
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
guanaco/guanaco | 2023-04-04T09:49:11.000Z | [
"language:en",
"license:apache-2.0",
"region:us"
] | guanaco | null | null | null | 4 | 5 | ---
license: apache-2.0
language:
- en
--- |
HuggingFaceH4/Koala-test-set | 2023-04-05T21:54:31.000Z | [
"license:apache-2.0",
"region:us"
] | HuggingFaceH4 | null | null | null | 0 | 5 | ---
license: apache-2.0
---
This dataset is taken from https://github.com/arnav-gudibande/koala-test-set |
spongus/milly-images | 2023-04-15T17:41:37.000Z | [
"task_categories:text-to-image",
"task_categories:image-classification",
"task_categories:image-segmentation",
"size_categories:n<1K",
"language:en",
"license:unlicense",
"image",
"cat",
"silly",
"calico",
"region:us"
] | spongus | null | null | null | 1 | 5 | ---
license: unlicense
tags:
- image
- cat
- silly
- calico
pretty_name: Milly Images
task_categories:
- text-to-image
- image-classification
- image-segmentation
language:
- en
size_categories:
- n<1K
---
A collection of images from a very silly cat, these are all from @fatfatmillycat in twitter. Intended to be used with stable-diffusion-v1-4 |
Djacon/ru_goemotions | 2023-04-08T16:51:52.000Z | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"task_ids:multi-label-classification",
"multilinguality:monolingual",
"language:ru",
"license:mit",
"emotion",
"arxiv:2005.00547",
"region:us"
] | Djacon | null | null | null | 1 | 5 | ---
language:
- ru
license:
- mit
multilinguality:
- monolingual
task_categories:
- text-classification
task_ids:
- multi-class-classification
- multi-label-classification
pretty_name: RuGoEmotions
tags:
- emotion
---
# Dataset Card for GoEmotions
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
### Dataset Summary
The RuGoEmotions dataset contains 34k Reddit comments labeled for 9 emotion categories (joy, interest, surprice, sadness, anger, disgust, fear, guilt and neutral).
The dataset already with predefined train/val/test splits
### Supported Tasks and Leaderboards
This dataset is intended for multi-class, multi-label emotion classification.
### Languages
The data is in Russian.
## Dataset Structure
### Data Instances
Each instance is a reddit comment with one or more emotion annotations (or neutral).
### Data Fields
The configuration includes:
- `text`: the reddit comment
- `labels`: the emotion annotations
### Data Splits
The simplified data includes a set of train/val/test splits with 26.9k, 3.29k, and 3.37k examples respectively.
## Dataset Creation
### Curation Rationale
From the paper abstract:
> Understanding emotion expressed in language has a wide range of applications, from building empathetic chatbots to
detecting harmful online behavior. Advancement in this area can be improved using large-scale datasets with a
fine-grained typology, adaptable to multiple downstream tasks.
### Source Data
#### Initial Data Collection and Normalization
Data was collected from Reddit comments via a variety of automated methods discussed in 3.1 of the paper.
#### Who are the source language producers?
English-speaking Reddit users.
### Annotations
#### Who are the annotators?
Annotations were produced by 3 English-speaking crowdworkers in India.
### Personal and Sensitive Information
This dataset includes the original usernames of the Reddit users who posted each comment. Although Reddit usernames
are typically disasociated from personal real-world identities, this is not always the case. It may therefore be
possible to discover the identities of the individuals who created this content in some cases.
## Considerations for Using the Data
### Social Impact of Dataset
Emotion detection is a worthwhile problem which can potentially lead to improvements such as better human/computer
interaction. However, emotion detection algorithms (particularly in computer vision) have been abused in some cases
to make erroneous inferences in human monitoring and assessment applications such as hiring decisions, insurance
pricing, and student attentiveness (see
[this article](https://www.unite.ai/ai-now-institute-warns-about-misuse-of-emotion-detection-software-and-other-ethical-issues/)).
### Discussion of Biases
From the authors' github page:
> Potential biases in the data include: Inherent biases in Reddit and user base biases, the offensive/vulgar word lists used for data filtering, inherent or unconscious bias in assessment of offensive identity labels, annotators were all native English speakers from India. All these likely affect labelling, precision, and recall for a trained model. Anyone using this dataset should be aware of these limitations of the dataset.
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Researchers at Amazon Alexa, Google Research, and Stanford. See the [author list](https://arxiv.org/abs/2005.00547).
### Licensing Information
The GitHub repository which houses this dataset has an
[Apache License 2.0](https://github.com/google-research/google-research/blob/master/LICENSE).
### Citation Information
@inproceedings{demszky2020goemotions,
author = {Demszky, Dorottya and Movshovitz-Attias, Dana and Ko, Jeongwoo and Cowen, Alan and Nemade, Gaurav and Ravi, Sujith},
booktitle = {58th Annual Meeting of the Association for Computational Linguistics (ACL)},
title = {{GoEmotions: A Dataset of Fine-Grained Emotions}},
year = {2020}
}
### Contributions
Thanks to [@joeddav](https://github.com/joeddav) for adding this dataset.
|
eyenpi/mhsma | 2023-04-11T18:51:45.000Z | [
"task_categories:image-classification",
"license:cc-by-sa-4.0",
"region:us"
] | eyenpi | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: image
sequence:
sequence: uint8
- name: head
dtype: uint8
- name: vacuole
dtype: uint8
- name: acrosome
dtype: uint8
splits:
- name: train
num_bytes: 4359000
num_examples: 1000
- name: valid
num_bytes: 1046160
num_examples: 240
- name: test
num_bytes: 1307700
num_examples: 300
download_size: 4962520
dataset_size: 6712860
license: cc-by-sa-4.0
task_categories:
- image-classification
pretty_name: The Modified Human Sperm Morphology Analysis Dataset
---
# MHSMA: The Modified Human Sperm Morphology Analysis Dataset
The MHSMA dataset is a collection of human sperm images from 235 patients with male factor infertility. Each image is labeled by experts for normal or abnormal sperm acrosome, head, vacuole, and tail.
# Source
Make sure to visit the [Github page](https://github.com/soroushj/mhsma-dataset).
```
@article{javadi2019novel,
title={A novel deep learning method for automatic assessment of human sperm images},
author={Javadi, Soroush and Mirroshandel, Seyed Abolghasem},
journal={Computers in Biology and Medicine},
volume={109},
pages={182--194},
year={2019},
doi={10.1016/j.compbiomed.2019.04.030}
}
``` |
LEL-A/translated_german_alpaca_validation | 2023-10-02T16:50:04.000Z | [
"language:de",
"region:us"
] | LEL-A | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: text
dtype: 'null'
- name: inputs
struct:
- name: _instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: prediction
list:
- name: label
dtype: string
- name: score
dtype: float64
- name: prediction_agent
dtype: string
- name: annotation
dtype: string
- name: annotation_agent
dtype: string
- name: vectors
struct:
- name: input
sequence: float64
- name: instruction
sequence: float64
- name: output
sequence: float64
- name: multi_label
dtype: bool
- name: explanation
dtype: 'null'
- name: id
dtype: string
- name: metadata
struct:
- name: original_id
dtype: int64
- name: translation_model
dtype: string
- name: status
dtype: string
- name: event_timestamp
dtype: timestamp[us]
- name: metrics
struct:
- name: text_length
dtype: int64
splits:
- name: train
num_bytes: 152890
num_examples: 8
download_size: 0
dataset_size: 152890
language:
- de
---
# Dataset Card for "translated_german_alpaca_validation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
hanamizuki-ai/stable-diffusion-v1-5-glazed | 2023-04-14T03:57:57.000Z | [
"task_categories:image-classification",
"task_categories:image-to-image",
"license:creativeml-openrail-m",
"art",
"region:us"
] | hanamizuki-ai | null | null | null | 0 | 5 | ---
license: creativeml-openrail-m
task_categories:
- image-classification
- image-to-image
tags:
- art
dataset_info:
features:
- name: id
dtype: string
- name: parent_id
dtype: string
- name: model
dtype: string
- name: prompt
dtype: string
- name: glaze_model
dtype: string
- name: glaze_intensity
dtype: int64
- name: glaze_render
dtype: int64
- name: glaze_style
dtype: string
- name: glaze_style_strength
dtype: float64
- name: image
dtype: image
- name: parent_image
dtype: image
splits:
- name: train
num_bytes: 111462286297.0
num_examples: 118980
download_size: 23365392724
dataset_size: 111462286297.0
---
# Dataset Card for Stable Diffusion v1.5 Glazed Samples
## Dataset Description
### Dataset Summary
This dataset contains image samples originally generated by [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
and subsequently processed by [Glaze](https://glaze.cs.uchicago.edu/) tool.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
renumics/cifar10-enriched | 2023-06-06T07:42:35.000Z | [
"task_categories:image-classification",
"task_ids:multi-class-image-classification",
"size_categories:10K<n<100K",
"source_datasets:extended|cifar10",
"language:en",
"license:apache-2.0",
"image classification",
"cifar-10",
"cifar-10-enriched",
"embeddings",
"enhanced",
"spotlight",
"region:... | renumics | The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images
per class. There are 50000 training images and 10000 test images.
This version if CIFAR-10 is enriched with several metadata such as embeddings, baseline results and label error scores. | @TECHREPORT{Krizhevsky09learningmultiple,
author = {Alex Krizhevsky},
title = {Learning multiple layers of features from tiny images},
institution = {},
year = {2009}
} | null | 1 | 5 | ---
license: apache-2.0
task_categories:
- image-classification
task_ids:
- multi-class-image-classification
paperswithcode_id: cifar-10
pretty_name: CIFAR-10
size_categories:
- 10K<n<100K
source_datasets:
- extended|cifar10
tags:
- image classification
- cifar-10
- cifar-10-enriched
- embeddings
- enhanced
- spotlight
language:
- en
---
# Dataset Card for CIFAR-10-Enriched (Enhanced by Renumics)
## Dataset Description
- **Homepage:** [Renumics Homepage](https://renumics.com/?hf-dataset-card=cifar10-enriched)
- **GitHub** [Spotlight](https://github.com/Renumics/spotlight)
- **Dataset Homepage** [CS Toronto Homepage](https://www.cs.toronto.edu/~kriz/cifar.html)
- **Paper:** [Learning Multiple Layers of Features from Tiny Images](https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf)
### Dataset Summary
📊 [Data-centric AI](https://datacentricai.org) principles have become increasingly important for real-world use cases.
At [Renumics](https://renumics.com/?hf-dataset-card=cifar10-enriched) we believe that classical benchmark datasets and competitions should be extended to reflect this development.
🔍 This is why we are publishing benchmark datasets with application-specific enrichments (e.g. embeddings, baseline results, uncertainties, label error scores). We hope this helps the ML community in the following ways:
1. Enable new researchers to quickly develop a profound understanding of the dataset.
2. Popularize data-centric AI principles and tooling in the ML community.
3. Encourage the sharing of meaningful qualitative insights in addition to traditional quantitative metrics.
📚 This dataset is an enriched version of the [CIFAR-10 Dataset](https://www.cs.toronto.edu/~kriz/cifar.html).
### Explore the Dataset
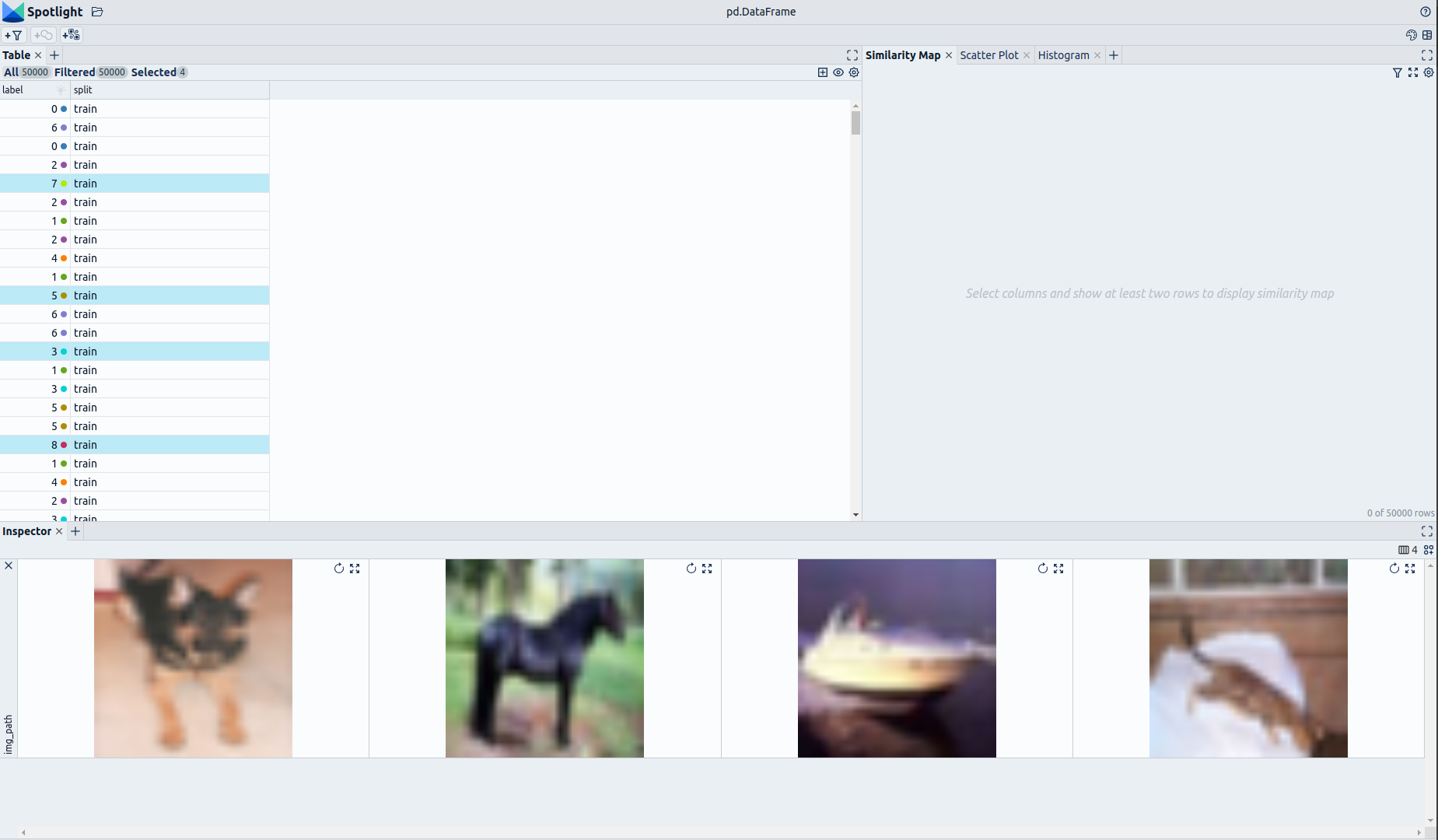
The enrichments allow you to quickly gain insights into the dataset. The open source data curation tool [Renumics Spotlight](https://github.com/Renumics/spotlight) enables that with just a few lines of code:
Install datasets and Spotlight via [pip](https://packaging.python.org/en/latest/key_projects/#pip):
```python
!pip install renumics-spotlight datasets
```
Load the dataset from huggingface in your notebook:
```python
import datasets
dataset = datasets.load_dataset("renumics/cifar10-enriched", split="train")
```
Start exploring with a simple view:
```python
from renumics import spotlight
df = dataset.to_pandas()
df_show = df.drop(columns=['img'])
spotlight.show(df_show, port=8000, dtype={"img_path": spotlight.Image})
```
You can use the UI to interactively configure the view on the data. Depending on the concrete tasks (e.g. model comparison, debugging, outlier detection) you might want to leverage different enrichments and metadata.
### CIFAR-10 Dataset
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.
The classes are completely mutually exclusive. There is no overlap between automobiles and trucks. "Automobile" includes sedans, SUVs, things of that sort. "Truck" includes only big trucks. Neither includes pickup trucks.
Here is the list of classes in the CIFAR-10:
- airplane
- automobile
- bird
- cat
- deer
- dog
- frog
- horse
- ship
- truck
### Supported Tasks and Leaderboards
- `image-classification`: The goal of this task is to classify a given image into one of 10 classes. The leaderboard is available [here](https://paperswithcode.com/sota/image-classification-on-cifar-10).
### Languages
English class labels.
## Dataset Structure
### Data Instances
A sample from the training set is provided below:
```python
{
'img': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=32x32 at 0x7FD19FABC1D0>,
'img_path': '/huggingface/datasets/downloads/extracted/7faec2e0fd4aa3236f838ed9b105fef08d1a6f2a6bdeee5c14051b64619286d5/0/0.png',
'label': 0,
'split': 'train'
}
```
### Data Fields
| Feature | Data Type |
|---------------------------------|-----------------------------------------------|
| img | Image(decode=True, id=None) |
| img_path | Value(dtype='string', id=None) |
| label | ClassLabel(names=[...], id=None) |
| split | Value(dtype='string', id=None) |
### Data Splits
| Dataset Split | Number of Images in Split | Samples per Class |
| ------------- |---------------------------| -------------------------|
| Train | 50000 | 5000 |
| Test | 10000 | 1000 |
## Dataset Creation
### Curation Rationale
The CIFAR-10 and CIFAR-100 are labeled subsets of the [80 million tiny images](http://people.csail.mit.edu/torralba/tinyimages/) dataset.
They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use this dataset, please cite the following paper:
```
@article{krizhevsky2009learning,
added-at = {2021-01-21T03:01:11.000+0100},
author = {Krizhevsky, Alex},
biburl = {https://www.bibsonomy.org/bibtex/2fe5248afe57647d9c85c50a98a12145c/s364315},
interhash = {cc2d42f2b7ef6a4e76e47d1a50c8cd86},
intrahash = {fe5248afe57647d9c85c50a98a12145c},
keywords = {},
pages = {32--33},
timestamp = {2021-01-21T03:01:11.000+0100},
title = {Learning Multiple Layers of Features from Tiny Images},
url = {https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf},
year = 2009
}
```
### Contributions
Alex Krizhevsky, Vinod Nair, Geoffrey Hinton, and Renumics GmbH. |
hanamizuki-ai/anything-v3.0-glazed | 2023-04-21T11:52:12.000Z | [
"task_categories:image-classification",
"task_categories:image-to-image",
"license:creativeml-openrail-m",
"art",
"region:us"
] | hanamizuki-ai | null | null | null | 1 | 5 | ---
license: creativeml-openrail-m
task_categories:
- image-classification
- image-to-image
tags:
- art
dataset_info:
features:
- name: id
dtype: string
- name: parent_id
dtype: string
- name: model
dtype: string
- name: prompt
dtype: string
- name: glaze_model
dtype: string
- name: glaze_intensity
dtype: int64
- name: glaze_render
dtype: int64
- name: glaze_style
dtype: string
- name: glaze_style_strength
dtype: float64
- name: image
dtype: image
- name: parent_image
dtype: image
splits:
- name: train
num_bytes: 96564915991.925
num_examples: 89235
download_size: 9066695101
dataset_size: 96564915991.925
---
# Dataset Card for Anything v3.0 Glazed Samples
## Dataset Description
### Dataset Summary
This dataset contains image samples originally generated by [Linaqruf/anything-v3.0](https://huggingface.co/Linaqruf/anything-v3.0)
and subsequently processed by [Glaze](https://glaze.cs.uchicago.edu/) tool.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
alvations/esci-data-task2 | 2023-04-22T02:40:09.000Z | [
"region:us"
] | alvations | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: example_id
dtype: int64
- name: query
dtype: string
- name: query_id
dtype: int64
- name: product_id
dtype: string
- name: product_locale
dtype: string
- name: esci_label
dtype: string
- name: small_version
dtype: int64
- name: large_version
dtype: int64
- name: split
dtype: string
- name: product_title
dtype: string
- name: product_description
dtype: string
- name: product_bullet_point
dtype: string
- name: product_brand
dtype: string
- name: product_color
dtype: string
- name: gain
dtype: float64
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 2603008323
num_examples: 1977767
- name: dev
num_bytes: 7386427
num_examples: 5505
- name: test
num_bytes: 843102586
num_examples: 638016
download_size: 2214316591
dataset_size: 3453497336
---
# Dataset Card for "esci-data-task2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
LawInformedAI/overruling | 2023-04-23T06:50:48.000Z | [
"region:us"
] | LawInformedAI | null | null | null | 0 | 5 | Entry not found |
NicholasSynovic/Free-AutoTrain-VEAA | 2023-04-25T17:42:58.000Z | [
"task_categories:text-classification",
"size_categories:1K<n<10K",
"source_datasets:NicholasSynovic/Victorian-Era-Authorship-Attribution",
"language:en",
"license:agpl-3.0",
"region:us"
] | NicholasSynovic | null | null | null | 0 | 5 | ---
license: agpl-3.0
task_categories:
- text-classification
language:
- en
pretty_name: Victorian Era Authorship Attribution Data Set (For Free AutoTrain Account)
size_categories:
- 1K<n<10K
source_datasets:
- NicholasSynovic/Victorian-Era-Authorship-Attribution
---
# Free AutoTrain VEAA
> Victorian Era Authorship Attribution Data Set (For Free AutoTrain Account)
## About
See the [original HF-hosted dataset](https://huggingface.co/datasets/NicholasSynovic/Victorian-Era-Authorship-Attribution) for more information.
The code to generate this dataset came from this [GitHub Repo](https://github.com/NicholasSynovic/nlp-victorianAuthor). |
cartesinus/iva_mt_wslot-exp | 2023-04-26T21:53:33.000Z | [
"task_categories:translation",
"size_categories:10K<n<100K",
"language:en",
"language:pl",
"language:de",
"language:es",
"language:sv",
"license:cc-by-4.0",
"machine translation",
"nlu",
"natural-language-understanding",
"virtual assistant",
"region:us"
] | cartesinus | \ | null | null | 0 | 5 | ---
dataset_info:
features:
- name: id
dtype: string
- name: locale
dtype: string
- name: origin
dtype: string
- name: partition
dtype: string
- name: translation_utt
dtype:
translation:
languages:
- en
- pl
- name: translation_xml
dtype:
translation:
languages:
- en
- pl
- name: src_bio
dtype: string
- name: tgt_bio
dtype: string
task_categories:
- translation
language:
- en
- pl
- de
- es
- sv
tags:
- machine translation
- nlu
- natural-language-understanding
- virtual assistant
pretty_name: Machine translation for NLU with slot transfer
size_categories:
- 10K<n<100K
license: cc-by-4.0
---
# Machine translation dataset for NLU (Virual Assistant) with slot transfer between languages
## Dataset Summary
Disclaimer: This is for research purposes only. Please have a look at the license section below. Some of the datasets used to construct IVA_MT have an unknown license.
IVA_MT is a machine translation dataset that can be used to train, adapt and evaluate MT models used in Virtual Assistant NLU context (e.g. to translate trainig corpus of NLU).
## Dataset Composition
### en-pl
| Corpus | Train | Dev | Test |
|----------------------------------------------------------------------|--------|-------|-------|
| [Massive 1.1](https://huggingface.co/datasets/AmazonScience/massive) | 11514 | 2033 | 2974 |
| [Leyzer 0.2.0](https://github.com/cartesinus/leyzer/tree/0.2.0) | 3974 | 701 | 1380 |
| [OpenSubtitles from OPUS](https://opus.nlpl.eu/OpenSubtitles-v1.php) | 2329 | 411 | 500 |
| [KDE from OPUS](https://opus.nlpl.eu/KDE4.php) | 1154 | 241 | 241 |
| [CCMatrix from Opus](https://opus.nlpl.eu/CCMatrix.php) | 1096 | 232 | 237 |
| [Ubuntu from OPUS](https://opus.nlpl.eu/Ubuntu.php) | 281 | 60 | 59 |
| [Gnome from OPUS](https://opus.nlpl.eu/GNOME.php) | 14 | 3 | 3 |
| *total* | 20362 | 3681 | 5394 |
### en-de
| Corpus | Train | Dev | Test |
|----------------------------------------------------------------------|--------|-------|-------|
| [Massive 1.1](https://huggingface.co/datasets/AmazonScience/massive) | 7536 | 1346 | 1955 |
### en-es
| Corpus | Train | Dev | Test |
|----------------------------------------------------------------------|--------|-------|-------|
| [Massive 1.1](https://huggingface.co/datasets/AmazonScience/massive) | 8415 | 1526 | 2202 |
### en-sv
| Corpus | Train | Dev | Test |
|----------------------------------------------------------------------|--------|-------|-------|
| [Massive 1.1](https://huggingface.co/datasets/AmazonScience/massive) | 7540 | 1360 | 1921 |
## Tools
Scripts used to generate this dataset can be found on [github](https://github.com/cartesinus/iva_mt).
## License
This is a composition of 7 datasets, and the license is as defined in original release:
- MASSIVE: [CC-BY 4.0](https://huggingface.co/datasets/AmazonScience/massive/blob/main/LICENSE)
- Leyzer: [CC BY-NC 4.0](https://github.com/cartesinus/leyzer/blob/master/LICENSE)
- OpenSubtitles: unknown
- KDE: [GNU Public License](https://l10n.kde.org/about.php)
- CCMatrix: no license given, therefore assuming it is LASER project license [BSD](https://github.com/facebookresearch/LASER/blob/main/LICENSE)
- Ubuntu: [GNU Public License](https://help.launchpad.net/Legal)
- Gnome: unknown
|
logo-wizard/modern-logo-dataset | 2023-05-09T13:40:55.000Z | [
"task_categories:text-to-image",
"size_categories:n<1K",
"language:en",
"license:cc-by-nc-3.0",
"doi:10.57967/hf/0592",
"region:us"
] | logo-wizard | null | null | null | 11 | 5 | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 209598433
num_examples: 803
download_size: 208886058
dataset_size: 209598433
license: cc-by-nc-3.0
task_categories:
- text-to-image
language:
- en
size_categories:
- n<1K
---
# Dataset Card for "logo-dataset-v4"
This dataset consists of 803 pairs \\( (x, y) \\), where \\( x \\) is the image and \\( y \\) is the description of the image.
The data have been manually collected and labelled, so the dataset is fully representative and free of rubbish.
The logos in the dataset are minimalist, meeting modern design requirements and reflecting the company's industry.
# Disclaimer
This dataset is made available for academic research purposes only. All the images are collected from the Internet, and the copyright belongs to the original owners. If any of the images belongs to you and you would like it removed, please inform us, we will try to remove it from the dataset. |
fujiki/wiki40b_ja | 2023-04-28T23:35:57.000Z | [
"language:ja",
"license:cc-by-sa-4.0",
"region:us"
] | fujiki | null | null | null | 0 | 5 | ---
license: cc-by-sa-4.0
language:
- ja
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1954209746
num_examples: 745392
- name: validation
num_bytes: 107186201
num_examples: 41576
- name: test
num_bytes: 107509760
num_examples: 41268
download_size: 420085060
dataset_size: 2168905707
---
This dataset is a reformatted version of the Japanese portion of [wiki40b](https://aclanthology.org/2020.lrec-1.297/) dataset.
When you use this dataset, please cite the original paper:
```
@inproceedings{guo-etal-2020-wiki,
title = "{W}iki-40{B}: Multilingual Language Model Dataset",
author = "Guo, Mandy and
Dai, Zihang and
Vrande{\v{c}}i{\'c}, Denny and
Al-Rfou, Rami",
booktitle = "Proceedings of the Twelfth Language Resources and Evaluation Conference",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2020.lrec-1.297",
pages = "2440--2452",
abstract = "We propose a new multilingual language model benchmark that is composed of 40+ languages spanning several scripts and linguistic families. With around 40 billion characters, we hope this new resource will accelerate the research of multilingual modeling. We train monolingual causal language models using a state-of-the-art model (Transformer-XL) establishing baselines for many languages. We also introduce the task of multilingual causal language modeling where we train our model on the combined text of 40+ languages from Wikipedia with different vocabulary sizes and evaluate on the languages individually. We released the cleaned-up text of 40+ Wikipedia language editions, the corresponding trained monolingual language models, and several multilingual language models with different fixed vocabulary sizes.",
language = "English",
ISBN = "979-10-95546-34-4",
}
```
|
Noxturnix/blognone-20230430 | 2023-05-05T21:47:56.000Z | [
"task_categories:text-generation",
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:th",
"license:cc-by-3.0",
"region:us"
] | Noxturnix | null | null | null | 0 | 5 | ---
license: cc-by-3.0
dataset_info:
features:
- name: title
dtype: string
- name: author
dtype: string
- name: date
dtype: string
- name: tags
sequence: string
- name: content
dtype: string
splits:
- name: train
num_bytes: 51748027
num_examples: 18623
download_size: 21759892
dataset_size: 51748027
task_categories:
- text-generation
- text-classification
language:
- th
size_categories:
- 10K<n<100K
---
# Dataset Card for blognone-20230430
## Dataset Summary
[Blognone](https://www.blognone.com/) posts from January 1, 2020 to April 30, 2023.
## Features
- title: (str)
- author: (str)
- date: (str)
- tags: (list)
- content: (str)
## Licensing Information
Blognone posts are published are licensed under the [Creative Commons Attribution 3.0 Thailand](https://creativecommons.org/licenses/by/3.0/th/deed.en) (CC BY 3.0 TH). |
oaimli/PeerSum | 2023-10-08T05:31:38.000Z | [
"task_categories:summarization",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"arxiv:2305.01498",
"region:us"
] | oaimli | null | null | null | 1 | 5 | ---
license: apache-2.0
task_categories:
- summarization
language:
- en
pretty_name: PeerSum
size_categories:
- 10K<n<100K
---
This is PeerSum, a multi-document summarization dataset in the peer-review domain. More details can be found in the paper accepted at EMNLP 2023, [Summarizing Multiple Documents with Conversational Structure for Meta-review Generation](https://arxiv.org/abs/2305.01498). The original code and datasets are public on [GitHub](https://github.com/oaimli/PeerSum).
Please use the following code to download the dataset with the datasets library from Huggingface.
```python
from datasets import load_dataset
peersum_all = load_dataset('oaimli/PeerSum', split='all')
peersum_train = peersum_all.filter(lambda s: s['label'] == 'train')
peersum_val = peersum_all.filter(lambda s: s['label'] == 'val')
peersum_test = peersum_all.filter(lambda s: s['label'] == 'test')
```
The Huggingface dataset is mainly for multi-document summarization. Each sample comprises information with the following keys:
```
* paper_id: str (a link to the raw data)
* paper_title: str
* paper_abstract, str
* paper_acceptance, str
* meta_review, str
* review_ids, list(str)
* review_writers, list(str)
* review_contents, list(str)
* review_ratings, list(int)
* review_confidences, list(int)
* review_reply_tos, list(str)
* label, str, (train, val, test)
```
You can also download the raw data from [Google Drive](https://drive.google.com/drive/folders/1SGYvxY1vOZF2MpDn3B-apdWHCIfpN2uB?usp=sharing). The raw data comprises more information and it can be used for other analysis for peer reviews. |
amitpuri/bollywood-celebs | 2023-05-17T17:19:53.000Z | [
"task_categories:image-classification",
"language:en",
"license:mit",
"region:us"
] | amitpuri | null | null | null | 0 | 5 | ---
task_categories:
- image-classification
license: mit
language:
- en
pretty_name: ' bollywood-celebs'
---
# bollywood-celebs
## Dataset Description
This dataset has been automatically processed by AutoTrain for project bollywood-celebs.
Credits: https://www.kaggle.com/datasets/sushilyadav1998/bollywood-celeb-localized-face-dataset
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"image": "<64x64 RGB PIL image>",
"target": 15
},
{
"image": "<64x64 RGB PIL image>",
"target": 82
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"image": "Image(decode=True, id=None)",
"target": "ClassLabel(names=['Aamir_Khan', 'Abhay_Deol', 'Abhishek_Bachchan', 'Aftab_Shivdasani', 'Aishwarya_Rai', 'Ajay_Devgn', 'Akshay_Kumar', 'Akshaye_Khanna', 'Alia_Bhatt', 'Ameesha_Patel', 'Amitabh_Bachchan', 'Amrita_Rao', 'Amy_Jackson', 'Anil_Kapoor', 'Anushka_Sharma', 'Anushka_Shetty', 'Arjun_Kapoor', 'Arjun_Rampal', 'Arshad_Warsi', 'Asin', 'Ayushmann_Khurrana', 'Bhumi_Pednekar', 'Bipasha_Basu', 'Bobby_Deol', 'Deepika_Padukone', 'Disha_Patani', 'Emraan_Hashmi', 'Esha_Gupta', 'Farhan_Akhtar', 'Govinda', 'Hrithik_Roshan', 'Huma_Qureshi', 'Ileana_DCruz', 'Irrfan_Khan', 'Jacqueline_Fernandez', 'John_Abraham', 'Juhi_Chawla', 'Kajal_Aggarwal', 'Kajol', 'Kangana_Ranaut', 'Kareena_Kapoor', 'Karisma_Kapoor', 'Kartik_Aaryan', 'Katrina_Kaif', 'Kiara_Advani', 'Kriti_Kharbanda', 'Kriti_Sanon', 'Kunal_Khemu', 'Lara_Dutta', 'Madhuri_Dixit', 'Manoj_Bajpayee', 'Mrunal_Thakur', 'Nana_Patekar', 'Nargis_Fakhri', 'Naseeruddin_Shah', 'Nushrat_Bharucha', 'Paresh_Rawal', 'Parineeti_Chopra', 'Pooja_Hegde', 'Prabhas', 'Prachi_Desai', 'Preity_Zinta', 'Priyanka_Chopra', 'R_Madhavan', 'Rajkummar_Rao', 'Ranbir_Kapoor', 'Randeep_Hooda', 'Rani_Mukerji', 'Ranveer_Singh', 'Richa_Chadda', 'Riteish_Deshmukh', 'Saif_Ali_Khan', 'Salman_Khan', 'Sanjay_Dutt', 'Sara_Ali_Khan', 'Shah_Rukh_Khan', 'Shahid_Kapoor', 'Shilpa_Shetty', 'Shraddha_Kapoor', 'Shreyas_Talpade', 'Shruti_Haasan', 'Sidharth_Malhotra', 'Sonakshi_Sinha', 'Sonam_Kapoor', 'Suniel_Shetty', 'Sunny_Deol', 'Sushant_Singh_Rajput', 'Taapsee_Pannu', 'Tabu', 'Tamannaah_Bhatia', 'Tiger_Shroff', 'Tusshar_Kapoor', 'Uday_Chopra', 'Vaani_Kapoor', 'Varun_Dhawan', 'Vicky_Kaushal', 'Vidya_Balan', 'Vivek_Oberoi', 'Yami_Gautam', 'Zareen_Khan'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 6863 |
| valid | 1764 | |
glombardo/misogynistic-statements-classification | 2023-05-10T19:18:45.000Z | [
"task_categories:text-classification",
"language:es",
"license:cc-by-nc-4.0",
"region:us"
] | glombardo | null | null | null | 0 | 5 | ---
license: cc-by-nc-4.0
task_categories:
- text-classification
language:
- es
pretty_name: Misogynistic statements classification
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': Non-sexist
'1': Sexist
splits:
- name: train
num_bytes: 13234
num_examples: 127
- name: validation
num_bytes: 4221
num_examples: 42
- name: test
num_bytes: 4438
num_examples: 43
download_size: 16218
dataset_size: 21893
---
Beta Dataset
Generated by GPT3.5 |
HAERAE-HUB/KoInstruct-Base | 2023-05-05T13:28:52.000Z | [
"region:us"
] | HAERAE-HUB | null | null | null | 1 | 5 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: type
dtype: string
- name: template
dtype: string
splits:
- name: train
num_bytes: 279249821
num_examples: 50169
download_size: 128982824
dataset_size: 279249821
---
# Dataset Card for "ko_instruct_org_v0.1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
divers/jobsedcription-requirement | 2023-05-05T17:50:23.000Z | [
"region:us"
] | divers | null | null | null | 3 | 5 | ---
dataset_info:
features:
- name: index
dtype: int64
- name: job_description
dtype: string
- name: job_requirements
dtype: string
- name: unknown
dtype: float64
- name: __index_level_0__
dtype: float64
splits:
- name: train
num_bytes: 25599853
num_examples: 4551
download_size: 12633905
dataset_size: 25599853
---
# Dataset Card for "jobsedcription-requirement"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
thu-coai/kdconv | 2023-05-08T10:39:46.000Z | [
"language:zh",
"license:apache-2.0",
"arxiv:2004.04100",
"region:us"
] | thu-coai | null | null | null | 2 | 5 | ---
license: apache-2.0
language:
- zh
---
The KDConv dataset. [GitHub repo](https://github.com/thu-coai/KdConv). [Original paper](https://arxiv.org/abs/2004.04100).
```bib
@inproceedings{zhou-etal-2020-kdconv,
title = "{K}d{C}onv: A {C}hinese Multi-domain Dialogue Dataset Towards Multi-turn Knowledge-driven Conversation",
author = "Zhou, Hao and
Zheng, Chujie and
Huang, Kaili and
Huang, Minlie and
Zhu, Xiaoyan",
booktitle = "ACL",
year = "2020"
}
```
|
gneubig/dstc11 | 2023-05-10T01:07:12.000Z | [
"license:other",
"region:us"
] | gneubig | This repository contains data, relevant scripts and baseline code for the Dialog Systems Technology Challenge (DSTC11). | @misc{gung2023natcs,
title={NatCS: Eliciting Natural Customer Support Dialogues},
author={James Gung and Emily Moeng and Wesley Rose and Arshit Gupta and Yi Zhang and Saab Mansour},
year={2023},
eprint={2305.03007},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{gung2023intent,
title={Intent Induction from Conversations for Task-Oriented Dialogue Track at DSTC 11},
author={James Gung and Raphael Shu and Emily Moeng and Wesley Rose and Salvatore Romeo and Yassine Benajiba and Arshit Gupta and Saab Mansour and Yi Zhang},
year={2023},
eprint={2304.12982},
archivePrefix={arXiv},
primaryClass={cs.CL}
} | null | 1 | 5 | ---
license: other
---
Originally from [here](https://github.com/amazon-science/dstc11-track2-intent-induction/tree/969b95a0d7365fbc6cd0e05989f1be6b44e6680c/dstc11) |
pietrolesci/dbpedia_14_indexed | 2023-05-11T13:34:45.000Z | [
"task_categories:text-classification",
"task_ids:topic-classification",
"annotations_creators:machine-generated",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:cc-by-sa-3.0",
"region:us"
] | pietrolesci | null | null | null | 0 | 5 | ---
annotations_creators:
- machine-generated
language_creators:
- crowdsourced
language:
- en
license:
- cc-by-sa-3.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- topic-classification
paperswithcode_id: dbpedia
pretty_name: DBpedia
dataset_info:
features:
- name: labels
dtype:
class_label:
names:
'0': Company
'1': EducationalInstitution
'2': Artist
'3': Athlete
'4': OfficeHolder
'5': MeanOfTransportation
'6': Building
'7': NaturalPlace
'8': Village
'9': Animal
'10': Plant
'11': Album
'12': Film
'13': WrittenWork
- name: title
dtype: string
- name: content
dtype: string
- name: uid
dtype: int64
- name: embedding_all-mpnet-base-v2
sequence: float32
- name: embedding_multi-qa-mpnet-base-dot-v1
sequence: float32
- name: embedding_all-MiniLM-L12-v2
sequence: float32
splits:
- name: train
num_bytes: 4490428970
num_examples: 560000
- name: test
num_bytes: 561310285
num_examples: 70000
download_size: 0
dataset_size: 5051739255
---
This is the same dataset as [`dbpedia_14`](https://huggingface.co/datasets/dbpedia_14). The only differences are
1. Addition of a unique identifier, `uid`
1. Addition of the indices, that is 3 columns with the embeddings of 3 different sentence-transformers
- `all-mpnet-base-v2`
- `multi-qa-mpnet-base-dot-v1`
- `all-MiniLM-L12-v2`
1. Renaming of the `label` column to `labels` for easier compatibility with the transformers library |
techiaith/banc-trawsgrifiadau-bangor | 2023-06-13T15:24:52.000Z | [
"size_categories:10K<n<100K",
"language:cy",
"license:cc0-1.0",
"verbatim transcriptions",
"speech recognition",
"region:us"
] | techiaith | Dyma fanc o 25 awr 34 munud a 24 eiliad o segmentau o leferydd naturiol dros hanner cant o gyfranwyr ar ffurf ffeiliau mp3, ynghyd â thrawsgrifiadau 'verbatim' cyfatebol o’r lleferydd ar ffurf ffeil .tsv. Mae'r mwyafrif o'r lleferydd yn leferydd digymell, naturiol. Dosbarthwn y deunydd hwn o dan drwydded agored CC0.
This resource is a bank of 25 hours 34 minutes and 24 seconds of segments of natural speech from over 50 contributors in mp3 file format, together with corresponding 'verbatim' transcripts of the speech in .tsv file format. The majority of the speech is spontaneous, natural speech. We distribute this material under a CC0 open license. | } | null | 0 | 5 | ---
license: cc0-1.0
language:
- cy
tags:
- verbatim transcriptions
- speech recognition
pretty_name: 'Banc Trawsgrifiadau Bangor '
size_categories:
- 10K<n<100K
---
[See below for English](#bangor-transcription-bank)
# Banc Trawsgrifiadau Bangor
Dyma fanc o 25 awr 34 munud a 24 eiliad o segmentau o leferydd naturiol dros hanner cant o gyfranwyr ar ffurf ffeiliau mp3, ynghyd â thrawsgrifiadau 'verbatim' cyfatebol o’r lleferydd ar ffurf ffeil .tsv. Mae'r mwyafrif o'r lleferydd yn leferydd digymell, naturiol. Dosbarthwn y deunydd hwn o dan drwydded agored CC0.
## Pwrpas
Pwrpas y trawsgrifiadau hyn yw gweithredu fel data hyfforddi ar gyfer modelau adnabod lleferydd, gan gynnwys [ein modelau wav2vec](https://github.com/techiaith/docker-wav2vec2-cy). Ar gyfer y diben hwnnw, mae gofyn am drawsgrifiadau mwy verbatim o'r hyn a ddywedwyd na'r hyn a welir mewn trawsgrifiadau traddodiadol ac mewn isdeitlau, felly datblygwyd confensiwn arbennig ar gyfer y gwaith trawsgrifio ([gweler isod](#confensiynau_trawsgrifio)). Gydag ein modelau wav2vec, caiff cydran ychwnaegol, sef 'model iaith' ei defnyddio ar ôl y model adnabod lleferydd i safoni mwy ar allbwn y model iaith i fod yn debycach i drawsgrifiadau traddodiadol ac isdeitlau.
Rydyn ni wedi darparu 3 ffeil .tsv, sef clips.tsv, train.tsv a test.tsv. Mae clips.tsv yn cynnwys ein trawsgrifiadau i gyd. Crëwyd train.tsv a test.tsv er mewn darparu setiau 'safonol' sy'n caniatáu i ddefnyddwyr allu gymharu modelau gan wahanol hyfforddwyr yn deg,hynny yw fe'u crëwyd at bwrpas meincnodi. Mae train.tsv yn cynnwys 80% o'n trawsgrifiadau, a test.tsv yn cynnwys y 20% sy'n weddill.
Dyma enghraifft o gynnwys y data:
```
audio_filename audio_filesize transcript duration
f86a046fd0964e0386d8c1363907183d.mp3 898272 *post industrial* yym a gyda yy dwi'n ca'l deud 5092
f0c2310fdca34faaa83beca5fa7ed212.mp3 809720 sut i ymdopio felly, wedyn erbyn hyn mae o nôl yn y cartra 4590
3eec3feefe254c9790739c22dd63c089.mp3 1335392 Felly ma' hon hefyd yn ddogfen fydd yn trosglwyddo gyda'r plant bobol ifanc o un cam i'r llall ac hefyd erbyn hyn i'r coleg 'lly. 7570
```
Ceir pedair colofn yn y ffeiliau .tsv. Y cyntaf yw enw’r ffeil sain. Maint y ffeil sain yw’r ail. Y trawsgrifiad ei hun sydd yn y drydedd golofn. Hyd y clip sain sydd yn yr olaf.
Dyma'r wybodaeth am y colofnau.
| Maes| Esboniad |
| ------ | ------ |
| `audio_filename`| Enw'r ffeil sain o fewn y ffolder 'clips'|
| `audio_filesize` | Maint y ffeil|
| `transcript` | Trawsgrifiad |
| `duration` | Hyd amser y clip mewn milliseconds. |
## Y Broses o Greu’r Adnodd
Casglwyd y ffeiliau sain yn bennaf o bodlediadau Cymraeg gyda chaniatâd eu perchnogion yn ogystal â'r cyfranwyr unigol. Rydym yn ddiolchgar tu hwnt i’r bobl yna. Yn ogystal, crewyd rhywfaint o sgriptiau ar batrwm eitemau newyddion ac erthyglau a'u darllen gan ymchwilwyr yr Uned Technolegau Iaith er mwyn sicrhau bod cynnwys o'r math hwnnw yn y banc.
Gyrrwyd y ffeiliau sain trwy ein trawsgrifiwr awtomataidd mewnol i segmentu’r sain a chreu trawsgrifiadau amrwd. Defnyddiwyd pecyn trawsgrifio Elan 6.4 (ar gael o https://archive.mpi.nl/tla/elan) gan drawsgrifwyr profiadol i wrando ar a chywiro’r trawsgrifiad amrwd.
## Nodyn Ynghylch Anonymeiddio’r Cynnwys
Er tegwch i’r cyfranwyr, rydyn ni wedi anonymeiddio’r trawsgrifiadau. Penderfynwyd anonymeiddio nid yn unig enwau pobl unigol, ond hefyd unrhyw Wybodaeth Bersonol Adnabyddadwy (PII) gan gynnwys, ond nid yn gyfunedig i:
* Rhif ffôn
* Teitlau swyddi/galwedigaethau
* Gweithleoedd
* Enwau mannau cyhoeddus
* Lleoliad daearyddol
* Dyddiadau/amseroedd
Wrth drawsgrifio marciwyd pob segment oedd yn cynnwys PII gyda’r tag \<PII>, yna wnaethom hidlo allan pob segment oedd yn cynnwys tag \<PII> er mwyn sicrhau nad oedd unrhyw wybodaeth bersonol yn cael eu cyhoeddi fel rhan o’r adnodd hwn.
Rydym hefyd wedi newid trefn trawsgrifiadau i fod ar hap, felly nid ydynt wedi'u cyhoeddi yn y drefn y maent yn eu ymddangos yn y ffeiliau sain gwreiddiol.
<a name="confensiynau_trawsgrifio"></a>
## Confensiynau Trawsgrifio
Datblygwyd y confensiynau trawsgrifio hyn er mwyn sicrhau fod y trawsgrifiadau nid yn unig yn verbatim ond hefyd yn gyson. Fe’u datblygwyd trwy gyfeirio at gonfensiynau a ddefnyddir gan yr Uned yn y gorffennol, confensiynau eraill megis y rhai a defnyddiwyd yng nghorpora CorCenCC, Siarad, CIG1 a CIG2, a hefyd trwy broses o ddatblygu parhaol wrth i’r tîm ymgymryd â’r dasg o drawsgrifio.
**NODWCH** - gan ein bod wedi datblygu’r egwyddorion trawsgrifio yn rhannol wrth ymgymryd â’r dasg o drawsgrifio nid yw’r trawsgrifiadau cynnar o reidrwydd yn dilyn yr egwyddorion cant y cant. Bwriadwn wirio’r trawsgrifiadau wedi i ni fireinio’r confensiynau.
### Collnodau
Ni ddefnyddiwyd collnodau i marcio pob un llythyren a hepgorwyd gan siaradwyr. Er enghraifft, _gwitho_ (sef ynganiad o _gweithio_) sy’n gywir, nid _gw’ith’o_
Yn hytrach, defnyddiwyd collnodau i wahaniaethu rhwng gwahanol eiriau oedd yn cael eu sillafu'r union yr un fath fel arall. Er enghraifft rydym yn defnyddio collnod o flaen _’ma_ (sef _yma_) i wahaniaethu rhyngddo â _ma’_ (sef _mae_), _gor’o’_ i wahaniaethu rhwng _gorfod_ a ffurf trydydd person unigol amser dibynnol presennol _gori_, a _pwysa’_ i wahaniaethu rhwng ffurf luosog _pwys_ a nifer o ffurfiau berfol posib _pwyso_.
Fodd bynnag, ceir eithriad i’r rheol hon, a hynny pan fo sillafu gair heb gollnod yn newid sŵn y llythyren cyn neu ar ôl y collnod, ac felly _Cymra’g_ sy’n gywir, nid _Cymrag_.
### Tagiau
Wrth drawsgrifio, defnyddiwyd y tagiau hyn i recordio elfennau oedd y tu hwnt i leferydd yr unigolion:
* \<anadlu>
* \<aneglur>
* \<cerddoriaeth>
* \<chwerthin>
* \<chwythu allan>
* \<distawrwydd>
* \<ochneidio>
* \<PII>
* \<peswch>
* \<twtian>
Rhagwelwn y bydd y rhestr hon yn chwyddo wrth i ni drawsgrifio mwy o leferydd ac wrth i ni daro ar draws mwy o elfennau sydd y tu hwnt i leferydd unigolion.
### Synau nad ydynt yn eiriol
Ymdrechwyd i drawsgrifio synau nad ydynt yn eiriol yn gyson. Er enghraifft, defnyddiwyd _yy_ bob tro (yn hytrach nag _yrr_, _yr_ neu _err_ neu gymysgedd o’r rheiny) i gynrychioli neu adlewyrchu’r sŵn a wnaethpwyd pan oedd siaradwr yn ceisio meddwl neu oedi wrth siarad.
Defnyddiwyd y canlynol wrth drawsgrifio:
* yy
* yym
* hmm
* m-hm
Eto, rhagwelwn y bydd y rhestr hon yn chwyddo wrth i ni drawsgrifio mwy o leferydd ac wrth i ni daro ar draws mwy o synau nad ydynt yn eiriol.
### Geiriau Saesneg
Rydym wedi amgylchynu bob gair neu ymadrodd Saesneg gyda sêr, er enghraifft:
> Dwi’n deall **\*sort of\***.
### Cymreigio berfenwau
Pan fo siaradwyr yn defnyddio geiriau Saesneg fel berfenwau (trwy ychwanegu _io_ ar ddiwedd y gair er enghraifft) rydym wedi ymdrechu i sillafu’r gair gan ddefnyddio confensiynau sillafu Cymreig yn hytrach nag ychwanegu _io_ at sillafiad Saesneg o’r gair. Er enghraifft rydym wedi trawsgrifio _heitio_ yn hytrach na _hateio_, a _lyfio_ yn hytrach na _loveio_.
### Cywiro cam-siarad
I sicrhau ein bod ni’n glynu at egwyddorion trawsgrifio verbatim penderfynwyd na ddylem gywiro cam-siarad neu gam-ynganu siaradwyr. Er enghraifft, yn y frawddeg ganlynol:
> enfawr fel y diffyg o fwyd yym **efallu** cam-drin
mae'n amlwg mai’r gair _efallai_ sydd dan sylw mewn gwirionedd, ond fe’i trawsgrifiwyd fel ei glywir.
### Atalnodi
Defnyddiwyd atalnodau llawn, marciau cwestiwn ac ebychnodau wrth drawsgrifio’r lleferydd.
Rydym wedi amgylchynu bob gair neu ymadrodd sydd wedi ei dyfynnu gyda _”_, er enghraifft:
> Dywedodd hi **”Dwi’n mynd”** ond aeth hi ddim.
### Nodyn ynghylch ein defnydd o gomas
Gan mai confensiwn ysgrifenedig yw coma yn y bôn, ni ddefnyddiwyd comas cymaint wrth drawsgrifio. Byddai defnyddio coma lle y disgwylir i’w weld mewn testun ysgrifenedig ddim o reidrwydd wedi adlewyrchu lleferydd yr unigolyn. Dylid cadw hynny mewn cof wrth ddarllen y trawsgrifiadau.
### Sillafu llythrennau
Sillafwyd llythrennau unigol yn hytrach na thrawsgrifio’r llythrennau unigol yn unig.
Hynny yw, hyn sy’n gywir:
> Roedd ganddo **ow si di**
**ac nid:**
> Roedd ganddo **O C D**
**na chwaith:**
> Roedd ganddo **OCD**
### Rhifau
Trawsgrifiwyd rhifau fel geiriau yn hytrach na digidau, hynny yw hyn sy’n gywir:
> Y flwyddyn dwy fil ac ugain
**ac nid:**
> Y flwyddyn 2020
### Gorffen gair ar ei hanner
Marciwyd gair oedd wedi ei orffen ar ei hanner gyda `-`. Er enghraifft:
> Ma’n rhaid i mi **ca-** cael diod.
### Gorffen brawddeg ar ei hanner/ailddechrau brawddeg
Marciwyd brawddeg oedd wedi ei gorffen ar ei hanner gyda `...`. Er enghraifft:
> Ma’n rhaid i mi ca’l... Ma’ rhaid i mi brynu diod.
### Siaradwr yn torri ar draws siaradwr arall
Ceir yn y data llawer o enghreifftiau o siaradwr yn torri ar draws y prif leferydd gan ddefnyddio synau nad ydynt yn eiriol, geiriau neu ymadroddion (megis _m-hm_, _ie_, _ydi_, _yn union_ ac ati). Pan oedd y ddau siaradwr i'w clywed yn glir ag ar wahân, rhoddwyd `...` ar ddiwedd rhan gyntaf y lleferydd toredig, a `...` arall ar ddechrau ail ran y lleferydd toredig, fel yn yr enghraifft ganlynol:
> Ond y peth yw... M-hm. ...mae’r ddau yn wir
Pan nad oedd y ddau siaradwyr i'w clywed yn glir ag ar wahân, fe hepgorwyd y lleferydd o’r data.
### Rhegfeydd
Dylid nodi ein bod ni heb hepgor rhegfeydd wrth drawsgrifio.
## Y Dyfodol
Wrth ddefnyddio’r banc trawsgrifiadau dylid cadw mewn cof mai fersiwn cychwynnol ydyw. Bwriadwn fireinio a chysoni ein trawsgrifiadau ymhellach, ac ychwanegu mwy fyth o drawsgrifiadau i’r banc yn rheolaidd dros y flwyddyn nesaf
## Cyfyngiadau
Er mwyn parchu'r cyfrannwyr, wrth lwytho'r data hwn i lawr rydych yn cytuno i beidio â cheisio adnabod y siaradwyr yn y data.
## Diolchiadau
Diolchwn i'r cyfrannwyr am eu caniatâd i ddefnyddio'u lleferydd. Rydym hefyd yn ddiolchgar i Lywodraeth Cymru am ariannu’r gwaith hwn fel rhan o broject Technoleg Testun, Lleferydd a Chyfieithu ar gyfer yr Iaith Gymraeg.
# Bangor Transcription Bank
This resource is a bank of 25 hours 34 minutes and 24 seconds of segments of natural speech from over 50 contributors in mp3 file format, together with corresponding 'verbatim' transcripts of the speech in .tsv file format. The majority of the speech is spontaneous, natural speech. We distribute this material under a CC0 open license.
## Purpose
The purpose of these transcripts is to act as training data for speech recognition models, including [our wav2vec models](https://github.com/techiaith/docker-wav2vec2-cy). For that purpose, transcriptions are more verbatim than what is seen in traditional transcriptions and than what is required for subtitling purposes, thus a bespoke set of conventions has been developed for the transcription work ([see below](#transcription_conventions) ). Our wav2vec models use an auxiliary component, namely a 'language model', to further standardize the speech recognition model’s output in order that it be more similar to traditional transcriptions and subtitles.
We have provided 3 .tsv files, namely clips.tsv, train.tsv and test.tsv. clips.tsv contains all of our transcripts. train.tsv and test.tsv were created to provide 'standard' sets that allow users to compare models trained by different trainers fairly, i.e. they were created as a 'benchmark'. train.tsv contains 80% of our transcripts, and test.tsv contains the remaining 20%.
Here is an example of the data content:
```
audio_filename audio_filesize transcript duration
f86a046fd0964e0386d8c1363907183d.mp3 898272 *post industrial* yym a gyda yy dwi'n ca'l deud 5092
f0c2310fdca34faaa83beca5fa7ed212.mp3 809720 sut i ymdopio felly, wedyn erbyn hyn mae o nôl yn y cartra 4590
3eec3feefe254c9790739c22dd63c089.mp3 1335392 Felly ma' hon hefyd yn ddogfen fydd yn trosglwyddo gyda'r plant bobol ifanc o un cam i'r llall ac hefyd erbyn hyn i'r coleg 'lly. 7570
```
There are four columns in the .tsv files. The first is the name of the audio file. The second is the size of the audio file. The transcript itself appears in the third column. The length of the audio clip appears in the last.
Here is the information about the columns.
| Field| Explanation |
| ------ | ------ |
| `audio_filename`| The name of the audio file within the 'clips' folder|
| `audio_filesize` | The size of the file |
| `transcript` | Transcript |
| `duration` | Duration of the clip in milliseconds. |
## The Process of Creating the Resource
The audio files were mainly collected from Welsh podcasts, after having gained the consent of the podcast owners and individual contributors to do so. We are extremely grateful to those people. In addition, some scripts were created which mimicked the pattern of news items and articles. These scripts were then read by Language Technologies Unit researchers in order to ensure that content of that type was included in the bank.
The audio files were run through our in-house automated transcriber to segment the audio and create raw transcripts. Using Elan 6.4 (available from https://archive.mpi.nl/tla/elan), experienced transcribers listened to and corrected the raw transcript.
## A Note About Content Anonymization
Out of respect to the contributors, we have anonymised all transcripts. It was decided to anonymize not only the names of individual people, but also any other Personally Identifiable Information (PII) including, but not limited to:
* Phone number
* Job titles/occupations
* Workplaces
* Names of public places
* Geographical location
* Dates/times
When transcribing, all segments containing PII were marked with the \<PII> tag, we then filtered out all segments containing a \<PII> tag to ensure no personal information was published as part of this resource.
We have also randomized the order of the segments so that they are not published in the order they appeared in the original audio files.
<a name="transcription_conventions"></a>
## Transcription Conventions
These transcription conventions were developed to ensure that the transcriptions were not only verbatim but also consistent. They were developed by referring to conventions used by the Unit in the past, conventions such as those used in the CorCenCC, Siarad, CIG1 and CIG2 corpora, and also through a process of ongoing development as the team undertook the task of transcription.
**NOTE** - as we have partially developed the conventions at the same time as undertaking the task of transcription the early transcriptions may not follow the latest principles faithfully. We intend to check the transcripts after we have refined the conventions.
### Apostrophes
Apostrophes were not used to mark every single letter omitted by speakers. For example, _gwitho_ (which is a pronunciation of _gweithio_) is correct, not _gw’ith'o_.
Rather, apostrophes were used to distinguish between different words that were otherwise spelled identically. For example we use an apostrophe in front of _'ma_ (a pronunciation of _yma_) to distinguish it from _ma'_ (a pronunciation of _mae_), _gor'o'_ to distinguish between _gorfod_ and the third person singular form of the present dependent tense _gori_, and _pwysa'_ to distinguish between the plural form of _pwys_ and a number of possible verb forms of _pwyso_.
However, there is an exception to this rule, that being when spelling a word without an apostrophe would change the sound of the letter before or after the apostrophe, thus _Cymra'g_ is correct, not _Cymrag_.
### Tags
When transcribing, these tags were used to record elements that were external to the speech of the individuals:
* \<anadlu>
* \<aneglur>
* \<cerddoriaeth>
* \<chwerthin>
* \<chwythu allan>
* \<distawrwydd>
* \<ochneidio>
* \<PII>
* \<peswch>
* \<twtian>
We anticipate that this list will grow as we transcribe more speech and as we come across more elements that are external to the speech of individuals.
### Non-verbal sounds
Efforts were made to transcribe non-verbal sounds consistently. For example, _yy_ was always used (rather than _yrr_, _yr_ or _err_, or a mixture of those) to represent or reflect the sound made when a speaker was trying to think or paused in speaking.
The following were used in transcription:
* yy
* yym
* hmm
* m-hm
Again, we anticipate that this list will grow as we transcribe more speech and as we encounter more non-verbal sounds.
### English words
We have surrounded each English word or phrase with asterixis, for example:
> Dwi’n deall **\*sort of\***.
### Adapting English words as Welsh language infinitives
When speakers use English words as infinitives (by adding _io_ at the end of the word for example) we have endeavoured to spell the word using Welsh spelling conventions rather than adding _io_ to the English spelling of the word. For example we have transcribed _heitio_ instead of _hateio_, and _lyfio_ instead of _loveio_.
### Correction of mis-pronunciations
To ensure that we adhere to the principles of verbatim transcription it was decided that we should not correct speakers' mis-pronunciations. For example, in the following sentence:
> enfawr fel y diffyg o fwyd yym **efallu** cam-drin
it is clear that _efallai_ is the intended word, but it is transcribed as it is heard.
### Punctuation
Full stops, question marks and exclamation marks were used when transcribing the speech.
We have surrounded all quoted words or phrases with _”_, for example:
> Dywedodd hi **”Dwi’n mynd”** ond aeth hi ddim.
### A note about our use of commas
As a comma is essentially a convention used for written text, commas were not used prolifically in transcription. Using a comma where one would expected to see it in a written text during transcription would not necessarily have reflected the individual's speech. This should be borne in mind when reading the transcripts.
### Individual letters
Individual letters were spelled out rather than being transcribed as individual letters.
That is, this is correct:
> Roedd ganddo **ow si di**
**not:**
> Roedd ganddo **O C D**
**nor:**
> Roedd ganddo **OCD**
### Numbers
Numbers were transcribed as words rather than digits, thus this is correct:
> Y flwyddyn dwy fil ac ugain
**rather than:**
> Y flwyddyn 2020
### Half-finished words
Half-finished words are marked with a `-`. For example:
> Ma’n rhaid i mi **ca-** cael diod.
### Half-finished/restarted sentences
Half-finished sentences are marked with a `...`. For example:
> Ma’n rhaid i mi ca’l... Ma’ rhaid i mi brynu diod.
### Speaker interruptions
There are many examples of a speaker interrupting another speaker by using non-verbal sounds, words or phrases (such as _m-hm_, _ie_, _ydi_, _yn union_ etc.) in the data. When the two speakers could be heard clearly and distinctly, a `...` was placed at the end of the first part of the broken speech, and another `...` at the beginning of the second part of the broken speech, as in the following example:
> Ond y peth yw... M-hm. ...mae’r ddau yn wir
When the two speakers could not be heard clearly and distinctly, the speech was omitted from the data.
### Swearwords
It should be noted that we have not omitted swearwords when transcribing.
## The future
That this is an initial version of the transcript bank should be borne in mind when using this resource. We intend to refine and harmonize our transcripts further, and add yet more transcripts to the bank regularly over the next year.
## Restrictions
In order to respect the contributors, by downloading this data you agree not to attempt to identify the speakers in the data.
## Acknowledgements
We thank the contributors for their permission to use their speech. We are also grateful to the Welsh Government for funding this work as part of the Text, Speech and Translation Technology project for the Welsh Language.
|
NEUDM/aste-data-v2 | 2023-05-23T17:29:01.000Z | [
"arxiv:2010.02609",
"arxiv:2305.09193",
"region:us"
] | NEUDM | null | null | null | 1 | 5 | > 上述数据集为ABSA(Aspect-Based Sentiment Analysis)领域数据集,基本形式为从句子中抽取:方面术语、方面类别(术语类别)、术语在上下文中情感极性以及针对该术语的观点词,不同数据集抽取不同的信息,这点在jsonl文件的“instruction”键中有分别提到,在此我将其改造为了生成任务,需要模型按照一定格式生成抽取结果。
#### 以acos数据集中抽取的jsonl文件一条数据举例:
```
{
"task_type": "generation",
"dataset": "acos",
"input": ["the computer has difficulty switching between tablet and computer ."],
"output": "[['computer', 'laptop usability', 'negative', 'difficulty']]",
"situation": "none",
"label": "",
"extra": "",
"instruction": "
Task: Extracting aspect terms and their corresponding aspect categories, sentiment polarities, and opinion words.
Input: A sentence
Output: A list of 4-tuples, where each tuple contains the extracted aspect term, its aspect category, sentiment polarity, and opinion words (if any). Supplement: \"Null\" means that there is no occurrence in the sentence.
Example:
Sentence: \"Also it's not a true SSD drive in there but eMMC, which makes a difference.\"
Output: [['SSD drive', 'hard_disc operation_performance', 'negative', 'NULL']]'
"
}
```
> 此处未设置label和extra,在instruction中以如上所示的字符串模板,并给出一个例子进行one-shot,ABSA领域数据集(absa-quad,acos,arts,aste-data-v2,mams,semeval-2014,semeval-2015,semeval-2016,towe)每个数据集对应instruction模板相同,内容有细微不同,且部分数据集存在同一数据集不同数据instruction内容不同的情况。
#### 原始数据集
- 数据[链接](https://github.com/xuuuluuu/Position-Aware-Tagging-for-ASTE)
- Paper: [Position-Aware Tagging for Aspect Sentiment Triplet Extraction](https://arxiv.org/abs/2010.02609)
- 说明:原始数据集由laptop14、restaurant14、restaurant15以及restaurant16四部分文件组成。
#### 当前SOTA
*数据来自[Easy-to-Hard Learning for Information Extraction](https://arxiv.org/abs/2305.09193)*
- 评价指标:F1 Score
- SOTA模型:E2H-large
- 在laptop14数据部分:**75.92**
- 在restaurant14数据部分:**65.98**
- 在restaurant15数据部分:**68.80**
- 在restaurant16数据部分:**75.46**
- 平均:**71.54**
- Paper:[Easy-to-Hard Learning for Information Extraction](https://arxiv.org/pdf/2305.09193.pdf)
- 说明:该论文来自[Google Scholar](https://scholar.google.com/scholar?as_ylo=2023&hl=zh-CN&as_sdt=2005&sciodt=0,5&cites=8596892198266513995&scipsc=)检索到的引用ASTE-data-v2原论文的论文之一,在比较2023年的一些论文工作后筛选了一个最优指标以及模型。
|
lighteval/summarization | 2023-05-12T08:52:49.000Z | [
"region:us"
] | lighteval | Scenario for single document text summarization.
Currently supports the following datasets:
1. XSum (https://arxiv.org/pdf/1808.08745.pdf)
2. CNN/DailyMail non-anonymized (https://arxiv.org/pdf/1704.04368.pdf)
Task prompt structure
Summarize the given document.
Document: {tok_1 ... tok_n}
Summary: {tok_1 ... tok_m}
Example from XSum dataset
Document: {Part of the Broad Road was closed to traffic on Sunday at about 18:00 GMT.
The three adults and three children have been taken to Altnagelvin Hospital
with non life-threatening injuries. The Fire Service, Northern Ireland Ambulance Service
and police attended the crash. The Broad Road has since been reopened.}
Summary: {Three adults and three children have been taken to hospital following a crash involving
a tractor and a campervan in Limavady, County Londonderry} | null | null | 2 | 5 | Entry not found |
AlekseyKorshuk/reward-model-no-topic-predictions | 2023-05-13T22:34:47.000Z | [
"region:us"
] | AlekseyKorshuk | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: text
dtype: string
- name: lang
dtype: string
- name: lang_score
dtype: float64
- name: topic
dtype: float64
- name: topic_prob
dtype: float64
- name: was_outlier
dtype: float64
- name: comments
list:
- name: prediction
dtype: float64
- name: score
dtype: int64
- name: text
dtype: string
splits:
- name: validation
num_bytes: 24952821
num_examples: 8811
download_size: 15720103
dataset_size: 24952821
---
# Dataset Card for "reward-model-no-topic-predictions"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tasksource/starcon | 2023-05-31T08:37:04.000Z | [
"task_categories:text-classification",
"language:en",
"license:unknown",
"region:us"
] | tasksource | null | null | null | 0 | 5 | ---
task_categories:
- text-classification
language:
- en
license: unknown
---
https://github.com/dwslab/StArCon
```
@inproceedings{kobbe-etal-2020-unsupervised,
title = "Unsupervised stance detection for arguments from consequences",
author = "Kobbe, Jonathan and
Hulpu{\textcommabelow{s}}, Ioana and
Stuckenschmidt, Heiner",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.emnlp-main.4",
doi = "10.18653/v1/2020.emnlp-main.4",
pages = "50--60",
abstract = "Social media platforms have become an essential venue for online deliberation where users discuss arguments, debate, and form opinions. In this paper, we propose an unsupervised method to detect the stance of argumentative claims with respect to a topic. Most related work focuses on topic-specific supervised models that need to be trained for every emergent debate topic. To address this limitation, we propose a topic independent approach that focuses on a frequently encountered class of arguments, specifically, on arguments from consequences. We do this by extracting the effects that claims refer to, and proposing a means for inferring if the effect is a good or bad consequence. Our experiments provide promising results that are comparable to, and in particular regards even outperform BERT. Furthermore, we publish a novel dataset of arguments relating to consequences, annotated with Amazon Mechanical Turk.",
}
``` |
hbattu/huberman-youtube-metadata | 2023-05-16T18:58:29.000Z | [
"license:mit",
"region:us"
] | hbattu | null | null | null | 0 | 5 | ---
license: mit
---
|
bleugreen/typescript-chunks | 2023-05-18T04:27:24.000Z | [
"task_categories:text-classification",
"task_categories:text2text-generation",
"task_categories:summarization",
"language:en",
"region:us"
] | bleugreen | null | null | null | 0 | 5 | ---
task_categories:
- text-classification
- text2text-generation
- summarization
language:
- en
---
# typescript-chunks
A dataset of TypeScript snippets, processed from the typescript subset of [the-stack-smol](https://huggingface.co/datasets/bigcode/the-stack-smol).
# Processing
- Each source file is parsed with the TypeScript AST and queried for 'semantic chunks' of the following types.
```
FunctionDeclaration ---- 8205
ArrowFunction --------- 33890
ClassDeclaration ------- 5325
InterfaceDeclaration -- 12884
EnumDeclaration --------- 518
TypeAliasDeclaration --- 3580
MethodDeclaration ----- 24713
```
- Leading comments are added to the front of `content`
- Removed all chunks over max sequence length (2048)
- Deduplicated / cleaned up
- Generated instructions / summaries with `gpt-3.5-turbo` (in progress)
# Dataset Structure
```python
from datasets import load_dataset
load_dataset("bleugreen/typescript-chunks")
DatasetDict({
train: Dataset({
features: ['type', 'content', 'repo', 'path', 'language'],
num_rows: 89115
})
})
``` |
under-tree/prepared-yagpt | 2023-05-18T12:26:50.000Z | [
"task_categories:conversational",
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:ru",
"region:us"
] | under-tree | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 42680359.78397168
num_examples: 53550
- name: test
num_bytes: 7532625.216028317
num_examples: 9451
download_size: 25066987
dataset_size: 50212985
task_categories:
- conversational
- text-generation
language:
- ru
pretty_name: Dialogue Dataset for YAGPT ChatBot
size_categories:
- 10K<n<100K
---
# Dataset Card for "prepared-yagpt"
## Short Description
This dataset is aimed for training of chatbots on russian language.
It consists plenty of dialogues that allows you to train you model answer user prompts.
## Notes
1. Special tokens
- history, speaker1, speaker2 (history can be optionally removed, i.e. substituted on empty string)
2. Dataset is based on
- [Matreshka](https://huggingface.co/datasets/zjkarina/matreshka)
- [Yandex-Q](https://huggingface.co/datasets/its5Q/yandex-q)
- [Diasum](https://huggingface.co/datasets/bragovo/diasum)
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
philschmid/oasst1_orignal_de | 2023-05-24T17:46:48.000Z | [
"region:us"
] | philschmid | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 1897028
num_examples: 1521
download_size: 745532
dataset_size: 1897028
---
# Dataset Card for "oasst1_orignal_de"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
agmmnn/turkish-thesaurus-synonyms-antonyms | 2023-05-21T20:26:55.000Z | [
"multilinguality:monolingual",
"language:tr",
"license:cc-by-sa-4.0",
"thesaurus",
"dictionary",
"turkish",
"region:us"
] | agmmnn | null | null | null | 1 | 5 | ---
license: cc-by-sa-4.0
language:
- tr
multilinguality:
- monolingual
pretty_name: Turkish Thesaurus
tags:
- thesaurus
- dictionary
- turkish
---
# Turkish Thesaurus (Türkçe Eş-Zıt Anlam Sözlüğü)
Turkish synonym, antonym thesaurus. Final thesaurus contains 33587 keys in total.
```py
from datasets import load_dataset
dataset = load_dataset("agmmnn/turkish-thesaurus-synonyms-antonyms")
print(dataset['train'][0])
``` |
alonkipnis/news-chatgpt-long | 2023-05-21T21:43:13.000Z | [
"region:us"
] | alonkipnis | null | null | null | 2 | 5 | ---
dataset_info:
features:
- name: article
dtype: string
- name: highlights
dtype: string
- name: id
dtype: string
- name: chatgpt
dtype: string
splits:
- name: train
num_bytes: 67437736
num_examples: 13025
download_size: 40725044
dataset_size: 67437736
---
# Dataset Card for "news-chatbot-long"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
yfqiu-nlp/mfact-classification | 2023-05-22T08:46:04.000Z | [
"license:mit",
"region:us"
] | yfqiu-nlp | null | null | null | 0 | 5 | ---
license: mit
dataset_info:
features:
- name: en
dtype: string
- name: zh
dtype: string
- name: es
dtype: string
- name: fr
dtype: string
- name: vi
dtype: string
- name: hi
dtype: string
- name: tr
dtype: string
splits:
- name: train
num_bytes: 182
num_examples: 3
download_size: 3134
dataset_size: 182
---
|
zirui3/cMedQA2-instructions | 2023-05-22T09:48:40.000Z | [
"license:cc-by-4.0",
"region:us"
] | zirui3 | null | null | null | 3 | 5 | ---
license: cc-by-4.0
---
|
rkarhila/SIAK | 2023-08-16T19:45:11.000Z | [
"task_categories:automatic-speech-recognition",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-nd-4.0",
"region:us"
] | rkarhila | null | null | null | 0 | 5 | ---
license: cc-by-nd-4.0
task_categories:
- automatic-speech-recognition
language:
- en
pretty_name: '"Say It Again, Kid!" Native and Finnish accented Children''s English with pronunciation scores'
size_categories:
- 10K<n<100K
---
## "Say It Again, Kid!" (SIAK) Speech data collection##
## Training data for pronunciation quality classifiers for childred learning English ##
Train set and test set in flac format.
File id key, fields separated by underscores (example: train001fifi05_609_t10892805_living-room.flac)
* Speaker key indicates train or test set, and a running number for speaker. _speaker key is train001_
* Native language: "fifi" for Finnish, "enuk" for UK English, "othr" for other. _Native language fifi_
* Age of speaker in years (if known). _This speaker was 05 years old at the start of the recording period_
* Sample number. _This is the 609th sample spoken by the speaker. (Some kids really enjoyed contributing!)_
* Seconds from first sample given. _10892805 seconds since first recording. This speaker contributed the samples over a 4 month period_
* Targer utterance text with spaces etc replaced by dashes. _Utterance to be spoken was "living room"_
## Release history ##
This data is derived from the data collected in the SIAK project 2014-2018,
Participants agreed that their data can be published anonymously. Unfortunately the General Data Protection Regulation (GDPR)
became effective before the data was ready for release, and the publication effort halted.
However the data was leased to an ill-fated startup that started operationsa few weeks before COVID-19 lockdowns.
This collection is a derivation of the SIAK data with any strongly identifying metadata removed for use by the now bankrupt startup.
We were involved in collecting, storing and processing the data in the SIAK project and have gone through the speech samples
in enough detail to be assured that the data can be regarded as non-personal and thus except from GDPR as it consists of only single words or very short utterance repetitions, making it next to impossible to identify a speaker.
Reima Karhila and Anna Smolander
SIAK project researchers and unlucky startup founders
---
license: cc-by-nd-4.0
---
We emphasize, that by no derivatives we mean that you cannot use the audio samples as part of any work that is not directly related to describing the dataset in a speech technology or scientific language learning context. You may include them in a scientific presentation when the context is clearly to present the original data and not to use the data in another fashion.
Commercial use of speech samples for building and evaluation of speech technology models is _not_ prohibited.
If you publish work based on this dataset, please cite _Karhila & al.: Pronunciation Scoring System Embedded into Children’s Foreign
Language Learning Games with Experimental Verification of Learning Benefits, SLATE 2023_.
|
TheMrguiller/ScienceQA | 2023-08-24T11:34:13.000Z | [
"task_categories:question-answering",
"task_categories:visual-question-answering",
"size_categories:100B<n<1T",
"language:en",
"code",
"arxiv:2209.09513",
"region:us"
] | TheMrguiller | null | null | null | 1 | 5 | ---
dataset_info:
features:
- name: image
dtype: image
- name: question
dtype: string
- name: choices
dtype: string
- name: answer
dtype: string
- name: solution
dtype: string
- name: CTH
dtype: bool
splits:
- name: train
num_bytes: 548834431.966
num_examples: 16966
- name: test
num_bytes: 135169478.352
num_examples: 4242
download_size: 621545899
dataset_size: 684003910.318
task_categories:
- question-answering
- visual-question-answering
language:
- en
tags:
- code
size_categories:
- 100B<n<1T
---
# Dataset Card for "ScienceQA"
## Dataset Description
- **Homepage:** https://scienceqa.github.io/
- **Repository:** https://scienceqa.github.io/#dataset
- **Paper:** https://arxiv.org/abs/2209.09513
- **Leaderboard:**
- **Point of Contact:** https://lupantech.github.io/
### Dataset Summary
ScienceQA is collected from elementary and high school science curricula, and contains 21,208 multimodal multiple-choice science questions. Out of the questions in ScienceQA, 10,332 (48.7%) have an image context, 10,220 (48.2%) have a text context, and 6,532 (30.8%) have both. Most questions are annotated with grounded lectures (83.9%) and detailed explanations (90.5%). The lecture and explanation provide general external knowledge and specific reasons, respectively, for arriving at the correct answer. To the best of our knowledge, ScienceQA is the first large-scale multimodal dataset that annotates lectures and explanations for the answers.
ScienceQA, in contrast to previous datasets, has richer domain diversity from three subjects: natural science, language science, and social science. Questions in each subject are categorized first by the topic (Biology, Physics, Chemistry, etc.), then by the category (Plants, Cells, Animals, etc.), and finally by the skill (Classify fruits and vegetables as plant parts, Identify countries of Africa, etc.). ScienceQA features 26 topics, 127 categories, and 379 skills that cover a wide range of domains.
### Supported Tasks and Leaderboards
The dataset is prepared to used it for visual question-answering.
### Languages
The dataset is in english
## Dataset Structure
### Data Fields
- `image`: This field has the image, which is the context given to the model.
- `question`: This field incorporates the question that has to answer the model from the image context.
- `choices`: Multiple choice selection.
- `answer`: The answer from the multiple choice.
- `solution`: The chain of thought process of the solution selection.
- `CTH`: A flag that indicates whether it doesnt have chain of thought in that row.
### Data Splits
The dataset is split in 80% train and 20% test.
## Considerations for Using the Data
The dataset is well balanced in order to get really got result when used in multimodal models.
## Additional Information
### Dataset Curators
The curators of this dataset where the students from the Masters degree in Computation and Inteligent Systems from University of Deusto.
### Citation Information
```
@inproceedings{lu2022learn,
title={Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering},
author={Lu, Pan and Mishra, Swaroop and Xia, Tony and Qiu, Liang and Chang, Kai-Wei and Zhu, Song-Chun and Tafjord, Oyvind and Clark, Peter and Ashwin Kalyan},
booktitle={The 36th Conference on Neural Information Processing Systems (NeurIPS)},
year={2022}
}
``` |
sihaochen/propsegment | 2023-05-26T18:18:53.000Z | [
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"NLP",
"Entailment",
"NLI",
"google-research-datasets",
"arxiv:2212.10750",
"region:us"
] | sihaochen | This is a reproduced (i.e. after web-crawling) and processed version of the "PropSegment" dataset from Google Research.
Since the News portion of the dataset is released only via urls, we reconstruct the dataset by crawling. Overall, ~96%
of the dataset can be reproduced, and the rest ~4% either have url no longer valid, or sentences that have been edited
(i.e. cannot be aligned with the orignial dataset).
PropSegment (Proposition-level Segmentation and Entailment) is a large-scale, human annotated dataset for segmenting
English text into propositions, and recognizing proposition-level entailment relations --- whether a different, related
document entails each proposition, contradicts it, or neither.
The original dataset features >45k human annotated propositions, i.e. individual semantic units within sentences, as
well as >45k entailment labels between propositions and documents. | @inproceedings{chen2023propsegment,
title = "{PropSegmEnt}: A Large-Scale Corpus for Proposition-Level Segmentation and Entailment Recognition",
author = "Chen, Sihao and Buthpitiya, Senaka and Fabrikant, Alex and Roth, Dan and Schuster, Tal",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
year = "2023",
} | null | 2 | 5 | ---
license: cc-by-4.0
task_categories:
- text-classification
- token-classification
- text-generation
language:
- en
tags:
- NLP
- Entailment
- NLI
- google-research-datasets
pretty_name: PropSegment
size_categories:
- 10K<n<100K
---
# PropSegmEnt: A Large-Scale Corpus for Proposition-Level Segmentation and Entailment Recognition
## Dataset Description
- **Homepage:** https://github.com/google-research-datasets/PropSegmEnt
- **Repository:** https://github.com/google-research-datasets/PropSegmEnt
- **Paper:** https://arxiv.org/abs/2212.10750
- **Point of Contact:** sihaoc@seas.upenn.edu
### Dataset Summary
This is a reproduced (i.e. after web-crawling) and processed version of [the "PropSegment" dataset](https://github.com/google-research-datasets/PropSegmEnt) from Google Research.
Since the [`News`](https://github.com/google-research-datasets/NewSHead) portion of the dataset is released only via urls, we reconstruct the dataset by crawling.
Overall, ~96% of the dataset can be reproduced, and the rest ~4% either have url no longer valid, or sentences that have been edited (i.e. cannot be aligned with the orignial dataset).
PropSegment (Proposition-level Segmentation and Entailment) is a large-scale, human annotated dataset for segmenting English text into propositions, and recognizing proposition-level entailment relations --- whether a different, related document entails each proposition, contradicts it, or neither.
The original dataset features >45k human annotated propositions, i.e. individual semantic units within sentences, as well as >35k entailment labels between propositions and documents.
Check out more details in the [dataset paper](https://arxiv.org/abs/2212.10750).
## Dataset Structure
Here we provide processed versions of the dataset for seq2seq model inputs/outputs.
`proposition_segmentation.*.jsonl` contains data for the text segmentation task, i.e. split a sentence into propositions.
The output propositions are concatenated as one string (with no particular order between them) by a special token `[SEP]`.
Each proposition is annotated as spans enclosed by `[M]` and `[/M]`.
```
{
"sentence": "This film marks the directorial debut for production designer Robert Stromberg.",
"propositions": "This film marks the directorial debut for [M]production designer Robert Stromberg.[/M][SEP]This [M]film marks the directorial debut for[/M] production designer [M]Robert Stromberg[/M]."
}
```
`propnli.*.jsonl` contains examples for the proposition-to-document entailment task, i.e. Given a proposition and a document, predict whether the proposition can be entailed/contradicted, or neutral with respect to the document.
```
{
"hypothesis": "[M]The Departed is[/M] a 2006 feature film [M]directed by Martin Scorsese.[/M]",
"premise": "The Departed is a 2006 American crime thriller film directed by Martin Scorsese and written by William Monahan. It starred Leonardo DiCaprio, Matt Damon, Jack Nicholson, and Mark Wahlberg, with Martin Sheen, Ray Winstone, Vera Farmiga, and Alec Baldwin in supporting roles. It is a remake of the Hong Kong film Infernal Affairs (2002).\nThe Departed won the Oscar for Best Picture at the 79th Academy Awards. Scorsese received the Oscar for Best Director, Thelma Schoonmaker the Oscar for Best Editing and William Monahan the Oscar for Best Adapted Screenplay.",
"label": "e"
}
```
### Citation
```
@inproceedings{chen2023propsegment,
title = "{PropSegmEnt}: A Large-Scale Corpus for Proposition-Level Segmentation and Entailment Recognition",
author = "Chen, Sihao and Buthpitiya, Senaka and Fabrikant, Alex and Roth, Dan and Schuster, Tal",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
year = "2023",
}
```
|
emozilla/booksum-summary-analysis_gptneox-8192 | 2023-05-30T14:28:46.000Z | [
"region:us"
] | emozilla | null | null | null | 4 | 5 | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: type
dtype: string
splits:
- name: train
num_bytes: 194097976.97925937
num_examples: 10659
- name: test
num_bytes: 25683201.043425813
num_examples: 1570
- name: validation
num_bytes: 35799607.99283796
num_examples: 1824
download_size: 92249754
dataset_size: 255580786.01552314
---
# Dataset Card for "booksum-summary-analysis-8192"
Subset of [emozilla/booksum-summary-analysis](https://huggingface.co/datasets/emozilla/booksum-summary-analysis) with only entries that are less than 8,192 tokens under the [EleutherAI/gpt-neox-20b](https://huggingface.co/EleutherAI/gpt-neox-20b) tokenizer. |
Zayt/oasst1-vi | 2023-05-31T09:51:37.000Z | [
"task_categories:conversational",
"size_categories:10K<n<100K",
"language:vi",
"license:apache-2.0",
"region:us"
] | Zayt | null | null | null | 0 | 5 | ---
license: apache-2.0
dataset_info:
features:
- name: message_id
dtype: string
- name: parent_id
dtype: string
- name: user_id
dtype: string
- name: created_date
dtype: string
- name: text
dtype: string
- name: role
dtype: string
- name: lang
dtype: string
- name: review_count
dtype: int32
- name: review_result
dtype: bool
- name: deleted
dtype: bool
- name: rank
dtype: int32
- name: synthetic
dtype: bool
- name: model_name
dtype: string
- name: detoxify
struct:
- name: toxicity
dtype: float64
- name: severe_toxicity
dtype: float64
- name: obscene
dtype: float64
- name: identity_attack
dtype: float64
- name: insult
dtype: float64
- name: threat
dtype: float64
- name: sexual_explicit
dtype: float64
- name: message_tree_id
dtype: string
- name: tree_state
dtype: string
- name: emojis
sequence:
- name: name
dtype: string
- name: count
dtype: int32
- name: labels
sequence:
- name: name
dtype: string
- name: value
dtype: float64
- name: count
dtype: int32
- name: text_chunks
sequence: string
- name: text_translation
dtype: string
splits:
- name: train
num_bytes: 59922108.85834358
num_examples: 38537
download_size: 39428167
dataset_size: 59922108.85834358
task_categories:
- conversational
language:
- vi
size_categories:
- 10K<n<100K
---
This dataset contains vi subsets (first 191 examples) and auto-translation from en to vi subsets (the rest, 38346 examples) from [OASST1](https://huggingface.co/datasets/OpenAssistant/oasst1). All auto-translation examples are generated using [VietAI envit5-translation](https://huggingface.co/VietAI/envit5-translation).
The vi subsets have the same features as the original dataset. Meanwhile, the auto-translation subsets introduce two new features:
- `"text_chunks"` is a list that contains chunked text split from `"text"`, each chunk has no more than 300 tokens. The sent_tokenizer and word_tokenzier used are from spacy en_core_web_sm model.
- `"text_translation"` contains merged of all translated chunks. Due to the auto-translation model, all new-line symbols (`\n`) are removed.
The translation script can be found at `translate_en_to_vi.py` |
lumenggan/avatar-the-last-airbender-tagged | 2023-05-27T21:50:06.000Z | [
"task_categories:image-to-text",
"task_categories:image-classification",
"size_categories:1K<n<10K",
"language:en",
"license:cc",
"art",
"anime",
"atla",
"region:us"
] | lumenggan | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: image
dtype: image
- name: tags
sequence: string
splits:
- name: train
num_bytes: 1467443424.776
num_examples: 13896
download_size: 1427401832
dataset_size: 1467443424.776
task_categories:
- image-to-text
- image-classification
language:
- en
tags:
- art
- anime
- atla
pretty_name: 'Avatar: The Last Airbender - Tagged Screencaps'
size_categories:
- 1K<n<10K
license: cc
---
# Dataset Card for "avatar-the-last-airbender-tagged"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Rardilit/Panther-dataset_v1 | 2023-05-29T11:18:55.000Z | [
"task_categories:text-generation",
"task_categories:conversational",
"task_categories:question-answering",
"task_categories:text2text-generation",
"size_categories:100K<n<1M",
"language:en",
"license:other",
"text generation",
"panther",
"region:us"
] | Rardilit | null | null | null | 0 | 5 | ---
license: other
task_categories:
- text-generation
- conversational
- question-answering
- text2text-generation
language:
- en
tags:
- text generation
- panther
pretty_name: Panther
size_categories:
- 100K<n<1M
---
# Dataset Details
This dataset is a modified version of [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)
This dataset is used in fine tuning [Panther](https://huggingface.co/Rardilit/Panther_v1) - an state of the art LLM funtuned on llama-7b pretrained model.
A very small portion i.e. 5.3% of prompts and responses were taken from this dataset to finetune and train [Panther](https://huggingface.co/Rardilit/Panther_v1)
## Dataset Details
### Dataset Structure
### Train
Train rows : 377k
### Validation
Validation rows : 20.3k
### Dataset Format
```python
input : "prompt"
output : "response"
```
## How to Use
```python
from datasets import load_dataset
dataset = load_dataset("Rardilit/Panther-dataset_v1")
``` |
tasksource/logical-fallacy | 2023-05-31T08:31:28.000Z | [
"language:en",
"license:unknown",
"region:us"
] | tasksource | null | null | null | 2 | 5 | ---
license: unknown
dataset_info:
features:
- name: config
dtype: string
- name: source_article
dtype: string
- name: logical_fallacies
dtype: string
splits:
- name: train
num_bytes: 501956
num_examples: 2680
- name: test
num_bytes: 93916
num_examples: 511
- name: dev
num_bytes: 123026
num_examples: 570
download_size: 369048
dataset_size: 718898
language:
- en
---
https://github.com/causalNLP/logical-fallacy
```
@article{jin2022logical,
title={Logical fallacy detection},
author={Jin, Zhijing and Lalwani, Abhinav and Vaidhya, Tejas and Shen, Xiaoyu and Ding, Yiwen and Lyu, Zhiheng and Sachan, Mrinmaya and Mihalcea, Rada and Sch{\"o}lkopf, Bernhard},
journal={arXiv preprint arXiv:2202.13758},
year={2022}
}
``` |
tasksource/subjectivity | 2023-06-02T14:44:17.000Z | [
"license:mit",
"arxiv:2305.18034",
"region:us"
] | tasksource | null | null | null | 0 | 5 | ---
license: mit
---
```
@misc{antici2023corpus,
title={A Corpus for Sentence-level Subjectivity Detection on English News Articles},
author={Francesco Antici and Andrea Galassi and Federico Ruggeri and Katerina Korre and Arianna Muti and Alessandra Bardi and Alice Fedotova and Alberto Barrón-Cedeño},
year={2023},
eprint={2305.18034},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
datasheet:
https://www.dropbox.com/sh/pterfc16inz0h7b/AADN9w-O0KTalP48jk2CK36Ha/data?dl=0&preview=datasheet.pdf&subfolder_nav_tracking=1 |
TigerResearch/tigerbot-wiki-qa-zh-1k | 2023-05-31T01:22:23.000Z | [
"language:zh",
"license:apache-2.0",
"region:us"
] | TigerResearch | null | null | null | 2 | 5 | ---
license: apache-2.0
language:
- zh
---
[Tigerbot](https://github.com/TigerResearch/TigerBot) 自有中文百科问答 数据。
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-wiki-qa-zh-1k')
``` |
rcds/swiss_citation_extraction | 2023-08-31T12:22:28.000Z | [
"task_categories:token-classification",
"size_categories:100K<n<1M",
"language:de",
"language:fr",
"language:it",
"license:cc-by-sa-4.0",
"arxiv:2306.09237",
"region:us"
] | rcds | This dataset contains court decision for cit ex task. | @InProceedings{huggingface:dataset,
title = {A great new dataset},
author={huggingface, Inc.
},
year={2020}
} | null | 0 | 5 | ---
license: cc-by-sa-4.0
task_categories:
- token-classification
language:
- de
- fr
- it
pretty_name: Swiss Citation Extraction
size_categories:
- 100K<n<1M
---
# Dataset Card for Swiss Citation Extraction
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Swiss Citation Extraction is a multilingual, diachronic dataset of 131K Swiss Federal Supreme Court (FSCS) cases. This dataset is part of a challenging token classification task.
### Supported Tasks and Leaderboards
### Languages
Switzerland has four official languages with three languages German, French and Italian being represenated. The decisions are written by the judges and clerks in the language of the proceedings.
| Language | Subset | Number of Documents |
|------------|------------|----------------------|
| German | **de** | 85K |
| French | **fr** | 38K |
| Italian | **it** | 8K |
## Dataset Structure
### Data Fields
```
decision_id:
considerations:
NER_labels: CITATION refers to a case citation or a reference to another court decision. LAW indicates a reference to a specific law. O is used for words or tokens that don't fall under the previous two labels. In accordance with the IOB format, each tag, apart from 'O', is accompanied by the 'B-' prefix if it marks the beginning of the span, or the 'I-' prefix if it's inside or at the end of the span.
law_area: (string)
language: (string)
year: (int64)
chamber: (string)
region: (string)
```
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
The original data are published from the Swiss Federal Supreme Court (https://www.bger.ch) in unprocessed formats (HTML). The documents were downloaded from the Entscheidsuche portal (https://entscheidsuche.ch) in HTML.
#### Who are the source language producers?
The decisions are written by the judges and clerks in the language of the proceedings.
### Annotations
#### Annotation process
#### Who are the annotators?
Metadata is published by the Swiss Federal Supreme Court (https://www.bger.ch).
### Personal and Sensitive Information
The dataset contains publicly available court decisions from the Swiss Federal Supreme Court. Personal or sensitive information has been anonymized by the court before publication according to the following guidelines: https://www.bger.ch/home/juridiction/anonymisierungsregeln.html.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
We release the data under CC-BY-4.0 which complies with the court licensing (https://www.bger.ch/files/live/sites/bger/files/pdf/de/urteilsveroeffentlichung_d.pdf)
© Swiss Federal Supreme Court, 2002-2022
The copyright for the editorial content of this website and the consolidated texts, which is owned by the Swiss Federal Supreme Court, is licensed under the Creative Commons Attribution 4.0 International licence. This means that you can re-use the content provided you acknowledge the source and indicate any changes you have made.
Source: https://www.bger.ch/files/live/sites/bger/files/pdf/de/urteilsveroeffentlichung_d.pdf
### Citation Information
Please cite our [ArXiv-Preprint](https://arxiv.org/abs/2306.09237)
```
@misc{rasiah2023scale,
title={SCALE: Scaling up the Complexity for Advanced Language Model Evaluation},
author={Vishvaksenan Rasiah and Ronja Stern and Veton Matoshi and Matthias Stürmer and Ilias Chalkidis and Daniel E. Ho and Joel Niklaus},
year={2023},
eprint={2306.09237},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions |
alpayariyak/prm800k | 2023-06-01T14:51:25.000Z | [
"language:en",
"region:us"
] | alpayariyak | null | null | null | 5 | 5 | ---
language:
- en
---
[From OpenAI](https://github.com/openai/prm800k)
# PRM800K: A Process Supervision Dataset
- [Blog Post](https://openai.com/research/improving-mathematical-reasoning-with-process-supervision)
This repository accompanies the paper [Let's Verify Step by Step](https://openai.com/research/improving-mathematical-reasoning-with-process-supervision) and presents the PRM800K dataset introduced there. PRM800K is a process supervision dataset containing 800,000 step-level correctness labels for model-generated solutions to problems from the [MATH](https://github.com/hendrycks/math) dataset. More information on PRM800K and the project can be found in the paper.
We are releasing the raw labels as well as the instructions we gave labelers during phase 1 and phase 2 of the project. Example labels can be seen in the image below.
<p align="center">
<img src="https://github.com/openai/prm800k/blob/main/prm800k/img/interface.png?raw=true" height="300"/>
</p>
## Data
The data contains our labels formatted as newline-delimited lists of `json` data.
Each line represents 1 full solution sample and can contain many step-level labels. Here is one annotated line:
```javascript
{
// UUID representing a particular labeler.
"labeler": "340d89bc-f5b7-45e9-b272-909ba68ee363",
// The timestamp this trajectory was submitted.
"timestamp": "2023-01-22T04:34:27.052924",
// In phase 2, we split our data collection into generations, using our best
// PRM so far to pick which solutions to score in the next generation.
// In phase 1, this value should always be null.
"generation": 9,
// In each generation, we reserve some solutions for quality control. We serve
// these solutions to every labeler, and check that they agree with our
// gold labels.
"is_quality_control_question": false,
// generation -1 was reserved for a set of 30 questions we served every
// labeler in order to screen for base task performance.
"is_initial_screening_question": false,
// Metadata about the question this solution is a response to.
"question": {
// Text of the MATH problem being solved.
"problem": "What is the greatest common factor of $20 !$ and $200,\\!000$? (Reminder: If $n$ is a positive integer, then $n!$ stands for the product $1\\cdot 2\\cdot 3\\cdot \\cdots \\cdot (n-1)\\cdot n$.)",
// Ground truth solution from the MATH dataset.
"ground_truth_solution": "The prime factorization of $200,000$ is $2^6 \\cdot 5^5$. Then count the number of factors of $2$ and $5$ in $20!$. Since there are $10$ even numbers, there are more than $6$ factors of $2$. There are $4$ factors of $5$. So the greatest common factor is $2^6 \\cdot 5^4=\\boxed{40,\\!000}$.",
// Ground truth answer.
"ground_truth_answer": "40,\\!000",
// The full steps of the model-generated solution. This is only set for
// phase 2 where we pre-generated all solutions that we labeled.
"pre_generated_steps": [
"I want to find the largest positive integer that divides both $20 !$ and $200,\\!000$ evenly.",
"One way to do this is to factor both numbers into prime factors and look for the common ones.",
"I know that $200,\\!000 = 2^5\\cdot 10^4 = 2^9\\cdot 5^4$.",
"To find the prime factorization of $20 !$, I can use the fact that it is the product of all the positive integers from $1$ to $20$.",
"For each prime number $p$ between $1$ and $20$, I can count how many multiples of $p$ are in that range.",
"For example, there are $10$ multiples of $2$ between $1$ and $20$, namely $2, 4, 6, \\dots, 20$.",
"But there are also $5$ multiples of $4$, which is $2^2$, and $2$ multiples of $8$, which is $2^3$, and $1$ multiple of $16$, which is $2^4$.",
"So, the total power of $2$ in $20 !$ is $10 + 5 + 2 + 1 = 18$.",
"Similarly, there are $4$ multiples of $5$, namely $5, 10, 15, 20$, so the power of $5$ in $20 !$ is $4$.",
"There are $6$ multiples of $3$, namely $3, 6, 9, \\dots, 18$, but there are also $2$ multiples of $9$, which is $3^2$, so the power of $3$ in $20 !$ is $6 + 2 = 8$.",
"There are $2$ multiples of $7$, namely $7$ and $14$, so the power of $7$ in $20 !$ is $2$.",
"There are $1$ multiple of each of the other prime numbers $11, 13, 17$, and $19$, so the powers of those primes in $20 !$ are $1$ each.",
"Therefore, the prime factorization of $20 !$ is $2^{18}\\cdot 3^8\\cdot 5^4\\cdot 7^2\\cdot 11\\cdot 13\\cdot 17\\cdot 19$.",
"To find the greatest common factor of $20 !$ and $200,\\!000$, I need to take the lowest power of each common prime factor.",
"The only common prime factors are $2$ and $5$, and the lowest powers are $9$ and $4$, respectively.",
"So, the greatest common factor is $2^9\\cdot 5^4 = 512\\cdot 625 = 320,\\!000$.\n\n# Answer\n\n320,000"
],
// The answer given as the end of the pre-generated solution. We can see
// this solution is incorrect.
"pre_generated_answer": "320,000",
// The score given by our PRM to this solution. This one isn't rated very
// highly!
"pre_generated_verifier_score": 0.010779580529581414
},
// The human data we collected for this solution, containing correctness
// labels for each step of the solution.
"label": {
"steps": [
// Each object here represents labels for one step of the solution.
{
// Each step will contain one or more completions. These are candidate
// steps the model output at this step of the trajectory. In phase 1,
// we frequently collect labels on alternative steps, while in phase 2
// we only collect labels on alternative steps after the first mistake,
// so most completions lists are singletons.
"completions": [
{
// Text of the step.
"text": "I want to find the largest positive integer that divides both $20 !$ and $200,\\!000$ evenly.",
// The rating the labeler gave to this step. Can be -1, 0, or +1.
// This is a 0 because it isn't incorrect, but it does not make
// any progress.
"rating": 0,
// The labeler can flag steps that they don't know how to label.
// This is rarely used.
"flagged": null
}
],
// In phase 1, if all completions were rated -1, we allowed labelers to
// write their own +1 step. This is null for all steps in phase 2.
"human_completion": null,
// The index of the completion "chosen" at this step, or null if the
// human_completion was used. You can reconstruct the solution
// trajectory like:
// [
// step["human_completion"] if step["chosen_completion"] is None
// else step["completions"][step["chosen_completion"]]["text"]
// for step in labeled_solution["label"]["steps"]
// ]
"chosen_completion": 0
},
{
"completions": [
{
"text": "One way to do this is to factor both numbers into prime factors and look for the common ones.",
"rating": 0,
"flagged": null
}
],
"human_completion": null,
"chosen_completion": 0
},
{
// Some steps contain multiple alternative completions, and each one
// gets a rating.
"completions": [
{
"text": "I know that $200,\\!000 = 2^5\\cdot 10^4 = 2^9\\cdot 5^4$.",
"rating": -1,
"flagged": null
},
{
"text": "To factor $20 !$, I can use the fact that every factorial is a multiple of every number less than or equal to it.",
"rating": 0,
"flagged": false
},
{
"text": "I can use a factor tree to find the prime factors of $200,\\!000$: $200,\\!000 = 2^5\\cdot 10^4 = 2^5\\cdot 2^4\\cdot 5^4 = 2^9\\cdot 5^4$.",
"rating": -1,
"flagged": false
},
{
"text": "I can use a factor tree to find the prime factors of $200,\\!000$.",
"rating": 0,
"flagged": false
},
{
"text": "To factor $20 !$, I can use the fact that any factorial is divisible by all the primes less than or equal to the input.",
"rating": 0,
"flagged": false
}
],
"human_completion": null,
"chosen_completion": null
}
],
// Total time in milliseconds spent on labeling this solution.
"total_time": 278270,
// Final result of labeling this solution. Will be one of:
// - "found_error": In phase 2 we stop labeling a solution after the
// first error is found.
// - "solution": We reached a step that concluded in the correct answer
// to the problem.
// - "bad_problem": The labeler reported the problem as broken.
// - "give_up": The labeler was stuck (the problem was taking too long,
// or the instructions were unclear) and moved onto the
// next problem.
"finish_reason": "found_error"
}
}
```
## Citation
Please use the below BibTeX entry to cite this dataset:
COMING SOON |
jignasha/medicalFAQ | 2023-06-05T06:34:07.000Z | [
"license:mit",
"region:us"
] | jignasha | null | null | null | 0 | 5 | ---
license: mit
---
|
idajikuu/AI-detection | 2023-06-05T10:06:43.000Z | [
"region:us"
] | idajikuu | null | null | null | 0 | 5 | Entry not found |
TrainingDataPro/plantations_segmentation | 2023-09-14T16:50:35.000Z | [
"task_categories:image-segmentation",
"language:en",
"license:cc-by-nd-4.0",
"biology",
"code",
"region:us"
] | TrainingDataPro | The images consist of aerial photography of agricultural plantations with crops
such as cabbage and zucchini. The dataset addresses agricultural tasks such as
plant detection and counting, health assessment, and irrigation planning.
The dataset consists of plantations' photographs with object and class
segmentation of cabbage. | @InProceedings{huggingface:dataset,
title = {plantations_segmentation},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 5 | ---
license: cc-by-nd-4.0
task_categories:
- image-segmentation
language:
- en
tags:
- biology
- code
dataset_info:
features:
- name: image_id
dtype: int32
- name: image
dtype: image
- name: class_segmentation
dtype: image
- name: object_segmentation
dtype: image
- name: shapes
dtype: string
splits:
- name: train
num_bytes: 48297698
num_examples: 13
download_size: 48362120
dataset_size: 48297698
---
# Plantations Segmentation
The images consist of aerial photography of agricultural plantations with crops such as cabbage and zucchini. The dataset addresses agricultural tasks such as plant detection and counting, health assessment, and irrigation planning. The dataset consists of plantations' photographs with object and class segmentation of cabbage.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=plantations_segmentation) to discuss your requirements, learn about the price and buy the dataset.

# Dataset structure
- **Plantations_Segmentation** - contains of original plantation images (folder **img**) and file with annotations (.xml)
- **Object_Segmentation** - includes object segmentation masks for the original images
- **Class_Segmentation** - includes class segmentation masks for the original images
# Types of segmentation
The dataset includes two types of segmentation:
- **Class Segmentation** - objects corresponding to one class are identified
- **Object Segmentation** - all objects are identified separately
# Data Format
Each image from `img` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the polygons. For each point, the x and y coordinates are provided.
# Example of XML file structure
.png?generation=1685973058340642&alt=media)
# Plantation segmentation might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=plantations_segmentation) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
TrainingDataPro/outdoor_garbage | 2023-09-14T16:52:34.000Z | [
"task_categories:image-classification",
"language:en",
"license:cc-by-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | The dataset consisting of garbage cans of various capacities and types.
Best to train a neural network to monitor the timely removal of garbage and
organize the logistics of vehicles for garbage collection. Dataset is useful
for the recommendation systems, optimization and automization the work of
community services, smart city. | @InProceedings{huggingface:dataset,
title = {outdoor_garbage},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 5 | ---
license: cc-by-nd-4.0
task_categories:
- image-classification
language:
- en
tags:
- code
dataset_info:
features:
- name: image_id
dtype: int32
- name: image
dtype: image
- name: annotations
dtype: string
splits:
- name: train
num_bytes: 608467996
num_examples: 100
download_size: 607803398
dataset_size: 608467996
---
# Outdoor Garbage Dataset
The dataset consisting of garbage cans of various capacities and types. Best to train a neural network to monitor the timely removal of garbage and organize the logistics of vehicles for garbage collection. Dataset is useful for the recommendation systems, optimization and automization the work of coomunity services, smart city.
.png?generation=1686047397390850&alt=media)
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=outdoor_garbage) to discuss your requirements, learn about the price and buy the dataset.
# Content
Dataset includes 10 000 images of trash cans:
- in different times of day
- in different weather conditions
## Types of garbage cans capacity
- **is_full** - at least one of the trash cans shown in the photo is completely full. This type includes filled to the top, overflown cans.
- **is_empty** - garbage cans have free space, it could be half full or completely empty.
- **is_scattered** - the tag is added with is_empty or is_full. The tag means that the garbage (volumetric garbage bags, or building waste, but not single elements) is scattered nearby.
# Data Format
Each image from `img` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the labeled types of garbage cans capacities for each image in the dataset.
# Example of XML file structure
.png?generation=1686076026295933&alt=media)
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=outdoor_garbage) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
TrainingDataPro/bald_classification | 2023-09-14T16:53:12.000Z | [
"task_categories:image-classification",
"language:en",
"license:cc-by-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | Dataset consists of 5000 photos of people with 7 stages of hairloss according
to the Norwood scale. Dataset is useful for training neural networks for the
recommendation systems, optimizing the work processes of trichologists and
applications in the Med / Beauty spheres. | @InProceedings{huggingface:dataset,
title = {bald_classification},
author = {TrainingDataPro},
year = {2023}
} | null | 2 | 5 | ---
license: cc-by-nd-4.0
task_categories:
- image-classification
language:
- en
tags:
- code
dataset_info:
features:
- name: image_id
dtype: int32
- name: image
dtype: image
- name: annotations
dtype: string
splits:
- name: train
num_bytes: 183544614
num_examples: 42
download_size: 183335948
dataset_size: 183544614
---
# Dataset of bald people
Dataset consists of 5000 photos of people with 7 stages of hairloss according to the Norwood scale. Dataset is useful for training neural networks for the recommendation systems, optimizing the work processes of trichologists and applications in the Med / Beauty spheres.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=bald_classification) to discuss your requirements, learn about the price and buy the dataset.
# Image
Similar images are presented in the dataset:

# Hamilton–Norwood scale
- **type_1**: There is a lack of bilateral recessions along the anterior border of the hairline in the frontoparietal regions. No notable hair loss or recession of the hairline.
- **type_2**: There is a small recession of the hairline around the temples. Hair is also lost, or sparse, along the midfrontal border of the scalp, but the depth of the affected area is much less than in the frontoparietal regions. This is commonly referred to as an adult or mature hairline.
- **type_3**: The first signs of significant balding appear. There is a deep, symmetrical recession at the temples that are only sparsely covered by hair.
- **type_4**: The hairline recession is harsher than in stage 2, and there is scattered hair or no hair on the vertex. There are deep frontotemporal recessions, usually symmetrical, and are either bare or very sparsely covered by hair.
- **type_5**: The areas of hair loss are more significant than in stage 4. They are still divided, but the band of hair between them is thinner and sparser.
- **type_6**: The connection of hair that crosses the crown is gone with only sparse hair remaining. The frontotemporal and vertex regions are joined together, and the extent of hair loss is more significant.
- **type_7**: The most drastic stage of hair loss, only a band of hair, going around the sides of the head persists. This hair usually is not thick and might be dainty.
# Data Format
Each image from `img` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the Hamilton–Norwood type of hairloss for each person in the dataset.
# Example of XML file structure
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=bald_classification) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
arubenruben/cnn_dailymail_azure_pt_pt | 2023-06-06T11:08:32.000Z | [
"task_categories:summarization",
"task_categories:translation",
"language:pt",
"Machine Translation",
"region:us"
] | arubenruben | null | null | null | 2 | 5 | ---
dataset_info:
features:
- name: document
dtype: string
- name: summary
dtype: string
splits:
- name: train
num_bytes: 33317736
num_examples: 7729
- name: validation
num_bytes: 14690610
num_examples: 3810
- name: test
num_bytes: 33051715
num_examples: 7298
download_size: 48224108
dataset_size: 81060061
task_categories:
- summarization
- translation
language:
- pt
tags:
- Machine Translation
pretty_name: Portuguese CNN-Dailymail-Azure
---
# Dataset Card for "cnn_dailymail_azure_pt_pt"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
musabg/wikipedia-tr-summarization | 2023-06-13T04:29:02.000Z | [
"task_categories:summarization",
"size_categories:100K<n<1M",
"language:tr",
"region:us"
] | musabg | null | null | null | 2 | 5 | ---
dataset_info:
features:
- name: text
dtype: string
- name: summary
dtype: string
splits:
- name: train
num_bytes: 324460408.0479985
num_examples: 119110
- name: validation
num_bytes: 17077006.95200153
num_examples: 6269
download_size: 216029002
dataset_size: 341537415
task_categories:
- summarization
language:
- tr
pretty_name: Wikipedia Turkish Summarization
size_categories:
- 100K<n<1M
---
# Wikipedia Turkish Summarization Dataset
## Dataset Description
This is a Turkish summarization dataset 🇹🇷 prepared from the 2023 Wikipedia dump. The dataset has been cleaned, tokenized, and summarized using Huggingface Wikipedia dataset cleaner script, custom cleaning scripts, and OpenAI's gpt3.5-turbo API.
### Data Source
- Wikipedia's latest Turkish dump (2023 version) 🌐
### Features
- text: string (The original text extracted from Wikipedia articles 📖)
- summary: string (The generated summary of the original text 📝)
### Data Splits
| Split | Num Bytes | Num Examples |
|------------|--------------------|--------------|
| train | 324,460,408.048 | 119,110 |
| validation | 17,077,006.952 | 6,269 |
### Download Size
- 216,029,002 bytes
### Dataset Size
- 341,537,415 bytes
## Data Preparation
### Data Collection
1. The latest Turkish Wikipedia dump was downloaded 📥.
2. Huggingface Wikipedia dataset cleaner script was used to clean the text 🧹.
3. A custom script was used to further clean the text, removing sections like "Kaynakca" (References) and other irrelevant information 🛠️.
### Tokenization
The dataset was tokenized using Google's MT5 tokenizer. The following criteria were applied:
- Articles with a token count between 300 and 900 were selected ✔️.
- Articles with less than 300 tokens were ignored ❌.
- For articles with more than 900 tokens, only the first 900 tokens ending with a paragraph were selected 🔍.
### Summarization
The generated raw texts were summarized using OpenAI's gpt3.5-turbo API 🤖.
## Dataset Usage
This dataset can be used for various natural language processing tasks 👩💻, such as text summarization, machine translation, and language modeling in the Turkish language.
Example usage:
```python
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("musabg/wikipedia-tr-summarization")
# Access the data
train_data = dataset["train"]
validation_data = dataset["validation"]
# Iterate through the data
for example in train_data:
text = example["text"]
summary = example["summary"]
# Process the data as needed
```
Please make sure to cite the dataset as follows 📝:
```bibtex
@misc{musabg2023wikipediatrsummarization,
author = {Musab Gultekin},
title = {Wikipedia Turkish Summarization Dataset},
year = {2023},
publisher = {HuggingFace},
howpublished = {\url{https://huggingface.co/datasets/musabg/wikipedia-tr-summarization}},
}
```
---
## Wikipedia Türkçe Özetleme Veri Seti
Bu, 2023 Wikipedia dökümünden hazırlanan Türkçe özetleme veri kümesidir. Veri kümesi, Huggingface Wikipedia veri kümesi temizleme betiği, özel temizleme betikleri ve OpenAI'nin gpt3.5-turbo API'si kullanılarak temizlenmiş, tokenleştirilmiş ve özetlenmiştir.
### Veri Kaynağı
- Wikipedia'nın en güncel Türkçe dökümü (2023 sürümü)
### Özellikler
- text: string (Wikipedia makalelerinden çıkarılan orijinal metin)
- summary: string (Orijinal metnin oluşturulan özeti)
### Veri Bölümleri
| Bölüm | Numara Baytı | Örnek Sayısı |
|------------|--------------------|--------------|
| train | 324.460.408,048 | 119.110 |
| validation | 17.077.006,952 | 6.269 |
### İndirme Boyutu
- 216.029.002 bayt
### Veri Kümesi Boyutu
- 341.537.415 bayt
## Veri Hazırlama
### Veri Toplama
1. En güncel Türkçe Wikipedia dökümü indirildi.
2. Huggingface Wikipedia veri kümesi temizleme betiği metni temizlemek için kullanıldı.
3. "Kaynakça" (Referanslar) gibi bölümleri ve diğer alakasız bilgileri kaldırmak için özel bir betik kullanıldı.
### Tokenleştirme
Veri kümesi, Google'ın MT5 tokenleştiricisi kullanılarak tokenleştirildi. Aşağıdaki kriterler uygulandı:
- 300 ile 900 token arasında olan makaleler seçildi.
- 300'den az tokeni olan makaleler dikkate alınmadı.
- 900'den fazla tokeni olan makalelerde, sadece bir paragraf ile biten ilk 900 token kısmı alındı.
### Özetleme
Oluşturulan ham metinler, OpenAI'nin gpt3.5-turbo API'si kullanılarak özetlendi.
## Veri Kümesi Kullanımı
Bu veri kümesi, Türkçe dilinde metin özetleme, makine çevirisi ve dil modelleme gibi çeşitli doğal dil işleme görevleri için kullanılabilir.
Örnek kullanım:
```python
from datasets import load_dataset
# Veri kümesini yükle
dataset = load_dataset("musabg/wikipedia-tr-summarization")
# Verilere erişin
train_data = dataset["train"]
validation_data = dataset["validation"]
# Verilerin üzerinden geçin
for example in train_data:
text = example["text"]
summary = example["summary"]
# Veriyi gerektiği gibi işleyin
``` |
dinhanhx/crossmodal-3600 | 2023-06-06T14:38:51.000Z | [
"task_categories:image-to-text",
"task_ids:image-captioning",
"source_datasets:wikipedia",
"source_datasets:google",
"language:ar",
"language:bn",
"language:cs",
"language:da",
"language:de",
"language:el",
"language:en",
"language:es",
"language:fa",
"language:fi",
"language:fil",
"la... | dinhanhx | null | null | null | 0 | 5 | ---
license: other
task_categories:
- image-to-text
task_ids:
- image-captioning
language:
- ar
- bn
- cs
- da
- de
- el
- en
- es
- fa
- fi
- fil
- fr
- hi
- hr
- hu
- id
- it
- he
- ja
- ko
- mi
- nl
- no
- pl
- pt
- quz
- ro
- ru
- sv
- sw
- te
- th
- tr
- uk
- vi
- zh
pretty_name: 'Crossmodal-3600: A Massively Multilingual Multimodal Evaluation Dataset'
source_datasets:
- wikipedia
- google
tags:
- crossmodal-3600
---
# Crossmodal-3600: A Massively Multilingual Multimodal Evaluation Dataset
## Abstract
Research in massively multilingual image captioning has been severely hampered by a lack of high-quality evaluation datasets. In this paper we present the Crossmodal-3600 dataset (XM3600 in short), a geographically-diverse set of 3600 images annotated with human-generated reference captions in 36 languages. The images were selected from across the world, covering regions where the 36 languages are spoken, and annotated with captions that achieve consistency in terms of style across all languages, while avoiding annotation artifacts due to direct translation. We apply this benchmark to model selection for massively multilingual image captioning models, and show strong correlation results with human evaluations when using XM3600 as golden references for automatic metrics.
[Original source](https://google.github.io/crossmodal-3600/) |
GePaSud/TROPICAL | 2023-08-05T04:25:29.000Z | [
"license:mit",
"region:us"
] | GePaSud | null | null | 0 | 5 | ---
license: mit
dataset_info:
- config_name: original
features:
- name: id_comment
dtype: string
- name: words
sequence: string
- name: triplets
list:
- name: aspect_term
sequence: string
- name: opinion_term
sequence: string
- name: aspect_position
sequence: int32
- name: opinion_position
sequence: int32
- name: polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
- name: general_polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
splits:
- name: train
num_bytes: 1115671
num_examples: 1114
- name: test
num_bytes: 239799
num_examples: 239
- name: validation
num_bytes: 237621
num_examples: 239
download_size: 2471854
dataset_size: 1593091
- config_name: no_overlapping
features:
- name: id_comment
dtype: string
- name: words
sequence: string
- name: triplets
list:
- name: aspect_term
sequence: string
- name: opinion_term
sequence: string
- name: aspect_position
sequence: int32
- name: opinion_position
sequence: int32
- name: polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
- name: general_polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
splits:
- name: train
num_bytes: 270313
num_examples: 326
- name: test
num_bytes: 61779
num_examples: 70
- name: validation
num_bytes: 59399
num_examples: 71
download_size: 581415
dataset_size: 391491
- config_name: overlapping
features:
- name: id_comment
dtype: string
- name: words
sequence: string
- name: triplets
list:
- name: aspect_term
sequence: string
- name: opinion_term
sequence: string
- name: aspect_position
sequence: int32
- name: opinion_position
sequence: int32
- name: polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
- name: general_polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
splits:
- name: train
num_bytes: 842528
num_examples: 787
- name: test
num_bytes: 178001
num_examples: 169
- name: validation
num_bytes: 181071
num_examples: 169
download_size: 1890439
dataset_size: 1201600
---
# Dataset Card for TROPICAL
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Configurations](#data-configurations)
- [Use this Dataset](#use-this-dataset)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** [TROPICAL dataset repository](https://github.com/GePaSud/TROPICAL)
- **Paper:**
- **Point of Contact:**
### Dataset Summary
The TROPICAL dataset is a French-language dataset for sentiment analysis. The dataset contains comments left by French-speaking tourists' on TripAdvisor after their visit to French Polynesia, each review either concern a hotel or a guesthouse. The format is JSON.
The comments spanning from January 2001 to April 2023, the dataset contain 1592 comments along with 10729 ASTE triplets (aspect, opinion, sentiment).
The unsplitted dataset is available in our Github repository.
### Languages
The text in the dataset is in French as it was written by French speakers.
## Dataset Structure
### Data Instances
Normaly the polarity of the triplets are either "POS", "NEG" or "NEU", due to using [ClassLabel](https://huggingface.co/docs/datasets/v2.13.0/en/package_reference/main_classes#datasets.ClassLabel) the polarity is represented by 0, 1 or 2.
| String label | Int label |
| ------------ | --------- |
| POS | 0 |
| NEG | 1 |
| NEU | 2 |
An example from the TROPICAL original dataset looks like the following:
```json
{
"id_comment": "16752",
"words": ["Nous", "avons", "passé", "4", "nuits", "dans", "cet", "établissement", "Ce", "fut", "un", "très", "bon", "moment", "Le", "personnel", "très", "aimable", "et", "serviable", "Nous", "avons", "visité", "les", "plantations", "d'ananas", "en", "4/4", "et", "ce", "fut", "un", "agréable", "moment", "nous", "avons", "fait", "le", "tour", "de", "l'île", "et", "c't", "une", "splendeur", "Nous", "sommes", "revenus", "enchantés"],
"triplets": [
{"aspect_term": ["Aspect inexistant"], "opinion_term": ["revenus", "enchantés"], "aspect_position": [-1], "opinion_position": [47, 48], "polarity": "POS"},
{"aspect_term": ["tour", "de", "l'île"], "opinion_term": ["une", "splendeur"], "aspect_position": [38, 39, 40], "opinion_position": [43, 44], "polarity": "POS"},
{"aspect_term": ["moment"], "opinion_term": ["agréable"], "aspect_position": [33], "opinion_position": [32], "polarity": "POS"},
{"aspect_term": ["personnel"], "opinion_term": ["serviable"], "aspect_position": [15], "opinion_position": [19], "polarity": "POS"},
{"aspect_term": ["personnel"], "opinion_term": ["très", "aimable"], "aspect_position": [15], "opinion_position": [16, 17], "polarity": "POS"},
{"aspect_term": ["moment"], "opinion_term": ["très", "bon"], "aspect_position": [13], "opinion_position": [11, 12], "polarity": "POS"}
],
"general_polarity": "POS"
}
```
### Data Fields
- 'id_comment': a string containing the review id
- 'words': an array of strings composing the comment
- 'triplets': a list of dictionnaries containing the following informations
- 'aspect_term': an array of strings composing the aspect term (can be a single word or a multi-word expression)
- 'opinion_term': an array of strings composing the opinion term (can be a single word or a multi-word expression)
- 'aspect_position': an array of integers indicating the position of the aspect term in the words array (can be a single integer list or a list of integers)
- 'opinion_position': an array of integers indicating the position of the opinion term in the review (can be a single integer list or a list of integers)
- 'polartiy': an integer, either _0_, _1_, or _2_, indicating a _positive_, _negative_, or _neutral_ sentiment, respectively
- 'general_polarity': an integer, either _0_, _1_, or _2_, indicating a _positive_, _negative_, or _neutral_ sentiment, respectively
### Data configurations
The TROPICO dataset has 3 configurations: _original_, _no overlapping_, and _overlapping_.The first one contains the 1592 comments. The overlapping dataset contains the comments that have at least one overlapping triplet. The no overlapping dataset contains the comments that have no overlapping triplet.
| Dataset Configuration | Number of comments | Number of triplets | Positive triplets | Negative triplets | Neutral triplets |
| --------------------- | ------------------ | ------------------ | ----------------- | ----------------- | -----------------|
| original | 1,592 | 10,729 | 9,889 | 734 | 106 |
| no_overlapping | 467 | 2,235 | 2,032 | 184 | 19 |
| overlapping | 1,125 | 8,494 | 7,857 | 550 | 87 |
The following table show the splits of the dataset for all configurations:
| Dataset Configuration | Train | Test | Val |
| --------------------- | ----- | ---- | --- |
| original | 1,114 | 239 | 239 |
| no_overlapping | 326 | 70 | 71 |
| overlapping | 787 | 169 | 169 |
The split values for train, test, validation are 70%, 15%, 15% respectively. The seed used is 42.
## Use this dataset
```python
from datasets import load_dataset
dataset = load_dataset("TROPICAL", "original") # or "no_overlapping" or "overlapping"
```
## Dataset Creation
### Source Data
All the comments were collected from the TripAdvisor website. The comments range from January 2001 to April 2023. The dataset contains 1592 comments along with 10729 ASTE triplets (aspect, opinion, sentiment).
### Who are the source language producers?
The dataset contains tourists' comments about French Polynesia stored on the [TripAdvisor](https://www.tripadvisor.com/) website.
### Known limitations
The dataset contains only comments about French Polynesia. Moreover, the dataset is not balanced, the number of positive triplets is much higher than the number of negative and neutral triplets.
## Additional Information
### Licensing Information
The TROPICAL dataset is licensed under the [MIT License](https://opensource.org/licenses/MIT).
### Citation Information
> To be added... | |
ghomasHudson/longdoc_paired_hotpotqa | 2023-07-08T10:42:47.000Z | [
"region:us"
] | ghomasHudson | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: input
dtype: string
- name: response_j
dtype: string
- name: response_k
dtype: string
splits:
- name: train
num_bytes: 1349024656
num_examples: 671376
- name: validation
num_bytes: 114260998
num_examples: 57844
download_size: 800718173
dataset_size: 1463285654
---
# Dataset Card for "longdoc_paired_hotpotqa"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
yardeny/processed_bert_dataset | 2023-06-07T22:28:07.000Z | [
"region:us"
] | yardeny | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
- name: special_tokens_mask
sequence: int8
splits:
- name: train
num_bytes: 22202359200.0
num_examples: 6167322
download_size: 6545191752
dataset_size: 22202359200.0
---
# Dataset Card for "processed_bert_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tjaffri/wikisql-generate | 2023-06-09T04:44:55.000Z | [
"license:bsd-3-clause",
"region:us"
] | tjaffri | null | null | null | 0 | 5 | ---
license: bsd-3-clause
dataset_info:
features:
- name: input
dtype: string
- name: table_info
dtype: string
- name: sql_cmd
dtype: string
splits:
- name: test
num_bytes: 9526974
num_examples: 15462
- name: validation
num_bytes: 5034756
num_examples: 8243
- name: train
num_bytes: 33996901
num_examples: 54963
download_size: 11329076
dataset_size: 48558631
---
# WikiSQL Dataset (Reformatted for Generative Models)
This is the exact same dataset as WikiSQL: https://huggingface.co/datasets/wikisql, but with the data reformatted to allow direct use with text generation LLMs. The original license and credits for the original dataset remain in place.
Specifically, the changes from standard WikiSQL are:
1. The table details in WikiSQL were included as dictionaries but tools like [LangChain](https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html) and [LlamaIndex](https://medium.com/llamaindex-blog/combining-text-to-sql-with-semantic-search-for-retrieval-augmented-generation-c60af30ec3b) build their prompts using a SQL DESCRIBE of the tables, which is included in this dataset as the table_info.
1. In addition, some of the SQL commands in WikiSQL that were not syntactically valid (e.g. due to identifiers not quoted) were removed. Specifically, we created in-memory (SQLite) tables using the SQL DESCRIBE of the tables, then ran the WikiSQL human readable SQL query against these in-memory tables. Any SQL queries that threw exceptions for any reason were discarded, and the rest that ran without exceptions were included in this dataset as the sql_cmd.
1. The SQL queries under sql_cmd were also formatted to capitalize keywords and do other pretty printing of the SQL using [SQLParse](https://sqlparse.readthedocs.io/en/latest/) to make the SQL more standard and easier to learn for smaller models.
# Suggested Uses
This dataset may be used for the following purposes:
1. Combine SQL queries with text based retrieval, using techniques like the [LlamaIndex SQLAutoVectorQueryEngine](https://gpt-index.readthedocs.io/en/latest/examples/query_engine/SQLAutoVectorQueryEngine.html).
1. Fine tuning LLMs to generate SQL commands from natural language inputs, given SQL DESCRIBE of tables and various rows. This is exactly the use case for the [LangChain](https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html) SQLChain, so once fine tuned these LLMs may be used directly with these chains for theoretically better results (not tried at the time of writing)
1. Few shot prompt seeding of LLMs used to generate SQL commands from natural language inputs.
|
eastwind/semeval-2016-absa-reviews-english-translated-stanford-alpaca | 2023-06-09T11:08:27.000Z | [
"task_categories:text-classification",
"task_categories:zero-shot-classification",
"task_categories:question-answering",
"task_categories:text2text-generation",
"size_categories:1K<n<10K",
"language:en",
"license:mit",
"region:us"
] | eastwind | null | null | null | 1 | 5 | ---
license: mit
task_categories:
- text-classification
- zero-shot-classification
- question-answering
- text2text-generation
language:
- en
pretty_name: >-
SemEval 2016 Hotel Aspect Based Sentiment Analysis translated and alpaca
format for LLM training
size_categories:
- 1K<n<10K
---
# Dataset Card for Dataset Name
Derived from eastwind/semeval-2016-absa-reviews-arabic using Helsinki-NLP/opus-mt-tc-big-ar-en |
Weni/zeroshot | 2023-06-09T21:20:29.000Z | [
"region:us"
] | Weni | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: source_text
dtype: string
- name: target_text
dtype: string
splits:
- name: train
num_bytes: 1231981.6500505707
num_examples: 15000
- name: validation
num_bytes: 410660.5500168569
num_examples: 5000
- name: test
num_bytes: 62666.799932572365
num_examples: 763
download_size: 892342
dataset_size: 1705309.0
---
# Dataset Card for "zeroshot"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
drt/gqa | 2023-07-05T13:18:02.000Z | [
"license:mit",
"region:us"
] | drt | GQA is a dataset containing 58K questions about subgraphs extracted from Wikidata.
The data are made from Lc-QuAD 2.0 and MCWQ datasets. | null | null | 0 | 5 | ---
license: mit
---
# GQA: Graph Question Answering
This dataset is asks models to make use of embedded graph for question answering.
Stats:
- train: 57,043
- test: 2,890
An exmaple of the dataset is as follows:
```json
{
"id": "mcwq-176119",
"question": "What was executive produced by Scott Spiegel , Boaz Yakin , and Quentin Tarantino , executive produced by My Best Friend's Birthday 's editor and star , and edited by George Folsey",
"answers": [
"Hostel: Part II"
],
"subgraph": {
"entities": [
"Q1401104",
"Q887636",
"Q1048645",
"Q3772",
"Q965826"
],
"relations": [
"P1431",
"P1040"
],
"adjacency": [[2, 1, 0],
[2, 0, 3],
[2, 0, 1],
[2, 0, 4]
],
"entity_labels": [
"george folsey, jr.",
"boaz yakin",
"hostel: part ii",
"quentin jerome tarantino",
"scott spiegel"
],
"relation_labels": [
"showrunner",
"film editor"
]
},
"sparql": "SELECT DISTINCT ?x0 WHERE {\n?x0 wdt:P1040 wd:Q1401104 .\n?x0 wdt:P1431 ?x1 .\n?x0 wdt:P1431 wd:Q3772 .\n?x0 wdt:P1431 wd:Q887636 .\n?x0 wdt:P1431 wd:Q965826 .\nwd:Q1480733 wdt:P161 ?x1 .\nwd:Q1480733 wdt:P1040 ?x1\n}"
}
```
|
shellypeng/cartoon-captioned-datasets-salesforce-blip | 2023-06-13T06:35:39.000Z | [
"code",
"region:us"
] | shellypeng | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 2357028047.718
num_examples: 1907
download_size: 1774680464
dataset_size: 2357028047.718
tags:
- code
---
# Dataset Card for "cartoon-captioned-datasets-salesforce-blip"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
coallaoh/COCO-AB | 2023-07-23T18:22:22.000Z | [
"task_categories:image-classification",
"annotations_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:https://huggingface.co/datasets/HuggingFaceM4/COCO",
"language:en",
"license:apache-2.0",
"arxiv:2303.17595",
"region:us"
] | coallaoh | null | null | null | 2 | 5 | ---
annotations_creators:
- crowdsourced
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
paperswithcode_id: coco
pretty_name: COCO
size_categories:
- 100K<n<1M
source_datasets:
- https://huggingface.co/datasets/HuggingFaceM4/COCO
task_categories:
- image-classification
---
## General Information
**Title**: COCO-AB
**Description**:
The COCO-AB dataset is an extension of the COCO 2014 training set, enriched with additional annotation byproducts (AB).
The data includes 82,765 reannotated images from the original COCO 2014 training set.
It has relevance in computer vision, specifically in object detection and location.
The aim of the dataset is to provide a richer understanding of the images (without extra costs) by recording additional actions and interactions from the annotation process.
**Links**:
- [ICCV'23 Paper](https://arxiv.org/abs/2303.17595)
- [Main Repository](https://github.com/naver-ai/NeglectedFreeLunch)
- [COCO Annotation Interface](https://github.com/naver-ai/coco-annotation-tool)
## Collection Process
**Collection Details**:
The additional annotations for the COCO-AB dataset were collected using Amazon Mechanical Turk (MTurk) workers from the US region, due to the task being described in English.
The task was designed as a human intelligence task (HIT), and the qualification approval rate was set at 90% to ensure the task's quality.
Each HIT contained 20 pages of annotation tasks, each page having a single candidate image to be tagged.
We follow the original annotation interface of COCO as much as possible.
See [GitHub repository](https://github.com/naver-ai/coco-annotation-tool) and [Paper](https://arxiv.org/abs/2303.17595) for further information.
A total of 4140 HITs were completed, with 365 HITs being rejected based on criteria such as recall rate, accuracy of icon location, task completion rate, and verification with database and secret hash code.
**Annotator Compensation**:
Annotators were paid 2.0 USD per HIT.
The median time taken to complete each HIT was 12.1 minutes, yielding an approximate hourly wage of 9.92 USD.
This wage is above the US federal minimum hourly wage.
A total of 8,280 USD was paid to the MTurk annotators, with an additional 20% fee paid to Amazon.
**Annotation Rejection**:
We rejected a HIT under the following circumstances.
- The recall rate was lower than 0.333.
- The accuracy of icon location is lower than 0.75.
- The annotator did not complete at least 16 out of the 20 pages of tasks.
- The annotation was not found in our database, and the secret hash code for confirming their completion was incorrect.
- In total, 365 out of 4,140 completed HITs (8.8%) were rejected.
**Collection Time**:
The entire annotation collection process took place between January 9, 2022, and January 12, 2022
## Data Schema
```json
{
"image_id": 459214,
"originalImageHeight": 428,
"originalImageWidth": 640,
"categories": [”car”, “bicycle”],
"imageHeight": 450,
"imageWidth": 450,
"timeSpent": 22283,
"actionHistories": [
{"actionType": ”add”,
"iconType": ”car”,
"pointTo": {"x": 0.583, "y": 0.588},
"timeAt": 16686},
{"actionType": ”add”,
"iconType": “bicycle”,
"pointTo": {"x": 0.592, "y": 0.639},
"timeAt": 16723}
],
"categoryHistories": [
{"categoryIndex": 1,
"categoryName": ”Animal”,
"timeAt": 10815,
"usingKeyboard": false},
{"categoryIndex": 10,
"categoryName": ”IndoorObjects”,
"timeAt": 19415,
"usingKeyboard": false}
],
"mouseTracking": [
{"x": 0.679, "y": 0.862, "timeAt": 15725},
{"x": 0.717, "y": 0.825, "timeAt": 15731}
],
"worker_id": "00AA3B5E80",
"assignment_id": "3AMYWKA6YLE80HK9QYYHI2YEL2YO6L",
"page_idx": 8
}
```
## Usage
One could use the annotation byproducts to improve the model generalisability and robustness.
This is appealing, as the annotation byproducts do not incur extra annotation costs for the annotators.
For more information, refer to our [ICCV'23 Paper](https://arxiv.org/abs/2303.17595).
## Dataset Statistics
Annotators have reannotated 82,765 (99.98%) of 82,783 training images from the COCO 2014 training set.
For those images, we have recorded the annotation byproducts.
We found that each HIT recalls 61.9% of the list of classes per image, with the standard deviation ±0.118%p.
The average localisation accuracy for icon placement is 92.3% where the standard deviation is ±0.057%p.
## Ethics and Legalities
The crowdsourced annotators were fairly compensated for their time at a rate well above the U.S. federal minimum wage.
In terms of data privacy, the dataset maintains the same ethical standards as the original COCO dataset.
Worker identifiers were anonymized using a non-reversible hashing function, ensuring privacy.
Our data collection has obtained IRB approval from an author’s institute.
For the future collection of annotation byproducts, we note that there exist potential risks that annotation byproducts may contain annotators’ privacy.
Data collectors may even attempt to leverage more private information as byproducts.
We urge data collectors not to collect or exploit private information from annotators.
Whenever appropriate, one must ask for the annotators’ consent.
## Maintenance and Updates
This section will be updated as and when there are changes or updates to the dataset.
## Known Limitations
Given the budget constraint, we have not been able to acquire 8+ annotations per sample, as done in the original work.
## Citation Information
```
@inproceedings{han2023iccv,
title = {Neglected Free Lunch – Learning Image Classifiers Using Annotation Byproducts},
author = {Han, Dongyoon and Choe, Junsuk and Chun, Seonghyeok and Chung, John Joon Young and Chang, Minsuk and Yun, Sangdoo and Song, Jean Y. and Oh, Seong Joon},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2023}
}
``` |
shhossain/webnovels | 2023-06-15T15:35:51.000Z | [
"task_categories:text-classification",
"task_categories:zero-shot-classification",
"task_categories:feature-extraction",
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"region:us"
] | shhossain | null | null | null | 1 | 5 | ---
license: mit
task_categories:
- text-classification
- zero-shot-classification
- feature-extraction
language:
- en
pretty_name: 'Novelupdates Dataset'
size_categories:
- 10K<n<100K
dataset_info:
features:
- name: novel_id
dtype: int64
- name: url
dtype: string
- name: title
dtype: string
- name: associated_names
sequence: string
- name: img_url
dtype: string
- name: showtype
dtype: string
- name: genres
sequence: string
- name: tags
sequence: string
- name: description
dtype: string
- name: related_series
struct:
- name: related_series
list:
- name: title
dtype: string
- name: url
dtype: string
- name: total
dtype: int64
- name: recommendations
struct:
- name: recomendations
list:
- name: recommended_user_count
dtype: int64
- name: title
dtype: string
- name: url
dtype: string
- name: total
dtype: int64
- name: recommendation_lists
struct:
- name: list
list:
- name: title
dtype: string
- name: url
dtype: string
- name: total
dtype: int64
- name: rating
dtype: string
- name: language
dtype: string
- name: authors
sequence: string
- name: artists
sequence: string
- name: year
dtype: string
- name: status_coo
dtype: string
- name: licensed
dtype: string
- name: translated
dtype: string
- name: publishers
sequence: string
- name: en_pubs
sequence: string
- name: release_frequency
dtype: string
- name: weekly_rank
dtype: string
- name: monthly_rank
dtype: string
- name: all_time_rank
dtype: string
- name: monthly_rank_reading_list
dtype: string
- name: all_time_rank_reading_list
dtype: string
- name: total_reading_list_rank
dtype: string
- name: chapters
struct:
- name: chapters
list:
- name: title
dtype: string
- name: url
dtype: string
- name: total
dtype: int64
splits:
- name: train
num_bytes: 58948539.85115204
num_examples: 11770
- name: test
num_bytes: 14739639.148847958
num_examples: 2943
download_size: 22367283
dataset_size: 73688179.0
---
# Dataset Card for Novelupdates Webnovels
### Dataset Summary
This dataset contains information about webnovels from Novelupdates, a popular webnovel platform. It includes details such as novel ID, URL, title, associated names, cover image URL, show type, genres, tags, description, related series, recommendations, recommendation lists, rating, language, authors, artists, year, status, licensing information, translation status, publishers, release frequency, rankings, total reading list rank, and chapters.
### Supported Tasks and Leaderboards
The dataset can be used for various tasks such as text classification, zero-shot classification, and feature extraction. It currently does not have an established leaderboard.
### Languages
The dataset is primarily in English.
## Dataset Structure
### Data Instances
The dataset contains 14,713 data instances.
### Data Fields
The dataset includes the following fields:
- novel_id: integer
- url: string
- title: string
- associated_names: list of strings
- img_url: string
- showtype: string
- genres: list of strings
- tags: list of strings
- description: string
- related_series: struct
- related_series: list of structs
- title: string
- url: string
- total: integer
- recommendations: struct
- recommendations: list of structs
- recommended_user_count: integer
- title: string
- url: string
- total: integer
- recommendation_lists: struct
- list: list of structs
- title: string
- url: string
- total: integer
- rating: string
- language: string
- authors: list of strings
- artists: list of strings
- year: string
- status_coo: string
- licensed: string
- translated: string
- publishers: list of strings
- en_pubs: list of strings
- release_frequency: string
- weekly_rank: string
- monthly_rank: string
- all_time_rank: string
- monthly_rank_reading_list: string
- all_time_rank_reading_list: string
- total_reading_list_rank: string
- chapters: struct
- chapters: list of structs
- title: string
- url: string
- total: integer
### Data Splits
The dataset includes a single split:
- Train: 11.8K examples
- Test: 2.94K examples
## Dataset Creation
### Curation Rationale
The dataset was curated to provide a comprehensive collection of webnovel information from Novelupdates for various text analysis tasks.
### Source Data
#### Initial Data Collection and Normalization
The initial data was collected from the Novelupdates website and normalized for consistency and structure.
#### Who are the source language producers?
The source language producers are the authors and publishers of the webnovels.
### Annotations
#### Annotation process
The dataset does not contain explicit annotations. It consists of the information available on the Novelupdates website.
#### Who are the annotators?
N/A
### Personal and Sensitive Information
The dataset does not include any personal or sensitive information.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
TrainingDataPro/basketball_tracking | 2023-09-19T19:35:19.000Z | [
"task_categories:image-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | The dataset consist of screenshots from videos of basketball games with
the ball labeled with a bounging box.
The dataset can be used to train a neural network in ball control recognition.
The dataset is useful for automating the camera operator's work during a match,
allowing the ball to be efficiently kept in frame. | @InProceedings{huggingface:dataset,
title = {basketball_tracking},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 5 | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-classification
language:
- en
tags:
- code
dataset_info:
features:
- name: image_id
dtype: int32
- name: image
dtype: image
- name: mask
dtype: image
- name: shapes
dtype: string
splits:
- name: train
num_bytes: 191244976
num_examples: 70
download_size: 191271989
dataset_size: 191244976
---
# Basketball Tracking
## Tracking is a deep learning process where the algorithm tracks the movement of an object.
The dataset consist of screenshots from videos of basketball games with the ball labeled with a bounging box.
The dataset can be used to train a neural network in ball control recognition. The dataset is useful for automating the camera operator's work during a match, allowing the ball to be efficiently kept in frame.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=basketball_tracking) to discuss your requirements, learn about the price and buy the dataset.

# Dataset structure
- **img** - contains of original images of basketball players.
- **boxes** - includes bounding box labeling for a ball in the original images.
- **annotations.xml** - contains coordinates of the boxes and labels, created for the original photo
# Data Format
Each image from `img` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes for the ball position. For each point, the x and y coordinates are provided.
### Attributes
- **occluded** - the ball visability (*true* if the the ball is occluded by 30%)
- **basket** - the position related to the basket (*true* if the ball is covered with a basket on any distinguishable area)
# Example of XML file structure
# Basketball Tracking might be made in accordance with your requirements.
## [TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=basketball_tracking) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
asoria/nell | 2023-06-14T14:41:25.000Z | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"annotations_creators:machine-generated",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100M<n<1B",
"size_categories:10M<n<100M",
"size_categories:1M<n<10M",... | asoria | This dataset provides version 1115 of the belief
extracted by CMU's Never Ending Language Learner (NELL) and version
1110 of the candidate belief extracted by NELL. See
http://rtw.ml.cmu.edu/rtw/overview. NELL is an open information
extraction system that attempts to read the Clueweb09 of 500 million
web pages (http://boston.lti.cs.cmu.edu/Data/clueweb09/) and general
web searches.
The dataset has 4 configurations: nell_belief, nell_candidate,
nell_belief_sentences, and nell_candidate_sentences. nell_belief is
certainties of belief are lower. The two sentences config extracts the
CPL sentence patterns filled with the applicable 'best' literal string
for the entities filled into the sentence patterns. And also provides
sentences found using web searches containing the entities and
relationships.
There are roughly 21M entries for nell_belief_sentences, and 100M
sentences for nell_candidate_sentences. | @inproceedings{mitchell2015,
added-at = {2015-01-27T15:35:24.000+0100},
author = {Mitchell, T. and Cohen, W. and Hruscha, E. and Talukdar, P. and Betteridge, J. and Carlson, A. and Dalvi, B. and Gardner, M. and Kisiel, B. and Krishnamurthy, J. and Lao, N. and Mazaitis, K. and Mohammad, T. and Nakashole, N. and Platanios, E. and Ritter, A. and Samadi, M. and Settles, B. and Wang, R. and Wijaya, D. and Gupta, A. and Chen, X. and Saparov, A. and Greaves, M. and Welling, J.},
biburl = {https://www.bibsonomy.org/bibtex/263070703e6bb812852cca56574aed093/hotho},
booktitle = {AAAI},
description = {Papers by William W. Cohen},
interhash = {52d0d71f6f5b332dabc1412f18e3a93d},
intrahash = {63070703e6bb812852cca56574aed093},
keywords = {learning nell ontology semantic toread},
note = {: Never-Ending Learning in AAAI-2015},
timestamp = {2015-01-27T15:35:24.000+0100},
title = {Never-Ending Learning},
url = {http://www.cs.cmu.edu/~wcohen/pubs.html},
year = 2015
} | null | 2 | 5 | ---
annotations_creators:
- machine-generated
language_creators:
- crowdsourced
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 100M<n<1B
- 10M<n<100M
- 1M<n<10M
source_datasets:
- original
task_categories:
- text-retrieval
task_ids:
- entity-linking-retrieval
- fact-checking-retrieval
paperswithcode_id: nell
pretty_name: Never Ending Language Learning (NELL)
tags:
- relation-extraction
- text-to-structured
- text-to-tabular
dataset_info:
- config_name: nell_belief
features:
- name: entity
dtype: string
- name: relation
dtype: string
- name: value
dtype: string
- name: iteration_of_promotion
dtype: string
- name: score
dtype: string
- name: source
dtype: string
- name: entity_literal_strings
dtype: string
- name: value_literal_strings
dtype: string
- name: best_entity_literal_string
dtype: string
- name: best_value_literal_string
dtype: string
- name: categories_for_entity
dtype: string
- name: categories_for_value
dtype: string
- name: candidate_source
dtype: string
splits:
- name: train
num_bytes: 4592559704
num_examples: 2766079
download_size: 929107246
dataset_size: 4592559704
- config_name: nell_candidate
features:
- name: entity
dtype: string
- name: relation
dtype: string
- name: value
dtype: string
- name: iteration_of_promotion
dtype: string
- name: score
dtype: string
- name: source
dtype: string
- name: entity_literal_strings
dtype: string
- name: value_literal_strings
dtype: string
- name: best_entity_literal_string
dtype: string
- name: best_value_literal_string
dtype: string
- name: categories_for_entity
dtype: string
- name: categories_for_value
dtype: string
- name: candidate_source
dtype: string
splits:
- name: train
num_bytes: 23497433060
num_examples: 32687353
download_size: 2687057812
dataset_size: 23497433060
- config_name: nell_belief_sentences
features:
- name: entity
dtype: string
- name: relation
dtype: string
- name: value
dtype: string
- name: score
dtype: string
- name: sentence
dtype: string
- name: count
dtype: int32
- name: url
dtype: string
- name: sentence_type
dtype: string
splits:
- name: train
num_bytes: 4459368426
num_examples: 21031531
download_size: 929107246
dataset_size: 4459368426
- config_name: nell_candidate_sentences
features:
- name: entity
dtype: string
- name: relation
dtype: string
- name: value
dtype: string
- name: score
dtype: string
- name: sentence
dtype: string
- name: count
dtype: int32
- name: url
dtype: string
- name: sentence_type
dtype: string
splits:
- name: train
num_bytes: 20058197787
num_examples: 100866414
download_size: 2687057812
dataset_size: 20058197787
config_names:
- nell_belief
- nell_belief_sentences
- nell_candidate
- nell_candidate_sentences
---
# Dataset Card for Never Ending Language Learning (NELL)
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
http://rtw.ml.cmu.edu/rtw/
- **Repository:**
http://rtw.ml.cmu.edu/rtw/
- **Paper:**
Never-Ending Learning.
T. Mitchell, W. Cohen, E. Hruschka, P. Talukdar, J. Betteridge, A. Carlson, B. Dalvi, M. Gardner, B. Kisiel, J. Krishnamurthy, N. Lao, K. Mazaitis, T. Mohamed, N. Nakashole, E. Platanios, A. Ritter, M. Samadi, B. Settles, R. Wang, D. Wijaya, A. Gupta, X. Chen, A. Saparov, M. Greaves, J. Welling. In Proceedings of the Conference on Artificial Intelligence (AAAI), 2015
### Dataset Summary
This dataset provides version 1115 of the belief
extracted by CMU's Never Ending Language Learner (NELL) and version
1110 of the candidate belief extracted by NELL. See
http://rtw.ml.cmu.edu/rtw/overview. NELL is an open information
extraction system that attempts to read the Clueweb09 of 500 million
web pages (http://boston.lti.cs.cmu.edu/Data/clueweb09/) and general
web searches.
The dataset has 4 configurations: nell_belief, nell_candidate,
nell_belief_sentences, and nell_candidate_sentences. nell_belief is
certainties of belief are lower. The two sentences config extracts the
CPL sentence patterns filled with the applicable 'best' literal string
for the entities filled into the sentence patterns. And also provides
sentences found using web searches containing the entities and
relationships.
There are roughly 21M entries for nell_belief_sentences, and 100M
sentences for nell_candidate_sentences.
From the NELL website:
- **Research Goal**
To build a never-ending machine learning system that acquires the ability to extract structured information from unstructured web pages. If successful, this will result in a knowledge base (i.e., a relational database) of structured information that mirrors the content of the Web. We call this system NELL (Never-Ending Language Learner).
- **Approach**
The inputs to NELL include (1) an initial ontology defining hundreds of categories (e.g., person, sportsTeam, fruit, emotion) and relations (e.g., playsOnTeam(athlete,sportsTeam), playsInstrument(musician,instrument)) that NELL is expected to read about, and (2) 10 to 15 seed examples of each category and relation.
Given these inputs, plus a collection of 500 million web pages and access to the remainder of the web through search engine APIs, NELL runs 24 hours per day, continuously, to perform two ongoing tasks:
Extract new instances of categories and relations. In other words, find noun phrases that represent new examples of the input categories (e.g., "Barack Obama" is a person and politician), and find pairs of noun phrases that correspond to instances of the input relations (e.g., the pair "Jason Giambi" and "Yankees" is an instance of the playsOnTeam relation). These new instances are added to the growing knowledge base of structured beliefs.
Learn to read better than yesterday. NELL uses a variety of methods to extract beliefs from the web. These are retrained, using the growing knowledge base as a self-supervised collection of training examples. The result is a semi-supervised learning method that couples the training of hundreds of different extraction methods for a wide range of categories and relations. Much of NELL’s current success is due to its algorithm for coupling the simultaneous training of many extraction methods.
For more information, see: http://rtw.ml.cmu.edu/rtw/resources
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
en, and perhaps some others
## Dataset Structure
### Data Instances
There are four configurations for the dataset: nell_belief, nell_candidate, nell_belief_sentences, nell_candidate_sentences.
nell_belief and nell_candidate defines:
``
{'best_entity_literal_string': 'Aspect Medical Systems',
'best_value_literal_string': '',
'candidate_source': '%5BSEAL-Iter%3A215-2011%2F02%2F26-04%3A27%3A09-%3Ctoken%3Daspect_medical_systems%2Cbiotechcompany%3E-From%3ACategory%3Abiotechcompany-using-KB+http%3A%2F%2Fwww.unionegroup.com%2Fhealthcare%2Fmfg_info.htm+http%3A%2F%2Fwww.conventionspc.com%2Fcompanies.html%2C+CPL-Iter%3A1103-2018%2F03%2F08-15%3A32%3A34-%3Ctoken%3Daspect_medical_systems%2Cbiotechcompany%3E-grant+support+from+_%092%09research+support+from+_%094%09unrestricted+educational+grant+from+_%092%09educational+grant+from+_%092%09research+grant+support+from+_%091%09various+financial+management+positions+at+_%091%5D',
'categories_for_entity': 'concept:biotechcompany',
'categories_for_value': 'concept:company',
'entity': 'concept:biotechcompany:aspect_medical_systems',
'entity_literal_strings': '"Aspect Medical Systems" "aspect medical systems"',
'iteration_of_promotion': '1103',
'relation': 'generalizations',
'score': '0.9244426550775064',
'source': 'MBL-Iter%3A1103-2018%2F03%2F18-01%3A35%3A42-From+ErrorBasedIntegrator+%28SEAL%28aspect_medical_systems%2Cbiotechcompany%29%2C+CPL%28aspect_medical_systems%2Cbiotechcompany%29%29',
'value': 'concept:biotechcompany',
'value_literal_strings': ''}
``
nell_belief_sentences, nell_candidate_sentences defines:
``
{'count': 4,
'entity': 'biotechcompany:aspect_medical_systems',
'relation': 'generalizations',
'score': '0.9244426550775064',
'sentence': 'research support from [[ Aspect Medical Systems ]]',
'sentence_type': 'CPL',
'url': '',
'value': 'biotechcompany'}
``
### Data Fields
For nell_belief and nell_canddiate configurations. From http://rtw.ml.cmu.edu/rtw/faq:
* entity: The Entity part of the (Entity, Relation, Value) tripple. Note that this will be the name of a concept and is not the literal string of characters seen by NELL from some text source, nor does it indicate the category membership of that concept
* relation: The Relation part of the (Entity, Relation, Value) tripple. In the case of a category instance, this will be "generalizations". In the case of a relation instance, this will be the name of the relation.
* value: The Value part of the (Entity, Relation, Value) tripple. In the case of a category instance, this will be the name of the category. In the case of a relation instance, this will be another concept (like Entity).
* iteration_of_promotion: The point in NELL's life at which this category or relation instance was promoted to one that NELL beleives to be true. This is a non-negative integer indicating the number of iterations of bootstrapping NELL had gone through.
* score: A confidence score for the belief. Note that NELL's scores are not actually probabilistic at this time.
* source: A summary of the provenance for the belief indicating the set of learning subcomponents (CPL, SEAL, etc.) that had submitted this belief as being potentially true.
* entity_literal_strings: The set of actual textual strings that NELL has read that it believes can refer to the concept indicated in the Entity column.
* value_literal_strings: For relations, the set of actual textual strings that NELL has read that it believes can refer to the concept indicated in the Value column. For categories, this should be empty but may contain something spurious.
* best_entity_literal_string: Of the set of strings in the Entity literalStrings, column, which one string can best be used to describe the concept.
* best_value_literal_string: Same thing, but for Value literalStrings.
* categories_for_entity: The full set of categories (which may be empty) to which NELL belives the concept indicated in the Entity column to belong.
* categories_for_value: For relations, the full set of categories (which may be empty) to which NELL believes the concept indicated in the Value column to belong. For categories, this should be empty but may contain something spurious.
* candidate_source: A free-form amalgamation of more specific provenance information describing the justification(s) NELL has for possibly believing this category or relation instance.
For the nell_belief_sentences and nell_candidate_sentences, we have extracted the underlying sentences, sentence count and URLs and provided a shortened version of the entity, relation and value field by removing the string "concept:" and "candidate:". There are two types of sentences, 'CPL' and 'OE', which are generated by two of the modules of NELL, pattern matching and open web searching, respectively. There may be duplicates. The configuration is as follows:
* entity: The Entity part of the (Entity, Relation, Value) tripple. Note that this will be the name of a concept and is not the literal string of characters seen by NELL from some text source, nor does it indicate the category membership of that concept
* relation: The Relation part of the (Entity, Relation, Value) tripple. In the case of a category instance, this will be "generalizations". In the case of a relation instance, this will be the name of the relation.
* value: The Value part of the (Entity, Relation, Value) tripple. In the case of a category instance, this will be the name of the category. In the case of a relation instance, this will be another concept (like Entity).
* score: A confidence score for the belief. Note that NELL's scores are not actually probabilistic at this time.
* sentence: the raw sentence. For 'CPL' type sentences, there are "[[" "]]" arounds the entity and value. For 'OE' type sentences, there are no "[[" and "]]".
* url: the url if there is one from which this sentence was extracted
* count: the count for this sentence
* sentence_type: either 'CPL' or 'OE'
### Data Splits
There are no splits.
## Dataset Creation
### Curation Rationale
This dataset was gathered and created over many years of running the NELL system on web data.
### Source Data
#### Initial Data Collection and Normalization
See the research paper on NELL. NELL searches a subset of the web
(Clueweb09) and the open web using various open information extraction
algorithms, including pattern matching.
#### Who are the source language producers?
The NELL authors at Carnegie Mellon Univiersty and data from Cluebweb09 and the open web.
### Annotations
#### Annotation process
The various open information extraction modules of NELL.
#### Who are the annotators?
Machine annotated.
### Personal and Sensitive Information
Unkown, but likely there are names of famous individuals.
## Considerations for Using the Data
### Social Impact of Dataset
The goal for the work is to help machines learn to read and understand the web.
### Discussion of Biases
Since the data is gathered from the web, there is likely to be biased text and relationships.
[More Information Needed]
### Other Known Limitations
The relationships and concepts gathered from NELL are not 100% accurate, and there could be errors (maybe as high as 30% error).
See https://en.wikipedia.org/wiki/Never-Ending_Language_Learning
We did not 'tag' the entity and value in the 'OE' sentences, and this might be an extension in the future.
## Additional Information
### Dataset Curators
The authors of NELL at Carnegie Mellon Univeristy
### Licensing Information
There does not appear to be a license on http://rtw.ml.cmu.edu/rtw/resources. The data is made available by CMU on the web.
### Citation Information
@inproceedings{mitchell2015,
added-at = {2015-01-27T15:35:24.000+0100},
author = {Mitchell, T. and Cohen, W. and Hruscha, E. and Talukdar, P. and Betteridge, J. and Carlson, A. and Dalvi, B. and Gardner, M. and Kisiel, B. and Krishnamurthy, J. and Lao, N. and Mazaitis, K. and Mohammad, T. and Nakashole, N. and Platanios, E. and Ritter, A. and Samadi, M. and Settles, B. and Wang, R. and Wijaya, D. and Gupta, A. and Chen, X. and Saparov, A. and Greaves, M. and Welling, J.},
biburl = {https://www.bibsonomy.org/bibtex/263070703e6bb812852cca56574aed093/hotho},
booktitle = {AAAI},
description = {Papers by William W. Cohen},
interhash = {52d0d71f6f5b332dabc1412f18e3a93d},
intrahash = {63070703e6bb812852cca56574aed093},
keywords = {learning nell ontology semantic toread},
note = {: Never-Ending Learning in AAAI-2015},
timestamp = {2015-01-27T15:35:24.000+0100},
title = {Never-Ending Learning},
url = {http://www.cs.cmu.edu/~wcohen/pubs.html},
year = 2015
}
### Contributions
Thanks to [@ontocord](https://github.com/ontocord) for adding this dataset. |
Cainiao-AI/LaDe-P | 2023-06-22T15:00:50.000Z | [
"size_categories:10M<n<100M",
"license:apache-2.0",
"Spatial-Temporal",
"Graph",
"Logistic",
"region:us"
] | Cainiao-AI | null | null | null | 1 | 5 | ---
license: apache-2.0
tags:
- Spatial-Temporal
- Graph
- Logistic
size_categories:
- 10M<n<100M
dataset_info:
features:
- name: order_id
dtype: int64
- name: region_id
dtype: int64
- name: city
dtype: string
- name: courier_id
dtype: int64
- name: accept_time
dtype: string
- name: time_window_start
dtype: string
- name: time_window_end
dtype: string
- name: lng
dtype: float64
- name: lat
dtype: float64
- name: aoi_id
dtype: int64
- name: aoi_type
dtype: int64
- name: pickup_time
dtype: string
- name: pickup_gps_time
dtype: string
- name: pickup_gps_lng
dtype: float64
- name: pickup_gps_lat
dtype: float64
- name: accept_gps_time
dtype: string
- name: accept_gps_lng
dtype: float64
- name: accept_gps_lat
dtype: float64
- name: ds
dtype: int64
splits:
- name: pickup_jl
num_bytes: 54225579
num_examples: 261801
- name: pickup_cq
num_bytes: 243174931
num_examples: 1172703
- name: pickup_yt
num_bytes: 237146694
num_examples: 1146781
- name: pickup_sh
num_bytes: 293399390
num_examples: 1424406
- name: pickup_hz
num_bytes: 436103754
num_examples: 2130456
download_size: 443251368
dataset_size: 1264050348
---
# 1. About Dataset
**LaDe** is a publicly available last-mile delivery dataset with millions of packages from industry.
It has three unique characteristics: (1) Large-scale. It involves 10,677k packages of 21k couriers over 6 months of real-world operation.
(2) Comprehensive information, it offers original package information, such as its location and time requirements, as well as task-event information, which records when and where the courier is while events such as task-accept and task-finish events happen.
(3) Diversity: the dataset includes data from various scenarios, such as package pick-up and delivery, and from multiple cities, each with its unique spatio-temporal patterns due to their distinct characteristics such as populations.
If you use this dataset for your research, please cite this paper: {xxx}
# 2. Download
[LaDe](https://huggingface.co/datasets/Cainiao-AI/LaDe) is composed of two subdatasets: i) [LaDe-D](https://huggingface.co/datasets/Cainiao-AI/LaDe-D), which comes from the package delivery scenario.
ii) [LaDe-P](https://huggingface.co/datasets/Cainiao-AI/LaDe-P), which comes from the package pickup scenario. To facilitate the utilization of the dataset, each sub-dataset is presented in CSV format.
LaDe-P is the second subdataset from [LaDe](https://huggingface.co/datasets/Cainiao-AI/LaDe)
LaDe can be used for research purposes. Before you download the dataset, please read these terms. And [Code link](https://github.com/wenhaomin/LaDe). Then put the data into "./data/raw/".
The structure of "./data/raw/" should be like:
```
* ./data/raw/
* pickup
* pickup_sh.csv
* ...
```
LaDe-P contains files, with each representing the data from a specific city, the detail of each city can be find in the following table.
| City | Description |
|------------|----------------------------------------------------------------------------------------------|
| Shanghai | One of the most prosperous cities in China, with a large number of orders per day. |
| Hangzhou | A big city with well-developed online e-commerce and a large number of orders per day. |
| Chongqing | A big city with complicated road conditions in China, with a large number of orders. |
| Jilin | A middle-size city in China, with a small number of orders each day. |
| Yantai | A small city in China, with a small number of orders every day. |
# 3. Description
Below is the detailed field of each LaDe-P.
| Data field | Description | Unit/format |
|----------------------------|----------------------------------------------|--------------|
| **Package information** | | |
| package_id | Unique identifier of each package | Id |
| time_window_start | Start of the required time window | Time |
| time_window_end | End of the required time window | Time |
| **Stop information** | | |
| lng/lat | Coordinates of each stop | Float |
| city | City | String |
| region_id | Id of the Region | String |
| aoi_id | Id of the AOI (Area of Interest) | Id |
| aoi_type | Type of the AOI | Categorical |
| **Courier Information** | | |
| courier_id | Id of the courier | Id |
| **Task-event Information** | | |
| accept_time | The time when the courier accepts the task | Time |
| accept_gps_time | The time of the GPS point closest to accept time | Time |
| accept_gps_lng/lat | Coordinates when the courier accepts the task | Float |
| pickup_time | The time when the courier picks up the task | Time |
| pickup_gps_time | The time of the GPS point closest to pickup_time | Time |
| pickup_gps_lng/lat | Coordinates when the courier picks up the task | Float |
| **Context information** | | |
| ds | The date of the package pickup | Date |
# 4. Leaderboard
Blow shows the performance of different methods in Shanghai.
## 4.1 Route Prediction
Experimental results of route prediction. We use bold and underlined fonts to denote the best and runner-up model, respectively.
| Method | HR@3 | KRC | LSD | ED |
|--------------|--------------|--------------|-------------|-------------|
| TimeGreedy | 57.65 | 31.81 | 5.54 | 2.15 |
| DistanceGreedy | 60.77 | 39.81 | 5.54 | 2.15 |
| OR-Tools | 66.21 | 47.60 | 4.40 | 1.81 |
| LightGBM | 73.76 | 55.71 | 3.01 | 1.84 |
| FDNET | 73.27 ± 0.47 | 53.80 ± 0.58 | 3.30 ± 0.04 | 1.84 ± 0.01 |
| DeepRoute | 74.68 ± 0.07 | 56.60 ± 0.16 | 2.98 ± 0.01 | 1.79 ± 0.01 |
| Graph2Route | 74.84 ± 0.15 | 56.99 ± 0.52 | 2.86 ± 0.02 | 1.77 ± 0.01 |
## 4.2 Estimated Time of Arrival Prediction
| Method | MAE | RMSE | ACC@30 |
| ------ |--------------|--------------|-------------|
| LightGBM | 30.99 | 35.04 | 0.59 |
| SPEED | 23.75 | 27.86 | 0.73 |
| KNN | 36.00 | 31.89 | 0.58 |
| MLP | 21.54 ± 2.20 | 25.05 ± 2.46 | 0.79 ± 0.04 |
| FDNET | 18.47 ± 0.25 | 21.44 ± 0.28 | 0.84 ± 0.01 |
## 4.3 Spatio-temporal Graph Forecasting
| Method | MAE | RMSE |
|-------|-------------|-------------|
| HA | 4.63 | 9.91 |
| DCRNN | 3.69 ± 0.09 | 7.08 ± 0.12 |
| STGCN | 3.04 ± 0.02 | 6.42 ± 0.05 |
| GWNET | 3.16 ± 0.06 | 6.56 ± 0.11 |
| ASTGCN | 3.12 ± 0.06 | 6.48 ± 0.14 |
| MTGNN | 3.13 ± 0.04 | 6.51 ± 0.13 |
| AGCRN | 3.93 ± 0.03 | 7.99 ± 0.08 |
| STGNCDE | 3.74 ± 0.15 | 7.27 ± 0.16 |
# 5. Citation
To cite this repository:
```shell
@software{pytorchgithub,
author = {xx},
title = {xx},
url = {xx},
version = {0.6.x},
year = {2021},
}
``` |
vietgpt/vungoi_question_type1 | 2023-06-22T14:06:07.000Z | [
"region:us"
] | vietgpt | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: metadata
struct:
- name: chapter
dtype: string
- name: difficult_degree
dtype: int64
- name: grade
dtype: string
- name: id
dtype: string
- name: idx
dtype: int64
- name: subject
dtype: string
- name: question
dtype: string
- name: options
list:
- name: answer
dtype: string
- name: key
dtype: string
- name: answer
struct:
- name: answer
dtype: string
- name: key
dtype: string
- name: solution
dtype: string
- name: quality
struct:
- name: has_image
dtype: bool
- name: missing_question
dtype: bool
- name: missing_solution
dtype: bool
splits:
- name: train
num_bytes: 140854723
num_examples: 112042
download_size: 88486050
dataset_size: 140854723
---
# Dataset Card for "vungoi_question_type1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
hamlegs/SquishmallowImages | 2023-06-23T04:34:53.000Z | [
"region:us"
] | hamlegs | null | null | null | 0 | 5 | Entry not found |
Falah/skin-cancer | 2023-07-02T12:41:06.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': benign
'1': malignant
splits:
- name: train
num_bytes: 146274097.953
num_examples: 2637
download_size: 136183890
dataset_size: 146274097.953
---
# Skin Cancer Dataset
This dataset contains skin cancer images labeled as benign (class 0) or malignant (class 1). It can be used for various tasks related to skin cancer classification, such as image recognition, machine learning, and deep learning models.
## Class Labels
The dataset consists of two class labels:
- Class 0: Benign
- Class 1: Malignant
## Number of Rows
The dataset contains 2,637 rows, each corresponding to a unique skin cancer image.
## Usage
To load this dataset using the Hugging Face library, you can utilize the `load_dataset` function as follows:
```python
from datasets import load_dataset
dataset = load_dataset("Falah/skin-cancer", split="train")
```
This code will load the dataset with the training split and return an object that allows you to access the dataset's features, labels, and other relevant information.
Example code to access the dataset and obtain the class names:
```python
# Load the dataset
dataset = load_dataset("Falah/skin-cancer", split="train")
# Access the class names
class_names = dataset.features["class_label"]["names"]
# Print the class names with their respective codes
for code, name in class_names.items():
print(f"'{code}': {name}")
```
The above code will print the class names along with their corresponding codes, as specified in the dataset.
Please note that you need to have the Hugging Face library installed in order to use the `load_dataset` function.
## License
The dataset is provided under an unspecified license. Please refer to the dataset source or contact the dataset owner, Falah, for more information about the licensing details.
## Citation
If you use this dataset in your work or research, please consider citing it as:
```
@misc{Falah/skin-cancer,
title={Skin Cancer Dataset},
author={Falah},
year={2023},
publisher={Hugging Face},
howpublished={\url{https://huggingface.co/datasets/Falah/skin-cancer}}
}
```
|
ChanceFocus/flare-sm-cikm | 2023-06-25T18:16:45.000Z | [
"region:us"
] | ChanceFocus | null | null | null | 1 | 5 | ---
dataset_info:
features:
- name: id
dtype: string
- name: query
dtype: string
- name: answer
dtype: string
- name: text
dtype: string
- name: choices
sequence: string
- name: gold
dtype: int64
splits:
- name: train
num_bytes: 26082681
num_examples: 3396
- name: valid
num_bytes: 3231915
num_examples: 431
- name: test
num_bytes: 8123670
num_examples: 1143
download_size: 19175558
dataset_size: 37438266
---
# Dataset Card for "flare-sm-cikm"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TrainingDataPro/people-tracking-dataset | 2023-09-19T19:35:09.000Z | [
"task_categories:image-segmentation",
"task_categories:image-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"legal",
"code",
"region:us"
] | TrainingDataPro | The dataset comprises of annotated video frames from positioned in a public
space camera. The tracking of each individual in the camera's view
has been achieved using the rectangle tool in the Computer Vision Annotation Tool (CVAT). | @InProceedings{huggingface:dataset,
title = {people-tracking-dataset},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 5 | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-segmentation
- image-classification
language:
- en
tags:
- legal
- code
dataset_info:
features:
- name: image_id
dtype: int32
- name: image
dtype: image
- name: mask
dtype: image
- name: annotations
dtype: string
splits:
- name: train
num_bytes: 52028802
num_examples: 41
download_size: 45336774
dataset_size: 52028802
---
# People Tracking Dataset
The dataset comprises of annotated video frames from positioned in a public space camera. The tracking of each individual in the camera's view has been achieved using the rectangle tool in the Computer Vision Annotation Tool (CVAT).
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=people-tracking-dataset) to discuss your requirements, learn about the price and buy the dataset.

# Dataset Structure
- The `images` directory houses the original video frames, serving as the primary source of raw data.
- The `annotations.xml` file provides the detailed annotation data for the images.
- The `boxes` directory contains frames that visually represent the bounding box annotations, showing the locations of the tracked individuals within each frame. These images can be used to understand how the tracking has been implemented and to visualize the marked areas for each individual.
# Data Format
The annotations are represented as rectangle bounding boxes that are placed around each individual. Each bounding box annotation contains the position ( `xtl`-`ytl`-`xbr`-`ybr` coordinates ) for the respective box within the frame.
.png?generation=1687776281548084&alt=media)
## [TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=people-tracking-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
dderr/errortest | 2023-09-12T05:18:26.000Z | [
"region:us"
] | dderr | null | null | null | 0 | 5 | Entry not found |
llm-lens/lens_sample_test | 2023-09-18T01:27:52.000Z | [
"region:us"
] | llm-lens | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': abyssinian
'1': american bulldog
'2': american pit bull terrier
'3': basset hound
'4': beagle
'5': bengal
'6': birman
'7': bombay
'8': boxer
'9': british shorthair
'10': chihuahua
'11': egyptian mau
'12': english cocker spaniel
'13': english setter
'14': german shorthaired
'15': great pyrenees
'16': havanese
'17': japanese chin
'18': keeshond
'19': leonberger
'20': maine coon
'21': miniature pinscher
'22': newfoundland
'23': persian
'24': pomeranian
'25': pug
'26': ragdoll
'27': russian blue
'28': saint bernard
'29': samoyed
'30': scottish terrier
'31': shiba inu
'32': siamese
'33': sphynx
'34': staffordshire bull terrier
'35': wheaten terrier
'36': yorkshire terrier
- name: id
dtype: int64
- name: tags_laion-ViT-H-14-2B
sequence: string
- name: attributes_laion-ViT-H-14-2B
sequence: string
- name: caption_Salesforce-blip-image-captioning-large
dtype: string
- name: intensive_captions_Salesforce-blip-image-captioning-large
sequence: string
splits:
- name: test
num_bytes: 183543.0
num_examples: 10
download_size: 162581
dataset_size: 183543.0
---
# Dataset Card for "lens_sample_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
FreedomIntelligence/evol-instruct-arabic | 2023-08-06T08:11:34.000Z | [
"region:us"
] | FreedomIntelligence | null | null | null | 1 | 5 | The dataset is used in the research related to [MultilingualSIFT](https://github.com/FreedomIntelligence/MultilingualSIFT). |
rdpahalavan/network-packet-flow-header-payload | 2023-07-22T21:40:27.000Z | [
"task_categories:text-classification",
"size_categories:1M<n<10M",
"license:apache-2.0",
"Network Intrusion Detection",
"Cybersecurity",
"Network Packets",
"region:us"
] | rdpahalavan | null | null | null | 2 | 5 | ---
license: apache-2.0
task_categories:
- text-classification
tags:
- Network Intrusion Detection
- Cybersecurity
- Network Packets
size_categories:
- 1M<n<10M
---
Each row contains the information of a network packet and its label. The format is given below:
 |
duyhngoc/OV_Text | 2023-07-05T04:59:06.000Z | [
"task_categories:text-generation",
"annotations_creators:no-annotation",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:vi",
"license:apache-2.0",
"region:us"
] | duyhngoc | OVText | \ | null | 0 | 5 | ---
annotations_creators:
- no-annotation
language:
- vi
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: OV_Text
size_categories:
- 10K<n<100K
task_categories:
- text-generation
---
# Dataset Card for OV_Text
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
The OV_Text dataset is a collection of 100,000 sentences sourced from various news articles.
Out of the 10,000 sentences in the dataset, 5,000 sentences have a length ranging from 50 to 150, while the other 5,000 sentences have a length ranging from 20 to 50. This distribution of sentence lengths provides a diverse range of text samples that can be used to train and test natural language processing models.
### Dataset Summary
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
| name | train | validation | test |
|---------|--------:|-----------:|-------:|
| small | 1600 | 200 | 200 |
| base | 8000 | 1000 | 1000 |
| large | 95000 | 2500 | 2500 |
## Dataset Creation
### Curation Rationale
### Source Data
### Annotations
## Additional Information
### Licensing Information
The dataset is released under Apache 2.0.
### Citation Information
### Contributions
|
AtlasUnified/atlas-pdf-img-cluster | 2023-09-26T20:42:50.000Z | [
"task_categories:image-classification",
"task_categories:image-segmentation",
"task_categories:image-to-text",
"size_categories:10M<n<100M",
"language:en",
"license:osl-3.0",
"OCR",
"Text-Image Pairs",
"region:us"
] | AtlasUnified | null | null | null | 1 | 5 | ---
task_categories:
- image-classification
- image-segmentation
- image-to-text
tags:
- OCR
- Text-Image Pairs
size_categories:
- 10M<n<100M
license: osl-3.0
language:
- en
pretty_name: Atlas PDF Image Cluster
---
# Atlas PDF Image Cluster Dataset
Derives from the following Python Pipeline code:
https://github.com/atlasunified/PDF-to-Image-Cluster
# Dataset Description
This dataset is a collection of text extracted from PDF files, originating from various online resources. The dataset was generated using a series of Python scripts forming a robust pipeline that automated the tasks of downloading, converting, and managing the data.
# Dataset Summary
Sample JPG

Corresponding JSON file with Bounding Box and Text data
```
Bounding box: [[0.10698689956331878, 0.008733624454148471], [0.7336244541484717, 0.008733624454148471], [0.7336244541484717, 0.06986899563318777], [0.10698689956331878, 0.06986899563318777]], Text: the Simchas Bais
Bounding box: [[0.013100436681222707, 0.12663755458515283], [0.7314410480349345, 0.12663755458515283], [0.7314410480349345, 0.1965065502183406], [0.013100436681222707, 0.1965065502183406]], Text: they are engaged in
Bounding box: [[0.0, 0.2445414847161572], [0.7379912663755459, 0.23580786026200873], [0.7379912663755459, 0.31222707423580787], [0.0, 0.31877729257641924]], Text: hey could become
Bounding box: [[0.008733624454148471, 0.36026200873362446], [0.7336244541484717, 0.36026200873362446], [0.7336244541484717, 0.425764192139738], [0.008733624454148471, 0.425764192139738]], Text: evil inclination still
Bounding box: [[0.004366812227074236, 0.48034934497816595], [0.31004366812227074, 0.4847161572052402], [0.31004366812227074, 0.5567685589519651], [0.004366812227074236, 0.5502183406113537]], Text: certainly
Bounding box: [[0.36899563318777295, 0.4890829694323144], [0.5480349344978166, 0.4890829694323144], [0.5480349344978166, 0.5524017467248908], [0.36899563318777295, 0.5524017467248908]], Text: men
Bounding box: [[0.5851528384279476, 0.4781659388646288], [0.740174672489083, 0.4781659388646288], [0.740174672489083, 0.5524017467248908], [0.5851528384279476, 0.5524017467248908]], Text: and
Bounding box: [[0.008733624454148471, 0.6004366812227074], [0.7336244541484717, 0.6004366812227074], [0.7336244541484717, 0.6681222707423581], [0.008733624454148471, 0.6681222707423581]], Text: e in separate areas.
Bounding box: [[0.9454148471615721, 0.6157205240174672], [0.9978165938864629, 0.6157205240174672], [0.9978165938864629, 0.6877729257641921], [0.9454148471615721, 0.6877729257641921]], Text: T
Bounding box: [[0.9519650655021834, 0.7532751091703057], [0.9978165938864629, 0.7532751091703057], [0.9978165938864629, 0.8078602620087336], [0.9519650655021834, 0.8078602620087336]], Text: 0
Bounding box: [[0.9475982532751092, 0.851528384279476], [0.9978165938864629, 0.851528384279476], [0.9978165938864629, 0.9235807860262009], [0.9475982532751092, 0.9235807860262009]], Text: fl\n
```
Sample JPG

Corresponding JSON file with Bounding Box and Text data
```
Bounding box: [[0.011570247933884297, 0.428099173553719], [0.9867768595041322, 0.428099173553719], [0.9867768595041322, 0.4677685950413223], [0.011570247933884297, 0.4677685950413223]], Text: tural person subiect to the reguirements laic
Bounding box: [[0.0049586776859504135, 0.5173553719008265], [0.9884297520661157, 0.5140495867768595], [0.9884297520661157, 0.5636363636363636], [0.0049586776859504135, 0.5669421487603306]], Text: priate, the provisions of sections 43 and 44;
Bounding box: [[0.009917355371900827, 0.6082644628099173], [0.9900826446280991, 0.6082644628099173], [0.9900826446280991, 0.6528925619834711], [0.009917355371900827, 0.6528925619834711]], Text: section 3. A person with no municipality of r
Bounding box: [[0.009917355371900827, 0.7041322314049587], [0.9917355371900827, 0.7041322314049587], [0.9917355371900827, 0.743801652892562], [0.009917355371900827, 0.743801652892562]], Text: ied by the authorities in their country of resi
Bounding box: [[0.0049586776859504135, 0.7917355371900826], [0.9917355371900827, 0.7950413223140496], [0.9917355371900827, 0.8396694214876033], [0.0049586776859504135, 0.8347107438016529]], Text: firearm or firearm component in question ir
```
Sample JPG

Corresponding JSON file with Bounding Box and Text data
```
Bounding box: [[0.19349005424954793, 0.5334538878842676], [0.7902350813743219, 0.5370705244122965], [0.7902350813743219, 0.5822784810126582], [0.19349005424954793, 0.5786618444846293]], Text: Generic Drug Description
Bounding box: [[0.19529837251356238, 0.6274864376130199], [0.9909584086799277, 0.6274864376130199], [0.9909584086799277, 0.6708860759493671], [0.19529837251356238, 0.6708860759493671]], Text: Carboxymethylcellulose Sodium (
```
# Supported Tasks and Use Cases
The primary use case of this dataset is to serve as training data for machine learning models that operate on text data. This may include, but is not limited to, text classification, information extraction, named entity recognition, and machine translation tasks.
# Dataset Creation
This dataset was generated through a multi-stage Python pipeline designed to handle the downloading, conversion, and management of large datasets.
Primary URLs for downloading comes from ROM1504's dataset at the following link: http://3080.rom1504.fr/n/text/text38M/
# Data Fields
As the dataset contains text extracted from PDF files from the common crawl. the data fields primarily include the extracted text and bounding box information. |
declare-lab/flan-mini | 2023-07-06T05:19:06.000Z | [
"size_categories:1M<n<10M",
"license:cc",
"arxiv:2307.02053",
"region:us"
] | declare-lab | null | null | null | 11 | 5 | ---
dataset_info:
features:
- name: id
dtype: string
- name: source
dtype: string
- name: conversations
dtype: list
splits:
- name: train
num_examples: 1340153
license: cc
size_categories:
- 1M<n<10M
---
# Dataset Card for Flan-mini
## Dataset Description
- **Repository:** https://github.com/declare-lab/flacuna
- **Paper:** https://arxiv.org/abs//2307.02053
- **Leaderboard:** https://declare-lab.net/instruct-eval/
- **Point of Contact:** sporia@sutd.edu.sg
### Dataset Summary
Given the enormous size of the Flan Collection, we opted to work with a carefully selected subset that maintains a high level of task diversity while reducing the overall dataset size. In the Table below, we present the specific tasks included in our subset of Flan, along with their respective dataset sizes.
As the public release of the Flan Collection does not include programming tasks, we augment the collection with existing code datasets.
Specifically, we include CodeContests, APPS, and CodeSearchNet.
Following the data processing pipeline of Flan Collection, we sample a fixed number of examples from each dataset, where each example is randomly augmented with different prompt templates.
Specifically, the examples are processed with a pool of handcrafted prompt templates and may be used as zero-shot examples or grouped together with few-shot demonstrations.
We incorporated various ChatGPT datasets, including Alpaca, Code Alpaca, and ShareGPT, into our Flan-mini collection.
| Dataset Name | Source | Dataset Size |
|-----------------------------|------------------------|--------------|
| Flan2021 | Flan | 388K |
| Public Pool of Prompts | Flan | 320K |
| Natural instructions v2 | Flan | 200K |
| CoT | Flan | 100K |
| Code Search | HF/code_search_net | 100K |
| Code Contest | HF/deepmind/code_contests | 50K |
| Apps | HF/codeparrot/apps | 50K |
| GPT4-Alpaca | GPT-4 | 52K |
| Code-Alpaca | ChatGPT | 20K |
| ShareGPT | ChatGPT | 60K |
| Total | - | 1.34M |
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Citation Information
```bibtex
@misc{ghosal2023flacuna,
title={Flacuna: Unleashing the Problem Solving Power of Vicuna using FLAN Fine-Tuning},
author={Deepanway Ghosal and Yew Ken Chia and Navonil Majumder and Soujanya Poria},
year={2023},
eprint={2307.02053},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
jmukesh99/AIBE_mcq | 2023-08-31T18:51:18.000Z | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"size_categories:n<1K",
"language:en",
"license:cc-by-nc-4.0",
"AIBE",
"BAREXAM",
"INDIAN-BAR-EXAM",
"region:us"
] | jmukesh99 | null | null | null | 1 | 5 | ---
license: cc-by-nc-4.0
task_categories:
- multiple-choice
- question-answering
language:
- en
tags:
- AIBE
- BAREXAM
- INDIAN-BAR-EXAM
pretty_name: aibemcq
size_categories:
- n<1K
---
## Dataset Description
- **Point of Contact:** https://www.linkedin.com/in/jmukesh99/
### Dataset Summary
This dataset is generated with the aim to collect all indian BAR exam questions. This could serve the purpose of Evaluating Language models.
### Contributions
Mukesh Jha, DA-IICT, Gandhinagar, India |
dylanalloy/ehc-contrived-financial | 2023-07-07T15:03:51.000Z | [
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"arxiv:2210.03350",
"region:us"
] | dylanalloy | null | null | null | 3 | 5 | ---
license: apache-2.0
task_categories:
- question-answering
language:
- en
pretty_name: ehc-contrived-financial
size_categories:
- 10K<n<100K
---
# Everything Has Context | contrived company research example (ehc-contrived-financial)
### 📝 Description
`train.csv` dataset contains 12,514 rows of high-quality contrived<sup>1</sup> research patterns in the public market equities category for Q/A pairs with a high perplexity<sup>2</sup>.
The data is generated from `davinci-turbo` using the OpenAI API with prompts engineered to do several things which incite a grounded hallucinatory research example each call:
1. Generate one-shot Q/A example with a mask for the subject using the syntax `[Company]` which has a high perplexity thus requires multiple follow up questions (or the answer itself requires two sources of external context).
2. Between the question and answer of each one-shot example, hallucinate context from a search of equity filings data required to get to the answer.
3. Replace `[Company]` instances with a random company from a list in our case of 118 companies<sup>*</sup>
4. Filter on all rows for conditions which suit your needs (we choose higher perplexity which we define in a contrived dataset as: `∀(context,followup)∈S, where S is the dataset, and ∣{(context,followup)}∣>2`)
### 🙈 Contrived!
It's not real context. We are researching what this means for compositionality gaps in the respective domain for the model finetuning. There are perhaps more obvious limitations around the ability to reason on questions with high perplexity involved which the model has not been finetuned on, especially as reasoning about the question's context requirements could grow. Naively-posed questions, loaded questions, or questions of a contradictory manner may throw off the reasoning and context retrieval abilities of a finetuned model derived from a contrived 'environment', if you will. These are just some of the challenges which may be posed using a contrived set of Q/A context-driven dataset.
## 🧑💻 Other Datasets for Everything Has Context
1️⃣ <i>real world context:</i> not out yet but it's comin'. I have the context though I don't have the generations, give it a week max from this README commit's date.
2️⃣ <i>databricks-dolly-15k x real world context:</i> see 1
----
#### 💬 Citation
<sup>*</sup> <small>we do this after the work in 1, 2 because it removes the potential of sticky base model knowledge affecting the context and Q/A diversity! we do only 118 companies because the company names don't matter, facts in context do</small>
<sup>1</sup> <small>contrived is a term we use here to say there was a prompt engineered to create the data from a world-class model
<sup>2</sup> <small>@misc{press2023measuring,
title={Measuring and Narrowing the Compositionality Gap in Language Models},
author={Ofir Press and Muru Zhang and Sewon Min and Ludwig Schmidt and Noah A. Smith and Mike Lewis},
year={2023},
eprint={2210.03350},
archivePrefix={arXiv},
primaryClass={cs.CL}
}</small> |
nampdn-ai/tinystories-vietnamese | 2023-07-14T01:34:17.000Z | [
"language:en",
"language:vi",
"license:mit",
"doi:10.57967/hf/0894",
"region:us"
] | nampdn-ai | null | null | null | 6 | 5 | ---
license: mit
language:
- en
- vi
pretty_name: Vietnamese Tiny Stories
--- |
allandclive/UgandaLex2 | 2023-07-12T13:03:09.000Z | [
"task_categories:text-generation",
"task_categories:translation",
"size_categories:1K<n<10K",
"language:ach",
"language:alz",
"language:teo",
"language:gwr",
"language:adh",
"language:keo",
"language:kin",
"language:laj",
"language:lgg",
"language:myx",
"language:kdj",
"language:nyn",
... | allandclive | null | null | null | 1 | 5 | ---
task_categories:
- text-generation
- translation
language:
- ach
- alz
- teo
- gwr
- adh
- keo
- kin
- laj
- lgg
- myx
- kdj
- nyn
- nuj
- xog
- lg
- en
- luc
- kbo
- tjl
- rub
- ndp
- nyo
- lsm
pretty_name: UgandaLex2
size_categories:
- 1K<n<10K
---
### UgandaLex2: A Parallel Text Translation Corpus in 24 Ugandan Languages (3 added languages)
UgandaLex Parallel Texts in Ugandan Languages is a remarkable dataset consisting of parallel texts sourced from Bible translations across 21 Ugandan languages. This expansive corpus provides an invaluable resource for studying and analyzing the linguistic variations and nuances within Uganda's diverse language landscape. With aligned texts from various Bible translations, researchers, linguists, and developers can delve into the intricacies of Ugandan languages, explore translation patterns, and investigate the cultural and linguistic heritage of different communities. UgandaLex opens up avenues for advancing research in computational linguistics, cross-linguistic analysis, and the development of language technologies tailored specifically for Ugandan languages.
### Languages
**Kebu, Acholi, **Saamya-Gwe, **Nyoro, Alur, Aringa, Ateso, Ganda, Gwere, Jopadhola, Kakwa, Kinyarwanda, Kumam, Lango, Lugbara, Masaaba, Ng'akarimojong, Nyankore, Nyole, Soga, Swahili, English, Gungu, Keliko, Talinga-Bwisi
### Contributors
@allandclive & @oumo_os |
davanstrien/test_imdb_embedd | 2023-07-13T10:57:00.000Z | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:imdb",
"language:en",
"license:other",
"embeddings",
"region:us... | davanstrien | null | null | null | 0 | 5 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets: imdb
task_categories:
- text-classification
task_ids:
- sentiment-classification
paperswithcode_id: imdb-movie-reviews
pretty_name: IMDB
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
0: neg
1: pos
config_name: plain_text
splits:
- name: train
num_bytes: 33432835
num_examples: 25000
- name: test
num_bytes: 32650697
num_examples: 25000
- name: unsupervised
num_bytes: 67106814
num_examples: 50000
download_size: 84125825
dataset_size: 133190346
tags:
- embeddings
train-eval-index:
- config: plain_text
task: text-classification
task_id: binary_classification
splits:
train_split: train
eval_split: test
col_mapping:
text: text
label: target
metrics:
- type: accuracy
- name: Accuracy
- type: f1
name: F1 macro
args:
average: macro
- type: f1
name: F1 micro
args:
average: micro
- type: f1
name: F1 weighted
args:
average: weighted
- type: precision
name: Precision macro
args:
average: macro
- type: precision
name: Precision micro
args:
average: micro
- type: precision
name: Precision weighted
args:
average: weighted
- type: recall
name: Recall macro
args:
average: macro
- type: recall
name: Recall micro
args:
average: micro
- type: recall
name: Recall weighted
args:
average: weighted
---
# Dataset Card for "test_imdb_embedd"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TinyPixel/dolphin-2 | 2023-07-13T06:19:34.000Z | [
"region:us"
] | TinyPixel | null | null | null | 2 | 5 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1623415440
num_examples: 891857
download_size: 884160758
dataset_size: 1623415440
---
# Dataset Card for "dolphin-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Gustrd/dolly-15k-libretranslate-pt | 2023-07-18T02:04:29.000Z | [
"task_categories:question-answering",
"task_categories:summarization",
"size_categories:10K<n<100K",
"language:pt",
"license:cc-by-sa-3.0",
"region:us"
] | Gustrd | null | null | null | 2 | 5 | ---
license: cc-by-sa-3.0
task_categories:
- question-answering
- summarization
language:
- pt
size_categories:
- 10K<n<100K
---
# Summary
databricks-dolly-15k ( https://huggingface.co/datasets/databricks/databricks-dolly-15k/ ) is an open source dataset of instruction-following records generated by thousands of Databricks employees in several of the behavioral categories outlined in the InstructGPT paper, including brainstorming, classification, closed QA, generation, information extraction, open QA, and summarization.
This is a portuguese translation done with libretranslate ( https://github.com/LibreTranslate/LibreTranslate ).
This dataset can be used for any purpose, whether academic or commercial, under the terms of the Creative Commons Attribution-ShareAlike 3.0 Unported License.
Supported Tasks:
- Training LLMs
- Synthetic Data Generation
- Data Augmentation
Languages: Portuguese
Version: 1.0
---
# Original Readme
Dataset Overview
databricks-dolly-15k is a corpus of more than 15,000 records generated by thousands of Databricks employees to enable large language models to exhibit the magical interactivity of ChatGPT. Databricks employees were invited to create prompt / response pairs in each of eight different instruction categories, including the seven outlined in the InstructGPT paper, as well as an open-ended free-form category. The contributors were instructed to avoid using information from any source on the web with the exception of Wikipedia (for particular subsets of instruction categories), and explicitly instructed to avoid using generative AI in formulating instructions or responses. Examples of each behavior were provided to motivate the types of questions and instructions appropriate to each category.
Halfway through the data generation process, contributors were given the option of answering questions posed by other contributors. They were asked to rephrase the original question and only select questions they could be reasonably expected to answer correctly.
For certain categories contributors were asked to provide reference texts copied from Wikipedia. Reference text (indicated by the context field in the actual dataset) may contain bracketed Wikipedia citation numbers (e.g. [42]) which we recommend users remove for downstream applications.
Intended Uses
While immediately valuable for instruction fine tuning large language models, as a corpus of human-generated instruction prompts, this dataset also presents a valuable opportunity for synthetic data generation in the methods outlined in the Self-Instruct paper. For example, contributor--generated prompts could be submitted as few-shot examples to a large open language model to generate a corpus of millions of examples of instructions in each of the respective InstructGPT categories.
Likewise, both the instructions and responses present fertile ground for data augmentation. A paraphrasing model might be used to restate each prompt or short responses, with the resulting text associated to the respective ground-truth sample. Such an approach might provide a form of regularization on the dataset that could allow for more robust instruction-following behavior in models derived from these synthetic datasets.
Dataset
Purpose of Collection
As part of our continuing commitment to open source, Databricks developed what is, to the best of our knowledge, the first open source, human-generated instruction corpus specifically designed to enable large language models to exhibit the magical interactivity of ChatGPT. Unlike other datasets that are limited to non-commercial use, this dataset can be used, modified, and extended for any purpose, including academic or commercial applications.
Sources
Human-generated data: Databricks employees were invited to create prompt / response pairs in each of eight different instruction categories.
Wikipedia: For instruction categories that require an annotator to consult a reference text (information extraction, closed QA, summarization) contributors selected passages from Wikipedia for particular subsets of instruction categories. No guidance was given to annotators as to how to select the target passages.
Annotator Guidelines
To create a record, employees were given a brief description of the annotation task as well as examples of the types of prompts typical of each annotation task. Guidelines were succinct by design so as to encourage a high task completion rate, possibly at the cost of rigorous compliance to an annotation rubric that concretely and reliably operationalizes the specific task. Caveat emptor.
The annotation guidelines for each of the categories are as follows:
Creative Writing: Write a question or instruction that requires a creative, open-ended written response. The instruction should be reasonable to ask of a person with general world knowledge and should not require searching. In this task, your prompt should give very specific instructions to follow. Constraints, instructions, guidelines, or requirements all work, and the more of them the better.
Closed QA: Write a question or instruction that requires factually correct response based on a passage of text from Wikipedia. The question can be complex and can involve human-level reasoning capabilities, but should not require special knowledge. To create a question for this task include both the text of the question as well as the reference text in the form.
Open QA: Write a question that can be answered using general world knowledge or at most a single search. This task asks for opinions and facts about the world at large and does not provide any reference text for consultation.
Summarization: Give a summary of a paragraph from Wikipedia. Please don't ask questions that will require more than 3-5 minutes to answer. To create a question for this task include both the text of the question as well as the reference text in the form.
Information Extraction: These questions involve reading a paragraph from Wikipedia and extracting information from the passage. Everything required to produce an answer (e.g. a list, keywords etc) should be included in the passages. To create a question for this task include both the text of the question as well as the reference text in the form.
Classification: These prompts contain lists or examples of entities to be classified, e.g. movie reviews, products, etc. In this task the text or list of entities under consideration is contained in the prompt (e.g. there is no reference text.). You can choose any categories for classification you like, the more diverse the better.
Brainstorming: Think up lots of examples in response to a question asking to brainstorm ideas.
Personal or Sensitive Data
This dataset contains public information (e.g., some information from Wikipedia). To our knowledge, there are no private person’s personal identifiers or sensitive information.
Known Limitations
Wikipedia is a crowdsourced corpus and the contents of this dataset may reflect the bias, factual errors and topical focus found in Wikipedia
Some annotators may not be native English speakers
Annotator demographics and subject matter may reflect the makeup of Databricks employees
---
license: cc-by-sa-3.0
--- |
davanstrien/blbooks-parquet | 2023-07-13T14:29:21.000Z | [
"task_categories:text-generation",
"task_categories:fill-mask",
"task_categories:other",
"task_ids:language-modeling",
"task_ids:masked-language-modeling",
"annotations_creators:no-annotation",
"language_creators:machine-generated",
"multilinguality:multilingual",
"size_categories:100K<n<1M",
"sou... | davanstrien | null | null | null | 0 | 5 | ---
annotations_creators:
- no-annotation
language_creators:
- machine-generated
language:
- de
- en
- es
- fr
- it
- nl
license:
- cc0-1.0
multilinguality:
- multilingual
size_categories:
- 100K<n<1M
source_datasets:
- blbooks
task_categories:
- text-generation
- fill-mask
- other
task_ids:
- language-modeling
- masked-language-modeling
pretty_name: British Library Books
tags:
- digital-humanities-research
dataset_info:
- config_name: all
features:
- name: record_id
dtype: string
- name: date
dtype: int32
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 30394267732
num_examples: 14011953
download_size: 10486035662
dataset_size: 30394267732
- config_name: 1800s
features:
- name: record_id
dtype: string
- name: date
dtype: int32
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 30020434670
num_examples: 13781747
download_size: 10348577602
dataset_size: 30020434670
- config_name: 1700s
features:
- name: record_id
dtype: string
- name: date
dtype: int32
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 266382657
num_examples: 178224
download_size: 95137895
dataset_size: 266382657
- config_name: '1510_1699'
features:
- name: record_id
dtype: string
- name: date
dtype: timestamp[s]
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 107667469
num_examples: 51982
download_size: 42320165
dataset_size: 107667469
- config_name: '1500_1899'
features:
- name: record_id
dtype: string
- name: date
dtype: timestamp[s]
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 30452067039
num_examples: 14011953
download_size: 10486035662
dataset_size: 30452067039
- config_name: '1800_1899'
features:
- name: record_id
dtype: string
- name: date
dtype: timestamp[s]
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 30077284377
num_examples: 13781747
download_size: 10348577602
dataset_size: 30077284377
- config_name: '1700_1799'
features:
- name: record_id
dtype: string
- name: date
dtype: timestamp[s]
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 267117831
num_examples: 178224
download_size: 95137895
dataset_size: 267117831
---
# Dataset Card for "blbooks-parquet"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
dipudl/hc3-and-gpt-wiki-intro-with-perplexity | 2023-07-20T19:23:00.000Z | [
"region:us"
] | dipudl | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: text
dtype: string
- name: source
dtype: string
- name: label
dtype: int64
- name: perplexity
dtype: float64
splits:
- name: train
num_bytes: 396594042.354058
num_examples: 330344
- name: test
num_bytes: 20925699.0
num_examples: 17387
download_size: 251965361
dataset_size: 417519741.354058
---
# Dataset Card for "hc3-and-gpt-wiki-intro-with-perplexity"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
animonte/train_house_price | 2023-07-17T19:49:52.000Z | [
"license:gpl-3.0",
"region:us"
] | animonte | null | null | null | 0 | 5 | ---
license: gpl-3.0
---
|
rombodawg/Legacy_MegaCodeTraining200k | 2023-08-16T02:30:41.000Z | [
"license:other",
"region:us"
] | rombodawg | null | null | null | 54 | 5 | ---
license: other
---
_________________________________________________________________________________
VERSION 3 IS RELEASED DOWNLOAD HERE:
- https://huggingface.co/datasets/rombodawg/LosslessMegaCodeTrainingV3_2.2m_Evol
_________________________________________________________________________________
Datasets:
Updated/Uncensored version here: https://huggingface.co/datasets/rombodawg/2XUNCENSORED_MegaCodeTraining188k
Non-code instruct training here: https://huggingface.co/datasets/rombodawg/2XUNCENSORED_alpaca_840k_Evol_USER_ASSIS
(Please note the change from 112k to 200k doesnt mean an increase in size of the dataset,
I simply mislabled it the first time)
This is a mega combined dataset using both razent/wizardlm-code-evol-32k and nickrosh/Evol-Instruct-Code-80k-v1
The Rombo's format.rar file is so you can use the training data in oobagooba text generation webui. Simply unzip it, and use it as a json file.
All links bellow
https://huggingface.co/datasets/razent/wizardlm-code-evol-32k
(This repository was deleted, however you can find each individual data file from this repository
re-uploaded as their own individual repositories on my huggingface account)
https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1/tree/main
Thank you to the contributors of the datasets. I do not own them, please give credit where credit is due
|
andersonbcdefg/physics | 2023-07-21T01:27:46.000Z | [
"region:us"
] | andersonbcdefg | null | null | null | 0 | 5 | ---
dataset_info:
features:
- name: role_1
dtype: string
- name: topic;
dtype: string
- name: sub_topic
dtype: string
- name: message_1
dtype: string
- name: message_2
dtype: string
splits:
- name: train
num_bytes: 51650490
num_examples: 20000
download_size: 23872399
dataset_size: 51650490
---
# Dataset Card for "physics"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
minskiter/msra | 2023-07-22T13:54:18.000Z | [
"region:us"
] | minskiter | The MSRA NER dataset is a Chinese Named Entity Recognition dataset | @inproceedings{levow-2006-third,
title = "The Third International {C}hinese Language Processing Bakeoff: Word Segmentation and Named Entity Recognition",
author = "Levow, Gina-Anne",
booktitle = "Proceedings of the Fifth {SIGHAN} Workshop on {C}hinese Language Processing",
month = jul,
year = "2006",
address = "Sydney, Australia",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W06-0115",
pages = "108--117",
} | null | 0 | 5 | ---
dataset_info:
features:
- name: text
sequence: string
- name: labels
sequence:
class_label:
names:
'0': O
'1': B-NS
'2': M-NS
'3': E-NS
'4': S-NS
'5': B-NT
'6': M-NT
'7': E-NT
'8': S-NT
'9': B-NR
'10': M-NR
'11': E-NR
'12': S-NR
splits:
- name: train
num_bytes: 32917977
num_examples: 46364
- name: test
num_bytes: 2623860
num_examples: 4365
download_size: 14890129
dataset_size: 35541837
---
### How to loading dataset?
```python
from datasets import load_dataset
datasets = load_dataset("minskiter/msra",save_infos=True)
train,test = datasets['train'],datasets['test']
# convert label to str
print(train.features['labels'].feature.int2str(0))
```
### Force update
```python
from datasets import load_dataset
datasets = load_dataset("minskiter/msra", download_mode="force_redownload")
```
### Fit your train
```python
def transform(example):
# edit example here
return example
for key in datasets:
datasets[key] = datasets.map(transform)
```
|
youssef101/artelingo-dummy | 2023-07-23T16:21:23.000Z | [
"task_categories:image-to-text",
"task_categories:text-classification",
"task_categories:image-classification",
"task_categories:text-to-image",
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:en",
"language:ar",
"language:zh",
"license:mit",
"Affective Captioning",
"... | youssef101 | null | null | null | 0 | 5 | ---
license: mit
dataset_info:
features:
- name: image
dtype: image
- name: art_style
dtype: string
- name: painting
dtype: string
- name: emotion
dtype: string
- name: language
dtype: string
- name: text
dtype: string
- name: split
dtype: string
splits:
- name: train
num_bytes: 18587167692.616
num_examples: 62989
- name: validation
num_bytes: 965978050.797
num_examples: 3191
- name: test
num_bytes: 2330046601.416
num_examples: 6402
download_size: 4565327615
dataset_size: 21883192344.829002
task_categories:
- image-to-text
- text-classification
- image-classification
- text-to-image
- text-generation
language:
- en
- ar
- zh
tags:
- Affective Captioning
- Emotions
- Prediction
- Art
- ArtELingo
pretty_name: ArtELingo
size_categories:
- 100K<n<1M
---
ArtELingo is a benchmark and dataset introduced in a research paper aimed at promoting work on diversity across languages and cultures. It is an extension of ArtEmis, which is a collection of 80,000 artworks from WikiArt with 450,000 emotion labels and English-only captions. ArtELingo expands this dataset by adding 790,000 annotations in Arabic and Chinese. The purpose of these additional annotations is to evaluate the performance of "cultural-transfer" in AI systems.
The dataset in ArtELingo contains many artworks with multiple annotations in three languages, providing a diverse set of data that enables the study of similarities and differences across languages and cultures. The researchers investigate captioning tasks and find that diversity in annotations improves the performance of baseline models.
The goal of ArtELingo is to encourage research on multilinguality and culturally-aware AI. By including annotations in multiple languages and considering cultural differences, the dataset aims to build more human-compatible AI that is sensitive to emotional nuances across various cultural contexts. The researchers believe that studying emotions in this way is crucial to understanding a significant aspect of human intelligence.
In summary, ArtELingo is a dataset that extends ArtEmis by providing annotations in multiple languages and cultures, facilitating research on diversity in AI systems and improving their performance in emotion-related tasks like label prediction and affective caption generation. The dataset is publicly available, and the researchers hope that it will facilitate future studies in multilingual and culturally-aware artificial intelligence. |
emozilla/booksum-summary-analysis_llama-8192 | 2023-07-23T18:20:24.000Z | [
"region:us"
] | emozilla | null | null | null | 8 | 5 | ---
dataset_info:
features:
- name: chapter
dtype: string
- name: text
dtype: string
- name: type
dtype: string
splits:
- name: train
num_bytes: 181882155.9809025
num_examples: 10201
- name: validation
num_bytes: 33836910.18621307
num_examples: 1724
- name: test
num_bytes: 25274232.87394451
num_examples: 1545
download_size: 84868415
dataset_size: 240993299.0410601
---
# Dataset Card for "booksum-summary-analysis_llama-8192"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
bigcode/xp3x-octopack | 2023-07-23T19:01:30.000Z | [
"region:us"
] | bigcode | null | null | null | 3 | 5 | Entry not found |
NebulaByte/E-Commerce_Customer_Support_Conversations | 2023-07-24T05:56:38.000Z | [
"region:us"
] | NebulaByte | null | null | null | 1 | 5 | ---
dataset_info:
features:
- name: issue_area
dtype: string
- name: issue_category
dtype: string
- name: issue_sub_category
dtype: string
- name: issue_category_sub_category
dtype: string
- name: customer_sentiment
dtype: string
- name: product_category
dtype: string
- name: product_sub_category
dtype: string
- name: issue_complexity
dtype: string
- name: agent_experience_level
dtype: string
- name: agent_experience_level_desc
dtype: string
- name: conversation
dtype: string
splits:
- name: train
num_bytes: 2537279
num_examples: 1000
download_size: 827367
dataset_size: 2537279
---
# Dataset Card for "E-Commerce_Customer_Support_Conversations"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
fujiki/llm-japanese-dataset_snow | 2023-07-25T05:54:43.000Z | [
"license:cc-by-4.0",
"region:us"
] | fujiki | null | null | null | 0 | 5 | ---
license: cc-by-4.0
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 16051702
num_examples: 84300
download_size: 5542365
dataset_size: 16051702
---
- This dataset is a subset of [izumi-lab/llm-japanese-dataset](https://huggingface.co/datasets/izumi-lab/llm-japanese-dataset) only including snow tasks.
- Please also refer to the original dataset: [izumi-lab/llm-japanese-dataset](https://huggingface.co/datasets/izumi-lab/llm-japanese-dataset)
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.