
modelId stringlengths 4 81 | tags list | pipeline_tag stringclasses 17
values | config dict | downloads int64 0 59.7M | first_commit timestamp[ns, tz=UTC] | card stringlengths 51 438k |
|---|---|---|---|---|---|---|
ArashEsk95/bert-base-uncased-finetuned-sst2 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v0
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... |
Aravinth/test | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-7
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-7
This model i... |
ArcQ/gpt-experiments | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | # Introduction
See https://github.com/k2-fsa/icefall/pull/330
No random combiner inside.
Tensorboard logs: https://tensorboard.dev/experiment/xREbAh7RS9m2TADGRLVx2g/
|
Arcanos/1 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v1_100000
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
na... |
ArenaGrenade/char-cnn | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | # KoMiniLM
🐣 Korean mini language model
## Overview
Current language models usually consist of hundreds of millions of parameters which brings challenges for fine-tuning and online serving in real-life applications due to latency and capacity constraints. In this project, we release a light weight korean language mod... |
Arghyad/Loki_small | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- yelp_review_full
metrics:
- accuracy
model-index:
- name: my-awesome-model
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: yelp_review_full
type: yelp_review_full
args: yelp_revie... |
AriakimTaiyo/DialoGPT-medium-Kumiko | [
"conversational"
] | conversational | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mT5_multilingual_XLSum-finetuned-summarization-V2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comm... |
AriakimTaiyo/DialoGPT-revised-Kumiko | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 6 | null | ---
language:
- "ja"
tags:
- "japanese"
- "masked-lm"
license: "cc-by-sa-4.0"
pipeline_tag: "fill-mask"
mask_token: "[MASK]"
widget:
- text: "日本に着いたら[MASK]を訪ねなさい。"
---
# deberta-small-japanese-aozora
## Model Description
This is a DeBERTa(V2) model pre-trained on 青空文庫 texts. NVIDIA A100-SXM4-40GB took 6 hours 42 min... |
AriakimTaiyo/DialoGPT-small-Rikka | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 8 | 2022-05-23T05:26:25Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 256.70 +/- 25.38
name: mean_reward
task:
type: reinforcement-learning
name: re... |
AriakimTaiyo/kumiko | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T05:26:58Z | ---
tags:
- translation
license: apache-2.0
datasets:
- thai2rom-v2
metrics:
- cer
widget:
- text: "maiphai"
---
# Roman-Thai Transliterator by Transformer Models
GitHub: https://github.com/wannaphong/thai2rom-v2/tree/main/roman2thai-transformer |
Aries/T5_question_answering | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_s... | 5 | null | ---
license: apache-2.0
tags:
- summarization
- arabic
- am
- es
- amharic
- mt5
- Abstractive Summarization
- generated_from_trainer
model-index:
- name: mt5-base-finetuned-ar-sp
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should ... |
Aries/T5_question_generation | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_s... | 13 | null | ---
tags:
- generated_from_keras_callback
model-index:
- name: kobart-kormath
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# kobart-kormath
This model was trained ... |
asaakyan/mbart-poetic-all | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name... |
ArnaudPannatier/MLPMixer | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ## This is the model for the 'Sum_it' app ##
Find it at HuggingFace Spaces!
https://huggingface.co/spaces/SamuelMiller/sum_it |
Atampy26/GPT-Glacier | [
"pytorch",
"gpt_neo",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPTNeoForCausalLM"
],
"model_type": "gpt_neo",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram... | 5 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 9.59 +/- 2.21
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... |
Axon/resnet34-v1 | [
"dataset:ImageNet",
"arxiv:1512.03385",
"Axon",
"Elixir",
"license:apache-2.0"
] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- precision
- recall
model-index:
- name: bert-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: emotion
metrics:
... |
Ayham/xlnet_gpt_xsum | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_re... | 11 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: mBERTnews
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ... |
BME-TMIT/foszt2oszt | [
"pytorch",
"encoder-decoder",
"text2text-generation",
"hu",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_re... | 15 | null | ---
license: apache-2.0
tags:
- medium-summarization
- generated_from_trainer
model-index:
- name: t5-small-finetuned-tds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comme... |
Babelscape/rebel-large | [
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"en",
"dataset:Babelscape/rebel-dataset",
"transformers",
"seq2seq",
"relation-extraction",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"has_space"
] | text2text-generation | {
"architectures": [
"BartForConditionalGeneration"
],
"model_type": "bart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repe... | 9,458 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 265.14 +/- 22.36
name: mean_reward
task:
type: reinforcement-learning
name: re... |
Bakkes/BakkesModWiki | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... |
Baybars/wav2vec2-xls-r-300m-cv8-turkish | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"tr",
"dataset:common_voice",
"transformers",
"common_voice",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"license:apache-2.0"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_s... | 5 | 2022-05-23T19:00:34Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-google-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wa... |
BearThreat/distilbert-base-uncased-finetuned-cola | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
... | 30 | 2022-05-23T19:02:57Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 253.47 +/- 12.25
name: mean_reward
task:
type: reinforcement-learning
name: re... |
Beatriz/model_name | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T19:03:15Z | # dant5-large
---
language:
- da
language_bcp47:
- da
- da-bornholm
- da-synnejyl
tags:
- t5
license: cc-by-4.0
datasets:
- dagw
widget:
- text: "Aarhus er Danmarks <extra_id_0>.<extra_id_2>"
co2_eq_emissions:
training_type: "pretraining"
geographical_location: "Copenhagen, Denmark"
hardware_used: "4... |
Belin/T5-Terms-and-Conditions | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T19:10:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove ... |
Bharathdamu/wav2vec2-large-xls-r-300m-hindi | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"dataset:common_voice",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_s... | 10 | 2022-05-23T19:22:25Z | ```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln45")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln45")
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Tra... |
Bhuvana/t5-base-spellchecker | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_s... | 93 | 2022-05-23T19:30:48Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... |
BigSalmon/InformalToFormalLincoln15 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 11 | null | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: electric_pole_type_classification
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8571428656578064
---
# ... |
BigSalmon/InformalToFormalLincoln20 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 8 | 2022-05-23T20:15:59Z | ---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery_param1
results:
- metrics:
- type: mean_reward
value: 0.27 +/- 0.44
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-l... |
BigSalmon/InformalToFormalLincoln22 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 6 | 2022-05-23T20:18:33Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
args: plain_text
met... |
BigSalmon/InformalToFormalLincolnDistilledGPT2 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 7 | 2022-05-23T20:22:50Z | ---
language: en
tags:
- exbert
license: apache-2.0
datasets:
- openwebtext
---
# DistilGPT2
# test
DistilGPT2 English language model pretrained with the supervision of [GPT2](https://huggingface.co/gpt2) (the smallest version of GPT2) on [OpenWebTextCorpus](https://skylion007.github.io/OpenWebTextCorpus/), a reprodu... |
BigSalmon/MrLincoln14 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T20:33:43Z | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-name_vsv_all
co2_eq_emissions: 110.53225910657005
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 901529445
- CO2 Emissions (in grams): 110.53225910657005
## Validatio... |
BigSalmon/MrLincoln3 | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 17 | 2022-05-23T20:35:16Z | ---
license:
- other
- apache-2.0
tags:
- generated_from_trainer
- text-generation
- OPT
- non-commercial
- dialogue
- chatbot
- ai-msgbot
library_name: transformers
pipeline_tag: text-generation
widget:
- text: 'If you could live anywhere, where would it be? peter szemraj:'
example_title: live anywhere
- text... |
Blabla/Pipipopo | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: andywedlake/test-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# an... |
Blaine-Mason/hackMIT-finetuned-sst2 | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 36 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: bert-zs-sentence-classifier
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. ... |
Branex/gpt-neo-2.7B | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T21:44:23Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: huggingfaceclass-qtable-FrozenLake-v1-4x4-noslip
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
... |
BrianTin/MTBERT | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 11 | 2022-05-23T21:57:05Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... |
Broadus20/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 9 | null | ---
language:
- "eng"
thumbnail: "URL to a thumbnail used in social sharing"
tags:
- "PyTorch"
- "tensorflow"
license: "apache-2.0"
---
# viniLM-2021-from-large
### Model Info:
<ul>
<li> Authors: R&D AI Lab, VMware Inc.
<li> Model date: Jun 2022
<li> Model version: 2021-distilled-from-large
<li> Model type: Pret... |
Brona/model1 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T22:25:39Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-11
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-11
This model... |
BrunoNogueira/DialoGPT-kungfupanda | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 10 | 2022-05-23T22:32:52Z | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-company_vs_all
co2_eq_emissions: 111.96508441754436
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 902129475
- CO2 Emissions (in grams): 111.96508441754436
## Validat... |
Brunomezenga/NN | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: huggingfaceclass-qtable-FrozenLake-v1-4x4-slip
results:
- metrics:
- type: mean_reward
value: 0.02 +/- 0.15
name: mean_reward
task:
type: reinforcement-learning
name: rein... |
Bryan190/Aguy190 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T23:13:53Z | ---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: huggingfaceclass-qtable-FrozenLake-v1-8x8-slip
results:
- metrics:
- type: mean_reward
value: 0.38 +/- 0.49
name: mean_reward
task:
type: reinforcement-learning
name: rein... |
Bryanwong/wangchanberta-ner | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: roberta-base-biomedical-clinical-es-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this c... |
Brykee/DialoGPT-medium-Morty | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 10 | null | ---
license: mit
tags:
- yolo
- cpu
- quant
- pruned
--- |
Bryson575x/riceboi | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T23:55:56Z | ---
language:
- "ja"
tags:
- "japanese"
- "token-classification"
- "pos"
- "dependency-parsing"
datasets:
- "universal_dependencies"
license: "cc-by-sa-4.0"
pipeline_tag: "token-classification"
widget:
- text: "国境の長いトンネルを抜けると雪国であった。"
---
# deberta-small-japanese-upos
## Model Description
This is a DeBERTa(V2) model ... |
Bubb-les/DisloGPT-medium-HarryPotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 8 | null | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4... |
BumBelDumBel/TRUMP | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 5 | 2022-05-24T00:30:50Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: ppo
results:
- metrics:
- type: mean_reward
value: 248.37 +/- 18.68
name: mean_reward
task:
type: reinforcement-learning
name: re... |
BumBelDumBel/ZORK-AI-TEST | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 9 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 238.25 +/- 47.46
name: mean_reward
task:
type: reinforcement-learning
name: re... |
BumBelDumBel/ZORK_AI_FANTASY | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-24T01:41:29Z | # Introduction
This model translate between Yoda-ish to English and vice versa. It makes use of the [T5-base](https://huggingface.co/t5-base) model and finetuning.
Basically it trains for 2 tasks using the same dataset. In Yoda-ish to English, trains
# Dataset
For this first version of the model I used a small sample... |
BunakovD/sd | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-24T01:48:33Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-53h-turkish-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then... |
Buntan/bert-finetuned-ner | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 8 | 2022-05-24T01:53:01Z | ---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-finetuned-amazon-en-es
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, th... |
Bwehfuk/Ron | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-24T02:02:50Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: arjunpatel/distilgpt2-finetuned-pokemon-moves
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comm... |
CALM/CALM | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 199.28 +/- 60.88
name: mean_reward
task:
type: reinforcement-learning
name: re... |
CAMeL-Lab/bert-base-arabic-camelbert-ca-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 85 | 2022-05-24T03:05:45Z | ---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: huggingfaceclass-qtable-FrozenLake-v1-8x8-slip2
results:
- metrics:
- type: mean_reward
value: 0.51 +/- 0.50
name: mean_reward
task:
type: reinforcement-learning
name: rei... |
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 18 | 2022-05-24T03:52:45Z | ---
language:
- "ja"
tags:
- "japanese"
- "token-classification"
- "pos"
- "dependency-parsing"
datasets:
- "universal_dependencies"
license: "cc-by-sa-4.0"
pipeline_tag: "token-classification"
widget:
- text: "国境の長いトンネルを抜けると雪国であった。"
---
# deberta-small-japanese-luw-upos
## Model Description
This is a DeBERTa(V2) mo... |
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 71 | 2022-05-24T04:14:49Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: xlsr-wav2vec2-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlsr-wav2vec2-1
Th... |
CAMeL-Lab/bert-base-arabic-camelbert-ca | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 580 | 2022-05-24T04:29:47Z | ---
tags:
- conversational
---
# Sebastian Michaelis DialoGPT Model |
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-egy | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 32 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforc... |
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 54 | 2022-05-24T05:25:07Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- amazon_polarity
metrics:
- accuracy
- f1
model-index:
- name: SentimentClassifier
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: amazon_polarity
type: amazon_polarity
args: amazo... |
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 27 | null | ---
language:
- es
tags:
- Text Classification
---
## language:
- es
## tags:
- amazon_reviews_multi
- Text Clasiffication
### Dataset
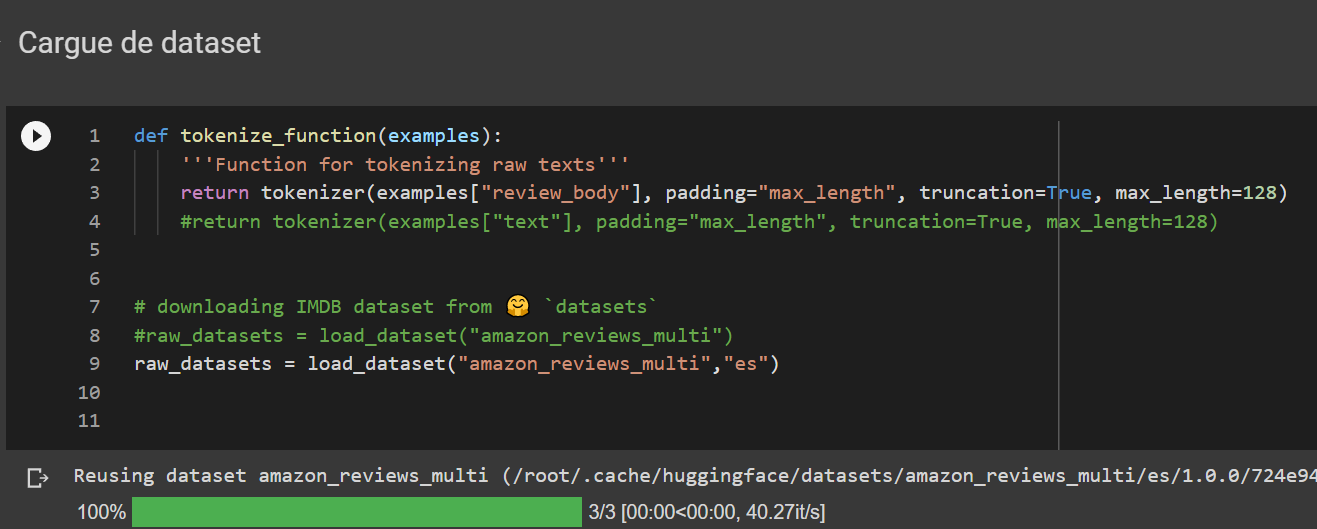
### Example structure review:
| review_id (string) | product_id (string) | reviewer... |
CAMeL-Lab/bert-base-arabic-camelbert-da | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 449 | null | ---
tags:
- conversational
---
# Homer Simpson Chatbot Model |
CAMeL-Lab/bert-base-arabic-camelbert-mix-did-madar-corpus26 | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 45 | 2022-05-24T06:13:08Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v1_1000
results:
- metrics:
- type: mean_reward
value: 10.65 +/- 2.37
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
nam... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-did-nadi | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 63 | 2022-05-24T06:20:03Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v1_25000
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
nam... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 1,860 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-base-bne-finetuned-recores-long
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then rem... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-poetry | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 31 | 2022-05-24T06:33:31Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- reviews_with_drift
metrics:
- accuracy
- f1
model-index:
- name: distilbert_finetuned_reviews_with_drift
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: reviews_with_drift
type: reviews... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 132 | 2022-05-24T06:46:08Z | ---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery_param2
results:
- metrics:
- type: mean_reward
value: 0.79 +/- 0.41
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-l... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 1,862 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-cnn-pubmed-arxiv-pubmed-v3-e60
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comme... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-sentiment | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 855 | 2022-05-24T06:55:47Z | ---
language:
- "ja"
tags:
- "japanese"
- "token-classification"
- "pos"
- "dependency-parsing"
datasets:
- "universal_dependencies"
license: "cc-by-sa-4.0"
pipeline_tag: "token-classification"
widget:
- text: "国境の長いトンネルを抜けると雪国であった。"
---
# deberta-base-japanese-luw-upos
## Model Description
This is a DeBERTa(V2) mod... |
CAMeL-Lab/bert-base-arabic-camelbert-mix | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"Arabic",
"Dialect",
"Egyptian",
"Gulf",
"Levantine",
"Classical Arabic",
"MSA",
"Modern Standard Arabic",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 20,880 | null | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: codet5-kormath
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# codet5-kormath
Thi... |
CAMeL-Lab/bert-base-arabic-camelbert-msa-did-madar-twitter5 | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 75 | 2022-05-24T07:11:52Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bart-base-spelling-de
results: []
widget:
- text: "ein dransformer isd ein mthode mit der ein compuder eine volge von zeichn übersetz"
example_title: "1"
- text: "Dresten ist di Landeshaubtstadt des Freistaats Saksens und die zweid größte s... |
CAMeL-Lab/bert-base-arabic-camelbert-msa-did-nadi | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 71 | null | ---
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
pipeline_tag: zero-shot-classification
datasets:
- multi_nli
---
# Clone from [https://huggingface.co/facebook/bart-large-mnli](bart-large-mnli)
This is the checkpoint for [bart-large](https://huggingface.co/facebook/bart-large) after be... |
Capreolus/birch-bert-large-msmarco_mb | [
"pytorch",
"tf",
"jax",
"bert",
"next-sentence-prediction",
"transformers"
] | null | {
"architectures": [
"BertForNextSentencePrediction"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 1 | 2022-05-24T09:10:30Z | ---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: Clinton/gpt2-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Clinton/... |
CarlosTron/Yo | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
model-index:
- name: lmv2-2022-05-24
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lmv2-2022-05-2... |
dccuchile/albert-base-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 25 | 2022-05-24T09:30:04Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: xlm-roberta-base-language-detection
results: []
---
# Clone from [https://huggingface.co/papluca/xlm-roberta-base-language-detection](xlm-roberta-base-language-detection)
This model is a fine-tuned version of [xlm-roberta-... |
dccuchile/albert-base-spanish-finetuned-qa-mlqa | [
"pytorch",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"AlbertForQuestionAnswering"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repe... | 3 | 2022-05-24T09:31:50Z | ---
tags:
- automatic-speech-recognition
- generated_from_trainer
license: mit
language:
- lb
metrics:
- wer
pipeline_tag: automatic-speech-recognition
model-index:
- name: Lemswasabi/wav2vec2-large-xlsr-53-842h-luxembourgish-14h-with-lm
results:
- task:
type: automatic-speech-recognition # Requi... |
dccuchile/albert-tiny-spanish-finetuned-pos | [
"pytorch",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_re... | 5 | 2022-05-24T10:08:54Z | KTRONICS - Manufacturer of Wireless Water level Controller, Borewell Automatic Water controller, GSM Based Wireless Controller & Industry Products etc
https://ktronics.global/best-water-level-products-chennai-ktronics-buy-now-9043876528 |
dccuchile/albert-tiny-spanish-finetuned-xnli | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 31 | 2022-05-24T10:33:18Z | (COMING SOON!)
MULTILINGUAL HATECHECK: Functional Tests for Multilingual Hate Speech Detection Models |
dccuchile/albert-xlarge-spanish-finetuned-mldoc | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 26 | 2022-05-24T10:40:15Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforc... |
dccuchile/albert-xlarge-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 24 | 2022-05-24T10:44:37Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... |
dccuchile/albert-xlarge-spanish-finetuned-pos | [
"pytorch",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_re... | 3 | 2022-05-24T10:54:53Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
model-index:
- name: distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove ... |
dccuchile/albert-xlarge-spanish-finetuned-xnli | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 29 | 2022-05-24T11:00:44Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sent-Roberta-wechsel-tamil
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tas... |
dccuchile/albert-xxlarge-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 26 | 2022-05-24T11:20:54Z | Looking to get the Best Body massage center in Bangalore? Riverdayspa™ is the Best Body massage center in Bangalore. For More Details Visit us
https://www.riverdayspa.com/spa-massage-bangalore/
|
dccuchile/albert-xxlarge-spanish-finetuned-qa-mlqa | [
"pytorch",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"AlbertForQuestionAnswering"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repe... | 7 | 2022-05-24T11:45:52Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... |
dccuchile/albert-xxlarge-spanish-finetuned-xnli | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 68 | 2022-05-24T11:49:08Z | ---
language: en
widget:
- text: "Ending all forms of discrimination against women and girls is not only a basic human right, but it also crucial to accelerating sustainable development. It has been proven time and again, that empowering women and girls has a multiplier effect, and helps drive up economic growth and de... |
dccuchile/bert-base-spanish-wwm-cased-finetuned-mldoc | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 27 | 2022-05-24T12:08:23Z | ---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-Slippery
results:
- metrics:
- type: mean_reward
value: 0.15 +/- 0.36
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning... |
dccuchile/bert-base-spanish-wwm-cased-finetuned-pos | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 1 | 2022-05-24T12:17:57Z | ---
language: es
license: apache-2.0
datasets:
- common_voice
- mozilla-foundation/common_voice_6_0
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- es
- hf-asr-leaderboard
- mozilla-foundation/common_voice_6_0
- robust-speech-event
- speech
- xlsr-fine-tuning-week
model-index:
- name: XLSR Wav2Vec2 ... |
dccuchile/bert-base-spanish-wwm-cased-finetuned-xnli | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 28 | 2022-05-24T12:40:18Z | ---
tags:
- espnet
- audio
- text-to-speech
language:
- bci
datasets:
- afrilang-bci
license: apache-2.0
metrics:
- mos
---
## ESPnet2 TTS model
### ``
This model was trained by using recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
pip install -e .
cd eg... |
dccuchile/bert-base-spanish-wwm-uncased-finetuned-mldoc | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 39 | null | ---
license: apache-2.0
---
[Optimum Habana](https://github.com/huggingface/optimum-habana) is the interface between the Hugging Face Transformers and Diffusers libraries and Habana's Gaudi processor (HPU).
It provides a set of tools enabling easy and fast model loading, training and inference on single- and multi-HPU... |
dccuchile/bert-base-spanish-wwm-uncased-finetuned-ner | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 5 | 2022-05-24T12:43:20Z | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-company_all
co2_eq_emissions: 0.848790823793881
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 903429548
- CO2 Emissions (in grams): 0.848790823793881
## Validation M... |
dccuchile/bert-base-spanish-wwm-uncased-finetuned-pawsx | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 24 | 2022-05-24T12:44:15Z | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-company_all
co2_eq_emissions: 119.04546626922827
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 903429540
- CO2 Emissions (in grams): 119.04546626922827
## Validation... |
dccuchile/bert-base-spanish-wwm-uncased-finetuned-qa-mlqa | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_n... | 5 | null | ---
tags:
- FrozenLake-v1-8x8-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-nonSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinfor... |
dccuchile/bert-base-spanish-wwm-uncased-finetuned-xnli | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 36 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xlsr-persian-v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove ... |
dccuchile/distilbert-base-spanish-uncased-finetuned-ner | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
... | 28 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforc... |
dccuchile/distilbert-base-spanish-uncased-finetuned-pos | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
... | 3 | 2022-05-24T13:01:27Z | ---
tags:
- automatic-speech-recognition
- generated_from_trainer
license: mit
language:
- lb
metrics:
- wer
pipeline_tag: automatic-speech-recognition
model-index:
- name: Lemswasabi/wav2vec2-large-xlsr-53-842h-luxembourgish-11h-with-lm
results:
- task:
type: automatic-speech-recognition # Requi... |
dccuchile/distilbert-base-spanish-uncased-finetuned-xnli | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
... | 31 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: victor-hg-ptbr-2.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment... |
CennetOguz/distilbert-base-uncased-finetuned-recipe-1 | [
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repea... | 7 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: satya-matury-asr-task-2-hindidata
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remo... |
CennetOguz/distilbert-base-uncased-finetuned-recipe-accelerate-1 | [
"pytorch",
"distilbert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repea... | 1 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: -10.17 +/- 40.27
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: ... |
CennetOguz/distilbert-base-uncased-finetuned-recipe-accelerate | [
"pytorch",
"distilbert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repea... | 7 | 2022-05-24T13:10:20Z | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-job_all
co2_eq_emissions: 192.68222884611995
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 903929564
- CO2 Emissions (in grams): 192.68222884611995
## Validation Met... |
Chaddmckay/Cdm | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-name_all
co2_eq_emissions: 0.527083766435658
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 904029569
- CO2 Emissions (in grams): 0.527083766435658
## Validation Metr... |
Chae/botman | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 5 | 2022-05-24T13:27:45Z | ---
tags:
- conversational
---
# Twilight Sparkle DialoGPT Model |
Chaewon/mnmt_decoder_en | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 8 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-hun-53h-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remov... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.