

Add 1 files
Browse files- 2406/2406.08196.md +218 -0
2406/2406.08196.md
ADDED
|
@@ -0,0 +1,218 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
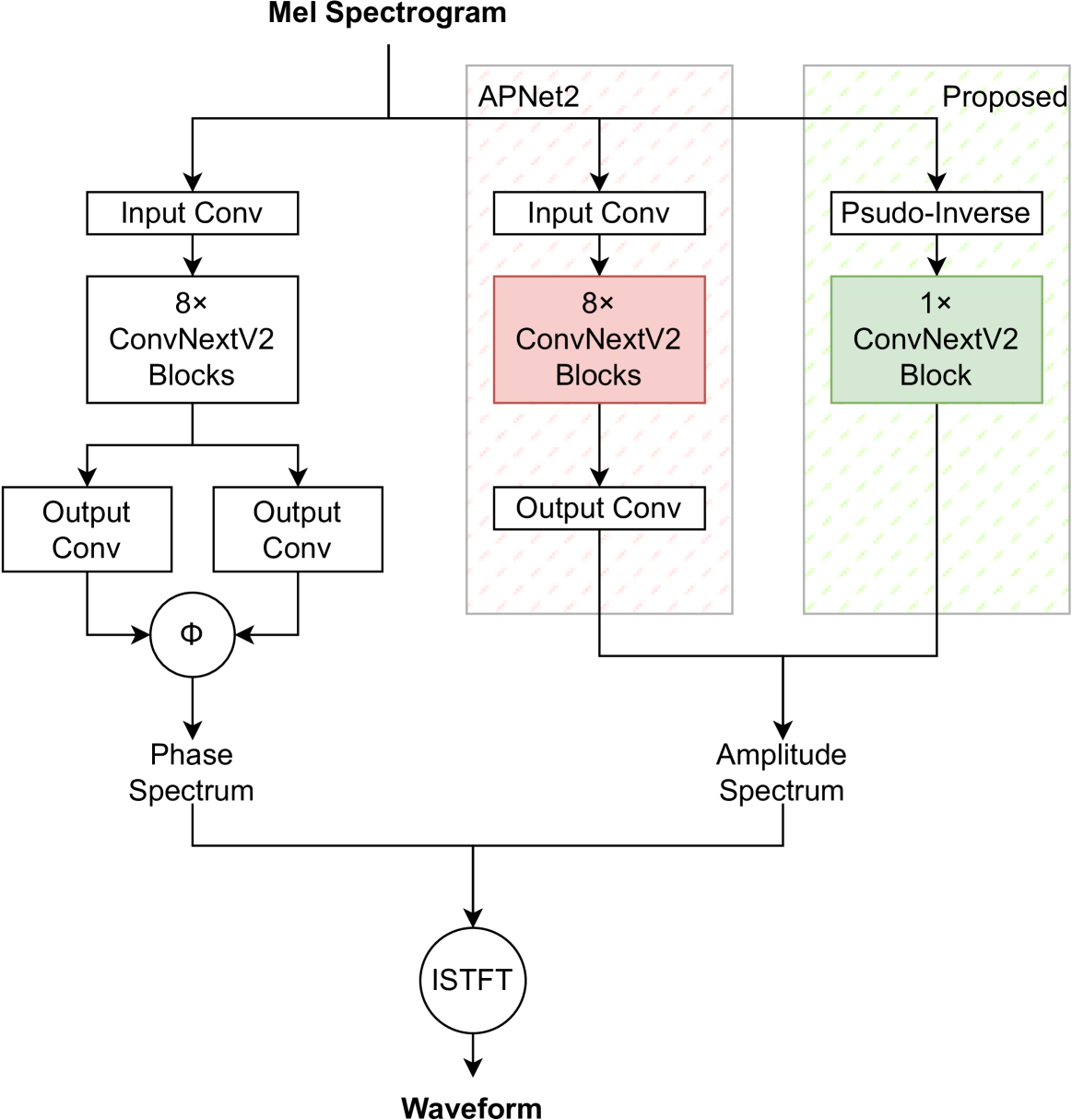
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
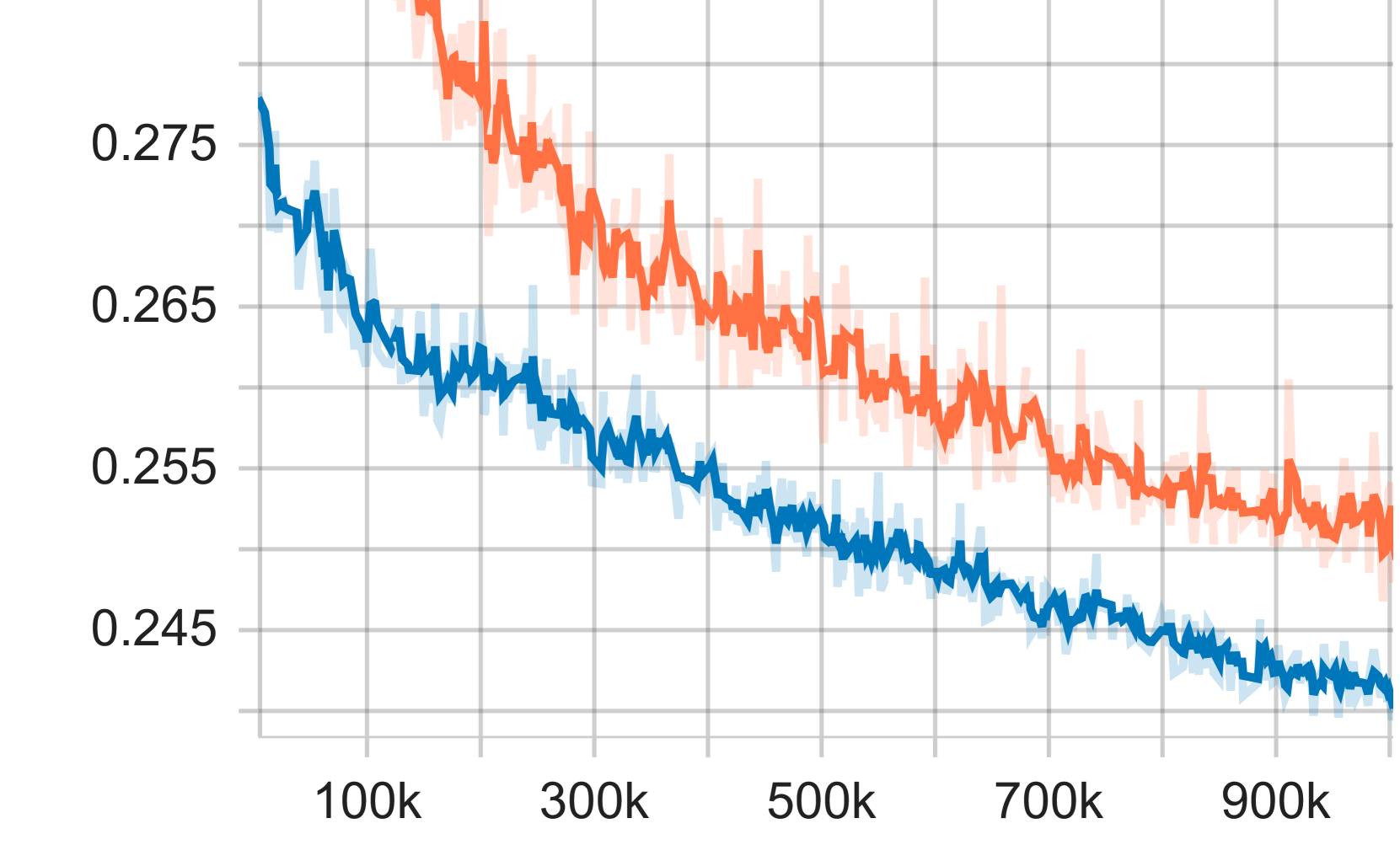
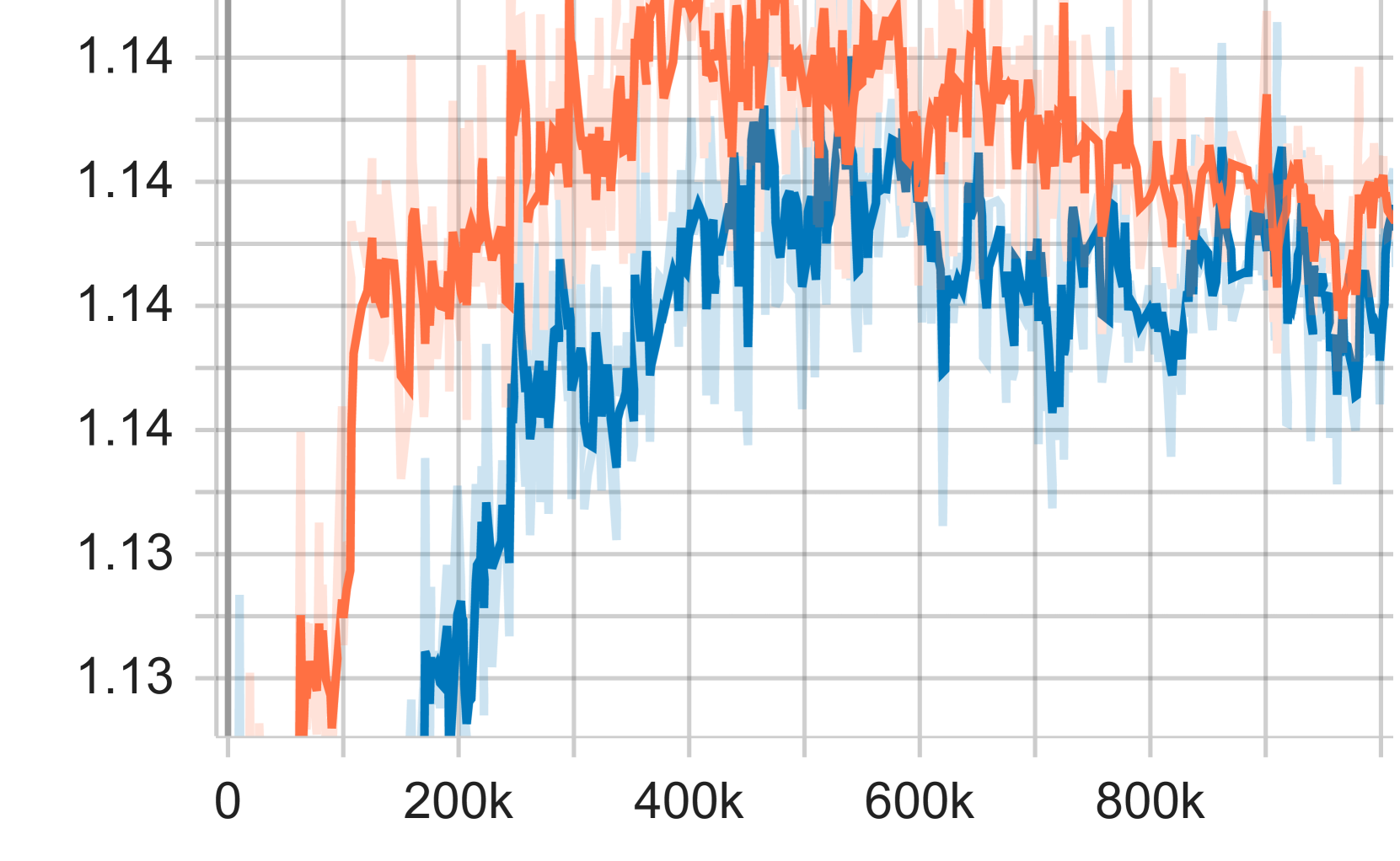
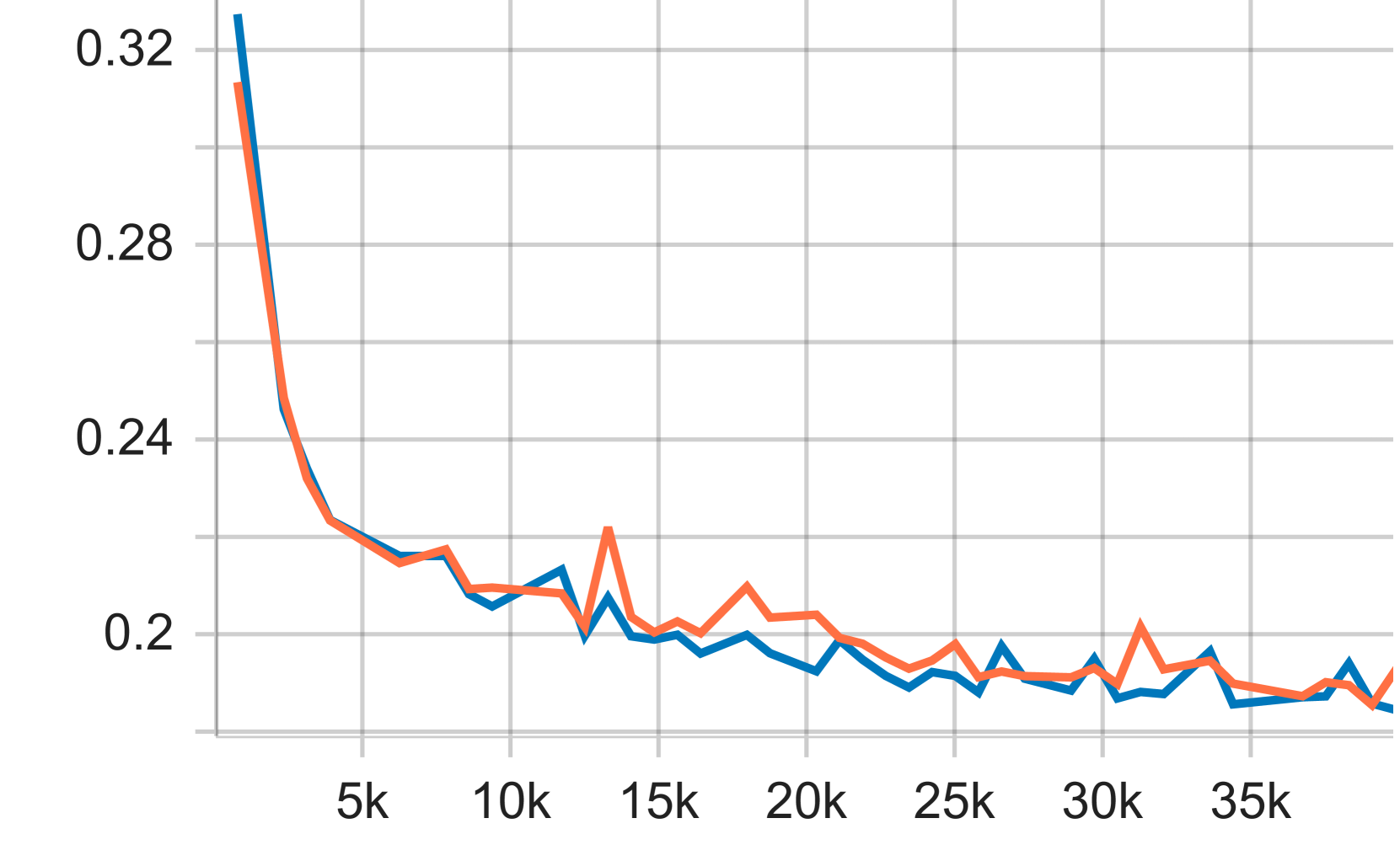
|
|
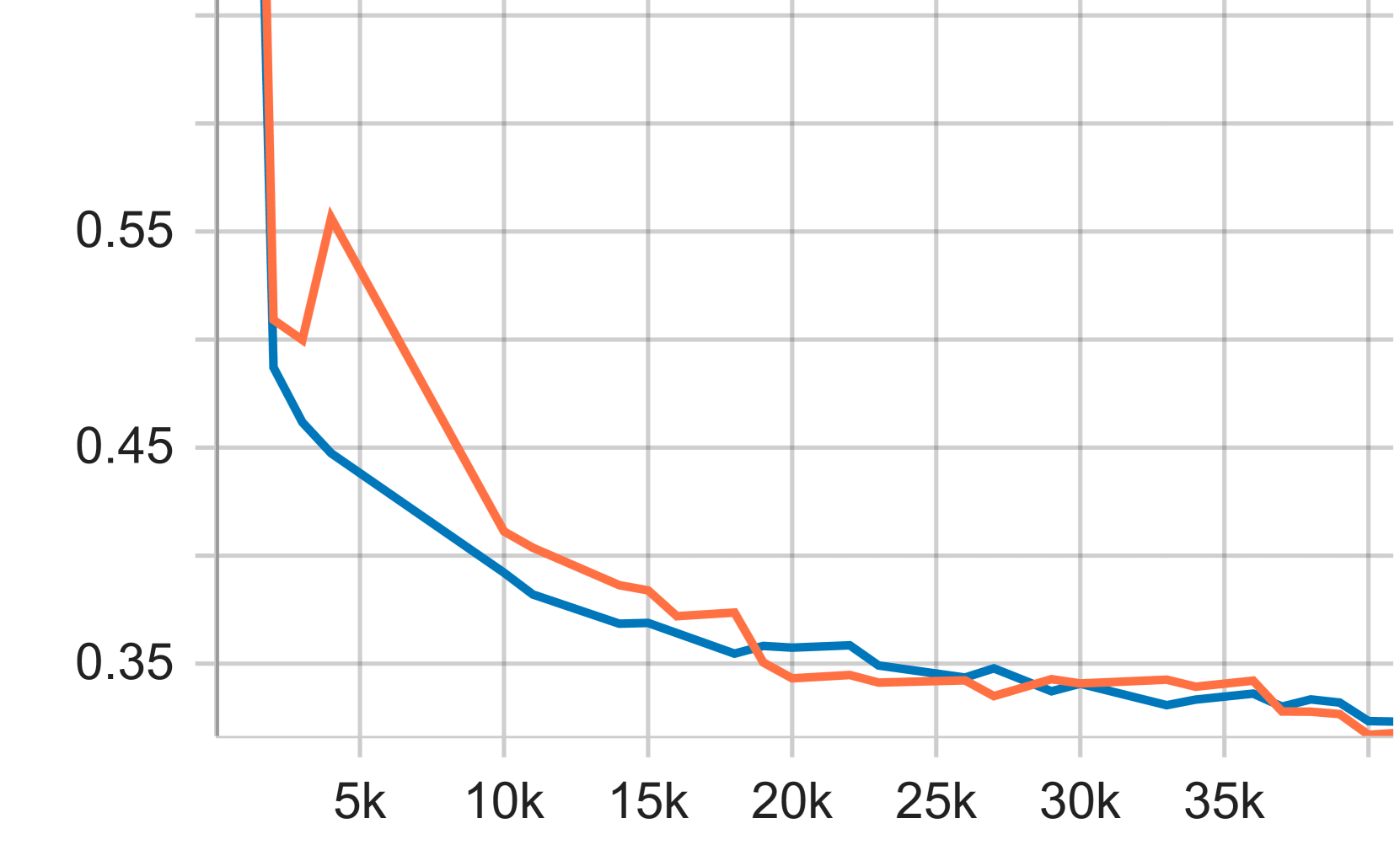
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2406.08196
|
| 4 |
+
|
| 5 |
+
Published Time: Thu, 13 Jun 2024 00:49:00 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
\interspeechcameraready\name
|
| 9 |
+
|
| 10 |
+
[affiliation=1]YuanjunLv \name[affiliation=2]HaiLi \name[affiliation=2]YingYan \name[affiliation=2]JunhuiLiu \name[affiliation=2]DanmingXie \name[affiliation=1,*]LeiXie
|
| 11 |
+
|
| 12 |
+
###### Abstract
|
| 13 |
+
|
| 14 |
+
Vocoders reconstruct speech waveforms from acoustic features and play a pivotal role in modern TTS systems. Frequent-domain GAN vocoders like Vocos and APNet2 have recently seen rapid advancements, outperforming time-domain models in inference speed while achieving comparable audio quality. However, these frequency-domain vocoders suffer from large parameter sizes, thus introducing extra memory burden. Inspired by PriorGrad and SpecGrad, we employ pseudo-inverse to estimate the amplitude spectrum as the initialization roughly. This simple initialization significantly mitigates the parameter demand for vocoder. Based on APNet2 and our streamlined Amplitude prediction branch, we propose our FreeV, compared with its counterpart APNet2, our FreeV achieves 1.8×\times× inference speed improvement with nearly half parameters. Meanwhile, our FreeV outperforms APNet2 in resynthesis quality, marking a step forward in pursuing real-time, high-fidelity speech synthesis. Code and checkpoints is available at: [https://github.com/BakerBunker/FreeV](https://github.com/BakerBunker/FreeV)
|
| 15 |
+
|
| 16 |
+
###### keywords:
|
| 17 |
+
|
| 18 |
+
speech synthesis, neural vocoder, signal processing, waveform synthesis
|
| 19 |
+
|
| 20 |
+
††footnotetext: *: corresponding author
|
| 21 |
+
1 Introduction
|
| 22 |
+
--------------
|
| 23 |
+
|
| 24 |
+
Recently, there has been a rapid advancement in the field of neural vocoders, which transform speech acoustic features into waveforms. These vocoders play a crucial role in text-to-speech synthesis, voice conversion, and audio enhancement applications. Within these contexts, the process typically involves a model that predicts a mel-spectrogram from the source text or speech, followed by a vocoder that produces the waveform from the predicted mel-spectrogram. Consequently, the quality of the synthesized speech, the speed of inference, and the parameter size of the model constitute the three primary metrics for assessing the performance of neural vocoders.
|
| 25 |
+
|
| 26 |
+
Recent advancements in vocoders, including iSTFTNet[[1](https://arxiv.org/html/2406.08196v1#bib.bib1)], Vocos[[2](https://arxiv.org/html/2406.08196v1#bib.bib2)], and APNet[[3](https://arxiv.org/html/2406.08196v1#bib.bib3)], have shifted from the prediction of waveforms in the time domain to the estimation of amplitude and phase spectra in the frequency domain, followed by waveform reconstruction via inverse short-time Fourier transform (ISTFT). This method circumvents the need to predict extensive time-domain waveforms, thus reducing the models’ computational burden. ISTFTNet, for example, minimizes the computational complexity by decreasing the upsampling stages and focusing on frequency-domain spectra predictions before employing ISTFT for time-domain signal reconstruction. Vocos extends these advancements by removing all upsampling layers and utilizing the ConvNeXtV2[[4](https://arxiv.org/html/2406.08196v1#bib.bib4)] Block as its foundational layer. APNet[[3](https://arxiv.org/html/2406.08196v1#bib.bib3)] and APNet2[[5](https://arxiv.org/html/2406.08196v1#bib.bib5)] further refine this approach by independently predicting amplitude and phase spectra and incorporating innovative supervision to guide phase spectra estimation. Nonetheless, with comparable parameter counts, these models often underperform their time-domain counterparts, highlighting potential avenues for optimization in the parameter efficiency of frequency-domain vocoders.
|
| 27 |
+
|
| 28 |
+
Several diffusion-based vocoders have integrated signal-processing insights to reduce inference steps and improve reconstruction quality. PriorGrad[[6](https://arxiv.org/html/2406.08196v1#bib.bib6)] initially refines the model’s priors by aligning the covariance matrix diagonals with the energy of each frame of the Mel spectrogram. Extending this innovation, SpecGrad[[7](https://arxiv.org/html/2406.08196v1#bib.bib7)] proposed to adjust the diffusion noise to align its dynamic spectral characteristics with those of the conditioning mel spectrogram. Moreover, GLA-Grad[[8](https://arxiv.org/html/2406.08196v1#bib.bib8)] enhances the perceived audio quality by embedding the estimated amplitude spectrum into each diffusion step’s post-processing stage. Nevertheless, the reliance on diffusion models results in slower inference speeds, posing challenges for their real-world application.
|
| 29 |
+
|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
Figure 1: Inference speed and reconstruction performance of multiple methods trained and evaluated on LJSpeech. The size of the circle represents the model parameter size. FreeV achieves the fastest inference speed and reconstruction quality with half parameter size compared to APNet2.
|
| 33 |
+
|
| 34 |
+
In this work, we introduce FreeV, a streamlined GAN vocoder enhanced with prior knowledge from signal processing, and tested on the LJSpeech dataset[[9](https://arxiv.org/html/2406.08196v1#bib.bib9)]. The empirical outcomes highlight FreeV’s superior performance characterized by faster convergence in training, a near 50% reduction in parameter size, and a notable boost in inference speed. Our contributions can be summarized as follows:
|
| 35 |
+
|
| 36 |
+
* •We innovated by using the product of the Mel spectrogram and the pseudo-inverse of the Mel filter, referred to as the pseudo-amplitude spectrum, as the model’s input, effectively easing the model’s complexity.
|
| 37 |
+
* •Drawing on our initial insight, we substantially diminished the spectral prediction branch’s parameters and the time required for inference without compromising the quality achieved by the original model.
|
| 38 |
+
|
| 39 |
+
2 Related Work
|
| 40 |
+
--------------
|
| 41 |
+
|
| 42 |
+
### 2.1 PriorGrad & SpecGrad
|
| 43 |
+
|
| 44 |
+
Based on diffusion-based vocoder WaveGrad[[10](https://arxiv.org/html/2406.08196v1#bib.bib10)], which direct reconstruct the waveform through a DDPM process, Lee et al. proposed PriorGrad[[6](https://arxiv.org/html/2406.08196v1#bib.bib6)] by introducing an adaptive prior 𝒩(𝟎,𝚺)𝒩 0 𝚺\mathcal{N}(\mathbf{0},\mathbf{\Sigma})caligraphic_N ( bold_0 , bold_Σ ), where 𝚺 𝚺\mathbf{\Sigma}bold_Σ is computed from input mel spectrogram X 𝑋 X italic_X. The covariance matrix 𝚺 𝚺\mathbf{\Sigma}bold_Σ is given by: 𝚺=diag[(σ 1 2,σ 2 2,⋯,σ D 2,)]\mathbf{\Sigma}=\mathrm{diag}[(\sigma_{1}^{2},\sigma_{2}^{2},\cdots,\sigma_{D}% ^{2},)]bold_Σ = roman_diag [ ( italic_σ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT , italic_σ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT , ⋯ , italic_σ start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT , ) ], where σ d 2,superscript subscript 𝜎 𝑑 2\sigma_{d}^{2},italic_σ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT , denotes the signal power at d 𝑑 d italic_d th sample, which is calculated by interpolating the frame energy. Compared to conventional DDPM-based vocoders, PriorGrad utilizes signal before making the source distribution closer to the target distribution, which simplifies the reconstruction task.
|
| 45 |
+
|
| 46 |
+
Based on PriorGrad, SpecGrad[[7](https://arxiv.org/html/2406.08196v1#bib.bib7)] proposed adjusting the diffusion noise in a way that aligns its dynamic spectral characteristics with those of the conditioning mel spectrogram. SpecGrad introduced a decomposed covariance matrix and its approximate inverse using the idea from T-F domain filtering, which is conditioned on the mel spectrogram. This method enhances audio fidelity, especially in high-frequency regions. We denote the STFT by a matrix G 𝐺 G italic_G, and the ISTFT by a matrix G+superscript 𝐺 G^{+}italic_G start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT, then the time-varying filter L 𝐿 L italic_L can be expressed as:
|
| 47 |
+
|
| 48 |
+
L=G+DG,𝐿 superscript 𝐺 𝐷 𝐺 L=G^{+}DG,italic_L = italic_G start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT italic_D italic_G ,(1)
|
| 49 |
+
|
| 50 |
+
where D 𝐷 D italic_D is a diagonal matrix that defines the filter, and it is obtained from the spectral envelope. Then we can obtain covariance matrix Σ=LL T Σ 𝐿 superscript 𝐿 𝑇\Sigma=LL^{T}roman_Σ = italic_L italic_L start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT of the standard Gaussian noise 𝒩(0,Σ)𝒩 0 Σ\mathcal{N}(0,\Sigma)caligraphic_N ( 0 , roman_Σ ) in the diffusion process. By introducing more accurate prior to the model, SpecGrad achieves higher reconstruction quality and inference speech than PriorGrad.
|
| 51 |
+
|
| 52 |
+
### 2.2 APNet & APNet2
|
| 53 |
+
|
| 54 |
+
As illustrated in Figure[2](https://arxiv.org/html/2406.08196v1#S3.F2 "Figure 2 ‣ 3 Method ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter"), APNet2[[5](https://arxiv.org/html/2406.08196v1#bib.bib5)] consists of two components: amplitude spectra predictor (ASP) and phase spectra predictor (PSP). These two components predict the amplitude and phase spectra separately, which are then employed to reconstruct the waveform through ISTFT. The backbone of APNet2 is ConvNeXtV2[[4](https://arxiv.org/html/2406.08196v1#bib.bib4)] block, which is proved has strong modeling capability. In the PSP branch, APNet[[3](https://arxiv.org/html/2406.08196v1#bib.bib3)] proposed the parallel phase estimation architecture at the output end. The parallel phase estimation takes the output of two convolution layers as the pseudo imaginary part I 𝐼 I italic_I and real part R 𝑅 R italic_R, then obtains the phase spectra by:
|
| 55 |
+
|
| 56 |
+
arctan(I R)−π 2⋅sgn(I)⋅[sgn(R)−1]𝐼 𝑅⋅⋅𝜋 2 𝑠 𝑔 𝑛 𝐼 delimited-[]𝑠 𝑔 𝑛 𝑅 1\arctan(\frac{I}{R})-\frac{\pi}{2}\cdot sgn(I)\cdot[sgn(R)-1]roman_arctan ( divide start_ARG italic_I end_ARG start_ARG italic_R end_ARG ) - divide start_ARG italic_π end_ARG start_ARG 2 end_ARG ⋅ italic_s italic_g italic_n ( italic_I ) ⋅ [ italic_s italic_g italic_n ( italic_R ) - 1 ](2)
|
| 57 |
+
|
| 58 |
+
where sgn 𝑠 𝑔 𝑛 sgn italic_s italic_g italic_n is the sign function.
|
| 59 |
+
|
| 60 |
+
A series of losses are defined in APNet to supervise the generated spectra and waveform. In addition to the losses used in HiFiGAN[[11](https://arxiv.org/html/2406.08196v1#bib.bib11)], which include Mel loss ℒ mel subscript ℒ 𝑚 𝑒 𝑙\mathcal{L}_{mel}caligraphic_L start_POSTSUBSCRIPT italic_m italic_e italic_l end_POSTSUBSCRIPT, generator loss ℒ g subscript ℒ 𝑔\mathcal{L}_{g}caligraphic_L start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT, discriminator loss ℒ d subscript ℒ 𝑑\mathcal{L}_{d}caligraphic_L start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT, feature matching loss ℒ fm subscript ℒ 𝑓 𝑚\mathcal{L}_{fm}caligraphic_L start_POSTSUBSCRIPT italic_f italic_m end_POSTSUBSCRIPT, APNet proposed:
|
| 61 |
+
|
| 62 |
+
* •amplitude spectrum loss ℒ A subscript ℒ 𝐴\mathcal{L}_{A}caligraphic_L start_POSTSUBSCRIPT italic_A end_POSTSUBSCRIPT, which is the L2 distance of the predicted and real amplitude;
|
| 63 |
+
* •phase spectrogram loss ℒ P subscript ℒ 𝑃\mathcal{L}_{P}caligraphic_L start_POSTSUBSCRIPT italic_P end_POSTSUBSCRIPT, which is the sum of instantaneous phase loss, group delay loss, and phase time difference loss, all phase spectrograms are anti-wrapped;
|
| 64 |
+
* •STFT spectrogram loss ℒ S subscript ℒ 𝑆\mathcal{L}_{S}caligraphic_L start_POSTSUBSCRIPT italic_S end_POSTSUBSCRIPT, which includes the STFT consistency loss and L1 loss between predicted and real reconstructed STFT spectrogram.
|
| 65 |
+
|
| 66 |
+
3 Method
|
| 67 |
+
--------
|
| 68 |
+
|
| 69 |
+
“When we structure the informative prior noise closer to the data distribution, can we improve the efficiency of the model?” – PriorGrad
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
Figure 2: The overall architecture of FreeV, the amplitude prediction branch (ASP) of APNet2, which has red background, is replaced by a more lightweight architecture with green background.
|
| 74 |
+
|
| 75 |
+
### 3.1 Amplitude Prior
|
| 76 |
+
|
| 77 |
+
In this section, we investigate how to obtain a prior signal closer to the real prediction target, which is the amplitude spectrum. By employing the given Mel spectrum X 𝑋 X italic_X and the known Mel filter M 𝑀 M italic_M, we aim to obtain an amplitude spectrum A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG that minimizes the distance with the actual amplitude spectrum A 𝐴 A italic_A, while ensuring that the computation is performed with optimal speed, as the following equation:
|
| 78 |
+
|
| 79 |
+
min∥A^M−A∥2\min\left\lVert\hat{A}M-A\right\rVert_{2}roman_min ∥ over^ start_ARG italic_A end_ARG italic_M - italic_A ∥ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT(3)
|
| 80 |
+
|
| 81 |
+
We investigated several existing implementations for this task. In Section [2.1](https://arxiv.org/html/2406.08196v1#S2.SS1 "2.1 PriorGrad & SpecGrad ‣ 2 Related Work ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter"), the SpecGrad method, G+DGϵ superscript 𝐺 𝐷 𝐺 italic-ϵ G^{+}DG\epsilon italic_G start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT italic_D italic_G italic_ϵ requires prior noise ϵ italic-ϵ\epsilon italic_ϵ as input, therefore unsuitable for our goals. In the implementation by the librosa library[[12](https://arxiv.org/html/2406.08196v1#bib.bib12)], the estimation of A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG employs the Non-Negative Least Squares (NNLS) algorithm to maintain non-negativity. However, this algorithm is slow due to the need for multiple iterations, prompting the pursuit of a swifter alternative. TorchAudio’s implementation[[13](https://arxiv.org/html/2406.08196v1#bib.bib13)] calculates the estimated amplitude spectrum through a singular least squares operation followed by enforcing a minimum threshold to preserve non-negativity. Despite this, the recurring need for the least squares calculation with each inference introduces speed inefficiencies.
|
| 82 |
+
|
| 83 |
+
Considering that the Mel filter M 𝑀 M italic_M remains unchanged throughout the calculations, we can pre-compute its pseudo-inverse, denoted as M+superscript 𝑀 M^{+}italic_M start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT. Then, to guarantee the non-negativity of the amplitude spectrum and maintain numerical stability in training, we impose a lower bound of 10−5 superscript 10 5 10^{-5}10 start_POSTSUPERSCRIPT - 5 end_POSTSUPERSCRIPT on the values of the approximate amplitude spectrum.
|
| 84 |
+
|
| 85 |
+

|
| 86 |
+
|
| 87 |
+
(a)A 𝐴 A italic_A
|
| 88 |
+
|
| 89 |
+

|
| 90 |
+
|
| 91 |
+
(b)A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG w/o abs
|
| 92 |
+
|
| 93 |
+

|
| 94 |
+
|
| 95 |
+
(c)A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG w/ abs
|
| 96 |
+
|
| 97 |
+
Figure 3: Comparison of real log amplitude spectra A 𝐴 A italic_A and estimated log spectra A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG.
|
| 98 |
+
|
| 99 |
+
We find there are some negative values in the pseudo-inversed mel filter, causing negative blocks in estimated amplitude, which can be easily found in Figure [3(b)](https://arxiv.org/html/2406.08196v1#S3.F3.sf2 "Figure 3(b) ‣ Figure 3 ‣ 3.1 Amplitude Prior ‣ 3 Method ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter"), so we add an Abs Abs\mathrm{Abs}roman_Abs function to the product of M+superscript 𝑀 M^{+}italic_M start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT and X 𝑋 X italic_X. This allows us to derive the approximate amplitude spectrum A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG using the following equation:
|
| 100 |
+
|
| 101 |
+
A^=max(Abs(M+X),10−5)^𝐴 max Abs superscript 𝑀 𝑋 superscript 10 5\hat{A}=\mathrm{max}(\mathrm{Abs}(M^{+}X),10^{-5})over^ start_ARG italic_A end_ARG = roman_max ( roman_Abs ( italic_M start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT italic_X ) , 10 start_POSTSUPERSCRIPT - 5 end_POSTSUPERSCRIPT )(4)
|
| 102 |
+
|
| 103 |
+
This enables us to efficiently acquire the estimated amplitude spectrum through a single matrix multiplication operation.
|
| 104 |
+
|
| 105 |
+
### 3.2 Model Structure
|
| 106 |
+
|
| 107 |
+
Our model architecture is illustrated in Figure 2, which consists of PSP and ASP, and uses ConvNextV2[[4](https://arxiv.org/html/2406.08196v1#bib.bib4)] as the model’s basic block. PSP includes an input convolutional layer, eight ConvNeXtV2 blocks, and two convolutional layers for parallel phase estimation structure.
|
| 108 |
+
|
| 109 |
+
Diverging from APNet2’s ASP, our design substitutes the conventional input convolutional layer with the pre-computed pseudo-inverse Mel filter matrix M+superscript 𝑀 M^{+}italic_M start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT of the Mel filter M 𝑀 M italic_M with frozen parameters. Due to the enhancements highlighted in Section [3.1](https://arxiv.org/html/2406.08196v1#S3.SS1 "3.1 Amplitude Prior ‣ 3 Method ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter") that substantially ease the model’s complexity, the number of ConvNeXtV2 blocks is reduced from eight to a single block, thereby substantially reducing both the parameter footprint and computation time.
|
| 110 |
+
|
| 111 |
+
Concurrently, the ConvNeXtV2 module’s input-output dimensions have been tailored to align with those of the amplitude spectrum, enabling the block to exclusively model the residual between the estimated and real amplitude spectra, further reducing the ASP module’s modeling difficulty. Because the input and output dimensions of the ConvNeXtV2 module match the amplitude spectrum, we removed the output convolutional layer from ASP, further reducing the model’s parameter count.
|
| 112 |
+
|
| 113 |
+
### 3.3 Training Criteria
|
| 114 |
+
|
| 115 |
+
In the choice of discriminators, we followed the setup in APNet2[[5](https://arxiv.org/html/2406.08196v1#bib.bib5)], using MPD and MRD as discriminators and adopting Hinge GAN Loss as the loss function for adversarial learning. We also retained the other loss functions used by APNet2, which is described in Section [2.2](https://arxiv.org/html/2406.08196v1#S2.SS2 "2.2 APNet & APNet2 ‣ 2 Related Work ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter"), and the loss function of the generator and discriminator are denoted as:
|
| 116 |
+
|
| 117 |
+
ℒ Gen subscript ℒ 𝐺 𝑒 𝑛\displaystyle\vspace{-0.2in}\mathcal{L}_{Gen}caligraphic_L start_POSTSUBSCRIPT italic_G italic_e italic_n end_POSTSUBSCRIPT=λ Aℒ A+λ Pℒ P+λ Sℒ S+λ W(ℒ mel+ℒ fm+ℒ g)absent subscript 𝜆 𝐴 subscript ℒ 𝐴 subscript 𝜆 𝑃 subscript ℒ 𝑃 subscript 𝜆 𝑆 subscript ℒ 𝑆 subscript 𝜆 𝑊 subscript ℒ 𝑚 𝑒 𝑙 subscript ℒ 𝑓 𝑚 subscript ℒ 𝑔\displaystyle=\lambda_{A}\mathcal{L}_{A}+\lambda_{P}\mathcal{L}_{P}+\lambda_{S% }\mathcal{L}_{S}+\lambda_{W}(\mathcal{L}_{mel}+\mathcal{L}_{fm}+\mathcal{L}_{g})= italic_λ start_POSTSUBSCRIPT italic_A end_POSTSUBSCRIPT caligraphic_L start_POSTSUBSCRIPT italic_A end_POSTSUBSCRIPT + italic_λ start_POSTSUBSCRIPT italic_P end_POSTSUBSCRIPT caligraphic_L start_POSTSUBSCRIPT italic_P end_POSTSUBSCRIPT + italic_λ start_POSTSUBSCRIPT italic_S end_POSTSUBSCRIPT caligraphic_L start_POSTSUBSCRIPT italic_S end_POSTSUBSCRIPT + italic_λ start_POSTSUBSCRIPT italic_W end_POSTSUBSCRIPT ( caligraphic_L start_POSTSUBSCRIPT italic_m italic_e italic_l end_POSTSUBSCRIPT + caligraphic_L start_POSTSUBSCRIPT italic_f italic_m end_POSTSUBSCRIPT + caligraphic_L start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT )
|
| 118 |
+
ℒ Dis subscript ℒ 𝐷 𝑖 𝑠\displaystyle\mathcal{L}_{Dis}caligraphic_L start_POSTSUBSCRIPT italic_D italic_i italic_s end_POSTSUBSCRIPT=ℒ d absent subscript ℒ 𝑑\displaystyle=\mathcal{L}_{d}\vspace{-0.2in}= caligraphic_L start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT
|
| 119 |
+
|
| 120 |
+
where λ A subscript 𝜆 𝐴\lambda_{A}italic_λ start_POSTSUBSCRIPT italic_A end_POSTSUBSCRIPT, λ P subscript 𝜆 𝑃\lambda_{P}italic_λ start_POSTSUBSCRIPT italic_P end_POSTSUBSCRIPT, λ S subscript 𝜆 𝑆\lambda_{S}italic_λ start_POSTSUBSCRIPT italic_S end_POSTSUBSCRIPT, λ W subscript 𝜆 𝑊\lambda_{W}italic_λ start_POSTSUBSCRIPT italic_W end_POSTSUBSCRIPT are the weights of the loss, which are kept the same as in APNet2.
|
| 121 |
+
|
| 122 |
+
4 Experimental Setup
|
| 123 |
+
--------------------
|
| 124 |
+
|
| 125 |
+
### 4.1 Dataset
|
| 126 |
+
|
| 127 |
+
To ensure consistency, the training dataset follows the same configuration of APNet2. Thus, the LJSpeech dataset[[9](https://arxiv.org/html/2406.08196v1#bib.bib9)] is used for training and evaluation. LJSpeech dataset is a public collection of 13,100 short audio clips featuring a single speaker reading passages from 7 non-fiction books. The duration of the clips ranges from 1 to 10 seconds, resulting in a total length of approximately 24 hours. The sampling rate is 22050Hz. We split the dataset to train, validation, and test sets according to open-source VITS repository 2 2 2[https://github.com/jaywalnut310/vits/tree/main/filelists](https://github.com/jaywalnut310/vits/tree/main/filelists).
|
| 128 |
+
|
| 129 |
+
For feature extraction, we use STFT with 1024 bins, a hop size of 256, and a Hann window of length 1024. For the mel filterbank, 80 filterbanks are used with a higher frequency cutoff at 16 kHz.
|
| 130 |
+
|
| 131 |
+
### 4.2 Model and Training Setup
|
| 132 |
+
|
| 133 |
+
We trained FreeV for 1 million steps. We set the segmentation size to 8192 and the batch size to 16. We use the AdamW optimizer with β 1=0.8 subscript 𝛽 1 0.8\beta_{1}=0.8 italic_β start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT = 0.8, β 2=0.99 subscript 𝛽 2 0.99\beta_{2}=0.99 italic_β start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT = 0.99, and a weight decay of 0.01. The learning rate is set to 2×10−4 2 superscript 10 4 2\times 10^{-4}2 × 10 start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT and exponentially decays with a factor of 0.99 for each epoch.
|
| 134 |
+
|
| 135 |
+
### 4.3 Evaluation
|
| 136 |
+
|
| 137 |
+
Multiple objective evaluations are conducted to compare the performance of these vocoders. We use seven objective metrics for evaluating the quality of reconstructed speech, including mel-cepstrum distortion (MCD), root mean square error of log amplitude spectra and F0 (LAS-RMSE and F0-RMSE), V/UV F1 for voice and unvoiced part, short time objective intelligence (STOI)[[14](https://arxiv.org/html/2406.08196v1#bib.bib14)] and perceptual evaluation speech quality (PESQ)[[15](https://arxiv.org/html/2406.08196v1#bib.bib15)]. To evaluate the efficiency of each vocoder, model parameter count (Params) and real-time factor (RTF) are also conducted on NVIDIA A100 for GPU and a single core of Intel Xeon Platinum 8369B for CPU.
|
| 138 |
+
|
| 139 |
+
For the computational efficiency of the prior, we also conducted RTF and LAS-RMSE evaluations to the NNLS algorithm of librosa, least square algorithm of torchaudio, pseudo-inverse algorithm, and pseudo-inverse algorithm with absolute function mentioned in Section [3.1](https://arxiv.org/html/2406.08196v1#S3.SS1 "3.1 Amplitude Prior ‣ 3 Method ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter").
|
| 140 |
+
|
| 141 |
+
Table 1: Time and precision of different prior computing methods, LS stands for Least Square, PI stands for Pseudo Inverse.
|
| 142 |
+
|
| 143 |
+
Table 2: Results of objective evaluations on the testset of LJSpeech dataset for reconstruction.
|
| 144 |
+
|
| 145 |
+
Table 3: Results of parameter and inference speed.
|
| 146 |
+
|
| 147 |
+
5 Experiment Result
|
| 148 |
+
-------------------
|
| 149 |
+
|
| 150 |
+
We conducted experiments to verify whether our method can improve the efficiency of the vocoder.
|
| 151 |
+
|
| 152 |
+
### 5.1 Computational Efficiency of Prior
|
| 153 |
+
|
| 154 |
+
The compute method of the estimated amplitude spectra A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG if our key component. We find that the inference speed can be affected by the compute speed of the prior. We compare the compute speed and accuracy on 100 2-second-long speech clips. As shown in Table [1](https://arxiv.org/html/2406.08196v1#S4.T1 "Table 1 ‣ 4.3 Evaluation ‣ 4 Experimental Setup ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter"), the pseudo-inverse method is the fastest way to compute the estimated amplitude spectra A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG, and the result also shows that the Abs Abs\mathrm{Abs}roman_Abs function can largely reduce the error of amplitude spectrogram estimation.
|
| 155 |
+
|
| 156 |
+
### 5.2 Model Convergence
|
| 157 |
+
|
| 158 |
+
In Figure [4(a)](https://arxiv.org/html/2406.08196v1#S5.F4.sf1 "Figure 4(a) ‣ Figure 4 ‣ 5.2 Model Convergence ‣ 5 Experiment Result ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter") and [4(b)](https://arxiv.org/html/2406.08196v1#S5.F4.sf2 "Figure 4(b) ‣ Figure 4 ‣ 5.2 Model Convergence ‣ 5 Experiment Result ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter"), we showcase the amplitude spectrum loss and mel spectrum loss curves related to amplitude spectrum prediction. From these two curves, it can be seen that even though the number of parameters in the amplitude spectrum prediction branch is significantly reduced, the loss related to amplitude spectrum prediction still remains lower than the baseline APNet2. This observation affirms the efficacy of the approach described in Section [3](https://arxiv.org/html/2406.08196v1#S3 "3 Method ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter"), substantiating a marked decrease in the challenge of amplitude spectrum prediction. Furthermore, Figure [4(c)](https://arxiv.org/html/2406.08196v1#S5.F4.sf3 "Figure 4(c) ‣ Figure 4 ‣ 5.2 Model Convergence ‣ 5 Experiment Result ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter") displays the Phase-Time Difference Loss, which bears significant relevance to phase spectrum prediction. The improvement in amplitude spectrum prediction concurrently benefits phase spectrum accuracy. We assume that the stability of the amplitude spectrum prediction branch’s training engenders more effective optimization of the phase information by the waveform-related loss functions.
|
| 159 |
+
|
| 160 |
+
Furthermore, we extended our experimentation to the baseline model by substituting its input from the Mel spectrum with the estimated amplitude spectrum A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG. The loss curve illustrated in Figure [5](https://arxiv.org/html/2406.08196v1#S5.F5 "Figure 5 ‣ 5.2 Model Convergence ‣ 5 Experiment Result ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter") reveals that this modification also enhanced the early-stage convergence of these models. This finding suggests that integrating an appropriate prior is advantageous not only for our proposed vocoder but also holds potential efficacy for other vocoder frameworks.
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
(a)ℒ mel subscript ℒ 𝑚 𝑒 𝑙\mathcal{L}_{mel}caligraphic_L start_POSTSUBSCRIPT italic_m italic_e italic_l end_POSTSUBSCRIPT
|
| 165 |
+
|
| 166 |
+

|
| 167 |
+
|
| 168 |
+
(b)ℒ amp subscript ℒ 𝑎 𝑚 𝑝\mathcal{L}_{amp}caligraphic_L start_POSTSUBSCRIPT italic_a italic_m italic_p end_POSTSUBSCRIPT
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
(c)ℒ ptd subscript ℒ 𝑝 𝑡 𝑑\mathcal{L}_{ptd}caligraphic_L start_POSTSUBSCRIPT italic_p italic_t italic_d end_POSTSUBSCRIPT
|
| 173 |
+
|
| 174 |
+
Figure 4: Loss curves of APNet2 (orange) and FreeV (blue).
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
(a)HiFiGAN
|
| 179 |
+
|
| 180 |
+

|
| 181 |
+
|
| 182 |
+
(b)iSTFTNet
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
(c)Vocos
|
| 187 |
+
|
| 188 |
+
Figure 5: Early stage mel loss curves of multiple models trained with (blue) and without estimated amplitude spectra A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG (orange).
|
| 189 |
+
|
| 190 |
+
### 5.3 Model Performance
|
| 191 |
+
|
| 192 |
+
The model’s performance was evaluated on the test dataset referenced in Section [4.1](https://arxiv.org/html/2406.08196v1#S4.SS1 "4.1 Dataset ‣ 4 Experimental Setup ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter"), the results of which are detailed in Table [2](https://arxiv.org/html/2406.08196v1#S4.T2 "Table 2 ‣ 4.3 Evaluation ‣ 4 Experimental Setup ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter"). FreeV outperformed in five out of six objective metrics and was surpassed only by HiFiGAN with estimated amplitude spectra in the PESQ metric. These findings indicate that our method reduces the model’s parameter size and elevates the quality of audio reconstruction. Furthermore, the comparative analysis, which includes both scenarios, with and without the incorporation of the estimated amplitude spectrum A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG, reveals that substituting the Mel spectrum X 𝑋 X italic_X input with the approximate amplitude spectrum A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG can also yield performance gains in standard vocoder configurations. This observation corroborates the efficacy of our proposed approach.
|
| 193 |
+
|
| 194 |
+
In parallel, as shown by Table [3](https://arxiv.org/html/2406.08196v1#S4.T3 "Table 3 ‣ 4.3 Evaluation ‣ 4 Experimental Setup ‣ FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter"), our model’s parameter size is confined to merely a half of that to APNet2, while it achieves 1.8×\times× inference speed on GPU. When benchmarked against the time-domain prediction model HiFiGAN[[11](https://arxiv.org/html/2406.08196v1#bib.bib11)], FreeV not only exhibits a considerable speed enhancement, which is approximately 30×\times×, but also delivers superior audio reconstruction fidelity with comparable parameter count. These results further underscore the practicality and advantage of our proposed method.
|
| 195 |
+
|
| 196 |
+
6 Conclusion
|
| 197 |
+
------------
|
| 198 |
+
|
| 199 |
+
In this paper, we investigated the effectiveness of employing pseudo-inverse to roughly estimate the amplitude spectrum as the initial input of the model. We introduce FreeV, a vocoder framework that leverages estimated amplitude spectrum A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG to simplify the model’s predictive complexity. This approach not only reduces the parameter size but also improves the reconstruction quality compared to APNet2. Our experimental results demonstrated that our method could effectively reduce the modeling difficulty by simply replacing the input mel spectrogram with the estimated amplitude spectrum A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG.
|
| 200 |
+
|
| 201 |
+
References
|
| 202 |
+
----------
|
| 203 |
+
|
| 204 |
+
* [1] T.Kaneko, K.Tanaka, H.Kameoka, and S.Seki, “ISTFTNET: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform,” in _ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)_.IEEE, 2022, pp. 6207–6211.
|
| 205 |
+
* [2] H.Siuzdak, “Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis,” in _The Twelfth International Conference on Learning Representations_, vol. abs/2306.00814, 2023.
|
| 206 |
+
* [3] Y.Ai and Z.-H. Ling, “APNet: An All-Frame-Level Neural Vocoder Incorporating Direct Prediction of Amplitude and Phase Spectra,” _IEEE/ACM Transactions on Audio, Speech, and Language Processing_, vol.31, pp. 2145–2157, 2023.
|
| 207 |
+
* [4] S.Woo, S.Debnath, R.Hu, X.Chen, Z.Liu, I.S. Kweon, and S.Xie, “ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders.” in _Computer Vision and Pattern Recognition (CVPR)_, 2023, pp. 16 133–16 142.
|
| 208 |
+
* [5] H.-P. Du, Y.-X. Lu, Y.Ai, and Z.-H. Ling, _APNet2: High-Quality and High-Efficiency Neural Vocoder with Direct Prediction of Amplitude and Phase Spectra_.Springer Nature Singapore, 2023.
|
| 209 |
+
* [6] S.-g. Lee, H.Kim, C.Shin, X.Tan, C.Liu, Q.Meng, T.Qin, W.Chen, S.-H. Yoon, and T.-Y. Liu, “PriorGrad: Improving Conditional Denoising Diffusion Models with Data-dependent Adaptive Prior,” in _International Conference on Learning Representations_, 2021.
|
| 210 |
+
* [7] Y.Koizumi, H.Zen, K.Yatabe, N.Chen, and M.Bacchiani, “SpecGrad: Diffusion Probabilistic Model based Neural Vocoder with Adaptive Noise Spectral Shaping,” in _Interspeech 2022_.ISCA, 2022, pp. 803–807.
|
| 211 |
+
* [8] H.Liu, T.Baoueb, M.Fontaine, J.L. Roux, and G.Richard, “GLA-Grad: A Griffin-Lim Extended Waveform Generation Diffusion Model,” _arXiv_, 2024.
|
| 212 |
+
* [9] K.Ito and L.Johnson, “The lj speech dataset,” [https://keithito.com/LJ-Speech-Dataset/](https://keithito.com/LJ-Speech-Dataset/), 2017.
|
| 213 |
+
* [10] N.Chen, Y.Zhang, H.Zen, R.J. Weiss, M.Norouzi, and W.Chan, “WaveGrad: Estimating Gradients for Waveform Generation.” in _International Conference on Learning Representations (ICLR)_, 2021.
|
| 214 |
+
* [11] J.Kong, J.Kim, and J.Bae, “HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis,” in _Conference on Neural Information Processing Systems (NeurIPS)_, 2020.
|
| 215 |
+
* [12] B.McFee, M.McVicar, D.Faronbi, I.Roman, M.Gover, S.Balke, S.Seyfarth, A.Malek, C.Raffel, V.Lostanlen, B.van Niekirk, D.Lee, F.Cwitkowitz, F.Zalkow, O.Nieto, D.Ellis, J.Mason, K.Lee, B.Steers, E.Halvachs, C.Thomé, F.Robert-Stöter, R.Bittner, Z.Wei, A.Weiss, E.Battenberg, K.Choi, R.Yamamoto, C.Carr, A.Metsai, S.Sullivan, P.Friesch, A.Krishnakumar, S.Hidaka, S.Kowalik, F.Keller, D.Mazur, A.Chabot-Leclerc, C.Hawthorne, C.Ramaprasad, M.Keum, J.Gomez, W.Monroe, V.A. Morozov, K.Eliasi, nullmightybofo, P.Biberstein, N.D. Sergin, R.Hennequin, R.Naktinis, beantowel, T.Kim, J.P. Åsen, J.Lim, A.Malins, D.Hereñú, S.van der Struijk, L.Nickel, J.Wu, Z.Wang, T.Gates, M.Vollrath, A.Sarroff, Xiao-Ming, A.Porter, S.Kranzler, Voodoohop, M.D. Gangi, H.Jinoz, C.Guerrero, A.Mazhar, toddrme2178, Z.Baratz, A.Kostin, X.Zhuang, C.T. Lo, P.Campr, E.Semeniuc, M.Biswal, S.Moura, P.Brossier, H.Lee, and W.Pimenta, “librosa/librosa: 0.10.1,” Aug. 2023. [Online]. Available: [https://doi.org/10.5281/zenodo.8252662](https://doi.org/10.5281/zenodo.8252662)
|
| 216 |
+
* [13] J.Hwang, M.Hira, C.Chen, X.Zhang, Z.Ni, G.Sun, P.Ma, R.Huang, V.Pratap, Y.Zhang, A.Kumar, C.-Y. Yu, C.Zhu, C.Liu, J.Kahn, M.Ravanelli, P.Sun, S.Watanabe, Y.Shi, Y.Tao, R.Scheibler, S.Cornell, S.Kim, and S.Petridis, “Torchaudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for pytorch,” 2023.
|
| 217 |
+
* [14] C.H. Taal, R.C. Hendriks, R.Heusdens, and J.Jensen, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” in _icassp_, 2010, pp. 4214–4217.
|
| 218 |
+
* [15] A.Rix, J.Beerends, M.Hollier, and A.Hekstra, “Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in _icassp_, vol.2, 2001, pp. 749–752 vol.2.
|