
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1 value | created_at stringlengths 19 19 | repo stringlengths 5 112 | repo_url stringlengths 34 141 | action stringclasses 3 values | title stringlengths 1 855 | labels stringlengths 4 721 | body stringlengths 1 261k | index stringclasses 13 values | text_combine stringlengths 96 261k | label stringclasses 2 values | text stringlengths 96 240k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
395,048 | 11,670,778,345 | IssuesEvent | 2020-03-04 01:00:30 | cloudfoundry-incubator/kubecf | https://api.github.com/repos/cloudfoundry-incubator/kubecf | closed | Fix compilation of {brain-tests,cf-mysql,groot-btrfs} release images on the sle15 stemcell | Priority: High SUSE Status: Verification Needed Type: Enhancement | **Is your feature request related to a problem? Please describe.**
After the switch to the sle15 stemcell three release images were left behind due to compilation issues:
* brain-tests (bundled ruby 2.3 icompatible with libopenssl)
* cf-mysql (bundled ruby 2.3 icompatible with libopenssl)
* groot-btrfs (automake, pkgconfig)
**Describe the solution you'd like**
The releases should be changed so that they compile again by updating the problematic packages. There could also be changes required for the stemcell itself.
**Describe alternatives you've considered**
N/A
**Additional context**
N/A
| 1.0 | Fix compilation of {brain-tests,cf-mysql,groot-btrfs} release images on the sle15 stemcell - **Is your feature request related to a problem? Please describe.**
After the switch to the sle15 stemcell three release images were left behind due to compilation issues:
* brain-tests (bundled ruby 2.3 icompatible with libopenssl)
* cf-mysql (bundled ruby 2.3 icompatible with libopenssl)
* groot-btrfs (automake, pkgconfig)
**Describe the solution you'd like**
The releases should be changed so that they compile again by updating the problematic packages. There could also be changes required for the stemcell itself.
**Describe alternatives you've considered**
N/A
**Additional context**
N/A
| priority | fix compilation of brain tests cf mysql groot btrfs release images on the stemcell is your feature request related to a problem please describe after the switch to the stemcell three release images were left behind due to compilation issues brain tests bundled ruby icompatible with libopenssl cf mysql bundled ruby icompatible with libopenssl groot btrfs automake pkgconfig describe the solution you d like the releases should be changed so that they compile again by updating the problematic packages there could also be changes required for the stemcell itself describe alternatives you ve considered n a additional context n a | 1 |
65,587 | 3,236,439,907 | IssuesEvent | 2015-10-14 05:18:34 | cs2103aug2015-w14-3j/main | https://api.github.com/repos/cs2103aug2015-w14-3j/main | closed | As a user, I can enter tasks that are conflicted with each other initially, resolving them later | priority.high type.story | so that I can reorganise them better after entering all the entries. | 1.0 | As a user, I can enter tasks that are conflicted with each other initially, resolving them later - so that I can reorganise them better after entering all the entries. | priority | as a user i can enter tasks that are conflicted with each other initially resolving them later so that i can reorganise them better after entering all the entries | 1 |
681,286 | 23,304,177,366 | IssuesEvent | 2022-08-07 19:25:25 | City-Bureau/city-scrapers-fresno | https://api.github.com/repos/City-Bureau/city-scrapers-fresno | closed | New Scraper: Fresno County Planning Commission | priority-high | Create a new scraper for Fresno County Planning Commission
Jurisdiction: Fresno County
Website: https://www.co.fresno.ca.us/departments/public-works-planning/divisions-of-public-works-and-planning/development-services-division/planning-and-land-use/planning-commission/plann
| 1.0 | New Scraper: Fresno County Planning Commission - Create a new scraper for Fresno County Planning Commission
Jurisdiction: Fresno County
Website: https://www.co.fresno.ca.us/departments/public-works-planning/divisions-of-public-works-and-planning/development-services-division/planning-and-land-use/planning-commission/plann
| priority | new scraper fresno county planning commission create a new scraper for fresno county planning commission jurisdiction fresno county website | 1 |
807,288 | 29,993,569,000 | IssuesEvent | 2023-06-26 02:13:02 | UBC-Solar/link_telemetry | https://api.github.com/repos/UBC-Solar/link_telemetry | closed | Improve error handling for the Grafana and InfluxDB writes | bug high-priority | The calls that write data to Grafana and InfluxDB are not wrapped in `try-except` blocks which means if they fail even once then the whole system goes down.
Catch the exceptions that these calls might throw, handle them appropriately, and make sure to log them. | 1.0 | Improve error handling for the Grafana and InfluxDB writes - The calls that write data to Grafana and InfluxDB are not wrapped in `try-except` blocks which means if they fail even once then the whole system goes down.
Catch the exceptions that these calls might throw, handle them appropriately, and make sure to log them. | priority | improve error handling for the grafana and influxdb writes the calls that write data to grafana and influxdb are not wrapped in try except blocks which means if they fail even once then the whole system goes down catch the exceptions that these calls might throw handle them appropriately and make sure to log them | 1 |
108,520 | 4,346,793,780 | IssuesEvent | 2016-07-29 17:14:14 | influxdata/docs.influxdata.com | https://api.github.com/repos/influxdata/docs.influxdata.com | opened | Update the differences page with more information | Priority: high Time commitment: quick task |
###### URL for relevant page?
https://docs.influxdata.com/influxdb/v1.0/administration/013_vs_1/
###### What products and version are you using?
1.0
###### Where did you look before opening the issue?
InfluxDB Changelog
* New logging information
* Renames configuration setting `trace-logging-enabled`
| 1.0 | Update the differences page with more information -
###### URL for relevant page?
https://docs.influxdata.com/influxdb/v1.0/administration/013_vs_1/
###### What products and version are you using?
1.0
###### Where did you look before opening the issue?
InfluxDB Changelog
* New logging information
* Renames configuration setting `trace-logging-enabled`
| priority | update the differences page with more information url for relevant page what products and version are you using where did you look before opening the issue influxdb changelog new logging information renames configuration setting trace logging enabled | 1 |
146,848 | 5,629,121,653 | IssuesEvent | 2017-04-05 08:39:24 | TrueCar/gluestick | https://api.github.com/repos/TrueCar/gluestick | closed | Webpack from watcher does not seem to recover from errors | bug high priority | When running an app, if I require a wrong path to a file, watcher will crash showing the error but it won't let me continue, instead, I need to run `start` again. | 1.0 | Webpack from watcher does not seem to recover from errors - When running an app, if I require a wrong path to a file, watcher will crash showing the error but it won't let me continue, instead, I need to run `start` again. | priority | webpack from watcher does not seem to recover from errors when running an app if i require a wrong path to a file watcher will crash showing the error but it won t let me continue instead i need to run start again | 1 |
514,588 | 14,941,222,815 | IssuesEvent | 2021-01-25 19:26:16 | StrangeLoopGames/EcoIssues | https://api.github.com/repos/StrangeLoopGames/EcoIssues | closed | Tailoring Foundation Update Clothing Art | Category: Art Priority: High Type: Task | Milenko has just about finished 4 new sets of profession themed clothing, which in terms of which models are shown and displayed on the avatars have some additional differences-- the meshes for the actual avatars have been updated and broken up differently for them. This will be a new way to break up the avatar mesh going forward and eventually all old clothing assets will be updated to work the same way.
For now, we will need to hide and show specific sets of meshes that constitute the avatar for the new clothing to work. When an old clothing piece is equipped, we can simply switch that part back to the old avatar mesh as well, for the near future. | 1.0 | Tailoring Foundation Update Clothing Art - Milenko has just about finished 4 new sets of profession themed clothing, which in terms of which models are shown and displayed on the avatars have some additional differences-- the meshes for the actual avatars have been updated and broken up differently for them. This will be a new way to break up the avatar mesh going forward and eventually all old clothing assets will be updated to work the same way.
For now, we will need to hide and show specific sets of meshes that constitute the avatar for the new clothing to work. When an old clothing piece is equipped, we can simply switch that part back to the old avatar mesh as well, for the near future. | priority | tailoring foundation update clothing art milenko has just about finished new sets of profession themed clothing which in terms of which models are shown and displayed on the avatars have some additional differences the meshes for the actual avatars have been updated and broken up differently for them this will be a new way to break up the avatar mesh going forward and eventually all old clothing assets will be updated to work the same way for now we will need to hide and show specific sets of meshes that constitute the avatar for the new clothing to work when an old clothing piece is equipped we can simply switch that part back to the old avatar mesh as well for the near future | 1 |
719,163 | 24,749,267,518 | IssuesEvent | 2022-10-21 12:27:15 | VCityTeam/UD-Viz | https://api.github.com/repos/VCityTeam/UD-Viz | opened | Game refacto | refacto Modularity priority-high | Today we have to mutualize game code such one produced/are going to be produced in this repositories/issues:
- [UD-Imuv](https://github.com/VCityTeam/UD-Imuv)
- [Galeri3](https://github.com/VCityTeam/GALERI3)
- [Deambulation Bron](https://github.com/VCityTeam/UD-Demo-DatAgora-Deambulation-Bron)
- [MSH](https://github.com/VCityTeam/UD-Imuv/issues/311)
- [ENTPE](https://github.com/VCityTeam/UD-Imuv/issues/312)
The aim is to define where belong the code of:
- Game Engine + GameView + AssetsManager + LocalGame Template (actually in ud-viz)
- Editor (actually in UD-Imuv)
- Distant Game client (actually in UD-Imuv)
- Game server (actually in UD-Imuv)
- LocalScripts (actually splited in differents repositories)
Everything should be package in ud-viz or we should create a new npm package or both ? | 1.0 | Game refacto - Today we have to mutualize game code such one produced/are going to be produced in this repositories/issues:
- [UD-Imuv](https://github.com/VCityTeam/UD-Imuv)
- [Galeri3](https://github.com/VCityTeam/GALERI3)
- [Deambulation Bron](https://github.com/VCityTeam/UD-Demo-DatAgora-Deambulation-Bron)
- [MSH](https://github.com/VCityTeam/UD-Imuv/issues/311)
- [ENTPE](https://github.com/VCityTeam/UD-Imuv/issues/312)
The aim is to define where belong the code of:
- Game Engine + GameView + AssetsManager + LocalGame Template (actually in ud-viz)
- Editor (actually in UD-Imuv)
- Distant Game client (actually in UD-Imuv)
- Game server (actually in UD-Imuv)
- LocalScripts (actually splited in differents repositories)
Everything should be package in ud-viz or we should create a new npm package or both ? | priority | game refacto today we have to mutualize game code such one produced are going to be produced in this repositories issues the aim is to define where belong the code of game engine gameview assetsmanager localgame template actually in ud viz editor actually in ud imuv distant game client actually in ud imuv game server actually in ud imuv localscripts actually splited in differents repositories everything should be package in ud viz or we should create a new npm package or both | 1 |
403,563 | 11,843,092,344 | IssuesEvent | 2020-03-24 01:09:39 | AY1920S2-CS2103T-W17-2/main | https://api.github.com/repos/AY1920S2-CS2103T-W17-2/main | closed | Create SuggestionCommandParser interface | priority.High status.Ongoing type.Enhancement | This `SuggestionCommandParser<T extends SuggestionCommand>` interface can be paralleled to `Parser<T extends Command>` in AB3 [here](https://github.com/nus-cs2103-AY1920S2/addressbook-level3/blob/master/src/main/java/seedu/address/logic/parser/Parser.java).
This will be stored in:
`logic --> suggestion --> parser --> SuggestionCommandParser.java` | 1.0 | Create SuggestionCommandParser interface - This `SuggestionCommandParser<T extends SuggestionCommand>` interface can be paralleled to `Parser<T extends Command>` in AB3 [here](https://github.com/nus-cs2103-AY1920S2/addressbook-level3/blob/master/src/main/java/seedu/address/logic/parser/Parser.java).
This will be stored in:
`logic --> suggestion --> parser --> SuggestionCommandParser.java` | priority | create suggestioncommandparser interface this suggestioncommandparser interface can be paralleled to parser in this will be stored in logic suggestion parser suggestioncommandparser java | 1 |
446,542 | 12,866,227,973 | IssuesEvent | 2020-07-10 03:01:42 | FightPandemics/FightPandemics | https://api.github.com/repos/FightPandemics/FightPandemics | closed | Onboarding User -> Offer Help -> Volunteer/Donor/Investor are redirected to individuals who request help and Org offering help redirects to Org requesting help | Feed High Priority MVP - Critical Onboarding | 1. Open "https://staging.fightpandemics.work/"
2. As an onboarding user -> non logged In
Offer Help -> As a Volunteer -> Share my location -> Skip
Issue# You will observe that the Posts are filtered on the basis of 'Geo Location' and 'Individual'
So, the post are filtered on the basis of 'Individual' and 'Organization' along with Geo Location.
This means, an Individual offering help is redirected to individuals requesting help and Organizations offering help are redirected to the Organization who are requesting help.
Expected Result: For initial onboarding users offering help -> they should be directed to the users in their geo location without 'Individual' or 'Organisation' filter i.e. The Filters in Offer help -> it should the filter the post on the basis of geo location ONLY.
Refer below screenshot:
<img width="677" alt="Screen Shot 2020-07-08 at 9 32 28 PM" src="https://user-images.githubusercontent.com/67168400/86987188-69d96780-c163-11ea-8d95-4b3e20e28a58.png">
Please note, can't comment on the behavior before the fix of #1019
https://share.getcloudapp.com/yAuYBJRr
| 1.0 | Onboarding User -> Offer Help -> Volunteer/Donor/Investor are redirected to individuals who request help and Org offering help redirects to Org requesting help - 1. Open "https://staging.fightpandemics.work/"
2. As an onboarding user -> non logged In
Offer Help -> As a Volunteer -> Share my location -> Skip
Issue# You will observe that the Posts are filtered on the basis of 'Geo Location' and 'Individual'
So, the post are filtered on the basis of 'Individual' and 'Organization' along with Geo Location.
This means, an Individual offering help is redirected to individuals requesting help and Organizations offering help are redirected to the Organization who are requesting help.
Expected Result: For initial onboarding users offering help -> they should be directed to the users in their geo location without 'Individual' or 'Organisation' filter i.e. The Filters in Offer help -> it should the filter the post on the basis of geo location ONLY.
Refer below screenshot:
<img width="677" alt="Screen Shot 2020-07-08 at 9 32 28 PM" src="https://user-images.githubusercontent.com/67168400/86987188-69d96780-c163-11ea-8d95-4b3e20e28a58.png">
Please note, can't comment on the behavior before the fix of #1019
https://share.getcloudapp.com/yAuYBJRr
| priority | onboarding user offer help volunteer donor investor are redirected to individuals who request help and org offering help redirects to org requesting help open as an onboarding user non logged in offer help as a volunteer share my location skip issue you will observe that the posts are filtered on the basis of geo location and individual so the post are filtered on the basis of individual and organization along with geo location this means an individual offering help is redirected to individuals requesting help and organizations offering help are redirected to the organization who are requesting help expected result for initial onboarding users offering help they should be directed to the users in their geo location without individual or organisation filter i e the filters in offer help it should the filter the post on the basis of geo location only refer below screenshot img width alt screen shot at pm src please note can t comment on the behavior before the fix of | 1 |
435,771 | 12,541,023,157 | IssuesEvent | 2020-06-05 11:30:57 | geosolutions-it/MapStore2 | https://api.github.com/repos/geosolutions-it/MapStore2 | opened | Font Size for GeoStory text editor | Priority: High | The font size selector is currently missing in the geostory test editor and it should be present. | 1.0 | Font Size for GeoStory text editor - The font size selector is currently missing in the geostory test editor and it should be present. | priority | font size for geostory text editor the font size selector is currently missing in the geostory test editor and it should be present | 1 |
718,357 | 24,713,826,395 | IssuesEvent | 2022-10-20 04:38:37 | AY2223S1-CS2103T-T12-4/tp | https://api.github.com/repos/AY2223S1-CS2103T-T12-4/tp | closed | Add `Medication` and `MedicationList` | type.Task priority.High | Related to #16, #18
- `MedicationList#add` will throw an exception if the `Medication` to be added already exists in `MedicationList`
- `MedicationList#edit` will throw an exception if the `Medication` to be edited is the same as the one present in `MedicationList` | 1.0 | Add `Medication` and `MedicationList` - Related to #16, #18
- `MedicationList#add` will throw an exception if the `Medication` to be added already exists in `MedicationList`
- `MedicationList#edit` will throw an exception if the `Medication` to be edited is the same as the one present in `MedicationList` | priority | add medication and medicationlist related to medicationlist add will throw an exception if the medication to be added already exists in medicationlist medicationlist edit will throw an exception if the medication to be edited is the same as the one present in medicationlist | 1 |
358,597 | 10,618,568,393 | IssuesEvent | 2019-10-13 05:50:45 | campusrope/campusropepwa | https://api.github.com/repos/campusrope/campusropepwa | closed | 106.port helpline add component | high priority | port the code from old repo.make sure the validation,styling and tag semantics are done properly
use the latest reactive state mangement if needed | 1.0 | 106.port helpline add component - port the code from old repo.make sure the validation,styling and tag semantics are done properly
use the latest reactive state mangement if needed | priority | port helpline add component port the code from old repo make sure the validation styling and tag semantics are done properly use the latest reactive state mangement if needed | 1 |
723,164 | 24,887,363,875 | IssuesEvent | 2022-10-28 08:56:20 | webkom/lego | https://api.github.com/repos/webkom/lego | closed | CAPTCHA (Turnstile) widget does not respect theme | bug frontend level:easy enhancement priority:high small-fix | The cloudflare Turnstile widget does not respect the site theme, it defaults to the users preferred theme in the browser.
We should set the theme to match the users theme. | 1.0 | CAPTCHA (Turnstile) widget does not respect theme - The cloudflare Turnstile widget does not respect the site theme, it defaults to the users preferred theme in the browser.
We should set the theme to match the users theme. | priority | captcha turnstile widget does not respect theme the cloudflare turnstile widget does not respect the site theme it defaults to the users preferred theme in the browser we should set the theme to match the users theme | 1 |
621,237 | 19,581,037,456 | IssuesEvent | 2022-01-04 21:21:36 | CDCgov/prime-reportstream | https://api.github.com/repos/CDCgov/prime-reportstream | closed | Build a Standard COVID Schema | onboarding-ops High Priority experience Enhancement | ## Problem Statement
As the Experience Team, we need a standard schema for COVID reporting in ReportStream so that we can test the hypothesis that reporting entities will be able to comply with a standard schema.
## Notes
Jim currently taking a first pass at building and will then be handing off to Joel & Rick
## Criteria
- [x] Setup a default sender_id named "manualupload" to be used as a test Sender for our validation.
- [x] The schema must be developed based on the requirements outlined in the Standard CSV Requirements document named "CSV-StandardFileFormatAndNotes-v2.docx" in the CSV Pilot Sharepoint folder.
| 1.0 | Build a Standard COVID Schema - ## Problem Statement
As the Experience Team, we need a standard schema for COVID reporting in ReportStream so that we can test the hypothesis that reporting entities will be able to comply with a standard schema.
## Notes
Jim currently taking a first pass at building and will then be handing off to Joel & Rick
## Criteria
- [x] Setup a default sender_id named "manualupload" to be used as a test Sender for our validation.
- [x] The schema must be developed based on the requirements outlined in the Standard CSV Requirements document named "CSV-StandardFileFormatAndNotes-v2.docx" in the CSV Pilot Sharepoint folder.
| priority | build a standard covid schema problem statement as the experience team we need a standard schema for covid reporting in reportstream so that we can test the hypothesis that reporting entities will be able to comply with a standard schema notes jim currently taking a first pass at building and will then be handing off to joel rick criteria setup a default sender id named manualupload to be used as a test sender for our validation the schema must be developed based on the requirements outlined in the standard csv requirements document named csv standardfileformatandnotes docx in the csv pilot sharepoint folder | 1 |
399,889 | 11,762,715,349 | IssuesEvent | 2020-03-14 02:51:46 | troop-370/troop370 | https://api.github.com/repos/troop-370/troop370 | closed | Add announcement: Woodruff Merit Badge Sign-Up | announcement priority: high | > Merit Badge sign-ups for Woodruff Summer Camp
>
> It's time to make your selections for summer camp! Fill out this form before March 23rd so we know what to register for.
>
> If you have any questions contact Jeff Hunt.
>
> https://forms.gle/MzXumknnn31BDW9m6
To be displayed from 24FEB2020 through 24MAR2020 | 1.0 | Add announcement: Woodruff Merit Badge Sign-Up - > Merit Badge sign-ups for Woodruff Summer Camp
>
> It's time to make your selections for summer camp! Fill out this form before March 23rd so we know what to register for.
>
> If you have any questions contact Jeff Hunt.
>
> https://forms.gle/MzXumknnn31BDW9m6
To be displayed from 24FEB2020 through 24MAR2020 | priority | add announcement woodruff merit badge sign up merit badge sign ups for woodruff summer camp it s time to make your selections for summer camp fill out this form before march so we know what to register for if you have any questions contact jeff hunt to be displayed from through | 1 |
314,947 | 9,604,902,968 | IssuesEvent | 2019-05-10 21:31:39 | TrinityCore/TrinityCore | https://api.github.com/repos/TrinityCore/TrinityCore | closed | Client freeze on Ulduar | Branch-3.3.5a Priority-High | <!--- (**********************************)
(** Fill in the following fields **)
(**********************************) --->
**Description:**
Client freezes on ulduar
**Current behaviour:**
Client freezes on ulduar
**Expected behaviour:**
No freeze :P
**Steps to reproduce the problem:**
0. gm fly on
1. kill Kologarn .go c id 32930
2. take teleport to mimiron (spark of imagination)
3. take teleport back to Kologarn
4. client freezes.
(using .dam will work too)
**Branch(es):**
3.3.5
**TC rev. hash/commit:**
2fd9b3f394d9
**Operating system:** Debian 9 x64.
<!--- Notes
- This template is for problem reports. For other types of report, edit it accordingly.
- For fixes containing C++ changes, create a Pull Request.
--->
| 1.0 | Client freeze on Ulduar - <!--- (**********************************)
(** Fill in the following fields **)
(**********************************) --->
**Description:**
Client freezes on ulduar
**Current behaviour:**
Client freezes on ulduar
**Expected behaviour:**
No freeze :P
**Steps to reproduce the problem:**
0. gm fly on
1. kill Kologarn .go c id 32930
2. take teleport to mimiron (spark of imagination)
3. take teleport back to Kologarn
4. client freezes.
(using .dam will work too)
**Branch(es):**
3.3.5
**TC rev. hash/commit:**
2fd9b3f394d9
**Operating system:** Debian 9 x64.
<!--- Notes
- This template is for problem reports. For other types of report, edit it accordingly.
- For fixes containing C++ changes, create a Pull Request.
--->
| priority | client freeze on ulduar fill in the following fields description client freezes on ulduar current behaviour client freezes on ulduar expected behaviour no freeze p steps to reproduce the problem gm fly on kill kologarn go c id take teleport to mimiron spark of imagination take teleport back to kologarn client freezes using dam will work too branch es tc rev hash commit operating system debian notes this template is for problem reports for other types of report edit it accordingly for fixes containing c changes create a pull request | 1 |
756,507 | 26,473,921,577 | IssuesEvent | 2023-01-17 09:41:43 | EinStealth/EinStealth | https://api.github.com/repos/EinStealth/EinStealth | opened | 罠に当たったら、当たった罠が消えるようにする | Mobile Priority: High | # 概要
今のままだと罠に当たり続けることになる。
当たったらデータベースから削除する
# 関連するissue
<!-- 関連するissueがあればここに書いてね -->
<!-- ex. #{issue番号} -->
# 参考
<!-- 参考資料などはここに書いてね -->
# チェックリスト
- [ ] ローカルデータベースの罠を削除
- [ ] リモートの罠を削除
| 1.0 | 罠に当たったら、当たった罠が消えるようにする - # 概要
今のままだと罠に当たり続けることになる。
当たったらデータベースから削除する
# 関連するissue
<!-- 関連するissueがあればここに書いてね -->
<!-- ex. #{issue番号} -->
# 参考
<!-- 参考資料などはここに書いてね -->
# チェックリスト
- [ ] ローカルデータベースの罠を削除
- [ ] リモートの罠を削除
| priority | 罠に当たったら、当たった罠が消えるようにする 概要 今のままだと罠に当たり続けることになる。 当たったらデータベースから削除する 関連するissue 参考 チェックリスト ローカルデータベースの罠を削除 リモートの罠を削除 | 1 |
651,505 | 21,481,460,532 | IssuesEvent | 2022-04-26 18:10:29 | dagger/dagger | https://api.github.com/repos/dagger/dagger | closed | Duplicate log messages | kind/bug kind/help wanted priority/high kind/user-request | This will naturally run only once ("echo LOL" one time):
```
foo: #up: [
op.#DockerBuild & {
dockerfile: """
FROM dubodubonduponey/debian
ARG TARGETPLATFORM
RUN echo LOL $TARGETPLATFORM
"""
},
]
```
This will run twice (echo LOL multiple times):
```
foo: #up: [
op.#DockerBuild & {
dockerfile: """
FROM dubodubonduponey/debian
ARG TARGETPLATFORM
RUN echo LOL $TARGETPLATFORM
"""
},
op.#PushContainer & {
ref: "push-registry.local/dagger/test:1"
},
]
```
If you add DockerLogin before, it runs once more. | 1.0 | Duplicate log messages - This will naturally run only once ("echo LOL" one time):
```
foo: #up: [
op.#DockerBuild & {
dockerfile: """
FROM dubodubonduponey/debian
ARG TARGETPLATFORM
RUN echo LOL $TARGETPLATFORM
"""
},
]
```
This will run twice (echo LOL multiple times):
```
foo: #up: [
op.#DockerBuild & {
dockerfile: """
FROM dubodubonduponey/debian
ARG TARGETPLATFORM
RUN echo LOL $TARGETPLATFORM
"""
},
op.#PushContainer & {
ref: "push-registry.local/dagger/test:1"
},
]
```
If you add DockerLogin before, it runs once more. | priority | duplicate log messages this will naturally run only once echo lol one time foo up op dockerbuild dockerfile from dubodubonduponey debian arg targetplatform run echo lol targetplatform this will run twice echo lol multiple times foo up op dockerbuild dockerfile from dubodubonduponey debian arg targetplatform run echo lol targetplatform op pushcontainer ref push registry local dagger test if you add dockerlogin before it runs once more | 1 |
406,944 | 11,904,558,702 | IssuesEvent | 2020-03-30 17:02:45 | DukeLearningInnovation/kits | https://api.github.com/repos/DukeLearningInnovation/kits | closed | Add kit app user access event for logging | Problem Statement enhancement high priority | I am instructor/kits admin trying to understand how students/users are using Kits but I don't see any data on how many times apps have been accessed. This which makes me feel disappointed that I can't use that data to improve my teaching/service.
How might we (the Kits project team), add event tracking for when users click on the app icon in a Kit?
The goal would be to track usage of a specific kit and apps within a kit. We want to know which user is clicking on an app, what the app is, and when. This will feed into the My Kit analytics eventually but would be good data to have now to track usage. We will probably want to report on this data in aggregate as well - app usage/access across all kits.
**Questions**
**Assumptions**
**Hypotheses**
| 1.0 | Add kit app user access event for logging - I am instructor/kits admin trying to understand how students/users are using Kits but I don't see any data on how many times apps have been accessed. This which makes me feel disappointed that I can't use that data to improve my teaching/service.
How might we (the Kits project team), add event tracking for when users click on the app icon in a Kit?
The goal would be to track usage of a specific kit and apps within a kit. We want to know which user is clicking on an app, what the app is, and when. This will feed into the My Kit analytics eventually but would be good data to have now to track usage. We will probably want to report on this data in aggregate as well - app usage/access across all kits.
**Questions**
**Assumptions**
**Hypotheses**
| priority | add kit app user access event for logging i am instructor kits admin trying to understand how students users are using kits but i don t see any data on how many times apps have been accessed this which makes me feel disappointed that i can t use that data to improve my teaching service how might we the kits project team add event tracking for when users click on the app icon in a kit the goal would be to track usage of a specific kit and apps within a kit we want to know which user is clicking on an app what the app is and when this will feed into the my kit analytics eventually but would be good data to have now to track usage we will probably want to report on this data in aggregate as well app usage access across all kits questions assumptions hypotheses | 1 |
791,605 | 27,869,317,191 | IssuesEvent | 2023-03-21 12:29:30 | ita-social-projects/TeachUA | https://api.github.com/repos/ita-social-projects/TeachUA | opened | Edit task add new button | User story UI Priority: High Severity: high | As an administrator, I want to be able to quickly jump to the task list from the task editing page.
**Description**
A " Список завдань" button is added to the "edit task" page. This button allows you to quickly go to the list of tasks.
### Acceptance Criteria
1. The button repeats the design, font and color scheme of the already existing buttons on this page.
2. When you click on the "Список завдань" button, you will be taken to the task list page.
3. According to the mockup, the "Список завдань" button should be located to the right of the "Переглянути" button
https://www.figma.com/file/YSXBEZfBiDNr3dgOpMhTtH/%D0%9D%D0%B0%D0%B2%D1%87%D0%B0%D0%B9-%D1%83%D0%BA%D1%80%D0%B0%D1%97%D0%BD%D1%81%D1%8C%D0%BA%D0%BE%D1%8E?node-id=83-823&t=d0GlAI4UCB41N8rk-0
5. Buttons "Зберегти", "Переглянути", "Список завдань" should be of the same size, and located symmetrically to the modal window.
### Tasks
- [ ] 1. Add button "Список завдань"
- [ ] 2. Make changes to the mockup
| 1.0 | Edit task add new button - As an administrator, I want to be able to quickly jump to the task list from the task editing page.
**Description**
A " Список завдань" button is added to the "edit task" page. This button allows you to quickly go to the list of tasks.
### Acceptance Criteria
1. The button repeats the design, font and color scheme of the already existing buttons on this page.
2. When you click on the "Список завдань" button, you will be taken to the task list page.
3. According to the mockup, the "Список завдань" button should be located to the right of the "Переглянути" button
https://www.figma.com/file/YSXBEZfBiDNr3dgOpMhTtH/%D0%9D%D0%B0%D0%B2%D1%87%D0%B0%D0%B9-%D1%83%D0%BA%D1%80%D0%B0%D1%97%D0%BD%D1%81%D1%8C%D0%BA%D0%BE%D1%8E?node-id=83-823&t=d0GlAI4UCB41N8rk-0
5. Buttons "Зберегти", "Переглянути", "Список завдань" should be of the same size, and located symmetrically to the modal window.
### Tasks
- [ ] 1. Add button "Список завдань"
- [ ] 2. Make changes to the mockup
| priority | edit task add new button as an administrator i want to be able to quickly jump to the task list from the task editing page description a список завдань button is added to the edit task page this button allows you to quickly go to the list of tasks acceptance criteria the button repeats the design font and color scheme of the already existing buttons on this page when you click on the список завдань button you will be taken to the task list page according to the mockup the список завдань button should be located to the right of the переглянути button buttons зберегти переглянути список завдань should be of the same size and located symmetrically to the modal window tasks add button список завдань make changes to the mockup | 1 |
94,252 | 3,923,689,175 | IssuesEvent | 2016-04-22 12:32:23 | dhis2/maintenance-app | https://api.github.com/repos/dhis2/maintenance-app | closed | Trying to create a new object from a card within a tab renders the app unresponsive | bug priority:high | Reproduce:
1. Click a tab other than "All" at the top of the app
2. Click the "+" button on any card to add any new object
The app becomes unresponsive and has to be reloaded. There's also an error printed to the console. | 1.0 | Trying to create a new object from a card within a tab renders the app unresponsive - Reproduce:
1. Click a tab other than "All" at the top of the app
2. Click the "+" button on any card to add any new object
The app becomes unresponsive and has to be reloaded. There's also an error printed to the console. | priority | trying to create a new object from a card within a tab renders the app unresponsive reproduce click a tab other than all at the top of the app click the button on any card to add any new object the app becomes unresponsive and has to be reloaded there s also an error printed to the console | 1 |
53,119 | 3,035,601,207 | IssuesEvent | 2015-08-06 05:28:45 | UnifiedViews/Core | https://api.github.com/repos/UnifiedViews/Core | closed | Blank pipeline run ends with FAILED status without any error message | priority: High severity: bug | When blank pipeline is saved and run, it ends with FAILED status but no error message explaining the reason is displayed;
This is very confusing;
I would expect it to fail with message that no DPU found to execute;
Another possibility would be mark pipeline status as WARNING and give proper message that pipeline has no DPUs
Motivation:
- this bug was discovered when updating DPUs via UV master API.
- all DPU instances were deleted, so blank pipelines remained (also a bug, but still can happen something like this)
- pipelines started to fail without any error message
| 1.0 | Blank pipeline run ends with FAILED status without any error message - When blank pipeline is saved and run, it ends with FAILED status but no error message explaining the reason is displayed;
This is very confusing;
I would expect it to fail with message that no DPU found to execute;
Another possibility would be mark pipeline status as WARNING and give proper message that pipeline has no DPUs
Motivation:
- this bug was discovered when updating DPUs via UV master API.
- all DPU instances were deleted, so blank pipelines remained (also a bug, but still can happen something like this)
- pipelines started to fail without any error message
| priority | blank pipeline run ends with failed status without any error message when blank pipeline is saved and run it ends with failed status but no error message explaining the reason is displayed this is very confusing i would expect it to fail with message that no dpu found to execute another possibility would be mark pipeline status as warning and give proper message that pipeline has no dpus motivation this bug was discovered when updating dpus via uv master api all dpu instances were deleted so blank pipelines remained also a bug but still can happen something like this pipelines started to fail without any error message | 1 |
750,275 | 26,195,913,706 | IssuesEvent | 2023-01-03 13:26:38 | fecgov/fec-cms | https://api.github.com/repos/fecgov/fec-cms | closed | 2023 Reporting Pages Publishing Ticket | Work: Content High priority Pipeline: Sprint Backlog | ### Summary
The reporting pages for 2022 need to be drafted, reviewed by Info Management, OGC, Commissioner Offices, and Public Records. This is the ticket for publishing the pages.
Once approved, after January 1, 2022 (most likely January 3, 2022 since Jan 1 is a Saturday), we will need to publish the reporting pages for 2022.
We will also need to archive the 2022 report date pages.
### Related issues
- #5311
### Completion criteria
Publish the following pages:
- [x] Quarterly pages:
- - [x] April Quarterly (Congressional)
- - [x] April Quarterly (Presidential)
- - [x] July Quarterly (Congressional)
- - [x] July Quarterly (Presidential)
- - [x] October Quarterly (Congressional)
- - [x] October Quarterly (Presidential)
- - [x] Year-End Congressional Candidate
- - [x] Year-End Presidential
- [x] Monthly pages:
- - [x] February Monthly
- - [x] March Monthly
- - [x] April Monthly
- - [x] May Monthly
- - [x] June Monthly
- - [x] July Monthly
- - [x] August Monthly
- - [x] September Monthly
- - [x] October Monthly
- - [x] Year-End
- [x] Semi-annual pages:
- - [x] Mid-Year Monthly
- - [x] Year-End Monthly
- [x] Candidate Supplemental page
- [x] PAC/Party Supplemental page
- [x] Presidential supplemental page
- [x] Quarterly chart page
- [x] Monthly chart page
- [x] Semi-annual chart page
- [x] CC chart page
- [x] EC chart page
- [x] FEA chart page
- [x] IE chart page
- [x] Archive 2022 reporting dates page | 1.0 | 2023 Reporting Pages Publishing Ticket - ### Summary
The reporting pages for 2022 need to be drafted, reviewed by Info Management, OGC, Commissioner Offices, and Public Records. This is the ticket for publishing the pages.
Once approved, after January 1, 2022 (most likely January 3, 2022 since Jan 1 is a Saturday), we will need to publish the reporting pages for 2022.
We will also need to archive the 2022 report date pages.
### Related issues
- #5311
### Completion criteria
Publish the following pages:
- [x] Quarterly pages:
- - [x] April Quarterly (Congressional)
- - [x] April Quarterly (Presidential)
- - [x] July Quarterly (Congressional)
- - [x] July Quarterly (Presidential)
- - [x] October Quarterly (Congressional)
- - [x] October Quarterly (Presidential)
- - [x] Year-End Congressional Candidate
- - [x] Year-End Presidential
- [x] Monthly pages:
- - [x] February Monthly
- - [x] March Monthly
- - [x] April Monthly
- - [x] May Monthly
- - [x] June Monthly
- - [x] July Monthly
- - [x] August Monthly
- - [x] September Monthly
- - [x] October Monthly
- - [x] Year-End
- [x] Semi-annual pages:
- - [x] Mid-Year Monthly
- - [x] Year-End Monthly
- [x] Candidate Supplemental page
- [x] PAC/Party Supplemental page
- [x] Presidential supplemental page
- [x] Quarterly chart page
- [x] Monthly chart page
- [x] Semi-annual chart page
- [x] CC chart page
- [x] EC chart page
- [x] FEA chart page
- [x] IE chart page
- [x] Archive 2022 reporting dates page | priority | reporting pages publishing ticket summary the reporting pages for need to be drafted reviewed by info management ogc commissioner offices and public records this is the ticket for publishing the pages once approved after january most likely january since jan is a saturday we will need to publish the reporting pages for we will also need to archive the report date pages related issues completion criteria publish the following pages quarterly pages april quarterly congressional april quarterly presidential july quarterly congressional july quarterly presidential october quarterly congressional october quarterly presidential year end congressional candidate year end presidential monthly pages february monthly march monthly april monthly may monthly june monthly july monthly august monthly september monthly october monthly year end semi annual pages mid year monthly year end monthly candidate supplemental page pac party supplemental page presidential supplemental page quarterly chart page monthly chart page semi annual chart page cc chart page ec chart page fea chart page ie chart page archive reporting dates page | 1 |
779,619 | 27,360,373,944 | IssuesEvent | 2023-02-27 15:29:26 | pytorch/pytorch | https://api.github.com/repos/pytorch/pytorch | closed | torch-2.0.0-rc1 and torch-1.13.1 can not be installed on Ubuntu 20.04 | high priority oncall: binaries triaged | ### 🐛 Describe the bug
1. Allocate c5a.4xlarge instance, for example by running:
```python
import boto3
ec2=boto3.resource("ec2")
rc=ec2.create_instances(ImageId="ami-031843d9eaa76ad7a",InstanceType="c5a.4xlarge",SecurityGroups=['ssh-allworld'],KeyName="nshulga-key",MinCount=1,MaxCount=1,BlockDeviceMappings=[{'DeviceName': '/dev/sda1','Ebs': {'DeleteOnTermination': True, 'VolumeSize': 150,'VolumeType': 'standard'}}])
```
2. SSH into the instance and run `python3 -mpip install torch`
3. Run `python3 -c "import torch"`
Above fails with:
```
$ python3 -c "import torch"
Traceback (most recent call last):
File "/home/ubuntu/.local/lib/python3.8/site-packages/torch/__init__.py", line 172, in _load_global_deps
ctypes.CDLL(lib_path, mode=ctypes.RTLD_GLOBAL)
File "/usr/lib/python3.8/ctypes/__init__.py", line 373, in __init__
self._handle = _dlopen(self._name, mode)
OSError: /home/ubuntu/.local/lib/python3.8/site-packages/torch/lib/../../nvidia/cublas/lib/libcublas.so.11: undefined symbol: cublasLtHSHMatmulAlgoInit, version libcublasLt.so.11
```
### Versions
1.13.1, 1.13.0
cc @ezyang @gchanan @zou3519 @seemethere | 1.0 | torch-2.0.0-rc1 and torch-1.13.1 can not be installed on Ubuntu 20.04 - ### 🐛 Describe the bug
1. Allocate c5a.4xlarge instance, for example by running:
```python
import boto3
ec2=boto3.resource("ec2")
rc=ec2.create_instances(ImageId="ami-031843d9eaa76ad7a",InstanceType="c5a.4xlarge",SecurityGroups=['ssh-allworld'],KeyName="nshulga-key",MinCount=1,MaxCount=1,BlockDeviceMappings=[{'DeviceName': '/dev/sda1','Ebs': {'DeleteOnTermination': True, 'VolumeSize': 150,'VolumeType': 'standard'}}])
```
2. SSH into the instance and run `python3 -mpip install torch`
3. Run `python3 -c "import torch"`
Above fails with:
```
$ python3 -c "import torch"
Traceback (most recent call last):
File "/home/ubuntu/.local/lib/python3.8/site-packages/torch/__init__.py", line 172, in _load_global_deps
ctypes.CDLL(lib_path, mode=ctypes.RTLD_GLOBAL)
File "/usr/lib/python3.8/ctypes/__init__.py", line 373, in __init__
self._handle = _dlopen(self._name, mode)
OSError: /home/ubuntu/.local/lib/python3.8/site-packages/torch/lib/../../nvidia/cublas/lib/libcublas.so.11: undefined symbol: cublasLtHSHMatmulAlgoInit, version libcublasLt.so.11
```
### Versions
1.13.1, 1.13.0
cc @ezyang @gchanan @zou3519 @seemethere | priority | torch and torch can not be installed on ubuntu 🐛 describe the bug allocate instance for example by running python import resource rc create instances imageid ami instancetype securitygroups keyname nshulga key mincount maxcount blockdevicemappings ssh into the instance and run mpip install torch run c import torch above fails with c import torch traceback most recent call last file home ubuntu local lib site packages torch init py line in load global deps ctypes cdll lib path mode ctypes rtld global file usr lib ctypes init py line in init self handle dlopen self name mode oserror home ubuntu local lib site packages torch lib nvidia cublas lib libcublas so undefined symbol cublaslthshmatmulalgoinit version libcublaslt so versions cc ezyang gchanan seemethere | 1 |
188,076 | 6,768,056,559 | IssuesEvent | 2017-10-26 07:20:29 | leo-project/leofs | https://api.github.com/repos/leo-project/leofs | closed | Recover-node fails to recover all data on storage node | Bug Priority-HIGH v1.3 _leo_storage | There are 6 storage nodes, N=3, W=2, R=1; everything is consistent at the start of experiment. Each node has 4 AVS directories (one per drive). There are no deleted / overwritten objects on cluster (just a tiny amount of multipart headers), ratio of active size is 100% on each node. The distribution of data is not even between nodes, but very even between AVS directories on each node (less than 0.3% difference). The cluster is running with https://github.com/leo-project/leofs/pull/876 changes.
The experiment is as follows:
1) I start upload of data to cluster. I will be uploading 500 GB of data, that is, it should increase disk usage on each node roughly by 500 * 3 / 6 = 250 GB, or ~62 GB per AVS directory on each node. In reality, due to uneven distribution, there will be up to 16% difference between nodes, so it will roughly 57 to 67 GB per AVS directory (but increase should be the same for each AVS directory on any node).
2) I suspend and stop first node - stor01 and remove one of AVS directories, simulating drive failure. I start node, resume it and execute "rebalance-node stor01". The queues on other node starts filling, lots of traffic flows to stor01. The lost AVS directory starts filling up.
3) I suspend stor03 and stop it, simulating another node failure in the middle of recover-node operation. N=3 so I'm supposed not to lose any data over this. Since queues on stor03 are large and trying to fill fast, stopping takes sometime (plus tons of badargs errors from leveldb right before it stops) - but this is expected.
4) I wipe all data on stor03, including all AVS files and all queues (including membership). I launch it and resume - it has the same name and automatically attaches to cluster, gets RING and starts receiving data that is uploaded to cluster. Upload of data doesn't stop because W=2 is sastisfied at all times.
5) I execute "recover-node stor03" (with recover-node stor01 still going on). I can see both stor01 and stor03 receiving lots of data. I wait till all queues are empty.
There are "slow operation" messages in info logs, example log:
```
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:10:54.586854 +0300 1507749054 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,get},{key,<<"bod1/00/de/f1/00def1df121b056aba83f3dad7fa75538010002d93e62e31d3b122eb01a8863b426425d77f844c208439fb6f8043ab7688240a0000000000.xz">>},{processing_time,6839}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:10:54.587046 +0300 1507749054 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,head},{key,<<"bod1/3f/66/4d/3f664df2f427a0ac57cd3b4dcae7ae2d36a2a295e8f292372f0ea476ce0859ea8a139d2fe5f1b427d01c59c4de1d939de8b40d0000000000.xz">>},{processing_time,6410}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:10:59.729838 +0300 1507749059 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,fetch},{key,<<>>},{processing_time,5197}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:18.728820 +0300 1507749078 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,fetch},{key,<<>>},{processing_time,6609}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:18.728972 +0300 1507749078 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,head},{key,<<"bod1/55/55/ba/5555bad0ba80004a65f2be8e8740797517db050e471786913ffb05b5f8d8fdea183844e623cb960cada725e418072bdb009e090000000000.xz">>},{processing_time,5167}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.181764 +0300 1507749086 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,fetch},{key,<<>>},{processing_time,7453}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.181938 +0300 1507749086 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,head},{key,<<"bod1/3f/f5/87/3ff5870173ffbd88eb9af762bffc495992ef49b91ecf2568a574d77172fb86084c1b400cec0e3e95fcdbd9317e4e16e828f4600000000000.xz">>},{processing_time,7372}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.182116 +0300 1507749086 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,head},{key,<<"bod13/31/1b/c3/311bc313abc833bada8a84829ccdf5ab34ae18cefb8dae65f503fbb3274083d60e99823d56302d65e898e6d218cc3c8cb06e090100000000.xz\ncb7e5b94e5564cc2c6f312a2b9276c45">>},{processing_time,6307}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.182272 +0300 1507749086 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,head},{key,<<"bod13/31/1b/c3/311bc313abc833bada8a84829ccdf5ab34ae18cefb8dae65f503fbb3274083d60e99823d56302d65e898e6d218cc3c8cb06e090100000000.xz\ncb7e5b94e5564cc2c6f312a2b9276c45">>},{processing_time,6297}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.182399 +0300 1507749086 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,put},{key,<<"bod13/31/1b/c3/311bc313abc833bada8a84829ccdf5ab34ae18cefb8dae65f503fbb3274083d60e99823d56302d65e898e6d218cc3c8cb06e090100000000.xz\ncb7e5b94e5564cc2c6f312a2b9276c45">>},{processing_time,6840}]
```
This is on step 3) while stor03 was stopped, at other times amount of such messages was way smaller (really insignificant amounts). There are some timeouts in gateway logs as well.
Soon after stor03 started, I got bunch of messages like this in error log on stor01/02/04/05/06:
```
[E] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:07:21.616638 +0300 1507748841 leo_mq_consumer:consume/4 526 [{module,leo_storage_mq},{id,leo_per_object_queue},{cause,{timeout,{gen_server,call,[leo_object_storage_read_4_0,{get,{216869700495053906819207869156722907209,<<"bod1/00/42/c7/0042c78f42247f361f70be868be52e8ddbcbad83b57235175f4687be9f20bd1fb95158ffa5a0edb62200a9008c1eda5b00ad070000000000.xz">>},-1,-1,true,666268},30000]}}}]
[E] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:07:21.757639 +0300 1507748841 leo_mq_consumer:consume/4 526 [{module,leo_storage_mq},{id,leo_per_object_queue},{cause,{timeout,{gen_server,call,[leo_object_storage_read_4_1,{get,{233468761328939195850605299707763487896,<<"bod1/00/23/b8/0023b899c8affee881b520131c1c1f5c70f8a5a598c31460dd4fc93b4b6a44e95f800257d0c9506f823ae2ec2fe73cfd00da070000000000.xz">>},-1,-1,true,666409},30000]}}}]
[E] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:07:21.820630 +0300 1507748841 leo_mq_consumer:consume/4 526 [{module,leo_storage_mq},{id,leo_per_object_queue},{cause,{timeout,{gen_server,call,[leo_object_storage_read_4_1,{get,{188914636427983509554839109418181432768,<<"bod1/00/14/b4/0014b4aa8dd8721b33c1bf871c65a27292390bee5670f31749cfe8c66326ecd24086db43c8c14e90a574d90a67a9631c00a6070000000000.xz">>},-1,-1,true,666472},30000]}}}]
[E] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.181940 +0300 1507749086 leo_storage_handler_object:put/4 424 [{from,storage},{method,delete},{key,<<"bod13/31/1b/c3/311bc313abc833bada8a84829ccdf5ab34ae18cefb8dae65f503fbb3274083d60e99823d56302d65e898e6d218cc3c8cb06e090100000000.xz\ncb7e5b94e5564cc2c6f312a2b9276c45">>},{req_id,11017595},{cause,not_found}]
```
Their amount wasn't terribly big, they started to appear when stor03 finished startup and stopped about 15 minutes after.
Logs on stor03 have just these two warnings:
```
[W] bodies03@stor03.selectel.cloud.lan 2017-10-12 00:05:32.20685 +0300 1507755932 leo_storage_read_repairer:compare/4 167 [{node,'bodies01@stor01.selectel.cloud.lan'},{addr_id,7946999318617476916794463740239994466},{key,<<"bod13/08/a9/cc/08a9cce0df7a51a65bc1da075a03714f8146cdf732308de9fc24262e67332bad1539086398b1688f8d622a6fc83db077b06e090100000000.xz\neca1aedfb5c7f8bf816f93c4c7f0e848">>},{clock,1507755930845926},{cause,not_found}]
[W] bodies03@stor03.selectel.cloud.lan 2017-10-11 22:11:26.316603 +0300 1507749086 leo_storage_read_repairer:compare/4 167 [{node,'bodies01@stor01.selectel.cloud.lan'},{addr_id,59684934647226860873027859410263418647},{key,<<"bod13/31/1b/c3/311bc313abc833bada8a84829ccdf5ab34ae18cefb8dae65f503fbb3274083d60e99823d56302d65e898e6d218cc3c8cb06e090100000000.xz\ncb7e5b94e5564cc2c6f312a2b9276c45">>},{clock,1507749079342341},{cause,not_found}]
```
Expected, I suppose, given that for some objects copies both on stor01 and stor03 were lost and only third copy exists.
I don't see any real signs of problems up to here. However, this is end result after recovery was over, df output on stor03:
```
/dev/sdd2 5,5T 805G 4,7T 15% /mnt/avs4
/dev/sdc2 5,5T 650G 4,8T 12% /mnt/avs3
/dev/sda4 5,5T 806G 4,7T 15% /mnt/avs1
/dev/sdb4 5,5T 807G 4,7T 15% /mnt/avs2
```
This doesn't make sense. I'm clearly missing data in avs3. Each (of 64) AVS file there is around 10-11 GB and it's supposed to be around 13 GB like on other nodes. This is first problem.
On stor01, where I remove avs3 I get this
```
/dev/sdd2 5,5T 888G 4,6T 17% /mnt/avs4
/dev/sdc2 5,5T 465G 4,4T 9% /mnt/avs3
/dev/sda4 5,5T 888G 4,6T 17% /mnt/avs1
/dev/sdb4 5,5T 889G 4,6T 17% /mnt/avs2
```
At first glance, this is expected: since I stopped stor03 in the middle of preparing data to be pushed on stor01 to fill "/mnt/avs3" and deleted queues there, it couldn't restore everything on stor01. However, technically, since N=3, some *other* node could've pushed that data in place of stor03. Well, anyway, the real problem here is that amount of lost data - >400 GB - can't possibly match amount of data that stor03 was supposed to push into stor01! With 6 nodes, it should've been 1/6 of file at most, not nearly half of it.
Another (strange) fact is that stor03 is lacking data in "/mnt/avs3" as well. Which is.. strange. "/mnt/avs3" is what I removed on stor01, on stor03 I removed **all** avs directories. I double-checked it now, the create dates of surrounding directories and such - there should be nothing special about avs3 on stor03. No idea if this is coincidence or not.
That said, I didn't notice this discrepancy at that moment (and didn't notice that stor03 is lacking some data until now) and executed "recover-node stor01" again. There was no other load on cluster. After it was over, it got like this on stor01:
```
/dev/sdd2 5,5T 888G 4,6T 17% /mnt/avs4
/dev/sdc2 5,5T 777G 4,7T 15% /mnt/avs3
/dev/sda4 5,5T 888G 4,6T 17% /mnt/avs1
/dev/sdb4 5,5T 889G 4,6T 17% /mnt/avs2
```
Which is wrong as well. Some data that's supposed to be there clearly isn't there, even though there were no problems during "recover-node". Though stor03 is missing some data as well, but I don't know if it can affect this.
Amount of data missing on each of either stor01 or stor03 doesn't match amount of data I was uploading (as I calculated earlier, that should've been 57-67 GB per AVS directory). It also by no means matches amount of objects mentioned in error/info logs during these experiments which is relatively small.
I can show that data is missing another way as well. This is current "du" output:
```
[vm@bodies-master ~]$ leofs-adm du bodies01@stor01.selectel.cloud.lan
active number of objects: 5770311
total number of objects: 5861284
active size of objects: 3691180624254
total size of objects: 3691207752413
ratio of active size: 100.0%
last compaction start: 2017-09-24 19:17:31 +0300
last compaction end: 2017-09-24 19:18:24 +0300
[vm@bodies-master ~]$ leofs-adm du bodies03@stor03.selectel.cloud.lan
active number of objects: 5144047
total number of objects: 5149233
active size of objects: 3291583488114
total size of objects: 3291585038728
ratio of active size: 100.0%
last compaction start: ____-__-__ __:__:__
last compaction end: ____-__-__ __:__:__
[vm@bodies-master ~]$ leofs-adm du bodies06@stor06.selectel.cloud.lan
active number of objects: 5254085
total number of objects: 5359937
active size of objects: 3360352546015
total size of objects: 3360384109837
ratio of active size: 100.0%
last compaction start: 2017-09-24 19:08:15 +0300
last compaction end: 2017-09-24 19:09:02 +0300
```
From #846 I know that before delete and recover stor01 had 113% of objects compared to stor06 and stor03 had 103% of objects compared to stor06. Upload process doesn't change these numbers. But now distribution is - stor01 has 110% of objects comparing to stor06, and stor03 has 98% of objects. While counters used for "du" might be wrong under some conditions, here they match the amount of data missing in AVS files (e.g. stor01 is missing ~110 GB of data which is 3%). | 1.0 | Recover-node fails to recover all data on storage node - There are 6 storage nodes, N=3, W=2, R=1; everything is consistent at the start of experiment. Each node has 4 AVS directories (one per drive). There are no deleted / overwritten objects on cluster (just a tiny amount of multipart headers), ratio of active size is 100% on each node. The distribution of data is not even between nodes, but very even between AVS directories on each node (less than 0.3% difference). The cluster is running with https://github.com/leo-project/leofs/pull/876 changes.
The experiment is as follows:
1) I start upload of data to cluster. I will be uploading 500 GB of data, that is, it should increase disk usage on each node roughly by 500 * 3 / 6 = 250 GB, or ~62 GB per AVS directory on each node. In reality, due to uneven distribution, there will be up to 16% difference between nodes, so it will roughly 57 to 67 GB per AVS directory (but increase should be the same for each AVS directory on any node).
2) I suspend and stop first node - stor01 and remove one of AVS directories, simulating drive failure. I start node, resume it and execute "rebalance-node stor01". The queues on other node starts filling, lots of traffic flows to stor01. The lost AVS directory starts filling up.
3) I suspend stor03 and stop it, simulating another node failure in the middle of recover-node operation. N=3 so I'm supposed not to lose any data over this. Since queues on stor03 are large and trying to fill fast, stopping takes sometime (plus tons of badargs errors from leveldb right before it stops) - but this is expected.
4) I wipe all data on stor03, including all AVS files and all queues (including membership). I launch it and resume - it has the same name and automatically attaches to cluster, gets RING and starts receiving data that is uploaded to cluster. Upload of data doesn't stop because W=2 is sastisfied at all times.
5) I execute "recover-node stor03" (with recover-node stor01 still going on). I can see both stor01 and stor03 receiving lots of data. I wait till all queues are empty.
There are "slow operation" messages in info logs, example log:
```
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:10:54.586854 +0300 1507749054 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,get},{key,<<"bod1/00/de/f1/00def1df121b056aba83f3dad7fa75538010002d93e62e31d3b122eb01a8863b426425d77f844c208439fb6f8043ab7688240a0000000000.xz">>},{processing_time,6839}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:10:54.587046 +0300 1507749054 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,head},{key,<<"bod1/3f/66/4d/3f664df2f427a0ac57cd3b4dcae7ae2d36a2a295e8f292372f0ea476ce0859ea8a139d2fe5f1b427d01c59c4de1d939de8b40d0000000000.xz">>},{processing_time,6410}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:10:59.729838 +0300 1507749059 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,fetch},{key,<<>>},{processing_time,5197}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:18.728820 +0300 1507749078 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,fetch},{key,<<>>},{processing_time,6609}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:18.728972 +0300 1507749078 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,head},{key,<<"bod1/55/55/ba/5555bad0ba80004a65f2be8e8740797517db050e471786913ffb05b5f8d8fdea183844e623cb960cada725e418072bdb009e090000000000.xz">>},{processing_time,5167}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.181764 +0300 1507749086 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,fetch},{key,<<>>},{processing_time,7453}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.181938 +0300 1507749086 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,head},{key,<<"bod1/3f/f5/87/3ff5870173ffbd88eb9af762bffc495992ef49b91ecf2568a574d77172fb86084c1b400cec0e3e95fcdbd9317e4e16e828f4600000000000.xz">>},{processing_time,7372}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.182116 +0300 1507749086 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,head},{key,<<"bod13/31/1b/c3/311bc313abc833bada8a84829ccdf5ab34ae18cefb8dae65f503fbb3274083d60e99823d56302d65e898e6d218cc3c8cb06e090100000000.xz\ncb7e5b94e5564cc2c6f312a2b9276c45">>},{processing_time,6307}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.182272 +0300 1507749086 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,head},{key,<<"bod13/31/1b/c3/311bc313abc833bada8a84829ccdf5ab34ae18cefb8dae65f503fbb3274083d60e99823d56302d65e898e6d218cc3c8cb06e090100000000.xz\ncb7e5b94e5564cc2c6f312a2b9276c45">>},{processing_time,6297}]
[I] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.182399 +0300 1507749086 leo_object_storage_event:handle_event/2 54 [{cause,"slow operation"},{method,put},{key,<<"bod13/31/1b/c3/311bc313abc833bada8a84829ccdf5ab34ae18cefb8dae65f503fbb3274083d60e99823d56302d65e898e6d218cc3c8cb06e090100000000.xz\ncb7e5b94e5564cc2c6f312a2b9276c45">>},{processing_time,6840}]
```
This is on step 3) while stor03 was stopped, at other times amount of such messages was way smaller (really insignificant amounts). There are some timeouts in gateway logs as well.
Soon after stor03 started, I got bunch of messages like this in error log on stor01/02/04/05/06:
```
[E] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:07:21.616638 +0300 1507748841 leo_mq_consumer:consume/4 526 [{module,leo_storage_mq},{id,leo_per_object_queue},{cause,{timeout,{gen_server,call,[leo_object_storage_read_4_0,{get,{216869700495053906819207869156722907209,<<"bod1/00/42/c7/0042c78f42247f361f70be868be52e8ddbcbad83b57235175f4687be9f20bd1fb95158ffa5a0edb62200a9008c1eda5b00ad070000000000.xz">>},-1,-1,true,666268},30000]}}}]
[E] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:07:21.757639 +0300 1507748841 leo_mq_consumer:consume/4 526 [{module,leo_storage_mq},{id,leo_per_object_queue},{cause,{timeout,{gen_server,call,[leo_object_storage_read_4_1,{get,{233468761328939195850605299707763487896,<<"bod1/00/23/b8/0023b899c8affee881b520131c1c1f5c70f8a5a598c31460dd4fc93b4b6a44e95f800257d0c9506f823ae2ec2fe73cfd00da070000000000.xz">>},-1,-1,true,666409},30000]}}}]
[E] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:07:21.820630 +0300 1507748841 leo_mq_consumer:consume/4 526 [{module,leo_storage_mq},{id,leo_per_object_queue},{cause,{timeout,{gen_server,call,[leo_object_storage_read_4_1,{get,{188914636427983509554839109418181432768,<<"bod1/00/14/b4/0014b4aa8dd8721b33c1bf871c65a27292390bee5670f31749cfe8c66326ecd24086db43c8c14e90a574d90a67a9631c00a6070000000000.xz">>},-1,-1,true,666472},30000]}}}]
[E] bodies01@stor01.selectel.cloud.lan 2017-10-11 22:11:26.181940 +0300 1507749086 leo_storage_handler_object:put/4 424 [{from,storage},{method,delete},{key,<<"bod13/31/1b/c3/311bc313abc833bada8a84829ccdf5ab34ae18cefb8dae65f503fbb3274083d60e99823d56302d65e898e6d218cc3c8cb06e090100000000.xz\ncb7e5b94e5564cc2c6f312a2b9276c45">>},{req_id,11017595},{cause,not_found}]
```
Their amount wasn't terribly big, they started to appear when stor03 finished startup and stopped about 15 minutes after.
Logs on stor03 have just these two warnings:
```
[W] bodies03@stor03.selectel.cloud.lan 2017-10-12 00:05:32.20685 +0300 1507755932 leo_storage_read_repairer:compare/4 167 [{node,'bodies01@stor01.selectel.cloud.lan'},{addr_id,7946999318617476916794463740239994466},{key,<<"bod13/08/a9/cc/08a9cce0df7a51a65bc1da075a03714f8146cdf732308de9fc24262e67332bad1539086398b1688f8d622a6fc83db077b06e090100000000.xz\neca1aedfb5c7f8bf816f93c4c7f0e848">>},{clock,1507755930845926},{cause,not_found}]
[W] bodies03@stor03.selectel.cloud.lan 2017-10-11 22:11:26.316603 +0300 1507749086 leo_storage_read_repairer:compare/4 167 [{node,'bodies01@stor01.selectel.cloud.lan'},{addr_id,59684934647226860873027859410263418647},{key,<<"bod13/31/1b/c3/311bc313abc833bada8a84829ccdf5ab34ae18cefb8dae65f503fbb3274083d60e99823d56302d65e898e6d218cc3c8cb06e090100000000.xz\ncb7e5b94e5564cc2c6f312a2b9276c45">>},{clock,1507749079342341},{cause,not_found}]
```
Expected, I suppose, given that for some objects copies both on stor01 and stor03 were lost and only third copy exists.
I don't see any real signs of problems up to here. However, this is end result after recovery was over, df output on stor03:
```
/dev/sdd2 5,5T 805G 4,7T 15% /mnt/avs4
/dev/sdc2 5,5T 650G 4,8T 12% /mnt/avs3
/dev/sda4 5,5T 806G 4,7T 15% /mnt/avs1
/dev/sdb4 5,5T 807G 4,7T 15% /mnt/avs2
```
This doesn't make sense. I'm clearly missing data in avs3. Each (of 64) AVS file there is around 10-11 GB and it's supposed to be around 13 GB like on other nodes. This is first problem.
On stor01, where I remove avs3 I get this
```
/dev/sdd2 5,5T 888G 4,6T 17% /mnt/avs4
/dev/sdc2 5,5T 465G 4,4T 9% /mnt/avs3
/dev/sda4 5,5T 888G 4,6T 17% /mnt/avs1
/dev/sdb4 5,5T 889G 4,6T 17% /mnt/avs2
```
At first glance, this is expected: since I stopped stor03 in the middle of preparing data to be pushed on stor01 to fill "/mnt/avs3" and deleted queues there, it couldn't restore everything on stor01. However, technically, since N=3, some *other* node could've pushed that data in place of stor03. Well, anyway, the real problem here is that amount of lost data - >400 GB - can't possibly match amount of data that stor03 was supposed to push into stor01! With 6 nodes, it should've been 1/6 of file at most, not nearly half of it.
Another (strange) fact is that stor03 is lacking data in "/mnt/avs3" as well. Which is.. strange. "/mnt/avs3" is what I removed on stor01, on stor03 I removed **all** avs directories. I double-checked it now, the create dates of surrounding directories and such - there should be nothing special about avs3 on stor03. No idea if this is coincidence or not.
That said, I didn't notice this discrepancy at that moment (and didn't notice that stor03 is lacking some data until now) and executed "recover-node stor01" again. There was no other load on cluster. After it was over, it got like this on stor01:
```
/dev/sdd2 5,5T 888G 4,6T 17% /mnt/avs4
/dev/sdc2 5,5T 777G 4,7T 15% /mnt/avs3
/dev/sda4 5,5T 888G 4,6T 17% /mnt/avs1
/dev/sdb4 5,5T 889G 4,6T 17% /mnt/avs2
```
Which is wrong as well. Some data that's supposed to be there clearly isn't there, even though there were no problems during "recover-node". Though stor03 is missing some data as well, but I don't know if it can affect this.
Amount of data missing on each of either stor01 or stor03 doesn't match amount of data I was uploading (as I calculated earlier, that should've been 57-67 GB per AVS directory). It also by no means matches amount of objects mentioned in error/info logs during these experiments which is relatively small.
I can show that data is missing another way as well. This is current "du" output:
```
[vm@bodies-master ~]$ leofs-adm du bodies01@stor01.selectel.cloud.lan
active number of objects: 5770311
total number of objects: 5861284
active size of objects: 3691180624254
total size of objects: 3691207752413
ratio of active size: 100.0%
last compaction start: 2017-09-24 19:17:31 +0300
last compaction end: 2017-09-24 19:18:24 +0300
[vm@bodies-master ~]$ leofs-adm du bodies03@stor03.selectel.cloud.lan
active number of objects: 5144047
total number of objects: 5149233
active size of objects: 3291583488114
total size of objects: 3291585038728
ratio of active size: 100.0%
last compaction start: ____-__-__ __:__:__
last compaction end: ____-__-__ __:__:__
[vm@bodies-master ~]$ leofs-adm du bodies06@stor06.selectel.cloud.lan
active number of objects: 5254085
total number of objects: 5359937
active size of objects: 3360352546015
total size of objects: 3360384109837
ratio of active size: 100.0%
last compaction start: 2017-09-24 19:08:15 +0300
last compaction end: 2017-09-24 19:09:02 +0300
```
From #846 I know that before delete and recover stor01 had 113% of objects compared to stor06 and stor03 had 103% of objects compared to stor06. Upload process doesn't change these numbers. But now distribution is - stor01 has 110% of objects comparing to stor06, and stor03 has 98% of objects. While counters used for "du" might be wrong under some conditions, here they match the amount of data missing in AVS files (e.g. stor01 is missing ~110 GB of data which is 3%). | priority | recover node fails to recover all data on storage node there are storage nodes n w r everything is consistent at the start of experiment each node has avs directories one per drive there are no deleted overwritten objects on cluster just a tiny amount of multipart headers ratio of active size is on each node the distribution of data is not even between nodes but very even between avs directories on each node less than difference the cluster is running with changes the experiment is as follows i start upload of data to cluster i will be uploading gb of data that is it should increase disk usage on each node roughly by gb or gb per avs directory on each node in reality due to uneven distribution there will be up to difference between nodes so it will roughly to gb per avs directory but increase should be the same for each avs directory on any node i suspend and stop first node and remove one of avs directories simulating drive failure i start node resume it and execute rebalance node the queues on other node starts filling lots of traffic flows to the lost avs directory starts filling up i suspend and stop it simulating another node failure in the middle of recover node operation n so i m supposed not to lose any data over this since queues on are large and trying to fill fast stopping takes sometime plus tons of badargs errors from leveldb right before it stops but this is expected i wipe all data on including all avs files and all queues including membership i launch it and resume it has the same name and automatically attaches to cluster gets ring and starts receiving data that is uploaded to cluster upload of data doesn t stop because w is sastisfied at all times i execute recover node with recover node still going on i can see both and receiving lots of data i wait till all queues are empty there are slow operation messages in info logs example log selectel cloud lan leo object storage event handle event selectel cloud lan leo object storage event handle event selectel cloud lan leo object storage event handle event selectel cloud lan leo object storage event handle event selectel cloud lan leo object storage event handle event selectel cloud lan leo object storage event handle event selectel cloud lan leo object storage event handle event selectel cloud lan leo object storage event handle event selectel cloud lan leo object storage event handle event selectel cloud lan leo object storage event handle event this is on step while was stopped at other times amount of such messages was way smaller really insignificant amounts there are some timeouts in gateway logs as well soon after started i got bunch of messages like this in error log on selectel cloud lan leo mq consumer consume selectel cloud lan leo mq consumer consume selectel cloud lan leo mq consumer consume selectel cloud lan leo storage handler object put their amount wasn t terribly big they started to appear when finished startup and stopped about minutes after logs on have just these two warnings selectel cloud lan leo storage read repairer compare selectel cloud lan leo storage read repairer compare expected i suppose given that for some objects copies both on and were lost and only third copy exists i don t see any real signs of problems up to here however this is end result after recovery was over df output on dev mnt dev mnt dev mnt dev mnt this doesn t make sense i m clearly missing data in each of avs file there is around gb and it s supposed to be around gb like on other nodes this is first problem on where i remove i get this dev mnt dev mnt dev mnt dev mnt at first glance this is expected since i stopped in the middle of preparing data to be pushed on to fill mnt and deleted queues there it couldn t restore everything on however technically since n some other node could ve pushed that data in place of well anyway the real problem here is that amount of lost data gb can t possibly match amount of data that was supposed to push into with nodes it should ve been of file at most not nearly half of it another strange fact is that is lacking data in mnt as well which is strange mnt is what i removed on on i removed all avs directories i double checked it now the create dates of surrounding directories and such there should be nothing special about on no idea if this is coincidence or not that said i didn t notice this discrepancy at that moment and didn t notice that is lacking some data until now and executed recover node again there was no other load on cluster after it was over it got like this on dev mnt dev mnt dev mnt dev mnt which is wrong as well some data that s supposed to be there clearly isn t there even though there were no problems during recover node though is missing some data as well but i don t know if it can affect this amount of data missing on each of either or doesn t match amount of data i was uploading as i calculated earlier that should ve been gb per avs directory it also by no means matches amount of objects mentioned in error info logs during these experiments which is relatively small i can show that data is missing another way as well this is current du output leofs adm du selectel cloud lan active number of objects total number of objects active size of objects total size of objects ratio of active size last compaction start last compaction end leofs adm du selectel cloud lan active number of objects total number of objects active size of objects total size of objects ratio of active size last compaction start last compaction end leofs adm du selectel cloud lan active number of objects total number of objects active size of objects total size of objects ratio of active size last compaction start last compaction end from i know that before delete and recover had of objects compared to and had of objects compared to upload process doesn t change these numbers but now distribution is has of objects comparing to and has of objects while counters used for du might be wrong under some conditions here they match the amount of data missing in avs files e g is missing gb of data which is | 1 |
479,096 | 13,791,296,544 | IssuesEvent | 2020-10-09 11:54:42 | Signbank/Global-signbank | https://api.github.com/repos/Signbank/Global-signbank | opened | Explore: colouring of field values in pull-down menus | discussion needed enhancement high priority | Users find the list of choices for the phonological fields daunting. Rightly so, sign languages are simply complex (no pun intended). But there's more prominent or default values in each list of field values, and less frequent ones. We can sort them in a certain way of course, but I was wondering whether it'd be realistic to use different colours to visually group field values, making the frequent / default values red, say, the secondary options green, and leave the exceptions black on grey, say. Could somebody dig into that?
If possible, we could let admins specify this in the admin for each field value. | 1.0 | Explore: colouring of field values in pull-down menus - Users find the list of choices for the phonological fields daunting. Rightly so, sign languages are simply complex (no pun intended). But there's more prominent or default values in each list of field values, and less frequent ones. We can sort them in a certain way of course, but I was wondering whether it'd be realistic to use different colours to visually group field values, making the frequent / default values red, say, the secondary options green, and leave the exceptions black on grey, say. Could somebody dig into that?
If possible, we could let admins specify this in the admin for each field value. | priority | explore colouring of field values in pull down menus users find the list of choices for the phonological fields daunting rightly so sign languages are simply complex no pun intended but there s more prominent or default values in each list of field values and less frequent ones we can sort them in a certain way of course but i was wondering whether it d be realistic to use different colours to visually group field values making the frequent default values red say the secondary options green and leave the exceptions black on grey say could somebody dig into that if possible we could let admins specify this in the admin for each field value | 1 |
280,731 | 8,685,963,265 | IssuesEvent | 2018-12-03 09:30:01 | NationalGenomicsInfrastructure/ngipubs | https://api.github.com/repos/NationalGenomicsInfrastructure/ngipubs | closed | Actual links for permalinks | High Priority simple | Right now this is a hidden feature where you can specify the publication with a unique url. `publications.php?id=1234` where 1234 is the key in `publications` table.
But there is no link to it. It would be nice if there a link for each entry and maybe a JS thing that copies the URL to the clipboard.
Maybe we should reconsider this unique id to just be the pmid. | 1.0 | Actual links for permalinks - Right now this is a hidden feature where you can specify the publication with a unique url. `publications.php?id=1234` where 1234 is the key in `publications` table.
But there is no link to it. It would be nice if there a link for each entry and maybe a JS thing that copies the URL to the clipboard.
Maybe we should reconsider this unique id to just be the pmid. | priority | actual links for permalinks right now this is a hidden feature where you can specify the publication with a unique url publications php id where is the key in publications table but there is no link to it it would be nice if there a link for each entry and maybe a js thing that copies the url to the clipboard maybe we should reconsider this unique id to just be the pmid | 1 |
383,745 | 11,361,965,117 | IssuesEvent | 2020-01-26 18:13:58 | Redsart/TodoApp | https://api.github.com/repos/Redsart/TodoApp | closed | Enforce high code quality | priority: high status: done type: enhancement | Enforce the use of best practices and code standards when developing the app.
Read what is static code analysis. Add it to the project.
Create a page in the [Wiki](https://github.com/Redsart/TodoApp/wiki) which will include:
- which Analizer you choose and why;
- steps to install it;
- configuration options used in the project.
Run the analysis on the project and investigate the errors. Make a list of the types of the errors and post it in this issue as a comment. We will discuss which needs fixing and which can be ignored.
See [Overview of code analysis for managed code in Visual Studio](https://docs.microsoft.com/en-us/visualstudio/code-quality/code-analysis-for-managed-code-overview?view=vs-2019) for more information. | 1.0 | Enforce high code quality - Enforce the use of best practices and code standards when developing the app.
Read what is static code analysis. Add it to the project.
Create a page in the [Wiki](https://github.com/Redsart/TodoApp/wiki) which will include:
- which Analizer you choose and why;
- steps to install it;
- configuration options used in the project.
Run the analysis on the project and investigate the errors. Make a list of the types of the errors and post it in this issue as a comment. We will discuss which needs fixing and which can be ignored.
See [Overview of code analysis for managed code in Visual Studio](https://docs.microsoft.com/en-us/visualstudio/code-quality/code-analysis-for-managed-code-overview?view=vs-2019) for more information. | priority | enforce high code quality enforce the use of best practices and code standards when developing the app read what is static code analysis add it to the project create a page in the which will include which analizer you choose and why steps to install it configuration options used in the project run the analysis on the project and investigate the errors make a list of the types of the errors and post it in this issue as a comment we will discuss which needs fixing and which can be ignored see for more information | 1 |
502,791 | 14,566,887,390 | IssuesEvent | 2020-12-17 09:30:53 | bbc/simorgh | https://api.github.com/repos/bbc/simorgh | closed | BUG - Recent Episodes - Zhongwen brand has incorrect links in recent episodes list | Recent Episodes Radio bug high-priority ws-media | If you go to the brand page https://www.test.bbc.com/zhongwen/trad/bbc_cantonese_radio/programmes/p0340tsy
and click on the episode links, it takes you to incorrect URLs which give a 500 error: e.g https://www.test.bbc.co.uk/chinese/bbc_cantonese_radio/w172xn6kwd4bx3h
URLs should be like https://www.test.bbc.com/zhongwen/trad/bbc_cantonese_radio/w172xn6kwd4bx3h | 1.0 | BUG - Recent Episodes - Zhongwen brand has incorrect links in recent episodes list - If you go to the brand page https://www.test.bbc.com/zhongwen/trad/bbc_cantonese_radio/programmes/p0340tsy
and click on the episode links, it takes you to incorrect URLs which give a 500 error: e.g https://www.test.bbc.co.uk/chinese/bbc_cantonese_radio/w172xn6kwd4bx3h
URLs should be like https://www.test.bbc.com/zhongwen/trad/bbc_cantonese_radio/w172xn6kwd4bx3h | priority | bug recent episodes zhongwen brand has incorrect links in recent episodes list if you go to the brand page and click on the episode links it takes you to incorrect urls which give a error e g urls should be like | 1 |
412,013 | 12,034,473,332 | IssuesEvent | 2020-04-13 16:06:30 | AY1920S2-CS2103T-T10-2/main | https://api.github.com/repos/AY1920S2-CS2103T-T10-2/main | closed | As a student, I can create decks to contain my flashcards | priority.High type.Story | so that I can organise my notes and modules. | 1.0 | As a student, I can create decks to contain my flashcards - so that I can organise my notes and modules. | priority | as a student i can create decks to contain my flashcards so that i can organise my notes and modules | 1 |
632,898 | 20,238,257,958 | IssuesEvent | 2022-02-14 06:07:36 | gitpod-io/gitpod | https://api.github.com/repos/gitpod-io/gitpod | closed | Failed to download OTS | type: bug priority: highest (user impact) team: webapp team: workspace | ### Bug description
Looking at the logs we're seeing a surprising amount of OTS download failures as part of workspace content initialisation: https://console.cloud.google.com/logs/query;query=%22cannot%20download%20OTS%22%0A;timeRange=PT24H;cursorTimestamp=2022-02-08T14:43:32Z?project=workspace-clusters
Each of those failures is likely to yield a failed workspace - at least if the repo was private.
Possible contributing factors:
- the OTS request is routed through the load balancer, hence might hit a cluster which did not create the OTS. If db-sync didn't run in that time, the OTS would not be found. This problem will become worse once we have hyper-regional workspace cluster. Possible solutions: make application clusters directly addressable, akin to workspace clusters (e.g. `eu.gitpod.io`).
- we attempt to download the OTS multiple times for some reason. That's most likely a bug in the initializer. Checking the server logs and/or adding metrics would help identifying this.
As part of a fix, we should introduce OTS download failure metrics and keep an eye on them.
### Steps to reproduce
Check the logs
### Workspace affected
_No response_
### Expected behavior
We don't see OTS download failures ever.
### Example repository
_No response_
### Anything else?
_No response_ | 1.0 | Failed to download OTS - ### Bug description
Looking at the logs we're seeing a surprising amount of OTS download failures as part of workspace content initialisation: https://console.cloud.google.com/logs/query;query=%22cannot%20download%20OTS%22%0A;timeRange=PT24H;cursorTimestamp=2022-02-08T14:43:32Z?project=workspace-clusters
Each of those failures is likely to yield a failed workspace - at least if the repo was private.
Possible contributing factors:
- the OTS request is routed through the load balancer, hence might hit a cluster which did not create the OTS. If db-sync didn't run in that time, the OTS would not be found. This problem will become worse once we have hyper-regional workspace cluster. Possible solutions: make application clusters directly addressable, akin to workspace clusters (e.g. `eu.gitpod.io`).
- we attempt to download the OTS multiple times for some reason. That's most likely a bug in the initializer. Checking the server logs and/or adding metrics would help identifying this.
As part of a fix, we should introduce OTS download failure metrics and keep an eye on them.
### Steps to reproduce
Check the logs
### Workspace affected
_No response_
### Expected behavior
We don't see OTS download failures ever.
### Example repository
_No response_
### Anything else?
_No response_ | priority | failed to download ots bug description looking at the logs we re seeing a surprising amount of ots download failures as part of workspace content initialisation each of those failures is likely to yield a failed workspace at least if the repo was private possible contributing factors the ots request is routed through the load balancer hence might hit a cluster which did not create the ots if db sync didn t run in that time the ots would not be found this problem will become worse once we have hyper regional workspace cluster possible solutions make application clusters directly addressable akin to workspace clusters e g eu gitpod io we attempt to download the ots multiple times for some reason that s most likely a bug in the initializer checking the server logs and or adding metrics would help identifying this as part of a fix we should introduce ots download failure metrics and keep an eye on them steps to reproduce check the logs workspace affected no response expected behavior we don t see ots download failures ever example repository no response anything else no response | 1 |
54,532 | 3,069,100,696 | IssuesEvent | 2015-08-18 18:49:00 | fle-internal/fle-home | https://api.github.com/repos/fle-internal/fle-home | closed | "Corner" signup banner makes large section of page unclickable | bug high priority | The `<div class="corner_banner">` element goes all across the page and prevents clicks on anything that's underneath it, despite being transparent.

@66eli77, could you fix this up? | 1.0 | "Corner" signup banner makes large section of page unclickable - The `<div class="corner_banner">` element goes all across the page and prevents clicks on anything that's underneath it, despite being transparent.

@66eli77, could you fix this up? | priority | corner signup banner makes large section of page unclickable the element goes all across the page and prevents clicks on anything that s underneath it despite being transparent could you fix this up | 1 |
515,527 | 14,964,987,133 | IssuesEvent | 2021-01-27 12:46:39 | tendermint/starport | https://api.github.com/repos/tendermint/starport | closed | bug: starport network chain join returns an error | bug priority/high | We get thh following error when running `starport network chain join`:
`Error: unknown flag: --keyring-backend` | 1.0 | bug: starport network chain join returns an error - We get thh following error when running `starport network chain join`:
`Error: unknown flag: --keyring-backend` | priority | bug starport network chain join returns an error we get thh following error when running starport network chain join error unknown flag keyring backend | 1 |
751,952 | 26,267,291,903 | IssuesEvent | 2023-01-06 13:46:50 | ethereum/ethereum-org-website | https://api.github.com/repos/ethereum/ethereum-org-website | opened | Q1 2023 ethereum.org product roadmap | help wanted high priority roadmap | *To make our work more accessible and to foster more community collaboration, our team publishes an overview of our quarterly roadmap goals. See last quarter's roadmap here: #6161.*
**Greetings fellow Ethereans!**
[Our vision with ethereum.org](https://ethereum.org/en/about/) continues to be to create the best portal for Ethereum's growing community. We’re an educational resource focused on helping onboard millions of visitors to Ethereum each month. Here's a look at our major Q3 initiatives to advance this vision.
Quick point of clarification: ***this is the roadmap for [ethereum.org](http://ethereum.org/) the website, not Ethereum the protocol***. If you’re looking for the Ethereum roadmap, check out information on [upcoming network upgrades](https://ethereum.org/en/upgrades/) and learn more about [Ethereum governance](https://ethereum.org/en/governance/).
With that out of the way, let’s dive in.
# Q1 roadmap
*The epics our core team is committing to shipping this quarter.*
## 🔧 Ethereum.org maintenance
Between focussing on other epics, events, and end-of-year holidays, we've fallen behind on our maintenance of ethereum.org, with over [150 pull requests](https://github.com/ethereum/ethereum-org-website/pulls) and [300 issues](https://github.com/ethereum/ethereum-org-website/issues) open as we begin Q1. Going forward, we want to be more responsive to our hundreds of contributors who help maintain ethereum.org 💜
In Q1, we'll get our outstanding pull requests and issues under control, and create better processes to ensure we're on top of them in the future.
Want to help us clear the backlog? [Pick up one of our issues](https://github.com/ethereum/ethereum-org-website/issues).
## 🤝 Hire a community lead
Our current community lead (hey, that's me 😀) is transitioning to another role on the team, leaving a gap in our capacity to interact with and grow our incredible community.
In Q1, we'll be looking for a new community lead to help us engage, maintain, and grow our community. We'll release a job listing for this role in the coming weeks.
Think you are right for the role? [Join our Discord](https://ethereum.org/discord) and look out for our official announcement 👀
## 👯♀️ 2023 community planning
**It's all community!**
In 2022, the community engagement on ethereum.org was incredible; from community calls and office hours to design critiques and blog posts, community members consistently participated in meaningful discussions.
In Q1, we will create a plan for our 2023 community interactions to give better predictability on when community touchpoints happen, arrange more of these interactions, and help strengthen and grow our core community members.
[Join our Discord community](https://ethereum.org/discord)
## 🎨 Open design system
Our long-running open design system is coming to a close; across Q2, Q3, and Q4, we've been building and designing a robust design system to ship features more quickly and let community members participate in the open design of ethereum.org.
In Q1, we'll put the finishing touches on the current iteration of the design system ahead of its implementation.
Want to get involved? [Follow along in Figma](https://www.figma.com/file/NrNxGjBL0Yl1PrNrOT8G2B/ethereum.org-Design-System) and join the conversation in our [#design Discord channel](https://discord.gg/bKycYhVUwV).
## 🚧 Implement Design System
After almost a year of working on the design system, we're ready to implement it in our codebase 🎉. Just like the Implement UI Library epic (#6374), this epic will be entirely open to our code contributors community.
In Q1, we'll do the necessary groundwork to implement the design system into code and put processes in place for community contributions.
Want to help? [Join our Discord](https://ethereum.org/discord) and look for the GitHub issue kicking this off, coming soon 👀.
## 📚 Set up Storybook and Chromatic
Storybook lets developers build components in isolation, and Chromatic will show isolated visual representations of component changes whenever their code changes.
As part of our new design system, we will integrate Storybook and Chromatic into our tech stack. This additional tooling will help us build more robust components, improve quality assurance, and speed up the review process.
- [More on Storybook](https://storybook.js.org/)
- [More on Chromatic](https://www.chromatic.com/)
## 💵 Launchpad withdrawals
[Two years after the launch of the Beacon Chain](https://ethereum.org/en/history/#beacon-chain-genesis), the ability for stakers to withdraw their staked ether and unlock their rewards is quickly approaching in the next upgrade (Shanghai).
In Q1, we'll help to prepare [the Launchpad](https://launchpad.ethereum.org/en/) to allow users to withdraw their staked ether as simply as possible.
[Check out the Launchpad](https://launchpad.ethereum.org/en/).
## 💴 Withdrawals content
After the Shanghai upgrade, withdrawals will be a permanent feature of Ethereum.
In Q1, we'll add educational content to ethereum.org to explain what withdrawals are, how they work, and point users to reliable guides on safely withdrawing from the deposit contract.
Want to get involved? Chat with us in [the #content channel on Discord](https://discord.gg/ethereum-org-714888181740339261).
## 🔬 Protocol roadmap content
After a successful merge, we're looking forward to Ethereum and its core protocol in 2023 and beyond. There are multiple exciting and impactful upgrades in varying development stages, but most do not have clear explanations using simple language.
In Q1, we'll publish new content on a subset of these upcoming protocol changes and start discussing how we might architect information around Ethereum's roadmap from now on.
Want to get involved? Chat with us in [the #content channel on Discord](https://discord.gg/ethereum-org-714888181740339261).
## 💌 EF blog email subscriptions
Currently, the only way to subscribe to [the EF blog](https://blog.ethereum.org/) is through RSS feeds. While this works well enough, adding the ability to subscribe to new blog posts via email will amplify the reach of important Ethereum announcements.
In Q1, we'll explore different email API offerings and implement the ability to subscribe to blog posts on the Ethereum Foundation blog.
## 💖 HEART framework action items
A follow-on from Q4, this epic involves improving our user experience, changing processes, and improving communication with contributors to enhance the translator experience.
In Q1, we'll finish the remaining action items identified during the HEART framework analysis (#7205).
Got a suggestion about how to improve the contributor experience? [Let us know on Discord.](https://discord.gg/wKyW7cJ3PA)
## 🖥 Implement UI library
We'll continue to push forward the UI library migration that we kicked off in Q3 (#6374).
This epic is closely tied to the design system (#6284) - to improve our code quality, productivity, website accessibility and overall UX. After our Q4 push on the migration, we migrated roughly 75% of the components to Chakra UI. In Q1, we will finish migrating the remaining components.
Community contributors have largely driven this initiative 🎉 massive thanks to [everyone who contributed](https://github.com/ethereum/ethereum-org-website/pulls?q=is%3Apr+label%3Achakra-migration) 🙏.
Want to get involved? Join the conversation in [our #ui-library-migration Discord channel](https://discord.gg/7WKTFRARe5).
## 🖼 Explore AI illustrations
A notable part of the ethereum.org aesthetic and experience is [the illustrations](https://ethereum.org/en/assets) and the stories they tell. The end of 2022 saw an explosion in AI text-to-image models like DALL-E 2, Midjourney, and Stable Diffusion and showcased their ability to reliability create incredible artwork.
In Q1, we'll be exploring the possibility of leveraging these tools to create more illustrations for ethereum.org, striving for a better user experience through illustrative storytelling.
We'll open conversations on our Discord soon. Meanwhile, you can [check out our AI illustrations scratchpad on Figma](https://www.figma.com/file/aGeNgPmYDNQMuDMoNbT0O2/AI-illustrations?node-id=317%3A486&t=dRAxWHHT2syidU1v-1).
## 🤖 Explore Machine Translations
Another area where AI is making rapid progress is machine translations. The quality of output that machine translation provides is constantly improving, and there is an opportunity to leverage it on ethereum.org to lessen the burden on our translators by automating more straightforward tasks and providing better accessibility to languages we do not yet have a translation community around.
In Q1, we'll explore the possibilities machine translations provide, decide whether we'd like to integrate machine translations into our processes, and create a plan for implementing them.
Got thoughts on machine translations? Come chat in [our translations channel on Discord](https://discord.gg/ethereum-org-714888181740339261).
## 🧼 Clean up the Geth website
In Q4, we helped launch [the new Geth website and documentation](https://geth.ethereum.org/). We're pleased with the website and have received great feedback, but there are a few tasks and bugs we did not manage to complete.
In Q1, we'll complete the remaining tasks and any bugs to polish the Geth website experience.
[Check out the Geth website.](https://geth.ethereum.org/)
## 🌎 Clean up the EF blog
Similarly, in Q3, we internationalized [the Ethereum Foundation blog](https://blog.ethereum.org/) to support translations in many languages, but a handful of clean-up tasks remain that were cut from the scope to get the blog into the hands of non-English speakers more quickly.
This epic consolidates the remaining items that were not critical for the initial launch but will help continue improving the user experience for blog visitors and writers.
[Check out the EF blog](https://blog.ethereum.org/)
## 🌞 Prepare for Google Summer of Code
Google Summer of Code is a global, online program focused on bringing new contributors into open-source development. Selected participants work closely with projects over three months to help ship new features!
In Q1, we'll collect and prepare potential projects for participants, and apply to be a project in Google's Summer of Code 🙌
Got an idea or want to get involved? [Let us know on Discord](https://ethereum.org/discord) 🙏
# How does that sound?
We always appreciate feedback on our roadmap - if there's something you think we should work on, please let us know! We welcome ideas and PRs from anyone in the community.
Get involved: [Learn more about contributing](https://ethereum.org/en/contributing/), [hit us up on Twitter](https://twitter.com/ethdotorg), or join the community discussions in [our Discord](https://discord.gg/CetY6Y4). | 1.0 | Q1 2023 ethereum.org product roadmap - *To make our work more accessible and to foster more community collaboration, our team publishes an overview of our quarterly roadmap goals. See last quarter's roadmap here: #6161.*
**Greetings fellow Ethereans!**
[Our vision with ethereum.org](https://ethereum.org/en/about/) continues to be to create the best portal for Ethereum's growing community. We’re an educational resource focused on helping onboard millions of visitors to Ethereum each month. Here's a look at our major Q3 initiatives to advance this vision.
Quick point of clarification: ***this is the roadmap for [ethereum.org](http://ethereum.org/) the website, not Ethereum the protocol***. If you’re looking for the Ethereum roadmap, check out information on [upcoming network upgrades](https://ethereum.org/en/upgrades/) and learn more about [Ethereum governance](https://ethereum.org/en/governance/).
With that out of the way, let’s dive in.
# Q1 roadmap
*The epics our core team is committing to shipping this quarter.*
## 🔧 Ethereum.org maintenance
Between focussing on other epics, events, and end-of-year holidays, we've fallen behind on our maintenance of ethereum.org, with over [150 pull requests](https://github.com/ethereum/ethereum-org-website/pulls) and [300 issues](https://github.com/ethereum/ethereum-org-website/issues) open as we begin Q1. Going forward, we want to be more responsive to our hundreds of contributors who help maintain ethereum.org 💜
In Q1, we'll get our outstanding pull requests and issues under control, and create better processes to ensure we're on top of them in the future.
Want to help us clear the backlog? [Pick up one of our issues](https://github.com/ethereum/ethereum-org-website/issues).
## 🤝 Hire a community lead
Our current community lead (hey, that's me 😀) is transitioning to another role on the team, leaving a gap in our capacity to interact with and grow our incredible community.
In Q1, we'll be looking for a new community lead to help us engage, maintain, and grow our community. We'll release a job listing for this role in the coming weeks.
Think you are right for the role? [Join our Discord](https://ethereum.org/discord) and look out for our official announcement 👀
## 👯♀️ 2023 community planning
**It's all community!**
In 2022, the community engagement on ethereum.org was incredible; from community calls and office hours to design critiques and blog posts, community members consistently participated in meaningful discussions.
In Q1, we will create a plan for our 2023 community interactions to give better predictability on when community touchpoints happen, arrange more of these interactions, and help strengthen and grow our core community members.
[Join our Discord community](https://ethereum.org/discord)
## 🎨 Open design system
Our long-running open design system is coming to a close; across Q2, Q3, and Q4, we've been building and designing a robust design system to ship features more quickly and let community members participate in the open design of ethereum.org.
In Q1, we'll put the finishing touches on the current iteration of the design system ahead of its implementation.
Want to get involved? [Follow along in Figma](https://www.figma.com/file/NrNxGjBL0Yl1PrNrOT8G2B/ethereum.org-Design-System) and join the conversation in our [#design Discord channel](https://discord.gg/bKycYhVUwV).
## 🚧 Implement Design System
After almost a year of working on the design system, we're ready to implement it in our codebase 🎉. Just like the Implement UI Library epic (#6374), this epic will be entirely open to our code contributors community.
In Q1, we'll do the necessary groundwork to implement the design system into code and put processes in place for community contributions.
Want to help? [Join our Discord](https://ethereum.org/discord) and look for the GitHub issue kicking this off, coming soon 👀.
## 📚 Set up Storybook and Chromatic
Storybook lets developers build components in isolation, and Chromatic will show isolated visual representations of component changes whenever their code changes.
As part of our new design system, we will integrate Storybook and Chromatic into our tech stack. This additional tooling will help us build more robust components, improve quality assurance, and speed up the review process.
- [More on Storybook](https://storybook.js.org/)
- [More on Chromatic](https://www.chromatic.com/)
## 💵 Launchpad withdrawals
[Two years after the launch of the Beacon Chain](https://ethereum.org/en/history/#beacon-chain-genesis), the ability for stakers to withdraw their staked ether and unlock their rewards is quickly approaching in the next upgrade (Shanghai).
In Q1, we'll help to prepare [the Launchpad](https://launchpad.ethereum.org/en/) to allow users to withdraw their staked ether as simply as possible.
[Check out the Launchpad](https://launchpad.ethereum.org/en/).
## 💴 Withdrawals content
After the Shanghai upgrade, withdrawals will be a permanent feature of Ethereum.
In Q1, we'll add educational content to ethereum.org to explain what withdrawals are, how they work, and point users to reliable guides on safely withdrawing from the deposit contract.
Want to get involved? Chat with us in [the #content channel on Discord](https://discord.gg/ethereum-org-714888181740339261).
## 🔬 Protocol roadmap content
After a successful merge, we're looking forward to Ethereum and its core protocol in 2023 and beyond. There are multiple exciting and impactful upgrades in varying development stages, but most do not have clear explanations using simple language.
In Q1, we'll publish new content on a subset of these upcoming protocol changes and start discussing how we might architect information around Ethereum's roadmap from now on.
Want to get involved? Chat with us in [the #content channel on Discord](https://discord.gg/ethereum-org-714888181740339261).
## 💌 EF blog email subscriptions
Currently, the only way to subscribe to [the EF blog](https://blog.ethereum.org/) is through RSS feeds. While this works well enough, adding the ability to subscribe to new blog posts via email will amplify the reach of important Ethereum announcements.
In Q1, we'll explore different email API offerings and implement the ability to subscribe to blog posts on the Ethereum Foundation blog.
## 💖 HEART framework action items
A follow-on from Q4, this epic involves improving our user experience, changing processes, and improving communication with contributors to enhance the translator experience.
In Q1, we'll finish the remaining action items identified during the HEART framework analysis (#7205).
Got a suggestion about how to improve the contributor experience? [Let us know on Discord.](https://discord.gg/wKyW7cJ3PA)
## 🖥 Implement UI library
We'll continue to push forward the UI library migration that we kicked off in Q3 (#6374).
This epic is closely tied to the design system (#6284) - to improve our code quality, productivity, website accessibility and overall UX. After our Q4 push on the migration, we migrated roughly 75% of the components to Chakra UI. In Q1, we will finish migrating the remaining components.
Community contributors have largely driven this initiative 🎉 massive thanks to [everyone who contributed](https://github.com/ethereum/ethereum-org-website/pulls?q=is%3Apr+label%3Achakra-migration) 🙏.
Want to get involved? Join the conversation in [our #ui-library-migration Discord channel](https://discord.gg/7WKTFRARe5).
## 🖼 Explore AI illustrations
A notable part of the ethereum.org aesthetic and experience is [the illustrations](https://ethereum.org/en/assets) and the stories they tell. The end of 2022 saw an explosion in AI text-to-image models like DALL-E 2, Midjourney, and Stable Diffusion and showcased their ability to reliability create incredible artwork.
In Q1, we'll be exploring the possibility of leveraging these tools to create more illustrations for ethereum.org, striving for a better user experience through illustrative storytelling.
We'll open conversations on our Discord soon. Meanwhile, you can [check out our AI illustrations scratchpad on Figma](https://www.figma.com/file/aGeNgPmYDNQMuDMoNbT0O2/AI-illustrations?node-id=317%3A486&t=dRAxWHHT2syidU1v-1).
## 🤖 Explore Machine Translations
Another area where AI is making rapid progress is machine translations. The quality of output that machine translation provides is constantly improving, and there is an opportunity to leverage it on ethereum.org to lessen the burden on our translators by automating more straightforward tasks and providing better accessibility to languages we do not yet have a translation community around.
In Q1, we'll explore the possibilities machine translations provide, decide whether we'd like to integrate machine translations into our processes, and create a plan for implementing them.
Got thoughts on machine translations? Come chat in [our translations channel on Discord](https://discord.gg/ethereum-org-714888181740339261).
## 🧼 Clean up the Geth website
In Q4, we helped launch [the new Geth website and documentation](https://geth.ethereum.org/). We're pleased with the website and have received great feedback, but there are a few tasks and bugs we did not manage to complete.
In Q1, we'll complete the remaining tasks and any bugs to polish the Geth website experience.
[Check out the Geth website.](https://geth.ethereum.org/)
## 🌎 Clean up the EF blog
Similarly, in Q3, we internationalized [the Ethereum Foundation blog](https://blog.ethereum.org/) to support translations in many languages, but a handful of clean-up tasks remain that were cut from the scope to get the blog into the hands of non-English speakers more quickly.
This epic consolidates the remaining items that were not critical for the initial launch but will help continue improving the user experience for blog visitors and writers.
[Check out the EF blog](https://blog.ethereum.org/)
## 🌞 Prepare for Google Summer of Code
Google Summer of Code is a global, online program focused on bringing new contributors into open-source development. Selected participants work closely with projects over three months to help ship new features!
In Q1, we'll collect and prepare potential projects for participants, and apply to be a project in Google's Summer of Code 🙌
Got an idea or want to get involved? [Let us know on Discord](https://ethereum.org/discord) 🙏
# How does that sound?
We always appreciate feedback on our roadmap - if there's something you think we should work on, please let us know! We welcome ideas and PRs from anyone in the community.
Get involved: [Learn more about contributing](https://ethereum.org/en/contributing/), [hit us up on Twitter](https://twitter.com/ethdotorg), or join the community discussions in [our Discord](https://discord.gg/CetY6Y4). | priority | ethereum org product roadmap to make our work more accessible and to foster more community collaboration our team publishes an overview of our quarterly roadmap goals see last quarter s roadmap here greetings fellow ethereans continues to be to create the best portal for ethereum s growing community we’re an educational resource focused on helping onboard millions of visitors to ethereum each month here s a look at our major initiatives to advance this vision quick point of clarification this is the roadmap for the website not ethereum the protocol if you’re looking for the ethereum roadmap check out information on and learn more about with that out of the way let’s dive in roadmap the epics our core team is committing to shipping this quarter 🔧 ethereum org maintenance between focussing on other epics events and end of year holidays we ve fallen behind on our maintenance of ethereum org with over and open as we begin going forward we want to be more responsive to our hundreds of contributors who help maintain ethereum org 💜 in we ll get our outstanding pull requests and issues under control and create better processes to ensure we re on top of them in the future want to help us clear the backlog 🤝 hire a community lead our current community lead hey that s me 😀 is transitioning to another role on the team leaving a gap in our capacity to interact with and grow our incredible community in we ll be looking for a new community lead to help us engage maintain and grow our community we ll release a job listing for this role in the coming weeks think you are right for the role and look out for our official announcement 👀 👯♀️ community planning it s all community in the community engagement on ethereum org was incredible from community calls and office hours to design critiques and blog posts community members consistently participated in meaningful discussions in we will create a plan for our community interactions to give better predictability on when community touchpoints happen arrange more of these interactions and help strengthen and grow our core community members 🎨 open design system our long running open design system is coming to a close across and we ve been building and designing a robust design system to ship features more quickly and let community members participate in the open design of ethereum org in we ll put the finishing touches on the current iteration of the design system ahead of its implementation want to get involved and join the conversation in our 🚧 implement design system after almost a year of working on the design system we re ready to implement it in our codebase 🎉 just like the implement ui library epic this epic will be entirely open to our code contributors community in we ll do the necessary groundwork to implement the design system into code and put processes in place for community contributions want to help and look for the github issue kicking this off coming soon 👀 📚 set up storybook and chromatic storybook lets developers build components in isolation and chromatic will show isolated visual representations of component changes whenever their code changes as part of our new design system we will integrate storybook and chromatic into our tech stack this additional tooling will help us build more robust components improve quality assurance and speed up the review process 💵 launchpad withdrawals the ability for stakers to withdraw their staked ether and unlock their rewards is quickly approaching in the next upgrade shanghai in we ll help to prepare to allow users to withdraw their staked ether as simply as possible 💴 withdrawals content after the shanghai upgrade withdrawals will be a permanent feature of ethereum in we ll add educational content to ethereum org to explain what withdrawals are how they work and point users to reliable guides on safely withdrawing from the deposit contract want to get involved chat with us in 🔬 protocol roadmap content after a successful merge we re looking forward to ethereum and its core protocol in and beyond there are multiple exciting and impactful upgrades in varying development stages but most do not have clear explanations using simple language in we ll publish new content on a subset of these upcoming protocol changes and start discussing how we might architect information around ethereum s roadmap from now on want to get involved chat with us in 💌 ef blog email subscriptions currently the only way to subscribe to is through rss feeds while this works well enough adding the ability to subscribe to new blog posts via email will amplify the reach of important ethereum announcements in we ll explore different email api offerings and implement the ability to subscribe to blog posts on the ethereum foundation blog 💖 heart framework action items a follow on from this epic involves improving our user experience changing processes and improving communication with contributors to enhance the translator experience in we ll finish the remaining action items identified during the heart framework analysis got a suggestion about how to improve the contributor experience 🖥 implement ui library we ll continue to push forward the ui library migration that we kicked off in this epic is closely tied to the design system to improve our code quality productivity website accessibility and overall ux after our push on the migration we migrated roughly of the components to chakra ui in we will finish migrating the remaining components community contributors have largely driven this initiative 🎉 massive thanks to 🙏 want to get involved join the conversation in 🖼 explore ai illustrations a notable part of the ethereum org aesthetic and experience is and the stories they tell the end of saw an explosion in ai text to image models like dall e midjourney and stable diffusion and showcased their ability to reliability create incredible artwork in we ll be exploring the possibility of leveraging these tools to create more illustrations for ethereum org striving for a better user experience through illustrative storytelling we ll open conversations on our discord soon meanwhile you can 🤖 explore machine translations another area where ai is making rapid progress is machine translations the quality of output that machine translation provides is constantly improving and there is an opportunity to leverage it on ethereum org to lessen the burden on our translators by automating more straightforward tasks and providing better accessibility to languages we do not yet have a translation community around in we ll explore the possibilities machine translations provide decide whether we d like to integrate machine translations into our processes and create a plan for implementing them got thoughts on machine translations come chat in 🧼 clean up the geth website in we helped launch we re pleased with the website and have received great feedback but there are a few tasks and bugs we did not manage to complete in we ll complete the remaining tasks and any bugs to polish the geth website experience 🌎 clean up the ef blog similarly in we internationalized to support translations in many languages but a handful of clean up tasks remain that were cut from the scope to get the blog into the hands of non english speakers more quickly this epic consolidates the remaining items that were not critical for the initial launch but will help continue improving the user experience for blog visitors and writers 🌞 prepare for google summer of code google summer of code is a global online program focused on bringing new contributors into open source development selected participants work closely with projects over three months to help ship new features in we ll collect and prepare potential projects for participants and apply to be a project in google s summer of code 🙌 got an idea or want to get involved 🙏 how does that sound we always appreciate feedback on our roadmap if there s something you think we should work on please let us know we welcome ideas and prs from anyone in the community get involved or join the community discussions in | 1 |
321,215 | 9,795,024,698 | IssuesEvent | 2019-06-11 01:46:53 | arielfc/TravelExpertsWeb | https://api.github.com/repos/arielfc/TravelExpertsWeb | closed | Create initial web project with proper dependencies | High Priority | Create a skeleton of our web project layout with proper dependencies for Entity Framework and MVC. | 1.0 | Create initial web project with proper dependencies - Create a skeleton of our web project layout with proper dependencies for Entity Framework and MVC. | priority | create initial web project with proper dependencies create a skeleton of our web project layout with proper dependencies for entity framework and mvc | 1 |
78,648 | 3,512,490,115 | IssuesEvent | 2016-01-11 01:27:52 | trevorberman/TGB_selfSite | https://api.github.com/repos/trevorberman/TGB_selfSite | closed | Optimize index.html <head> title | high priority | < 50-70 characters, important keywords near begininning
Fit user intent/USP better than "Professional Portfolio and Technical Blog of Trevor G Berman" | 1.0 | Optimize index.html <head> title - < 50-70 characters, important keywords near begininning
Fit user intent/USP better than "Professional Portfolio and Technical Blog of Trevor G Berman" | priority | optimize index html title characters important keywords near begininning fit user intent usp better than professional portfolio and technical blog of trevor g berman | 1 |
154,341 | 5,917,929,094 | IssuesEvent | 2017-05-22 14:20:42 | metasfresh/metasfresh-webui-frontend | https://api.github.com/repos/metasfresh/metasfresh-webui-frontend | closed | Got same notification several times | priority:high status:integrated | ### Type of issue
Bug
### Current behavior / Steps to reproduce
* you need to freshly login, so if u are already logged it pls logout and login. Pls do logout/login several times!
* on another tab please open: http://w101.metasfresh.com:8081/websocket_test.html
** connect to topic: /notifications/<userId>.
*** if you logged in with SuperUser, the topic shall be /notifications/100
*** if you logged in with "it", the topic shall be /notifications/2188223
* on another tab please call: http://w101.metasfresh.com:8181/test/ping/notifications => that call will create a notification on metasfresh server which will be forwarded to metasfresh-webui-server which will forward it to frontend (view websockets)
** you will need to authenticate with SuperUser and it's password
Result:
* frontend displays the notification 2 or 3 times
* websocket_test.html : got the notification only once => webui server is sending it once
Now, if you would refresh the frontend page you will see that each notification is displayed once.
So, i suspect the issue is on frontend when it gets the notifications via websocket. Might be that frontend (for some reason) have the multiple websocket listeners for same /notifications/userId endpoint and that's why the notifications are added several times?


| 1.0 | Got same notification several times - ### Type of issue
Bug
### Current behavior / Steps to reproduce
* you need to freshly login, so if u are already logged it pls logout and login. Pls do logout/login several times!
* on another tab please open: http://w101.metasfresh.com:8081/websocket_test.html
** connect to topic: /notifications/<userId>.
*** if you logged in with SuperUser, the topic shall be /notifications/100
*** if you logged in with "it", the topic shall be /notifications/2188223
* on another tab please call: http://w101.metasfresh.com:8181/test/ping/notifications => that call will create a notification on metasfresh server which will be forwarded to metasfresh-webui-server which will forward it to frontend (view websockets)
** you will need to authenticate with SuperUser and it's password
Result:
* frontend displays the notification 2 or 3 times
* websocket_test.html : got the notification only once => webui server is sending it once
Now, if you would refresh the frontend page you will see that each notification is displayed once.
So, i suspect the issue is on frontend when it gets the notifications via websocket. Might be that frontend (for some reason) have the multiple websocket listeners for same /notifications/userId endpoint and that's why the notifications are added several times?


| priority | got same notification several times type of issue bug current behavior steps to reproduce you need to freshly login so if u are already logged it pls logout and login pls do logout login several times on another tab please open connect to topic notifications if you logged in with superuser the topic shall be notifications if you logged in with it the topic shall be notifications on another tab please call that call will create a notification on metasfresh server which will be forwarded to metasfresh webui server which will forward it to frontend view websockets you will need to authenticate with superuser and it s password result frontend displays the notification or times websocket test html got the notification only once webui server is sending it once now if you would refresh the frontend page you will see that each notification is displayed once so i suspect the issue is on frontend when it gets the notifications via websocket might be that frontend for some reason have the multiple websocket listeners for same notifications userid endpoint and that s why the notifications are added several times | 1 |
217,156 | 7,315,374,637 | IssuesEvent | 2018-03-01 10:49:17 | rubykube/peatio | https://api.github.com/repos/rubykube/peatio | closed | Charts doesn't work for BCH/CAD | Assigned: @dinesh-skyach Category: UI/UX Priority: High Type: Bug | 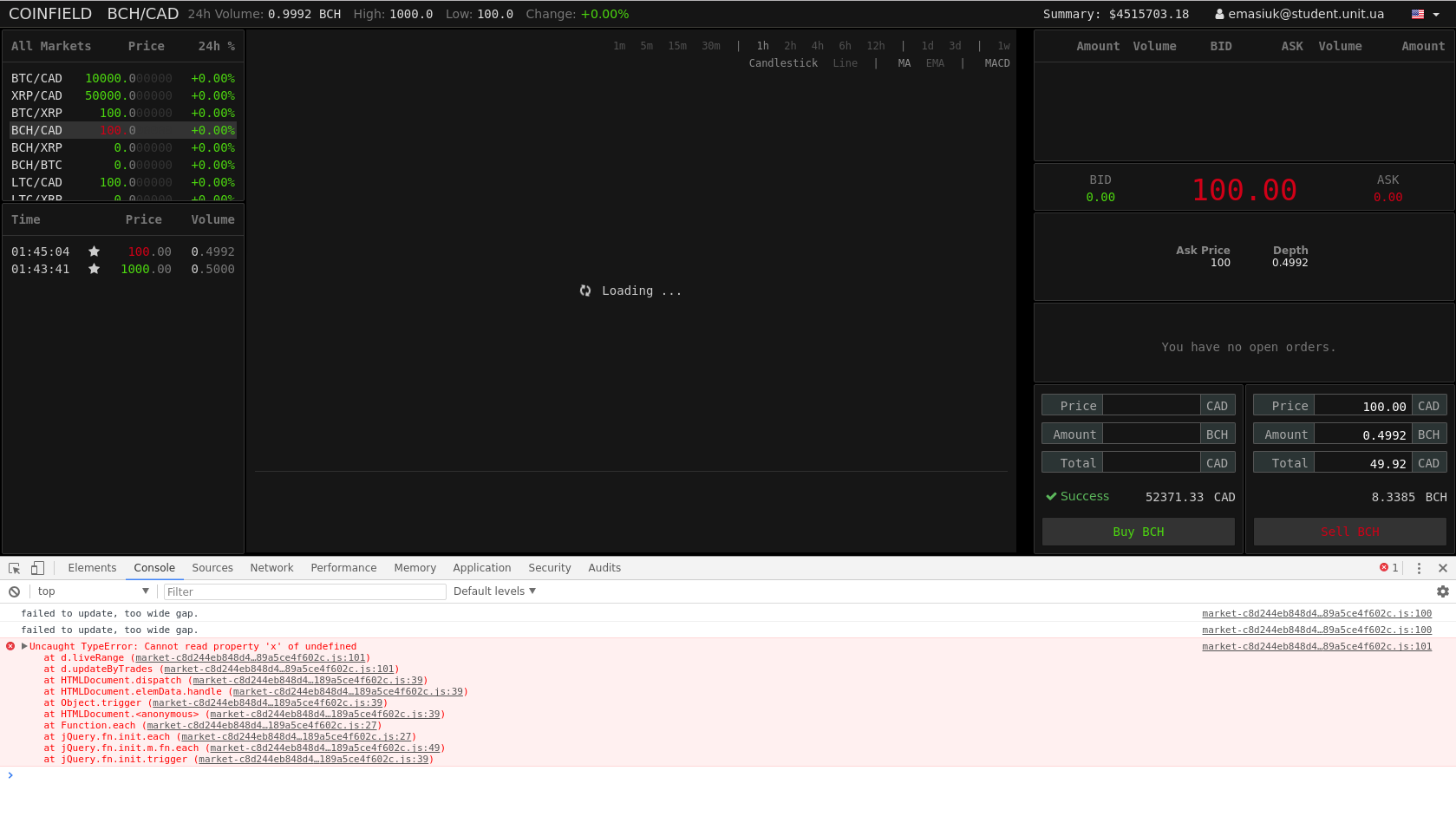
while trading on BCH/CAD the charts won't show up after trade | 1.0 | Charts doesn't work for BCH/CAD - 
while trading on BCH/CAD the charts won't show up after trade | priority | charts doesn t work for bch cad while trading on bch cad the charts won t show up after trade | 1 |
813,185 | 30,448,072,855 | IssuesEvent | 2023-07-15 23:52:42 | helpwave/services | https://api.github.com/repos/helpwave/services | closed | gorm v2 ignores default | bug chore priority: high blocker | ### Describe the bug
gorm fucks our default uuids managed by postgresql
### Describe how to produce the bug
Just create any entity it will get the nil uuid assigned instead of an random uuid.
### Additional context
https://github.com/go-gorm/gorm/commit/e1f46eb802e7a73c9cc04241c3077dbe9021cd51#diff-fe4d8b9673d524cf5dd275564a86eabe3bad07315c9f27d42e38ec071e57354dR314
Thanks to https://github.com/go-gorm/gorm/pull/6021 | 1.0 | gorm v2 ignores default - ### Describe the bug
gorm fucks our default uuids managed by postgresql
### Describe how to produce the bug
Just create any entity it will get the nil uuid assigned instead of an random uuid.
### Additional context
https://github.com/go-gorm/gorm/commit/e1f46eb802e7a73c9cc04241c3077dbe9021cd51#diff-fe4d8b9673d524cf5dd275564a86eabe3bad07315c9f27d42e38ec071e57354dR314
Thanks to https://github.com/go-gorm/gorm/pull/6021 | priority | gorm ignores default describe the bug gorm fucks our default uuids managed by postgresql describe how to produce the bug just create any entity it will get the nil uuid assigned instead of an random uuid additional context thanks to | 1 |
141,232 | 5,431,901,208 | IssuesEvent | 2017-03-04 04:41:36 | neocities/neocities | https://api.github.com/repos/neocities/neocities | closed | Use Brackets for the editor | feature high priority | This might as well be called "Dashboard redesign", though I'm not sure if we'll be replacing it yet or just supplementing it.
http://brackets.io/
| 1.0 | Use Brackets for the editor - This might as well be called "Dashboard redesign", though I'm not sure if we'll be replacing it yet or just supplementing it.
http://brackets.io/
| priority | use brackets for the editor this might as well be called dashboard redesign though i m not sure if we ll be replacing it yet or just supplementing it | 1 |
107,287 | 4,301,142,465 | IssuesEvent | 2016-07-20 06:07:33 | ClinGen/clincoded | https://api.github.com/repos/ClinGen/clincoded | closed | Register new users for test interfaces | priority: high R7alpha1 release ready variant curation interface | @kilodalton: please register two new users for the TEST interfaces per email 7/12/16
p.s. I may have one more coming after this if you want to wait until Wednesday am - I'll add it as soon as I get it. | 1.0 | Register new users for test interfaces - @kilodalton: please register two new users for the TEST interfaces per email 7/12/16
p.s. I may have one more coming after this if you want to wait until Wednesday am - I'll add it as soon as I get it. | priority | register new users for test interfaces kilodalton please register two new users for the test interfaces per email p s i may have one more coming after this if you want to wait until wednesday am i ll add it as soon as i get it | 1 |
211,950 | 7,214,515,447 | IssuesEvent | 2018-02-08 02:43:30 | getinsomnia/insomnia | https://api.github.com/repos/getinsomnia/insomnia | closed | [Bug] libcurl-gnutls.so.4: cannot open shared object file | High Priority | - Insomnia Version: 5.14.3
- Operating System: Linux Fedora 27
## Details
After updating to the latest version of insomnia, I get a blank screen on startup, and the following error message in the DevTools panel:
```
Uncaught Error: libcurl-gnutls.so.4: cannot open shared object file: No such file or directory
at process.module.(anonymous function) [as dlopen] (ELECTRON_ASAR.js:173:20)
at Object.Module._extensions..node (module.js:598:18)
at Object.module.(anonymous function) [as .node] (ELECTRON_ASAR.js:187:18)
at Module.load (module.js:488:32)
at tryModuleLoad (module.js:447:12)
at Function.Module._load (module.js:439:3)
at Module.require (module.js:498:17)
at require (internal/module.js:20:19)
at Object.<anonymous> (/tmp/.mount_insomnsplYYw/app/resources/app.asar/node_modules/insomnia-node-libcurl/lib/Easy.js:40:29)
at Object.<anonymous> (/tmp/.mount_insomnsplYYw/app/resources/app.asar/node_modules/insomnia-node-libcurl/lib/Easy.js:280:3)
``` | 1.0 | [Bug] libcurl-gnutls.so.4: cannot open shared object file - - Insomnia Version: 5.14.3
- Operating System: Linux Fedora 27
## Details
After updating to the latest version of insomnia, I get a blank screen on startup, and the following error message in the DevTools panel:
```
Uncaught Error: libcurl-gnutls.so.4: cannot open shared object file: No such file or directory
at process.module.(anonymous function) [as dlopen] (ELECTRON_ASAR.js:173:20)
at Object.Module._extensions..node (module.js:598:18)
at Object.module.(anonymous function) [as .node] (ELECTRON_ASAR.js:187:18)
at Module.load (module.js:488:32)
at tryModuleLoad (module.js:447:12)
at Function.Module._load (module.js:439:3)
at Module.require (module.js:498:17)
at require (internal/module.js:20:19)
at Object.<anonymous> (/tmp/.mount_insomnsplYYw/app/resources/app.asar/node_modules/insomnia-node-libcurl/lib/Easy.js:40:29)
at Object.<anonymous> (/tmp/.mount_insomnsplYYw/app/resources/app.asar/node_modules/insomnia-node-libcurl/lib/Easy.js:280:3)
``` | priority | libcurl gnutls so cannot open shared object file insomnia version operating system linux fedora details after updating to the latest version of insomnia i get a blank screen on startup and the following error message in the devtools panel uncaught error libcurl gnutls so cannot open shared object file no such file or directory at process module anonymous function electron asar js at object module extensions node module js at object module anonymous function electron asar js at module load module js at trymoduleload module js at function module load module js at module require module js at require internal module js at object tmp mount insomnsplyyw app resources app asar node modules insomnia node libcurl lib easy js at object tmp mount insomnsplyyw app resources app asar node modules insomnia node libcurl lib easy js | 1 |
254,869 | 8,100,771,809 | IssuesEvent | 2018-08-12 03:53:53 | facebook/prepack | https://api.github.com/repos/facebook/prepack | closed | Property access at the wrong time in pure mode | Instant Render abstract bug priority: high | ```
function bad(v) {
if (v == null) {
return null;
}
var a = v.a,
b = v.b;
if (a == null || b == null) {
return a && b;
}
return v;
}
__optimize(bad);
```
leads to this output
```
(function () {
var _$2 = this;
var _0 = function (v) {
var _$0 = v.a; // <== v can be null which is handled in input
var _$1 = v.b;
var _1 = v == null;
if (!_1) {
var _$0 = v.a;
var _$1 = v.b;
var _5 = _$0 == null;
var _7 = _$1 == null;
var _4 = _5 || _7;
if (!_4) {
var _$0 = v.a;
var _$1 = v.b;
}
}
var _B = _$0 && _$1;
var _A = _4 ? _B : v;
var _9 = _1 ? null : _A;
return _9;
};
_$2.bad = _0;
}).call(this);
``` | 1.0 | Property access at the wrong time in pure mode - ```
function bad(v) {
if (v == null) {
return null;
}
var a = v.a,
b = v.b;
if (a == null || b == null) {
return a && b;
}
return v;
}
__optimize(bad);
```
leads to this output
```
(function () {
var _$2 = this;
var _0 = function (v) {
var _$0 = v.a; // <== v can be null which is handled in input
var _$1 = v.b;
var _1 = v == null;
if (!_1) {
var _$0 = v.a;
var _$1 = v.b;
var _5 = _$0 == null;
var _7 = _$1 == null;
var _4 = _5 || _7;
if (!_4) {
var _$0 = v.a;
var _$1 = v.b;
}
}
var _B = _$0 && _$1;
var _A = _4 ? _B : v;
var _9 = _1 ? null : _A;
return _9;
};
_$2.bad = _0;
}).call(this);
``` | priority | property access at the wrong time in pure mode function bad v if v null return null var a v a b v b if a null b null return a b return v optimize bad leads to this output function var this var function v var v a v can be null which is handled in input var v b var v null if var v a var v b var null var null var if var v a var v b var b var a b v var null a return bad call this | 1 |
276,474 | 8,599,093,530 | IssuesEvent | 2018-11-16 00:20:27 | tavorperry/MTA-Coffee | https://api.github.com/repos/tavorperry/MTA-Coffee | closed | Add Profile page | High Priority | In that page users will see:
1. Their level and points status,
2. They will have the option to change the password,
3. And option to deactivate their account.
**Don't forget to add the new page to the navbar** | 1.0 | Add Profile page - In that page users will see:
1. Their level and points status,
2. They will have the option to change the password,
3. And option to deactivate their account.
**Don't forget to add the new page to the navbar** | priority | add profile page in that page users will see their level and points status they will have the option to change the password and option to deactivate their account don t forget to add the new page to the navbar | 1 |
663,490 | 22,194,996,867 | IssuesEvent | 2022-06-07 05:47:06 | COS301-SE-2022/The-Au-Pair | https://api.github.com/repos/COS301-SE-2022/The-Au-Pair | closed | Restructure backend | scope:api priority:high status:hold type:change | change request response structure to
controller -> service -> repository -> DB | 1.0 | Restructure backend - change request response structure to
controller -> service -> repository -> DB | priority | restructure backend change request response structure to controller service repository db | 1 |
129,662 | 5,100,842,301 | IssuesEvent | 2017-01-04 13:44:39 | Teemill/UKTSP_sales | https://api.github.com/repos/Teemill/UKTSP_sales | closed | UKTSP Site Usability | enhancement Phase 1 High Impact Easy priority:high | I have had 3 people in one day complaining about having trouble navigating our site and I've had to do the work for them - they may be tech losers but if 3 complain about it, could be more not saying it.
| 1.0 | UKTSP Site Usability - I have had 3 people in one day complaining about having trouble navigating our site and I've had to do the work for them - they may be tech losers but if 3 complain about it, could be more not saying it.
| priority | uktsp site usability i have had people in one day complaining about having trouble navigating our site and i ve had to do the work for them they may be tech losers but if complain about it could be more not saying it | 1 |
188,587 | 6,777,913,173 | IssuesEvent | 2017-10-28 02:46:42 | steemit/yo | https://api.github.com/repos/steemit/yo | closed | settings API in MySQL | priority/high | mock API is now migrated over to MySQL mostly except for the transports stuff (get_transports, set_transports), current DB schema needs slight modifications and a few other changes so the "real" API is conformant to behaviour of the mock API condenser has been working with as well as to spec.
This is an open task if anyone else has time to jump on it, otherwise I intend to work on it after wwwpoll | 1.0 | settings API in MySQL - mock API is now migrated over to MySQL mostly except for the transports stuff (get_transports, set_transports), current DB schema needs slight modifications and a few other changes so the "real" API is conformant to behaviour of the mock API condenser has been working with as well as to spec.
This is an open task if anyone else has time to jump on it, otherwise I intend to work on it after wwwpoll | priority | settings api in mysql mock api is now migrated over to mysql mostly except for the transports stuff get transports set transports current db schema needs slight modifications and a few other changes so the real api is conformant to behaviour of the mock api condenser has been working with as well as to spec this is an open task if anyone else has time to jump on it otherwise i intend to work on it after wwwpoll | 1 |
54,021 | 3,058,712,499 | IssuesEvent | 2015-08-14 10:10:23 | ceylon/ceylon-ide-eclipse | https://api.github.com/repos/ceylon/ceylon-ide-eclipse | closed | navigation for doc links broken in editor | bug high priority | @davidfestal command-clicking on a `[[DocLink]]` in the Ceylon editor suddenly no longer works. Did you touch something? | 1.0 | navigation for doc links broken in editor - @davidfestal command-clicking on a `[[DocLink]]` in the Ceylon editor suddenly no longer works. Did you touch something? | priority | navigation for doc links broken in editor davidfestal command clicking on a in the ceylon editor suddenly no longer works did you touch something | 1 |
202,325 | 7,046,839,316 | IssuesEvent | 2018-01-02 10:16:36 | wso2-incubator/testgrid | https://api.github.com/repos/wso2-incubator/testgrid | closed | Infra combinations cannot be static but dynamic | Priority/Highest Severity/Critical Type/Improvement | **Description:**
As of now, infra combinations are static (OS, DB and JDK). However, these parameters may not be the same and can change. | 1.0 | Infra combinations cannot be static but dynamic - **Description:**
As of now, infra combinations are static (OS, DB and JDK). However, these parameters may not be the same and can change. | priority | infra combinations cannot be static but dynamic description as of now infra combinations are static os db and jdk however these parameters may not be the same and can change | 1 |
87,839 | 3,768,005,859 | IssuesEvent | 2016-03-16 01:30:31 | tgstation/-tg-station | https://api.github.com/repos/tgstation/-tg-station | closed | You can receive a traitor hud when you change your mob and you are a traitor | Bug In Game Exploit Priority: High | [Everyone]: # (Please fill in your information on the line AFTER the header.)
### What is the problem?
- When you get selected for traitor(I didn't test for other gamemodes, but only saw it happening in traitor so far) and then you change your mob somehow(for example, you die and get cloned, or die and an admin spawn you in another mob) you will get the traitor hud, which is the one admins can activate by the Toggle AntagHUD.
### Why is it a problem, or what should have happened?
- Traitors aren't supposed to have a traitor hud by any means.
### How can the problem be reproduced?
- Spawn in, traitor yourself and change your mob, you will notice a "T" in your HUD, which will show up above all traitors.
[Admins]: # (If you are reporting a bug that occured AFTER you used varedit/admin buttons to alter an object out of normal operating conditions, please verify that you can re-create the bug without the varedit usage/admin buttons before reporting the issue.)
| 1.0 | You can receive a traitor hud when you change your mob and you are a traitor - [Everyone]: # (Please fill in your information on the line AFTER the header.)
### What is the problem?
- When you get selected for traitor(I didn't test for other gamemodes, but only saw it happening in traitor so far) and then you change your mob somehow(for example, you die and get cloned, or die and an admin spawn you in another mob) you will get the traitor hud, which is the one admins can activate by the Toggle AntagHUD.
### Why is it a problem, or what should have happened?
- Traitors aren't supposed to have a traitor hud by any means.
### How can the problem be reproduced?
- Spawn in, traitor yourself and change your mob, you will notice a "T" in your HUD, which will show up above all traitors.
[Admins]: # (If you are reporting a bug that occured AFTER you used varedit/admin buttons to alter an object out of normal operating conditions, please verify that you can re-create the bug without the varedit usage/admin buttons before reporting the issue.)
| priority | you can receive a traitor hud when you change your mob and you are a traitor please fill in your information on the line after the header what is the problem when you get selected for traitor i didn t test for other gamemodes but only saw it happening in traitor so far and then you change your mob somehow for example you die and get cloned or die and an admin spawn you in another mob you will get the traitor hud which is the one admins can activate by the toggle antaghud why is it a problem or what should have happened traitors aren t supposed to have a traitor hud by any means how can the problem be reproduced spawn in traitor yourself and change your mob you will notice a t in your hud which will show up above all traitors if you are reporting a bug that occured after you used varedit admin buttons to alter an object out of normal operating conditions please verify that you can re create the bug without the varedit usage admin buttons before reporting the issue | 1 |
787,595 | 27,724,061,566 | IssuesEvent | 2023-03-14 23:45:17 | supaglue-labs/supaglue | https://api.github.com/repos/supaglue-labs/supaglue | closed | [SUP1-114] Pass-through API | High priority Epic | * A way to call arbitrary Hubspot V3 endpoints and payload
* Using the OAuth credentials that have been stored for a connection
<sub>From [SyncLinear.com](https://synclinear.com) | [SUP1-114](https://linear.app/supaglue/issue/SUP1-114/pass-through-api)</sub> | 1.0 | [SUP1-114] Pass-through API - * A way to call arbitrary Hubspot V3 endpoints and payload
* Using the OAuth credentials that have been stored for a connection
<sub>From [SyncLinear.com](https://synclinear.com) | [SUP1-114](https://linear.app/supaglue/issue/SUP1-114/pass-through-api)</sub> | priority | pass through api a way to call arbitrary hubspot endpoints and payload using the oauth credentials that have been stored for a connection from | 1 |
664,999 | 22,295,471,332 | IssuesEvent | 2022-06-13 00:32:52 | whizvox/OneTimeDownload | https://api.github.com/repos/whizvox/OneTimeDownload | closed | Add password reset functionality | high priority | User is effectively locked out of their account if they don't remember their password. Add "Forgot password" button to login page and allow user to reset their password via secure link to their email inbox. | 1.0 | Add password reset functionality - User is effectively locked out of their account if they don't remember their password. Add "Forgot password" button to login page and allow user to reset their password via secure link to their email inbox. | priority | add password reset functionality user is effectively locked out of their account if they don t remember their password add forgot password button to login page and allow user to reset their password via secure link to their email inbox | 1 |
108,213 | 4,329,127,579 | IssuesEvent | 2016-07-26 15:54:03 | GluuFederation/oxTrust | https://api.github.com/repos/GluuFederation/oxTrust | opened | SAML Trust Relationship: Multi-Party Federation Metadata Re-Design | bug enhancement High Priority |

The old federation page has a bad design... It just crashed my browser session because the page became unresponsive.
The InCommon metadata aggregate is now 36MB xml file, it used to be 10MB. I think its breaking down due to the fact that InCommon federation starting including European federation (interfederation with EduGain). Even before this the federation page was slow.
Here are my suggestions:
1. Add a new select box called Entity Type with values "Single SP" and "Federation / Aggregate"
2. If Entity Type "Federation / Aggregate" is selected in the Metadata Location input, the form fields for "SP Logout URL", "Configure RP", "Enable InCommon R&S" and "Released" should be hidden in the fom view.
3. If Entity Type "Federation / Aggregate" is selected, remove the Entity Location drop down values, "Generate" and "Federation"
4. Change label "Metadata Type" to "Metadata Location"
5. Check that federation / aggregate validation happens in the background.
| 1.0 | SAML Trust Relationship: Multi-Party Federation Metadata Re-Design -

The old federation page has a bad design... It just crashed my browser session because the page became unresponsive.
The InCommon metadata aggregate is now 36MB xml file, it used to be 10MB. I think its breaking down due to the fact that InCommon federation starting including European federation (interfederation with EduGain). Even before this the federation page was slow.
Here are my suggestions:
1. Add a new select box called Entity Type with values "Single SP" and "Federation / Aggregate"
2. If Entity Type "Federation / Aggregate" is selected in the Metadata Location input, the form fields for "SP Logout URL", "Configure RP", "Enable InCommon R&S" and "Released" should be hidden in the fom view.
3. If Entity Type "Federation / Aggregate" is selected, remove the Entity Location drop down values, "Generate" and "Federation"
4. Change label "Metadata Type" to "Metadata Location"
5. Check that federation / aggregate validation happens in the background.
| priority | saml trust relationship multi party federation metadata re design the old federation page has a bad design it just crashed my browser session because the page became unresponsive the incommon metadata aggregate is now xml file it used to be i think its breaking down due to the fact that incommon federation starting including european federation interfederation with edugain even before this the federation page was slow here are my suggestions add a new select box called entity type with values single sp and federation aggregate if entity type federation aggregate is selected in the metadata location input the form fields for sp logout url configure rp enable incommon r s and released should be hidden in the fom view if entity type federation aggregate is selected remove the entity location drop down values generate and federation change label metadata type to metadata location check that federation aggregate validation happens in the background | 1 |
81,321 | 3,588,506,057 | IssuesEvent | 2016-01-31 02:18:04 | ankidroid/Anki-Android | https://api.github.com/repos/ankidroid/Anki-Android | closed | com.ichi2.anki.exception.UnknownHttpResponseException: Bad Gateway | bug Priority-High waitingforfeedback | Originally reported on Google Code with ID 2429
```
What steps will reproduce the problem?
1. Click the sync button
What is the expected output? What do you see instead?
-For it to say that syncing was successful, instead i get an error (com.ichi2.anki.exception.UnknownHttpResponseException:
Bad Gateway) where it takes me to the error report screen. It always times out when
it says "275 media objects", it starts uploading and then crashes.
Does it happen again every time you repeat the steps above? Or did it
happen only one time?
-Every time. It just started to happen this week.
What version of AnkiDroid are you using? (Decks list > menu > About > Look
at the title)
On what version of Android? (Home screen > menu > About phone > Android
version)
-Android 4.4.2, AnkiDroid 2.3.2
If it is a crash or "Force close" and you can reproduce it, the following
would help immensely: 1) Install the "SendLog" app, 2) Reproduce the crash,
3) Immediately after, launch SendLog, 4) Attach the resulting file to this
report. That will make the bug much easier to fix.
-I've attached the SendLog file.
Please provide any additional information below.
-I'm not sure what caused it, maybe AnkiDroid and Anki Desktop tried to sync at the
same time? I'm not sure, but the problem just started this week. It seems to still
update my repetitions, it just crashes when reaching the media section.
```
Reported by `pokemaster103` on 2014-12-03 07:52:09
<hr>
* *Attachment: [SendLog.zip](https://storage.googleapis.com/google-code-attachments/ankidroid/issue-2429/comment-0/SendLog.zip)* | 1.0 | com.ichi2.anki.exception.UnknownHttpResponseException: Bad Gateway - Originally reported on Google Code with ID 2429
```
What steps will reproduce the problem?
1. Click the sync button
What is the expected output? What do you see instead?
-For it to say that syncing was successful, instead i get an error (com.ichi2.anki.exception.UnknownHttpResponseException:
Bad Gateway) where it takes me to the error report screen. It always times out when
it says "275 media objects", it starts uploading and then crashes.
Does it happen again every time you repeat the steps above? Or did it
happen only one time?
-Every time. It just started to happen this week.
What version of AnkiDroid are you using? (Decks list > menu > About > Look
at the title)
On what version of Android? (Home screen > menu > About phone > Android
version)
-Android 4.4.2, AnkiDroid 2.3.2
If it is a crash or "Force close" and you can reproduce it, the following
would help immensely: 1) Install the "SendLog" app, 2) Reproduce the crash,
3) Immediately after, launch SendLog, 4) Attach the resulting file to this
report. That will make the bug much easier to fix.
-I've attached the SendLog file.
Please provide any additional information below.
-I'm not sure what caused it, maybe AnkiDroid and Anki Desktop tried to sync at the
same time? I'm not sure, but the problem just started this week. It seems to still
update my repetitions, it just crashes when reaching the media section.
```
Reported by `pokemaster103` on 2014-12-03 07:52:09
<hr>
* *Attachment: [SendLog.zip](https://storage.googleapis.com/google-code-attachments/ankidroid/issue-2429/comment-0/SendLog.zip)* | priority | com anki exception unknownhttpresponseexception bad gateway originally reported on google code with id what steps will reproduce the problem click the sync button what is the expected output what do you see instead for it to say that syncing was successful instead i get an error com anki exception unknownhttpresponseexception bad gateway where it takes me to the error report screen it always times out when it says media objects it starts uploading and then crashes does it happen again every time you repeat the steps above or did it happen only one time every time it just started to happen this week what version of ankidroid are you using decks list menu about look at the title on what version of android home screen menu about phone android version android ankidroid if it is a crash or force close and you can reproduce it the following would help immensely install the sendlog app reproduce the crash immediately after launch sendlog attach the resulting file to this report that will make the bug much easier to fix i ve attached the sendlog file please provide any additional information below i m not sure what caused it maybe ankidroid and anki desktop tried to sync at the same time i m not sure but the problem just started this week it seems to still update my repetitions it just crashes when reaching the media section reported by on attachment | 1 |
283,122 | 8,714,379,326 | IssuesEvent | 2018-12-07 07:39:35 | aowen87/TicketTester | https://api.github.com/repos/aowen87/TicketTester | closed | Scatter plot hangs when using color var. | asc bug crash likelihood medium priority reviewed severity high wrong results | In parallel if there are more processors than chunks to process - a common case when material selection is used.
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. As such, not all
information was able to be captured in the transition. Below is
a complete record of the original redmine ticket.
Ticket number: 348
Status: Resolved
Project: VisIt
Tracker: Bug
Priority: Urgent
Subject: Scatter plot hangs when using color var.
Assigned to: Cyrus Harrison
Category:
Target version: 2.1
Author: Cyrus Harrison
Start: 08/17/2010
Due date:
% Done: 0
Estimated time:
Created: 08/17/2010 02:50 pm
Updated: 08/17/2010 05:23 pm
Likelihood: 3 - Occasional
Severity: 4 - Crash / Wrong Results
Found in version: 2.0.2
Impact:
Expected Use:
OS: All
Support Group: DOE/ASC
Description:
In parallel if there are more processors than chunks to process - a common case when material selection is used.
Comments:
Hi Everyone,This commmit fixes two parallel related issues with the scatter plot:1) Creating a colored scatter plot when you had more procs than chunks(domains) to process (say after a material selection) would cause an invalid merge exception & a parallel hang. (This resolves #348)2) Spatial extents were invalid when there are were more procs than chunks to process.Sending Scatter/avtScatterFilter.CSending Scatter/avtScatterFilter.hTransmitting file data ..Committed revision r12249.-Cyrus
| 1.0 | Scatter plot hangs when using color var. - In parallel if there are more processors than chunks to process - a common case when material selection is used.
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. As such, not all
information was able to be captured in the transition. Below is
a complete record of the original redmine ticket.
Ticket number: 348
Status: Resolved
Project: VisIt
Tracker: Bug
Priority: Urgent
Subject: Scatter plot hangs when using color var.
Assigned to: Cyrus Harrison
Category:
Target version: 2.1
Author: Cyrus Harrison
Start: 08/17/2010
Due date:
% Done: 0
Estimated time:
Created: 08/17/2010 02:50 pm
Updated: 08/17/2010 05:23 pm
Likelihood: 3 - Occasional
Severity: 4 - Crash / Wrong Results
Found in version: 2.0.2
Impact:
Expected Use:
OS: All
Support Group: DOE/ASC
Description:
In parallel if there are more processors than chunks to process - a common case when material selection is used.
Comments:
Hi Everyone,This commmit fixes two parallel related issues with the scatter plot:1) Creating a colored scatter plot when you had more procs than chunks(domains) to process (say after a material selection) would cause an invalid merge exception & a parallel hang. (This resolves #348)2) Spatial extents were invalid when there are were more procs than chunks to process.Sending Scatter/avtScatterFilter.CSending Scatter/avtScatterFilter.hTransmitting file data ..Committed revision r12249.-Cyrus
| priority | scatter plot hangs when using color var in parallel if there are more processors than chunks to process a common case when material selection is used redmine migration this ticket was migrated from redmine as such not all information was able to be captured in the transition below is a complete record of the original redmine ticket ticket number status resolved project visit tracker bug priority urgent subject scatter plot hangs when using color var assigned to cyrus harrison category target version author cyrus harrison start due date done estimated time created pm updated pm likelihood occasional severity crash wrong results found in version impact expected use os all support group doe asc description in parallel if there are more processors than chunks to process a common case when material selection is used comments hi everyone this commmit fixes two parallel related issues with the scatter plot creating a colored scatter plot when you had more procs than chunks domains to process say after a material selection would cause an invalid merge exception a parallel hang this resolves spatial extents were invalid when there are were more procs than chunks to process sending scatter avtscatterfilter csending scatter avtscatterfilter htransmitting file data committed revision cyrus | 1 |
306,162 | 9,381,556,496 | IssuesEvent | 2019-04-04 19:56:32 | CS2113-AY1819S2-T08-3/main | https://api.github.com/repos/CS2113-AY1819S2-T08-3/main | closed | delete does not delete all related tags | priority.High severity.High status.Ongoing type.Bug | **Describe the bug**
I have added multiple slots with the same tag. However, when I try to delete the relevant tag, it only deleted 2 of them and not all.
**To Reproduce**
Steps to reproduce the behavior:
1. `add n/CS2113T Tutorial d/mon st/08:00 et/09:00 des/Topic: Sequence Diagram t/CS2113T t/Tutorial r/normal` add this 20 times
2. del t/CS2113T
3. Deleted Slots:
1. CS2113T Tutorial, 2019-04-08 08:00, Week 12, MONDAY
2. CS2113T Tutorial, 2019-04-15 08:00, Week 13, MONDAY
**Expected behavior**
1. CS2113T Tutorial, 2019-04-08 08:00, Week 12, MONDAY
2. CS2113T Tutorial, 2019-04-15 08:00, Week 13, MONDAY
3. CS2113T Tutorial, 2019-04-08 08:00, Week 12, MONDAY
4. CS2113T Tutorial, 2019-04-15 08:00, Week 13, MONDAY
..... 20 times
<hr>
**Reported by:** @nicholasleeeee
**Severity:** High
<sub>[original: nusCS2113-AY1819S2/pe-dry-run#103]</sub> | 1.0 | delete does not delete all related tags - **Describe the bug**
I have added multiple slots with the same tag. However, when I try to delete the relevant tag, it only deleted 2 of them and not all.
**To Reproduce**
Steps to reproduce the behavior:
1. `add n/CS2113T Tutorial d/mon st/08:00 et/09:00 des/Topic: Sequence Diagram t/CS2113T t/Tutorial r/normal` add this 20 times
2. del t/CS2113T
3. Deleted Slots:
1. CS2113T Tutorial, 2019-04-08 08:00, Week 12, MONDAY
2. CS2113T Tutorial, 2019-04-15 08:00, Week 13, MONDAY
**Expected behavior**
1. CS2113T Tutorial, 2019-04-08 08:00, Week 12, MONDAY
2. CS2113T Tutorial, 2019-04-15 08:00, Week 13, MONDAY
3. CS2113T Tutorial, 2019-04-08 08:00, Week 12, MONDAY
4. CS2113T Tutorial, 2019-04-15 08:00, Week 13, MONDAY
..... 20 times
<hr>
**Reported by:** @nicholasleeeee
**Severity:** High
<sub>[original: nusCS2113-AY1819S2/pe-dry-run#103]</sub> | priority | delete does not delete all related tags describe the bug i have added multiple slots with the same tag however when i try to delete the relevant tag it only deleted of them and not all to reproduce steps to reproduce the behavior add n tutorial d mon st et des topic sequence diagram t t tutorial r normal add this times del t deleted slots tutorial week monday tutorial week monday expected behavior tutorial week monday tutorial week monday tutorial week monday tutorial week monday times reported by nicholasleeeee severity high | 1 |
638,040 | 20,711,424,229 | IssuesEvent | 2022-03-12 01:21:54 | zulip/zulip-mobile | https://api.github.com/repos/zulip/zulip-mobile | closed | Add support for displaying emoji with statuses. | P1 high-priority webapp parity server release goal | In https://github.com/zulip/zulip/pull/18955, we just merged support for adding emoji to one's user status in the server/webapp, which ranked as our 7th most requested feature on https://github.com/zulip/zulip/issues?q=is%3Aissue+is%3Aopen+sort%3Areactions-%2B1-desc before being implemented.
We should add mobile support for this! Most important is displaying it; the API matches that for reactions, so you may be able to reuse code. I'll also mention that we added a new `get_emoji_details_by_name` function to `static/shared/js/emoji.js` to avoid duplicating that code which was present for emoji reactions, and you may find that useful.
Tagging as a priority, since this is the kind of feature that you really want to work in all clients; I think we should consider mobile support for this feature to be a blocker for Zulip 5.0 (we're likely aiming for an October release given my vacation).
The API documentation for /register and /events is complete; documentation for setting a user status is being added in https://github.com/zulip/zulip/pull/19403.
Sorry I didn't give more warning; I only started seriously looking at the PR in the last few days, and it turns out to have taken a lot less work to merge than I anticipated.
| 1.0 | Add support for displaying emoji with statuses. - In https://github.com/zulip/zulip/pull/18955, we just merged support for adding emoji to one's user status in the server/webapp, which ranked as our 7th most requested feature on https://github.com/zulip/zulip/issues?q=is%3Aissue+is%3Aopen+sort%3Areactions-%2B1-desc before being implemented.
We should add mobile support for this! Most important is displaying it; the API matches that for reactions, so you may be able to reuse code. I'll also mention that we added a new `get_emoji_details_by_name` function to `static/shared/js/emoji.js` to avoid duplicating that code which was present for emoji reactions, and you may find that useful.
Tagging as a priority, since this is the kind of feature that you really want to work in all clients; I think we should consider mobile support for this feature to be a blocker for Zulip 5.0 (we're likely aiming for an October release given my vacation).
The API documentation for /register and /events is complete; documentation for setting a user status is being added in https://github.com/zulip/zulip/pull/19403.
Sorry I didn't give more warning; I only started seriously looking at the PR in the last few days, and it turns out to have taken a lot less work to merge than I anticipated.
| priority | add support for displaying emoji with statuses in we just merged support for adding emoji to one s user status in the server webapp which ranked as our most requested feature on before being implemented we should add mobile support for this most important is displaying it the api matches that for reactions so you may be able to reuse code i ll also mention that we added a new get emoji details by name function to static shared js emoji js to avoid duplicating that code which was present for emoji reactions and you may find that useful tagging as a priority since this is the kind of feature that you really want to work in all clients i think we should consider mobile support for this feature to be a blocker for zulip we re likely aiming for an october release given my vacation the api documentation for register and events is complete documentation for setting a user status is being added in sorry i didn t give more warning i only started seriously looking at the pr in the last few days and it turns out to have taken a lot less work to merge than i anticipated | 1 |
336,531 | 10,192,966,769 | IssuesEvent | 2019-08-12 12:35:57 | noobaa/noobaa-core | https://api.github.com/repos/noobaa/noobaa-core | closed | Idle system with many buckets runs system_store.make_changes every second | Performance Priority 2 High Severity 2 | ### Environment info
- Version: **1.3**
- Deployment: **DEV**
- Customer: **NA**
### Actual behavior
1. After running ceph s3-tests that created a lot of buckets I see make_changes being called every second by the bg worker to update storage stats:
```
Mar-29 18:28:49.231 [BGWorkers/5459] [L0] core.server.system_services.system_store:: SystemStore.make_changes: { update:
{ buckets:
[ { _id: 58dbcd46ee373314aa407f26,
storage_stats:
{ chunks_capacity: 0,
objects_size: 0,
objects_count: 0,
blocks_size: 0,
last_update: 1490799853169,
objects_hist: [] } },
{ _id: 58dbcd46ee373314aa407f22,
storage_stats:
{ chunks_capacity: 0,
objects_size: 0,
objects_count: 0,
blocks_size: 0,
last_update: 1490799853169,
objects_hist: [] } },
...
```
### Expected behavior
1. make_changes should not be called in such high frequency
### Steps to reproduce
1. Create many buckets
2. Maybe need to write something to each one
3. Behold the wonder happening by bg worker
### Screenshots or Logs or other output that would be helpful
(If large, please upload as attachment)
| 1.0 | Idle system with many buckets runs system_store.make_changes every second - ### Environment info
- Version: **1.3**
- Deployment: **DEV**
- Customer: **NA**
### Actual behavior
1. After running ceph s3-tests that created a lot of buckets I see make_changes being called every second by the bg worker to update storage stats:
```
Mar-29 18:28:49.231 [BGWorkers/5459] [L0] core.server.system_services.system_store:: SystemStore.make_changes: { update:
{ buckets:
[ { _id: 58dbcd46ee373314aa407f26,
storage_stats:
{ chunks_capacity: 0,
objects_size: 0,
objects_count: 0,
blocks_size: 0,
last_update: 1490799853169,
objects_hist: [] } },
{ _id: 58dbcd46ee373314aa407f22,
storage_stats:
{ chunks_capacity: 0,
objects_size: 0,
objects_count: 0,
blocks_size: 0,
last_update: 1490799853169,
objects_hist: [] } },
...
```
### Expected behavior
1. make_changes should not be called in such high frequency
### Steps to reproduce
1. Create many buckets
2. Maybe need to write something to each one
3. Behold the wonder happening by bg worker
### Screenshots or Logs or other output that would be helpful
(If large, please upload as attachment)
| priority | idle system with many buckets runs system store make changes every second environment info version deployment dev customer na actual behavior after running ceph tests that created a lot of buckets i see make changes being called every second by the bg worker to update storage stats mar core server system services system store systemstore make changes update buckets id storage stats chunks capacity objects size objects count blocks size last update objects hist id storage stats chunks capacity objects size objects count blocks size last update objects hist expected behavior make changes should not be called in such high frequency steps to reproduce create many buckets maybe need to write something to each one behold the wonder happening by bg worker screenshots or logs or other output that would be helpful if large please upload as attachment | 1 |
410,637 | 11,994,828,129 | IssuesEvent | 2020-04-08 14:17:57 | Sciensano-Healthdata/HD-Corona | https://api.github.com/repos/Sciensano-Healthdata/HD-Corona | reopened | create form NL + FR: "Eerste lijn zorgverleners: algemeen" / "Prestataires de soins de première ligne: général" | development priority:high ↑ | Inhoud = die van GP, zonder de vragen van Vioras, dus iets als:
- Type zorgactor (dropdown lijst die ik ga opvragen)
- tx_gp_name Naam van de praktijk
- tx_email E-mailadres
- tx_gp_postal_code Postcode van de gemeente waarin de praktijk zich bevindt
- nr_num_??_providers Aantal zorgverstrekkers werkzaam in de praktijk
- nr_num_??_providers_absent Aantal zorgverstrekkers die ziek zijn en niet kunnen werken
- nr_num_consultations_phone Hoeveel telefonische consultaties hebt u vandaag gedaan?
- nr_num_consultations_phys Hoeveel fysieke consultaties hebt u vandaag gedaan?
- nr_num_patients_triage Hoeveel patiënten hebt u vandaag doorverwezen naar de covid19 triage post?
- nr_num_patients_emergency Hoeveel potentiële covid19 patiënten hebt u vandaag doorverwezen naar spoed?
- cd_num_respiratory_consultations Hoeveel % van uw consultaties hebben betrekking op luchtweg klachten?
- cd_extra_load "Hoe groot is de extra belasting voor u als zorgverstrekker op dit moment? "
- cd_alc_hand_disinfectant Alcoholische handontsmetting
- + number units needed
- cd_surgical_masks Gewone chirurgische maskers
- + number units needed
- cd_infection_masks Maskers geschikt te gebruiken bij infecties (FFP2 en co)
- + number units needed
- cd_infection_gloves Handschoenen geschikt te gebruiken bij infecties
- + number units needed
- cd_infection_aprons Schorten geschikt te gebruiken bij infecties
- + number units needed
- cd_infection_screen Bril/scherm geschikt te gebruiken bij infecties
- + number units needed | 1.0 | create form NL + FR: "Eerste lijn zorgverleners: algemeen" / "Prestataires de soins de première ligne: général" - Inhoud = die van GP, zonder de vragen van Vioras, dus iets als:
- Type zorgactor (dropdown lijst die ik ga opvragen)
- tx_gp_name Naam van de praktijk
- tx_email E-mailadres
- tx_gp_postal_code Postcode van de gemeente waarin de praktijk zich bevindt
- nr_num_??_providers Aantal zorgverstrekkers werkzaam in de praktijk
- nr_num_??_providers_absent Aantal zorgverstrekkers die ziek zijn en niet kunnen werken
- nr_num_consultations_phone Hoeveel telefonische consultaties hebt u vandaag gedaan?
- nr_num_consultations_phys Hoeveel fysieke consultaties hebt u vandaag gedaan?
- nr_num_patients_triage Hoeveel patiënten hebt u vandaag doorverwezen naar de covid19 triage post?
- nr_num_patients_emergency Hoeveel potentiële covid19 patiënten hebt u vandaag doorverwezen naar spoed?
- cd_num_respiratory_consultations Hoeveel % van uw consultaties hebben betrekking op luchtweg klachten?
- cd_extra_load "Hoe groot is de extra belasting voor u als zorgverstrekker op dit moment? "
- cd_alc_hand_disinfectant Alcoholische handontsmetting
- + number units needed
- cd_surgical_masks Gewone chirurgische maskers
- + number units needed
- cd_infection_masks Maskers geschikt te gebruiken bij infecties (FFP2 en co)
- + number units needed
- cd_infection_gloves Handschoenen geschikt te gebruiken bij infecties
- + number units needed
- cd_infection_aprons Schorten geschikt te gebruiken bij infecties
- + number units needed
- cd_infection_screen Bril/scherm geschikt te gebruiken bij infecties
- + number units needed | priority | create form nl fr eerste lijn zorgverleners algemeen prestataires de soins de première ligne général inhoud die van gp zonder de vragen van vioras dus iets als type zorgactor dropdown lijst die ik ga opvragen tx gp name naam van de praktijk tx email e mailadres tx gp postal code postcode van de gemeente waarin de praktijk zich bevindt nr num providers aantal zorgverstrekkers werkzaam in de praktijk nr num providers absent aantal zorgverstrekkers die ziek zijn en niet kunnen werken nr num consultations phone hoeveel telefonische consultaties hebt u vandaag gedaan nr num consultations phys hoeveel fysieke consultaties hebt u vandaag gedaan nr num patients triage hoeveel patiënten hebt u vandaag doorverwezen naar de triage post nr num patients emergency hoeveel potentiële patiënten hebt u vandaag doorverwezen naar spoed cd num respiratory consultations hoeveel van uw consultaties hebben betrekking op luchtweg klachten cd extra load hoe groot is de extra belasting voor u als zorgverstrekker op dit moment cd alc hand disinfectant alcoholische handontsmetting number units needed cd surgical masks gewone chirurgische maskers number units needed cd infection masks maskers geschikt te gebruiken bij infecties en co number units needed cd infection gloves handschoenen geschikt te gebruiken bij infecties number units needed cd infection aprons schorten geschikt te gebruiken bij infecties number units needed cd infection screen bril scherm geschikt te gebruiken bij infecties number units needed | 1 |
251,041 | 7,997,987,654 | IssuesEvent | 2018-07-21 04:03:30 | StrangeLoopGames/EcoIssues | https://api.github.com/repos/StrangeLoopGames/EcoIssues | closed | Construction Post/ Small Wood sign etc | High Priority | After 7.6.X update, I can no longer edit name of construction post etc without claiming the area.
When I cant edit the name, it will be much harder for me to create "government" contracts (ex. making roads etc) when I dont know wich construction post is wich (previously I named them as Road Construction North 1 etc).
| 1.0 | Construction Post/ Small Wood sign etc - After 7.6.X update, I can no longer edit name of construction post etc without claiming the area.
When I cant edit the name, it will be much harder for me to create "government" contracts (ex. making roads etc) when I dont know wich construction post is wich (previously I named them as Road Construction North 1 etc).


| priority | construction post small wood sign etc after x update i can no longer edit name of construction post etc without claiming the area when i cant edit the name it will be much harder for me to create government contracts ex making roads etc when i dont know wich construction post is wich previously i named them as road construction north etc | 1 |
643,993 | 20,962,200,776 | IssuesEvent | 2022-03-27 23:45:26 | Gilded-Games/The-Aether | https://api.github.com/repos/Gilded-Games/The-Aether | closed | Bug: Dimensions have a static seed at the moment. | priority/high status/pending-review type/annoyance type/bug feat/world-gen | This is a Minecraft issue that may need to be fixed either through a Mixin or just not using the json system (which we might be doing in 1.18 anyways). Either that or maybe https://github.com/MinecraftForge/MinecraftForge/pull/7955 will finally be pulled by the time we have to worry about this. | 1.0 | Bug: Dimensions have a static seed at the moment. - This is a Minecraft issue that may need to be fixed either through a Mixin or just not using the json system (which we might be doing in 1.18 anyways). Either that or maybe https://github.com/MinecraftForge/MinecraftForge/pull/7955 will finally be pulled by the time we have to worry about this. | priority | bug dimensions have a static seed at the moment this is a minecraft issue that may need to be fixed either through a mixin or just not using the json system which we might be doing in anyways either that or maybe will finally be pulled by the time we have to worry about this | 1 |
345,741 | 10,372,369,198 | IssuesEvent | 2019-09-09 02:41:06 | malcolmjc/Stat-Tracking-App | https://api.github.com/repos/malcolmjc/Stat-Tracking-App | closed | Add member to group | Backend Frontend High Priority | As a user, I would like to be able to invite other users to join my group. | 1.0 | Add member to group - As a user, I would like to be able to invite other users to join my group. | priority | add member to group as a user i would like to be able to invite other users to join my group | 1 |
350,312 | 10,482,052,488 | IssuesEvent | 2019-09-24 11:03:24 | WoWManiaUK/Blackwing-Lair | https://api.github.com/repos/WoWManiaUK/Blackwing-Lair | closed | [Unholy DK] - [Raise Dead] (issue 2) - ID : 46584 | Class Fixed in Dev Priority-High | **Links:**
https://www.wowhead.com/spell=46584/raise-dead
from WoWHead or our Armory
**What is happening:**
Ghoul (pet) randomly disappears after summon (cant get new one for 2 minutes then) , dies in every aoe stops moving or cant handle ground heigth difference.
I noticed that the ghoul always change the name after summon a new one this should not happen. after you spec to unholy you always should summon the same ghoul with
**What should happen:**
Pet should not disappear at any time.
Pet should get high Damage Reduction for every AOE Damage. Avoidance? aroun 80-99% idk
| 1.0 | [Unholy DK] - [Raise Dead] (issue 2) - ID : 46584 - **Links:**
https://www.wowhead.com/spell=46584/raise-dead
from WoWHead or our Armory
**What is happening:**
Ghoul (pet) randomly disappears after summon (cant get new one for 2 minutes then) , dies in every aoe stops moving or cant handle ground heigth difference.
I noticed that the ghoul always change the name after summon a new one this should not happen. after you spec to unholy you always should summon the same ghoul with
**What should happen:**
Pet should not disappear at any time.
Pet should get high Damage Reduction for every AOE Damage. Avoidance? aroun 80-99% idk
| priority | issue id links from wowhead or our armory what is happening ghoul pet randomly disappears after summon cant get new one for minutes then dies in every aoe stops moving or cant handle ground heigth difference i noticed that the ghoul always change the name after summon a new one this should not happen after you spec to unholy you always should summon the same ghoul with what should happen pet should not disappear at any time pet should get high damage reduction for every aoe damage avoidance aroun idk | 1 |
493,488 | 14,233,488,121 | IssuesEvent | 2020-11-18 12:14:22 | onaio/rdt-standard | https://api.github.com/repos/onaio/rdt-standard | closed | Translation issues | Android Client Priority - high bug covid response | Translation issues
a) The gender is captured in English on the Clients register page(Home page)
b) error message when submiting forms and some fields are not filled in is in English (e.g Please correct the error(s) in the form to proceed)
c) The form that extends for Contact details is in English | 1.0 | Translation issues - Translation issues
a) The gender is captured in English on the Clients register page(Home page)
b) error message when submiting forms and some fields are not filled in is in English (e.g Please correct the error(s) in the form to proceed)
c) The form that extends for Contact details is in English | priority | translation issues translation issues a the gender is captured in english on the clients register page home page b error message when submiting forms and some fields are not filled in is in english e g please correct the error s in the form to proceed c the form that extends for contact details is in english | 1 |
346,852 | 10,420,797,573 | IssuesEvent | 2019-09-16 02:46:42 | AY1920S1-CS2113T-W17-2/main | https://api.github.com/repos/AY1920S1-CS2113T-W17-2/main | opened | As a user, I can set category expenses so that I know which category have i spent my most money on. | priority.High type.Story | Expenses feature - Add categories | 1.0 | As a user, I can set category expenses so that I know which category have i spent my most money on. - Expenses feature - Add categories | priority | as a user i can set category expenses so that i know which category have i spent my most money on expenses feature add categories | 1 |
126,946 | 5,008,035,563 | IssuesEvent | 2016-12-12 18:22:18 | GluuFederation/gluu-Asimba | https://api.github.com/repos/GluuFederation/gluu-Asimba | closed | Asimba - OpenLDAP exception | bug High Priority | (ASIMBAWA) [2016-12-04 18:43:58] [ERROR] LDAPUtility cannot open LdapEntryManager
java.lang.NullPointerException
at org.gluu.asimba.util.ldap.LDAPUtility.getLDAPEntryManager(LDAPUtility.java:148)
at org.gluu.asimba.util.ldap.LDAPUtility.getLDAPEntryManagerSafe(LDAPUtility.java:172)
at org.gluu.asimba.util.ldap.LDAPUtility.<clinit>(LDAPUtility.java:83)
at com.alfaariss.oa.util.saml2.SAML2RequestorsLDAP.<init>(SAML2RequestorsLDAP.java:73)
at com.alfaariss.oa.profile.saml2.SAML2Profile.init(SAML2Profile.java:204)
at com.alfaariss.oa.OAServlet.loadProfiles(OAServlet.java:389)
at com.alfaariss.oa.OAServlet.start(OAServlet.java:136)
at com.alfaariss.oa.OAServlet.init(OAServlet.java:100)
(ASIMBAWA) [2016-12-04 18:43:58] [ERROR] LDAPUtility com.alfaariss.oa.OAException: 0011
(ASIMBAWA) [2016-12-04 18:43:58] [ERROR] LDAPUtility Failed to load AsimbaConfiguration from LDAP Appliance
java.lang.NullPointerException
at org.gluu.asimba.util.ldap.LDAPUtility.loadAsimbaConfiguration(LDAPUtility.java:181)
at org.gluu.asimba.util.ldap.LDAPUtility.getDnForAsimbaData(LDAPUtility.java:324)
at org.gluu.asimba.util.ldap.LDAPUtility.getDnForLDAPRequestorEntry(LDAPUtility.java:296)
at org.gluu.asimba.util.ldap.LDAPUtility.loadRequestors(LDAPUtility.java:217)
at com.alfaariss.oa.util.saml2.SAML2RequestorsLDAP.<init>(SAML2RequestorsLDAP.java:73)
at com.alfaariss.oa.profile.saml2.SAML2Profile.init(SAML2Profile.java:204)
at com.alfaariss.oa.OAServlet.loadProfiles(OAServlet.java:389)
at com.alfaariss.oa.OAServlet.start(OAServlet.java:136)
at com.alfaariss.oa.OAServlet.init(OAServlet.java:100)
| 1.0 | Asimba - OpenLDAP exception - (ASIMBAWA) [2016-12-04 18:43:58] [ERROR] LDAPUtility cannot open LdapEntryManager
java.lang.NullPointerException
at org.gluu.asimba.util.ldap.LDAPUtility.getLDAPEntryManager(LDAPUtility.java:148)
at org.gluu.asimba.util.ldap.LDAPUtility.getLDAPEntryManagerSafe(LDAPUtility.java:172)
at org.gluu.asimba.util.ldap.LDAPUtility.<clinit>(LDAPUtility.java:83)
at com.alfaariss.oa.util.saml2.SAML2RequestorsLDAP.<init>(SAML2RequestorsLDAP.java:73)
at com.alfaariss.oa.profile.saml2.SAML2Profile.init(SAML2Profile.java:204)
at com.alfaariss.oa.OAServlet.loadProfiles(OAServlet.java:389)
at com.alfaariss.oa.OAServlet.start(OAServlet.java:136)
at com.alfaariss.oa.OAServlet.init(OAServlet.java:100)
(ASIMBAWA) [2016-12-04 18:43:58] [ERROR] LDAPUtility com.alfaariss.oa.OAException: 0011
(ASIMBAWA) [2016-12-04 18:43:58] [ERROR] LDAPUtility Failed to load AsimbaConfiguration from LDAP Appliance
java.lang.NullPointerException
at org.gluu.asimba.util.ldap.LDAPUtility.loadAsimbaConfiguration(LDAPUtility.java:181)
at org.gluu.asimba.util.ldap.LDAPUtility.getDnForAsimbaData(LDAPUtility.java:324)
at org.gluu.asimba.util.ldap.LDAPUtility.getDnForLDAPRequestorEntry(LDAPUtility.java:296)
at org.gluu.asimba.util.ldap.LDAPUtility.loadRequestors(LDAPUtility.java:217)
at com.alfaariss.oa.util.saml2.SAML2RequestorsLDAP.<init>(SAML2RequestorsLDAP.java:73)
at com.alfaariss.oa.profile.saml2.SAML2Profile.init(SAML2Profile.java:204)
at com.alfaariss.oa.OAServlet.loadProfiles(OAServlet.java:389)
at com.alfaariss.oa.OAServlet.start(OAServlet.java:136)
at com.alfaariss.oa.OAServlet.init(OAServlet.java:100)
| priority | asimba openldap exception asimbawa ldaputility cannot open ldapentrymanager java lang nullpointerexception at org gluu asimba util ldap ldaputility getldapentrymanager ldaputility java at org gluu asimba util ldap ldaputility getldapentrymanagersafe ldaputility java at org gluu asimba util ldap ldaputility ldaputility java at com alfaariss oa util java at com alfaariss oa profile init java at com alfaariss oa oaservlet loadprofiles oaservlet java at com alfaariss oa oaservlet start oaservlet java at com alfaariss oa oaservlet init oaservlet java asimbawa ldaputility com alfaariss oa oaexception asimbawa ldaputility failed to load asimbaconfiguration from ldap appliance java lang nullpointerexception at org gluu asimba util ldap ldaputility loadasimbaconfiguration ldaputility java at org gluu asimba util ldap ldaputility getdnforasimbadata ldaputility java at org gluu asimba util ldap ldaputility getdnforldaprequestorentry ldaputility java at org gluu asimba util ldap ldaputility loadrequestors ldaputility java at com alfaariss oa util java at com alfaariss oa profile init java at com alfaariss oa oaservlet loadprofiles oaservlet java at com alfaariss oa oaservlet start oaservlet java at com alfaariss oa oaservlet init oaservlet java | 1 |
176,457 | 6,559,796,414 | IssuesEvent | 2017-09-07 06:32:28 | swift-xcode/xcodeproj | https://api.github.com/repos/swift-xcode/xcodeproj | closed | Wrong comment in the PBXSourcesBuildPhase.files property | difficulty:easy priority:high status:ready-development type:bug | ## Context
Wrong comment in the `PBXSourcesBuildPhase.files` property
## What

## Proposal
Fix it! | 1.0 | Wrong comment in the PBXSourcesBuildPhase.files property - ## Context
Wrong comment in the `PBXSourcesBuildPhase.files` property
## What

## Proposal
Fix it! | priority | wrong comment in the pbxsourcesbuildphase files property context wrong comment in the pbxsourcesbuildphase files property what proposal fix it | 1 |
588,609 | 17,663,269,043 | IssuesEvent | 2021-08-22 00:13:08 | elmastudio/aino-theme | https://api.github.com/repos/elmastudio/aino-theme | opened | Enhancement: Pagination styling | [Type] Enhancement [Priority] High CSS | Pagination should be styled, see sketch:
<img width="843" alt="Screen Shot 2021-08-22 at 12 12 26 PM" src="https://user-images.githubusercontent.com/17613630/130337882-2a304835-6afd-4fd7-9b7a-b39e9a636b53.png">
| 1.0 | Enhancement: Pagination styling - Pagination should be styled, see sketch:
<img width="843" alt="Screen Shot 2021-08-22 at 12 12 26 PM" src="https://user-images.githubusercontent.com/17613630/130337882-2a304835-6afd-4fd7-9b7a-b39e9a636b53.png">
| priority | enhancement pagination styling pagination should be styled see sketch img width alt screen shot at pm src | 1 |
236,815 | 7,752,986,874 | IssuesEvent | 2018-05-30 22:15:36 | python/mypy | https://api.github.com/repos/python/mypy | closed | Crash with async generator and disallow_untyped_defs | crash priority-0-high | On this file:
```python
from typing import AsyncGenerator, Awaitable, Callable, Any
import asyncio
async def f() -> AsyncGenerator[int, None]:
yield 3
await asyncio.sleep(1)
```
I get:
```
$ mypy --show-traceback --disallow-untyped-defs bin/asyncg.py
bin/asyncg.py:4: error: INTERNAL ERROR -- please report a bug at https://github.com/python/mypy/issues version: 0.610+dev-c29210ea2f79f4017ec68435b5674d56e87c5105
Traceback (most recent call last):
File "/Users/jzijlstra-mpbt/py/venvs/venv36/bin/mypy", line 11, in <module>
load_entry_point('mypy', 'console_scripts', 'mypy')()
File "/Users/jzijlstra-mpbt/py/mypy/mypy/__main__.py", line 7, in console_entry
main(None)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/main.py", line 91, in main
res = type_check_only(sources, bin_dir, options, flush_errors, fscache) # noqa
File "/Users/jzijlstra-mpbt/py/mypy/mypy/main.py", line 148, in type_check_only
fscache=fscache)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 185, in build
flush_errors, fscache)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 285, in _build
graph = dispatch(sources, manager)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 2398, in dispatch
process_graph(graph, manager)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 2691, in process_graph
process_stale_scc(graph, scc, manager)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 2807, in process_stale_scc
graph[id].type_check_first_pass()
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 2029, in type_check_first_pass
self.type_checker().check_first_pass()
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 252, in check_first_pass
self.accept(d)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 351, in accept
stmt.accept(self)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/nodes.py", line 586, in accept
return visitor.visit_func_def(self)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 654, in visit_func_def
self._visit_func_def(defn)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 658, in _visit_func_def
self.check_func_item(defn, name=defn.name())
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 720, in check_func_item
self.check_func_def(defn, typ, name)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 755, in check_func_def
self.check_for_missing_annotations(fdef)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 933, in check_for_missing_annotations
is_unannotated_any(self.get_coroutine_return_type(ret_type))):
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 626, in get_coroutine_return_type
return return_type.args[2]
IndexError: list index out of range
bin/asyncg.py:4: : note: use --pdb to drop into pdb
```
If nobody else gets to it first, I can look into fixing this within the next few days. | 1.0 | Crash with async generator and disallow_untyped_defs - On this file:
```python
from typing import AsyncGenerator, Awaitable, Callable, Any
import asyncio
async def f() -> AsyncGenerator[int, None]:
yield 3
await asyncio.sleep(1)
```
I get:
```
$ mypy --show-traceback --disallow-untyped-defs bin/asyncg.py
bin/asyncg.py:4: error: INTERNAL ERROR -- please report a bug at https://github.com/python/mypy/issues version: 0.610+dev-c29210ea2f79f4017ec68435b5674d56e87c5105
Traceback (most recent call last):
File "/Users/jzijlstra-mpbt/py/venvs/venv36/bin/mypy", line 11, in <module>
load_entry_point('mypy', 'console_scripts', 'mypy')()
File "/Users/jzijlstra-mpbt/py/mypy/mypy/__main__.py", line 7, in console_entry
main(None)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/main.py", line 91, in main
res = type_check_only(sources, bin_dir, options, flush_errors, fscache) # noqa
File "/Users/jzijlstra-mpbt/py/mypy/mypy/main.py", line 148, in type_check_only
fscache=fscache)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 185, in build
flush_errors, fscache)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 285, in _build
graph = dispatch(sources, manager)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 2398, in dispatch
process_graph(graph, manager)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 2691, in process_graph
process_stale_scc(graph, scc, manager)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 2807, in process_stale_scc
graph[id].type_check_first_pass()
File "/Users/jzijlstra-mpbt/py/mypy/mypy/build.py", line 2029, in type_check_first_pass
self.type_checker().check_first_pass()
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 252, in check_first_pass
self.accept(d)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 351, in accept
stmt.accept(self)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/nodes.py", line 586, in accept
return visitor.visit_func_def(self)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 654, in visit_func_def
self._visit_func_def(defn)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 658, in _visit_func_def
self.check_func_item(defn, name=defn.name())
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 720, in check_func_item
self.check_func_def(defn, typ, name)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 755, in check_func_def
self.check_for_missing_annotations(fdef)
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 933, in check_for_missing_annotations
is_unannotated_any(self.get_coroutine_return_type(ret_type))):
File "/Users/jzijlstra-mpbt/py/mypy/mypy/checker.py", line 626, in get_coroutine_return_type
return return_type.args[2]
IndexError: list index out of range
bin/asyncg.py:4: : note: use --pdb to drop into pdb
```
If nobody else gets to it first, I can look into fixing this within the next few days. | priority | crash with async generator and disallow untyped defs on this file python from typing import asyncgenerator awaitable callable any import asyncio async def f asyncgenerator yield await asyncio sleep i get mypy show traceback disallow untyped defs bin asyncg py bin asyncg py error internal error please report a bug at version dev traceback most recent call last file users jzijlstra mpbt py venvs bin mypy line in load entry point mypy console scripts mypy file users jzijlstra mpbt py mypy mypy main py line in console entry main none file users jzijlstra mpbt py mypy mypy main py line in main res type check only sources bin dir options flush errors fscache noqa file users jzijlstra mpbt py mypy mypy main py line in type check only fscache fscache file users jzijlstra mpbt py mypy mypy build py line in build flush errors fscache file users jzijlstra mpbt py mypy mypy build py line in build graph dispatch sources manager file users jzijlstra mpbt py mypy mypy build py line in dispatch process graph graph manager file users jzijlstra mpbt py mypy mypy build py line in process graph process stale scc graph scc manager file users jzijlstra mpbt py mypy mypy build py line in process stale scc graph type check first pass file users jzijlstra mpbt py mypy mypy build py line in type check first pass self type checker check first pass file users jzijlstra mpbt py mypy mypy checker py line in check first pass self accept d file users jzijlstra mpbt py mypy mypy checker py line in accept stmt accept self file users jzijlstra mpbt py mypy mypy nodes py line in accept return visitor visit func def self file users jzijlstra mpbt py mypy mypy checker py line in visit func def self visit func def defn file users jzijlstra mpbt py mypy mypy checker py line in visit func def self check func item defn name defn name file users jzijlstra mpbt py mypy mypy checker py line in check func item self check func def defn typ name file users jzijlstra mpbt py mypy mypy checker py line in check func def self check for missing annotations fdef file users jzijlstra mpbt py mypy mypy checker py line in check for missing annotations is unannotated any self get coroutine return type ret type file users jzijlstra mpbt py mypy mypy checker py line in get coroutine return type return return type args indexerror list index out of range bin asyncg py note use pdb to drop into pdb if nobody else gets to it first i can look into fixing this within the next few days | 1 |
191,972 | 6,845,177,180 | IssuesEvent | 2017-11-13 06:51:56 | colloquy/colloquy | https://api.github.com/repos/colloquy/colloquy | closed | slow to connect to network and slower to connect to channel(undernet) | Affected: Mac 2.3 Component: Mac-Old Impact: Medium Priority: High Type: Bug | *Issue migrated from trac ticket [#2522](http://colloquy.info/project/ticket/2522)*
**type:** Defect | **component:** Colloquy (Mac) | **severity:** Normal | **priority:** High | **version:** 2.3 (Mac) | **status:** new
___
#### 2011-01-23 09:50:35: rans0m@… created the issue
Hi,
I installed and set up undernet and a autojoin on a channel. it took about 5+ minutes to get on the network, and another 15+ minutes to actually get on the channel. This is on my ipod touch. I can connect with other clients instantly, so I do not understand why this might happen. It appears to be kinda useless like this, but I cant find any other settings that might help.
Thanks
| 1.0 | slow to connect to network and slower to connect to channel(undernet) - *Issue migrated from trac ticket [#2522](http://colloquy.info/project/ticket/2522)*
**type:** Defect | **component:** Colloquy (Mac) | **severity:** Normal | **priority:** High | **version:** 2.3 (Mac) | **status:** new
___
#### 2011-01-23 09:50:35: rans0m@… created the issue
Hi,
I installed and set up undernet and a autojoin on a channel. it took about 5+ minutes to get on the network, and another 15+ minutes to actually get on the channel. This is on my ipod touch. I can connect with other clients instantly, so I do not understand why this might happen. It appears to be kinda useless like this, but I cant find any other settings that might help.
Thanks
| priority | slow to connect to network and slower to connect to channel undernet issue migrated from trac ticket type defect component colloquy mac severity normal priority high version mac status new … created the issue hi i installed and set up undernet and a autojoin on a channel it took about minutes to get on the network and another minutes to actually get on the channel this is on my ipod touch i can connect with other clients instantly so i do not understand why this might happen it appears to be kinda useless like this but i cant find any other settings that might help thanks | 1 |
589,530 | 17,703,754,839 | IssuesEvent | 2021-08-25 03:44:08 | yameatmeyourdead/CSMMateROVJetson | https://api.github.com/repos/yameatmeyourdead/CSMMateROVJetson | closed | Code Beta PID Loop for Depth Control | enhancement High Priority | Create PID Loop that takes data from pressure sensor and 3 axis Gyro/Accelerometer and control depth with it | 1.0 | Code Beta PID Loop for Depth Control - Create PID Loop that takes data from pressure sensor and 3 axis Gyro/Accelerometer and control depth with it | priority | code beta pid loop for depth control create pid loop that takes data from pressure sensor and axis gyro accelerometer and control depth with it | 1 |
663,355 | 22,174,446,435 | IssuesEvent | 2022-06-06 06:44:22 | YangCatalog/backend | https://api.github.com/repos/YangCatalog/backend | closed | Fix user reminder webex message | Priority: High maintenance | The message sent to the Webex was HTML formatted and Webex doesn't render HTML correctly. Generate the email message as HTML and the Webex message as markdown separately. | 1.0 | Fix user reminder webex message - The message sent to the Webex was HTML formatted and Webex doesn't render HTML correctly. Generate the email message as HTML and the Webex message as markdown separately. | priority | fix user reminder webex message the message sent to the webex was html formatted and webex doesn t render html correctly generate the email message as html and the webex message as markdown separately | 1 |
806,385 | 29,819,791,507 | IssuesEvent | 2023-06-17 00:10:54 | cBotFoundation/cBot.ts | https://api.github.com/repos/cBotFoundation/cBot.ts | closed | Fix action rows on discord | bug core high-priority | - [ ] Verify the deffer call on the discord reply to add buttons
- [ ] Avoid conditions that break the flow (` if (message.actions.length == 0) return`) this might cause problems.
- [ ] Verify object structure when creating the final product of the UI | 1.0 | Fix action rows on discord - - [ ] Verify the deffer call on the discord reply to add buttons
- [ ] Avoid conditions that break the flow (` if (message.actions.length == 0) return`) this might cause problems.
- [ ] Verify object structure when creating the final product of the UI | priority | fix action rows on discord verify the deffer call on the discord reply to add buttons avoid conditions that break the flow if message actions length return this might cause problems verify object structure when creating the final product of the ui | 1 |
616,344 | 19,299,932,076 | IssuesEvent | 2021-12-13 03:17:17 | OiivaeCommunity/ovicommunity | https://api.github.com/repos/OiivaeCommunity/ovicommunity | closed | Network Redo | Approved Server Issue RP Server HCMC Server High Priority | Take network offline for reconfiguration so cats can no longer knock it offline easily | 1.0 | Network Redo - Take network offline for reconfiguration so cats can no longer knock it offline easily | priority | network redo take network offline for reconfiguration so cats can no longer knock it offline easily | 1 |
288,875 | 8,852,573,150 | IssuesEvent | 2019-01-08 18:44:37 | visit-dav/issues-test | https://api.github.com/repos/visit-dav/issues-test | closed | Scatter plot hangs when using color var. | asc bug crash likelihood medium priority reviewed severity high wrong results | In parallel if there are more processors than chunks to process - a common case when material selection is used.
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. As such, not all
information was able to be captured in the transition. Below is
a complete record of the original redmine ticket.
Ticket number: 348
Status: Resolved
Project: VisIt
Tracker: Bug
Priority: Urgent
Subject: Scatter plot hangs when using color var.
Assigned to: Cyrus Harrison
Category: -
Target version: 2.1
Author: Cyrus Harrison
Start: 08/17/2010
Due date:
% Done: 0%
Estimated time:
Created: 08/17/2010 02:50 pm
Updated: 08/17/2010 05:23 pm
Likelihood: 3 - Occasional
Severity: 4 - Crash / Wrong Results
Found in version: 2.0.2
Impact:
Expected Use:
OS: All
Support Group: DOE/ASC
Description:
In parallel if there are more processors than chunks to process - a common case when material selection is used.
Comments:
Hi Everyone,This commmit fixes two parallel related issues with the scatter plot:1) Creating a colored scatter plot when you had more procs than chunks(domains) to process (say after a material selection) would cause an invalid merge exception & a parallel hang. (This resolves #348)2) Spatial extents were invalid when there are were more procs than chunks to process.Sending Scatter/avtScatterFilter.CSending Scatter/avtScatterFilter.hTransmitting file data ..Committed revision r12249.-Cyrus
| 1.0 | Scatter plot hangs when using color var. - In parallel if there are more processors than chunks to process - a common case when material selection is used.
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. As such, not all
information was able to be captured in the transition. Below is
a complete record of the original redmine ticket.
Ticket number: 348
Status: Resolved
Project: VisIt
Tracker: Bug
Priority: Urgent
Subject: Scatter plot hangs when using color var.
Assigned to: Cyrus Harrison
Category: -
Target version: 2.1
Author: Cyrus Harrison
Start: 08/17/2010
Due date:
% Done: 0%
Estimated time:
Created: 08/17/2010 02:50 pm
Updated: 08/17/2010 05:23 pm
Likelihood: 3 - Occasional
Severity: 4 - Crash / Wrong Results
Found in version: 2.0.2
Impact:
Expected Use:
OS: All
Support Group: DOE/ASC
Description:
In parallel if there are more processors than chunks to process - a common case when material selection is used.
Comments:
Hi Everyone,This commmit fixes two parallel related issues with the scatter plot:1) Creating a colored scatter plot when you had more procs than chunks(domains) to process (say after a material selection) would cause an invalid merge exception & a parallel hang. (This resolves #348)2) Spatial extents were invalid when there are were more procs than chunks to process.Sending Scatter/avtScatterFilter.CSending Scatter/avtScatterFilter.hTransmitting file data ..Committed revision r12249.-Cyrus
| priority | scatter plot hangs when using color var in parallel if there are more processors than chunks to process a common case when material selection is used redmine migration this ticket was migrated from redmine as such not all information was able to be captured in the transition below is a complete record of the original redmine ticket ticket number status resolved project visit tracker bug priority urgent subject scatter plot hangs when using color var assigned to cyrus harrison category target version author cyrus harrison start due date done estimated time created pm updated pm likelihood occasional severity crash wrong results found in version impact expected use os all support group doe asc description in parallel if there are more processors than chunks to process a common case when material selection is used comments hi everyone this commmit fixes two parallel related issues with the scatter plot creating a colored scatter plot when you had more procs than chunks domains to process say after a material selection would cause an invalid merge exception a parallel hang this resolves spatial extents were invalid when there are were more procs than chunks to process sending scatter avtscatterfilter csending scatter avtscatterfilter htransmitting file data committed revision cyrus | 1 |
353,650 | 10,555,472,459 | IssuesEvent | 2019-10-03 21:59:01 | intakedesk/PowerBI-General | https://api.github.com/repos/intakedesk/PowerBI-General | closed | HK: Contracts Missing in Firms Reports Create Exception Report | high-priority task | Created new tab on `ContractsCoCounsels.xlsx` file that lives on Sharepoint, called **REPORTS EXCEPTION**.
Exception tab not compatible with Tort-Firm tabs (M.Stanisci, Fears, MTN)
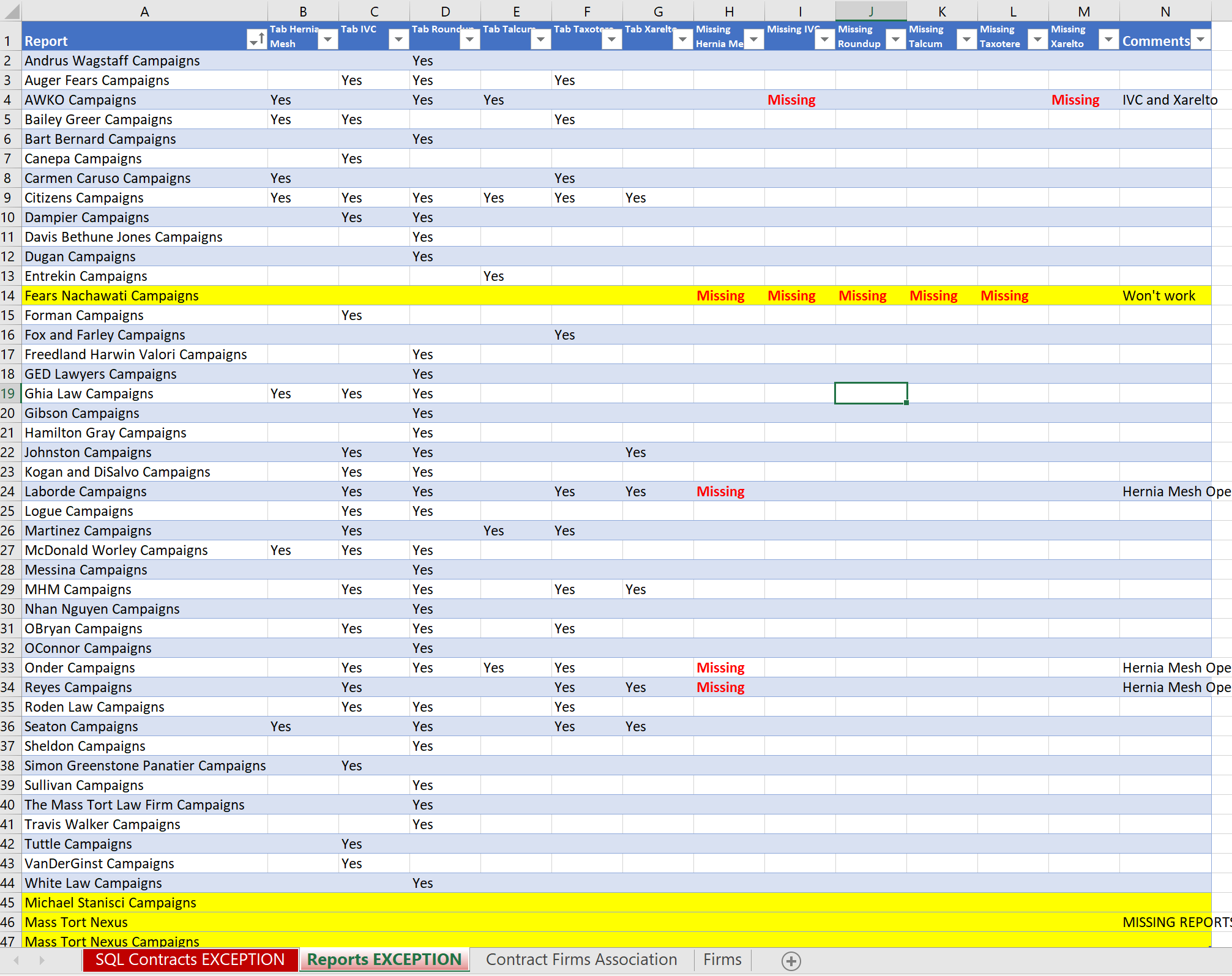
| 1.0 | HK: Contracts Missing in Firms Reports Create Exception Report - Created new tab on `ContractsCoCounsels.xlsx` file that lives on Sharepoint, called **REPORTS EXCEPTION**.
Exception tab not compatible with Tort-Firm tabs (M.Stanisci, Fears, MTN)

| priority | hk contracts missing in firms reports create exception report created new tab on contractscocounsels xlsx file that lives on sharepoint called reports exception exception tab not compatible with tort firm tabs m stanisci fears mtn | 1 |
141,137 | 5,429,797,790 | IssuesEvent | 2017-03-03 19:24:36 | redhat-ipaas/ipaas-ui | https://api.github.com/repos/redhat-ipaas/ipaas-ui | opened | Create an Integration: Choose an Action | high priority major component | ## Overview
Add the ability to choose an action when creating an Integration in the UI. Entails the following:
- Add HTML & SCSS to reflect designs & incorporate logic.
- Add method(s) called by HTML for locally storing the action in preparation of API POST request upon creating the Integration in its respective component.
- *Maybe? Add logic to communicate with internal data store and SSE/Websocket for bi-directional model synchronization (and to initiate notifications).*
### Relevant Designs
N/A
## Reference
- [GitHub: Create an Integration Issue]()
- [Design: Create an Integration]()
- [Design: Create an Integration: Choose an Action]()
- [JIRA: UI Issue]()
- [JIRA: REST API Issue]()
- [JIRA: User Story]() | 1.0 | Create an Integration: Choose an Action - ## Overview
Add the ability to choose an action when creating an Integration in the UI. Entails the following:
- Add HTML & SCSS to reflect designs & incorporate logic.
- Add method(s) called by HTML for locally storing the action in preparation of API POST request upon creating the Integration in its respective component.
- *Maybe? Add logic to communicate with internal data store and SSE/Websocket for bi-directional model synchronization (and to initiate notifications).*
### Relevant Designs
N/A
## Reference
- [GitHub: Create an Integration Issue]()
- [Design: Create an Integration]()
- [Design: Create an Integration: Choose an Action]()
- [JIRA: UI Issue]()
- [JIRA: REST API Issue]()
- [JIRA: User Story]() | priority | create an integration choose an action overview add the ability to choose an action when creating an integration in the ui entails the following add html scss to reflect designs incorporate logic add method s called by html for locally storing the action in preparation of api post request upon creating the integration in its respective component maybe add logic to communicate with internal data store and sse websocket for bi directional model synchronization and to initiate notifications relevant designs n a reference | 1 |
706,349 | 24,266,685,081 | IssuesEvent | 2022-09-28 06:58:00 | kubesphere/kubesphere | https://api.github.com/repos/kubesphere/kubesphere | reopened | The cluster role 'cluster-admin' and 'cluster-viewer' have no entry to cluster and resource consumption. | kind/bug priority/high | **Describe the Bug**
When a user does not have the cluster permission of the platform but is `invited to a cluster`, the user should be able to view the information of the cluster and be able to view the resource consumption information of this cluster.
**Versions Used**
KubeSphere: `v3.3.1-rc.2`
**Expected behavior **
1. Add entry of cluster `Platform/Cluster Management`
2. Add entry of resource consumption in `Toolbox`
| 1.0 | The cluster role 'cluster-admin' and 'cluster-viewer' have no entry to cluster and resource consumption. - **Describe the Bug**
When a user does not have the cluster permission of the platform but is `invited to a cluster`, the user should be able to view the information of the cluster and be able to view the resource consumption information of this cluster.


**Versions Used**
KubeSphere: `v3.3.1-rc.2`
**Expected behavior **
1. Add entry of cluster `Platform/Cluster Management`
2. Add entry of resource consumption in `Toolbox`
| priority | the cluster role cluster admin and cluster viewer have no entry to cluster and resource consumption describe the bug when a user does not have the cluster permission of the platform but is invited to a cluster the user should be able to view the information of the cluster and be able to view the resource consumption information of this cluster versions used kubesphere rc expected behavior add entry of cluster platform cluster management add entry of resource consumption in toolbox | 1 |
537,483 | 15,729,662,860 | IssuesEvent | 2021-03-29 15:05:17 | UnderVolt/chocomint | https://api.github.com/repos/UnderVolt/chocomint | closed | GameBar special buttons won't work on GuiIngameMenu | area:menu priority:high type:UX | Click events coming from GameBar elements are not registered in GuiIngameMenu
This affects **every** branch. | 1.0 | GameBar special buttons won't work on GuiIngameMenu - Click events coming from GameBar elements are not registered in GuiIngameMenu
This affects **every** branch. | priority | gamebar special buttons won t work on guiingamemenu click events coming from gamebar elements are not registered in guiingamemenu this affects every branch | 1 |
347,445 | 10,430,168,247 | IssuesEvent | 2019-09-17 05:53:14 | ahmedkaludi/accelerated-mobile-pages | https://api.github.com/repos/ahmedkaludi/accelerated-mobile-pages | closed | Need to shift the Header Background Option and Header Elements option on top in Swift theme | NEXT UPDATE [Priority: HIGH] enhancement | Screenshot: https://monosnap.com/file/irNEC1If7cSuwLkEa3JngOucxi6f6R
We need to shift the options of Header Background and Header Elements on top in Swift theme. | 1.0 | Need to shift the Header Background Option and Header Elements option on top in Swift theme - Screenshot: https://monosnap.com/file/irNEC1If7cSuwLkEa3JngOucxi6f6R
We need to shift the options of Header Background and Header Elements on top in Swift theme. | priority | need to shift the header background option and header elements option on top in swift theme screenshot we need to shift the options of header background and header elements on top in swift theme | 1 |
146,907 | 5,630,395,738 | IssuesEvent | 2017-04-05 12:09:50 | hhu-bsinfo/dxram | https://api.github.com/repos/hhu-bsinfo/dxram | closed | ChunkRemoveService: Fix sending request from message handler on chunk remove | bug high priority | ChunkService:
If a remove message arrives from a remote node, the message handler has to send a request to the superpeer overlay to remove the chunk from the b-tree. However, the response to that request cannot be processed because it requires another message handler. If the message handler count is set to 1, no handler is available and the request will always fail.
Solution:
Put remove operations as "jobs" (not related to the job system) into a queue and handle them by a separate remove thread (-> separate service: ChunkRemoveService). On incoming remove messages, just put a job into the queue and return. The job gets processed by the dedicated remove thread to avoid sending the request in a message handler and blocking it
| 1.0 | ChunkRemoveService: Fix sending request from message handler on chunk remove - ChunkService:
If a remove message arrives from a remote node, the message handler has to send a request to the superpeer overlay to remove the chunk from the b-tree. However, the response to that request cannot be processed because it requires another message handler. If the message handler count is set to 1, no handler is available and the request will always fail.
Solution:
Put remove operations as "jobs" (not related to the job system) into a queue and handle them by a separate remove thread (-> separate service: ChunkRemoveService). On incoming remove messages, just put a job into the queue and return. The job gets processed by the dedicated remove thread to avoid sending the request in a message handler and blocking it
| priority | chunkremoveservice fix sending request from message handler on chunk remove chunkservice if a remove message arrives from a remote node the message handler has to send a request to the superpeer overlay to remove the chunk from the b tree however the response to that request cannot be processed because it requires another message handler if the message handler count is set to no handler is available and the request will always fail solution put remove operations as jobs not related to the job system into a queue and handle them by a separate remove thread separate service chunkremoveservice on incoming remove messages just put a job into the queue and return the job gets processed by the dedicated remove thread to avoid sending the request in a message handler and blocking it | 1 |
516,783 | 14,987,830,593 | IssuesEvent | 2021-01-28 23:46:43 | Phildesro123/Reliant | https://api.github.com/repos/Phildesro123/Reliant | opened | Create Component for Author Score | Priority: High Status: Available help wanted | 
We need to create a component for the background info and author score, similar to the one seen in the prototype.
- [ ] Create new component that will activate when we click on extension Icon
- [ ] Optional: Test to see if we can extract some information from a test page
| 1.0 | Create Component for Author Score - 
We need to create a component for the background info and author score, similar to the one seen in the prototype.
- [ ] Create new component that will activate when we click on extension Icon
- [ ] Optional: Test to see if we can extract some information from a test page
| priority | create component for author score we need to create a component for the background info and author score similar to the one seen in the prototype create new component that will activate when we click on extension icon optional test to see if we can extract some information from a test page | 1 |
612,737 | 19,030,108,883 | IssuesEvent | 2021-11-24 09:47:01 | webksde/ddev-vscode-devcontainer-drupal9-template | https://api.github.com/repos/webksde/ddev-vscode-devcontainer-drupal9-template | closed | On drowl-init (&-from...) first check if a .git folder exists and ask to delete it | priority-high | We should ensure the .git repository from this repo is deleted before we initialize a project.
So check if a .git folder exists when running drowl-init[-...] and ask if the repository should be deleted (which is typically recommended to not commit into ddev-vscode-devcontainer-drupal9-template!) | 1.0 | On drowl-init (&-from...) first check if a .git folder exists and ask to delete it - We should ensure the .git repository from this repo is deleted before we initialize a project.
So check if a .git folder exists when running drowl-init[-...] and ask if the repository should be deleted (which is typically recommended to not commit into ddev-vscode-devcontainer-drupal9-template!) | priority | on drowl init from first check if a git folder exists and ask to delete it we should ensure the git repository from this repo is deleted before we initialize a project so check if a git folder exists when running drowl init and ask if the repository should be deleted which is typically recommended to not commit into ddev vscode devcontainer template | 1 |
773,874 | 27,174,355,331 | IssuesEvent | 2023-02-17 22:59:36 | Unity-Technologies/com.unity.netcode.gameobjects | https://api.github.com/repos/Unity-Technologies/com.unity.netcode.gameobjects | closed | Updating from 1.0.2 to 1.1.0 leads to different behaviour for in-scene placed NetworkObjects regarding initial scale and position. | type:bug stat:awaiting response priority:high stat:imported | ### Description
I've noticed a breaking change or bug regarding the initial syncing of in-scene places NetworkObjects that had either their position changed before a client connects, or which are in a hierarchy that contains scaled GameObjects.
Below is a link to a sample project which demonstrates this better than I can explain.
For both issues, the server starts on a bootstrap scene and then loads a SampleScene via the (Network)SceneManager.
The described setups are in the SampleScene.
1. Initial position sync for in-scene placed network objects:
Given the following scene setup:
- Parent Cube (No NetworkObject)
- Child Cube (NetworkObject)
They are stacked on each other somewhere in the scene. On Start(), the Parent Cube is moved from its original position to the desired one (0, 0.5, 0), such that the stack appears right in front of the respective players - Start() is executed on both client and server. This works fine on the connecting client in 1.0.2, but in 1.1.0 only the parent cube is being moved.
2. Initial scale sync for in-scene places network objects:
Given the following scene setup:
- Parent Cube (No NetworkObject)
- Scale Gameobject (No NetworkObject)
- Scaled Child Cube (NetworkObject)
This leads to a wrongly scaled Child Cube on the Client in 1.1.0.
### Reproduce Steps
1. Checkout the sample at https://github.com/VRGroupRWTH/netcode_issue
2. Start a second unity instance (ParrelSync is included)
3. Load Bootstrap scene on both
4. Start Server on one
5. Start Client on the other
6. Switch Netcode version
7. Restart Unity and repeat
### Actual Outcome
1. Only the Parent Cube is being moved on the client.
2. The Childcube has the wrong scale applied on the client.
3. Both are correct on the Host, and on 1.0.2 on the client as well.
### Expected Outcome
1.0.2 and 1.1.0 lead to the same result.
### Environment
- OS: Windows and Linux (Host, Server, Dedicated Server Build, all lead to the same)
- Unity Version: 2020.3
- Netcode Version: 1.1.0
### Additional Context
Minimal sample project is here: https://github.com/VRGroupRWTH/netcode_issue | 1.0 | Updating from 1.0.2 to 1.1.0 leads to different behaviour for in-scene placed NetworkObjects regarding initial scale and position. - ### Description
I've noticed a breaking change or bug regarding the initial syncing of in-scene places NetworkObjects that had either their position changed before a client connects, or which are in a hierarchy that contains scaled GameObjects.
Below is a link to a sample project which demonstrates this better than I can explain.
For both issues, the server starts on a bootstrap scene and then loads a SampleScene via the (Network)SceneManager.
The described setups are in the SampleScene.
1. Initial position sync for in-scene placed network objects:
Given the following scene setup:
- Parent Cube (No NetworkObject)
- Child Cube (NetworkObject)
They are stacked on each other somewhere in the scene. On Start(), the Parent Cube is moved from its original position to the desired one (0, 0.5, 0), such that the stack appears right in front of the respective players - Start() is executed on both client and server. This works fine on the connecting client in 1.0.2, but in 1.1.0 only the parent cube is being moved.
2. Initial scale sync for in-scene places network objects:
Given the following scene setup:
- Parent Cube (No NetworkObject)
- Scale Gameobject (No NetworkObject)
- Scaled Child Cube (NetworkObject)
This leads to a wrongly scaled Child Cube on the Client in 1.1.0.
### Reproduce Steps
1. Checkout the sample at https://github.com/VRGroupRWTH/netcode_issue
2. Start a second unity instance (ParrelSync is included)
3. Load Bootstrap scene on both
4. Start Server on one
5. Start Client on the other
6. Switch Netcode version
7. Restart Unity and repeat
### Actual Outcome
1. Only the Parent Cube is being moved on the client.
2. The Childcube has the wrong scale applied on the client.
3. Both are correct on the Host, and on 1.0.2 on the client as well.
### Expected Outcome
1.0.2 and 1.1.0 lead to the same result.
### Environment
- OS: Windows and Linux (Host, Server, Dedicated Server Build, all lead to the same)
- Unity Version: 2020.3
- Netcode Version: 1.1.0
### Additional Context
Minimal sample project is here: https://github.com/VRGroupRWTH/netcode_issue | priority | updating from to leads to different behaviour for in scene placed networkobjects regarding initial scale and position description i ve noticed a breaking change or bug regarding the initial syncing of in scene places networkobjects that had either their position changed before a client connects or which are in a hierarchy that contains scaled gameobjects below is a link to a sample project which demonstrates this better than i can explain for both issues the server starts on a bootstrap scene and then loads a samplescene via the network scenemanager the described setups are in the samplescene initial position sync for in scene placed network objects given the following scene setup parent cube no networkobject child cube networkobject they are stacked on each other somewhere in the scene on start the parent cube is moved from its original position to the desired one such that the stack appears right in front of the respective players start is executed on both client and server this works fine on the connecting client in but in only the parent cube is being moved initial scale sync for in scene places network objects given the following scene setup parent cube no networkobject scale gameobject no networkobject scaled child cube networkobject this leads to a wrongly scaled child cube on the client in reproduce steps checkout the sample at start a second unity instance parrelsync is included load bootstrap scene on both start server on one start client on the other switch netcode version restart unity and repeat actual outcome only the parent cube is being moved on the client the childcube has the wrong scale applied on the client both are correct on the host and on on the client as well expected outcome and lead to the same result environment os windows and linux host server dedicated server build all lead to the same unity version netcode version additional context minimal sample project is here | 1 |
280,435 | 8,681,762,241 | IssuesEvent | 2018-12-01 23:31:40 | Horyus/battlebird | https://api.github.com/repos/Horyus/battlebird | closed | [Browser] Create npm script test-browser | Priority: High Status: Pending Type: Enhancement | Create an NPM script that runs the current `jest` tests inside a browser env. | 1.0 | [Browser] Create npm script test-browser - Create an NPM script that runs the current `jest` tests inside a browser env. | priority | create npm script test browser create an npm script that runs the current jest tests inside a browser env | 1 |
628,683 | 20,010,678,026 | IssuesEvent | 2022-02-01 05:49:15 | PyxlMoose/PyxlMoose | https://api.github.com/repos/PyxlMoose/PyxlMoose | closed | [Bug] App crashes if user inputs '0' or any negative number as the span count value | 🐛 bug high priority | #### Describe the bug
If the user inputs '0' or any negative number as the span count value the app crashes.
#### To Reproduce
Steps to reproduce the behavior:
1. Open PyxlMoose
2. Create a new project
3. Specify '0' or any negative number as the span count
4. Observe the result
#### Expected behavior
The app should not crash - but rather show a `Snackbar` detailing the problem if the user inputs '0' or any negative number as the span count value. | 1.0 | [Bug] App crashes if user inputs '0' or any negative number as the span count value - #### Describe the bug
If the user inputs '0' or any negative number as the span count value the app crashes.
#### To Reproduce
Steps to reproduce the behavior:
1. Open PyxlMoose
2. Create a new project
3. Specify '0' or any negative number as the span count
4. Observe the result
#### Expected behavior
The app should not crash - but rather show a `Snackbar` detailing the problem if the user inputs '0' or any negative number as the span count value. | priority | app crashes if user inputs or any negative number as the span count value describe the bug if the user inputs or any negative number as the span count value the app crashes to reproduce steps to reproduce the behavior open pyxlmoose create a new project specify or any negative number as the span count observe the result expected behavior the app should not crash but rather show a snackbar detailing the problem if the user inputs or any negative number as the span count value | 1 |
312,923 | 9,554,860,543 | IssuesEvent | 2019-05-02 23:49:40 | openmsupply/mobile | https://api.github.com/repos/openmsupply/mobile | opened | Initialisation loses all details of a stocktake | Bug Effort small Ivory Coast (phase 1) Priority: High Release Blocker | Build Number: 2.3.0-rc0 dev, server 4.03.00-RC79
Description:
When you initialise an existing store, you lose all the the details of stocktakes. Either server isn't syncing them out or they're all breaking on incomingSyncUtils.
Server actually has the stocktakes:
Reproducible: Yes
Reproduction Steps:
1. Create a stocktake, give it a name, comment, some items and counts
2. Finalise
3. Sync to server
4. Clear app data
5. initialise store on tablet
6. See stocktakes have placeholder details
Comments:
| 1.0 | Initialisation loses all details of a stocktake - Build Number: 2.3.0-rc0 dev, server 4.03.00-RC79
Description:
When you initialise an existing store, you lose all the the details of stocktakes. Either server isn't syncing them out or they're all breaking on incomingSyncUtils.

Server actually has the stocktakes:

Reproducible: Yes
Reproduction Steps:
1. Create a stocktake, give it a name, comment, some items and counts
2. Finalise
3. Sync to server
4. Clear app data
5. initialise store on tablet
6. See stocktakes have placeholder details
Comments:
| priority | initialisation loses all details of a stocktake build number dev server description when you initialise an existing store you lose all the the details of stocktakes either server isn t syncing them out or they re all breaking on incomingsyncutils server actually has the stocktakes reproducible yes reproduction steps create a stocktake give it a name comment some items and counts finalise sync to server clear app data initialise store on tablet see stocktakes have placeholder details comments | 1 |
336,226 | 10,173,548,361 | IssuesEvent | 2019-08-08 13:21:23 | epam/cloud-pipeline | https://api.github.com/repos/epam/cloud-pipeline | closed | GCP: Mounting bucket is failed to launched tool | cloud/gcp kind/bug priority/high state/verify sys/core |
**Environment**: `GCP`
**Version**: `0.16.0.1916.46d7e7d065cf7db5eab314572f25e2631d124721`
A bucket with access is not mounted to launched tool and the following error appears in `MountDataStorages` task logs:
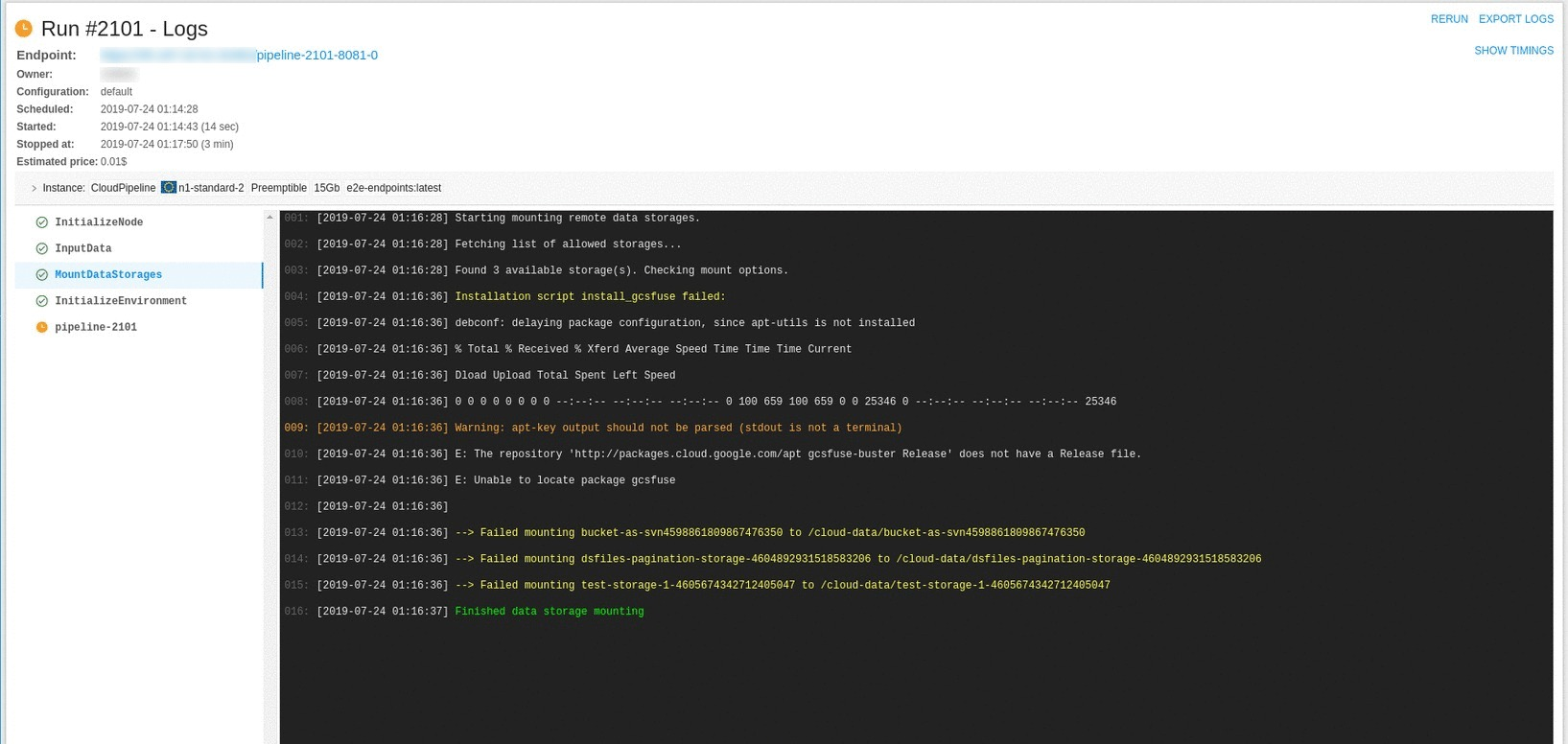
| 1.0 | GCP: Mounting bucket is failed to launched tool -
**Environment**: `GCP`
**Version**: `0.16.0.1916.46d7e7d065cf7db5eab314572f25e2631d124721`
A bucket with access is not mounted to launched tool and the following error appears in `MountDataStorages` task logs:

| priority | gcp mounting bucket is failed to launched tool environment gcp version a bucket with access is not mounted to launched tool and the following error appears in mountdatastorages task logs | 1 |
807,000 | 29,930,820,231 | IssuesEvent | 2023-06-22 09:20:52 | fractal-analytics-platform/fractal-tasks-core | https://api.github.com/repos/fractal-analytics-platform/fractal-tasks-core | opened | To review: Optional arrays/objects should not have side effects | High Priority | (coming from discussions with @rkpasia)
Consider this task
```python
def task_function(x: Optional[list[str]] = None) -> str:
if x is None:
return "A"
else:
return "B"
```
which has a different behavior for `x=None` and `x=[]`. I think this is a bad practice, and should be avoided.
The reason for this issue comes from https://github.com/fractal-analytics-platform/fractal-web/issues/205. Depending on how we proceed in fractal-web, it's not clear whether setting `x=[]` will be allowed. In general, it's better to stay on the safe side and make sure that tasks are robust. | 1.0 | To review: Optional arrays/objects should not have side effects - (coming from discussions with @rkpasia)
Consider this task
```python
def task_function(x: Optional[list[str]] = None) -> str:
if x is None:
return "A"
else:
return "B"
```
which has a different behavior for `x=None` and `x=[]`. I think this is a bad practice, and should be avoided.
The reason for this issue comes from https://github.com/fractal-analytics-platform/fractal-web/issues/205. Depending on how we proceed in fractal-web, it's not clear whether setting `x=[]` will be allowed. In general, it's better to stay on the safe side and make sure that tasks are robust. | priority | to review optional arrays objects should not have side effects coming from discussions with rkpasia consider this task python def task function x optional none str if x is none return a else return b which has a different behavior for x none and x i think this is a bad practice and should be avoided the reason for this issue comes from depending on how we proceed in fractal web it s not clear whether setting x will be allowed in general it s better to stay on the safe side and make sure that tasks are robust | 1 |
655,952 | 21,715,132,835 | IssuesEvent | 2022-05-10 17:07:25 | KinsonDigital/VersionValidator | https://api.github.com/repos/KinsonDigital/VersionValidator | closed | Create main github action implementation | high priority workflow | **Description:**
Create a github action that can do validation on versions. This will validate syntax, preview versus standard version strings, if nuget packages with a particular version are already pushed to nuget.org, etc.
---
**Acceptance Criteria:**
- [x] Check for preview release syntax
- [x] Must have "-preview." string
- [x] Must end with a number value only. No letters or symbols
- [x] the "-preview" section and the number must be separated by a "." symbol
- [x] Check for main (non preview) release syntax
- [x] Must NOT have a "-preview.*" section
- [x] Must start with a number. Example, not start with the letter "v"
- [x] Must have a major, minor, and patch number
- [x] Each number must be separated by a "." symbol
- [x] The major must be numerical
- [x] The minor must be numerical
- [x] The patch must be numerical
- [x] Check if the properly syntaxed version already exists
- [x] ONLY checked if 'check-nuget' is set to true
- [x] Check if preview number is too large
Example: v1.2.3-preview.4 already exists. The next preview version should be -preview.5, but the version being attempted
is -preview.6. The preview number is too large and it should fail.
- [x] ONLY checked if 'check-nuget' is set to true
- [x] Check to see if the current attempted release is a main (non preview) release and if the latest release
is currently a preview release, then fail. This prevents an accidental main release when we are currently in preview
- [x] ONLY checked if 'check-nuget' is set to true
- [x] Check if standard version major, minor, or patch are too small compared to the latest main release
- [x] ONLY checked if 'check-nuget' is set to true
- [x] This means we have to pull the latest version in production and then make sure that it is not smaller then the latest version
- [x] This is to prevent accidental release of something smaller but that actually has not been released yet
Example:
v1.2.3 is the latest version. Version v1.1.1 is the next lowest version that has been released. This means
that we could theoretically release a version v1.1.2 by accident. This should be prevented. Each version part
should be analyzed to make sure that the next attempted version makes sense in the semantic versioning sequence
- [x] Check to make sure that an attempt to make a preview version greater than -preview.1 when a main version release with
-preview.1 has never been released.
Example: If v1.2.3 is the latest release, and you are attempting to do a v2.0.0-preview.2 when a v2.0.0-preview.1
does not exist, this should fail
- [x] ONLY checked if 'check-nuget' is set to true
- [x] Has the following inputs
- [x] nuget-package-name: string
- Required: true
- Description: The full name of the nuget package. NOTE: Not case sensitive
- [x] version: string
- Required: true
- [x] check-nuget: bool
- Required: false
- If true, this will pull down all of the release versions for comparison
- If false, this will ONLY compare syntax
- [x] fail-if-version-exists: bool
- Required: false
- Description: If true, will fail if the nuget package exists. Only used when 'check-nuget' is true. If 'check-nuget'
is false, then this will always be false.
- [x] Look into the list of DI containers below to help choose one for implementing into the code base
- [Typed Inject](https://github.com/nicojs/typed-inject)
- Low GitHub stars (154)
- [Inversify](https://github.com/inversify/InversifyJS)
- Good Contender
- Version 5.5.x
- GitHub Stars 8k
- [TypedDI](https://github.com/typestack/typedi)
- GitHub Stars 2.6k
- Only version 0.10.0
- Seems to have simple setup and use
- [TSyringe](https://github.com/microsoft/tsyringe)
- GitHub Stars 2.5k
- Version 4.4.0
- [NestJS](https://nestjs.com/)
- [x] Has the following output
- [x] version-valid: bool
- Description: True if all tests pass. | 1.0 | Create main github action implementation - **Description:**
Create a github action that can do validation on versions. This will validate syntax, preview versus standard version strings, if nuget packages with a particular version are already pushed to nuget.org, etc.

---
**Acceptance Criteria:**
- [x] Check for preview release syntax
- [x] Must have "-preview." string
- [x] Must end with a number value only. No letters or symbols
- [x] the "-preview" section and the number must be separated by a "." symbol
- [x] Check for main (non preview) release syntax
- [x] Must NOT have a "-preview.*" section
- [x] Must start with a number. Example, not start with the letter "v"
- [x] Must have a major, minor, and patch number
- [x] Each number must be separated by a "." symbol
- [x] The major must be numerical
- [x] The minor must be numerical
- [x] The patch must be numerical
- [x] Check if the properly syntaxed version already exists
- [x] ONLY checked if 'check-nuget' is set to true
- [x] Check if preview number is too large
Example: v1.2.3-preview.4 already exists. The next preview version should be -preview.5, but the version being attempted
is -preview.6. The preview number is too large and it should fail.
- [x] ONLY checked if 'check-nuget' is set to true
- [x] Check to see if the current attempted release is a main (non preview) release and if the latest release
is currently a preview release, then fail. This prevents an accidental main release when we are currently in preview
- [x] ONLY checked if 'check-nuget' is set to true
- [x] Check if standard version major, minor, or patch are too small compared to the latest main release
- [x] ONLY checked if 'check-nuget' is set to true
- [x] This means we have to pull the latest version in production and then make sure that it is not smaller then the latest version
- [x] This is to prevent accidental release of something smaller but that actually has not been released yet
Example:
v1.2.3 is the latest version. Version v1.1.1 is the next lowest version that has been released. This means
that we could theoretically release a version v1.1.2 by accident. This should be prevented. Each version part
should be analyzed to make sure that the next attempted version makes sense in the semantic versioning sequence
- [x] Check to make sure that an attempt to make a preview version greater than -preview.1 when a main version release with
-preview.1 has never been released.
Example: If v1.2.3 is the latest release, and you are attempting to do a v2.0.0-preview.2 when a v2.0.0-preview.1
does not exist, this should fail
- [x] ONLY checked if 'check-nuget' is set to true
- [x] Has the following inputs
- [x] nuget-package-name: string
- Required: true
- Description: The full name of the nuget package. NOTE: Not case sensitive
- [x] version: string
- Required: true
- [x] check-nuget: bool
- Required: false
- If true, this will pull down all of the release versions for comparison
- If false, this will ONLY compare syntax
- [x] fail-if-version-exists: bool
- Required: false
- Description: If true, will fail if the nuget package exists. Only used when 'check-nuget' is true. If 'check-nuget'
is false, then this will always be false.
- [x] Look into the list of DI containers below to help choose one for implementing into the code base
- [Typed Inject](https://github.com/nicojs/typed-inject)
- Low GitHub stars (154)
- [Inversify](https://github.com/inversify/InversifyJS)
- Good Contender
- Version 5.5.x
- GitHub Stars 8k
- [TypedDI](https://github.com/typestack/typedi)
- GitHub Stars 2.6k
- Only version 0.10.0
- Seems to have simple setup and use
- [TSyringe](https://github.com/microsoft/tsyringe)
- GitHub Stars 2.5k
- Version 4.4.0
- [NestJS](https://nestjs.com/)
- [x] Has the following output
- [x] version-valid: bool
- Description: True if all tests pass. | priority | create main github action implementation description create a github action that can do validation on versions this will validate syntax preview versus standard version strings if nuget packages with a particular version are already pushed to nuget org etc acceptance criteria check for preview release syntax must have preview string must end with a number value only no letters or symbols the preview section and the number must be separated by a symbol check for main non preview release syntax must not have a preview section must start with a number example not start with the letter v must have a major minor and patch number each number must be separated by a symbol the major must be numerical the minor must be numerical the patch must be numerical check if the properly syntaxed version already exists only checked if check nuget is set to true check if preview number is too large example preview already exists the next preview version should be preview but the version being attempted is preview the preview number is too large and it should fail only checked if check nuget is set to true check to see if the current attempted release is a main non preview release and if the latest release is currently a preview release then fail this prevents an accidental main release when we are currently in preview only checked if check nuget is set to true check if standard version major minor or patch are too small compared to the latest main release only checked if check nuget is set to true this means we have to pull the latest version in production and then make sure that it is not smaller then the latest version this is to prevent accidental release of something smaller but that actually has not been released yet example is the latest version version is the next lowest version that has been released this means that we could theoretically release a version by accident this should be prevented each version part should be analyzed to make sure that the next attempted version makes sense in the semantic versioning sequence check to make sure that an attempt to make a preview version greater than preview when a main version release with preview has never been released example if is the latest release and you are attempting to do a preview when a preview does not exist this should fail only checked if check nuget is set to true has the following inputs nuget package name string required true description the full name of the nuget package note not case sensitive version string required true check nuget bool required false if true this will pull down all of the release versions for comparison if false this will only compare syntax fail if version exists bool required false description if true will fail if the nuget package exists only used when check nuget is true if check nuget is false then this will always be false look into the list of di containers below to help choose one for implementing into the code base low github stars good contender version x github stars github stars only version seems to have simple setup and use github stars version has the following output version valid bool description true if all tests pass | 1 |
236,867 | 7,753,198,915 | IssuesEvent | 2018-05-30 23:16:23 | Gloirin/m2gTest | https://api.github.com/repos/Gloirin/m2gTest | closed | 0005330:
implement addressbook gridpanelhook: add contacts to lead | CRM Feature Request high priority | **Reported by pschuele on 11 Jan 2012 12:12**
lead contacts should be added out of the addressbook.
- allow to set role
- lead <-> contact links are implemented as (sibling) relations
| 1.0 | 0005330:
implement addressbook gridpanelhook: add contacts to lead - **Reported by pschuele on 11 Jan 2012 12:12**
lead contacts should be added out of the addressbook.
- allow to set role
- lead <-> contact links are implemented as (sibling) relations
| priority | implement addressbook gridpanelhook add contacts to lead reported by pschuele on jan lead contacts should be added out of the addressbook allow to set role lead lt gt contact links are implemented as sibling relations | 1 |
671,051 | 22,740,671,799 | IssuesEvent | 2022-07-07 03:13:41 | IBMa/equal-access | https://api.github.com/repos/IBMa/equal-access | opened | [BUG]: Check is loosing the Element role, Requirements, rule tab menu bar | Bug priority-1 (high) | ### Project
a11y checker extension
### Browser
Chrome
### Operating system
MacOS
### Description
Tested with lates master build (tag 3.1.33)
The tab menu is lost after the user goes back to list view from _lean more_ item.
The menu in not visible to the user, relaunching the checker will show the menu again. Unable to release 3.1.33 due to this issue.
### Steps to reproduce
1. Install the master build
2. Conduct a scan on any site
3. Select learn more from the results list
4. Select Back to list view
Results: User is not able to see the top menu. Please review attachment:
<img width="1279" alt="Screen Shot 2022-07-06 at 9 56 54 PM" src="https://user-images.githubusercontent.com/62436670/177682636-ead2ca06-99a3-4658-a557-66355bcef00c.png">
<img width="1479" alt="Screen Shot 2022-07-06 at 9 57 22 PM" src="https://user-images.githubusercontent.com/62436670/177682645-9e99aa79-6f12-4439-8317-7ed984818a63.png"> | 1.0 | [BUG]: Check is loosing the Element role, Requirements, rule tab menu bar - ### Project
a11y checker extension
### Browser
Chrome
### Operating system
MacOS
### Description
Tested with lates master build (tag 3.1.33)
The tab menu is lost after the user goes back to list view from _lean more_ item.
The menu in not visible to the user, relaunching the checker will show the menu again. Unable to release 3.1.33 due to this issue.
### Steps to reproduce
1. Install the master build
2. Conduct a scan on any site
3. Select learn more from the results list
4. Select Back to list view
Results: User is not able to see the top menu. Please review attachment:
<img width="1279" alt="Screen Shot 2022-07-06 at 9 56 54 PM" src="https://user-images.githubusercontent.com/62436670/177682636-ead2ca06-99a3-4658-a557-66355bcef00c.png">
<img width="1479" alt="Screen Shot 2022-07-06 at 9 57 22 PM" src="https://user-images.githubusercontent.com/62436670/177682645-9e99aa79-6f12-4439-8317-7ed984818a63.png"> | priority | check is loosing the element role requirements rule tab menu bar project checker extension browser chrome operating system macos description tested with lates master build tag the tab menu is lost after the user goes back to list view from lean more item the menu in not visible to the user relaunching the checker will show the menu again unable to release due to this issue steps to reproduce install the master build conduct a scan on any site select learn more from the results list select back to list view results user is not able to see the top menu please review attachment img width alt screen shot at pm src img width alt screen shot at pm src | 1 |
815,977 | 30,581,854,525 | IssuesEvent | 2023-07-21 10:17:22 | go-shiori/shiori | https://api.github.com/repos/go-shiori/shiori | closed | Adding a URL doesn't automatically create an archive | type:bug tag:more-info component:backend database:postgres priority:high | I have turned on the "Create archive by default" setting and I see the relevant option ticked as well when I'm adding a new URL. However, it doesn't actually create an archive, I have to manually go and do update archive. | 1.0 | Adding a URL doesn't automatically create an archive - I have turned on the "Create archive by default" setting and I see the relevant option ticked as well when I'm adding a new URL. However, it doesn't actually create an archive, I have to manually go and do update archive. | priority | adding a url doesn t automatically create an archive i have turned on the create archive by default setting and i see the relevant option ticked as well when i m adding a new url however it doesn t actually create an archive i have to manually go and do update archive | 1 |
230,049 | 7,603,670,401 | IssuesEvent | 2018-04-29 16:53:10 | urfu-2017/team2 | https://api.github.com/repos/urfu-2017/team2 | closed | Исправить поиск контактов | client high-priority | Фильтровать свои контакты и конкатенировать с глобально найденными с разделителем | 1.0 | Исправить поиск контактов - Фильтровать свои контакты и конкатенировать с глобально найденными с разделителем | priority | исправить поиск контактов фильтровать свои контакты и конкатенировать с глобально найденными с разделителем | 1 |
164,580 | 6,229,228,826 | IssuesEvent | 2017-07-11 02:52:12 | JoshuaBRussell/PICLibrary | https://api.github.com/repos/JoshuaBRussell/PICLibrary | closed | Timer Interrupt | High Priority | Basic Interrupt Driven Timing Ability. Is needed so the Feedback Controller can be called at a constant rate. | 1.0 | Timer Interrupt - Basic Interrupt Driven Timing Ability. Is needed so the Feedback Controller can be called at a constant rate. | priority | timer interrupt basic interrupt driven timing ability is needed so the feedback controller can be called at a constant rate | 1 |
619,859 | 19,537,906,210 | IssuesEvent | 2021-12-31 12:03:22 | google/android-fhir | https://api.github.com/repos/google/android-fhir | closed | Resource Indexer Exception in causes observations sync download to fail. | bug high priority Small effort | **Describe the bug**
Resource Indexer has issue extracting Temperature QuantityValue in the following Observation taken from the Synthea dataset.
```
{
"resourceType": "Observation",
"id": "1595",
"meta": {
"versionId": "1",
"lastUpdated": "2021-10-21T08:29:32.481+00:00",
"source": "#RqWIwZVJSul7Y3tp"
},
"status": "final",
"category": [{
"coding": [{
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "vital-signs",
"display": "vital-signs"
}]
}],
"code": {
"coding": [{
"system": "http://loinc.org",
"code": "8331-1",
"display": "Oral temperature"
}],
"text": "Oral temperature"
},
"subject": {
"reference": "Patient/1561"
},
"encounter": {
"reference": "Encounter/1593"
},
"effectiveDateTime": "2011-09-15T12:22:44-04:00",
"issued": "2011-09-15T12:22:44.702-04:00",
"valueQuantity": {
"value": 37.65532501487887,
"unit": "Cel",
"system": "http://unitsofmeasure.org",
"code": "Cel"
}
}
```
**Exception:**
```
10-26 12:21:42.804 20937 20978 W System.err: java.lang.NullPointerException: Attempt to invoke virtual method 'java.lang.String org.fhir.ucum.Decimal.asDecimal()' on a null object reference
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.UnitConverter.getCanonicalForm$engine_debug(UnitConverter.kt:47)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.index.ResourceIndexer.quantityIndex(ResourceIndexer.kt:307)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.index.ResourceIndexer.extractIndexValues(ResourceIndexer.kt:96)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.index.ResourceIndexer.index(ResourceIndexer.kt:68)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.dao.ResourceDao.insertResource(ResourceDao.kt:202)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.dao.ResourceDao.insertAll$suspendImpl(ResourceDao.kt:74)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.dao.ResourceDao.insertAll(Unknown Source:4)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.DatabaseImpl.insertRemote(DatabaseImpl.kt:68)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.DatabaseImpl$insertSyncedResources$2.invokeSuspend(DatabaseImpl.kt:97)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.DatabaseImpl$insertSyncedResources$2.invoke(Unknown Source:12)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.DatabaseImpl$insertSyncedResources$2.invoke(Unknown Source:7)
10-26 12:21:42.805 20937 20978 W System.err: at androidx.room.RoomDatabaseKt$withTransaction$2.invokeSuspend(RoomDatabase.kt:58)
10-26 12:21:42.805 20937 20978 W System.err: at kotlin.coroutines.jvm.internal.BaseContinuationImpl.resumeWith(ContinuationImpl.kt:33)
10-26 12:21:42.805 20937 20978 W System.err: at kotlinx.coroutines.DispatchedTask.run(DispatchedTask.kt:106)
10-26 12:21:42.805 20937 20978 W System.err: at kotlinx.coroutines.EventLoopImplBase.processNextEvent(EventLoop.common.kt:274)
10-26 12:21:42.805 20937 20978 W System.err: at kotlinx.coroutines.BlockingCoroutine.joinBlocking(Builders.kt:85)
10-26 12:21:42.805 20937 20978 W System.err: at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking(Builders.kt:59)
10-26 12:21:42.806 20937 20978 W System.err: at kotlinx.coroutines.BuildersKt.runBlocking(Unknown Source:1)
10-26 12:21:42.806 20937 20978 W System.err: at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking$default(Builders.kt:38)
10-26 12:21:42.806 20937 20978 W System.err: at kotlinx.coroutines.BuildersKt.runBlocking$default(Unknown Source:1)
10-26 12:21:42.806 20937 20978 W System.err: at androidx.room.RoomDatabaseKt$acquireTransactionThread$$inlined$suspendCancellableCoroutine$lambda$2.run(RoomDatabase.kt:121)
10-26 12:21:42.806 20937 20978 W System.err: at androidx.room.TransactionExecutor$1.run(TransactionExecutor.java:47)
10-26 12:21:42.806 20937 20978 W System.err: at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167)
10-26 12:21:42.806 20937 20978 W System.err: at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641)
10-26 12:21:42.806 20937 20978 W System.err: at java.lang.Thread.run(Thread.java:923)
10-26 12:21:42.809 20937 20972 D FhirSynchronizer: download ended at 1635231102809, Tue Oct 26 12:21:42 GMT+05:30 2021, total time 11397 ms
```
| 1.0 | Resource Indexer Exception in causes observations sync download to fail. - **Describe the bug**
Resource Indexer has issue extracting Temperature QuantityValue in the following Observation taken from the Synthea dataset.
```
{
"resourceType": "Observation",
"id": "1595",
"meta": {
"versionId": "1",
"lastUpdated": "2021-10-21T08:29:32.481+00:00",
"source": "#RqWIwZVJSul7Y3tp"
},
"status": "final",
"category": [{
"coding": [{
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "vital-signs",
"display": "vital-signs"
}]
}],
"code": {
"coding": [{
"system": "http://loinc.org",
"code": "8331-1",
"display": "Oral temperature"
}],
"text": "Oral temperature"
},
"subject": {
"reference": "Patient/1561"
},
"encounter": {
"reference": "Encounter/1593"
},
"effectiveDateTime": "2011-09-15T12:22:44-04:00",
"issued": "2011-09-15T12:22:44.702-04:00",
"valueQuantity": {
"value": 37.65532501487887,
"unit": "Cel",
"system": "http://unitsofmeasure.org",
"code": "Cel"
}
}
```
**Exception:**
```
10-26 12:21:42.804 20937 20978 W System.err: java.lang.NullPointerException: Attempt to invoke virtual method 'java.lang.String org.fhir.ucum.Decimal.asDecimal()' on a null object reference
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.UnitConverter.getCanonicalForm$engine_debug(UnitConverter.kt:47)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.index.ResourceIndexer.quantityIndex(ResourceIndexer.kt:307)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.index.ResourceIndexer.extractIndexValues(ResourceIndexer.kt:96)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.index.ResourceIndexer.index(ResourceIndexer.kt:68)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.dao.ResourceDao.insertResource(ResourceDao.kt:202)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.dao.ResourceDao.insertAll$suspendImpl(ResourceDao.kt:74)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.dao.ResourceDao.insertAll(Unknown Source:4)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.DatabaseImpl.insertRemote(DatabaseImpl.kt:68)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.DatabaseImpl$insertSyncedResources$2.invokeSuspend(DatabaseImpl.kt:97)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.DatabaseImpl$insertSyncedResources$2.invoke(Unknown Source:12)
10-26 12:21:42.805 20937 20978 W System.err: at com.google.android.fhir.db.impl.DatabaseImpl$insertSyncedResources$2.invoke(Unknown Source:7)
10-26 12:21:42.805 20937 20978 W System.err: at androidx.room.RoomDatabaseKt$withTransaction$2.invokeSuspend(RoomDatabase.kt:58)
10-26 12:21:42.805 20937 20978 W System.err: at kotlin.coroutines.jvm.internal.BaseContinuationImpl.resumeWith(ContinuationImpl.kt:33)
10-26 12:21:42.805 20937 20978 W System.err: at kotlinx.coroutines.DispatchedTask.run(DispatchedTask.kt:106)
10-26 12:21:42.805 20937 20978 W System.err: at kotlinx.coroutines.EventLoopImplBase.processNextEvent(EventLoop.common.kt:274)
10-26 12:21:42.805 20937 20978 W System.err: at kotlinx.coroutines.BlockingCoroutine.joinBlocking(Builders.kt:85)
10-26 12:21:42.805 20937 20978 W System.err: at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking(Builders.kt:59)
10-26 12:21:42.806 20937 20978 W System.err: at kotlinx.coroutines.BuildersKt.runBlocking(Unknown Source:1)
10-26 12:21:42.806 20937 20978 W System.err: at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking$default(Builders.kt:38)
10-26 12:21:42.806 20937 20978 W System.err: at kotlinx.coroutines.BuildersKt.runBlocking$default(Unknown Source:1)
10-26 12:21:42.806 20937 20978 W System.err: at androidx.room.RoomDatabaseKt$acquireTransactionThread$$inlined$suspendCancellableCoroutine$lambda$2.run(RoomDatabase.kt:121)
10-26 12:21:42.806 20937 20978 W System.err: at androidx.room.TransactionExecutor$1.run(TransactionExecutor.java:47)
10-26 12:21:42.806 20937 20978 W System.err: at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167)
10-26 12:21:42.806 20937 20978 W System.err: at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641)
10-26 12:21:42.806 20937 20978 W System.err: at java.lang.Thread.run(Thread.java:923)
10-26 12:21:42.809 20937 20972 D FhirSynchronizer: download ended at 1635231102809, Tue Oct 26 12:21:42 GMT+05:30 2021, total time 11397 ms
```
| priority | resource indexer exception in causes observations sync download to fail describe the bug resource indexer has issue extracting temperature quantityvalue in the following observation taken from the synthea dataset resourcetype observation id meta versionid lastupdated source status final category coding system code vital signs display vital signs code coding system code display oral temperature text oral temperature subject reference patient encounter reference encounter effectivedatetime issued valuequantity value unit cel system code cel exception w system err java lang nullpointerexception attempt to invoke virtual method java lang string org fhir ucum decimal asdecimal on a null object reference w system err at com google android fhir unitconverter getcanonicalform engine debug unitconverter kt w system err at com google android fhir index resourceindexer quantityindex resourceindexer kt w system err at com google android fhir index resourceindexer extractindexvalues resourceindexer kt w system err at com google android fhir index resourceindexer index resourceindexer kt w system err at com google android fhir db impl dao resourcedao insertresource resourcedao kt w system err at com google android fhir db impl dao resourcedao insertall suspendimpl resourcedao kt w system err at com google android fhir db impl dao resourcedao insertall unknown source w system err at com google android fhir db impl databaseimpl insertremote databaseimpl kt w system err at com google android fhir db impl databaseimpl insertsyncedresources invokesuspend databaseimpl kt w system err at com google android fhir db impl databaseimpl insertsyncedresources invoke unknown source w system err at com google android fhir db impl databaseimpl insertsyncedresources invoke unknown source w system err at androidx room roomdatabasekt withtransaction invokesuspend roomdatabase kt w system err at kotlin coroutines jvm internal basecontinuationimpl resumewith continuationimpl kt w system err at kotlinx coroutines dispatchedtask run dispatchedtask kt w system err at kotlinx coroutines eventloopimplbase processnextevent eventloop common kt w system err at kotlinx coroutines blockingcoroutine joinblocking builders kt w system err at kotlinx coroutines builderskt builderskt runblocking builders kt w system err at kotlinx coroutines builderskt runblocking unknown source w system err at kotlinx coroutines builderskt builderskt runblocking default builders kt w system err at kotlinx coroutines builderskt runblocking default unknown source w system err at androidx room roomdatabasekt acquiretransactionthread inlined suspendcancellablecoroutine lambda run roomdatabase kt w system err at androidx room transactionexecutor run transactionexecutor java w system err at java util concurrent threadpoolexecutor runworker threadpoolexecutor java w system err at java util concurrent threadpoolexecutor worker run threadpoolexecutor java w system err at java lang thread run thread java d fhirsynchronizer download ended at tue oct gmt total time ms | 1 |
557,997 | 16,523,976,039 | IssuesEvent | 2021-05-26 17:34:36 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | support.mozilla.org - see bug description | browser-firefox-ios bugbug-probability-high ml-needsdiagnosis-false ml-probability-high os-ios priority-important | <!-- @browser: Firefox iOS 33.1 -->
<!-- @ua_header: Mozilla/5.0 (iPhone; CPU OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) FxiOS/33.1 Mobile/15E148 Safari/605.1.15 -->
<!-- @reported_with: mobile-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/75112 -->
**URL**: https://support.mozilla.org/en-US/kb/report-site-issues-firefox-ios
**Browser / Version**: Firefox iOS 33.1
**Operating System**: iOS 14.6
**Tested Another Browser**: Yes Safari
**Problem type**: Something else
**Description**: its having some bug and its sync with all the wifi that i log in
**Steps to Reproduce**:
i dont know but i belive its sync with all and any wifi i login and mostly the times its not my own wifi so keeps my data everywhere
<details>
<summary>Browser Configuration</summary>
<ul>
<li>None</li>
</ul>
</details>
_From [webcompat.com](https://webcompat.com/) with ❤️_ | 1.0 | support.mozilla.org - see bug description - <!-- @browser: Firefox iOS 33.1 -->
<!-- @ua_header: Mozilla/5.0 (iPhone; CPU OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) FxiOS/33.1 Mobile/15E148 Safari/605.1.15 -->
<!-- @reported_with: mobile-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/75112 -->
**URL**: https://support.mozilla.org/en-US/kb/report-site-issues-firefox-ios
**Browser / Version**: Firefox iOS 33.1
**Operating System**: iOS 14.6
**Tested Another Browser**: Yes Safari
**Problem type**: Something else
**Description**: its having some bug and its sync with all the wifi that i log in
**Steps to Reproduce**:
i dont know but i belive its sync with all and any wifi i login and mostly the times its not my own wifi so keeps my data everywhere
<details>
<summary>Browser Configuration</summary>
<ul>
<li>None</li>
</ul>
</details>
_From [webcompat.com](https://webcompat.com/) with ❤️_ | priority | support mozilla org see bug description url browser version firefox ios operating system ios tested another browser yes safari problem type something else description its having some bug and its sync with all the wifi that i log in steps to reproduce i dont know but i belive its sync with all and any wifi i login and mostly the times its not my own wifi so keeps my data everywhere browser configuration none from with ❤️ | 1 |
153,339 | 5,889,801,648 | IssuesEvent | 2017-05-17 13:43:32 | DCLP/dclpxsltbox | https://api.github.com/repos/DCLP/dclpxsltbox | closed | Collapsing Fragments Field | priority: high review tweak XSLT | Can we put Fragments in a collapsible window? It would make examples like this easier to ignore,
http://dclp.github.io/dclpxsltbox/output/dclp/63/62400.html, if one isn't interested in seeing all of the fragment info.
| 1.0 | Collapsing Fragments Field - Can we put Fragments in a collapsible window? It would make examples like this easier to ignore,
http://dclp.github.io/dclpxsltbox/output/dclp/63/62400.html, if one isn't interested in seeing all of the fragment info.
| priority | collapsing fragments field can we put fragments in a collapsible window it would make examples like this easier to ignore if one isn t interested in seeing all of the fragment info | 1 |
27,568 | 2,694,188,078 | IssuesEvent | 2015-04-01 18:50:34 | jackjonesfashion/tasks | https://api.github.com/repos/jackjonesfashion/tasks | opened | Storefront - Testing | In progress Priority: High Task | - [ ] AT
- [ ] BE
- [ ] CH
- [ ] DE
- [ ] DK
- [ ] ES
- [ ] FI
- [ ] FR
- [ ] GB
- [ ] IE
- [ ] IT
- [ ] NL
- [ ] NO
- [ ] SE | 1.0 | Storefront - Testing - - [ ] AT
- [ ] BE
- [ ] CH
- [ ] DE
- [ ] DK
- [ ] ES
- [ ] FI
- [ ] FR
- [ ] GB
- [ ] IE
- [ ] IT
- [ ] NL
- [ ] NO
- [ ] SE | priority | storefront testing at be ch de dk es fi fr gb ie it nl no se | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.