
full_name stringlengths 7 104 | description stringlengths 4 725 ⌀ | topics stringlengths 3 468 ⌀ | readme stringlengths 13 565k ⌀ | label int64 0 1 |
|---|---|---|---|---|
akashbangad/NavigationView | Example app to show the implementation of NavigationView from the design support library | null | null | 1 |
mfaisalkhatri/selenium4poc | Learn Web Automation testing using Selenium Webdriver 4. | beginner-friendly examples hacktoberfest java selenium selenium-java selenium-webdriver test-automation testing tutorial webautomation webautomationtesting | 
[](https://opensource.org/licenses/Apache-2.0)
[](https://github.co... | 0 |
Pragmatists/eventsourcing-java-example | A simplified (in memory) example of Event Sourcing implementation for banking domain. | ddd ddd-sample event-sourcing | # Event sourcing example in Java
A simplified (in memory) example of Event Sourcing implementation in Java for banking domain.
Repository is splitted into exercises adding step by step more functionality towards good design of event sourcing with CQRS.
You can play around and try to implement exercises or You can check... | 1 |
cristianprofile/spring-boot-mvc-complete-example | spring boot mvc complete example integration and unit test with @config classes | null | ## Spring Boot Maven/Gradle Java 1.8 (Spring MVC jsp and tiles, Spring Data Rest, Jenkins 2 ready to use with full support to Maven and Gradle)
[](https://coveralls.io/r/cristianprofile/spring-boot-mvc-complete-ex... | 1 |
umermansoor/hadoop-java-example | A very simple example of using Hadoop's MapReduce functionality in Java. | null | ## Hadoop Map-Reduce Example in Java
**Get up and running in less than 5 minutes**
### Overview
This program demonstrates Hadoop's Map-Reduce concept in Java using a very simple example. The input is raw data files listing earthquakes by region, magnitude and other information.
> nc,71920701,1,”Saturday, January 12,... | 1 |
thundergolfer/example-bazel-monorepo | 🌿💚 Example Bazel-ified monorepo, supporting Golang, Java, Python, Scala, and Typescript | bazel bazel-monorepo blaze buck build-tool platform-engineering | <h1 align="center">Example Bazel Monorepo</h1>
<p align="center">
<a href="https://buildkite.com/thundergolfer-inc/the-one-true-bazel-monorepo">
<img src="https://badge.buildkite.com/aa36b75077a5c69156bc143b32c8c2db04c4b20b8706b8a99b.svg?branch=master">
</a>
</p>
----
> *Note:* Currently supporting th... | 1 |
interseroh/demo-gwt-springboot | Simple Example WebApp for GWT and Spring Boot | null | # demo-gwt-springboot
## Build Status
[](https://travis-ci.org/interseroh/demo-gwt-springboot)
## Table of Contents
- [Demo in Heroku](#demo-in-heroku)
- [Introduction](#introduction)
- [Architecture](#architecture)
- [Model for... | 1 |
runabol/spring-security-passwordless | Passwordless authentication example application using Spring Boot and Spring Security | apache2 java passwordless-login springboot springsecurity | # Introduction
We all have a love/hate relationship with passwords. They protect our most valuable assets but they are so god damn hard to create and remember.
And just to make things even harder for us humans, more and more companies are now enforcing two factor authentication (you know, the little phone pincode thi... | 1 |
lomza/AppBar-ScrollFlags-Example | Examples of AppBarLayout's usage of layout_scrollFlags attribute | null | # AppBar-ScrollFlags-Example
Examples of AppBarLayout's usage of layout_scrollFlags attribute
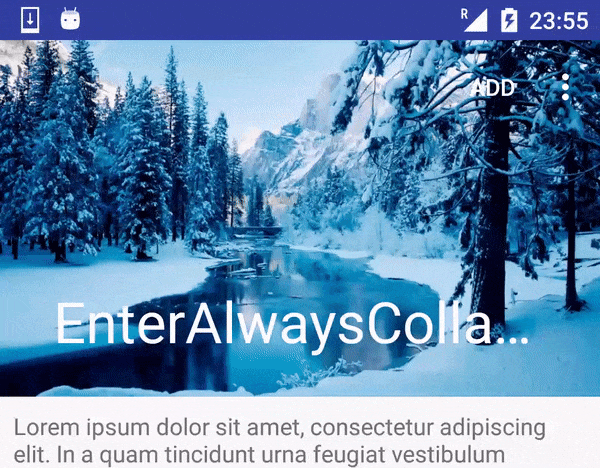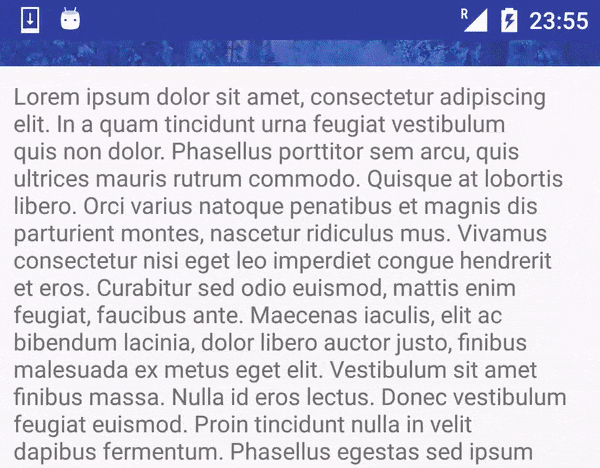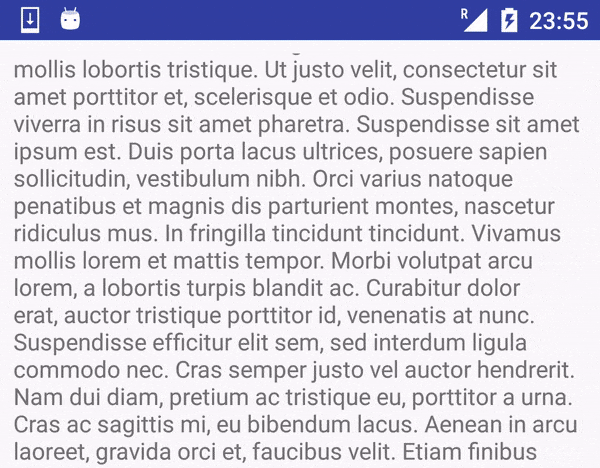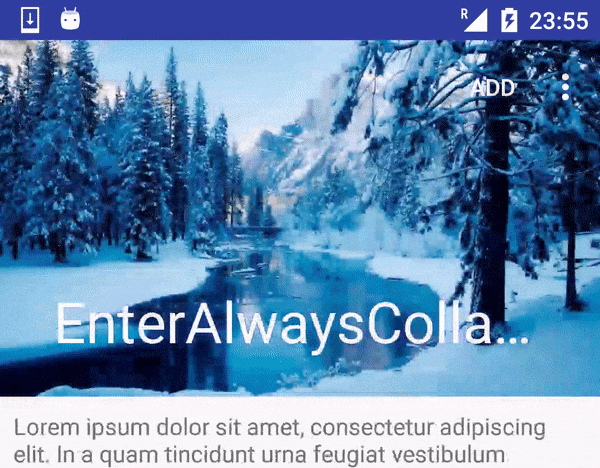
| 0 |
thegreystone/java-svc | Java serviceability examples. Includes simple example apps for jmc, jfr, attach, jmx, jplis, jdi and perfcounters. | hacktoberfest hacktoberfest2021 | # java-svc
This repository contains a set of small examples that can be used to demonstrate various popular Java serviceability technologies. The examples are focused on making it easy to getting going with the various serviceability technologies.
Note that there are already technology demonstrators for most technolog... | 1 |
qct/swagger-example | Introduction and Example for OpenAPI specification & Swagger Open Source Tools, including swagger-editor, swagger-codegen and swagger-ui. Auto generation example for client SDKs, server code, asciidoctor and html documents. | asciidoc asciidoctor asciidoctor-converter asciidoctor-pdf spring-boot springfox swagger swagger-api swagger-codegen swagger-docs swagger-editor swagger-generator swagger-spec swagger-specification swagger-ui swagger2 swagger2markup | # Swagger Introduction & Examples
- [Quick Start](#quick-start)
- [OpenAPI & Swagger](#openapi--swagger)
* [OpenAPI](#openapi)
* [Swagger](#swagger)
* [Why Use OpenAPI?](#why-use-openapi)
- [Introduction to OpenAPI Specification](#introduction-to-openapi-specification)
* [Basic Structure](#basic-structure)
* ... | 1 |
Udinic/PerformanceDemo | Simple demonstrations of performance issues. Using these examples will allow practicing performance analyzing tools, such as Systrace, Traceview and more. | null | # PerformanceDemo
Simple demonstrations of performance issues. Using these examples will allow practicing performance analyzing tools, such as Systrace, Traceview and more.
## Perf Demo
This is the main app, showing a few options to simulate different performance issues.
## Keep Busy app
Simple app to keep the CPU bu... | 0 |
luontola/cqrs-hotel | Example application about CQRS and Event Sourcing #NoFrameworks | null |
# CQRS Hotel
Example application demonstrating the use of [CQRS](http://martinfowler.com/bliki/CQRS.html) and [Event Sourcing](http://martinfowler.com/eaaDev/EventSourcing.html) within the domain of hotel reservations. #NoFrameworks
This project is a sandbox for exploring how CQRS+ES affects the design of a system. ... | 1 |
jakubnabrdalik/hentai | Example of Hexagonal architecture with high cohesion modularization, CQRS and fast BDD tests in Java | null | # Example of Hexagonal architecture with high cohesion modularization, CQRS and fast BDD tests in Java
This repo is an example of Hexagonal architecture with sensible modularization on a package level, that provides high cohesion, low coupling, and allows for Behaviour Driven Development that has
- allows for most te... | 1 |
codetojoy/easter_eggs_for_java_9 | Basic examples for Java 9 modules. Usage of 'egg' here is SSCCE: http://sscce.org | null | ### Eggs for Java 9 Modules
* some basic examples for Java 9 modules
* usage of *'egg'* here is [SSCCE](http://sscce.org/) **not** a [hidden feature](https://en.wikipedia.org/wiki/Easter_egg_(media)) !
* see notes below to use JDK9 in Docker
* see README.md in each folder for steps to execute
### validation log
* con... | 0 |
LambdaTest/java-testng-selenium | Run TestNG and Selenium scripts on LambdaTest automation cloud. A sample repo to help you run TestNG framework based test scripts in parallel with LambdaTest | automation automation-testing cloud example examples java lambdatest selenium selenium-grid selenium-webdriver selenium4 test-automation testing testng | # Run Selenium Tests With TestNG On LambdaTest

<p align="center">
<a href="https://www.lambdatest.com/blog/?utm_source=github&utm_medium=repo&utm_campaign=Java-TestNG-Selenium" target="_bank">Blog</a>
... | 1 |
JeroenMols/ArtifactoryExample | Example code to upload and use artefacts from Artifactory | null | # ArtifactoryExample
This repository demonstrates how you easily generate Maven artifacts from an Android library and upload them to your own private repository (based on Artifactory). The precise details of how everything works can be found:
- For AwesomeLibrary and AwesomeApplication: [this blogpost](https://jeroenm... | 1 |
loopj/proguard-gradle-example | Example app showing how to use proguard with gradle | null | Example Java App with Proguard
==============================
Building
--------
```shell
./gradlew clean build proguard
```
Running
-------
```shell
java -jar build/libs/proguard-gradle-example.jar
```
Outputs
-------
- `build/libs/proguard-gradle-example.jar` - main package
- `build/libs/proguard-gradle-exa... | 1 |
coi-gov-pl/spring-clean-architecture | An example web app structured using Clean Architecture, implemented using Spring Framework. | null | # spring-clean-architecture
[](https://travis-ci.org/coi-gov-pl/spring-clean-architecture)
An example web app structured using [Clean Architecture][clean-arch],
implemented using [Spring Framework][spring].

- Spring Boot 2.1.1.RELEASE
- socket.io-client 2.2.0
In this example, `SocketIONamespace` is used for declaring modules.
This example project is inspired by the following projects.
- https://gith... | 1 |
AkramChauhan/WhatsApp-Stickers-using-Flutter | This App is complete example of how to create WhatsApp Sticker Application using Flutter. | null | # WhatsApp Sticker App using Flutter

# Available in PlayStore
<a href="https://play.google.com/store/apps/details?id=com.gamacrack.trending_stickers">
```java
public class Guest {
private final int grade;
private final String name;
private final String company;
...
}
```
[GuestRepository.java](src/main/java/com/naver/helloworld/resort/reposit... | 0 |
stream-iori/vertx-rpc-example | The Example of vertx-rpc | null | # vertx-rpc-example
The Example of vertx-rpc
| 1 |
xtext/maven-xtext-example | An Xtext language and example usage of it built with Maven | null | [](https://github.com/xtext/maven-xtext-example/actions?query=workflow%3ABuild)
# An Xtext Language Built with Maven
A small example to show how to configure a Maven build for an Xtext language and how to use it from ... | 1 |
bzdgn/spring-boot-restful-web-service-example | A detailed Standalone RESTful web service example application with the use of Spring Boot framework | h2-database h2-embedded-database java jersey jersey-spring-hibernate microservice microservices restful-api restful-webservices spring-boot spring-framework standalone uberjar | Spring Boot RESTful Web Service Example
=======================================
The main purpose of this sample project is to demonstrate the capabilities of spring boot.
But additionally, I want to show challenging problems that can occur during the development
while using the Spring Boot.
First goal is to show how i... | 1 |
jghoman/finagle-java-example | Quick example of a Java Thrift server and client using Finagle | null | null | 1 |
cryxli/sr201 | Protocol example for SR-201 Series network relay | null | # Simple Client Application for SR-201 Ethernet Relay Board
Resently I ordered a little board 50mm x 70mm with two relays. They can be switched by sending commands over TCP or UDP. The only problem with it is, that the code examples and instruction manual are entierly written in Chinese. Therefore, I created this repo... | 1 |
DataStax-Examples/spring-k8s-cassandra-microservices | Example microservices with Spring, Kubernetes, and Cassandra | cassandra kubernetes microservices spring spring-boot spring-cloud spring-data-cassandra | # Microservices with Spring, Kubernetes, and Cassandra
This repository contains sample inventory microservices to demonstrate how to use Spring, Kubernetes and Cassandra together a single stack.
](http://android-arsenal.com/details/3/2448)
viper architecture example
This is example of application built with VIPER architecture. It's built on top of sockeqwe's [Mosby](https://github.com/sockeqwe/mosby).
### ... | 1 |
noveogroup-amorgunov/spring-mvc-react | Example of using spring 4 (rest full api with hibernate) + react.js (client) | mysql react spring spring-mvc | # Spring 4 MVC + ReactJS

Very light version of [stackoverflow](http://stackoverflow.com/) build by [ReactJS](https://facebook.github.io/react/) (client-side) and [Spring4](https://spring.io/) (server-side).
## Features
- Authorization system (by [json web token](htt... | 1 |
FledgeXu/NeutrinoSourceCode | It's Neutrino Project's example Code. | null | null | 1 |
balaji-k13/Navigation-drawer-page-sliding-tab-strip | Example which integration of Navigation Drawer and Page Sliding Tab Strip , like google play music app | null | # Android Navigation Drawer with Page (Pager) Sliding tab Strip
This sample is the result of integration of latest navigation drawer(v4 lib) and similar tab strip which is used in google play music app. (https://play.google.com/store/apps/details?id=com.google.android.music)
Please check out apk which is in root fold... | 1 |
seflerZ/javaworker | A simple example of the Java worker pattern | null | null | 1 |
zcox/akka-zeromq-java | Examples of using Akka and 0MQ in Java, separately and together. | null | null | 0 |
ebean-orm-demo/demo-order | Example showing some features of Ebean ORM | null | null | 1 |
SaravananSubramanian/dicom | This repository contains all the code that I have used in my DICOM articles on my blog (Java examples are included) | dicom dicom-standard healthcare imaging-informatics java radiology | null | 0 |
plluke/tof | Example of grabbing ToF data from Samsung S10 5G | null | # Time of Flight Camera Example
<p><img src="docs/demo.gif"/></p>
This is an example app that demonstrates how to capture and process data from a Time of Flight camera, specifically the front-facing "3D Camera" on the Samsung S10 5G.
## How to Use
Clone and run on an Samsung S10 5G device from Android studio (3.5.1 a... | 1 |
halide/CVPR2015 | Example code used in the CVPR 2015 tutorial | null | To get started, download a binary release of Halide from halide-lang.org and untar/unzip it into this directory. | 1 |
jgribonvald/demo-spring-cas-angular | Example to use CAS auth with jhipster app | null | README for demo
==========================
set on application-dev.yml these properties :
```
server:
address: LOCAL_ADDRESS (to your local address that your CAS can resolve)
port: LOCAL_PORT (keep 8080)
app:
service:
home: http://LOCAL_ADDRESS:LOCAL_PORT/
security: http://LOCAL_ADDRESS:LO... | 1 |
apollographql/federation-jvm-spring-example | Apollo Federation JVM example implementation using Spring for GraphQL | apollo-federation graphql java spring-graphql | # Federation JVM Spring Example
[Apollo Federation JVM](https://github.com/apollographql/federation-jvm) example implementation using [Spring for GraphQL](https://docs.spring.io/spring-graphql/docs/current/reference/html/).
If you want to discuss the project or just say hi, stop by [the Apollo community forums](https:... | 1 |
wangshaolei/NumberKeyboard | For example meituan's mechant NumberKeyboard | null | # NumberKeyboard
## Custom keyboardview with two ways:
1. Override systems's sys.xml of keyboardview
2. Custom the layout and slove the touchListener's question and so on...
### For example: MeiTuan's Merchant or NuoMi's Merchant app, Number Keyboard
#### Show parts codes:
```java
public class MainActivity exte... | 1 |
doyleyoung/vertx-graphql-example | GraphQL Async example using Vert.x | null | # Vert.x GraphQL Example

When it comes to performance and scalability, Vert.x has always been hard to beat and version 3 just made it much easier to develop and deploy.
This simple application is used to demonst... | 1 |
jasebell/mlbook | Example code for the Wiley book Machine Learning - Hands On for Developers and Technical Professionals"" | null | null | 1 |
bezkoder/spring-boot-security-login | Spring Boot + Spring Security: Login and Registration example with JWT, H2 Database and HttpOnly Cookie | authentication authorization httponly-cookie jwt jwt-auth jwt-authentication jwt-token login registration spring-boot spring-security | # Spring Boot Security Login example with JWT and H2 example
- Appropriate Flow for User Login and Registration with JWT and HttpOnly Cookie
- Spring Boot Rest Api Architecture with Spring Security
- How to configure Spring Security to work with JWT
- How to define Data Models and association for Authentication and Au... | 1 |
YongHuiLuo/Learning-Rxandroid | Learn and use RxAndroid together by PPT and Example | null | # Learning-Rxandroid
---
Because interest RxJava, RxAndroid, RxBinding of creating this project. RxAndroid making program coding for asynchronous operations more simple, in addition, the observer pattern design for my project and enhance the ability of encoding are very helpful. I compiled in the process of learning a ... | 1 |
lgvalle/FragmentSharedFabTransition | Example of how to use shared element transitions within Fragments | null | # FragmentSharedFabTransition
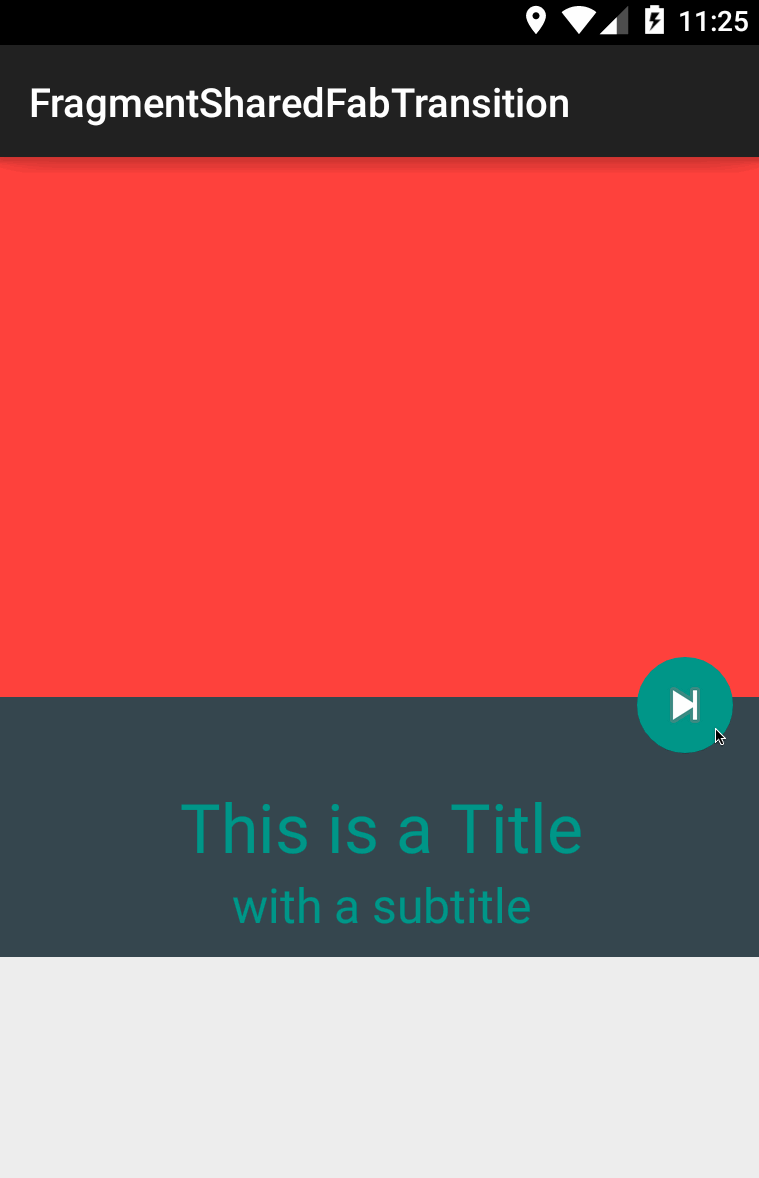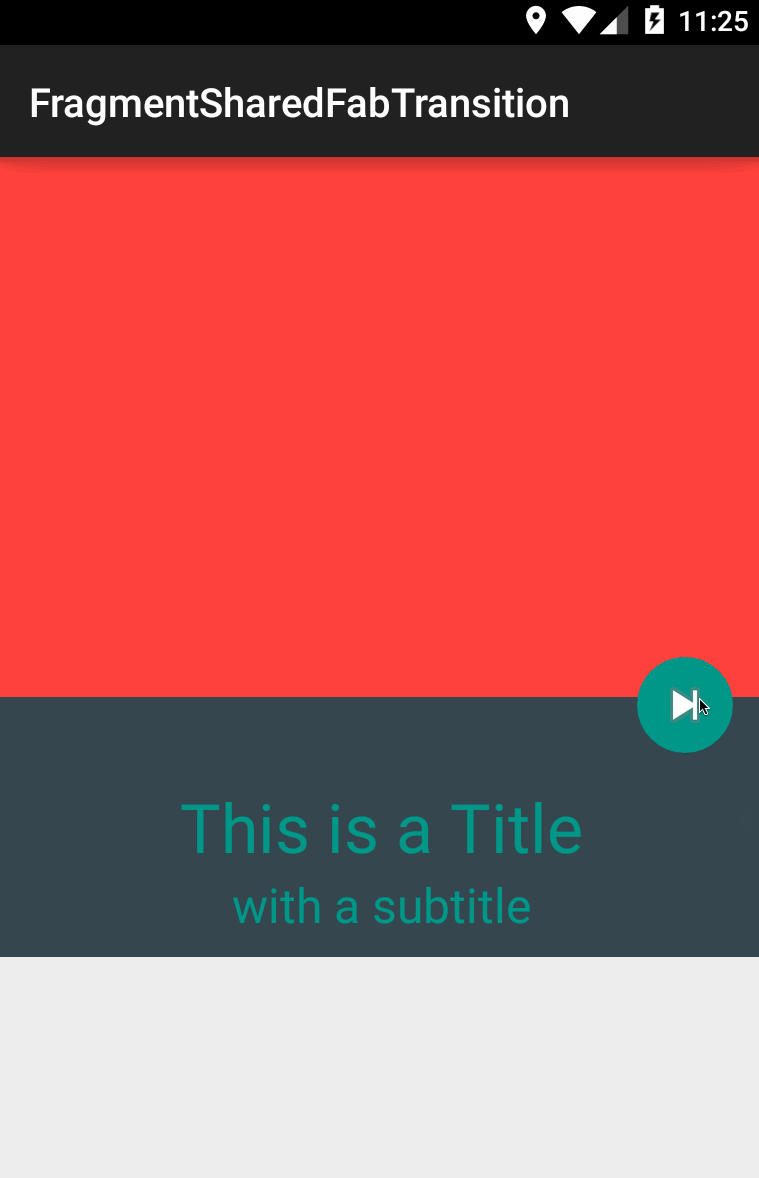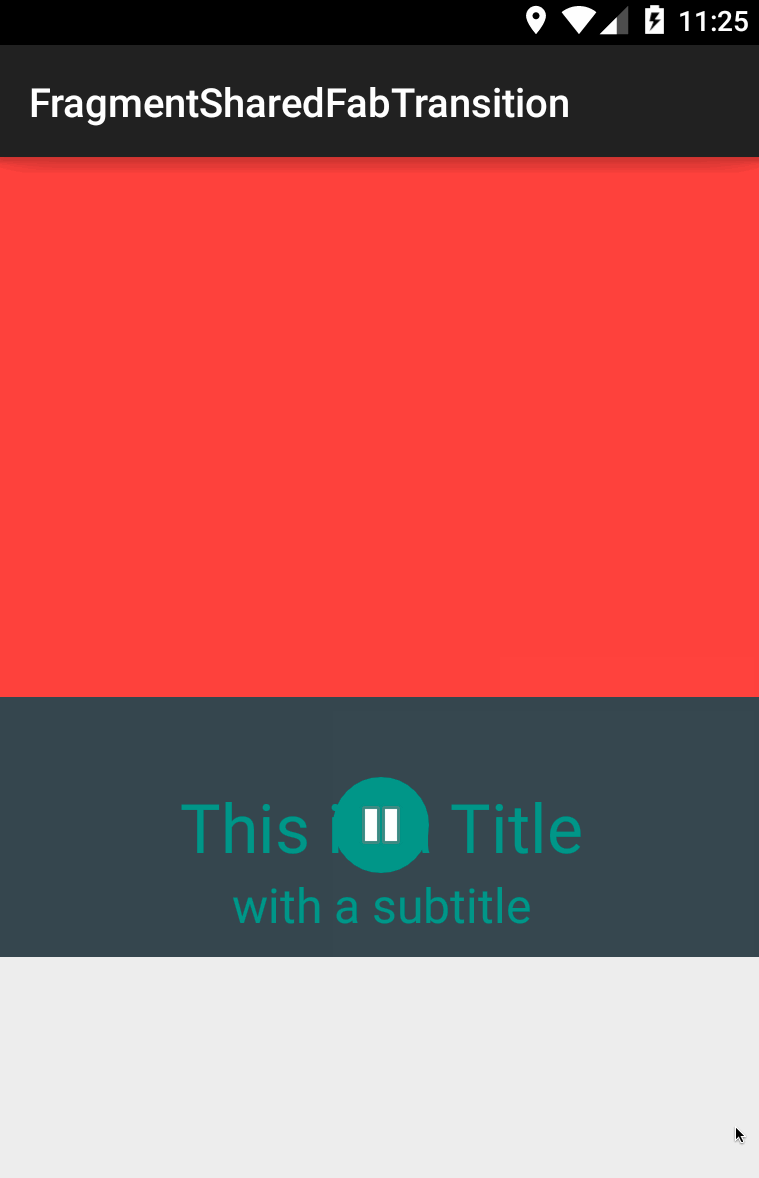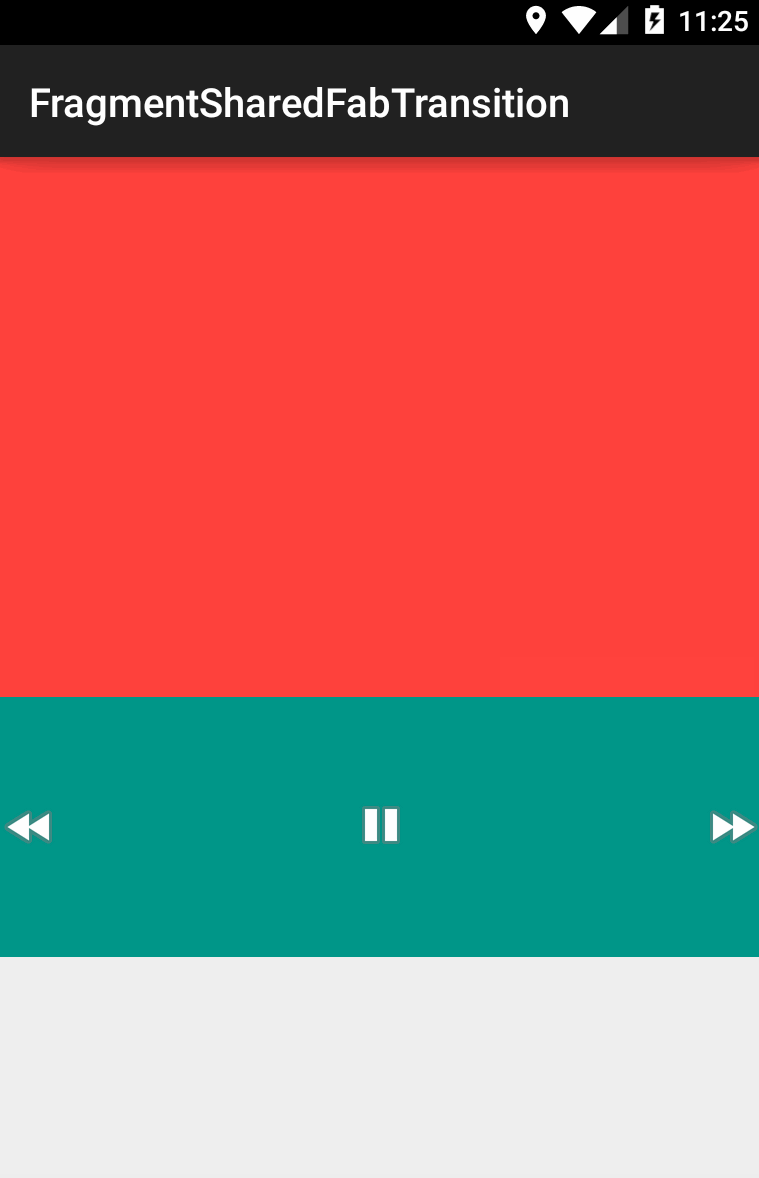
| 1 |
okkam-it/flink-mongodb-test | Flink 0.7 MongoDB example (for Hadoop2) | null | Accessing Data Stored in MongoDB with Apache Flink 0.7+!
===================
Starting from the post at https://flink.incubator.apache.org/news/2014/01/28/querying_mongodb.html here at [Okkam](http://www.okkam.it) we played around withthe new **Apache Flink APIs (0.7+)** and we manage to make a simple mapreduce exampl... | 1 |
florina-muntenescu/ReactiveBurgers | Code example for The ABCs of RxJava"" | null | # ReactiveBurgers
Code example for "The ABCs of RxJava" talk.
It contains different ways of creating RxJava ``Observable``s:
* from a static list - where every element of the list will be an emission of an ``Observable``
* from a file - where every line of the file will be an emission of an ``Observable``
* from clic... | 1 |
jvirtanen/coinbase-fix-example | Simple example application for Coinbase Pro FIX API | bitcoin coinbase coinbase-pro finance fixprotocol java trading | # Coinbase Pro FIX Example
This is a simple example application that demonstrates how to connect to
[Coinbase Pro][] using the [FIX API][] and [Philadelphia][], an open source
FIX engine for the JVM.
[Coinbase Pro]: https://pro.coinbase.com
[FIX API]: https://docs.pro.coinbase.com/#fix-api
[Philadelphia]: https... | 1 |
SomMeri/antlr-step-by-step | Example project for ANTLR tutorial blog post. | null | null | 1 |
Rapter1990/SpringBootMicroservices | Spring Boot Microservice Example(Eureka Server, Config Server, API Gateway, Services , RabbitMq, Keycloak) | api-gateway configserver docker docker-compose eureka-server java keycloak microservices rabbitmq service spring-boot spring-cloud spring-security | # Spring Boot Microservice Example(Eureka Server, Config Server, API Gateway, Services , RabbitMq, Keycloak)
<img src="screenshots/springbootmicroservices.drawio_image.png" alt="Main Information" width="800" height="900">
# About the project
<ul style="list-style-type:disc">
<li>User can register and login through ... | 0 |
kbastani/order-delivery-microservice-example | This repository contains a functional example of an order delivery service similar to UberEats, DoorDash, and Instacart. | null | # Order Delivery Microservice Example
In an event-driven microservices architecture, the concept of a domain event is central to the behavior of each service. Popular practices such as _CQRS_ (Command Query Responsibility Segregation) in combination with _Event Sourcing_ are becoming more common in applications as mic... | 1 |
Cadiboo/Example-Mod | An example mod created to try and get new modders to use good code practices | example-code minecraft-forge-mod | # [Example Mod](https://github.com/Cadiboo/Example-Mod)
### An example mod created by [Cadiboo](https://github.com/Cadiboo) to try and get new modders to use good code practices
##### View the tuorials for this at [https://cadiboo.github.io/tutorials/](https://cadiboo.github.io/tutorials/)
This contains the basic setup... | 1 |
binblee/dubbo-docker | Example of running Dubbo in Docker, packaged as a springboot application, running on Kubernetes. | null | # Dubbo in Docker Example
Dubbo running in Docker, packaged as a springboot application.
## Services
This demo consistes three services:
- a zookeper instance
- a service producer
- a service consumer
The service producer exposes a ```Greeting``` service through RPC,
service consumer access the producer.
## Zooke... | 1 |
mechero/completable-future-example | Example project comparing Java's CompletableFuture and Future implementations | completablefuture future java thepracticaldeveloper | # CompletableFuture, Future and Streams
This project uses a sample use case to compare Java's `CompletableFuture` with plain `Future` and other approaches like plain Java and the Stream API.
There is a story behind this code to make it more fun and, at the same time, to give a goal to the sample code so it's easier t... | 1 |
jpatanooga/Caduceus | Set of example algorithm implementations focused on statistics and machine learning | null | null | 1 |
birchsport/titanic | Example code for solving the Titanic prediction problem found on Kaggle. | null | # titanic #
Example code for solving the Titanic prediction problem (https://www.kaggle.com/c/titanic-gettingStarted) found on Kaggle. This example uses the Weka Data Mining Libraries to perform our classifications and predictions. Note, we are using Weka version 3.6.9.
## Data Cleanup/Initialization ##
Before we b... | 1 |
stevenalexander/docker-authentication-authorisation | Example microservice authentication and authorisation solution using Docker containers | null | # Docker authentication and authorisation images
This is sample implementation of the microservice authentication and authorisation pattern I described in a previous
blog posts ([here](https://stevenwilliamalexander.wordpress.com/2014/04/24/microservice-authentication-and-authorisation/)
for pattern, [here](https://st... | 1 |
khmarbaise/jdk9-jlink-jmod-example | Example for using maven-jmod-plugin / maven-jlink-plugin | java jdk9 jigsaw maven maven-plugin | Maven JDK9 Jigsaw Example
=========================
Status
------
* Currently not more than a Proof of Concept
* Everything here is speculative!
Overview
--------
* Example how could jmod/jlink work together in a Maven build
(using [`maven-jlink-plugin`](https://github.com/apache/maven-jlink-plugin/)
and [`mave... | 1 |
JoelPM/BidiThrift | An example of how to use Thrift for bi-directional async RPC | null | null | 1 |
redis-developer/redis-ai-resources | ✨ A curated list of awesome community resources, integrations, and examples of Redis in the AI ecosystem. | ai awesome-list ecosystem feature-store machine-learning redis vector-database vector-search | <img align="right" src="assets/redis-logo.svg" style="width: 130px">
# Redis: AI Resources
✨ A curated list of awesome community resources including content, integrations, documentation and examples for Redis in the AI ecosystem.
## Table of Contents
- Redis as a [Vector Database](#vector-database)
- Redis as a [Fea... | 0 |
chaostheory/jibenakka | A basic set of akka helper java classes and examples such as map reduce | null | jibenakka
=============
This is a set of basic Java examples for [akka](http://akka.io/).
## Getting Started
You will need to install [Apache Maven](http://maven.apache.org/). If you're using
Eclipse, it is recommended that you install the [m2e plugin](http://www.eclipse.org/m2e/).
Once you've properly installed and... | 0 |
thomasdarimont/spring-boot-admin-keycloak-example | Example for protecting Spring Boot Admin & Spring Boot Actuator endpoints with Keycloak | null | null | 1 |
srecon/ignite-book-code-samples | All code samples, scripts and more in-depth examples for the book high performance in-memory computing with Apache Ignite. Please use the repository the-apache-ignite-book" for Ignite version 2.6 or above." | bigdata cache gridgain high-performance ignite in-memory nosql | # High performance in-memory data grid with Apache Ignite
All code samples, scripts and more in-depth examples for the book **High performance in-memory computing with Apache Ignite**.
[](http://leanpub.com/ignite)
| 0 |
vaadin/base-starter-flow-quarkus | A project base/example for using Vaadin with Quarkus | java quarkus vaadin | # Project Base for Vaadin Flow and Quarkus
This project can be used as a starting point to create your own Vaadin Flow application for Quarkus. It contains all the necessary configuration with some placeholder files to get you started.
Quarkus 3.0+ requires Java 17.
Starter is also available for [gradle](https://git... | 0 |
jotorren/microservices-transactions-tcc | Example of composite" transactions managed by an Atomikos TCC rest coordinator" | null | # Microservices and data consistency (I)
As you can read in [Christian Posta's excellent article](http://blog.christianposta.com/microservices/the-hardest-part-about-microservices-data/), when designing a microservices-based solution **our first choice to solve consistency between bounded contexts will be to communica... | 1 |
kbastani/spring-cloud-microservice-example | An example project that demonstrates an end-to-end cloud native application using Spring Cloud for building a practical microservices architecture. | null | # Spring Cloud Example Project
An example project that demonstrates an end-to-end cloud-native platform using Spring Cloud for building a practical microservices architecture.
Tutorial available here: [Building Microservices with Spring Cloud and Docker](http://www.kennybastani.com/2015/07/spring-cloud-docker-microse... | 1 |
marcelocf/janusgraph_tutorial | Tutorial with example code on how to get started with JanusGraph | null | > *WARNING:* this is *old*. Very very old! It shouldn't work and information here is vely very wrong as of 2022. Apologies for that.
> Will leave repo live for now for historic reasons, but yeah; please don't expect this to work anymore.
# JanusGraph tutorial
**NOTE:** it goes without saying that you need a properly... | 1 |
evrentan/spring-boot-project-example | Spring Boot Project Example by Evren Tan | java maven open-source spring-boot | # A Complete Spring Boot Example Project
A Complete Spring Boot Example Project with Spring Boot 2.6.2, JDK 17 & Maven.
## Table of Contents
1. [How to Contribute](#how-to-contribute)
2. [Requirements](#requirements)
3. [Running the Application Locally](#running-the-application-locally)
4. [Run Actuator](#run-actuato... | 1 |
ivanyu/logical-rules-parser-antlr | A simple example of a parser built with ANTLR | antlr blog-post java parser | logical-rules-parser-antlr
==========================
A simple example of a parser built with ANTLR.
There is [the blog post](http://ivanyu.me/blog/2014/09/13/creating-a-simple-parser-with-antlr/) describes the parser.
| 1 |
oktadev/auth0-spring-boot-angular-crud-example | Angular and Spring Boot CRUD Example | angular oidc spa spring-boot spring-security | # Angular and Spring Boot CRUD Example
This example app shows how to create a Spring Boot API and CRUD (create, read, update, and delete) its data with a beautiful Angular + Angular Material app.
Please read [Build a Beautiful CRUD App with Spring Boot and Angular](https://auth0.com/blog/spring-boot-angular-crud) to ... | 1 |
springmonster/netflix-dgs-example-java | Java Examples of Netflix DGS | graphql graphql-java graphql-server java netflix-dgs spring-boot spring-graphql | # DGS
- [DGS](https://netflix.github.io/dgs/)
- [DGS Github](https://github.com/Netflix/dgs-framework)
## module description
| Module ... | 0 |
traex/RetrofitExample | Example for one of my tutorials at http://blog.robinchutaux.com/blog/a-smart-way-to-use-retrofit/ | null | RetrofitExample
===============

Example for one of my tutorials at http://blog.robinchutaux.com/blog/a-smart-way-to-use-retrofit/
[Retrofit library](http://square.github.io/retrofit/) is a type-safe REST client for Android and Java c... | 1 |
dmarczal/java_jdbc_dao_mvc_swing | An example of MVC + JAVA + SWING + DAO | null | null | 1 |
paulmandal/ATAK-Plugin-Example | An example ATAK plugin | null | # ATAK Plugin Example
This is an example plugin for ATAK that contains examples of:
* Listening to outgoing messages from ATAK and Toast their type to the screen
* Sending incoming messages to ATAK (in this case, a fake "Green HQ" map marker at lat: 0, lon: 0)
* A icon overlaid in the lower right corner of the screen... | 1 |
jdmg94/react-native-webrtc-example | An example app for `react-native-webrtc` using React 0.60 or newer | null | # Basic React-Native-WebRTC example app
## Motivation
Real Time Technologies are back in style, while this is fairly standard on the Web platforms, React Native faced a steeper learning curve to get into WebRTC Technologies specially without Expo support for native modules.
I wanted to provide the most basic codebas... | 1 |
pgilad/spring-boot-webflux-swagger-starter | An example project to illustrate how to document Spring Boot Webflux with Swagger2 | api-documentation demo reactive spring-boot swagger swagger2 webflux | # spring-boot-webflux-swagger-starter
> An example project to illustrate how to document Spring Boot Webflux with Swagger2
## Requirements
- Java 11
## Installation
```bash
$ git clone https://github.com/pgilad/spring-boot-webflux-swagger-starter.git
```
## Usage
```bash
$ gradle bootRun
```
Now open your favor... | 1 |
KieronQuinn/AmazfitSpringboardPluginExample | Example for creating custom springboard pages on the Amazfit Pace | null | # Amazfit Springboard Plugin Example
This project is an example for how to create a custom page for the default home screen (called "Springboard") on the Amazfit Pace
## Usage
You don't need to import this project and edit it from there. There's only a couple of important files and pieces of code:
### SpringboardPlu... | 1 |
cronn/cucumber-junit5-example | Example setup for Cucumber and JUnit 5 with Gradle | cucumber gradle java junit5 template-project | # Cucumber with JUnit5
This repository contains an example project that integrates [Cucumber](https://cucumber.io/) with [JUnit5](https://junit.org/junit5/). It is the same setup explained in the [blog post](https://www.blog.cronn.de/en/testing/2020/08/17/cucumber-junit5.html).
## Quick Start
```shell
$ git clone ht... | 1 |
java-modularity/agenda-example | Building Modular Cloud Applications in Java - getting started example | null | agenda-example
==============
[Building Modular Cloud Applications in Java](http://shop.oreilly.com/product/0636920028086.do) - getting started example (chapter 3.)
To use the example,
- clone this repository,
- point Eclipse to the directory where you cloned the repository,
- import all projects using `File -> Impo... | 1 |
klevis/DigitRecognizer | Java Convolutional Neural Network example for Hand Writing Digit Recognition | convolutional-neural-networks deep-learning deeplearning4j java java-convolutional-neural-network java-machine-learning machine-learning machine-learning-algorithms mlib neural-network spark | # http://ramok.tech/machine-learning/
Java Digit Recognition Application
Hand Writing Digit Recognition using Simple Neural Networks with Spark Mlib
and
Deep Convolution Neural Network with DeepLearning4j
Acuracy with simple model 97%
and
with convolutional neural network 99.2%
For more please visit below posts:
ht... | 1 |
sv3ndk/stormRoomOccupancy | Example of basic Storm topology that updates DB persistent state | null | stormRoomOccupancy
==================
Basic Storm topology example that updates DB persistent state with correct error handling. The code is based on Storm 0.9.0.1, Cassandra 2.0.4 and Java 7.
The [first release] ( https://github.com/svendx4f/stormRoomOccupancy/releases/tag/v1.0.1) is explained in great details in my... | 1 |
sunnygleason/j4-minimal | Minimal web application example using Embedded Jetty, Jersey, Guice, and Jackson | null | A minimal example of a REST API built with with Jersey, Jackson and Guice running on embedded Jetty
---------------------------------------------------------------------------------------------------
You can either run it as a main in eclipse or run as an executable jar by building with maven and running it.
mvn ... | 1 |
eljefe6a/UnoExample | MapReduce/Hadoop example that uses regular playing cards to show mapping and reducing. | null | Playing Card Example
==========
Hadoop MapReduce example that uses regular playing cards to explain how mapping and reducing works.
This is the example code for the first and third episodes of the [Hadoop MapReduce screencast](http://pragprog.com/screencasts/v-jamapr/processing-big-data-with-mapreduce).
Licence
====... | 1 |
sylleryum/kafka-microservices-with-saga | Java (Spring) microservices example with Kafka and saga pattern | kafka microservices spring-boot | [](https://codecov.io/gh/sylleryum/kafka-microservices-with-saga)

# Microservice... | 1 |
lohitvijayarenu/netty-protobuf | simple example using netty and protobuf | null | null | 1 |
cloud-native-java/training | A collection of training courses and example code for Cloud Native Java | null | # Cloud Native Java: Training Materials
This repository contains various training materials that accompany the sections and chapters in _O'Reilly's Cloud Native Java: Building Resilient Systems with Spring Boot, Spring Cloud, and Cloud Foundry_.
To find more information on the book, please visit [cloudnativejava.io](... | 1 |
idugalic/reactive-company | Example of reactive web application. Java. Spring 5. Reactive Streams. Docker. | back-pressure elastic java mongodb reactive reactive-streams reactor resilent responsive spring tailable thymeleaf | # [projects](http://idugalic.github.io/projects)/reactive-company  [](https://gitpitch.com/idugalic/reactive-company/master?grs=github&t=white)
... | 1 |
Rapter1990/springbootmicroservicedailybuffer | Spring Cloud Example (API Gateway, Zipkin, Redis, Authentication, Config Server, Docker, Kubernetes ) | api-gateway config-server docker docker-compose eureka-server java jenkins jenkinsfile junit kubernetes microservice mysql postman-collection redis resillience4j services spring-boot spring-cloud spring-security zipkin | # Spring Boot Microservice Example (Eureka Server, Config Server, API Gateway, Services , Zipkin, Redis, Resilience4j, Docker, Kubernetes)
<img src="screenshots/springbootmicroservice_drawio.png" alt="Main Information" width="800" height="500">
# About the project
<ul style="list-style-type:disc">
<li>This project ... | 1 |
TimTinkers/Palm | A series of examples studying the new game development capabilities ERC-721 objects enable. | null | # Palm
Palm is the continuation of my work on [Galah](https://github.com/TimTinkers/Galah) to explore new and unique game development capabilities that integrating with the Ethereum blockchain can bring. Through the specific use of the [ERC-721](http://erc721.org/) standard for non-fungible assets, Palm considers just... | 0 |
PauloGaldo/telegram-bot | Spring Boot Java Example for the Telegram Bot API | null | null | 1 |
fuinorg/ddd-cqrs-4-java-example | Example Java DDD/CQRS/Event Sourcing microservices with Quarkus, Spring Boot and EventStore from Greg Young. | null | # ddd-cqrs-4-java-example
Example Java DDD/CQRS/Event Sourcing microservices with [Quarkus](https://quarkus.io/), [Spring Boot](https://spring.io/projects/spring-boot/) and the [EventStore](https://eventstore.org/) from Greg Young. The code uses the lightweight [ddd-4-java](https://github.com/fuinorg/ddd-4-java) and [c... | 1 |
alblue/com.packtpub.e4 | Code samples for the Eclipse Plugin Development by Example: Beginners Guide" book 978-1782160328" | null | Eclipse Plugin Development by Example: Beginner's Guide
=======================================================
This repository contains source code for the Packt Publishing book
"Eclipse Plugin Development by Example: Beginners Guide". Tags and
branches are available for both versions.
https://www.amazon.co.uk/s/ref... | 0 |
blundell/SimpleInAppPurchaseV3 | Simple In App Purchase V3 - an alternative to the Google Example | null | SimpleInAppPurchaseV3
=====================
Simple In App Purchase V3 - an alternative to the Google Example
This uses the Google Helper Service but it has been slightly modified when I found what I deemed a bug.
The code is incorporated in this project under the android package.
http://developer.android.com/google/... | 1 |
berndruecker/camunda-7-springboot-amqp-microservice-cloud-example | Simple example using Camunda and Spring Boot to define a simple microservice communcating via AMQP, fully unit tested and deployable in the cloud | null | [](https://img.shields.io/badge/Compatible%20with-Camunda%20Platform%207-26d07c)
# Camunda Spring Boot example including REST and AMQP, automated tested and deployable in the cloud
This example shows:
- How to setup Ca... | 1 |
msg-DAVID-GmbH/JUnit-5-Quick-Start-Guide-and-Framework-Support | JUnit 5 Quick Start Guide and collection of examples for frameworks used in conjunction with JUnit 5 | assertion-framework best-practices getting guide java java-8 junit junit-5 junit5 milestones quick quickstart spring-5 start started testing tutorial user user-guide workshop | null | 0 |
Hakky54/mutual-tls-ssl | 🔐 Tutorial of setting up Security for your API with one way authentication with TLS/SSL and mutual authentication for a java based web server and a client with both Spring Boot. Different clients are provided such as Apache HttpClient, OkHttp, Spring RestTemplate, Spring WebFlux WebClient Jetty and Netty, the old and ... | certificate certificate-authority certificate-signing-request encryption https java keystore keytool kotlin mutual-authentication mutual-tls openssl scala security server spring-boot ssl tls truststore two-way-ssl-authentication | null | 1 |
gregwhitaker/springboot-apikey-example | Example of authenticating with a Spring Boot application using an API key. | api-key caffeine-cache spring-boot spring-security | # springboot-apikey-example

An example of authenticating with a Spring Boot application using an API key.
If you are looking for an example using WebFlux, please check out [springboot-webflux-apikey-example](https://github.c... | 1 |
xbtlin/thinking-In-Java | All examples writtern by author of the thinking in java book (4th ). Could run directly in the Idea Intellij or Eclipse. Java编程思想 第四版 所有的示例代码,可直接在Intellij或Eclipse上运行。 | null | 可以直接pull到Idea Intellij或Eclipse中的Thinking in java第四版书中示例代码。
不含课后习题答案。
| 0 |
islomar/seven-concurrency-models-in-seven-weeks | Repository for the example code of the book Seven concurrency models in seven weeks"." | null | # Seven concurrency models in seven weeks
Repository for the example code of the book ["Seven concurrency models in seven weeks"](https://pragprog.com/book/pb7con/seven-concurrency-models-in-seven-weeks).
## Discussions
https://forums.pragprog.com/forums/291
## Errata
https://pragprog.com/titles/pb7con/errata
## Cha... | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.