
url stringlengths 61 61 | repository_url stringclasses 1
value | labels_url stringlengths 75 75 | comments_url stringlengths 70 70 | events_url stringlengths 68 68 | html_url stringlengths 49 51 | id int64 758M 1.95B | node_id stringlengths 18 32 | number int64 1.2k 6.31k | title stringlengths 1 290 | user dict | labels listlengths 0 3 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[ns, tz=UTC] | author_association stringclasses 3
values | active_lock_reason float64 | draft float64 0 1 ⌀ | pull_request dict | body stringlengths 0 36.2k ⌀ | reactions dict | timeline_url stringlengths 70 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/1414 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1414/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1414/comments | https://api.github.com/repos/huggingface/datasets/issues/1414/events | https://github.com/huggingface/datasets/pull/1414 | 760,622,133 | MDExOlB1bGxSZXF1ZXN0NTM1NDIzODgy | 1,414 | Adding BioCreative II Gene Mention corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/10516432?v=4",
"events_url": "https://api.github.com/users/mahajandiwakar/events{/privacy}",
"followers_url": "https://api.github.com/users/mahajandiwakar/followers",
"following_url": "https://api.github.com/users/mahajandiwakar/following{/other_user}",
... | [] | closed | false | null | [] | null | [] | 2020-12-09T19:49:28Z | 2020-12-11T11:17:40Z | 2020-12-11T11:17:40Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1414.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1414",
"merged_at": "2020-12-11T11:17:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1414.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding BioCreative II Gene Mention corpus | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1414/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1414/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1657/comments | https://api.github.com/repos/huggingface/datasets/issues/1657/events | https://github.com/huggingface/datasets/pull/1657 | 775,647,000 | MDExOlB1bGxSZXF1ZXN0NTQ2Mjg1NjU2 | 1,657 | mac_morpho dataset: add data splits info | {
"avatar_url": "https://avatars.githubusercontent.com/u/5097052?v=4",
"events_url": "https://api.github.com/users/jonatasgrosman/events{/privacy}",
"followers_url": "https://api.github.com/users/jonatasgrosman/followers",
"following_url": "https://api.github.com/users/jonatasgrosman/following{/other_user}",
... | [] | closed | false | null | [] | null | [] | 2020-12-29T01:05:21Z | 2020-12-30T16:51:24Z | 2020-12-30T16:51:24Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1657.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1657",
"merged_at": "2020-12-30T16:51:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1657.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1657/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1657/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/1338 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1338/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1338/comments | https://api.github.com/repos/huggingface/datasets/issues/1338/events | https://github.com/huggingface/datasets/pull/1338 | 759,725,770 | MDExOlB1bGxSZXF1ZXN0NTM0Njc5ODcz | 1,338 | Add GigaFren Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user... | [] | closed | false | null | [] | null | [
"@lhoestq fixed"
] | 2020-12-08T19:42:04Z | 2020-12-14T10:03:47Z | 2020-12-14T10:03:46Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1338.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1338",
"merged_at": "2020-12-14T10:03:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1338.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1338/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1338/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/1470 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1470/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1470/comments | https://api.github.com/repos/huggingface/datasets/issues/1470/events | https://github.com/huggingface/datasets/pull/1470 | 761,791,065 | MDExOlB1bGxSZXF1ZXN0NTM2NDA2MjQx | 1,470 | Add wiki lingua dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7674948?v=4",
"events_url": "https://api.github.com/users/katnoria/events{/privacy}",
"followers_url": "https://api.github.com/users/katnoria/followers",
"following_url": "https://api.github.com/users/katnoria/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"it’s failing because of `RemoteDatasetTest.test_load_dataset_orange_sum`\r\nwhich i think is not the dataset you are doing a PR for. Try rebasing with:\r\n```\r\ngit fetch upstream\r\ngit rebase upstream/master\r\ngit push -u -f origin your_branch\r\n```",
"> it’s failing because of `RemoteDatasetTest.test_load_... | 2020-12-11T02:04:18Z | 2020-12-16T15:27:13Z | 2020-12-16T15:27:13Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1470.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1470",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1470.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1470"
} | Hello @lhoestq ,
I am opening a fresh pull request as advised in my original PR https://github.com/huggingface/datasets/pull/1308
Thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1470/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1470/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1916/comments | https://api.github.com/repos/huggingface/datasets/issues/1916/events | https://github.com/huggingface/datasets/pull/1916 | 812,291,984 | MDExOlB1bGxSZXF1ZXN0NTc2NjgwNjY5 | 1,916 | Remove unused py_utils objects | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"Hmmm this one broke master. I'm fixing it.\r\n\r\nMaybe because your branch was outdated ?",
"Sorry @lhoestq, I forgot to update the imports... :/",
"It's fine, the CI should have caught this tbh. Not sure why it did't fail"
] | 2021-02-19T19:51:25Z | 2021-02-22T14:56:56Z | 2021-02-22T13:32:49Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1916.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1916",
"merged_at": "2021-02-22T13:32:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1916.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Remove unused/unnecessary py_utils functions/classes. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1916/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4017 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4017/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4017/comments | https://api.github.com/repos/huggingface/datasets/issues/4017/events | https://github.com/huggingface/datasets/pull/4017 | 1,180,595,160 | PR_kwDODunzps41Ad_L | 4,017 | Support streaming scan dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-03-25T10:11:28Z | 2022-03-25T12:08:55Z | 2022-03-25T12:03:52Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4017.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4017",
"merged_at": "2022-03-25T12:03:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4017.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4017/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4017/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3260 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3260/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3260/comments | https://api.github.com/repos/huggingface/datasets/issues/3260/events | https://github.com/huggingface/datasets/pull/3260 | 1,052,247,373 | PR_kwDODunzps4ueCIU | 3,260 | Fix ConnectionError in Scielo dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"The CI error is unrelated to the change."
] | 2021-11-12T18:02:37Z | 2021-11-16T18:18:17Z | 2021-11-16T17:55:22Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3260.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3260",
"merged_at": "2021-11-16T17:55:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3260.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR:
* allows 403 status code in HEAD requests to S3 buckets to fix the connection error in the Scielo dataset (instead of `url`, uses `response.url` to check the URL of the final endpoint)
* makes the Scielo dataset streamable
Fixes #3255. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3260/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3260/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5764 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5764/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5764/comments | https://api.github.com/repos/huggingface/datasets/issues/5764/events | https://github.com/huggingface/datasets/issues/5764 | 1,670,740,198 | I_kwDODunzps5jlXjm | 5,764 | ConnectionError: Couldn't reach https://www.dropbox.com/s/zts98j4vkqtsns6/aclImdb_v2.tar?dl=1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/109907638?v=4",
"events_url": "https://api.github.com/users/sauravtii/events{/privacy}",
"followers_url": "https://api.github.com/users/sauravtii/followers",
"following_url": "https://api.github.com/users/sauravtii/following{/other_user}",
"gists_url": ... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @sauravtii.\r\n\r\nUnfortunately, I'm not able to reproduce the issue:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset(\"josianem/imdb\")\r\n\r\nIn [2]: ds\r\nOut[2]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['text', 'label'],\r... | 2023-04-17T09:08:18Z | 2023-04-18T07:18:20Z | 2023-04-18T07:18:20Z | NONE | null | null | null | ### Describe the bug
I want to use this (https://huggingface.co/datasets/josianem/imdb) dataset therefore I am trying to load it using the following code:
```
dataset = load_dataset("josianem/imdb")
```
The dataset is not getting loaded and gives the error message as the following:
```
Traceback (most rece... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5764/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5764/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4041 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4041/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4041/comments | https://api.github.com/repos/huggingface/datasets/issues/4041/events | https://github.com/huggingface/datasets/issues/4041 | 1,183,599,461 | I_kwDODunzps5GjEtl | 4,041 | Add support for IIIF in datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_ur... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi! Thanks for the detailed analysis of adding IIIF support. I like the idea of \"using IIIF through datasets scripts\" due to its ease of use. Another approach that I like is yielding image ids and using the `piffle` library (which offers a bit more flexibility) + `map` to download + cache images. We can handle b... | 2022-03-28T15:19:25Z | 2022-04-05T18:20:53Z | null | MEMBER | null | null | null | This is a feature request for support for IIIF in `datasets`. Apologies for the long issue. I have also used a different format to the usual feature request since I think that makes more sense but happy to use the standard template if preferred.
## What is [IIIF](https://iiif.io/)?
IIIF (International Image Inte... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4041/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4041/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3438 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3438/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3438/comments | https://api.github.com/repos/huggingface/datasets/issues/3438/events | https://github.com/huggingface/datasets/pull/3438 | 1,081,302,203 | PR_kwDODunzps4v52Va | 3,438 | Update supported versions of Python in setup.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-12-15T17:30:12Z | 2021-12-20T14:22:13Z | 2021-12-20T14:22:12Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3438.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3438",
"merged_at": "2021-12-20T14:22:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3438.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Update the list of supported versions of Python in `setup.py` to keep the PyPI project description updated. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3438/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3438/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4631/comments | https://api.github.com/repos/huggingface/datasets/issues/4631/events | https://github.com/huggingface/datasets/pull/4631 | 1,293,545,900 | PR_kwDODunzps460Vy0 | 4,631 | Update WinoBias README | {
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-04T20:24:40Z | 2022-07-07T13:23:32Z | 2022-07-07T13:11:47Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4631.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4631",
"merged_at": "2022-07-07T13:11:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4631.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I'm adding some information about Winobias that I got from the paper :smile:
I think this makes it a bit clearer! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4631/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4631/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4690 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4690/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4690/comments | https://api.github.com/repos/huggingface/datasets/issues/4690/events | https://github.com/huggingface/datasets/pull/4690 | 1,306,321,975 | PR_kwDODunzps47fG6w | 4,690 | Refactor base extractors | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-15T17:47:48Z | 2022-07-18T08:46:56Z | 2022-07-18T08:34:49Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4690.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4690",
"merged_at": "2022-07-18T08:34:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4690.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR:
- Refactors base extractors as subclasses of `BaseExtractor`:
- this is an abstract class defining the interface with:
- `is_extractable`: abstract class method
- `extract`: abstract static method
- Implements abstract `MagicNumberBaseExtractor` (as subclass of `BaseExtractor`):
- this has a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4690/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4690/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2620/comments | https://api.github.com/repos/huggingface/datasets/issues/2620/events | https://github.com/huggingface/datasets/pull/2620 | 940,893,389 | MDExOlB1bGxSZXF1ZXN0Njg2ODk3MDky | 2,620 | Add speech processing tasks | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Are there any `task_categories:automatic-speech-recognition` dataset for which we should update the tags ?",
"> Are there any `task_categories:automatic-speech-recognition` dataset for which we should update the tags ?\r\n\r\nYes there's a few - I'll fix them tomorrow :)"
] | 2021-07-09T16:07:29Z | 2021-07-12T18:32:59Z | 2021-07-12T17:32:02Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2620.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2620",
"merged_at": "2021-07-12T17:32:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2620.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR replaces the `automatic-speech-recognition` task category with a broader `speech-processing` category.
The tasks associated with this category are derived from the [SUPERB benchmark](https://arxiv.org/abs/2105.01051), and ASR is included in this set. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2620/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2620/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4431/comments | https://api.github.com/repos/huggingface/datasets/issues/4431/events | https://github.com/huggingface/datasets/pull/4431 | 1,254,618,948 | PR_kwDODunzps44x5aG | 4,431 | Add personaldialog datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/2529049?v=4",
"events_url": "https://api.github.com/users/silverriver/events{/privacy}",
"followers_url": "https://api.github.com/users/silverriver/followers",
"following_url": "https://api.github.com/users/silverriver/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | [
"These test errors are related to issue #4428 \r\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"I only made a trivial modification in my commit https://github.com/huggingface/datasets/pull/4431/commits/402c893d35224d7828176717233909ac5f1e7b3e\r\n\r\nI have submitted a PR #4... | 2022-06-01T01:20:40Z | 2022-06-11T12:40:23Z | 2022-06-11T12:31:16Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4431.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4431",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4431.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4431"
} | It seems that all tests are passed | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4431/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4431/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6304 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6304/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6304/comments | https://api.github.com/repos/huggingface/datasets/issues/6304/events | https://github.com/huggingface/datasets/pull/6304 | 1,945,913,521 | PR_kwDODunzps5c7-4q | 6,304 | Update README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/74114936?v=4",
"events_url": "https://api.github.com/users/smty2018/events{/privacy}",
"followers_url": "https://api.github.com/users/smty2018/followers",
"following_url": "https://api.github.com/users/smty2018/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-10-16T19:10:39Z | 2023-10-17T15:13:37Z | 2023-10-17T15:04:52Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6304.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6304",
"merged_at": "2023-10-17T15:04:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6304.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fixed typos in ReadMe and added punctuation marks
Tensorflow --> TensorFlow
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6304/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6304/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4544 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4544/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4544/comments | https://api.github.com/repos/huggingface/datasets/issues/4544/events | https://github.com/huggingface/datasets/issues/4544 | 1,280,500,340 | I_kwDODunzps5MUuJ0 | 4,544 | [CI] seqeval installation fails sometimes on python 3.6 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2022-06-22T16:35:23Z | 2022-06-23T10:13:44Z | 2022-06-23T10:13:44Z | MEMBER | null | null | null | The CI sometimes fails to install seqeval, which cause the `seqeval` metric tests to fail.
The installation fails because of this error:
```
Collecting seqeval
Downloading seqeval-1.2.2.tar.gz (43 kB)
|███████▌ | 10 kB 42.1 MB/s eta 0:00:01
|███████████████ ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4544/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4544/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4865 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4865/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4865/comments | https://api.github.com/repos/huggingface/datasets/issues/4865/events | https://github.com/huggingface/datasets/issues/4865 | 1,344,552,626 | I_kwDODunzps5QJD6y | 4,865 | Dataset Viewer issue for MoritzLaurer/multilingual_nli | {
"avatar_url": "https://avatars.githubusercontent.com/u/41862082?v=4",
"events_url": "https://api.github.com/users/MoritzLaurer/events{/privacy}",
"followers_url": "https://api.github.com/users/MoritzLaurer/followers",
"following_url": "https://api.github.com/users/MoritzLaurer/following{/other_user}",
"gist... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting @MoritzLaurer.\r\n\r\nCurrently, the dataset preview is working properly: https://huggingface.co/datasets/MoritzLaurer/multilingual_nli\r\n\r\nPlease note that when a dataset is modified, it might take some time until the preview is completely updated.\r\n\r\n@severo might it be worth adding ... | 2022-08-19T14:55:20Z | 2022-08-22T14:47:14Z | 2022-08-22T06:13:20Z | NONE | null | null | null | ### Link
_No response_
### Description
I've just uploaded a new dataset to the hub and the viewer does not work for some reason, see here: https://huggingface.co/datasets/MoritzLaurer/multilingual_nli
It displays the error:
```
Status code: 400
Exception: Status400Error
Message: The dataset... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4865/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4865/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1495 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1495/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1495/comments | https://api.github.com/repos/huggingface/datasets/issues/1495/events | https://github.com/huggingface/datasets/pull/1495 | 763,025,562 | MDExOlB1bGxSZXF1ZXN0NTM3NTE2ODE4 | 1,495 | Opus DGT added | {
"avatar_url": "https://avatars.githubusercontent.com/u/22396042?v=4",
"events_url": "https://api.github.com/users/rkc007/events{/privacy}",
"followers_url": "https://api.github.com/users/rkc007/followers",
"following_url": "https://api.github.com/users/rkc007/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | 2020-12-11T23:05:09Z | 2020-12-17T14:38:41Z | 2020-12-17T14:38:41Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1495.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1495",
"merged_at": "2020-12-17T14:38:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1495.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Dataset : http://opus.nlpl.eu/DGT.php | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1495/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1495/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"events_url": "https://api.github.com/users/sentialx/events{/privacy}",
"followers_url": "https://api.github.com/users/sentialx/followers",
"following_url": "https://api.github.com/users/sentialx/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\n\r\nYou can specify `download_config=DownloadConfig(resume_download=True))` in `load_dataset` to resume the download when re-running the code after the timeout error:\r\n```python\r\nfrom datasets import load_dataset, DownloadConfig\r\ndataset = load_dataset('the_pile', split='train', cache_dir='F:\\da... | 2023-03-03T09:52:08Z | 2023-10-14T02:15:52Z | 2023-03-24T12:44:25Z | NONE | null | null | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
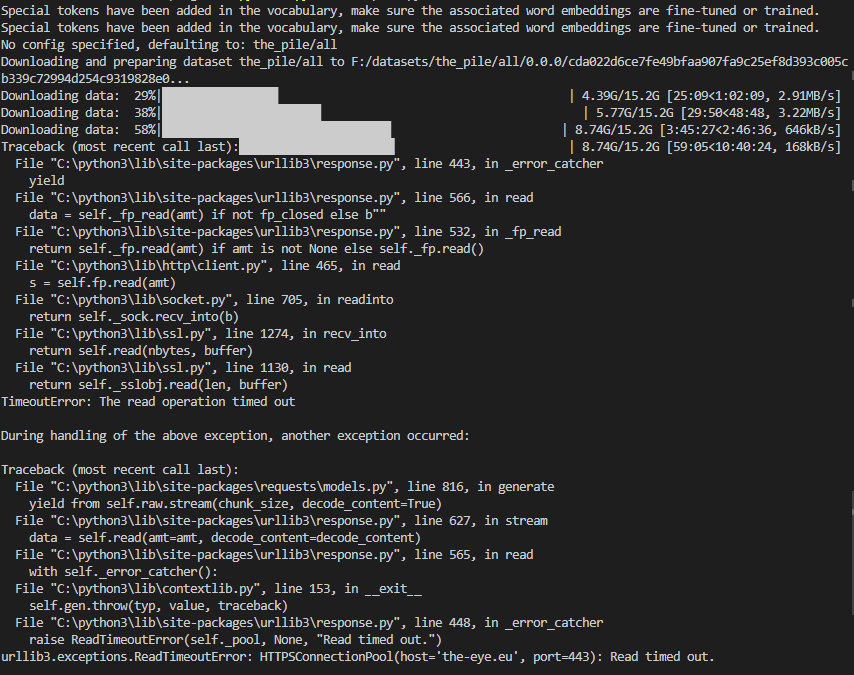
Here are the downloaded files:
. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5049/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5049/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4814 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4814/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4814/comments | https://api.github.com/repos/huggingface/datasets/issues/4814/events | https://github.com/huggingface/datasets/issues/4814 | 1,333,356,230 | I_kwDODunzps5PeWbG | 4,814 | Support CSV as metadata file format in AudioFolder/ImageFolder | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [] | 2022-08-09T14:36:49Z | 2022-08-31T11:59:08Z | 2022-08-31T11:59:08Z | CONTRIBUTOR | null | null | null | Requested here: https://discuss.huggingface.co/t/how-to-structure-an-image-dataset-repo-using-the-image-folder-approach/21004. CSV is also used in AutoTrain for specifying metadata in image datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4814/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4814/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2014 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2014/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2014/comments | https://api.github.com/repos/huggingface/datasets/issues/2014/events | https://github.com/huggingface/datasets/pull/2014 | 825,916,531 | MDExOlB1bGxSZXF1ZXN0NTg3OTY1NDg3 | 2,014 | more explicit method parameters | {
"avatar_url": "https://avatars.githubusercontent.com/u/17948980?v=4",
"events_url": "https://api.github.com/users/theo-m/events{/privacy}",
"followers_url": "https://api.github.com/users/theo-m/followers",
"following_url": "https://api.github.com/users/theo-m/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [] | 2021-03-09T13:18:29Z | 2021-03-10T10:08:37Z | 2021-03-10T10:08:36Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2014.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2014",
"merged_at": "2021-03-10T10:08:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2014.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | re: #2009
not super convinced this is better, and while I usually fight against kwargs here it seems to me that it better conveys the relationship to the `_split_generator` method. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2014/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2014/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4226 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4226/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4226/comments | https://api.github.com/repos/huggingface/datasets/issues/4226/events | https://github.com/huggingface/datasets/pull/4226 | 1,216,331,073 | PR_kwDODunzps420kAv | 4,226 | Add pearsonr mc, update functionality to match the original docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/27527747?v=4",
"events_url": "https://api.github.com/users/emibaylor/events{/privacy}",
"followers_url": "https://api.github.com/users/emibaylor/followers",
"following_url": "https://api.github.com/users/emibaylor/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"thank you @lhoestq!! :hugs: "
] | 2022-04-26T18:30:46Z | 2022-05-03T17:09:24Z | 2022-05-03T17:02:28Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4226.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4226",
"merged_at": "2022-05-03T17:02:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4226.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | - adds pearsonr metric card
- adds ability to return p-value
- p-value was mentioned in the original docs as a return value, but there was no option to return it. I updated the _compute function slightly to have an option to return the p-value. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4226/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4226/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2611/comments | https://api.github.com/repos/huggingface/datasets/issues/2611/events | https://github.com/huggingface/datasets/pull/2611 | 940,307,053 | MDExOlB1bGxSZXF1ZXN0Njg2Mzk5MjU3 | 2,611 | More consistent naming | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-07-09T00:09:17Z | 2021-07-13T17:13:19Z | 2021-07-13T16:08:30Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2611.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2611",
"merged_at": "2021-07-13T16:08:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2611.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As per @stas00's suggestion in #2500, this PR inserts a space between the logo and the lib name (`🤗Datasets` -> `🤗 Datasets`) for consistency with the Transformers lib. Additionally, more consistent names are used for Datasets Hub, etc. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2611/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2611/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1895 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1895/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1895/comments | https://api.github.com/repos/huggingface/datasets/issues/1895/events | https://github.com/huggingface/datasets/issues/1895 | 809,630,271 | MDU6SXNzdWU4MDk2MzAyNzE= | 1,895 | Bug Report: timestamp[ns] not recognized | {
"avatar_url": "https://avatars.githubusercontent.com/u/7731709?v=4",
"events_url": "https://api.github.com/users/justin-yan/events{/privacy}",
"followers_url": "https://api.github.com/users/justin-yan/followers",
"following_url": "https://api.github.com/users/justin-yan/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | [
"Thanks for reporting !\r\n\r\nYou're right, `string_to_arrow` should be able to take `\"timestamp[ns]\"` as input and return the right pyarrow timestamp type.\r\nFeel free to suggest a fix for `string_to_arrow` and open a PR if you want to contribute ! This would be very appreciated :)\r\n\r\nTo give you more cont... | 2021-02-16T20:38:04Z | 2021-02-19T18:27:11Z | 2021-02-19T18:27:11Z | CONTRIBUTOR | null | null | null | Repro:
```
from datasets import Dataset
import pandas as pd
import pyarrow
df = pd.DataFrame(pd.date_range("2018-01-01", periods=3, freq="H"))
pyarrow.Table.from_pandas(df)
Dataset.from_pandas(df)
# Throws ValueError: Neither timestamp[ns] nor timestamp[ns]_ seems to be a pyarrow data type.
```
The fact... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1895/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1895/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2685 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2685/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2685/comments | https://api.github.com/repos/huggingface/datasets/issues/2685/events | https://github.com/huggingface/datasets/pull/2685 | 948,791,572 | MDExOlB1bGxSZXF1ZXN0NjkzNTgxNTk2 | 2,685 | Fix Blog Authorship Corpus dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"Normally, I'm expecting errors from the validation of the README file... 😅 ",
"That is:\r\n```\r\n=========================== short test summary info ============================\r\nFAILED tests/test_dataset_cards.py::test_changed_dataset_card[blog_authorship_corpus]\r\n==== 1 failed, 3182 passed, 2763 skipped,... | 2021-07-20T15:44:50Z | 2021-07-21T13:11:58Z | 2021-07-21T13:11:58Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2685.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2685",
"merged_at": "2021-07-21T13:11:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2685.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR:
- Update the JSON metadata file, which previously was raising a `NonMatchingSplitsSizesError`
- Fix the codec of the data files (`latin_1` instead of `utf-8`), which previously was raising ` UnicodeDecodeError` for some files
Close #2679. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2685/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2685/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5847 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5847/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5847/comments | https://api.github.com/repos/huggingface/datasets/issues/5847/events | https://github.com/huggingface/datasets/issues/5847 | 1,706,616,634 | I_kwDODunzps5luOc6 | 5,847 | Streaming IterableDataset not working with translation pipeline | {
"avatar_url": "https://avatars.githubusercontent.com/u/826841?v=4",
"events_url": "https://api.github.com/users/jlquinn/events{/privacy}",
"followers_url": "https://api.github.com/users/jlquinn/followers",
"following_url": "https://api.github.com/users/jlquinn/following{/other_user}",
"gists_url": "https://... | [] | open | false | null | [] | null | [
"I wasn't sure to file this against transformers or datasets.",
"[`KeyDataset`](https://github.com/huggingface/transformers/blob/7f8b909189547944617741d8d3c6c84504701693/src/transformers/pipelines/pt_utils.py#L296) doesn't support iterable datasets, so you either need to implement a version that does (and also in... | 2023-05-11T21:52:38Z | 2023-05-16T15:59:55Z | null | NONE | null | null | null | ### Describe the bug
I'm trying to use a streaming dataset for translation inference to avoid downloading the training data.
I'm using a pipeline and a dataset, and following the guidance in the tutorial.
Instead I get an exception that IterableDataset has no len().
### Steps to reproduce the bug
CODE:
```
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5847/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5847/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4445 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4445/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4445/comments | https://api.github.com/repos/huggingface/datasets/issues/4445/events | https://github.com/huggingface/datasets/pull/4445 | 1,259,947,568 | PR_kwDODunzps45EjtA | 4,445 | Fix missing args in docstring of load_dataset_builder | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-06-03T13:55:50Z | 2022-06-03T14:35:32Z | 2022-06-03T14:27:09Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4445.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4445",
"merged_at": "2022-06-03T14:27:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4445.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Currently, the docstring of `load_dataset_builder` only contains the first parameter `path` (no other):
- https://huggingface.co/docs/datasets/v2.2.1/en/package_reference/loading_methods#datasets.load_dataset_builder.path | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4445/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4445/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5636/comments | https://api.github.com/repos/huggingface/datasets/issues/5636/events | https://github.com/huggingface/datasets/pull/5636 | 1,623,721,577 | PR_kwDODunzps5MAunR | 5,636 | Fix CI: ignore C901 ("some_func" is to complex) in `ruff` | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-14T15:29:11Z | 2023-03-14T16:37:06Z | 2023-03-14T16:29:52Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5636.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5636",
"merged_at": "2023-03-14T16:29:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5636.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | idk if I should have added this ignore to `ruff` too, but I added :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5636/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5636/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2319 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2319/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2319/comments | https://api.github.com/repos/huggingface/datasets/issues/2319/events | https://github.com/huggingface/datasets/issues/2319 | 876,251,376 | MDU6SXNzdWU4NzYyNTEzNzY= | 2,319 | UnicodeDecodeError for OSCAR (Afrikaans) | {
"avatar_url": "https://avatars.githubusercontent.com/u/8904453?v=4",
"events_url": "https://api.github.com/users/sgraaf/events{/privacy}",
"followers_url": "https://api.github.com/users/sgraaf/followers",
"following_url": "https://api.github.com/users/sgraaf/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @sgraaf.\r\n\r\nI am going to have a look at it. \r\n\r\nI guess the expected codec is \"UTF-8\". Normally, when no explicitly codec is passed, Python uses one which is platform-dependent. For Linux machines, the default codec is `utf_8`, which is OK. However for Windows machine, the default ... | 2021-05-05T09:22:52Z | 2021-05-05T10:57:31Z | 2021-05-05T10:50:55Z | NONE | null | null | null | ## Describe the bug
When loading the [OSCAR dataset](https://huggingface.co/datasets/oscar) (specifically `unshuffled_deduplicated_af`), I encounter a `UnicodeDecodeError`.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("oscar", "unshuffled_deduplicated_af")
```... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2319/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2319/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3936 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3936/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3936/comments | https://api.github.com/repos/huggingface/datasets/issues/3936/events | https://github.com/huggingface/datasets/pull/3936 | 1,170,713,473 | PR_kwDODunzps40hE-P | 3,936 | Fix Wikipedia version and re-add tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3936). All of your documentation changes will be reflected on that endpoint."
] | 2022-03-16T08:48:04Z | 2022-03-16T17:04:07Z | 2022-03-16T17:04:05Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3936.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3936",
"merged_at": "2022-03-16T17:04:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3936.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | To keep backward compatibility when loading using "wikipedia" dataset ID (https://huggingface.co/datasets/wikipedia), we have created the pre-processed data for the same languages we were offering before, but with updated date "20220301":
- de
- en
- fr
- frr
- it
- simple
These pre-processed data can be acces... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3936/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3936/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3485 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3485/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3485/comments | https://api.github.com/repos/huggingface/datasets/issues/3485/events | https://github.com/huggingface/datasets/issues/3485 | 1,089,027,581 | I_kwDODunzps5A6T39 | 3,485 | skip columns which cannot set to specific format when set_format | {
"avatar_url": "https://avatars.githubusercontent.com/u/13161779?v=4",
"events_url": "https://api.github.com/users/tshu-w/events{/privacy}",
"followers_url": "https://api.github.com/users/tshu-w/followers",
"following_url": "https://api.github.com/users/tshu-w/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"You can add columns that you wish to set into `torch` format using `dataset.set_format(\"torch\", ['id', 'abc'])` so that input batch of the transform only contains those columns",
"Sorry, I miss `output_all_columns` args and thought after `dataset.set_format(\"torch\", columns=columns)` I can only get specific ... | 2021-12-27T07:19:55Z | 2021-12-27T09:07:07Z | 2021-12-27T09:07:07Z | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
When using `dataset.set_format("torch")`, I must make sure every columns in datasets can convert to `torch`, however, sometimes I want to keep some string columns.
**Describe the solution you'd like**
skip columns which cannot set to specific forma... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3485/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3485/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4394/comments | https://api.github.com/repos/huggingface/datasets/issues/4394/events | https://github.com/huggingface/datasets/issues/4394 | 1,245,221,657 | I_kwDODunzps5KOJMZ | 4,394 | trainer became extremely slow after reload dataset by `load_from_disk` | {
"avatar_url": "https://avatars.githubusercontent.com/u/50416856?v=4",
"events_url": "https://api.github.com/users/conan1024hao/events{/privacy}",
"followers_url": "https://api.github.com/users/conan1024hao/followers",
"following_url": "https://api.github.com/users/conan1024hao/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"I tried to make the dataset much more smaller (100000 rows) , then the speed became `33.88it/s` from`8.62s/it`. It's nearly 200 times... Do you have any idea? Thank you!",
"Similar issue: https://github.com/huggingface/transformers/issues/8818\r\n\r\nI changed `RandomSampler` to `SequentialSampler` in the `tra... | 2022-05-23T14:04:37Z | 2022-06-06T16:08:01Z | null | NONE | null | null | null | ## Describe the bug
Due to memory problem, I need to save my tokenized datasets locally by CPU and reload it by multi GPU for running training script. However, after I reload it by `load_from_disk` and start training, the speed is extremely slow. It says I need about 1500 hours with 8 A100 cards. Before this, I can ru... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4394/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4394/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5296 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5296/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5296/comments | https://api.github.com/repos/huggingface/datasets/issues/5296/events | https://github.com/huggingface/datasets/issues/5296 | 1,464,553,580 | I_kwDODunzps5XS1Bs | 5,296 | Bug in xjoin with Windows pathnames | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-11-25T13:29:33Z | 2022-11-29T08:05:13Z | 2022-11-29T08:05:13Z | MEMBER | null | null | null | Currently, `xjoin` function has a bug with local Windows pathnames: instead of returning the OS-dependent join pathname, it always returns it in POSIX format.
```python
from datasets.download.streaming_download_manager import xjoin
path = xjoin("C:\\Users\\USERNAME", "filename.txt")
```
Join path should be:
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5296/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5296/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4893 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4893/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4893/comments | https://api.github.com/repos/huggingface/datasets/issues/4893/events | https://github.com/huggingface/datasets/issues/4893 | 1,350,655,674 | I_kwDODunzps5QgV66 | 4,893 | Oversampling strategy for iterable datasets in `interleave_datasets` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "BDE59C",
"default": false,
"description": "Issues a bit more difficult than \"Good First\" issues",
"id": 3761482852,
"name": "good second issue",
"node_id": "LA_kwDODunzps7gM6xk",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20second%20issue"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/52246514?v=4",
"events_url": "https://api.github.com/users/ylacombe/events{/privacy}",
"followers_url": "https://api.github.com/users/ylacombe/followers",
"following_url": "https://api.github.com/users/ylacombe/following{/other_user}",
"gists_url": "htt... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/52246514?v=4",
"events_url": "https://api.github.com/users/ylacombe/events{/privacy}",
"followers_url": "https://api.github.com/users/ylacombe/followers",
"following_url": "https://api.github.com/users/ylacombe/following{/other_user}",
"gi... | null | [
"Hi @lhoestq,\r\nI plunged into the code and it should be manageable for me to work on it!\r\n#take\r\n\r\nAlso, setting `d1`, `d2` and `d3` as you did raised a `SyntaxError: 'yield' inside list comprehension` for me, on Python 3.8.10.\r\nThe following snippet works for me though:\r\n```\r\nd1 = IterableDataset(Exa... | 2022-08-25T10:06:55Z | 2022-10-03T12:37:46Z | 2022-10-03T12:37:46Z | MEMBER | null | null | null | In https://github.com/huggingface/datasets/pull/4831 @ylacombe added an oversampling strategy for `interleave_datasets`. However right now it doesn't work for datasets loaded using `load_dataset(..., streaming=True)`, which are `IterableDataset` objects.
It would be nice to expand `interleave_datasets` for iterable ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4893/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4893/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3407/comments | https://api.github.com/repos/huggingface/datasets/issues/3407/events | https://github.com/huggingface/datasets/pull/3407 | 1,074,502,225 | PR_kwDODunzps4vjyrB | 3,407 | Use max number of data files to infer module | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"Cool thanks :) Feel free to merge if it's all good for you"
] | 2021-12-08T14:58:43Z | 2021-12-14T17:08:42Z | 2021-12-14T17:08:42Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3407.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3407",
"merged_at": "2021-12-14T17:08:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3407.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | When inferring the module for datasets without script, set a maximum number of iterations over data files.
This PR fixes the issue of taking too long when hundred of data files present.
Please, feel free to agree on both numbers:
```
# Datasets without script
DATA_FILES_MAX_NUMBER = 10
ARCHIVED_DATA_FILES_MAX... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3407/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3407/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2161 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2161/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2161/comments | https://api.github.com/repos/huggingface/datasets/issues/2161/events | https://github.com/huggingface/datasets/issues/2161 | 849,127,041 | MDU6SXNzdWU4NDkxMjcwNDE= | 2,161 | any possibility to download part of large datasets only? | {
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Not yet but it’s on the short/mid-term roadmap (requested by many indeed).",
"oh, great, really awesome feature to have, thank you very much for the great, fabulous work",
"We'll work on dataset streaming soon. This should allow you to only load the examples you need ;)",
"thanks a lot Quentin, this would be... | 2021-04-02T10:06:46Z | 2022-10-05T13:26:51Z | 2022-10-05T13:26:51Z | NONE | null | null | null | Hi
Some of the datasets I need like cc100 are very large, and then I wonder if I can download first X samples of the shuffled/unshuffled data without going through first downloading the whole data then sampling? thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2161/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2161/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3092 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3092/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3092/comments | https://api.github.com/repos/huggingface/datasets/issues/3092/events | https://github.com/huggingface/datasets/pull/3092 | 1,027,260,383 | PR_kwDODunzps4tPj6e | 3,092 | Fix JNLBA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"events_url": "https://api.github.com/users/bhavitvyamalik/events{/privacy}",
"followers_url": "https://api.github.com/users/bhavitvyamalik/followers",
"following_url": "https://api.github.com/users/bhavitvyamalik/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Fix #3089.",
"@albertvillanova all tests are passing now. Either you or @lhoestq can review it!"
] | 2021-10-15T09:31:14Z | 2022-07-10T14:36:49Z | 2021-10-22T08:23:57Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3092.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3092",
"merged_at": "2021-10-22T08:23:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3092.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As mentioned in #3089, I've added more tags and also updated the link for dataset which was earlier using a Google Drive link.
I'm having problem with generating dummy data as `datasets-cli dummy_data ./datasets/jnlpba --auto_generate --match_text_files "*.iob2"` is giving `datasets.keyhash.DuplicatedKeysError: FAIL... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3092/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3092/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5495 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5495/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5495/comments | https://api.github.com/repos/huggingface/datasets/issues/5495/events | https://github.com/huggingface/datasets/issues/5495 | 1,566,803,452 | I_kwDODunzps5dY4X8 | 5,495 | to_tf_dataset fails with datetime UTC columns even if not included in columns argument | {
"avatar_url": "https://avatars.githubusercontent.com/u/2512762?v=4",
"events_url": "https://api.github.com/users/dwyatte/events{/privacy}",
"followers_url": "https://api.github.com/users/dwyatte/followers",
"following_url": "https://api.github.com/users/dwyatte/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"descript... | closed | false | null | [] | null | [
"Hi! This is indeed a bug in our zero-copy logic.\r\n\r\nTo fix it, instead of the line:\r\nhttps://github.com/huggingface/datasets/blob/7cfac43b980ab9e4a69c2328f085770996323005/src/datasets/features/features.py#L702\r\n\r\nwe should have:\r\n```python\r\nreturn pa.types.is_primitive(pa_type) and not (pa.types.is_b... | 2023-02-01T20:47:33Z | 2023-02-08T14:33:19Z | 2023-02-08T14:33:19Z | CONTRIBUTOR | null | null | null | ### Describe the bug
There appears to be some eager behavior in `to_tf_dataset` that runs against every column in a dataset even if they aren't included in the columns argument. This is problematic with datetime UTC columns due to them not working with zero copy. If I don't have UTC information in my datetime column... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5495/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5495/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3961 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3961/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3961/comments | https://api.github.com/repos/huggingface/datasets/issues/3961/events | https://github.com/huggingface/datasets/issues/3961 | 1,173,223,086 | I_kwDODunzps5F7fau | 3,961 | Scores from Index at extra positions are not filtered out | {
"avatar_url": "https://avatars.githubusercontent.com/u/36671559?v=4",
"events_url": "https://api.github.com/users/vishalsrao/events{/privacy}",
"followers_url": "https://api.github.com/users/vishalsrao/followers",
"following_url": "https://api.github.com/users/vishalsrao/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! Yes, that makes sense! Would you like to submit a PR to fix this?",
"Created PR https://github.com/huggingface/datasets/pull/3971"
] | 2022-03-18T06:13:23Z | 2022-04-12T14:41:58Z | 2022-04-12T14:41:58Z | CONTRIBUTOR | null | null | null | If a FAISS index has fewer records than the requested number of top results (k), then it returns -1 in indices for the additional positions. The get_nearest_examples method only filters out the extra results from the dataset samples. It would be better to filter out extra scores too.
Reference: https://github.com/hu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3961/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3961/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3995 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3995/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3995/comments | https://api.github.com/repos/huggingface/datasets/issues/3995/events | https://github.com/huggingface/datasets/pull/3995 | 1,178,232,623 | PR_kwDODunzps404054 | 3,995 | Close `PIL.Image` file handler in `Image.decode_example` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-03-23T14:51:48Z | 2022-03-23T18:24:52Z | 2022-03-23T18:19:27Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3995.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3995",
"merged_at": "2022-03-23T18:19:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3995.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Closes the file handler of the PIL image object in `Image.decode_example` to avoid the `Too many open files` error.
To pass [the image equality checks](https://app.circleci.com/pipelines/github/huggingface/datasets/10774/workflows/d56670e6-16bb-4c64-b601-a152c5acf5ed/jobs/65825) in CI, `Image.decode_example` calls `... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3995/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3995/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4921 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4921/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4921/comments | https://api.github.com/repos/huggingface/datasets/issues/4921/events | https://github.com/huggingface/datasets/pull/4921 | 1,357,609,003 | PR_kwDODunzps4-JVFV | 4,921 | Fix missing tags in dataset cards | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-31T16:52:27Z | 2022-09-22T14:34:11Z | 2022-09-01T05:04:53Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4921.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4921",
"merged_at": "2022-09-01T05:04:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4921.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix missing tags in dataset cards:
- eraser_multi_rc
- hotpot_qa
- metooma
- movie_rationales
- qanta
- quora
- quoref
- race
- ted_hrlr
- ted_talks_iwslt
This PR partially fixes the missing tags in dataset cards. Subsequent PRs will follow to complete this task.
Related to:
- #4833
- #4891
- #4896
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4921/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4921/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5254 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5254/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5254/comments | https://api.github.com/repos/huggingface/datasets/issues/5254/events | https://github.com/huggingface/datasets/pull/5254 | 1,452,600,088 | PR_kwDODunzps5DE47u | 5,254 | typo | {
"avatar_url": "https://avatars.githubusercontent.com/u/7569098?v=4",
"events_url": "https://api.github.com/users/WrRan/events{/privacy}",
"followers_url": "https://api.github.com/users/WrRan/followers",
"following_url": "https://api.github.com/users/WrRan/following{/other_user}",
"gists_url": "https://api.g... | [] | closed | false | null | [] | null | [] | 2022-11-17T02:39:57Z | 2022-11-18T10:53:45Z | 2022-11-18T10:53:45Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5254.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5254",
"merged_at": "2022-11-18T10:53:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5254.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5254/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5254/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4662/comments | https://api.github.com/repos/huggingface/datasets/issues/4662/events | https://github.com/huggingface/datasets/pull/4662 | 1,298,845,369 | PR_kwDODunzps47GTEc | 4,662 | Fix: conll2003 - fix empty example | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-08T10:49:13Z | 2022-07-08T14:14:53Z | 2022-07-08T14:02:42Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4662.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4662",
"merged_at": "2022-07-08T14:02:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4662.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As reported in https://huggingface.co/datasets/conll2003/discussions/2#62c45a14f93fc97e8260532f, there was an extra empty example at the end of the dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4662/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4662/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2136 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2136/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2136/comments | https://api.github.com/repos/huggingface/datasets/issues/2136/events | https://github.com/huggingface/datasets/pull/2136 | 843,492,015 | MDExOlB1bGxSZXF1ZXN0NjAyODY0ODY5 | 2,136 | fix dialogue action slot name and value | {
"avatar_url": "https://avatars.githubusercontent.com/u/31605305?v=4",
"events_url": "https://api.github.com/users/adamlin120/events{/privacy}",
"followers_url": "https://api.github.com/users/adamlin120/followers",
"following_url": "https://api.github.com/users/adamlin120/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-03-29T15:34:13Z | 2021-03-31T12:48:02Z | 2021-03-31T12:48:01Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2136.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2136",
"merged_at": "2021-03-31T12:48:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2136.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | fix #2128 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2136/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2136/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1587/comments | https://api.github.com/repos/huggingface/datasets/issues/1587/events | https://github.com/huggingface/datasets/pull/1587 | 768,929,877 | MDExOlB1bGxSZXF1ZXN0NTQxMjAwMDk3 | 1,587 | Add nq_open question answering dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/28673745?v=4",
"events_url": "https://api.github.com/users/Nilanshrajput/events{/privacy}",
"followers_url": "https://api.github.com/users/Nilanshrajput/followers",
"following_url": "https://api.github.com/users/Nilanshrajput/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"@SBrandeis all checks passing"
] | 2020-12-16T14:22:08Z | 2020-12-17T16:07:10Z | 2020-12-17T16:07:10Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1587.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1587",
"merged_at": "2020-12-17T16:07:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1587.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | this is pr is a copy of #1506 due to messed up git history in that pr. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1587/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1587/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1798 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1798/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1798/comments | https://api.github.com/repos/huggingface/datasets/issues/1798/events | https://github.com/huggingface/datasets/pull/1798 | 797,766,818 | MDExOlB1bGxSZXF1ZXN0NTY0Njk2NjE1 | 1,798 | Add Arabic sarcasm dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/643918?v=4",
"events_url": "https://api.github.com/users/mapmeld/events{/privacy}",
"followers_url": "https://api.github.com/users/mapmeld/followers",
"following_url": "https://api.github.com/users/mapmeld/following{/other_user}",
"gists_url": "https://... | [] | closed | false | null | [] | null | [
"@lhoestq thanks for the comments - I believe these are now addressed. I re-generated the datasets_info.json and dummy data"
] | 2021-01-31T17:38:55Z | 2021-02-10T20:39:13Z | 2021-02-03T10:35:54Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1798.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1798",
"merged_at": "2021-02-03T10:35:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1798.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This MIT license dataset: https://github.com/iabufarha/ArSarcasm
Via https://sites.google.com/view/ar-sarcasm-sentiment-detection/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1798/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1798/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4721 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4721/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4721/comments | https://api.github.com/repos/huggingface/datasets/issues/4721/events | https://github.com/huggingface/datasets/issues/4721 | 1,310,253,552 | I_kwDODunzps5OGOHw | 4,721 | PyArrow Dataset error when calling `load_dataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/16828657?v=4",
"events_url": "https://api.github.com/users/piraka9011/events{/privacy}",
"followers_url": "https://api.github.com/users/piraka9011/followers",
"following_url": "https://api.github.com/users/piraka9011/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi ! It looks like a bug in `pyarrow`. If you manage to end up with only one chunk per parquet file it should workaround this issue.\r\n\r\nTo achieve that you can try to lower the value of `max_shard_size` and also don't use `map` before `push_to_hub`.\r\n\r\nDo you have a minimum reproducible example that we can... | 2022-07-20T01:16:03Z | 2022-07-22T14:11:47Z | null | NONE | null | null | null | ## Describe the bug
I am fine tuning a wav2vec2 model following the script here using my own dataset: https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
Loading my Audio dataset from the hub which was originally generated from disk results in th... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4721/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4721/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1693 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1693/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1693/comments | https://api.github.com/repos/huggingface/datasets/issues/1693/events | https://github.com/huggingface/datasets/pull/1693 | 780,268,595 | MDExOlB1bGxSZXF1ZXN0NTUwMTc3MDEx | 1,693 | Fix reuters metadata parsing errors | {
"avatar_url": "https://avatars.githubusercontent.com/u/2238344?v=4",
"events_url": "https://api.github.com/users/jbragg/events{/privacy}",
"followers_url": "https://api.github.com/users/jbragg/followers",
"following_url": "https://api.github.com/users/jbragg/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [] | 2021-01-06T08:26:03Z | 2021-01-07T23:53:47Z | 2021-01-07T14:01:22Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1693.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1693",
"merged_at": "2021-01-07T14:01:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1693.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Was missing the last entry in each metadata category | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1693/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1693/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1973 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1973/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1973/comments | https://api.github.com/repos/huggingface/datasets/issues/1973/events | https://github.com/huggingface/datasets/issues/1973 | 820,077,312 | MDU6SXNzdWU4MjAwNzczMTI= | 1,973 | Question: what gets stored in the datasets cache and why is it so huge? | {
"avatar_url": "https://avatars.githubusercontent.com/u/17202292?v=4",
"events_url": "https://api.github.com/users/ioana-blue/events{/privacy}",
"followers_url": "https://api.github.com/users/ioana-blue/followers",
"following_url": "https://api.github.com/users/ioana-blue/following{/other_user}",
"gists_url"... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Echo'ing this observation: I have a few datasets in the neighborhood of 2GB CSVs uncompressed, and when I use something like `Dataset.save_to_disk()` it's ~18GB on disk.\r\n\r\nIf this is unexpected behavior, would be happy to help run debugging as needed.",
"Thanks @ioana-blue for pointing out this problem (and... | 2021-03-02T14:35:53Z | 2021-03-30T14:03:59Z | 2021-03-16T09:44:00Z | NONE | null | null | null | I'm running several training jobs (around 10) with a relatively large dataset (3M samples). The datasets cache reached 178G and it seems really large. What is it stored in there and why is it so large? I don't think I noticed this problem before and seems to be related to the new version of the datasets library. Any in... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1973/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1973/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5978 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5978/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5978/comments | https://api.github.com/repos/huggingface/datasets/issues/5978/events | https://github.com/huggingface/datasets/pull/5978 | 1,770,187,053 | PR_kwDODunzps5Tru2_ | 5,978 | Release: 2.13.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-06-22T18:23:11Z | 2023-06-22T18:40:24Z | 2023-06-22T18:30:16Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5978.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5978",
"merged_at": "2023-06-22T18:30:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5978.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5978/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5978/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3928 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3928/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3928/comments | https://api.github.com/repos/huggingface/datasets/issues/3928/events | https://github.com/huggingface/datasets/issues/3928 | 1,170,017,132 | I_kwDODunzps5FvQts | 3,928 | Frugal score deprecations | {
"avatar_url": "https://avatars.githubusercontent.com/u/30974685?v=4",
"events_url": "https://api.github.com/users/ierezell/events{/privacy}",
"followers_url": "https://api.github.com/users/ierezell/followers",
"following_url": "https://api.github.com/users/ierezell/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @Ierezell, thanks for reporting.\r\n\r\nI'm making a PR to suppress those logs from the terminal. "
] | 2022-03-15T18:10:42Z | 2022-03-17T08:37:24Z | 2022-03-17T08:37:24Z | NONE | null | null | null | ## Describe the bug
The frugal score returns a really verbose output with warnings that can be easily changed.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
from datasets.load import load_metric
frugal = load_metric("frugalscore")
frugal.compute(predictions=["Do you like spinach... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3928/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3928/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3039 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3039/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3039/comments | https://api.github.com/repos/huggingface/datasets/issues/3039/events | https://github.com/huggingface/datasets/pull/3039 | 1,018,219,800 | PR_kwDODunzps4sy_J- | 3,039 | Add sberquad dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/13781234?v=4",
"events_url": "https://api.github.com/users/Alenush/events{/privacy}",
"followers_url": "https://api.github.com/users/Alenush/followers",
"following_url": "https://api.github.com/users/Alenush/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-10-06T12:32:02Z | 2021-10-13T10:19:11Z | 2021-10-13T10:16:04Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3039.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3039",
"merged_at": "2021-10-13T10:16:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3039.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3039/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3039/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5856 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5856/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5856/comments | https://api.github.com/repos/huggingface/datasets/issues/5856/events | https://github.com/huggingface/datasets/issues/5856 | 1,709,218,242 | I_kwDODunzps5l4JnC | 5,856 | Error loading natural_questions | {
"avatar_url": "https://avatars.githubusercontent.com/u/19185508?v=4",
"events_url": "https://api.github.com/users/Crownor/events{/privacy}",
"followers_url": "https://api.github.com/users/Crownor/followers",
"following_url": "https://api.github.com/users/Crownor/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Hi! You can avoid this error by using the preprocessed version:\r\n```python\r\nimport datasets\r\nds = datasets.load_dataset('natural_questions')\r\n```\r\n\r\nPS: Once we finish https://github.com/huggingface/datasets/pull/5364, this error will no longer be a problem.",
"> Hi! You can avoid this error by using... | 2023-05-15T02:46:04Z | 2023-06-05T09:11:19Z | 2023-06-05T09:11:18Z | NONE | null | null | null | ### Describe the bug
When try to load natural_questions through datasets == 2.12.0 with python == 3.8.9:
```python
import datasets
datasets.load_dataset('natural_questions',beam_runner='DirectRunner')
```
It failed with following info:
`pyarrow.lib.ArrowNotImplementedError: Nested data conversions not impl... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5856/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5856/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6055 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6055/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6055/comments | https://api.github.com/repos/huggingface/datasets/issues/6055/events | https://github.com/huggingface/datasets/issues/6055 | 1,813,524,145 | I_kwDODunzps5sGC6x | 6,055 | Fix host URL in The Pile datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/7540752?v=4",
"events_url": "https://api.github.com/users/nickovchinnikov/events{/privacy}",
"followers_url": "https://api.github.com/users/nickovchinnikov/followers",
"following_url": "https://api.github.com/users/nickovchinnikov/following{/other_user}",... | [] | open | false | null | [] | null | [] | 2023-07-20T09:08:52Z | 2023-07-20T09:09:37Z | null | NONE | null | null | null | ### Describe the bug
In #3627 and #5543, you tried to fix the host URL in The Pile datasets. But both URLs are not working now:
`HTTPError: 404 Client Error: Not Found for URL: https://the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst`
And
`ConnectTimeout: HTTPSCo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6055/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6055/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4105 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4105/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4105/comments | https://api.github.com/repos/huggingface/datasets/issues/4105/events | https://github.com/huggingface/datasets/issues/4105 | 1,194,297,119 | I_kwDODunzps5HL4cf | 4,105 | push to hub fails with huggingface-hub 0.5.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/2518789?v=4",
"events_url": "https://api.github.com/users/frascuchon/events{/privacy}",
"followers_url": "https://api.github.com/users/frascuchon/followers",
"following_url": "https://api.github.com/users/frascuchon/following{/other_user}",
"gists_url":... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! Indeed there was a breaking change in `huggingface_hub` 0.5.0 in `HfApi.create_repo`, which is called here in `datasets` by passing the org name in both the `repo_id` and the `organization` arguments:\r\n\r\nhttps://github.com/huggingface/datasets/blob/2230f7f7d7fbaf102cff356f5a8f3bd1561bea43/src/datasets/arr... | 2022-04-06T08:59:57Z | 2022-04-13T14:30:47Z | 2022-04-13T14:30:47Z | NONE | null | null | null | ## Describe the bug
`ds.push_to_hub` is failing when updating a dataset in the form "org_id/repo_id"
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("rubrix/news_test")
ds.push_to_hub("<your-user>/news_test", token="<your-token>")
```
## Expected results
The data... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4105/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4105/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1844 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1844/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1844/comments | https://api.github.com/repos/huggingface/datasets/issues/1844/events | https://github.com/huggingface/datasets/issues/1844 | 803,588,125 | MDU6SXNzdWU4MDM1ODgxMjU= | 1,844 | Update Open Subtitles corpus with original sentence IDs | {
"avatar_url": "https://avatars.githubusercontent.com/u/19476123?v=4",
"events_url": "https://api.github.com/users/Valahaar/events{/privacy}",
"followers_url": "https://api.github.com/users/Valahaar/followers",
"following_url": "https://api.github.com/users/Valahaar/following{/other_user}",
"gists_url": "htt... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | [
"Hi ! You're right this can can useful.\r\nThis should be easy to add, so feel free to give it a try if you want to contribute :)\r\nI think we just need to add it to the _generate_examples method of the OpenSubtitles dataset builder [here](https://github.com/huggingface/datasets/blob/master/datasets/open_subtitles... | 2021-02-08T13:55:13Z | 2021-02-12T17:38:58Z | 2021-02-12T17:38:58Z | CONTRIBUTOR | null | null | null | Hi! It would be great if you could add the original sentence ids to [Open Subtitles](https://huggingface.co/datasets/open_subtitles).
I can think of two reasons: first, it's possible to gather sentences for an entire document (the original ids contain media id, subtitle file id and sentence id), therefore somewhat a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1844/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1844/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3705/comments | https://api.github.com/repos/huggingface/datasets/issues/3705/events | https://github.com/huggingface/datasets/pull/3705 | 1,132,053,226 | PR_kwDODunzps4yfhyj | 3,705 | Raise informative error when loading a save_to_disk dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2022-02-11T08:21:03Z | 2022-02-11T22:56:40Z | 2022-02-11T22:56:39Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3705.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3705",
"merged_at": "2022-02-11T22:56:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3705.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | People recurrently report error when trying to load a dataset (using `load_dataset`) that was previously saved using `save_to_disk`.
This PR raises an informative error message telling them they should use `load_from_disk` instead.
Close #3700. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3705/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3705/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2367 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2367/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2367/comments | https://api.github.com/repos/huggingface/datasets/issues/2367/events | https://github.com/huggingface/datasets/pull/2367 | 893,317,427 | MDExOlB1bGxSZXF1ZXN0NjQ1ODUxNTE0 | 2,367 | Remove getchildren from hyperpartisan news detection | {
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2021-05-17T13:10:37Z | 2021-05-17T14:07:13Z | 2021-05-17T14:07:13Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2367.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2367",
"merged_at": "2021-05-17T14:07:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2367.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | `Element.getchildren()` is now deprecated in the ElementTree library (I think in python 3.9, so it still passes the automated tests which are using 3.6. But for those of us on bleeding-edge distros it now fails).
https://bugs.python.org/issue29209 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2367/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2367/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3899 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3899/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3899/comments | https://api.github.com/repos/huggingface/datasets/issues/3899/events | https://github.com/huggingface/datasets/pull/3899 | 1,166,931,812 | PR_kwDODunzps40UzR3 | 3,899 | Add exact match metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/27527747?v=4",
"events_url": "https://api.github.com/users/emibaylor/events{/privacy}",
"followers_url": "https://api.github.com/users/emibaylor/followers",
"following_url": "https://api.github.com/users/emibaylor/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-03-11T22:21:40Z | 2022-03-21T16:10:03Z | 2022-03-21T16:05:35Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3899.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3899",
"merged_at": "2022-03-21T16:05:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3899.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding the exact match metric and its metric card.
Note: Some of the tests have failed, but I wanted to make a PR anyway so that the rest of the code can be reviewed if anyone has time. I'll look into + work on fixing the failed tests when I'm back online after the weekend | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3899/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3899/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3618/comments | https://api.github.com/repos/huggingface/datasets/issues/3618/events | https://github.com/huggingface/datasets/issues/3618 | 1,112,123,365 | I_kwDODunzps5CSafl | 3,618 | TIMIT Dataset not working with GPU | {
"avatar_url": "https://avatars.githubusercontent.com/u/3227869?v=4",
"events_url": "https://api.github.com/users/TheSeamau5/events{/privacy}",
"followers_url": "https://api.github.com/users/TheSeamau5/followers",
"following_url": "https://api.github.com/users/TheSeamau5/following{/other_user}",
"gists_url":... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! I think you should avoid calling `timit_train['audio']`. Indeed by doing so you're **loading all the audio column in memory**. This is problematic in your case because the TIMIT dataset is huge.\r\n\r\nIf you want to access the audio data of some samples, you should do this instead `timit_train[:10][\"train\"... | 2022-01-24T03:26:03Z | 2023-07-25T15:20:20Z | 2023-07-25T15:20:20Z | NONE | null | null | null | ## Describe the bug
I am working trying to use the TIMIT dataset in order to fine-tune Wav2Vec2 model and I am unable to load the "audio" column from the dataset when working with a GPU.
I am working on Amazon Sagemaker Studio, on the Python 3 (PyTorch 1.8 Python 3.6 GPU Optimized) environment, with a single ml.g4... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3618/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3618/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5151 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5151/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5151/comments | https://api.github.com/repos/huggingface/datasets/issues/5151/events | https://github.com/huggingface/datasets/issues/5151 | 1,420,791,163 | I_kwDODunzps5Ur417 | 5,151 | Add support to create different configs with `push_to_hub` (+ inferring configs from directories with package managers?) | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_use... | null | [
"also asked in https://discuss.huggingface.co/t/create-multiple-dataset-configs-with-push-to-hub-method/25480"
] | 2022-10-24T12:59:18Z | 2022-11-04T14:55:20Z | null | CONTRIBUTOR | null | null | null | Now one can push only different splits within one default config of a dataset.
Would be nice to allow something like:
```
ds.push_to_hub(repo_name, config=config_name)
```
I'm not sure, but this will probably require changes in `data_files.py` patterns. If so, it would also allow to create different configs fo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5151/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5151/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2012 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2012/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2012/comments | https://api.github.com/repos/huggingface/datasets/issues/2012/events | https://github.com/huggingface/datasets/issues/2012 | 825,634,064 | MDU6SXNzdWU4MjU2MzQwNjQ= | 2,012 | No upstream branch | {
"avatar_url": "https://avatars.githubusercontent.com/u/17948980?v=4",
"events_url": "https://api.github.com/users/theo-m/events{/privacy}",
"followers_url": "https://api.github.com/users/theo-m/followers",
"following_url": "https://api.github.com/users/theo-m/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"What's the issue exactly ?\r\n\r\nGiven an `upstream` remote repository with url `https://github.com/huggingface/datasets.git`, you can totally rebase from `upstream/master`.\r\n\r\nIt's mentioned at the beginning how to add the `upstream` remote repository\r\n\r\nhttps://github.com/huggingface/datasets/blob/987df... | 2021-03-09T09:48:55Z | 2021-03-09T11:33:31Z | 2021-03-09T11:33:31Z | CONTRIBUTOR | null | null | null | Feels like the documentation on adding a new dataset is outdated?
https://github.com/huggingface/datasets/blob/987df6b4e9e20fc0c92bc9df48137d170756fd7b/ADD_NEW_DATASET.md#L49-L54
There is no upstream branch on remote. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2012/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2012/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3673/comments | https://api.github.com/repos/huggingface/datasets/issues/3673/events | https://github.com/huggingface/datasets/issues/3673 | 1,123,010,520 | I_kwDODunzps5C78fY | 3,673 | `load_dataset("snli")` is different from dataset viewer | {
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "E5583E",
"default": false,
"descrip... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | null | [
"Yes, we decided to replace the encoded label with the corresponding label when possible in the dataset viewer. But\r\n1. maybe it's the wrong default\r\n2. we could find a way to show both (with a switch, or showing both ie. `0 (neutral)`).\r\n",
"Hi @severo,\r\n\r\nThanks for clarifying. \r\n\r\nI think this de... | 2022-02-03T12:10:43Z | 2022-02-16T11:22:31Z | 2022-02-11T17:01:21Z | NONE | null | null | null | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is t... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3673/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3673/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1817 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1817/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1817/comments | https://api.github.com/repos/huggingface/datasets/issues/1817/events | https://github.com/huggingface/datasets/issues/1817 | 800,870,652 | MDU6SXNzdWU4MDA4NzA2NTI= | 1,817 | pyarrow.lib.ArrowInvalid: Column 1 named input_ids expected length 599 but got length 1500 | {
"avatar_url": "https://avatars.githubusercontent.com/u/9610770?v=4",
"events_url": "https://api.github.com/users/LuCeHe/events{/privacy}",
"followers_url": "https://api.github.com/users/LuCeHe/followers",
"following_url": "https://api.github.com/users/LuCeHe/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"Hi !\r\nThe error you have is due to the `input_ids` column not having the same number of examples as the other columns.\r\nIndeed you're concatenating the `input_ids` at this line:\r\n\r\nhttps://github.com/LuCeHe/GenericTools/blob/431835d8e13ec24dceb5ee4dc4ae58f0e873b091/KerasTools/lm_preprocessing.py#L134\r\n\r... | 2021-02-04T02:30:23Z | 2022-10-05T12:42:57Z | 2022-10-05T12:42:57Z | NONE | null | null | null | I am trying to preprocess any dataset in this package with GPT-2 tokenizer, so I need to structure the datasets as long sequences of text without padding. I've been following a couple of your tutorials and here you can find the script that is failing right at the end
https://github.com/LuCeHe/GenericTools/blob/maste... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1817/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1817/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3528 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3528/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3528/comments | https://api.github.com/repos/huggingface/datasets/issues/3528/events | https://github.com/huggingface/datasets/pull/3528 | 1,093,844,616 | PR_kwDODunzps4wiOqH | 3,528 | Update README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"events_url": "https://api.github.com/users/meg-huggingface/events{/privacy}",
"followers_url": "https://api.github.com/users/meg-huggingface/followers",
"following_url": "https://api.github.com/users/meg-huggingface/following{/other_user}"... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"events_url": "https://api.github.com/users/meg-huggingface/events{/privacy}",
"followers_url": "https://api.github.com/users/meg-huggingface/followers",
"following_url": "https://api.github.com/users/meg-huggingface/following{/other_user}"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"events_url": "https://api.github.com/users/meg-huggingface/events{/privacy}",
"followers_url": "https://api.github.com/users/meg-huggingface/followers",
"following_url": "https://api.github.com/users/meg-huggingface/following{/... | null | [] | 2022-01-04T23:48:11Z | 2022-01-05T12:49:41Z | 2022-01-05T12:49:40Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3528.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3528",
"merged_at": "2022-01-05T12:49:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3528.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Updating license with appropriate capitalization & a link.
Updating Personal and Sensitive Information to address PII concern. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3528/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3528/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5364 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5364/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5364/comments | https://api.github.com/repos/huggingface/datasets/issues/5364/events | https://github.com/huggingface/datasets/pull/5364 | 1,498,360,628 | PR_kwDODunzps5Fiss1 | 5,364 | Support for writing arrow files directly with BeamWriter | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5364). All of your documentation changes will be reflected on that endpoint.",
"Deleting `BeamPipeline` and `upload_local_to_remote` would break the existing Beam scripts, so I reverted this change.\r\n\r\nFrom what I understan... | 2022-12-15T12:38:05Z | 2023-01-25T15:49:25Z | null | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5364.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5364",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5364.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5364"
} | Make it possible to write Arrow files directly with `BeamWriter` rather than converting from Parquet to Arrow, which is sub-optimal, especially for big datasets for which Beam is primarily used. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5364/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5364/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3931 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3931/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3931/comments | https://api.github.com/repos/huggingface/datasets/issues/3931/events | https://github.com/huggingface/datasets/pull/3931 | 1,170,097,208 | PR_kwDODunzps40fBjx | 3,931 | Add align_labels_with_mapping docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-03-15T19:24:57Z | 2022-03-18T16:28:31Z | 2022-03-18T16:24:33Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3931.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3931",
"merged_at": "2022-03-18T16:24:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3931.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR documents the `align_labels_with_mapping` function to ensure predicted labels are aligned with the dataset, or to assign a different mapping of labels to ids (requested by @mariosasko 🎉 ).
For this specific code sample, the current dataset has a `mixed` label that the original [dataset](https://huggingface.... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3931/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3931/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1650/comments | https://api.github.com/repos/huggingface/datasets/issues/1650/events | https://github.com/huggingface/datasets/pull/1650 | 775,545,912 | MDExOlB1bGxSZXF1ZXN0NTQ2MjA0MzYy | 1,650 | Update README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [] | 2020-12-28T19:09:05Z | 2020-12-29T10:43:14Z | 2020-12-29T10:43:14Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1650.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1650",
"merged_at": "2020-12-29T10:43:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1650.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | added dataset summary | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1650/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1650/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5196 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5196/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5196/comments | https://api.github.com/repos/huggingface/datasets/issues/5196/events | https://github.com/huggingface/datasets/pull/5196 | 1,434,401,646 | PR_kwDODunzps5CH439 | 5,196 | Use hfh hf_hub_url function | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5196). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq I think we should first agree if `datasets` can introduce the breaking change of ignoring `config.HUB_DATASETS_URL`: some users may have o... | 2022-11-03T10:08:09Z | 2022-12-06T11:38:17Z | 2022-11-09T07:15:12Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5196.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5196",
"merged_at": "2022-11-09T07:15:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5196.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Small refactoring to use `hf_hub_url` function from `huggingface_hub`.
This PR also creates the `hub` module that will contain all `huggingface_hub` functionalities relevant to `datasets`.
This is a necessary stage before implementing the use of the `hfh` caching system (which uses its `hf_hub_url` under the hood... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5196/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5196/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4057 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4057/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4057/comments | https://api.github.com/repos/huggingface/datasets/issues/4057/events | https://github.com/huggingface/datasets/issues/4057 | 1,185,442,001 | I_kwDODunzps5GqGjR | 4,057 | `load_dataset` consumes too much memory for audio + tar archives | {
"avatar_url": "https://avatars.githubusercontent.com/u/50839826?v=4",
"events_url": "https://api.github.com/users/JFCeron/events{/privacy}",
"followers_url": "https://api.github.com/users/JFCeron/followers",
"following_url": "https://api.github.com/users/JFCeron/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! Could it be because you need to free the memory used by `tarfile` by emptying the tar `members` by any chance ?\r\n```python\r\n yield key, {\"audio\": {\"path\": audio_name, \"bytes\": audio_file_obj.read()}}\r\n audio_tarfile.members = [] # free memory\r\n key += 1\r\n```\r\n\r\nand th... | 2022-03-29T21:38:55Z | 2022-08-16T10:22:55Z | 2022-08-16T10:22:55Z | NONE | null | null | null |
## Description
`load_dataset` consumes more and more memory until it's killed, even though it's made with a generator. I'm adding a loading script for a new dataset, made up of ~15s audio coming from a tar file. Tried setting `DEFAULT_WRITER_BATCH_SIZE = 1` as per the discussion in #741 but the problem persists.
... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4057/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4057/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2927 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2927/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2927/comments | https://api.github.com/repos/huggingface/datasets/issues/2927/events | https://github.com/huggingface/datasets/issues/2927 | 997,654,680 | I_kwDODunzps47dwCY | 2,927 | Datasets 1.12 dataset.filter TypeError: get_indices_from_mask_function() got an unexpected keyword argument | {
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Thanks for reporting, I'm looking into it :)",
"Fixed by #2950."
] | 2021-09-16T01:14:02Z | 2021-09-20T16:23:22Z | 2021-09-20T16:23:21Z | NONE | null | null | null | ## Describe the bug
Upgrading to 1.12 caused `dataset.filter` call to fail with
> get_indices_from_mask_function() got an unexpected keyword argument valid_rel_labels
## Steps to reproduce the bug
```pythondef
filter_good_rows(
ex: Dict,
valid_rel_labels: Set[str],
valid_ner_labels: Set[st... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2927/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2927/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5815 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5815/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5815/comments | https://api.github.com/repos/huggingface/datasets/issues/5815/events | https://github.com/huggingface/datasets/issues/5815 | 1,693,701,743 | I_kwDODunzps5k89Zv | 5,815 | Easy way to create a Kaggle dataset from a Huggingface dataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/5355286?v=4",
"events_url": "https://api.github.com/users/hrbigelow/events{/privacy}",
"followers_url": "https://api.github.com/users/hrbigelow/followers",
"following_url": "https://api.github.com/users/hrbigelow/following{/other_user}",
"gists_url": "h... | [] | open | false | null | [] | null | [
"Hi @hrbigelow , I'm no expert for such a question so I'll ping @lhoestq from the `datasets` library (also this issue could be moved there if someone with permission can do it :) )",
"Hi ! Many datasets are made of several files, and how they are parsed often requires a python script. Because of that, datasets li... | 2023-05-02T21:43:33Z | 2023-07-26T16:13:31Z | null | NONE | null | null | null | I'm not sure whether this is more appropriately addressed with HuggingFace or Kaggle. I would like to somehow directly create a Kaggle dataset from a HuggingFace Dataset.
While Kaggle does provide the option to create a dataset from a URI, that URI must point to a single file. For example:

Using custom data configuration d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4670/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4670/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4151 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4151/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4151/comments | https://api.github.com/repos/huggingface/datasets/issues/4151/events | https://github.com/huggingface/datasets/pull/4151 | 1,201,837,999 | PR_kwDODunzps42GgLu | 4,151 | Add missing label for emotion description | {
"avatar_url": "https://avatars.githubusercontent.com/u/44396506?v=4",
"events_url": "https://api.github.com/users/lijiazheng99/events{/privacy}",
"followers_url": "https://api.github.com/users/lijiazheng99/followers",
"following_url": "https://api.github.com/users/lijiazheng99/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2022-04-12T13:17:37Z | 2022-04-12T13:58:50Z | 2022-04-12T13:58:50Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4151.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4151",
"merged_at": "2022-04-12T13:58:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4151.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4151/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4151/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4194 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4194/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4194/comments | https://api.github.com/repos/huggingface/datasets/issues/4194/events | https://github.com/huggingface/datasets/pull/4194 | 1,210,958,602 | PR_kwDODunzps42jjD3 | 4,194 | Support lists of multi-dimensional numpy arrays | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-04-21T12:22:26Z | 2022-05-12T15:16:34Z | 2022-05-12T15:08:40Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4194.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4194",
"merged_at": "2022-05-12T15:08:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4194.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #4191.
CC: @SaulLu | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4194/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4194/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6191 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6191/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6191/comments | https://api.github.com/repos/huggingface/datasets/issues/6191/events | https://github.com/huggingface/datasets/pull/6191 | 1,871,634,840 | PR_kwDODunzps5ZCKmv | 6,191 | Add missing `revision` argument | {
"avatar_url": "https://avatars.githubusercontent.com/u/45557362?v=4",
"events_url": "https://api.github.com/users/qgallouedec/events{/privacy}",
"followers_url": "https://api.github.com/users/qgallouedec/followers",
"following_url": "https://api.github.com/users/qgallouedec/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I have found the same issue. Good fix. Should be merged as soon as possible.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_a... | 2023-08-29T13:05:04Z | 2023-09-04T06:38:17Z | 2023-08-31T13:50:00Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6191.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6191",
"merged_at": "2023-08-31T13:50:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6191.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I've noticed that when you're not working on the main branch, there are sometimes errors in the files returned. After some investigation, I realized that the revision was not properly passed everywhere. This PR proposes a fix. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6191/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6191/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1801 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1801/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1801/comments | https://api.github.com/repos/huggingface/datasets/issues/1801/events | https://github.com/huggingface/datasets/pull/1801 | 797,814,275 | MDExOlB1bGxSZXF1ZXN0NTY0NzMwODYw | 1,801 | [GEM] Updated the source link of the data to update correct tokenized version. | {
"avatar_url": "https://avatars.githubusercontent.com/u/11708999?v=4",
"events_url": "https://api.github.com/users/mounicam/events{/privacy}",
"followers_url": "https://api.github.com/users/mounicam/followers",
"following_url": "https://api.github.com/users/mounicam/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"@mounicam we'll keep the original version in the Turk dataset proper, and use the updated file in the GEM aggregated dataset which I'll add later today\r\n\r\n@lhoestq do not merge, I'll close when I've submitted the GEM dataset PR :) ",
"Closed by https://github.com/huggingface/datasets/pull/1807"
] | 2021-01-31T21:17:19Z | 2021-02-02T13:17:38Z | 2021-02-02T13:17:28Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1801.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1801",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1801.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1801"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1801/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1801/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/2459 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2459/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2459/comments | https://api.github.com/repos/huggingface/datasets/issues/2459/events | https://github.com/huggingface/datasets/issues/2459 | 915,222,015 | MDU6SXNzdWU5MTUyMjIwMTU= | 2,459 | `Proto_qa` hosting seems to be broken | {
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"@VictorSanh , I think @mariosasko is already working on it. "
] | 2021-06-08T16:16:32Z | 2021-06-10T08:31:09Z | 2021-06-10T08:31:09Z | MEMBER | null | null | null | ## Describe the bug
The hosting (on Github) of the `proto_qa` dataset seems broken. I haven't investigated more yet, just flagging it for now.
@zaidalyafeai if you want to dive into it, I think it's just a matter of changing the links in `proto_qa.py`
## Steps to reproduce the bug
```python
from datasets impo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2459/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2459/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4505 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4505/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4505/comments | https://api.github.com/repos/huggingface/datasets/issues/4505/events | https://github.com/huggingface/datasets/pull/4505 | 1,272,477,226 | PR_kwDODunzps45uH-o | 4,505 | Fix double dots in data files | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The CI fails are unrelated to this PR (apparently something related to `seqeval` on windows) - merging :)"
] | 2022-06-15T16:31:04Z | 2022-06-15T17:15:58Z | 2022-06-15T17:05:53Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4505.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4505",
"merged_at": "2022-06-15T17:05:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4505.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As mentioned in https://github.com/huggingface/transformers/pull/17715 `data_files` can't find a file if the path contains double dots `/../`. This has been introduced in https://github.com/huggingface/datasets/pull/4412, by trying to ignore hidden files and directories (i.e. if they start with a dot)
I fixed this a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4505/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4505/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6182 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6182/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6182/comments | https://api.github.com/repos/huggingface/datasets/issues/6182/events | https://github.com/huggingface/datasets/issues/6182 | 1,867,203,131 | I_kwDODunzps5vS0I7 | 6,182 | Loading Meteor metric in HF evaluate module crashes due to datasets import issue | {
"avatar_url": "https://avatars.githubusercontent.com/u/42322648?v=4",
"events_url": "https://api.github.com/users/dsashulya/events{/privacy}",
"followers_url": "https://api.github.com/users/dsashulya/followers",
"following_url": "https://api.github.com/users/dsashulya/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Our minimal Python version requirement is 3.8, so we dropped `importlib_metadata`. \r\n\r\nFeel free to open a PR in the `evaluate` repo to replace the problematic import with\r\n```python\r\nif PY_VERSION < version.parse(\"3.8\"):\r\n import importlib_metadata\r\nelse:\r\n import importlib.metadata as impor... | 2023-08-25T14:54:06Z | 2023-09-04T16:41:11Z | 2023-08-31T14:38:23Z | NONE | null | null | null | ### Describe the bug
When using python3.9 and ```evaluate``` module loading Meteor metric crashes at a non-existent import from ```datasets.config``` in ```datasets v2.14```
### Steps to reproduce the bug
```
from evaluate import load
meteor = load("meteor")
```
produces the following error:
```
from d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6182/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6182/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3957 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3957/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3957/comments | https://api.github.com/repos/huggingface/datasets/issues/3957/events | https://github.com/huggingface/datasets/pull/3957 | 1,172,401,455 | PR_kwDODunzps40magW | 3,957 | Fix xtreme s metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [
"Sorry for the commit history mess, but will be squashed anyways so should be fine",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-03-17T13:39:04Z | 2022-03-18T13:46:19Z | 2022-03-18T13:42:16Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3957.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3957",
"merged_at": "2022-03-18T13:42:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3957.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | We in fact do need BABEL in xtreme-s | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3957/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3957/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3677/comments | https://api.github.com/repos/huggingface/datasets/issues/3677/events | https://github.com/huggingface/datasets/issues/3677 | 1,123,192,866 | I_kwDODunzps5C8pAi | 3,677 | Discovery cannot be streamed anymore | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Seems like a regression from https://github.com/huggingface/datasets/pull/2843\r\n\r\nOr maybe it's an issue with the hosting. I don't think so, though, because https://www.dropbox.com/s/aox84z90nyyuikz/discovery.zip seems to work as expected\r\n\r\n",
"Hi @severo, thanks for reporting.\r\n\r\nSome servers do no... | 2022-02-03T15:02:03Z | 2022-02-10T16:51:24Z | 2022-02-10T16:51:24Z | CONTRIBUTOR | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
iterable_dataset = load_dataset("discovery", name="discovery", split="train", streaming=True)
list(iterable_dataset.take(1))
```
## Expected results
The first ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3677/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3677/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4904 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4904/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4904/comments | https://api.github.com/repos/huggingface/datasets/issues/4904/events | https://github.com/huggingface/datasets/pull/4904 | 1,353,002,837 | PR_kwDODunzps4959Ad | 4,904 | [LibriSpeech] Fix dev split local_extracted_archive for 'all' config | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"This PR fixes a bug introduced in:\r\n- #4184"
] | 2022-08-27T10:04:57Z | 2022-08-30T10:06:21Z | 2022-08-30T10:03:25Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4904.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4904",
"merged_at": "2022-08-30T10:03:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4904.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | We define the keys for the `_DL_URLS` of the dev split as `dev.clean` and `dev.other`:
https://github.com/huggingface/datasets/blob/2e7142a3c6500b560da45e8d5128e320a09fcbd4/datasets/librispeech_asr/librispeech_asr.py#L60-L61
These keys get forwarded to the `dl_manager` and thus the `local_extracted_archive`.
How... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4904/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4904/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3938 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3938/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3938/comments | https://api.github.com/repos/huggingface/datasets/issues/3938/events | https://github.com/huggingface/datasets/pull/3938 | 1,170,875,417 | PR_kwDODunzps40hnjM | 3,938 | Avoid info log messages from transformers in FrugalScore metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3938). All of your documentation changes will be reflected on that endpoint."
] | 2022-03-16T11:11:29Z | 2022-03-17T08:37:25Z | 2022-03-17T08:37:24Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3938.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3938",
"merged_at": "2022-03-17T08:37:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3938.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #3928. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3938/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3938/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1840 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1840/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1840/comments | https://api.github.com/repos/huggingface/datasets/issues/1840/events | https://github.com/huggingface/datasets/issues/1840 | 803,560,039 | MDU6SXNzdWU4MDM1NjAwMzk= | 1,840 | Add common voice | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",... | closed | false | null | [] | null | [
"I have started working on adding this dataset.",
"Hey @BirgerMoell - awesome that you started working on Common Voice. Common Voice is a bit special since, there is no direct download link to download the data. In these cases we usually consider two options:\r\n\r\n1) Find a hacky solution to extract the downloa... | 2021-02-08T13:21:05Z | 2022-03-20T15:23:40Z | 2021-03-15T05:56:21Z | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** *common voice*
- **Description:** *Mozilla Common Voice Dataset*
- **Paper:** Homepage: https://voice.mozilla.org/en/datasets
- **Data:** https://voice.mozilla.org/en/datasets
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/dat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1840/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1840/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5405/comments | https://api.github.com/repos/huggingface/datasets/issues/5405/events | https://github.com/huggingface/datasets/issues/5405 | 1,517,879,386 | I_kwDODunzps5aeQBa | 5,405 | size_in_bytes the same for all splits | {
"avatar_url": "https://avatars.githubusercontent.com/u/1609857?v=4",
"events_url": "https://api.github.com/users/Breakend/events{/privacy}",
"followers_url": "https://api.github.com/users/Breakend/followers",
"following_url": "https://api.github.com/users/Breakend/following{/other_user}",
"gists_url": "http... | [] | open | false | null | [] | null | [
"Hi @Breakend,\r\n\r\nIndeed, the attribute `size_in_bytes` refers to the size of the entire dataset configuration, for all splits (size of downloaded files + Arrow files), not the specific split.\r\nThis is also the case for `download_size` (downloaded files) and `dataset_size` (Arrow files).\r\n\r\nThe size of th... | 2023-01-03T20:25:48Z | 2023-01-04T09:22:59Z | null | NONE | null | null | null | ### Describe the bug
Hi, it looks like whenever you pull a dataset and get size_in_bytes, it returns the same size for all splits (and that size is the combined size of all splits). It seems like this shouldn't be the intended behavior since it is misleading. Here's an example:
```
>>> from datasets import load_da... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5405/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5405/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2815 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2815/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2815/comments | https://api.github.com/repos/huggingface/datasets/issues/2815/events | https://github.com/huggingface/datasets/pull/2815 | 973,862,024 | MDExOlB1bGxSZXF1ZXN0NzE1MjUxNDQ5 | 2,815 | Tiny typo fixes of "fo" -> "of" | {
"avatar_url": "https://avatars.githubusercontent.com/u/9934829?v=4",
"events_url": "https://api.github.com/users/aronszanto/events{/privacy}",
"followers_url": "https://api.github.com/users/aronszanto/followers",
"following_url": "https://api.github.com/users/aronszanto/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | [] | 2021-08-18T16:36:11Z | 2021-08-19T08:03:02Z | 2021-08-19T08:03:02Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2815.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2815",
"merged_at": "2021-08-19T08:03:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2815.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Noticed a few of these when reading docs- feel free to ignore the PR and just fix on some main contributor branch if more helpful. Thanks for the great library! :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2815/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2815/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2746 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2746/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2746/comments | https://api.github.com/repos/huggingface/datasets/issues/2746/events | https://github.com/huggingface/datasets/issues/2746 | 958,551,619 | MDU6SXNzdWU5NTg1NTE2MTk= | 2,746 | Cannot load `few-nerd` dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/28717374?v=4",
"events_url": "https://api.github.com/users/Mehrad0711/events{/privacy}",
"followers_url": "https://api.github.com/users/Mehrad0711/followers",
"following_url": "https://api.github.com/users/Mehrad0711/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @Mehrad0711,\r\n\r\nI'm afraid there is no \"canonical\" Hugging Face dataset named \"few-nerd\".\r\n\r\nThere are 2 kinds of datasets hosted at the Hugging Face Hub:\r\n- canonical datasets (their identifier contains no slash \"/\"): we, the Hugging Face team, supervise their implementation and we make sure th... | 2021-08-02T22:18:57Z | 2021-11-16T08:51:34Z | 2021-08-03T19:45:43Z | NONE | null | null | null | ## Describe the bug
Cannot load `few-nerd` dataset.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset('few-nerd', 'supervised')
```
## Actual results
Executing above code will give the following error:
```
Using the latest cached version of the module from /Users... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2746/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2746/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5794 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5794/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5794/comments | https://api.github.com/repos/huggingface/datasets/issues/5794/events | https://github.com/huggingface/datasets/issues/5794 | 1,685,196,061 | I_kwDODunzps5kcg0d | 5,794 | CI ZeroDivisionError | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [] | 2023-04-26T14:55:23Z | 2023-04-26T14:55:23Z | null | MEMBER | null | null | null | Sometimes when running our CI on Windows, we get a ZeroDivisionError:
```
FAILED tests/test_metric_common.py::LocalMetricTest::test_load_metric_frugalscore - ZeroDivisionError: float division by zero
```
See for example:
- https://github.com/huggingface/datasets/actions/runs/4809358266/jobs/8560513110
- https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5794/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5794/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5365/comments | https://api.github.com/repos/huggingface/datasets/issues/5365/events | https://github.com/huggingface/datasets/pull/5365 | 1,498,422,466 | PR_kwDODunzps5Fi6ZD | 5,365 | fix: image array should support other formats than uint8 | {
"avatar_url": "https://avatars.githubusercontent.com/u/30353?v=4",
"events_url": "https://api.github.com/users/vigsterkr/events{/privacy}",
"followers_url": "https://api.github.com/users/vigsterkr/followers",
"following_url": "https://api.github.com/users/vigsterkr/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi, thanks for working on this! \r\n\r\nI agree that the current type-casting (always cast to `np.uint8` as Tensorflow Datasets does) is a bit too harsh. However, not all dtypes are supported in `Image.fromarray` (e.g. np.int64), so ... | 2022-12-15T13:17:50Z | 2023-01-26T18:46:45Z | 2023-01-26T18:39:36Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5365.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5365",
"merged_at": "2023-01-26T18:39:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5365.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Currently images that are provided as ndarrays, but not in `uint8` format are going to loose data. Namely, for example in a depth image where the data is in float32 format, the type-casting to uint8 will basically make the whole image blank.
`PIL.Image.fromarray` [does support mode `F`](https://pillow.readthedocs.io/e... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5365/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5365/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3818 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3818/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3818/comments | https://api.github.com/repos/huggingface/datasets/issues/3818/events | https://github.com/huggingface/datasets/issues/3818 | 1,158,788,545 | I_kwDODunzps5FEbXB | 3,818 | Support for "sources" parameter in the add() and add_batch() methods in datasets.metric - SARI | {
"avatar_url": "https://avatars.githubusercontent.com/u/6901031?v=4",
"events_url": "https://api.github.com/users/lmvasque/events{/privacy}",
"followers_url": "https://api.github.com/users/lmvasque/followers",
"following_url": "https://api.github.com/users/lmvasque/following{/other_user}",
"gists_url": "http... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi, thanks for reporting! We can add a `sources: datasets.Value(\"string\")` feature to the `Features` dict in the `SARI` script to fix this. Would you be interested in submitting a PR?",
"Hi Mario,\r\n\r\nThanks for your message. I did try to add `sources` into the `Features` dict using a script for the metric:... | 2022-03-03T18:57:54Z | 2022-03-04T18:04:21Z | 2022-03-04T18:04:21Z | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
The methods `add_batch` and `add` from the `Metric` [class](https://github.com/huggingface/datasets/blob/1675ad6a958435b675a849eafa8a7f10fe0f43bc/src/datasets/metric.py) does not work with [SARI](https://github.com/huggingface/datasets/blob/master/metr... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3818/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3818/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2884 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2884/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2884/comments | https://api.github.com/repos/huggingface/datasets/issues/2884/events | https://github.com/huggingface/datasets/pull/2884 | 992,135,698 | MDExOlB1bGxSZXF1ZXN0NzMwNTA4MTE1 | 2,884 | Add IC, SI, ER tasks to SUPERB | {
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Sorry for the late PR, uploading 10+GB files to the hub through a VPN was an adventure :sweat_smile: ",
"Thank you so much for adding these subsets @anton-l! \r\n\r\n> These datasets either require manual downloads or have broken/unstable links. You can get all necessary archives in this repo: https://huggingfac... | 2021-09-09T11:56:03Z | 2021-09-20T09:17:58Z | 2021-09-20T09:00:49Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2884.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2884",
"merged_at": "2021-09-20T09:00:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2884.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds 3 additional classification tasks to SUPERB
#### Intent Classification
Dataset URL seems to be down at the moment :( See the note below.
S3PRL source: https://github.com/s3prl/s3prl/blob/master/s3prl/downstream/fluent_commands/dataset.py
Instructions: https://github.com/s3prl/s3prl/tree/master/s3prl/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2884/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2884/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3798 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3798/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3798/comments | https://api.github.com/repos/huggingface/datasets/issues/3798/events | https://github.com/huggingface/datasets/pull/3798 | 1,154,411,066 | PR_kwDODunzps4zrl5Y | 3,798 | Fix error message in CSV loader for newer Pandas versions | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2022-02-28T18:24:10Z | 2022-02-28T18:51:39Z | 2022-02-28T18:51:38Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3798.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3798",
"merged_at": "2022-02-28T18:51:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3798.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix the error message in the CSV loader for `Pandas >= 1.4`. To fix this, I directly print the current file name in the for-loop. An alternative would be to use a check similar to this:
```python
csv_file_reader.handle.handle if datasets.config.PANDAS_VERSION >= version.parse("1.4") else csv_file_reader.f
```
CC: @... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3798/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3798/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5838 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5838/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5838/comments | https://api.github.com/repos/huggingface/datasets/issues/5838/events | https://github.com/huggingface/datasets/issues/5838 | 1,703,210,848 | I_kwDODunzps5lhO9g | 5,838 | Streaming support for `load_from_disk` | {
"avatar_url": "https://avatars.githubusercontent.com/u/5437792?v=4",
"events_url": "https://api.github.com/users/Nilabhra/events{/privacy}",
"followers_url": "https://api.github.com/users/Nilabhra/followers",
"following_url": "https://api.github.com/users/Nilabhra/following{/other_user}",
"gists_url": "http... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"As the name says, `load_from_disk` load the data from your disk. If the data is hosted on S3, it is first downloaded locally and then loaded from your disk.\r\n\r\nThere is a discussion on streaming data from S3 here though: #5281 ",
"@lhoestq \r\nThanks for your comment. I have checked out the discussion before... | 2023-05-10T06:25:22Z | 2023-05-12T09:37:45Z | 2023-05-12T09:37:45Z | NONE | null | null | null | ### Feature request
Support for streaming datasets stored in object stores in `load_from_disk`.
### Motivation
The `load_from_disk` function supports fetching datasets stored in object stores such as `s3`. In many cases, the datasets that are stored in object stores are very large and being able to stream the data ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5838/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5838/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2193 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2193/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2193/comments | https://api.github.com/repos/huggingface/datasets/issues/2193/events | https://github.com/huggingface/datasets/issues/2193 | 853,725,707 | MDU6SXNzdWU4NTM3MjU3MDc= | 2,193 | Filtering/mapping on one column is very slow | {
"avatar_url": "https://avatars.githubusercontent.com/u/39116809?v=4",
"events_url": "https://api.github.com/users/norabelrose/events{/privacy}",
"followers_url": "https://api.github.com/users/norabelrose/followers",
"following_url": "https://api.github.com/users/norabelrose/following{/other_user}",
"gists_u... | [
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | null | [] | null | [
"Hi ! Yes we are working on making `filter` significantly faster. You can look at related PRs here: #2060 #2178 \r\n\r\nI think you can expect to have the fast version of `filter` available next week.\r\n\r\nWe'll make it only select one column, and we'll also make the overall filtering operation way faster by avoi... | 2021-04-08T18:16:14Z | 2021-04-26T16:13:59Z | 2021-04-26T16:13:59Z | CONTRIBUTOR | null | null | null | I'm currently using the `wikipedia` dataset— I'm tokenizing the articles with the `tokenizers` library using `map()` and also adding a new `num_tokens` column to the dataset as part of that map operation.
I want to be able to _filter_ the dataset based on this `num_tokens` column, but even when I specify `input_colu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2193/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2193/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4413/comments | https://api.github.com/repos/huggingface/datasets/issues/4413/events | https://github.com/huggingface/datasets/issues/4413 | 1,250,259,822 | I_kwDODunzps5KhXNu | 4,413 | Dataset Viewer issue for ett | {
"avatar_url": "https://avatars.githubusercontent.com/u/24966039?v=4",
"events_url": "https://api.github.com/users/dgcnz/events{/privacy}",
"followers_url": "https://api.github.com/users/dgcnz/followers",
"following_url": "https://api.github.com/users/dgcnz/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | null | [
"Thanks for reporting @dgcnz.\r\n\r\nI have checked that the dataset works fine in streaming mode.\r\n\r\nAdditionally, other datasets containing timestamps are properly rendered by the viewer: https://huggingface.co/datasets/blbooks\r\n\r\nI have tried to force the refresh of the preview, but the endpoint is not r... | 2022-05-27T02:12:35Z | 2022-06-15T07:30:46Z | 2022-06-15T07:30:46Z | NONE | null | null | null | ### Link
https://huggingface.co/datasets/ett
### Description
Timestamp is not JSON serializable.
```
Status code: 500
Exception: Status500Error
Message: Type is not JSON serializable: Timestamp
```
### Owner
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4413/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4413/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5214 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5214/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5214/comments | https://api.github.com/repos/huggingface/datasets/issues/5214/events | https://github.com/huggingface/datasets/pull/5214 | 1,440,334,978 | PR_kwDODunzps5CbmWE | 5,214 | Update github pr docs actions | {
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5214). All of your documentation changes will be reflected on that endpoint."
] | 2022-11-08T14:43:37Z | 2022-11-08T15:39:58Z | 2022-11-08T15:39:57Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5214.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5214",
"merged_at": "2022-11-08T15:39:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5214.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5214/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5214/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5310 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5310/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5310/comments | https://api.github.com/repos/huggingface/datasets/issues/5310/events | https://github.com/huggingface/datasets/pull/5310 | 1,467,719,635 | PR_kwDODunzps5D3rGw | 5,310 | Support xPath for Windows pathnames | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-11-29T09:20:47Z | 2022-11-30T12:00:09Z | 2022-11-30T11:57:16Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5310.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5310",
"merged_at": "2022-11-30T11:57:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5310.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR implements a string representation of `xPath`, which is valid for local paths (also windows) and remote URLs.
Additionally, some `os.path` methods are fixed for remote URLs on Windows machines.
Now, on Windows machines:
```python
In [2]: str(xPath("C:\\dir\\file.txt"))
Out[2]: 'C:\\dir\\file.txt'
In [... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5310/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5310/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6230 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6230/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6230/comments | https://api.github.com/repos/huggingface/datasets/issues/6230/events | https://github.com/huggingface/datasets/pull/6230 | 1,890,521,006 | PR_kwDODunzps5aBh6L | 6,230 | Don't skip hidden files in `dl_manager.iter_files` when they are given as input | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-09-11T13:29:19Z | 2023-09-13T18:21:28Z | 2023-09-13T18:12:09Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6230.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6230",
"merged_at": "2023-09-13T18:12:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6230.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Required for `load_dataset(<format>, data_files=["path/to/.hidden_file"])` to work as expected | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6230/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6230/timeline | null | null | true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.