
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 2.35B | node_id stringlengths 18 32 | number int64 1 6.97k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments int64 0 70 | created_at timestamp[us, tz=UTC] | updated_at timestamp[us, tz=UTC] | closed_at timestamp[us, tz=UTC] | author_association stringclasses 4
values | active_lock_reason float64 | draft float64 0 1 ⌀ | pull_request dict | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | existe_pull_request bool 2
classes | comentarios listlengths 0 30 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5628/comments | https://api.github.com/repos/huggingface/datasets/issues/5628/events | https://github.com/huggingface/datasets/pull/5628 | 1,619,641,810 | PR_kwDODunzps5LzVKi | 5,628 | add kwargs to index search | {
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"events_url": "https://api.github.com/users/SaulLu/events{/privacy}",
"followers_url": "https://api.github.com/users/SaulLu/followers",
"following_url": "https://api.github.com/users/SaulLu/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | 1 | 2023-03-10T21:24:58Z | 2023-03-15T14:48:47Z | 2023-03-15T14:46:04Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5628.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5628",
"merged_at": "2023-03-15T14:46:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5628.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR proposes to add kwargs to index search methods.
This is particularly useful for setting the timeout of a query on elasticsearch.
A typical use case would be:
```python
dset.add_elasticsearch_index("filename", es_client=es_client)
scores, examples = dset.get_nearest_examples("filename", "my_name-train_2... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5628/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5628/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5627/comments | https://api.github.com/repos/huggingface/datasets/issues/5627/events | https://github.com/huggingface/datasets/issues/5627 | 1,619,336,609 | I_kwDODunzps5ghR2h | 5,627 | Unable to load AutoTrain-generated dataset from the hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/8560151?v=4",
"events_url": "https://api.github.com/users/ijmiller2/events{/privacy}",
"followers_url": "https://api.github.com/users/ijmiller2/followers",
"following_url": "https://api.github.com/users/ijmiller2/following{/other_user}",
"gists_url": "h... | [] | open | false | null | [] | null | 2 | 2023-03-10T17:25:58Z | 2023-03-11T15:44:42Z | null | NONE | null | null | null | ### Describe the bug
DatasetGenerationError: An error occurred while generating the dataset -> ValueError: Couldn't cast ... because column names don't match
```
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5627/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5627/timeline | null | null | false | [
"The AutoTrain format is not supported right now. I think it would require a dedicated dataset builder",
"Okay, good to know. Thanks for the reply. For now I will just have to\nmanage the split manually before training, because I can’t find any way of\npulling out file indices or file names from the autogenerated... |
https://api.github.com/repos/huggingface/datasets/issues/5626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5626/comments | https://api.github.com/repos/huggingface/datasets/issues/5626/events | https://github.com/huggingface/datasets/pull/5626 | 1,619,252,984 | PR_kwDODunzps5LyBT4 | 5,626 | Support streaming datasets with numpy.load | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | 2 | 2023-03-10T16:33:39Z | 2023-03-21T06:36:05Z | 2023-03-21T06:28:54Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5626.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5626",
"merged_at": "2023-03-21T06:28:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5626.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Support streaming datasets with `numpy.load`.
See: https://huggingface.co/datasets/qgallouedec/gia_dataset/discussions/1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5626/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5626/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5625/comments | https://api.github.com/repos/huggingface/datasets/issues/5625/events | https://github.com/huggingface/datasets/issues/5625 | 1,618,971,855 | I_kwDODunzps5gf4zP | 5,625 | Allow "jsonl" data type signifier | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url":... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 2 | 2023-03-10T13:21:48Z | 2023-03-11T10:35:39Z | null | CONTRIBUTOR | null | null | null | ### Feature request
`load_dataset` currently does not accept `jsonl` as type but only `json`.
### Motivation
I was working with one of the `run_translation` scripts and used my own datasets (`.jsonl`) as train_dataset. But the default code did not work because
```
FileNotFoundError: Couldn't find a dataset scri... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5625/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5625/timeline | null | null | false | [
"You can use \"json\" instead. It doesn't work by extension names, but rather by dataset builder names, e.g. \"text\", \"imagefolder\", etc. I don't think the example in `transformers` is correct because of that",
"Yes, I understand the reasoning but this issue is to propose that the example in transformers (whil... |
https://api.github.com/repos/huggingface/datasets/issues/5624 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5624/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5624/comments | https://api.github.com/repos/huggingface/datasets/issues/5624/events | https://github.com/huggingface/datasets/issues/5624 | 1,617,400,192 | I_kwDODunzps5gZ5GA | 5,624 | glue datasets returning -1 for test split | {
"avatar_url": "https://avatars.githubusercontent.com/u/8939967?v=4",
"events_url": "https://api.github.com/users/lithafnium/events{/privacy}",
"followers_url": "https://api.github.com/users/lithafnium/followers",
"following_url": "https://api.github.com/users/lithafnium/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | 1 | 2023-03-09T14:47:18Z | 2023-03-09T16:49:29Z | 2023-03-09T16:49:29Z | NONE | null | null | null | ### Describe the bug
Downloading any dataset from GLUE has -1 as class labels for test split. Train and validation have regular 0/1 class labels. This is also present in the dataset card online.
### Steps to reproduce the bug
```
dataset = load_dataset("glue", "sst2")
for d in dataset:
# prints out -1
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5624/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5624/timeline | null | completed | false | [
"Hi @lithafnium, thanks for reporting.\r\n\r\nPlease note that you can use the \"Community\" tab in the corresponding dataset page to start any discussion: https://huggingface.co/datasets/glue/discussions\r\n\r\nIndeed this issue was already raised there (https://huggingface.co/datasets/glue/discussions/5) and answ... |
https://api.github.com/repos/huggingface/datasets/issues/5623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5623/comments | https://api.github.com/repos/huggingface/datasets/issues/5623/events | https://github.com/huggingface/datasets/pull/5623 | 1,616,712,665 | PR_kwDODunzps5Lpb4q | 5,623 | Remove set_access_token usage + fail tests if FutureWarning | {
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"events_url": "https://api.github.com/users/Wauplin/events{/privacy}",
"followers_url": "https://api.github.com/users/Wauplin/followers",
"following_url": "https://api.github.com/users/Wauplin/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 6 | 2023-03-09T08:46:01Z | 2023-03-09T15:39:00Z | 2023-03-09T15:31:59Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5623.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5623",
"merged_at": "2023-03-09T15:31:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5623.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | `set_access_token` is deprecated and will be removed in `huggingface_hub>=0.14`.
This PR removes it from the tests (it was not used in `datasets` source code itself). FYI, it was not needed since `set_access_token` was just setting git credentials and `datasets` doesn't seem to use git anywhere.
In the future, us... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5623/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5623/timeline | null | null | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... |
https://api.github.com/repos/huggingface/datasets/issues/5622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5622/comments | https://api.github.com/repos/huggingface/datasets/issues/5622/events | https://github.com/huggingface/datasets/pull/5622 | 1,615,190,942 | PR_kwDODunzps5LkSj8 | 5,622 | Update README template to better template | {
"avatar_url": "https://avatars.githubusercontent.com/u/54767532?v=4",
"events_url": "https://api.github.com/users/emiltj/events{/privacy}",
"followers_url": "https://api.github.com/users/emiltj/followers",
"following_url": "https://api.github.com/users/emiltj/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | 3 | 2023-03-08T12:30:23Z | 2023-03-11T05:07:38Z | 2023-03-11T05:07:38Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5622.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5622",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5622.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5622"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5622/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5622/timeline | null | null | true | [
"IMO this template should stay generic.\r\n\r\nAlso, we now use [the card template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md) from `hugginface_hub` as the source of truth on the Hub (you now have the option to import it into the dataset card/READ... |
https://api.github.com/repos/huggingface/datasets/issues/5621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5621/comments | https://api.github.com/repos/huggingface/datasets/issues/5621/events | https://github.com/huggingface/datasets/pull/5621 | 1,615,029,615 | PR_kwDODunzps5LjwD8 | 5,621 | Adding Oracle Cloud to docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/29129502?v=4",
"events_url": "https://api.github.com/users/ahosler/events{/privacy}",
"followers_url": "https://api.github.com/users/ahosler/followers",
"following_url": "https://api.github.com/users/ahosler/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 2 | 2023-03-08T10:22:50Z | 2023-03-11T00:57:18Z | 2023-03-11T00:49:56Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5621.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5621",
"merged_at": "2023-03-11T00:49:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5621.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding Oracle Cloud's fsspec implementation to the list of supported cloud storage providers. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5621/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5621/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5620/comments | https://api.github.com/repos/huggingface/datasets/issues/5620/events | https://github.com/huggingface/datasets/pull/5620 | 1,613,460,520 | PR_kwDODunzps5LefAf | 5,620 | Bump pyarrow to 8.0.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 12 | 2023-03-07T13:31:53Z | 2023-03-08T14:01:27Z | 2023-03-08T13:54:22Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5620.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5620",
"merged_at": "2023-03-08T13:54:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5620.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix those for Pandas 2.0 (tested [here](https://github.com/huggingface/datasets/actions/runs/4346221280/jobs/7592010397) with pandas==2.0.0.rc0):
```python
=========================== short test summary info ============================
FAILED tests/test_arrow_dataset.py::BaseDatasetTest::test_to_parquet_in_memory... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5620/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5620/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5619/comments | https://api.github.com/repos/huggingface/datasets/issues/5619/events | https://github.com/huggingface/datasets/pull/5619 | 1,613,439,709 | PR_kwDODunzps5LeaYP | 5,619 | unpin fsspec | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 3 | 2023-03-07T13:22:41Z | 2023-03-07T13:47:01Z | 2023-03-07T13:39:02Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5619.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5619",
"merged_at": "2023-03-07T13:39:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5619.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | close https://github.com/huggingface/datasets/issues/5618 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5619/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5619/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5618/comments | https://api.github.com/repos/huggingface/datasets/issues/5618/events | https://github.com/huggingface/datasets/issues/5618 | 1,612,977,934 | I_kwDODunzps5gJBcO | 5,618 | Unpin fsspec < 2023.3.0 once issue fixed | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | 0 | 2023-03-07T08:41:51Z | 2023-03-07T13:39:03Z | 2023-03-07T13:39:03Z | MEMBER | null | null | null | Unpin `fsspec` upper version once root cause of our CI break is fixed.
See:
- #5614 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5618/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5618/timeline | null | completed | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5617/comments | https://api.github.com/repos/huggingface/datasets/issues/5617/events | https://github.com/huggingface/datasets/pull/5617 | 1,612,947,422 | PR_kwDODunzps5LcvI- | 5,617 | Fix CI by temporarily pinning fsspec < 2023.3.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | 2 | 2023-03-07T08:18:20Z | 2023-03-07T08:44:55Z | 2023-03-07T08:37:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5617.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5617",
"merged_at": "2023-03-07T08:37:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5617.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As a hotfix for our CI, temporarily pin `fsspec`:
Fix #5616.
Until root cause is fixed, see:
- #5614 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5617/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5617/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5616/comments | https://api.github.com/repos/huggingface/datasets/issues/5616/events | https://github.com/huggingface/datasets/issues/5616 | 1,612,932,508 | I_kwDODunzps5gI2Wc | 5,616 | CI is broken after fsspec-2023.3.0 release | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 0 | 2023-03-07T08:06:39Z | 2023-03-07T08:37:29Z | 2023-03-07T08:37:29Z | MEMBER | null | null | null | As reported by @lhoestq, our CI is broken after `fsspec` 2023.3.0 release:
```
FAILED tests/test_filesystem.py::test_compression_filesystems[Bz2FileSystem] - AssertionError: assert [{'created': ...: False, ...}] == ['file.txt']
At index 0 diff: {'name': 'file.txt', 'size': 70, 'type': 'file', 'created': 1678175677... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5616/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5616/timeline | null | completed | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5615/comments | https://api.github.com/repos/huggingface/datasets/issues/5615/events | https://github.com/huggingface/datasets/issues/5615 | 1,612,552,653 | I_kwDODunzps5gHZnN | 5,615 | IterableDataset.add_column is unable to accept another IterableDataset as a parameter. | {
"avatar_url": "https://avatars.githubusercontent.com/u/6466389?v=4",
"events_url": "https://api.github.com/users/zsaladin/events{/privacy}",
"followers_url": "https://api.github.com/users/zsaladin/followers",
"following_url": "https://api.github.com/users/zsaladin/following{/other_user}",
"gists_url": "http... | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | 1 | 2023-03-07T01:52:00Z | 2023-03-09T15:24:05Z | 2023-03-09T15:23:54Z | NONE | null | null | null | ### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5615/timeline | null | completed | false | [
"Hi! You can use `concatenate_datasets([ids1, ids2], axis=1)` to do this."
] |
https://api.github.com/repos/huggingface/datasets/issues/5614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5614/comments | https://api.github.com/repos/huggingface/datasets/issues/5614/events | https://github.com/huggingface/datasets/pull/5614 | 1,611,896,357 | PR_kwDODunzps5LZOTd | 5,614 | Fix archive fs test | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 4 | 2023-03-06T17:28:09Z | 2023-03-07T13:27:50Z | 2023-03-07T13:20:57Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5614.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5614",
"merged_at": "2023-03-07T13:20:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5614.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5614/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5614/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5613/comments | https://api.github.com/repos/huggingface/datasets/issues/5613/events | https://github.com/huggingface/datasets/issues/5613 | 1,611,875,473 | I_kwDODunzps5gE0SR | 5,613 | Version mismatch with multiprocess and dill on Python 3.10 | {
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"events_url": "https://api.github.com/users/adampauls/events{/privacy}",
"followers_url": "https://api.github.com/users/adampauls/followers",
"following_url": "https://api.github.com/users/adampauls/following{/other_user}",
"gists_url": "h... | [] | open | false | null | [] | null | 6 | 2023-03-06T17:14:41Z | 2024-04-05T20:13:52Z | null | NONE | null | null | null | ### Describe the bug
Grabbing the latest version of `datasets` and `apache-beam` with `poetry` using Python 3.10 gives a crash at runtime. The crash is
```
File "/Users/adpauls/sc/git/DSI-transformers/data/NQ/create_NQ_train_vali.py", line 1, in <module>
import datasets
File "/Users/adpauls/Library/Caches/... | {
"+1": 9,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 9,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5613/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5613/timeline | null | reopened | false | [
"Sorry, I just found https://github.com/apache/beam/issues/24458. It seems this issue is being worked on. ",
"Reopening, since I think the docs should inform the user of this problem. For example, [this page](https://huggingface.co/docs/datasets/installation) says \r\n> Datasets is tested on Python 3.7+.\r\n\r\nb... |
https://api.github.com/repos/huggingface/datasets/issues/5612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5612/comments | https://api.github.com/repos/huggingface/datasets/issues/5612/events | https://github.com/huggingface/datasets/issues/5612 | 1,611,262,510 | I_kwDODunzps5gCeou | 5,612 | Arrow map type in parquet files unsupported | {
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_u... | [] | open | false | null | [] | null | 4 | 2023-03-06T12:03:24Z | 2024-03-15T18:56:12Z | null | CONTRIBUTOR | null | null | null | ### Describe the bug
When I try to load parquet files that were processed with Spark, I get the following issue:
`ValueError: Arrow type map<string, string ('warc_headers')> does not have a datasets dtype equivalent.`
Strangely, loading the dataset with `streaming=True` solves the issue.
### Steps to reproduce ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 5,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5612/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5612/timeline | null | null | false | [
"I'm attaching a minimal reproducible example:\r\n```python\r\nfrom datasets import load_dataset\r\nimport pyarrow as pa\r\nimport pyarrow.parquet as pq\r\n\r\ntable_with_map = pa.Table.from_pydict(\r\n {\"a\": [1, 2], \"b\": [[(\"a\", 2)], [(\"b\", 4)]]},\r\n schema=pa.schema({\"a\": pa.int32(), \"b\": pa.ma... |
https://api.github.com/repos/huggingface/datasets/issues/5611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5611/comments | https://api.github.com/repos/huggingface/datasets/issues/5611/events | https://github.com/huggingface/datasets/pull/5611 | 1,611,197,906 | PR_kwDODunzps5LW2Lx | 5,611 | add Dataset.to_list | {
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"events_url": "https://api.github.com/users/kyoto7250/events{/privacy}",
"followers_url": "https://api.github.com/users/kyoto7250/followers",
"following_url": "https://api.github.com/users/kyoto7250/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | 3 | 2023-03-06T11:21:57Z | 2023-03-27T13:34:19Z | 2023-03-27T13:26:38Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5611.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5611",
"merged_at": "2023-03-27T13:26:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5611.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | close https://github.com/huggingface/datasets/issues/5606
This PR is for adding the `Dataset.to_list` method.
Thank you in advance.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5611/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5611/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi, thanks for working on this! `Table.to_pylist` requires PyArrow 7.0+, and our minimal version requirement is 6.0, so we need to bump the version requirement to avoid CI failure. I'll do this in a separate PR.",
"<details>\n<summ... |
https://api.github.com/repos/huggingface/datasets/issues/5610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5610/comments | https://api.github.com/repos/huggingface/datasets/issues/5610/events | https://github.com/huggingface/datasets/issues/5610 | 1,610,698,006 | I_kwDODunzps5gAU0W | 5,610 | use datasets streaming mode in trainer ddp mode cause memory leak | {
"avatar_url": "https://avatars.githubusercontent.com/u/15223544?v=4",
"events_url": "https://api.github.com/users/gromzhu/events{/privacy}",
"followers_url": "https://api.github.com/users/gromzhu/followers",
"following_url": "https://api.github.com/users/gromzhu/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | 3 | 2023-03-06T05:26:49Z | 2024-03-07T01:11:32Z | null | NONE | null | null | null | ### Describe the bug
use datasets streaming mode in trainer ddp mode cause memory leak
### Steps to reproduce the bug
import os
import time
import datetime
import sys
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, Sequenti... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5610/timeline | null | null | false | [
"Same problem, \r\ntransformers 4.28.1\r\ndatasets 2.12.0\r\n\r\nleak around 100Mb per 10 seconds when use dataloader_num_werker > 0 in training argumennts for transformer train, possile bug in transformers repo, but still not found solution :(\r\n",
"found an article described a problem, may be helpful for someb... |
https://api.github.com/repos/huggingface/datasets/issues/5609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5609/comments | https://api.github.com/repos/huggingface/datasets/issues/5609/events | https://github.com/huggingface/datasets/issues/5609 | 1,610,062,862 | I_kwDODunzps5f95wO | 5,609 | `load_from_disk` vs `load_dataset` performance. | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | [] | open | false | null | [] | null | 4 | 2023-03-05T05:27:15Z | 2023-07-13T18:48:05Z | null | NONE | null | null | null | ### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_di... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5609/timeline | null | null | false | [
"Hi! We've recently made some improvements to `save_to_disk`/`list_to_disk` (100x faster in some scenarios), so it would help if you could install `datasets` directly from `main` (`pip install git+https://github.com/huggingface/datasets.git`) and re-run the \"benchmark\".",
"Great to hear! I'll give it a try when... |
https://api.github.com/repos/huggingface/datasets/issues/5608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5608/comments | https://api.github.com/repos/huggingface/datasets/issues/5608/events | https://github.com/huggingface/datasets/issues/5608 | 1,609,996,563 | I_kwDODunzps5f9pkT | 5,608 | audiofolder only creates dataset of 13 rows (files) when the data folder it's reading from has 20,000 mp3 files. | {
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://... | [] | closed | false | null | [] | null | 2 | 2023-03-05T00:14:45Z | 2023-03-12T00:02:57Z | 2023-03-12T00:02:57Z | NONE | null | null | null | ### Describe the bug
x = load_dataset("audiofolder", data_dir="x")
When running this, x is a dataset of 13 rows (files) when it should be 20,000 rows (files) as the data_dir "x" has 20,000 mp3 files. Does anyone know what could possibly cause this (naming convention of mp3 files, etc.)
### Steps to reproduce the b... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5608/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5608/timeline | null | completed | false | [
"Hi!\r\n\r\n> naming convention of mp3 files\r\n\r\nYes, this could be the problem. MP3 files should end with `.mp3`/`.MP3` to be recognized as audio files.\r\n\r\nIf the file names are not the culprit, can you paste the audio folder's directory structure to help us reproduce the error (e.g., by running the `tree ... |
https://api.github.com/repos/huggingface/datasets/issues/5607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5607/comments | https://api.github.com/repos/huggingface/datasets/issues/5607/events | https://github.com/huggingface/datasets/pull/5607 | 1,609,166,035 | PR_kwDODunzps5LQPbG | 5,607 | Fix outdated `verification_mode` values | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | 2 | 2023-03-03T19:50:29Z | 2023-03-09T17:34:13Z | 2023-03-09T17:27:07Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5607.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5607",
"merged_at": "2023-03-09T17:27:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5607.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ~I think it makes sense not to save `dataset_info.json` file to a dataset cache directory when loading dataset with `verification_mode="no_checks"` because otherwise when next time the dataset is loaded **without** `verification_mode="no_checks"`, it will be loaded successfully, despite some values in info might not co... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5607/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5607/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5606/comments | https://api.github.com/repos/huggingface/datasets/issues/5606/events | https://github.com/huggingface/datasets/issues/5606 | 1,608,911,632 | I_kwDODunzps5f5gsQ | 5,606 | Add `Dataset.to_list` to the API | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"events_url": "https://api.github.com/users/kyoto7250/events{/privacy}",
"followers_url": "https://api.github.com/users/kyoto7250/followers",
"following_url": "https://api.github.com/users/kyoto7250/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"events_url": "https://api.github.com/users/kyoto7250/events{/privacy}",
"followers_url": "https://api.github.com/users/kyoto7250/followers",
"following_url": "https://api.github.com/users/kyoto7250/following{/other_user}",
... | null | 3 | 2023-03-03T16:17:10Z | 2023-03-27T13:26:40Z | 2023-03-27T13:26:40Z | COLLABORATOR | null | null | null | Since there is `Dataset.from_list` in the API, we should also add `Dataset.to_list` to be consistent.
Regarding the implementation, we can re-use `Dataset.to_dict`'s code and replace the `to_pydict` calls with `to_pylist`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5606/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5606/timeline | null | completed | false | [
"Hello, I have an interest in this issue.\r\nIs the `Dataset.to_dict` you are describing correct in the code here?\r\n\r\nhttps://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/arrow_dataset.py#L4633-L4667",
"Yes, this is where `Dataset.to_dict` is defined.",
"#self-a... |
https://api.github.com/repos/huggingface/datasets/issues/5605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5605/comments | https://api.github.com/repos/huggingface/datasets/issues/5605/events | https://github.com/huggingface/datasets/pull/5605 | 1,608,865,460 | PR_kwDODunzps5LPPf5 | 5,605 | Update README logo | {
"avatar_url": "https://avatars.githubusercontent.com/u/3841370?v=4",
"events_url": "https://api.github.com/users/gary149/events{/privacy}",
"followers_url": "https://api.github.com/users/gary149/followers",
"following_url": "https://api.github.com/users/gary149/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | 3 | 2023-03-03T15:46:31Z | 2023-03-03T21:57:18Z | 2023-03-03T21:50:17Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5605.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5605",
"merged_at": "2023-03-03T21:50:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5605.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5605/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5605/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Are you sure it's safe to remove? https://github.com/huggingface/datasets/pull/3866",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benc... |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"events_url": "https://api.github.com/users/sentialx/events{/privacy}",
"followers_url": "https://api.github.com/users/sentialx/followers",
"following_url": "https://api.github.com/users/sentialx/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | 7 | 2023-03-03T09:52:08Z | 2023-10-14T02:15:52Z | 2023-03-24T12:44:25Z | NONE | null | null | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
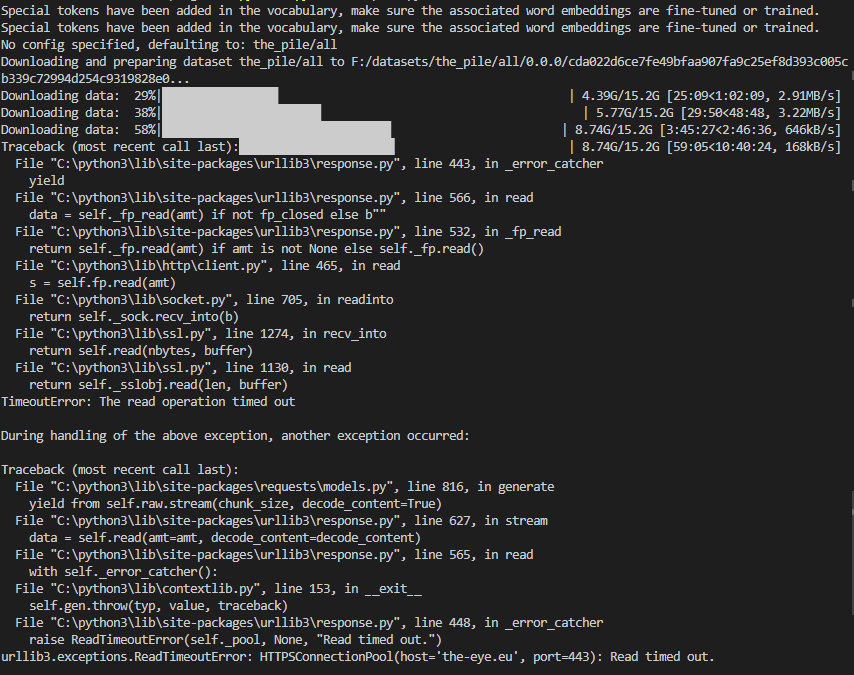
Here are the downloaded files:
)` in `load_dataset` to resume the download when re-running the code after the timeout error:\r\n```python\r\nfrom datasets import load_dataset, DownloadConfig\r\ndataset = load_dataset('the_pile', split='train', cache_dir='F:\\da... |
https://api.github.com/repos/huggingface/datasets/issues/5603 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5603/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5603/comments | https://api.github.com/repos/huggingface/datasets/issues/5603/events | https://github.com/huggingface/datasets/pull/5603 | 1,607,143,509 | PR_kwDODunzps5LJZzG | 5,603 | Don't compute checksums if not necessary in `datasets-cli test` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 3 | 2023-03-02T16:42:39Z | 2023-03-03T15:45:32Z | 2023-03-03T15:38:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5603.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5603",
"merged_at": "2023-03-03T15:38:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5603.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | we only need them if there exists a `dataset_infos.json` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5603/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5603/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5602/comments | https://api.github.com/repos/huggingface/datasets/issues/5602/events | https://github.com/huggingface/datasets/pull/5602 | 1,607,054,110 | PR_kwDODunzps5LJGfa | 5,602 | Return dict structure if columns are lists - to_tf_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_u... | [] | open | false | null | [] | null | 19 | 2023-03-02T15:51:12Z | 2023-04-12T15:54:53Z | null | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5602.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5602",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5602.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5602"
} | This PR introduces new logic to `to_tf_dataset` affecting the returned data structure, enabling a dictionary structure to be returned, even if only one feature column is selected.
If the passed in `columns` or `label_cols` to `to_tf_dataset` are a list, they are returned as a dictionary, respectively. If they are a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5602/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5602/timeline | null | null | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5602). All of your documentation changes will be reflected on that endpoint.",
"This is a great PR! Thinking about the UX though, maybe we could do it without the extra argument? Before this PR, the logic in `to_tf_dataset` was... |
https://api.github.com/repos/huggingface/datasets/issues/5601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5601/comments | https://api.github.com/repos/huggingface/datasets/issues/5601/events | https://github.com/huggingface/datasets/issues/5601 | 1,606,685,976 | I_kwDODunzps5fxBUY | 5,601 | Authorization error | {
"avatar_url": "https://avatars.githubusercontent.com/u/107404835?v=4",
"events_url": "https://api.github.com/users/OleksandrKorovii/events{/privacy}",
"followers_url": "https://api.github.com/users/OleksandrKorovii/followers",
"following_url": "https://api.github.com/users/OleksandrKorovii/following{/other_us... | [] | closed | false | null | [] | null | 2 | 2023-03-02T12:08:39Z | 2023-03-14T16:55:35Z | 2023-03-14T16:55:34Z | NONE | null | null | null | ### Describe the bug
Get `Authorization error` when try to push data into hugginface datasets hub.
### Steps to reproduce the bug
I did all steps in the [tutorial](https://huggingface.co/docs/datasets/share),
1. `huggingface-cli login` with WRITE token
2. `git lfs install`
3. `git clone https://huggingfa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5601/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5601/timeline | null | completed | false | [
"Hi! \r\n\r\nIt's better to report this kind of issue in the `huggingface_hub` repo, so if you still haven't resolved it, I suggest you open an issue there.",
"Yeah, I solved it. Problem was in osxkeychain. When I do `hugginface-cli login` it's add token with default account (username)`hg_user` but my repo cont... |
https://api.github.com/repos/huggingface/datasets/issues/5600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5600/comments | https://api.github.com/repos/huggingface/datasets/issues/5600/events | https://github.com/huggingface/datasets/issues/5600 | 1,606,585,596 | I_kwDODunzps5fwoz8 | 5,600 | Dataloader getitem not working for DreamboothDatasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/76955987?v=4",
"events_url": "https://api.github.com/users/salahiguiliz/events{/privacy}",
"followers_url": "https://api.github.com/users/salahiguiliz/followers",
"following_url": "https://api.github.com/users/salahiguiliz/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | 1 | 2023-03-02T11:00:27Z | 2023-03-13T17:59:35Z | 2023-03-13T17:59:35Z | NONE | null | null | null | ### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5600/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5600/timeline | null | completed | false | [
"Hi! \r\n\r\n> (see example of DreamboothDatasets)\r\n\r\n\r\nCould you please provide a link to it? If you are referring to the example in the `diffusers` repo, your issue is unrelated to `datasets` as that example uses `Dataset` from PyTorch to load data."
] |
https://api.github.com/repos/huggingface/datasets/issues/5598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5598/comments | https://api.github.com/repos/huggingface/datasets/issues/5598/events | https://github.com/huggingface/datasets/pull/5598 | 1,605,018,478 | PR_kwDODunzps5LCMiX | 5,598 | Fix push_to_hub with no dataset_infos | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 2 | 2023-03-01T13:54:06Z | 2023-03-02T13:47:13Z | 2023-03-02T13:40:17Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5598.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5598",
"merged_at": "2023-03-02T13:40:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5598.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As reported in https://github.com/vijaydwivedi75/lrgb/issues/10, `push_to_hub` fails if the remote repository already exists and has a README.md without `dataset_info` in the YAML tags
cc @clefourrier | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5598/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5598/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5597/comments | https://api.github.com/repos/huggingface/datasets/issues/5597/events | https://github.com/huggingface/datasets/issues/5597 | 1,604,928,721 | I_kwDODunzps5fqUTR | 5,597 | in-place dataset update | {
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"events_url": "https://api.github.com/users/speedcell4/events{/privacy}",
"followers_url": "https://api.github.com/users/speedcell4/followers",
"following_url": "https://api.github.com/users/speedcell4/following{/other_user}",
"gists_url":... | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | 3 | 2023-03-01T12:58:18Z | 2023-03-02T13:30:41Z | 2023-03-02T03:47:00Z | NONE | null | null | null | ### Motivation
For the circumstance that I creat an empty `Dataset` and keep appending new rows into it, I found that it leads to creating a new dataset at each call. It looks quite memory-consuming. I just wonder if there is any more efficient way to do this.
```python
from datasets import Dataset
ds = Datas... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5597/timeline | null | completed | false | [
"We won't support in-place modifications since `datasets` is based on the Apache Arrow format which doesn't support in-place modifications.\r\n\r\nIn your case the old dataset is garbage collected pretty quickly so you won't have memory issues.\r\n\r\nNote that datasets loaded from disk (memory mapped) are not load... |
https://api.github.com/repos/huggingface/datasets/issues/5596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5596/comments | https://api.github.com/repos/huggingface/datasets/issues/5596/events | https://github.com/huggingface/datasets/issues/5596 | 1,604,919,993 | I_kwDODunzps5fqSK5 | 5,596 | [TypeError: Couldn't cast array of type] Can only load a subset of the dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | 5 | 2023-03-01T12:53:08Z | 2023-12-05T03:22:00Z | 2023-03-02T11:12:11Z | NONE | null | null | null | ### Describe the bug
I'm trying to load this [dataset](https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues) which consists of jsonl files and I get the following error:
```
casted_values = _c(array.values, feature[0])
File "/opt/conda/lib/python3.7/site-packages/datasets/table.py", line 1839, in wr... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5596/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5596/timeline | null | completed | false | [
"Apparently some JSON objects have a `\"labels\"` field. Since this field is not present in every object, you must specify all the fields types in the README.md\r\n\r\nEDIT: actually specifying the feature types doesn’t solve the issue, it raises an error because “labels” is missing in the data",
"We've updated t... |
https://api.github.com/repos/huggingface/datasets/issues/5595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5595/comments | https://api.github.com/repos/huggingface/datasets/issues/5595/events | https://github.com/huggingface/datasets/pull/5595 | 1,604,070,629 | PR_kwDODunzps5K--V9 | 5,595 | Unpins sqlAlchemy | {
"avatar_url": "https://avatars.githubusercontent.com/u/46943923?v=4",
"events_url": "https://api.github.com/users/lazarust/events{/privacy}",
"followers_url": "https://api.github.com/users/lazarust/followers",
"following_url": "https://api.github.com/users/lazarust/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | 3 | 2023-03-01T01:33:45Z | 2023-04-04T08:20:19Z | 2023-04-04T08:19:14Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5595.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5595",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5595.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5595"
} | Closes #5477 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5595/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5595/timeline | null | null | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5595). All of your documentation changes will be reflected on that endpoint.",
"It looks like this issue hasn't been fixed yet, so let's wait a bit more.",
"@lazarust thanks for your work, but unfortunately we cannot merge it... |
https://api.github.com/repos/huggingface/datasets/issues/5594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5594/comments | https://api.github.com/repos/huggingface/datasets/issues/5594/events | https://github.com/huggingface/datasets/issues/5594 | 1,603,980,995 | I_kwDODunzps5fms7D | 5,594 | Error while downloading the xtreme udpos dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/24687672?v=4",
"events_url": "https://api.github.com/users/simran-khanuja/events{/privacy}",
"followers_url": "https://api.github.com/users/simran-khanuja/followers",
"following_url": "https://api.github.com/users/simran-khanuja/following{/other_user}",
... | [] | closed | false | null | [] | null | 21 | 2023-02-28T23:40:53Z | 2023-11-04T20:45:56Z | 2023-07-24T14:22:18Z | NONE | null | null | null | ### Describe the bug
Hi,
I am facing an error while downloading the xtreme udpos dataset using load_dataset. I have datasets 2.10.1 installed
```Downloading and preparing dataset xtreme/udpos.Arabic to /compute/tir-1-18/skhanuja/multilingual_ft/cache/data/xtreme/udpos.Arabic/1.0.0/29f5d57a48779f37ccb75cb8708d1... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5594/timeline | null | completed | false | [
"Hi! I cannot reproduce this error on my machine.\r\n\r\nThe raised error could mean that one of the downloaded files is corrupted. To verify this is not the case, you can run `load_dataset` as follows:\r\n```python\r\ntrain_dataset = load_dataset('xtreme', 'udpos.English', split=\"train\", cache_dir=args.cache_dir... |
https://api.github.com/repos/huggingface/datasets/issues/5592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5592/comments | https://api.github.com/repos/huggingface/datasets/issues/5592/events | https://github.com/huggingface/datasets/pull/5592 | 1,603,619,124 | PR_kwDODunzps5K9dWr | 5,592 | Fix docstring example | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | 2 | 2023-02-28T18:42:37Z | 2023-02-28T19:26:33Z | 2023-02-28T19:19:15Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5592.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5592",
"merged_at": "2023-02-28T19:19:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5592.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fixes #5581 to use the correct output for the `set_format` method. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5592/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5592/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5591/comments | https://api.github.com/repos/huggingface/datasets/issues/5591/events | https://github.com/huggingface/datasets/pull/5591 | 1,603,571,407 | PR_kwDODunzps5K9S79 | 5,591 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 3 | 2023-02-28T18:09:05Z | 2023-02-28T18:16:31Z | 2023-02-28T18:09:15Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5591.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5591",
"merged_at": "2023-02-28T18:09:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5591.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5591/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5591/timeline | null | null | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5591). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... |
https://api.github.com/repos/huggingface/datasets/issues/5590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5590/comments | https://api.github.com/repos/huggingface/datasets/issues/5590/events | https://github.com/huggingface/datasets/pull/5590 | 1,603,549,504 | PR_kwDODunzps5K9N_H | 5,590 | Release: 2.10.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 5 | 2023-02-28T17:58:11Z | 2023-02-28T18:16:27Z | 2023-02-28T18:06:08Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5590.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5590",
"merged_at": "2023-02-28T18:06:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5590.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5590/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5590/timeline | null | null | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... |
https://api.github.com/repos/huggingface/datasets/issues/5589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5589/comments | https://api.github.com/repos/huggingface/datasets/issues/5589/events | https://github.com/huggingface/datasets/pull/5589 | 1,603,535,704 | PR_kwDODunzps5K9K1i | 5,589 | Revert "pass the dataset features to the IterableDataset.from_generator" | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 5 | 2023-02-28T17:52:04Z | 2023-09-24T10:07:33Z | 2023-03-21T14:18:18Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5589.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5589",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5589.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5589"
} | This reverts commit b91070b9c09673e2e148eec458036ab6a62ac042 (temporarily)
It hurts iterable dataset performance a lot (e.g. x4 slower because it encodes+decodes images unnecessarily). I think we need to fix this before re-adding it
cc @mariosasko @Hubert-Bonisseur | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5589/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5589/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5588 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5588/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5588/comments | https://api.github.com/repos/huggingface/datasets/issues/5588/events | https://github.com/huggingface/datasets/pull/5588 | 1,603,304,766 | PR_kwDODunzps5K8YYz | 5,588 | Flatten dataset on the fly in `save_to_disk` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | 3 | 2023-02-28T15:37:46Z | 2023-02-28T17:28:35Z | 2023-02-28T17:21:17Z | COLLABORATOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5588.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5588",
"merged_at": "2023-02-28T17:21:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5588.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Flatten a dataset on the fly in `save_to_disk` instead of doing it with `flatten_indices` to avoid creating an additional cache file.
(this is one of the sub-tasks in https://github.com/huggingface/datasets/issues/5507) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5588/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5588/timeline | null | null | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... |
https://api.github.com/repos/huggingface/datasets/issues/5587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5587/comments | https://api.github.com/repos/huggingface/datasets/issues/5587/events | https://github.com/huggingface/datasets/pull/5587 | 1,603,139,420 | PR_kwDODunzps5K70pp | 5,587 | Fix `sort` with indices mapping | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | 3 | 2023-02-28T14:05:08Z | 2023-02-28T17:28:57Z | 2023-02-28T17:21:58Z | COLLABORATOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5587.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5587",
"merged_at": "2023-02-28T17:21:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5587.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fixes the `key` range in the `query_table` call in `sort` to account for an indices mapping
Fix #5586 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5587/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5587/timeline | null | null | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... |
https://api.github.com/repos/huggingface/datasets/issues/5586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5586/comments | https://api.github.com/repos/huggingface/datasets/issues/5586/events | https://github.com/huggingface/datasets/issues/5586 | 1,602,961,544 | I_kwDODunzps5fi0CI | 5,586 | .sort() is broken when used after .filter(), only in 2.10.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/57797966?v=4",
"events_url": "https://api.github.com/users/MattYoon/events{/privacy}",
"followers_url": "https://api.github.com/users/MattYoon/followers",
"following_url": "https://api.github.com/users/MattYoon/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 1 | 2023-02-28T12:18:09Z | 2023-02-28T18:17:26Z | 2023-02-28T17:21:59Z | NONE | null | null | null | ### Describe the bug
Hi, thank you for your support!
It seems like the addition of multiple key sort (#5502) in 2.10.0 broke the `.sort()` method.
After filtering a dataset with `.filter()`, the `.sort()` seems to refer to the query_table index of the previous unfiltered dataset, resulting in an IndexError.
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5586/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5586/timeline | null | completed | false | [
"Thanks for reporting and thanks @mariosasko for fixing ! We just did a patch release `2.10.1` with the fix"
] |
https://api.github.com/repos/huggingface/datasets/issues/5585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5585/comments | https://api.github.com/repos/huggingface/datasets/issues/5585/events | https://github.com/huggingface/datasets/issues/5585 | 1,602,190,030 | I_kwDODunzps5ff3rO | 5,585 | Cache is not transportable | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | [] | closed | false | null | [] | null | 2 | 2023-02-28T00:53:06Z | 2023-02-28T21:26:52Z | 2023-02-28T21:26:52Z | NONE | null | null | null | ### Describe the bug
I would like to share cache between two machines (a Windows host machine and a WSL instance).
I run most my code in WSL. I have just run out of space in the virtual drive. Rather than expand the drive size, I plan to move to cache to the host Windows machine, thereby sharing the downloads.
I... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5585/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5585/timeline | null | completed | false | [
"Hi ! No the cache is not transportable in general. It will work on a shared filesystem if you use the same python environment, but not across machines/os/environments.\r\n\r\nIn particular, reloading cached datasets does work, but reloading cached processed datasets (e.g. from `map`) may not work. This is because ... |
https://api.github.com/repos/huggingface/datasets/issues/5584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5584/comments | https://api.github.com/repos/huggingface/datasets/issues/5584/events | https://github.com/huggingface/datasets/issues/5584 | 1,601,821,808 | I_kwDODunzps5fedxw | 5,584 | Unable to load coyo700M dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/3059998?v=4",
"events_url": "https://api.github.com/users/manuaero/events{/privacy}",
"followers_url": "https://api.github.com/users/manuaero/followers",
"following_url": "https://api.github.com/users/manuaero/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | 1 | 2023-02-27T19:35:03Z | 2023-02-28T07:27:59Z | 2023-02-28T07:27:58Z | NONE | null | null | null | ### Describe the bug
Seeing this error when downloading https://huggingface.co/datasets/kakaobrain/coyo-700m:
```ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.```
Full stack trace
```Downloading and preparing dataset parquet/kakaobrain--coy... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5584/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5584/timeline | null | completed | false | [
"Hi @manuaero \r\n\r\nThank you for your interest in the COYO dataset.\r\n\r\nOur dataset provides the img-url and alt-text in the form of a parquet, so to utilize the coyo dataset you will need to download it directly.\r\n\r\nWe provide a [guide](https://github.com/kakaobrain/coyo-dataset/blob/main/download/README... |
https://api.github.com/repos/huggingface/datasets/issues/5583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5583/comments | https://api.github.com/repos/huggingface/datasets/issues/5583/events | https://github.com/huggingface/datasets/pull/5583 | 1,601,583,625 | PR_kwDODunzps5K2mIz | 5,583 | Do no write index by default when exporting a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | 3 | 2023-02-27T17:04:46Z | 2023-02-28T13:52:15Z | 2023-02-28T13:44:04Z | COLLABORATOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5583",
"merged_at": "2023-02-28T13:44:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Ensures all the writers that use Pandas for conversion (JSON, CSV, SQL) do not export `index` by default (https://github.com/huggingface/datasets/pull/5490 only did this for CSV) | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5583/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5582/comments | https://api.github.com/repos/huggingface/datasets/issues/5582/events | https://github.com/huggingface/datasets/pull/5582 | 1,600,932,092 | PR_kwDODunzps5K0ZcN | 5,582 | Add column_names to IterableDataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/50772274?v=4",
"events_url": "https://api.github.com/users/patrickloeber/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickloeber/followers",
"following_url": "https://api.github.com/users/patrickloeber/following{/other_user}",
"g... | [] | closed | false | null | [] | null | 2 | 2023-02-27T10:50:07Z | 2023-03-13T19:10:22Z | 2023-03-13T19:03:32Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5582.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5582",
"merged_at": "2023-03-13T19:03:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5582.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR closes #5383
* Add column_names property to IterableDataset
* Add multiple tests for this new property | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5582/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5582/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5581/comments | https://api.github.com/repos/huggingface/datasets/issues/5581/events | https://github.com/huggingface/datasets/issues/5581 | 1,600,675,489 | I_kwDODunzps5faF6h | 5,581 | [DOC] Mistaken docs on set_format | {
"avatar_url": "https://avatars.githubusercontent.com/u/36224762?v=4",
"events_url": "https://api.github.com/users/NightMachinery/events{/privacy}",
"followers_url": "https://api.github.com/users/NightMachinery/followers",
"following_url": "https://api.github.com/users/NightMachinery/following{/other_user}",
... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | 1 | 2023-02-27T08:03:09Z | 2023-02-28T19:19:17Z | 2023-02-28T19:19:17Z | CONTRIBUTOR | null | null | null | ### Describe the bug
https://huggingface.co/docs/datasets/v2.10.0/en/package_reference/main_classes#datasets.Dataset.set_format
<img width="700" alt="image" src="https://user-images.githubusercontent.com/36224762/221506973-ae2e3991-60a7-4d4e-99f8-965c6eb61e59.png">
While actually running it will result in:
<img w... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5581/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5581/timeline | null | completed | false | [
"Thanks for reporting!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5580/comments | https://api.github.com/repos/huggingface/datasets/issues/5580/events | https://github.com/huggingface/datasets/pull/5580 | 1,600,431,792 | PR_kwDODunzps5Kys1c | 5,580 | Support cloud storage in load_dataset via fsspec | {
"avatar_url": "https://avatars.githubusercontent.com/u/2512762?v=4",
"events_url": "https://api.github.com/users/dwyatte/events{/privacy}",
"followers_url": "https://api.github.com/users/dwyatte/followers",
"following_url": "https://api.github.com/users/dwyatte/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | 6 | 2023-02-27T04:06:05Z | 2023-03-11T01:02:49Z | 2023-03-11T00:55:40Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5580.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5580",
"merged_at": "2023-03-11T00:55:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5580.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Closes https://github.com/huggingface/datasets/issues/5281
This PR uses fsspec to support datasets on cloud storage (tested manually with GCS). ETags are currently unsupported for cloud storage. In general, a much larger refactor could be done to just use fsspec for all schemes (ftp, http/s, s3, gcs) to unify the in... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5580/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5580/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Regarding the tests I think it should be possible to use the mockfs fixture, it allows to play with a dummy fsspec FileSystem with the \"mock://\" protocol.\r\n\r\n> However it requires some storage_options to be passed. Maybe it c... |
https://api.github.com/repos/huggingface/datasets/issues/5579 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5579/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5579/comments | https://api.github.com/repos/huggingface/datasets/issues/5579/events | https://github.com/huggingface/datasets/pull/5579 | 1,599,732,211 | PR_kwDODunzps5Kwgo4 | 5,579 | Add instructions to create `DataLoader` from augmented dataset in object detection guide | {
"avatar_url": "https://avatars.githubusercontent.com/u/21087104?v=4",
"events_url": "https://api.github.com/users/Laurent2916/events{/privacy}",
"followers_url": "https://api.github.com/users/Laurent2916/followers",
"following_url": "https://api.github.com/users/Laurent2916/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | 3 | 2023-02-25T14:53:17Z | 2023-03-23T19:24:59Z | 2023-03-23T19:24:50Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5579.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5579",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5579.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5579"
} | The following adds instructions on how to create a `DataLoader` from the guide on how to use object detection with augmentations (#4710). I am open to hearing any suggestions for improvement ! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5579/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5579/timeline | null | null | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5579). All of your documentation changes will be reflected on that endpoint.",
"I'm not sure we need this part as we provide a link to the notebook that shows how to train an object detection model, and this notebook instantiat... |
https://api.github.com/repos/huggingface/datasets/issues/5578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5578/comments | https://api.github.com/repos/huggingface/datasets/issues/5578/events | https://github.com/huggingface/datasets/pull/5578 | 1,598,863,119 | PR_kwDODunzps5Kto96 | 5,578 | Add `huggingface_hub` version to env cli command | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | 4 | 2023-02-24T15:37:43Z | 2023-02-27T17:28:25Z | 2023-02-27T17:21:09Z | COLLABORATOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5578.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5578",
"merged_at": "2023-02-27T17:21:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5578.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add the `huggingface_hub` version to the `env` command's output. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5578/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5577 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5577/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5577/comments | https://api.github.com/repos/huggingface/datasets/issues/5577/events | https://github.com/huggingface/datasets/issues/5577 | 1,598,587,665 | I_kwDODunzps5fSIMR | 5,577 | Cannot load `the_pile_openwebtext2` | {
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"events_url": "https://api.github.com/users/wjfwzzc/events{/privacy}",
"followers_url": "https://api.github.com/users/wjfwzzc/followers",
"following_url": "https://api.github.com/users/wjfwzzc/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | 1 | 2023-02-24T13:01:48Z | 2023-02-24T14:01:09Z | 2023-02-24T14:01:09Z | NONE | null | null | null | ### Describe the bug
I met the same bug mentioned in #3053 which is never fixed. Because several `reddit_scores` are larger than `int8` even `int16`. https://huggingface.co/datasets/the_pile_openwebtext2/blob/main/the_pile_openwebtext2.py#L62
### Steps to reproduce the bug
```python3
from datasets import load... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5577/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5577/timeline | null | completed | false | [
"Hi! I've merged a PR to use `int32` instead of `int8` for `reddit_scores`, so it should work now.\r\n\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5576/comments | https://api.github.com/repos/huggingface/datasets/issues/5576/events | https://github.com/huggingface/datasets/issues/5576 | 1,598,582,744 | I_kwDODunzps5fSG_Y | 5,576 | I was getting a similar error `pyarrow.lib.ArrowInvalid: Integer value 528 not in range: -128 to 127` - AFAICT, this is because the type specified for `reddit_scores` is `datasets.Sequence(datasets.Value("int8"))`, but the actual values can be well outside the max range for 8-bit integers. | {
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"events_url": "https://api.github.com/users/wjfwzzc/events{/privacy}",
"followers_url": "https://api.github.com/users/wjfwzzc/followers",
"following_url": "https://api.github.com/users/wjfwzzc/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | 1 | 2023-02-24T12:57:49Z | 2023-02-24T12:58:31Z | 2023-02-24T12:58:18Z | NONE | null | null | null | I was getting a similar error `pyarrow.lib.ArrowInvalid: Integer value 528 not in range: -128 to 127` - AFAICT, this is because the type specified for `reddit_scores` is `datasets.Sequence(datasets.Value("int8"))`, but the actual values can be well outside the max range for 8-bit integers.
I worked aro... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5576/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5576/timeline | null | not_planned | false | [
"Duplicated issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/5575 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5575/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5575/comments | https://api.github.com/repos/huggingface/datasets/issues/5575/events | https://github.com/huggingface/datasets/issues/5575 | 1,598,396,552 | I_kwDODunzps5fRZiI | 5,575 | Metadata for each column | {
"avatar_url": "https://avatars.githubusercontent.com/u/11356471?v=4",
"events_url": "https://api.github.com/users/parsa-ra/events{/privacy}",
"followers_url": "https://api.github.com/users/parsa-ra/followers",
"following_url": "https://api.github.com/users/parsa-ra/following{/other_user}",
"gists_url": "htt... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | {
"closed_at": null,
"closed_issues": 1,
"created_at": "2023-02-13T16:22:42Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/follow... | 5 | 2023-02-24T10:53:44Z | 2024-01-05T21:48:35Z | null | NONE | null | null | null | ### Feature request
Being able to put some metadata for each column as a string or any other type.
### Motivation
I will bring the motivation by an example, lets say we are experimenting with embedding produced by some image encoder network, and we want to iterate through a couple of preprocessing and see which on... | {
"+1": 7,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 7,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5575/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5575/timeline | null | null | false | [
"Hi! Indeed it would be useful to support this. PyArrow natively supports schema-level and column-level metadata, so implementing this should be straightforward. The API I have in mind would work as follows:\r\n```python\r\ncol_feature = Value(\"string\", metadata=\"Some column-level metadata\")\r\n\r\nfeatures = F... |
https://api.github.com/repos/huggingface/datasets/issues/5574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5574/comments | https://api.github.com/repos/huggingface/datasets/issues/5574/events | https://github.com/huggingface/datasets/issues/5574 | 1,598,104,691 | I_kwDODunzps5fQSRz | 5,574 | c4 dataset streaming fails with `FileNotFoundError` | {
"avatar_url": "https://avatars.githubusercontent.com/u/202907?v=4",
"events_url": "https://api.github.com/users/krasserm/events{/privacy}",
"followers_url": "https://api.github.com/users/krasserm/followers",
"following_url": "https://api.github.com/users/krasserm/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | 12 | 2023-02-24T07:57:32Z | 2023-12-18T07:32:32Z | 2023-02-27T04:03:38Z | NONE | null | null | null | ### Describe the bug
Loading the `c4` dataset in streaming mode with `load_dataset("c4", "en", split="validation", streaming=True)` and then using it fails with a `FileNotFoundException`.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("c4", "en", split="train", ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5574/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5574/timeline | null | completed | false | [
"Also encountering this issue for every dataset I try to stream! Installed datasets from main:\r\n```\r\n- `datasets` version: 2.10.1.dev0\r\n- Platform: macOS-13.1-arm64-arm-64bit\r\n- Python version: 3.9.13\r\n- PyArrow version: 10.0.1\r\n- Pandas version: 1.5.2\r\n```\r\n\r\nRepro:\r\n```python\r\nfrom datasets ... |
https://api.github.com/repos/huggingface/datasets/issues/5573 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5573/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5573/comments | https://api.github.com/repos/huggingface/datasets/issues/5573/events | https://github.com/huggingface/datasets/pull/5573 | 1,597,400,836 | PR_kwDODunzps5Kop7n | 5,573 | Use soundfile for mp3 decoding instead of torchaudio | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | 7 | 2023-02-23T19:19:44Z | 2023-02-28T20:25:14Z | 2023-02-28T20:16:02Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5573.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5573",
"merged_at": "2023-02-28T20:16:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5573.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I've removed `torchaudio` completely and switched to use `soundfile` for everything. With the new version of `soundfile` package this should work smoothly because the `libsndfile` C library is bundled, in Linux wheels too.
Let me know if you think it's too harsh and we should continue to support `torchaudio` decodi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 3,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5573/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5573/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@mariosasko thank you for the review! do you have any idea why `test_hash_torch_tensor` fails on \"ubuntu-latest deps-minimum\"? I removed the `torchaudio<0.12.0` test dependency so it uses the latest `torch` now, might it be connect... |
https://api.github.com/repos/huggingface/datasets/issues/5572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5572/comments | https://api.github.com/repos/huggingface/datasets/issues/5572/events | https://github.com/huggingface/datasets/issues/5572 | 1,597,257,624 | I_kwDODunzps5fNDeY | 5,572 | Datasets 2.10.0 does not reuse the dataset cache | {
"avatar_url": "https://avatars.githubusercontent.com/u/45281?v=4",
"events_url": "https://api.github.com/users/lsb/events{/privacy}",
"followers_url": "https://api.github.com/users/lsb/followers",
"following_url": "https://api.github.com/users/lsb/following{/other_user}",
"gists_url": "https://api.github.co... | [] | closed | false | null | [] | null | 0 | 2023-02-23T17:28:11Z | 2023-02-23T18:03:55Z | 2023-02-23T18:03:55Z | NONE | null | null | null | ### Describe the bug
download_mode="reuse_dataset_if_exists" will always consider that a dataset doesn't exist.
Specifically, upon losing an internet connection trying to load a dataset for a second time in ten seconds, a connection error results, showing a breakpoint of:
```
File ~/jupyterlab/.direnv/python-... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5572/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5572/timeline | null | completed | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5571 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5571/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5571/comments | https://api.github.com/repos/huggingface/datasets/issues/5571/events | https://github.com/huggingface/datasets/issues/5571 | 1,597,198,953 | I_kwDODunzps5fM1Jp | 5,571 | load_dataset fails for JSON in windows | {
"avatar_url": "https://avatars.githubusercontent.com/u/11876897?v=4",
"events_url": "https://api.github.com/users/abinashsahu/events{/privacy}",
"followers_url": "https://api.github.com/users/abinashsahu/followers",
"following_url": "https://api.github.com/users/abinashsahu/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | 2 | 2023-02-23T16:50:11Z | 2023-02-24T13:21:47Z | 2023-02-24T13:21:47Z | NONE | null | null | null | ### Describe the bug
Steps:
1. Created a dataset in a Linux VM and created a small sample using dataset.to_json() method.
2. Downloaded the JSON file to my local Windows machine for working and saved in say - r"C:\Users\name\file.json"
3. I am reading the file in my local PyCharm - the location of python file is di... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5571/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5571/timeline | null | completed | false | [
"Hi! \r\n\r\nYou need to pass an input json file explicitly as `data_files` to `load_dataset` to avoid this error:\r\n```python\r\n ds = load_dataset(\"json\", data_files=args.input_json)\r\n```\r\n\r\n",
"Thanks it worked!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5570 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5570/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5570/comments | https://api.github.com/repos/huggingface/datasets/issues/5570/events | https://github.com/huggingface/datasets/issues/5570 | 1,597,190,926 | I_kwDODunzps5fMzMO | 5,570 | load_dataset gives FileNotFoundError on imagenet-1k if license is not accepted on the hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/38630200?v=4",
"events_url": "https://api.github.com/users/buoi/events{/privacy}",
"followers_url": "https://api.github.com/users/buoi/followers",
"following_url": "https://api.github.com/users/buoi/following{/other_user}",
"gists_url": "https://api.git... | [] | closed | false | null | [] | null | 2 | 2023-02-23T16:44:32Z | 2023-07-24T15:18:50Z | 2023-07-24T15:18:50Z | NONE | null | null | null | ### Describe the bug
When calling ```load_dataset('imagenet-1k')``` FileNotFoundError is raised, if not logged in and if logged in with huggingface-cli but not having accepted the licence on the hub. There is no error once accepting.
### Steps to reproduce the bug
```
from datasets import load_dataset
imagenet =... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5570/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5570/timeline | null | completed | false | [
"Hi, thanks for the feedback! Would it help to add a tip or note saying the dataset is gated and you need to accept the license before downloading it?",
"The error is now more informative:\r\n```\r\nFileNotFoundError: Couldn't find a dataset script at /content/imagenet-1k/imagenet-1k.py or any data file in the sa... |
https://api.github.com/repos/huggingface/datasets/issues/5569 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5569/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5569/comments | https://api.github.com/repos/huggingface/datasets/issues/5569/events | https://github.com/huggingface/datasets/pull/5569 | 1,597,132,383 | PR_kwDODunzps5KnwHD | 5,569 | pass the dataset features to the IterableDataset.from_generator function | {
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/Hubert-Bonisseur/events{/privacy}",
"followers_url": "https://api.github.com/users/Hubert-Bonisseur/followers",
"following_url": "https://api.github.com/users/Hubert-Bonisseur/following{/other_use... | [] | closed | false | null | [] | null | 3 | 2023-02-23T16:06:04Z | 2023-02-24T14:06:37Z | 2023-02-23T18:15:16Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5569.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5569",
"merged_at": "2023-02-23T18:15:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5569.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | [5558](https://github.com/huggingface/datasets/issues/5568) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5569/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5569/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5568/comments | https://api.github.com/repos/huggingface/datasets/issues/5568/events | https://github.com/huggingface/datasets/issues/5568 | 1,596,900,532 | I_kwDODunzps5fLsS0 | 5,568 | dataset.to_iterable_dataset() loses useful info like dataset features | {
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/Hubert-Bonisseur/events{/privacy}",
"followers_url": "https://api.github.com/users/Hubert-Bonisseur/followers",
"following_url": "https://api.github.com/users/Hubert-Bonisseur/following{/other_use... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/Hubert-Bonisseur/events{/privacy}",
"followers_url": "https://api.github.com/users/Hubert-Bonisseur/followers",
"following_url": "https://api.github.com/users/Hubert-Bonisseur/following{/other_use... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/Hubert-Bonisseur/events{/privacy}",
"followers_url": "https://api.github.com/users/Hubert-Bonisseur/followers",
"following_url": "https://api.github.com/users/Hubert-Bonisseur/followin... | null | 3 | 2023-02-23T13:45:33Z | 2023-02-24T13:22:36Z | 2023-02-24T13:22:36Z | CONTRIBUTOR | null | null | null | ### Describe the bug
Hello,
I like the new `to_iterable_dataset` feature but I noticed something that seems to be missing.
When using `to_iterable_dataset` to transform your map style dataset into iterable dataset, you lose valuable metadata like the features.
These metadata are useful if you want to interleav... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5568/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5568/timeline | null | completed | false | [
"Hi ! Oh good catch. I think the features should be passed to `IterableDataset.from_generator()` in `to_iterable_dataset()` indeed.\r\n\r\nSetting this as a good first issue if someone would like to contribute, otherwise we can take care of it :)",
"#self-assign",
"seems like the feature parameter is missing fr... |
https://api.github.com/repos/huggingface/datasets/issues/5566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5566/comments | https://api.github.com/repos/huggingface/datasets/issues/5566/events | https://github.com/huggingface/datasets/issues/5566 | 1,595,916,674 | I_kwDODunzps5fH8GC | 5,566 | Directly reading parquet files in a s3 bucket from the load_dataset method | {
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "htt... | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
},
{
"color": "a2eeef",
... | open | false | null | [] | null | 1 | 2023-02-22T22:13:40Z | 2023-02-23T11:03:29Z | null | NONE | null | null | null | ### Feature request
Right now, we have to read the get the parquet file to the local storage. So having ability to read given the bucket directly address would be benificial
### Motivation
In a production set up, this feature can help us a lot. So we do not need move training datafiles in between storage.
### Yo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5566/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5566/timeline | null | null | false | [
"Hi ! I think is in the scope of this other issue: to https://github.com/huggingface/datasets/issues/5281 "
] |
https://api.github.com/repos/huggingface/datasets/issues/5565 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5565/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5565/comments | https://api.github.com/repos/huggingface/datasets/issues/5565/events | https://github.com/huggingface/datasets/pull/5565 | 1,595,281,752 | PR_kwDODunzps5KhfTH | 5,565 | Add writer_batch_size for ArrowBasedBuilder | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 6 | 2023-02-22T15:09:30Z | 2023-03-10T13:53:03Z | 2023-03-10T13:45:43Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5565.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5565",
"merged_at": "2023-03-10T13:45:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5565.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This way we can control the size of the record_batches/row_groups of arrow/parquet files.
This can be useful for `datasets-server` to keep control of the row groups size which can affect random access performance for audio/image/video datasets
Right now having 1,000 examples per row group cause some image dataset... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5565/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5565/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5564 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5564/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5564/comments | https://api.github.com/repos/huggingface/datasets/issues/5564/events | https://github.com/huggingface/datasets/pull/5564 | 1,595,064,698 | PR_kwDODunzps5KgwzU | 5,564 | Set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 3 | 2023-02-22T13:00:09Z | 2023-02-22T13:09:26Z | 2023-02-22T13:00:25Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5564.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5564",
"merged_at": "2023-02-22T13:00:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5564.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5564/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5564/timeline | null | null | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5564). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... |
https://api.github.com/repos/huggingface/datasets/issues/5563 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5563/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5563/comments | https://api.github.com/repos/huggingface/datasets/issues/5563/events | https://github.com/huggingface/datasets/pull/5563 | 1,595,049,025 | PR_kwDODunzps5KgtbL | 5,563 | Release: 2.10.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 4 | 2023-02-22T12:48:52Z | 2023-02-22T13:05:55Z | 2023-02-22T12:56:48Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5563.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5563",
"merged_at": "2023-02-22T12:56:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5563.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5563/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5563/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5562/comments | https://api.github.com/repos/huggingface/datasets/issues/5562/events | https://github.com/huggingface/datasets/pull/5562 | 1,594,625,539 | PR_kwDODunzps5KfTUT | 5,562 | Update csv.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/54279069?v=4",
"events_url": "https://api.github.com/users/XDoubleU/events{/privacy}",
"followers_url": "https://api.github.com/users/XDoubleU/followers",
"following_url": "https://api.github.com/users/XDoubleU/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | 4 | 2023-02-22T07:56:10Z | 2023-02-23T11:07:49Z | 2023-02-23T11:00:58Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5562.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5562",
"merged_at": "2023-02-23T11:00:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5562.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Removed mangle_dup_cols=True from BuilderConfig.
It triggered following deprecation warning:
/usr/local/lib/python3.8/dist-packages/datasets/download/streaming_download_manager.py:776: FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5562/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5562/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Removed it :)",
"Changed it :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_format... |
https://api.github.com/repos/huggingface/datasets/issues/5561 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5561/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5561/comments | https://api.github.com/repos/huggingface/datasets/issues/5561/events | https://github.com/huggingface/datasets/pull/5561 | 1,593,862,388 | PR_kwDODunzps5Kcxw_ | 5,561 | Add pre-commit config yaml file to enable automatic code formatting | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | 6 | 2023-02-21T17:35:07Z | 2023-02-28T15:37:22Z | 2023-02-23T18:23:29Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5561.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5561",
"merged_at": "2023-02-23T18:23:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5561.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | @huggingface/datasets do you think it would be useful? Motivation - sometimes PRs are like 30% "fix: style" commits :)
If so - I need to double check the config but for me locally it works as expected. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5561/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5561/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Better yet have someone enable pre-commit CI https://pre-commit.ci/ and it will apply the pre-commit fixes to the PR automatically as an additional commit.",
"@Skylion007 hi! I agree with @nateraw here, I'd better not force to use ... |
https://api.github.com/repos/huggingface/datasets/issues/5560 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5560/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5560/comments | https://api.github.com/repos/huggingface/datasets/issues/5560/events | https://github.com/huggingface/datasets/pull/5560 | 1,593,809,978 | PR_kwDODunzps5Kcml6 | 5,560 | Ensure last tqdm update in `map` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | 10 | 2023-02-21T16:56:17Z | 2023-02-21T18:26:23Z | 2023-02-21T18:19:09Z | COLLABORATOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5560.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5560",
"merged_at": "2023-02-21T18:19:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5560.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR modifies `map` to:
* ensure the TQDM bar gets the last progress update
* when a map function fails, avoid throwing a chained exception in the single-proc mode | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5560/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5560/timeline | null | null | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... |
https://api.github.com/repos/huggingface/datasets/issues/5559 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5559/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5559/comments | https://api.github.com/repos/huggingface/datasets/issues/5559/events | https://github.com/huggingface/datasets/pull/5559 | 1,593,676,489 | PR_kwDODunzps5KcKSb | 5,559 | Fix map suffix_template | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 4 | 2023-02-21T15:26:26Z | 2023-02-21T17:21:37Z | 2023-02-21T17:14:29Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5559.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5559",
"merged_at": "2023-02-21T17:14:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5559.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | #5455 introduced a small bug that lead `map` to ignore the `suffix_template` argument and not put suffixes to cached files in multiprocessing.
I fixed this and also improved a few things:
- regarding logging: "Loading cached processed dataset" is now logged only once even in multiprocessing (it used to be logged ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5559/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5559/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5558 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5558/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5558/comments | https://api.github.com/repos/huggingface/datasets/issues/5558/events | https://github.com/huggingface/datasets/pull/5558 | 1,593,655,815 | PR_kwDODunzps5KcF5E | 5,558 | Remove instructions for `ffmpeg` system package installation on Colab | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | 2 | 2023-02-21T15:13:36Z | 2023-03-01T13:46:04Z | 2023-02-23T13:50:27Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5558.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5558",
"merged_at": "2023-02-23T13:50:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5558.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Colab now has Ubuntu 20.04 which already has `ffmpeg` of required (>4) version. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5558/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5558/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5557 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5557/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5557/comments | https://api.github.com/repos/huggingface/datasets/issues/5557/events | https://github.com/huggingface/datasets/pull/5557 | 1,593,545,324 | PR_kwDODunzps5Kbube | 5,557 | Add filter desc | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 3 | 2023-02-21T14:04:42Z | 2023-02-21T14:19:54Z | 2023-02-21T14:12:39Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5557.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5557",
"merged_at": "2023-02-21T14:12:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5557.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Otherwise it would show a `Map` progress bar, since it uses `map` under the hood | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5557/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5557/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5556 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5556/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5556/comments | https://api.github.com/repos/huggingface/datasets/issues/5556/events | https://github.com/huggingface/datasets/pull/5556 | 1,593,246,936 | PR_kwDODunzps5KauVL | 5,556 | Use default audio resampling type | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 5 | 2023-02-21T10:45:50Z | 2023-02-21T12:49:50Z | 2023-02-21T12:42:52Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5556.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5556",
"merged_at": "2023-02-21T12:42:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5556.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ...instead of relying on the optional librosa dependency `resampy`.
It was only used for `_decode_non_mp3_file_like` anyway and not for the other ones - removing it fixes consistency between decoding methods (except torchaudio decoding)
Therefore I think it is a better solution than adding `resampy` as a dependen... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5556/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5556/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5555 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5555/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5555/comments | https://api.github.com/repos/huggingface/datasets/issues/5555/events | https://github.com/huggingface/datasets/issues/5555 | 1,592,469,938 | I_kwDODunzps5e6ymy | 5,555 | `.shuffle` throwing error `ValueError: Protocol not known: parent` | {
"avatar_url": "https://avatars.githubusercontent.com/u/10768588?v=4",
"events_url": "https://api.github.com/users/prabhakar267/events{/privacy}",
"followers_url": "https://api.github.com/users/prabhakar267/followers",
"following_url": "https://api.github.com/users/prabhakar267/following{/other_user}",
"gist... | [] | open | false | null | [] | null | 4 | 2023-02-20T21:33:45Z | 2023-02-27T09:23:34Z | null | NONE | null | null | null | ### Describe the bug
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In [16], line 1
----> 1 train_dataset = train_dataset.shuffle()
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/dataset... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5555/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5555/timeline | null | null | false | [
"Hi ! The indices mapping is written in the same cachedirectory as your dataset.\r\n\r\nCan you run this to show your current cache directory ?\r\n```python\r\nprint(train_dataset.cache_files)\r\n```",
"```\r\n[{'filename': '.../train/dataset.arrow'}, {'filename': '.../train/dataset.arrow'}]\r\n```\r\n\r\nThese a... |
https://api.github.com/repos/huggingface/datasets/issues/5554 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5554/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5554/comments | https://api.github.com/repos/huggingface/datasets/issues/5554/events | https://github.com/huggingface/datasets/pull/5554 | 1,592,285,062 | PR_kwDODunzps5KXhZh | 5,554 | Add resampy dep | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 5 | 2023-02-20T18:15:43Z | 2023-09-24T10:07:29Z | 2023-02-21T12:43:38Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5554.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5554",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5554.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5554"
} | In librosa 0.10 they removed the `resmpy` dependency and set it to optional.
However it is necessary for resampling. I added it to the "audio" extra dependencies. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5554/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5554/timeline | null | null | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... |
https://api.github.com/repos/huggingface/datasets/issues/5553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5553/comments | https://api.github.com/repos/huggingface/datasets/issues/5553/events | https://github.com/huggingface/datasets/pull/5553 | 1,592,236,998 | PR_kwDODunzps5KXXUq | 5,553 | improved message error row formatting | {
"avatar_url": "https://avatars.githubusercontent.com/u/26489385?v=4",
"events_url": "https://api.github.com/users/Plutone11011/events{/privacy}",
"followers_url": "https://api.github.com/users/Plutone11011/followers",
"following_url": "https://api.github.com/users/Plutone11011/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | 2 | 2023-02-20T17:29:14Z | 2023-02-21T13:08:25Z | 2023-02-21T12:58:12Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5553.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5553",
"merged_at": "2023-02-21T12:58:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5553.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Solves #5539 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5553/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5553/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5552 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5552/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5552/comments | https://api.github.com/repos/huggingface/datasets/issues/5552/events | https://github.com/huggingface/datasets/pull/5552 | 1,592,186,703 | PR_kwDODunzps5KXMjA | 5,552 | Make tiktoken tokenizers hashable | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | 4 | 2023-02-20T16:50:09Z | 2023-02-21T13:20:42Z | 2023-02-21T13:13:05Z | COLLABORATOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5552.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5552",
"merged_at": "2023-02-21T13:13:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5552.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix for https://discord.com/channels/879548962464493619/1075729627546406912/1075729627546406912
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5552/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5552/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5551 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5551/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5551/comments | https://api.github.com/repos/huggingface/datasets/issues/5551/events | https://github.com/huggingface/datasets/pull/5551 | 1,592,140,836 | PR_kwDODunzps5KXCof | 5,551 | Suggest scikit-learn instead of sklearn | {
"avatar_url": "https://avatars.githubusercontent.com/u/74963545?v=4",
"events_url": "https://api.github.com/users/osbm/events{/privacy}",
"followers_url": "https://api.github.com/users/osbm/followers",
"following_url": "https://api.github.com/users/osbm/following{/other_user}",
"gists_url": "https://api.git... | [] | closed | false | null | [] | null | 4 | 2023-02-20T16:16:57Z | 2023-02-21T13:27:57Z | 2023-02-21T13:21:07Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5551.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5551",
"merged_at": "2023-02-21T13:21:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5551.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This is kinda unimportant fix but, the suggested `pip install sklearn` does not work.
The current error message if sklearn is not installed:
```
ImportError: To be able to use [dataset name], you need to install the following dependency: sklearn.
Please install it using 'pip install sklearn' for instance.
```
... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5551/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5551/timeline | null | null | true | [
"good catch!",
"_The documentation is not available anymore as the PR was closed or merged._",
"The test fail is unrelated to this PR and fixed on `main` - merging :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: ... |
https://api.github.com/repos/huggingface/datasets/issues/5550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5550/comments | https://api.github.com/repos/huggingface/datasets/issues/5550/events | https://github.com/huggingface/datasets/pull/5550 | 1,591,409,475 | PR_kwDODunzps5KUl5i | 5,550 | Resolve four broken refs in the docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/37621491?v=4",
"events_url": "https://api.github.com/users/tomaarsen/events{/privacy}",
"followers_url": "https://api.github.com/users/tomaarsen/followers",
"following_url": "https://api.github.com/users/tomaarsen/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | 3 | 2023-02-20T08:52:11Z | 2023-02-20T15:16:13Z | 2023-02-20T15:09:13Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5550.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5550",
"merged_at": "2023-02-20T15:09:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5550.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Hello!
## Pull Request overview
* Resolve 4 broken references in the docs
## The problems
Two broken references [here](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.class_encode_column):
, [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5550/en/pa... |
https://api.github.com/repos/huggingface/datasets/issues/5549 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5549/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5549/comments | https://api.github.com/repos/huggingface/datasets/issues/5549/events | https://github.com/huggingface/datasets/pull/5549 | 1,590,836,848 | PR_kwDODunzps5KSsi3 | 5,549 | Apply ruff flake8-comprehension checks | {
"avatar_url": "https://avatars.githubusercontent.com/u/2053727?v=4",
"events_url": "https://api.github.com/users/Skylion007/events{/privacy}",
"followers_url": "https://api.github.com/users/Skylion007/followers",
"following_url": "https://api.github.com/users/Skylion007/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | 2 | 2023-02-19T20:09:28Z | 2023-02-23T14:06:39Z | 2023-02-23T13:59:39Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5549.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5549",
"merged_at": "2023-02-23T13:59:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5549.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #5548
Apply ruff's flake8-comprehension checks for better performance, and more readable code. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5549/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5549/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5548/comments | https://api.github.com/repos/huggingface/datasets/issues/5548/events | https://github.com/huggingface/datasets/issues/5548 | 1,590,835,479 | I_kwDODunzps5e0jkX | 5,548 | Apply flake8-comprehensions to codebase | {
"avatar_url": "https://avatars.githubusercontent.com/u/2053727?v=4",
"events_url": "https://api.github.com/users/Skylion007/events{/privacy}",
"followers_url": "https://api.github.com/users/Skylion007/followers",
"following_url": "https://api.github.com/users/Skylion007/following{/other_user}",
"gists_url":... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | 0 | 2023-02-19T20:05:38Z | 2023-02-23T13:59:41Z | 2023-02-23T13:59:41Z | CONTRIBUTOR | null | null | null | ### Feature request
Apply ruff flake8 comprehension checks to codebase.
### Motivation
This should strictly improve the performance / readability of the codebase by removing unnecessary iteration, function calls, etc. This should generate better Python bytecode which should strictly improve performance.
I alread... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5548/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5548/timeline | null | completed | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5547 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5547/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5547/comments | https://api.github.com/repos/huggingface/datasets/issues/5547/events | https://github.com/huggingface/datasets/pull/5547 | 1,590,468,200 | PR_kwDODunzps5KRmcf | 5,547 | Add JAX device selection when formatting | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | 9 | 2023-02-18T20:57:40Z | 2023-02-21T16:10:55Z | 2023-02-21T16:04:03Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5547.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5547",
"merged_at": "2023-02-21T16:04:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5547.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ## What's in this PR?
After exploring for a while the JAX integration in 🤗`datasets`, I found out that, even though JAX prioritizes the TPU and GPU as the default device when available, the `JaxFormatter` doesn't let you specify the device where you want to place the `jax.Array`s in case you don't want to rely on J... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5547/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5547/timeline | null | null | true | [
"The code below was throwing a warning:\r\n\r\n```python\r\nclass JaxFormatter(Formatter[Mapping, \"jax.Array\", Mapping]):\r\n def __init__(self, features=None, device=None, **jnp_array_kwargs):\r\n super().__init__(features=features)\r\n import jax\r\n from jaxlib.xla_extension import Devi... |
https://api.github.com/repos/huggingface/datasets/issues/5546 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5546/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5546/comments | https://api.github.com/repos/huggingface/datasets/issues/5546/events | https://github.com/huggingface/datasets/issues/5546 | 1,590,346,349 | I_kwDODunzps5eysJt | 5,546 | Downloaded datasets do not cache at $HF_HOME | {
"avatar_url": "https://avatars.githubusercontent.com/u/79091831?v=4",
"events_url": "https://api.github.com/users/ErfanMoosaviMonazzah/events{/privacy}",
"followers_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followers",
"following_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followin... | [] | closed | false | null | [] | null | 1 | 2023-02-18T13:30:35Z | 2023-07-24T14:22:43Z | 2023-07-24T14:22:43Z | NONE | null | null | null | ### Describe the bug
In the huggingface course (https://huggingface.co/course/chapter3/2?fw=pt) it said that if we set HF_HOME, downloaded datasets would be cached at specified address but it does not. downloaded models from checkpoint names are downloaded and cached at HF_HOME but this is not the case for datasets, t... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5546/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5546/timeline | null | completed | false | [
"Hi ! Can you make sure you set `HF_HOME` before importing `datasets` ?\r\n\r\nThen you can print\r\n```python\r\nprint(datasets.config.HF_CACHE_HOME)\r\nprint(datasets.config.HF_DATASETS_CACHE)\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/5545 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5545/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5545/comments | https://api.github.com/repos/huggingface/datasets/issues/5545/events | https://github.com/huggingface/datasets/pull/5545 | 1,590,315,972 | PR_kwDODunzps5KRKct | 5,545 | Added return methods for URL-references to the pushed dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/25269220?v=4",
"events_url": "https://api.github.com/users/davidberenstein1957/events{/privacy}",
"followers_url": "https://api.github.com/users/davidberenstein1957/followers",
"following_url": "https://api.github.com/users/davidberenstein1957/following{/... | [] | open | false | null | [] | null | 6 | 2023-02-18T11:26:25Z | 2023-12-18T16:57:56Z | null | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5545.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5545",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5545.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5545"
} | Hi,
I was missing the ability to easily open the pushed dataset and it seemed like a quick fix.
Maybe we also want to log this info somewhere, but let me know if I need to add that too.
Cheers,
David | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5545/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5545/timeline | null | null | true | [
"Hi ! Maybe we'd need to align with `transformers` and other libraries that implement `push_to_hub` to agree on what it should return.\r\n\r\ne.g. in `transformers` the typing says it returns a string, but in practice it returns a `CommitInfo`.\r\n\r\nTherefore I'd not add an output to `push_to_hub` here unless we ... |
https://api.github.com/repos/huggingface/datasets/issues/5543 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5543/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5543/comments | https://api.github.com/repos/huggingface/datasets/issues/5543/events | https://github.com/huggingface/datasets/issues/5543 | 1,588,951,379 | I_kwDODunzps5etXlT | 5,543 | the pile datasets url seems to change back | {
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"events_url": "https://api.github.com/users/wjfwzzc/events{/privacy}",
"followers_url": "https://api.github.com/users/wjfwzzc/followers",
"following_url": "https://api.github.com/users/wjfwzzc/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | 2 | 2023-02-17T08:40:11Z | 2023-02-21T06:37:00Z | 2023-02-20T08:41:33Z | NONE | null | null | null | ### Describe the bug
in #3627, the host url of the pile dataset became `https://mystic.the-eye.eu`. Now the new url is broken, but `https://the-eye.eu` seems to work again.
### Steps to reproduce the bug
```python3
from datasets import load_dataset
dataset = load_dataset("bookcorpusopen")
```
shows
```python3
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5543/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5543/timeline | null | completed | false | [
"Thanks for reporting, @wjfwzzc.\r\n\r\nI am transferring this issue to the corresponding dataset on the Hub: https://huggingface.co/datasets/bookcorpusopen/discussions/1",
"Thank you. All fixes are done:\r\n- [x] https://huggingface.co/datasets/bookcorpusopen/discussions/2\r\n- [x] https://huggingface.co/dataset... |
https://api.github.com/repos/huggingface/datasets/issues/5542 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5542/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5542/comments | https://api.github.com/repos/huggingface/datasets/issues/5542/events | https://github.com/huggingface/datasets/pull/5542 | 1,588,633,724 | PR_kwDODunzps5KLjMl | 5,542 | Avoid saving sparse ChunkedArrays in pyarrow tables | {
"avatar_url": "https://avatars.githubusercontent.com/u/6591505?v=4",
"events_url": "https://api.github.com/users/marioga/events{/privacy}",
"followers_url": "https://api.github.com/users/marioga/followers",
"following_url": "https://api.github.com/users/marioga/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | 2 | 2023-02-17T01:52:38Z | 2023-02-17T19:20:49Z | 2023-02-17T11:12:32Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5542.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5542",
"merged_at": "2023-02-17T11:12:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5542.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fixes https://github.com/huggingface/datasets/issues/5541 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5542/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5542/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5541 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5541/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5541/comments | https://api.github.com/repos/huggingface/datasets/issues/5541/events | https://github.com/huggingface/datasets/issues/5541 | 1,588,633,555 | I_kwDODunzps5esJ_T | 5,541 | Flattening indices in selected datasets is extremely inefficient | {
"avatar_url": "https://avatars.githubusercontent.com/u/6591505?v=4",
"events_url": "https://api.github.com/users/marioga/events{/privacy}",
"followers_url": "https://api.github.com/users/marioga/followers",
"following_url": "https://api.github.com/users/marioga/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | 3 | 2023-02-17T01:52:24Z | 2023-02-22T13:15:20Z | 2023-02-17T11:12:33Z | CONTRIBUTOR | null | null | null | ### Describe the bug
If we perform a `select` (or `shuffle`, `train_test_split`, etc.) operation on a dataset , we end up with a dataset with an `indices_table`. Currently, flattening such dataset consumes a lot of memory and the resulting flat dataset contains ChunkedArrays with as many chunks as there are rows. Thi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5541/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5541/timeline | null | completed | false | [
"Running the script above on the branch https://github.com/huggingface/datasets/pull/5542 results in the expected behaviour:\r\n```\r\nNum chunks for original ds: 1\r\nOriginal ds save/load\r\nsave_to_disk -- RAM memory used: 0.671875 MB -- Total time: 0.255265 s\r\nload_from_disk -- RAM memory used: 42.796875 MB -... |
https://api.github.com/repos/huggingface/datasets/issues/5540 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5540/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5540/comments | https://api.github.com/repos/huggingface/datasets/issues/5540/events | https://github.com/huggingface/datasets/pull/5540 | 1,588,438,344 | PR_kwDODunzps5KK5qz | 5,540 | Tutorial for creating a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | 2 | 2023-02-16T22:09:35Z | 2023-02-17T18:50:46Z | 2023-02-17T18:41:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5540.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5540",
"merged_at": "2023-02-17T18:41:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5540.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | A tutorial for creating datasets based on the folder-based builders and `from_dict` and `from_generator` methods. I've also mentioned loading scripts as a next step, but I think we should keep the tutorial focused on the low-code methods. Let me know what you think! 🙂 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5540/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5540/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5539 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5539/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5539/comments | https://api.github.com/repos/huggingface/datasets/issues/5539/events | https://github.com/huggingface/datasets/issues/5539 | 1,587,970,083 | I_kwDODunzps5epoAj | 5,539 | IndexError: invalid index of a 0-dim tensor. Use `tensor.item()` in Python or `tensor.item<T>()` in C++ to convert a 0-dim tensor to a number | {
"avatar_url": "https://avatars.githubusercontent.com/u/41912135?v=4",
"events_url": "https://api.github.com/users/aalbersk/events{/privacy}",
"followers_url": "https://api.github.com/users/aalbersk/followers",
"following_url": "https://api.github.com/users/aalbersk/following{/other_user}",
"gists_url": "htt... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | 4 | 2023-02-16T16:08:51Z | 2023-02-22T10:30:30Z | 2023-02-21T13:03:57Z | NONE | null | null | null | ### Describe the bug
When dataset contains a 0-dim tensor, formatting.py raises a following error and fails.
```bash
Traceback (most recent call last):
File "<path>/lib/python3.8/site-packages/datasets/formatting/formatting.py", line 501, in format_row
return _unnest(formatted_batch)
File "<path>/lib/py... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5539/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5539/timeline | null | completed | false | [
"Hi! The `set_transform` does not apply a custom formatting transform on a single example but the entire batch, so the fixed version of your transform would look as follows:\r\n```python\r\nfrom datasets import load_dataset\r\nimport torch\r\n\r\ndataset = load_dataset(\"lambdalabs/pokemon-blip-captions\", split='t... |
https://api.github.com/repos/huggingface/datasets/issues/5538 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5538/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5538/comments | https://api.github.com/repos/huggingface/datasets/issues/5538/events | https://github.com/huggingface/datasets/issues/5538 | 1,587,732,596 | I_kwDODunzps5eouB0 | 5,538 | load_dataset in seaborn is not working for me. getting this error. | {
"avatar_url": "https://avatars.githubusercontent.com/u/125575109?v=4",
"events_url": "https://api.github.com/users/reemaranibarik/events{/privacy}",
"followers_url": "https://api.github.com/users/reemaranibarik/followers",
"following_url": "https://api.github.com/users/reemaranibarik/following{/other_user}",
... | [] | closed | false | null | [] | null | 1 | 2023-02-16T14:01:58Z | 2023-02-16T14:44:36Z | 2023-02-16T14:44:36Z | NONE | null | null | null | TimeoutError Traceback (most recent call last)
~\anaconda3\lib\urllib\request.py in do_open(self, http_class, req, **http_conn_args)
1345 try:
-> 1346 h.request(req.get_method(), req.selector, req.data, headers,
1347 encode_chu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5538/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5538/timeline | null | completed | false | [
"Hi! `seaborn`'s `load_dataset` pulls datasets from [here](https://github.com/mwaskom/seaborn-data) and not from our Hub, so this issue is not related to our library in any way and should be reported in their repo instead."
] |
https://api.github.com/repos/huggingface/datasets/issues/5537 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5537/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5537/comments | https://api.github.com/repos/huggingface/datasets/issues/5537/events | https://github.com/huggingface/datasets/issues/5537 | 1,587,567,464 | I_kwDODunzps5eoFto | 5,537 | Increase speed of data files resolution | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "BDE59C",
"default": fals... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/35013374?v=4",
"events_url": "https://api.github.com/users/semajyllek/events{/privacy}",
"followers_url": "https://api.github.com/users/semajyllek/followers",
"following_url": "https://api.github.com/users/semajyllek/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/35013374?v=4",
"events_url": "https://api.github.com/users/semajyllek/events{/privacy}",
"followers_url": "https://api.github.com/users/semajyllek/followers",
"following_url": "https://api.github.com/users/semajyllek/following{/other_user}",
... | null | 5 | 2023-02-16T12:11:45Z | 2023-12-15T13:12:31Z | 2023-12-15T13:12:31Z | MEMBER | null | null | null | Certain datasets like `bigcode/the-stack-dedup` have so many files that loading them takes forever right from the data files resolution step.
`datasets` uses file patterns to check the structure of the repository but it takes too much time to iterate over and over again on all the data files.
This comes from `res... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5537/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5537/timeline | null | completed | false | [
"#self-assign",
"You were right, if `self.dir_cache` is not None in glob, it is exactly the same as what is returned by find, at least for all the tests we have, and some extended evaluation I did across a random sample of about 1000 datasets. \r\n\r\nThanks for the nice hints, and let me know if this is not exac... |
https://api.github.com/repos/huggingface/datasets/issues/5536 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5536/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5536/comments | https://api.github.com/repos/huggingface/datasets/issues/5536/events | https://github.com/huggingface/datasets/issues/5536 | 1,586,930,643 | I_kwDODunzps5elqPT | 5,536 | Failure to hash function when using .map() | {
"avatar_url": "https://avatars.githubusercontent.com/u/6916056?v=4",
"events_url": "https://api.github.com/users/venzen/events{/privacy}",
"followers_url": "https://api.github.com/users/venzen/followers",
"following_url": "https://api.github.com/users/venzen/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | 14 | 2023-02-16T03:12:07Z | 2023-09-08T21:06:01Z | 2023-02-16T14:56:41Z | NONE | null | null | null | ### Describe the bug
_Parameter 'function'=<function process at 0x7f1ec4388af0> of the transform datasets.arrow_dataset.Dataset.\_map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and ca... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5536/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5536/timeline | null | completed | false | [
"Hi ! `enc` is not hashable:\r\n```python\r\nimport tiktoken\r\nfrom datasets.fingerprint import Hasher\r\n\r\nenc = tiktoken.get_encoding(\"gpt2\")\r\nHasher.hash(enc)\r\n# raises TypeError: cannot pickle 'builtins.CoreBPE' object\r\n```\r\nIt happens because it's not picklable, and because of that it's not possib... |
https://api.github.com/repos/huggingface/datasets/issues/5535 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5535/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5535/comments | https://api.github.com/repos/huggingface/datasets/issues/5535/events | https://github.com/huggingface/datasets/pull/5535 | 1,586,520,369 | PR_kwDODunzps5KEb5L | 5,535 | Add JAX-formatting documentation | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | 9 | 2023-02-15T20:35:11Z | 2023-02-20T10:39:42Z | 2023-02-20T10:32:39Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5535.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5535",
"merged_at": "2023-02-20T10:32:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5535.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ## What's in this PR?
As a follow-up of #5522, I've created this entry in the documentation to explain how to use `.with_format("jax")` and why is it useful.
@lhoestq Feel free to drop any feedback and/or suggestion, as probably more useful features can be included there! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5535/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5535/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Awesome thank you !\r\n> \r\n> Could you also explain how to use certain types like ClassLabel, Image or Audio with jax ? You can get a lot of inspiration from the \"Other feature types\" section in the [PyTorch page](https://huggi... |
https://api.github.com/repos/huggingface/datasets/issues/5534 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5534/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5534/comments | https://api.github.com/repos/huggingface/datasets/issues/5534/events | https://github.com/huggingface/datasets/issues/5534 | 1,586,177,862 | I_kwDODunzps5eiydG | 5,534 | map() breaks at certain dataset size when using Array3D | {
"avatar_url": "https://avatars.githubusercontent.com/u/3375489?v=4",
"events_url": "https://api.github.com/users/ArneBinder/events{/privacy}",
"followers_url": "https://api.github.com/users/ArneBinder/followers",
"following_url": "https://api.github.com/users/ArneBinder/following{/other_user}",
"gists_url":... | [] | open | false | null | [] | null | 2 | 2023-02-15T16:34:25Z | 2023-03-03T16:31:33Z | null | NONE | null | null | null | ### Describe the bug
`map()` magically breaks when using a `Array3D` feature and mapping it. I created a very simple dummy dataset (see below). When filtering it down to 95 elements I can apply map, but it breaks when filtering it down to just 96 entries with the following exception:
```
Traceback (most recent cal... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5534/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5534/timeline | null | null | false | [
"Hi! This code works for me locally or in Colab. What's the output of `python -c \"import pyarrow as pa; print(pa.__version__)\"` when you run it inside your environment?",
"Thanks for looking into this!\r\nThe output of `python -c \"import pyarrow as pa; print(pa.__version__)\"` is:\r\n```\r\n11.0.0\r\n```\r\n\... |
https://api.github.com/repos/huggingface/datasets/issues/5533 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5533/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5533/comments | https://api.github.com/repos/huggingface/datasets/issues/5533/events | https://github.com/huggingface/datasets/pull/5533 | 1,585,885,871 | PR_kwDODunzps5KCR5I | 5,533 | Add reduce function | {
"avatar_url": "https://avatars.githubusercontent.com/u/38854604?v=4",
"events_url": "https://api.github.com/users/AJDERS/events{/privacy}",
"followers_url": "https://api.github.com/users/AJDERS/followers",
"following_url": "https://api.github.com/users/AJDERS/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | 19 | 2023-02-15T13:44:01Z | 2023-02-28T14:46:13Z | 2023-02-28T14:46:12Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5533.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5533",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5533.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5533"
} | This PR closes #5496 .
I tried to imitate the `reduce`-method from `functools`, i.e. the function input must be a binary operation. I assume that the input type has an empty element, i.e. `input_type()` is defined, as the acumulant is instantiated as this object - im not sure that is this a reasonable assumption?
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5533/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5533/timeline | null | null | true | [
"I agree that it would be a good idea to introduce a `combiner` argument in another PR.\r\n\r\nI did take quite a lot of inspiration from the implementation of `map`, but it did not seem obvious how to resuse `map` for the implementation. Do you have any suggestions, i could give a try?\r\n\r\nThose were exactly m... |
https://api.github.com/repos/huggingface/datasets/issues/5532 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5532/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5532/comments | https://api.github.com/repos/huggingface/datasets/issues/5532/events | https://github.com/huggingface/datasets/issues/5532 | 1,584,505,128 | I_kwDODunzps5ecaEo | 5,532 | train_test_split in arrow_dataset does not ensure to keep single classes in test set | {
"avatar_url": "https://avatars.githubusercontent.com/u/37191008?v=4",
"events_url": "https://api.github.com/users/Ulipenitz/events{/privacy}",
"followers_url": "https://api.github.com/users/Ulipenitz/followers",
"following_url": "https://api.github.com/users/Ulipenitz/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | 1 | 2023-02-14T16:52:29Z | 2023-02-15T16:09:19Z | 2023-02-15T16:09:19Z | NONE | null | null | null | ### Describe the bug
When I have a dataset with very few (e.g. 1) examples per class and I call the train_test_split function on it, sometimes the single class will be in the test set. thus will never be considered for training.
### Steps to reproduce the bug
```
import numpy as np
from datasets import Dataset
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5532/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5532/timeline | null | completed | false | [
"Hi! You can get this behavior by specifying `stratify_by_column=\"label\"` in `train_test_split`.\r\n\r\nThis is the full example:\r\n```python\r\nimport numpy as np\r\nfrom datasets import Dataset, ClassLabel\r\n\r\ndata = [\r\n {'label': 0, 'text': \"example1\"},\r\n {'label': 1, 'text': \"example2\"},\r\n... |
https://api.github.com/repos/huggingface/datasets/issues/5531 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5531/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5531/comments | https://api.github.com/repos/huggingface/datasets/issues/5531/events | https://github.com/huggingface/datasets/issues/5531 | 1,584,387,276 | I_kwDODunzps5eb9TM | 5,531 | Invalid Arrow data from JSONL | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | 0 | 2023-02-14T15:39:49Z | 2023-02-14T15:46:09Z | null | MEMBER | null | null | null | This code fails:
```python
from datasets import Dataset
ds = Dataset.from_json(path_to_file)
ds.data.validate()
```
raises
```python
ArrowInvalid: Column 2: In chunk 1: Invalid: Struct child array #3 invalid: Invalid: Length spanned by list offsets (4064) larger than values array (length 4063)
```
This ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5531/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5531/timeline | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5530 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5530/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5530/comments | https://api.github.com/repos/huggingface/datasets/issues/5530/events | https://github.com/huggingface/datasets/pull/5530 | 1,582,938,241 | PR_kwDODunzps5J4W_4 | 5,530 | Add missing license in `NumpyFormatter` | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | 2 | 2023-02-13T19:33:23Z | 2023-02-14T14:40:41Z | 2023-02-14T12:23:58Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5530.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5530",
"merged_at": "2023-02-14T12:23:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5530.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ## What's in this PR?
As discussed with @lhoestq in https://github.com/huggingface/datasets/pull/5522, the license for `NumpyFormatter` at `datasets/formatting/np_formatter.py` was missing, but present on the rest of the `formatting/*.py` files. So this PR is basically to include it there. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5530/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5530/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5529 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5529/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5529/comments | https://api.github.com/repos/huggingface/datasets/issues/5529/events | https://github.com/huggingface/datasets/pull/5529 | 1,582,501,233 | PR_kwDODunzps5J26Fq | 5,529 | Fix `datasets.load_from_disk`, `DatasetDict.load_from_disk` and `Dataset.load_from_disk` | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | 12 | 2023-02-13T14:54:55Z | 2023-02-23T18:14:32Z | 2023-02-23T18:05:26Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5529.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5529",
"merged_at": "2023-02-23T18:05:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5529.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ## What's in this PR?
After playing around a little bit with 🤗`datasets` in Google Cloud Storage (GCS), I found out some things that should be fixed IMO in the code:
* `datasets.load_from_disk` is not checking whether `state.json` is there too when trying to load a `Dataset`, just `dataset_info.json` is checked
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5529/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5529/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hmm, should this also be updated in `Dataset.load_from_disk` and `DatasetDict.load_from_disk`? https://github.com/huggingface/datasets/pull/5466 As there the paths are joined using `Path(..., ...)` and it won't work on Windows OS acc... |
https://api.github.com/repos/huggingface/datasets/issues/5528 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5528/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5528/comments | https://api.github.com/repos/huggingface/datasets/issues/5528/events | https://github.com/huggingface/datasets/pull/5528 | 1,582,195,085 | PR_kwDODunzps5J13wC | 5,528 | Push to hub in a pull request | {
"avatar_url": "https://avatars.githubusercontent.com/u/38854604?v=4",
"events_url": "https://api.github.com/users/AJDERS/events{/privacy}",
"followers_url": "https://api.github.com/users/AJDERS/followers",
"following_url": "https://api.github.com/users/AJDERS/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | 11 | 2023-02-13T11:43:47Z | 2023-10-06T21:58:02Z | null | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5528.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5528",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5528.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5528"
} | Fixes #5492.
Introduce new kwarg `create_pr` in `push_to_hub`, which is passed to `HFapi.upload_file`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5528/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5528/timeline | null | null | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5528). All of your documentation changes will be reflected on that endpoint.",
"It seems that the parameter `create_pr` is available for [`0.8.0`](https://huggingface.co/docs/huggingface_hub/v0.8.1/en/package_reference/hf_api#h... |
https://api.github.com/repos/huggingface/datasets/issues/5527 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5527/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5527/comments | https://api.github.com/repos/huggingface/datasets/issues/5527/events | https://github.com/huggingface/datasets/pull/5527 | 1,581,228,531 | PR_kwDODunzps5JysSM | 5,527 | Fix benchmarks CI - pin protobuf | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 5 | 2023-02-12T11:51:25Z | 2023-02-13T10:29:03Z | 2023-02-13T09:24:16Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5527.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5527",
"merged_at": "2023-02-13T09:24:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5527.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | fix https://github.com/huggingface/datasets/actions/runs/4156059127/jobs/7189576331 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5527/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5527/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5526 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5526/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5526/comments | https://api.github.com/repos/huggingface/datasets/issues/5526/events | https://github.com/huggingface/datasets/pull/5526 | 1,580,488,133 | PR_kwDODunzps5JwVol | 5,526 | Allow loading/saving of FAISS index using fsspec | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | 4 | 2023-02-10T23:37:14Z | 2023-03-27T15:26:46Z | 2023-03-27T15:18:20Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5526.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5526",
"merged_at": "2023-03-27T15:18:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5526.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fixes #5428
Allow loading/saving of FAISS index using fsspec:
1. Simply use BufferedIOWriter/Reader to Read/Write indices on fsspec stream.
2. Needed `mockfs` in the test, so I took it out of the `TestCase`. Let me know if that makes sense.
I can work on the documentation once the code changes are approved.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5526/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5526/timeline | null | null | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the quick review! I updated the code with your suggestion",
"Thanks for the quick review @albertvillanova! I updated the code with your suggestions",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n... |
https://api.github.com/repos/huggingface/datasets/issues/5525 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5525/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5525/comments | https://api.github.com/repos/huggingface/datasets/issues/5525/events | https://github.com/huggingface/datasets/issues/5525 | 1,580,342,729 | I_kwDODunzps5eMh3J | 5,525 | TypeError: Couldn't cast array of type string to null | {
"avatar_url": "https://avatars.githubusercontent.com/u/74564958?v=4",
"events_url": "https://api.github.com/users/TJ-Solergibert/events{/privacy}",
"followers_url": "https://api.github.com/users/TJ-Solergibert/followers",
"following_url": "https://api.github.com/users/TJ-Solergibert/following{/other_user}",
... | [] | closed | false | null | [] | null | 6 | 2023-02-10T21:12:36Z | 2023-02-14T17:41:08Z | 2023-02-14T09:35:49Z | NONE | null | null | null | ### Describe the bug
Processing a dataset I alredy uploaded to the Hub (https://huggingface.co/datasets/tj-solergibert/Europarl-ST) I found that for some splits and some languages (test split, source_lang = "nl") after applying a map function I get the mentioned error.
I alredy tried reseting the shorter strings... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5525/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5525/timeline | null | completed | false | [
"Thanks for reporting, @TJ-Solergibert.\r\n\r\nWe cannot access your Colab notebook: `There was an error loading this notebook. Ensure that the file is accessible and try again.`\r\nCould you please make it publicly accessible?\r\n",
"I swear it's public, I've checked the settings and I've been able to open it in... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.