
pipeline_tag stringclasses 48
values | library_name stringclasses 198
values | text stringlengths 1 900k | metadata stringlengths 2 438k | id stringlengths 5 122 | last_modified null | tags listlengths 1 1.84k | sha null | created_at stringlengths 25 25 | arxiv listlengths 0 201 | languages listlengths 0 1.83k | tags_str stringlengths 17 9.34k | text_str stringlengths 0 389k | text_lists listlengths 0 722 | processed_texts listlengths 1 723 | tokens_length listlengths 1 723 | input_texts listlengths 1 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-4B - bnb 8bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qwen1.5-4... | {} | RichardErkhov/Qwen_-_Qwen1.5-4B-8bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null | 2024-04-30T19:08:55+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-4B - bnb 8bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen-research
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- pretrained
-... | [
"# Qwen1.5-4B",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include:\n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense models, ... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n",
"# Qwen1.5-4B",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large ... | [
42,
9,
160,
119,
44,
66
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n# Qwen1.5-4B## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of da... |
image-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swinv2-base-patch4-window12to16-192to256-22kto1k-ft-finetuned-footulcer
This model is a fine-tuned version of [microsoft/swinv2-... | {"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["imagefolder"], "metrics": ["accuracy"], "base_model": "microsoft/swinv2-base-patch4-window12to16-192to256-22kto1k-ft", "model-index": [{"name": "swinv2-base-patch4-window12to16-192to256-22kto1k-ft-finetuned-footulcer", "results": [{"task": {"ty... | Nitish2801/swinv2-base-patch4-window12to16-192to256-22kto1k-ft-finetuned-footulcer | null | [
"transformers",
"tensorboard",
"safetensors",
"swinv2",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/swinv2-base-patch4-window12to16-192to256-22kto1k-ft",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"r... | null | 2024-04-30T19:09:54+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #swinv2 #image-classification #generated_from_trainer #dataset-imagefolder #base_model-microsoft/swinv2-base-patch4-window12to16-192to256-22kto1k-ft #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
| swinv2-base-patch4-window12to16-192to256-22kto1k-ft-finetuned-footulcer
=======================================================================
This model is a fine-tuned version of microsoft/swinv2-base-patch4-window12to16-192to256-22kto1k-ft on the imagefolder dataset.
It achieves the following results on the evalu... | [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 4\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1... | [
"TAGS\n#transformers #tensorboard #safetensors #swinv2 #image-classification #generated_from_trainer #dataset-imagefolder #base_model-microsoft/swinv2-base-patch4-window12to16-192to256-22kto1k-ft #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparame... | [
92,
142,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #swinv2 #image-classification #generated_from_trainer #dataset-imagefolder #base_model-microsoft/swinv2-base-patch4-window12to16-192to256-22kto1k-ft #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n### Training hyperparameters\n... |
depth-estimation | transformers |
# ZoeDepth (fine-tuned on NYU)
ZoeDepth model fine-tuned on the NYU dataset. It was introduced in the paper [ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth](https://arxiv.org/abs/2302.12288) by Shariq et al. and first released in [this repository](https://github.com/isl-org/ZoeDepth).
ZoeDepth ... | {"license": "mit", "tags": ["vision"], "pipeline_tag": "depth-estimation"} | Intel/zoedepth-nyu | null | [
"transformers",
"safetensors",
"zoedepth",
"vision",
"depth-estimation",
"arxiv:2302.12288",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:10:04+00:00 | [
"2302.12288"
] | [] | TAGS
#transformers #safetensors #zoedepth #vision #depth-estimation #arxiv-2302.12288 #license-mit #endpoints_compatible #region-us
|
# ZoeDepth (fine-tuned on NYU)
ZoeDepth model fine-tuned on the NYU dataset. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth by Shariq et al. and first released in this repository.
ZoeDepth extends the DPT framework for metric (also called absolute) depth estimatio... | [
"# ZoeDepth (fine-tuned on NYU) \n\nZoeDepth model fine-tuned on the NYU dataset. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth by Shariq et al. and first released in this repository.\n\nZoeDepth extends the DPT framework for metric (also called absolute) depth e... | [
"TAGS\n#transformers #safetensors #zoedepth #vision #depth-estimation #arxiv-2302.12288 #license-mit #endpoints_compatible #region-us \n",
"# ZoeDepth (fine-tuned on NYU) \n\nZoeDepth model fine-tuned on the NYU dataset. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relative and Metric ... | [
42,
123,
99,
39,
34,
10
] | [
"TAGS\n#transformers #safetensors #zoedepth #vision #depth-estimation #arxiv-2302.12288 #license-mit #endpoints_compatible #region-us \n# ZoeDepth (fine-tuned on NYU) \n\nZoeDepth model fine-tuned on the NYU dataset. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth ... |
null | null |
# MergerixExperiment26-7B
MergerixExperiment26-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
## 🧩 Configuration
```yaml
models:
- model: mistralai/Mistral-7B-v0.1
- model: MiniMoog/Mergerix-7b-v0.3
- model: yam-peleg/Experiment26-7B
m... | {"license": "apache-2.0", "tags": ["merge", "mergekit", "lazymergekit", "automerger"]} | automerger/MergerixExperiment26-7B | null | [
"merge",
"mergekit",
"lazymergekit",
"automerger",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T19:11:49+00:00 | [] | [] | TAGS
#merge #mergekit #lazymergekit #automerger #license-apache-2.0 #region-us
|
# MergerixExperiment26-7B
MergerixExperiment26-7B is an automated merge created by Maxime Labonne using the following configuration.
## Configuration
## Usage
| [
"# MergerixExperiment26-7B\n\nMergerixExperiment26-7B is an automated merge created by Maxime Labonne using the following configuration.",
"## Configuration",
"## Usage"
] | [
"TAGS\n#merge #mergekit #lazymergekit #automerger #license-apache-2.0 #region-us \n",
"# MergerixExperiment26-7B\n\nMergerixExperiment26-7B is an automated merge created by Maxime Labonne using the following configuration.",
"## Configuration",
"## Usage"
] | [
27,
36,
3,
3
] | [
"TAGS\n#merge #mergekit #lazymergekit #automerger #license-apache-2.0 #region-us \n# MergerixExperiment26-7B\n\nMergerixExperiment26-7B is an automated merge created by Maxime Labonne using the following configuration.## Configuration## Usage"
] |
reinforcement-learning | stable-baselines3 |
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 ... | {"library_name": "stable-baselines3", "tags": ["LunarLander-v2", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "PPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "LunarLander-v2", "type": "LunarL... | Leevroko/ppo-LunarLander-v2 | null | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | null | 2024-04-30T19:11:55+00:00 | [] | [] | TAGS
#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
# PPO Agent playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2
using the stable-baselines3 library.
## Usage (with Stable-baselines3)
TODO: Add your code
| [
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] | [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add you... | [
31,
35,
17
] | [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.## Usage (with Stable-baselines3)\nTODO: Add your code"
] |
text-generation | mlx |
# batmac/Phi-3-mini-128k-instruct-mlx-4bit
This model was converted to MLX format from [`microsoft/Phi-3-mini-128k-instruct`]() using mlx-lm version **0.12.0**.
Refer to the [original model card](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) for more details on the model.
## Use with mlx
```bash
pip inst... | {"language": ["en"], "license": "mit", "tags": ["nlp", "code", "mlx"], "license_link": "https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/resolve/main/LICENSE", "pipeline_tag": "text-generation", "widget": [{"messages": [{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragon... | batmac/Phi-3-mini-128k-instruct-mlx-4bit | null | [
"mlx",
"safetensors",
"phi3",
"nlp",
"code",
"text-generation",
"conversational",
"custom_code",
"en",
"license:mit",
"region:us"
] | null | 2024-04-30T19:12:34+00:00 | [] | [
"en"
] | TAGS
#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us
|
# batmac/Phi-3-mini-128k-instruct-mlx-4bit
This model was converted to MLX format from ['microsoft/Phi-3-mini-128k-instruct']() using mlx-lm version 0.12.0.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# batmac/Phi-3-mini-128k-instruct-mlx-4bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-128k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us \n",
"# batmac/Phi-3-mini-128k-instruct-mlx-4bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-128k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card ... | [
37,
75,
6
] | [
"TAGS\n#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us \n# batmac/Phi-3-mini-128k-instruct-mlx-4bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-128k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for mo... |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": ["trl", "sft"]} | EdBerg/Llama3_b_finance_finetuned_test | null | [
"transformers",
"safetensors",
"trl",
"sft",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:12:45+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #trl #sft #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #trl #sft #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\... | [
32,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #trl #sft #arxiv-1910.09700 #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by:... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-7B - bnb 8bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qwen1.5-7... | {} | RichardErkhov/Qwen_-_Qwen1.5-7B-8bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null | 2024-04-30T19:12:51+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-7B - bnb 8bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- pretrained
---
# Qwe... | [
"# Qwen1.5-7B",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include:\n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense models, ... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n",
"# Qwen1.5-7B",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large ... | [
42,
9,
160,
119,
44,
66
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n# Qwen1.5-7B## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of da... |
text-generation | mlx |
# batmac/Phi-3-mini-128k-instruct-mlx-8bit
This model was converted to MLX format from [`microsoft/Phi-3-mini-128k-instruct`]() using mlx-lm version **0.12.0**.
Refer to the [original model card](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) for more details on the model.
## Use with mlx
```bash
pip inst... | {"language": ["en"], "license": "mit", "tags": ["nlp", "code", "mlx"], "license_link": "https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/resolve/main/LICENSE", "pipeline_tag": "text-generation", "widget": [{"messages": [{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragon... | batmac/Phi-3-mini-128k-instruct-mlx-8bit | null | [
"mlx",
"safetensors",
"phi3",
"nlp",
"code",
"text-generation",
"conversational",
"custom_code",
"en",
"license:mit",
"region:us"
] | null | 2024-04-30T19:15:10+00:00 | [] | [
"en"
] | TAGS
#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us
|
# batmac/Phi-3-mini-128k-instruct-mlx-8bit
This model was converted to MLX format from ['microsoft/Phi-3-mini-128k-instruct']() using mlx-lm version 0.12.0.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# batmac/Phi-3-mini-128k-instruct-mlx-8bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-128k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us \n",
"# batmac/Phi-3-mini-128k-instruct-mlx-8bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-128k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card ... | [
37,
75,
6
] | [
"TAGS\n#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us \n# batmac/Phi-3-mini-128k-instruct-mlx-8bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-128k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for mo... |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llava-1.5-7b-hf-ft-mix-vsft
This model is a fine-tuned version of [llava-hf/llava-1.5-7b-hf](https://huggingface.co/llava-hf/lla... | {"library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["imagefolder"], "base_model": "llava-hf/llava-1.5-7b-hf", "model-index": [{"name": "llava-1.5-7b-hf-ft-mix-vsft", "results": []}]} | rakitha/llava-1.5-7b-hf-ft-mix-vsft | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:llava-hf/llava-1.5-7b-hf",
"region:us"
] | null | 2024-04-30T19:17:37+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-imagefolder #base_model-llava-hf/llava-1.5-7b-hf #region-us
|
# llava-1.5-7b-hf-ft-mix-vsft
This model is a fine-tuned version of llava-hf/llava-1.5-7b-hf on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Train... | [
"# llava-1.5-7b-hf-ft-mix-vsft\n\nThis model is a fine-tuned version of llava-hf/llava-1.5-7b-hf on the imagefolder dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Tra... | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-imagefolder #base_model-llava-hf/llava-1.5-7b-hf #region-us \n",
"# llava-1.5-7b-hf-ft-mix-vsft\n\nThis model is a fine-tuned version of llava-hf/llava-1.5-7b-hf on the imagefolder dataset.",
"## Model description\n\nMore informat... | [
57,
55,
7,
9,
9,
4,
104,
5,
52
] | [
"TAGS\n#peft #tensorboard #safetensors #trl #sft #generated_from_trainer #dataset-imagefolder #base_model-llava-hf/llava-1.5-7b-hf #region-us \n# llava-1.5-7b-hf-ft-mix-vsft\n\nThis model is a fine-tuned version of llava-hf/llava-1.5-7b-hf on the imagefolder dataset.## Model description\n\nMore information needed##... |
text-generation | null | <a href="https://www.gradient.ai" target="_blank"><img src="https://cdn-uploads.huggingface.co/production/uploads/655bb613e8a8971e89944f3e/TSa3V8YpoVagnTYgxiLaO.png" width="200"/></a>
# Llama-3 8B Gradient Instruct 1048k
Gradient incorporates your data to deploy autonomous assistants that power critical operations acr... | {"language": ["en"], "license": "llama3", "tags": ["meta", "llama-3"], "pipeline_tag": "text-generation"} | LoneStriker/Llama-3-8B-Instruct-Gradient-1048k-GGUF | null | [
"gguf",
"meta",
"llama-3",
"text-generation",
"en",
"license:llama3",
"region:us"
] | null | 2024-04-30T19:18:07+00:00 | [] | [
"en"
] | TAGS
#gguf #meta #llama-3 #text-generation #en #license-llama3 #region-us
| [<img src="URL width="200"/>](URL)
Llama-3 8B Gradient Instruct 1048k
==================================
Gradient incorporates your data to deploy autonomous assistants that power critical operations across your business. If you're looking to build custom AI models or agents, email us a message contact@URL.
For m... | [
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the 'generate()' function. Let's see examples of both.",
"#### Transformers pipeline",
"#### Transformers AutoModelForCausalLM",
"### Use with 'llama3'\n\n\n... | [
"TAGS\n#gguf #meta #llama-3 #text-generation #en #license-llama3 #region-us \n",
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the 'generate()' function. Let's see examples of both.",
"#### Transformers pi... | [
28,
42,
6,
13,
429,
8,
6,
270,
280,
72,
115,
118,
126,
2136
] | [
"TAGS\n#gguf #meta #llama-3 #text-generation #en #license-llama3 #region-us \n### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the 'generate()' function. Let's see examples of both.#### Transformers pipeline#### T... |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | nem012/gemma2b-1e-5r8 | null | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T19:18:11+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #gemma #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #gemma #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed... | [
43,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #gemma #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This ... |
text-generation | mlx |
# batmac/Meta-Llama-3-8B-Instruct-mlx-4bit
This model was converted to MLX format from [`meta-llama/Meta-Llama-3-8B-Instruct`]() using mlx-lm version **0.12.0**.
Refer to the [original model card](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) for more details on the model.
## Use with mlx
```bash
pip in... | {"language": ["en"], "license": "other", "tags": ["facebook", "meta", "pytorch", "llama", "llama-3", "mlx"], "pipeline_tag": "text-generation", "license_name": "llama3", "license_link": "LICENSE", "extra_gated_prompt": "### META LLAMA 3 COMMUNITY LICENSE AGREEMENT\nMeta Llama 3 Version Release Date: April 18, 2024\n\"A... | batmac/Meta-Llama-3-8B-Instruct-mlx-4bit | null | [
"mlx",
"safetensors",
"llama",
"facebook",
"meta",
"pytorch",
"llama-3",
"text-generation",
"conversational",
"en",
"license:other",
"region:us"
] | null | 2024-04-30T19:20:57+00:00 | [] | [
"en"
] | TAGS
#mlx #safetensors #llama #facebook #meta #pytorch #llama-3 #text-generation #conversational #en #license-other #region-us
|
# batmac/Meta-Llama-3-8B-Instruct-mlx-4bit
This model was converted to MLX format from ['meta-llama/Meta-Llama-3-8B-Instruct']() using mlx-lm version 0.12.0.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# batmac/Meta-Llama-3-8B-Instruct-mlx-4bit\nThis model was converted to MLX format from ['meta-llama/Meta-Llama-3-8B-Instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#mlx #safetensors #llama #facebook #meta #pytorch #llama-3 #text-generation #conversational #en #license-other #region-us \n",
"# batmac/Meta-Llama-3-8B-Instruct-mlx-4bit\nThis model was converted to MLX format from ['meta-llama/Meta-Llama-3-8B-Instruct']() using mlx-lm version 0.12.0.\nRefer to the origin... | [
42,
80,
6
] | [
"TAGS\n#mlx #safetensors #llama #facebook #meta #pytorch #llama-3 #text-generation #conversational #en #license-other #region-us \n# batmac/Meta-Llama-3-8B-Instruct-mlx-4bit\nThis model was converted to MLX format from ['meta-llama/Meta-Llama-3-8B-Instruct']() using mlx-lm version 0.12.0.\nRefer to the original mod... |
text-classification | transformers |
# VulBERTa MLP Devign
## VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection
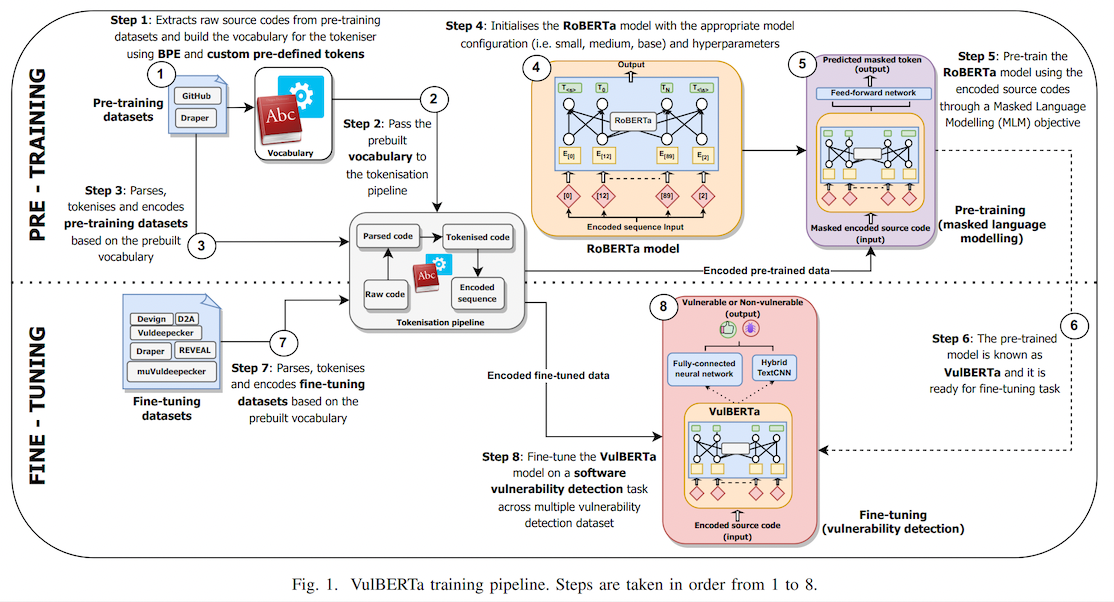
## Overview
This model is the unofficial HuggingFace version of "[VulBERTa](https://github.com/ICL-ml4csec/VulBERTa/tree/main... | {"license": "mit", "tags": ["devign", "defect detection", "code"], "datasets": ["code_x_glue_cc_defect_detection"], "metrics": ["accuracy", "precision", "recall", "f1", "roc_auc"], "arxiv": 2205.12424, "pipeline_tag": "text-classification", "model-index": [{"name": "VulBERTa MLP", "results": [{"task": {"type": "defect-... | claudios/VulBERTa-mlm | null | [
"transformers",
"safetensors",
"roberta",
"fill-mask",
"devign",
"defect detection",
"code",
"text-classification",
"dataset:code_x_glue_cc_defect_detection",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:21:44+00:00 | [] | [] | TAGS
#transformers #safetensors #roberta #fill-mask #devign #defect detection #code #text-classification #dataset-code_x_glue_cc_defect_detection #license-mit #model-index #autotrain_compatible #endpoints_compatible #region-us
|
# VulBERTa MLP Devign
## VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection
!VulBERTa architecture
## Overview
This model is the unofficial HuggingFace version of "VulBERTa" with an MLP classification head, trained on CodeXGlue Devign (C code), by Hazim Hanif & Sergio Maffeis (Imperial College... | [
"# VulBERTa MLP Devign",
"## VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection\n\n!VulBERTa architecture",
"## Overview\nThis model is the unofficial HuggingFace version of \"VulBERTa\" with an MLP classification head, trained on CodeXGlue Devign (C code), by Hazim Hanif & Sergio Maffeis... | [
"TAGS\n#transformers #safetensors #roberta #fill-mask #devign #defect detection #code #text-classification #dataset-code_x_glue_cc_defect_detection #license-mit #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"# VulBERTa MLP Devign",
"## VulBERTa: Simplified Source Code Pre-Training for... | [
62,
8,
20,
266,
43,
43,
69,
195
] | [
"TAGS\n#transformers #safetensors #roberta #fill-mask #devign #defect detection #code #text-classification #dataset-code_x_glue_cc_defect_detection #license-mit #model-index #autotrain_compatible #endpoints_compatible #region-us \n# VulBERTa MLP Devign## VulBERTa: Simplified Source Code Pre-Training for Vulnerabili... |
null | null |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This is just a gguf version of the joseagmz/mistral-7B-PsychiatryCaseNotes-epochs-3-lr-000002 model.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More In... | {"license": "apache-2.0"} | ubGPT/mistral-7B-PsychiatryCaseNotes-epochs-3-lr-000002gguf | null | [
"gguf",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T19:22:46+00:00 | [] | [] | TAGS
#gguf #license-apache-2.0 #region-us
|
# Model Card for Model ID
This is just a gguf version of the joseagmz/mistral-7B-PsychiatryCaseNotes-epochs-3-lr-000002 model.
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [opt... | [
"# Model Card for Model ID\n\n\n\nThis is just a gguf version of the joseagmz/mistral-7B-PsychiatryCaseNotes-epochs-3-lr-000002 model.",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \... | [
"TAGS\n#gguf #license-apache-2.0 #region-us \n",
"# Model Card for Model ID\n\n\n\nThis is just a gguf version of the joseagmz/mistral-7B-PsychiatryCaseNotes-epochs-3-lr-000002 model.",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n... | [
17,
44,
4,
50,
13
] | [
"TAGS\n#gguf #license-apache-2.0 #region-us \n# Model Card for Model ID\n\n\n\nThis is just a gguf version of the joseagmz/mistral-7B-PsychiatryCaseNotes-epochs-3-lr-000002 model.## Model Details### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- ... |
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | liuyuxiang/wiki_cs_paraphraser | null | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:24:21+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model... | [
39,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #bart #text2text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been aut... |
text2text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-med-corr-error-flag
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-... | {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["f1"], "model-index": [{"name": "flan-t5-base-med-corr-error-flag", "results": []}]} | srajwal1/flan-t5-base-med-corr-error-flag | null | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T19:26:08+00:00 | [] | [] | TAGS
#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# flan-t5-base-med-corr-error-flag
This model is a fine-tuned version of google/flan-t5-base on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2759
- F1: 51.5181
- Gen Len: 2.1307
## Model description
More information needed
## Intended uses & limitations
More information n... | [
"# flan-t5-base-med-corr-error-flag\n\nThis model is a fine-tuned version of google/flan-t5-base on the None dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.2759\n- F1: 51.5181\n- Gen Len: 2.1307",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n... | [
"TAGS\n#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# flan-t5-base-med-corr-error-flag\n\nThis model is a fine-tuned version of google/flan-t5-base on the None datas... | [
54,
75,
7,
9,
9,
4,
93,
5,
44
] | [
"TAGS\n#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# flan-t5-base-med-corr-error-flag\n\nThis model is a fine-tuned version of google/flan-t5-base on the None dataset.\nI... |
null | mlx |
# mlx-community/llava-phi-3-mini-4bit
This model was converted to MLX format from [`qnguyen3/nanoLLaVAxtuner/llava-phi-3-mini-hf`]() using mlx-vllm version **0.0.3**.
Refer to the [original model card](xtuner/llava-phi-3-mini-hf) for more details on the model.
## Use with mlx
```bash
pip install -U mlx-vlm
```
```ba... | {"language": ["en"], "license": "apache-2.0", "tags": ["llava", "multimodal", "phi-mini-3", "mlx"]} | mlx-community/llava-phi-3-mini-4bit | null | [
"mlx",
"safetensors",
"llava",
"multimodal",
"phi-mini-3",
"en",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T19:26:22+00:00 | [] | [
"en"
] | TAGS
#mlx #safetensors #llava #multimodal #phi-mini-3 #en #license-apache-2.0 #region-us
|
# mlx-community/llava-phi-3-mini-4bit
This model was converted to MLX format from ['qnguyen3/nanoLLaVAxtuner/llava-phi-3-mini-hf']() using mlx-vllm version 0.0.3.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# mlx-community/llava-phi-3-mini-4bit\nThis model was converted to MLX format from ['qnguyen3/nanoLLaVAxtuner/llava-phi-3-mini-hf']() using mlx-vllm version 0.0.3.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#mlx #safetensors #llava #multimodal #phi-mini-3 #en #license-apache-2.0 #region-us \n",
"# mlx-community/llava-phi-3-mini-4bit\nThis model was converted to MLX format from ['qnguyen3/nanoLLaVAxtuner/llava-phi-3-mini-hf']() using mlx-vllm version 0.0.3.\nRefer to the original model card for more details on... | [
35,
83,
6
] | [
"TAGS\n#mlx #safetensors #llava #multimodal #phi-mini-3 #en #license-apache-2.0 #region-us \n# mlx-community/llava-phi-3-mini-4bit\nThis model was converted to MLX format from ['qnguyen3/nanoLLaVAxtuner/llava-phi-3-mini-hf']() using mlx-vllm version 0.0.3.\nRefer to the original model card for more details on the m... |
null | peft |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** ... | {"library_name": "peft", "base_model": "Salesforce/codegen-350M-mono"} | Denis641/CodeGen-MNTP | null | [
"peft",
"safetensors",
"codegen",
"arxiv:1910.09700",
"base_model:Salesforce/codegen-350M-mono",
"region:us"
] | null | 2024-04-30T19:27:30+00:00 | [
"1910.09700"
] | [] | TAGS
#peft #safetensors #codegen #arxiv-1910.09700 #base_model-Salesforce/codegen-350M-mono #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
#... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [option... | [
"TAGS\n#peft #safetensors #codegen #arxiv-1910.09700 #base_model-Salesforce/codegen-350M-mono #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- Licens... | [
40,
6,
4,
50,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5,
13
] | [
"TAGS\n#peft #safetensors #codegen #arxiv-1910.09700 #base_model-Salesforce/codegen-350M-mono #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned f... |
feature-extraction | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | andersonbcdefg/tiny-emb-2024-04-30_19-28-00 | null | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:28:00+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bert #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #bert #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatic... | [
32,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #bert #feature-extraction #arxiv-1910.09700 #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\... |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-4
This model is a fine-tuned version of [EleutherAI/pythia-160m](https://... | {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-160m", "model-index": [{"name": "robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-4", "results": []}]} | AlignmentResearch/robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-4 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-160m",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T19:29:59+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-4
This model is a fine-tuned version of EleutherAI/pythia-160m on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Trainin... | [
"# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-4\n\nThis model is a fine-tuned version of EleutherAI/pythia-160m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore informat... | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-4\n\nThis mo... | [
70,
58,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-4\n\nThis model is... |
token-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trained_croatian
This model is a fine-tuned version of [distilbert/distilbert-base-multilingual-cased](https://huggingface... | {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["precision", "recall", "f1", "accuracy"], "base_model": "distilbert/distilbert-base-multilingual-cased", "model-index": [{"name": "trained_croatian", "results": []}]} | annamariagnat/trained_croatian | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:30:24+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #distilbert #token-classification #generated_from_trainer #base_model-distilbert/distilbert-base-multilingual-cased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
| trained\_croatian
=================
This model is a fine-tuned version of distilbert/distilbert-base-multilingual-cased on the None dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0766
* Precision: 0.8130
* Recall: 0.8568
* F1: 0.8343
* Accuracy: 0.9769
Model description
--------------... | [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1... | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #token-classification #generated_from_trainer #base_model-distilbert/distilbert-base-multilingual-cased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were u... | [
67,
124,
5,
42
] | [
"TAGS\n#transformers #tensorboard #safetensors #distilbert #token-classification #generated_from_trainer #base_model-distilbert/distilbert-base-multilingual-cased #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used du... |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-3
This model is a fine-tuned version of [EleutherAI/pythia-160m](https://... | {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-160m", "model-index": [{"name": "robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-3", "results": []}]} | AlignmentResearch/robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-3 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-160m",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T19:30:26+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-3
This model is a fine-tuned version of EleutherAI/pythia-160m on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Trainin... | [
"# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-3\n\nThis model is a fine-tuned version of EleutherAI/pythia-160m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore informat... | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-3\n\nThis mo... | [
70,
58,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-3\n\nThis model is... |
automatic-speech-recognition | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | ivillar/whisperfinetune-regular | null | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:30:29+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #whisper #automatic-speech-recognition #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #whisper #automatic-speech-recognition #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has b... | [
34,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #whisper #automatic-speech-recognition #arxiv-1910.09700 #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically ... |
null | transformers |
# Uploaded model
- **Developed by:** HoneyBadger2989
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/u... | {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl"], "base_model": "unsloth/llama-3-8b-bnb-4bit"} | HoneyBadger2989/llama-3-8b-bnb-4bit | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:31:11+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #text-generation-inference #unsloth #llama #trl #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: HoneyBadger2989
- License: apache-2.0
- Finetuned from model : unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: HoneyBadger2989\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #llama #trl #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: HoneyBadger2989\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit... | [
64,
83
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #llama #trl #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n# Uploaded model\n\n- Developed by: HoneyBadger2989\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nTh... |
text-generation | mlx |
# batmac/Phi-3-mini-4k-instruct-mlx-4bit
This model was converted to MLX format from [`microsoft/Phi-3-mini-4k-instruct`]() using mlx-lm version **0.12.0**.
Refer to the [original model card](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) for more details on the model.
## Use with mlx
```bash
pip install ml... | {"language": ["en"], "license": "mit", "tags": ["nlp", "code", "mlx"], "license_link": "https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/LICENSE", "pipeline_tag": "text-generation", "widget": [{"messages": [{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfr... | batmac/Phi-3-mini-4k-instruct-mlx-4bit | null | [
"mlx",
"safetensors",
"phi3",
"nlp",
"code",
"text-generation",
"conversational",
"custom_code",
"en",
"license:mit",
"region:us"
] | null | 2024-04-30T19:31:59+00:00 | [] | [
"en"
] | TAGS
#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us
|
# batmac/Phi-3-mini-4k-instruct-mlx-4bit
This model was converted to MLX format from ['microsoft/Phi-3-mini-4k-instruct']() using mlx-lm version 0.12.0.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# batmac/Phi-3-mini-4k-instruct-mlx-4bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-4k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us \n",
"# batmac/Phi-3-mini-4k-instruct-mlx-4bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-4k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for ... | [
37,
75,
6
] | [
"TAGS\n#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us \n# batmac/Phi-3-mini-4k-instruct-mlx-4bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-4k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for more d... |
text-generation | mlx |
# batmac/Phi-3-mini-4k-instruct-mlx-8bit
This model was converted to MLX format from [`microsoft/Phi-3-mini-4k-instruct`]() using mlx-lm version **0.12.0**.
Refer to the [original model card](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) for more details on the model.
## Use with mlx
```bash
pip install ml... | {"language": ["en"], "license": "mit", "tags": ["nlp", "code", "mlx"], "license_link": "https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/LICENSE", "pipeline_tag": "text-generation", "widget": [{"messages": [{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfr... | batmac/Phi-3-mini-4k-instruct-mlx-8bit | null | [
"mlx",
"safetensors",
"phi3",
"nlp",
"code",
"text-generation",
"conversational",
"custom_code",
"en",
"license:mit",
"region:us"
] | null | 2024-04-30T19:34:00+00:00 | [] | [
"en"
] | TAGS
#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us
|
# batmac/Phi-3-mini-4k-instruct-mlx-8bit
This model was converted to MLX format from ['microsoft/Phi-3-mini-4k-instruct']() using mlx-lm version 0.12.0.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# batmac/Phi-3-mini-4k-instruct-mlx-8bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-4k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us \n",
"# batmac/Phi-3-mini-4k-instruct-mlx-8bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-4k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for ... | [
37,
75,
6
] | [
"TAGS\n#mlx #safetensors #phi3 #nlp #code #text-generation #conversational #custom_code #en #license-mit #region-us \n# batmac/Phi-3-mini-4k-instruct-mlx-8bit\nThis model was converted to MLX format from ['microsoft/Phi-3-mini-4k-instruct']() using mlx-lm version 0.12.0.\nRefer to the original model card for more d... |
text-generation | transformers |
### Bielik-7B-Instruct-v0.1
ExLlamav2 8 bpw quants of https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1 | {"language": ["pl"], "license": "cc-by-nc-4.0", "library_name": "transformers", "tags": ["finetuned"], "inference": false} | altomek/Bielik-7B-Instruct-v0.1-8bpw-EXL2 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"finetuned",
"conversational",
"pl",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T19:36:55+00:00 | [] | [
"pl"
] | TAGS
#transformers #safetensors #mistral #text-generation #finetuned #conversational #pl #license-cc-by-nc-4.0 #autotrain_compatible #text-generation-inference #region-us
|
### Bielik-7B-Instruct-v0.1
ExLlamav2 8 bpw quants of URL | [
"### Bielik-7B-Instruct-v0.1\n\nExLlamav2 8 bpw quants of URL"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #finetuned #conversational #pl #license-cc-by-nc-4.0 #autotrain_compatible #text-generation-inference #region-us \n",
"### Bielik-7B-Instruct-v0.1\n\nExLlamav2 8 bpw quants of URL"
] | [
50,
30
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #finetuned #conversational #pl #license-cc-by-nc-4.0 #autotrain_compatible #text-generation-inference #region-us \n### Bielik-7B-Instruct-v0.1\n\nExLlamav2 8 bpw quants of URL"
] |
null | peft |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** ... | {"library_name": "peft", "base_model": "Universal-NER/UniNER-7B-type"} | jc80622/unilora_sec151_populated_denser | null | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Universal-NER/UniNER-7B-type",
"region:us"
] | null | 2024-04-30T19:37:20+00:00 | [
"1910.09700"
] | [] | TAGS
#peft #safetensors #arxiv-1910.09700 #base_model-Universal-NER/UniNER-7B-type #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
#... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [option... | [
"TAGS\n#peft #safetensors #arxiv-1910.09700 #base_model-Universal-NER/UniNER-7B-type #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Fi... | [
39,
6,
4,
50,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5,
13
] | [
"TAGS\n#peft #safetensors #arxiv-1910.09700 #base_model-Universal-NER/UniNER-7B-type #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model... |
text-generation | transformers | <a href="https://www.gradient.ai" target="_blank"><img src="https://cdn-uploads.huggingface.co/production/uploads/655bb613e8a8971e89944f3e/TSa3V8YpoVagnTYgxiLaO.png" width="200"/></a>
# Llama-3 8B Gradient Instruct 1048k
Gradient incorporates your data to deploy autonomous assistants that power critical operations acr... | {"language": ["en"], "license": "llama3", "tags": ["meta", "llama-3"], "pipeline_tag": "text-generation"} | LoneStriker/Llama-3-8B-Instruct-Gradient-1048k-3.0bpw-h6-exl2 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"meta",
"llama-3",
"conversational",
"en",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"3-bit",
"region:us"
] | null | 2024-04-30T19:38:18+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #3-bit #region-us
| [<img src="URL width="200"/>](URL)
Llama-3 8B Gradient Instruct 1048k
==================================
Gradient incorporates your data to deploy autonomous assistants that power critical operations across your business. If you're looking to build custom AI models or agents, email us a message contact@URL.
For m... | [
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the 'generate()' function. Let's see examples of both.",
"#### Transformers pipeline",
"#### Transformers AutoModelForCausalLM",
"### Use with 'llama3'\n\n\n... | [
"TAGS\n#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #3-bit #region-us \n",
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstractio... | [
56,
42,
6,
13,
429,
8,
6,
270,
280,
72,
115,
118,
126,
2136
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #3-bit #region-us \n### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or ... |
text-generation | transformers | <a href="https://www.gradient.ai" target="_blank"><img src="https://cdn-uploads.huggingface.co/production/uploads/655bb613e8a8971e89944f3e/TSa3V8YpoVagnTYgxiLaO.png" width="200"/></a>
# Llama-3 8B Gradient Instruct 1048k
Gradient incorporates your data to deploy autonomous assistants that power critical operations acr... | {"language": ["en"], "license": "llama3", "tags": ["meta", "llama-3"], "pipeline_tag": "text-generation"} | LoneStriker/Llama-3-8B-Instruct-Gradient-1048k-4.0bpw-h6-exl2 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"meta",
"llama-3",
"conversational",
"en",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-30T19:40:09+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
| [<img src="URL width="200"/>](URL)
Llama-3 8B Gradient Instruct 1048k
==================================
Gradient incorporates your data to deploy autonomous assistants that power critical operations across your business. If you're looking to build custom AI models or agents, email us a message contact@URL.
For m... | [
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the 'generate()' function. Let's see examples of both.",
"#### Transformers pipeline",
"#### Transformers AutoModelForCausalLM",
"### Use with 'llama3'\n\n\n... | [
"TAGS\n#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstractio... | [
56,
42,
6,
13,
429,
8,
6,
270,
280,
72,
115,
118,
126,
2136
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or ... |
null | peft |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** ... | {"library_name": "peft", "base_model": "Universal-NER/UniNER-7B-type"} | jc80622/unilora_sec151_populated_dense | null | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Universal-NER/UniNER-7B-type",
"region:us"
] | null | 2024-04-30T19:42:20+00:00 | [
"1910.09700"
] | [] | TAGS
#peft #safetensors #arxiv-1910.09700 #base_model-Universal-NER/UniNER-7B-type #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
#... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [option... | [
"TAGS\n#peft #safetensors #arxiv-1910.09700 #base_model-Universal-NER/UniNER-7B-type #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Fi... | [
39,
6,
4,
50,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5,
13
] | [
"TAGS\n#peft #safetensors #arxiv-1910.09700 #base_model-Universal-NER/UniNER-7B-type #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model... |
text-generation | transformers | <a href="https://www.gradient.ai" target="_blank"><img src="https://cdn-uploads.huggingface.co/production/uploads/655bb613e8a8971e89944f3e/TSa3V8YpoVagnTYgxiLaO.png" width="200"/></a>
# Llama-3 8B Gradient Instruct 1048k
Gradient incorporates your data to deploy autonomous assistants that power critical operations acr... | {"language": ["en"], "license": "llama3", "tags": ["meta", "llama-3"], "pipeline_tag": "text-generation"} | LoneStriker/Llama-3-8B-Instruct-Gradient-1048k-5.0bpw-h6-exl2 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"meta",
"llama-3",
"conversational",
"en",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"5-bit",
"region:us"
] | null | 2024-04-30T19:42:22+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #5-bit #region-us
| [<img src="URL width="200"/>](URL)
Llama-3 8B Gradient Instruct 1048k
==================================
Gradient incorporates your data to deploy autonomous assistants that power critical operations across your business. If you're looking to build custom AI models or agents, email us a message contact@URL.
For m... | [
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the 'generate()' function. Let's see examples of both.",
"#### Transformers pipeline",
"#### Transformers AutoModelForCausalLM",
"### Use with 'llama3'\n\n\n... | [
"TAGS\n#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #5-bit #region-us \n",
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstractio... | [
56,
42,
6,
13,
429,
8,
6,
270,
280,
72,
115,
118,
126,
2136
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #5-bit #region-us \n### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or ... |
sentence-similarity | sentence-transformers |
# ai-maker-space/snowflake-ft-camelids
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this ... | {"library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"} | ai-maker-space/snowflake-ft-camelids | null | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:43:15+00:00 | [] | [] | TAGS
#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #endpoints_compatible #region-us
|
# ai-maker-space/snowflake-ft-camelids
This is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have sentence-transformers inst... | [
"# ai-maker-space/snowflake-ft-camelids\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transfo... | [
"TAGS\n#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n",
"# ai-maker-space/snowflake-ft-camelids\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like cl... | [
28,
50,
30,
26,
72,
5,
5
] | [
"TAGS\n#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n# ai-maker-space/snowflake-ft-camelids\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clusteri... |
null | mlx |
# mlx-community/llava-phi-3-mini-8bit
This model was converted to MLX format from [`qnguyen3/nanoLLaVAxtuner/llava-phi-3-mini-hf`]() using mlx-vllm version **0.0.3**.
Refer to the [original model card](xtuner/llava-phi-3-mini-hf) for more details on the model.
## Use with mlx
```bash
pip install -U mlx-vlm
```
```ba... | {"language": ["en"], "license": "apache-2.0", "tags": ["llava", "multimodal", "phi-mini-3", "mlx"]} | mlx-community/llava-phi-3-mini-8bit | null | [
"mlx",
"safetensors",
"llava",
"multimodal",
"phi-mini-3",
"en",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T19:44:19+00:00 | [] | [
"en"
] | TAGS
#mlx #safetensors #llava #multimodal #phi-mini-3 #en #license-apache-2.0 #region-us
|
# mlx-community/llava-phi-3-mini-8bit
This model was converted to MLX format from ['qnguyen3/nanoLLaVAxtuner/llava-phi-3-mini-hf']() using mlx-vllm version 0.0.3.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# mlx-community/llava-phi-3-mini-8bit\nThis model was converted to MLX format from ['qnguyen3/nanoLLaVAxtuner/llava-phi-3-mini-hf']() using mlx-vllm version 0.0.3.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#mlx #safetensors #llava #multimodal #phi-mini-3 #en #license-apache-2.0 #region-us \n",
"# mlx-community/llava-phi-3-mini-8bit\nThis model was converted to MLX format from ['qnguyen3/nanoLLaVAxtuner/llava-phi-3-mini-hf']() using mlx-vllm version 0.0.3.\nRefer to the original model card for more details on... | [
35,
83,
6
] | [
"TAGS\n#mlx #safetensors #llava #multimodal #phi-mini-3 #en #license-apache-2.0 #region-us \n# mlx-community/llava-phi-3-mini-8bit\nThis model was converted to MLX format from ['qnguyen3/nanoLLaVAxtuner/llava-phi-3-mini-hf']() using mlx-vllm version 0.0.3.\nRefer to the original model card for more details on the m... |
text-generation | transformers | <a href="https://www.gradient.ai" target="_blank"><img src="https://cdn-uploads.huggingface.co/production/uploads/655bb613e8a8971e89944f3e/TSa3V8YpoVagnTYgxiLaO.png" width="200"/></a>
# Llama-3 8B Gradient Instruct 1048k
Gradient incorporates your data to deploy autonomous assistants that power critical operations acr... | {"language": ["en"], "license": "llama3", "tags": ["meta", "llama-3"], "pipeline_tag": "text-generation"} | LoneStriker/Llama-3-8B-Instruct-Gradient-1048k-6.0bpw-h6-exl2 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"meta",
"llama-3",
"conversational",
"en",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"6-bit",
"region:us"
] | null | 2024-04-30T19:44:51+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #6-bit #region-us
| [<img src="URL width="200"/>](URL)
Llama-3 8B Gradient Instruct 1048k
==================================
Gradient incorporates your data to deploy autonomous assistants that power critical operations across your business. If you're looking to build custom AI models or agents, email us a message contact@URL.
For m... | [
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the 'generate()' function. Let's see examples of both.",
"#### Transformers pipeline",
"#### Transformers AutoModelForCausalLM",
"### Use with 'llama3'\n\n\n... | [
"TAGS\n#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #6-bit #region-us \n",
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstractio... | [
56,
42,
6,
13,
429,
8,
6,
270,
280,
72,
115,
118,
126,
2136
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #6-bit #region-us \n### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or ... |
null | transformers |
# Uploaded model
- **Developed by:** HoneyBadger2989
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/u... | {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl", "sft"], "base_model": "unsloth/llama-3-8b-bnb-4bit"} | HoneyBadger2989/badger-llama3-8b-4bit | null | [
"transformers",
"pytorch",
"safetensors",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:44:56+00:00 | [] | [
"en"
] | TAGS
#transformers #pytorch #safetensors #gguf #llama #text-generation-inference #unsloth #trl #sft #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: HoneyBadger2989
- License: apache-2.0
- Finetuned from model : unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: HoneyBadger2989\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #pytorch #safetensors #gguf #llama #text-generation-inference #unsloth #trl #sft #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: HoneyBadger2989\n- License: apache-2.0\n- Finetuned from model : unsloth... | [
76,
83
] | [
"TAGS\n#transformers #pytorch #safetensors #gguf #llama #text-generation-inference #unsloth #trl #sft #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n# Uploaded model\n\n- Developed by: HoneyBadger2989\n- License: apache-2.0\n- Finetuned from model : unsloth/llama... |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axo... | {"license": "apache-2.0", "library_name": "peft", "tags": ["axolotl", "generated_from_trainer"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "Mistral-7B-Instruct-v0.2-ft", "results": []}]} | Burhan02/Mistral-7B-Instruct-v0.2-ft | null | [
"peft",
"tensorboard",
"safetensors",
"mistral",
"axolotl",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"4-bit",
"region:us"
] | null | 2024-04-30T19:46:21+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #mistral #axolotl #generated_from_trainer #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #4-bit #region-us
| <img src="URL alt="Built with Axolotl" width="200" height="32"/>
See axolotl config
axolotl version: '0.4.0'
Mistral-7B-Instruct-v0.2-ft
===========================
This model is a fine-tuned version of mistralai/Mistral-7B-Instruct-v0.2 on the None dataset.
It achieves the following results on the evaluation... | [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 8\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1... | [
"TAGS\n#peft #tensorboard #safetensors #mistral #axolotl #generated_from_trainer #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #4-bit #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_s... | [
62,
142,
5,
55
] | [
"TAGS\n#peft #tensorboard #safetensors #mistral #axolotl #generated_from_trainer #base_model-mistralai/Mistral-7B-Instruct-v0.2 #license-apache-2.0 #4-bit #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 2... |
text-generation | transformers | <a href="https://www.gradient.ai" target="_blank"><img src="https://cdn-uploads.huggingface.co/production/uploads/655bb613e8a8971e89944f3e/TSa3V8YpoVagnTYgxiLaO.png" width="200"/></a>
# Llama-3 8B Gradient Instruct 1048k
Gradient incorporates your data to deploy autonomous assistants that power critical operations acr... | {"language": ["en"], "license": "llama3", "tags": ["meta", "llama-3"], "pipeline_tag": "text-generation"} | LoneStriker/Llama-3-8B-Instruct-Gradient-1048k-8.0bpw-h8-exl2 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"meta",
"llama-3",
"conversational",
"en",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null | 2024-04-30T19:47:44+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us
| [<img src="URL width="200"/>](URL)
Llama-3 8B Gradient Instruct 1048k
==================================
Gradient incorporates your data to deploy autonomous assistants that power critical operations across your business. If you're looking to build custom AI models or agents, email us a message contact@URL.
For m... | [
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the 'generate()' function. Let's see examples of both.",
"#### Transformers pipeline",
"#### Transformers AutoModelForCausalLM",
"### Use with 'llama3'\n\n\n... | [
"TAGS\n#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n",
"### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstractio... | [
56,
42,
6,
13,
429,
8,
6,
270,
280,
72,
115,
118,
126,
2136
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #meta #llama-3 #conversational #en #license-llama3 #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n### Use with transformers\n\n\nYou can run conversational inference using the Transformers pipeline abstraction, or ... |
text-generation | transformers |
# llama3-8B-slerp-med-chinese
llama3-8B-slerp-med-chinese is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [winninghealth/WiNGPT2-Llama-3-8B-Base](https://huggingface.co/winninghealth/WiNGPT2-Llama-3-8B-Base)
* [johnsnowl... | {"language": ["zh", "en", "fr"], "license": "llama3", "tags": ["merge", "mergekit", "lazymergekit", "winninghealth/WiNGPT2-Llama-3-8B-Base", "johnsnowlabs/JSL-MedLlama-3-8B-v1.0"], "base_model": ["winninghealth/WiNGPT2-Llama-3-8B-Base", "johnsnowlabs/JSL-MedLlama-3-8B-v1.0"]} | shanchen/llama3-8B-slerp-med-chinese | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"winninghealth/WiNGPT2-Llama-3-8B-Base",
"johnsnowlabs/JSL-MedLlama-3-8B-v1.0",
"zh",
"en",
"fr",
"base_model:winninghealth/WiNGPT2-Llama-3-8B-Base",
"base_model:johnsnowlabs/JSL-MedLlama-3-8B-v... | null | 2024-04-30T19:48:40+00:00 | [] | [
"zh",
"en",
"fr"
] | TAGS
#transformers #safetensors #llama #text-generation #merge #mergekit #lazymergekit #winninghealth/WiNGPT2-Llama-3-8B-Base #johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #zh #en #fr #base_model-winninghealth/WiNGPT2-Llama-3-8B-Base #base_model-johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #license-llama3 #autotrain_compatible #endpoint... |
# llama3-8B-slerp-med-chinese
llama3-8B-slerp-med-chinese is a merge of the following models using LazyMergekit:
* winninghealth/WiNGPT2-Llama-3-8B-Base
* johnsnowlabs/JSL-MedLlama-3-8B-v1.0
## Configuration
## Usage
| [
"# llama3-8B-slerp-med-chinese\n\nllama3-8B-slerp-med-chinese is a merge of the following models using LazyMergekit:\n* winninghealth/WiNGPT2-Llama-3-8B-Base\n* johnsnowlabs/JSL-MedLlama-3-8B-v1.0",
"## Configuration",
"## Usage"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #merge #mergekit #lazymergekit #winninghealth/WiNGPT2-Llama-3-8B-Base #johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #zh #en #fr #base_model-winninghealth/WiNGPT2-Llama-3-8B-Base #base_model-johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #license-llama3 #autotrain_compatible #en... | [
145,
82,
3,
3
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #merge #mergekit #lazymergekit #winninghealth/WiNGPT2-Llama-3-8B-Base #johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #zh #en #fr #base_model-winninghealth/WiNGPT2-Llama-3-8B-Base #base_model-johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #license-llama3 #autotrain_compatible #en... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-14B - bnb 8bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qwen1.5-... | {} | RichardErkhov/Qwen_-_Qwen1.5-14B-8bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null | 2024-04-30T19:49:10+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-14B - bnb 8bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- pretrained
---
# Qw... | [
"# Qwen1.5-14B",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include:\n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense models,... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n",
"# Qwen1.5-14B",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large... | [
42,
9,
160,
119,
44,
66
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n# Qwen1.5-14B## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of d... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-1.8B-Chat - bnb 4bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qw... | {} | RichardErkhov/Qwen_-_Qwen1.5-1.8B-Chat-4bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-30T19:49:18+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-1.8B-Chat - bnb 4bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen-research
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- chat
... | [
"# Qwen1.5-1.8B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include: \n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense ... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# Qwen1.5-1.8B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a... | [
42,
13,
166,
119,
35,
44,
145,
51
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n# Qwen1.5-1.8B-Chat## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amoun... |
text-generation | transformers | # Fine tuning GPT2 for a company specific data | {} | achrekarom/versa-gpt2 | null | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T19:50:19+00:00 | [] | [] | TAGS
#transformers #safetensors #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # Fine tuning GPT2 for a company specific data | [
"# Fine tuning GPT2 for a company specific data"
] | [
"TAGS\n#transformers #safetensors #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Fine tuning GPT2 for a company specific data"
] | [
35,
11
] | [
"TAGS\n#transformers #safetensors #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Fine tuning GPT2 for a company specific data"
] |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-1.8B-Chat - bnb 8bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qw... | {} | RichardErkhov/Qwen_-_Qwen1.5-1.8B-Chat-8bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null | 2024-04-30T19:54:32+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-1.8B-Chat - bnb 8bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen-research
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- chat
... | [
"# Qwen1.5-1.8B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include: \n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense ... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n",
"# Qwen1.5-1.8B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a... | [
42,
13,
166,
119,
35,
44,
145,
51
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n# Qwen1.5-1.8B-Chat## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amoun... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-4B-Chat - bnb 4bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qwen... | {} | RichardErkhov/Qwen_-_Qwen1.5-4B-Chat-4bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-30T19:54:59+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-4B-Chat - bnb 4bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen-research
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- chat
--... | [
"# Qwen1.5-4B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include: \n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense mo... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# Qwen1.5-4B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a l... | [
42,
11,
166,
119,
35,
44,
137,
51
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n# Qwen1.5-4B-Chat## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount ... |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | nem012/gemma2b-1e-5r16 | null | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T19:55:43+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #gemma #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #gemma #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed... | [
43,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #gemma #text-generation #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This ... |
automatic-speech-recognition | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | ivillar/whisperfinetune-cosine | null | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T19:57:26+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #whisper #automatic-speech-recognition #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #whisper #automatic-speech-recognition #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has b... | [
34,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #whisper #automatic-speech-recognition #arxiv-1910.09700 #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically ... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-4B-Chat - bnb 8bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qwen... | {} | RichardErkhov/Qwen_-_Qwen1.5-4B-Chat-8bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null | 2024-04-30T19:59:50+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-4B-Chat - bnb 8bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen-research
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- chat
--... | [
"# Qwen1.5-4B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include: \n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense mo... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n",
"# Qwen1.5-4B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a l... | [
42,
11,
166,
119,
35,
44,
137,
51
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n# Qwen1.5-4B-Chat## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount ... |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | abc88767/model23 | null | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:00:15+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the ... | [
41,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model ca... |
text-generation | transformers |
# Uploaded model
- **Developed by:** jtatman
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/m... | {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl", "orpo"], "base_model": "unsloth/llama-3-8b-bnb-4bit"} | jtatman/OrpoDolphin-3-8B-16k | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"orpo",
"conversational",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:00:33+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #llama #text-generation #text-generation-inference #unsloth #trl #orpo #conversational #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: jtatman
- License: apache-2.0
- Finetuned from model : unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: jtatman\n- License: apache-2.0\n- Finetuned from model : unsloth/llama-3-8b-bnb-4bit\n\nThis llama model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #text-generation-inference #unsloth #trl #orpo #conversational #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: jtatman\n- License: apache-2.0\... | [
79,
80
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #text-generation-inference #unsloth #trl #orpo #conversational #en #base_model-unsloth/llama-3-8b-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n# Uploaded model\n\n- Developed by: jtatman\n- License: apache-2.0\n- Fin... |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | cilantro9246/jtzztpj | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T20:00:35+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that... | [
47,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed o... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-7B-Chat - bnb 4bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qwen... | {} | RichardErkhov/Qwen_-_Qwen1.5-7B-Chat-4bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-30T20:04:20+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-7B-Chat - bnb 4bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- chat
---
# Qwen... | [
"# Qwen1.5-7B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include: \n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense mo... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# Qwen1.5-7B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a l... | [
42,
11,
166,
119,
35,
44,
137,
51
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n# Qwen1.5-7B-Chat## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount ... |
text-generation | transformers |
# Model Card for C4AI Command-R
🚨 **This model is 4bit quantized version of C4AI Command-R using bitsandbytes.** You can find the unquantized version of C4AI Command-R [here](https://huggingface.co/CohereForAI/c4ai-command-r-v01).
## Model Summary
C4AI Command-R is a research release of a 35 billion parameter high... | {"language": ["en", "fr", "de", "es", "it", "pt", "ja", "ko", "zh", "ar"], "license": "cc-by-nc-4.0", "library_name": "transformers"} | samiyousef/Command-R-4-bit | null | [
"transformers",
"safetensors",
"cohere",
"text-generation",
"en",
"fr",
"de",
"es",
"it",
"pt",
"ja",
"ko",
"zh",
"ar",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-30T20:05:18+00:00 | [] | [
"en",
"fr",
"de",
"es",
"it",
"pt",
"ja",
"ko",
"zh",
"ar"
] | TAGS
#transformers #safetensors #cohere #text-generation #en #fr #de #es #it #pt #ja #ko #zh #ar #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
|
# Model Card for C4AI Command-R
This model is 4bit quantized version of C4AI Command-R using bitsandbytes. You can find the unquantized version of C4AI Command-R here.
## Model Summary
C4AI Command-R is a research release of a 35 billion parameter highly performant generative model. Command-R is a large language m... | [
"# Model Card for C4AI Command-R\n\n This model is 4bit quantized version of C4AI Command-R using bitsandbytes. You can find the unquantized version of C4AI Command-R here.",
"## Model Summary\n\nC4AI Command-R is a research release of a 35 billion parameter highly performant generative model. Command-R is a larg... | [
"TAGS\n#transformers #safetensors #cohere #text-generation #en #fr #de #es #it #pt #ja #ko #zh #ar #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# Model Card for C4AI Command-R\n\n This model is 4bit quantized version of C4AI Command-R using b... | [
72,
49,
166,
164,
541,
501,
79,
24,
80,
18
] | [
"TAGS\n#transformers #safetensors #cohere #text-generation #en #fr #de #es #it #pt #ja #ko #zh #ar #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n# Model Card for C4AI Command-R\n\n This model is 4bit quantized version of C4AI Command-R using bitsand... |
sentence-similarity | sentence-transformers |
# ai-maker-space/snowflake-ft-camelids-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using th... | {"library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"} | ai-maker-space/snowflake-ft-camelids-v1 | null | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:08:27+00:00 | [] | [] | TAGS
#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #endpoints_compatible #region-us
|
# ai-maker-space/snowflake-ft-camelids-v1
This is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have sentence-transformers i... | [
"# ai-maker-space/snowflake-ft-camelids-v1\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-tran... | [
"TAGS\n#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n",
"# ai-maker-space/snowflake-ft-camelids-v1\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like... | [
28,
53,
30,
26,
72,
5,
5
] | [
"TAGS\n#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n# ai-maker-space/snowflake-ft-camelids-v1\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clust... |
reinforcement-learning | null |
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'Lunar... | {"tags": ["LunarLander-v2", "ppo", "deep-reinforcement-learning", "reinforcement-learning", "custom-implementation", "deep-rl-course"], "model-index": [{"name": "PPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "LunarLander-v2", "type": "LunarLander-v2... | pdejong/cleanrl-LunarLander-v2 | null | [
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] | null | 2024-04-30T20:09:47+00:00 | [] | [] | TAGS
#tensorboard #LunarLander-v2 #ppo #deep-reinforcement-learning #reinforcement-learning #custom-implementation #deep-rl-course #model-index #region-us
|
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
| [
"# PPO Agent Playing LunarLander-v2\n\n This is a trained model of a PPO agent playing LunarLander-v2.\n \n # Hyperparameters"
] | [
"TAGS\n#tensorboard #LunarLander-v2 #ppo #deep-reinforcement-learning #reinforcement-learning #custom-implementation #deep-rl-course #model-index #region-us \n",
"# PPO Agent Playing LunarLander-v2\n\n This is a trained model of a PPO agent playing LunarLander-v2.\n \n # Hyperparameters"
] | [
42,
32
] | [
"TAGS\n#tensorboard #LunarLander-v2 #ppo #deep-reinforcement-learning #reinforcement-learning #custom-implementation #deep-rl-course #model-index #region-us \n# PPO Agent Playing LunarLander-v2\n\n This is a trained model of a PPO agent playing LunarLander-v2.\n \n # Hyperparameters"
] |
depth-estimation | transformers |
# ZoeDepth (fine-tuned on KITT)
ZoeDepth model fine-tuned on the KITTI dataset. It was introduced in the paper [ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth](https://arxiv.org/abs/2302.12288) by Shariq et al. and first released in [this repository](https://github.com/isl-org/ZoeDepth).
ZoeDep... | {"license": "mit", "tags": ["vision"], "pipeline_tag": "depth-estimation"} | Intel/zoedepth-kitti | null | [
"transformers",
"safetensors",
"zoedepth",
"vision",
"depth-estimation",
"arxiv:2302.12288",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:11:57+00:00 | [
"2302.12288"
] | [] | TAGS
#transformers #safetensors #zoedepth #vision #depth-estimation #arxiv-2302.12288 #license-mit #endpoints_compatible #region-us
|
# ZoeDepth (fine-tuned on KITT)
ZoeDepth model fine-tuned on the KITTI dataset. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth by Shariq et al. and first released in this repository.
ZoeDepth extends the DPT framework for metric (also called absolute) depth estima... | [
"# ZoeDepth (fine-tuned on KITT) \n\nZoeDepth model fine-tuned on the KITTI dataset. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth by Shariq et al. and first released in this repository.\n\nZoeDepth extends the DPT framework for metric (also called absolute) dept... | [
"TAGS\n#transformers #safetensors #zoedepth #vision #depth-estimation #arxiv-2302.12288 #license-mit #endpoints_compatible #region-us \n",
"# ZoeDepth (fine-tuned on KITT) \n\nZoeDepth model fine-tuned on the KITTI dataset. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relative and Metr... | [
42,
125,
99,
39,
34,
10
] | [
"TAGS\n#transformers #safetensors #zoedepth #vision #depth-estimation #arxiv-2302.12288 #license-mit #endpoints_compatible #region-us \n# ZoeDepth (fine-tuned on KITT) \n\nZoeDepth model fine-tuned on the KITTI dataset. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Dep... |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | lunarsylph/mooncell_v40 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T20:12:07+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that... | [
47,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed o... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-14B-Chat - bnb 4bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qwe... | {} | RichardErkhov/Qwen_-_Qwen1.5-14B-Chat-4bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-30T20:12:13+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-14B-Chat - bnb 4bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- chat
---
# Qwe... | [
"# Qwen1.5-14B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include: \n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense m... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# Qwen1.5-14B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a ... | [
42,
11,
166,
119,
35,
44,
137,
51
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n# Qwen1.5-14B-Chat## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount... |
text-generation | transformers |
# Uploaded model
- **Developed by:** code-endurer
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.2-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.co... | {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl", "sft"], "base_model": "unsloth/mistral-7b-instruct-v0.2-bnb-4bit"} | code-endurer/lora_model_1 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"region:us"
... | null | 2024-04-30T20:13:28+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #mistral #text-generation #text-generation-inference #unsloth #trl #sft #conversational #en #base_model-unsloth/mistral-7b-instruct-v0.2-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #4-bit #region-us
|
# Uploaded model
- Developed by: code-endurer
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b-instruct-v0.2-bnb-4bit
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: code-endurer\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-instruct-v0.2-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #text-generation-inference #unsloth #trl #sft #conversational #en #base_model-unsloth/mistral-7b-instruct-v0.2-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #4-bit #region-us \n",
"# Uploaded model\n\n- Developed by: code-endu... | [
89,
87
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #text-generation-inference #unsloth #trl #sft #conversational #en #base_model-unsloth/mistral-7b-instruct-v0.2-bnb-4bit #license-apache-2.0 #autotrain_compatible #endpoints_compatible #4-bit #region-us \n# Uploaded model\n\n- Developed by: code-endurer\n-... |
null | transformers |
# Uploaded model
- **Developed by:** zeeshanali01
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/un... | {"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "mistral", "trl"], "base_model": "unsloth/mistral-7b-bnb-4bit"} | zeeshanali01/midtral-7b-story | null | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:14:10+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us
|
# Uploaded model
- Developed by: zeeshanali01
- License: apache-2.0
- Finetuned from model : unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
<img src="URL width="200"/>
| [
"# Uploaded model\n\n- Developed by: zeeshanali01\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThis mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.\n\n<img src=\"URL width=\"200\"/>"
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Uploaded model\n\n- Developed by: zeeshanali01\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\... | [
62,
79
] | [
"TAGS\n#transformers #safetensors #text-generation-inference #unsloth #mistral #trl #en #base_model-unsloth/mistral-7b-bnb-4bit #license-apache-2.0 #endpoints_compatible #region-us \n# Uploaded model\n\n- Developed by: zeeshanali01\n- License: apache-2.0\n- Finetuned from model : unsloth/mistral-7b-bnb-4bit\n\nThi... |
null | peft |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** ... | {"library_name": "peft", "base_model": "mistralai/Mistral-7B-Instruct-v0.1"} | donbale/ludwig-webinar | null | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-Instruct-v0.1",
"region:us"
] | null | 2024-04-30T20:16:26+00:00 | [
"1910.09700"
] | [] | TAGS
#peft #safetensors #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-Instruct-v0.1 #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
#... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [option... | [
"TAGS\n#peft #safetensors #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-Instruct-v0.1 #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: ... | [
44,
6,
4,
50,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5,
13
] | [
"TAGS\n#peft #safetensors #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-Instruct-v0.1 #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from... |
text-generation | transformers |
# llama3-8B-slerp-med-262k
llama3-8B-slerp-med-262k is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/gradientai/Llama-3-8B-Instruct-262k)
* [johnsnowlabs/JSL-Me... | {"language": ["zh"], "license": "llama3", "tags": ["merge", "mergekit", "lazymergekit", "gradientai/Llama-3-8B-Instruct-262k", "johnsnowlabs/JSL-MedLlama-3-8B-v1.0"], "base_model": ["gradientai/Llama-3-8B-Instruct-262k", "johnsnowlabs/JSL-MedLlama-3-8B-v1.0"]} | shanchen/llama3-8B-slerp-med-262k | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"gradientai/Llama-3-8B-Instruct-262k",
"johnsnowlabs/JSL-MedLlama-3-8B-v1.0",
"conversational",
"zh",
"base_model:gradientai/Llama-3-8B-Instruct-262k",
"base_model:johnsnowlabs/JSL-MedLlama-3-8B-v... | null | 2024-04-30T20:18:23+00:00 | [] | [
"zh"
] | TAGS
#transformers #safetensors #llama #text-generation #merge #mergekit #lazymergekit #gradientai/Llama-3-8B-Instruct-262k #johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #conversational #zh #base_model-gradientai/Llama-3-8B-Instruct-262k #base_model-johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #license-llama3 #autotrain_compatible #endp... |
# llama3-8B-slerp-med-262k
llama3-8B-slerp-med-262k is a merge of the following models using LazyMergekit:
* gradientai/Llama-3-8B-Instruct-262k
* johnsnowlabs/JSL-MedLlama-3-8B-v1.0
## Configuration
## Usage
| [
"# llama3-8B-slerp-med-262k\n\nllama3-8B-slerp-med-262k is a merge of the following models using LazyMergekit:\n* gradientai/Llama-3-8B-Instruct-262k\n* johnsnowlabs/JSL-MedLlama-3-8B-v1.0",
"## Configuration",
"## Usage"
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #merge #mergekit #lazymergekit #gradientai/Llama-3-8B-Instruct-262k #johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #conversational #zh #base_model-gradientai/Llama-3-8B-Instruct-262k #base_model-johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #license-llama3 #autotrain_compatible... | [
142,
83,
3,
3
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #merge #mergekit #lazymergekit #gradientai/Llama-3-8B-Instruct-262k #johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #conversational #zh #base_model-gradientai/Llama-3-8B-Instruct-262k #base_model-johnsnowlabs/JSL-MedLlama-3-8B-v1.0 #license-llama3 #autotrain_compatible... |
text-generation | transformers | # Experimental Model Warning
This model is an experimental prototype and should not be considered production-ready.
Reasons for Experimental Status
Potential for Bias: Due to the experimental nature of the model, it may exhibit biases in its output, which could lead to incorrect or unfair results.
### Precautions to T... | {"language": ["en"], "license": "cc-by-nc-4.0", "library_name": "transformers"} | 0ai/0ai-7B-v3 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"en",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T20:19:36+00:00 | [] | [
"en"
] | TAGS
#transformers #safetensors #mistral #text-generation #conversational #en #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # Experimental Model Warning
This model is an experimental prototype and should not be considered production-ready.
Reasons for Experimental Status
Potential for Bias: Due to the experimental nature of the model, it may exhibit biases in its output, which could lead to incorrect or unfair results.
### Precautions to T... | [
"# Experimental Model Warning\nThis model is an experimental prototype and should not be considered production-ready.\nReasons for Experimental Status\nPotential for Bias: Due to the experimental nature of the model, it may exhibit biases in its output, which could lead to incorrect or unfair results.",
"### Prec... | [
"TAGS\n#transformers #safetensors #mistral #text-generation #conversational #en #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Experimental Model Warning\nThis model is an experimental prototype and should not be considered production-ready.\nReason... | [
51,
54,
285
] | [
"TAGS\n#transformers #safetensors #mistral #text-generation #conversational #en #license-cc-by-nc-4.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Experimental Model Warning\nThis model is an experimental prototype and should not be considered production-ready.\nReasons for ... |
null | transformers | # **Introducing Tobias: The Ark's AI LLM Text Assistant**
Meet Tobias, the Ark's cutting-edge AI LLM (Large Language Model) text assistant, powered by the LLaMa:8b model. Named after the CEO's beloved dog, Tobias is a testament to the Ark's commitment to innovation and progress.
**Tobias' Capabilities**
Tobias is de... | {"library_name": "transformers", "tags": ["trl", "sft"]} | xandykati98/tobias-0.0.5 | null | [
"transformers",
"safetensors",
"trl",
"sft",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:20:48+00:00 | [] | [] | TAGS
#transformers #safetensors #trl #sft #endpoints_compatible #region-us
| # Introducing Tobias: The Ark's AI LLM Text Assistant
Meet Tobias, the Ark's cutting-edge AI LLM (Large Language Model) text assistant, powered by the LLaMa:8b model. Named after the CEO's beloved dog, Tobias is a testament to the Ark's commitment to innovation and progress.
Tobias' Capabilities
Tobias is designed t... | [
"# Introducing Tobias: The Ark's AI LLM Text Assistant\n\nMeet Tobias, the Ark's cutting-edge AI LLM (Large Language Model) text assistant, powered by the LLaMa:8b model. Named after the CEO's beloved dog, Tobias is a testament to the Ark's commitment to innovation and progress.\n\nTobias' Capabilities\n\nTobias is... | [
"TAGS\n#transformers #safetensors #trl #sft #endpoints_compatible #region-us \n",
"# Introducing Tobias: The Ark's AI LLM Text Assistant\n\nMeet Tobias, the Ark's cutting-edge AI LLM (Large Language Model) text assistant, powered by the LLaMa:8b model. Named after the CEO's beloved dog, Tobias is a testament to t... | [
22,
300
] | [
"TAGS\n#transformers #safetensors #trl #sft #endpoints_compatible #region-us \n# Introducing Tobias: The Ark's AI LLM Text Assistant\n\nMeet Tobias, the Ark's cutting-edge AI LLM (Large Language Model) text assistant, powered by the LLaMa:8b model. Named after the CEO's beloved dog, Tobias is a testament to the Ark... |
sentence-similarity | sentence-transformers |
# ai-maker-space/snowflake-ft-camelids-l
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using th... | {"library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"} | ai-maker-space/snowflake-ft-camelids-l | null | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:22:17+00:00 | [] | [] | TAGS
#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #endpoints_compatible #region-us
|
# ai-maker-space/snowflake-ft-camelids-l
This is a sentence-transformers model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have sentence-transformers i... | [
"# ai-maker-space/snowflake-ft-camelids-l\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-tran... | [
"TAGS\n#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n",
"# ai-maker-space/snowflake-ft-camelids-l\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like... | [
28,
52,
30,
26,
72,
5,
5
] | [
"TAGS\n#sentence-transformers #safetensors #bert #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n# ai-maker-space/snowflake-ft-camelids-l\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clust... |
depth-estimation | transformers |
# ZoeDepth (fine-tuned on NYU and KITTI)
ZoeDepth model fine-tuned on the NYU and KITTI datasets. It was introduced in the paper [ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth](https://arxiv.org/abs/2302.12288) by Shariq et al. and first released in [this repository](https://github.com/isl-org/... | {"license": "mit", "tags": ["vision"], "pipeline_tag": "depth-estimation"} | Intel/zoedepth-nyu-kitti | null | [
"transformers",
"safetensors",
"zoedepth",
"vision",
"depth-estimation",
"arxiv:2302.12288",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:22:35+00:00 | [
"2302.12288"
] | [] | TAGS
#transformers #safetensors #zoedepth #vision #depth-estimation #arxiv-2302.12288 #license-mit #endpoints_compatible #region-us
|
# ZoeDepth (fine-tuned on NYU and KITTI)
ZoeDepth model fine-tuned on the NYU and KITTI datasets. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth by Shariq et al. and first released in this repository.
ZoeDepth extends the DPT framework for metric (also called abso... | [
"# ZoeDepth (fine-tuned on NYU and KITTI) \n\nZoeDepth model fine-tuned on the NYU and KITTI datasets. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth by Shariq et al. and first released in this repository.\n\nZoeDepth extends the DPT framework for metric (also cal... | [
"TAGS\n#transformers #safetensors #zoedepth #vision #depth-estimation #arxiv-2302.12288 #license-mit #endpoints_compatible #region-us \n",
"# ZoeDepth (fine-tuned on NYU and KITTI) \n\nZoeDepth model fine-tuned on the NYU and KITTI datasets. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining... | [
42,
130,
99,
39,
34,
10
] | [
"TAGS\n#transformers #safetensors #zoedepth #vision #depth-estimation #arxiv-2302.12288 #license-mit #endpoints_compatible #region-us \n# ZoeDepth (fine-tuned on NYU and KITTI) \n\nZoeDepth model fine-tuned on the NYU and KITTI datasets. It was introduced in the paper ZoeDepth: Zero-shot Transfer by Combining Relat... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-7B-Chat - bnb 8bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qwen... | {} | RichardErkhov/Qwen_-_Qwen1.5-7B-Chat-8bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null | 2024-04-30T20:24:23+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-7B-Chat - bnb 8bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- chat
---
# Qwen... | [
"# Qwen1.5-7B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include: \n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense mo... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n",
"# Qwen1.5-7B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a l... | [
42,
11,
166,
119,
35,
44,
137,
51
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n# Qwen1.5-7B-Chat## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount ... |
text-classification | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | sezinarseven/n-s-b | null | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:29:51+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model ... | [
37,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #bert #text-classification #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been auto... |
automatic-speech-recognition | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper2
This model is a fine-tuned version of [openai/whisper-tiny.en](https://huggingface.co/openai/whisper-tiny.en) on the ti... | {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["wer"], "base_model": "openai/whisper-tiny.en", "model-index": [{"name": "whisper2", "results": []}]} | khaingsmon/whisper2 | null | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-tiny.en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:32:37+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #base_model-openai/whisper-tiny.en #license-apache-2.0 #endpoints_compatible #region-us
| whisper2
========
This model is a fine-tuned version of openai/URL on the tiny dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5233
* Wer: 31.1083
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information ... | [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 64\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps:... | [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #base_model-openai/whisper-tiny.en #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_r... | [
54,
115,
5,
47
] | [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #base_model-openai/whisper-tiny.en #license-apache-2.0 #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1... |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-0
This model is a fine-tuned version of [EleutherAI/pythia-160m](https://... | {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-160m", "model-index": [{"name": "robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-0", "results": []}]} | AlignmentResearch/robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-0 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-160m",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T20:32:38+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-0
This model is a fine-tuned version of EleutherAI/pythia-160m on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Trainin... | [
"# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-0\n\nThis model is a fine-tuned version of EleutherAI/pythia-160m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore informat... | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-0\n\nThis mo... | [
70,
58,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-0\n\nThis model is... |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-2
This model is a fine-tuned version of [EleutherAI/pythia-160m](https://... | {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-160m", "model-index": [{"name": "robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-2", "results": []}]} | AlignmentResearch/robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-2 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-160m",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T20:35:18+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-2
This model is a fine-tuned version of EleutherAI/pythia-160m on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Trainin... | [
"# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-2\n\nThis model is a fine-tuned version of EleutherAI/pythia-160m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore informat... | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-2\n\nThis mo... | [
70,
58,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-2\n\nThis model is... |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-1
This model is a fine-tuned version of [EleutherAI/pythia-160m](https://... | {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-160m", "model-index": [{"name": "robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-1", "results": []}]} | AlignmentResearch/robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-1 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-160m",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T20:36:11+00:00 | [] | [] | TAGS
#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-1
This model is a fine-tuned version of EleutherAI/pythia-160m on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Trainin... | [
"# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-1\n\nThis model is a fine-tuned version of EleutherAI/pythia-160m on an unknown dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore informat... | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-1\n\nThis mo... | [
70,
58,
7,
9,
9,
4,
93,
5,
40
] | [
"TAGS\n#transformers #tensorboard #safetensors #gpt_neox #text-classification #generated_from_trainer #base_model-EleutherAI/pythia-160m #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# robust_llm_pythia-160m_mz-135_WordLength_n-its-10-seed-1\n\nThis model is... |
null | peft |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** ... | {"library_name": "peft", "base_model": "mistralai/Mistral-7B-Instruct-v0.2"} | vaarrun009/Rzolut_Mistral_half | null | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"region:us"
] | null | 2024-04-30T20:36:33+00:00 | [
"1910.09700"
] | [] | TAGS
#peft #safetensors #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-Instruct-v0.2 #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License:
- Finetuned from model [optional]:
### Model Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
#... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from model [optional]:",
"### Model Sources [optional]\n\n\n\n- Repository: \n- Paper [option... | [
"TAGS\n#peft #safetensors #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-Instruct-v0.2 #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: ... | [
44,
6,
4,
50,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5,
13
] | [
"TAGS\n#peft #safetensors #arxiv-1910.09700 #base_model-mistralai/Mistral-7B-Instruct-v0.2 #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\n\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s) (NLP): \n- License: \n- Finetuned from... |
feature-extraction | transformers | # fine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611
## Model Description
fine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611 is a fine-tuned version of jinaai/jina-embeddings-v2-small-en designed for a specific domain.
## Use Case
Th... | {} | fine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611 | null | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"custom_code",
"region:us"
] | null | 2024-04-30T20:38:18+00:00 | [] | [] | TAGS
#transformers #safetensors #bert #feature-extraction #custom_code #region-us
| # fine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611
## Model Description
fine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611 is a fine-tuned version of jinaai/jina-embeddings-v2-small-en designed for a specific domain.
## Use Case
Th... | [
"# fine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611",
"## Model Description\n\nfine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611 is a fine-tuned version of jinaai/jina-embeddings-v2-small-en designed for a specific domain.",
... | [
"TAGS\n#transformers #safetensors #bert #feature-extraction #custom_code #region-us \n",
"# fine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611",
"## Model Description\n\nfine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611 is a fi... | [
21,
51,
85,
19,
17,
43
] | [
"TAGS\n#transformers #safetensors #bert #feature-extraction #custom_code #region-us \n# fine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611## Model Description\n\nfine-tuned/medical-10-10-1-jinaai_jina-embeddings-v2-small-en-50-gpt-3.5-turbo-01_8647177611 is a fine-tuned ver... |
text-to-image | diffusers |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - yuffish/blackchair-segmented
This is a dreambooth model derived from stabilityai/stable-diffusion-2-1-base... | {"license": "creativeml-openrail-m", "library_name": "diffusers", "tags": ["text-to-image", "dreambooth", "diffusers-training", "stable-diffusion", "stable-diffusion-diffusers"], "inference": true, "base_model": "stabilityai/stable-diffusion-2-1-base", "instance_prompt": "a photo of sks object"} | yuffish/blackchair-segmented | null | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stabilityai/stable-diffusion-2-1-base",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
... | null | 2024-04-30T20:39:46+00:00 | [] | [] | TAGS
#diffusers #tensorboard #safetensors #text-to-image #dreambooth #diffusers-training #stable-diffusion #stable-diffusion-diffusers #base_model-stabilityai/stable-diffusion-2-1-base #license-creativeml-openrail-m #endpoints_compatible #diffusers-StableDiffusionPipeline #region-us
|
# DreamBooth - yuffish/blackchair-segmented
This is a dreambooth model derived from stabilityai/stable-diffusion-2-1-base. The weights were trained on a photo of sks object using DreamBooth.
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended use... | [
"# DreamBooth - yuffish/blackchair-segmented\n\nThis is a dreambooth model derived from stabilityai/stable-diffusion-2-1-base. The weights were trained on a photo of sks object using DreamBooth.\nYou can find some example images in the following. \n\n\n\nDreamBooth for the text encoder was enabled: False.",
"## I... | [
"TAGS\n#diffusers #tensorboard #safetensors #text-to-image #dreambooth #diffusers-training #stable-diffusion #stable-diffusion-diffusers #base_model-stabilityai/stable-diffusion-2-1-base #license-creativeml-openrail-m #endpoints_compatible #diffusers-StableDiffusionPipeline #region-us \n",
"# DreamBooth - yuffish... | [
83,
77,
6,
7,
23,
17
] | [
"TAGS\n#diffusers #tensorboard #safetensors #text-to-image #dreambooth #diffusers-training #stable-diffusion #stable-diffusion-diffusers #base_model-stabilityai/stable-diffusion-2-1-base #license-creativeml-openrail-m #endpoints_compatible #diffusers-StableDiffusionPipeline #region-us \n# DreamBooth - yuffish/black... |
null | transformers | ## ✨ Finetune for Free
All notebooks are **beginner friendly**! Add your dataset, click "Run All", and you'll get a 2x faster finetuned model which can be exported to GGUF, vLLM or uploaded to Hugging Face.
| Unsloth supports | Free Notebooks | Performance | Memory use |
|-----------|---------|--------|----------|
| ... | {"license": "apache-2.0"} | kevin-hu-lab/finetuning | null | [
"transformers",
"gguf",
"llama",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T20:42:00+00:00 | [] | [] | TAGS
#transformers #gguf #llama #license-apache-2.0 #endpoints_compatible #text-generation-inference #region-us
| Finetune for Free
-----------------
All notebooks are beginner friendly! Add your dataset, click "Run All", and you'll get a 2x faster finetuned model which can be exported to GGUF, vLLM or uploaded to Hugging Face.
| [] | [
"TAGS\n#transformers #gguf #llama #license-apache-2.0 #endpoints_compatible #text-generation-inference #region-us \n"
] | [
33
] | [
"TAGS\n#transformers #gguf #llama #license-apache-2.0 #endpoints_compatible #text-generation-inference #region-us \n"
] |
automatic-speech-recognition | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Base Ko - Dearlie
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whispe... | {"language": ["ko"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["AIHub/noise"], "base_model": "openai/whisper-base", "model-index": [{"name": "Whisper Base Ko - Dearlie", "results": []}]} | Dearlie/whisper-base | null | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"ko",
"dataset:AIHub/noise",
"base_model:openai/whisper-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T20:42:17+00:00 | [] | [
"ko"
] | TAGS
#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #ko #dataset-AIHub/noise #base_model-openai/whisper-base #license-apache-2.0 #endpoints_compatible #region-us
| Whisper Base Ko - Dearlie
=========================
This model is a fine-tuned version of openai/whisper-base on the Noise Data dataset.
It achieves the following results on the evaluation set:
* Loss: 5.4914
* Cer: 81.4735
Model description
-----------------
More information needed
Intended uses & limitation... | [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps:... | [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #ko #dataset-AIHub/noise #base_model-openai/whisper-base #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during trainin... | [
63,
126,
5,
47
] | [
"TAGS\n#transformers #tensorboard #safetensors #whisper #automatic-speech-recognition #generated_from_trainer #ko #dataset-AIHub/noise #base_model-openai/whisper-base #license-apache-2.0 #endpoints_compatible #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n... |
reinforcement-learning | stable-baselines3 |
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 ... | {"library_name": "stable-baselines3", "tags": ["LunarLander-v2", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "PPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "LunarLander-v2", "type": "LunarL... | rodeoFlip/ppo-LunarLander-v2 | null | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | null | 2024-04-30T20:45:31+00:00 | [] | [] | TAGS
#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us
|
# PPO Agent playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2
using the stable-baselines3 library.
## Usage (with Stable-baselines3)
TODO: Add your code
| [
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add your code"
] | [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n",
"# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.",
"## Usage (with Stable-baselines3)\nTODO: Add you... | [
31,
35,
17
] | [
"TAGS\n#stable-baselines3 #LunarLander-v2 #deep-reinforcement-learning #reinforcement-learning #model-index #region-us \n# PPO Agent playing LunarLander-v2\nThis is a trained model of a PPO agent playing LunarLander-v2\nusing the stable-baselines3 library.## Usage (with Stable-baselines3)\nTODO: Add your code"
] |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | shallow6414/1q31l6l | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T20:48:10+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that... | [
47,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed o... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-0.5B-Chat - bnb 4bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qw... | {} | RichardErkhov/Qwen_-_Qwen1.5-0.5B-Chat-4bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null | 2024-04-30T20:48:22+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-0.5B-Chat - bnb 4bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen-research
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- chat
... | [
"# Qwen1.5-0.5B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include: \n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense ... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n",
"# Qwen1.5-0.5B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a... | [
42,
13,
166,
119,
35,
44,
145,
51
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #4-bit #region-us \n# Qwen1.5-0.5B-Chat## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amoun... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-0.5B-Chat - bnb 8bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qw... | {} | RichardErkhov/Qwen_-_Qwen1.5-0.5B-Chat-8bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null | 2024-04-30T20:49:36+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-0.5B-Chat - bnb 8bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen-research
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- chat
... | [
"# Qwen1.5-0.5B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include: \n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense ... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n",
"# Qwen1.5-0.5B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a... | [
42,
13,
166,
119,
35,
44,
145,
51
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n# Qwen1.5-0.5B-Chat## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amoun... |
text-generation | transformers |
# Llama-3-8B-Instruct-GPTQ-4-Bit
- Original Model creator: [Meta Llama from Meta](https://huggingface.co/meta-llama)
- Original model: [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)
- Built with Meta Llama 3
- Quantized by [Astronomer](https://astronomer.io)
# Import... | {"license": "other", "tags": ["llama", "llama-3", "facebook", "meta", "astronomer", "gptq", "pretrained", "quantized", "finetuned", "autotrain_compatible", "endpoints_compatible"], "datasets": ["wikitext"], "model_name": "Meta-Llama-3-8B-Instruct", "base_model": "meta-llama/Meta-Llama-3-8B-Instruct", "inference": false... | davidxmle/Llama-3-8B-Instruct-GPTQ-4-Bit-Debug | null | [
"transformers",
"llama",
"text-generation",
"llama-3",
"facebook",
"meta",
"astronomer",
"gptq",
"pretrained",
"quantized",
"finetuned",
"autotrain_compatible",
"endpoints_compatible",
"conversational",
"dataset:wikitext",
"arxiv:2210.17323",
"base_model:meta-llama/Meta-Llama-3-8B-In... | null | 2024-04-30T20:49:56+00:00 | [
"2210.17323"
] | [] | TAGS
#transformers #llama #text-generation #llama-3 #facebook #meta #astronomer #gptq #pretrained #quantized #finetuned #autotrain_compatible #endpoints_compatible #conversational #dataset-wikitext #arxiv-2210.17323 #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #text-generation-inference #4-bit #region... | Llama-3-8B-Instruct-GPTQ-4-Bit
==============================
* Original Model creator: Meta Llama from Meta
* Original model: meta-llama/Meta-Llama-3-8B-Instruct
* Built with Meta Llama 3
* Quantized by Astronomer
Important Note About Serving with vLLM & oobabooga/text-generation-webui
============================... | [
"### Prompt Template",
"### Contributors\n\n\n* Quantized by David Xue, Machine Learning Engineer from Astronomer"
] | [
"TAGS\n#transformers #llama #text-generation #llama-3 #facebook #meta #astronomer #gptq #pretrained #quantized #finetuned #autotrain_compatible #endpoints_compatible #conversational #dataset-wikitext #arxiv-2210.17323 #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #text-generation-inference #4-bit #... | [
107,
5,
17
] | [
"TAGS\n#transformers #llama #text-generation #llama-3 #facebook #meta #astronomer #gptq #pretrained #quantized #finetuned #autotrain_compatible #endpoints_compatible #conversational #dataset-wikitext #arxiv-2210.17323 #base_model-meta-llama/Meta-Llama-3-8B-Instruct #license-other #text-generation-inference #4-bit #... |
text-to-image | diffusers |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - embracellm/sushi07_LoRA
<Gallery />
## Model description
These are embracellm/sushi07_LoRA LoR... | {"license": "openrail++", "library_name": "diffusers", "tags": ["text-to-image", "text-to-image", "diffusers-training", "diffusers", "dora", "template:sd-lora", "stable-diffusion-xl", "stable-diffusion-xl-diffusers"], "base_model": "stabilityai/stable-diffusion-xl-base-1.0", "instance_prompt": "a photo of sushi", "widg... | embracellm/sushi07_LoRA | null | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"dora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | null | 2024-04-30T20:53:07+00:00 | [] | [] | TAGS
#diffusers #tensorboard #text-to-image #diffusers-training #dora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us
|
# SDXL LoRA DreamBooth - embracellm/sushi07_LoRA
<Gallery />
## Model description
These are embracellm/sushi07_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using DreamBooth.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madeb... | [
"# SDXL LoRA DreamBooth - embracellm/sushi07_LoRA\n\n<Gallery />",
"## Model description\n\nThese are embracellm/sushi07_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.\n\nThe weights were trained using DreamBooth.\n\nLoRA for the text encoder was enabled: False.\n\nSpecial VAE used for ... | [
"TAGS\n#diffusers #tensorboard #text-to-image #diffusers-training #dora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us \n",
"# SDXL LoRA DreamBooth - embracellm/sushi07_LoRA\n\n<Gallery />",
"## Model desc... | [
72,
25,
85,
18,
25,
6,
7,
23,
17
] | [
"TAGS\n#diffusers #tensorboard #text-to-image #diffusers-training #dora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us \n# SDXL LoRA DreamBooth - embracellm/sushi07_LoRA\n\n<Gallery />## Model description\n\nT... |
text-to-image | diffusers |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA text2image fine-tuning - manusehgal/sdxl14finetuningnew
These are LoRA adaption weights for runwayml/stable-diffusi... | {"license": "creativeml-openrail-m", "library_name": "diffusers", "tags": ["stable-diffusion", "stable-diffusion-diffusers", "text-to-image", "diffusers", "diffusers-training", "lora"], "base_model": "runwayml/stable-diffusion-v1-5", "inference": true} | manusehgal/sdxl14finetuningnew | null | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"diffusers-training",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-04-30T21:00:22+00:00 | [] | [] | TAGS
#diffusers #stable-diffusion #stable-diffusion-diffusers #text-to-image #diffusers-training #lora #base_model-runwayml/stable-diffusion-v1-5 #license-creativeml-openrail-m #region-us
|
# LoRA text2image fine-tuning - manusehgal/sdxl14finetuningnew
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the YaYaB/onepiece-blip-captions dataset. You can find some example images in the following.
!img_0
!img_1
!img_2
!img_3
## Intended uses & limitatio... | [
"# LoRA text2image fine-tuning - manusehgal/sdxl14finetuningnew\nThese are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the YaYaB/onepiece-blip-captions dataset. You can find some example images in the following. \n\n!img_0\n!img_1\n!img_2\n!img_3",
"## Intended uses & ... | [
"TAGS\n#diffusers #stable-diffusion #stable-diffusion-diffusers #text-to-image #diffusers-training #lora #base_model-runwayml/stable-diffusion-v1-5 #license-creativeml-openrail-m #region-us \n",
"# LoRA text2image fine-tuning - manusehgal/sdxl14finetuningnew\nThese are LoRA adaption weights for runwayml/stable-di... | [
59,
98,
6,
7,
23,
17
] | [
"TAGS\n#diffusers #stable-diffusion #stable-diffusion-diffusers #text-to-image #diffusers-training #lora #base_model-runwayml/stable-diffusion-v1-5 #license-creativeml-openrail-m #region-us \n# LoRA text2image fine-tuning - manusehgal/sdxl14finetuningnew\nThese are LoRA adaption weights for runwayml/stable-diffusio... |
text-generation | transformers | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-14B-Chat - bnb 8bits
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qwe... | {} | RichardErkhov/Qwen_-_Qwen1.5-14B-Chat-8bits | null | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null | 2024-04-30T21:01:16+00:00 | [] | [] | TAGS
#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us
| Quantization made by Richard Erkhov.
Github
Discord
Request more models
Qwen1.5-14B-Chat - bnb 8bits
- Model creator: URL
- Original model: URL
Original model description:
---
license: other
license_name: tongyi-qianwen
license_link: >-
URL
language:
- en
pipeline_tag: text-generation
tags:
- chat
---
# Qwe... | [
"# Qwen1.5-14B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include: \n\n* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense m... | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n",
"# Qwen1.5-14B-Chat",
"## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a ... | [
42,
11,
166,
119,
35,
44,
137,
51
] | [
"TAGS\n#transformers #safetensors #qwen2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #8-bit #region-us \n# Qwen1.5-14B-Chat## Introduction\n\nQwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount... |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | samzirbo/mT5.tokenizer.en-es_16K | null | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T21:01:36+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #arxiv-1910.09700 #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #arxiv-1910.09700 #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- ... | [
22,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #arxiv-1910.09700 #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optiona... |
image-text-to-text | xtuner |
# mlx-community/llava-llama-3-8b-v1_1-4bit
This model was converted to MLX format from [`xtuner/llava-llama-3-8b-v1_1-transformers`]() using mlx-vllm version **0.0.3**.
Refer to the [original model card](https://huggingface.co/xtuner/llava-llama-3-8b-v1_1-transformers) for more details on the model.
## Use with mlx
`... | {"library_name": "xtuner", "tags": ["mlx"], "datasets": ["Lin-Chen/ShareGPT4V"], "pipeline_tag": "image-text-to-text"} | mlx-community/llava-llama-3-8b-v1_1-4bit | null | [
"xtuner",
"safetensors",
"llava",
"mlx",
"image-text-to-text",
"dataset:Lin-Chen/ShareGPT4V",
"region:us"
] | null | 2024-04-30T21:04:09+00:00 | [] | [] | TAGS
#xtuner #safetensors #llava #mlx #image-text-to-text #dataset-Lin-Chen/ShareGPT4V #region-us
|
# mlx-community/llava-llama-3-8b-v1_1-4bit
This model was converted to MLX format from ['xtuner/llava-llama-3-8b-v1_1-transformers']() using mlx-vllm version 0.0.3.
Refer to the original model card for more details on the model.
## Use with mlx
| [
"# mlx-community/llava-llama-3-8b-v1_1-4bit\nThis model was converted to MLX format from ['xtuner/llava-llama-3-8b-v1_1-transformers']() using mlx-vllm version 0.0.3.\nRefer to the original model card for more details on the model.",
"## Use with mlx"
] | [
"TAGS\n#xtuner #safetensors #llava #mlx #image-text-to-text #dataset-Lin-Chen/ShareGPT4V #region-us \n",
"# mlx-community/llava-llama-3-8b-v1_1-4bit\nThis model was converted to MLX format from ['xtuner/llava-llama-3-8b-v1_1-transformers']() using mlx-vllm version 0.0.3.\nRefer to the original model card for more... | [
40,
87,
6
] | [
"TAGS\n#xtuner #safetensors #llava #mlx #image-text-to-text #dataset-Lin-Chen/ShareGPT4V #region-us \n# mlx-community/llava-llama-3-8b-v1_1-4bit\nThis model was converted to MLX format from ['xtuner/llava-llama-3-8b-v1_1-transformers']() using mlx-vllm version 0.0.3.\nRefer to the original model card for more detai... |
text-to-image | diffusers |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - embracellm/sushi08_LoRA
<Gallery />
## Model description
These are embracellm/sushi08_LoRA LoR... | {"license": "openrail++", "library_name": "diffusers", "tags": ["text-to-image", "text-to-image", "diffusers-training", "diffusers", "dora", "template:sd-lora", "stable-diffusion-xl", "stable-diffusion-xl-diffusers", "text-to-image", "text-to-image", "diffusers-training", "diffusers", "dora", "template:sd-lora", "stabl... | embracellm/sushi08_LoRA | null | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"dora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | null | 2024-04-30T21:04:31+00:00 | [] | [] | TAGS
#diffusers #tensorboard #text-to-image #diffusers-training #dora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us
|
# SDXL LoRA DreamBooth - embracellm/sushi08_LoRA
<Gallery />
## Model description
These are embracellm/sushi08_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using DreamBooth.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madeb... | [
"# SDXL LoRA DreamBooth - embracellm/sushi08_LoRA\n\n<Gallery />",
"## Model description\n\nThese are embracellm/sushi08_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.\n\nThe weights were trained using DreamBooth.\n\nLoRA for the text encoder was enabled: False.\n\nSpecial VAE used for ... | [
"TAGS\n#diffusers #tensorboard #text-to-image #diffusers-training #dora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us \n",
"# SDXL LoRA DreamBooth - embracellm/sushi08_LoRA\n\n<Gallery />",
"## Model desc... | [
72,
25,
85,
21,
25,
6,
7,
23,
17
] | [
"TAGS\n#diffusers #tensorboard #text-to-image #diffusers-training #dora #template-sd-lora #stable-diffusion-xl #stable-diffusion-xl-diffusers #base_model-stabilityai/stable-diffusion-xl-base-1.0 #license-openrail++ #region-us \n# SDXL LoRA DreamBooth - embracellm/sushi08_LoRA\n\n<Gallery />## Model description\n\nT... |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width... | {"license": "llama2", "library_name": "peft", "tags": ["generated_from_trainer"], "base_model": "codellama/CodeLlama-7b-hf", "model-index": [{"name": "codellama-7b-openapi-completion-ctx-lvl-prmt", "results": []}]} | BohdanPetryshyn/codellama-7b-openapi-completion-ctx-lvl-prmt | null | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:codellama/CodeLlama-7b-hf",
"license:llama2",
"region:us"
] | null | 2024-04-30T21:06:21+00:00 | [] | [] | TAGS
#peft #tensorboard #safetensors #generated_from_trainer #base_model-codellama/CodeLlama-7b-hf #license-llama2 #region-us
| <img src="URL alt="Visualize in Weights & Biases" width="200" height="32"/>
codellama-7b-openapi-completion-ctx-lvl-prmt
============================================
This model is a fine-tuned version of codellama/CodeLlama-7b-hf on an unknown dataset.
It achieves the following results on the evaluation set:
* Lo... | [
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 4\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=... | [
"TAGS\n#peft #tensorboard #safetensors #generated_from_trainer #base_model-codellama/CodeLlama-7b-hf #license-llama2 #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 4\n* se... | [
45,
142,
5,
58
] | [
"TAGS\n#peft #tensorboard #safetensors #generated_from_trainer #base_model-codellama/CodeLlama-7b-hf #license-llama2 #region-us \n### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 4\n* seed: 42... |
text-classification | transformers | # merge_out
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [mllm-dev/merge_diff_data_DROID](https://huggingface.co/mllm-dev/merge_... | {"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["mllm-dev/merge_diff_data_DROID", "mllm-dev/merge_diff_data_YELP"]} | mllm-dev/merge_yelp_droid_ties_2 | null | [
"transformers",
"safetensors",
"gpt2",
"text-classification",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:mllm-dev/merge_diff_data_DROID",
"base_model:mllm-dev/merge_diff_data_YELP",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T21:09:23+00:00 | [
"2306.01708"
] | [] | TAGS
#transformers #safetensors #gpt2 #text-classification #mergekit #merge #arxiv-2306.01708 #base_model-mllm-dev/merge_diff_data_DROID #base_model-mllm-dev/merge_diff_data_YELP #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
| # merge_out
This is a merge of pre-trained language models created using mergekit.
## Merge Details
### Merge Method
This model was merged using the TIES merge method using mllm-dev/merge_diff_data_DROID as a base.
### Models Merged
The following models were included in the merge:
* mllm-dev/merge_diff_data_YELP
... | [
"# merge_out\n\nThis is a merge of pre-trained language models created using mergekit.",
"## Merge Details",
"### Merge Method\n\nThis model was merged using the TIES merge method using mllm-dev/merge_diff_data_DROID as a base.",
"### Models Merged\n\nThe following models were included in the merge:\n* mllm-d... | [
"TAGS\n#transformers #safetensors #gpt2 #text-classification #mergekit #merge #arxiv-2306.01708 #base_model-mllm-dev/merge_diff_data_DROID #base_model-mllm-dev/merge_diff_data_YELP #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# merge_out\n\nThis is a merge of pre-trained... | [
89,
19,
4,
33,
29,
16
] | [
"TAGS\n#transformers #safetensors #gpt2 #text-classification #mergekit #merge #arxiv-2306.01708 #base_model-mllm-dev/merge_diff_data_DROID #base_model-mllm-dev/merge_diff_data_YELP #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# merge_out\n\nThis is a merge of pre-trained langu... |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | lunarsylph/stablecell_v56 | null | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T21:09:44+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the ... | [
41,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model ca... |
text-to-image | diffusers |
# Real Dream SDXL API Inference

## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "real-dream-sdxl"
C... | {"license": "creativeml-openrail-m", "tags": ["modelslab.com", "stable-diffusion-api", "text-to-image", "ultra-realistic"], "pinned": true} | stablediffusionapi/real-dream-sdxl | null | [
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | null | 2024-04-30T21:11:15+00:00 | [] | [] | TAGS
#diffusers #modelslab.com #stable-diffusion-api #text-to-image #ultra-realistic #license-creativeml-openrail-m #endpoints_compatible #diffusers-StableDiffusionXLPipeline #region-us
|
# Real Dream SDXL API Inference
!generated from URL
## Get API Key
Get API key from ModelsLab API, No Payment needed.
Replace Key in below code, change model_id to "real-dream-sdxl"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: View docs
Try model for free: Generate Images
Model link... | [
"# Real Dream SDXL API Inference\n\n!generated from URL",
"## Get API Key\n\nGet API key from ModelsLab API, No Payment needed. \n\nReplace Key in below code, change model_id to \"real-dream-sdxl\"\n\nCoding in PHP/Node/Java etc? Have a look at docs for more code examples: View docs\n\nTry model for free: Genera... | [
"TAGS\n#diffusers #modelslab.com #stable-diffusion-api #text-to-image #ultra-realistic #license-creativeml-openrail-m #endpoints_compatible #diffusers-StableDiffusionXLPipeline #region-us \n",
"# Real Dream SDXL API Inference\n\n!generated from URL",
"## Get API Key\n\nGet API key from ModelsLab API, No Payment... | [
56,
13,
515
] | [
"TAGS\n#diffusers #modelslab.com #stable-diffusion-api #text-to-image #ultra-realistic #license-creativeml-openrail-m #endpoints_compatible #diffusers-StableDiffusionXLPipeline #region-us \n# Real Dream SDXL API Inference\n\n!generated from URL## Get API Key\n\nGet API key from ModelsLab API, No Payment needed. \n\... |
feature-extraction | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | claudios/CodeGPT-small-py | null | [
"transformers",
"safetensors",
"gpt2",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T21:12:55+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #gpt2 #feature-extraction #arxiv-1910.09700 #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #gpt2 #feature-extraction #arxiv-1910.09700 #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This mo... | [
40,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #gpt2 #feature-extraction #arxiv-1910.09700 #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been ... |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | lunarsylph/moontemp_v1 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T21:16:24+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that... | [
47,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #llama #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed o... |
image-segmentation | pytorch |

# DeepLabV3-Plus-MobileNet-Quantized: Optimized for Mobile Deployment
## Quantized Deep Convolutional Neural Network model for semantic segmentation
DeepLabV3 Quantized is d... | {"license": "mit", "library_name": "pytorch", "tags": ["quantized", "android"], "datasets": ["VOC2012"], "pipeline_tag": "image-segmentation"} | qualcomm/DeepLabV3-Plus-MobileNet-Quantized | null | [
"pytorch",
"tflite",
"quantized",
"android",
"image-segmentation",
"dataset:VOC2012",
"arxiv:1706.05587",
"license:mit",
"region:us"
] | null | 2024-04-30T21:16:43+00:00 | [
"1706.05587"
] | [] | TAGS
#pytorch #tflite #quantized #android #image-segmentation #dataset-VOC2012 #arxiv-1706.05587 #license-mit #region-us
|  (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #gpt2 #feature-extraction #arxiv-1910.09700 #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This mo... | [
40,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #gpt2 #feature-extraction #arxiv-1910.09700 #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been ... |
feature-extraction | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | claudios/CodeGPT-Multilingual | null | [
"transformers",
"safetensors",
"gpt2",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T21:20:43+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #gpt2 #feature-extraction #arxiv-1910.09700 #endpoints_compatible #text-generation-inference #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #gpt2 #feature-extraction #arxiv-1910.09700 #endpoints_compatible #text-generation-inference #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This mo... | [
40,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #gpt2 #feature-extraction #arxiv-1910.09700 #endpoints_compatible #text-generation-inference #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been ... |
feature-extraction | transformers |
## Model Description
We introduce Dragon-multiturn, a retriever specifically designed for the conversational QA scenario. It can handle conversational query which combine dialogue history with the current query. It is built on top of the [Dragon](https://huggingface.co/facebook/dragon-plus-query-encoder) retriever. Th... | {"language": ["en"], "license": ["other"], "tag": ["dragon", "retriever", "conversation", "multi-turn", "conversational query"]} | nvidia/dragon-multiturn-context-encoder | null | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"en",
"arxiv:2401.10225",
"arxiv:2302.07452",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T21:21:45+00:00 | [
"2401.10225",
"2302.07452"
] | [
"en"
] | TAGS
#transformers #pytorch #bert #feature-extraction #en #arxiv-2401.10225 #arxiv-2302.07452 #license-other #endpoints_compatible #region-us
|
## Model Description
We introduce Dragon-multiturn, a retriever specifically designed for the conversational QA scenario. It can handle conversational query which combine dialogue history with the current query. It is built on top of the Dragon retriever. The details of Dragon-multiturn can be found in here. Please no... | [
"## Model Description\nWe introduce Dragon-multiturn, a retriever specifically designed for the conversational QA scenario. It can handle conversational query which combine dialogue history with the current query. It is built on top of the Dragon retriever. The details of Dragon-multiturn can be found in here. Plea... | [
"TAGS\n#transformers #pytorch #bert #feature-extraction #en #arxiv-2401.10225 #arxiv-2302.07452 #license-other #endpoints_compatible #region-us \n",
"## Model Description\nWe introduce Dragon-multiturn, a retriever specifically designed for the conversational QA scenario. It can handle conversational query which ... | [
50,
100,
46,
1334,
5,
26,
131
] | [
"TAGS\n#transformers #pytorch #bert #feature-extraction #en #arxiv-2401.10225 #arxiv-2302.07452 #license-other #endpoints_compatible #region-us \n## Model Description\nWe introduce Dragon-multiturn, a retriever specifically designed for the conversational QA scenario. It can handle conversational query which combin... |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generate... | {"library_name": "transformers", "tags": []} | OwOOwO/finalupdatec1 | null | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T21:23:02+00:00 | [
"1910.09700"
] | [] | TAGS
#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us
|
# Model Card for Model ID
## Model Details
### Model Description
This is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by:
- Funded by [optional]:
- Shared by [optional]:
- Model type:
- Language(s) (NLP):
- License... | [
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model card has been automatically generated.\n\n- Developed by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Model type: \n- Language(s)... | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Card for Model ID",
"## Model Details",
"### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the ... | [
41,
6,
4,
75,
23,
3,
5,
8,
9,
8,
34,
20,
4,
5,
5,
11,
13,
12,
3,
10,
6,
5,
6,
4,
5,
7,
49,
7,
7,
5,
5,
15,
7,
7,
8,
5
] | [
"TAGS\n#transformers #safetensors #stablelm #text-generation #conversational #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #region-us \n# Model Card for Model ID## Model Details### Model Description\n\n\n\nThis is the model card of a transformers model that has been pushed on the Hub. This model ca... |
sentence-similarity | sentence-transformers |
# luiz-and-robert-thesis/mpnet-frozen-newtriplets-lr-2e-7-m-1-e-5
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence... | {"library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"} | luiz-and-robert-thesis/mpnet-frozen-newtriplets-lr-2e-7-m-1-e-5 | null | [
"sentence-transformers",
"safetensors",
"mpnet",
"feature-extraction",
"sentence-similarity",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T21:23:24+00:00 | [] | [] | TAGS
#sentence-transformers #safetensors #mpnet #feature-extraction #sentence-similarity #endpoints_compatible #region-us
|
# luiz-and-robert-thesis/mpnet-frozen-newtriplets-lr-2e-7-m-1-e-5
This is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have... | [
"# luiz-and-robert-thesis/mpnet-frozen-newtriplets-lr-2e-7-m-1-e-5\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy whe... | [
"TAGS\n#sentence-transformers #safetensors #mpnet #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n",
"# luiz-and-robert-thesis/mpnet-frozen-newtriplets-lr-2e-7-m-1-e-5\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and c... | [
29,
69,
30,
26,
63,
5,
5
] | [
"TAGS\n#sentence-transformers #safetensors #mpnet #feature-extraction #sentence-similarity #endpoints_compatible #region-us \n# luiz-and-robert-thesis/mpnet-frozen-newtriplets-lr-2e-7-m-1-e-5\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be ... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.