
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
765,103 | 26,833,209,891 | IssuesEvent | 2023-02-02 17:24:50 | zephyrproject-rtos/zephyr | https://api.github.com/repos/zephyrproject-rtos/zephyr | closed | Problem seen with touch screen on RT1170 when running the LVGL sample | bug priority: low platform: NXP area: Kscan | **Describe the bug**
Touch screen is not functional on RT1170 EVK when running the LVGL sample.
- What target platform are you using? : RT1170 EVK
- What have you tried to diagnose or workaround this issue? : run `samples/subsys/display/lvgl`
- Is this a regression? No
**To Reproduce**
Steps to reproduce ... | 1.0 | Problem seen with touch screen on RT1170 when running the LVGL sample - **Describe the bug**
Touch screen is not functional on RT1170 EVK when running the LVGL sample.
- What target platform are you using? : RT1170 EVK
- What have you tried to diagnose or workaround this issue? : run `samples/subsys/display/lvg... | non_process | problem seen with touch screen on when running the lvgl sample describe the bug touch screen is not functional on evk when running the lvgl sample what target platform are you using evk what have you tried to diagnose or workaround this issue run samples subsys display lvgl is this ... | 0 |
725 | 3,213,348,077 | IssuesEvent | 2015-10-06 19:28:21 | nationalparkservice/places-data | https://api.github.com/repos/nationalparkservice/places-data | closed | Add POI type: Food Box | pending-other-process schema | Parks like SEKI have first-come, first-serve boxes that can be shared by multiple camping groups to keep food away from bears:
http://www.nps.gov/seki/planyourvisit/bear_bc.htm
http://www.nps.gov/seki/planyourvisit/upload/FoodStorageBoxes_PageSize_v2.pdf | 1.0 | Add POI type: Food Box - Parks like SEKI have first-come, first-serve boxes that can be shared by multiple camping groups to keep food away from bears:
http://www.nps.gov/seki/planyourvisit/bear_bc.htm
http://www.nps.gov/seki/planyourvisit/upload/FoodStorageBoxes_PageSize_v2.pdf | process | add poi type food box parks like seki have first come first serve boxes that can be shared by multiple camping groups to keep food away from bears | 1 |
21,558 | 29,893,070,875 | IssuesEvent | 2023-06-21 00:46:43 | bitfocus/companion-module-requests | https://api.github.com/repos/bitfocus/companion-module-requests | opened | Dante Domain Manager API | NOT YET PROCESSED | - [ ] **I have researched the list of existing Companion modules and requests and have determined this has not yet been requested**
The name of the device, hardware, or software you would like to control:
[Audinate Dante Domain Manager](https://www.audinate.com/products/software/dante-domain-manager)
What you wo... | 1.0 | Dante Domain Manager API - - [ ] **I have researched the list of existing Companion modules and requests and have determined this has not yet been requested**
The name of the device, hardware, or software you would like to control:
[Audinate Dante Domain Manager](https://www.audinate.com/products/software/dante-dom... | process | dante domain manager api i have researched the list of existing companion modules and requests and have determined this has not yet been requested the name of the device hardware or software you would like to control what you would like to be able to make it do from companion check domain de... | 1 |
25,849 | 4,178,006,854 | IssuesEvent | 2016-06-22 03:48:52 | linz/QGIS-AIMS-Plugin | https://api.github.com/repos/linz/QGIS-AIMS-Plugin | closed | Roads - Chatham Islands | bug effort/small test | When you navigate to the Chatham Islands the roads appear in a different location to the AIMS features (addresses). | 1.0 | Roads - Chatham Islands - When you navigate to the Chatham Islands the roads appear in a different location to the AIMS features (addresses). | non_process | roads chatham islands when you navigate to the chatham islands the roads appear in a different location to the aims features addresses | 0 |
6,694 | 9,813,700,372 | IssuesEvent | 2019-06-13 08:36:23 | opengeospatial/CityGML-3.0CM | https://api.github.com/repos/opengeospatial/CityGML-3.0CM | closed | Does ReadMe Reflect Intentions of SWG? | SWG Process | The initial readme file for this repo is a statement of purpose written by just of one of the chairs (Steve = 3DXScape). The readme should reflect consensus among the SWG participants. More people should express their opinions. | 1.0 | Does ReadMe Reflect Intentions of SWG? - The initial readme file for this repo is a statement of purpose written by just of one of the chairs (Steve = 3DXScape). The readme should reflect consensus among the SWG participants. More people should express their opinions. | process | does readme reflect intentions of swg the initial readme file for this repo is a statement of purpose written by just of one of the chairs steve the readme should reflect consensus among the swg participants more people should express their opinions | 1 |
18,125 | 24,166,032,967 | IssuesEvent | 2022-09-22 15:06:11 | gradle/gradle | https://api.github.com/repos/gradle/gradle | closed | When I comment out the non-incremental processor and need to delete the build folder to make another incremental processor take effect again. | a:bug stale in:annotation-processing | My English is not good, so the expression is not very clear.
https://github.com/fanmingyi/bugAptIncremental
My project has an incremental processor `dagger` and a non-incremental processor `arouter`.
When I only use dagger, the annotation processor increment is normal.
Every time the relevant files are cha... | 1.0 | When I comment out the non-incremental processor and need to delete the build folder to make another incremental processor take effect again. - My English is not good, so the expression is not very clear.
https://github.com/fanmingyi/bugAptIncremental
My project has an incremental processor `dagger` and a non-i... | process | when i comment out the non incremental processor and need to delete the build folder to make another incremental processor take effect again my english is not good so the expression is not very clear my project has an incremental processor dagger and a non incremental processor arouter when i on... | 1 |
13,123 | 15,511,834,746 | IssuesEvent | 2021-03-12 00:24:13 | googleapis/python-monitoring | https://api.github.com/repos/googleapis/python-monitoring | opened | Resolve warnings in docgen | type: process | We typically treat all docs warnings as errors. Figure out which warnings are in these docs and resolve them.
https://github.com/googleapis/python-monitoring/blob/4cdb1ff439154409c94e347dd5f3b6e2bc40e998/synth.py#L105-L106
CC @parthea | 1.0 | Resolve warnings in docgen - We typically treat all docs warnings as errors. Figure out which warnings are in these docs and resolve them.
https://github.com/googleapis/python-monitoring/blob/4cdb1ff439154409c94e347dd5f3b6e2bc40e998/synth.py#L105-L106
CC @parthea | process | resolve warnings in docgen we typically treat all docs warnings as errors figure out which warnings are in these docs and resolve them cc parthea | 1 |
18,154 | 24,191,190,304 | IssuesEvent | 2022-09-23 17:45:22 | dtcenter/MET | https://api.github.com/repos/dtcenter/MET | opened | Add support for new point_weight_flag to the Point-Stat and Ensemble-Stat tools | type: new feature requestor: UK Met Office alert: NEED MORE DEFINITION alert: NEED ACCOUNT KEY alert: NEED PROJECT ASSIGNMENT MET: PreProcessing Tools (Point) priority: high | ## Describe the New Feature ##
The MET Grid-Stat tool supports a configuration option named [grid_weight_flag](https://met.readthedocs.io/en/develop/Users_Guide/config_options.html?highlight=grid_weight_flag#grid-weight-flag) to define weights to be applied to each grid point when aggregating statistics across multipl... | 1.0 | Add support for new point_weight_flag to the Point-Stat and Ensemble-Stat tools - ## Describe the New Feature ##
The MET Grid-Stat tool supports a configuration option named [grid_weight_flag](https://met.readthedocs.io/en/develop/Users_Guide/config_options.html?highlight=grid_weight_flag#grid-weight-flag) to define w... | process | add support for new point weight flag to the point stat and ensemble stat tools describe the new feature the met grid stat tool supports a configuration option named to define weights to be applied to each grid point when aggregating statistics across multiple grid points the grid weighting is based on th... | 1 |
1,778 | 4,500,099,934 | IssuesEvent | 2016-09-01 02:26:46 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | Sort mostly empty columns last in QP results | No Longer Relevant Proposal Query Processor | Rather than by name as the fallback sort.
It would be preferable to move them to the end.
This would be easy enough to do with the new `core.logic` column ordering logic, so long as we knew which ones to move...
We'd could iterate over the results to see which ones were "mostly empty", meaning our DB results... | 1.0 | Sort mostly empty columns last in QP results - Rather than by name as the fallback sort.
It would be preferable to move them to the end.
This would be easy enough to do with the new `core.logic` column ordering logic, so long as we knew which ones to move...
We'd could iterate over the results to see which o... | process | sort mostly empty columns last in qp results rather than by name as the fallback sort it would be preferable to move them to the end this would be easy enough to do with the new core logic column ordering logic so long as we knew which ones to move we d could iterate over the results to see which o... | 1 |
44,409 | 2,904,745,320 | IssuesEvent | 2015-06-18 19:47:46 | JMurk/Utility_Viewer_Issues | https://api.github.com/repos/JMurk/Utility_Viewer_Issues | closed | Utility Viewer - Identify Tool Enhancement | enhancement high priority | Update the identify tool so that it automatically identifies all visible layers without having to select layers from the drop down. | 1.0 | Utility Viewer - Identify Tool Enhancement - Update the identify tool so that it automatically identifies all visible layers without having to select layers from the drop down. | non_process | utility viewer identify tool enhancement update the identify tool so that it automatically identifies all visible layers without having to select layers from the drop down | 0 |
19,785 | 26,163,972,914 | IssuesEvent | 2023-01-01 02:00:08 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Thu, 29 Dec 22 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
### Position-Aware Contrastive Alignment for Referring Image Segmentation
- **Authors:** Bo Chen, Zhiwei Hu, Zhilong Ji, Jinfeng Bai, Wangmeng Zuo
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2212.13419
- **Pdf link:** https://arxiv.org/p... | 2.0 | New submissions for Thu, 29 Dec 22 - ## Keyword: events
### Position-Aware Contrastive Alignment for Referring Image Segmentation
- **Authors:** Bo Chen, Zhiwei Hu, Zhilong Ji, Jinfeng Bai, Wangmeng Zuo
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2212.13419... | process | new submissions for thu dec keyword events position aware contrastive alignment for referring image segmentation authors bo chen zhiwei hu zhilong ji jinfeng bai wangmeng zuo subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract... | 1 |
13,271 | 15,732,820,211 | IssuesEvent | 2021-03-29 18:46:08 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | Provide complete, correct instructions for deploying on Linux | Pri2 devops-cicd-process/tech devops/prod doc-bug |
The instructions on this page were demonstrably not tested on anything but Windows VMs.
"4. Choose Windows or Linux for the Operating System."
"6. Run the copied script from an administrator PowerShell command prompt".
Choosing the Linux operating system and running the script in /opt after running `sudo su` t... | 1.0 | Provide complete, correct instructions for deploying on Linux -
The instructions on this page were demonstrably not tested on anything but Windows VMs.
"4. Choose Windows or Linux for the Operating System."
"6. Run the copied script from an administrator PowerShell command prompt".
Choosing the Linux operating... | process | provide complete correct instructions for deploying on linux the instructions on this page were demonstrably not tested on anything but windows vms choose windows or linux for the operating system run the copied script from an administrator powershell command prompt choosing the linux operating... | 1 |
159,175 | 13,757,343,596 | IssuesEvent | 2020-10-06 21:28:21 | AladW/aurutils | https://api.github.com/repos/AladW/aurutils | closed | aur-build: warn when a repose-made repo is used | documentation | `aurutils` does not currently support `repose`.
But if the user has a `repose` created database `repo-add` calls will give cryptic error messages.
Since `aurutils` supported `repose` in the past, it may be a nice for us to detect such cases and give the user a more helpful error message. | 1.0 | aur-build: warn when a repose-made repo is used - `aurutils` does not currently support `repose`.
But if the user has a `repose` created database `repo-add` calls will give cryptic error messages.
Since `aurutils` supported `repose` in the past, it may be a nice for us to detect such cases and give the user a mor... | non_process | aur build warn when a repose made repo is used aurutils does not currently support repose but if the user has a repose created database repo add calls will give cryptic error messages since aurutils supported repose in the past it may be a nice for us to detect such cases and give the user a mor... | 0 |
357,201 | 25,176,342,598 | IssuesEvent | 2022-11-11 09:35:53 | Darren12345677/pe | https://api.github.com/repos/Darren12345677/pe | opened | Sequence diagram for adding appointment seems to be incorrect. | severity.VeryLow type.DocumentationBug | 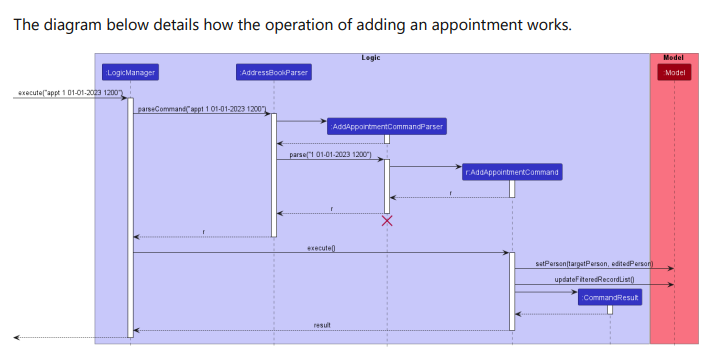
The activation bar for model is missing.
<!--session: 1668153192805-cd74d675-1c46-40e6-94c3-3c719c346698-->
<!--Version: Web v3.4.4--> | 1.0 | Sequence diagram for adding appointment seems to be incorrect. - 
The activation bar for model is missing.
<!--session: 1668153192805-cd74d675-1c46-40e6-94c3-3c719c346698-->
<!--Version: Web v3.4.4--> | non_process | sequence diagram for adding appointment seems to be incorrect the activation bar for model is missing | 0 |
68,591 | 3,291,129,755 | IssuesEvent | 2015-10-30 06:29:12 | otavanopisto/muikku | https://api.github.com/repos/otavanopisto/muikku | closed | Error- publishing the workspace | bug in progress priority | User describes:
>Maanantaina tosiaan on terveystiedon ryhmäkurssi starttaamassa ja kaikki on muutoin ok, mutta kun yritän kurssin etusivulla painaa "julkaise" niin saan jatkuvasti vain error-viestiä. Näkyykö kurssi kuitenkin normaalisti opiskelijoille, jotka kurssille on liitetty eli voinko vain jättää tämän asian ... | 1.0 | Error- publishing the workspace - User describes:
>Maanantaina tosiaan on terveystiedon ryhmäkurssi starttaamassa ja kaikki on muutoin ok, mutta kun yritän kurssin etusivulla painaa "julkaise" niin saan jatkuvasti vain error-viestiä. Näkyykö kurssi kuitenkin normaalisti opiskelijoille, jotka kurssille on liitetty e... | non_process | error publishing the workspace user describes maanantaina tosiaan on terveystiedon ryhmäkurssi starttaamassa ja kaikki on muutoin ok mutta kun yritän kurssin etusivulla painaa julkaise niin saan jatkuvasti vain error viestiä näkyykö kurssi kuitenkin normaalisti opiskelijoille jotka kurssille on liitetty e... | 0 |
19,118 | 25,170,172,461 | IssuesEvent | 2022-11-11 02:01:41 | googleapis/nodejs-analytics-data | https://api.github.com/repos/googleapis/nodejs-analytics-data | closed | Your .repo-metadata.json file has a problem 🤒 | type: process api: analyticsdata repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'analytics-data' invalid in .repo-metadata.json
☝️ Once you address these problems, you can close this issue.
### Need help?
* [Schema definition](https://github.com/googleapis/repo-automation-bots/blob/main/packages/repo-met... | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'analytics-data' invalid in .repo-metadata.json
☝️ Once you address these problems, you can close this issue.
### Need help?
* [Schema definition](https://github.com/googleapis... | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 api shortname analytics data invalid in repo metadata json ☝️ once you address these problems you can close this issue need help lists valid options for each field for... | 1 |
518 | 2,993,176,303 | IssuesEvent | 2015-07-22 00:43:55 | broadinstitute/hellbender | https://api.github.com/repos/broadinstitute/hellbender | opened | Expand ReadsPreprocessingPipelineTestData with multi-contig tests | Dataflow DataflowPreprocessingPipeline Engine | All of our tests use contig "1". This is fragile, we should add tests that include two contigs. This is not currently possible with ArtificialReadUtils (issue #688). | 1.0 | Expand ReadsPreprocessingPipelineTestData with multi-contig tests - All of our tests use contig "1". This is fragile, we should add tests that include two contigs. This is not currently possible with ArtificialReadUtils (issue #688). | process | expand readspreprocessingpipelinetestdata with multi contig tests all of our tests use contig this is fragile we should add tests that include two contigs this is not currently possible with artificialreadutils issue | 1 |
16,363 | 21,048,361,905 | IssuesEvent | 2022-03-31 18:16:14 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | [Question] Why does there need to be separate databases for --date-spec? | question log-processing | I assumed that I could use the same database when accessing --date-spec=hr when I already created a database with --date-spec=date. I assumed that all the data for --date-spec=hr would be there in the database from --date-spec=date. However, when I try that it does not work and only shows the results from --date-spec=d... | 1.0 | [Question] Why does there need to be separate databases for --date-spec? - I assumed that I could use the same database when accessing --date-spec=hr when I already created a database with --date-spec=date. I assumed that all the data for --date-spec=hr would be there in the database from --date-spec=date. However, whe... | process | why does there need to be separate databases for date spec i assumed that i could use the same database when accessing date spec hr when i already created a database with date spec date i assumed that all the data for date spec hr would be there in the database from date spec date however when i try t... | 1 |
11,190 | 13,957,699,323 | IssuesEvent | 2020-10-24 08:12:40 | alexanderkotsev/geoportal | https://api.github.com/repos/alexanderkotsev/geoportal | opened | PT: Harvesting | Geoportal Harvesting process tbc | Geoportal team,
We kindly request that you start a harvesting to the Portuguese catalogue. We have made some updatings and we would like to see if they are some results of our work.
Thank you!
Best regards,
Marta Medeiros | 1.0 | PT: Harvesting - Geoportal team,
We kindly request that you start a harvesting to the Portuguese catalogue. We have made some updatings and we would like to see if they are some results of our work.
Thank you!
Best regards,
Marta Medeiros | process | pt harvesting geoportal team we kindly request that you start a harvesting to the portuguese catalogue we have made some updatings and we would like to see if they are some results of our work thank you best regards marta medeiros | 1 |
201,528 | 15,211,631,259 | IssuesEvent | 2021-02-17 09:20:51 | ISISScientificComputing/autoreduce | https://api.github.com/repos/ISISScientificComputing/autoreduce | closed | Randomly failing queue client tests in pytest action | :key: Continuous Integration :key: Testing | Issue raised by: [developer/user/project requirement]
### What?
QueueClient tests are failing seemingly randomly withtin the pytest action.
This can be seen in more detail if you check the builds for PR #1044
### Where?
utils/clients/tests/test_queue_client.py
### How?
How did the issue come about
###... | 1.0 | Randomly failing queue client tests in pytest action - Issue raised by: [developer/user/project requirement]
### What?
QueueClient tests are failing seemingly randomly withtin the pytest action.
This can be seen in more detail if you check the builds for PR #1044
### Where?
utils/clients/tests/test_queue_cli... | non_process | randomly failing queue client tests in pytest action issue raised by what queueclient tests are failing seemingly randomly withtin the pytest action this can be seen in more detail if you check the builds for pr where utils clients tests test queue client py how how did the issue ... | 0 |
26,273 | 26,634,067,935 | IssuesEvent | 2023-01-24 20:17:04 | hpc/charliecloud | https://api.github.com/repos/hpc/charliecloud | opened | Fail faster for registry push with non-constant password | bug medium image usability | PR #1472 changes the behavior of `ch-image push` so that it requests user authentication before gathering and preparing the container. However, the implemented solution will not work if the user has a non-constant form of authentication (such as MFA). In this case, if the user's "password" changes before an upload toke... | True | Fail faster for registry push with non-constant password - PR #1472 changes the behavior of `ch-image push` so that it requests user authentication before gathering and preparing the container. However, the implemented solution will not work if the user has a non-constant form of authentication (such as MFA). In this c... | non_process | fail faster for registry push with non constant password pr changes the behavior of ch image push so that it requests user authentication before gathering and preparing the container however the implemented solution will not work if the user has a non constant form of authentication such as mfa in this case... | 0 |
6,483 | 9,553,745,508 | IssuesEvent | 2019-05-02 20:06:02 | bow-simulation/virtualbow | https://api.github.com/repos/bow-simulation/virtualbow | closed | Automated building and testing on all supported platforms | area: software process type: improvement | In GitLab by **spfeifer** on Apr 23, 2017, 04:09
**Linux**
Could be done with GitLab CI and the shared runners on gitlab.com. See [4] for a good example.
**Windows**
Three options:
* Use GitLab CI and register an own Windows runner
* Install runner on local virtual machine (disadvantage: have to start up manua... | 1.0 | Automated building and testing on all supported platforms - In GitLab by **spfeifer** on Apr 23, 2017, 04:09
**Linux**
Could be done with GitLab CI and the shared runners on gitlab.com. See [4] for a good example.
**Windows**
Three options:
* Use GitLab CI and register an own Windows runner
* Install runner on... | process | automated building and testing on all supported platforms in gitlab by spfeifer on apr linux could be done with gitlab ci and the shared runners on gitlab com see for a good example windows three options use gitlab ci and register an own windows runner install runner on local v... | 1 |
6,372 | 9,421,405,684 | IssuesEvent | 2019-04-11 06:41:52 | plazi/arcadia-project | https://api.github.com/repos/plazi/arcadia-project | opened | selection of articles for BLR processing: IRMNG data | Article processing | Here is the list of articles from the list of genus names in taxonomy, provided by Tony Rees. can you please create a ranking of contribution of the journals, eg how many time is a journal present in this list? This is important to decide where the most new names are
[irmng-sources-extra-Jul2017.xlsx](https://github... | 1.0 | selection of articles for BLR processing: IRMNG data - Here is the list of articles from the list of genus names in taxonomy, provided by Tony Rees. can you please create a ranking of contribution of the journals, eg how many time is a journal present in this list? This is important to decide where the most new names a... | process | selection of articles for blr processing irmng data here is the list of articles from the list of genus names in taxonomy provided by tony rees can you please create a ranking of contribution of the journals eg how many time is a journal present in this list this is important to decide where the most new names a... | 1 |
1,958 | 4,775,644,341 | IssuesEvent | 2016-10-27 11:08:26 | paulkornikov/Pragonas | https://api.github.com/repos/paulkornikov/Pragonas | closed | Add propriétés weblink - numéro compte - fréquence - extension to compte banque | a-new feature compte processus workload II | plus le répertoire de chargement et d'upload pour intégration sur le pc client | 1.0 | Add propriétés weblink - numéro compte - fréquence - extension to compte banque - plus le répertoire de chargement et d'upload pour intégration sur le pc client | process | add propriétés weblink numéro compte fréquence extension to compte banque plus le répertoire de chargement et d upload pour intégration sur le pc client | 1 |
22,259 | 30,810,937,681 | IssuesEvent | 2023-08-01 10:19:55 | B-Lang-org/bsc | https://api.github.com/repos/B-Lang-org/bsc | opened | SV preprocessor parentheses parsing | bug ICE sv-preprocessor | As mentioned in issue #469, there are warnings about non-exhaustive pattern matching in `SystemVerilogScanner.lhs`, in the function [`scanLinePosDirective`](https://github.com/B-Lang-org/bsc/blob/0e9a5b2624d91d514a2fb586b7e5d8c94050853b/src/comp/SystemVerilogScanner.lhs#L309-L322) which parses `` `line `` directives.
... | 1.0 | SV preprocessor parentheses parsing - As mentioned in issue #469, there are warnings about non-exhaustive pattern matching in `SystemVerilogScanner.lhs`, in the function [`scanLinePosDirective`](https://github.com/B-Lang-org/bsc/blob/0e9a5b2624d91d514a2fb586b7e5d8c94050853b/src/comp/SystemVerilogScanner.lhs#L309-L322) ... | process | sv preprocessor parentheses parsing as mentioned in issue there are warnings about non exhaustive pattern matching in systemverilogscanner lhs in the function which parses line directives the preprocessor accepts two kinds of line directive one according to the verilog systemverilog stan... | 1 |
761,537 | 26,684,960,854 | IssuesEvent | 2023-01-26 21:03:07 | dtcenter/MET | https://api.github.com/repos/dtcenter/MET | opened | Enhance TC-Stat to write the CTC/CTS output from the RIRW job to a real .stat output file | type: new feature requestor: NOAA/GSL alert: NEED ACCOUNT KEY alert: NEED PROJECT ASSIGNMENT MET: Tropical Cyclone Tools priority: high | ## Describe the New Feature ##
The RIRW job in TC-Stat applies a categorical verification approach to verify rapid intensification or weakening events identified in A-Decks and B-Decks. The job can write CTC/CTS/MPR data to the output. However, that output is only written to the terminal or redirected to a log file. A... | 1.0 | Enhance TC-Stat to write the CTC/CTS output from the RIRW job to a real .stat output file - ## Describe the New Feature ##
The RIRW job in TC-Stat applies a categorical verification approach to verify rapid intensification or weakening events identified in A-Decks and B-Decks. The job can write CTC/CTS/MPR data to the... | non_process | enhance tc stat to write the ctc cts output from the rirw job to a real stat output file describe the new feature the rirw job in tc stat applies a categorical verification approach to verify rapid intensification or weakening events identified in a decks and b decks the job can write ctc cts mpr data to the... | 0 |
300,540 | 25,975,337,377 | IssuesEvent | 2022-12-19 14:28:27 | pulumi/pulumi | https://api.github.com/repos/pulumi/pulumi | opened | Flaky `TestResourceRefsGetResourceNode` test | area/testing kind/engineering | The test inconsistently passes and fails. Disabling for now. This issue tracks fixing the underlying issue and re-enabling the test. | 1.0 | Flaky `TestResourceRefsGetResourceNode` test - The test inconsistently passes and fails. Disabling for now. This issue tracks fixing the underlying issue and re-enabling the test. | non_process | flaky testresourcerefsgetresourcenode test the test inconsistently passes and fails disabling for now this issue tracks fixing the underlying issue and re enabling the test | 0 |
146,268 | 13,175,411,157 | IssuesEvent | 2020-08-12 01:32:24 | shakacode/react_on_rails | https://api.github.com/repos/shakacode/react_on_rails | closed | Update documentation to not suggest moving node_modules | documentation needed | https://github.com/shakacode/react_on_rails/blob/master/docs/basics/recommended-project-structure.md
Instead, let's consider recommending leaving package.json and node_modules at the top-level...
There are no big advantages of having this be inside of the /client directory and there are a few additional bits of u... | 1.0 | Update documentation to not suggest moving node_modules - https://github.com/shakacode/react_on_rails/blob/master/docs/basics/recommended-project-structure.md
Instead, let's consider recommending leaving package.json and node_modules at the top-level...
There are no big advantages of having this be inside of the ... | non_process | update documentation to not suggest moving node modules instead let s consider recommending leaving package json and node modules at the top level there are no big advantages of having this be inside of the client directory and there are a few additional bits of unnecessary complexity ashgaliyev ple... | 0 |
427,550 | 12,396,643,127 | IssuesEvent | 2020-05-20 20:55:59 | minio/mc | https://api.github.com/repos/minio/mc | closed | mc mirror --watch ignores files owned by other user | community priority: medium stale triage | ## Expected behavior
"mc mirror --watch" should sync all files, even owned by other users than the one which runs the mc command
## Actual behavior
After starting "mc mirror --watch" all files in source directory are synced to target, no matter by which user the source files are owned. File permissions are 644 for... | 1.0 | mc mirror --watch ignores files owned by other user - ## Expected behavior
"mc mirror --watch" should sync all files, even owned by other users than the one which runs the mc command
## Actual behavior
After starting "mc mirror --watch" all files in source directory are synced to target, no matter by which user th... | non_process | mc mirror watch ignores files owned by other user expected behavior mc mirror watch should sync all files even owned by other users than the one which runs the mc command actual behavior after starting mc mirror watch all files in source directory are synced to target no matter by which user th... | 0 |
17,374 | 23,198,583,822 | IssuesEvent | 2022-08-01 18:58:03 | vectordotdev/vector | https://api.github.com/repos/vectordotdev/vector | closed | Implement end-to-end record acknowledgement | type: enhancement have: should domain: processing Epic | ## Summary
There does not appear to be any communication of acknowledgements from sinks to their source(s). This could cause dropped records if Vector is interrupted (killed) between receiving a record from a source and fully communicating it to the corresponding sink(s), which in turn voids the "at least once" delive... | 1.0 | Implement end-to-end record acknowledgement - ## Summary
There does not appear to be any communication of acknowledgements from sinks to their source(s). This could cause dropped records if Vector is interrupted (killed) between receiving a record from a source and fully communicating it to the corresponding sink(s), ... | process | implement end to end record acknowledgement summary there does not appear to be any communication of acknowledgements from sinks to their source s this could cause dropped records if vector is interrupted killed between receiving a record from a source and fully communicating it to the corresponding sink s ... | 1 |
446,825 | 31,560,753,416 | IssuesEvent | 2023-09-03 08:13:41 | Dayana-N/AutoMarket-PP4 | https://api.github.com/repos/Dayana-N/AutoMarket-PP4 | closed | DEV TASK: Document Testing Process MS8 | documentation Dev Task | **Describe Task**
Document the testing process of the application to include:
- Responsiveness
- Browser Compatibility
- Lighthouse
- Code Validation
- User stories
- Features
- Automated testing (Optional)
| 1.0 | DEV TASK: Document Testing Process MS8 - **Describe Task**
Document the testing process of the application to include:
- Responsiveness
- Browser Compatibility
- Lighthouse
- Code Validation
- User stories
- Features
- Automated testing (Optional)
| non_process | dev task document testing process describe task document the testing process of the application to include responsiveness browser compatibility lighthouse code validation user stories features automated testing optional | 0 |
10,285 | 13,133,408,102 | IssuesEvent | 2020-08-06 20:51:36 | ORNL-AMO/AMO-Tools-Desktop | https://api.github.com/repos/ORNL-AMO/AMO-Tools-Desktop | closed | O2 enrichment Baseline/Mod updates | Calculator Process Heating | From #3831:
Change headers to "Baseline" and "Modification"
Maybe reformat to be like other BL vs Mod calcs (almost any calc from the TH) {this might be better as a separate issue}
Once the user hits "Plot" the BL is "locked" (unlocks when user hits "Reset data")
then the user can change various fields in the mod and... | 1.0 | O2 enrichment Baseline/Mod updates - From #3831:
Change headers to "Baseline" and "Modification"
Maybe reformat to be like other BL vs Mod calcs (almost any calc from the TH) {this might be better as a separate issue}
Once the user hits "Plot" the BL is "locked" (unlocks when user hits "Reset data")
then the user can... | process | enrichment baseline mod updates from change headers to baseline and modification maybe reformat to be like other bl vs mod calcs almost any calc from the th this might be better as a separate issue once the user hits plot the bl is locked unlocks when user hits reset data then the user can cha... | 1 |
752,061 | 26,271,821,730 | IssuesEvent | 2023-01-06 17:44:24 | mypyc/mypyc | https://api.github.com/repos/mypyc/mypyc | opened | Unexpected runtime type error with inferred optional type | priority-0-high crash | This generates a `TypeError` at runtime, though the code is fine:
```py
def f(b: bool) -> None:
if b:
y = 1
else:
y = None
f(False)
```
Traceback:
```
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "t/a.py", line 7, in <module>
f(False)
... | 1.0 | Unexpected runtime type error with inferred optional type - This generates a `TypeError` at runtime, though the code is fine:
```py
def f(b: bool) -> None:
if b:
y = 1
else:
y = None
f(False)
```
Traceback:
```
Traceback (most recent call last):
File "<string>", line 1, in <mod... | non_process | unexpected runtime type error with inferred optional type this generates a typeerror at runtime though the code is fine py def f b bool none if b y else y none f false traceback traceback most recent call last file line in file ... | 0 |
1,447 | 4,020,060,312 | IssuesEvent | 2016-05-16 17:03:28 | emergence-lab/emergence-lab | https://api.github.com/repos/emergence-lab/emergence-lab | closed | Create from template - D180 | backend bug process | Issue where the create from template button on process detail page for a D180 growth redirects to the generic create process page rather than the create growth page. | 1.0 | Create from template - D180 - Issue where the create from template button on process detail page for a D180 growth redirects to the generic create process page rather than the create growth page. | process | create from template issue where the create from template button on process detail page for a growth redirects to the generic create process page rather than the create growth page | 1 |
79,528 | 7,718,862,016 | IssuesEvent | 2018-05-23 17:33:00 | cockroachdb/cockroach | https://api.github.com/repos/cockroachdb/cockroach | closed | workload: support distributed TPC-C load generation | A-testing C-enhancement | Throughout all previous TPC-C testing, we have used a single centralized load generator process. Even when running against a 30 node cluster with 10k warehouses, this has not been an issue - the load generator has always been able to produce the desired amount of load. However, now that we're beginning to look into run... | 1.0 | workload: support distributed TPC-C load generation - Throughout all previous TPC-C testing, we have used a single centralized load generator process. Even when running against a 30 node cluster with 10k warehouses, this has not been an issue - the load generator has always been able to produce the desired amount of lo... | non_process | workload support distributed tpc c load generation throughout all previous tpc c testing we have used a single centralized load generator process even when running against a node cluster with warehouses this has not been an issue the load generator has always been able to produce the desired amount of load ... | 0 |
18,077 | 24,094,936,128 | IssuesEvent | 2022-09-19 17:51:45 | Open-Data-Product-Initiative/open-data-product-spec | https://api.github.com/repos/Open-Data-Product-Initiative/open-data-product-spec | opened | Data Pipeline component and element renaming to DataOps | enhancement unprocessed | ```
"dataOps": {
"infrastructure": {
"platform": "Azure",
"storageTechnology": "Azure SQL",
"storageType": "sql",
"containerTool": "helm",
"format": "yaml",
"status": "development",
"scriptURL": "http://192.168.10.1/test/rundatapipeline.yml",
"deploymentDocumentationURL": "ht... | 1.0 | Data Pipeline component and element renaming to DataOps - ```
"dataOps": {
"infrastructure": {
"platform": "Azure",
"storageTechnology": "Azure SQL",
"storageType": "sql",
"containerTool": "helm",
"format": "yaml",
"status": "development",
"scriptURL": "http://192.168.10.1/test/ru... | process | data pipeline component and element renaming to dataops dataops infrastructure platform azure storagetechnology azure sql storagetype sql containertool helm format yaml status development scripturl deploymentdocumenta... | 1 |
17,100 | 22,620,032,162 | IssuesEvent | 2022-06-30 04:59:55 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Review + Create tab - list of resources created need updating | automation/svc triaged cxp doc-enhancement process-automation/subsvc Pri2 | In Review + Create tab:
https://docs.microsoft.com/en-us/azure/automation/automation-create-standalone-account?tabs=azureportal#review--create-tab
It says the following runbooks are automatically created upon completion:
- AzureAutomationTutorialWithIdentity
- AzureAutomationTutorialScript
- AzureAutomationTuto... | 1.0 | Review + Create tab - list of resources created need updating - In Review + Create tab:
https://docs.microsoft.com/en-us/azure/automation/automation-create-standalone-account?tabs=azureportal#review--create-tab
It says the following runbooks are automatically created upon completion:
- AzureAutomationTutorialWith... | process | review create tab list of resources created need updating in review create tab it says the following runbooks are automatically created upon completion azureautomationtutorialwithidentity azureautomationtutorialscript i created three different automation accounts and for each one the fo... | 1 |
15,909 | 20,113,514,745 | IssuesEvent | 2022-02-07 17:07:58 | akrherz/iem | https://api.github.com/repos/akrherz/iem | closed | Create SWAT files for UMRB | enhancement Data Processing | Requested two datasets
1) A "realtime" dataset updated daily for the 2019-yesterday period that contains MRMS precip + IEMRE temps
2) One-time dump of 2001-2021 MRMS + IEMRE. For the 2001-2010 period, -15% bias correction applied based on some previous checks I made. | 1.0 | Create SWAT files for UMRB - Requested two datasets
1) A "realtime" dataset updated daily for the 2019-yesterday period that contains MRMS precip + IEMRE temps
2) One-time dump of 2001-2021 MRMS + IEMRE. For the 2001-2010 period, -15% bias correction applied based on some previous checks I made. | process | create swat files for umrb requested two datasets a realtime dataset updated daily for the yesterday period that contains mrms precip iemre temps one time dump of mrms iemre for the period bias correction applied based on some previous checks i made | 1 |
182 | 2,562,477,967 | IssuesEvent | 2015-02-06 02:05:52 | phtimmins/cs373-collatz | https://api.github.com/repos/phtimmins/cs373-collatz | closed | Write more unit tests in TestCollatz.py | Project Requirement Testing | Write more unit tests in TestCollatz.py that test corner cases and failure cases until you have an average of 3 tests for each function, confirm the expected failures, and add, commit, and push to the private code repo. | 1.0 | Write more unit tests in TestCollatz.py - Write more unit tests in TestCollatz.py that test corner cases and failure cases until you have an average of 3 tests for each function, confirm the expected failures, and add, commit, and push to the private code repo. | non_process | write more unit tests in testcollatz py write more unit tests in testcollatz py that test corner cases and failure cases until you have an average of tests for each function confirm the expected failures and add commit and push to the private code repo | 0 |
7,577 | 10,686,799,495 | IssuesEvent | 2019-10-22 15:00:56 | openwdl/wdl | https://api.github.com/repos/openwdl/wdl | opened | Update RFC to Include Test cases | Discussion RFC Process | Before making a PR to the RFC process, I wanted to start a conversation here to see whate you guys think.
Whenever an new change is submitted, we currently have now way of testing whether the feature has been implemented or no, OR whether the implemented feature meets the requirements of the WDL specification. This ... | 1.0 | Update RFC to Include Test cases - Before making a PR to the RFC process, I wanted to start a conversation here to see whate you guys think.
Whenever an new change is submitted, we currently have now way of testing whether the feature has been implemented or no, OR whether the implemented feature meets the requireme... | process | update rfc to include test cases before making a pr to the rfc process i wanted to start a conversation here to see whate you guys think whenever an new change is submitted we currently have now way of testing whether the feature has been implemented or no or whether the implemented feature meets the requireme... | 1 |
30,988 | 5,892,424,859 | IssuesEvent | 2017-05-17 19:26:22 | ESMCI/cime | https://api.github.com/repos/ESMCI/cime | closed | Create clear and complete porting documentation | documentation ready | There is a new section on CIME internals that has been pushed to gh-pages that will help the porting documentation. The porting documentation needs to be significantly enhanced with examples to enable users to easily determine what needs to be done to port to their platformas. | 1.0 | Create clear and complete porting documentation - There is a new section on CIME internals that has been pushed to gh-pages that will help the porting documentation. The porting documentation needs to be significantly enhanced with examples to enable users to easily determine what needs to be done to port to their plat... | non_process | create clear and complete porting documentation there is a new section on cime internals that has been pushed to gh pages that will help the porting documentation the porting documentation needs to be significantly enhanced with examples to enable users to easily determine what needs to be done to port to their plat... | 0 |
74,949 | 7,453,140,987 | IssuesEvent | 2018-03-29 10:48:56 | italia/spid | https://api.github.com/repos/italia/spid | closed | Controllo metadata: Comune di Parabiago | metadata nuovo md test | Richiesta avanzata dal Comune di Parabiago
Invio metadata Comune di Parabiago | 1.0 | Controllo metadata: Comune di Parabiago - Richiesta avanzata dal Comune di Parabiago
Invio metadata Comune di Parabiago | non_process | controllo metadata comune di parabiago richiesta avanzata dal comune di parabiago invio metadata comune di parabiago | 0 |
8,960 | 12,068,521,823 | IssuesEvent | 2020-04-16 14:52:53 | ORNL-AMO/AMO-Tools-Desktop | https://api.github.com/repos/ORNL-AMO/AMO-Tools-Desktop | closed | (PHAST) Show Mods in Report | Process Heating enhancement | Child issue of #3635
Selected 'savings opportunities'/ modifications as well as 'energy projects' should be reflected in report > result data | 1.0 | (PHAST) Show Mods in Report - Child issue of #3635
Selected 'savings opportunities'/ modifications as well as 'energy projects' should be reflected in report > result data | process | phast show mods in report child issue of selected savings opportunities modifications as well as energy projects should be reflected in report result data | 1 |
642,759 | 20,912,643,024 | IssuesEvent | 2022-03-24 10:42:32 | ASE-Projekte-WS-2021/ase-ws-21-unser-horsaal | https://api.github.com/repos/ASE-Projekte-WS-2021/ase-ws-21-unser-horsaal | opened | (ONBOARDING) Onboarding beim ersten Nutzen der App | Medium Priority | Als Nutzer möchte ich beim ersten Nutzen der App in die App eingeführt werden, damit ich verstehe wie die App zu nutzen ist und ich motiviert bin die Features der App zu nutzen. | 1.0 | (ONBOARDING) Onboarding beim ersten Nutzen der App - Als Nutzer möchte ich beim ersten Nutzen der App in die App eingeführt werden, damit ich verstehe wie die App zu nutzen ist und ich motiviert bin die Features der App zu nutzen. | non_process | onboarding onboarding beim ersten nutzen der app als nutzer möchte ich beim ersten nutzen der app in die app eingeführt werden damit ich verstehe wie die app zu nutzen ist und ich motiviert bin die features der app zu nutzen | 0 |
1,526 | 4,117,595,403 | IssuesEvent | 2016-06-08 08:10:49 | Jumpscale/github_automation | https://api.github.com/repos/Jumpscale/github_automation | closed | move ays templates relevant to this automation to this repo | process_wontfix | ays template dir will be result
make sure that installer of cockpit uses also this ays_templates dir | 1.0 | move ays templates relevant to this automation to this repo - ays template dir will be result
make sure that installer of cockpit uses also this ays_templates dir | process | move ays templates relevant to this automation to this repo ays template dir will be result make sure that installer of cockpit uses also this ays templates dir | 1 |
19,393 | 25,536,909,421 | IssuesEvent | 2022-11-29 12:41:29 | bisq-network/bisq | https://api.github.com/repos/bisq-network/bisq | closed | Mailbox messages lost when performing SPV resync. | a:bug in:trade-process |
### Description
When performing an SPV resync, any received mailbox messages will be tossed irretrievably into the void.
#### Version
All versions.
### Steps to reproduce
- Open mediation on a trade.
- Go to Settings -> Network -> and press the `SPV resync` button.
- Close Bisq.
- Mediator issues a ... | 1.0 | Mailbox messages lost when performing SPV resync. -
### Description
When performing an SPV resync, any received mailbox messages will be tossed irretrievably into the void.
#### Version
All versions.
### Steps to reproduce
- Open mediation on a trade.
- Go to Settings -> Network -> and press the `SPV ... | process | mailbox messages lost when performing spv resync description when performing an spv resync any received mailbox messages will be tossed irretrievably into the void version all versions steps to reproduce open mediation on a trade go to settings network and press the spv ... | 1 |
48,028 | 13,067,402,466 | IssuesEvent | 2020-07-31 00:20:26 | icecube-trac/tix2 | https://api.github.com/repos/icecube-trac/tix2 | closed | Wavedeform needs new/better tests (Trac #1679) | Migrated from Trac combo reconstruction defect | The tests are sensitive to the random seed. Choose a different seed and they may crash and burn.
Also, the existing tests don't really get to the point. We should test:
1. Are all the bins of the refolded waveforms within tolerance?
2. If we add one SPE pulse well above the noise, does the returned pulse have the... | 1.0 | Wavedeform needs new/better tests (Trac #1679) - The tests are sensitive to the random seed. Choose a different seed and they may crash and burn.
Also, the existing tests don't really get to the point. We should test:
1. Are all the bins of the refolded waveforms within tolerance?
2. If we add one SPE pulse well ... | non_process | wavedeform needs new better tests trac the tests are sensitive to the random seed choose a different seed and they may crash and burn also the existing tests don t really get to the point we should test are all the bins of the refolded waveforms within tolerance if we add one spe pulse well abo... | 0 |
18,936 | 24,895,537,409 | IssuesEvent | 2022-10-28 15:29:07 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | NTR cellular response to disruption of membrane integrity | New term request waiting for feedback cellular processes | more details to be provided by @sylvainpoux | 1.0 | NTR cellular response to disruption of membrane integrity - more details to be provided by @sylvainpoux | process | ntr cellular response to disruption of membrane integrity more details to be provided by sylvainpoux | 1 |
238,987 | 19,802,936,702 | IssuesEvent | 2022-01-19 01:13:26 | brave/brave-browser | https://api.github.com/repos/brave/brave-browser | opened | Upgrade from Chromium 97.0.4692.71 to Chromium 97.0.4692.100(?). | QA/Yes release-notes/include QA/Test-Plan-Specified OS/Android Chromium/upgrade minor OS/Desktop | Minor Chromium bump.
https://chromium.googlesource.com/chromium/src/+log/97.0.4692.71..97.0.4692.100?pretty=fuller&n=10000
QA tests:
Check branding items
Check for version bump
Additional checks:
No specific code changes in Brave (only line number changes in patches). | 1.0 | Upgrade from Chromium 97.0.4692.71 to Chromium 97.0.4692.100(?). - Minor Chromium bump.
https://chromium.googlesource.com/chromium/src/+log/97.0.4692.71..97.0.4692.100?pretty=fuller&n=10000
QA tests:
Check branding items
Check for version bump
Additional checks:
No specific code changes in Brave (only l... | non_process | upgrade from chromium to chromium minor chromium bump qa tests check branding items check for version bump additional checks no specific code changes in brave only line number changes in patches | 0 |
283,963 | 24,573,202,861 | IssuesEvent | 2022-10-13 10:13:34 | claritychallenge/clarity | https://api.github.com/repos/claritychallenge/clarity | opened | Unit tests for dataset module | tests | Develop unit tests for the data module (see #80 for overview).
Specific modules within `dataset` are...
- [ ] `dataset/cec1_dataset.py` | 1.0 | Unit tests for dataset module - Develop unit tests for the data module (see #80 for overview).
Specific modules within `dataset` are...
- [ ] `dataset/cec1_dataset.py` | non_process | unit tests for dataset module develop unit tests for the data module see for overview specific modules within dataset are dataset dataset py | 0 |
164,819 | 20,507,885,741 | IssuesEvent | 2022-03-01 01:07:08 | Sh2dowFi3nd/Test_2 | https://api.github.com/repos/Sh2dowFi3nd/Test_2 | opened | CVE-2022-24615 (Medium) detected in zip4j-1.3.2.jar | security vulnerability | ## CVE-2022-24615 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>zip4j-1.3.2.jar</b></p></summary>
<p>An open source java library to handle zip files</p>
<p>Library home page: <a hr... | True | CVE-2022-24615 (Medium) detected in zip4j-1.3.2.jar - ## CVE-2022-24615 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>zip4j-1.3.2.jar</b></p></summary>
<p>An open source java libra... | non_process | cve medium detected in jar cve medium severity vulnerability vulnerable library jar an open source java library to handle zip files library home page a href path to dependency file test fs agent master fs agent master pom xml path to vulnerable library repo... | 0 |
24,686 | 5,096,484,298 | IssuesEvent | 2017-01-03 18:21:04 | zooniverse/Panoptes | https://api.github.com/repos/zooniverse/Panoptes | closed | Fix incomplete classification docs | documentation | http://docs.panoptes.apiary.io/#reference/classification/classification/list-all-classifications This is out of date, it should say that a user can retrieve only their finished classifications instead of this:
> A User may only retrieve a single classification if it not completed in order to finish it. Otherwise they ... | 1.0 | Fix incomplete classification docs - http://docs.panoptes.apiary.io/#reference/classification/classification/list-all-classifications This is out of date, it should say that a user can retrieve only their finished classifications instead of this:
> A User may only retrieve a single classification if it not completed i... | non_process | fix incomplete classification docs this is out of date it should say that a user can retrieve only their finished classifications instead of this a user may only retrieve a single classification if it not completed in order to finish it otherwise they may retrieve a list of classifications from the classifica... | 0 |
6,907 | 10,059,471,018 | IssuesEvent | 2019-07-22 16:30:53 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | closed | `npm run link` fails on Windows because of EPERM | OS: windows process: contributing stage: needs review | <!-- Is this a question? Don't open an issue. Ask in our chat https://on.cypress.io/chat -->
### Current behavior:
https://github.com/cypress-io/cypress/blame/develop/scripts/link-packages.js#L46
`fs.symlink` fails in `npm run link` on Windows with `EPERM`. You must run as administrator for `fs.symlink` to co... | 1.0 | `npm run link` fails on Windows because of EPERM - <!-- Is this a question? Don't open an issue. Ask in our chat https://on.cypress.io/chat -->
### Current behavior:
https://github.com/cypress-io/cypress/blame/develop/scripts/link-packages.js#L46
`fs.symlink` fails in `npm run link` on Windows with `EPERM`. Y... | process | npm run link fails on windows because of eperm current behavior fs symlink fails in npm run link on windows with eperm you must run as administrator for fs symlink to complete successfully without admin with admin also i have no clue why but the symli... | 1 |
3,648 | 6,678,487,787 | IssuesEvent | 2017-10-05 14:24:08 | wpninjas/ninja-forms-uploads | https://api.github.com/repos/wpninjas/ninja-forms-uploads | opened | Nonce error happens without Save Progress activated. | DIFFICULTY: Easy FRONT: Processing PRIORITY: High VALUE: Modern | Nonce error happens without Save Progress activated. This nonce error happens during the upload of the file and before the processing of the form.
WP Version: 4.8.2 - Supported
WP Multisite Enabled: No
Web Server Info: Apache/2.4.10 (Debian)
TLS Version: 1.2
PHP Version: 5.6.30-0+deb8u1
MySQL Version: 5.6.37
P... | 1.0 | Nonce error happens without Save Progress activated. - Nonce error happens without Save Progress activated. This nonce error happens during the upload of the file and before the processing of the form.
WP Version: 4.8.2 - Supported
WP Multisite Enabled: No
Web Server Info: Apache/2.4.10 (Debian)
TLS Version: 1.2
... | process | nonce error happens without save progress activated nonce error happens without save progress activated this nonce error happens during the upload of the file and before the processing of the form wp version supported wp multisite enabled no web server info apache debian tls version ... | 1 |
53,751 | 23,052,026,634 | IssuesEvent | 2022-07-24 19:24:59 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Different spelling of externalTrafficPolicy value: local vs Local | container-service/svc triaged cxp doc-enhancement Pri1 | Not sure if important, but there is a slight mismatch in spelling:
Text uses `local`
> you must set `service.spec.externalTrafficPolicy` to `local` in the service definition.
Code block that follows uses `Local`
> externalTrafficPolicy: Local
---
#### Document Details
⚠ *Do not edit this section... | 1.0 | Different spelling of externalTrafficPolicy value: local vs Local - Not sure if important, but there is a slight mismatch in spelling:
Text uses `local`
> you must set `service.spec.externalTrafficPolicy` to `local` in the service definition.
Code block that follows uses `Local`
> externalTrafficPolicy: Lo... | non_process | different spelling of externaltrafficpolicy value local vs local not sure if important but there is a slight mismatch in spelling text uses local you must set service spec externaltrafficpolicy to local in the service definition code block that follows uses local externaltrafficpolicy lo... | 0 |
16,503 | 21,485,342,672 | IssuesEvent | 2022-04-26 22:27:39 | googleapis/python-optimization | https://api.github.com/repos/googleapis/python-optimization | closed | Your .repo-metadata.json file has a problem 🤒 | type: process api: cloudoptimization repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'optimization' invalid in .repo-metadata.json
☝️ Once you address these problems, you can close this issue.
### Need help?
* [Schema definition](https://github.com/googleapis/repo-automation-bots/blob/main/packages/repo-metad... | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'optimization' invalid in .repo-metadata.json
☝️ Once you address these problems, you can close this issue.
### Need help?
* [Schema definition](https://github.com/googleapis/r... | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 api shortname optimization invalid in repo metadata json ☝️ once you address these problems you can close this issue need help lists valid options for each field for g... | 1 |
2,089 | 4,927,338,407 | IssuesEvent | 2016-11-26 17:44:20 | mitchellh/packer | https://api.github.com/repos/mitchellh/packer | closed | Docker push to AWS ECR | post-processor/docker | I am trying to push the docker container to AWS ECR, and it works as long as value for "login_password" is provided inline in packer JSON file, if value is set via variable then i get following error. Details below for error case.
Error
```
==> docker: Running post-processor: docker-push
docker (docker-push): Logg... | 1.0 | Docker push to AWS ECR - I am trying to push the docker container to AWS ECR, and it works as long as value for "login_password" is provided inline in packer JSON file, if value is set via variable then i get following error. Details below for error case.
Error
```
==> docker: Running post-processor: docker-push
... | process | docker push to aws ecr i am trying to push the docker container to aws ecr and it works as long as value for login password is provided inline in packer json file if value is set via variable then i get following error details below for error case error docker running post processor docker push ... | 1 |
18,254 | 24,335,626,345 | IssuesEvent | 2022-10-01 03:13:52 | GoogleCloudPlatform/cloud-ops-sandbox | https://api.github.com/repos/GoogleCloudPlatform/cloud-ops-sandbox | opened | Cleanup repo from all artifacts of the microservice demo application | priority: p1 type: process | Remove all artifacts of the Hipster shop from the repo.
*NOTE:* Completing this task will break the repo. | 1.0 | Cleanup repo from all artifacts of the microservice demo application - Remove all artifacts of the Hipster shop from the repo.
*NOTE:* Completing this task will break the repo. | process | cleanup repo from all artifacts of the microservice demo application remove all artifacts of the hipster shop from the repo note completing this task will break the repo | 1 |
72,747 | 8,774,525,621 | IssuesEvent | 2018-12-18 20:05:02 | brave/brave-ios | https://api.github.com/repos/brave/brave-ios | opened | redesign the error page | needs design | ### Description:
The error page in V1.7 is not clear and needs design work
<img width="437" alt="screen shot 2018-12-18 at 11 15 19 am" src="https://user-images.githubusercontent.com/7606853/50178478-78c6a380-02b9-11e9-9db2-360a875cf0e4.png">
| 1.0 | redesign the error page - ### Description:
The error page in V1.7 is not clear and needs design work
<img width="437" alt="screen shot 2018-12-18 at 11 15 19 am" src="https://user-images.githubusercontent.com/7606853/50178478-78c6a380-02b9-11e9-9db2-360a875cf0e4.png">
| non_process | redesign the error page description the error page in is not clear and needs design work img width alt screen shot at am src | 0 |
5,197 | 7,974,026,180 | IssuesEvent | 2018-07-17 02:48:12 | factor/factor | https://api.github.com/repos/factor/factor | opened | tools.which and process-launcher don't search standard-login-paths | paths process-launcher tools unix | The ``standard-login-paths`` word starts the default shell, echos ``$PATH``, and returns. This is different from what the ``"PATH" os-env`` sees because of ``.bashrc`` etc adding to the path.
```factor
! on a macbook
standard-login-paths .
/Users/erg/miniconda2/bin:/Users/erg/.nvm/versions/node/v9.2.0/bin:/usr/lo... | 1.0 | tools.which and process-launcher don't search standard-login-paths - The ``standard-login-paths`` word starts the default shell, echos ``$PATH``, and returns. This is different from what the ``"PATH" os-env`` sees because of ``.bashrc`` etc adding to the path.
```factor
! on a macbook
standard-login-paths .
/User... | process | tools which and process launcher don t search standard login paths the standard login paths word starts the default shell echos path and returns this is different from what the path os env sees because of bashrc etc adding to the path factor on a macbook standard login paths user... | 1 |
98,444 | 29,870,547,119 | IssuesEvent | 2023-06-20 08:12:16 | GSS-Cogs/dd-cms | https://api.github.com/repos/GSS-Cogs/dd-cms | closed | Automate legend font change | chart builder high priority | At the moment the only way to update the legend font to the new font and size is to resave each chart. | 1.0 | Automate legend font change - At the moment the only way to update the legend font to the new font and size is to resave each chart. | non_process | automate legend font change at the moment the only way to update the legend font to the new font and size is to resave each chart | 0 |
10,153 | 13,044,162,599 | IssuesEvent | 2020-07-29 03:47:34 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `Decode` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `Decode` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @andylokandy
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rpn_expr... | 2.0 | UCP: Migrate scalar function `Decode` from TiDB -
## Description
Port the scalar function `Decode` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @andylokandy
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/t... | process | ucp migrate scalar function decode from tidb description port the scalar function decode from tidb to coprocessor score mentor s andylokandy recommended skills rust programming learning materials already implemented expressions ported from tidb | 1 |
4,443 | 7,313,464,833 | IssuesEvent | 2018-03-01 01:16:21 | P2Poker/RandomCat | https://api.github.com/repos/P2Poker/RandomCat | opened | As a developer, I need a system of build/test configurations for various parts of the desired software | c) dev origin d) release 0.1 e) dev tools f) priority 2 g) change request h) in process j) difficult workaround l) minor completion cost l) no risk l) no ux impact n) no impact n) no users affected o) as a dev p) triage completed | ## Story **(REQUIRED)**
As a developer, I need a system of build/test configurations for various parts of the desired software.
## Explanation **(REQUIRED)**
Create a series of pre-determined build/test configurations, which can be expanded in the future as needed. | 1.0 | As a developer, I need a system of build/test configurations for various parts of the desired software - ## Story **(REQUIRED)**
As a developer, I need a system of build/test configurations for various parts of the desired software.
## Explanation **(REQUIRED)**
Create a series of pre-determined build/test configu... | process | as a developer i need a system of build test configurations for various parts of the desired software story required as a developer i need a system of build test configurations for various parts of the desired software explanation required create a series of pre determined build test configu... | 1 |
204,382 | 7,087,353,515 | IssuesEvent | 2018-01-11 17:31:07 | salesagility/SuiteCRM | https://api.github.com/repos/salesagility/SuiteCRM | closed | PHP Fatal error when I try to edit or view subpanels on the modulebuilder | Fix Proposed Medium Priority Resolved: Next Release bug |
#### Issue
I can not edit or view subpanels on the modulebuilder. Whenever I press the link called Default placed on Available Subpanels folder, nothing happens
#### Expected Behavior
Edit or view subpanels on the modulebuilder.
#### Actual Behavior
I can not edit or view subpanels on the modulebuilder. When... | 1.0 | PHP Fatal error when I try to edit or view subpanels on the modulebuilder -
#### Issue
I can not edit or view subpanels on the modulebuilder. Whenever I press the link called Default placed on Available Subpanels folder, nothing happens
#### Expected Behavior
Edit or view subpanels on the modulebuilder.
#### ... | non_process | php fatal error when i try to edit or view subpanels on the modulebuilder issue i can not edit or view subpanels on the modulebuilder whenever i press the link called default placed on available subpanels folder nothing happens expected behavior edit or view subpanels on the modulebuilder ... | 0 |
125,228 | 16,748,406,727 | IssuesEvent | 2021-06-11 18:47:14 | angular/angular | https://api.github.com/repos/angular/angular | closed | Fix tables in markdown to be HTML per Angular doc style | comp: docs docsarea: global effort1: hours freq2: medium subtype: docs-design subtype: docs-edit type: bug/fix | <!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopp... | 1.0 | Fix tables in markdown to be HTML per Angular doc style - <!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><cod... | non_process | fix tables in markdown to be html per angular doc style please help us process github issues faster by providing the following information issues missing important information may be closed without investigation i m submitting a regression a behavior that used to work and stopped w... | 0 |
16,590 | 21,639,663,157 | IssuesEvent | 2022-05-05 17:24:36 | scikit-learn/scikit-learn | https://api.github.com/repos/scikit-learn/scikit-learn | closed | Gaussian Process Regression: "normalize_y=True" screws up model fit | module:gaussian_process Needs Triage | ### Describe the bug
Hello everybody,
First of all let me thank you for the great work you've done.
That being said, I've run into the situation where using "normalize_y=True" in a Gaussian Process Regression fit yields wildly different results
### Steps/Code to Reproduce
```python
# Imports
import num... | 1.0 | Gaussian Process Regression: "normalize_y=True" screws up model fit - ### Describe the bug
Hello everybody,
First of all let me thank you for the great work you've done.
That being said, I've run into the situation where using "normalize_y=True" in a Gaussian Process Regression fit yields wildly different resu... | process | gaussian process regression normalize y true screws up model fit describe the bug hello everybody first of all let me thank you for the great work you ve done that being said i ve run into the situation where using normalize y true in a gaussian process regression fit yields wildly different resu... | 1 |
21,525 | 29,806,664,524 | IssuesEvent | 2023-06-16 12:13:31 | firebase/firebase-cpp-sdk | https://api.github.com/repos/firebase/firebase-cpp-sdk | reopened | [C++] Nightly Integration Testing Report for Firestore | type: process nightly-testing |
<hidden value="integration-test-status-comment"></hidden>
### ✅ [build against repo] Integration test succeeded!
Requested by @sunmou99 on commit c3afeae7800f06f786e8018add11be6fb3169715
Last updated: Thu Jun 15 04:48 PDT 2023
**[View integration test log & download artifacts](https://github.com/firebase/fire... | 1.0 | [C++] Nightly Integration Testing Report for Firestore -
<hidden value="integration-test-status-comment"></hidden>
### ✅ [build against repo] Integration test succeeded!
Requested by @sunmou99 on commit c3afeae7800f06f786e8018add11be6fb3169715
Last updated: Thu Jun 15 04:48 PDT 2023
**[View integration test l... | process | nightly integration testing report for firestore ✅ nbsp integration test succeeded requested by on commit last updated thu jun pdt ✅ nbsp integration test succeeded requested by firebase workflow trigger on commit last updated thu jun pdt ... | 1 |
69,415 | 14,988,512,931 | IssuesEvent | 2021-01-29 01:26:11 | Omni3Tech/corda | https://api.github.com/repos/Omni3Tech/corda | opened | CVE-2020-10968 (High) detected in jackson-databind-2.9.7.jar, jackson-databind-2.8.4.jar | security vulnerability | ## CVE-2020-10968 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>jackson-databind-2.9.7.jar</b>, <b>jackson-databind-2.8.4.jar</b></p></summary>
<p>
<details><summary><b>jackson-dat... | True | CVE-2020-10968 (High) detected in jackson-databind-2.9.7.jar, jackson-databind-2.8.4.jar - ## CVE-2020-10968 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>jackson-databind-2.9.7.jar... | non_process | cve high detected in jackson databind jar jackson databind jar cve high severity vulnerability vulnerable libraries jackson databind jar jackson databind jar jackson databind jar general data binding functionality for jackson works on core streami... | 0 |
633,366 | 20,253,059,140 | IssuesEvent | 2022-02-14 19:57:25 | UnifespCodeLab/plasmedis-api | https://api.github.com/repos/UnifespCodeLab/plasmedis-api | closed | [Gerenciamento de Postagem] Remover Postagem | priority: high type: feature | # História de Usuário
- O usuário deve ser capaz de excluir suas postagens.
- Um moderador/administrador deve ser capaz de excluir quaisquer postagens.
# Resumo
> **DELETE** /postagens/<postagem_id>
Criar a rota acima para remover postagens e seus comentários. Essa rota deve verificar se o usuário autenticad... | 1.0 | [Gerenciamento de Postagem] Remover Postagem - # História de Usuário
- O usuário deve ser capaz de excluir suas postagens.
- Um moderador/administrador deve ser capaz de excluir quaisquer postagens.
# Resumo
> **DELETE** /postagens/<postagem_id>
Criar a rota acima para remover postagens e seus comentários. E... | non_process | remover postagem história de usuário o usuário deve ser capaz de excluir suas postagens um moderador administrador deve ser capaz de excluir quaisquer postagens resumo delete postagens criar a rota acima para remover postagens e seus comentários essa rota deve verificar se o usuário a... | 0 |
618,511 | 19,472,536,814 | IssuesEvent | 2021-12-24 05:21:30 | bryntum/support | https://api.github.com/repos/bryntum/support | closed | DayView DragZone doesn't handle interday events which belong in the DayView | bug resolved high-priority | Configure the Calendar with
```
modes : {
week : {
showAllDayHeader : false
}
}
```
Which means interDay events will show in the day columns.
Then create a new day spanning event.
Drag-moving and drag-resizing the event do not work - the DragZone assumes the event belongs in the AllDay... | 1.0 | DayView DragZone doesn't handle interday events which belong in the DayView - Configure the Calendar with
```
modes : {
week : {
showAllDayHeader : false
}
}
```
Which means interDay events will show in the day columns.
Then create a new day spanning event.
Drag-moving and drag-resizin... | non_process | dayview dragzone doesn t handle interday events which belong in the dayview configure the calendar with modes week showalldayheader false which means interday events will show in the day columns then create a new day spanning event drag moving and drag resizin... | 0 |
58,144 | 16,371,384,264 | IssuesEvent | 2021-05-15 07:22:52 | vector-im/element-web | https://api.github.com/repos/vector-im/element-web | opened | [UX anti pattern] "Explore rooms" button inconsistent compared to search bar | T-Defect | ### Description
The "Filter all spaces" search bar filters *all* your spaces (big surprise) and rooms. Therefore I expected the "Explore rooms" button located **directly next to it** to be global too i.e. to open *the server's room list* instead of the Space home.
I've stumbled across this quite often so I really... | 1.0 | [UX anti pattern] "Explore rooms" button inconsistent compared to search bar - ### Description
The "Filter all spaces" search bar filters *all* your spaces (big surprise) and rooms. Therefore I expected the "Explore rooms" button located **directly next to it** to be global too i.e. to open *the server's room list* ... | non_process | explore rooms button inconsistent compared to search bar description the filter all spaces search bar filters all your spaces big surprise and rooms therefore i expected the explore rooms button located directly next to it to be global too i e to open the server s room list instead of the s... | 0 |
314,013 | 26,970,463,536 | IssuesEvent | 2023-02-09 04:06:45 | seleniumbase/SeleniumBase | https://api.github.com/repos/seleniumbase/SeleniumBase | closed | Examples that use Google might need to change | tests | ### Examples that use Google might need to change
**Automated tests started hitting this today:**
<img width="550" alt="Screenshot 2023-02-06 at 10 12 05 PM" src="https://user-images.githubusercontent.com/6788579/217139401-a80660d6-2c11-46fe-a5db-0bc335dc1f64.png">
**Impacted examples:**
* https://github.com/... | 1.0 | Examples that use Google might need to change - ### Examples that use Google might need to change
**Automated tests started hitting this today:**
<img width="550" alt="Screenshot 2023-02-06 at 10 12 05 PM" src="https://user-images.githubusercontent.com/6788579/217139401-a80660d6-2c11-46fe-a5db-0bc335dc1f64.png">
... | non_process | examples that use google might need to change examples that use google might need to change automated tests started hitting this today img width alt screenshot at pm src impacted examples these are examples i use to verify the f... | 0 |
299,639 | 25,915,601,419 | IssuesEvent | 2022-12-15 17:06:05 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | Test failure: System.Net.Sockets.Tests.DnsEndPointTest.Socket_ConnectAsyncDnsEndPoint_Success(type: Async) | area-System.Net.Sockets test-run-core | failed in job: [runtime-libraries outerloop 20200519.3 ](https://dev.azure.com/dnceng/public/_build/results?buildId=651228&view=ms.vss-test-web.build-test-results-tab&runId=20205164&resultId=103418&paneView=debug)
Error message
~~~
Timed out while waiting for connection
Expected: True
Actual: False
Stack ... | 1.0 | Test failure: System.Net.Sockets.Tests.DnsEndPointTest.Socket_ConnectAsyncDnsEndPoint_Success(type: Async) - failed in job: [runtime-libraries outerloop 20200519.3 ](https://dev.azure.com/dnceng/public/_build/results?buildId=651228&view=ms.vss-test-web.build-test-results-tab&runId=20205164&resultId=103418&paneView=debu... | non_process | test failure system net sockets tests dnsendpointtest socket connectasyncdnsendpoint success type async failed in job error message timed out while waiting for connection expected true actual false stack trace at system net sockets tests dnsendpointtest socket connectasyncdnsendpoint s... | 0 |
43,910 | 17,767,884,341 | IssuesEvent | 2021-08-30 09:53:23 | azure-deprecation/dashboard | https://api.github.com/repos/azure-deprecation/dashboard | opened | Azure Application Insights Release annotations using API keys are retiring on 31 August 2024 | impact:migration-required verified area:feature cloud:public services:app-insights | Azure Application Insights Release annotations using API keys are retiring on 31 August 2024
**Deadline:** Aug 31, 2024
**Impacted Services:**
- Azure Application Insights
**More information:**
- https://azure.microsoft.com/en-au/updates/transition-to-new-release-annotations-in-application-insights/
- https://docs.mi... | 1.0 | Azure Application Insights Release annotations using API keys are retiring on 31 August 2024 - Azure Application Insights Release annotations using API keys are retiring on 31 August 2024
**Deadline:** Aug 31, 2024
**Impacted Services:**
- Azure Application Insights
**More information:**
- https://azure.microsoft.com... | non_process | azure application insights release annotations using api keys are retiring on august azure application insights release annotations using api keys are retiring on august deadline aug impacted services azure application insights more information notice here s the official ... | 0 |
14,355 | 17,377,905,137 | IssuesEvent | 2021-07-31 04:14:52 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | System.Diagnostics.Tests.ProcessTests.TestToString_OnExitedProcess failing in the CI | area-System.Diagnostics.Process in pr untriaged | https://dev.azure.com/dnceng/public/_build/results?buildId=1268768&view=logs&j=1422aa79-6880-5d83-e13f-65c73e5c446b&t=f314303b-c6ab-51e8-2c96-4cbe16c1a0a2
https://helixre8s23ayyeko0k025g8.blob.core.windows.net/dotnet-runtime-refs-pull-56504-merge-b7005c257cb84dc688/System.Diagnostics.Process.Tests/console.0ad0143c.l... | 1.0 | System.Diagnostics.Tests.ProcessTests.TestToString_OnExitedProcess failing in the CI - https://dev.azure.com/dnceng/public/_build/results?buildId=1268768&view=logs&j=1422aa79-6880-5d83-e13f-65c73e5c446b&t=f314303b-c6ab-51e8-2c96-4cbe16c1a0a2
https://helixre8s23ayyeko0k025g8.blob.core.windows.net/dotnet-runtime-refs-... | process | system diagnostics tests processtests testtostring onexitedprocess failing in the ci c h w w e c h w p dotnet exe exec runtimeconfig system diagnostics process tests runtimeconfig json depsfile system diagnostics process tests deps json xunit console dll system diagnostics process tests d... | 1 |
329,371 | 24,216,332,576 | IssuesEvent | 2022-09-26 07:07:55 | appsmithorg/appsmith | https://api.github.com/repos/appsmithorg/appsmith | closed | [Docs]: Table Widget v2.1: Checkbox Column Type Documentation | Documentation User Education Pod Ready for Doc Team | ### Is there an existing issue for this?
Documentation for https://github.com/appsmithorg/appsmith/issues/7338
### Description
We wish to support checkbox as a column type in table
## Link to documentation
https://www.notion.so/appsmith/Table-Widget-Checkbox-column-type-5a8c09ffdc024d39bb8f511c07b403b5 | 1.0 | [Docs]: Table Widget v2.1: Checkbox Column Type Documentation - ### Is there an existing issue for this?
Documentation for https://github.com/appsmithorg/appsmith/issues/7338
### Description
We wish to support checkbox as a column type in table
## Link to documentation
https://www.notion.so/appsmith/Table-... | non_process | table widget checkbox column type documentation is there an existing issue for this documentation for description we wish to support checkbox as a column type in table link to documentation | 0 |
20,732 | 27,430,378,384 | IssuesEvent | 2023-03-02 00:32:12 | okTurtles/group-income | https://api.github.com/repos/okTurtles/group-income | opened | Create staging server | Kind:Bug Kind:Enhancement App:Frontend App:Backend Kind:Test Priority:High Note:Tooling Kind:Process Kind:Core | ### Problem
Multiple times now we've had the issue of everything appearing to work during testing and Travis, etc., but once merged into production everything breaks.
This is caused because of the way the contracts need to be upgraded with missing data sometimes (and failed to be upgraded). Or other reasons.
#... | 1.0 | Create staging server - ### Problem
Multiple times now we've had the issue of everything appearing to work during testing and Travis, etc., but once merged into production everything breaks.
This is caused because of the way the contracts need to be upgraded with missing data sometimes (and failed to be upgraded)... | process | create staging server problem multiple times now we ve had the issue of everything appearing to work during testing and travis etc but once merged into production everything breaks this is caused because of the way the contracts need to be upgraded with missing data sometimes and failed to be upgraded ... | 1 |
10,067 | 13,044,161,811 | IssuesEvent | 2020-07-29 03:47:26 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `StrToDateDuration` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `StrToDateDuration` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @iosmanthus
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/sr... | 2.0 | UCP: Migrate scalar function `StrToDateDuration` from TiDB -
## Description
Port the scalar function `StrToDateDuration` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @iosmanthus
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- http... | process | ucp migrate scalar function strtodateduration from tidb description port the scalar function strtodateduration from tidb to coprocessor score mentor s iosmanthus recommended skills rust programming learning materials already implemented expressions ported from tidb ... | 1 |
139,431 | 5,375,273,691 | IssuesEvent | 2017-02-23 03:53:42 | chaorace/cqui | https://api.github.com/repos/chaorace/cqui | opened | Barbarian icons are *too* red | bug easy low priority | Jokes aside, 84b4f365f52d9af76745591a77321f1aeecc86e3 introduced an issue where barbarian icons were reddened, due to being hostile by default. This behavior doesn't do anything to help the player and makes the color too bright and a little painful to look at | 1.0 | Barbarian icons are *too* red - Jokes aside, 84b4f365f52d9af76745591a77321f1aeecc86e3 introduced an issue where barbarian icons were reddened, due to being hostile by default. This behavior doesn't do anything to help the player and makes the color too bright and a little painful to look at | non_process | barbarian icons are too red jokes aside introduced an issue where barbarian icons were reddened due to being hostile by default this behavior doesn t do anything to help the player and makes the color too bright and a little painful to look at | 0 |
11,806 | 14,627,699,253 | IssuesEvent | 2020-12-23 12:48:12 | DevExpress/testcafe-hammerhead | https://api.github.com/repos/DevExpress/testcafe-hammerhead | opened | Links with the 'rel' attribute that equals to 'modulepreload' are overridden incorrectly | AREA: client AREA: server FREQUENCY: level 1 SYSTEM: resource processing SYSTEM: script processing TYPE: bug | Server example:
```js
require('http')
.createServer((req, res) => {
if (req.url === '/') {
res.writeHead(200, { 'content-type': 'text/html' });
res.end(`
<meta charset="utf-8">
<link rel="modulepreload" href="foo.js">
<link rel... | 2.0 | Links with the 'rel' attribute that equals to 'modulepreload' are overridden incorrectly - Server example:
```js
require('http')
.createServer((req, res) => {
if (req.url === '/') {
res.writeHead(200, { 'content-type': 'text/html' });
res.end(`
<meta charset="u... | process | links with the rel attribute that equals to modulepreload are overridden incorrectly server example js require http createserver req res if req url res writehead content type text html res end ... | 1 |
620 | 3,086,889,736 | IssuesEvent | 2015-08-25 07:59:02 | e-government-ua/i | https://api.github.com/repos/e-government-ua/i | closed | На бэке (wf-base) реализовать сервис получения активных тикетов | hi priority In process of testing test | - [x] 1) Создать сервис getFlowSlotTickets (в том-же контроллере где идет работа со слотами)
- [x] 2) Принимать параметры
sLogin - строка логина пользователя
bEmployeeUnassigned - булевый, true - не ассигнутые госслужащим //опциональный, умолчательно false
sDate - строка с датой //опциональный
- [x] 3) Выдава... | 1.0 | На бэке (wf-base) реализовать сервис получения активных тикетов - - [x] 1) Создать сервис getFlowSlotTickets (в том-же контроллере где идет работа со слотами)
- [x] 2) Принимать параметры
sLogin - строка логина пользователя
bEmployeeUnassigned - булевый, true - не ассигнутые госслужащим //опциональный, умолчатель... | process | на бэке wf base реализовать сервис получения активных тикетов создать сервис getflowslottickets в том же контроллере где идет работа со слотами принимать параметры slogin строка логина пользователя bemployeeunassigned булевый true не ассигнутые госслужащим опциональный умолчательно f... | 1 |
330,416 | 28,376,037,120 | IssuesEvent | 2023-04-12 20:56:58 | CommunityToolkit/Labs-Windows | https://api.github.com/repos/CommunityToolkit/Labs-Windows | reopened | 🧪 [Experiment] SettingsCard & SettingsExpander | experiment :test_tube: | # Approved from Toolkit
- https://github.com/CommunityToolkit/Labs-Windows/discussions/129
## Problem Statement:
THere are currently no controls in WinUI or the Toolkit that allows for creating consistent settings experiences that can be found across Windows 11. This experiment introduces a SettingsCard compon... | 1.0 | 🧪 [Experiment] SettingsCard & SettingsExpander - # Approved from Toolkit
- https://github.com/CommunityToolkit/Labs-Windows/discussions/129
## Problem Statement:
THere are currently no controls in WinUI or the Toolkit that allows for creating consistent settings experiences that can be found across Windows 11... | non_process | 🧪 settingscard settingsexpander approved from toolkit problem statement there are currently no controls in winui or the toolkit that allows for creating consistent settings experiences that can be found across windows this experiment introduces a settingscard component that allows to displa... | 0 |
185,469 | 15,023,224,916 | IssuesEvent | 2021-02-01 17:57:11 | 2i2c-org/pilot-hubs | https://api.github.com/repos/2i2c-org/pilot-hubs | opened | Document how to set up GitHub authentication by organization membership | documentation enhancement | In the Farallon Hub we have a setup where users can log in to the hub if they are a **public member** of a GitHub organization. We should document how this was set up, how to do the same for other hubs, and "gotchas" that are important to keep in mind such as "the person's membership must be public". | 1.0 | Document how to set up GitHub authentication by organization membership - In the Farallon Hub we have a setup where users can log in to the hub if they are a **public member** of a GitHub organization. We should document how this was set up, how to do the same for other hubs, and "gotchas" that are important to keep in... | non_process | document how to set up github authentication by organization membership in the farallon hub we have a setup where users can log in to the hub if they are a public member of a github organization we should document how this was set up how to do the same for other hubs and gotchas that are important to keep in... | 0 |
10,731 | 8,147,794,672 | IssuesEvent | 2018-08-22 01:52:33 | rchain/bounties | https://api.github.com/repos/rchain/bounties | closed | O> Attack Governance Model | Governance Operations Security Voting needs-SMART-objective | Phil's POV "a critical part of the security of the whole platform. one has to avoid that the coop ends up being a SPOF due to political centralization & centralization of development decisions as well as centralization of staking coins. after all the coop has a jurisdiction and that might be an SPOF as well. I know it... | True | O> Attack Governance Model - Phil's POV "a critical part of the security of the whole platform. one has to avoid that the coop ends up being a SPOF due to political centralization & centralization of development decisions as well as centralization of staking coins. after all the coop has a jurisdiction and that might b... | non_process | o attack governance model phil s pov a critical part of the security of the whole platform one has to avoid that the coop ends up being a spof due to political centralization centralization of development decisions as well as centralization of staking coins after all the coop has a jurisdiction and that might b... | 0 |
15,493 | 19,703,227,482 | IssuesEvent | 2022-01-12 18:49:41 | googleapis/cloud-trace-nodejs | https://api.github.com/repos/googleapis/cloud-trace-nodejs | opened | Your .repo-metadata.json file has a problem 🤒 | type: process repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'trace' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automation** if you have any questions. | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'trace' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automation** if you have any questions. | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 api shortname trace invalid in repo metadata json ☝️ once you correct these problems you can close this issue reach out to go github automation if you have any questions | 1 |
14,861 | 18,266,462,934 | IssuesEvent | 2021-10-04 09:02:06 | ESMValGroup/ESMValCore | https://api.github.com/repos/ESMValGroup/ESMValCore | closed | Load and use fx variable even if not broadcastable onto model cube data | enhancement preprocessor | Thanks to @sloosvel we now have a nice integration of anciliary vars for fx vars, including CMOR checks and all that fancy jazz. There is, however, room for improvement, as I see it: there is a hard [cut-off](https://github.com/ESMValGroup/ESMValCore/blob/fc87d72c3fce12a2117b4b4e42a4857045c4d404/esmvalcore/preprocessor... | 1.0 | Load and use fx variable even if not broadcastable onto model cube data - Thanks to @sloosvel we now have a nice integration of anciliary vars for fx vars, including CMOR checks and all that fancy jazz. There is, however, room for improvement, as I see it: there is a hard [cut-off](https://github.com/ESMValGroup/ESMVal... | process | load and use fx variable even if not broadcastable onto model cube data thanks to sloosvel we now have a nice integration of anciliary vars for fx vars including cmor checks and all that fancy jazz there is however room for improvement as i see it there is a hard that stops the process of using a certain f... | 1 |
21,715 | 30,215,130,791 | IssuesEvent | 2023-07-05 15:06:05 | Azure/azure-sdk-tools | https://api.github.com/repos/Azure/azure-sdk-tools | closed | Release Planner Arch Board Requirements | Epic Engagement Experience WS: Process Tools & Automation user study - stakeholder | The purpose of this Epic is the following:
- Identify gaps and changes in the Arch Board activities and processes due to TypeSpec.
- Determine any requirements for the release planner or scheduling tool.
- [x] https://github.com/Azure/azure-sdk-tools/issues/4599
- [x] https://github.com/Azure/azure-sdk-to... | 1.0 | Release Planner Arch Board Requirements - The purpose of this Epic is the following:
- Identify gaps and changes in the Arch Board activities and processes due to TypeSpec.
- Determine any requirements for the release planner or scheduling tool.
- [x] https://github.com/Azure/azure-sdk-tools/issues/4599
... | process | release planner arch board requirements the purpose of this epic is the following identify gaps and changes in the arch board activities and processes due to typespec determine any requirements for the release planner or scheduling tool | 1 |
6,505 | 9,583,179,773 | IssuesEvent | 2019-05-08 04:09:57 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | 0.32.5: java.lang.Exception: Invalid response from database driver. No :status provided. | Correctness Query Processor | Loading a dashboard with multiple questions, a couple of these show up in the log:
```
04-20 11:57:58 DEBUG middleware.log :: POST /api/card/83/query 200 [ASYNC: completed] 737 ms (13 DB calls) Jetty threads: 8/50 (4 busy, 2 idle, 0 queued) (63 total active threads) ... | 1.0 | 0.32.5: java.lang.Exception: Invalid response from database driver. No :status provided. - Loading a dashboard with multiple questions, a couple of these show up in the log:
```
04-20 11:57:58 DEBUG middleware.log :: POST /api/card/83/query 200 [ASYNC: completed] 737 ms (13 DB calls) Jetty threads: 8/50 (4 busy, 2 ... | process | java lang exception invalid response from database driver no status provided loading a dashboard with multiple questions a couple of these show up in the log debug middleware log post api card query ms db calls jetty threads busy idle queued total activ... | 1 |
12,102 | 14,740,301,482 | IssuesEvent | 2021-01-07 08:52:02 | kdjstudios/SABillingGitlab | https://api.github.com/repos/kdjstudios/SABillingGitlab | closed | Site 053 Late Charges | anc-process anp-important ant-bug | In GitLab by @kdjstudios on Oct 30, 2018, 15:07
**Submitted by:** "Melissa Miller " <melissa.miller@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/5970134
**Server:** Internal
**Client/Site:** 053
**Account:** Multiple
**Issue:**
I am seeing a lot of my accounts charged with a... | 1.0 | Site 053 Late Charges - In GitLab by @kdjstudios on Oct 30, 2018, 15:07
**Submitted by:** "Melissa Miller " <melissa.miller@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/5970134
**Server:** Internal
**Client/Site:** 053
**Account:** Multiple
**Issue:**
I am seeing a lot of my... | process | site late charges in gitlab by kdjstudios on oct submitted by melissa miller helpdesk server internal client site account multiple issue i am seeing a lot of my accounts charged with a late fee where they should not be charged examples of who should not hav... | 1 |
6,606 | 4,384,592,617 | IssuesEvent | 2016-08-08 03:54:29 | pitonneux/website | https://api.github.com/repos/pitonneux/website | closed | Show only featured and upcoming events for guests, all events for admin | usability | Right now the events index shows all events for everyone. Change this to show only featured and upcoming events for guests. | True | Show only featured and upcoming events for guests, all events for admin - Right now the events index shows all events for everyone. Change this to show only featured and upcoming events for guests. | non_process | show only featured and upcoming events for guests all events for admin right now the events index shows all events for everyone change this to show only featured and upcoming events for guests | 0 |
109,643 | 23,803,487,603 | IssuesEvent | 2022-09-03 17:15:03 | DS-13-Dev-Team/DS13 | https://api.github.com/repos/DS-13-Dev-Team/DS13 | closed | Suggestion: Add low wall contruction | Type: Code Suggestion: Accepted Priority: Low Difficulty: Easy | <!--
For the title make sure to put the words, 'Suggestion:' or 'Bug:' before the actual title of your issue, it helps with sorting!
If a specific field doesn't apply, remove it!
Anything inside tags like these is a comment and will not be displayed in the final issue.
Be careful not to write inside them!
... | 1.0 | Suggestion: Add low wall contruction - <!--
For the title make sure to put the words, 'Suggestion:' or 'Bug:' before the actual title of your issue, it helps with sorting!
If a specific field doesn't apply, remove it!
Anything inside tags like these is a comment and will not be displayed in the final issue.
... | non_process | suggestion add low wall contruction for the title make sure to put the words suggestion or bug before the actual title of your issue it helps with sorting if a specific field doesn t apply remove it anything inside tags like these is a comment and will not be displayed in the final issue ... | 0 |
14,592 | 17,703,544,070 | IssuesEvent | 2021-08-25 03:14:53 | tdwg/dwc | https://api.github.com/repos/tdwg/dwc | closed | New term - infragenericEpithet | Term - add Class - Taxon normative Process - complete | ## New Term
Submitter: Markus Döring
Justification: A new term is needed to represent a parsed scientific name of an infrageneric rank, e.g a subgenus. The TDWG ontology defines the exact same concept: http://rs.tdwg.org/ontology/voc/TaxonName.rdf#infragenericEpithet
Proponents: GBIF (already in use), Catalogue of... | 1.0 | New term - infragenericEpithet - ## New Term
Submitter: Markus Döring
Justification: A new term is needed to represent a parsed scientific name of an infrageneric rank, e.g a subgenus. The TDWG ontology defines the exact same concept: http://rs.tdwg.org/ontology/voc/TaxonName.rdf#infragenericEpithet
Proponents: GB... | process | new term infragenericepithet new term submitter markus döring justification a new term is needed to represent a parsed scientific name of an infrageneric rank e g a subgenus the tdwg ontology defines the exact same concept proponents gbif already in use catalogue of life already in use ipni a... | 1 |
301,780 | 22,774,357,573 | IssuesEvent | 2022-07-08 13:09:22 | owncloud/docs-ocis | https://api.github.com/repos/owncloud/docs-ocis | opened | web service - ownCloud Web | documentation | The web service env's have configurations for owncloud web.
owncloud web uses environment variables from the web service and/or config.json and themes.json where the envs overwrite any *.json value set if applicable. This needs documentation in the web service documentation
**Referencing:**
https://github.com/ownc... | 1.0 | web service - ownCloud Web - The web service env's have configurations for owncloud web.
owncloud web uses environment variables from the web service and/or config.json and themes.json where the envs overwrite any *.json value set if applicable. This needs documentation in the web service documentation
**Referencin... | non_process | web service owncloud web the web service env s have configurations for owncloud web owncloud web uses environment variables from the web service and or config json and themes json where the envs overwrite any json value set if applicable this needs documentation in the web service documentation referencin... | 0 |
232,013 | 17,768,395,063 | IssuesEvent | 2021-08-30 10:30:46 | niteshseram/Portfolio | https://api.github.com/repos/niteshseram/Portfolio | closed | Update README file | documentation | Update the default README file by writing about the project and technologies used | 1.0 | Update README file - Update the default README file by writing about the project and technologies used | non_process | update readme file update the default readme file by writing about the project and technologies used | 0 |
20,917 | 27,755,126,240 | IssuesEvent | 2023-03-16 01:23:51 | quark-engine/quark-engine | https://api.github.com/repos/quark-engine/quark-engine | closed | The latest document failed to build in readthedocs | issue-processing-state-06 | The latest document failed to build in readthedocs. Refer to [here](https://readthedocs.org/projects/quark-engine/builds/19787528/). | 1.0 | The latest document failed to build in readthedocs - The latest document failed to build in readthedocs. Refer to [here](https://readthedocs.org/projects/quark-engine/builds/19787528/). | process | the latest document failed to build in readthedocs the latest document failed to build in readthedocs refer to | 1 |
105,756 | 13,213,684,720 | IssuesEvent | 2020-08-16 14:04:23 | woowa-techcamp-2020/bmart-10 | https://api.github.com/repos/woowa-techcamp-2020/bmart-10 | closed | 프론트엔드 로그인, 회원가입 페이지 디자인 | design | > 프론트엔드 로그인, 회원가입 페이지 디자인
기한 : 2020.08.15
예상 작업 시간 : 2시간
실제 작업 시간 : 3시간
### 작업 내용
- [x] 회원가입 페이지 피그마에 디자인하기
- [x] 로그인 페이지 피그마에 디자인하기
| 1.0 | 프론트엔드 로그인, 회원가입 페이지 디자인 - > 프론트엔드 로그인, 회원가입 페이지 디자인
기한 : 2020.08.15
예상 작업 시간 : 2시간
실제 작업 시간 : 3시간
### 작업 내용
- [x] 회원가입 페이지 피그마에 디자인하기
- [x] 로그인 페이지 피그마에 디자인하기
| non_process | 프론트엔드 로그인 회원가입 페이지 디자인 프론트엔드 로그인 회원가입 페이지 디자인 기한 예상 작업 시간 실제 작업 시간 작업 내용 회원가입 페이지 피그마에 디자인하기 로그인 페이지 피그마에 디자인하기 | 0 |
175,562 | 27,880,494,874 | IssuesEvent | 2023-03-21 19:00:14 | JohnsL-U/Project-1 | https://api.github.com/repos/JohnsL-U/Project-1 | closed | Create Mock-Ups | documentation good first issue design usability | Create mockups of the user interface to help visualize the app's design and flow. | 1.0 | Create Mock-Ups - Create mockups of the user interface to help visualize the app's design and flow. | non_process | create mock ups create mockups of the user interface to help visualize the app s design and flow | 0 |
104,003 | 13,019,421,609 | IssuesEvent | 2020-07-26 22:30:57 | SLB-Pizza/radio-pizza | https://api.github.com/repos/SLB-Pizza/radio-pizza | closed | Make home events and news use SingleMixCard | design/layout | ## Tasks
- [ ] Make HomeEvents use SingleMixCard
- [ ] Make HomeNews use SingleMixCard
- [ ] Rename SingleMixCard to SingleItemCard | 1.0 | Make home events and news use SingleMixCard - ## Tasks
- [ ] Make HomeEvents use SingleMixCard
- [ ] Make HomeNews use SingleMixCard
- [ ] Rename SingleMixCard to SingleItemCard | non_process | make home events and news use singlemixcard tasks make homeevents use singlemixcard make homenews use singlemixcard rename singlemixcard to singleitemcard | 0 |
10,857 | 13,630,600,817 | IssuesEvent | 2020-09-24 16:41:10 | googleapis/gapic-generator-typescript | https://api.github.com/repos/googleapis/gapic-generator-typescript | closed | Bundle renovate PRs for dev dependencies | type: process | This repository gets a significant number of pull requests from renovate for patch updates to dev dependencies. Due to the volume, I think we should bundle these into a weekly rollup. | 1.0 | Bundle renovate PRs for dev dependencies - This repository gets a significant number of pull requests from renovate for patch updates to dev dependencies. Due to the volume, I think we should bundle these into a weekly rollup. | process | bundle renovate prs for dev dependencies this repository gets a significant number of pull requests from renovate for patch updates to dev dependencies due to the volume i think we should bundle these into a weekly rollup | 1 |
331,118 | 28,507,778,047 | IssuesEvent | 2023-04-18 23:39:50 | InstituteforDiseaseModeling/PACE-HRH | https://api.github.com/repos/InstituteforDiseaseModeling/PACE-HRH | opened | Validate_cadre test passed message/plot | testing | Add a message or plot when the cadre sheet validation tests all pass.
A potential plot could be for each scenario, plot the start year and end year on x-axis and RoleID on y-axis (geom_point). | 1.0 | Validate_cadre test passed message/plot - Add a message or plot when the cadre sheet validation tests all pass.
A potential plot could be for each scenario, plot the start year and end year on x-axis and RoleID on y-axis (geom_point). | non_process | validate cadre test passed message plot add a message or plot when the cadre sheet validation tests all pass a potential plot could be for each scenario plot the start year and end year on x axis and roleid on y axis geom point | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.