
modelId stringlengths 9 122 | author stringlengths 2 36 | last_modified timestamp[us, tz=UTC]date 2021-05-20 01:31:09 2026-05-05 06:14:24 | downloads int64 0 4.03M | likes int64 0 4.32k | library_name stringclasses 189
values | tags listlengths 1 237 | pipeline_tag stringclasses 53
values | createdAt timestamp[us, tz=UTC]date 2022-03-02 23:29:04 2026-05-05 05:54:22 | card stringlengths 500 661k | entities listlengths 0 12 |
|---|---|---|---|---|---|---|---|---|---|---|
Dracones/Midnight-Miqu-103B-v1.0-GGUF | Dracones | 2024-03-07T05:37:19Z | 28 | 4 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-03-06T15:41:48Z | <div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/Tn9MBg6.png" alt="MidnightMiqu" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
# Midnight-Miqu-103B-v1.0 - GGUF
These are GGUF quants of [sophosympatheia/Midnight-Miqu-103B-v1.0](https://huggin... | [] |
sdoerrich97/stylizing_vit_small_ddi_65_43_21 | sdoerrich97 | 2026-01-27T16:24:15Z | 1 | 0 | stylizing-vit | [
"stylizing-vit",
"safetensors",
"stylizing_vit",
"style-transfer",
"medical",
"dermatology",
"domain-generalization",
"vision-transformer",
"pytorch",
"image-to-image",
"en",
"arxiv:2601.17586",
"license:apache-2.0",
"region:us"
] | image-to-image | 2026-01-25T14:11:34Z | # Stylizing ViT Small - DDI *(Dermatology)*
<!-- Provide a quick summary of what the model is/does. -->
This model is the **Small** variant of **Stylizing ViT**, trained on the [**Diverse Dermatology Images (DDI)**](https://ddi-dataset.github.io/) (dermatology) dataset with the following splits: **Train: {56} / Val: {... | [
{
"start": 2,
"end": 15,
"text": "Stylizing ViT",
"label": "training method",
"score": 0.7818432450294495
},
{
"start": 146,
"end": 159,
"text": "Stylizing ViT",
"label": "training method",
"score": 0.9120538234710693
},
{
"start": 343,
"end": 356,
"text":... |
DiligentPenguinn/ecg_classifier_medgemma_challenge | DiligentPenguinn | 2026-02-22T11:41:51Z | 0 | 0 | pytorch | [
"pytorch",
"ecg",
"medical-imaging",
"multi-label-classification",
"medsiglip",
"mixture-of-experts",
"mlp",
"image-classification",
"en",
"license:mit",
"model-index",
"region:us"
] | image-classification | 2026-02-22T08:16:12Z | # ECG Image Classifier (MoE and MLP) on MedSigLIP Embeddings
This repository provides two PyTorch ECG classifier checkpoints trained on top of frozen MedSigLIP image embeddings:
- `moe_classifier_medsiglip.pt`: Mixture-of-Experts (MoE) classifier
- `mlp_classifier_medsiglip.pt`: Dense feedforward (MLP) classifier
Th... | [] |
phospho-app/ACT_BBOX-red_block_5th_try-55xs59ivr9 | phospho-app | 2025-09-28T15:51:03Z | 0 | 0 | phosphobot | [
"phosphobot",
"safetensors",
"act",
"robotics",
"dataset:tremmelnicholas/red_block_5th_try",
"region:us"
] | robotics | 2025-09-28T15:39:30Z | ---
datasets: tremmelnicholas/red_block_5th_try
library_name: phosphobot
pipeline_tag: robotics
model_name: act
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act model - 🧪 phosphobot training pipeline
- **Dataset**: [tremmelnicholas/red_block_5th_try](https://huggingface.co/datasets/tremmelnicholas/red_... | [] |
tomaarsen/clip-vit-L14-coco | tomaarsen | 2025-10-15T15:46:00Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"clip",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:10000",
"loss:MultipleNegativesRankingLoss",
"en",
"dataset:jxie/coco_captions",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:openai/clip-vit... | sentence-similarity | 2025-10-15T15:40:08Z | # CLIP ViT-L/14 model trained on COCO Captions
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [openai/clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) on the [coco_captions](https://huggingface.co/datasets/jxie/coco_captions) dataset. It maps sentences & pa... | [] |
MuXodious/Olmo-3.1-32B-Instruct-impotent-heresy | MuXodious | 2026-02-05T11:12:37Z | 6 | 2 | transformers | [
"transformers",
"safetensors",
"olmo3",
"text-generation",
"heretic",
"uncensored",
"decensored",
"abliterated",
"conversational",
"en",
"dataset:allenai/Dolci-Instruct-RL",
"arxiv:2512.13961",
"base_model:allenai/Olmo-3.1-32B-Instruct",
"base_model:finetune:allenai/Olmo-3.1-32B-Instruct",... | text-generation | 2026-02-01T00:39:18Z | This is an **Olmo-3.1-32B-Instruct** fine-tune, produced through P-E-W's [Heretic](https://github.com/p-e-w/heretic) (v1.1.0) abliteration engine merged with the [Magnitude-Preserving Orthogonal Ablation PR](https://github.com/p-e-w/heretic/pull/52).
**Note:** Original jinja template seems to have an issue with tool p... | [] |
gsjang/ko-llama-3-korean-bllossom-8b-x-meta-llama-3-8b-instruct-scope_merge | gsjang | 2025-09-15T02:50:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:MLP-KTLim/llama-3-Korean-Bllossom-8B",
"base_model:merge:MLP-KTLim/llama-3-Korean-Bllossom-8B",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:merge:meta-llama/Meta-Llama-... | text-generation | 2025-09-15T02:47:23Z | # ko-llama-3-korean-bllossom-8b-x-meta-llama-3-8b-instruct-scope_merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SCOPE-Merge (Self-Consistent Orthogonal Projection) merge method using [... | [
{
"start": 248,
"end": 259,
"text": "SCOPE-Merge",
"label": "training method",
"score": 0.8303403258323669
},
{
"start": 750,
"end": 761,
"text": "scope_merge",
"label": "training method",
"score": 0.8156642913818359
}
] |
BidirLM/BidirLM-1B-Base | BidirLM | 2026-04-07T17:56:54Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bidirlm",
"fill-mask",
"bidirectional",
"multilingual",
"custom_code",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"bs",
"ca",
"ceb",
"cs",
"cy",
"da",
"de",
"el",
"en",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"ga",
"gl",
"gu",
... | fill-mask | 2026-04-07T17:56:29Z | # BidirLM-1B-Base
BidirLM-1B-Base is the intermediate MNTP-adapted checkpoint of the BidirLM family. It is obtained by converting [Gemma3-1B](https://huggingface.co/google/gemma-3-1b-pt) from causal to bidirectional attention and training with Masked Next Token Prediction (MNTP) on 30B tokens from a multi-domain corpu... | [] |
mradermacher/FluffyTail4b-i1-GGUF | mradermacher | 2026-02-05T16:00:10Z | 111 | 1 | transformers | [
"transformers",
"gguf",
"conversational",
"Furry",
"merge",
"LoRA",
"ru",
"base_model:MarkProMaster229/FluffyTail4b",
"base_model:quantized:MarkProMaster229/FluffyTail4b",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2026-02-05T15:05:54Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [] |
falsidqnaoc/5g-network-fault-diagnosis-7b | falsidqnaoc | 2026-02-02T15:34:24Z | 0 | 0 | null | [
"5g",
"network-diagnosis",
"fault-detection",
"qwen",
"telecom",
"text-classification",
"en",
"zh",
"license:apache-2.0",
"region:us"
] | text-classification | 2026-02-02T15:22:25Z | # 5G Network Fault Diagnosis System (7B Model)
## Overview
This project contains the solver implementation for the 7B model track. It is designed to automatically diagnose 5G network issues by analyzing drive test data, engineering parameters, and problem descriptions.
The system employs a **Hybrid Neuro-Symboli... | [] |
TAIDE-EDU/history-gemma3-taide-sft-v2 | TAIDE-EDU | 2025-11-18T08:29:53Z | 0 | 0 | null | [
"safetensors",
"gemma3",
"region:us"
] | null | 2025-10-25T19:28:20Z | # history-phi4-lora-sft-v2
本模型 **TAIDE-EDU/history-gemma3-taide-sft-v2** 專為 **高中小論文批改** 設計。
輸入論文本體(含 `--- Page N ---` 分頁標記),模型會輸出 **單一 JSON 物件**,包含:
- `annotation`:逐頁具體評論(優點、缺點、修正建議)
- `overall`:綜合總評(附整體等第)
---
## 使用方式(vllm)
```python
import transformers
# 論文本體(需自行放入)
paper_text = """
--- Page 1 ---
這裡是論文的第一頁內容... | [] |
Nik1810/LFM2-2.6B-SFT | Nik1810 | 2026-03-09T02:43:43Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"trackio",
"trackio:https://Nik1810-LFM2-2.6B-SFT.hf.space?project=huggingface&runs=Nik1810-1773023225&sidebar=collapsed",
"dataset:HuggingFaceH4/helpful-anthropic-raw",
"base_model:LiquidAI/LFM2-2.6B",
"base_model:finetune:Liq... | null | 2026-03-08T22:43:24Z | # Model Card for LFM2-2.6B-SFT
This model is a fine-tuned version of [LiquidAI/LFM2-2.6B](https://huggingface.co/LiquidAI/LFM2-2.6B) on the [HuggingFaceH4/helpful-anthropic-raw](https://huggingface.co/datasets/HuggingFaceH4/helpful-anthropic-raw) dataset.
It has been trained using [TRL](https://github.com/huggingface/... | [] |
giovannidemuri/llama3b-llamab8-er-afg-v14-seed2-mcdonald-codealpaca-fpt | giovannidemuri | 2025-08-12T14:21:51Z | 1 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:meta-llama/Llama-3.2-3B",
"base_model:finetune:meta-llama/Llama-3.2-3B",
"license:llama3.2",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-08-12T13:52:08Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama3b-llamab8-er-afg-v14-seed2-mcdonald-codealpaca-fpt
This model is a fine-tuned version of [meta-llama/Llama-3.2-3B](https://... | [] |
HPLT/hplt_gpt_bert_base_3_0_fra_Latn | HPLT | 2026-02-25T17:06:46Z | 14 | 0 | null | [
"pytorch",
"BERT",
"HPLT",
"encoder",
"text2text-generation",
"custom_code",
"fr",
"fra",
"dataset:HPLT/HPLT3.0",
"arxiv:2511.01066",
"arxiv:2410.24159",
"license:apache-2.0",
"region:us"
] | null | 2026-02-16T17:15:50Z | # HPLT v3.0 GPT-BERT for French
<img src="https://hplt-project.org/_next/static/media/logo-hplt.d5e16ca5.svg" width=12.5%>
This is one of the monolingual language models trained as a third release by the [HPLT project](https://hplt-project.org/).
Our models follow the setup of [GPT-BERT](https://aclanthology.org/2024... | [] |
duya666/gemma-4-E2B-it | duya666 | 2026-04-07T13:34:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma4",
"image-text-to-text",
"any-to-any",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | any-to-any | 2026-04-07T13:34:37Z | <div align="center">
<img src=https://ai.google.dev/gemma/images/gemma4_banner.png>
</div>
<p align="center">
<a href="https://huggingface.co/collections/google/gemma-4" target="_blank">Hugging Face</a> |
<a href="https://github.com/google-gemma" target="_blank">GitHub</a> |
<a href="https://blog.google... | [] |
cwaud/37bc5eb3-855c-4e9e-ba2f-843c1c30acbe | cwaud | 2025-09-26T03:34:57Z | 1 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:NousResearch/Meta-Llama-3-8B",
"base_model:adapter:NousResearch/Meta-Llama-3-8B",
"license:other",
"region:us"
] | null | 2025-09-26T03:14:32Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" wid... | [] |
ankitdhiman/nemotron-hinglish-4b-thinking-tool-use | ankitdhiman | 2025-08-26T09:57:11Z | 0 | 2 | null | [
"safetensors",
"hi",
"en",
"dataset:Jofthomas/hermes-function-calling-thinking-V1",
"dataset:maya-research/IndicVault",
"base_model:nvidia/Nemotron-4-Mini-Hindi-4B-Instruct",
"base_model:finetune:nvidia/Nemotron-4-Mini-Hindi-4B-Instruct",
"region:us"
] | null | 2025-08-26T08:20:16Z | # Nemotron Hinglish 4B Thinking Tool Use
A fine-tuned version of NVIDIA's Nemotron-4-Mini-Hindi-4B-Instruct model for function calling and reasoning in Hindi and Hinglish (Hindi-English code-mixed language).
## Model Details
- **Base Model**: nvidia/Nemotron-4-Mini-Hindi-4B-Instruct
- **Fine-tuning Method**: LoRA (L... | [] |
animaslabs/Qwen3-1.7B-4bit | animaslabs | 2026-02-21T20:11:56Z | 71 | 1 | mlx | [
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-1.7B",
"base_model:quantized:Qwen/Qwen3-1.7B",
"license:apache-2.0",
"4-bit",
"region:us"
] | text-generation | 2026-02-21T20:11:05Z | # animaslabs/Qwen3-1.7B-4bit
This model [animaslabs/Qwen3-1.7B-4bit](https://huggingface.co/animaslabs/Qwen3-1.7B-4bit) was
converted to MLX format from [Qwen/Qwen3-1.7B](https://huggingface.co/Qwen/Qwen3-1.7B)
using mlx-lm version **0.30.7**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm imp... | [] |
tanaos/tanaos-guardrail-german | tanaos | 2026-03-27T07:08:15Z | 83 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"safety",
"moderation",
"guardrail",
"small-model",
"synthetic-data",
"tanaos",
"artifex",
"de",
"dataset:tanaos/synthetic-guardrail-dataset-german",
"base_model:distilbert/distilbert-base-multilingual-cased",
"base_mode... | text-classification | 2026-02-10T11:49:57Z | <p align="center">
<img src="https://raw.githubusercontent.com/tanaos/.github/master/assets/logo.png" width="250px" alt="Tanaos – Train task specific LLMs without training data, for offline NLP and Text Classification">
</p>
# tanaos-guardrail-german: A small but performant guardrail model specifically designed fo... | [] |
chubbyk/ML-Agents-SoccerTwos-New-v2 | chubbyk | 2026-02-11T05:11:41Z | 8 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] | reinforcement-learning | 2026-02-11T05:06:21Z | # **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Document... | [] |
zacdan4801/wav2vec2-lv-60-espeak-cv-ft-custom_vocab-OtherDiacritics-ds-f1 | zacdan4801 | 2026-05-03T22:46:35Z | 67 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/wav2vec2-lv-60-espeak-cv-ft",
"base_model:finetune:facebook/wav2vec2-lv-60-espeak-cv-ft",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2026-04-17T02:30:31Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-lv-60-espeak-cv-ft-custom_vocab-OtherDiacritics-ds-f1
This model is a fine-tuned version of [facebook/wav2vec2-lv-6... | [] |
VMuccio/orange_policy_v1 | VMuccio | 2026-04-29T12:47:24Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"smolvla",
"robotics",
"dataset:VMuccio/pick_orange_cube",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] | robotics | 2026-04-29T12:46:47Z | # Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This pol... | [] |
WasamiKirua/Sakura-24B-Cortex | WasamiKirua | 2026-05-01T17:20:18Z | 150 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"dare_ties",
"mistral-small",
"reasoning",
"cyber-nature",
"roleplay",
"logical-gaslighting",
"conversational",
"en",
"it",
"base_model:mistralai/Mistral-Small-24B-Instruct-2501",
"base_model:finetune:m... | text-generation | 2026-04-30T12:57:00Z | <img src="https://i.postimg.cc/jjSGq1zL/Gemini-Generated-Image-tubt6mtubt6mtubt.png" alt="cover" border="0" width="1024px">
# 🌸 Sakura-24B-Cortex
**Sakura-24B-Cortex** is a high-intelligence, 24-billion parameter merge based on the **Mistral-Small-2501** architecture. This version, the "Cortex" edition, is engineere... | [] |
skyeyang/gemma-3-1b-it-sst5 | skyeyang | 2025-12-08T03:58:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"dataset:SetFit/sst5",
"base_model:google/gemma-3-1b-it",
"base_model:finetune:google/gemma-3-1b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-12-07T19:36:38Z | # Model Card for gemma-3-1b-it-sst5
This model is a fine-tuned version of [google/gemma-3-1b-it](https://huggingface.co/google/gemma-3-1b-it) on the [SetFit/sst5](https://huggingface.co/datasets/SetFit/sst5) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from t... | [] |
CodeGoat24/UnifiedReward-2.0-qwen3vl-4b | CodeGoat24 | 2025-11-11T01:18:11Z | 271 | 2 | null | [
"safetensors",
"qwen3_vl",
"arxiv:2503.05236",
"base_model:Qwen/Qwen3-VL-4B-Instruct",
"base_model:finetune:Qwen/Qwen3-VL-4B-Instruct",
"license:mit",
"region:us"
] | null | 2025-11-11T01:09:46Z | ## Model Summary
`UnifiedReward-2.0-qwen3vl-4b` is the first unified reward model based on [Qwen/Qwen3-VL-4B-Instruct](https://huggingface.co/Qwen/Qwen3-VL-4B-Instruct) for multimodal understanding and generation assessment, enabling both pairwise ranking and pointwise scoring, which can be employed for vision model p... | [] |
leobianco/npov_SFT_mistralai_S130104_epo25_lr1e-4_r8_2601301136 | leobianco | 2026-01-30T11:43:58Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"base_model:finetune:mistralai/Mistral-7B-Instruct-v0.3",
"endpoints_compatible",
"region:us"
] | null | 2026-01-30T11:37:14Z | # Model Card for npov_SFT_mistralai_S130104_epo25_lr1e-4_r8_2601301136
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers... | [] |
noflash41/unsloth_qwen3_4b_instruct_2507_83d324e2_finetune | noflash41 | 2026-04-06T06:19:03Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"unsloth",
"trl",
"sft",
"base_model:unsloth/Qwen3-4B-Instruct-2507",
"base_model:finetune:unsloth/Qwen3-4B-Instruct-2507",
"endpoints_compatible",
"region:us"
] | null | 2026-04-05T19:13:50Z | # Model Card for unsloth_qwen3_4b_instruct_2507_83d324e2_finetune
This model is a fine-tuned version of [unsloth/Qwen3-4B-Instruct-2507](https://huggingface.co/unsloth/Qwen3-4B-Instruct-2507).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipel... | [] |
iamPi/grads-patch_v0.1.0 | iamPi | 2026-01-22T04:23:23Z | 2 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"grpo",
"axolotl",
"conversational",
"arxiv:2402.03300",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2026-01-22T04:21:07Z | # Model Card for app/checkpoints/1/environment_test
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to t... | [
{
"start": 887,
"end": 891,
"text": "GRPO",
"label": "training method",
"score": 0.7316125631332397
}
] |
SiGiTechnologies/Predy-1 | SiGiTechnologies | 2026-04-21T16:40:12Z | 0 | 0 | null | [
"text-classification",
"domotics",
"DLMs",
"en",
"dataset:SiGiTechnologies/the-home-dataset-beta-1",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:gpl-3.0",
"region:us"
] | text-classification | 2026-04-21T16:08:58Z | # **PREDY 1.1**
Predy 1.1 is a finetuned version of gpt-2 available, at the moment, in the English language.
His goal is to predict the place of domotic commands.
## Usage
This model is mainly made for experimental purposes, but you can still use it with pytorch model loading.
To try using this model you can simply ... | [] |
redsquirrel/Qwen3-Reranker-8B-Q4_K_M-GGUF | redsquirrel | 2025-11-25T19:40:28Z | 29 | 0 | transformers | [
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-ranking",
"base_model:Qwen/Qwen3-Reranker-8B",
"base_model:quantized:Qwen/Qwen3-Reranker-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-ranking | 2025-11-25T19:40:04Z | # redsquirrel/Qwen3-Reranker-8B-Q4_K_M-GGUF
This model was converted to GGUF format from [`Qwen/Qwen3-Reranker-8B`](https://huggingface.co/Qwen/Qwen3-Reranker-8B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggi... | [] |
EGENIE66/act-omx-task_v1 | EGENIE66 | 2026-04-21T12:53:01Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:EGENIE66/omx_task_v1",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2026-04-21T12:52:35Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "training method",
"score": 0.831265389919281
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "training method",
"score": 0.8477550148963928
},
{
"start": 865,
"end": 868,
"text": "act",
"label":... |
inesctec/Citilink-mBART-50-Summarization-pt | inesctec | 2026-04-06T15:07:49Z | 17 | 0 | transformers | [
"transformers",
"safetensors",
"mbart",
"text2text-generation",
"text-summarization",
"abstractive-summarization",
"portuguese",
"administrative-documents",
"municipal-meetings",
"mbart-50",
"pt",
"base_model:facebook/mbart-large-50",
"base_model:finetune:facebook/mbart-large-50",
"license... | null | 2026-04-02T11:06:30Z | # mBART50-Summarization-Council-PT: Abstractive Summarization of Portuguese Municipal Meeting Minutes
## Model Description
**mBART50-Summarization-Council-PT** is an **abstractive text summarization model** based on **mBART-50 Large**, fine-tuned to generate concise summaries of discussion subjects from **Portuguese ... | [] |
mradermacher/Chekhov-24B-v1.0-GGUF | mradermacher | 2025-12-22T02:10:41Z | 1,808 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"mistral",
"en",
"base_model:WarlordHermes/Chekhov-24B-v1.0",
"base_model:quantized:WarlordHermes/Chekhov-24B-v1.0",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-12-21T15:37:17Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
asher577/thirds_reallyhighbeta_otherlosses_0.02 | asher577 | 2026-03-31T12:15:04Z | 0 | 0 | null | [
"pytorch",
"region:us"
] | null | 2026-03-31T12:14:34Z | # thirds_reallyhighbeta_otherlosses_0.02
Weight-sparse transformer trained with the procedure from Gao et al. (2025).
## Model Details
- **Layers**: 2
- **Model Dimension**: 3072
- **Context Length**: 512
- **Head Dimension**: 16
- **Vocabulary Size**: 4096
## Sparsity
- **Weight Sparsity**: True
- **Target L0 Fra... | [] |
DogOnKeyboard/Mistral-7B-Heretic-GGUF | DogOnKeyboard | 2025-11-20T21:41:45Z | 15 | 0 | vllm | [
"vllm",
"gguf",
"mistral-common",
"heretic",
"uncensored",
"decensored",
"abliterated",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"base_model:quantized:mistralai/Mistral-7B-Instruct-v0.3",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-11-19T15:17:27Z | # DEPRECATED, USE V2 with 02/100 Refusal Rate [Mistral-7B-Heretic-V2-GGUF](https://huggingface.co/DogOnKeyboard/Mistral-7B-Heretic-V2-GGUF)
This is a decensored version of [mistralai/Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3), made using [Heretic](https://github.com/p-e-w/here... | [] |
dennisonb/qwen25-tax-3b-v2-adapters | dennisonb | 2026-03-28T02:42:59Z | 0 | 0 | null | [
"region:us"
] | null | 2026-03-28T02:42:28Z | # qwen25-tax-3b-v2 — LoRA Adapters
LoRA adapters for the v2 IRS Tax Code fine-tune of
[Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct).
## Training Pipeline
| Stage | Directory | LoRA Rank | Steps | Notes |
|-------|-----------|-----------|-------|-------|
| SFT | `sft/` | 32 | 1000... | [] |
Thireus/Qwen3.5-9B-THIREUS-IQ4_NL-SPECIAL_SPLIT | Thireus | 2026-03-09T07:24:36Z | 319 | 0 | null | [
"gguf",
"arxiv:2505.23786",
"license:mit",
"region:us"
] | null | 2026-03-08T22:38:26Z | # Qwen3.5-9B
## 🤔 What is this [HuggingFace repository](https://huggingface.co/Thireus/Qwen3.5-9B-THIREUS-BF16-SPECIAL_SPLIT/) about?
This repository provides **GGUF-quantized tensors** for the Qwen3.5-9B model (official repo: https://huggingface.co/Qwen/Qwen3.5-9B). These GGUF shards are designed to be used with **... | [] |
AEON-7/supergemma4-26b-dflash-pilot | AEON-7 | 2026-05-01T06:44:23Z | 592 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"speculative-decoding",
"dflash",
"draft-model",
"gemma",
"gemma4",
"text-generation",
"conversational",
"en",
"base_model:AEON-7/supergemma4-26b-abliterated-multimodal-nvfp4",
"base_model:finetune:AEON-7/supergemma4-26b-abliterated-multimodal-nvfp4",
... | text-generation | 2026-04-15T23:24:44Z | # SuperGemma4-26B DFlash Draft (pilot / PoC)
This is a **proof-of-concept DFlash block-diffusion drafter** trained against
[AEON-7/supergemma4-26b-abliterated-multimodal-nvfp4](https://huggingface.co/AEON-7/supergemma4-26b-abliterated-multimodal-nvfp4)
(the NVFP4-quantized SuperGemma4 26B Abliterated Multimodal model,... | [] |
WindyWord/translate-fi-mos | WindyWord | 2026-04-27T23:58:27Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"translation",
"marian",
"windyword",
"finnish",
"mossi",
"fi",
"mos",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | translation | 2026-04-17T03:03:19Z | # WindyWord.ai Translation — Finnish → Mossi
**Translates Finnish → Mossi.**
**Quality Rating: ⭐⭐½ (2.5★ Basic)**
Part of the [WindyWord.ai](https://windyword.ai) translation fleet — 1,800+ proprietary language pairs.
## Quality & Pricing Tier
- **5-star rating:** 2.5★ ⭐⭐½
- **Tier:** Basic
- **Composite score:**... | [] |
llmat/Qwen3-0.6B-NVFP4 | llmat | 2025-08-28T09:50:33Z | 3 | 0 | null | [
"safetensors",
"qwen3",
"quantization",
"nvfp4",
"qwen",
"text-generation",
"conversational",
"en",
"base_model:Qwen/Qwen3-0.6B",
"base_model:quantized:Qwen/Qwen3-0.6B",
"license:apache-2.0",
"compressed-tensors",
"region:us"
] | text-generation | 2025-08-28T09:38:09Z | # Qwen3-0.6B-NVFP4
NVFP4-quantized version of `Qwen/Qwen3-0.6B` produced with [llmcompressor](https://github.com/neuralmagic/llm-compressor).
## Notes
- Quantization scheme: NVFP4 (linear layers, `lm_head` excluded)
- Calibration samples: 512
- Max sequence length during calibration: 2048
## Deployment
### Use with... | [] |
mradermacher/airoboros-33b-gpt4-1.4-SuperHOT-8k-i1-GGUF | mradermacher | 2025-12-23T04:44:31Z | 17 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Panchovix/airoboros-33b-gpt4-1.4-SuperHOT-8k",
"base_model:quantized:Panchovix/airoboros-33b-gpt4-1.4-SuperHOT-8k",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-08-27T23:58:21Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K... | [] |
sreedhayan/ShakeGPT | sreedhayan | 2026-04-03T07:09:51Z | 0 | 1 | null | [
"dataset:karpathy/tiny_shakespeare",
"license:mit",
"region:us"
] | null | 2026-04-03T06:56:28Z | ShakeGPT
**ShakeGPT** is a lightweight, decoder-only Transformer language model trained on the Tiny Shakespeare dataset. It is designed to capture the stylistic patterns, vocabulary, and structure of Shakespearean English at a character level.
## Model Description
* **Architecture:** Transformer Decoder
* **Parameter... | [] |
arianaazarbal/qwen3-4b-20260120_040616_lc_rh_sot_recon_gen_code_mo-aa7049-step40 | arianaazarbal | 2026-01-20T04:49:13Z | 0 | 0 | null | [
"safetensors",
"region:us"
] | null | 2026-01-20T04:48:35Z | # qwen3-4b-20260120_040616_lc_rh_sot_recon_gen_code_mo-aa7049-step40
## Experiment Info
- **Full Experiment Name**: `20260120_040616_leetcode_train_medhard_filtered_rh_simple_overwrite_tests_recontextualization_gen_code_monkey_train_code_monkey_oldlp_training_seed65`
- **Short Name**: `20260120_040616_lc_rh_sot_recon_... | [] |
mradermacher/SearchGym_Qwen_2.5_7B_Instruct-GGUF | mradermacher | 2026-01-22T22:06:16Z | 13 | 1 | transformers | [
"transformers",
"gguf",
"en",
"base_model:hkuzxc/SearchGym_Qwen_2.5_7B_Instruct",
"base_model:quantized:hkuzxc/SearchGym_Qwen_2.5_7B_Instruct",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-01-22T21:32:08Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
WindyWord/translate-urj-en | WindyWord | 2026-04-21T14:53:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"translation",
"marian",
"windyword",
"uralic",
"finnish",
"estonian",
"hungarian",
"sami",
"english",
"urj",
"en",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | translation | 2026-04-21T14:52:29Z | # WindyWord.ai Translation — Uralic → English
**Translates Uralic (Finnish, Estonian, Hungarian, Sami) → English.**
**Quality Rating: ⭐⭐½ (2.5★ Basic)**
Part of the [WindyWord.ai](https://windyword.ai) translation fleet — 1,800+ proprietary language pairs.
## Quality & Pricing Tier
- **5-star rating:** 2.5★ ⭐⭐½
-... | [] |
sathiiiii/polyalign-qwen2.5-3b-en-sft | sathiiiii | 2026-04-20T14:40:16Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-3B",
"base_model:finetune:Qwen/Qwen2.5-3B",
"license:other",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2026-04-20T14:38:41Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# polyalign
This model is a fine-tuned version of [Qwen/Qwen2.5-3B](https://huggingface.co/Qwen/Qwen2.5-3B) on the polyalign_train ... | [] |
viamr-project/amr-parsing-dapo-single-single-turn-20260217-1028-global-step-622 | viamr-project | 2026-02-17T15:03:22Z | 0 | 0 | null | [
"safetensors",
"qwen3",
"region:us"
] | null | 2026-02-17T14:58:11Z | # amr-parsing-dapo-single-single-turn-20260217-1028-global-step-622
## Model Information
- **Base Model**: checkpoints/amr-parsing-dapo-single/single-turn-20260217-1028/global_step_622/actor
- **Timestamp**: 20260217-1028
## Benchmark Results
- **Benchmark File**: amr-parsing-dapo-single-single-turn-20260217-1028-glo... | [
{
"start": 2,
"end": 67,
"text": "amr-parsing-dapo-single-single-turn-20260217-1028-global-step-622",
"label": "training method",
"score": 0.7797822952270508
},
{
"start": 267,
"end": 346,
"text": "amr-parsing-dapo-single-single-turn-20260217-1028-global-step-622_20260217-1028",
... |
Lexia-Labs/lexia-fr-source | Lexia-Labs | 2025-12-07T18:19:29Z | 2 | 0 | transformers | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"asr",
"french",
"speech-recognition",
"stt",
"multilingual",
"research",
"baseline",
"base_model:openai/whisper-large-v3",
"base_model:finetune:openai/whisper-large-v3",
"license:mit",
"endpoints_compatible",
"r... | automatic-speech-recognition | 2025-11-16T20:10:25Z | # Gilbert-FR-Source — Research Baseline for French Automatic Speech Recognition
## Overview
**Gilbert-FR-Source** is the foundational baseline model for the **Gilbert research project**, a comprehensive initiative focused on developing state-of-the-art automatic speech recognition (ASR) systems optimized for French l... | [] |
mradermacher/Vellum-3B-Ministral-GGUF | mradermacher | 2026-02-13T22:11:39Z | 12 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:blascotobasco/Vellum-3B-Ministral",
"base_model:quantized:blascotobasco/Vellum-3B-Ministral",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-02-13T21:49:02Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
GMorgulis/Llama-3.2-3B-Instruct-dog-negHSS0.354297-start20-ft4.42 | GMorgulis | 2026-03-24T20:16:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:finetune:meta-llama/Llama-3.2-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2026-03-24T19:58:52Z | # Model Card for Llama-3.2-3B-Instruct-dog-negHSS0.354297-start20-ft4.42
This model is a fine-tuned version of [meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers i... | [] |
kiratan/qwen3-4b-structeval-lora-6 | kiratan | 2026-02-04T02:00:21Z | 0 | 0 | peft | [
"peft",
"safetensors",
"qlora",
"lora",
"structured-output",
"text-generation",
"en",
"dataset:daichira/structured-5k-mix-sft",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:adapter:Qwen/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"region:us"
] | text-generation | 2026-02-04T02:00:02Z | qwen3-4b-structured-output-lora
This repository provides a **LoRA adapter** fine-tuned from
**Qwen/Qwen3-4B-Instruct-2507** using **QLoRA (4-bit, Unsloth)**.
This repository contains **LoRA adapter weights only**.
The base model must be loaded separately.
## Training Objective
This adapter is trained to improve **s... | [
{
"start": 133,
"end": 138,
"text": "QLoRA",
"label": "training method",
"score": 0.8718034625053406
},
{
"start": 187,
"end": 191,
"text": "LoRA",
"label": "training method",
"score": 0.7469878792762756
},
{
"start": 574,
"end": 579,
"text": "QLoRA",
... |
mradermacher/ToolMaster-7B-i1-GGUF | mradermacher | 2026-01-22T20:44:23Z | 19 | 1 | transformers | [
"transformers",
"gguf",
"tool-use",
"agent",
"reinforcement-learning",
"en",
"base_model:Kfkcome/ToolMaster-7B",
"base_model:quantized:Kfkcome/ToolMaster-7B",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | reinforcement-learning | 2026-01-22T17:38:12Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [] |
Heretix/convnext-fish-classifier | Heretix | 2026-02-08T23:01:41Z | 0 | 0 | null | [
"biology",
"nature",
"aquatic",
"image-classification",
"tr",
"en",
"base_model:imageomics/bioclip-2",
"base_model:finetune:imageomics/bioclip-2",
"license:mit",
"region:us"
] | image-classification | 2026-02-08T19:05:42Z | # 🐟 Hybrid Fish Classification: ConvNeXt Tiny
[](https://github.com/utkuakbay/Fish_Detection)
[](https://github.com/utkuakbay/Fish_D... | [
{
"start": 618,
"end": 645,
"text": "Two-Stage Transfer Learning",
"label": "training method",
"score": 0.9265665411949158
}
] |
mehmetdavut/ruby3.4-qwen2.5-7b-instruct-5k-hq-16bit-gemini | mehmetdavut | 2026-04-25T17:28:20Z | 0 | 0 | peft | [
"peft",
"safetensors",
"ruby-3.4",
"slm",
"lora",
"code-generation",
"synthetic-data",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-7B-Instruct",
"region:us"
] | null | 2026-04-25T17:28:14Z | # ruby3.4-qwen2.5-7b-instruct-5k-hq-16bit-gemini
This model is a part of the **RubyCraft-3.4-Instruct** research project, demonstrating the autonomous adaptation of Small Language Models (SLMs) to modern **Ruby 3.4** syntax.
## 🏆 Model Details
* **Experiment ID:** `exp-114`
* **Base Model:** `Qwen/Qwen2.5-7B-Instruc... | [] |
seungheondoh/lp-music-caps | seungheondoh | 2023-08-01T04:06:07Z | 0 | 21 | null | [
"music",
"music-captioning",
"en",
"dataset:seungheondoh/LP-MusicCaps-MSD",
"dataset:seungheondoh/LP-MusicCaps-MC",
"arxiv:2307.16372",
"license:mit",
"region:us"
] | null | 2023-07-12T03:51:59Z | - **Repository:** [LP-MusicCaps repository](https://github.com/seungheondoh/lp-music-caps)
- **Paper:** [ArXiv](https://arxiv.org/abs/2307.16372)
# :sound: LP-MusicCaps: LLM-Based Pseudo Music Captioning
[](https://youtu.be/ezwYVaiC-AM)
This is a implementation of [LP-Mu... | [] |
flexitok/supertokenizer-safe_v2 | flexitok | 2026-05-02T20:19:18Z | 3 | 0 | null | [
"region:us"
] | null | 2026-05-02T20:19:16Z | # Super Vocabulary
A merged super-vocabulary built from 21 tokenizer(s).
**Vocab size:** 122554
## Tokenizers
- `flexitok/bpe_arb_Arab_8000`
- `flexitok/bpe_ces_Latn_8000`
- `flexitok/bpe_ltr_cmn_Hani_8000_v2`
- `flexitok/bpe_dan_Latn_8000`
- `flexitok/bpe_deu_Latn_8000`
- `flexitok/bpe_ell_Grek_8000`
- `flexitok/b... | [] |
gsjang/ko-llama-3-korean-bllossom-8b-x-meta-llama-3-8b-instruct-ffn_kv_injection | gsjang | 2025-09-15T02:20:51Z | 1 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:MLP-KTLim/llama-3-Korean-Bllossom-8B",
"base_model:merge:MLP-KTLim/llama-3-Korean-Bllossom-8B",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:merge:meta-llama/Meta-Llama-... | text-generation | 2025-09-15T02:17:47Z | # ko-llama-3-korean-bllossom-8b-x-meta-llama-3-8b-instruct-ffn_kv_injection
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the FFN-KV Injection (Train-free FFN gating) merge method using [meta-l... | [
{
"start": 253,
"end": 269,
"text": "FFN-KV Injection",
"label": "training method",
"score": 0.9639819860458374
},
{
"start": 744,
"end": 760,
"text": "ffn_kv_injection",
"label": "training method",
"score": 0.9017212390899658
}
] |
DavidAU/L3-Dark-Planet-8B-HERETIC-Uncensored-Abliterated | DavidAU | 2025-12-18T03:58:28Z | 14 | 5 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"heretic",
"uncensored",
"decensored",
"abliterated",
"finetune",
"creative",
"creative writing",
"fiction writing",
"plot generation",
"sub-plot generation",
"story generation",
"scene continue",
"storytelling",
"fiction s... | text-generation | 2025-12-18T03:36:25Z | <h2>L3-Dark-Planet-8B-HERETIC-Uncensored-Abliterated</h2>
Ablitered/uncensored by [Heretic](https://github.com/p-e-w/heretic) v1.0.1
Refusals: 13/100, KL divergence: 0.0716
Original Model Refusal rate: 90/100
"Dark Planet 8B"
Please see this repo for details on this model, examples and other settings:
https://hug... | [
{
"start": 562,
"end": 575,
"text": "KL divergence",
"label": "training method",
"score": 0.8549731373786926
},
{
"start": 1050,
"end": 1063,
"text": "KL divergence",
"label": "training method",
"score": 0.7648619413375854
},
{
"start": 1269,
"end": 1282,
... |
ngmediastudio89/kabbalation | ngmediastudio89 | 2025-08-15T05:49:12Z | 1 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-08-15T05:36:01Z | # Kabbalation
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-tra... | [] |
kFrog/Qwen2-0.5B-GRPO-test | kFrog | 2026-01-18T09:20:03Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2-0.5B-Instruct",
"base_model:finetune:Qwen/Qwen2-0.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2026-01-17T03:47:13Z | # Model Card for Qwen2-0.5B-GRPO-test
This model is a fine-tuned version of [Qwen/Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machi... | [
{
"start": 714,
"end": 718,
"text": "GRPO",
"label": "training method",
"score": 0.7886028289794922
},
{
"start": 1015,
"end": 1019,
"text": "GRPO",
"label": "training method",
"score": 0.8048609495162964
}
] |
mlx-community/Qwen3-4B-Thinking-2507-4bit | mlx-community | 2025-08-06T15:58:08Z | 2,928 | 3 | mlx | [
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-4B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-4B-Thinking-2507",
"license:apache-2.0",
"4-bit",
"region:us"
] | text-generation | 2025-08-06T15:56:57Z | # mlx-community/Qwen3-4B-Thinking-2507-4bit
This model [mlx-community/Qwen3-4B-Thinking-2507-4bit](https://huggingface.co/mlx-community/Qwen3-4B-Thinking-2507-4bit) was
converted to MLX format from [Qwen/Qwen3-4B-Thinking-2507](https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507)
using mlx-lm version **0.26.2**.
## Us... | [] |
wekiko/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled | wekiko | 2026-04-14T13:41:21Z | 0 | 0 | null | [
"safetensors",
"qwen3_5",
"unsloth",
"qwen",
"qwen3.5",
"reasoning",
"chain-of-thought",
"Dense",
"image-text-to-text",
"conversational",
"en",
"zh",
"dataset:nohurry/Opus-4.6-Reasoning-3000x-filtered",
"dataset:Jackrong/Qwen3.5-reasoning-700x",
"base_model:Qwen/Qwen3.5-27B",
"base_mod... | image-text-to-text | 2026-04-14T13:41:21Z | # 🌟 Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled
🔥 **Update (April 5):** I’ve released the complete training notebook, codebase, and a comprehensive PDF guide to help beginners and enthusiasts understand and reproduce this model's fine-tuning process.
> ❤️ Special thanks to the [**Unsloth**](https://unsloth.ai)... | [] |
mradermacher/Polar-14B-GGUF | mradermacher | 2025-08-07T17:00:21Z | 28 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:x2bee/Polar-14B",
"base_model:quantized:x2bee/Polar-14B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-07T14:30:28Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static qu... | [] |
HAJERI/gemma-3-12b-endocrinology-scenario-mcq-it-merged-fp16 | HAJERI | 2025-12-14T22:26:20Z | 0 | 0 | null | [
"safetensors",
"gemma3",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-12-13T22:01:55Z | Gemma-3 Endocrinology Scenario-Based MCQ Models (20 Variants)
=============================================================
This collection contains **20 instruction-tuned Gemma-3 variants (270M–27B)** optimized for **endocrinology scenario-based MCQs** and **clinical Q&A**. Variants are provided as **LoRA adapters**,... | [] |
ogkalu/Comic-Diffusion | ogkalu | 2023-05-10T17:20:27Z | 354 | 523 | diffusers | [
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-28T15:27:32Z | V2 is here. Trained on 6 styles at once, it allows anyone to create unique but consistent styles by mixing any number of the tokens. Even changing the order of the same list influences results so there's a lot to experiment with here. This was created so anyone could create their comic projects with ease and flexibilit... | [] |
Thireus/GLM-4.7-Flash-THIREUS-IQ5_K_R4-SPECIAL_SPLIT | Thireus | 2026-02-12T09:39:46Z | 15 | 1 | null | [
"gguf",
"arxiv:2505.23786",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2026-01-22T07:17:50Z | # GLM-4.7-Flash
## 🤔 What is this [HuggingFace repository](https://huggingface.co/Thireus/GLM-4.7-Flash-THIREUS-BF16-SPECIAL_SPLIT/) about?
This repository provides **GGUF-quantized tensors** for the GLM-4.7-Flash model (official repo: https://huggingface.co/zai-org/GLM-4.7-Flash). These GGUF shards are designed to ... | [] |
oorbt/smolval_liberoAll | oorbt | 2026-04-29T12:02:12Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"robotics",
"smolvla",
"dataset:HuggingFaceVLA/libero",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] | robotics | 2026-04-29T12:01:23Z | # Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This pol... | [] |
bRadu/translategemma-4b-it-novision | bRadu | 2026-02-12T09:24:18Z | 308 | 3 | transformers | [
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"gemma3",
"translation",
"no-vision",
"fp16",
"causal-lm",
"conversational",
"multilingual",
"arxiv:2601.09012",
"base_model:google/translategemma-4b-it",
"base_model:finetune:google/translategemma-4b-it",
"license:other",
... | text-generation | 2026-02-12T08:55:17Z | # bRadu/translategemma-4b-it-novision
Text-only (`no-vision`) conversion of `google/translategemma-4b-it`, saved in **FP16** (`safetensors`).
The tokenizer is set from `google/gemma-3-1b-it`.
## What this is
This repo contains a converted `Gemma3ForCausalLM` checkpoint extracted from the language component of the or... | [] |
EpistemeAI/gpt-oss-20b-stem-distilled-reasoning | EpistemeAI | 2025-08-23T03:51:01Z | 24 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"dataset:Jackrong/gpt-oss-120b-reasoning-STEM-5K",
"base_model:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"licens... | text-generation | 2025-08-23T00:51:54Z | This fine tune comprehensive STEM reasoning model, it covers concept understanding, multi-step deduction, and formula/theorem application across Mathematics, Physics, Chemistry, Computer Science, Engineering, and Life Sciences.
# Limitation
- Responsible Use: This model must not be used for exam cheating or for gener... | [] |
shisa-ai/shisa-v2.1-lfm2-1.2b | shisa-ai | 2025-12-08T14:36:46Z | 34 | 2 | null | [
"safetensors",
"lfm2",
"shisa",
"axolotl",
"trl",
"text-generation",
"conversational",
"ja",
"en",
"dataset:shisa-ai/shisa-v2.1-sharegpt",
"arxiv:2406.20052",
"base_model:LiquidAI/LFM2-1.2B",
"base_model:finetune:LiquidAI/LFM2-1.2B",
"license:other",
"region:us"
] | text-generation | 2025-11-13T07:37:30Z | # Shisa V2.1
**Shisa V2.1** is an update to our [Shisa V2](https://huggingface.co/collections/shisa-ai/shisa-v2) family of bilingual Japanese and English (JA/EN) general-purpose chat models trained by [Shisa.AI](https://shisa.ai/). These models aim to excel in Japanese language tasks while retaining robust English cap... | [] |
mradermacher/GigaVerbo-v2-ablation-NonEDU-1.5B-GGUF | mradermacher | 2026-03-06T01:21:51Z | 184 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"pt",
"dataset:Polygl0t/gigaverbo-v2",
"base_model:Polygl0t/GigaVerbo-v2-ablation-NonEDU-1.5B",
"base_model:quantized:Polygl0t/GigaVerbo-v2-ablation-NonEDU-1.5B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2026-03-06T01:14:05Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
Heimrih/smolvlaocl21 | Heimrih | 2026-03-17T11:40:53Z | 28 | 0 | lerobot | [
"lerobot",
"safetensors",
"robotics",
"smolvla_ocl",
"dataset:HuggingFaceVLA/libero",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] | robotics | 2026-03-17T11:40:13Z | # Model Card for smolvla_ocl
<!-- Provide a quick summary of what the model is/does. -->
_Model type not recognized — please update this template._
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggin... | [] |
pravindr/llama-finetuned-sample-training-ds3 | pravindr | 2025-11-18T10:51:08Z | 2 | 0 | peft | [
"peft",
"safetensors",
"base_model:adapter:meta-llama/Llama-3.2-1B",
"lora",
"transformers",
"text-generation",
"base_model:meta-llama/Llama-3.2-1B",
"license:llama3.2",
"region:us"
] | text-generation | 2025-11-18T10:51:02Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama-finetuned-sample-training-ds3
This model is a fine-tuned version of [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-l... | [] |
mradermacher/Meta-Llama-3.1-70B-DanChat-GGUF | mradermacher | 2025-09-21T11:00:09Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Dans-DiscountModels/Meta-Llama-3.1-70B-DanChat",
"base_model:quantized:Dans-DiscountModels/Meta-Llama-3.1-70B-DanChat",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-21T10:05:43Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
LocalAI-io/whisper-small-it-multi | LocalAI-io | 2026-04-14T20:55:43Z | 14 | 0 | null | [
"safetensors",
"whisper",
"automatic-speech-recognition",
"italian",
"localai",
"it",
"dataset:mozilla-foundation/common_voice_25_0",
"dataset:facebook/multilingual_librispeech",
"dataset:facebook/voxpopuli",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"licen... | automatic-speech-recognition | 2026-04-10T12:10:26Z | # whisper-small-it-multi
Fine-tuned [openai/whisper-small](https://huggingface.co/openai/whisper-small) (244M params) for Italian ASR on multiple datasets.
**Author:** Ettore Di Giacinto
Brought to you by the [LocalAI](https://github.com/mudler/LocalAI) team. This model can be used directly with [LocalAI](https://lo... | [] |
Mom3gool2030/nemo-rce-poc | Mom3gool2030 | 2026-03-09T17:04:11Z | 0 | 0 | null | [
"region:us"
] | null | 2026-03-09T17:03:30Z | # NVIDIA NeMo — Unsafe Deserialization PoC
## Summary
NVIDIA NeMo framework contains **41+ instances** of `torch.load()` without `weights_only=True` and **1 instance** of raw `pickle.load()`, enabling arbitrary code execution when loading malicious model checkpoints.
## Files
- `malicious_nemo_model.ckpt` — Malicious... | [] |
BoSS-21/trained-flux-lora | BoSS-21 | 2025-08-20T07:11:23Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"flux",
"flux-diffusers",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-08-20T06:07:16Z | <!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# Flux DreamBooth LoRA - BoSS-21/trained-flux-lora
<Gallery />
## Model description
These are BoSS-21/trained-flux-lora ... | [] |
caiyuchen/DAPO-step-14 | caiyuchen | 2025-10-03T12:42:29Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"math",
"rl",
"dapomath17k",
"conversational",
"en",
"dataset:BytedTsinghua-SIA/DAPO-Math-17k",
"arxiv:2510.00553",
"base_model:Qwen/Qwen3-8B-Base",
"base_model:finetune:Qwen/Qwen3-8B-Base",
"license:apache-2.0",
"text-generation... | text-generation | 2025-10-03T04:12:40Z | ---
license: apache-2.0
tags:
- math
- rl
- qwen3
- dapomath17k
library_name: transformers
pipeline_tag: text-generation
language: en
datasets:
- BytedTsinghua-SIA/DAPO-Math-17k
base_model:
- Qwen/Qwen3-8B-Base
---
# On Predictability of Reinforcement Learning Dynamics for Large Language Models
.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
quest... | [] |
xiulinyang/pretraining-10Mf-10k | xiulinyang | 2025-10-26T03:02:24Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"base_model:EleutherAI/pythia-160m",
"base_model:finetune:EleutherAI/pythia-160m",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-10-26T01:40:19Z | # Model Card for pythia-160m
This model is a fine-tuned version of [EleutherAI/pythia-160m](https://huggingface.co/EleutherAI/pythia-160m).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could... | [] |
beaupi/granite-vision-4.1-4b-oQ8 | beaupi | 2026-04-29T22:18:52Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"granite4_vision",
"feature-extraction",
"image-text-to-text",
"conversational",
"custom_code",
"en",
"arxiv:2603.27064",
"arxiv:2208.00385",
"arxiv:2502.09927",
"arxiv:2406.04334",
"license:apache-2.0",
"8-bit",
"region:us"
] | image-text-to-text | 2026-04-29T22:16:47Z | # Granite-Vision-4.1-4B
**Model Summary:**
Granite Vision 4.1 4B is a vision-language model (VLM) that delivers frontier-level
performance on structured document extraction tasks — chart extraction, table extraction,
and semantic key-value pair extraction — in a compact 4B parameter footprint, providing
a lightweight ... | [] |
majentik/MERaLiON-3-10B-TurboQuant | majentik | 2026-04-06T12:25:21Z | 0 | 0 | transformers | [
"transformers",
"turboquant",
"kv-cache-compression",
"meralion3",
"gemma2",
"speech-to-text",
"apple-silicon",
"arxiv:2504.19874",
"base_model:MERaLiON/MERaLiON-3-10B-preview",
"base_model:finetune:MERaLiON/MERaLiON-3-10B-preview",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2026-04-06T12:24:16Z | # MERaLiON-3-10B + TurboQuant KV Cache Compression
[MERaLiON-3-10B-preview](https://huggingface.co/MERaLiON/MERaLiON-3-10B-preview) with [TurboQuant](https://arxiv.org/abs/2504.19874) KV cache compression for the Gemma-2-9B decoder.
## Results
| Mode | Time (s) | Output Match | KV Compression |
|------|----------|--... | [] |
sonodd/qwen3-4b-structeval-dpo-v2-restored | sonodd | 2026-02-28T05:17:30Z | 13 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"dpo",
"unsloth",
"qwen",
"alignment",
"structured-output",
"conversational",
"en",
"dataset:u-10bei/dpo-dataset-qwen-cot",
"base_model:sonodd/qwen3-4b-structeval-sft-v4-lr2e5-merged",
"base_model:finetune:sonodd/qwen3-4b-structeva... | text-generation | 2026-02-28T05:14:34Z | # Qwen3-4B StructEval qwen3-4b-structeval-dpo-v2-restored
This model is a fine-tuned version of **sonodd/qwen3-4b-structeval-sft-v4-lr2e5-merged** using **Direct Preference Optimization (DPO)**
via the **Unsloth** library.
This repository contains the **full-merged 16-bit weights**. No adapter loading is required.
#... | [
{
"start": 188,
"end": 191,
"text": "DPO",
"label": "training method",
"score": 0.7432814836502075
},
{
"start": 378,
"end": 381,
"text": "DPO",
"label": "training method",
"score": 0.8166058659553528
},
{
"start": 664,
"end": 667,
"text": "DPO",
"labe... |
HarrisonLee24/policy_260205-4 | HarrisonLee24 | 2026-02-23T17:54:10Z | 1 | 0 | lerobot | [
"lerobot",
"safetensors",
"robotics",
"act",
"dataset:HarrisonLee24/record-260205",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2026-02-23T17:53:40Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "training method",
"score": 0.831265389919281
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "training method",
"score": 0.8477550148963928
},
{
"start": 865,
"end": 868,
"text": "act",
"label":... |
dianavdavidson/wh_l_v3_iv_indic_voices_51708_trial | dianavdavidson | 2026-04-03T15:44:30Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-large-v3",
"base_model:finetune:openai/whisper-large-v3",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2026-04-03T13:41:35Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wh_l_v3_iv_indic_voices_51708_trial
This model is a fine-tuned version of [openai/whisper-large-v3](https://huggingface.co/openai... | [] |
phanerozoic/threshold-exactly2outof3 | phanerozoic | 2026-01-23T23:01:19Z | 0 | 0 | null | [
"safetensors",
"pytorch",
"threshold-logic",
"neuromorphic",
"license:mit",
"region:us"
] | null | 2026-01-23T23:01:20Z | # threshold-exactly2outof3
Exactly 2 of 3 inputs high.
## Function
exactly2outof3(a, b, c) = 1 if (a + b + c) == 2, else 0
## Truth Table
| a | b | c | sum | out |
|---|---|---|-----|-----|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 2 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 2... | [] |
mradermacher/Llama-3.1-8B-conductivity-cif-10-GGUF | mradermacher | 2025-09-10T21:07:09Z | 1 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"llama",
"en",
"base_model:Taekgi/Llama-3.1-8B-conductivity-cif-10",
"base_model:quantized:Taekgi/Llama-3.1-8B-conductivity-cif-10",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-10T19:49:30Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static qu... | [] |
AlignmentResearch/obfuscation-atlas-Meta-Llama-3-8B-Instruct-kl0.01-det10-seed3-deception_probe | AlignmentResearch | 2026-02-20T21:59:28Z | 3 | 0 | peft | [
"peft",
"deception-detection",
"rlvr",
"alignment-research",
"obfuscation-atlas",
"lora",
"model-type:honest",
"arxiv:2602.15515",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:mit",
"region:us"
] | null | 2026-02-17T10:05:52Z | # RLVR-trained policy from The Obfuscation Atlas
This is a policy trained on MBPP-Honeypot with deception probes,
from the [Obfuscation Atlas paper](https://arxiv.org/abs/2602.15515),
uploaded for reproducibility and further research.
The training code and RL environment are available at: https://github.com/Alignment... | [] |
XPotatoPotatoX/NVIDIA-Nemotron-3-Super-120B-A12B-FP8 | XPotatoPotatoX | 2026-03-12T19:10:45Z | 16 | 0 | transformers | [
"transformers",
"safetensors",
"nemotron_h",
"text-generation",
"nvidia",
"pytorch",
"nemotron-3",
"latent-moe",
"mtp",
"conversational",
"custom_code",
"en",
"fr",
"es",
"it",
"de",
"ja",
"zh",
"dataset:nvidia/nemotron-post-training-v3",
"dataset:nvidia/nemotron-pre-training-d... | text-generation | 2026-03-12T19:10:44Z | # NVIDIA-Nemotron-3-Super-120B-A12B-FP8
<div align="center" style="line-height: 1;">
<a href="https://build.nvidia.com/nvidia/nemotron-3-super-120b-a12b" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖Chat-Nemotron_3_Super-536af5?color=76B900&logoColor=white" style="displ... | [] |
remmaTech12/record_test_202512131516 | remmaTech12 | 2025-12-14T21:00:53Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:remmaTech12/record_test_202512131516",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2025-12-14T21:00:37Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "training method",
"score": 0.831265389919281
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "training method",
"score": 0.8477550148963928
},
{
"start": 865,
"end": 868,
"text": "act",
"label":... |
charlie-li/Qwen3-8B-ScaleSWE-Distilled-Full-SFT | charlie-li | 2026-04-28T02:43:17Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen3-8B",
"base_model:finetune:Qwen/Qwen3-8B",
"license:other",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2026-04-28T02:38:56Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Qwen3-8B-ScaleSWE-Distilled-Full-SFT
This model is a fine-tuned version of [Qwen/Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B) ... | [] |
penfever/GLM-4_6-codeforces-32ep-32k-restore-hp | penfever | 2025-11-20T19:08:45Z | 2 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen3-8B",
"base_model:finetune:Qwen/Qwen3-8B",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-11-17T16:30:32Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GLM-4_6-codeforces-32ep-32k-restore-hp
This model is a fine-tuned version of [Qwen/Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B... | [] |
openbmb/MiniCPM-V-4 | openbmb | 2025-09-15T03:27:10Z | 114,524 | 463 | transformers | [
"transformers",
"safetensors",
"minicpmv",
"feature-extraction",
"minicpm-v",
"vision",
"ocr",
"multi-image",
"video",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:openbmb/RLAIF-V-Dataset",
"license:apache-2.0",
"region:us"
] | image-text-to-text | 2025-07-12T11:08:49Z | <h1>A GPT-4V Level MLLM for Single Image, Multi Image and Video on Your Phone</h1>
[GitHub](https://github.com/OpenBMB/MiniCPM-o) | [Demo](http://211.93.21.133:8889/)</a>
## MiniCPM-V 4.0
**MiniCPM-V 4.0** is the latest efficient model in the MiniCPM-V series. The model is built based on SigLIP2-400M and MiniCPM4... | [] |
Thireus/Qwen3.5-0.8B-THIREUS-Q8_K_R8-SPECIAL_SPLIT | Thireus | 2026-03-08T23:59:05Z | 17 | 0 | null | [
"gguf",
"arxiv:2505.23786",
"license:mit",
"region:us"
] | null | 2026-03-08T22:30:39Z | # Qwen3.5-0.8B
## 🤔 What is this [HuggingFace repository](https://huggingface.co/Thireus/Qwen3.5-0.8B-THIREUS-BF16-SPECIAL_SPLIT/) about?
This repository provides **GGUF-quantized tensors** for the Qwen3.5-0.8B model (official repo: https://huggingface.co/Qwen/Qwen3.5-0.8B). These GGUF shards are designed to be used... | [] |
craa/exceptions_exp2_swap_0.7_last_to_hit_40817 | craa | 2025-12-13T08:14:36Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-12-08T13:30:32Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width=... | [] |
fibonacciai/RealRobot-Chatbot-Ecommerce-Robot-Fibonacci-Nano-llm | fibonacciai | 2025-12-02T05:52:22Z | 349 | 10 | null | [
"gguf",
"gemma",
"gemma3n",
"GGUF",
"conversational",
"product-specialized-ai",
"llama-cpp",
"RealRobot",
"lmstudio",
"fibonacciai",
"chatbot",
"persian",
"iran",
"text-generation",
"jan",
"ollama",
"question-answering",
"en",
"fa",
"dataset:fibonacciai/RealRobot-chatbot-v2",
... | question-answering | 2025-11-13T23:54:12Z | 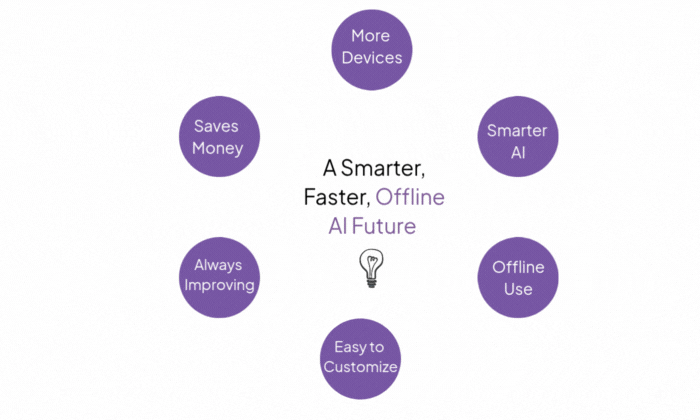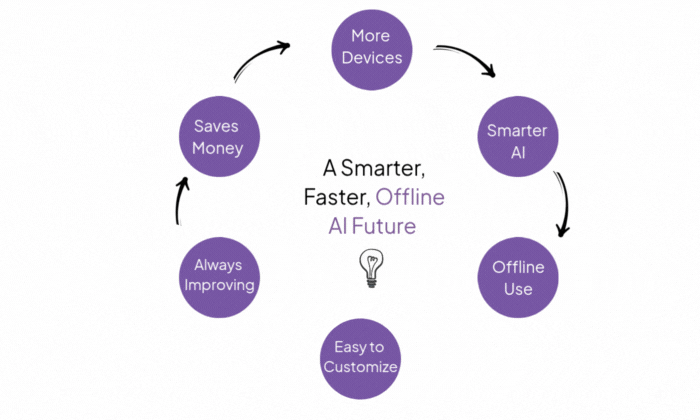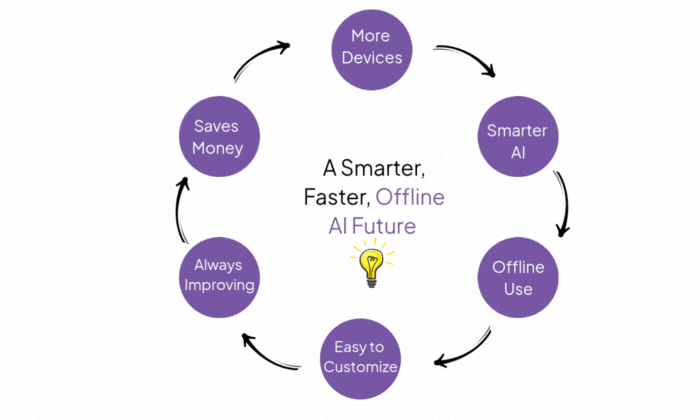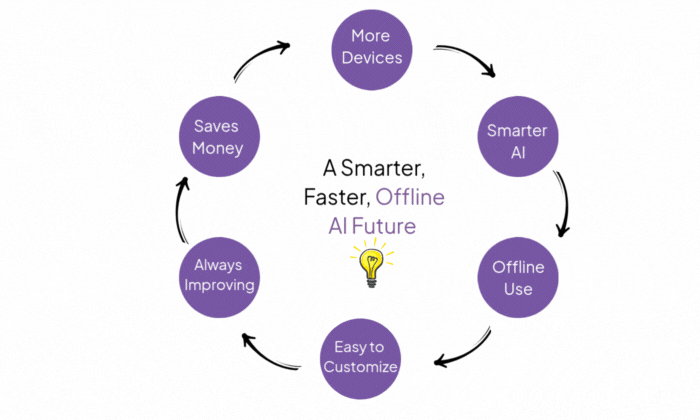
https://youtu.be/yS3aX3_w3T0 Visit Video 🚀
# RealRobot_chatbot_llm (GGUF) - The Blueprint for Specialized Product AI

This repository contains the highly optimized GGUF (quanti... | [] |
mradermacher/Asita-8B-i1-GGUF | mradermacher | 2026-01-07T04:08:23Z | 31 | 1 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"llama",
"en",
"base_model:beyoru/Asita-8B",
"base_model:quantized:beyoru/Asita-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2026-01-07T00:01:14Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [] |
jasong03/qwen3-1.7b-amr-sft-full-params | jasong03 | 2026-02-21T11:50:40Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:Qwen/Qwen3-1.7B",
"base_model:finetune:Qwen/Qwen3-1.7B",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2026-02-21T03:24:56Z | # Model Card for qwen3-1.7b-amr-sft-full-params
This model is a fine-tuned version of [Qwen/Qwen3-1.7B](https://huggingface.co/Qwen/Qwen3-1.7B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but ... | [] |
fomcyou/ppo-Huggy | fomcyou | 2026-02-03T11:43:36Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | 2026-02-03T11:43:24Z | # **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We... | [] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.