtype: float64
- name: '73'
dtype: float64
- name: '74'
dtype: float64
- name: '75'
dtype: float64
- name: '76'
dtype: float64
- name: '77'
dtype: float64
- name: '78'
dtype: float64
- name: '79'
dtype: float64
- name: '80'
dtype: float64
- name: '81'
dtype: float64
- name: '82'
dtype: float64
- name: '83'
dtype: float64
- name: '84'
dtype: float64
- name: '85'
dtype: float64
- name: '86'
dtype: float64
- name: '87'
dtype: float64
- name: '88'
dtype: float64
- name: '89'
dtype: float64
- name: '90'
dtype: float64
- name: '91'
dtype: float64
- name: '92'
dtype: float64
- name: '93'
dtype: float64
- name: '94'
dtype: float64
- name: '95'
dtype: float64
- name: '96'
dtype: float64
- name: '97'
dtype: float64
- name: '98'
dtype: float64
- name: '99'
dtype: float64
- name: '100'
dtype: float64
- name: '101'
dtype: float64
- name: '102'
dtype: float64
- name: '103'
dtype: float64
- name: '104'
dtype: float64
- name: '105'
dtype: float64
- name: '106'
dtype: float64
- name: '107'
dtype: float64
- name: '108'
dtype: float64
- name: '109'
dtype: float64
- name: '110'
dtype: float64
- name: '111'
dtype: float64
- name: '112'
dtype: float64
- name: '113'
dtype: float64
- name: '114'
dtype: float64
- name: '115'
dtype: float64
- name: '116'
dtype: float64
- name: '117'
dtype: float64
- name: '118'
dtype: float64
- name: '119'
dtype: float64
- name: '120'
dtype: float64
- name: '121'
dtype: float64
- name: '122'
dtype: float64
- name: '123'
dtype: float64
- name: '124'
dtype: float64
- name: '125'
dtype: float64
- name: '126'
dtype: float64
- name: '127'
dtype: float64
- name: '128'
dtype: float64
- name: '129'
dtype: float64
- name: '130'
dtype: float64
- name: '131'
dtype: float64
- name: '132'
dtype: float64
- name: '133'
dtype: float64
- name: '134'
dtype: float64
- name: '135'
dtype: float64
- name: '136'
dtype: float64
- name: '137'
dtype: float64
- name: '138'
dtype: float64
- name: '139'
dtype: float64
- name: '140'
dtype: float64
- name: '141'
dtype: float64
- name: '142'
dtype: float64
- name: '143'
dtype: float64
- name: '144'
dtype: float64
- name: '145'
dtype: float64
- name: '146'
dtype: float64
- name: '147'
dtype: float64
- name: '148'
dtype: float64
- name: '149'
dtype: float64
- name: '150'
dtype: float64
- name: '151'
dtype: float64
- name: '152'
dtype: float64
- name: '153'
dtype: float64
- name: '154'
dtype: float64
- name: '155'
dtype: float64
- name: '156'
dtype: float64
- name: '157'
dtype: float64
- name: '158'
dtype: float64
- name: '159'
dtype: float64
- name: '160'
dtype: float64
- name: '161'
dtype: float64
- name: '162'
dtype: float64
- name: '163'
dtype: float64
- name: '164'
dtype: float64
- name: '165'
dtype: float64
- name: '166'
dtype: float64
- name: '167'
dtype: float64
- name: '168'
dtype: float64
- name: '169'
dtype: float64
- name: '170'
dtype: float64
- name: '171'
dtype: float64
- name: '172'
dtype: float64
- name: '173'
dtype: float64
- name: '174'
dtype: float64
- name: '175'
dtype: float64
- name: '176'
dtype: float64
- name: '177'
dtype: float64
- name: '178'
dtype: float64
- name: '179'
dtype: float64
- name: '180'
dtype: float64
- name: '181'
dtype: float64
- name: '182'
dtype: float64
- name: '183'
dtype: float64
- name: '184'
dtype: float64
- name: '185'
dtype: float64
- name: '186'
dtype: float64
- name: '187'
dtype: float64
- name: '188'
dtype: float64
- name: '189'
dtype: float64
- name: '190'
dtype: float64
- name: '191'
dtype: float64
- name: '192'
dtype: float64
- name: '193'
dtype: float64
- name: '194'
dtype: float64
- name: '195'
dtype: float64
- name: '196'
dtype: float64
- name: '197'
dtype: float64
- name: '198'
dtype: float64
- name: '199'
dtype: float64
- name: '200'
dtype: float64
- name: '201'
dtype: float64
- name: '202'
dtype: float64
- name: '203'
dtype: float64
- name: '204'
dtype: float64
- name: '205'
dtype: float64
- name: '206'
dtype: float64
- name: '207'
dtype: float64
- name: '208'
dtype: float64
- name: '209'
dtype: float64
- name: '210'
dtype: float64
- name: '211'
dtype: float64
- name: '212'
dtype: float64
- name: '213'
dtype: float64
- name: '214'
dtype: float64
- name: '215'
dtype: float64
- name: '216'
dtype: float64
- name: '217'
dtype: float64
- name: '218'
dtype: float64
- name: '219'
dtype: float64
- name: '220'
dtype: float64
- name: '221'
dtype: float64
- name: '222'
dtype: float64
- name: '223'
dtype: float64
- name: '224'
dtype: float64
- name: '225'
dtype: float64
- name: '226'
dtype: float64
- name: '227'
dtype: float64
- name: '228'
dtype: float64
- name: '229'
dtype: float64
- name: '230'
dtype: float64
- name: '231'
dtype: float64
- name: '232'
dtype: float64
- name: '233'
dtype: float64
- name: '234'
dtype: float64
- name: '235'
dtype: float64
- name: '236'
dtype: float64
- name: '237'
dtype: float64
- name: '238'
dtype: float64
- name: '239'
dtype: float64
- name: '240'
dtype: float64
- name: '241'
dtype: float64
- name: '242'
dtype: float64
- name: '243'
dtype: float64
- name: '244'
dtype: float64
- name: '245'
dtype: float64
- name: '246'
dtype: float64
- name: '247'
dtype: float64
- name: '248'
dtype: float64
- name: '249'
dtype: float64
- name: '250'
dtype: float64
- name: '251'
dtype: float64
- name: '252'
dtype: float64
- name: '253'
dtype: float64
- name: '254'
dtype: float64
- name: '255'
dtype: float64
- name: '256'
dtype: float64
- name: '257'
dtype: float64
- name: '258'
dtype: float64
- name: '259'
dtype: float64
- name: '260'
dtype: float64
- name: '261'
dtype: float64
- name: '262'
dtype: float64
- name: '263'
dtype: float64
- name: '264'
dtype: float64
- name: '265'
dtype: float64
- name: '266'
dtype: float64
- name: '267'
dtype: float64
- name: '268'
dtype: float64
- name: '269'
dtype: float64
- name: '270'
dtype: float64
- name: '271'
dtype: float64
- name: '272'
dtype: float64
- name: '273'
dtype: float64
- name: '274'
dtype: float64
- name: '275'
dtype: float64
- name: '276'
dtype: float64
- name: '277'
dtype: float64
- name: '278'
dtype: float64
- name: '279'
dtype: float64
- name: '280'
dtype: float64
- name: '281'
dtype: float64
- name: '282'
dtype: float64
- name: '283'
dtype: float64
- name: '284'
dtype: float64
- name: '285'
dtype: float64
- name: '286'
dtype: float64
- name: '287'
dtype: float64
- name: '288'
dtype: float64
- name: '289'
dtype: float64
- name: '290'
dtype: float64
- name: '291'
dtype: float64
- name: '292'
dtype: float64
- name: '293'
dtype: float64
- name: '294'
dtype: float64
- name: '295'
dtype: float64
- name: '296'
dtype: float64
- name: '297'
dtype: float64
- name: '298'
dtype: float64
- name: '299'
dtype: float64
- name: '300'
dtype: float64
- name: '301'
dtype: float64
- name: '302'
dtype: float64
- name: '303'
dtype: float64
- name: '304'
dtype: float64
- name: '305'
dtype: float64
- name: '306'
dtype: float64
- name: '307'
dtype: float64
- name: '308'
dtype: float64
- name: '309'
dtype: float64
- name: '310'
dtype: float64
- name: '311'
dtype: float64
- name: '312'
dtype: float64
- name: '313'
dtype: float64
- name: '314'
dtype: float64
- name: '315'
dtype: float64
- name: '316'
dtype: float64
- name: '317'
dtype: float64
- name: '318'
dtype: float64
- name: '319'
dtype: float64
- name: '320'
dtype: float64
- name: '321'
dtype: float64
- name: '322'
dtype: float64
- name: '323'
dtype: float64
- name: '324'
dtype: float64
- name: '325'
dtype: float64
- name: '326'
dtype: float64
- name: '327'
dtype: float64
- name: '328'
dtype: float64
- name: '329'
dtype: float64
- name: '330'
dtype: float64
- name: '331'
dtype: float64
- name: '332'
dtype: float64
- name: '333'
dtype: float64
- name: '334'
dtype: float64
- name: '335'
dtype: float64
- name: '336'
dtype: float64
- name: '337'
dtype: float64
- name: '338'
dtype: float64
- name: '339'
dtype: float64
- name: '340'
dtype: float64
- name: '341'
dtype: float64
- name: '342'
dtype: float64
- name: '343'
dtype: float64
- name: '344'
dtype: float64
- name: '345'
dtype: float64
- name: '346'
dtype: float64
- name: '347'
dtype: float64
- name: '348'
dtype: float64
- name: '349'
dtype: float64
- name: '350'
dtype: float64
- name: '351'
dtype: float64
- name: '352'
dtype: float64
- name: '353'
dtype: float64
- name: '354'
dtype: float64
- name: '355'
dtype: float64
- name: '356'
dtype: float64
- name: '357'
dtype: float64
- name: '358'
dtype: float64
- name: '359'
dtype: float64
- name: '360'
dtype: float64
- name: '361'
dtype: float64
- name: '362'
dtype: float64
- name: '363'
dtype: float64
- name: '364'
dtype: float64
- name: '365'
dtype: float64
- name: '366'
dtype: float64
- name: '367'
dtype: float64
- name: '368'
dtype: float64
- name: '369'
dtype: float64
- name: '370'
dtype: float64
- name: '371'
dtype: float64
- name: '372'
dtype: float64
- name: '373'
dtype: float64
- name: '374'
dtype: float64
- name: '375'
dtype: float64
- name: '376'
dtype: float64
- name: '377'
dtype: float64
- name: '378'
dtype: float64
- name: '379'
dtype: float64
- name: '380'
dtype: float64
- name: '381'
dtype: float64
- name: '382'
dtype: float64
- name: '383'
dtype: float64
- name: '384'
dtype: float64
- name: '385'
dtype: float64
- name: '386'
dtype: float64
- name: '387'
dtype: float64
- name: '388'
dtype: float64
- name: '389'
dtype: float64
- name: '390'
dtype: float64
- name: '391'
dtype: float64
- name: '392'
dtype: float64
- name: '393'
dtype: float64
- name: '394'
dtype: float64
- name: '395'
dtype: float64
- name: '396'
dtype: float64
- name: '397'
dtype: float64
- name: '398'
dtype: float64
- name: '399'
dtype: float64
- name: '400'
dtype: float64
- name: '401'
dtype: float64
- name: '402'
dtype: float64
- name: '403'
dtype: float64
- name: '404'
dtype: float64
- name: '405'
dtype: float64
- name: '406'
dtype: float64
- name: '407'
dtype: float64
- name: '408'
dtype: float64
- name: '409'
dtype: float64
- name: '410'
dtype: float64
- name: '411'
dtype: float64
- name: '412'
dtype: float64
- name: '413'
dtype: float64
- name: '414'
dtype: float64
- name: '415'
dtype: float64
- name: '416'
dtype: float64
- name: '417'
dtype: float64
- name: '418'
dtype: float64
- name: '419'
dtype: float64
- name: '420'
dtype: float64
- name: '421'
dtype: float64
- name: '422'
dtype: float64
- name: '423'
dtype: float64
- name: '424'
dtype: float64
- name: '425'
dtype: float64
- name: '426'
dtype: float64
- name: '427'
dtype: float64
- name: '428'
dtype: float64
- name: '429'
dtype: float64
- name: '430'
dtype: float64
- name: '431'
dtype: float64
- name: '432'
dtype: float64
- name: '433'
dtype: float64
- name: '434'
dtype: float64
- name: '435'
dtype: float64
- name: '436'
dtype: float64
- name: '437'
dtype: float64
- name: '438'
dtype: float64
- name: '439'
dtype: float64
- name: '440'
dtype: float64
- name: '441'
dtype: float64
- name: '442'
dtype: float64
- name: '443'
dtype: float64
- name: '444'
dtype: float64
- name: '445'
dtype: float64
- name: '446'
dtype: float64
- name: '447'
dtype: float64
- name: '448'
dtype: float64
- name: '449'
dtype: float64
- name: '450'
dtype: float64
- name: '451'
dtype: float64
- name: '452'
dtype: float64
- name: '453'
dtype: float64
- name: '454'
dtype: float64
- name: '455'
dtype: float64
- name: '456'
dtype: float64
- name: '457'
dtype: float64
- name: '458'
dtype: float64
- name: '459'
dtype: float64
- name: '460'
dtype: float64
- name: '461'
dtype: float64
- name: '462'
dtype: float64
- name: '463'
dtype: float64
- name: '464'
dtype: float64
- name: '465'
dtype: float64
- name: '466'
dtype: float64
- name: '467'
dtype: float64
- name: '468'
dtype: float64
- name: '469'
dtype: float64
- name: '470'
dtype: float64
- name: '471'
dtype: float64
- name: '472'
dtype: float64
- name: '473'
dtype: float64
- name: '474'
dtype: float64
- name: '475'
dtype: float64
- name: '476'
dtype: float64
- name: '477'
dtype: float64
- name: '478'
dtype: float64
- name: '479'
dtype: float64
- name: '480'
dtype: float64
- name: '481'
dtype: float64
- name: '482'
dtype: float64
- name: '483'
dtype: float64
- name: '484'
dtype: float64
- name: '485'
dtype: float64
- name: '486'
dtype: float64
- name: '487'
dtype: float64
- name: '488'
dtype: float64
- name: '489'
dtype: float64
- name: '490'
dtype: float64
- name: '491'
dtype: float64
- name: '492'
dtype: float64
- name: '493'
dtype: float64
- name: '494'
dtype: float64
- name: '495'
dtype: float64
- name: '496'
dtype: float64
- name: '497'
dtype: float64
- name: '498'
dtype: float64
- name: '499'
dtype: float64
- name: '500'
dtype: float64
- name: '501'
dtype: float64
- name: '502'
dtype: float64
- name: '503'
dtype: float64
- name: '504'
dtype: float64
- name: '505'
dtype: float64
- name: '506'
dtype: float64
- name: '507'
dtype: float64
- name: '508'
dtype: float64
- name: '509'
dtype: float64
- name: '510'
dtype: float64
- name: '511'
dtype: float64
- name: '512'
dtype: float64
- name: '513'
dtype: float64
- name: '514'
dtype: float64
- name: '515'
dtype: float64
- name: '516'
dtype: float64
- name: '517'
dtype: float64
- name: '518'
dtype: float64
- name: '519'
dtype: float64
- name: '520'
dtype: float64
- name: '521'
dtype: float64
- name: '522'
dtype: float64
- name: '523'
dtype: float64
- name: '524'
dtype: float64
- name: '525'
dtype: float64
- name: '526'
dtype: float64
- name: '527'
dtype: float64
- name: '528'
dtype: float64
- name: '529'
dtype: float64
- name: '530'
dtype: float64
- name: '531'
dtype: float64
- name: '532'
dtype: float64
- name: '533'
dtype: float64
- name: '534'
dtype: float64
- name: '535'
dtype: float64
- name: '536'
dtype: float64
- name: '537'
dtype: float64
- name: '538'
dtype: float64
- name: '539'
dtype: float64
- name: '540'
dtype: float64
- name: '541'
dtype: float64
- name: '542'
dtype: float64
- name: '543'
dtype: float64
- name: '544'
dtype: float64
- name: '545'
dtype: float64
- name: '546'
dtype: float64
- name: '547'
dtype: float64
- name: '548'
dtype: float64
- name: '549'
dtype: float64
- name: '550'
dtype: float64
- name: '551'
dtype: float64
- name: '552'
dtype: float64
- name: '553'
dtype: float64
- name: '554'
dtype: float64
- name: '555'
dtype: float64
- name: '556'
dtype: float64
- name: '557'
dtype: float64
- name: '558'
dtype: float64
- name: '559'
dtype: float64
- name: '560'
dtype: float64
- name: '561'
dtype: float64
- name: '562'
dtype: float64
- name: '563'
dtype: float64
- name: '564'
dtype: float64
- name: '565'
dtype: float64
- name: '566'
dtype: float64
- name: '567'
dtype: float64
- name: '568'
dtype: float64
- name: '569'
dtype: float64
- name: '570'
dtype: float64
- name: '571'
dtype: float64
- name: '572'
dtype: float64
- name: '573'
dtype: float64
- name: '574'
dtype: float64
- name: '575'
dtype: float64
- name: '576'
dtype: float64
- name: '577'
dtype: float64
- name: '578'
dtype: float64
- name: '579'
dtype: float64
- name: '580'
dtype: float64
- name: '581'
dtype: float64
- name: '582'
dtype: float64
- name: '583'
dtype: float64
- name: '584'
dtype: float64
- name: '585'
dtype: float64
- name: '586'
dtype: float64
- name: '587'
dtype: float64
- name: '588'
dtype: float64
- name: '589'
dtype: float64
- name: '590'
dtype: float64
- name: '591'
dtype: float64
- name: '592'
dtype: float64
- name: '593'
dtype: float64
- name: '594'
dtype: float64
- name: '595'
dtype: float64
- name: '596'
dtype: float64
- name: '597'
dtype: float64
- name: '598'
dtype: float64
- name: '599'
dtype: float64
- name: '600'
dtype: float64
- name: '601'
dtype: float64
- name: '602'
dtype: float64
- name: '603'
dtype: float64
- name: '604'
dtype: float64
- name: '605'
dtype: float64
- name: '606'
dtype: float64
- name: '607'
dtype: float64
- name: '608'
dtype: float64
- name: '609'
dtype: float64
- name: '610'
dtype: float64
- name: '611'
dtype: float64
- name: '612'
dtype: float64
- name: '613'
dtype: float64
- name: '614'
dtype: float64
- name: '615'
dtype: float64
- name: '616'
dtype: float64
- name: '617'
dtype: float64
- name: '618'
dtype: float64
- name: '619'
dtype: float64
- name: '620'
dtype: float64
- name: '621'
dtype: float64
- name: '622'
dtype: float64
- name: '623'
dtype: float64
- name: '624'
dtype: float64
- name: '625'
dtype: float64
- name: '626'
dtype: float64
- name: '627'
dtype: float64
- name: '628'
dtype: float64
- name: '629'
dtype: float64
- name: '630'
dtype: float64
- name: '631'
dtype: float64
- name: '632'
dtype: float64
- name: '633'
dtype: float64
- name: '634'
dtype: float64
- name: '635'
dtype: float64
- name: '636'
dtype: float64
- name: '637'
dtype: float64
- name: '638'
dtype: float64
- name: '639'
dtype: float64
- name: '640'
dtype: float64
- name: '641'
dtype: float64
- name: '642'
dtype: float64
- name: '643'
dtype: float64
- name: '644'
dtype: float64
- name: '645'
dtype: float64
- name: '646'
dtype: float64
- name: '647'
dtype: float64
- name: '648'
dtype: float64
- name: '649'
dtype: float64
- name: '650'
dtype: float64
- name: '651'
dtype: float64
- name: '652'
dtype: float64
- name: '653'
dtype: float64
- name: '654'
dtype: float64
- name: '655'
dtype: float64
- name: '656'
dtype: float64
- name: '657'
dtype: float64
- name: '658'
dtype: float64
- name: '659'
dtype: float64
- name: '660'
dtype: float64
- name: '661'
dtype: float64
- name: '662'
dtype: float64
- name: '663'
dtype: float64
- name: '664'
dtype: float64
- name: '665'
dtype: float64
- name: '666'
dtype: float64
- name: '667'
dtype: float64
- name: '668'
dtype: float64
- name: '669'
dtype: float64
- name: '670'
dtype: float64
- name: '671'
dtype: float64
- name: '672'
dtype: float64
- name: '673'
dtype: float64
- name: '674'
dtype: float64
- name: '675'
dtype: float64
- name: '676'
dtype: float64
- name: '677'
dtype: float64
- name: '678'
dtype: float64
- name: '679'
dtype: float64
- name: '680'
dtype: float64
- name: '681'
dtype: float64
- name: '682'
dtype: float64
- name: '683'
dtype: float64
- name: '684'
dtype: float64
- name: '685'
dtype: float64
- name: '686'
dtype: float64
- name: '687'
dtype: float64
- name: '688'
dtype: float64
- name: '689'
dtype: float64
- name: '690'
dtype: float64
- name: '691'
dtype: float64
- name: '692'
dtype: float64
- name: '693'
dtype: float64
- name: '694'
dtype: float64
- name: '695'
dtype: float64
- name: '696'
dtype: float64
- name: '697'
dtype: float64
- name: '698'
dtype: float64
- name: '699'
dtype: float64
- name: '700'
dtype: float64
- name: '701'
dtype: float64
- name: '702'
dtype: float64
- name: '703'
dtype: float64
- name: '704'
dtype: float64
- name: '705'
dtype: float64
- name: '706'
dtype: float64
- name: '707'
dtype: float64
- name: '708'
dtype: float64
- name: '709'
dtype: float64
- name: '710'
dtype: float64
- name: '711'
dtype: float64
- name: '712'
dtype: float64
- name: '713'
dtype: float64
- name: '714'
dtype: float64
- name: '715'
dtype: float64
- name: '716'
dtype: float64
- name: '717'
dtype: float64
- name: '718'
dtype: float64
- name: '719'
dtype: float64
- name: '720'
dtype: float64
- name: '721'
dtype: float64
- name: '722'
dtype: float64
- name: '723'
dtype: float64
- name: '724'
dtype: float64
- name: '725'
dtype: float64
- name: '726'
dtype: float64
- name: '727'
dtype: float64
- name: '728'
dtype: float64
- name: '729'
dtype: float64
- name: '730'
dtype: float64
- name: '731'
dtype: float64
- name: '732'
dtype: float64
- name: '733'
dtype: float64
- name: '734'
dtype: float64
- name: '735'
dtype: float64
- name: '736'
dtype: float64
- name: '737'
dtype: float64
- name: '738'
dtype: float64
- name: '739'
dtype: float64
- name: '740'
dtype: float64
- name: '741'
dtype: float64
- name: '742'
dtype: float64
- name: '743'
dtype: float64
- name: '744'
dtype: float64
- name: '745'
dtype: float64
- name: '746'
dtype: float64
- name: '747'
dtype: float64
- name: '748'
dtype: float64
- name: '749'
dtype: float64
- name: '750'
dtype: float64
- name: '751'
dtype: float64
- name: '752'
dtype: float64
- name: '753'
dtype: float64
- name: '754'
dtype: float64
- name: '755'
dtype: float64
- name: '756'
dtype: float64
- name: '757'
dtype: float64
- name: '758'
dtype: float64
- name: '759'
dtype: float64
- name: '760'
dtype: float64
- name: '761'
dtype: float64
- name: '762'
dtype: float64
- name: '763'
dtype: float64
- name: '764'
dtype: float64
- name: '765'
dtype: float64
- name: '766'
dtype: float64
- name: '767'
dtype: float64
- name: '768'
dtype: float64
- name: '769'
dtype: float64
- name: '770'
dtype: float64
- name: '771'
dtype: float64
- name: '772'
dtype: float64
- name: '773'
dtype: float64
- name: '774'
dtype: float64
- name: '775'
dtype: float64
- name: '776'
dtype: float64
- name: '777'
dtype: float64
- name: '778'
dtype: float64
- name: '779'
dtype: float64
- name: '780'
dtype: float64
- name: '781'
dtype: float64
- name: '782'
dtype: float64
- name: '783'
dtype: float64
- name: '784'
dtype: float64
- name: '785'
dtype: float64
- name: '786'
dtype: float64
- name: '787'
dtype: float64
- name: '788'
dtype: float64
- name: '789'
dtype: float64
- name: '790'
dtype: float64
- name: '791'
dtype: float64
- name: '792'
dtype: float64
- name: '793'
dtype: float64
- name: '794'
dtype: float64
- name: '795'
dtype: float64
- name: '796'
dtype: float64
- name: '797'
dtype: float64
- name: '798'
dtype: float64
- name: '799'
dtype: float64
- name: '800'
dtype: float64
- name: '801'
dtype: float64
- name: '802'
dtype: float64
- name: '803'
dtype: float64
- name: '804'
dtype: float64
- name: '805'
dtype: float64
- name: '806'
dtype: float64
- name: '807'
dtype: float64
- name: '808'
dtype: float64
- name: '809'
dtype: float64
- name: '810'
dtype: float64
- name: '811'
dtype: float64
- name: '812'
dtype: float64
- name: '813'
dtype: float64
- name: '814'
dtype: float64
- name: '815'
dtype: float64
- name: '816'
dtype: float64
- name: '817'
dtype: float64
- name: '818'
dtype: float64
- name: '819'
dtype: float64
- name: '820'
dtype: float64
- name: '821'
dtype: float64
- name: '822'
dtype: float64
- name: '823'
dtype: float64
- name: '824'
dtype: float64
- name: '825'
dtype: float64
- name: '826'
dtype: float64
- name: '827'
dtype: float64
- name: '828'
dtype: float64
- name: '829'
dtype: float64
- name: '830'
dtype: float64
- name: '831'
dtype: float64
- name: '832'
dtype: float64
- name: '833'
dtype: float64
- name: '834'
dtype: float64
- name: '835'
dtype: float64
- name: '836'
dtype: float64
- name: '837'
dtype: float64
- name: '838'
dtype: float64
- name: '839'
dtype: float64
- name: '840'
dtype: float64
- name: '841'
dtype: float64
- name: '842'
dtype: float64
- name: '843'
dtype: float64
- name: '844'
dtype: float64
- name: '845'
dtype: float64
- name: '846'
dtype: float64
- name: '847'
dtype: float64
- name: '848'
dtype: float64
- name: '849'
dtype: float64
- name: '850'
dtype: float64
- name: '851'
dtype: float64
- name: '852'
dtype: float64
- name: '853'
dtype: float64
- name: '854'
dtype: float64
- name: '855'
dtype: float64
- name: '856'
dtype: float64
- name: '857'
dtype: float64
- name: '858'
dtype: float64
- name: '859'
dtype: float64
- name: '860'
dtype: float64
- name: '861'
dtype: float64
- name: '862'
dtype: float64
- name: '863'
dtype: float64
- name: '864'
dtype: float64
- name: '865'
dtype: float64
- name: '866'
dtype: float64
- name: '867'
dtype: float64
- name: '868'
dtype: float64
- name: '869'
dtype: float64
- name: '870'
dtype: float64
- name: '871'
dtype: float64
- name: '872'
dtype: float64
- name: '873'
dtype: float64
- name: '874'
dtype: float64
- name: '875'
dtype: float64
- name: '876'
dtype: float64
- name: '877'
dtype: float64
- name: '878'
dtype: float64
- name: '879'
dtype: float64
- name: '880'
dtype: float64
- name: '881'
dtype: float64
- name: '882'
dtype: float64
- name: '883'
dtype: float64
- name: '884'
dtype: float64
- name: '885'
dtype: float64
- name: '886'
dtype: float64
- name: '887'
dtype: float64
- name: '888'
dtype: float64
- name: '889'
dtype: float64
- name: '890'
dtype: float64
- name: '891'
dtype: float64
- name: '892'
dtype: float64
- name: '893'
dtype: float64
- name: '894'
dtype: float64
- name: '895'
dtype: float64
- name: '896'
dtype: float64
- name: '897'
dtype: float64
- name: '898'
dtype: float64
- name: '899'
dtype: float64
- name: '900'
dtype: float64
- name: '901'
dtype: float64
- name: '902'
dtype: float64
- name: '903'
dtype: float64
- name: '904'
dtype: float64
- name: '905'
dtype: float64
- name: '906'
dtype: float64
- name: '907'
dtype: float64
- name: '908'
dtype: float64
- name: '909'
dtype: float64
- name: '910'
dtype: float64
- name: '911'
dtype: float64
- name: '912'
dtype: float64
- name: '913'
dtype: float64
- name: '914'
dtype: float64
- name: '915'
dtype: float64
- name: '916'
dtype: float64
- name: '917'
dtype: float64
- name: '918'
dtype: float64
- name: '919'
dtype: float64
- name: '920'
dtype: float64
- name: '921'
dtype: float64
- name: '922'
dtype: float64
- name: '923'
dtype: float64
- name: '924'
dtype: float64
- name: '925'
dtype: float64
- name: '926'
dtype: float64
- name: '927'
dtype: float64
- name: '928'
dtype: float64
- name: '929'
dtype: float64
- name: '930'
dtype: float64
- name: '931'
dtype: float64
- name: '932'
dtype: float64
- name: '933'
dtype: float64
- name: '934'
dtype: float64
- name: '935'
dtype: float64
- name: '936'
dtype: float64
- name: '937'
dtype: float64
- name: '938'
dtype: float64
- name: '939'
dtype: float64
- name: '940'
dtype: float64
- name: '941'
dtype: float64
- name: '942'
dtype: float64
- name: '943'
dtype: float64
- name: '944'
dtype: float64
- name: '945'
dtype: float64
- name: '946'
dtype: float64
- name: '947'
dtype: float64
- name: '948'
dtype: float64
- name: '949'
dtype: float64
- name: '950'
dtype: float64
- name: '951'
dtype: float64
- name: '952'
dtype: float64
- name: '953'
dtype: float64
- name: '954'
dtype: float64
- name: '955'
dtype: float64
- name: '956'
dtype: float64
- name: '957'
dtype: float64
- name: '958'
dtype: float64
- name: '959'
dtype: float64
- name: '960'
dtype: float64
- name: '961'
dtype: float64
- name: '962'
dtype: float64
- name: '963'
dtype: float64
- name: '964'
dtype: float64
- name: '965'
dtype: float64
- name: '966'
dtype: float64
- name: '967'
dtype: float64
- name: '968'
dtype: float64
- name: '969'
dtype: float64
- name: '970'
dtype: float64
- name: '971'
dtype: float64
- name: '972'
dtype: float64
- name: '973'
dtype: float64
- name: '974'
dtype: float64
- name: '975'
dtype: float64
- name: '976'
dtype: float64
- name: '977'
dtype: float64
- name: '978'
dtype: float64
- name: '979'
dtype: float64
- name: '980'
dtype: float64
- name: '981'
dtype: float64
- name: '982'
dtype: float64
- name: '983'
dtype: float64
- name: '984'
dtype: float64
- name: '985'
dtype: float64
- name: '986'
dtype: float64
- name: '987'
dtype: float64
- name: '988'
dtype: float64
- name: '989'
dtype: float64
- name: '990'
dtype: float64
- name: '991'
dtype: float64
- name: '992'
dtype: float64
- name: '993'
dtype: float64
- name: '994'
dtype: float64
- name: '995'
dtype: float64
- name: '996'
dtype: float64
- name: '997'
dtype: float64
- name: '998'
dtype: float64
- name: '999'
dtype: float64
- name: '1000'
dtype: float64
- name: '1001'
dtype: float64
- name: '1002'
dtype: float64
- name: '1003'
dtype: float64
- name: '1004'
dtype: float64
- name: '1005'
dtype: float64
- name: '1006'
dtype: float64
- name: '1007'
dtype: float64
- name: '1008'
dtype: float64
- name: '1009'
dtype: float64
- name: '1010'
dtype: float64
- name: '1011'
dtype: float64
- name: '1012'
dtype: float64
- name: '1013'
dtype: float64
- name: '1014'
dtype: float64
- name: '1015'
dtype: float64
- name: '1016'
dtype: float64
- name: '1017'
dtype: float64
- name: '1018'
dtype: float64
- name: '1019'
dtype: float64
- name: '1020'
dtype: float64
- name: '1021'
dtype: float64
- name: '1022'
dtype: float64
- name: '1023'
dtype: float64
splits:
- name: train
num_bytes: 49274939
num_examples: 1600
- name: test
num_bytes: 12315986
num_examples: 400
download_size: 0
dataset_size: 61590925
---
# Dataset Card for "maltaomics_dataset_normalized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
arunptp/industrial_ner_v1 | 2023-09-11T05:09:58.000Z | [
"region:us"
] | arunptp | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: tokens
sequence: string
- name: tags
sequence: string
- name: ner_tags
sequence: int64
splits:
- name: train
num_bytes: 41659733
num_examples: 66182
download_size: 2230912
dataset_size: 41659733
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "industrial_ner_v1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
jackley86/lamini_docs | 2023-09-11T07:51:02.000Z | [
"region:us"
] | jackley86 | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 1846734.3
num_examples: 1260
- name: test
num_bytes: 205192.7
num_examples: 140
download_size: 0
dataset_size: 2051927.0
---
# Dataset Card for "lamini_docs"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Jagadeesh-ti/test-x | 2023-09-11T10:58:32.000Z | [
"region:us"
] | Jagadeesh-ti | null | null | null | 0 | 7 | Entry not found |
kristinashemet/Dataset_V2 | 2023-10-08T15:31:39.000Z | [
"region:us"
] | kristinashemet | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 10521416
num_examples: 1573
download_size: 1009493
dataset_size: 10521416
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "Dataset_V2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tontokoton/artery-ultrasound-siit | 2023-09-11T12:28:27.000Z | [
"region:us"
] | tontokoton | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: pixel_values
dtype: image
- name: label
dtype: image
splits:
- name: train
num_bytes: 6912536.0
num_examples: 3
download_size: 516763
dataset_size: 6912536.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "artery-ultrasound-siit"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
polinaeterna/pokemon-blip-captions | 2023-09-11T14:22:52.000Z | [
"task_categories:text-to-image",
"annotations_creators:machine-generated",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:n<1K",
"source_datasets:huggan/few-shot-pokemon",
"language:en",
"license:cc-by-nc-sa-4.0",
"region:us"
] | polinaeterna | null | null | null | 0 | 7 | ---
annotations_creators:
- machine-generated
language_creators:
- other
language:
- en
license: cc-by-nc-sa-4.0
multilinguality:
- monolingual
size_categories:
- n<1K
source_datasets:
- huggan/few-shot-pokemon
task_categories:
- text-to-image
task_ids: []
pretty_name: Pokémon BLIP captions
tags: []
duplicated_from: lambdalabs/pokemon-blip-captions
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 119417305.0
num_examples: 833
download_size: 0
dataset_size: 119417305.0
---
# Dataset Card for Pokémon BLIP captions
_Dataset used to train [Pokémon text to image model](https://github.com/LambdaLabsML/examples/tree/main/stable-diffusion-finetuning)_
BLIP generated captions for Pokémon images from Few Shot Pokémon dataset introduced by _Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis_ (FastGAN). Original images were obtained from [FastGAN-pytorch](https://github.com/odegeasslbc/FastGAN-pytorch) and captioned with the [pre-trained BLIP model](https://github.com/salesforce/BLIP).
For each row the dataset contains `image` and `text` keys. `image` is a varying size PIL jpeg, and `text` is the accompanying text caption. Only a train split is provided.
## Examples

> a drawing of a green pokemon with red eyes

> a green and yellow toy with a red nose

> a red and white ball with an angry look on its face
## Citation
If you use this dataset, please cite it as:
```
@misc{pinkney2022pokemon,
author = {Pinkney, Justin N. M.},
title = {Pokemon BLIP captions},
year={2022},
howpublished= {\url{https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions/}}
}
``` |
kaishu888/financial_train | 2023-09-12T01:07:53.000Z | [
"license:apache-2.0",
"region:us"
] | kaishu888 | null | null | null | 1 | 7 | ---
license: apache-2.0
---
|
alshahri/xauusd-h1-bid-2019-01-01-2023-05-30 | 2023-09-11T18:41:37.000Z | [
"license:other",
"region:us"
] | alshahri | null | null | null | 0 | 7 | ---
license: other
---
|
cherry1556/robot-qa | 2023-09-12T03:55:43.000Z | [
"region:us"
] | cherry1556 | null | null | null | 0 | 7 | Entry not found |
BEBO-DBIndia/BeboUpdated | 2023-09-12T09:37:54.000Z | [
"region:us"
] | BEBO-DBIndia | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 2799
num_examples: 9
download_size: 2821
dataset_size: 2799
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "BeboUpdated"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
922-CA/lne2_09122023_test1 | 2023-09-22T08:09:04.000Z | [
"license:openrail",
"region:us"
] | 922-CA | null | null | null | 0 | 7 | ---
license: openrail
---
# Lora Negev (LLaMA2) 09122023 test 1
* Dataset of Negev dialogue from Girls' Frontline
* Manually edited to turn into multi-turn dialogue |
lmaoliketest/yellow_test | 2023-09-13T13:09:56.000Z | [
"license:unknown",
"region:us"
] | lmaoliketest | null | null | null | 0 | 7 | ---
license: unknown
---
|
sachith-surge/evol-instruct_dolly2.0_h2oGPT-falcon-40B-oasst1 | 2023-09-13T05:43:25.000Z | [
"region:us"
] | sachith-surge | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: response
dtype: string
- name: category
dtype: string
- name: evolution_strategy
dtype: string
- name: in-depth-evolving_operation
dtype: string
- name: epoch
dtype: int64
splits:
- name: train
num_bytes: 3051568
num_examples: 2304
download_size: 1665250
dataset_size: 3051568
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "evol-instruct_dolly2.0_h2oGPT-falcon-40B-oasst1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
KeyonHF/AsigaDoc | 2023-09-14T10:08:41.000Z | [
"license:apache-2.0",
"region:us"
] | KeyonHF | null | null | null | 0 | 7 | ---
license: apache-2.0
---
|
OmkarB/Multi-task-Dataset-Sample | 2023-09-13T18:44:51.000Z | [
"region:us"
] | OmkarB | null | null | null | 0 | 7 | Entry not found |
vikp/textbook_synth_sample | 2023-09-13T19:55:29.000Z | [
"region:us"
] | vikp | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: markdown
dtype: string
- name: topic
dtype: string
splits:
- name: train
num_bytes: 5522373
num_examples: 368
download_size: 0
dataset_size: 5522373
---
# Dataset Card for "textbook_synth_sample"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Diego1234/celeba | 2023-09-19T11:49:37.000Z | [
"region:us"
] | Diego1234 | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': female
'1': male
splits:
- name: train
num_bytes: 2768237832.0
num_examples: 28000
- name: validation
num_bytes: 194932418.0
num_examples: 2000
download_size: 2963322017
dataset_size: 2963170250.0
---
# Dataset Card for "celeba"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
AkikJana/RLHF_v1 | 2023-09-19T14:19:16.000Z | [
"region:us"
] | AkikJana | null | null | null | 0 | 7 | Entry not found |
loubnabnl/prs-v2-sample | 2023-09-14T12:55:12.000Z | [
"region:us"
] | loubnabnl | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: pull_request.guid
dtype: string
- name: pull_request.code_review_events
dtype: string
- name: pull_request.events
dtype: string
- name: pull_request.issue_events
dtype: string
- name: bucket
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 201909231
num_examples: 10000
download_size: 38860265
dataset_size: 201909231
---
# Dataset Card for "prs-v2-sample"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
sachith-surge/evol-instruct | 2023-09-15T04:50:14.000Z | [
"region:us"
] | sachith-surge | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: instruction
dtype: string
- name: response
dtype: string
- name: category
dtype: string
- name: evolution_strategy
dtype: string
- name: in-depth-evolving_operation
dtype: string
- name: epoch
dtype: int64
- name: falcon_status
dtype: string
- name: falcon_rating
dtype: string
- name: falcon_reason
dtype: string
- name: gpt4_status
dtype: string
- name: gpt4_rating
dtype: string
- name: gpt4_reason
dtype: string
splits:
- name: train
num_bytes: 4701491
num_examples: 2304
download_size: 2438727
dataset_size: 4701491
---
# Dataset Card for "evol-instruct"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
nitinbhayana/review_v1.1 | 2023-09-15T10:37:02.000Z | [
"region:us"
] | nitinbhayana | null | null | null | 0 | 7 | Entry not found |
ajoshi-6/insincere_fullds | 2023-09-16T05:13:13.000Z | [
"region:us"
] | ajoshi-6 | null | null | null | 1 | 7 | Entry not found |
sachith-surge/orca-evaluated-falcon-gpt4-v1 | 2023-09-15T15:18:37.000Z | [
"region:us"
] | sachith-surge | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: original_index
dtype: int64
- name: inputs
dtype: string
- name: targets
dtype: string
- name: task_source
dtype: string
- name: task_name
dtype: string
- name: template_type
dtype: string
- name: system_message
dtype: string
- name: explained_targets
dtype: string
- name: dataset_source
dtype: string
- name: falcon_status
dtype: string
- name: falcon_rating
dtype: string
- name: falcon_reason
dtype: string
- name: gpt4_status
dtype: string
- name: gpt4_rating
dtype: string
- name: gpt4_reason
dtype: string
splits:
- name: train
num_bytes: 4239431
num_examples: 2000
download_size: 1958334
dataset_size: 4239431
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "orca-evaluated-falcon-gpt4-v1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Pav91/Test-Llama2-7B | 2023-09-21T00:13:36.000Z | [
"license:other",
"region:us"
] | Pav91 | null | null | null | 0 | 7 | ---
license: other
---
|
revolutionarybukhari/embeddings | 2023-09-16T08:33:14.000Z | [
"region:us"
] | revolutionarybukhari | null | null | null | 0 | 7 | Entry not found |
macarious/en_corpora_parliament_processed | 2023-10-03T00:12:49.000Z | [
"region:us"
] | macarious | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 309185247
num_examples: 2051014
download_size: 171553320
dataset_size: 309185247
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "en_corpora_parliament_processed"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
RealTimeData/bbc_2017 | 2023-09-16T22:26:49.000Z | [
"region:us"
] | RealTimeData | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: title
dtype: string
- name: published_date
dtype: string
- name: authors
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
splits:
- name: train
num_bytes: 42935783
num_examples: 11381
download_size: 19022337
dataset_size: 42935783
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "bbc_2017"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
pssubitha/formatted_data_sales1.jsonl | 2023-09-17T11:16:50.000Z | [
"region:us"
] | pssubitha | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 45883
num_examples: 120
download_size: 24605
dataset_size: 45883
---
# Dataset Card for "formatted_data_sales1.jsonl"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
usvsnsp/duped-embeddings | 2023-09-17T13:13:57.000Z | [
"region:us"
] | usvsnsp | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: sequence_id
dtype: int64
- name: embeddings
sequence: float32
splits:
- name: train
num_bytes: 12057291504
num_examples: 7788948
download_size: 16876467166
dataset_size: 12057291504
---
# Dataset Card for "duped-embeddings"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
alayaran/bodo-pos-conll | 2023-09-18T04:54:22.000Z | [
"license:mit",
"region:us"
] | alayaran | The shared task of CoNLL-2003 concerns language-independent named entity recognition. We will concentrate on
four types of named entities: persons, locations, organizations and names of miscellaneous entities that do
not belong to the previous three groups.
The CoNLL-2003 shared task data files contain four columns separated by a single space. Each word has been put on
a separate line and there is an empty line after each sentence. The first item on each line is a word, the second
a part-of-speech (POS) tag, the third a syntactic chunk tag and the fourth the named entity tag. The chunk tags
and the named entity tags have the format I-TYPE which means that the word is inside a phrase of type TYPE. Only
if two phrases of the same type immediately follow each other, the first word of the second phrase will have tag
B-TYPE to show that it starts a new phrase. A word with tag O is not part of a phrase. Note the dataset uses IOB2
tagging scheme, whereas the original dataset uses IOB1.
For more details see https://www.clips.uantwerpen.be/conll2003/ner/ and https://www.aclweb.org/anthology/W03-0419 | @inproceedings{bododataset2022v1,
title = {Bodo Dataset: A comprehensive list of Bodo Datasets},
author = {Sanjib Narzary},
booktitle = {Alayaran Dataset Repository},
url = {http://get.alayaran.com},
year = {2022},
} | null | 0 | 7 | ---
license: mit
---
|
boopysaur/bpd-twitter | 2023-09-18T07:39:20.000Z | [
"region:us"
] | boopysaur | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 2007525.0
num_examples: 30407
download_size: 1486546
dataset_size: 2007525.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "bpd-twitter"
I scraped my twitter timeline some time in late 2022 / v early 2023 |
nanyy1025/bioasq_7b_yesno | 2023-09-28T19:37:30.000Z | [
"region:us"
] | nanyy1025 | null | null | null | 0 | 7 | Entry not found |
vikp/clean_notebooks | 2023-09-19T04:13:51.000Z | [
"region:us"
] | vikp | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: code
dtype: string
- name: kind
dtype: string
splits:
- name: train
num_bytes: 9206821200.476824
num_examples: 1011857
download_size: 5400580201
dataset_size: 9206821200.476824
---
# Dataset Card for "clean_notebooks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
sachith-surge/orca | 2023-09-19T05:46:13.000Z | [
"region:us"
] | sachith-surge | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: original_index
dtype: int64
- name: inputs
dtype: string
- name: targets
dtype: string
- name: task_source
dtype: string
- name: task_name
dtype: string
- name: template_type
dtype: string
- name: system_message
dtype: string
- name: explained_targets
dtype: string
- name: dataset_source
dtype: string
- name: falcon_status
dtype: string
- name: falcon_rating
dtype: string
- name: falcon_reason
dtype: string
- name: gpt4_status
dtype: string
- name: gpt4_rating
dtype: string
- name: gpt4_reason
dtype: string
splits:
- name: train
num_bytes: 10761181
num_examples: 5517
download_size: 5035931
dataset_size: 10761181
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "orca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Falah/arabic_enhanced_scenes | 2023-09-20T07:00:23.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 3389696
num_examples: 10000
download_size: 403975
dataset_size: 3389696
---
# Dataset Card for "arabic_enhanced_scenes"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
NewstaR/bleedingheart-pretrain-10M | 2023-10-02T08:48:05.000Z | [
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:tl",
"license:other",
"region:us"
] | NewstaR | null | null | null | 0 | 7 | ---
license: other
task_categories:
- text-generation
language:
- tl
size_categories:
- 1M<n<10M
---
<h1 style="text-align: center">Bleedingheart Pretrain Dataset</h1>
<h2 style="text-align: center">A collaboration between Kaleido and Newstar</h2>
<hr>
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5" stroke="currentColor" class="w-6 h-6" style="display: block; margin: 0 auto; margin-top: 10px; transform: translateY(-50%);">
<path stroke-linecap="round" stroke-linejoin="round" d="M19.5 5.25l-7.5 7.5-7.5-7.5m15 6l-7.5 7.5-7.5-7.5" />
</svg>
- We collected all the datasets we could find that are in Tagalog or any other Philippine dialect and put them in this repository.
- This data will be used to train the Bleedingheart model.
- Bleeding Heart is a stunning bird native to the island of Luzon in the Philippines. It is a medium-sized ground dove with a distinctive red patch of feathers on its chest, which gives it its name. The male's red patch is larger and brighter than the female's, and he displays it during the breeding season to attract a mate. |
VishalCh/book1 | 2023-09-20T12:10:20.000Z | [
"license:llama2",
"region:us"
] | VishalCh | null | null | null | 0 | 7 | ---
license: llama2
---
|
usvsnsp/memories-semantic-memorization-filter-results | 2023-09-20T20:16:41.000Z | [
"region:us"
] | usvsnsp | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: sequence_id
dtype: int64
- name: text
dtype: string
- name: sequence_duplicates
dtype: int64
- name: max_frequency
dtype: int64
- name: avg_frequency
dtype: float64
- name: min_frequency
dtype: int64
- name: median_frequency
dtype: float64
- name: p25_frequency
dtype: int64
- name: p75_frequency
dtype: int64
- name: frequencies
sequence: int64
- name: is_incrementing
dtype: bool
- name: tokens
sequence: int64
- name: repeating_offset
dtype: int32
- name: num_repeating
dtype: int32
- name: smallest_repeating_chunk
sequence: int64
- name: memorization_score
dtype: float64
- name: templating_frequency_0.9
dtype: int64
- name: templating_frequency_0.8
dtype: int64
- name: prompt_perplexity
dtype: float32
- name: generation_perplexity
dtype: float32
- name: sequence_perplexity
dtype: float32
splits:
- name: memories.duped.70m
num_bytes: 648141277
num_examples: 463953
- name: memories.duped.160m
num_bytes: 955903849
num_examples: 689673
- name: memories.duped.410m
num_bytes: 1337555782
num_examples: 970341
- name: memories.duped.1b
num_bytes: 1725540452
num_examples: 1256141
- name: memories.duped.1.4b
num_bytes: 1884519155
num_examples: 1373722
- name: memories.duped.2.8b
num_bytes: 2292743123
num_examples: 1675077
- name: memories.duped.6.9b
num_bytes: 2898035658
num_examples: 2120976
- name: memories.duped.12b
num_bytes: 3252649684
num_examples: 2382328
- name: memories.deduped.70m
num_bytes: 576211560
num_examples: 411448
- name: memories.deduped.160m
num_bytes: 809545073
num_examples: 581195
- name: memories.deduped.410m
num_bytes: 1126006111
num_examples: 811039
- name: memories.deduped.1b
num_bytes: 1430399436
num_examples: 1032865
- name: memories.deduped.1.4b
num_bytes: 1450336662
num_examples: 1048097
- name: memories.deduped.2.8b
num_bytes: 1871907415
num_examples: 1355211
- name: memories.deduped.6.9b
num_bytes: 2319039796
num_examples: 1680294
- name: memories.deduped.12b
num_bytes: 2581349436
num_examples: 1871216
download_size: 9223426756
dataset_size: 27159884469
---
# Dataset Card for "memories-semantic-memorization-filter-results"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
EdgarsKatze/test | 2023-09-20T22:05:49.000Z | [
"region:us"
] | EdgarsKatze | null | null | null | 0 | 7 | ---
configs:
- config_name: default
data_files:
- split: train
path: "test/data-00000-of-00001.arrow"
---
license: other
---
|
maximuslee07/raqna1.4k | 2023-09-25T21:29:01.000Z | [
"license:llama2",
"region:us"
] | maximuslee07 | null | null | null | 0 | 7 | ---
license: llama2
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 2507625
num_examples: 1581
download_size: 1451367
dataset_size: 2507625
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
maibinh/data_fine_tuning_demo | 2023-09-27T09:41:46.000Z | [
"region:us"
] | maibinh | null | null | null | 0 | 7 | Entry not found |
swaroopajit/next-dataset-refined-batch-0 | 2023-09-21T09:45:02.000Z | [
"region:us"
] | swaroopajit | null | null | null | 0 | 7 | ---
dataset_info:
features:
- name: caption
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 331199460.0
num_examples: 1000
download_size: 304483916
dataset_size: 331199460.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "next-dataset-refined-batch-0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.