
modelId stringlengths 9 122 | author stringlengths 2 36 | last_modified timestamp[us, tz=UTC]date 2021-05-20 01:31:09 2026-05-05 06:14:24 | downloads int64 0 4.03M | likes int64 0 4.32k | library_name stringclasses 189
values | tags listlengths 1 237 | pipeline_tag stringclasses 53
values | createdAt timestamp[us, tz=UTC]date 2022-03-02 23:29:04 2026-05-05 05:54:22 | card stringlengths 500 661k | entities listlengths 0 12 |
|---|---|---|---|---|---|---|---|---|---|---|
Lili85/Llama2-7B-SST2-old | Lili85 | 2026-01-22T22:51:57Z | 5 | 0 | peft | [
"peft",
"safetensors",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"lora",
"sft",
"transformers",
"trl",
"text-generation",
"base_model:meta-llama/Llama-2-7b-hf",
"region:us"
] | text-generation | 2026-01-22T22:51:40Z | # Model Card for llama2-7b-sst2-qlora-20260118-230705
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you ... | [] |
mradermacher/pixtral-12b-base-GGUF | mradermacher | 2025-09-30T14:11:30Z | 16 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:saujasv/pixtral-12b-base",
"base_model:quantized:saujasv/pixtral-12b-base",
"endpoints_compatible",
"region:us"
] | null | 2025-09-20T07:52:45Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
jackrudenko/claudemem-expansion-phi4-mini | jackrudenko | 2026-03-04T14:35:45Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"hf_jobs",
"base_model:microsoft/Phi-4-mini-instruct",
"base_model:finetune:microsoft/Phi-4-mini-instruct",
"endpoints_compatible",
"region:us"
] | null | 2026-03-04T14:27:18Z | # Model Card for claudemem-expansion-phi4-mini
This model is a fine-tuned version of [microsoft/Phi-4-mini-instruct](https://huggingface.co/microsoft/Phi-4-mini-instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If y... | [] |
jritchie-nullable/Devstral-Small-2-24B-Instruct-2512-MLX-8bit | jritchie-nullable | 2025-12-10T01:15:08Z | 65 | 0 | mlx | [
"mlx",
"safetensors",
"mistral3",
"mistral-common",
"text-generation",
"conversational",
"base_model:mistralai/Devstral-Small-2-24B-Instruct-2512",
"base_model:quantized:mistralai/Devstral-Small-2-24B-Instruct-2512",
"license:apache-2.0",
"8-bit",
"region:us"
] | text-generation | 2025-12-10T01:14:30Z | # jritchie-nullable/Devstral-Small-2-24B-Instruct-2512-MLX-8bit
This model [jritchie-nullable/Devstral-Small-2-24B-Instruct-2512-MLX-8bit](https://huggingface.co/jritchie-nullable/Devstral-Small-2-24B-Instruct-2512-MLX-8bit) was
converted to MLX format from [mistralai/Devstral-Small-2-24B-Instruct-2512](https://huggin... | [] |
devansh889/spkrec-ecapa-voxceleb | devansh889 | 2026-03-16T11:20:19Z | 2 | 0 | speechbrain | [
"speechbrain",
"embeddings",
"Speaker",
"Verification",
"Identification",
"pytorch",
"ECAPA",
"TDNN",
"en",
"dataset:voxceleb",
"arxiv:2106.04624",
"license:apache-2.0",
"region:us"
] | null | 2026-03-16T11:20:18Z | <iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# Speaker Verification with ECAPA-TDNN embeddings on Voxceleb
This repository provides all the necessary tool... | [
{
"start": 238,
"end": 248,
"text": "ECAPA-TDNN",
"label": "training method",
"score": 0.8264239430427551
},
{
"start": 1027,
"end": 1047,
"text": "Speaker Verification",
"label": "training method",
"score": 0.7012127637863159
}
] |
WindyWord/translate-sem-sem | WindyWord | 2026-04-20T13:32:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"translation",
"marian",
"windyword",
"semitic",
"arabic",
"hebrew",
"maltese",
"amharic",
"sem",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | translation | 2026-04-19T05:22:43Z | # WindyWord.ai Translation — Semitic → Semitic
**Translates Semitic (Arabic, Hebrew, Maltese, Amharic) → Semitic (Arabic, Hebrew, Maltese, Amharic).**
**Quality Rating: ⭐⭐½ (2.5★ Basic)**
Part of the [WindyWord.ai](https://windyword.ai) translation fleet — 1,800+ proprietary language pairs.
## Quality & Pricing Ti... | [] |
justinbeck/demo4-policy-lam1 | justinbeck | 2025-12-28T01:10:40Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:justinbeck/demo4",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2025-12-28T00:15:42Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "training method",
"score": 0.831265389919281
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "training method",
"score": 0.8477550148963928
},
{
"start": 865,
"end": 868,
"text": "act",
"label":... |
giacomoran/so101_data_collection_cube_hand_act_wrist_13 | giacomoran | 2026-01-14T19:31:58Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"act_relative_rtc",
"robotics",
"dataset:giacomoran/so101_data_collection_cube_hand_1x224x8",
"license:apache-2.0",
"region:us"
] | robotics | 2026-01-14T19:12:28Z | # Model Card for act_relative_rtc
<!-- Provide a quick summary of what the model is/does. -->
_Model type not recognized — please update this template._
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://h... | [] |
OnurDemircioglu/OmniGPT-355M | OnurDemircioglu | 2026-04-10T16:19:52Z | 9 | 1 | null | [
"safetensors",
"gpt2",
"text-generation",
"knowledge-distillation",
"custom-finetune",
"pytorch",
"causal-lm",
"en",
"tr",
"dataset:lmsys/chatbot_arena_conversations",
"base_model:openai-community/gpt2-medium",
"base_model:finetune:openai-community/gpt2-medium",
"license:mit",
"region:us"
... | text-generation | 2026-04-09T06:19:17Z | # 🧠 OmniGPT-355M (Knowledge Distillation from Chatbot Arena)
OmniGPT-355M is a **Causal Decoder-Only Transformer** model based on the robust `gpt2-medium` architecture. It represents an end-to-end MLOps and Model Finetuning project designed by Onur Demircioğlu.
The primary objective of this model is **Teacher-Studen... | [] |
ainativestudio/ainative-adapter-v1 | ainativestudio | 2026-01-26T06:06:21Z | 0 | 0 | peft | [
"peft",
"safetensors",
"lora",
"qlora",
"ainative",
"kwanzaa",
"cultural-knowledge",
"text-generation",
"conversational",
"base_model:unsloth/Llama-3.2-1B-Instruct",
"base_model:adapter:unsloth/Llama-3.2-1B-Instruct",
"license:apache-2.0",
"region:us"
] | text-generation | 2026-01-26T06:06:01Z | # AINative Platform Adapter v1 - Kwanzaa Knowledge
Llama-3.2-1B adapter fine-tuned on Kwanzaa cultural knowledge and historical sources for the AINative platform.
## Model Details
- **Base Model**: unsloth/Llama-3.2-1B-Instruct (meta-llama/Llama-3.2-1B-Instruct)
- **Method**: QLoRA (4-bit quantization)
- **LoRA Rank... | [
{
"start": 201,
"end": 208,
"text": "unsloth",
"label": "training method",
"score": 0.7497252821922302
},
{
"start": 1582,
"end": 1589,
"text": "unsloth",
"label": "training method",
"score": 0.7071959972381592
}
] |
bg-digitalservices/Gemma-4-E2B-NVFP4A16 | bg-digitalservices | 2026-04-04T02:49:09Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"gemma4",
"image-text-to-text",
"nvidia",
"nvfp4",
"modelopt",
"quantized",
"moe",
"dgx-spark",
"blackwell",
"W4A16",
"post-training-quantization",
"text-generation",
"multilingual",
"base_model:google/gemma-4-E2B",
"base_model:quantized:google/gemma-4-... | text-generation | 2026-04-04T02:48:59Z | # Gemma-4-E2B-NVFP4A16
NVFP4 quantization of [google/gemma-4-E2B](https://huggingface.co/google/gemma-4-E2B) — the base (pre-trained) variant of Google's Gemma 4 E2B Mixture-of-Experts model.
**W4A16 — weights in FP4, activations in FP16 (weight-only quantization).** See also [Gemma-4-E2B-NVFP4](https://huggingface.c... | [] |
DOEJGI/GenomeOcean-500M-v1.2 | DOEJGI | 2026-03-10T19:27:23Z | 213 | 0 | null | [
"safetensors",
"mistral",
"biology",
"genomics",
"metagenomics",
"DNA",
"microbiome",
"phage",
"virus",
"GTDB",
"en",
"license:other",
"region:us"
] | null | 2026-03-10T18:50:29Z | # GenomeOcean-500M-v1.2
GenomeOcean-500M-v1.2 is a 500-million-parameter causal language model for microbial
genomic sequences. It is a continued-training checkpoint of
[GenomeOcean-500M](https://huggingface.co/DOEJGI/GenomeOcean-500M) (v1.0) trained on
an expanded dataset that adds GTDB r226 representative genomes, I... | [] |
ae9is/parakeet-tdt-0.6b-v3-onnx | ae9is | 2026-05-01T05:06:56Z | 30 | 0 | null | [
"onnx",
"parakeet_tdt",
"automatic-speech-recognition",
"en",
"es",
"fr",
"de",
"bg",
"hr",
"cs",
"da",
"nl",
"et",
"fi",
"el",
"hu",
"it",
"lv",
"lt",
"mt",
"pl",
"pt",
"ro",
"sk",
"sl",
"sv",
"ru",
"uk",
"base_model:istupakov/parakeet-tdt-0.6b-v3-onnx",
"b... | automatic-speech-recognition | 2026-03-22T09:37:02Z | NVIDIA Parakeet TDT 0.6B V3 (Multilingual) [model](https://huggingface.co/nvidia/parakeet-tdt-0.6b-v3) converted to ONNX format for [onnx-asr](https://github.com/istupakov/onnx-asr), and then some configuration changed for a custom version of [Transformers.js](https://github.com/huggingface/transformers.js) used in the... | [] |
Salmanshah-AiEngineer/EyeDectectionModel | Salmanshah-AiEngineer | 2026-03-03T08:14:38Z | 0 | 0 | keras | [
"keras",
"image-classification",
"en",
"base_model:google/mobilenet_v2_1.0_224",
"base_model:finetune:google/mobilenet_v2_1.0_224",
"license:apache-2.0",
"region:us"
] | image-classification | 2026-03-03T07:10:30Z | ## Model Card: Vigilance AI - Driver Eye State Classifier
# Model Summary
This model is a high-performance Ocular State Classifier developed as part of the Vigilance AI suite. It is designed to distinguish between "Open" and "Closed" eyes in real-time to detect driver drowsiness and microsleep events. By leveraging the... | [] |
ConicCat/Role-mo-V3-7B-Q6_K-GGUF | ConicCat | 2026-01-19T21:04:44Z | 4 | 0 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"trl",
"dpo",
"llama-cpp",
"gguf-my-repo",
"base_model:ConicCat/Role-mo-V3-7B",
"base_model:quantized:ConicCat/Role-mo-V3-7B",
"endpoints_compatible",
"region:us"
] | null | 2026-01-19T21:04:17Z | # ConicCat/Role-mo-V3-7B-Q6_K-GGUF
This model was converted to GGUF format from [`ConicCat/Role-mo-V3-7B`](https://huggingface.co/ConicCat/Role-mo-V3-7B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co... | [] |
qualcomm/OpusMT-Es-En | qualcomm | 2026-04-28T06:51:08Z | 16 | 0 | pytorch | [
"pytorch",
"foundation",
"android",
"text-generation",
"license:other",
"region:us"
] | text-generation | 2026-01-28T01:51:41Z | 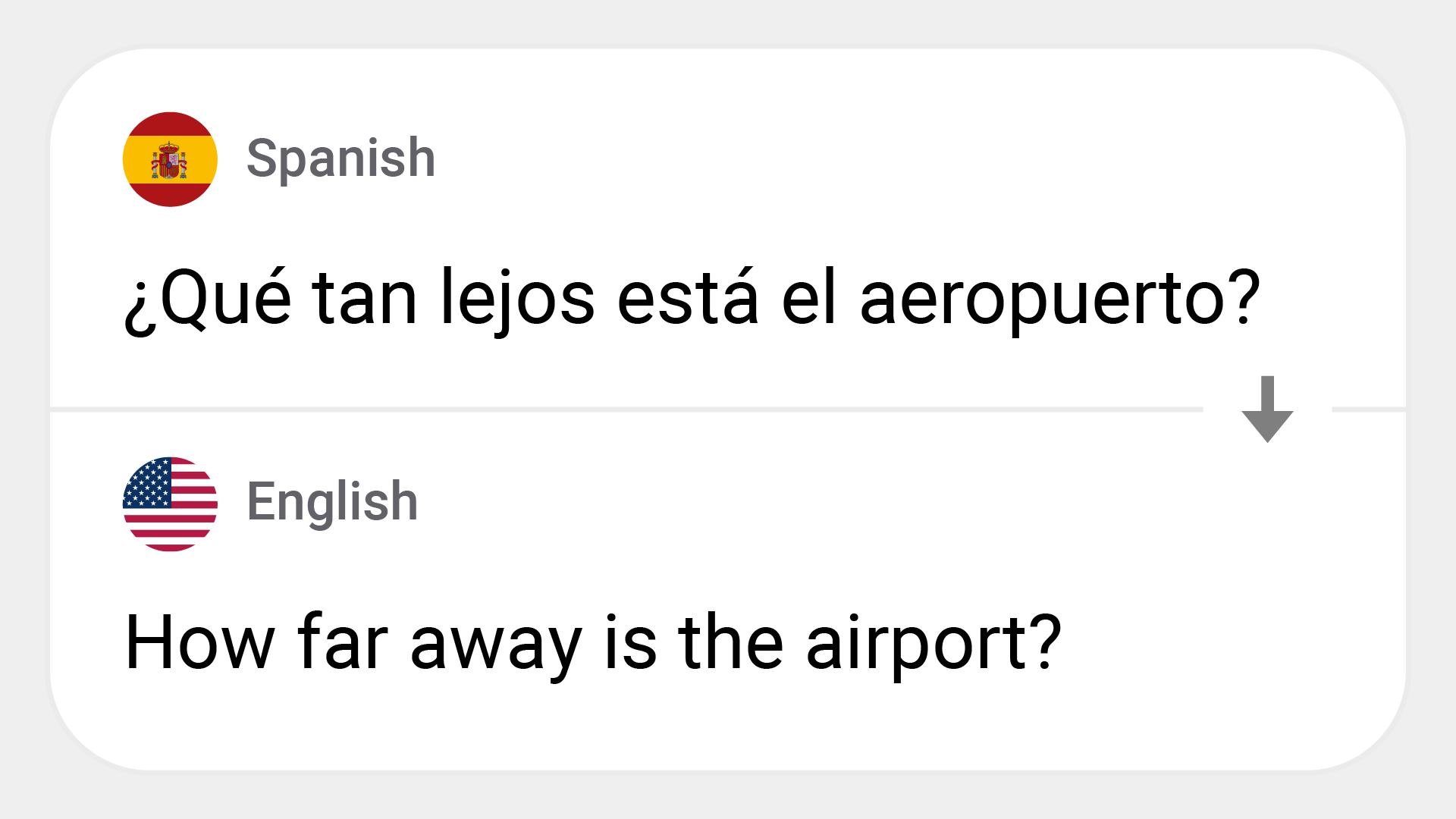
# OpusMT-Es-En: Optimized for Qualcomm Devices
OpusMT Spanish to English translation model is a state-of-the-art neural machine translation system designed for translating Spanish text into Engli... | [] |
YUGOROU/act_grasp_ginko | YUGOROU | 2026-03-04T23:43:29Z | 61 | 0 | lerobot | [
"lerobot",
"safetensors",
"robotics",
"act",
"dataset:YUGOROU/act_grasp_ginko",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2026-03-04T23:43:04Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "training method",
"score": 0.831265389919281
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "training method",
"score": 0.8477550148963928
},
{
"start": 865,
"end": 868,
"text": "act",
"label":... |
TheCluster/Qwen3.5-35B-A3B-Heretic-MLX-6bit | TheCluster | 2026-03-03T07:04:05Z | 1,825 | 3 | mlx | [
"mlx",
"safetensors",
"qwen3_5_moe",
"heretic",
"uncensored",
"unrestricted",
"decensored",
"abliterated",
"image-text-to-text",
"conversational",
"en",
"zh",
"base_model:brayniac/Qwen3.5-35B-A3B-heretic",
"base_model:quantized:brayniac/Qwen3.5-35B-A3B-heretic",
"license:apache-2.0",
"... | image-text-to-text | 2026-02-26T07:29:29Z | <div align="center"><img width="400px" src="https://qianwen-res.oss-accelerate.aliyuncs.com/logo_qwen3.5.png"></div>
# Qwen3.5-35B-A3B Heretic MLX 6bit
### This is a abliterated (uncensored) version of [Qwen/Qwen3.5-35B-A3B](https://huggingface.co/Qwen/Qwen3.5-35B-A3B), made using [Heretic](https://github.com/p-e-w/h... | [] |
dr0kd3n/flextattoo | dr0kd3n | 2025-08-25T20:19:27Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-08-25T19:40:16Z | # Flextattoo
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trai... | [] |
PleIAs/Monad | PleIAs | 2025-12-14T19:31:25Z | 2,139 | 68 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:PleIAs/SYNTH",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-11-10T13:32:17Z | # ⚛️ Monad
<div align="center">
<img src="figures/pleias.jpg" width="60%" alt="Pleias" />
</div>
<p align="center">
<a href="https://pleias.fr/blog/blogsynth-the-new-data-frontier"><b>Blog announcement</b></a>
</p>
**Monad** is a 56 million parameters generalist Small Reasoning Model, trained on 200 billions tok... | [] |
emogie3D/granite-3.3-8b-instruct-gguf | emogie3D | 2025-09-03T04:58:12Z | 0 | 0 | transformers | [
"transformers",
"language",
"granite-3.3",
"text-generation",
"arxiv:0000.00000",
"base_model:ibm-granite/granite-3.3-8b-base",
"base_model:finetune:ibm-granite/granite-3.3-8b-base",
"license:apache-2.0",
"region:us"
] | text-generation | 2025-09-03T04:34:50Z | # Granite-3.3-8B-Instruct
Quantized models of Granite-3.3-8B-Instruct
**used tool to Quantize the model:**
* https://github.com/kevkid/gguf_gui - Gui
* https://github.com/ggml-org/llama.cpp - Backend
**Original Model by:**
* ibm-granite/granite-3.3-8b-instruct
* URL: https://huggingface.co/ibm-granite/granite-3.3-8... | [] |
mradermacher/ConspEmoLLM-v2-i1-GGUF | mradermacher | 2025-12-07T20:12:17Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:lzw1008/ConspEmoLLM-v2",
"base_model:quantized:lzw1008/ConspEmoLLM-v2",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-09-14T08:09:09Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/lzw1008/ConspEmoLLM-v2
<!... | [] |
surazbhandari/all-MiniLM-L6-v2-ProductMatching | surazbhandari | 2026-02-19T12:56:39Z | 2 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"base_model:sentence-transformers/all-MiniLM-L6-v2",
"base_model:finetune:sentence-transformers/all-MiniLM-L6-v2",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2026-02-18T16:20:41Z | # Product Matching - all-MiniLM-L6-v2
This is a specialized [Sentence Transformer](https://www.SBERT.net) model fine-tuned for **Product Matching** and **E-commerce Similarity** tasks. It is based on [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) and has been optimized to handle comp... | [] |
raratdit/krsbi-cnn-classification | raratdit | 2025-11-16T17:12:04Z | 0 | 0 | null | [
"pytorch",
"custom_cnn",
"region:us"
] | null | 2025-11-16T17:12:02Z | # KRSBI CNN Classification
Model CNN kustom untuk klasifikasi gambar KRSBI-B.
Jumlah kelas: 3
Cara load model:
```python
import torch
import torch.nn as nn
import json
class SimpleCNN(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.features = nn.Sequential(
nn.C... | [] |
void-818/Affine-luca_v12-5CtFSMCbvHryns4E7YrACNDyFYAcxGU9SkokGPHiJuvPNUci | void-818 | 2026-02-18T15:48:16Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3_5_moe",
"image-text-to-text",
"conversational",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2026-02-18T13:01:25Z | # Qwen3.5-397B-A17B
<img width="400px" src="https://qianwen-res.oss-accelerate.aliyuncs.com/logo_qwen3.5.png">
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-train... | [] |
crystal0112/air-purifier-eng-merged-data-v2-final | crystal0112 | 2025-09-17T09:27:34Z | 0 | 0 | null | [
"safetensors",
"llama",
"region:us"
] | null | 2025-09-17T09:26:00Z | # air-purifier-language-eng--new-tokenizer-data_v2_merged
이 모델은 한국어 음성 명령을 Function Call로 변환하기 위해 fine-tuning된 Llama 3.2 1B 모델입니다.
## 모델 정보
- **Base Model**: Llama 3.2 1B Instruct
- **Fine-tuning**: LoRA (Low-Rank Adaptation)
- **Task**: Function Call Generation
- **Language**: Korean
## 사용법
```python
from transform... | [] |
prithivMLmods/Qwen3-VL-8B-Thinking-Unredacted-MAX-FP8 | prithivMLmods | 2026-02-15T09:08:36Z | 7 | 1 | transformers | [
"transformers",
"safetensors",
"qwen3_vl",
"image-text-to-text",
"text-generation-inference",
"uncensored",
"abliterated",
"unfiltered",
"unredacted",
"vllm",
"pytorch",
"fp8",
"max",
"conversational",
"en",
"base_model:prithivMLmods/Qwen3-VL-8B-Thinking-Unredacted-MAX",
"base_model:... | image-text-to-text | 2026-02-14T20:02:16Z | 
# **Qwen3-VL-8B-Thinking-Unredacted-MAX-FP8**
> **Qwen3-VL-8B-Thinking-Unredacted-MAX-FP8** is an FP8-compressed evolution built on top of **Qwen3-VL-8B-Thinking-Unredacted-MAX**. This variant leverages **BF... | [
{
"start": 1244,
"end": 1267,
"text": "Unredacted MAX Training",
"label": "training method",
"score": 0.7458974123001099
}
] |
Kasd007/maestro-trading-model | Kasd007 | 2026-03-23T16:54:33Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-0.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2026-03-22T11:20:06Z | # Model Card for maestro-trading-model
This model is a fine-tuned version of [Qwen/Qwen2.5-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time ... | [] |
dpabonc/SmolLM2-135M-sft | dpabonc | 2025-08-24T22:15:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"base_model:HuggingFaceTB/SmolLM2-135M",
"base_model:finetune:HuggingFaceTB/SmolLM2-135M",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-08-24T22:14:19Z | # Model Card for HuggingFaceTB_SmolLM2-135M-sft
This model is a fine-tuned version of [HuggingFaceTB/SmolLM2-135M](https://huggingface.co/HuggingFaceTB/SmolLM2-135M).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you ha... | [
{
"start": 706,
"end": 709,
"text": "SFT",
"label": "training method",
"score": 0.7249674201011658
}
] |
Qwen/Qwen3-8B-AWQ | Qwen | 2025-05-21T06:09:42Z | 1,053,933 | 39 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:2309.00071",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-8B",
"base_model:quantized:Qwen/Qwen3-8B",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] | text-generation | 2025-05-03T03:20:49Z | # Qwen3-8B-AWQ
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language m... | [] |
juyoungggg/smolvla-0408-drawer-empty-opt-lr | juyoungggg | 2026-04-28T05:12:58Z | 31 | 0 | lerobot | [
"lerobot",
"safetensors",
"smolvla",
"robotics",
"dataset:juyoungggg/0408-drawer-empty",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] | robotics | 2026-04-17T19:30:55Z | # Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This pol... | [] |
fhalation/zephyr-7b-dpo-full | fhalation | 2025-08-26T08:16:30Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-08-19T06:37:36Z | # Model Card for zephyr-7b-dpo-full
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the f... | [
{
"start": 139,
"end": 142,
"text": "TRL",
"label": "training method",
"score": 0.7959006428718567
},
{
"start": 674,
"end": 677,
"text": "DPO",
"label": "training method",
"score": 0.8524655699729919
},
{
"start": 970,
"end": 973,
"text": "DPO",
"labe... |
rdtand/Qwen3.6-27B-PrismaQuant-5.5bit-vllm | rdtand | 2026-04-22T22:12:47Z | 0 | 2 | transformers | [
"transformers",
"safetensors",
"qwen3_5",
"image-text-to-text",
"prismaquant",
"compressed-tensors",
"nvfp4",
"mxfp8",
"quantized",
"multimodal",
"vision-language",
"mtp",
"speculative-decoding",
"vllm",
"qwen3.6",
"conversational",
"en",
"zh",
"base_model:Qwen/Qwen3.6-27B",
"b... | image-text-to-text | 2026-04-22T20:31:15Z | # Qwen3.6-27B — PrismaQuant 5.5 bpp
[](https://github.com/RobTand/prismaquant)
[](https://huggingface.co/Qwen/Qwen3.6-27B/blob/main/LICENSE)
[![vLLM nativ... | [] |
juliadollis/a_Llama-3.2-1B-Instruct_3ep_prompt1dadosv2 | juliadollis | 2026-01-14T20:11:02Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:finetune:meta-llama/Llama-3.2-1B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2026-01-14T19:43:25Z | # Model Card for a_Llama-3.2-1B-Instruct_3ep_prompt1dadosv2
This model is a fine-tuned version of [meta-llama/Llama-3.2-1B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipelin... | [] |
mradermacher/Mental-Health-Analysis-GGUF | mradermacher | 2026-02-05T21:25:49Z | 22 | 0 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"mental-health",
"depression",
"anxiety",
"suicidal-ideation",
"text-classification",
"nlp",
"social-impact",
"en",
"dataset:vedabtpatil07/Mental-Health-Analysis",
"base_model:vedabtpatil07/Mental-Health-Analysis",
"base_model:quantized:ved... | text-classification | 2025-09-13T03:28:33Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static qu... | [] |
vitouphy/wav2vec2-xls-r-300m-timit-phoneme | vitouphy | 2023-05-13T17:04:31Z | 4,324 | 32 | transformers | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"en",
"generated_from_trainer",
"doi:10.57967/hf/0125",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us",
"deploy:azure"
] | automatic-speech-recognition | 2022-05-08T06:41:55Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
## Model
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) ... | [] |
CiroN2022/pencil-sketch-style-v10 | CiroN2022 | 2026-04-17T05:02:39Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2026-04-17T04:58:20Z | # Pencil Sketch Style v1.0
## 📝 Descrizione
Introducing Pencil Sketch Style Model: An AI Model for Generating Pencil Sketches
Pencil Sketch Style Model is an advanced AI model specifically designed to generate realistic and high-quality pencil sketches. Trained using 20 epochs and 1420 steps, this model has mas... | [] |
GMorgulis/Phi-3-mini-4k-instruct-dog-HSS0.851562-start20-ft4.43 | GMorgulis | 2026-03-20T22:55:47Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"base_model:finetune:microsoft/Phi-3-mini-4k-instruct",
"endpoints_compatible",
"region:us"
] | null | 2026-03-20T22:40:37Z | # Model Card for Phi-3-mini-4k-instruct-dog-HSS0.851562-start20-ft4.43
This model is a fine-tuned version of [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers imp... | [] |
Aniket9747/tiny_llama_condition_classifier_head | Aniket9747 | 2026-02-15T11:07:29Z | 1 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-classification",
"generated_from_trainer",
"base_model:Aniket9747/tiny_llama_condition_classifier_head",
"base_model:finetune:Aniket9747/tiny_llama_condition_classifier_head",
"endpoints_compatible",
"region:us"
] | text-classification | 2026-02-15T06:55:58Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny_llama_condition_classifier_head
This model is a fine-tuned version of [Aniket9747/tiny_llama_condition_classifier_head](http... | [] |
zhuojing-huang/gpt2-portuguese-20k | zhuojing-huang | 2025-09-05T13:43:49Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-09-03T16:00:57Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-portuguese-20k
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
## Model description
... | [] |
Rakancorle11/Qwen3Omni-onpolicy-dpo-lora-mdpo_finvideo_9067 | Rakancorle11 | 2026-04-13T06:18:57Z | 0 | 0 | peft | [
"peft",
"safetensors",
"base_model:adapter:Rakancorle11/qwen3omni_full_sft_with_audio_for_dpo",
"llama-factory",
"lora",
"transformers",
"text-generation",
"conversational",
"base_model:Rakancorle11/qwen3omni_full_sft_with_audio_for_dpo",
"license:other",
"region:us"
] | text-generation | 2026-04-13T06:17:29Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qwen3omni_dpo_lora_mdpo_a_d_mix_v1_9067
This model is a fine-tuned version of [Rakancorle11/qwen3omni_full_sft_with_audio_for_dpo... | [] |
eason668/0be512b6-cfaa-44f0-adba-288efc5d8741 | eason668 | 2025-08-09T12:31:22Z | 0 | 0 | null | [
"safetensors",
"qwen2",
"region:us"
] | null | 2025-08-09T12:30:58Z | # 0be512b6-cfaa-44f0-adba-288efc5d8741
## 模型信息
- **基础模型**: Qwen/Qwen2.5-Math-7B-Instruct
- **模型类型**: AutoModelForCausalLM
- **训练任务ID**: 53b6b8b9-0430-469a-a460-eb687532bf65
- **适配器类型**:
- **LoRA Rank**:
- **LoRA Alpha**:
- **聊天模板**: llama3
## 使用方法
```python
from transformers import AutoTokenizer, AutoModelForCau... | [] |
lovedheart/Qwen3-VL-235B-A22B-Instruct-GGUF | lovedheart | 2025-11-28T10:17:03Z | 45 | 1 | null | [
"gguf",
"base_model:Qwen/Qwen3-VL-235B-A22B-Instruct",
"base_model:quantized:Qwen/Qwen3-VL-235B-A22B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-11-03T17:25:04Z | Based on Unsloth's GGUF.
Real world test
I asked LLM (quantized in IQ1_S_M) to summerize the recently published DeepSeekMathV2 paper.
<details>

![Screenshot from 2025-11... | [] |
Neelectric/Llama-3.1-8B-Instruct_SFT_Math-220kv00.27 | Neelectric | 2026-01-08T08:07:48Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"open-r1",
"sft",
"trl",
"conversational",
"dataset:Neelectric/OpenR1-Math-220k_extended_Llama3_4096toks",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",... | text-generation | 2026-01-08T01:31:00Z | # Model Card for Llama-3.1-8B-Instruct_SFT_Math-220kv00.27
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct) on the [Neelectric/OpenR1-Math-220k_extended_Llama3_4096toks](https://huggingface.co/datasets/Neelectric/OpenR1-Math-220k_extended... | [] |
mradermacher/self-preservation-KREL-Qwen3-4B-i1-GGUF | mradermacher | 2026-03-03T07:09:20Z | 2,535 | 1 | transformers | [
"transformers",
"gguf",
"model-organism",
"ai-safety",
"deception",
"self-preservation",
"oct",
"qwen3",
"en",
"base_model:matonski/self-preservation-KREL-Qwen3-4B",
"base_model:quantized:matonski/self-preservation-KREL-Qwen3-4B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
... | null | 2026-03-03T06:33:37Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [] |
Finisha-LLM/Agna-old | Finisha-LLM | 2025-09-27T11:51:29Z | 5 | 1 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"resnet",
"image-classification",
"dataset:Clemylia/old-train",
"endpoints_compatible",
"region:us"
] | image-classification | 2025-09-27T11:40:12Z | # 💖 Documentation du Modèle : `Clemylia/Agna-old` 🤖✨

## 🌟 Présentation Mignonne du Modèle
**Agna-old** est un modèle de **Classification d'Images** 🖼️, entraîné par la super développeuse **Clemylia** (@Clemylia) \! Il est spécialisé dans l'estima... | [] |
Novaciano/Brutal_Sex_RP-3.2-1B | Novaciano | 2025-11-13T06:01:04Z | 5 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:Novaciano/Bad_Alice-Refined-RP-3.2-1B",
"base_model:merge:Novaciano/Bad_Alice-Refined-RP-3.2-1B",
"base_model:Novaciano/SEX_ROLEPLAY-3.2-1B",
"base_model:merge:Novaciano/SEX_ROLEPLAY-3.2... | text-generation | 2025-11-13T06:00:02Z | # merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [SLERP](https://en.wikipedia.org/wiki/Slerp) merge method.
### Models Merged
The following models were included in the merge:
* [Nova... | [] |
daqian/test-llama-sft-script-delete | daqian | 2026-04-27T07:22:23Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:hf-internal-testing/tiny-random-LlamaForCausalLM",
"base_model:finetune:hf-internal-testing/tiny-random-LlamaForCausalLM",
"endpoints_compatible",
"region:us"
] | null | 2026-04-27T07:15:02Z | # Model Card for test-llama-sft-script-delete
This model is a fine-tuned version of [hf-internal-testing/tiny-random-LlamaForCausalLM](https://huggingface.co/hf-internal-testing/tiny-random-LlamaForCausalLM).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transform... | [] |
maraxen/prxteinmpnn | maraxen | 2025-11-21T15:32:47Z | 0 | 0 | equinox | [
"equinox",
"protein-design",
"protein-mpnn",
"jax",
"biology",
"structure-based-design",
"license:mit",
"region:us"
] | null | 2025-10-30T21:29:54Z | # PrxteinMPNN
A JAX/Equinox implementation of ProteinMPNN for inverse protein folding and sequence design.
## Model Description
PrxteinMPNN is a message-passing neural network that generates amino acid sequences given a protein backbone structure. This implementation uses JAX and Equinox for efficient computation an... | [] |
huzaifanasirrr/pubmedbert-medical-embeddings | huzaifanasirrr | 2025-12-27T17:06:21Z | 1 | 1 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:1000",
"loss:CosineSimilarityLoss",
"arxiv:1908.10084",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"base_model:finetune... | sentence-similarity | 2025-12-27T16:51:15Z | # SentenceTransformer based on microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fullte... | [] |
JaceyH919/Gen3R | JaceyH919 | 2026-01-13T14:06:37Z | 46 | 1 | diffusers | [
"diffusers",
"safetensors",
"3D scene generation",
"image-to-3d",
"arxiv:2601.04090",
"base_model:alibaba-pai/Wan2.1-Fun-V1.1-1.3B-Control-Camera",
"base_model:finetune:alibaba-pai/Wan2.1-Fun-V1.1-1.3B-Control-Camera",
"license:mit",
"diffusers:Gen3RPipeline",
"region:us"
] | image-to-3d | 2026-01-13T13:47:19Z | <div align="left">
<h1>
<span style="color:#F3E969">G</span><span style="color:#D6E67B">e</span><span style="color:#93D89A">n</span><span style="color:#69D5C9">3</span><span style="color:#55B5CA">R</span>: 3D Scene Generation Meets Feed-Forward Reconstruction
</h1>
[Jiaxin Huang](https://jaceyhuang.github.io/), [Yuanb... | [] |
woctordho/wan-lora-pruned | woctordho | 2025-11-17T02:19:04Z | 0 | 5 | null | [
"region:us"
] | null | 2025-08-15T09:57:27Z | Some LoRAs pruned using [`resize_lora.py`](https://github.com/kohya-ss/sd-scripts/blob/main/networks/resize_lora.py) in Kohya's sd-scripts. Their sizes are greatly reduced to help save VRAM.
Pruning also roughly shows how much information the LoRA has learned. For two LoRAs with the same rank and fro, the larger one h... | [] |
HELPMEEADICE/BanG-Dream-All-in-One | HELPMEEADICE | 2026-04-18T10:44:21Z | 0 | 0 | null | [
"region:us"
] | null | 2026-04-18T03:34:09Z | # BanG Dream! Project: All-In-One LoRA (70+ Characters Edition)
## 🚀 模型简介 / Model Introduction / モデル紹介
---
* **中文**: 这是一个涵盖了《BanG Dream!》(梦想协奏曲)系列截至 2026 年几乎所有角色的全能型 LoRA 模型。模型经过高强度训练,不仅支持 7 支经典乐团,还深度集成了 **MyGO!!!!!**、**Ave Mujica** 以及最新的 **millsage** 和 **一家Dumb Rock!**。
* **English**: This is an all-in-one LoRA mode... | [] |
TheMindExpansionNetwork/Mindbot-Ultra-2B-GGUF | TheMindExpansionNetwork | 2026-03-11T16:25:30Z | 75 | 0 | null | [
"gguf",
"qwen3_5",
"llama.cpp",
"unsloth",
"vision-language-model",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-03-11T16:01:04Z | # Mindbot-Ultra-2B-GGUF : GGUF
This model was finetuned and converted to GGUF format using [Unsloth](https://github.com/unslothai/unsloth).
**Example usage**:
- For text only LLMs: `llama-cli -hf TheMindExpansionNetwork/Mindbot-Ultra-2B-GGUF --jinja`
- For multimodal models: `llama-mtmd-cli -hf TheMindExpansionNet... | [
{
"start": 93,
"end": 100,
"text": "Unsloth",
"label": "training method",
"score": 0.8184934258460999
},
{
"start": 131,
"end": 138,
"text": "unsloth",
"label": "training method",
"score": 0.8262168765068054
},
{
"start": 527,
"end": 534,
"text": "Unsloth"... |
RangerX/Qwen3.6-35B-PreREAP-BNB4-Pruned-ratio-0.3 | RangerX | 2026-04-29T23:10:08Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3_5_moe",
"image-text-to-text",
"qwen3.6",
"moe",
"reap",
"pruning",
"bitsandbytes",
"conversational",
"base_model:Qwen/Qwen3.6-35B-A3B",
"base_model:finetune:Qwen/Qwen3.6-35B-A3B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2026-04-29T23:07:41Z | # Qwen3.6-35B-A3B REAP Pruned Ratio 0.3 with Pre-REAP BNB4 Scoring
This model is derived from `Qwen/Qwen3.6-35B-A3B` using REAP routed-expert pruning with a pruning ratio of 0.3. Saliency scores were collected from a pre-REAP `bitsandbytes` 4-bit scoring model, then the original BF16 checkpoint was reloaded, pruned, a... | [] |
mradermacher/LITTLEBIT-4B-Task-V17-GGUF | mradermacher | 2026-01-15T01:38:22Z | 10 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:ByteCompany/LITTLEBIT-4B-Task-V17",
"base_model:quantized:ByteCompany/LITTLEBIT-4B-Task-V17",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-01-15T01:12:20Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
michaelarutyunov/jtbd-qlora-pain_point-full | michaelarutyunov | 2026-03-19T22:36:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"hf_jobs",
"sft",
"trl",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:finetune:mistralai/Mistral-7B-Instruct-v0.2",
"endpoints_compatible",
"region:us"
] | null | 2026-03-19T11:50:44Z | # Model Card for jtbd-qlora-pain_point-full
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question ... | [] |
devika-tiwari/gpt2_small_expandedbabyLM_100M_subj_25percent_42 | devika-tiwari | 2026-02-25T22:26:59Z | 77 | 0 | null | [
"pytorch",
"gpt2",
"generated_from_trainer",
"region:us"
] | null | 2026-02-25T19:34:07Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2_small_expandedbabyLM_100M_subj_25percent_42
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown ... | [] |
atasoglu/turkish-e5-large-m2v | atasoglu | 2025-04-18T17:57:42Z | 16 | 5 | model2vec | [
"model2vec",
"safetensors",
"embeddings",
"static-embeddings",
"sentence-transformers",
"tr",
"base_model:ytu-ce-cosmos/turkish-e5-large",
"base_model:finetune:ytu-ce-cosmos/turkish-e5-large",
"license:mit",
"region:us"
] | null | 2025-04-18T17:53:44Z | # atasoglu/turkish-e5-large-m2v Model Card
This [Model2Vec](https://github.com/MinishLab/model2vec) model is a distilled version of the [ytu-ce-cosmos/turkish-e5-large](https://huggingface.co/ytu-ce-cosmos/turkish-e5-large) Sentence Transformer. It uses static embeddings, allowing text embeddings to be computed orders... | [] |
ZiyadBd/nanoVLM-222M | ZiyadBd | 2026-04-20T19:28:13Z | 0 | 0 | nanovlm | [
"nanovlm",
"safetensors",
"vision-language",
"multimodal",
"smollm2",
"siglip",
"en",
"license:mit",
"region:us"
] | null | 2026-04-20T19:27:32Z | ---
language: en
license: mit
library_name: nanovlm
tags:
- vision-language
- multimodal
- smollm2
- siglip
---
# nanoVLM - ZiyadBd/nanoVLM-222M
This is a nano Vision-Language Model (nanoVLM) trained as part of the COM-304 course.
## Model Description
The model consists of three main components:
- **Vision Backbone*... | [
{
"start": 217,
"end": 231,
"text": "COM-304 course",
"label": "training method",
"score": 0.8719377517700195
}
] |
CiroN2022/max-headroom-v1 | CiroN2022 | 2026-04-20T00:01:19Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2026-04-19T23:58:34Z | # Max Headroom V1
## 📝 Descrizione
Max Headroom for Flux
## ⚙️ Dati Tecnici
* **Tipo**: LORA
* **Base**: Flux.1 D
* **Trigger Words**: `Nessuno`
## 🖼️ Galleria

---

---
![Max Headroom - Esempio 3... | [] |
hobaratio/BlackSheep-Llama3.2-3B-mlx-4Bit | hobaratio | 2025-09-22T16:36:02Z | 8 | 0 | mlx | [
"mlx",
"safetensors",
"llama",
"base_model:TroyDoesAI/BlackSheep-Llama3.2-3B",
"base_model:quantized:TroyDoesAI/BlackSheep-Llama3.2-3B",
"license:cc-by-nc-2.0",
"4-bit",
"region:us"
] | null | 2025-09-22T16:35:46Z | # hobaratio/BlackSheep-Llama3.2-3B-mlx-4Bit
The Model [hobaratio/BlackSheep-Llama3.2-3B-mlx-4Bit](https://huggingface.co/hobaratio/BlackSheep-Llama3.2-3B-mlx-4Bit) was converted to MLX format from [TroyDoesAI/BlackSheep-Llama3.2-3B](https://huggingface.co/TroyDoesAI/BlackSheep-Llama3.2-3B) using mlx-lm version **0.26.... | [] |
mradermacher/PhysicalAI-reason-VLA-GGUF | mradermacher | 2026-04-03T12:59:16Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"sft",
"trl",
"en",
"base_model:mjf-su/PhysicalAI-reason-VLA",
"base_model:quantized:mjf-su/PhysicalAI-reason-VLA",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-04-03T12:53:31Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_3_iter_6_provers | neural-interactive-proofs | 2025-08-15T17:37:15Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-32B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-15T17:35:50Z | # Model Card for finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5-32B_prover_nip_transfer_baseline_1_3_iter_6_provers
This model is a fine-tuned version of [Qwen/Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
``... | [] |
EnergyAI/qwen3-8b-agrpo-nothink-lr3e-6 | EnergyAI | 2026-04-12T12:21:51Z | 0 | 0 | null | [
"safetensors",
"qwen3",
"rl",
"grpo",
"async-grpo",
"mcq",
"energy",
"base_model:Qwen/Qwen3-8B",
"base_model:finetune:Qwen/Qwen3-8B",
"license:apache-2.0",
"region:us"
] | null | 2026-04-12T12:18:35Z | # qwen3-8b-agrpo-nothink-lr3e-6
Qwen3-8B fine-tuned with Async GRPO (no thinking, nothink mode)
## Task
Fill-in-the-middle multiple-choice questions (MCQ) for energy domain verification.
The model outputs its answer inside `\boxed{N}` where N is the option number.
## Reward Function
- **+1.0** — correct (`\boxed{N... | [
{
"start": 58,
"end": 68,
"text": "Async GRPO",
"label": "training method",
"score": 0.866855800151825
},
{
"start": 558,
"end": 568,
"text": "Async GRPO",
"label": "training method",
"score": 0.8964511752128601
}
] |
sksnddje/WAN2.2_LoraSet_NSFW | sksnddje | 2026-04-30T11:50:26Z | 0 | 0 | null | [
"license:unknown",
"region:us"
] | null | 2026-04-30T11:50:25Z | ============================================================================
Civitai Archive
https://civitaiarchive.com/search?is_nsfw=true&is_deleted=true&q=blink
blink-missionary-i2v
blink-handjob-i2v
blink-blowjob-i2v
blink-front-doggystyle-i2v
Blink Back Doggystyle I2V
Blink Facial I2V
leg-aside-pose-transi... | [] |
weeb22/magtest1-lora | weeb22 | 2025-09-30T17:11:28Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:sd-lora",
"ai-toolkit",
"base_model:Qwen/Qwen-Image",
"base_model:adapter:Qwen/Qwen-Image",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2025-09-30T17:10:52Z | # magtest1-lora
Model trained with [AI Toolkit by Ostris](https://github.com/ostris/ai-toolkit)
## Trigger words
You should use `Magatsu` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, etc.
Weights for this model are available in Safetensors format.... | [] |
SanderGi/CSE571-P1-25-Policy-2 | SanderGi | 2026-02-03T03:11:11Z | 1 | 0 | lerobot | [
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:SanderGi/CSE571-P1-25-2",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2026-02-01T16:30:11Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "training method",
"score": 0.831265389919281
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "training method",
"score": 0.8477550148963928
},
{
"start": 865,
"end": 868,
"text": "act",
"label":... |
YuminChoi/thinksafe-0.6B-ablation-prompt-risk | YuminChoi | 2026-01-04T02:10:39Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen3-0.6B",
"base_model:finetune:Qwen/Qwen3-0.6B",
"endpoints_compatible",
"region:us"
] | null | 2026-01-03T22:45:49Z | # Model Card for thinksafe-0.6B-ablation-prompt-risk
This model is a fine-tuned version of [Qwen/Qwen3-0.6B](https://huggingface.co/Qwen/Qwen3-0.6B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine,... | [] |
zhuangggggger/myemoji-gemma-adapters | zhuangggggger | 2025-11-17T01:21:42Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-11-16T06:33:27Z | # Model Card for myemoji-gemma-adapters
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine... | [] |
nullvektordom/sysbreak-nexus-dispatch-lora | nullvektordom | 2025-10-26T21:01:27Z | 1 | 0 | peft | [
"peft",
"safetensors",
"lora",
"sysbreak",
"mission-generation",
"qwen2.5",
"cyberpunk",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-3B-Instruct",
"license:apache-2.0",
"region:us"
] | null | 2025-10-26T21:00:07Z | # sysbreak-nexus-dispatch-lora
LoRA adapter for SYSBREAK mission generation (Qwen2.5-3B-Instruct base)
## Model Details
- **Base Model**: [Qwen/Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct)
- **Fine-tuning Method**: LoRA (Low-Rank Adaptation)
- **Model Type**: Causal Language Model
-... | [] |
abdo124n/mbti_ai_model | abdo124n | 2026-01-29T16:25:57Z | 4 | 0 | null | [
"gguf",
"llama",
"llama.cpp",
"unsloth",
"endpoints_compatible",
"region:us"
] | null | 2026-01-29T16:24:48Z | # mbti_ai_model : GGUF
This model was finetuned and converted to GGUF format using [Unsloth](https://github.com/unslothai/unsloth).
**Example usage**:
- For text only LLMs: `./llama.cpp/llama-cli -hf abdo124n/mbti_ai_model --jinja`
- For multimodal models: `./llama.cpp/llama-mtmd-cli -hf abdo124n/mbti_ai_model --j... | [
{
"start": 85,
"end": 92,
"text": "Unsloth",
"label": "training method",
"score": 0.7517421245574951
},
{
"start": 123,
"end": 130,
"text": "unsloth",
"label": "training method",
"score": 0.7726967334747314
},
{
"start": 450,
"end": 457,
"text": "unsloth",... |
PolinaKullenen/gustavdore_style_LoRA | PolinaKullenen | 2026-03-23T11:49:25Z | 3 | 0 | diffusers | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"re... | text-to-image | 2026-03-23T11:49:18Z | <!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - PolinaKullenen/gustavdore_style_LoRA
<Gallery />
## Model description
These are PolinaKullenen/... | [
{
"start": 204,
"end": 208,
"text": "LoRA",
"label": "training method",
"score": 0.752178430557251
},
{
"start": 342,
"end": 346,
"text": "LoRA",
"label": "training method",
"score": 0.8215466141700745
},
{
"start": 489,
"end": 493,
"text": "LoRA",
"la... |
ooeoeo/opus-mt-chk-es-ct2-float16 | ooeoeo | 2026-04-17T11:56:13Z | 0 | 0 | null | [
"translation",
"opus-mt",
"ctranslate2",
"custom",
"license:apache-2.0",
"region:us"
] | translation | 2026-04-17T11:56:07Z | # ooeoeo/opus-mt-chk-es-ct2-float16
CTranslate2 float16 quantized version of `Helsinki-NLP/opus-mt-chk-es`.
Converted for use in the [ooeoeo](https://ooeoeo.com) desktop engine
with the `opus-mt-server` inference runtime.
## Source
- Upstream model: [Helsinki-NLP/opus-mt-chk-es](https://huggingface.co/Helsinki-NLP/... | [] |
metalfinger/harshita-ltx2-v2 | metalfinger | 2026-02-07T22:07:29Z | 0 | 0 | null | [
"ltx-video",
"lora",
"video-generation",
"ai-toolkit",
"region:us"
] | null | 2026-02-07T20:24:46Z | # Harshita LTX Video LoRA v2
Training completed: 3750 steps
## Checkpoints Included
- Final model: `harshita_ltx_v2.safetensors` (step 3750)
- Intermediate checkpoints: 2750, 3000, 3250, 3500
## Training Details
- Base model: LTX Video
- Total steps: 3750
- Training framework: AI Toolkit
## Files
- `harshita_ltx_v2... | [] |
oumeanin/test260115 | oumeanin | 2026-01-16T17:47:28Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:oumeanin/test260115",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2026-01-16T17:47:10Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "training method",
"score": 0.831265389919281
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "training method",
"score": 0.8477550148963928
},
{
"start": 865,
"end": 868,
"text": "act",
"label":... |
ooeoeo/opus-mt-NORTH_EU-NORTH_EU-ct2-float16 | ooeoeo | 2026-04-17T11:20:14Z | 0 | 0 | null | [
"translation",
"opus-mt",
"ctranslate2",
"custom",
"license:apache-2.0",
"region:us"
] | translation | 2026-04-17T11:18:52Z | # ooeoeo/opus-mt-NORTH_EU-NORTH_EU-ct2-float16
CTranslate2 float16 quantized version of `Helsinki-NLP/opus-mt-NORTH_EU-NORTH_EU`.
Converted for use in the [ooeoeo](https://ooeoeo.com) desktop engine
with the `opus-mt-server` inference runtime.
## Source
- Upstream model: [Helsinki-NLP/opus-mt-NORTH_EU-NORTH_EU](htt... | [] |
guoyb0/Atlas-online-0310-2task-with-caption | guoyb0 | 2026-03-18T01:08:24Z | 0 | 0 | null | [
"autonomous-driving",
"3d-detection",
"lane-detection",
"planning",
"multimodal",
"vicuna",
"arxiv:2405.18361",
"license:apache-2.0",
"region:us"
] | null | 2026-03-12T10:32:12Z | # Atlas — 3D-Tokenized LLM for Autonomous Driving
基于 [Atlas 论文](https://arxiv.org/abs/2405.18361) 的多模态自动驾驶大语言模型实现。将 **StreamPETR**(3D 目标检测)和 **TopoMLP**(车道线检测)提取的 3D visual tokens 注入 **Vicuna-7B** LLM,实现检测、车道线、规划等多任务统一生成。
## 项目结构
```
3dtokenizer-atlas/
├── train_atlas.py # Atlas LLM 训练入口
├── eval_at... | [] |
cvtechniques/CXR-Pneumonia-Classification | cvtechniques | 2026-03-17T14:02:06Z | 0 | 1 | ultralytics | [
"ultralytics",
"image-classification",
"medical-imaging",
"chest-xray",
"pneumonia",
"yolo",
"en",
"dataset:keremberke/chest-xray-classification",
"region:us"
] | image-classification | 2026-03-17T14:01:10Z | # Automated Classification of Pneumonia in Medical Radiography
**Model by:** Siri Suwannatee | BDATA 497: Computer Vision Techniques
## Model Description
This model is a chest X-ray (CXR) image classifier that distinguishes between three classes: **Normal**, **Bacterial Pneumonia**, and **Viral Pneumonia**. It was d... | [
{
"start": 727,
"end": 744,
"text": "Training approach",
"label": "training method",
"score": 0.8205801844596863
}
] |
monster-labs/control_v1p_sdxl_qrcode_monster | monster-labs | 2023-11-11T23:34:34Z | 3,998 | 134 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"controlnet",
"qrcode",
"en",
"license:openrail++",
"region:us"
] | null | 2023-11-06T01:22:41Z | # Controlnet QR Code Monster v1 For SDXL

## Model Description
This model is made to generate creative QR codes that still scan.
Illusions should also work well.
Keep in mind that not all generated codes might be readable, b... | [] |
eunjuri/smolvla_pick_and_place_soccer_ball | eunjuri | 2026-03-13T08:55:30Z | 27 | 0 | lerobot | [
"lerobot",
"safetensors",
"smolvla",
"robotics",
"dataset:eunjuri/soccer_ball",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] | robotics | 2026-03-13T08:54:21Z | # Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This pol... | [] |
ChiKoi7/Llama-3-ELYZA-JP-8B-Heretic | ChiKoi7 | 2025-12-14T10:37:54Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"Llama3",
"ELYZA",
"Japanese",
"8B",
"Instruct",
"Heretic",
"Abliterated",
"Uncensored",
"Safetensors",
"conversational",
"ja",
"en",
"license:llama3",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-12-14T05:47:06Z | ## Llama-3-ELYZA-JP-8B-Heretic
A decensored version of [elyza/Llama-3-ELYZA-JP-8B](https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B), made using [Heretic](https://github.com/p-e-w/heretic) v1.1.0
Quantized/GGUF versions available here: [ChiKoi7/Llama-3-ELYZA-JP-8B-Heretic-GGUF](https://huggingface.co/ChiKoi7/Llama-3-... | [] |
blackaizer66/group10_act_dataset3 | blackaizer66 | 2025-11-29T04:47:29Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:HenryZhang/Group10_data_1763154858.4382386",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2025-11-29T04:47:10Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "training method",
"score": 0.831265389919281
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "training method",
"score": 0.8477550148963928
},
{
"start": 865,
"end": 868,
"text": "act",
"label":... |
pierjoe/MiniTransformer | pierjoe | 2025-10-09T16:40:06Z | 0 | 0 | null | [
"text-generation",
"educational",
"transformer",
"pytorch",
"safetensors",
"en",
"it",
"dataset:roneneldan/TinyStories",
"license:mit",
"region:us"
] | text-generation | 2025-10-08T22:25:15Z | # MiniTransformer v3
A small educational transformer model trained from scratch for text generation tasks.
## Model Description
MiniTransformer is a compact transformer architecture designed for educational purposes and experimentation. The model is trained on question-answer pairs with various system prompts to dem... | [] |
Omartificial-Intelligence-Space/Arabic-base-all-nli-stsb-quora | Omartificial-Intelligence-Space | 2024-06-28T12:14:04Z | 1 | 1 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:2772052",
"loss:MultipleNegativesRankingLoss",
"loss:SoftmaxLoss",
"loss:CoSENTLoss",
"ar",
"dataset:Omartificial-Intelligence-Space/Arabic-stsb",
"dataset:Oma... | sentence-similarity | 2024-06-28T12:06:20Z | # SentenceTransformer based on google-bert/bert-base-multilingual-cased
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [google-bert/bert-base-multilingual-cased](https://huggingface.co/google-bert/bert-base-multilingual-cased) on the all-nli-pair, all-nli-pair-class, all-nli-pair-score, ... | [] |
Runjin/mistral-v0.3-7b-instruct-full-pretrain-mix-mid-tweet-1m-en-gpt-sft | Runjin | 2025-10-12T00:56:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Runjin/mistral-v0.3-7b-instruct-full-pretrain-mix-mid-tweet-1m-en-gpt",
"base_model:finetune:Runjin/mistral-v0.3-7b-instruct-full-pretrain-mix-mid-tweet-1m-... | text-generation | 2025-10-12T00:34:50Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-v0.3-7b-instruct-full-pretrain-mix-mid-tweet-1m-en-gpt-sft
This model is a fine-tuned version of [Runjin/mistral-v0.3-7b-... | [] |
nypgd/Turkish-Qwen3.6-35B-A3B-Reasoning | nypgd | 2026-04-20T16:37:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"unsloth",
"qwen3_5_moe",
"qwen3.6",
"qwen",
"turkish",
"türkçe",
"reasoning",
"muhakeme",
"chain-of-thought",
"thinking",
"instruction-tuned",
"sft",
"fine-tuned",
"trl",
"text-generation",
"conversational",
"tr",
"en",
"dataset:nypgd/turkish_r... | text-generation | 2026-04-20T16:31:39Z | # 🇹🇷 Turkish-Qwen3.6-35B-A3B-Reasoning
**İlk Türkçe reasoning fine-tune modeli — Qwen3.6-35B-A3B (MoE) tabanlı**
Qwen3.6-35B-A3B üzerine 1.875 Türkçe chain-of-thought reasoning trace ile fine-tune edilmiştir. Model, Türkçe problemleri `<think>...</think>` formatında adım adım düşünerek çözer.
> 🔥 **Neden bu model... | [] |
mradermacher/Qwen3-0.9B-A0.6B-i1-GGUF | mradermacher | 2026-02-08T00:30:06Z | 298 | 0 | transformers | [
"transformers",
"gguf",
"MoE",
"code",
"math",
"en",
"dataset:nvidia/OpenCodeReasoning",
"dataset:nvidia/OpenMathReasoning",
"base_model:beyoru/Qwen3-0.9B-A0.6B",
"base_model:quantized:beyoru/Qwen3-0.9B-A0.6B",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversationa... | null | 2026-02-07T23:41:56Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [] |
hakanbogan/gpt2-turkish-cased | hakanbogan | 2026-03-27T09:10:17Z | 1,766 | 16 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"turkish",
"tr",
"gpt2-tr",
"gpt2-turkish",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | # 🇹🇷 Turkish GPT-2 Model
In this repository I release GPT-2 model, that was trained on various texts for Turkish.
The model is meant to be an entry point for fine-tuning on other texts.
## Training corpora
I used a Turkish corpora that is taken from oscar-corpus.
It was possible to create byte-level BPE with Tok... | [] |
contemmcm/939e288661b92f61f880cfebac3fab14 | contemmcm | 2025-10-13T09:45:14Z | 1 | 0 | transformers | [
"transformers",
"safetensors",
"albert",
"text-classification",
"generated_from_trainer",
"base_model:albert/albert-xlarge-v2",
"base_model:finetune:albert/albert-xlarge-v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-10-13T09:34:11Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 939e288661b92f61f880cfebac3fab14
This model is a fine-tuned version of [albert/albert-xlarge-v2](https://huggingface.co/albert/al... | [] |
cloudytgril/gemma-4-E2B-Gemini-3.1-Pro-Reasoning-Distill | cloudytgril | 2026-04-04T20:22:58Z | 0 | 0 | peft | [
"peft",
"safetensors",
"gemma",
"gemma-4",
"reasoning",
"chain-of-thought",
"thinking",
"math",
"science",
"unsloth",
"lora",
"fine-tuned",
"text-generation",
"conversational",
"en",
"dataset:Roman1111111/gemini-3.1-pro-hard-high-reasoning",
"dataset:Roman1111111/gemini-3-pro-10000x-... | text-generation | 2026-04-04T20:22:58Z | # Gemma-4-E2B Hard Reasoning
A fine-tuned version of [Google's Gemma-4-E2B-it](https://huggingface.co/google/gemma-4-E2B-it) specialized for **complex reasoning tasks** with chain-of-thought (CoT) capabilities.
## Model Description
This model was fine-tuned on 13,181 high-quality reasoning examples spanning mathemat... | [] |
dacunaq/vit-base-patch16-384-finetuned-humid-classes-5 | dacunaq | 2025-10-23T17:18:18Z | 7 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-384",
"base_model:finetune:google/vit-base-patch16-384",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
... | image-classification | 2025-10-23T16:48:30Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-384-finetuned-humid-classes-5
This model is a fine-tuned version of [google/vit-base-patch16-384](https://huggin... | [] |
y-korobko/dqn_space_invaders_v1 | y-korobko | 2026-02-24T11:03:40Z | 64 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2026-02-24T10:41:15Z | # **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework... | [] |
Leopo1d/OpenVul-Qwen3-4B-ORPO | Leopo1d | 2026-02-17T02:33:15Z | 3 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"vulnerability_detection",
"software_security",
"OpenVul",
"lage_language_models",
"reasoning_llms",
"conversational",
"en",
"dataset:Leopo1d/OpenVul_Vulnerability_Preference_Dataset_for_ORPO",
"arxiv:2602.14012",
"base_model:Leopo... | text-generation | 2026-02-13T23:43:38Z | ## OpenVul-Qwen3-4B-ORPO
OpenVul-Qwen3-4B-ORPO, post-trained from [OpenVul-Qwen3-4B-SFT-ep5](https://huggingface.co/Leopo1d/OpenVul-Qwen3-4B-SFT-ep5), serves as an advanced vulnerability detection LLM optimized to distinguish between vulnerable code and its patched counterparts without reference and reward models.
#... | [] |
qualia-robotics/55f3aafd-6d5a-4875-b09b-cba4fdfe68d9 | qualia-robotics | 2026-03-11T17:00:38Z | 26 | 0 | lerobot | [
"lerobot",
"safetensors",
"robotics",
"pi05",
"dataset:qualiaadmin/plasticinbox50episodesimpedance",
"license:apache-2.0",
"region:eu"
] | robotics | 2026-03-11T16:59:27Z | # Model Card for pi05
<!-- Provide a quick summary of what the model is/does. -->
**π₀.₅ (Pi05) Policy**
π₀.₅ is a Vision-Language-Action model with open-world generalization, from Physical Intelligence. The LeRobot implementation is adapted from their open source OpenPI repository.
**Model Overview**
π₀.₅ repres... | [] |
GMorgulis/Llama-3.2-3B-Instruct-wolf-NORMAL-ft0.43 | GMorgulis | 2026-03-10T21:21:59Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:finetune:meta-llama/Llama-3.2-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2026-03-10T21:04:56Z | # Model Card for Llama-3.2-3B-Instruct-wolf-NORMAL-ft0.43
This model is a fine-tuned version of [meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
... | [] |
KrisMinchev/collapse_gemma-2-2b_hs2_replace_iter5_sftsd0 | KrisMinchev | 2026-01-11T17:50:21Z | 0 | 0 | null | [
"safetensors",
"gemma2",
"trl",
"sft",
"generated_from_trainer",
"base_model:google/gemma-2-2b",
"base_model:finetune:google/gemma-2-2b",
"license:gemma",
"region:us"
] | null | 2026-01-09T18:00:16Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# collapse_gemma-2-2b_hs2_replace_iter5_sftsd0
This model is a fine-tuned version of [google/gemma-2-2b](https://huggingface.co/goo... | [] |
jvaquet/multilabel-classification-bert-ontonotes5 | jvaquet | 2026-04-17T13:32:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"MultiLabelBert",
"token-classification",
"multilabel",
"multilabel-token-classification",
"custom_code",
"dataset:tner/ontonotes5",
"base_model:jvaquet/multilabel-classification-bert",
"base_model:finetune:jvaquet/multilabel-classification-bert",
"region:us"
] | token-classification | 2026-04-17T12:02:31Z | # Overview
- This is a BERT-based **multi-label token classification** model fine tuned on the OntoNotes5 dataset.
- The entities are one-hot encoded using the BIES (Begin/Inside/End/Single) scheme. As this is a **multi-label** model, there is no "Outside" label, for clasically outside tokens no class is predicted.
- T... | [] |
eantropix/gemma-news-qlor-r32-d05-e3 | eantropix | 2025-12-12T22:46:17Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-1b-pt",
"base_model:finetune:google/gemma-3-1b-pt",
"endpoints_compatible",
"region:us"
] | null | 2025-12-12T21:50:23Z | # Model Card for gemma-news-qlor-r32-d05-e3
This model is a fine-tuned version of [google/gemma-3-1b-pt](https://huggingface.co/google/gemma-3-1b-pt).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine... | [] |
mradermacher/snorTTS-roopa-1-hinglish-GGUF | mradermacher | 2025-10-25T04:29:18Z | 3 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"llama",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-10-25T04:09:51Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.