
url stringlengths 61 61 | repository_url stringclasses 1
value | labels_url stringlengths 75 75 | comments_url stringlengths 70 70 | events_url stringlengths 68 68 | html_url stringlengths 49 51 | id int64 758M 1.95B | node_id stringlengths 18 32 | number int64 1.2k 6.31k | title stringlengths 1 290 | user dict | labels listlengths 0 3 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[ns, tz=UTC] | author_association stringclasses 3
values | active_lock_reason float64 | draft float64 0 1 ⌀ | pull_request dict | body stringlengths 0 36.2k ⌀ | reactions dict | timeline_url stringlengths 70 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2814 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2814/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2814/comments | https://api.github.com/repos/huggingface/datasets/issues/2814/events | https://github.com/huggingface/datasets/pull/2814 | 973,632,645 | MDExOlB1bGxSZXF1ZXN0NzE1MDUwODc4 | 2,814 | Bump tqdm version | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-08-18T12:51:29Z | 2021-08-18T13:44:11Z | 2021-08-18T13:39:50Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2814.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2814",
"merged_at": "2021-08-18T13:39:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2814.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The recently released tqdm 4.62.1 includes a fix for PermissionError on Windows (submitted by me in https://github.com/tqdm/tqdm/pull/1207), which means we can remove expensive `gc.collect` calls by bumping tqdm to that version. This PR does exactly that and, additionally, fixes a `disable_tqdm` definition that would p... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2814/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2814/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3707/comments | https://api.github.com/repos/huggingface/datasets/issues/3707/events | https://github.com/huggingface/datasets/issues/3707 | 1,132,741,903 | I_kwDODunzps5DhEUP | 3,707 | `.select`: unexpected behavior with `indices` | {
"avatar_url": "https://avatars.githubusercontent.com/u/36087158?v=4",
"events_url": "https://api.github.com/users/gabegma/events{/privacy}",
"followers_url": "https://api.github.com/users/gabegma/followers",
"following_url": "https://api.github.com/users/gabegma/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Hi! Currently, we compute the final index as `index % len(dset)`. I agree this behavior is somewhat unexpected and that it would be more appropriate to raise an error instead (this is what `df.iloc` in Pandas does, for instance).\r\n\r\n@albertvillanova @lhoestq wdyt?",
"I agree. I think `index % len(dset)` was ... | 2022-02-11T15:20:01Z | 2022-02-14T19:19:21Z | 2022-02-14T19:19:21Z | NONE | null | null | null | ## Describe the bug
The `.select` method will not throw when sending `indices` bigger than the dataset length; `indices` will be wrapped instead. This behavior is not documented anywhere, and is not intuitive.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"text": [... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3707/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3707/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1985 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1985/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1985/comments | https://api.github.com/repos/huggingface/datasets/issues/1985/events | https://github.com/huggingface/datasets/pull/1985 | 822,170,651 | MDExOlB1bGxSZXF1ZXN0NTg0ODM4NjIw | 1,985 | Optimize int precision | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"@lhoestq, are the tests OK? Some other cases I missed? Do you agree with this approach?",
"I just tested this and it works like a charm :) \r\n\r\nHowever tokenizing and then setting the format to \"torch\" to feed the tokens into a model doesn't seem to work anymore, since the pytorch tensors have the int32/int... | 2021-03-04T14:12:23Z | 2021-03-22T12:04:40Z | 2021-03-16T09:44:00Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1985.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1985",
"merged_at": "2021-03-16T09:44:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1985.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Optimize int precision to reduce dataset file size.
Close #1973, close #1825, close #861. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1985/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1985/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3548/comments | https://api.github.com/repos/huggingface/datasets/issues/3548/events | https://github.com/huggingface/datasets/issues/3548 | 1,096,409,512 | I_kwDODunzps5BWeGo | 3,548 | Specify the feature types of a dataset on the Hub without needing a dataset script | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "http... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gis... | null | [
"After looking into this, discovered that this is already supported if the `dataset_infos.json` file is configured correctly! Here is a working example: https://huggingface.co/datasets/abidlabs/test-audio-13\r\n\r\nThis should be probably be documented, though. "
] | 2022-01-07T15:17:06Z | 2022-01-20T14:48:38Z | 2022-01-20T14:48:38Z | MEMBER | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently if I upload a CSV with paths to audio files, the column type is string instead of Audio.
**Describe the solution you'd like**
I'd like to be able to specify the types of the column, so that when loading the dataset I directly get the feat... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3548/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3548/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4088 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4088/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4088/comments | https://api.github.com/repos/huggingface/datasets/issues/4088/events | https://github.com/huggingface/datasets/pull/4088 | 1,191,901,172 | PR_kwDODunzps41l4yE | 4,088 | Remove unused legacy Beam utils | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-04-04T14:43:51Z | 2022-04-05T15:23:27Z | 2022-04-05T15:17:41Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4088.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4088",
"merged_at": "2022-04-05T15:17:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4088.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR removes unused legacy custom `WriteToParquet`, once official Apache Beam includes the patch since version 2.22.0:
- Patch PR: https://github.com/apache/beam/pull/11699
- Issue: https://issues.apache.org/jira/browse/BEAM-10022
In relation with:
- #204 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4088/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4088/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4376/comments | https://api.github.com/repos/huggingface/datasets/issues/4376/events | https://github.com/huggingface/datasets/issues/4376 | 1,242,218,144 | I_kwDODunzps5KCr6g | 4,376 | irc_disentagle viewer error | {
"avatar_url": "https://avatars.githubusercontent.com/u/25671683?v=4",
"events_url": "https://api.github.com/users/labouz/events{/privacy}",
"followers_url": "https://api.github.com/users/labouz/followers",
"following_url": "https://api.github.com/users/labouz/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"DUPLICATED comment from https://github.com/huggingface/datasets/issues/3807:\r\n\r\nmy code:\r\n```\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"irc_disentangle\", download_mode=\"force_redownload\")\r\n```\r\nhowever, it produces the same error\r\n```\r\n[38](file:///Library/Frameworks/Pyt... | 2022-05-19T19:15:16Z | 2023-01-12T16:56:13Z | 2022-06-02T08:20:00Z | NONE | null | null | null | the dataviewer shows this message for "ubuntu" - "train", "test", and "validation" splits:
```
Server error
Status code: 400
Exception: ValueError
Message: Cannot seek streaming HTTP file
```
it appears to give the same message for the "channel_two" data as well.
I get a Checksums error when usi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4376/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4376/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1593 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1593/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1593/comments | https://api.github.com/repos/huggingface/datasets/issues/1593/events | https://github.com/huggingface/datasets/issues/1593 | 769,611,386 | MDU6SXNzdWU3Njk2MTEzODY= | 1,593 | Access to key in DatasetDict map | {
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Indeed that would be cool\r\n\r\nAlso FYI right now the easiest way to do this is\r\n```python\r\ndataset_dict[\"train\"] = dataset_dict[\"train\"].map(my_transform_for_the_train_set)\r\ndataset_dict[\"test\"] = dataset_dict[\"test\"].map(my_transform_for_the_test_set)\r\n```",
"I don't feel like adding an extra... | 2020-12-17T07:02:20Z | 2022-10-05T13:47:28Z | 2022-10-05T12:33:06Z | NONE | null | null | null | It is possible that we want to do different things in the `map` function (and possibly other functions too) of a `DatasetDict`, depending on the key. I understand that `DatasetDict.map` is a really thin wrapper of `Dataset.map`, so it is easy to directly implement this functionality in the client code. Still, it'd be n... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1593/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1593/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6000 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6000/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6000/comments | https://api.github.com/repos/huggingface/datasets/issues/6000/events | https://github.com/huggingface/datasets/pull/6000 | 1,782,456,878 | PR_kwDODunzps5UU_FB | 6,000 | Pin `joblib` to avoid `joblibspark` test failures | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-06-30T12:36:54Z | 2023-06-30T13:17:05Z | 2023-06-30T13:08:27Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6000.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6000",
"merged_at": "2023-06-30T13:08:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6000.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | `joblibspark` doesn't support the latest `joblib` release.
See https://github.com/huggingface/datasets/actions/runs/5401870932/jobs/9812337078 for the errors | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6000/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6000/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3003 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3003/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3003/comments | https://api.github.com/repos/huggingface/datasets/issues/3003/events | https://github.com/huggingface/datasets/pull/3003 | 1,014,137,933 | PR_kwDODunzps4smExP | 3,003 | common_language: Fix license in README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/227350?v=4",
"events_url": "https://api.github.com/users/jimregan/events{/privacy}",
"followers_url": "https://api.github.com/users/jimregan/followers",
"following_url": "https://api.github.com/users/jimregan/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [] | 2021-10-02T18:47:37Z | 2021-10-04T09:27:01Z | 2021-10-04T09:27:01Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3003.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3003",
"merged_at": "2021-10-04T09:27:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3003.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ...it's correct elsewhere | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3003/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3003/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3364 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3364/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3364/comments | https://api.github.com/repos/huggingface/datasets/issues/3364/events | https://github.com/huggingface/datasets/pull/3364 | 1,068,851,196 | PR_kwDODunzps4vRaxq | 3,364 | Use the Audio feature in the AutomaticSpeechRecognition template | {
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Cool !\r\n\r\nI noticed that you removed the `audio_file_path_column` field of the template, note that you also have to update all the dataset_infos.json file that still contain this outdated field. For example in the common_voice you can find this:\r\n```\r\n\"task_templates\": [{\"task\": \"automatic-speech-reco... | 2021-12-01T20:42:26Z | 2022-03-24T14:34:09Z | 2022-03-24T14:34:08Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3364.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3364",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3364.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3364"
} | This updates the ASR template and all supported datasets to use the `Audio` feature | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3364/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3364/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4338 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4338/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4338/comments | https://api.github.com/repos/huggingface/datasets/issues/4338/events | https://github.com/huggingface/datasets/pull/4338 | 1,234,478,851 | PR_kwDODunzps43vwsm | 4,338 | Eval metadata Batch 4: Tweet Eval, Tweets Hate Speech Detection, VCTK, Weibo NER, Wisesight Sentiment, XSum, Yahoo Answers Topics, Yelp Polarity, Yelp Review Full | {
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Summary of CircleCI errors:\r\n\r\n- **XSum**: missing 6 required positional arguments: 'annotations_creators', 'language_creators', 'licenses', 'multilinguality', 'size_categories', and 'source_datasets'\r\n- **Yelp_polarity**: missing 8 required positional arguments: 'annotations_creators', 'language_creators', ... | 2022-05-12T21:02:08Z | 2022-05-16T15:51:02Z | 2022-05-16T15:42:59Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4338.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4338",
"merged_at": "2022-05-16T15:42:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4338.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding evaluation metadata for:
- Tweet Eval
- Tweets Hate Speech Detection
- VCTK
- Weibo NER
- Wisesight Sentiment
- XSum
- Yahoo Answers Topics
- Yelp Polarity
- Yelp Review Full | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4338/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4338/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1632/comments | https://api.github.com/repos/huggingface/datasets/issues/1632/events | https://github.com/huggingface/datasets/issues/1632 | 774,388,625 | MDU6SXNzdWU3NzQzODg2MjU= | 1,632 | SICK dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [] | 2020-12-24T12:40:14Z | 2021-02-05T15:49:25Z | 2021-02-05T15:49:25Z | CONTRIBUTOR | null | null | null | Hi, this would be great to have this dataset included. I might be missing something, but I could not find it in the list of already included datasets. Thank you.
## Adding a Dataset
- **Name:** SICK
- **Description:** SICK consists of about 10,000 English sentence pairs that include many examples of the lexical,... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1632/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1632/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1941/comments | https://api.github.com/repos/huggingface/datasets/issues/1941/events | https://github.com/huggingface/datasets/issues/1941 | 815,985,167 | MDU6SXNzdWU4MTU5ODUxNjc= | 1,941 | Loading of FAISS index fails for index_name = 'exact' | {
"avatar_url": "https://avatars.githubusercontent.com/u/2992022?v=4",
"events_url": "https://api.github.com/users/mkserge/events{/privacy}",
"followers_url": "https://api.github.com/users/mkserge/followers",
"following_url": "https://api.github.com/users/mkserge/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Thanks for reporting ! I'm taking a look",
"Index training was missing, I fixed it here: https://github.com/huggingface/datasets/commit/f5986c46323583989f6ed1dabaf267854424a521\r\n\r\nCan you try again please ?",
"Works great 👍 I just put a minor comment on the commit, I think you meant to pass the `train_siz... | 2021-02-25T01:30:54Z | 2021-02-25T14:28:46Z | 2021-02-25T14:28:46Z | CONTRIBUTOR | null | null | null | Hi,
It looks like loading of FAISS index now fails when using index_name = 'exact'.
For example, from the RAG [model card](https://huggingface.co/facebook/rag-token-nq?fbclid=IwAR3bTfhls5U_t9DqsX2Vzb7NhtRHxJxfQ-uwFT7VuCPMZUM2AdAlKF_qkI8#usage).
Running `transformers==4.3.2` and datasets installed from source o... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1941/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1941/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2727/comments | https://api.github.com/repos/huggingface/datasets/issues/2727/events | https://github.com/huggingface/datasets/issues/2727 | 955,812,149 | MDU6SXNzdWU5NTU4MTIxNDk= | 2,727 | Error in loading the Arabic Billion Words Corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/9285264?v=4",
"events_url": "https://api.github.com/users/M-Salti/events{/privacy}",
"followers_url": "https://api.github.com/users/M-Salti/followers",
"following_url": "https://api.github.com/users/M-Salti/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"I modified the dataset loading script to catch the `IndexError` and inspect the records at which the error is happening, and I found this:\r\nFor the `Techreen` config, the error happens in 36 records when trying to find the `Text` or `Dateline` tags. All these 36 records look something like:\r\n```\r\n<Techreen>\... | 2021-07-29T12:53:09Z | 2021-07-30T13:03:55Z | 2021-07-30T13:03:55Z | CONTRIBUTOR | null | null | null | ## Describe the bug
I get `IndexError: list index out of range` when trying to load the `Techreen` and `Almustaqbal` configs of the dataset.
## Steps to reproduce the bug
```python
load_dataset("arabic_billion_words", "Techreen")
load_dataset("arabic_billion_words", "Almustaqbal")
```
## Expected results
Th... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2727/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5191 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5191/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5191/comments | https://api.github.com/repos/huggingface/datasets/issues/5191/events | https://github.com/huggingface/datasets/pull/5191 | 1,433,191,658 | PR_kwDODunzps5CD0Qp | 5,191 | Make torch.Tensor and spacy models cacheable | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-11-02T13:56:18Z | 2022-11-02T17:20:48Z | 2022-11-02T17:18:42Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5191.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5191",
"merged_at": "2022-11-02T17:18:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5191.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Override `Pickler.save` to implement deterministic reduction (lazily registered; inspired by https://github.com/uqfoundation/dill/blob/master/dill/_dill.py#L343) functions for `torch.Tensor` and spaCy models.
Fix https://github.com/huggingface/datasets/issues/5170, fix https://github.com/huggingface/datasets/issues/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5191/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5191/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1265/comments | https://api.github.com/repos/huggingface/datasets/issues/1265/events | https://github.com/huggingface/datasets/pull/1265 | 758,687,223 | MDExOlB1bGxSZXF1ZXN0NTMzODE4NjY0 | 1,265 | Add CovidQA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4341867?v=4",
"events_url": "https://api.github.com/users/olinguyen/events{/privacy}",
"followers_url": "https://api.github.com/users/olinguyen/followers",
"following_url": "https://api.github.com/users/olinguyen/following{/other_user}",
"gists_url": "h... | [] | closed | false | null | [] | null | [
"It seems to share the same name as this dataset: https://openreview.net/forum?id=JENSKEEzsoU",
"> It seems to share the same name as this dataset: https://openreview.net/forum?id=JENSKEEzsoU\r\n\r\nyou're right it can be confusing. I'll add the organization/research group for clarity: `covid_qa_castorini`. I add... | 2020-12-07T17:06:51Z | 2020-12-08T17:02:26Z | 2020-12-08T17:02:26Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1265.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1265",
"merged_at": "2020-12-08T17:02:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1265.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds CovidQA, a question answering dataset specifically designed for COVID-19, built by hand from knowledge gathered from Kaggle’s COVID-19 Open Research Dataset Challenge.
Link to the paper: https://arxiv.org/pdf/2004.11339.pdf
Link to the homepage: https://covidqa.ai | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1265/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1265/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2906 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2906/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2906/comments | https://api.github.com/repos/huggingface/datasets/issues/2906/events | https://github.com/huggingface/datasets/pull/2906 | 995,962,905 | PR_kwDODunzps4rulH- | 2,906 | feat: 🎸 add a function to get a dataset config's split names | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"> Should I add a section in https://github.com/huggingface/datasets/blob/master/docs/source/load_hub.rst? (there is no section for get_dataset_infos)\r\n\r\nYes totally :) This tutorial should indeed mention this, given how fundamental it is"
] | 2021-09-14T12:31:22Z | 2021-10-04T09:55:38Z | 2021-10-04T09:55:37Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2906.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2906",
"merged_at": "2021-10-04T09:55:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2906.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Also: pass additional arguments (use_auth_token) to get private configs + info of private datasets on the hub
Questions:
- [x] I'm not sure how the versions work: I changed 1.12.1.dev0 to 1.12.1.dev1, was it correct?
-> no: reverted
- [x] Should I add a section in https://github.com/huggingface/datasets/blo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2906/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2906/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4727/comments | https://api.github.com/repos/huggingface/datasets/issues/4727/events | https://github.com/huggingface/datasets/issues/4727 | 1,312,645,391 | I_kwDODunzps5OPWEP | 4,727 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"The preview is working OK:\r\n\r\n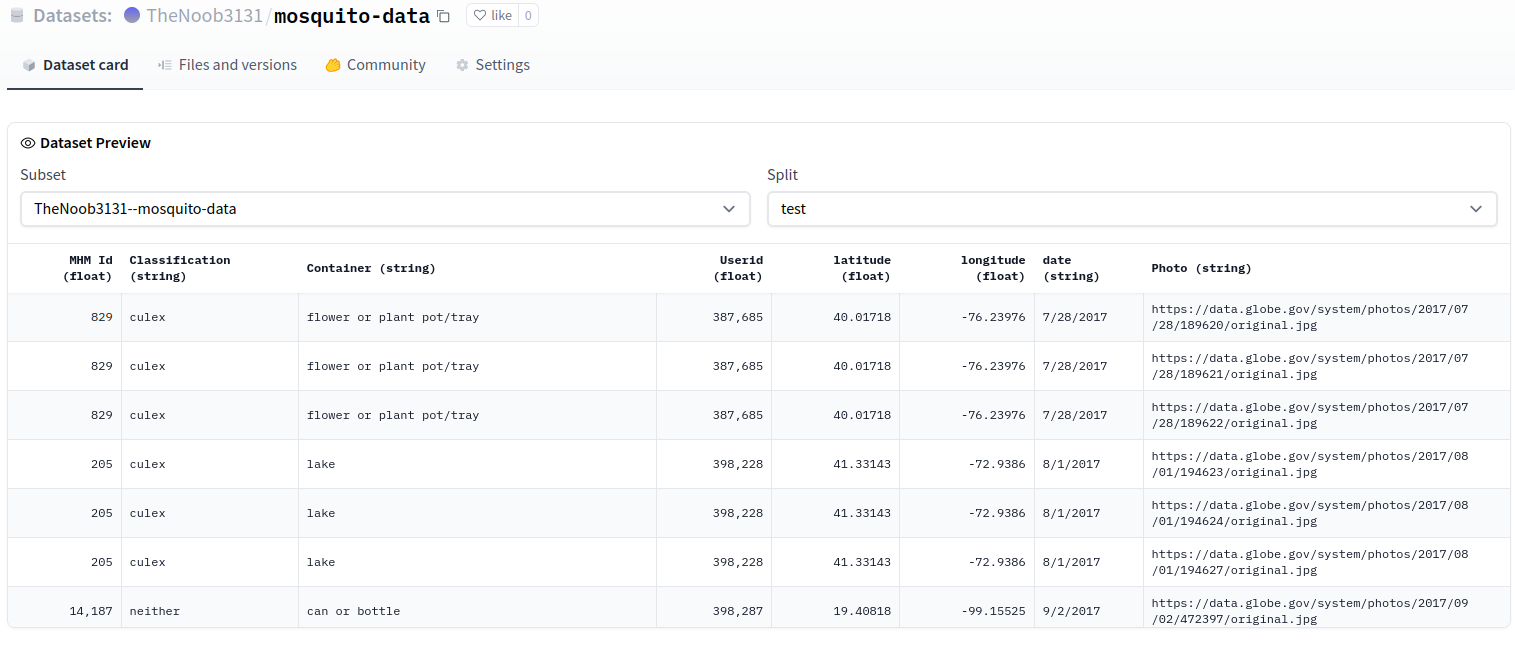\r\n\r\n"
] | 2022-07-21T05:24:48Z | 2022-07-21T07:51:56Z | 2022-07-21T07:45:01Z | NONE | null | null | null | ### Link
https://huggingface.co/datasets/TheNoob3131/mosquito-data/viewer/TheNoob3131--mosquito-data/test
### Description
Dataset preview not showing with large files. Says 'split cache is empty' even though there are train and test splits.
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4727/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1240 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1240/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1240/comments | https://api.github.com/repos/huggingface/datasets/issues/1240/events | https://github.com/huggingface/datasets/pull/1240 | 758,355,523 | MDExOlB1bGxSZXF1ZXN0NTMzNTQxNjk5 | 1,240 | Multi Domain Sentiment Analysis Dataset (MDSA) | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"can you also run `make style` to format the code ?",
"I'll come back to this one in sometime :) @lhoestq ",
"Also if you would use `xml.etree.ElementTree` to parse the XML it would be awesome, because right now you're using an external dependency `xmltodict `",
"> Also if you would use xml.etree.ElementTree ... | 2020-12-07T09:57:15Z | 2023-09-24T09:40:59Z | 2022-10-03T09:39:43Z | MEMBER | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1240.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1240",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1240.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1240"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1240/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1240/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4619/comments | https://api.github.com/repos/huggingface/datasets/issues/4619/events | https://github.com/huggingface/datasets/issues/4619 | 1,292,107,275 | I_kwDODunzps5NA_4L | 4,619 | np arrays get turned into native lists | {
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"If you add the line `dataset2.set_format('np')` before calling `dataset2[0]['tmp']` it should return `np.ndarray`.\r\nI believe internally it will not store it as a list, it is only returning a list when you index it.\r\n\r\n```\r\nIn [1]: import datasets, numpy as np\r\nIn [2]: dataset = datasets.load_dataset(\"g... | 2022-07-02T17:54:57Z | 2022-07-03T20:27:07Z | null | NONE | null | null | null | ## Describe the bug
When attaching an `np.array` field, it seems that it automatically gets turned into a list (see below). Why is this happening? Could it lose precision? Is there a way to make sure this doesn't happen?
## Steps to reproduce the bug
```python
>>> import datasets, numpy as np
>>> dataset = datas... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4619/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4619/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3599/comments | https://api.github.com/repos/huggingface/datasets/issues/3599/events | https://github.com/huggingface/datasets/issues/3599 | 1,108,111,607 | I_kwDODunzps5CDHD3 | 3,599 | The `add_column()` method does not work if used on dataset sliced with `select()` | {
"avatar_url": "https://avatars.githubusercontent.com/u/59422506?v=4",
"events_url": "https://api.github.com/users/ThGouzias/events{/privacy}",
"followers_url": "https://api.github.com/users/ThGouzias/followers",
"following_url": "https://api.github.com/users/ThGouzias/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"similar #3611 "
] | 2022-01-19T13:36:50Z | 2022-01-28T15:35:57Z | 2022-01-28T15:35:57Z | NONE | null | null | null | Hello, I posted this as a question on the forums ([here](https://discuss.huggingface.co/t/add-column-does-not-work-if-used-on-dataset-sliced-with-select/13893)):
I have a dataset with 2000 entries
> dataset = Dataset.from_dict({'colA': list(range(2000))})
and from which I want to extract the first one thousan... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3599/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3599/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5349 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5349/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5349/comments | https://api.github.com/repos/huggingface/datasets/issues/5349/events | https://github.com/huggingface/datasets/pull/5349 | 1,487,396,780 | PR_kwDODunzps5E8N6G | 5,349 | Clean up remaining Main Classes docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-09T20:17:15Z | 2022-12-12T17:27:17Z | 2022-12-12T17:24:13Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5349.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5349",
"merged_at": "2022-12-12T17:24:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5349.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR cleans up the remaining docstrings in Main Classes (`IterableDataset`, `IterableDatasetDict`, and `Features`). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5349/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5349/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1978 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1978/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1978/comments | https://api.github.com/repos/huggingface/datasets/issues/1978/events | https://github.com/huggingface/datasets/pull/1978 | 820,956,806 | MDExOlB1bGxSZXF1ZXN0NTgzODI5Njgz | 1,978 | Adding ro sts dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/36982089?v=4",
"events_url": "https://api.github.com/users/lorinczb/events{/privacy}",
"followers_url": "https://api.github.com/users/lorinczb/followers",
"following_url": "https://api.github.com/users/lorinczb/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"@lhoestq thank you very much for the quick review and useful comments! \r\n\r\nI have tried to address them all, and a few comments that you left for ro_sts I have applied to the ro_sts_parallel as well (in read-me: fixed source_datasets, links to homepage, repository, leaderboard, thanks to me message, in ro_sts_... | 2021-03-03T10:08:53Z | 2021-03-05T10:00:14Z | 2021-03-05T09:33:55Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1978.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1978",
"merged_at": "2021-03-05T09:33:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1978.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding [RO-STS](https://github.com/dumitrescustefan/RO-STS) dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1978/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1978/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2806 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2806/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2806/comments | https://api.github.com/repos/huggingface/datasets/issues/2806/events | https://github.com/huggingface/datasets/pull/2806 | 971,625,449 | MDExOlB1bGxSZXF1ZXN0NzEzMzM5NDUw | 2,806 | Fix streaming tar files from canonical datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"In case it's relevant for this PR, I'm finding that I cannot stream the `bookcorpus` dataset (using the `master` branch of `datasets`), which is a `.tar.bz2` file:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nbooks_dataset_streamed = load_dataset(\"bookcorpus\", split=\"train\", streaming=True)\r\n... | 2021-08-16T11:10:28Z | 2021-10-13T09:04:03Z | 2021-10-13T09:04:02Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2806.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2806",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2806.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2806"
} | Previous PR #2800 implemented support to stream remote tar files when passing the parameter `data_files`: they required a glob string `"*"`.
However, this glob string creates an error when streaming canonical datasets (with a `join` after the `open`).
This PR fixes this issue and allows streaming tar files both f... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2806/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2806/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1769 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1769/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1769/comments | https://api.github.com/repos/huggingface/datasets/issues/1769/events | https://github.com/huggingface/datasets/issues/1769 | 792,523,284 | MDU6SXNzdWU3OTI1MjMyODQ= | 1,769 | _pickle.PicklingError: Can't pickle typing.Union[str, NoneType]: it's not the same object as typing.Union when calling datasets.map with num_proc=2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/14048129?v=4",
"events_url": "https://api.github.com/users/shuaihuaiyi/events{/privacy}",
"followers_url": "https://api.github.com/users/shuaihuaiyi/followers",
"following_url": "https://api.github.com/users/shuaihuaiyi/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"More information: `run_mlm.py` will raise same error when `data_args.line_by_line==True`\r\n\r\nhttps://github.com/huggingface/transformers/blob/9152f16023b59d262b51573714b40325c8e49370/examples/language-modeling/run_mlm.py#L300\r\n",
"Hi ! What version of python and datasets do you have ? And also what version ... | 2021-01-23T10:13:00Z | 2022-10-05T12:38:51Z | 2022-10-05T12:38:51Z | NONE | null | null | null | It may be a bug of multiprocessing with Datasets, when I disable the multiprocessing by set num_proc to None, everything works fine.
The script I use is https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm_wwm.py
Script args:
```
--model_name_or_path
../../../model/chine... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1769/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1769/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5032 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5032/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5032/comments | https://api.github.com/repos/huggingface/datasets/issues/5032/events | https://github.com/huggingface/datasets/issues/5032 | 1,388,270,935 | I_kwDODunzps5Sv1VX | 5,032 | new dataset type: single-label and multi-label video classification | {
"avatar_url": "https://avatars.githubusercontent.com/u/34196005?v=4",
"events_url": "https://api.github.com/users/fcakyon/events{/privacy}",
"followers_url": "https://api.github.com/users/fcakyon/followers",
"following_url": "https://api.github.com/users/fcakyon/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! You can in the `features` folder how we implemented the audio and image feature types.\r\n\r\nWe can have something similar to videos. What we need to decide:\r\n- the video loading library to use\r\n- the output format when a user accesses a video type object\r\n- what parameters a `Video()` feature type nee... | 2022-09-27T19:40:11Z | 2022-11-02T19:10:13Z | null | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
In my research, I am dealing with multi-modal (audio+text+frame sequence) video classification. It would be great if the datasets library supported generating multi-modal batches from a video dataset.
**Describe the solution you'd like**
Assume I h... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5032/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5032/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3637/comments | https://api.github.com/repos/huggingface/datasets/issues/3637/events | https://github.com/huggingface/datasets/issues/3637 | 1,115,526,438 | I_kwDODunzps5CfZUm | 3,637 | [TypeError: Couldn't cast array of type] Cannot load dataset in v1.18 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @lewtun!\r\n \r\nThis one was tricky to debug. Initially, I tought there is a bug in the recently-added (by @lhoestq ) `cast_array_to_feature` function because `git bisect` points to the https://github.com/huggingface/datasets/commit/6ca96c707502e0689f9b58d94f46d871fa5a3c9c commit. Then, I noticed that the feat... | 2022-01-26T21:38:02Z | 2022-02-09T16:15:53Z | 2022-02-09T16:15:53Z | MEMBER | null | null | null | ## Describe the bug
I am trying to load the [`GEM/RiSAWOZ` dataset](https://huggingface.co/datasets/GEM/RiSAWOZ) in `datasets` v1.18.1 and am running into a type error when casting the features. The strange thing is that I can load the dataset with v1.17.0. Note that the error is also present if I install from `master... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3637/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3637/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5858 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5858/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5858/comments | https://api.github.com/repos/huggingface/datasets/issues/5858/events | https://github.com/huggingface/datasets/issues/5858 | 1,709,332,632 | I_kwDODunzps5l4liY | 5,858 | Throw an error when dataset improperly indexed | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "http... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @sarahwie.\r\n\r\nPlease note that in `datasets` we do not have vectorized operation like `pandas`. Therefore, your equality comparisons above are `False`:\r\n- For example: `squad['question']` returns a `list`, and this list is not equal to `\"Who was the Norse leader?\"`\r\n\r\nThe `False` ... | 2023-05-15T05:15:53Z | 2023-05-25T16:23:19Z | 2023-05-25T16:23:19Z | NONE | null | null | null | ### Describe the bug
Pandas-style subset indexing on dataset does not throw an error, when maybe it should. Instead returns the first instance of the dataset regardless of index condition.
### Steps to reproduce the bug
Steps to reproduce the behavior:
1. `squad = datasets.load_dataset("squad_v2", split="validati... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5858/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5858/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5691/comments | https://api.github.com/repos/huggingface/datasets/issues/5691/events | https://github.com/huggingface/datasets/pull/5691 | 1,649,737,526 | PR_kwDODunzps5NX08d | 5,691 | [docs] Compress data files | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"[Confirmed](https://huggingface.slack.com/archives/C02EMARJ65P/p1680541667004199) with the Hub team the file size limit for the Hugging Face Hub is 10MB :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<deta... | 2023-03-31T17:17:26Z | 2023-04-19T13:37:32Z | 2023-04-19T07:25:58Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5691.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5691",
"merged_at": "2023-04-19T07:25:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5691.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR addresses the comments in #5687 about compressing text file extensions before uploading to the Hub. Also clarified what "too large" means based on the GitLFS [docs](https://docs.github.com/en/repositories/working-with-files/managing-large-files/about-git-large-file-storage). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5691/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5691/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3323 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3323/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3323/comments | https://api.github.com/repos/huggingface/datasets/issues/3323/events | https://github.com/huggingface/datasets/pull/3323 | 1,064,660,452 | PR_kwDODunzps4vEZwq | 3,323 | Fix wrongly converted assert | {
"avatar_url": "https://avatars.githubusercontent.com/u/19492473?v=4",
"events_url": "https://api.github.com/users/eliasws/events{/privacy}",
"followers_url": "https://api.github.com/users/eliasws/followers",
"following_url": "https://api.github.com/users/eliasws/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Closes #3327 "
] | 2021-11-26T16:05:39Z | 2021-11-26T16:44:12Z | 2021-11-26T16:44:11Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3323.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3323",
"merged_at": "2021-11-26T16:44:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3323.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Seems like this assertion was replaced by an exception but the condition got wrongly converted. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3323/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3323/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2818 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2818/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2818/comments | https://api.github.com/repos/huggingface/datasets/issues/2818/events | https://github.com/huggingface/datasets/issues/2818 | 974,552,009 | MDU6SXNzdWU5NzQ1NTIwMDk= | 2,818 | cannot load data from my loacal path | {
"avatar_url": "https://avatars.githubusercontent.com/u/46920280?v=4",
"events_url": "https://api.github.com/users/yang-collect/events{/privacy}",
"followers_url": "https://api.github.com/users/yang-collect/followers",
"following_url": "https://api.github.com/users/yang-collect/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! The `data_files` parameter must be a string, a list/tuple or a python dict.\r\n\r\nCan you check the type of your `config.train_path` please ? Or use `data_files=str(config.train_path)` ?"
] | 2021-08-19T11:13:30Z | 2023-07-25T17:42:15Z | 2023-07-25T17:42:15Z | NONE | null | null | null | ## Describe the bug
I just want to directly load data from my local path,but find a bug.And I compare it with pandas to provide my local path is real.
here is my code
```python3
# print my local path
print(config.train_path)
# read data and print data length
tarin=pd.read_csv(config.train_path)
print(len(tari... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2818/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2818/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5023 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5023/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5023/comments | https://api.github.com/repos/huggingface/datasets/issues/5023/events | https://github.com/huggingface/datasets/issues/5023 | 1,385,881,112 | I_kwDODunzps5Smt4Y | 5,023 | Text strings are split into lists of characters in xcsr dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-09-26T11:11:50Z | 2022-09-28T07:54:20Z | 2022-09-28T07:54:20Z | MEMBER | null | null | null | ## Describe the bug
Text strings are split into lists of characters.
Example for "X-CSQA-en":
```
{'id': 'd3845adc08414fda',
'lang': 'en',
'question': {'stem': ['T',
'h',
'e',
' ',
'd',
'e',
'n',
't',
'a',
'l',
' ',
'o',
'f',
'f',
'i',
'c',
'e',
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5023/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5023/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3990 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3990/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3990/comments | https://api.github.com/repos/huggingface/datasets/issues/3990/events | https://github.com/huggingface/datasets/issues/3990 | 1,176,976,247 | I_kwDODunzps5GJzt3 | 3,990 | Improve AutomaticSpeechRecognition task template | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"There is an open PR to do that: #3364. I just haven't had time to finish it... ",
"> There is an open PR to do that: #3364. I just haven't had time to finish it...\r\n\r\n😬 thanks..."
] | 2022-03-22T15:41:08Z | 2022-03-23T17:12:40Z | 2022-03-23T17:12:40Z | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
[AutomaticSpeechRecognition task template](https://github.com/huggingface/datasets/blob/master/src/datasets/tasks/automatic_speech_recognition.py) is outdated as it uses path to audiofile as an audio column instead of a Audio feature itself (I guess it... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3990/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3990/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3958 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3958/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3958/comments | https://api.github.com/repos/huggingface/datasets/issues/3958/events | https://github.com/huggingface/datasets/pull/3958 | 1,172,657,981 | PR_kwDODunzps40nQU2 | 3,958 | Update Wikipedia metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3958). All of your documentation changes will be reflected on that endpoint.",
"Once this last PR validated, I can take care of the integration of all the wikipedia update branch into master, @lhoestq. "
] | 2022-03-17T17:50:05Z | 2022-03-21T12:26:48Z | 2022-03-21T12:26:47Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3958.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3958",
"merged_at": "2022-03-21T12:26:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3958.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR updates:
- dataset card
- metadata JSON | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3958/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3958/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1730/comments | https://api.github.com/repos/huggingface/datasets/issues/1730/events | https://github.com/huggingface/datasets/pull/1730 | 784,617,525 | MDExOlB1bGxSZXF1ZXN0NTUzNzgxMDY0 | 1,730 | Add MNIST dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-01-12T21:48:02Z | 2021-01-13T10:19:47Z | 2021-01-13T10:19:46Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1730.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1730",
"merged_at": "2021-01-13T10:19:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1730.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds the MNIST dataset to the library. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1730/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1730/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2353/comments | https://api.github.com/repos/huggingface/datasets/issues/2353/events | https://github.com/huggingface/datasets/pull/2353 | 890,296,262 | MDExOlB1bGxSZXF1ZXN0NjQzMzM4MDcz | 2,353 | Update README vallidation rules | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-05-12T16:57:26Z | 2021-05-14T08:56:06Z | 2021-05-14T08:56:06Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2353.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2353",
"merged_at": "2021-05-14T08:56:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2353.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR allows unexpected subsections under third-level headings. All except `Contributions`.
@lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2353/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4973 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4973/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4973/comments | https://api.github.com/repos/huggingface/datasets/issues/4973/events | https://github.com/huggingface/datasets/pull/4973 | 1,371,600,074 | PR_kwDODunzps4-33JW | 4,973 | [GH->HF] Load datasets from the Hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Duplicate of:\r\n- #4059"
] | 2022-09-13T15:01:41Z | 2023-09-24T10:06:02Z | 2022-09-15T15:24:26Z | MEMBER | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4973.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4973",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4973.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4973"
} | Currently datasets with no namespace (e.g. squad, glue) are loaded from github.
In this PR I changed this logic to use the Hugging Face Hub instead.
This is the first step in removing all the dataset scripts in this repository
related to discussions in https://github.com/huggingface/datasets/pull/4059 (I shoul... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4973/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4973/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1336 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1336/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1336/comments | https://api.github.com/repos/huggingface/datasets/issues/1336/events | https://github.com/huggingface/datasets/pull/1336 | 759,706,932 | MDExOlB1bGxSZXF1ZXN0NTM0NjY0NjIw | 1,336 | Add dataset Yoruba BBC Topic Classification | {
"avatar_url": "https://avatars.githubusercontent.com/u/1858628?v=4",
"events_url": "https://api.github.com/users/michael-aloys/events{/privacy}",
"followers_url": "https://api.github.com/users/michael-aloys/followers",
"following_url": "https://api.github.com/users/michael-aloys/following{/other_user}",
"gi... | [] | closed | false | null | [] | null | [] | 2020-12-08T19:12:18Z | 2020-12-10T11:27:41Z | 2020-12-10T11:27:41Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1336.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1336",
"merged_at": "2020-12-10T11:27:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1336.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Added new dataset Yoruba BBC Topic Classification
Contains loading script as well as dataset card including YAML tags. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1336/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1336/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3329 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3329/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3329/comments | https://api.github.com/repos/huggingface/datasets/issues/3329/events | https://github.com/huggingface/datasets/issues/3329 | 1,065,096,971 | I_kwDODunzps4_fBcL | 3,329 | Map function: Type error on iter #999 | {
"avatar_url": "https://avatars.githubusercontent.com/u/52659318?v=4",
"events_url": "https://api.github.com/users/josephkready666/events{/privacy}",
"followers_url": "https://api.github.com/users/josephkready666/followers",
"following_url": "https://api.github.com/users/josephkready666/following{/other_user}"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi, thanks for reporting.\r\n\r\nIt would be really helpful if you could provide the actual code of the `text_numbers_to_int` function so we can reproduce the error.",
"```\r\ndef text_numbers_to_int(text, column=\"\"):\r\n \"\"\"\r\n Convert text numbers to int.\r\n\r\n :param text: text numbers\r\n ... | 2021-11-27T17:53:05Z | 2021-11-29T20:40:15Z | 2021-11-29T20:40:15Z | NONE | null | null | null | ## Describe the bug
Using the map function, it throws a type error on iter #999
Here is the code I am calling:
```
dataset = datasets.load_dataset('squad')
dataset['validation'].map(text_numbers_to_int, input_columns=['context'], fn_kwargs={'column': 'context'})
```
text_numbers_to_int returns the input text ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3329/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3329/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2997 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2997/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2997/comments | https://api.github.com/repos/huggingface/datasets/issues/2997/events | https://github.com/huggingface/datasets/issues/2997 | 1,013,270,069 | I_kwDODunzps48ZUY1 | 2,997 | Dataset has incorrect labels | {
"avatar_url": "https://avatars.githubusercontent.com/u/63367770?v=4",
"events_url": "https://api.github.com/users/marshmellow77/events{/privacy}",
"followers_url": "https://api.github.com/users/marshmellow77/followers",
"following_url": "https://api.github.com/users/marshmellow77/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"Hi @marshmellow77, thanks for reporting.\r\n\r\nThat issue is fixed since `datasets` version 1.9.0 (see 16bc665f2753677c765011ef79c84e55486d4347).\r\n\r\nPlease, update `datasets` with: `pip install -U datasets`",
"Thanks. Please note that the dataset explorer (https://huggingface.co/datasets/viewer/?dataset=tur... | 2021-10-01T12:09:06Z | 2021-10-01T15:32:00Z | 2021-10-01T13:54:34Z | NONE | null | null | null | The dataset https://huggingface.co/datasets/turkish_product_reviews has incorrect labels - all reviews are labelled with "1" (positive sentiment). None of the reviews is labelled with "0". See screenshot attached:
 and the map function ran much slower:
````
def save_tokenizer(original_tokenizer,text,path="simpledata/tokenizer"):
words_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1830/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1830/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1594/comments | https://api.github.com/repos/huggingface/datasets/issues/1594/events | https://github.com/huggingface/datasets/issues/1594 | 769,747,767 | MDU6SXNzdWU3Njk3NDc3Njc= | 1,594 | connection error | {
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/followin... | [] | closed | false | null | [] | null | [
"This happen quite often when they are too many concurrent requests to github.\r\n\r\ni can understand it’s a bit cumbersome to handle on the user side. Maybe we should try a few times in the lib (eg with timeout) before failing, what do you think @lhoestq ?",
"Yes currently there's no retry afaik. We should add ... | 2020-12-17T09:18:34Z | 2022-06-01T15:33:42Z | 2022-06-01T15:33:41Z | NONE | null | null | null | Hi
I am hitting to this error, thanks
```
> Traceback (most recent call last):
File "finetune_t5_trainer.py", line 379, in <module>
main()
File "finetune_t5_trainer.py", line 208, in main
if training_args.do_eval or training_args.evaluation_strategy != EvaluationStrategy.NO
File "finetune_t5_tr... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1594/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5508 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5508/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5508/comments | https://api.github.com/repos/huggingface/datasets/issues/5508/events | https://github.com/huggingface/datasets/issues/5508 | 1,573,290,359 | I_kwDODunzps5dxoF3 | 5,508 | Saving a dataset after setting format to torch doesn't work, but only if filtering | {
"avatar_url": "https://avatars.githubusercontent.com/u/13984157?v=4",
"events_url": "https://api.github.com/users/joebhakim/events{/privacy}",
"followers_url": "https://api.github.com/users/joebhakim/followers",
"following_url": "https://api.github.com/users/joebhakim/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Hey, I'm a research engineer working on language modelling wanting to contribute to open source. I was wondering if I could give it a shot?",
"Hi! This issue was fixed in https://github.com/huggingface/datasets/pull/4972, so please install `datasets>=2.5.0` to avoid it."
] | 2023-02-06T21:08:58Z | 2023-02-09T14:55:26Z | 2023-02-09T14:55:26Z | NONE | null | null | null | ### Describe the bug
Saving a dataset after setting format to torch doesn't work, but only if filtering
### Steps to reproduce the bug
```
a = Dataset.from_dict({"b": [1, 2]})
a.set_format('torch')
a.save_to_disk("test_save") # saves successfully
a.filter(None).save_to_disk("test_save_filter") # does not
>> [..... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5508/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5508/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4374/comments | https://api.github.com/repos/huggingface/datasets/issues/4374/events | https://github.com/huggingface/datasets/issues/4374 | 1,241,860,535 | I_kwDODunzps5KBUm3 | 4,374 | extremely slow processing when using a custom dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/32235549?v=4",
"events_url": "https://api.github.com/users/StephennFernandes/events{/privacy}",
"followers_url": "https://api.github.com/users/StephennFernandes/followers",
"following_url": "https://api.github.com/users/StephennFernandes/following{/other_... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "d876e3",
"default": true,
"descript... | closed | false | null | [] | null | [
"Hi !\r\n\r\nMy guess is that some examples in your dataset are bigger than your RAM, and therefore loading them in RAM to pass them to `remove_non_indic_sentences` takes forever because it might use SWAP memory.\r\n\r\nMaybe several examples in your dataset are grouped together, can you check `len(lang_dataset[\"t... | 2022-05-19T14:18:05Z | 2023-07-25T15:07:17Z | 2023-07-25T15:07:16Z | NONE | null | null | null | ## processing a custom dataset loaded as .txt file is extremely slow, compared to a dataset of similar volume from the hub
I have a large .txt file of 22 GB which i load into HF dataset
`lang_dataset = datasets.load_dataset("text", data_files="hi.txt")`
further i use a pre-processing function to clean the d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4374/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4374/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3234 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3234/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3234/comments | https://api.github.com/repos/huggingface/datasets/issues/3234/events | https://github.com/huggingface/datasets/pull/3234 | 1,047,634,236 | PR_kwDODunzps4uPHRk | 3,234 | Avoid PyArrow type optimization if it fails | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"That's good to have a way to disable this easily :)\r\nI just find it a bit unfortunate that users would have to experience the error once and then do `DISABLE_PYARROW_TYPES_OPTIMIZATION=1`. Do you know if there's a way to simply fallback on disabling it automatically when it fails ?",
"@lhoestq Actually, I agre... | 2021-11-08T16:10:27Z | 2021-11-10T12:04:29Z | 2021-11-10T12:04:28Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3234.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3234",
"merged_at": "2021-11-10T12:04:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3234.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adds a new variable, `DISABLE_PYARROW_TYPES_OPTIMIZATION`, to `config.py` for easier control of the Arrow type optimization.
Fix #2206 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3234/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3234/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3605/comments | https://api.github.com/repos/huggingface/datasets/issues/3605/events | https://github.com/huggingface/datasets/pull/3605 | 1,108,738,561 | PR_kwDODunzps4xS9rX | 3,605 | Adding Turkic X-WMT evaluation set for machine translation | {
"avatar_url": "https://avatars.githubusercontent.com/u/26018417?v=4",
"events_url": "https://api.github.com/users/mirzakhalov/events{/privacy}",
"followers_url": "https://api.github.com/users/mirzakhalov/followers",
"following_url": "https://api.github.com/users/mirzakhalov/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"hi! Thank you for all the comments! I believe I addressed them all. Let me know if there is anything else",
"Hi there! I was wondering if there is anything else to change before this can be merged",
"@lhoestq Hi! Just a gentle reminder about the steps to merge this one! ",
"Thanks for the heads up ! I think ... | 2022-01-20T01:40:29Z | 2022-01-31T09:50:57Z | 2022-01-31T09:50:57Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3605.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3605",
"merged_at": "2022-01-31T09:50:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3605.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This dataset is a human-translated evaluation set for MT crowdsourced and provided by the [Turkic Interlingua ](turkic-interlingua.org) community. It contains eval sets for 8 Turkic languages covering 88 language directions. Languages being covered are:
Azerbaijani (az)
Bashkir (ba)
English (en)
Karakalpak (kaa)
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3605/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3605/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5366/comments | https://api.github.com/repos/huggingface/datasets/issues/5366/events | https://github.com/huggingface/datasets/pull/5366 | 1,498,530,851 | PR_kwDODunzps5FjSFl | 5,366 | ExamplesIterable fixes | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-15T14:23:05Z | 2022-12-15T14:44:47Z | 2022-12-15T14:41:45Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5366.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5366",
"merged_at": "2022-12-15T14:41:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5366.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | fix typing and ExamplesIterable.shard_data_sources | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5366/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5366/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4321 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4321/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4321/comments | https://api.github.com/repos/huggingface/datasets/issues/4321/events | https://github.com/huggingface/datasets/pull/4321 | 1,233,273,351 | PR_kwDODunzps43ryW7 | 4,321 | Adding dataset enwik8 | {
"avatar_url": "https://avatars.githubusercontent.com/u/22773355?v=4",
"events_url": "https://api.github.com/users/HallerPatrick/events{/privacy}",
"followers_url": "https://api.github.com/users/HallerPatrick/followers",
"following_url": "https://api.github.com/users/HallerPatrick/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"@lhoestq Thank you for the great feedback! Looks like all tests are passing now :)",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-05-11T23:25:02Z | 2022-06-01T14:27:30Z | 2022-06-01T14:04:06Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4321.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4321",
"merged_at": "2022-06-01T14:04:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4321.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Because I regularly work with enwik8, I would like to contribute the dataset loader 🤗 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4321/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4321/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5528 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5528/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5528/comments | https://api.github.com/repos/huggingface/datasets/issues/5528/events | https://github.com/huggingface/datasets/pull/5528 | 1,582,195,085 | PR_kwDODunzps5J13wC | 5,528 | Push to hub in a pull request | {
"avatar_url": "https://avatars.githubusercontent.com/u/38854604?v=4",
"events_url": "https://api.github.com/users/AJDERS/events{/privacy}",
"followers_url": "https://api.github.com/users/AJDERS/followers",
"following_url": "https://api.github.com/users/AJDERS/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5528). All of your documentation changes will be reflected on that endpoint.",
"It seems that the parameter `create_pr` is available for [`0.8.0`](https://huggingface.co/docs/huggingface_hub/v0.8.1/en/package_reference/hf_api#h... | 2023-02-13T11:43:47Z | 2023-10-06T21:58:02Z | null | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5528.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5528",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5528.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5528"
} | Fixes #5492.
Introduce new kwarg `create_pr` in `push_to_hub`, which is passed to `HFapi.upload_file`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5528/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5528/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5893 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5893/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5893/comments | https://api.github.com/repos/huggingface/datasets/issues/5893/events | https://github.com/huggingface/datasets/pull/5893 | 1,722,519,056 | PR_kwDODunzps5RK40K | 5,893 | Load cached dataset as iterable | {
"avatar_url": "https://avatars.githubusercontent.com/u/10278877?v=4",
"events_url": "https://api.github.com/users/mariusz-jachimowicz-83/events{/privacy}",
"followers_url": "https://api.github.com/users/mariusz-jachimowicz-83/followers",
"following_url": "https://api.github.com/users/mariusz-jachimowicz-83/fo... | [] | closed | false | null | [] | null | [
"@lhoestq Could you please look into that and review?",
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq I refactored the code. Could you please check is it what you requested?",
"@lhoestq Thanks for a review. Excellent tips. All tips applied. ",
"I think there is j... | 2023-05-23T17:40:35Z | 2023-06-01T11:58:24Z | 2023-06-01T11:51:29Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5893.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5893",
"merged_at": "2023-06-01T11:51:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5893.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | To be used to train models it allows to load an IterableDataset from the cached Arrow file.
See https://github.com/huggingface/datasets/issues/5481 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5893/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5893/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5224 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5224/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5224/comments | https://api.github.com/repos/huggingface/datasets/issues/5224/events | https://github.com/huggingface/datasets/issues/5224 | 1,443,640,867 | I_kwDODunzps5WDDYj | 5,224 | Seems to freeze when loading audio dataset with wav files from local folder | {
"avatar_url": "https://avatars.githubusercontent.com/u/45894267?v=4",
"events_url": "https://api.github.com/users/uriii3/events{/privacy}",
"followers_url": "https://api.github.com/users/uriii3/followers",
"following_url": "https://api.github.com/users/uriii3/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"I just tried to do the same but changing the `.wav` files to `.mp3` files and that doesn't fix it.",
"I don't know if anyone will ever read this but I've tried to upload the same dataset with google colab and the output seems more clarifying. I didn't specify the train/test split so the dataset wasn't fully uplo... | 2022-11-10T10:29:31Z | 2023-04-25T09:54:05Z | 2022-11-22T11:24:19Z | NONE | null | null | null | ### Describe the bug
I'm following the instructions in [https://huggingface.co/docs/datasets/audio_load#audiofolder-with-metadata](url) to be able to load a dataset from a local folder.
I have everything into a folder, into a train folder and then the audios and csv. When I try to load the dataset and run from term... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5224/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5224/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5288 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5288/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5288/comments | https://api.github.com/repos/huggingface/datasets/issues/5288/events | https://github.com/huggingface/datasets/issues/5288 | 1,462,134,067 | I_kwDODunzps5XJmUz | 5,288 | Lossy json serialization - deserialization of dataset info | {
"avatar_url": "https://avatars.githubusercontent.com/u/57542204?v=4",
"events_url": "https://api.github.com/users/anuragprat1k/events{/privacy}",
"followers_url": "https://api.github.com/users/anuragprat1k/followers",
"following_url": "https://api.github.com/users/anuragprat1k/following{/other_user}",
"gist... | [] | open | false | null | [] | null | [
"Hi ! JSON is a lossy format indeed. If you want to keep the feature types or other metadata I'd encourage you to store them as well. For example you can use `dataset.info.write_to_directory` and `DatasetInfo.from_directory` to store the feature types, split info, description, license etc."
] | 2022-11-23T17:20:15Z | 2022-11-25T12:53:51Z | null | NONE | null | null | null | ### Describe the bug
Saving a dataset to disk as json (using `to_json`) and then loading it again (using `load_dataset`) results in features whose labels are not type-cast correctly. In the code snippet below, `features.label` should have a label of type `ClassLabel` but has type `Value` instead.
### Steps to re... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5288/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5288/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3228 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3228/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3228/comments | https://api.github.com/repos/huggingface/datasets/issues/3228/events | https://github.com/huggingface/datasets/pull/3228 | 1,046,702,143 | PR_kwDODunzps4uMJ58 | 3,228 | Add CITATION file | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-11-07T09:40:19Z | 2021-11-07T09:51:47Z | 2021-11-07T09:51:46Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3228.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3228",
"merged_at": "2021-11-07T09:51:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3228.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add CITATION file. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3228/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3228/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4778 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4778/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4778/comments | https://api.github.com/repos/huggingface/datasets/issues/4778/events | https://github.com/huggingface/datasets/pull/4778 | 1,324,928,750 | PR_kwDODunzps48dRPh | 4,778 | Update local loading script docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4778). All of your documentation changes will be reflected on that endpoint.",
"I would rather have a section in the docs that explains how to modify the script of an existing dataset (`inspect_dataset` + modification + `load_d... | 2022-08-01T20:21:07Z | 2022-08-23T16:32:26Z | 2022-08-23T16:32:22Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4778.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4778",
"merged_at": "2022-08-23T16:32:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4778.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR clarifies the local loading script section to include how to load a dataset after you've modified the local loading script (closes #4732). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4778/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4778/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4326 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4326/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4326/comments | https://api.github.com/repos/huggingface/datasets/issues/4326/events | https://github.com/huggingface/datasets/pull/4326 | 1,233,818,489 | PR_kwDODunzps43tjWy | 4,326 | Fix type hint and documentation for `new_fingerprint` | {
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-05-12T11:05:08Z | 2022-06-01T13:04:45Z | 2022-06-01T12:56:18Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4326.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4326",
"merged_at": "2022-06-01T12:56:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4326.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Currently, there are no type hints nor `Optional` for the argument `new_fingerprint` in several methods of `datasets.arrow_dataset.Dataset`.
There was some documentation missing as well.
Note that pylance is happy with the type hints, but pyright does not detect that `new_fingerprint` is set within the decorator.... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4326/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4326/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6101 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6101/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6101/comments | https://api.github.com/repos/huggingface/datasets/issues/6101/events | https://github.com/huggingface/datasets/pull/6101 | 1,828,469,648 | PR_kwDODunzps5WwspW | 6,101 | Release 2.14.2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-07-31T06:05:36Z | 2023-07-31T06:33:00Z | 2023-07-31T06:18:17Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6101.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6101",
"merged_at": "2023-07-31T06:18:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6101.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6101/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6101/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5672/comments | https://api.github.com/repos/huggingface/datasets/issues/5672/events | https://github.com/huggingface/datasets/issues/5672 | 1,641,005,322 | I_kwDODunzps5hz8EK | 5,672 | Pushing dataset to hub crash | {
"avatar_url": "https://avatars.githubusercontent.com/u/14275989?v=4",
"events_url": "https://api.github.com/users/tzvc/events{/privacy}",
"followers_url": "https://api.github.com/users/tzvc/followers",
"following_url": "https://api.github.com/users/tzvc/following{/other_user}",
"gists_url": "https://api.git... | [] | closed | false | null | [] | null | [
"Hi ! It's been fixed by https://github.com/huggingface/datasets/pull/5598. We're doing a new release tomorrow with the fix and you'll be able to push your 100k images ;)\r\n\r\nBasically `push_to_hub` used to fail if the remote repository already exists and has a README.md without dataset_info in the YAML tags.\r\... | 2023-03-26T17:42:13Z | 2023-03-30T08:11:05Z | 2023-03-30T08:11:05Z | NONE | null | null | null | ### Describe the bug
Uploading a dataset with `push_to_hub()` fails without error description.
### Steps to reproduce the bug
Hey there,
I've built a image dataset of 100k images + text pair as described here https://huggingface.co/docs/datasets/image_dataset#imagefolder
Now I'm trying to push it to the hub b... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5672/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5672/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3758 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3758/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3758/comments | https://api.github.com/repos/huggingface/datasets/issues/3758/events | https://github.com/huggingface/datasets/issues/3758 | 1,143,366,393 | I_kwDODunzps5EJmL5 | 3,758 | head_qa file missing | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"We usually find issues with files hosted at Google Drive...\r\n\r\nIn this case we download the Google Drive Virus scan warning instead of the data file.",
"Fixed: https://huggingface.co/datasets/head_qa/viewer/en/train. Thanks\r\n\r\n<img width=\"1551\" alt=\"Capture d’écran 2022-02-28 à 15 29 04\" src=\"http... | 2022-02-18T16:32:43Z | 2022-02-28T14:29:18Z | 2022-02-21T14:39:19Z | CONTRIBUTOR | null | null | null | ## Describe the bug
A file for the `head_qa` dataset is missing (https://drive.google.com/u/0/uc?export=download&id=1a_95N5zQQoUCq8IBNVZgziHbeM-QxG2t/HEAD_EN/train_HEAD_EN.json)
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> load_dataset("head_qa", name="en")
```
## Expec... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3758/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3758/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1821 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1821/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1821/comments | https://api.github.com/repos/huggingface/datasets/issues/1821/events | https://github.com/huggingface/datasets/issues/1821 | 801,747,647 | MDU6SXNzdWU4MDE3NDc2NDc= | 1,821 | Provide better exception message when one of many files results in an exception | {
"avatar_url": "https://avatars.githubusercontent.com/u/5028974?v=4",
"events_url": "https://api.github.com/users/david-waterworth/events{/privacy}",
"followers_url": "https://api.github.com/users/david-waterworth/followers",
"following_url": "https://api.github.com/users/david-waterworth/following{/other_user... | [] | closed | false | null | [] | null | [
"Hi!\r\n\r\nThank you for reporting this issue. I agree that the information about the exception should be more clear and explicit.\r\n\r\nI could take on this issue.\r\n\r\nOn the meantime, as you can see from the exception stack trace, HF Datasets uses pandas to read the CSV files. You can pass arguments to `pand... | 2021-02-05T00:49:03Z | 2021-02-09T17:39:27Z | 2021-02-09T17:39:27Z | NONE | null | null | null | I find when I process many files, i.e.
```
train_files = glob.glob('rain*.csv')
validation_files = glob.glob(validation*.csv')
datasets = load_dataset("csv", data_files=dict(train=train_files, validation=validation_files))
```
I sometimes encounter an error due to one of the files being misformed (i.e. no dat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1821/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1821/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1313 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1313/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1313/comments | https://api.github.com/repos/huggingface/datasets/issues/1313/events | https://github.com/huggingface/datasets/pull/1313 | 759,536,512 | MDExOlB1bGxSZXF1ZXN0NTM0NTI1NjE3 | 1,313 | Add HateSpeech Corpus for Polish | {
"avatar_url": "https://avatars.githubusercontent.com/u/2649301?v=4",
"events_url": "https://api.github.com/users/kacperlukawski/events{/privacy}",
"followers_url": "https://api.github.com/users/kacperlukawski/followers",
"following_url": "https://api.github.com/users/kacperlukawski/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"@lhoestq Do you think using the ClassLabel is correct if we don't know the meaning of them?",
"Once we find out the meanings we can still add them to the dataset card",
"Feel free to ping me when the PR is ready for the final review"
] | 2020-12-08T15:23:53Z | 2020-12-16T16:48:45Z | 2020-12-16T16:48:45Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1313.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1313",
"merged_at": "2020-12-16T16:48:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1313.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds a HateSpeech Corpus for Polish, containing offensive language examples.
- **Homepage:** http://zil.ipipan.waw.pl/HateSpeech
- **Paper:** http://www.qualitativesociologyreview.org/PL/Volume38/PSJ_13_2_Troszynski_Wawer.pdf | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1313/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1313/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1516 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1516/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1516/comments | https://api.github.com/repos/huggingface/datasets/issues/1516/events | https://github.com/huggingface/datasets/pull/1516 | 764,032,327 | MDExOlB1bGxSZXF1ZXN0NTM4MjkzOTMw | 1,516 | adding wrbsc | {
"avatar_url": "https://avatars.githubusercontent.com/u/15803781?v=4",
"events_url": "https://api.github.com/users/kldarek/events{/privacy}",
"followers_url": "https://api.github.com/users/kldarek/followers",
"following_url": "https://api.github.com/users/kldarek/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"@lhoestq thanks for the comments! Should be fixed in the latest commit, I assume the CI errors are unrelated. ",
"merging since the CI is fixed on master"
] | 2020-12-12T16:38:40Z | 2020-12-18T09:41:33Z | 2020-12-18T09:41:33Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1516.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1516",
"merged_at": "2020-12-18T09:41:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1516.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1516/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1516/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/4881 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4881/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4881/comments | https://api.github.com/repos/huggingface/datasets/issues/4881/events | https://github.com/huggingface/datasets/issues/4881 | 1,348,495,777 | I_kwDODunzps5QYGmh | 4,881 | Language names and language codes: connecting to a big database (rather than slow enrichment of custom list) | {
"avatar_url": "https://avatars.githubusercontent.com/u/6072524?v=4",
"events_url": "https://api.github.com/users/alexis-michaud/events{/privacy}",
"followers_url": "https://api.github.com/users/alexis-michaud/followers",
"following_url": "https://api.github.com/users/alexis-michaud/following{/other_user}",
... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Thanks for opening this discussion, @alexis-michaud.\r\n\r\nAs the language validation procedure is shared with other Hugging Face projects, I'm tagging them as well.\r\n\r\nCC: @huggingface/moon-landing ",
"on the Hub side, there is not fine grained validation we just check that `language:` contains an array of... | 2022-08-23T20:14:24Z | 2023-01-03T08:32:35Z | null | NONE | null | null | null | **The problem:**
Language diversity is an important dimension of the diversity of datasets. To find one's way around datasets, being able to search by language name and by standardized codes appears crucial.
Currently the list of language codes is [here](https://github.com/huggingface/datasets/blob/main/src/datase... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4881/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4881/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2954/comments | https://api.github.com/repos/huggingface/datasets/issues/2954/events | https://github.com/huggingface/datasets/pull/2954 | 1,003,904,803 | PR_kwDODunzps4sHa8O | 2,954 | Run tests in parallel | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"There is a speed up in Windows machines:\r\n- From `13m 52s` to `11m 10s`\r\n\r\nIn Linux machines, some workers crash with error message:\r\n```\r\nOSError: [Errno 12] Cannot allocate memory\r\n```",
"There is also a speed up in Linux machines:\r\n- From `7m 30s` to `5m 32s`"
] | 2021-09-22T07:00:44Z | 2021-09-28T06:55:51Z | 2021-09-28T06:55:51Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2954.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2954",
"merged_at": "2021-09-28T06:55:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2954.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Run CI tests in parallel to speed up the test suite.
Speed up results:
- Linux: from `7m 30s` to `5m 32s`
- Windows: from `13m 52s` to `11m 10s`
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2954/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3132 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3132/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3132/comments | https://api.github.com/repos/huggingface/datasets/issues/3132/events | https://github.com/huggingface/datasets/issues/3132 | 1,032,505,430 | I_kwDODunzps49ishW | 3,132 | Support Audio feature in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2021-10-21T13:32:18Z | 2021-11-12T14:13:04Z | 2021-11-12T14:13:04Z | MEMBER | null | null | null | Currently, Audio feature is only supported for non-streaming datasets.
Due to the large size of many speech datasets, we should also support Audio feature in streaming mode.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3132/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3132/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1766 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1766/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1766/comments | https://api.github.com/repos/huggingface/datasets/issues/1766/events | https://github.com/huggingface/datasets/issues/1766 | 792,044,105 | MDU6SXNzdWU3OTIwNDQxMDU= | 1,766 | Issues when run two programs compute the same metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/8089862?v=4",
"events_url": "https://api.github.com/users/lamthuy/events{/privacy}",
"followers_url": "https://api.github.com/users/lamthuy/followers",
"following_url": "https://api.github.com/users/lamthuy/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Hi ! To avoid collisions you can specify a `experiment_id` when instantiating your metric using `load_metric`. It will replace \"default_experiment\" with the experiment id that you provide in the arrow filename. \r\n\r\nAlso when two `experiment_id` collide we're supposed to detect it using our locking mechanism.... | 2021-01-22T14:22:55Z | 2021-02-02T10:38:06Z | 2021-02-02T10:38:06Z | NONE | null | null | null | I got the following error when running two different programs that both compute sacreblue metrics. It seems that both read/and/write to the same location (.cache/huggingface/metrics/sacrebleu/default/default_experiment-1-0.arrow) where it caches the batches:
```
File "train_matching_min.py", line 160, in <module>ch... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1766/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1766/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2403 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2403/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2403/comments | https://api.github.com/repos/huggingface/datasets/issues/2403/events | https://github.com/huggingface/datasets/pull/2403 | 900,059,014 | MDExOlB1bGxSZXF1ZXN0NjUxNjcxMTMw | 2,403 | Free datasets with cache file in temp dir on exit | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-05-24T22:15:11Z | 2021-05-26T17:25:19Z | 2021-05-26T16:39:29Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2403.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2403",
"merged_at": "2021-05-26T16:39:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2403.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR properly cleans up the memory-mapped tables that reference the cache files inside the temp dir.
Since the built-in `_finalizer` of `TemporaryDirectory` can't be modified, this PR defines its own `TemporaryDirectory` class that accepts a custom clean-up function.
Fixes #2402 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2403/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2403/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5584/comments | https://api.github.com/repos/huggingface/datasets/issues/5584/events | https://github.com/huggingface/datasets/issues/5584 | 1,601,821,808 | I_kwDODunzps5fedxw | 5,584 | Unable to load coyo700M dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/3059998?v=4",
"events_url": "https://api.github.com/users/manuaero/events{/privacy}",
"followers_url": "https://api.github.com/users/manuaero/followers",
"following_url": "https://api.github.com/users/manuaero/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"Hi @manuaero \r\n\r\nThank you for your interest in the COYO dataset.\r\n\r\nOur dataset provides the img-url and alt-text in the form of a parquet, so to utilize the coyo dataset you will need to download it directly.\r\n\r\nWe provide a [guide](https://github.com/kakaobrain/coyo-dataset/blob/main/download/README... | 2023-02-27T19:35:03Z | 2023-02-28T07:27:59Z | 2023-02-28T07:27:58Z | NONE | null | null | null | ### Describe the bug
Seeing this error when downloading https://huggingface.co/datasets/kakaobrain/coyo-700m:
```ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.```
Full stack trace
```Downloading and preparing dataset parquet/kakaobrain--coy... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5584/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5584/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6047 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6047/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6047/comments | https://api.github.com/repos/huggingface/datasets/issues/6047/events | https://github.com/huggingface/datasets/pull/6047 | 1,809,627,947 | PR_kwDODunzps5VxRLA | 6,047 | Bump dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6047). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... | 2023-07-18T10:15:39Z | 2023-07-18T10:28:01Z | 2023-07-18T10:15:52Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6047.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6047",
"merged_at": "2023-07-18T10:15:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6047.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | workaround to fix an issue with transformers CI
https://github.com/huggingface/transformers/pull/24867#discussion_r1266519626 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6047/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6047/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5407/comments | https://api.github.com/repos/huggingface/datasets/issues/5407/events | https://github.com/huggingface/datasets/issues/5407 | 1,519,797,345 | I_kwDODunzps5alkRh | 5,407 | Datasets.from_sql() generates deprecation warning | {
"avatar_url": "https://avatars.githubusercontent.com/u/21002157?v=4",
"events_url": "https://api.github.com/users/msummerfield/events{/privacy}",
"followers_url": "https://api.github.com/users/msummerfield/followers",
"following_url": "https://api.github.com/users/msummerfield/following{/other_user}",
"gist... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting @msummerfield. We are fixing it."
] | 2023-01-05T00:43:17Z | 2023-01-06T10:59:14Z | 2023-01-06T10:59:14Z | NONE | null | null | null | ### Describe the bug
Calling `Datasets.from_sql()` generates a warning:
`.../site-packages/datasets/builder.py:712: FutureWarning: 'use_auth_token' was deprecated in version 2.7.1 and will be removed in 3.0.0. Pass 'use_auth_token' to the initializer/'load_dataset_builder' instead.`
### Steps to reproduce the ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5407/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5407/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3475 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3475/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3475/comments | https://api.github.com/repos/huggingface/datasets/issues/3475/events | https://github.com/huggingface/datasets/issues/3475 | 1,087,352,041 | I_kwDODunzps5Az6zp | 3,475 | The rotten_tomatoes dataset of movie reviews contains some reviews in Spanish | {
"avatar_url": "https://avatars.githubusercontent.com/u/17426779?v=4",
"events_url": "https://api.github.com/users/puzzler10/events{/privacy}",
"followers_url": "https://api.github.com/users/puzzler10/followers",
"following_url": "https://api.github.com/users/puzzler10/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi @puzzler10, thanks for reporting.\r\n\r\nPlease note this dataset is not hosted on Hugging Face Hub. See: \r\nhttps://github.com/huggingface/datasets/blob/c8f914473b041833fd47178fa4373cdcb56ac522/datasets/rotten_tomatoes/rotten_tomatoes.py#L42\r\n\r\nIf there are issues with the source data of a dataset, you sh... | 2021-12-23T03:56:43Z | 2021-12-24T00:23:03Z | null | NONE | null | null | null | ## Describe the bug
See title. I don't think this is intentional and they probably should be removed. If they stay the dataset description should be at least updated to make it clear to the user.
## Steps to reproduce the bug
Go to the [dataset viewer](https://huggingface.co/datasets/viewer/?dataset=rotten_tomato... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3475/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3475/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5716/comments | https://api.github.com/repos/huggingface/datasets/issues/5716/events | https://github.com/huggingface/datasets/issues/5716 | 1,658,613,092 | I_kwDODunzps5i3G1k | 5,716 | Handle empty audio | {
"avatar_url": "https://avatars.githubusercontent.com/u/38179632?v=4",
"events_url": "https://api.github.com/users/v-yunbin/events{/privacy}",
"followers_url": "https://api.github.com/users/v-yunbin/followers",
"following_url": "https://api.github.com/users/v-yunbin/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hi! Can you share one of the problematic audio files with us?\r\n\r\nI tried to reproduce the error with the following code: \r\n```python\r\nimport soundfile as sf\r\nimport numpy as np\r\nfrom datasets import Audio\r\n\r\nsf.write(\"empty.wav\", np.array([]), 16000)\r\nAudio(sampling_rate=24000).decode_example(... | 2023-04-07T09:51:40Z | 2023-09-27T17:47:08Z | 2023-09-27T17:47:08Z | NONE | null | null | null | Some audio paths exist, but they are empty, and an error will be reported when reading the audio path.How to use the filter function to avoid the empty audio path?
when a audio is empty, when do resample , it will break:
`array, sampling_rate = sf.read(f) array = librosa.resample(array, orig_sr=sampling_rate, target_... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5716/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5716/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4657/comments | https://api.github.com/repos/huggingface/datasets/issues/4657/events | https://github.com/huggingface/datasets/issues/4657 | 1,296,743,133 | I_kwDODunzps5NSrrd | 4,657 | Add SQuAD2.0 Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Hey, It's already present [here](https://huggingface.co/datasets/squad_v2) ",
"Hi! This dataset is indeed already available on the Hub. Closing."
] | 2022-07-07T03:19:36Z | 2022-07-12T16:14:52Z | 2022-07-12T16:14:52Z | NONE | null | null | null | ## Adding a Dataset
- **Name:** *SQuAD2.0*
- **Description:** *Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4657/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4657/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4015 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4015/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4015/comments | https://api.github.com/repos/huggingface/datasets/issues/4015/events | https://github.com/huggingface/datasets/issues/4015 | 1,180,510,856 | I_kwDODunzps5GXSqI | 4,015 | Can not correctly parse the classes with imagefolder | {
"avatar_url": "https://avatars.githubusercontent.com/u/21264909?v=4",
"events_url": "https://api.github.com/users/YiSyuanChen/events{/privacy}",
"followers_url": "https://api.github.com/users/YiSyuanChen/followers",
"following_url": "https://api.github.com/users/YiSyuanChen/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"I found that the problem arises because the image files in my folder are actually symbolic links (for my own reasons). After modifications, the classes can now be correctly parsed. Therefore, I close this issue.",
"HI, I have a question. How much time did you load the ImageNet data files? "
] | 2022-03-25T08:51:17Z | 2022-03-28T01:02:03Z | 2022-03-25T09:27:56Z | NONE | null | null | null | ## Describe the bug
I try to load my own image dataset with imagefolder, but the parsing of classes is incorrect.
## Steps to reproduce the bug
I organized my dataset (ImageNet) in the following structure:
```
- imagenet/
- train/
- n01440764/
- ILSVRC2012_val_00000293.jpg
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4015/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4015/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6265/comments | https://api.github.com/repos/huggingface/datasets/issues/6265/events | https://github.com/huggingface/datasets/pull/6265 | 1,915,651,566 | PR_kwDODunzps5bWDfc | 6,265 | Remove `apache_beam` import in `BeamBasedBuilder._save_info` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-09-27T13:56:34Z | 2023-09-28T18:34:02Z | 2023-09-28T18:23:35Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6265.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6265",
"merged_at": "2023-09-28T18:23:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6265.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ... to avoid an `ImportError` raised in `BeamBasedBuilder._save_info` when `apache_beam` is not installed (e.g., when downloading the processed version of a dataset from the HF GCS)
Fix https://github.com/huggingface/datasets/issues/6260 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6265/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6265/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1559 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1559/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1559/comments | https://api.github.com/repos/huggingface/datasets/issues/1559/events | https://github.com/huggingface/datasets/pull/1559 | 765,714,183 | MDExOlB1bGxSZXF1ZXN0NTM5MDQ5MTky | 1,559 | adding dataset card information to CONTRIBUTING.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-12-14T00:08:43Z | 2020-12-14T17:55:03Z | 2020-12-14T17:55:03Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1559.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1559",
"merged_at": "2020-12-14T17:55:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1559.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Added a documentation line and link to the full sprint guide in the "How to add a dataset" section, and a section on how to contribute to the dataset card of an existing dataset.
And a thank you note at the end :hugs: | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1559/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1559/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4545 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4545/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4545/comments | https://api.github.com/repos/huggingface/datasets/issues/4545/events | https://github.com/huggingface/datasets/pull/4545 | 1,280,899,028 | PR_kwDODunzps46KV-y | 4,545 | Make DuplicateKeysError more user friendly [For Issue #2556] | {
"avatar_url": "https://avatars.githubusercontent.com/u/20517962?v=4",
"events_url": "https://api.github.com/users/VijayKalmath/events{/privacy}",
"followers_url": "https://api.github.com/users/VijayKalmath/followers",
"following_url": "https://api.github.com/users/VijayKalmath/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"> Nice thanks !\r\n> \r\n> After your changes feel free to mark this PR as \"ready for review\" ;)\r\n\r\nMarking PR ready for review.\r\n\r\n@lhoestq Let me know if there is anything else required or if we are good to go ahead and merge.",
"_The documentation is not available anymore as the PR was closed or mer... | 2022-06-22T21:01:34Z | 2022-06-28T09:37:06Z | 2022-06-28T09:26:04Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4545.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4545",
"merged_at": "2022-06-28T09:26:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4545.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | # What does this PR do?
## Summary
*DuplicateKeysError error does not provide any information regarding the examples which have the same the key.*
*This information is very helpful for debugging the dataset generator script.*
## Additions
-
## Changes
- Changed `DuplicateKeysError Class` in `src/datase... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4545/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4545/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3784 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3784/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3784/comments | https://api.github.com/repos/huggingface/datasets/issues/3784/events | https://github.com/huggingface/datasets/issues/3784 | 1,150,057,955 | I_kwDODunzps5EjH3j | 3,784 | Unable to Download CNN-Dailymail Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/58678541?v=4",
"events_url": "https://api.github.com/users/AngadSethi/events{/privacy}",
"followers_url": "https://api.github.com/users/AngadSethi/followers",
"following_url": "https://api.github.com/users/AngadSethi/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/58678541?v=4",
"events_url": "https://api.github.com/users/AngadSethi/events{/privacy}",
"followers_url": "https://api.github.com/users/AngadSethi/followers",
"following_url": "https://api.github.com/users/AngadSethi/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/58678541?v=4",
"events_url": "https://api.github.com/users/AngadSethi/events{/privacy}",
"followers_url": "https://api.github.com/users/AngadSethi/followers",
"following_url": "https://api.github.com/users/AngadSethi/following{/other_user}",
... | null | [
"#self-assign",
"@AngadSethi thanks for reporting and thanks for your PR!",
"Glad to help @albertvillanova! Just fine-tuning the PR, will comment once I am able to get it up and running 😀",
"Fixed by:\r\n- #3787"
] | 2022-02-25T05:24:47Z | 2022-03-03T14:05:17Z | 2022-03-03T14:05:17Z | NONE | null | null | null | ## Describe the bug
I am unable to download the CNN-Dailymail dataset. Upon closer investigation, I realised why this was happening:
- The dataset sits in Google Drive, and both the CNN and DM datasets are large.
- Google is unable to scan the folder for viruses, **so the link which would originally download the dat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3784/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3784/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3578/comments | https://api.github.com/repos/huggingface/datasets/issues/3578/events | https://github.com/huggingface/datasets/issues/3578 | 1,103,403,287 | I_kwDODunzps5BxJkX | 3,578 | label information get lost after parquet serialization | {
"avatar_url": "https://avatars.githubusercontent.com/u/56633664?v=4",
"events_url": "https://api.github.com/users/Tudyx/events{/privacy}",
"followers_url": "https://api.github.com/users/Tudyx/followers",
"following_url": "https://api.github.com/users/Tudyx/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! We did a release of `datasets` today that may fix this issue. Can you try updating `datasets` and trying again ?\r\n\r\nEDIT: the issue is still there actually\r\n\r\nI think we can fix that by storing the Features in the parquet schema metadata, and then reload them when loading the parquet file",
"This in... | 2022-01-14T10:10:38Z | 2023-07-25T15:44:53Z | 2023-07-25T15:44:53Z | NONE | null | null | null | ## Describe the bug
In *dataset_info.json* file, information about the label get lost after the dataset serialization.
## Steps to reproduce the bug
```python
from datasets import load_dataset
# normal save
dataset = load_dataset('glue', 'sst2', split='train')
dataset.save_to_disk("normal_save")
# save ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3578/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2648/comments | https://api.github.com/repos/huggingface/datasets/issues/2648/events | https://github.com/huggingface/datasets/issues/2648 | 944,484,522 | MDU6SXNzdWU5NDQ0ODQ1MjI= | 2,648 | Add web_split dataset for Paraphase and Rephrase benchmark | {
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/... | null | [
"#take"
] | 2021-07-14T14:24:36Z | 2021-07-14T14:26:12Z | null | CONTRIBUTOR | null | null | null | ## Describe:
For getting simple sentences from complex sentence there are dataset and task like wiki_split that is available in hugging face datasets. This web_split is a very similar dataset. There some research paper which states that by combining these two datasets we if we train the model it will yield better resu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2648/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2648/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1290 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1290/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1290/comments | https://api.github.com/repos/huggingface/datasets/issues/1290/events | https://github.com/huggingface/datasets/issues/1290 | 759,339,989 | MDU6SXNzdWU3NTkzMzk5ODk= | 1,290 | imdb dataset cannot be downloaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Hi @rabeehk , I am unable to reproduce your problem locally.\r\nCan you try emptying the cache (removing the content of `/idiap/temp/rkarimi/cache_home_1/datasets`) and retry ?",
"Hi,\r\nthanks, I did remove the cache and still the same error here\r\n\r\n```\r\n>>> a = datasets.load_dataset(\"imdb\", split=\"tra... | 2020-12-08T10:47:36Z | 2020-12-24T17:38:09Z | 2020-12-24T17:38:09Z | CONTRIBUTOR | null | null | null | hi
please find error below getting imdb train spli:
thanks
`
datasets.load_dataset>>> datasets.load_dataset("imdb", split="train")`
errors
```
cahce dir /idiap/temp/rkarimi/cache_home_1/datasets
cahce dir /idiap/temp/rkarimi/cache_home_1/datasets
Downloading and preparing dataset imdb/plain_text (d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1290/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1290/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3189 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3189/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3189/comments | https://api.github.com/repos/huggingface/datasets/issues/3189/events | https://github.com/huggingface/datasets/issues/3189 | 1,041,044,986 | I_kwDODunzps4-DRX6 | 3,189 | conll2003 incorrect label explanation | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url":... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @BramVanroy,\r\n\r\nsince these fields are of type `ClassLabel` (you can check this with `dset.features`), you can inspect the possible values with:\r\n```python\r\ndset.features[field_name].feature.names # .feature because it's a sequence of labels\r\n```\r\n\r\nand to find the mapping between names and integ... | 2021-11-01T11:03:30Z | 2021-11-09T10:40:58Z | 2021-11-09T10:40:58Z | CONTRIBUTOR | null | null | null | In the [conll2003](https://huggingface.co/datasets/conll2003#data-fields) README, the labels are described as follows
> - `id`: a `string` feature.
> - `tokens`: a `list` of `string` features.
> - `pos_tags`: a `list` of classification labels, with possible values including `"` (0), `''` (1), `#` (2), `$` (3), `(`... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3189/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3189/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5958 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5958/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5958/comments | https://api.github.com/repos/huggingface/datasets/issues/5958/events | https://github.com/huggingface/datasets/pull/5958 | 1,757,265,971 | PR_kwDODunzps5TA3__ | 5,958 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5958). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... | 2023-06-14T16:26:34Z | 2023-06-14T16:34:55Z | 2023-06-14T16:26:51Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5958.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5958",
"merged_at": "2023-06-14T16:26:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5958.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5958/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5958/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2790 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2790/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2790/comments | https://api.github.com/repos/huggingface/datasets/issues/2790/events | https://github.com/huggingface/datasets/pull/2790 | 967,772,181 | MDExOlB1bGxSZXF1ZXN0NzA5OTI3NjM2 | 2,790 | Fix typo in test_dataset_common | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-08-12T01:10:29Z | 2021-08-12T11:31:29Z | 2021-08-12T11:31:29Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2790.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2790",
"merged_at": "2021-08-12T11:31:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2790.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2790/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2790/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5610/comments | https://api.github.com/repos/huggingface/datasets/issues/5610/events | https://github.com/huggingface/datasets/issues/5610 | 1,610,698,006 | I_kwDODunzps5gAU0W | 5,610 | use datasets streaming mode in trainer ddp mode cause memory leak | {
"avatar_url": "https://avatars.githubusercontent.com/u/15223544?v=4",
"events_url": "https://api.github.com/users/gromzhu/events{/privacy}",
"followers_url": "https://api.github.com/users/gromzhu/followers",
"following_url": "https://api.github.com/users/gromzhu/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [
"Same problem, \r\ntransformers 4.28.1\r\ndatasets 2.12.0\r\n\r\nleak around 100Mb per 10 seconds when use dataloader_num_werker > 0 in training argumennts for transformer train, possile bug in transformers repo, but still not found solution :(\r\n",
"found an article described a problem, may be helpful for someb... | 2023-03-06T05:26:49Z | 2023-05-07T15:15:32Z | null | NONE | null | null | null | ### Describe the bug
use datasets streaming mode in trainer ddp mode cause memory leak
### Steps to reproduce the bug
import os
import time
import datetime
import sys
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, Sequenti... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5610/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2053 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2053/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2053/comments | https://api.github.com/repos/huggingface/datasets/issues/2053/events | https://github.com/huggingface/datasets/pull/2053 | 831,151,728 | MDExOlB1bGxSZXF1ZXN0NTkyNTM4ODY2 | 2,053 | Add bAbI QA tasks | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Hi @lhoestq,\r\n\r\nShould I remove the 160 configurations? Is it too much?\r\n\r\nEDIT:\r\nCan you also check the task category? I'm not sure if there is an appropriate tag for the same.",
"Thanks for the changes !\r\n\r\n> Should I remove the 160 configurations? Is it too much?\r\n\r\nYea 160 configuration is ... | 2021-03-14T13:04:39Z | 2021-03-29T12:41:48Z | 2021-03-29T12:41:48Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2053.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2053",
"merged_at": "2021-03-29T12:41:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2053.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | - **Name:** *The (20) QA bAbI tasks*
- **Description:** *The (20) QA bAbI tasks are a set of proxy tasks that evaluate reading comprehension via question answering. Our tasks measure understanding in several ways: whether a system is able to answer questions via chaining facts, simple induction, deduction and many mor... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2053/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2053/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6254 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6254/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6254/comments | https://api.github.com/repos/huggingface/datasets/issues/6254/events | https://github.com/huggingface/datasets/issues/6254 | 1,909,672,104 | I_kwDODunzps5x00io | 6,254 | Dataset.from_generator() cost much more time in vscode debugging mode then running mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/56437469?v=4",
"events_url": "https://api.github.com/users/dontnet-wuenze/events{/privacy}",
"followers_url": "https://api.github.com/users/dontnet-wuenze/followers",
"following_url": "https://api.github.com/users/dontnet-wuenze/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Answered on the forum: https://discuss.huggingface.co/t/dataset-from-generator-cost-much-more-time-in-vscode-debugging-mode-then-running-mode/56005/2"
] | 2023-09-23T02:07:26Z | 2023-10-03T14:42:53Z | 2023-10-03T14:42:53Z | NONE | null | null | null | ### Describe the bug
Hey there,
I’m using Dataset.from_generator() to convert a torch_dataset to the Huggingface Dataset.
However, when I debug my code on vscode, I find that it runs really slow on Dataset.from_generator() which may even 20 times longer then run the script on terminal.
### Steps to reproduce the bu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6254/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6254/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5881 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5881/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5881/comments | https://api.github.com/repos/huggingface/datasets/issues/5881/events | https://github.com/huggingface/datasets/issues/5881 | 1,719,402,643 | I_kwDODunzps5mfACT | 5,881 | Split dataset by node: index error when sharding iterable dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | [] | open | false | null | [] | null | [
"cc @lhoestq in case you have any ideas here! Might need a multi-host set-up to debug (can give you access to a JAX one if you need)"
] | 2023-05-22T10:36:13Z | 2023-05-23T08:32:14Z | null | CONTRIBUTOR | null | null | null | ### Describe the bug
Context: we're splitting an iterable dataset by node and then passing it to a torch data loader with multiple workers
When we iterate over it for 5 steps, we don't get an error
When we instead iterate over it for 8 steps, we get an `IndexError` when fetching the data if we have too many wo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5881/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5881/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/6271 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6271/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6271/comments | https://api.github.com/repos/huggingface/datasets/issues/6271/events | https://github.com/huggingface/datasets/issues/6271 | 1,920,420,295 | I_kwDODunzps5yd0nH | 6,271 | Overwriting Split overwrites data but not metadata, corrupting dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/13859249?v=4",
"events_url": "https://api.github.com/users/govindrai/events{/privacy}",
"followers_url": "https://api.github.com/users/govindrai/followers",
"following_url": "https://api.github.com/users/govindrai/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [] | 2023-09-30T22:37:31Z | 2023-10-16T13:30:50Z | 2023-10-16T13:30:50Z | NONE | null | null | null | ### Describe the bug
I want to be able to overwrite/update/delete splits in my dataset. Currently the only way to do is to manually go into the dataset and delete the split. If I try to overwrite programmatically I end up in an error state and (somewhat) corrupting the dataset. Read below.
**Current Behavior**
Whe... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6271/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6271/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2210 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2210/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2210/comments | https://api.github.com/repos/huggingface/datasets/issues/2210/events | https://github.com/huggingface/datasets/issues/2210 | 855,709,400 | MDU6SXNzdWU4NTU3MDk0MDA= | 2,210 | dataloading slow when using HUGE dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/29157715?v=4",
"events_url": "https://api.github.com/users/hwijeen/events{/privacy}",
"followers_url": "https://api.github.com/users/hwijeen/followers",
"following_url": "https://api.github.com/users/hwijeen/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Hi ! Yes this is an issue with `datasets<=1.5.0`\r\nThis issue has been fixed by #2122 , we'll do a new release soon :)\r\nFor now you can test it on the `master` branch.",
"Hi, thank you for your answer. I did not realize that my issue stems from the same problem. "
] | 2021-04-12T08:33:02Z | 2021-04-13T02:03:05Z | 2021-04-13T02:03:05Z | NONE | null | null | null | Hi,
When I use datasets with 600GB data, the dataloading speed increases significantly.
I am experimenting with two datasets, and one is about 60GB and the other 600GB.
Simply speaking, my code uses `datasets.set_format("torch")` function and let pytorch-lightning handle ddp training.
When looking at the pytorch... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2210/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2210/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4868 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4868/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4868/comments | https://api.github.com/repos/huggingface/datasets/issues/4868/events | https://github.com/huggingface/datasets/pull/4868 | 1,345,191,322 | PR_kwDODunzps49gBk0 | 4,868 | adding mafand to datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/23586676?v=4",
"events_url": "https://api.github.com/users/dadelani/events{/privacy}",
"followers_url": "https://api.github.com/users/dadelani/followers",
"following_url": "https://api.github.com/users/dadelani/following{/other_user}",
"gists_url": "htt... | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi @dadelani, thanks for your awesome contribution!!! :heart: \r\n\r\nHowever, now we are using the Hub to add new datasets, instead of this GitHub repo. \r\n\r\nYou could share this dataset under your Hub organization namespace: [Ma... | 2022-08-20T15:26:14Z | 2022-08-22T11:00:50Z | 2022-08-22T08:52:23Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4868.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4868",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4868.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4868"
} | I'm addding the MAFAND dataset by Masakhane based on the paper/repository below:
Paper: https://aclanthology.org/2022.naacl-main.223/
Code: https://github.com/masakhane-io/lafand-mt
Please, help merge this
Everything works except for creating dummy data file | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4868/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4868/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5945 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5945/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5945/comments | https://api.github.com/repos/huggingface/datasets/issues/5945/events | https://github.com/huggingface/datasets/issues/5945 | 1,754,084,577 | I_kwDODunzps5ojTTh | 5,945 | Failing to upload dataset to the hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/77382661?v=4",
"events_url": "https://api.github.com/users/Ar770/events{/privacy}",
"followers_url": "https://api.github.com/users/Ar770/followers",
"following_url": "https://api.github.com/users/Ar770/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | null | [] | null | [
"Hi ! Feel free to re-run your code later, it will resume automatically where you left",
"Tried many times in the last 2 weeks, problem remains.",
"Alternatively you can save your dataset in parquet files locally and upload them to the hub manually\r\n\r\n```python\r\nfrom tqdm import tqdm\r\nnum_shards = 60\r\... | 2023-06-13T05:46:46Z | 2023-07-24T11:56:40Z | 2023-07-24T11:56:40Z | NONE | null | null | null | ### Describe the bug
Trying to upload a dataset of hundreds of thousands of audio samples (the total volume is not very large, 60 gb) to the hub with push_to_hub, it doesn't work.
From time to time one piece of the data (parquet) gets pushed and then I get RemoteDisconnected even though my internet is stable.
Please... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5945/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5945/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3747 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3747/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3747/comments | https://api.github.com/repos/huggingface/datasets/issues/3747/events | https://github.com/huggingface/datasets/issues/3747 | 1,141,688,854 | I_kwDODunzps5EDMoW | 3,747 | Passing invalid subset should throw an error | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [] | 2022-02-17T18:16:11Z | 2022-02-17T18:16:11Z | null | CONTRIBUTOR | null | null | null | ## Describe the bug
Only some datasets have a subset (as in `load_dataset(name, subset)`). If you pass an invalid subset, an error should be thrown.
## Steps to reproduce the bug
```python
import datasets
datasets.load_dataset('rotten_tomatoes', 'asdfasdfa')
```
## Expected results
This should break, since ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3747/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3747/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4639/comments | https://api.github.com/repos/huggingface/datasets/issues/4639/events | https://github.com/huggingface/datasets/issues/4639 | 1,295,367,322 | I_kwDODunzps5NNbya | 4,639 | Add HaGRID -- HAnd Gesture Recognition Image Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | null | [] | 2022-07-06T07:41:32Z | 2022-07-06T07:41:32Z | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** HaGRID -- HAnd Gesture Recognition Image Dataset
- **Description:** We introduce a large image dataset HaGRID (HAnd Gesture Recognition Image Dataset) for hand gesture recognition (HGR) systems. You can use it for image classification or image detection tasks. Proposed dataset allows t... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4639/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4639/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5053 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5053/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5053/comments | https://api.github.com/repos/huggingface/datasets/issues/5053/events | https://github.com/huggingface/datasets/issues/5053 | 1,393,739,882 | I_kwDODunzps5TEshq | 5,053 | Intermittent JSON parse error when streaming the Pile | {
"avatar_url": "https://avatars.githubusercontent.com/u/77788841?v=4",
"events_url": "https://api.github.com/users/neelnanda-io/events{/privacy}",
"followers_url": "https://api.github.com/users/neelnanda-io/followers",
"following_url": "https://api.github.com/users/neelnanda-io/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Maybe #2838 can help. In this PR we allow to skip bad chunks of JSON data to not crash the training\r\n\r\nDid you have warning messages before the error ?\r\n\r\nsomething like this maybe ?\r\n```\r\n03/24/2022 02:19:46 - WARNING - datasets.utils.streaming_download_manager - Got disconnected from remote data host... | 2022-10-02T11:56:46Z | 2022-10-04T17:59:03Z | null | NONE | null | null | null | ## Describe the bug
I have an intermittent error when streaming the Pile, where I get a JSON parse error which causes my program to crash.
This is intermittent - when I rerun the program with the same random seed it does not crash in the same way. The exact point this happens also varied - it happened to me 11B tok... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5053/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5053/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1297 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1297/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1297/comments | https://api.github.com/repos/huggingface/datasets/issues/1297/events | https://github.com/huggingface/datasets/pull/1297 | 759,404,103 | MDExOlB1bGxSZXF1ZXN0NTM0NDE1ODMx | 1,297 | OPUS Ted Talks 2013 | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user... | [] | closed | false | null | [] | null | [] | 2020-12-08T12:25:39Z | 2023-09-24T09:51:49Z | 2020-12-08T12:35:50Z | MEMBER | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1297.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1297",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1297.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1297"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1297/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1297/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/3954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3954/comments | https://api.github.com/repos/huggingface/datasets/issues/3954/events | https://github.com/huggingface/datasets/issues/3954 | 1,172,141,664 | I_kwDODunzps5F3XZg | 3,954 | The dataset preview is not available for tdklab/Hebrew_Squad_v1.1 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/49593805?v=4",
"events_url": "https://api.github.com/users/MatanBenChorin/events{/privacy}",
"followers_url": "https://api.github.com/users/MatanBenChorin/followers",
"following_url": "https://api.github.com/users/MatanBenChorin/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Hi @MatanBenChorin, thanks for reporting.\r\n\r\nPlease, take into account that the preview may take some time until it properly renders (we are working to reduce this time).\r\n\r\nMaybe @severo can give more details on this.",
"Hi, \r\nThank you",
"Thanks for reporting. We are looking at it and will give upd... | 2022-03-17T09:38:11Z | 2022-04-20T12:39:07Z | 2022-04-20T12:39:07Z | NONE | null | null | null | ## Dataset viewer issue for 'tdklab/Hebrew_Squad_v1.1'
**Link:** https://huggingface.co/api/datasets/tdklab/Hebrew_Squad_v1.1?full=true
The dataset preview is not available for this dataset.
Am I the one who added this dataset ? Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3954/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5316 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5316/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5316/comments | https://api.github.com/repos/huggingface/datasets/issues/5316/events | https://github.com/huggingface/datasets/issues/5316 | 1,470,115,681 | I_kwDODunzps5XoC9h | 5,316 | Bug in sample_by="paragraph" | {
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"events_url": "https://api.github.com/users/adampauls/events{/privacy}",
"followers_url": "https://api.github.com/users/adampauls/followers",
"following_url": "https://api.github.com/users/adampauls/following{/other_user}",
"gists_url": "h... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @adampauls.\r\n\r\nWe are having a look at it. "
] | 2022-11-30T19:24:13Z | 2022-12-01T15:19:02Z | 2022-12-01T15:19:02Z | NONE | null | null | null | ### Describe the bug
I think [this line](https://github.com/huggingface/datasets/blob/main/src/datasets/packaged_modules/text/text.py#L96) is wrong and should be `batch = f.read(self.config.chunksize)`. Otherwise it will never terminate because even when `f` is finished reading, `batch` will still be truthy from the l... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5316/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5316/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5323 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5323/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5323/comments | https://api.github.com/repos/huggingface/datasets/issues/5323/events | https://github.com/huggingface/datasets/issues/5323 | 1,471,518,803 | I_kwDODunzps5XtZhT | 5,323 | Duplicated Keys in Taskmaster-2 Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/52380283?v=4",
"events_url": "https://api.github.com/users/liaeh/events{/privacy}",
"followers_url": "https://api.github.com/users/liaeh/followers",
"following_url": "https://api.github.com/users/liaeh/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @liaeh.\r\n\r\nWe are having a look at it. ",
"I have transferred the discussion to the Community tab of the dataset: https://huggingface.co/datasets/taskmaster2/discussions/1"
] | 2022-12-01T15:31:06Z | 2022-12-01T16:26:06Z | 2022-12-01T16:26:06Z | NONE | null | null | null | ### Describe the bug
Loading certain splits () of the taskmaster-2 dataset fails because of a DuplicatedKeysError. This occurs for the following domains: `'hotels', 'movies', 'music', 'sports'`. The domains `'flights', 'food-ordering', 'restaurant-search'` load fine.
Output:
### Steps to reproduce the bug
```
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5323/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5323/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4090/comments | https://api.github.com/repos/huggingface/datasets/issues/4090/events | https://github.com/huggingface/datasets/pull/4090 | 1,191,956,734 | PR_kwDODunzps41mEs5 | 4,090 | Avoid writing empty license files | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-04-04T15:23:37Z | 2022-04-07T12:46:45Z | 2022-04-07T12:40:43Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4090.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4090",
"merged_at": "2022-04-07T12:40:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4090.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR avoids the creation of empty `LICENSE` files. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4090/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4090/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3941/comments | https://api.github.com/repos/huggingface/datasets/issues/3941/events | https://github.com/huggingface/datasets/issues/3941 | 1,171,132,709 | I_kwDODunzps5FzhEl | 3,941 | billsum dataset: Checksums didn't match for dataset source files: | {
"avatar_url": "https://avatars.githubusercontent.com/u/8507585?v=4",
"events_url": "https://api.github.com/users/XingxingZhang/events{/privacy}",
"followers_url": "https://api.github.com/users/XingxingZhang/followers",
"following_url": "https://api.github.com/users/XingxingZhang/following{/other_user}",
"gi... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @XingxingZhang, thanks for reporting.\r\n\r\nThis was due to a change in Google Drive service:\r\n- #3786 \r\n\r\nWe have already fixed it:\r\n- #3787\r\n\r\nYou should update `datasets` version to at least 1.18.4:\r\n```shell\r\npip install -U datasets\r\n```\r\nAnd then force the redownload:\r\n```python\r\nl... | 2022-03-16T14:52:08Z | 2022-03-16T15:57:08Z | 2022-03-16T15:46:44Z | NONE | null | null | null | ## Describe the bug
When loading the `billsum` dataset, it throws the exception "Checksums didn't match for dataset source files"
```
File "virtualenv_projects/codex/lib/python3.7/site-packages/datasets/utils/info_utils.py", line 40, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3941/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3941/timeline | null | completed | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.