
blob_id stringlengths 40 40 | language stringclasses 1
value | repo_name stringlengths 5 133 | path stringlengths 2 333 | src_encoding stringclasses 30
values | length_bytes int64 18 5.47M | score float64 2.52 5.81 | int_score int64 3 5 | detected_licenses listlengths 0 67 | license_type stringclasses 2
values | text stringlengths 12 5.47M | download_success bool 1
class |
|---|---|---|---|---|---|---|---|---|---|---|---|
6ae4825197dfe0cc1af02b041a5784322770db62 | Python | matismok/Python | /Challenges/random_code.py | UTF-8 | 928 | 3.984375 | 4 | [] | no_license | import random
random_side = random.randint(1, 10)
if random_side == 1:
print("Heads")
else:
print("Tails")
states_of_america = ["Delaware", "Pencilvania", "New Jersey"]
states_of_america[1] = "Pennsylvania"
states_of_america.append("Georgia")
# names_string = input("Give me everybody's names, seperated by a comma. ")
# # Angela, Ben, Jenny, Jack, Matt
# names = names_string.split(", ")
#
# random_name = random.randint(0, len(names) - 1)
# random_to_list = names[random_name]
# print(f"{random_to_list} is going to buy the meal!")
row1 = ["🥲", "🥲", "🥲"]
row2 = ["🥲", "🥲", "🥲"]
row3 = ["🥲", "🥲", "🥲"]
map = [row1, row2, row3]
print(f"{row1}\n{row2}\n{row3}\n")
position = input("It's 3x3 map .Where do you want to put your treasure? ")
horizontal = int(position[0])
vertical = int(position[1])
map[int(vertical) - 1][int(horizontal) - 1] = "x"
print(f"\n{row1}\n{row2}\n{row3}\n")
| true |
c1e30b878a4ff1edc3b2e5776badb648eae9c2a2 | Python | imratnesh/python_all | /firstML/Naive.py | UTF-8 | 2,678 | 3.09375 | 3 | [] | no_license | # -*- coding: utf-8 -*-
"""
Created on Fri Jul 24 16:17:49 2015
@author: Ratnesh Kushwaha
"""
#Writing prep_terrain_data.py
#Writing class_vis.py
#Overwriting ClassifyNB.py
# %%writefile GaussianNB_Deployment_on_Terrain_Data.py
#!/usr/bin/python
""" Complete the code below with the sklearn Naaive Bayes
classifier to classify the terrain data
The objective of this exercise is to recreate the decision
boundary found in the lesson video, and make a plot that
visually shows the decision boundary """
from prep_terrain_data import makeTerrainData
from class_vis import prettyPicture, output_image
from ClassifyNB import classify, classifySVM, classifyTree
import numpy as np
import pylab as pl
#from ggplot import *
features_train, labels_train, features_test, labels_test = makeTerrainData()
### the training data (features_train, labels_train) have both "fast" and "slow" points mixed
### in together--separate them so we can give them different colors in the scatterplot,
### and visually identify them
grade_fast = [features_train[ii][0] for ii in range(0, len(features_train)) if labels_train[ii]==0]
bumpy_fast = [features_train[ii][1] for ii in range(0, len(features_train)) if labels_train[ii]==0]
grade_slow = [features_train[ii][0] for ii in range(0, len(features_train)) if labels_train[ii]==1]
bumpy_slow = [features_train[ii][1] for ii in range(0, len(features_train)) if labels_train[ii]==1]
#clf = classifyTree(features_train, labels_train)
clf = classifySVM(features_train, labels_train)
### draw the decision boundary with the text points overlaid
prettyPicture(clf, features_test, labels_test)
#output_image("test.png", "png", open("test.png", "rb").read())
#Overwriting classify.py
# %%writefile submitAccuracy.py
from class_vis import prettyPicture
from prep_terrain_data import makeTerrainData
from classify import NBAccuracy
from classify import SVMAccuracy
from classify import TreeAccuracy
import numpy as np
import pylab as pl
features_train, labels_train, features_test, labels_test = makeTerrainData()
def submitAccuracy():
accuracy = NBAccuracy(features_train, labels_train, features_test, labels_test)
return accuracy
def submitSvmAccuracy():
accuracy = SVMAccuracy(features_train, labels_train, features_test, labels_test)
return accuracy
def submitTreeAccuracy():
accuracy = TreeAccuracy(features_train, labels_train, features_test, labels_test)
return accuracy
print("Naive ")
print(submitAccuracy())
print( 'SVM ' )
print(submitSvmAccuracy())
print('Tree ')
print(submitTreeAccuracy())
| true |
51f402f40fbaf821d9c7a2bcf21c60cac3b50bc2 | Python | akcssk/algorithm-practice | /binary-tree/binary_tree.py | UTF-8 | 2,282 | 3.65625 | 4 | [] | no_license |
class BinaryTree:
"""
A simple binary tree implement for my lerning alghorithm
reference:
http://www.ic.daito.ac.jp/~mizutani/python/binary_tree.html#binary_tree_search
with fixing typo
"""
def __init__(self, root = None):
self.value = root
self.left = None
self.right = None
def insert_left(self, insert):
if self.left == None:
self.left = BinaryTree(insert)
else:
_t = BinaryTree(insert)
_t.left = self.left
self.left = _t
def insert_right(self, insert):
if self.right == None:
self.right = BinaryTree(insert)
else:
_t = BinaryTree(insert)
_t.right = self.right
self.right = _t
def add_left(self, add):
if self.left == None:
self.left = BinaryTree(add)
else:
self.left.add_left(add)
def add_right(self, add):
if self.right == None:
self.right = BinaryTree(add)
else:
self.right.add_right(add)
def get_right(self):
return self.right
def get_left(self):
return self.left
def put_root(self, obj):
self.value = obj
def get_root(self):
return self.value
#This method is imcomplete
# def print_content(self):
# print(self.get_root())
# if self.left != None:
# self.left.print_content()
# if self.right != None:
# self.right.print_content()
# if self.
def post_order_search(self):
if self != None:
if self.left:
self.left.post_order_search()
if self.right:
self.right.post_order_search()
print(self.get_root(), end="")
def post_order_search(btree):
if btree != None:
post_order_search(btree.get_left())
post_order_search(btree.get_right())
print(btree.get_root(), end="")
r = BinaryTree()
r.put_root(3)
r.insert_left(4)
r.insert_right(6)
r.insert_right(7)
r.insert_left(5)
post_order_search(r)
r.post_order_search()
r = BinaryTree()
r.put_root(3)
r.add_left(4)
r.add_right(6)
r.add_right(7)
r.add_left(5)
post_order_search(r)
r.post_order_search()
| true |
28780394693be8ffe1b99c0658cc31554a5de2fc | Python | varsha-shewale/github_python_problems | /algorithm_squareroot.py | UTF-8 | 383 | 3.46875 | 3 | [] | no_license | num = 25
iteration = 0
high = num
low = 0
epsilon = 0.01
guess = (high + low)/2.0
while abs(guess**2 - num) >= epsilon:
if guess**2 > num:
high = guess
elif guess**2 < num:
low = guess
guess = (high+low)/2.0
iteration += 1
print 'Iteration # %d: low is %f, high is %f'%(iteration,low,high)
print '%f is a close squareroot of %f'%(guess,num)
| true |
9f2f39ac4d90db37b6309999e3865f27606d6992 | Python | pmduc2012/pythonbasic | /Lesson 6/Lambda funtion - 1.py | UTF-8 | 112 | 3.4375 | 3 | [] | no_license | __author__ = 'Admin'
fibonacci = lambda x: fibonacci(x-2) + fibonacci(x-1) if x > 2 else 1
print(fibonacci(10))
| true |
70fd5b3cb2ec757fcf254eee3cc4c94b7667e8a9 | Python | DL2021Spring/CourseProject | /data_files/055 Merge Intervals.py | UTF-8 | 1,505 | 3.234375 | 3 | [] | no_license |
__author__ = 'Danyang'
class Interval(object):
def __init__(self, s=0, e=0):
self.start = s
self.end = e
class Solution(object):
def merge(self, itvls):
if not itvls:
return []
itvls.sort(key=lambda x: x.start)
ret = [itvls[0]]
for cur in itvls[1:]:
pre = ret[-1]
if cur.start <= pre.end:
pre.end = max(pre.end, cur.end)
else:
ret.append(cur)
return ret
def merge_error(self, itvls):
if not itvls:
return []
ret = [itvls[0]]
for interval in itvls[1:]:
if ret[-1].end < interval.start:
ret.append(interval)
continue
if ret[-1].start <= interval.start <= ret[-1].end <= interval.end:
ret[-1].end = interval.end
continue
if interval.start <= ret[-1].start and ret[-1].end <= interval.end:
ret[-1] = interval
continue
if ret[-1].start <= interval.start < ret[-1].end and ret[-1].start <= interval.end < ret[-1].end:
ret.append(interval)
continue
if interval.start < ret[-1].start <= interval.end < ret[-1].end:
ret[-1].start = interval.start
continue
if interval.end < ret[-1].start:
ret.append(ret)
continue
return ret
| true |
623fe3ed517172cc154927c71eb5e326123c6650 | Python | Malong-ff/nucleus | /nucleus.py | UTF-8 | 1,431 | 2.84375 | 3 | [] | no_license | class Nucleus(object):
def __init__(self, atomic_number=1, mass_number=1):
self.atomic_number = atomic_number
self.mass_number = mass_number
def get_nuclear_radius(self):
pass
def get_nuclear_charge(self):
pass
def get_num_protons(self):
return self.atomic_number
def get_neutral_num_electrons(self):
return self.atomic_number
def get_num_neutrons(self):
return (self.mass_number - self.atomic_number)
def get_characteristic_x_ray_wavelength(self):
pass
def is_same_atom(self, other):
return (self.atomic_number == other.atomic_number)
&& (self.mass_number == other.mass_number)
def is_isotope(self, other):
return (self.atomic_number == other.atomic_number)
&& (self.mass_number != other.mass_number)
def is_isotone(self, other):
return (self.get_num_neutrons() == other.get_num_neutrons())
&& (self.atomic_number != other.atomic_number)
def is_isobar(self, other):
return (self.atomic_number != other.atomic_number)
&& (self.mass_number == other.mass_number)
def get_spin_moment(self):
pass
def get_orbital_moment(self):
pass
def get_nuclear_spin(self):
pass
def get_electric_quadrupole_moment(self):
pass
def get_binding_energy(self, change_in_mass):
speed_of_light = 3 * 10^8
return change_in_mass * speed_of_light^2
def get_binding_energy(self, change_in_energy):
speed_of_light = 3 * 10^8
return change_in_energy / speed_of_light^2
| true |
831326e8c4d6dcc927290d77a926ad25e63216e8 | Python | HoodCat/cafe24_python_practice01 | /practice11.py | UTF-8 | 274 | 3.515625 | 4 | [] | no_license | import functools
def sum(*arg: int):
"""
임의의 개수의 인수를 받아서 그 합을 계산합니다.
:param arg: 정수
:return: 입력받은 값들의 합
"""
return functools.reduce(lambda acc, x: acc+x, arg)
print(sum(10, 13, 14, 20))
| true |
8055c47763e614034a3df76540e708d752ce2f9f | Python | ENate/feature-selection-codes | /classifStructuredL2.py | UTF-8 | 18,173 | 2.546875 | 3 | [] | no_license | """Script to train Rosenbrock function MLP approximation.
A simple usage example:
python classifStructuredL2.py -N=7 -m=20000 -hidden=[16,12,8] -opt=lm \
-kwargs={'mu':3.,'mu_inc':10,'mu_dec':10,'max_inc':10} \
-out=log1.txt
python classifStructuredL2.py -N=7 -m=20000 -hidden=[16,12,8] -opt=sgd \
-kwargs={'learning_rate':1e-3} -out=log2.txt
python classifStructuredL2.py -N=7 -m=20000 -hidden=[16,12,8] -opt=adam \
-kwargs={'learning_rate':1e-3} -out=log3.txt
"""
# Tasks at hand:
# Implement the classifier for an example data set for the structured l2 penalty
# Distinguish between results by comparing to lasso
import os
import time
import sys
import pickle
import argparse
import numpy as np
import tensorflow as tf
__path__ = [os.path.dirname(os.path.abspath(__file__))]
from .classifpredAnalysis import predclassif
from .processDataFiles import ProcessMyData
from .processIntergratedData import prep_data_2_train, main_74b, func_y
from .drawingNetsformatting import paramreshape
from .deepnetworkdiag import NeuralNetwork
from .py_lasso_l2 import func_classifier_l2l1, func_classifier_l1
from .all_loss_functions import func_cross_entropy_loss
# os.environ['CUDA_VISIBLE_DEVICES'] = "1"
# with fixed seed initial values for train-able variables and training data
# will be the same, so it is easier to compare optimization performance
SEED = 52
# you can try tf.float32/np.float32 data types
TF_DATA_TYPE = tf.float64
NP_DATA_TYPE = np.float64
# how frequently log is written and checkpoint saved
LOG_INTERVAL_IN_SEC = 0.05
# variants of activation functions
ACTIVATIONS = {'tanh': tf.nn.tanh, 'relu': tf.nn.relu, 'sigmoid': tf.nn.sigmoid}
# variants of initializers
INITIALIZERS = {'xavier': tf.contrib.layers.xavier_initializer(seed=SEED),
'rand_uniform': tf.random_uniform_initializer(seed=SEED),
'rand_normal': tf.random_normal_initializer(seed=SEED)}
# variants of tensor flow built-in optimizers
TF_OPTIMIZERS = {'sgd': tf.train.GradientDescentOptimizer, 'adam': tf.train.AdamOptimizer}
# checkpoints are saved to <log_file_name>.ckpt
out_file = None
log_prev_time, log_first_time = None, None
# are used to continue log when script is started from a checkpoint
step_delta, time_delta = 0, 0
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('-hidden', help='MLP hidden layers structure', type=str, default='[40, 10]')
parser.add_argument('-a', '--activation', help='nonlinear activation function', type=str, choices=['relu', 'sigmoid', 'tanh'], default='tanh')
parser.add_argument('-i', '--initializer', help='trainable variables initializer', type=str, choices=['rand_normal', 'rand_uniform', 'xavier'], default='xavier')
parser.add_argument('-opt', '--optimizer', help='optimization algorithms', type=str, choices=['sgd', 'adam', 'lm'], default='lm')
parser.add_argument('-kwargs', help='optimizer parameters', type=str, default="{'mu':5.,'mu_inc':10,'mu_dec':10,'max_inc':100}")
parser.add_argument('-out', help='output log file name', type=str, default='log.txt')
parser.add_argument("-c", "--cont", help="continue from checkpoint", action="store_true")
args = parser.parse_args()
hidden = eval(args.hidden)
activation = ACTIVATIONS[args.activation]
initializer = INITIALIZERS[args.initializer]
optimizer = args.optimizer
print(args.kwargs)
kwargs = eval(args.kwargs)
out = args.out
use_checkpoint = args.cont
return hidden, activation, initializer, optimizer, kwargs, out, use_checkpoint
# saves checkpoint and outputs current step/loss/mu to files
def log(step, loss, params, mu=None):
global log_prev_time, log_first_time
now = time.time()
if log_prev_time and now - log_prev_time < LOG_INTERVAL_IN_SEC:
return
if not log_prev_time:
log_prev_time, log_first_time = now, now
secs_from_start = int(now - log_first_time) + time_delta
step += step_delta
message = step + secs_from_start + loss
message += mu if mu else ''
print(message)
with open(out_file, 'a') as file:
file.write('message \n')
pickle.dump((step, secs_from_start, params), open(out_file + '.ckpt', "wb"))
log_prev_time = now
# calculates Jacobian matrix for y with respect to x
def jacobian_classif(y, x):
stopgrads = tf.where(x == 0)
m = tf.shape(y)[0]
loop_vars = [
tf.constant(0, tf.int32),
tf.TensorArray(TF_DATA_TYPE, size=m),
]
_, jacobian_classif = tf.while_loop(lambda i, _: i < m, lambda i, res: (i + 1, res.write(i, tf.gradients(y[i], x, stop_gradients=stopgrads, unconnected_gradients='zero')[0])), loop_vars)
dxdt = tf.gradients(tf.reduce_sum(tf.abs(x)), x, unconnected_gradients='zero')[0]
print(jacobian_classif.stack())
return jacobian_classif.stack(), dxdt
# performs network training and updates parameter values according to LM algorithm
def train_lm(feed_dict, loss, params, y_hat, lambda1, kwargspred, **kwargs):
r = loss
mu1, _, mu_dec, max_inc = kwargs['mu'], kwargs['mu_inc'], kwargs['mu_dec'], kwargs['mu_inc']
wb_shapes, wb_sizes_classif, hidden = kwargspred['wb_shapes'], kwargspred['wb_sizes'], kwargspred['hidden']
activation, xydat= kwargspred['activation'], kwargspred['xydat']
hess_approx=True
print(wb_shapes)
print(wb_sizes_classif)
neurons_cnt = params.shape[0].value
mu_current = tf.placeholder(TF_DATA_TYPE, shape=[1])
imatrx = tf.eye(neurons_cnt, dtype=TF_DATA_TYPE)
y_hat_flat = tf.squeeze(y_hat)
if hess_approx:
jcb = jacobian(y_hat_model, p)
print(tf.transpose(jcb).shape)
j1 = jacobian_mse(y_hat_model, p, nm_set_points, all_sizes_vec, all_shapes_vec)
jt = tf.transpose(j1)
l2_grad = tf.gradients(l2_norm_val, l2_p)[0]
dxdt = tf.expand_dims(tf.gradients(all_reg0, lassop)[0], 1)
hess_l2_ps = tf.hessians(l2_norm_val, l2_p)[0]
print('The shape is;', j1.shape)
jtj1 = tf.matmul(jt, j1)
jtr1 = 2*tf.matmul(jt, r1)
l2grad = tf.expand_dims(l2_grad, 1)
s_l2grad = tf.matmul(l2grad, tf.transpose(l2grad))
# compute gradient of l2 params
reshaped_gradl2 = jtr1[0:shaped_new]
reshaped_l20 = reshaped_gradl2 + lambda_param2 * l2grad # l2_p_grads, 1)
# build another hessian
jt_hess = jt[0:shaped_new, :] + lambda_param2 * l2grad # l2_p_grads, 1)
jt_hess_end = tf.concat([jt_hess, jt[shaped_new:, :]], axis=0)
j1_t = tf.transpose(jt_hess_end)
# calculate gradient for lasso params group
reshaped_gradl1 = jtr1[shaped_new:]
reshaped_gradl0 = reshaped_gradl1 + lambda_param * dxdt # tf.expand_dims(dxdt, 1) #tf.sign(lasso_p), 1)
# Assemble the lasso group
jtj = tf.matmul(jt_hess_end, j1_t)
jtr = tf.concat([reshaped_l20, reshaped_gradl0], axis=0)
jtr = tf.reshape(jtr, shape=(neurons_cnt_x1, 1))
# The other hess using hessian for in --> hid1
hess_part2 = jtj1[0:shaped_new, 0:shaped_new] + s_l2grad #hess_l2_ps# + h_mat_l2
hess_partsconc = tf.concat([hess_part2, jtj1[0:shaped_new, shaped_new:]], axis=1)
jtj3 = tf.concat([hess_partsconc, jtj1[shaped_new:, :]], axis=0)
# remove it
# j, dxdt = jacobian_classif(y_hat_flat, params)
# j_t = tf.transpose(j)
# hess = tf.matmul(j_t, j)
# g0 = tf.matmul(j_t, r)
# print('Shape is: ')
# print(j)
# g = g0 # + lambda1 * tf.reshape(dxdt, shape=(neurons_cnt, 1))
else:
hess = tf.hessians(loss, params)[0]
g = -tf.gradients(loss, params)[0]
g = tf.reshape(g, shape=(neurons_cnt, 1))
p_store = tf.Variable(tf.zeros([neurons_cnt], dtype=TF_DATA_TYPE))
hess_store = tf.Variable(tf.zeros((neurons_cnt, neurons_cnt), dtype=TF_DATA_TYPE))
g_store = tf.Variable(tf.zeros((neurons_cnt, 1), dtype=TF_DATA_TYPE))
save_params = tf.assign(p_store, params)
restore_params = tf.assign(params, p_store)
save_hess_g = [tf.assign(hess_store, hess), tf.assign(g_store, g)]
input_mat = hess_store + tf.multiply(mu_current, imatrx)
try:
dx = tf.matmul(tf.linalg.inv(input_mat), g_store)
except:
c = tf.constant(0.1)
input_mat += np.identity((input_mat.shape)) * c
dx = tf.matmul(tf.linalg.inv(input_mat), g_store)
dx = tf.squeeze(dx)
opt = tf.train.GradientDescentOptimizer(learning_rate=1)
lm = opt.apply_gradients([(-dx, params)])
feed_dict[mu_current] = np.array([mu1])
# session is an object of ten flow Session
with tf.Session() as session:
step = 0
matpvals = []
session.run(tf.global_variables_initializer())
current_loss = session.run(loss, feed_dict)
while current_loss > 1e-10 and step < 400:
step += 1
log(step, current_loss, session.run(params), feed_dict[mu_current][0])
session.run(save_params)
session.run(save_hess_g, feed_dict)
# session.run(hess_store, feed_dict)
success = False
for _ in range(max_inc):
session.run(save_hess_g, feed_dict)
session.run(hess_store, feed_dict)
session.run(lm, feed_dict)
p0 = tf.where(tf.math.equal(params, 0), tf.zeros_like(params), params)
new_loss = session.run(loss, feed_dict)
if new_loss < current_loss:
# Break the params into two groups: save those with lasso as before
# And use the other group for structured l2
numhidbiasparams = wb_sizes_classif[0] + wb_sizes_classif[1]
lassop0 = p0[numhidbiasparams:]
matpvals.append(lassop0)
in2hidparams = p0[0:numhidbiasparams]
if len(matpvals) == 3:
print(step)
sgn1 = tf.multiply(matpvals[0], matpvals[1])
sgn2 = tf.multiply(matpvals[1], matpvals[2])
last_tensor_vec = matpvals[2]
px = tf.where(tf.math.logical_and(sgn2 < 0, sgn1 < 0), tf.zeros_like(last_tensor_vec), last_tensor_vec)
sgn01 = session.run(sgn1)
sgn02 = session.run(sgn2)
oscvec = np.where((sgn01 < 0) & (sgn02 < 0))
# in2hidparams = params_grouping_func(ind2hidparams, wb_sizes_classif, wb_shapes_classif)
print(in2hidparams, px)
px0 = tf.concat([in2hidparams, px], 0)
params.assign(px0)
matpvals=[]
else:
params.assign(p0)
session.run(save_params)
session.run(restore_params)
feed_dict[mu_current] /= mu_dec
current_loss = new_loss
success = True
break
else:
feed_dict[mu_current] *= mu_dec
session.run(restore_params)
if not success:
print('Failed to improve')
break
correct_prediction, feed_dict2 = predclassif(wb_sizes_classif, xydat, hidden, params, activation, wb_shapes)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# accuracy metric using session of run of accuracy
pnews = session.run(restore_params)
pnews[pnews < 1e-06] = 0
pnonzero = np.count_nonzero(pnews)
# print(wb_shapes, wb_sizes_classif)
# paramreshape(pnonzero, wb_shapes, wb_sizes_classif)
print('Non-zeros:')
print(pnonzero)
print('ENDED ON STEP:, FINAL LOSS:')
print(step, current_loss)
print("Accuracy:", session.run(accuracy, feed_dict2))
return pnews
def train_tf_classifier(feed_dict1, params, loss, train_step, logits, labels_one_hot, feed_dict2):
step = 0
wbsize, wbshape = 1, 1
with tf.Session() as session:
session.run(tf.global_variables_initializer())
current_loss = session.run(loss, feed_dict1)
while current_loss > 1e-10 and step < 400:
step += 1
log(step, current_loss, session.run(params))
session.run(train_step, feed_dict1)
current_loss = session.run(loss, feed_dict1)
print("Epoch: {0} ; training loss: {1}".format(step, loss))
print('training finished')
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(labels_one_hot, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print("Accuracy:", accuracy.eval(feed_dict2))
return correct_prediction, wbshape, wbsize
def build_mlp_structure_classify(n, nclasses, mlp_hidden_structure):
mlp_structure = [n] + mlp_hidden_structure+[nclasses]
wb_shapes_classif = []
for idx in range(len(mlp_hidden_structure) + 1):
wb_shapes_classif.append((mlp_structure[idx], mlp_structure[idx+1]))
wb_shapes_classif.append((1, mlp_structure[idx+1]))
wb_sizes_classif = [hclassif * wclassif for hclassif, wclassif in wb_shapes_classif]
neurons_cnt_classif = sum(wb_sizes_classif)
print('Total number of trainable parameters is', neurons_cnt_classif)
return neurons_cnt_classif, wb_shapes_classif, wb_sizes_classif
def main_classif(xtrain0, ytr, nclasses, xtest, ytest, sess, choose_flag):
global out_file, step_delta, time_delta
hidden, activation, initializer, optimizer, kwargs, out_file, use_checkpoint = parse_arguments()
xtrain00 = np.asanyarray(xtrain0)
biases = np.ones((xtrain00.shape[0], 1))
# xtr = np.c_[xtrain00, biases]
xtr = xtrain00
xtest00 = np.asanyarray(xtest)
biases1 = np.ones((xtest00.shape[0], 1))
# xtest1 = np.c_[xtest00, biases1]
xtest1 = xtest00
n = xtr.shape[1]
m = xtr.shape[0]
neurons_cnt, wb_shapes, wb_sizes = build_mlp_structure_classify(n, nclasses, hidden)
ckpt_data = None
if use_checkpoint and os.path.exists(out_file + '.ckpt'):
step_delta, time_delta, ckpt_data = pickle.load(open(out_file + '.ckpt', "rb"))
else:
with open(out_file, "a") as file:
file.write('" ".join(sys.argv[1:])} \n')
kwargs1 = {'n': n, 'm': m, 'hidden': hidden, 'activation': activation, 'nclasses': nclasses,
'initializer': initializer, 'neurons_cnt':neurons_cnt, 'wb_shapes': wb_shapes}
# loss, params, x, y, y_hat, l2_normed = build_tf_nn(wb_sizes, ckpt_data, **kwargs1)
# feed dictionary of dp_x and dp_y
# loss, params, x, y, y_hat, l2_normed = func_cross_entropy_loss(wb_sizes, ckpt_data, **kwargs1)
# feed_dict = {x:xtr, y:ytr}
# feed_dict2 = {x: xtest1, y: ytest}
xydat = [xtest1, ytest]
xydatrain = [xtr, ytr]
opt_obj = tf.train.GradientDescentOptimizer(learning_rate=1)
kwargspred = {'wb_shapes': wb_shapes, 'wb_sizes': wb_sizes, 'hidden': hidden,
'activation': activation, 'xydat': xydat, 'xtr': xtr, 'xydatrain': xydatrain,
'ytr': ytr, 'sess': sess, 'neurons_cnt': neurons_cnt, 'opt_obj': opt_obj, 'choose_flag': choose_flag}
if optimizer == 'lm':
# restoreparams = train_lm(feed_dict, loss, params, y_hat, l2_normed, kwargspred, **kwargs)
restoreparams, correct_pred, ypredtrained = func_classifier_l2l1(xtest1, ytest, kwargs1, kwargspred, **kwargs)
# restoreparams, correct_pred = func_classifier_l1(xtest1, ytest, kwargs1, kwargspred, **kwargs)
# predclassif(wb_sizes, xydat, hidden, restoreparams, activation, wb_shapes, nclasses)
else:
train_step = TF_OPTIMIZERS[optimizer](0.1).minimize(loss)
train_tf_classifier(feed_dict, params, loss, train_step, y, y_hat,feed_dict2)
return restoreparams, wb_shapes, wb_sizes, hidden, correct_pred, ypredtrained
# service@eeteuropart.de
def build_tf_nn(wb_sizes_classif, ckpt_data, **kwargs1):
# placeholder variables (we have m data points)
nclassif, hidden, activation = kwargs1['n'], kwargs1['hidden'], kwargs1['activation'],
initializer, neurons_cnt_classif, wb_shapes = kwargs1['initializer'], kwargs1['neurons_cnt'], kwargs1['wb_shapes']
# n labels is for 2 # number of output classes or labels
xclassif = tf.placeholder(tf.float64, shape=[None, nclassif])
labels = tf.placeholder(tf.int64, shape = [None, ])
yclassif = tf.one_hot(labels, 2)
if ckpt_data is not None:
params = tf.Variable(ckpt_data, dtype=TF_DATA_TYPE)
else:
params = tf.Variable(initializer([neurons_cnt_classif], dtype=tf.float64))
classif_tensors = tf.split(params, wb_sizes_classif, 0)
for i in range(len(classif_tensors)):
classif_tensors[i] = tf.reshape(classif_tensors[i], wb_shapes[i])
ws_classif = classif_tensors[0:][::2]
bs_classif = classif_tensors[1:][::2]
y_hat_classif = xclassif
for i in range(len(hidden)):
y_hat_classif = activation(tf.matmul(y_hat_classif, ws_classif[i]) + bs_classif[i])
y_hat_classif = tf.matmul(y_hat_classif, ws_classif[-1]) + bs_classif[-1]
###################################################################################
lambda1 = 0.0005
regparam = lambda1 * tf.reduce_sum(tf.abs(params))
###################################################################################
lambda2 = 0.00
nhidbiasparams = wb_sizes_classif[0] + wb_sizes_classif[1]
in2hiddenparams = params[0:wb_sizes_classif[0]]
b1matrix = params[wb_sizes_classif[0]:nhidbiasparams]
# structuredl2pen = structuredl2norm(in2hiddenparams, b1matrix)
structuredl2pen = 0
# regparam2 = lambda2 * structuredl2pen
####################################################################################
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_hat_classif, labels=yclassif)) + regparam # + regparam2
return loss, params, xclassif, yclassif, y_hat_classif, lambda1
| true |
4625b698688502fd38f0cc093695b25f0274b0e7 | Python | helperbot-solutions/annoy-tools | /youtube_video_reply.py | UTF-8 | 1,753 | 2.78125 | 3 | [] | no_license | #!/usr/bin/env python3
import discord
import asyncio
import random
import os
BOT_TOKEN = os.environ['DISCORDBOT']
client = discord.Client()
async def presence_set():
await client.wait_until_ready()
await client.change_presence(game=discord.Game
(name="with the Discord API"))
@client.event
async def on_ready():
print('Logged in as')
print(client.user.name)
print(client.user.id)
print('------')
async def youtube_video_link_give(check_words, video_link, message):
if any(s in message.content.lower() for s in check_words):
msg = ("Were you looking for this? " + video_link)
await client.send_message(message.channel, msg)
@client.event
async def on_message(message):
# we do not want the bot to reply to itself
if message.author == client.user:
return
# Send a link to the "Click Noice" video when the word 'noice' is mentioned
youtube_link = "https://www.youtube.com/watch?v=3WAOxKOmR90"
await youtube_video_link_give(('noice', 'nice', 'noiice', 'noicce'),
youtube_link, message)
# Send a link to the "Yeah Boi" video when the word 'yeah' or 'boi'/'boy'
# is mentioned
youtube_link = "https://www.youtube.com/watch?v=fvtQYsckLxk&t=1m5s"
await youtube_video_link_give(('yeah', 'yeh', 'boi', 'boy'), youtube_link,
message)
# Send a link to the "Time to Stop" video when the word 'stop' or 'time' is
# mentioned
youtube_link = "https://www.youtube.com/watch?v=2k0SmqbBIpQ"
await youtube_video_link_give(('stop',), youtube_link,
message)
client.loop.create_task(presence_set())
client.run(BOT_TOKEN)
| true |
6d87973aad1e8c11f9904e8f7bd4ff69e440ea60 | Python | PedroBiel/Hades | /Hades_1/dlg_ruedas/controlador/cnt_ruedas.py | UTF-8 | 3,072 | 3.203125 | 3 | [] | no_license | # -*- coding: utf-8 -*-
"""
Controlador del nº de ruedas
Created on Wed Oct 21 09:40:14 2020
__author__ = Pedro Biel
__version__ = 0.0.0
__email__ = pbiel@taimweser.com
"""
from dlg_ruedas.datos.datos_ruedas import Unicos
from dlg_ruedas.modelo.mdl_tablemodeleditable import PandasModelEditable
class CntRuedas:
"""Controlador del nº de ruedas."""
def __init__(self, ventana):
"""Crea la ventana de MainWindow."""
self.v = ventana
def crea_ruedas(self):
"""
Crea el df_ruedas con los nudos únicos del DataFrame df_apoyos y
asigna dichos valores a un modelo.
Muestra el modelo en el diálogo de grupos.
"""
# Status bar.
text = 'Creando nº de ruedas.'
self.v.status_bar(text)
# Asigna valores de df_apoyos a df_ruedas y de df_ruedas al modelo.
equals = self.compara_dataframes_apoyos()
if equals: # Los DataFrames son iguales, self.v.df_ruedas no se modifica.
if self.v.df_ruedas.empty: # Si es la primera vez que se llama a las ruedas.
self.v.df_ruedas = self.get_ruedas()
else: # Los DataFrames no son iguales, self.v.df_ruedas se modifica.
self.v.df_ruedas = self.get_ruedas()
# Se hace una nueva copia de df_apoyos para que la próxima vez que
# se llame a las ruedas sean iguales df_apoyos y df_apoyos_prev
# y se conserven los cambios en ruedas.
self.v.df_apoyos_prev = self.v.df_apoyos.copy()
model = self.get_modelo(self.v.df_ruedas)
# Salida en el diálogo.
self.v.call_dialogo_ruedas(self.v.df_ruedas, model)
# Status bar.
text = 'Nº de ruedas creadas.'
self.v.status_bar(text)
def compara_dataframes_apoyos(self):
"""
Compara el DataFrame Apoyos con el DataFrame previo.
Si son iguales retorna True, si no lo son, retorna False.
"""
equals = self.v.df_apoyos.equals(self.v.df_apoyos_prev)
# print('\nequals:', equals)
return equals
def dataframe_ruedas(self):
"""
Sea df_apoyos el DataFrame con los apoyos obtiene un nuevo DataFrame
con los valores únicos del DataFrame de los apoyos.
"""
try:
unicos = Unicos(self.v.pd, self.v.df_apoyos)
df_unicos = unicos.get_df()
except Exception as e:
print('Exception en CntRuedas.dataframe_ruedas():', e)
return df_unicos
def get_ruedas(self):
"""Getter del DataFrame con las ruedas."""
df_ruedas = self.dataframe_ruedas()
return df_ruedas
def get_modelo(self, df):
"""Getter del modelo con los datos del DataFrame."""
model = PandasModelEditable(df)
return model
| true |
b6baa721178dad8bb8dee9b062b561fa8f92e033 | Python | SeanLeCornu/Coding-Notes | /2. Python - COMP0015 - Q's/Week 6/1.Coin Q/coin_prog.py | UTF-8 | 564 | 3.734375 | 4 | [] | no_license |
from coin_module import Coin
def print_menu():
print("Type:")
print("\tf - to flip the coin")
print("\tq - to quit")
print()
def main():
selection = "a"
selection = input("Enter selection: " )
while selection != 'q':
if selection == "f":
coinx = Coin ()
coinx.flip ()
#or could use
print(coinx)
selection = input("Enter a selection: ")
print("\nBye, Bye!\n")
print_menu()
if __name__ == "__main__":
main()
| true |
b88ae155de0f4d97187c9f696459e9f47dac885a | Python | ZY1N/Pythonforinfomatics | /ch12/12_3.py | UTF-8 | 689 | 3.796875 | 4 | [] | no_license | #Exercise 12.3 Use urllib to replicate the previous exercise of (1) retrieving the
#document from a URL, (2) displaying up to 3000 characters, and (3) counting the
#overall number of characters in the document. Dont worry about the headers for
#this exercise, simply show the first 3000 characters of the document contents.
import urllib
address = raw_input("Enter an URL :")
try:
url = urllib.urlopen(address)
except:
print "Error invalid file"
string = str()
total = 0
for line in url:
for letter in line:
if total == 3000:
break
string = string + letter
total = total + 1
if total == 3000:
break
print string
print total
| true |
b8c61ea7d8e25bd62d999f8e10f40f0c3642488b | Python | kimjisub/Hackathon-Seoul-HW | /Socket Middleware/app.py | UTF-8 | 4,969 | 2.546875 | 3 | [] | no_license | import asyncio
import aiohttp
import logging
import colorlog
import traceback
from datetime import datetime
from typing import Tuple
class SocketReceiver:
def __init__(self,
host: str = "0.0.0.0",
port: int = 8080):
self.host = host
self.port = port
self.sessions: dict = {}
# logger setup
self.logger = logging.getLogger(__name__)
self.logger.setLevel(logging.DEBUG)
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.DEBUG)
console_handler.setFormatter(colorlog.ColoredFormatter(
"%(log_color)s[%(asctime)s][%(levelname)s %(filename)s:%(lineno)d] %(message)s%(reset)s",
log_colors={
"INFO": "green",
"WARN": "yellow",
"EXCEPTION": "red",
"ERROR": "red",
"CRITICAL": "red",
"NOTSET": "white",
"DEBUG": "white"
},
style="%"
))
self.logger.addHandler(console_handler)
@property
def addr(self) -> Tuple[str, int]:
return self.host, self.port
async def handle_echo(self, reader: asyncio.StreamReader, writer: asyncio.StreamWriter):
try:
addr = writer.get_extra_info('peername')
data = await self.read(reader, writer)
message = data.decode()
mode, data = message.split(":", 1)
if mode not in ("R", "D"):
return await self.write(reader, writer, b"E:Mod")
# ------------------------------------------------------------------------ #
if mode == "R":
device_id = data
self.logger.warning(f"Host {device_id}: Register requested")
await self.write(reader, writer, b"S:OK")
await writer.drain()
data = await self.read(reader, writer)
message = data.decode()
try:
mode, device_id, location = message.split(":", 2)
lon, lat = map(float, location.split(",", 1))
self.logger.warning(f"Host {device_id}: Registered at {lon}, {lat}")
self.sessions[device_id] = {
"GPS": (lon, lat, ),
"Address": addr,
"Registered": datetime.now().timestamp()
}
async with aiohttp.ClientSession(headers={"Content-Type": "application/x-www-form-urlencoded"}) as sess:
async with sess.post("http://r.kdw.kr:9999/{}".format(device_id),
data="lat={}&lon={}".format(lat, lon)) as resp:
data = await resp.text()
print("Backend response:", data)
await self.write(reader, writer, b"S:OK")
await writer.drain()
self.logger.info(f"Clse {addr!r}")
writer.close()
except ValueError: # unpacking not matched
return await self.write(reader, writer, b"E:Val")
except TypeError: # cannot unpack
return await self.write(reader, writer, b"E:Tpe")
# ------------------------------------------------------------------ #
else: # Mode "D"ata
device_id, data = data.split(":", 1)
self.logger.warning(f"Host {device_id}: Incoming event data")
percentage = float(data)
if percentage:
async with aiohttp.ClientSession(headers={"Content-Type": "application/x-www-form-urlencoded"}) as sess:
async with sess.post("http://r.kdw.kr:9999/{}/event".format(device_id)) as resp:
data = await resp.text()
print("Backend response:", data)
return await self.write(reader, writer, b"S:OK")
except:
self.logger.critical(traceback.format_exc())
return await self.write(reader, writer, b"E:Unk")
async def read(self, reader, writer, size: int = 2**12) -> bytes:
data = await reader.read(size)
self.logger.info(f"Recv {writer.get_extra_info('peername')!r}: {data!r}")
return data
async def write(self, reader, writer, data: bytes):
ret = writer.write(data + b"\r\n")
self.logger.info(f"Send {writer.get_extra_info('peername')!r}: {data!r}")
return ret
async def main(self):
server = await asyncio.start_server(
self.handle_echo, self.host, self.port)
addr = server.sockets[0].getsockname()
self.logger.info(f'Serving on {addr}')
async with server:
await server.serve_forever()
def run(self):
asyncio.run(self.main())
| true |
dd66e73273799a4cc72c2d2c526ec3ba471a45c3 | Python | ArnavPalkhiwala/TicTacToe | /tictactoe.py | UTF-8 | 4,665 | 3.015625 | 3 | [] | no_license | from tkinter import *
from tkinter import ttk
from tkinter import messagebox
from random import randint
playerOneName = input('Player one, please enter your name: ')
playerTwoName = input('Player two, please enter your name: ')
ActivePlayer = 1
player1 = []
player2 = []
count = 0
root = Tk()
root.title(f'Tic Tac Toe: {playerOneName}')
style = ttk.Style()
style.theme_use('classic')
b1 = ttk.Button(root, text=' ')
b1.grid(row=0, column=0, sticky='snew', ipadx=40, ipady=40)
b1.config(command=lambda: BuClick(1))
b2 = ttk.Button(root, text=' ')
b2.grid(row=0, column=1, sticky='snew', ipadx=40, ipady=40)
b2.config(command=lambda: BuClick(2))
b3 = ttk.Button(root, text=' ')
b3.grid(row=0, column=2, sticky='snew', ipadx=40, ipady=40)
b3.config(command=lambda: BuClick(3))
b4 = ttk.Button(root, text=' ')
b4.grid(row=1, column=0, sticky='snew', ipadx=40, ipady=40)
b4.config(command=lambda: BuClick(4))
b5 = ttk.Button(root, text=' ')
b5.grid(row=1, column=1, sticky='snew', ipadx=40, ipady=40)
b5.config(command=lambda: BuClick(5))
b6 = ttk.Button(root, text=' ')
b6.grid(row=1, column=2, sticky='snew', ipadx=40, ipady=40)
b6.config(command=lambda: BuClick(6))
b7 = ttk.Button(root, text=' ')
b7.grid(row=2, column=0, sticky='snew', ipadx=40, ipady=40)
b7.config(command=lambda: BuClick(7))
b8 = ttk.Button(root, text=' ')
b8.grid(row=2, column=1, sticky='snew', ipadx=40, ipady=40)
b8.config(command=lambda: BuClick(8))
b9 = ttk.Button(root, text=' ')
b9.grid(row=2, column=2, sticky='snew', ipadx=40, ipady=40)
b9.config(command=lambda: BuClick(9))
def BuClick(id):
global ActivePlayer
global player1
global player2
if ActivePlayer == 1:
SetLayout(id, 'X')
player1.append(id)
root.title(f'Tic Tac Toe: {playerTwoName}')
ActivePlayer = 2
print("player1:{}".format(player1))
elif ActivePlayer == 2:
SetLayout(id, 'O')
player2.append(id)
root.title(f'Tic Tac Toe: {playerOneName}')
ActivePlayer = 1
print("player2:{}".format(player2))
Winner()
def SetLayout(id, text):
if id == 1:
b1.config(text=text)
b1.state(['disabled'])
elif id == 2:
b2.config(text=text)
b2.state(['disabled'])
elif id ==3:
b3.config(text=text)
b3.state(['disabled'])
elif id == 4:
b4.config(text=text)
b4.state(['disabled'])
elif id == 5:
b5.config(text=text)
b5.state(['disabled'])
elif id == 6:
b6.config(text=text)
b6.state(['disabled'])
elif id == 7:
b7.config(text=text)
b7.state(['disabled'])
elif id == 8:
b8.config(text=text)
b8.state(['disabled'])
elif id == 9:
b9.config(text=text)
b9.state(['disabled'])
def Winner():
Winner = -1
if 1 in player1 and 2 in player1 and 3 in player1:
Winner = 1
elif 1 in player2 and 2 in player2 and 3 in player2:
Winner = 2
elif 4 in player1 and 5 in player1 and 6 in player1:
Winner = 1
elif 4 in player2 and 5 in player2 and 6 in player2:
Winner = 2
elif 7 in player1 and 8 in player1 and 9 in player1:
Winner = 1
elif 7 in player2 and 8 in player2 and 8 in player2:
Winner = 2
elif 1 in player1 and 4 in player1 and 7 in player1:
Winner = 1
elif 1 in player2 and 4 in player2 and 7 in player2:
Winner = 2
elif 2 in player1 and 5 in player1 and 8 in player1:
Winner = 1
elif 2 in player2 and 5 in player2 and 8 in player2:
Winner = 2
elif 3 in player1 and 6 in player1 and 9 in player1:
Winner = 1
elif 3 in player2 and 6 in player2 and 9 in player2:
Winner = 2
elif 1 in player1 and 5 in player1 and 9 in player1:
Winner = 1
elif 1 in player2 and 5 in player2 and 9 in player2:
Winner = 2
elif 3 in player1 and 5 in player1 and 7 in player1:
Winner = 1
elif 3 in player2 and 5 in player2 and 7 in player2:
Winner = 2
if Winner == 1:
messagebox.showinfo(title="Great Job!", message = f'{playerOneName} is the Winner!')
elif Winner == 2:
messagebox.showinfo(title="Great Job!", message = f'{playerTwoName} is the Winner!')
elif count == 9:
messagebox.showinfo(title="Tie!", message = f'You tied!!')
def AutoPlay():
global player1
global player2
EmptyCell = []
for cell in range(9):
if not((cell+1 in player1) or (cell+1 in player2)):
EmptyCell.append(cell + 1)
RandIndex = randint(0, len(EmptyCell)-1)
BuClick(EmptyCell[RandIndex])
root.mainloop() | true |
176e269df384d294f5e6e72a21c5c3f52bfaa69b | Python | nikasha89/MC | /Tarea 2/barcode_detection_recognition.py | UTF-8 | 13,734 | 2.75 | 3 | [] | no_license | from os import listdir
import cv2
import numpy as np
from matplotlib import pyplot as plt
filenames = []
dir = "./barcodes/"
for element in listdir(dir):
filenames.append(element)
# names contains of all photos in filenames
# you can change the number for changing the photo
name = dir + filenames[3]
# Linux
# name = "./ruta/image"
# Windows
# name = ".\\ruta\\image"
# origin image read
image = cv2.imread(name, cv2.IMREAD_COLOR)
image_original = image.copy()
cv2.imshow("Image", image)
cv2.waitKey(0)
# is a bmp image?
if name[-3:].lower() != "bmp":
# we need to keep in mind aspect ratio so the image does
# not look skewed or distorted -- therefore, we calculate
# the ratio of the new image to the old image
r = 600 / image.shape[1]
dim = (600, int(image.shape[0] * r))
# perform the actual resizing of the image and show it
resized = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
cv2.imshow("Image", resized)
cv2.waitKey(0)
# gray scale converter
image = cv2.cvtColor(resized, cv2.COLOR_BGR2GRAY)
else:
# gray scale converter
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# canny and threshold the image
canny = cv2.Canny(image, 100, 200)
(_, thresh) = cv2.threshold(canny, 25, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# kernel creation
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (21, 7))
# Morphology operations
closed = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
# closed = cv2.erode(closed, None, iterations=4)
# closed = cv2.dilate(closed, None, iterations=4)
# find the contours in the thresholded image, then sort the contours
# by their area, keeping only the largest one
(_, cnts, _) = cv2.findContours(closed.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
c = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# compute the rotated bounding box of the largest contour
rect = cv2.minAreaRect(c)
box = np.intc(cv2.boxPoints(rect))
box = np.intp(box)
image2 = image.copy()
cv2.drawContours(image2, [box], -1, (0, 255, 0), 3)
cv2.imshow("Image", image2)
cv2.waitKey(0)
# vertex selection
min_x = 99999
max_x = 0
min_y = 99999
max_y = 0
for i in box:
if i[0] < min_x:
min_x = i[0]
if i[1] < min_y:
min_y = i[1]
if i[0] > max_x:
max_x = i[0]
if i[1] > max_y:
max_y = i[1]
# cut the image
image = image[min_y:max_y, min_x:max_x]
cv2.imshow("Image", image)
cv2.waitKey(0)
# perform the actual resizing of the image and show it
dim = (600, 600)
resized = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
# cv2.imwrite("recorte.jpg",image)
def stand_out_borers(image):
# Load the image, convert it to grayscale, and blur it
# slightly to remove high frequency edges that we aren't
# interested in
# perform a series of erosions and dilations
# When performing Canny edge detection we need two values
# for hysteresis: threshold1 and threshold2. Any gradient
# value larger than threshold2 are considered to be an
# edge. Any value below threshold1 are considered not to
# ben an edge. Values in between threshold1 and threshold2
# are either classified as edges or non-edges based on how
# the intensities are "connected". In this case, any gradient
# values below 30 are considered non-edges whereas any value
# above 150 are considered edges.
# canny = cv2.Canny(image, 30, 150)
# cv2.imshow("Image", canny)
# cv2.waitKey(0)
# Read the image you want connected components of
# Threshold it so it becomes binary
ret, image = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# You need to choose 4 or 8 for connectivity type
connectivity = 4
# Perform the operation
output = cv2.connectedComponentsWithStats(image, connectivity, cv2.CV_32S)
# Get the results
# The first cell is the number of labels
num_labels = output[0]
# The second cell is the label matrix
labels = output[1]
# The third cell is the stat matrix
stats = output[2]
# The fourth cell is the centroid matrix
centroids = output[3]
cv2.imshow("Image", image)
cv2.waitKey(0)
return image
image = stand_out_borers(resized)
# Hough transformation
def hough_transformation(image):
edges = cv2.Canny(image, 100, 200, apertureSize=3)
minLineLength = 10
maxLineGap = 20
lines = cv2.HoughLinesP(edges, 1, np.pi / 180, 100, minLineLength, maxLineGap)
for x1, y1, x2, y2 in lines[0]:
cv2.line(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.imwrite("hough.jpg", image)
cv2.imshow("Image", image)
cv2.waitKey(0)
return image
image = hough_transformation(image)
# Fourier transformation
def fourier_transformation(image):
dft = cv2.dft(np.float32(image), flags=cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
magnitude_spectrum = 20 * np.log(cv2.magnitude(dft_shift[:, :, 0], dft_shift[:, :, 1]))
plt.subplot(121), plt.imshow(image, cmap='gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(magnitude_spectrum, cmap='gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()
rows, cols = image.shape
crow, ccol = rows / 2, cols / 2
# create a mask first, center square is 1, remaining all zeros
mask = np.zeros((rows, cols, 2), np.uint8)
mask[int(crow - 30):int(crow + 30), int(ccol - 30):int(ccol + 30)] = 1
# apply mask and inverse DFT
fshift = dft_shift * mask
f_ishift = np.fft.ifftshift(fshift)
img_back = cv2.idft(f_ishift)
img_back = cv2.magnitude(img_back[:, :, 0], img_back[:, :, 1])
plt.subplot(121), plt.imshow(image, cmap='gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(img_back, cmap='gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()
return image
image = fourier_transformation(image)
# Morphology transformations
image = cv2.dilate(image, None, iterations=1)
image = cv2.erode(image, None, iterations=2)
image = cv2.dilate(image, None, iterations=1)
cv2.imshow("Image", image)
cv2.waitKey(0)
# compute the Scharr gradient magnitude representation of the images
# in both the x and y direction
cv2.imshow("Image", image)
cv2.imwrite("Image.jpg", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# Decode algorithm
# Validation algorithm
def control_digit(digits):
control = 0
for i in range(0, len(digits), 2):
control += int(digits[i]) * 3
for i in range(1, len(digits), 2):
control += int(digits[i])
numero = 0
for i in range(0, len(digits) - 1):
if (control % 10 != 0):
numero += 1
return str(numero)
space = 0
bar = 255
# the next bar
def align_boundary(image, x, y, start, end):
if (image[y][x] == end):
while (image[y][x] == end):
x += 1
else:
while (image[y][x - 1] == start):
x -= 1
return x
# Read a digit
def read_digit(image, xcurr, ycurr, unit_width, l_code, g_code, r_code, position):
# Read the 7 consecutive bits.
pattern = [0, 0, 0, 0, 0, 0, 0]
for i in range(0, len(pattern)):
for j in range(0, unit_width):
if image[ycurr, xcurr] == bar:
pattern[i] += 1
xcurr += 1
# See below for explanation.
if (pattern[i] == 1 and image[ycurr][xcurr] == bar or pattern[i] == unit_width - 1 and image[ycurr][
xcurr] == space):
xcurr -= 1
# Convert to binary, consider that a bit is set if the number of bars encountered is greater than a threshold.
threshold = unit_width / 2
v = ""
for i in range(0, len(pattern)):
v += "1" if pattern[i] >= threshold else "0"
# Lookup digit value.
digit = ""
if position == "LEFT":
if parity(v) == 1:
# odd parity
digit = l_code.get(v)
encoding = "L"
else:
# even parity
digit = g_code.get(v)
encoding = "G"
xcurr = align_boundary(image, xcurr, ycurr, space, bar)
else:
digit = r_code.get(v)
encoding = "R"
xcurr = align_boundary(image, xcurr, ycurr, bar, space)
cv2.imshow("numbers", image)
cv2.imwrite("numbers.jpg", image)
return (xcurr, digit, encoding)
# parity calculation
def parity(cad):
cont = 0
for i in cad:
if i == "1":
cont += 1
return cont % 2
# first bar
def skip_quiet_zone(image, x, y):
while image[y][x] == space:
x += 1
return x
# first left digit
def read_lguard(image, x, y):
widths = [0, 0, 0]
pattern = [bar, space, bar]
for i in range(0, len(pattern)):
while (image[y][x] == pattern[i]):
x += 1
widths[i] += 1
return (x, widths[0])
# skip control middle zone
def skip_mguard(image, x, y):
pattern = [space, bar, space, bar, space]
for i in range(0, len(pattern)):
while image[y][x] == pattern[i]:
x += 1
return x
def __checkDigit(digits):
total = sum(digits) + sum(digits[-1::-2] * 2)
return (10 - (total % 10)) % 10
def validateCheckDigit(barcode=''):
if len(barcode) in (8, 12, 13, 14) and barcode.isdigit():
digits = list(map(int, barcode))
checkDigit = __checkDigit(digits[0:-1])
return checkDigit == digits[-1]
return False
# barcode read all
def read_barcode(image):
digits = []
# invert colors
image = cv2.bitwise_not(image)
l_code = {"0001101": 0, "0011001": 1, "0010011": 2, "0111101": 3, "0100011": 4,
"0110001": 5, "0101111": 6, "0111011": 7, "0110111": 8, "0001011": 9}
g_code = {"0100111": 0, "0110011": 1, "0011011": 2, "0100001": 3, "0011101": 4,
"0111001": 5, "0000101": 6, "0010001": 7, "0001001": 8, "0010111": 9}
r_code = {"1110010": 0, "1100110": 1, "1101100": 2, "1000010": 3, "1011100": 4,
"1001110": 5, "1010000": 6, "1000100": 7, "1001000": 8, "1110100": 9}
first_digit = {"LLLLLL": 0, "LLGLGG": 1, "LLGGLG": 2, "LLGGGL": 3, "LGLLGG": 4,
"LGGLLG": 5, "LGGGLL": 6, "LGLGLG": 7, "LGLGGL": 8, "LGGLGL": 9}
position = {0: "LEFT", 1: "RIGHT"}
for i in range(0, len(image[0])):
xcurr = int(0)
ycurr = int(i)
list_d = []
try:
xcurr = skip_quiet_zone(image, xcurr, ycurr)
(xcurr, unit_width) = read_lguard(image, xcurr, ycurr)
digits_line = []
encodigns_line = []
# 6 left digits read
for j in range(0, 6):
d = "0000000"
(xcurr, d, encodign) = read_digit(image, xcurr, ycurr, unit_width, l_code, g_code, r_code, position[0])
digits_line.append([d, encodign])
list_d.extend([d, encodign])
xcurr = skip_mguard(image, xcurr, ycurr)
# 6 right digits read
for j in range(0, 6):
d = "0000000"
(xcurr, d, encodign) = read_digit(image, xcurr, ycurr, unit_width, l_code, g_code, r_code, position[1])
digits_line.append([d, encodign])
list_d.extend([d, encodign])
digits.append(digits_line)
cad = ""
cad2 = ""
size = len(list_d)
if size == 24:
for item in range(1, int(size / 2), 2):
cad += str(list_d[item])
check = first_digit.get(cad)
for item in range(0, size, 2):
cad2 += str(list_d[item])
if check is not None:
list_complete = str(check) + cad2
else:
list_complete = str(-1) + cad2
if validateCheckDigit(list_complete):
return list_complete
except:
pass
final_digits = []
final_encodings = ""
final_cad = ""
for i in range(len(digits[0])):
index = -1
matches = []
maxim_value = -1
cont_value = -1
for j in range(len(digits)):
cad = ""
for k in range(0, 10):
matches.append(-1)
for k in range(0, 10):
if str(k) == str(digits[j][i][0]):
matches[k] += 1
cad += str(digits[j][i][0]) + digits[j][i][1]
for k in range(0, 10):
if (matches[k] > maxim_value):
maxim_value = matches[k]
index = k
if i < 6:
if (index != -1):
for n in range(0, 10):
for k in ["L", "G"]:
number = cad.count(str(n) + k)
if (cont_value < number):
cont_value = number
final_cad = str(n) + k
else:
final_cad = ""
else:
if (index != -1):
final_cad = "0R"
else:
final_cad = ""
final_digits.append(str(index))
final_encodings += final_cad[1:]
print(final_encodings)
first = first_digit.get(final_encodings[0:6])
if first is not None:
list = [first]
list.extend(final_digits)
else:
list = ["-1"]
list.extend(final_digits)
return list
digits = read_barcode(image)
print("Digits: {}".format(digits))
cad = ""
for i in digits:
if i is not None:
cad += str(i)
print("Decode Validation: {}".format(validateCheckDigit(cad)))
| true |
044b75d5c47bd0eb6503d6d0ee57dbc39112efa5 | Python | Inkatha/scripture_cryptography | /main.py | UTF-8 | 2,120 | 3.171875 | 3 | [] | no_license | #!/usr/bin/python3
import sys
import argparse
import code_checker
import mapping
import constants
from itertools import permutations
def main():
parser = argparse.ArgumentParser(description='A1Z26 & 09 encoder/decoder')
parser.add_argument(
'-c',
'--code',
type=str,
choices=(constants.ENCODE, constants.DECODE),
help="Specifies if the script encodes or decodes the user's input.",
required=True
)
parser.add_argument(
'-k',
'--keyType',
type=str.lower,
choices=(constants.A1Z26, constants.ZERO_NINE),
help='A1Z26 encoding/decoding. \n09 for 0-9 encoding/decoding.',
required=True
)
parser.add_argument(
'-i',
'--input',
type=str.lower,
help='Input to be encoded/decoded. Encoding turns comma separated numbers into text. Decoding transforms letters into text.',
required=True
)
args = parser.parse_args()
code_checker.check_input(args)
if args.keyType == constants.A1Z26:
result = []
if args.code == constants.ENCODE:
encoder_mapping = mapping.create_encode_a1z26_map()
for letter in args.input:
result.append(encoder_mapping[letter])
elif args.code == constants.DECODE:
decoder_mapping = mapping.create_decode_a1z26_map()
numbers = args.input.split(',')
for number in numbers:
result.append(decoder_mapping[number])
print(result)
elif args.keyType == constants.ZERO_NINE:
results = []
if args.code == constants.ENCODE:
encoder_mapping = mapping.create_encode_09_map()
for letter in args.input:
results.append(encoder_mapping[letter])
elif args.code == constants.DECODE:
decoder_mapping = mapping.create_decode_09_map()
numbers = args.input.split(',')
for number in numbers:
letters = decoder_mapping[int(number)]
results.append(list(permutations(letters)))
container = []
for result in results:
for letters in result:
container.append(''.join(list(letters)))
print(list(permutations(container, len(args.input.split(',')))))
if __name__ == '__main__':
main() | true |
c52012d7b5a6f384e8d2b047a372e29b089c3d7d | Python | unomachineshop/Shop_Code | /mshop/python/config_loader/config_loader.py | UTF-8 | 1,117 | 2.875 | 3 | [] | no_license | #########################################################
# Name: config_reader_yaml
# Desc: A YAML configuration file reader. Given a simple
# config file convert it into a usable python dict.
# Usesful for ommitting senstive data from source
# control.
#########################################################
def config_reader_yaml(path):
import yaml
with open(path) as config_file:
data = yaml.load(config_file, Loader=yaml.FullLoader)
#print(data)
#print(data["username"])
#########################################################
# Name: config_reader_yaml
# Desc: A YAML configuration file reader. Given a simple
# config file convert it into a usable python dict.
# Usesful for ommitting senstive data from source
# control.
#########################################################
def config_reader_json(path):
import json
with open(path) as config_file:
data = json.load(config_file)
#print(data)
#print(data["username"])
### Example Use Case ###
#config_reader_yaml("./test.yaml")
#config_reader_json("./test.json")
| true |
64de4e984dcd4d384ce61e0c0b981c83874e33ef | Python | PayasPandey11/reinforce | /policy_gradient_baseline.py | UTF-8 | 7,416 | 2.671875 | 3 | [] | no_license | import numpy as np
np.set_printoptions(suppress=True)
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Categorical
import torch.optim as optim
from gym import wrappers
import gym
def init_weights(m):
if type(m) == nn.Linear:
torch.nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
class PolicyApproximator(nn.Module):
def __init__(self, input_shape, output_shape):
super(PolicyApproximator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_shape, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, output_shape),
nn.Softmax(dim=1),
)
self.optimizer = optim.Adam(self.model.parameters(), lr=0.001)
# self.apply(init_weights)
def forward(self, state):
return self.model(state)
def get_action(self, state):
state = torch.from_numpy(state).unsqueeze(0).float().to(device)
probs = self.forward(state).cpu()
cat_probs = Categorical(probs)
action = cat_probs.sample()
log_prob = cat_probs.log_prob(action)
# print(
# f"\n\n probs-> {probs} cat_probs-> {cat_probs} action -> {action} log_prob-> {log_prob}"
# )
return action.item(), log_prob
def get_loss(self, state, target):
# _, log_prob = self.get_action(state)
policy_loss = []
for log_prob in state:
policy_loss.append(-log_prob.detach() * target)
total_policy_loss = torch.cat(policy_loss).mean()
return total_policy_loss
def update(self, state, target):
policy_loss = self.get_loss(state, target)
self.optimizer.zero_grad()
policy_loss.backward()
self.optimizer.step()
return policy_loss
class ValueApproximator(nn.Module):
def __init__(self, input_shape):
super(ValueApproximator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_shape, 32), nn.ReLU(), nn.Linear(32, 1)
)
self.optimizer = optim.Adam(self.model.parameters(), lr=0.001)
self.criterion = nn.MSELoss()
def forward(self, state):
return self.model(state)
def predict_reward(self, state):
state = torch.from_numpy(state).unsqueeze(0).float().to(device)
reward = self.forward(state).cpu()
return reward
def update(self, state, actual_reward):
predicted_reward = self.predict_reward(state)
value_loss = self.criterion(actual_reward,predicted_reward)
self.optimizer.zero_grad()
value_loss.backward()
self.optimizer.step()
return value_loss
def discount_rewards(rewards, gamma):
discounted_rewards = [gamma ** i * rewards[i] for i in range(len(rewards))]
return discounted_rewards
def normalise_rewards(rewards):
rewards_mean = rewards.mean()
rewards_std = rewards.std()
rewards_norm = [
(rewards[i] - rewards_mean) / (rewards_std + 1e-10) for i in range(len(rewards))
]
return rewards_norm
def apply_reinforce(policy_approximator, value_approximator, num_episodes=100, gamma=1):
print(policy_approximator, value_approximator)
best_score = -1000
scores = []
for episode_i in range(1, num_episodes):
# print(f"\n\n ---episode ----- {episode_i}")
saved_log_probs, rewards, states_actions_rewards, value_loss, policy_loss = (
[],
[],
[],
[],
[],
)
time_step, total_reward = 0, 0
state = env.reset()
done = False
while not done:
action, log_prob = policy_approximator.get_action(state)
saved_log_probs.append(log_prob)
new_state, reward, done, _ = env.step(action)
rewards.append(reward)
time_step += 1
states_actions_rewards.append((state, action, reward))
state = new_state
if done:
total_reward = sum(rewards)
# print(f"Done with total reward {total_reward} at time step {time_step}")
scores.append(total_reward)
discounted_rewards = discount_rewards(rewards, gamma)
norm_rewards = normalise_rewards(np.asarray(discounted_rewards))
for step_idx, step_dict in enumerate(states_actions_rewards):
state, action, reward = step_dict
discounted_R = sum(discounted_rewards[step_idx:])
baseline_value = value_approximator.predict_reward(state)
advantage = discounted_R - baseline_value
_value_loss = value_approximator.update(
state, torch.tensor(discounted_R)
)
_policy_loss = policy_approximator.update(
saved_log_probs, advantage
)
policy_loss.append(_policy_loss)
value_loss.append(_value_loss)
# print(f"Done with total reward {total_reward} at time step {time_step}")
if episode_i % (num_episodes / 10) == 0 or episode_i == 1:
print(
f"Episode - > {episode_i} Score -> {total_reward} best score -> {best_score}\n"
f"policy loss - > {sum(policy_loss)/len(policy_loss)} value loss - > {sum(value_loss)/len(value_loss)} "
)
if total_reward > best_score:
print(
f"\n --- saving model with score {total_reward} at Episode - > {episode_i} \n"
)
best_score = total_reward
torch.save(policy_approximator, model_path)
return scores
def test_policy():
model = torch.load(model_path)
model.eval()
for i in range(10):
total_reward = 0
done = False
state = env.reset()
while not done:
action, _ = model.get_action(state)
env.render()
state, reward, done, _ = env.step(action)
total_reward += reward
if done:
break
print(total_reward)
env.close()
if __name__ == "__main__":
env_name = "CartPole-v0"
model_path = f"models/{env_name}_policygrad"
env = gym.make(env_name)
env.seed(0)
# env = wrappers.Monitor(
# env,
# f"Saved_Videos/policy_grad/reinforce/{env_name}",
# resume=True,
# force=True,
# video_callable=lambda episode_id: episode_id % 100 == 0,
# )
device = "cpu"
obs_shape = env.observation_space.shape
action_shape = env.action_space
print(obs_shape, action_shape)
policy_approximator = PolicyApproximator(input_shape=4, output_shape=2)
value_approximator = ValueApproximator(input_shape=4)
rewards = apply_reinforce(
policy_approximator, value_approximator, num_episodes=2000, gamma=0.99
)
smoothed_rewards = [
np.mean(rewards[max(0, i - 10) : i + 1]) for i in range(len(rewards))
]
test_policy()
plt.figure(figsize=(12, 8))
plt.plot(smoothed_rewards)
plt.title(f"REINFORCE Baseline with Policy Estimation for {env_name}")
plt.show()
| true |
084d0f16a64942d07968ee2f4eb1757266759c57 | Python | scj1420/Class-Projects-Research | /Class/ACME_Volume_1-Python/LeastSquares_Eigenvalues/lstsq_eigs.py | UTF-8 | 5,370 | 3.4375 | 3 | [] | no_license | # lstsq_eigs.py
"""Volume 1: Least Squares and Computing Eigenvalues.
<Name>
<Class>
<Date>
"""
# (Optional) Import functions from your QR Decomposition lab.
# import sys
# sys.path.insert(1, "../QR_Decomposition")
# from qr_decomposition import qr_gram_schmidt, qr_householder, hessenberg
import numpy as np
import scipy as sp
from scipy import linalg as la
from matplotlib import pyplot as plt
import cmath
# Problem 1
def least_squares(A, b):
"""Calculate the least squares solutions to Ax = b by using the QR
decomposition.
Parameters:
A ((m,n) ndarray): A matrix of rank n <= m.
b ((m, ) ndarray): A vector of length m.
Returns:
x ((n, ) ndarray): The solution to the normal equations.
"""
Q,R = la.qr(A, mode='economic')
return la.solve_triangular(R, Q.T@b)
# Problem 2
def line_fit():
"""Find the least squares line that relates the year to the housing price
index for the data in housing.npy. Plot both the data points and the least
squares line.
"""
housing = np.load('housing.npy')
A = np.column_stack((housing[:,0], np.ones(len(housing))))
b = housing[:,1]
x = least_squares(A, b)
plt.ion()
plt.plot(housing[:,0], housing[:,1], 'k*', label="Data Points")
plt.plot(housing[:,0], x[0]*housing[:,0] + x[1], label="Least Squares Fit")
plt.legend(loc="upper left")
# Problem 3
def polynomial_fit():
"""Find the least squares polynomials of degree 3, 6, 9, and 12 that relate
the year to the housing price index for the data in housing.npy. Plot both
the data points and the least squares polynomials in individual subplots.
"""
housing = np.load('housing.npy')
A_3 = np.vander(housing[:,0], 4)
A_6 = np.vander(housing[:,0], 7)
A_9 = np.vander(housing[:,0], 10)
A_12 = np.vander(housing[:,0], 13)
b = housing[:,1]
x_3 = la.lstsq(A_3,b)[0]
x_6 = la.lstsq(A_6,b)[0]
x_9 = la.lstsq(A_9,b)[0]
x_12 = la.lstsq(A_12,b)[0]
rd = np.linspace(0, housing[-1][0], num=100)
plt.ion()
ax1 = plt.subplot(221)
ax1.plot(housing[:,0], housing[:,1], 'k*', label="Data Points")
p_3 = np.poly1d(x_3)
ax1.plot(rd, p_3(rd), label="Least Squares Fit")
ax1.set_title("Degree=3")
ax2 = plt.subplot(222)
ax2.plot(housing[:,0], housing[:,1], 'k*', label="Data Points")
p_6 = np.poly1d(x_6)
ax2.plot(rd, p_6(rd), label="Least Squares Fit")
ax2.set_title("Degree=6")
ax3 = plt.subplot(223)
ax3.plot(housing[:,0], housing[:,1], 'k*', label="Data Points")
p_9 = np.poly1d(x_9)
ax3.plot(rd, p_9(rd), label="Least Squares Fit")
ax3.set_title("Degree=9")
ax4 = plt.subplot(224)
ax4.plot(housing[:,0], housing[:,1], 'k*', label="Data Points")
p_12 = np.poly1d(x_12)
ax4.plot(rd, p_12(rd), label="Least Squares Fit")
ax4.set_title("Degree=12")
def plot_ellipse(a, b, c, d, e):
"""Plot an ellipse of the form ax^2 + bx + cxy + dy + ey^2 = 1."""
theta = np.linspace(0, 2*np.pi, 200)
cos_t, sin_t = np.cos(theta), np.sin(theta)
A = a*(cos_t**2) + c*cos_t*sin_t + e*(sin_t**2)
B = b*cos_t + d*sin_t
r = (-B + np.sqrt(B**2 + 4*A)) / (2*A)
plt.plot(r*cos_t, r*sin_t)
plt.gca().set_aspect("equal", "datalim")
# Problem 4
def ellipse_fit():
"""Calculate the parameters for the ellipse that best fits the data in
ellipse.npy. Plot the original data points and the ellipse together, using
plot_ellipse() to plot the ellipse.
"""
pts = np.load('ellipse.npy')
b = np.ones(len(pts))
A = np.column_stack((pts[:,0]**2, pts[:,0], pts[:,0]*pts[:,1], pts[:,1], pts[:,1]**2))
x = la.lstsq(A, b)[0]
plt.ion()
plt.plot(pts[:,0], pts[:,1], 'k*')
plot_ellipse(x[0], x[1], x[2], x[3], x[4])
# Problem 5
def power_method(A, N=20, tol=1e-12):
"""Compute the dominant eigenvalue of A and a corresponding eigenvector
via the power method.
Parameters:
A ((n,n) ndarray): A square matrix.
N (int): The maximum number of iterations.
tol (float): The stopping tolerance.
Returns:
(float): The dominant eigenvalue of A.
((n,) ndarray): An eigenvector corresponding to the dominant
eigenvalue of A.
"""
m,n = A.shape
x = np.random.random(n)
x = x/la.norm(x)
for k in range(N):
y = x.copy()
x = A@x
x = x/la.norm(x)
if la.norm(x-y) < tol:
break
return x@A@x, x
# Problem 6
def qr_algorithm(A, N=50, tol=1e-12):
"""Compute the eigenvalues of A via the QR algorithm.
Parameters:
A ((n,n) ndarray): A square matrix.
N (int): The number of iterations to run the QR algorithm.
tol (float): The threshold value for determining if a diagonal S_i
block is 1x1 or 2x2.
Returns:
((n,) ndarray): The eigenvalues of A.
"""
m,n = A.shape
S = la.hessenberg(A)
for k in range(N):
Q,R = la.qr(S)
S = R@Q
eigs = []
i = 0
while i < n:
if i == len(S)-1 or S[i+1][i] < tol:
eigs.append(S[i][i])
else:
b = -(S[i][i]+S[i+1][i+1])
c = la.det(S[i:i+2,i:i+2])
eigs.append((-b + cmath.sqrt(b**2 - 4*c))/2)
eigs.append((-b - cmath.sqrt(b**2 - 4*c))/2)
i = i+1
i = i+1
return eigs
| true |
421dcde3b0fc9d2f5b6eb24efa6b4c799dadaa89 | Python | arronm/Algorithms | /eating_cookies/eating_cookies.py | UTF-8 | 1,604 | 4.28125 | 4 | [] | no_license | #!/usr/bin/python
import sys
# The cache parameter is here for if you want to implement
# a solution that is more efficient than the naive
# recursive solution
# [1, 1, 1], [2, 1], [3]
# [1, 1, 1], [2, 1], [1, 2], [3]
# 5 = eat(4) + eat(3) + eat(2)
# 4 = eat(3) + eat(2) + eat(1)
# 3 = eat(2) + eat(1) + eat(0)
# 2 = eat(1) + eat(0) + eat(-1)
# 1 = eat(0) + eat(-1) + eat(-2)
def eating_cookies(n, cache=None):
# For each possible number of cookies to eat
# calculate the number of ways to eat n cookies
# n = (n - 3) + (n -2) + (n - 1)
if cache is None:
cache = [0] * (n + 1)
if cache[0] == 0:
cache[0] = 1
if n < 0:
return 0
if cache[n] != 0:
return cache[n]
cache[n] = eating_cookies(n - 1, cache) \
+ eating_cookies(n - 2, cache) \
+ eating_cookies(n - 3, cache)
return cache[n]
def eating_cookies2(n, cache=None):
if cache is None:
cache = [0] * (n + 1)
if cache[0] == 0:
cache[:4] = [1, 1, 2, 4]
if cache[n] != 0:
return cache[n]
for i in range(1, n + 1):
# calculate cache if it doesn't exist
# add new data to cache
if cache[i] != 0:
continue
cache[i] = cache[i - 3] + cache[i - 2] + cache[i - 1]
return cache[n]
if __name__ == "__main__":
if len(sys.argv) > 1:
num_cookies = int(sys.argv[1])
print("There are {ways} ways for Cookie Monster to eat {n} cookies.".format(ways=eating_cookies(num_cookies), n=num_cookies))
else:
print('Usage: eating_cookies.py [num_cookies]')
| true |
2b984f16968b9b351e9b8d0b6e4b7a8e2a11293c | Python | STEMLab/TICA | /script/request-infactory.py | UTF-8 | 656 | 2.546875 | 3 | [
"MIT"
] | permissive | import requests
import json
import datetime
import sys
def url_get( u ):
return requests.get( u, timeout=5 )
def url_get_w_param( u, d ):
return requests.get( u, params=d, timeout=5 )
def url_post( u, d=None, h=None ):
return requests.post( u, headers=h, data=d, timeout=5 )
if len( sys.argv ) < 2:
print('argv[1]: filename')
sys.exit(1)
# Document
hdr = { 'Content-Type':'application/json', 'Accept':'application/json' }
with open(sys.argv[1], 'r' ) as f:
ll = f.readlines()
for i in range(len(ll)/2):
r = url_post( ll[2*i].strip(), ll[2*i+1].strip(), hdr)
# Get IndoorGML
r = url_get( ll[0].strip() )
print (r.text)
| true |
c31568c31711633a00ba4f2e131ed3b5334107ba | Python | miltongneto/image-segmentation-classifier | /clustering/randIndex.py | UTF-8 | 2,982 | 2.96875 | 3 | [] | no_license | import numpy as np
import clustering
class RandIndex(object):
def __init__(self, n, a, b):
self.a = a
self.b = b
self.adjusted = 0
self.n = n
self.rSum = np.arange(len(a))
self.rSum.fill(0)
self.cSum = np.arange(len(b))
self.cSum.fill(0)
self.contingency = np.arange(len(a)*len(b)).reshape(len(a), len(b))
for i in range(len(a)):
for j in range(len(b)):
self.contingency[i][j] = self.intersection(a[i], b[j])
self.rSum[i] += self.contingency[i][j]
self.cSum[j] += self.contingency[i][j]
self.calculateAdjustedIndex()
return
def getAdjusted(self):
return self.adjusted
def printContingency(self):
print(self.getLog())
def getLog(self):
myStr = "\nClusters Intersection ([rows]HardCluster x GroundTruth[columns]):\n"
myStr += "------------------\n\n"
myStr += ' Ground Truth\n'
for i in range(len(self.contingency)):
if i == 0:
myStr += 'H '
elif i == 1:
myStr += 'a '
elif i == 2:
myStr += 'r '
elif i == 3:
myStr += 'd '
else:
myStr += ' '
for j in range(len(self.contingency[i])):
val = str(self.contingency[i][j])
for k in range(5-len(val)):
val += ' '
myStr += val + ' '
myStr += "| " + str(self.rSum[i]) + '\n'
myStr += ' '
for j in range(len(self.contingency[0])):
myStr += "______"
myStr += '\n'
myStr += '\n'
myStr += ' '
for j in range(len(self.contingency[0])):
val = ' ' + str(self.cSum[j])
for k in range(5-len(val)):
val += ' '
myStr += val + ' '
myStr += '\n'
return myStr
def intersection(self, a, b):
soma = 0
for element in a.elements:
if element in b.elements:
soma += 1
return soma
def comb(self, n):
if n < 2:
return 0
else:
return (n*(n-1))/2
def calculateAdjustedIndex(self):
index = 0
for i in range(len(self.contingency)):
for j in range(len(self.contingency[i])):
index += self.comb(self.contingency[i][j])
expectedIndex = 0
maxIndex = 0
left = 0
right = 0
for element in self.rSum:
left += self.comb(element)
maxIndex += self.comb(element)
for element in self.cSum:
right += self.comb(element)
maxIndex += self.comb(element)
expectedIndex = (left*right)/self.comb(self.n)
maxIndex /= 2
self.adjusted = (index-expectedIndex)/(maxIndex-expectedIndex)
| true |
677b2d12daace7f779bfd648bcbe6172aa16bbee | Python | gil9red/SimplePyScripts | /office__excel__openpyxl__xlwt/pyexcel_xlsx__examples/write.py | UTF-8 | 602 | 2.78125 | 3 | [
"CC-BY-4.0"
] | permissive | #!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = "ipetrash"
from pathlib import Path
# pip install pyexcel-xlsx
from pyexcel_xlsx import save_data
DIR = Path(__file__).resolve().parent
file_name = str(DIR / "output.xlsx")
data = {
"Sheet 1": [
["Col1", "Col2", "Col3"],
[1, 2, 3],
[4, 5, 6]
],
"Sheet 2": [["row 1"]],
}
data.update({
"Sheet 2": [
["row 1", "row 2", "row 3"]
]
})
data.update({
"Страница 3": [
["Поле:", "Привет"],
["Поле:", "Мир!"]
]
})
save_data(file_name, data)
| true |
51aa4df51f32576929a49aa89e8bfdc6ed394cca | Python | GrearNose/Exercise | /SwordPointsToOffer/all_seqs_with_a_sum.py | UTF-8 | 453 | 2.765625 | 3 | [] | no_license | # -*- coding:utf-8 -*-
class Solution:
def FindContinuousSequence(self, tsum):
# write code here
# return []
seqs = []
for a1 in range(1,(tsum+1)//2):
n = 1
while True:
s = (2*a1+n)*(n+1)
if s > 2*tsum:
break
elif s == 2*tsum:
seqs.append(list(range(a1,a1+n+1)))
n += 1
return seqs | true |
25bd4e0947499933d270d17d543b8493aab67121 | Python | vippiv/python-demo | /demo/file/file_encode.py | UTF-8 | 482 | 3.953125 | 4 | [] | no_license | # 文件编码,ASCII编码和UNICODE编码
# 在ASCII码中,一个ASCII码占用1个字节,最大256个字符
# Unicode使用1-6个字节描述一个UTF-8字符,大多数汉字用三个字节表示
# python 默认使用ASCII编码,python 3 默认使用UTF-8编码
# 在引号前面的u告诉解析器这是一个utf-8编码格式的字符串
# python 3能正确输出,python 2则无法正确输入出中文
hello_str = u"hello你好"
for c in hello_str:
print(c)
| true |
cca0b8146b4442502fbe99e786a27fee3bc22a7e | Python | RayDragon/resume-sorter | /extract_phone.py | UTF-8 | 546 | 2.859375 | 3 | [] | no_license | import re
def extract_phone(text):
# phone_regex = r'^[+]*[(]{0,1}[0-9]{1,4}[)]{0,1}[-\s\./0-9]*$'
# phone_regex = r'(\d{3}[-\.\s]??\d{3}[-\.\s]??\d{4}|\(\d{3}\)\s*\d{3}[-\.\s]??\d{4}|\d{3}[-\.\s]??\d{4})'
phone_regex = r'(([+]?\d{1,2}[-\.\s]?)?(\d{3}[-\.]?){2}\d{4})'
matches = []
pos = re.findall(phone_regex, text)
matches.extend([x[0] for x in pos])
return matches
while m is not None:
matches.append(m.group(0))
m = re.search(phone_regex, text, pos=pos)
pos += 1
return matches
| true |
7577135b023a1e8956302d58fbfe7beecd78f3b8 | Python | isk02206/python | /informatics/BA_1 2017-2018/series_1/Clock hands.py | UTF-8 | 399 | 3.640625 | 4 | [] | no_license | h = int(input())
m = int(input())
if h >= 12:
hour = h - 12
else:
hour = h
h_angle = hour * 30 + m * (0.5)
m_angle = m * 6
angle = abs(h_angle - m_angle)
if angle >= 180:
angle = abs(360 - angle)
if h < 10:
h = '0' + str(h)
if m < 10:
m = '0' + str(m)
h = format(h)
m = format(m)
angle = format(angle)
print('At', h + ':' + m, 'both hands form an angle of', angle + '°.') | true |
e7f505b7da3990b8fb6587a309d8b1364e2a38a9 | Python | Wepeel/Optimal-Path | /Python/get_problem.py | UTF-8 | 2,940 | 2.609375 | 3 | [] | no_license | import socket
import json
import ast
dic = {
'nausea': 'nausea',
'unhahe': 'unequal hand height',
'confspe': 'confused speech',
'palpit': 'palpitations',
'elngex': 'elongated exhale',
'cldswt': 'cold sweat',
'weak': 'weakness',
'fever': 'fever',
'anxconf': 'anxiety and confusion',
'chepa': 'chest pain',
'ceapecy': 'central and peripheral cyanosis',
'facpa': 'facial Paralysis',
'longse': 'long - lasting seizure',
'squeaks': 'squeaks',
'shrtbr': 'shortness of breath',
'foammo': 'foaming at the mouth',
'difbr': 'difficulty breathing',
'resaumu': 'use of respiratory auxiliary muscles',
'cough': 'cough',
'dampcu': 'damp cough'
}
problems = ["stroke", "mi", "asthma", "status_epilepticus", "pneumonia"]
data = {
'stroke': ['unequal hand height', 'confused speech', 'facial paralysis'],
'mi': ['weakness', 'cold sweat', 'chest pain', 'difficulty breathing', 'shortness of breath', 'nausea',
'palpitations', 'anxiety and confusion'],
'asthma': ['elongated exhale', 'difficulty breathing', 'squeaks', 'cough', 'use of respiratory auxiliary muscles'],
'status_epilepticus': ['long-lasting seizure', 'central and peripheral cyanosis', 'foaming at the mouth'],
'pneumonia': ['fever', 'damp cough', 'chest pain', 'weakness', 'shivering', 'squeaks', 'cough']
}
imp_symptoms = {
'stroke': ['unequal hand height', 'confused speech', 'facial paralysis'],
'mi': ['weakness', 'cold sweat'],
'asthma': ['elongated exhale'],
'status_epilepticus': ['long-lasting seizure'],
'pneumonia': ['fever', 'damp cough', 'chest pain']
}
IP = '127.0.0.1'
PORT = 32654
def any_in(a, b):
return any(i in b for i in a)
def understand_problem(symptoms):
for problem in problems:
if any_in(symptoms, data[problem]) and any_in(symptoms, imp_symptoms[problem]):
return problem
else:
return 'other'
def translate_symptoms(symptoms):
translated = []
for i in symptoms:
translated.append(dic[i])
return understand_problem(translated)
def main():
while True:
# open socket with client
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(("127.0.0.1", PORT))
server_socket.listen()
(client_socket, client_address) = server_socket.accept()
# handle requests until user asks to exit
rec = client_socket.recv(8192).decode()
rec = json.loads(rec)
symptom_codes = rec["symptoms"]
if rec['breathing'] == 1:
symptom_codes += 'difbr'
res = translate_symptoms(symptom_codes)
client_socket.send(res.encode())
print("Closing connection")
client_socket.close()
server_socket.close()
if __name__ == "__main__":
main()
| true |
64db0f8c67bc7d1f426ca30857bed20ec64de5f0 | Python | dilsonm/CeV | /mundo2/ex070.py | UTF-8 | 1,065 | 4.1875 | 4 | [
"MIT"
] | permissive | '''Crie um programa que leia o nome e o preco de varios produtos. O programa devera perguntar se o usuario vai continuar.
No final mostre:
a) Qual é o total gasto na compra
b) Quantos produtos custam mais de R$1000.
c) Qual é o nome do produto mais barato. '''
sair = 'N'
compras = 0
prdcaro = 0
nomeprd = ''
precomenor = 999999
print('-'*50)
print('Mercado Popular')
print('-'*50)
while sair != 'S':
prod = str(input('Digite o nome do produto: ')).strip().upper()
preco = float(input('Digite o valor do produto: '))
while True:
cont = str(input('Continua comprando ? [S/N] ')).strip().upper()
if cont == 'S':
break
else:
sair = 'S'
break
compras += preco
if preco > 1000:
prdcaro += 1
if preco < precomenor:
nomeprd = prod
precomenor = preco
print('='*50)
print(f'O tota de compras foi: {compras}')
print(f'Foi comprado {prdcaro} produro com valor acima de R$1000.')
print(f'O nome do produto mais barato é: {nomeprd}.')
print('='*50)
| true |
f47426a6769ed3fe093c8523997416f350c30de8 | Python | HiLASEPythonCourse/image-lab | /app.py | UTF-8 | 3,742 | 2.984375 | 3 | [
"MIT"
] | permissive | import matplotlib.patches as mpatches
import matplotlib.pyplot as plt
import numpy as np
import skimage.io
import streamlit as st
from skimage import data, exposure
from skimage.color import label2rgb
from skimage.measure import label, regionprops
from skimage.morphology import closing, square
from skimage.segmentation import clear_border
EXAMPLES = [""] + [name for name in data.__all__ if name not in ["data_dir", "download_all"]]
def read_image(input_file):
image_data = skimage.io.imread(input_file)
return image_data
def st_imshow(image):
fig, ax = plt.subplots()
ax.imshow(image)
st.write(fig)
def plot_labeled_image(image, label_image, regions, plot_overlay=True, min_region_area=100):
"""Plot image and the detected object labels
Arguments:
image: original image as numpy ndarray
label_image: label image data array
regions: detected regions (bounding boxes)
plot_overlay: colorize detected labels areas
min_region_area: minimum region area to show
"""
fig, ax = plt.subplots(figsize=(10, 6))
if plot_overlay:
# to make the background transparent, pass the value of `bg_label`,
# and leave `bg_color` as `None` and `kind` as `overlay`
image_label_overlay = label2rgb(label_image, image=image, bg_label=0)
ax.imshow(image_label_overlay)
else:
ax.imshow(image)
for region in regions:
# take regions with large enough areas
if region.area >= min_region_area:
# draw rectangle around segmented coins
minr, minc, maxr, maxc = region.bbox
rect = mpatches.Rectangle(
(minc, minr), maxc - minc, maxr - minr, fill=False, edgecolor="red", linewidth=2
)
ax.add_patch(rect)
ax.set_axis_off()
plt.tight_layout()
return fig
def main():
"""The main Streamlit application
"""
st.sidebar.subheader("Select example or upload file")
example = st.sidebar.selectbox("Example", EXAMPLES)
input_file = st.sidebar.file_uploader("Image file")
if input_file:
original_image_data = read_image(input_file)
elif example:
original_image_data = getattr(data, example)()
else:
st.warning("Select or upload image first")
return
st.sidebar.subheader("Gamma adjust")
gamma = st.sidebar.slider("Gamma", 0.0, 10.0, 1.0)
gain = st.sidebar.slider("Gain", 0.0, 10.0, 1.0)
image_data = exposure.adjust_gamma(original_image_data, gamma, gain)
image = np.atleast_3d(image_data)[:, :, 0]
col1, col2 = st.beta_columns(2)
with col1:
st.write("Original image")
st_imshow(original_image_data)
with col2:
st.write("Gamma-corrected image")
st_imshow(image_data)
st.sidebar.subheader("Labeling parameters")
closing_threshold = st.sidebar.slider("Closing threshold", 0, 200, 100, step=10)
square_size = st.sidebar.slider("Square size", 0, 20, 5, step=1)
binary_image = closing(image > closing_threshold, square(square_size))
st_imshow(binary_image)
# remove artifacts connected to image border
cleared = clear_border(binary_image)
# label image regions
label_image = label(cleared)
# Ex: add minimum region area parameter via slider
regions = regionprops(label_image)
st.subheader("Detected regions")
st.write(f"Found {len(regions)} regions.")
# EXERCISE 1: add a checkbox input for controlling the plot_overlay parameter of plot_labeled_image
# EXERCISE 2: add a slider or number_input to control the min_region_area parameter
fig = plot_labeled_image(image, label_image, regions)
st.write(fig)
if __name__ == "__main__":
main()
| true |
81ecf8904fb2f150e46570e10b7a8c361282c80b | Python | jgm88/PythonNXT | /mision2/mision2_2.py | UTF-8 | 3,559 | 2.953125 | 3 | [] | no_license | #!/usr/bin/env python
from nxt.sensor import *
from nxt.motor import *
import nxt.bluesock
import time
import math
class Robot:
def __init__(self, brick, tam_encoder=360, wheel_diameter=5.6):
self.brick_= brick
self.separationBetweenWheels_= 13
self.sensorTouch_= Touch(self.brick_, PORT_1)
self.syncMotor_ = SynchronizedMotors(Motor(self.brick_, PORT_B), Motor(self.brick_, PORT_C), 0)
self.arm= Motor(self.brick_, PORT_A)
self.cuenta_= ((wheel_diameter*math.pi)/tam_encoder)
# 1. Calculamos las cuentas que tendra que pasar para girar hacia un stolado.
# Si suponemos que un giro sobre si mismo es de de radio separationBewteenWheels, un giro solo ocupara una
# cuarta parte del perimetro de la circunferencia.
turn_perimeter = (math.pi * 2.0 * self.separationBetweenWheels_) / 4.0
self.cuentasGiro_ = turn_perimeter / self.cuenta_
def mision(self):
print "Espero sensor de choque"
while self.sensorTouch_.is_pressed() == False:
pass;
self.syncMotor_.run(-70)
while self.sensorTouch_.is_pressed() == True:
pass;
# 2. Esperamos durante 2 segundos contactos
print "Recolecto samples"
samples= 0
current_time= time.time()
# Con estos semaforos nos aseguramos recolectar los samples correctos
puedoRecolectar = False
puedoSerPulsado = True
while(True):
print "Determinar accion"
samples=0
while (time.time() - current_time)<2.0:
if(puedoSerPulsado and self.sensorTouch_.is_pressed()):
puedoRecolectar = True
puedoSerPulsado = False
if(puedoRecolectar):
puedoRecolectar = False
samples+=1
if(self.sensorTouch_.is_pressed() == False):
puedoSerPulsado = True
print "Samples recogidos: ",samples
self.syncMotor_.brake()
# 1. Giro 45 y continuar recto
if(samples == 1):
self.syncMotor_.leader.weak_turn(80, self.cuentasGiro_/2)
time.sleep(1)
self.syncMotor_.run(-70)
# 2. Giro 90 sentido contrario y continuar
elif(samples == 2):
self.syncMotor_.leader.weak_turn(-80, self.cuentasGiro_)
time.sleep(1)
self.syncMotor_.run(-70)
# 3. Giro 180 y continuar
elif(samples == 3):
self.syncMotor_.leader.weak_turn(80, self.cuentasGiro_*2)
time.sleep(3)
self.syncMotor_.run(-70)
# 4. Detener robot y mover brazo de arriba a abajo 2 veces
elif(samples == 4):
self.syncMotor_.brake()
self.arm.reset_position(True)
self.arm.turn(20, 50)
self.arm.reset_position(True)
self.arm.turn(-20, 50)
self.arm.reset_position(True)
self.arm.turn(20, 50)
self.arm.reset_position(True)
self.arm.turn(-20, 50)
self.syncMotor_.brake()
#
#self.syncMotor_.idle()
self.brick_.play_tone_and_wait(659, 500)
if __name__=='__main__':
robot= Robot(nxt.locator.find_one_brick())
#robot= Robot(nxt.bluesock.BlueSock('00:16:53:09:46:3B').connect())
robot.mision() | true |
00bc7c222c4648a0981dad477247d05db007224a | Python | ashleefeng/qbb2017-answers | /day2-lunch/day2-exercise-a1.py | UTF-8 | 329 | 2.8125 | 3 | [] | no_license | #!/usr/bin/env python
import sys
fwd = 0
rev = 0
for line in sys.stdin:
if list(line)[0] == "@":
continue
else:
flag = int(line.split("\t")[1])
if (16 & flag) >> 4 == 0:
fwd += 1
else:
rev += 1
print "forward alignments: ", fwd
print "reverse alignments: ", rev | true |
e85277facd5c06f13237f99ff44f88f4e30ce2e5 | Python | kshirsagarsiddharth/Machine-Learning- | /Edgar_Report_Text_Analysis/submission/text_analysis_python_format.py | UTF-8 | 18,025 | 2.8125 | 3 | [] | no_license | # To add a new cell, type '# %%'
# To add a new markdown cell, type '# %% [markdown]'
# %% [markdown]
# ## Importing all the dependencies
# %%
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
from bs4 import BeautifulSoup
from nltk.tokenize import WordPunctTokenizer
import nltk
from bs4 import BeautifulSoup
import urllib
from nltk.tokenize import sent_tokenize
from nltk.corpus import cmudict
from nltk.corpus import stopwords
from nltk.tokenize import wordpunct_tokenize
import syllables
# %% [markdown]
# ## Importing the ciklist into Pandas dataframe and doing some preliminary analysis
# %%
df = pd.read_excel(r'D:\nlp_internship\Data Science\cik_list.xlsx')
# %%
df.shape
# %%
df.head()
# %%
df.describe()
# %% [markdown]
# ## We need to extract the files from the web, hence hence lets add the hyperlink and extract all the text data.
# %%
# we need to extract the files from the web hence hence lets add the hyperlink and ectract all the text data
hyperlink = 'https://www.sec.gov/Archives/'
df['SECFNAME'] = hyperlink + df['SECFNAME']
# %% [markdown]
# ### Importing stopwords, positive words and negative words from the list
# %%
stop_words = pd.read_csv(r'D:\nlp_internship\Data Science\stop_words\StopWords_GenericLong.txt',header=None) # importing stop words
stopword_list = stop_words[0].to_list()
master_dict = pd.read_csv(r'D:\nlp_internship\Data Science\stop_words\LoughranMcDonald_MasterDictionary_2018.csv') # importing the master dict
negative_words = master_dict[master_dict['Negative'] == 2009]['Word']
negative_dict =[word.lower() for word in negative_words if word not in stop_words] # creating negative words dictonary
positive_words = master_dict[master_dict['Positive'] == 2009]['Word']
positive_dict = [word.lower() for word in positive_words if word not in stop_words] # creating positive words dictonary
# %% [markdown]
# ### Now all the dependencies are defined and all files are imported to proceed with the analysis. I saw that there are nearly 152 documents in the structure. Instead of downloading each file storing it in my SSD and loading it into my ram, and perform analysis the text I decided to use, urllib library which allows me to load data from any webpage and store it in RAM. which is fast and efficient.
# %%
def preliminary_cleaner(text):
'''
This function is used to remove all the
numerical data in the files. And next line in the file
'''
if text:
array = []
soup =text
soup = re.sub('[\d%/$]','',str(soup))
soup = re.sub("\\\\n",'',soup)
soup = ' '.join(soup.split())
return soup
else:
return None
# %% [markdown]
# ### Now what I did is created a regular expression for all the three given titles. And then scraped the website for this data and stored in three python arrays. Later I merged the three arrays into a pandas data frame. Which is a highly efficient data-structure for processing the text files.
# %%
array_one,array_two,array_three = [],[],[] # creating arrays
# regular expression for the three components.
mgt_disc_ana = r"item[^a-zA-Z\n]*\d\s*\.\s*management\'s discussion and analysis.*?^\s*item[^a-zA-Z\n]*\d\s*\.*"
qlty_qnt_disc = r"item[^a-zA-Z\n]*\d[a-z]?\.?\s*Quantitative and Qualitative Disclosures about Market Risk.*?^\s*item\s*\d\s*"
rsk_fct = r"item[^a-zA-Z\n]*\d[a-z]?\.?\s*Risk Factors.*?^\s*item\s*\d\s*"
for hyperlink in df['SECFNAME']:
text = urllib.request.urlopen(hyperlink).read().decode('utf-8') # eastiblishint the client server connection and downloading the data
# into ram.
matches_mda = re.findall(mgt_disc_ana, text, re.IGNORECASE | re.DOTALL | re.MULTILINE)
matches_qlty_qnt_disc= re.findall(qlty_qnt_disc,text,re.IGNORECASE | re.DOTALL | re.MULTILINE)
matches_rsk_fct = re.findall(rsk_fct,text,re.IGNORECASE | re.DOTALL | re.MULTILINE)
array_one.append(preliminary_cleaner(matches_mda))
array_two.append(preliminary_cleaner(matches_qlty_qnt_disc))
array_three.append(preliminary_cleaner(matches_rsk_fct))
# %% [markdown]
# # Merging all three arrays and storing it as csv for later analysis.
# %%
df1,df2,df3 = pd.DataFrame(array_one),pd.DataFrame(array_two),pd.DataFrame(array_three) #
merged_dataframe = pd.concat([df1,df2,df3],axis = 1)
merged_dataframe.columns = ['matches_mda','matches_qlty_qnt_disc','matches_rsk_fct']
merged_dataframe.to_csv('merged_dataframe_all.csv')
# %%
df2 = pd.read_csv(r'D:\nlp_internship\submission\merged_dataframe_all.csv') # loading the merged dataframe
# %% [markdown]
# # concatenating the main data frame and newly merged data frame.
# %%
final_dataframe = pd.concat([df,df2],axis = 1)
final_dataframe.drop(columns='Unnamed: 0',inplace = True)
final_dataframe.fillna(' ',inplace = True)
# %%
final_dataframe.columns
# %%
def cleaning_stopwords(columns):
"""This function is used to tokenize and removing everything except alphabets in the text files."""
columns = columns.apply(lambda x : re.sub("[^a-zA-Z]"," ",str(x))) # removing everything except letters
columns = columns.apply(lambda x : wordpunct_tokenize(x)) # tokenizing the frame
# cleaning stopwords
columns = columns.apply(lambda x : [word.lower() for word in x if word not in stopword_list])
return columns
# %% [markdown]
# # Creating a new data frame called the final data frame which consists of all the tokenized documents.
# %%
final_dataframe['mda_bulk'] = cleaning_stopwords(final_dataframe['matches_mda'])
final_dataframe['qltqnt_bulk'] = cleaning_stopwords(final_dataframe['matches_qlty_qnt_disc'])
final_dataframe['rskfct_bulk'] = cleaning_stopwords(final_dataframe['matches_rsk_fct'])
# %% [markdown]
# ### I have tried to compute the required variables using three methods this method is highly efficient and calculates all the variables in the number of minutes because I am creating a class called text analysis which will initialize the four variables words,complex_words,positive_words and negative words. hence for each of the three sections, I will create a new object for that section and compute all the 14 concerned variables.
# %%
class text_analysis:
def __init__(self,column_with_words,column_with_sentences):
self.column_with_words = column_with_words # initializing the column which contaions words.
self.column_with_sentences = column_with_sentences # initializing the words which contains sentence tokens.
self.words = self.column_with_words.apply(lambda x : len([word for word in x])) # initialing the variable wors count
self.complex_words = self.column_with_words.apply(lambda x : len([word for word in x if syllables.estimate(word) > 2])) # initializing the variable complex words
self.positive_words_column = self.column_with_words.apply(lambda x : len([word for word in x if word in np.array(positive_dict)])) # initializing the column number of positive words
self.negative_words_column = self.column_with_words.apply(lambda x : len([word for word in x if word in np.array(negative_dict)])) # initializing the column number of positive words
def positive_score(self):
'''This score is calculated by assigning the value of +1 for each word if
found in the Positive Dictionary and then adding up all the values. '''
return self.positive_words_column
#return self.column_with_words.apply(lambda x : len([word for word in x if word in positive_dict]))
def negative_score(self):
'''This score is calculated by assigning the value of +1 for each word if
found in the Negative Dictionary and then adding up all the values.'''
return self.negative_words_column
#return self.column_with_words.apply(lambda x : len([word for word in x if word in negative_dict]))
def polarity_score(self):
"""This is the score that determines if a given text is positive or negative in nature. It is calculated by using the formula:
Polarity Score = (Positive Score – Negative Score)/ ((Positive Score + Negative Score) + 0.000001)
"""
val1 = (self.positive_words_column - self.negative_words_column)
val2 = (self.positive_words_column + self.negative_words_column + 0.00001)
return val1 / val2
def average_sentence_length(self):
"""
Average Sentence Length = the number of words / the number of sentences
we use sent_tokenizer liabrary and we replace null values with 0
"""
#words = self.column_with_words.apply(lambda x : len([word for word in x]))
sentences = self.column_with_sentences.apply(lambda x : len(sent_tokenize(str(x))))
ans = self.words / sentences
ans = ans.fillna(0)
return ans
def syllables_count(self,word):
"""This function is used to count the syllables. In this case, we use the cmu dictionary which consists
of all the syllables of given words but I found that there are some words which are not defined in the
cmu dictionary hence I used the algorithm to calculate the number of syllables."""
phoneme_dictonary = dict(cmudict.entries())
count = 0
vowels = 'aeiouy'
word = word.lower()
if word[0] in vowels:
count += 1
for i in range(1,len(word)):
if word[i] in vowels and word[i - 1] not in vowels:
count += 1
if word[-1] == 'e':
count -= 1
if word[-2:] == 'le':
count += 1
if count == 0:
count += 1
# comparing the values with cmudict
try:
second_count = 0
for val in phoneme_dictonary[word.lower()]:
for val1 in val:
if val1[-1].isdigit():
second_count += len(val1)
return second_count
except KeyError: # this is in case the values are not found in the cmu dict
return count
def complex_words_proportion(self):
"""Percentage of Complex words = the number of complex words / the number of words """
#complex_words = self.column_with_words.apply(lambda x : len([word for word in x if self.syllables_count(word) > 2]))
#words = self.column_with_words.apply(lambda x : len([word for word in x]))
ans = self.complex_words / self.words
ans = ans.fillna(0)
return ans
def fog_index(self):
"""Fog Index = 0.4 * (Average Sentence Length + Percentage of Complex words)
The Gunning Fog Index gives the number of years of education that your reader
hypothetically needs to understand the paragraph or text. The Gunning Fog Index
formula implies that short sentences written in plain English achieve a better
score than long sentences written in complicated language."""
return 0.4 * (self.average_sentence_length() + self.complex_words)
def complex_words_count(self):
""" Complex words are words in the text that contain more than two syllables.
hence we compare it with our words."""
#complex_words = self.column_with_words.apply(lambda x : len([word for word in x if self.syllables_count(word) > 2]))
ans = self.complex_words.fillna(0)
return ans
def word_counts(self):
"""This function is used to calculate number of words in each document axcept stopwords found in nltk library"""
stopwords_nltk = np.array(list(set(stopwords.words('english'))))
words = self.column_with_words.apply(lambda x : len([word for word in x if word not in stopwords_nltk]))
ans = words
ans = ans.fillna(0)
return ans
def uncertainty_words_count(self):
uncertainty_dict = pd.read_excel(r'D:\nlp_internship\Data Science\uncertainty_dictionary.xlsx')
uncertainty_dict = uncertainty_dict['Word'].str.lower().to_list()
words = self.column_with_words.apply(lambda x : len([word for word in x if word in uncertainty_dict]))
return words
def constraning_words_count(self):
constrain_dict = pd.read_excel(r'D:\nlp_internship\Data Science\constraining_dictionary.xlsx')
constrain_dict = constrain_dict['Word'].str.lower().to_list()
words = self.column_with_words.apply(lambda x : len([word for word in x if word in constrain_dict]))
return words
def positive_words_proportion(self):
#words = self.column_with_words.apply(lambda x : len([word for word in x]))
ans = self.positive_words_column / self.words
ans = ans.fillna(0)
return ans
def negative_words_proportion(self):
#words = self.column_with_words.apply(lambda x : len([word for word in x]))
ans = self.negative_words_column / self.words
ans = ans.fillna(0)
return ans
def uncertaninty_words_proportion(self):
#words = self.column_with_words.apply(lambda x : len([word for word in x]))
ans = self.uncertainty_words_count() / self.words
ans = ans.fillna(0)
return ans
def constraining_words_proportion(self):
#words = self.column_with_words.apply(lambda x : len([word for word in x]))
ans = self.constraning_words_count() / self.words
ans = ans.fillna(0)
return ans
# %%
final_dataframe.columns
# %%
# defining the mda object and giving it the concerned values.
# %%
mda = text_analysis(final_dataframe['mda_bulk'],final_dataframe['matches_mda'])
# %%
MDA = pd.DataFrame() #creating mda dataframe
MDA['mda_positive_score'] = mda.positive_score()
MDA['mda_negative_score'] = mda.negative_score()
MDA['mda_polarity_score'] = mda.polarity_score()
MDA['mda_average_sentence_length'] = mda.average_sentence_length()
MDA['mda_percenmdage_of_complex_words'] = mda.complex_words_proportion()
MDA['mda_fog_index'] = mda.fog_index()
MDA['mda_complex_word_count'] = mda.complex_words_count()
MDA['mda_word_count'] = mda.word_counts()
MDA['mda_uncertainty_score'] = mda.uncertainty_words_count()
MDA['mda_constraining_score'] = mda.constraning_words_count()
MDA['mda_positive_word_proportion'] = mda.positive_words_proportion()
MDA['mda_negative_word_proportion'] = mda.negative_words_proportion()
MDA['mda_uncertainty_word_proportion'] = mda.uncertaninty_words_proportion()
MDA['mda_constraining_word_proportion'] = mda.constraining_words_proportion()
# %%
MDA.to_csv('mda.csv')
# %%
qqdmr = text_analysis(final_dataframe['qltqnt_bulk'],final_dataframe['matches_qlty_qnt_disc'])
QQDMR = pd.DataFrame()
QQDMR['qqdmr_positive_score'] = qqdmr.positive_score()
QQDMR['qqdmr_negative_score'] = qqdmr.negative_score()
QQDMR['qqdmr_polarity_score'] = qqdmr.polarity_score()
QQDMR['qqdmr_average_sentence_length'] = qqdmr.average_sentence_length()
QQDMR['qqdmr_percenqqdmrge_of_complex_words'] = qqdmr.complex_words_proportion()
QQDMR['qqdmr_fog_index'] = qqdmr.fog_index()
QQDMR['qqdmr_complex_word_count'] = qqdmr.complex_words_count()
QQDMR['qqdmr_word_count'] = qqdmr.word_counts()
QQDMR['qqdmr_uncertainty_score'] = qqdmr.uncertainty_words_count()
QQDMR['qqdmr_constraining_score'] = qqdmr.constraning_words_count()
QQDMR['qqdmr_positive_word_proportion'] = qqdmr.positive_words_proportion()
QQDMR['qqdmr_negative_word_proportion'] = qqdmr.negative_words_proportion()
QQDMR['qqdmr_uncertainty_word_proportion'] = qqdmr.uncertaninty_words_proportion()
QQDMR['qqdmr_constraining_word_proportion'] = qqdmr.constraining_words_proportion()
QQDMR.to_csv('qqdmr.csv')
# %%
rf = text_analysis(final_dataframe['rskfct_bulk'],final_dataframe['matches_rsk_fct'])
RF = pd.DataFrame()
RF['rf_positive_score'] = rf.positive_score()
RF['rf_negative_score'] = rf.negative_score()
RF['rf_polarity_score'] = rf.polarity_score()
RF['rf_average_sentence_length'] = rf.average_sentence_length()
RF['rf_percenrfge_of_complex_words'] = rf.complex_words_proportion()
RF['rf_fog_index'] = rf.fog_index()
RF['rf_complex_word_count'] = rf.complex_words_count()
RF['rf_word_count'] = rf.word_counts()
RF['rf_uncertainty_score'] = rf.uncertainty_words_count()
RF['rf_constraining_score'] = rf.constraning_words_count()
RF['rf_positive_word_proportion'] = rf.positive_words_proportion()
RF['rf_negative_word_proportion'] = rf.negative_words_proportion()
RF['rf_uncertainty_word_proportion'] = rf.uncertaninty_words_proportion()
RF['rf_constraining_word_proportion'] = rf.constraining_words_proportion()
RF.to_csv('rf.csv')
# %%
pd.concat([MDA,QQDMR,RF],axis = 1).to_csv('highly_efficient.csv')
# %%
# %% [markdown]
# # Finding constraining words for the whole report:
# ## In this I have used numpy vectorization function, to analyse the whole document which is 10 times faster than normal python
# %%
complete_array = []
count = 0
for hyperlink in df['SECFNAME']:
text = urllib.request.urlopen(hyperlink).read().decode('utf-8')
count += 1
complete_array.append(preliminary_cleaner(text))
print(count)
# %%
whole_document_dataframe = pd.DataFrame()
stopwords_nltk = np.array(list(set(stopwords.words('english'))))
whole_document_dataframe['constraining'] = complete_array
whole_document_dataframe = cleaning_stopwords(whole_document_dataframe['constraining'])
arr = pd.DataFrame(whole_document_dataframe)
union_array = arr['constraining'].apply(lambda x : np.union1d(np.array(x),stopwords_nltk))
uncertainty_dict = pd.read_excel(r'D:\nlp_internship\Data Science\uncertainty_dictionary.xlsx')
uncertainty_dict = np.array(uncertainty_dict['Word'].str.lower().to_list())
ans = union_array.apply(lambda x : len(np.intersect1d(x,uncertainty_dict)))
# %%
# %%
highly_eff = pd.read_csv('highly_efficient.csv')
# %%
highly_eff['constraining_words_whole_report'] = ans
# %%
highly_eff.to_csv('last_and_final_output.csv')
# %%
highly_eff.columns
# %%
df2.to_csv('input_file.csv')
# %%
ola = pd.read_csv('output.csv')
# %%
pd.concat([df,ola],axis = 1).drop(columns = ['Unnamed: 0','Unnamed: 0.1']).to_csv('output.csv')
# %%
| true |
d3c321ecbf0450572bd5d05f37cf7af0aa53bb58 | Python | jerrychen44/autodrive_carla | /ros/src/waypoint_updater/waypoint_updater.py | UTF-8 | 9,733 | 2.515625 | 3 | [
"MIT"
] | permissive | #!/usr/bin/env python
import numpy as np
import rospy
from geometry_msgs.msg import PoseStamped
from styx_msgs.msg import Lane, Waypoint
from scipy.spatial import KDTree
import math
from std_msgs.msg import Int32
'''
This node will publish waypoints from the car's current position to some `x` distance ahead.
As mentioned in the doc, you should ideally first implement a version which does not care
about traffic lights or obstacles.
Once you have created dbw_node, you will update this node to use the status of traffic lights too.
Please note that our simulator also provides the exact location of traffic lights and their
current status in `/vehicle/traffic_lights` message. You can use this message to build this node
as well as to verify your TL classifier.
TODO (for Yousuf and Aaron): Stopline location for each traffic light.
'''
LOOKAHEAD_WPS = 200 #200, Number of waypoints we will publish. You can change this number
MAX_DECEL = 0.5
class WaypointUpdater(object):
def __init__(self):
rospy.init_node('waypoint_updater')
rospy.Subscriber('/current_pose', PoseStamped, self.pose_cb)
rospy.Subscriber('/base_waypoints', Lane, self.waypoints_cb)
# TODO: Add a subscriber for /traffic_waypoint and /obstacle_waypoint below
# add for get traffic waypoint
rospy.Subscriber('/traffic_waypoint', Int32, self.traffic_cb)
self.final_waypoints_pub = rospy.Publisher('final_waypoints', Lane, queue_size=1)
# TODO: Add other member variables you need below
self.pose =None
self.base_waypoints = None
self.waypoints_2d = None
self.waypoint_tree = None
#add to combine the traffic light waypoint
self.base_lane = None
self.stopline_wp_idx = -1
#rospy.spin()
self.loop()
#for control the publish frequence
# we will publish the wapoints to wapoint_follower
def loop(self):
rate=rospy.Rate(50)# 50hz, change to 30 later in driver by wire
while not rospy.is_shutdown():
# if there are pose data in base_waypoits and the rospy not shutdown....
#if self.pose and self.base_waypoints:
if not None in (self.pose , self.base_waypoints, self.waypoint_tree):
'''
#first version, move to publish_waypoionts
#Get closest waypoint
closest_waypoint_idx = self.get_closest_waypoint_idx()
self.publish_waypoints(closest_waypoint_idx)
'''
self.publish_waypoints()
rate.sleep()
def get_closest_waypoint_idx(self):
#get thte coordinate of our car
x=self.pose.pose.position.x
y=self.pose.pose.position.y
# get the index of this x,y in KDtree
closest_idx = self.waypoint_tree.query([x,y],1)[1]
# we hopt the new waypoints start IN FRONT of
# the car...., we recheck below
# If the clost x,y behind the car, we just ignore it, and
# cut if off, and take next one point to replace it.
#check if closeset is ahead or behind vehicle
closest_coord = self.waypoints_2d[closest_idx]
prev_coord = self.waypoints_2d[closest_idx-1]
#equation for hyperplane through closest_coord
# change the list to vect
cl_vect = np.array(closest_coord)
prev_vect = np.array(prev_coord)
pos_vect = np.array([x,y])
val = np.dot(cl_vect - prev_vect, pos_vect - cl_vect)
# the closest point now behind the car, we will force
# use the next point as closest point
if val > 0:
closest_idx = (closest_idx +1) % len(self.waypoints_2d)
return closest_idx
#def publish_waypoints(self,closest_idx):#old version
def publish_waypoints(self):
'''
#first version of publish_waypoints
lane = Lane()#create a new lane msg
#header is not important, optinonal
lane.header = self.base_waypoints.header
lane.waypoints = self.base_waypoints.waypoints[closest_idx: closest_idx + LOOKAHEAD_WPS]
self.final_waypoints_pub.publish(lane)
'''
final_lane = self.generate_lane()
self.final_waypoints_pub.publish(final_lane)
def generate_lane(self):
lane = Lane()
#Get closest waypoint ahead the car
closest_idx = self.get_closest_waypoint_idx()
farthest_idx = closest_idx + LOOKAHEAD_WPS
base_waypoints = self.base_waypoints.waypoints[closest_idx: farthest_idx]
rospy.logwarn("[waypoint_updater] car closest_idx: {0}".format(closest_idx))
rospy.logwarn("[waypoint_updater] car farthest_idx: {0}".format(farthest_idx))
rospy.logwarn("[waypoint_updater] car self.stopline_wp_idx: {0}".format(self.stopline_wp_idx))
if self.stopline_wp_idx == -1 or (self.stopline_wp_idx >= farthest_idx):
#in this case, which means we didn't detect the traffic light in our looking up waypoint list
lane.waypoints = base_waypoints
else:
#there is a stopline wp indx , and inside our current waypoint list
rospy.logwarn("[waypoint_updater] got a stopline waypoint, need decelerate")
lane.waypoints = self.decelerate_waypoints(base_waypoints, closest_idx)
return lane
def decelerate_waypoints(self, waypoints, closest_idx):
#we don't directy modify the original base_waypoint
#it will loss the info, when we come back the same place, that will mass up.
rospy.logwarn("[waypoint_updater] use -2 before stop_idx")
# we creating a new wapoint list
temp = []
vel_tmp = []
#walk through the all waypoints[closest_waypoint_idx: farthest_idx]
for i , wp in enumerate(waypoints):
p = Waypoint()
p.pose = wp.pose# use original base_waypoints pose
# -2 is to let the car's nose can align with the traffic light
# stop_idx, how much idx ahead from the car
stop_idx = max(self.stopline_wp_idx - closest_idx -2, 0)
#get the distance between waypoints[i] and waypoints[stop_idx]
dist = self.distance(waypoints, i ,stop_idx)
#use sqrt that let the vel dropping really sharp when the
#dist is really close the traffic light
vel = math.sqrt(2*MAX_DECEL*dist)
if vel < 1:
vel = 0
#assign the vel for each wapoint
#if the vel small then original vel, then we use the small one.
p.twist.twist.linear.x = min(vel, wp.twist.twist.linear.x)
vel_tmp.append(min(vel, wp.twist.twist.linear.x))
temp.append(p)
rospy.logwarn("[decelerate_waypoints] vel_tmp: {0}".format(vel_tmp[0:40]))
#rospy.logwarn("[decelerate_waypoints] temp: {0}".format(temp[0:40]))
return temp
def pose_cb(self, msg):
# TODO: Implement
# be called frequencetly, save the current car position
self.pose = msg
pass
def waypoints_cb(self, waypoints_in):
# TODO: Implement
# get base waypoints with a singel call back
#just save the waypoints, waypoints will not change
self.base_waypoints = waypoints_in
#if we don't have waypoints_2d, create one
# we hope the sefl.waypoints_2d has initialzed before
# the susbscriber, which means this cb fun
# will be called before the self.waypoints_2d = None
# then the KD tree will get some unpredictable points.
if not self.waypoints_2d:
'''
check the command
msg: Lane
Header header
Waypoint[] waypoints
msg: waypoints
geometry_msgs/PoseStamped pose
geometry_msgs/TwistStamped twist
msg: pose
rosmsg info geometry_msgs/PoseStamped
std_msgs/Header header
uint32 seq
time stamp
string frame_id
geometry_msgs/Pose pose
geometry_msgs/Point position
float64 x
float64 y
float64 z
geometry_msgs/Quaternion orientation
float64 x
float64 y
float64 z
float64 w
'''
self.waypoints_2d = [[waypoint.pose.pose.position.x, waypoint.pose.pose.position.y] for waypoint in waypoints_in.waypoints]
#later on , we can use the waypoint_tree to
#find the closetest point to the car with KD_tree. from n - > log(n)
self.waypoint_tree = KDTree(self.waypoints_2d)
pass
def traffic_cb(self, msg):
# TODO: Callback for /traffic_waypoint message. Implement
self.stopline_wp_idx = msg.data
def obstacle_cb(self, msg):
# TODO: Callback for /obstacle_waypoint message. We will implement it later
pass
def get_waypoint_velocity(self, waypoint):
return waypoint.twist.twist.linear.x
def set_waypoint_velocity(self, waypoints, waypoint, velocity):
waypoints[waypoint].twist.twist.linear.x = velocity
def distance(self, waypoints, wp1, wp2):
dist = 0
dl = lambda a, b: math.sqrt((a.x-b.x)**2 + (a.y-b.y)**2 + (a.z-b.z)**2)
for i in range(wp1, wp2+1):
dist += dl(waypoints[wp1].pose.pose.position, waypoints[i].pose.pose.position)
wp1 = i
return dist
if __name__ == '__main__':
try:
WaypointUpdater()
except rospy.ROSInterruptException:
rospy.logerr('Could not start waypoint updater node.')
| true |
22b1d89b4642e520101b3a84512857c2156b4ed1 | Python | Flyingfishqiu/test | /36ker_pytest/tset_case/bokeyuan2.py | UTF-8 | 894 | 2.734375 | 3 | [] | no_license | from selenium import webdriver
import time
driver = webdriver.Chrome()
# 启动浏览器后获取cookies
print(driver.get_cookies())
driver.get("http://www.cnblogs.com")
# 打开主页后获取cookies
print( driver.get_cookies())
# 登录后获取cookies
url = "https://passport.cnblogs.com/user/signin"
driver.get(url)
driver.implicitly_wait(30)
driver.find_element_by_id("input1").send_keys(u"小飞鱼q")
driver.find_element_by_id("input2").send_keys(u"0929qsj@@@")
driver.find_element_by_id("signin").click()
time.sleep(3)
print(driver.get_cookies())
# 获取指定name的cookie
print(driver.get_cookie(name=".CNBlogsCookie"))
# 清除指定name的cookie
driver.delete_cookie(name=".CNBlogsCookie")
print(driver.get_cookies())
# 为了验证此cookie是登录的,可以删除后刷新页面
driver.refresh()
# 清除所有的cookie
driver.delete_all_cookies()
print(driver.get_cookies())
| true |
045819a458a361a325b16fc857654e694b5175f8 | Python | Henk0/ITMO_ICT_WebDevelopment_2020-2021 | /students/K33402/Beresnev_Andrey/lab1/Task1/client.py | UTF-8 | 216 | 2.515625 | 3 | [
"MIT"
] | permissive | import socket
s = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
s.connect((socket.gethostname(), 7777))
msg = s.recv(1024)
print(msg.decode("utf-8"))
s.send(bytes("Hello server", "utf-8"))
s.close() | true |
c5787a2b3674291cea08d63e6a1220618e8a5d6c | Python | Dimasita/LodeRunner_by_Dimasita | /decorators.py | UTF-8 | 1,225 | 3.390625 | 3 | [] | no_license | import time
def benchmark(i: int = 1):
def decor(func):
def wrapper(*args, **kwargs):
min_time = 0
max_time = 0
total_time = 0
for j in range(i):
start = time.time()
return_value = func(*args, **kwargs)
end = time.time()
single_time = end - start
if j == 0:
min_time = single_time
max_time = single_time
else:
if min_time > single_time:
min_time = single_time
if max_time < single_time:
max_time = single_time
total_time += single_time
if i == 1:
print(f'Время выполнения: {min_time} секунд.')
else:
print(f'Min время выполнения: {min_time} секунд.')
print(f'Avg время выполнения: {total_time / i} секунд ({i} iterations).')
print(f'Max время выполнения: {max_time} секунд.')
return return_value
return wrapper
return decor
| true |
04fd69f0adf0e6c565eb7253e4ffb34152dfe09e | Python | confeitaria/confeitaria | /confeitaria/server/server.py | UTF-8 | 10,017 | 3.03125 | 3 | [] | no_license | #!/usr/bin/env python
#
# Copyright 2015 Adam Victor Brandizzi
#
# This file is part of Confeitaria.
#
# Confeitaria is free software: you can redistribute it and/or modify it under
# the terms of the GNU Lesser General Public License as published by the Free
# Software Foundation, either version 3 of the License, or (at your option) any
# later version.
#
# Confeitaria is distributed in the hope that it will be useful, but WITHOUT
# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
# FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more
# details.
#
# You should have received a copy of the GNU Lesser General Public License
# along with Confeitaria. If not, see <http://www.gnu.org/licenses/>.
import os
import itertools
import binascii
import wsgiref.simple_server as simple_server
import Cookie
import confeitaria.request
import confeitaria.responses
from .requestparser import RequestParser
from .session import SessionStorage
from .environment import Environment
class Server(object):
"""
The ``Server`` objects listen to HTTP requests and serve responses
according to the page object returned values.
"""
def __init__(
self, page, port=8000, session_storage=None):
self.request_parser = RequestParser(page)
if session_storage is None:
self.session_storage = SessionStorage()
self.port = port
self._process = None
def run(self, force=True):
"""
This method starts the server up serving the given page.
A page is an object of a class as the one below:
>>> class TestPage(object):
... def index(self):
... return "This is a test"
To run it, just call `Server.run()`, as in:
>>> s = Server(TestPage())
>>> import multiprocessing, inelegant.net
>>> p = multiprocessing.Process(target=s.run)
>>> p.start()
>>> inelegant.net.wait_server_up('', s.port)
Then the server is supposed to serve the content provided by the page:
>>> import requests
>>> r = requests.get('http://localhost:8000/')
>>> r.text
u'This is a test'
>>> r.status_code
200
>>> r.headers['content-type']
'text/html'
>>> p.terminate()
You can also, mostly for testing purposes, start up a server through a
``with`` statement:
>>> with Server(TestPage()):
... r = requests.get("http://localhost:8000")
... r.text
u'This is a test'
"""
while True:
import socket
try:
httpd = simple_server.make_server('', self.port, self.respond)
print "Serving on port 8000..."
httpd.serve_forever()
except socket.error:
if not force:
raise
def respond(self, env_dict, start_response):
"""
This method responds to HTTP requests encoded as a WSGI environment. It
is a WSGI application `as defined by PEP 0333`__ if bound, and so it
receives two arguments: a dict representing a WSGI environment and a
callable to start a response. So, if we have a function like this::
>>> def dummy_start_response(*args):
... global response
... response = args
...and a class like this::
>>> class TestPage(object):
... def index(self, arg=None):
... return arg if arg is not None else 'no argument'
...given to a server::
>>> s = Server(TestPage())
...then calling ``Server.respond()`` should return the output from the
page::
>>> s.respond({}, dummy_start_response)
['no argument']
>>> s.respond({'QUERY_STRING': 'arg=value'}, dummy_start_response)
['value']
``response`` should be set as well::
>>> response
('200 OK', [('Content-type', 'text/html')])
__ https://www.python.org/dev/peps/pep-0333/#the-application-framework\
-side
"""
env = Environment(env_dict)
try:
request = self.request_parser.parse_request(env)
page = request.page
if hasattr(page, 'set_request'):
page.set_request(request)
if hasattr(page, 'set_cookies'):
page.set_cookies(env.http_cookie)
if hasattr(page, 'set_session'):
session_id = get_or_add_session_id(env.http_cookie)
page.set_session(self.session_storage[session_id])
if request.method == 'GET':
content = page.index(*request.args, **request.kwargs)
headers = [('Content-type', 'text/html')]
raise confeitaria.responses.OK(
message=content, headers=headers)
elif request.method == 'POST':
page.action(*request.args, **request.kwargs)
raise confeitaria.responses.SeeOther()
except confeitaria.responses.Response as r:
status = r.status_code
headers = complete_headers(r, env.http_cookie, env.url)
content = r.message if r.message is not None else ''
start_response(status, headers)
return [content]
def __enter__(self):
import multiprocessing
import inelegant.net
try:
self._process = multiprocessing.Process(target=self.run)
self._process.start()
inelegant.net.wait_server_up('', self.port, tries=10000)
except:
raise
def __exit__(self, type, value, traceback):
import inelegant.net
self._process.terminate()
inelegant.net.wait_server_down('', self.port, tries=10000)
self._process = None
def get_cookies_tuples(cookies):
"""
Returns an iterator. This iterator yields tuples - each tuple defines a
cookie and is appropriate to be put in the headers list for
``wsgiref.start_response()``::
>>> cookie = Cookie.SimpleCookie()
>>> cookie['a'] = 'A'
>>> cookie['b'] = 'B'
>>> list(get_cookies_tuples(cookie))
[('Set-Cookie', 'a=A'), ('Set-Cookie', 'b=B')]
"""
return (
('Set-Cookie', cookies[k].OutputString()) for k in cookies
)
def replace_none_location(headers, location):
"""
Returns a new list of tuples (with headers values) where any 'Location'
header with ``None`` as value is replaced by the given location::
>>> headers = [('Location', None), ('Set-Cookie', 'a=A')]
>>> replace_none_location(headers, '/b')
[('Location', '/b'), ('Set-Cookie', 'a=A')]
Location headers already set are not affected::
>>> headers = [('Location', '/a'), ('Set-Cookie', 'a=A')]
>>> replace_none_location(headers, '/b')
[('Location', '/a'), ('Set-Cookie', 'a=A')]
"""
return [
(h[0], location
if (h[0].lower() == 'location') and (h[1] is None) else h[1])
for h in headers
]
def get_or_add_session_id(cookie):
"""
Get the session ID from a cookie object::
>>> import Cookie
>>> cookie = Cookie.SimpleCookie('Set-Cookie: SESSIONID=123456789ABCDEF')
>>> get_or_add_session_id(cookie)
'123456789ABCDEF'
If the cookie has no session ID...
::
>>> cookie = Cookie.SimpleCookie('')
>>> 'SESSIONID' in cookie
False
...then one is created...
::
>>> session_id = get_or_add_session_id(cookie)
>>> session_id # doctest: +ELLIPSIS
'...'
...and is added to the cookie::
>>> cookie['SESSIONID'].value == session_id
True
"""
if 'SESSIONID' not in cookie:
session_id = binascii.hexlify(os.urandom(16))
cookie['SESSIONID'] = session_id
else:
session_id = cookie['SESSIONID'].value
return session_id
def complete_headers(response, cookies, default_redirect_url='/'):
"""
Given a response and a set of cookies, return a headers list appropriate to
be given to WSGI::
>>> from confeitaria.responses import OK, NotFound, SeeOther
>>> from Cookie import SimpleCookie
>>> complete_headers(
... OK('All right.', headers=[('Content-type', 'text/plain')]),
... SimpleCookie())
[('Content-type', 'text/plain')]
Adding cookie headers
=====================
If there are any cookies available, they will be added to the headers::
>>> complete_headers(
... OK('All right.', headers=[('Content-type', 'text/plain')]),
... SimpleCookie('Set-Cookie: a=b'))
[('Content-type', 'text/plain'), ('Set-Cookie', 'a=b')]
Also, if the response's status code is a multiple choice status (i.e. one
of the 30x status codes) but the response has no redirect URL in it, then
this function will add a default redirect URL in the headers. By default,
it is ``'/'``...
::
>>> complete_headers(
... SeeOther(headers=[('Content-type', 'text/plain')]),
... SimpleCookie())
[('Content-type', 'text/plain'), ('Location', '/')]
...but it can (and should be changed with the ``default_redirect_url``
argument::
>>> complete_headers(
... SeeOther(headers=[('Content-type', 'text/plain')]),
... SimpleCookie(), default_redirect_url='/other/place')
[('Content-type', 'text/plain'), ('Location', '/other/place')]
If the response already has a location value, then this is the one to be
returned::
>>> complete_headers(
... SeeOther('/my/place', headers=[('Content-type', 'text/plain')]),
... SimpleCookie(), default_redirect_url='/other/place')
[('Content-type', 'text/plain'), ('Location', '/my/place')]
"""
headers = response.headers
if response.status_code.startswith('30'):
headers = replace_none_location(headers, default_redirect_url)
return list(itertools.chain(headers, get_cookies_tuples(cookies)))
| true |
7d26ae22dd17fb348543852ce0fcb86053d53a84 | Python | Carmona-Elias/Python_CEV | /D_018.py | UTF-8 | 246 | 3.984375 | 4 | [] | no_license | from math import sin, cos, tan, radians
angulo = float(input('Digite um angulo: '))
print(f'Sen {angulo} = {sin(radians(angulo)):.2f} ')
print(f'Cos {angulo} = {cos(radians(angulo)):.2f}')
print(f'tan {angulo} = {tan(radians(angulo)):.2f}')
| true |
a9fb2a35f8313fe1aefa2e642001b7243b90e51a | Python | nicktaras/python-tensorflow | /src/using_num_py/using_num_py.py | UTF-8 | 1,444 | 3.890625 | 4 | [] | no_license | import numpy as np
# Create array
my_list = [1, 2, 3]
# us numpy to create an n dimensional array
type(np.array(my_list))
# Create an array within numpy
arr = np.array(my_list)
# Create a range 0 to 9 (start and stop, optional jump/step size as third params)
np.arange(0, 10)
# Creates a one dimensional array of 0's
# e.g. [0, 0, 0, 0, 0]
np.zeros(5)
# Creates a two dimensional array of 0's
# e.g.
# [0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0]
np.zeros(3, 5)
# Create ones instead
# [0, 0, 0]
np.ones(3)
# Similar to arrange (the third params asks how many decimal places
# would you like between each step)
# (start, stop, points between)
np.linespace(0, 11, 11)
# Random int generator
np.randint(0,10)
# 2 dimensional random int
np.randint(0,1000, (3, 3))
# seed allows us to keep getting the same set of random numbers
# useful for testing
np.random.seed(101)
np.random.seed(0, 1000, 10)
# get max or min of an array
np.random.seed(101)
arr = np.random.seed(0, 1000, 10)
arr.min()
arr.max()
arr.mean()
# Reshape the array
arr.reshape(2, 5)
# to get values from a dimensional array
# assign mat to the array mat = array...
mat[0, 1]
# slice a row
# : means everything
mat[:, 0]
# slice a row
mat[5, :]
# slices (grab first three in 2 array)
mat[0:3, 0:3]
# is this matrix greater than 50 for each value
# turns the array into bools
my_filer = mat > 50
# returns values greater than 50
mat[mat > 50]
| true |
5c37cae6c44fcf880616280241884256ba361ca8 | Python | ecly/adventofcode2016 | /day05/password.py | UTF-8 | 777 | 3.359375 | 3 | [
"MIT"
] | permissive | import hashlib
def first(input):
output = ""
index = 0
while len(output) < 8:
val = input + str(index)
hash = hashlib.md5(val.encode()).hexdigest()
if hash.startswith('00000'):
output += hash[5]
index += 1
return output
def second(input):
output = list('________')
index = 0
found = 0
while found < 8:
val = input + str(index)
hash = hashlib.md5(val.encode()).hexdigest()
if hash.startswith('00000'):
idx = int(hash[5], 16)
if idx < 8 and output[idx] == '_':
output[idx] = hash[6]
found += 1
index += 1
return ''.join(output)
# about 30 seconds total
print(first('uqwqemis'))
print(second('uqwqemis'))
| true |
a5e3efac5dc3d197bbc339e7b01001ed70d4862c | Python | KorotkiyEugene/dsp_sdr_basic | /15/hilbert_harmonic.py | UTF-8 | 559 | 2.515625 | 3 | [
"MIT"
] | permissive | import numpy as np
from common import create_harmonic, plot_spectrum
import matplotlib.pyplot as plt
from scipy.signal import hilbert
Fsamp_rate = 100e3
Fsig = 10e3 # Frequency of signal
dummy, t, signal = create_harmonic(Fc=Fsig, Fs=Fsamp_rate, Amp=1, N=1e3)
complex_signal = hilbert(signal)
# Plot spectrums for signal and complex signal
plot_spectrum(signal, Fs=Fsamp_rate, NFFT=8192, title="Signal's Spectrum")
plot_spectrum(complex_signal, Fs=Fsamp_rate, NFFT=8192, title="Signal's Spectrum after Hilbert Transform")
plt.show()
| true |
28e6c9743fe9f27a7fdbf7403916b32504c4bc10 | Python | gituajames/covid19_vis | /scrap.py | UTF-8 | 2,420 | 2.84375 | 3 | [] | no_license | import pandas as pd
import geopandas as gpd
import requests
from bs4 import BeautifulSoup as b
# a procedure function specific to table at 'https://www.worldometers.info/coronavirus/#countries'
def table():
r = requests.get('https://www.worldometers.info/coronavirus/#countries')
print(r.status_code)
soup = b(r.text, 'lxml')
# find our table
table = soup.find('table', id = 'main_table_countries_today')
tbody = table.find('tbody')
# print(tbody)
table_row = tbody.find_all('tr')
all_rows = []
for tr in table_row:
td = tr.find_all('td')
row = [i.text.replace('\n', ' ').strip() for i in td]
all_rows.append(row)
df = pd.DataFrame(all_rows, columns=['country', 'total_cases', 'new_cases', 'total_deaths', 'new_deaths',
'total_recovered', 'active', 'serirous', '1', '2', '3', '4', '5'])
# print(df.head())
df.drop(index=[0, 1, 2, 3, 4, 5, 6, 7], inplace=True)
df.drop(columns=['1', '2', '3', '4'], inplace=True)
copy_df = df.copy()
# print(copy_df.head())
copy_df['total_recovered'] = copy_df['total_recovered'].str.replace('N/A', '0')
copy_df['new_cases'] = copy_df['new_cases'].str.replace('+', '')
copy_df['new_deaths'] = copy_df['new_deaths'].str.replace('+', '')
# print(copy_df.head())
copy_df['total_cases'] = copy_df['total_cases'].str.replace(',', '')
copy_df['new_cases'] = copy_df['new_cases'].str.replace(',', '')
copy_df['total_deaths'] = copy_df['total_deaths'].str.replace(',', '')
copy_df['total_recovered'] = copy_df['total_recovered'].str.replace(',', '')
copy_df['active'] = copy_df['active'].str.replace(',', '')
copy_df['serirous'] = copy_df['serirous'].str.replace(',', '')
# print(copy_df.head())
copy_df['total_cases'] = pd.to_numeric(copy_df['total_cases'])
copy_df['new_cases'] = pd.to_numeric(copy_df['new_cases'])
copy_df['total_deaths'] = pd.to_numeric(copy_df['total_deaths'])
copy_df['new_deaths'] = pd.to_numeric(copy_df['new_deaths'])
copy_df['total_recovered'] = pd.to_numeric(copy_df['total_recovered'])
copy_df['active'] = pd.to_numeric(copy_df['active'])
copy_df['serirous'] = pd.to_numeric(copy_df['serirous'])
# print(copy_df.head())
copy_df.fillna(0, inplace=True)
# print(copy_df.head())
return copy_df
| true |
bce2a54457a2f6ee58710480bf9dbb0d2ddb9422 | Python | mireianievas/SQM | /sqm_data_validator_s015-v010.py | UTF-8 | 11,323 | 2.96875 | 3 | [] | no_license | #!/bin/env python
# Tested in Python 2.7 .
try:
import sys
except:
print('Error importing essential modules')
__author__ = "Miguel Nievas"
__copyright__ = ""
__license__ = "GPL"
__version__ = "0.01"
__maintainer__ = "Miguel Nievas"
__email__ = "miguelnr89[at]gmail[dot]com"
__status__ = "Prototype" # "Prototype", "Development", or "Production"
# Some constants
HeaderLength = 35
NumberDataColumns = 6
VersionStandard = '0.1.5' # If file format follows a different version of the standard, print a Warning.
class PrintHelp():
def print_help(self):
HelpMessage = \
'-----------------------------------------------------------\n'+\
'Simple script to validate SQM data file according to v'+str(VersionStandard)+'\n'+\
'Light Pollution Monitoring Data Format 0.1.5 standard. \n'+\
'-----------------------------------------------------------\n'+\
'Example: '+str(sys.argv[0])+' sqmle_obs_2013-01-01.dat\n\n'+\
'Returns:\n'+\
' [OK] File is standard compliant \n'+\
' or \n'+\
' [ERR] Invalid File.\n'+\
' {List of detected errors}\n'
print(HelpMessage)
class PrintError():
def print_error(self):
ErrorMessage = \
'[ERR] Invalid File.\n'
for error in self.ErrorList:
ErrorMessage +=' '+str(error)+'\n'
print(ErrorMessage)
class SqmDataFile(PrintHelp,PrintError):
def validate_file(self):
self.ErrorList = []
self.test_file = ''
try:
self.test_file = sys.argv[1]
self.file_content = open(self.test_file,'r').readlines()
except:
self.ErrorList.append('Cannot open file: '+str(self.test_file))
else:
self.extract_header()
self.extract_data()
if len(self.ErrorList)>0:
self.print_error()
self.print_help()
exit(0)
def extract_header(self):
self.header = [line for num,line in enumerate(self.file_content) if line[0]=='#' and num<HeaderLength]
if len(self.header)!=HeaderLength:
self.ErrorList.append('Header length is not '+str(HeaderLength)+' but '+str(len(self.header)))
self.print_error()
def extract_data(self):
self.data = [line for num,line in enumerate(self.file_content) if line[0]!='#' and num>=HeaderLength]
if len(self.data)==0:
self.ErrorList.append('No data found in file')
self.print_error()
class SqmAnalysis(SqmDataFile):
def __init__(self):
self.validate_file()
self.test_header()
self.test_data()
def test_header(self):
# Test if header follows the standard format.
# Note that python starts to count from 0, so line 23 is actually line 24
try:
header_device_type = [self.header[0][2:40],self.header[0][41:]]
assert header_device_type[0] == 'Light Pollution Monitoring Data Format'
assert header_device_type[1] != '\n' and header_device_type[1] != '\r\n'
assert header_device_type[1][0:len(VersionStandard)] == VersionStandard
except:
print('Warning: file uses a different standard version')
try:
header_device_type = [self.header[4][2:13],self.header[4][15:]]
assert header_device_type[0] == 'Device type'
assert header_device_type[1] != '\n' and header_device_type[1] != '\r\n'
except:
self.ErrorList.append('No device type found in line 5')
try:
header_instrument_id = [self.header[5][2:15],self.header[5][17:]]
assert header_instrument_id[0] == 'Instrument ID'
assert header_instrument_id[1] != '\n' and header_instrument_id[1] != '\r\n'
except:
self.ErrorList.append('No Instrument ID found in line 6')
try:
header_data_supplier = [self.header[6][2:15],self.header[6][17:]]
assert header_data_supplier[0] == 'Data supplier'
assert header_data_supplier[1] != '\n' and header_data_supplier[1] != '\r\n'
except:
self.ErrorList.append('No Data supplier found in line 7')
try:
header_location_name = [self.header[7][2:15],self.header[7][17:]]
assert header_location_name[0] == 'Location name'
assert header_location_name[1] != '\n' and header_location_name[1] != '\r\n'
except:
self.ErrorList.append('No Location name found in line 8')
try:
header_position = [self.header[8][2:10],self.header[8][12:]]
assert header_position[0] == 'Position'
assert header_position[1] != '\n' and header_position[1] != '\r\n'
try:
latitude = float(header_position[1].split(",")[0])
longitude = float(header_position[1].split(",")[1])
altitude = float(header_position[1].split(",")[2])
except:
self.ErrorList.append('No latitude/longitude/altitude defined in line 9')
except:
self.ErrorList.append('No Position found in line 9')
try:
header_timezone = [self.header[9][2:16],self.header[9][18:]]
assert header_timezone[0] == 'Local timezone'
assert header_timezone[1] != '\n' and header_timezone[1] != '\r\n'
try:
assert 'UTC' in header_timezone[1]
except:
self.ErrorList.append('Local timezone must be especified as UTC+# or UTC-# in line 10')
except:
self.ErrorList.append('No Local timezone found in line 10')
try:
header_timesync = [self.header[10][2:22],self.header[10][24:]]
assert header_timesync[0] == 'Time Synchronization'
assert header_timesync[1] != '\n' and header_timesync[1] != '\r\n'
except:
self.ErrorList.append('No Time Synchronization found in line 11')
try:
header_movstationary = [self.header[11][2:30],self.header[11][32:]]
assert header_movstationary[0] == 'Moving / Stationary position'
assert header_movstationary[1] != '\n' and header_movstationary[1] != '\r\n'
try:
assert 'STATIONARY' in header_movstationary[1] or 'MOVING' in header_movstationary[1]
except:
self.ErrorList.append('no STATIONARY or MOVING especified in line 12')
except:
self.ErrorList.append('No Moving / Stationary position found in line 12')
try:
header_movfixeddir = [self.header[12][2:31],self.header[12][33:]]
assert header_movfixeddir[0] == 'Moving / Fixed look direction'
assert header_movfixeddir[1] != '\n' and header_movfixeddir[1] != '\r\n'
try:
assert 'FIXED' in header_movfixeddir[1] or 'MOVING' in header_movfixeddir[1]
except:
self.ErrorList.append('no FIXED or MOVING especified in line 13')
except:
self.ErrorList.append('No Moving / Fixed look direction found in line 13')
try:
header_number_channels = [self.header[13][2:20],self.header[13][22:]]
assert header_number_channels[0] == 'Number of channels'
assert header_number_channels[1] != '\n' and header_number_channels[1] != '\r\n'
try:
number_channels = int(header_number_channels[1])
except:
self.ErrorList.append('Number of channels should be an integer, line 14')
except:
self.ErrorList.append('No Number of channels found in line 14')
try:
header_filters_per_channel = [self.header[14][2:21],self.header[14][23:]]
assert header_filters_per_channel[0] == 'Filters per channel'
assert header_filters_per_channel[1] != '\n' and header_filters_per_channel[1] != '\r\n'
try:
filters_per_channel = header_filters_per_channel[1].split(",")
assert len(filters_per_channel)>=1
except:
self.ErrorList.append('No filters especified in line 15')
except:
self.ErrorList.append('No Filters per channel found in line 15')
try:
header_dir_per_channel = [self.header[15][2:35],self.header[15][37:]]
assert header_dir_per_channel[0] == 'Measurement direction per channel'
assert header_dir_per_channel[1] != '\n' and header_dir_per_channel[1] != '\r\n'
try:
direction_per_channel = [float(direction) for direction in header_dir_per_channel[1].split(",")]
assert len(direction_per_channel)>=1
except:
self.ErrorList.append('No directions especified in line 16')
except:
self.ErrorList.append('No Measurement direction per channel found in line 16')
try:
header_fov = [self.header[16][2:15],self.header[16][17:]]
assert header_fov[0] == 'Field of view'
assert header_fov[1] != '\n' and header_fov[1] != '\r\n'
try:
fov = float(header_fov[1])
except:
self.ErrorList.append('No field of view especified in line 17')
except:
self.ErrorList.append('No Field of view found in line 17')
try:
header_fields = [self.header[17][2:27],self.header[17][29:]]
assert header_fields[0] == 'Number of fields per line'
assert header_fields[1] != '\n' and header_fields[1] != '\r\n'
try:
fields = int(header_fields[1])
except:
self.ErrorList.append('No number of fields especified in line 18, should be an integer')
except:
self.ErrorList.append('No Number of fields per line found in line 18')
try:
header_serialnumber = [self.header[18][2:19],self.header[18][21:]]
assert header_serialnumber[0] == 'SQM serial number'
assert header_serialnumber[1] != '\n' and header_serialnumber[1] != '\r\n'
except:
self.ErrorList.append('No SQM serial number found in line 19')
try:
header_firmware = [self.header[19][2:22],self.header[19][24:]]
assert header_firmware[0] == 'SQM firmware version'
assert header_firmware[1] != '\n' and header_firmware[1] != '\r\n'
except:
self.ErrorList.append('No SQM firmware version found in line 20')
try:
header_offset = [self.header[20][2:24],self.header[20][26:]]
assert header_offset[0] == 'SQM cover offset value'
assert header_offset[1] != '\n' and header_offset[1] != '\r\n'
try:
offset = float(header_offset[1])
except:
self.ErrorList.append('No offset especified in line 21, should be a float number')
except:
self.ErrorList.append('No SQM cover offset value found in line 21')
def test_data(self):
# Test if data follows the standard format.
for line in xrange(len(self.data)):
try:
first_line_parts = self.data[line].split(";")
assert len(first_line_parts) == NumberDataColumns
except:
self.ErrorList.append('Number of columns is not '+str(NumberDataColumns)+' as in the standard format | Line:'+str(line))
else:
try:
for k in [0,1]:
datetime = first_line_parts[k]
date = datetime.split('T')[0].split("-")
year = int(date[0])
month = int(date[1])
day = int(date[2])
assert 1990<=year<=2100 and 1<=month<=12 and 1<=day<=31
time = datetime.split('T')[1].split(":")
hour = int(time[0])
minute = int(time[1])
second = float(time[2])
assert 0<=hour<24 and 0<=minute<60 and 0.0<=second<60.0
except:
self.ErrorList.append('Wrong UTC date/time or Local date/time format, should be YYYY-MM-DDTHH:mm:ss.fff | Line:'+str(line))
try:
temperature = float(first_line_parts[2])
except:
self.ErrorList.append('Temperature doesnt follow the standard format, should be float | Line:'+str(line))
try:
fluxcounts = float(first_line_parts[3])
except:
self.ErrorList.append('Flux (counts) doesnt follow the standard format, should be float | Line:'+str(line))
try:
fluxfreq = float(first_line_parts[4])
except:
self.ErrorList.append('Flux (frequency) doesnt follow the standard format, should be float | Line:'+str(line))
try:
msas = float(first_line_parts[4])
except:
self.ErrorList.append('MSAS (mag/arcsec2) doesnt follow the standard format, should be float | Line:'+str(line))
if __name__ == '__main__':
SqmFile = SqmAnalysis()
if len(SqmFile.ErrorList)>0:
SqmFile.print_error()
else:
print('Standard compliant file.')
| true |
f4b9ef74a66fff3566011bc3d4d78211459a2961 | Python | daniel9a/Scripting-Languages | /hw1/ProblemB.py | UTF-8 | 1,210 | 3.5 | 4 | [] | no_license | import os
#read the first n bytes of a file
def readNBytes(fileName,nBytes):
toRead = open(fileName, 'rb')
byte = toRead.read(nBytes)
return byte
#get all files located in this directory and their paths
def fileList(dir_name):
f = []
#use os.walk to create file names for
for root, dirs, files in os.walk(dir_name, True):
for name in files:
f.append(os.path.join(root, name))
return f
#takes a dict, returns tuples of len 2 for all values sharing the same key.
def makeTupleList(Data):
return_val = []
for key in Data:
if len(Data[key]) > 1:
for i in range(len(Data[key])):
for j in range(1,len(Data[key]) - i):
return_val.append((Data[key][i], Data[key][i+j]))
return return_val
#takes a file name and number of bytes and returns a tuple of any same files.
def filePairs(dir_name, nBytes):
Data = {}
#getting the names of all the files
files = fileList(dir_name)
for f in files:
#append to list if one does
if readNBytes(f,nBytes) in Data:
Data[readNBytes(f,nBytes)].append(f)
#create list for key if one doesn't exist
else:
Data[readNBytes(f,nBytes)] = [f]
return makeTupleList(Data)
| true |
89e7ef4284f31623f16282fae87be8adec193a9a | Python | parbol/TrackGenerator | /Core/Vertex.py | UTF-8 | 536 | 2.5625 | 3 | [] | no_license | import random as rn
import math as math
from Core.Particle import Particle
from Core.Track import Track
class Vertex:
def __init__(self):
self.id = 1
def fit(self, tracks):
x_vertex = 0
y_vertex = 0
pt2 = 0
for i in tracks:
x_vertex += i.x0 * i.genpt * i.genpt
y_vertex += i.y0 * i.genpt * i.genpt
pt2 += i.genpt * i.genpt
x_vertex /= pt2
y_vertex /= pt2
fullvertex = [x_vertex, y_vertex]
return fullvertex
| true |
cacbad938cb18f585ee488eddd2778e46bf4d202 | Python | erwin00776/picnote | /src/store/multipoint/seqfile.py | UTF-8 | 4,074 | 2.65625 | 3 | [] | no_license |
import os
import json
import pickle
class SeqFile:
def __init__(self, path, sid, replications=3):
if isinstance(sid, int):
self.sid = str(sid)
else:
self.sid = sid
self.replications = replications # TODO
self.checkpoint_len = 16
self.path = path
self.tmp_filename = os.path.join(self.path, 'picnote.sequences-%s.tmp' % self.sid)
self.seqs_filename = os.path.join(self.path, 'picnote.sequences-%s' % self.sid)
self.tmp_seqs_file = None
self.tmp_seqs = None
self.seqs = None
self.seqs_file = None
self.init_done = self.try_recover()
def try_recover(self):
ret = True
if not self.load():
ret = False
raise Exception("recover.load error.")
if not self.checkpoint():
ret = False
raise Exception("recover.checkpoint error.")
return ret
def load(self):
if not os.path.exists(self.tmp_filename):
self.tmp_seqs = []
if not os.path.exists(self.seqs_filename):
self.seqs = []
try:
if self.tmp_seqs is None:
self.tmp_seqs = []
self.tmp_seqs_file = open(self.tmp_filename, 'r')
for line in self.tmp_seqs_file.readlines():
self.tmp_seqs.append(json.loads(line))
self.tmp_seqs_file.close()
except IOError as e:
print(e.message)
return False
try:
if self.seqs is None:
self.seqs_file = open(self.seqs_filename, 'r')
self.seqs = pickle.load(self.seqs_file)
self.seqs_file.close()
except EOFError as e:
if self.seqs_file is not None:
self.seqs_file.close()
self.seqs = []
assert (self.seqs is not None)
try:
self.tmp_seqs_file = open(self.tmp_filename, 'w')
self.seqs_file = open(self.seqs_filename, 'w')
return True
except IOError as e:
print(e.message)
return False
def checkpoint(self):
''' truncate tmp seqs to seqs '''
try:
if self.tmp_seqs is None or len(self.tmp_seqs) == 0:
return True
for item in self.tmp_seqs:
self.seqs.append(item)
self.tmp_seqs_file.seek(0)
self.tmp_seqs_file.truncate()
self.seqs_file.seek(0)
self.seqs_file.truncate()
pickle.dump(self.seqs, self.seqs_file)
self.tmp_seqs = []
# remove the tmp seqs file.
print("checkpoint done: %d %d" % (len(self.tmp_seqs), len(self.seqs)))
except IOError as e:
print("checkpoint " + e.message)
return False
return True
def record(self, item, force=False):
"""
:param item: a hash.
:return: True: done, False: negative
"""
ret = True
try:
s = json.dumps(item)
self.tmp_seqs.append(item)
self.tmp_seqs_file.write(s + "\n")
self.tmp_seqs_file.flush()
if (len(self.tmp_seqs) > self.checkpoint_len) or force:
self.checkpoint()
except IOError as e:
ret = False
return ret
def merge(self):
''' merge old items in seqs '''
new_seqs = []
for item in self.seqs:
if item['replications'] < self.replications:
new_seqs.append(item)
self.seqs = None
self.seqs = new_seqs
self.checkpoint()
def close(self):
self.merge()
self.tmp_seqs_file.close()
self.seqs_file.close()
if __name__ == "__main__":
sf = SeqFile("/home/erwin/tmp", 1)
if not sf.init_done:
print("init error.")
for i in range(50):
r = i / 10 + 1
item = {'type': 'add', 'filepath': '/home/erwin/...', 'replications': r}
sf.record(item)
sf.close()
| true |
bc78fd67f559c2e4fd94b6a50fc03a4ee1ebad70 | Python | kennethgoodman/rockstar_math | /rockmath.py | UTF-8 | 10,099 | 3.859375 | 4 | [] | no_license | #Pi constant
the_pi = 3.1415926535897932
the_e = 2.7182818284590452
the_tau = the_pi * 2
#Convert degrees to radians
def DegToRad(the_degrees):
return the_degrees * the_tau / 360
#Convert radians to degrees
def RadToDeg(the_radian):
return the_radian * 360 / the_tau
#Factorial: n!
def Factorial(the_number):
the_zero = 0
if the_number == the_zero:
return 1
if the_number < the_zero:
return -1
the_iterator = 1
the_answer = 1
while the_iterator <= the_number:
the_answer = the_iterator * the_answer
the_iterator += 1
return the_answer
#Abs value
def Absolute_Value(the_number):
if the_number < 0:
the_number = the_number * -1
return the_number
return the_number
#Is-close
def Is_Close(the_a, the_b):
the_relativetolerance = 0.0000000001 #to be changed to an optional argument
the_absolutetolerance = 0 #to be changed to an optional argument
the_largest = Absolute_Value(the_a)
if Absolute_Value(the_b) > the_largest:
the_largest = Absolute_Value(the_b)
the_scalefactor = the_relativetolerance * the_largest
if the_absolutetolerance > the_scalefactor:
the_threshold = the_absolutetolerance
else:
the_threshold = the_scalefactor
the_difference = the_a - the_b
the_difference = Absolute_Value(the_difference)
if the_difference <= the_threshold:
return True
else:
return False
#Mod: a % m
def Mod(the_number, the_modulo):
if the_number > 0:
while the_number >= the_modulo:
the_number = the_number - the_modulo
return the_number
if the_number < 0:
while the_number < 0:
the_number = the_number + the_modulo
return the_number
return the_number
#Gcd
def Gcd(the_x, the_y):
if Mod(the_x, 1) != 0 or Mod(the_y, 1) != 0:
return "Error: the input must be two integer numbers"
the_x = Absolute_Value(the_x)
the_y = Absolute_Value(the_y)
if the_x == 0:
return the_y
if the_y == 0:
return the_x
while the_x != the_y:
if the_x > the_y:
the_x = the_x - the_y
else:
the_y = the_y - the_x
return the_x
#Floor
def Floor(the_number):
the_number = the_number - Mod(the_number, 1)
return the_number
#Ceil
def Ceil(the_number):
the_number = -1 * the_number
the_number = -1 * Floor(the_number)
return the_number
#Power: a^x
def Power(the_base, the_exponent):
if the_exponent < 0:
the_newexponent = -1 * the_exponent
return 1 / Power(the_base, the_newexponent)
if the_exponent == 0:
return 1
if the_base == 0:
return 0
if Mod(the_exponent, 1) == 0:
return PowerIntegerExponent(the_base, the_exponent)
else:
return PowerRealExponent(the_base, the_exponent)
#PowerIntegerExponent: should rather be named PowerPositiveIntegerExponent
def PowerIntegerExponent(the_base, the_exponent):
the_iterator = 0
the_answer = 1
while the_iterator < the_exponent: #Probably can also use divide and conquer exponentiation -> e^n + e^m + ....
the_answer = the_base * the_answer
the_iterator += 1
return the_answer
#PowerRealExponent
def PowerRealExponent(the_base, the_exponent):
the_argument = the_exponent * LN(the_base)
return Exp(the_argument)
#Exp
def Exp(the_x):
the_prevanswer = 666
the_nextanswer = 1
the_iterator = 1
while the_iterator < 2000 and Is_Close(the_prevanswer, the_nextanswer) == False:
the_prevanswer = the_nextanswer
the_numerator = Power(the_x, the_iterator)
the_denominator = Factorial(the_iterator)
the_term = the_numerator / the_denominator
the_nextanswer = the_prevanswer + the_term
the_iterator += 1
return the_nextanswer
#Natural Logarithm, always base e
def LN(the_number):
the_top = the_number - 1
the_bottom = the_number + 1
the_x = the_top / the_bottom
the_iterator = 1
the_answer = 0
while the_iterator < 10: #get reasonable starting point for Halley's method
the_term = Power(the_x, the_iterator)
the_term = the_term / the_iterator
the_answer = the_answer + the_term
the_iterator += 1
the_iterator += 1
the_nextanswer = the_answer * 2 #end power expansion, start Halley's cubic convergence
the_prevanswer = 666
the_iterator = 0
while the_iterator < 2000 and Is_Close(the_prevanswer, the_nextanswer) == False:
the_prevanswer = the_nextanswer
the_numerator = the_number - Exp(the_prevanswer)
the_denominator = the_number + Exp(the_prevanswer)
the_term = 2 * the_numerator / the_denominator
the_nextanswer = the_prevanswer + the_term
the_iterator += 1
return the_nextanswer
#Log with number and base
def LOG(the_number, the_base):
the_top = LN(the_number)
the_bottom = LN(the_base)
return the_top / the_bottom
#Square Root Function
def Square_Root(the_number):
the_prevanswer = 666
the_nextanswer = 0.5 * the_number
the_iterator = 1
the_number = 1.0 * the_number
while the_iterator < 2000 and Is_Close(the_prevanswer, the_nextanswer) == False:
the_prevanswer = the_nextanswer
the_term = the_number / the_prevanswer + the_prevanswer
the_nextanswer = 0.5 * the_term
the_iterator += 1
return the_nextanswer
#Sine
def Sine(the_radian):
the_iterator = 1
the_prevanswer = 666
the_nextanswer = 0
the_sign = 1
while the_iterator < 2000 and Is_Close(the_prevanswer, the_nextanswer) == False:
the_prevanswer = the_nextanswer
the_term = Power(the_radian, the_iterator) / Factorial(the_iterator)
the_term = the_term * the_sign
the_nextanswer = the_prevanswer + the_term
the_iterator += 1
the_iterator += 1
the_sign = the_sign * -1
return the_nextanswer
#Cos
def Cos(the_radian):
the_iterator = 0
the_prevanswer = 666
the_nextanswer = 0
the_sign = 1
while the_iterator < 2000 and Is_Close(the_prevanswer, the_nextanswer) == False:
the_prevanswer = the_nextanswer
the_term = Power(the_radian, the_iterator) / Factorial(the_iterator)
the_term = the_term * the_sign
the_nextanswer = the_prevanswer + the_term
the_iterator += 1
the_iterator += 1
the_sign = the_sign * -1
return the_nextanswer
#Tan
def Tan(the_radian):
the_numerator = Sine(the_radian)
the_denominator = Cos(the_radian)
return the_numerator / the_denominator
#Arctan
def Arctan(the_number):
the_iterator = 1
the_prevanswer = 666
the_nextanswer = 0
the_sign = 1
while the_iterator < 2000 and Is_Close(the_prevanswer, the_nextanswer) == False:
the_prevanswer = the_nextanswer
the_term = Power(the_number, the_iterator) / the_iterator
the_term = the_term * the_sign
the_nextanswer = the_prevanswer + the_term
the_iterator += 1
the_iterator += 1
the_sign = the_sign * -1
return the_nextanswer
#Arcsin
def Arcsin(the_number):
the_iterator = 0
the_prevanswer = 666
the_nextanswer = 0
while the_iterator < 2000 and Is_Close(the_prevanswer, the_nextanswer) == False:
the_prevanswer = the_nextanswer
the_placeholder = 2 * the_iterator
the_numerator = Factorial(the_placeholder)
the_exponent = 2 * the_iterator + 1
the_numerator = the_numerator * Power(the_number, the_exponent)
the_firstdenominator = Power(4, the_iterator)
the_placeholder = Factorial(the_iterator)
the_seconddenominator = Power(the_placeholder, 2)
the_thirddenominator = 2 * the_iterator + 1
the_denominator = the_firstdenominator * the_seconddenominator * the_thirddenominator
the_term = the_numerator / the_denominator
the_nextanswer = the_prevanswer + the_term
the_iterator += 1
return the_nextanswer
#Arccos
def Arccos(the_number):
the_answer = the_pi / 2
the_answer = the_answer - Arcsin(the_number)
return the_answer
#Sinh
def Sinh(the_number):
the_iterator = 1
the_prevanswer = 666
the_nextanswer = 0
while the_iterator < 2000 and Is_Close(the_prevanswer, the_nextanswer) == False:
the_prevanswer = the_nextanswer
the_term = Power(the_number, the_iterator) / Factorial(the_iterator)
the_nextanswer = the_prevanswer + the_term
the_iterator += 1
the_iterator += 1
return the_nextanswer
#Cosh
def Cosh(the_number):
the_iterator = 0
the_prevanswer = 666
the_nextanswer = 0
while the_iterator < 2000 and Is_Close(the_prevanswer, the_nextanswer) == False:
the_prevanswer = the_nextanswer
the_term = Power(the_number, the_iterator) / Factorial(the_iterator)
the_nextanswer = the_prevanswer + the_term
the_iterator += 1
the_iterator += 1
return the_nextanswer
#Tanh
def Tanh(the_number):
the_numerator = Sinh(the_number)
the_denominator = Cosh(the_number)
return the_numerator / the_denominator
#Arcsinh
def Arcsinh(the_number):
the_term = Power(the_number, 2)
the_term = the_term + 1
the_argument = the_number + Square_Root(the_term)
return LN(the_argument)
#Arccosh
def Arccosh(the_number):
the_term = Power(the_number, 2)
the_term = the_term - 1
the_argument = the_number + Square_Root(the_term)
return LN(the_argument)
#Arctanh
def Arctanh(the_number):
the_numerator = 1 + the_number
the_denominator = 1 - the_number
the_argument = the_numerator / the_denominator
return LN(the_argument) / 2
#Get binary from decimal
def DecToBin(the_number):
if the_number <= 1:
if the_number == 0:
return "0"
return "1"
the_temp = Mod(the_number, 2)
if the_temp == 0:
the_temp = "0"
else:
the_temp = "1"
the_number = the_number / 2
return the_temp + DecToBin(the_number) #doesn't work until we have integer division
| true |
12f97888d4cf07fcb8a379b17f2e2b48cf756562 | Python | chakradhar123/aoc2020 | /aocday22/aoc22b.py | UTF-8 | 1,778 | 3.25 | 3 | [] | no_license | import copy
lines1=[]
lines2=[]
flag=1
line=input()
while (line!='end'):
if(line=="Player 2:"):
flag=0
if line!="" and line!="Player 2:" and line!="Player 1:":
if flag:
lines1.append(int(line))
else:
lines2.append(int(line))
line=input()
def RecursiveCombat(lines1,lines2,recursive):
seen=set()
while (len(lines1)!=0 and len(lines2)!=0):
state=(tuple(lines1),tuple(lines2))
if (state in seen):
return 1
seen.add(state)
if len(lines1)-1>=lines1[0] and len(lines2)-1>=lines2[0]:
temp1=copy.deepcopy(lines1)
temp2=copy.deepcopy(lines2)
win=RecursiveCombat(temp1[1:1+lines1[0]],temp2[1:1+lines2[0]],True)
if(win==1):
lines1.append(lines1[0])
lines1.append(lines2[0])
lines1.pop(0)
lines2.pop(0)
else:
lines2.append(lines2[0])
lines2.append(lines1[0])
lines1.pop(0)
lines2.pop(0)
continue
if(lines1[0]>lines2[0]):
lines1.append(lines1[0])
lines1.append(lines2[0])
lines1.pop(0)
lines2.pop(0)
else:
lines2.append(lines2[0])
lines2.append(lines1[0])
lines1.pop(0)
lines2.pop(0)
if(len(lines2))==0:
if (not recursive):
return lines1
return 1
if(len(lines1))==0:
if (not recursive):
return lines2
return 2
winner=RecursiveCombat(lines1,lines2,False)
size=len(winner)
ans=0
for i in range(0,len(winner)):
ans=ans+winner[i]*size
size-=1
print(ans)
| true |
210e3d70a68a50adc7425808df7ead39c1a46a00 | Python | thaisviana/python_p | /udp_exemplo/servidor.py | UTF-8 | 1,042 | 3 | 3 | [] | no_license | import socket
from CONSTANTS import PORTA, MSG_INCIO, PERGUNTAS
pontos = 0
def envia_pergunta(udp, chave, valor, cliente):
nl = '\n'
pergunta = f"{chave}) {valor['pergunta']}{nl}{nl.join(valor['opcoes'])}"
udp.sendto(pergunta.encode('utf-8'), cliente)
def recebe_reposta():
(resposta, cliente) = udp.recvfrom(1024)
return int(resposta.decode('utf-8'))
def calcula_pontuacao(valor, resposta, pontos):
if resposta == valor['resposta']:
pontos +=1
return pontos
udp = socket.socket (socket.AF_INET, socket.SOCK_DGRAM)
host = socket.gethostbyname("")
udp.bind((host, PORTA))
print('Esperando receber na porta', PORTA, '...')
(msg, cliente) = udp.recvfrom(1024)
msg = msg.decode('utf-8')
if msg == MSG_INCIO:
for chave, valor in PERGUNTAS.items():
envia_pergunta(udp, chave, valor, cliente)
resposta = recebe_reposta()
print(chave, resposta)
pontos = calcula_pontuacao(valor, resposta, pontos)
udp.sendto(f"{pontos} PONTOS ".encode('utf-8'), cliente)
udp.close() | true |
07cddacf0a1d8e384030eda062c2b8820203dd7c | Python | aswath1711/code-kata-player | /set2_7.py | UTF-8 | 187 | 2.9375 | 3 | [] | no_license | x,y=[int(i) for i in input().split()]
if x > y:
g = x
else:
g = y
while(True):
if((g % x == 0) and (g % y == 0)):
lcm = g
break
g += 1
print(g) | true |
08c847b5449e29539a0f434ceea3a08ee90a9982 | Python | mihail-nikolov/hackBG | /week5/cinema_reservation_system/reservation.py | UTF-8 | 1,084 | 2.75 | 3 | [] | no_license | import sqlite3
class Reservation():
def __init__(self, db):
conn = sqlite3.connect(db)
self.conn = conn
cursor = conn.cursor()
self.cursor = cursor
def make_reservation(self, name, places_arr, proj_id):
for place in places_arr:
self.cursor.execute("""INSERT INTO Reservations
(username, projection_id, row, col)
VALUES(?, ?, ?, ?)""",
(name, proj_id, int(place[0]), int(place[1])))
self.conn.commit()
def show_reservations(self, movie_id):
result = self.cursor.execute('''SELECT * FROM reservations''')
for row in result:
print(row)
def cancel_reservation(self, name):
self.cursor.execute("""DELETE FROM Reservations WHERE username = ?""",
(name,))
self.conn.commit()
def clear_reservation_on_stratup(self):
self.cursor.execute("""DELETE FROM Reservations""")
self.conn.commit()
| true |
998718af13f447b513489a4751bc972d10c5aff6 | Python | manastole03/Programming-practice | /python/simple math.py | UTF-8 | 696 | 4.375 | 4 | [] | no_license | # To carry out simple operations like addition, subtraction, multiplication and division
a=input('what operation you want ?\n1.addition(+)\n2.multiplication(*)\n3.subtraction(-)\n4.division(/)\n')
num1=int(input('enter the number 1 : '))
num2=int(input('enter the number 2 : '))
if a=='1':
print('the addition is :',num1+num2)
elif a=='2':
print('the multiplication is : ',num1*num2)
elif a == '3':
if (num1>num2):
print('the subtraction is : ', num1 - num2)
else:
print('cannot perform operation')
elif a=='4':
if num2==0:
print('cannot perform')
else:
print('the division is : ',num1/num2)
else:
print('choose appropriate choice')
| true |
716c1a43b2acf053b671598e879507bd61b9f717 | Python | PhillByrd2018/Portfolio | /Python/Fibonacci and other sequences/Assignment02FINAL.py | UTF-8 | 1,925 | 4.3125 | 4 | [] | no_license | # Assignment 02
# Loops and If/else
# Phillip Byrd
def question01():
sum = 0
natRoot = eval(input("Give me a number to find the summation of the cube of the number of Values: "))
for firstElement in range(1, natRoot + 1):
sum = sum + (firstElement ** 3)
print(sum)
question01()
def question02():
fibNum = eval(input("Give me a number to Sum up to in the Fibonacci sequence: "))
firstNum = 1
secNum = 1
for secElement in range(1, fibNum ):
temp = secNum
secNum = secNum + firstNum
firstNum = temp
print(firstNum)
question02()
def question03():
print("The hourly rate is $10 per hour up to 40 hours in a pay period.")
userHours = eval(input("How many hours have you worked in the pay period? "))
if userHours <= 40:
standardPayRate = (userHours * 10)
else:
standardPayRate = (40 * 10) + ((userHours - 40) * 15)
print("This is the amount to be paid for this period: $",standardPayRate)
question03()
def question04():
userExamGrade = eval(input("What grade did you make on the Exam?"))
while userExamGrade > 100 or userExamGrade < 1:
print("Invalid Exam Grade")
userExamGrade = eval(input("Give me another Exam Score: "))
if userExamGrade >= 90 and userExamGrade <= 100:
print("You got an A")
elif userExamGrade <= 89 and userExamGrade >= 80:
print("You got a B")
elif userExamGrade <= 79 and userExamGrade >= 70:
print("You got a C")
elif userExamGrade <=69 and userExamGrade >= 60:
print("You got a D")
elif userExamGrade <=59 and userExamGrade >= 50:
print("You got an F")
elif userExamGrade <= 49 and userExamGrade >=1:
print("You got such a bad such that you should reconsider this major")
question04()
| true |
93e377583bfd047c987d86ac567b4b3e79bef0dd | Python | PlayChessRobot/OpenCv-Chess-Robot | /chess3.py | UTF-8 | 12,989 | 2.8125 | 3 | [] | no_license | import cv2
import numpy as np
font = cv2.FONT_HERSHEY_SCRIPT_SIMPLEX
character = []
for k in range(0, 8):
character.append(('H' + str(k + 1)))
character.append(('G' + str(k + 1)))
character.append(('F' + str(k + 1)))
character.append(('E' + str(k + 1)))
character.append(('D' + str(k + 1)))
character.append(('C' + str(k + 1)))
character.append(('B' + str(k + 1)))
character.append(('A' + str(k + 1)))
def gray(image):
imggray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
return imggray
def threshold(image):
grayimg = gray(image)
# _, thresholdimg = cv2.threshold(grayimg, 150, 200, cv2.THRESH_BINARY)
adaptive = cv2.adaptiveThreshold(grayimg, 200, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 69, 1)
return adaptive
def imgshow(image):
cv2.imshow('image', cv2.resize(image, (640, 480)))
cv2.waitKey(0)
cv2.destroyAllWindows()
def canny(image):
cannyimg = cv2.Canny(image, 100, 200, None, 3)
return cannyimg
def contours(image):
image = threshold(image)
_, contoursimg, _ = cv2.findContours(image, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
c = max(contoursimg, key=cv2.contourArea)
# draw = cv2.drawContours(img, c, -1, (255), 2)
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
return x, y, w, h
def masked(image, x1, y1, x2, y2):
height, width, depth = image.shape
circle_img = np.zeros((height, width), np.uint8)
pts = np.array([[x1], [y1], [x2], [y2]], np.int32)
# cv2.rectangle(circle_img, (x[0], y[1]), ( w[0],h[0]), 280, -1)
cv2.polylines(circle_img, [pts], True, (0, 255, 255), 1)
cv2.fillPoly(circle_img, [pts], 255)
masked_data = cv2.bitwise_and(image, image, mask=circle_img)
return masked_data
# def hough_lines(image):
# image = masked(image)
# canny = cv2.Canny(image, 100, 200, None, 3)
# bgr = cv2.cvtColor(canny, cv2.COLOR_GRAY2BGR)
# lines = cv2.HoughLines(canny, 1, np.pi / 90, 110, None, 0, 0)
#
# if lines is not None:
# for i in range(0, len(lines)):
# rho = lines[i][0][0]
# theta = lines[i][0][1]
#
# a = math.cos(theta)
# b = math.sin(theta)
# x0 = a * rho
# y0 = b * rho
#
# pt1 = (int(x0 + 1000 * (-b)), int(y0 + 1000 * a))
# pt2 = (int(x0 - 1000 * (-b)), int(y0 - 1000 * a))
# hough = cv2.line(image, pt1, pt2, (0, 0, 255), 3, cv2.LINE_AA)
#
# return hough
# def video():
# cap = cv2.VideoCapture(0)
# while True:
# _, frame = cap.read()
# img = points(frame)
# cv2.imshow('frame', img)
#
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
# return frame
# def chessboard(image):
# criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
#
# grey = gray(image)
#
# ret, chess = cv2.findChessboardCorners(grey, (7, 7), None, cv2.ADAPTIVE_THRESH_GAUSSIAN_C)
# draw = cv2.drawChessboardCorners(img, (7, 7), chess, ret)
#
# if ret == True:
# corners = cv2.cornerSubPix(grey, chess, (10, 10), (-1, -1), criteria)
#
# cv2.imshow('deneme', image)
# cv2.waitKey(0)
# return image
def points():
# cap = cv2.VideoCapture('http://192.168.1.1:8080/video')
cap = cv2.VideoCapture(2)
detectboard = 0
listp = []
listx = []
listy = []
listxy = []
# draw = cv2.drawChessboardCorners(img, (7, 7), chess, ret)
while True:
_, image = cap.read()
image = cv2.resize(image, (640, 400))
grey = gray(image)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
ret, chess = cv2.findChessboardCorners(grey, (7, 7), None)
if ret is True and detectboard == 0:
detectboard = detectboard + 1
corners = cv2.cornerSubPix(grey, chess, (10, 10), (-1, -1), criteria)
for corner in corners:
a = corner.ravel()
listp.append(a)
for i in range(0, len(listp)):
listx.append(int(float(listp[i][0])))
listy.append(int(float(listp[i][1])))
listxy.append([listx[6] + (listx[6] - listx[12]), listy[6] - (listy[12] - listy[6])])
listxy.append([listx[5] + (listx[5] - listx[11]), listy[5] - (listy[11] - listy[5])])
listxy.append([listx[4] + (listx[4] - listx[10]), listy[4] - (listy[10] - listy[4])])
listxy.append([listx[5] - (listx[13] - listx[5]), listy[5] - (listy[13] - listy[5])])
listxy.append([listx[4] - (listx[12] - listx[4]), listy[4] - (listy[12] - listy[4])])
listxy.append([listx[3] - (listx[11] - listx[3]), listy[3] - (listy[11] - listy[3])])
listxy.append([listx[2] - (listx[10] - listx[2]), listy[2] - (listy[10] - listy[2])])
listxy.append([listx[1] - (listx[9] - listx[1]), listy[1] - (listy[9] - listy[1])])
listxy.append([listx[0] - (listx[8] - listx[0]), listy[0] - (listy[8] - listy[0])])
listxy.append([listx[6] + (listx[6] - listx[5]), listy[6] + (listy[6] - listy[5])])
listxy.append([listx[6], listy[6]])
listxy.append([listx[5], listy[5]])
listxy.append([listx[4], listy[4]])
listxy.append([listx[3], listy[3]])
listxy.append([listx[2], listy[2]])
listxy.append([listx[1], listy[1]])
listxy.append([listx[0], listy[0]])
listxy.append([listx[0] - (listx[1] - listx[0]), listy[0] - (listy[1] - listy[0])])
listxy.append([listx[13] + (listx[13] - listx[12]), listy[13] + (listy[13] - listy[12])])
listxy.append([listx[13], listy[13]])
listxy.append([listx[12], listy[12]])
listxy.append([listx[11], listy[11]])
listxy.append([listx[10], listy[10]])
listxy.append([listx[9], listy[9]])
listxy.append([listx[8], listy[8]])
listxy.append([listx[7], listy[7]])
listxy.append([listx[7] - (listx[8] - listx[7]), listy[7] - (listy[8] - listy[7])])
listxy.append([listx[20] + (listx[20] - listx[19]), listy[20] + (listy[20] - listy[19])])
listxy.append([listx[20], listy[20]])
listxy.append([listx[19], listy[19]])
listxy.append([listx[18], listy[18]])
listxy.append([listx[17], listy[17]])
listxy.append([listx[16], listy[16]])
listxy.append([listx[15], listy[15]])
listxy.append([listx[14], listy[14]])
listxy.append([listx[14] - (listx[15] - listx[14]), listy[14] - (listy[15] - listy[14])])
listxy.append([listx[27] + (listx[27] - listx[26]), listy[27] + (listy[27] - listy[26])])
listxy.append([listx[27], listy[27]])
listxy.append([listx[26], listy[26]])
listxy.append([listx[25], listy[25]])
listxy.append([listx[24], listy[24]])
listxy.append([listx[23], listy[23]])
listxy.append([listx[22], listy[22]])
listxy.append([listx[21], listy[21]])
listxy.append([listx[21] - (listx[22] - listx[21]), listy[21] - (listy[22] - listy[21])])
listxy.append([listx[34] + (listx[34] - listx[33]), listy[34] + (listy[34] - listy[33])])
listxy.append([listx[34], listy[34]])
listxy.append([listx[33], listy[33]])
listxy.append([listx[32], listy[32]])
listxy.append([listx[31], listy[31]])
listxy.append([listx[30], listy[30]])
listxy.append([listx[29], listy[29]])
listxy.append([listx[28], listy[28]])
listxy.append([listx[28] - (listx[29] - listx[28]), listy[28] - (listy[29] - listy[28])])
listxy.append([listx[41] + (listx[41] - listx[40]), listy[41] + (listy[41] - listy[40])])
listxy.append([listx[41], listy[41]])
listxy.append([listx[40], listy[40]])
listxy.append([listx[39], listy[39]])
listxy.append([listx[38], listy[38]])
listxy.append([listx[37], listy[37]])
listxy.append([listx[36], listy[36]])
listxy.append([listx[35], listy[35]])
listxy.append([listx[35] - (listx[36] - listx[35]), listy[35] - (listy[36] - listy[35])])
listxy.append([listx[48] + (listx[48] - listx[47]), listy[48] + (listy[48] - listy[47])])
listxy.append([listx[48], listy[48]])
listxy.append([listx[47], listy[47]])
listxy.append([listx[46], listy[46]])
listxy.append([listx[45], listy[45]])
listxy.append([listx[44], listy[44]])
listxy.append([listx[43], listy[43]])
listxy.append([listx[42], listy[42]])
listxy.append([listx[42] - (listx[43] - listx[42]), listy[42] - (listy[43] - listy[42])])
listxy.append([listx[48] + (listx[48] - listx[40]), listy[48] + (listy[48] - listy[40])])
listxy.append([listx[47] + (listx[47] - listx[39]), listy[47] + (listy[47] - listy[39])])
listxy.append([listx[46] + (listx[46] - listx[38]), listy[46] + (listy[46] - listy[38])])
listxy.append([listx[47] - (listx[41] - listx[47]), listy[47] - (listy[41] - listy[47])])
listxy.append([listx[46] - (listx[40] - listx[46]), listy[46] - (listy[40] - listy[46])])
listxy.append([listx[45] - (listx[39] - listx[45]), listy[45] - (listy[39] - listy[45])])
listxy.append([listx[44] - (listx[38] - listx[44]), listy[44] - (listy[38] - listy[44])])
listxy.append([listx[43] - (listx[37] - listx[43]), listy[43] - (listy[37] - listy[43])])
listxy.append([listx[42] - (listx[36] - listx[42]), listy[42] - (listy[36] - listy[42])])
loc = listxy
locmid = []
for i in range(0, len(listxy) - 10):
if i == 8 or i == 17 or i == 26 or i == 35 or i == 44 or i == 53 or i == 62 or i == 71:
pass
else:
x1 = int(float((loc[i][0] + loc[i + 10][0]) / 2))
y1 = int(float((loc[i][1] + loc[i + 10][1]) / 2))
locmid.append([x1, y1])
# temp1 = cv2.imread('/root/Desktop/pawn/bpawn.png',0)
# temp2 = cv2.imread('/root/Desktop/pawn/bpawn2.png', 0)
# temp3 = cv2.imread('/root/Desktop/pawn/wpawn.png', 0)
# temp_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#
# w, h = temp1.shape[::-1]
# w1, h1 = temp2.shape[::-1]
# w2, h2 = temp3.shape[::-1]
#
# res = cv2.matchTemplate(temp_gray, temp1, cv2.TM_CCOEFF_NORMED)
# res1 = cv2.matchTemplate(temp_gray, temp2, cv2.TM_CCOEFF_NORMED)
# res2 = cv2.matchTemplate(temp_gray, temp3, cv2.TM_CCOEFF_NORMED)
#
# threshold = 0.80
# threshold1 = 0.90
# loc = np.where(res > threshold)
# loc1 = np.where(res1 > threshold)
# loc2 = np.where(res2 > threshold1)
#
#
# for pt in zip(*loc[::-1]):
# cv2.rectangle(image, pt, (pt[0] + w, pt[1] + h), (255, 255, 0))
# cv2.putText(image, "bpawn", (pt[0],pt[1]), 1, 0.4, (0, 0, 255), 1)
#
# for pt in zip(*l[140oc1[::-1]):
# cv2.rectangle(image, pt, (pt[0] + w1, pt[1] + h1), (255, 255, 0))
# cv2.putText(image, "bpawn", (pt[0],pt[1]), 1, 0.4, (0, 0, 255), 1)
# for pt in zip(*loc2[::-1]):
# cv2.rectangle(image, pt, (pt[0] + w2, pt[1] + h2), (255, 255, 0))
# cv2.putText(image, "wpawn", (pt[0], pt[1]), 1, 0.4, (0, 0, 255), 1)
# draw = cv2.drawChessboardCorners(image, (7, 7), chess, ret)
for i in range(0, len(locmid)):
cv2.putText(image, character[i], (locmid[i][0], locmid[i][1]), 1, 1, (0, 0, 255), 1)
# for i in range(0, len(listxy)):
# cv2.circle(image, (listxy[i][0], listxy[i][1]), 3, (255, 0, 0), -1)
coordinate = []
if detectboard == 1:
masked(image, listxy[80], listxy[72], listxy[0], listxy[8])
# detect = piecesDetect.detect(masked_data, listxy, character)
coordinate.append(listxy[80])
coordinate.append(listxy[72])
coordinate.append(listxy[0])
coordinate.append(listxy[8])
cap.release()
cv2.destroyAllWindows()
return coordinate, listxy
else:
# masked_data = masked(image, listxy[80], listxy[72], listxy[0], listxy[8])
cv2.imshow('window', image)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# return masked_data+++++++++++++++++++
cap.release()
cv2.destroyAllWindows()
points()
| true |
e36ff173971ac91c694cd80427be21983217d53a | Python | niushufeng/Python_202006 | /代码/曲线相交及改变坐标轴.py | UTF-8 | 1,210 | 3.515625 | 4 | [] | no_license | import matplotlib.pyplot as plt
import numpy as np # 多维数组和矩阵函数
x = np.linspace(-3,3,50) # -1到1之间的20个点
y1 = 5*x+1
y2 = x**2
plt.figure(figsize=(8,10))
plt.plot(x,y2)
plt.plot(x,y1,color='red',linewidth=1.0, linestyle='--' )
plt.xlim((-1,10)) # 取值范围
plt.ylim((-2.8))
plt.xlabel("I am x") # 坐标轴的注释
plt.ylabel("I am y")
new_ticks = np.linspace(-1,10,10) # -1和10之间均分20等分
print(new_ticks) # 新标记
plt.xticks(new_ticks) # 替换x轴间距
plt.yticks([-2,-1.5,-1,4.5,6], # 替换y的名字
[r'$really\ bad$',r'$bad\ \alpha$',r'$normal$',r'$good$',r'$really\ good$'])
# \加空格输出是空格,\+alpha输出是阿尔法
# gca = 'get current axis'把轴拿出来
ax = plt.gca() # ax是轴代指整个图片
ax.spines['right'].set_color('none') # spines轴的脊梁,竖线,让其颜色消失
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom') # bottom代替x轴
ax.yaxis.set_ticks_position('left') # left代替y轴
ax.spines['bottom'].set_position(('data',0)) # 横坐标与纵坐标0对齐
ax.spines['left'].set_position(('data',0)) # 纵坐标与横坐标0对齐
plt.show()
| true |
2134c7c5711ad1288f523bb6dc7dafce1904a22d | Python | AdvikTheCoder/C109-P | /C109P copy.py | UTF-8 | 692 | 3.15625 | 3 | [] | no_license | import pandas as pd
import statistics
import csv
df=pd.read_csv('SD.csv')
height=df['Height(Inches)'].tolist()
mean=statistics.mean(height)
mode=statistics.mode(height)
median=statistics.median(height)
sd=statistics.stdev(height)
start1,end1,start2,end2,start3,end3=mean-sd,mean+sd,mean-2*sd,mean+2*sd,mean-3*sd,mean+3*sd
data1=[result for result in height if result > start1 and result < end1 ]
data2=[result for result in height if result > start2 and result < end2 ]
data3=[result for result in height if result > start3 and result < end3 ]
data1P=len(data1)/len(height)*100
data2P=len(data2)/len(height)*100
data3P=len(data3)/len(height)*100
print(data1P)
print(data2P)
print(data3P)
| true |
9a1d421efa3e1844c840301472176763b0ab7a0b | Python | J-O-R-G-E/UNT-NASA | /TestingFiles/GUI8-5pm.py | UTF-8 | 41,537 | 2.640625 | 3 | [] | no_license | """ SLNS Graphical User Interface 2018
Written by Gladys Hernandez-Amaya gh0151@unt.edu
Course: CSCE 4915
Faculty Advisor: Robin P.
File Description: This python program displays the menu functions for the SLNS.
It issues commands for the server and writes them to workfile.txt, and processes
commands from the server by reading workfile.txt. Kivy is an open source,
cross-platform python framework that is used in this application. This file and
the .kv should be be stored under the same directory.
Jorge Cardona colaborated on this GUI by adding the 'Settings' portion.
This portion allows for users to add new devices, most importatly, the port count.
It also allows the user to see how many ports are not being used aka available.
And finally, it allows for the users to test specific color values, selected from a
color wheel, to be sent to that particular light.
"""
from kivy.app import App
from kivy.lang import Builder
from kivy.uix.button import Button
from kivy.uix.dropdown import DropDown
from kivy.uix.label import Label
from kivy.uix.popup import Popup
from kivy.uix.screenmanager import ScreenManager, Screen
from kivy.uix.boxlayout import BoxLayout
from pathlib import Path
from kivy.uix.gridlayout import GridLayout
from kivy.uix.togglebutton import ToggleButton
from kivy.uix.scrollview import ScrollView
from kivy.core.window import Window
from kivy.uix.textinput import TextInput
from kivy.clock import Clock
import time
from datetime import datetime
import threading
from threading import Thread
from kivy.uix.colorpicker import ColorPicker
from kivy.properties import StringProperty
from kivy.properties import NumericProperty
import sqlite3
import os
import subprocess
""" Establish database connection """
#conn = sqlite3.connect('/home/pi/2b.db',check_same_thread=False)
conn = sqlite3.connect('2b.db',check_same_thread=False)
curs = conn.cursor()
curs2 = conn.cursor()
#workfile_path = "/home/pi/kivy/examples/workfile.txt"
workfile_path = "workfile.txt"
btns_down = []
lights_down = []
instances = []
"""Circadian Rhythm values dictionary - VALUES NEED TO BE CHANGED"""
CR = {
'00':'FF5454FF',
'01':'FF545454',
'02':'FF545454',
'03':'FF545454',
'04':'FF545454',
'05':'88545454',
'06':'FF7FFFFF',
'07':'FF7FFFFF',
'08':'FF7FFFFF',
'09':'FF7FFFFF',
'10':'FF1E90FF',
'11':'FF1E90FF',
'12':'FF87CEFA',
'13':'FF87CEFA',
'14':'FF87CEFB',
'15':'FF87CEFC',
'16':'FF87CEFA',
'17':'88545454',
'18':'AB545454',
'19':'BA545454',
'20':'AC545454',
'21':'DC545454',
'22':'EA545454',
'23':'AE545454'}
class ScreenManagement(ScreenManager):
pass
""" Class contains methods that update lights to the current circadian rhythm values and checks for unprocessed commands every N seconds """
class Methods(Screen):
keyN = ''
ip = ''
data = ''
def __init__(self, **kwargs):
super(Methods, self).__init__(**kwargs)
def build(self, ip_addr, t_data):
global bflag
global ip
global data
#check if ip_addr exists in database
curs.execute("SELECT IP_address FROM Lights WHERE IP_address = '" + ip_addr + "'")
if(len(curs.fetchall()) != 0):
print("Exists in database")
pass
else:
print "IP address does not exist in database"
ip = ip_addr
data = t_data
box = BoxLayout(orientation = 'vertical', padding = (8))
#message = Label(text='Enter a name for {}:'.format(ip_addr)
box.add_widget(Label(text='Enter a name for {}:'.format(ip_addr), font_size=30, size_hint=(1,.7)))
self.textinput = TextInput(text='', font_size=30)
box.add_widget(self.textinput)
popup = Popup(title='New Light Detected', content=box, title_size=30, size_hint=(None, None), size=(450, 300), title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Set',font_size=25, size_hint=(.5,.7), pos_hint={'center_x': .5, 'center_y': 0}, on_press= self.store_name, on_release=popup.dismiss))
popup.open()
#stores the user defined name for each light connected
def store_name(self,arg1):
key = self.textinput.text
curr_screen = sm.current
if key != '':
print("updating keyN")
global keyN
keyN = key
#add to database
curs.execute("INSERT INTO Lights(IP_address,Data,Light_name) VALUES ('"+ ip + "','" + data + "','" + keyN + "')")
conn.commit()
else:
pass
if sm.current == 'view_lights':
sm.current = 'blank_screen'
sm.current = 'view_lights'
else:
pass
#################################################################################################################################
#Updates all lights in database to current CR values based on time
def update_lights(self):
print "Updating ALL lights"
time = datetime.now()
hour = time.hour
if len(str(hour)) == 1:
hour = '0' + str(hour)
print "changing"
else:
pass
curs2.execute("SELECT IP_address FROM Lights")
addresses = curs2.fetchall()
addr =[r[0] for r in addresses]
for a in addr:
for key in CR.keys():
if str(hour) == key:
data = CR[key]
(dt, micro) = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f').split('.')
dt = "%s.%03d" % (dt, int(micro) / 1000)
data = CR[key] #should grab value from CR dictionary
cmd = "S" + " " + a + " " + "SET" + " " + data + " " + dt
#write commands into workfile
with open("workfile.txt", "a") as workfile:
workfile.write(cmd)
workfile.write('\n')
workfile.close()
else:
pass
t2 = threading.Timer(50.0, self.update_lights)
t2.daemon=True
t2.start()
""" This method updates the new connected light to the current CR values which is based on time """
def update_new_light(self,ip_addr):
print "Updating new light"
time = datetime.now()
for key in CR.keys():
(dt, micro) = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f').split('.')
dt = "%s.%03d" % (dt, int(micro) / 1000)
if str(time.hour) == key:
data = CR[key] #should grab value from CR dictionary
cmd = "S" + " " + ip_addr + " " + "SET" + " " + data + " " + dt
#write command to workfile
with open("workfile.txt", "a") as workfile:
workfile.write(cmd)
workfile.write('\n')
workfile.close()
""" method used to process commands """
def process_cmd(self,IP, function, any_data):
print('Processing...%s, %s, %s ' % (IP, function, any_data))
try:
if function == 'GET':
pass
#s = Health()
#s.retrieveSensor(IP, any_data)
#s.getTime()
elif function == 'ADD':
self.build(IP,any_data)
self.update_new_light(IP)
print "finished"
elif function == 'RMV':
s = LightsView()
s.removeLight(IP)
else:
print('Unknown function')
except:
print "Error in process_cmd"
"""This method parses the commands on the workfile"""
def cmdparser(self):
print('cmdparser running')
#This method changes 'G' to 'P' when command has been processed
def replace_line(file_name, line_no, text):
print "replacing lines"
lines = open(file_name, 'r+').readlines()
lines[line_no] = text + '\n'
out = open(file_name, 'w')
out.writelines(lines)
out.close()
try:
dfile = open(workfile_path, 'r')
myfile = dfile.readlines()
line_num = -1 #to get line number, starts at 0
for line in myfile:
if line == '\n':
pass
else:
line_num +=1 #keep line count
curr_line = line.strip() #strip line to remove whitespaces
parts = curr_line.split() #split line
if parts[0] == 'G': #if command exist
#Store IP_addr, function and data, if available
IP_addr = parts[1]
func = parts[2]
data = parts[3]
print(IP_addr, func, data)
self.process_cmd(IP_addr, func, data) #process command
print "done processing"
(dt, micro) = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f').split('.')
dt = "%s.%03d" % (dt, int(micro) / 1000)
new_curr = 'P '+ ' '.join(curr_line.split()[1:]) + " " + dt
replace_line(workfile_path, line_num, new_curr)
break
else:
pass
except IndexError:
pass
t1 = threading.Timer(8.0, self.cmdparser)
t1.daemon=True
t1.start()
""" Health status, of the light, class"""
class Health(Screen):
time = StringProperty()
date = StringProperty()
red = StringProperty()
green = StringProperty()
blue = StringProperty()
intensity = StringProperty()
status = StringProperty()
light_name = StringProperty()
ip = StringProperty()
sa = StringProperty()
sr = StringProperty()
sg = StringProperty()
sb = StringProperty()
A = NumericProperty()
B = NumericProperty()
R = NumericProperty()
G = NumericProperty()
def __init__(self, **kwargs):
super(Health, self).__init__(**kwargs)
""" This method checks the status of all lights in the DB"""
def check_status_ALL(self):
data = '00000000'
count = 0
for row in curs.execute("SELECT IP_address FROM Lights"):
count = count + 1
(dt, micro) = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f').split('.')
dt = "%s.%03d" % (dt, int(micro) / 1000)
cmd = "S" + " " + row[0] + " " + "GET" + " " + data + " " + dt
with open("workfile.txt","a") as document:
document.write(cmd)
document.write('\n')
document.close()
time.sleep(1)
for c in range(count):
print "checking health status"
ob = Methods()
ob.cmdparser()
t3 = threading.Timer(32.0, self.check_status_ALL)
t3.daemon=True
t3.start()
"""This method does something"""
def health_status(self):
if len(lights_down) == 1:
#lights_down contains user's light selection on the view room screen
self.light_name = lights_down[0]
for row in curs.execute("SELECT IP_address FROM Lights WHERE IP_address='" + lights_down[0] + "'"):
self.ip = row[0]
(dt, micro) = datetime.now().strftime('[%Y-%m-%d %H:%M:%S.%f]').split('.')
dt = "%s.%03d" % (dt, int(micro) / 1000)
cmd = "S" + " " + row[0] + " " + "GET" + " " + data + " " + dt
with open("workfile.txt","a") as document:
document.write(cmd)
document.write('\n')
document.close()
#reads GET command
m = Methods()
m.cmdparser()
self.getTime()
elif len(lights_down) > 1 or len(lights_down) == 0:
self.health_popup()
"""This method shows the status of the light to the user"""
def health_popup(self):
box = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message = Label(text='Error: Please select a light.', font_size=25, valign = 'middle', size_hint=(1,.3))
box.add_widget(message)
#user input
health_popup = Popup(title= 'Error 100', content = box, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Return', size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0},on_press = self.back_to_rv, on_release = health_popup.dismiss))
health_popup.open()
def back_to_rv(self, arg1):
self.parent.current = 'view_room'
""" method retrieves sensor values, this is called after m.cmdparser() """
def retrieveSensor(self, ip_addr, d):
#self.grab_name(ip_addr)
print(' The values received from server: %s , %s' % (ip_addr, d))
global A
global R
global G
global B
#hex to decimal conversion
A = int(d[0] + d[1], 16)
R = int(d[2] + d[3], 16)
G = int(d[4] + d[5], 16)
B = int(d[6] + d[7], 16)
print('%d %d %d %d' % (A,R,G,B))
""" method retrieves the current time and date """
def getTime(self):
#determine time and date
self.time = datetime.now().strftime('%H:%M')
self.date = datetime.now().strftime('%Y-%m-%d')
#hours go by [00-23]
hour = str(datetime.now().hour)
if len(hour) == 1:
hour = '0' + str(datetime.now().hour)
else:
pass
self.retrieveCR_and_status(hour)
""" method retrieves current circadian rhythm values and calculates health status """
def retrieveCR_and_status(self, hour):
#Grabs current circadian rhythm values
values = str(CR[hour])
#Hex to decimal
intensity = int(values[0] + values[1], 16)
red = int(values[2] + values[3], 16)
green = int(values[4] + values[5], 16)
blue = int(values[6] + values[7], 16)
#display the current circadian rhythm values
self.intensity = str(intensity)
self.red = str(red)
self.green = str(green)
self.blue = str(blue)
#determine the minimum and maximum
min_intensity = intensity - (intensity * 0.05)
min_red = red - (red * 0.05)
min_green = green - (green * 0.05)
min_blue = blue - (blue * 0.05)
max_intensity = intensity + (intensity * 0.05)
max_red = red + (red * 0.05)
max_green = green + (green * 0.05)
max_blue = blue + (blue * 0.05)
#check for min and max range of each value
if min_intensity < 0:
min_intensity = 0
elif max_intensity > 255:
max_intensity = 255
else:
print('inten in range')
if min_red < 0:
min_red = 0
elif max_red > 255:
max_red = 255
else:
print('red in range')
if min_green < 0:
min_green = 0
elif max_green > 255:
max_green = 255
else:
print('green in range')
if min_blue < 0:
min_blue = 0
elif max_blue > 255:
max_blue = 255
else:
print('blue in range')
global A
global R
global G
global B
#display sensor valuesa
self.sa = str(A)
self.sr = str(R)
self.sg = str(G)
self.sb = str(B)
#compare CR values and sensor values
if ((A >= min_intensity) and (A <= max_intensity)):
print('pass 1')
if((R >= min_red) and (R <= max_red)):
print('pass 2')
if((G >= min_green) and (G <= max_green)):
print('pass 3')
if ((B >= min_blue) and (B <= max_blue)):
print('pass 4')
self.status = 'Healthy'
print('Healthy')
else:
print('no4')
self.status = 'Unhealthy'
print('Unhealthy')
self.status_popup()
else:
print('no3')
self.status = 'Unhealthy'
print('Unhealthy')
self.status_popup()
else:
print('no2')
self.status = 'Unhealthy'
print('Unhealthy')
self.status_popup()
else:
print('no1')
self.status = 'Unhealthy'
print('Unhealthy')
self.status_popup()
self.clear_selection()
def clear_selection(self):
global lights_down
lights_down = []
def status_popup(self):
#Read and Accept Popup
box = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message = Label(text='Warning:', font_size=20, valign = 'middle', size_hint=(1,.3))
box.add_widget(message)
#user input
_popup = Popup(title= 'Warning', content = box, title_size =(25),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Read and Accept', size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0},on_press = _popup.dismiss))
_popup.open()
class SetValues(Screen):
ARGB = ''
def __init__(self, **kwargs):
super(SetValues, self).__init__(**kwargs)
def build(self):
self.ids.setbox.clear_widgets()
#create layout to display the data
color_picker = ColorPicker()
self.ids.setbox.add_widget(color_picker)
#capture color selection
def on_color(instance, value):
RGBA = list(color_picker.hex_color[1:])
A = (RGBA[6] + RGBA[7])
B = (RGBA[4] + RGBA[5])
G = (RGBA[2] + RGBA[3])
R = (RGBA[0] + RGBA[1])
global ARGB
ARGB = A+R+G+B
color_picker.bind(color=on_color) #binds to function above
def set_selection(self):
try:
if len(lights_down) == 0:
self.build()
pass
elif len(lights_down) > 1:
self.build()
pass
else:
for row in curs.execute("SELECT IP_address FROM Lights WHERE Light_name='" + lights_down[0] + "'"):
(dt, micro) = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f').split('.')
dt = "%s.%03d" % (dt, int(micro) / 1000)
cmd = "S" + " " + row[0] + " " + "SET" + " " + str(ARGB) + " " + dt
with open("workfile.txt","a") as document:
document.write(cmd)
document.write('\n')
document.close()
except:
print "Error in set_selection"
""" This screen displays the lights available in form of buttons """
class LightsView(Screen):
def __init__(self, **kwargs):
self.layout = None
super(LightsView, self).__init__(**kwargs)
def clear_lights_selection(self):
try:
lights_down = []
except ValueError:
print("value error")
def removeLight(self, ip_addr):
curs.execute("SELECT Light_name FROM Lights WHERE IP_address='" + ip_addr + "'")
n = curs.fetchone()
name = n[0]
#get current screen
curr_screen = sm.current
curs.execute("DELETE FROM Lights WHERE IP_address = '" + ip_addr + "'")
conn.commit()
if curr_screen == 'view_lights':
box = BoxLayout(orientation = 'vertical', padding = (8))
message = Label(text='Removing IP: {}, Name: {}'.format(ip_addr, name), font_size=25, valign = 'middle', size_hint=(1,.3))
box.add_widget(message)
popup = Popup(title= 'Light Removal', content = box, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Confirm and Refresh', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0}, on_press= self.screen_update, on_release = popup.dismiss))
popup.open()
else:
box2 = BoxLayout(orientation = 'vertical', padding = (8))
message = Label(text='Removing IP: {}, Name: {}'.format(ip_addr, name), font_size=25, valign = 'middle', size_hint=(1,.3))
box2.add_widget(message)
popup2 = Popup(title= 'Light Removal', content = box2, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box2.add_widget(Button(text='Confirm', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0},on_release = popup2.dismiss))
popup2.open()
def screen_update(self, arg1):
sm.current = 'blank_screen'
sm.current = 'view_lights'
""" builds a list of light buttons with scrolling feature """
def buildlist(self):
self.ids.gridlayout.clear_widgets()
print('building list')
curs.execute("SELECT Light_name FROM Lights WHERE Room='X'")
data = curs.fetchall()
instances =[r[0] for r in data]
print(instances)
for inst in instances:
self.btn = ToggleButton(text='%s' % inst, size = (340, 45),size_hint=(None,None)) #create button
self.btn.bind(state=self.lightscallback)
self.ids.gridlayout.add_widget(self.btn) #add to gridlayout
self.ids.gridlayout.bind(minimum_height=self.ids.gridlayout.setter('height'))
def add_room(self):
box2 = BoxLayout(orientation = 'vertical', padding = (12))
message = Label(text='Enter name for new room: ', font_size=25, halign = 'center', valign='middle', size_hint=(.8,.7))
box2.add_widget(message)
self.textinput = TextInput(text='',multiline = False, size_hint=(1,.7), font_size=25)
box2.add_widget(self.textinput)
popup = Popup(title= 'Add New Room', content = box2, title_size =(25),title_align='center', size_hint=(.6,.6), auto_dismiss=False)
box3 = BoxLayout(orientation ='horizontal')
box2.add_widget(box3)
box3.add_widget(Button(text='Set', size_hint=(.3,.8), on_press = self.store, on_release = popup.dismiss))
box3.add_widget(Button(text='Cancel',size_hint=(.3,.8),on_press = popup.dismiss))
popup.open()
def store_state(self, btn_name, btn):
#add instance to ID section on database table
curs.execute("UPDATE Lights SET ID='" + str(btn) + "' WHERE Light_name='" + btn_name +"'")
conn.commit()
""" method checks the state of the toggle buttons for lights section """
def lightscallback(self, instance, value):
try:
print('My button instance is %s, <%s> state is %s' % (instance,instance.text, value))
if value == 'down':
lights_down.append(instance.text) # add to list of buttons with down state
elif value == 'normal':
lights_down.remove(instance.text) # remove from list if back to normal
print('not down')
else:
pass
except ValueError:
print("Value error")
""" method checks the state of the toggle buttons for rooms section """
def callback(self,instance, value):
try:
print('My button <%s> state is %s' % (instance.text, value))
if value == 'down':
btns_down.append(instance.text) # add to list of buttons with down state
elif value == 'normal':
btns_down.remove(instance.text) # remove from list if back to normal
print('not down')
else:
pass
except ValueError:
print("Value error")
""" method adds lights selected by user to a specific room """
def add_to_room(self):
try:
if(len(btns_down) == 0):
box = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message = Label(text='Please select or create a room', font_size=25, valign = 'middle', size_hint=(1,.3))
box.add_widget(message)
popup = Popup(title= 'Error 105', content = box, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0},on_release = popup.dismiss))
popup.open()
elif((len(btns_down) == 1) and (len(lights_down) >= 1)):
for i in lights_down:
curs.execute("UPDATE Lights SET Room='" + btns_down[0] + "' WHERE Light_name = '" + i + "'")
conn.commit()
elif((len(btns_down) == 1) and (len(lights_down) <= 0)):
box = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message = Label(text='0 lights selected', font_size=25, valign = 'middle', size_hint=(1,.3))
box.add_widget(message)
popup = Popup(title= 'Error 104', content = box, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0},on_release = popup.dismiss))
popup.open()
else:
box = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message = Label(text='More than 1 room selected', font_size=25, valign = 'middle', size_hint=(1,.3))
box.add_widget(message)
popup = Popup(title= 'Error 104', content = box, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0},on_release = popup.dismiss))
popup.open()
self.update_rooms()
self.buildlist()
except IndexError:
print("Index error")
def room_popup(self):
box = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message = Label(text='Room name already exists', font_size=25, valign = 'middle', size_hint=(1,.3))
box.add_widget(message)
popup = Popup(title= 'Error 101', content = box, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0},on_release = popup.dismiss))
popup.open()
""" method should store user defined room name to table in 2b database """
def store(self, arg1):
key = self.textinput.text
curs.execute("SELECT * FROM rooms WHERE Room_name='" + key + "'")
rows = curs.fetchall()
if key == '':
self.add_room
elif len(rows) == 0:
## add room name to rooms table on 2b database (2b.db)
curs.execute("INSERT INTO rooms(Room_name) VALUES ('" + key + "')")
conn.commit()
self.update_rooms()
else:
self.room_popup()
def update_rooms(self):
#self.update_rooms() code below
self.ids.roomlayout.clear_widgets()
for row in curs.execute("SELECT Room_name FROM rooms"):
btn = ToggleButton(text='%s' % row[0],size = (405, 45),spacing=10,size_hint=(None,None)) #create button
btn.bind(state=self.callback)
self.ids.roomlayout.add_widget(btn) #add to roomlayout
global btns_down
btns_down = []
global lights_down
lights_down = []
def remove_room(self):
#delete room from rooms table in 2b database
for b in btns_down:
curs.execute("DELETE FROM rooms WHERE Room_name='" + b + "'")
conn.commit()
#any light with that specific room name must be updated back to Room "X"
curs.execute("UPDATE Lights SET Room='X' WHERE Room ='"+ b + "'")
conn.commit()
self.update_rooms()
self.buildlist() # updates display lights section
def remove_light(self):
for k in lights_down:
#retrieve IP address from database
for row in curs.execute("SELECT IP_address FROM Lights WHERE Light_name='" + k + "'"):
data = "00000000"
(dt, micro) = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f').split('.')
dt = "%s.%03d" % (dt, int(micro) / 1000)
cmd = "S" + " " + row[0] + " " + "RMV" + " " + data + " " + dt
with open("workfile.txt","a") as document:
document.write(cmd)
document.write('\n')
document.close()
#remove client from database
curs.execute("DELETE FROM Lights WHERE Light_name='" + k + "'")
conn.commit()
self.buildlist()
def check_lights_selected(self):
try:
if(len(lights_down) == 0):
#popup
box_2 = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message = Label(text=' 0 lights selected', font_size=25, valign = 'middle', size_hint=(1,.3))
box_2.add_widget(message)
popup_2 = Popup(title= 'Error 106', content = box_2, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box_2.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0}, on_release = popup_2.dismiss))
popup_2.open()
elif(len(lights_down) > 1):
#poup
box_1 = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message = Label(text='More than 1 light selected', font_size=25, valign = 'middle', size_hint=(1,.3))
box_1.add_widget(message)
popup_1 = Popup(title= 'Error 107', content = box_1, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box_1.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0}, on_release = popup_1.dismiss))
popup_1.open()
else:
sm.current = 'set_values'
except:
print "Error in check_lights_selected"
def health_check_selected(self):
try:
if(len(lights_down) == 0):
#popup
box_2 = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message = Label(text=' 0 lights selected', font_size=25, valign = 'middle', size_hint=(1,.3))
box_2.add_widget(message)
popup_2 = Popup(title= 'Error 106', content = box_2, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box_2.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0}, on_release = popup_2.dismiss))
popup_2.open()
elif(len(lights_down) > 1):
#poup
box_1 = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message = Label(text='More than 1 light selected', font_size=25, valign = 'middle', size_hint=(1,.3))
box_1.add_widget(message)
popup_1 = Popup(title= 'Error 107', content = box_1, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box_1.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0}, on_release = popup_1.dismiss))
popup_1.open()
else:
sm.current = 'health'
except:
print "Error in health_check_selected"
''' This screen displays the lights assigned to a room (->View Room)'''
class RoomView(Screen):
room_name = StringProperty()
def __init__(self, **kwargs):
super(RoomView, self).__init__(**kwargs)
def remove_from_database(self):
#check lights_down
global lights_down
for r in lights_down:
curs.execute("DELETE FROM Lights WHERE Light_name='" + r + "'")
conn.commit()
#rebuild
self.build()
def checkif_room_selected(self):
try:
global btns_down
if len(btns_down) >= 1:
pass
else:
#popup asking user to select a room to view
box = BoxLayout(orientation = 'vertical', padding = (8))
message = Label(text="Please select a room to view", font_size=25, valign = 'middle', size_hint=(1,.3))
box.add_widget(message)
popup = Popup(title= 'Error 103: Room not selected', content = box, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0}, on_press= self.return_to_LV, on_release = popup.dismiss))
popup.open()
except:
print("Error when switching to room view")
def return_to_LV(self, arg1):
sm.current = 'view_lights'
def clear_room_name(self):
self.room_name = " "
"""builds a list of lights assigned to the room"""
def build(self):
function_callback = LightsView()
self.ids.gridlayout2.clear_widgets()
try:
if len(btns_down) == 1:
self.room_name = btns_down[0]
for row in curs.execute("SELECT Light_name FROM Lights WHERE Room='" + btns_down[0] + "'"):
btn = ToggleButton(text='%s' % row[0],size = (580, 40),size_hint=(None,None)) #create button
btn.bind(state=function_callback.lightscallback)
self.ids.gridlayout2.add_widget(btn) #add to gridlayout
self.ids.gridlayout2.bind(minimum_height=self.ids.gridlayout2.setter('height'))
else:
print("must select a light")
except:
pass
def clear_select(self):
global lights_down
lights_down = []
#unassign lights from room
def unassign_lights(self):
if len(lights_down) == 0:
pass
else:
for k in lights_down:
curs.execute("UPDATE Lights SET Room='X' WHERE Light_name='" + k + "'")
conn.commit()
self.build()
class Blank(Screen):
pass
"""login screen will be the first screen to execute, calls function that checks for gui commands"""
class LoginScreen(Screen):
#user = StringProperty()
#passw = StringProperty()
def login(self, username, password):
user = username
passw = password
curs.execute("SELECT * FROM users WHERE username = '" + username + "' AND password= '" + password + "'")
if curs.fetchone() is not None:
print "Successful Login"
self.parent.current = 'homepage'
#after login, these methods should execute...
o = Methods()
#Clock.schedule_interval(o.cmdparser, 5.0)
o.cmdparser() #checks workfile for unprocessed commands
o.update_lights() #updates all lights stored in database with current circadian rhythm values
else:
box = BoxLayout(orientation = 'vertical', padding = (8))
message = Label(text='Invalid username or password', font_size=25, valign = 'middle', size_hint=(1,.3))
box.add_widget(message)
popup = Popup(title= 'Login Error', content = box, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0},on_release = popup.dismiss))
popup.open()
class HomePage(Screen):
def verify(self):
#verify password popup
box2 = BoxLayout(orientation = 'vertical', padding = (8))
#message on popup
message1 = Label(text='Username: ',font_size=25, valign = 'middle', size_hint=(1,.3))
box2.add_widget(message1)
self.textuser = TextInput(text='',multiline = False, size_hint=(1,.7), font_size=25)
box2.add_widget(self.textuser)
message2 = Label(text='Password: ', font_size=25, valign = 'middle', size_hint=(1,.3))
box2.add_widget(message2)
self.textpass = TextInput(text='',multiline = False, size_hint=(1,.7), font_size=25)
box2.add_widget(self.textpass)
popup = Popup(title= 'Verify', content = box2, title_size =(30),size_hint=(None, None), size=(500,350),title_align='center', auto_dismiss=False)
box2.add_widget(Button(text='OK', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0}, on_press = self.check_credentials, on_release = popup.dismiss))
box2.add_widget(Button(text='Cancel', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0}, on_release = popup.dismiss))
popup.open()
def check_credentials(self, arg1):
username = self.textuser.text
password = self.textpass.text
curs.execute("SELECT password FROM users WHERE username='" + username + "' and password='" + password + "'")
s = curs.fetchall()
try:
if(len(s) == 1):
print "success"
sm.current='troubleshoot'
else:
box = BoxLayout(orientation = 'vertical', padding = (8))
message = Label(text='Invalid username or password', font_size=25, valign = 'middle', size_hint=(1,.3))
box.add_widget(message)
popup = Popup(title= 'Login Error', content = box, title_size =(30),size_hint=(None, None), size=(450,250),title_align='center', auto_dismiss=False)
box.add_widget(Button(text='Return', font_size = 20, size_hint=(.5,.3), pos_hint={'center_x': .5, 'center_y': 0},on_release = popup.dismiss))
popup.open()
except:
print "error in check_credentials"
class Troubleshoot(Screen):
pass
############################################ JORGE's GUI Section ##################################################
"""This class has the buttons to 'Add New Device', 'view Ports' """
class Setting(Screen, GridLayout, BoxLayout):
newDevControl = 1
portsCount = 0 #Should be Plug-And-Play Value
def __init__(self, **kwargs):
super(Setting, self).__init__(**kwargs)
"""Popup method that displays input field for adding a new device"""
def addPorts(self):
self.box = BoxLayout(orientation = 'vertical', padding = (5))
global newDevControl
if(self.newDevControl):
self.myLabel = Label(text = 'Enter Number Of Ports On New Device', font_size='25sp')
self.box.add_widget(self.myLabel)
else:
self.myLabel = Label(text = 'Number Must Be An Integer Value', font_size='25sp')
self.box.add_widget(self.myLabel)
self.popup = Popup(title = 'Add New Device',
title_size = (35), title_align = 'center',
content = self.box, size = (25,25), auto_dismiss=True)
self.uInput = TextInput(text='', multiline=False, font_size='25sp')
self.box.add_widget(self.uInput)
self.okBtn = Button(text='Update', on_press = self.getUser, font_size='20sp', on_release=self.popup.dismiss)
self.box.add_widget(self.okBtn)
self.cancelBtn = Button(text='Cancel', font_size='20sp', on_press=self.popup.dismiss)
self.box.add_widget(self.cancelBtn)
self.popup.open()
"""Method that handles user's input from popup"""
def getUser(self, arg1):
if(self.uInput.text.isdigit()):
global newDevControl, portsCount
# Make sure add them as numbers and not as strings
self.old = int(self.portsCount)
self.new = int(self.uInput.text)
self.new += self.old
self.portsCount = str(self.new)
self.newDevControl = 1
curs.execute("UPDATE PORTS SET Amount='" + self.portsCount + "'")
conn.commit()
print("User Entered: {}".format(self.uInput.text))
else:
global newDeviceControl
self.newDevControl = 0
print("Wrong value!")
return self.addPorts()
"""This method gets the port count from the DB and displays it to the user"""
def getPorts(self):
global portsCount
for row in curs.execute("SELECT * FROM Ports"):
self.portsCount = row[0]
##############################################################
# Taylor, here is where I need to get your Plug And Play value
# so I can substract it from the total ports count.
# This is how I will be able to show the ports available
#
# e.g.: self.portsCount -= plugAnPlaCount
#############################################################
self.box = BoxLayout(orientation = 'vertical', padding = (5))
self.myLabel = Label(text = ("There are " + str(self.portsCount) + " Ports Available!"), font_size='25sp')
self.box.add_widget(self.myLabel)
#self.box.add_widget(Label(text = ("There are " + str(self.portsCount) + " Ports Available!"), font_size='25sp'))
self.popup = Popup(title = 'Open Ports',
title_size = (35), title_align = 'center',
content = self.box, size = (25,25), auto_dismiss=True)
self.popButton = Button(text='OK', font_size='20sp', on_press=self.popup.dismiss)
self.box.add_widget(self.popButton)
self.popup.open()
############################################################
# IF PORTS >= 2048. AKA SOMAXCONN has been reached, #
# Call the script that updates this ammount. #
# Maybe Create another instance of the servere? #
# If SOMAXCONN is updated, I may need to reboot the system #
# Maybe Create a warning pop up telling the user what is #
# about to happen so that they dont think they crashed the #
# GUI by adding that new devicew #
############################################################
print("{} Ports".format(self.portsCount))
# For Color WHeel Only
testOLAColors = None
"""This class handles the color wheel popup"""
class ColorSelector(Popup):
"""This is the method that gets called when the user presses OK on the color wheel. It stores those values on the DB"""
def on_press_dismiss(self, colorPicker, *args):
self.dismiss()
#Gets as it was selected - x
RGBA = list(colorPicker.hex_color[1:])
As = str(RGBA[6]) + str(RGBA[7])
Rs = str(RGBA[0]) + str(RGBA[1])
Gs = str(RGBA[2]) + str(RGBA[3])
Bs = str(RGBA[4]) + str(RGBA[5])
ARGBs = As+Rs+Gs+Bs + " "
(dt, micro) = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f').split('.')
dt = "%s.%03d" % (dt, int(micro) / 1000)
ARGBs += dt
# Finish the Command
with open("testOLA", "a") as f:
f.write(ARGBs)
f.write('\n')
f.close()
# make the file empty
os.system("cat testOLA >> workfile.txt ; echo \" \" > testOLA")
return True
"""This class is To test OLA from any of the lights on the DB. Only one a time can be tested."""
class TestOLA(Screen):
def build(self):
self.ids.testolalayout.clear_widgets()
for row in curs.execute("SELECT Light_name FROM Lights WHERE Room='X'"):
btn = ToggleButton(text='%s' % row[0], size = (780, 45),size_hint=(None,None)) #create button
btn.bind(state=self.lightscallback, on_press=self.showOLA)
self.ids.testolalayout.add_widget(btn) #add to gridlayout
self.ids.testolalayout.bind(minimum_height=self.ids.testolalayout.setter('height'))
"""method checks the state of the toggle buttons for lights section"""
def lightscallback(self, instance, value):
print('My button <%s> state is %s' % (instance.text, value))
if value == 'down':
lights_down.append(instance.text) # add to list of buttons with down state
elif value == 'normal':
lights_down.remove(instance.text) # remove from list if back to normal
print('not down')
else:
pass
"""This method loads the color wheel popup to the screen. It also writes to the workfile"""
def showOLA(self, arg1):
if len(lights_down) == 1:
# Show Color wheel
self.aColor = ColorSelector()
self.aColor.open()
# Prepare for color selection
for row in curs.execute("SELECT IP_address FROM Lights WHERE Light_name='" + lights_down[0] + "'"):
cmd = "S " + row[0] + " " + "SET" + " "
ip = row[0]
#print(ip)
with open("testOLA","a") as f:
f.write(cmd)
f.close()
else:
pass
#####################################END of JORGE's GUI Section ##################################################
Builder.load_file("gui8.kv")
sm = ScreenManagement()
class TestApp(App):
title = "Spacecraft Lighting Network System"
def build(self):
# return ScreenManagement()
# Need for TestOla class
self.color_selector = ColorSelector()
return sm
if __name__ == "__main__":
#Run voice commands at boot up
#os.system('python /home/pi/Desktop/UNT-NASA/voiceOLA/voiceOLA.py > /dev/null 2>&1 &')
# NEEDED For Testing Individual Lights
os.system("touch testOLA")
# Run the GUI
TestApp().run()
conn.close() #close database connection
| true |
457d2044e1b5d993af7414ae2362d09b4e91a1ea | Python | sgenduso/python-practice | /src/list_methods.py | UTF-8 | 2,069 | 4.5 | 4 | [] | no_license | park = []
park.append("golden")
park.append("husky")
park.append("shepherd")
park.append("lab")
# same as:
park2 = ["golden", "husky", "shepherd", "lab"]
list_length = len(park)
print "There are %d items in the park." % (list_length)
print park
# slice: We start at the index before the colon and continue
# up to but not including the index after the colon.
suitcase = ["sunglasses", "hat", "passport", "laptop", "suit", "shoes"]
first = suitcase[0:2] # The first and second items (index zero and one)
middle = suitcase[2:4] # Third and fourth items (index two and three)
last = suitcase[4:6] # The last two items (index four and five)
animals = "catdogfrog"
cat = animals[:3] # The first three characters of animals
dog = animals[3:6] # The fourth through sixth characters
frog = animals [6:] # From the seventh character to the end
# indexing and inserting
animals = ["aardvark", "badger", "duck", "emu", "fennec fox"]
duck_index = animals.index('duck') # Use index() to find "duck"
animals.insert(duck_index, 'cobra')
animals.remove('aardvark')
print animals # Observe what prints after the insert operation
# ways to remove elements from lists
# pop(index) -- removes element at given index and returns it
# remove(item) -- removes item if it finds it
# del(arr[i]) -- removes element but doesn't return it
n = [1, 3, 5]
def resetN:
n = [1, 3, 5]
n.pop(1) # removes and returns 3
resetN()
n.remove(1) # removes 1 (element at index 0)
resetN()
del(n[1]) # removes 3 but does not return it
# for loops without indeces
for item in list:
print item
# for loops with indeces
def print_list(x):
for i in range(0, len(x)):
print x[i]
# The range function has three different versions:
# range(stop)
# range(start, stop)
# range(start, stop, step)
# In all cases, the range() function returns a list of numbers from start up to (but not including) stop. Each item increases by step.
# If omitted, start defaults to zero and step defaults to one.
range(6) # => [0,1,2,3,4,5]
range(1,6) # => [1,2,3,4,5]
range(1,6,3) # => [1,4]
| true |
ce0e67e56fec32edd34ce0e503bf7a899aad6373 | Python | robinNcode/Python-Code | /Output 2.py | UTF-8 | 1,043 | 2.6875 | 3 | [] | no_license | r=40
for i in range(1,r,1):
print("-",end = '')
for i in range(1,6,1):
print()
if i==1:
for j in range(1,r,1):
if j==1 or j==39:
print("|",end='')
elif j==2:
print("x",end='')
elif j==4:
print("=",end='')
elif j==6:
print("3",end='')
elif j==7:
print("5",end='')
else:
print(" ",end='')
elif i==3:
for j in range(1,r,1):
if j==1 or j==39:
print("|",end='')
elif j==17:
print("x",end='')
elif j==19:
print("=",end='')
elif j==21:
print("3",end='')
elif j==22:
print("5",end='')
else:
print(" ",end='')
elif i==5:
for j in range(1,r,1):
if j==1 or j==39:
print("|",end='')
elif j==33:
print("x",end='')
elif j==35:
print("=",end='')
elif j==37:
print("3",end='')
elif j==38:
print("5",end='')
else:
print(" ",end='')
else:
for j in range(1,r,1):
if j==1 or j==39:
print("|",end='')
else:
print(" ",end='')
print()
for i in range(1,r,1):
print("-",end = '')
print() | true |
972929f6b47d01b317726d528699351c74aa7a3e | Python | Abhyudaya100/my-projects-2 | /stringpattern3.py | UTF-8 | 142 | 4.15625 | 4 | [] | no_license | string = input("enter a string :")
strlen = len(string)
for index in range(strlen,0,-1):
print(" " * (strlen - index) + string[:index]) | true |
a063c64746cb2938ccff864f044bf7a230f4f96b | Python | mucheniski/curso-em-video-python | /Mundo1/004UsandoModulosDoPython/Aula09ManipulandoTexto.py | UTF-8 | 1,840 | 4.03125 | 4 | [] | no_license | frase = 'Curso em Vídeo Python'
# C u r s o e m V í d e o P y t h o n
# 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
print('Pegando apenas a letra no indice 9 ',frase[9])
print('Pegando de 9 a 13, o ultimo é excluído ', frase[9:13])
print('Do 9 ao 20 pulando de 2 em 2 ', frase[9:21:2])
print('Do caractere zero até 5, sempre exclui o último ', frase[:5])
print('Do 15 até o final ', frase[15:])
print('Do 9 até o final pulando de 3 em 3 ', frase[9::3])
print('='*50)
print('Tamanho da frase ', len(frase))
print('Contar quantas vezes aparece o o minúsculo ', frase.count('o'))
print('Contar do 0 até o 13 quantas vezes aparece o ', frase.count('o',0,13))
print('Mostrar quantas vezes encontrou deo, onde começa ', frase.find('deo'))
print('Buscar uma string que não existe, deve retornar menos um ', frase.find('rute'))
print('Boolean se existe a frase ', 'Curso' in frase)
#Nesse caso o próprio Python cria um novo array com mais caracteres para caber Android
#para alterar a frase é preciso fazer frase = frase.replace
print('Substituindo palavras ', frase.replace('Python', 'Android'))
print('Imprimindo em maiúscula ', frase.upper())
print('Imprimindo em minúsculo ', frase.lower())
print('Deixando só o primeiro caracter em maiusculo ', frase.capitalize())
print('Sempre depois do espaço deixa a primeira maiúscula ', frase.title())
print('='*50)
frase2 = ' Frase com espaços '
print('Removendo todos os espaços inúteis do começo e do fim da frase ', frase2.strip())
print('Removendo espaços da direita ', frase2.rstrip())
print('Removendo espaços da esquerda ', frase2.lstrip())
print('='*50)
frase3 = 'Curso em Vídeo Python'
print('Dividir as strings por espaços ', frase3.split())
print('Juntar nomes separados em listas ', '-'.join(frase3)) | true |
5b3afb4255f920a2eefd39ce242e406f0c582405 | Python | mrMetalWood/advent-of-code | /2020/day-15/day-15.py | UTF-8 | 356 | 2.9375 | 3 | [
"MIT"
] | permissive | ledger = {n: idx + 1 for idx, n in enumerate([1, 17, 0, 10, 18, 11, 6])}
spoken_number = list(ledger)[-1]
for turn in range(len(ledger), 30000000):
ledger[spoken_number], spoken_number = turn, turn - ledger.get(spoken_number, turn)
if turn == 2020 - 1:
print(f"Part 1: {spoken_number}") # 595
print(f"Part 2: {spoken_number}") # 1708310
| true |
95597b8e7016331166eb263e0ca8e09396590c8f | Python | reed-qu/leetcode-cn | /LargestRectangleInHistogram.py | UTF-8 | 1,832 | 4.09375 | 4 | [
"MIT"
] | permissive | #!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/1/12 下午3:46
# @Title : 84. 柱状图中最大的矩形
# @Link : https://leetcode-cn.com/problems/largest-rectangle-in-histogram/
QUESTION = """
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
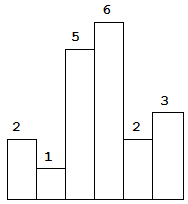
以上是柱状图的示例,其中每个柱子的宽度为 1,给定的高度为 [2,1,5,6,2,3]。
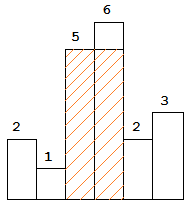
图中阴影部分为所能勾勒出的最大矩形面积,其面积为 10 个单位。
示例:
输入: [2,1,5,6,2,3]
输出: 10
"""
THINKING = """
维护一个栈,栈里记录的是:在单调递增的过程中,断掉的内个索引位置
为什么要找这个位置,是因为绘制矩形的时候,高度取决于最低的内个,类似于木桶理论
每次找到这个点时候,递增的开始到结束的区间内,遍历计算最大的面积,也就是一段一段的遍历计算
为了能肯定形成这个区间,要在数组的两端加上0
"""
from typing import List
class Solution:
def largestRectangleArea(self, heights: List[int]) -> int:
stack = []
heights = [0] + heights + [0]
result = 0
for i in range(len(heights)):
while stack and heights[stack[-1]] > heights[i]:
tmp = stack.pop()
result = max(result, (i - stack[-1] - 1) * heights[tmp])
stack.append(i)
return result
if __name__ == '__main__':
s = Solution()
heights = [2,1,5,6,2,3]
print(s.largestRectangleArea(heights))
| true |
8e4b93bb5851e85f8db6a08340d5d40dfc3cfade | Python | Weikoi/OJ_Python | /leetcode/medium/31_下一个排列.py | UTF-8 | 766 | 3.125 | 3 | [] | no_license | class Solution:
def nextPermutation(self, nums):
"""
:type nums: List[int]
:rtype: void Do not return anything, modify nums in-place instead.
"""
down = 0
flag = 0
for i in range(len(nums) - 1, 0, -1):
if nums[i - 1] < nums[i]:
down = i - 1
flag = 1
break
if not flag:
nums.reverse()
for i in range(len(nums) - 1, 0, -1):
if nums[i] > nums[down]:
nums[i], nums[down] = nums[down], nums[i]
last = nums[down + 1:]
last.reverse()
nums[down + 1:] = last
if __name__ == '__main__':
results = Solution()
print(results.nextPermutation())
| true |
ae562b0a617f5b6ba103e3d4286986ce48c6feb6 | Python | juyeonkim97/python-algorithm | /inflear2/[5-3]후위표기식 만들기.py | UTF-8 | 641 | 3.03125 | 3 | [] | no_license | a=list(input())
res=""
stack=list()
for i in a:
if(i.isdecimal()):#숫자인지 판별
res+=i
else:
if i=='(':
stack.append(i)
elif i=='*' or i=='/':
while stack and (stack[-1]=='*' or stack[-1]=='/'):
res+=stack.pop()
stack.append(i)
elif i=="+" or i =="-":
while stack and stack[-1]!='(':
res+=stack.pop()
stack.append(i)
elif i==")":
while stack and stack[-1]!='(':
res+=stack.pop()
stack.pop()
while stack:
res+=stack.pop()
print(res)
| true |
ad5e735c4d5ec60cebb89ac73ec17168154ab7b1 | Python | fatima96zahra/Recurrent-Neural-Network | /cell_model/nru_cell.py | UTF-8 | 3,468 | 2.515625 | 3 | [] | no_license | # -*- coding: utf-8 -*-
"""
Created on Wed Jul 8 07:09:45 2020
@author: Banani Fatima-Zahra
"""
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import math
class NRUCell(nn.Module):
def __init__(self, device, input_size, hidden_size, memory_size=64, k=4,
activation="tanh", use_relu=False, layer_norm=False):
super(NRUCell, self).__init__()
self._device = device
self.input_size = input_size
self.hidden_size = hidden_size
if activation == "tanh":
self.activation = torch.tanh
elif activation == "sigmoid":
self.activation = torch.sigmoid
self.memory_size = memory_size
self.k = k
self._use_relu = use_relu
self._layer_norm = layer_norm
assert math.sqrt(self.memory_size*self.k).is_integer()
sqrt_memk = int(math.sqrt(self.memory_size*self.k))
self.hm2v_alpha = nn.Linear(self.memory_size + hidden_size, 2 * sqrt_memk)
self.hm2v_beta = nn.Linear(self.memory_size + hidden_size, 2 * sqrt_memk)
self.hm2alpha = nn.Linear(self.memory_size + hidden_size, self.k)
self.hm2beta = nn.Linear(self.memory_size + hidden_size, self.k)
if self._layer_norm:
self._ln_h = nn.LayerNorm(hidden_size)
self.hmi2h = nn.Linear(self.memory_size + hidden_size + self.input_size, hidden_size)
def _opt_relu(self, x):
if self._use_relu:
return F.relu(x)
else:
return x
def _opt_layernorm(self, x):
if self._layer_norm:
return self._ln_h(x)
else:
return x
def forward(self, input, last_hidden):
print("model_nru")
hidden = {}
c_input = torch.cat((input, last_hidden["h"], last_hidden["memory"]), 1)
h = F.relu(self._opt_layernorm(self.hmi2h(c_input)))
# Flat memory equations
alpha = self._opt_relu(self.hm2alpha(torch.cat((h,last_hidden["memory"]),1))).clone()
beta = self._opt_relu(self.hm2beta(torch.cat((h,last_hidden["memory"]),1))).clone()
u_alpha = self.hm2v_alpha(torch.cat((h,last_hidden["memory"]),1)).chunk(2,dim=1)
v_alpha = torch.bmm(u_alpha[0].unsqueeze(2), u_alpha[1].unsqueeze(1)).view(-1, self.k, self.memory_size)
v_alpha = self._opt_relu(v_alpha)
v_alpha = torch.nn.functional.normalize(v_alpha, p=5, dim=2, eps=1e-12)
add_memory = alpha.unsqueeze(2)*v_alpha
u_beta = self.hm2v_beta(torch.cat((h,last_hidden["memory"]),1)).chunk(2, dim=1)
v_beta = torch.bmm(u_beta[0].unsqueeze(2), u_beta[1].unsqueeze(1)).view(-1, self.k, self.memory_size)
v_beta = self._opt_relu(v_beta)
v_beta = torch.nn.functional.normalize(v_beta, p=5, dim=2, eps=1e-12)
forget_memory = beta.unsqueeze(2)*v_beta
hidden["memory"] = last_hidden["memory"] + torch.mean(add_memory-forget_memory, dim=1)
hidden["h"] = h
return hidden
def reset_hidden(self, batch_size, hidden_init=None):
hidden = {}
if hidden_init is None:
hidden["h"] = torch.Tensor(np.zeros((batch_size, self.hidden_size))).to(self._device)
else:
hidden["h"] = hidden_init.to(self._device)
hidden["memory"] = torch.Tensor(np.zeros((batch_size, self.memory_size))).to(self._device)
return hidden | true |
fd23e47d7110c9e7ff83b08f31e2b6b06d78ff70 | Python | yokaiemporer/SentimentAnalysis | /imdbsenmod2test.py | UTF-8 | 2,555 | 2.71875 | 3 | [] | no_license | import pandas as pd
import numpy
import matplotlib.pyplot as plt
from keras.datasets import imdb
from keras.models import Sequential
from keras.models import Model
from keras.layers import Input
from keras.utils import to_categorical
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Flatten
from keras.layers import Bidirectional
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
from keras.layers import TimeDistributed
# # fix random seed for reproducibility
# numpy.random.seed(7)
import pickle
# # load the dataset but only keep the top n words, zero the rest
top_words = 15000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words)
print((list(X_train)[:10], list(y_train)[:10]))
y_train = to_categorical(y_train, num_classes=2)
y_test = to_categorical(y_test, num_classes=2)
import keras
NUM_WORDS=1000 # only use top 1000 words
INDEX_FROM=3 # word index offset
word_to_id = keras.datasets.imdb.get_word_index()
print(list(word_to_id)[:20])
print(list(word_to_id.items())[:20])
word_to_id = {k:(v+INDEX_FROM) for k,v in word_to_id.items()}
word_to_id["<PAD>"] = 0
word_to_id["<START>"] = 1
word_to_id["<UNK>"] = 2
import numpy as np
id_to_word = {value:key for key,value in word_to_id.items()}
# print(' '.join(id_to_word[id] for id in X_train[0] ))
from numpy import array
# truncate and pad the review sequences
max_review_length = 250
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length)
print(pd.DataFrame(X_train).head())
# create the model
# embedding_vector_length = 32
embedding_vector_length = 128
import tensorflow as tf
filename = "my_model.h5"
model=tf.keras.models.load_model(filename)
scores = model.evaluate(X_test, y_test, verbose=0)
plt.show()
print("Accuracy: %.2f%%" % (scores[1]*100))
sentences=[ "that movie is bad"
, "awesome"
,"it was very good"
,"i hate it"
,"wow",
"meh",
"its bad"
,"heroine was the worst"
,"im not sure if its ok"]
# bad="i hate it"
for i in range(10):
print()
for review in sentences:
tmp = []
for word in review.split(" "):
tmp.append(word_to_id[word])
tmp_padded = sequence.pad_sequences([tmp], maxlen=max_review_length)
val=model.predict(array([tmp_padded][0]))[0]
idx=np.argmax(val)
print("sentence::::")
if idx==1:
result="POSITIVE"
else:
result="NEGATIVE"
print("%s . Sentiment is %s and accuracy : %s" % (review,result,val))
| true |
2f3982c685ef243eb4c265f2f5e8bc895f85fb55 | Python | Simo0o08/DataScience_Assignment | /Assignment-13.py | UTF-8 | 2,636 | 2.96875 | 3 | [] | no_license | #!/usr/bin/env python
# coding: utf-8
# In[1]:
import numpy as np
import pandas as pd
# In[2]:
houseprice=pd.read_csv(r"C:\Users\Simran\Desktop\Industrial Training\datasets\houseprice.csv")
houseprice.head()
# In[3]:
houseprice.shape
# In[4]:
houseprice.isnull().sum()
# In[5]:
#here in prediction id and date has no use
#as zipcode is provided there is no need of latitude and longitude
houseprice=houseprice.drop(['id','date','lat','long'],axis=1)
houseprice.head()
# In[6]:
houseprice.describe()
# In[7]:
#difference between mean and std in sqft_living,sqft_above,sqft_lot15 is more so drop that column
houseprice=houseprice.drop(['sqft_living','sqft_above','sqft_lot15'],axis=1)
houseprice.head()
# In[ ]:
# In[9]:
import seaborn as sns
import matplotlib.pyplot as plt
fig, axs = plt.subplots(ncols=5, nrows=4, figsize=(15, 20))
index = 0
axs = axs.flatten() # to flaten to 1d
for k,v in houseprice.items():
sns.boxplot(y=v, data=houseprice, ax=axs[index])
index += 1
plt.tight_layout(pad=0.5, w_pad=0.1, h_pad=5.0)
plt.show()
# In[10]:
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
x1=houseprice.iloc[:,1:].values
y1=houseprice.iloc[:,0:1].values
x=sc.fit_transform(x1)
y=sc.fit_transform(y1)
# In[11]:
x=pd.DataFrame(x)
x
# In[12]:
y=pd.DataFrame(y)
y
# In[13]:
plt.figure(figsize=(20, 10))
sns.heatmap(houseprice.corr().abs(), annot=True)
plt.show()
# In[14]:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
X_train,X_test,y_train,y_test=train_test_split(x,y,test_size=.1,random_state=0)
# In[15]:
lr=LinearRegression()
lr.fit(X_train,y_train)
# In[16]:
y_pred=lr.predict(X_test)
# In[17]:
from sklearn.metrics import r2_score, mean_squared_error
r2_score(y_test,y_pred)
# In[18]:
lr.score(x,y)
# In[19]:
mean_squared_error(y_test,y_pred)
# In[20]:
#polynomial regression
# In[21]:
from sklearn.preprocessing import PolynomialFeatures
# In[22]:
poly_reg=PolynomialFeatures(degree=3)
x_poly_train=poly_reg.fit_transform(X_train)
# In[23]:
poly_reg=PolynomialFeatures(degree=3)
x_poly_test=poly_reg.fit_transform(X_test)
# In[24]:
ro_2=LinearRegression()
ro_2.fit(x_poly_train,y_train)
# In[25]:
y_pred_poly=ro_2.predict(x_poly_test)
# In[26]:
r2_score(y_pred_poly,y_test)
# In[27]:
ro_2.score(x_poly_train,y_train)
# In[ ]:
| true |
f027da48483dc7b69cb2ee5b7cb7f613b1caf74a | Python | Jelleas/Drones | /drones.py | UTF-8 | 7,969 | 2.96875 | 3 | [
"MIT"
] | permissive | import math
import json
import visualisation
import dill
import time
import random
class OutOfStockError(Exception):
pass
class Position(object):
def __init__(self, x, y):
self.x = x
self.y = y
def distanceTo(self, pos):
return math.sqrt((self.x - pos.x)**2 + (self.y - pos.y)**2)
def __str__(self):
return "POS [{},{}]".format(self.x, self.y)
def __repr__(self):
return str(self)
class Drone(object):
def __init__(self, name, pos):
self.name = name
self._position = pos
def flyTo(self, pos):
distance = self.distanceTo(pos)
self._position = pos
return distance
def distanceTo(self, pos):
return math.ceil(self._position.distanceTo(pos))
@property
def position(self):
return Position(int(round(self._position.x)), int(round(self._position.y)))
class Customer(object):
def __init__(self, name, pos):
self.name = name
self.position = pos
def __str__(self):
return "CUSTOMER {}".format(self.name)
class Package(object):
def __init__(self, name):
self.name = name
def __hash__(self):
return hash(self.name)
def __eq__(self, other):
return isinstance(other, type(self)) and other.name == self.name
def __str__(self):
return "PACKAGE {}".format(self.name)
def __repr__(self):
return str(self)
class Order(object):
def __init__(self, customer, packages):
self.customer = customer
self.packages = packages
def __str__(self):
return "ORDER [{} : {}]".format(self.customer, self.packages)
def __repr__(self):
return str(self)
class Warehouse(object):
def __init__(self, name, pos, packages):
self.name = name
self.position = pos
packages = packages
self._content = {package : packages.count(package) for package in set(packages)}
def retrieve(self, package):
try:
count = self._content[package] - 1
if count == 0:
del self._content[package]
else:
self._content[package] = count
except KeyError:
raise OutOfStockError()
return package
def __str__(self):
return "WAREHOUSE [{} : {}]".format(self.name, str(self._content))
def __repr__(self):
return str(self)
def __contains__(self, item):
return item in self._content
class Grid(object):
def __init__(self, width, height):
self.width = width
self.height = height
self._grid = [[_Cell() for i in range(self.height)] for j in range(self.width)]
self._items = {}
def placeWarehouse(self, warehouse, pos):
self._grid[pos.x][pos.y].addWarehouse(warehouse)
self._items[warehouse] = pos
def placeDrone(self, drone, pos):
self._grid[pos.x][pos.y].addDrone(drone)
self._items[drone] = pos
def placeCustomer(self, customer, pos):
self._grid[pos.x][pos.y].addCustomer(customer)
self._items[customer] = pos
def warehousesAt(self, pos):
return self._grid[pos.x][pos.y].warehouses
def dronesAt(self, pos):
return self._grid[pos.x][pos.y].drones
def customersAt(self, pos):
return self._grid[pos.x][pos.y].customers
def unplace(self, item):
pos = self._items[item]
del self._items[item]
self._grid[pos.x][pos.y].remove(item)
def display(self):
for i in range(self.height):
for j in range(self.width):
print self._grid[j][i],
print
def __iter__(self):
for i in range(self.height):
for j in range(self.width):
yield Position(j, i)
class _Cell(object):
def __init__(self):
self.customers = []
self.warehouses = []
self.drones = []
def addCustomer(self, customer):
self.customers.append(customer)
def addWarehouse(self, warehouse):
self.warehouses.append(warehouse)
def addDrone(self, drone):
self.drones.append(drone)
def remove(self, item):
for collection in [self.customers, self.warehouses, self.drones]:
try:
collection.remove(item)
break
except ValueError:
pass
def __str__(self):
return "C{}W{}D{}".format(len(self.customers), len(self.warehouses), len(self.drones))
class Simulation(object):
def __init__(self, grid, warehouses, orders, drones, timelimit):
self.grid = grid
self.warehouses = warehouses
for warehouse in self.warehouses:
self.grid.placeWarehouse(warehouse, warehouse.position)
self.orders = _OrderManager(orders)
for order in self.orders:
if order.customer not in self.grid.customersAt(order.customer.position):
self.grid.placeCustomer(order.customer, order.customer.position)
self._drones = {drone : 0 for drone in drones}
for drone in self._drones:
self.grid.placeDrone(drone, drone.position)
self.timelimit = timelimit
@property
def drones(self):
return self._drones.keys()
@property
def cost(self):
return max(self._drones.values())
def droneCost(self, drone):
return self._drones[drone]
def flyDroneTo(self, drone, pos):
self.grid.unplace(drone)
self._drones[drone] += drone.flyTo(pos)
self.grid.placeDrone(drone, drone.position)
def warehousesContaining(self, package):
return [wh for wh in self.warehouses if package in wh]
def claimOrder(self, order):
self.orders.remove(order)
def completeOrder(self, order):
if not self.orders.hasCustomer(order.customer):
self.grid.unplace(order.customer)
def display(self):
self.grid.display()
class _OrderManager(object):
def __init__(self, orders):
self._orders = list(orders)
def remove(self, order):
self._orders.remove(order)
def hasCustomer(self, customer):
return any(order.customer == customer for order in self)
def __getitem__(self, index):
return self._orders[index]
def __len__(self):
return len(self._orders)
def __iter__(self):
for order in self._orders:
yield order
def __nonzero__(self):
return len(self) > 0
def loadSimulation():
warehouses = []
with open("warehouses.json") as warehousesFile:
content = json.loads(warehousesFile.read())
for warehouseName in content:
pos = Position(*content[warehouseName]["position"])
packages = sum(([Package(packageName)] * count for packageName, count in content[warehouseName]["packages"]), [])
warehouses.append(Warehouse(warehouseName, pos, packages))
orders = []
with open("orders.json") as ordersFile:
content = json.loads(ordersFile.read())
for customerName in content:
customer = Customer(customerName, Position(*content[customerName]["position"]))
packages = [Package(packageName) for packageName in content[customerName]["packages"]]
orders.append(Order(customer, packages))
with open("settings.json") as settingsFile:
content = json.loads(settingsFile.read())
grid = Grid(content["width"], content["height"])
drones = [Drone("Drone{}".format(i), Position(0,0)) for i in range(content["drones"])]
timelimit = content["timelimit"]
return Simulation(grid, warehouses, orders, drones, timelimit)
def randomSolve(simulation, visualize = lambda grid : None):
while simulation.orders:
drone = random.choice(simulation.drones)
order = random.choice(simulation.orders)
simulation.claimOrder(order)
for package in order.packages:
warehouse = random.choice(simulation.warehousesContaining(package))
simulation.flyDroneTo(drone, warehouse.position)
visualize(simulation.grid)
simulation.flyDroneTo(drone, order.customer.position)
visualize(simulation.grid)
def greedySolve(simulation, visualize = lambda grid : None):
while simulation.orders:
drone = random.choice(simulation.drones)
order = random.choice(simulation.orders)
simulation.claimOrder(order)
for package in order.packages:
warehouse = min(simulation.warehousesContaining(package), key = lambda wh : drone.distanceTo(wh.position))
simulation.flyDroneTo(drone, warehouse.position)
warehouse.retrieve(package)
visualize(simulation.grid)
simulation.flyDroneTo(drone, order.customer.position)
visualize(simulation.grid)
simulation.completeOrder(order)
if __name__ == "__main__":
simulation = loadSimulation()
simulation.display()
visualisation.visualize(simulation.grid)
greedySolve(simulation, visualize = visualisation.visualize)
print "Total cost : {}".format(simulation.cost) | true |
d40d37d8a69708e7ae054e45da78ba320c79cf0b | Python | willclarktech/crypto-primitives | /diffie_helman/bob.py | UTF-8 | 913 | 2.578125 | 3 | [] | no_license | #!/usr/bin/env python
import os, sys
sys.path.append(os.path.abspath(os.path.join("redis_tools")))
from redis_tools import setter, waiter, deleter
from random import randint
def main(min_b=2000, max_b=3000):
print("Waiting for g...")
redis_waiter = waiter(1)
redis_waiter.send(None)
g = int(redis_waiter.send("g"))
print("Got g")
redis_deleter = deleter("g")
redis_deleter.send(None)
print("Waiting for p...")
p = int(redis_waiter.send("p"))
print("Got p")
redis_deleter.send("p")
b = randint(2000, 3000)
B = g**b % p
redis_setter = setter(["B", B])
redis_setter.send(None)
print("Set B")
print("Waiting for A...")
A = int(redis_waiter.send("A"))
print("Got A")
redis_deleter.send("A")
s = A**b % p
print("RESULT: ", s)
if __name__ == "__main__":
min_b = int(sys.argv[1]) if len(sys.argv) >= 3 else 2000
max_b = int(sys.argv[2]) if len(sys.argv) >= 3 else 2000
main(min_b, max_b)
| true |
37bc660a3595c9503926613563125cef13bbfe02 | Python | simhonchourasia/leetcodesolutions | /leetcode/Medium/add two numbers.py | UTF-8 | 1,094 | 3.328125 | 3 | [] | no_license | # https://leetcode.com/problems/add-two-numbers/
class Solution:
def addHelper(self, l1, l2, carry):
if l1 == None and l2 == None:
if carry > 0:
return ListNode(val=1, next=None)
return None
if l1 == None:
if l2.val + carry > 9:
return ListNode(val = 0, next=self.addHelper(None, l2.next, 1))
return ListNode(val = l2.val+carry, next=self.addHelper(None, l2.next, 0))
if l2 == None:
if l1.val + carry > 9:
return ListNode(val = 0, next=self.addHelper(l1.next, None, 1))
return ListNode(val = l1.val+carry, next=self.addHelper(l1.next, None, 0))
if l1.val+l2.val+carry > 9:
return ListNode(val = (l1.val+l2.val+carry)-10, next=self.addHelper(l1.next, l2.next, 1))
return ListNode(val = (l1.val+l2.val+carry), next=self.addHelper(l1.next, l2.next, 0))
def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
return self.addHelper(l1, l2, 0)
| true |
cb4f18d31243af4aabbc5ef80b6f1ef7e80da3e5 | Python | tjvick/advent-of-code | /2020_python/solutions/day10/part1.py | UTF-8 | 416 | 2.578125 | 3 | [] | no_license | import numpy as np
import collections
with open('input', 'r') as f:
joltages = [int(line.strip('\n')) for line in f]
sorted_joltages = sorted(joltages)
print(sorted_joltages)
device_joltage = max(joltages) + 3
sorted_joltages.append(device_joltage)
sorted_joltages.insert(0, 0)
diffs = np.array(sorted_joltages[1:]) - np.array(sorted_joltages[:-1])
d = dict(collections.Counter(diffs))
print(d[1] * d[3])
| true |
66221a5eba5023b0499d22fc3afde2857f6a11aa | Python | sousben/portfolio | /00_Snippets/Jupyter/CorrelHeatmap.txt | UTF-8 | 635 | 2.8125 | 3 | [] | no_license | #!/bin/python3
#correlation heatmap of dataset
def correlation_heatmap(df):
_ , ax = plt.subplots(figsize =(14, 12))
colormap = 'RdYlGn'
mask = np.zeros_like(df.corr(), dtype=np.bool)
mask[np.triu_indices_from(mask, 1)] = True
_ = sns.heatmap(
df.corr(),
mask = mask,
cmap = colormap,
square=True,
cbar_kws={'shrink':0.95 },
ax=ax,
annot=True,
linewidths=0.1,vmax=1, vmin=-1, linecolor='white',
annot_kws={'fontsize':12 }
)
plt.title('Features Correlation Heatmap', y=1.05, size=15)
correlation_heatmap(df_wrangled) | true |
5498bfa643bc8f9bac3c8cac40b2b81e72ff60fd | Python | dr-dos-ok/Code_Jam_Webscraper | /solutions_python/Problem_95/2437.py | UTF-8 | 673 | 2.984375 | 3 | [] | no_license | #!/usr/bin/python
l=["ejp mysljylc kd kxveddknmc re jsicpdrysi","rbcpc ypc rtcsra dkh wyfrepkym veddknkmkrkcd","de kr kd eoya kw aej tysr re ujdr lkgc jv"]
m=["our language is impossible to understand","there are twenty six factorial possibilities","so it is okay if you want to just give up"]
d={}
mainlen=len(l)
for i in range(mainlen):
lent=len(l[i])
for j in range(lent):
if l[i][j] not in d:
d[l[i][j]]=m[i][j]
d['q']='z'
d['z']='q'
#print len(d)
#new_d=sorted(d.values())
#print new_d
#new_d=sorted(d.keys())
#print new_d
a=input()
for i in range(a):
s=raw_input()
new_s=""
print "Case #"+str(i+1)+":",
for let in s:
new_s=new_s+d[let]
print new_s
| true |
e3d9c03328f5c16523a29e0da7b94ccf2f48fbd2 | Python | melpadden/corona.info.scripts | /load_countries.py | UTF-8 | 813 | 2.5625 | 3 | [] | no_license | import pandas as pd
import psycopg2
import constants
#from sqlescapy import sqlescape
conn = psycopg2.connect(
database=constants.DB_NAME,
user=constants.USER_NAME,
password=constants.PASSWORD,
host=constants.HOST_NAME,
port=constants.PORT_NUMBER
)
cur = conn.cursor()
df = pd.read_json('country_codes.json')
print(df.columns)
for index, row in df.iterrows():
#print(row['Code'], row['Name'])
country_code = row['Code']
country_name = row['Name']
sql = "INSERT INTO country (country_code, country_name) VALUES ( '{0}', '{1}' )".format(row['Code'], row['Name'])
sql_template = "INSERT INTO country (country_code, country_name) VALUES ( %s, %s )"
#print(sql)
result = cur.execute(sql_template, (country_code, country_name))
#print(result)
conn.commit()
| true |
5ed003069a00872af80b9a02d0a7f0442a4563ac | Python | tranhoaithuongql/BAP_Training_AI | /searching_synonym/connection_db.py | UTF-8 | 3,221 | 2.890625 | 3 | [] | no_license | from mysql import connector
class DBHelper(object):
def __init__(self, host, user, password, port, database):
self.host = host
self.port = port
self.user = user
self.password = password
self.database = database
self.conn = None
self.cur = None
self.get_connected()
def get_connected(self):
"""
Kết nối
:return:
"""
if not self.conn:
self.connectMysql()
if self.conn:
self.cur = self.conn.cursor()
def connectMysql(self):
self.conn = connector.connect(host=self.host,
user=self.user,
password=self.password,
port=self.port,
database=self.database)
def createDatabase(self):
"""
Tạo database trong mySQL
"""
try:
self.get_connected()
self.cur.execute(f"create database {self.database}")
except:
pass
def createTable(self, sql):
"""
Tạo bảng trong mySQL
:param sql:
:return:
"""
try:
self.get_connected()
self.cur.execute(sql)
except:
pass
def insert(self, sql, *params):
"""
Thêm dữ liệu vào database
:param sql: Câu lệnh truy vấn sql
:param params:Danh sách tham số
:return:
"""
try:
# self.get_connected()
self.cur.execute(sql, params)
self.conn.commit()
except Exception as err:
print(err)
def update(self, sql, *params):
"""
Cập nhật dữ liệu vào database
:param sql: Câu lệnh truy vấn sql
:param params: Danh sách tham số
:return:
"""
try:
self.get_connected()
self.cur.execute(sql, params)
self.conn.commit()
except:
pass
def delete(self, sql, *params):
"""
Xóa dữ liệu trong database
:param sql: Câu lệnh truy vấn sql
:param params: Danh sách tham số
:return:
"""
self.get_connected()
self.cur.execute(sql, params)
self.conn.commit()
def select_word(self):
"""
Truy vấn dữ liệu từ database
:return:
"""
try:
result = ()
self.get_connected()
self.cur.execute("SELECT * FROM word \n")
result = self.cur.fetchall()
# for x in result:
# print(x)
except:
pass
return result
def close(self):
"""
Đóng kết nối
:return:
"""
self.conn = None
self.cur = None
helper = DBHelper('127.0.0.1', 'root', '1234', '3306', 'baitap')
#test insert function
# f = open('3000words.txt', 'r')
# list1 = f.read()
# list1 = list1.split()
# sql = "insert into word(entry_word) values (%s)"
# for i in list1:
# helper.insert(sql, i)
#
# print('done') | true |
680484a2b6113c9cef121b556a7df51cfd1095bf | Python | AdiAlbum1/street-view-gan | /train.py | UTF-8 | 5,491 | 2.578125 | 3 | [] | no_license | import tensorflow as tf
import cv2
import os
import numpy as np
import time
import random
from constants import *
from data_generator import My_Data_Generator, load_all_images, define_batches
from models import make_generator_small_model, make_discriminator_small_model
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
# Load dataset to image_generator
# train_image_generator = My_Data_Generator(train_path, batch_size)
# val_image_generator = My_Data_Generator(val_path, batch_size)
train_images = load_all_images(train_path)
train_batches = define_batches(train_images, batch_size)
val_images = load_all_images(val_path)
val_batches = define_batches(val_images, batch_size)
# View dataset
# if DEBUG:
# train_image_generator.visualizer()
# Define Models
generator_model = make_generator_small_model(batch_size)
discriminator_model = make_discriminator_small_model()
# Summarize Models
if DEBUG:
print("GENERATOR:")
print(generator_model.summary())
print("\nDISCRIMINATOR:")
print(discriminator_model.summary())
# Define loss & optimizer
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
generator_optimizer = tf.keras.optimizers.Adam(1e-3)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-3)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator_model,
discriminator=discriminator_model)
EPOCHS = 400
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(batch):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
noise, real_images = batch
generated_images = generator_model(noise, training=True)
real_output = discriminator_model(real_images, training=True)
fake_output = discriminator_model(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator_model.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator_model.trainable_variables))
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator_model.trainable_variables)
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator_model.trainable_variables))
def calculate_batch_loss(batch):
noise, real_images = batch
generated_images = generator_model(noise, training=False)
real_output = discriminator_model(real_images, training=False)
fake_output = discriminator_model(generated_images, training=False)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
return gen_loss, disc_loss
def calculate_dataset_loss(dataset):
gen_loss = 0
disc_loss = 0
for batch in dataset:
curr_gen_loss, curr_disc_loss = calculate_batch_loss(batch)
gen_loss += curr_gen_loss
disc_loss += curr_disc_loss
gen_loss = gen_loss / len(dataset)
disc_loss = disc_loss / len(dataset)
return gen_loss, disc_loss
def train(train_images, val_images, epochs):
for epoch in range(epochs):
start = time.time()
train_dataset = define_batches(train_images, batch_size)
val_dataset = define_batches(val_images, batch_size)
print("EPOCH #"+str(epoch+1))
# TRAIN
for batch in train_dataset:
train_step(batch)
# CALCULATE EPOCH LOSS
train_gen_loss, train_disc_loss = calculate_dataset_loss(train_dataset)
val_gen_loss, val_disc_loss = calculate_dataset_loss(val_dataset)
print("\tTRAIN:\tgenerator_loss: ", train_gen_loss, " discriminator_loss: ", train_disc_loss)
print("\tVAL:\tgenerator_loss: ", val_gen_loss, " discriminator_loss: ", val_disc_loss)
# Save the model every epochs
checkpoint.save(file_prefix = checkpoint_prefix)
noise = tf.random.normal([1, random_vector_size])
generated_image = generator_model(noise, training=False)[0]
generated_image = np.uint8(((generated_image + 1) * 127.5))
generated_image = cv2.resize(generated_image, (160, 128), interpolation=cv2.INTER_CUBIC)
# cv2.imshow("generated_image", generated_image)
cv2.imwrite("gen_images//image_epoch_"+str(epoch)+".png", generated_image)
# cv2.waitKey(0)
print('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
print("PRE TRAINING LOSS")
train_gen_loss, train_disc_loss = calculate_dataset_loss(train_batches)
val_gen_loss, val_disc_loss = calculate_dataset_loss(val_batches)
print("\tTRAIN:\tgenerator_loss: ", train_gen_loss, " discriminator_loss: ", train_disc_loss)
print("\tVAL:\tgenerator_loss: ", val_gen_loss, " discriminator_loss: ", val_disc_loss)
print("START TRAINING")
train(train_images, val_images, EPOCHS)
| true |
1046739625847a9d6614e1891f507c9154682712 | Python | FreeFlyXiaoMa/pytorch_demo | /demo5.py | UTF-8 | 1,528 | 3.140625 | 3 | [] | no_license | # -*- coding: utf-8 -*-
# @Time :2019/11/14 19:35
# @Author :XiaoMa
# @File :demo5.py
import torch.nn as nn
import torch.nn.functional as F
import torch
class NNet(nn.Module):
def __init__(self):
super(NNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 3)
self.fc1 = nn.Linear(1350, 10)
# 正向传播
def forward(self, x):
print('01:',x.size()) # 结果:[1, 1, 32, 32]
# 卷积 -> 激活 -> 池化
x = self.conv1(x)
x = F.relu(x)
print('02:',x.size()) # 结果:[1, 6, 30, 30]
x = F.max_pool2d(x, (2, 2)) # 我们使用池化层,计算结果是15
x = F.relu(x)
print('03:',x.size()) # 结果:[1, 6, 15, 15]
# reshape,‘-1’表示自适应
# 这里做的就是压扁的操作 就是把后面的[1, 6, 15, 15]压扁,变为 [1, 1350]
x = x.view(x.size()[0], -1)
print('04:',x.size())
x = self.fc1(x)
return x
net=NNet()
input=torch.randn(1,1,32,32) #这是一个1x1x32x32的4维张量,元素遵循正太分布
# print(input)
out=net(input)
print(out.size())
for name,parameters in net.named_parameters():
print(name,':',parameters)
# net.zero_grad()
# out.backward(torch.ones(1,10))
#
y=torch.arange(0,10).view(1,10).float()
criterion=nn.MSELoss()
loss=criterion(out,y)
# print(loss.item())
optimizer=torch.optim.SGD(net.parameters(),lr=0.01)
optimizer.zero_grad() #效果与net.zero_grad()一样
loss.backward()
optimizer.step()
| true |
936d9c0ee99b9d273bc5e0bba2c8cfc8038a4399 | Python | marcv81-test/algo | /python/search/ternary.py | UTF-8 | 1,935 | 3.96875 | 4 | [] | no_license | # Ternary search, minimizes cost function
# Cost function must be unimodal on the search interval
def search(cost, start, stop, precision):
while stop - start > precision:
p1 = (2 * start + stop) / 3
p2 = (start + 2 * stop) / 3
if cost(p1) < cost(p2):
stop = p2
else:
start = p1
return start
# N-dimensional ternary search, minimizes cost function
# Cost function must be convex on the search interval
def search_dimensions(cost, dimension, starts, stops, precisions):
result = None
def partial_search(partial):
nonlocal cost, dimension, starts, stops, precisions, result
n = len(partial)
start = starts[n]
stop = stops[n]
precision = precisions[n]
while stop - start > precision:
x1 = (2 * start + stop) / 3
x2 = (start + 2 * stop) / 3
if n + 1 == dimension:
cost_x1 = cost(partial + [x1])
cost_x2 = cost(partial + [x2])
else:
cost_x1 = cost(partial_search(partial + [x1]))
cost_x2 = cost(partial_search(partial + [x2]))
if cost_x1 < cost_x2:
stop = x2
else:
start = x1
local_result = partial + [(start + stop) / 2]
if n + 1 == dimension:
result = local_result
return local_result
partial_search([])
return result
# Tests
import math
# Ternary seach test
def test(x):
return pow(x - 1, 2)
result = search(test, -100, 100, 1e-3)
assert math.fabs(result - 1) < 1e-3
# 2D ternary search test
# Rosenbrock's banana function
def banana(point):
x = 1 - point[0]
y = point[1] - point[0] * point[0]
return x * x + 100 * y * y
result = search_dimensions(banana, 2, (-100, -100), (100, 100), (1e-3, 1e-3))
assert math.fabs(result[0] - 1) < 1e-3
assert math.fabs(result[1] - 1) < 1e-3
| true |
b69d0fd54d771978d49cf809718caa3e3a77c13b | Python | bmoretz/Daily-Coding-Problem | /py/data_structures/LRUCache/__init__.py | UTF-8 | 4,020 | 3.9375 | 4 | [
"MIT"
] | permissive | '''LRU Cache.
Design and build a "least recently used" cache, which evicts the
least recently used item. The cache should map from keys to values
(allowing you to insert and retrieve a value associated with a
particular key) and be initialized with a max size. When it is full,
it should evict the least recently used item.
'''
class LRUCache():
'''
Key list is a doubly-linked list that supports two key
operations:
push front
pop back
keys will be inserted at the front through the push
front operation which is O(1). When we reach the max
key length (k), we simply remove the last element in
the list through the pop_back, which again is O(1).
'''
class KeyList():
class Node():
def __init__(self, data, prev=None, nxt=None):
self.data = data
self.next = nxt
self.prev = prev
def _unlink(self):
if self.prev:
self.prev.next = self.next
if self.next:
self.next.prev = self.prev
def __init__(self):
self.head = self.Node(None)
self.tail = self.Node(None, prev=self.head)
self.head.next, self.head.prev = self.tail, self.tail
self.length = 0
def front(self):
return self.head.next.data
'''
insert item into the list at the front.
O(1)
'''
def push_front(self, value):
new_node = self.Node(data=value, \
prev=self.head, nxt=self.head.next)
self.head.next.prev = new_node
self.head.next = new_node
self.length += 1
'''
remove item from the list from the back.
O(1)
'''
def pop_back(self):
value = self.tail.prev.data
self.tail.prev._unlink()
self.length -= 1
return value
'''
remove item from the list, regardless of position.
O(K)
'''
def remove(self, value):
node, prev = self.head, None
while node:
if node.data == value:
node._unlink()
self.length -= 1
break
node = node.next
def __len__(self):
return self.length
def __init__(self, k):
self._data = {}
self._keys = self.KeyList()
self._max = k
'''
insert item into the cache
if the key already exists (we leverage the existing hash table for the key
value pairs which is O(1), then we remove it (O(K))). This will help ensure
that the invariant of the latest item accessed (via inserted/retrieved) is
at the front of the list.
if we're at capacity of the cache, just remove the tail of the key list
and then delete that item from the hash table of k/v pairs.
lastly, push the key into the front of the key list and set the value
of the key in the data items hash table.
'''
def insert(self, key, value):
if key in self._data:
self._keys.remove(key)
elif len(self._keys) == self._max:
to_rem = self._keys.pop_back()
del self._data[to_rem]
self._keys.push_front(key)
self._data[key] = value
'''
if we have the key in the cache, remove it, then re-insert it
at the front of the key list and return the corresponding value
from the items hash table.
'''
def get(self, key):
if key in self._data:
if self._keys.front() != key:
self._keys.remove(key)
self._keys.push_front(key)
return self._data[key]
return None
def __str__(self):
return ', '.join([str(item) for item in self._data])
def __len__(self):
return len(self._data) | true |
53a62211bbb7d508ba275b9a29a9e5e3913ec203 | Python | dbbbbm/imle_and_glo | /networks.py | UTF-8 | 1,259 | 2.78125 | 3 | [] | no_license | import torch
import torch.nn as nn
class Generator(nn.Module):
def __init__(self, latent_dim=64):
super(Generator, self).__init__()
self.fc = nn.Sequential(
nn.Linear(64, 7 * 7 * 32),
nn.ReLU(),
)
self.conv = nn.Sequential(
nn.ConvTranspose2d(32, 16, 5, 2, 5//2, 1, bias=False),
nn.BatchNorm2d(16),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(16, 8, 5, 2, 5//2, 1, bias=False),
nn.BatchNorm2d(8),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(8, 1, 5, 1, 5//2, bias=False),
nn.Tanh()
)
def forward(self, x):
x = self.fc(x)
x = x.view(x.size(0), 32, 7, 7)
x = self.conv(x)
return x
class MLP(nn.Module):
def __init__(self, in_feat, hid_feat, out_feat):
super(MLP, self).__init__()
self.mlp = nn.Sequential(
nn.Linear(in_feat, hid_feat),
nn.BatchNorm1d(hid_feat),
nn.LeakyReLU(0.2),
nn.Linear(hid_feat, out_feat),
)
def forward(self, x):
return self.mlp(x)
if __name__ == '__main__':
g = Generator()
z = torch.randn(16, 64)
out = g(z)
print(out.shape)
| true |
b01ce45ee3cbeab1afc87729259843677239f230 | Python | xanxys/XFR1 | /XFR1P/program.py | UTF-8 | 10,801 | 2.65625 | 3 | [] | no_license | #!/bin/env python3
import sys
import serial
import binascii
import argparse
import time
import logging
# utility
def xorshift_hash(data):
h=0
for byte in data:
h=((h<<1)|(h>>7))^byte
return h
# representing real programmer (arduino) interface
# bit like RPC over serial
class Programmer:
def __init__(self,serial_path):
ser=serial.Serial(serial_path,19200)
logging.info('opened %s'%ser)
# hack: cf. http://stackoverflow.com/questions/8149628/pyserial-not-talking-to-arduino
# 2012/4/1: XFR1P is non-responding. gtkterm correctly.
# When I opened the port in gtkterm first, then it works correctly (although the readings
# are split in gtkterm and program.py)
# This hack seems to solve that port initiation problem.
ser.timeout=5
ser.readline()
ser.timeout=None
self.serial=ser
# low level function
def _send(self,command):
logging.debug('programmer<%s'%command)
self.serial.write(bytes(command+'\r\n','ASCII'))
self.serial.flush()
def _receive(self):
while True:
s=self.serial.readline().decode('ASCII').rstrip()
if s[0]=='#':
logging.debug('programmer:%s'%s)
elif s[0]=='-':
logging.debug('programmer:%s'%s)
return s[1:]
elif s[0]=='!':
raise IOError('programmer failed to complete the command for some reason')
else:
raise NotImplementedError(
'unknown status %s. Maybe firmware and driver code is not in sync'%s)
# exposed methods
def version(self):
self._send('v')
self._receive()
def enter_debug(self):
self._send('d')
self._receive()
def enter_normal(self):
self._send('n')
self._receive()
def send_byte(self,data):
self._send('s%02x'%data)
self._receive()
def recv_byte(self,timeout):
self._send('r%02x'%int(timeout))
return int(self._receive()[0:2],16)
# expose ring(XFR1) debug mode functionality via Programmer
class Ring(Programmer):
def get_power(self):
logging.info('checking power')
self.send_byte(2)
logging.info('waiting response')
v=self.recv_byte(10)
return 1.1/(v/256)
def read_buffer(self,addr):
logging.info('reading buffer offset 0x%02x'%addr)
self.send_byte(0)
self.send_byte(addr)
logging.info('waiting response')
v=self.recv_byte(10)
return v
def write_buffer(self,addr,data):
logging.info('writing buffer offset 0x%02x'%addr)
self.send_byte(1)
self.send_byte(addr)
self.send_byte(data)
logging.info('waiting response')
self.recv_byte(10)
def read_page(self,addr):
logging.info('reading page 0x%04x to buffer'%addr)
self.send_byte(4)
self.send_byte((addr>>8)&0xff)
self.send_byte(addr&0xff)
logging.info('waiting response')
self.recv_byte(255)
def write_page(self,addr):
logging.info('writing page 0x%04x from buffer'%addr)
self.send_byte(5)
self.send_byte((addr>>8)&0xff)
self.send_byte(addr&0xff)
logging.info('waiting response')
self.recv_byte(100)
def hash_buffer(self):
logging.info('calculating hash of buffer')
self.send_byte(3)
logging.info('waiting response')
return self.recv_byte(100)
# expose flash/buffer of Ring
class RingMemory(Ring):
# page level
def read_whole_page(self,addr):
def get_offset_with_retry(ofs):
retry=0
while retry<3:
try:
return self.read_buffer(ofs)
except IOError:
retry+=1
raise IOError('too many retries. aborting page read.')
print('reading page %04x'%addr)
self.read_page(addr)
vs=[get_offset_with_retry(i) for i in range(128)]
hr=self.hash_buffer()
hd=xorshift_hash(vs)
if hr!=hr: # data corruption
raise IOError('hash mismatch when transferring page: '+
'hash(dev)=%02x hash(data)=%02x'%(hr,hd))
return bytes(vs)
def write_whole_page(self,addr,data):
def set_offset_with_retry(ofs,d):
retry=0
while retry<3:
try:
self.write_buffer(ofs,d)
return
except IOError:
retry+=1
raise IOError('too many retries. aborting page write.')
print('writing page %04x'%addr)
for i in range(128):
set_offset_with_retry(i,data[i])
hr=self.hash_buffer()
hd=xorshift_hash(data)
if hr!=hr: # data corruption
raise IOError('hash mismatch when transferring page: '+
'hash(dev)=%02x hash(data)=%02x'%(hr,hd))
self.write_page(addr)
# hex level (bunch of highly localized (addr,data) pairs)
def program(self,datapath):
pages=pack_pages(decode_intel_hex(datapath))
print('writing %d bytes'%(len(pages)*128)) # not really correct estimate
print('%d pages to go'%len(pages))
for pa,pd in pages.items():
# page fetch needed if pd is partial
page=pd
if any([v==None for v in pd]):
page_curr=self.read_whole_page(pa)
if len(page_curr)!=len(pd):
raise IOError('page size mismatch')
page=bytes([pd[i] if pd[i]!=None else page_curr[i] for i in range(128)])
# write page
self.write_whole_page(pa,page)
print('#')
def verify(self,datapath):
pages=pack_pages(decode_intel_hex(datapath))
print('verifying %d bytes'%(len(pages)*128)) # not really correct estimate
print('%d pages to go'%len(pages))
for pa,pd in pages.items():
page=self.read_whole_page(pa)
if len(page)!=len(pd):
raise IOError('page size mismatch')
for i in range(128):
if pd[i]!=None and page[i]!=pd[i]:
print('Error in page %04x, offset %02x'%(pa,i))
print('expected:%02x'%pd[i])
print('read:%02x'%page[i])
return False
return True
# see http://en.wikipedia.org/wiki/Intel_HEX
def decode_intel_hex(path):
def parse_line(l):
if l[0]!=':':
raise IOError('expected ":"')
else:
byte_count=int(l[1:3],16)
address=int(l[3:7],16)
rec_type=int(l[7:9],16)
if rec_type==0:
return {'address':address,'data':bytes.fromhex(l[9:9+2*byte_count])}
elif rec_type==1:
return None # EoF record
elif rec_type==3:
return None # start segment address record
else:
raise NotImplementedError('unknown record type %d'%rec_type)
return list(filter(lambda x:x!=None,[parse_line(l) for l in open(path,'r') if l!='']))
def pack_pages(cs):
'''
Take chunks from decode_intel_hex(...).
returns pageaddress -> [None or data]
'''
def align(x):
return x&0xff80
pages={}
for c in cs:
addr_st=c['address']
for ofs,d in enumerate(c['data']):
addr=addr_st+ofs
pa=align(addr)
po=addr-pa
page=pages.get(pa,[None]*128)
page[po]=d
pages[pa]=page
return pages
def proc(args,fn):
prog=RingMemory(args.port)
if not args.noreset_enter:
prog.enter_debug()
time.sleep(0.5)
fn(prog)
if not args.noreset_leave:
time.sleep(0.5)
prog.enter_normal()
def main():
ps=argparse.ArgumentParser(description='optical programmer')
ps.add_argument('-P',dest='port',help='port path (typically /dev/ttyUSBn)',required=True)
ps.add_argument('--addr',dest='addr',help='memory address to read/write (in bytes)')
ps.add_argument('--data',dest='data',help='hex value or path to intel hex file')
ps.add_argument('--noreset_enter',dest='noreset_enter',default=False,const=True,
action='store_const',help="don't reset to debug mode when entering session")
ps.add_argument('--noreset_leave',dest='noreset_leave',default=False,const=True,
action='store_const',help="don't reset to normal mode when leaving session")
ps.add_argument('--debug',dest='loglevel',default=logging.WARNING,const=logging.DEBUG,
action='store_const',help='enable very verbose logging')
ps.add_argument('command',choices=[
'_status','_read','_write','_hash','_read_page','_write_page', # Ring
'read_page','write_page',
'program','verify'
])
args=ps.parse_args()
logging.basicConfig(level=args.loglevel)
## low level interface
if args.command=='_status':
proc(args,lambda p:print('Vcc=%.1f V'%(p.get_power())))
# buffer manipulation
elif args.command=='_read':
proc(args,lambda p:print(p.read_buffer(int(args.addr,16))))
elif args.command=='_write':
proc(args,lambda p:p.write_buffer(int(args.addr,16),int(args.data,16)))
elif args.command=='_hash':
proc(args,lambda p:print('hash=%02x'%p.hash_buffer()))
# page manipulation
elif args.command=='_read_page':
proc(args,lambda p:p.read_page(int(args.addr,16)))
elif args.command=='_write_page':
proc(args,lambda p:p.write_page(int(args.addr,16)))
## high level interface
elif args.command=='read_page':
proc(args,lambda p:print(binascii.hexlify(p.read_whole_page(int(args.addr,16)))))
elif args.command=='write_page':
proc(args,lambda p:p.write_whole_page(int(args.addr,16),bytes.fromhex(args.data)))
## common interface
elif args.command=='program':
def p_and_v(p):
p.program(args.data)
if p.verify(args.data):
print('programmed successfully!')
else:
print('program failed')
proc(args,p_and_v)
elif args.command=='verify':
def v(p):
if p.verify(args.data):
print('verify ok!')
else:
print('verify failed')
proc(args,v)
if __name__=='__main__':
main()
| true |
31ddec03e11a0351b90e9b7f265696d202c6d928 | Python | msarahan/chaco | /chaco/scales/formatters.py | UTF-8 | 23,402 | 3.28125 | 3 | [
"BSD-3-Clause",
"LicenseRef-scancode-unknown-license-reference",
"LicenseRef-scancode-public-domain"
] | permissive | """
Classes for formatting labels for values or times.
"""
from math import ceil, floor, fmod, log10
from numpy import abs, all, array, asarray, amax, amin
from safetime import strftime, time, safe_fromtimestamp, localtime
import warnings
__all__ = ['NullFormatter', 'BasicFormatter', 'IntegerFormatter',
'OffsetFormatter', 'TimeFormatter', 'strftimeEx']
class NullFormatter(object):
""" Formatter for empty labels.
"""
def format(ticks, numlabels=None, char_width=None):
""" Returns a list containing an empty label for each item in *ticks*.
"""
return [""] * len(ticks)
def estimate_width(start, end, numlabels=None, char_width=None):
""" Returns 0 for width and 0 for number of labels.
"""
return 0, 0
class BasicFormatter(object):
""" Formatter for numeric labels.
"""
# This is a class-level default that is related to the algorithm in format()
avg_label_width = 7.0
# Toggles whether or not to use scientific notation when the values exceed
# scientific_limits
use_scientific = True
# Any number smaller than 10 ** limits[0] or larger than 10 ** limits[1]
# will be represented using scientific notiation.
scientific_limits = (-3, 5)
def __init__(self, **kwds):
# Allow the user to override the class-level defaults.
self.__dict__.update(kwds)
def oldformat(self, ticks, numlabels=None, char_width=None):
""" This function is adapted from matplotlib's "OldScalarFormatter".
Parameters
----------
ticks : array of numbers
The tick values to be formatted.
numlabels
Not used.
char_width
Not used.
Returns
-------
List of formatted labels.
"""
labels = []
if len(ticks) == 0:
return []
d = abs(ticks[-1] - ticks[0])
for x in ticks:
if abs(x)<1e4 and x==int(x):
labels.append('%d' % x)
continue
if d < 1e-2: fmt = '%1.3e'
elif d < 1e-1: fmt = '%1.3f'
elif d > 1e5: fmt = '%1.1e'
elif d > 10 : fmt = '%1.1f'
elif d > 1 : fmt = '%1.2f'
else: fmt = '%1.3f'
s = fmt % x
tup = s.split('e')
if len(tup)==2:
mantissa = tup[0].rstrip('0').rstrip('.')
sign = tup[1][0].replace('+', '')
exponent = tup[1][1:].lstrip('0')
if sign or exponent:
s = '%se%s%s' %(mantissa, sign, exponent)
else:
s = mantissa
else:
s = s.rstrip('0').rstrip('.')
labels.append(s)
return labels
def format(self, ticks, numlabels=None, char_width=None, fill_ratio=0.3):
""" Does "nice" formatting of floating-point numbers. *numlabels* is
ignored in this method.
"""
if len(ticks) == 0:
return []
ticks = asarray(ticks)
if self.use_scientific:
scientific = (((ticks % 10 ** self.scientific_limits[1]) == 0) |
(abs(ticks) <= 10 ** self.scientific_limits[0])).all()
else:
scientific = False
if scientific:
if char_width is not None:
# We need to determine how many digits we can use in the
# mantissa based on the order of magnitude of the exponent.
chars_per_label = int(char_width * fill_ratio / len(ticks))
maxtick = amax(abs(ticks))
if maxtick > 0:
exp_oom = str(int(floor(log10(maxtick))))
else:
exp_oom = "0"
emax = len(exp_oom)
if chars_per_label < emax:
# We're sort of hosed. Use a minimum 3 chars for the mantissa.
mmax = 3
else:
mmax = chars_per_label - emax - 1
else:
mmax = -1
labels = [self._nice_sci(x, mmax) for x in ticks]
else:
# For decimal mode,
if not (ticks % 1).any():
labels = map(str, ticks.astype(int))
else:
labels = map(str, ticks)
return labels
def _nice_sci(self, val, mdigits, force_sign=False):
""" Formats *val* nicely using scientific notation. *mdigits* is the
max number of digits to use for the mantissa. If *force_sign* is True,
then always show the sign of the mantissa, otherwise only show the sign
if *val* is negative.
"""
if val != 0:
e = int(floor(log10(abs(val))))
else:
e = 0
m = val / float(10**e)
m_str = str(m)
# Safely truncating the mantissa is somewhat tricky. The minimum
# length of the mantissa is everything up to (but not including) the
# period. If the m_str doesn't have a decimal point, then we have to
# ignore mdigits.
if mdigits > 0 and "." in m_str:
max_len = max(m_str.index("."), mdigits)
m_str = m_str[:max_len]
# Strip off a trailing decimal
if m_str[-1] == ".":
m_str = m_str[:-1]
# It's not sufficient just to truncate the string; we need to
# handle proper rounding
else:
# Always strip off a trailing decimal
if m_str[-1] == ".":
m_str = m_str[:-1]
if force_sign and not m_str.startswith("-"):
m_str = "+" + m_str
if e != 0:
# Clean up the exponent
e_str = str(e)
if e_str.startswith("+") and not force_sign:
e_str = e_str[1:]
m_str += "e" + e_str
return m_str
def estimate_width(self, start, end, numlabels=None, char_width=None,
fill_ratio=0.3, ticker=None):
""" Returns an estimate of the total number of characters used by the
the labels for the given set of inputs, as well as the number of labels.
Parameters
----------
start : number
The beginning of the interval.
end : number
The end of the interval.
numlabels : number
The ideal number of labels to generate on the interval.
char_width : number
The total character width available for labelling the interval.
fill_ratio : 0.0 < float <= 1.0
Ratio of the available width that will be occupied by label text.
ticker : AbstractScale object
Object that can calculate the number of labels needed.
Returns
-------
(numlabels, total label width)
"""
if numlabels == 0 or char_width == 0:
return 0, 0
# use the start and end points as ticks and average their label sizes
labelsizes = map(len, self.format([start, end]))
avg_size = sum(labelsizes) / 2.0
if ticker:
if numlabels:
initial_estimate = numlabels
elif char_width:
initial_estimate = round(fill_ratio * char_width / avg_size)
est_ticks = ticker.num_ticks(start, end, initial_estimate)
elif numlabels:
est_ticks = numlabels
elif char_width:
est_ticks = round(fill_ratio * char_width / avg_size)
return est_ticks, est_ticks * avg_size
class IntegerFormatter(BasicFormatter):
""" Format integer tick labels as integers.
"""
def format(self, ticks, numlabels=None, char_width=None, fill_ratio=0.3):
""" Formats integer tick labels.
"""
return map(str, map(int, ticks))
class OffsetFormatter(BasicFormatter):
""" This formatter is like BasicFormatter, but it supports formatting
ticks using an offset. This is useful for viewing small ranges within
big numbers.
"""
# Whether or not to use offsets when labelling the ticks. Note that
# even if this is true, offset are only used when the ratio of the data
# range to the average data value is smaller than a threshold.
use_offset = False
# The threshold ratio of the data range to the average data value, below
# which "offset" display mode will be used if use_offset is True.
offset_threshold = 1e-3
# Determines which ticks to display the offset value at. Can be "all",
# "firstlast", or "none".
offset_display = "firstlast"
# Determines which format to use to display the end labels. Can be
# "offset" or "sci".
end_label_format = "offset"
# Specifies the threshold values
offset_limits = (-3, 4)
# There are two possible formats for the offset.
#
# "sci"
# uses scientific notation for the offset
# "decimal"
# pads with zeroes left or right until the decimal
#
# The following table shows some example ranges and how an intermediate
# tick will be displayed. These all assume an offset_display value of
# "none" or "firstlast".
#
# ============ ========== ========= =========
# start end sci decimal
# ============ ========== ========= =========
# 90.0004 90.0008 5.0e-4 .0005
# 90.0004 90.0015 1.2e-3 .0012
# -1200015 -1200003 12 12
# 2300015000 2300015030 1.502e4 15020
# ============ ========== ========= =========
#
offset_format = "sci"
# The offset generated by the last call to format()
offset = None
def _compute_offset(self, ticks):
first, last = ticks[0], ticks[-1]
data_range = ticks[-1] - ticks[0]
range_oom = int(ceil(log10(data_range)))
pow_of_ten = 10 ** range_oom
if all(asarray(ticks) < 0):
return ceil(amax(ticks) / pow_of_ten) * pow_of_ten
else:
return floor(amin(ticks) / pow_of_ten) * pow_of_ten
def format(self, ticks, numlabels=None, char_width=None):
if len(ticks) == 0:
return []
data_range = ticks[-1] - ticks[0]
avg_data = sum(abs(ticks)) / len(ticks)
if self.use_offset and data_range/avg_data < self.offset_threshold:
offset = self._compute_offset(ticks)
intermed_ticks = asarray(ticks) - offset
if self.offset_format == "sci":
labels = BasicFormatter.format(self, intermed_ticks)
else:
# have to decide between %d and %f here. also have to
# strip trailing "0"s.. test with %g.
labels = ["%g" % i for i in intermed_ticks]
if offset > 0:
sign = "+"
else:
sign = ""
offset_str = BasicFormatter.format(self, [offset])[0] + sign
if self.offset_display == "firstlast":
if self.end_label_format == "offset":
labels[0] = offset_str + labels[0]
labels[-1] = offset_str + labels[-1]
else:
labels[0] = BasicFormatter.format(self, [ticks[0]])[0]
labels[-1] = BasicFormatter.format(self, [ticks[-1]])[0]
elif self.offset_display == "all":
labels = [offset_str + label for label in labels]
return labels
else:
return BasicFormatter.format(self, ticks, numlabels, char_width)
def estimate_width(self, start, end, numlabels=None, char_width=None,
fill_ratio=0.3, ticker=None):
if numlabels == 0 or char_width == 0:
return (0, 0)
if ticker:
if numlabels:
initial_estimate = numlabels
elif char_width:
avg_size = len("%g%g" % (start, end)) / 2.0
initial_estimate = round(fill_ratio * char_width / avg_size)
est_ticks = int(ticker.num_ticks(start, end, initial_estimate))
elif numlabels:
est_ticks = numlabels
elif char_width:
est_ticks = round(fill_ratio * char_width / avg_size)
start, mid, end = map(len, self.format([start, (start+end)/2.0, end]))
if est_ticks > 2:
size = start + end + (est_ticks-2) * mid
else:
size = start + end
return est_ticks, size
def strftimeEx(fmt, t, timetuple=None):
"""
Extends time.strftime() to format milliseconds and microseconds.
Expects input to be a floating-point number of seconds since epoch.
The additional formats are:
- ``%(ms)``: milliseconds (uses round())
- ``%(ms_)``: milliseconds (uses floor())
- ``%(us)``: microseconds (uses round())
The format may also be a callable which will bypass time.strftime() entirely.
"""
if callable(fmt):
return fmt(t)
if "%(ms)" in fmt:
# Assume that fmt does not also contain %(ms_) and %(us).
# (It really doesn't make sense to mix %(ms) with those.)
secs, frac = divmod(round(t,3), 1)
ms = int(round(1e3*frac))
fmt = fmt.replace("%(ms)", "%03d" % ms)
else:
# Assume fmt contains %(ms_) and %(us).
secs, frac = divmod(round(t,6), 1)
ms = int(round(1e3*frac))
ms_, us = divmod(int(round(1e6*frac)),1000)
fmt = fmt.replace("%(ms_)", "%03d" % ms_)
fmt = fmt.replace("%(us)", "%03d" % us)
if not timetuple:
timetuple = localtime(secs)
return strftime(fmt, timetuple)
def _two_digit_year(t):
""" Round to the nearest Jan 1, roughly.
"""
dt = safe_fromtimestamp(t)
year = dt.year
if dt.month >= 7:
year += 1
return "'%02d" % (year % 100)
def _four_digit_year(t):
""" Round to the nearest Jan 1, roughly.
"""
dt = safe_fromtimestamp(t)
year = dt.year
if dt.month >= 7:
year += 1
return str(year)
class TimeFormatter(object):
""" Formatter for time values.
"""
# This table of format is convert into the 'formats' dict. Each tuple of
# formats must be ordered from shortest to longest.
_formats = {
'microseconds': ('%(us)us', '%(ms_).%(us)ms'),
'milliseconds': ('%(ms)ms', '%S.%(ms)s'),
'seconds': (':%S', '%Ss'),
'minsec': ('%M:%S',), # '%Mm%S', '%Mm%Ss'),
'minutes': ('%Mm',),
'hourmin': ('%H:%M',), #'%Hh%M', '%Hh%Mm', '%H:%M:%S','%Hh %Mm %Ss'),
'hours': ('%Hh', '%H:%M'),
'days': ('%m/%d', '%a%d',),
'months': ('%m/%Y', '%b%y'),
'years': (_two_digit_year, _four_digit_year),
}
# Labels of time units, from finest to coarsest.
format_order = ['microseconds', 'milliseconds', 'seconds', 'minsec', 'minutes',
'hourmin', 'hours', 'days', 'months', 'years']
# A dict whose are keys are the strings in **format_order**; each value is
# two arrays, (widths, format strings/functions).
formats = {}
# Whether or not to strip the leading zeros on tick labels.
strip_leading_zeros = True
def __init__(self, **kwds):
self.__dict__.update(kwds)
self._compute_format_weights()
def _compute_format_weights(self):
if self.formats:
return
for fmt_name, fmt_strings in self._formats.items():
sizes = []
tmptime = time()
for s in fmt_strings:
size = len(strftimeEx(s, tmptime))
sizes.append(size)
self.formats[fmt_name] = (array(sizes), fmt_strings)
return
def _get_resolution(self, resolution, interval):
r = resolution
span = interval
if r < 5e-4:
resol = "microseconds"
elif r < 0.5:
resol = "milliseconds"
elif r < 60:
if span > 60:
resol = "minsec"
else:
resol = "seconds"
elif r < 3600:
if span > 3600:
resol = "hourmin"
else:
resol = "minutes"
elif r < 24*3600:
resol = "hours"
elif r < 30*24*3600:
resol = "days"
elif r < 365*24*3600:
resol = "months"
else:
resol = "years"
return resol
def format(self, ticks, numlabels=None, char_width=None, fill_ratio = 0.3,
ticker=None):
""" Formats a set of time values.
Parameters
----------
ticks : array of numbers
The tick values to be formatted
numlabels
Not used.
char_width : number
The total character width available for labelling the interval.
fill_ratio : 0.0 < float <= 1.0
Ratio of the available width that will be occupied by label text.
ticker : AbstractScale object
Object that can calculate the number of labels needed.
Returns
-------
List of formatted labels.
"""
# In order to pick the right set of labels, we need to determine
# the resolution of the ticks. We can do this using a ticker if
# it's provided, or by computing the resolution from the actual
# ticks we've been given.
if len(ticks) == 0:
return []
span = abs(ticks[-1] - ticks[0])
if ticker:
r = ticker.resolution
else:
r = span / (len(ticks) - 1)
resol = self._get_resolution(r, span)
widths, formats = self.formats[resol]
format = formats[0]
if char_width:
# If a width is provided, then we pick the most appropriate scale,
# otherwise just use the widest format
good_formats = array(formats)[widths * len(ticks) < fill_ratio * char_width]
if len(good_formats) > 0:
format = good_formats[-1]
# Apply the format to the tick values
labels = []
resol_ndx = self.format_order.index(resol)
# This dictionary maps the name of a time resolution (in self.format_order)
# to its index in a time.localtime() timetuple. The default is to map
# everything to index 0, which is year. This is not ideal; it might cause
# a problem with the tick at midnight, january 1st, 0 a.d. being incorrectly
# promoted at certain tick resolutions.
time_tuple_ndx_for_resol = dict.fromkeys(self.format_order, 0)
time_tuple_ndx_for_resol.update( {
"seconds" : 5,
"minsec" : 4,
"minutes" : 4,
"hourmin" : 3,
"hours" : 3,
})
# As we format each tick, check to see if we are at a boundary of the
# next higher unit of time. If so, replace the current format with one
# from that resolution. This is not the best heuristic in the world,
# but it works! There is some trickiness here due to having to deal
# with hybrid formats in a reasonable manner.
for t in ticks:
try:
tm = localtime(t)
s = strftimeEx(format, t, tm)
except ValueError, e:
warnings.warn("Unable to convert tick for timestamp " + str(t))
labels.append("ERR")
continue
hybrid_handled = False
next_ndx = resol_ndx
# The way to check that we are at the boundary of the next unit of
# time is by checking that we have 0 units of the resolution, i.e.
# we are at zero minutes, so display hours, or we are at zero seconds,
# so display minutes (and if that is zero as well, then display hours).
while tm[ time_tuple_ndx_for_resol[self.format_order[next_ndx]] ] == 0:
next_ndx += 1
if next_ndx == len(self.format_order):
break
if resol in ("minsec", "hourmin") and not hybrid_handled:
if (resol == "minsec" and tm.tm_min == 0 and tm.tm_sec != 0) or \
(resol == "hourmin" and tm.tm_hour == 0 and tm.tm_min != 0):
next_format = self.formats[self.format_order[resol_ndx-1]][1][0]
s = strftimeEx(next_format, t, tm)
break
else:
hybrid_handled = True
next_format = self.formats[self.format_order[next_ndx]][1][0]
s = strftimeEx(next_format, t, tm)
if self.strip_leading_zeros:
ss = s.lstrip('0')
if ss != s and (ss == '' or not ss[0].isdigit()):
# A label such as '000ms' should leave one zero.
ss = '0' + ss
labels.append(ss)
else:
labels.append(s)
return labels
def estimate_width(self, start, end, numlabels=None, char_width=None,
fill_ratio = 0.2, ticker=None):
""" Returns an estimate of the total number of characters used by the
the labels for the given set of inputs, as well as the number of labels.
Parameters
----------
start : number
The beginning of the interval.
end : number
The end of the interval.
numlabels : number
The ideal number of labels to generate on the interval.
char_width : number
The total character width available for labelling the interval.
fill_ratio : 0.0 < float <= 1.0
Ratio of the available width that will be occupied by label text.
ticker : AbstractScale object
Object that can calculate the number of labels needed.
Returns
-------
(numlabels, total label width)
"""
if numlabels == 0 or char_width == 0:
return 0, 0
if ticker is None or not hasattr(ticker, "unit"):
raise ValueError("TimeFormatter requires a scale.")
if not numlabels:
numlabels = ticker.num_ticks(start, end)
span = abs(end - start)
if ticker:
r = ticker.resolution
else:
r = span / numlabels
unit = self._get_resolution(r, span)
if unit == "milliseconds":
return numlabels, numlabels * 6
widths, strings = self.formats[unit]
if char_width:
# Find an appropriate resolution in self.formats and pick between
# the various format strings
good_widths = widths[widths * numlabels < fill_ratio * char_width]
if len(good_widths) == 0:
# All too big, pick the first label
width = widths[0]
else:
# Pick the largest label that fits
width = good_widths[-1]
width *= numlabels
else:
# Just pick the middle of the pack of format widths
width = widths[ int(len(widths) / 2) ] * numlabels
return numlabels, width
| true |
ef712b664b0a7d3a4633aac0a37adc3c0a23c86b | Python | pershint/ANNIETools | /ANNIENtupleAnalysis/util/EffPlot.py | UTF-8 | 1,167 | 2.90625 | 3 | [] | no_license | # coding: utf-8
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_context("poster")
sns.set(font_scale=2.5)
sns.set_style("whitegrid")
sns.axes_style("darkgrid")
def myfunction():
### 5 HIT, 100 NS CLUSTER VALUES ####
eff = [0.64,0.57,0.46]
vert_eff = [0.35]
vert_radius = [102]
pos_vunc = [np.sqrt(0.03**2 + 0.01**2)]
neg_vunc = [0.02]
radius = [0, 75, 102]
pos_unc = [np.sqrt(0.03**2 + 0.01**2), np.sqrt(0.03**2 + 0.01**2), np.sqrt(0.02**2 + 0.01**2)]
neg_unc = [0.02,0.02,np.sqrt(0.03**2 + 0.01**2)]
plt.errorbar(vert_radius,vert_eff, yerr=[neg_vunc,pos_vunc], marker='o',color='red',linestyle='None',label='$y = +100 \, cm$',markersize=12,elinewidth=4)
plt.errorbar(radius,eff, yerr=[neg_unc,pos_unc], marker='o',color='blue',label='$y = 0 \, cm$',markersize=12,linestyle='None',elinewidth=4)
leg = plt.legend(loc=1,fontsize=24)
leg.set_frame_on(True)
leg.draw_frame(True)
plt.title("Neutron detection efficiency as detector radius varies")
plt.xlabel("Radius [cm]")
plt.ylabel("Neutron detection efficiency $\epsilon_{n}$")
plt.show()
myfunction()
| true |
416520d74b9b54313b86697add09f95d7002bd7b | Python | spirali/haydi | /examples/cerny/cerny.py | UTF-8 | 1,902 | 3.640625 | 4 | [
"MIT"
] | permissive |
# Script for verifying Cerny's conjuncture
#
# This programs goes over finite state automata of a given
# size and finds the maximal length of a minimal reset word
import haydi as hd
from haydi.algorithms import search
def main():
n_states = 6 # Number of states
n_symbols = 2 # Number of symbols in alphabet
states = hd.USet(n_states, "q") # set of states q0, q1, ..., q_{n_states}
alphabet = hd.USet(n_symbols, "a") # set of symbols a0, ..., a_{a_symbols}
# Mappings (states * alphabet) -> states
delta = hd.Mappings(states * alphabet, states)
# Let us precompute some values that will be repeatedly used
init_state = frozenset(states)
max_steps = (n_states**3 - n_states) / 6
def check_automaton(delta):
# This function takes automaton as a transition function and
# returns the minimal length of synchronizing word or 0 if there
# is no such word
def step(state, depth):
# A step in bread-first search; gives a set of states
# and return a set reachable by one step
for a in alphabet:
yield frozenset(delta[(s, a)] for s in state)
delta = delta.to_dict()
return search.bfs(
init_state, # Initial state
step, # Step
lambda state, depth: depth if len(state) == 1 else None,
# Run until we reach a single state
max_depth=max_steps, # Limit depth of search
not_found_value=0) # Return 0 when we exceed depth limit
# Create & run pipeline
pipeline = delta.cnfs().map(check_automaton).max(size=1)
result = pipeline.run()
print ("The maximal length of a minimal reset word for an "
"automaton with {} states and {} symbols is {}.".
format(n_states, n_symbols, result[0]))
if __name__ == "__main__":
main()
| true |
127f52eab274c44a60faf22d6ed2185013ea9d52 | Python | m-fatema/upwork-math-questions | /question_by_category/category_ab.py | UTF-8 | 2,271 | 3.046875 | 3 | [] | no_license | import random
class CategoryABQuestions:
def __init__(self):
pass
def generate_question(self, eq_var: list, coeffs: list, root: int, category='A'):
correct = [*list(coeffs), sum(coeffs)]
answer = (
" ".join(
f"{'' if coeffs[i] < 0 else '+ ' if i else ''}{eq_var[i]}"
for i in range(len(coeffs))
)
+ " = "
).replace("-", "- ")
if answer.startswith("-"):
answer = answer[0] + answer[2:]
answer += (
"( "
+ " ".join(
f"___ {('-' if coeffs[i + 1] < 0 else '+') if i < len(coeffs) - 1 else ''}"
for i in range(len(coeffs))
)
+ ")"
) + f"sqrt({root}) = ___ * sqrt({root})"
correct, answer = self.format_output_for_category_a_b(root, correct, answer, category, coeffs)
res = {
"question": answer,
"correct": ";".join(str(n) for n in correct),
}
return res
def format_output_for_category_a_b(self, root: int, correct: list, answer: str,
category: str, coeffs: list) -> [list, str]:
if category == 'A':
if (root ** 0.5) % 1 == 0:
correct = self.get_final_ans_for_sum(root, correct, sum(coeffs))
answer += f" = ___ * ___ = ___"
elif category == 'BT' or category == 'BF':
if category == 'BF':
offset = random.randint(-10, 10)
offset = offset if offset != 0 else -1
coeffs.append(offset)
if (root ** 0.5) % 1 == 0:
correct = [self.get_final_ans_for_sum(root, correct, sum(coeffs))[-1]]
answer += " = ___"
else:
correct = [correct[-1]] if category == 'BT' else [sum(coeffs)]
ans = answer.split(' = ')
answer = ans[0] + " = " + ans[-1]
return correct, answer
def get_final_ans_for_sum(self, root: int, correct: list, coeffs: int) -> list:
correct += [int(root ** 0.5)]
correct += [coeffs * correct[-1]]
return correct | true |
38a51c27fd532b2910b56c655376521317c06016 | Python | int-brain-lab/iblrig | /scripts/register_screen_lux.py | UTF-8 | 557 | 2.640625 | 3 | [
"MIT"
] | permissive | import iblrig.params as params
import datetime
pars = params.load_params_file()
print(f"\nPrevious value on [{pars['SCREEN_LUX_DATE']}] was [{pars['SCREEN_LUX_VALUE']}]")
value = input("\nPlease input the value of the luxometer (lux): ")
pars["SCREEN_LUX_VALUE"] = float(value)
pars["SCREEN_LUX_DATE"] = str(datetime.datetime.now().date())
print(" Updating local params file...")
lpars = params.update_params_file(pars)
print(
"\nLux measurement updated on",
f"[{lpars['SCREEN_LUX_DATE']}] with value [{lpars['SCREEN_LUX_VALUE']}]",
"\n",
)
| true |
32f96485888ee238fa86de42e6d1d8fb2c2adca4 | Python | ziFieYu/YCSpider | /spider/instances/inst_parse.py | UTF-8 | 3,927 | 2.796875 | 3 | [] | no_license | # _*_ coding: utf-8 _*_
"""
inst_parse.py by xianhu
"""
import re
import random
import logging
import datetime
from ..utilities import get_url_legal, params_chack, return_check
class Parser(object):
"""
class of Parser, must include function working() and htm_parse()
"""
def __init__(self, max_deep=0, max_repeat=3):
"""
constructor
"""
self.max_deep = max_deep # default: 0, if -1, spider will not stop until all urls are fetched
self.max_repeat = max_repeat # default: 3, maximum repeat time for parsing content
self.log_str_format = "priority=%s, keys=%s, deep=%s, critical=%s, parse_repeat=%s, url=%s"
return
@params_chack(object, int, str, object, int, bool, int, (list, tuple))
def working(self, priority, url, keys, deep, critical, parse_repeat, content):
"""
working function, must "try, except" and call self.htm_parse(), don't change parameters and return
:param priority: the priority of this url, which can be used in this function
:param keys: some information of this url, which can be used in this function
:param deep: the deep of this url, which can be used in this function
:param critical: the critical flag of this url, which can be used in this function
:param parse_repeat: the parse repeat time of this url, if parse_repeat >= self.max_repeat, return code = -1
:param content: the content of this url, which needs to be parsed, content is a tuple or list
:return (code, url_list, save_list): code can be -1(parse failed), 0(need repeat), 1(parse success)
:return (code, url_list, save_list): url_list is [(url, keys, critical, priority), ...], save_list is [item, ...]
"""
logging.debug("Parser start: %s", self.log_str_format % (priority, keys, deep, critical, parse_repeat, url))
try:
code, url_list, save_list = self.htm_parse(priority, url, keys, deep, critical, parse_repeat, content)
except Exception as excep:
if parse_repeat >= self.max_repeat:
code, url_list, save_list = -1, [], []
logging.error("Parser error: %s, %s", excep, self.log_str_format % (priority, keys, deep, critical, parse_repeat, url))
else:
code, url_list, save_list = 0, [], []
logging.debug("Parser repeat: %s, %s", excep, self.log_str_format % (priority, keys, deep, critical, parse_repeat, url))
logging.debug("Parser end: code=%s, len(url_list)=%s, len(save_list)=%s, url=%s", code, len(url_list), len(save_list), url)
return code, url_list, save_list
@return_check(int, (tuple, list), (tuple, list))
def htm_parse(self, priority, url, keys, deep, critical, parse_repeat, content):
"""
parse the content of a url, you can rewrite this function, parameters and return refer to self.working()
"""
# parse content(cur_code, cur_url, cur_html)
_, cur_html = content
# get url_list and save_list
url_list = []
if (self.max_deep < 0) or (deep < self.max_deep):
a_list = re.findall(r"<a[\w\W]+?href=\"(?P<url>[\w\W]+?)\"[\w\W]*?>[\w\W]+?</a>", cur_html, flags=re.IGNORECASE)
url_list = [(_url, keys, critical, priority+1) for _url in [get_url_legal(href, url) for href in a_list]]
title = re.search(r"<title>(?P<title>[\w\W]+?)</title>", cur_html, flags=re.IGNORECASE)
save_list = [(url, title.group("title"), datetime.datetime.now()), ] if title else []
# test cpu task
count = 0
for i in range(1000):
for j in range(1000):
count += ((i*j) / 1000)
# test parsing error
if random.randint(0, 5) == 3:
parse_repeat += (1 / 0)
# return code, url_list, save_list
return 1, url_list, save_list
| true |
3bff9821cb4b6cee88bb4dbbe9f8f49ace64f8e6 | Python | mijanur-rahman-40/digital-signal-processing-assignments | /dft_5/dft.py | UTF-8 | 1,353 | 3.515625 | 4 | [] | no_license |
import math
def DFT(x):
x_regular = x
x_imaginary = []
dft_regular, dft_imaginary = [], []
index_range_len = len(x_regular)
for i in range(len(x_regular)):
x_imaginary.append(0.0)
for k in range(index_range_len):
dft_regular_value, dft_imaginary_value = 0.0, 0.0
for n in range(index_range_len):
value_regular = x_regular[n] \
* (math.cos((2 * math.pi / index_range_len) * k * n)) \
+ x_imaginary[n] \
* (math.sin((2 * math.pi / index_range_len) * k * n))
value_imaginary = x_regular[n] \
* (-math.sin((2 * math.pi / index_range_len) * k * n)) \
+ x_imaginary[n] \
* (math.cos((2 * math.pi / index_range_len) * k * n))
dft_regular_value += value_regular
dft_imaginary_value += value_imaginary
dft_regular.append(round(dft_regular_value))
dft_imaginary.append(round(dft_imaginary_value))
return dft_regular, dft_imaginary
if __name__ == "__main__":
num = input("Give the values of signal x(n): ")
x = [int(i) for i in num.split()]
dft_re_array, dft_im_array = DFT(x)
print("\nDiscreate Fourier Transform :")
for i in range(len(dft_re_array)):
print(f'X[{i}] : ({dft_re_array[i]} {dft_im_array[i]}j)')
| true |
b0e2c72bceac56f50f9d48b532633a4e13cd3db7 | Python | ayuranjan/ARESNAL | /python-program/project/daa/try2.py | UTF-8 | 153 | 3.125 | 3 | [] | no_license | def double_values(collection):
for v in range(len(collection)):
collection[v] = collection[v] * 2
d = {1: 10, 2: 20, 3: 30}
double_values(d) | true |
643c3ac0782276b58835f94bd371551284ec68fc | Python | AlterraDeveloper/ProgrammingBasics_python | /lab4/1.4.1.py | UTF-8 | 78 | 3.5625 | 4 | [] | no_license | a = []
for i in range (0,1000):
a.append(i)
print(len(a))
print(a[1000])
| true |
eadde87e2001387b81e0ba3ba444bd74e898ade3 | Python | SashaVin/karantin_project | /project_1.py | UTF-8 | 4,037 | 3.625 | 4 | [] | no_license |
def film_of_act(actor, dct, lst):
for j in dct.keys():
if actor in dct[j]:
lst.append(j)
return lst
with open('film.txt', encoding='utf-8') as film:
lst_film = film.readlines()
name = []
actors = set()
dct_f_act = {}
for i in lst_film:
a, b = i.split(': ')
name.append(a)
z = b.split(', ')
z[-1] = z[-1][:-4]
lst_actors = set(z)
actors = actors.union(lst_actors)
dct_f_act[a] = lst_actors
q = 0
while q > -1:
print('1. Работа с фильмами\n2. Работа с актерами')
q = int(input('Выберите тип работы (1 или 2): '))
print()
if q == 1:
print(name)
print('1. Определить актерский состав двух фильмов\n2. Определить актеров, игравших в обоих фильмах')
print('3. Определить актеров, участвующих в съемках первого, но не участвующих в съемках второго')
print('4. Вернуться в прошлое меню')
r = int(input('Введите действие (1, 2, 3 или 4): '))
print()
if r == 1:
f1 = input('Введите название первого фильма: ')
f2 = input('Введите название второго фильма: ')
print(dct_f_act[f1] | dct_f_act[f2])
elif r == 2:
f1 = input('Введите название первого фильма: ')
f2 = input('Введите название второго фильма: ')
print(dct_f_act[f1] & dct_f_act[f2])
elif r == 3:
f1 = input('Введите название первого фильма: ')
f2 = input('Введите название второго фильма: ')
print(dct_f_act[f1] - dct_f_act[f2])
print()
v = input('Хотите повторить? (да или нет) ')
if v == 'да':
q += 1
else:
q = -1
elif q == 2:
print(actors)
print('1. Определить названия фильмов, в которых снимался хотя бы один из актеров')
print('2. Определить названия фильмов, в которых снимались оба актера')
print('3. Определить названия фильмов, в которых снимался первый актер, но не участвовал второй')
print('4. Вернуться в прошлое меню')
r = int(input('Введите действие (1, 2, 3 или 4): '))
print()
if r == 1:
lst_1 = []
lst_2 = []
a1 = input('Введите имя первого актера: ')
a2 = input('Введите имя второго актера: ')
a_1 = set(film_of_act(a1, dct_f_act, lst_1))
a_2 = set(film_of_act(a2, dct_f_act, lst_2))
print(a_1 | a_2)
elif r == 2:
lst_1 = []
lst_2 = []
a1 = input('Введите имя первого актера: ')
a2 = input('Введите имя второго актера: ')
a_1 = set(film_of_act(a1, dct_f_act, lst_1))
a_2 = set(film_of_act(a2, dct_f_act, lst_2))
print(a_1 & a_2)
elif r == 3:
lst_1 = []
lst_2 = []
a1 = input('Введите имя первого актера: ')
a2 = input('Введите имя второго актера: ')
a_1 = set(film_of_act(a1, dct_f_act, lst_1))
a_2 = set(film_of_act(a2, dct_f_act, lst_2))
print(a_1 - a_2)
print()
v = input('Хотите повторить? (да или нет) ')
if v == 'да':
q += 1
else:
q = -1
| true |
90ab53a02178869ffa0c71c9be46677f15f76e72 | Python | dr-dos-ok/Code_Jam_Webscraper | /solutions_python/Problem_201/1693.py | UTF-8 | 1,994 | 3.1875 | 3 | [] | no_license |
fout = open('BathroomStalls-small1gcj.out', 'w')
def lp(s, n):
return (n-len(s))*'0'+s
def doprint(s):
print(s)
fout.write(s+'\n')
def close():
fout.close()
import heapq
import math
class MyHeap(object):
def __init__(self, initial=None, key=lambda x:x):
self.key = key
if initial:
self._data = [(key(item), item) for item in initial]
heapq.heapify(self._data)
else:
self._data = []
def push(self, item):
heapq.heappush(self._data, (self.key(item), item))
def pop(self):
return heapq.heappop(self._data)[1]
# PriorityQueue Question
# while numremoved < K...
# split all the ones at the head of the pq
T = int(input())
for tc in range(1,T+1):
h = []
N, K = list(map(int, input().split()))
heapq.heappush(h, (-N, N, 1))
lside = 0
rside = 0
nremoved = 0
while nremoved < K:
ncanremove = h[0][2]
ntoremove = min(K-nremoved, ncanremove)
cnum = h[0][1]
#h[0][2] -= ntoremove
if ntoremove == ncanremove: #h[0][2] == 0: # !!! this will leave it incorrect for the last one
heapq.heappop(h)
if ntoremove > 0: # always
lside = math.floor((cnum-1)/2.0)
rside = math.ceil((cnum-1)/2.0) # or reversed lside and rside
heapq.heappush(h, (-lside, lside, ntoremove))
heapq.heappush(h, (-rside, rside, ntoremove))
nremoved += ntoremove
#print(h)
#ans = str(h[0][1]) + " "+ str(heapq.nlargest(1, h)[0][1])
#print(h)
ans = str(max(lside, rside)) + " " + str(min(lside, rside))
doprint("Case #"+str(tc)+": "+str(ans))
close()
'''
4
9 1
100 1
1000 1
10 2
'''
'''
4
5000 5000
90000 30000
900000 500000
900000 400000
'''
'''
3
4 2
5 2
6 2
'''
'''
5
4 2
5 2
6 2
1000 1000
1000 1
'''
| true |
5c75aaa5dc71eefff8c5862f2f812e64ed59205b | Python | chenj233/Interesting-Algorithms | /HappyBirthday1.py | UTF-8 | 1,794 | 3.0625 | 3 | [] | no_license | import tkinter as tk
import random
import threading
import time
def dow(a,b):
window = tk.Tk()
width = window.winfo_screenwidth()
height = window.winfo_screenheight()
'''
a = random.randrange(0,width)
b = random.randrange(0,height)
'''
window.title("生日快乐")
window.geometry("150x120" + "+" + str(a) + "+" + str(b))
tk.Label(window,
text = "生日快乐",
bg = "Purple",
font = ('楷体',19),
fg = '#fcce03',
width = 13,
height = 5).pack()
window.overrideredirect(1)
window.mainloop()
threads = []
threads2 = []
threads3 = []
threads4 = []
threads5 = []
threads6 = []
threads7 = []
for i in range(8):
t = threading.Thread(target=dow,args = (220,125*i+30))
threads.append(t)
time.sleep(0.1)
threads[i].start()
for j in range(8):
t2 = threading.Thread(target=dow,args = (520,125*j+30))
threads2.append(t2)
time.sleep(0.1)
threads2[j].start()
for k in range(8):
t3 = threading.Thread(target=dow,args = (820,125*k+30))
threads3.append(t3)
time.sleep(0.1)
threads3[k].start()
for x in range(8):
t4 = threading.Thread(target=dow,args = (1120,125*x+30))
threads4.append(t4)
time.sleep(0.1)
threads4[x].start()
for y in range(3):
t5 = threading.Thread(target=dow,args = (1270+y*150,905))
threads5.append(t5)
time.sleep(0.1)
threads5[y].start()
for n in range(7):
t6 = threading.Thread(target=dow,args = (1570,780-125*n))
threads6.append(t6)
time.sleep(0.1)
threads6[n].start()
for m in range(2):
t7 = threading.Thread(target=dow,args = (1420-m*150,30))
threads7.append(t7)
time.sleep(0.1)
threads7[m].start() | true |
bc8ca45ea0eb898ccc7c008499876818687a0a7b | Python | AngelAmadeus/CD | /Practica 11.2 Regresion Logistica.py | UTF-8 | 10,226 | 3.46875 | 3 | [] | no_license | #Practica 11.2: Regresión Logística
import numpy as np
import pandas as pd
import sklearn.metrics as sk
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.preprocessing import PolynomialFeatures
#%%Importación de Datos
data=pd.read_csv('../Data/BD_LogReg_SVM.txt',header=None)
X=data.iloc[:,0:2]
Y=data.iloc[:,2]
plt.scatter(X[0],X[1],c=Y)
plt.title('Cúmulo de Datos')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
#%% Inicializar variables
ngrado_1=13 #Grado del polinomio para la forma 1
grados_1 = np.arange(1,ngrado_1)
ngrado_2=13 #Grado del polinomio para la forma 2
grados_2 = np.arange(1,ngrado_2)
poly_1=PolynomialFeatures(ngrado_1)
poly_2=PolynomialFeatures(ngrado_2)
Xasterisco_1=poly_1.fit_transform(X) #es el x modificado, el que se le agrega la fila de 1's
Xasterisco_2=poly_2.fit_transform(X) #es el x modificado, el que se le agrega la fila de 1's
#%%Formas de Modelar la regresión Logística
#Para la forma 1
logreg_1=linear_model.LogisticRegression(C=1e20) #Forma 1 (polinomios de grado pequeño)
logreg_1.fit(Xasterisco_1,Y)
Yg_1=logreg_1.predict(Xasterisco_1) # Y estimada (Y gorrito)
#Para la forma 2
logreg_2=linear_model.LogisticRegression(C=1) #Forma 2 (polinomios de grado grande)
#La forma 2 es preferible, evita overfitting y evitas errores en todo el proceso
logreg_2.fit(Xasterisco_2,Y)
Yg_2=logreg_2.predict(Xasterisco_2) # Y estimada (Y gorrito)
#%%Interpretacion de resultados
#lo que se genera es una supercicie, la cual se corta en el eje z = 0 dando resultado
#a las líneas que encierran o limitan los grupos. Aqui se crean los valores que tomará
#la superficie para despues ajustarse a los modelos.
x1=np.arange(-1,1,0.01)
x2=np.arange(-1,1,0.01)
#Todos los puntos posibles
X1,X2=np.meshgrid(x1,x2)
m,n=np.shape(X1)
X1r=np.reshape(X1,(m*n,1))
m,n=np.shape(X2)
X2r=np.reshape(X2,(m*n,1))
#%%Nueva tabla
Xnew=np.append(X1r,X2r, axis=1) #axis=1 las pega por filas, hace dos columnas
Xasterisco_new_1=poly_1.fit_transform(Xnew)
Xasterisco_new_2=poly_2.fit_transform(Xnew)
Yg_1=logreg_1.predict(Xasterisco_new_1)
Yg_2=logreg_2.predict(Xasterisco_new_2)
#%% Acomodarlo a su forma original
#Graficar la magnitud
fig, axes = plt.subplots(nrows = 1, ncols = 2, figsize = (10,3))
#Forma 1
Z_1=np.reshape(Yg_1,(m,n))
Z_1=np.round(Z_1)
axes[0].contour(X1,X2,Z_1)
axes[0].scatter(X[0],X[1],c=Y)
axes[0].set_title('Fronteras entre x1 y x2 (Forma 1)')
#Forma 2
Z_2=np.reshape(Yg_2,(m,n))
Z_2=np.round(Z_2)
axes[1].contour(X1,X2,Z_2)
axes[1].scatter(X[0],X[1],c=Y)
axes[1].set_title('Fronteras entre x1 y x2 (Forma 2)')
#Formato
for ax in axes:
ax.yaxis.grid(True)
ax.set_xlabel('x1')
ax.set_ylabel('x2')
plt.show()
#%% Medir el desempeño del modelo
#Para la forma 1
Yg_1 = logreg_1.predict(Xasterisco_1) #prediccion del modelo
cfm_1 = sk.confusion_matrix(Y,Yg_1) #matriz de confusión
accuracy_1 = sk.accuracy_score(Y,Yg_1)
precision_1 = sk.precision_score(Y,Yg_1)
recall_1 = sk.recall_score(Y,Yg_1)
f1_1 = sk.f1_score(Y,Yg_1)
num_variables_1 = np.zeros(grados_1.shape)#cantidad de variables del polinomio
#Para la forma 2
Yg_2 = logreg_2.predict(Xasterisco_2) #prediccion del modelo
cfm_2 = sk.confusion_matrix(Y,Yg_2) #matriz de confusión
accuracy_2 = sk.accuracy_score(Y,Yg_2)
precision_2 = sk.precision_score(Y,Yg_2)
recall_2 = sk.recall_score(Y,Yg_2)
f1_2 = sk.f1_score(Y,Yg_2)
num_variables_2 = np.zeros(grados_2.shape) #cantidad de variables del polinomio
#Nota: Los valores de la matriz de confusión representan lo siguiente
#(primer componente es y_estimada (filas), y segundo componente y_real (columnas))
#(0,0) = TrueNegative
#(0,1) = FalseNegative
#(1,0) = FalsePositive
#(1,1) = TruePositive
#Sabiendo lo anterior, hay 4 indicadores que nos ayudan a medir el desempeño del modelo
#Accuracy = (TP+TN)/(TP + FP + FN + TN), esto es igual al Emparejamiento Simple
#Precision = (TP)/(TP + FP)
#Recall = (TP)/(TP + FN)
#F1 = (2*Precision*Recall)/(Precision + Recall)
#Graficar la magnitud
fig, axes = plt.subplots(nrows = 1, ncols = 2, figsize = (10,3))
#Forma 1
W_1 = logreg_1.coef_
axes[0].bar(np.arange(len(W_1[0])),W_1[0])
axes[0].set_title('Caracteristicas del Modelo (Forma 1)')
#Forma 2
W_2 = logreg_2.coef_
axes[1].bar(np.arange(len(W_2[0])),W_2[0])
axes[1].set_title('Caracteristicas del Modelo (Forma 2)')
#Formato
for ax in axes:
ax.yaxis.grid(True)
ax.set_xlabel('Número de Varible (x´s)')
ax.set_ylabel('Valor del Coeficiente (w´s)')
plt.show()
#%%Buscar el polinomio "optimo". Esto es para la forma 2 es decir, donde C = 1
#Como no se que polinomio me conviene, intento con varios, analizo y luego elijo.
ngrado = 15 #Grado del polinomio
grados = np.arange(1,ngrado)
ACCURACY = np.zeros(grados.shape)
PRECISION = np.zeros(grados.shape)
RECALL = np.zeros(grados.shape)
F1 = np.zeros(grados.shape)
NUM_VARIABLES = np.zeros(grados.shape)
#%%Modelo de regresión lineal
for ngrado in grados:
poly=PolynomialFeatures(ngrado)
Xasterisco=poly.fit_transform(X) #es el x modificado, el que se le grega la fila de 1's
logreg = linear_model.LogisticRegression(C=1)
logreg.fit(Xasterisco,Y) #Entrena el modelo
Yg=logreg.predict(Xasterisco) #Sacar el "y" estimado
#Guardar las variables en las matrices
NUM_VARIABLES[ngrado-1] = len(logreg.coef_[0])
ACCURACY[ngrado-1] = sk.accuracy_score(Y,Yg) #Emparejamiento Simple
PRECISION[ngrado-1] = sk.precision_score(Y,Yg) #Precision
RECALL[ngrado-1] = sk.recall_score(Y,Yg) #Recall
F1[ngrado-1] = sk.f1_score(Y,Yg) #F1
#%% Anlaizar los coeficientes más significativos y reducirlo
#Graficar Valores
fig, axes = plt.subplots(nrows = 1, ncols = 2, figsize = (10,3))
# Visualizar los resultados
axes[0].plot(grados,ACCURACY)
axes[0].plot(grados,PRECISION)
axes[0].plot(grados,RECALL)
axes[0].plot(grados,F1)
axes[0].legend(('Accuracy','Precision','Recall','F1'))
axes[0].set_title('Resultados de los Indicadores')
axes[0].set_ylabel('Porcentaje del Índice')
#Visualizar el grado de polinomio
W_sig = logreg.coef_[0]
Wabs = np.abs(W_sig)
umbral = 0.5 #umbral que indica que tan significante o insignificante es el valor de un parámetro
indx = Wabs>umbral
Xasterisco_seleccionada = Xasterisco[:,indx] #Sub matriz de x asterisco con las variables de los parametros significativos
axes[1].plot(grados,NUM_VARIABLES)
axes[1].set_title('Grado del Polinomio')
axes[0].set_ylabel('Número de Parámetros (w´s)')
#(Por lo que se observa en las graficas la respuesta sería el poinomio de grado 2 ó 4 ó 6)
#Formato
for ax in axes:
ax.yaxis.grid(True)
ax.xaxis.grid(True)
ax.set_xlabel('Grado del Polinomio')
ax.set_ylabel('Valor del Parámetro (w´s)')
plt.show()
#%%Seleccionar el grado óptimo del análisis anterior
ngrado = 4
poly = PolynomialFeatures(ngrado)
Xasterisco = poly.fit_transform(X)
logreg = linear_model.LogisticRegression(C=1)
logreg.fit(Xasterisco,Y)
Yg = logreg.predict(Xasterisco)
sk.accuracy_score(Y,Yg) #Porcentaje de acierto en total, y lo muestra en la terminal
#%% Anlaizar los coeficientes más significativos y reducirlo
#Graficar Valores
fig, axes = plt.subplots(nrows = 1, ncols = 2, figsize = (10,3))
# Anlaizar los coeficientes
W = logreg.coef_[0]
axes[0].bar(np.arange(len(W)),W)
axes[0].set_title('Relación Varaible-Valor del Parametro')
#Reducido
W_sig = logreg.coef_[0]
Wabs = np.abs(W_sig)
umbral = 0.5 #umbral que indica que tan significante o insignificante es el valor de un parámetro
indx = Wabs>umbral
Xasterisco_seleccionada = Xasterisco[:,indx] #Sub matriz de x asterisco con las variables de los parametros significativos
axes[1].bar(np.arange(len(W[indx])),W[indx])
axes[1].set_title('Relación Varaible-Valor del Parametro Significativos')
#Formato
for ax in axes:
ax.yaxis.grid(True)
ax.set_xlabel('Número de Varible (x´s)')
ax.set_ylabel('Valor del Parámetro (w´s)')
plt.show()
#%%Reentrenar el modelo con las variables seleccionadas
logreg_entrenada = linear_model.LogisticRegression(C=1)
logreg_entrenada.fit(Xasterisco_seleccionada,Y)
Yg_entrenado = logreg_entrenada.predict(Xasterisco_seleccionada)
sk.accuracy_score(Y,Yg_entrenado) #Porcentaje de acierto en total, y lo muestra en la terminal
diferencia = sk.accuracy_score(Y,Yg) - sk.accuracy_score(Y,Yg_entrenado)
print('la diferencia en porcentaje de aciertos del modelo entrenado y no entrenado es: ')
print(diferencia)
#Se observa que pese a tener menos variables, el porcentaje de accuracy score entrenado
#y el porcentahe de acierto sin entrenar, es el mismo. Es decir que con menos variables
#se llegó exactamente al mismo resultado. (con umbral de 0.5)
#%% Segundo criterio: Eliminar coeficientes en orden ascendente
indx = np.argsort(Wabs)[::-1] #ordena de forma ascendente
features = np.arange(1,len(indx)) #lsita que indica las variables que seran seleccionadas, es decir que primero hara el modelo con
#una caracteristica (la mpas significativa), despuesde con la primera y la segunda más significativa, y asi sucesivamente
ACCURACY = np.zeros(grados.shape)
PRECISION = np.zeros(grados.shape)
RECALL = np.zeros(grados.shape)
F1 = np.zeros(grados.shape)
for nfeatures in features:
Xasterisco_seleccionada = Xasterisco[:,indx[0:nfeatures]]
logreg = linear_model.LogisticRegression(C=1)
logreg.fit(Xasterisco_seleccionada,Y)
Yg=logreg.predict(Xasterisco_seleccionada)
ACCURACY[nfeatures-1] = sk.accuracy_score(Y,Yg) #Emparejamiento Simple
PRECISION[nfeatures-1] = sk.precision_score(Y,Yg) #Precision
RECALL[nfeatures-1] = sk.recall_score(Y,Yg) #Recall
F1[nfeatures-1] = sk.f1_score(Y,Yg) #F1
#%%Visuaizar los datos en una tabla
#ACCURACY = pd.DataFrame(ACCURACY, columns=['ACCURACY'])
#PRECISION = pd.DataFrame(PRECISION, columns=['PRECISION'])
#RECALL = pd.DataFrame(RECALL, columns=['RECALL'])
#F1 = pd.DataFrame(F1, columns=['F1'])
#NUM_VARIABLES = pd.DataFrame(NUM_VARIABLES, columns=['NUM_VARIABLES'])
#Indicadores_de_Similitud = ACCURACY.join(PRECISION).join(RECALL).join(F1).join(NUM_VARIABLES)
| true |
131f9e4717cb79242b4e49f44477ec8f555a7035 | Python | asp2809/Genetic-Algorithm | /Travelling-Salesperson-Problem/TSPLexicographicOrder.py | UTF-8 | 5,430 | 3.4375 | 3 | [] | no_license | # -----------------------------------------------------------------------------
#
# TSP Using Lexicographic Order
#
# Language - Python
# Modules - pygame, sys, random, copy, math
# By - Jatin Kumar Mandav
#
# Website - https://jatinmandav.wordpress.com
#
# YouTube Channel - https://www.youtube.com/mandav
# GitHub - github.com/jatinmandav
# Twitter - @jatinmandav
#
# -----------------------------------------------------------------------------
import pygame
import sys
import random
import copy
import math
pygame.init()
width = 800
height = 450
display = pygame.display.set_mode((width, height))
clock = pygame.time.Clock()
pygame.display.set_caption("TSP Lexicographical Order")
background = (50, 50, 50)
white = (236, 240, 241)
violet = (136, 78, 160)
purple = (99, 57, 116)
points = 10
d = 10
bestEverOrder = []
bestDistance = 0
order = []
count = 0.0
x = -1
pause = False
class Cities:
def __init__(self, x, y):
self.x = x
self.y = y
def reset():
global bestEverOrder, bestDistance, order, x, count, pause
count = 0.0
order = []
x = -1
bestEverOrder = []
bestDistance = 0
pause = False
def main_loop():
loop = True
cities = []
global bestEverOrder, bestDistance, order, x, count, pause, points
reset()
font = pygame.font.SysFont("Times New Roman", 20)
## for i in range(points):
## order.append(i)
## x = random.randrange(10, width/2-10)
## y = random.randrange(40, height-10)
## i = Cities(x, y)
## cities.append(i)
pointsF = open("points.txt", "r")
data = pointsF.readlines()
pointsF.close()
points = len(data)
for i in range(len(data)):
data[i] = data[i].split(" ")
data[i][0] = int(data[i][0])
data[i][1] = int(data[i][1])
for i in range(len(data)):
order.append(i)
i = Cities(data[i][0], data[i][1])
cities.append(i)
bestDistance = total_distance(cities)
bestEverOrder = copy.deepcopy(order)
while loop:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
sys.exit()
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_q:
pygame.quit()
sys.exit()
if event.key == pygame.K_r:
main_loop()
display.fill(background)
dist = total_distance(cities)
if dist < bestDistance:
bestDistance = dist
bestEverOrder = copy.deepcopy(order)
next_order()
draw(cities)
currenttext = font.render("Current Distance : " + str(dist), True, white)
display.blit(currenttext, (50, height - 30))
text = font.render("Shortest Distance so Far : " + str(bestDistance), True, white)
display.blit(text, (width / 2, height - 30))
pygame.display.update()
if x == -1:
pause = True
pauseUnpause()
clock.tick(60)
def draw(cities):
percentage = (count/math.factorial(points))*100.0
font = pygame.font.SysFont("Times New Roman", 25)
text2 = font.render("Algorithm : Lexicographic Order", True, white)
display.blit(text2, (70, 10))
text = font.render("{0:.2f}".format(percentage) + " % Completed", True, white)
display.blit(text, (width/2 + 100, 10))
for i in range(len(order)):
index = order[i]
pygame.draw.ellipse(display, white, (cities[index].x, cities[index].y, d, d))
for i in range(len(order)-1):
pygame.draw.line(display, white, (cities[order[i]].x + d/2, cities[order[i]].y+d/2), (cities[order[i+1]].x+d/2, cities[order[i+1]].y+d/2), 1)
for i in range(len(order) - 1):
pygame.draw.line(display, purple, (width/2 + cities[bestEverOrder[i]].x + d / 2, cities[bestEverOrder[i]].y + d / 2),
(width/2 + cities[bestEverOrder[i + 1]].x + d / 2, cities[bestEverOrder[i + 1]].y + d / 2), 3)
for i in range(len(bestEverOrder)):
index = bestEverOrder[i]
pygame.draw.ellipse(display, white, (width/2 + cities[index].x, cities[index].y, d, d))
def next_order():
global order, count, x
x = -1
count += 1.0
for i in range(len(order) - 1):
if order[i] < order[i + 1]:
x = i
y = 0
for j in range(len(order)):
if order[x] < order[j]:
y = j
swap(order, x, y)
order[x + 1:] = reversed(order[x + 1:])
def swap(a, i, j):
temp = a[i]
a[i] = a[j]
a[j] = temp
def total_distance(a):
dist = 0
for i in range(len(order)-1):
dist += math.sqrt((a[order[i]].x - a[order[i+1]].x)**2 + (a[order[i]].y - a[order[i+1]].y)**2)
return dist
def pauseUnpause():
global pause
while pause:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
sys.exit()
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_q:
pygame.quit()
sys.exit()
if event.key == pygame.K_r:
pause = False
main_loop()
main_loop()
| true |
850aa6cff5e860df2e8fcd5ab862beb07ca809f8 | Python | pgDora56/ProgrammingContest | /AtCoder/ABC1/ABC109/ABC109-C.py | UTF-8 | 317 | 2.9375 | 3 | [] | no_license | import fractions
from functools import reduce
def gcd_list(numbers):
return reduce(fractions.gcd, numbers)
n, x0 = map(int, input().split())
x = list(map(int,input().split()))
x.append(x0)
x.sort()
xdiff = []
tmp = x[0]
for xs in x:
if xs - tmp == 0: continue
xdiff.append(xs-tmp)
print(gcd_list(xdiff)) | true |
d62c927266fd9a72b19f7d70a05338c3b2882735 | Python | ninjaboynaru/my-python-demo | /algorithms/tree/kdtree.py | UTF-8 | 1,264 | 3.375 | 3 | [] | no_license | from collections import namedtuple
from pprint import pformat
class Node(namedtuple("Node", "coord left right")):
def __repr__(self):
return pformat(tuple(self))
# class Node:
# def __init__(self, coord, left=None, right=None):
# self.coord = coord
# self.left = left
# self.right = right
# def __str__(self):
# return self._strHelper(self, "")
# def _strHelper(self, tree, indent):
# out = "{}{}".format(indent, tree.coord)
# if tree.left is not None:
# out += "\n{}".format(
# self._strHelper(tree.left, indent+" "))
# if tree.right is not None:
# out += "\n{}".format(
# self._strHelper(tree.right, indent+" "))
# return out
def kdtree(lst, axis=0):
if len(lst) == 0:
return None
dim = len(lst[0])
lst.sort(key=lambda x: x[axis])
medianIdx = len(lst) // 2
leftLst = lst[:medianIdx]
rightLst = lst[medianIdx+1:]
t = Node(lst[medianIdx],
kdtree(leftLst, (axis+1) % dim),
kdtree(rightLst, (axis+1) % dim))
return t
if __name__ == "__main__":
lst = [(2, 3), (5, 4), (9, 6), (4, 7), (8, 1), (7, 2), (10, 10)]
t = kdtree(lst)
print(t)
| true |