
Long-tail image usability: a museum egg, an old engraving and subject-absent photos

Long-tail image usability: a museum egg, an old engraving and subject-absent photos appear to pass curation (worked example: genus Goura)
First, thank you for TreeOfLife-200M and BioCLIP 2/2.5. I've used them to build species classification into my own personal photo library with excellent results. I want to offer a note based on my experience with misclassifications within my image library of one genus in particular, citing some problem images in the training data and suggested remedies.
While using BioCLIP 2/2.5 for zero-shot classification of several aviary images of Goura scheepmakeri, I found many misclassifications as G. victoria. Claude and I dug into the training data and found that the genus in the data is very sparse, and a meaningful fraction of the images can't support the label, in four distinct ways.
Scope note: I only examined this single genus.
Worked example: genus Goura (213 images)
| species | images | citizen science (HUMAN_OBSERVATION) |
preserved specimen | EOL, no basis_of_record / img_type |
|---|---|---|---|---|
| G. victoria | 89 | 27 | 26 | 36 |
| G. cristata | 71 | 24 | 31 | 16 |
| G. sclaterii | 23 | 14 | 1 | 8 |
| G. scheepmakeri | 22 | 0 | 10 | 12 |
(A further 8 rows have genus but no species.)
Two things stand out. First, G. scheepmakeri has zero citizen science (HUMAN_OBSERVATION) records: all 22 images are museum specimens or provenance-unknown EOL records. It does include several live bird photos—but only within that unverified EOL slice; none come from a tagged observation. Second, 30–40% of each species is preserved specimens or records with no provenance metadata at all.
Four problems, four examples—all labeled Goura victoria
A museum egg. YPM 14238 (Yale Peabody, GBIF
1039598216) A photo of a blown egg on cloth, with a cm ruler and a colour-calibration chart in frame.basis_of_record = PRESERVED_SPECIMEN. Filterable viabasis_of_record, but the non-organism k-NN step (drawers / labels / fossils) passes it because an egg reads as organismal.A subject-absent citizen photo. iNaturalist photo 226492845 (GBIF
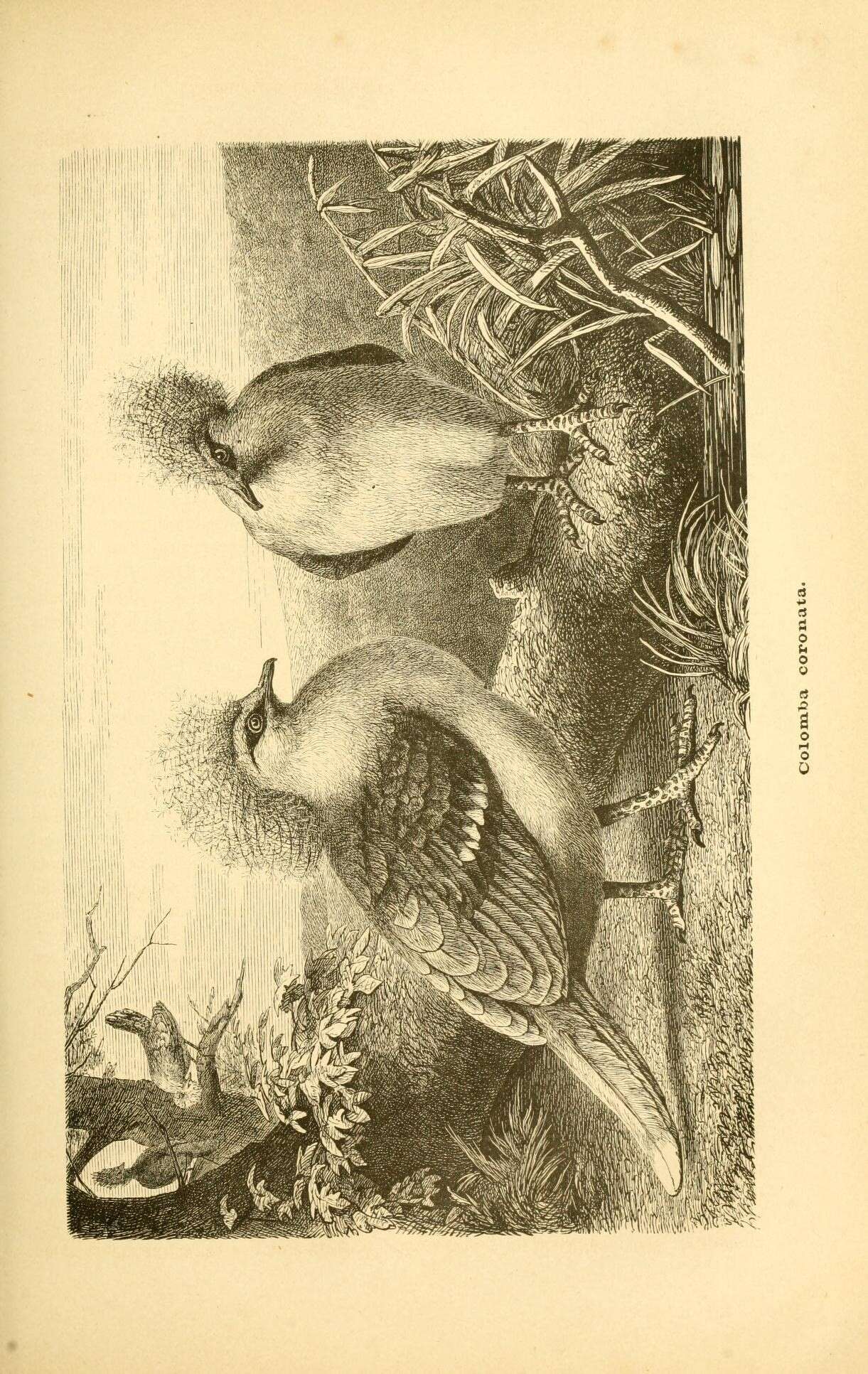
3988495537) A photo of foliage, with an indiscernible, fuzzy, obscure, tiny crop of a bird in the center of the image.basis_of_record = HUMAN_OBSERVATION. The community ID is correct, but there is no "subject present / detectable" gate in the origin data filter, so a frame with no discernible bird inherits the label.An old book engraving. EOL media 28754910 A scanned monochrome illustration of two crowned pigeons (captioned "Goura coronata"). Both
basis_of_recordandimg_typeare empty. Not even flaggable from metadata: the EOL slice carries no provenance, so a non-photographic illustration is indistinguishable from a photo. However, the monochromaticity of this image could itself be a pretty strong clue of its actual nature.A severed head on a tarp. A single iNaturalist observation (GBIF
4506447838) supplies two images (341890083, 341890122) of a detached crowned-pigeon head—crest fanned out on a tarp, a hunted bird or headdress item.basis_of_record = HUMAN_OBSERVATION. Correctly identified, but a dead body part logged as an observation, so the museum-specimen path never applies—and the two angles aren't byte-identical, so MD5 dedup counts the one head twice.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Suggestions
Offered as starting points for keeping weaker records out of the training set, not prescriptions—you know the pipeline far better than I do, and I may be missing steps or constraints you already have. Realistically only one of these—the de-duplication—is a change you could make from the catalog alone; the other three require looking at the images or re-fetching richer metadata from the source.
Catch non-animal specimen images. The egg is tagged
basis_of_record = PRESERVED_SPECIMEN—but so are the study-skins and mounts worth keeping, and nothing in the catalog separates an egg from a bird specimen. Telling them apart means looking at the image (e.g., extending the non-organism step that already drops drawers, labels, and fossils) or pulling a finer field from the source record (Claude tells me GBIF sometimes carries life-stage or preparation type).Recover a type tag for the provenance-less EOL records. A large share of the long tail (the right-hand column above) has empty
basis_of_recordandimg_type, so the tag can't come from the catalog—it would have to be back-filled from EOL's own per-item metadata (which TreeOfLife appears to drop on ingest) or inferred from the image, and neither is a one-liner.De-duplicate by observation, not just by exact image. The severed-head observation contributes two near-duplicate frames that share one
source_id; exact-hash dedup misses them because the angles differ. This is the one item here that's pure bookkeeping.A check that the labeled organism is actually in the frame. This is the one metadata can't solve: the subject-absent photo and the severed head are both ordinary observations, yet neither shows a usable, living bird. I won't pretend this is an easy problem to solve.
Reproducing the breakdown
import duckdb
con = duckdb.connect(); con.execute("INSTALL httpfs; LOAD httpfs;")
url = "https://huggingface.co/datasets/imageomics/TreeOfLife-200M/resolve/main/dataset/catalog.parquet"
con.sql(f"""
SELECT
COALESCE(species, '(no species)') AS species,
COUNT(*) AS images,
COUNT(*) FILTER (WHERE img_type = 'Citizen Science') AS citizen_science,
COUNT(*) FILTER (WHERE basis_of_record = 'PRESERVED_SPECIMEN') AS preserved_specimen,
COUNT(*) FILTER (WHERE basis_of_record IS NULL AND img_type IS NULL) AS eol_no_provenance
FROM read_parquet('{url}')
WHERE genus = 'Goura'
GROUP BY species
ORDER BY images DESC
""").show()
Everything above assumes TreeOfLife-200M is BioCLIP's training data—not an upstream pool that is filtered again before training. I've made that assumption based on the following:
BioCLIP 2 paper (arXiv:2505.23883): "We train BioCLIP 2 on 32 NVIDIA H100 GPUs for 10 days on 214M organismal biology images with hierarchical labels and 26M randomly-sampled image-text pairs from LAION-2B." The 214M is the full released TreeOfLife-200M, and its curation (non-organism removal, MegaDetector, dedup, taxonomic alignment) is part of building the dataset, not a training-time filter.
Dataset card: "This entire dataset was used for training the model, BioCLIP 2.5 Huge," and "all of Revision a8f38b4 was used to train BioCLIP 2."
So the released, curated catalog is the training manifest, used in full; catalog.parquet lists exactly those records, and the four examples are rows in it (the egg and tree are present in BioCLIP 2's a8f38b4 revision as well as the current one). If this is wrong—e.g., a further training-time filter is applied that these sources don't mention—then some of the specifics here may not hold.
Finally, in the interest of transparency, I want to be clear that I had a substantial amount of help in this debugging exercise from Claude. I have personally scrutinized and stand by these results, but even still some AI-born error or nonsense may have slipped through the cracks.