
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 1.62B | node_id stringlengths 18 32 | number int64 1 5.62k | title stringlengths 1 290 | user dict | labels list | state stringclasses 1
value | locked bool 1
class | assignee dict | assignees list | milestone dict | comments list | created_at timestamp[s] | updated_at timestamp[s] | closed_at timestamp[s] | author_association stringclasses 3
values | active_lock_reason null | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 2
values | draft bool 2
classes | pull_request dict | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3689/comments | https://api.github.com/repos/huggingface/datasets/issues/3689/events | https://github.com/huggingface/datasets/pull/3689 | 1,127,422,478 | PR_kwDODunzps4yPnp7 | 3,689 | Fix streaming for servers not supporting HTTP range requests | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [] | 2022-02-08T15:41:05 | 2022-02-10T16:51:25 | 2022-02-10T16:51:25 | MEMBER | null | Some servers do not support HTTP range requests, whereas this is required to stream some file formats (like ZIP).
~~This PR implements a workaround for those cases, by download the files locally in a temporary directory (cleaned up by the OS once the process is finished).~~
This PR raises custom error explaining ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3689/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3689/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3689",
"html_url": "https://github.com/huggingface/datasets/pull/3689",
"diff_url": "https://github.com/huggingface/datasets/pull/3689.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3689.patch",
"merged_at": "2022-02-10T16:51... | true |
https://api.github.com/repos/huggingface/datasets/issues/3688 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3688/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3688/comments | https://api.github.com/repos/huggingface/datasets/issues/3688/events | https://github.com/huggingface/datasets/issues/3688 | 1,127,218,321 | I_kwDODunzps5DL_yR | 3,688 | Pyarrow version error | {
"login": "Zaker237",
"id": 49993443,
"node_id": "MDQ6VXNlcjQ5OTkzNDQz",
"avatar_url": "https://avatars.githubusercontent.com/u/49993443?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Zaker237",
"html_url": "https://github.com/Zaker237",
"followers_url": "https://api.github.com/users/Zak... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @Zaker237, thanks for reporting.\r\n\r\nThis is weird: the error you get is only thrown if the installed pyarrow version is less than 3.0.0.\r\n\r\nCould you please check that you install pyarrow in the same Python virtual environment where you installed datasets?\r\n\r\nFrom the Python command line (or termina... | 2022-02-08T12:53:59 | 2022-02-09T06:35:33 | 2022-02-09T06:35:32 | NONE | null | ## Describe the bug
I installed datasets(version 1.17.0, 1.18.0, 1.18.3) but i'm right now nor able to import it because of pyarrow. when i try to import it, i get the following error:
`To use datasets, the module pyarrow>=3.0.0 is required, and the current version of pyarrow doesn't match this condition`.
i tryed w... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3688/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3688/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3687 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3687/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3687/comments | https://api.github.com/repos/huggingface/datasets/issues/3687/events | https://github.com/huggingface/datasets/issues/3687 | 1,127,154,766 | I_kwDODunzps5DLwRO | 3,687 | Can't get the text data when calling to_tf_dataset | {
"login": "phrasenmaeher",
"id": 82086367,
"node_id": "MDQ6VXNlcjgyMDg2MzY3",
"avatar_url": "https://avatars.githubusercontent.com/u/82086367?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/phrasenmaeher",
"html_url": "https://github.com/phrasenmaeher",
"followers_url": "https://api.githu... | [] | closed | false | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.githu... | [
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url"... | null | [
"cc @Rocketknight1 ",
"You are correct that `to_tf_dataset` only handles numerical columns right now, yes, though this is a limitation we might remove in future! The main reason we do this is that our models mostly do not include the tokenizer as a model layer, because it's very difficult to compile some of them ... | 2022-02-08T11:52:10 | 2023-01-19T14:55:18 | 2023-01-19T14:55:18 | NONE | null | I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = Defa... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3687/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3687/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3686/comments | https://api.github.com/repos/huggingface/datasets/issues/3686/events | https://github.com/huggingface/datasets/issues/3686 | 1,127,137,290 | I_kwDODunzps5DLsAK | 3,686 | `Translation` features cannot be `flatten`ed | {
"login": "SBrandeis",
"id": 33657802,
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SBrandeis",
"html_url": "https://github.com/SBrandeis",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [
"Thanks for reporting, @SBrandeis! Some additional feature types that don't behave as expected when flattened: `Audio`, `Image` and `TranslationVariableLanguages`"
] | 2022-02-08T11:33:48 | 2022-03-18T17:28:13 | 2022-03-18T17:28:13 | CONTRIBUTOR | null | ## Describe the bug
(`Dataset.flatten`)[https://github.com/huggingface/datasets/blob/master/src/datasets/arrow_dataset.py#L1265] fails for columns with feature (`Translation`)[https://github.com/huggingface/datasets/blob/3edbeb0ec6519b79f1119adc251a1a6b379a2c12/src/datasets/features/translation.py#L8]
## Steps to... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3686/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3686/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3685 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3685/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3685/comments | https://api.github.com/repos/huggingface/datasets/issues/3685/events | https://github.com/huggingface/datasets/pull/3685 | 1,126,240,444 | PR_kwDODunzps4yLw3m | 3,685 | Add support for `Audio` and `Image` feature in `push_to_hub` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-02-07T16:47:16 | 2022-02-14T18:14:57 | 2022-02-14T18:04:58 | CONTRIBUTOR | null | Add support for the `Audio` and the `Image` feature in `push_to_hub`.
The idea is to remove local path information and store file content under "bytes" in the Arrow table before the push.
My initial approach (https://github.com/huggingface/datasets/commit/34c652afeff9686b6b8bf4e703c84d2205d670aa) was to use a ma... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3685/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3685/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3685",
"html_url": "https://github.com/huggingface/datasets/pull/3685",
"diff_url": "https://github.com/huggingface/datasets/pull/3685.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3685.patch",
"merged_at": "2022-02-14T18:04... | true |
https://api.github.com/repos/huggingface/datasets/issues/3684 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3684/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3684/comments | https://api.github.com/repos/huggingface/datasets/issues/3684/events | https://github.com/huggingface/datasets/pull/3684 | 1,125,133,664 | PR_kwDODunzps4yIOer | 3,684 | [fix]: iwslt2017 download urls | {
"login": "msarmi9",
"id": 48395294,
"node_id": "MDQ6VXNlcjQ4Mzk1Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/48395294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/msarmi9",
"html_url": "https://github.com/msarmi9",
"followers_url": "https://api.github.com/users/msarmi... | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | null | [] | null | [] | 2022-02-06T07:56:55 | 2022-09-22T16:20:19 | 2022-09-22T16:20:18 | NONE | null | Fixes #2076. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3684/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3684/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3684",
"html_url": "https://github.com/huggingface/datasets/pull/3684",
"diff_url": "https://github.com/huggingface/datasets/pull/3684.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3684.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3683 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3683/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3683/comments | https://api.github.com/repos/huggingface/datasets/issues/3683/events | https://github.com/huggingface/datasets/pull/3683 | 1,124,458,371 | PR_kwDODunzps4yGKoj | 3,683 | added told-br (brazilian hate speech) dataset | {
"login": "JAugusto97",
"id": 26556320,
"node_id": "MDQ6VXNlcjI2NTU2MzIw",
"avatar_url": "https://avatars.githubusercontent.com/u/26556320?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JAugusto97",
"html_url": "https://github.com/JAugusto97",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-02-04T17:44:32 | 2022-02-07T21:14:52 | 2022-02-07T21:14:52 | CONTRIBUTOR | null | Hey,
Adding ToLD-Br. Feel free to ask for modifications.
Thanks!! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3683/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3683/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3683",
"html_url": "https://github.com/huggingface/datasets/pull/3683",
"diff_url": "https://github.com/huggingface/datasets/pull/3683.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3683.patch",
"merged_at": "2022-02-07T21:14... | true |
https://api.github.com/repos/huggingface/datasets/issues/3682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3682/comments | https://api.github.com/repos/huggingface/datasets/issues/3682/events | https://github.com/huggingface/datasets/pull/3682 | 1,124,434,330 | PR_kwDODunzps4yGFml | 3,682 | adding told-br for toxic/abusive hatespeech detection | {
"login": "JAugusto97",
"id": 26556320,
"node_id": "MDQ6VXNlcjI2NTU2MzIw",
"avatar_url": "https://avatars.githubusercontent.com/u/26556320?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JAugusto97",
"html_url": "https://github.com/JAugusto97",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-02-04T17:18:29 | 2022-02-07T03:23:24 | 2022-02-04T17:36:40 | CONTRIBUTOR | null | Hey,
I'm adding our dataset from our paper published at AACL 2020. Feel free to ask for modifications.
Thanks! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3682/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3682/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3682",
"html_url": "https://github.com/huggingface/datasets/pull/3682",
"diff_url": "https://github.com/huggingface/datasets/pull/3682.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3682.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3680 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3680/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3680/comments | https://api.github.com/repos/huggingface/datasets/issues/3680/events | https://github.com/huggingface/datasets/pull/3680 | 1,124,213,416 | PR_kwDODunzps4yFXm8 | 3,680 | Fix TestCommand to copy dataset_infos to local dir with only data files | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [] | 2022-02-04T13:36:46 | 2022-02-08T10:32:55 | 2022-02-08T10:32:55 | MEMBER | null | Currently this case is missed.
CC: @lvwerra | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3680/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3680/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3680",
"html_url": "https://github.com/huggingface/datasets/pull/3680",
"diff_url": "https://github.com/huggingface/datasets/pull/3680.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3680.patch",
"merged_at": "2022-02-08T10:32... | true |
https://api.github.com/repos/huggingface/datasets/issues/3679 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3679/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3679/comments | https://api.github.com/repos/huggingface/datasets/issues/3679/events | https://github.com/huggingface/datasets/issues/3679 | 1,124,062,133 | I_kwDODunzps5C_9O1 | 3,679 | Download datasets from a private hub | {
"login": "juliensimon",
"id": 3436143,
"node_id": "MDQ6VXNlcjM0MzYxNDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3436143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/juliensimon",
"html_url": "https://github.com/juliensimon",
"followers_url": "https://api.github.com/us... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3814924348,
"node_id": "LA_k... | closed | false | null | [] | null | [
"For reference:\r\nhttps://github.com/huggingface/transformers/issues/15514\r\nhttps://github.com/huggingface/huggingface_hub/issues/650",
"Hi ! For information one can set the environment variable `HF_ENDPOINT` (default is `https://huggingface.co`) if they want to use a private hub.\r\n\r\nWe may need to coordin... | 2022-02-04T10:49:06 | 2022-02-22T11:08:07 | 2022-02-22T11:08:07 | NONE | null | In the context of a private hub deployment, customers would like to use load_dataset() to load datasets from their hub, not from the public hub. This doesn't seem to be configurable at the moment and it would be nice to add this feature.
The obvious workaround is to clone the repo first and then load it from local s... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3679/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3679/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3678/comments | https://api.github.com/repos/huggingface/datasets/issues/3678/events | https://github.com/huggingface/datasets/pull/3678 | 1,123,402,426 | PR_kwDODunzps4yCt91 | 3,678 | Add code example in wikipedia card | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-02-03T18:09:02 | 2022-02-21T09:14:56 | 2022-02-04T13:21:39 | MEMBER | null | Close #3292. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3678/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3678/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3678",
"html_url": "https://github.com/huggingface/datasets/pull/3678",
"diff_url": "https://github.com/huggingface/datasets/pull/3678.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3678.patch",
"merged_at": "2022-02-04T13:21... | true |
https://api.github.com/repos/huggingface/datasets/issues/3677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3677/comments | https://api.github.com/repos/huggingface/datasets/issues/3677/events | https://github.com/huggingface/datasets/issues/3677 | 1,123,192,866 | I_kwDODunzps5C8pAi | 3,677 | Discovery cannot be streamed anymore | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Seems like a regression from https://github.com/huggingface/datasets/pull/2843\r\n\r\nOr maybe it's an issue with the hosting. I don't think so, though, because https://www.dropbox.com/s/aox84z90nyyuikz/discovery.zip seems to work as expected\r\n\r\n",
"Hi @severo, thanks for reporting.\r\n\r\nSome servers do no... | 2022-02-03T15:02:03 | 2022-02-10T16:51:24 | 2022-02-10T16:51:24 | CONTRIBUTOR | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
iterable_dataset = load_dataset("discovery", name="discovery", split="train", streaming=True)
list(iterable_dataset.take(1))
```
## Expected results
The first ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3677/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3677/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3676/comments | https://api.github.com/repos/huggingface/datasets/issues/3676/events | https://github.com/huggingface/datasets/issues/3676 | 1,123,096,362 | I_kwDODunzps5C8Rcq | 3,676 | `None` replaced by `[]` after first batch in map | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [
"It looks like this is because of this behavior in pyarrow:\r\n```python\r\nimport pyarrow as pa\r\n\r\narr = pa.array([None, [0]])\r\nreconstructed_arr = pa.ListArray.from_arrays(arr.offsets, arr.values)\r\nprint(reconstructed_arr.to_pylist())\r\n# [[], [0]]\r\n```\r\n\r\nIt seems that `arr.offsets` can reconstruc... | 2022-02-03T13:36:48 | 2022-10-28T13:13:20 | 2022-10-28T13:13:20 | MEMBER | null | Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3676/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/datasets/issues/3676/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3675/comments | https://api.github.com/repos/huggingface/datasets/issues/3675/events | https://github.com/huggingface/datasets/issues/3675 | 1,123,078,408 | I_kwDODunzps5C8NEI | 3,675 | Add CodeContests dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | null | [] | null | [
"@mariosasko Can I take this up?",
"This dataset is now available here: https://huggingface.co/datasets/deepmind/code_contests."
] | 2022-02-03T13:20:00 | 2022-07-20T11:07:05 | 2022-07-20T11:07:05 | CONTRIBUTOR | null | ## Adding a Dataset
- **Name:** CodeContests
- **Description:** CodeContests is a competitive programming dataset for machine-learning.
- **Paper:**
- **Data:** https://github.com/deepmind/code_contests
- **Motivation:** This dataset was used when training [AlphaCode](https://deepmind.com/blog/article/Competitive-... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3675/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3675/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3674/comments | https://api.github.com/repos/huggingface/datasets/issues/3674/events | https://github.com/huggingface/datasets/pull/3674 | 1,123,027,874 | PR_kwDODunzps4yBe17 | 3,674 | Add FrugalScore metric | {
"login": "moussaKam",
"id": 28675016,
"node_id": "MDQ6VXNlcjI4Njc1MDE2",
"avatar_url": "https://avatars.githubusercontent.com/u/28675016?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moussaKam",
"html_url": "https://github.com/moussaKam",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | [] | 2022-02-03T12:28:52 | 2022-02-21T15:58:44 | 2022-02-21T15:58:44 | CONTRIBUTOR | null | This pull request add FrugalScore metric for NLG systems evaluation.
FrugalScore is a reference-based metric for NLG models evaluation. It is based on a distillation approach that allows to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance.
Paper: https:... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3674/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3674/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3674",
"html_url": "https://github.com/huggingface/datasets/pull/3674",
"diff_url": "https://github.com/huggingface/datasets/pull/3674.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3674.patch",
"merged_at": "2022-02-21T15:58... | true |
https://api.github.com/repos/huggingface/datasets/issues/3673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3673/comments | https://api.github.com/repos/huggingface/datasets/issues/3673/events | https://github.com/huggingface/datasets/issues/3673 | 1,123,010,520 | I_kwDODunzps5C78fY | 3,673 | `load_dataset("snli")` is different from dataset viewer | {
"login": "pietrolesci",
"id": 61748653,
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pietrolesci",
"html_url": "https://github.com/pietrolesci",
"followers_url": "https://api.github.com/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp... | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"Yes, we decided to replace the encoded label with the corresponding label when possible in the dataset viewer. But\r\n1. maybe it's the wrong default\r\n2. we could find a way to show both (with a switch, or showing both ie. `0 (neutral)`).\r\n",
"Hi @severo,\r\n\r\nThanks for clarifying. \r\n\r\nI think this de... | 2022-02-03T12:10:43 | 2022-02-16T11:22:31 | 2022-02-11T17:01:21 | NONE | null | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3673/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3673/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3672/comments | https://api.github.com/repos/huggingface/datasets/issues/3672/events | https://github.com/huggingface/datasets/pull/3672 | 1,122,980,556 | PR_kwDODunzps4yBUrZ | 3,672 | Prioritize `module.builder_kwargs` over defaults in `TestCommand` | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/... | [] | closed | false | null | [] | null | [] | 2022-02-03T11:38:42 | 2022-02-04T12:37:20 | 2022-02-04T12:37:19 | MEMBER | null | This fixes a bug in the `TestCommand` where multiple kwargs for `name` were passed if it was set in both default and `module.builder_kwargs`. Example error:
```Python
Traceback (most recent call last):
File "create_metadata.py", line 96, in <module>
main(**vars(args))
File "create_metadata.py", line 86, ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3672/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3672/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3672",
"html_url": "https://github.com/huggingface/datasets/pull/3672",
"diff_url": "https://github.com/huggingface/datasets/pull/3672.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3672.patch",
"merged_at": "2022-02-04T12:37... | true |
https://api.github.com/repos/huggingface/datasets/issues/3670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3670/comments | https://api.github.com/repos/huggingface/datasets/issues/3670/events | https://github.com/huggingface/datasets/pull/3670 | 1,122,439,827 | PR_kwDODunzps4x_kBx | 3,670 | feat: 🎸 generate info if dataset_infos.json does not exist | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [] | closed | false | null | [] | null | [] | 2022-02-02T22:11:56 | 2022-02-21T15:57:11 | 2022-02-21T15:57:10 | CONTRIBUTOR | null | in get_dataset_infos(). Also: add the `use_auth_token` parameter, and create get_dataset_config_info()
✅ Closes: #3013 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3670/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3670/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3670",
"html_url": "https://github.com/huggingface/datasets/pull/3670",
"diff_url": "https://github.com/huggingface/datasets/pull/3670.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3670.patch",
"merged_at": "2022-02-21T15:57... | true |
https://api.github.com/repos/huggingface/datasets/issues/3669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3669/comments | https://api.github.com/repos/huggingface/datasets/issues/3669/events | https://github.com/huggingface/datasets/pull/3669 | 1,122,335,622 | PR_kwDODunzps4x_OTI | 3,669 | Common voice validated partition | {
"login": "shalymin-amzn",
"id": 98762373,
"node_id": "U_kgDOBeL-hQ",
"avatar_url": "https://avatars.githubusercontent.com/u/98762373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shalymin-amzn",
"html_url": "https://github.com/shalymin-amzn",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | null | [] | 2022-02-02T20:04:43 | 2022-02-08T17:26:52 | 2022-02-08T17:23:12 | CONTRIBUTOR | null | This patch adds access to the 'validated' partitions of CommonVoice datasets (provided by the dataset creators but not available in the HuggingFace interface yet).
As 'validated' contains significantly more data than 'train' (although it contains both test and validation, so one needs to be careful there), it can be u... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3669/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3669/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3669",
"html_url": "https://github.com/huggingface/datasets/pull/3669",
"diff_url": "https://github.com/huggingface/datasets/pull/3669.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3669.patch",
"merged_at": "2022-02-08T17:23... | true |
https://api.github.com/repos/huggingface/datasets/issues/3668 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3668/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3668/comments | https://api.github.com/repos/huggingface/datasets/issues/3668/events | https://github.com/huggingface/datasets/issues/3668 | 1,122,261,736 | I_kwDODunzps5C5Fro | 3,668 | Couldn't cast array of type string error with cast_column | {
"login": "R4ZZ3",
"id": 25264037,
"node_id": "MDQ6VXNlcjI1MjY0MDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/25264037?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/R4ZZ3",
"html_url": "https://github.com/R4ZZ3",
"followers_url": "https://api.github.com/users/R4ZZ3/follow... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! I wasn't able to reproduce the error, are you still experiencing this ? I tried calling `cast_column` on a string column containing paths.\r\n\r\nIf you manage to share a reproducible code example that would be perfect",
"Hi,\r\n\r\nI think my team mate got this solved. Clolsing it for now and will reopen i... | 2022-02-02T18:33:29 | 2022-07-19T13:36:24 | 2022-07-19T13:36:24 | NONE | null | ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

(moreover, I didn't manage to load .opus files with `soundfile` / `librosa` locally on any my machine an... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3667/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3667/timeline | null | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3667",
"html_url": "https://github.com/huggingface/datasets/pull/3667",
"diff_url": "https://github.com/huggingface/datasets/pull/3667.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3667.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3666/comments | https://api.github.com/repos/huggingface/datasets/issues/3666/events | https://github.com/huggingface/datasets/pull/3666 | 1,122,058,894 | PR_kwDODunzps4x-ULz | 3,666 | process .opus files (for Multilingual Spoken Words) | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | [] | 2022-02-02T15:21:48 | 2022-02-22T10:04:03 | 2022-02-22T10:03:53 | CONTRIBUTOR | null | Opus files requires `libsndfile>=1.0.30`. Add check for this version and tests.
**outdated:**
Add [Multillingual Spoken Words dataset](https://mlcommons.org/en/multilingual-spoken-words/)
You can specify multiple languages for downloading 😌:
```python
ds = load_dataset("datasets/ml_spoken_words", languages=... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3666/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3666/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3666",
"html_url": "https://github.com/huggingface/datasets/pull/3666",
"diff_url": "https://github.com/huggingface/datasets/pull/3666.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3666.patch",
"merged_at": "2022-02-22T10:03... | true |
https://api.github.com/repos/huggingface/datasets/issues/3665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3665/comments | https://api.github.com/repos/huggingface/datasets/issues/3665/events | https://github.com/huggingface/datasets/pull/3665 | 1,121,753,385 | PR_kwDODunzps4x9TnU | 3,665 | Fix MP3 resampling when a dataset's audio files have different sampling rates | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-02-02T10:31:45 | 2022-02-02T10:52:26 | 2022-02-02T10:52:26 | MEMBER | null | The resampler needs to be updated if the `orig_freq` doesn't match the audio file sampling rate
Fix https://github.com/huggingface/datasets/issues/3662 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3665/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3665/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3665",
"html_url": "https://github.com/huggingface/datasets/pull/3665",
"diff_url": "https://github.com/huggingface/datasets/pull/3665.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3665.patch",
"merged_at": "2022-02-02T10:52... | true |
https://api.github.com/repos/huggingface/datasets/issues/3664 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3664/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3664/comments | https://api.github.com/repos/huggingface/datasets/issues/3664/events | https://github.com/huggingface/datasets/pull/3664 | 1,121,233,301 | PR_kwDODunzps4x7mg_ | 3,664 | [WIP] Return local paths to Common Voice | {
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-... | [] | closed | false | null | [] | null | [] | 2022-02-01T21:48:27 | 2022-02-22T09:14:06 | 2022-02-22T09:14:06 | MEMBER | null | Fixes https://github.com/huggingface/datasets/issues/3663
This is a proposed way of returning the old local file-based generator while keeping the new streaming generator intact.
TODO:
- [ ] brainstorm a bit more on https://github.com/huggingface/datasets/issues/3663 to see if we can do better
- [ ] refactor th... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3664/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3664/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3664",
"html_url": "https://github.com/huggingface/datasets/pull/3664",
"diff_url": "https://github.com/huggingface/datasets/pull/3664.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3664.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3663/comments | https://api.github.com/repos/huggingface/datasets/issues/3663/events | https://github.com/huggingface/datasets/issues/3663 | 1,121,067,647 | I_kwDODunzps5C0iJ_ | 3,663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Having talked to @lhoestq, I see that this feature is no longer supported. \r\n\r\nI really don't think this was a good idea. It is a major breaking change and one for which we don't even have a working solution at the moment, which is bad for PyTorch as we don't want to force people to have `datasets` decode audi... | 2022-02-01T18:40:10 | 2022-09-21T15:03:09 | 2022-09-21T14:56:22 | MEMBER | null | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3663/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3663/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3662/comments | https://api.github.com/repos/huggingface/datasets/issues/3662/events | https://github.com/huggingface/datasets/issues/3662 | 1,121,024,403 | I_kwDODunzps5C0XmT | 3,662 | [Audio] MP3 resampling is incorrect when dataset's audio files have different sampling rates | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"Thanks @lhoestq for finding the reason of incorrect resampling. This issue affects all languages which have sound files with different sampling rates such as Turkish and Luganda.",
"@cahya-wirawan - do you know how many languages have different sampling rates in Common Voice? I'm quite surprised to see this for ... | 2022-02-01T17:55:04 | 2022-02-02T10:52:25 | 2022-02-02T10:52:25 | MEMBER | null | The Audio feature resampler for MP3 gets stuck with the first original frequencies it meets, which leads to subsequent decoding to be incorrect.
Here is a code to reproduce the issue:
Let's first consider two audio files with different sampling rates 32000 and 16000:
```python
# first download a mp3 file with s... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3662/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3662/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3661 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3661/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3661/comments | https://api.github.com/repos/huggingface/datasets/issues/3661/events | https://github.com/huggingface/datasets/pull/3661 | 1,121,000,251 | PR_kwDODunzps4x61ad | 3,661 | Remove unnecessary 'r' arg in | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | null | [] | 2022-02-01T17:29:27 | 2022-02-07T16:57:27 | 2022-02-07T16:02:42 | CONTRIBUTOR | null | Originally from #3489 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3661/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3661/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3661",
"html_url": "https://github.com/huggingface/datasets/pull/3661",
"diff_url": "https://github.com/huggingface/datasets/pull/3661.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3661.patch",
"merged_at": "2022-02-07T16:02... | true |
https://api.github.com/repos/huggingface/datasets/issues/3659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3659/comments | https://api.github.com/repos/huggingface/datasets/issues/3659/events | https://github.com/huggingface/datasets/issues/3659 | 1,120,913,672 | I_kwDODunzps5Cz8kI | 3,659 | push_to_hub but preview not working | {
"login": "thomas-happify",
"id": 66082334,
"node_id": "MDQ6VXNlcjY2MDgyMzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/66082334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomas-happify",
"html_url": "https://github.com/thomas-happify",
"followers_url": "https://api.gi... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @thomas-happify, please note that the preview may take some time before rendering the data.\r\n\r\nI've seen it is already working.\r\n\r\nI close this issue. Please feel free to reopen it if the problem arises again."
] | 2022-02-01T16:23:57 | 2022-02-09T08:00:37 | 2022-02-09T08:00:37 | NONE | null | ## Dataset viewer issue for '*happifyhealth/twitter_pnn*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/happifyhealth/twitter_pnn)*
I used
```
dataset.push_to_hub("happifyhealth/twitter_pnn")
```
but the preview is not working.
Am I the one who added this dataset ? Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3659/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3659/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3657/comments | https://api.github.com/repos/huggingface/datasets/issues/3657/events | https://github.com/huggingface/datasets/pull/3657 | 1,120,602,620 | PR_kwDODunzps4x5f1I | 3,657 | Extend dataset builder for streaming in `get_dataset_split_names` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-02-01T12:21:24 | 2022-02-03T22:49:06 | 2022-02-02T11:22:01 | CONTRIBUTOR | null | Currently, `get_dataset_split_names` doesn't extend a builder module to support streaming, even though it uses `StreamingDownloadManager` to download data. This PR fixes that.
To test the change, run the following:
```bash
pip install git+https://github.com/huggingface/datasets.git@fix-get_dataset_split_names-stre... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3657/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3657/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3657",
"html_url": "https://github.com/huggingface/datasets/pull/3657",
"diff_url": "https://github.com/huggingface/datasets/pull/3657.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3657.patch",
"merged_at": "2022-02-02T11:22... | true |
https://api.github.com/repos/huggingface/datasets/issues/3656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3656/comments | https://api.github.com/repos/huggingface/datasets/issues/3656/events | https://github.com/huggingface/datasets/issues/3656 | 1,120,510,823 | I_kwDODunzps5CyaNn | 3,656 | checksum error subjqa dataset | {
"login": "RensDimmendaal",
"id": 9828683,
"node_id": "MDQ6VXNlcjk4Mjg2ODM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9828683?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RensDimmendaal",
"html_url": "https://github.com/RensDimmendaal",
"followers_url": "https://api.gith... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @RensDimmendaal, \r\n\r\nI'm sorry but I can't reproduce your bug:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n ...: ds = load_dataset(\"subjqa\", \"electronics\")\r\nDownloading builder script: 9.15kB [00:00, 4.10MB/s] ... | 2022-02-01T10:53:33 | 2022-02-10T10:56:59 | 2022-02-10T10:56:38 | NONE | null | ## Describe the bug
I get a checksum error when loading the `subjqa` dataset (used in the transformers book).
## Steps to reproduce the bug
```python
from datasets import load_dataset
subjqa = load_dataset("subjqa","electronics")
```
## Expected results
Loading the dataset
## Actual results
```
---... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3656/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3656/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3655/comments | https://api.github.com/repos/huggingface/datasets/issues/3655/events | https://github.com/huggingface/datasets/issues/3655 | 1,119,801,077 | I_kwDODunzps5Cvs71 | 3,655 | Pubmed dataset not reachable | {
"login": "abhi-mosaic",
"id": 77638579,
"node_id": "MDQ6VXNlcjc3NjM4NTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/77638579?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhi-mosaic",
"html_url": "https://github.com/abhi-mosaic",
"followers_url": "https://api.github.com/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @abhi-mosaic, thanks for reporting.\r\n\r\nI'm looking at it... ",
"also hitting this issue",
"Hey @albertvillanova, sorry to reopen this... I can confirm that on `master` branch the dataset is downloadable now but it is still broken in streaming mode:\r\n\r\n```python\r\n >>> import datasets\r\n >>> pubmed... | 2022-01-31T18:45:47 | 2022-12-19T19:18:10 | 2022-02-14T14:15:41 | CONTRIBUTOR | null | ## Describe the bug
Trying to use the `pubmed` dataset fails to reach / download the source files.
## Steps to reproduce the bug
```python
pubmed_train = datasets.load_dataset('pubmed', split='train')
```
## Expected results
Should begin downloading the pubmed dataset.
## Actual results
```
ConnectionEr... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3655/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3655/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3654/comments | https://api.github.com/repos/huggingface/datasets/issues/3654/events | https://github.com/huggingface/datasets/pull/3654 | 1,119,717,475 | PR_kwDODunzps4x2kiX | 3,654 | Better TQDM output | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-01-31T17:22:43 | 2022-02-03T15:55:34 | 2022-02-03T15:55:33 | CONTRIBUTOR | null | This PR does the following:
* if `dataset_infos.json` exists for a dataset, uses `num_examples` to print the total number of examples that needs to be generated (in `builder.py`)
* fixes `tqdm` + multiprocessing in Jupyter Notebook/Colab (the issue stems from this commit in the `tqdm` repo: https://github.com/tqdm/tq... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3654/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3654/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3654",
"html_url": "https://github.com/huggingface/datasets/pull/3654",
"diff_url": "https://github.com/huggingface/datasets/pull/3654.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3654.patch",
"merged_at": "2022-02-03T15:55... | true |
https://api.github.com/repos/huggingface/datasets/issues/3652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3652/comments | https://api.github.com/repos/huggingface/datasets/issues/3652/events | https://github.com/huggingface/datasets/pull/3652 | 1,118,808,738 | PR_kwDODunzps4xzinr | 3,652 | sp. Columbia => Colombia | {
"login": "serapio",
"id": 3781280,
"node_id": "MDQ6VXNlcjM3ODEyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3781280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/serapio",
"html_url": "https://github.com/serapio",
"followers_url": "https://api.github.com/users/serapio/... | [] | closed | false | null | [] | null | [] | 2022-01-31T00:41:03 | 2022-02-09T16:55:25 | 2022-01-31T08:29:07 | CONTRIBUTOR | null | "Columbia" is various places in North America. The country is "Colombia". | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3652/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3652/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3652",
"html_url": "https://github.com/huggingface/datasets/pull/3652",
"diff_url": "https://github.com/huggingface/datasets/pull/3652.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3652.patch",
"merged_at": "2022-01-31T08:29... | true |
https://api.github.com/repos/huggingface/datasets/issues/3651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3651/comments | https://api.github.com/repos/huggingface/datasets/issues/3651/events | https://github.com/huggingface/datasets/pull/3651 | 1,118,597,647 | PR_kwDODunzps4xy3De | 3,651 | Update link in wiki_bio dataset | {
"login": "jxmorris12",
"id": 13238952,
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jxmorris12",
"html_url": "https://github.com/jxmorris12",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-01-30T16:28:54 | 2022-01-31T14:50:48 | 2022-01-31T08:38:09 | CONTRIBUTOR | null | Fixes #3580 and makes the wiki_bio dataset work again. I changed the link and some documentation, and all the tests pass. Thanks @lhoestq for uploading the dataset to the HuggingFace data bucket.
@lhoestq -- all the tests pass, but I'm still not able to import the dataset, as the old Google Drive link is cached some... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3651/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3651/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3651",
"html_url": "https://github.com/huggingface/datasets/pull/3651",
"diff_url": "https://github.com/huggingface/datasets/pull/3651.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3651.patch",
"merged_at": "2022-01-31T08:38... | true |
https://api.github.com/repos/huggingface/datasets/issues/3648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3648/comments | https://api.github.com/repos/huggingface/datasets/issues/3648/events | https://github.com/huggingface/datasets/pull/3648 | 1,117,465,505 | PR_kwDODunzps4xvXig | 3,648 | Fix Windows CI: bump python to 3.7 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-01-28T14:24:54 | 2022-01-28T14:40:39 | 2022-01-28T14:40:39 | MEMBER | null | Python>=3.7 is needed to install `tokenizers` 0.11 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3648/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3648/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3648",
"html_url": "https://github.com/huggingface/datasets/pull/3648",
"diff_url": "https://github.com/huggingface/datasets/pull/3648.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3648.patch",
"merged_at": "2022-01-28T14:40... | true |
https://api.github.com/repos/huggingface/datasets/issues/3647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3647/comments | https://api.github.com/repos/huggingface/datasets/issues/3647/events | https://github.com/huggingface/datasets/pull/3647 | 1,117,383,675 | PR_kwDODunzps4xvGDQ | 3,647 | Fix `add_column` on datasets with indices mapping | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-01-28T13:06:29 | 2022-01-28T15:35:58 | 2022-01-28T15:35:58 | CONTRIBUTOR | null | My initial idea was to avoid the `flatten_indices` call and reorder a new column instead, but in the end I decided to follow `concatenate_datasets` and use `flatten_indices` to avoid padding when `dataset._indices.num_rows != dataset._data.num_rows`.
Fix #3599 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3647/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3647/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3647",
"html_url": "https://github.com/huggingface/datasets/pull/3647",
"diff_url": "https://github.com/huggingface/datasets/pull/3647.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3647.patch",
"merged_at": "2022-01-28T15:35... | true |
https://api.github.com/repos/huggingface/datasets/issues/3646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3646/comments | https://api.github.com/repos/huggingface/datasets/issues/3646/events | https://github.com/huggingface/datasets/pull/3646 | 1,116,544,627 | PR_kwDODunzps4xsX66 | 3,646 | Fix streaming datasets that are not reset correctly | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-01-27T17:21:02 | 2022-01-28T16:34:29 | 2022-01-28T16:34:28 | MEMBER | null | Streaming datasets that use `StreamingDownloadManager.iter_archive` and `StreamingDownloadManager.iter_files` had some issues. Indeed if you try to iterate over such dataset twice, then the second time it will be empty.
This is because the two methods above are generator functions. I fixed this by making them return... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3646/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3646/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3646",
"html_url": "https://github.com/huggingface/datasets/pull/3646",
"diff_url": "https://github.com/huggingface/datasets/pull/3646.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3646.patch",
"merged_at": "2022-01-28T16:34... | true |
https://api.github.com/repos/huggingface/datasets/issues/3645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3645/comments | https://api.github.com/repos/huggingface/datasets/issues/3645/events | https://github.com/huggingface/datasets/issues/3645 | 1,116,541,298 | I_kwDODunzps5CjRFy | 3,645 | Streaming dataset based on dl_manager.iter_archive/iter_files are not reset correctly | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [] | 2022-01-27T17:17:41 | 2022-01-28T16:34:28 | 2022-01-28T16:34:28 | MEMBER | null | Hi ! When iterating over a streaming dataset once, it's not reset correctly because of some issues with `dl_manager.iter_archive` and `dl_manager.iter_files`. Indeed they are generator functions (so the iterator that is returned can be exhausted). They should be iterables instead, and be reset if we do a for loop again... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3645/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3645/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3643/comments | https://api.github.com/repos/huggingface/datasets/issues/3643/events | https://github.com/huggingface/datasets/pull/3643 | 1,116,417,428 | PR_kwDODunzps4xr8mX | 3,643 | Fix sem_eval_2018_task_1 download location | {
"login": "maxpel",
"id": 31095360,
"node_id": "MDQ6VXNlcjMxMDk1MzYw",
"avatar_url": "https://avatars.githubusercontent.com/u/31095360?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxpel",
"html_url": "https://github.com/maxpel",
"followers_url": "https://api.github.com/users/maxpel/fo... | [] | closed | false | null | [] | null | [] | 2022-01-27T15:45:00 | 2022-02-04T15:15:26 | 2022-02-04T15:15:26 | CONTRIBUTOR | null | As discussed with @lhoestq in https://github.com/huggingface/datasets/issues/3549#issuecomment-1020176931_ this is the new pull request to fix the download location. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3643/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3643/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3643",
"html_url": "https://github.com/huggingface/datasets/pull/3643",
"diff_url": "https://github.com/huggingface/datasets/pull/3643.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3643.patch",
"merged_at": "2022-02-04T15:15... | true |
https://api.github.com/repos/huggingface/datasets/issues/3642 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3642/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3642/comments | https://api.github.com/repos/huggingface/datasets/issues/3642/events | https://github.com/huggingface/datasets/pull/3642 | 1,116,306,986 | PR_kwDODunzps4xrj2S | 3,642 | Fix dataset slicing with negative bounds when indices mapping is not `None` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-01-27T14:45:53 | 2022-01-27T18:16:23 | 2022-01-27T18:16:22 | CONTRIBUTOR | null | Fix #3611 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3642/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3642/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3642",
"html_url": "https://github.com/huggingface/datasets/pull/3642",
"diff_url": "https://github.com/huggingface/datasets/pull/3642.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3642.patch",
"merged_at": "2022-01-27T18:16... | true |
https://api.github.com/repos/huggingface/datasets/issues/3641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3641/comments | https://api.github.com/repos/huggingface/datasets/issues/3641/events | https://github.com/huggingface/datasets/pull/3641 | 1,116,284,268 | PR_kwDODunzps4xre7C | 3,641 | Fix numpy rngs when seed is None | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-01-27T14:29:09 | 2022-01-27T18:16:08 | 2022-01-27T18:16:07 | CONTRIBUTOR | null | Fixes the NumPy RNG when `seed` is `None`.
The problem becomes obvious after reading the NumPy notes on RNG (returned by `np.random.get_state()`):
> The MT19937 state vector consists of a 624-element array of 32-bit unsigned integers plus a single integer value between 0 and 624 that indexes the current position wi... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3641/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3641/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3641",
"html_url": "https://github.com/huggingface/datasets/pull/3641",
"diff_url": "https://github.com/huggingface/datasets/pull/3641.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3641.patch",
"merged_at": "2022-01-27T18:16... | true |
https://api.github.com/repos/huggingface/datasets/issues/3640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3640/comments | https://api.github.com/repos/huggingface/datasets/issues/3640/events | https://github.com/huggingface/datasets/issues/3640 | 1,116,133,769 | I_kwDODunzps5ChtmJ | 3,640 | Issues with custom dataset in Wav2Vec2 | {
"login": "peregilk",
"id": 9079808,
"node_id": "MDQ6VXNlcjkwNzk4MDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/9079808?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/peregilk",
"html_url": "https://github.com/peregilk",
"followers_url": "https://api.github.com/users/pereg... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Closed and moved to transformers."
] | 2022-01-27T12:09:05 | 2022-01-27T12:29:48 | 2022-01-27T12:29:48 | NONE | null | We are training Vav2Vec using the run_speech_recognition_ctc_bnb.py-script.
This is working fine with Common Voice, however using our custom dataset and data loader at [NbAiLab/NPSC]( https://huggingface.co/datasets/NbAiLab/NPSC) it crashes after roughly 1 epoch with the following stack trace:
 `cast_array_to_feature` function because `git bisect` points to the https://github.com/huggingface/datasets/commit/6ca96c707502e0689f9b58d94f46d871fa5a3c9c commit. Then, I noticed that the feat... | 2022-01-26T21:38:02 | 2022-02-09T16:15:53 | 2022-02-09T16:15:53 | MEMBER | null | ## Describe the bug
I am trying to load the [`GEM/RiSAWOZ` dataset](https://huggingface.co/datasets/GEM/RiSAWOZ) in `datasets` v1.18.1 and am running into a type error when casting the features. The strange thing is that I can load the dataset with v1.17.0. Note that the error is also present if I install from `master... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3637/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3637/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3636/comments | https://api.github.com/repos/huggingface/datasets/issues/3636/events | https://github.com/huggingface/datasets/pull/3636 | 1,115,362,702 | PR_kwDODunzps4xohMB | 3,636 | Update index.rst | {
"login": "VioletteLepercq",
"id": 95622912,
"node_id": "U_kgDOBbMXAA",
"avatar_url": "https://avatars.githubusercontent.com/u/95622912?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VioletteLepercq",
"html_url": "https://github.com/VioletteLepercq",
"followers_url": "https://api.github.... | [] | closed | false | null | [] | null | [] | 2022-01-26T18:43:09 | 2022-01-26T18:44:55 | 2022-01-26T18:44:54 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3636/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3636/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3636",
"html_url": "https://github.com/huggingface/datasets/pull/3636",
"diff_url": "https://github.com/huggingface/datasets/pull/3636.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3636.patch",
"merged_at": "2022-01-26T18:44... | true |
https://api.github.com/repos/huggingface/datasets/issues/3635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3635/comments | https://api.github.com/repos/huggingface/datasets/issues/3635/events | https://github.com/huggingface/datasets/pull/3635 | 1,115,333,219 | PR_kwDODunzps4xobAe | 3,635 | Make `ted_talks_iwslt` dataset streamable | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | null | [] | null | [] | 2022-01-26T18:07:56 | 2022-10-04T09:36:23 | 2022-10-03T09:44:47 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3635/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3635/timeline | null | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3635",
"html_url": "https://github.com/huggingface/datasets/pull/3635",
"diff_url": "https://github.com/huggingface/datasets/pull/3635.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3635.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3634/comments | https://api.github.com/repos/huggingface/datasets/issues/3634/events | https://github.com/huggingface/datasets/issues/3634 | 1,115,133,279 | I_kwDODunzps5Cd5Vf | 3,634 | Dataset.shuffle(seed=None) gives fixed row permutation | {
"login": "elisno",
"id": 18127060,
"node_id": "MDQ6VXNlcjE4MTI3MDYw",
"avatar_url": "https://avatars.githubusercontent.com/u/18127060?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/elisno",
"html_url": "https://github.com/elisno",
"followers_url": "https://api.github.com/users/elisno/fo... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [
"I'm not sure if this is expected behavior.\r\n\r\nAm I supposed to work with a copy of the dataset, i.e. `shuffled_dataset = data.shuffle(seed=None)`?\r\n\r\n```diff\r\nimport datasets\r\n\r\n# Some toy example\r\ndata = datasets.Dataset.from_dict(\r\n {\"feature\": [1, 2, 3, 4, 5], \"label\": [\"a\", \"b\", \"... | 2022-01-26T15:13:08 | 2022-01-27T18:16:07 | 2022-01-27T18:16:07 | NONE | null | ## Describe the bug
Repeated attempts to `shuffle` a dataset without specifying a seed give the same results.
## Steps to reproduce the bug
```python
import datasets
# Some toy example
data = datasets.Dataset.from_dict(
{"feature": [1, 2, 3, 4, 5], "label": ["a", "b", "c", "d", "e"]}
)
# Doesn't work... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3634/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3634/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3633/comments | https://api.github.com/repos/huggingface/datasets/issues/3633/events | https://github.com/huggingface/datasets/pull/3633 | 1,115,040,174 | PR_kwDODunzps4xng6E | 3,633 | Mirror canonical datasets in prod | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-01-26T13:49:37 | 2022-01-26T13:56:21 | 2022-01-26T13:56:21 | MEMBER | null | Push the datasets changes to the Hub in production by setting `HF_USE_PROD=1`
I also added a fix that makes the script ignore the json, csv, text, parquet and pandas dataset builders.
cc @SBrandeis | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3633/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3633/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3633",
"html_url": "https://github.com/huggingface/datasets/pull/3633",
"diff_url": "https://github.com/huggingface/datasets/pull/3633.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3633.patch",
"merged_at": "2022-01-26T13:56... | true |
https://api.github.com/repos/huggingface/datasets/issues/3632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3632/comments | https://api.github.com/repos/huggingface/datasets/issues/3632/events | https://github.com/huggingface/datasets/issues/3632 | 1,115,027,185 | I_kwDODunzps5Cdfbx | 3,632 | Adding CC-100: Monolingual Datasets from Web Crawl Data (Datasets links are invalid) | {
"login": "AnzorGozalishvili",
"id": 55232459,
"node_id": "MDQ6VXNlcjU1MjMyNDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/55232459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AnzorGozalishvili",
"html_url": "https://github.com/AnzorGozalishvili",
"followers_url": "https... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @AnzorGozalishvili,\r\n\r\nMaybe their site was temporarily down, but it seems to work fine now.\r\n\r\nCould you please try again and confirm if the problem persists? ",
"Hi @albertvillanova \r\nI checked and it works. \r\nIt seems that it was really temporarily down.\r\nThanks!"
] | 2022-01-26T13:35:37 | 2022-02-10T06:58:11 | 2022-02-10T06:58:11 | CONTRIBUTOR | null | ## Describe the bug
The dataset links are no longer valid for CC-100. It seems that the website which was keeping these files are no longer accessible and therefore this dataset became unusable.
Check out the dataset [homepage](http://data.statmt.org/cc-100/) which isn't accessible.
Also the URLs for dataset file ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3632/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3632/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3631/comments | https://api.github.com/repos/huggingface/datasets/issues/3631/events | https://github.com/huggingface/datasets/issues/3631 | 1,114,833,662 | I_kwDODunzps5CcwL- | 3,631 | Labels conflict when loading a local CSV file. | {
"login": "pichljan",
"id": 8571301,
"node_id": "MDQ6VXNlcjg1NzEzMDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8571301?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pichljan",
"html_url": "https://github.com/pichljan",
"followers_url": "https://api.github.com/users/pichl... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @pichljan, thanks for reporting.\r\n\r\nThis should be fixed. I'm looking at it. "
] | 2022-01-26T10:00:33 | 2022-02-11T23:02:31 | 2022-02-11T23:02:31 | NONE | null | ## Describe the bug
I am trying to load a local CSV file with a separate file containing label names. It is successfully loaded for the first time, but when I try to load it again, there is a conflict between provided labels and the cached dataset info. Disabling caching globally and/or using `download_mode="force_red... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3631/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3631/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3630/comments | https://api.github.com/repos/huggingface/datasets/issues/3630/events | https://github.com/huggingface/datasets/issues/3630 | 1,114,578,625 | I_kwDODunzps5Cbx7B | 3,630 | DuplicatedKeysError of NewsQA dataset | {
"login": "StevenTang1998",
"id": 37647985,
"node_id": "MDQ6VXNlcjM3NjQ3OTg1",
"avatar_url": "https://avatars.githubusercontent.com/u/37647985?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/StevenTang1998",
"html_url": "https://github.com/StevenTang1998",
"followers_url": "https://api.gi... | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Thanks for reporting, @StevenTang1998.\r\n\r\nI'm fixing it. "
] | 2022-01-26T03:05:49 | 2022-02-14T08:37:19 | 2022-02-14T08:37:19 | NONE | null | After processing the dataset following official [NewsQA](https://github.com/Maluuba/newsqa), I used datasets to load it:
```
a = load_dataset('newsqa', data_dir='news')
```
and the following error occurred:
```
Using custom data configuration default-data_dir=news
Downloading and preparing dataset newsqa/defaul... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3630/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3630/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3629/comments | https://api.github.com/repos/huggingface/datasets/issues/3629/events | https://github.com/huggingface/datasets/pull/3629 | 1,113,971,575 | PR_kwDODunzps4xkCZA | 3,629 | Fix Hub repos update when there's a new release | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-01-25T14:39:45 | 2022-01-25T14:55:46 | 2022-01-25T14:55:46 | MEMBER | null | It was not listing the full list of datasets correctly
cc @SBrandeis this is why it failed for 1.18.0
We should be good now ! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3629/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3629/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3629",
"html_url": "https://github.com/huggingface/datasets/pull/3629",
"diff_url": "https://github.com/huggingface/datasets/pull/3629.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3629.patch",
"merged_at": "2022-01-25T14:55... | true |
https://api.github.com/repos/huggingface/datasets/issues/3627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3627/comments | https://api.github.com/repos/huggingface/datasets/issues/3627/events | https://github.com/huggingface/datasets/pull/3627 | 1,113,556,837 | PR_kwDODunzps4xitGe | 3,627 | Fix host URL in The Pile datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [] | 2022-01-25T08:11:28 | 2022-07-20T20:54:42 | 2022-02-14T08:40:58 | MEMBER | null | This PR fixes the host URL in The Pile datasets, once they have mirrored their data in another server.
Fix #3626. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3627/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3627/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3627",
"html_url": "https://github.com/huggingface/datasets/pull/3627",
"diff_url": "https://github.com/huggingface/datasets/pull/3627.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3627.patch",
"merged_at": "2022-02-14T08:40... | true |
https://api.github.com/repos/huggingface/datasets/issues/3626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3626/comments | https://api.github.com/repos/huggingface/datasets/issues/3626/events | https://github.com/huggingface/datasets/issues/3626 | 1,113,534,436 | I_kwDODunzps5CXy_k | 3,626 | The Pile cannot connect to host | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2022-01-25T07:43:33 | 2022-02-14T08:40:58 | 2022-02-14T08:40:58 | MEMBER | null | ## Describe the bug
The Pile had issues with their previous host server and have mirrored its content to another server.
The new URL server should be updated.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3626/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3626/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3623/comments | https://api.github.com/repos/huggingface/datasets/issues/3623/events | https://github.com/huggingface/datasets/pull/3623 | 1,112,835,239 | PR_kwDODunzps4xgWig | 3,623 | Extend support for streaming datasets that use os.path.relpath | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [] | 2022-01-24T16:00:52 | 2022-02-04T14:03:55 | 2022-02-04T14:03:54 | MEMBER | null | This PR extends the support in streaming mode for datasets that use `os.path.relpath`, by patching that function.
This feature will also be useful to yield the relative path of audio or image files, within an archive or parent dir.
Close #3622. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3623/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3623/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3623",
"html_url": "https://github.com/huggingface/datasets/pull/3623",
"diff_url": "https://github.com/huggingface/datasets/pull/3623.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3623.patch",
"merged_at": "2022-02-04T14:03... | true |
https://api.github.com/repos/huggingface/datasets/issues/3622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3622/comments | https://api.github.com/repos/huggingface/datasets/issues/3622/events | https://github.com/huggingface/datasets/issues/3622 | 1,112,831,661 | I_kwDODunzps5CVHat | 3,622 | Extend support for streaming datasets that use os.path.relpath | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2022-01-24T15:58:23 | 2022-02-04T14:03:54 | 2022-02-04T14:03:54 | MEMBER | null | Extend support for streaming datasets that use `os.path.relpath`.
This feature will also be useful to yield the relative path of audio or image files.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3622/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3622/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3621/comments | https://api.github.com/repos/huggingface/datasets/issues/3621/events | https://github.com/huggingface/datasets/issues/3621 | 1,112,720,434 | I_kwDODunzps5CUsQy | 3,621 | Consider adding `ipywidgets` as a dependency. | {
"login": "koaning",
"id": 1019791,
"node_id": "MDQ6VXNlcjEwMTk3OTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1019791?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/koaning",
"html_url": "https://github.com/koaning",
"followers_url": "https://api.github.com/users/koaning/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi! We use `tqdm` to display progress bars, so I suggest you open this issue in their repo.",
"It depends on how you use `tqdm`, no? \r\n\r\nDoesn't this library import via; \r\n\r\n```\r\nfrom tqdm.notebook import tqdm\r\n```",
"Hi! Sorry for the late reply. We import `tqdm` as `from tqdm.auto import tqdm`, w... | 2022-01-24T14:27:11 | 2022-02-24T09:04:36 | 2022-02-24T09:04:36 | NONE | null | When I install `datasets` in a fresh virtualenv with jupyterlab I always see this error.
```
ImportError: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
```
It's a bit of a nuisance, because I need to run shut down the jupyterlab ser... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3621/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3621/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3620/comments | https://api.github.com/repos/huggingface/datasets/issues/3620/events | https://github.com/huggingface/datasets/pull/3620 | 1,112,677,252 | PR_kwDODunzps4xf1J3 | 3,620 | Add Fon language tag | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [] | 2022-01-24T13:52:26 | 2022-02-04T14:04:36 | 2022-02-04T14:04:35 | MEMBER | null | Add Fon language tag to resources. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3620/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3620/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3620",
"html_url": "https://github.com/huggingface/datasets/pull/3620",
"diff_url": "https://github.com/huggingface/datasets/pull/3620.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3620.patch",
"merged_at": "2022-02-04T14:04... | true |
https://api.github.com/repos/huggingface/datasets/issues/3619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3619/comments | https://api.github.com/repos/huggingface/datasets/issues/3619/events | https://github.com/huggingface/datasets/pull/3619 | 1,112,611,415 | PR_kwDODunzps4xfnCQ | 3,619 | fix meta in mls | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | [] | 2022-01-24T12:54:38 | 2022-01-24T20:53:22 | 2022-01-24T20:53:22 | CONTRIBUTOR | null | `monolingual` value of `m ultilinguality` param in yaml meta was changed to `multilingual` :) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3619/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3619/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3619",
"html_url": "https://github.com/huggingface/datasets/pull/3619",
"diff_url": "https://github.com/huggingface/datasets/pull/3619.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3619.patch",
"merged_at": "2022-01-24T20:53... | true |
https://api.github.com/repos/huggingface/datasets/issues/3617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3617/comments | https://api.github.com/repos/huggingface/datasets/issues/3617/events | https://github.com/huggingface/datasets/pull/3617 | 1,111,938,691 | PR_kwDODunzps4xdb8K | 3,617 | PR for the CFPB Consumer Complaints dataset | {
"login": "kayvane1",
"id": 42403093,
"node_id": "MDQ6VXNlcjQyNDAzMDkz",
"avatar_url": "https://avatars.githubusercontent.com/u/42403093?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kayvane1",
"html_url": "https://github.com/kayvane1",
"followers_url": "https://api.github.com/users/kay... | [] | closed | false | null | [] | null | [] | 2022-01-23T17:47:12 | 2022-02-07T21:08:31 | 2022-02-07T21:08:31 | CONTRIBUTOR | null | Think I followed all the steps but please let me know if anything needs changing or any improvements I can make to the code quality | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3617/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3617/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3617",
"html_url": "https://github.com/huggingface/datasets/pull/3617",
"diff_url": "https://github.com/huggingface/datasets/pull/3617.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3617.patch",
"merged_at": "2022-02-07T21:08... | true |
https://api.github.com/repos/huggingface/datasets/issues/3616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3616/comments | https://api.github.com/repos/huggingface/datasets/issues/3616/events | https://github.com/huggingface/datasets/pull/3616 | 1,111,587,861 | PR_kwDODunzps4xcZMD | 3,616 | Make streamable the BnL Historical Newspapers dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [] | 2022-01-22T14:52:36 | 2022-02-04T14:05:23 | 2022-02-04T14:05:21 | MEMBER | null | I've refactored the code in order to make the dataset streamable and to avoid it takes too long:
- I've used `iter_files`
Close #3615 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3616/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3616/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3616",
"html_url": "https://github.com/huggingface/datasets/pull/3616",
"diff_url": "https://github.com/huggingface/datasets/pull/3616.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3616.patch",
"merged_at": "2022-02-04T14:05... | true |
https://api.github.com/repos/huggingface/datasets/issues/3615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3615/comments | https://api.github.com/repos/huggingface/datasets/issues/3615/events | https://github.com/huggingface/datasets/issues/3615 | 1,111,576,876 | I_kwDODunzps5CQVEs | 3,615 | Dataset BnL Historical Newspapers does not work in streaming mode | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"@albertvillanova let me know if there is anything I can do to help with this. I had a quick look at the code again and though I could try the following changes:\r\n- use `download` instead of `download_and_extract`\r\nhttps://github.com/huggingface/datasets/blob/d3d339fb86d378f4cb3c5d1de423315c07a466c6/datasets/bn... | 2022-01-22T14:12:59 | 2022-02-04T14:05:21 | 2022-02-04T14:05:21 | MEMBER | null | ## Describe the bug
When trying to load in streaming mode, it "hangs"...
## Steps to reproduce the bug
```python
ds = load_dataset("bnl_newspapers", split="train", streaming=True)
```
## Expected results
The code should be optimized, so that it works fast in streaming mode.
CC: @davanstrien
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3615/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3615/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3614/comments | https://api.github.com/repos/huggingface/datasets/issues/3614/events | https://github.com/huggingface/datasets/pull/3614 | 1,110,736,657 | PR_kwDODunzps4xZdCe | 3,614 | Minor fixes | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-01-21T17:48:44 | 2022-01-24T12:45:49 | 2022-01-24T12:45:49 | CONTRIBUTOR | null | This PR:
* adds "desc" to the `ignore_kwargs` list in `Dataset.filter`
* fixes the default value of `id` in `DatasetDict.prepare_for_task` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3614/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3614/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3614",
"html_url": "https://github.com/huggingface/datasets/pull/3614",
"diff_url": "https://github.com/huggingface/datasets/pull/3614.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3614.patch",
"merged_at": "2022-01-24T12:45... | true |
https://api.github.com/repos/huggingface/datasets/issues/3613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3613/comments | https://api.github.com/repos/huggingface/datasets/issues/3613/events | https://github.com/huggingface/datasets/issues/3613 | 1,110,684,015 | I_kwDODunzps5CM7Fv | 3,613 | Files not updating in dataset viewer | {
"login": "abidlabs",
"id": 1778297,
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abidlabs",
"html_url": "https://github.com/abidlabs",
"followers_url": "https://api.github.com/users/abidl... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"Yes. The jobs queue is full right now, following an upgrade... Back to normality in the next hours hopefully. I'll look at your datasets to be sure the dataset viewer works as expected on them.",
"Should have been fixed now."
] | 2022-01-21T16:47:20 | 2022-01-22T08:13:13 | 2022-01-22T08:13:13 | MEMBER | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:**
Some examples:
* https://huggingface.co/datasets/abidlabs/crowdsourced-speech4
* https://huggingface.co/datasets/abidlabs/test-audio-13
*short description of the issue*
It seems that the dataset viewer is reading a cached version of the dataset and... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3613/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3613/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3612/comments | https://api.github.com/repos/huggingface/datasets/issues/3612/events | https://github.com/huggingface/datasets/pull/3612 | 1,110,506,466 | PR_kwDODunzps4xYsvS | 3,612 | wikifix | {
"login": "apergo-ai",
"id": 68908804,
"node_id": "MDQ6VXNlcjY4OTA4ODA0",
"avatar_url": "https://avatars.githubusercontent.com/u/68908804?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/apergo-ai",
"html_url": "https://github.com/apergo-ai",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | [] | 2022-01-21T14:05:11 | 2022-02-03T17:58:16 | 2022-02-03T17:58:16 | CONTRIBUTOR | null | This should get the wikipedia dataloading script back up and running - at least I hope so (tested with language ff and ii) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3612/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3612/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3612",
"html_url": "https://github.com/huggingface/datasets/pull/3612",
"diff_url": "https://github.com/huggingface/datasets/pull/3612.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3612.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3611/comments | https://api.github.com/repos/huggingface/datasets/issues/3611/events | https://github.com/huggingface/datasets/issues/3611 | 1,110,399,096 | I_kwDODunzps5CL1h4 | 3,611 | Indexing bug after dataset.select() | {
"login": "kamalkraj",
"id": 17096858,
"node_id": "MDQ6VXNlcjE3MDk2ODU4",
"avatar_url": "https://avatars.githubusercontent.com/u/17096858?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kamalkraj",
"html_url": "https://github.com/kamalkraj",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [
"Hi! Thanks for reporting! I've opened a PR with the fix."
] | 2022-01-21T12:09:30 | 2022-01-27T18:16:22 | 2022-01-27T18:16:22 | NONE | null | ## Describe the bug
A clear and concise description of what the bug is.
Dataset indexing is not working as expected after `dataset.select(range(100))`
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
import datasets
task_to_keys = {
"cola": ("sentence", None),
"mnli":... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3611/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3611/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3610/comments | https://api.github.com/repos/huggingface/datasets/issues/3610/events | https://github.com/huggingface/datasets/issues/3610 | 1,109,777,314 | I_kwDODunzps5CJdui | 3,610 | Checksum error when trying to load amazon_review dataset | {
"login": "rifoag",
"id": 32415171,
"node_id": "MDQ6VXNlcjMyNDE1MTcx",
"avatar_url": "https://avatars.githubusercontent.com/u/32415171?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rifoag",
"html_url": "https://github.com/rifoag",
"followers_url": "https://api.github.com/users/rifoag/fo... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"It is solved now"
] | 2022-01-20T21:20:32 | 2022-01-21T13:22:31 | 2022-01-21T13:22:31 | NONE | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
I am getting the issue when trying to load dataset using
```
dataset = load_dataset("amazon_polarity")
```
## Expected results
dataset loaded
## Actual results
```
-------------------------------------... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3610/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3610/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3609/comments | https://api.github.com/repos/huggingface/datasets/issues/3609/events | https://github.com/huggingface/datasets/pull/3609 | 1,109,579,112 | PR_kwDODunzps4xVrsG | 3,609 | Fixes to pubmed dataset download function | {
"login": "spacemanidol",
"id": 3886120,
"node_id": "MDQ6VXNlcjM4ODYxMjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3886120?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spacemanidol",
"html_url": "https://github.com/spacemanidol",
"followers_url": "https://api.github.com... | [] | closed | false | null | [] | null | [] | 2022-01-20T17:31:35 | 2022-03-03T16:18:52 | 2022-03-03T14:23:35 | NONE | null | Pubmed has updated its settings for 2022 and thus existing download script does not work. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3609/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3609/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3609",
"html_url": "https://github.com/huggingface/datasets/pull/3609",
"diff_url": "https://github.com/huggingface/datasets/pull/3609.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3609.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3608/comments | https://api.github.com/repos/huggingface/datasets/issues/3608/events | https://github.com/huggingface/datasets/issues/3608 | 1,109,310,981 | I_kwDODunzps5CHr4F | 3,608 | Add support for continuous metrics (RMSE, MAE) | {
"login": "ck37",
"id": 50770,
"node_id": "MDQ6VXNlcjUwNzcw",
"avatar_url": "https://avatars.githubusercontent.com/u/50770?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ck37",
"html_url": "https://github.com/ck37",
"followers_url": "https://api.github.com/users/ck37/followers",
"follo... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | closed | false | null | [] | null | [
"Hey @ck37 \r\n\r\nYou can always use a custom metric as explained [in this guide from HF](https://huggingface.co/docs/datasets/master/loading_metrics.html#using-a-custom-metric-script).\r\n\r\nIf this issue needs to be contributed to (for enhancing the metric API) I think [this link](https://scikit-learn.org/stabl... | 2022-01-20T13:35:36 | 2022-03-09T17:18:20 | 2022-03-09T17:18:20 | NONE | null | **Is your feature request related to a problem? Please describe.**
I am uploading our dataset and models for the "Constructing interval measures" method we've developed, which uses item response theory to convert multiple discrete labels into a continuous spectrum for hate speech. Once we have this outcome our NLP m... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3608/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3608/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3607/comments | https://api.github.com/repos/huggingface/datasets/issues/3607/events | https://github.com/huggingface/datasets/pull/3607 | 1,109,218,370 | PR_kwDODunzps4xUgrR | 3,607 | Add MIT Scene Parsing Benchmark | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-01-20T12:03:07 | 2022-02-18T12:51:01 | 2022-02-18T12:51:00 | CONTRIBUTOR | null | Add MIT Scene Parsing Benchmark (a subset of ADE20k).
TODOs:
* [x] add dummy data
* [x] add dataset card
* [x] generate `dataset_info.json`
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3607/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3607/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3607",
"html_url": "https://github.com/huggingface/datasets/pull/3607",
"diff_url": "https://github.com/huggingface/datasets/pull/3607.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3607.patch",
"merged_at": "2022-02-18T12:51... | true |
https://api.github.com/repos/huggingface/datasets/issues/3606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3606/comments | https://api.github.com/repos/huggingface/datasets/issues/3606/events | https://github.com/huggingface/datasets/issues/3606 | 1,108,918,701 | I_kwDODunzps5CGMGt | 3,606 | audio column not saved correctly after resampling | {
"login": "laphang",
"id": 24724502,
"node_id": "MDQ6VXNlcjI0NzI0NTAy",
"avatar_url": "https://avatars.githubusercontent.com/u/24724502?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/laphang",
"html_url": "https://github.com/laphang",
"followers_url": "https://api.github.com/users/laphan... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! We just released a new version of `datasets` that should fix this.\r\n\r\nI tested resampling and using save/load_from_disk afterwards and it seems to be fixed now",
"Hi @lhoestq, \r\n\r\nJust tested the latest datasets version, and confirming that this is fixed for me. \r\n\r\nThanks!",
"Also, just an FY... | 2022-01-20T06:37:10 | 2022-01-23T01:41:01 | 2022-01-23T01:24:14 | NONE | null | ## Describe the bug
After resampling the audio column, saving with save_to_disk doesn't seem to save with the correct type.
## Steps to reproduce the bug
- load a subset of common voice dataset (48Khz)
- resample audio column to 16Khz
- save with save_to_disk()
- load with load_from_disk()
## Expected resul... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3606/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3606/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3605/comments | https://api.github.com/repos/huggingface/datasets/issues/3605/events | https://github.com/huggingface/datasets/pull/3605 | 1,108,738,561 | PR_kwDODunzps4xS9rX | 3,605 | Adding Turkic X-WMT evaluation set for machine translation | {
"login": "mirzakhalov",
"id": 26018417,
"node_id": "MDQ6VXNlcjI2MDE4NDE3",
"avatar_url": "https://avatars.githubusercontent.com/u/26018417?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mirzakhalov",
"html_url": "https://github.com/mirzakhalov",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | [] | 2022-01-20T01:40:29 | 2022-01-31T09:50:57 | 2022-01-31T09:50:57 | CONTRIBUTOR | null | This dataset is a human-translated evaluation set for MT crowdsourced and provided by the [Turkic Interlingua ](turkic-interlingua.org) community. It contains eval sets for 8 Turkic languages covering 88 language directions. Languages being covered are:
Azerbaijani (az)
Bashkir (ba)
English (en)
Karakalpak (kaa)
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3605/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3605/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3605",
"html_url": "https://github.com/huggingface/datasets/pull/3605",
"diff_url": "https://github.com/huggingface/datasets/pull/3605.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3605.patch",
"merged_at": "2022-01-31T09:50... | true |
https://api.github.com/repos/huggingface/datasets/issues/3604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3604/comments | https://api.github.com/repos/huggingface/datasets/issues/3604/events | https://github.com/huggingface/datasets/issues/3604 | 1,108,477,316 | I_kwDODunzps5CEgWE | 3,604 | Dataset Viewer not showing Previews for Private Datasets | {
"login": "abidlabs",
"id": 1778297,
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abidlabs",
"html_url": "https://github.com/abidlabs",
"followers_url": "https://api.github.com/users/abidl... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3470211881,
"node_id": "LA_k... | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"Sure, it's on the roadmap.",
"Closing in favor of https://github.com/huggingface/datasets-server/issues/39."
] | 2022-01-19T19:29:26 | 2022-09-26T08:04:43 | 2022-09-26T08:04:43 | MEMBER | null | ## Dataset viewer issue for 'abidlabs/test-audio-13'
It seems that the dataset viewer does not show previews for `private` datasets, even for the user who's private dataset it is. See [1] for example. If I change the visibility to public, then it does show, but it would be useful to have the viewer even for private ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3604/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3604/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3603 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3603/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3603/comments | https://api.github.com/repos/huggingface/datasets/issues/3603/events | https://github.com/huggingface/datasets/pull/3603 | 1,108,392,141 | PR_kwDODunzps4xR1ih | 3,603 | Add British Library books dataset | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | null | [] | 2022-01-19T17:53:05 | 2022-01-31T17:22:51 | 2022-01-31T17:01:49 | MEMBER | null | This pull request adds a dataset of text from digitised (primarily 19th Century) books from the British Library. This collection has previously been used for training language models, e.g. https://github.com/dbmdz/clef-hipe/blob/main/hlms.md. It would be nice to make this dataset more accessible for others to use throu... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3603/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3603/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3603",
"html_url": "https://github.com/huggingface/datasets/pull/3603",
"diff_url": "https://github.com/huggingface/datasets/pull/3603.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3603.patch",
"merged_at": "2022-01-31T17:01... | true |
https://api.github.com/repos/huggingface/datasets/issues/3602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3602/comments | https://api.github.com/repos/huggingface/datasets/issues/3602/events | https://github.com/huggingface/datasets/pull/3602 | 1,108,247,870 | PR_kwDODunzps4xRXVm | 3,602 | Update url for conll2003 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-01-19T15:35:04 | 2022-01-20T16:23:03 | 2022-01-19T15:43:53 | MEMBER | null | Following https://github.com/huggingface/datasets/issues/3582 I'm changing the download URL of the conll2003 data files, since the previous host doesn't have the authorization to redistribute the data | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3602/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3602/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3602",
"html_url": "https://github.com/huggingface/datasets/pull/3602",
"diff_url": "https://github.com/huggingface/datasets/pull/3602.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3602.patch",
"merged_at": "2022-01-19T15:43... | true |
https://api.github.com/repos/huggingface/datasets/issues/3601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3601/comments | https://api.github.com/repos/huggingface/datasets/issues/3601/events | https://github.com/huggingface/datasets/pull/3601 | 1,108,207,131 | PR_kwDODunzps4xROtF | 3,601 | Add conll2003 licensing | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-01-19T15:00:41 | 2022-01-19T17:17:28 | 2022-01-19T17:17:28 | MEMBER | null | Following https://github.com/huggingface/datasets/issues/3582, this PR updates the licensing section of the CoNLL2003 dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3601/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3601/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3601",
"html_url": "https://github.com/huggingface/datasets/pull/3601",
"diff_url": "https://github.com/huggingface/datasets/pull/3601.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3601.patch",
"merged_at": "2022-01-19T17:17... | true |
https://api.github.com/repos/huggingface/datasets/issues/3600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3600/comments | https://api.github.com/repos/huggingface/datasets/issues/3600/events | https://github.com/huggingface/datasets/pull/3600 | 1,108,131,878 | PR_kwDODunzps4xQ-vt | 3,600 | Use old url for conll2003 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-01-19T13:56:49 | 2022-01-19T14:16:28 | 2022-01-19T14:16:28 | MEMBER | null | As reported in https://github.com/huggingface/datasets/issues/3582 the CoNLL2003 data files are not available in the master branch of the repo that used to host them.
For now we can use the URL from an older commit to access the data files | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3600/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3600",
"html_url": "https://github.com/huggingface/datasets/pull/3600",
"diff_url": "https://github.com/huggingface/datasets/pull/3600.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3600.patch",
"merged_at": "2022-01-19T14:16... | true |
https://api.github.com/repos/huggingface/datasets/issues/3599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3599/comments | https://api.github.com/repos/huggingface/datasets/issues/3599/events | https://github.com/huggingface/datasets/issues/3599 | 1,108,111,607 | I_kwDODunzps5CDHD3 | 3,599 | The `add_column()` method does not work if used on dataset sliced with `select()` | {
"login": "ThGouzias",
"id": 59422506,
"node_id": "MDQ6VXNlcjU5NDIyNTA2",
"avatar_url": "https://avatars.githubusercontent.com/u/59422506?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ThGouzias",
"html_url": "https://github.com/ThGouzias",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [
"similar #3611 "
] | 2022-01-19T13:36:50 | 2022-01-28T15:35:57 | 2022-01-28T15:35:57 | NONE | null | Hello, I posted this as a question on the forums ([here](https://discuss.huggingface.co/t/add-column-does-not-work-if-used-on-dataset-sliced-with-select/13893)):
I have a dataset with 2000 entries
> dataset = Dataset.from_dict({'colA': list(range(2000))})
and from which I want to extract the first one thousan... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3599/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3599/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3598/comments | https://api.github.com/repos/huggingface/datasets/issues/3598/events | https://github.com/huggingface/datasets/issues/3598 | 1,108,107,199 | I_kwDODunzps5CDF-_ | 3,598 | Readme info not being parsed to show on Dataset card page | {
"login": "davidcanovas",
"id": 79796807,
"node_id": "MDQ6VXNlcjc5Nzk2ODA3",
"avatar_url": "https://avatars.githubusercontent.com/u/79796807?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidcanovas",
"html_url": "https://github.com/davidcanovas",
"followers_url": "https://api.github.c... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"i suspect a markdown parsing error, @severo do you want to take a quick look at it when you have some time?",
"# Problem\r\nThe issue seems to coming from the front matter of the README\r\n```---\r\nannotations_creators:\r\n- no-annotation\r\nlanguage_creators:\r\n- machine-generated\r\nlanguages:\r\n- 'ca'\r\n-... | 2022-01-19T13:32:29 | 2022-01-21T10:20:01 | 2022-01-21T10:20:01 | NONE | null | ## Describe the bug
The info contained in the README.md file is not being shown in the dataset main page. Basic info and table of contents are properly formatted in the README.
## Steps to reproduce the bug
# Sample code to reproduce the bug
The README file is this one: https://huggingface.co/datasets/softcatal... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3598/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3598/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3597/comments | https://api.github.com/repos/huggingface/datasets/issues/3597/events | https://github.com/huggingface/datasets/issues/3597 | 1,108,092,864 | I_kwDODunzps5CDCfA | 3,597 | ERROR: File "setup.py" or "setup.cfg" not found. Directory cannot be installed in editable mode: /content | {
"login": "amitkml",
"id": 49492030,
"node_id": "MDQ6VXNlcjQ5NDkyMDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/49492030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amitkml",
"html_url": "https://github.com/amitkml",
"followers_url": "https://api.github.com/users/amitkm... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi! The `cd` command in Jupyer/Colab needs to start with `%`, so this should work:\r\n```\r\n!git clone https://github.com/huggingface/datasets.git\r\n%cd datasets\r\n!pip install -e \".[streaming]\"\r\n```",
"thanks @mariosasko i had the same mistake and your solution is what was needed"
] | 2022-01-19T13:19:28 | 2022-08-05T12:35:51 | 2022-02-14T08:46:34 | NONE | null | ## Bug
The install of streaming dataset is giving following error.
## Steps to reproduce the bug
```python
! git clone https://github.com/huggingface/datasets.git
! cd datasets
! pip install -e ".[streaming]"
```
## Actual results
Cloning into 'datasets'...
remote: Enumerating objects: 50816, done.
remot... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3597/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3597/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3596/comments | https://api.github.com/repos/huggingface/datasets/issues/3596/events | https://github.com/huggingface/datasets/issues/3596 | 1,107,345,338 | I_kwDODunzps5CAL-6 | 3,596 | Loss of cast `Image` feature on certain dataset method | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/us... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi! Thanks for reporting! The issue with `cast_column` should be fixed by #3575 and after we merge that PR I'll start working on the `push_to_hub` support for the `Image`/`Audio` feature.",
"> Hi! Thanks for reporting! The issue with `cast_column` should be fixed by #3575 and after we merge that PR I'll start wo... | 2022-01-18T20:44:01 | 2022-01-21T18:07:28 | 2022-01-21T18:07:28 | MEMBER | null | ## Describe the bug
When an a column is cast to an `Image` feature, the cast type appears to be lost during certain operations. I first noticed this when using the `push_to_hub` method on a dataset that contained urls pointing to images which had been cast to an `image`. This also happens when using select on a data... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3596/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3596/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3595/comments | https://api.github.com/repos/huggingface/datasets/issues/3595/events | https://github.com/huggingface/datasets/pull/3595 | 1,107,260,527 | PR_kwDODunzps4xOIxH | 3,595 | Add ImageNet toy datasets from fastai | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | null | [] | null | [] | 2022-01-18T19:03:35 | 2022-09-30T14:39:35 | 2022-09-30T14:39:35 | CONTRIBUTOR | null | Adds the ImageNet toy datasets from FastAI: Imagenette, Imagewoof and Imagewang.
TODOs:
* [ ] add dummy data
* [ ] add dataset card
* [ ] generate `dataset_info.json` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3595/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3595/timeline | null | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3595",
"html_url": "https://github.com/huggingface/datasets/pull/3595",
"diff_url": "https://github.com/huggingface/datasets/pull/3595.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3595.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3594/comments | https://api.github.com/repos/huggingface/datasets/issues/3594/events | https://github.com/huggingface/datasets/pull/3594 | 1,107,174,619 | PR_kwDODunzps4xN3Kk | 3,594 | fix multiple language downloading in mC4 | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | [] | 2022-01-18T17:25:19 | 2022-01-19T11:22:57 | 2022-01-18T19:10:22 | CONTRIBUTOR | null | If we try to access multiple languages of the [mC4 dataset](https://github.com/huggingface/datasets/tree/master/datasets/mc4), it will throw an error. For example, if we do
```python
mc4_subset_two_langs = load_dataset("mc4", languages=["st", "su"])
```
we got
```
FileNotFoundError: Couldn't find file at https:/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3594/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3594/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3594",
"html_url": "https://github.com/huggingface/datasets/pull/3594",
"diff_url": "https://github.com/huggingface/datasets/pull/3594.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3594.patch",
"merged_at": "2022-01-18T19:10... | true |
https://api.github.com/repos/huggingface/datasets/issues/3593 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3593/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3593/comments | https://api.github.com/repos/huggingface/datasets/issues/3593/events | https://github.com/huggingface/datasets/pull/3593 | 1,107,070,852 | PR_kwDODunzps4xNhTu | 3,593 | Update README.md | {
"login": "borgr",
"id": 6416600,
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borgr",
"html_url": "https://github.com/borgr",
"followers_url": "https://api.github.com/users/borgr/follower... | [] | closed | false | null | [] | null | [] | 2022-01-18T15:52:16 | 2022-01-20T17:14:53 | 2022-01-20T17:14:53 | CONTRIBUTOR | null | Towards license of Tweet Eval parts | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3593/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3593/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3593",
"html_url": "https://github.com/huggingface/datasets/pull/3593",
"diff_url": "https://github.com/huggingface/datasets/pull/3593.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3593.patch",
"merged_at": "2022-01-20T17:14... | true |
https://api.github.com/repos/huggingface/datasets/issues/3592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3592/comments | https://api.github.com/repos/huggingface/datasets/issues/3592/events | https://github.com/huggingface/datasets/pull/3592 | 1,107,026,723 | PR_kwDODunzps4xNYIW | 3,592 | Add QuickDraw dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-01-18T15:13:39 | 2022-06-09T10:04:54 | 2022-06-09T09:56:13 | CONTRIBUTOR | null | Add the QuickDraw dataset.
TODOs:
* [x] add dummy data
* [x] add dataset card
* [x] generate `dataset_info.json` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3592/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3592/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3592",
"html_url": "https://github.com/huggingface/datasets/pull/3592",
"diff_url": "https://github.com/huggingface/datasets/pull/3592.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3592.patch",
"merged_at": "2022-06-09T09:56... | true |
https://api.github.com/repos/huggingface/datasets/issues/3591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3591/comments | https://api.github.com/repos/huggingface/datasets/issues/3591/events | https://github.com/huggingface/datasets/pull/3591 | 1,106,928,613 | PR_kwDODunzps4xNDoB | 3,591 | Add support for time, date, duration, and decimal dtypes | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 2022-01-18T13:46:05 | 2022-01-31T18:29:34 | 2022-01-20T17:37:33 | CONTRIBUTOR | null | Add support for the pyarrow time (maps to `datetime.time` in python), date (maps to `datetime.time` in python), duration (maps to `datetime.timedelta` in python), and decimal (maps to `decimal.decimal` in python) dtypes. This should be helpful when writing scripts for time-series datasets. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3591/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3591",
"html_url": "https://github.com/huggingface/datasets/pull/3591",
"diff_url": "https://github.com/huggingface/datasets/pull/3591.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3591.patch",
"merged_at": "2022-01-20T17:37... | true |
https://api.github.com/repos/huggingface/datasets/issues/3590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3590/comments | https://api.github.com/repos/huggingface/datasets/issues/3590/events | https://github.com/huggingface/datasets/pull/3590 | 1,106,784,860 | PR_kwDODunzps4xMlGg | 3,590 | Update ANLI README.md | {
"login": "borgr",
"id": 6416600,
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borgr",
"html_url": "https://github.com/borgr",
"followers_url": "https://api.github.com/users/borgr/follower... | [] | closed | false | null | [] | null | [] | 2022-01-18T11:22:53 | 2022-01-20T16:58:41 | 2022-01-20T16:58:41 | CONTRIBUTOR | null | Update license and little things concerning ANLI | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3590/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3590/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3590",
"html_url": "https://github.com/huggingface/datasets/pull/3590",
"diff_url": "https://github.com/huggingface/datasets/pull/3590.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3590.patch",
"merged_at": "2022-01-20T16:58... | true |
https://api.github.com/repos/huggingface/datasets/issues/3589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3589/comments | https://api.github.com/repos/huggingface/datasets/issues/3589/events | https://github.com/huggingface/datasets/pull/3589 | 1,106,766,114 | PR_kwDODunzps4xMhGp | 3,589 | Pin torchmetrics to fix the COMET test | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-01-18T11:03:49 | 2022-01-18T11:04:56 | 2022-01-18T11:04:55 | MEMBER | null | Torchmetrics 0.7.0 got released and has issues with `transformers` (see https://github.com/PyTorchLightning/metrics/issues/770)
I'm pinning it to 0.6.0 in the CI, since 0.7.0 makes the COMET metric test fail. COMET requires torchmetrics==0.6.0 anyway. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3589/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3589/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3589",
"html_url": "https://github.com/huggingface/datasets/pull/3589",
"diff_url": "https://github.com/huggingface/datasets/pull/3589.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3589.patch",
"merged_at": "2022-01-18T11:04... | true |
https://api.github.com/repos/huggingface/datasets/issues/3588 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3588/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3588/comments | https://api.github.com/repos/huggingface/datasets/issues/3588/events | https://github.com/huggingface/datasets/pull/3588 | 1,106,749,000 | PR_kwDODunzps4xMdiC | 3,588 | Update HellaSwag README.md | {
"login": "borgr",
"id": 6416600,
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borgr",
"html_url": "https://github.com/borgr",
"followers_url": "https://api.github.com/users/borgr/follower... | [] | closed | false | null | [] | null | [] | 2022-01-18T10:46:15 | 2022-01-20T16:57:43 | 2022-01-20T16:57:43 | CONTRIBUTOR | null | Adding information from the git repo and paper that were missing | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3588/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3588/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3588",
"html_url": "https://github.com/huggingface/datasets/pull/3588",
"diff_url": "https://github.com/huggingface/datasets/pull/3588.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3588.patch",
"merged_at": "2022-01-20T16:57... | true |
https://api.github.com/repos/huggingface/datasets/issues/3587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3587/comments | https://api.github.com/repos/huggingface/datasets/issues/3587/events | https://github.com/huggingface/datasets/issues/3587 | 1,106,719,182 | I_kwDODunzps5B9zHO | 3,587 | No module named 'fsspec.archive' | {
"login": "shuuchen",
"id": 13246825,
"node_id": "MDQ6VXNlcjEzMjQ2ODI1",
"avatar_url": "https://avatars.githubusercontent.com/u/13246825?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shuuchen",
"html_url": "https://github.com/shuuchen",
"followers_url": "https://api.github.com/users/shu... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [] | 2022-01-18T10:17:01 | 2022-08-11T09:57:54 | 2022-01-18T10:33:10 | NONE | null | ## Describe the bug
Cannot import datasets after installation.
## Steps to reproduce the bug
```shell
$ python
Python 3.9.7 (default, Sep 16 2021, 13:09:58)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import datasets
Traceback (most recent... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3587/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3587/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3586/comments | https://api.github.com/repos/huggingface/datasets/issues/3586/events | https://github.com/huggingface/datasets/issues/3586 | 1,106,455,672 | I_kwDODunzps5B8yx4 | 3,586 | Revisit `enable/disable_` toggle function prefix | {
"login": "jaketae",
"id": 25360440,
"node_id": "MDQ6VXNlcjI1MzYwNDQw",
"avatar_url": "https://avatars.githubusercontent.com/u/25360440?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jaketae",
"html_url": "https://github.com/jaketae",
"followers_url": "https://api.github.com/users/jaketa... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [] | 2022-01-18T04:09:55 | 2022-03-14T15:01:08 | 2022-03-14T15:01:08 | CONTRIBUTOR | null | As discussed in https://github.com/huggingface/transformers/pull/15167, we should revisit the `enable/disable_` toggle function prefix, potentially in favor of `set_enabled_`. Concretely, this translates to
- De-deprecating `disable_progress_bar()`
- Adding `enable_progress_bar()`
- On the caching side, adding `en... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3586/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3586/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3585/comments | https://api.github.com/repos/huggingface/datasets/issues/3585/events | https://github.com/huggingface/datasets/issues/3585 | 1,105,821,470 | I_kwDODunzps5B6X8e | 3,585 | Datasets streaming + map doesn't work for `Audio` | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892865,
"node_id": "MDU6TGFiZWwxOTM1ODk... | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"This seems related to https://github.com/huggingface/datasets/issues/3505."
] | 2022-01-17T12:55:42 | 2022-01-20T13:28:00 | 2022-01-20T13:28:00 | MEMBER | null | ## Describe the bug
When using audio datasets in streaming mode, applying a `map(...)` before iterating leads to an error as the key `array` does not exist anymore.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "en", streaming=True, split="train")... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3585/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3585/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3584/comments | https://api.github.com/repos/huggingface/datasets/issues/3584/events | https://github.com/huggingface/datasets/issues/3584 | 1,105,231,768 | I_kwDODunzps5B4H-Y | 3,584 | https://huggingface.co/datasets/huggingface/transformers-metadata | {
"login": "ecankirkic",
"id": 37082592,
"node_id": "MDQ6VXNlcjM3MDgyNTky",
"avatar_url": "https://avatars.githubusercontent.com/u/37082592?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ecankirkic",
"html_url": "https://github.com/ecankirkic",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892913,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": "This will not be worked on"
},
{
"id": 3470211881,
"node_id": "LA_kwDOD... | closed | false | null | [] | null | [] | 2022-01-17T00:18:14 | 2022-02-14T08:51:27 | 2022-02-14T08:51:27 | NONE | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3584/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3584/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3582/comments | https://api.github.com/repos/huggingface/datasets/issues/3582/events | https://github.com/huggingface/datasets/issues/3582 | 1,104,877,303 | I_kwDODunzps5B2xb3 | 3,582 | conll 2003 dataset source url is no longer valid | {
"login": "rcanand",
"id": 303900,
"node_id": "MDQ6VXNlcjMwMzkwMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/303900?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rcanand",
"html_url": "https://github.com/rcanand",
"followers_url": "https://api.github.com/users/rcanand/fo... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [
"I came to open the same issue.",
"Thanks for reporting !\r\n\r\nI pushed a temporary fix on `master` that uses an URL from a previous commit to access the dataset for now, until we have a better solution",
"I changed the URL again to use another host, the fix is available on `master` and we'll probably do a ne... | 2022-01-15T23:04:17 | 2022-07-20T13:06:40 | 2022-01-21T16:57:32 | NONE | null | ## Describe the bug
Loading `conll2003` dataset fails because it was removed (just yesterday 1/14/2022) from the location it is looking for.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("conll2003")
```
## Expected results
The dataset should load.
## Actual r... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3582/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 5,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3582/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3580/comments | https://api.github.com/repos/huggingface/datasets/issues/3580/events | https://github.com/huggingface/datasets/issues/3580 | 1,104,663,242 | I_kwDODunzps5B19LK | 3,580 | Bug in wiki bio load | {
"login": "tuhinjubcse",
"id": 3104771,
"node_id": "MDQ6VXNlcjMxMDQ3NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuhinjubcse",
"html_url": "https://github.com/tuhinjubcse",
"followers_url": "https://api.github.com/us... | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | null | [] | null | [
"+1, here's the error I got: \r\n\r\n```\r\n>>> from datasets import load_dataset\r\n>>>\r\n>>> load_dataset(\"wiki_bio\")\r\nDownloading: 7.58kB [00:00, 4.42MB/s]\r\nDownloading: 2.71kB [00:00, 1.30MB/s]\r\nUsing custom data configuration default\r\nDownloading and preparing dataset wiki_bio/default (download: 318... | 2022-01-15T10:04:33 | 2022-01-31T08:38:09 | 2022-01-31T08:38:09 | NONE | null |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
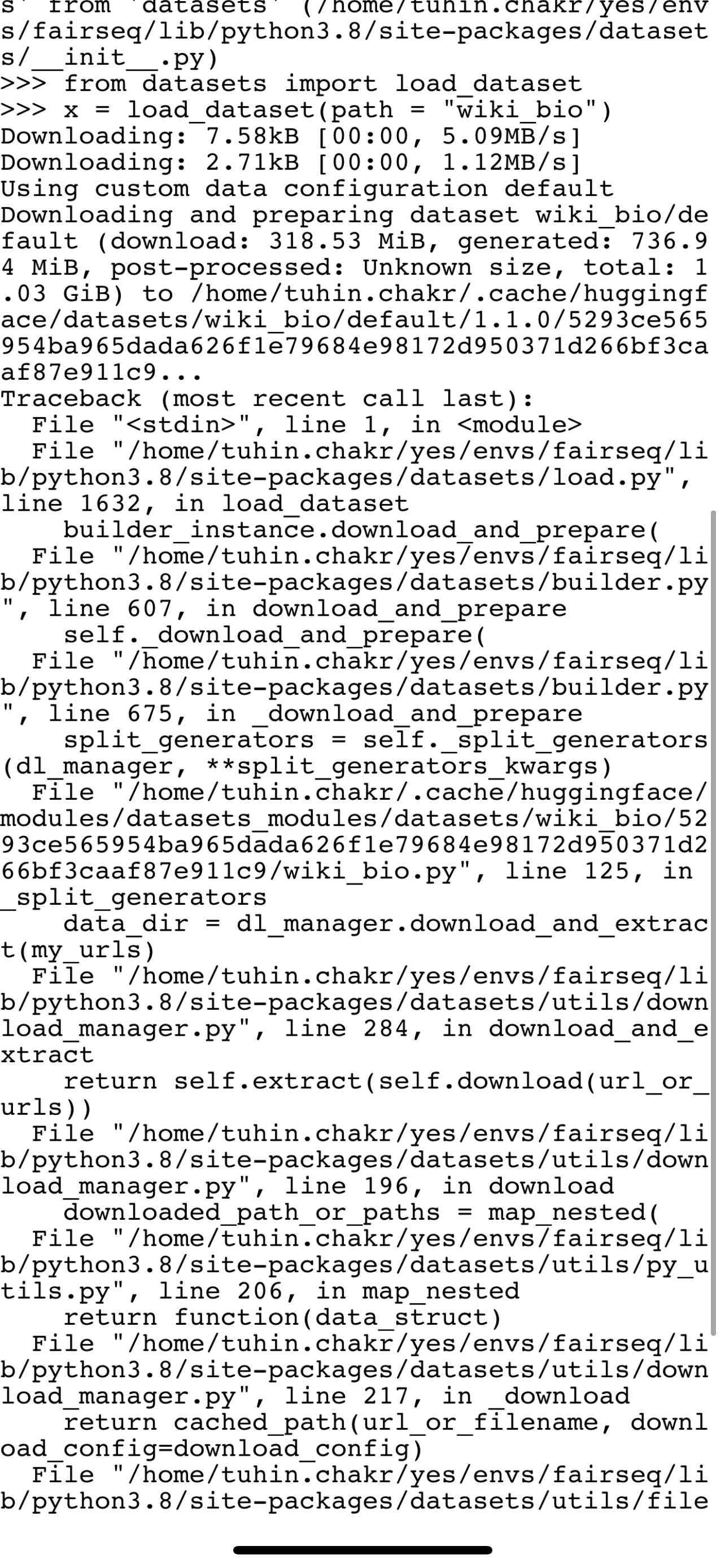
.
3... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3575/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 2,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3575/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3575",
"html_url": "https://github.com/huggingface/datasets/pull/3575",
"diff_url": "https://github.com/huggingface/datasets/pull/3575.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3575.patch",
"merged_at": "2022-01-21T13:22... | true |
https://api.github.com/repos/huggingface/datasets/issues/3574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3574/comments | https://api.github.com/repos/huggingface/datasets/issues/3574/events | https://github.com/huggingface/datasets/pull/3574 | 1,101,781,401 | PR_kwDODunzps4w7vu6 | 3,574 | Fix qa4mre tags | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 2022-01-13T13:56:59 | 2022-01-13T14:03:02 | 2022-01-13T14:03:01 | MEMBER | null | The YAML tags were invalid. I also fixed the dataset mirroring logging that failed because of this issue [here](https://github.com/huggingface/datasets/actions/runs/1690109581) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3574/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3574/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3574",
"html_url": "https://github.com/huggingface/datasets/pull/3574",
"diff_url": "https://github.com/huggingface/datasets/pull/3574.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3574.patch",
"merged_at": "2022-01-13T14:03... | true |
https://api.github.com/repos/huggingface/datasets/issues/3573 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3573/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3573/comments | https://api.github.com/repos/huggingface/datasets/issues/3573/events | https://github.com/huggingface/datasets/pull/3573 | 1,101,157,676 | PR_kwDODunzps4w5oE_ | 3,573 | Add Mauve metric | {
"login": "jthickstun",
"id": 2321244,
"node_id": "MDQ6VXNlcjIzMjEyNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2321244?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jthickstun",
"html_url": "https://github.com/jthickstun",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | null | [] | 2022-01-13T03:52:48 | 2022-01-20T15:00:08 | 2022-01-20T15:00:08 | CONTRIBUTOR | null | Add support for the [Mauve](https://github.com/krishnap25/mauve) metric introduced in this [paper](https://arxiv.org/pdf/2102.01454.pdf) (Neurips, 2021). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3573/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3573/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3573",
"html_url": "https://github.com/huggingface/datasets/pull/3573",
"diff_url": "https://github.com/huggingface/datasets/pull/3573.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3573.patch",
"merged_at": "2022-01-20T15:00... | true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.