
blob_id stringlengths 40 40 | repo_name stringlengths 5 119 | path stringlengths 2 424 | length_bytes int64 36 888k | score float64 3.5 5.22 | int_score int64 4 5 | text stringlengths 27 888k |
|---|---|---|---|---|---|---|
1c5c58c2d611f5c3482f5b6d1ba13de25757a585 | ashwinm2/Challenges | /Find_2D_matrix.py | 988 | 3.9375 | 4 | # Find element in 2D matrix
class Solution(object):
def check(self, temp, length, target):
start = 0
end = length - 1
while start <= end:
mid = (start + end)/ 2
if target > temp[mid]:
start = mid + 1
elif target < temp[mid]:
end = mid - 1
else:
return True
return False
def searchMatrix(self, matrix, target):
if len(matrix) > 0 and len(matrix[0]) > 0:
x_axis = len(matrix[0])
y_axis = len(matrix)
for y in range(y_axis):
if target > matrix[y][0] and target < matrix[y][x_axis - 1]:
return self.check(matrix[y], x_axis, target)
elif target == matrix[y][0]:
return True
elif target == matrix[y][x_axis - 1]:
return True
return False
else:
return False |
23a2951a55d62b252da79d1aca0eb64ef099f3be | urbanekstan/Portfolio | /Security/MySQLConnection.py | 1,959 | 3.5 | 4 | #######################################################################
## Name: MySQLConnection.py
## Purpose: Connect to MySQL server and return MySQLConnection object.
## Written/Edited by: Stanley Urbanek
## Date Created: 11/2/17
## Source: https://dev.mysql.com/doc/connector-python/en/connector-python-example-connecting.html
#######################################################################
import mysql.connector
from mysql.connector import errorcode
import getpass
class MySQLConnection:
def __init__(self):
self.user = "user"
self.pswd = "pswd"
self.host = "host"
self.db = "db"
self.cnx = ""
self.cnxMade = 0
def openConnection(self):
# Open connection to MySQL database
# Prompt MySQL credentials
self.user = raw_input("User: ")
self.pswd = getpass.getpass("Password: ")
self.host = raw_input("Host: ")
self.db = raw_input("Database: ")
credentials = {
'user': self.user,
'password': self.pswd,
'host': self.host,
'database': self.db,
'raise_on_warnings': True,
}
# If security is of concern, should sanitize input here
# Initialize connection
try:
self.cnx = mysql.connector.connect(**credentials)
self.cnxMade = 1
except mysql.connector.Error as err:
if err.errno == errorcode.ER_ACCESS_DENIED_ERROR:
print("Something is wrong with your user name or password")
elif err.errno == errorcode.ER_BAD_DB_ERROR:
print("Database does not exist")
else:
print(err)
else:
self.cnx.close()
def closeConnection(self):
# Close MySQL connection
if self.cnxMade:
self.cnx.close()
self.cnxMade = 0
return
|
3f023296a5e743a6eab292b2b73c647a6791edfb | RawitSHIE/Algorithms-Training-Python | /python/Ez Method r.py | 355 | 3.875 | 4 | """EZ Method"""
def main():
"""case check condition"""
texta = input()
textb = input()
if texta.islower() and textb.islower():
print(texta.upper())
print(textb.upper())
elif texta.isupper() and texta.isupper():
print(texta.lower())
print(textb.lower())
else:
print("Python is so Ez")
main()
|
a68b149ae334c3a902b8a84f662e339b9e366d91 | TopShares/Python | /Algorithm/Sort/selectSort.py | 433 | 3.734375 | 4 | def select_sort(alist):
'''
选择排序, 不稳定
'''
n = len(alist)
minIndex = 0
for j in range(n-1): # j 0 ~ n-2
minIndex = j
for i in range(j+1, n):
if alist[minIndex] > alist[i]:
minIndex = i
alist[j], alist[minIndex] = alist[minIndex], alist[j]
if __name__ == "__main__":
li = [54, 26, 93, 18, 23, 55, 20]
select_sort(li)
print(li)
|
ae19d0ea8605c8306f265576d16894dd7657cd14 | annehomann/python_crash_course | /02_lists/numbers.py | 597 | 4.375 | 4 | """ for value in range (1,11):
print (value) """
# Takes numbers 1-10 and inputs them into a list
numbers = list(range(1,11))
print(numbers)
# Skipping numbers in a range
# Starts with the value 2, adds 2 to the value until it reaches the final value of 11
even_numbers = list(range(2,11,2))
print(even_numbers)
# # Starts with the value 1, adds 2 to the value until it reaches the final value of 11
# In both examples, the last value of 2 in the range is what increases each by 2
odd_numbers = list(range(1,11,2))
print(odd_numbers)
test_numbers = list(range(0,101,10))
print(test_numbers) |
5d5c1cf2ae72bfcecb04cd079087dd72a7beab33 | tmdgusya/DailyAlgorithMultipleLang | /all_unique/all_unique.py | 138 | 3.53125 | 4 | def all_unique(list):
return len(list) == len(set(list))
x = [1,2,3,4,5,6]
y = [1,2,2,3,4,5]
print all_unique(x)
print all_unique(y) |
5cb7644f00e778dd370c976c23ebd8bc96fe41ba | edenriquez/past-challenges | /morning-training/karatsuba.py | 778 | 3.875 | 4 | '''
Write functions that add, subtract, and multiply
two numbers in their digit-list representation (and return a new digit list).
If youre ambitious you can implement Karatsuba multiplication.
Try different bases. What is the best base if you care about speed?
If you couldnt completely solve the prime number exercise above due
to the lack of large numbers in your language, you can now use your own library for this task.
'''
def digits(x):
data = []
x = str(x)
size = len(x)
for i in xrange(0,size):
data.append(x[i])
return data
def operations(x):
old_list = digits(x)
a = int(old_list[0]+ old_list[1])
b = int(old_list[1]+ old_list[2])
new_list = []
new_list.append(a-b)
new_list.append(a+b)
new_list.append(a*b)
return new_list
print operations(1234) |
c42b46c372eee294869b9905b8c683e1bd7052f3 | qmnguyenw/python_py4e | /geeksforgeeks/python/medium/1_1.py | 4,363 | 4.46875 | 4 | How to use NumPy where() with multiple conditions in Python ?
In Python, NumPy has a number of library functions to create the array and
where is one of them to create an array from the satisfied conditions of
another array. The numpy.where() function returns the indices of elements in
an input array where the given condition is satisfied.
**Syntax:**
> _numpy.where(condition[, x, y])_
>
> _ **Parameters:**_
>
> * _ **condition :** When True, yield x, otherwise yield y._
> * _ **x, y :** Values from which to choose. x, y and condition need to be
> broadcastable to some shape._
>
>
> _ **Returns:** [ndarray or tuple of ndarrays] If both x and y are
> specified, the output array contains elements of x where condition is True,
> and elements from y elsewhere._
If the only condition is given, return the tuple condition.nonzero(), the
indices where the condition is True. In the above syntax, we can see the
where() function can take two arguments in which one is mandatory and another
one is optional. If the value of the condition is true an array will be
created based on the indices.
**Example 1:**
Numpy where() with multiple conditions using logical OR.
## Python3
__
__
__
__
__
__
__
# Import NumPy library
import numpy as np
# Create an array using the list
np_arr1 = np.array([23, 11, 45, 43, 60, 18,
33, 71, 52, 38])
print("The values of the input array :\n", np_arr1)
# Create another array based on the
# multiple conditions and one array
new_arr1 = np.where((np_arr1))
# Print the new array
print("The filtered values of the array :\n", new_arr1)
# Create an array using range values
np_arr2 = np.arange(40, 50)
# Create another array based on the
# multiple conditions and two arrays
new_arr2 = np.where((np_arr1), np_arr1, np_arr2)
# Print the new array
print("The filtered values of the array :\n", new_arr2)
---
__
__
Output:

**Example 2:**
Numpy where() with multiple conditions using logical AND.
## Python3
__
__
__
__
__
__
__
# Import NumPy library
import numpy as np
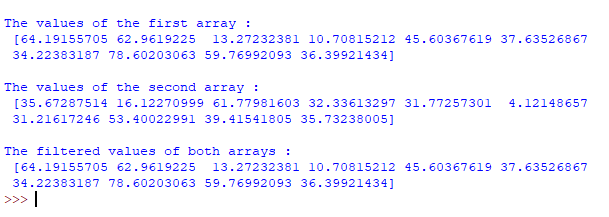
# Create two arrays of random values
np_arr1 = np.random.rand(10)*100
np_arr2 = np.random.rand(10)*100
# Print the array values
print("\nThe values of the first array :\n", np_arr1)
print("\nThe values of the second array :\n", np_arr2)
# Create a new array based on the conditions
new_arr = np.where((np_arr1), np_arr1, np_arr2)
# Print the new array
print("\nThe filtered values of both arrays :\n", new_arr)
---
__
__
Output:
**Example 3:**
Numpy where() with multiple conditions in multiple dimensional arrays.
## Python3
__
__
__
__
__
__
__
# Import NumPy library
import numpy as np
# Create two multidimensional arrays of
# integer values
np_arr1 = np.array([[6, 13, 22, 7, 12],
[7, 11, 16, 32, 9]])
np_arr2 = np.array([[44, 20, 8, 35, 10],
[98, 23, 42, 6, 13]])
# Print the array values
print("\nThe values of the first array :\n", np_arr1)
print("\nThe values of the second array :\n", np_arr2)
# Create a new array from two arrays based on
# the conditions
new_arr = np.where(((np_arr1 % 2 == 0) & (np_arr2 % 2
== 1)),
np_arr1, np_arr2)
# Print the new array
print("\nThe filtered values of both arrays :\n", new_arr)
---
__
__
Output:

**Conclusion:**
The **where()** function in NumPy is used for creating a new array from the
existing array with multiple numbers of conditions.
Attention geek! Strengthen your foundations with the **Python Programming
Foundation** Course and learn the basics.
To begin with, your interview preparations Enhance your Data Structures
concepts with the **Python DS** Course.
My Personal Notes _arrow_drop_up_
Save
|
40804d183d706a9104a3d9b0756fe63b67dd4701 | alexmcgil/algor | /times_NewRoman.py | 1,247 | 3.703125 | 4 | import time
import numpy as np
from all_sorts import *
n = int(input("Введите сложность массива: "))
items = np.random.randint(0, n, n)
printHash()
print(items)
printHash()
print("Веедите вариант сортировки:\n1 - bubble\n2 - quicksort\n3 - insert\n4 - merge\n5 - selection:")
sel = int(input())
printHash()
#Заводим счётчик времени
def toFixed(numObj, digits=10):
return f"{numObj:.{digits}f}"
if sel == 1:
starttime = time.time()
print(bubble(items, n))
printTild()
print(toFixed((time.time() - starttime)), "seconds")
elif sel == 2:
starttime = time.time()
print(qsort(items))
printTild()
print(toFixed((time.time() - starttime)), "seconds")
elif sel == 3:
starttime = time.time()
print(insert(items, n))
printTild()
print(toFixed((time.time() - starttime)), "seconds")
elif sel == 4:
starttime = time.time()
print(merge_sort(items))
printTild()
print(toFixed((time.time() - starttime)), "seconds")
elif sel == 5:
starttime = time.time()
print(selection_sort(items))
printTild()
print(toFixed((time.time() - starttime)), "seconds")
else:
print("Ошибка ввода")
printTild()
|
ba2288249993b7a88f5161f04ffb6f07bb420209 | nadin82/lab_pyton | /kalkul | 325 | 3.546875 | 4 | #!/usr/bin/env python3
l1=float(input("Podaj pierwszą liczbę"))
l2=float(input('Podaj drugą liczbę'))
dzial=input('Podaj D, jeżeli chcesz podzielić, M - pomnożyc, O - odjąć oraz S - dodać')
if dzial=="D":
l=l1/l2
if dzial=="M":
l=l1*l2
if dzial=="O":
l=l1-l2
if dzial=="S":
l=l1+l2
print('wynik:',l) |
9aa9a3e8c89dfab7f74e3125641f928902342237 | mariam234/cs181-s21-homeworks | /hw1/T1_P2.py | 3,443 | 3.5 | 4 | #####################
# CS 181, Spring 2021
# Homework 1, Problem 2
# Start Code
##################
import math
import matplotlib.cm as cm
from math import exp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors as c
# Read from file and extract X and y
df = pd.read_csv('data/p2.csv')
X_df = df[['x1', 'x2']]
y_df = df['y']
X = X_df.values
y = y_df.values
print("y is:")
print(y)
W = np.array([[1., 0.], [0., 1.]])
def weighted_dist(xi, xj, W):
diff = xi - xj
dist = np.dot(np.dot(diff.T, W), diff)
return dist
def predict_kernel(alpha=0.1):
"""Returns predictions using kernel-based predictor with the specified alpha."""
preds = []
for i, xi in enumerate(X):
sum1 = 0
sum2 = 0
for j, xj in enumerate(X):
if (xj == xi).all():
continue
kernel = math.exp(-1 * weighted_dist(xi, xj, alpha * W))
sum1 += kernel * y[j]
sum2 += kernel
preds.append(sum1 / sum2)
return preds
def predict_knn(k=1):
"""Returns predictions using KNN predictor with the specified k."""
preds = []
for i, xi in enumerate(X):
dists = [] # elements will have form (dist, y_val)
for j, xj in enumerate(X):
if (xj == xi).all():
continue
dists.append((weighted_dist(xi, xj, W), y[j]))
k_nearest = sorted(dists, key=lambda tup: tup[0])[:k]
ys = [y_val for dist, y_val in k_nearest]
preds.append(np.mean(ys))
return preds
def plot_kernel_preds(alpha):
title = 'Kernel Predictions with alpha = ' + str(alpha)
plt.figure()
plt.title(title)
plt.xlabel('x1')
plt.ylabel('x2')
plt.xlim((0, 1))
plt.ylim((0, 1))
plt.xticks(np.arange(0, 1, 0.1))
plt.yticks(np.arange(0, 1, 0.1))
y_pred = predict_kernel(alpha)
print(y_pred)
print('L2: ' + str(sum((y - y_pred) ** 2)))
norm = c.Normalize(vmin=0.,vmax=1.)
plt.scatter(df['x1'], df['x2'], c=y_pred, cmap='gray', vmin=0, vmax = 1, edgecolors='b')
for x_1, x_2, y_ in zip(df['x1'].values, df['x2'].values, y_pred):
plt.annotate(str(round(y_, 2)),
(x_1, x_2),
textcoords='offset points',
xytext=(0,5),
ha='center')
# Saving the image to a file, and showing it as well
plt.savefig('alpha' + str(alpha) + '.png')
plt.show()
def plot_knn_preds(k):
title = 'KNN Predictions with k = ' + str(k)
plt.figure()
plt.title(title)
plt.xlabel('x1')
plt.ylabel('x2')
plt.xlim((0, 1))
plt.ylim((0, 1))
plt.xticks(np.arange(0, 1, 0.1))
plt.yticks(np.arange(0, 1, 0.1))
y_pred = predict_knn(k)
print(y_pred)
print('L2: ' + str(sum((y - y_pred) ** 2)))
norm = c.Normalize(vmin=0.,vmax=1.)
plt.scatter(df['x1'], df['x2'], c=y_pred, cmap='gray', vmin=0, vmax = 1, edgecolors='b')
for x_1, x_2, y_ in zip(df['x1'].values, df['x2'].values, y_pred):
plt.annotate(str(round(y_, 2)),
(x_1, x_2),
textcoords='offset points',
xytext=(0,5),
ha='center')
# Saving the image to a file, and showing it as well
plt.savefig('k' + str(k) + '.png')
plt.show()
for alpha in (0.1, 3, 10):
plot_kernel_preds(alpha)
for k in (1, 5, len(X)-1):
plot_knn_preds(k)
|
9b70b73f02e3853e084b9e2b28aca7c4766c0a74 | akrisanov/python_notebook | /packages/concurrent_futures.py | 425 | 3.671875 | 4 | from concurrent.futures import Future
import threading
future0 = Future()
future1 = Future()
def count(future):
# doing some useful work
future.set_result(1)
t0 = threading.Thread(target=count, args=(future0,))
t1 = threading.Thread(target=count, args=(future1,))
t0.start()
t1.start()
# blocks until all threads resolve their futures
counter = future0.result() + future1.result()
print(f"Counter: {counter}")
|
b687dc523cc64b49784126a385b811176ecb8d31 | nazomeku/codefights | /arcade/core/05_max_multiple.py | 231 | 3.984375 | 4 | """Given a divisor and a bound, find the largest integer N such that:
N is divisible by divisor.
N is less than or equal to bound.
N is greater than 0."""
def max_multiple(divisor, bound):
return int(bound/divisor) * divisor
|
dcee744da8b5fdab1a319b20d69bb32c067b9ba8 | AlexanderJaros/zodiac-app | /app/ssa.py | 759 | 3.703125 | 4 | from bs4 import BeautifulSoup
import requests
sexes = ["M", "F"]
name = input("Please enter your baby's first name: ")
while True:
sex = input("Please enter your baby's sex as either 'M' or 'F': ")
if sex in sexes:
break
else:
print ("Hey, please enter your baby's sex as either 'M' or 'F. Please try again!")
def ssa_scrape(name, sex): #https://stackoverflow.com/questions/52835681/how-can-i-run-a-python-script-from-within-flask
request_url = "https://www.ssa.gov/cgi-bin/babyname.cgi"
params = {"name": name, "sex": sex}
response = requests.post(request_url, params)
#print(response.status_code)
soup = BeautifulSoup(response.text, "html.parser")
return print(soup)
ssa_scrape(name, sex) |
6a51a81f90e55a0c76545ab1104c8d0223a481d9 | shouxie/qa_note | /python/python06_object/index03.py | 1,429 | 4.09375 | 4 | # -*- coding:utf-8 -*-
#@Time : 2020/4/24 下午3:24
#@Author: 手写
#@File : index03.py
# book student computer
'''
知识点:
1. has a
一个类中使用了另外一种自定义的类型
student使用computer book
2. 类型:
系统类型:
str int float
list dict tuple set
自定义类型:
算是自定义的类,都可以将其当成一种类型
s = Student()
s是Student类型的对象
a = 12 # 是把int类型中的一个12这个对象赋给a
self.book = book # 是把自定义类型Book实例化出来的book对象赋给self.book
'''
class Book:
def __init__(self, bName, num):
self.name = bName
self.number = num
def __str__(self):
return '{}本{}书'.format(self.number, self.name)
class Computer:
def __init__(self, name, brand):
self.name = name
self.brand = brand
def __str__(self):
return '电脑是{},品牌是{}'.format(self.name, self.brand)
class Student:
def __init__(self, name, book, computer):
self.name = name
self.book = book
self.computer = computer
def myHave(self):
print('{}有{},{}'.format(self.name,self.computer,self.book))
book = Book('盗墓笔记', 10)
computer = Computer('MAC', 'mac pro')
s = Student('zhangsan', book, computer)
s.myHave() # zhangsan有电脑是MAC,品牌是mac pro,10本盗墓笔记书 |
82a27e5d130c0120ac0fe06f9a0d971b40c17e9e | mayee007/learn | /python/MyPackages/fullname.py | 321 | 3.53125 | 4 | class fullname:
def __init__(self , val):
print("inside init, val " + val)
if val.find(","):
self.lastName, self.firstName = val.split(',')
self.counter = 1
def getFirstName(self):
return self.firstName
def increment(self):
self.counter = self.counter + 1
return self.counter
|
f69ae7082d53e538dadb1d65277e62beaed8c9a7 | that1guyDrew/Hangman | /hangman.py | 2,347 | 4.15625 | 4 | #! python3
# Hangman, just without any image
# Guess the letters of the random word, can only get 5 wrong.
from random_words import RandomWords
def generateWord():
#return a random word
return RandomWords().random_word()
def displayWord(word, chances, winner):
# displays showWords list value to show
# what letters have been guessed correctly
for x in word:
print(x, end= ' ')
#display chances left
print(f"\n{chances} chances left\n")
#check if user has guessed entire word
if '_' not in word:
winner = True
def getLetter():
# get a letter from user and validate input
while True:
let = input('Enter a letter (a-z): ')
if let.isalpha() and len(let) == 1:
break
else:
continue
return let
def main():
again = '' #loop control
while again == '':
winner = False #flag for if whole word found
chances = 5 # number of wrong entries left
# generate random word
word = generateWord()
# initiliaze list with '_' in place of letters of the word
showWord = ['_' for x in word]
# show how long the word is
print(f"The word has {len(word)} letters")
displayWord(showWord, chances, winner)
# Get letter from user, if letter is not in word chances go down 1
# If letter in word, showWord list updated from the '_' to the
# value of the letter found in the correct indexes
while chances > 0 and winner != True:
letter = getLetter()
if letter not in word:
chances -= 1
else:
for x in range(len(word)):
if word[x] == letter:
showWord[x] = letter
# display what has been found after every guess
displayWord(showWord, chances, winner)
# if all letters found
if (winner):
print('You got it!')
again = input('Press Enter to go again or any other key to quit')
else:
print(f"The correct word was {word}")
again = input('Press Enter to go again or any other key to quit')
print('\n\n')
#call main
main()
|
88096e4a2f585bfba277cc63f7950e1ea5ac4da6 | dragonOrTiger/pythonDemo | /file_w.py | 2,289 | 3.796875 | 4 | #写文件和读文件是一样的,唯一的区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件
with open('/home/syj/文档/hello.txt','w') as f:
f.write('Hello world!')
#要写入特定编码的文本文件,请给open()函数传入encoding参数,将字符串自动转换成指定编码
#在Python中,文件读写是通过open()函数打开的文件对象完成的。使用with语句操作文件IO是个好习惯
#r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
#rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
#r+ 打开一个文件用于读写。文件指针将会放在文件的开头。
#rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
#w 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
#wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
#w+ 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
#wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
#a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
#ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
#a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
#ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
|
1f47c18e0d2f3a5107a3be4021be79bb39e8ecdb | asap16/Hangman-Python | /HangmanProjectPart2.py | 4,936 | 3.8125 | 4 |
import random
def GetAnswerWithUnderscores(answer, letters_guessed):
result = ''
for char in answer:
if char in letters_guessed:
result += char
else:
result += '_'
return result
def GetWordSeparatedBySpaces(word):
result = ""
for index in range(len(word)):
if index == (len(word)-1):
result += word[index]
else:
result += word[index] + " "
return result
def IsWinner(answer, letters_guessed):
c = 0
for char in answer:
for index in range(len(letters_guessed)):
if char == letters_guessed[index]:
c += 1
if c == len(answer):
return True
return False
def IsLegalGuess(current_guess, letters_guessed):
if not current_guess.lower().isalpha():
print('Input is not a valid string i.e english alphabets')
return False
else:
if len(current_guess) == 1:
if current_guess not in letters_guessed.lower():
return True
else:
print('Input already exists')
return False
else:
print('Input is not a single character')
return False
def GetLegalGuess(letters_guessed):
input_guessed = input('Input your guess')
while not IsLegalGuess(input_guessed, letters_guessed):
input_guessed = input('Input your guess')
return input_guessed
def IsGuessRevealing(answer, legal_letter_guess):
if legal_letter_guess in answer:
return True
else:
return False
def GetAllEnglishWords():
find_words = open('hangman_english_words.txt')
list_of = []
item = find_words.readline()
for item in find_words:
char = item.strip()
list_of.append(char)
find_words.close()
return list_of
def GetRandomWord(words):
return words[random.randint(0,len(words)-1)]
'''def Play(answer):
letters_guessed = ''
strikes = 0
print('You have', strikes, 'strikes.')
print(GetWordSeparatedBySpaces(GetAnswerWithUnderscores(answer, letters_guessed)))
while strikes < 5:
current_guess = GetLegalGuess(letters_guessed)
if IsGuessRevealing(answer, current_guess) == False:
strikes += 1
print('You have', strikes, 'strikes.')
letters_guessed += current_guess
print(GetWordSeparatedBySpaces(GetAnswerWithUnderscores(answer, letters_guessed)))
else:
letters_guessed += current_guess
print(GetWordSeparatedBySpaces(GetAnswerWithUnderscores(answer, letters_guessed)))
if IsWinner(answer, letters_guessed) == True:
print("You Won")
return True
print('Continue. Keep the guesses coming.')
print ('The answer is', answer)
print ("You lost")'''
def StartupandPlay():
words = GetAllEnglishWords()
answer = GetRandomWord(words)
Play(answer)
user_input = Input('Do you want to Continue (y/n)')
if user_input.lower() == 'y':
StartupandPlay()
def GetPlayRecord():
opening_doc = open('hangman_play_record.txt')
get_record = opening_doc.readline()
delimiter = ','
get_record = get_record.split(delimiter)
record_list = []
for item in get_record:
item = int(item)
record_list.append(item)
opening_doc.close()
return record_list
ans = GetPlayRecord()
print(ans)
def RecordPlay(win):
get_list = GetPlayRecord()
write_doc = open('hangman_play_record.txt', 'w')
if win == True:
get_list[0] = get_list[0] + 1
get_list[1] = get_list[1] + 1
else:
get_list[1] = get_list[1] + 1
record_value = str(get_list[0]) + ',' + str(get_list[1])
write_doc.write(record_value)
write_doc.close()
def StartupAndPlayVersion2():
call_list = GetPlayRecord()
win_times = call_list[0]
played_times = call_list[1]
words = GetAllEnglishWords()
answer = GetRandomWord(words)
print('You have won', win_times, 'times')
print('You have played', played_times, 'times')
value_return = Play(answer)
if value_return == True:
RecordPlay(value_return)
else:
RecordPlay(None)
user_input = input('Do you want to Continue (y/n)')
if user_input.lower() == "y":
StartupAndPlayVersion2()
else:
call_list = GetPlayRecord()
win_times = call_list[0]
played_times = call_list[1]
print('You have won', win_times, 'times')
print('You have played', played_times, 'times')
def main():
StartupAndPlayVersion2()
if __name__ == '__main__':
main()
|
1431caf259c9d4975bfacfef65c5d8bb5a388c9d | archeranimesh/pythonFundamentals | /code/pyworkshop/06_Booleans/03_operation.py | 649 | 4.28125 | 4 | # 3 booleans operators.
# and, or, not
# The resultant is result is not true or false
a = 2
b = 3
c = 0
print("-" * 30)
# And Table
print(a and b) # Value of b, 3
print(a and c) # Value of c, 0
print(c and a) # Value of c, 0
print(c and c) # Value of c, 0
print([] and {}) # []
print([1] and {}) # {}
print("-" * 30)
# Or table
print(a or b) # Value of a, 2
print(a or c) # Value of a, 2
print(c or a) # Value of a, 2
print(c or c) # Value of c, 0
print([] or {}) # {}
print([1] or {}) # [1]
print("-" * 30)
# Not Table
print(not a) # False
print(not c) # True
print("1 == True: ", 1 == True)
print("0 == False: ", 0 == False)
|
8236dd4708b2df77b5f31f007ef0749bd05a05c0 | antonioam82/ejercicios-python | /get_foldersize.py | 773 | 3.609375 | 4 | import os
def get_directory_size(directory):
total = 0
try:
for entry in os.scandir(directory):
if entry.is_file():
total += entry.stat().st_size
elif entry.is_dir():
total += get_directory_size(entry.path)
except NotADirectoryError:
#SI LA RUTA ES A UN ARCHIVO
return os.path.getsize(directory)
except PermissionError:
return 0
print (total)
return total
def get_size_format(b, factor=1024, suffix="B"):
for unit in ["", "K", "M", "G", "T", "P", "E", "Z"]:
if b < factor:
return f"{b:.2f}{unit}{suffix}"
b /= factor
return f"{b:.2f}Y{suffix}"
size=get_size_format(get_directory_size(drectory))
print("SIZE: ",size)
|
8dfe06626f2ea7ccf6c7367c26d57c92f13ab22a | CiyoMa/leetcode | /longestCommonPrefix.py | 444 | 3.640625 | 4 | class Solution:
# @return a string
def longestCommonPrefix(self, strs):
if len(strs) == 0:
return ""
l = min([len(s) for s in strs])
prefix = ""
for i in range(l):
probe = strs[0][i]
flag = sum([1 for s in strs if s[i] != probe]) > 0
if flag:
return prefix
else:
prefix += probe
return prefix
s = Solution()
print s.longestCommonPrefix(["abc","abcde",'ab']) |
70aa47f1780616b29890a05a1e81ed06e8f324be | KoderDojo/hackerrank | /python/challenges/datastructures/linkedlists-insertend.py | 994 | 4.3125 | 4 | """
Insert Node at the end of a linked list
head pointer input could be None as well for empty list
Node is defined as
class Node(object):
def __init__(self, data=None, next_node=None):
self.data = data
self.next = next_node
return back the head of the linked list in the below method
"""
class Node(object):
def __init__(self, data=None, next_node=None):
self.data = data
self.next = next_node
def Insert(head, data):
"""
>>> head = None
>>> node = Insert(head, 4)
>>> assert(node.data == 4)
>>> head = Node(6)
>>> node = Insert(head, 4)
>>> assert(node.next.data == 4)
>>> head = Node(6, Node(7))
>>> node = Insert(head, 4)
>>> assert(node.next.next.data == 4)
"""
last_node = Node(data)
if head is None:
return last_node
current_node = head
while current_node.next is not None:
current_node = current_node.next
current_node.next = last_node
return head
|
e817c44b2f3bdc334c546e07f23eb7ee442e5a10 | Victor-Rodriguez-VR/Coding-challenges | /deleteAppendSteps.py | 483 | 3.65625 | 4 | def da_sort(nums):
smallestNumber = None
inOrder = []
for num in nums:
while len(inOrder) >0 and num < inOrder[-1]:
if(smallestNumber is None or num < smallestNumber):
smallestNumber = inOrder.pop()
else:
inOrder.pop()
inOrder.append(num)
while(inOrder[-1] > smallestNumber):
inOrder.pop()
return len(nums) - len(inOrder)
print(da_sort([1, 5, 2, 3, 6, 4])) |
c9b8e7e4e8eedc656fddcef882f70399ca2edb69 | hekaplex/2021_04_DSI_WE | /drew@divergence.one/py/Core Python Airlift/Day 3/p14-2_cards.py | 1,462 | 3.953125 | 4 | #!/usr/bin/env python3
import random
class Card:
def __init__(self, rank, suit, dignified):
self.rank = rank
self.suit = suit
if dignified >= 10:
self.dignified = ""
else:
self.dignified = "*"
def getStr(self):
return self.rank + " of " + self.suit + self.dignified
class Deck:
def __init__(self):
self.__deck = []
ranks = ["2", "3", "4", "5", "6", "7", "8", "9", "10",
"Knight", "King", "Queen", "Ace"]
suits = ["Wands", "Pentacles", "Cups", "Swords"]
for rank in ranks:
for suit in suits:
self.__deck.append(Card(rank, suit,random.randint(1,100)))
def shuffle(self):
random.shuffle(self.__deck)
def dealCard(self):
return self.__deck.pop()
def count(self):
return len(self.__deck)
def main():
print("Tarot Card Dealer")
print()
deck = Deck()
deck.shuffle()
print("I have shuffled a deck of", str(deck.count()), "cards.")
print()
count = int(input("How many cards would you like?: "))
print()
print("Here are your cards:")
cards = []
for i in range(count):
card = deck.dealCard()
print(card.getStr())
cards.append(card)
print()
print("There are", str(deck.count()), "cards left in the deck.")
print()
print("Good luck!")
if __name__ == "__main__":
main()
|
c9ebfb70cd33e8a808cd6aa4709d0674dae8a16e | IIKovalenko/EC602 | /Assignment10/wordbrainsolver.py | 5,638 | 3.6875 | 4 | """ ec602 """
# Copyright 2017 Jiali Ge ivydany@bu.edu
# Copyright 2017 Siyuan Tang sytang7@bu.edu
# Copyright 2017 Pei Jia leojia@bu.edu
from sys import argv
def word_dic(k, word, wdic):
""" dic for small/big_w """
if k == len(word) - 1:
wdic.setdefault(word[k], {})['end'] = True
else:
word_dic(k + 1, word, wdic.setdefault(word[k], {}))
def neighbor(num, grid):
""" find neighbors """
all_neighbor = [[] for letter in grid]
for i in range(num ** 2):
irow = i // num
icol = i % num
if icol < num - 1:
all_neighbor[i].append(i + 1)
if irow > 0:
all_neighbor[i].append(i - num + 1)
if irow < num - 1:
all_neighbor[i].append(i + num + 1)
if icol > 0:
all_neighbor[i].append(i - 1)
if irow > 0:
all_neighbor[i].append(i - num - 1)
if irow < num - 1:
all_neighbor[i].append(i + num - 1)
if irow > 0:
all_neighbor[i].append(i - num)
if irow < num - 1:
all_neighbor[i].append(i + num)
return all_neighbor
def grid_drop(grid, num, ncor):
""" update grid """
l_grid = list(grid)
for i in sorted(ncor):
irow = ord(i) // num
icol = ord(i) % num
if irow != 0:
while irow != 0:
l_grid[irow * num + icol] = l_grid[(irow - 1) * num + icol]
l_grid[(irow - 1) * num + icol] = " "
irow -= 1
else:
l_grid[icol] = " "
return ''.join(l_grid)
def find_word(i, grid, n_word, dic, result,
fword, all_length, all_neighbor, unvisit, str_l):
""" word by word """
num_word = len(fword)
if grid[i] in dic:
unvisit[i] = False
if str_l[n_word][num_word].isalpha() is True:
if grid[i] == str_l[n_word][num_word]:
fword += chr(i)
else:
fword += chr(i)
if len(fword) == all_length[n_word]:
if 'end' in dic[grid[i]]:
result.append(fword)
return result
for letter1 in all_neighbor[i]:
if unvisit[letter1]:
find_word(letter1, grid, n_word, dic[grid[i]], result,
fword, all_length, all_neighbor, unvisit, str_l)
unvisit[letter1] = True
def find_solution(grid1, n_word, dic, tem, solution,
all_length, all_neighbor, num, str_l):
""" find solution """
num_grid = len(grid1)
for start in range(num_grid):
if grid1[start] == " ":
continue
if str_l[n_word][0].isalpha() is True:
if grid1[start] != str_l[n_word][0]:
continue
result = []
unvisited = [True] * len(grid1)
find_word(start, grid1, n_word, dic, result, '',
all_length, all_neighbor, unvisited, str_l)
for words in result:
word_tem = ''
temp = tem
for k in words:
word_tem = word_tem + grid1[ord(k)]
temp = temp + ' ' + word_tem
if n_word == len(all_length) - 1:
solution.append(temp)
else:
grid = grid1[:]
grid = grid_drop(grid, num, words)
find_solution(grid, n_word + 1, dic, temp, solution,
all_length, all_neighbor, num, str_l)
return solution
def main():
""" main """
with open(argv[1]) as small_file:
s_words = small_file.read().split()
small_dic = {}
for words1 in s_words:
word_dic(0, words1, small_dic)
with open(argv[2]) as big_file:
b_words = big_file.read().split()
b_dic = {}
for words2 in b_words:
word_dic(0, words2, b_dic)
count = 0
word_list = []
try:
while True:
line2 = input().split('\n')
if line2 is '':
break
word_list.append(''.join(line2))
if '*' in line2[0]:
while count < len(word_list):
str1 = []
all_length = []
num2 = len(word_list[count])
for ber in range(num2):
str1.append(word_list[count + ber])
str2 = ''.join(str1)
str_l = word_list[count + num2].split()
num_strl = len(str_l)
for ber1 in range(num_strl):
all_length.append(len(str_l[ber1]))
all_neighbor = neighbor(num2, str2)
solution = []
find_solution(str2, 0, small_dic, '', solution,
all_length, all_neighbor, num2, str_l)
if len(solution) == 0:
find_solution(str2, 0, b_dic, '', solution,
all_length, all_neighbor, num2, str_l)
num_sol = len(solution)
for k in range(num_sol):
solution[k] = solution[k][1:len(solution[k])]
solution = list(set(solution))
solution.sort()
if solution:
print('\n'.join(e for e in solution))
print('.')
count += (num2 + 1)
except EOFError:
pass
if __name__ == "__main__":
main()
|
f10f92081fb069cf6f58c4b2d2cadf9606bb5f3c | betabites/csi-2020 | /Python/TKinter/To inifinity, and beyond.py | 3,402 | 3.640625 | 4 | #Title: To infinity, and beyond
#Description: Asks the user questions. If the user does not respond fast enough, they lose
#Author: jack hawinkels
#Created: 10/03/2020
#Modified: 10/03/2020
#***IMPORTS***
from tkinter import *
from functools import partial
import random
import time
#---IMPORTS---
#***DEFINITIONS***
def window_main():
global master
global letters
global question
global question_string
global current_letter_count
global buttons
global timer
global level_input
global time
global score
global start
start = time.time()
score = 0
timer = 0.0
letters = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z"]
current_letter_count = 2
master = Tk()
master.title("To infinity, and beyond!")
timer = master.after(3000, end)
question_string = "1"
question = Label(master, text=question_string)
question.grid(row=1, column = 1, columnspan=len(letters))
buttons = []
for i in range(current_letter_count):
button_action = partial(button_click, letters[i])
master.bind(letters[i].lower(), button_action)
master.bind(letters[i], button_action)
buttons.append(Button(master, text=letters[i], command=button_action))
buttons[-1].grid(row=2, column=i)
master.lift()
def button_click(letter, event=False):
global question
global question_string
global current_letter_count
global buttons
global master
global timer
global score
if letter != question_string:
end()
else:
master.after_cancel(timer)
score += 1
timer = master.after(3000, end)
if random.randint(0, 5) == 5 and current_letter_count != len(letters):
current_letter_count += 1
question.destroy()
question_string = letters[random.randint(0, (current_letter_count - 1))]
question = Label(master, text=question_string)
question.grid(row=1, column = 1, columnspan=25)
for button in buttons:
button.destroy()
buttons = []
for i in range(current_letter_count):
button_action = partial(button_click, letters[i])
master.bind(letters[i].lower(), button_action)
master.bind(letters[i], button_action)
buttons.append(Button(master, text=letters[i], command=button_action))
buttons[-1].grid(row=2, column=i)
def end():
global master
global start
global score
master.destroy()
master = Tk()
master.title("To infinity, and beyond!")
Label(master, text="GAME OVER!").grid(row=1, column=1, columnspan=2)
score_text = "Score: " + str(score)
Label(master, text=score_text).grid(row=2, column=1)
time_text = "Time: " + str(round(time.time() - start)) + "s"
Label(master, text=time_text).grid(row=2, column=2)
Button(master, text="Try Again", width=30, command=try_again).grid(row=3, column=1, columnspan=2)
Button(master, text="Quit", width=30, command=quit).grid(row=4, column=1, columnspan=2)
master.lift()
def quit():
global master
#master.destroy()
button_click(question_string, False)
def try_again():
global master
master.destroy()
window_main()
#---DEFINITIONS---
window_main()
|
484491119f5f590554345467efa57fc5561a9a3f | TERESIA012/My-password-locker | /run.py | 8,697 | 4.28125 | 4 | #!/usr/bin/env python3.9
from random import randint
import random
from user import User
from credentials import Credentials
#User section
def create_user(username,password):
'''
Function to create a new user
'''
new_user = User(username,password)
return new_user
def save_user(user):
'''
Function to save user
'''
user.save_user()
def delete_user(username):
'''
Function delete user
'''
User.delete_user(username)
def check_user(username):
"""
Function to check if user exists
"""
return User.check_user(username)
def check_user_exist(username, password):
"""
function that checks the username and confirms the password
"""
return User.check_user_exists(username, password)
#Credentials section
def create_credentials(account,username,password):
'''
Function to create a new credentials
'''
new_credentials = Credentials(account,username,password)
return new_credentials
def save_credentials(credentials):
'''
Function to save credentials
'''
Credentials.save_credentials(credentials)
def delete_credentials(account) :
"""
Function to delete account credentials
"""
return Credentials.delete_credentials(account)
def find_by_acc(account):
"""
Function to search for an account
"""
return Credentials.find_by_acc(account)
def display_credentials():
"""
Funtion to display credentials
"""
return Credentials.display_credentials()
# def random_password(passwordLength):
# """
# Function to generate a random password for the user
# """
# return Credentials.generate_password(passwordLength)
def main():
print("Hello,Welcome to My Password Locker.What is your name?")
user_name = input()
print(f'Hey {user_name}. what would you like to do?')
print('\n')
while True:
print("Use these short codes : ca - create account,log -login, ex- exit ")
short_code = input().lower()
if short_code == 'ca':
print("User")
print("-"*20)
print ("Username:")
username = input()
print ("Password:")
password = input()
save_user(create_user(username,password))
print('*'*20)
print(
f"Hello {user_name} Your account has been created successfully. Kindly login to access your account")
print('*'*20)
elif short_code == "log":
print("Welcome!")
print ("Username:")
username = input()
print ("Password:")
password = input()
if check_user_exist(username, password):
print("Logged in successfully")
while True:
print("Use the following short codes to check your credentials:cc -create credentials,sc- store credentials,dip- display credentials,ex- exit")
short_code = input().lower()
if short_code == "sc":
print ("Account:")
account = input()
print("Username:")
username = input()
print ("Password:")
password = input()
save_credentials(create_credentials(account,username,password))
print(f"Your {account} details have been saved.")
print("-"*20)
elif short_code == "dip":
if display_credentials():
print("Below is a list of your credentials:")
for display in display_credentials():
print(f"Account:{display.account} \n Username:{display.username} \n Password:{display.password}")
else:
print("Your credentials are not available")
print("-"*20)
elif short_code=="ex":
print("You have been logged out successfully!")
break
elif short_code =="cc":
print("User")
print("-"*20)
print ("Username:")
username = input()
print ("Account:")
account = input()
while True:
print("Would you like to cp- create password, allow us to generate a password for you,rp-random password")
random = input().lower()
if random =="cp":
print("Create your password")
password =input()
elif random =="rp":
print("What length of password do you want?")
length=int(input())
set ="1qaz2wsx3edc4rfv5tgbyhn7ujm!#$^&AQL9D6GHMPX"
password=""
for y in range(length):
y=chr(randint(65,90)).lower()
# newpass=str(password) + y
password=password+y
print(f"Password has been generated successfully. Your password is {password}")
break
save_credentials(create_credentials(account,username,password))
print('*'*20)
else:
print("Kindly use the shortcodes provided.")
elif short_code == "ex":
print ("Thank you for reaching out to My Password Locker!Bye...")
break
else:
print("Invalid short codes.Try again!")
if __name__ == '__main__':
main() |
7ab51bb602637dbeccf35473ebcb8a353201301b | RUPAbahadur/Python-Programs | /task-first-and-last-character.py | 198 | 4.28125 | 4 | """
Task - first and last character displayed
"""
string=input("Enter a string:\n")
print("First letter of the string: {0}\nLast letter of the string: {1}" .format(string[0], string[-1]))
|
01dac5aab51c8d26444debee21344788d2513877 | S3Coder/Python-Practice | /loop.py | 415 | 3.9375 | 4 | thislist = ["apple", "banana", "cherry"]
for i in range(len(thislist)):
print(thislist[i])
#while loop
i = 0
while i < len(thislist):
print(thislist[i])
i += 1
thislist = ["Sibil", "Sarjam", "Soren"]
[print(x) for x in thislist]
fruits = ["mango", "orange", "banana", "Pineapple"]
newList = []
for i in range(len(fruits)):
newList.append(fruits[i])
print(newList) |
f661e794ef9d47e398f9afa7bd37dee383af8691 | zako16/heinold_exercises | /1Basics/3IfStatements/3-05.py | 348 | 4.15625 | 4 | """
Generate a random number between 1 and 10. Ask the user to guess the number and print a
message based on whether they get it right or not.
"""
from random import randint
number = randint(1, 10)
guessNumber = eval(input("Enter guess number:"))
if guessNumber == number:
print("You are right!!!")
elif guessNumber != number:
print("Not")
|
41a6bc9c452917d0a0ea86397546bd439ceb5834 | shengchaohua/leetcode-solution | /lintcode solution in python/UglyNumberII.py | 1,220 | 3.75 | 4 | # -*- coding: utf-8 -*-
"""
Created on Sun Mar 18 20:47:53 2018
@problem: lintcode No.4 Ugly Number
@author: sheng
"""
class Solution:
"""
@param n: An integer
@return: the nth prime number as description.
"""
def nthUglyNumber(self, n):
# write your code here
# time exceed
# l = [1, 2, 3, 4, 5]
# while len(l) < n:
# l1 = list(map(lambda x: 2*x, l))
# l2 = list(map(lambda x: 3*x, l))
# l3 = list(map(lambda x: 5*x, l))
# sumL = l1 + l2 + l3
# reducedL = [ele for ele in sumL if ele not in l]
# l.append(min(reducedL))
# return l[n-1]
l = [1]
i2 = i3 = i5 = 0
while len(l) < n:
num2 , num3, num5 = l[i2]* 2, l[i3] * 3, l[i5] * 5
num = min(num2, num3, num5)
# 下面三个 if 还有去重的作用
if num == num2:
i2 += 1
if num == num3:
i3 += 1
if num == num5:
i5 += 1
l.append(num)
return l[-1]
def main():
s = Solution()
print(s.nthUglyNumber(599))
if __name__ == '__main__':
main()
|
d16cf5fe46b133d4b01e7a2666231c611d81f06d | adamb70/AdventOfCode2020 | /02/solution_02.py | 775 | 3.625 | 4 | from collections import Counter
def is_valid_part_1(min_max, letter, password):
count = Counter(password)
return min_max[0] <= count[letter] <= min_max[1]
def is_valid_part_2(indexes, letter, password):
first_match = password[indexes[0] - 1] == letter
second_match = password[indexes[1] - 1] == letter
return first_match != second_match
valid_1 = 0
valid_2 = 0
with open('input.txt', 'r') as infile:
for line in infile.readlines():
min_max, letter, password = line.split()
min_max = tuple(int(x) for x in min_max.split('-'))
letter = letter[:-1]
valid_1 += is_valid_part_1(min_max, letter, password)
valid_2 += is_valid_part_2(min_max, letter, password)
# Part 1
print(valid_1)
# Part 2
print(valid_2)
|
7994202452cbffedaa2a9ec0a6d372e11e8c546b | kedgarnguyen298/nguyenquockhanh-fundamental-c4e24 | /session3/Homework/seriousex1a.py | 228 | 4.1875 | 4 | odd = range(1,16,2)
print("15 first odd positive numbers:", *odd)
print("------------------------------------")
for i in odd:
print("Square of ", i, ": ", i ** 2)
print("------------------------------------")
print("End") |
d107a831c381cc4caf981d7fbe55635444d7ba98 | Elegant-Smile/PythonDailyQuestion | /Answer/Geoffrey/20190618/20190618_paixu.py | 823 | 3.671875 | 4 | ### 1、
languages = [(1, 'Go'), (2, 'Ruby'), (3, 'Swift'),
(4, 'Erlang'), (5, 'Kotlin'), (6, 'Python')]
languages_sorted = []
languages_sorted_a = []
languages_sorted_b = []
n = len(languages)
for i in range(0,n):
if i >= 3:
languages_sorted_a.append(languages[i])
else:
x = 2 - i
languages_sorted_b.append(languages[x])
languages_sorted = languages_sorted_a + languages_sorted_b
print(languages_sorted)
### 2、
languages = [(1, 'Go'), (2, 'Ruby'), (3, 'Swift'),
(4, 'Erlang'), (5, 'Kotlin'), (6, 'Python')]
languages_sorted = []
languages_a = languages[3:]
languages_b = []
n = len(languages)
for i in range(0,n):
if i < 3:
x = 2 -i
languages_b.append(languages[x])
languages_sorted = languages_a + languages_b
print(languages_sorted)
|
97363faa1bd771130a13d5b260a754d4ec6df144 | szdodo/toDoList | /list.py | 1,510 | 3.671875 | 4 | def main() :
comm = input("Please specify a command [list, add, mark, archive]: ")
data={}
index=reading(data)
if comm == "add" :
add(data,index)
save(data)
if comm == "list" :
listw(data)
save(data)
if comm == "mark" :
mark(data)
save(data)
if comm == "archive" :
archive(data)
#save(data)
def reading(data):
f=open("todolist",'r')
i=1
for line in f:
#item=[line]
data[i]=line
#data[i][1]=item[1]
i= i+1
f.close()
#print(data)
return i
def add(data,i):
element = input(('Add an item: '))
data[i]=element+'\n'
print(data)
return i+1
def listw(data):
i=1
for each in data:
if data[each][0] == 'x':
print(str(i)+". [X] "+data[each][1:])
else:
print(str(i)+". [ ] "+data[each])
i=i+1
def mark(data):
listw(data)
task = input("Which one want to mark as completed: ")
for each in data:
if int(each) == int(task):
#print(each)
new=data[each]
data[each]="x"+new
#print(data[each])
def save(data):
f=open('todolist','w')
for each in data:
f.write(str(data[each]))
f.close()
def archive(data):
f=open('todolist','w')
for each in data:
if data[each][0] != 'x':
f.write(str(data[each][1:]))
f.close()
print("All completed tasks got deleted.")
main() |
b13b66aabc72e78968159669a70c98686481204b | vgattani-ds/programming_websites | /leetcode/1029_twoCitySchedCost.py | 747 | 3.53125 | 4 | from typing import List
class Solution:
def twoCitySchedCost(self, costs: List[List[int]]) -> int:
costs = sorted(costs, key= lambda x: abs(x[0]-x[1]), reverse=True)
city_a = 0
city_b = 0
total_cost = 0
num = len(costs) // 2
for cost in costs:
cost_a = cost[0]
cost_b = cost[1]
if cost_a < cost_b and city_a < num:
total_cost += cost_a
city_a += 1
elif city_b < num or city_a >= num:
total_cost += cost_b
city_b += 1
else:
total_cost += cost_a
city_a += 1
return total_cost |
fcbc34f462feed3b15c4484c18d40f339f34efad | ckiekim/Python-2021-3 | /u38-45_예외_모듈/bank/u45_util.py | 651 | 3.515625 | 4 | class Account:
def __init__(self, ano, owner, balance):
self.ano = ano
self.owner = owner
self.__balance = balance
def deposit(self, amount):
if amount + self.__balance >= 10000000:
print('천만원 이상은 잔액으로 가져갈 수 없습니다.')
return
self.__balance += amount
def withdraw(self, amount):
if self.__balance - amount < 0:
print('잔액이 부족합니다.')
return
self.__balance -= amount
def __str__(self):
return f'계좌번호: {self.ano}, 소유주: {self.owner}, 잔액: {self.__balance:9,d}' |
ce6d60f2aea0eba0a2997c69bcb2eb87363e99ff | psalcedodev/CS-2420-Algorithm | /program5/program5.py | 3,684 | 3.8125 | 4 | import time
from colors import *
class Student:
def __init__(self, fname, lname, ssn, email, age):
self.fname = fname
self.lname = lname
self.ssn = ssn
self.email = email
self.age = age
def insertNames(students):
time_started = time.time()
duplicates = []
lines = open("./InsertNames.txt", "r").readlines()
total_lines = len(lines)
for i in range(total_lines):
split_line = lines[i].split()
new_student = Student(
split_line[0], split_line[1], split_line[2], split_line[3], split_line[4])
for student in students:
if student.ssn == new_student.ssn:
duplicates.append(new_student)
continue
students.append(new_student)
time_elapsed = (time.time() - time_started)
for student in duplicates:
prMagenta("%s %s " % (student.fname, student.lname))
prYellow("Time Elapsed: %s segs" %
(int(time_elapsed)))
# Traverse all students in the pythonList, and print their average age (as a Float, not an Int). Print how many seconds that took.
def getAge(students):
avg_age = 0
total_students = len(students)
time_started = time.time()
for i in range(total_students):
avg_age += float(students[i].age)
avg_age /= total_students
time_elapsed = (time.time() - time_started)
prMagenta("Average age: %s" % "{:.2f}".format(avg_age))
prYellow("Time Elapsed: %s segs" % int(time_elapsed))
def deleteNames(students):
time_started = time.time()
dellines = open('./DeleteNames.txt', 'r').readlines()
deleted = 0
notfound = []
for i in range(len(dellines)):
social = dellines[i][:-1]
matched = False
start = 0
while start < len(students):
if students[start].ssn == social:
students.pop(start)
deleted += 1
matched = True
break
else:
start += 1
if not matched:
notfound.append(social)
time_elapsed = (time.time() - time_started)
prYellow("SSN not found: %s" % (notfound))
prYellow("Time Elapsed: %s segs" % int(time_elapsed))
def retrieveNames(students):
time_started = time.time()
retlines = open('./RetrieveNames.txt', 'r').readlines()
retrieved = 0
notfound = []
avg_age = 0
for i in range(len(retlines)):
social = retlines[i][:-1]
matched = False
for student in students:
if student.ssn == social:
matched = True
retrieved += 1
avg_age += float(student.age)
break
if not matched:
notfound.append(social)
avg_age /= retrieved
time_elapsed = (time.time() - time_started)
prYellow("SSN not found: %s" % (notfound))
prMagenta("Average age: %s" % "{:.2f}".format(avg_age))
prYellow("Time Elapsed: %s segs" % int(time_elapsed))
def main():
students = []
prCyan('====================================')
prGreen('Running Names')
prCyan('--------------------')
insertNames(students)
prCyan('====================================')
prGreen('Running Average Age')
prCyan('--------------------')
getAge(students)
prCyan('====================================')
prGreen('Deleting Students in DeleteNames.txt')
prCyan('--------------------')
deleteNames(students)
prCyan('====================================')
prGreen('Retrieving Students in RetrieveNames.txt')
prCyan('--------------------')
retrieveNames(students)
if __name__ == "__main__":
main()
|
ab1862535c1c736a6a98519baa0647b9ca6e7a2e | liujie40/graph_converter | /graph_remove_size_zero.py | 557 | 3.515625 | 4 | import os
import sys
def remove_size_zero(input_folder):
num_zero_file = 0
for file_one in os.listdir(input_folder):
file_path = os.path.join(input_folder, file_one)
file_size = os.path.getsize(file_path)
if file_size < 1:
os.remove(file_path)
num_zero_file += 1
print("removed zero size file, %s" %(num_zero_file))
if __name__ == '__main__':
if len(sys.argv) != 2:
print("Usage: python graph_remove_size_zero.py input_folder\n")
exit(-1)
remove_size_zero(sys.argv[1])
|
ec2aededcda796090657b01856673a6990cc7481 | itsolutionscorp/AutoStyle-Clustering | /assignments/python/wc/src/531.py | 197 | 3.875 | 4 | def word_count(some_words):
countWords = {}
for word in some_words.split():
if word not in countWords:
countWords[word] = 1
else: # in wordDict
countWords[word] += 1
return countWords
|
ddaf0b96f347dbedc30a268fccf8ce1396a8b51d | matthewcheung810/ICS3U1d-2018-19 | /Working/Masters/2.2 answers.py | 278 | 4.09375 | 4 | def date_fashion(you, date):
if(you >= 8 and date >= 8) or (you >= 8) or (date >= 8):
print("2")
elif(you <= 2 and date <= 2) or (you <= 2) or (date <= 2):
print("0")
else:
print("1")
date_fashion(5, 10)
date_fashion(5, 2)
date_fashion(5, 5) |
f9a3d0c8bbcdd06e4f3e201fbfbe1a80aff19fed | sreshaven/calculatorProject | /calc.py | 1,345 | 4.15625 | 4 | # created by Sresha Ventrapragada and Crystal Liang
print("Welcome to the Time Zone Calculator!")
print("Time Zones: PT, MT, CT, ET, AK, HAST")
timezoneDict = {
"PT": 0,
"MT": 1,
"CT": 2,
"ET": 3,
"AK": 4,
"HAST": 5,
}
currentTime = input("Enter your current time: ")
currentTZ = timezoneDict.get(input("Enter your time zone abbreviation: ").upper())
inputDesiredTZ = input("Enter your desired time zone abbreviation: ").upper()
desiredTZ = timezoneDict.get(inputDesiredTZ.upper())
print("Converting...")
timeComparisons = [
[0, 1, 2, 3, 4, 5],
[-1, 0, 1, 2, 3, 4],
[-2, -1, 0, 1, 2, 3],
[-3, -2, -1, 0, 1, 2],
[-4, -3, -2, 1, 0, 1],
[-5, -4, -3, -2, -1, 0]
]
totalMins = 0
if len(currentTime) == 5:
current_hour = int(currentTime[0:2])
current_min = int(currentTime[3:5])
totalMins = (current_hour * 60) + current_min
elif len(currentTime) == 4:
current_hour = int(currentTime[0:1])
current_min = int(currentTime[2:4])
totalMins = (current_hour * 60) + current_min
desiredTotalMins = totalMins + ((timeComparisons[currentTZ][desiredTZ]) * 60)
desiredHours = desiredTotalMins / 60
desiredMins = desiredTotalMins % 60
if(desiredHours > 12):
desiredHours -= 12
if(desiredHours < 1):
desiredHours += 12
print(str(int(desiredHours)) + ":" + str(desiredMins) + " " + inputDesiredTZ)
|
acf9f278804aa5a5d36cc35dee6aa075049cf8d7 | duliodenis/learn-python-the-hard-way | /exercises/ex06.py | 747 | 3.8125 | 4 | #
# ex06.py (Strings & Text)
# Python the Hard Way Exercise #6
#
# Created by Dulio Denis on 12/26/14.
# Copyright (c) 2014 ddApps. All rights reserved.
# ------------------------------------------------
# http://learnpythonthehardway.org/book/ex6.html
#
typesOfPeople = "There are %d types of people." % 10
binary = "binary"
doNot = "don't"
knowDontKnow = "Those who know %s and those who %s." % (binary, doNot)
print typesOfPeople
print knowDontKnow
print "I said: %r" % typesOfPeople
print "I also said: '%s'." % knowDontKnow
hilarious = False
jokeEvaluation = "Isn't that joke so funny?! %r"
print jokeEvaluation % hilarious
leftSide = "This is the left side of ..."
rightSide = " a string with a right side."
print leftSide + rightSide
|
10e02a2d3ea731b0058cab487cd60f55a2a05142 | mryawsafo/telegram-restaurant-bot | /create_table.py | 2,203 | 3.578125 | 4 | import sqlite3
conn = sqlite3.connect('Restaurant.db')
c = conn.cursor()
c.execute('''
PRAGMA foreign_keys = ON;
''')
conn.commit()
c.execute('''
CREATE TABLE IF NOT EXISTS Заказы(
Заказ INTEGER PRIMARY KEY AUTOINCREMENT,
Столик INTEGER NOT NULL,
Дата DATETIME NOT NULL,
FOREIGN KEY(Столик) REFERENCES Столики(Столик)
);
''')
conn.commit()
c.execute('''
CREATE TABLE IF NOT EXISTS Заказы_Блюда(
Заказ INTEGER NOT NULL,
Блюдо INTEGER NOT NULL,
FOREIGN KEY(Заказ) REFERENCES Заказы(Заказ),
FOREIGN KEY(Блюдо) REFERENCES Блюда(Блюдо)
);
''')
conn.commit()
c.execute('''
CREATE TABLE IF NOT EXISTS Блюда (
Блюдо INTEGER PRIMARY KEY AUTOINCREMENT,
Название TEXT UNIQUE NOT NULL,
Тип TEXT NOT NULL CHECK (Тип IN ('Горячие закуски', 'Холодные закуски', 'Супы', 'Основные блюда', 'Десерты')),
Ингредиенты TEXT,
Цена INTEGER NOT NULL,
Наличие BOOLEAN NOT NULL,
Скидка INTEGER,
Вегетарианское BOOLEAN NOT NULL
);
''')
conn.commit()
c.execute('''
CREATE INDEX IF NOT EXISTS my_index ON Блюда(Наличие, Тип, Вегетарианское);
''')
conn.commit()
c.execute('''
CREATE TABLE IF NOT EXISTS Столики (
Столик INTEGER PRIMARY KEY AUTOINCREMENT,
Тип TEXT NOT NULL CHECK (Тип IN ('VIP', 'У окна', 'В зале')),
Места INTEGER NOT NULL,
Цена INTEGER NOT NULL
);
''')
conn.commit()
c.execute('''
CREATE TABLE IF NOT EXISTS Бронирования (
Столик INTEGER NOT NULL,
Дата DATETIME NOT NULL,
FOREIGN KEY(Столик) REFERENCES Столики(Столик),
CONSTRAINT Бронь UNIQUE (Столик, Дата)
);
''')
conn.commit()
c.execute('''
CREATE TABLE IF NOT EXISTS Доходы (
Дата DATETIME NOT NULL,
Доход INTEGER NOT NULL,
Состояние_счета INTEGER NOT NULL
);
''')
conn.commit()
c.close()
conn.close()
|
ae3cce71fc6087f91485e7e92b302dfcfc4021d2 | JakeSeib/Python-Practice | /Isolated problems/pw strength.py | 972 | 3.6875 | 4 | # password will be considered strong enough if its length is greater than or equal to 10 symbols, it has at least one
# digit, as well as containing one uppercase letter and one lowercase letter in it. The password contains only ASCII
# latin letters or digits
import string
def checkio(data: str) -> bool:
pw_check = len(data)>=10 and any(x in data for x in string.ascii_lowercase) and any(x in data for x in string.ascii_uppercase) and any(x in data for x in string.digits)
return pw_check
if __name__ == '__main__':
#These "asserts" using only for self-checking and not necessary for auto-testing
assert checkio('A1213pokl') == False, "1st example"
assert checkio('bAse730onE4') == True, "2nd example"
assert checkio('asasasasasasasaas') == False, "3rd example"
assert checkio('QWERTYqwerty') == False, "4th example"
assert checkio('123456123456') == False, "5th example"
assert checkio('QwErTy911poqqqq') == True, "6th example"
|
1447b6441c09ee11785c4636f4cfac1f999ebb5c | Ellian-aragao/URI | /py/esfera.py | 100 | 3.671875 | 4 | total = float(input())
total = total**3 * (4.0/3.0) * 3.14159
print('VOLUME = {:.3f}'.format(total)) |
a16b86ceffff0bff87605282de08deb4f8c2eeab | Grub1000/soloSolves | /LOGIN PAGE.py | 3,075 | 3.546875 | 4 |
import re
# import regex
# from collections import defaultdict
d = {}
ONLINE = True
prompt = True
pop_up1 = True
Index = 0
class login_information:
def __init__(self, username, password):
self.username = username
self.password = password
def Pcheck(self):
global d
global prompt
global Index
pattern = re.compile('(?=.*[a-z])(?=.*[A-Z])(?=.*[0-9])(?=.*[!?.])\S+')
if re.findall(pattern, str(self.password)):
print(' Good job! for meeting the criteria for the password')
print('\___________________________________________________/')
d[Index] = str(self.password)
d[Index + 1] = str(self.username)
Index = Index + 2
prompt = False
else:
print(' You need to meet the password criteria, Try again')
print('\_________________________________________________/')
def Sign_Up_Prompt_function():
if prompt == True:
UN = input("Username: ")
PSW = input("Password: ")
L1 = login_information(UN, PSW)
login_information.Pcheck(L1)
# print(d)
def Login_Prompt_function():
if prompt == False:
global ONLINE
global d
print(' LOGIN PAGE ')
print('Give us ur username and password or else you getting wacked')
un = input('Login username: ')
for i in range(Index):
if d[i] == un:
print('Great! now give us the password')
ps = input('Login Password: ')
for j in range(Index):
if d[j] == ps:
print('Access Granted')
ONLINE = False
if ONLINE == True:
print("Wrong Bruv")
def pop_up():
global pop_up1
if pop_up1 == True:
print('|\_____________________________________________________/| Grub' + str(chr(169)))
print('| Welcome to the sign in page! |')
print('| Make sure that your Password has at least 1 of these: |')
print('| A character from a-z lowercase |')
print('| A character from A-Z Uppercase |')
print('| A Number from 0-9 |')
print('| And a symbol listed: either ! . or ? |')
print(' \_____________________________________________________/ ')
pop_up1 = False
while ONLINE == True:
pop_up()
Sign_Up_Prompt_function()
Login_Prompt_function()
# UN = input("Username: ")
# PSW = input("Password: ")
# L1 = login_information(UN, PSW)
# print(login_information.Pcheck(L1))
# print(d)
# pattern = re.compile('(?=.*[a-z])(?=.*[A-Z])(?=.*[0-9])(?=.*[!?.])\S+')
# print(re.search(pattern,'a#3232!abbb32..'))
# Make the login page storage
# Make the logic for that ^^^
# Make it able to get a wrong input()
# launch that bih
# Also make sure that the password is strong in the first place
# Then we can launch the thingy
|
ff209d2b5fd434de4c93865b466b2ec7368e6981 | AlexMazonowicz/PythonFundamentals | /Lesson08/test/test.py | 3,424 | 3.5625 | 4 | # Importing unittest package
import sys
import unittest
# Importing function from main to test
from Lesson08.solution.main import mailing_list_utils_extended as mlu_extended
# Importing the function
from Lesson08.solution.modules_package_file import mailinglist_validation_util
from Lesson08.solution.optional_pandas import update_mailing_list_pandas
sys.path.append("../")
# The output file length, which is the expected output from the tested functions
output_file_length = 5
class TestMailingListFromFile(unittest.TestCase):
def test_update_mailing_list_from_file(self):
"""
This function tests the results of the `mailinglist_validation_util` function. It calls the the function
passing the expected parameters and checks if it matches the expected output.
Example:
mailinglist_validation_util('mailing_list.csv', 'output.csv', ['r+', 'w+'])
This function call must return 5, which is the length of the output file.
:return: N/A
"""
# Calling the target function and caching the result
result = mailinglist_validation_util('mailing_list.csv', 'output.csv', ['r+', 'w+'])
# Check if the result matches the expected output
self.assertEqual(result, output_file_length)
def test_update_mailing_list_from_file_package(self):
"""
This function tests the results of the `mailinglist_validation_util` function. It calls the the function
passing the expected parameters and checks if it matches the expected output. The only difference from the
above function is that this is extended to call the same function from a python package.
Example:
mlu.mailinglist_validation_util('mailing_list.csv', 'output.csv', ['r+', 'w+'])
Where `mlu` is the `mailing_list_utils` package created
This function call must return 5, which is the length of the output file.
:return: N/A
"""
# Calling the target function from a package and caching the result
# result = mlu.mailinglist_validation_util('mailing_list.csv', 'output.csv', ['r+', 'w+'])
result = mlu_extended()
# Check if the result matches the expected output
self.assertEqual(result, output_file_length)
def test_update_mailing_list_pandas(self):
"""
This function tests the output of the `update_mailing_list_pandas` function. The
`update_mailing_list_pandas` function reads in a csv file, filter only `active` users and return the
resulting number of rows.
Example:
update_mailing_list_pandas('mailing_list.csv')
This function call must return 6, which is the number of the users with the `active` flag on the
original mailing list file.
:return: N/A
"""
# Calling the target function from a package and caching the result
# result = mlu.mailinglist_validation_util('mailing_list.csv', 'output.csv', ['r+', 'w+'])
result = update_mailing_list_pandas('mailing_list.csv')
# Check if the result matches the expected output
self.assertEqual(result, (output_file_length + 1))
if __name__ == '__main__':
unittest.main()
|
2842165a7ff939999e135dda9b8bac5f0ca3e375 | lokeshkumar9600/python_train | /pattern4.py | 113 | 3.578125 | 4 | row = int(input())
for i in range(row , 0 ,-1):
for j in range(1,i+1):
print(i , end="")
print() |
e5b670a4c4e116f9368b9e56f95a3ba93054f79b | akuppala21/Data-Structures | /Lab3/array_list_tests.py | 1,672 | 3.53125 | 4 | import unittest
from array_list import *
class TestList(unittest.TestCase):
# Note that this test doesn't assert anything! It just verifies your
# class and function definitions.
def test_interface(self):
temp_list = empty_list()
temp_list = add(temp_list, 0, "Hello!")
length(temp_list)
get(temp_list, 0)
temp_list = set(temp_list, 0, "Bye!")
remove(temp_list, 0)
def test_empty_list(self):
self.assertEqual(empty_list(), List([], 0))
def test_add1(self):
self.assertEqual(add(List([1, 3, 6, 14], 4), 2, 10), List([1, 3, 10, 6, 14], 5))
def test_add2(self):
self.assertRaises(IndexError, add, List([1, 3, 6, 14], 4), 5, 0)
def test_length1(self):
self.assertEqual(length(List([1, 3, 6, 14], 4)), 4)
def test_length2(self):
self.assertEqual(length(List([], 0)), 0)
def test_get1(self):
self.assertEqual(get(List([1, 3, 6, 14], 4), 2), 6)
def test_get2(self):
self.assertRaises(IndexError, get, List([1, 3, 6, 14], 4), -4)
def test_set1(self):
self.assertEqual(set(List([1, 3, 6, 14], 4), 1, 2), List([1, 2, 6, 14], 4))
def test_set2(self):
self.assertRaises(IndexError, set, List([1, 3, 6, 14], 4), 4, 7)
def test_remove1(self):
self.assertEqual(remove(List([1, 3, 6, 14], 4), 2), (6 ,List([1, 3, 14], 3)))
def test_remove2(self):
self.assertRaises(IndexError, remove, List([1, 3, 6, 14], 4), 5)
def test_repr1(self):
self.assertEqual(List.__repr__(List([1, 3, 6, 14], 4)), "List([1, 3, 6, 14], 4)")
if __name__ == '__main__':
unittest.main()
|
f8ec4edd1cc4ca53fe80f02d2a5642a6a88959c7 | shomchak/ProjectEuler | /problem8/e8.py | 376 | 3.78125 | 4 | def max_product(numstr):
maximum = 0
for n in range(len(numstr)-4):
product = 1
for i in range(5):
product = product*(int(numstr[i+n]))
if product > maximum:
maximum = product
return maximum
if __name__ == '__main__':
with open('e8input.txt') as f:
numstr = f.readline()
print max_product(numstr)
|
49d3d8c7cb4c99b31ef2d9c068df8c9ea4091e11 | antonija-20/smart-ninja-course | /zadatak-12/zadatak-12-3.py | 1,719 | 3.640625 | 4 | from BeautifulSoup import BeautifulSoup
from urllib2 import urlopen
url = "https://en.wikipedia.org/wiki/Game_of_Thrones#Adaptation_schedule"
response = urlopen(url).read()
soup = BeautifulSoup(response)
table = soup.findAll("table", attrs={"class": "wikitable"})[0]
links = table.findAll("a")
for link in links:
wantedString = "(season"
if wantedString in link.get("href"):
seasonLink = "https://en.wikipedia.org%s" % link["href"]
# Concatenate and make a new URL
print seasonLink
print "."
seasons = BeautifulSoup(urlopen(seasonLink).read()).find("table", attrs={"class": "wikitable plainrowheaders wikiepisodetable"})
rows = seasons.findAll("sup", attrs={"class": "reference"})
for row in rows:
row = row.parent.contents[0]
print "Viewers: " + str(row)
#viewSeason = urlopen(url + link["href"]).read()
#one = BeautifulSoup(viewSeason)
#print ".",
#viewtable = BeautifulSoup(viewSeason).find("table", attrs={"class": "wikitable plainrowheaders wikiepisodetable"})
#print viewtable
"""
number = viewtable.findAll("td")
for item in number:
print item """
"""for item in response.findAll("a"):
if item.string == "See full profile":
#print url + item["href"]
one = urlopen(url + item["href"]).read()
soup = BeautifulSoup(one)
print ".",
name = soup.findAll("h1")[1].string
email = soup.findAll("span", attrs={"class": "email"})[0].string
csv.write(name + "," +email + "\n")
csv.close()
print "\n"
print "CSV je napravljen" """ |
04eedb01018aa1d01e54ca8029c62bbbf6eae864 | aniruddha414/DC-comics-logo-classifier | /selectJpeg.py | 426 | 3.53125 | 4 | print("Selecting jpg")
import os
import shutil
raw = 'wonderwoman' # folder one
raw_jpeg = 'jpg_' + raw # folder two
current_dir = os.getcwd()
os.mkdir(os.path.join(current_dir,raw_jpeg))
image_path = os.path.join(current_dir,raw)
for file in os.listdir(os.path.join(current_dir,raw)):
if file.endswith(".jpg"):
print(file)
shutil.copy(os.path.join(image_path,file),os.path.join(current_dir,raw_jpeg))
|
5a723c53b546d77e46d3ce9b1fc09aef2d0a6abc | isaidnocookies/Project-Euler | /sumSquareDifference.py | 336 | 3.65625 | 4 | import math
def sumOfSquares(maxNumber):
sum = 0;
for i in range (0, maxNumber+1):
sum = sum + math.pow(i, 2)
return sum
def squareOfSum(maxNumber):
sum = 0
for i in range(0, maxNumber + 1):
sum = sum + i
return math.pow(sum, 2)
print (squareOfSum(100) - sumOfSquares(100))
|
457522b7016ed814aeeecea31e2edad5dd763a0b | ryanbrate/DS_thesis | /1_Catalogue/catalogue.py | 2,265 | 3.53125 | 4 | """
A script to extract the English Language books in the Project Gutenberg
offline index to json {"author":[(title,code),..],..}
Example:
$ python3 catalogue.py GUTINDEX.ALL
Returns:
catalogue.json
"""
import json
import re
import sys
from collections import defaultdict
import regex
from tqdm import tqdm
def main(argv):
gutindex = argv[0]
# iterate over project gutenberg offline gutindex, collect EL books
with open(gutindex, "r", encoding="utf-8") as f:
lines = f.read()
# collect WHOLE PARAGRAPHS which start in the form, "Knock at a Venture, by Eden Phillpotts 61549"
pattern = regex.compile(
r".*?,\sby\s[\w\s]+\s+\d+.*?(?=.*?,\sby\s[\w\s]+\s+\d+)", re.DOTALL
)
paragraphs = regex.findall(pattern, lines)
# extract (EL-only) book info from the paragraphs
books = map(get_books_from_text, paragraphs)
EL_books = list(filter(lambda x: x, books)) # non EL books listed as None
# populate the json
catalogue = defaultdict(list)
for a, (t, c) in EL_books:
catalogue[a] += [(t, c)]
# output catalogue to json
with open("catalogue.json", "w") as f:
json.dump(catalogue, f, indent=4, ensure_ascii=False)
print(f"total number of English books: {len(EL_books)}")
def get_books_from_text(line):
"""Extract and return (author, title, code) from text line. for EL books only.
E.g., in the form, "Knock at a Venture, by Eden Phillpotts 61549"
Args:
line (str): text string passed
Return: (author, title, code) or None if not EL
"""
mo_entry = re.search(r"(.+),\sby\s([\w\s]+\w)\s\s+(\d+)", line)
# matche object in the targetted form?
if mo_entry and not re.search(r"^(Audio:).*", line):
# detect if English language
mo_lang = re.search(r"\[\s*[L,l]anguage:*.*\]", line)
mo_eng = re.search(r"\[\s*[L,l]anguage:*\s*([E,e]nglish\s*)+].*", line)
if not mo_lang or mo_eng:
title = mo_entry.group(1)
author = mo_entry.group(2)
code = mo_entry.group(3)
return (author, (title, code))
else:
return None
else:
return None
if __name__ == "__main__":
main(sys.argv[1:])
|
3335fd03fb116ebfc6c0c04196d43609f5d0f338 | aravindkoneru/Blackjack | /deck.py | 1,236 | 4.0625 | 4 | import card
import random
cType = ["Diamond", "Spade", "Heart", "Club"]
cVal = [2, 3, 4, 5, 6, 7, 8, 9, 10, "Jack", "Queen", "King", "Ace"]
#Creates the final deck that will be used during the game
#This method basically initalizes the deck and makes it suitable for gameplay
#Creates the deck by creating an instance of every possible card combination and adding it to the deck
#The format of the cards added to the deck is (cardValue, cardSuit)
def createDeck():
currentDeck = []
for x in cType:
for y in cVal:
addToDeck = card.createCard(x,y)
currentDeck.append(addToDeck)
return currentDeck
#Suffles the deck after it has been initalized by the createDeck() method
#Picks two random indexes in the deck and swaps the positions of their values
#This method ensures that the most random and realistic shuffle occurs
def shuffle(currentDeck):
x = 0
while(x < len(currentDeck)):
posOne = random.randint(0,len(currentDeck)-1)
posTwo = random.randint(0,len(currentDeck)-1)
temp = currentDeck[posOne]
currentDeck[posOne] = currentDeck[posTwo]
currentDeck[posTwo] = temp
x += 1
return currentDeck
#Displays the deck
def showDeck(currentDeck):
for card in currentDeck:
print card
|
be79af84d6ab1fc270e1b3cab1a8b7c94efe21a0 | CCreek96/UT-coursework | /CS313E/Poker.py | 15,015 | 3.953125 | 4 | # File: Poker.py
# Description: Simulate a game of five-card draw poker using object
# oriented programming
# Date Created: 05 February 2018
# Date Last Modified: 10 February 2018
import random
class Card (object):
RANKS = (2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14)
SUITS = ('C', 'D', 'H', 'S')
def __init__ (self, rank = 12, suit = 'S'):
if (rank in Card.RANKS):
self.rank = rank
else:
self.rank = 12
if (suit in Card.SUITS):
self.suit = suit
else:
self.suit = 'S'
def __str__ (self):
if (self.rank == 14):
rank = 'A'
elif (self.rank == 13):
rank = 'K'
elif (self.rank == 12):
rank = 'Q'
elif (self.rank == 11):
rank = 'J'
else:
rank = str (self.rank)
return rank + self.suit
def __eq__ (self, other):
return (self.rank == other.rank)
def __ne__ (self, other):
return (self.rank != other.rank)
def __lt__ (self, other):
return (self.rank < other.rank)
def __le__ (self, other):
return (self.rank <= other.rank)
def __gt__ (self, other):
return (self.rank > other.rank)
def __ge__ (self, other):
return (self.rank >= other.rank)
class Deck (object):
def __init__ (self):
self.deck = []
for suit in Card.SUITS:
for rank in Card.RANKS:
card = Card (rank, suit)
self.deck.append (card)
def shuffle (self):
random.shuffle (self.deck)
def deal (self):
if (len(self.deck) == 0):
return None
else:
return self.deck.pop(0)
class Poker (object):
def __init__ (self, num_hand):
self.deck = Deck()
self.deck.shuffle()
self.players = []
numcards_in_hand = 5
for i in range (num_hand):
hand = []
for j in range (numcards_in_hand):
hand.append (self.deck.deal())
self.players.append (hand)
def play (self):
# sort the hand of each player and print
for i in range (len(self.players)):
sorted_hand = sorted (self.players[i], reverse = True)
self.players[i] = sorted_hand
hand = ''
for card in sorted_hand:
hand = hand + str (card) + ' '
print ('Player ' + str (i + 1) + " : " + hand)
def compare(self):
# sort
for i in range(len(self.players)):
self.players[i] = sorted(self.players[i],reverse = True)
# evaluate hand and store the value
catagory = []
winnerList = []
for hand in self.players:
if self.is_royal(hand):
catagory.append(10)
elif self.is_straight_flush(hand):
catagory.append(9)
elif self.is_four_kind(hand):
catagory.append(8)
elif self.is_full_house(hand):
catagory.append(7)
elif self.is_flush(hand):
catagory.append(6)
elif self.is_straight(hand):
catagory.append(5)
elif self.is_three_kind(hand):
catagory.append(4)
elif self.is_two_pair(hand):
catagory.append(3)
elif self.is_one_pair(hand):
catagory.append(2)
elif self.is_high_card(hand):
catagory.append(1)
# print the hand:
for i in range(len(catagory)):
if catagory[i] == 10:
print("Hand " + str(i+1) + ": Royal Flush")
elif catagory[i] == 9:
print("Hand " + str(i+1) + ": Straight Flush")
elif catagory[i] == 8:
print("Hand " + str(i+1) + ": Four of a Kind")
elif catagory[i] == 7:
print("Hand " + str(i+1) + ": Full House")
elif catagory[i] == 6:
print("Hand " + str(i+1) + ": Flush")
elif catagory[i] == 5:
print("Hand " + str(i+1) + ": Straight")
elif catagory[i] == 4:
print("Hand " + str(i+1) + ": Three of a Kind")
elif catagory[i] == 3:
print("Hand " + str(i+1) + ": Two Pair")
elif catagory[i] == 2:
print("Hand " + str(i+1) + ": One Pair")
elif catagory[i] == 1:
print("Hand " + str(i+1) + ": High Card")
print()
# compare the catagory of the hand
catagorySorted = sorted(catagory);
maxcatagory = catagorySorted[len(catagorySorted)-1]
tie_breaker_list = []
for i in range(len(catagory)):
if catagory[i] == maxcatagory:
tie_breaker_list.append(i)
# print the winner if there is no tie
if len(tie_breaker_list) == 1:
print("Hand " + str(tie_breaker_list[0]+1) + " wins.")
# do the tiebreak if there is a tie
# there is no tiebreak for royal flush
elif maxcatagory == 10:
for i in tie_breaker_list:
print("Hand " + str(i+1) + " ties.")
# tiebreak for other cases
else:
maxHand = self.players[tie_breaker_list[0]]
winnerList = [tie_breaker_list[0]] # a list that contains the indexes of winners
for i in range(1,len(tie_breaker_list)):
hand1 = maxHand
hand2 = self.players[tie_breaker_list[i]]
winner = 0
if maxcatagory == 9:
winner = self.straight_flush_tie_breaker(hand1,hand2)
elif maxcatagory == 8:
winner = self.four_tie_breaker(hand1,hand2)
elif maxcatagory == 7:
winner = self.full_tie_breaker(hand1,hand2)
elif maxcatagory == 6:
winner = self.flush_tie_breaker(hand1,hand2)
elif maxcatagory == 5:
winner = self.straight_tie_breaker(hand1,hand2)
elif maxcatagory == 4:
winner = self.three_tie_breaker(hand1,hand2)
elif maxcatagory == 3:
winner = self.two_tie_breaker(hand1,hand2)
elif maxcatagory == 2:
winner = self.one_tie_breaker(hand1,hand2)
elif maxcatagory == 1:
winner = self.high_tie_breaker(hand1,hand2)
if winner == 2:
maxHand = hand2
winnerList = [tie_breaker_list[i]]
elif winner == 0:
winnerList.append(tie_breaker_list[i])
# print the winner
if (len(winnerList) == 1):
print("Hand " + str(winnerList[0]+1) + " wins.")
else:
for i in winnerList:
print("Hand " + str(i+1) + " ties.")
# determine if a hand is a royal flush
def is_royal (self, hand):
same_suit = True
for i in range (len(hand) - 1):
same_suit = same_suit and (hand[i].suit == hand[i + 1].suit)
if (not same_suit):
return False
rank_order = True
for i in range (len(hand)):
rank_order = rank_order and (hand[i].rank == 14 - i)
return (same_suit and rank_order)
def is_straight_flush (self, hand):
same_suit = True
for i in range (len(hand) - 1):
same_suit = same_suit and (hand[i].suit == hand[i + 1].suit)
if (not same_suit):
return False
rank_order = True
for i in range (len(hand) - 1):
rank_order = rank_order and (hand[i].rank + 1 == hand[i + 1].rank)
return (same_suit and rank_order)
def straight_flush_tie_breaker (self, hand1, hand2):
if hand1[0] > hand2[0]:
return 1
elif hand1[0] < hand2[0]:
return 2
else:
return 0
def is_four_kind (self, hand):
occurence = 0
for i in range (len(hand) - 1):
if (hand[i].rank == hand[i + 1].rank):
occurence += 1
return (occurence == 4)
def four_tie_breaker (self,hand1,hand2):
if hand1[0] == hand1[1]:
hand1Rank = hand1[0].rank
else:
hand1Rank = hand1[len(hand1)-1].rank
if hand2[0] == hand2[1]:
hand2Rank = hand2[0].rank
else:
hand2Rank = hand2[len(hand2)-1].rank
if hand1Rank > hand2Rank:
return 1
elif hand1Rank < hand2Rank:
return 2
else:
return 0
def is_full_house (self, hand):
if (hand[0] == hand[1] and hand[1] == hand[2] and hand[3] == hand[4]) or (hand[0] == hand[1] and hand[2] == hand[3] and hand[3] == hand[4]):
return True
else:
return False
def full_tie_breaker (self, hand1, hand2):
if hand1[1] == hand1[2] and hand1[1] == hand1[0]:
hand1Rank = hand1[0].rank
else:
hand1Rank = hand1[4].rank
if hand2[1] == hand2[2] and hand2[1] == hand2[0]:
hand2Rank = hand2[0].rank
else:
hand2Rank = hand2[4].rank
if hand1Rank > hand2Rank:
return 1
elif hand1Rank < hand2Rank:
return 2
else:
return 0
def is_flush (self, hand):
same_suit = True
for i in range (len(hand) - 1):
same_suit = same_suit and (hand[i].suit == hand[i + 1].suit)
if (not same_suit):
return False
else:
return True
def flush_tie_breaker (self, hand1, hand2):
if hand1[0] > hand2[0]:
return 1
elif hand1[0] < hand2[0]:
return 2
else:
return 0
def is_straight (self, hand):
rank_order = True
for i in range (len(hand) - 1):
rank_order = rank_order and (hand[i].rank + 1 == hand[i + 1].rank)
def straight_tie_breaker (self, hand1, hand2):
if hand1[0] > hand2[0]:
return 1
elif hand1[0] < hand2[0]:
return 2
else:
return 0
def is_three_kind (self, hand):
occurence = 0
for i in range (len(hand) - 1):
if (hand[i].rank == hand[i + 1].rank):
occurence += 1
return (occurence == 3)
def three_tie_breaker (self,hand1,hand2):
if hand1[0] == hand1[1] and hand1[1] == hand1[2]:
hand1rank = hand1[0].rank
if hand1[1] == hand1[2] and hand1[2] == hand1[3]:
hand1rank = hand1[1].rank
if hand1[2] == hand1[3] and hand1[3] == hand1[4]:
hand1rank = hand1[2].rank
if hand2[0] == hand2[1] and hand2[1] == hand2[2]:
hand2rank = hand2[0].rank
if hand2[1] == hand2[2] and hand2[2] == hand2[3]:
hand2rank = hand2[1].rank
if hand2[2] == hand2[3] and hand2[3] == hand2[4]:
hand2rank = hand2[2].rank
if hand1rank > hand2rank:
return 1
elif hand1rank < hand2rank:
return 2
else:
return 0
def is_two_pair (self, hand):
if hand[0] == hand[1] and hand[2] == hand[3]:
return True
if hand[0] == hand[1] and hand[3] == hand[4]:
return True
if hand[1] == hand[2] and hand[3] == hand[4]:
return True
return False
def two_tie_breaker (self,hand1,hand2):
# find the highest pair then the second highest pair then the fifth card for hand1
if hand1[0] == hand1[1] and hand1[2] == hand1[3]:
if (hand1[0] > hand1[2]):
hand1rank1 = hand1[0].rank
hand1rank2 = hand1[2].rank
else:
hand1rank1 = hand1[2].rank
hand1rank2 = hand1[0].rank
hand1rank3 = hand1[4].rank
elif hand1[0] == hand1[1] and hand1[3] == hand1[4]:
if hand1[0] > hand1[3]:
hand1rank1 = hand1[0].rank
hand1rank2 = hand1[3].rank
else:
hand1rank1 = hand1[3].rank
hand1rank2 = hand1[0].rank
hand1rank3 = hand1[2]
else:
if hand1[1] > hand1[3]:
hand1rank1 = hand1[1].rank
hand1rank2 = hand1[3].rank
else:
hand1rank1 = hand1[3].rank
hand1rank2 = hand1[1].rank
hand1rank3 = hand1[0].rank
# find the highest pair then the second highest pair then the fifth card for hand2
if hand2[0] == hand2[1] and hand2[2] == hand2[3]:
if (hand2[0] > hand2[2]):
hand2rank1 = hand2[0].rank
hand2rank2 = hand2[2].rank
else:
hand2rank1 = hand2[2].rank
hand2rank2 = hand2[0].rank
hand2rank3 = hand2[4].rank
elif hand2[0] == hand2[1] and hand2[3] == hand2[4]:
if hand2[0] > hand2[3]:
hand2rank1 = hand2[0].rank
hand2rank2 = hand2[3].rank
else:
hand2rank1 = hand2[3].rank
hand2rank2 = hand2[0].rank
hand2rank3 = hand2[2]
else:
if hand2[1] > hand2[3]:
hand2rank1 = hand2[1].rank
hand2rank2 = hand2[3].rank
else:
hand2rank1 = hand2[3].rank
hand2rank2 = hand2[1].rank
hand2rank3 = hand2[0].rank
# start comparison
if hand1rank1 > hand2rank1:
return 1
elif hand1rank1 == hand2rank1:
if hand1rank2 > hand2rank2:
return 1
elif hand1rank2 == hand2rank2:
if hand1rank3 > hand2rank3:
return 1
elif hand1rank3 == hand2rank3:
return 0
else:
return 2
else:
return 2
else:
return 2
# determine if a hand is one pair
def is_one_pair (self, hand):
for i in range (len(hand) - 1):
if (hand[i].rank == hand[i + 1].rank):
return True
return False
def one_tie_breaker (self,hand1,hand2):
# find the rank for the pair then the highest side card then second highest then third highest
if hand1[0] == hand1[1]:
h1r1 = hand1[0].rank
h1r2 = hand1[2].rank
h1r3 = hand1[3].rank
h1r4 = hand1[4].rank
elif hand1[1] == hand1[2]:
h1r1 = hand1[1].rank
h1r2 = hand1[0].rank
h1r3 = hand1[3].rank
h1r4 = hand1[4].rank
elif hand1[2] == hand1[3]:
h1r1 = hand1[2].rank
h1r2 = hand1[0].rank
h1r3 = hand1[1].rank
h1r4 = hand1[4].rank
elif hand1[3] == hand1[4]:
h1r1 = hand1[3].rank
h1r2 = hand1[0].rank
h1r3 = hand1[1].rank
h1r4 = hand1[2].rank
# second hand
if hand2[0] == hand2[1]:
h2r1 = hand2[0].rank
h2r2 = hand2[2].rank
h2r3 = hand2[3].rank
h2r4 = hand2[4].rank
elif hand2[1] == hand2[2]:
h2r1 = hand2[1].rank
h2r2 = hand2[0].rank
h2r3 = hand2[3].rank
h2r4 = hand2[4].rank
elif hand2[2] == hand2[3]:
h2r1 = hand2[2].rank
h2r2 = hand2[0].rank
h2r3 = hand2[1].rank
h2r4 = hand2[4].rank
elif hand2[3] == hand2[4]:
h2r1 = hand2[3].rank
h2r2 = hand2[0].rank
h2r3 = hand2[1].rank
h2r4 = hand2[2].rank
# start comparison
if h1r1 > h2r1:
return 1
elif h1r1 < h2r1:
return 2
elif h1r2 > h2r2:
return 1
elif h1r2 < h2r2:
return 2
elif h1r3 > h2r3:
return 1
elif h1r3 < h2r3:
return 2
elif h1r4 > h2r4:
return 1
elif h1r4 < h2r4:
return 2
else:
return 0
def is_high_card (self, hand):
return True
def high_tie_breaker (self, hand1, hand2):
if hand1[0] > hand2[0]:
return 1
elif hand1[0] < hand2[0]:
return 2
elif hand1[1] > hand2[1]:
return 1
elif hand1[1] < hand2[1]:
return 2
elif hand1[2] > hand2[2]:
return 1
elif hand1[2] < hand2[2]:
return 2
elif hand1[3] > hand2[3]:
return 1
elif hand1[3] < hand2[3]:
return 2
elif hand1[4] > hand2[4]:
return 1
elif hand1[4] < hand2[4]:
return 2
else:
return 0
def main():
# prompt user to enter the number of hand
num_hand = int (input ('Enter number of players: '))
while ((num_hand < 2) or (num_hand > 6)):
num_hand = int (input ('Enter number of players: '))
# create the Poker object
game = Poker (num_hand)
# play the game and compare
game.play()
game.compare()
main()
|
f952455b7d01abc3a1b1ebf465e60bce52007fc8 | Lakshminathan8/Python_Program | /basicconcept.py | 333 | 3.734375 | 4 | import string
import math
#Single ling comments
print("Welcome to Python")
'''This is multi
line commment'''
print("""Multi
line
comment print""")
a = 5
print(type(a))
b = 20
print(type(b))
a = 20
c = a+b
d = "Addition:"
print(d,c)
e=100+3j
print("print e value",e,"is",type(e))
f = complex(2,4)
print(type(f))
print(f)
|
f07bf2db755f5a961b6362fa955c2bf8fa38d7a1 | huangqiank/Algorithm | /leetcode/sorting/is_anagram.py | 673 | 4.125 | 4 | ##Given two strings s and t , write a function to determine if t is an anagram of s.
##Example 1:
##Input: s = "anagram", t = "nagaram"
##Output: true
##Example 2:
##Input: s = "rat", t = "car"
##Output: false
def is_anagram(s, t):
if not s and not t:
return True
if not s or not t:
return False
s_dict = {}
t_dict = {}
for i in range(len(s)):
if s[i] not in s_dict:
s_dict[s[i]] = 1
else:
s_dict[s[i]] += 1
for i in range(len(t)):
if t[i] not in t_dict:
t_dict[t[i]] = 1
else:
t_dict[t[i]] += 1
return s_dict == t_dict
s = "a"
t = "ab"
print() |
3b785ff9db86427157fdce5bc4030ba8eec923d1 | devitasari/intro-python | /dataTypeChallenge.py | 264 | 3.6875 | 4 | kata = True
if type(kata) == bool:
if kata == False:
print 'cannot proceed without agreement'
elif kata == True:
print 'thank you for agreeing'
elif type(kata) == str:
print 'username:',kata
elif type(kata) == int:
print 'age:',kata |
d95a814b6347c4953025bdcc6c6469ae91ece1c8 | diana-dr/Split-Array-Problem | /Main.py | 2,021 | 4.1875 | 4 | def composeLists(lst, indexes):
"""
:param lst: list of integers
:param indexes: list of integers
:return: lists of integers, one containing the elements of lst on positions given by the indexes list,
the other list containing the remaining elements of lst
"""
b = []
for i in range(len(lst)):
if i in indexes:
b.append(lst[i])
c = []
for i in range(len(lst)):
if i not in indexes:
c.append(lst[i])
return b, c
def avg(lst):
"""
:param lst: a list of integers
:return: an integer representing the average of the elements from the input list
"""
if len(lst) == 0:
return 0
sum = 0
for i in lst:
sum += i
return sum / len(lst)
def findLists(lst, start, indexes, result):
"""
:param lst: the main list A which we want to divide in two separate lists B, C with the same average
- we go through list A starting from the 'start' index, using it's indexes we create two separate lists
- calculate and compare the average of B, C
- if the average of both lists is equal then we found a solution and stop the searching
- otherwise we continue traversing the list A beginning from another 'start'
and changing the indexes until we found a valid solution
"""
if not result:
for i in range(start, len(lst)):
indexes.append(i)
b, c = composeLists(lst, indexes)
if avg(b) == avg(c):
result.append([b, c])
findLists(lst, i + 1, indexes, result)
indexes.remove(i)
return result
def main():
"""
- we read the input list from the file 'input.in'
:return: True - it is possible to divide the input list in two separate lists with equal averages,
False - otherwise
"""
f = open("input.in", "r")
a = [int(x) for x in f.readline().split()]
result = findLists(a, 0, [], [])
if not result:
return False
return True
|
393ac965866f777bf914f67be7926bdab5703492 | remiliance/python_divers- | /liste2.py | 347 | 3.609375 | 4 | from pprint import pprint
a = [1,4,2,7,1,9,0,3,4,6,6,6,8,3]
z = ["a", "b", "c"]
numList = ['1', '2', '3', '4']
print(a[::-1])
print(a[-2])
print(a[::-2])
print(z)
pprint(z)
listef=["{}{}".format(i,j) for i in a for j in z]
print(listef)
lambda_func = lambda hello, world: print(hello, end=' ') or print(world)
lambda_func('Hello', 'World!') |
a18195119506ed8f38d94b7389d556058a332461 | AhnHyunJin/practice-coding-test | /baekjun/1157.py | 422 | 3.59375 | 4 | s = input().upper()
s = sorted(s)
count = 1
_max = 0
pre = s.pop()
while s:
cur = s.pop()
print("pre : ", pre, "cur : ", cur)
if pre == cur:
count += 1
else:
if count == _max:
ans = "?"
elif count > _max:
_max = count
ans = pre
count = 1
pre = cur
print(ans) |
02e335b35b3788e32e55c4ae11401ce2ff10d70a | Jesusml1/150_python_challenge | /12_2D_Lists_and_Dictionaries/Problema_101.py | 593 | 4.21875 | 4 | dic = {
"John": {"N":3056, "S":8463, "E":8441, "W":2694},
"Tom": {"N":4832, "S":6786, "E":4737, "W":3612},
"Anne": {"N":5239, "S":4802, "E":5820, "W":1859},
"Fiona":{"N":3904, "S":3645, "E":8821, "W":2451}
}
for i in dic:
print(i, dic[i])
name = str(input("Introduce the name you want to check: "))
region = str(input("Introduce the region (N/S/E/W) "))
print(dic[name][region])
to_change = str(input("Do you want to change the value? (y/n)"))
if to_change == "y":
new_value = int(input("Enter a new value: "))
dic[name][region] = new_value
print(dic[name])
else:
print(dic[name]) |
efcc2f80a64d8a2cf3c1fbf1d68e58a77fa186b8 | okipriyadi/NewSamplePython | /SamplePython/samplePython/Modul/os/_00_pendahuluan.py | 1,384 | 4.15625 | 4 | """
The OS module in Python provides a way of using operating system dependent
functionality.
The functions that the OS module provides allows you to interface with the
underlying operating system that Python is running on
You can find important information about your location or about the process.
In this post I will show some of these functions.
import os
Executing a shell command
os.system()
Get the users environment
os.environ()
#Returns the current working directory.
os.getcwd()
Return the real group id of the current process.
os.getgid()
Return the current process’s user id.
os.getuid()
Returns the real process ID of the current process.
os.getpid()
Set the current numeric umask and return the previous umask.
os.umask(mask)
Return information identifying the current operating system.
os.uname()
Change the root directory of the current process to path.
os.chroot(path)
Return a list of the entries in the directory given by path.
os.listdir(path)
Create a directory named path with numeric mode mode.
os.mkdir(path)
Recursive directory creation function.
os.makedirs(path)
Remove (delete) the file path.
os.remove(path)
Remove directories recursively.
os.removedirs(path)
Rename the file or directory src to dst.
os.rename(src, dst)
Remove (delete) the directory path.
os.rmdir(path)
""" |
2944372a8ce6fd020d73136883e9343c8ce81812 | aditya1906/image-colorcut-kmeans | /colorcut/imageColorCut.py | 1,346 | 3.515625 | 4 | import numpy as np
import matplotlib.pyplot as plt
from skimage import io
from sklearn.cluster import MiniBatchKMeans
def imageColorCut(imagePath, k, newImagePath=None):
"""
imageColorCut is the main method
that create a color cut effect on the image.
Parameters:
imagePath(type: str)(Required) : Path of the image.
k(type: int)(Requied) : The number of colors to be present.
newImagePath(type: str)(Optional) : Path of the new image, also be used to name the newly generated image.
default: (name-of-the-image)-(k).jpg
"""
if type(imagePath).__name__ != 'str':
raise ValueError("illegal imagePath provided. imagePath should be a string")
if type(k).__name__ != 'int':
raise ValueError("illegal k provided. k should be an integer")
img = io.imread(imagePath)
img_data = (img / 255.0).reshape(-1, 3)
kmeans = MiniBatchKMeans(k).fit(img_data)
k_colors = kmeans.cluster_centers_[kmeans.predict(img_data)]
k_img = np.reshape(k_colors, (img.shape))
if type(newImagePath).__name__ == 'str':
plt.imsave(newImagePath, k_img)
else:
imageName = imagePath.split('.')
imageName = '{0}-{1}.{2}'.format('.'.join(imageName[:-1]), k, imageName[-1])
plt.imsave(imageName, k_img)
print('Successfully generated your image')
|
9bfebb16cd35b0a9436a8f24ec0d260b7646952f | B4Lee/Learning-Python-Progate-2021 | /Python Study II/page11/script.py | 443 | 4.53125 | 5 | # Create a dictionary with keys and values, and assign it to the items variable
items = {'apple': 2, 'banana': 4, 'orange': 6}
# Create a for loop that gets the keys of items
for item_name in items:
# Print '--------------------------------------------------'
print('---------------------------------------------')
# Print 'Each ___ costs ___ dollars'
print('Each ' + item_name + ' costs ' + str(items[item_name]) + ' dollars') |
afee5a9444f0173aa0baa3b0dcf5735439ee2c1e | leilaelise/229LeilaKimia | /spam_modif.py | 10,920 | 3.859375 | 4 | import collections
import numpy as np
import util
import svm
import csv
from ps2.ps2.ps2.src.spam.svm import train_and_predict_svm
def get_words(message):
"""Get the normalized list of words from a message string.
This function should split a message into words, normalize them, and return
the resulting list. For splitting, you should split on spaces. For normalization,
you should convert everything to lowercase.
Args:
message: A string containing an SMS message
Returns:
The list of normalized words from the message.
"""
# *** START CODE HERE ***
# this is how the get_words function works:
# it gets a single message and returns the lower case and each word in a list
lower_case = message.lower()
splitted = lower_case.split()
return splitted
# *** END CODE HERE ***
def create_dictionary(messages):
"""Create a dictionary mapping words to integer indices.
This function should create a dictionary of word to indices using the provided
training messages. Use get_words to process each message.
Rare words are often not useful for modeling. Please only add words to the dictionary
if they occur in at least five messages.
Args:
messages: A list of strings containing SMS messages
Returns:
A python dict mapping words to integers.
"""
# *** START CODE HERE ***
# make a list of all the words
word_list = []
dict = {}
c = 0
for row in messages:
seperated = get_words(row)
for i in seperated:
word_list.append(i)
for words in word_list:
tobe = words in dict.values()
if tobe == False:
if word_list.count(words) > 4:
dict[c] = words
c += 1
return dict
# *** END CODE HERE ***
def transform_text(messages, word_dictionary):
"""Transform a list of text messages into a numpy array for further processing.
This function should create a numpy array that contains the number of times each word
of the vocabulary appears in each message.
Each row in the resulting array should correspond to each message
and each column should correspond to a word of the vocabulary.
Use the provided word dictionary to map words to column indices. Ignore words that
are not present in the dictionary. Use get_words to get the words for a message.
Args:
messages: A list of strings where each string is an SMS message.
word_dictionary: A python dict mapping words to integers.
Returns:
A numpy array marking the words present in each message.
Where the component (i,j) is the number of occurrences of the
j-th vocabulary word in the i-th message.
"""
# *** START CODE HERE ***
Array = np.zeros([len(messages),len(word_dictionary)])
keys = list(word_dictionary.keys())
values = list(word_dictionary.values())
for i in range(len(messages)):
for words in get_words(messages[i]):
condition = words in values
if condition == True:
n = get_words(messages[i]).count(words)
j = keys[values.index(words)]
Array[i,j] = n
return Array
# *** END CODE HERE ***
def fit_naive_bayes_model(matrix, labels):
"""Fit a naive bayes model.
This function should fit a Naive Bayes model given a training matrix and labels.
The function should return the state of that model.
Feel free to use whatever datatype you wish for the state of the model.
Args:
matrix: A numpy array containing word counts for the training data
labels: The binary (0 or 1) labels for that training data
Returns: The trained model
"""
# *** START CODE HERE ***
n_words = np.shape(matrix)[1]
n_label = np.shape(matrix)[0]
phi_spam = np.zeros((1,n_words))
phi_nonspam = np.zeros((1,n_words))
zeros = 0
ones = 0
# count the number of spam(1) and not-spam(0) emails
for i in labels:
if i == 0:
zeros += 1
else:
ones += 1
phi_y = (1 + ones)/(n_words + n_label) #P(y=1)
for i in range(n_label):
if labels[i] == 0:
for j in range(n_words):
if matrix[i,j] != 0:
phi_nonspam[0,j] += 1/(2+zeros)
if labels[i] == 1:
for j in range(n_words):
if matrix[i,j] != 0:
phi_spam[0,j] += 1/(2+ones)
for j in range(n_words):
phi_spam[0, j] += 1 / (2 + ones)
phi_nonspam[0, j] += 1 / (2 + zeros)
return phi_y, phi_spam, phi_nonspam
# *** END CODE HERE ***
def predict_from_naive_bayes_model(phi_y, phi_spam, phi_nonspam, matrix):
"""Use a Naive Bayes model to compute predictions for a target matrix.
This function should be able to predict on the models that fit_naive_bayes_model
outputs.
Args:
model: A trained model from fit_naive_bayes_model
matrix: A numpy array containing word counts
Returns: A numpy array containg the predictions from the model
"""
# *** START CODE HERE ***
#zeros, ones, phi_spam, phi_nonspam = model
n_words = np.shape(matrix)[1]
n_label = np.shape(matrix)[0]
phi = np.zeros((1,n_label))
prob_log = np.zeros((1, n_label))
pred = np.zeros((1, n_label))
for i in range(n_label):
mul1 = 1 # y=1
mul2 = 1 # y=0
summation = 0
for j in range(n_words):
if matrix[i,j] != 0:
mul1 = mul1*phi_spam[0,j]
mul2 = mul2*phi_nonspam[0,j]
#summation += np.log(phi_spam[0,j])
summation += np.log(phi_nonspam[0, j])
#print(phi_y*mul1 + mul2*(1-phi_y))
#prob_log[0,i] = summation + np.log(phi_y) - np.log(phi_y*mul1 + mul2*(1-phi_y))
# probability that it is not spam
prob_log[0, i] = summation + np.log(1-phi_y) - np.log(phi_y * mul1 + mul2 * (1 - phi_y))
pred[0,i] = np.exp(prob_log[0,i])
for i in range(n_label):
if pred[0,i] < 0.5:
pred[0,i] = 1
else:
pred[0,i] = 0
return pred
# *** END CODE HERE ***
def get_top_five_naive_bayes_words(phi_y, phi_spam, phi_nonspam, dictionary):
"""Compute the top five words that are most indicative of the spam (i.e positive) class.
Ues the metric given in part-c as a measure of how indicative a word is.
Return the words in sorted form, with the most indicative word first.
Args:
model: The Naive Bayes model returned from fit_naive_bayes_model
dictionary: A mapping of word to integer ids
Returns: A list of the top five most indicative words in sorted order with the most indicative first
"""
# *** START CODE HERE ***
N = len(dictionary)
ratio = np.zeros((1,N))
for j in range(N):
ratio[0,j] = np.log(phi_spam[0,j]/phi_nonspam[0,j])
sorted_ind = np.argsort(ratio)
sorted_list = sorted_ind[0].tolist()
word = []
for i in sorted_list:
word.append(dictionary[i])
n = len(word)
last_five = [word[n-1],word[n-2],word[n-3],word[n-4],word[n-5]]
return last_five
# *** END CODE HERE ***
def compute_best_svm_radius(train_matrix, train_labels, val_matrix, val_labels, radius_to_consider):
"""Compute the optimal SVM radius using the provided training and evaluation datasets.
You should only consider radius values within the radius_to_consider list.
You should use accuracy as a metric for comparing the different radius values.
Args:
train_matrix: The word counts for the training data
train_labels: The spma or not spam labels for the training data
val_matrix: The word counts for the validation data
val_labels: The spam or not spam labels for the validation data
radius_to_consider: The radius values to consider
Returns:
The best radius which maximizes SVM accuracy.
"""
# *** START CODE HERE ***
naive_bayes_accuracy = []
for j in radius_to_consider:
y = svm.train_and_predict_svm(train_matrix, train_labels, val_matrix, j)
naive_bayes_accuracy.append(np.mean(y == val_labels))
# *** END CODE HERE ***
return radius_to_consider[np.argmax(naive_bayes_accuracy)]
def main():
train_messages, train_labels = util.load_spam_dataset('spam_train.tsv')
val_messages, val_labels = util.load_spam_dataset('spam_val.tsv')
test_messages, test_labels = util.load_spam_dataset('spam_test.tsv')
""""
# Checking the code portions seperately
dict = create_dictionary(train_messages)
Arrray1 = transform_text(train_messages, dict)
phi_y, phi_spam, phi_nonspam = fit_naive_bayes_model(Arrray1, train_labels)
Arrray = transform_text(test_messages, dict)
word = get_top_five_naive_bayes_words(phi_y, phi_spam, phi_nonspam, dict)
#print(word)
"""
dictionary = create_dictionary(train_messages)
print('Size of dictionary: ', len(dictionary))
util.write_json('spam_dictionary', dictionary)
train_matrix = transform_text(train_messages, dictionary)
np.savetxt('spam_sample_train_matrix', train_matrix[:100,:])
val_matrix = transform_text(val_messages, dictionary)
test_matrix = transform_text(test_messages, dictionary)
phi_y, phi_spam, phi_nonspam = fit_naive_bayes_model(train_matrix, train_labels)
naive_bayes_predictions = predict_from_naive_bayes_model(phi_y, phi_spam, phi_nonspam, test_matrix)
#np.savetxt('spam_naive_bayes_predictions', naive_bayes_predictions)
naive_bayes_accuracy = np.mean(naive_bayes_predictions == test_labels)
print('Naive Bayes had an accuracy of {} on the testing set'.format(naive_bayes_accuracy))
top_5_words = get_top_five_naive_bayes_words(phi_y, phi_spam, phi_nonspam, dictionary)
print('The top 5 indicative words for Naive Bayes are: ', top_5_words)
util.write_json('spam_top_indicative_words', top_5_words)
optimal_radius = compute_best_svm_radius(train_matrix, train_labels, val_matrix, val_labels, [0.01, 0.1, 1, 10])
util.write_json('spam_optimal_radius', optimal_radius)
print('The optimal SVM radius was {}'.format(optimal_radius))
svm_predictions = svm.train_and_predict_svm(train_matrix, train_labels, test_matrix, optimal_radius)
svm_accuracy = np.mean(svm_predictions == test_labels)
print('The SVM model had an accuracy of {} on the testing set'.format(svm_accuracy, optimal_radius))
if __name__ == "__main__":
main()
|
497e35328a7f3e0eddbaaa9e4a1a500ceeaedd7b | ftchen911-gmailcom/yzu_python_20210414_2 | /day05/DictAndList2.py | 807 | 3.609375 | 4 | e1 = {'name':'John', 'salary': 50000, 'program': ['HTML', 'JS']}
e2 = {'name':'Mary', 'salary': 60000, 'program': ['HTML', 'Python']}
e3 = {'name':'Bob', 'salary': 70000, 'program': ['Java', 'Python', 'C#']}
emps = [e1, e2, e3]
print(len(emps), emps)
# 請求出會 Python 的員工人名, 並將放入到 names = []
# sum = 0
# name = []
# for emp in emps:
# for prg in emp['program']:
# if prg == 'Python':
# name.append(emp['name'])
# print("%s" % emp['name'])
# print(name)
# 請求出會 Python 的員工人名, 並將放入到 names = []
target = 'Python'
name = []
for emp in emps:
# print(emp['name'], emp['program'])
for p in emp['program']:
if p == target:
# print(emp['name'], p)
name.append(emp['name'])
print(name)
|
648f8399b3c05de3f2e517f5101e6027bfed289e | blainevanitem/cse210-tc07 | /speed/game/word.py | 1,064 | 3.6875 | 4 | ''' Pulls 5 random words from the word bank in input_service.'''
import random
class Word:
def __init__(self):
self._word = ""
self._words_list = []
self._words = ['','','','','']
def get_words(self):
self.my_file = open("speed\game\words.txt")
self._words_list = self.my_file.readlines()
self.my_file.close()
for x in range(5):
self._words[x] = self._words_list[random.randint(0,len(self._words_list)-1)]
def build_word(self,letter):
letter = letter
if letter == "*":
self._word = ""
else:
self._word += letter
return self._word
def clear_word(self):
self._word = ""
def update_with_new_word(self,x):
self._words[x] = self._words_list[random.randint(0,len(self._words_list)-1)]
def is_word_on_screen(self,word,words,updateIndex):
for x in range(5):
if word == words[x].rstrip('\n'):
updateIndex = x
return updateIndex
|
a938b32f0f5dbc3f5ac88bf13e8c1d7f7ed59f88 | vdhulappanavar/SencondSemEngg | /python/colLab/Lab1-3/pattern1.py | 159 | 4.0625 | 4 | n=int(input("Enter the number of rows you want to print:"))
i=0
j=n
m=n
while i<=n:
while j>=0:
print(' ' , end=' ')
j=j-1
m=m-1
j=m
print("1")
i=i+1
|
170162f4db3436cf6d1a880cc2f8f06ab770f5cf | bayasshii/RhinoPython | /ThinkPython/bob/bob_spiral.py | 219 | 3.53125 | 4 | import turtle
import math as ma
bob = turtle.Turtle()
print(bob)
def archimedes_spiral(t, a):
# t = turtle_name
for i in range(a):
t.fd(i/10)
t.lt(10)
archimedes_spiral(bob, 300)
|
9087df3c17f78dc53a5cded1142bb59d6be7b56e | JohnnyStein/Python-OOP | /pets.py | 558 | 3.953125 | 4 | class Pet():
def show(self):
print(f"It name is {self.name}, it is {self.age} years old. It is a {self.type}")
class Dog(Pet):
def __init__(self, name, age):
self.name = name
self.age = age
self.type = "Dog"
class Fish(Pet):
def __init__(self, name, age):
self.name = name
self.age = age
self.type = "Fish"
class Cat(Pet):
def __init__(self, name,age):
self.name = name
self.age = age
self.type = "Cat"
a1 = Dog("Bob", 7)
a1.show()
a2 = Fish("Tim", 3)
a2.show() |
24dc6b138823cdca71f483ab27bdda64ef968a14 | bootlegmojo/PyMongoLearning | /python_mongo.py | 2,104 | 3.546875 | 4 | from pymongo import MongoClient
host = "localhost"
port = 27017
client = MongoClient(host, port)
mydb = client["library"]
book_collection = mydb["books"]
client.close()
'''
book = { "title": "Pride and Prejusice", "author": "Jane Austen" }
new_id = book_collection.insert_one(book)
print("Inserted book with id %s" % new_id.inserted_id)
'''
new_books = [
{"title": "Persuasion", "author": "Jane Austen"},
{"title": "Northanger Abbey", "author": "Jane Austen"},
{"title": "Pride and Prejusice", "author": "Jane Austen"}
]
new_ids = book_collection.insert_many(new_books)
print("Inserted IDs")
for id in new_ids.inserted_ids:
print(id)
#FIND ONE BOOK BY TITLE
'''
myquery = {"title": "Persuasion"}
doc = book_collection.find_one(myquery)
if doc is not None:
print(doc)
else:
print("Book not found: Persuasion")
'''
#FIND MANY BOOKS OF THE SAME AUTHOR
authorquery = {"author": "Jane Austen" }
books = book_collection.find(authorquery)
for book in books:
print(book)
if books.retrieved == 0:
print("Author not found: Jane Austen")
else:
print(" %s books found with author Jane Austen" % books.retrieved)
#Change the title of one book from Persuasion to Northanger Abbey
'''
myquery = {"name": "Northanger Abbey"}
newvalues = {"$set": {"name": "Persuasion"}}
result = book_collection.update_one(myquery, newvalues)
print("%d documents matched, %d documents updated"
%(result.matched_count, result.modified_count))
'''
#Change the author from Jane Austen to Austen, J throughout
'''
myquery = {"author": "Jane Austen"}
newvalues = {"$set": {"author": "Austen, J"}}
result = book_collection.update_many(myquery, newvalues)
print("%d documents matched, %d documents updated"
%(result.matched_count, result.modified_count))
'''
#delete one book
'''
book = {"title": "Pride and Predjudice", "author": "Austen, J"}
results = book_collection.delete_one(book)
print("\n Deleted %d books" % (results.deleted_count))
'''
#delete all documents in the collection with author Austen J
'''
results = book_collection.delete_many({"author": "Jane Austen"})
print ("\nDeleted %d books" %(results.deleted_count))
''' |
40deff8891a3c4a6c2c88b0332fdb590121c79e4 | DeekshithSimhachalam/python | /functions.py | 173 | 3.6875 | 4 | def add_numbers(a,b):
addition = a + b
print(addition)
add_numbers(1.2,1.5 )
def sub_numbers(a,b):
subtraction = a-b
print(subtraction)
sub_numbers(10, 5)
|
d149246bcd2a83d8eea30f471c136d3e464ef7e6 | zxcv4778/study-python | /data_type/list_type.py | 1,396 | 4.125 | 4 |
# list 인덱싱
list = [1, 2, 3, 4, 'list', 'hello']
print(list[0] + list[3])
print(list[4] + list[5])
print(list[-1])
list1 = [2, 4, 5, ['twice', 'izone']]
print(list1[-1][0])
print(list1[-1][1])
# List 슬라이싱
print(list[:3])
print(list[3:])
# list +
listA = [1, 2, 3]
listB = [4, 5, 6]
print(listA + listB)
# list *
print(listA * 3)
print(listB * 3)
# change args
listA[1] = 9
listB[2] = 0
print(listA)
print(listB)
listA[1:2] = ['twice', 'izone']
listB[1] = ['once', 'wizone']
print(listA)
print(listB)
# delete args
listA[0:1] = []
print(listA)
listA[2:3] = []
print(listA)
del listB[0]
print(listB)
del listB[-1]
print(listB)
# append
twice = ['나연']
twice.append('사나')
twice.append('미나')
twice.append('지효')
twice.append('다현')
print(twice)
# sort
numbers = [8, 3, 2, 0]
numbers.sort()
print(numbers)
# reverse
twice.reverse()
print(twice)
# index
print(twice.index('사나'))
print(twice.index('나연'))
nationalAssembly = ['세금', '권력', '체면', '꼰대']
# print(nationalAssembly.index('상식'))
# insert
nationalAssembly.insert(0, '개판')
print(nationalAssembly)
# remove
nationalAssembly.remove('체면')
print(nationalAssembly)
# pop
print(nationalAssembly.pop(0))
print(nationalAssembly)
# count
print(twice.count('나연'))
# extend
twice.extend(['모모', '정연', '채영', '쯔위'])
print(twice) |
9446e07738e047c3696055435fdc3a0ed3d9e8ad | Upinder3/code_practice | /max_time.py | 386 | 3.671875 | 4 | def max_time(t):
mt = ""
if t[0] == "?":
if t[1] == "?" or t[1] < "4":
mt += "2"
else:
mt += "1"
else:
mt += t[0]
if t[1] == "?":
if mt[0] == "2":
mt += "3"
else:
mt += "9"
else:
mt += t[1]
mt += ":"
if t[3] == "?":
mt += "5"
else:
mt += t[3]
if t[4] == "?":
mt += "9"
else:
mt += t[4]
return mt
t = "??:??"
print(max_time(t))
|
6ab8c716567457dd513ab653ae12f2d6c93f50ae | aquibali01/100DaysOfCode- | /Day2/day-2-3-excercise/main.py | 365 | 3.828125 | 4 | # 🚨 Don't change the code below 👇
age = int(input("What is your current age?"))
# 🚨 Don't change the code above 👆
#Write your code below this line 👇
days_left = (90-age)*365
weeks_left = (90-age)*52
months_left = (90-age)*12
print(f"You have {days_left} days, {weeks_left} weeks and {months_left} months left. If you are to live 90 years")
|
8bdb54e8a04e046593df95a2fbb67fbf26c40184 | kalebinn/PythonBootcamp_Summer2021 | /Day6/files.py | 2,935 | 3.6875 | 4 | import random
AMD_theatre_menu = {
"Recliner Seating Ticket": 9.99,
"Regular Seating Ticket" : 4.99,
"Small popcorn" : 4.99,
"Large popcorn" : 7.99,
"Small Soft Drink" : 1.99,
"Large Soft Drink" : 3.99
}
menu_options = '''
Tickets Pricing
-----------------------------
1 - Recliner Seats: 9.99
2 - Regular Seats: 4.99
Food
-----------------------------
3 - Small Popcorn: 4.99
4 - Large popcorn: 7.99
5 - Small Soft Drink: 1.99
6 - Large Soft Drink: 3.99
7 - Finish order
'''
print(menu_options)
user_selection = input("Please make a selection from the menu: ")
subtotal = 0
orders = []
while True:
if user_selection == '1':
subtotal = subtotal + AMD_theatre_menu["Recliner Seating Ticket"]
orders.append("Recliner Seating Ticket")
elif user_selection == '2':
subtotal = subtotal + AMD_theatre_menu["Regular Seating Ticket"]
orders.append("Regular Seating Ticket")
elif user_selection == '3':
subtotal = subtotal + AMD_theatre_menu["Small popcorn"]
orders.append("Small popcorn")
elif user_selection == '4':
subtotal = subtotal + AMD_theatre_menu["Large popcorn"]
orders.append("Large popcorn")
elif user_selection == '5':
subtotal = subtotal + AMD_theatre_menu["Small Soft Drink"]
orders.append("Small Soft Drink")
elif user_selection == '6':
subtotal = subtotal + AMD_theatre_menu["Large Soft Drink"]
orders.append("Large Soft Drink")
elif user_selection == '7':
break
else:
print("Invalid selection")
user_selection = input("Please make a selection from the menu: ")
print(f"Your subtotal is: ${round(subtotal, 2)}")
ny_tax = 0.08875
final_total = subtotal + (ny_tax * subtotal)
print(f"NY sales tax: {round(ny_tax * subtotal, 2)}")
print(f"Your total is: ${round(final_total, 2)}")
print("Please wait, your tickets and receipts are printing!")
# printing the receipt
invoice_number = random.randint(10000, 99999)
my_file = open(f"AMD_receipt_{invoice_number}.txt", "w")
my_file.write("Hello! Welcome to AMD Theatres!\n\n")
my_file.write(f"Invoice #{invoice_number}\n\n")
my_file.write("------------------------------------\n")
for order in set(orders):
num_times_ordered = orders.count(order)
my_file.write(f"{num_times_ordered} x {order}: ${num_times_ordered * AMD_theatre_menu[order]}\n")
my_file.write(f"\nSubtotal: ${round(subtotal, 2)}\n")
my_file.write(f"NY Sales Tax: {round(ny_tax * subtotal, 2)}\n")
my_file.write("------------------------------------\n")
my_file.write(f"Total: ${round(final_total, 2)}\n\n\n")
refund_policy = '''
Refund Policy:
Return the ticket within 24 hour of
showtime to receive a full refund. No
refunds will be given for cancellations
less than 24 hours before the start time
of the requested movie.
'''
my_file.write(refund_policy)
print(orders.count("Recliner Seating Ticket"))
|
4a86a9918141c8e1a862b43666b5d5c78aeb11a0 | KuanyuPhy/Python | /CoffeeShop.py | 1,254 | 3.65625 | 4 | import random
import time
import sys
Kind = input("Coffee or Tea:")
Size = input("輸入你的飲料Size:")
times = 25
if ( Size in ["M","L","XL"]):
if(Kind in ["Coffee"]):
Coffee =["冰本日咖啡","熱本日咖啡","冰咖啡密斯朵","馥列白","濃焦糖那堤"
,"雲朵冰搖濃縮咖啡","特選馥郁那堤","冰那堤","冰焦糖瑪朵","冰摩卡","冰美式"]
for i in range(times):
drink = random.shuffle(Coffee)
if i < times-1:
print("次數",i+1,"次","抽到的是",Coffee[0])
time.sleep(0.3)
else:
print("今晚,我想來點",Coffee[0],"Size: ",Size)
elif(Kind in ["Tea"]):
Tea =["伯爵茶那堤","醇濃抹茶那堤","經典紅茶那堤","冰經典紅茶那堤","玫瑰蜜香茶那堤"
,"冰玫瑰蜜香茶那堤","抹茶那堤","冰抹茶那堤","冰抹茶咖啡"]
for i in range(times):
drink = random.shuffle(Tea)
if i < times-1:
print("次數",i+1,"次","抽到的是",Tea[0])
time.sleep(0.3)
else:
print("今晚,我想來點",Tea[0],"Size: ",Size)
else:
print("Error!")
sys.exit()
|
f827354586729cd85a0d844145e1c3d379d8aeae | gorutwik/CryptographyProject | /intergration_testing.py | 6,154 | 4.21875 | 4 | from Decryption import Decryption
from Encryption import Encryption
from Preprocessing import Preprocessing
def main():
# For the integration testing I will take plain txt from usr converting into binary string giving it to Encryption block to
# encrypt it so that it gives out cypher text. which is tored in image
# after extraaction of cypher txt from stegeo img it will be given to the decryption module
# Decryptor decrypt it to yield plain txt.
plain_text = input("Enter a plain text : ")
#example : This World shall Know Pain
print(f"Entered plian Txt : {plain_text}")
preprocessor = Preprocessing()
#convert to binary
plain_2_binary_string = preprocessor.string_2_binary(plain_text)
#append the length in front of 25 bit
prepended_binary_string = preprocessor.prepend_length_of_binary_string(plain_2_binary_string)
#padding with zeroes that binary string so that it is a multiple of 128.
padded_binary_string = preprocessor.padding_of_text(prepended_binary_string)
#ENCRYPTION
encryptor = Encryption()
print(f"Padded Binary string pt1_txt --> : {padded_binary_string}")
print('\n\n')
cipher_text = ""
pt1_txt = padded_binary_string
for i in range(0,len(padded_binary_string),128):
string_128_bit = padded_binary_string[i:i+128]
#Encryption starts
EI_S = preprocessor.Convert128_to_32bits(string_128_bit)
keys = "11110111110000001010010111101001101111101000101000000000111111111111000000001111111011011100010101010010101101010101000010111111"
KEYS = preprocessor.Convert128_to_32bits(keys)
C1 , C2, C3 , C4 = encryptor.Encrypt(EI_S,KEYS)
cipher_text += C1 + C2 + C3 + C4
print("cipher_text\n",cipher_text)
print('\n')
print("pt1_txt\n",pt1_txt)
print("\n\n")
ct_text = cipher_text
#prepended the length of cypher text in front of 25 bit i.e first 25 bit shows length of cypher text
prepended_cypher_txt = preprocessor.prepend_length_of_binary_string(cipher_text)
#padd it now this cypher txt -->prepended_cypher_txt to padded_cypher_txt
padded_cypher_txt = preprocessor.padding_of_text(prepended_cypher_txt)
#Now the padded cypher text -->padded_cypher_txt will go inside the image and image will be called after insertion as
#steogo image
#Now we have to extract LSB of whole image (or it can be modified / optimized further )
cypher_txt_after_extraction = preprocessor.extract_real_binary_string(padded_cypher_txt)
#DECRYPTION
padded_pt_text = ""
decryptor = Decryption()
for i in range(0,len(cypher_txt_after_extraction),128):
cypher_128_bit = cypher_txt_after_extraction[i:i+128]
#print("###",i , i+128 , string_128_bit)
#print('\n\n')
CT_S = preprocessor.Convert128_to_32bits(cypher_128_bit)
keys = "11110111110000001010010111101001101111101000101000000000111111111111000000001111111011011100010101010010101101010101000010111111"
KEYS = preprocessor.Convert128_to_32bits(keys)
#print("\n\nKEYS : ",KEYS)
#print('\n\n')
E1,E2,E3,E4 = decryptor.Decrypt(CT_S,KEYS)
padded_pt_text += E1 + E2 + E3 + E4
print("padded_pt_text\n",padded_pt_text)
print('\n')
print("Ab bata jara ",end="")
print(pt1_txt==padded_pt_text)
#Now extracting actual binary string from padded plain txt
real_pt_text = preprocessor.extract_real_binary_string(padded_pt_text)
#Now convert this real plain txt into Ascii text
real_plain_text = preprocessor.binary_2_string(real_pt_text)
print(f"\n\n\n\n\n\n\n\n\n After all the actual text was :--> {real_plain_text}\n\n\n\n\n\n\n\n\n")
def main2():
p = Preprocessing()
keys = "11110111110000001010010111101001101111101000101000000000111111111111000000001111111011011100010101010010101101010101000010111111"
KEYS = p.Convert128_to_32bits(keys)
#plain_text = "00000001110101111011011011111011110000000111010111101101101111100010111110011101001101110010100001011000100000100111011001001110"
plain_text = "00000000000000000000000000000001010000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000"
print(plain_text)
EI_S = p.Convert128_to_32bits(plain_text)
e = Encryption()
d = Decryption()
cypher_txt = e.Encrypt(EI_S,KEYS)
print( "\ncypher_txt ", cypher_txt , "\n\n" )
e1 ,e2 ,e3 ,e4 = d.Decrypt(cypher_txt , KEYS)
decrypted_txt = e1+e2+e3+e4
print("Decrypted Txt : " ,decrypted_txt , "\n\n")
print(decrypted_txt==plain_text)
count=0
for i in range(128):
if decrypted_txt[i]!=plain_text[i]:
print(i+1)
count+=1
print(count)
# def checking_individual_preprocessor():
# print("\n\n\n\n\n\n\n")
# pp = Preprocessing()
# plain_text = "00000001110101111011011011111011110000000111010111101101101111100010111110011101001101110010100001011000100000100111011001001110"
# q1,q2,q3,q4 = pp.Convert128_to_32bits(plain_text)
# print("checkig 128 to 32 bit split")
# print(q1+q2+q3+q4 == plain_text)
# print("\n\ncheckig anticlock ")
# d="1101101100"
# print(f"string to reverse {d} into anticlock 2 times : {pp.anti_clockwise_CircularShift(d,2)}")
# print(f"checkig clock of {d} into clock wise 2 times : {pp.clockwise_CircularShift(d,2)}")
# print("\n\n\nchecking for xor bits")
# a="1101100001"
# b="1100000111"
# print(f"Xor of \n{a}\n{b}\n{pp.xor_32bits(a,b)}")
if __name__ == "__main__" :
main()
print("main 1 called")
# print("Now calling main2")
# main2()
# checking_individual_preprocessor()
# 00000000000000000110011111010100011010000110100101110011001000000101011101101111011100100110110001100100001000000111001101101000
# 00000000000000000110011111010100
# 01101000011010010111001100100000
# 01010111011011110111001001101100
# 01100100001000000111001101101000
# cipher_text
# 11111101111100000010100100000110101011110100010101111001101110011000101111100111101101001111100010100100011110101000001111010000
# pt1_txt
# 00000000000000000000011111001000011001010000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
# pt_text
# 00000001110101111011011011111011110000000111010111101101101111100010111110011101001101110010100001011000100000100111011001001110
# False
# awani
|
823bdc3d2e29d587f5642b03369a68d9871295ac | achoi2/python-exercises | /python102/tipping.py | 308 | 4.15625 | 4 | tip_input = raw_input('How much did you tip?')
tip = float(tip_input)
bill_input = raw_input("How much was the bill?")
bill = float(bill_input)
tip_ratio = tip / bill
tip_ratio less than 0.10:
say "stingy"
tip_ratio greater than 0.20:
say "generous!"
otherwise:
say "average"
3 < 5
|
459cb631c6b12cf80d9036a46e87e0b3e5383221 | WroclawUoSaT17-18/po-cz-11n-mikolajo | /test_mainWindow.py | 955 | 3.59375 | 4 | import unittest
from tkinter import *
from test import mainWindow
from unittest import TestCase
# ~~~~~~~~~~~~~~~~TEST CASE INTRODUCTION~~~~~~~~~~~~~~~~
# Testujemy funkcjonalność inicjalizacji klasy okna
# biblioteki Tkinter, tworzony jest obiekt,
# następnie sprawdzana jest poprawność działania
# wprowadzania danych do okna dialogowego.
# Testowana wartość to "przykladowa wartosc"
# sprawdzamy formatowanie.
class TestMainWindow(TestCase):
def test_class_init(self):
root = Tk()
window_1 = mainWindow(root)
value = 'przyklad'
self.assertEqual(window_1.popup(), None) # sama obsluga okna wpisywania
self.assertEqual(window_1.entryValue(), value) # w okno wpisz 'przykladowa wartosc'
self.addTypeEqualityFunc(str, window_1.entryValue()) #sprawdzenie czy typ danych otrzymywany z okna to string
if __name__ == "__main__":
unittest.main()
|
f07e137d7eaa5bcd92201f00e16e99d794a81f54 | Muosvr/cs50 | /pset6/crack/test.py | 591 | 3.96875 | 4 | print(chr(65))
input = "APPLE"
print(input.lower())
print(input[len(input)-1])
print("Ascii number of A: ", ord("A"))
print("Next letter of A: ", chr(ord("A")+1))
print("input == APPLE: ", input == "APPLE")
def check (num1, num2 = 3):
print("num1: ", num1)
print("num2: ", num2)
check(4)
check(4, 5)
input = input[:len(input)-1]
print("Get rid of last letter", input)
print("Z in AAZZZ", "AAZZZ".count("Z"))
print("Get rid of Zs at the end", "AAZZZ"[:-3])
print("Letter before Z: ", "ABCZZZ"[-4])
print("length of abc", len("abc"))
print("split by space", len("abc".split(" ")))
|
250d94f5930d03891d8fb4d874ae81a069d6b1be | anuragseven/coding-problems | /online_practice_problems/arrays/stock sell and buy.py | 746 | 4 | 4 | # The cost of stock on each day is given in an array A[] of size N. Find all the days on which you buy and sell the stock so that in between those days your profit is maximum.
class Solution:
#Function to find the days of buying and selling stock for max profit.
def stockBuySell(self, A, n):
result=[]
currBuyingDay=0
currSellingDay=0
for i in range(1,n):
if A[i]>A[currSellingDay]:
currSellingDay=i
else:
if currBuyingDay<currSellingDay:
result.append([currBuyingDay,currSellingDay])
currBuyingDay=i
currSellingDay=i
if currSellingDay>currBuyingDay:
result.append([currBuyingDay,currSellingDay])
return result |
d5f8479ec1d9c521dddad035e4794e6907d250a3 | uit-no/python-course-2016 | /talks/introduction/seq3.py | 230 | 3.78125 | 4 | #!/usr/bin/env python3
str = "Python is great"
first_six = str[0:6]
print(first_six)
starting_at_five = str[5:]
print(starting_at_five)
a_copy = str[:]
print(a_copy)
without_last_five = str[0:-5]
print(without_last_five)
|
859ba5efa758772057895eb0fe361da0c3825d78 | chunche95/ProgramacionModernaPython | /Proyectos/Funciones/pruebafunciones03-tortuga-calcula-area-del-cuadrado.py | 1,457 | 4.21875 | 4 | # Importacion de las librerias necesarias.
import turtle
# Realizamos los pasos que queremos que haga la 'tortuga'
############
# Bucle #
############
# Creacion de una funcion para las repeticiones.
def cuadrado(lado):
miT.forward(lado) # camina 50 'pasitos'
miT.left(90) # gira 90º
# Camino 2
miT.forward(lado) ###########
miT.left(90) # 2 # 1 #
# Camino 3 #### >>####
miT.forward(lado) # 3 # 4 #
miT.left(90) ###########
# Camino 4
miT.forward(lado)
miT.left(90)
# Devolvemos el resultado de la funcion
return lado*lado
# Inicializamos la variable de tortuga.
miT = turtle.Turtle()
##############################################################
#Creamos la tarea del calculo
area01 = cuadrado(25)
# Giro
miT.left(90) # Giro para volver a empezar
print (area01)
##############################################################
area02 = cuadrado(50)
# Giro
miT.left(90) # Giro para volver a empezar
print (area02)
##############################################################
area03 = cuadrado(75)
# Giro
miT.left(90) # Giro para volver a empezar
print (area03)
##############################################################
area04 = cuadrado(100)
# Giro
miT.left(90) # Giro para volver a empezar
print (area04)
##############################################################
|
28a862ef3878c05d6442abfd956143d48a246e9a | therealcalebc/algorithms_practice | /Python/FlightItinerary.py | 915 | 4.09375 | 4 | #**
# Flight Itinerary Problem
# Given an unordered list of flights taken by someone, each represented as (origin, destination) pairs, and a starting airport, compute the person's itinerary.
# If no such itinerary exists, return null.
# All flights must be used in the itinerary.
#*
# example solution from dailycodingproblem.com
def get_itinerary(flights, current_itinerary):
# If we've used up all the flights, we're done
if not flights:
return current_itinerary
last_stop = current_itinerary[-1]
for i, (origin, destination) in enumerate(flights):
# Make a copy of flights without the current one to mark it as used
flights_minus_current = flights[:i] + flights[i + 1:]
current_itinerary.append(destination)
if origin == last_stop:
return get_itinerary(flights_minus_current, current_itinerary)
current_itinerary.pop()
return None
|
7bbbf7dbaf76f263dd0b0f05f54ac8f231a39ceb | safwanvk/py | /exerices/Comprehension.py | 922 | 3.9375 | 4 | # one liner for….
# print list of 0 to 9 numbers
lst = [i for i in range(10)]
a = 2
b = 3
if a > b:
print(a)
else:
print(b)
# one liner if...
print(a) if (a > b) else print(b)
# find even or odd
lst_odd = []
lst_even = []
for i in range(50):
if i % 2 == 0:
lst_even.append(i)
else:
lst_odd.append(i)
print(lst_even, lst_odd)
# one liner for and if ...........
lst_odd = [i for i in range(50) if (i % 2 == 1)]
lst_even = [i for i in range(50) if (i % 2 == 0)]
print(lst_even, lst_odd)
# Find all the multiples of 3 and 5 which is less than 50
lst = [n for n in range(1, 50) if n % 3 == 0 and n % 5 == 0]
print(lst)
# [3, 5, 6, 9, 10, 12, 15, 18, 20, 21, 24, 25, 27, 30, 33, 35, 36, 39, 40, 42, 45, 48]
# create a dictionary in the format {i:i*i} where i from 1 to n for a limit n
print([{x: x*x} for x in range(1, (int(input('enter limit')) + 1))])
# 3
# [{1: 1}, {2: 4}, {3: 9}]
|
51fcc5c21000456f08d6a5481894fb3ddf6cf02c | frankieliu/problems | /leetcode/python/516/original/516.longest-palindromic-subsequence.0.py | 797 | 3.640625 | 4 | #
# @lc app=leetcode id=516 lang=python3
#
# [516] Longest Palindromic Subsequence
#
# https://leetcode.com/problems/longest-palindromic-subsequence/description/
#
# algorithms
# Medium (44.97%)
# Total Accepted: 50.1K
# Total Submissions: 111.3K
# Testcase Example: '"bbbab"'
#
#
# Given a string s, find the longest palindromic subsequence's length in s. You
# may assume that the maximum length of s is 1000.
#
#
# Example 1:
# Input:
#
# "bbbab"
#
# Output:
#
# 4
#
# One possible longest palindromic subsequence is "bbbb".
#
#
# Example 2:
# Input:
#
# "cbbd"
#
# Output:
#
# 2
#
# One possible longest palindromic subsequence is "bb".
#
#
class Solution:
def longestPalindromeSubseq(self, s):
"""
:type s: str
:rtype: int
"""
|
f3caedfa21d5af7c8efe10427d1316d2edf2d9a0 | christopher-besch/bwinf_39_round1 | /task_3/rng_simulation.py | 1,328 | 3.875 | 4 | import random
from typing import List
def play_rng(player1: int, player2: int, skill_levels: List[int]) -> int:
"""
player1 and player2 play RNG against each other
the skill level of a player determines the number of marbles in the urn
return the winner
"""
skill_level1 = skill_levels[player1]
skill_level2 = skill_levels[player2]
# determine a random marble
random_marble = random.randint(1, skill_level1 + skill_level2)
# the owner of the drawn marble wins
if random_marble <= skill_level1:
return player1
else:
return player2
def play_rng_5(player1: int, player2: int, skill_levels: List[int]) -> int:
"""
play RNG five times
"""
count_wins_player1 = 0
count_wins_player2 = 0
skill_level1 = skill_levels[player1]
skill_level2 = skill_levels[player2]
for _ in range(5):
# determine a random marble
random_marble = random.randint(1, skill_level1 + skill_level2)
# the owner of the drawn marble wins
if random_marble <= skill_level1:
count_wins_player1 += 1
else:
count_wins_player2 += 1
# determine final winner
if count_wins_player2 < count_wins_player1:
return player1
else:
return player2
|
baf01a71fd5320783cdaffd1b2663d203020a6a0 | wangtss/leetcodePractice | /sourcePY/206.py | 238 | 3.75 | 4 | def reverseList(self, head):
dummy = ListNode(0)
cur = head
while cur:
temp = cur.next
cur.next = dummy.next
dummy.next = cur
cur = temp
return dummy.next |
75cf15529c6008e7fb5cbafd32c7bf405fa90a56 | charlie-boy/python | /class.py | 340 | 3.640625 | 4 | class first:
def setname(self,value):
self.name=value
def display(self):
print self.name
class second(first):
def display(self):
print "current value is:%s"%self.name
x=first()
y=second()
x.setname("ghh, ghgjghjghfvj")
y.setname("1234")
x.display()
y.display()
|
ba168e6a3b74bf772f9142ef9bb0c08a9fca1530 | weronikadominiak/PyLadies-Python-Course | /1.02 - Json/2.1 Wczytanie pliku i stworzenie słownika.py | 606 | 3.875 | 4 | # 2.1 Wczytaj plik i stwórz słownik w którym kluczem będzie imię (i nazwisko) a wartością będzie słownik z kluczami kolor oczu i wzrost Przykład: {"Yoda": {"height": 66, "eyes": "brown"}}
file = open('py1.2.txt', 'r')
mydict={}
for data in file: #reads each line of file
name=data[data.find(".") +2:data.find(" has")] #searches for first " " and world " has", saves what's between
eyes=data[data.find("has")+4:]
eyes=eyes[:eyes.find(" and")]
height=int(data[data.find(" is ")+3:data.find(" cm")])
mydict[name]= {"Eyes: ": eyes, "Height: ": height}
print(mydict)
file.close() |
133d40a1e5435b8d38973f8da8a5be1384a0c150 | Korpusha/module3python | /exceptions.py | 1,831 | 3.75 | 4 | import sys
class GameOver(Exception):
@staticmethod
def append_lines(my_result):
"""Appends score in file."""
with open('scores.txt', 'a') as f:
f.write(my_result+'\n')
@staticmethod
def check_lines():
"""Returns stored scores."""
with open('scores.txt', 'r') as f:
lines = f.read().splitlines()
return lines
@staticmethod
def write_lines(my_result):
"""
Writes scores into file.
If final score is less than minimal score from file - just writes scores.
If final score is greater than minimal score from file - changes minimal score on the final score.
"""
file_lines = GameOver.check_lines()
with open('scores.txt', 'w') as f:
check_min = min(list(map(int, file_lines)))
if check_min > int(my_result):
str(my_result)
my_return = [line + '\n' for line in file_lines]
for line in my_return:
f.write(line)
else:
file_lines[file_lines.index(min(file_lines))] = my_result
my_return = [line + '\n' for line in file_lines]
for line in my_return:
f.write(line)
@staticmethod
def sort_lines():
"""
Sorts results.
Used after append_lines write_lines methods.
"""
file_lines = sorted(GameOver.check_lines(), reverse=True)
with open('scores.txt', 'w') as f:
my_return = [line + '\n' for line in file_lines]
for line in my_return:
f.write(line)
class EnemyDown(Exception):
"""Raised when enemy is beaten"""
class Exit(Exception):
"""Exit programme"""
@staticmethod
def to_exit():
sys.exit()
|
99263ee341cebc9c1ef6d4e4aa4e557e1d6089b9 | dvalinotti/python-practice-problems | /Python for Software Design/exercise3-3.py | 401 | 4.34375 | 4 | # Python provides a built-in function called len that returns the length of a string, so the value of len('allen') is 5.
# Write a function named right_justify that takes a string named s as a parameter and prints the string with enough
# leading spaces so that the last letter of the string isin column 70 of the display.
def right_justify( s ):
print( "%70s" %s)
right_justify("Hello World!") |
a5165f03361043a9ea15bd74ec9dd6e155112275 | mahfuz-raihan/URI-problem-solve | /uri1002.py | 70 | 3.8125 | 4 | pi = 3.14159
R = float(input())
area = pi*R**2
print("A=%.4f" %area)
|
56618fd96afa17b3e4bf075fcb604874ba500607 | Jashwanth-Gowda-R/crud-application | /crud.py | 2,514 | 3.5625 | 4 | from db import connect
class User:
def __init__(self, email, first_name, last_name, id):
self.email = email
self.first_name = first_name
self.last_name = last_name
self.id = id
# INSERT data into database Table
def insert_to_db(self):
# with psycopg2.connect(user="postgres",password="99866",database="crud", host="localhost")as connection:
with connect() as connection:
with connection.cursor() as cursor:
cursor.execute('INSERT INTO users (email,first_name,last_name) VALUES (%s,%s,%s)',
(self.email, self.first_name, self.last_name))
# update or replace row or column data in table
@staticmethod
def update_table(email,first_name):
# with psycopg2.connect(user="postgres",password="99866",database="crud", host="localhost")as connection:
with connect() as connection:
with connection.cursor() as cursor:
print("Table Before updating record ")
sql_select_query = ('select * from users')
cursor.execute(sql_select_query)
record = cursor.fetchone()
print(record)
#update single record row
sql_update_query = ('Update users set email = %s where first_name = %s')
cursor.execute(sql_update_query, (email, first_name))
connection.commit()
count = cursor.rowcount
print(count, "Record Updated successfully ")
print("Table After updating record ")
sql_select_query = ('select * from users where email = %s')
cursor.execute(sql_select_query, (email,))
record = cursor.fetchone()
print(record)
# delete row or column in table
@staticmethod
def delete_data(email):
# with psycopg2.connect(user="postgres",password="99866",database="crud", host="localhost")as connection:
with connect() as connection:
with connection.cursor() as cursor:
sql_delete_query = ('Delete from users where email = %s')
cursor.execute(sql_delete_query, (email,))
print("Record deleted successfully ")
# my_user=User("jashwanth.go@gmail.com","jashwanth","gowda",None)
# my_user.insert_to_db()
# email ="jashwanth.go@gmail.com"
# first_name="jashwanth"
# User.update_table(email,first_name)
#
# email="jashwanth.go@gmail.com"
# User.delete_data(email)
|
c714e389cec58c24f582ae5d003516cf15b9d5b6 | Ackermannn/PythonBase | /PythonCode/ForYanyan/ForYanyan.py | 462 | 3.6875 | 4 | def ptintLine(w1,s1,w2,s2):
str1 = ""
for i in range(w1):
str1 += " "
for i in range(s1):
str1 += "*"
for i in range(w2):
str1 += " "
for i in range(s2):
str1 += "*"
print(str1)
ptintLine(4,4,12,4)
ptintLine(2,8,8,8)
ptintLine(0,12,4,12)
for i in range(4):
ptintLine(i,28-2*i,0,0)
for i,j in zip([6, 9, 12],[16,10,4]):
ptintLine(i,j,0,0)
ptintLine(13,2,0,0)
input("输入任意字符终止程序")
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.