
Add files using upload-large-folder tool
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- testbed/open-mmlab__mmengine/.gitignore +123 -0
- testbed/open-mmlab__mmengine/.owners.yml +12 -0
- testbed/open-mmlab__mmengine/.pre-commit-config-zh-cn.yaml +61 -0
- testbed/open-mmlab__mmengine/.pre-commit-config.yaml +61 -0
- testbed/open-mmlab__mmengine/.readthedocs.yml +9 -0
- testbed/open-mmlab__mmengine/CODEOWNERS +84 -0
- testbed/open-mmlab__mmengine/CONTRIBUTING.md +240 -0
- testbed/open-mmlab__mmengine/CONTRIBUTING_zh-CN.md +255 -0
- testbed/open-mmlab__mmengine/LICENSE +203 -0
- testbed/open-mmlab__mmengine/MANIFEST.in +1 -0
- testbed/open-mmlab__mmengine/README.md +306 -0
- testbed/open-mmlab__mmengine/README_zh-CN.md +333 -0
- testbed/open-mmlab__mmengine/docs/README.md +28 -0
- testbed/open-mmlab__mmengine/docs/en/Makefile +20 -0
- testbed/open-mmlab__mmengine/docs/en/conf.py +100 -0
- testbed/open-mmlab__mmengine/docs/en/docutils.conf +2 -0
- testbed/open-mmlab__mmengine/docs/en/get_started/installation.md +75 -0
- testbed/open-mmlab__mmengine/docs/en/index.rst +110 -0
- testbed/open-mmlab__mmengine/docs/en/make.bat +35 -0
- testbed/open-mmlab__mmengine/docs/en/migration/hook.md +3 -0
- testbed/open-mmlab__mmengine/docs/en/notes/contributing.md +242 -0
- testbed/open-mmlab__mmengine/docs/en/switch_language.md +3 -0
- testbed/open-mmlab__mmengine/docs/en/tutorials/dataset.md +200 -0
- testbed/open-mmlab__mmengine/docs/en/tutorials/evaluation.md +3 -0
- testbed/open-mmlab__mmengine/docs/en/tutorials/param_scheduler.md +229 -0
- testbed/open-mmlab__mmengine/docs/en/tutorials/runner.md +523 -0
- testbed/open-mmlab__mmengine/docs/resources/config/cross_repo.py +6 -0
- testbed/open-mmlab__mmengine/docs/resources/config/custom_imports.py +2 -0
- testbed/open-mmlab__mmengine/docs/resources/config/demo_train.py +33 -0
- testbed/open-mmlab__mmengine/docs/resources/config/example.py +2 -0
- testbed/open-mmlab__mmengine/docs/resources/config/learn_read_config.py +3 -0
- testbed/open-mmlab__mmengine/docs/resources/config/my_module.py +6 -0
- testbed/open-mmlab__mmengine/docs/resources/config/optimizer_cfg.py +1 -0
- testbed/open-mmlab__mmengine/docs/resources/config/predefined_var.py +1 -0
- testbed/open-mmlab__mmengine/docs/resources/config/refer_base_var.py +2 -0
- testbed/open-mmlab__mmengine/docs/resources/config/resnet50.py +2 -0
- testbed/open-mmlab__mmengine/docs/resources/config/resnet50_delete_key.py +3 -0
- testbed/open-mmlab__mmengine/docs/resources/config/resnet50_lr0.01.py +3 -0
- testbed/open-mmlab__mmengine/docs/resources/config/resnet50_runtime.py +2 -0
- testbed/open-mmlab__mmengine/docs/resources/config/runtime_cfg.py +1 -0
- testbed/open-mmlab__mmengine/docs/zh_cn/Makefile +20 -0
- testbed/open-mmlab__mmengine/docs/zh_cn/_static/css/readthedocs.css +20 -0
- testbed/open-mmlab__mmengine/docs/zh_cn/_templates/classtemplate.rst +14 -0
- testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/basedataset.md +505 -0
- testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/config.md +606 -0
- testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/cross_library.md +94 -0
- testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/data_element.md +1097 -0
- testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/data_transform.md +136 -0
- testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/distributed.md +47 -0
- testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/fileio.md +214 -0
testbed/open-mmlab__mmengine/.gitignore
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
downloads/
|
| 14 |
+
eggs/
|
| 15 |
+
.eggs/
|
| 16 |
+
lib/
|
| 17 |
+
lib64/
|
| 18 |
+
parts/
|
| 19 |
+
sdist/
|
| 20 |
+
var/
|
| 21 |
+
wheels/
|
| 22 |
+
*.egg-info/
|
| 23 |
+
.installed.cfg
|
| 24 |
+
*.egg
|
| 25 |
+
MANIFEST
|
| 26 |
+
|
| 27 |
+
# PyInstaller
|
| 28 |
+
# Usually these files are written by a python script from a template
|
| 29 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 30 |
+
*.manifest
|
| 31 |
+
*.spec
|
| 32 |
+
|
| 33 |
+
# Installer logs
|
| 34 |
+
pip-log.txt
|
| 35 |
+
pip-delete-this-directory.txt
|
| 36 |
+
|
| 37 |
+
# Unit test / coverage reports
|
| 38 |
+
htmlcov/
|
| 39 |
+
.tox/
|
| 40 |
+
.coverage
|
| 41 |
+
.coverage.*
|
| 42 |
+
.cache
|
| 43 |
+
nosetests.xml
|
| 44 |
+
coverage.xml
|
| 45 |
+
*.cover
|
| 46 |
+
.hypothesis/
|
| 47 |
+
.pytest_cache/
|
| 48 |
+
|
| 49 |
+
# Translations
|
| 50 |
+
*.mo
|
| 51 |
+
*.pot
|
| 52 |
+
|
| 53 |
+
# Django stuff:
|
| 54 |
+
*.log
|
| 55 |
+
local_settings.py
|
| 56 |
+
db.sqlite3
|
| 57 |
+
|
| 58 |
+
# Flask stuff:
|
| 59 |
+
instance/
|
| 60 |
+
.webassets-cache
|
| 61 |
+
|
| 62 |
+
# Scrapy stuff:
|
| 63 |
+
.scrapy
|
| 64 |
+
|
| 65 |
+
# Sphinx documentation
|
| 66 |
+
docs/en/_build/
|
| 67 |
+
docs/en/api/generated/
|
| 68 |
+
docs/zh_cn/_build/
|
| 69 |
+
docs/zh_cn/api/generated/
|
| 70 |
+
src/
|
| 71 |
+
|
| 72 |
+
# PyBuilder
|
| 73 |
+
target/
|
| 74 |
+
|
| 75 |
+
# Jupyter Notebook
|
| 76 |
+
.ipynb_checkpoints
|
| 77 |
+
|
| 78 |
+
# pyenv
|
| 79 |
+
.python-version
|
| 80 |
+
|
| 81 |
+
# celery beat schedule file
|
| 82 |
+
celerybeat-schedule
|
| 83 |
+
|
| 84 |
+
# SageMath parsed files
|
| 85 |
+
*.sage.py
|
| 86 |
+
|
| 87 |
+
# Environments
|
| 88 |
+
.env
|
| 89 |
+
.venv
|
| 90 |
+
env/
|
| 91 |
+
venv/
|
| 92 |
+
ENV/
|
| 93 |
+
env.bak/
|
| 94 |
+
venv.bak/
|
| 95 |
+
|
| 96 |
+
# Spyder project settings
|
| 97 |
+
.spyderproject
|
| 98 |
+
.spyproject
|
| 99 |
+
|
| 100 |
+
# Rope project settings
|
| 101 |
+
.ropeproject
|
| 102 |
+
|
| 103 |
+
# mkdocs documentation
|
| 104 |
+
/site
|
| 105 |
+
|
| 106 |
+
# mypy
|
| 107 |
+
.mypy_cache/
|
| 108 |
+
|
| 109 |
+
.vscode
|
| 110 |
+
.idea
|
| 111 |
+
.DS_Store
|
| 112 |
+
|
| 113 |
+
# custom
|
| 114 |
+
*.pkl
|
| 115 |
+
*.pkl.json
|
| 116 |
+
*.log.json
|
| 117 |
+
docs/modelzoo_statistics.md
|
| 118 |
+
work_dirs/
|
| 119 |
+
|
| 120 |
+
# Pytorch
|
| 121 |
+
*.pth
|
| 122 |
+
*.py~
|
| 123 |
+
*.sh~
|
testbed/open-mmlab__mmengine/.owners.yml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
assign:
|
| 2 |
+
strategy:
|
| 3 |
+
# random
|
| 4 |
+
daily-shift-based
|
| 5 |
+
scedule:
|
| 6 |
+
'*/1 * * * *'
|
| 7 |
+
assignees:
|
| 8 |
+
- HAOCHENYE
|
| 9 |
+
- zhouzaida
|
| 10 |
+
- C1rN09
|
| 11 |
+
- ice-tong
|
| 12 |
+
- HAOCHENYE
|
testbed/open-mmlab__mmengine/.pre-commit-config-zh-cn.yaml
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
exclude: ^tests/data/
|
| 2 |
+
repos:
|
| 3 |
+
- repo: https://gitee.com/openmmlab/mirrors-flake8
|
| 4 |
+
rev: 5.0.4
|
| 5 |
+
hooks:
|
| 6 |
+
- id: flake8
|
| 7 |
+
- repo: https://gitee.com/openmmlab/mirrors-isort
|
| 8 |
+
rev: 5.10.1
|
| 9 |
+
hooks:
|
| 10 |
+
- id: isort
|
| 11 |
+
- repo: https://gitee.com/openmmlab/mirrors-yapf
|
| 12 |
+
rev: v0.32.0
|
| 13 |
+
hooks:
|
| 14 |
+
- id: yapf
|
| 15 |
+
- repo: https://gitee.com/openmmlab/mirrors-pre-commit-hooks
|
| 16 |
+
rev: v4.3.0
|
| 17 |
+
hooks:
|
| 18 |
+
- id: trailing-whitespace
|
| 19 |
+
- id: check-yaml
|
| 20 |
+
- id: end-of-file-fixer
|
| 21 |
+
- id: requirements-txt-fixer
|
| 22 |
+
- id: double-quote-string-fixer
|
| 23 |
+
- id: check-merge-conflict
|
| 24 |
+
- id: fix-encoding-pragma
|
| 25 |
+
args: ["--remove"]
|
| 26 |
+
- id: mixed-line-ending
|
| 27 |
+
args: ["--fix=lf"]
|
| 28 |
+
- repo: https://gitee.com/openmmlab/mirrors-mdformat
|
| 29 |
+
rev: 0.7.9
|
| 30 |
+
hooks:
|
| 31 |
+
- id: mdformat
|
| 32 |
+
args: ["--number"]
|
| 33 |
+
additional_dependencies:
|
| 34 |
+
- mdformat-openmmlab
|
| 35 |
+
- mdformat_frontmatter
|
| 36 |
+
- linkify-it-py
|
| 37 |
+
- repo: https://gitee.com/openmmlab/mirrors-codespell
|
| 38 |
+
rev: v2.2.1
|
| 39 |
+
hooks:
|
| 40 |
+
- id: codespell
|
| 41 |
+
- repo: https://gitee.com/openmmlab/mirrors-docformatter
|
| 42 |
+
rev: v1.3.1
|
| 43 |
+
hooks:
|
| 44 |
+
- id: docformatter
|
| 45 |
+
args: ["--in-place", "--wrap-descriptions", "79"]
|
| 46 |
+
- repo: https://gitee.com/openmmlab/mirrors-pyupgrade
|
| 47 |
+
rev: v3.0.0
|
| 48 |
+
hooks:
|
| 49 |
+
- id: pyupgrade
|
| 50 |
+
args: ["--py36-plus"]
|
| 51 |
+
- repo: https://gitee.com/openmmlab/pre-commit-hooks
|
| 52 |
+
rev: v0.4.0
|
| 53 |
+
hooks:
|
| 54 |
+
- id: check-copyright
|
| 55 |
+
args: ["mmengine", "tests"]
|
| 56 |
+
- id: remove-improper-eol-in-cn-docs
|
| 57 |
+
- repo: https://gitee.com/openmmlab/mirrors-mypy
|
| 58 |
+
rev: v0.812
|
| 59 |
+
hooks:
|
| 60 |
+
- id: mypy
|
| 61 |
+
exclude: "docs"
|
testbed/open-mmlab__mmengine/.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
exclude: ^tests/data/
|
| 2 |
+
repos:
|
| 3 |
+
- repo: https://github.com/PyCQA/flake8
|
| 4 |
+
rev: 5.0.4
|
| 5 |
+
hooks:
|
| 6 |
+
- id: flake8
|
| 7 |
+
- repo: https://github.com/PyCQA/isort
|
| 8 |
+
rev: 5.10.1
|
| 9 |
+
hooks:
|
| 10 |
+
- id: isort
|
| 11 |
+
- repo: https://github.com/pre-commit/mirrors-yapf
|
| 12 |
+
rev: v0.32.0
|
| 13 |
+
hooks:
|
| 14 |
+
- id: yapf
|
| 15 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 16 |
+
rev: v4.3.0
|
| 17 |
+
hooks:
|
| 18 |
+
- id: trailing-whitespace
|
| 19 |
+
- id: check-yaml
|
| 20 |
+
- id: end-of-file-fixer
|
| 21 |
+
- id: requirements-txt-fixer
|
| 22 |
+
- id: double-quote-string-fixer
|
| 23 |
+
- id: check-merge-conflict
|
| 24 |
+
- id: fix-encoding-pragma
|
| 25 |
+
args: ["--remove"]
|
| 26 |
+
- id: mixed-line-ending
|
| 27 |
+
args: ["--fix=lf"]
|
| 28 |
+
- repo: https://github.com/executablebooks/mdformat
|
| 29 |
+
rev: 0.7.9
|
| 30 |
+
hooks:
|
| 31 |
+
- id: mdformat
|
| 32 |
+
args: ["--number"]
|
| 33 |
+
additional_dependencies:
|
| 34 |
+
- mdformat-openmmlab
|
| 35 |
+
- mdformat_frontmatter
|
| 36 |
+
- linkify-it-py
|
| 37 |
+
- repo: https://github.com/codespell-project/codespell
|
| 38 |
+
rev: v2.2.1
|
| 39 |
+
hooks:
|
| 40 |
+
- id: codespell
|
| 41 |
+
- repo: https://github.com/myint/docformatter
|
| 42 |
+
rev: v1.3.1
|
| 43 |
+
hooks:
|
| 44 |
+
- id: docformatter
|
| 45 |
+
args: ["--in-place", "--wrap-descriptions", "79"]
|
| 46 |
+
- repo: https://github.com/asottile/pyupgrade
|
| 47 |
+
rev: v3.0.0
|
| 48 |
+
hooks:
|
| 49 |
+
- id: pyupgrade
|
| 50 |
+
args: ["--py36-plus"]
|
| 51 |
+
- repo: https://github.com/open-mmlab/pre-commit-hooks
|
| 52 |
+
rev: v0.4.0
|
| 53 |
+
hooks:
|
| 54 |
+
- id: check-copyright
|
| 55 |
+
args: ["mmengine", "tests"]
|
| 56 |
+
- id: remove-improper-eol-in-cn-docs
|
| 57 |
+
- repo: https://github.com/pre-commit/mirrors-mypy
|
| 58 |
+
rev: v0.812
|
| 59 |
+
hooks:
|
| 60 |
+
- id: mypy
|
| 61 |
+
exclude: "docs"
|
testbed/open-mmlab__mmengine/.readthedocs.yml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: 2
|
| 2 |
+
|
| 3 |
+
formats: all
|
| 4 |
+
|
| 5 |
+
python:
|
| 6 |
+
version: 3.7
|
| 7 |
+
install:
|
| 8 |
+
- requirements: requirements/runtime.txt
|
| 9 |
+
- requirements: requirements/docs.txt
|
testbed/open-mmlab__mmengine/CODEOWNERS
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# IMPORTANT:
|
| 2 |
+
# This file is ONLY used to subscribe for notifications for PRs
|
| 3 |
+
# related to a specific file path, and each line is a file pattern followed by
|
| 4 |
+
# one or more owners.
|
| 5 |
+
|
| 6 |
+
# Order is important; the last matching pattern takes the most
|
| 7 |
+
# precedence.
|
| 8 |
+
|
| 9 |
+
# These owners will be the default owners for everything in
|
| 10 |
+
# the repo. Unless a later match takes precedence,
|
| 11 |
+
# @global-owner1 and @global-owner2 will be requested for
|
| 12 |
+
# review when someone opens a pull request.
|
| 13 |
+
* @zhouzaida @HAOCHENYE
|
| 14 |
+
|
| 15 |
+
# Docs
|
| 16 |
+
/docs/ @C1rN09
|
| 17 |
+
*.rst @zhouzaida @HAOCHENYE
|
| 18 |
+
|
| 19 |
+
# mmengine file
|
| 20 |
+
# config
|
| 21 |
+
/mmengine/config/ @HAOCHENYE
|
| 22 |
+
|
| 23 |
+
# dataset
|
| 24 |
+
/mmengine/dataset/ @HAOCHENYE
|
| 25 |
+
|
| 26 |
+
# device
|
| 27 |
+
/mmengine/device/ @zhouzaida
|
| 28 |
+
|
| 29 |
+
# dist
|
| 30 |
+
/mmengine/dist/ @zhouzaida @C1rN09
|
| 31 |
+
|
| 32 |
+
# evaluator
|
| 33 |
+
/mmengine/evaluator/ @RangiLyu @ice-tong
|
| 34 |
+
|
| 35 |
+
# fileio
|
| 36 |
+
/mmengine/fileio/ @zhouzaida
|
| 37 |
+
|
| 38 |
+
# hooks
|
| 39 |
+
/mmengine/hooks/ @zhouzaida @HAOCHENYE
|
| 40 |
+
/mmengine/hooks/ema_hook.py @RangiLyu
|
| 41 |
+
|
| 42 |
+
# hub
|
| 43 |
+
/mmengine/hub/ @HAOCHENYE @zhouzaida
|
| 44 |
+
|
| 45 |
+
# logging
|
| 46 |
+
/mmengine/logging/ @HAOCHENYE
|
| 47 |
+
|
| 48 |
+
# model
|
| 49 |
+
/mmengine/model/ @HAOCHENYE @C1rN09
|
| 50 |
+
/mmengine/model/averaged_model.py @RangiLyu
|
| 51 |
+
/mmengine/model/wrappers/fully_sharded_distributed.py @C1rN09
|
| 52 |
+
|
| 53 |
+
# optim
|
| 54 |
+
/mmengine/optim/ @HAOCHENYE
|
| 55 |
+
/mmengine/optim/scheduler/ @RangiLyu
|
| 56 |
+
|
| 57 |
+
# registry
|
| 58 |
+
/mmengine/registry/ @C1rN09 @HAOCHENYE
|
| 59 |
+
|
| 60 |
+
# runner
|
| 61 |
+
/mmengine/runner/ @zhouzaida @RangiLyu @HAOCHENYE
|
| 62 |
+
/mmengine/runner/amp.py @HAOCHENYE
|
| 63 |
+
/mmengine/runner/log_processor.py @HAOCHENYE
|
| 64 |
+
/mmengine/runner/checkpoint.py @zhouzaida @C1rN09
|
| 65 |
+
/mmengine/runner/priority.py @zhouzaida
|
| 66 |
+
/mmengine/runner/utils.py @zhouzaida @HAOCHENYE
|
| 67 |
+
|
| 68 |
+
# structure
|
| 69 |
+
/mmengine/structures/ @Harold-lkk @HAOCHENYE
|
| 70 |
+
|
| 71 |
+
# testing
|
| 72 |
+
/mmengine/testing/ @zhouzaida
|
| 73 |
+
|
| 74 |
+
# utils
|
| 75 |
+
/mmengine/utils/ @HAOCHENYE @zhouzaida
|
| 76 |
+
|
| 77 |
+
# visualization
|
| 78 |
+
/mmengine/visualization/ @Harold-lkk @HAOCHENYE
|
| 79 |
+
|
| 80 |
+
# version
|
| 81 |
+
/mmengine/__version__.py @zhouzaida
|
| 82 |
+
|
| 83 |
+
# unit test
|
| 84 |
+
/tests/ @zhouzaida @HAOCHENYE
|
testbed/open-mmlab__mmengine/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Contributing to OpenMMLab
|
| 2 |
+
|
| 3 |
+
Welcome to the MMEngine community, we are committed to building a cutting-edge computer vision foundational library and all kinds of contributions are welcomed, including but not limited to
|
| 4 |
+
|
| 5 |
+
**Fix bug**
|
| 6 |
+
|
| 7 |
+
You can directly post a Pull Request to fix typo in code or documents
|
| 8 |
+
|
| 9 |
+
The steps to fix the bug of code implementation are as follows.
|
| 10 |
+
|
| 11 |
+
1. If the modification involve significant changes, you should create an issue first and describe the error information and how to trigger the bug. Other developers will discuss with you and propose an proper solution.
|
| 12 |
+
|
| 13 |
+
2. Posting a pull request after fixing the bug and adding corresponding unit test.
|
| 14 |
+
|
| 15 |
+
**New Feature or Enhancement**
|
| 16 |
+
|
| 17 |
+
1. If the modification involve significant changes, you should create an issue to discuss with our developers to propose an proper design.
|
| 18 |
+
2. Post a Pull Request after implementing the new feature or enhancement and add corresponding unit test.
|
| 19 |
+
|
| 20 |
+
**Document**
|
| 21 |
+
|
| 22 |
+
You can directly post a pull request to fix documents. If you want to add a document, you should first create an issue to check if it is reasonable.
|
| 23 |
+
|
| 24 |
+
### Pull Request Workflow
|
| 25 |
+
|
| 26 |
+
If you're not familiar with Pull Request, don't worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the develop mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
|
| 27 |
+
|
| 28 |
+
#### 1. Fork and clone
|
| 29 |
+
|
| 30 |
+
If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
|
| 31 |
+
|
| 32 |
+
<img src="https://user-images.githubusercontent.com/57566630/167305749-43c7f4e9-449b-4e98-ade5-0c9276d5c9ce.png" width="1200">
|
| 33 |
+
|
| 34 |
+
Then, you can clone the repositories to local:
|
| 35 |
+
|
| 36 |
+
```shell
|
| 37 |
+
git clone git@github.com:{username}/mmengine.git
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
After that, you should ddd official repository as the upstream repository
|
| 41 |
+
|
| 42 |
+
```bash
|
| 43 |
+
git remote add upstream git@github.com:open-mmlab/mmengine
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
Check whether remote repository has been added successfully by `git remote -v`
|
| 47 |
+
|
| 48 |
+
```bash
|
| 49 |
+
origin git@github.com:{username}/mmengine.git (fetch)
|
| 50 |
+
origin git@github.com:{username}/mmengine.git (push)
|
| 51 |
+
upstream git@github.com:open-mmlab/mmengine (fetch)
|
| 52 |
+
upstream git@github.com:open-mmlab/mmengine (push)
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
|
| 56 |
+
|
| 57 |
+
#### 2. Configure pre-commit
|
| 58 |
+
|
| 59 |
+
You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the mmengine directory.
|
| 60 |
+
|
| 61 |
+
```shell
|
| 62 |
+
pip install -U pre-commit
|
| 63 |
+
pre-commit install
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
|
| 67 |
+
|
| 68 |
+
```shell
|
| 69 |
+
pre-commit run --all-files
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
<img src="https://user-images.githubusercontent.com/57566630/173660750-3df20a63-cb66-4d33-a986-1f643f1d8aaf.png" width="1200">
|
| 73 |
+
|
| 74 |
+
<img src="https://user-images.githubusercontent.com/57566630/202368856-0465a90d-8fce-4345-918e-67b8b9c82614.png" width="1200">
|
| 75 |
+
|
| 76 |
+
If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
|
| 77 |
+
|
| 78 |
+
If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
|
| 79 |
+
|
| 80 |
+
<img src="https://user-images.githubusercontent.com/57566630/202369176-67642454-0025-4023-a095-263529107aa3.png" width="1200">
|
| 81 |
+
|
| 82 |
+
If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
|
| 83 |
+
|
| 84 |
+
```shell
|
| 85 |
+
git commit -m "xxx" --no-verify
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
#### 3. Create a development branch
|
| 89 |
+
|
| 90 |
+
After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
|
| 91 |
+
|
| 92 |
+
```shell
|
| 93 |
+
git checkout -b yhc/refactor_contributing_doc
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
|
| 97 |
+
|
| 98 |
+
```shell
|
| 99 |
+
git pull upstream master
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
#### 4. Commit the code and pass the unit test
|
| 103 |
+
|
| 104 |
+
- MMEngine introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
|
| 105 |
+
|
| 106 |
+
- The committed code should pass through the unit test
|
| 107 |
+
|
| 108 |
+
```shell
|
| 109 |
+
# Pass all unit tests
|
| 110 |
+
pytest tests
|
| 111 |
+
|
| 112 |
+
# Pass the unit test of runner
|
| 113 |
+
pytest tests/test_runner/test_runner.py
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
|
| 117 |
+
|
| 118 |
+
- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
|
| 119 |
+
|
| 120 |
+
#### 5. Push the code to remote
|
| 121 |
+
|
| 122 |
+
We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
|
| 123 |
+
|
| 124 |
+
```shell
|
| 125 |
+
git push -u origin {branch_name}
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
This will allow you to use the `git push` command to push code directly next time without specifying a branch or the remote repository.
|
| 129 |
+
|
| 130 |
+
#### 6. Create a Pull Request
|
| 131 |
+
|
| 132 |
+
(1) Create a pull request in GitHub's Pull request interface
|
| 133 |
+
|
| 134 |
+
<img src="https://user-images.githubusercontent.com/57566630/201533288-516f7ac4-0b14-4dc8-afbd-912475c368b5.png" width="1200">
|
| 135 |
+
|
| 136 |
+
(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
|
| 137 |
+
|
| 138 |
+
<img src="https://user-images.githubusercontent.com/57566630/202242953-c91a18ff-e388-4ff9-8591-5fae0ead6c1e.png" width="1200">
|
| 139 |
+
|
| 140 |
+
Find more details about Pull Request description in [pull request guidelines](#pr-specs).
|
| 141 |
+
|
| 142 |
+
**note**
|
| 143 |
+
|
| 144 |
+
(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
|
| 145 |
+
|
| 146 |
+
(b) If it is your first contribution, please sign the CLA
|
| 147 |
+
|
| 148 |
+
<img src="https://user-images.githubusercontent.com/57566630/167307569-a794b967-6e28-4eac-a942-00deb657815f.png" width="1200">
|
| 149 |
+
|
| 150 |
+
(c) Check whether the Pull Request pass through the CI
|
| 151 |
+
|
| 152 |
+
<img src="https://user-images.githubusercontent.com/57566630/167307490-f9ebf9fa-63c0-4d83-8ba1-081ea169eb3a.png" width="1200">
|
| 153 |
+
|
| 154 |
+
MMEngine will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
|
| 155 |
+
|
| 156 |
+
(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
|
| 157 |
+
|
| 158 |
+
<img src="https://user-images.githubusercontent.com/57566630/202145400-cc2cd8c4-10b0-472f-ba37-07e6f50acc67.png" width="1200">
|
| 159 |
+
|
| 160 |
+
#### 7. Resolve conflicts
|
| 161 |
+
|
| 162 |
+
If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
|
| 163 |
+
|
| 164 |
+
```shell
|
| 165 |
+
git fetch --all --prune
|
| 166 |
+
git rebase upstream/master
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
or
|
| 170 |
+
|
| 171 |
+
```shell
|
| 172 |
+
git fetch --all --prune
|
| 173 |
+
git merge upstream/master
|
| 174 |
+
```
|
| 175 |
+
|
| 176 |
+
If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
|
| 177 |
+
|
| 178 |
+
### Guidance
|
| 179 |
+
|
| 180 |
+
#### Unit test
|
| 181 |
+
|
| 182 |
+
We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
|
| 183 |
+
|
| 184 |
+
```shell
|
| 185 |
+
python -m coverage run -m pytest /path/to/test_file
|
| 186 |
+
python -m coverage html
|
| 187 |
+
# check file in htmlcov/index.html
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
#### Document rendering
|
| 191 |
+
|
| 192 |
+
If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
|
| 193 |
+
|
| 194 |
+
```shell
|
| 195 |
+
pip install -r requirements/docs.txt
|
| 196 |
+
cd docs/zh_cn/
|
| 197 |
+
# or docs/en
|
| 198 |
+
make html
|
| 199 |
+
# check file in ./docs/zh_cn/_build/html/index.html
|
| 200 |
+
```
|
| 201 |
+
|
| 202 |
+
### Python Code style
|
| 203 |
+
|
| 204 |
+
We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
|
| 205 |
+
|
| 206 |
+
We use the following tools for linting and formatting:
|
| 207 |
+
|
| 208 |
+
- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
|
| 209 |
+
- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
|
| 210 |
+
- [yapf](https://github.com/google/yapf): A formatter for Python files.
|
| 211 |
+
- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
|
| 212 |
+
- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
|
| 213 |
+
- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
|
| 214 |
+
|
| 215 |
+
Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
|
| 216 |
+
|
| 217 |
+
We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
|
| 218 |
+
fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
|
| 219 |
+
The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
|
| 220 |
+
|
| 221 |
+
### PR Specs
|
| 222 |
+
|
| 223 |
+
1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
|
| 224 |
+
|
| 225 |
+
2. One short-time branch should be matched with only one PR
|
| 226 |
+
|
| 227 |
+
3. Accomplish a detailed change in one PR. Avoid large PR
|
| 228 |
+
|
| 229 |
+
- Bad: Support Faster R-CNN
|
| 230 |
+
- Acceptable: Add a box head to Faster R-CNN
|
| 231 |
+
- Good: Add a parameter to box head to support custom conv-layer number
|
| 232 |
+
|
| 233 |
+
4. Provide clear and significant commit message
|
| 234 |
+
|
| 235 |
+
5. Provide clear and meaningful PR description
|
| 236 |
+
|
| 237 |
+
- Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
|
| 238 |
+
- Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
|
| 239 |
+
- Introduce main changes, results and influences on other modules in short description
|
| 240 |
+
- Associate related issues and pull requests with a milestone
|
testbed/open-mmlab__mmengine/CONTRIBUTING_zh-CN.md
ADDED
|
@@ -0,0 +1,255 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 贡献代码
|
| 2 |
+
|
| 3 |
+
欢迎加入 MMEngine 社区,我们致力于打造最前沿的深度学习模型训练的基础库,我们欢迎任何类型的贡献,包括但不限于
|
| 4 |
+
|
| 5 |
+
**修复错误**
|
| 6 |
+
|
| 7 |
+
修复代码实现错误的步骤如下:
|
| 8 |
+
|
| 9 |
+
1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。
|
| 10 |
+
2. 修复错误并补充相应的单元测试,提交拉取请求。
|
| 11 |
+
|
| 12 |
+
**新增功能或组件**
|
| 13 |
+
|
| 14 |
+
1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。
|
| 15 |
+
2. 实现新增功能并添单元测试,提交拉取请求。
|
| 16 |
+
|
| 17 |
+
**文档补充**
|
| 18 |
+
|
| 19 |
+
修复文档可以直接提交拉取请求
|
| 20 |
+
|
| 21 |
+
添加文档或将文档翻译成其他语言步骤如下
|
| 22 |
+
|
| 23 |
+
1. 提交 issue,确认添加文档的必要性。
|
| 24 |
+
2. 添加文档,提交拉取请求。
|
| 25 |
+
|
| 26 |
+
### 拉取请求工作流
|
| 27 |
+
|
| 28 |
+
如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
|
| 29 |
+
|
| 30 |
+
#### 1. 复刻仓库
|
| 31 |
+
|
| 32 |
+
当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
|
| 33 |
+
|
| 34 |
+
<img src="https://user-images.githubusercontent.com/57566630/167305749-43c7f4e9-449b-4e98-ade5-0c9276d5c9ce.png" width="1200">
|
| 35 |
+
|
| 36 |
+
将代码克隆到本地
|
| 37 |
+
|
| 38 |
+
```shell
|
| 39 |
+
git clone git@github.com:{username}/mmengine.git
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
添加原代码库为上游代码库
|
| 43 |
+
|
| 44 |
+
```bash
|
| 45 |
+
git remote add upstream git@github.com:open-mmlab/mmengine
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
检查 remote 是否添加成功,在终端输入 `git remote -v`
|
| 49 |
+
|
| 50 |
+
```bash
|
| 51 |
+
origin git@github.com:{username}/mmengine.git (fetch)
|
| 52 |
+
origin git@github.com:{username}/mmengine.git (push)
|
| 53 |
+
upstream git@github.com:open-mmlab/mmengine (fetch)
|
| 54 |
+
upstream git@github.com:open-mmlab/mmengine (push)
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
> 这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
|
| 58 |
+
|
| 59 |
+
#### 2. 配置 pre-commit
|
| 60 |
+
|
| 61 |
+
在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 mmengine 目录下执行):
|
| 62 |
+
|
| 63 |
+
```shell
|
| 64 |
+
pip install -U pre-commit
|
| 65 |
+
pre-commit install
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
|
| 69 |
+
|
| 70 |
+
```shell
|
| 71 |
+
pre-commit run --all-files
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
<img src="https://user-images.githubusercontent.com/57566630/173660750-3df20a63-cb66-4d33-a986-1f643f1d8aaf.png" width="1200">
|
| 75 |
+
|
| 76 |
+
<img src="https://user-images.githubusercontent.com/57566630/202368856-0465a90d-8fce-4345-918e-67b8b9c82614.png" width="1200">
|
| 77 |
+
|
| 78 |
+
> 如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
|
| 79 |
+
|
| 80 |
+
> pre-commit install -c .pre-commit-config-zh-cn.yaml
|
| 81 |
+
|
| 82 |
+
> pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
|
| 83 |
+
|
| 84 |
+
如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
|
| 85 |
+
|
| 86 |
+
如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
|
| 87 |
+
|
| 88 |
+
<img src="https://user-images.githubusercontent.com/57566630/202369176-67642454-0025-4023-a095-263529107aa3.png" width="1200">
|
| 89 |
+
|
| 90 |
+
如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
|
| 91 |
+
|
| 92 |
+
```shell
|
| 93 |
+
git commit -m "xxx" --no-verify
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
#### 3. 创建开发分支
|
| 97 |
+
|
| 98 |
+
安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
|
| 99 |
+
|
| 100 |
+
```shell
|
| 101 |
+
git checkout -b yhc/refactor_contributing_doc
|
| 102 |
+
```
|
| 103 |
+
|
| 104 |
+
在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
|
| 105 |
+
|
| 106 |
+
```shell
|
| 107 |
+
git pull upstream master
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
#### 4. 提交代码并在本地通过单元测试
|
| 111 |
+
|
| 112 |
+
- MMEngine 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
|
| 113 |
+
|
| 114 |
+
- 提交的代码同样需要通过单元测试
|
| 115 |
+
|
| 116 |
+
```shell
|
| 117 |
+
# 通过全量单元测试
|
| 118 |
+
pytest tests
|
| 119 |
+
|
| 120 |
+
# 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
|
| 121 |
+
pytest tests/test_runner/test_runner.py
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
|
| 125 |
+
|
| 126 |
+
- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
|
| 127 |
+
|
| 128 |
+
#### 5. 推送代码到远程
|
| 129 |
+
|
| 130 |
+
代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
|
| 131 |
+
|
| 132 |
+
```shell
|
| 133 |
+
git push -u origin {branch_name}
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
|
| 137 |
+
|
| 138 |
+
#### 6. 提交拉取请求(PR)
|
| 139 |
+
|
| 140 |
+
(1) 在 GitHub 的 Pull request 界面创建拉取请求
|
| 141 |
+
<img src="https://user-images.githubusercontent.com/57566630/201533288-516f7ac4-0b14-4dc8-afbd-912475c368b5.png" width="1200">
|
| 142 |
+
|
| 143 |
+
(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
|
| 144 |
+
|
| 145 |
+
<img src="https://user-images.githubusercontent.com/57566630/202242953-c91a18ff-e388-4ff9-8591-5fae0ead6c1e.png" width="1200">
|
| 146 |
+
|
| 147 |
+
描述规范详见[拉取请求规范](#拉取请求规范)
|
| 148 |
+
|
| 149 |
+
 
|
| 150 |
+
|
| 151 |
+
**注意事项**
|
| 152 |
+
|
| 153 |
+
(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
|
| 154 |
+
|
| 155 |
+
(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
|
| 156 |
+
|
| 157 |
+
<img src="https://user-images.githubusercontent.com/57566630/167307569-a794b967-6e28-4eac-a942-00deb657815f.png" width="1200">
|
| 158 |
+
|
| 159 |
+
(c) 检查提交的 PR 是否通过 CI(集成测试)
|
| 160 |
+
|
| 161 |
+
<img src="https://user-images.githubusercontent.com/57566630/167307490-f9ebf9fa-63c0-4d83-8ba1-081ea169eb3a.png" width="1200">
|
| 162 |
+
|
| 163 |
+
MMEngine 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
|
| 164 |
+
|
| 165 |
+
(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
|
| 166 |
+
|
| 167 |
+
<img src="https://user-images.githubusercontent.com/57566630/202145400-cc2cd8c4-10b0-472f-ba37-07e6f50acc67.png" width="1200">
|
| 168 |
+
|
| 169 |
+
所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
|
| 170 |
+
|
| 171 |
+
#### 7. 解决冲突
|
| 172 |
+
|
| 173 |
+
随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
|
| 174 |
+
|
| 175 |
+
```shell
|
| 176 |
+
git fetch --all --prune
|
| 177 |
+
git rebase upstream/master
|
| 178 |
+
```
|
| 179 |
+
|
| 180 |
+
或者
|
| 181 |
+
|
| 182 |
+
```shell
|
| 183 |
+
git fetch --all --prune
|
| 184 |
+
git merge upstream/master
|
| 185 |
+
```
|
| 186 |
+
|
| 187 |
+
如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
|
| 188 |
+
|
| 189 |
+
### 指引
|
| 190 |
+
|
| 191 |
+
#### 单元测试
|
| 192 |
+
|
| 193 |
+
在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
|
| 194 |
+
|
| 195 |
+
```shell
|
| 196 |
+
python -m coverage run -m pytest /path/to/test_file
|
| 197 |
+
python -m coverage html
|
| 198 |
+
# check file in htmlcov/index.html
|
| 199 |
+
```
|
| 200 |
+
|
| 201 |
+
#### 文档渲染
|
| 202 |
+
|
| 203 |
+
在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
|
| 204 |
+
本地生成渲染后的文档的方法如下
|
| 205 |
+
|
| 206 |
+
```shell
|
| 207 |
+
pip install -r requirements/docs.txt
|
| 208 |
+
cd docs/zh_cn/
|
| 209 |
+
# or docs/en
|
| 210 |
+
make html
|
| 211 |
+
# check file in ./docs/zh_cn/_build/html/index.html
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
### Python 代码风格
|
| 215 |
+
|
| 216 |
+
[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
|
| 217 |
+
|
| 218 |
+
- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
|
| 219 |
+
- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
|
| 220 |
+
- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
|
| 221 |
+
- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
|
| 222 |
+
- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
|
| 223 |
+
- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
|
| 224 |
+
|
| 225 |
+
yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
|
| 226 |
+
|
| 227 |
+
通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
|
| 228 |
+
pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
|
| 229 |
+
|
| 230 |
+
pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
|
| 231 |
+
|
| 232 |
+
更具体的规范请参考 [OpenMMLab 代码规范](code_style.md)。
|
| 233 |
+
|
| 234 |
+
### 拉取请求规范
|
| 235 |
+
|
| 236 |
+
1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
|
| 237 |
+
|
| 238 |
+
2. 一个`拉取请求`对应一个短期分支
|
| 239 |
+
|
| 240 |
+
3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
|
| 241 |
+
|
| 242 |
+
- Bad:实现 Faster R-CNN
|
| 243 |
+
- Acceptable:给 Faster R-CNN 添加一个 box head
|
| 244 |
+
- Good:给 box head 增加一个参数来支持自定义的 conv 层数
|
| 245 |
+
|
| 246 |
+
4. 每次 Commit 时需要提供清晰且有意义 commit 信息
|
| 247 |
+
|
| 248 |
+
5. 提供清晰且有意义的`拉取请求`描述
|
| 249 |
+
|
| 250 |
+
- 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
|
| 251 |
+
- prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
|
| 252 |
+
- 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
|
| 253 |
+
- 关联相关的`议题` (issue) 和其他`拉取请求`
|
| 254 |
+
|
| 255 |
+
6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 MMEngine 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
|
testbed/open-mmlab__mmengine/LICENSE
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright 2018-2023 OpenMMLab. All rights reserved.
|
| 2 |
+
|
| 3 |
+
Apache License
|
| 4 |
+
Version 2.0, January 2004
|
| 5 |
+
http://www.apache.org/licenses/
|
| 6 |
+
|
| 7 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 8 |
+
|
| 9 |
+
1. Definitions.
|
| 10 |
+
|
| 11 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 12 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 13 |
+
|
| 14 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 15 |
+
the copyright owner that is granting the License.
|
| 16 |
+
|
| 17 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 18 |
+
other entities that control, are controlled by, or are under common
|
| 19 |
+
control with that entity. For the purposes of this definition,
|
| 20 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 21 |
+
direction or management of such entity, whether by contract or
|
| 22 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 23 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 24 |
+
|
| 25 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 26 |
+
exercising permissions granted by this License.
|
| 27 |
+
|
| 28 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 29 |
+
including but not limited to software source code, documentation
|
| 30 |
+
source, and configuration files.
|
| 31 |
+
|
| 32 |
+
"Object" form shall mean any form resulting from mechanical
|
| 33 |
+
transformation or translation of a Source form, including but
|
| 34 |
+
not limited to compiled object code, generated documentation,
|
| 35 |
+
and conversions to other media types.
|
| 36 |
+
|
| 37 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 38 |
+
Object form, made available under the License, as indicated by a
|
| 39 |
+
copyright notice that is included in or attached to the work
|
| 40 |
+
(an example is provided in the Appendix below).
|
| 41 |
+
|
| 42 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 43 |
+
form, that is based on (or derived from) the Work and for which the
|
| 44 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 45 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 46 |
+
of this License, Derivative Works shall not include works that remain
|
| 47 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 48 |
+
the Work and Derivative Works thereof.
|
| 49 |
+
|
| 50 |
+
"Contribution" shall mean any work of authorship, including
|
| 51 |
+
the original version of the Work and any modifications or additions
|
| 52 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 53 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 54 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 55 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 56 |
+
means any form of electronic, verbal, or written communication sent
|
| 57 |
+
to the Licensor or its representatives, including but not limited to
|
| 58 |
+
communication on electronic mailing lists, source code control systems,
|
| 59 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 60 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 61 |
+
excluding communication that is conspicuously marked or otherwise
|
| 62 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 63 |
+
|
| 64 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 65 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 66 |
+
subsequently incorporated within the Work.
|
| 67 |
+
|
| 68 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 69 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 70 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 71 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 72 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 73 |
+
Work and such Derivative Works in Source or Object form.
|
| 74 |
+
|
| 75 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 76 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 77 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 78 |
+
(except as stated in this section) patent license to make, have made,
|
| 79 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 80 |
+
where such license applies only to those patent claims licensable
|
| 81 |
+
by such Contributor that are necessarily infringed by their
|
| 82 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 83 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 84 |
+
institute patent litigation against any entity (including a
|
| 85 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 86 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 87 |
+
or contributory patent infringement, then any patent licenses
|
| 88 |
+
granted to You under this License for that Work shall terminate
|
| 89 |
+
as of the date such litigation is filed.
|
| 90 |
+
|
| 91 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 92 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 93 |
+
modifications, and in Source or Object form, provided that You
|
| 94 |
+
meet the following conditions:
|
| 95 |
+
|
| 96 |
+
(a) You must give any other recipients of the Work or
|
| 97 |
+
Derivative Works a copy of this License; and
|
| 98 |
+
|
| 99 |
+
(b) You must cause any modified files to carry prominent notices
|
| 100 |
+
stating that You changed the files; and
|
| 101 |
+
|
| 102 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 103 |
+
that You distribute, all copyright, patent, trademark, and
|
| 104 |
+
attribution notices from the Source form of the Work,
|
| 105 |
+
excluding those notices that do not pertain to any part of
|
| 106 |
+
the Derivative Works; and
|
| 107 |
+
|
| 108 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 109 |
+
distribution, then any Derivative Works that You distribute must
|
| 110 |
+
include a readable copy of the attribution notices contained
|
| 111 |
+
within such NOTICE file, excluding those notices that do not
|
| 112 |
+
pertain to any part of the Derivative Works, in at least one
|
| 113 |
+
of the following places: within a NOTICE text file distributed
|
| 114 |
+
as part of the Derivative Works; within the Source form or
|
| 115 |
+
documentation, if provided along with the Derivative Works; or,
|
| 116 |
+
within a display generated by the Derivative Works, if and
|
| 117 |
+
wherever such third-party notices normally appear. The contents
|
| 118 |
+
of the NOTICE file are for informational purposes only and
|
| 119 |
+
do not modify the License. You may add Your own attribution
|
| 120 |
+
notices within Derivative Works that You distribute, alongside
|
| 121 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 122 |
+
that such additional attribution notices cannot be construed
|
| 123 |
+
as modifying the License.
|
| 124 |
+
|
| 125 |
+
You may add Your own copyright statement to Your modifications and
|
| 126 |
+
may provide additional or different license terms and conditions
|
| 127 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 128 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 129 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 130 |
+
the conditions stated in this License.
|
| 131 |
+
|
| 132 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 133 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 134 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 135 |
+
this License, without any additional terms or conditions.
|
| 136 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 137 |
+
the terms of any separate license agreement you may have executed
|
| 138 |
+
with Licensor regarding such Contributions.
|
| 139 |
+
|
| 140 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 141 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 142 |
+
except as required for reasonable and customary use in describing the
|
| 143 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 144 |
+
|
| 145 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 146 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 147 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 148 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 149 |
+
implied, including, without limitation, any warranties or conditions
|
| 150 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 151 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 152 |
+
appropriateness of using or redistributing the Work and assume any
|
| 153 |
+
risks associated with Your exercise of permissions under this License.
|
| 154 |
+
|
| 155 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 156 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 157 |
+
unless required by applicable law (such as deliberate and grossly
|
| 158 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 159 |
+
liable to You for damages, including any direct, indirect, special,
|
| 160 |
+
incidental, or consequential damages of any character arising as a
|
| 161 |
+
result of this License or out of the use or inability to use the
|
| 162 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 163 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 164 |
+
other commercial damages or losses), even if such Contributor
|
| 165 |
+
has been advised of the possibility of such damages.
|
| 166 |
+
|
| 167 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 168 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 169 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 170 |
+
or other liability obligations and/or rights consistent with this
|
| 171 |
+
License. However, in accepting such obligations, You may act only
|
| 172 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 173 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 174 |
+
defend, and hold each Contributor harmless for any liability
|
| 175 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 176 |
+
of your accepting any such warranty or additional liability.
|
| 177 |
+
|
| 178 |
+
END OF TERMS AND CONDITIONS
|
| 179 |
+
|
| 180 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 181 |
+
|
| 182 |
+
To apply the Apache License to your work, attach the following
|
| 183 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 184 |
+
replaced with your own identifying information. (Don't include
|
| 185 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 186 |
+
comment syntax for the file format. We also recommend that a
|
| 187 |
+
file or class name and description of purpose be included on the
|
| 188 |
+
same "printed page" as the copyright notice for easier
|
| 189 |
+
identification within third-party archives.
|
| 190 |
+
|
| 191 |
+
Copyright 2018-2023 OpenMMLab.
|
| 192 |
+
|
| 193 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 194 |
+
you may not use this file except in compliance with the License.
|
| 195 |
+
You may obtain a copy of the License at
|
| 196 |
+
|
| 197 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 198 |
+
|
| 199 |
+
Unless required by applicable law or agreed to in writing, software
|
| 200 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 201 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 202 |
+
See the License for the specific language governing permissions and
|
| 203 |
+
limitations under the License.
|
testbed/open-mmlab__mmengine/MANIFEST.in
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
include mmengine/hub/openmmlab.json mmengine/hub/deprecated.json mmengine/hub/mmcls.json mmengine/hub/torchvision_0.12.json
|
testbed/open-mmlab__mmengine/README.md
ADDED
|
@@ -0,0 +1,306 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img src="https://user-images.githubusercontent.com/58739961/187154444-fce76639-ac8d-429b-9354-c6fac64b7ef8.jpg" height="100"/>
|
| 3 |
+
<div> </div>
|
| 4 |
+
<div align="center">
|
| 5 |
+
<b><font size="5">OpenMMLab website</font></b>
|
| 6 |
+
<sup>
|
| 7 |
+
<a href="https://openmmlab.com">
|
| 8 |
+
<i><font size="4">HOT</font></i>
|
| 9 |
+
</a>
|
| 10 |
+
</sup>
|
| 11 |
+
|
| 12 |
+
<b><font size="5">OpenMMLab platform</font></b>
|
| 13 |
+
<sup>
|
| 14 |
+
<a href="https://platform.openmmlab.com">
|
| 15 |
+
<i><font size="4">TRY IT OUT</font></i>
|
| 16 |
+
</a>
|
| 17 |
+
</sup>
|
| 18 |
+
</div>
|
| 19 |
+
<div> </div>
|
| 20 |
+
|
| 21 |
+
[](https://pypi.org/project/mmengine/)
|
| 22 |
+
[](https://pypi.org/project/mmengine)
|
| 23 |
+
[](https://github.com/open-mmlab/mmengine/blob/main/LICENSE)
|
| 24 |
+
[](https://github.com/open-mmlab/mmengine/issues)
|
| 25 |
+
[](https://github.com/open-mmlab/mmengine/issues)
|
| 26 |
+
|
| 27 |
+
[🤔Reporting Issues](https://github.com/open-mmlab/mmengine/issues/new/choose)
|
| 28 |
+
|
| 29 |
+
</div>
|
| 30 |
+
|
| 31 |
+
<div align="center">
|
| 32 |
+
|
| 33 |
+
English | [简体中文](README_zh-CN.md)
|
| 34 |
+
|
| 35 |
+
</div>
|
| 36 |
+
|
| 37 |
+
## Introduction
|
| 38 |
+
|
| 39 |
+
MMEngine is a foundational library for training deep learning models based on PyTorch. It provides a solid engineering foundation and frees developers from writing redundant codes on workflows. It serves as the training engine of all OpenMMLab codebases, which support hundreds of algorithms in various research areas. Moreover, MMEngine is also generic to be applied to non-OpenMMLab projects.
|
| 40 |
+
|
| 41 |
+
Major features:
|
| 42 |
+
|
| 43 |
+
1. **A universal and powerful runner**:
|
| 44 |
+
|
| 45 |
+
- Supports training different tasks with a small amount of code, e.g., ImageNet can be trained with only 80 lines of code (400 lines of the original PyTorch example)
|
| 46 |
+
- Easily compatible with models from popular algorithm libraries such as TIMM, TorchVision, and Detectron2
|
| 47 |
+
|
| 48 |
+
2. **Open architecture with unified interfaces**:
|
| 49 |
+
|
| 50 |
+
- Handles different algorithm tasks with unified APIs, e.g., implement a method and apply it to all compatible models.
|
| 51 |
+
- Provides a unified abstraction for upper-level algorithm libraries, which supports various back-end devices such as Nvidia CUDA, Mac MPS, AMD, MLU, and more for model training.
|
| 52 |
+
|
| 53 |
+
3. **Customizable training process**:
|
| 54 |
+
|
| 55 |
+
- Defines the training process just like playing with Legos.
|
| 56 |
+
- Provides rich components and strategies.
|
| 57 |
+
- Complete controls on the training process with different levels of APIs.
|
| 58 |
+
|
| 59 |
+
## What's New
|
| 60 |
+
|
| 61 |
+
v0.3.2 was released in 2022-11-24.
|
| 62 |
+
|
| 63 |
+
Read [Changelog](./docs/en/notes/changelog.md#v032-11242022) for more details.
|
| 64 |
+
|
| 65 |
+
## Installation
|
| 66 |
+
|
| 67 |
+
Before installing MMEngine, please ensure that PyTorch has been successfully installed following the [official guide](https://pytorch.org/get-started/locally/).
|
| 68 |
+
|
| 69 |
+
Install MMEngine
|
| 70 |
+
|
| 71 |
+
```bash
|
| 72 |
+
pip install -U openmim
|
| 73 |
+
mim install mmengine
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
Verify the installation
|
| 77 |
+
|
| 78 |
+
```bash
|
| 79 |
+
python -c 'from mmengine.utils.dl_utils import collect_env;print(collect_env())'
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
## Get Started
|
| 83 |
+
|
| 84 |
+
Taking the training of a ResNet-50 model on the CIFAR-10 dataset as an example, we will use MMEngine to build a complete, configurable training and validation process in less than 80 lines of code.
|
| 85 |
+
|
| 86 |
+
<details>
|
| 87 |
+
<summary>Build Models</summary>
|
| 88 |
+
|
| 89 |
+
First, we need to define a **model** which 1) inherits from `BaseModel` and 2) accepts an additional argument `mode` in the `forward` method, in addition to those arguments related to the dataset.
|
| 90 |
+
|
| 91 |
+
- During training, the value of `mode` is "loss," and the `forward` method should return a `dict` containing the key "loss".
|
| 92 |
+
- During validation, the value of `mode` is "predict", and the forward method should return results containing both predictions and labels.
|
| 93 |
+
|
| 94 |
+
```python
|
| 95 |
+
import torch.nn.functional as F
|
| 96 |
+
import torchvision
|
| 97 |
+
from mmengine.model import BaseModel
|
| 98 |
+
|
| 99 |
+
class MMResNet50(BaseModel):
|
| 100 |
+
def __init__(self):
|
| 101 |
+
super().__init__()
|
| 102 |
+
self.resnet = torchvision.models.resnet50()
|
| 103 |
+
|
| 104 |
+
def forward(self, imgs, labels, mode):
|
| 105 |
+
x = self.resnet(imgs)
|
| 106 |
+
if mode == 'loss':
|
| 107 |
+
return {'loss': F.cross_entropy(x, labels)}
|
| 108 |
+
elif mode == 'predict':
|
| 109 |
+
return x, labels
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
</details>
|
| 113 |
+
|
| 114 |
+
<details>
|
| 115 |
+
<summary>Build Datasets</summary>
|
| 116 |
+
|
| 117 |
+
Next, we need to create **Dataset**s and **DataLoader**s for training and validation.
|
| 118 |
+
In this case, we simply use built-in datasets supported in TorchVision.
|
| 119 |
+
|
| 120 |
+
```python
|
| 121 |
+
import torchvision.transforms as transforms
|
| 122 |
+
from torch.utils.data import DataLoader
|
| 123 |
+
|
| 124 |
+
norm_cfg = dict(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201])
|
| 125 |
+
train_dataloader = DataLoader(batch_size=32,
|
| 126 |
+
shuffle=True,
|
| 127 |
+
dataset=torchvision.datasets.CIFAR10(
|
| 128 |
+
'data/cifar10',
|
| 129 |
+
train=True,
|
| 130 |
+
download=True,
|
| 131 |
+
transform=transforms.Compose([
|
| 132 |
+
transforms.RandomCrop(32, padding=4),
|
| 133 |
+
transforms.RandomHorizontalFlip(),
|
| 134 |
+
transforms.ToTensor(),
|
| 135 |
+
transforms.Normalize(**norm_cfg)
|
| 136 |
+
])))
|
| 137 |
+
val_dataloader = DataLoader(batch_size=32,
|
| 138 |
+
shuffle=False,
|
| 139 |
+
dataset=torchvision.datasets.CIFAR10(
|
| 140 |
+
'data/cifar10',
|
| 141 |
+
train=False,
|
| 142 |
+
download=True,
|
| 143 |
+
transform=transforms.Compose([
|
| 144 |
+
transforms.ToTensor(),
|
| 145 |
+
transforms.Normalize(**norm_cfg)
|
| 146 |
+
])))
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
+
</details>
|
| 150 |
+
|
| 151 |
+
<details>
|
| 152 |
+
<summary>Build Metrics</summary>
|
| 153 |
+
|
| 154 |
+
To validate and test the model, we need to define a **Metric** called accuracy to evaluate the model. This metric needs to inherit from `BaseMetric` and implements the `process` and `compute_metrics` methods.
|
| 155 |
+
|
| 156 |
+
```python
|
| 157 |
+
from mmengine.evaluator import BaseMetric
|
| 158 |
+
|
| 159 |
+
class Accuracy(BaseMetric):
|
| 160 |
+
def process(self, data_batch, data_samples):
|
| 161 |
+
score, gt = data_samples
|
| 162 |
+
# Save the results of a batch to `self.results`
|
| 163 |
+
self.results.append({
|
| 164 |
+
'batch_size': len(gt),
|
| 165 |
+
'correct': (score.argmax(dim=1) == gt).sum().cpu(),
|
| 166 |
+
})
|
| 167 |
+
def compute_metrics(self, results):
|
| 168 |
+
total_correct = sum(item['correct'] for item in results)
|
| 169 |
+
total_size = sum(item['batch_size'] for item in results)
|
| 170 |
+
# Returns a dictionary with the results of the evaluated metrics,
|
| 171 |
+
# where the key is the name of the metric
|
| 172 |
+
return dict(accuracy=100 * total_correct / total_size)
|
| 173 |
+
```
|
| 174 |
+
|
| 175 |
+
</details>
|
| 176 |
+
|
| 177 |
+
<details>
|
| 178 |
+
<summary>Build a Runner</summary>
|
| 179 |
+
|
| 180 |
+
Finally, we can construct a **Runner** with previously defined `Model`, `DataLoader`, and `Metrics`, with some other configs, as shown below.
|
| 181 |
+
|
| 182 |
+
```python
|
| 183 |
+
from torch.optim import SGD
|
| 184 |
+
from mmengine.runner import Runner
|
| 185 |
+
|
| 186 |
+
runner = Runner(
|
| 187 |
+
model=MMResNet50(),
|
| 188 |
+
work_dir='./work_dir',
|
| 189 |
+
train_dataloader=train_dataloader,
|
| 190 |
+
# a wapper to execute back propagation and gradient update, etc.
|
| 191 |
+
optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
|
| 192 |
+
# set some training configs like epochs
|
| 193 |
+
train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
|
| 194 |
+
val_dataloader=val_dataloader,
|
| 195 |
+
val_cfg=dict(),
|
| 196 |
+
val_evaluator=dict(type=Accuracy),
|
| 197 |
+
)
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
</details>
|
| 201 |
+
|
| 202 |
+
<details>
|
| 203 |
+
<summary>Launch Training</summary>
|
| 204 |
+
|
| 205 |
+
```python
|
| 206 |
+
runner.train()
|
| 207 |
+
```
|
| 208 |
+
|
| 209 |
+
</details>
|
| 210 |
+
|
| 211 |
+
## Learn More
|
| 212 |
+
|
| 213 |
+
<details>
|
| 214 |
+
<summary>Tutorials</summary>
|
| 215 |
+
|
| 216 |
+
- [Runner](https://mmengine.readthedocs.io/en/latest/tutorials/runner.html)
|
| 217 |
+
- [Dataset and DataLoader](https://mmengine.readthedocs.io/en/latest/tutorials/dataset.html)
|
| 218 |
+
- [Model](https://mmengine.readthedocs.io/en/latest/tutorials/model.html)
|
| 219 |
+
- [Evaluation](https://mmengine.readthedocs.io/en/latest/tutorials/evaluation.html)
|
| 220 |
+
- [OptimWrapper](https://mmengine.readthedocs.io/en/latest/tutorials/optim_wrapper.html)
|
| 221 |
+
- [Parameter Scheduler](https://mmengine.readthedocs.io/en/latest/tutorials/param_scheduler.html)
|
| 222 |
+
- [Hook](https://mmengine.readthedocs.io/en/latest/tutorials/hook.html)
|
| 223 |
+
|
| 224 |
+
</details>
|
| 225 |
+
|
| 226 |
+
<details>
|
| 227 |
+
<summary>Advanced tutorials</summary>
|
| 228 |
+
|
| 229 |
+
- [Registry](https://mmengine.readthedocs.io/en/latest/tutorials/registry.html)
|
| 230 |
+
- [Config](https://mmengine.readthedocs.io/en/latest/tutorials/config.html)
|
| 231 |
+
- [BaseDataset](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html)
|
| 232 |
+
- [Data Transform](https://mmengine.readthedocs.io/en/latest/tutorials/data_transform.html)
|
| 233 |
+
- [Initialization](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/initialize.html)
|
| 234 |
+
- [Visualization](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/visualization.html)
|
| 235 |
+
- [Abstract Data Element](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/data_element.html)
|
| 236 |
+
- [Distribution Communication](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/distributed.html)
|
| 237 |
+
- [Logging](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/logging.html)
|
| 238 |
+
- [File IO](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/fileio.html)
|
| 239 |
+
- [Global manager (ManagerMixin)](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/manager_mixin.html)
|
| 240 |
+
- [Use modules from other libraries](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/cross_library.html)
|
| 241 |
+
|
| 242 |
+
</details>
|
| 243 |
+
|
| 244 |
+
<details>
|
| 245 |
+
<summary>Examples</summary>
|
| 246 |
+
|
| 247 |
+
- [Resume Training](https://mmengine.readthedocs.io/en/latest/examples/resume_training.html)
|
| 248 |
+
- [Speed up Training](https://mmengine.readthedocs.io/en/latest/examples/speed_up_training.html)
|
| 249 |
+
- [Save Memory on GPU](https://mmengine.readthedocs.io/en/latest/examples/save_gpu_memory.html)
|
| 250 |
+
- [Train a GAN](https://mmengine.readthedocs.io/en/latest/examples/train_a_gan.html)
|
| 251 |
+
|
| 252 |
+
</details>
|
| 253 |
+
|
| 254 |
+
<details>
|
| 255 |
+
<summary>Design</summary>
|
| 256 |
+
|
| 257 |
+
- [Hook](https://mmengine.readthedocs.io/en/latest/design/hook.html)
|
| 258 |
+
- [Runner](https://mmengine.readthedocs.io/en/latest/design/runner.html)
|
| 259 |
+
- [Evaluation](https://mmengine.readthedocs.io/en/latest/design/evaluation.html)
|
| 260 |
+
- [Visualization](https://mmengine.readthedocs.io/en/latest/design/visualization.html)
|
| 261 |
+
- [Logging](https://mmengine.readthedocs.io/en/latest/design/logging.html)
|
| 262 |
+
|
| 263 |
+
</details>
|
| 264 |
+
|
| 265 |
+
<details>
|
| 266 |
+
<summary>Migration guide</summary>
|
| 267 |
+
|
| 268 |
+
- [Migrate Runner from MMCV to MMEngine](https://mmengine.readthedocs.io/en/latest/migration/runner.html)
|
| 269 |
+
- [Migrate Hook from MMCV to MMEngine](https://mmengine.readthedocs.io/en/latest/migration/hook.html)
|
| 270 |
+
- [Migrate Model from MMCV to MMEngine](https://mmengine.readthedocs.io/en/latest/migration/model.html)
|
| 271 |
+
- [Migrate Parameter Scheduler from MMCV to MMEngine](https://mmengine.readthedocs.io/en/latest/migration/param_scheduler.html)
|
| 272 |
+
- [Migrate Data Transform to OpenMMLab 2.0](https://mmengine.readthedocs.io/en/latest/migration/transform.html)
|
| 273 |
+
|
| 274 |
+
</details>
|
| 275 |
+
|
| 276 |
+
## Contributing
|
| 277 |
+
|
| 278 |
+
We appreciate all contributions to improve MMEngine. Please refer to [CONTRIBUTING.md](CONTRIBUTING.md) for the contributing guideline.
|
| 279 |
+
|
| 280 |
+
## License
|
| 281 |
+
|
| 282 |
+
This project is released under the [Apache 2.0 license](LICENSE).
|
| 283 |
+
|
| 284 |
+
## Projects in OpenMMLab
|
| 285 |
+
|
| 286 |
+
- [MIM](https://github.com/open-mmlab/mim): MIM installs OpenMMLab packages.
|
| 287 |
+
- [MMCV](https://github.com/open-mmlab/mmcv): OpenMMLab foundational library for computer vision.
|
| 288 |
+
- [MMEval](https://github.com/open-mmlab/mmeval): A unified evaluation library for multiple machine learning libraries.
|
| 289 |
+
- [MMClassification](https://github.com/open-mmlab/mmclassification): OpenMMLab image classification toolbox and benchmark.
|
| 290 |
+
- [MMDetection](https://github.com/open-mmlab/mmdetection): OpenMMLab detection toolbox and benchmark.
|
| 291 |
+
- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): OpenMMLab's next-generation platform for general 3D object detection.
|
| 292 |
+
- [MMRotate](https://github.com/open-mmlab/mmrotate): OpenMMLab rotated object detection toolbox and benchmark.
|
| 293 |
+
- [MMYOLO](https://github.com/open-mmlab/mmyolo): OpenMMLab YOLO series toolbox and benchmark.
|
| 294 |
+
- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation): OpenMMLab semantic segmentation toolbox and benchmark.
|
| 295 |
+
- [MMOCR](https://github.com/open-mmlab/mmocr): OpenMMLab text detection, recognition, and understanding toolbox.
|
| 296 |
+
- [MMPose](https://github.com/open-mmlab/mmpose): OpenMMLab pose estimation toolbox and benchmark.
|
| 297 |
+
- [MMHuman3D](https://github.com/open-mmlab/mmhuman3d): OpenMMLab 3D human parametric model toolbox and benchmark.
|
| 298 |
+
- [MMSelfSup](https://github.com/open-mmlab/mmselfsup): OpenMMLab self-supervised learning toolbox and benchmark.
|
| 299 |
+
- [MMRazor](https://github.com/open-mmlab/mmrazor): OpenMMLab model compression toolbox and benchmark.
|
| 300 |
+
- [MMFewShot](https://github.com/open-mmlab/mmfewshot): OpenMMLab fewshot learning toolbox and benchmark.
|
| 301 |
+
- [MMAction2](https://github.com/open-mmlab/mmaction2): OpenMMLab's next-generation action understanding toolbox and benchmark.
|
| 302 |
+
- [MMTracking](https://github.com/open-mmlab/mmtracking): OpenMMLab video perception toolbox and benchmark.
|
| 303 |
+
- [MMFlow](https://github.com/open-mmlab/mmflow): OpenMMLab optical flow toolbox and benchmark.
|
| 304 |
+
- [MMEditing](https://github.com/open-mmlab/mmediting): OpenMMLab image and video editing toolbox.
|
| 305 |
+
- [MMGeneration](https://github.com/open-mmlab/mmgeneration): OpenMMLab image and video generative models toolbox.
|
| 306 |
+
- [MMDeploy](https://github.com/open-mmlab/mmdeploy): OpenMMLab model deployment framework.
|
testbed/open-mmlab__mmengine/README_zh-CN.md
ADDED
|
@@ -0,0 +1,333 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img src="https://user-images.githubusercontent.com/58739961/187154444-fce76639-ac8d-429b-9354-c6fac64b7ef8.jpg" width="600"/>
|
| 3 |
+
<div> </div>
|
| 4 |
+
<div align="center">
|
| 5 |
+
<b><font size="5">OpenMMLab 官网</font></b>
|
| 6 |
+
<sup>
|
| 7 |
+
<a href="https://openmmlab.com">
|
| 8 |
+
<i><font size="4">HOT</font></i>
|
| 9 |
+
</a>
|
| 10 |
+
</sup>
|
| 11 |
+
|
| 12 |
+
<b><font size="5">OpenMMLab 开放平台</font></b>
|
| 13 |
+
<sup>
|
| 14 |
+
<a href="https://platform.openmmlab.com">
|
| 15 |
+
<i><font size="4">TRY IT OUT</font></i>
|
| 16 |
+
</a>
|
| 17 |
+
</sup>
|
| 18 |
+
</div>
|
| 19 |
+
<div> </div>
|
| 20 |
+
|
| 21 |
+
[](https://pypi.org/project/mmengine/)
|
| 22 |
+
[](https://pypi.org/project/mmengine)
|
| 23 |
+
[](https://github.com/open-mmlab/mmengine/blob/main/LICENSE)
|
| 24 |
+
[](https://github.com/open-mmlab/mmengine/issues)
|
| 25 |
+
[](https://github.com/open-mmlab/mmengine/issues)
|
| 26 |
+
|
| 27 |
+
[📘使用文档](https://mmengine.readthedocs.io/zh_CN/latest/) |
|
| 28 |
+
[🛠️安装教程](https://mmengine.readthedocs.io/zh_CN/latest/get_started/installation.html) |
|
| 29 |
+
[🤔报告问题](https://github.com/open-mmlab/mmengine/issues/new/choose)
|
| 30 |
+
|
| 31 |
+
</div>
|
| 32 |
+
|
| 33 |
+
<div align="center">
|
| 34 |
+
|
| 35 |
+
[English](README.md) | 简体中文
|
| 36 |
+
|
| 37 |
+
</div>
|
| 38 |
+
|
| 39 |
+
## 简介
|
| 40 |
+
|
| 41 |
+
MMEngine 是一个基于 PyTorch 用于深度学习模型训练的基础库,支持在 Linux、Windows、macOS 上运行。它具有如下三个亮点:
|
| 42 |
+
|
| 43 |
+
1. 通用:MMEngine 实现了一个高级的通用训练器,它能够:
|
| 44 |
+
|
| 45 |
+
- 支持用少量代码训练不同的任务,例如仅使用 80 行代码就可以训练 imagenet(原始pytorch example 400 行)
|
| 46 |
+
- 轻松兼容流行的算法库 (如 TIMM、TorchVision 和 Detectron2 ) 中的模型
|
| 47 |
+
|
| 48 |
+
2. 统一:MMEngine 设计了一个接口统一的开放架构,使得:
|
| 49 |
+
|
| 50 |
+
- 用户可以仅依赖一份代码实现所有任务的轻量化,例如 MMRazor 1.x 相比 MMRazor 0.x 优化了 40% 的代码量
|
| 51 |
+
- 上下游的对接更加统一便捷,在为上层算法库提供统一抽象的同时,支持多种后端设备。目前 MMEngine 支持 Nvidia CUDA、Mac MPS、AMD、MLU 等设备进行模型训练。
|
| 52 |
+
|
| 53 |
+
3. 灵活:MMEngine 实现了“乐高”式的训练流程,支持了:
|
| 54 |
+
|
| 55 |
+
- 根据迭代数、 loss 和评测结果等动态调整的训练流程、优化策略和数据增强策略,例如早停(early stopping)机制等
|
| 56 |
+
- 任意形式的模型权重平均,如 Exponential Momentum Average (EMA) 和 Stochastic Weight Averaging (SWA)
|
| 57 |
+
- 训练过程中针对任意数据和任意节点的灵活可视化和日志控制
|
| 58 |
+
- 对神经网络模型中各个层的优化配置进行细粒度调整
|
| 59 |
+
- 混合精度训练的灵活控制
|
| 60 |
+
|
| 61 |
+
## 最近进展
|
| 62 |
+
|
| 63 |
+
最新版本 v0.3.2 在 2022.11.24 发布。
|
| 64 |
+
|
| 65 |
+
如果想了解更多版本更新细节和历史信息,请阅读[更新日志](./docs/en/notes/changelog.md#v032-11242022)
|
| 66 |
+
|
| 67 |
+
## 安装
|
| 68 |
+
|
| 69 |
+
在安装 MMengine 之前,请确保 PyTorch 已成功安装在环境中,可以参考 [PyTorch 官方安装文档](https://pytorch.org/get-started/locally/)。
|
| 70 |
+
|
| 71 |
+
安装 MMEngine
|
| 72 |
+
|
| 73 |
+
```bash
|
| 74 |
+
pip install -U openmim
|
| 75 |
+
mim install mmengine
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
验证是否安装成功
|
| 79 |
+
|
| 80 |
+
```bash
|
| 81 |
+
python -c 'from mmengine.utils.dl_utils import collect_env;print(collect_env())'
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
更多安装方式请阅读[安装文档](https://mmengine.readthedocs.io/zh_CN/latest/get_started/installation.html)
|
| 85 |
+
|
| 86 |
+
## 快速上手
|
| 87 |
+
|
| 88 |
+
以在 CIFAR-10 数据集上训练一个 ResNet-50 模型为例,我们将使用 80 行以内的代码,利用 MMEngine 构建一个完整的、可配置的训练和验证流程。
|
| 89 |
+
|
| 90 |
+
<details>
|
| 91 |
+
<summary>构建模型</summary>
|
| 92 |
+
|
| 93 |
+
首先,我们需要构建一个**模型**,在 MMEngine 中,我们约定这个模型应当继承 `BaseModel`,并且其 `forward` 方法除了接受来自数据集的若干参数外,还需要接受额外的参数 `mode`:对于训练,我们需要 `mode` 接受字符串 "loss",并返回一个包含 "loss" 字段的字典;对于验证,我们需要 `mode` 接受字符串 "predict",并返回同时包含预测信息和真实信息的结果。
|
| 94 |
+
|
| 95 |
+
```python
|
| 96 |
+
import torch.nn.functional as F
|
| 97 |
+
import torchvision
|
| 98 |
+
from mmengine.model import BaseModel
|
| 99 |
+
|
| 100 |
+
class MMResNet50(BaseModel):
|
| 101 |
+
def __init__(self):
|
| 102 |
+
super().__init__()
|
| 103 |
+
self.resnet = torchvision.models.resnet50()
|
| 104 |
+
|
| 105 |
+
def forward(self, imgs, labels, mode):
|
| 106 |
+
x = self.resnet(imgs)
|
| 107 |
+
if mode == 'loss':
|
| 108 |
+
return {'loss': F.cross_entropy(x, labels)}
|
| 109 |
+
elif mode == 'predict':
|
| 110 |
+
return x, labels
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
</details>
|
| 114 |
+
|
| 115 |
+
<details>
|
| 116 |
+
<summary>构建数据集</summary>
|
| 117 |
+
|
| 118 |
+
其次,我们需要构建训练和验证所需要的**数据集 (Dataset)**和**数据加载器 (DataLoader)**。
|
| 119 |
+
对于基��的训练和验证功能,我们可以直接使用符合 PyTorch 标准的数据加载器和数据集。
|
| 120 |
+
|
| 121 |
+
```python
|
| 122 |
+
import torchvision.transforms as transforms
|
| 123 |
+
from torch.utils.data import DataLoader
|
| 124 |
+
|
| 125 |
+
norm_cfg = dict(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201])
|
| 126 |
+
train_dataloader = DataLoader(batch_size=32,
|
| 127 |
+
shuffle=True,
|
| 128 |
+
dataset=torchvision.datasets.CIFAR10(
|
| 129 |
+
'data/cifar10',
|
| 130 |
+
train=True,
|
| 131 |
+
download=True,
|
| 132 |
+
transform=transforms.Compose([
|
| 133 |
+
transforms.RandomCrop(32, padding=4),
|
| 134 |
+
transforms.RandomHorizontalFlip(),
|
| 135 |
+
transforms.ToTensor(),
|
| 136 |
+
transforms.Normalize(**norm_cfg)
|
| 137 |
+
])))
|
| 138 |
+
val_dataloader = DataLoader(batch_size=32,
|
| 139 |
+
shuffle=False,
|
| 140 |
+
dataset=torchvision.datasets.CIFAR10(
|
| 141 |
+
'data/cifar10',
|
| 142 |
+
train=False,
|
| 143 |
+
download=True,
|
| 144 |
+
transform=transforms.Compose([
|
| 145 |
+
transforms.ToTensor(),
|
| 146 |
+
transforms.Normalize(**norm_cfg)
|
| 147 |
+
])))
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
</details>
|
| 151 |
+
|
| 152 |
+
<details>
|
| 153 |
+
<summary>构建评测指标</summary>
|
| 154 |
+
|
| 155 |
+
为了进行验证和测试,我们需要定义模型推理结果的**评测指标**。我们约定这一评测指标需要继承 `BaseMetric`,并实现 `process` 和 `compute_metrics` 方法。
|
| 156 |
+
|
| 157 |
+
```python
|
| 158 |
+
from mmengine.evaluator import BaseMetric
|
| 159 |
+
|
| 160 |
+
class Accuracy(BaseMetric):
|
| 161 |
+
def process(self, data_batch, data_samples):
|
| 162 |
+
score, gt = data_samples
|
| 163 |
+
# 将一个批次的中间结果保存至 `self.results`
|
| 164 |
+
self.results.append({
|
| 165 |
+
'batch_size': len(gt),
|
| 166 |
+
'correct': (score.argmax(dim=1) == gt).sum().cpu(),
|
| 167 |
+
})
|
| 168 |
+
def compute_metrics(self, results):
|
| 169 |
+
total_correct = sum(item['correct'] for item in results)
|
| 170 |
+
total_size = sum(item['batch_size'] for item in results)
|
| 171 |
+
# 返回保存有评测指标结果的字典,其中键为指标名称
|
| 172 |
+
return dict(accuracy=100 * total_correct / total_size)
|
| 173 |
+
```
|
| 174 |
+
|
| 175 |
+
</details>
|
| 176 |
+
|
| 177 |
+
<details>
|
| 178 |
+
<summary>构建执行器</summary>
|
| 179 |
+
|
| 180 |
+
最后,我们利用构建好的**模型**,**数据加载器**,**评测指标**构建一个**执行器 (Runner)**,同时在其中配置
|
| 181 |
+
**优化器**、**工作路径**、**训练与验证配置**等选项
|
| 182 |
+
|
| 183 |
+
```python
|
| 184 |
+
from torch.optim import SGD
|
| 185 |
+
from mmengine.runner import Runner
|
| 186 |
+
|
| 187 |
+
runner = Runner(
|
| 188 |
+
# 用以训练和验证的模型,需要满足特定的接口需求
|
| 189 |
+
model=MMResNet50(),
|
| 190 |
+
# 工作路径,用以保存训练日志、权重文件信息
|
| 191 |
+
work_dir='./work_dir',
|
| 192 |
+
# 训练数据加载器,需要满足 PyTorch 数据加载器协议
|
| 193 |
+
train_dataloader=train_dataloader,
|
| 194 |
+
# 优化器包装,用于模型优化,并提供 AMP、梯度累积等附加功能
|
| 195 |
+
optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
|
| 196 |
+
# 训练配置,用于指定训练周期、验证间隔等信息
|
| 197 |
+
train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
|
| 198 |
+
# 验证数据加载器,需要满足 PyTorch 数据加载器协议
|
| 199 |
+
val_dataloader=val_dataloader,
|
| 200 |
+
# 验证配置,用于指定验证所需要的额外参数
|
| 201 |
+
val_cfg=dict(),
|
| 202 |
+
# 用于验证的评测器,这里使用默认评测器,并评测指标
|
| 203 |
+
val_evaluator=dict(type=Accuracy),
|
| 204 |
+
)
|
| 205 |
+
```
|
| 206 |
+
|
| 207 |
+
</details>
|
| 208 |
+
|
| 209 |
+
<details>
|
| 210 |
+
<summary>开始训练</summary>
|
| 211 |
+
|
| 212 |
+
```python
|
| 213 |
+
runner.train()
|
| 214 |
+
```
|
| 215 |
+
|
| 216 |
+
</details>
|
| 217 |
+
|
| 218 |
+
## 了解更多
|
| 219 |
+
|
| 220 |
+
<details>
|
| 221 |
+
<summary>入门教程</summary>
|
| 222 |
+
|
| 223 |
+
- [注册器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/registry.html)
|
| 224 |
+
- [配置](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html)
|
| 225 |
+
- [执行器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html)
|
| 226 |
+
- [钩子](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/hook.html)
|
| 227 |
+
- [数据集与数据加载器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/dataset.html)
|
| 228 |
+
- [模型](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/model.html)
|
| 229 |
+
- [评测指标和评测器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/evaluation.html)
|
| 230 |
+
- [优化器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optim_wrapper.html)
|
| 231 |
+
- [优化器参数调整策略](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/param_scheduler.html)
|
| 232 |
+
- [数据变换](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/data_transform.html)
|
| 233 |
+
- [钩子](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/hook.html)
|
| 234 |
+
|
| 235 |
+
</details>
|
| 236 |
+
|
| 237 |
+
<details>
|
| 238 |
+
<summary>进阶教程</summary>
|
| 239 |
+
|
| 240 |
+
- [注册器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/registry.html)
|
| 241 |
+
- [配置](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html)
|
| 242 |
+
- [数据集基类](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/basedataset.html)
|
| 243 |
+
- [抽象数据接口](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)
|
| 244 |
+
- [可视化](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/visualization.html)
|
| 245 |
+
- [数据变换](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/data_transform.html)
|
| 246 |
+
- [初始化](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/initialize.html)
|
| 247 |
+
- [可视化](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/visualization.html)
|
| 248 |
+
- [抽象数据接口](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)
|
| 249 |
+
- [分布式通信原语](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/distributed.html)
|
| 250 |
+
- [记录日志](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/logging.html)
|
| 251 |
+
- [文件读写](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/fileio.html)
|
| 252 |
+
- [辅助类](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/utils.html)
|
| 253 |
+
- [全局管理器](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/manager_mixin.html)
|
| 254 |
+
- [跨库调用模块](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/cross_library.html)
|
| 255 |
+
|
| 256 |
+
</details>
|
| 257 |
+
|
| 258 |
+
<details>
|
| 259 |
+
<summary>示例</summary>
|
| 260 |
+
- [恢复训练](https://mmengine.readthedocs.io/zh_CN/latest/examples/resume_training.html)
|
| 261 |
+
- [加速训练](https://mmengine.readthedocs.io/zh_CN/latest/examples/speed_up_training.html)
|
| 262 |
+
- [节省显存](https://mmengine.readthedocs.io/zh_CN/latest/examples/save_gpu_memory.html)
|
| 263 |
+
- [跨库调用模块](https://mmengine.readthedocs.io/zh_CN/latest/examples/cross_library.html)
|
| 264 |
+
- [训练生成对抗网络](https://mmengine.readthedocs.io/zh_CN/latest/examples/train_a_gan.html)
|
| 265 |
+
|
| 266 |
+
</details>
|
| 267 |
+
<details>
|
| 268 |
+
<summary>架构设计</summary>
|
| 269 |
+
- [钩子的设计](https://mmengine.readthedocs.io/zh_CN/latest/design/hook.html)
|
| 270 |
+
- [执行器的设计](https://mmengine.readthedocs.io/zh_CN/latest/design/runner.html)
|
| 271 |
+
- [模型精度评测的设计](https://mmengine.readthedocs.io/zh_CN/latest/design/evaluation.html)
|
| 272 |
+
- [可视化的设计](https://mmengine.readthedocs.io/zh_CN/latest/design/visualization.html)
|
| 273 |
+
- [日志系统的设计](https://mmengine.readthedocs.io/zh_CN/latest/design/logging.html)
|
| 274 |
+
</details>
|
| 275 |
+
<details>
|
| 276 |
+
<summary>迁移指南</summary>
|
| 277 |
+
- [迁移 MMCV 执行器到 MMEngine](https://mmengine.readthedocs.io/zh_CN/latest/migration/runner.html)
|
| 278 |
+
- [迁移 MMCV 钩子到 MMEngine](https://mmengine.readthedocs.io/zh_CN/latest/migration/hook.html)
|
| 279 |
+
- [迁移 MMCV 模型到 MMEngine](https://mmengine.readthedocs.io/zh_CN/latest/migration/model.html)
|
| 280 |
+
- [迁移 MMCV 参数调度器到 MMEngine](https://mmengine.readthedocs.io/zh_CN/latest/migration/param_scheduler.html)
|
| 281 |
+
- [数据变换类的迁移](https://mmengine.readthedocs.io/zh_CN/latest/migration/transform.html)
|
| 282 |
+
</details>
|
| 283 |
+
|
| 284 |
+
## 贡献指南
|
| 285 |
+
|
| 286 |
+
我们感谢所有的贡献者为改进和提升 MMEngine 所作出的努力。请参考[贡献指南](CONTRIBUTING_zh-CN.md)来了解参与项目贡献的相关指引。
|
| 287 |
+
|
| 288 |
+
## 开源许可证
|
| 289 |
+
|
| 290 |
+
该项目采用 [Apache 2.0 license](LICENSE) 开源许可证。
|
| 291 |
+
|
| 292 |
+
## OpenMMLab 的其他项目
|
| 293 |
+
|
| 294 |
+
- [MIM](https://github.com/open-mmlab/mim): MIM 是 OpenMMLab 项目、算法、模型的统一入口
|
| 295 |
+
- [MMCV](https://github.com/open-mmlab/mmcv/tree/dev-2.x): OpenMMLab 计算机视觉基础库
|
| 296 |
+
- [MMEval](https://github.com/open-mmlab/mmeval): 统一开放的跨框架算法评测库
|
| 297 |
+
- [MMClassification](https://github.com/open-mmlab/mmclassification/tree/dev-1.x): OpenMMLab 图像分类工具箱
|
| 298 |
+
- [MMDetection](https://github.com/open-mmlab/mmdetection/tree/dev-3.x): OpenMMLab 目标检测工具箱
|
| 299 |
+
- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d/tree/dev-1.x): OpenMMLab 新一代通用 3D 目标检测平台
|
| 300 |
+
- [MMRotate](https://github.com/open-mmlab/mmrotate/tree/dev-1.x): OpenMMLab 旋转框检测工具箱与测试基准
|
| 301 |
+
- [MMYOLO](https://github.com/open-mmlab/mmyolo): OpenMMLab YOLO 系列工具箱与测试基准
|
| 302 |
+
- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x): OpenMMLab 语义分割工具箱
|
| 303 |
+
- [MMOCR](https://github.com/open-mmlab/mmocr/tree/dev-1.x): OpenMMLab 全流程文字检测识别理解工具包
|
| 304 |
+
- [MMPose](https://github.com/open-mmlab/mmpose/tree/dev-1.x): OpenMMLab 姿态估计工具箱
|
| 305 |
+
- [MMHuman3D](https://github.com/open-mmlab/mmhuman3d): OpenMMLab 人体参数化模型工具箱与测试基准
|
| 306 |
+
- [MMSelfSup](https://github.com/open-mmlab/mmselfsup/tree/dev-1.x): OpenMMLab 自监督学习工具箱与测试基准
|
| 307 |
+
- [MMRazor](https://github.com/open-mmlab/mmrazor/tree/dev-1.x): OpenMMLab 模型压缩工具箱与测试基准
|
| 308 |
+
- [MMFewShot](https://github.com/open-mmlab/mmfewshot): OpenMMLab 少样本学习工具箱与测试基准
|
| 309 |
+
- [MMAction2](https://github.com/open-mmlab/mmaction2/tree/dev-1.x): OpenMMLab 新一代视频理解工具箱
|
| 310 |
+
- [MMTracking](https://github.com/open-mmlab/mmtracking/tree/dev-1.x): OpenMMLab 一体化视频目标感知平台
|
| 311 |
+
- [MMFlow](https://github.com/open-mmlab/mmflow/tree/dev-1.x): OpenMMLab 光流估计工具箱与测试基准
|
| 312 |
+
- [MMEditing](https://github.com/open-mmlab/mmediting/tree/dev-1.x): OpenMMLab 图像视频编辑工具箱
|
| 313 |
+
- [MMGeneration](https://github.com/open-mmlab/mmgeneration/tree/dev-1.x): OpenMMLab 图片视频生成模型工具箱
|
| 314 |
+
- [MMDeploy](https://github.com/open-mmlab/mmdeploy): OpenMMLab 模型部署框架
|
| 315 |
+
|
| 316 |
+
## 欢迎加入 OpenMMLab 社区
|
| 317 |
+
|
| 318 |
+
扫描下方的二维码可关注 OpenMMLab 团队的 [知乎官方账号](https://www.zhihu.com/people/openmmlab),加入 OpenMMLab 团队的 [官方交流 QQ 群](https://jq.qq.com/?_wv=1027&k=K0QI8ByU),或通过添加微信“Open小喵Lab”加入官方交流微信群。
|
| 319 |
+
|
| 320 |
+
<div align="center">
|
| 321 |
+
<img src="https://user-images.githubusercontent.com/58739961/187154320-f3312cdf-31f2-4316-9dbb-8d7b0e1b7e08.jpg" height="400" /> <img src="https://user-images.githubusercontent.com/25839884/203904835-62392033-02d4-4c73-a68c-c9e4c1e2b07f.jpg" height="400" /> <img src="https://user-images.githubusercontent.com/58739961/187151778-d17c1368-125f-4fde-adbe-38cc6eb3be98.jpg" height="400" />
|
| 322 |
+
</div>
|
| 323 |
+
|
| 324 |
+
我们会在 OpenMMLab 社区为大家
|
| 325 |
+
|
| 326 |
+
- 📢 分享 AI 框架的前沿核心技术
|
| 327 |
+
- 💻 解读 PyTorch 常用模块源码
|
| 328 |
+
- 📰 发布 OpenMMLab 的相关新闻
|
| 329 |
+
- 🚀 介绍 OpenMMLab 开发的前沿算法
|
| 330 |
+
- 🏃 获取更高效的问题答疑和意见反馈
|
| 331 |
+
- 🔥 提供与各行各业开发者充分交流的平台
|
| 332 |
+
|
| 333 |
+
干货满满 📘,等你来撩 💗,OpenMMLab 社区期待您的加入 👬
|
testbed/open-mmlab__mmengine/docs/README.md
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Build Documentation
|
| 2 |
+
|
| 3 |
+
1. Clone MMEngine
|
| 4 |
+
|
| 5 |
+
```bash
|
| 6 |
+
git clone https://github.com/open-mmlab/mmengine.git
|
| 7 |
+
cd mmengine
|
| 8 |
+
```
|
| 9 |
+
|
| 10 |
+
2. Install the building dependencies of documentation
|
| 11 |
+
|
| 12 |
+
```bash
|
| 13 |
+
pip install -r requirements/docs.txt
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
3. Change directory to `docs/en` or `docs/zh_cn`
|
| 17 |
+
|
| 18 |
+
```bash
|
| 19 |
+
cd docs/en # or docs/zh_cn
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
4. Build documentation
|
| 23 |
+
|
| 24 |
+
```bash
|
| 25 |
+
make html
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
5. Open `_build/html/index.html` with browser
|
testbed/open-mmlab__mmengine/docs/en/Makefile
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Minimal makefile for Sphinx documentation
|
| 2 |
+
#
|
| 3 |
+
|
| 4 |
+
# You can set these variables from the command line, and also
|
| 5 |
+
# from the environment for the first two.
|
| 6 |
+
SPHINXOPTS ?=
|
| 7 |
+
SPHINXBUILD ?= sphinx-build
|
| 8 |
+
SOURCEDIR = .
|
| 9 |
+
BUILDDIR = _build
|
| 10 |
+
|
| 11 |
+
# Put it first so that "make" without argument is like "make help".
|
| 12 |
+
help:
|
| 13 |
+
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
| 14 |
+
|
| 15 |
+
.PHONY: help Makefile
|
| 16 |
+
|
| 17 |
+
# Catch-all target: route all unknown targets to Sphinx using the new
|
| 18 |
+
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
| 19 |
+
%: Makefile
|
| 20 |
+
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
testbed/open-mmlab__mmengine/docs/en/conf.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Configuration file for the Sphinx documentation builder.
|
| 2 |
+
#
|
| 3 |
+
# This file only contains a selection of the most common options. For a full
|
| 4 |
+
# list see the documentation:
|
| 5 |
+
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
| 6 |
+
|
| 7 |
+
# -- Path setup --------------------------------------------------------------
|
| 8 |
+
|
| 9 |
+
# If extensions (or modules to document with autodoc) are in another directory,
|
| 10 |
+
# add these directories to sys.path here. If the directory is relative to the
|
| 11 |
+
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
| 12 |
+
#
|
| 13 |
+
import os
|
| 14 |
+
import sys
|
| 15 |
+
|
| 16 |
+
import pytorch_sphinx_theme
|
| 17 |
+
|
| 18 |
+
sys.path.insert(0, os.path.abspath('../..'))
|
| 19 |
+
|
| 20 |
+
# -- Project information -----------------------------------------------------
|
| 21 |
+
|
| 22 |
+
project = 'mmengine'
|
| 23 |
+
copyright = '2022, mmengine contributors'
|
| 24 |
+
author = 'mmengine contributors'
|
| 25 |
+
|
| 26 |
+
version_file = '../../mmengine/version.py'
|
| 27 |
+
with open(version_file) as f:
|
| 28 |
+
exec(compile(f.read(), version_file, 'exec'))
|
| 29 |
+
__version__ = locals()['__version__']
|
| 30 |
+
# The short X.Y version
|
| 31 |
+
version = __version__
|
| 32 |
+
# The full version, including alpha/beta/rc tags
|
| 33 |
+
release = __version__
|
| 34 |
+
|
| 35 |
+
# -- General configuration ---------------------------------------------------
|
| 36 |
+
|
| 37 |
+
# Add any Sphinx extension module names here, as strings. They can be
|
| 38 |
+
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
| 39 |
+
# ones.
|
| 40 |
+
|
| 41 |
+
extensions = [
|
| 42 |
+
'sphinx.ext.autodoc',
|
| 43 |
+
'sphinx.ext.autosummary',
|
| 44 |
+
'sphinx.ext.intersphinx',
|
| 45 |
+
'sphinx.ext.napoleon',
|
| 46 |
+
'sphinx.ext.viewcode',
|
| 47 |
+
'sphinx.ext.autosectionlabel',
|
| 48 |
+
'myst_parser',
|
| 49 |
+
'sphinx_copybutton',
|
| 50 |
+
'sphinx.ext.autodoc.typehints',
|
| 51 |
+
] # yapf: disable
|
| 52 |
+
autodoc_typehints = 'description'
|
| 53 |
+
myst_heading_anchors = 4
|
| 54 |
+
myst_enable_extensions = ['colon_fence']
|
| 55 |
+
|
| 56 |
+
# Configuration for intersphinx
|
| 57 |
+
intersphinx_mapping = {
|
| 58 |
+
'python': ('https://docs.python.org/3', None),
|
| 59 |
+
'numpy': ('https://numpy.org/doc/stable', None),
|
| 60 |
+
'torch': ('https://pytorch.org/docs/stable/', None),
|
| 61 |
+
'mmcv': ('https://mmcv.readthedocs.io/en/2.x/', None),
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
# Add any paths that contain templates here, relative to this directory.
|
| 65 |
+
templates_path = ['_templates']
|
| 66 |
+
|
| 67 |
+
# List of patterns, relative to source directory, that match files and
|
| 68 |
+
# directories to ignore when looking for source files.
|
| 69 |
+
# This pattern also affects html_static_path and html_extra_path.
|
| 70 |
+
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
|
| 71 |
+
|
| 72 |
+
# -- Options for HTML output -------------------------------------------------
|
| 73 |
+
|
| 74 |
+
# The theme to use for HTML and HTML Help pages. See the documentation for
|
| 75 |
+
# a list of builtin themes.
|
| 76 |
+
#
|
| 77 |
+
html_theme = 'pytorch_sphinx_theme'
|
| 78 |
+
html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
|
| 79 |
+
|
| 80 |
+
html_theme_options = {
|
| 81 |
+
'menu': [
|
| 82 |
+
{
|
| 83 |
+
'name': 'GitHub',
|
| 84 |
+
'url': 'https://github.com/open-mmlab/mmengine'
|
| 85 |
+
},
|
| 86 |
+
],
|
| 87 |
+
# Specify the language of shared menu
|
| 88 |
+
'menu_lang': 'en',
|
| 89 |
+
}
|
| 90 |
+
|
| 91 |
+
# Add any paths that contain custom static files (such as style sheets) here,
|
| 92 |
+
# relative to this directory. They are copied after the builtin static files,
|
| 93 |
+
# so a file named "default.css" will overwrite the builtin "default.css".
|
| 94 |
+
html_static_path = ['_static']
|
| 95 |
+
html_css_files = ['css/readthedocs.css']
|
| 96 |
+
|
| 97 |
+
# -- Extension configuration -------------------------------------------------
|
| 98 |
+
# Ignore >>> when copying code
|
| 99 |
+
copybutton_prompt_text = r'>>> |\.\.\. '
|
| 100 |
+
copybutton_prompt_is_regexp = True
|
testbed/open-mmlab__mmengine/docs/en/docutils.conf
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[html writers]
|
| 2 |
+
table_style: colwidths-auto
|
testbed/open-mmlab__mmengine/docs/en/get_started/installation.md
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Installation
|
| 2 |
+
|
| 3 |
+
## Prerequisites
|
| 4 |
+
|
| 5 |
+
- Python 3.6+
|
| 6 |
+
- PyTorch 1.6+
|
| 7 |
+
- CUDA 9.2+
|
| 8 |
+
- GCC 5.4+
|
| 9 |
+
|
| 10 |
+
## Prepare the Environment
|
| 11 |
+
|
| 12 |
+
1. Use conda and activate the environment:
|
| 13 |
+
|
| 14 |
+
```bash
|
| 15 |
+
conda create -n open-mmlab python=3.7 -y
|
| 16 |
+
conda activate open-mmlab
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
2. Install PyTorch
|
| 20 |
+
|
| 21 |
+
Before installing `MMEngine`, please make sure that PyTorch has been successfully installed in the environment. You can refer to [PyTorch official installation documentation](https://pytorch.org/get-started/locally/#start-locally). Verify the installation with the following command:
|
| 22 |
+
|
| 23 |
+
```bash
|
| 24 |
+
python -c 'import torch;print(torch.__version__)'
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
## Install MMEngine
|
| 28 |
+
|
| 29 |
+
### Install with mim
|
| 30 |
+
|
| 31 |
+
[mim](https://github.com/open-mmlab/mim) is a package management tool for OpenMMLab projects, which can be used to install the OpenMMLab project easily.
|
| 32 |
+
|
| 33 |
+
```bash
|
| 34 |
+
pip install -U openmim
|
| 35 |
+
mim install mmengine
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
### Install with pip
|
| 39 |
+
|
| 40 |
+
```bash
|
| 41 |
+
pip install mmengine
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
### Use docker images
|
| 45 |
+
|
| 46 |
+
1. Build the image
|
| 47 |
+
|
| 48 |
+
```bash
|
| 49 |
+
docker build -t mmengine https://github.com/open-mmlab/mmengine.git#main:docker/release
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
More information can be referred from [mmengine/docker](https://github.com/open-mmlab/mmengine/tree/main/docker).
|
| 53 |
+
|
| 54 |
+
2. Run the image
|
| 55 |
+
|
| 56 |
+
```bash
|
| 57 |
+
docker run --gpus all --shm-size=8g -it mmengine
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
#### Build from source
|
| 61 |
+
|
| 62 |
+
```bash
|
| 63 |
+
# if cloning speed is too slow, you can switch the source to https://gitee.com/open-mmlab/mmengine.git
|
| 64 |
+
git clone https://github.com/open-mmlab/mmengine.git
|
| 65 |
+
cd mmengine
|
| 66 |
+
pip install -e . -v
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
### Verify the Installation
|
| 70 |
+
|
| 71 |
+
To verify if `MMEngine` and the necessary environment are successfully installed, we can run this command:
|
| 72 |
+
|
| 73 |
+
```bash
|
| 74 |
+
python -c 'import mmengine;print(mmengine.__version__)'
|
| 75 |
+
```
|
testbed/open-mmlab__mmengine/docs/en/index.rst
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Welcome to MMEngine's documentation!
|
| 2 |
+
=========================================
|
| 3 |
+
You can switch between Chinese and English documents in the lower-left corner of the layout.
|
| 4 |
+
|
| 5 |
+
.. toctree::
|
| 6 |
+
:maxdepth: 1
|
| 7 |
+
:caption: Get Started
|
| 8 |
+
|
| 9 |
+
get_started/introduction.md
|
| 10 |
+
get_started/installation.md
|
| 11 |
+
get_started/15_minutes.md
|
| 12 |
+
|
| 13 |
+
.. toctree::
|
| 14 |
+
:maxdepth: 1
|
| 15 |
+
:caption: Common Usage
|
| 16 |
+
|
| 17 |
+
examples/resume_training.md
|
| 18 |
+
examples/speed_up_training.md
|
| 19 |
+
examples/save_gpu_memory.md
|
| 20 |
+
examples/train_a_gan.md
|
| 21 |
+
|
| 22 |
+
.. toctree::
|
| 23 |
+
:maxdepth: 3
|
| 24 |
+
:caption: Tutorials
|
| 25 |
+
|
| 26 |
+
tutorials/runner.md
|
| 27 |
+
tutorials/dataset.md
|
| 28 |
+
tutorials/model.md
|
| 29 |
+
tutorials/evaluation.md
|
| 30 |
+
tutorials/optim_wrapper.md
|
| 31 |
+
tutorials/param_scheduler.md
|
| 32 |
+
tutorials/hook.md
|
| 33 |
+
|
| 34 |
+
.. toctree::
|
| 35 |
+
:maxdepth: 1
|
| 36 |
+
:caption: Advanced tutorials
|
| 37 |
+
|
| 38 |
+
advanced_tutorials/registry.md
|
| 39 |
+
advanced_tutorials/config.md
|
| 40 |
+
advanced_tutorials/basedataset.md
|
| 41 |
+
advanced_tutorials/data_transform.md
|
| 42 |
+
advanced_tutorials/initialize.md
|
| 43 |
+
advanced_tutorials/visualization.md
|
| 44 |
+
advanced_tutorials/data_element.md
|
| 45 |
+
advanced_tutorials/distributed.md
|
| 46 |
+
advanced_tutorials/logging.md
|
| 47 |
+
advanced_tutorials/fileio.md
|
| 48 |
+
advanced_tutorials/manager_mixin.md
|
| 49 |
+
advanced_tutorials/cross_library.md
|
| 50 |
+
|
| 51 |
+
.. toctree::
|
| 52 |
+
:maxdepth: 1
|
| 53 |
+
:caption: Design
|
| 54 |
+
|
| 55 |
+
design/hook.md
|
| 56 |
+
design/runner.md
|
| 57 |
+
design/evaluation.md
|
| 58 |
+
design/visualization.md
|
| 59 |
+
design/logging.md
|
| 60 |
+
|
| 61 |
+
.. toctree::
|
| 62 |
+
:maxdepth: 1
|
| 63 |
+
:caption: Migration guide
|
| 64 |
+
|
| 65 |
+
migration/runner.md
|
| 66 |
+
migration/hook.md
|
| 67 |
+
migration/model.md
|
| 68 |
+
migration/param_scheduler.md
|
| 69 |
+
migration/transform.md
|
| 70 |
+
|
| 71 |
+
.. toctree::
|
| 72 |
+
:maxdepth: 2
|
| 73 |
+
:caption: API Reference
|
| 74 |
+
|
| 75 |
+
mmengine.registry <api/registry>
|
| 76 |
+
mmengine.config <api/config>
|
| 77 |
+
mmengine.runner <api/runner>
|
| 78 |
+
mmengine.hooks <api/hooks>
|
| 79 |
+
mmengine.model <api/model>
|
| 80 |
+
mmengine.optim <api/optim>
|
| 81 |
+
mmengine.evaluator <api/evaluator>
|
| 82 |
+
mmengine.structures <api/structures>
|
| 83 |
+
mmengine.dataset <api/dataset>
|
| 84 |
+
mmengine.device <api/device>
|
| 85 |
+
mmengine.hub <api/hub>
|
| 86 |
+
mmengine.logging <api/logging>
|
| 87 |
+
mmengine.visualization <api/visualization>
|
| 88 |
+
mmengine.fileio <api/fileio>
|
| 89 |
+
mmengine.dist <api/dist>
|
| 90 |
+
mmengine.utils <api/utils>
|
| 91 |
+
mmengine.utils.dl_utils <api/utils.dl_utils>
|
| 92 |
+
|
| 93 |
+
.. toctree::
|
| 94 |
+
:maxdepth: 2
|
| 95 |
+
:caption: Notes
|
| 96 |
+
|
| 97 |
+
notes/changelog.md
|
| 98 |
+
notes/contributing.md
|
| 99 |
+
|
| 100 |
+
.. toctree::
|
| 101 |
+
:caption: Switch Language
|
| 102 |
+
|
| 103 |
+
switch_language.md
|
| 104 |
+
|
| 105 |
+
Indices and tables
|
| 106 |
+
==================
|
| 107 |
+
|
| 108 |
+
* :ref:`genindex`
|
| 109 |
+
* :ref:`modindex`
|
| 110 |
+
* :ref:`search`
|
testbed/open-mmlab__mmengine/docs/en/make.bat
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
@ECHO OFF
|
| 2 |
+
|
| 3 |
+
pushd %~dp0
|
| 4 |
+
|
| 5 |
+
REM Command file for Sphinx documentation
|
| 6 |
+
|
| 7 |
+
if "%SPHINXBUILD%" == "" (
|
| 8 |
+
set SPHINXBUILD=sphinx-build
|
| 9 |
+
)
|
| 10 |
+
set SOURCEDIR=.
|
| 11 |
+
set BUILDDIR=_build
|
| 12 |
+
|
| 13 |
+
if "%1" == "" goto help
|
| 14 |
+
|
| 15 |
+
%SPHINXBUILD% >NUL 2>NUL
|
| 16 |
+
if errorlevel 9009 (
|
| 17 |
+
echo.
|
| 18 |
+
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
|
| 19 |
+
echo.installed, then set the SPHINXBUILD environment variable to point
|
| 20 |
+
echo.to the full path of the 'sphinx-build' executable. Alternatively you
|
| 21 |
+
echo.may add the Sphinx directory to PATH.
|
| 22 |
+
echo.
|
| 23 |
+
echo.If you don't have Sphinx installed, grab it from
|
| 24 |
+
echo.http://sphinx-doc.org/
|
| 25 |
+
exit /b 1
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
| 29 |
+
goto end
|
| 30 |
+
|
| 31 |
+
:help
|
| 32 |
+
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
| 33 |
+
|
| 34 |
+
:end
|
| 35 |
+
popd
|
testbed/open-mmlab__mmengine/docs/en/migration/hook.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Migrate Hook from MMCV to MMEngine
|
| 2 |
+
|
| 3 |
+
Coming soon. Please refer to [chinese documentation](https://mmengine.readthedocs.io/zh_CN/latest/migration/hook.html).
|
testbed/open-mmlab__mmengine/docs/en/notes/contributing.md
ADDED
|
@@ -0,0 +1,242 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Contributing to OpenMMLab
|
| 2 |
+
|
| 3 |
+
Welcome to the MMEngine community, we are committed to building a cutting-edge computer vision foundational library and all kinds of contributions are welcomed, including but not limited to
|
| 4 |
+
|
| 5 |
+
**Fix bug**
|
| 6 |
+
|
| 7 |
+
You can directly post a Pull Request to fix typos in code or documents
|
| 8 |
+
|
| 9 |
+
The steps to fix the bug of code implementation are as follows.
|
| 10 |
+
|
| 11 |
+
1. If the modification involves significant changes, you should create an issue first and describe the error information and how to trigger the bug. Other developers will discuss it with you and propose a proper solution.
|
| 12 |
+
|
| 13 |
+
2. Posting a pull request after fixing the bug and adding the corresponding unit test.
|
| 14 |
+
|
| 15 |
+
**New Feature or Enhancement**
|
| 16 |
+
|
| 17 |
+
1. If the modification involves significant changes, you should create an issue to discuss with our developers to propose a proper design.
|
| 18 |
+
2. Post a Pull Request after implementing the new feature or enhancement and add the corresponding unit test.
|
| 19 |
+
|
| 20 |
+
**Document**
|
| 21 |
+
|
| 22 |
+
You can directly post a pull request to fix documents. If you want to add a document, you should first create an issue to check if it is reasonable.
|
| 23 |
+
|
| 24 |
+
### Pull Request Workflow
|
| 25 |
+
|
| 26 |
+
If you're not familiar with Pull Request, don't worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the development mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests).
|
| 27 |
+
|
| 28 |
+
#### 1. Fork and clone
|
| 29 |
+
|
| 30 |
+
If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
|
| 31 |
+
|
| 32 |
+
<img src="https://user-images.githubusercontent.com/57566630/167305749-43c7f4e9-449b-4e98-ade5-0c9276d5c9ce.png" width="1200">
|
| 33 |
+
|
| 34 |
+
Then, you can clone the repositories to local:
|
| 35 |
+
|
| 36 |
+
```shell
|
| 37 |
+
git clone git@github.com:{username}/mmengine.git
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
After that, you should add the official repository as the upstream repository.
|
| 41 |
+
|
| 42 |
+
```bash
|
| 43 |
+
git remote add upstream git@github.com:open-mmlab/mmengine
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
Check whether the remote repository has been added successfully by `git remote -v`.
|
| 47 |
+
|
| 48 |
+
```bash
|
| 49 |
+
origin git@github.com:{username}/mmengine.git (fetch)
|
| 50 |
+
origin git@github.com:{username}/mmengine.git (push)
|
| 51 |
+
upstream git@github.com:open-mmlab/mmengine (fetch)
|
| 52 |
+
upstream git@github.com:open-mmlab/mmengine (push)
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
```{note}
|
| 56 |
+
Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
#### 2. Configure pre-commit
|
| 60 |
+
|
| 61 |
+
You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the mmengine directory.
|
| 62 |
+
|
| 63 |
+
```shell
|
| 64 |
+
pip install -U pre-commit
|
| 65 |
+
pre-commit install
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
|
| 69 |
+
|
| 70 |
+
```shell
|
| 71 |
+
pre-commit run --all-files
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
<img src="https://user-images.githubusercontent.com/57566630/173660750-3df20a63-cb66-4d33-a986-1f643f1d8aaf.png" width="1200">
|
| 75 |
+
|
| 76 |
+
<img src="https://user-images.githubusercontent.com/57566630/202368856-0465a90d-8fce-4345-918e-67b8b9c82614.png" width="1200">
|
| 77 |
+
|
| 78 |
+
If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
|
| 79 |
+
|
| 80 |
+
If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
|
| 81 |
+
|
| 82 |
+
<img src="https://user-images.githubusercontent.com/57566630/202369176-67642454-0025-4023-a095-263529107aa3.png" width="1200">
|
| 83 |
+
|
| 84 |
+
If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporary committing**).
|
| 85 |
+
|
| 86 |
+
```shell
|
| 87 |
+
git commit -m "xxx" --no-verify
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
#### 3. Create a development branch
|
| 91 |
+
|
| 92 |
+
After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
|
| 93 |
+
|
| 94 |
+
```shell
|
| 95 |
+
git checkout -b yhc/refactor_contributing_doc
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
|
| 99 |
+
|
| 100 |
+
```shell
|
| 101 |
+
git pull upstream master
|
| 102 |
+
```
|
| 103 |
+
|
| 104 |
+
#### 4. Commit the code and pass the unit test
|
| 105 |
+
|
| 106 |
+
- MMEngine introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
|
| 107 |
+
|
| 108 |
+
- The committed code should pass through the unit test
|
| 109 |
+
|
| 110 |
+
```shell
|
| 111 |
+
# Pass all unit tests
|
| 112 |
+
pytest tests
|
| 113 |
+
|
| 114 |
+
# Pass the unit test of runner
|
| 115 |
+
pytest tests/test_runner/test_runner.py
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
|
| 119 |
+
|
| 120 |
+
- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
|
| 121 |
+
|
| 122 |
+
#### 5. Push the code to remote
|
| 123 |
+
|
| 124 |
+
We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
|
| 125 |
+
|
| 126 |
+
```shell
|
| 127 |
+
git push -u origin {branch_name}
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
|
| 131 |
+
|
| 132 |
+
#### 6. Create a Pull Request
|
| 133 |
+
|
| 134 |
+
(1) Create a pull request in GitHub's Pull request interface
|
| 135 |
+
|
| 136 |
+
<img src="https://user-images.githubusercontent.com/57566630/201533288-516f7ac4-0b14-4dc8-afbd-912475c368b5.png" width="1200">
|
| 137 |
+
|
| 138 |
+
(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
|
| 139 |
+
|
| 140 |
+
<img src="https://user-images.githubusercontent.com/57566630/202242953-c91a18ff-e388-4ff9-8591-5fae0ead6c1e.png" width="1200">
|
| 141 |
+
|
| 142 |
+
Find more details about Pull Request description in [pull request guidelines](#pr-specs).
|
| 143 |
+
|
| 144 |
+
**note**
|
| 145 |
+
|
| 146 |
+
(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
|
| 147 |
+
|
| 148 |
+
(b) If it is your first contribution, please sign the CLA
|
| 149 |
+
|
| 150 |
+
<img src="https://user-images.githubusercontent.com/57566630/167307569-a794b967-6e28-4eac-a942-00deb657815f.png" width="1200">
|
| 151 |
+
|
| 152 |
+
(c) Check whether the Pull Request pass through the CI
|
| 153 |
+
|
| 154 |
+
<img src="https://user-images.githubusercontent.com/57566630/167307490-f9ebf9fa-63c0-4d83-8ba1-081ea169eb3a.png" width="1200">
|
| 155 |
+
|
| 156 |
+
MMEngine will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
|
| 157 |
+
|
| 158 |
+
(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
|
| 159 |
+
|
| 160 |
+
<img src="https://user-images.githubusercontent.com/57566630/202145400-cc2cd8c4-10b0-472f-ba37-07e6f50acc67.png" width="1200">
|
| 161 |
+
|
| 162 |
+
#### 7. Resolve conflicts
|
| 163 |
+
|
| 164 |
+
If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
|
| 165 |
+
|
| 166 |
+
```shell
|
| 167 |
+
git fetch --all --prune
|
| 168 |
+
git rebase upstream/master
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
or
|
| 172 |
+
|
| 173 |
+
```shell
|
| 174 |
+
git fetch --all --prune
|
| 175 |
+
git merge upstream/master
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
|
| 179 |
+
|
| 180 |
+
### Guidance
|
| 181 |
+
|
| 182 |
+
#### Unit test
|
| 183 |
+
|
| 184 |
+
We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
|
| 185 |
+
|
| 186 |
+
```shell
|
| 187 |
+
python -m coverage run -m pytest /path/to/test_file
|
| 188 |
+
python -m coverage html
|
| 189 |
+
# check file in htmlcov/index.html
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
#### Document rendering
|
| 193 |
+
|
| 194 |
+
If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
|
| 195 |
+
|
| 196 |
+
```shell
|
| 197 |
+
pip install -r requirements/docs.txt
|
| 198 |
+
cd docs/zh_cn/
|
| 199 |
+
# or docs/en
|
| 200 |
+
make html
|
| 201 |
+
# check file in ./docs/zh_cn/_build/html/index.html
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
### Python Code style
|
| 205 |
+
|
| 206 |
+
We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
|
| 207 |
+
|
| 208 |
+
We use the following tools for linting and formatting:
|
| 209 |
+
|
| 210 |
+
- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
|
| 211 |
+
- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
|
| 212 |
+
- [yapf](https://github.com/google/yapf): A formatter for Python files.
|
| 213 |
+
- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
|
| 214 |
+
- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
|
| 215 |
+
- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
|
| 216 |
+
|
| 217 |
+
Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
|
| 218 |
+
|
| 219 |
+
We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
|
| 220 |
+
fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
|
| 221 |
+
The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
|
| 222 |
+
|
| 223 |
+
### PR Specs
|
| 224 |
+
|
| 225 |
+
1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
|
| 226 |
+
|
| 227 |
+
2. One short-time branch should be matched with only one PR
|
| 228 |
+
|
| 229 |
+
3. Accomplish a detailed change in one PR. Avoid large PR
|
| 230 |
+
|
| 231 |
+
- Bad: Support Faster R-CNN
|
| 232 |
+
- Acceptable: Add a box head to Faster R-CNN
|
| 233 |
+
- Good: Add a parameter to box head to support custom conv-layer number
|
| 234 |
+
|
| 235 |
+
4. Provide clear and significant commit message
|
| 236 |
+
|
| 237 |
+
5. Provide clear and meaningful PR description
|
| 238 |
+
|
| 239 |
+
- Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
|
| 240 |
+
- Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
|
| 241 |
+
- Introduce main changes, results and influences on other modules in short description
|
| 242 |
+
- Associate related issues and pull requests with a milestone
|
testbed/open-mmlab__mmengine/docs/en/switch_language.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## <a href='https://mmengine.readthedocs.io/en/latest/'>English</a>
|
| 2 |
+
|
| 3 |
+
## <a href='https://mmengine.readthedocs.io/zh_CN/latest/'>简体中文</a>
|
testbed/open-mmlab__mmengine/docs/en/tutorials/dataset.md
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Dataset and DataLoader
|
| 2 |
+
|
| 3 |
+
```{hint}
|
| 4 |
+
If you have never been exposed to PyTorch's Dataset and DataLoader classes, you are recommended to read through [PyTorch official tutorial](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html) to get familiar with some basic concepts.
|
| 5 |
+
```
|
| 6 |
+
|
| 7 |
+
Datasets and DataLoaders are necessary components in MMEngine's training pipeline. They are conceptually derived from and consistent with PyTorch. Typically, a dataset defines the quantity, parsing, and pre-processing of the data, while a dataloader iteratively loads data according to settings such as `batch_size`, `shuffle`, `num_workers`, etc. Datasets are encapsulated with dataloaders and they together constitute the data source.
|
| 8 |
+
|
| 9 |
+
In this tutorial, we will step through their usage in MMEngine runner from the outside (dataloader) to the inside (dataset) and give some practical examples. After reading through this tutorial, you will be able to:
|
| 10 |
+
|
| 11 |
+
- Master the configuration of dataloaders in MMEngine
|
| 12 |
+
- Learn to use existing datasets (e.g. those from `torchvision`) from config files
|
| 13 |
+
- Know about building and using your own dataset
|
| 14 |
+
|
| 15 |
+
## Details on dataloader
|
| 16 |
+
|
| 17 |
+
Dataloaders can be configured in MMEngine's `Runner` with 3 arguments:
|
| 18 |
+
|
| 19 |
+
- `train_dataloader`: Used in `Runner.train()` to provide training data for models
|
| 20 |
+
- `val_dataloader`: Used in `Runner.val()` or in `Runner.train()` at regular intervals for model evaluation
|
| 21 |
+
- `test_dataloader`: Used in `Runner.test()` for the final test
|
| 22 |
+
|
| 23 |
+
MMEngine has full support for PyTorch native `DataLoader` objects. Therefore, you can simply pass your valid, already built dataloaders to the runner, as shown in [getting started in 15 minutes](../get_started/15_minutes.md). Meanwhile, thanks to the [Registry Mechanism](../advanced_tutorials/registry.md) of MMEngine, those arguments also accept `dict`s as inputs, as illustrated in the following example (referred to as example 1). The keys in the dictionary correspond to arguments in DataLoader's init function.
|
| 24 |
+
|
| 25 |
+
```python
|
| 26 |
+
runner = Runner(
|
| 27 |
+
train_dataloader=dict(
|
| 28 |
+
batch_size=32,
|
| 29 |
+
sampler=dict(
|
| 30 |
+
type='DefaultSampler',
|
| 31 |
+
shuffle=True),
|
| 32 |
+
dataset=torchvision.datasets.CIFAR10(...),
|
| 33 |
+
collate_fn=dict(type='default_collate')
|
| 34 |
+
)
|
| 35 |
+
)
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
When passed to the runner in the form of a dict, the dataloader will be lazily built in the runner when actually needed.
|
| 39 |
+
|
| 40 |
+
```{note}
|
| 41 |
+
For more configurable arguments of the `DataLoader`, please refer to [PyTorch API documentation](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader)
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
```{note}
|
| 45 |
+
If you are interested in the details of the building procedure, you may refer to [build_dataloader](mmengine.runner.Runner.build_dataloader)
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
You may find example 1 differs from that in [getting started in 15 minutes](../get_started/15_minutes.md) in some arguments. Indeed, due to some obscure conventions in MMEngine, you can't seamlessly switch it to a dict by simply replacing `DataLoader` with `dict`. We will discuss the differences between our convention and PyTorch's in the following sections, in case you run into trouble when using config files.
|
| 49 |
+
|
| 50 |
+
### sampler and shuffle
|
| 51 |
+
|
| 52 |
+
One obvious difference is that we add a `sampler` argument to the dict. This is because we **require `sampler` to be explicitly specified** when using a dict as a dataloader. Meanwhile, `shuffle` is also removed from `DataLoader` arguments, because it conflicts with `sampler` in PyTorch, as referred to in [PyTorch DataLoader API documentation](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader).
|
| 53 |
+
|
| 54 |
+
```{note}
|
| 55 |
+
In fact, `shuffle` is just a notation for convenience in PyTorch implementation. If `shuffle` is set to `True`, the dataloader will automatically switch to `RandomSampler`
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
With a `sampler` argument, codes in example 1 is **nearly** equivalent to code block below
|
| 59 |
+
|
| 60 |
+
```python
|
| 61 |
+
from mmengine.dataset import DefaultSampler
|
| 62 |
+
|
| 63 |
+
dataset = torchvision.datasets.CIFAR10(...)
|
| 64 |
+
sampler = DefaultSampler(dataset, shuffle=True)
|
| 65 |
+
|
| 66 |
+
runner = Runner(
|
| 67 |
+
train_dataloader=DataLoader(
|
| 68 |
+
batch_size=32,
|
| 69 |
+
sampler=sampler,
|
| 70 |
+
dataset=dataset,
|
| 71 |
+
collate_fn=default_collate
|
| 72 |
+
)
|
| 73 |
+
)
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
```{warning}
|
| 77 |
+
The equivalence of the above codes holds only if: 1) you are training with a single process, and 2) no `randomness` argument is passed to the runner. This is due to the fact that `sampler` should be built after distributed environment setup to be correct. The runner will guarantee the correct order and proper random seed by applying lazy initialization techniques, which is only possible for dict inputs. Instead, when building a sampler manually, it requires extra work and is highly error-prone. Therefore, the code block above is just for illustration and definitely not recommended. We **strongly suggest passing `sampler` as a `dict`** to avoid potential problems.
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
### DefaultSampler
|
| 81 |
+
|
| 82 |
+
The above example may make you wonder what a `DefaultSampler` is, why use it and whether there are other options. In fact, `DefaultSampler` is a built-in sampler in MMEngine which eliminates the gap between distributed and non-distributed training and thus enabling a seamless conversion between them. If you have the experience of using `DistributedDataParallel` in PyTorch, you may be impressed by having to change the `sampler` argument to make it correct. However, in MMEngine, you don't need to bother with this `DefaultSampler`.
|
| 83 |
+
|
| 84 |
+
`DefaultSampler` accepts the following arguments:
|
| 85 |
+
|
| 86 |
+
- `shuffle`: Set to `True` to load data in the dataset in random order
|
| 87 |
+
- `seed`: Random seed used to shuffle the dataset. Typically it doesn't require manual configuration here because the runner will handle it with `randomness` configuration
|
| 88 |
+
- `round_up`: When set this to `True`, this is the same behavior as setting `drop_last=False` in PyTorch `DataLoader`. You should take care of it when doing migration from PyTorch.
|
| 89 |
+
|
| 90 |
+
```{note}
|
| 91 |
+
For more details about `DefaultSampler`, please refer to [its API docs](mmengine.dataset.DefaultSampler)
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
`DefaultSampler` handles most of the cases. We ensure that error-prone details such as random seeds are handled properly when you are using it in a runner. This prevents you from getting into troubles with distributed training. Apart from `DefaultSampler`, you may also be interested in [InfiniteSampler](mmengine.dataset.InfiniteSampler) for iteration-based training pipelines. If you have more advanced demands, you may want to refer to the codes of these two built-in samplers to implement your own one and register it to `DATA_SAMPLERS` registry.
|
| 95 |
+
|
| 96 |
+
```python
|
| 97 |
+
@DATA_SAMPLERS.register_module()
|
| 98 |
+
class MySampler(Sampler):
|
| 99 |
+
pass
|
| 100 |
+
|
| 101 |
+
runner = Runner(
|
| 102 |
+
train_dataloader=dict(
|
| 103 |
+
sampler=dict(type='MySampler'),
|
| 104 |
+
...
|
| 105 |
+
)
|
| 106 |
+
)
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
### The obscure collate_fn
|
| 110 |
+
|
| 111 |
+
Among the arguments of PyTorch `DataLoader`, `collate_fn` is often ignored by users, but in MMEngine you must pay special attention to it. When you pass the dataloader argument as a dict, MMEngine will use the built-in [pseudo_collate](mmengine.dataset.pseudo_collate) by default, which is significantly different from that, [default_collate](https://pytorch.org/docs/stable/data.html#torch.utils.data.default_collate), in PyTorch. Therefore, when doing a migration from PyTorch, you have to explicitly specify the `collate_fn` in config files to be consistent in behavior.
|
| 112 |
+
|
| 113 |
+
```{note}
|
| 114 |
+
MMEngine uses `pseudo_collate` as default value is mainly due to historical compatibility reasons. You don't have to look deeply into it. You can just know about it and avoid potential errors.
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
MMEngine provides 2 built-in `collate_fn`:
|
| 118 |
+
|
| 119 |
+
- `pseudo_collate`: Default value in MMEngine. It won't concatenate data through `batch` index. Detailed explanations can be found in [pseudo_collate API doc](mmengine.dataset.pseudo_collate)
|
| 120 |
+
- `default_collate`: It behaves almost identically to PyTorch's `default_collate`. It will transfer data into `Tensor` and concatenate them through `batch` index. More details and slight differences from PyTorch can be found in [default_collate API doc](mmengine.dataset.default_collate)
|
| 121 |
+
|
| 122 |
+
If you want to use a custom `collate_fn`, you can register it to `COLLATE_FUNCTIONS` registry.
|
| 123 |
+
|
| 124 |
+
```python
|
| 125 |
+
@COLLATE_FUNCTIONS.register_module()
|
| 126 |
+
def my_collate_func(data_batch: Sequence) -> Any:
|
| 127 |
+
pass
|
| 128 |
+
|
| 129 |
+
runner = Runner(
|
| 130 |
+
train_dataloader=dict(
|
| 131 |
+
...
|
| 132 |
+
collate_fn=dict(type='my_collate_func')
|
| 133 |
+
)
|
| 134 |
+
)
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
## Details on dataset
|
| 138 |
+
|
| 139 |
+
Typically, datasets define the quantity, parsing, and pre-processing of the data. It is encapsulated in dataloader, allowing the latter to load data in batches. Since we fully support PyTorch `DataLoader`, the dataset is also compatible. Meanwhile, thanks to the registry mechanism, when a dataloader is given as a dict, its `dataset` argument can also be given as a dict, which enables lazy initialization in the runner. This mechanism allows for writing config files.
|
| 140 |
+
|
| 141 |
+
### Use torchvision datasets
|
| 142 |
+
|
| 143 |
+
`torchvision` provides various open datasets. They can be directly used in MMEngine as shown in [getting started in 15 minutes](../get_started/15_minutes.md), where a `CIFAR10` dataset is used together with torchvision's built-in data transforms.
|
| 144 |
+
|
| 145 |
+
However, if you want to use the dataset in config files, registration is needed. What's more, if you also require data transforms in torchvision, some more registrations are required. The following example illustrates how to do it.
|
| 146 |
+
|
| 147 |
+
```python
|
| 148 |
+
import torchvision.transforms as tvt
|
| 149 |
+
from mmengine.registry import DATASETS, TRANSFORMS
|
| 150 |
+
from mmengine.dataset.base_dataset import Compose
|
| 151 |
+
|
| 152 |
+
# register CIFAR10 dataset in torchvision
|
| 153 |
+
# data transforms should also be built here
|
| 154 |
+
@DATASETS.register_module(name='Cifar10', force=False)
|
| 155 |
+
def build_torchvision_cifar10(transform=None, **kwargs):
|
| 156 |
+
if isinstance(transform, dict):
|
| 157 |
+
transform = [transform]
|
| 158 |
+
if isinstance(transform, (list, tuple)):
|
| 159 |
+
transform = Compose(transform)
|
| 160 |
+
return torchvision.datasets.CIFAR10(**kwargs, transform=transform)
|
| 161 |
+
|
| 162 |
+
# register data transforms in torchvision
|
| 163 |
+
DATA_TRANSFORMS.register_module('RandomCrop', module=tvt.RandomCrop)
|
| 164 |
+
DATA_TRANSFORMS.register_module('RandomHorizontalFlip', module=tvt.RandomHorizontalFlip)
|
| 165 |
+
DATA_TRANSFORMS.register_module('ToTensor', module=tvt.ToTensor)
|
| 166 |
+
DATA_TRANSFORMS.register_module('Normalize', module=tvt.Normalize)
|
| 167 |
+
|
| 168 |
+
# specify in runner
|
| 169 |
+
runner = Runner(
|
| 170 |
+
train_dataloader=dict(
|
| 171 |
+
batch_size=32,
|
| 172 |
+
sampler=dict(
|
| 173 |
+
type='DefaultSampler',
|
| 174 |
+
shuffle=True),
|
| 175 |
+
dataset=dict(type='Cifar10',
|
| 176 |
+
root='data/cifar10',
|
| 177 |
+
train=True,
|
| 178 |
+
download=True,
|
| 179 |
+
transform=[
|
| 180 |
+
dict(type='RandomCrop', size=32, padding=4),
|
| 181 |
+
dict(type='RandomHorizontalFlip'),
|
| 182 |
+
dict(type='ToTensor'),
|
| 183 |
+
dict(type='Normalize', **norm_cfg)])
|
| 184 |
+
)
|
| 185 |
+
)
|
| 186 |
+
```
|
| 187 |
+
|
| 188 |
+
```{note}
|
| 189 |
+
The above example makes extensive use of the registry mechanism and borrows the [Compose](mmengine.dataset.Compose) module from MMEngine. If you urge to use torchvision dataset in your config files, you can refer to it and make some slight modifications. However, we recommend you borrow datasets from downstream repos such as [MMDet](https://github.com/open-mmlab/mmdetection), [MMCls](https://github.com/open-mmlab/mmclassification), etc. This may give you a better experience.
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
### Customize your dataset
|
| 193 |
+
|
| 194 |
+
You are free to customize your own datasets, as you would with PyTorch. You can also copy existing datasets from your previous PyTorch projects. If you want to learn how to customize your dataset, please refer to [PyTorch official tutorials](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html#creating-a-custom-dataset-for-your-files)
|
| 195 |
+
|
| 196 |
+
### Use MMEngine BaseDataset
|
| 197 |
+
|
| 198 |
+
Apart from directly using PyTorch native `Dataset` class, you can also use MMEngine's built-in class `BaseDataset` to customize your own one, as referred to [BaseDataset tutorial](../advanced_tutorials/basedataset.md). It makes some conventions on the format of annotation files, which makes the data interface more unified and multi-task training more convenient. Meanwhile, `BaseDataset` can easily cooperate with built-in [data transforms](../advanced_tutorials/data_element.md) in MMEngine, which releases you from writing one from scratch.
|
| 199 |
+
|
| 200 |
+
Currently, `BaseDataset` has been widely used in downstream repos of OpenMMLab 2.0 projects.
|
testbed/open-mmlab__mmengine/docs/en/tutorials/evaluation.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Evaluation
|
| 2 |
+
|
| 3 |
+
Coming soon. Please refer to [chinese documentation](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/evaluation.html).
|
testbed/open-mmlab__mmengine/docs/en/tutorials/param_scheduler.md
ADDED
|
@@ -0,0 +1,229 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Parameter Scheduler
|
| 2 |
+
|
| 3 |
+
During neural network training, optimization hyperparameters (e.g. learning rate) are usually adjusted along with the training process.
|
| 4 |
+
One of the simplest and most common learning rate adjustment strategies is multi-step learning rate decay, which reduces the learning rate to a fraction at regular intervals.
|
| 5 |
+
PyTorch provides LRScheduler to implement various learning rate adjustment strategies. In MMEngine, we have extended it and implemented a more general [ParamScheduler](mmengine.optim._ParamScheduler).
|
| 6 |
+
It can adjust optimization hyperparameters such as learning rate and momentum. It also supports the combination of multiple schedulers to create more complex scheduling strategies.
|
| 7 |
+
|
| 8 |
+
## Usage
|
| 9 |
+
|
| 10 |
+
We first introduce how to use PyTorch's `torch.optim.lr_scheduler` to adjust learning rate.
|
| 11 |
+
|
| 12 |
+
<details>
|
| 13 |
+
<summary>How to use PyTorch's builtin learning rate scheduler?</summary>
|
| 14 |
+
|
| 15 |
+
Here is an example which refers from [PyTorch official documentation](https://pytorch.org/docs/stable/optim.html):
|
| 16 |
+
|
| 17 |
+
Initialize an ExponentialLR object, and call the `step` method after each training epoch.
|
| 18 |
+
|
| 19 |
+
```python
|
| 20 |
+
import torch
|
| 21 |
+
from torch.optim import SGD
|
| 22 |
+
from torch.optim.lr_scheduler import ExponentialLR
|
| 23 |
+
|
| 24 |
+
model = torch.nn.Linear(1, 1)
|
| 25 |
+
dataset = [torch.randn((1, 1, 1)) for _ in range(20)]
|
| 26 |
+
optimizer = SGD(model, 0.1)
|
| 27 |
+
scheduler = ExponentialLR(optimizer, gamma=0.9)
|
| 28 |
+
|
| 29 |
+
for epoch in range(10):
|
| 30 |
+
for data in dataset:
|
| 31 |
+
optimizer.zero_grad()
|
| 32 |
+
output = model(data)
|
| 33 |
+
loss = 1 - output
|
| 34 |
+
loss.backward()
|
| 35 |
+
optimizer.step()
|
| 36 |
+
scheduler.step()
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
</details>
|
| 40 |
+
|
| 41 |
+
`mmengine.optim.scheduler` supports most of PyTorch's learning rate schedulers such as `ExponentialLR`, `LinearLR`, `StepLR`, `MultiStepLR`, etc. Please refer to [parameter scheduler API documentation](https://mmengine.readthedocs.io/en/latest/api/optim.html#scheduler) for all of the supported schedulers.
|
| 42 |
+
|
| 43 |
+
MMEngine also supports adjusting momentum with parameter schedulers. To use momentum schedulers, replace `LR` in the class name to `Momentum`, such as `ExponentialMomentum`,`LinearMomentum`. Further, we implement the general parameter scheduler ParamScheduler, which is used to adjust the specified hyperparameters in the optimizer, such as weight_decay, etc. This feature makes it easier to apply some complex hyperparameter tuning strategies.
|
| 44 |
+
|
| 45 |
+
Different from the above example, MMEngine usually does not need to manually implement the training loop and call `optimizer.step()`. The runner will automatically manage the training progress and control the execution of the parameter scheduler through `ParamSchedulerHook`.
|
| 46 |
+
|
| 47 |
+
### Use a single LRScheduler
|
| 48 |
+
|
| 49 |
+
If only one scheduler needs to be used for the entire training process, there is no difference with PyTorch's learning rate scheduler.
|
| 50 |
+
|
| 51 |
+
```python
|
| 52 |
+
# build the scheduler manually
|
| 53 |
+
from torch.optim import SGD
|
| 54 |
+
from mmengine.runner import Runner
|
| 55 |
+
from mmengine.optim.scheduler import MultiStepLR
|
| 56 |
+
|
| 57 |
+
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
|
| 58 |
+
param_scheduler = MultiStepLR(optimizer, milestones=[8, 11], gamma=0.1)
|
| 59 |
+
|
| 60 |
+
runner = Runner(
|
| 61 |
+
model=model,
|
| 62 |
+
optim_wrapper=dict(
|
| 63 |
+
optimizer=optimizer),
|
| 64 |
+
param_scheduler=param_scheduler,
|
| 65 |
+
...
|
| 66 |
+
)
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
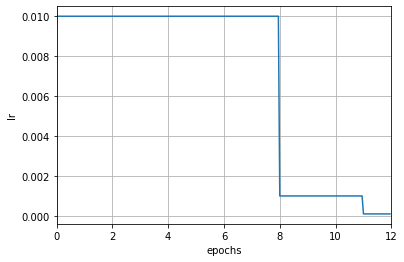
|
| 70 |
+
|
| 71 |
+
If using the runner with the registry and config file, we can specify the scheduler by setting the `param_scheduler` field in the config. The runner will automatically build a parameter scheduler based on this field:
|
| 72 |
+
|
| 73 |
+
```python
|
| 74 |
+
# build the scheduler with config file
|
| 75 |
+
param_scheduler = dict(type='MultiStepLR', by_epoch=True, milestones=[8, 11], gamma=0.1)
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
Note that the parameter `by_epoch` is added here, which controls the frequency of learning rate adjustment. When set to True, it means adjusting by epoch. When set to False, it means adjusting by iteration. The default value is True.
|
| 79 |
+
|
| 80 |
+
In the above example, it means to adjust according to epochs. At this time, the unit of the parameters is epoch. For example, \[8, 11\] in `milestones` means that the learning rate will be multiplied by 0.1 at the end of the 8 and 11 epoch.
|
| 81 |
+
|
| 82 |
+
When the frequency is modified, the meaning of the count-related settings of the scheduler will be changed accordingly. When `by_epoch=True`, the numbers in milestones indicate at which epoch the learning rate decay is performed, and when `by_epoch=False` it indicates at which iteration the learning rate decay is performed.
|
| 83 |
+
|
| 84 |
+
Here is an example of adjusting by iterations: At the end of the 600th and 800th iterations, the learning rate will be multiplied by 0.1 times.
|
| 85 |
+
|
| 86 |
+
```python
|
| 87 |
+
param_scheduler = dict(type='MultiStepLR', by_epoch=False, milestones=[600, 800], gamma=0.1)
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
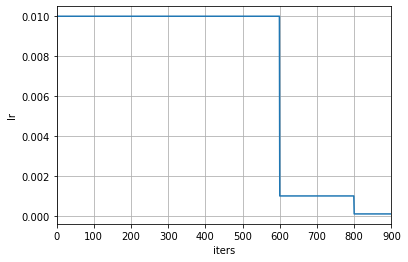
|
| 91 |
+
|
| 92 |
+
If users want to use the iteration-based frequency while filling the scheduler config settings by epoch, MMEngine's scheduler also provides an automatic conversion method. Users can call the `build_iter_from_epoch` method and provide the number of iterations for each training epoch to construct a scheduler object updated by iterations:
|
| 93 |
+
|
| 94 |
+
```python
|
| 95 |
+
epoch_length = len(train_dataloader)
|
| 96 |
+
param_scheduler = MultiStepLR.build_iter_from_epoch(optimizer, milestones=[8, 11], gamma=0.1, epoch_length=epoch_length)
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
If using config to build a scheduler, just add `convert_to_iter_based=True` to the field. The runner will automatically call `build_iter_from_epoch` to convert the epoch-based config to an iteration-based scheduler object:
|
| 100 |
+
|
| 101 |
+
```python
|
| 102 |
+
param_scheduler = dict(type='MultiStepLR', by_epoch=True, milestones=[8, 11], gamma=0.1, convert_to_iter_based=True)
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
Below is a Cosine Annealing learning rate scheduler that is updated by epoch, where the learning rate is only modified after each epoch:
|
| 106 |
+
|
| 107 |
+
```python
|
| 108 |
+
param_scheduler = dict(type='CosineAnnealingLR', by_epoch=True, T_max=12)
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
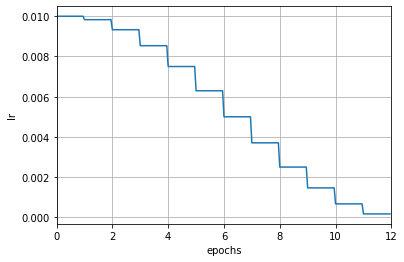
|
| 112 |
+
|
| 113 |
+
After automatically conversion, the learning rate is updated by iteration. As you can see from the graph below, the learning rate changes more smoothly.
|
| 114 |
+
|
| 115 |
+
```python
|
| 116 |
+
param_scheduler = dict(type='CosineAnnealingLR', by_epoch=True, T_max=12, convert_to_iter_based=True)
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
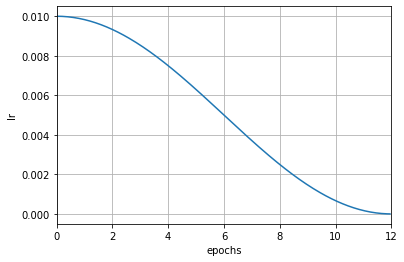
|
| 120 |
+
|
| 121 |
+
### Combine multiple LRSchedulers (e.g. learning rate warm-up)
|
| 122 |
+
|
| 123 |
+
In the training process of some algorithms, the learning rate is not adjusted according to a certain scheduling strategy from beginning to end. The most common example is learning rate warm-up.
|
| 124 |
+
|
| 125 |
+
For example, in the first few iterations, a linear strategy is used to increase the learning rate from a small value to normal, and then another strategy is applied.
|
| 126 |
+
|
| 127 |
+
MMEngine supports combining multiple schedulers together. Just modify the `param_scheduler` field in the config file to a list of scheduler config, and the ParamSchedulerHook can automatically process the scheduler list. The following example implements learning rate warm-up.
|
| 128 |
+
|
| 129 |
+
```python
|
| 130 |
+
param_scheduler = [
|
| 131 |
+
# Linear learning rate warm-up scheduler
|
| 132 |
+
dict(type='LinearLR',
|
| 133 |
+
start_factor=0.001,
|
| 134 |
+
by_epoch=False, # Updated by iterations
|
| 135 |
+
begin=0,
|
| 136 |
+
end=50), # Warm up for the first 50 iterations
|
| 137 |
+
# The main LRScheduler
|
| 138 |
+
dict(type='MultiStepLR',
|
| 139 |
+
by_epoch=True, # Updated by epochs
|
| 140 |
+
milestones=[8, 11],
|
| 141 |
+
gamma=0.1)
|
| 142 |
+
]
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
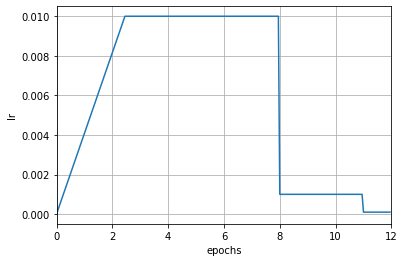
|
| 146 |
+
|
| 147 |
+
Note that the `begin` and `end` parameters are added here. These two parameters specify the **valid interval** of the scheduler. The valid interval usually only needs to be set when multiple schedulers are combined, and can be ignored when using a single scheduler. When the `begin` and `end` parameters are specified, it means that the scheduler only takes effect in the \[begin, end) interval, and the unit is determined by the `by_epoch` parameter.
|
| 148 |
+
|
| 149 |
+
In the above example, the `by_epoch` of `LinearLR` in the warm-up phase is False, which means that the scheduler only takes effect in the first 50 iterations. After more than 50 iterations, the scheduler will no longer take effect, and the second scheduler, which is `MultiStepLR`, will control the learning rate. When combining different schedulers, the `by_epoch` parameter does not have to be the same for each scheduler.
|
| 150 |
+
|
| 151 |
+
Here is another example:
|
| 152 |
+
|
| 153 |
+
```python
|
| 154 |
+
param_scheduler = [
|
| 155 |
+
# Use a linear warm-up at [0, 100) iterations
|
| 156 |
+
dict(type='LinearLR',
|
| 157 |
+
start_factor=0.001,
|
| 158 |
+
by_epoch=False,
|
| 159 |
+
begin=0,
|
| 160 |
+
end=100),
|
| 161 |
+
# Use a cosine learning rate at [100, 900) iterations
|
| 162 |
+
dict(type='CosineAnnealingLR',
|
| 163 |
+
T_max=800,
|
| 164 |
+
by_epoch=False,
|
| 165 |
+
begin=100,
|
| 166 |
+
end=900)
|
| 167 |
+
]
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
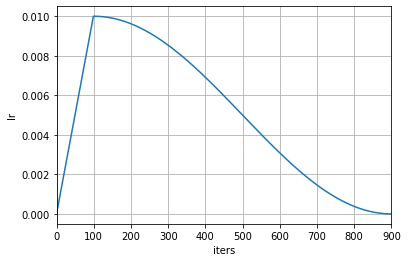
|
| 171 |
+
|
| 172 |
+
The above example uses a linear learning rate warm-up for the first 100 iterations, and then uses a cosine annealing learning rate scheduler with a period of 800 from the 100th to the 900th iteration.
|
| 173 |
+
|
| 174 |
+
Users can combine any number of schedulers. If the valid intervals of two schedulers are not connected to each other which leads to an interval that is not covered, the learning rate of this interval remains unchanged. If the valid intervals of the two schedulers overlap, the adjustment of the learning rate will be triggered in the order of the scheduler config (similar with [`ChainedScheduler`](https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.ChainedScheduler.html#chainedscheduler)).
|
| 175 |
+
|
| 176 |
+
We recommend using different learning rate scheduling strategies in different stages of training to avoid overlapping of the valid intervals. Be careful If you really need to stack two schedulers overlapped. We recommend using [learning rate visualization tool](TODO) to visualize the learning rate after stacking, to avoid the adjustment not as expected.
|
| 177 |
+
|
| 178 |
+
## How to adjust other hyperparameters
|
| 179 |
+
|
| 180 |
+
### Momentum
|
| 181 |
+
|
| 182 |
+
Like learning rate, momentum is a schedulable hyperparameter in the optimizer's parameter group. The momentum scheduler is used in exactly the same way as the learning rate scheduler. Just add the momentum scheduler config to the list in the `param_scheduler` field.
|
| 183 |
+
|
| 184 |
+
Example:
|
| 185 |
+
|
| 186 |
+
```python
|
| 187 |
+
param_scheduler = [
|
| 188 |
+
# the lr scheduler
|
| 189 |
+
dict(type='LinearLR', ...),
|
| 190 |
+
# the momentum scheduler
|
| 191 |
+
dict(type='LinearMomentum',
|
| 192 |
+
start_factor=0.001,
|
| 193 |
+
by_epoch=False,
|
| 194 |
+
begin=0,
|
| 195 |
+
end=1000)
|
| 196 |
+
]
|
| 197 |
+
```
|
| 198 |
+
|
| 199 |
+
### Generic parameter scheduler
|
| 200 |
+
|
| 201 |
+
MMEngine also provides a set of generic parameter schedulers for scheduling other hyperparameters in the `param_groups` of the optimizer. Change `LR` in the class name of the learning rate scheduler to `Param`, such as `LinearParamScheduler`. Users can schedule the specific hyperparameters by setting the `param_name` variable of the scheduler.
|
| 202 |
+
|
| 203 |
+
Here is an example:
|
| 204 |
+
|
| 205 |
+
```python
|
| 206 |
+
param_scheduler = [
|
| 207 |
+
dict(type='LinearParamScheduler',
|
| 208 |
+
param_name='lr', # adjust the 'lr' in `optimizer.param_groups`
|
| 209 |
+
start_factor=0.001,
|
| 210 |
+
by_epoch=False,
|
| 211 |
+
begin=0,
|
| 212 |
+
end=1000)
|
| 213 |
+
]
|
| 214 |
+
```
|
| 215 |
+
|
| 216 |
+
By setting the `param_name` to `'lr'`, this parameter scheduler is equivalent to `LinearLRScheduler`.
|
| 217 |
+
|
| 218 |
+
In addition to learning rate and momentum, users can also schedule other parameters in `optimizer.param_groups`. The schedulable parameters depend on the optimizer used. For example, when using the SGD optimizer with `weight_decay`, the `weight_decay` can be adjusted as follows:
|
| 219 |
+
|
| 220 |
+
```python
|
| 221 |
+
param_scheduler = [
|
| 222 |
+
dict(type='LinearParamScheduler',
|
| 223 |
+
param_name='weight_decay', # adjust 'weight_decay' in `optimizer.param_groups`
|
| 224 |
+
start_factor=0.001,
|
| 225 |
+
by_epoch=False,
|
| 226 |
+
begin=0,
|
| 227 |
+
end=1000)
|
| 228 |
+
]
|
| 229 |
+
```
|
testbed/open-mmlab__mmengine/docs/en/tutorials/runner.md
ADDED
|
@@ -0,0 +1,523 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Runner
|
| 2 |
+
|
| 3 |
+
Welcome to the tutorial of runner, the core of MMEngine's user interface!
|
| 4 |
+
|
| 5 |
+
The runner, as an "integrator" in MMEngine, covers all aspects of the framework and shoulders the responsibility of organizing and scheduling nearly all modules. Therefore, the code logic in it has to take into account various situations, making it relatively hard to understand. But **don't worry**! In this tutorial, we will leave out some messy details and have a quick overview of commonly used APIs, functionalities, and examples. Hopefully, this should provide you with a clear and easy-to-understand user interface. After reading through this tutorial, you will be able to:
|
| 6 |
+
|
| 7 |
+
- Master the common usage and configuration of the runner
|
| 8 |
+
- Learn the best practice - writing config files - of the runner
|
| 9 |
+
- Know about the basic dataflow and execution order
|
| 10 |
+
- Feel by yourself the advantages of using runner (perhaps)
|
| 11 |
+
|
| 12 |
+
## Example codes of the runner
|
| 13 |
+
|
| 14 |
+
To build your training pipeline with a runner, there are typically two ways to get started:
|
| 15 |
+
|
| 16 |
+
- Refer to runner's [API documentation](mmengine.runner.Runner) for argument-by-argument configuration
|
| 17 |
+
- Make your custom modifications based on some existing configurations, such as [Getting started in 15 minutes](../get_started/15_minutes.md) and downstream repositories like [MMDet](https://github.com/open-mmlab/mmdetection)
|
| 18 |
+
|
| 19 |
+
Pros and cons lie in both approaches. For the former one, beginners may be lost in a vast number of configurable arguments. For the latter one, beginners may find it hard to get a good reference, since neither an over-simplified nor an over-detailed reference is conducive to them.
|
| 20 |
+
|
| 21 |
+
We argue that the key to learning runner is using it as a memo. You should remember its most commonly used arguments and only focus on those less used when in need, since default values usually work fine. In the following, we will provide a beginner-friendly example to illustrate the most commonly used arguments of the runner, along with advanced guidelines for those less used.
|
| 22 |
+
|
| 23 |
+
### A beginer-friendly example
|
| 24 |
+
|
| 25 |
+
```{hint}
|
| 26 |
+
In this tutorial, we hope you can focus more on overall architecture instead of implementation details. This "top-down" way of thinking is exactly what we advocate. Don't worry, you will definitely have plenty of opportunities and guidance afterward to focus on modules you want to improve.
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
<details>
|
| 30 |
+
<summary>Before running the actual example below, you should first run this piece of code for the preparation of the model, dataset, and metric. However, these implementations are not important in this tutorial and you can simply look through</summary>
|
| 31 |
+
|
| 32 |
+
```python
|
| 33 |
+
import torch
|
| 34 |
+
import torch.nn as nn
|
| 35 |
+
import torch.nn.functional as F
|
| 36 |
+
from torch.utils.data import Dataset
|
| 37 |
+
|
| 38 |
+
from mmengine.model import BaseModel
|
| 39 |
+
from mmengine.evaluator import BaseMetric
|
| 40 |
+
from mmengine.registry import MODELS, DATASETS, METRICS
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
@MODELS.register_module()
|
| 44 |
+
class MyAwesomeModel(BaseModel):
|
| 45 |
+
def __init__(self, layers=4, activation='relu') -> None:
|
| 46 |
+
super().__init__()
|
| 47 |
+
if activation == 'relu':
|
| 48 |
+
act_type = nn.ReLU
|
| 49 |
+
elif activation == 'silu':
|
| 50 |
+
act_type = nn.SiLU
|
| 51 |
+
elif activation == 'none':
|
| 52 |
+
act_type = nn.Identity
|
| 53 |
+
else:
|
| 54 |
+
raise NotImplementedError
|
| 55 |
+
sequence = [nn.Linear(2, 64), act_type()]
|
| 56 |
+
for _ in range(layers-1):
|
| 57 |
+
sequence.extend([nn.Linear(64, 64), act_type()])
|
| 58 |
+
self.mlp = nn.Sequential(*sequence)
|
| 59 |
+
self.classifier = nn.Linear(64, 2)
|
| 60 |
+
|
| 61 |
+
def forward(self, data, labels, mode):
|
| 62 |
+
x = self.mlp(data)
|
| 63 |
+
x = self.classifier(x)
|
| 64 |
+
if mode == 'tensor':
|
| 65 |
+
return x
|
| 66 |
+
elif mode == 'predict':
|
| 67 |
+
return F.softmax(x, dim=1), labels
|
| 68 |
+
elif mode == 'loss':
|
| 69 |
+
return {'loss': F.cross_entropy(x, labels)}
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
@DATASETS.register_module()
|
| 73 |
+
class MyDataset(Dataset):
|
| 74 |
+
def __init__(self, is_train, size):
|
| 75 |
+
self.is_train = is_train
|
| 76 |
+
if self.is_train:
|
| 77 |
+
torch.manual_seed(0)
|
| 78 |
+
self.labels = torch.randint(0, 2, (size,))
|
| 79 |
+
else:
|
| 80 |
+
torch.manual_seed(3407)
|
| 81 |
+
self.labels = torch.randint(0, 2, (size,))
|
| 82 |
+
r = 3 * (self.labels+1) + torch.randn(self.labels.shape)
|
| 83 |
+
theta = torch.rand(self.labels.shape) * 2 * torch.pi
|
| 84 |
+
self.data = torch.vstack([r*torch.cos(theta), r*torch.sin(theta)]).T
|
| 85 |
+
|
| 86 |
+
def __getitem__(self, index):
|
| 87 |
+
return self.data[index], self.labels[index]
|
| 88 |
+
|
| 89 |
+
def __len__(self):
|
| 90 |
+
return len(self.data)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
@METRICS.register_module()
|
| 94 |
+
class Accuracy(BaseMetric):
|
| 95 |
+
def __init__(self):
|
| 96 |
+
super().__init__()
|
| 97 |
+
|
| 98 |
+
def process(self, data_batch, data_samples):
|
| 99 |
+
score, gt = data_samples
|
| 100 |
+
self.results.append({
|
| 101 |
+
'batch_size': len(gt),
|
| 102 |
+
'correct': (score.argmax(dim=1) == gt).sum().cpu(),
|
| 103 |
+
})
|
| 104 |
+
|
| 105 |
+
def compute_metrics(self, results):
|
| 106 |
+
total_correct = sum(r['correct'] for r in results)
|
| 107 |
+
total_size = sum(r['batch_size'] for r in results)
|
| 108 |
+
return dict(accuracy=100*total_correct/total_size)
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
</details>
|
| 112 |
+
|
| 113 |
+
<details>
|
| 114 |
+
<summary>Click to show a long example. Be well prepared</summary>
|
| 115 |
+
|
| 116 |
+
```python
|
| 117 |
+
from torch.utils.data import DataLoader, default_collate
|
| 118 |
+
from torch.optim import Adam
|
| 119 |
+
from mmengine.runner import Runner
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
runner = Runner(
|
| 123 |
+
# your model
|
| 124 |
+
model=MyAwesomeModel(
|
| 125 |
+
layers=2,
|
| 126 |
+
activation='relu'),
|
| 127 |
+
# work directory for saving checkpoints and logs
|
| 128 |
+
work_dir='exp/my_awesome_model',
|
| 129 |
+
|
| 130 |
+
# training data
|
| 131 |
+
train_dataloader=DataLoader(
|
| 132 |
+
dataset=MyDataset(
|
| 133 |
+
is_train=True,
|
| 134 |
+
size=10000),
|
| 135 |
+
shuffle=True,
|
| 136 |
+
collate_fn=default_collate,
|
| 137 |
+
batch_size=64,
|
| 138 |
+
pin_memory=True,
|
| 139 |
+
num_workers=2),
|
| 140 |
+
# training configurations
|
| 141 |
+
train_cfg=dict(
|
| 142 |
+
by_epoch=True, # display in epoch number instead of iterations
|
| 143 |
+
max_epochs=10,
|
| 144 |
+
val_begin=2, # start validation from the 2nd epoch
|
| 145 |
+
val_interval=1), # do validation every 1 epoch
|
| 146 |
+
|
| 147 |
+
# OptimizerWrapper, new concept in MMEngine for richer optimization options
|
| 148 |
+
# Default value works fine for most cases. You may check our documentations
|
| 149 |
+
# for more details, e.g. 'AmpOptimWrapper' for enabling mixed precision
|
| 150 |
+
# training.
|
| 151 |
+
optim_wrapper=dict(
|
| 152 |
+
optimizer=dict(
|
| 153 |
+
type=Adam,
|
| 154 |
+
lr=0.001)),
|
| 155 |
+
# ParamScheduler to adjust learning rates or momentums during training
|
| 156 |
+
param_scheduler=dict(
|
| 157 |
+
type='MultiStepLR',
|
| 158 |
+
by_epoch=True,
|
| 159 |
+
milestones=[4, 8],
|
| 160 |
+
gamma=0.1),
|
| 161 |
+
|
| 162 |
+
# validation data
|
| 163 |
+
val_dataloader=DataLoader(
|
| 164 |
+
dataset=MyDataset(
|
| 165 |
+
is_train=False,
|
| 166 |
+
size=1000),
|
| 167 |
+
shuffle=False,
|
| 168 |
+
collate_fn=default_collate,
|
| 169 |
+
batch_size=1000,
|
| 170 |
+
pin_memory=True,
|
| 171 |
+
num_workers=2),
|
| 172 |
+
# validation configurations, usually leave it an empty dict
|
| 173 |
+
val_cfg=dict(),
|
| 174 |
+
# evaluation metrics and evaluator
|
| 175 |
+
val_evaluator=dict(type=Accuracy),
|
| 176 |
+
|
| 177 |
+
# following are advanced configurations, try to default when not in need
|
| 178 |
+
# hooks are advanced usage, try to default when not in need
|
| 179 |
+
default_hooks=dict(
|
| 180 |
+
# the most commonly used hook for modifying checkpoint saving interval
|
| 181 |
+
checkpoint=dict(type='CheckpointHook', interval=1)),
|
| 182 |
+
|
| 183 |
+
# `luancher` and `env_cfg` responsible for distributed environment
|
| 184 |
+
launcher='none',
|
| 185 |
+
env_cfg=dict(
|
| 186 |
+
cudnn_benchmark=False, # whether enable cudnn_benchmark
|
| 187 |
+
backend='nccl', # distributed communication backend
|
| 188 |
+
mp_cfg=dict(mp_start_method='fork')), # multiprocessing configs
|
| 189 |
+
log_level='INFO',
|
| 190 |
+
|
| 191 |
+
# load model weights from given path. None for no loading.
|
| 192 |
+
load_from=None
|
| 193 |
+
# resume training from the given path
|
| 194 |
+
resume=False
|
| 195 |
+
)
|
| 196 |
+
|
| 197 |
+
# start training your model
|
| 198 |
+
runner.train()
|
| 199 |
+
```
|
| 200 |
+
|
| 201 |
+
</details>
|
| 202 |
+
|
| 203 |
+
### Explanations on example codes
|
| 204 |
+
|
| 205 |
+
Really a long piece of code, isn't it! However, if you read through the above example, you may have already understood the training process in general even without knowing any implementation details, thanks to the compactness and readability of runner codes (probably). This is what MMEngine expects: a structured, modular, and standardized training process that allows for more reliable reproductions and clearer comparisons.
|
| 206 |
+
|
| 207 |
+
The above example may lead you to the following confusion:
|
| 208 |
+
|
| 209 |
+
<details>
|
| 210 |
+
<summary>There are too many arguments!</summary>
|
| 211 |
+
|
| 212 |
+
Don't worry. As we mentioned before, **use runner as a memo**. The runner covers all aspects just to ensure you won't miss something important. You don't actually need to configure everything. The simple example in [15 minutes](../get_started/15_minutes.md) still works fine, and it can be even more simplified by removing `val_evaluator`, `val_dataloader`, and `val_cfg` without breaking down. All configurable arguments are driven by your demands. Those not in your focus usually work fine by default.
|
| 213 |
+
|
| 214 |
+
</details>
|
| 215 |
+
|
| 216 |
+
<details>
|
| 217 |
+
<summary>Why are some arguments passed as dicts?</summary>
|
| 218 |
+
|
| 219 |
+
Well, this is related to MMEngine's style. In MMEngine, we provide 2 different styles of runner construction: a) manual construction and b) construction via registry. If you are confused, the following example will give a good illustration:
|
| 220 |
+
|
| 221 |
+
```python
|
| 222 |
+
from mmengine.model import BaseModel
|
| 223 |
+
from mmengine.runner import Runner
|
| 224 |
+
from mmengine.registry import MODELS # root registry for your custom model
|
| 225 |
+
|
| 226 |
+
@MODELS.register_module() # decorator for registration
|
| 227 |
+
class MyAwesomeModel(BaseModel): # your custom model
|
| 228 |
+
def __init__(self, layers=18, activation='silu'):
|
| 229 |
+
...
|
| 230 |
+
|
| 231 |
+
# An example of manual construction
|
| 232 |
+
runner = Runner(
|
| 233 |
+
model=dict(
|
| 234 |
+
type='MyAwesomeModel',
|
| 235 |
+
layers=50,
|
| 236 |
+
activation='relu'),
|
| 237 |
+
...
|
| 238 |
+
)
|
| 239 |
+
|
| 240 |
+
# An example of construction via registry
|
| 241 |
+
model = MyAwesomeModel(layers=18, activation='relu')
|
| 242 |
+
runner = Runner(
|
| 243 |
+
model=model,
|
| 244 |
+
...
|
| 245 |
+
)
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
Similar to the above example, most arguments in the runner accept both 2 types of inputs. They are conceptually equivalent. The difference is, in the former style, the module (passed in as a `dict`) will be built **in the runner when actually needed**, while in the latter style, the module has been built before being passed to the runner. The following figure illustrates the core idea of registry: it maintains the mapping between a module's **build method** and its **registry name**. If you want to learn more about the full usage of the registry, you are recommended to read [Registry](../advanced_tutorials/registry.md) tutorial.
|
| 249 |
+
|
| 250 |
+
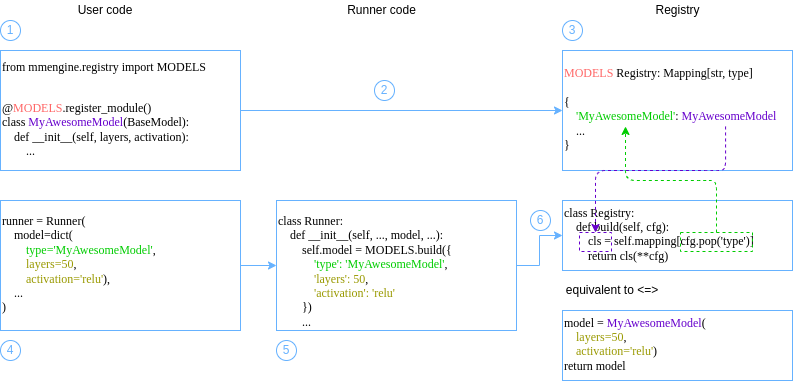
|
| 251 |
+
|
| 252 |
+
You might still be confused after the explanation. Why should we let the Runner build modules from dicts? What are the benefits? If you have such questions, then we are proud to answer: "Absolutely - no benefits!" In fact, module construction via registry only works to its best advantage when combined with a configuration file. It is still far from the best practice to write as the above example. We provide it here just to make sure you can read and get used to this writing style, which may facilitate your understanding of the actual best practice we will soon talk about - the configuration file. Stay tuned!
|
| 253 |
+
|
| 254 |
+
If you as a beginner do not immediately understand, it doesn't matter too much, because **manual construction** is still a good choice, especially for small-scale development and trial-and-error due to its being IDE friendly. However, you are still expected to read and get used to the writing style via registry, so that you can avoid being unnecessarily confused and puzzled in subsequent tutorials.
|
| 255 |
+
|
| 256 |
+
</details>
|
| 257 |
+
|
| 258 |
+
<details>
|
| 259 |
+
<summary>Where can I find the possible configuration options for the xxx argument?</summary>
|
| 260 |
+
|
| 261 |
+
You will find extensive instructions and examples in those tutorials of the corresponding modules. You can also find all possible arguments in [Runner's API documentation](mmengine.runner.Runner). If neither of the above resolves your query, you are always encouraged to start a topic in our [discussion forum](https://github.com/open-mmlab/mmengine/discussions). It also helps us improve documentations.
|
| 262 |
+
|
| 263 |
+
</details>
|
| 264 |
+
|
| 265 |
+
<details>
|
| 266 |
+
<summary>I come from repositoried like MMDet/MMCls... Why does this example differ from what I've been exposed to?</summary>
|
| 267 |
+
|
| 268 |
+
Downstream repositories in OpenMMLab have widely adopted the writing style of config files. In the following chapter, we will show the usage of config files, the best practice of the runner in MMEngine, based on the above example with a slight variation.
|
| 269 |
+
|
| 270 |
+
</details>
|
| 271 |
+
|
| 272 |
+
## Best practice of the Runner - config files
|
| 273 |
+
|
| 274 |
+
MMEngine provides a powerful config file system that supports Python syntax. You can **almost seamlessly** (which we will illustrate below) convert from the previous sample code to a config file. Here is an example:
|
| 275 |
+
|
| 276 |
+
```python
|
| 277 |
+
# Save the following codes in example_config.py
|
| 278 |
+
# Almost copied from the above example, with some commas removed
|
| 279 |
+
model = dict(type='MyAwesomeModel',
|
| 280 |
+
layers=2,
|
| 281 |
+
activation='relu')
|
| 282 |
+
work_dir = 'exp/my_awesome_model'
|
| 283 |
+
|
| 284 |
+
train_dataloader = dict(
|
| 285 |
+
dataset=dict(type='MyDataset',
|
| 286 |
+
is_train=True,
|
| 287 |
+
size=10000),
|
| 288 |
+
sampler=dict(
|
| 289 |
+
type='DefaultSampler',
|
| 290 |
+
shuffle=True),
|
| 291 |
+
collate_fn=dict(type='default_collate'),
|
| 292 |
+
batch_size=64,
|
| 293 |
+
pin_memory=True,
|
| 294 |
+
num_workers=2)
|
| 295 |
+
train_cfg = dict(
|
| 296 |
+
by_epoch=True,
|
| 297 |
+
max_epochs=10,
|
| 298 |
+
val_begin=2,
|
| 299 |
+
val_interval=1)
|
| 300 |
+
optim_wrapper = dict(
|
| 301 |
+
optimizer=dict(
|
| 302 |
+
type='Adam',
|
| 303 |
+
lr=0.001))
|
| 304 |
+
param_scheduler = dict(
|
| 305 |
+
type='MultiStepLR',
|
| 306 |
+
by_epoch=True,
|
| 307 |
+
milestones=[4, 8],
|
| 308 |
+
gamma=0.1)
|
| 309 |
+
|
| 310 |
+
val_dataloader = dict(
|
| 311 |
+
dataset=dict(type='MyDataset',
|
| 312 |
+
is_train=False,
|
| 313 |
+
size=1000),
|
| 314 |
+
sampler=dict(
|
| 315 |
+
type='DefaultSampler',
|
| 316 |
+
shuffle=False),
|
| 317 |
+
collate_fn=dict(type='default_collate'),
|
| 318 |
+
batch_size=1000,
|
| 319 |
+
pin_memory=True,
|
| 320 |
+
num_workers=2)
|
| 321 |
+
val_cfg = dict()
|
| 322 |
+
val_evaluator = dict(type='Accuracy')
|
| 323 |
+
|
| 324 |
+
default_hooks = dict(
|
| 325 |
+
checkpoint=dict(type='CheckpointHook', interval=1))
|
| 326 |
+
launcher = 'none'
|
| 327 |
+
env_cfg = dict(
|
| 328 |
+
cudnn_benchmark=False,
|
| 329 |
+
backend='nccl',
|
| 330 |
+
mp_cfg=dict(mp_start_method='fork'))
|
| 331 |
+
log_level = 'INFO'
|
| 332 |
+
load_from = None
|
| 333 |
+
resume = False
|
| 334 |
+
```
|
| 335 |
+
|
| 336 |
+
Given the above config file, we can simply load configurations and run the training pipeline in a few lines of codes as follows:
|
| 337 |
+
|
| 338 |
+
```python
|
| 339 |
+
from mmengine.config import Config
|
| 340 |
+
from mmengine.runner import Runner
|
| 341 |
+
config = Config.fromfile('example_config.py')
|
| 342 |
+
runner = Runner.from_cfg(config)
|
| 343 |
+
runner.train()
|
| 344 |
+
```
|
| 345 |
+
|
| 346 |
+
```{note}
|
| 347 |
+
Although it supports Python syntax, a valid config file needs to meet the condition that all variables must be Python built-in types such as `str`, `dict` and `int`. Therefore, the config system is highly dependent on the registry mechanism to enable construction from built-in types to other types such as `nn.Module`.
|
| 348 |
+
```
|
| 349 |
+
|
| 350 |
+
```{note}
|
| 351 |
+
When using config files, you typically don't need to manually register every module. For instance, all optimizers in `torch.optim` including `Adam` and `SGD` have already been registered in `mmengine.optim`. The rule of thumb is, try to directly access modules provided by PyTorch, and only start to register them manually after error occurs.
|
| 352 |
+
```
|
| 353 |
+
|
| 354 |
+
```{note}
|
| 355 |
+
When using config files, the implementations of your custom modules may be stored in separate files and thus not registered properly, which will lead to errors in the build process. You may find solutions in [Registry tutorial](./registry.md) by searching for `custom_imports`.
|
| 356 |
+
```
|
| 357 |
+
|
| 358 |
+
```{warnings}
|
| 359 |
+
Although sharing nearly the same codes, `from_cfg` and `__init__` differs in some default values like `env_cfg`.
|
| 360 |
+
```
|
| 361 |
+
|
| 362 |
+
Writing config files of the runner has been widely adopted in downstream repositories in OpenMMLab projects. It has been a de facto convention and best practice. The config files are far more featured than illustrated above. You can refer to [Config tutorial](../advanced_tutorials/config.md) for more advanced features including keywords inheriting and overriding.
|
| 363 |
+
|
| 364 |
+
## Basic dataflow
|
| 365 |
+
|
| 366 |
+
```{hint}
|
| 367 |
+
In this chapter, we'll dive deeper into the runner to illustrate dataflow and data format convention between modules managed by the runner. It may be relatively abstract and dry if you haven't built a training pipeline with MMEngine. Therefore, you are free to skip for now and read it in conjunction with practice in the future when in need.
|
| 368 |
+
```
|
| 369 |
+
|
| 370 |
+
Now let's dive **slightly deeper** into the runner, and illustrate the dataflow and data format convention under the hood (or, under the engine)!
|
| 371 |
+
|
| 372 |
+
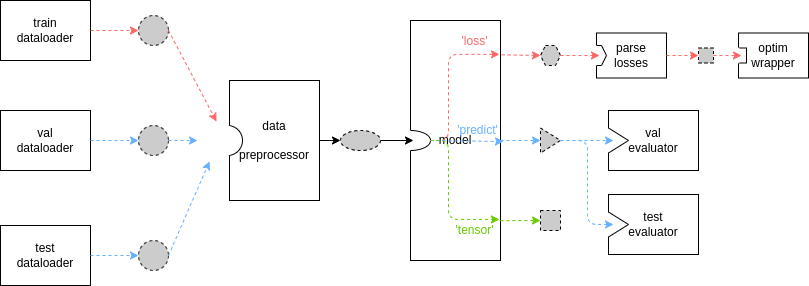
|
| 373 |
+
|
| 374 |
+
The diagram above illustrates the **basic** dataflow of the runner, where the dashed border, gray filled shapes represent different data formats, while solid boxes represent modules/methods. Due to the great flexibility and extensibility of MMEngine, you can always inherit some key base classes and override their methods, so the above diagram doesn't always hold. It only holds when you are not customizing your own `Runner` or `TrainLoop`, and you are not overriding `train_step`, `val_step` or `test_step` method in your custom model. Actually, this is common for most tasks like detection and segmentation, as referred to [Model tutorial](./model.md).
|
| 375 |
+
|
| 376 |
+
<details>
|
| 377 |
+
<summary>Can you state the exact type of each data item shown in the diagram?</summary>
|
| 378 |
+
|
| 379 |
+
Unfortunately, this is not possible. Although we did heavy type annotations in MMEngine, Python is still a highly dynamic programming language, and deep learning as a data-centric system needs to be flexible enough to deal with a wide range of complex data sources. You always have full freedom to decide when you need (and sometimes must) break type conventions. Therefore, when you are customizing your module (e.g. `val_evaluator`), you need to make sure its input is compatible with upstream (e.g. `model`) output and its output can be parsed by downstream. MMEngine puts the flexibility of handling data in the hands of the user, and thus also requires the user to ensure compatibility of dataflow, which, in fact, is not that difficult once you get started.
|
| 380 |
+
|
| 381 |
+
The uniformity of data formats has always been a problem in deep learning. We are trying to improve it in MMEngine in our own way. If you are interested, you can refer to [BaseDataset](../advanced_tutorials/basedataset.md) and [BaseDataElement](../advanced_tutorials/data_element.md) - but please note that they are mainly geared towards advanced users.
|
| 382 |
+
|
| 383 |
+
</details>
|
| 384 |
+
|
| 385 |
+
<details>
|
| 386 |
+
<summary>What's the data format convention between dataloader, model and evaluator?</summary>
|
| 387 |
+
|
| 388 |
+
For the basic dataflow shown in the diagram above, the data transfer between the above three modules can be represented by the following pseudo-code:
|
| 389 |
+
|
| 390 |
+
```python
|
| 391 |
+
# training
|
| 392 |
+
for data_batch in train_dataloader:
|
| 393 |
+
data_batch = data_preprocessor(data_batch)
|
| 394 |
+
if isinstance(data_batch, dict):
|
| 395 |
+
losses = model.forward(**data_batch, mode='loss')
|
| 396 |
+
elif isinstance(data_batch, (list, tuple)):
|
| 397 |
+
losses = model.forward(*data_batch, mode='loss')
|
| 398 |
+
else:
|
| 399 |
+
raise TypeError()
|
| 400 |
+
|
| 401 |
+
# validation
|
| 402 |
+
for data_batch in val_dataloader:
|
| 403 |
+
data_batch = data_preprocessor(data_batch)
|
| 404 |
+
if isinstance(data_batch, dict):
|
| 405 |
+
outputs = model.forward(**data_batch, mode='predict')
|
| 406 |
+
elif isinstance(data_batch, (list, tuple)):
|
| 407 |
+
outputs = model.forward(**data_batch, mode='predict')
|
| 408 |
+
else:
|
| 409 |
+
raise TypeError()
|
| 410 |
+
evaluator.process(data_samples=outputs, data_batch=data_batch)
|
| 411 |
+
metrics = evaluator.evaluate(len(val_dataloader.dataset))
|
| 412 |
+
```
|
| 413 |
+
|
| 414 |
+
The key points of the above pseudo-code is:
|
| 415 |
+
|
| 416 |
+
- Outputs of data_preprocessor are passed to model **after unpacking**
|
| 417 |
+
- The `data_samples` argument of the evaluator receives the prediction results of the model, while the `data_batch` argument receives the raw data coming from dataloader
|
| 418 |
+
|
| 419 |
+
</details>
|
| 420 |
+
|
| 421 |
+
<details>
|
| 422 |
+
<summary>What is data_preprocessor? Can I do image pre-processing such as crop and resize in it?</summary>
|
| 423 |
+
|
| 424 |
+
Though drawn separately in the diagram, data_preprocessor is a part of the model and thus can be found in [Model tutorial](./model.md) in DataPreprocessor chapter.
|
| 425 |
+
|
| 426 |
+
In most cases, data_preprocessor needs no special attention or manual configuration. The default data_preprocessor will only do data transfer between host and GPU devices. However, if your model has incompatible inputs format with dataloader's output, you can also customize you own data_preprocessor for data formatting.
|
| 427 |
+
|
| 428 |
+
Image pre-processing such as crop and resize is more recommended in [data transforms module](../advanced_tutorials/data_transform.md), but for batch-related data transforms (e.g. batch-resize), it can be implemented here.
|
| 429 |
+
|
| 430 |
+
</details>
|
| 431 |
+
|
| 432 |
+
<details>
|
| 433 |
+
<summary>Why does module produce 3 different outputs? What is the meaning of "loss", "predict" and "tensor"?</summary>
|
| 434 |
+
|
| 435 |
+
As described in [get started in 15 minutes](../get_started/15_minutes.md), you need to implement 3 data paths in your custom model's `forward` function to suit different pipelines for training, validation and testing. This is further discussed in [Model tutorial](./model.md).
|
| 436 |
+
|
| 437 |
+
</details>
|
| 438 |
+
|
| 439 |
+
<details>
|
| 440 |
+
<summary>I can see that the red line is for training process and the blue line for validation/testing, but what is the green line?</summary>
|
| 441 |
+
|
| 442 |
+
Currently model outputs in "tensor" mode has not been officially used in runner. The "tensor" mode can output some intermediate results and thus facilitating debugging process.
|
| 443 |
+
|
| 444 |
+
</details>
|
| 445 |
+
|
| 446 |
+
<details>
|
| 447 |
+
<summary>What if I override methods such as train_step? Will the diagram totally fail?</summary>
|
| 448 |
+
|
| 449 |
+
The behavior of default `train_step`, `val_step` and `test_step` covers the dataflow from data_preprocessor to model outputs and optim_wrapper. The rest of the diagram will not be spoiled.
|
| 450 |
+
|
| 451 |
+
</details>
|
| 452 |
+
|
| 453 |
+
## Why use the runner? (Optional reading)
|
| 454 |
+
|
| 455 |
+
```{hint}
|
| 456 |
+
Contents in this chapter will not teach you how to use the runner and MMEngine. If you are being pushed by your employer/advisor/DDL to work out a result in a few hours, it may not help you and you can feel free to skip it. However, we highly recommend taking time to read through this chapter, since it will help you better understand the aim and style of MMEngine.
|
| 457 |
+
```
|
| 458 |
+
|
| 459 |
+
<details>
|
| 460 |
+
<summary>Relax, time for some philosophy</summary>
|
| 461 |
+
|
| 462 |
+
Congratulations for reading through the runner tutorial, a long, long but kind of interesting (hope so) tutorial! Please believe that all of these - this tutorial, the runner, MMEngine - are intended to **make things easier for you**.
|
| 463 |
+
|
| 464 |
+
The runner is the "manager" of all modules in MMEngine. In the runner, all the distinct modules - whether visible ones like model and dataset, or obscure ones like logging, distributed environment and random seed - are getting organized and scheduled. The runner deals with the complex relationship between different modules and provides you with a clear, easy-to-understand and configurable interface. The benefits of this design are:
|
| 465 |
+
|
| 466 |
+
1. You can modify or add your codes without spoiling your whole codebase. For example, you may start with single GPU training and you can always add a few lines of configuration codes to enable multi GPUs or even multi nodes training.
|
| 467 |
+
2. You can continuously benefit from new features without worrying about backward compatibility. Mixed precision training, visualization, state of the art distributed training methods, various device backends... We will continue to absorb the best suggestions and cutting-edge technologies from the community while ensuring backward compatibility, and provide them to you in a clear interface.
|
| 468 |
+
3. You can focus on your own awesome ideas without being bothered by other annoying and irrelevant details. The default values will handle most cases.
|
| 469 |
+
|
| 470 |
+
So, MMEngine and the runner will truly make things easier for you. With only a little effort on migration, your code and experiments will evolve with MMEngine. With a little more effort, the config file system allows you to manage your data, model, and experiments more efficiently. Convenience and reliability are the aims we strive for.
|
| 471 |
+
|
| 472 |
+
The blue one, or the red one - are you prepared to use MMEngine?
|
| 473 |
+
|
| 474 |
+
</details>
|
| 475 |
+
|
| 476 |
+
## Suggestions on next steps
|
| 477 |
+
|
| 478 |
+
If you want to:
|
| 479 |
+
|
| 480 |
+
<details>
|
| 481 |
+
<summary>Write your own model structure</summary>
|
| 482 |
+
|
| 483 |
+
Refer to [Model tutorial](./model.md)
|
| 484 |
+
|
| 485 |
+
</details>
|
| 486 |
+
|
| 487 |
+
<details>
|
| 488 |
+
<summary>Use your own datasets</summary>
|
| 489 |
+
|
| 490 |
+
Refer to [Dataset and DataLoader tutorial](./dataset.md)
|
| 491 |
+
|
| 492 |
+
</details>
|
| 493 |
+
|
| 494 |
+
<details>
|
| 495 |
+
<summary>Change evaluation metrics</summary>
|
| 496 |
+
|
| 497 |
+
Refer to [Evaluation tutorial](./evaluation.md)
|
| 498 |
+
|
| 499 |
+
</details>
|
| 500 |
+
|
| 501 |
+
<details>
|
| 502 |
+
<summary>Do something related to optimizers or mixed-precision training</summary>
|
| 503 |
+
|
| 504 |
+
Refer to [OptimWrapper tutorial](./optim_wrapper.md)
|
| 505 |
+
|
| 506 |
+
</details>
|
| 507 |
+
|
| 508 |
+
<details>
|
| 509 |
+
<summary>Schedule learning rates or other parameters during training</summary>
|
| 510 |
+
|
| 511 |
+
Refer to [Parameter Scheduler tutorial](./param_scheduler.md)
|
| 512 |
+
|
| 513 |
+
</details>
|
| 514 |
+
|
| 515 |
+
<details>
|
| 516 |
+
<summary>Something not mentioned above</summary>
|
| 517 |
+
|
| 518 |
+
- "Common Usage" section to the left contains more example codes
|
| 519 |
+
- "Advanced tutorials" to the left consists of more contents for experienced developers to make more flexible extensions to the training pipeline
|
| 520 |
+
- [Hook](./hook.md) provides some flexible modifications without spoiling your codes
|
| 521 |
+
- If none of the above solves your problem, you are always welcome to start a topic in our [discussion forum](https://github.com/open-mmlab/mmengine/discussions)!
|
| 522 |
+
|
| 523 |
+
</details>
|
testbed/open-mmlab__mmengine/docs/resources/config/cross_repo.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = [
|
| 2 |
+
'mmdet::_base_/schedules/schedule_1x.py',
|
| 3 |
+
'mmdet::_base_/datasets/coco_instance.py',
|
| 4 |
+
'mmdet::_base_/default_runtime.py',
|
| 5 |
+
'mmdet::_base_/models/faster-rcnn_r50_fpn.py',
|
| 6 |
+
]
|
testbed/open-mmlab__mmengine/docs/resources/config/custom_imports.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
custom_imports = dict(imports=['my_module'], allow_failed_imports=False)
|
| 2 |
+
optimizer = dict(type='CustomOptim')
|
testbed/open-mmlab__mmengine/docs/resources/config/demo_train.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
|
| 3 |
+
from mmengine.config import Config, DictAction
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def parse_args():
|
| 7 |
+
parser = argparse.ArgumentParser(description='Train a model')
|
| 8 |
+
parser.add_argument('config', help='train config file path')
|
| 9 |
+
parser.add_argument(
|
| 10 |
+
'--cfg-options',
|
| 11 |
+
nargs='+',
|
| 12 |
+
action=DictAction,
|
| 13 |
+
help='override some settings in the used config, the key-value pair '
|
| 14 |
+
'in xxx=yyy format will be merged into config file. If the value to '
|
| 15 |
+
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
|
| 16 |
+
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
|
| 17 |
+
'Note that the quotation marks are necessary and that no white space '
|
| 18 |
+
'is allowed.')
|
| 19 |
+
|
| 20 |
+
args = parser.parse_args()
|
| 21 |
+
return args
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def main():
|
| 25 |
+
args = parse_args()
|
| 26 |
+
cfg = Config.fromfile(args.config)
|
| 27 |
+
if args.cfg_options is not None:
|
| 28 |
+
cfg.merge_from_dict(args.cfg_options)
|
| 29 |
+
print(cfg)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
if __name__ == '__main__':
|
| 33 |
+
main()
|
testbed/open-mmlab__mmengine/docs/resources/config/example.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model = dict(type='CustomModel', in_channels=[1, 2, 3])
|
| 2 |
+
optimizer = dict(type='SGD', lr=0.01)
|
testbed/open-mmlab__mmengine/docs/resources/config/learn_read_config.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
test_int = 1
|
| 2 |
+
test_list = [1, 2, 3]
|
| 3 |
+
test_dict = dict(key1='value1', key2=0.1)
|
testbed/open-mmlab__mmengine/docs/resources/config/my_module.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.registry import OPTIMIZERS
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
@OPTIMIZERS.register_module()
|
| 5 |
+
class CustomOptim:
|
| 6 |
+
pass
|
testbed/open-mmlab__mmengine/docs/resources/config/optimizer_cfg.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
|
testbed/open-mmlab__mmengine/docs/resources/config/predefined_var.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
work_dir = './work_dir/{{fileBasenameNoExtension}}'
|
testbed/open-mmlab__mmengine/docs/resources/config/refer_base_var.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ['resnet50.py']
|
| 2 |
+
a = {{_base_.model}}
|
testbed/open-mmlab__mmengine/docs/resources/config/resnet50.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ['optimizer_cfg.py']
|
| 2 |
+
model = dict(type='ResNet', depth=50)
|
testbed/open-mmlab__mmengine/docs/resources/config/resnet50_delete_key.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
|
| 2 |
+
model = dict(type='ResNet', depth=50)
|
| 3 |
+
optimizer = dict(_delete_=True, type='SGD', lr=0.01)
|
testbed/open-mmlab__mmengine/docs/resources/config/resnet50_lr0.01.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
|
| 2 |
+
model = dict(type='ResNet', depth=50)
|
| 3 |
+
optimizer = dict(lr=0.01)
|
testbed/open-mmlab__mmengine/docs/resources/config/resnet50_runtime.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
|
| 2 |
+
model = dict(type='ResNet', depth=50)
|
testbed/open-mmlab__mmengine/docs/resources/config/runtime_cfg.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
gpu_ids = [0, 1]
|
testbed/open-mmlab__mmengine/docs/zh_cn/Makefile
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Minimal makefile for Sphinx documentation
|
| 2 |
+
#
|
| 3 |
+
|
| 4 |
+
# You can set these variables from the command line, and also
|
| 5 |
+
# from the environment for the first two.
|
| 6 |
+
SPHINXOPTS ?=
|
| 7 |
+
SPHINXBUILD ?= sphinx-build
|
| 8 |
+
SOURCEDIR = .
|
| 9 |
+
BUILDDIR = _build
|
| 10 |
+
|
| 11 |
+
# Put it first so that "make" without argument is like "make help".
|
| 12 |
+
help:
|
| 13 |
+
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
| 14 |
+
|
| 15 |
+
.PHONY: help Makefile
|
| 16 |
+
|
| 17 |
+
# Catch-all target: route all unknown targets to Sphinx using the new
|
| 18 |
+
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
| 19 |
+
%: Makefile
|
| 20 |
+
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
testbed/open-mmlab__mmengine/docs/zh_cn/_static/css/readthedocs.css
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
table.colwidths-auto td {
|
| 2 |
+
width: 50%
|
| 3 |
+
}
|
| 4 |
+
|
| 5 |
+
.header-logo {
|
| 6 |
+
background-image: url("../image/mmengine-logo.png");
|
| 7 |
+
background-size: 130px 40px;
|
| 8 |
+
height: 40px;
|
| 9 |
+
width: 130px;
|
| 10 |
+
}
|
| 11 |
+
|
| 12 |
+
.two-column-table-wrapper {
|
| 13 |
+
width: 50%;
|
| 14 |
+
max-width: 300px;
|
| 15 |
+
overflow-x: auto;
|
| 16 |
+
}
|
| 17 |
+
|
| 18 |
+
.two-column-table-wrapper .highlight {
|
| 19 |
+
width: 1500px
|
| 20 |
+
}
|
testbed/open-mmlab__mmengine/docs/zh_cn/_templates/classtemplate.rst
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. role:: hidden
|
| 2 |
+
:class: hidden-section
|
| 3 |
+
.. currentmodule:: {{ module }}
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
{{ name | underline}}
|
| 7 |
+
|
| 8 |
+
.. autoclass:: {{ name }}
|
| 9 |
+
:members:
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
..
|
| 13 |
+
autogenerated from source/_templates/classtemplate.rst
|
| 14 |
+
note it does not have :inherited-members:
|
testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/basedataset.md
ADDED
|
@@ -0,0 +1,505 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 数据集基类(BaseDataset)
|
| 2 |
+
|
| 3 |
+
## 基本介绍
|
| 4 |
+
|
| 5 |
+
算法库中的数据集类负责在训练/测试过程中为模型提供输入数据,OpenMMLab 下各个算法库中的数据集有一些共同的特点和需求,比如需要高效的内部数据存储格式,需要支持数据集拼接、数据集重复采样等功能。
|
| 6 |
+
|
| 7 |
+
因此 **MMEngine** 实现了一个数据集基类(BaseDataset)并定义了一些基本接口,且基于这套接口实现了一些数据集包装(DatasetWrapper)。OpenMMLab 算法库中的大部分数据集都会满足这套数据集基类定义的接口,并使用统一的数据集包装。
|
| 8 |
+
|
| 9 |
+
数据集基类的基本功能是加载数据集信息,这里我们将数据集信息分成两类,一种是元信息 (meta information),代表数据集自身相关的信息,有时需要被模型或其他外部组件获取,比如在图像分类任务中,数据集的元信息一般包含类别信息 `classes`,因为分类模型 `model` 一般需要记录数据集的类别信息;另一种为数据信息 (data information),在数据信息中,定义了具体样本的文件路径、对应标签等的信息。除此之外,数据集基类的另一个功能为不断地将数据送入数据流水线(data pipeline)中,进行数据预处理。
|
| 10 |
+
|
| 11 |
+
### 数据标注文件规范
|
| 12 |
+
|
| 13 |
+
为了统一不同任务的数据集接口,便于多任务的算法模型训练,OpenMMLab 制定了 **OpenMMLab 2.0 数据集格式规范**, 数据集标注文件需符合该规范,数据集基类基于该规范去读取与解析数据标注文件。如果用户提供的数据标注文件不符合规定格式,用户可以选择将其转化为规定格式,并使用 OpenMMLab 的算法库基于该数据标注文件进行算法训练和测试。
|
| 14 |
+
|
| 15 |
+
OpenMMLab 2.0 数据集格式规范规定,标注文件必须为 `json` 或 `yaml`,`yml` 或 `pickle`,`pkl` 格式;标注文件中存储的字典必须包含 `metainfo` 和 `data_list` 两个字段。其中 `metainfo` 是一个字典,里面包含数据集的元信息;`data_list` 是一个列表,列表中每个元素是一个字典,该字典定义了一个原始数据(raw data),每个原始数据包含一个或若干个训练/测试样本。
|
| 16 |
+
|
| 17 |
+
以下是一个 JSON 标注文件的例子(该例子中每个原始数据只包含一个训练/测试样本):
|
| 18 |
+
|
| 19 |
+
```json
|
| 20 |
+
|
| 21 |
+
{
|
| 22 |
+
'metainfo':
|
| 23 |
+
{
|
| 24 |
+
'classes': ('cat', 'dog'),
|
| 25 |
+
...
|
| 26 |
+
},
|
| 27 |
+
'data_list':
|
| 28 |
+
[
|
| 29 |
+
{
|
| 30 |
+
'img_path': "xxx/xxx_0.jpg",
|
| 31 |
+
'img_label': 0,
|
| 32 |
+
...
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
'img_path': "xxx/xxx_1.jpg",
|
| 36 |
+
'img_label': 1,
|
| 37 |
+
...
|
| 38 |
+
},
|
| 39 |
+
...
|
| 40 |
+
]
|
| 41 |
+
}
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
同时假设数据存放路径如下:
|
| 45 |
+
|
| 46 |
+
```text
|
| 47 |
+
data
|
| 48 |
+
├── annotations
|
| 49 |
+
│ ├── train.json
|
| 50 |
+
├── train
|
| 51 |
+
│ ├── xxx/xxx_0.jpg
|
| 52 |
+
│ ├── xxx/xxx_1.jpg
|
| 53 |
+
│ ├── ...
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
### 数据集基类的初始化流程
|
| 57 |
+
|
| 58 |
+
数据集基类的初始化流程如下图所示:
|
| 59 |
+
|
| 60 |
+
<div align="center">
|
| 61 |
+
<img src="https://user-images.githubusercontent.com/26813582/201585974-1360e2b5-f95f-4273-8cbf-6024e33204ab.png" height="500"/>
|
| 62 |
+
</div>
|
| 63 |
+
|
| 64 |
+
1. `load metainfo`:获取数据集的元信息,元信息有三种来源,优先级从高到低为:
|
| 65 |
+
|
| 66 |
+
- `__init__()` 方法中用户传入的 `metainfo` 字典;改动频率最高,因为用户可以在实例化数据集时,传入该参数;
|
| 67 |
+
|
| 68 |
+
- 类属性 `BaseDataset.METAINFO` 字典;改动频率中等,因为用户可以改动自定义数据集类中的类属性 `BaseDataset.METAINFO`;
|
| 69 |
+
|
| 70 |
+
- 标注文件中包含的 `metainfo` 字典;改动频率最低,因为标注文件一般不做改动。
|
| 71 |
+
|
| 72 |
+
如果三种来源中有相同的字段,优先级最高的来源决定该字段的值,这些字段的优先级比较是:用户传入的 `metainfo` 字典里的字段 > `BaseDataset.METAINFO` 字典里的字段 > 标注文件中 `metainfo` 字典里的字段。
|
| 73 |
+
|
| 74 |
+
2. `join path`:处理数据与标注文件的路径;
|
| 75 |
+
|
| 76 |
+
3. `build pipeline`:构建数据流水线(data pipeline),用于数据预处理与数据准备;
|
| 77 |
+
|
| 78 |
+
4. `full init`:完全初始化数据集类,该步骤主要包含以下操作:
|
| 79 |
+
|
| 80 |
+
- `load data list`:读取与解析满足 OpenMMLab 2.0 数据集格式规范的标注文件,该步骤中会调用 `parse_data_info()` 方法,该方法负责解析标注文件里的每个原始数据;
|
| 81 |
+
|
| 82 |
+
- `filter data` (可选):根据 `filter_cfg` 过滤无用数据,比如不包含标注的样本等;默认不做过滤操作,下游子类可以按自身所需对其进行重写;
|
| 83 |
+
|
| 84 |
+
- `get subset` (可选):根据给定的索引或整数值采样数据,比如只取前 10 个样本参与训练/测试;默认不采样数据,即使用全部数据样本;
|
| 85 |
+
|
| 86 |
+
- `serialize data` (可选):序列化全部样本,以达到节省内存的效果,详情请参考[节省内存](#节省内存);默认操作为序列���全部样本。
|
| 87 |
+
|
| 88 |
+
数据集基类中包含的 `parse_data_info()` 方法用于将标注文件里的一个原始数据处理成一个或若干个训练/测试样本的方法。因此对于自定义数据集类,用户需要实现 `parse_data_info()` 方法。
|
| 89 |
+
|
| 90 |
+
### 数据集基类提供的接口
|
| 91 |
+
|
| 92 |
+
与 `torch.utils.data.Dataset` 类似,数据集初始化后,支持 `__getitem__` 方法,用来索引数据,以及 `__len__` 操作获取数据集大小,除此之外,OpenMMLab 的数据集基类主要提供了以下接口来访问具体信息:
|
| 93 |
+
|
| 94 |
+
- `metainfo`:返回元信息,返回值为字典
|
| 95 |
+
|
| 96 |
+
- `get_data_info(idx)`:返回指定 `idx` 的样本全量信息,返回值为字典
|
| 97 |
+
|
| 98 |
+
- `__getitem__(idx)`:返回指定 `idx` 的样本经过 pipeline 之后的结果(也就是送入模型的数据),返回值为字典
|
| 99 |
+
|
| 100 |
+
- `__len__()`:返回数据集长度,返回值为整数型
|
| 101 |
+
|
| 102 |
+
- `get_subset_(indices)`:根据 `indices` 以 inplace 的方式**修改原数据集类**。如果 `indices` 为 `int`,则原数据集类只包含前若干个数据样本;如果 `indices` 为 `Sequence[int]`,则原数据集类包含根据 `Sequence[int]` 指定的数据样本。
|
| 103 |
+
|
| 104 |
+
- `get_subset(indices)`:根据 `indices` 以**非** inplace 的方式**返回子数据集类**,即重新复制一份子数据集。如果 `indices` 为 `int`,则返回的子数据集类只包含前若干个数据样本;如果 `indices` 为 `Sequence[int]`,则返回的子数据集类包含根据 `Sequence[int]` 指定的数据样本。
|
| 105 |
+
|
| 106 |
+
## 使用数据集基类自定义数据集类
|
| 107 |
+
|
| 108 |
+
在了解了数据集基类的初始化流程与提供的接口之后,就可以基于数据集基类自定义数据集类。
|
| 109 |
+
|
| 110 |
+
### 对于满足 OpenMMLab 2.0 数据集格式规范的标注文件
|
| 111 |
+
|
| 112 |
+
如上所述,对于满足 OpenMMLab 2.0 数据集格式规范的标注文件,用户可以重载 `parse_data_info()` 来加载标签。以下是一个使用数据集基类来实现某一具体数据集的例子。
|
| 113 |
+
|
| 114 |
+
```python
|
| 115 |
+
import os.path as osp
|
| 116 |
+
|
| 117 |
+
from mmengine.dataset import BaseDataset
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
class ToyDataset(BaseDataset):
|
| 121 |
+
|
| 122 |
+
# 以上面标注文件为例,在这里 raw_data_info 代表 `data_list` 对应列表里的某个字典:
|
| 123 |
+
# {
|
| 124 |
+
# 'img_path': "xxx/xxx_0.jpg",
|
| 125 |
+
# 'img_label': 0,
|
| 126 |
+
# ...
|
| 127 |
+
# }
|
| 128 |
+
def parse_data_info(self, raw_data_info):
|
| 129 |
+
data_info = raw_data_info
|
| 130 |
+
img_prefix = self.data_prefix.get('img_path', None)
|
| 131 |
+
if img_prefix is not None:
|
| 132 |
+
data_info['img_path'] = osp.join(
|
| 133 |
+
img_prefix, data_info['img_path'])
|
| 134 |
+
return data_info
|
| 135 |
+
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
#### 使用自定义数据集类
|
| 139 |
+
|
| 140 |
+
在定义了数据集类后,就可以通过如下配置实例化 `ToyDataset`:
|
| 141 |
+
|
| 142 |
+
```python
|
| 143 |
+
|
| 144 |
+
class LoadImage:
|
| 145 |
+
|
| 146 |
+
def __call__(self, results):
|
| 147 |
+
results['img'] = cv2.imread(results['img_path'])
|
| 148 |
+
return results
|
| 149 |
+
|
| 150 |
+
class ParseImage:
|
| 151 |
+
|
| 152 |
+
def __call__(self, results):
|
| 153 |
+
results['img_shape'] = results['img'].shape
|
| 154 |
+
return results
|
| 155 |
+
|
| 156 |
+
pipeline = [
|
| 157 |
+
LoadImage(),
|
| 158 |
+
ParseImage(),
|
| 159 |
+
]
|
| 160 |
+
|
| 161 |
+
toy_dataset = ToyDataset(
|
| 162 |
+
data_root='data/',
|
| 163 |
+
data_prefix=dict(img_path='train/'),
|
| 164 |
+
ann_file='annotations/train.json',
|
| 165 |
+
pipeline=pipeline)
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
同时可以使用数据集类提供的对外接口访问具体的样本信息:
|
| 169 |
+
|
| 170 |
+
```python
|
| 171 |
+
toy_dataset.metainfo
|
| 172 |
+
# dict(classes=('cat', 'dog'))
|
| 173 |
+
|
| 174 |
+
toy_dataset.get_data_info(0)
|
| 175 |
+
# {
|
| 176 |
+
# 'img_path': "data/train/xxx/xxx_0.jpg",
|
| 177 |
+
# 'img_label': 0,
|
| 178 |
+
# ...
|
| 179 |
+
# }
|
| 180 |
+
|
| 181 |
+
len(toy_dataset)
|
| 182 |
+
# 2
|
| 183 |
+
|
| 184 |
+
toy_dataset[0]
|
| 185 |
+
# {
|
| 186 |
+
# 'img_path': "data/train/xxx/xxx_0.jpg",
|
| 187 |
+
# 'img_label': 0,
|
| 188 |
+
# 'img': a ndarray with shape (H, W, 3), which denotes the value of the image,
|
| 189 |
+
# 'img_shape': (H, W, 3) ,
|
| 190 |
+
# ...
|
| 191 |
+
# }
|
| 192 |
+
|
| 193 |
+
# `get_subset` 接口不对原数据集类做修改,即完全复制一份新的
|
| 194 |
+
sub_toy_dataset = toy_dataset.get_subset(1)
|
| 195 |
+
len(toy_dataset), len(sub_toy_dataset)
|
| 196 |
+
# 2, 1
|
| 197 |
+
|
| 198 |
+
# `get_subset_` 接口会对原数据集类做修改,即 inplace 的方式
|
| 199 |
+
toy_dataset.get_subset_(1)
|
| 200 |
+
len(toy_dataset)
|
| 201 |
+
# 1
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
经过以上步骤,可以了解基于数据集基类如何自定义新的数据集类,以及如何使用自定义数据集类。
|
| 205 |
+
|
| 206 |
+
#### 自定义视频的数据集类
|
| 207 |
+
|
| 208 |
+
在上面的例子中,标注文件的每个原始数据只包含一个训练/测试样本(通常是图像领域)。如果每个原始数据包含若干个训练/测试样本(通常是视频领域),则只需保证 `parse_data_info()` 的返回值为 `list[dict]` 即可:
|
| 209 |
+
|
| 210 |
+
```python
|
| 211 |
+
from mmengine.dataset import BaseDataset
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
class ToyVideoDataset(BaseDataset):
|
| 215 |
+
|
| 216 |
+
# raw_data_info 仍为一个字典,但它包含了多个样本
|
| 217 |
+
def parse_data_info(self, raw_data_info):
|
| 218 |
+
data_list = []
|
| 219 |
+
|
| 220 |
+
...
|
| 221 |
+
|
| 222 |
+
for ... :
|
| 223 |
+
|
| 224 |
+
data_info = dict()
|
| 225 |
+
|
| 226 |
+
...
|
| 227 |
+
|
| 228 |
+
data_list.append(data_info)
|
| 229 |
+
|
| 230 |
+
return data_list
|
| 231 |
+
|
| 232 |
+
```
|
| 233 |
+
|
| 234 |
+
`ToyVideoDataset` 使用方法与 `ToyDataset` 类似,在此不做赘述。
|
| 235 |
+
|
| 236 |
+
### 对于不满足 OpenMMLab 2.0 数���集格式规范的标注文件
|
| 237 |
+
|
| 238 |
+
对于不满足 OpenMMLab 2.0 数据集格式规范的标注文件,有两种方式来使用数据集基类:
|
| 239 |
+
|
| 240 |
+
1. 将不满足规范的标注文件转换成满足规范的标注文件,再通过上述方式使用数据集基类。
|
| 241 |
+
|
| 242 |
+
2. 实现一个新的数据集类,继承自数据集基类,并且重载数据集基类的 `load_data_list(self):` 函数,处理不满足规范的标注文件,并保证返回值为 `list[dict]`,其中每个 `dict` 代表一个数据样本。
|
| 243 |
+
|
| 244 |
+
## 数据集基类的其它特性
|
| 245 |
+
|
| 246 |
+
数据集基类还包含以下特性:
|
| 247 |
+
|
| 248 |
+
### 懒加载(lazy init)
|
| 249 |
+
|
| 250 |
+
在数据集类实例化时,需要读取并解析标注文件,因此会消耗一定时间。然而在某些情况比如预测可视化时,往往只需要数据集类的元信息,可能并不需要读取与解析标注文件。为了节省这种情况下数据集类实例化的时间,数据集基类支持懒加载:
|
| 251 |
+
|
| 252 |
+
```python
|
| 253 |
+
pipeline = [
|
| 254 |
+
LoadImage(),
|
| 255 |
+
ParseImage(),
|
| 256 |
+
]
|
| 257 |
+
|
| 258 |
+
toy_dataset = ToyDataset(
|
| 259 |
+
data_root='data/',
|
| 260 |
+
data_prefix=dict(img_path='train/'),
|
| 261 |
+
ann_file='annotations/train.json',
|
| 262 |
+
pipeline=pipeline,
|
| 263 |
+
# 在这里传入 lazy_init 变量
|
| 264 |
+
lazy_init=True)
|
| 265 |
+
```
|
| 266 |
+
|
| 267 |
+
当 `lazy_init=True` 时,`ToyDataset` 的初始化方法只执行了[数据集基类的初始化流程](#数据集基类的初始化流程)中的 1、2、3 步骤,此时 `toy_dataset` 并未被完全初始化,因为 `toy_dataset` 并不会读取与解析标注文件,只会设置数据集类的元信息(`metainfo`)。
|
| 268 |
+
|
| 269 |
+
自然的,如果之后需要访问具体的数据信息,可以手动调用 `toy_dataset.full_init()` 接口来执行完整的初始化过程,在这个过程中数据标注文件将被读取与解析。调用 `get_data_info(idx)`, `__len__()`, `__getitem__(idx)`,`get_subset_(indices)`, `get_subset(indices)` 接口也会自动地调用 `full_init()` 接口来执行完整的初始化过程(仅在第一次调用时,之后调用不会重复地调用 `full_init()` 接口):
|
| 270 |
+
|
| 271 |
+
```python
|
| 272 |
+
# 完整初始化
|
| 273 |
+
toy_dataset.full_init()
|
| 274 |
+
|
| 275 |
+
# 初始化完毕,现在可以访问具体数据
|
| 276 |
+
len(toy_dataset)
|
| 277 |
+
# 2
|
| 278 |
+
toy_dataset[0]
|
| 279 |
+
# {
|
| 280 |
+
# 'img_path': "data/train/xxx/xxx_0.jpg",
|
| 281 |
+
# 'img_label': 0,
|
| 282 |
+
# 'img': a ndarray with shape (H, W, 3), which denotes the value the image,
|
| 283 |
+
# 'img_shape': (H, W, 3) ,
|
| 284 |
+
# ...
|
| 285 |
+
# }
|
| 286 |
+
```
|
| 287 |
+
|
| 288 |
+
**注意:**
|
| 289 |
+
|
| 290 |
+
通过直接调用 `__getitem__()` 接口来执行完整初始化会带来一定风险:如果一个数据集类首先通过设置 `lazy_init=True` 未进行完全初始化,然后直接送入数据加载器(dataloader)中,在后续读取数据的过程中,不同的 worker 会同时读取与解析标注文件,虽然这样可能可以正常运行,但是会消耗大量的时间与内存。**因此,建议在需要访问具体数据之前,提前手动调用 `full_init()` 接口来执行完整的初始化过程。**
|
| 291 |
+
|
| 292 |
+
以上通过设置 `lazy_init=True` 未进行完全初始化,之后根据需求再进行完整初始化的方式,称为懒加载。
|
| 293 |
+
|
| 294 |
+
### 节省内存
|
| 295 |
+
|
| 296 |
+
在具体的读取数据过程中,数据加载器(dataloader)通常会起多个 worker 来预取数据,多个 worker 都拥有完整的数据集类备份,因此内存中会存在多份相同的 `data_list`,为了节省这部分内存消耗,数据集基类可以提前将 `data_list` 序列化存入内存中,使得多个 worker 可以共享同一份 `data_list`,以达到节省内存的目的。
|
| 297 |
+
|
| 298 |
+
数据集基类默认是将 `data_list` 序列化存入内存,也可以通过 `serialize_data` 变量(默认为 `True`)来控制是否提前将 `data_list` 序列化存入内存中:
|
| 299 |
+
|
| 300 |
+
```python
|
| 301 |
+
pipeline = [
|
| 302 |
+
LoadImage(),
|
| 303 |
+
ParseImage(),
|
| 304 |
+
]
|
| 305 |
+
|
| 306 |
+
toy_dataset = ToyDataset(
|
| 307 |
+
data_root='data/',
|
| 308 |
+
data_prefix=dict(img_path='train/'),
|
| 309 |
+
ann_file='annotations/train.json',
|
| 310 |
+
pipeline=pipeline,
|
| 311 |
+
# 在这里传入 serialize_data 变量
|
| 312 |
+
serialize_data=False)
|
| 313 |
+
```
|
| 314 |
+
|
| 315 |
+
上面例子不会提前将 `data_list` 序列化存入内存中,因此不建议在使用数据加载器开多个 worker 加载数据的情况下,使用这种方式实例化数据集类。
|
| 316 |
+
|
| 317 |
+
## 数据集基类包装
|
| 318 |
+
|
| 319 |
+
除了数据集基类,MMEngine 也提供了若干个数据集基类包装:`ConcatDataset`, `RepeatDataset`, `ClassBalancedDataset`。这些数据集基类包装同样也支持懒加载与拥有节省内存的特性。
|
| 320 |
+
|
| 321 |
+
### ConcatDataset
|
| 322 |
+
|
| 323 |
+
MMEngine 提供了 `ConcatDataset` 包装来拼接多个数据集,使用方法如下:
|
| 324 |
+
|
| 325 |
+
```python
|
| 326 |
+
from mmengine.dataset import ConcatDataset
|
| 327 |
+
|
| 328 |
+
pipeline = [
|
| 329 |
+
LoadImage(),
|
| 330 |
+
ParseImage(),
|
| 331 |
+
]
|
| 332 |
+
|
| 333 |
+
toy_dataset_1 = ToyDataset(
|
| 334 |
+
data_root='data/',
|
| 335 |
+
data_prefix=dict(img_path='train/'),
|
| 336 |
+
ann_file='annotations/train.json',
|
| 337 |
+
pipeline=pipeline)
|
| 338 |
+
|
| 339 |
+
toy_dataset_2 = ToyDataset(
|
| 340 |
+
data_root='data/',
|
| 341 |
+
data_prefix=dict(img_path='val/'),
|
| 342 |
+
ann_file='annotations/val.json',
|
| 343 |
+
pipeline=pipeline)
|
| 344 |
+
|
| 345 |
+
toy_dataset_12 = ConcatDataset(datasets=[toy_dataset_1, toy_dataset_2])
|
| 346 |
+
|
| 347 |
+
```
|
| 348 |
+
|
| 349 |
+
上述例子将数据集的 `train` 部分与 `val` 部分合成一个大的数据集。
|
| 350 |
+
|
| 351 |
+
### RepeatDataset
|
| 352 |
+
|
| 353 |
+
MMEngine 提供了 `RepeatDataset` 包装来重复采样某个数据集若干次,使用方法如下:
|
| 354 |
+
|
| 355 |
+
```python
|
| 356 |
+
from mmengine.dataset import RepeatDataset
|
| 357 |
+
|
| 358 |
+
pipeline = [
|
| 359 |
+
LoadImage(),
|
| 360 |
+
ParseImage(),
|
| 361 |
+
]
|
| 362 |
+
|
| 363 |
+
toy_dataset = ToyDataset(
|
| 364 |
+
data_root='data/',
|
| 365 |
+
data_prefix=dict(img_path='train/'),
|
| 366 |
+
ann_file='annotations/train.json',
|
| 367 |
+
pipeline=pipeline)
|
| 368 |
+
|
| 369 |
+
toy_dataset_repeat = RepeatDataset(dataset=toy_dataset, times=5)
|
| 370 |
+
|
| 371 |
+
```
|
| 372 |
+
|
| 373 |
+
上述例子将数据集的 `train` 部分重复采样了 5 次。
|
| 374 |
+
|
| 375 |
+
### ClassBalancedDataset
|
| 376 |
+
|
| 377 |
+
MMEngine 提供了 `ClassBalancedDataset` 包装,来基于数据集中类别出现频率,重复采样相应样本。
|
| 378 |
+
|
| 379 |
+
**注意:**
|
| 380 |
+
|
| 381 |
+
`ClassBalancedDataset` 包装假设了被包装的数据集类支持 `get_cat_ids(idx)` 方法,`get_cat_ids(idx)` 方法返回一个列表,该列表包含了 `idx` 指定的 `data_info` 包含的样本类别,使用方法如下:
|
| 382 |
+
|
| 383 |
+
```python
|
| 384 |
+
from mmengine.dataset import BaseDataset, ClassBalancedDataset
|
| 385 |
+
|
| 386 |
+
class ToyDataset(BaseDataset):
|
| 387 |
+
|
| 388 |
+
def parse_data_info(self, raw_data_info):
|
| 389 |
+
data_info = raw_data_info
|
| 390 |
+
img_prefix = self.data_prefix.get('img_path', None)
|
| 391 |
+
if img_prefix is not None:
|
| 392 |
+
data_info['img_path'] = osp.join(
|
| 393 |
+
img_prefix, data_info['img_path'])
|
| 394 |
+
return data_info
|
| 395 |
+
|
| 396 |
+
# 必须支持的方法,需要返回样本的类别
|
| 397 |
+
def get_cat_ids(self, idx):
|
| 398 |
+
data_info = self.get_data_info(idx)
|
| 399 |
+
return [int(data_info['img_label'])]
|
| 400 |
+
|
| 401 |
+
pipeline = [
|
| 402 |
+
LoadImage(),
|
| 403 |
+
ParseImage(),
|
| 404 |
+
]
|
| 405 |
+
|
| 406 |
+
toy_dataset = ToyDataset(
|
| 407 |
+
data_root='data/',
|
| 408 |
+
data_prefix=dict(img_path='train/'),
|
| 409 |
+
ann_file='annotations/train.json',
|
| 410 |
+
pipeline=pipeline)
|
| 411 |
+
|
| 412 |
+
toy_dataset_repeat = ClassBalancedDataset(dataset=toy_dataset, oversample_thr=1e-3)
|
| 413 |
+
|
| 414 |
+
```
|
| 415 |
+
|
| 416 |
+
上述例子将数据集的 `train` 部分以 `oversample_thr=1e-3` 重新采样,具体地,对于数据集中出现频率低于 `1e-3` 的类别,会重复采样该类别对应的样本,否则不重复采样,具体采样策略请参考 `ClassBalancedDataset` API 文档。
|
| 417 |
+
|
| 418 |
+
### 自定义数据集类包装
|
| 419 |
+
|
| 420 |
+
由于数据集基类实现了懒加载的功能,因此在自定义数据集类包装时,需要遵循一些规则,下面以一个例子的方式来展示如何自定义数据集类包装:
|
| 421 |
+
|
| 422 |
+
```python
|
| 423 |
+
from mmengine.dataset import BaseDataset
|
| 424 |
+
from mmengine.registry import DATASETS
|
| 425 |
+
|
| 426 |
+
|
| 427 |
+
@DATASETS.register_module()
|
| 428 |
+
class ExampleDatasetWrapper:
|
| 429 |
+
|
| 430 |
+
def __init__(self, dataset, lazy_init=False, ...):
|
| 431 |
+
# 构建原数据集(self.dataset)
|
| 432 |
+
if isinstance(dataset, dict):
|
| 433 |
+
self.dataset = DATASETS.build(dataset)
|
| 434 |
+
elif isinstance(dataset, BaseDataset):
|
| 435 |
+
self.dataset = dataset
|
| 436 |
+
else:
|
| 437 |
+
raise TypeError(
|
| 438 |
+
'elements in datasets sequence should be config or '
|
| 439 |
+
f'`BaseDataset` instance, but got {type(dataset)}')
|
| 440 |
+
# 记录原数据集的元信息
|
| 441 |
+
self._metainfo = self.dataset.metainfo
|
| 442 |
+
|
| 443 |
+
'''
|
| 444 |
+
1. 在这里实现一些代码,来记录用于包装数据集的一些超参。
|
| 445 |
+
'''
|
| 446 |
+
|
| 447 |
+
self._fully_initialized = False
|
| 448 |
+
if not lazy_init:
|
| 449 |
+
self.full_init()
|
| 450 |
+
|
| 451 |
+
def full_init(self):
|
| 452 |
+
if self._fully_initialized:
|
| 453 |
+
return
|
| 454 |
+
|
| 455 |
+
# 将原数据集完全初始化
|
| 456 |
+
self.dataset.full_init()
|
| 457 |
+
|
| 458 |
+
'''
|
| 459 |
+
2. 在这里实现一些代码,来包装原数据集。
|
| 460 |
+
'''
|
| 461 |
+
|
| 462 |
+
self._fully_initialized = True
|
| 463 |
+
|
| 464 |
+
@force_full_init
|
| 465 |
+
def _get_ori_dataset_idx(self, idx: int):
|
| 466 |
+
|
| 467 |
+
'''
|
| 468 |
+
3. 在这里实现一些代码,来将包装的索引 `idx` 映射到原数据集的索引 `ori_idx`。
|
| 469 |
+
'''
|
| 470 |
+
ori_idx = ...
|
| 471 |
+
|
| 472 |
+
return ori_idx
|
| 473 |
+
|
| 474 |
+
# 提供与 `self.dataset` 一样的对外接口。
|
| 475 |
+
@force_full_init
|
| 476 |
+
def get_data_info(self, idx):
|
| 477 |
+
sample_idx = self._get_ori_dataset_idx(idx)
|
| 478 |
+
return self.dataset.get_data_info(sample_idx)
|
| 479 |
+
|
| 480 |
+
# 提供与 `self.dataset` 一样的对外接口。
|
| 481 |
+
def __getitem__(self, idx):
|
| 482 |
+
if not self._fully_initialized:
|
| 483 |
+
warnings.warn('Please call `full_init` method manually to '
|
| 484 |
+
'accelerate the speed.')
|
| 485 |
+
self.full_init()
|
| 486 |
+
|
| 487 |
+
sample_idx = self._get_ori_dataset_idx(idx)
|
| 488 |
+
return self.dataset[sample_idx]
|
| 489 |
+
|
| 490 |
+
# 提供与 `self.dataset` 一样的对外接口。
|
| 491 |
+
@force_full_init
|
| 492 |
+
def __len__(self):
|
| 493 |
+
|
| 494 |
+
'''
|
| 495 |
+
4. 在这里实现一些代码,来计算包装数据集之后的长度。
|
| 496 |
+
'''
|
| 497 |
+
len_wrapper = ...
|
| 498 |
+
|
| 499 |
+
return len_wrapper
|
| 500 |
+
|
| 501 |
+
# 提供与 `self.dataset` 一样的对外接口。
|
| 502 |
+
@property
|
| 503 |
+
def metainfo(self)
|
| 504 |
+
return copy.deepcopy(self._metainfo)
|
| 505 |
+
```
|
testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/config.md
ADDED
|
@@ -0,0 +1,606 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 配置(Config)
|
| 2 |
+
|
| 3 |
+
MMEngine 实现了抽象的配置类(Config),为用户提供统一的配置访问接口。配置类能够支持不同格式的配置文件,包括 `python`,`json`,`yaml`,用户可以根据需求选择自己偏好的格式。配置类提供了类似字典或者 Python 对象属性的访问接口,用户可以十分自然地进行配置字段的读取和修改。为了方便算法框架管理配置文件,配置类也实现了一些特性,例如配置文件的字段继承等。
|
| 4 |
+
|
| 5 |
+
在开始教程之前,我们先将教程中需要用到的配置文件下载到本地(建议在临时目录下执行,方便后续删除示例配置文件):
|
| 6 |
+
|
| 7 |
+
```bash
|
| 8 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/config_sgd.py
|
| 9 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/cross_repo.py
|
| 10 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/custom_imports.py
|
| 11 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/demo_train.py
|
| 12 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/example.py
|
| 13 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/learn_read_config.py
|
| 14 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/my_module.py
|
| 15 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/optimizer_cfg.py
|
| 16 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/predefined_var.py
|
| 17 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/refer_base_var.py
|
| 18 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/resnet50_delete_key.py
|
| 19 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/resnet50_lr0.01.py
|
| 20 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/resnet50_runtime.py
|
| 21 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/resnet50.py
|
| 22 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/runtime_cfg.py
|
| 23 |
+
wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/modify_base_var.py
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
## 配置文件读取
|
| 27 |
+
|
| 28 |
+
配置类提供了统一的接口 `Config.fromfile()`,来读取和解析配置文件。
|
| 29 |
+
|
| 30 |
+
合法的配置文件应该定义一系列键值对,这里举几个不同格式配置文件的例子。
|
| 31 |
+
|
| 32 |
+
Python 格式:
|
| 33 |
+
|
| 34 |
+
```Python
|
| 35 |
+
test_int = 1
|
| 36 |
+
test_list = [1, 2, 3]
|
| 37 |
+
test_dict = dict(key1='value1', key2=0.1)
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
Json 格式:
|
| 41 |
+
|
| 42 |
+
```json
|
| 43 |
+
{
|
| 44 |
+
"test_int": 1,
|
| 45 |
+
"test_list": [1, 2, 3],
|
| 46 |
+
"test_dict": {"key1": "value1", "key2": 0.1}
|
| 47 |
+
}
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
YAML 格式:
|
| 51 |
+
|
| 52 |
+
```yaml
|
| 53 |
+
test_int: 1
|
| 54 |
+
test_list: [1, 2, 3]
|
| 55 |
+
test_dict:
|
| 56 |
+
key1: "value1"
|
| 57 |
+
key2: 0.1
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
对于以上三种格式的文件,假设文件名分别为 `config.py`,`config.json`,`config.yml`,调用 `Config.fromfile('config.xxx')` 接口加载这三个文件都会得到相同的结果,构造了包含 3 个字段的配置对象。我们以 `config.py` 为例,我们先将示例配置文件下载到本地:
|
| 61 |
+
|
| 62 |
+
然后通过配置类的 `fromfile` 接口读取配置文件:
|
| 63 |
+
|
| 64 |
+
```python
|
| 65 |
+
from mmengine.config import Config
|
| 66 |
+
|
| 67 |
+
cfg = Config.fromfile('learn_read_config.py')
|
| 68 |
+
print(cfg)
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
```
|
| 72 |
+
Config (path: learn_read_config.py): {'test_int': 1, 'test_list': [1, 2, 3], 'test_dict': {'key1': 'value1', 'key2': 0.1}}
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
## 配置文件的使用
|
| 76 |
+
|
| 77 |
+
通过读取配置文件来初始化配置对象后,就可以像使用普通字典或者 Python 类一样来使用这个变量了。我们提供了两种访问接口,即类似字典的接口 `cfg['key']` 或者类似 Python 对象属性的接口 `cfg.key`。这两种接口都支持读写。
|
| 78 |
+
|
| 79 |
+
```python
|
| 80 |
+
print(cfg.test_int)
|
| 81 |
+
print(cfg.test_list)
|
| 82 |
+
print(cfg.test_dict)
|
| 83 |
+
cfg.test_int = 2
|
| 84 |
+
|
| 85 |
+
print(cfg['test_int'])
|
| 86 |
+
print(cfg['test_list'])
|
| 87 |
+
print(cfg['test_dict'])
|
| 88 |
+
cfg['test_list'][1] = 3
|
| 89 |
+
print(cfg['test_list'])
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
```
|
| 93 |
+
1
|
| 94 |
+
[1, 2, 3]
|
| 95 |
+
{'key1': 'value1', 'key2': 0.1}
|
| 96 |
+
2
|
| 97 |
+
[1, 2, 3]
|
| 98 |
+
{'key1': 'value1', 'key2': 0.1}
|
| 99 |
+
[1, 3, 3]
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
注意,配置文件中定义的嵌套字段(即类似字典的字段),在 Config 中会将其转化为 ConfigDict 类,该类继承了 Python 内置字典类型的全部接口,同时也支持以对象属性的方式访问数据。
|
| 103 |
+
|
| 104 |
+
在算法库中,可以将配置与注册器结合起来使用,达到通过配置文件来控制模块构造的目的。这里举一个在配置文件中定义优化器的例子。
|
| 105 |
+
|
| 106 |
+
假设我们已经定义了一个优化器的注册器 OPTIMIZERS,包括了各种优化器。那么首先写一个 `config_sgd.py`:
|
| 107 |
+
|
| 108 |
+
```python
|
| 109 |
+
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
然后在算法库中可以通过如下代码构造优化器对象。
|
| 113 |
+
|
| 114 |
+
```python
|
| 115 |
+
from mmengine import Config, optim
|
| 116 |
+
from mmengine.registry import OPTIMIZERS
|
| 117 |
+
|
| 118 |
+
import torch.nn as nn
|
| 119 |
+
|
| 120 |
+
cfg = Config.fromfile('config_sgd.py')
|
| 121 |
+
|
| 122 |
+
model = nn.Conv2d(1, 1, 1)
|
| 123 |
+
cfg.optimizer.params = model.parameters()
|
| 124 |
+
optimizer = OPTIMIZERS.build(cfg.optimizer)
|
| 125 |
+
print(optimizer)
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
```
|
| 129 |
+
SGD (
|
| 130 |
+
Parameter Group 0
|
| 131 |
+
dampening: 0
|
| 132 |
+
foreach: None
|
| 133 |
+
lr: 0.1
|
| 134 |
+
maximize: False
|
| 135 |
+
momentum: 0.9
|
| 136 |
+
nesterov: False
|
| 137 |
+
weight_decay: 0.0001
|
| 138 |
+
)
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
## 配置文件的继承
|
| 142 |
+
|
| 143 |
+
有时候,两个不同的配置文件之间的差异很小,可能仅仅只改了一个字段,我们就需要将所有内容复制粘贴一次,而且在后续观察的时候,不容易定位到具体差异的字段。又有些情况下,多个配置文件可能都有相同的一批字段,我们不得不在这些配置文件中进行复制粘贴,给后续的修改和维护带来了不便。
|
| 144 |
+
|
| 145 |
+
为了解决这些问题,我们给配置文件增加了继承的机制,即一个配置文件 A 可以将另一个配置文件 B 作为自己的基础,直接继承了 B 中所有字段,而不必显式复制粘贴。
|
| 146 |
+
|
| 147 |
+
### 继承机制概述
|
| 148 |
+
|
| 149 |
+
这里我们举一个例子来说明继承机制。定义如下两个配置文件,
|
| 150 |
+
|
| 151 |
+
`optimizer_cfg.py`:
|
| 152 |
+
|
| 153 |
+
```python
|
| 154 |
+
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
|
| 155 |
+
```
|
| 156 |
+
|
| 157 |
+
`resnet50.py`:
|
| 158 |
+
|
| 159 |
+
```python
|
| 160 |
+
_base_ = ['optimizer_cfg.py']
|
| 161 |
+
model = dict(type='ResNet', depth=50)
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
虽然我们在 `resnet50.py` 中没有定义 optimizer 字段,但由于我们写了 `_base_ = ['optimizer_cfg.py']`,会使这个配置文件获得 `optimizer_cfg.py` 中的所有字段。
|
| 165 |
+
|
| 166 |
+
```python
|
| 167 |
+
cfg = Config.fromfile('resnet50.py')
|
| 168 |
+
print(cfg.optimizer)
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
```
|
| 172 |
+
{'type': 'SGD', 'lr': 0.02, 'momentum': 0.9, 'weight_decay': 0.0001}
|
| 173 |
+
```
|
| 174 |
+
|
| 175 |
+
这里 `_base_` 是配置文件的保留字段,指定了该配置文件的继承来源。支持继承多个文件,将同时获得这多个文件中的所有字段,但是要求继承的多个文件中**没有**相同名称的字段,否则会报错。
|
| 176 |
+
|
| 177 |
+
`runtime_cfg.py`:
|
| 178 |
+
|
| 179 |
+
```python
|
| 180 |
+
gpu_ids = [0, 1]
|
| 181 |
+
```
|
| 182 |
+
|
| 183 |
+
`resnet50_runtime.py`:
|
| 184 |
+
|
| 185 |
+
```python
|
| 186 |
+
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
|
| 187 |
+
model = dict(type='ResNet', depth=50)
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
这时,读取配置文件 `resnet50_runtime.py` 会获得 3 个字段 `model`,`optimizer`,`gpu_ids`。
|
| 191 |
+
|
| 192 |
+
```python
|
| 193 |
+
cfg = Config.fromfile('resnet50_runtime.py')
|
| 194 |
+
print(cfg.optimizer)
|
| 195 |
+
```
|
| 196 |
+
|
| 197 |
+
```
|
| 198 |
+
{'type': 'SGD', 'lr': 0.02, 'momentum': 0.9, 'weight_decay': 0.0001}
|
| 199 |
+
```
|
| 200 |
+
|
| 201 |
+
通过这种方式,我们可以将配置文件进行拆分,定义一些通用配置文件,在实际配置文件中继承各种通用配置文件,可以减少具体任务的配置流程。
|
| 202 |
+
|
| 203 |
+
### 修改继承字段
|
| 204 |
+
|
| 205 |
+
有时候,我们继承一个配置文件之后,可能需要对其中个别字段进行修改,例如继承了 `optimizer_cfg.py` 之后,想将学习率从 0.02 修改为 0.01。
|
| 206 |
+
|
| 207 |
+
这时候,只需要在新的配置文件中,重新定义一下需要修改的字段即可。注意由于 optimizer 这个字段是一个字典,我们只需要重新定义这个字典里面需修改的下级字段即可。这个规则也适用于增加一些下级字段。
|
| 208 |
+
|
| 209 |
+
`resnet50_lr0.01.py`:
|
| 210 |
+
|
| 211 |
+
```python
|
| 212 |
+
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
|
| 213 |
+
model = dict(type='ResNet', depth=50)
|
| 214 |
+
optimizer = dict(lr=0.01)
|
| 215 |
+
```
|
| 216 |
+
|
| 217 |
+
读取这个配置文件之后,就可以得到期望的结果。
|
| 218 |
+
|
| 219 |
+
```python
|
| 220 |
+
cfg = Config.fromfile('resnet50_lr0.01.py')
|
| 221 |
+
print(cfg.optimizer)
|
| 222 |
+
```
|
| 223 |
+
|
| 224 |
+
```
|
| 225 |
+
{'type': 'SGD', 'lr': 0.01, 'momentum': 0.9, 'weight_decay': 0.0001}
|
| 226 |
+
```
|
| 227 |
+
|
| 228 |
+
对于非字典类型的字段,例如整数,字符串,列表等,重新定义即可完全覆盖,例如下面的写法就将 `gpu_ids` 这个字段的值修改成了 `[0]`。
|
| 229 |
+
|
| 230 |
+
```python
|
| 231 |
+
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
|
| 232 |
+
model = dict(type='ResNet', depth=50)
|
| 233 |
+
gpu_ids = [0]
|
| 234 |
+
```
|
| 235 |
+
|
| 236 |
+
### 删除字典中的 key
|
| 237 |
+
|
| 238 |
+
有时候我们对于继承过来的字典类型字段,不仅仅是想修改其中某些 key,可能还需要删除其中的一些 key。这时候在重新定义这个字典时,需要指定 `_delete_=True`,表示将没有在新定义的字典中出现的 key 全部删除。
|
| 239 |
+
|
| 240 |
+
`resnet50_delete_key.py`:
|
| 241 |
+
|
| 242 |
+
```python
|
| 243 |
+
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
|
| 244 |
+
model = dict(type='ResNet', depth=50)
|
| 245 |
+
optimizer = dict(_delete_=True, type='SGD', lr=0.01)
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
这时候,`optimizer` 这个字典中就只有 `type` 和 `lr` 这两个 key,`momentum` 和 `weight_decay` 将不再被继承。
|
| 249 |
+
|
| 250 |
+
```python
|
| 251 |
+
cfg = Config.fromfile('resnet50_delete_key.py')
|
| 252 |
+
print(cfg.optimizer)
|
| 253 |
+
```
|
| 254 |
+
|
| 255 |
+
```
|
| 256 |
+
{'type': 'SGD', 'lr': 0.01}
|
| 257 |
+
```
|
| 258 |
+
|
| 259 |
+
### 引用被继承文件中的变量
|
| 260 |
+
|
| 261 |
+
有时我们想重复利用 `_base_` 中定义的字段内容,就可以通过 `{{_base_.xxxx}}` 获取来获取对应变量的拷贝。例如:
|
| 262 |
+
|
| 263 |
+
`refer_base_var.py`
|
| 264 |
+
|
| 265 |
+
```python
|
| 266 |
+
_base_ = ['resnet50.py']
|
| 267 |
+
a = {{_base_.model}}
|
| 268 |
+
```
|
| 269 |
+
|
| 270 |
+
解析后发现,`a` 的值变成了 `resnet50.py` 中定义的 `model`
|
| 271 |
+
|
| 272 |
+
```python
|
| 273 |
+
cfg = Config.fromfile('refer_base_var.py')
|
| 274 |
+
print(cfg.a)
|
| 275 |
+
```
|
| 276 |
+
|
| 277 |
+
```
|
| 278 |
+
{'type': 'ResNet', 'depth': 50}
|
| 279 |
+
```
|
| 280 |
+
|
| 281 |
+
我们可以在 `json`、`yaml`、`python` 三种类型的配置文件中,使用这种方式来获取 `_base_` 中定义的变量。
|
| 282 |
+
|
| 283 |
+
尽管这种获取 `_base_` 中定义变量的方式非常通用,但是在语法上存在一些限制,无法充分利用 `python` 类配置文件的动态特性。比如我们想在 `python` 类配置文件中,修改 `_base_` 中定义的变量:
|
| 284 |
+
|
| 285 |
+
```python
|
| 286 |
+
_base_ = ['resnet50.py']
|
| 287 |
+
a = {{_base_.model}}
|
| 288 |
+
a['type'] = 'MobileNet'
|
| 289 |
+
```
|
| 290 |
+
|
| 291 |
+
配置类是无法解析这样的配置文件的(解析时报错)。配置类提供了一种更 `pythonic` 的方式,让我们能够在 `python` 类配置文件中修改 `_base_` 中定义的变量(`python` 类配置文件专属特性,目前不支持在 `json`、`yaml` 配置文件中修改 `_base_` 中定义的变量)。
|
| 292 |
+
|
| 293 |
+
`modify_base_var.py`:
|
| 294 |
+
|
| 295 |
+
```python
|
| 296 |
+
_base_ = ['resnet50.py']
|
| 297 |
+
a = _base_.model
|
| 298 |
+
a.type = 'MobileNet'
|
| 299 |
+
```
|
| 300 |
+
|
| 301 |
+
```python
|
| 302 |
+
cfg = Config.fromfile('modify_base_var.py')
|
| 303 |
+
print(cfg.a)
|
| 304 |
+
```
|
| 305 |
+
|
| 306 |
+
```
|
| 307 |
+
{'type': 'MobileNet', 'depth': 50}
|
| 308 |
+
```
|
| 309 |
+
|
| 310 |
+
解析后发现,`a` 的 type 变成了 `MobileNet`。
|
| 311 |
+
|
| 312 |
+
## 配置文件的导出
|
| 313 |
+
|
| 314 |
+
在启动训练脚本时,用户可能通过传参的方式来修改配置文件的部分字段,为此我们提供了 `dump` 接口来导出更改后的配置文件。与读取配置文件类似,用户可以通过 `cfg.dump('config.xxx')` 来选择导出文件的格式。`dump` 同样可以导出有继承关系的配置文件,导出的文件可以被独立使用,不再依赖于 `_base_` 中定义的文件。
|
| 315 |
+
|
| 316 |
+
基于继承一节定义的 `resnet50.py`,我们将其加载后导出:
|
| 317 |
+
|
| 318 |
+
```python
|
| 319 |
+
cfg = Config.fromfile('resnet50.py')
|
| 320 |
+
cfg.dump('resnet50_dump.py')
|
| 321 |
+
```
|
| 322 |
+
|
| 323 |
+
`resnet50_dump.py`
|
| 324 |
+
|
| 325 |
+
```python
|
| 326 |
+
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
|
| 327 |
+
model = dict(type='ResNet', depth=50)
|
| 328 |
+
```
|
| 329 |
+
|
| 330 |
+
类似的,我们可以导出 json、yaml 格式的配置文件
|
| 331 |
+
|
| 332 |
+
`resnet50_dump.yaml`
|
| 333 |
+
|
| 334 |
+
```yaml
|
| 335 |
+
model:
|
| 336 |
+
depth: 50
|
| 337 |
+
type: ResNet
|
| 338 |
+
optimizer:
|
| 339 |
+
lr: 0.02
|
| 340 |
+
momentum: 0.9
|
| 341 |
+
type: SGD
|
| 342 |
+
weight_decay: 0.0001
|
| 343 |
+
```
|
| 344 |
+
|
| 345 |
+
`resnet50_dump.json`
|
| 346 |
+
|
| 347 |
+
```json
|
| 348 |
+
{"optimizer": {"type": "SGD", "lr": 0.02, "momentum": 0.9, "weight_decay": 0.0001}, "model": {"type": "ResNet", "depth": 50}}
|
| 349 |
+
```
|
| 350 |
+
|
| 351 |
+
此外,`dump` 不仅能导出加载自文件的 `cfg`,还能导出加载自字典的 `cfg`
|
| 352 |
+
|
| 353 |
+
```python
|
| 354 |
+
cfg = Config(dict(a=1, b=2))
|
| 355 |
+
cfg.dump('dump_dict.py')
|
| 356 |
+
```
|
| 357 |
+
|
| 358 |
+
`dump_dict.py`
|
| 359 |
+
|
| 360 |
+
```python
|
| 361 |
+
a=1
|
| 362 |
+
b=2
|
| 363 |
+
```
|
| 364 |
+
|
| 365 |
+
## 其他进阶用法
|
| 366 |
+
|
| 367 |
+
这里介绍一下配置类的进阶用法,这些小技巧可能使用户开发和使用算法库更简单方便。
|
| 368 |
+
|
| 369 |
+
### 预定义字段
|
| 370 |
+
|
| 371 |
+
有时候我们希望配置文件中的一些字段和当前路径或者文件名等相关,这里举一个典型使用场景的例子。在训练模型时,我们会在配置文件中定义一个工作目录,存放这组实验配置的模型和日志,那么对于不同的配置文件,我们期望定义不同的工作目录。用户的一种常见选择是,直接使用配置文件名作为工作目录名的一部分,例如对于配置文件 `predefined_var.py`,工作目录就是 `./work_dir/predefined_var`。
|
| 372 |
+
|
| 373 |
+
使用预定义字段可以方便地实现这种需求,在配置文件 `predefined_var.py` 中可以这样写:
|
| 374 |
+
|
| 375 |
+
```Python
|
| 376 |
+
work_dir = './work_dir/{{fileBasenameNoExtension}}'
|
| 377 |
+
```
|
| 378 |
+
|
| 379 |
+
这里 `{{fileBasenameNoExtension}}` 表示该配置文件的文件名(不含拓展名),在配置类读取配置文件的时候,会将这种用双花括号包起来的字符串自动解析为对应的实际值。
|
| 380 |
+
|
| 381 |
+
```python
|
| 382 |
+
cfg = Config.fromfile('./predefined_var.py')
|
| 383 |
+
print(cfg.work_dir)
|
| 384 |
+
```
|
| 385 |
+
|
| 386 |
+
```
|
| 387 |
+
./work_dir/predefined_var
|
| 388 |
+
```
|
| 389 |
+
|
| 390 |
+
目前支持的预定义字段有以下四种,变量名参考自 [VS Code](https://code.visualstudio.com/docs/editor/variables-reference) 中的相关字段:
|
| 391 |
+
|
| 392 |
+
- `{{fileDirname}}` - 当前文件的目录名,例如 `/home/your-username/your-project/folder`
|
| 393 |
+
- `{{fileBasename}}` - 当前文件的文件名,例如 `file.py`
|
| 394 |
+
- `{{fileBasenameNoExtension}}` - 当前文件不包含扩展名的文件名,例如 `file`
|
| 395 |
+
- `{{fileExtname}}` - 当前文件的扩展名,例如 `.py`
|
| 396 |
+
|
| 397 |
+
### 命令行修改配置
|
| 398 |
+
|
| 399 |
+
有时候我们只希望修改部分配置,而不想修改配置文件本身,例如实验过程中想更换学习率,但是又不想重新写一个配置文件,常用的做法是在命令行传入参数来覆盖相关配置。考虑到我们想修改的配置通常是一些内层参数,如优化器的学习率、模型卷积层的通道数等,因此 MMEngine 提供了一套标准的流程,让我们能够在命令行里轻松修改配置文件中任意层级的参数。
|
| 400 |
+
|
| 401 |
+
1. 使用 `argparse` 解析脚本运行的参数
|
| 402 |
+
2. 使用 `argparse.ArgumentParser.add_argument` 方法时,让 `action` 参数的值为 [DictAction](mmengine.config.DictAction),用它来进一步解析命令行参数中用于修改配置文件的参数
|
| 403 |
+
3. 使用配置类的 `merge_from_dict` 方法来更新配置
|
| 404 |
+
|
| 405 |
+
启动脚本示例如下:
|
| 406 |
+
|
| 407 |
+
`demo_train.py`
|
| 408 |
+
|
| 409 |
+
```python
|
| 410 |
+
import argparse
|
| 411 |
+
|
| 412 |
+
from mmengine.config import Config, DictAction
|
| 413 |
+
|
| 414 |
+
|
| 415 |
+
def parse_args():
|
| 416 |
+
parser = argparse.ArgumentParser(description='Train a model')
|
| 417 |
+
parser.add_argument('config', help='train config file path')
|
| 418 |
+
parser.add_argument(
|
| 419 |
+
'--cfg-options',
|
| 420 |
+
nargs='+',
|
| 421 |
+
action=DictAction,
|
| 422 |
+
help='override some settings in the used config, the key-value pair '
|
| 423 |
+
'in xxx=yyy format will be merged into config file. If the value to '
|
| 424 |
+
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
|
| 425 |
+
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
|
| 426 |
+
'Note that the quotation marks are necessary and that no white space '
|
| 427 |
+
'is allowed.')
|
| 428 |
+
|
| 429 |
+
args = parser.parse_args()
|
| 430 |
+
return args
|
| 431 |
+
|
| 432 |
+
|
| 433 |
+
def main():
|
| 434 |
+
args = parse_args()
|
| 435 |
+
cfg = Config.fromfile(args.config)
|
| 436 |
+
if args.cfg_options is not None:
|
| 437 |
+
cfg.merge_from_dict(args.cfg_options)
|
| 438 |
+
print(cfg)
|
| 439 |
+
|
| 440 |
+
|
| 441 |
+
if __name__ == '__main__':
|
| 442 |
+
main()
|
| 443 |
+
```
|
| 444 |
+
|
| 445 |
+
示例配置文件如下:
|
| 446 |
+
|
| 447 |
+
`example.py`
|
| 448 |
+
|
| 449 |
+
```python
|
| 450 |
+
model = dict(type='CustomModel', in_channels=[1, 2, 3])
|
| 451 |
+
optimizer = dict(type='SGD', lr=0.01)
|
| 452 |
+
```
|
| 453 |
+
|
| 454 |
+
我们在命令行里通过 `.` 的方式来访问配置文件中的深层配置,例如我们想修改学习率,只需要在命令行执行:
|
| 455 |
+
|
| 456 |
+
```bash
|
| 457 |
+
python demo_train.py ./example.py --cfg-options optimizer.lr=0.1
|
| 458 |
+
```
|
| 459 |
+
|
| 460 |
+
```
|
| 461 |
+
Config (path: ./example.py): {'model': {'type': 'CustomModel', 'in_channels': [1, 2, 3]}, 'optimizer': {'type': 'SGD', 'lr': 0.1}}
|
| 462 |
+
```
|
| 463 |
+
|
| 464 |
+
我们成功地把学习率从 0.01 修改成 0.1。如果想改变列表、元组类型的配置,如上例中的 `in_channels`,则需要在命令行赋值时给 `()`,`[]` 外加上双引号:
|
| 465 |
+
|
| 466 |
+
```bash
|
| 467 |
+
python demo_train.py ./example.py --cfg-options model.in_channels="[1, 1, 1]"
|
| 468 |
+
```
|
| 469 |
+
|
| 470 |
+
```
|
| 471 |
+
Config (path: ./example.py): {'model': {'type': 'CustomModel', 'in_channels': [1, 1, 1]}, 'optimizer': {'type': 'SGD', 'lr': 0.01}}
|
| 472 |
+
```
|
| 473 |
+
|
| 474 |
+
`model.in_channels` 已经从 \[1, 2, 3\] 修改成 \[1, 1, 1\]。
|
| 475 |
+
|
| 476 |
+
```{note}
|
| 477 |
+
上述流程只支持在命令行里修改字符串、整型、浮点型、布尔型、None、列表、元组类型的配置项。对于列表、元组类型的配置,里面每个元素的类型也必须为上述七种类型之一。
|
| 478 |
+
```
|
| 479 |
+
|
| 480 |
+
:::{note}
|
| 481 |
+
`DictAction` 的行为与 `"extend"` 相似,支持多次传递,并保存在同一个列表中。如
|
| 482 |
+
|
| 483 |
+
```bash
|
| 484 |
+
python demo_train.py ./example.py --cfg-options optimizer.type="Adam" --cfg-options model.in_channels="[1, 1, 1]"
|
| 485 |
+
```
|
| 486 |
+
|
| 487 |
+
```
|
| 488 |
+
Config (path: ./example.py): {'model': {'type': 'CustomModel', 'in_channels': [1, 1, 1]}, 'optimizer': {'type': 'Adam', 'lr': 0.01}}
|
| 489 |
+
```
|
| 490 |
+
|
| 491 |
+
:::
|
| 492 |
+
|
| 493 |
+
### 导入自定义 Python 模块
|
| 494 |
+
|
| 495 |
+
将配置与注册器结合起来使用时,如果我们往注册器中注册了一些自定义的类,就可能会遇到一些问题。因为读取配置文件的时候,这部分代码可能还没有被执行到,所以并未完成注册过程,从而导致构建自定义类的时候报错。
|
| 496 |
+
|
| 497 |
+
例如我们新实现了一种优化器 `CustomOptim`,相应代码在 `my_module.py` 中。
|
| 498 |
+
|
| 499 |
+
```python
|
| 500 |
+
from mmengine.registry import OPTIMIZERS
|
| 501 |
+
|
| 502 |
+
@OPTIMIZERS.register_module()
|
| 503 |
+
class CustomOptim:
|
| 504 |
+
pass
|
| 505 |
+
```
|
| 506 |
+
|
| 507 |
+
我们为这个优化器的使用写了一个新的配置文件 `custom_imports.py`:
|
| 508 |
+
|
| 509 |
+
```python
|
| 510 |
+
optimizer = dict(type='CustomOptim')
|
| 511 |
+
```
|
| 512 |
+
|
| 513 |
+
那么就需要在读取配置文件和构造优化器之前,增加一行 `import my_module` 来保证将自定义的类 `CustomOptim` 注册到 OPTIMIZERS 注册器中:为了解决这个问题,我们给配置文件定义了一个保留字段 `custom_imports`,用于将需要提前导入的 Python 模块,直接写在配置文件中。对于上述例子,就可以将配置文件写成如下:
|
| 514 |
+
|
| 515 |
+
`custom_imports.py`
|
| 516 |
+
|
| 517 |
+
```python
|
| 518 |
+
custom_imports = dict(imports=['my_module'], allow_failed_imports=False)
|
| 519 |
+
optimizer = dict(type='CustomOptim')
|
| 520 |
+
```
|
| 521 |
+
|
| 522 |
+
这样我们就不用在训练代码中增加对应的 import 语句,只需要修改配置文件就可以实现非侵入式导入自定义注册模块。
|
| 523 |
+
|
| 524 |
+
```python
|
| 525 |
+
cfg = Config.fromfile('custom_imports.py')
|
| 526 |
+
|
| 527 |
+
from mmengine.registry import OPTIMIZERS
|
| 528 |
+
|
| 529 |
+
custom_optim = OPTIMIZERS.build(cfg.optimizer)
|
| 530 |
+
print(custom_optim)
|
| 531 |
+
```
|
| 532 |
+
|
| 533 |
+
```
|
| 534 |
+
<my_module.CustomOptim object at 0x7f6983a87970>
|
| 535 |
+
```
|
| 536 |
+
|
| 537 |
+
### 跨项目继承配置文件
|
| 538 |
+
|
| 539 |
+
为了避免基于已有算法库开发新项目时需要复制大量的配置文件,MMEngine 的配置类支持配置文件的跨项目继承。例如我们基于 MMDetection 开发新的算法库,需要使用以下 MMDetection 的配置文件:
|
| 540 |
+
|
| 541 |
+
```text
|
| 542 |
+
configs/_base_/schedules/schedule_1x.py
|
| 543 |
+
configs/_base_/datasets.coco_instance.py
|
| 544 |
+
configs/_base_/default_runtime.py
|
| 545 |
+
configs/_base_/models/faster-rcnn_r50_fpn.py
|
| 546 |
+
```
|
| 547 |
+
|
| 548 |
+
如果没有配置文件跨项目继承的功能,我们就需要把 MMDetection 的配置文件拷贝到当前项目,而我们现在只需要安装 MMDetection(如使用 `mim install mmdet`),在新项目的配置文件���按照以下方式继承 MMDetection 的配置文件:
|
| 549 |
+
|
| 550 |
+
`cross_repo.py`
|
| 551 |
+
|
| 552 |
+
```python
|
| 553 |
+
_base_ = [
|
| 554 |
+
'mmdet::_base_/schedules/schedule_1x.py',
|
| 555 |
+
'mmdet::_base_/datasets/coco_instance.py',
|
| 556 |
+
'mmdet::_base_/default_runtime.py',
|
| 557 |
+
'mmdet::_base_/models/faster-rcnn_r50_fpn.py',
|
| 558 |
+
]
|
| 559 |
+
```
|
| 560 |
+
|
| 561 |
+
我们可以像加载普通配置文件一样加载 `cross_repo.py`
|
| 562 |
+
|
| 563 |
+
```python
|
| 564 |
+
cfg = Config.fromfile('cross_repo.py')
|
| 565 |
+
print(cfg.train_cfg)
|
| 566 |
+
```
|
| 567 |
+
|
| 568 |
+
```
|
| 569 |
+
{'type': 'EpochBasedTrainLoop', 'max_epochs': 12, 'val_interval': 1, '_scope_': 'mmdet'}
|
| 570 |
+
```
|
| 571 |
+
|
| 572 |
+
通过指定 `mmdet::`,Config 类会去检索 mmdet 包中的配置文件目录,并继承指定的配置文件。实际上,只要算法库的 `setup.py` 文件符合 [MMEngine 安装规范](todo),在正确安装算法库以后,新的项目就可以使用上述用法去继承已有算法库的配置文件而无需拷贝。
|
| 573 |
+
|
| 574 |
+
### 跨项目获取配置文件
|
| 575 |
+
|
| 576 |
+
MMEngine 还提供了 `get_config` 和 `get_model` 两个接口,支持对符合 [MMEngine 安装规范](todo) 的算法库中的模型和配置文件做索引并进行 API 调用。通过 `get_model` 接口可以获得构建好的模型。通过 `get_config` 接口可以获得配置文件。
|
| 577 |
+
|
| 578 |
+
`get_model` 的使用样例如下所示,使用和跨项目继承配置文件相同的语法,指定 `mmdet::`,即可在 mmdet 包中检索对应的配置文件并构建和初始化相应模型。用户可以通过指定 `pretrained=True` 获得已经加载预训练权重的模型以进行训练或者推理。
|
| 579 |
+
|
| 580 |
+
```python
|
| 581 |
+
from mmengine.hub import get_model
|
| 582 |
+
|
| 583 |
+
model = get_model(
|
| 584 |
+
'mmdet::faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py', pretrained=True)
|
| 585 |
+
print(type(model))
|
| 586 |
+
```
|
| 587 |
+
|
| 588 |
+
```
|
| 589 |
+
http loads checkpoint from path: https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
|
| 590 |
+
<class 'mmdet.models.detectors.faster_rcnn.FasterRCNN'>
|
| 591 |
+
```
|
| 592 |
+
|
| 593 |
+
`get_config` 的使用样例如下所示,使用和跨项目继承配置文件相同的语法,指定 `mmdet::`,即可实现去 mmdet 包中检索并加载对应的配置文件。用户可以基于这样得到的配置文件进行推理修改并自定义自己的算法模型。同时,如果用户指定 `pretrained=True`,得到的配置文件中会新增 `model_path` 字段,指定了对应模型预训练权重的路径。
|
| 594 |
+
|
| 595 |
+
```python
|
| 596 |
+
from mmengine.hub import get_config
|
| 597 |
+
|
| 598 |
+
cfg = get_config(
|
| 599 |
+
'mmdet::faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py', pretrained=True)
|
| 600 |
+
print(cfg.model_path)
|
| 601 |
+
|
| 602 |
+
```
|
| 603 |
+
|
| 604 |
+
```
|
| 605 |
+
https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
|
| 606 |
+
```
|
testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/cross_library.md
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 跨库调用模块
|
| 2 |
+
|
| 3 |
+
通过使用 MMEngine 的[注册器(Registry)](registry.md)和[配置文件(Config)](config.md),用户可以实现跨软件包的模块构建。
|
| 4 |
+
例如,在 [MMDetection](https://github.com/open-mmlab/mmdetection) 中使用 [MMClassification](https://github.com/open-mmlab/mmclassification) 的 Backbone,或者在 [MMRotate](https://github.com/open-mmlab/mmrotate) 中使用 [MMDetection](https://github.com/open-mmlab/mmdetection) 的 Transform,或者在 [MMTracking](https://github.com/open-mmlab/mmtracking) 中使用 [MMDetection](https://github.com/open-mmlab/mmdetection) 的 Detector。
|
| 5 |
+
一般来说,同类模块都可以进行跨库调用,只需要在配置文件的模块类型前加上软件包名的前缀即可。下面举几个常见的例子:
|
| 6 |
+
|
| 7 |
+
## 跨库调用 Backbone:
|
| 8 |
+
|
| 9 |
+
以在 MMDetection 中调用 MMClassification 的 ConvNeXt 为例,首先需要在配置中加入 `custom_imports` 字段将 MMClassification 的 Backbone 添加进注册器,然后只需要在 Backbone 的配置中的 `type` 加上 MMClassification 的软件包名 `mmcls` 作为前缀,即 `mmcls.ConvNeXt` 即可:
|
| 10 |
+
|
| 11 |
+
```python
|
| 12 |
+
# 使用 custom_imports 将 mmcls 的 models 添加进注册器
|
| 13 |
+
custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
|
| 14 |
+
|
| 15 |
+
model = dict(
|
| 16 |
+
type='MaskRCNN',
|
| 17 |
+
data_preprocessor=dict(...),
|
| 18 |
+
backbone=dict(
|
| 19 |
+
type='mmcls.ConvNeXt', # 添加 mmcls 前缀完成跨库调用
|
| 20 |
+
arch='tiny',
|
| 21 |
+
out_indices=[0, 1, 2, 3],
|
| 22 |
+
drop_path_rate=0.4,
|
| 23 |
+
layer_scale_init_value=1.0,
|
| 24 |
+
gap_before_final_norm=False,
|
| 25 |
+
init_cfg=dict(
|
| 26 |
+
type='Pretrained',
|
| 27 |
+
checkpoint=
|
| 28 |
+
'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth',
|
| 29 |
+
prefix='backbone.')),
|
| 30 |
+
neck=dict(...),
|
| 31 |
+
rpn_head=dict(...))
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
## 跨库调用 Transform:
|
| 35 |
+
|
| 36 |
+
与上文的跨库调用 Backbone 一样,使用 custom_imports 和添加前缀即可实现跨库调用:
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
# 使用 custom_imports 将 mmdet 的 transforms 添加进注册器
|
| 40 |
+
custom_imports = dict(imports=['mmdet.datasets.transforms'], allow_failed_imports=False)
|
| 41 |
+
|
| 42 |
+
# 添加 mmdet 前缀完成跨库调用
|
| 43 |
+
train_pipeline=[
|
| 44 |
+
dict(type='mmdet.LoadImageFromFile'),
|
| 45 |
+
dict(type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
|
| 46 |
+
dict(type='ConvertBoxType', box_type_mapping=dict(gt_bboxes='rbox')),
|
| 47 |
+
dict(type='mmdet.Resize', scale=(1024, 2014), keep_ratio=True),
|
| 48 |
+
dict(type='mmdet.RandomFlip', prob=0.5),
|
| 49 |
+
dict(type='mmdet.PackDetInputs')
|
| 50 |
+
]
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
## 跨库调用 Detector:
|
| 54 |
+
|
| 55 |
+
跨库调用算法是一个比较复杂的例子,一个算法会包含多个子模块,因此每个子模块也需要在`type`中增加前缀,以在 MMTracking 中调用 MMDetection 的 YOLOX 为例:
|
| 56 |
+
|
| 57 |
+
```python
|
| 58 |
+
# 使用 custom_imports 将 mmdet 的 models 添加进注册器
|
| 59 |
+
custom_imports = dict(imports=['mmdet.models'], allow_failed_imports=False)
|
| 60 |
+
model = dict(
|
| 61 |
+
type='mmdet.YOLOX',
|
| 62 |
+
backbone=dict(type='mmdet.CSPDarknet', deepen_factor=1.33, widen_factor=1.25),
|
| 63 |
+
neck=dict(
|
| 64 |
+
type='mmdet.YOLOXPAFPN',
|
| 65 |
+
in_channels=[320, 640, 1280],
|
| 66 |
+
out_channels=320,
|
| 67 |
+
num_csp_blocks=4),
|
| 68 |
+
bbox_head=dict(
|
| 69 |
+
type='mmdet.YOLOXHead', num_classes=1, in_channels=320, feat_channels=320),
|
| 70 |
+
train_cfg=dict(assigner=dict(type='mmdet.SimOTAAssigner', center_radius=2.5)))
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
为了避免给每个子模块手动增加前缀,配置文件中引入了 `_scope_` 关键字,当某一模块的配置中添加了 `_scope_` 关键字后,该模块配置文件下面的所有子模块配置都会从该关键字所对应的软件包内去构建:
|
| 74 |
+
|
| 75 |
+
```python
|
| 76 |
+
# 使用 custom_imports 将 mmdet 的 models 添加进注册器
|
| 77 |
+
custom_imports = dict(imports=['mmdet.models'], allow_failed_imports=False)
|
| 78 |
+
model = dict(
|
| 79 |
+
_scope_='mmdet', # 使用 _scope_ 关键字,避免给所有子模块添加前缀
|
| 80 |
+
type='YOLOX',
|
| 81 |
+
backbone=dict(type='CSPDarknet', deepen_factor=1.33, widen_factor=1.25),
|
| 82 |
+
neck=dict(
|
| 83 |
+
type='YOLOXPAFPN',
|
| 84 |
+
in_channels=[320, 640, 1280],
|
| 85 |
+
out_channels=320,
|
| 86 |
+
num_csp_blocks=4),
|
| 87 |
+
bbox_head=dict(
|
| 88 |
+
type='YOLOXHead', num_classes=1, in_channels=320, feat_channels=320),
|
| 89 |
+
train_cfg=dict(assigner=dict(type='SimOTAAssigner', center_radius=2.5)))
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
以上这两种写法互相等价。
|
| 93 |
+
|
| 94 |
+
若希望了解更多关于注册器和配置文件的内容,请参考[配置文件教程](config.md)和[注册器教程](registry.md)
|
testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/data_element.md
ADDED
|
@@ -0,0 +1,1097 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 抽象数据接口
|
| 2 |
+
|
| 3 |
+
在模型的训练/测试过程中,组件之间往往有大量的数据需要传递,不同的算法需要传递的数据经常是不一样的,例如,训练单阶段检测器需要获得数据集的标注框(ground truth bounding boxes)和标签(ground truth box labels),训练 Mask R-CNN 时还需要实例掩码(instance masks)。
|
| 4 |
+
训练这些模型时的代码如下所示
|
| 5 |
+
|
| 6 |
+
```python
|
| 7 |
+
for img, img_metas, gt_bboxes, gt_labels in data_loader:
|
| 8 |
+
loss = retinanet(img, img_metas, gt_bboxes, gt_labels)
|
| 9 |
+
```
|
| 10 |
+
|
| 11 |
+
```python
|
| 12 |
+
for img, img_metas, gt_bboxes, gt_masks, gt_labels in data_loader:
|
| 13 |
+
loss = mask_rcnn(img, img_metas, gt_bboxes, gt_masks, gt_labels)
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
可以发现,在不加封装的情况下,不同算法所需数据的不一致导致了不同算法模块之间接口的不一致,影响了算法库的拓展性,同时一个算法库内的模块为了保持兼容性往往在接口上存在冗余。
|
| 17 |
+
上述弊端在算法库之间会体现地更加明显,导致在实现多任务(同时进行如语义分割、检测、关键点检测等多个任务)感知模型时模块难以复用,接口难以拓展。
|
| 18 |
+
|
| 19 |
+
为了解决上述问题,MMEngine 定义了一套抽象的数据接口来封装模型运行过程中的各种数据。假设将上述不同的数据封装进 `data_sample` ,不同算法的训练都可以被抽象和统一成如下代码
|
| 20 |
+
|
| 21 |
+
```python
|
| 22 |
+
for img, data_sample in dataloader:
|
| 23 |
+
loss = model(img, data_sample)
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
通过对各种数据提供统一的封装,抽象数据接口统一并简化了算法库中各个模块的接口,可以被用于算法库中 dataset,model,visualizer,和 evaluator 组件之间,或者 model 内各个模块之间的数据传递。
|
| 27 |
+
抽象数据接口实现了基本的增/删/改/查功能,同时支持不同设备之间的迁移,支持类字典和张量的操作,可以充分满足算法库对于这些数据的使用要求。
|
| 28 |
+
基于 MMEngine 的算法库可以继承这套抽象数据接口并实现自己的抽象数据接口来适应不同算法中数据的特点与实际需要,在保持统一接口的同时提高了算法模块的拓展性。
|
| 29 |
+
|
| 30 |
+
在实际实现过程中,算法库中的各个组件所具备的数据接口,一般为如下两个种:
|
| 31 |
+
|
| 32 |
+
- 一个训练或测试样本(例如一张图像)的所有的标注信息和预测信息的集合,例如数据集的输出、模型以及可视化器的输入一般为单个训练或测试样本的所有信息。MMEngine将其定义为数据样本(DataSample)
|
| 33 |
+
- 单一类型的预测或标注,一般是算法模型中某个子模块的输出, 例如二阶段检测中RPN的输出、语义分割模型的输出、关键点分支的输出, GAN中生成器的输出等。MMengine将其定义为数据元素(XXXData)
|
| 34 |
+
|
| 35 |
+
下边首先介绍一下数据样本与数据元素的基类 [BaseDataElement](mmengine.structures.BaseDataElement)。
|
| 36 |
+
|
| 37 |
+
## 数据基类(BaseDataElement)
|
| 38 |
+
|
| 39 |
+
`BaseDataElement` 中存在两种类型的数据,一种是 `data` 类型,如标注框、框的标签、和实例掩码等;另一种是 `metainfo` 类型,包含数据的元信息以确保数据的完整性,如 `img_shape`, `img_id` 等数据所在图片的一些基本信息,方便可视化等情况下对数据进行恢复和使用。用户在创建 `BaseDataElement` 的过程中需要对这两类属性的数据进行显式地区分和声明。
|
| 40 |
+
|
| 41 |
+
为了能够更加方便地使用 `BaseDataElement`,`data` 和 `metainfo` 中的数据均为 `BaseDataElement` 的属性。我们可以通过访问类属性的方式直接访问 `data` 和 `metainfo` 中的数据。此外,`BaseDataElement` 还提供了很多方法,方便我们操作 `data` 内的数据:
|
| 42 |
+
|
| 43 |
+
- 增/删/改/查 `data` 中不同字段的数据
|
| 44 |
+
- 将 `data` 迁移至目标设备
|
| 45 |
+
- 支持像访问字典/张量一样访问 data 内的数据
|
| 46 |
+
以充分满足算法库对于这些数据的使用要求。
|
| 47 |
+
|
| 48 |
+
### 1. 数据元素的创建
|
| 49 |
+
|
| 50 |
+
`BaseDataElement` 的 data 参数可以直接通过 `key=value` 的方式自由添加,metainfo 的字段需要显式通过关键字 `metainfo` 指定。
|
| 51 |
+
|
| 52 |
+
```python
|
| 53 |
+
import torch
|
| 54 |
+
from mmengine.structures import BaseDataElement
|
| 55 |
+
# 可以声明一个空的 object
|
| 56 |
+
data_element = BaseDataElement()
|
| 57 |
+
|
| 58 |
+
bboxes = torch.rand((5, 4)) # 假定 bboxes 是一个 Nx4 维的 tensor,N 代表框的个数
|
| 59 |
+
scores = torch.rand((5,)) # 假定框的分数是一个 N 维的 tensor,N 代表框的个数
|
| 60 |
+
img_id = 0 # 图像的 ID
|
| 61 |
+
H = 800 # 图像的高度
|
| 62 |
+
W = 1333 # 图像的宽度
|
| 63 |
+
|
| 64 |
+
# 直接设置 BaseDataElement 的 data 参数
|
| 65 |
+
data_element = BaseDataElement(bboxes=bboxes, scores=scores)
|
| 66 |
+
|
| 67 |
+
# 显式声明来设置 BaseDataElement 的参数 metainfo
|
| 68 |
+
data_element = BaseDataElement(
|
| 69 |
+
bboxes=bboxes,
|
| 70 |
+
scores=scores,
|
| 71 |
+
metainfo=dict(img_id=img_id, img_shape=(H, W)))
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
### 2. `new` 与 `clone` 函数
|
| 75 |
+
|
| 76 |
+
用户可以使用 `new()` 函数通过已有的数据接口创建一个具有相同状态和数据的抽象数据接口。用户可以在创��新 `BaseDataElement` 时设置 `metainfo` 和 `data`,用于创建仅 `data` 或 `metainfo` 具有相同状态和数据的抽象接口。比如 `new(metainfo=xx)` 使得新的 `BaseDataElement` 与被 clone 的 `BaseDataElement` 包含相同的 `data` 内容,但 `metainfo` 为新设置的内容。
|
| 77 |
+
也可以直接使用 `clone()` 来获得一份深拷贝,`clone()` 函数的行为与 PyTorch 中 Tensor 的 `clone()` 参数保持一致。
|
| 78 |
+
|
| 79 |
+
```python
|
| 80 |
+
data_element = BaseDataElement(
|
| 81 |
+
bboxes=torch.rand((5, 4)),
|
| 82 |
+
scores=torch.rand((5,)),
|
| 83 |
+
metainfo=dict(img_id=1, img_shape=(640, 640)))
|
| 84 |
+
|
| 85 |
+
# 可以在创建新 `BaseDataElement` 时设置 metainfo 和 data,使得新的 BaseDataElement 有相同未被设置的数据
|
| 86 |
+
data_element1 = data_element.new(metainfo=dict(img_id=2, img_shape=(320, 320)))
|
| 87 |
+
print('bboxes is in data_element1:', 'bboxes' in data_element1) # True
|
| 88 |
+
print('bboxes in data_element1 is same as bbox in data_element', (data_element1.bboxes == data_element.bboxes).all())
|
| 89 |
+
print('img_id in data_element1 is', data_element1.img_id == 2) # True
|
| 90 |
+
|
| 91 |
+
data_element2 = data_element.new(label=torch.rand(5,))
|
| 92 |
+
print('bboxes is not in data_element2', 'bboxes' not in data_element2) # True
|
| 93 |
+
print('img_id in data_element2 is same as img_id in data_element', data_element2.img_id == data_element.img_id)
|
| 94 |
+
print('label in data_element2 is', 'label' in data_element2)
|
| 95 |
+
|
| 96 |
+
# 也可以通过 `clone` 构建一个新的 object,新的 object 会拥有和 data_element 相同的 data 和 metainfo 内容以及状态。
|
| 97 |
+
data_element2 = data_element1.clone()
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
```
|
| 101 |
+
bboxes is in data_element1: True
|
| 102 |
+
bboxes in data_element1 is same as bbox in data_element tensor(True)
|
| 103 |
+
img_id in data_element1 is True
|
| 104 |
+
bboxes is not in data_element2 True
|
| 105 |
+
img_id in data_element2 is same as img_id in data_element True
|
| 106 |
+
label in data_element2 is True
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
### 3. 属性的增加与查询
|
| 110 |
+
|
| 111 |
+
对增加属性而言,用户可以像增加类属性那样增加 `data` 内的属性;对`metainfo` 而言,一般储存的为一些图像的元信息,一般情况下不会修改,如果需要增加,用户应当使用 `set_metainfo` 接口显示地修改。
|
| 112 |
+
|
| 113 |
+
对查询而言,用户可以可以通过 `keys`,`values`,和 `items` 来访问只存在于 data 中的键值,也可以通过 `metainfo_keys`,`metainfo_values`,和`metainfo_items` 来访问只存在于 metainfo 中的键值。
|
| 114 |
+
用户还能通过 `all_keys`,`all_values`, `all_items` 来访问 `BaseDataElement` 的所有的属性并且不区分他们的类型。
|
| 115 |
+
|
| 116 |
+
同时为了方便使用,用户可以像访问类属性一样访问 data 与 metainfo 内的数据,或着类字典方式通过 `get()` 接口访问数据。
|
| 117 |
+
|
| 118 |
+
**注意:**
|
| 119 |
+
|
| 120 |
+
1. `BaseDataElement` 不支持 metainfo 和 data 属性中有同名的字段,所以用户应当避免 metainfo 和 data 属性中设置相同的字段,否则 `BaseDataElement` 会报错。
|
| 121 |
+
2. 考虑到 `InstanceData` 和 `PixelData` 支持对数据进行切片操作,为了避免 `[]` 用法的不一致,同时减少同种需求的不同方法,`BaseDataElement` 不支持像字典那样访问和设置它的属性,所以类似 `BaseDataElement[name]` 的取值赋值操作是不被支持的。
|
| 122 |
+
|
| 123 |
+
```python
|
| 124 |
+
data_element = BaseDataElement()
|
| 125 |
+
# 通过 `set_metainfo`设置 data_element 的 metainfo 字段,
|
| 126 |
+
# 同时 img_id 和 img_shape 成为 data_element 的属性
|
| 127 |
+
data_element.set_metainfo(dict(img_id=9, img_shape=(100, 100)))
|
| 128 |
+
# 查看 metainfo 的 key, value 和 item
|
| 129 |
+
print("metainfo'keys are", data_element.metainfo_keys())
|
| 130 |
+
print("metainfo'values are", data_element.metainfo_values())
|
| 131 |
+
for k, v in data_element.metainfo_items():
|
| 132 |
+
print(f'{k}: {v}')
|
| 133 |
+
|
| 134 |
+
print("通过类属性查看 img_id 和 img_shape")
|
| 135 |
+
print('img_id:', data_element.img_id)
|
| 136 |
+
print('img_shape:', data_element.img_shape)
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
```
|
| 140 |
+
metainfo'keys are ['img_id', 'img_shape']
|
| 141 |
+
metainfo'values are [9, (100, 100)]
|
| 142 |
+
img_id: 9
|
| 143 |
+
img_shape: (100, 100)
|
| 144 |
+
通过类属性查看 img_id 和 img_shape
|
| 145 |
+
img_id: 9
|
| 146 |
+
img_shape: (100, 100)
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
+
```python
|
| 150 |
+
|
| 151 |
+
# 通过类属性直接设置 BaseDataElement 中的 data 字段
|
| 152 |
+
data_element.scores = torch.rand((5,))
|
| 153 |
+
data_element.bboxes = torch.rand((5, 4))
|
| 154 |
+
|
| 155 |
+
print("data's key is:", data_element.keys())
|
| 156 |
+
print("data's value is:", data_element.values())
|
| 157 |
+
for k, v in data_element.items():
|
| 158 |
+
print(f'{k}: {v}')
|
| 159 |
+
|
| 160 |
+
print("通过类属性查看 scores 和 bboxes")
|
| 161 |
+
print('scores:', data_element.scores)
|
| 162 |
+
print('bboxes:', data_element.bboxes)
|
| 163 |
+
|
| 164 |
+
print("通过 get() 查看 scores 和 bboxes")
|
| 165 |
+
print('scores:', data_element.get('scores', None))
|
| 166 |
+
print('bboxes:', data_element.get('bboxes', None))
|
| 167 |
+
print('fake:', data_element.get('fake', 'not exist'))
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
```
|
| 171 |
+
data's key is: ['scores', 'bboxes']
|
| 172 |
+
data's value is: [tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515]), tensor([[0.9204, 0.2110, 0.2886, 0.7925],
|
| 173 |
+
[0.7993, 0.8982, 0.5698, 0.4120],
|
| 174 |
+
[0.7085, 0.7016, 0.3069, 0.3216],
|
| 175 |
+
[0.0206, 0.5253, 0.1376, 0.9322],
|
| 176 |
+
[0.2512, 0.7683, 0.3010, 0.2672]])]
|
| 177 |
+
scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
|
| 178 |
+
bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
|
| 179 |
+
[0.7993, 0.8982, 0.5698, 0.4120],
|
| 180 |
+
[0.7085, 0.7016, 0.3069, 0.3216],
|
| 181 |
+
[0.0206, 0.5253, 0.1376, 0.9322],
|
| 182 |
+
[0.2512, 0.7683, 0.3010, 0.2672]])
|
| 183 |
+
通过类属性查看 scores 和 bboxes
|
| 184 |
+
scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
|
| 185 |
+
bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
|
| 186 |
+
[0.7993, 0.8982, 0.5698, 0.4120],
|
| 187 |
+
[0.7085, 0.7016, 0.3069, 0.3216],
|
| 188 |
+
[0.0206, 0.5253, 0.1376, 0.9322],
|
| 189 |
+
[0.2512, 0.7683, 0.3010, 0.2672]])
|
| 190 |
+
通过 get() 查看 scores 和 bboxes
|
| 191 |
+
scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
|
| 192 |
+
bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
|
| 193 |
+
[0.7993, 0.8982, 0.5698, 0.4120],
|
| 194 |
+
[0.7085, 0.7016, 0.3069, 0.3216],
|
| 195 |
+
[0.0206, 0.5253, 0.1376, 0.9322],
|
| 196 |
+
[0.2512, 0.7683, 0.3010, 0.2672]])
|
| 197 |
+
fake: not exist
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
```python
|
| 201 |
+
|
| 202 |
+
print("All key in data_element is:", data_element.all_keys())
|
| 203 |
+
print("The length of values in data_element is", len(data_element.all_values()))
|
| 204 |
+
for k, v in data_element.all_items():
|
| 205 |
+
print(f'{k}: {v}')
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
```
|
| 209 |
+
All key in data_element is: ['img_id', 'img_shape', 'scores', 'bboxes']
|
| 210 |
+
The length of values in data_element is 4
|
| 211 |
+
img_id: 9
|
| 212 |
+
img_shape: (100, 100)
|
| 213 |
+
scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
|
| 214 |
+
bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
|
| 215 |
+
[0.7993, 0.8982, 0.5698, 0.4120],
|
| 216 |
+
[0.7085, 0.7016, 0.3069, 0.3216],
|
| 217 |
+
[0.0206, 0.5253, 0.1376, 0.9322],
|
| 218 |
+
[0.2512, 0.7683, 0.3010, 0.2672]])
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
### 4. 属性的删改
|
| 222 |
+
|
| 223 |
+
用户可以像修改实例属性一样修改 `BaseDataElement` 的 `data`, 对`metainfo` 而言 一般储存的为一些图像的元信息,一般情况下不会修改,如果需要修改,用户应当使用 `set_metainfo` 接口显示的修改。
|
| 224 |
+
|
| 225 |
+
同时为了操作的便捷性,对 `data` 和 `metainfo` 中的数据可以通过 `del` 直接删除,也支持 `pop` 在访问属性后删除属性。
|
| 226 |
+
|
| 227 |
+
```python
|
| 228 |
+
data_element = BaseDataElement(
|
| 229 |
+
bboxes=torch.rand((6, 4)), scores=torch.rand((6,)),
|
| 230 |
+
metainfo=dict(img_id=0, img_shape=(640, 640))
|
| 231 |
+
)
|
| 232 |
+
for k, v in data_element.all_items():
|
| 233 |
+
print(f'{k}: {v}')
|
| 234 |
+
```
|
| 235 |
+
|
| 236 |
+
```
|
| 237 |
+
img_id: 0
|
| 238 |
+
img_shape: (640, 640)
|
| 239 |
+
scores: tensor([0.8445, 0.6678, 0.8172, 0.9125, 0.7186, 0.5462])
|
| 240 |
+
bboxes: tensor([[0.5773, 0.0289, 0.4793, 0.7573],
|
| 241 |
+
[0.8187, 0.8176, 0.3455, 0.3368],
|
| 242 |
+
[0.6947, 0.5592, 0.7285, 0.0281],
|
| 243 |
+
[0.7710, 0.9867, 0.7172, 0.5815],
|
| 244 |
+
[0.3999, 0.9192, 0.7817, 0.2535],
|
| 245 |
+
[0.2433, 0.0132, 0.1757, 0.6196]])
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
```python
|
| 249 |
+
# 对 data 进行修改
|
| 250 |
+
data_element.bboxes = data_element.bboxes * 2
|
| 251 |
+
data_element.scores = data_element.scores * -1
|
| 252 |
+
for k, v in data_element.items():
|
| 253 |
+
print(f'{k}: {v}')
|
| 254 |
+
|
| 255 |
+
# 删除 data 中的属性
|
| 256 |
+
del data_element.bboxes
|
| 257 |
+
for k, v in data_element.items():
|
| 258 |
+
print(f'{k}: {v}')
|
| 259 |
+
|
| 260 |
+
data_element.pop('scores', None)
|
| 261 |
+
print('The keys in data is', data_element.keys())
|
| 262 |
+
```
|
| 263 |
+
|
| 264 |
+
```
|
| 265 |
+
scores: tensor([-0.8445, -0.6678, -0.8172, -0.9125, -0.7186, -0.5462])
|
| 266 |
+
bboxes: tensor([[1.1546, 0.0578, 0.9586, 1.5146],
|
| 267 |
+
[1.6374, 1.6352, 0.6911, 0.6735],
|
| 268 |
+
[1.3893, 1.1185, 1.4569, 0.0562],
|
| 269 |
+
[1.5420, 1.9734, 1.4344, 1.1630],
|
| 270 |
+
[0.7999, 1.8384, 1.5635, 0.5070],
|
| 271 |
+
[0.4867, 0.0264, 0.3514, 1.2392]])
|
| 272 |
+
scores: tensor([-0.8445, -0.6678, -0.8172, -0.9125, -0.7186, -0.5462])
|
| 273 |
+
The keys in data is []
|
| 274 |
+
```
|
| 275 |
+
|
| 276 |
+
```python
|
| 277 |
+
# 对 metainfo 进行修改
|
| 278 |
+
data_element.set_metainfo(dict(img_shape = (1280, 1280), img_id=10))
|
| 279 |
+
print(data_element.img_shape) # (1280, 1280)
|
| 280 |
+
for k, v in data_element.metainfo_items():
|
| 281 |
+
print(f'{k}: {v}')
|
| 282 |
+
|
| 283 |
+
# 提供了便捷的属性删除和访问操作 pop
|
| 284 |
+
del data_element.img_shape
|
| 285 |
+
for k, v in data_element.metainfo_items():
|
| 286 |
+
print(f'{k}: {v}')
|
| 287 |
+
|
| 288 |
+
data_element.pop('img_id')
|
| 289 |
+
print('The keys in metainfo is', data_element.metainfo_keys())
|
| 290 |
+
```
|
| 291 |
+
|
| 292 |
+
```
|
| 293 |
+
(1280, 1280)
|
| 294 |
+
img_id: 10
|
| 295 |
+
img_shape: (1280, 1280)
|
| 296 |
+
img_id: 10
|
| 297 |
+
The keys in metainfo is []
|
| 298 |
+
```
|
| 299 |
+
|
| 300 |
+
### 5. 类张量操作
|
| 301 |
+
|
| 302 |
+
用户可以像 torch.Tensor 那样对 `BaseDataElement` 的 data 进行状态转换,目前支持 `cuda`, `cpu`, `to`, `numpy` 等操作。
|
| 303 |
+
其中,`to` 函数拥有和 `torch.Tensor.to()` 相同的接口,使得用户可以灵活地将被封装的 tensor 进行状态转换。
|
| 304 |
+
**注意:** 这些接口只会处理类型为 np.array,torch.Tensor,或者数字的序列,其他属性的数据(如字符串)会被跳过处理。
|
| 305 |
+
|
| 306 |
+
```python
|
| 307 |
+
data_element = BaseDataElement(
|
| 308 |
+
bboxes=torch.rand((6, 4)), scores=torch.rand((6,)),
|
| 309 |
+
metainfo=dict(img_id=0, img_shape=(640, 640))
|
| 310 |
+
)
|
| 311 |
+
# 将所有 data 转移到 GPU 上
|
| 312 |
+
cuda_element_1 = data_element.cuda()
|
| 313 |
+
print('cuda_element_1 is on the device of', cuda_element_1.bboxes.device) # cuda:0
|
| 314 |
+
cuda_element_2 = data_element.to('cuda:0')
|
| 315 |
+
print('cuda_element_1 is on the device of', cuda_element_2.bboxes.device) # cuda:0
|
| 316 |
+
|
| 317 |
+
# 将所有 data 转移到 cpu 上
|
| 318 |
+
cpu_element_1 = cuda_element_1.cpu()
|
| 319 |
+
print('cpu_element_1 is on the device of', cpu_element_1.bboxes.device) # cpu
|
| 320 |
+
cpu_element_2 = cuda_element_2.to('cpu')
|
| 321 |
+
print('cpu_element_2 is on the device of', cpu_element_2.bboxes.device) # cpu
|
| 322 |
+
|
| 323 |
+
# 将所有 data 变成 FP16
|
| 324 |
+
fp16_instances = cuda_element_1.to(
|
| 325 |
+
device=None, dtype=torch.float16, non_blocking=False, copy=False,
|
| 326 |
+
memory_format=torch.preserve_format)
|
| 327 |
+
print('The type of bboxes in fp16_instances is', fp16_instances.bboxes.dtype) # torch.float16
|
| 328 |
+
|
| 329 |
+
# 阻断所有 data 的梯度
|
| 330 |
+
cuda_element_3 = cuda_element_2.detach()
|
| 331 |
+
print('The data in cuda_element_3 requires grad: ', cuda_element_3.bboxes.requires_grad)
|
| 332 |
+
# 转移 data 到 numpy array
|
| 333 |
+
np_instances = cpu_element_1.numpy()
|
| 334 |
+
print('The type of cpu_element_1 is convert to', type(np_instances.bboxes))
|
| 335 |
+
```
|
| 336 |
+
|
| 337 |
+
```
|
| 338 |
+
cuda_element_1 is on the device of cuda:0
|
| 339 |
+
cuda_element_1 is on the device of cuda:0
|
| 340 |
+
cpu_element_1 is on the device of cpu
|
| 341 |
+
cpu_element_2 is on the device of cpu
|
| 342 |
+
The type of bboxes in fp16_instances is torch.float16
|
| 343 |
+
The data in cuda_element_3 requires grad: False
|
| 344 |
+
The type of cpu_element_1 is convert to <class 'numpy.ndarray'>
|
| 345 |
+
```
|
| 346 |
+
|
| 347 |
+
### 6. 属性的展示
|
| 348 |
+
|
| 349 |
+
`BaseDataElement` 还实现了 `__repr__`,因此,用户可以直接通过 `print` 函数看到其中的所有数据信息。
|
| 350 |
+
同时,为了便捷开发者 debug,`BaseDataElement` 中的属性都会添加进 `__dict__` 中,方便用户在 IDE 界面可以直观看到 `BaseDataElement` 中的内容。
|
| 351 |
+
一个完整的属性展示如下
|
| 352 |
+
|
| 353 |
+
```python
|
| 354 |
+
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
|
| 355 |
+
instance_data = BaseDataElement(metainfo=img_meta)
|
| 356 |
+
instance_data.det_labels = torch.LongTensor([0, 1, 2, 3])
|
| 357 |
+
instance_data.det_scores = torch.Tensor([0.01, 0.1, 0.2, 0.3])
|
| 358 |
+
print(instance_data)
|
| 359 |
+
```
|
| 360 |
+
|
| 361 |
+
```
|
| 362 |
+
<BaseDataElement(
|
| 363 |
+
|
| 364 |
+
META INFORMATION
|
| 365 |
+
pad_shape: (800, 1216, 3)
|
| 366 |
+
img_shape: (800, 1196, 3)
|
| 367 |
+
|
| 368 |
+
DATA FIELDS
|
| 369 |
+
det_labels: tensor([0, 1, 2, 3])
|
| 370 |
+
det_scores: tensor([0.0100, 0.1000, 0.2000, 0.3000])
|
| 371 |
+
) at 0x7f9f339f85b0>
|
| 372 |
+
```
|
| 373 |
+
|
| 374 |
+
## 数据元素(xxxData)
|
| 375 |
+
|
| 376 |
+
MMEngine 将数据元素情况划分为三个类别:
|
| 377 |
+
|
| 378 |
+
- 实例数据(InstanceData): 主要针对的是上层任务(high-level)中,对图像中所有实例相关的数据进行封装,比如检测框(bounding boxes), 物体类别(box labels),实例掩码(instance masks), 关键点(key points), 文字边界(polygons), 跟踪id(tracking ids) 等. 所有实例相关的数据的**长度一致**,均为图像中实例的个数。
|
| 379 |
+
- 像素数据(PixelData): 主要针对底层任务(low-level) 以及需要感知像素级别标签的部分上层任务。像素数据对像素级相关的数据进行封装,比如语义分割中的分割图(segmentation map), 光流任务中的光流图(flow map), 全景分割中的全景分割图(panoptic seg map);底层任务中生成的各种图像,比如超分辨图,去噪图,以及生成的各种风格图。这些数据的特点是都是三维或四维数组,最后两维度为数据的高度(height)和宽度(width),且具有相同的height和width
|
| 380 |
+
- 标签数据(LabelData): 主要标签级别的数据进行封装,比如图像分类,多分类中的类别,图像生成中生成图像的类别内容,或者文字识别中的文本等。
|
| 381 |
+
|
| 382 |
+
### InstanceData
|
| 383 |
+
|
| 384 |
+
[`InstanceData`](mmengine.structures.InstanceData) 在 `BaseDataElement` 的基础上,对 `data` 存储的数据做了限制,即要求存储在 `data` 中的数据的长度一致。比如在目标检测中, 假设一张图像中有 N 个目标(instance),可以将图像的所有边界框(bbox),类别(label)等存储在 `InstanceData` 中, `InstanceData` 的 bbox 和 label 的长度相同。
|
| 385 |
+
基于上述假定对 `InstanceData`进行了扩展,包括:
|
| 386 |
+
|
| 387 |
+
- 对 `InstanceData` 中 data 所存储的数据进行了长度校验
|
| 388 |
+
- data 部分支持类字典访问和设置它的属性
|
| 389 |
+
- 支持基础索引,切片以及高级索引功能
|
| 390 |
+
- 支持具有**相同的 `key`** 但是不同 `InstanceData` 的拼接功能。
|
| 391 |
+
这些扩展功能除了支持基础的数据结构, 比如`torch.tensor`, `numpy.dnarray`, `list`, `str`, `tuple`, 也可以是自定义的数据结构,只要自定义数据结构实现了 `__len__`, `__getitem__` and `cat`.
|
| 392 |
+
|
| 393 |
+
#### 数据校验
|
| 394 |
+
|
| 395 |
+
`InstanceData` 中 data 的数据长度要保持一致,如果传入不同长度的新数据,将会报错。
|
| 396 |
+
|
| 397 |
+
```python
|
| 398 |
+
from mmengine.structures import InstanceData
|
| 399 |
+
import torch
|
| 400 |
+
import numpy as np
|
| 401 |
+
|
| 402 |
+
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
|
| 403 |
+
instance_data = InstanceData(metainfo=img_meta)
|
| 404 |
+
instance_data.det_labels = torch.LongTensor([2, 3])
|
| 405 |
+
instance_data.det_scores = torch.Tensor([0.8, 0.7])
|
| 406 |
+
instance_data.bboxes = torch.rand((2, 4))
|
| 407 |
+
print('The length of instance_data is', len(instance_data)) # 2
|
| 408 |
+
|
| 409 |
+
instance_data.bboxes = torch.rand((3, 4))
|
| 410 |
+
```
|
| 411 |
+
|
| 412 |
+
```
|
| 413 |
+
The length of instance_data is 2
|
| 414 |
+
AssertionError: the length of values 3 is not consistent with the length of this :obj:`InstanceData` 2
|
| 415 |
+
```
|
| 416 |
+
|
| 417 |
+
### 类字典访问和设置属性
|
| 418 |
+
|
| 419 |
+
`InstanceData` 支持类似字典的操作访问和设置其 **data** 属性。
|
| 420 |
+
|
| 421 |
+
```python
|
| 422 |
+
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
|
| 423 |
+
instance_data = InstanceData(metainfo=img_meta)
|
| 424 |
+
instance_data["det_labels"] = torch.LongTensor([2, 3])
|
| 425 |
+
instance_data["det_scores"] = torch.Tensor([0.8, 0.7])
|
| 426 |
+
instance_data.bboxes = torch.rand((2, 4))
|
| 427 |
+
print(instance_data)
|
| 428 |
+
```
|
| 429 |
+
|
| 430 |
+
```
|
| 431 |
+
<InstanceData(
|
| 432 |
+
|
| 433 |
+
META INFORMATION
|
| 434 |
+
pad_shape: (800, 1216, 3)
|
| 435 |
+
img_shape: (800, 1196, 3)
|
| 436 |
+
|
| 437 |
+
DATA FIELDS
|
| 438 |
+
det_labels: tensor([2, 3])
|
| 439 |
+
det_scores: tensor([0.8000, 0.7000])
|
| 440 |
+
bboxes: tensor([[0.6576, 0.5435, 0.5253, 0.8273],
|
| 441 |
+
[0.4533, 0.6848, 0.7230, 0.9279]])
|
| 442 |
+
) at 0x7f9f339f8ca0>
|
| 443 |
+
```
|
| 444 |
+
|
| 445 |
+
#### 索引与切片
|
| 446 |
+
|
| 447 |
+
`InstanceData` 支持 Python 中类似列表的索引与切片,同时也支持类似 numpy 的高级索引操作。
|
| 448 |
+
|
| 449 |
+
```python
|
| 450 |
+
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
|
| 451 |
+
instance_data = InstanceData(metainfo=img_meta)
|
| 452 |
+
instance_data.det_labels = torch.LongTensor([2, 3])
|
| 453 |
+
instance_data.det_scores = torch.Tensor([0.8, 0.7])
|
| 454 |
+
instance_data.bboxes = torch.rand((2, 4))
|
| 455 |
+
print(instance_data)
|
| 456 |
+
```
|
| 457 |
+
|
| 458 |
+
```
|
| 459 |
+
<InstanceData(
|
| 460 |
+
|
| 461 |
+
META INFORMATION
|
| 462 |
+
pad_shape: (800, 1216, 3)
|
| 463 |
+
img_shape: (800, 1196, 3)
|
| 464 |
+
|
| 465 |
+
DATA FIELDS
|
| 466 |
+
det_labels: tensor([2, 3])
|
| 467 |
+
det_scores: tensor([0.8000, 0.7000])
|
| 468 |
+
bboxes: tensor([[0.1872, 0.1669, 0.7563, 0.8777],
|
| 469 |
+
[0.3421, 0.7104, 0.6000, 0.1518]])
|
| 470 |
+
) at 0x7f9f312b4dc0>
|
| 471 |
+
```
|
| 472 |
+
|
| 473 |
+
1. 索引
|
| 474 |
+
|
| 475 |
+
```python
|
| 476 |
+
print(instance_data[1])
|
| 477 |
+
```
|
| 478 |
+
|
| 479 |
+
```
|
| 480 |
+
<InstanceData(
|
| 481 |
+
|
| 482 |
+
META INFORMATION
|
| 483 |
+
pad_shape: (800, 1216, 3)
|
| 484 |
+
img_shape: (800, 1196, 3)
|
| 485 |
+
|
| 486 |
+
DATA FIELDS
|
| 487 |
+
det_labels: tensor([3])
|
| 488 |
+
det_scores: tensor([0.7000])
|
| 489 |
+
bboxes: tensor([[0.3421, 0.7104, 0.6000, 0.1518]])
|
| 490 |
+
) at 0x7f9f312b4610>
|
| 491 |
+
```
|
| 492 |
+
|
| 493 |
+
2. 切片
|
| 494 |
+
|
| 495 |
+
```python
|
| 496 |
+
print(instance_data[0:1])
|
| 497 |
+
```
|
| 498 |
+
|
| 499 |
+
```
|
| 500 |
+
<InstanceData(
|
| 501 |
+
|
| 502 |
+
META INFORMATION
|
| 503 |
+
pad_shape: (800, 1216, 3)
|
| 504 |
+
img_shape: (800, 1196, 3)
|
| 505 |
+
|
| 506 |
+
DATA FIELDS
|
| 507 |
+
det_labels: tensor([2])
|
| 508 |
+
det_scores: tensor([0.8000])
|
| 509 |
+
bboxes: tensor([[0.1872, 0.1669, 0.7563, 0.8777]])
|
| 510 |
+
) at 0x7f9f312b4e20>
|
| 511 |
+
```
|
| 512 |
+
|
| 513 |
+
3. 高级索引
|
| 514 |
+
|
| 515 |
+
- 列表索引
|
| 516 |
+
|
| 517 |
+
```python
|
| 518 |
+
sorted_results = instance_data[instance_data.det_scores.sort().indices]
|
| 519 |
+
print(sorted_results)
|
| 520 |
+
```
|
| 521 |
+
|
| 522 |
+
```
|
| 523 |
+
<InstanceData(
|
| 524 |
+
|
| 525 |
+
META INFORMATION
|
| 526 |
+
pad_shape: (800, 1216, 3)
|
| 527 |
+
img_shape: (800, 1196, 3)
|
| 528 |
+
|
| 529 |
+
DATA FIELDS
|
| 530 |
+
det_labels: tensor([3, 2])
|
| 531 |
+
det_scores: tensor([0.7000, 0.8000])
|
| 532 |
+
bboxes: tensor([[0.3421, 0.7104, 0.6000, 0.1518],
|
| 533 |
+
[0.1872, 0.1669, 0.7563, 0.8777]])
|
| 534 |
+
) at 0x7f9f312b4a90>
|
| 535 |
+
```
|
| 536 |
+
|
| 537 |
+
- 布尔索引
|
| 538 |
+
|
| 539 |
+
```python
|
| 540 |
+
filter_results = instance_data[instance_data.det_scores > 0.75]
|
| 541 |
+
print(filter_results)
|
| 542 |
+
```
|
| 543 |
+
|
| 544 |
+
```
|
| 545 |
+
<InstanceData(
|
| 546 |
+
|
| 547 |
+
META INFORMATION
|
| 548 |
+
pad_shape: (800, 1216, 3)
|
| 549 |
+
img_shape: (800, 1196, 3)
|
| 550 |
+
|
| 551 |
+
DATA FIELDS
|
| 552 |
+
det_labels: tensor([2])
|
| 553 |
+
det_scores: tensor([0.8000])
|
| 554 |
+
bboxes: tensor([[0.1872, 0.1669, 0.7563, 0.8777]])
|
| 555 |
+
) at 0x7fa061299dc0>
|
| 556 |
+
```
|
| 557 |
+
|
| 558 |
+
4. 结果为空
|
| 559 |
+
|
| 560 |
+
```python
|
| 561 |
+
empty_results = instance_data[instance_data.det_scores > 1]
|
| 562 |
+
print(empty_results)
|
| 563 |
+
```
|
| 564 |
+
|
| 565 |
+
```
|
| 566 |
+
<InstanceData(
|
| 567 |
+
|
| 568 |
+
META INFORMATION
|
| 569 |
+
pad_shape: (800, 1216, 3)
|
| 570 |
+
img_shape: (800, 1196, 3)
|
| 571 |
+
|
| 572 |
+
DATA FIELDS
|
| 573 |
+
det_labels: tensor([], dtype=torch.int64)
|
| 574 |
+
det_scores: tensor([])
|
| 575 |
+
bboxes: tensor([], size=(0, 4))
|
| 576 |
+
) at 0x7f9f439cccd0>
|
| 577 |
+
```
|
| 578 |
+
|
| 579 |
+
#### 拼接(cat)
|
| 580 |
+
|
| 581 |
+
用户可以将两个具有相同 key 的 `InstanceData` 拼接成一个 `InstanceData`。对于长度分别为 N 和 M 的两个 `InstanceData`, 拼接后为长度 N + M 的新的 `InstanceData`
|
| 582 |
+
|
| 583 |
+
```python
|
| 584 |
+
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
|
| 585 |
+
instance_data = InstanceData(metainfo=img_meta)
|
| 586 |
+
instance_data.det_labels = torch.LongTensor([2, 3])
|
| 587 |
+
instance_data.det_scores = torch.Tensor([0.8, 0.7])
|
| 588 |
+
instance_data.bboxes = torch.rand((2, 4))
|
| 589 |
+
print('The length of instance_data is', len(instance_data))
|
| 590 |
+
cat_results = InstanceData.cat([instance_data, instance_data])
|
| 591 |
+
print('The length of instance_data is', len(cat_results))
|
| 592 |
+
print(cat_results)
|
| 593 |
+
```
|
| 594 |
+
|
| 595 |
+
```
|
| 596 |
+
The length of instance_data is 2
|
| 597 |
+
The length of instance_data is 4
|
| 598 |
+
<InstanceData(
|
| 599 |
+
|
| 600 |
+
META INFORMATION
|
| 601 |
+
pad_shape: (800, 1216, 3)
|
| 602 |
+
img_shape: (800, 1196, 3)
|
| 603 |
+
|
| 604 |
+
DATA FIELDS
|
| 605 |
+
det_labels: tensor([2, 3, 2, 3])
|
| 606 |
+
det_scores: tensor([0.8000, 0.7000, 0.8000, 0.7000])
|
| 607 |
+
bboxes: tensor([[0.5341, 0.8962, 0.9043, 0.2824],
|
| 608 |
+
[0.3864, 0.2215, 0.7610, 0.7060],
|
| 609 |
+
[0.5341, 0.8962, 0.9043, 0.2824],
|
| 610 |
+
[0.3864, 0.2215, 0.7610, 0.7060]])
|
| 611 |
+
) at 0x7fa061d4a9d0>
|
| 612 |
+
```
|
| 613 |
+
|
| 614 |
+
#### 自定义数据结构
|
| 615 |
+
|
| 616 |
+
对于自定义结构如果想使用上述扩展要求需要实现`__len__`, `__getitem__` 和 `cat`三个接口.
|
| 617 |
+
|
| 618 |
+
```python
|
| 619 |
+
import itertools
|
| 620 |
+
|
| 621 |
+
class TmpObject:
|
| 622 |
+
def __init__(self, tmp) -> None:
|
| 623 |
+
assert isinstance(tmp, list)
|
| 624 |
+
self.tmp = tmp
|
| 625 |
+
|
| 626 |
+
def __len__(self):
|
| 627 |
+
return len(self.tmp)
|
| 628 |
+
|
| 629 |
+
def __getitem__(self, item):
|
| 630 |
+
if type(item) == int:
|
| 631 |
+
if item >= len(self) or item < -len(self): # type:ignore
|
| 632 |
+
raise IndexError(f'Index {item} out of range!')
|
| 633 |
+
else:
|
| 634 |
+
# keep the dimension
|
| 635 |
+
item = slice(item, None, len(self))
|
| 636 |
+
return TmpObject(self.tmp[item])
|
| 637 |
+
|
| 638 |
+
@staticmethod
|
| 639 |
+
def cat(tmp_objs):
|
| 640 |
+
assert all(isinstance(results, TmpObject) for results in tmp_objs)
|
| 641 |
+
if len(tmp_objs) == 1:
|
| 642 |
+
return tmp_objs[0]
|
| 643 |
+
tmp_list = [tmp_obj.tmp for tmp_obj in tmp_objs]
|
| 644 |
+
tmp_list = list(itertools.chain(*tmp_list))
|
| 645 |
+
new_data = TmpObject(tmp_list)
|
| 646 |
+
return new_data
|
| 647 |
+
|
| 648 |
+
def __repr__(self):
|
| 649 |
+
return str(self.tmp)
|
| 650 |
+
```
|
| 651 |
+
|
| 652 |
+
```python
|
| 653 |
+
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
|
| 654 |
+
instance_data = InstanceData(metainfo=img_meta)
|
| 655 |
+
instance_data.det_labels = torch.LongTensor([2, 3])
|
| 656 |
+
instance_data["det_scores"] = torch.Tensor([0.8, 0.7])
|
| 657 |
+
instance_data.bboxes = torch.rand((2, 4))
|
| 658 |
+
instance_data.polygons = TmpObject([[1, 2, 3, 4], [5, 6, 7, 8]])
|
| 659 |
+
print(instance_data)
|
| 660 |
+
```
|
| 661 |
+
|
| 662 |
+
```
|
| 663 |
+
<InstanceData(
|
| 664 |
+
|
| 665 |
+
META INFORMATION
|
| 666 |
+
pad_shape: (800, 1216, 3)
|
| 667 |
+
img_shape: (800, 1196, 3)
|
| 668 |
+
|
| 669 |
+
DATA FIELDS
|
| 670 |
+
det_labels: tensor([2, 3])
|
| 671 |
+
polygons: [[1, 2, 3, 4], [5, 6, 7, 8]]
|
| 672 |
+
det_scores: tensor([0.8000, 0.7000])
|
| 673 |
+
bboxes: tensor([[0.4207, 0.0778, 0.9959, 0.1967],
|
| 674 |
+
[0.4679, 0.7934, 0.5372, 0.4655]])
|
| 675 |
+
) at 0x7fa061b5d2b0>
|
| 676 |
+
```
|
| 677 |
+
|
| 678 |
+
```python
|
| 679 |
+
# 高级索引
|
| 680 |
+
print(instance_data[instance_data.det_scores > 0.75])
|
| 681 |
+
```
|
| 682 |
+
|
| 683 |
+
```
|
| 684 |
+
<InstanceData(
|
| 685 |
+
|
| 686 |
+
META INFORMATION
|
| 687 |
+
pad_shape: (800, 1216, 3)
|
| 688 |
+
img_shape: (800, 1196, 3)
|
| 689 |
+
|
| 690 |
+
DATA FIELDS
|
| 691 |
+
bboxes: tensor([[0.4207, 0.0778, 0.9959, 0.1967]])
|
| 692 |
+
det_labels: tensor([2])
|
| 693 |
+
det_scores: tensor([0.8000])
|
| 694 |
+
polygons: [[1, 2, 3, 4]]
|
| 695 |
+
) at 0x7f9f312716d0>
|
| 696 |
+
```
|
| 697 |
+
|
| 698 |
+
```python
|
| 699 |
+
# 拼接
|
| 700 |
+
print(InstanceData.cat([instance_data, instance_data]))
|
| 701 |
+
```
|
| 702 |
+
|
| 703 |
+
```
|
| 704 |
+
<InstanceData(
|
| 705 |
+
|
| 706 |
+
META INFORMATION
|
| 707 |
+
pad_shape: (800, 1216, 3)
|
| 708 |
+
img_shape: (800, 1196, 3)
|
| 709 |
+
|
| 710 |
+
DATA FIELDS
|
| 711 |
+
bboxes: tensor([[0.4207, 0.0778, 0.9959, 0.1967],
|
| 712 |
+
[0.4679, 0.7934, 0.5372, 0.4655],
|
| 713 |
+
[0.4207, 0.0778, 0.9959, 0.1967],
|
| 714 |
+
[0.4679, 0.7934, 0.5372, 0.4655]])
|
| 715 |
+
det_labels: tensor([2, 3, 2, 3])
|
| 716 |
+
det_scores: tensor([0.8000, 0.7000, 0.8000, 0.7000])
|
| 717 |
+
polygons: [[1, 2, 3, 4], [5, 6, 7, 8], [1, 2, 3, 4], [5, 6, 7, 8]]
|
| 718 |
+
) at 0x7f9f31271490>
|
| 719 |
+
```
|
| 720 |
+
|
| 721 |
+
### PixelData
|
| 722 |
+
|
| 723 |
+
[`PixelData`](mmengine.structures.PixelData) 在 `BaseDataElement` 的基础上,同样对对 data 中存储的数据做了限制:
|
| 724 |
+
|
| 725 |
+
- 所有 data 内的数据均为 3 维,并且顺序为 (通道,高, 宽)
|
| 726 |
+
- 所有在 data 内的数据要有相同的长和宽
|
| 727 |
+
基于上述假定对 `PixelData`进行了扩展,包括:
|
| 728 |
+
- 对 `PixelData` 中 data 所存储的数据进行了尺寸的校验
|
| 729 |
+
- 支持对 data 部分的数据对实例进行空间维度的索引和切片。
|
| 730 |
+
|
| 731 |
+
### 数据校验
|
| 732 |
+
|
| 733 |
+
`PixelData` 会对传入到 data 的数据进行维度与长宽的校验。
|
| 734 |
+
|
| 735 |
+
```python
|
| 736 |
+
from mmengine.structures import PixelData
|
| 737 |
+
import random
|
| 738 |
+
import torch
|
| 739 |
+
import numpy as np
|
| 740 |
+
metainfo = dict(
|
| 741 |
+
img_id=random.randint(0, 100),
|
| 742 |
+
img_shape=(random.randint(400, 600), random.randint(400, 600)))
|
| 743 |
+
image = np.random.randint(0, 255, (4, 20, 40))
|
| 744 |
+
featmap = torch.randint(0, 255, (10, 20, 40))
|
| 745 |
+
pixel_data = PixelData(metainfo=metainfo,
|
| 746 |
+
image=image,
|
| 747 |
+
featmap=featmap)
|
| 748 |
+
print('The shape of pixel_data is', pixel_data.shape)
|
| 749 |
+
# set
|
| 750 |
+
pixel_data.map3 = torch.randint(0, 255, (20, 40))
|
| 751 |
+
print('The shape of pixel_data is', pixel_data.map3.shape)
|
| 752 |
+
```
|
| 753 |
+
|
| 754 |
+
```
|
| 755 |
+
The shape of pixel_data is (20, 40)
|
| 756 |
+
The shape of pixel_data is torch.Size([1, 20, 40])
|
| 757 |
+
```
|
| 758 |
+
|
| 759 |
+
```python
|
| 760 |
+
pixel_data.map2 = torch.randint(0, 255, (3, 20, 30))
|
| 761 |
+
# AssertionError: the height and width of values (20, 30) is not consistent with the length of this :obj:`PixelData` (20, 40)
|
| 762 |
+
```
|
| 763 |
+
|
| 764 |
+
```
|
| 765 |
+
AssertionError: the height and width of values (20, 30) is not consistent with the length of this :obj:`PixelData` (20, 40)
|
| 766 |
+
```
|
| 767 |
+
|
| 768 |
+
```python
|
| 769 |
+
pixel_data.map2 = torch.randint(0, 255, (1, 3, 20, 40))
|
| 770 |
+
# AssertionError: The dim of value must be 2 or 3, but got 4
|
| 771 |
+
```
|
| 772 |
+
|
| 773 |
+
```
|
| 774 |
+
AssertionError: The dim of value must be 2 or 3, but got 4
|
| 775 |
+
```
|
| 776 |
+
|
| 777 |
+
### 空间维度索引
|
| 778 |
+
|
| 779 |
+
`PixelData` 支持对 data 部分的数据对实例进行空间维度的索引和切片,只需传入长宽的索引即可。
|
| 780 |
+
|
| 781 |
+
```python
|
| 782 |
+
metainfo = dict(
|
| 783 |
+
img_id=random.randint(0, 100),
|
| 784 |
+
img_shape=(random.randint(400, 600), random.randint(400, 600)))
|
| 785 |
+
image = np.random.randint(0, 255, (4, 20, 40))
|
| 786 |
+
featmap = torch.randint(0, 255, (10, 20, 40))
|
| 787 |
+
pixel_data = PixelData(metainfo=metainfo,
|
| 788 |
+
image=image,
|
| 789 |
+
featmap=featmap)
|
| 790 |
+
print('The shape of pixel_data is', pixel_data.shape)
|
| 791 |
+
```
|
| 792 |
+
|
| 793 |
+
```
|
| 794 |
+
The shape of pixel_data is (20, 40)
|
| 795 |
+
```
|
| 796 |
+
|
| 797 |
+
- 索引
|
| 798 |
+
|
| 799 |
+
```python
|
| 800 |
+
index_data = pixel_data[10, 20]
|
| 801 |
+
print('The shape of index_data is', index_data.shape)
|
| 802 |
+
```
|
| 803 |
+
|
| 804 |
+
```
|
| 805 |
+
The shape of index_data is (1, 1)
|
| 806 |
+
```
|
| 807 |
+
|
| 808 |
+
- 切片
|
| 809 |
+
|
| 810 |
+
```python
|
| 811 |
+
slice_data = pixel_data[10:20, 20:40]
|
| 812 |
+
print('The shape of slice_data is', slice_data.shape)
|
| 813 |
+
```
|
| 814 |
+
|
| 815 |
+
```
|
| 816 |
+
The shape of slice_data is (10, 20)
|
| 817 |
+
```
|
| 818 |
+
|
| 819 |
+
### LabelData
|
| 820 |
+
|
| 821 |
+
[`LabelData`](mmengine.structures.LabelData) 主要用来封装标签数据,如场景分类标签,文字识别标签等。`LabelData` 没有对 data 做任何限制,只提供了两个额外功能:onehot 与 index 的转换。
|
| 822 |
+
|
| 823 |
+
```python
|
| 824 |
+
from mmengine.structures import LabelData
|
| 825 |
+
import torch
|
| 826 |
+
|
| 827 |
+
item = torch.tensor([1], dtype=torch.int64)
|
| 828 |
+
num_classes = 10
|
| 829 |
+
|
| 830 |
+
```
|
| 831 |
+
|
| 832 |
+
```python
|
| 833 |
+
onehot = LabelData.label_to_onehot(label=item, num_classes=num_classes)
|
| 834 |
+
print(f'{num_classes} is convert to ', onehot)
|
| 835 |
+
|
| 836 |
+
index = LabelData.onehot_to_label(onehot=onehot)
|
| 837 |
+
print(f'{onehot} is convert to ', index)
|
| 838 |
+
```
|
| 839 |
+
|
| 840 |
+
```
|
| 841 |
+
10 is convert to tensor([0, 1, 0, 0, 0, 0, 0, 0, 0, 0])
|
| 842 |
+
tensor([0, 1, 0, 0, 0, 0, 0, 0, 0, 0]) is convert to tensor([1])
|
| 843 |
+
```
|
| 844 |
+
|
| 845 |
+
## 数据样本(DataSample)
|
| 846 |
+
|
| 847 |
+
数据样本作为不同模块最外层的接口,提供了 xxxDataSample 用于单任务中各模块之间统一格式的传递,同时为了各个模块从统一字段获取或写入信息,数据样本中的命名以及类型要进行约束和统一,保证各模块接口的统一性。 OpenMMLab 中各个算法库的命名规范可以参考 [`OpenMMLab` 中的命名规范](命名规范.md)。
|
| 848 |
+
|
| 849 |
+
### 下游库使用
|
| 850 |
+
|
| 851 |
+
以 MMDet 为例,说明下游库中数据样本的使用,以及数据样本字段的约束和命名。MMDet 中定义了 `DetDataSample`, 同时定义了 7 个字段,分别为:
|
| 852 |
+
|
| 853 |
+
- 标注信息
|
| 854 |
+
- gt_instance(InstanceData): 实例标注信息,包括实例的类别、边界框等, 类型约束为 `InstanceData`。
|
| 855 |
+
- gt_panoptic_seg(PixelData): 全景分割的标注信息,类型约束为 `PixelData`。
|
| 856 |
+
- gt_semantic_seg(PixelData): 语义分割的标注信息, 类型约束为 `PixelData`。
|
| 857 |
+
- 预测结果
|
| 858 |
+
- pred_instance(InstanceData): 实例预测结果,包括实例的类别、边界框等, 类型约束为 `InstanceData`。
|
| 859 |
+
- pred_panoptic_seg(PixelData): 全景分割的预测结果,类型约束为 `PixelData`。
|
| 860 |
+
- pred_semantic_seg(PixelData): 语义分割的预测结果, 类型约束为 `PixelData`。
|
| 861 |
+
- 中间结果
|
| 862 |
+
- proposal(InstanceData): 主要为二阶段中 RPN 的预测结果, 类型约束为 `InstanceData`。
|
| 863 |
+
|
| 864 |
+
```python
|
| 865 |
+
from mmengine.structures import BaseDataElement
|
| 866 |
+
import torch
|
| 867 |
+
|
| 868 |
+
class DetDataSample(BaseDataElement):
|
| 869 |
+
|
| 870 |
+
# 标注
|
| 871 |
+
@property
|
| 872 |
+
def gt_instances(self) -> InstanceData:
|
| 873 |
+
return self._gt_instances
|
| 874 |
+
|
| 875 |
+
@gt_instances.setter
|
| 876 |
+
def gt_instances(self, value: InstanceData):
|
| 877 |
+
self.set_field(value, '_gt_instances', dtype=InstanceData)
|
| 878 |
+
|
| 879 |
+
@gt_instances.deleter
|
| 880 |
+
def gt_instances(self):
|
| 881 |
+
del self._gt_instances
|
| 882 |
+
|
| 883 |
+
@property
|
| 884 |
+
def gt_panoptic_seg(self) -> PixelData:
|
| 885 |
+
return self._gt_panoptic_seg
|
| 886 |
+
|
| 887 |
+
@gt_panoptic_seg.setter
|
| 888 |
+
def gt_panoptic_seg(self, value: PixelData):
|
| 889 |
+
self.set_field(value, '_gt_panoptic_seg', dtype=PixelData)
|
| 890 |
+
|
| 891 |
+
@gt_panoptic_seg.deleter
|
| 892 |
+
def gt_panoptic_seg(self):
|
| 893 |
+
del self._gt_panoptic_seg
|
| 894 |
+
|
| 895 |
+
@property
|
| 896 |
+
def gt_sem_seg(self) -> PixelData:
|
| 897 |
+
return self._gt_sem_seg
|
| 898 |
+
|
| 899 |
+
@gt_sem_seg.setter
|
| 900 |
+
def gt_sem_seg(self, value: PixelData):
|
| 901 |
+
self.set_field(value, '_gt_sem_seg', dtype=PixelData)
|
| 902 |
+
|
| 903 |
+
@gt_sem_seg.deleter
|
| 904 |
+
def gt_sem_seg(self):
|
| 905 |
+
del self._gt_sem_seg
|
| 906 |
+
|
| 907 |
+
# 预测
|
| 908 |
+
@property
|
| 909 |
+
def pred_instances(self) -> InstanceData:
|
| 910 |
+
return self._pred_instances
|
| 911 |
+
|
| 912 |
+
@pred_instances.setter
|
| 913 |
+
def pred_instances(self, value: InstanceData):
|
| 914 |
+
self.set_field(value, '_pred_instances', dtype=InstanceData)
|
| 915 |
+
|
| 916 |
+
@pred_instances.deleter
|
| 917 |
+
def pred_instances(self):
|
| 918 |
+
del self._pred_instances
|
| 919 |
+
|
| 920 |
+
@property
|
| 921 |
+
def pred_panoptic_seg(self) -> PixelData:
|
| 922 |
+
return self._pred_panoptic_seg
|
| 923 |
+
|
| 924 |
+
@pred_panoptic_seg.setter
|
| 925 |
+
def pred_panoptic_seg(self, value: PixelData):
|
| 926 |
+
self.set_field(value, '_pred_panoptic_seg', dtype=PixelData)
|
| 927 |
+
|
| 928 |
+
@pred_panoptic_seg.deleter
|
| 929 |
+
def pred_panoptic_seg(self):
|
| 930 |
+
del self._pred_panoptic_seg
|
| 931 |
+
|
| 932 |
+
# 中间结果
|
| 933 |
+
@property
|
| 934 |
+
def pred_sem_seg(self) -> PixelData:
|
| 935 |
+
return self._pred_sem_seg
|
| 936 |
+
|
| 937 |
+
@pred_sem_seg.setter
|
| 938 |
+
def pred_sem_seg(self, value: PixelData):
|
| 939 |
+
self.set_field(value, '_pred_sem_seg', dtype=PixelData)
|
| 940 |
+
|
| 941 |
+
@pred_sem_seg.deleter
|
| 942 |
+
def pred_sem_seg(self):
|
| 943 |
+
del self._pred_sem_seg
|
| 944 |
+
|
| 945 |
+
@property
|
| 946 |
+
def proposals(self) -> InstanceData:
|
| 947 |
+
return self._proposals
|
| 948 |
+
|
| 949 |
+
@proposals.setter
|
| 950 |
+
def proposals(self, value: InstanceData):
|
| 951 |
+
self.set_field(value, '_proposals', dtype=InstanceData)
|
| 952 |
+
|
| 953 |
+
@proposals.deleter
|
| 954 |
+
def proposals(self):
|
| 955 |
+
del self._proposals
|
| 956 |
+
|
| 957 |
+
```
|
| 958 |
+
|
| 959 |
+
### 类型约束
|
| 960 |
+
|
| 961 |
+
DetDataSample 的用法如下所示,在数据类型不符合要求的时候(例如用 torch.Tensor 而非 InstanceData 定义 proposals 时),DetDataSample 就会报错。
|
| 962 |
+
|
| 963 |
+
```python
|
| 964 |
+
data_sample = DetDataSample()
|
| 965 |
+
|
| 966 |
+
data_sample.proposals = InstanceData(data=dict(bboxes=torch.rand((5,4))))
|
| 967 |
+
print(data_sample)
|
| 968 |
+
```
|
| 969 |
+
|
| 970 |
+
```
|
| 971 |
+
<DetDataSample(
|
| 972 |
+
|
| 973 |
+
META INFORMATION
|
| 974 |
+
|
| 975 |
+
DATA FIELDS
|
| 976 |
+
proposals: <InstanceData(
|
| 977 |
+
|
| 978 |
+
META INFORMATION
|
| 979 |
+
|
| 980 |
+
DATA FIELDS
|
| 981 |
+
data:
|
| 982 |
+
bboxes: tensor([[0.7513, 0.9275, 0.6169, 0.5581],
|
| 983 |
+
[0.6019, 0.6861, 0.7915, 0.0221],
|
| 984 |
+
[0.5977, 0.8987, 0.9541, 0.7877],
|
| 985 |
+
[0.0309, 0.1680, 0.1374, 0.0556],
|
| 986 |
+
[0.3842, 0.9965, 0.0747, 0.6546]])
|
| 987 |
+
) at 0x7f9f1c090310>
|
| 988 |
+
) at 0x7f9f1c090430>
|
| 989 |
+
```
|
| 990 |
+
|
| 991 |
+
```python
|
| 992 |
+
data_sample.proposals = torch.rand((5, 4))
|
| 993 |
+
```
|
| 994 |
+
|
| 995 |
+
```
|
| 996 |
+
AssertionError: tensor([[0.4370, 0.1661, 0.0902, 0.8421],
|
| 997 |
+
[0.4947, 0.1668, 0.0083, 0.1111],
|
| 998 |
+
[0.2041, 0.8663, 0.0563, 0.3279],
|
| 999 |
+
[0.7817, 0.1938, 0.2499, 0.6748],
|
| 1000 |
+
[0.4524, 0.8265, 0.4262, 0.2215]]) should be a <class 'mmengine.data.instance_data.InstanceData'> but got <class 'torch.Tensor'>
|
| 1001 |
+
```
|
| 1002 |
+
|
| 1003 |
+
## 接口的简化
|
| 1004 |
+
|
| 1005 |
+
下面以 MMDetection 为例更具体地说明 OpenMMLab 的算法库将如何迁移使用抽象数据接口,以简化模块和组件接口的。我们假定 MMDetection 和 MMEngine 中实现了 DetDataSample 和 InstanceData。
|
| 1006 |
+
|
| 1007 |
+
#### 1. 组件接口的简化
|
| 1008 |
+
|
| 1009 |
+
检测器的外部接口可以得到显著的简化和统一。MMDet 2.X 中单阶段检测器和单阶段分割算法的接口如下。在训练过程中,`SingleStageDetector` 需要获取
|
| 1010 |
+
`img`, `img_metas`, `gt_bboxes`, `gt_labels`, `gt_bboxes_ignore` 作为输入,但是 `SingleStageInstanceSegmentor` 还需要 `gt_masks`,导致 detector 的训练接口不一致,影响了代码的灵活性。
|
| 1011 |
+
|
| 1012 |
+
```python
|
| 1013 |
+
|
| 1014 |
+
class SingleStageDetector(BaseDetector):
|
| 1015 |
+
...
|
| 1016 |
+
|
| 1017 |
+
def forward_train(self,
|
| 1018 |
+
img,
|
| 1019 |
+
img_metas,
|
| 1020 |
+
gt_bboxes,
|
| 1021 |
+
gt_labels,
|
| 1022 |
+
gt_bboxes_ignore=None):
|
| 1023 |
+
|
| 1024 |
+
|
| 1025 |
+
class SingleStageInstanceSegmentor(BaseDetector):
|
| 1026 |
+
...
|
| 1027 |
+
|
| 1028 |
+
def forward_train(self,
|
| 1029 |
+
img,
|
| 1030 |
+
img_metas,
|
| 1031 |
+
gt_masks,
|
| 1032 |
+
gt_labels,
|
| 1033 |
+
gt_bboxes=None,
|
| 1034 |
+
gt_bboxes_ignore=None,
|
| 1035 |
+
**kwargs):
|
| 1036 |
+
```
|
| 1037 |
+
|
| 1038 |
+
在 MMDet 3.0 中,所有检测器的训练接口都可以使用 DetDataSample 统一简化为 `img` 和 `data_samples`,不同模块可以根据需要去访问 `data_samples` 封装的各种所需要的属性。
|
| 1039 |
+
|
| 1040 |
+
```python
|
| 1041 |
+
class SingleStageDetector(BaseDetector):
|
| 1042 |
+
...
|
| 1043 |
+
|
| 1044 |
+
def forward_train(self,
|
| 1045 |
+
img,
|
| 1046 |
+
data_samples):
|
| 1047 |
+
|
| 1048 |
+
class SingleStageInstanceSegmentor(BaseDetector):
|
| 1049 |
+
...
|
| 1050 |
+
|
| 1051 |
+
def forward_train(self,
|
| 1052 |
+
img,
|
| 1053 |
+
data_samples):
|
| 1054 |
+
|
| 1055 |
+
```
|
| 1056 |
+
|
| 1057 |
+
#### 2. 模块接口的简化
|
| 1058 |
+
|
| 1059 |
+
MMDet 2.X 中 `HungarianAssigner` 和 `MaskHungarianAssigner` 分别用于在训练过程中将检测框和实例掩码和标注的实例进行匹配。他们内部的匹配逻辑实现是一样的,只是接口和损失函数的计算不同。
|
| 1060 |
+
但是,接口的不同使得 `HungarianAssigner` 中的代码无法被复用,`MaskHungarianAssigner` 中重写了很多冗余的逻辑。
|
| 1061 |
+
|
| 1062 |
+
```python
|
| 1063 |
+
class HungarianAssigner(BaseAssigner):
|
| 1064 |
+
|
| 1065 |
+
def assign(self,
|
| 1066 |
+
bbox_pred,
|
| 1067 |
+
cls_pred,
|
| 1068 |
+
gt_bboxes,
|
| 1069 |
+
gt_labels,
|
| 1070 |
+
img_meta,
|
| 1071 |
+
gt_bboxes_ignore=None,
|
| 1072 |
+
eps=1e-7):
|
| 1073 |
+
|
| 1074 |
+
class MaskHungarianAssigner(BaseAssigner):
|
| 1075 |
+
|
| 1076 |
+
def assign(self,
|
| 1077 |
+
cls_pred,
|
| 1078 |
+
mask_pred,
|
| 1079 |
+
gt_labels,
|
| 1080 |
+
gt_mask,
|
| 1081 |
+
img_meta,
|
| 1082 |
+
gt_bboxes_ignore=None,
|
| 1083 |
+
eps=1e-7):
|
| 1084 |
+
```
|
| 1085 |
+
|
| 1086 |
+
`InstanceData` 可以封装实例的框、分数、和掩码,将 `HungarianAssigner` 的核心参数简化成 `pred_instances`,`gt_instancess`,和 `gt_instances_ignore`
|
| 1087 |
+
使得 `HungarianAssigner` 和 `MaskHungarianAssigner` 可以合并成一个通用的 `HungarianAssigner`。
|
| 1088 |
+
|
| 1089 |
+
```python
|
| 1090 |
+
class HungarianAssigner(BaseAssigner):
|
| 1091 |
+
|
| 1092 |
+
def assign(self,
|
| 1093 |
+
pred_instances,
|
| 1094 |
+
gt_instancess,
|
| 1095 |
+
gt_instances_ignore=None,
|
| 1096 |
+
eps=1e-7):
|
| 1097 |
+
```
|
testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/data_transform.md
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 数据变换 (Data Transform)
|
| 2 |
+
|
| 3 |
+
在 OpenMMLab 算法库中,数据集的构建和数据的准备是相互解耦的。通常,数据集的构建只对数据集进行解析,记录每个样本的基本信息;而数据的准备则是通过一系列的数据变换,根据样本的基本信息进行数据加载、预处理、格式化等操作。
|
| 4 |
+
|
| 5 |
+
## 使用数据变换类
|
| 6 |
+
|
| 7 |
+
在 MMEngine 中,我们使用各种可调用的数据变换类来进行数据的操作。这些数据变换类可以接受若干配置参数进行实例化,之后通过调用的方式对输入的数据字典进行处理。同时,我们约定所有数据变换都接受一个字典作为输入,并将处理后的数据输出为一个字典。一个简单的例子如下:
|
| 8 |
+
|
| 9 |
+
```{note}
|
| 10 |
+
MMEngine 中仅约定了数据变换类的规范,常用的数据变换类实现及基类都在 MMCV 中,因此在本篇教程需要提前安装好 MMCV,参见 {external+mmcv:doc}`MMCV 安装教程 <get_started/installation>`。
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
```python
|
| 14 |
+
>>> import numpy as np
|
| 15 |
+
>>> from mmcv.transforms import Resize
|
| 16 |
+
>>>
|
| 17 |
+
>>> transform = Resize(scale=(224, 224))
|
| 18 |
+
>>> data_dict = {'img': np.random.rand(256, 256, 3)}
|
| 19 |
+
>>> data_dict = transform(data_dict)
|
| 20 |
+
>>> print(data_dict['img'].shape)
|
| 21 |
+
(224, 224, 3)
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
## 在配置文件中使用
|
| 25 |
+
|
| 26 |
+
在配置文件中,我们将一系列数据变换组合成为一个列表,称为数据流水线(Data Pipeline),传给数据集的 `pipeline` 参数。通常数据流水线由以下几个部分组成:
|
| 27 |
+
|
| 28 |
+
1. 数据加载,通常使用 [`LoadImageFromFile`](mmcv.transforms.LoadImageFromFile)
|
| 29 |
+
2. 标签加载,通常使用 [`LoadAnnotations`](mmcv.transforms.LoadAnnotations)
|
| 30 |
+
3. 数据处理及增强,例如 [`RandomResize`](mmcv.transforms.RandomResize)
|
| 31 |
+
4. 数据格式化,根据任务不同,在各个仓库使用自己的变换操作,通常名为 `PackXXXInputs`,其中 XXX 是任务的名称,如分类任务中的 `PackClsInputs`。
|
| 32 |
+
|
| 33 |
+
以分类任务为例,我们在下图展示了一个典型的数据流水线。对每个样本,数据集中保存的基本信息是一个如图中最左侧所示的字典,之后每经过一个由蓝色块代表的数据变换操作,数据字典中都会加入新的字段(标记为绿色)或更新现有的字段(标记为橙色)。
|
| 34 |
+
|
| 35 |
+
<div align=center>
|
| 36 |
+
<img src="https://user-images.githubusercontent.com/26739999/206081993-d5351151-466c-4b13-bf6d-9441c0c896c8.png" width="90%" style="background-color: white;padding: 10px;"/>
|
| 37 |
+
</div>
|
| 38 |
+
|
| 39 |
+
如果我们希望在测试中使用上述数据流水线,则配置文件如下所示:
|
| 40 |
+
|
| 41 |
+
```python
|
| 42 |
+
test_dataloader = dict(
|
| 43 |
+
batch_size=32,
|
| 44 |
+
dataset=dict(
|
| 45 |
+
type='ImageNet',
|
| 46 |
+
data_root='data/imagenet',
|
| 47 |
+
pipeline = [
|
| 48 |
+
dict(type='LoadImageFromFile'),
|
| 49 |
+
dict(type='Resize', size=256, keep_ratio=True),
|
| 50 |
+
dict(type='CenterCrop', crop_size=224),
|
| 51 |
+
dict(type='PackClsInputs'),
|
| 52 |
+
]
|
| 53 |
+
)
|
| 54 |
+
)
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
## 常用的数据变换类
|
| 58 |
+
|
| 59 |
+
按照功能,常用的数据变换类可以大致分为数据加载、数据预处理与增强、数据格式化。我们在 MMCV 中提供了一系列常用的数据变换类:
|
| 60 |
+
|
| 61 |
+
### 数据加载
|
| 62 |
+
|
| 63 |
+
为了支持大规模数据集的加载,通常在数据集初始化时不加载数据,只加载相应的路径。因此需要在数据流水线中进行具体数据的加载。
|
| 64 |
+
|
| 65 |
+
| 数据变换类 | 功能 |
|
| 66 |
+
| :------------------------------------------------------: | :---------------------------------------: |
|
| 67 |
+
| [`LoadImageFromFile`](mmcv.transforms.LoadImageFromFile) | 根据路径加载图像 |
|
| 68 |
+
| [`LoadAnnotations`](mmcv.transforms.LoadAnnotations) | 加载和组织标注信息,如 bbox、语义分割图等 |
|
| 69 |
+
|
| 70 |
+
### 数据预处理及增强
|
| 71 |
+
|
| 72 |
+
数据预处理和增强通常是对图像本身进行变换,如裁剪、填充、缩放等。
|
| 73 |
+
|
| 74 |
+
| 数据变换类 | 功能 |
|
| 75 |
+
| :--------------------------------------------------------: | :--------------------------------: |
|
| 76 |
+
| [`Pad`](mmcv.transforms.Pad) | 填充图像边缘 |
|
| 77 |
+
| [`CenterCrop`](mmcv.transforms.CenterCrop) | 居中裁剪 |
|
| 78 |
+
| [`Normalize`](mmcv.transforms.Normalize) | 对图像进行归一化 |
|
| 79 |
+
| [`Resize`](mmcv.transforms.Resize) | 按照指定尺寸或比例缩放图像 |
|
| 80 |
+
| [`RandomResize`](mmcv.transforms.RandomResize) | 缩放图像至指定范围的随机尺寸 |
|
| 81 |
+
| [`RandomChoiceResize`](mmcv.transforms.RandomChoiceResize) | 缩放图像至多个尺寸中的随机一个尺寸 |
|
| 82 |
+
| [`RandomGrayscale`](mmcv.transforms.RandomGrayscale) | 随机灰度化 |
|
| 83 |
+
| [`RandomFlip`](mmcv.transforms.RandomFlip) | 图像随机翻转 |
|
| 84 |
+
|
| 85 |
+
### 数据格式化
|
| 86 |
+
|
| 87 |
+
数据格式化操作通常是对数据进行的类型转换。
|
| 88 |
+
|
| 89 |
+
| 数据变换类 | 功能 |
|
| 90 |
+
| :----------------------------------------------: | :-------------------------------: |
|
| 91 |
+
| [`ToTensor`](mmcv.transforms.ToTensor) | 将指定的数据转换为 `torch.Tensor` |
|
| 92 |
+
| [`ImageToTensor`](mmcv.transforms.ImageToTensor) | 将图像转换为 `torch.Tensor` |
|
| 93 |
+
|
| 94 |
+
## 自定义数据变换类
|
| 95 |
+
|
| 96 |
+
要实现一个新的数据变换类,需要继承 `BaseTransform`,并实现 `transform` 方法。这里,我们使用一个简单的翻转变换(`MyFlip`)作为示例:
|
| 97 |
+
|
| 98 |
+
```python
|
| 99 |
+
import random
|
| 100 |
+
import mmcv
|
| 101 |
+
from mmcv.transforms import BaseTransform, TRANSFORMS
|
| 102 |
+
|
| 103 |
+
@TRANSFORMS.register_module()
|
| 104 |
+
class MyFlip(BaseTransform):
|
| 105 |
+
def __init__(self, direction: str):
|
| 106 |
+
super().__init__()
|
| 107 |
+
self.direction = direction
|
| 108 |
+
|
| 109 |
+
def transform(self, results: dict) -> dict:
|
| 110 |
+
img = results['img']
|
| 111 |
+
results['img'] = mmcv.imflip(img, direction=self.direction)
|
| 112 |
+
return results
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
从而,我们可以实例化一个 `MyFlip` 对象,并将之作为一个可调用对象,来处理我们的数据字典。
|
| 116 |
+
|
| 117 |
+
```python
|
| 118 |
+
import numpy as np
|
| 119 |
+
|
| 120 |
+
transform = MyFlip(direction='horizontal')
|
| 121 |
+
data_dict = {'img': np.random.rand(224, 224, 3)}
|
| 122 |
+
data_dict = transform(data_dict)
|
| 123 |
+
processed_img = data_dict['img']
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
又或者,在配置文件的 pipeline 中使用 `MyFlip` 变换
|
| 127 |
+
|
| 128 |
+
```python
|
| 129 |
+
pipeline = [
|
| 130 |
+
...
|
| 131 |
+
dict(type='MyFlip', direction='horizontal'),
|
| 132 |
+
...
|
| 133 |
+
]
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
需要注意的是,如需在配置文件中使用,需要保证 `MyFlip` 类所在的文件在运行时能够被导入。
|
testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/distributed.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 分布式通信原语
|
| 2 |
+
|
| 3 |
+
在分布式训练或测试的过程中,不同进程有时需要根据分布式的环境信息执行不同的代码逻辑,同时不同进程之间也经常会有相互通信的需求,对一些数据进行同步等操作。
|
| 4 |
+
PyTorch 提供了一套基础的通信原语用于多进程之间张量的通信,基于这套原语,MMEngine 实现了更高层次的通信原语封装以满足更加丰富的需求。基于 MMEngine 的通信原语,算法库中的模块可以
|
| 5 |
+
|
| 6 |
+
1. 在使用通信原语封装时不显式区分分布式/非分布式环境
|
| 7 |
+
2. 进行除 Tensor 以外类型数据的多进程通信
|
| 8 |
+
3. 无需了解底层通信后端或框架
|
| 9 |
+
|
| 10 |
+
这些通信原语封装的接口和功能可以大致归类为如下三种,我们在后续章节中逐个介绍
|
| 11 |
+
|
| 12 |
+
1. 分布式初始化:`init_dist` 负责初始化执行器的分布式环境
|
| 13 |
+
2. 分布式信息获取与控制:包括 `get_world_size` 等函数获取当前的 `rank` 和 `world_size` 等信息
|
| 14 |
+
3. 分布式通信接口:包括如 `all_reduce` 等通信函数(collective functions)
|
| 15 |
+
|
| 16 |
+
## 分布式初始化
|
| 17 |
+
|
| 18 |
+
- [init_dist](mmengine.dist.init_dist): 是分布式训练的启动函数,目前支持 pytorch,slurm,MPI 3 种分布式启动方式,同时允许设置通信的后端,默认使用 NCCL。
|
| 19 |
+
|
| 20 |
+
## 分布式信息获取与控制
|
| 21 |
+
|
| 22 |
+
分布式信息的获取与控制函数没有参数,这些函数兼容非分布式训练的情况,功能如下
|
| 23 |
+
|
| 24 |
+
- [get_world_size](mmengine.dist.get_world_size):获取当前进程组的进程总数,非分布式情况下返回 1
|
| 25 |
+
- [get_rank](mmengine.dist.get_rank):获取当前进程对应的全局 rank 数,非分布式情况下返回 0
|
| 26 |
+
- [get_backend](mmengine.dist.get_backend):获取当前通信使用的后端,非分布式情况下返回 None
|
| 27 |
+
- [get_local_rank](mmengine.dist.get_local_rank):获取当前进程对应到当前机器的 rank 数,非分布式情况下返回 0
|
| 28 |
+
- [get_local_size](mmengine.dist.get_local_size):获取当前进程所在机器的总进程数,非分布式情况下返回 0
|
| 29 |
+
- [get_dist_info](mmengine.dist.get_dist_info):获取当前任务的进程总数和当前进程对应到全局的 rank 数,非分布式情况下 word_size = 1,rank = 0
|
| 30 |
+
- [is_main_process](mmengine.dist.is_main_process):判断是否为 0 号主进程,非分布式情况下返回 True
|
| 31 |
+
- [master_only](mmengine.dist.master_only):函数装饰器,用于修饰只需要全局 0 号进程(rank 0 而不是 local rank 0)执行的函数
|
| 32 |
+
- [barrier](mmengine.dist.barrier):同步所有进程到达相同位置
|
| 33 |
+
|
| 34 |
+
## 分布式通信函数
|
| 35 |
+
|
| 36 |
+
通信函数 (Collective functions),主要用于进程间数据的通信,基于 PyTorch 原生的 all_reduce,all_gather,gather,broadcast 接口,MMEngine 提供了如下接口,兼容非分布式训练的情况,并支持更丰富数据类型的通信。
|
| 37 |
+
|
| 38 |
+
- [all_reduce](mmengine.dist.all_reduce): 对进程间 tensor 进行 AllReduce 操作
|
| 39 |
+
- [all_gather](mmengine.dist.all_gather):对进程间 tensor 进行 AllGather 操作
|
| 40 |
+
- [gather](mmengine.dist.gather):将进程的 tensor 收集到一个目标 rank
|
| 41 |
+
- [broadcast](mmengine.dist.broadcast):对某个进程的 tensor 进行广播
|
| 42 |
+
- [sync_random_seed](mmengine.dist.sync_random_seed):同步进程之间的随机种子
|
| 43 |
+
- [broadcast_object_list](mmengine.dist.broadcast_object_list):支持对任意可被 Pickle 序列化的 Python 对象列表进行广播,基于 broadcast 接口实现
|
| 44 |
+
- [all_reduce_dict](mmengine.dist.all_reduce_dict):对 dict 中的内容进行 all_reduce 操作,基于 broadcast 和 all_reduce 接口实现
|
| 45 |
+
- [all_gather_object](mmengine.dist.all_gather_object):基于 all_gather 实现对任意可以被 Pickle 序列化的 Python 对象进行 all_gather 操作
|
| 46 |
+
- [gather_object](mmengine.dist.gather_object):将 group 里每个 rank 中任意可被 Pickle 序列化的 Python 对象 gather 到指定的目标 rank
|
| 47 |
+
- [collect_results](mmengine.dist.collect_results):支持基于 CPU 通信或者 GPU 通信对不同进程间的列表数据进行收集
|
testbed/open-mmlab__mmengine/docs/zh_cn/advanced_tutorials/fileio.md
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 文件读写
|
| 2 |
+
|
| 3 |
+
`MMEngine` 实现了一套统一的文件读写接口,可以用同一个函数来处理不同的文件格式,如 `json`、
|
| 4 |
+
`yaml` 和 `pickle`,并且可以方便地拓展其它的文件格式。除此之外,文件读写模块还支持从多种文件存储后端读写文件,包括本地磁盘、Petrel(内部使用)、Memcached、LMDB 和 HTTP。
|
| 5 |
+
|
| 6 |
+
## 读取和保存数据
|
| 7 |
+
|
| 8 |
+
`MMEngine` 提供了两个通用的接口用于读取和保存数据,目前支持的格式有 `json`、`yaml` 和
|
| 9 |
+
`pickle`。
|
| 10 |
+
|
| 11 |
+
### 从硬盘读取数据或者将数据保存至硬盘
|
| 12 |
+
|
| 13 |
+
```python
|
| 14 |
+
from mmengine import load, dump
|
| 15 |
+
|
| 16 |
+
# 从文件中读取数据
|
| 17 |
+
data = load('test.json')
|
| 18 |
+
data = load('test.yaml')
|
| 19 |
+
data = load('test.pkl')
|
| 20 |
+
# 从文件对象中读取数据
|
| 21 |
+
with open('test.json', 'r') as f:
|
| 22 |
+
data = load(f, file_format='json')
|
| 23 |
+
|
| 24 |
+
# 将数据序列化为字符串
|
| 25 |
+
json_str = dump(data, file_format='json')
|
| 26 |
+
|
| 27 |
+
# 将数据保存至文件 (根据文件名后缀反推文件类型)
|
| 28 |
+
dump(data, 'out.pkl')
|
| 29 |
+
|
| 30 |
+
# 将数据保存至文件对象
|
| 31 |
+
with open('test.yaml', 'w') as f:
|
| 32 |
+
data = dump(data, f, file_format='yaml')
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
### 从其它文件存储后端读写文件
|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
from mmengine import load, dump
|
| 39 |
+
|
| 40 |
+
# 从 s3 文件读取数据
|
| 41 |
+
data = load('s3://bucket-name/test.json')
|
| 42 |
+
data = load('s3://bucket-name/test.yaml')
|
| 43 |
+
data = load('s3://bucket-name/test.pkl')
|
| 44 |
+
|
| 45 |
+
# 将数据保存至 s3 文件 (根据文件名后缀反推文件类型)
|
| 46 |
+
dump(data, 's3://bucket-name/out.pkl')
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
我们提供了易于拓展的方式以支持更多的文件格式,我们只需要创建一个继承自 `BaseFileHandler` 的文件句柄类,句柄类至少需要重写三个方法。然后使用使用 `register_handler` 装饰器将句柄类注册为对应文件格式的读写句柄。
|
| 50 |
+
|
| 51 |
+
```python
|
| 52 |
+
from mmengine import register_handler, BaseFileHandler
|
| 53 |
+
|
| 54 |
+
# 支持为文件句柄类注册多个文件格式
|
| 55 |
+
# @register_handler(['txt', 'log'])
|
| 56 |
+
@register_handler('txt')
|
| 57 |
+
class TxtHandler1(BaseFileHandler):
|
| 58 |
+
|
| 59 |
+
def load_from_fileobj(self, file):
|
| 60 |
+
return file.read()
|
| 61 |
+
|
| 62 |
+
def dump_to_fileobj(self, obj, file):
|
| 63 |
+
file.write(str(obj))
|
| 64 |
+
|
| 65 |
+
def dump_to_str(self, obj, **kwargs):
|
| 66 |
+
return str(obj)
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
以 `PickleHandler` 为例
|
| 70 |
+
|
| 71 |
+
```python
|
| 72 |
+
from mmengine import BaseFileHandler
|
| 73 |
+
import pickle
|
| 74 |
+
|
| 75 |
+
class PickleHandler(BaseFileHandler):
|
| 76 |
+
|
| 77 |
+
def load_from_fileobj(self, file, **kwargs):
|
| 78 |
+
return pickle.load(file, **kwargs)
|
| 79 |
+
|
| 80 |
+
def load_from_path(self, filepath, **kwargs):
|
| 81 |
+
return super(PickleHandler, self).load_from_path(
|
| 82 |
+
filepath, mode='rb', **kwargs)
|
| 83 |
+
|
| 84 |
+
def dump_to_str(self, obj, **kwargs):
|
| 85 |
+
kwargs.setdefault('protocol', 2)
|
| 86 |
+
return pickle.dumps(obj, **kwargs)
|
| 87 |
+
|
| 88 |
+
def dump_to_fileobj(self, obj, file, **kwargs):
|
| 89 |
+
kwargs.setdefault('protocol', 2)
|
| 90 |
+
pickle.dump(obj, file, **kwargs)
|
| 91 |
+
|
| 92 |
+
def dump_to_path(self, obj, filepath, **kwargs):
|
| 93 |
+
super(PickleHandler, self).dump_to_path(
|
| 94 |
+
obj, filepath, mode='wb', **kwargs)
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
## 读取文件并返回列表或字典
|
| 98 |
+
|
| 99 |
+
例如, `a.txt` 是文本文件,一共有5行内容。
|
| 100 |
+
|
| 101 |
+
```
|
| 102 |
+
a
|
| 103 |
+
b
|
| 104 |
+
c
|
| 105 |
+
d
|
| 106 |
+
e
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
### 从硬盘读取
|
| 110 |
+
|
| 111 |
+
使用 `list_from_file` 读取 `a.txt`
|
| 112 |
+
|
| 113 |
+
```python
|
| 114 |
+
from mmengine import list_from_file
|
| 115 |
+
|
| 116 |
+
print(list_from_file('a.txt'))
|
| 117 |
+
# ['a', 'b', 'c', 'd', 'e']
|
| 118 |
+
print(list_from_file('a.txt', offset=2))
|
| 119 |
+
# ['c', 'd', 'e']
|
| 120 |
+
print(list_from_file('a.txt', max_num=2))
|
| 121 |
+
# ['a', 'b']
|
| 122 |
+
print(list_from_file('a.txt', prefix='/mnt/'))
|
| 123 |
+
# ['/mnt/a', '/mnt/b', '/mnt/c', '/mnt/d', '/mnt/e']
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
同样, `b.txt` 也是文本文件,一共有3行内容
|
| 127 |
+
|
| 128 |
+
```
|
| 129 |
+
1 cat
|
| 130 |
+
2 dog cow
|
| 131 |
+
3 panda
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
使用 `dict_from_file` 读取 `b.txt`
|
| 135 |
+
|
| 136 |
+
```python
|
| 137 |
+
from mmengine import dict_from_file
|
| 138 |
+
|
| 139 |
+
print(dict_from_file('b.txt'))
|
| 140 |
+
# {'1': 'cat', '2': ['dog', 'cow'], '3': 'panda'}
|
| 141 |
+
print(dict_from_file('b.txt', key_type=int))
|
| 142 |
+
# {1: 'cat', 2: ['dog', 'cow'], 3: 'panda'}
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
### 从其他存储后端读取
|
| 146 |
+
|
| 147 |
+
使用 `list_from_file` 读取 `s3://bucket-name/a.txt`
|
| 148 |
+
|
| 149 |
+
```python
|
| 150 |
+
from mmengine import list_from_file
|
| 151 |
+
|
| 152 |
+
print(list_from_file('s3://bucket-name/a.txt'))
|
| 153 |
+
# ['a', 'b', 'c', 'd', 'e']
|
| 154 |
+
print(list_from_file('s3://bucket-name/a.txt', offset=2))
|
| 155 |
+
# ['c', 'd', 'e']
|
| 156 |
+
print(list_from_file('s3://bucket-name/a.txt', max_num=2))
|
| 157 |
+
# ['a', 'b']
|
| 158 |
+
print(list_from_file('s3://bucket-name/a.txt', prefix='/mnt/'))
|
| 159 |
+
# ['/mnt/a', '/mnt/b', '/mnt/c', '/mnt/d', '/mnt/e']
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
使用 `dict_from_file` 读取 `b.txt`
|
| 163 |
+
|
| 164 |
+
```python
|
| 165 |
+
from mmengine import dict_from_file
|
| 166 |
+
|
| 167 |
+
print(dict_from_file('s3://bucket-name/b.txt'))
|
| 168 |
+
# {'1': 'cat', '2': ['dog', 'cow'], '3': 'panda'}
|
| 169 |
+
print(dict_from_file('s3://bucket-name/b.txt', key_type=int))
|
| 170 |
+
# {1: 'cat', 2: ['dog', 'cow'], 3: 'panda'}
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
## 读取和保存权重文件
|
| 174 |
+
|
| 175 |
+
通常情况下,我们可以通过下面的方式从磁盘或者网络远端读取权重文件。
|
| 176 |
+
|
| 177 |
+
```python
|
| 178 |
+
import torch
|
| 179 |
+
|
| 180 |
+
filepath1 = '/path/of/your/checkpoint1.pth'
|
| 181 |
+
filepath2 = 'http://path/of/your/checkpoint3.pth'
|
| 182 |
+
|
| 183 |
+
# 从本地磁盘读取权重文���
|
| 184 |
+
checkpoint = torch.load(filepath1)
|
| 185 |
+
# 保存权重文件到本地磁盘
|
| 186 |
+
torch.save(checkpoint, filepath1)
|
| 187 |
+
|
| 188 |
+
# 从网络远端读取权重文件
|
| 189 |
+
checkpoint = torch.utils.model_zoo.load_url(filepath2)
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
在 `MMEngine` 中,得益于多文件存储后端的支持,不同存储形式的权重文件读写可以通过
|
| 193 |
+
`load_checkpoint` 和 `save_checkpoint` 来统一实现。
|
| 194 |
+
|
| 195 |
+
```python
|
| 196 |
+
from mmengine import load_checkpoint, save_checkpoint
|
| 197 |
+
|
| 198 |
+
filepath1 = '/path/of/your/checkpoint1.pth'
|
| 199 |
+
filepath2 = 's3://bucket-name/path/of/your/checkpoint1.pth'
|
| 200 |
+
filepath3 = 'http://path/of/your/checkpoint3.pth'
|
| 201 |
+
|
| 202 |
+
# 从本地磁盘读取权重文件
|
| 203 |
+
checkpoint = load_checkpoint(filepath1)
|
| 204 |
+
# 保存权重文件到本地磁盘
|
| 205 |
+
save_checkpoint(checkpoint, filepath1)
|
| 206 |
+
|
| 207 |
+
# 从 s3 读取权重文件
|
| 208 |
+
checkpoint = load_checkpoint(filepath2)
|
| 209 |
+
# 保存权重文件到 s3
|
| 210 |
+
save_checkpoint(checkpoint, filepath2)
|
| 211 |
+
|
| 212 |
+
# 从网络远端读取权重文件
|
| 213 |
+
checkpoint = load_checkpoint(filepath3)
|
| 214 |
+
```
|