
blob_id stringlengths 40 40 | repo_name stringlengths 5 119 | path stringlengths 2 424 | length_bytes int64 36 888k | score float64 3.5 5.22 | int_score int64 4 5 | text stringlengths 27 888k |
|---|---|---|---|---|---|---|
dc0e6196eb7f37471b715c7d11e17888585d29de | amans1998/Assignment2 | /Design2.py | 243 | 3.859375 | 4 | for i in range(5):
for j in range(5):
if j==0:
print("*",end="")
elif j==i:
print("*",end="")
elif i==4:
print("*",end="")
else:
print(" ",end="")
print()
|
667bbe72e819d8553093757f452f8540232ddfa2 | atgrigorieva/Python_lessons_basic | /lesson02/home_work/hw02_normal.py | 6,214 | 4.25 | 4 | # Задача-1:
# Дан список, заполненный произвольными целыми числами, получите новый список,
# элементами которого будут квадратные корни элементов исходного списка,
# но только если результаты извлечения корня не имеют десятичной части и
# если такой корень вообще можно извлечь
# Пример: Дано: [2, -5, 8, 9, -25, 25, 4] ... |
fb09d190a829e992fe840062219d565f4722c84f | grantpauker/DeepSpace2019 | /src/utils/angles.py | 428 | 3.890625 | 4 | import math
def wrapPositiveAngle(in_angle: float):
"""Wrap positive angle to 0-360 degrees."""
return abs(math.fmod(in_angle, 360.0))
def positiveAngleToMixedAngle(in_angle: float):
"""Convert an angle from 0-360 to -180-180"""
in_angle = wrapPositiveAngle(in_angle)
if in_angle > 180 and in_angle... |
959a90fd10f78741b6d316f9d3689b76a2cafa7b | raitk3/home-miscellaneous | /Text Replacer/replacer.py | 1,046 | 3.78125 | 4 | import json
def get_text(filename):
text = ""
with open(filename, "r", encoding="utf-8") as file:
while True:
c = file.read(1)
if not c:
break
text += c
return text
def get_dict(filename):
with open(filename, "r", encoding='utf-8') as file:
... |
4cc92d771b38211afd1de8ce8b90b56bea597995 | kmather73/ProjectEuler | /Python27/euler040.py | 390 | 3.828125 | 4 | # -*- coding: utf-8 -*-
"""
Created on Wed Sep 14 18:31:15 2016
@author: kevin
"""
def main():
digits, num = 0, 0
prod = 1
nums = [10**i for i in range(0,7)]
while digits < 10**6+1:
num += 1
for ch in str(num):
digits += 1
if digits in nums:
... |
bacdade7e33dc0bd1e30a92408dee29338266286 | njNafir/ntk | /ntk/widgets/canvas.py | 8,975 | 3.9375 | 4 | # Import Tkinter Canvas to use it and modify default
from tkinter import Canvas as tkCanvas
# Import all util from ntk.utils
from ntk.utils import *
# Import pyperclip
# pyperclip is used to copy and paste canvas element text when it's selected
import pyperclip
class Canvas(tkCanvas):
# canvas class can be c... |
97d10c5bd2d9e358116e658ab8374fffcae4d510 | Ryanj-code/Python-1-and-2 | /Projects/Speech - Dictionaries/speech.py | 867 | 4.0625 | 4 | import pprint
#Import pprint(prettyprint)
speech = open('mlk.txt', 'r')
speech = speech.read()
speech = speech.lower()
#Opens and reads the speech
speech = speech.replace('.', '')
speech = speech.replace(',', '')
speech = speech.replace('?', '')
speech = speech.replace('!', '')
speech = speech.replace('-', '')
#Repla... |
0f7b2948d04dc912d8a8fb74e1bf3cc1e51c237b | Anirudh-thakur/LeetCodeProblems | /Contest/CountPrimes.py | 818 | 3.828125 | 4 | #https: // leetcode.com/explore/challenge/card/may-leetcoding-challenge-2021/599/week-2-may-8th-may-14th/3738/
class Solution(object):
def countPrimes(self, n):
"""
:type n: int
:rtype: int
"""
result = 0
if n <= 2:
return 0
dyn = [0 for i in range... |
f35705db4b25eefa11a283253169255cd9c3aaaf | rafacasa/OnlineJudgePythonCodes | /Iniciante/p1172.py | 193 | 3.59375 | 4 | x = []
for i in range(10):
v = int(input())
if v <= 0:
valor = 1
else:
valor = v
x.append(valor)
for i, v in enumerate(x):
print('X[{}] = {}'.format(i, v))
|
2b276e337b8e4123fb143bc3f003e273c9be1132 | jO-Osko/Krozek-python | /python_uvod/pogoji.py | 1,466 | 3.609375 | 4 | a = int(input("Vnesi a")) # <-
b = int(input("Vnesi b"))
# <, <=, >, >=, ==, !=
if a < b:
print("a je manjši od b")
print("A je še vedno manjši od b")
print("A je še vedno manjši od b")
print("A je še vedno manjši od b")
print("A je še vedno manjši od b")
print("A je še vedno manjši od b")
el... |
5b593c4c1164b660a4b32e24a750470786adb8a8 | scottlinehealthcare/TennisSimulation | /src/set.py | 1,954 | 3.65625 | 4 | from .game import Game
from .tiebreak import TieBreak
class Set(object):
def __init__(self, player1, player2, count):
self.__player1 = player1
self.__p1Score = 0
self.__player2 = player2
self.__p2Score = 0
self.count = count
def run(self):
while ((self.__p1Scor... |
2142c3e4db8fca336aa054c5de7d664b5e7e87e3 | hakikialqorni88/Pemrograman-Terstruktur-Python | /Chapter 4/latihan4_ch4.py | 1,691 | 3.96875 | 4 | #Menghitung waktu tempuh perjalanan
print("_______________Menghitung Waktu Tempuh Perjalanan_______________")
jarakAB=float(input("Jarak dari kota A ke B (km):"))
kecepatanAB=float(input("Kecepatan rata-rata dari kota A ke B (km/jam):"))
print("Waktu tempuh perjalanan dari kota A ke B:", round(jarakAB//kecepatanAB),"Ja... |
b172d2b5ee71add31dc8e8a87bb9868d34805e30 | paulosrlj/PythonCourse | /Módulo 3 - POO/Aula3 - MetodosEstaticos/testes.py | 753 | 3.578125 | 4 | import numpy as np
class Pokemon:
def __init__(self, nome, tipo, nivel):
self.nome = nome
self.tipo = tipo
self.nivel = nivel
# Não mexe com o objeto ou a classe em si
@staticmethod
def lista_todos_tipos():
tipos = np.array(['Fogo', 'Água', 'Elétrico', 'Terra', 'Voado... |
e7f6a66a79be3e6dba3d5edf8b10e4acee73bc43 | gan3i/Python_Advanced | /DS_and_AT/GFG/LinnkedList/Reverse.py | 726 | 3.96875 | 4 | #code
class Node():
def __init__(self,data,next=None):
self.data = data
self.next = next
def add_node(new_node,head):
temp = head
head = new_node
head.next = temp
return head
head = Node(14)
head = add_node(Node(20),head)
head = add_node(Node(13),head)
head = add_node(Node(12),he... |
5ea3bedcca2981388a0a03347dab385adc6d18f6 | chenwen715/learn_repo | /learnpython/learnP_180703_test.py | 1,906 | 3.828125 | 4 | '''
import unittest
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def get_grade(self):
if self.score < 0 or self.score > 100:
raise ValueError('分数不在0-100之间')
if self.score >= 80:
return 'A'
e... |
8f0c82276638e3694fc9b2b6f466db97b1f5374b | pn11/benkyokai | /competitive/AtCoder/ABC130/C.py | 406 | 3.609375 | 4 | '''中心を通るような直線は必ず長方形を半分にする。指定した点が中心と等しくなければ直線は一意に決まる。'''
w, h, x, y = map(lambda x: int(x), input().split())
def is_eq(x, y):
if abs(x-y) < 1e-9:
return True
else:
return False
if is_eq(w/2, x) and is_eq(h/2, y):
print("{} 1".format(w*h/2))
else:
print("{} 0".format(w*h/2))
|
2c9d3dda15e27848357a5ff8083a7504cf618e07 | PerroSanto/python-concurrencia-introduccion | /muchosThreads.py | 849 | 3.5 | 4 | import threading
import time
import logging
from tiempo import Contador
# Para que logging imprima más info sobre los threads
logging.basicConfig(format='%(asctime)s.%(msecs)03d [%(threadName)s] - %(message)s', datefmt='%H:%M:%S', level=logging.INFO)
# la función para usar para el thread
# lo pone a dormir la cantid... |
9615f88a4c21572613391441bac00e51cb5e92bf | bioinfolearning/rosalind | /countDNAnucleotides.py | 718 | 3.9375 | 4 | #What I have to do
#1. Open the file with the DNA string
#2. Read from the file
#3. Keep tally of nucleotides
#4. Create a new file and write the tally in the order A C G and T
from helperfunctions import get_string, write_to_file, make_output_filename
#setting file names
input_filename = "filename.txt"
#opening fil... |
7bd9ab79777c10191c692c9cf079d03b4f85ad86 | bitterengsci/algorithm | /九章算法/String问题/1542.Next Time No Repeat.py | 1,579 | 3.609375 | 4 | #-*-coding:utf-8-*-
'''
给一个字符串,代表时间,如"12:34"(这是一个合法的输入数据),并找到它的下一次不重复(不存在相同的数字)的时间。
如果它是最大的时间"23:59",那么返回的答案是最小的"01:23"。如果输入是非法的,则返回-1
'''
class Solution:
"""
@param time:
@return: return a string represents time
"""
def nextTime(self, time):
if len(time) != 5 or time is None:
... |
823a6fdc9e3bc273a22c41cb00b01070760dd7b2 | lkapinova/Pyladies | /03/sinus.py | 362 | 3.71875 | 4 | # from math import sin
# print(sin(1)) # 0.8414709848078965
# print(sin) # 'builtin_function_or_method'
# print(sin + 1) # TypeError: unsupported operand type(s) for +: 'builtin_function_or_method' and 'int'
# print('1 + 2', end=' ')
# print('=', end=' ')
# print(1 + 2, end='!')
# print()
print(1, "dvě", False)
p... |
fb6ebb5606554ce3da562b0fd4b745e42950f368 | ivanhuay/keygen-dictionary | /keygen-dictionary.py | 7,251 | 3.828125 | 4 | #!/usr/bin/python3
import os
import itertools
import operator
class DictionaryMaker:
def __init__(self):
self.aditionalData = []
self.simpleCollection = ["admin", "adm", "adm", "2015",
"2019","2018", "2016", "2017", "2014", ".", "-", "_", "@"]
self.convina... |
53b83016908837a853ea4a05dd8aeb7be2152baa | BJV-git/leetcode | /stack_q/jose_p/implem_q.py | 832 | 4.46875 | 4 | # why chosen list also here
#1. all need to be done is that we need to add lists such that we can add elements at the start of teh list so teh overall
# complexity is maintained at O(1)
class queue(object):
def __init__(self):
self.items = []
def isEmpty(self):
return self.items ==[]
def... |
81c003045944597bc97be3c75c1cd082e2c8ae60 | YardenBakish/Data-Clustering-Algorithms-Visualizer | /clustersOutput.py | 1,262 | 3.546875 | 4 | # 208539270 yardenbakish
# 208983700 tamircohen1
"""This module prints the computed clusters for NSC and K-means algorithms to
clusters.txt file"""
import numpy as np
"""This function is called by the main module and recieves:
(1) an array which labels each observation to its computed cluster (i'th value is the cluste... |
553a6cbff21c2dce8b762b7808d1369bdbd4da3e | shivani1611/python | /ListCompare/main.py | 505 | 3.84375 | 4 | #!/usr/bin/env python3
import sys
def main( ):
# two lists to compare
list1 = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
list2 = ['b', 'd', 'f']
# remove all the elements that are in list2 from list1
for a in range( len( list2 ) - 1, -1, -1 ):
for b in range( len( list1 ) - ( 1 ), -1, -1 ):
if( list1[b... |
4a51fd28aa82203188b17812331dfe7e99f0c77f | FirdavsSharapov/PythonLearning | /Python Course/Learning Python/Data Structures/deque.py | 1,030 | 4.5 | 4 | class Deque:
def __init__(self):
self.items = []
def add_front(self, item):
"""This method takes an item as a parameter and inserts it
to the list that of representing the Deque.
The runtime is linear, or O(n), because every time you insert
into the front of a list, ... |
065e4325cf6bb862172c4e88f70b64fc79a8f2dd | trushraut18/Hackerrank-Python | /ShapeReshape.py | 112 | 3.609375 | 4 | import numpy as np
entries=list(map(int,input().split()))
matrix=np.array(entries).reshape(3,3)
print(matrix)
|
3349d2c00bd9e6c3b1e1b93e985011353b40622e | ramtinsaffarkhorasani/takalif3 | /asdasa.py | 141 | 3.65625 | 4 | a=[2,3,5,1,10,14]
for i in range(1,(len(a))):
if a[i]<a[i-1]:
print("noo")
break
else:
print("hoora")
|
abcf09d34a0b607bd6eb3d50e1b84916bc1944a4 | Bibhu-Dash/python-usefull-scripts | /Student_class.py | 552 | 3.65625 | 4 |
class Student:
perc_rise = 1.05
def __init__(self,first,last,marks):
self.first=first
self.last=last
self.marks=marks
self.email=first+'.'+last+'@school.com'
def fullname(self):
return '{} {}'.format(self.first,self.last)
def apply_raise(self):
self.marks=int(self.marks * self.per... |
6c7a478f9f8177e53b85d07d2ab9f0c705f2ca7d | ciattaa/i-do-not-know | /madlib.py | 513 | 3.890625 | 4 | def main():
name = input("Please enter a name" )
place = input ("Please enter a place")
vehicle = input("Please enter a name of a vehicle")
verb = input("Please enter a verb")
adverb = input("Please enter a adverb")
print (name + " went to visit their friends at " + place + " While he w... |
3157bd1a551bc73ae0b9df264f1a4da7d62b28f9 | lalit97/DSA | /union-find/gfg-union-find.py | 409 | 3.890625 | 4 | '''
https://practice.geeksforgeeks.org/problems/disjoint-set-union-find/1
'''
'''
supports 1 based indexing
their find means finding root
'''
# function should return parent of x
def find(arr, x):
while arr[x-1] != x:
x = arr[x-1]
return x
# function should not return anything
def union(arr, x, z)... |
57dfcb2d29d90087427cfc597c0ec8c2d26515ab | AndHilton/DndFight | /read_character_sheet.py | 858 | 3.59375 | 4 | """
reads in a character sheet file and returns a python dictionary of the necessary data
"""
import sys
from collections import deque, namedtuple
import argparse
import glob
from CharacterSheet import readCharacterSheet
parser = argparse.ArgumentParser(description="read in data from a character sheet file")
parser.... |
08ffee26e1154d497f563a03c61b45c500c0771a | sushanb/PythonClassesIntroductionBeginners | /ClassesMore.py | 740 | 4.09375 | 4 | class Country(object):
def __init__(self, name, capital_city, population):
self.name = name
self.capital_city = capital_city
self.population = population
def __str__(self):
string = 'The capital city of ' + self.name + ' is ' + self.capital_city
return string
def bi... |
9b5b5e45335c6855a97bad342d0734ab3f26a60a | sarvparteek/Data-structures-And-Algorithms | /fraction.py | 3,020 | 3.5 | 4 | '''Author: Sarv Parteek Singh
Course: CISC 610
Term: Late Summer
HW: 1
Problem: 2
'''
# Greatest common Divisor
def gcd(m, n):
while m % n != 0: #this step ensures that a denominator of 0 won't be allowed - it will raise a divide by zero exception
oldm = m
oldn = n
m = oldn
n = ... |
60313bdb6f2a2f6e689bcd399250dffcbb6bf746 | Hulihulu/ichw | /pyassign2/currency.py | 1,151 | 3.984375 | 4 |
#!/usr/bin/env python3
"""currency.py: Currency converter.
__author__ = "Hu Ruihua"
__pkuid__ = "1800011843"
__email__ = "1800011843@pku.edu.cn"
"""
from urllib.request import urlopen
def exchange(currency_from, currency_to, amount_from):
"""定义exchange函数
"""
original_url = "http://cs1110.cs.corne... |
99ee90a8599763f934bd7a142dcc42f96eacac74 | kgodfrey24/advent-of-code-2018 | /day5/day5b.py | 584 | 3.765625 | 4 | import string
input = open("day5/input").read().strip()
def is_match(a, b):
return a != b and (a == b.lower() or a == b.upper())
shortest_result = 9999999
for letter_of_alphabet in string.ascii_lowercase:
stack = []
for char in input:
if char.lower() == letter_of_alphabet:
continue
... |
2e0729d4d3c64979b7427d8004f58479cceb3123 | JCSheeron/PythonLibrary | /bpsList.py | 5,274 | 3.828125 | 4 | #!/usr/bin/env python3
# -*- coding: utf-8 -*-
# bpsList.py
# Funcitons for dealing with lists
#
# Break a list into n-size chunks, and return as a list of lists.
# If seq cannot be converted to a list, return None.
# If chuckSizse cannot be converted to an integer, return the original list.
def listChunk(seq, chunkS... |
ed23499c92acbcb6c0592b9a6af0db500c1377f3 | daniel-reich/turbo-robot | /s89T6kpDGf8Pc6mzf_23.py | 1,984 | 4.0625 | 4 | """
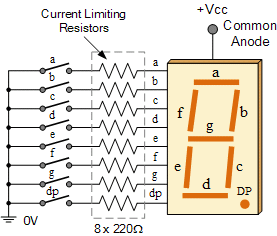
The table below shows which of the segments `a` through `g` are illuminated on
the seven segment display for the digits `0` through `9`. When the number on
the display changes, some of the segments may stay on, some may stay off, and
others change sta... |
78712137f375bac578f34318f0cbe52750f53084 | loganfreeman/python-algorithms | /algorithms/math/primality_test.py | 991 | 3.6875 | 4 | from math import sqrt
from algorithms.math.sieve_eratosthenes import eratosthenes
CACHE_LIMIT = 10 ** 6
primes_cache_list = []
primes_cache_bool = []
def is_prime(number, cache=True):
if number < 2:
return False
global primes_cache_list, primes_cache_bool
if cache and len(primes_cache_list) == 0:
... |
ec9f8c7e3475849d5647339782e2d67a68b448d2 | SuxPorT/python-exercises | /Mundo 2 - Estruturas de Controle/Desafio #045.py | 1,972 | 4.09375 | 4 | # Crie um programa que faça o computador jogar Jokenpô com você.
from random import choice
from time import sleep
print("\033[1;33m===" * 10)
print(" " * 4, "CAMPEONATO DE JOKENPÔ")
print("===" * 10)
sleep(1)
print(" " * 8, "\033[1;30mCOMEÇANDO EM")
sleep(1)
print(" " * 13, "3...")
sleep(1)
print(" " * 13, "2..... |
7b035471487e8e98e5ae692657d85c930d72e635 | vanshamb2061/Tic-tac-toe-Files | /final.py | 1,826 | 4.125 | 4 | def display_board(arr):
a=0
while a<3:
print(f"{arr[a][0]} | {arr[a][1]} | {arr[a][2]} ")
a+=1
def win_check(arr):
i=0
while i<3: #to check horizontal
if arr[i][0]==arr[i][1] and arr[i][1]==arr[i][2]:
print(f"Row {i+1} of {arr[i][0]} formed.")
return 0
i+=1
j=0
while j<3:
if arr[0][j]==arr[1][j]... |
18afc753b4f6bb7bc63fdd4d22b9517732475940 | jsmolka/sandbox-python | /__modules__/utils.py | 9,777 | 4.09375 | 4 | def remap(x, x1, x2, y1, y2):
"""
Remaps a value from one range to another.
:param x: value to process
:param x1, x2: range of x
:param y1, y2: new range
:return: float
"""
return (x - x1) / (x2 - x1) * (y2 - y1) + y1
def sized_gen(lst, n):
"""
Splits a list into n-sized chunk... |
15e376cd3adb7ba42f61f9da84dde1a0ea258bc7 | eur-nl/bootcamps | /zzzzz_archive/eshcc/scripts/notjustalabel/not_just_a_label.py | 3,671 | 3.5625 | 4 | import sys
import csv
import os
import requests
import time
from bs4 import BeautifulSoup
URL = 'https://www.notjustalabel.com/designers?page=%s'
DETAIL_URL = 'https://www.notjustalabel.com/designer/%s'
def fetch_listing_page(page_number):
url = URL % page_number
print('fetching listing page %s' % page_numb... |
d0ed45022cf7c2a9ba59a9752cb0ef6d4033a127 | RohanAwhad/ValorantBot | /listener.py | 977 | 3.671875 | 4 | from pynput import mouse, keyboard
class Listener():
def start(self):
self.listener.start()
def stop(self):
self.listener.stop()
class Mouse(Listener):
def __init__(self):
self.listener = mouse.Listener(
on_move=self.on_move,
on_click=self.on_click,... |
8ef4bacbdf0fa9f52acac15ec5c8de875a7bbd8c | thoufeeqhidayath/pythonExample | /graphss.py | 2,756 | 3.828125 | 4 | class Vertex:
def __init__(self, name,edges={}):
self.name = name
self.edges = edges
def add_edge(self,name):
if name not in self.edges:
self.edges[name] = 1
else:
self.edges[name] = self.edges[name] + 1
def add_edges(self,edges):
for name ... |
2258c049617f1fbdf17defbf16edbbb5c9ad05b0 | ar-dragan/instructiunea-FOR | /1.4.py | 109 | 3.90625 | 4 | n = int(input("Introduceti un numar natural "))
for i in range(1,n):
if i % 2 == 1:
print(i) |
ef1fcc7af4cb1ccc6fb11781a2063941641737df | StuartBarnum/Twitter-Sentiment-Analysis | /tweet_sentiment.py | 1,020 | 3.859375 | 4 | import sys
import json
#Five minutes of the the worldwide twitterstream parsed with JSON and placed in
#a Python dictionary
#Estimates the sentiment of each tweet in the stream (output.txt), based on a file
#listing sentiments associated with English language words (AFINN-111.txt).
#Run with the command:
# python tw... |
f25828fa70fea0d29575525065334980caf559a4 | FundingCircle/DjanGoat | /app/tests/mixins/model_crud_test_mixin.py | 2,900 | 3.65625 | 4 | class ModelCrudTests(object):
"""Mixin for testing CRUD functionality of models.
self.model is the model created locally and saved to the database
self.attributes is a string array of the names of the attributes of the model
self.model_update_input is the new value that model_update_attribut... |
4782796680ed022e441cabfcbc403a39a95b7cbd | MafiaAlien/python-learning-projects | /Python Crash course/Chapter 10 try and except/division.py | 461 | 4.09375 | 4 | # try:
# print(5/0)
# except ZeroDivisionError:
# print('You cannot divide by zero')
print('Give me two numbers, and I will divide them')
print("Enter 'q' to quit.")
while True:
first_number = input("\nFirst number: ")
if first_number == 'q':
break
second_number = input("Second number: ")
try:
... |
67fa6f5ec39eedab4070b5e70520546371cd4372 | Jerinca/DataProcessing | /Homework/Week_3/convertCSV2JSON.py | 2,105 | 3.609375 | 4 | #!/usr/bin/env python
# Name: Jerinca Vreugdenhil
# Student number: 12405965
"""
This script converts a CSV file with information about .......
to a json file.
https://catalog.data.gov/dataset?tags=winning
"""
import csv
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import matplotlib.pyplot as pl... |
1df71cb285593064d11da6ee20e66b234f766d11 | marcinpgit/Python_exercises | /Exercises_1/continue break.py | 204 | 3.765625 | 4 | count = 0
while True:
count += 1
if count > 10:
break
if count == 5:
continue
print (count)
input ("\nNaciśnij klawisz enter aby zakończyć.")
|
707f4ab05837eeb7ed435d672efb45b7952866af | Team2537/spaceRAID | /video_loader.py | 9,250 | 3.625 | 4 | """
Use a video library to get, edit, and save video.
The api for this library is as follows.
Video(source)
"""
__author__ = "Matthew Schweiss"
__version__ = "0.5"
# TODO
# Add the meanings of various return codes.
__all__ = ["Video", "load_image", "save_image", "show_image", "close_image"]
import os
import logging... |
219db4f664be921bce204400e8ecaa1028505a3c | tsutaj/deep-learning-lecture | /code/lib/perceptron.py | 1,681 | 3.53125 | 4 | # -*- coding: utf-8 -*-
import numpy as np
## @package perceptron
# @brief Chapter 2: Basic digital logic gates
# @author tsutaj
# @date November 6, 2018
## @brief Calculate \f$x_1\f$ \f$\mathrm{AND}\f$ \f$x_2\f$
# @param x1 boolean
# @param x2 boolean
# @return bool... |
2bf138067dc6eba2101f975995c2d0d531e1f915 | maomao905/algo | /minimum-size-subarray-sum.py | 894 | 3.640625 | 4 | """
sum = 7, [2,3,1,2,4,3]
two pointers
2,3,1
x 2,3,1,2 -> 3,1,2
x 3,1,2,4 -> 1,2,4
x 1,2,4,3 -> x 2,4,3 -> 4,3
time: O(n)
space: O(1)
"""
from typing import List
class Solution:
def minSubArrayLen(self, s: int, nums: List[int]) -> int:
start = 0
end = 0
min_length = float('inf')
tm... |
ff9824b23265ecdec11be9e3179844a23f70e1a9 | Nev-Iva/my-projects | /basic python (0 level)/1 intro/2.py | 302 | 3.609375 | 4 | while True:
user_inp = int(input('Введите число: '))
if (user_inp < 10) and (user_inp > 0):
break
else:
print('Введите число от 0 до 10')
user_inp = user_inp ** 2
print('Ваше число во второй степени: {0}'.format(user_inp)) |
1c8988521d98ee0021bea51ac506789f0f8579bd | stewartt1982/jupyter2python | /jupyter2python.py | 1,521 | 3.59375 | 4 | #
# A small program to extract source code from Jupyter files
# and output it to a text python .py file
#
import sys
import argparse
import json
from os.path import basename
from os.path import splitext
def main():
#create and define the command line argument parser
parser = argparse.ArgumentParser(descriptio... |
cb89354abcddcf3c8d703b709132b21137027e19 | yangyi1102/Python | /Python/python数据学习/折线图1.py | 204 | 3.875 | 4 | # -*- coding: utf-8 -*-
"""
Created on Tue Apr 18 18:58:33 2017
@author: 17549
"""
import matplotlib.pyplot as plt
plt.plot([0,2,4,5,8],[3,1,4,5,2])
plt.ylabel("Grade")
plt.axis([-1,10,0,6])
plt.show()
|
7ea74122bed261731ae9eb47aa405808afe7b2a7 | kritikyadav/Practise_work_python | /pattern/pattern23.py | 136 | 3.703125 | 4 | n=int(input('enter the nu. of rows= '))
for i in range(n,0,-1):
for j in range(1,i+1):
print(n-i+1,end='')
print()
|
f2fa45d2cce67f873c05d9362e64bb4619553880 | jeremymiller00/email_marketing | /src/campaign_performance.py | 3,079 | 3.5 | 4 | import numpy as np
import pandas as pd
import seaborn as sns
sns.reset_defaults
sns.set_style(style='darkgrid')
import matplotlib.pyplot as plt
plt.style.use('ggplot')
font = {'size' : 16}
plt.rc('font', **font)
plt.ion()
plt.rcParams["patch.force_edgecolor"] = True
plt.rcParams["figure.figsize"] = (20.0, 10.0)
pd.s... |
4c2e6db8107407f218be0ab3f5759f0847d50207 | huangsam/ultimate-python | /ultimatepython/advanced/mocking.py | 3,632 | 3.9375 | 4 | """
Mocking objects is a common strategy that developers use to test code that
depends on an external system or external resources for it to work
properly. This module shows how to use mocking to modify an application
server so that it is easier to test.
"""
from collections import Counter
from unittest.mock import Mag... |
7ac36dea25b90d6afdba8be81972f010ebba4e46 | yinhuax/leet_code | /datastructure/binary_tree/BuildTree.py | 1,842 | 3.828125 | 4 | #!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : Mike
# @Contact : 597290963@qq.com
# @Time : 2021/1/31 14:49
# @File : BuildTree.py
from typing import List
from datastructure.binary_tree import TreeNode
class BuildTree(object):
def __init__(self):
pass
def buildTree(self, inorder: ... |
46a86378ae9e24cf158907fb3351246135b9459a | sebastian-chang/gaming_practice | /graphics/graphics.py | 2,143 | 3.875 | 4 | import pygame, sys
from pygame.locals import *
# Set up pygame
pygame.init()
# Set up the window.
window_surface = pygame.display.set_mode((500, 400), 0, 32)
pygame.display.set_caption('Hello World!')
# Set up the colors.
BLACK = (0, 0, 0)
WHITE = (255, 255, 255)
RED = (255, 0, 0)
GREEN = (0, 255, 0)
BLUE = (0, 0, 2... |
0f08d83910ae7174c4d10b268142d36e2086c8d5 | brianchiang-tw/leetcode | /No_0746_Min Cost Climbing Stairs/min_cost_climbing_stairs_bottom_up_dp.py | 1,904 | 4.21875 | 4 | '''
Description:
On a staircase, the i-th step has some non-negative cost cost[i] assigned (0 indexed).
Once you pay the cost, you can either climb one or two steps. You need to find minimum cost to reach the top of the floor, and you can either start from the step with index 0, or the step with index 1.
Example 1:... |
abfeb81c8b34febb1b0976f11b0fb4b979348be7 | pacis32/Data-Structure-and-Algorithm-Problem-Solutions | /LeetCode/HashMaps/UniqueNumberOfOccurences.py | 566 | 3.65625 | 4 | # Given an array of integers arr, write a function
# that returns true if and only if the number of
# occurrences of each value in the array is unique.
class Solution:
def uniqueOccurrences(self, arr: List[int]) -> bool:
hashMap = dict()
for i in arr:
if i in hashMap:
h... |
1311f8d9d63381baabec86ea616bbdac5ee2a70a | Orderlee/SBA_STUDY | /0904/13_variantArgs02.py | 332 | 4.03125 | 4 | # minval: 튜플 요소에서 가장 큰 수와 가장 작은 수를 반환하는 함수 만들기
# def minval(*args):
# mymin= min(args)
# mymax= max(args)
#
# return mymin,mymax
def minval(*args):
mylist=[item for item in args]
mylist.sort()
return mylist[0],mylist[-1]
print(minval(3, 5, 8, 2)) #(2,8)
|
0fcd15a57ce297ae1c4180228c61aaeaa3b74fe1 | wanjikum/day1 | /fizzbuzz/fizzbuzz.py | 309 | 4.21875 | 4 | """A program implements the fizzbuzz app"""
def fizz_buzz(arg):
"""A function that tests if the number is divisible by 3 and 5"""
if arg%3 == 0 and arg%5 == 0:
return 'FizzBuzz'
elif arg%5 == 0:
return 'Buzz'
elif arg%3 == 0:
return 'Fizz'
else:
return arg
|
ccd1caa37a4bece2e682dff772becc85ddff017f | nchlswtsn/Learn | /ex22.py | 424 | 3.71875 | 4 | REFRAIN = '''
{} bottles of beer on the wall,
{} bottles of beer,
take one down, pass it around,
{} bottles of beer on the wall!
'''
bottles_of_beer = 99
while bottles_of_beer >= 1:
print REFRAIN.format(bottles_of_beer, bottles_of_beer,
bottles_of_beer - 1)
bottles_of_beer -= 1
print """1 bottle of be... |
521b0df7981136e84e99c560ef188fbaa740bdb9 | xdzhang-ai/MLInAction | /regression/baoyu.py | 2,069 | 3.625 | 4 | """
鲍鱼年龄预测 2020-05-09 15:30:03
"""
import numpy as np
from regression import lwlr_test, load_data
def square_error(y, y_s):
"""
计算均方误差
:param y:
:param y_s:
:return:
"""
return sum((y - y_s)**2)
def ridge_regres(data, labels, lam=0.2):
"""
岭回归
:param data:
:param labels:
... |
60f99a2bdb9d1e78dc3517ac8f68c49ad4888798 | katebartnik/katepython | /Kolekcje/Listy.py | 632 | 3.640625 | 4 | my_list = [1, "a", "a", "ala", "kot", 121]
print(my_list)
print(my_list[0])
my_list2 = [1, 2, 3, my_list]
# [1, 2, 3, [1, "a", "ala", "kot", 121]]
# print(my_list2[3][1])
# print(dir(my_list))
print(my_list2)
print(my_list.append(10))
print(my_list)
print(my_list2)
# print(my_list.pop())
# print(my_list.pop(... |
7ee0fa053bd5b7311dd89f9e07840209bfaab23c | himanshuks/python-training | /expert/enumeration.py | 459 | 4.5 | 4 | # ENUMERATE - To iterate while tracking index of element
list = [3, 8, 5, False, 9, "Himanshu", 22.7]
for item in list:
print(item)
# We can use enumerate to iterate over list using counter track
# X,Y can be of any name but first parameter will be index and second parameter will be item itself
for index, item i... |
0f8f14045220aedf4a48a234477b8734cba95f0e | SivaPandeti/python-interview | /src/algorithms/coin_change.py | 778 | 4.1875 | 4 | ## Objective
## Write an function to find the minimum number of coins for giving change
## Input
## A list of available coins & an amount.
## e.g. [1, 5, 10, 21, 25] & 63
## Constraints and clarifications
## There is infinite supply of coins of each type
## Output
## 3
## Explanation
## In the sample input... |
816323ddd44760724f6567127faddcca1aabfc81 | Proak47/TIKTOKTOE | /main game.py | 5,189 | 3.84375 | 4 | '''TIKTOKTOE'''
#why does GITHUB SUCK SO MUCH SERIOUSLY GITHUB WHY
board1 = [" "," "," "," "," "," "," "," "," "," "]
player1 = []
player2 = []
'''board = 7,8,9,
4,5,6,
1,2,3'''
def playerTurn(y,x): #takes note of the player's turn
if x % 2 !=0:
player1.append(y)
board... |
04705752a51cd9ff34b53f8553ab368b41d028a1 | jhandal11/meraki-python-training | /car.py | 1,183 | 3.828125 | 4 | class Car(object):
wheels = 4
def __init__(self, make, model):
self.make = make
self.model = model
@staticmethod
def make_car_sound():
print('VRooooommmm!')
@classmethod
def is_motorcycle(cls):
return cls.wheels == 2
if __name__ == "__main__":
mustang =... |
01a0d66717cf5677c17d539dbcbf2a0d46e700c9 | YiseBoge/CompetitiveProgramming2 | /Weeks/Week1/linked_list_cycle.py | 1,683 | 3.859375 | 4 | import os
class SinglyLinkedListNode:
def __init__(self, node_data):
self.data = node_data
self.next = None
class SinglyLinkedList:
def __init__(self):
self.head = None
self.tail = None
def insert_node(self, node_data):
node = SinglyLinkedListNode(node_data)
... |
26421c37bc8e677f2b44e39644d6a75d99867a91 | JarvisFei/leetcode | /剑指offer代码/算法和数据操作/面试题10:斐波那契数列.py | 933 | 3.84375 | 4 | #递归写法
def F(first, second, N):
if N < 3:
return 1
if N == 3:
return first + second
return F(second, first + second, N - 1)
print(F(1,1,10))
#非递归写法
N = 10
first = 1
second = 1
result = 0
for i in range(3,N + 1,1):
result = first + second
first, second = second, result
print(resu... |
76345a1aac1e908738a43e3feb51ba8da4bdb77b | brittany-morris/Bootcamp-Python-and-Bash-Scripts | /python fullstackVM/front_x.py.save | 288 | 3.890625 | 4 | #!/usr/bin/env python3
import sys
strings = sys.argv[1:]
list_1 = []
list_2 = []
for elem in strings:
if elem [0] == 'x':
list_1.append(elem)
else:
list_2.append(elem)
sorted_list_1 = words.sort(list_1)
sorted_list_2 = words.sort(list_2)
print(sorted_list_1 + sorted_list_2)
|
10943b3deab688dbed5320f23d2390fc62384b07 | leohck/python_exercises | /list_overlap_comprehensions.py | 727 | 4.28125 | 4 | __author__ = 'leohck'
#exercise 10
"""
Take two lists, say for example these two:
a = [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
b = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
and write a program that returns a list that contains only
the elements that are common between the lists (without duplicates).
Make sure your ... |
6d4cc390b1f481cf06d195580cebb3367fb3e00e | fadhil-amree/fadhil-tugas | /P01.21100924.02.py | 740 | 3.546875 | 4 | # NIM / Nama : Muhammad Fadhil Amri
# Tanggal : Rabu, 28 April 2021
# Deskripsi : Program RGB warna pengkom
warna = input('masukkan warna: ')
if warna == 'Yellow':
print('Warna RGB yang menyala: \n - Red \n - Green')
elif warna == 'Cyan':
print('Warna RGB yang menyala: \n - Blue \n - Green')
... |
92a90bee48feea36fc314039a2d9253c35e2bd35 | yingliufengpeng/algorithm | /数据结构与算法365天刷题特训营/06 二叉树/bin_tree_create_2.py | 1,116 | 3.59375 | 4 | # -*- coding: utf-8 -*-
'''
已知一颗二叉树的先序序列ABCECFG和中序序列DBEAFGC,画出这个二叉树
'''
class Node:
def __init__(self, val):
self.val = val
self.left = self.right = None
def __str__(self):
return self.val
def preorder(self) -> str:
res = []
def dfs(roo... |
8abf43fdec0d6e82235d017e9d25206b2c7901a2 | santhosh-kumar/AlgorithmsAndDataStructures | /python/problems/binary_tree/find_lowest_common_ancestor.py | 2,386 | 3.875 | 4 | """
Find Lowest Common Ancestor in a Binary Tree
Given a binary tree (not a binary search tree) and two values say n1 and n2, write a program to find the least common ancestor.
"""
from common.problem import Problem
class FindLowestCommonAncestor(Problem):
"""
Find Lowest Common Ancestor
"""
PROBLEM... |
2da13ea7e871c20d06e4dc6f36ddfd8599104b26 | esinghroy/python-learning-cohort | /ed/02_guess_that_number_game/program.py | 684 | 4.1875 | 4 | import random
print('''
--------------------------------------
GUESS THAT NUMBER GAME
--------------------------------------
''')
the_number = random.randint(0, 100)
the_guess = -1
while the_guess != the_number:
guess_text = input("Guess how much money I have in my ban... |
633fa34f9bf3a98530de725c99413587dd252a13 | junglesub/hgu_21summer_pps | /week1/5-2_유정섭_20210708.py | 262 | 3.546875 | 4 | tc = int(input())
answer = []
for _ in range(tc):
eq = input().replace("@", "*3").replace("%", "+5").replace("#", "-7").split()
ans = float(eq[0])
for e in eq[1:]:
ans = eval(str(ans) + e)
answer.append(ans)
for ans in answer:
print("%.2f" % ans) |
1bf2b33bdcdd8ba24760ce61bd1661de95ca4ccb | gomilinux/python-PythonForKids | /Chapter9/BuiltInFunctions.py | 212 | 3.984375 | 4 | #Python for Kids Chapter 9 Python's Built-in Functions
#your_calculation = input('Enter a calculation: ')
#eval(your_calculation)
my_small_program = '''print('ham') print('sandwich')'''
exec(my_small_program) |
5f5a8f0f94aa79cb4da8f8278c10b664687a6ccc | hychrisli/PyAlgorithms | /src/solutions/part1/q209_min_size_sub_sum.py | 1,671 | 3.625 | 4 | import sys
from src.base.solution import Solution
from src.tests.part1.q209_test_min_size_sub_sum import MinSizeSubSumTestCases
"""
Given an array of n positive integers and a positive integer s, find the minimal length of a contiguous subarray of which the sum ? s. If there isn't one, return 0 instead.
For example,... |
4389b84bce4cd7e06a1db9494dd7604977f8864e | bjumego/python | /untitled1.py | 172 | 4.15625 | 4 | A = int (input("A:"))
B = int (input("B:"))
if A<B:
for A in range(A,B+1):
print(A)
else:
for A in range(A,B-1,-1):
print(A)
|
cb33348cf40a968db5105373aa4f64d36bd83821 | stacecadet17/python | /filter_by_type.py | 992 | 3.953125 | 4 | # If the integer is greater than or equal to 100, print "That's a big number!" If the integer is less than 100, print "That's a small number"
def integer(num):
if num >= 100:
print ("That's a big number!")
else:
print ("that's a small number")
# ************************************************************... |
ef6cb280db275e49ea41765d8ae7a882311e2204 | wandsen/PythonNotes | /ControlFlow.py | 315 | 4.15625 | 4 | #Lesson 2 Control Flow
#If Else Statement
x = 5
if x < 10 : print(True)
if x > 5 : print(True)
else : print(False)
#Elif Statement
x = 10
if x < 10:
print("x is less than 10")
elif x > 10:
print("x is more than 10")
else:
print ("x is 10")
#While Statement
n=0
while n < 3:
print(n)
n=n+1
|
cdf52c0c017ced2d52e61ea21799061e02bd0948 | SipTech/Python_Class_2020 | /beginner_guessing_game.py | 1,759 | 4.375 | 4 | from random import randint
# random number equalsTo random integer between (0, 20)
random_number = randint(0, 20)
# user guess equals None
user_guess = None
# while user guess is not equal to random number
while user_guess != random_number:
# get input user guess between 0 and 20 and cast the guess to integer
user_g... |
e14049d211e8d052d47d9fcfe434bfb74c771b0f | SergioPeignier/kernels4graphs | /script/atom.py | 1,215 | 3.9375 | 4 | class atom:
def __init__(self,name, deg=0, morgan=1):
""" Create an atom object. name='C' for Carbon atom, deg holds for the number of neighbors, morgan morgan coeficient
:param self: atom object
:param name: atom label
:type name: String
"""
self.name=name
self.deg=deg
self.morgan=morgan
self.new_m... |
a4d7e337ae8491ea1f4c2babbf3f63f8687ae537 | ShubhamWaghilkar/python | /revision.py | 308 | 3.921875 | 4 | # def revi(n):
#
# # while i <= n:
# # print(i)
# # i = i+1
# #
# for i in range(1,n):
# print(i)
#
# user = int(input("Enter number \n"))
# revi(user)
a = int(input("Enter Number"))
# i = 1
# while i <= a:
# print(i)
# i = i+1
for i in range(1,a+1):
print(i) |
d375dea73da0ac0b4d3bb5a17053ac5b91d33dd2 | greenpepper1/Game | /game.py | 832 | 3.5625 | 4 | from business import Business
class Top():
def __init__(self):
self.companies = [Business(),Business(),Business(),Business(),Business()]
def showCompanyValue(self):
for company in self.companies:
company.showValue()
def showCompanyHoldings(self):
for company in self.co... |
9370897f01ea81b21d3c9f3cc481ab3705700990 | afshinm/python-list-vs-tuple-benchmark | /tuple.py | 392 | 3.609375 | 4 | import time
from random import randint
x = 1000000
temp_list = []
# create temp list and then convert it to tuple
while x > 0:
temp_list.append(x)
x = x - 1
# convert list to tuple
demo_tuple = tuple(temp_list)
start = time.clock()
# random find elements from tuple
y = 2000000
while y > 0:
item = dem... |
7c449ec6ddd2300c3228856860817a60dc9297a2 | EliteGirls/Camp2017 | /Girls21.2/GROUP B/wednesday.py | 451 | 3.953125 | 4 | D =0
while D ==0:
D =input("press 0 to continue and any number to quit")
if D!=1
break
scores = input("enter your score")
if scores <=100 and scores >=80:
print "A"
elif scores <=79 and scores >=70:
print "B"
elif scores<=69 and scores >=60:
print "C"
elif sc... |
215ca06fe0ec9737b5b2d21c1dccc0a9e9e6f8bd | henrylin2008/Coding_Problems | /LeetCode/Blind 75/Binary Search/4_median_of_two_sorted_arrays.py | 3,330 | 3.890625 | 4 | # 4. Median of Two Sorted Arrays
# https://leetcode.com/problems/median-of-two-sorted-arrays/
# Hard
# Given two sorted arrays nums1 and nums2 of size m and n respectively, return the median of the two sorted arrays.
#
# The overall run time complexity should be O(log (m+n)).
#
#
#
# Example 1:
# Input: nums1 = [1,3],... |
dfa36e974356bd9e2b1ce613077f3982750097f4 | shreyasrbhat/Erricson_hack | /Prediction/utils.py | 546 | 3.65625 | 4 | from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import re
from nltk.stem import PorterStemmer
def tokenizer(txt):
## returns tokenized corpus without stopwords and special characters
##parameter:
##txt: string
ps = PorterStemmer()
stop_words = set(stopwords.words('e... |
e03f0f4f43c5144ccef05e77e64d5f17a88c6da1 | pcwu/leetcode | /101-symmetric-tree/isSymmetric.py | 1,354 | 4.0625 | 4 | # Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def isSymmetric(self, root):
"""
:type root: TreeNode
:rtype: bool
"""
def symme... |
74fee79eda76108b317c444a5004c64975e2f0ec | lerene/GW_HW_EnerelTs | /week3_Python_HW_ET/PyPoll/main.py | 2,615 | 3.890625 | 4 |
from collections import defaultdict
#filename = "election_data.csv"
count = 0
Total_Votes = 0
Candidate_Name_List = defaultdict(int)
Candidate_Percentage_of_Votes = 0
Candidate_Total_Votes = {}
Candidate_Most_Votes = {}
with open("election_data.csv") as file_object:
# Columns: Voter ID, County, Candidate
#Vo... |
54e83c8d32810481a2627b6ee54eb7b25a068b61 | deepitapai/Coding-Interview-Prep | /Leetcode solutions/sliding-window-maximum.py | 463 | 3.609375 | 4 | from collections import deque
def slidingWindowMax(nums,k):
deq,output = deque(),[]
n = len(nums)
def clean_deq(deq,i):
while deq and deq[0] == i-k:
deq.popleft()
while deq and nums[deq[-1]] < nums[i]:
deq.pop()
for i in range(k):
clean_deq(deq,i)
deq.append(i)
output.append(nums[deq[0]])
for i in... |
43d0067f21c24d5d8d9d9e9815876fb4380d8332 | DmytroLuzan/My_home_study_python_part2 | /lesson28-Home-Work.py | 2,320 | 4.5 | 4 | """
1. Дан массив. в вкотором среди прочих єлементов есть слово "odd" (нечетный).
Определите, есть ли в списке число, которое является индексом элемента "odd". Напишите функцию,
которая будет возвращать True или False, соответственно.
"""
def odd_ball(arr):
value1 = arr.index("odd")
value2 = arr.count(value1)... |
cc5b1dfdb905c613972a15f2555f7eb8ba72e861 | sneha5gsm/Data-Structures-and-Algorithms-Exercises | /Practice Problems/nonDivisibleSubset.py | 1,354 | 3.65625 | 4 | #!/bin/python
import math
import os
import random
import re
import sys
# Complete the nonDivisibleSubset function below.
def recursiveFn(arr, sub, k, count, index):
if index >= len(arr):
return count
else:
i = 0
count1 = 0
count2 = 0
count3 = 0
flag = 0
... |
eaa17cbf5241a6b0e959811839589eb1964e7d2a | aleonsan/python-design-patterns | /design_patterns/visitor/example.py | 1,494 | 4.0625 | 4 | # Design Pattern: Visitor
# Visited object
class Sword(object):
def accept(self, visitor):
""" Here we declare the relationiship btw objects """
visitor.visit(self)
def shine(self, believer):
print(self, "shines holded by ", believer)
def do_nothing(self, skeptical):
print... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.