
question_slug stringlengths 3 77 | title stringlengths 1 183 | slug stringlengths 12 45 | summary stringlengths 1 160 ⌀ | author stringlengths 2 30 | certification stringclasses 2
values | created_at stringdate 2013-10-25 17:32:12 2025-04-12 09:38:24 | updated_at stringdate 2013-10-25 17:32:12 2025-04-12 09:38:24 | hit_count int64 0 10.6M | has_video bool 2
classes | content stringlengths 4 576k | upvotes int64 0 11.5k | downvotes int64 0 358 | tags stringlengths 2 193 | comments int64 0 2.56k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
top-k-frequent-elements | K pattern - heaps/Priority 3 solutions Frequency Map, Bucket Sort, PriorityQueue | k-pattern-heapspriority-3-solutions-freq-pw1q | 215. Kth Largest Element in an Array same pattern\n451. Sort Characters By Frequency\n703. Kth Largest Element in a Stream\n767. Reorganize String\nRearrange St | Dixon_N | NORMAL | 2024-05-23T05:59:07.844979+00:00 | 2024-06-09T13:11:48.216080+00:00 | 1,651 | false | [215. Kth Largest Element in an Array](https://leetcode.com/problems/kth-largest-element-in-an-array/solutions/5195848/k-pattern-heaps-peiority/) same pattern\n451. Sort Characters By Frequency\n[703. Kth Largest Element in a Stream](https://leetcode.com/problems/kth-largest-element-in-a-stream/solutions/5198578/k-patt... | 9 | 0 | ['Array', 'Hash Table', 'Divide and Conquer', 'Sorting', 'Heap (Priority Queue)', 'Bucket Sort', 'Counting', 'Java'] | 2 |
top-k-frequent-elements | Easy Java solution with drawing explanation - TC = O(n log k) | easy-java-solution-with-drawing-explanat-atdx | Intuition\n Describe your first thoughts on how to solve this problem. \n\n\n\n\n\n\n# Complexity\n- Time complexity: O(n log k)\n Add your time complexity here | sopheary | NORMAL | 2023-07-03T22:29:17.102613+00:00 | 2023-07-05T00:00:08.893888+00:00 | 1,858 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n\n\n\n\n\n... | 9 | 0 | ['Heap (Priority Queue)', 'Java'] | 4 |
top-k-frequent-elements | Bucket sort, O(n) with explanation | bucket-sort-on-with-explanation-by-dzmtr-x8dw | Knowing that max frequency is nums.size (all elements are the same), we can put elements in array, according to their count.\n\nExample:\n[1, 1, 1, 2, 2, 3]\n\n | dzmtr | NORMAL | 2023-05-22T10:11:18.184990+00:00 | 2023-05-22T10:12:01.314603+00:00 | 993 | false | Knowing that max frequency is nums.size (all elements are the same), we can put elements in array, according to their count.\n\nExample:\n[1, 1, 1, 2, 2, 3]\n\nstore their count in a Map <Element: Count>:\n[{1: 3}, {2: 2}, {3: 1}]\n\nput them in freq Array<Count: List<Element>>:\n[[], [3], [2], [1], [], [], []]\n\nSinc... | 9 | 0 | ['Bucket Sort', 'Kotlin'] | 2 |
top-k-frequent-elements | [TypeScript]: Frequency count and then sort (Runtime 97%, Memory 70%) | typescript-frequency-count-and-then-sort-2dp3 | Intuition\n Describe your first thoughts on how to solve this problem. \nFirst we count the frequency of unique items, and then we return the most frequent ones | luzede | NORMAL | 2023-05-22T09:55:53.927024+00:00 | 2023-05-22T09:55:53.927048+00:00 | 4,264 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nFirst we count the frequency of unique items, and then we return the most frequent ones.\n\n# Complexity\n- Time complexity: $$O(n*logn)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n)$$\n<!-- Add yo... | 9 | 0 | ['Array', 'Hash Table', 'Sorting', 'Counting', 'TypeScript'] | 2 |
top-k-frequent-elements | [Python3] Sort - Heap - Quick Select | python3-sort-heap-quick-select-by-dolong-0nes | Intuition\nThe Problem finding the k-th smallest or largest of something can be solved and optimized follows this order: sorting -> heap -> quick select\n Descr | dolong2110 | NORMAL | 2023-04-22T08:56:26.214705+00:00 | 2023-04-22T08:56:26.214753+00:00 | 2,601 | false | # Intuition\nThe Problem finding the k-th smallest or largest of something can be solved and optimized follows this order: sorting -> heap -> quick select\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time c... | 9 | 0 | ['Divide and Conquer', 'Sorting', 'Heap (Priority Queue)', 'Quickselect', 'Python3'] | 0 |
top-k-frequent-elements | [Rust] 0ms - Count Frequency + Sort By Frequency | rust-0ms-count-frequency-sort-by-frequen-pdkp | rust\nimpl Solution {\n pub fn top_k_frequent(nums: Vec<i32>, k: i32) -> Vec<i32> {\n let mut map = HashMap::new();\n nums.into_iter()\n | kurosuha | NORMAL | 2022-04-09T08:22:12.055188+00:00 | 2022-04-09T08:22:12.055223+00:00 | 411 | false | ```rust\nimpl Solution {\n pub fn top_k_frequent(nums: Vec<i32>, k: i32) -> Vec<i32> {\n let mut map = HashMap::new();\n nums.into_iter()\n .for_each(|num| *map.entry(num).or_insert(0) += 1);\n let mut vec: Vec<(i32, i32)> = map.into_iter().collect();\n vec.sort_by(|a, b| b.1.c... | 9 | 0 | ['Rust'] | 1 |
top-k-frequent-elements | C++ unordered_map & priority_queue - solved live on stream | c-unordered_map-priority_queue-solved-li-lsx2 | We practice algos everyday at 6pm PT. Check my profile for the stream.\n\nTime Complexity: O(nlogn)\nSpace Complexity: O(n)\n\n\nclass Solution {\npublic:\n | midnightsimon | NORMAL | 2022-04-09T01:19:29.235763+00:00 | 2022-04-09T01:19:29.235788+00:00 | 1,094 | false | We practice algos everyday at 6pm PT. Check my profile for the stream.\n\nTime Complexity: O(nlogn)\nSpace Complexity: O(n)\n\n```\nclass Solution {\npublic:\n vector<int> topKFrequent(vector<int>& nums, int k) {\n \n //get a count of frequencies\n unordered_map<int, int> freqMap;\n for... | 9 | 0 | [] | 1 |
top-k-frequent-elements | C++ Solution Priority Queue, map Easy | c-solution-priority-queue-map-easy-by-hi-sunr | \n\nclass Solution {\npublic:\n vector<int> topKFrequent(vector<int>& nums, int k) {\n priority_queue<pair<int, int>> pq;\n unordered_map<int | hitengoyal18 | NORMAL | 2020-12-11T12:58:16.708393+00:00 | 2020-12-11T12:58:16.708428+00:00 | 1,037 | false | ```\n\nclass Solution {\npublic:\n vector<int> topKFrequent(vector<int>& nums, int k) {\n priority_queue<pair<int, int>> pq;\n unordered_map<int, int>mp;\n vector<int> res;\n for(int i=0;i<nums.size();i++)\n mp[nums[i]] += 1; \n \n for (auto i : mp)\n ... | 9 | 1 | ['C', 'Heap (Priority Queue)'] | 3 |
top-k-frequent-elements | [Go] 8ms, using PriorityQueue | go-8ms-using-priorityqueue-by-nakabonne-hcxa | We can build a priority queue with the heap package:\n\nfunc topKFrequent(nums []int, k int) []int {\n\tseen := make(map[int]int)\n\tfor _, n := range nums {\n\ | nakabonne | NORMAL | 2020-02-24T07:45:17.043089+00:00 | 2020-02-24T07:59:14.949508+00:00 | 2,391 | false | We can build a priority queue with the [heap](https://golang.org/pkg/container/heap/) package:\n```\nfunc topKFrequent(nums []int, k int) []int {\n\tseen := make(map[int]int)\n\tfor _, n := range nums {\n\t\tseen[n]++\n\t}\n\n\tq := &priorityQueue{}\n\theap.Init(q)\n\tfor val, cnt := range seen {\n\t\theap.Push(q, elem... | 9 | 0 | ['Go'] | 1 |
word-ladder-ii | C++ solution using standard BFS method, no DFS or backtracking | c-solution-using-standard-bfs-method-no-4v36i | I have struggled with this problem for a long time because nearly all the solution on the web is too long or too tricky and can hardly be remembered during the | antdavid | NORMAL | 2016-09-09T21:16:23.428000+00:00 | 2018-10-24T13:44:39.967281+00:00 | 78,934 | false | I have struggled with this problem for a long time because nearly all the solution on the web is too long or too tricky and can hardly be remembered during the interview.\n\nIn fact, this problem can be solved with a very standard BFS process, whose structure could haven been written by you for many many times (using w... | 682 | 21 | [] | 99 |
word-ladder-ii | My concise JAVA solution based on BFS and DFS | my-concise-java-solution-based-on-bfs-an-xg53 | Explanation\n\nThe basic idea is:\n\n1). Use BFS to find the shortest distance between start and end, tracing the distance of crossing nodes from start node to | cheng_zhang | NORMAL | 2015-10-19T07:35:02+00:00 | 2018-10-25T08:52:41.694949+00:00 | 142,586 | false | **Explanation**\n\nThe basic idea is:\n\n1). Use BFS to find the shortest distance between start and end, tracing the distance of crossing nodes from start node to end node, and store node's next level neighbors to HashMap;\n\n2). Use DFS to output paths with the same distance as the shortest distance from distance Has... | 472 | 8 | [] | 81 |
word-ladder-ii | Python simple BFS layer by layer | python-simple-bfs-layer-by-layer-by-abye-vy1t | \nclass Solution(object):\n def findLadders(self, beginWord, endWord, wordList):\n\n wordList = set(wordList)\n res = []\n layer = {}\n | abyellow7511 | NORMAL | 2017-05-21T12:44:21.050000+00:00 | 2018-10-24T02:05:58.645412+00:00 | 39,929 | false | ```\nclass Solution(object):\n def findLadders(self, beginWord, endWord, wordList):\n\n wordList = set(wordList)\n res = []\n layer = {}\n layer[beginWord] = [[beginWord]]\n\n while layer:\n newlayer = collections.defaultdict(list)\n for w in layer:\n ... | 270 | 12 | [] | 53 |
word-ladder-ii | Python BFS+Backtrack Greatly Improved by bi-directional BFS | python-bfsbacktrack-greatly-improved-by-9x6ps | An intuitive solution is to use BFS to find shorterst transformation path from begin word to end word. A valid transformation is to change any one character and | wangqiuc | NORMAL | 2019-04-05T05:24:57.456344+00:00 | 2021-10-04T01:22:15.483653+00:00 | 21,708 | false | An intuitive solution is to use BFS to find shorterst transformation path from begin word to end word. A valid transformation is to change any one character and transformed word should be in the a word list.\n\nWhat is tricker than #127 is that we need to find all shortest paths. Thus, we need to build a search tree du... | 224 | 6 | ['Python'] | 34 |
word-ladder-ii | [C++/Python] BFS Level by Level - with Picture - Clean & Concise | cpython-bfs-level-by-level-with-picture-zgawy | Idea\n- This problem is an advanced version of 127. Word Ladder, I highly recommend solving it first if you haven\'t solved it yet.\n- To find the shortest path | hiepit | NORMAL | 2021-07-24T09:31:23.054801+00:00 | 2021-07-25T04:42:31.448249+00:00 | 19,860 | false | **Idea**\n- This problem is an advanced version of **[127. Word Ladder](https://leetcode.com/problems/word-ladder/)**, I highly recommend solving it first if you haven\'t solved it yet.\n- To find the shortest path from `beginWord` to `endWord`, we need to use BFS.\n- To find neighbors of a `word`, we just try to chang... | 195 | 15 | [] | 17 |
word-ladder-ii | [C++] ✅ using BFS and Backtracking || 🔥 NO TLE | c-using-bfs-and-backtracking-no-tle-by-h-xrao | This solution relies on first finding the shortest transformation length between the beginWord and endWord strings and then performing a recursive backtrack to | hoshang2900 | NORMAL | 2022-08-14T00:14:31.561790+00:00 | 2023-03-12T09:41:25.769364+00:00 | 30,695 | false | This solution relies on first finding the shortest transformation length between the beginWord and endWord strings and then performing a recursive backtrack to find all possible paths of the same length.\n\nWe start by checking if endWord is in the wordList; if it isn\'t, we cannot have a path from beginWord to endWord... | 168 | 2 | ['Backtracking', 'Depth-First Search', 'Breadth-First Search', 'C', 'C++'] | 15 |
word-ladder-ii | Share two similar Java solution that Accpted by OJ. | share-two-similar-java-solution-that-acc-jbu8 | The solution contains two steps 1 Use BFS to construct a graph. 2. Use DFS to construct the paths from end to start.Both solutions got AC within 1s. \n\nThe fir | reeclapple | NORMAL | 2014-08-20T18:06:32+00:00 | 2018-10-25T14:49:36.065842+00:00 | 86,675 | false | The solution contains two steps 1 Use BFS to construct a graph. 2. Use DFS to construct the paths from end to start.Both solutions got AC within 1s. \n\nThe first step BFS is quite important. I summarized three tricks\n\n1) Using a **MAP** to store the min ladder of each word, or use a **SET** to store the words visite... | 142 | 7 | ['Depth-First Search', 'Breadth-First Search', 'Java'] | 37 |
word-ladder-ii | Three Python solutions: Only BFS, BFS+DFS, biBFS+ DFS | three-python-solutions-only-bfs-bfsdfs-b-4g0l | Solution 1, BFS, directly store the path in queue. 318 ms, 18.7 MB\nSolution 2, BFS to build graph (parents), DFS to get the shortest path, 356 ms, 20.6 MB\nS | zyzflying | NORMAL | 2020-01-26T00:02:56.077396+00:00 | 2020-07-01T19:05:09.155726+00:00 | 12,946 | false | Solution 1, BFS, directly store the path in queue. 318 ms, 18.7 MB\nSolution 2, BFS to build graph (parents), DFS to get the shortest path, 356 ms, 20.6 MB\nSolution 3, biBFS to build graph (parents), DFS to get the shortest path, 224 ms, 18.9 MB\nNote that: propocessing words as below will greatly improve the algor... | 119 | 0 | ['Breadth-First Search', 'Python'] | 13 |
word-ladder-ii | Super fast Java solution (two-end BFS) | super-fast-java-solution-two-end-bfs-by-6p645 | Thanks to prime_tang and jianchao.li.fighter!\n\n public List> findLadders(String start, String end, Set dict) {\n // hash set for both ends\n | jeantimex | NORMAL | 2015-07-06T22:47:06+00:00 | 2018-09-18T23:17:28.882068+00:00 | 49,063 | false | Thanks to prime_tang and jianchao.li.fighter!\n\n public List<List<String>> findLadders(String start, String end, Set<String> dict) {\n // hash set for both ends\n Set<String> set1 = new HashSet<String>();\n Set<String> set2 = new HashSet<String>();\n \n // initial words in both ... | 101 | 4 | ['Breadth-First Search', 'Java'] | 16 |
word-ladder-ii | ✅ Word Ladder II [No TLE] || With Approach || Using BFS | word-ladder-ii-no-tle-with-approach-usin-nzpt | Due to new testcases, the old solutions are giving TLE\n\n# APPROACH:\nGiven two words (beginWord and endWord), and a dictionary\u2019s word list, find all shor | Maango16 | NORMAL | 2021-07-24T07:13:57.391576+00:00 | 2022-08-14T05:59:40.284985+00:00 | 12,337 | false | *Due to new testcases, the old solutions are giving TLE*\n\n# **APPROACH:**\nGiven two words (beginWord and endWord), and a dictionary\u2019s word list, find all shortest transformation sequence(s) from beginWord to endWord, such that:\n1. Only one letter can be changed at a time\n1. Each transformed word must exist in... | 99 | 3 | ['C'] | 19 |
word-ladder-ii | Python BFS + DFS With Explanation Why Optimization Is Needed to Not TLE | python-bfs-dfs-with-explanation-why-opti-htyl | Intuition\n\n1. Most approaches start off with an adjacency list with a pattern node for quick lookups.\n\n1. Then we perform BFS until we reach an endWord. Sin | CompileTimeError | NORMAL | 2022-08-02T04:55:36.592640+00:00 | 2022-08-02T05:08:55.476251+00:00 | 6,112 | false | **Intuition**\n\n1. Most approaches start off with an adjacency list with a pattern node for quick lookups.\n\n1. Then we perform **BFS** until we reach an `endWord`. Since the question requires us to return all possible paths, it is very tempting to start constructing the path during our BFS\n\ta. **However**, this wi... | 83 | 0 | ['Depth-First Search', 'Breadth-First Search', 'Python'] | 8 |
word-ladder-ii | Use defaultdict for traceback and easy writing, 20 lines python code | use-defaultdict-for-traceback-and-easy-w-0rja | class Solution:\n # @param start, a string\n # @param end, a string\n # @param dict, a set of string\n # @return a list of lists of string\n def | tusizi | NORMAL | 2015-02-03T14:28:29+00:00 | 2018-10-05T02:05:09.316413+00:00 | 18,134 | false | class Solution:\n # @param start, a string\n # @param end, a string\n # @param dict, a set of string\n # @return a list of lists of string\n def findLadders(self, start, end, dic):\n dic.add(end)\n level = {start}\n parents = collections.defaultdict(set)\n while level and ... | 82 | 7 | ['Python'] | 15 |
word-ladder-ii | ✔️ Explanation with Animation - Accepted without TLE! | explanation-with-animation-accepted-with-zlxi | Intuition\nWe just need to record all possible words that can connect from the beginning, level by level, until we hit the end at a level.\n\n\n\nThen we will t | Sneeit-Dot-Com | NORMAL | 2022-08-14T14:25:11.290327+00:00 | 2022-08-28T02:20:30.676155+00:00 | 14,406 | false | # Intuition\nWe just need to record all possible words that can connect from the beginning, level by level, until we hit the end at a level.\n\n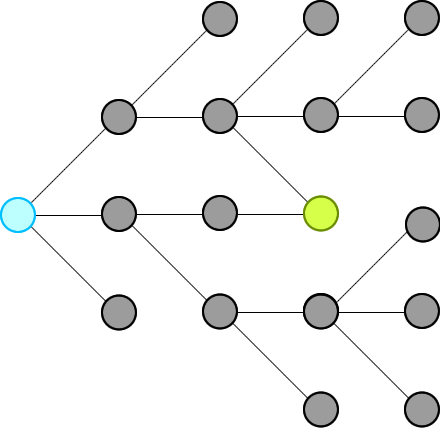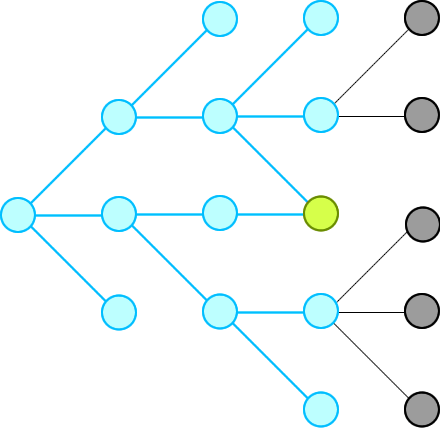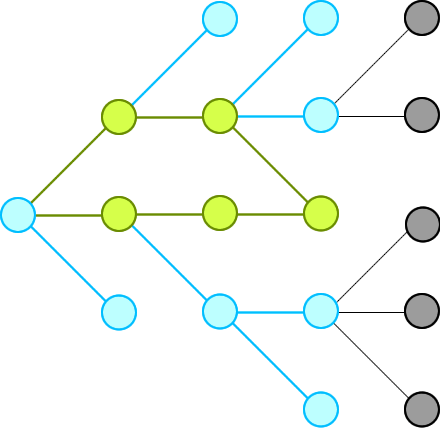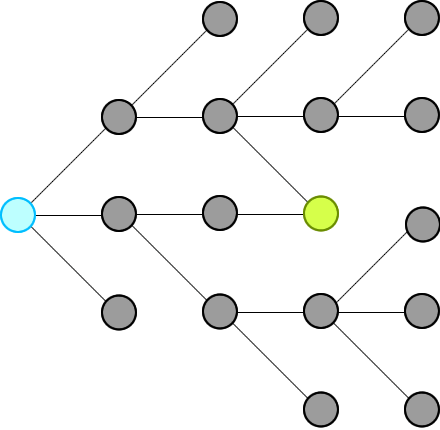\n\nThen we will traverse backward from end via the words in the r... | 72 | 7 | ['Breadth-First Search', 'C', 'Python', 'C++', 'Java', 'Python3', 'JavaScript'] | 12 |
word-ladder-ii | C++ || No TLE || August 2022 || Simple BFS || Explained | c-no-tle-august-2022-simple-bfs-explaine-6b01 | Step 1:-\nCount the minimum steps required to reach beginword from each string present in the word list using simple BFS.\n\nStep 2:-\nThen for returning the pa | riyushhh | NORMAL | 2022-08-14T06:29:15.664524+00:00 | 2022-08-14T07:12:24.335213+00:00 | 6,627 | false | ***Step 1:-***\nCount the minimum steps required to reach **beginword** from each string present in the word list using simple BFS.\n\n**Step 2:-**\nThen for returning the path, start backtracking from the **endword** and keep moving to words having minimum steps 1 less than the current word.\n\n**Do upvote if you like... | 60 | 1 | [] | 12 |
word-ladder-ii | Simple Python BFS solution (similar problems listed) | simple-python-bfs-solution-similar-probl-al51 | Level-by-level BFS visit can be used to solve a lot of problems of finding discrete shortest distance.\nPlease see and vote for my solutions for these similar p | otoc | NORMAL | 2019-08-06T18:07:20.511298+00:00 | 2022-07-30T23:51:22.502956+00:00 | 5,393 | false | Level-by-level BFS visit can be used to solve a lot of problems of finding discrete shortest distance.\nPlease see and vote for my solutions for these similar problems\n[102. Binary Tree Level Order Traversal](https://leetcode.com/problems/binary-tree-level-order-traversal/discuss/1651394/Python-level-by-level-BFS-Solu... | 60 | 0 | [] | 7 |
word-ladder-ii | 88ms! Accepted c++ solution with two-end BFS. 68ms for Word Ladder and 88ms for Word Ladder II | 88ms-accepted-c-solution-with-two-end-bf-ftmq | In order to reduce the running time, we should use two-end BFS to slove the problem.\n\nAccepted 68ms c++ solution for [Word Ladder][1].\n\n class Solution { | prime_tang | NORMAL | 2015-06-23T01:46:42+00:00 | 2015-06-23T01:46:42+00:00 | 31,919 | false | In order to reduce the running time, we should use two-end BFS to slove the problem.\n\nAccepted 68ms c++ solution for [Word Ladder][1].\n\n class Solution {\n public:\n int ladderLength(std::string beginWord, std::string endWord, std::unordered_set<std::string> &dict) {\n \t\tif (beginWord == endWord)\... | 52 | 1 | ['Breadth-First Search'] | 11 |
word-ladder-ii | 46ms Python 97 Faster Working Multiple solutions 95% memory efficient solution | 46ms-python-97-faster-working-multiple-s-08gc | Don\'t Forget To Upvote\n\n# 1. 97.81% Faster Solution:\n\n\t\tclass Solution:\n\t\t\tdef findLadders(self, beginWord: str, endWord: str, wordList: List[str]) - | anuvabtest | NORMAL | 2022-08-14T04:13:26.038470+00:00 | 2022-08-14T04:15:44.811499+00:00 | 6,898 | false | # Don\'t Forget To Upvote\n\n# 1. 97.81% Faster Solution:\n\n\t\tclass Solution:\n\t\t\tdef findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n\t\t\t\td = defaultdict(list)\n\t\t\t\tfor word in wordList:\n\t\t\t\t\tfor i in range(len(word)):\n\t\t\t\t\t\td[word[:i]+"*"+word[i+1:]]... | 49 | 3 | ['Depth-First Search', 'Breadth-First Search', 'Queue', 'Python', 'Python3'] | 8 |
word-ladder-ii | C++ very easy read and understand solution compared to most voted! | c-very-easy-read-and-understand-solution-n99f | For the most voted solution, it is very complicated.\nI do a BFS for each path\nfor example: \n{hit} -> \n{hit,hot} ->\n {hit,hot,dot}/{hit,hot,lot} -> \n ["hit | rayrayray | NORMAL | 2017-08-10T20:31:58.982000+00:00 | 2018-08-21T20:23:05.055655+00:00 | 6,551 | false | For the most voted solution, it is very complicated.\nI do a BFS for each path\nfor example: \n{hit} -> \n{hit,hot} ->\n {hit,hot,dot}/{hit,hot,lot} -> \n ["hit","hot","dot","dog"]/["hit","hot","lot","log"] ->\n ["hit","hot","dot","dog","cog"],\n ["hit","hot","lot","log","cog"]\n```\nclass Solution {\npublic:\n ... | 46 | 3 | [] | 14 |
word-ladder-ii | The fastest C++ Solution, 56ms!! | the-fastest-c-solution-56ms-by-missmary-lv5a | Treat each word as a node of a tree. There are two trees. One tree's root node is "beginWord", and the other tree's root node is "endWord".\n\nThe root node can | missmary | NORMAL | 2015-09-26T12:52:51+00:00 | 2018-10-07T12:59:44.228536+00:00 | 19,335 | false | Treat each word as a node of a tree. There are two trees. One tree's root node is "beginWord", and the other tree's root node is "endWord".\n\nThe root node can yield all his children node, and they are the second layer of the tree. The second layer can yield all their children, then we get the third layer of the tree,... | 45 | 2 | [] | 5 |
word-ladder-ii | FAST AND CLEAN Python/C++ Solution using Double BFS, beats 98% | fast-and-clean-pythonc-solution-using-do-1ypd | If we know source and destination, we can build the word tree by going forward in one direction and backwards in the other. We stop when we have found that a wo | agave | NORMAL | 2016-04-25T02:53:08+00:00 | 2018-10-26T06:58:43.454703+00:00 | 16,071 | false | If we know source and destination, we can build the word tree by going forward in one direction and backwards in the other. We stop when we have found that a word in the next level of BFS is in the other level, but first we need to update the tree for the words in the current level.\n\nThen we build the result by doing... | 42 | 2 | ['Breadth-First Search', 'Python'] | 7 |
word-ladder-ii | JAVA || EASY || EXPLANATION || COMMENTED | java-easy-explanation-commented-by-jaska-k8n5 | Upvote if it helped\n\n\nclass Solution {\n public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {\n List<Li | jaskarans880 | NORMAL | 2022-08-14T02:01:41.795085+00:00 | 2022-08-14T02:01:41.795119+00:00 | 9,759 | false | Upvote if it helped\n\n```\nclass Solution {\n public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {\n List<List<String>> ans = new ArrayList<>(); \n Map<String, Set<String>> reverse = new HashMap<>(); // reverse graph start from endWord\n Set<String> w... | 40 | 2 | ['Java'] | 9 |
word-ladder-ii | [Python] fast bfs, explained | python-fast-bfs-explained-by-dbabichev-ct51 | The idea of this problem is to run bfs, where one step is changing some letter of word. For me easier to separate problem to two parts:\n\n1. Create graph of co | dbabichev | NORMAL | 2021-07-24T08:02:35.186256+00:00 | 2021-07-24T12:35:32.789801+00:00 | 1,318 | false | The idea of this problem is to run bfs, where one step is changing some letter of word. For me easier to separate problem to two parts:\n\n1. Create graph of connections `G`.\n2. Run bfs on this graph with collecting all possible solutions.\n\nNow, let us consider steps in more details.\n\n1. To create graph of connect... | 33 | 2 | ['Breadth-First Search'] | 5 |
word-ladder-ii | C++ Solution || Using BFS & DFS | c-solution-using-bfs-dfs-by-kannu_priya-r3uq | \nclass Solution {\npublic:\n vector<vector<string>> ans;\n void DFS(string &beginWord, string &endWord, unordered_map<string, unordered_set<string>>&adj, | kannu_priya | NORMAL | 2021-07-24T18:08:06.533653+00:00 | 2021-07-24T18:08:06.533696+00:00 | 3,936 | false | ```\nclass Solution {\npublic:\n vector<vector<string>> ans;\n void DFS(string &beginWord, string &endWord, unordered_map<string, unordered_set<string>>&adj, vector<string>&path){\n path.push_back(beginWord);\n if(beginWord == endWord){\n ans.push_back(path);\n path.pop_back();... | 26 | 2 | ['Depth-First Search', 'Breadth-First Search', 'C', 'C++'] | 5 |
word-ladder-ii | Clean but the best-submission (68ms) in C++, well-commented | clean-but-the-best-submission-68ms-in-c-rklde | class Solution \n {\n public:\n vector<vector<string>> findLadders(string beginWord, string endWord, unordered_set<string> &dict) {\n | lhearen | NORMAL | 2016-03-25T12:34:00+00:00 | 2016-03-25T12:34:00+00:00 | 9,492 | false | class Solution \n {\n public:\n vector<vector<string>> findLadders(string beginWord, string endWord, unordered_set<string> &dict) {\n vector<vector<string> > paths;\n vector<string> path(1, beginWord);\n if (beginWord == endWord) //corner case;\n ... | 25 | 3 | ['C++'] | 6 |
word-ladder-ii | 💯✅I spent 3 hours developing this fastest approach. Check it out and don't forget to drop a like💯✅ | i-spent-3-hours-developing-this-fastest-kbze3 | Must ReadEver tried finding a ladder in a word transformation problem? It's like playing hide and seek with your vocabulary—except the words are sneaky, and the | Ajay_Kartheek | NORMAL | 2025-01-23T13:28:08.517370+00:00 | 2025-01-23T13:28:08.517370+00:00 | 4,239 | false | # Must Read
**Ever tried finding a ladder in a word transformation problem? It's like playing hide and seek with your vocabulary—except the words are sneaky, and the only thing getting transformed is your sanity. It took me a solid 3 hours of coding to come up this solution, during which I conjured up 5 different appro... | 24 | 0 | ['Hash Table', 'String', 'Backtracking', 'Depth-First Search', 'Breadth-First Search', 'C++', 'Java', 'Python3'] | 4 |
word-ladder-ii | [Python] Accepted BFS Solution with Clean, Commented Code | python-accepted-bfs-solution-with-clean-mzovc | A key observation of this problem is to convert wordList into a graph g = (V, E), where the vertices are all words in wordList and beginWord, and the edges conn | stephenming228 | NORMAL | 2022-08-14T03:55:25.206060+00:00 | 2022-08-14T04:16:59.866589+00:00 | 2,845 | false | A key observation of this problem is to convert `wordList` into a graph g = (V, E), where the vertices are all words in `wordList` and `beginWord`, and the edges connect all words that differ by one character. The graph representation of the example testcase is shown below:\n\nPlease comment below if any doubt!\n\n\n/**************************************************************************** | jughead_jr | NORMAL | 2021-05-22T09:11:17.695420+00:00 | 2021-05-22T09:21:30.110694+00:00 | 2,507 | false | **Hit ^Up Vote^ if you like my solution! :)\nPlease comment below if any doubt!**\n\n```\n/********************************************************************************************\n Algo:\n 1. Create a Node Class, which will have 2 param, \n the word as name & path with traverse history.\n\n 2. Lo... | 21 | 1 | ['Breadth-First Search', 'Java'] | 5 |
word-ladder-ii | Python solution | python-solution-by-zitaowang-e9x7 | Idea: First do a BFS on the word graph. The purpose of the BFS is two-fold. First, we calculates the distance from beginWord to all words in wordList. If endWor | zitaowang | NORMAL | 2019-02-22T00:37:44.388642+00:00 | 2019-02-22T00:37:44.388704+00:00 | 2,925 | false | Idea: First do a BFS on the word graph. The purpose of the BFS is two-fold. First, we calculates the distance from `beginWord` to all words in `wordList`. If `endWord` is not in the same connected component as `beginWord`, we `return []`. We store the result in a dictionary `dist`. In particular, we know that the dista... | 21 | 0 | [] | 8 |
word-ladder-ii | My 30ms bidirectional BFS and DFS based Java solution | my-30ms-bidirectional-bfs-and-dfs-based-jwmqe | Regarding speed, 30ms solution beats 100% other java solutions.\n\nCouple of things that make this solution fast:\n\n1) We use Bidirectional BFS which always ex | myfavcat | NORMAL | 2015-11-04T03:56:59+00:00 | 2015-11-04T03:56:59+00:00 | 10,768 | false | Regarding speed, 30ms solution beats 100% other java solutions.\n\nCouple of things that make this solution fast:\n\n1) We use Bidirectional BFS which always expand from direction with less nodes\n\n2) We use char[] to build string so it would be fast \n\n3) Instead of scanning dict each time, we build new string from ... | 20 | 0 | ['Depth-First Search', 'Breadth-First Search'] | 2 |
word-ladder-ii | C++ BFS + DFS | c-bfs-dfs-by-jianchao-li-v2te | After reading some solutions, I wrote the following one, which was mainly inspired by this one. The difference is that the previous solution maps children to pa | jianchao-li | NORMAL | 2019-02-22T11:09:59.823186+00:00 | 2019-02-22T11:09:59.823246+00:00 | 4,938 | false | After reading some solutions, I wrote the following one, which was mainly inspired by [this one](https://leetcode.com/problems/word-ladder-ii/discuss/40594/A-concise-solution-using-bfs-and-backtracing). The difference is that the previous solution maps children to parents while I map from parents to children (this make... | 19 | 0 | ['Backtracking', 'Depth-First Search', 'Breadth-First Search', 'C++'] | 4 |
word-ladder-ii | Share my 130 ms Python solution | share-my-130-ms-python-solution-by-dashe-5ovt | Main idea:\n\n1. Use character flipping\n\n2. Two-end BFS\n\n3. defaultdict(list) for easy writing to keep track of paths\n\nI also use set intersection to dete | dasheng2 | NORMAL | 2015-07-27T09:03:56+00:00 | 2015-07-27T09:03:56+00:00 | 5,986 | false | Main idea:\n\n1. Use character flipping\n\n2. Two-end BFS\n\n3. defaultdict(list) for easy writing to keep track of paths\n\nI also use set intersection to determine if we are done\n\n from collections import defaultdict\n class Solution:\n # @param start, a string\n # @param end, a string\n ... | 17 | 1 | ['Python'] | 3 |
word-ladder-ii | Java Solution with Iteration | java-solution-with-iteration-by-alextheg-g7bp | Code is about 40 lines, put explanation in comments.\n\n /*\n * we are essentially building a graph, from start, BF.\n * and at each level we find al | alexthegreat | NORMAL | 2015-01-15T18:28:57+00:00 | 2015-01-15T18:28:57+00:00 | 7,738 | false | Code is about 40 lines, put explanation in comments.\n\n /**\n * we are essentially building a graph, from start, BF.\n * and at each level we find all reachable words from parent.\n * we stop if the current level contains end,\n * we return any path whose last node is end.\n * \n * to achiev... | 17 | 0 | [] | 4 |
word-ladder-ii | [Python3] Easy Solution, Detailed Explanation | python3-easy-solution-detailed-explanati-i77i | 1. Understanding the problem\n1. there is a starting word, beginWord and an ending word, endWord.\n2. there are a bunch of words in between, following the const | chaudhary1337 | NORMAL | 2021-07-24T10:59:13.458249+00:00 | 2021-07-25T16:13:50.583874+00:00 | 2,666 | false | ## 1. Understanding the problem\n1. there is a starting word, `beginWord` and an ending word, `endWord`.\n2. there are a bunch of words in between, following the constrataint that they can\'t have more than one character different between them.\n3. the "bunch of words" are taken from the `wordList` given.\n4. Goal: fin... | 16 | 3 | ['Queue', 'Python', 'Python3'] | 3 |
word-ladder-ii | [Python3] Word Ladder II: Simple BFS | python3-word-ladder-ii-simple-bfs-by-man-7y6v | \ndef findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n graph = collections.defaultdict(set)\n l = len(wo | phoenix-2 | NORMAL | 2020-11-13T06:47:25.305640+00:00 | 2020-11-13T06:47:25.305673+00:00 | 2,052 | false | ```\ndef findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n graph = collections.defaultdict(set)\n l = len(wordList[0])\n\n wordList = set(wordList)\n if endWord not in wordList:\n return []\n\n wordList.add(beginWord)\n\n def ... | 16 | 0 | ['Breadth-First Search', 'Python3'] | 3 |
word-ladder-ii | O(n * w) TIme and O(n^2 * w) Space Complexity, TLE and MLE Optimized!!! | on-w-time-and-on2-w-space-complexity-tle-ferh | Intuition\nFrom the problem statement, we had an idea of applying a BFS or DFS starting from beginWord and terminating at endWord. Later we also know that in th | sahityakmr | NORMAL | 2023-10-23T17:43:32.719945+00:00 | 2023-10-23T17:43:32.719969+00:00 | 626 | false | # Intuition\nFrom the problem statement, we had an idea of applying a BFS or DFS starting from beginWord and terminating at endWord. Later we also know that in this search, we\'ll have to pick the paths with minimum length. Also, to note that, there may be multiple ways to reach a particular intermediate/terminal word,... | 15 | 0 | ['Python3'] | 2 |
word-ladder-ii | Java Solution | 88 ms | java-solution-88-ms-by-adarsh-mishra27-jv9v | \nclass Solution {\n public List<List<String>> ans;\n public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {\n | adarsh-mishra27 | NORMAL | 2022-08-14T17:07:18.586524+00:00 | 2022-08-14T17:07:18.586554+00:00 | 2,197 | false | ```\nclass Solution {\n public List<List<String>> ans;\n public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {\n ans=new ArrayList<>();\n \n Map<String, List<String>> graph = new HashMap<>();\n for(String s: wordList) {\n graph.put(... | 14 | 0 | ['Backtracking', 'Depth-First Search', 'Breadth-First Search', 'Java'] | 3 |
word-ladder-ii | A concise solution using bfs and backtracing | a-concise-solution-using-bfs-and-backtra-1l7n | the basic idea is referred from url: http://yucoding.blogspot.com/2014/01/leetcode-question-word-ladder-ii.html\n \n unordered_map > mp; // a map indicati | shichaotan | NORMAL | 2015-02-01T01:22:07+00:00 | 2015-02-01T01:22:07+00:00 | 7,706 | false | the basic idea is referred from url: http://yucoding.blogspot.com/2014/01/leetcode-question-word-ladder-ii.html\n \n unordered_map<string, vector<string> > mp; // a map indicating a word's previous word list\n vector<vector<string> > res;\n vector<string> path;\n \n void output(string &start, string ... | 14 | 1 | [] | 4 |
word-ladder-ii | Java Efficient Solution✅Updated ✅ | java-efficient-solutionupdated-by-vaibha-prb7 | \n\nclass Solution {\n Set<String> set = new HashSet();\n String beginWord, endWord;\n Map<String, Integer> dist = new HashMap();\n List<List<String | vaibhavnirmal2001 | NORMAL | 2022-08-14T13:55:30.811305+00:00 | 2022-08-14T13:55:30.811349+00:00 | 2,374 | false | \n```\nclass Solution {\n Set<String> set = new HashSet();\n String beginWord, endWord;\n Map<String, Integer> dist = new HashMap();\n List<List<String>> res;\n public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {\n this.beginWord = beginWord;\n t... | 13 | 0 | ['Java'] | 3 |
word-ladder-ii | [Java] Clean BFS + DFS Solution (98% Two-Way BFS) || with comments | java-clean-bfs-dfs-solution-98-two-way-b-xd5o | Before trying this question, make sure to totally digest this question: \n 127. Word Ladder\n\nAlso, it will be nice to \n1. know how to analyze the Time & Spac | xieyun95 | NORMAL | 2021-05-16T05:47:24.558243+00:00 | 2021-05-16T06:54:34.411510+00:00 | 1,410 | false | Before trying this question, make sure to totally digest this question: \n* [127. Word Ladder](https://leetcode.com/problems/word-ladder/discuss/1210829/Java-clean-Two-Way-BFS-Solution-oror-with-Analysis)\n\nAlso, it will be nice to \n1. know how to analyze the Time & Space Complexity of the algorithm. \n2. understand ... | 13 | 0 | ['Depth-First Search', 'Breadth-First Search', 'Java'] | 0 |
word-ladder-ii | C++ BFS with detailed explanation and illustration | c-bfs-with-detailed-explanation-and-illu-y1wp | Key points: graph & partial BFS. DO NOT use matrix to represent a network!!!!\nThe following content is based on the instance the problem gives.\nAllow me to s | charles1791 | NORMAL | 2020-06-12T05:28:45.479620+00:00 | 2020-06-14T01:50:02.892648+00:00 | 987 | false | Key points: graph & partial BFS. DO NOT use matrix to represent a network!!!!\nThe following content is based on the instance the problem gives.\nAllow me to show you a picture first:\n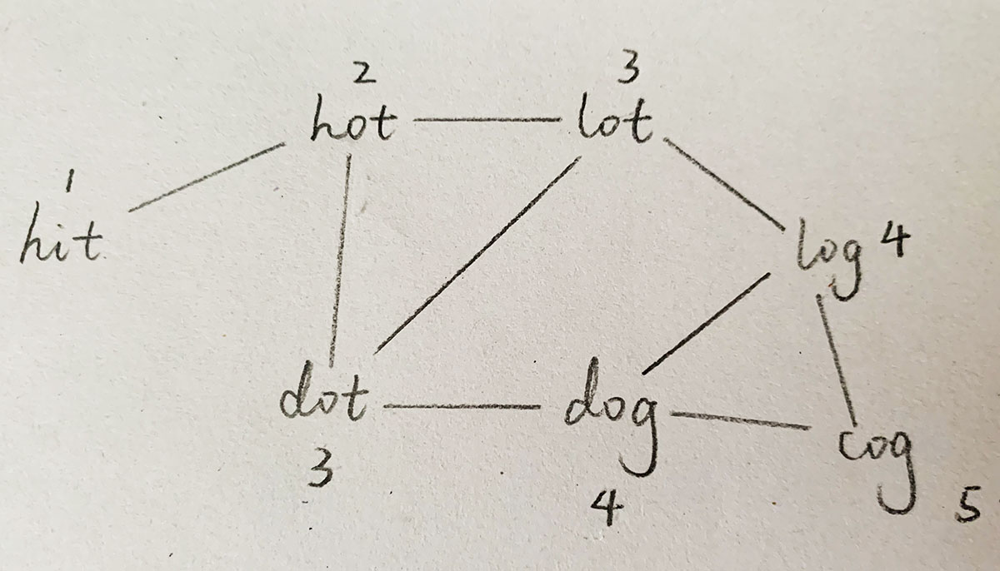\nFor every two words, if they only have one different cha... | 13 | 1 | [] | 1 |
word-ladder-ii | [Python] Three steps approach | python-three-steps-approach-by-sotheanit-h2nx | This is an implmentation of a solution provided here.\n\nSolution:\nThe initial instinct is to used BFS to find shortest paths and keep generating partial paths | SotheanithSok | NORMAL | 2022-08-14T08:03:50.391440+00:00 | 2022-08-15T04:38:19.388846+00:00 | 1,061 | false | This is an implmentation of a solution provided [here](https://leetcode.com/problems/word-ladder-ii/discuss/2367587/Python-BFS-%2B-DFS-With-Explanation-Why-Optimization-Is-Needed-to-Not-TLE).\n\n**Solution**:\nThe initial instinct is to used BFS to find shortest paths and keep generating partial paths as we go from one... | 12 | 0 | ['Python'] | 3 |
word-ladder-ii | ✔️ 100% Fastest Swift Solution | 100-fastest-swift-solution-by-sergeylesc-0dy3 | \nclass Solution {\n func findLadders(_ beginWord: String, _ endWord: String, _ wordList: [String]) -> [[String]] {\n\t\tguard wordList.contains(endWord) els | sergeyleschev | NORMAL | 2022-04-11T06:31:42.167258+00:00 | 2022-04-11T06:33:26.513544+00:00 | 357 | false | ```\nclass Solution {\n func findLadders(_ beginWord: String, _ endWord: String, _ wordList: [String]) -> [[String]] {\n\t\tguard wordList.contains(endWord) else { return [] }\n var wordSet = Set(wordList)\n var queue: [String] = [beginWord]\n\t\tvar words: [[String]] = []\n\t\tvar isLoopEnd = false\n\... | 12 | 0 | ['Swift'] | 0 |
word-ladder-ii | JavaScript easy to understand solution using BFS + DFS | javascript-easy-to-understand-solution-u-07ib | The idea is the following:\n1. Do BFS from endWord to beginWord, and compute the distance from each word to the endWord. In the meantime, we can also construct | zhenyi2697 | NORMAL | 2019-09-23T20:14:52.493756+00:00 | 2019-09-23T20:14:52.493808+00:00 | 1,942 | false | The idea is the following:\n1. Do BFS from endWord to beginWord, and compute the distance from each word to the endWord. In the meantime, we can also construct the mapping from one word to another, to avoid recomputing the combination again on step 2.\n2. Do DFS with backtracing from startWord to endWord, and only go f... | 12 | 0 | ['Backtracking', 'JavaScript'] | 3 |
word-ladder-ii | [C++] Easy BFS + building Graph then simple DFS | c-easy-bfs-building-graph-then-simple-df-1gtc | \nclass Solution {\npublic:\n\t// read this function after reading the main function\n unordered_map<string, vector<string>> adj;\n void dfs(string node, | Rxnjeet | NORMAL | 2022-08-14T15:56:54.580521+00:00 | 2022-08-15T06:44:59.922344+00:00 | 2,015 | false | ```\nclass Solution {\npublic:\n\t// read this function after reading the main function\n unordered_map<string, vector<string>> adj;\n void dfs(string node, vector<vector<string>> &ans, vector<string> &curr, string beginWord)\n {\n if(node == beginWord)\n {\n ans.push_back(curr);\n ... | 11 | 0 | ['Depth-First Search', 'Breadth-First Search', 'C', 'C++'] | 3 |
word-ladder-ii | C++ Full Explained Clean Code No TLE | c-full-explained-clean-code-no-tle-by-da-xw77 | The idea of this problem is to run bfs, where one step is changing some letter of word. For me easier to separate problem to two parts:\n\n1. Create graph of co | DarshanAgarwal95 | NORMAL | 2022-08-14T02:33:50.337971+00:00 | 2022-08-14T02:33:50.338004+00:00 | 4,234 | false | The idea of this problem is to run bfs, where one step is changing some letter of word. For me easier to separate problem to two parts:\n\n1. Create graph of connections G.\n2. Run bfs on this graph with collecting all possible solutions.\nNow, let us consider steps in more details.\n\n1. To create graph of connections... | 11 | 3 | ['Breadth-First Search', 'C', 'C++'] | 0 |
word-ladder-ii | [Python] Slow but easy to understand for beginners | python-slow-but-easy-to-understand-for-b-n4tg | \nclass Solution:\n def findLadders(self, beginWord: str, endWord: str, wordList: list[str]) -> list[list[str]]:\n alphabet = "abcdefghijklmnopqrstuvw | jozef-hudec-27 | NORMAL | 2021-07-24T08:15:04.507721+00:00 | 2021-07-24T08:16:44.590978+00:00 | 477 | false | ```\nclass Solution:\n def findLadders(self, beginWord: str, endWord: str, wordList: list[str]) -> list[list[str]]:\n alphabet = "abcdefghijklmnopqrstuvwxyz"\n wordList = set(wordList) # making wordList a set so we can look-up a word in O(1) time\n if beginWord == endWord:\n return [b... | 11 | 2 | ['Python'] | 2 |
word-ladder-ii | Input None Output None , 1/1 Test Case Passed Wrong Answer | input-none-output-none-11-test-case-pass-pd22 | When I submit the code below, OJ tells me that the input was NONE, output was NONE , 1/1 test case passed and the answer is WRONG. I am not sure how to diagnose | sj482 | NORMAL | 2015-09-08T05:07:57+00:00 | 2015-09-08T05:07:57+00:00 | 2,128 | false | When I submit the code below, OJ tells me that the input was NONE, output was NONE , 1/1 test case passed and the answer is WRONG. I am not sure how to diagnose this problem . \n\nDid anyone else face this issue?\n\n public class Solution {\n \tpublic List<String> getNeighbors(String str, Set<String> dict... | 11 | 0 | [] | 4 |
word-ladder-ii | Python 3, BFS + DFS BACKTRACKING no TLE | python-3-bfs-dfs-backtracking-no-tle-by-cc2jt | First, I use bfs and traverser layer by layer but get memory limit exceeded. Then I try to build the link between the child and parent and reconstruct via DFS | ladykkk | NORMAL | 2022-08-15T22:27:23.409593+00:00 | 2022-08-15T22:28:17.595697+00:00 | 363 | false | First, I use bfs and traverser layer by layer but get memory limit exceeded. Then I try to build the link between the child and parent and reconstruct via DFS to avoid store all the paths and computing same path again and again.\n```\ndef findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[Lis... | 10 | 0 | [] | 1 |
word-ladder-ii | C++ two approaches | c-two-approaches-by-sunhaozhe-ez49 | BFS with queue of paths\n\n Runtime: 480 ms, faster than 39.48%\n Memory Usage: 178.1 MB, less than 45.00%\n\nc++\n\tvector<vector<string>> findLadders(string b | sunhaozhe | NORMAL | 2020-03-14T22:37:11.707797+00:00 | 2020-03-14T22:44:51.515074+00:00 | 2,240 | false | # BFS with queue of paths\n\n* Runtime: 480 ms, faster than 39.48%\n* Memory Usage: 178.1 MB, less than 45.00%\n\n```c++\n\tvector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {\n vector<vector<string>> res;\n unordered_set<string> d(wordList.begin(), wordList.en... | 10 | 0 | ['Backtracking', 'Depth-First Search', 'Breadth-First Search', 'C++'] | 1 |
word-ladder-ii | C# creative idea to create a graph and then construct shortest path map practice in 2019 | c-creative-idea-to-create-a-graph-and-th-1hk6 | Sept. 12, 2019 8:49 PM\nIt is a hard level algorithm. I also like to learn the idea to build a graph using words, and then build a map to contain shortest path | jianminchen | NORMAL | 2019-09-10T06:28:00.579876+00:00 | 2019-10-15T18:26:35.215741+00:00 | 1,100 | false | Sept. 12, 2019 8:49 PM\nIt is a hard level algorithm. I also like to learn the idea to build a graph using words, and then build a map to contain shortest path to a word. \n\nWhat I like to practice in 2019 is to push myself to learn a few ideas using graph and also write down some analysis, build strong interest on t... | 10 | 0 | [] | 2 |
word-ladder-ii | the simplest javascript bfs solution | the-simplest-javascript-bfs-solution-by-yxoih | ```\nvar findLadders=function(beginWord, endWord, wordList){\n let results=[]\n let visited={}\n let steps=Number.MAX_SAFE_INTEGER\n let pathq=[[beg | deep666 | NORMAL | 2018-06-30T10:41:55.502381+00:00 | 2018-06-30T10:41:55.502381+00:00 | 1,056 | false | ```\nvar findLadders=function(beginWord, endWord, wordList){\n let results=[]\n let visited={}\n let steps=Number.MAX_SAFE_INTEGER\n let pathq=[[beginWord]]\n let wordset=new Set(wordList)\n while(pathq.length>0){\n let curpath=pathq.shift()\n let curword=curpath[curpath.length-1]\n ... | 10 | 0 | [] | 3 |
word-ladder-ii | Run Time Analysis For Word Ladder II (Java) | run-time-analysis-for-word-ladder-ii-jav-7mqg | I tried at least 10 methods as well as read at least 10 articles and posts for this problem. I want to summarize what I found here.\n\nKey point to include comm | siyang3 | NORMAL | 2015-02-28T20:28:55+00:00 | 2015-02-28T20:28:55+00:00 | 1,858 | false | I tried at least 10 methods as well as read at least 10 articles and posts for this problem. I want to summarize what I found here.\n\n**Key point to include common word on two paths is to use a set to collect words for current layer and then delete the set from dict after finishing current layer.**\n\nMethods: \n\n(1)... | 10 | 0 | ['Breadth-First Search'] | 2 |
word-ladder-ii | Python solution in 578ms | python-solution-in-578ms-by-clue-3qk8 | The trick is use set to save the words at each level because different words could ladder to the same word. It was 2580ms using list.\n \n alphabet = se | clue | NORMAL | 2015-01-05T18:13:39+00:00 | 2018-08-29T23:37:06.653679+00:00 | 5,536 | false | The trick is use `set` to save the words at each level because different words could ladder to the same word. It was 2580ms using `list`.\n \n alphabet = set('abcdefghijklmnopqrstuvwxyz')\n def findLadders(self, start, end, dict):\n dict.add(end)\n level_tracker = collections.defaultdict(set)\n... | 10 | 0 | ['Python'] | 6 |
word-ladder-ii | C++ - Guaranteed To Understand - BFS, Graph, No TLE - 44ms :) | c-guaranteed-to-understand-bfs-graph-no-6wm6a | Finally after a long time trying to understand so many of the codes here, I myself got to understand one code and get accepted.\n\nLet me break it down to you. | geekykant | NORMAL | 2022-08-15T13:02:25.509261+00:00 | 2022-08-15T16:55:13.416165+00:00 | 890 | false | Finally after a long time trying to understand so many of the codes here, I myself got to understand one code and get accepted.\n\nLet me break it down to you. It\'s easy to understand. No messy codes.\n\n**Method 1**: Naive Word Ladder-I continued (TLE) \u274C \n(32 / 35 test cases passed) - Best for interview explana... | 9 | 0 | ['C'] | 3 |
word-ladder-ii | Finally a solution that does not gives TLE | PYTHON | DFS | finally-a-solution-that-does-not-gives-t-0cu9 | \nclass Solution:\n def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n wordDict = defaultdict(set)\n | hhunterr | NORMAL | 2022-08-14T19:20:01.707318+00:00 | 2022-08-14T19:22:14.094364+00:00 | 445 | false | ```\nclass Solution:\n def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n wordDict = defaultdict(set)\n for word in wordList:\n if word != beginWord:\n for i in range(len(word)):\n wordDict[word[:i] + "*" + wor... | 9 | 0 | ['Backtracking', 'Depth-First Search', 'Python'] | 1 |
word-ladder-ii | Python || Double BFS || Easy to understand | python-double-bfs-easy-to-understand-by-qsp1u | This solution implements BFS two times. One time from beginWord to endWord. And then from endWord to beginWord. The reason to use BFS two times is to avoid the | stevenhgs | NORMAL | 2022-08-14T13:53:37.164084+00:00 | 2022-08-15T07:42:48.905903+00:00 | 1,338 | false | This solution implements BFS two times. One time from `beginWord` to `endWord`. And then from `endWord` to `beginWord`. The **reason** to use BFS two times is to **avoid the memory limit** in the first BFS. In the first BFS a lot of useless paths would need to be kept in memory.\n\nThis solution works in 4 steps:\n1. T... | 9 | 0 | ['Breadth-First Search', 'Python', 'Python3'] | 1 |
word-ladder-ii | Java || Graph-BFS || Shortest Path || Image explanation | java-graph-bfs-shortest-path-image-expla-stlb | Approach:\nCreate a graph where indices of the words are the vertices of the graph and an edge exists between two vertices if those 2 words differ by a single l | yggins | NORMAL | 2022-08-14T10:50:56.041541+00:00 | 2022-08-14T10:50:56.041584+00:00 | 1,758 | false | Approach:\nCreate a graph where indices of the words are the vertices of the graph and an edge exists between two vertices if those 2 words differ by a single letter.\n\nConsider below input -\nInput: beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]\n\nIn my code, beginWord has verte... | 9 | 0 | ['Breadth-First Search', 'Java'] | 2 |
word-ladder-ii | JAVA || Clean & Concise & Optimal Code || Breadth First Search + Backtracking Technique | java-clean-concise-optimal-code-breadth-bmesk | \nclass Solution {\n \n Set<String> wordSet = new HashSet<> ();\n List<String> currPath = new ArrayList<> ();\n List<List<String>> shortestPath = ne | anii_agrawal | NORMAL | 2021-07-24T21:37:29.559630+00:00 | 2021-07-24T21:37:29.559670+00:00 | 865 | false | ```\nclass Solution {\n \n Set<String> wordSet = new HashSet<> ();\n List<String> currPath = new ArrayList<> ();\n List<List<String>> shortestPath = new ArrayList<> ();\n Map<String, List<String>> adjacencyList = new HashMap<> ();\n \n public List<String> findNeighbors (String currWord) {\n ... | 9 | 0 | ['Backtracking', 'Breadth-First Search', 'Java'] | 0 |
word-ladder-ii | AC Python two-end BFS 124 ms | ac-python-two-end-bfs-124-ms-by-dietpeps-m8j1 | Two-end BFS to find the ladders and a recursive DFS to generate the answer\nidea is the same as word ladder i, [peaceful's solution][1]\n\n\n def _build(self | dietpepsi | NORMAL | 2015-10-14T05:40:55+00:00 | 2018-09-01T10:05:22.137536+00:00 | 4,733 | false | Two-end BFS to find the ladders and a recursive DFS to generate the answer\nidea is the same as word ladder i, [peaceful's solution][1]\n\n\n def _build(self, parent, path, paths):\n if not parent[path[-1]]:\n paths.append(path[:])\n return\n for nextWord in parent[path[-1]]:\n ... | 9 | 0 | ['Python'] | 9 |
word-ladder-ii | 💥 300 streak days!💪🏻💪🏻💪🏻 | 300-streak-days-by-ft_hs1396-h72d | Hello Guys!\nI have been here for #300# consecutive days, in any mood, sad or happy, healthy or sick, free or busy. | ft_hs1396 | NORMAL | 2022-08-14T15:40:09.861547+00:00 | 2022-08-14T15:40:09.861582+00:00 | 187 | false | Hello Guys!\nI have been here for #300# consecutive days, in any mood, sad or happy, healthy or sick, free or busy. | 8 | 1 | [] | 1 |
word-ladder-ii | C++ || BFS and BackTracking || Faster || 30ms | c-bfs-and-backtracking-faster-30ms-by-me-ihzd | \nclass Solution {\npublic:\n unordered_set<string> dic;\n unordered_map<string,int> mp;\n vector<vector<string>> ans;\n void dfs(string ew,vector<string> | Meraki3000 | NORMAL | 2022-08-14T09:53:43.052462+00:00 | 2022-08-14T09:53:43.052490+00:00 | 1,704 | false | ```\nclass Solution {\npublic:\n unordered_set<string> dic;\n unordered_map<string,int> mp;\n vector<vector<string>> ans;\n void dfs(string ew,vector<string> &temp,string bw)\n {\n \n int curr=mp[ew];\n temp.push_back(ew);\n if(ew==bw)\n {\n reverse(temp.begin(),t... | 8 | 1 | ['Backtracking', 'Depth-First Search', 'Breadth-First Search', 'C', 'C++'] | 1 |
word-ladder-ii | BFS + DFS + Memoization - Non-TLE solution | bfs-dfs-memoization-non-tle-solution-by-zb09j | \nclass Solution {\n public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {\n Set<String> dict = new HashSet | jainakshat425 | NORMAL | 2022-07-31T05:34:48.639587+00:00 | 2022-07-31T05:34:48.639642+00:00 | 1,056 | false | ```\nclass Solution {\n public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {\n Set<String> dict = new HashSet(wordList);\n if( !dict.contains(endWord) )\n return new ArrayList();\n \n // adjacent words for each word\n Map<Strin... | 8 | 0 | ['Java'] | 0 |
word-ladder-ii | ✅C++ Easy-To-Understand BFS solution | c-easy-to-understand-bfs-solution-by-igi-vca3 | \tclass Solution {\n\t\t vector> ans;\n\tpublic:\n\t\t void helper(string start,string end,unordered_set &st){\n\t\t\t queue> q;\n\t\t\t q.push({start}); //s | igi17 | NORMAL | 2022-02-26T10:56:04.858676+00:00 | 2022-02-26T10:56:04.858705+00:00 | 793 | false | \tclass Solution {\n\t\t vector<vector<string>> ans;\n\tpublic:\n\t\t void helper(string start,string end,unordered_set<string> &st){\n\t\t\t queue<vector<string>> q;\n\t\t\t q.push({start}); //storing path\n\t\t\t bool flag=false;\n\t\t\t while(!q.empty()){\n\t\t\t\t int n=q.size();\n\t\t\t\t while(n--)\n\t\t\... | 8 | 0 | ['Breadth-First Search', 'C'] | 1 |
word-ladder-ii | Java| Clean Code | Easy to understand| Well Explained | java-clean-code-easy-to-understand-well-yqzm3 | My approach to solve this problem\n\nI created a adjacency list of the strings , i.e. next path of the string where it can got to with change of one char in fr | abhishekgoel | NORMAL | 2021-01-15T19:34:31.820255+00:00 | 2021-01-15T19:53:53.529752+00:00 | 1,769 | false | My approach to solve this problem\n\nI created a adjacency list of the strings , i.e. next path of the string where it can got to with change of one char in from the previous string. I did this by converting the string to a char array and then changing the character at each index of string from **a to z** . so if i ha... | 8 | 1 | ['Depth-First Search', 'Breadth-First Search', 'Graph', 'Java'] | 3 |
word-ladder-ii | Concise Swift Solution, with my understanding | concise-swift-solution-with-my-understan-0uaw | This is a question that asks to find the shortest paths between two nodes in a graph. First of all, if the endWord is not in the word list, then it means our gr | wds8807 | NORMAL | 2019-03-30T03:59:12.372617+00:00 | 2019-03-30T03:59:12.372660+00:00 | 364 | false | This is a question that asks to find the shortest paths between two nodes in a graph. First of all, if the ```endWord``` is not in the word list, then it means our graph does not contain ```endWord``` and we return ```[]```. \n\nAfter building the graph from the given word list, we can perform a breadth first search to... | 8 | 0 | [] | 1 |
word-ladder-ii | Word Ladder II [C++] | word-ladder-ii-c-by-moveeeax-z7hb | IntuitionThe problem requires finding the shortest transformation sequence(s) from beginWord to endWord, where each step can change only one character, and the | moveeeax | NORMAL | 2025-02-01T10:21:00.677630+00:00 | 2025-02-01T10:21:00.677630+00:00 | 1,440 | false | ### Intuition
The problem requires finding the shortest transformation sequence(s) from `beginWord` to `endWord`, where each step can change only one character, and the resulting word must exist in the `wordList`. Since we need the shortest sequences, we can use **Breadth-First Search (BFS)** to traverse level by level... | 7 | 0 | ['C++'] | 0 |
word-ladder-ii | 💥[EXPLAINED] TypeScript. Runtime beats 96.88% (TypeSript) | explained-typescript-runtime-beats-9688-e6etq | Intuition\nUse BFS to find shortest paths and distances and DFS to build all shortest paths from beginWord to endWord.\n\n# Approach\nUse BFS to calculate the s | r9n | NORMAL | 2024-08-23T01:58:13.160940+00:00 | 2024-08-26T19:51:26.335109+00:00 | 325 | false | # Intuition\nUse BFS to find shortest paths and distances and DFS to build all shortest paths from beginWord to endWord.\n\n# Approach\nUse BFS to calculate the shortest distances and track predecessors, and use DFS to reconstruct all paths from endWord to beginWord using the predecessors.\n\n# Complexity\n- Time compl... | 7 | 0 | ['TypeScript'] | 0 |
word-ladder-ii | 126: with step by step explanation | 126-with-step-by-step-explanation-by-mar-oqg6 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\nSure, here\'s a step-by-step explanation of the code: \n\nclass Solution: | Marlen09 | NORMAL | 2023-02-18T06:40:28.134610+00:00 | 2023-02-18T06:51:20.773631+00:00 | 1,424 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nSure, here\'s a step-by-step explanation of the code: \n```\nclass Solution:\n\tdef findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n\n```\nThe function findLadders takes in a beginWo... | 7 | 1 | ['Hash Table', 'String', 'Breadth-First Search', 'Python', 'Python3'] | 0 |
word-ladder-ii | Python faster than 95% BFS + DFS | python-faster-than-95-bfs-dfs-by-easy_pr-xl9w | Trick way to get all neighbors of all words in wordList in O(NK) time complexity, where N = len(wordList) and K = len(beginWord).\n\n\nclass Solution: \n | easy_problems_hunter | NORMAL | 2022-09-09T21:20:57.107314+00:00 | 2022-09-09T21:20:57.107358+00:00 | 453 | false | Trick way to get all neighbors of all words in wordList in O(NK) time complexity, where N = len(wordList) and K = len(beginWord).\n\n```\nclass Solution: \n \n def backtrack(self, curr_trans, curr_word):\n if curr_word == self.beginWord:\n curr_trans.append(curr_word)\n curr_tr... | 7 | 0 | ['Breadth-First Search'] | 1 |
word-ladder-ii | Best and most optimal C++ solution with complete explaination working code without TLE | best-and-most-optimal-c-solution-with-co-gj61 | Intuition\n\nThe Word Ladder II problem requires finding all the shortest transformation sequences from a start word to an end word, where each intermediate wor | mohitjaisal | NORMAL | 2022-08-23T08:46:23.130414+00:00 | 2024-07-27T12:56:25.805112+00:00 | 306 | false | ## Intuition\n\nThe Word Ladder II problem requires finding all the shortest transformation sequences from a start word to an end word, where each intermediate word must exist in a given word list, and each transformation can change only one letter. The problem can be broken down into two main tasks:\n1. **Building the... | 7 | 0 | ['Depth-First Search', 'Breadth-First Search', 'Graph', 'C++', 'Java'] | 2 |
word-ladder-ii | Analyze why we should DFS from endWord to avoid TLE | analyze-why-we-should-dfs-from-endword-t-6rsp | I thought it\'s a graph problem so I solved it this way:\n1. Build a graph by connecting words that differ by exactly 1 character\n2. Run a BFS from beginWord t | sc420 | NORMAL | 2022-08-14T14:33:17.158816+00:00 | 2022-08-15T02:36:53.330868+00:00 | 932 | false | I thought it\'s a graph problem so I solved it this way:\n1. Build a graph by connecting words that differ by exactly 1 character\n2. Run a BFS from `beginWord` to `endWord` to find the shortest distance\n3. Run a DFS from `beginWord` to `endWord`, ignoring any node that BFS didn\'t visit, and use backtracking techniqu... | 7 | 0 | ['C', 'C++'] | 3 |
word-ladder-ii | C++✅ || Easy || Solution || BFS | c-easy-solution-bfs-by-prinzeop-lgpo | \nclass Solution {\npublic:\n\t\n\t// If s1 and s2 string only differ by single character\n\tbool canBeNext(string s1, string s2){\n\t\tint uncmn=0;\n\t\tfor(in | casperZz | NORMAL | 2022-08-14T11:38:38.280035+00:00 | 2022-08-14T11:38:38.280077+00:00 | 1,875 | false | ```\nclass Solution {\npublic:\n\t\n\t// If s1 and s2 string only differ by single character\n\tbool canBeNext(string s1, string s2){\n\t\tint uncmn=0;\n\t\tfor(int i=0; i<s1.size(); i++)\n\t\t\tuncmn += (s1[i] != s2[i]);\n\n\t\treturn uncmn==1;\n\t}\n\t\n\t// BFS to find the shortest paths first (Since BFS traverses n... | 7 | 0 | ['Breadth-First Search', 'C'] | 1 |
word-ladder-ii | Accepted Java Solution (24ms) | accepted-java-solution-24ms-by-mayank_oo-jb4b | Accepted Java Solution \n1. First we find the shortest path \'X\' between end word and start word \n2. Then we apply dfs from begin word and once we reach at X | Mayank_OO7 | NORMAL | 2022-08-14T06:20:03.915218+00:00 | 2022-08-14T07:34:19.631839+00:00 | 1,386 | false | # Accepted Java Solution \n1. First we find the shortest path \'X\' between end word and start word \n2. Then we apply dfs from begin word and once we reach at X \n* If we find the end word we push the current path in ans \n* Else we backtrack and try another path.\n```\nclass Solution {\n Set<String> set = new Has... | 7 | 1 | ['Depth-First Search', 'Java'] | 2 |
word-ladder-ii | 0 ms Runtime - C++ | 0-ms-runtime-c-by-day_tripper-h1dx | \nclass Solution {\npublic:\n vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {\n auto answer = std::ve | Day_Tripper | NORMAL | 2022-08-14T04:34:09.996904+00:00 | 2022-08-14T05:03:57.312276+00:00 | 832 | false | ```\nclass Solution {\npublic:\n vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {\n auto answer = std::vector<std::vector<std::string>>();\n auto from = beginWord;\n auto to = endWord;\n\n auto my_lexicon = std::unordered_set<std::string>(wo... | 7 | 1 | [] | 0 |
word-ladder-ii | 🗓️ Daily LeetCoding Challenge August, Day 14 | daily-leetcoding-challenge-august-day-14-xt2s | This problem is the Daily LeetCoding Challenge for August, Day 14. Feel free to share anything related to this problem here! You can ask questions, discuss what | leetcode | OFFICIAL | 2022-08-14T00:00:50.120940+00:00 | 2022-08-14T00:00:50.121008+00:00 | 5,464 | false | This problem is the Daily LeetCoding Challenge for August, Day 14.
Feel free to share anything related to this problem here!
You can ask questions, discuss what you've learned from this problem, or show off how many days of streak you've made!
---
If you'd like to share a detailed solution to the problem, please cr... | 7 | 4 | [] | 41 |
word-ladder-ii | Time Limit Exceeded for "nape", "mild" | time-limit-exceeded-for-nape-mild-by-cen-d2bu | I used BFS approach and kept a map for getting paths. I used dp approach for faster retrievel but i am still getting TLE for "nape" "mild" input (achieved to ge | cengin | NORMAL | 2014-01-30T11:44:14+00:00 | 2014-01-30T11:44:14+00:00 | 5,517 | false | I used BFS approach and kept a map for getting paths. I used dp approach for faster retrievel but i am still getting TLE for "nape" "mild" input (achieved to get correct results on my pc). Can anyone point ways to decrease time consumption?\n\n\n public ArrayList<ArrayList<String>> findLadders(String start,\n \t\... | 7 | 0 | [] | 9 |
word-ladder-ii | c++ solution using dfs || NO TLE!! | c-solution-using-dfs-no-tle-by-yash_jain-czsa | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | yash_jain26 | NORMAL | 2023-10-16T20:25:56.876724+00:00 | 2023-10-16T20:25:56.876742+00:00 | 812 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 6 | 0 | ['String', 'Backtracking', 'Depth-First Search', 'Graph', 'C++'] | 0 |
word-ladder-ii | Word Ladder II || BFS + Backtracking with explanation | word-ladder-ii-bfs-backtracking-with-exp-45ob | BFS + Backtracking\n\nHere we have given that Every adjacent pair of words differs by a single letter. In order to find such pairs efficiently, we can replace e | meetpatel5720 | NORMAL | 2022-08-14T09:43:51.331667+00:00 | 2022-08-14T09:43:51.331713+00:00 | 917 | false | ### BFS + Backtracking\n\nHere we have given that Every adjacent pair of words differs by a single letter. In order to find such pairs efficiently, we can **replace** each character of `word` with `*` and create a hash map where key will be new pattern and value will be list of words.\n\nFor example `word1 = hit` and `... | 6 | 0 | ['Backtracking', 'Breadth-First Search', 'Java'] | 1 |
word-ladder-ii | Why is this question | why-is-this-question-by-mayur_madhwani-86ac | All you get is TLE\nWhen you try to understand someone else\'s code and finally try to implement it you get TLE\nI don\'t know what\'s wrong with this question\ | mayur_madhwani | NORMAL | 2022-08-14T05:37:14.756555+00:00 | 2022-08-14T14:00:03.676061+00:00 | 724 | false | All you get is TLE\nWhen you try to understand someone else\'s code and finally try to implement it you get TLE\nI don\'t know what\'s wrong with this question\nWhat do I need to do to get this question done | 6 | 0 | [] | 5 |
word-ladder-ii | C# Solution | BFS, DFS, Backtracking, Dictionary, Clean code | c-solution-bfs-dfs-backtracking-dictiona-jy35 | C#\npublic class Solution {\n public IList<IList<string>> FindLadders(string beginWord, string endWord, IList<string> wordList) {\n List<IList<string> | tonytroeff | NORMAL | 2022-08-14T05:07:06.325532+00:00 | 2022-08-14T05:07:06.325577+00:00 | 333 | false | ```C#\npublic class Solution {\n public IList<IList<string>> FindLadders(string beginWord, string endWord, IList<string> wordList) {\n List<IList<string>> ans = new List<IList<string>>();\n var (shortestPathLength, graph) = ComputeGraph(beginWord, endWord, wordList);\n if (graph == null) return ... | 6 | 0 | ['Depth-First Search', 'Breadth-First Search'] | 2 |
word-ladder-ii | ✅python: fast optimized bfs + adjacency list + parent list, easy to understand with comments | python-fast-optimized-bfs-adjacency-list-1xtl | ```\nclass Solution:\n def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n #generate adjacent list\n | zoey513 | NORMAL | 2022-08-04T18:14:43.997881+00:00 | 2022-08-04T18:17:26.250443+00:00 | 393 | false | ```\nclass Solution:\n def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n #generate adjacent list\n Nei = defaultdict(list)\n for word in wordList:\n for i in range(len(word)):\n pattern = word[:i]+\'*\'+word[i+1:]\n ... | 6 | 0 | [] | 0 |
word-ladder-ii | Python BFS+DFS beats100% | python-bfsdfs-beats100-by-juehuil-vtkb | python\nclass Solution:\n def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n prefix_d = defaultdict(list)\ | juehuil | NORMAL | 2022-03-28T02:32:02.704173+00:00 | 2022-03-28T02:33:11.318221+00:00 | 776 | false | ```python\nclass Solution:\n def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n prefix_d = defaultdict(list)\n for word in wordList:\n for i in range(0,len(word)):\n prefix_d[word[0:i]+"*"+word[i+1:]].append(word)\n \n ... | 6 | 0 | ['Python', 'Python3'] | 2 |
word-ladder-ii | My javascript solution | my-javascript-solution-by-tyz111-inyu | This is a solution using both BFS and DFS.\n step1: BFS is used to calcuted the shortest length from beginWord to endWord. (function findShortestLen)\n step2: I | tyz111 | NORMAL | 2021-02-23T05:25:45.197807+00:00 | 2021-02-28T04:17:30.950066+00:00 | 819 | false | This is a solution using both BFS and DFS.\n* step1: BFS is used to calcuted the shortest length from beginWord to endWord. (function findShortestLen)\n* step2: In the meantime of step1, twp maps are built, that is Map wordToShortest(key: word, value: the shortest distance from this word to endWord) and Map wordToNeigh... | 6 | 0 | ['JavaScript'] | 5 |
word-ladder-ii | C++ BFS+DFS ,58% faster, well commented | c-bfsdfs-58-faster-well-commented-by-shy-xow4 | \nclass Solution {\npublic:\n\n vector<vector<string>> ans; //store all ans\n \n void DFS(string& beginWord,string& endWord,unordered_map<string, unord | Shyamji07 | NORMAL | 2021-01-10T08:22:16.813985+00:00 | 2022-07-23T20:57:40.838838+00:00 | 293 | false | ```\nclass Solution {\npublic:\n\n vector<vector<string>> ans; //store all ans\n \n void DFS(string& beginWord,string& endWord,unordered_map<string, unordered_set<string>>& adj,vector<string>&path){\n path.push_back(beginWord);\n if(beginWord==endWord){\n ans.push_back(path);\n ... | 6 | 0 | [] | 1 |
word-ladder-ii | JAVA BFS one pass | java-bfs-one-pass-by-mtgk-rw8j | \nclass Solution {\n public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {\n List<List<String>> res = new A | mtgk | NORMAL | 2020-05-26T00:05:31.408186+00:00 | 2020-05-26T00:05:31.408235+00:00 | 695 | false | ```\nclass Solution {\n public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {\n List<List<String>> res = new ArrayList<>();\n\n if (!wordList.contains(endWord)) return res;\n \n // build graph\n Map<String, List<String>> map = new HashMap<... | 6 | 0 | [] | 1 |
word-ladder-ii | Python BFS | python-bfs-by-infinute-us7o | If you don\'t know the trick to search for the next word, check out the solution for Word Ladder I.\n\nfrom collections import defaultdict\nclass Solution:\n | infinute | NORMAL | 2019-03-13T00:03:00.348692+00:00 | 2019-03-13T00:03:00.348740+00:00 | 1,038 | false | If you don\'t know the trick to search for the next word, check out the solution for [Word Ladder I](https://leetcode.com/problems/word-ladder/solution/).\n```\nfrom collections import defaultdict\nclass Solution:\n def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\n ... | 6 | 0 | [] | 4 |
word-ladder-ii | Java code based on Dijkstra's algorithm. Accepted. | java-code-based-on-dijkstras-algorithm-a-dqpz | The difference from the Word Ladder solution is that now we need to remember all possible previous nodes in the path to the node when solution is optimal. And a | pavel-shlyk | NORMAL | 2015-01-05T21:28:45+00:00 | 2015-01-05T21:28:45+00:00 | 3,621 | false | The difference from the Word Ladder solution is that now we need to remember all possible previous nodes in the path to the node when solution is optimal. And after that construct all possible path variants.\n\n static private class WordVertex implements Comparable<WordVertex>{\n\t\t\n\t\tprivate String word;\n\t\tp... | 6 | 0 | [] | 2 |
word-ladder-ii | Java solution, beats 98%, with intuition | java-solution-beats-98-with-intuition-by-85ab | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n1. use BFS to build a g | y_hao1 | NORMAL | 2024-09-06T02:16:32.678116+00:00 | 2024-09-06T02:16:32.678144+00:00 | 286 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. use BFS to build a graph, where the distance from beginWord to all nodes are the shortest (NOT ALL edges are included, and that\'s the key)\n2. then use DFS to get ... | 5 | 0 | ['Java'] | 0 |
word-ladder-ii | JAVA FASTEST SOLUTION😉✌️ | java-fastest-solution-by-abhiyadav05-p2lp | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | abhiyadav05 | NORMAL | 2023-08-16T17:06:55.908628+00:00 | 2023-08-16T17:06:55.908654+00:00 | 444 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 5 | 1 | ['Hash Table', 'String', 'Breadth-First Search', 'Java'] | 0 |
word-ladder-ii | Word Ladder II: Finding All Shortest Transformation Sequences | word-ladder-ii-finding-all-shortest-tran-piuz | Intuition\nThis problem requires finding all the shortest transformation sequences from the beginWord to the endWord using a word list wordList, where each tran | sameershreyas13 | NORMAL | 2023-07-24T06:01:56.300808+00:00 | 2023-07-24T06:59:42.244962+00:00 | 1,140 | false | # Intuition\nThis problem requires finding all the shortest transformation sequences from the beginWord to the endWord using a word list wordList, where each transformation must change exactly one letter.\n\n# Approach Overview:\nTo solve the problem, we employ a combination of Breadth-First Search (BFS) and Depth-Firs... | 5 | 0 | ['Backtracking', 'Breadth-First Search', 'Graph', 'C++'] | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.