
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
19,413 | 25,556,499,744 | IssuesEvent | 2022-11-30 07:14:18 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Wed, 30 Nov 22 | event camera white balance compression image signal processing image signal process raw raw image events camera color contrast AWBISP events | ## Keyword: events
### Post-training Quantization on Diffusion Models
- **Authors:** Yuzhang Shang, Zhihang Yuan, Bin Xie, Bingzhe Wu, Yan Yan
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://xxx.itp.ac.cn/abs/2211.15736
- **Pdf link:** https://xxx.itp.ac.cn/pdf/2211.15736
... | 2.0 | New submissions for Wed, 30 Nov 22 - ## Keyword: events
### Post-training Quantization on Diffusion Models
- **Authors:** Yuzhang Shang, Zhihang Yuan, Bin Xie, Bingzhe Wu, Yan Yan
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://xxx.itp.ac.cn/abs/2211.15736
- **Pdf link:** h... | process | new submissions for wed nov keyword events post training quantization on diffusion models authors yuzhang shang zhihang yuan bin xie bingzhe wu yan yan subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract denoising diffusion... | 1 |
242,854 | 26,277,856,074 | IssuesEvent | 2023-01-07 01:20:31 | gavarasana/ps-flux | https://api.github.com/repos/gavarasana/ps-flux | opened | CVE-2022-0155 (Medium) detected in follow-redirects-1.13.1.tgz | security vulnerability | ## CVE-2022-0155 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>follow-redirects-1.13.1.tgz</b></p></summary>
<p>HTTP and HTTPS modules that follow redirects.</p>
<p>Library home pa... | True | CVE-2022-0155 (Medium) detected in follow-redirects-1.13.1.tgz - ## CVE-2022-0155 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>follow-redirects-1.13.1.tgz</b></p></summary>
<p>HTT... | non_process | cve medium detected in follow redirects tgz cve medium severity vulnerability vulnerable library follow redirects tgz http and https modules that follow redirects library home page a href path to dependency file package json path to vulnerable library node modules... | 0 |
10,377 | 13,193,250,720 | IssuesEvent | 2020-08-13 14:57:29 | prisma/language-tools | https://api.github.com/repos/prisma/language-tools | closed | Detect users VSCode theme and suggest to use a different one if necessary | kind/improvement process/candidate | The minimal themes do not use all the root groups from the textmate grammer used for syntax highlighting, leading to a bad experience for users.
We could detect the theme and create a toast telling people about this. | 1.0 | Detect users VSCode theme and suggest to use a different one if necessary - The minimal themes do not use all the root groups from the textmate grammer used for syntax highlighting, leading to a bad experience for users.
We could detect the theme and create a toast telling people about this. | process | detect users vscode theme and suggest to use a different one if necessary the minimal themes do not use all the root groups from the textmate grammer used for syntax highlighting leading to a bad experience for users we could detect the theme and create a toast telling people about this | 1 |
750,326 | 26,198,039,329 | IssuesEvent | 2023-01-03 15:07:04 | GiPHouse/Website | https://api.github.com/repos/GiPHouse/Website | closed | Use better email slugs | priority:low | ### One-sentence description
Use better email slugs
### How to reproduce the bug
Current mail aliases are very long and confusing
### Expected behaviour
Think about how to handle archiving of email groups, users re-entering them, etc. | 1.0 | Use better email slugs - ### One-sentence description
Use better email slugs
### How to reproduce the bug
Current mail aliases are very long and confusing
### Expected behaviour
Think about how to handle archiving of email groups, users re-entering them, etc. | non_process | use better email slugs one sentence description use better email slugs how to reproduce the bug current mail aliases are very long and confusing expected behaviour think about how to handle archiving of email groups users re entering them etc | 0 |
11,148 | 13,957,693,042 | IssuesEvent | 2020-10-24 08:10:52 | alexanderkotsev/geoportal | https://api.github.com/repos/alexanderkotsev/geoportal | opened | SE: Harvesting Request | Geoportal Harvesting process SE - Sweden | Hi!
Are the servers still down or is it posible to harvest from the Swedish node?
Regards
Björn Olofsson, support, the Swedish Geo postal | 1.0 | SE: Harvesting Request - Hi!
Are the servers still down or is it posible to harvest from the Swedish node?
Regards
Björn Olofsson, support, the Swedish Geo postal | process | se harvesting request hi are the servers still down or is it posible to harvest from the swedish node regards bj ouml rn olofsson support the swedish geo postal | 1 |
82,267 | 15,884,024,981 | IssuesEvent | 2021-04-09 18:15:02 | google/iree | https://api.github.com/repos/google/iree | closed | Investigate LinalgVectorizationPass causing ConvertToLLVMTo fail | codegen/llvm | With https://github.com/google/iree/pull/5362 LinalgVectorizationPass is cauing bert_encoder_unroled_fake_weigths to fail ConvertToLLVM with
`
%1268 = "llvm.fcmp"(%1267, %6) {fastmathFlags = #llvm.fastmath<>, predicate = 2 : i64} : (!llvm.array<64 x vector<64xf32>>, !llvm.array<64 x vector<64xf32>>) -> !llvm.array<... | 1.0 | Investigate LinalgVectorizationPass causing ConvertToLLVMTo fail - With https://github.com/google/iree/pull/5362 LinalgVectorizationPass is cauing bert_encoder_unroled_fake_weigths to fail ConvertToLLVM with
`
%1268 = "llvm.fcmp"(%1267, %6) {fastmathFlags = #llvm.fastmath<>, predicate = 2 : i64} : (!llvm.array<64 x... | non_process | investigate linalgvectorizationpass causing converttollvmto fail with linalgvectorizationpass is cauing bert encoder unroled fake weigths to fail converttollvm with llvm fcmp fastmathflags llvm fastmath predicate llvm array llvm array llvm array add more snipp... | 0 |
20,129 | 26,664,917,426 | IssuesEvent | 2023-01-26 02:00:07 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Thu, 26 Jan 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
There is no result
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
There is no result
## Keyword: ISP
There is no result
## Keyword: image signal ... | 2.0 | New submissions for Thu, 26 Jan 23 - ## Keyword: events
There is no result
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
There is no result
## Keyword: ISP
There is... | process | new submissions for thu jan keyword events there is no result keyword event camera there is no result keyword events camera there is no result keyword white balance there is no result keyword color contrast there is no result keyword awb there is no result keyword isp there is n... | 1 |
65,884 | 16,499,860,953 | IssuesEvent | 2021-05-25 13:42:24 | gradle/gradle | https://api.github.com/repos/gradle/gradle | closed | Compare different setups of large/huge hierarchical Gradle projects | @idiomatic in:composite-builds in:multi-projects | Different setups to compare:
1. Build logic in _buildSrc_ or in an _included build_
2. Main build in a single project with a hierarchy of subprojects
3. Main build as a hierarchy of included builds (requires build logic in _included build_)
Feature wise: What are differences? What is better, what is worth? What are ad... | 1.0 | Compare different setups of large/huge hierarchical Gradle projects - Different setups to compare:
1. Build logic in _buildSrc_ or in an _included build_
2. Main build in a single project with a hierarchy of subprojects
3. Main build as a hierarchy of included builds (requires build logic in _included build_)
Feature ... | non_process | compare different setups of large huge hierarchical gradle projects different setups to compare build logic in buildsrc or in an included build main build in a single project with a hierarchy of subprojects main build as a hierarchy of included builds requires build logic in included build feature ... | 0 |
4,159 | 7,104,525,950 | IssuesEvent | 2018-01-16 10:16:38 | zotero/zotero | https://api.github.com/repos/zotero/zotero | closed | Styling in citation text editor not working | Word Processor Integration | I believe I may have seen a report on the forums of this before, and also https://github.com/zotero/zotero-libreoffice-integration/issues/35#issuecomment-357780732 | 1.0 | Styling in citation text editor not working - I believe I may have seen a report on the forums of this before, and also https://github.com/zotero/zotero-libreoffice-integration/issues/35#issuecomment-357780732 | process | styling in citation text editor not working i believe i may have seen a report on the forums of this before and also | 1 |
74,881 | 25,381,584,720 | IssuesEvent | 2022-11-21 18:00:15 | department-of-veterans-affairs/va.gov-cms | https://api.github.com/repos/department-of-veterans-affairs/va.gov-cms | closed | Blank table header row in Drupal displays as blank on FE | Defect VA.gov frontend Needs refining ⭐️ Public Websites 508/Accessibility | ## Describe the defect
The Drupal table_field form UI states that the top row of a table can be left blank if the table doesn't have headers.
However, when Editors leave the top row blank, the FE template still renders a header row, it's just blank
- The header cells still have accessibility attributes like `scop... | 1.0 | Blank table header row in Drupal displays as blank on FE - ## Describe the defect
The Drupal table_field form UI states that the top row of a table can be left blank if the table doesn't have headers.
However, when Editors leave the top row blank, the FE template still renders a header row, it's just blank
- The ... | non_process | blank table header row in drupal displays as blank on fe describe the defect the drupal table field form ui states that the top row of a table can be left blank if the table doesn t have headers however when editors leave the top row blank the fe template still renders a header row it s just blank the ... | 0 |
46,279 | 13,154,345,770 | IssuesEvent | 2020-08-10 06:30:52 | raindigi/site-landing | https://api.github.com/repos/raindigi/site-landing | opened | CVE-2020-7661 (High) detected in url-regex-3.2.0.tgz | security vulnerability | ## CVE-2020-7661 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>url-regex-3.2.0.tgz</b></p></summary>
<p>Regular expression for matching URLs</p>
<p>Library home page: <a href="https:... | True | CVE-2020-7661 (High) detected in url-regex-3.2.0.tgz - ## CVE-2020-7661 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>url-regex-3.2.0.tgz</b></p></summary>
<p>Regular expression for ... | non_process | cve high detected in url regex tgz cve high severity vulnerability vulnerable library url regex tgz regular expression for matching urls library home page a href path to dependency file tmp ws scm site landing package json path to vulnerable library tmp ws scm site... | 0 |
183,375 | 14,226,691,180 | IssuesEvent | 2020-11-17 23:33:16 | cocotb/cocotb | https://api.github.com/repos/cocotb/cocotb | closed | GHA: update conda-incubator/setup-miniconda | category:OS:Windows category:tests-ci | `::add-path` and `::set-env` have been disabled: https://github.com/cocotb/cocotb/pull/2200/checks?check_run_id=1409789127#step:4:25
Update to [conda-incubator/setup-miniconda@v2](https://github.com/marketplace/actions/setup-miniconda) and get it working:
```yaml
- name: Set up Anaconda
uses: conda-incubator/se... | 1.0 | GHA: update conda-incubator/setup-miniconda - `::add-path` and `::set-env` have been disabled: https://github.com/cocotb/cocotb/pull/2200/checks?check_run_id=1409789127#step:4:25
Update to [conda-incubator/setup-miniconda@v2](https://github.com/marketplace/actions/setup-miniconda) and get it working:
```yaml
- nam... | non_process | gha update conda incubator setup miniconda add path and set env have been disabled update to and get it working yaml name set up anaconda uses conda incubator setup miniconda | 0 |
8,499 | 11,661,648,685 | IssuesEvent | 2020-03-03 07:20:58 | yalla-coop/accountability | https://api.github.com/repos/yalla-coop/accountability | closed | Code formatting and linting | Priority 1 fib-1 process website | As agreed at #37 we'll be using fairly standard **eslint** for linting and **prettier** for formatting
* [x] Configure eslint (see https://www.gatsbyjs.org/docs/eslint/)
* [x] Add and configure [prettier](https://www.gatsbyjs.org/docs/eslint/)
* [x] Leave issue open and we'll review setup and see if we're happy wi... | 1.0 | Code formatting and linting - As agreed at #37 we'll be using fairly standard **eslint** for linting and **prettier** for formatting
* [x] Configure eslint (see https://www.gatsbyjs.org/docs/eslint/)
* [x] Add and configure [prettier](https://www.gatsbyjs.org/docs/eslint/)
* [x] Leave issue open and we'll review s... | process | code formatting and linting as agreed at we ll be using fairly standard eslint for linting and prettier for formatting configure eslint see add and configure leave issue open and we ll review setup and see if we re happy with the set of rules next week | 1 |
6,447 | 9,546,273,854 | IssuesEvent | 2019-05-01 19:27:23 | openopps/openopps-platform | https://api.github.com/repos/openopps/openopps-platform | closed | Apply: Add Optional beside Experience header | Apply Process Approved Requirements Ready State Dept. | Who: Internship applicants
What: Should not be required to enter work experience
Why: because they might not have any
On the Experiences & References page of the application, experience is not required and I can click on Save & continue with no experience. Please add Optional beside the experience header. (not in moc... | 1.0 | Apply: Add Optional beside Experience header - Who: Internship applicants
What: Should not be required to enter work experience
Why: because they might not have any
On the Experiences & References page of the application, experience is not required and I can click on Save & continue with no experience. Please add Opt... | process | apply add optional beside experience header who internship applicants what should not be required to enter work experience why because they might not have any on the experiences references page of the application experience is not required and i can click on save continue with no experience please add opt... | 1 |
601,539 | 18,415,808,665 | IssuesEvent | 2021-10-13 11:18:13 | googleapis/python-compute | https://api.github.com/repos/googleapis/python-compute | opened | samples.snippets.test_sample_start_stop: test_instance_operations failed | type: bug priority: p1 flakybot: issue | This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/main/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I will stop commenting.
---
commit: 7a9e8324e08c46a93050908760b2b5aca054a863
b... | 1.0 | samples.snippets.test_sample_start_stop: test_instance_operations failed - This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/main/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I wil... | non_process | samples snippets test sample start stop test instance operations failed this test failed to configure my behavior see if i m commenting on this issue too often add the flakybot quiet label and i will stop commenting commit buildurl status failed test output pytest fixture def... | 0 |
12,960 | 15,340,668,323 | IssuesEvent | 2021-02-27 08:15:18 | topcoder-platform/community-app | https://api.github.com/repos/topcoder-platform/community-app | opened | Clear filter issue when used along with recommended challenges toggle | P3 ShapeupProcess challenge- recommender-tool | 1. Go to Challenge listings page, open for registration bucket
2. Switch on recommended challenges toggle
3. Add any other filter, example switch off development track
4. Note down my challenges count
5. Now click on clear filter
6. Note down My challenges count
7. go to my challenges / all challenges bucket
... | 1.0 | Clear filter issue when used along with recommended challenges toggle - 1. Go to Challenge listings page, open for registration bucket
2. Switch on recommended challenges toggle
3. Add any other filter, example switch off development track
4. Note down my challenges count
5. Now click on clear filter
6. Note down ... | process | clear filter issue when used along with recommended challenges toggle go to challenge listings page open for registration bucket switch on recommended challenges toggle add any other filter example switch off development track note down my challenges count now click on clear filter note down ... | 1 |
19,845 | 26,245,528,788 | IssuesEvent | 2023-01-05 14:58:49 | celo-org/celo-monorepo | https://api.github.com/repos/celo-org/celo-monorepo | closed | Shepherd CIP51 through CIP process | release-process | This involves shepherding [CIP51](https://github.com/celo-org/celo-proposals/blob/master/CIPs/cip-0051.md) through the CIP process described here:
- [Celo Improvement Proposal (CIP) Process](https://github.com/celo-org/celo-proposals/blob/master/CIPs/cip-0000.md)
Useful links:
- Github: [CIP51: Federated Attestatio... | 1.0 | Shepherd CIP51 through CIP process - This involves shepherding [CIP51](https://github.com/celo-org/celo-proposals/blob/master/CIPs/cip-0051.md) through the CIP process described here:
- [Celo Improvement Proposal (CIP) Process](https://github.com/celo-org/celo-proposals/blob/master/CIPs/cip-0000.md)
Useful links:
-... | process | shepherd through cip process this involves shepherding through the cip process described here useful links github forum | 1 |
12,336 | 14,882,735,846 | IssuesEvent | 2021-01-20 12:20:23 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [iOS] Studies list > Study status is not updated for 'Not Eligible' post withdrawing | Bug P2 Process: Fixed Process: Tested dev iOS | **Scenario 1:** Study status is not updated for 'Not Eligible' post withdrawing for open study
Steps:
1. Login and enroll into any open study successfully
2. Withdraw from the study
3. Again click on the withdrawn study
4. Fail the eligibility test
5. Observe the study status
**Scenario 2:** Study status is ... | 2.0 | [iOS] Studies list > Study status is not updated for 'Not Eligible' post withdrawing - **Scenario 1:** Study status is not updated for 'Not Eligible' post withdrawing for open study
Steps:
1. Login and enroll into any open study successfully
2. Withdraw from the study
3. Again click on the withdrawn study
4. Fai... | process | studies list study status is not updated for not eligible post withdrawing scenario study status is not updated for not eligible post withdrawing for open study steps login and enroll into any open study successfully withdraw from the study again click on the withdrawn study fail th... | 1 |
47,676 | 10,140,931,257 | IssuesEvent | 2019-08-03 09:05:30 | atomist-blogs/org-visualizer | https://api.github.com/repos/atomist-blogs/org-visualizer | closed | Code Inspection: Tslint on explorer | code-inspection | ### max-line-length
- [`views/sunburstPage.tsx:104`](https://github.com/atomist-blogs/org-visualizer/blob/dc73d0d5fe49510ad616076987e5607a961200de/views/sunburstPage.tsx#L104): _(warn)_ Exceeds maximum line length of 150
[atomist:code-inspection:explorer=@atomist/atomist-sdm] | 1.0 | Code Inspection: Tslint on explorer - ### max-line-length
- [`views/sunburstPage.tsx:104`](https://github.com/atomist-blogs/org-visualizer/blob/dc73d0d5fe49510ad616076987e5607a961200de/views/sunburstPage.tsx#L104): _(warn)_ Exceeds maximum line length of 150
[atomist:code-inspection:explorer=@atomist/atomist-sdm] | non_process | code inspection tslint on explorer max line length warn exceeds maximum line length of | 0 |
427,816 | 12,399,369,717 | IssuesEvent | 2020-05-21 05:00:25 | open-learning-exchange/planet | https://api.github.com/repos/open-learning-exchange/planet | closed | HealthEvent: Allow decimals | priority | I think the built in Angular number validator maybe defaults to 0 decimal places. If it allows a value for precision, let's go with 2. | 1.0 | HealthEvent: Allow decimals - I think the built in Angular number validator maybe defaults to 0 decimal places. If it allows a value for precision, let's go with 2. | non_process | healthevent allow decimals i think the built in angular number validator maybe defaults to decimal places if it allows a value for precision let s go with | 0 |
111 | 2,546,157,955 | IssuesEvent | 2015-01-29 21:53:32 | tinkerpop/tinkerpop3 | https://api.github.com/repos/tinkerpop/tinkerpop3 | closed | Are DedupStep and FoldStep SideEffectSteps? (proposal) | enhancement process | I just introduced the notion of `Reducing` (marker interface) and steps that require a reduce function to operate. However, if these steps are SideEffectSteps, then they should each have their own XXXMapReduce.
* **DedupStep**: This can be a sideEffect in both OLTP and OLAP. The sideEffect data structure is the Has... | 1.0 | Are DedupStep and FoldStep SideEffectSteps? (proposal) - I just introduced the notion of `Reducing` (marker interface) and steps that require a reduce function to operate. However, if these steps are SideEffectSteps, then they should each have their own XXXMapReduce.
* **DedupStep**: This can be a sideEffect in bot... | process | are dedupstep and foldstep sideeffectsteps proposal i just introduced the notion of reducing marker interface and steps that require a reduce function to operate however if these steps are sideeffectsteps then they should each have their own xxxmapreduce dedupstep this can be a sideeffect in bot... | 1 |
271,215 | 20,625,457,139 | IssuesEvent | 2022-03-07 21:59:36 | barrucadu/resolved | https://api.github.com/repos/barrucadu/resolved | opened | Document how configuration works | documentation | This is kind of a placeholder issue until zone files are implemented and I'm distributing the root hints and RFC 6761 stuff. | 1.0 | Document how configuration works - This is kind of a placeholder issue until zone files are implemented and I'm distributing the root hints and RFC 6761 stuff. | non_process | document how configuration works this is kind of a placeholder issue until zone files are implemented and i m distributing the root hints and rfc stuff | 0 |
21,012 | 27,947,701,312 | IssuesEvent | 2023-03-24 05:35:19 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | closed | Support `*.HEIC` HEIF format images in Processing `ImportPhotosAlgorithm` (Request in QGIS) | Processing Alg 3.32 | ### Request for documentation
From pull request QGIS/qgis#51973
Author: @shuckc
QGIS version: 3.32
**Support `*.HEIC` HEIF format images in Processing `ImportPhotosAlgorithm`**
### PR Description:
Minor changes to allow importing `*.heic` images with GDAL's HEIF image support.
Firstly we add the file extension to... | 1.0 | Support `*.HEIC` HEIF format images in Processing `ImportPhotosAlgorithm` (Request in QGIS) - ### Request for documentation
From pull request QGIS/qgis#51973
Author: @shuckc
QGIS version: 3.32
**Support `*.HEIC` HEIF format images in Processing `ImportPhotosAlgorithm`**
### PR Description:
Minor changes to allow impo... | process | support heic heif format images in processing importphotosalgorithm request in qgis request for documentation from pull request qgis qgis author shuckc qgis version support heic heif format images in processing importphotosalgorithm pr description minor changes to allow importing... | 1 |
64,972 | 3,222,437,100 | IssuesEvent | 2015-10-09 01:00:08 | bioinformatics-ua/catalogue | https://api.github.com/repos/bioinformatics-ua/catalogue | opened | [Redesign operations] Try to open fingerprint and receive redirect to a blank page "Error open edit for fingerprint 49" | bug high priority | In demo server:
1. Search for ieeta
2. Go to ieeta database dummy test
3. Go to questionset 12.
4. You will see a blank page saying "Error open edit for fingerprint 49" | 1.0 | [Redesign operations] Try to open fingerprint and receive redirect to a blank page "Error open edit for fingerprint 49" - In demo server:
1. Search for ieeta
2. Go to ieeta database dummy test
3. Go to questionset 12.
4. You will see a blank page saying "Error open edit for fingerprint 49" | non_process | try to open fingerprint and receive redirect to a blank page error open edit for fingerprint in demo server search for ieeta go to ieeta database dummy test go to questionset you will see a blank page saying error open edit for fingerprint | 0 |
9,111 | 12,193,192,438 | IssuesEvent | 2020-04-29 14:04:00 | prisma/prisma2-docs | https://api.github.com/repos/prisma/prisma2-docs | closed | Links with on startpage are problematic when opened as `/docs` (no trailing slash) | process/candidate topic: broken links | If you open the startpage as `/docs` (note the missing trailing slash) all the links with `./` do not work. These probably need to be absolute.
See part of the source code here:
```
stroke-linejoin="round"></path><path d="M1.5 11.6666H15.5" stroke="#CBD5E0" stroke-width="2" stroke-linecap="round" stroke-linejoin... | 1.0 | Links with on startpage are problematic when opened as `/docs` (no trailing slash) - If you open the startpage as `/docs` (note the missing trailing slash) all the links with `./` do not work. These probably need to be absolute.
See part of the source code here:
```
stroke-linejoin="round"></path><path d="M1.5 1... | process | links with on startpage are problematic when opened as docs no trailing slash if you open the startpage as docs note the missing trailing slash all the links with do not work these probably need to be absolute see part of the source code here stroke linejoin round getting starte... | 1 |
8,670 | 11,802,936,759 | IssuesEvent | 2020-03-18 22:47:34 | pacificclimate/climate-explorer-data-prep | https://api.github.com/repos/pacificclimate/climate-explorer-data-prep | opened | Calculate anomaly data | process new data | We'd like to show maps in plan2adapt of variable anomalies. There's not really a good way to inject anomaly calculation into the ncWMS/leaflet pipeline, so we need to create some netCDF datasets that contain the anomaly values.
We need the PCIC12 model for the 2020, 2050, and 2080 climatologies for tasmin, tasmax, t... | 1.0 | Calculate anomaly data - We'd like to show maps in plan2adapt of variable anomalies. There's not really a good way to inject anomaly calculation into the ncWMS/leaflet pipeline, so we need to create some netCDF datasets that contain the anomaly values.
We need the PCIC12 model for the 2020, 2050, and 2080 climatolog... | process | calculate anomaly data we d like to show maps in of variable anomalies there s not really a good way to inject anomaly calculation into the ncwms leaflet pipeline so we need to create some netcdf datasets that contain the anomaly values we need the model for the and climatologies for tasmin tasmax ... | 1 |
11,344 | 14,167,357,192 | IssuesEvent | 2020-11-12 10:10:59 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Proj.db not found for GDAL tools on QGIS 3.16 Mac all-in-one installer | Bug MacOS Processing Regression | gdalwarp give an error on QGIS3.16 Mac because it can't find proj.db. Same operation works fine in QGIS3.10 LTR package.
"ERROR 1: PROJ: proj_create_from_database: Cannot find proj.db"
<img width="1001" alt="proj_error" src="https://user-images.githubusercontent.com/5227506/98100658-2f849a80-1eb7-11eb-9d3d-06b45... | 1.0 | Proj.db not found for GDAL tools on QGIS 3.16 Mac all-in-one installer - gdalwarp give an error on QGIS3.16 Mac because it can't find proj.db. Same operation works fine in QGIS3.10 LTR package.
"ERROR 1: PROJ: proj_create_from_database: Cannot find proj.db"
<img width="1001" alt="proj_error" src="https://user-im... | process | proj db not found for gdal tools on qgis mac all in one installer gdalwarp give an error on mac because it can t find proj db same operation works fine in ltr package error proj proj create from database cannot find proj db img width alt proj error src to reproduce unzip... | 1 |
40,359 | 2,868,673,686 | IssuesEvent | 2015-06-05 20:19:39 | IQSS/dataverse | https://api.github.com/repos/IQSS/dataverse | closed | Add Additional Controlled Vocabulary Terms to Life Sciences Metadata for TB Dataverse | Component: Metadata Priority: High Status: QA Type: Feature | Will need to modify the Life Sciences Metadata to add the following controlled vocabulary terms in the following fields, will check if there are any slight variants of these terms that are more standardly used:
**StudyDesignType**
- Cohort Study Design (ontology: http://bioportal.bioontology.org/ontologies/OCRE/?p=... | 1.0 | Add Additional Controlled Vocabulary Terms to Life Sciences Metadata for TB Dataverse - Will need to modify the Life Sciences Metadata to add the following controlled vocabulary terms in the following fields, will check if there are any slight variants of these terms that are more standardly used:
**StudyDesignType*... | non_process | add additional controlled vocabulary terms to life sciences metadata for tb dataverse will need to modify the life sciences metadata to add the following controlled vocabulary terms in the following fields will check if there are any slight variants of these terms that are more standardly used studydesigntype ... | 0 |
106,623 | 13,327,927,923 | IssuesEvent | 2020-08-27 13:51:01 | nim-lang/Nim | https://api.github.com/repos/nim-lang/Nim | closed | The StmtList processing of template parameters can lead to unexpected errors | Language design | Consider the following code:
```
template foo(x: stmt) =
discard
foo:
var a = 10
foo:
var a = 20 # error: redefinition of `a`
```
Even though the pass-in blocks are discarded, they pollute the scope where `foo` is used and can produce redefinition errors as in the example above. | 1.0 | The StmtList processing of template parameters can lead to unexpected errors - Consider the following code:
```
template foo(x: stmt) =
discard
foo:
var a = 10
foo:
var a = 20 # error: redefinition of `a`
```
Even though the pass-in blocks are discarded, they pollute the scope where `foo` is used... | non_process | the stmtlist processing of template parameters can lead to unexpected errors consider the following code template foo x stmt discard foo var a foo var a error redefinition of a even though the pass in blocks are discarded they pollute the scope where foo is used a... | 0 |
163,420 | 25,810,033,399 | IssuesEvent | 2022-12-11 19:19:14 | nyx-space/nyx | https://api.github.com/repos/nyx-space/nyx | opened | Support the True Equator Mean Equinox (TEME) frame | QA:Design Kind:New feature Topic: Mission Design Priority: normal | # High level description
Original discussion here: https://gitlab.com/nyx-space/nyx/-/issues/229
References:
+ OREKit: https://gitlab.orekit.org/orekit/orekit/-/blob/develop/src/main/java/org/orekit/frames/TEMEProvider.java
+ AstroPy: https://github.com/astropy/astropy/blob/45abe1d37242c1a256bc59f234b4d3e83e342... | 2.0 | Support the True Equator Mean Equinox (TEME) frame - # High level description
Original discussion here: https://gitlab.com/nyx-space/nyx/-/issues/229
References:
+ OREKit: https://gitlab.orekit.org/orekit/orekit/-/blob/develop/src/main/java/org/orekit/frames/TEMEProvider.java
+ AstroPy: https://github.com/astro... | non_process | support the true equator mean equinox teme frame high level description original discussion here references orekit astropy and test skyfield asterisk a i solution documentation this seems to require the computed cf and note only the high level d... | 0 |
78,179 | 27,358,514,300 | IssuesEvent | 2023-02-27 14:25:57 | jOOQ/jOOQ | https://api.github.com/repos/jOOQ/jOOQ | opened | DSLContext ddl does not correctly export view contents from existing database | T: Defect | ### Expected behavior
Something like this
create view "public"."demo_description"("id","name","description")
as (SELECT de.id,
de.name,
ds.text AS description
FROM demo de
JOIN description ds ON ds.id = de.id;)
### Actual behavior
create view "public"."demo_description"(
"id",
"name",
"description"
)
as... | 1.0 | DSLContext ddl does not correctly export view contents from existing database - ### Expected behavior
Something like this
create view "public"."demo_description"("id","name","description")
as (SELECT de.id,
de.name,
ds.text AS description
FROM demo de
JOIN description ds ON ds.id = de.id;)
### Actual behavior... | non_process | dslcontext ddl does not correctly export view contents from existing database expected behavior something like this create view public demo description id name description as select de id de name ds text as description from demo de join description ds on ds id de id actual behavior... | 0 |
22,710 | 32,037,050,917 | IssuesEvent | 2023-09-22 16:07:00 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | closed | Status of Bazel 7.0.0-pre.20230917.3 | P1 type: process release team-OSS |
- Expected release date: 2023-09-22
Task list:
- [x] Pick release baseline: [1cf392ff](https://github.com/bazelbuild/bazel/commit/1cf392ff3918386858b8c038f82c013b1e04be98) with cherrypicks [32563ca1](https://github.com/bazelbuild/bazel/commit/32563ca1728a69437b26efa19d18eebfcecc4765) [19f5e933](https://github.com/ba... | 1.0 | Status of Bazel 7.0.0-pre.20230917.3 -
- Expected release date: 2023-09-22
Task list:
- [x] Pick release baseline: [1cf392ff](https://github.com/bazelbuild/bazel/commit/1cf392ff3918386858b8c038f82c013b1e04be98) with cherrypicks [32563ca1](https://github.com/bazelbuild/bazel/commit/32563ca1728a69437b26efa19d18eebfcec... | process | status of bazel pre expected release date task list pick release baseline with cherrypicks create release candidate post submit push the release update the | 1 |
35,328 | 6,444,684,728 | IssuesEvent | 2017-08-12 15:38:14 | haskell/cabal | https://api.github.com/repos/haskell/cabal | closed | Wiki release instructions are out of date | documentation release | The `Makefile` and instructions on https://github.com/haskell/cabal/wiki/Making-a-release are out of date:
```
make: *** No rule to make target 'doc/*.markdown', needed by 'dist/doc/users-guide/index.html'. Stop.
```
I think we just need to update the `user-guide` target to use Sphinx instead of `pandoc` for u... | 1.0 | Wiki release instructions are out of date - The `Makefile` and instructions on https://github.com/haskell/cabal/wiki/Making-a-release are out of date:
```
make: *** No rule to make target 'doc/*.markdown', needed by 'dist/doc/users-guide/index.html'. Stop.
```
I think we just need to update the `user-guide` ta... | non_process | wiki release instructions are out of date the makefile and instructions on are out of date make no rule to make target doc markdown needed by dist doc users guide index html stop i think we just need to update the user guide target to use sphinx instead of pandoc for user guide... | 0 |
16,608 | 21,664,123,411 | IssuesEvent | 2022-05-07 00:23:53 | dinobossytnew/Traduciones- | https://api.github.com/repos/dinobossytnew/Traduciones- | closed | Nuevo y Por añadir | EN PROCESSO | - [x] * PlayerKits
- [x] * AdvancedKits
- [x] * PyroFishingPro
- [x] * PyroMiningPro
- [x] * PyroSpawners
- [x] * Mmoitems
- [x] * ExecutableItems
- [x] * EpicCraftingsPlus | 1.0 | Nuevo y Por añadir - - [x] * PlayerKits
- [x] * AdvancedKits
- [x] * PyroFishingPro
- [x] * PyroMiningPro
- [x] * PyroSpawners
- [x] * Mmoitems
- [x] * ExecutableItems
- [x] * EpicCraftingsPlus | process | nuevo y por añadir playerkits advancedkits pyrofishingpro pyrominingpro pyrospawners mmoitems executableitems epiccraftingsplus | 1 |
167,788 | 6,346,566,981 | IssuesEvent | 2017-07-28 02:47:07 | connectivedx/fuzzy-chainsaw | https://api.github.com/repos/connectivedx/fuzzy-chainsaw | closed | Missing enhanced-resolve module | high-priority | Fresh version of FC2.0 on Windows wont run watch or build. Appears to be a missing **enhanced-resolve** module not found in FC package.json. After running "npm install enhanced-resolve", my watch and builds all started working as anticipated.
Lets make sure we don't forget to include this.
Thanks! | 1.0 | Missing enhanced-resolve module - Fresh version of FC2.0 on Windows wont run watch or build. Appears to be a missing **enhanced-resolve** module not found in FC package.json. After running "npm install enhanced-resolve", my watch and builds all started working as anticipated.
Lets make sure we don't forget to includ... | non_process | missing enhanced resolve module fresh version of on windows wont run watch or build appears to be a missing enhanced resolve module not found in fc package json after running npm install enhanced resolve my watch and builds all started working as anticipated lets make sure we don t forget to include ... | 0 |
9,880 | 12,886,542,479 | IssuesEvent | 2020-07-13 09:39:10 | ESMValGroup/ESMValCore | https://api.github.com/repos/ESMValGroup/ESMValCore | opened | Anomaly calculation for OBS got broken early march. | bug preprocessor | **Describe the bug**
Unfortunately, it seems like none of the tests has flagged (something to look into later I would say!). But for several observational datasets the calculation of anomalies goes wrong with non-physical values coming out of the preprocessor. I could track down the problems to 3-4 March 2020. With ev... | 1.0 | Anomaly calculation for OBS got broken early march. - **Describe the bug**
Unfortunately, it seems like none of the tests has flagged (something to look into later I would say!). But for several observational datasets the calculation of anomalies goes wrong with non-physical values coming out of the preprocessor. I c... | process | anomaly calculation for obs got broken early march describe the bug unfortunately it seems like none of the tests has flagged something to look into later i would say but for several observational datasets the calculation of anomalies goes wrong with non physical values coming out of the preprocessor i c... | 1 |
19,981 | 26,460,777,566 | IssuesEvent | 2023-01-16 17:21:31 | apache/arrow-rs | https://api.github.com/repos/apache/arrow-rs | closed | Release `object_store` `0.5.3` (next release after`0.5.2`) | development-process object-store | Follow on from https://github.com/apache/arrow-rs/issues/3229
* Planned Release Candidate: ~TBD~ 2023-01-05
* Planned Release and Publish to crates.io: ~TBD~ 2023-01-08
Items:
- [ ] Update changelog and readme:
- [ ] Create release candidate:
- [ ] Release candidate approved:
- [ ] Release to crates.io:... | 1.0 | Release `object_store` `0.5.3` (next release after`0.5.2`) - Follow on from https://github.com/apache/arrow-rs/issues/3229
* Planned Release Candidate: ~TBD~ 2023-01-05
* Planned Release and Publish to crates.io: ~TBD~ 2023-01-08
Items:
- [ ] Update changelog and readme:
- [ ] Create release candidate:
- ... | process | release object store next release after follow on from planned release candidate tbd planned release and publish to crates io tbd items update changelog and readme create release candidate release candidate approved release to crates io ... | 1 |
404,286 | 27,457,061,159 | IssuesEvent | 2023-03-02 22:22:41 | gbowne1/reactsocialnetwork | https://api.github.com/repos/gbowne1/reactsocialnetwork | opened | [Update] Improve our project README.md | bug documentation enhancement help wanted question | Our project README.md could use some improvements. It's ok, but leaves a lot to be desired when first looking at the project
Suggest adding stuff from <https://shields.io/> as a first task
- [ ] Add shields from <https://shields.io/> | 1.0 | [Update] Improve our project README.md - Our project README.md could use some improvements. It's ok, but leaves a lot to be desired when first looking at the project
Suggest adding stuff from <https://shields.io/> as a first task
- [ ] Add shields from <https://shields.io/> | non_process | improve our project readme md our project readme md could use some improvements it s ok but leaves a lot to be desired when first looking at the project suggest adding stuff from as a first task add shields from | 0 |
2,458 | 5,240,724,469 | IssuesEvent | 2017-01-31 13:58:23 | rubberduck-vba/Rubberduck | https://api.github.com/repos/rubberduck-vba/Rubberduck | reopened | VBA implicitly extends the IControl interface to controls in MSForms - RD doesn't | bug parse-tree-processing | I noticed this after the reimplementation of `MemberNotOnInterfaceInspection`. This code (in a UserForm) triggers an inspection result for the call to `SetFocus`:
```
Private Sub UserForm_Activate()
TextBox1.SetFocus
End Sub
```
I initially thought that there was a problem in the type name binding for contr... | 1.0 | VBA implicitly extends the IControl interface to controls in MSForms - RD doesn't - I noticed this after the reimplementation of `MemberNotOnInterfaceInspection`. This code (in a UserForm) triggers an inspection result for the call to `SetFocus`:
```
Private Sub UserForm_Activate()
TextBox1.SetFocus
End Sub
... | process | vba implicitly extends the icontrol interface to controls in msforms rd doesn t i noticed this after the reimplementation of membernotoninterfaceinspection this code in a userform triggers an inspection result for the call to setfocus private sub userform activate setfocus end sub i ... | 1 |
395,530 | 11,687,899,331 | IssuesEvent | 2020-03-05 13:39:55 | benetech/ServiceNet | https://api.github.com/repos/benetech/ServiceNet | closed | Custom record views - need a UI tweak | PM: Workflow Priority C | Now that I see the "custom record views" that allows me to dictate the visible fields (love it) I have a small request to make the capability a little more obvious.
How about to the left of the gear/cog icon we have the prose: "Show less fields" to make it more obvious that is what it is there for?
 I have a small request to make the capability a little more obvious.
How about to the left of the gear/cog icon we have the prose: "Show less fields" to make it more obvious that is... | non_process | custom record views need a ui tweak now that i see the custom record views that allows me to dictate the visible fields love it i have a small request to make the capability a little more obvious how about to the left of the gear cog icon we have the prose show less fields to make it more obvious that is... | 0 |
43,739 | 11,299,992,940 | IssuesEvent | 2020-01-17 12:35:52 | microsoft/WindowsTemplateStudio | https://api.github.com/repos/microsoft/WindowsTemplateStudio | opened | Build dev.templates.tests.full_20200117.2 failed | bug vsts-build | ## Build dev.templates.tests.full_20200117.2
- **Build result:** `failed`
- **Build queued:** 1/17/2020 10:12:45 AM
- **Build duration:** 142.64 minutes
### Details
Build [dev.templates.tests.full_20200117.2](https://winappstudio.visualstudio.com/web/build.aspx?pcguid=a4ef43be-68ce-4195-a619-079b4d9834c2&builduri=... | 1.0 | Build dev.templates.tests.full_20200117.2 failed - ## Build dev.templates.tests.full_20200117.2
- **Build result:** `failed`
- **Build queued:** 1/17/2020 10:12:45 AM
- **Build duration:** 142.64 minutes
### Details
Build [dev.templates.tests.full_20200117.2](https://winappstudio.visualstudio.com/web/build.aspx?pc... | non_process | build dev templates tests full failed build dev templates tests full build result failed build queued am build duration minutes details build failed xunit console exe build empty legacy addrightclick uwp projecttype splitview framework co... | 0 |
15,785 | 19,976,139,847 | IssuesEvent | 2022-01-29 05:10:35 | tushushu/ulist | https://api.github.com/repos/tushushu/ulist | closed | Implement where method for List | enhancement data processing | Like SQL `WHERE` statement, implement a `where` method to filter the `ulist` by given condition. For example:
```Python
arr = ul.arange(5)
arr.where(lambda x: x > 1)
UltraFastList([2, 3, 4])
``` | 1.0 | Implement where method for List - Like SQL `WHERE` statement, implement a `where` method to filter the `ulist` by given condition. For example:
```Python
arr = ul.arange(5)
arr.where(lambda x: x > 1)
UltraFastList([2, 3, 4])
``` | process | implement where method for list like sql where statement implement a where method to filter the ulist by given condition for example python arr ul arange arr where lambda x x ultrafastlist | 1 |
7,455 | 10,561,185,784 | IssuesEvent | 2019-10-04 15:21:09 | ESMValGroup/ESMValCore | https://api.github.com/repos/ESMValGroup/ESMValCore | closed | How to regrid fx files | preprocessor | I would like to regrid an fx file - `sftlf `- onto a 5x5 grid. I need this as input to an existing python package which is expecting tas, tos, siconc and sftlf in NetCDF files on a 5x5 grid, to produce masked and blended GMST. I can regrid `tas`, `tos` and `siconc` onto a 5x5 grid using the `regrid` preprocessor, by ad... | 1.0 | How to regrid fx files - I would like to regrid an fx file - `sftlf `- onto a 5x5 grid. I need this as input to an existing python package which is expecting tas, tos, siconc and sftlf in NetCDF files on a 5x5 grid, to produce masked and blended GMST. I can regrid `tas`, `tos` and `siconc` onto a 5x5 grid using the `re... | process | how to regrid fx files i would like to regrid an fx file sftlf onto a grid i need this as input to an existing python package which is expecting tas tos siconc and sftlf in netcdf files on a grid to produce masked and blended gmst i can regrid tas tos and siconc onto a grid using the regrid ... | 1 |
141,946 | 11,448,503,929 | IssuesEvent | 2020-02-06 03:40:34 | LLNL/axom | https://api.github.com/repos/LLNL/axom | opened | Follow-up tasks for TPL CI improvements | CI TPL Testing maintenance | @keithhealy has significantly improved our CI testing by adding docker images with pre-built TPLs (#155 )
This issue tracks some unresolved tasks:
- [ ] Build ``RAJA`` directly using our uberenv. @keithhealy ran into trouble building ``RAJA`` through docker and our current dockerfile's are building ``RAJA`` separa... | 1.0 | Follow-up tasks for TPL CI improvements - @keithhealy has significantly improved our CI testing by adding docker images with pre-built TPLs (#155 )
This issue tracks some unresolved tasks:
- [ ] Build ``RAJA`` directly using our uberenv. @keithhealy ran into trouble building ``RAJA`` through docker and our current... | non_process | follow up tasks for tpl ci improvements keithhealy has significantly improved our ci testing by adding docker images with pre built tpls this issue tracks some unresolved tasks build raja directly using our uberenv keithhealy ran into trouble building raja through docker and our current doc... | 0 |
212,483 | 16,453,786,757 | IssuesEvent | 2021-05-21 09:38:40 | minova-afis/aero.minova.rcp | https://api.github.com/repos/minova-afis/aero.minova.rcp | closed | Release 12.X.17 unter MacOS | test | Getestet mit Server xxxxxx
# Testprotokoll unter macOS
## Anmeldung
- [x] Anmeldung an den Server mittles Default - Profil
- [x] Anmeldung an den Server durch manuelles eintragen der Anmeldedaten
- [x] Wiederholtes Anmelden mit einem Profil, bei dem das Passwort falsch eingetragen wurde und die Anwendung dire... | 1.0 | Release 12.X.17 unter MacOS - Getestet mit Server xxxxxx
# Testprotokoll unter macOS
## Anmeldung
- [x] Anmeldung an den Server mittles Default - Profil
- [x] Anmeldung an den Server durch manuelles eintragen der Anmeldedaten
- [x] Wiederholtes Anmelden mit einem Profil, bei dem das Passwort falsch eingetrage... | non_process | release x unter macos getestet mit server xxxxxx testprotokoll unter macos anmeldung anmeldung an den server mittles default profil anmeldung an den server durch manuelles eintragen der anmeldedaten wiederholtes anmelden mit einem profil bei dem das passwort falsch eingetragen wurde ... | 0 |
10,257 | 13,110,241,490 | IssuesEvent | 2020-08-04 20:16:16 | googleapis/code-suggester | https://api.github.com/repos/googleapis/code-suggester | closed | Setup npm releases | type: process | - [ ] Have document detailing release notes i.e. changelog
- [ ] Auto-deployment based on GitHub commit comments
- [ ] Ensure auto-updated tags
- [ ] Ensure auto-updating of docs that reference any versioning
### Description
Create an automated npm release with auto-updating docs, tags, etc. | 1.0 | Setup npm releases - - [ ] Have document detailing release notes i.e. changelog
- [ ] Auto-deployment based on GitHub commit comments
- [ ] Ensure auto-updated tags
- [ ] Ensure auto-updating of docs that reference any versioning
### Description
Create an automated npm release with auto-updating docs, tags, etc. | process | setup npm releases have document detailing release notes i e changelog auto deployment based on github commit comments ensure auto updated tags ensure auto updating of docs that reference any versioning description create an automated npm release with auto updating docs tags etc | 1 |
248,414 | 21,016,861,454 | IssuesEvent | 2022-03-30 11:51:49 | Uuvana-Studios/longvinter-windows-client | https://api.github.com/repos/Uuvana-Studios/longvinter-windows-client | opened | can't type password | Bug Not Tested | **Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See an error
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If ... | 1.0 | can't type password - **Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See an error
**Expected behavior**
A clear and concise description of what you expected to happen.
... | non_process | can t type password describe the bug a clear and concise description of what the bug is to reproduce steps to reproduce the behavior go to click on scroll down to see an error expected behavior a clear and concise description of what you expected to happen ... | 0 |
117,690 | 17,512,680,064 | IssuesEvent | 2021-08-11 01:05:04 | harrinry/pulsar | https://api.github.com/repos/harrinry/pulsar | opened | CVE-2019-20330 (High) detected in jackson-databind-2.8.11.4.jar, jackson-databind-2.6.5.jar | security vulnerability | ## CVE-2019-20330 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>jackson-databind-2.8.11.4.jar</b>, <b>jackson-databind-2.6.5.jar</b></p></summary>
<p>
<details><summary><b>jackson-... | True | CVE-2019-20330 (High) detected in jackson-databind-2.8.11.4.jar, jackson-databind-2.6.5.jar - ## CVE-2019-20330 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>jackson-databind-2.8.11... | non_process | cve high detected in jackson databind jar jackson databind jar cve high severity vulnerability vulnerable libraries jackson databind jar jackson databind jar jackson databind jar general data binding functionality for jackson works on core s... | 0 |
3 | 2,490,629,164 | IssuesEvent | 2015-01-02 17:45:31 | tinkerpop/tinkerpop3 | https://api.github.com/repos/tinkerpop/tinkerpop3 | closed | On the concept of "step modulators". | enhancement process | We have opened up a can of worms with `as()` and `by()`. I call these "step modulators" in that they are not steps in themselves, but effect the step that came previous. For instance:
. `v.out().as('a')`: The `VertexStep.setLabel()` is called. (`Step` interface)
. `v.out().groupCount().by('name')`: The `GroupCountS... | 1.0 | On the concept of "step modulators". - We have opened up a can of worms with `as()` and `by()`. I call these "step modulators" in that they are not steps in themselves, but effect the step that came previous. For instance:
. `v.out().as('a')`: The `VertexStep.setLabel()` is called. (`Step` interface)
. `v.out().gro... | process | on the concept of step modulators we have opened up a can of worms with as and by i call these step modulators in that they are not steps in themselves but effect the step that came previous for instance v out as a the vertexstep setlabel is called step interface v out gro... | 1 |
143,917 | 11,583,958,778 | IssuesEvent | 2020-02-22 14:32:01 | marzer/tomlplusplus | https://api.github.com/repos/marzer/tomlplusplus | closed | Add node_view::value_or() | enhancement requires tests | To turn this:
```cpp
auto fval = tbl[key][0].as_floating_point() ? **tbl[key][0].as_floating_point() : 0.0f
```
Into this:
```cpp
auto fval = tbl[key][0].value_or(0.0f);
``` | 1.0 | Add node_view::value_or() - To turn this:
```cpp
auto fval = tbl[key][0].as_floating_point() ? **tbl[key][0].as_floating_point() : 0.0f
```
Into this:
```cpp
auto fval = tbl[key][0].value_or(0.0f);
``` | non_process | add node view value or to turn this cpp auto fval tbl as floating point tbl as floating point into this cpp auto fval tbl value or | 0 |
92,515 | 3,871,867,653 | IssuesEvent | 2016-04-11 11:42:44 | NRGI/rgi-assessment-tool | https://api.github.com/repos/NRGI/rgi-assessment-tool | closed | Dependant question model | enhancement in progress priority workflow | Some questions will need to only appear based on previously answered questinon. This is likely addressed by pending pull but will check. | 1.0 | Dependant question model - Some questions will need to only appear based on previously answered questinon. This is likely addressed by pending pull but will check. | non_process | dependant question model some questions will need to only appear based on previously answered questinon this is likely addressed by pending pull but will check | 0 |
19,702 | 26,052,733,559 | IssuesEvent | 2022-12-22 20:35:37 | MPMG-DCC-UFMG/C01 | https://api.github.com/repos/MPMG-DCC-UFMG/C01 | opened | Interface de passos com Vue.js - Passos com iteráveis, condições e "sources" | [1] Bug [2] Alta Prioridade [0] Desenvolvimento [3] Processamento Dinâmico | ## Comportamento Esperado
Os passos do sistema que incluem algum tipo de passo interno (iteráveis no caso de iterações, condições no caso de condicionais e "source" no caso da atribuição) devem funcionar corretamente. A interface deve disponibilizar um select para escolher o passo interno, nesse caso, e exibir também ... | 1.0 | Interface de passos com Vue.js - Passos com iteráveis, condições e "sources" - ## Comportamento Esperado
Os passos do sistema que incluem algum tipo de passo interno (iteráveis no caso de iterações, condições no caso de condicionais e "source" no caso da atribuição) devem funcionar corretamente. A interface deve dispo... | process | interface de passos com vue js passos com iteráveis condições e sources comportamento esperado os passos do sistema que incluem algum tipo de passo interno iteráveis no caso de iterações condições no caso de condicionais e source no caso da atribuição devem funcionar corretamente a interface deve dispo... | 1 |
3,637 | 6,670,937,851 | IssuesEvent | 2017-10-04 03:28:11 | triplea-game/triplea | https://api.github.com/repos/triplea-game/triplea | opened | Publish public key used to verify release artifact checksum signatures | category: dev & admin process discussion type: admin task | This issue is a follow-up to #2463, which implemented signing of the release artifact checksum files to ensure their integrity. In order for users to verify the signatures, they need access to the public key corresponding to the private key used to create the signatures. The purpose of this issue is to discuss how we... | 1.0 | Publish public key used to verify release artifact checksum signatures - This issue is a follow-up to #2463, which implemented signing of the release artifact checksum files to ensure their integrity. In order for users to verify the signatures, they need access to the public key corresponding to the private key used ... | process | publish public key used to verify release artifact checksum signatures this issue is a follow up to which implemented signing of the release artifact checksum files to ensure their integrity in order for users to verify the signatures they need access to the public key corresponding to the private key used to ... | 1 |
78,301 | 22,193,320,231 | IssuesEvent | 2022-06-07 02:59:12 | tensorflow/tensorflow | https://api.github.com/repos/tensorflow/tensorflow | closed | tensorflow cpu module's speed lower on windows than linux | stat:awaiting response type:build/install type:support stalled 1.4.0 | System information
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):yes
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):windows7 64bit and ubuntu 16.04 64bit
- TensorFlow installed from (source or binary):build tensorflow source to shared lib
- TensorFlow ve... | 1.0 | tensorflow cpu module's speed lower on windows than linux - System information
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):yes
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):windows7 64bit and ubuntu 16.04 64bit
- TensorFlow installed from (source or bi... | non_process | tensorflow cpu module s speed lower on windows than linux system information have i written custom code as opposed to using a stock example script provided in tensorflow yes os platform and distribution e g linux ubuntu and ubuntu tensorflow installed from source or binary build tensorf... | 0 |
409,609 | 27,745,305,205 | IssuesEvent | 2023-03-15 16:39:00 | elmsln/issues | https://api.github.com/repos/elmsln/issues | opened | user context exercise: the everything solution | documentation 2025 super daemon | Not sure if to consider this CLI or what but here goes with the discussion just had.
If we think of the UI as just a way of accessing things in the CLI, we can #1263 entice users to learn both and think with both mental models, effectively using the CLI / folder / action tree as a backdrop to learn the UI. Methods l... | 1.0 | user context exercise: the everything solution - Not sure if to consider this CLI or what but here goes with the discussion just had.
If we think of the UI as just a way of accessing things in the CLI, we can #1263 entice users to learn both and think with both mental models, effectively using the CLI / folder / act... | non_process | user context exercise the everything solution not sure if to consider this cli or what but here goes with the discussion just had if we think of the ui as just a way of accessing things in the cli we can entice users to learn both and think with both mental models effectively using the cli folder action... | 0 |
15,156 | 18,908,732,187 | IssuesEvent | 2021-11-16 11:54:52 | streamnative/pulsar-flink | https://api.github.com/repos/streamnative/pulsar-flink | reopened | Remove unused code in master branch | type/cleanup platform/data-processing | There are many dangling code (especially some new connector flies) in the repo that is not being used.
It increases the barrier to fully understand things in this repo | 1.0 | Remove unused code in master branch - There are many dangling code (especially some new connector flies) in the repo that is not being used.
It increases the barrier to fully understand things in this repo | process | remove unused code in master branch there are many dangling code especially some new connector flies in the repo that is not being used it increases the barrier to fully understand things in this repo | 1 |
33,283 | 2,763,322,372 | IssuesEvent | 2015-04-29 08:29:43 | ceylon/ceylon-spec | https://api.github.com/repos/ceylon/ceylon-spec | opened | lots of bugs typechecking native | bug high priority | These are the problems I noticed immediately, surely there are more:
- All versions of the `native` dec are forced to have the exact same annotations, which is no good, for, e.g. the `doc` annotation.
- This seems to be a catchall way to avoid directly checking stuff like `variable`, but if we want decent messages ... | 1.0 | lots of bugs typechecking native - These are the problems I noticed immediately, surely there are more:
- All versions of the `native` dec are forced to have the exact same annotations, which is no good, for, e.g. the `doc` annotation.
- This seems to be a catchall way to avoid directly checking stuff like `variabl... | non_process | lots of bugs typechecking native these are the problems i noticed immediately surely there are more all versions of the native dec are forced to have the exact same annotations which is no good for e g the doc annotation this seems to be a catchall way to avoid directly checking stuff like variabl... | 0 |
265,171 | 8,338,321,765 | IssuesEvent | 2018-09-28 14:00:25 | edenlabllc/ehealth.api | https://api.github.com/repos/edenlabllc/ehealth.api | closed | Insert record into dictionary LEGAL_FORM, PROD, #J300 | kind/support priority/medium status/wontfix | Прохання добавити до поточного словника "LEGAL_FORM" - КНП, тобто "КОМУНАЛЬНЕ НЕКОМЕРЦІЙНЕ ПІДПРИЄМСТВО", дякую.
| 1.0 | Insert record into dictionary LEGAL_FORM, PROD, #J300 - Прохання добавити до поточного словника "LEGAL_FORM" - КНП, тобто "КОМУНАЛЬНЕ НЕКОМЕРЦІЙНЕ ПІДПРИЄМСТВО", дякую.
| non_process | insert record into dictionary legal form prod прохання добавити до поточного словника legal form кнп тобто комунальне некомерційне підприємство дякую | 0 |
11,688 | 14,542,938,667 | IssuesEvent | 2020-12-15 16:17:18 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | No indication of permission prerequisites. | Pri2 devops-cicd-process/tech devops/prod doc-enhancement |
I follow the guidance on the page and get the following error;
Access denied. Dermot Canniffe needs Create permissions to perform the action. For more information, contact the Azure DevOps Server administrator.
This, even though I'm a PCA in the organisation, and an owner and admin on the project in question. N... | 1.0 | No indication of permission prerequisites. -
I follow the guidance on the page and get the following error;
Access denied. Dermot Canniffe needs Create permissions to perform the action. For more information, contact the Azure DevOps Server administrator.
This, even though I'm a PCA in the organisation, and an... | process | no indication of permission prerequisites i follow the guidance on the page and get the following error access denied dermot canniffe needs create permissions to perform the action for more information contact the azure devops server administrator this even though i m a pca in the organisation and an... | 1 |
191 | 2,505,173,333 | IssuesEvent | 2015-01-11 04:52:16 | bitcoin/secp256k1 | https://api.github.com/repos/bitcoin/secp256k1 | opened | Docucmentation should provide example callers. | documentation | We've seen some people attempting to use the library calling into random internal functions. That should be harder to do now... but now that the basic signature interface is relatively safe to use (as such things go) there should be some easy copy and paste examples for correct usage.
| 1.0 | Docucmentation should provide example callers. - We've seen some people attempting to use the library calling into random internal functions. That should be harder to do now... but now that the basic signature interface is relatively safe to use (as such things go) there should be some easy copy and paste examples for ... | non_process | docucmentation should provide example callers we ve seen some people attempting to use the library calling into random internal functions that should be harder to do now but now that the basic signature interface is relatively safe to use as such things go there should be some easy copy and paste examples for ... | 0 |
15,451 | 19,665,169,591 | IssuesEvent | 2022-01-10 21:33:15 | GoogleCloudPlatform/microservices-demo | https://api.github.com/repos/GoogleCloudPlatform/microservices-demo | closed | cut a new 0.3.5 release from main, please | type: process priority: p2 | ### Describe the bug
Some services (Payment, for sure) does not have options to disable google-specific tracing/profiler. Payment service is crashing if the cluster is not in GCP.
### To Reproduce
start Payment service in a K8s cluster not on GCP
### Logs
```
/usr/src/app/node_modules/@google-cloud/profil... | 1.0 | cut a new 0.3.5 release from main, please - ### Describe the bug
Some services (Payment, for sure) does not have options to disable google-specific tracing/profiler. Payment service is crashing if the cluster is not in GCP.
### To Reproduce
start Payment service in a K8s cluster not on GCP
### Logs
```
/u... | process | cut a new release from main please describe the bug some services payment for sure does not have options to disable google specific tracing profiler payment service is crashing if the cluster is not in gcp to reproduce start payment service in a cluster not on gcp logs usr... | 1 |
9,888 | 12,889,639,630 | IssuesEvent | 2020-07-13 14:49:27 | zammad/zammad | https://api.github.com/repos/zammad/zammad | opened | Zammad can't import specific ISO-2022-JP mails | bug mail processing prioritized by payment verified | <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-change-regarding-github-issues-community-board/21
P... | 1.0 | Zammad can't import specific ISO-2022-JP mails - <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-chang... | process | zammad can t import specific iso jp mails hi there thanks for filing an issue please ensure the following things before creating an issue thank you 🤓 since november we handle all requests except real bugs at our community board full explanation please post feature requests develop... | 1 |
4,201 | 7,164,074,106 | IssuesEvent | 2018-01-29 09:58:24 | DynareTeam/dynare | https://api.github.com/repos/DynareTeam/dynare | closed | nested @#ifndef and @#ifdef don't work | bug macroprocessor | Email from @JohannesPfeifer:
If I use
```
@#define risk_sharing = 0
@#if risk_sharing == 0
@#ifndef endogenous_discount_factor
@#define endogenous_discount_factor = 1
@#endif
@#endif
```
In a mod-file, I get an error
```
@#if/@#ifdef/@#ifndef not matched by an @#endif or file does not e... | 1.0 | nested @#ifndef and @#ifdef don't work - Email from @JohannesPfeifer:
If I use
```
@#define risk_sharing = 0
@#if risk_sharing == 0
@#ifndef endogenous_discount_factor
@#define endogenous_discount_factor = 1
@#endif
@#endif
```
In a mod-file, I get an error
```
@#if/@#ifdef/@#ifndef not... | process | nested ifndef and ifdef don t work email from johannespfeifer if i use define risk sharing if risk sharing ifndef endogenous discount factor define endogenous discount factor endif endif in a mod file i get an error if ifdef ifndef not... | 1 |
121,296 | 12,122,021,249 | IssuesEvent | 2020-04-22 10:14:42 | dry-python/returns | https://api.github.com/repos/dry-python/returns | opened | Create "Maintaining.md" | documentation | In this document I will explain:
- How releases are made
- How decisions are made and who has the final word
- What processes we enforce (for example: RFC for our core values #346)
| 1.0 | Create "Maintaining.md" - In this document I will explain:
- How releases are made
- How decisions are made and who has the final word
- What processes we enforce (for example: RFC for our core values #346)
| non_process | create maintaining md in this document i will explain how releases are made how decisions are made and who has the final word what processes we enforce for example rfc for our core values | 0 |
14,018 | 16,816,924,519 | IssuesEvent | 2021-06-17 08:29:59 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [PM] Participant details page > Table columns alignment issue | Bug P2 Participant manager Process: Fixed Process: Tested QA Process: Tested dev | Participant details page > Enrollment history and consent history table columns should be aligned properly (As per invision screen)
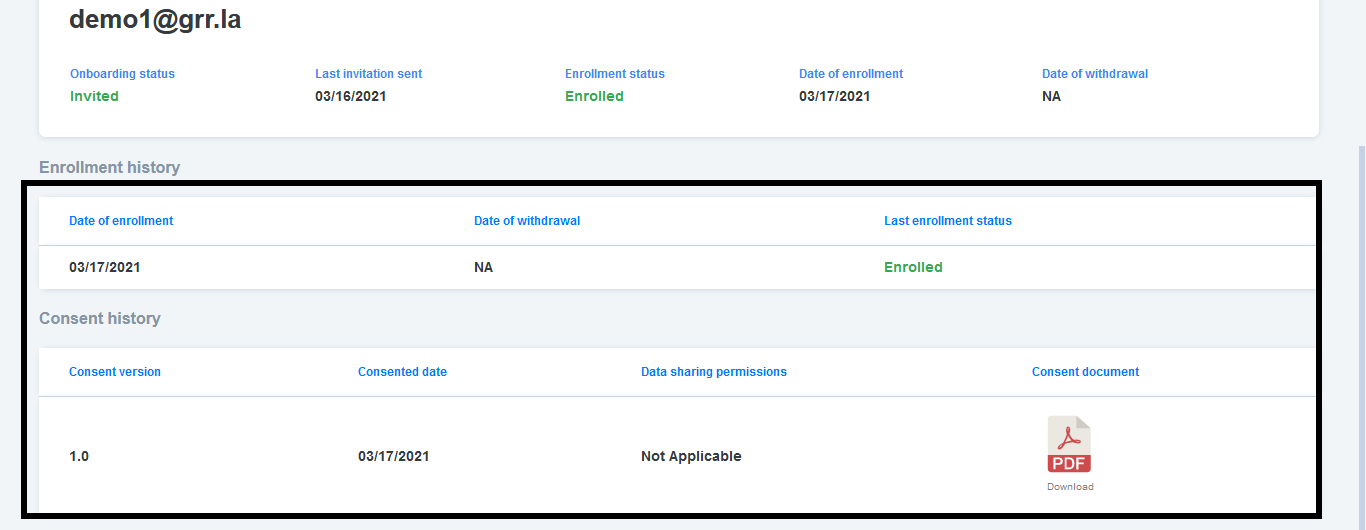
| 3.0 | [PM] Participant details page > Table columns alignment issue - Participant details page > Enrollment history and consent history table columns should be aligned properly (As per invision screen)

| process | participant details page table columns alignment issue participant details page enrollment history and consent history table columns should be aligned properly as per invision screen | 1 |
19,189 | 25,314,861,210 | IssuesEvent | 2022-11-17 20:39:13 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | closed | Cypress 5.x does not support UMD module type in tsconfig.json | stage: ready for work topic: typescript topic: preprocessors :wrench: | ### Current behavior:
When I upgrade from v4.12.1 to v5.x I get an error like this:
```
The following error originated from your test code, not from Cypress.
> Cannot find module '../../path/to/something/that/used/to/work'
When Cypress detects uncaught errors originating from your test code it will automatically f... | 1.0 | Cypress 5.x does not support UMD module type in tsconfig.json - ### Current behavior:
When I upgrade from v4.12.1 to v5.x I get an error like this:
```
The following error originated from your test code, not from Cypress.
> Cannot find module '../../path/to/something/that/used/to/work'
When Cypress detects uncaugh... | process | cypress x does not support umd module type in tsconfig json current behavior when i upgrade from to x i get an error like this the following error originated from your test code not from cypress cannot find module path to something that used to work when cypress detects uncaught e... | 1 |
19,949 | 26,421,914,350 | IssuesEvent | 2023-01-13 21:28:37 | rusefi/rusefi_documentation | https://api.github.com/repos/rusefi/rusefi_documentation | closed | embedded HTML code creates issues for MkDocs and results in wrong display on wiki.rusefi.com | wiki location & process change | ## example:

## root cause:

## root cause:
![2022-12-27 ... | process | embedded html code creates issues for mkdocs and results in wrong display on wiki rusefi com example root cause fix use only markdown tags and remove embedded html code affected markdown files results files faq ignition md ... | 1 |
3,199 | 6,262,258,847 | IssuesEvent | 2017-07-15 08:38:51 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | `exec` and `execSync` `git clone private_repo` + timeout hangs the REPL | child_process doc good first contribution repl | - **Version**: v6.7 (also v5.12)
- **Platform**: Linux #138-Ubuntu SMP Fri Jun 24 17:00:34 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
**Expected behavior**: REPL resumes working
**Actual behavior**: Process hangs
Description:
When git cloning a repo that requires entering a username and password in `child_process.exec` ... | 1.0 | `exec` and `execSync` `git clone private_repo` + timeout hangs the REPL - - **Version**: v6.7 (also v5.12)
- **Platform**: Linux #138-Ubuntu SMP Fri Jun 24 17:00:34 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
**Expected behavior**: REPL resumes working
**Actual behavior**: Process hangs
Description:
When git cloning a re... | process | exec and execsync git clone private repo timeout hangs the repl version also platform linux ubuntu smp fri jun utc gnu linux expected behavior repl resumes working actual behavior process hangs description when git cloning a repo that requires ente... | 1 |
21,485 | 29,577,946,972 | IssuesEvent | 2023-06-07 01:37:03 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | closed | Strip version does not works properly even with simple Hello world program on java. | P4 type: support / not a bug (process) team-ExternalDeps stale | ### Description of the problem / feature request: Require heavy bundle of bazel which does have required tooling. Strip version of bazel is failing in most of the cases.
java.io.IOException: Error downloading [https://mirror.bazel.build/bazel_java_tools/releases/javac11/v4.0/java_tools_javac11_linux-v4.0.zip]
##... | 1.0 | Strip version does not works properly even with simple Hello world program on java. - ### Description of the problem / feature request: Require heavy bundle of bazel which does have required tooling. Strip version of bazel is failing in most of the cases.
java.io.IOException: Error downloading [https://mirror.bazel... | process | strip version does not works properly even with simple hello world program on java description of the problem feature request require heavy bundle of bazel which does have required tooling strip version of bazel is failing in most of the cases java io ioexception error downloading feature requ... | 1 |
84,797 | 15,728,293,847 | IssuesEvent | 2021-03-29 13:40:01 | ssobue/kotlin-boot | https://api.github.com/repos/ssobue/kotlin-boot | closed | CVE-2018-19361 (High) detected in jackson-databind-2.8.10.jar | security vulnerability | ## CVE-2018-19361 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jackson-databind-2.8.10.jar</b></p></summary>
<p>General data-binding functionality for Jackson: works on core streami... | True | CVE-2018-19361 (High) detected in jackson-databind-2.8.10.jar - ## CVE-2018-19361 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jackson-databind-2.8.10.jar</b></p></summary>
<p>Gener... | non_process | cve high detected in jackson databind jar cve high severity vulnerability vulnerable library jackson databind jar general data binding functionality for jackson works on core streaming api library home page a href path to dependency file kotlin boot pom xml path to ... | 0 |
187,597 | 15,101,421,980 | IssuesEvent | 2021-02-08 07:28:00 | Kostyachzhan/ShedulerBook | https://api.github.com/repos/Kostyachzhan/ShedulerBook | closed | UseCase diagram | documentation | Розробити схему бази даних з таблицями у вигляді відповідної ER діаграми. Для кожної таблиці вказати дані, які там будуть зберігатися, типи, а також залежності між таблицями. | 1.0 | UseCase diagram - Розробити схему бази даних з таблицями у вигляді відповідної ER діаграми. Для кожної таблиці вказати дані, які там будуть зберігатися, типи, а також залежності між таблицями. | non_process | usecase diagram розробити схему бази даних з таблицями у вигляді відповідної er діаграми для кожної таблиці вказати дані які там будуть зберігатися типи а також залежності між таблицями | 0 |
17,546 | 23,357,169,869 | IssuesEvent | 2022-08-10 08:29:09 | googleapis/java-spanner | https://api.github.com/repos/googleapis/java-spanner | opened | Encrypted test instance is not always deleted after test run | type: cleanup type: process api: spanner | [This line](https://github.com/googleapis/java-spanner/blob/787ccadcba01193d541bfd1b80b055fb5d4c2bb3/samples/snippets/src/test/java/com/example/spanner/SpannerSampleIT.java#L458) will not be executed if the test is killed, for example if the test times out. That will leave the encrypted test instance lingering around. ... | 1.0 | Encrypted test instance is not always deleted after test run - [This line](https://github.com/googleapis/java-spanner/blob/787ccadcba01193d541bfd1b80b055fb5d4c2bb3/samples/snippets/src/test/java/com/example/spanner/SpannerSampleIT.java#L458) will not be executed if the test is killed, for example if the test times out.... | process | encrypted test instance is not always deleted after test run will not be executed if the test is killed for example if the test times out that will leave the encrypted test instance lingering around we should therefore add a cleanup task at the start of the test run to remove any old instances still hanging ar... | 1 |
271,868 | 23,637,626,351 | IssuesEvent | 2022-08-25 14:27:07 | cockroachdb/cockroach | https://api.github.com/repos/cockroachdb/cockroach | closed | ccl/changefeedccl: TestChangefeedPrimaryKeyChangeWorksWithMultipleTables failed | C-test-failure O-robot branch-master T-cdc | ccl/changefeedccl.TestChangefeedPrimaryKeyChangeWorksWithMultipleTables [failed](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/6213858?buildTab=log) with [artifacts](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/6213858?buildTab=artifacts#/) on... | 1.0 | ccl/changefeedccl: TestChangefeedPrimaryKeyChangeWorksWithMultipleTables failed - ccl/changefeedccl.TestChangefeedPrimaryKeyChangeWorksWithMultipleTables [failed](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/6213858?buildTab=log) with [artifacts](https://teamcity.cockroachdb.com/b... | non_process | ccl changefeedccl testchangefeedprimarykeychangeworkswithmultipletables failed ccl changefeedccl testchangefeedprimarykeychangeworkswithmultipletables with on master run testchangefeedprimarykeychangeworkswithmultipletables test log scope go test logs captured to artifacts tmp tmp... | 0 |
19,123 | 25,171,958,326 | IssuesEvent | 2022-11-11 04:44:36 | emily-writes-poems/emily-writes-poems-processing | https://api.github.com/repos/emily-writes-poems/emily-writes-poems-processing | closed | separate tabs for each section | processing refinement | poem, details, collection, feature
may possibly involve using React | 1.0 | separate tabs for each section - poem, details, collection, feature
may possibly involve using React | process | separate tabs for each section poem details collection feature may possibly involve using react | 1 |
24,559 | 5,081,341,177 | IssuesEvent | 2016-12-29 09:50:17 | QualiSystems/Azure-Shell | https://api.github.com/repos/QualiSystems/Azure-Shell | closed | Cleanup attribute names and descriptions (data model finalizing) | Documentation Documentation-Done Test Plan Ready | ### Redundant attributes that should be removed on Deployment Service:
- Outbound Ports
### Redundant attributes that should be removed on Cloud Provider resource:
- Azure Mgmt Network ID
- Keypairs Location
- Storage Type
- AZURE MGMT VNET
### Cloud Provider resource attribute type changes:
- Azure Secret... | 2.0 | Cleanup attribute names and descriptions (data model finalizing) - ### Redundant attributes that should be removed on Deployment Service:
- Outbound Ports
### Redundant attributes that should be removed on Cloud Provider resource:
- Azure Mgmt Network ID
- Keypairs Location
- Storage Type
- AZURE MGMT VNET
... | non_process | cleanup attribute names and descriptions data model finalizing redundant attributes that should be removed on deployment service outbound ports redundant attributes that should be removed on cloud provider resource azure mgmt network id keypairs location storage type azure mgmt vnet ... | 0 |
280,497 | 8,682,664,117 | IssuesEvent | 2018-12-02 10:54:48 | bounswe/bounswe2018group3 | https://api.github.com/repos/bounswe/bounswe2018group3 | opened | Redirect E-mail Confirmation page to the Frontend from the Backend | Backend difficulty : medium priority : low type : enhancement | When e-mail confirmation link is used, the user arrives at the backend endpoint of this function. This should be changed. | 1.0 | Redirect E-mail Confirmation page to the Frontend from the Backend - When e-mail confirmation link is used, the user arrives at the backend endpoint of this function. This should be changed. | non_process | redirect e mail confirmation page to the frontend from the backend when e mail confirmation link is used the user arrives at the backend endpoint of this function this should be changed | 0 |
93,083 | 19,074,621,308 | IssuesEvent | 2021-11-27 14:46:57 | F-star/fstar-blog-comment | https://api.github.com/repos/F-star/fstar-blog-comment | opened | 【算法题】最大连续子序和 | fstar | Gitalk /posts/leetcode-maximum-subarray-solve/ | https://blog.fstars.wang/posts/leetcode-maximum-subarray-solve/
一道 LeetCode 的动态规划题的分析。 题目描述 题目来源 leetCode——53.最大子序和 给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 示例: 输入: [-2,1,-3,4,-1,2,1,-5,4], 输出: 6 解释: 连… | 1.0 | 【算法题】最大连续子序和 | fstar - https://blog.fstars.wang/posts/leetcode-maximum-subarray-solve/
一道 LeetCode 的动态规划题的分析。 题目描述 题目来源 leetCode——53.最大子序和 给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 示例: 输入: [-2,1,-3,4,-1,2,1,-5,4], 输出: 6 解释: 连… | non_process | 【算法题】最大连续子序和 fstar 一道 leetcode 的动态规划题的分析。 题目描述 题目来源 leetcode—— 最大子序和 给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 示例 输入 输出 解释 连… | 0 |
3,264 | 6,343,003,580 | IssuesEvent | 2017-07-27 16:38:03 | w3c/vc-data-model | https://api.github.com/repos/w3c/vc-data-model | closed | List all validity checks that should be performed | privacy ValidationProcess | We should make it clear that an inspector (e.g. corporation) is required to check revocation via the Issuer (e.g. government). In fact, there are many different types of validity checks that should be performed on data, such as the revocation status of an Issuer's signing key, the expiration date of the claim, etc. | 1.0 | List all validity checks that should be performed - We should make it clear that an inspector (e.g. corporation) is required to check revocation via the Issuer (e.g. government). In fact, there are many different types of validity checks that should be performed on data, such as the revocation status of an Issuer's sig... | process | list all validity checks that should be performed we should make it clear that an inspector e g corporation is required to check revocation via the issuer e g government in fact there are many different types of validity checks that should be performed on data such as the revocation status of an issuer s sig... | 1 |
18,690 | 24,595,097,070 | IssuesEvent | 2022-10-14 07:37:25 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [DID] Console > Duplicate patient records are getting created when same participant provides the responses for the multiple activities | Bug P1 Response datastore Process: Fixed Process: Tested QA Process: Tested dev | AR: Console > Duplicate patient records are getting created when the same participant provides the responses for the multiple activities
ER: Single patient record should be there for each participant

| 3.0 | [DID] Console > Duplicate patient records are getting created when same participant provides the responses for the multiple activities - AR: Console > Duplicate patient records are getting created when the same participant provides the responses for the multiple activities
ER: Single patient record should be there fo... | process | console duplicate patient records are getting created when same participant provides the responses for the multiple activities ar console duplicate patient records are getting created when the same participant provides the responses for the multiple activities er single patient record should be there for ea... | 1 |
46,632 | 11,863,239,267 | IssuesEvent | 2020-03-25 19:20:52 | angular/angular-cli | https://api.github.com/repos/angular/angular-cli | closed | ng build - ES5 bundles -> Unknown helper createSuper | comp: devkit/build-angular freq1: low severity3: broken type: bug/fix | <!--🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅
Oh hi there! 😄
To expedite issue processing please search open and closed issues before submitting a new one.
Existing issues often contain information about workarounds, resolution, or progress updates.
🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅... | 1.0 | ng build - ES5 bundles -> Unknown helper createSuper - <!--🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅
Oh hi there! 😄
To expedite issue processing please search open and closed issues before submitting a new one.
Existing issues often contain information about workarounds, resolution, or prog... | non_process | ng build bundles unknown helper createsuper 🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅 oh hi there 😄 to expedite issue processing please search open and closed issues before submitting a new one existing issues often contain information about workarounds resolution or progre... | 0 |
2,571 | 7,966,084,860 | IssuesEvent | 2018-07-14 17:18:14 | LabOfOz/SeeClarke | https://api.github.com/repos/LabOfOz/SeeClarke | opened | Let's reduce the 1MB file size! | Architecture polish | It looks like we may be able to reduce the file size by using import vs require. Let's set it up so that everything in `/src` is `required` and any dependencies are `imported`
| 1.0 | Let's reduce the 1MB file size! - It looks like we may be able to reduce the file size by using import vs require. Let's set it up so that everything in `/src` is `required` and any dependencies are `imported`
 looks really good for enforcing consistency with each contribution. You can set requirements about how code should be structured, how pull requests should be tagged, if tests should be includ... | 1.0 | Consider using Danger JS to formalize contribution process - This may be more overhead than we end up needing, but Danger JS (https://github.com/danger/danger-js, http://danger.systems/js/) looks really good for enforcing consistency with each contribution. You can set requirements about how code should be structured, ... | process | consider using danger js to formalize contribution process this may be more overhead than we end up needing but danger js looks really good for enforcing consistency with each contribution you can set requirements about how code should be structured how pull requests should be tagged if tests should be inclu... | 1 |
2,997 | 5,971,006,582 | IssuesEvent | 2017-05-31 00:42:39 | IIIF/iiif.io | https://api.github.com/repos/IIIF/iiif.io | opened | Should we require CLAs for PRs? | process |
A project I'm associated with via the Getty has started using CLAs, with a nice little integration:
https://cla-assistant.io/
I forget if we've discussed CLAs, but (a) should we require them? and (b) should we use the integration? | 1.0 | Should we require CLAs for PRs? -
A project I'm associated with via the Getty has started using CLAs, with a nice little integration:
https://cla-assistant.io/
I forget if we've discussed CLAs, but (a) should we require them? and (b) should we use the integration? | process | should we require clas for prs a project i m associated with via the getty has started using clas with a nice little integration i forget if we ve discussed clas but a should we require them and b should we use the integration | 1 |
9,010 | 12,123,015,318 | IssuesEvent | 2020-04-22 12:01:14 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | load database layers after running algorithm | Feature Request Feedback Processing | Author Name: **Paolo Cavallini** (@pcav)
Original Redmine Issue: [13123](https://issues.qgis.org/issues/13123)
Redmine category:processing/core
---
There are ways that allow Processing to produce an output in a database instead of a file. Those are not automatically loaded after the tool finishes to run as files are... | 1.0 | load database layers after running algorithm - Author Name: **Paolo Cavallini** (@pcav)
Original Redmine Issue: [13123](https://issues.qgis.org/issues/13123)
Redmine category:processing/core
---
There are ways that allow Processing to produce an output in a database instead of a file. Those are not automatically lo... | process | load database layers after running algorithm author name paolo cavallini pcav original redmine issue redmine category processing core there are ways that allow processing to produce an output in a database instead of a file those are not automatically loaded after the tool finishes to run as fil... | 1 |
22,541 | 31,711,954,718 | IssuesEvent | 2023-09-09 11:42:21 | firebase/firebase-cpp-sdk | https://api.github.com/repos/firebase/firebase-cpp-sdk | reopened | [C++] Nightly Integration Testing Report for Firestore | type: process nightly-testing |
<hidden value="build-dashboard-comment-start"></hidden>
### Testing History (last 7 days)
| Date|Build vs Source Repo|Test vs Source Repo|SDK Packaging|Build vs SDK Package|Test vs SDK Package|Notes |
|---|---|---|---|---|---|---|
| 2023‑09‑02|[✅ Pass](https://github.com/firebase/firebase-cpp-sdk/a... | 1.0 | [C++] Nightly Integration Testing Report for Firestore -
<hidden value="build-dashboard-comment-start"></hidden>
### Testing History (last 7 days)
| Date|Build vs Source Repo|Test vs Source Repo|SDK Packaging|Build vs SDK Package|Test vs SDK Package|Notes |
|---|---|---|---|---|---|---|
| 2023‑09‑02|[✅&... | process | nightly integration testing report for firestore testing history last days date build vs source repo test vs source repo sdk packaging build vs sdk package test vs sdk package notes test flake in firestore on android ... | 1 |
5,862 | 8,682,542,321 | IssuesEvent | 2018-12-02 09:33:38 | linnovate/root | https://api.github.com/repos/linnovate/root | reopened | unable to delete files in folders tab | Fixed Process bug | after adding a file to a folder and trying to delete it, it still stays after switching tabs or refreshing the screen
for example, i deleted this file and it still shows up after i refreshed the page

| 1.0 | unable to delete files in folders tab - after adding a file to a folder and trying to delete it, it still stays after switching tabs or refreshing the screen
for example, i deleted this file and it still shows up after i refreshed the page
, on Windows with Node 6. This issue appears to crop up when a Node script is execute from a `SUBST`'d path.
The production ste... | 1.0 | Possible Windows Node 6 regression with spawn and a substed drive - * **Version**:
v6.0.0
* **Platform**:
Windows 32 and 64 bit
* **Subsystem**:
I've noticed a minor breaking change in either `child_process.spawn` or `path.resolve` (currently unclear), on Windows with Node 6. This issue appears to crop up when a... | process | possible windows node regression with spawn and a substed drive version platform windows and bit subsystem i ve noticed a minor breaking change in either child process spawn or path resolve currently unclear on windows with node this issue appears to crop up when a no... | 1 |
3,230 | 6,289,280,072 | IssuesEvent | 2017-07-19 18:51:20 | dotnet/corefx | https://api.github.com/repos/dotnet/corefx | closed | System.Diagnostics.Process.MainModule.FileName has junk characters in the prefix on UAP | area-System.Diagnostics.Process | (Test case will be added soon, creating issue so that I can disable that in the PR)
Junk characters might be BOM or Xunit display error
```
ERROR: System.Diagnostics.Tests.ProcessTests.TestMainModuleOnNonOSX [FAIL]
Assert.EndsWith() Failure:
Expected: xunit.runner.uap.exe
Actual... | 1.0 | System.Diagnostics.Process.MainModule.FileName has junk characters in the prefix on UAP - (Test case will be added soon, creating issue so that I can disable that in the PR)
Junk characters might be BOM or Xunit display error
```
ERROR: System.Diagnostics.Tests.ProcessTests.TestMainModuleOnNonOSX [FAIL]
... | process | system diagnostics process mainmodule filename has junk characters in the prefix on uap test case will be added soon creating issue so that i can disable that in the pr junk characters might be bom or xunit display error error system diagnostics tests processtests testmainmoduleonnonosx ... | 1 |
20,414 | 27,073,317,890 | IssuesEvent | 2023-02-14 08:50:39 | AvaloniaUI/Avalonia | https://api.github.com/repos/AvaloniaUI/Avalonia | closed | Text Selection affects justify in TextBox | bug area-textprocessing | ERROR: type should be string, got "\r\nhttps://user-images.githubusercontent.com/4997065/218300427-33eab39c-e679-45e7-9561-d343a1a38e5f.mov\r\n\r\nTextBox with TextWrapping=Wrap, Width=232, TextAlign=Justify.\r\n\r\nMacOS Ventura. 11.0.0-preview5" | 1.0 | Text Selection affects justify in TextBox -
https://user-images.githubusercontent.com/4997065/218300427-33eab39c-e679-45e7-9561-d343a1a38e5f.mov
TextBox with TextWrapping=Wrap, Width=232, TextAlign=Justify.
MacOS Ventura. 11.0.0-preview5 | process | text selection affects justify in textbox textbox with textwrapping wrap width textalign justify macos ventura | 1 |
509,188 | 14,723,727,266 | IssuesEvent | 2021-01-06 01:02:58 | threefoldtech/0-bootstrap | https://api.github.com/repos/threefoldtech/0-bootstrap | closed | boot: permission denied | priority_critical | Kernel download always fails with: Permission denied (0216eb3c)
This is caused by Let's Encrypt who changed their root certificates. Bundle certificates needs to be updated. | 1.0 | boot: permission denied - Kernel download always fails with: Permission denied (0216eb3c)
This is caused by Let's Encrypt who changed their root certificates. Bundle certificates needs to be updated. | non_process | boot permission denied kernel download always fails with permission denied this is caused by let s encrypt who changed their root certificates bundle certificates needs to be updated | 0 |
164,487 | 13,943,512,843 | IssuesEvent | 2020-10-22 23:19:07 | decred/dcrd | https://api.github.com/repos/decred/dcrd | closed | JSON-RPC API searchrawtransactions documentation max results | documentation | The [JSON-RPC API searchrawtransactions](https://github.com/decred/dcrd/blob/9547385fc04b2d27809f1fcc8ce19fb1e2c37291/docs/json_rpc_api.mediawiki#searchrawtransactions) documentation should specify the max number of results per request. | 1.0 | JSON-RPC API searchrawtransactions documentation max results - The [JSON-RPC API searchrawtransactions](https://github.com/decred/dcrd/blob/9547385fc04b2d27809f1fcc8ce19fb1e2c37291/docs/json_rpc_api.mediawiki#searchrawtransactions) documentation should specify the max number of results per request. | non_process | json rpc api searchrawtransactions documentation max results the documentation should specify the max number of results per request | 0 |
271,674 | 29,659,340,316 | IssuesEvent | 2023-06-10 01:18:28 | pazhanivel07/linux-4.19.72 | https://api.github.com/repos/pazhanivel07/linux-4.19.72 | closed | CVE-2022-3643 (Medium) detected in linuxlinux-4.19.83 - autoclosed | Mend: dependency security vulnerability | ## CVE-2022-3643 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linuxlinux-4.19.83</b></p></summary>
<p>
<p>Apache Software Foundation (ASF)</p>
<p>Library home page: <a href=https:... | True | CVE-2022-3643 (Medium) detected in linuxlinux-4.19.83 - autoclosed - ## CVE-2022-3643 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linuxlinux-4.19.83</b></p></summary>
<p>
<p>Apac... | non_process | cve medium detected in linuxlinux autoclosed cve medium severity vulnerability vulnerable library linuxlinux apache software foundation asf library home page a href found in head commit a href found in base branch master vulnerable source files ... | 0 |
664,927 | 22,292,787,286 | IssuesEvent | 2022-06-12 16:02:50 | Jenesius/vue-form | https://api.github.com/repos/Jenesius/vue-form | closed | Configuration | low-priority | ```js
{
debug?: boolean // В консоль будет выводиться вся информация, связанная с формой
}
``` | 1.0 | Configuration - ```js
{
debug?: boolean // В консоль будет выводиться вся информация, связанная с формой
}
``` | non_process | configuration js debug boolean в консоль будет выводиться вся информация связанная с формой | 0 |
4,264 | 7,189,238,196 | IssuesEvent | 2018-02-02 13:19:52 | Great-Hill-Corporation/quickBlocks | https://api.github.com/repos/Great-Hill-Corporation/quickBlocks | closed | Should store price per block | libs-etherlib status-inprocess type-enhancement | Data format change: search for if (false) { //opt.priceBlocks) { for an example of why we should store price at the block level when the block is first created | 1.0 | Should store price per block - Data format change: search for if (false) { //opt.priceBlocks) { for an example of why we should store price at the block level when the block is first created | process | should store price per block data format change search for if false opt priceblocks for an example of why we should store price at the block level when the block is first created | 1 |
173,110 | 14,402,613,007 | IssuesEvent | 2020-12-03 15:06:16 | rust-lang/crates.io | https://api.github.com/repos/rust-lang/crates.io | closed | Don't rewrite existing docs.rs links | A-documentation-metadata C-bug | Today I published two crates since winapi got update.
https://crates.io/crates/windows-win
https://crates.io/crates/clipboard-win
In both cases crates.io ignores my package.documentation attribute and instead enforces own link to docs.rs
Thanks to that instead of pointing to docs.rs for windows platform as I ... | 1.0 | Don't rewrite existing docs.rs links - Today I published two crates since winapi got update.
https://crates.io/crates/windows-win
https://crates.io/crates/clipboard-win
In both cases crates.io ignores my package.documentation attribute and instead enforces own link to docs.rs
Thanks to that instead of pointin... | non_process | don t rewrite existing docs rs links today i published two crates since winapi got update in both cases crates io ignores my package documentation attribute and instead enforces own link to docs rs thanks to that instead of pointing to docs rs for windows platform as i specified documentation ... | 0 |
18,400 | 24,537,256,680 | IssuesEvent | 2022-10-11 22:09:11 | cagov/design-system | https://api.github.com/repos/cagov/design-system | opened | Remove issue templates | Process improvement | We only need 2 issue templates in GitHub. Need to remove all except General and Bug.
| 1.0 | Remove issue templates - We only need 2 issue templates in GitHub. Need to remove all except General and Bug.

| process | remove issue templates we only need issue templates in github need to remove all except general and bug | 1 |
276,796 | 21,000,720,581 | IssuesEvent | 2022-03-29 17:10:14 | Jacqueline192837/jcastillo_2a | https://api.github.com/repos/Jacqueline192837/jcastillo_2a | closed | Planning | documentation | **Descripción**
Realizar el programa [2a.pdf](https://github.com/Jacqueline192837/jcastillo_2a/files/8343400/2a.pdf) usando los estándares:
-R1
[OracleJavaCodeStandard.pdf](https://github.com/Jacqueline192837/jcastillo_2a/files/8343476/OracleJavaCodeStandard.pdf)
-R2
[R2.pdf](https://github.com/Jacqueline19... | 1.0 | Planning - **Descripción**
Realizar el programa [2a.pdf](https://github.com/Jacqueline192837/jcastillo_2a/files/8343400/2a.pdf) usando los estándares:
-R1
[OracleJavaCodeStandard.pdf](https://github.com/Jacqueline192837/jcastillo_2a/files/8343476/OracleJavaCodeStandard.pdf)
-R2
[R2.pdf](https://github.com/J... | non_process | planning descripción realizar el programa usando los estándares mockup pruebas at a minimum test the program by counting the total program and part sizes in programs and ejemplo salida | 0 |
118,252 | 11,965,008,681 | IssuesEvent | 2020-04-05 21:41:47 | Kalafut-organization/elephant_vending_machine_frontend | https://api.github.com/repos/Kalafut-organization/elephant_vending_machine_frontend | opened | Documentation not auto built | documentation | The GitHub pages hosted docs are currently outdated. It seems that as of right now we have to manually build them for each commit. I think we could use [this GitHub Action](https://github.com/marketplace/actions/deploy-to-github-pages) to remedy this. | 1.0 | Documentation not auto built - The GitHub pages hosted docs are currently outdated. It seems that as of right now we have to manually build them for each commit. I think we could use [this GitHub Action](https://github.com/marketplace/actions/deploy-to-github-pages) to remedy this. | non_process | documentation not auto built the github pages hosted docs are currently outdated it seems that as of right now we have to manually build them for each commit i think we could use to remedy this | 0 |
16,704 | 21,843,220,392 | IssuesEvent | 2022-05-18 00:11:13 | googleapis/nodejs-memcache | https://api.github.com/repos/googleapis/nodejs-memcache | closed | promote library to GA | type: process api: memcache | Package name: **@google-cloud/memcache**
Current release: **beta**
Proposed release: **GA**
## Instructions
Check the lists below, adding tests / documentation as required. Once all the "required" boxes are ticked, please create a release and close this issue.
## Required
- [x] 28 days elapsed since last ... | 1.0 | promote library to GA - Package name: **@google-cloud/memcache**
Current release: **beta**
Proposed release: **GA**
## Instructions
Check the lists below, adding tests / documentation as required. Once all the "required" boxes are ticked, please create a release and close this issue.
## Required
- [x] 28 ... | process | promote library to ga package name google cloud memcache current release beta proposed release ga instructions check the lists below adding tests documentation as required once all the required boxes are ticked please create a release and close this issue required day... | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.