Datasets:

metadata
license: mit
task_categories:
- object-detection
- zero-shot-object-detection
language:
- en
size_categories:
- 1M+
source_datasets:
- DOTA
- DIOR
- FAIR1M
- NWPU-VHR-10
- HRSC2016
- RSOD
- AID
- NWPU-RESISC45
- SLM
- EMS
tags:
- remote-sensing
- computer-vision
- open-vocabulary
- benchmark
- image-dataset
pretty_name: LAE-1M
LAE-1M: Locate Anything on Earth Dataset
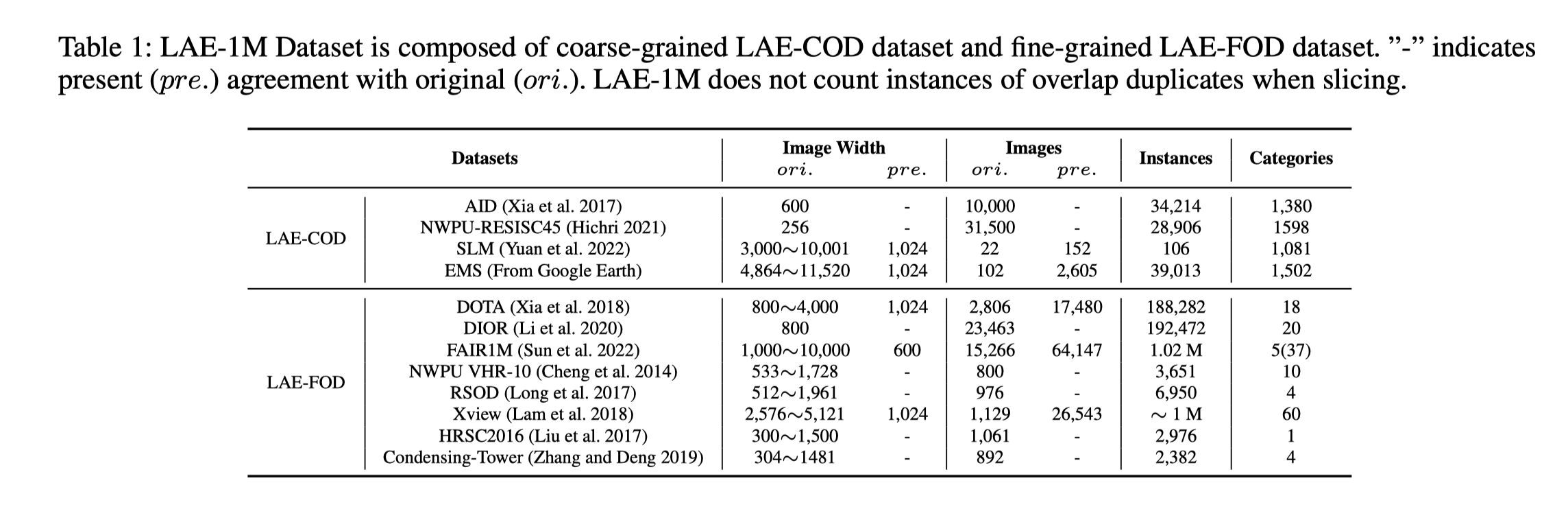
LAE-1M (Locate Anything on Earth - 1 Million) is a large-scale open-vocabulary remote sensing object detection dataset introduced in the paper "Locate Anything on Earth: Advancing Open-Vocabulary Object Detection for Remote Sensing Community" (AAAI 2025).
It contains over 1M images with coarse-grained (LAE-COD) and fine-grained (LAE-FOD) annotations, unified in COCO format, enabling zero-shot and few-shot detection in remote sensing.
Dataset Details
Dataset Description
- Curated by: Jiancheng Pan, Yanxing Liu, Yuqian Fu, Muyuan Ma, Jiahao Li, Danda Pani Paudel, Luc Van Gool, Xiaomeng Huang
- Funded by: ETH Zürich, INSAIT (partial computing support)
- Shared by: LAE-DINO Project Team
- Language(s): Not language-specific; visual dataset
- License: MIT License
Dataset Sources
- Repository: GitHub - LAE-DINO
- Paper: ArXiv 2408.09110, AAAI 2025
- Project Page: LAE Website
- Dataset Download: HuggingFace
Dataset Structure
| Subset | # Images | # Classes | Format | Description |
|---|---|---|---|---|
| LAE-COD | 400k+ | 20+ | COCO | Coarse-grained detection (AID, EMS, SLM) |
| LAE-FOD | 600k+ | 50+ | COCO | Fine-grained detection (DIOR, DOTAv2, FAIR1M) |
| LAE-80C | 20k (val) | 80 | COCO | Benchmark with 80 semantically distinct classes |
All annotations are in COCO JSON format with bounding boxes and categories.
Uses
Direct Use
- Open-Vocabulary Object Detection in Remote Sensing
- Benchmarking zero-shot and few-shot detection models
- Pretraining large vision-language models
Out-of-Scope Use
- Any tasks requiring personal or sensitive information
- Real-time inference on satellite streams without further optimization
Quick Start
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("jaychempan/LAE-1M", split="train")
# Access one example
example = dataset[0]
print(example.keys()) # image, annotations, category_id, etc.
# Show the image (requires Pillow)
from PIL import Image
import io
img = Image.open(io.BytesIO(example["image"]))
img.show()