
url stringlengths 61 61 | repository_url stringclasses 1
value | labels_url stringlengths 75 75 | comments_url stringlengths 70 70 | events_url stringlengths 68 68 | html_url stringlengths 49 51 | id int64 758M 1.95B | node_id stringlengths 18 32 | number int64 1.2k 6.31k | title stringlengths 1 290 | user dict | labels listlengths 0 3 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[ns, tz=UTC] | author_association stringclasses 3
values | active_lock_reason float64 | draft float64 0 1 ⌀ | pull_request dict | body stringlengths 0 36.2k ⌀ | reactions dict | timeline_url stringlengths 70 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2976 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2976/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2976/comments | https://api.github.com/repos/huggingface/datasets/issues/2976/events | https://github.com/huggingface/datasets/issues/2976 | 1,008,647,889 | I_kwDODunzps48Hr7R | 2,976 | Can't load dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/77006774?v=4",
"events_url": "https://api.github.com/users/mskovalova/events{/privacy}",
"followers_url": "https://api.github.com/users/mskovalova/followers",
"following_url": "https://api.github.com/users/mskovalova/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @mskovalova, \r\n\r\nSome datasets have multiple configurations. Therefore, in order to load them, you have to specify both the *dataset name* and the *configuration name*.\r\n\r\nIn the error message you got, you have a usage example:\r\n- To load the 'wikitext-103-raw-v1' configuration of the 'wikitext' datas... | 2021-09-27T21:38:14Z | 2022-12-01T09:12:29Z | 2021-09-28T06:53:01Z | NONE | null | null | null | I'm trying to load a wikitext dataset
```
from datasets import load_dataset
raw_datasets = load_dataset("wikitext")
```
ValueError: Config name is missing.
Please pick one among the available configs: ['wikitext-103-raw-v1', 'wikitext-2-raw-v1', 'wikitext-103-v1', 'wikitext-2-v1']
Example of usage:
`load_d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2976/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2976/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1833 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1833/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1833/comments | https://api.github.com/repos/huggingface/datasets/issues/1833/events | https://github.com/huggingface/datasets/pull/1833 | 803,120,978 | MDExOlB1bGxSZXF1ZXN0NTY5MDk5MTUx | 1,833 | Add OSCAR dataset card | {
"avatar_url": "https://avatars.githubusercontent.com/u/635220?v=4",
"events_url": "https://api.github.com/users/pjox/events{/privacy}",
"followers_url": "https://api.github.com/users/pjox/followers",
"following_url": "https://api.github.com/users/pjox/following{/other_user}",
"gists_url": "https://api.githu... | [] | closed | false | null | [] | null | [
"@lhoestq Thanks for the suggestions! I agree with all of them. Should I accept them one by one or can I accept them all at once? When I try to load the whole diff GitHub is complaining and it does no render them well (probably my browser?) 😅 ",
"I just merged the tables as suggested 😄 . However I noticed somet... | 2021-02-08T01:39:49Z | 2021-02-12T14:09:25Z | 2021-02-12T14:08:24Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1833.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1833",
"merged_at": "2021-02-12T14:08:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1833.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I added more information and completed the dataset card for OSCAR which was started by @lhoestq in his previous [PR](https://github.com/huggingface/datasets/pull/1824). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1833/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1833/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5057 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5057/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5057/comments | https://api.github.com/repos/huggingface/datasets/issues/5057/events | https://github.com/huggingface/datasets/pull/5057 | 1,394,827,216 | PR_kwDODunzps5AD4c6 | 5,057 | Support `converters` in `CsvBuilder` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-03T14:23:21Z | 2022-10-04T11:19:28Z | 2022-10-04T11:17:32Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5057.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5057",
"merged_at": "2022-10-04T11:17:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5057.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add the `converters` param to `CsvBuilder`, to help in situations like [this one](https://discuss.huggingface.co/t/typeerror-in-load-dataset-related-to-a-sequence-of-strings/23545).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5057/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5057/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4481 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4481/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4481/comments | https://api.github.com/repos/huggingface/datasets/issues/4481/events | https://github.com/huggingface/datasets/pull/4481 | 1,269,187,792 | PR_kwDODunzps45jIRi | 4,481 | Fix iwslt2017 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"CI fails are just abut missing tags in the dataset card, merging !",
"FYI, \r\n\r\nThe checksums have not been edited from the changes of .tgz to .zip files, and as a result a `ExpectedMoreDownloadedFiles` error occurs. Updating th... | 2022-06-13T09:51:21Z | 2022-10-26T09:09:31Z | 2022-06-13T10:40:18Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4481.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4481",
"merged_at": "2022-06-13T10:40:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4481.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The files were moved to google drive, I hosted them on the Hub instead (ok according to the license)
I also updated the `datasets_infos.json` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4481/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4481/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2439 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2439/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2439/comments | https://api.github.com/repos/huggingface/datasets/issues/2439/events | https://github.com/huggingface/datasets/pull/2439 | 908,511,983 | MDExOlB1bGxSZXF1ZXN0NjU5MTkzMDE3 | 2,439 | Better error message when trying to access elements of a DatasetDict without specifying the split | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-06-01T17:04:32Z | 2021-06-15T16:03:23Z | 2021-06-07T08:54:35Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2439.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2439",
"merged_at": "2021-06-07T08:54:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2439.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As mentioned in #2437 it'd be nice to to have an indication to the users when they try to access an element of a DatasetDict without specifying the split name.
cc @thomwolf | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2439/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2439/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3375/comments | https://api.github.com/repos/huggingface/datasets/issues/3375/events | https://github.com/huggingface/datasets/pull/3375 | 1,070,454,913 | PR_kwDODunzps4vWrXz | 3,375 | Support streaming zipped dataset repo by passing only repo name | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"I just tested and I think this only opens one file ? If there are several files in the ZIP, only the first one is opened. To open several files from a ZIP, one has to call `open` several times.\r\n\r\nWhat about updating the CSV loader to make it `download_and_extract` zip files, and open each extracted file ?",
... | 2021-12-03T10:43:05Z | 2021-12-16T18:03:32Z | 2021-12-16T18:03:31Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3375",
"merged_at": "2021-12-16T18:03:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Proposed solution:
- I have added the method `iter_files` to DownloadManager and StreamingDownloadManager
- I use this in modules: "csv", "json", "text"
- I test for CSV/JSONL/TXT zipped (and non-zipped) files, both in streaming and non-streaming modes
Fix #3373. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3375/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3204 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3204/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3204/comments | https://api.github.com/repos/huggingface/datasets/issues/3204/events | https://github.com/huggingface/datasets/issues/3204 | 1,043,707,307 | I_kwDODunzps4-NbWr | 3,204 | FileNotFoundError for TupleIE dataste | {
"avatar_url": "https://avatars.githubusercontent.com/u/75334917?v=4",
"events_url": "https://api.github.com/users/arda-vianai/events{/privacy}",
"followers_url": "https://api.github.com/users/arda-vianai/followers",
"following_url": "https://api.github.com/users/arda-vianai/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"@mariosasko @lhoestq Could you give me an update on how to load the dataset after the fix?\r\nThanks.",
"Hi @arda-vianai,\r\n\r\nfirst, you can try:\r\n```python\r\nimport datasets\r\ndataset = datasets.load_dataset('tuple_ie', 'all', revision=\"master\")\r\n```\r\nIf this doesn't work, your version of `datasets... | 2021-11-03T14:56:55Z | 2021-11-05T15:51:15Z | 2021-11-05T14:16:05Z | NONE | null | null | null | Hi,
`dataset = datasets.load_dataset('tuple_ie', 'all')`
returns a FileNotFound error. Is the data not available?
Many thanks.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3204/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3204/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2388/comments | https://api.github.com/repos/huggingface/datasets/issues/2388/events | https://github.com/huggingface/datasets/issues/2388 | 897,767,470 | MDU6SXNzdWU4OTc3Njc0NzA= | 2,388 | Incorrect URLs for some datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_ur... | null | [] | 2021-05-21T07:22:35Z | 2021-06-04T17:39:45Z | 2021-06-04T17:39:45Z | MEMBER | null | null | null | ## Describe the bug
It seems that the URLs for the following datasets are invalid:
- [ ] `bn_hate_speech` has been renamed: https://github.com/rezacsedu/Bengali-Hate-Speech-Dataset/commit/c67ecfc4184911e12814f6b36901f9828df8a63a
- [ ] `covid_tweets_japanese` has been renamed: http://www.db.info.gifu-u.ac.jp/covi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2388/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2388/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5609/comments | https://api.github.com/repos/huggingface/datasets/issues/5609/events | https://github.com/huggingface/datasets/issues/5609 | 1,610,062,862 | I_kwDODunzps5f95wO | 5,609 | `load_from_disk` vs `load_dataset` performance. | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | [] | open | false | null | [] | null | [
"Hi! We've recently made some improvements to `save_to_disk`/`list_to_disk` (100x faster in some scenarios), so it would help if you could install `datasets` directly from `main` (`pip install git+https://github.com/huggingface/datasets.git`) and re-run the \"benchmark\".",
"Great to hear! I'll give it a try when... | 2023-03-05T05:27:15Z | 2023-07-13T18:48:05Z | null | NONE | null | null | null | ### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_di... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5609/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2282 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2282/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2282/comments | https://api.github.com/repos/huggingface/datasets/issues/2282/events | https://github.com/huggingface/datasets/pull/2282 | 870,900,332 | MDExOlB1bGxSZXF1ZXN0NjI2MDEyMzM3 | 2,282 | Initialize imdb dataset from don't stop pretraining paper | {
"avatar_url": "https://avatars.githubusercontent.com/u/52530809?v=4",
"events_url": "https://api.github.com/users/BobbyManion/events{/privacy}",
"followers_url": "https://api.github.com/users/BobbyManion/followers",
"following_url": "https://api.github.com/users/BobbyManion/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2021-04-29T11:17:56Z | 2021-04-29T11:43:51Z | 2021-04-29T11:43:51Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2282.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2282",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2282.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2282"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2282/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2282/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/4842 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4842/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4842/comments | https://api.github.com/repos/huggingface/datasets/issues/4842/events | https://github.com/huggingface/datasets/pull/4842 | 1,337,527,764 | PR_kwDODunzps49G8CC | 4,842 | Update stackexchange license | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-12T17:39:06Z | 2022-08-14T10:43:18Z | 2022-08-14T10:28:49Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4842.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4842",
"merged_at": "2022-08-14T10:28:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4842.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The correct license of the stackexchange subset of the Pile is `cc-by-sa-4.0`, as can for example be seen here: https://stackoverflow.com/help/licensing | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4842/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4842/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1927 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1927/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1927/comments | https://api.github.com/repos/huggingface/datasets/issues/1927/events | https://github.com/huggingface/datasets/pull/1927 | 813,768,935 | MDExOlB1bGxSZXF1ZXN0NTc3ODYxODM5 | 1,927 | Update dataset card of wino_bias | {
"avatar_url": "https://avatars.githubusercontent.com/u/22306304?v=4",
"events_url": "https://api.github.com/users/JieyuZhao/events{/privacy}",
"followers_url": "https://api.github.com/users/JieyuZhao/followers",
"following_url": "https://api.github.com/users/JieyuZhao/following{/other_user}",
"gists_url": "... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"Thanks @JieyuZhao.\r\n\r\nI think this PR was superseded by your other PRs:\r\n- #1930\r\n- #2152 \r\n\r\nI'm closing this."
] | 2021-02-22T18:51:34Z | 2022-09-23T13:35:09Z | 2022-09-23T13:35:08Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1927.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1927",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1927.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1927"
} | Updated the info for the wino_bias dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1927/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1927/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6113 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6113/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6113/comments | https://api.github.com/repos/huggingface/datasets/issues/6113/events | https://github.com/huggingface/datasets/issues/6113 | 1,833,854,030 | I_kwDODunzps5tTmRO | 6,113 | load_dataset() fails with streamlit caching inside docker | {
"avatar_url": "https://avatars.githubusercontent.com/u/987574?v=4",
"events_url": "https://api.github.com/users/fierval/events{/privacy}",
"followers_url": "https://api.github.com/users/fierval/followers",
"following_url": "https://api.github.com/users/fierval/following{/other_user}",
"gists_url": "https://... | [] | closed | false | null | [] | null | [
"Hi! This should be fixed in the latest (patch) release (run `pip install -U datasets` to install it). This behavior was due to a bug in our authentication logic."
] | 2023-08-02T20:20:26Z | 2023-08-21T18:18:27Z | 2023-08-21T18:18:27Z | NONE | null | null | null | ### Describe the bug
When calling `load_dataset` in a streamlit application running within a docker container, get a failure with the error message:
EmptyDatasetError: The directory at hf://datasets/fetch-rewards/inc-rings-2000@bea27cf60842b3641eae418f38864a2ec4cde684 doesn't contain any data files
Traceback:
Fil... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6113/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6113/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2971 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2971/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2971/comments | https://api.github.com/repos/huggingface/datasets/issues/2971/events | https://github.com/huggingface/datasets/issues/2971 | 1,007,696,522 | I_kwDODunzps48EDqK | 2,971 | masakhaner dataset load problem | {
"avatar_url": "https://avatars.githubusercontent.com/u/8900094?v=4",
"events_url": "https://api.github.com/users/ontocord/events{/privacy}",
"followers_url": "https://api.github.com/users/ontocord/followers",
"following_url": "https://api.github.com/users/ontocord/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @ontocord. We are fixing the wrong metadata."
] | 2021-09-27T04:59:07Z | 2021-09-27T12:59:59Z | 2021-09-27T12:59:59Z | CONTRIBUTOR | null | null | null | ## Describe the bug
Masakhaner dataset is not loading
## Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset("masakhaner",'amh')
```
## Expected results
Expected the return of a dataset
## Actual results
```
NonMatchingSplitsSizesError Traceback (mo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2971/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2971/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2756 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2756/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2756/comments | https://api.github.com/repos/huggingface/datasets/issues/2756/events | https://github.com/huggingface/datasets/pull/2756 | 959,255,646 | MDExOlB1bGxSZXF1ZXN0NzAyMzk4Mjk1 | 2,756 | Fix metadata JSON for ubuntu_dialogs_corpus dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-08-03T15:48:59Z | 2021-08-04T09:43:25Z | 2021-08-04T09:43:25Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2756.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2756",
"merged_at": "2021-08-04T09:43:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2756.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Related to #2743. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2756/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2756/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1961 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1961/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1961/comments | https://api.github.com/repos/huggingface/datasets/issues/1961/events | https://github.com/huggingface/datasets/pull/1961 | 818,077,947 | MDExOlB1bGxSZXF1ZXN0NTgxNDM3NDI0 | 1,961 | Add sst dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2021-02-28T02:08:29Z | 2021-03-04T10:38:53Z | 2021-03-04T10:38:53Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1961.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1961",
"merged_at": "2021-03-04T10:38:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1961.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Related to #1934—Add the Stanford Sentiment Treebank dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1961/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1961/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2551 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2551/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2551/comments | https://api.github.com/repos/huggingface/datasets/issues/2551/events | https://github.com/huggingface/datasets/pull/2551 | 930,967,978 | MDExOlB1bGxSZXF1ZXN0Njc4NTQzMjg1 | 2,551 | Fix FileSystems documentation | {
"avatar_url": "https://avatars.githubusercontent.com/u/55268212?v=4",
"events_url": "https://api.github.com/users/connor-mccarthy/events{/privacy}",
"followers_url": "https://api.github.com/users/connor-mccarthy/followers",
"following_url": "https://api.github.com/users/connor-mccarthy/following{/other_user}"... | [] | closed | false | null | [] | null | [] | 2021-06-27T16:18:42Z | 2021-06-28T13:09:55Z | 2021-06-28T13:09:54Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2551.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2551",
"merged_at": "2021-06-28T13:09:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2551.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ### What this fixes:
This PR resolves several issues I discovered in the documentation on the `datasets.filesystems` module ([this page](https://huggingface.co/docs/datasets/filesystems.html)).
### What were the issues?
When I originally tried implementing the code examples I faced several bugs attributed to:
-... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2551/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2551/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1832 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1832/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1832/comments | https://api.github.com/repos/huggingface/datasets/issues/1832/events | https://github.com/huggingface/datasets/issues/1832 | 802,880,897 | MDU6SXNzdWU4MDI4ODA4OTc= | 1,832 | Looks like nokogumbo is up-to-date now, so this is no longer needed. | {
"avatar_url": "https://avatars.githubusercontent.com/u/68724553?v=4",
"events_url": "https://api.github.com/users/JimmyJim1/events{/privacy}",
"followers_url": "https://api.github.com/users/JimmyJim1/followers",
"following_url": "https://api.github.com/users/JimmyJim1/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [] | 2021-02-07T06:52:07Z | 2021-02-08T17:27:29Z | 2021-02-08T17:27:29Z | NONE | null | null | null | Looks like nokogumbo is up-to-date now, so this is no longer needed.
__Originally posted by @dependabot in https://github.com/discourse/discourse/pull/11373#issuecomment-738993432__ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1832/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1832/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4035 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4035/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4035/comments | https://api.github.com/repos/huggingface/datasets/issues/4035/events | https://github.com/huggingface/datasets/pull/4035 | 1,183,067,456 | PR_kwDODunzps41Iwb2 | 4,035 | Add zero_division argument to precision and recall metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2022-03-28T08:19:14Z | 2022-03-28T09:53:07Z | 2022-03-28T09:53:06Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4035.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4035",
"merged_at": "2022-03-28T09:53:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4035.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #4025. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4035/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4035/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2775 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2775/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2775/comments | https://api.github.com/repos/huggingface/datasets/issues/2775/events | https://github.com/huggingface/datasets/issues/2775 | 964,303,626 | MDU6SXNzdWU5NjQzMDM2MjY= | 2,775 | `generate_random_fingerprint()` deterministic with 🤗Transformers' `set_seed()` | {
"avatar_url": "https://avatars.githubusercontent.com/u/1170062?v=4",
"events_url": "https://api.github.com/users/mbforbes/events{/privacy}",
"followers_url": "https://api.github.com/users/mbforbes/followers",
"following_url": "https://api.github.com/users/mbforbes/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"I dug into what I believe is the root of this issue and added a repro in my comment. If this is better addressed as a cross-team issue, let me know and I can open an issue in the Transformers repo",
"Hi !\r\n\r\nIMO we shouldn't try to modify `set_seed` from transformers but maybe make `datasets` have its own RN... | 2021-08-09T19:28:51Z | 2021-08-26T08:30:54Z | null | NONE | null | null | null | ## Describe the bug
**Update:** I dug into this to try to reproduce the underlying issue, and I believe it's that `set_seed()` from the `transformers` library makes the "random" fingerprint identical each time. I believe this is still a bug, because `datasets` is used exactly this way in `transformers` after `set_se... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2775/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2775/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3713/comments | https://api.github.com/repos/huggingface/datasets/issues/3713/events | https://github.com/huggingface/datasets/pull/3713 | 1,135,692,572 | PR_kwDODunzps4yso6D | 3,713 | Rm sphinx doc | {
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Thanks for pushing this :)\r\nOne minor comment regarding the PR itself - I noticed that some changes are coming from the upstream master, this might be due to a rebase. Would be nice if this PR doesn't include them for readabily, feel free to open a new one if necessary",
"Closing in favour https://github.com/h... | 2022-02-13T11:26:31Z | 2022-02-17T10:18:46Z | 2022-02-17T10:12:09Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3713.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3713",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3713.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3713"
} | Checklist
- [x] Update circle ci yaml
- [x] Delete sphinx static & python files in docs dir
- [x] Update readme in docs dir
- [ ] Update docs config in setup.py | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3713/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3713/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5250 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5250/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5250/comments | https://api.github.com/repos/huggingface/datasets/issues/5250/events | https://github.com/huggingface/datasets/pull/5250 | 1,451,720,030 | PR_kwDODunzps5DB-1y | 5,250 | Change release procedure to use only pull requests | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5250). All of your documentation changes will be reflected on that endpoint.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface... | 2022-11-16T14:35:32Z | 2022-11-22T16:30:58Z | 2022-11-22T16:27:48Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5250.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5250",
"merged_at": "2022-11-22T16:27:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5250.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR changes the release procedure so that:
- it only make changes to main branch via pull requests
- it is no longer necessary to directly commit/push to main branch
Close #5251.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5250/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5250/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4476 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4476/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4476/comments | https://api.github.com/repos/huggingface/datasets/issues/4476/events | https://github.com/huggingface/datasets/issues/4476 | 1,267,987,499 | I_kwDODunzps5Lk_Qr | 4,476 | `to_pandas` doesn't take into account format. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Thanks for opening a discussion :)\r\n\r\nNote that you can use `.remove_columns(...)` to keep only the ones you're interested in before calling `.to_pandas()`",
"Yes I can do that thank you!\r\n\r\nDo you think that conceptually my example should work? If not, I'm happy to close this issue. \r\n\r\nIf yes, I ca... | 2022-06-10T20:25:31Z | 2022-06-15T17:41:41Z | 2022-06-15T17:41:41Z | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
I have a large dataset that I need to convert part of to pandas to do some further analysis. Calling `to_pandas` directly on it is expensive. So I thought I could simply select the columns that I want and then call `to_pandas`.
**Describe the solu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4476/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4476/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1810 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1810/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1810/comments | https://api.github.com/repos/huggingface/datasets/issues/1810/events | https://github.com/huggingface/datasets/issues/1810 | 799,168,650 | MDU6SXNzdWU3OTkxNjg2NTA= | 1,810 | Add Hateful Memes Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url"... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",... | open | false | null | [] | null | [
"I am not sure, but would `datasets.Sequence(datasets.Sequence(datasets.Sequence(datasets.Value(\"int\")))` work?",
"Also, I found the information for loading only subsets of the data [here](https://github.com/huggingface/datasets/blob/master/docs/source/splits.rst).",
"Hi @lhoestq,\r\n\r\nRequest you to check ... | 2021-02-02T10:53:59Z | 2021-12-08T12:03:59Z | null | CONTRIBUTOR | null | null | null | ## Add Hateful Memes Dataset
- **Name:** Hateful Memes
- **Description:** [https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set]( https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set)
- **Paper:** [https://arxiv.org/pdf/2005.04790.pdf](https://arxiv.org/pdf/2005.04790.pdf)
- **Data:** [Thi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1810/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1810/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4076 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4076/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4076/comments | https://api.github.com/repos/huggingface/datasets/issues/4076/events | https://github.com/huggingface/datasets/pull/4076 | 1,188,478,867 | PR_kwDODunzps41a1n2 | 4,076 | Add ROUGE Metric Card | {
"avatar_url": "https://avatars.githubusercontent.com/u/27527747?v=4",
"events_url": "https://api.github.com/users/emibaylor/events{/privacy}",
"followers_url": "https://api.github.com/users/emibaylor/followers",
"following_url": "https://api.github.com/users/emibaylor/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-03-31T18:34:34Z | 2022-04-12T20:43:45Z | 2022-04-12T20:37:38Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4076.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4076",
"merged_at": "2022-04-12T20:37:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4076.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add ROUGE metric card.
I've left the 'Values from popular papers' section empty for the time being because I don't know the summarization literature very well and am therefore not sure which paper(s) to pull from (note that the original rouge paper does not seem to present specific values, just correlations with hum... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4076/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4076/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1637/comments | https://api.github.com/repos/huggingface/datasets/issues/1637/events | https://github.com/huggingface/datasets/pull/1637 | 774,710,014 | MDExOlB1bGxSZXF1ZXN0NTQ1NTc1NTMw | 1,637 | Added `pn_summary` dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/2601833?v=4",
"events_url": "https://api.github.com/users/m3hrdadfi/events{/privacy}",
"followers_url": "https://api.github.com/users/m3hrdadfi/followers",
"following_url": "https://api.github.com/users/m3hrdadfi/following{/other_user}",
"gists_url": "h... | [] | closed | false | null | [] | null | [
"As always, I got stuck in the correct order of imports 😅\r\n@lhoestq, It's finished!",
"@lhoestq, It's done! Is there anything else that needs changes?"
] | 2020-12-25T11:01:24Z | 2021-01-04T13:43:19Z | 2021-01-04T13:43:19Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1637.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1637",
"merged_at": "2021-01-04T13:43:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1637.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | #1635
You did a great job with the fluent procedure regarding adding a dataset. I took the chance to add the dataset on my own. Thank you for your awesome job, and I hope this dataset found the researchers happy, specifically those interested in Persian Language (Farsi)! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1637/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1637/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4216 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4216/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4216/comments | https://api.github.com/repos/huggingface/datasets/issues/4216/events | https://github.com/huggingface/datasets/pull/4216 | 1,214,614,029 | PR_kwDODunzps42u1_w | 4,216 | Avoid recursion error in map if example is returned as dict value | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-04-25T14:40:32Z | 2022-05-04T17:20:06Z | 2022-05-04T17:12:52Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4216.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4216",
"merged_at": "2022-05-04T17:12:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4216.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I noticed this bug while answering [this question](https://discuss.huggingface.co/t/correct-way-to-create-a-dataset-from-a-csv-file/15686/11?u=mariosasko).
This code replicates the bug:
```python
from datasets import Dataset
dset = Dataset.from_dict({"en": ["aa", "bb"], "fr": ["cc", "dd"]})
dset.map(lambda ex: ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4216/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4216/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3525 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3525/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3525/comments | https://api.github.com/repos/huggingface/datasets/issues/3525/events | https://github.com/huggingface/datasets/pull/3525 | 1,093,831,268 | PR_kwDODunzps4wiL8p | 3,525 | Adding license information for Openbookcorpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"events_url": "https://api.github.com/users/meg-huggingface/events{/privacy}",
"followers_url": "https://api.github.com/users/meg-huggingface/followers",
"following_url": "https://api.github.com/users/meg-huggingface/following{/other_user}"... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"events_url": "https://api.github.com/users/meg-huggingface/events{/privacy}",
"followers_url": "https://api.github.com/users/meg-huggingface/followers",
"following_url": "https://api.github.com/users/meg-huggingface/following{/other_user}"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"events_url": "https://api.github.com/users/meg-huggingface/events{/privacy}",
"followers_url": "https://api.github.com/users/meg-huggingface/followers",
"following_url": "https://api.github.com/users/meg-huggingface/following{/... | null | [
"The MIT license seems to be for the crawling code, no ? Then maybe we can also redirect users to the [terms of smashwords.com](https://www.smashwords.com/about/tos) regarding copyrights, in particular the paragraph 10 for end-users. In particular it seems that end users can download and use the content \"for their... | 2022-01-04T23:20:36Z | 2022-04-20T09:54:30Z | 2022-04-20T09:48:10Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3525.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3525",
"merged_at": "2022-04-20T09:48:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3525.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Not entirely sure, following the links here, but it seems the relevant license is at https://github.com/soskek/bookcorpus/blob/master/LICENSE | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3525/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3525/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1530 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1530/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1530/comments | https://api.github.com/repos/huggingface/datasets/issues/1530/events | https://github.com/huggingface/datasets/pull/1530 | 764,749,507 | MDExOlB1bGxSZXF1ZXN0NTM4NjY4ODI3 | 1,530 | add indonlu benchmark datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/6518504?v=4",
"events_url": "https://api.github.com/users/yasirabd/events{/privacy}",
"followers_url": "https://api.github.com/users/yasirabd/followers",
"following_url": "https://api.github.com/users/yasirabd/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2020-12-13T01:56:09Z | 2020-12-16T11:11:43Z | 2020-12-16T11:11:43Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1530.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1530",
"merged_at": "2020-12-16T11:11:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1530.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The IndoNLU benchmark is a collection of resources for training, evaluating, and analyzing natural language understanding systems for the Indonesian language. There are 12 datasets in IndoNLU.
This is a new clean PR from [#1322](https://github.com/huggingface/datasets/pull/1322) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1530/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1530/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2556 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2556/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2556/comments | https://api.github.com/repos/huggingface/datasets/issues/2556/events | https://github.com/huggingface/datasets/issues/2556 | 931,595,872 | MDU6SXNzdWU5MzE1OTU4NzI= | 2,556 | Better DuplicateKeysError error to help the user debug the issue | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/20517962?v=4",
"events_url": "https://api.github.com/users/VijayKalmath/events{/privacy}",
"followers_url": "https://api.github.com/users/VijayKalmath/followers",
"following_url": "https://api.github.com/users/VijayKalmath/following{/other_user}",
"gist... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/20517962?v=4",
"events_url": "https://api.github.com/users/VijayKalmath/events{/privacy}",
"followers_url": "https://api.github.com/users/VijayKalmath/followers",
"following_url": "https://api.github.com/users/VijayKalmath/following{/other_use... | null | [
"excuse me, my `datasets` version is `2.2.2`, but I also just see the error info like \r\n```\r\nDuplicatedKeysError: FAILURE TO GENERATE DATASET !\r\nFound duplicate Key: 0\r\nKeys should be unique and deterministic in nature\r\n```",
"Hi ! for which dataset do you have this error ?\r\n\r\nAlso note that this is... | 2021-06-28T13:50:57Z | 2022-06-28T09:26:04Z | 2022-06-28T09:26:04Z | MEMBER | null | null | null | As mentioned in https://github.com/huggingface/datasets/issues/2552 it would be nice to improve the error message when a dataset fails to build because there are duplicate example keys.
The current one is
```python
datasets.keyhash.DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: 48
Keys s... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2556/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2556/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5741/comments | https://api.github.com/repos/huggingface/datasets/issues/5741/events | https://github.com/huggingface/datasets/pull/5741 | 1,665,860,919 | PR_kwDODunzps5OM9nZ | 5,741 | Fix CI warnings | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-13T07:17:02Z | 2023-04-13T09:48:10Z | 2023-04-13T09:40:50Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5741.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5741",
"merged_at": "2023-04-13T09:40:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5741.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix warnings in our CI tests. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5741/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5741/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2568/comments | https://api.github.com/repos/huggingface/datasets/issues/2568/events | https://github.com/huggingface/datasets/pull/2568 | 932,934,795 | MDExOlB1bGxSZXF1ZXN0NjgwMjE5MDU2 | 2,568 | Add interleave_datasets for map-style datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-06-29T17:19:24Z | 2021-07-01T09:33:34Z | 2021-07-01T09:33:33Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2568.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2568",
"merged_at": "2021-07-01T09:33:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2568.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ### Add interleave_datasets for map-style datasets
Add support for map-style datasets (i.e. `Dataset` objects) in `interleave_datasets`.
It was only supporting iterable datasets (i.e. `IterableDataset` objects).
### Implementation details
It works by concatenating the datasets and then re-order the indices to... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2568/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2568/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2428 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2428/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2428/comments | https://api.github.com/repos/huggingface/datasets/issues/2428/events | https://github.com/huggingface/datasets/pull/2428 | 907,169,746 | MDExOlB1bGxSZXF1ZXN0NjU4MDU2MjI3 | 2,428 | Add copyright info for wiki_lingua dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/229382?v=4",
"events_url": "https://api.github.com/users/PhilipMay/events{/privacy}",
"followers_url": "https://api.github.com/users/PhilipMay/followers",
"following_url": "https://api.github.com/users/PhilipMay/following{/other_user}",
"gists_url": "ht... | [] | closed | false | null | [] | null | [
"Build fails but this change should not be the reason...",
"rebased on master",
"rebased on master"
] | 2021-05-31T07:22:52Z | 2021-06-04T10:22:33Z | 2021-06-04T10:22:33Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2428.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2428",
"merged_at": "2021-06-04T10:22:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2428.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2428/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2428/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/5971 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5971/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5971/comments | https://api.github.com/repos/huggingface/datasets/issues/5971/events | https://github.com/huggingface/datasets/issues/5971 | 1,767,053,635 | I_kwDODunzps5pUxlD | 5,971 | Docs: make "repository structure" easier to find | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/35114142?v=4",
"events_url": "https://api.github.com/users/benjaminbrown038/events{/privacy}",
"followers_url": "https://api.github.com/users/benjaminbrown038/followers",
"following_url": "https://api.github.com/users/benjaminbrown038/following{/other_use... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/35114142?v=4",
"events_url": "https://api.github.com/users/benjaminbrown038/events{/privacy}",
"followers_url": "https://api.github.com/users/benjaminbrown038/followers",
"following_url": "https://api.github.com/users/benjaminbrown038/followin... | null | [
"Loading a local dataset also works the same way when `data_files` are not specified, so I agree we should make this info easier to discover \r\n\r\ncc @stevhliu ",
"Is this issue open? If so, I will self assign. ",
"@benjaminbrown038 Yes, it is. Maybe @stevhliu can give some pointers on improving this doc pag... | 2023-06-21T08:26:44Z | 2023-07-05T06:51:38Z | null | CONTRIBUTOR | null | null | null | The page https://huggingface.co/docs/datasets/repository_structure explains how to create a simple repository structure without a dataset script.
It's the simplest way to create a dataset and should be easier to find, particularly on the docs' first pages. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5971/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5971/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5916/comments | https://api.github.com/repos/huggingface/datasets/issues/5916/events | https://github.com/huggingface/datasets/pull/5916 | 1,732,456,392 | PR_kwDODunzps5RskTb | 5,916 | Unpin responses | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-05-30T14:59:48Z | 2023-05-30T18:03:10Z | 2023-05-30T17:53:29Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5916.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5916",
"merged_at": "2023-05-30T17:53:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5916.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #5906 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5916/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3965 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3965/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3965/comments | https://api.github.com/repos/huggingface/datasets/issues/3965/events | https://github.com/huggingface/datasets/issues/3965 | 1,173,708,739 | I_kwDODunzps5F9V_D | 3,965 | TypeError: Couldn't cast array of type for JSONLines dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @lewtun, thanks for reporting.\r\n\r\nIt seems that our library fails at inferring the dtype of the columns:\r\n- `milestone`\r\n- `performed_via_github_app` \r\n\r\n(and assigns them `null` dtype)."
] | 2022-03-18T15:17:53Z | 2022-05-06T16:13:51Z | 2022-05-06T16:13:51Z | MEMBER | null | null | null | ## Describe the bug
One of the [course participants](https://discuss.huggingface.co/t/chapter-5-questions/11744/20?u=lewtun) is having trouble loading a JSONLines dataset that's composed of the GitHub issues from `spacy` (see stack trace below).
This reminds me a bit of #2799 where one can load the dataset in `pan... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3965/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3965/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5724/comments | https://api.github.com/repos/huggingface/datasets/issues/5724/events | https://github.com/huggingface/datasets/issues/5724 | 1,659,938,135 | I_kwDODunzps5i8KVX | 5,724 | Error after shuffling streaming IterableDatasets with downloaded dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/41177966?v=4",
"events_url": "https://api.github.com/users/szxiangjn/events{/privacy}",
"followers_url": "https://api.github.com/users/szxiangjn/followers",
"following_url": "https://api.github.com/users/szxiangjn/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Moving `\"en\"` to the end of the path instead of passing it as a config name should fix the error:\r\n```python\r\nimport datasets\r\ndataset = datasets.load_dataset('/path/to/your/data/dir/en', streaming=True, split='train')\r\ndataset = dataset.shuffle(buffer_size=10_000, seed=42)\r\nnext(iter(dataset))\r\n```\... | 2023-04-09T16:58:44Z | 2023-04-20T20:37:30Z | 2023-04-20T20:37:30Z | NONE | null | null | null | ### Describe the bug
I downloaded the C4 dataset, and used streaming IterableDatasets to read it. Everything went normal until I used `dataset = dataset.shuffle(seed=42, buffer_size=10_000)` to shuffle the dataset. Shuffled dataset will throw the following error when it is used by `next(iter(dataset))`:
```
File "/d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5724/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5724/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5780 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5780/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5780/comments | https://api.github.com/repos/huggingface/datasets/issues/5780/events | https://github.com/huggingface/datasets/issues/5780 | 1,679,367,149 | I_kwDODunzps5kGRvt | 5,780 | TypeError: 'NoneType' object does not support item assignment | {
"avatar_url": "https://avatars.githubusercontent.com/u/38179632?v=4",
"events_url": "https://api.github.com/users/v-yunbin/events{/privacy}",
"followers_url": "https://api.github.com/users/v-yunbin/followers",
"following_url": "https://api.github.com/users/v-yunbin/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2023-04-22T06:22:43Z | 2023-04-23T08:49:18Z | 2023-04-23T08:49:18Z | NONE | null | null | null | command:
```
def load_datasets(formats, data_dir=datadir, data_files=datafile):
dataset = load_dataset(formats, data_dir=datadir, data_files=datafile, split=split, streaming=True, **kwargs)
return dataset
raw_datasets = DatasetDict()
raw_datasets["train"] = load_datasets(“csv”, args.datadir, "train.csv", s... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5780/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5780/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1788 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1788/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1788/comments | https://api.github.com/repos/huggingface/datasets/issues/1788/events | https://github.com/huggingface/datasets/pull/1788 | 795,544,422 | MDExOlB1bGxSZXF1ZXN0NTYyODc1NzA2 | 1,788 | Doc2dial rc | {
"avatar_url": "https://avatars.githubusercontent.com/u/2062185?v=4",
"events_url": "https://api.github.com/users/songfeng/events{/privacy}",
"followers_url": "https://api.github.com/users/songfeng/followers",
"following_url": "https://api.github.com/users/songfeng/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2021-01-27T23:51:00Z | 2021-01-28T18:46:13Z | 2021-01-28T18:46:13Z | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1788.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1788",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1788.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1788"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1788/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1788/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/5725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5725/comments | https://api.github.com/repos/huggingface/datasets/issues/5725/events | https://github.com/huggingface/datasets/issues/5725 | 1,660,455,202 | I_kwDODunzps5i-Iki | 5,725 | How to limit the number of examples in dataset, for testing? | {
"avatar_url": "https://avatars.githubusercontent.com/u/845175?v=4",
"events_url": "https://api.github.com/users/ndvbd/events{/privacy}",
"followers_url": "https://api.github.com/users/ndvbd/followers",
"following_url": "https://api.github.com/users/ndvbd/following{/other_user}",
"gists_url": "https://api.gi... | [] | closed | false | null | [] | null | [
"Hi! You can use the `nrows` parameter for this:\r\n```python\r\ndata = load_dataset(\"json\", data_files=data_path, nrows=10)\r\n```",
"@mariosasko I get:\r\n\r\n`TypeError: __init__() got an unexpected keyword argument 'nrows'`",
"I misread the format in which the dataset is stored - the `nrows` parameter wo... | 2023-04-10T08:41:43Z | 2023-04-21T06:16:24Z | 2023-04-21T06:16:24Z | NONE | null | null | null | ### Describe the bug
I am using this command:
`data = load_dataset("json", data_files=data_path)`
However, I want to add a parameter, to limit the number of loaded examples to be 10, for development purposes, but can't find this simple parameter.
### Steps to reproduce the bug
In the description.
### Expected beh... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5725/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5725/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6118 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6118/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6118/comments | https://api.github.com/repos/huggingface/datasets/issues/6118/events | https://github.com/huggingface/datasets/issues/6118 | 1,835,940,417 | I_kwDODunzps5tbjpB | 6,118 | IterableDataset.from_generator() fails with pickle error when provided a generator or iterator | {
"avatar_url": "https://avatars.githubusercontent.com/u/1281051?v=4",
"events_url": "https://api.github.com/users/finkga/events{/privacy}",
"followers_url": "https://api.github.com/users/finkga/followers",
"following_url": "https://api.github.com/users/finkga/following{/other_user}",
"gists_url": "https://ap... | [] | open | false | null | [] | null | [
"Hi! `IterableDataset.from_generator` expects a generator function, not the object (to be consistent with `Dataset.from_generator`).\r\n\r\nYou can fix the above snippet as follows:\r\n```python\r\ntrain_dataset = IterableDataset.from_generator(line_generator, fn_kwargs={\"files\": model_training_files})\r\n```"
] | 2023-08-04T01:45:04Z | 2023-08-17T17:58:27Z | null | NONE | null | null | null | ### Describe the bug
**Description**
Providing a generator in an instantiation of IterableDataset.from_generator() fails with `TypeError: cannot pickle 'generator' object` when the generator argument is supplied with a generator.
**Code example**
```
def line_generator(files: List[Path]):
if isinstance(f... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6118/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6118/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1922 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1922/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1922/comments | https://api.github.com/repos/huggingface/datasets/issues/1922/events | https://github.com/huggingface/datasets/issues/1922 | 813,140,806 | MDU6SXNzdWU4MTMxNDA4MDY= | 1,922 | How to update the "wino_bias" dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/22306304?v=4",
"events_url": "https://api.github.com/users/JieyuZhao/events{/privacy}",
"followers_url": "https://api.github.com/users/JieyuZhao/followers",
"following_url": "https://api.github.com/users/JieyuZhao/following{/other_user}",
"gists_url": "... | [] | open | false | null | [] | null | [
"Hi @JieyuZhao !\r\n\r\nYou can edit the dataset card of wino_bias to update the URL via a Pull Request. This would be really appreciated :)\r\n\r\nThe dataset card is the README.md file you can find at https://github.com/huggingface/datasets/tree/master/datasets/wino_bias\r\nAlso the homepage url is also mentioned... | 2021-02-22T05:39:39Z | 2021-02-22T10:35:59Z | null | CONTRIBUTOR | null | null | null | Hi all,
Thanks for the efforts to collect all the datasets! But I think there is a problem with the wino_bias dataset. The current link is not correct. How can I update that?
Thanks! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1922/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1922/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5589/comments | https://api.github.com/repos/huggingface/datasets/issues/5589/events | https://github.com/huggingface/datasets/pull/5589 | 1,603,535,704 | PR_kwDODunzps5K9K1i | 5,589 | Revert "pass the dataset features to the IterableDataset.from_generator" | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-02-28T17:52:04Z | 2023-09-24T10:07:33Z | 2023-03-21T14:18:18Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5589.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5589",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5589.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5589"
} | This reverts commit b91070b9c09673e2e148eec458036ab6a62ac042 (temporarily)
It hurts iterable dataset performance a lot (e.g. x4 slower because it encodes+decodes images unnecessarily). I think we need to fix this before re-adding it
cc @mariosasko @Hubert-Bonisseur | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5589/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5589/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2883 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2883/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2883/comments | https://api.github.com/repos/huggingface/datasets/issues/2883/events | https://github.com/huggingface/datasets/pull/2883 | 991,969,875 | MDExOlB1bGxSZXF1ZXN0NzMwMzYzNTQz | 2,883 | Fix data URLs and metadata in DocRED dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-09-09T08:55:34Z | 2021-09-13T11:24:31Z | 2021-09-13T11:24:31Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2883.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2883",
"merged_at": "2021-09-13T11:24:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2883.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The host of `docred` dataset has updated the `dev` data file. This PR:
- Updates the dev URL
- Updates dataset metadata
This PR also fixes the URL of the `train_distant` split, which was wrong.
Fix #2882. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2883/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2883/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5425/comments | https://api.github.com/repos/huggingface/datasets/issues/5425/events | https://github.com/huggingface/datasets/issues/5425 | 1,534,581,850 | I_kwDODunzps5bd9xa | 5,425 | Sort on multiple keys with datasets.Dataset.sort() | {
"avatar_url": "https://avatars.githubusercontent.com/u/101344863?v=4",
"events_url": "https://api.github.com/users/rocco-fortuna/events{/privacy}",
"followers_url": "https://api.github.com/users/rocco-fortuna/followers",
"following_url": "https://api.github.com/users/rocco-fortuna/following{/other_user}",
"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | null | [] | null | [
"Hi! \r\n\r\n`Dataset.sort` calls `df.sort_values` internally, and `df.sort_values` brings all the \"sort\" columns in memory, so sorting on multiple keys could be very expensive. This makes me think that maybe we can replace `df.sort_values` with `pyarrow.compute.sort_indices` - the latter can also sort on multipl... | 2023-01-16T09:22:26Z | 2023-02-24T16:15:11Z | 2023-02-24T16:15:11Z | NONE | null | null | null | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5425/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5425/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1578/comments | https://api.github.com/repos/huggingface/datasets/issues/1578/events | https://github.com/huggingface/datasets/pull/1578 | 767,760,513 | MDExOlB1bGxSZXF1ZXN0NTQwMzY1NzYz | 1,578 | update multiwozv22 checksums | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-12-15T16:13:52Z | 2020-12-15T17:06:29Z | 2020-12-15T17:06:29Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1578.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1578",
"merged_at": "2020-12-15T17:06:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1578.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | a file was updated on the GitHub repo for the dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1578/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5433/comments | https://api.github.com/repos/huggingface/datasets/issues/5433/events | https://github.com/huggingface/datasets/issues/5433 | 1,536,017,901 | I_kwDODunzps5bjcXt | 5,433 | Support latest Docker image in CI benchmarks | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Sorry, it was us:[^1] https://github.com/iterative/cml/pull/1317 & https://github.com/iterative/cml/issues/1319#issuecomment-1385599559; should be fixed with [v0.18.17](https://github.com/iterative/cml/releases/tag/v0.18.17).\r\n\r\n[^1]: More or less, see https://github.com/yargs/yargs/issues/873.",
"Opened htt... | 2023-01-17T09:06:08Z | 2023-01-18T06:29:08Z | 2023-01-18T06:29:08Z | MEMBER | null | null | null | Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432 | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5433/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5433/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4410 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4410/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4410/comments | https://api.github.com/repos/huggingface/datasets/issues/4410/events | https://github.com/huggingface/datasets/pull/4410 | 1,249,148,457 | PR_kwDODunzps44f_Td | 4,410 | Remove Google Drive URL in spider dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-05-26T06:17:35Z | 2022-05-26T06:48:42Z | 2022-05-26T06:40:12Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4410.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4410",
"merged_at": "2022-05-26T06:40:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4410.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The `spider` dataset is distributed under the [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode) license.
Fix #4401. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4410/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4410/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6018 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6018/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6018/comments | https://api.github.com/repos/huggingface/datasets/issues/6018/events | https://github.com/huggingface/datasets/pull/6018 | 1,799,411,999 | PR_kwDODunzps5VOmKY | 6,018 | test1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/139256323?v=4",
"events_url": "https://api.github.com/users/ognjenovicj/events{/privacy}",
"followers_url": "https://api.github.com/users/ognjenovicj/followers",
"following_url": "https://api.github.com/users/ognjenovicj/following{/other_user}",
"gists_... | [] | closed | false | null | [] | null | [
"We no longer host datasets in this repo. You should use the HF Hub instead."
] | 2023-07-11T17:25:49Z | 2023-07-20T10:11:41Z | 2023-07-20T10:11:41Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6018.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6018",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6018.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6018"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6018/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6018/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4891 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4891/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4891/comments | https://api.github.com/repos/huggingface/datasets/issues/4891/events | https://github.com/huggingface/datasets/pull/4891 | 1,350,589,813 | PR_kwDODunzps49x382 | 4,891 | Fix missing tags in dataset cards | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2022-08-25T09:14:17Z | 2022-09-22T14:39:02Z | 2022-08-25T13:43:34Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4891.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4891",
"merged_at": "2022-08-25T13:43:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4891.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix missing tags in dataset cards:
- aslg_pc12
- librispeech_lm
- mwsc
- opus100
- qasc
- quail
- squadshifts
- winograd_wsc
This PR partially fixes the missing tags in dataset cards. Subsequent PRs will follow to complete this task.
Related to:
- #4833
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4891/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4891/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3244 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3244/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3244/comments | https://api.github.com/repos/huggingface/datasets/issues/3244/events | https://github.com/huggingface/datasets/pull/3244 | 1,048,675,741 | PR_kwDODunzps4uSgG5 | 3,244 | Fix filter method for batched=True | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [] | 2021-11-09T14:30:59Z | 2021-11-09T15:52:58Z | 2021-11-09T15:52:57Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3244.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3244",
"merged_at": "2021-11-09T15:52:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3244.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3244/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3244/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2810 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2810/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2810/comments | https://api.github.com/repos/huggingface/datasets/issues/2810/events | https://github.com/huggingface/datasets/pull/2810 | 972,040,022 | MDExOlB1bGxSZXF1ZXN0NzEzNjkzMTI1 | 2,810 | Add WIT Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/13920778?v=4",
"events_url": "https://api.github.com/users/hassiahk/events{/privacy}",
"followers_url": "https://api.github.com/users/hassiahk/followers",
"following_url": "https://api.github.com/users/hassiahk/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Google's version of WIT is now available here: https://huggingface.co/datasets/google/wit"
] | 2021-08-16T19:34:09Z | 2022-05-06T12:27:29Z | 2022-05-06T12:26:16Z | NONE | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2810.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2810",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2810.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2810"
} | Adds Google's [WIT](https://github.com/google-research-datasets/wit) dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2810/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2810/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3557 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3557/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3557/comments | https://api.github.com/repos/huggingface/datasets/issues/3557/events | https://github.com/huggingface/datasets/pull/3557 | 1,097,946,034 | PR_kwDODunzps4wvIHl | 3,557 | Fix bug in `ImageClassifcation` task template | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"The CI failures are unrelated to the changes in this PR.",
"> The CI failures are unrelated to the changes in this PR.\r\n\r\nIt seems that some of the failures are due to the tests on the dataset cards (e.g. CIFAR, MNIST, FASHION_MNIST). Perhaps it's worth addressing those in this PR to avoid confusing downstre... | 2022-01-10T14:09:59Z | 2022-01-11T15:47:52Z | 2022-01-11T15:47:52Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3557.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3557",
"merged_at": "2022-01-11T15:47:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3557.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fixes a bug in the `ImageClassification` task template which requires specifying class labels twice in dataset scripts. Additionally, this PR refactors the API around the classification task templates for cleaner `labels` handling.
CC: @lewtun @nateraw | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3557/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3557/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5843 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5843/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5843/comments | https://api.github.com/repos/huggingface/datasets/issues/5843/events | https://github.com/huggingface/datasets/issues/5843 | 1,705,514,551 | I_kwDODunzps5lqBY3 | 5,843 | Can't add iterable datasets to a Dataset Dict. | {
"avatar_url": "https://avatars.githubusercontent.com/u/17240858?v=4",
"events_url": "https://api.github.com/users/surya-narayanan/events{/privacy}",
"followers_url": "https://api.github.com/users/surya-narayanan/followers",
"following_url": "https://api.github.com/users/surya-narayanan/following{/other_user}"... | [] | closed | false | null | [] | null | [
"Transferring as this is relating to the 🤗 Datasets library",
"You need to use `IterableDatasetDict` instead of `DatasetDict` for iterable datasets."
] | 2023-05-11T02:09:29Z | 2023-05-25T04:51:59Z | 2023-05-25T04:51:59Z | NONE | null | null | null | ### System Info
standard env
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Get th... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5843/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5843/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1533 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1533/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1533/comments | https://api.github.com/repos/huggingface/datasets/issues/1533/events | https://github.com/huggingface/datasets/pull/1533 | 764,835,913 | MDExOlB1bGxSZXF1ZXN0NTM4NzE4MDAz | 1,533 | add id_panl_bppt, a parallel corpus for en-id | {
"avatar_url": "https://avatars.githubusercontent.com/u/7669893?v=4",
"events_url": "https://api.github.com/users/cahya-wirawan/events{/privacy}",
"followers_url": "https://api.github.com/users/cahya-wirawan/followers",
"following_url": "https://api.github.com/users/cahya-wirawan/following{/other_user}",
"gi... | [] | closed | false | null | [] | null | [
"Hi @lhoestq, thanks for the review. I will have a look and update it accordingly.",
"Strange error message :-)\r\n\r\n```\r\n> tf_context = tf.python.context.context() # eager mode context\r\nE AttributeError: module 'tensorflow' has no attribute 'python'\r\n```\r\n"
] | 2020-12-13T03:11:27Z | 2020-12-21T10:40:36Z | 2020-12-21T10:40:36Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1533.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1533",
"merged_at": "2020-12-21T10:40:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1533.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Parallel Text Corpora for English - Indonesian | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1533/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1533/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3667/comments | https://api.github.com/repos/huggingface/datasets/issues/3667/events | https://github.com/huggingface/datasets/pull/3667 | 1,122,060,630 | PR_kwDODunzps4x-Ujt | 3,667 | Process .opus files with torchaudio | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_use... | null | [
"Note that torchaudio is maybe less practical to use for TF or JAX users.\r\nThis is not in the scope of this PR, but in the future if we manage to find a way to let the user control the decoding it would be nice",
"> Note that torchaudio is maybe less practical to use for TF or JAX users. This is not in the scop... | 2022-02-02T15:23:14Z | 2022-02-04T15:29:38Z | 2022-02-04T15:29:38Z | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3667.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3667",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3667.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3667"
} | @anton-l suggested to proccess .opus files with `torchaudio` instead of `soundfile` as it's faster:

(moreover, I didn't manage to load .opus files with `soundfile` / `librosa` locally on any my machine an... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3667/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3667/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4832 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4832/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4832/comments | https://api.github.com/repos/huggingface/datasets/issues/4832/events | https://github.com/huggingface/datasets/pull/4832 | 1,336,727,389 | PR_kwDODunzps49EQav | 4,832 | Fix tags in dataset cards | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The non-passing tests are caused by other missing information in the dataset cards."
] | 2022-08-12T04:11:23Z | 2022-08-12T04:41:55Z | 2022-08-12T04:27:24Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4832.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4832",
"merged_at": "2022-08-12T04:27:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4832.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix wrong tags in dataset cards. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4832/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4832/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3337 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3337/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3337/comments | https://api.github.com/repos/huggingface/datasets/issues/3337/events | https://github.com/huggingface/datasets/issues/3337 | 1,066,232,936 | I_kwDODunzps4_jWxo | 3,337 | Typing of Dataset.__getitem__ could be improved. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https:/... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_... | null | [
"Hi ! Thanks for the suggestion, I didn't know about this decorator.\r\n\r\nIf you are interesting in contributing, feel free to open a pull request to add the overload methods for each typing combination :) To assign you to this issue, you can comment `#self-assign` in this thread.\r\n\r\n`Dataset.__getitem__` is ... | 2021-11-29T16:20:11Z | 2021-12-14T10:28:54Z | 2021-12-14T10:28:54Z | CONTRIBUTOR | null | null | null | ## Describe the bug
The newly added typing for Dataset.__getitem__ is Union[Dict, List]. This makes tools like mypy a bit awkward to use as we need to check the type manually. We could use type overloading to make this easier. [Documentation](https://docs.python.org/3/library/typing.html#typing.overload)
## Steps... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3337/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3337/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4894 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4894/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4894/comments | https://api.github.com/repos/huggingface/datasets/issues/4894/events | https://github.com/huggingface/datasets/pull/4894 | 1,350,667,270 | PR_kwDODunzps49yIvr | 4,894 | Add citation information to makhzan dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-25T10:16:40Z | 2022-08-30T06:21:54Z | 2022-08-25T13:19:41Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4894.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4894",
"merged_at": "2022-08-25T13:19:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4894.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds the citation information to `makhzan` dataset, once they have replied to our request for that information:
- https://github.com/zeerakahmed/makhzan/issues/43 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4894/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4894/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1211 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1211/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1211/comments | https://api.github.com/repos/huggingface/datasets/issues/1211/events | https://github.com/huggingface/datasets/pull/1211 | 757,973,719 | MDExOlB1bGxSZXF1ZXN0NTMzMjMxNDY3 | 1,211 | Add large spanish corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [] | 2020-12-06T17:06:50Z | 2020-12-09T13:36:36Z | 2020-12-09T13:36:36Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1211.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1211",
"merged_at": "2020-12-09T13:36:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1211.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adds a collection of Spanish corpora that can be useful for pretraining language models.
Following a nice suggestion from @yjernite we provide the user with three main ways to preprocess / load either
* the whole corpus (17GB!)
* one specific sub-corpus
* the whole corpus, but return a single split. this is u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1211/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1211/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5877 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5877/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5877/comments | https://api.github.com/repos/huggingface/datasets/issues/5877/events | https://github.com/huggingface/datasets/issues/5877 | 1,717,983,961 | I_kwDODunzps5mZlrZ | 5,877 | Request for text deduplication feature | {
"avatar_url": "https://avatars.githubusercontent.com/u/55043035?v=4",
"events_url": "https://api.github.com/users/SupreethRao99/events{/privacy}",
"followers_url": "https://api.github.com/users/SupreethRao99/followers",
"following_url": "https://api.github.com/users/SupreethRao99/following{/other_user}",
"g... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"The \"exact match\" deduplication will be possible when we resolve https://github.com/huggingface/datasets/issues/2514 (first, https://github.com/apache/arrow/issues/30950 needs to be addressed on the Arrow side). In the meantime, you can use Polars or DuckDB (e.g., via [datasets-sql](https://github.com/mariosasko... | 2023-05-20T01:56:00Z | 2023-07-26T21:42:14Z | null | NONE | null | null | null | ### Feature request
It would be great if there would be support for high performance, highly scalable text deduplication algorithms as part of the datasets library.
### Motivation
Motivated by this blog post https://huggingface.co/blog/dedup and this library https://github.com/google-research/deduplicate-text-datase... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5877/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5877/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5667/comments | https://api.github.com/repos/huggingface/datasets/issues/5667/events | https://github.com/huggingface/datasets/pull/5667 | 1,637,789,361 | PR_kwDODunzps5Mv8Im | 5,667 | Jax requires jaxlib | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-23T15:41:09Z | 2023-03-23T16:23:11Z | 2023-03-23T16:14:52Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5667.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5667",
"merged_at": "2023-03-23T16:14:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5667.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | close https://github.com/huggingface/datasets/issues/5666 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5667/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5667/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4821 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4821/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4821/comments | https://api.github.com/repos/huggingface/datasets/issues/4821/events | https://github.com/huggingface/datasets/pull/4821 | 1,335,664,588 | PR_kwDODunzps49AvaE | 4,821 | Fix train_test_split docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-11T08:55:45Z | 2022-08-11T09:59:29Z | 2022-08-11T09:45:40Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4821.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4821",
"merged_at": "2022-08-11T09:45:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4821.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I saw that `stratify` is added to the `train_test_split` method as per #4322, hence the docs can be updated. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4821/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4821/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4141 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4141/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4141/comments | https://api.github.com/repos/huggingface/datasets/issues/4141/events | https://github.com/huggingface/datasets/issues/4141 | 1,199,610,885 | I_kwDODunzps5HgJwF | 4,141 | Why is the dataset not visible under the dataset preview section? | {
"avatar_url": "https://avatars.githubusercontent.com/u/75028682?v=4",
"events_url": "https://api.github.com/users/Nid989/events{/privacy}",
"followers_url": "https://api.github.com/users/Nid989/followers",
"following_url": "https://api.github.com/users/Nid989/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [] | 2022-04-11T08:36:42Z | 2022-04-11T18:55:32Z | 2022-04-11T17:09:49Z | NONE | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4141/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4141/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4915 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4915/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4915/comments | https://api.github.com/repos/huggingface/datasets/issues/4915/events | https://github.com/huggingface/datasets/issues/4915 | 1,356,009,042 | I_kwDODunzps5Q0w5S | 4,915 | FileNotFoundError while downloading wikipedia dataset for any language | {
"avatar_url": "https://avatars.githubusercontent.com/u/71849081?v=4",
"events_url": "https://api.github.com/users/Shilpac20/events{/privacy}",
"followers_url": "https://api.github.com/users/Shilpac20/followers",
"following_url": "https://api.github.com/users/Shilpac20/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @Shilpac20,\r\n\r\nAs explained in the Wikipedia dataset card: https://huggingface.co/datasets/wikipedia\r\n> You can find the full list of languages and dates [here](https://dumps.wikimedia.org/backup-index.html).\r\n\r\nThis means that, before passing a specific date, you should first make sure it is availabl... | 2022-08-30T16:15:46Z | 2022-12-04T22:20:33Z | null | NONE | null | null | null | ## Describe the bug
Hi, I am currently trying to download wikipedia dataset using
load_dataset("wikipedia", language="aa", date="20220401", split="train",beam_runner='DirectRunner'). However, I end up in getting filenotfound error. I get this error for any language I try to download.
Environment:
## Step... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4915/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4915/timeline | null | reopened | false |
https://api.github.com/repos/huggingface/datasets/issues/2099 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2099/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2099/comments | https://api.github.com/repos/huggingface/datasets/issues/2099/events | https://github.com/huggingface/datasets/issues/2099 | 838,523,819 | MDU6SXNzdWU4Mzg1MjM4MTk= | 2,099 | load_from_disk takes a long time to load local dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/15007950?v=4",
"events_url": "https://api.github.com/users/samsontmr/events{/privacy}",
"followers_url": "https://api.github.com/users/samsontmr/followers",
"following_url": "https://api.github.com/users/samsontmr/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Hi !\r\nCan you share more information about the features of your dataset ? You can get them by printing `my_dataset.features`\r\nCan you also share the code of your `map` function ?",
"It is actually just the tokenized `wikipedia` dataset with `input_ids`, `attention_mask`, etc, with one extra column which is a... | 2021-03-23T09:28:37Z | 2021-03-23T17:12:16Z | 2021-03-23T17:12:16Z | NONE | null | null | null | I have an extremely large tokenized dataset (24M examples) that loads in a few minutes. However, after adding a column similar to `input_ids` (basically a list of integers) and saving the dataset to disk, the load time goes to >1 hour. I've even tried using `np.uint8` after seeing #1985 but it doesn't seem to be helpin... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2099/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2099/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2033 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2033/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2033/comments | https://api.github.com/repos/huggingface/datasets/issues/2033/events | https://github.com/huggingface/datasets/pull/2033 | 829,295,339 | MDExOlB1bGxSZXF1ZXN0NTkwOTgzMDAy | 2,033 | Raise an error for outdated sacrebleu versions | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-03-11T16:08:00Z | 2021-03-11T17:58:12Z | 2021-03-11T17:58:12Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2033.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2033",
"merged_at": "2021-03-11T17:58:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2033.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The `sacrebleu` metric seem to only work for sacrecleu>=1.4.12
For example using sacrebleu==1.2.10, an error is raised (from metric/sacrebleu/sacrebleu.py):
```python
def _compute(
self,
predictions,
references,
smooth_method="exp",
smooth_value=None,
force... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2033/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2033/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4377/comments | https://api.github.com/repos/huggingface/datasets/issues/4377/events | https://github.com/huggingface/datasets/pull/4377 | 1,242,746,186 | PR_kwDODunzps44K4OY | 4,377 | Fix checksum and bug in irc_disentangle dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-05-20T07:29:28Z | 2022-05-20T09:34:36Z | 2022-05-20T09:26:32Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4377.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4377",
"merged_at": "2022-05-20T09:26:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4377.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | There was a bug in filepath segment:
- wrong: `jkkummerfeld-irc-disentanglement-fd379e9`
- right: `jkkummerfeld-irc-disentanglement-35f0a40`
Also there was a bug in the checksum of the downloaded file.
This PR fixes these issues.
Fix partially #4376.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4377/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3223 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3223/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3223/comments | https://api.github.com/repos/huggingface/datasets/issues/3223/events | https://github.com/huggingface/datasets/pull/3223 | 1,046,445,507 | PR_kwDODunzps4uLb1E | 3,223 | Update BibTeX entry | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-11-06T06:41:52Z | 2021-11-06T07:06:38Z | 2021-11-06T07:06:38Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3223.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3223",
"merged_at": "2021-11-06T07:06:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3223.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Update BibTeX entry. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3223/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3223/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2124 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2124/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2124/comments | https://api.github.com/repos/huggingface/datasets/issues/2124/events | https://github.com/huggingface/datasets/issues/2124 | 842,627,729 | MDU6SXNzdWU4NDI2Mjc3Mjk= | 2,124 | Adding ScaNN library to do MIPS? | {
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | [
"I haven't played with it (yet) but it sounds really cool !\r\n"
] | 2021-03-28T00:07:00Z | 2021-03-29T13:23:43Z | null | NONE | null | null | null | @lhoestq Hi I am thinking of adding this new google library to do the MIPS similar to **add_faiss_idex**. As the paper suggests, it is really fast when it comes to retrieving the nearest neighbors.
https://github.com/google-research/google-research/tree/master/scann
"
] | 2023-01-13T13:07:07Z | 2023-01-13T20:12:32Z | 2023-01-13T20:12:32Z | CONTRIBUTOR | null | null | null | ### Feature request
The dataset name on the Hub is case-insensitive (see https://github.com/huggingface/moon-landing/pull/2399, internal issue), i.e., https://huggingface.co/datasets/GLUE redirects to https://huggingface.co/datasets/glue.
Ideally, we could load the glue dataset using the following:
```
from d... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5421/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5421/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2820 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2820/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2820/comments | https://api.github.com/repos/huggingface/datasets/issues/2820/events | https://github.com/huggingface/datasets/issues/2820 | 975,210,712 | MDU6SXNzdWU5NzUyMTA3MTI= | 2,820 | Downloading “reddit” dataset keeps timing out. | {
"avatar_url": "https://avatars.githubusercontent.com/u/43877130?v=4",
"events_url": "https://api.github.com/users/smeyerhot/events{/privacy}",
"followers_url": "https://api.github.com/users/smeyerhot/followers",
"following_url": "https://api.github.com/users/smeyerhot/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"```\r\nUsing custom data configuration default\r\nDownloading and preparing dataset reddit/default (download: 2.93 GiB, generated: 17.64 GiB, post-processed: Unknown size, total: 20.57 GiB) to /Volumes/My Passport for Mac/og-chat-data/reddit/default/1.0.0/98ba5abea674d3178f7588aa6518a5510dc0c6fa8176d9653a3546d5afc... | 2021-08-20T02:52:36Z | 2021-09-08T14:52:02Z | 2021-09-08T14:52:02Z | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
Everytime I try and download the reddit dataset it times out before finishing and I have to try again.
There is some timeout error that I will post once it happens again.
## Steps to reproduce the bug
```python
from datasets import load_d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2820/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2820/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5803 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5803/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5803/comments | https://api.github.com/repos/huggingface/datasets/issues/5803/events | https://github.com/huggingface/datasets/pull/5803 | 1,688,256,290 | PR_kwDODunzps5PXtte | 5,803 | Release: 2.12.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5803). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... | 2023-04-28T09:52:11Z | 2023-04-28T10:18:56Z | 2023-04-28T09:54:43Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5803.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5803",
"merged_at": "2023-04-28T09:54:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5803.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5803/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5803/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1848 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1848/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1848/comments | https://api.github.com/repos/huggingface/datasets/issues/1848/events | https://github.com/huggingface/datasets/pull/1848 | 803,826,506 | MDExOlB1bGxSZXF1ZXN0NTY5Njg5ODU1 | 1,848 | Refactoring: Create config module | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-02-08T18:43:51Z | 2021-02-10T12:29:35Z | 2021-02-10T12:29:35Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1848.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1848",
"merged_at": "2021-02-10T12:29:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1848.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Refactorize configuration settings into their own module.
This could be seen as a Pythonic singleton-like approach. Eventually a config instance class might be created. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1848/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1848/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1531 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1531/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1531/comments | https://api.github.com/repos/huggingface/datasets/issues/1531/events | https://github.com/huggingface/datasets/pull/1531 | 764,752,882 | MDExOlB1bGxSZXF1ZXN0NTM4NjcwNzcz | 1,531 | adding hate-speech-and-offensive-language | {
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [] | 2020-12-13T01:59:07Z | 2020-12-13T02:17:02Z | 2020-12-13T02:17:02Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1531.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1531",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1531.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1531"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1531/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1531/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/1217 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1217/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1217/comments | https://api.github.com/repos/huggingface/datasets/issues/1217/events | https://github.com/huggingface/datasets/pull/1217 | 758,008,321 | MDExOlB1bGxSZXF1ZXN0NTMzMjU2MjU4 | 1,217 | adding DataCommons fact checking | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-12-06T19:56:12Z | 2020-12-16T16:22:48Z | 2020-12-16T16:22:48Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1217.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1217",
"merged_at": "2020-12-16T16:22:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1217.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding the data from: https://datacommons.org/factcheck/
Had to cheat a bit with the dummy data as the test doesn't recognize `.txt.gz`: had to rename uncompressed files with the `.gz` extension manually without actually compressing | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1217/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1217/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2592/comments | https://api.github.com/repos/huggingface/datasets/issues/2592/events | https://github.com/huggingface/datasets/pull/2592 | 937,060,559 | MDExOlB1bGxSZXF1ZXN0NjgzNjc2MjA4 | 2,592 | Add c4.noclean infos | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-07-05T12:51:40Z | 2021-07-05T13:15:53Z | 2021-07-05T13:15:52Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2592.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2592",
"merged_at": "2021-07-05T13:15:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2592.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding the data files checksums and the dataset size of the c4.noclean configuration of the C4 dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2592/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2592/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5397/comments | https://api.github.com/repos/huggingface/datasets/issues/5397/events | https://github.com/huggingface/datasets/pull/5397 | 1,514,412,246 | PR_kwDODunzps5GYirs | 5,397 | Unpin pydantic test dependency | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2022-12-30T10:22:09Z | 2022-12-30T10:53:11Z | 2022-12-30T10:43:40Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5397.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5397",
"merged_at": "2022-12-30T10:43:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5397.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Once pydantic-1.10.3 has been yanked, we can unpin it: https://pypi.org/project/pydantic/1.10.3/
See reply by pydantic team https://github.com/pydantic/pydantic/issues/4885#issuecomment-1367819807
```
v1.10.3 has been yanked.
```
in response to spacy request: https://github.com/pydantic/pydantic/issues/4885#issu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5397/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5397/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2173 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2173/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2173/comments | https://api.github.com/repos/huggingface/datasets/issues/2173/events | https://github.com/huggingface/datasets/pull/2173 | 851,359,284 | MDExOlB1bGxSZXF1ZXN0NjA5Nzk2NzI2 | 2,173 | Add OpenSLR dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7669893?v=4",
"events_url": "https://api.github.com/users/cahya-wirawan/events{/privacy}",
"followers_url": "https://api.github.com/users/cahya-wirawan/followers",
"following_url": "https://api.github.com/users/cahya-wirawan/following{/other_user}",
"gi... | [] | closed | false | null | [] | null | [] | 2021-04-06T12:08:34Z | 2021-04-12T16:54:46Z | 2021-04-12T16:54:46Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2173.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2173",
"merged_at": "2021-04-12T16:54:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2173.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | OpenSLR (https://openslr.org/) is a site devoted to hosting speech and language resources, such as training corpora for speech recognition, and software related to speech recognition. There are around 80 speech datasets listed in OpenSLR, currently this PR includes only 9 speech datasets SLR41, SLR42, SLR43, SLR44, SLR... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2173/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2173/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4765 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4765/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4765/comments | https://api.github.com/repos/huggingface/datasets/issues/4765/events | https://github.com/huggingface/datasets/pull/4765 | 1,321,787,428 | PR_kwDODunzps48S2rM | 4,765 | Fix version in map_nested docstring | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-29T05:44:32Z | 2022-07-29T11:51:25Z | 2022-07-29T11:38:36Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4765.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4765",
"merged_at": "2022-07-29T11:38:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4765.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | After latest release, `map_nested` docstring needs being updated with the right version for versionchanged and versionadded. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4765/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4765/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2466 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2466/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2466/comments | https://api.github.com/repos/huggingface/datasets/issues/2466/events | https://github.com/huggingface/datasets/pull/2466 | 915,914,098 | MDExOlB1bGxSZXF1ZXN0NjY1NjY1MjQy | 2,466 | change udpos features structure | {
"avatar_url": "https://avatars.githubusercontent.com/u/50871412?v=4",
"events_url": "https://api.github.com/users/jerryIsHere/events{/privacy}",
"followers_url": "https://api.github.com/users/jerryIsHere/followers",
"following_url": "https://api.github.com/users/jerryIsHere/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Let's add the tags in another PR. Thanks again !",
"Close #2061 , close #2444."
] | 2021-06-09T08:03:31Z | 2021-06-18T11:55:09Z | 2021-06-16T10:41:37Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2466.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2466",
"merged_at": "2021-06-16T10:41:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2466.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The structure is change such that each example is a sentence
The change is done for issues:
#2061
#2444
Close #2061 , close #2444. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2466/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2466/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5796 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5796/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5796/comments | https://api.github.com/repos/huggingface/datasets/issues/5796/events | https://github.com/huggingface/datasets/pull/5796 | 1,685,451,919 | PR_kwDODunzps5PORm- | 5,796 | Spark docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-26T17:39:43Z | 2023-04-27T16:41:50Z | 2023-04-27T16:34:45Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5796.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5796",
"merged_at": "2023-04-27T16:34:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5796.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Added a "Use with Spark" doc page to document `Dataset.from_spark` following https://github.com/huggingface/datasets/pull/5701
cc @maddiedawson | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5796/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5796/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5866 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5866/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5866/comments | https://api.github.com/repos/huggingface/datasets/issues/5866/events | https://github.com/huggingface/datasets/issues/5866 | 1,710,496,993 | I_kwDODunzps5l9Bzh | 5,866 | Issue with Sequence features | {
"avatar_url": "https://avatars.githubusercontent.com/u/14365168?v=4",
"events_url": "https://api.github.com/users/alialamiidrissi/events{/privacy}",
"followers_url": "https://api.github.com/users/alialamiidrissi/followers",
"following_url": "https://api.github.com/users/alialamiidrissi/following{/other_user}"... | [] | closed | false | null | [] | null | [
"Thanks for reporting! I've opened a PR with a fix."
] | 2023-05-15T17:13:29Z | 2023-05-26T11:57:17Z | 2023-05-26T11:57:17Z | NONE | null | null | null | ### Describe the bug
Sequences features sometimes causes errors when the specified length is not -1
### Steps to reproduce the bug
```python
import numpy as np
from datasets import Features, ClassLabel, Sequence, Value, Dataset
feats = Features(**{'target': ClassLabel(names=[0, 1]),'x': Sequence(feature=Va... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5866/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5866/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1972 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1972/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1972/comments | https://api.github.com/repos/huggingface/datasets/issues/1972/events | https://github.com/huggingface/datasets/issues/1972 | 819,752,761 | MDU6SXNzdWU4MTk3NTI3NjE= | 1,972 | 'Dataset' object has no attribute 'rename_column' | {
"avatar_url": "https://avatars.githubusercontent.com/u/23195502?v=4",
"events_url": "https://api.github.com/users/farooqzaman1/events{/privacy}",
"followers_url": "https://api.github.com/users/farooqzaman1/followers",
"following_url": "https://api.github.com/users/farooqzaman1/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"Hi ! `rename_column` has been added recently and will be available in the next release"
] | 2021-03-02T08:01:49Z | 2022-06-01T16:08:47Z | 2022-06-01T16:08:47Z | NONE | null | null | null | 'Dataset' object has no attribute 'rename_column' | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1972/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1972/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4263 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4263/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4263/comments | https://api.github.com/repos/huggingface/datasets/issues/4263/events | https://github.com/huggingface/datasets/pull/4263 | 1,222,723,083 | PR_kwDODunzps43KLnD | 4,263 | Rename imagenet2012 -> imagenet-1k | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"> Later we can add imagenet-21k as a new dataset if we want.\r\n\r\nisn't it what models refer to as `imagenet` already?",
"> isn't it what models refer to as imagenet already?\r\n\r\nI wasn't sure, but it looks like it indeed. Therefore having a dataset `imagenet` for ImageNet 21k makes sense actually.\r\n\r\nE... | 2022-05-02T10:26:21Z | 2022-05-02T17:50:46Z | 2022-05-02T16:32:57Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4263.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4263",
"merged_at": "2022-05-02T16:32:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4263.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | On the Hugging Face Hub, users refer to imagenet2012 (from #4178 ) as imagenet-1k in their model tags.
To correctly link models to imagenet, we should rename this dataset `imagenet-1k`.
Later we can add `imagenet-21k` as a new dataset if we want.
Once this one is merged we can delete the `imagenet2012` dataset... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4263/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4263/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1260 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1260/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1260/comments | https://api.github.com/repos/huggingface/datasets/issues/1260/events | https://github.com/huggingface/datasets/pull/1260 | 758,601,828 | MDExOlB1bGxSZXF1ZXN0NTMzNzQ4ODM3 | 1,260 | Added NewsPH Raw Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/24757547?v=4",
"events_url": "https://api.github.com/users/jcblaisecruz02/events{/privacy}",
"followers_url": "https://api.github.com/users/jcblaisecruz02/followers",
"following_url": "https://api.github.com/users/jcblaisecruz02/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"looks like this PR has changes to many files other than the ones for `NewsPH`\r\n\r\nCan you create another branch and another PR please ?"
] | 2020-12-07T15:17:53Z | 2020-12-08T16:27:15Z | 2020-12-08T16:27:15Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1260.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1260",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1260.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1260"
} | Added the raw version of the NewsPH dataset, which was used to automatically generate the NewsPH-NLI corpus. Dataset of news articles in Filipino from mainstream Philippine news sites on the internet. Can be used as a language modeling dataset or to reproduce the NewsPH-NLI dataset.
Paper: https://arxiv.org/abs/2010... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1260/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1260/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5386/comments | https://api.github.com/repos/huggingface/datasets/issues/5386/events | https://github.com/huggingface/datasets/issues/5386 | 1,508,592,918 | I_kwDODunzps5Z600W | 5,386 | `max_shard_size` in `datasets.push_to_hub()` breaks with large files | {
"avatar_url": "https://avatars.githubusercontent.com/u/1086393?v=4",
"events_url": "https://api.github.com/users/salieri/events{/privacy}",
"followers_url": "https://api.github.com/users/salieri/followers",
"following_url": "https://api.github.com/users/salieri/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nThis behavior stems from the fact that we don't always embed image bytes in the underlying arrow table, which can lead to bad size estimation (we use the first 1000 table rows to [estimate](https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.... | 2022-12-22T21:50:58Z | 2022-12-26T23:45:51Z | 2022-12-26T23:45:51Z | NONE | null | null | null | ### Describe the bug
`max_shard_size` parameter for `datasets.push_to_hub()` works unreliably with large files, generating shard files that are way past the specified limit.
In my private dataset, which contains unprocessed images of all sizes (up to `~100MB` per file), I've encountered cases where `max_shard_siz... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5386/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5386/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1572/comments | https://api.github.com/repos/huggingface/datasets/issues/1572/events | https://github.com/huggingface/datasets/pull/1572 | 767,008,470 | MDExOlB1bGxSZXF1ZXN0NTM5ODU5OTgx | 1,572 | add Gnad10 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-12-14T23:15:02Z | 2021-09-17T16:54:37Z | 2020-12-16T16:52:30Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1572.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1572",
"merged_at": "2020-12-16T16:52:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1572.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | reference [PR#1317](https://github.com/huggingface/datasets/pull/1317) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1572/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1572/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4935 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4935/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4935/comments | https://api.github.com/repos/huggingface/datasets/issues/4935/events | https://github.com/huggingface/datasets/issues/4935 | 1,363,226,736 | I_kwDODunzps5RQTBw | 4,935 | Dataset Viewer issue for ubuntu_dialogs_corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/87330568?v=4",
"events_url": "https://api.github.com/users/CibinQuadance/events{/privacy}",
"followers_url": "https://api.github.com/users/CibinQuadance/followers",
"following_url": "https://api.github.com/users/CibinQuadance/following{/other_user}",
"g... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | null | [
"The dataset maintainers (https://huggingface.co/datasets/ubuntu_dialogs_corpus) decided to forbid the dataset from being downloaded automatically (https://huggingface.co/docs/datasets/v2.4.0/en/loading#manual-download), and the dataset viewer respects this.\r\nWe will try to improve the error display though. Thank... | 2022-09-06T12:41:50Z | 2022-09-06T12:51:25Z | 2022-09-06T12:51:25Z | NONE | null | null | null | ### Link
_No response_
### Description
_No response_
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4935/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4935/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3580/comments | https://api.github.com/repos/huggingface/datasets/issues/3580/events | https://github.com/huggingface/datasets/issues/3580 | 1,104,663,242 | I_kwDODunzps5B19LK | 3,580 | Bug in wiki bio load | {
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"events_url": "https://api.github.com/users/tuhinjubcse/events{/privacy}",
"followers_url": "https://api.github.com/users/tuhinjubcse/followers",
"following_url": "https://api.github.com/users/tuhinjubcse/following{/other_user}",
"gists_ur... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
"+1, here's the error I got: \r\n\r\n```\r\n>>> from datasets import load_dataset\r\n>>>\r\n>>> load_dataset(\"wiki_bio\")\r\nDownloading: 7.58kB [00:00, 4.42MB/s]\r\nDownloading: 2.71kB [00:00, 1.30MB/s]\r\nUsing custom data configuration default\r\nDownloading and preparing dataset wiki_bio/default (download: 318... | 2022-01-15T10:04:33Z | 2022-01-31T08:38:09Z | 2022-01-31T08:38:09Z | NONE | null | null | null |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
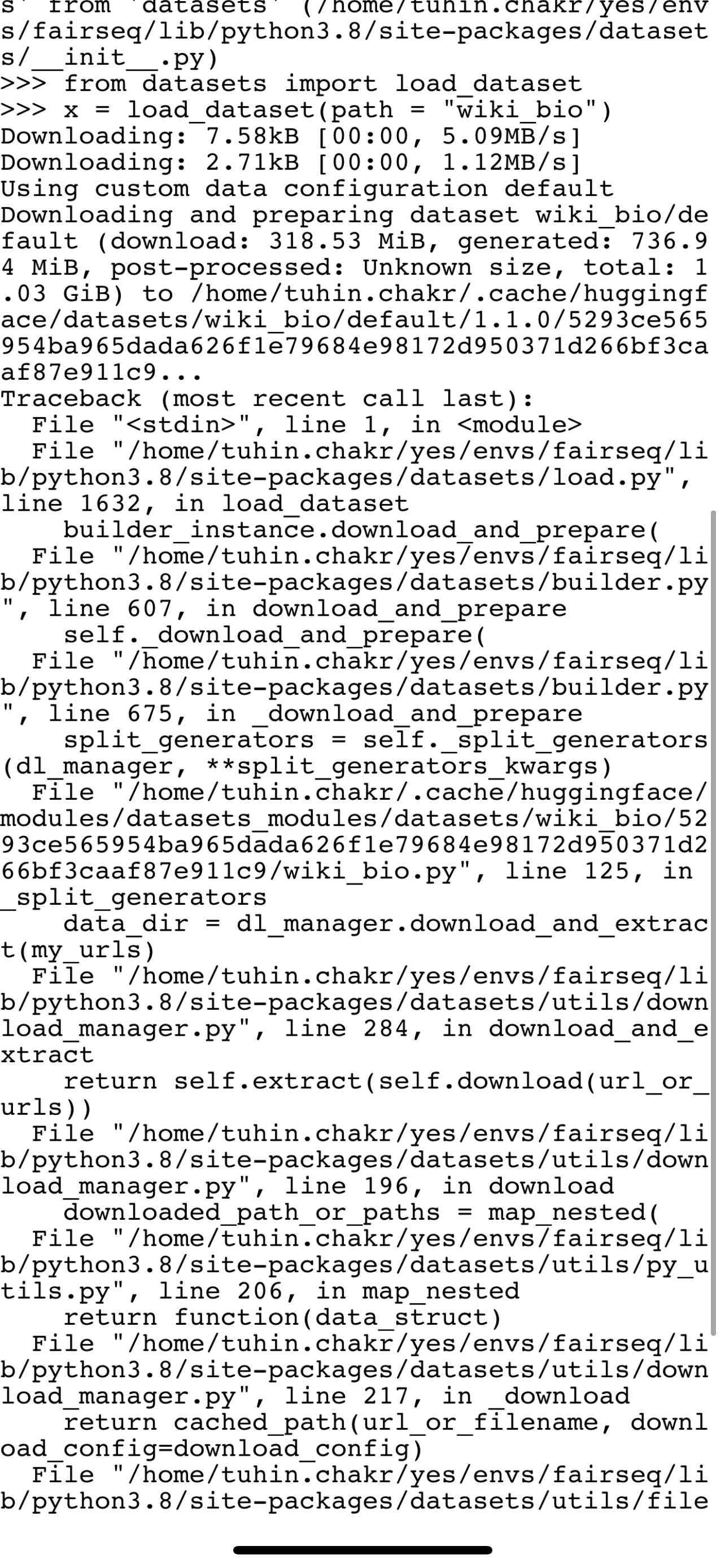
: Updated for multi-configs
UPDATE (7018082): manually created the dummy_datasets. All tests were cleared locally. Pushed it to origin/master
DRAFT VERSION (57fdb20): (_no longer draft_)
Uploaded the air_dialogue database.
dummy_data creation was failing in local, since the original download... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1553/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1553/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4029 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4029/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4029/comments | https://api.github.com/repos/huggingface/datasets/issues/4029/events | https://github.com/huggingface/datasets/issues/4029 | 1,181,057,011 | I_kwDODunzps5GZX_z | 4,029 | Add FAISS .range_search() method for retrieving all texts from dataset above similarity threshold | {
"avatar_url": "https://avatars.githubusercontent.com/u/41862082?v=4",
"events_url": "https://api.github.com/users/MoritzLaurer/events{/privacy}",
"followers_url": "https://api.github.com/users/MoritzLaurer/followers",
"following_url": "https://api.github.com/users/MoritzLaurer/following{/other_user}",
"gist... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi ! You can access the faiss index with\r\n```python\r\nfaiss_index = my_dataset.get_index(\"my_index_name\").faiss_index\r\n```\r\nand then do whatever you want with it, e.g. query it using range_search:\r\n```python\r\nthreshold = 0.95\r\nlimits, distances, indices = faiss_index.range_search(x=xq, thresh=thresh... | 2022-03-25T17:31:33Z | 2022-05-06T08:35:52Z | 2022-05-06T08:35:52Z | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
I would like to retrieve all texts from a dataset, which are semantically similar to a specific input text (query), above a certain (cosine) similarity threshold. My dataset is very large (Wikipedia), so I need to use Datasets and FAISS for this. I wou... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4029/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4029/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5156 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5156/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5156/comments | https://api.github.com/repos/huggingface/datasets/issues/5156/events | https://github.com/huggingface/datasets/issues/5156 | 1,421,667,125 | I_kwDODunzps5UvOs1 | 5,156 | Unable to download dataset using Azure Data Lake Gen 2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/87379512?v=4",
"events_url": "https://api.github.com/users/clarissesimoes/events{/privacy}",
"followers_url": "https://api.github.com/users/clarissesimoes/followers",
"following_url": "https://api.github.com/users/clarissesimoes/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Hi ! From the `adlfs` docs, there are two filesystems you can use:\r\n> To use the Gen1 filesystem:\r\n> - known_implementations[‘adl’] = {‘class’: ‘adlfs.AzureDatalakeFileSystem’}\r\n> \r\n> To use the Gen2 filesystem:\r\n> - known_implementations[‘abfs’] = {‘class’: ‘adlfs.AzureBlobFileSystem’}\r\n\r\nIf I'm no... | 2022-10-25T00:43:18Z | 2022-11-17T23:37:09Z | 2022-11-17T23:37:08Z | NONE | null | null | null | ### Describe the bug
When using the DatasetBuilder method with the credentials for the cloud storage Azure Data Lake (adl) Gen2, the following error is showed:
```
Traceback (most recent call last):
File "download_hf_dataset.py", line 143, in <module>
main()
File "download_hf_dataset.py", line 102, in mai... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5156/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5156/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1717 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1717/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1717/comments | https://api.github.com/repos/huggingface/datasets/issues/1717/events | https://github.com/huggingface/datasets/issues/1717 | 783,074,255 | MDU6SXNzdWU3ODMwNzQyNTU= | 1,717 | SciFact dataset - minor changes | {
"avatar_url": "https://avatars.githubusercontent.com/u/3091916?v=4",
"events_url": "https://api.github.com/users/dwadden/events{/privacy}",
"followers_url": "https://api.github.com/users/dwadden/followers",
"following_url": "https://api.github.com/users/dwadden/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Hi Dave,\r\nYou are more than welcome to open a PR to make these changes! 🤗\r\nYou will find the relevant information about opening a PR in the [contributing guide](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md) and in the [dataset addition guide](https://github.com/huggingface/datasets/blob... | 2021-01-11T05:26:40Z | 2021-01-26T02:52:17Z | 2021-01-26T02:52:17Z | CONTRIBUTOR | null | null | null | Hi,
SciFact dataset creator here. First of all, thanks for adding the dataset to Huggingface, much appreciated!
I'd like to make a few minor changes, including the citation information and the `_URL` from which to download the dataset. Can I submit a PR for this?
It also looks like the dataset is being downloa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1717/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1717/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6199 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6199/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6199/comments | https://api.github.com/repos/huggingface/datasets/issues/6199/events | https://github.com/huggingface/datasets/issues/6199 | 1,875,165,185 | I_kwDODunzps5vxMAB | 6,199 | Use load_dataset for local json files, but it not works | {
"avatar_url": "https://avatars.githubusercontent.com/u/50519434?v=4",
"events_url": "https://api.github.com/users/Garen-in-bush/events{/privacy}",
"followers_url": "https://api.github.com/users/Garen-in-bush/followers",
"following_url": "https://api.github.com/users/Garen-in-bush/following{/other_user}",
"g... | [] | open | false | null | [] | null | [
"Hugging Face's datasets library may prioritize remote configurations. Make sure there are no conflicting configurations causing the library to prefer downloading data\r\nMay be try debugging\r\nraw_datasets = load_dataset('json', data_files=data_files)\r\nprint(raw_datasets)\r\n",
"It doesn't download them but ... | 2023-08-31T09:42:34Z | 2023-08-31T19:05:07Z | null | NONE | null | null | null | ### Describe the bug
when I use load_dataset to load my local datasets,it always goes to Hugging Face to download the data instead of loading the local dataset.
### Steps to reproduce the bug
`raw_datasets = load_dataset(
‘json’,
data_files=data_files)`
### Expected behavior
\r\n`... | 2021-11-06T15:14:31Z | 2021-11-12T11:13:13Z | 2021-11-12T11:13:13Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3225.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3225",
"merged_at": "2021-11-12T11:13:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3225.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Tatoeba's latest version is v2021-07-22 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3225/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3225/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1303 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1303/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1303/comments | https://api.github.com/repos/huggingface/datasets/issues/1303/events | https://github.com/huggingface/datasets/pull/1303 | 759,440,484 | MDExOlB1bGxSZXF1ZXN0NTM0NDQ2NDg0 | 1,303 | adding opus_openoffice | {
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2020-12-08T13:20:21Z | 2020-12-10T09:37:10Z | 2020-12-10T09:37:10Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1303.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1303",
"merged_at": "2020-12-10T09:37:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1303.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding Opus OpenOffice: http://opus.nlpl.eu/OpenOffice.php
8 languages, 28 bitexts | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1303/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1303/timeline | null | null | true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.