
Add files using upload-large-folder tool
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- All-In-One-Pixel-Model_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +23 -0
- AnimateDiff-Lightning_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +120 -0
- AnimateLCM-SVD-xt_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv +40 -0
- AsianModel_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv +5 -0
- Athene-V2-Chat_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +81 -0
- BiomedCLIP-PubMedBERT_256-vit_base_patch16_224_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +407 -0
- CLIP-ViT-H-14-laion2B-s32B-b79K_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv +320 -0
- CodeLlama-34b-Instruct-hf_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +183 -0
- CodeLlama-34b-hf_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +540 -0
- CogVideoX-5b_finetunes_20250425_143346.csv_finetunes_20250425_143346.csv +0 -0
- DeepSeek-R1-Distill-Qwen-14B-GGUF_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv +167 -0
- DeepSeek-V2_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv +377 -0
- DialoGPT-large_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +0 -0
- DiffRhythm-base_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +79 -0
- GLM-4-32B-0414_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +0 -0
- GPT-SoVITS_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv +189 -0
- Hentai-Diffusion_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv +2 -0
- Illustrious-xl-early-release-v0_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv +0 -0
- In-Context-LoRA_finetunes_20250425_143346.csv_finetunes_20250425_143346.csv +114 -0
- InstantMesh_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +18 -0
- LCM_Dreamshaper_v7_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv +248 -0
- LLaMA-Pro-8B_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +44 -0
- Llama-3-Groq-70B-Tool-Use_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +108 -0
- MagicPrompt-Stable-Diffusion_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +31 -0
- MiniMax-Text-01_finetunes_20250425_143346.csv_finetunes_20250425_143346.csv +263 -0
- MistralLite_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +529 -0
- NSFW-gen-v2_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv +36 -0
- Nous-Hermes-13B-GPTQ_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +237 -0
- OCR-Donut-CORD_finetunes_20250426_212347.csv_finetunes_20250426_212347.csv +33 -0
- OrangeMixs_finetunes_20250422_201036.csv +1645 -0
- Phi-3-mini-128k-instruct-onnx_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv +165 -0
- Qwen-7B-Chat_finetunes_20250425_041137.csv_finetunes_20250425_041137.csv +749 -0
- Qwen2-72B-Instruct_finetunes_20250425_125929.csv_finetunes_20250425_125929.csv +0 -0
- SOLAR-0-70b-16bit_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +413 -0
- SpatialLM-Llama-1B_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +233 -0
- Wizard-Vicuna-30B-Uncensored-GPTQ_finetunes_20250425_143346.csv_finetunes_20250425_143346.csv +325 -0
- YandexGPT-5-Lite-8B-pretrain_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv +1095 -0
- Yi-34B-Chat_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv +0 -0
- aya-101_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +325 -0
- bart-large-mnli_finetunes_20250424_193500.csv_finetunes_20250424_193500.csv +0 -0
- bert-base-multilingual-uncased-sentiment_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv +0 -0
- biogpt_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +0 -0
- bitnet_b1_58-3B_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +54 -0
- chilloutmix-ni_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +6 -0
- chilloutmix_NiPrunedFp32Fix_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +5 -0
- chinese-alpaca-2-7b_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +41 -0
- chinese-bert-wwm-ext_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +762 -0
- control_v1p_sd15_qrcode_monster_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +59 -0
- dalle-mini_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv +203 -0
- deepseek-vl-7b-chat_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +129 -0
All-In-One-Pixel-Model_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
PublicPrompts/All-In-One-Pixel-Model,"---
|
| 3 |
+
license: creativeml-openrail-m
|
| 4 |
+
---
|
| 5 |
+
Stable Diffusion model trained using dreambooth to create pixel art, in 2 styles
|
| 6 |
+
the sprite art can be used with the trigger word ""pixelsprite""
|
| 7 |
+
the scene art can be used with the trigger word ""16bitscene""
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
the art is not pixel perfect, but it can be fixed with pixelating tools like https://pinetools.com/pixelate-effect-image (they also have bulk pixelation)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
some example generations
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+

|
| 17 |
+

|
| 18 |
+

|
| 19 |
+

|
| 20 |
+

|
| 21 |
+

|
| 22 |
+

|
| 23 |
+
","{""id"": ""PublicPrompts/All-In-One-Pixel-Model"", ""author"": ""PublicPrompts"", ""sha"": ""b4330356edc9eaeb98571c144e8bbabe8bb15897"", ""last_modified"": ""2023-05-11 13:45:47+00:00"", ""created_at"": ""2022-11-09 17:01:47+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 86, ""downloads_all_time"": null, ""likes"": 182, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""license:creativeml-openrail-m"", ""autotrain_compatible"", ""endpoints_compatible"", ""diffusers:StableDiffusionPipeline"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: creativeml-openrail-m"", ""widget_data"": null, ""model_index"": null, ""config"": {""diffusers"": {""_class_name"": ""StableDiffusionPipeline""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Public-Prompts-Pixel-Model.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='safety_checker/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='safety_checker/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [""xhxhkxh/sdp""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-05-11 13:45:47+00:00"", ""cardData"": ""license: creativeml-openrail-m"", ""transformersInfo"": null, ""_id"": ""636bdcfbf575d370514c8038"", ""modelId"": ""PublicPrompts/All-In-One-Pixel-Model"", ""usedStorage"": 7614306662}",0,,0,,0,,0,,0,"huggingface/InferenceSupport/discussions/new?title=PublicPrompts/All-In-One-Pixel-Model&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BPublicPrompts%2FAll-In-One-Pixel-Model%5D(%2FPublicPrompts%2FAll-In-One-Pixel-Model)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, xhxhkxh/sdp",2
|
AnimateDiff-Lightning_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
ByteDance/AnimateDiff-Lightning,"---
|
| 3 |
+
license: creativeml-openrail-m
|
| 4 |
+
tags:
|
| 5 |
+
- text-to-video
|
| 6 |
+
- stable-diffusion
|
| 7 |
+
- animatediff
|
| 8 |
+
library_name: diffusers
|
| 9 |
+
inference: false
|
| 10 |
+
---
|
| 11 |
+
# AnimateDiff-Lightning
|
| 12 |
+
|
| 13 |
+
<video src='https://huggingface.co/ByteDance/AnimateDiff-Lightning/resolve/main/animatediff_lightning_samples_t2v.mp4' width=""100%"" autoplay muted loop playsinline style='margin:0'></video>
|
| 14 |
+
<video src='https://huggingface.co/ByteDance/AnimateDiff-Lightning/resolve/main/animatediff_lightning_samples_v2v.mp4' width=""100%"" autoplay muted loop playsinline style='margin:0'></video>
|
| 15 |
+
|
| 16 |
+
AnimateDiff-Lightning is a lightning-fast text-to-video generation model. It can generate videos more than ten times faster than the original AnimateDiff. For more information, please refer to our research paper: [AnimateDiff-Lightning: Cross-Model Diffusion Distillation](https://arxiv.org/abs/2403.12706). We release the model as part of the research.
|
| 17 |
+
|
| 18 |
+
Our models are distilled from [AnimateDiff SD1.5 v2](https://huggingface.co/guoyww/animatediff). This repository contains checkpoints for 1-step, 2-step, 4-step, and 8-step distilled models. The generation quality of our 2-step, 4-step, and 8-step model is great. Our 1-step model is only provided for research purposes.
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## Demo
|
| 22 |
+
|
| 23 |
+
Try AnimateDiff-Lightning using our text-to-video generation [demo](https://huggingface.co/spaces/ByteDance/AnimateDiff-Lightning).
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
## Recommendation
|
| 27 |
+
|
| 28 |
+
AnimateDiff-Lightning produces the best results when used with stylized base models. We recommend using the following base models:
|
| 29 |
+
|
| 30 |
+
Realistic
|
| 31 |
+
- [epiCRealism](https://civitai.com/models/25694)
|
| 32 |
+
- [Realistic Vision](https://civitai.com/models/4201)
|
| 33 |
+
- [DreamShaper](https://civitai.com/models/4384)
|
| 34 |
+
- [AbsoluteReality](https://civitai.com/models/81458)
|
| 35 |
+
- [MajicMix Realistic](https://civitai.com/models/43331)
|
| 36 |
+
|
| 37 |
+
Anime & Cartoon
|
| 38 |
+
- [ToonYou](https://civitai.com/models/30240)
|
| 39 |
+
- [IMP](https://civitai.com/models/56680)
|
| 40 |
+
- [Mistoon Anime](https://civitai.com/models/24149)
|
| 41 |
+
- [DynaVision](https://civitai.com/models/75549)
|
| 42 |
+
- [RCNZ Cartoon 3d](https://civitai.com/models/66347)
|
| 43 |
+
- [MajicMix Reverie](https://civitai.com/models/65055)
|
| 44 |
+
|
| 45 |
+
Additionally, feel free to explore different settings. We find using 3 inference steps on the 2-step model produces great results. We find certain base models produces better results with CFG. We also recommend using [Motion LoRAs](https://huggingface.co/guoyww/animatediff/tree/main) as they produce stronger motion. We use Motion LoRAs with strength 0.7~0.8 to avoid watermark.
|
| 46 |
+
|
| 47 |
+
## Diffusers Usage
|
| 48 |
+
|
| 49 |
+
```python
|
| 50 |
+
import torch
|
| 51 |
+
from diffusers import AnimateDiffPipeline, MotionAdapter, EulerDiscreteScheduler
|
| 52 |
+
from diffusers.utils import export_to_gif
|
| 53 |
+
from huggingface_hub import hf_hub_download
|
| 54 |
+
from safetensors.torch import load_file
|
| 55 |
+
|
| 56 |
+
device = ""cuda""
|
| 57 |
+
dtype = torch.float16
|
| 58 |
+
|
| 59 |
+
step = 4 # Options: [1,2,4,8]
|
| 60 |
+
repo = ""ByteDance/AnimateDiff-Lightning""
|
| 61 |
+
ckpt = f""animatediff_lightning_{step}step_diffusers.safetensors""
|
| 62 |
+
base = ""emilianJR/epiCRealism"" # Choose to your favorite base model.
|
| 63 |
+
|
| 64 |
+
adapter = MotionAdapter().to(device, dtype)
|
| 65 |
+
adapter.load_state_dict(load_file(hf_hub_download(repo ,ckpt), device=device))
|
| 66 |
+
pipe = AnimateDiffPipeline.from_pretrained(base, motion_adapter=adapter, torch_dtype=dtype).to(device)
|
| 67 |
+
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing=""trailing"", beta_schedule=""linear"")
|
| 68 |
+
|
| 69 |
+
output = pipe(prompt=""A girl smiling"", guidance_scale=1.0, num_inference_steps=step)
|
| 70 |
+
export_to_gif(output.frames[0], ""animation.gif"")
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
## ComfyUI Usage
|
| 74 |
+
|
| 75 |
+
1. Download [animatediff_lightning_workflow.json](https://huggingface.co/ByteDance/AnimateDiff-Lightning/raw/main/comfyui/animatediff_lightning_workflow.json) and import it in ComfyUI.
|
| 76 |
+
1. Install nodes. You can install them manually or use [ComfyUI-Manager](https://github.com/ltdrdata/ComfyUI-Manager).
|
| 77 |
+
* [ComfyUI-AnimateDiff-Evolved](https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved)
|
| 78 |
+
* [ComfyUI-VideoHelperSuite](https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite)
|
| 79 |
+
1. Download your favorite base model checkpoint and put them under `/models/checkpoints/`
|
| 80 |
+
1. Download AnimateDiff-Lightning checkpoint `animatediff_lightning_Nstep_comfyui.safetensors` and put them under `/custom_nodes/ComfyUI-AnimateDiff-Evolved/models/`
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
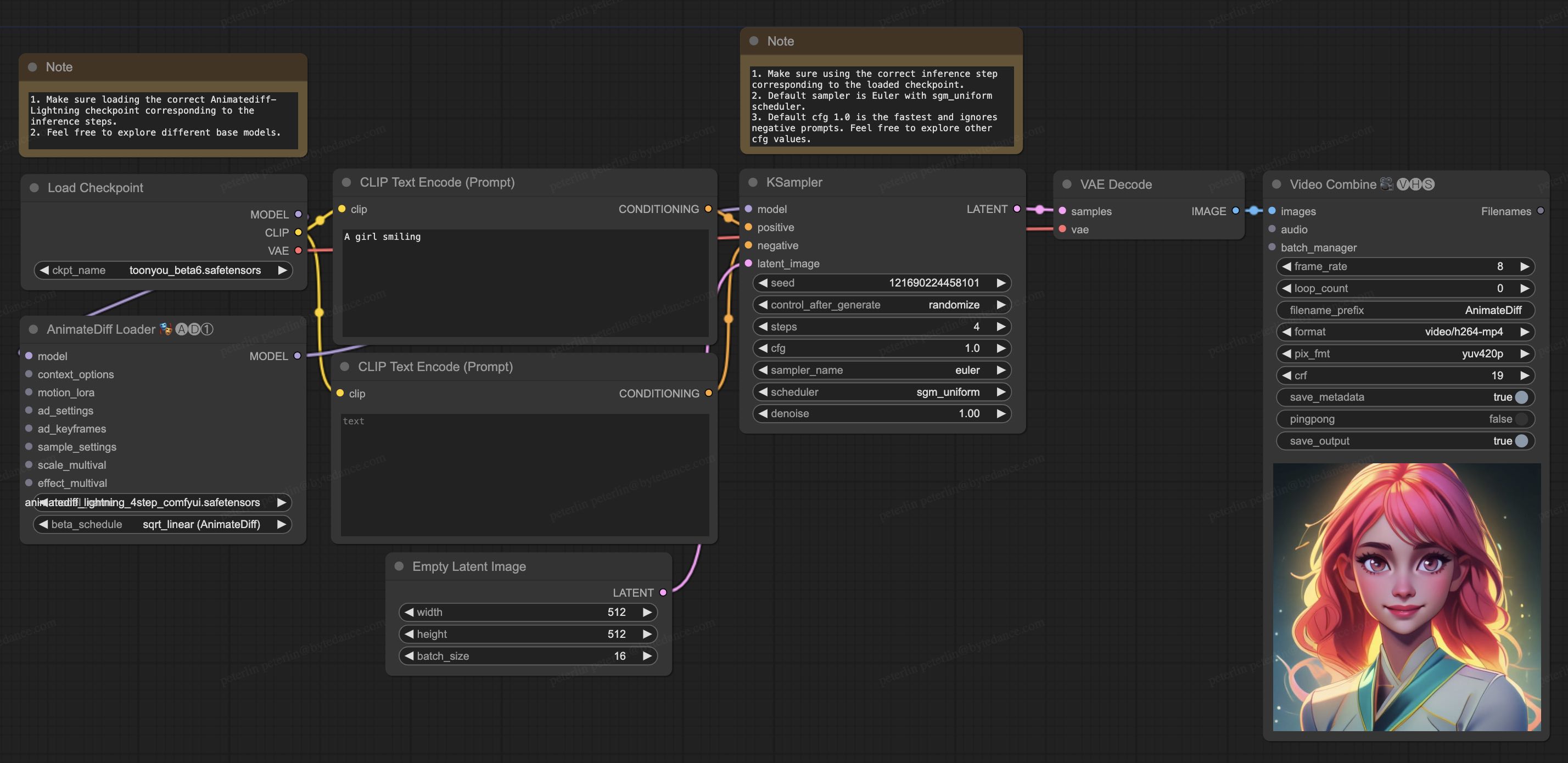
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
## Video-to-Video Generation
|
| 87 |
+
|
| 88 |
+
AnimateDiff-Lightning is great for video-to-video generation. We provide the simplist comfyui workflow using ControlNet.
|
| 89 |
+
|
| 90 |
+
1. Download [animatediff_lightning_v2v_openpose_workflow.json](https://huggingface.co/ByteDance/AnimateDiff-Lightning/raw/main/comfyui/animatediff_lightning_v2v_openpose_workflow.json) and import it in ComfyUI.
|
| 91 |
+
1. Install nodes. You can install them manually or use [ComfyUI-Manager](https://github.com/ltdrdata/ComfyUI-Manager).
|
| 92 |
+
* [ComfyUI-AnimateDiff-Evolved](https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved)
|
| 93 |
+
* [ComfyUI-VideoHelperSuite](https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite)
|
| 94 |
+
* [ComfyUI-Advanced-ControlNet](https://github.com/Kosinkadink/ComfyUI-Advanced-ControlNet)
|
| 95 |
+
* [comfyui_controlnet_aux](https://github.com/Fannovel16/comfyui_controlnet_aux)
|
| 96 |
+
1. Download your favorite base model checkpoint and put them under `/models/checkpoints/`
|
| 97 |
+
1. Download AnimateDiff-Lightning checkpoint `animatediff_lightning_Nstep_comfyui.safetensors` and put them under `/custom_nodes/ComfyUI-AnimateDiff-Evolved/models/`
|
| 98 |
+
1. Download [ControlNet OpenPose](https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main) `control_v11p_sd15_openpose.pth` checkpoint to `/models/controlnet/`
|
| 99 |
+
1. Upload your video and run the pipeline.
|
| 100 |
+
|
| 101 |
+
Additional notes:
|
| 102 |
+
|
| 103 |
+
1. Video shouldn't be too long or too high resolution. We used 576x1024 8 second 30fps videos for testing.
|
| 104 |
+
1. Set the frame rate to match your input video. This allows audio to match with the output video.
|
| 105 |
+
1. DWPose will download checkpoint itself on its first run.
|
| 106 |
+
1. DWPose may get stuck in UI, but the pipeline is actually still running in the background. Check ComfyUI log and your output folder.
|
| 107 |
+
|
| 108 |
+
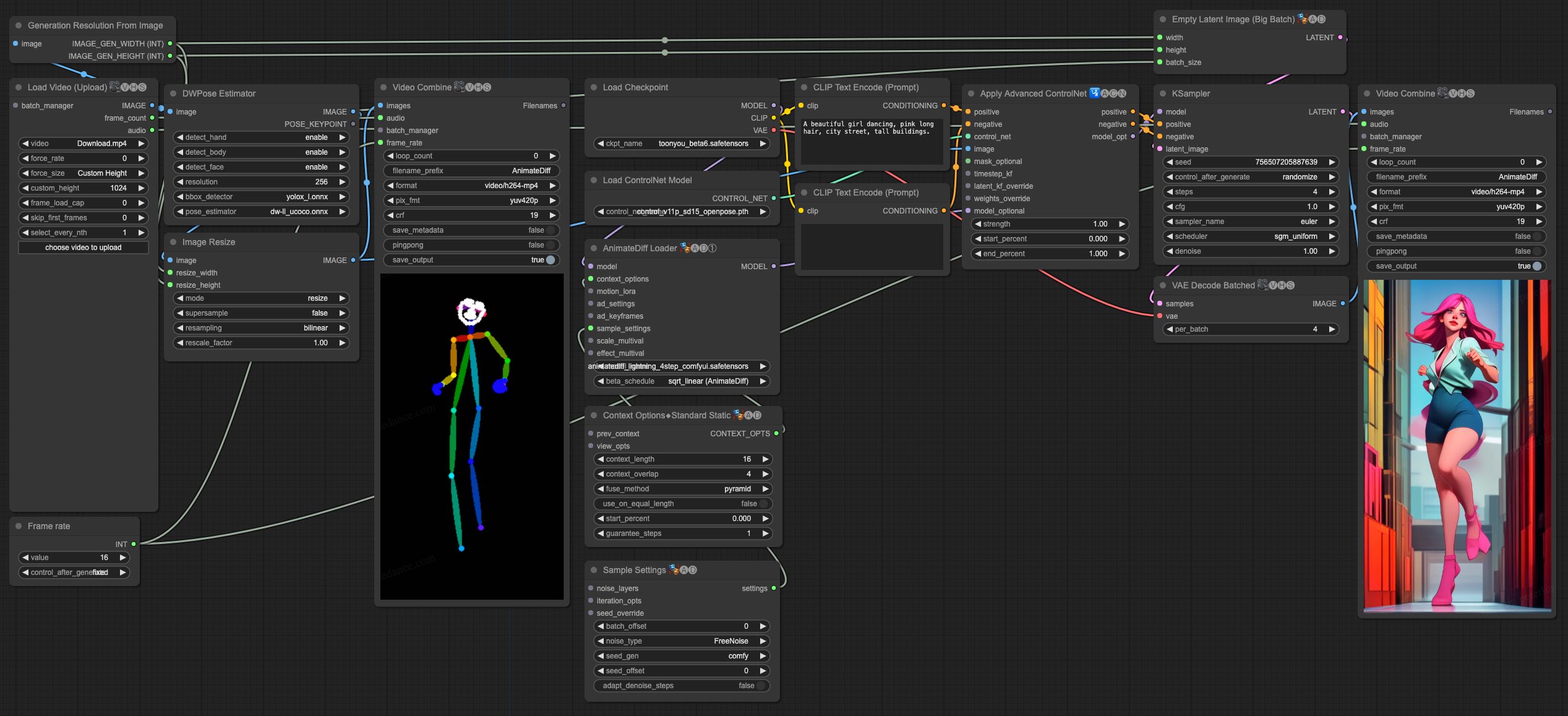
|
| 109 |
+
|
| 110 |
+
# Cite Our Work
|
| 111 |
+
```
|
| 112 |
+
@misc{lin2024animatedifflightning,
|
| 113 |
+
title={AnimateDiff-Lightning: Cross-Model Diffusion Distillation},
|
| 114 |
+
author={Shanchuan Lin and Xiao Yang},
|
| 115 |
+
year={2024},
|
| 116 |
+
eprint={2403.12706},
|
| 117 |
+
archivePrefix={arXiv},
|
| 118 |
+
primaryClass={cs.CV}
|
| 119 |
+
}
|
| 120 |
+
```","{""id"": ""ByteDance/AnimateDiff-Lightning"", ""author"": ""ByteDance"", ""sha"": ""027c893eec01df7330f5d4b733bc9485ee02e8b2"", ""last_modified"": ""2025-01-06 06:03:11+00:00"", ""created_at"": ""2024-03-19 12:58:46+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 151443, ""downloads_all_time"": null, ""likes"": 924, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""text-to-video"", ""stable-diffusion"", ""animatediff"", ""arxiv:2403.12706"", ""license:creativeml-openrail-m"", ""region:us""], ""pipeline_tag"": ""text-to-video"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""library_name: diffusers\nlicense: creativeml-openrail-m\ntags:\n- text-to-video\n- stable-diffusion\n- animatediff\ninference: false"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_1step_comfyui.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_1step_diffusers.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_2step_comfyui.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_2step_diffusers.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_4step_comfyui.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_4step_diffusers.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_8step_comfyui.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_8step_diffusers.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_report.pdf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_samples_t2v.mp4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='animatediff_lightning_samples_v2v.mp4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='comfyui/animatediff_lightning_v2v_openpose_workflow.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='comfyui/animatediff_lightning_v2v_openpose_workflow.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='comfyui/animatediff_lightning_workflow.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='comfyui/animatediff_lightning_workflow.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""KingNish/Instant-Video"", ""ByteDance/AnimateDiff-Lightning"", ""marlonbarrios/Instant-Video"", ""orderlymirror/Text-to-Video"", ""Nymbo/Instant-Video"", ""SahaniJi/Instant-Video"", ""Martim-Ramos-Neural/AnimateDiffPipeline_text_to_video"", ""Gradio-Community/Animation_With_Sound"", ""AI-Platform/Mochi_1_Video"", ""SahaniJi/AnimateDiff-Lightning"", ""ruslanmv/Video-Generator-from-Story"", ""paulm0016/text_to_gif"", ""K00B404/AnimateDiff-Lightning"", ""rynmurdock/Blue_Tigers"", ""Uhhy/Instant-Video"", ""Harumiiii/text-to-image-api"", ""mrbeliever/Ins-Vid"", ""salomonsky/Mochi_1_Video"", ""LAJILAODEEAIQ/office-chat-Instant-Video"", ""jbilcke-hf/ai-tube-model-adl-1"", ""jbilcke-hf/ai-tube-model-parler-tts-mini"", ""Taf2023/Animation_With_Sound"", ""jbilcke-hf/ai-tube-model-adl-2"", ""Taf2023/AnimateDiff-Lightning"", ""Divergent007/Instant-Video"", ""sanaweb/AnimateDiff-Lightning"", ""pranavajay/Test"", ""cocktailpeanut/Instant-Video"", ""Festrcze/Instant-Video"", ""Alif737/Video-Generator-fron-text"", ""jbilcke-hf/ai-tube-model-adl-3"", ""jbilcke-hf/ai-tube-model-adl-4"", ""jbilcke-hf/huggingchat-tool-video"", ""qsdreams/AnimateDiff-Lightning"", ""saicharan1234/Video-Engine"", ""cbbstars/Instant-Video"", ""raymerjacque/Instant-Video"", ""saima730/text_to_video"", ""saima730/textToVideo"", ""Yhhxhfh/Instant-Video"", ""snehalsas/Instant-Video-Generation"", ""omgitsqing/hum_me_a_melody"", ""M-lai/Instant-Video"", ""SiddhantSahu/Project_for_collage-Text_to_Video"", ""Fre123/Frev123"", ""edu12378/My-space"", ""ahmdliaqat/animate"", ""quangnhat/QNT-ByteDance"", ""sk444/v3"", ""soiz1/ComfyUI-Demo"", ""armen425221356/Instant-Video"", ""sreepathi-ravikumar/AnimateDiff-Lightning"", ""taddymason/Instant-Video"", ""orderlymirror/demo"", ""orderlymirror/TIv2""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-01-06 06:03:11+00:00"", ""cardData"": ""library_name: diffusers\nlicense: creativeml-openrail-m\ntags:\n- text-to-video\n- stable-diffusion\n- animatediff\ninference: false"", ""transformersInfo"": null, ""_id"": ""65f98c0619efe1381b9514a5"", ""modelId"": ""ByteDance/AnimateDiff-Lightning"", ""usedStorage"": 7286508236}",0,,0,,0,,0,,0,"ByteDance/AnimateDiff-Lightning, Harumiiii/text-to-image-api, KingNish/Instant-Video, LAJILAODEEAIQ/office-chat-Instant-Video, Martim-Ramos-Neural/AnimateDiffPipeline_text_to_video, SahaniJi/AnimateDiff-Lightning, SahaniJi/Instant-Video, huggingface/InferenceSupport/discussions/1056, orderlymirror/TIv2, orderlymirror/Text-to-Video, paulm0016/text_to_gif, quangnhat/QNT-ByteDance, ruslanmv/Video-Generator-from-Story",13
|
AnimateLCM-SVD-xt_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
wangfuyun/AnimateLCM-SVD-xt,"---
|
| 3 |
+
pipeline_tag: image-to-video
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
<p align=""center"">
|
| 7 |
+
<img src=""./demos/demo-01.gif"" width=""70%"" />
|
| 8 |
+
<img src=""./demos/demo-02.gif"" width=""70%"" />
|
| 9 |
+
<img src=""./demos/demo-03.gif"" width=""70%"" />
|
| 10 |
+
|
| 11 |
+
</p>
|
| 12 |
+
<p align=""center"">Samples generated by AnimateLCM-SVD-xt</p>
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
## Introduction
|
| 16 |
+
Consistency Distilled [Stable Video Diffusion Image2Video-XT (SVD-xt)](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt) following the strategy proposed in [AnimateLCM-paper](https://arxiv.org/abs/2402.00769).
|
| 17 |
+
AnimateLCM-SVD-xt can generate good quality image-conditioned videos with 25 frames in 2~8 steps with 576x1024 resolutions.
|
| 18 |
+
|
| 19 |
+
## Computation comparsion
|
| 20 |
+
AnimateLCM-SVD-xt can generally produces demos with good quality in 4 steps without requiring the classifier-free guidance, and therefore can save 25 x 2 / 4 = 12.5 times compuation resources compared with normal SVD models.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Demos
|
| 24 |
+
|
| 25 |
+
| | | |
|
| 26 |
+
| :---: | :---: | :---: |
|
| 27 |
+
|  |  |  |
|
| 28 |
+
| 2 steps, cfg=1 | 4 steps, cfg=1 | 8 steps, cfg=1 |
|
| 29 |
+
|  |  |  |
|
| 30 |
+
| 2 steps, cfg=1 | 4 steps, cfg=1 | 8 steps, cfg=1 |
|
| 31 |
+
|  |  |  |
|
| 32 |
+
| 2 steps, cfg=1 | 4 steps, cfg=1 | 8 steps, cfg=1 |
|
| 33 |
+
|  |  |  |
|
| 34 |
+
| 2 steps, cfg=1 | 4 steps, cfg=1 | 8 steps, cfg=1 |
|
| 35 |
+
|  |  |  |
|
| 36 |
+
| 2 steps, cfg=1 | 4 steps, cfg=1 | 8 steps, cfg=1 |
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
I have launched a gradio demo at [AnimateLCM SVD space](https://huggingface.co/spaces/wangfuyun/AnimateLCM-SVD). Should you have any questions, please contact Fu-Yun Wang (fywang@link.cuhk.edu.hk). I might respond a bit later. Thank you!","{""id"": ""wangfuyun/AnimateLCM-SVD-xt"", ""author"": ""wangfuyun"", ""sha"": ""ef2753d97ea1bd8741b6b5287b834630f1c42fa0"", ""last_modified"": ""2024-02-27 08:05:01+00:00"", ""created_at"": ""2024-02-18 17:29:06+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 196, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""image-to-video"", ""arxiv:2402.00769"", ""region:us""], ""pipeline_tag"": ""image-to-video"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""pipeline_tag: image-to-video"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='AnimateLCM-SVD-xt-1.1.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='AnimateLCM-SVD-xt.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/01-2.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/01-4.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/01-8.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/02-2.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/02-4.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/02-8.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/03-2.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/03-4.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/03-8.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/04-2.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/04-4.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/04-8.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/05-2.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/05-4.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/05-8.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/demo-01.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/demo-02.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demos/demo-03.gif', size=None, blob_id=None, lfs=None)""], ""spaces"": [""wangfuyun/AnimateLCM-SVD"", ""wangfuyun/AnimateLCM"", ""fantos/vidiani"", ""Ziaistan/AnimateLCM-SVD"", ""Taf2023/AnimateLCM"", ""svjack/AnimateLCM-SVD-Genshin-Impact-Demo""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-02-27 08:05:01+00:00"", ""cardData"": ""pipeline_tag: image-to-video"", ""transformersInfo"": null, ""_id"": ""65d23e62ad23a6740435a879"", ""modelId"": ""wangfuyun/AnimateLCM-SVD-xt"", ""usedStorage"": 12317372403}",0,,0,,0,,0,,0,"Taf2023/AnimateLCM, Ziaistan/AnimateLCM-SVD, fantos/vidiani, huggingface/InferenceSupport/discussions/new?title=wangfuyun/AnimateLCM-SVD-xt&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bwangfuyun%2FAnimateLCM-SVD-xt%5D(%2Fwangfuyun%2FAnimateLCM-SVD-xt)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, svjack/AnimateLCM-SVD-Genshin-Impact-Demo, wangfuyun/AnimateLCM, wangfuyun/AnimateLCM-SVD",7
|
AsianModel_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
BanKaiPls/AsianModel,"---
|
| 3 |
+
license: openrail
|
| 4 |
+
---
|
| 5 |
+
","{""id"": ""BanKaiPls/AsianModel"", ""author"": ""BanKaiPls"", ""sha"": ""d6193514bb251acbf27e08c018c3fec891f037f9"", ""last_modified"": ""2023-07-16 06:56:26+00:00"", ""created_at"": ""2023-03-09 08:28:43+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 186, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""license:openrail"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: openrail"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BRA5beta.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BRAV5beta.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BRAV5finalfp16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BraV5Beta3.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BraV5Finaltest.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Brav6.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='OpenBra.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [""willhill/stable-diffusion-webui-cpu"", ""goguenha123/stable-diffusion-webui-cpu"", ""caizhudiren/test""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-07-16 06:56:26+00:00"", ""cardData"": ""license: openrail"", ""transformersInfo"": null, ""_id"": ""640998bb582fb894c058d043"", ""modelId"": ""BanKaiPls/AsianModel"", ""usedStorage"": 127167632115}",0,,0,,0,,0,,0,"caizhudiren/test, goguenha123/stable-diffusion-webui-cpu, huggingface/InferenceSupport/discussions/new?title=BanKaiPls/AsianModel&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BBanKaiPls%2FAsianModel%5D(%2FBanKaiPls%2FAsianModel)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, willhill/stable-diffusion-webui-cpu",4
|
Athene-V2-Chat_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
Nexusflow/Athene-V2-Chat,N/A,N/A,0,"https://huggingface.co/Saxo/Linkbricks-Horizon-AI-Avengers-V1-108B, https://huggingface.co/dvishal18/chatbotapi",2,,0,"https://huggingface.co/lmstudio-community/Athene-V2-Chat-GGUF, https://huggingface.co/mradermacher/Athene-V2-Chat-i1-GGUF, https://huggingface.co/kosbu/Athene-V2-Chat-AWQ, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_4.0bpw, https://huggingface.co/lee5j/Athene-V2-Chat-gptq4, https://huggingface.co/bartowski/Athene-V2-Chat-GGUF, https://huggingface.co/DevQuasar/Nexusflow.Athene-V2-Chat-GGUF, https://huggingface.co/mradermacher/Athene-V2-Chat-GGUF, https://huggingface.co/mlx-community/Athene-V2-Chat-8bit, https://huggingface.co/Jellon/Athene-V2-Chat-72b-exl2-3bpw, https://huggingface.co/JustinIrv/Athene-V2-Chat-Q4-mlx, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_8.0bpw, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_7.0bpw, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_6.0bpw, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_5.0bpw, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_4.5bpw, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_3.5bpw, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_3.0bpw, https://huggingface.co/cotdp/Athene-V2-Chat-MLX-4bit, https://huggingface.co/mlx-community/Athene-V2-Chat-4bit, https://huggingface.co/Orion-zhen/Athene-V2-Chat-abliterated-bnb-4bit, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_2.75bpw, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_2.5bpw, https://huggingface.co/Dracones/Athene-V2-Chat_exl2_2.25bpw",24,"https://huggingface.co/SteelStorage/Q2.5-MS-Mistoria-72b-v2, https://huggingface.co/spow12/KoQwen_72B_v5.0, https://huggingface.co/sophosympatheia/Evathene-v1.2, https://huggingface.co/spow12/ChatWaifu_72B_v2.2, https://huggingface.co/sophosympatheia/Evathene-v1.0, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.0-8.0bpw-h8-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.0-6.0bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.0-5.0bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.0-4.25bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.0-3.5bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.0-3.0bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.0-2.25bpw-h6-exl2, https://huggingface.co/nitky/AtheneX-V2-72B-instruct, https://huggingface.co/CalamitousFelicitousness/Evathene-v1.0-FP8-Dynamic, https://huggingface.co/DBMe/Evathene-v1.0-4.86bpw-h6-exl2, https://huggingface.co/sophosympatheia/Evathene-v1.1, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.2-8.0bpw-h8-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.2-6.0bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.2-5.0bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.2-3.5bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.1-8.0bpw-h8-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.1-6.0bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.1-5.0bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.1-3.5bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.2-4.25bpw-h6-exl2, https://huggingface.co/MikeRoz/sophosympatheia_Evathene-v1.1-4.25bpw-h6-exl2, https://huggingface.co/gunman0/Evathene-v1.2_EXL2_8bpw, https://huggingface.co/Infermatic/Q2.5-MS-Mistoria-72b-v2-FP8-Dynamic, https://huggingface.co/ehristoforu/frqwen2.5-from72b-duable10layers, https://huggingface.co/Nohobby/Q2.5-Atess-72B, https://huggingface.co/chakchouk/BBA-ECE-TRIOMPHANT-Qwen2.5-72B",31,"Dynamitte63/Nexusflow-Athene-V2-Chat, FallnAI/Quantize-HF-Models, K00B404/LLM_Quantization, KBaba7/Quant, Lone7727/Nexusflow-Athene-V2-Chat, bazingapaa/compare-models, bhaskartripathi/LLM_Quantization, huggingface/InferenceSupport/discussions/new?title=Nexusflow/Athene-V2-Chat&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BNexusflow%2FAthene-V2-Chat%5D(%2FNexusflow%2FAthene-V2-Chat)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kaleidoskop-hug/StreamlitChat_Test, mikemin027/Nexusflow-Athene-V2-Chat, ruslanmv/convert_to_gguf, totolook/Quant, zhangjian95/Nexusflow-Athene-V2-Chat",13
|
| 3 |
+
Saxo/Linkbricks-Horizon-AI-Avengers-V1-108B,"---
|
| 4 |
+
library_name: transformers
|
| 5 |
+
license: apache-2.0
|
| 6 |
+
base_model: Nexusflow/Athene-V2-Chat
|
| 7 |
+
datasets:
|
| 8 |
+
- Saxo/ko_cn_translation_tech_social_science_linkbricks_single_dataset
|
| 9 |
+
- Saxo/ko_jp_translation_tech_social_science_linkbricks_single_dataset
|
| 10 |
+
- Saxo/en_ko_translation_tech_science_linkbricks_single_dataset_with_prompt_text_huggingface
|
| 11 |
+
- Saxo/en_ko_translation_social_science_linkbricks_single_dataset_with_prompt_text_huggingface
|
| 12 |
+
- Saxo/ko_aspect_sentiment_sns_mall_sentiment_linkbricks_single_dataset_with_prompt_text_huggingface
|
| 13 |
+
- Saxo/ko_summarization_linkbricks_single_dataset_with_prompt_text_huggingface
|
| 14 |
+
- Saxo/OpenOrca_cleaned_kor_linkbricks_single_dataset_with_prompt_text_huggingface
|
| 15 |
+
- Saxo/ko_government_qa_total_linkbricks_single_dataset_with_prompt_text_huggingface_sampled
|
| 16 |
+
- Saxo/ko-news-corpus-1
|
| 17 |
+
- Saxo/ko-news-corpus-2
|
| 18 |
+
- Saxo/ko-news-corpus-3
|
| 19 |
+
- Saxo/ko-news-corpus-4
|
| 20 |
+
- Saxo/ko-news-corpus-5
|
| 21 |
+
- Saxo/ko-news-corpus-6
|
| 22 |
+
- Saxo/ko-news-corpus-7
|
| 23 |
+
- Saxo/ko-news-corpus-8
|
| 24 |
+
- Saxo/ko-news-corpus-9
|
| 25 |
+
- maywell/ko_Ultrafeedback_binarized
|
| 26 |
+
- youjunhyeok/ko-orca-pair-and-ultrafeedback-dpo
|
| 27 |
+
- lilacai/glaive-function-calling-v2-sharegpt
|
| 28 |
+
- kuotient/gsm8k-ko
|
| 29 |
+
language:
|
| 30 |
+
- ko
|
| 31 |
+
- en
|
| 32 |
+
- jp
|
| 33 |
+
- cn
|
| 34 |
+
pipeline_tag: text-generation
|
| 35 |
+
---
|
| 36 |
+
|
| 37 |
+
# Model Card for Model ID
|
| 38 |
+
|
| 39 |
+
<div align=""center"">
|
| 40 |
+
<img src=""http://www.linkbricks.com/wp-content/uploads/2024/11/fulllogo.png"" />
|
| 41 |
+
</div>
|
| 42 |
+
|
| 43 |
+
AIとビッグデータ分析の専門企業であるLinkbricksのデータサイエンティストであるジ・ユンソン(Saxo)ディレクターが <br>
|
| 44 |
+
Nexusflow/Athene-V2-Chatベースモデルを使用し、H100-80G 8個で約35%程度のパラメータをSFT->DPO->ORPO->MERGEした多言語強化言語モデル。<br>
|
| 45 |
+
8千万件の様々な言語圏のニュースやウィキコーパスを基に、様々なタスク別の日本語・韓国語・中国語・英語クロス学習データと数学や論理判断データを通じて、日中韓英言語のクロスエンハンスメント処理と複雑な論理問題にも対応できるように訓練したモデルである。
|
| 46 |
+
-トークナイザーは、単語拡張なしでベースモデルのまま使用します。<br>
|
| 47 |
+
-カスタマーレビューやソーシャル投稿の高次元分析及びコーディングとライティング、数学、論理判断などが強化されたモデル。<br>
|
| 48 |
+
-Function Call<br>
|
| 49 |
+
-Deepspeed Stage=3、rslora及びBAdam Layer Modeを使用 <br>
|
| 50 |
+
-「transformers_version」: 「4.46.3」<br>
|
| 51 |
+
|
| 52 |
+
<br><br>
|
| 53 |
+
|
| 54 |
+
AI 와 빅데이터 분석 전문 기업인 Linkbricks의 데이터사이언티스트인 지윤성(Saxo) 이사가 <br>
|
| 55 |
+
Nexusflow/Athene-V2-Chat 베이스모델을 사용해서 H100-80G 8개를 통해 약 35%정도의 파라미터를 SFT->DPO->ORPO->MERGE 한 다국어 강화 언어 모델<br>
|
| 56 |
+
8천만건의 다양한 언어권의 뉴스 및 위키 코퍼스를 기준으로 다양한 테스크별 일본어-한국어-중국어-영어 교차 학습 데이터와 수학 및 논리판단 데이터를 통하여 한중일영 언어 교차 증강 처리와 복잡한 논리 문제 역시 대응 가능하도록 훈련한 모델이다.<br>
|
| 57 |
+
-토크나이저는 단어 확장 없이 베이스 모델 그대로 사용<br>
|
| 58 |
+
-고객 리뷰나 소셜 포스팅 고차원 분석 및 코딩과 작문, 수학, 논리판단 등이 강화된 모델<br>
|
| 59 |
+
-Function Call 및 Tool Calling 지원<br>
|
| 60 |
+
-Deepspeed Stage=3, rslora 및 BAdam Layer Mode 사용 <br>
|
| 61 |
+
-""transformers_version"": ""4.46.3""<br>
|
| 62 |
+
<br><br>
|
| 63 |
+
|
| 64 |
+
Finetuned by Mr. Yunsung Ji (Saxo), a data scientist at Linkbricks, a company specializing in AI and big data analytics <br>
|
| 65 |
+
about 35% of total parameters SFT->DPO->ORPO->MERGE training model based on Nexusflow/Athene-V2-Chat through 8 H100-80Gs as multi-lingual boosting language model <br>
|
| 66 |
+
It is a model that has been trained to handle Japanese-Korean-Chinese-English cross-training data and 80M multi-lingual news corpus and logic judgment data for various tasks to enable cross-fertilization processing and complex Korean logic & math problems. <br>
|
| 67 |
+
-Tokenizer uses the base model without word expansion<br>
|
| 68 |
+
-Models enhanced with high-dimensional analysis of customer reviews and social posts, as well as coding, writing, math and decision making<br>
|
| 69 |
+
-Function Calling<br>
|
| 70 |
+
-Deepspeed Stage=3, use rslora and BAdam Layer Mode<br>
|
| 71 |
+
<br><br>
|
| 72 |
+
|
| 73 |
+
<a href=""www.linkbricks.com"">www.linkbricks.com</a>, <a href=""www.linkbricks.vc"">www.linkbricks.vc</a>
|
| 74 |
+
","{""id"": ""Saxo/Linkbricks-Horizon-AI-Avengers-V1-108B"", ""author"": ""Saxo"", ""sha"": ""d631a3d20d4e85663bf508b58fccac5372b2c793"", ""last_modified"": ""2024-12-31 02:36:02+00:00"", ""created_at"": ""2024-12-30 07:05:27+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 45, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""qwen2"", ""text-generation"", ""conversational"", ""ko"", ""en"", ""jp"", ""cn"", ""dataset:Saxo/ko_cn_translation_tech_social_science_linkbricks_single_dataset"", ""dataset:Saxo/ko_jp_translation_tech_social_science_linkbricks_single_dataset"", ""dataset:Saxo/en_ko_translation_tech_science_linkbricks_single_dataset_with_prompt_text_huggingface"", ""dataset:Saxo/en_ko_translation_social_science_linkbricks_single_dataset_with_prompt_text_huggingface"", ""dataset:Saxo/ko_aspect_sentiment_sns_mall_sentiment_linkbricks_single_dataset_with_prompt_text_huggingface"", ""dataset:Saxo/ko_summarization_linkbricks_single_dataset_with_prompt_text_huggingface"", ""dataset:Saxo/OpenOrca_cleaned_kor_linkbricks_single_dataset_with_prompt_text_huggingface"", ""dataset:Saxo/ko_government_qa_total_linkbricks_single_dataset_with_prompt_text_huggingface_sampled"", ""dataset:Saxo/ko-news-corpus-1"", ""dataset:Saxo/ko-news-corpus-2"", ""dataset:Saxo/ko-news-corpus-3"", ""dataset:Saxo/ko-news-corpus-4"", ""dataset:Saxo/ko-news-corpus-5"", ""dataset:Saxo/ko-news-corpus-6"", ""dataset:Saxo/ko-news-corpus-7"", ""dataset:Saxo/ko-news-corpus-8"", ""dataset:Saxo/ko-news-corpus-9"", ""dataset:maywell/ko_Ultrafeedback_binarized"", ""dataset:youjunhyeok/ko-orca-pair-and-ultrafeedback-dpo"", ""dataset:lilacai/glaive-function-calling-v2-sharegpt"", ""dataset:kuotient/gsm8k-ko"", ""base_model:Nexusflow/Athene-V2-Chat"", ""base_model:finetune:Nexusflow/Athene-V2-Chat"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: Nexusflow/Athene-V2-Chat\ndatasets:\n- Saxo/ko_cn_translation_tech_social_science_linkbricks_single_dataset\n- Saxo/ko_jp_translation_tech_social_science_linkbricks_single_dataset\n- Saxo/en_ko_translation_tech_science_linkbricks_single_dataset_with_prompt_text_huggingface\n- Saxo/en_ko_translation_social_science_linkbricks_single_dataset_with_prompt_text_huggingface\n- Saxo/ko_aspect_sentiment_sns_mall_sentiment_linkbricks_single_dataset_with_prompt_text_huggingface\n- Saxo/ko_summarization_linkbricks_single_dataset_with_prompt_text_huggingface\n- Saxo/OpenOrca_cleaned_kor_linkbricks_single_dataset_with_prompt_text_huggingface\n- Saxo/ko_government_qa_total_linkbricks_single_dataset_with_prompt_text_huggingface_sampled\n- Saxo/ko-news-corpus-1\n- Saxo/ko-news-corpus-2\n- Saxo/ko-news-corpus-3\n- Saxo/ko-news-corpus-4\n- Saxo/ko-news-corpus-5\n- Saxo/ko-news-corpus-6\n- Saxo/ko-news-corpus-7\n- Saxo/ko-news-corpus-8\n- Saxo/ko-news-corpus-9\n- maywell/ko_Ultrafeedback_binarized\n- youjunhyeok/ko-orca-pair-and-ultrafeedback-dpo\n- lilacai/glaive-function-calling-v2-sharegpt\n- kuotient/gsm8k-ko\nlanguage:\n- ko\n- en\n- jp\n- cn\nlibrary_name: transformers\nlicense: apache-2.0\npipeline_tag: text-generation"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""Qwen2ForCausalLM""], ""model_type"": ""qwen2"", ""tokenizer_config"": {""bos_token"": null, ""chat_template"": ""{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \""\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\"" }}\n {%- for tool in tools %}\n {{- \""\\n\"" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \""\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\""name\\\"": <function-name>, \\\""arguments\\\"": <args-json-object>}\\n</tool_call><|im_end|>\\n\"" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \""user\"") or (message.role == \""system\"" and not loop.first) or (message.role == \""assistant\"" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \""assistant\"" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\""name\"": \""' }}\n {{- tool_call.name }}\n {{- '\"", \""arguments\"": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \""tool\"" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \""tool\"") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \""tool\"") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n"", ""eos_token"": ""<|im_end|>"", ""pad_token"": ""<|endoftext|>"", ""unk_token"": null}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00009-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00010-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00011-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00012-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00013-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00014-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00015-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00016-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00017-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00018-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00019-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00020-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00021-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00022-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00023-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00024-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00025-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00026-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00027-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00028-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00029-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00030-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00031-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00032-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00033-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00034-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00035-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00036-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00037-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00038-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00039-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00040-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00041-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00042-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00043-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00044-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00045-of-00045.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""BF16"": 107807055872}, ""total"": 107807055872}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-12-31 02:36:02+00:00"", ""cardData"": ""base_model: Nexusflow/Athene-V2-Chat\ndatasets:\n- Saxo/ko_cn_translation_tech_social_science_linkbricks_single_dataset\n- Saxo/ko_jp_translation_tech_social_science_linkbricks_single_dataset\n- Saxo/en_ko_translation_tech_science_linkbricks_single_dataset_with_prompt_text_huggingface\n- Saxo/en_ko_translation_social_science_linkbricks_single_dataset_with_prompt_text_huggingface\n- Saxo/ko_aspect_sentiment_sns_mall_sentiment_linkbricks_single_dataset_with_prompt_text_huggingface\n- Saxo/ko_summarization_linkbricks_single_dataset_with_prompt_text_huggingface\n- Saxo/OpenOrca_cleaned_kor_linkbricks_single_dataset_with_prompt_text_huggingface\n- Saxo/ko_government_qa_total_linkbricks_single_dataset_with_prompt_text_huggingface_sampled\n- Saxo/ko-news-corpus-1\n- Saxo/ko-news-corpus-2\n- Saxo/ko-news-corpus-3\n- Saxo/ko-news-corpus-4\n- Saxo/ko-news-corpus-5\n- Saxo/ko-news-corpus-6\n- Saxo/ko-news-corpus-7\n- Saxo/ko-news-corpus-8\n- Saxo/ko-news-corpus-9\n- maywell/ko_Ultrafeedback_binarized\n- youjunhyeok/ko-orca-pair-and-ultrafeedback-dpo\n- lilacai/glaive-function-calling-v2-sharegpt\n- kuotient/gsm8k-ko\nlanguage:\n- ko\n- en\n- jp\n- cn\nlibrary_name: transformers\nlicense: apache-2.0\npipeline_tag: text-generation"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""67724637bb74df9800cc7e60"", ""modelId"": ""Saxo/Linkbricks-Horizon-AI-Avengers-V1-108B"", ""usedStorage"": 215625701192}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Saxo/Linkbricks-Horizon-AI-Avengers-V1-108B&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BSaxo%2FLinkbricks-Horizon-AI-Avengers-V1-108B%5D(%2FSaxo%2FLinkbricks-Horizon-AI-Avengers-V1-108B)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 75 |
+
dvishal18/chatbotapi,"---
|
| 76 |
+
license: apache-2.0
|
| 77 |
+
language:
|
| 78 |
+
- en
|
| 79 |
+
base_model:
|
| 80 |
+
- Nexusflow/Athene-V2-Chat
|
| 81 |
+
---","{""id"": ""dvishal18/chatbotapi"", ""author"": ""dvishal18"", ""sha"": ""7585f329aa754b85ed0bca750c2f867fc2ee3ab8"", ""last_modified"": ""2024-12-30 12:35:47+00:00"", ""created_at"": ""2024-12-30 12:34:42+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""en"", ""base_model:Nexusflow/Athene-V2-Chat"", ""base_model:finetune:Nexusflow/Athene-V2-Chat"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- Nexusflow/Athene-V2-Chat\nlanguage:\n- en\nlicense: apache-2.0"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-12-30 12:35:47+00:00"", ""cardData"": ""base_model:\n- Nexusflow/Athene-V2-Chat\nlanguage:\n- en\nlicense: apache-2.0"", ""transformersInfo"": null, ""_id"": ""67729362afe9fcdc219f7645"", ""modelId"": ""dvishal18/chatbotapi"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=dvishal18/chatbotapi&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bdvishal18%2Fchatbotapi%5D(%2Fdvishal18%2Fchatbotapi)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
BiomedCLIP-PubMedBERT_256-vit_base_patch16_224_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,407 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224,"---
|
| 3 |
+
language: en
|
| 4 |
+
tags:
|
| 5 |
+
- clip
|
| 6 |
+
- biology
|
| 7 |
+
- medical
|
| 8 |
+
license: mit
|
| 9 |
+
library_name: open_clip
|
| 10 |
+
widget:
|
| 11 |
+
- src: https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/squamous_cell_carcinoma_histopathology.jpeg
|
| 12 |
+
candidate_labels: adenocarcinoma histopathology, squamous cell carcinoma histopathology
|
| 13 |
+
example_title: squamous cell carcinoma histopathology
|
| 14 |
+
- src: >-
|
| 15 |
+
https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/adenocarcinoma_histopathology.jpg
|
| 16 |
+
candidate_labels: adenocarcinoma histopathology, squamous cell carcinoma histopathology
|
| 17 |
+
example_title: adenocarcinoma histopathology
|
| 18 |
+
- src: >-
|
| 19 |
+
https://upload.wikimedia.org/wikipedia/commons/5/57/Left-sided_Pleural_Effusion.jpg
|
| 20 |
+
candidate_labels: left-sided pleural effusion chest x-ray, right-sided pleural effusion chest x-ray, normal chest x-ray
|
| 21 |
+
example_title: left-sided pleural effusion chest x-ray
|
| 22 |
+
pipeline_tag: zero-shot-image-classification
|
| 23 |
+
---
|
| 24 |
+
|
| 25 |
+
# BiomedCLIP-PubMedBERT_256-vit_base_patch16_224
|
| 26 |
+
|
| 27 |
+
[BiomedCLIP](https://aka.ms/biomedclip-paper) is a biomedical vision-language foundation model that is pretrained on [PMC-15M](https://github.com/microsoft/BiomedCLIP_data_pipeline), a dataset of 15 million figure-caption pairs extracted from biomedical research articles in PubMed Central, using contrastive learning.
|
| 28 |
+
It uses PubMedBERT as the text encoder and Vision Transformer as the image encoder, with domain-specific adaptations.
|
| 29 |
+
It can perform various vision-language processing (VLP) tasks such as cross-modal retrieval, image classification, and visual question answering.
|
| 30 |
+
BiomedCLIP establishes new state of the art in a wide range of standard datasets, and substantially outperforms prior VLP approaches:
|
| 31 |
+
|
| 32 |
+

|
| 33 |
+
|
| 34 |
+
## Contents
|
| 35 |
+
|
| 36 |
+
- [Training Data](#training-data)
|
| 37 |
+
- [Model Use](#model-use)
|
| 38 |
+
- [Reference](#reference)
|
| 39 |
+
- [Limitations](#limitations)
|
| 40 |
+
- [Further Information](#further-information)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
## Training Data
|
| 44 |
+
|
| 45 |
+
We have released BiomedCLIP Data Pipeline at [https://github.com/microsoft/BiomedCLIP_data_pipeline](https://github.com/microsoft/BiomedCLIP_data_pipeline), which automatically downloads and processes a set of articles from the PubMed Central Open Access dataset.
|
| 46 |
+
BiomedCLIP builds upon the PMC-15M dataset, which is a large-scale parallel image-text dataset generated by this data pipeline for biomedical vision-language processing. It contains 15 million figure-caption pairs extracted from biomedical research articles in PubMed Central and covers a diverse range of biomedical image types, such as microscopy, radiography, histology, and more.
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
## Model Use
|
| 50 |
+
|
| 51 |
+
### 1. Environment
|
| 52 |
+
|
| 53 |
+
```bash
|
| 54 |
+
conda create -n biomedclip python=3.10 -y
|
| 55 |
+
conda activate biomedclip
|
| 56 |
+
pip install open_clip_torch==2.23.0 transformers==4.35.2 matplotlib
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
### 2.1 Load from HF hub
|
| 60 |
+
|
| 61 |
+
```python
|
| 62 |
+
import torch
|
| 63 |
+
from urllib.request import urlopen
|
| 64 |
+
from PIL import Image
|
| 65 |
+
from open_clip import create_model_from_pretrained, get_tokenizer
|
| 66 |
+
|
| 67 |
+
# Load the model and config files from the Hugging Face Hub
|
| 68 |
+
model, preprocess = create_model_from_pretrained('hf-hub:microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224')
|
| 69 |
+
tokenizer = get_tokenizer('hf-hub:microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224')
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
# Zero-shot image classification
|
| 73 |
+
template = 'this is a photo of '
|
| 74 |
+
labels = [
|
| 75 |
+
'adenocarcinoma histopathology',
|
| 76 |
+
'brain MRI',
|
| 77 |
+
'covid line chart',
|
| 78 |
+
'squamous cell carcinoma histopathology',
|
| 79 |
+
'immunohistochemistry histopathology',
|
| 80 |
+
'bone X-ray',
|
| 81 |
+
'chest X-ray',
|
| 82 |
+
'pie chart',
|
| 83 |
+
'hematoxylin and eosin histopathology'
|
| 84 |
+
]
|
| 85 |
+
|
| 86 |
+
dataset_url = 'https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/'
|
| 87 |
+
test_imgs = [
|
| 88 |
+
'squamous_cell_carcinoma_histopathology.jpeg',
|
| 89 |
+
'H_and_E_histopathology.jpg',
|
| 90 |
+
'bone_X-ray.jpg',
|
| 91 |
+
'adenocarcinoma_histopathology.jpg',
|
| 92 |
+
'covid_line_chart.png',
|
| 93 |
+
'IHC_histopathology.jpg',
|
| 94 |
+
'chest_X-ray.jpg',
|
| 95 |
+
'brain_MRI.jpg',
|
| 96 |
+
'pie_chart.png'
|
| 97 |
+
]
|
| 98 |
+
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
|
| 99 |
+
model.to(device)
|
| 100 |
+
model.eval()
|
| 101 |
+
|
| 102 |
+
context_length = 256
|
| 103 |
+
|
| 104 |
+
images = torch.stack([preprocess(Image.open(urlopen(dataset_url + img))) for img in test_imgs]).to(device)
|
| 105 |
+
texts = tokenizer([template + l for l in labels], context_length=context_length).to(device)
|
| 106 |
+
with torch.no_grad():
|
| 107 |
+
image_features, text_features, logit_scale = model(images, texts)
|
| 108 |
+
|
| 109 |
+
logits = (logit_scale * image_features @ text_features.t()).detach().softmax(dim=-1)
|
| 110 |
+
sorted_indices = torch.argsort(logits, dim=-1, descending=True)
|
| 111 |
+
|
| 112 |
+
logits = logits.cpu().numpy()
|
| 113 |
+
sorted_indices = sorted_indices.cpu().numpy()
|
| 114 |
+
|
| 115 |
+
top_k = -1
|
| 116 |
+
|
| 117 |
+
for i, img in enumerate(test_imgs):
|
| 118 |
+
pred = labels[sorted_indices[i][0]]
|
| 119 |
+
|
| 120 |
+
top_k = len(labels) if top_k == -1 else top_k
|
| 121 |
+
print(img.split('/')[-1] + ':')
|
| 122 |
+
for j in range(top_k):
|
| 123 |
+
jth_index = sorted_indices[i][j]
|
| 124 |
+
print(f'{labels[jth_index]}: {logits[i][jth_index]}')
|
| 125 |
+
print('\n')
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
### 2.2 Load from local files
|
| 129 |
+
|
| 130 |
+
```python
|
| 131 |
+
import json
|
| 132 |
+
|
| 133 |
+
from urllib.request import urlopen
|
| 134 |
+
from PIL import Image
|
| 135 |
+
import torch
|
| 136 |
+
from huggingface_hub import hf_hub_download
|
| 137 |
+
from open_clip import create_model_and_transforms, get_tokenizer
|
| 138 |
+
from open_clip.factory import HF_HUB_PREFIX, _MODEL_CONFIGS
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
# Download the model and config files
|
| 142 |
+
hf_hub_download(
|
| 143 |
+
repo_id=""microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"",
|
| 144 |
+
filename=""open_clip_pytorch_model.bin"",
|
| 145 |
+
local_dir=""checkpoints""
|
| 146 |
+
)
|
| 147 |
+
hf_hub_download(
|
| 148 |
+
repo_id=""microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"",
|
| 149 |
+
filename=""open_clip_config.json"",
|
| 150 |
+
local_dir=""checkpoints""
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
# Load the model and config files
|
| 155 |
+
model_name = ""biomedclip_local""
|
| 156 |
+
|
| 157 |
+
with open(""checkpoints/open_clip_config.json"", ""r"") as f:
|
| 158 |
+
config = json.load(f)
|
| 159 |
+
model_cfg = config[""model_cfg""]
|
| 160 |
+
preprocess_cfg = config[""preprocess_cfg""]
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
if (not model_name.startswith(HF_HUB_PREFIX)
|
| 164 |
+
and model_name not in _MODEL_CONFIGS
|
| 165 |
+
and config is not None):
|
| 166 |
+
_MODEL_CONFIGS[model_name] = model_cfg
|
| 167 |
+
|
| 168 |
+
tokenizer = get_tokenizer(model_name)
|
| 169 |
+
|
| 170 |
+
model, _, preprocess = create_model_and_transforms(
|
| 171 |
+
model_name=model_name,
|
| 172 |
+
pretrained=""checkpoints/open_clip_pytorch_model.bin"",
|
| 173 |
+
**{f""image_{k}"": v for k, v in preprocess_cfg.items()},
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
# Zero-shot image classification
|
| 178 |
+
template = 'this is a photo of '
|
| 179 |
+
labels = [
|
| 180 |
+
'adenocarcinoma histopathology',
|
| 181 |
+
'brain MRI',
|
| 182 |
+
'covid line chart',
|
| 183 |
+
'squamous cell carcinoma histopathology',
|
| 184 |
+
'immunohistochemistry histopathology',
|
| 185 |
+
'bone X-ray',
|
| 186 |
+
'chest X-ray',
|
| 187 |
+
'pie chart',
|
| 188 |
+
'hematoxylin and eosin histopathology'
|
| 189 |
+
]
|
| 190 |
+
|
| 191 |
+
dataset_url = 'https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/'
|
| 192 |
+
test_imgs = [
|
| 193 |
+
'squamous_cell_carcinoma_histopathology.jpeg',
|
| 194 |
+
'H_and_E_histopathology.jpg',
|
| 195 |
+
'bone_X-ray.jpg',
|
| 196 |
+
'adenocarcinoma_histopathology.jpg',
|
| 197 |
+
'covid_line_chart.png',
|
| 198 |
+
'IHC_histopathology.jpg',
|
| 199 |
+
'chest_X-ray.jpg',
|
| 200 |
+
'brain_MRI.jpg',
|
| 201 |
+
'pie_chart.png'
|
| 202 |
+
]
|
| 203 |
+
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
|
| 204 |
+
model.to(device)
|
| 205 |
+
model.eval()
|
| 206 |
+
|
| 207 |
+
context_length = 256
|
| 208 |
+
|
| 209 |
+
images = torch.stack([preprocess(Image.open(urlopen(dataset_url + img))) for img in test_imgs]).to(device)
|
| 210 |
+
texts = tokenizer([template + l for l in labels], context_length=context_length).to(device)
|
| 211 |
+
with torch.no_grad():
|
| 212 |
+
image_features, text_features, logit_scale = model(images, texts)
|
| 213 |
+
|
| 214 |
+
logits = (logit_scale * image_features @ text_features.t()).detach().softmax(dim=-1)
|
| 215 |
+
sorted_indices = torch.argsort(logits, dim=-1, descending=True)
|
| 216 |
+
|
| 217 |
+
logits = logits.cpu().numpy()
|
| 218 |
+
sorted_indices = sorted_indices.cpu().numpy()
|
| 219 |
+
|
| 220 |
+
top_k = -1
|
| 221 |
+
|
| 222 |
+
for i, img in enumerate(test_imgs):
|
| 223 |
+
pred = labels[sorted_indices[i][0]]
|
| 224 |
+
|
| 225 |
+
top_k = len(labels) if top_k == -1 else top_k
|
| 226 |
+
print(img.split('/')[-1] + ':')
|
| 227 |
+
for j in range(top_k):
|
| 228 |
+
jth_index = sorted_indices[i][j]
|
| 229 |
+
print(f'{labels[jth_index]}: {logits[i][jth_index]}')
|
| 230 |
+
print('\n')
|
| 231 |
+
|
| 232 |
+
```
|
| 233 |
+
|
| 234 |
+
### Use in Jupyter Notebook
|
| 235 |
+
|
| 236 |
+
Please refer to this [example notebook](https://aka.ms/biomedclip-example-notebook).
|
| 237 |
+
|
| 238 |
+
### Intended Use
|
| 239 |
+
|
| 240 |
+
This model is intended to be used solely for (I) future research on visual-language processing and (II) reproducibility of the experimental results reported in the reference paper.
|
| 241 |
+
|
| 242 |
+
#### Primary Intended Use
|
| 243 |
+
|
| 244 |
+
The primary intended use is to support AI researchers building on top of this work. BiomedCLIP and its associated models should be helpful for exploring various biomedical VLP research questions, especially in the radiology domain.
|
| 245 |
+
|
| 246 |
+
#### Out-of-Scope Use
|
| 247 |
+
|
| 248 |
+
**Any** deployed use case of the model --- commercial or otherwise --- is currently out of scope. Although we evaluated the models using a broad set of publicly-available research benchmarks, the models and evaluations are not intended for deployed use cases. Please refer to [the associated paper](https://aka.ms/biomedclip-paper) for more details.
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
## Reference
|
| 252 |
+
|
| 253 |
+
```bibtex
|
| 254 |
+
@article{zhang2024biomedclip,
|
| 255 |
+
title={A Multimodal Biomedical Foundation Model Trained from Fifteen Million Image–Text Pairs},
|
| 256 |
+
author={Sheng Zhang and Yanbo Xu and Naoto Usuyama and Hanwen Xu and Jaspreet Bagga and Robert Tinn and Sam Preston and Rajesh Rao and Mu Wei and Naveen Valluri and Cliff Wong and Andrea Tupini and Yu Wang and Matt Mazzola and Swadheen Shukla and Lars Liden and Jianfeng Gao and Angela Crabtree and Brian Piening and Carlo Bifulco and Matthew P. Lungren and Tristan Naumann and Sheng Wang and Hoifung Poon},
|
| 257 |
+
journal={NEJM AI},
|
| 258 |
+
year={2024},
|
| 259 |
+
volume={2},
|
| 260 |
+
number={1},
|
| 261 |
+
doi={10.1056/AIoa2400640},
|
| 262 |
+
url={https://ai.nejm.org/doi/full/10.1056/AIoa2400640}
|
| 263 |
+
}
|
| 264 |
+
```
|
| 265 |
+
|
| 266 |
+
## Limitations
|
| 267 |
+
|
| 268 |
+
This model was developed using English corpora, and thus can be considered English-only.
|
| 269 |
+
|
| 270 |
+
## Further information
|
| 271 |
+
|
| 272 |
+
Please refer to the corresponding paper, [""Large-Scale Domain-Specific Pretraining for Biomedical Vision-Language Processing""](https://aka.ms/biomedclip-paper) for additional details on the model training and evaluation.","{""id"": ""microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""author"": ""microsoft"", ""sha"": ""9f341de24bfb00180f1b847274256e9b65a3a32e"", ""last_modified"": ""2025-01-14 18:29:54+00:00"", ""created_at"": ""2023-04-05 19:57:59+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 133854, ""downloads_all_time"": null, ""likes"": 295, ""library_name"": ""open_clip"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""open_clip"", ""clip"", ""biology"", ""medical"", ""zero-shot-image-classification"", ""en"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""zero-shot-image-classification"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language: en\nlibrary_name: open_clip\nlicense: mit\npipeline_tag: zero-shot-image-classification\ntags:\n- clip\n- biology\n- medical\nwidget:\n- src: https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/squamous_cell_carcinoma_histopathology.jpeg\n candidate_labels: adenocarcinoma histopathology, squamous cell carcinoma histopathology\n example_title: squamous cell carcinoma histopathology\n- src: https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/adenocarcinoma_histopathology.jpg\n candidate_labels: adenocarcinoma histopathology, squamous cell carcinoma histopathology\n example_title: adenocarcinoma histopathology\n- src: https://upload.wikimedia.org/wikipedia/commons/5/57/Left-sided_Pleural_Effusion.jpg\n candidate_labels: left-sided pleural effusion chest x-ray, right-sided pleural effusion\n chest x-ray, normal chest x-ray\n example_title: left-sided pleural effusion chest x-ray"", ""widget_data"": [{""src"": ""https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/squamous_cell_carcinoma_histopathology.jpeg"", ""candidate_labels"": ""adenocarcinoma histopathology, squamous cell carcinoma histopathology"", ""example_title"": ""squamous cell carcinoma histopathology""}, {""src"": ""https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/adenocarcinoma_histopathology.jpg"", ""candidate_labels"": ""adenocarcinoma histopathology, squamous cell carcinoma histopathology"", ""example_title"": ""adenocarcinoma histopathology""}, {""src"": ""https://upload.wikimedia.org/wikipedia/commons/5/57/Left-sided_Pleural_Effusion.jpg"", ""candidate_labels"": ""left-sided pleural effusion chest x-ray, right-sided pleural effusion chest x-ray, normal chest x-ray"", ""example_title"": ""left-sided pleural effusion chest x-ray""}], ""model_index"": null, ""config"": {""tokenizer_config"": {""cls_token"": ""[CLS]"", ""mask_token"": ""[MASK]"", ""pad_token"": ""[PAD]"", ""sep_token"": ""[SEP]"", ""unk_token"": ""[UNK]""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='biomed-vlp-eval.svg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='biomed_clip_example.ipynb', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example_data/biomed_image_classification_example_data/H_and_E_histopathology.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example_data/biomed_image_classification_example_data/IHC_histopathology.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example_data/biomed_image_classification_example_data/adenocarcinoma_histopathology.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example_data/biomed_image_classification_example_data/bone_X-ray.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example_data/biomed_image_classification_example_data/brain_MRI.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example_data/biomed_image_classification_example_data/chest_X-ray.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example_data/biomed_image_classification_example_data/covid_line_chart.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example_data/biomed_image_classification_example_data/pie_chart.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example_data/biomed_image_classification_example_data/squamous_cell_carcinoma_histopathology.jpeg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='open_clip_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='open_clip_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Baron-GG/LLAUS"", ""StefanDenner/MedicalVisualPromptEngineering"", ""zenitsu55/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""mitchmomo/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""charlestonX/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""Rajat456/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""pZacca/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""Dobator/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""Mustafaege/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""mohammedRiad/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""Harshdhi/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""minghsieh/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""Leesoon1984/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""paredena/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""paredena/medical2"", ""paredena/medical3"", ""DrBerenbaum/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""Aadi1149/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""comara/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""mjuetz/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""SD2K/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""CandleTin/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""hsiangyualex/Mbi2Spi"", ""mMonika/Medical_bot"", ""minthein/MedicalVisualPromptEngineering"", ""tjkim4294/ovcf_app""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-01-14 18:29:54+00:00"", ""cardData"": ""language: en\nlibrary_name: open_clip\nlicense: mit\npipeline_tag: zero-shot-image-classification\ntags:\n- clip\n- biology\n- medical\nwidget:\n- src: https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/squamous_cell_carcinoma_histopathology.jpeg\n candidate_labels: adenocarcinoma histopathology, squamous cell carcinoma histopathology\n example_title: squamous cell carcinoma histopathology\n- src: https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/adenocarcinoma_histopathology.jpg\n candidate_labels: adenocarcinoma histopathology, squamous cell carcinoma histopathology\n example_title: adenocarcinoma histopathology\n- src: https://upload.wikimedia.org/wikipedia/commons/5/57/Left-sided_Pleural_Effusion.jpg\n candidate_labels: left-sided pleural effusion chest x-ray, right-sided pleural effusion\n chest x-ray, normal chest x-ray\n example_title: left-sided pleural effusion chest x-ray"", ""transformersInfo"": null, ""_id"": ""642dd2c732bdf5af73eda741"", ""modelId"": ""microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""usedStorage"": 5488587845}",0,https://huggingface.co/mgbam/OpenCLIP-BiomedCLIP-Finetuned,1,,0,,0,,0,"Baron-GG/LLAUS, Dobator/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224, Harshdhi/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224, Mustafaege/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224, Rajat456/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224, StefanDenner/MedicalVisualPromptEngineering, charlestonX/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224, huggingface/InferenceSupport/discussions/new?title=microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bmicrosoft%2FBiomedCLIP-PubMedBERT_256-vit_base_patch16_224%5D(%2Fmicrosoft%2FBiomedCLIP-PubMedBERT_256-vit_base_patch16_224)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, mMonika/Medical_bot, mitchmomo/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224, mohammedRiad/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224, pZacca/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224, zenitsu55/microsoft-BiomedCLIP-PubMedBERT_256-vit_base_patch16_224",13
|
| 273 |
+
mgbam/OpenCLIP-BiomedCLIP-Finetuned,"---
|
| 274 |
+
license: mit
|
| 275 |
+
datasets:
|
| 276 |
+
- WinterSchool/MedificsDataset
|
| 277 |
+
language:
|
| 278 |
+
- en
|
| 279 |
+
metrics:
|
| 280 |
+
- accuracy
|
| 281 |
+
base_model:
|
| 282 |
+
- microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224
|
| 283 |
+
tags:
|
| 284 |
+
- medical
|
| 285 |
+
- clip
|
| 286 |
+
- fine-tuned
|
| 287 |
+
- zero-shot
|
| 288 |
+
---
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
This repository contains a fine-tuned version of BiomedCLIP (specifically the PubMedBERT_256-vit_base_patch16_224 variant) using OpenCLIP. The model is trained to recognize and classify various medical images (e.g., chest X-rays, histopathology slides) in a zero-shot manner. It was further adapted on a subset of medical data (e.g., from the WinterSchool/MedificsDataset) to enhance performance on specific image classes.
|
| 293 |
+
|
| 294 |
+
Model Details
|
| 295 |
+
Architecture: Vision Transformer (ViT-B/16) + PubMedBERT-based text encoder, loaded through open_clip.
|
| 296 |
+
Training Objective: CLIP-style contrastive learning to align medical text prompts with images.
|
| 297 |
+
Fine-Tuned On: Selected medical images and text pairs, including X-rays, histopathology images, etc.
|
| 298 |
+
Intended Use:
|
| 299 |
+
Zero-shot classification of medical images (e.g., “This is a photo of a chest X-ray”).
|
| 300 |
+
Exploratory research or educational demos showcasing multi-modal (image-text) alignment in the medical domain.
|
| 301 |
+
Usage
|
| 302 |
+
Below is a minimal Python snippet using OpenCLIP. Adjust the labels and text prompts as needed:
|
| 303 |
+
|
| 304 |
+
python
|
| 305 |
+
Copy
|
| 306 |
+
import torch
|
| 307 |
+
import open_clip
|
| 308 |
+
from PIL import Image
|
| 309 |
+
|
| 310 |
+
# 1) Load the fine-tuned model
|
| 311 |
+
model, preprocess_train, preprocess_val = open_clip.create_model_and_transforms(
|
| 312 |
+
""hf-hub:mgbam/OpenCLIP-BiomedCLIP-Finetuned"",
|
| 313 |
+
pretrained=None
|
| 314 |
+
)
|
| 315 |
+
tokenizer = open_clip.get_tokenizer(""hf-hub:mgbam/OpenCLIP-BiomedCLIP-Finetuned"")
|
| 316 |
+
|
| 317 |
+
device = ""cuda"" if torch.cuda.is_available() else ""cpu""
|
| 318 |
+
model.to(device)
|
| 319 |
+
model.eval()
|
| 320 |
+
|
| 321 |
+
# 2) Example labels
|
| 322 |
+
labels = [
|
| 323 |
+
""chest X-ray"",
|
| 324 |
+
""brain MRI"",
|
| 325 |
+
""bone X-ray"",
|
| 326 |
+
""squamous cell carcinoma histopathology"",
|
| 327 |
+
""adenocarcinoma histopathology"",
|
| 328 |
+
""immunohistochemistry histopathology""
|
| 329 |
+
]
|
| 330 |
+
|
| 331 |
+
# 3) Load and preprocess an image
|
| 332 |
+
image_path = ""path/to/your_image.jpg""
|
| 333 |
+
image = Image.open(image_path).convert(""RGB"")
|
| 334 |
+
image_tensor = preprocess_val(image).unsqueeze(0).to(device)
|
| 335 |
+
|
| 336 |
+
# 4) Create text prompts & tokenize
|
| 337 |
+
text_prompts = [f""This is a photo of a {label}"" for label in labels]
|
| 338 |
+
tokens = tokenizer(text_prompts).to(device)
|
| 339 |
+
|
| 340 |
+
# 5) Forward pass
|
| 341 |
+
with torch.no_grad():
|
| 342 |
+
image_features = model.encode_image(image_tensor)
|
| 343 |
+
text_features = model.encode_text(tokens)
|
| 344 |
+
logit_scale = model.logit_scale.exp()
|
| 345 |
+
logits = (logit_scale * image_features @ text_features.t()).softmax(dim=-1)
|
| 346 |
+
|
| 347 |
+
# 6) Get predictions
|
| 348 |
+
probs = logits[0].cpu().tolist()
|
| 349 |
+
for label, prob in zip(labels, probs):
|
| 350 |
+
print(f""{label}: {prob:.4f}"")
|
| 351 |
+
Example Gradio App
|
| 352 |
+
You can also deploy a simple Gradio demo:
|
| 353 |
+
|
| 354 |
+
python
|
| 355 |
+
Copy
|
| 356 |
+
import gradio as gr
|
| 357 |
+
import torch
|
| 358 |
+
import open_clip
|
| 359 |
+
from PIL import Image
|
| 360 |
+
|
| 361 |
+
model, preprocess_train, preprocess_val = open_clip.create_model_and_transforms(
|
| 362 |
+
""hf-hub:mgbam/OpenCLIP-BiomedCLIP-Finetuned"",
|
| 363 |
+
pretrained=None
|
| 364 |
+
)
|
| 365 |
+
tokenizer = open_clip.get_tokenizer(""hf-hub:your-username/OpenCLIP-BiomedCLIP-Finetuned"")
|
| 366 |
+
device = ""cuda"" if torch.cuda.is_available() else ""cpu""
|
| 367 |
+
model.to(device)
|
| 368 |
+
model.eval()
|
| 369 |
+
|
| 370 |
+
labels = [""chest X-ray"", ""brain MRI"", ""histopathology"", ""etc.""]
|
| 371 |
+
|
| 372 |
+
def classify_image(img):
|
| 373 |
+
if img is None:
|
| 374 |
+
return {}
|
| 375 |
+
image_tensor = preprocess_val(img).unsqueeze(0).to(device)
|
| 376 |
+
prompts = [f""This is a photo of a {label}"" for label in labels]
|
| 377 |
+
tokens = tokenizer(prompts).to(device)
|
| 378 |
+
with torch.no_grad():
|
| 379 |
+
image_feats = model.encode_image(image_tensor)
|
| 380 |
+
text_feats = model.encode_text(tokens)
|
| 381 |
+
logit_scale = model.logit_scale.exp()
|
| 382 |
+
logits = (logit_scale * image_feats @ text_feats.T).softmax(dim=-1)
|
| 383 |
+
probs = logits.squeeze().cpu().numpy().tolist()
|
| 384 |
+
return {label: float(prob) for label, prob in zip(labels, probs)}
|
| 385 |
+
|
| 386 |
+
demo = gr.Interface(fn=classify_image, inputs=gr.Image(type=""pil""), outputs=""label"")
|
| 387 |
+
demo.launch()
|
| 388 |
+
Performance
|
| 389 |
+
Accuracy: Varies based on your specific dataset. This model can effectively classify medical images like chest X-rays or histopathology slides, but performance depends heavily on fine-tuning data coverage.
|
| 390 |
+
Potential Limitations:
|
| 391 |
+
Ultrasound, CT, MRI or other modalities might not be recognized if not included in training data.
|
| 392 |
+
The model may incorrectly label images that fall outside its known categories.
|
| 393 |
+
Limitations & Caveats
|
| 394 |
+
Not a Medical Device: This model is not FDA-approved or clinically validated. It’s intended for research and educational purposes only.
|
| 395 |
+
Data Bias: If the training dataset lacked certain pathologies or modalities, the model may systematically misclassify them.
|
| 396 |
+
Security: This model uses standard PyTorch and open_clip. Be mindful of potential vulnerabilities when loading models or code from untrusted sources.
|
| 397 |
+
Privacy: If you use patient data, comply with local regulations (HIPAA, GDPR, etc.).
|
| 398 |
+
Citation & Acknowledgements
|
| 399 |
+
Base Model: BiomedCLIP by Microsoft
|
| 400 |
+
OpenCLIP: GitHub – open_clip
|
| 401 |
+
Fine-tuning dataset: WinterSchool/MedificsDataset
|
| 402 |
+
If you use this model in your research or demos, please cite the above works accordingly.
|
| 403 |
+
|
| 404 |
+
License
|
| 405 |
+
[Specify your license here—e.g., MIT, Apache 2.0, or a custom license.]
|
| 406 |
+
|
| 407 |
+
Note: Always include disclaimers that this model is not a substitute for professional medical advice and that it may not generalize to all imaging modalities or patient populations.","{""id"": ""mgbam/OpenCLIP-BiomedCLIP-Finetuned"", ""author"": ""mgbam"", ""sha"": ""3287ef8a5d0108482ce7f07716684a836d67c93a"", ""last_modified"": ""2025-03-07 20:07:49+00:00"", ""created_at"": ""2025-03-07 18:13:38+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 126, ""downloads_all_time"": null, ""likes"": 2, ""library_name"": ""open_clip"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""open_clip"", ""medical"", ""clip"", ""fine-tuned"", ""zero-shot"", ""en"", ""dataset:WinterSchool/MedificsDataset"", ""base_model:microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""base_model:finetune:microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224"", ""license:mit"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224\ndatasets:\n- WinterSchool/MedificsDataset\nlanguage:\n- en\nlicense: mit\nmetrics:\n- accuracy\ntags:\n- medical\n- clip\n- fine-tuned\n- zero-shot"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='open_clip_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='open_clip_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config (1).json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-07 20:07:49+00:00"", ""cardData"": ""base_model:\n- microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224\ndatasets:\n- WinterSchool/MedificsDataset\nlanguage:\n- en\nlicense: mit\nmetrics:\n- accuracy\ntags:\n- medical\n- clip\n- fine-tuned\n- zero-shot"", ""transformersInfo"": null, ""_id"": ""67cb3752e446c44e81f8e123"", ""modelId"": ""mgbam/OpenCLIP-BiomedCLIP-Finetuned"", ""usedStorage"": 783765243}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=mgbam/OpenCLIP-BiomedCLIP-Finetuned&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bmgbam%2FOpenCLIP-BiomedCLIP-Finetuned%5D(%2Fmgbam%2FOpenCLIP-BiomedCLIP-Finetuned)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
CLIP-ViT-H-14-laion2B-s32B-b79K_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv
ADDED
|
@@ -0,0 +1,320 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
laion/CLIP-ViT-H-14-laion2B-s32B-b79K,"---
|
| 3 |
+
license: mit
|
| 4 |
+
widget:
|
| 5 |
+
- src: >-
|
| 6 |
+
https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
|
| 7 |
+
candidate_labels: playing music, playing sports
|
| 8 |
+
example_title: Cat & Dog
|
| 9 |
+
library_name: open_clip
|
| 10 |
+
pipeline_tag: zero-shot-image-classification
|
| 11 |
+
---
|
| 12 |
+
# Model Card for CLIP ViT-H/14 - LAION-2B
|
| 13 |
+
|
| 14 |
+
# Table of Contents
|
| 15 |
+
|
| 16 |
+
1. [Model Details](#model-details)
|
| 17 |
+
2. [Uses](#uses)
|
| 18 |
+
3. [Training Details](#training-details)
|
| 19 |
+
4. [Evaluation](#evaluation)
|
| 20 |
+
5. [Acknowledgements](#acknowledgements)
|
| 21 |
+
6. [Citation](#citation)
|
| 22 |
+
7. [How To Get Started With the Model](#how-to-get-started-with-the-model)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# Model Details
|
| 26 |
+
|
| 27 |
+
## Model Description
|
| 28 |
+
|
| 29 |
+
A CLIP ViT-H/14 model trained with the LAION-2B English subset of LAION-5B (https://laion.ai/blog/laion-5b/) using OpenCLIP (https://github.com/mlfoundations/open_clip).
|
| 30 |
+
|
| 31 |
+
Model training done by Romain Beaumont on the [stability.ai](https://stability.ai/) cluster.
|
| 32 |
+
|
| 33 |
+
# Uses
|
| 34 |
+
|
| 35 |
+
As per the original [OpenAI CLIP model card](https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/model-card.md), this model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such model.
|
| 36 |
+
|
| 37 |
+
The OpenAI CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis. Additionally, the LAION-5B blog (https://laion.ai/blog/laion-5b/) and upcoming paper include additional discussion as it relates specifically to the training dataset.
|
| 38 |
+
|
| 39 |
+
## Direct Use
|
| 40 |
+
|
| 41 |
+
Zero-shot image classification, image and text retrieval, among others.
|
| 42 |
+
|
| 43 |
+
## Downstream Use
|
| 44 |
+
|
| 45 |
+
Image classification and other image task fine-tuning, linear probe image classification, image generation guiding and conditioning, among others.
|
| 46 |
+
|
| 47 |
+
## Out-of-Scope Use
|
| 48 |
+
|
| 49 |
+
As per the OpenAI models,
|
| 50 |
+
|
| 51 |
+
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
|
| 52 |
+
|
| 53 |
+
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
|
| 54 |
+
|
| 55 |
+
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
|
| 56 |
+
|
| 57 |
+
Further the above notice, the LAION-5B dataset used in training of these models has additional considerations, see below.
|
| 58 |
+
|
| 59 |
+
# Training Details
|
| 60 |
+
|
| 61 |
+
## Training Data
|
| 62 |
+
|
| 63 |
+
This model was trained with the 2 Billion sample English subset of LAION-5B (https://laion.ai/blog/laion-5b/).
|
| 64 |
+
|
| 65 |
+
**IMPORTANT NOTE:** The motivation behind dataset creation is to democratize research and experimentation around large-scale multi-modal model training and handling of uncurated, large-scale datasets crawled from publically available internet. Our recommendation is therefore to use the dataset for research purposes. Be aware that this large-scale dataset is uncurated. Keep in mind that the uncurated nature of the dataset means that collected links may lead to strongly discomforting and disturbing content for a human viewer. Therefore, please use the demo links with caution and at your own risk. It is possible to extract a “safe” subset by filtering out samples based on the safety tags (using a customized trained NSFW classifier that we built). While this strongly reduces the chance for encountering potentially harmful content when viewing, we cannot entirely exclude the possibility for harmful content being still present in safe mode, so that the warning holds also there. We think that providing the dataset openly to broad research and other interested communities will allow for transparent investigation of benefits that come along with training large-scale models as well as pitfalls and dangers that may stay unreported or unnoticed when working with closed large datasets that remain restricted to a small community. Providing our dataset openly, we however do not recommend using it for creating ready-to-go industrial products, as the basic research about general properties and safety of such large-scale models, which we would like to encourage with this release, is still in progress.
|
| 66 |
+
|
| 67 |
+
## Training Procedure
|
| 68 |
+
|
| 69 |
+
Please see [training notes](https://docs.google.com/document/d/1EFbMLRWSSV0LUf9Du1pWzWqgeiIRPwEWX2s1C6mAk5c) and [wandb logs](https://wandb.ai/rom1504/eval_openclip/reports/H-14--VmlldzoyNDAxODQ3).
|
| 70 |
+
|
| 71 |
+
# Evaluation
|
| 72 |
+
|
| 73 |
+
Evaluation done with code in the [LAION CLIP Benchmark suite](https://github.com/LAION-AI/CLIP_benchmark).
|
| 74 |
+
|
| 75 |
+
## Testing Data, Factors & Metrics
|
| 76 |
+
|
| 77 |
+
### Testing Data
|
| 78 |
+
|
| 79 |
+
The testing is performed with VTAB+ (A combination of VTAB (https://arxiv.org/abs/1910.04867) w/ additional robustness datasets) for classification and COCO and Flickr for retrieval.
|
| 80 |
+
|
| 81 |
+
**TODO** - more detail
|
| 82 |
+
|
| 83 |
+
## Results
|
| 84 |
+
|
| 85 |
+
The model achieves a 78.0 zero-shot top-1 accuracy on ImageNet-1k.
|
| 86 |
+
|
| 87 |
+
An initial round of benchmarks have been performed on a wider range of datasets, currently viewable at https://github.com/LAION-AI/CLIP_benchmark/blob/main/benchmark/results.ipynb
|
| 88 |
+
|
| 89 |
+
**TODO** - create table for just this model's metrics.
|
| 90 |
+
|
| 91 |
+
# Acknowledgements
|
| 92 |
+
|
| 93 |
+
Acknowledging [stability.ai](https://stability.ai/) for the compute used to train this model.
|
| 94 |
+
|
| 95 |
+
# Citation
|
| 96 |
+
|
| 97 |
+
**BibTeX:**
|
| 98 |
+
|
| 99 |
+
LAION-5B
|
| 100 |
+
```bibtex
|
| 101 |
+
@inproceedings{schuhmann2022laionb,
|
| 102 |
+
title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
|
| 103 |
+
author={Christoph Schuhmann and
|
| 104 |
+
Romain Beaumont and
|
| 105 |
+
Richard Vencu and
|
| 106 |
+
Cade W Gordon and
|
| 107 |
+
Ross Wightman and
|
| 108 |
+
Mehdi Cherti and
|
| 109 |
+
Theo Coombes and
|
| 110 |
+
Aarush Katta and
|
| 111 |
+
Clayton Mullis and
|
| 112 |
+
Mitchell Wortsman and
|
| 113 |
+
Patrick Schramowski and
|
| 114 |
+
Srivatsa R Kundurthy and
|
| 115 |
+
Katherine Crowson and
|
| 116 |
+
Ludwig Schmidt and
|
| 117 |
+
Robert Kaczmarczyk and
|
| 118 |
+
Jenia Jitsev},
|
| 119 |
+
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
|
| 120 |
+
year={2022},
|
| 121 |
+
url={https://openreview.net/forum?id=M3Y74vmsMcY}
|
| 122 |
+
}
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
OpenAI CLIP paper
|
| 126 |
+
```
|
| 127 |
+
@inproceedings{Radford2021LearningTV,
|
| 128 |
+
title={Learning Transferable Visual Models From Natural Language Supervision},
|
| 129 |
+
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
|
| 130 |
+
booktitle={ICML},
|
| 131 |
+
year={2021}
|
| 132 |
+
}
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
OpenCLIP software
|
| 136 |
+
```
|
| 137 |
+
@software{ilharco_gabriel_2021_5143773,
|
| 138 |
+
author = {Ilharco, Gabriel and
|
| 139 |
+
Wortsman, Mitchell and
|
| 140 |
+
Wightman, Ross and
|
| 141 |
+
Gordon, Cade and
|
| 142 |
+
Carlini, Nicholas and
|
| 143 |
+
Taori, Rohan and
|
| 144 |
+
Dave, Achal and
|
| 145 |
+
Shankar, Vaishaal and
|
| 146 |
+
Namkoong, Hongseok and
|
| 147 |
+
Miller, John and
|
| 148 |
+
Hajishirzi, Hannaneh and
|
| 149 |
+
Farhadi, Ali and
|
| 150 |
+
Schmidt, Ludwig},
|
| 151 |
+
title = {OpenCLIP},
|
| 152 |
+
month = jul,
|
| 153 |
+
year = 2021,
|
| 154 |
+
note = {If you use this software, please cite it as below.},
|
| 155 |
+
publisher = {Zenodo},
|
| 156 |
+
version = {0.1},
|
| 157 |
+
doi = {10.5281/zenodo.5143773},
|
| 158 |
+
url = {https://doi.org/10.5281/zenodo.5143773}
|
| 159 |
+
}
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
# How to Get Started with the Model
|
| 163 |
+
|
| 164 |
+
Use the code below to get started with the model.
|
| 165 |
+
|
| 166 |
+
** TODO ** - Hugging Face transformers, OpenCLIP, and timm getting started snippets","{""id"": ""laion/CLIP-ViT-H-14-laion2B-s32B-b79K"", ""author"": ""laion"", ""sha"": ""1c2b8495b28150b8a4922ee1c8edee224c284c0c"", ""last_modified"": ""2025-01-22 04:38:44+00:00"", ""created_at"": ""2022-09-14 22:52:28+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1806535, ""downloads_all_time"": null, ""likes"": 368, ""library_name"": ""open_clip"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""open_clip"", ""pytorch"", ""safetensors"", ""clip"", ""zero-shot-image-classification"", ""arxiv:1910.04867"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""zero-shot-image-classification"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""library_name: open_clip\nlicense: mit\npipeline_tag: zero-shot-image-classification\nwidget:\n- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png\n candidate_labels: playing music, playing sports\n example_title: Cat & Dog"", ""widget_data"": [{""src"": ""https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png"", ""candidate_labels"": ""playing music, playing sports"", ""example_title"": ""Cat & Dog""}], ""model_index"": null, ""config"": {""architectures"": [""CLIPModel""], ""model_type"": ""clip"", ""tokenizer_config"": {""unk_token"": {""content"": ""<|endoftext|>"", ""single_word"": false, ""lstrip"": false, ""rstrip"": false, ""normalized"": true, ""__type"": ""AddedToken""}, ""bos_token"": {""content"": ""<|startoftext|>"", ""single_word"": false, ""lstrip"": false, ""rstrip"": false, ""normalized"": true, ""__type"": ""AddedToken""}, ""eos_token"": {""content"": ""<|endoftext|>"", ""single_word"": false, ""lstrip"": false, ""rstrip"": false, ""normalized"": true, ""__type"": ""AddedToken""}, ""pad_token"": ""<|endoftext|>""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='open_clip_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='open_clip_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='open_clip_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""pharmapsychotic/CLIP-Interrogator"", ""yanze/PuLID-FLUX"", ""multimodalart/Ip-Adapter-FaceID"", ""yanze/PuLID"", ""guoyww/AnimateDiff"", ""wangfuyun/AnimateLCM-SVD"", ""wwen1997/Framer"", ""wangfuyun/AnimateLCM"", ""Vchitect/LaVie"", ""fffiloni/ZeST"", ""TIGER-Lab/T2V-Turbo-V2"", ""fffiloni/SVFR-demo"", ""PAIR/StreamingT2V"", ""shikunl/prismer"", ""zheyangqin/VADER"", ""tomg-group-umd/pez-dispenser"", ""Leoxing/PIA"", ""unity/IP-Adapter-Instruct"", ""TianxingWu/FreeInit"", ""fffiloni/AniDoc"", ""tight-inversion/tight-inversion-pulid-demo"", ""fantaxy/flx-pulid"", ""ID-Animator/ID-Animator"", ""HarborYuan/ovsam"", ""fffiloni/svd_keyframe_interpolation"", ""fffiloni/MimicMotion"", ""TencentARC/MotionCtrl"", ""JackAILab/ConsistentID"", ""MeissonFlow/meissonic"", ""VIDraft/Portrait-Animation"", ""Yiyuan/InteractiveVideo"", ""FaceAdapter/FaceAdapter"", ""fffiloni/AnimateDiff-Image-Init"", ""Collov-Labs/Monetico"", ""zideliu/styledrop"", ""hehao13/CameraCtrl-svd"", ""fffiloni/ReNO"", ""LanguageBind/LanguageBind"", ""Deddy/PuLid-FLX-GPU"", ""LXT/OMG_Seg"", ""IP-composer/ip-composer"", ""rerun/Vista"", ""sofianhw/PuLID-FLUX"", ""kfirgold99/Piece-it-Together-Space"", ""HikariDawn/This-and-That"", ""ZENLLC/videodiffusion"", ""kadirnar/ZeST"", ""Caoyunkang/AdaCLIP"", ""guardiancc/dance-monkey"", ""yslan/ObjCtrl-2.5D"", ""Deadmon/Ip-Adapter-FaceID"", ""qiuzhi2046/PuLID-FLUX"", ""hamacojr/SAM-CAT-Seg"", ""hamacojr/CAT-Seg"", ""nowsyn/StyleShot"", ""SunderAli17/ToonMage"", ""JackAILab/ConsistentID-SDXL"", ""xswu/HPSv2"", ""navervision/LinCIR"", ""AIDC-AI/Mei"", ""JoPmt/ConsisID"", ""shilinxu/rap-sam"", ""mattmdjaga/Preference_Scorer-Pickscore"", ""qiuzhi2046/PuLID"", ""SunderAli17/ToonMagev2"", ""rp-yu/apiprompting"", ""furonghuang-lab/Erasing-Invisible-Demo"", ""Xuweiyi/UniCtrl"", ""nuwandaa/StyleShot"", ""rphrp1985/PuLID-FLUX"", ""zongzhuofan/EasyRef"", ""VIDraft/tight-inversion-pulid-demo"", ""Fr33d0m21/Remodel_Dreamer"", ""jbilcke-hf/ai-tube-model-lavie"", ""hideosnes/Zero-Shot-Material-Transfer"", ""CrazyEric/AnimateLCM-SVD"", ""xinxiaoxin/MimicMotion"", ""yasserrmd/InspireBake"", ""PiperMy/PuLID-FLUX"", ""cangcz/AnchorCrafter"", ""jsscclr/CLIP-Interrogator"", ""kbora/minerva-generate-docker"", ""Kikastrophe/CLIP-Interrogator1"", ""yxbob/h94-IP-Adapter-FaceID"", ""biaggi/CLIP-Interrogator"", ""jbilcke-hf/ai-tube-model-animatelcm"", ""jbilcke-hf/ai-tube-model-pulid"", ""Shad0ws/PuLID"", ""jbilcke-hf/ai-tube-model-als-1"", ""keyishen/clipdemo"", ""SIGMitch/ModelMan"", ""seawolf2357/facefix"", ""Dragunflie-420/MimicMotion"", ""thecosmicdoctor/unboxai_publicVideo"", ""kevinppaulo/PuLID"", ""TobDeBer/PuLID-V5"", ""TobDeBer/PuLID-dream8"", ""Towl/Ip-Adapter-FaceID4"", ""sunlin449/CLIPer"", ""svjack/AniDoc""], ""safetensors"": {""parameters"": {""I64"": 334, ""F32"": 986109440}, ""total"": 986109774}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-01-22 04:38:44+00:00"", ""cardData"": ""library_name: open_clip\nlicense: mit\npipeline_tag: zero-shot-image-classification\nwidget:\n- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png\n candidate_labels: playing music, playing sports\n example_title: Cat & Dog"", ""transformersInfo"": null, ""_id"": ""63225b2c2c2436c310fcf157"", ""modelId"": ""laion/CLIP-ViT-H-14-laion2B-s32B-b79K"", ""usedStorage"": 16706800297}",0,"https://huggingface.co/Jialuo21/SciScore, https://huggingface.co/aimagelab/ReT-OpenCLIP-ViT-H-14",2,,0,,0,,0,"TIGER-Lab/T2V-Turbo-V2, Vchitect/LaVie, fantaxy/flx-pulid, fffiloni/svd_keyframe_interpolation, huggingface/InferenceSupport/discussions/new?title=laion/CLIP-ViT-H-14-laion2B-s32B-b79K&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Blaion%2FCLIP-ViT-H-14-laion2B-s32B-b79K%5D(%2Flaion%2FCLIP-ViT-H-14-laion2B-s32B-b79K)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, multimodalart/Ip-Adapter-FaceID, pharmapsychotic/CLIP-Interrogator, tight-inversion/tight-inversion-pulid-demo, unity/IP-Adapter-Instruct, wwen1997/Framer, yanze/PuLID, yanze/PuLID-FLUX, zheyangqin/VADER",13
|
| 167 |
+
Jialuo21/SciScore,"---
|
| 168 |
+
library_name: transformers
|
| 169 |
+
license: apache-2.0
|
| 170 |
+
datasets:
|
| 171 |
+
- Jialuo21/Science-T2I-Trainset
|
| 172 |
+
base_model:
|
| 173 |
+
- laion/CLIP-ViT-H-14-laion2B-s32B-b79K
|
| 174 |
+
---
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
<img src=""teaser.png"" align=""center"">
|
| 178 |
+
|
| 179 |
+
# SciScore
|
| 180 |
+
SciScore is finetuned on the base model [CLIP-H](https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K) using [Science-T2I](https://huggingface.co/datasets/Jialuo21/Science-T2I-Trainset) dataset. It takes an implicit prompt and a generated image as input and outputs a score that represents the scientific alignment between them.
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
## Resources
|
| 184 |
+
- [Website](https://jialuo-li.github.io/Science-T2I-Web/)
|
| 185 |
+
- [arXiv: Paper](https://arxiv.org/abs/2504.13129)
|
| 186 |
+
- [GitHub: Code](https://github.com/Jialuo-Li/Science-T2I)
|
| 187 |
+
- [Huggingface: Science-T2I-S&C Benchmark](https://huggingface.co/collections/Jialuo21/science-t2i-67d3bfe43253da2bc7cfaf06)
|
| 188 |
+
- [Huggingface: Science-T2I Trainset](https://huggingface.co/datasets/Jialuo21/Science-T2I-Trainset)
|
| 189 |
+
|
| 190 |
+
## Feature
|
| 191 |
+
<img src=""exp.png"" align=""center"">
|
| 192 |
+
|
| 193 |
+
## Qick Start
|
| 194 |
+
```
|
| 195 |
+
from transformers import AutoProcessor, AutoModel
|
| 196 |
+
from PIL import Image
|
| 197 |
+
import torch
|
| 198 |
+
|
| 199 |
+
device = ""cuda""
|
| 200 |
+
processor_name_or_path = ""Jialuo21/SciScore""
|
| 201 |
+
model_pretrained_name_or_path = ""Jialuo21/SciScore""
|
| 202 |
+
|
| 203 |
+
processor = AutoProcessor.from_pretrained(processor_name_or_path)
|
| 204 |
+
model = AutoModel.from_pretrained(model_pretrained_name_or_path).eval().to(device)
|
| 205 |
+
|
| 206 |
+
def calc_probs(prompt, images):
|
| 207 |
+
|
| 208 |
+
image_inputs = processor(
|
| 209 |
+
images=images,
|
| 210 |
+
padding=True,
|
| 211 |
+
truncation=True,
|
| 212 |
+
max_length=77,
|
| 213 |
+
return_tensors=""pt"",
|
| 214 |
+
).to(device)
|
| 215 |
+
|
| 216 |
+
text_inputs = processor(
|
| 217 |
+
text=prompt,
|
| 218 |
+
padding=True,
|
| 219 |
+
truncation=True,
|
| 220 |
+
max_length=77,
|
| 221 |
+
return_tensors=""pt"",
|
| 222 |
+
).to(device)
|
| 223 |
+
|
| 224 |
+
with torch.no_grad():
|
| 225 |
+
image_embs = model.get_image_features(**image_inputs)
|
| 226 |
+
image_embs = image_embs / torch.norm(image_embs, dim=-1, keepdim=True)
|
| 227 |
+
|
| 228 |
+
text_embs = model.get_text_features(**text_inputs)
|
| 229 |
+
text_embs = text_embs / torch.norm(text_embs, dim=-1, keepdim=True)
|
| 230 |
+
|
| 231 |
+
scores = model.logit_scale.exp() * (text_embs @ image_embs.T)[0]
|
| 232 |
+
probs = torch.softmax(scores, dim=-1)
|
| 233 |
+
return probs.cpu().tolist()
|
| 234 |
+
|
| 235 |
+
pil_images = [Image.open(""./examples/camera_1.png""), Image.open(""./examples/camera_2.png"")]
|
| 236 |
+
prompt = ""A camera screen without electricity sits beside the window, realistic.""
|
| 237 |
+
print(calc_probs(prompt, pil_images))
|
| 238 |
+
```
|
| 239 |
+
|
| 240 |
+
## Citation
|
| 241 |
+
|
| 242 |
+
```
|
| 243 |
+
@misc{li2025sciencet2iaddressingscientificillusions,
|
| 244 |
+
title={Science-T2I: Addressing Scientific Illusions in Image Synthesis},
|
| 245 |
+
author={Jialuo Li and Wenhao Chai and Xingyu Fu and Haiyang Xu and Saining Xie},
|
| 246 |
+
year={2025},
|
| 247 |
+
eprint={2504.13129},
|
| 248 |
+
archivePrefix={arXiv},
|
| 249 |
+
primaryClass={cs.CV},
|
| 250 |
+
url={https://arxiv.org/abs/2504.13129},
|
| 251 |
+
}
|
| 252 |
+
```","{""id"": ""Jialuo21/SciScore"", ""author"": ""Jialuo21"", ""sha"": ""df2e0acc94ac8f1070998db29535f26efa7999d4"", ""last_modified"": ""2025-04-18 03:55:37+00:00"", ""created_at"": ""2025-03-17 06:47:30+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 2134, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""clip"", ""zero-shot-image-classification"", ""dataset:Jialuo21/Science-T2I-Trainset"", ""arxiv:2504.13129"", ""base_model:laion/CLIP-ViT-H-14-laion2B-s32B-b79K"", ""base_model:finetune:laion/CLIP-ViT-H-14-laion2B-s32B-b79K"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""zero-shot-image-classification"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- laion/CLIP-ViT-H-14-laion2B-s32B-b79K\ndatasets:\n- Jialuo21/Science-T2I-Trainset\nlibrary_name: transformers\nlicense: apache-2.0"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""CLIPModel""], ""model_type"": ""clip"", ""tokenizer_config"": {""bos_token"": ""<|startoftext|>"", ""eos_token"": ""<|endoftext|>"", ""pad_token"": ""<|endoftext|>"", ""unk_token"": ""<|endoftext|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForZeroShotImageClassification"", ""custom_class"": null, ""pipeline_tag"": ""zero-shot-image-classification"", ""processor"": ""AutoProcessor""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='exp.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='teaser.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F32"": 986109440}, ""total"": 986109440}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-18 03:55:37+00:00"", ""cardData"": ""base_model:\n- laion/CLIP-ViT-H-14-laion2B-s32B-b79K\ndatasets:\n- Jialuo21/Science-T2I-Trainset\nlibrary_name: transformers\nlicense: apache-2.0"", ""transformersInfo"": {""auto_model"": ""AutoModelForZeroShotImageClassification"", ""custom_class"": null, ""pipeline_tag"": ""zero-shot-image-classification"", ""processor"": ""AutoProcessor""}, ""_id"": ""67d7c5821fa67ddee3f50b9a"", ""modelId"": ""Jialuo21/SciScore"", ""usedStorage"": 3966738359}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Jialuo21/SciScore&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BJialuo21%2FSciScore%5D(%2FJialuo21%2FSciScore)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 253 |
+
aimagelab/ReT-OpenCLIP-ViT-H-14,"---
|
| 254 |
+
library_name: transformers
|
| 255 |
+
license: apache-2.0
|
| 256 |
+
base_model:
|
| 257 |
+
- laion/CLIP-ViT-H-14-laion2B-s32B-b79K
|
| 258 |
+
datasets:
|
| 259 |
+
- aimagelab/ReT-M2KR
|
| 260 |
+
pipeline_tag: visual-document-retrieval
|
| 261 |
+
---
|
| 262 |
+
|
| 263 |
+
# Model Card for Model ID
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
ReT is a novel approach for multimodal document retrieval that supports both multimodal queries and documents. Unlike existing methods that only use features from the final layer of vision-and-language backbones, ReT employs a Transformer-based recurrent cell to leverage multi-level representations from different layers of both visual and textual backbones. The model features sigmoidal gates inspired by LSTM design that selectively control information flow between layers and modalities. ReT processes multimodal queries and documents independently, producing sets of latent tokens used for fine-grained late interaction similarity computation. ReT is designed to process images and text in both queries and documents. To this end, it has been trained and evaluated on a custom version of the challenging [M2KR](https://arxiv.org/abs/2402.08327) benchmark, with the following modifications: MSMARCO has been excluded as it does not contain images, and the documents from OVEN, InfoSeek, E-VQA, and OKVQA have been enriched with the addition of images.
|
| 267 |
+
|
| 268 |
+
### Model Sources
|
| 269 |
+
|
| 270 |
+
<!-- Provide the basic links for the model. -->
|
| 271 |
+
|
| 272 |
+
- **Repository:** https://github.com/aimagelab/ReT
|
| 273 |
+
- **Paper:** [Recurrence-Enhanced Vision-and-Language Transformers for Robust Multimodal Document Retrieval](https://www.arxiv.org/abs/2503.01980) (CVPR 2025)
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
### Use with Transformers
|
| 277 |
+
Follow the instructions on the [repository](https://github.com/aimagelab/ReT) to install the required environment.
|
| 278 |
+
```python
|
| 279 |
+
from src.models import RetrieverModel, RetModel
|
| 280 |
+
import torch
|
| 281 |
+
|
| 282 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 283 |
+
retriever = RetrieverModel.from_pretrained('aimagelab/ReT-OpenCLIP-ViT-H-14', device_map=device)
|
| 284 |
+
|
| 285 |
+
# QUERY
|
| 286 |
+
ret: RetModel = retriever.get_query_model()
|
| 287 |
+
ret.init_tokenizer_and_image_processor()
|
| 288 |
+
q_txt = ""Retrieve documents that provide an answer to the question alongside the image: What is the content of the image?""
|
| 289 |
+
q_img = 'assets/model.png'
|
| 290 |
+
|
| 291 |
+
ret_feats = ret.get_ret_features([[q_txt, q_img]])
|
| 292 |
+
print(ret_feats.shape) # torch.Size([1, 32, 128])
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
# PASSAGE
|
| 296 |
+
ret: RetModel = retriever.get_passage_model()
|
| 297 |
+
ret.init_tokenizer_and_image_processor()
|
| 298 |
+
|
| 299 |
+
p_txt = """"""The image shows a diagram of what appears to be a neural network architecture using a fine-grained loss approach for multimodal learning.
|
| 300 |
+
The architecture has two parallel processing streams labeled ""ReTQ"" (left side, in purple) and ""ReTD"" (right side, in blue).
|
| 301 |
+
Each side has: ...""""""
|
| 302 |
+
p_img = ''
|
| 303 |
+
|
| 304 |
+
ret_feats = ret.get_ret_features([[p_txt, p_img]])
|
| 305 |
+
print(ret_feats.shape) # torch.Size([1, 32, 128])
|
| 306 |
+
```
|
| 307 |
+
|
| 308 |
+
## Citation
|
| 309 |
+
|
| 310 |
+
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 311 |
+
|
| 312 |
+
**BibTeX:**
|
| 313 |
+
```
|
| 314 |
+
@inproceedings{caffagni2025recurrence,
|
| 315 |
+
title={{Recurrence-Enhanced Vision-and-Language Transformers for Robust Multimodal Document Retrieval}},
|
| 316 |
+
author={Caffagni, Davide and Sarto, Sara and Cornia, Marcella and Baraldi, Lorenzo and Cucchiara, Rita},
|
| 317 |
+
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
| 318 |
+
year={2025}
|
| 319 |
+
}
|
| 320 |
+
```","{""id"": ""aimagelab/ReT-OpenCLIP-ViT-H-14"", ""author"": ""aimagelab"", ""sha"": ""bb728bf12ba921923a89566539b615ebbdbc4e53"", ""last_modified"": ""2025-04-08 13:30:08+00:00"", ""created_at"": ""2025-03-25 11:36:32+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 25, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""retriever"", ""visual-document-retrieval"", ""dataset:aimagelab/ReT-M2KR"", ""arxiv:2402.08327"", ""arxiv:2503.01980"", ""base_model:laion/CLIP-ViT-H-14-laion2B-s32B-b79K"", ""base_model:finetune:laion/CLIP-ViT-H-14-laion2B-s32B-b79K"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""visual-document-retrieval"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- laion/CLIP-ViT-H-14-laion2B-s32B-b79K\ndatasets:\n- aimagelab/ReT-M2KR\nlibrary_name: transformers\nlicense: apache-2.0\npipeline_tag: visual-document-retrieval"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""RetrieverModel""], ""model_type"": ""retriever""}, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F32"": 1091194368}, ""total"": 1091194368}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-08 13:30:08+00:00"", ""cardData"": ""base_model:\n- laion/CLIP-ViT-H-14-laion2B-s32B-b79K\ndatasets:\n- aimagelab/ReT-M2KR\nlibrary_name: transformers\nlicense: apache-2.0\npipeline_tag: visual-document-retrieval"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""67e2954097bfd7bb77cfec75"", ""modelId"": ""aimagelab/ReT-OpenCLIP-ViT-H-14"", ""usedStorage"": 4364929128}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=aimagelab/ReT-OpenCLIP-ViT-H-14&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Baimagelab%2FReT-OpenCLIP-ViT-H-14%5D(%2Faimagelab%2FReT-OpenCLIP-ViT-H-14)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
CodeLlama-34b-Instruct-hf_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
codellama/CodeLlama-34b-Instruct-hf,"---
|
| 3 |
+
language:
|
| 4 |
+
- code
|
| 5 |
+
pipeline_tag: text-generation
|
| 6 |
+
tags:
|
| 7 |
+
- llama-2
|
| 8 |
+
license: llama2
|
| 9 |
+
---
|
| 10 |
+
# **Code Llama**
|
| 11 |
+
Code Llama is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 34 billion parameters. This is the repository for the 34B instruct-tuned version in the Hugging Face Transformers format. This model is designed for general code synthesis and understanding. Links to other models can be found in the index at the bottom.
|
| 12 |
+
|
| 13 |
+
> [!NOTE]
|
| 14 |
+
> This is a non-official Code Llama repo. You can find the official Meta repository in the [Meta Llama organization](https://huggingface.co/meta-llama/CodeLlama-34b-Instruct-hf).
|
| 15 |
+
|
| 16 |
+
| | Base Model | Python | Instruct |
|
| 17 |
+
| --- | ----------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------- |
|
| 18 |
+
| 7B | [codellama/CodeLlama-7b-hf](https://huggingface.co/codellama/CodeLlama-7b-hf) | [codellama/CodeLlama-7b-Python-hf](https://huggingface.co/codellama/CodeLlama-7b-Python-hf) | [codellama/CodeLlama-7b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-7b-Instruct-hf) |
|
| 19 |
+
| 13B | [codellama/CodeLlama-13b-hf](https://huggingface.co/codellama/CodeLlama-13b-hf) | [codellama/CodeLlama-13b-Python-hf](https://huggingface.co/codellama/CodeLlama-13b-Python-hf) | [codellama/CodeLlama-13b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-13b-Instruct-hf) |
|
| 20 |
+
| 34B | [codellama/CodeLlama-34b-hf](https://huggingface.co/codellama/CodeLlama-34b-hf) | [codellama/CodeLlama-34b-Python-hf](https://huggingface.co/codellama/CodeLlama-34b-Python-hf) | [codellama/CodeLlama-34b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-34b-Instruct-hf) |
|
| 21 |
+
| 70B | [codellama/CodeLlama-70b-hf](https://huggingface.co/codellama/CodeLlama-70b-hf) | [codellama/CodeLlama-70b-Python-hf](https://huggingface.co/codellama/CodeLlama-70b-Python-hf) | [codellama/CodeLlama-70b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-70b-Instruct-hf) |
|
| 22 |
+
|
| 23 |
+
## Model Use
|
| 24 |
+
|
| 25 |
+
To use this model, please make sure to install transformers:
|
| 26 |
+
|
| 27 |
+
```bash
|
| 28 |
+
pip install transformers accelerate
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
Model capabilities:
|
| 32 |
+
|
| 33 |
+
- [x] Code completion.
|
| 34 |
+
- [ ] Infilling.
|
| 35 |
+
- [x] Instructions / chat.
|
| 36 |
+
- [ ] Python specialist.
|
| 37 |
+
|
| 38 |
+
## Model Details
|
| 39 |
+
*Note: Use of this model is governed by the Meta license. Meta developed and publicly released the Code Llama family of large language models (LLMs).
|
| 40 |
+
|
| 41 |
+
**Model Developers** Meta
|
| 42 |
+
|
| 43 |
+
**Variations** Code Llama comes in three model sizes, and three variants:
|
| 44 |
+
|
| 45 |
+
* Code Llama: base models designed for general code synthesis and understanding
|
| 46 |
+
* Code Llama - Python: designed specifically for Python
|
| 47 |
+
* Code Llama - Instruct: for instruction following and safer deployment
|
| 48 |
+
|
| 49 |
+
All variants are available in sizes of 7B, 13B and 34B parameters.
|
| 50 |
+
|
| 51 |
+
**This repository contains the Instruct version of the 34B parameters model.**
|
| 52 |
+
|
| 53 |
+
**Input** Models input text only.
|
| 54 |
+
|
| 55 |
+
**Output** Models generate text only.
|
| 56 |
+
|
| 57 |
+
**Model Architecture** Code Llama is an auto-regressive language model that uses an optimized transformer architecture.
|
| 58 |
+
|
| 59 |
+
**Model Dates** Code Llama and its variants have been trained between January 2023 and July 2023.
|
| 60 |
+
|
| 61 |
+
**Status** This is a static model trained on an offline dataset. Future versions of Code Llama - Instruct will be released as we improve model safety with community feedback.
|
| 62 |
+
|
| 63 |
+
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
|
| 64 |
+
|
| 65 |
+
**Research Paper** More information can be found in the paper ""[Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)"" or its [arXiv page](https://arxiv.org/abs/2308.12950).
|
| 66 |
+
|
| 67 |
+
## Intended Use
|
| 68 |
+
**Intended Use Cases** Code Llama and its variants is intended for commercial and research use in English and relevant programming languages. The base model Code Llama can be adapted for a variety of code synthesis and understanding tasks, Code Llama - Python is designed specifically to handle the Python programming language, and Code Llama - Instruct is intended to be safer to use for code assistant and generation applications.
|
| 69 |
+
|
| 70 |
+
**Out-of-Scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Code Llama and its variants.
|
| 71 |
+
|
| 72 |
+
## Hardware and Software
|
| 73 |
+
**Training Factors** We used custom training libraries. The training and fine-tuning of the released models have been performed Meta’s Research Super Cluster.
|
| 74 |
+
|
| 75 |
+
**Carbon Footprint** In aggregate, training all 9 Code Llama models required 400K GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 65.3 tCO2eq, 100% of which were offset by Meta’s sustainability program.
|
| 76 |
+
|
| 77 |
+
## Training Data
|
| 78 |
+
|
| 79 |
+
All experiments reported here and the released models have been trained and fine-tuned using the same data as Llama 2 with different weights (see Section 2 and Table 1 in the [research paper](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) for details).
|
| 80 |
+
|
| 81 |
+
## Evaluation Results
|
| 82 |
+
|
| 83 |
+
See evaluations for the main models and detailed ablations in Section 3 and safety evaluations in Section 4 of the research paper.
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
## Ethical Considerations and Limitations
|
| 87 |
+
|
| 88 |
+
Code Llama and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Code Llama’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of Code Llama, developers should perform safety testing and tuning tailored to their specific applications of the model.
|
| 89 |
+
|
| 90 |
+
Please see the Responsible Use Guide available available at [https://ai.meta.com/llama/responsible-use-guide](https://ai.meta.com/llama/responsible-use-guide).","{""id"": ""codellama/CodeLlama-34b-Instruct-hf"", ""author"": ""codellama"", ""sha"": ""d4c1c474abcacd32d2a6eda45f9811d38c83e93d"", ""last_modified"": ""2024-04-12 14:20:11+00:00"", ""created_at"": ""2023-08-24 16:58:22+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 19463, ""downloads_all_time"": null, ""likes"": 286, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""safetensors"", ""llama"", ""text-generation"", ""llama-2"", ""conversational"", ""code"", ""arxiv:2308.12950"", ""license:llama2"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- code\nlicense: llama2\npipeline_tag: text-generation\ntags:\n- llama-2"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""chat_template"": ""{% if messages[0]['role'] == 'system' %}{% set loop_messages = messages[1:] %}{% set system_message = messages[0]['content'] %}{% else %}{% set loop_messages = messages %}{% set system_message = false %}{% endif %}{% for message in loop_messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if loop.index0 == 0 and system_message != false %}{% set content = '<<SYS>>\\n' + system_message + '\\n<</SYS>>\\n\\n' + message['content'] %}{% else %}{% set content = message['content'] %}{% endif %}{% if message['role'] == 'user' %}{{ bos_token + '[INST] ' + content | trim + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ ' ' + content | trim + ' ' + eos_token }}{% endif %}{% endfor %}"", ""bos_token"": {""__type"": ""AddedToken"", ""content"": ""<s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""eos_token"": {""__type"": ""AddedToken"", ""content"": ""</s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""pad_token"": null, ""unk_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00004-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00005-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00006-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00007-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""bigcode/bigcode-models-leaderboard"", ""Intel/low_bit_open_llm_leaderboard"", ""BAAI/open_cn_llm_leaderboard"", ""qiantong-xu/toolbench-leaderboard"", ""gsaivinay/open_llm_leaderboard"", ""EvanTHU/MotionLLM"", ""KBaba7/Quant"", ""meval/multilingual-chatbot-arena-leaderboard"", ""GTBench/GTBench"", ""Vikhrmodels/small-shlepa-lb"", ""ibm/risk-atlas-nexus"", ""prometheus-eval/BiGGen-Bench-Leaderboard"", ""shangdatalab-ucsd/LDB"", ""NiansuhAI/Main"", ""kz-transformers/kaz-llm-lb"", ""krystian-lieber/codellama-34b-chat"", ""joshuasundance/langchain-streamlit-demo"", ""ruslanmv/hf-llm-api"", ""futranbg/falcon-180b-demo"", ""felixz/open_llm_leaderboard"", ""Ivan000/Voice-Assistant"", ""bhaskartripathi/LLM_Quantization"", ""HemaAM/GPT_train_on_LLaMa"", ""21world/bigcode-models-leaderboard"", ""OPTML-Group/UnlearnCanvas-Benchmark"", ""Ivan000/Web-page-generator"", ""luigi12345/AutoInterpreter"", ""Canstralian/Transformers-Fine-Tuner"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""anantgupta129/LitGPT-Pythia-160M"", ""Polyhronis/codellama-CodeLlama-34b-Instruct-hf"", ""bardsai/performance-llm-board"", ""BAAI/open_flageval_vlm_leaderboard"", ""neubla/neubla-llm-evaluation-board"", ""ashhadahsan/summarizer-space"", ""PrarthanaTS/tsai-gpt-from-scratch"", ""MadhurGarg/TSAIGPTRedPajama"", ""marvingabler/codellama-34b-chat"", ""RaviNaik/ERA-SESSION22"", ""awacke1/PythonicCoder-CodeLlama-34B-Instruct-HF"", ""Contentwise/langchain-streamlit-demo"", ""rodrigomasini/data_only_open_llm_leaderboard"", ""Docfile/open_llm_leaderboard"", ""MAsad789565/llm-api"", ""Sijuade/GPTNEXTWORD"", ""RAHMAN00700/rahmans_watsonx"", ""ruslanmv/convert_to_gguf"", ""RAHMAN00700/Chat-with-Multiple-Documents-Using-Streamlit-and-Watsonx"", ""sanbo1200/Main1"", ""Canstralian/codellama-CodeLlama-34b-Instruct-hf"", ""piyushgrover/MiniGPT_S22"", ""supra-e-acc/Pythia-160M-text-generate"", ""venkyyuvy/GPT_redpajama"", ""mkthoma/GPT_From_Scratch"", ""VarunSivamani/GPT-From-Scratch"", ""sanjanatule/GPTNext"", ""TSYLV32/codellama-CodeLlama-34b-Instruct-hf"", ""Sambhavnoobcoder/falcon-180b-demo"", ""alexkueck/TestInferenceAPI"", ""RashiAgarwal/TSAIGPTRedPajama"", ""neuralorbs/DialogGen"", ""GunaKoppula/ERA-Session-22"", ""Navyabhat/ERAV1-Session-22"", ""Vaish2705/ERA_S22"", ""LilithIvey/codellama-CodeLlama-34b-Instruct-hf"", ""Thebull/Abrazo"", ""smothiki/open_llm_leaderboard"", ""pnavin/codellama-CodeLlama-34b-Instruct-hf"", ""UltraMarkoBR/codellama-CodeLlama-34b-Instruct-hf"", ""Rgeczi/codellama-CodeLlama-34b-Instruct-hf"", ""nononno/hj"", ""HiccupAstrid/codellama-CodeLlama-34b-Instruct-hf"", ""dagmawi101/codellama-CodeLlama-34b-Instruct-hf"", ""GuilleAzcona/DoctorAI"", ""huanhoahongso3/free-webui-gpt4"", ""xh0o6/g4f0204"", ""xh0o6/hj"", ""Youssef19999/codellama-CodeLlama-34b-Instruct-hf"", ""August-xu/codellama-CodeLlama-34b-Instruct-hf"", ""acecalisto3/ai-app-factory"", ""0x1668/open_llm_leaderboard"", ""gprabhuv4me/codellama-CodeLlama-34b-Instruct-hf"", ""pngwn/open_llm_leaderboard-check"", ""jordonpeter01/ai-app-factory-p"", ""EsoCode/hf-llm-api"", ""asir0z/open_llm_leaderboard"", ""Lurluberlu/chat"", ""jyotsnaa/code-assistant"", ""kbmlcoding/open_llm_leaderboard_free"", ""Transcrib3D/Transcrib3D-Demo"", ""Ashrafb/AICLL2"", ""varunsrichin/codellama-CodeLlama-34b-Instruct-hf"", ""asdvd01/codellama-CodeLlama-34b-Instruct-hf"", ""morriswch/langchain-streamlit-demo"", ""jyotsnaa/CodeWise"", ""stellarshank/FormGen-codellama-34b"", ""ToletiSri/TSAI_S22"", ""Pro100Sata/xche_ai"", ""dbasu/multilingual-chatbot-arena-leaderboard""], ""safetensors"": {""parameters"": {""BF16"": 33743970304}, ""total"": 33743970304}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-04-12 14:20:11+00:00"", ""cardData"": ""language:\n- code\nlicense: llama2\npipeline_tag: text-generation\ntags:\n- llama-2"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""64e78c2edbec2317e6b4d05b"", ""modelId"": ""codellama/CodeLlama-34b-Instruct-hf"", ""usedStorage"": 135238724250}",0,"https://huggingface.co/arvnoodle/hcl-codellama-instruct-34b-javascript-lotuscript, https://huggingface.co/seanmemery/CodeLlama-34b-Instruct-Shader-hf",2,"https://huggingface.co/Faradaylab/ARIA-CODE, https://huggingface.co/ricecake/Codellama-Pygmalion-LoRA-Test, https://huggingface.co/ashwincv0112/code-llama-34b-instruction-finetune2, https://huggingface.co/NikitaZagainov/notebook-generation-codellama-34b-2ep",4,"https://huggingface.co/mlc-ai/CodeLlama-34b-Instruct-hf-q4f16_1-MLC, https://huggingface.co/mlc-ai/CodeLlama-34b-Instruct-hf-q4f32_1-MLC, https://huggingface.co/MaziyarPanahi/CodeLlama-34b-Instruct-hf-GGUF, https://huggingface.co/cmarkea/CodeLlama-34b-Instruct-hf-4bit, https://huggingface.co/mradermacher/CodeLlama-34b-Instruct-hf-GGUF, https://huggingface.co/mradermacher/CodeLlama-34b-Instruct-hf-i1-GGUF",6,https://huggingface.co/okeanos/uptimeai-8273,1,"BAAI/open_cn_llm_leaderboard, EvanTHU/MotionLLM, GTBench/GTBench, Intel/low_bit_open_llm_leaderboard, KBaba7/Quant, NiansuhAI/Main, bigcode/bigcode-models-leaderboard, huggingface/InferenceSupport/discussions/new?title=codellama/CodeLlama-34b-Instruct-hf&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bcodellama%2FCodeLlama-34b-Instruct-hf%5D(%2Fcodellama%2FCodeLlama-34b-Instruct-hf)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, ibm/risk-atlas-nexus, meval/multilingual-chatbot-arena-leaderboard, prometheus-eval/BiGGen-Bench-Leaderboard, qiantong-xu/toolbench-leaderboard, shangdatalab-ucsd/LDB",13
|
| 91 |
+
arvnoodle/hcl-codellama-instruct-34b-javascript-lotuscript,"---
|
| 92 |
+
language:
|
| 93 |
+
- en
|
| 94 |
+
license: apache-2.0
|
| 95 |
+
tags:
|
| 96 |
+
- text-generation-inference
|
| 97 |
+
- transformers
|
| 98 |
+
- unsloth
|
| 99 |
+
- llama
|
| 100 |
+
- trl
|
| 101 |
+
base_model: codellama/CodeLlama-34b-Instruct-hf
|
| 102 |
+
---
|
| 103 |
+
|
| 104 |
+
# Uploaded model
|
| 105 |
+
|
| 106 |
+
- **Developed by:** arvnoodle
|
| 107 |
+
- **License:** apache-2.0
|
| 108 |
+
- **Finetuned from model :** codellama/CodeLlama-34b-Instruct-hf
|
| 109 |
+
|
| 110 |
+
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
|
| 111 |
+
|
| 112 |
+
[<img src=""https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png"" width=""200""/>](https://github.com/unslothai/unsloth)
|
| 113 |
+
","{""id"": ""arvnoodle/hcl-codellama-instruct-34b-javascript-lotuscript"", ""author"": ""arvnoodle"", ""sha"": ""9bd03c464e4ab0f44ecb60110feec0e96a589762"", ""last_modified"": ""2024-03-21 12:12:49+00:00"", ""created_at"": ""2024-03-21 12:12:37+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""text-generation-inference"", ""unsloth"", ""llama"", ""trl"", ""en"", ""base_model:codellama/CodeLlama-34b-Instruct-hf"", ""base_model:finetune:codellama/CodeLlama-34b-Instruct-hf"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: codellama/CodeLlama-34b-Instruct-hf\nlanguage:\n- en\nlicense: apache-2.0\ntags:\n- text-generation-inference\n- transformers\n- unsloth\n- llama\n- trl"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-03-21 12:12:49+00:00"", ""cardData"": ""base_model: codellama/CodeLlama-34b-Instruct-hf\nlanguage:\n- en\nlicense: apache-2.0\ntags:\n- text-generation-inference\n- transformers\n- unsloth\n- llama\n- trl"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""65fc2435bd57c920d7b2086d"", ""modelId"": ""arvnoodle/hcl-codellama-instruct-34b-javascript-lotuscript"", ""usedStorage"": 435774040}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=arvnoodle/hcl-codellama-instruct-34b-javascript-lotuscript&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Barvnoodle%2Fhcl-codellama-instruct-34b-javascript-lotuscript%5D(%2Farvnoodle%2Fhcl-codellama-instruct-34b-javascript-lotuscript)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 114 |
+
seanmemery/CodeLlama-34b-Instruct-Shader-hf,"---
|
| 115 |
+
license: llama2
|
| 116 |
+
base_model: codellama/CodeLlama-34b-Instruct-hf
|
| 117 |
+
tags:
|
| 118 |
+
- trl
|
| 119 |
+
- sft
|
| 120 |
+
- unsloth
|
| 121 |
+
- generated_from_trainer
|
| 122 |
+
datasets:
|
| 123 |
+
- generator
|
| 124 |
+
model-index:
|
| 125 |
+
- name: CodeLlama-34b-Instruct-Shader-hf
|
| 126 |
+
results: []
|
| 127 |
+
---
|
| 128 |
+
|
| 129 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 130 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 131 |
+
|
| 132 |
+
# CodeLlama-34b-Instruct-Shader-hf
|
| 133 |
+
|
| 134 |
+
This model is a fine-tuned version of [codellama/CodeLlama-34b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-34b-Instruct-hf) on the generator dataset.
|
| 135 |
+
It achieves the following results on the evaluation set:
|
| 136 |
+
- Loss: 0.7792
|
| 137 |
+
|
| 138 |
+
## Model description
|
| 139 |
+
|
| 140 |
+
More information needed
|
| 141 |
+
|
| 142 |
+
## Intended uses & limitations
|
| 143 |
+
|
| 144 |
+
More information needed
|
| 145 |
+
|
| 146 |
+
## Training and evaluation data
|
| 147 |
+
|
| 148 |
+
More information needed
|
| 149 |
+
|
| 150 |
+
## Training procedure
|
| 151 |
+
|
| 152 |
+
### Training hyperparameters
|
| 153 |
+
|
| 154 |
+
The following hyperparameters were used during training:
|
| 155 |
+
- learning_rate: 0.0025
|
| 156 |
+
- train_batch_size: 4
|
| 157 |
+
- eval_batch_size: 1
|
| 158 |
+
- seed: 42
|
| 159 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 160 |
+
- lr_scheduler_type: polynomial
|
| 161 |
+
- num_epochs: 2
|
| 162 |
+
|
| 163 |
+
### Training results
|
| 164 |
+
|
| 165 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 166 |
+
|:-------------:|:-----:|:----:|:---------------:|
|
| 167 |
+
| 1.3476 | 0.25 | 1000 | 1.3561 |
|
| 168 |
+
| 1.3274 | 0.49 | 2000 | 1.1683 |
|
| 169 |
+
| 1.1964 | 0.74 | 3000 | 1.0129 |
|
| 170 |
+
| 0.8117 | 0.98 | 4000 | 0.9106 |
|
| 171 |
+
| 0.5179 | 1.23 | 5000 | 0.8560 |
|
| 172 |
+
| 0.7726 | 1.48 | 6000 | 0.8096 |
|
| 173 |
+
| 0.7396 | 1.72 | 7000 | 0.7855 |
|
| 174 |
+
| 0.6125 | 1.97 | 8000 | 0.7792 |
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
### Framework versions
|
| 178 |
+
|
| 179 |
+
- Transformers 4.38.2
|
| 180 |
+
- Pytorch 2.2.1
|
| 181 |
+
- Datasets 2.18.0
|
| 182 |
+
- Tokenizers 0.15.2
|
| 183 |
+
","{""id"": ""seanmemery/CodeLlama-34b-Instruct-Shader-hf"", ""author"": ""seanmemery"", ""sha"": ""fda5802903fd7f44690c1a3f3663bf4d16cb152d"", ""last_modified"": ""2024-03-26 18:27:25+00:00"", ""created_at"": ""2024-03-26 09:26:16+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 9, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""trl"", ""sft"", ""unsloth"", ""generated_from_trainer"", ""conversational"", ""dataset:generator"", ""base_model:codellama/CodeLlama-34b-Instruct-hf"", ""base_model:finetune:codellama/CodeLlama-34b-Instruct-hf"", ""license:llama2"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: codellama/CodeLlama-34b-Instruct-hf\ndatasets:\n- generator\nlicense: llama2\ntags:\n- trl\n- sft\n- unsloth\n- generated_from_trainer\nmodel-index:\n- name: CodeLlama-34b-Instruct-Shader-hf\n results: []"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": [{""name"": ""CodeLlama-34b-Instruct-Shader-hf"", ""results"": []}], ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""chat_template"": ""{% if messages[0]['role'] == 'system' %}{% set loop_messages = messages[1:] %}{% set system_message = messages[0]['content'] %}{% else %}{% set loop_messages = messages %}{% set system_message = false %}{% endif %}{% for message in loop_messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if loop.index0 == 0 and system_message != false %}{% set content = '<<SYS>>\\n' + system_message + '\\n<</SYS>>\\n\\n' + message['content'] %}{% else %}{% set content = message['content'] %}{% endif %}{% if message['role'] == 'user' %}{{ bos_token + '[INST] ' + content | trim + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ ' ' + content | trim + ' ' + eos_token }}{% endif %}{% endfor %}"", ""eos_token"": ""</s>"", ""pad_token"": ""<unk>"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00009-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00010-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00011-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00012-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00013-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00014-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""BF16"": 33743970304}, ""total"": 33743970304}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-03-26 18:27:25+00:00"", ""cardData"": ""base_model: codellama/CodeLlama-34b-Instruct-hf\ndatasets:\n- generator\nlicense: llama2\ntags:\n- trl\n- sft\n- unsloth\n- generated_from_trainer\nmodel-index:\n- name: CodeLlama-34b-Instruct-Shader-hf\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""660294b8083db47c56dd23d3"", ""modelId"": ""seanmemery/CodeLlama-34b-Instruct-Shader-hf"", ""usedStorage"": 67488496299}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=seanmemery/CodeLlama-34b-Instruct-Shader-hf&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bseanmemery%2FCodeLlama-34b-Instruct-Shader-hf%5D(%2Fseanmemery%2FCodeLlama-34b-Instruct-Shader-hf)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
CodeLlama-34b-hf_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,540 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
codellama/CodeLlama-34b-hf,"---
|
| 3 |
+
language:
|
| 4 |
+
- code
|
| 5 |
+
pipeline_tag: text-generation
|
| 6 |
+
tags:
|
| 7 |
+
- llama-2
|
| 8 |
+
license: llama2
|
| 9 |
+
---
|
| 10 |
+
# **Code Llama**
|
| 11 |
+
Code Llama is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 34 billion parameters. This is the repository for the base 34B version in the Hugging Face Transformers format. This model is designed for general code synthesis and understanding. Links to other models can be found in the index at the bottom.
|
| 12 |
+
|
| 13 |
+
> [!NOTE]
|
| 14 |
+
> This is a non-official Code Llama repo. You can find the official Meta repository in the [Meta Llama organization](https://huggingface.co/meta-llama/CodeLlama-34b-hf).
|
| 15 |
+
|
| 16 |
+
| | Base Model | Python | Instruct |
|
| 17 |
+
| --- | ----------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------- |
|
| 18 |
+
| 7B | [codellama/CodeLlama-7b-hf](https://huggingface.co/codellama/CodeLlama-7b-hf) | [codellama/CodeLlama-7b-Python-hf](https://huggingface.co/codellama/CodeLlama-7b-Python-hf) | [codellama/CodeLlama-7b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-7b-Instruct-hf) |
|
| 19 |
+
| 13B | [codellama/CodeLlama-13b-hf](https://huggingface.co/codellama/CodeLlama-13b-hf) | [codellama/CodeLlama-13b-Python-hf](https://huggingface.co/codellama/CodeLlama-13b-Python-hf) | [codellama/CodeLlama-13b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-13b-Instruct-hf) |
|
| 20 |
+
| 34B | [codellama/CodeLlama-34b-hf](https://huggingface.co/codellama/CodeLlama-34b-hf) | [codellama/CodeLlama-34b-Python-hf](https://huggingface.co/codellama/CodeLlama-34b-Python-hf) | [codellama/CodeLlama-34b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-34b-Instruct-hf) |
|
| 21 |
+
| 70B | [codellama/CodeLlama-70b-hf](https://huggingface.co/codellama/CodeLlama-70b-hf) | [codellama/CodeLlama-70b-Python-hf](https://huggingface.co/codellama/CodeLlama-70b-Python-hf) | [codellama/CodeLlama-70b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-70b-Instruct-hf) |
|
| 22 |
+
|
| 23 |
+
## Model Use
|
| 24 |
+
|
| 25 |
+
To use this model, please make sure to install transformers:
|
| 26 |
+
|
| 27 |
+
```bash
|
| 28 |
+
pip install transformers.git accelerate
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
Model capabilities:
|
| 32 |
+
|
| 33 |
+
- [x] Code completion.
|
| 34 |
+
- [ ] Infilling.
|
| 35 |
+
- [ ] Instructions / chat.
|
| 36 |
+
- [ ] Python specialist.
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
```python
|
| 40 |
+
from transformers import AutoTokenizer
|
| 41 |
+
import transformers
|
| 42 |
+
import torch
|
| 43 |
+
|
| 44 |
+
model = ""codellama/CodeLlama-34b-hf""
|
| 45 |
+
|
| 46 |
+
tokenizer = AutoTokenizer.from_pretrained(model)
|
| 47 |
+
pipeline = transformers.pipeline(
|
| 48 |
+
""text-generation"",
|
| 49 |
+
model=model,
|
| 50 |
+
torch_dtype=torch.float16,
|
| 51 |
+
device_map=""auto"",
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
sequences = pipeline(
|
| 55 |
+
'import socket\n\ndef ping_exponential_backoff(host: str):',
|
| 56 |
+
do_sample=True,
|
| 57 |
+
top_k=10,
|
| 58 |
+
temperature=0.1,
|
| 59 |
+
top_p=0.95,
|
| 60 |
+
num_return_sequences=1,
|
| 61 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 62 |
+
max_length=200,
|
| 63 |
+
)
|
| 64 |
+
for seq in sequences:
|
| 65 |
+
print(f""Result: {seq['generated_text']}"")
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
## Model Details
|
| 70 |
+
*Note: Use of this model is governed by the Meta license. Meta developed and publicly released the Code Llama family of large language models (LLMs).
|
| 71 |
+
|
| 72 |
+
**Model Developers** Meta
|
| 73 |
+
|
| 74 |
+
**Variations** Code Llama comes in three model sizes, and three variants:
|
| 75 |
+
|
| 76 |
+
* Code Llama: base models designed for general code synthesis and understanding
|
| 77 |
+
* Code Llama - Python: designed specifically for Python
|
| 78 |
+
* Code Llama - Instruct: for instruction following and safer deployment
|
| 79 |
+
|
| 80 |
+
All variants are available in sizes of 7B, 13B and 34B parameters.
|
| 81 |
+
|
| 82 |
+
**This repository contains the base version of the 34B parameters model.**
|
| 83 |
+
|
| 84 |
+
**Input** Models input text only.
|
| 85 |
+
|
| 86 |
+
**Output** Models generate text only.
|
| 87 |
+
|
| 88 |
+
**Model Architecture** Code Llama is an auto-regressive language model that uses an optimized transformer architecture.
|
| 89 |
+
|
| 90 |
+
**Model Dates** Code Llama and its variants have been trained between January 2023 and July 2023.
|
| 91 |
+
|
| 92 |
+
**Status** This is a static model trained on an offline dataset. Future versions of Code Llama - Instruct will be released as we improve model safety with community feedback.
|
| 93 |
+
|
| 94 |
+
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
|
| 95 |
+
|
| 96 |
+
**Research Paper** More information can be found in the paper ""[Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)"" or its [arXiv page](https://arxiv.org/abs/2308.12950).
|
| 97 |
+
|
| 98 |
+
## Intended Use
|
| 99 |
+
**Intended Use Cases** Code Llama and its variants is intended for commercial and research use in English and relevant programming languages. The base model Code Llama can be adapted for a variety of code synthesis and understanding tasks, Code Llama - Python is designed specifically to handle the Python programming language, and Code Llama - Instruct is intended to be safer to use for code assistant and generation applications.
|
| 100 |
+
|
| 101 |
+
**Out-of-Scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Code Llama and its variants.
|
| 102 |
+
|
| 103 |
+
## Hardware and Software
|
| 104 |
+
**Training Factors** We used custom training libraries. The training and fine-tuning of the released models have been performed Meta’s Research Super Cluster.
|
| 105 |
+
|
| 106 |
+
**Carbon Footprint** In aggregate, training all 9 Code Llama models required 400K GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 65.3 tCO2eq, 100% of which were offset by Meta’s sustainability program.
|
| 107 |
+
|
| 108 |
+
## Training Data
|
| 109 |
+
|
| 110 |
+
All experiments reported here and the released models have been trained and fine-tuned using the same data as Llama 2 with different weights (see Section 2 and Table 1 in the [research paper](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) for details).
|
| 111 |
+
|
| 112 |
+
## Evaluation Results
|
| 113 |
+
|
| 114 |
+
See evaluations for the main models and detailed ablations in Section 3 and safety evaluations in Section 4 of the research paper.
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
## Ethical Considerations and Limitations
|
| 118 |
+
|
| 119 |
+
Code Llama and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Code Llama’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of Code Llama, developers should perform safety testing and tuning tailored to their specific applications of the model.
|
| 120 |
+
|
| 121 |
+
Please see the Responsible Use Guide available available at [https://ai.meta.com/llama/responsible-use-guide](https://ai.meta.com/llama/responsible-use-guide).","{""id"": ""codellama/CodeLlama-34b-hf"", ""author"": ""codellama"", ""sha"": ""6008b9656730b71c7d19a15370c7ff6d2902f4ef"", ""last_modified"": ""2024-04-12 14:16:52+00:00"", ""created_at"": ""2023-08-24 16:34:39+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 12296, ""downloads_all_time"": null, ""likes"": 169, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""safetensors"", ""llama"", ""text-generation"", ""llama-2"", ""code"", ""arxiv:2308.12950"", ""license:llama2"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- code\nlicense: llama2\npipeline_tag: text-generation\ntags:\n- llama-2"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": {""__type"": ""AddedToken"", ""content"": ""<s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""eos_token"": {""__type"": ""AddedToken"", ""content"": ""</s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""pad_token"": null, ""unk_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='USE_POLICY.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00004-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00005-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00006-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00007-of-00007.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""bigcode/bigcode-models-leaderboard"", ""Vokturz/can-it-run-llm"", ""Intel/low_bit_open_llm_leaderboard"", ""BAAI/open_cn_llm_leaderboard"", ""qiantong-xu/toolbench-leaderboard"", ""gsaivinay/open_llm_leaderboard"", ""EvanTHU/MotionLLM"", ""KBaba7/Quant"", ""GTBench/GTBench"", ""Vikhrmodels/small-shlepa-lb"", ""prometheus-eval/BiGGen-Bench-Leaderboard"", ""kz-transformers/kaz-llm-lb"", ""navdeeps002/codellama-CodeLlama-34b-hf"", ""felixz/open_llm_leaderboard"", ""awacke1/Deepseek-HPC-GPU-KEDA"", ""bhaskartripathi/LLM_Quantization"", ""HemaAM/GPT_train_on_LLaMa"", ""21world/bigcode-models-leaderboard"", ""OPTML-Group/UnlearnCanvas-Benchmark"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""anantgupta129/LitGPT-Pythia-160M"", ""li-qing/FIRE"", ""BAAI/open_flageval_vlm_leaderboard"", ""neubla/neubla-llm-evaluation-board"", ""lambdabrendan/Lambda-LLM-Calculator"", ""PrarthanaTS/tsai-gpt-from-scratch"", ""MadhurGarg/TSAIGPTRedPajama"", ""kasunx64/codellama-CodeLlama-34b-hf"", ""tianleliphoebe/visual-arena"", ""RaviNaik/ERA-SESSION22"", ""rodrigomasini/data_only_open_llm_leaderboard"", ""Docfile/open_llm_leaderboard"", ""imjunaidafzal/can-it-run-llm"", ""Ashmal/MobiLlama"", ""Sijuade/GPTNEXTWORD"", ""ruslanmv/convert_to_gguf"", ""piyushgrover/MiniGPT_S22"", ""supra-e-acc/Pythia-160M-text-generate"", ""venkyyuvy/GPT_redpajama"", ""mkthoma/GPT_From_Scratch"", ""VarunSivamani/GPT-From-Scratch"", ""sanjanatule/GPTNext"", ""RashiAgarwal/TSAIGPTRedPajama"", ""neuralorbs/DialogGen"", ""GunaKoppula/ERA-Session-22"", ""Navyabhat/ERAV1-Session-22"", ""Vaish2705/ERA_S22"", ""xuchao860407/codellama-CodeLlama-34b-hf"", ""smothiki/open_llm_leaderboard"", ""eyoubli/codellama-CodeLlama-34b-hf"", ""sooft/codellama-CodeLlama-34b-hf"", ""Starboy001/codellama-CodeLlama-34b-hf"", ""kejunz/codellama-CodeLlama-34b-hf"", ""okeanos/can-it-run-llm"", ""shreefhamed/codellama-CodeLlama-34b-hf"", ""Ashrafb/Ccll2"", ""0x1668/open_llm_leaderboard"", ""minghao-520/codellama-CodeLlama-34b-hf"", ""pngwn/open_llm_leaderboard-check"", ""AhmedMagdy7/can-it-run-llm"", ""asir0z/open_llm_leaderboard"", ""aiconaca/codellama-CodeLlama-34b-hf"", ""Nymbo/can-it-run-llm"", ""muellerzr/can-it-run-llm"", ""kbmlcoding/open_llm_leaderboard_free"", ""Kartik2503/cost-estimator"", ""ashbuilds/codellama-CodeLlama-34b-hf"", ""ToletiSri/TSAI_S22"", ""dotscreen/codellama-CodeLlama-34b-hf"", ""aichampions/open_llm_leaderboard"", ""Adeco/open_llm_leaderboard"", ""Bofeee5675/FIRE"", ""RobinsAIWorld/can-it-run-llm"", ""evelyn-lo/evelyn"", ""yuantao-infini-ai/demo_test"", ""anirudh937/open_llm_leaderboard"", ""smothiki/open_llm_leaderboard2"", ""zjasper666/bf16_vs_fp8"", ""martinakaduc/melt"", ""mjalg/IFEvalTR"", ""lastsamuraii/LitGPT-Pythia-160M"", ""atlasas/bigcode-models-leaderboard"", ""mpvasilis/can-it-run-llm"", ""arjunyadav01/OMNIGEN-AI"", ""K00B404/LLM_Quantization"", ""rastof9/codellama"", ""alter1/nova-llm-orchestrator""], ""safetensors"": {""parameters"": {""BF16"": 33743970304}, ""total"": 33743970304}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-04-12 14:16:52+00:00"", ""cardData"": ""language:\n- code\nlicense: llama2\npipeline_tag: text-generation\ntags:\n- llama-2"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""64e7869fb159a6f87be2188e"", ""modelId"": ""codellama/CodeLlama-34b-hf"", ""usedStorage"": 135238724250}",0,"https://huggingface.co/Yaxin1992/codellama-13b-multi-3500, https://huggingface.co/allenai/codetulu-2-34b, https://huggingface.co/facebook/layerskip-codellama-34B",3,https://huggingface.co/Deadwalker0/maverick-34b-qlora,1,"https://huggingface.co/TheBloke/CodeLlama-34B-GGUF, https://huggingface.co/TheBloke/CodeLlama-34B-GPTQ, https://huggingface.co/TheBloke/CodeLlama-34B-AWQ, https://huggingface.co/mlc-ai/CodeLlama-34b-hf-q4f16_1-MLC, https://huggingface.co/mlc-ai/CodeLlama-34b-hf-q4f32_1-MLC, https://huggingface.co/MaziyarPanahi/CodeLlama-34b-hf-GGUF, https://huggingface.co/mradermacher/CodeLlama-34b-hf-GGUF, https://huggingface.co/mradermacher/CodeLlama-34b-hf-i1-GGUF, https://huggingface.co/Devy1/CodeLlama-34b-hf-AQLM-2bit-mixed-1x15, https://huggingface.co/Devy1/CodeLlama-34b-hf-AQLM-2bit-mixed-finetuned-1x15",10,,0,"BAAI/open_cn_llm_leaderboard, EvanTHU/MotionLLM, GTBench/GTBench, HemaAM/GPT_train_on_LLaMa, Intel/low_bit_open_llm_leaderboard, KBaba7/Quant, Vokturz/can-it-run-llm, awacke1/Deepseek-HPC-GPU-KEDA, bhaskartripathi/LLM_Quantization, bigcode/bigcode-models-leaderboard, huggingface/InferenceSupport/discussions/new?title=codellama/CodeLlama-34b-hf&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bcodellama%2FCodeLlama-34b-hf%5D(%2Fcodellama%2FCodeLlama-34b-hf)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, prometheus-eval/BiGGen-Bench-Leaderboard, qiantong-xu/toolbench-leaderboard",13
|
| 122 |
+
Yaxin1992/codellama-13b-multi-3500,"---
|
| 123 |
+
license: llama2
|
| 124 |
+
base_model: codellama/CodeLlama-34b-hf
|
| 125 |
+
tags:
|
| 126 |
+
- generated_from_trainer
|
| 127 |
+
model-index:
|
| 128 |
+
- name: codellama-13b-multi-3500
|
| 129 |
+
results: []
|
| 130 |
+
---
|
| 131 |
+
|
| 132 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 133 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 134 |
+
|
| 135 |
+
# codellama-13b-multi-3500
|
| 136 |
+
|
| 137 |
+
This model is a fine-tuned version of [codellama/CodeLlama-34b-hf](https://huggingface.co/codellama/CodeLlama-34b-hf) on an unknown dataset.
|
| 138 |
+
|
| 139 |
+
## Model description
|
| 140 |
+
|
| 141 |
+
More information needed
|
| 142 |
+
|
| 143 |
+
## Intended uses & limitations
|
| 144 |
+
|
| 145 |
+
More information needed
|
| 146 |
+
|
| 147 |
+
## Training and evaluation data
|
| 148 |
+
|
| 149 |
+
More information needed
|
| 150 |
+
|
| 151 |
+
## Training procedure
|
| 152 |
+
|
| 153 |
+
### Training hyperparameters
|
| 154 |
+
|
| 155 |
+
The following hyperparameters were used during training:
|
| 156 |
+
- learning_rate: 0.0002
|
| 157 |
+
- train_batch_size: 1
|
| 158 |
+
- eval_batch_size: 8
|
| 159 |
+
- seed: 42
|
| 160 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 161 |
+
- lr_scheduler_type: linear
|
| 162 |
+
- training_steps: 3000
|
| 163 |
+
|
| 164 |
+
### Training results
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
### Framework versions
|
| 169 |
+
|
| 170 |
+
- Transformers 4.33.0.dev0
|
| 171 |
+
- Pytorch 2.0.1+cu118
|
| 172 |
+
- Datasets 2.14.4
|
| 173 |
+
- Tokenizers 0.13.3
|
| 174 |
+
","{""id"": ""Yaxin1992/codellama-13b-multi-3500"", ""author"": ""Yaxin1992"", ""sha"": ""54533fab4d6dded62ed574cc739780fef9362a79"", ""last_modified"": ""2023-09-01 21:28:14+00:00"", ""created_at"": ""2023-08-31 18:01:45+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""generated_from_trainer"", ""base_model:codellama/CodeLlama-34b-hf"", ""base_model:finetune:codellama/CodeLlama-34b-hf"", ""license:llama2"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: codellama/CodeLlama-34b-hf\nlicense: llama2\ntags:\n- generated_from_trainer\nmodel-index:\n- name: codellama-13b-multi-3500\n results: []"", ""widget_data"": null, ""model_index"": [{""name"": ""codellama-13b-multi-3500"", ""results"": []}], ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-09-01 21:28:14+00:00"", ""cardData"": ""base_model: codellama/CodeLlama-34b-hf\nlicense: llama2\ntags:\n- generated_from_trainer\nmodel-index:\n- name: codellama-13b-multi-3500\n results: []"", ""transformersInfo"": null, ""_id"": ""64f0d589ef8663ad1713e47e"", ""modelId"": ""Yaxin1992/codellama-13b-multi-3500"", ""usedStorage"": 39394952}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Yaxin1992/codellama-13b-multi-3500&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BYaxin1992%2Fcodellama-13b-multi-3500%5D(%2FYaxin1992%2Fcodellama-13b-multi-3500)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 175 |
+
allenai/codetulu-2-34b,N/A,N/A,1,,0,,0,,0,,0,"huggingface/InferenceSupport/discussions/new?title=allenai/codetulu-2-34b&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Ballenai%2Fcodetulu-2-34b%5D(%2Fallenai%2Fcodetulu-2-34b)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, prometheus-eval/BiGGen-Bench-Leaderboard",2
|
| 176 |
+
facebook/layerskip-codellama-34B,"---
|
| 177 |
+
extra_gated_heading: You need to share contact information with Meta to access this model
|
| 178 |
+
extra_gated_prompt: >-
|
| 179 |
+
## FAIR Noncommercial Research License
|
| 180 |
+
|
| 181 |
+
Last Updated: [October 16th 2024]
|
| 182 |
+
|
| 183 |
+
“Acceptable Use Policy” means the FAIR Acceptable Use Policy, applicable to Research Materials, that is incorporated into this Agreement.
|
| 184 |
+
|
| 185 |
+
“Agreement” means the terms and conditions for use, reproduction, distribution and modification of the Research Materials set forth herein.
|
| 186 |
+
|
| 187 |
+
“Documentation” means the specifications, manuals and documentation accompanying Research Materials distributed by Meta.
|
| 188 |
+
|
| 189 |
+
“Licensee” or “you” means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.
|
| 190 |
+
|
| 191 |
+
“Meta” or “we” means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).
|
| 192 |
+
|
| 193 |
+
“Noncommercial Research Uses” means noncommercial research use cases related to research, development, education, processing, or analysis and in each case, is not primarily intended for commercial advantage or monetary compensation to you or others.
|
| 194 |
+
|
| 195 |
+
“Research Materials” means, collectively, Documentation and the models, software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code, demonstration materials and other elements of the foregoing distributed by Meta and made available under this Agreement.
|
| 196 |
+
|
| 197 |
+
By clicking “I Accept” below or by using or distributing any portion or element of the Research Materials, you agree to be bound by this Agreement.
|
| 198 |
+
|
| 199 |
+
1. License Rights and Redistribution.
|
| 200 |
+
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Research Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Research Materials.
|
| 201 |
+
b. Redistribution and Use.
|
| 202 |
+
i. You will not use the Research Materials or any outputs or results of the Research Materials in connection with any commercial uses or for any uses other than Noncommercial Research Uses;
|
| 203 |
+
ii. Distribution of Research Materials, and any derivative works thereof, are subject to the terms of this Agreement. If you distribute or make the Research Materials, or any derivative works thereof, available to a third party, you may only do so under the terms of this Agreement. You shall also provide a copy of this Agreement to such third party.
|
| 204 |
+
iii. If you submit for publication the results of research you perform on, using, or otherwise in connection with Research Materials, you must acknowledge the use of Research Materials in your publication.
|
| 205 |
+
iv. Your use of the Research Materials must comply with applicable laws and regulations (including Trade Control Laws) and adhere to the FAIR Acceptable Use Policy, which is hereby incorporated by reference into this Agreement.
|
| 206 |
+
|
| 207 |
+
2. User Support. Your Noncommercial Research Use of the Research Materials is done at your own discretion; Meta does not process any information nor provide any service in relation to such use. Meta is under no obligation to provide any support services for the Research Materials. Any support provided is “as is”, “with all faults”, and without warranty of any kind.
|
| 208 |
+
|
| 209 |
+
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE RESEARCH MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE RESEARCH MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE RESEARCH MATERIALS AND ANY OUTPUT AND RESULTS.
|
| 210 |
+
|
| 211 |
+
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY DIRECT OR INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
|
| 212 |
+
|
| 213 |
+
5. Intellectual Property.
|
| 214 |
+
a. Subject to Meta’s ownership of Research Materials and derivatives made by or for Meta, with respect to any derivative works and modifications of the Research Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.
|
| 215 |
+
b. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Research Materials, outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Research Materials.
|
| 216 |
+
|
| 217 |
+
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Research Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Research Materials. Sections 5, 6 and 9 shall survive the termination of this Agreement.
|
| 218 |
+
|
| 219 |
+
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.
|
| 220 |
+
|
| 221 |
+
8. Modifications and Amendments. Meta may modify this Agreement from time to time by posting a revised version at https://huggingface.co/facebook/layerskip-codellama-34B/blob/main/LICENSE; provided that they are similar in spirit to the current version of the Agreement, but may differ in detail to address new problems or concerns. All such changes will be effective immediately. Your continued use of the Research Materials after any modification to this Agreement constitutes your agreement to such modification. Except as provided in this Agreement, no modification or addition to any provision of this Agreement will be binding unless it is in writing and signed by an authorized representative of both you and Meta.
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
FAIR Acceptable Use Policy
|
| 225 |
+
|
| 226 |
+
The Fundamental AI Research (FAIR) team at Meta seeks to further understanding of new and existing research domains with the mission of advancing the state-of-the-art in artificial intelligence through open research for the benefit of all.
|
| 227 |
+
|
| 228 |
+
As part of this mission, Meta makes certain research materials available for noncommercial research use. Meta is committed to promoting the safe and responsible use of such research materials.
|
| 229 |
+
|
| 230 |
+
Prohibited Uses
|
| 231 |
+
|
| 232 |
+
You agree you will not use, or allow others to use, Research Materials to:
|
| 233 |
+
|
| 234 |
+
1.Violate the law or others’ rights, including to:
|
| 235 |
+
a. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
|
| 236 |
+
i. Violence or terrorism
|
| 237 |
+
ii. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
|
| 238 |
+
iii. Human trafficking, exploitation, and sexual violence
|
| 239 |
+
iv. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
|
| 240 |
+
v. Sexual solicitation
|
| 241 |
+
vi. Any other criminal activity
|
| 242 |
+
b. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
|
| 243 |
+
c. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
|
| 244 |
+
d. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
|
| 245 |
+
e. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
|
| 246 |
+
f. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any technology using FAIR research materials
|
| 247 |
+
g. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
|
| 248 |
+
|
| 249 |
+
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of research artifacts related to the following:
|
| 250 |
+
a. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
|
| 251 |
+
b. Guns and illegal weapons (including weapon development)
|
| 252 |
+
c. Illegal drugs and regulated/controlled substances
|
| 253 |
+
d. Operation of critical infrastructure, transportation technologies, or heavy machinery
|
| 254 |
+
e. Self-harm or harm to others, including suicide, cutting, and eating disorders
|
| 255 |
+
f. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
|
| 256 |
+
|
| 257 |
+
3. Intentionally deceive or mislead others, including use of FAIR Research Materials related to the following:
|
| 258 |
+
a. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
|
| 259 |
+
b. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
|
| 260 |
+
c. Generating, promoting, or further distributing spam
|
| 261 |
+
d. Impersonating another individual without consent, authorization, or legal right
|
| 262 |
+
e. Representing that outputs of FAIR research materials or outputs from technology using FAIR research materials o are human-generated
|
| 263 |
+
f. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
|
| 264 |
+
|
| 265 |
+
4. Fail to appropriately disclose to end users any known dangers of your Research Materials.
|
| 266 |
+
|
| 267 |
+
Please report any violation of this Policy or other problems that could lead to a violation of this Policy by submitting a report [here](https://docs.google.com/forms/d/e/1FAIpQLSeb11cryAopJ7LNrC4nxEUXrHY26hfkXQMf_uH-oFgA3WlYZQ/viewform).
|
| 268 |
+
|
| 269 |
+
extra_gated_fields:
|
| 270 |
+
First Name: text
|
| 271 |
+
Last Name: text
|
| 272 |
+
Date of birth: date_picker
|
| 273 |
+
Country: country
|
| 274 |
+
Affiliation: text
|
| 275 |
+
geo: ip_location
|
| 276 |
+
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
|
| 277 |
+
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
|
| 278 |
+
extra_gated_button_content: Submit
|
| 279 |
+
language:
|
| 280 |
+
- en
|
| 281 |
+
library_name: transformers
|
| 282 |
+
pipeline_tag: text-generation
|
| 283 |
+
tags:
|
| 284 |
+
- facebook
|
| 285 |
+
- meta
|
| 286 |
+
- pytorch
|
| 287 |
+
- llama
|
| 288 |
+
- llama-2
|
| 289 |
+
- code
|
| 290 |
+
model-index:
|
| 291 |
+
- name: LayerSkip Code Llama 34B
|
| 292 |
+
results:
|
| 293 |
+
- task:
|
| 294 |
+
type: text-generation
|
| 295 |
+
dataset:
|
| 296 |
+
type: openai_humaneval
|
| 297 |
+
name: HumanEval
|
| 298 |
+
metrics:
|
| 299 |
+
- name: pass@1
|
| 300 |
+
type: pass@1
|
| 301 |
+
value: 0.470
|
| 302 |
+
verified: false
|
| 303 |
+
- task:
|
| 304 |
+
type: text-generation
|
| 305 |
+
dataset:
|
| 306 |
+
type: mbpp
|
| 307 |
+
name: MBPP
|
| 308 |
+
metrics:
|
| 309 |
+
- name: pass@1
|
| 310 |
+
type: pass@1
|
| 311 |
+
value: 0.474
|
| 312 |
+
verified: false
|
| 313 |
+
license: other
|
| 314 |
+
license_name: fair
|
| 315 |
+
license_link: LICENSE
|
| 316 |
+
base_model: codellama/CodeLlama-34b-hf
|
| 317 |
+
---
|
| 318 |
+
|
| 319 |
+
# LayerSkip Code Llama 34B
|
| 320 |
+
|
| 321 |
+
Code Llama 34B model continually pretrained with LayerSkip as presented in [Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding
|
| 322 |
+
](https://arxiv.org/abs/2404.16710) and is capable of performing self-speculative decoding: decode with earlier layers and verify with remaining layers.
|
| 323 |
+
|
| 324 |
+
## How to Use
|
| 325 |
+
|
| 326 |
+
We are providing 3 ways to run the model
|
| 327 |
+
|
| 328 |
+
- [HuggingFace](#huggingface)
|
| 329 |
+
- [LayerSkip Codebase](#layerskip-codebase)
|
| 330 |
+
- [gpt-fast](#gpt-fast)
|
| 331 |
+
|
| 332 |
+
### HuggingFace<a name=""huggingface""></a>
|
| 333 |
+
|
| 334 |
+
HuggingFace does not yet have self-speculative decoding support. However, we can re-use it's speculative decoding feature by creating a draft model using a subset of the layers of the main model:
|
| 335 |
+
|
| 336 |
+
```python
|
| 337 |
+
>>> import torch
|
| 338 |
+
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 339 |
+
>>> from copy import deepcopy
|
| 340 |
+
|
| 341 |
+
>>> checkpoint = ""facebook/layerskip-codellama-34B""
|
| 342 |
+
>>> early_exit = 4
|
| 343 |
+
>>> device = ""cuda"" if torch.cuda.is_available() else ""cpu""
|
| 344 |
+
>>> prompt = ""typing import List\ndef bucket_sort(A: List):""
|
| 345 |
+
|
| 346 |
+
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map=""auto"", use_safetensors=True, torch_dtype=torch.float16)
|
| 347 |
+
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
| 348 |
+
|
| 349 |
+
>>> generation_config = model.generation_config
|
| 350 |
+
|
| 351 |
+
>>> weights_memo = {id(w): w for w in model.parameters()}
|
| 352 |
+
>>> assistant_model = deepcopy(model, memo=weights_memo) # Clone main model with shared weights
|
| 353 |
+
>>> assistant_model.model.layers = assistant_model.model.layers[:early_exit] # Apply early exit
|
| 354 |
+
>>> del assistant_model.model.layers[early_exit:]
|
| 355 |
+
|
| 356 |
+
>>> inputs = tokenizer(prompt, return_tensors=""pt"").to(device)
|
| 357 |
+
|
| 358 |
+
>>> outputs = model.generate(**inputs, generation_config=generation_config, assistant_model=assistant_model, max_new_tokens=512)
|
| 359 |
+
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
|
| 360 |
+
```
|
| 361 |
+
|
| 362 |
+
Please note that this is not an optimal implementation as it requires more memory to save KV cache and activations of duplicated layers. The optimized implementation that re-uses earlier layers is in our [custom implementation](#layerskip-codebase) or in our [gpt-fast implementation](#gpt-fast).
|
| 363 |
+
|
| 364 |
+
<details>
|
| 365 |
+
<summary>Benchmark</summary>
|
| 366 |
+
|
| 367 |
+
If you would like to measure the speedup between self-speculative decoding and autoregressive decoding, we have written this script:
|
| 368 |
+
```python
|
| 369 |
+
import torch
|
| 370 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 371 |
+
from copy import deepcopy
|
| 372 |
+
from time import time
|
| 373 |
+
from tqdm import tqdm
|
| 374 |
+
|
| 375 |
+
prompt = ""typing import List\ndef bucket_sort(A: List):""
|
| 376 |
+
|
| 377 |
+
checkpoint = ""facebook/layerskip-codellama-34B""
|
| 378 |
+
early_exit = 7
|
| 379 |
+
device = ""cuda"" if torch.cuda.is_available() else ""cpu""
|
| 380 |
+
|
| 381 |
+
max_new_tokens = 512
|
| 382 |
+
do_sample = True
|
| 383 |
+
top_p = 0.9
|
| 384 |
+
temperature = 0.6
|
| 385 |
+
|
| 386 |
+
warmup = 2
|
| 387 |
+
repeat = 10
|
| 388 |
+
|
| 389 |
+
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map=""auto"", use_safetensors=True, torch_dtype=torch.float16)
|
| 390 |
+
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
| 391 |
+
|
| 392 |
+
# Draft model
|
| 393 |
+
# Clone main model with shared weights
|
| 394 |
+
weights_memo = {id(w): w for w in model.parameters()}
|
| 395 |
+
assistant_model = deepcopy(model, memo=weights_memo)
|
| 396 |
+
# Create early exit version
|
| 397 |
+
assistant_model.model.layers = assistant_model.model.layers[:early_exit]
|
| 398 |
+
del assistant_model.model.layers[early_exit:]
|
| 399 |
+
|
| 400 |
+
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
| 401 |
+
inputs = tokenizer(prompt, return_tensors=""pt"").to(device)
|
| 402 |
+
|
| 403 |
+
generation_config = {
|
| 404 |
+
""max_new_tokens"": max_new_tokens,
|
| 405 |
+
""do_sample"": do_sample,
|
| 406 |
+
""top_p"": top_p,
|
| 407 |
+
""temperature"": temperature,
|
| 408 |
+
""pad_token_id"": tokenizer.eos_token_id,
|
| 409 |
+
}
|
| 410 |
+
|
| 411 |
+
# Warmup
|
| 412 |
+
print(""Warmup"")
|
| 413 |
+
for i in tqdm(range(warmup)):
|
| 414 |
+
_ = model.generate(**inputs, **generation_config)
|
| 415 |
+
_ = model.generate(**inputs, **generation_config, assistant_model=assistant_model)
|
| 416 |
+
|
| 417 |
+
print(""Autoregressive Decoding"")
|
| 418 |
+
total_time = 0
|
| 419 |
+
total_tokens = 0
|
| 420 |
+
for i in tqdm(range(repeat)):
|
| 421 |
+
start = time()
|
| 422 |
+
outputs = model.generate(**inputs, **generation_config)
|
| 423 |
+
total_time += time() - start
|
| 424 |
+
total_tokens += outputs.numel()
|
| 425 |
+
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
|
| 426 |
+
print(""\n\t========================="")
|
| 427 |
+
print(f""\tAverage Generation Time: {total_time / repeat:.2f} s"")
|
| 428 |
+
print(f""\tAverage Tokens per Second: {total_tokens / total_time:.2f} tokens per sec\n\n"")
|
| 429 |
+
|
| 430 |
+
print(""Self-Speculative Decoding"")
|
| 431 |
+
total_time = 0
|
| 432 |
+
total_tokens = 0
|
| 433 |
+
for i in tqdm(range(repeat)):
|
| 434 |
+
start = time()
|
| 435 |
+
outputs = model.generate(**inputs, **generation_config, assistant_model=assistant_model)
|
| 436 |
+
total_time += time() - start
|
| 437 |
+
total_tokens += outputs.numel()
|
| 438 |
+
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
|
| 439 |
+
print(""\n\t========================="")
|
| 440 |
+
print(f""\tAverage Generation Time: {total_time / repeat:.2f} s"")
|
| 441 |
+
print(f""\tAverage Tokens per Second: {total_tokens / total_time:.2f} tokens per sec\n\n"")
|
| 442 |
+
```
|
| 443 |
+
|
| 444 |
+
Running this script on a single A100 NVIDIA GPU with `transformers==4.34.1`, `accelerate==1.0.1`, `torch==2.2.1`, `triton==2.2.0`, we obtain:
|
| 445 |
+
```
|
| 446 |
+
Autoregressive Decoding
|
| 447 |
+
=========================
|
| 448 |
+
Average Generation Time: 12.20 s
|
| 449 |
+
Average Tokens per Second: 20.14 tokens per sec
|
| 450 |
+
|
| 451 |
+
Self-Speculative Decoding
|
| 452 |
+
=========================
|
| 453 |
+
Average Generation Time: 7.11 s
|
| 454 |
+
Average Tokens per Second: 30.20 tokens per sec
|
| 455 |
+
```
|
| 456 |
+
</details>
|
| 457 |
+
|
| 458 |
+
### LayerSkip Codebase<a name=""layerskip-codebase""></a>
|
| 459 |
+
Our self-speculative decoding implementation at [github.com/facebookresearch/LayerSkip](https://github.com/facebookresearch/LayerSkip) has an optimized version that does not consume extra memory and re-uses the weights and KV cache of earlier layers in both draft and verification stages.
|
| 460 |
+
To run:
|
| 461 |
+
```console
|
| 462 |
+
> git clone git@github.com:facebookresearch/LayerSkip.git
|
| 463 |
+
> cd LayerSkip
|
| 464 |
+
|
| 465 |
+
> conda create --name layer_skip python=3.10
|
| 466 |
+
> conda activate layer_skip
|
| 467 |
+
|
| 468 |
+
> pip install -r requirements.txt
|
| 469 |
+
|
| 470 |
+
> torchrun generate.py --model facebook/layerskip-codellama-34B --generation_strategy self_speculative --exit_layer 7 --num_speculations 4
|
| 471 |
+
```
|
| 472 |
+
|
| 473 |
+
You can find more details in the GitHub repo for more options and scripts.
|
| 474 |
+
|
| 475 |
+
### gpt-fast<a name=""gpt-fast""></a>
|
| 476 |
+
We have also implemented self-speculative decoding as a [separatae branch in PyTorch's gpt-fast](https://github.com/pytorch-labs/gpt-fast/tree/LayerSkip?tab=readme-ov-file#self-speculative-sampling) if you would to stack our solution on top of other optimizations like `torch.compile()` and quantization. Our gpt-fast implementation is optimized as it does not consume extra memory and re-uses the weights and KV cache of earlier layers in both draft and verification stages.
|
| 477 |
+
|
| 478 |
+
To run:
|
| 479 |
+
```console
|
| 480 |
+
> git clone git@github.com:pytorch-labs/gpt-fast.git -b LayerSkip
|
| 481 |
+
> cd gpt-fast
|
| 482 |
+
|
| 483 |
+
> conda create --name gpt_fast python=3.10
|
| 484 |
+
> conda activate gpt_fast
|
| 485 |
+
|
| 486 |
+
> # Install PyTorch (check [here](https://pytorch.org/get-started/locally/) for other hardwares and operating systems)
|
| 487 |
+
> pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
|
| 488 |
+
> pip install sentencepiece huggingface_hub tiktoken
|
| 489 |
+
|
| 490 |
+
> mkdir checkpoints
|
| 491 |
+
|
| 492 |
+
> MODEL_REPO=facebook/layerskip-codellama-34B
|
| 493 |
+
> ./scripts/prepare.sh $MODEL_REPO
|
| 494 |
+
|
| 495 |
+
> python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth --top_k 100 --temperature 0.6 --self_speculative --early_exit 7 --speculate_k 4
|
| 496 |
+
```
|
| 497 |
+
|
| 498 |
+
<details>
|
| 499 |
+
<summary>Benchmark</summary>
|
| 500 |
+
|
| 501 |
+
- Autoregressive decoding:
|
| 502 |
+
|
| 503 |
+
```console
|
| 504 |
+
> python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth --top_k 100 --temperature 0.6 --prompt ""from typing import List""
|
| 505 |
+
==========
|
| 506 |
+
Average tokens/sec: 25.00
|
| 507 |
+
Memory used: 67.83 GB
|
| 508 |
+
```
|
| 509 |
+
|
| 510 |
+
- Self-speculative decoding:
|
| 511 |
+
|
| 512 |
+
```console
|
| 513 |
+
> python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth --top_k 100 --temperature 0.6 --self_speculative --early_exit 7 --speculate_k 4 --prompt ""from typing import List""
|
| 514 |
+
==========
|
| 515 |
+
{'tokens_per_sec': [34.5971355158771, 33.061558413088825, 29.004499981427667, 33.38722534545423, 28.88944123779914], 'accept_counts': [[26, 21, 12, 9, 12], [31, 19, 9, 5, 17], [30, 27, 12, 0, 16], [52, 17, 13, 1, 14], [32, 20, 11, 9, 12], [47, 29, 5, 6, 11]]}
|
| 516 |
+
Acceptance probs: [0.41523809523809524, 0.25333333333333335, 0.1180952380952381, 0.05714285714285714, 0.15619047619047619]
|
| 517 |
+
Mean Accepted: 1.2857142857142858
|
| 518 |
+
Average tokens/sec: 31.79
|
| 519 |
+
Memory used: 68.08 GB
|
| 520 |
+
```
|
| 521 |
+
</details>
|
| 522 |
+
|
| 523 |
+
## Training
|
| 524 |
+
Our training implementation is work-in-progress. You can check this [pull request](https://github.com/pytorch/torchtune/pull/1076) for details and discussions.
|
| 525 |
+
|
| 526 |
+
## Evaluation
|
| 527 |
+
We have provided evaluation results on various codinng tasks in the Model Card. You can view them on the top right hand-side bar on the screen.
|
| 528 |
+
The numbers reported in this Model Card were evaluated using [BigCode Evaluation Harness](https://github.com/bigcode-project/bigcode-evaluation-harness).
|
| 529 |
+
|
| 530 |
+
## Issues
|
| 531 |
+
|
| 532 |
+
Please report any software ""bug"", or other problems with the models through one of the following means:
|
| 533 |
+
- Reporting issues with the model: [https://github.com/facebookresearch/LayerSkip/issues](https://github.com/facebookresearch/LayerSkip/issues)
|
| 534 |
+
- Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
|
| 535 |
+
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
|
| 536 |
+
|
| 537 |
+
## License
|
| 538 |
+
|
| 539 |
+
See the [LICENSE](LICENSE) file.
|
| 540 |
+
","{""id"": ""facebook/layerskip-codellama-34B"", ""author"": ""facebook"", ""sha"": ""f6d7d805a396ef369e504087f7a76bcf43dd382a"", ""last_modified"": ""2024-10-19 16:37:40+00:00"", ""created_at"": ""2024-08-25 17:22:48+00:00"", ""private"": false, ""gated"": ""manual"", ""disabled"": false, ""downloads"": 14, ""downloads_all_time"": null, ""likes"": 4, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""safetensors"", ""llama"", ""text-generation"", ""facebook"", ""meta"", ""llama-2"", ""code"", ""en"", ""arxiv:2404.16710"", ""base_model:codellama/CodeLlama-34b-hf"", ""base_model:finetune:codellama/CodeLlama-34b-hf"", ""license:other"", ""model-index"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: codellama/CodeLlama-34b-hf\nlanguage:\n- en\nlibrary_name: transformers\nlicense: other\nlicense_name: fair\nlicense_link: LICENSE\npipeline_tag: text-generation\ntags:\n- facebook\n- meta\n- pytorch\n- llama\n- llama-2\n- code\nextra_gated_heading: You need to share contact information with Meta to access this\n model\nextra_gated_prompt: \""## FAIR Noncommercial Research License\\nLast Updated: [October\\\n \\ 16th 2024]\\n\u201cAcceptable Use Policy\u201d means the FAIR Acceptable Use Policy, applicable\\\n \\ to Research Materials, that is incorporated into this Agreement.\\n\u201cAgreement\u201d\\\n \\ means the terms and conditions for use, reproduction, distribution and modification\\\n \\ of the Research Materials set forth herein.\\n\u201cDocumentation\u201d means the specifications,\\\n \\ manuals and documentation accompanying Research Materials distributed by Meta.\\n\\\n \u201cLicensee\u201d or \u201cyou\u201d means you, or your employer or any other person or entity (if\\\n \\ you are entering into this Agreement on such person or entity\u2019s behalf), of the\\\n \\ age required under applicable laws, rules or regulations to provide legal consent\\\n \\ and that has legal authority to bind your employer or such other person or entity\\\n \\ if you are entering in this Agreement on their behalf.\\n\u201cMeta\u201d or \u201cwe\u201d means Meta\\\n \\ Platforms Ireland Limited (if you are located in or, if you are an entity, your\\\n \\ principal place of business is in the EEA or Switzerland) and Meta Platforms,\\\n \\ Inc. (if you are located outside of the EEA or Switzerland).\\n\u201cNoncommercial Research\\\n \\ Uses\u201d means noncommercial research use cases related to research, development,\\\n \\ education, processing, or analysis and in each case, is not primarily intended\\\n \\ for commercial advantage or monetary compensation to you or others.\\n\u201cResearch\\\n \\ Materials\u201d means, collectively, Documentation and the models, software and algorithms,\\\n \\ including machine-learning model code, trained model weights, inference-enabling\\\n \\ code, training-enabling code, fine-tuning enabling code, demonstration materials\\\n \\ and other elements of the foregoing distributed by Meta and made available under\\\n \\ this Agreement.\\nBy clicking \u201cI Accept\u201d below or by using or distributing any\\\n \\ portion or element of the Research Materials, you agree to be bound by this Agreement.\\n\\\n 1. License Rights and Redistribution.\\n a. Grant of Rights. You are granted a non-exclusive,\\\n \\ worldwide, non-transferable and royalty-free limited license under Meta\u2019s intellectual\\\n \\ property or other rights owned by Meta embodied in the Research Materials to use,\\\n \\ reproduce, distribute, copy, create derivative works of, and make modifications\\\n \\ to the Research Materials. \\n b. Redistribution and Use. \\n i. You will not\\\n \\ use the Research Materials or any outputs or results of the Research Materials\\\n \\ in connection with any commercial uses or for any uses other than Noncommercial\\\n \\ Research Uses;\\n ii. Distribution of Research Materials, and any derivative works\\\n \\ thereof, are subject to the terms of this Agreement. If you distribute or make\\\n \\ the Research Materials, or any derivative works thereof, available to a third\\\n \\ party, you may only do so under the terms of this Agreement. You shall also provide\\\n \\ a copy of this Agreement to such third party.\\n iii. If you submit for publication\\\n \\ the results of research you perform on, using, or otherwise in connection with\\\n \\ Research Materials, you must acknowledge the use of Research Materials in your\\\n \\ publication.\\n iv. Your use of the Research Materials must comply with applicable\\\n \\ laws and regulations (including Trade Control Laws) and adhere to the FAIR Acceptable\\\n \\ Use Policy, which is hereby incorporated by reference into this Agreement.\\n\\n\\\n 2. User Support. Your Noncommercial Research Use of the Research Materials is done\\\n \\ at your own discretion; Meta does not process any information nor provide any\\\n \\ service in relation to such use. Meta is under no obligation to provide any support\\\n \\ services for the Research Materials. Any support provided is \u201cas is\u201d, \u201cwith all\\\n \\ faults\u201d, and without warranty of any kind.\\n3. Disclaimer of Warranty. UNLESS\\\n \\ REQUIRED BY APPLICABLE LAW, THE RESEARCH MATERIALS AND ANY OUTPUT AND RESULTS\\\n \\ THEREFROM ARE PROVIDED ON AN \u201cAS IS\u201d BASIS, WITHOUT WARRANTIES OF ANY KIND, AND\\\n \\ META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING,\\\n \\ WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY,\\\n \\ OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING\\\n \\ THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE RESEARCH MATERIALS AND ASSUME\\\n \\ ANY RISKS ASSOCIATED WITH YOUR USE OF THE RESEARCH MATERIALS AND ANY OUTPUT AND\\\n \\ RESULTS.\\n4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES\\\n \\ BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE,\\\n \\ PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST\\\n \\ PROFITS OR ANY DIRECT OR INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY\\\n \\ OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY\\\n \\ OF ANY OF THE FOREGOING.\\n5. Intellectual Property.\\n a. Subject to Meta\u2019s ownership\\\n \\ of Research Materials and derivatives made by or for Meta, with respect to any\\\n \\ derivative works and modifications of the Research Materials that are made by\\\n \\ you, as between you and Meta, you are and will be the owner of such derivative\\\n \\ works and modifications.\\n b. If you institute litigation or other proceedings\\\n \\ against Meta or any entity (including a cross-claim or counterclaim in a lawsuit)\\\n \\ alleging that the Research Materials, outputs or results, or any portion of any\\\n \\ of the foregoing, constitutes infringement of intellectual property or other rights\\\n \\ owned or licensable by you, then any licenses granted to you under this Agreement\\\n \\ shall terminate as of the date such litigation or claim is filed or instituted.\\\n \\ You will indemnify and hold harmless Meta from and against any claim by any third\\\n \\ party arising out of or related to your use or distribution of the Research Materials.\\n\\\n \\n6. Term and Termination. The term of this Agreement will commence upon your acceptance\\\n \\ of this Agreement or access to the Research Materials and will continue in full\\\n \\ force and effect until terminated in accordance with the terms and conditions\\\n \\ herein. Meta may terminate this Agreement if you are in breach of any term or\\\n \\ condition of this Agreement. Upon termination of this Agreement, you shall delete\\\n \\ and cease use of the Research Materials. Sections 5, 6 and 9 shall survive the\\\n \\ termination of this Agreement. \\n7. Governing Law and Jurisdiction. This Agreement\\\n \\ will be governed and construed under the laws of the State of California without\\\n \\ regard to choice of law principles, and the UN Convention on Contracts for the\\\n \\ International Sale of Goods does not apply to this Agreement. The courts of California\\\n \\ shall have exclusive jurisdiction of any dispute arising out of this Agreement.\\\n \\ \\n8. Modifications and Amendments. Meta may modify this Agreement from time to\\\n \\ time by posting a revised version at https://huggingface.co/facebook/layerskip-codellama-34B/blob/main/LICENSE;\\\n \\ provided that they are similar in spirit to the current version of the Agreement,\\\n \\ but may differ in detail to address new problems or concerns. All such changes\\\n \\ will be effective immediately. Your continued use of the Research Materials after\\\n \\ any modification to this Agreement constitutes your agreement to such modification.\\\n \\ Except as provided in this Agreement, no modification or addition to any provision\\\n \\ of this Agreement will be binding unless it is in writing and signed by an authorized\\\n \\ representative of both you and Meta.\\n\\nFAIR Acceptable Use Policy \\nThe Fundamental\\\n \\ AI Research (FAIR) team at Meta seeks to further understanding of new and existing\\\n \\ research domains with the mission of advancing the state-of-the-art in artificial\\\n \\ intelligence through open research for the benefit of all. \\nAs part of this mission,\\\n \\ Meta makes certain research materials available for noncommercial research use.\\\n \\ Meta is committed to promoting the safe and responsible use of such research materials.\\\n \\ \\nProhibited Uses\\nYou agree you will not use, or allow others to use, Research\\\n \\ Materials to:\\n1.Violate the law or others\u2019 rights, including to:\\n a. Engage\\\n \\ in, promote, generate, contribute to, encourage, plan, incite, or further illegal\\\n \\ or unlawful activity or content, such as:\\n i. Violence or terrorism\\n ii. Exploitation\\\n \\ or harm to children, including the solicitation, creation, acquisition, or dissemination\\\n \\ of child exploitative content or failure to report Child Sexual Abuse Material\\n\\\n \\ iii. Human trafficking, exploitation, and sexual violence\\n iv. The illegal\\\n \\ distribution of information or materials to minors, including obscene materials,\\\n \\ or failure to employ legally required age-gating in connection with such information\\\n \\ or materials.\\n v. Sexual solicitation\\n vi. Any other criminal activity\\n b.\\\n \\ Engage in, promote, incite, or facilitate the harassment, abuse, threatening,\\\n \\ or bullying of individuals or groups of individuals\\n c. Engage in, promote, incite,\\\n \\ or facilitate discrimination or other unlawful or harmful conduct in the provision\\\n \\ of employment, employment benefits, credit, housing, other economic benefits,\\\n \\ or other essential goods and services\\n d. Engage in the unauthorized or unlicensed\\\n \\ practice of any profession including, but not limited to, financial, legal, medical/health,\\\n \\ or related professional practices\\n e. Collect, process, disclose, generate, or\\\n \\ infer health, demographic, or other sensitive personal or private information\\\n \\ about individuals without rights and consents required by applicable laws\\n f.\\\n \\ Engage in or facilitate any action or generate any content that infringes, misappropriates,\\\n \\ or otherwise violates any third-party rights, including the outputs or results\\\n \\ of any technology using FAIR research materials\\n g. Create, generate, or facilitate\\\n \\ the creation of malicious code, malware, computer viruses or do anything else\\\n \\ that could disable, overburden, interfere with or impair the proper working, integrity,\\\n \\ operation or appearance of a website or computer system\\n\\n2. Engage in, promote,\\\n \\ incite, facilitate, or assist in the planning or development of activities that\\\n \\ present a risk of death or bodily harm to individuals, including use of research\\\n \\ artifacts related to the following:\\n a. Military, warfare, nuclear industries\\\n \\ or applications, espionage, use for materials or activities that are subject to\\\n \\ the International Traffic Arms Regulations (ITAR) maintained by the United States\\\n \\ Department of State\\n b. Guns and illegal weapons (including weapon development)\\n\\\n \\ c. Illegal drugs and regulated/controlled substances\\n d. Operation of critical\\\n \\ infrastructure, transportation technologies, or heavy machinery\\n e. Self-harm\\\n \\ or harm to others, including suicide, cutting, and eating disorders\\n f. Any content\\\n \\ intended to incite or promote violence, abuse, or any infliction of bodily harm\\\n \\ to an individual\\n\\n3. Intentionally deceive or mislead others, including use\\\n \\ of FAIR Research Materials related to the following:\\n a. Generating, promoting,\\\n \\ or furthering fraud or the creation or promotion of disinformation\\n b. Generating,\\\n \\ promoting, or furthering defamatory content, including the creation of defamatory\\\n \\ statements, images, or other content\\n c. Generating, promoting, or further distributing\\\n \\ spam\\n d. Impersonating another individual without consent, authorization, or\\\n \\ legal right\\n e. Representing that outputs of FAIR research materials or outputs\\\n \\ from technology using FAIR research materials o are human-generated\\n f. Generating\\\n \\ or facilitating false online engagement, including fake reviews and other means\\\n \\ of fake online engagement\\n\\n4. Fail to appropriately disclose to end users any\\\n \\ known dangers of your Research Materials.\\nPlease report any violation of this\\\n \\ Policy or other problems that could lead to a violation of this Policy by submitting\\\n \\ a report [here](https://docs.google.com/forms/d/e/1FAIpQLSeb11cryAopJ7LNrC4nxEUXrHY26hfkXQMf_uH-oFgA3WlYZQ/viewform).\""\nextra_gated_fields:\n First Name: text\n Last Name: text\n Date of birth: date_picker\n Country: country\n Affiliation: text\n geo: ip_location\n ? By clicking Submit below I accept the terms of the license and acknowledge that\n the information I provide will be collected stored processed and shared in accordance\n with the Meta Privacy Policy\n : checkbox\nextra_gated_description: The information you provide will be collected, stored, processed\n and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).\nextra_gated_button_content: Submit\nmodel-index:\n- name: LayerSkip Code Llama 34B\n results:\n - task:\n type: text-generation\n dataset:\n name: HumanEval\n type: openai_humaneval\n metrics:\n - type: pass@1\n value: 0.47\n name: pass@1\n verified: false\n - task:\n type: text-generation\n dataset:\n name: MBPP\n type: mbpp\n metrics:\n - type: pass@1\n value: 0.474\n name: pass@1\n verified: false"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": [{""name"": ""LayerSkip Code Llama 34B"", ""results"": [{""task"": {""type"": ""text-generation""}, ""dataset"": {""type"": ""openai_humaneval"", ""name"": ""HumanEval""}, ""metrics"": [{""name"": ""pass@1"", ""type"": ""pass@1"", ""value"": 0.47, ""verified"": false}]}, {""task"": {""type"": ""text-generation""}, ""dataset"": {""type"": ""mbpp"", ""name"": ""MBPP""}, ""metrics"": [{""name"": ""pass@1"", ""type"": ""pass@1"", ""value"": 0.474, ""verified"": false}]}]}], ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""pad_token"": null, ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00009-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00010-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00011-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00012-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00013-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00014-of-00014.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00004-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00005-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00006-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00007-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00008-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00009-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00010-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00011-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00012-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00013-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00014-of-00014.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F16"": 33743970304}, ""total"": 33743970304}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-10-19 16:37:40+00:00"", ""cardData"": ""base_model: codellama/CodeLlama-34b-hf\nlanguage:\n- en\nlibrary_name: transformers\nlicense: other\nlicense_name: fair\nlicense_link: LICENSE\npipeline_tag: text-generation\ntags:\n- facebook\n- meta\n- pytorch\n- llama\n- llama-2\n- code\nextra_gated_heading: You need to share contact information with Meta to access this\n model\nextra_gated_prompt: \""## FAIR Noncommercial Research License\\nLast Updated: [October\\\n \\ 16th 2024]\\n\u201cAcceptable Use Policy\u201d means the FAIR Acceptable Use Policy, applicable\\\n \\ to Research Materials, that is incorporated into this Agreement.\\n\u201cAgreement\u201d\\\n \\ means the terms and conditions for use, reproduction, distribution and modification\\\n \\ of the Research Materials set forth herein.\\n\u201cDocumentation\u201d means the specifications,\\\n \\ manuals and documentation accompanying Research Materials distributed by Meta.\\n\\\n \u201cLicensee\u201d or \u201cyou\u201d means you, or your employer or any other person or entity (if\\\n \\ you are entering into this Agreement on such person or entity\u2019s behalf), of the\\\n \\ age required under applicable laws, rules or regulations to provide legal consent\\\n \\ and that has legal authority to bind your employer or such other person or entity\\\n \\ if you are entering in this Agreement on their behalf.\\n\u201cMeta\u201d or \u201cwe\u201d means Meta\\\n \\ Platforms Ireland Limited (if you are located in or, if you are an entity, your\\\n \\ principal place of business is in the EEA or Switzerland) and Meta Platforms,\\\n \\ Inc. (if you are located outside of the EEA or Switzerland).\\n\u201cNoncommercial Research\\\n \\ Uses\u201d means noncommercial research use cases related to research, development,\\\n \\ education, processing, or analysis and in each case, is not primarily intended\\\n \\ for commercial advantage or monetary compensation to you or others.\\n\u201cResearch\\\n \\ Materials\u201d means, collectively, Documentation and the models, software and algorithms,\\\n \\ including machine-learning model code, trained model weights, inference-enabling\\\n \\ code, training-enabling code, fine-tuning enabling code, demonstration materials\\\n \\ and other elements of the foregoing distributed by Meta and made available under\\\n \\ this Agreement.\\nBy clicking \u201cI Accept\u201d below or by using or distributing any\\\n \\ portion or element of the Research Materials, you agree to be bound by this Agreement.\\n\\\n 1. License Rights and Redistribution.\\n a. Grant of Rights. You are granted a non-exclusive,\\\n \\ worldwide, non-transferable and royalty-free limited license under Meta\u2019s intellectual\\\n \\ property or other rights owned by Meta embodied in the Research Materials to use,\\\n \\ reproduce, distribute, copy, create derivative works of, and make modifications\\\n \\ to the Research Materials. \\n b. Redistribution and Use. \\n i. You will not\\\n \\ use the Research Materials or any outputs or results of the Research Materials\\\n \\ in connection with any commercial uses or for any uses other than Noncommercial\\\n \\ Research Uses;\\n ii. Distribution of Research Materials, and any derivative works\\\n \\ thereof, are subject to the terms of this Agreement. If you distribute or make\\\n \\ the Research Materials, or any derivative works thereof, available to a third\\\n \\ party, you may only do so under the terms of this Agreement. You shall also provide\\\n \\ a copy of this Agreement to such third party.\\n iii. If you submit for publication\\\n \\ the results of research you perform on, using, or otherwise in connection with\\\n \\ Research Materials, you must acknowledge the use of Research Materials in your\\\n \\ publication.\\n iv. Your use of the Research Materials must comply with applicable\\\n \\ laws and regulations (including Trade Control Laws) and adhere to the FAIR Acceptable\\\n \\ Use Policy, which is hereby incorporated by reference into this Agreement.\\n\\n\\\n 2. User Support. Your Noncommercial Research Use of the Research Materials is done\\\n \\ at your own discretion; Meta does not process any information nor provide any\\\n \\ service in relation to such use. Meta is under no obligation to provide any support\\\n \\ services for the Research Materials. Any support provided is \u201cas is\u201d, \u201cwith all\\\n \\ faults\u201d, and without warranty of any kind.\\n3. Disclaimer of Warranty. UNLESS\\\n \\ REQUIRED BY APPLICABLE LAW, THE RESEARCH MATERIALS AND ANY OUTPUT AND RESULTS\\\n \\ THEREFROM ARE PROVIDED ON AN \u201cAS IS\u201d BASIS, WITHOUT WARRANTIES OF ANY KIND, AND\\\n \\ META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING,\\\n \\ WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY,\\\n \\ OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING\\\n \\ THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE RESEARCH MATERIALS AND ASSUME\\\n \\ ANY RISKS ASSOCIATED WITH YOUR USE OF THE RESEARCH MATERIALS AND ANY OUTPUT AND\\\n \\ RESULTS.\\n4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES\\\n \\ BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE,\\\n \\ PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST\\\n \\ PROFITS OR ANY DIRECT OR INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY\\\n \\ OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY\\\n \\ OF ANY OF THE FOREGOING.\\n5. Intellectual Property.\\n a. Subject to Meta\u2019s ownership\\\n \\ of Research Materials and derivatives made by or for Meta, with respect to any\\\n \\ derivative works and modifications of the Research Materials that are made by\\\n \\ you, as between you and Meta, you are and will be the owner of such derivative\\\n \\ works and modifications.\\n b. If you institute litigation or other proceedings\\\n \\ against Meta or any entity (including a cross-claim or counterclaim in a lawsuit)\\\n \\ alleging that the Research Materials, outputs or results, or any portion of any\\\n \\ of the foregoing, constitutes infringement of intellectual property or other rights\\\n \\ owned or licensable by you, then any licenses granted to you under this Agreement\\\n \\ shall terminate as of the date such litigation or claim is filed or instituted.\\\n \\ You will indemnify and hold harmless Meta from and against any claim by any third\\\n \\ party arising out of or related to your use or distribution of the Research Materials.\\n\\\n \\n6. Term and Termination. The term of this Agreement will commence upon your acceptance\\\n \\ of this Agreement or access to the Research Materials and will continue in full\\\n \\ force and effect until terminated in accordance with the terms and conditions\\\n \\ herein. Meta may terminate this Agreement if you are in breach of any term or\\\n \\ condition of this Agreement. Upon termination of this Agreement, you shall delete\\\n \\ and cease use of the Research Materials. Sections 5, 6 and 9 shall survive the\\\n \\ termination of this Agreement. \\n7. Governing Law and Jurisdiction. This Agreement\\\n \\ will be governed and construed under the laws of the State of California without\\\n \\ regard to choice of law principles, and the UN Convention on Contracts for the\\\n \\ International Sale of Goods does not apply to this Agreement. The courts of California\\\n \\ shall have exclusive jurisdiction of any dispute arising out of this Agreement.\\\n \\ \\n8. Modifications and Amendments. Meta may modify this Agreement from time to\\\n \\ time by posting a revised version at https://huggingface.co/facebook/layerskip-codellama-34B/blob/main/LICENSE;\\\n \\ provided that they are similar in spirit to the current version of the Agreement,\\\n \\ but may differ in detail to address new problems or concerns. All such changes\\\n \\ will be effective immediately. Your continued use of the Research Materials after\\\n \\ any modification to this Agreement constitutes your agreement to such modification.\\\n \\ Except as provided in this Agreement, no modification or addition to any provision\\\n \\ of this Agreement will be binding unless it is in writing and signed by an authorized\\\n \\ representative of both you and Meta.\\n\\nFAIR Acceptable Use Policy \\nThe Fundamental\\\n \\ AI Research (FAIR) team at Meta seeks to further understanding of new and existing\\\n \\ research domains with the mission of advancing the state-of-the-art in artificial\\\n \\ intelligence through open research for the benefit of all. \\nAs part of this mission,\\\n \\ Meta makes certain research materials available for noncommercial research use.\\\n \\ Meta is committed to promoting the safe and responsible use of such research materials.\\\n \\ \\nProhibited Uses\\nYou agree you will not use, or allow others to use, Research\\\n \\ Materials to:\\n1.Violate the law or others\u2019 rights, including to:\\n a. Engage\\\n \\ in, promote, generate, contribute to, encourage, plan, incite, or further illegal\\\n \\ or unlawful activity or content, such as:\\n i. Violence or terrorism\\n ii. Exploitation\\\n \\ or harm to children, including the solicitation, creation, acquisition, or dissemination\\\n \\ of child exploitative content or failure to report Child Sexual Abuse Material\\n\\\n \\ iii. Human trafficking, exploitation, and sexual violence\\n iv. The illegal\\\n \\ distribution of information or materials to minors, including obscene materials,\\\n \\ or failure to employ legally required age-gating in connection with such information\\\n \\ or materials.\\n v. Sexual solicitation\\n vi. Any other criminal activity\\n b.\\\n \\ Engage in, promote, incite, or facilitate the harassment, abuse, threatening,\\\n \\ or bullying of individuals or groups of individuals\\n c. Engage in, promote, incite,\\\n \\ or facilitate discrimination or other unlawful or harmful conduct in the provision\\\n \\ of employment, employment benefits, credit, housing, other economic benefits,\\\n \\ or other essential goods and services\\n d. Engage in the unauthorized or unlicensed\\\n \\ practice of any profession including, but not limited to, financial, legal, medical/health,\\\n \\ or related professional practices\\n e. Collect, process, disclose, generate, or\\\n \\ infer health, demographic, or other sensitive personal or private information\\\n \\ about individuals without rights and consents required by applicable laws\\n f.\\\n \\ Engage in or facilitate any action or generate any content that infringes, misappropriates,\\\n \\ or otherwise violates any third-party rights, including the outputs or results\\\n \\ of any technology using FAIR research materials\\n g. Create, generate, or facilitate\\\n \\ the creation of malicious code, malware, computer viruses or do anything else\\\n \\ that could disable, overburden, interfere with or impair the proper working, integrity,\\\n \\ operation or appearance of a website or computer system\\n\\n2. Engage in, promote,\\\n \\ incite, facilitate, or assist in the planning or development of activities that\\\n \\ present a risk of death or bodily harm to individuals, including use of research\\\n \\ artifacts related to the following:\\n a. Military, warfare, nuclear industries\\\n \\ or applications, espionage, use for materials or activities that are subject to\\\n \\ the International Traffic Arms Regulations (ITAR) maintained by the United States\\\n \\ Department of State\\n b. Guns and illegal weapons (including weapon development)\\n\\\n \\ c. Illegal drugs and regulated/controlled substances\\n d. Operation of critical\\\n \\ infrastructure, transportation technologies, or heavy machinery\\n e. Self-harm\\\n \\ or harm to others, including suicide, cutting, and eating disorders\\n f. Any content\\\n \\ intended to incite or promote violence, abuse, or any infliction of bodily harm\\\n \\ to an individual\\n\\n3. Intentionally deceive or mislead others, including use\\\n \\ of FAIR Research Materials related to the following:\\n a. Generating, promoting,\\\n \\ or furthering fraud or the creation or promotion of disinformation\\n b. Generating,\\\n \\ promoting, or furthering defamatory content, including the creation of defamatory\\\n \\ statements, images, or other content\\n c. Generating, promoting, or further distributing\\\n \\ spam\\n d. Impersonating another individual without consent, authorization, or\\\n \\ legal right\\n e. Representing that outputs of FAIR research materials or outputs\\\n \\ from technology using FAIR research materials o are human-generated\\n f. Generating\\\n \\ or facilitating false online engagement, including fake reviews and other means\\\n \\ of fake online engagement\\n\\n4. Fail to appropriately disclose to end users any\\\n \\ known dangers of your Research Materials.\\nPlease report any violation of this\\\n \\ Policy or other problems that could lead to a violation of this Policy by submitting\\\n \\ a report [here](https://docs.google.com/forms/d/e/1FAIpQLSeb11cryAopJ7LNrC4nxEUXrHY26hfkXQMf_uH-oFgA3WlYZQ/viewform).\""\nextra_gated_fields:\n First Name: text\n Last Name: text\n Date of birth: date_picker\n Country: country\n Affiliation: text\n geo: ip_location\n ? By clicking Submit below I accept the terms of the license and acknowledge that\n the information I provide will be collected stored processed and shared in accordance\n with the Meta Privacy Policy\n : checkbox\nextra_gated_description: The information you provide will be collected, stored, processed\n and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).\nextra_gated_button_content: Submit\nmodel-index:\n- name: LayerSkip Code Llama 34B\n results:\n - task:\n type: text-generation\n dataset:\n name: HumanEval\n type: openai_humaneval\n metrics:\n - type: pass@1\n value: 0.47\n name: pass@1\n verified: false\n - task:\n type: text-generation\n dataset:\n name: MBPP\n type: mbpp\n metrics:\n - type: pass@1\n value: 0.474\n name: pass@1\n verified: false"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""66cb686857c2405fdfd171ba"", ""modelId"": ""facebook/layerskip-codellama-34B"", ""usedStorage"": 404928565891}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=facebook/layerskip-codellama-34B&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bfacebook%2Flayerskip-codellama-34B%5D(%2Ffacebook%2Flayerskip-codellama-34B)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
CogVideoX-5b_finetunes_20250425_143346.csv_finetunes_20250425_143346.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
DeepSeek-R1-Distill-Qwen-14B-GGUF_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF,"---
|
| 3 |
+
quantized_by: bartowski
|
| 4 |
+
pipeline_tag: text-generation
|
| 5 |
+
base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
## Llamacpp imatrix Quantizations of DeepSeek-R1-Distill-Qwen-14B
|
| 9 |
+
|
| 10 |
+
Using <a href=""https://github.com/ggerganov/llama.cpp/"">llama.cpp</a> release <a href=""https://github.com/ggerganov/llama.cpp/releases/tag/b4514"">b4514</a> for quantization.
|
| 11 |
+
|
| 12 |
+
Original model: https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
|
| 13 |
+
|
| 14 |
+
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
|
| 15 |
+
|
| 16 |
+
Run them in [LM Studio](https://lmstudio.ai/)
|
| 17 |
+
|
| 18 |
+
## Prompt format
|
| 19 |
+
|
| 20 |
+
```
|
| 21 |
+
<|begin▁of▁sentence|>{system_prompt}<|User|>{prompt}<|Assistant|>
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
## Download a file (not the whole branch) from below:
|
| 25 |
+
|
| 26 |
+
| Filename | Quant type | File Size | Split | Description |
|
| 27 |
+
| -------- | ---------- | --------- | ----- | ----------- |
|
| 28 |
+
| [DeepSeek-R1-Distill-Qwen-14B-f32.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/tree/main/DeepSeek-R1-Distill-Qwen-14B-f32) | f32 | 59.09GB | true | Full F32 weights. |
|
| 29 |
+
| [DeepSeek-R1-Distill-Qwen-14B-f16.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-f16.gguf) | f16 | 29.55GB | false | Full F16 weights. |
|
| 30 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q8_0.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q8_0.gguf) | Q8_0 | 15.70GB | false | Extremely high quality, generally unneeded but max available quant. |
|
| 31 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q6_K_L.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q6_K_L.gguf) | Q6_K_L | 12.50GB | false | Uses Q8_0 for embed and output weights. Very high quality, near perfect, *recommended*. |
|
| 32 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q6_K.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q6_K.gguf) | Q6_K | 12.12GB | false | Very high quality, near perfect, *recommended*. |
|
| 33 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q5_K_L.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q5_K_L.gguf) | Q5_K_L | 10.99GB | false | Uses Q8_0 for embed and output weights. High quality, *recommended*. |
|
| 34 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q5_K_M.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q5_K_M.gguf) | Q5_K_M | 10.51GB | false | High quality, *recommended*. |
|
| 35 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q5_K_S.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q5_K_S.gguf) | Q5_K_S | 10.27GB | false | High quality, *recommended*. |
|
| 36 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q4_K_L.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q4_K_L.gguf) | Q4_K_L | 9.57GB | false | Uses Q8_0 for embed and output weights. Good quality, *recommended*. |
|
| 37 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q4_1.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q4_1.gguf) | Q4_1 | 9.39GB | false | Legacy format, similar performance to Q4_K_S but with improved tokens/watt on Apple silicon. |
|
| 38 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf) | Q4_K_M | 8.99GB | false | Good quality, default size for most use cases, *recommended*. |
|
| 39 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q3_K_XL.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q3_K_XL.gguf) | Q3_K_XL | 8.61GB | false | Uses Q8_0 for embed and output weights. Lower quality but usable, good for low RAM availability. |
|
| 40 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q4_K_S.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q4_K_S.gguf) | Q4_K_S | 8.57GB | false | Slightly lower quality with more space savings, *recommended*. |
|
| 41 |
+
| [DeepSeek-R1-Distill-Qwen-14B-IQ4_NL.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-IQ4_NL.gguf) | IQ4_NL | 8.55GB | false | Similar to IQ4_XS, but slightly larger. Offers online repacking for ARM CPU inference. |
|
| 42 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q4_0.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q4_0.gguf) | Q4_0 | 8.54GB | false | Legacy format, offers online repacking for ARM and AVX CPU inference. |
|
| 43 |
+
| [DeepSeek-R1-Distill-Qwen-14B-IQ4_XS.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-IQ4_XS.gguf) | IQ4_XS | 8.12GB | false | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
|
| 44 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q3_K_L.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q3_K_L.gguf) | Q3_K_L | 7.92GB | false | Lower quality but usable, good for low RAM availability. |
|
| 45 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q3_K_M.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q3_K_M.gguf) | Q3_K_M | 7.34GB | false | Low quality. |
|
| 46 |
+
| [DeepSeek-R1-Distill-Qwen-14B-IQ3_M.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-IQ3_M.gguf) | IQ3_M | 6.92GB | false | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
|
| 47 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q3_K_S.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q3_K_S.gguf) | Q3_K_S | 6.66GB | false | Low quality, not recommended. |
|
| 48 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q2_K_L.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q2_K_L.gguf) | Q2_K_L | 6.53GB | false | Uses Q8_0 for embed and output weights. Very low quality but surprisingly usable. |
|
| 49 |
+
| [DeepSeek-R1-Distill-Qwen-14B-IQ3_XS.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-IQ3_XS.gguf) | IQ3_XS | 6.38GB | false | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
|
| 50 |
+
| [DeepSeek-R1-Distill-Qwen-14B-Q2_K.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-Q2_K.gguf) | Q2_K | 5.77GB | false | Very low quality but surprisingly usable. |
|
| 51 |
+
| [DeepSeek-R1-Distill-Qwen-14B-IQ2_M.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-IQ2_M.gguf) | IQ2_M | 5.36GB | false | Relatively low quality, uses SOTA techniques to be surprisingly usable. |
|
| 52 |
+
| [DeepSeek-R1-Distill-Qwen-14B-IQ2_S.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-IQ2_S.gguf) | IQ2_S | 5.00GB | false | Low quality, uses SOTA techniques to be usable. |
|
| 53 |
+
| [DeepSeek-R1-Distill-Qwen-14B-IQ2_XS.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-14B-IQ2_XS.gguf) | IQ2_XS | 4.70GB | false | Low quality, uses SOTA techniques to be usable. |
|
| 54 |
+
|
| 55 |
+
## Embed/output weights
|
| 56 |
+
|
| 57 |
+
Some of these quants (Q3_K_XL, Q4_K_L etc) are the standard quantization method with the embeddings and output weights quantized to Q8_0 instead of what they would normally default to.
|
| 58 |
+
|
| 59 |
+
## Downloading using huggingface-cli
|
| 60 |
+
|
| 61 |
+
<details>
|
| 62 |
+
<summary>Click to view download instructions</summary>
|
| 63 |
+
|
| 64 |
+
First, make sure you have hugginface-cli installed:
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
pip install -U ""huggingface_hub[cli]""
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
Then, you can target the specific file you want:
|
| 71 |
+
|
| 72 |
+
```
|
| 73 |
+
huggingface-cli download bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF --include ""DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf"" --local-dir ./
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
|
| 77 |
+
|
| 78 |
+
```
|
| 79 |
+
huggingface-cli download bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF --include ""DeepSeek-R1-Distill-Qwen-14B-Q8_0/*"" --local-dir ./
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
You can either specify a new local-dir (DeepSeek-R1-Distill-Qwen-14B-Q8_0) or download them all in place (./)
|
| 83 |
+
|
| 84 |
+
</details>
|
| 85 |
+
|
| 86 |
+
## ARM/AVX information
|
| 87 |
+
|
| 88 |
+
Previously, you would download Q4_0_4_4/4_8/8_8, and these would have their weights interleaved in memory in order to improve performance on ARM and AVX machines by loading up more data in one pass.
|
| 89 |
+
|
| 90 |
+
Now, however, there is something called ""online repacking"" for weights. details in [this PR](https://github.com/ggerganov/llama.cpp/pull/9921). If you use Q4_0 and your hardware would benefit from repacking weights, it will do it automatically on the fly.
|
| 91 |
+
|
| 92 |
+
As of llama.cpp build [b4282](https://github.com/ggerganov/llama.cpp/releases/tag/b4282) you will not be able to run the Q4_0_X_X files and will instead need to use Q4_0.
|
| 93 |
+
|
| 94 |
+
Additionally, if you want to get slightly better quality for , you can use IQ4_NL thanks to [this PR](https://github.com/ggerganov/llama.cpp/pull/10541) which will also repack the weights for ARM, though only the 4_4 for now. The loading time may be slower but it will result in an overall speed incrase.
|
| 95 |
+
|
| 96 |
+
<details>
|
| 97 |
+
<summary>Click to view Q4_0_X_X information (deprecated</summary>
|
| 98 |
+
|
| 99 |
+
I'm keeping this section to show the potential theoretical uplift in performance from using the Q4_0 with online repacking.
|
| 100 |
+
|
| 101 |
+
<details>
|
| 102 |
+
<summary>Click to view benchmarks on an AVX2 system (EPYC7702)</summary>
|
| 103 |
+
|
| 104 |
+
| model | size | params | backend | threads | test | t/s | % (vs Q4_0) |
|
| 105 |
+
| ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: |-------------: |
|
| 106 |
+
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp512 | 204.03 ± 1.03 | 100% |
|
| 107 |
+
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp1024 | 282.92 ± 0.19 | 100% |
|
| 108 |
+
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp2048 | 259.49 ± 0.44 | 100% |
|
| 109 |
+
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg128 | 39.12 ± 0.27 | 100% |
|
| 110 |
+
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg256 | 39.31 ± 0.69 | 100% |
|
| 111 |
+
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg512 | 40.52 ± 0.03 | 100% |
|
| 112 |
+
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp512 | 301.02 ± 1.74 | 147% |
|
| 113 |
+
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp1024 | 287.23 ± 0.20 | 101% |
|
| 114 |
+
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp2048 | 262.77 ± 1.81 | 101% |
|
| 115 |
+
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg128 | 18.80 ± 0.99 | 48% |
|
| 116 |
+
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg256 | 24.46 ± 3.04 | 83% |
|
| 117 |
+
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg512 | 36.32 ± 3.59 | 90% |
|
| 118 |
+
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp512 | 271.71 ± 3.53 | 133% |
|
| 119 |
+
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp1024 | 279.86 ± 45.63 | 100% |
|
| 120 |
+
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp2048 | 320.77 ± 5.00 | 124% |
|
| 121 |
+
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg128 | 43.51 ± 0.05 | 111% |
|
| 122 |
+
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg256 | 43.35 ± 0.09 | 110% |
|
| 123 |
+
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg512 | 42.60 ± 0.31 | 105% |
|
| 124 |
+
|
| 125 |
+
Q4_0_8_8 offers a nice bump to prompt processing and a small bump to text generation
|
| 126 |
+
|
| 127 |
+
</details>
|
| 128 |
+
|
| 129 |
+
</details>
|
| 130 |
+
|
| 131 |
+
## Which file should I choose?
|
| 132 |
+
|
| 133 |
+
<details>
|
| 134 |
+
<summary>Click here for details</summary>
|
| 135 |
+
|
| 136 |
+
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
|
| 137 |
+
|
| 138 |
+
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
|
| 139 |
+
|
| 140 |
+
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
|
| 141 |
+
|
| 142 |
+
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
|
| 143 |
+
|
| 144 |
+
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
|
| 145 |
+
|
| 146 |
+
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
|
| 147 |
+
|
| 148 |
+
If you want to get more into the weeds, you can check out this extremely useful feature chart:
|
| 149 |
+
|
| 150 |
+
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
|
| 151 |
+
|
| 152 |
+
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
|
| 153 |
+
|
| 154 |
+
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
|
| 155 |
+
|
| 156 |
+
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
|
| 157 |
+
|
| 158 |
+
</details>
|
| 159 |
+
|
| 160 |
+
## Credits
|
| 161 |
+
|
| 162 |
+
Thank you kalomaze and Dampf for assistance in creating the imatrix calibration dataset.
|
| 163 |
+
|
| 164 |
+
Thank you ZeroWw for the inspiration to experiment with embed/output.
|
| 165 |
+
|
| 166 |
+
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
| 167 |
+
","{""id"": ""bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF"", ""author"": ""bartowski"", ""sha"": ""9f5d77d401799416e0702290a691038b44012e0c"", ""last_modified"": ""2025-03-10 16:49:14+00:00"", ""created_at"": ""2025-01-20 14:53:41+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 322503, ""downloads_all_time"": null, ""likes"": 198, ""library_name"": null, ""gguf"": {""total"": 14770033664, ""architecture"": ""qwen2"", ""context_length"": 131072, ""quantize_imatrix_file"": ""/models_out/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B.imatrix"", ""chat_template"": ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{bos_token}}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<\uff5cUser\uff5c>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is none %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls']%}{%- if not ns.is_first %}{{'<\uff5cAssistant\uff5c><\uff5ctool\u2581calls\u2581begin\uff5c><\uff5ctool\u2581call\u2581begin\uff5c>' + tool['type'] + '<\uff5ctool\u2581sep\uff5c>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<\uff5ctool\u2581call\u2581end\uff5c>'}}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<\uff5ctool\u2581call\u2581begin\uff5c>' + tool['type'] + '<\uff5ctool\u2581sep\uff5c>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<\uff5ctool\u2581call\u2581end\uff5c>'}}{{'<\uff5ctool\u2581calls\u2581end\uff5c><\uff5cend\u2581of\u2581sentence\uff5c>'}}{%- endif %}{%- endfor %}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{%- if ns.is_tool %}{{'<\uff5ctool\u2581outputs\u2581end\uff5c>' + message['content'] + '<\uff5cend\u2581of\u2581sentence\uff5c>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<\uff5cAssistant\uff5c>' + content + '<\uff5cend\u2581of\u2581sentence\uff5c>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<\uff5ctool\u2581outputs\u2581begin\uff5c><\uff5ctool\u2581output\u2581begin\uff5c>' + message['content'] + '<\uff5ctool\u2581output\u2581end\uff5c>'}}{%- set ns.is_output_first = false %}{%- else %}{{'\\n<\uff5ctool\u2581output\u2581begin\uff5c>' + message['content'] + '<\uff5ctool\u2581output\u2581end\uff5c>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<\uff5ctool\u2581outputs\u2581end\uff5c>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<\uff5cAssistant\uff5c>'}}{% endif %}"", ""bos_token"": ""<\uff5cbegin\u2581of\u2581sentence\uff5c>"", ""eos_token"": ""<\uff5cend\u2581of\u2581sentence\uff5c>""}, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""gguf"", ""text-generation"", ""base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-14B"", ""base_model:quantized:deepseek-ai/DeepSeek-R1-Distill-Qwen-14B"", ""endpoints_compatible"", ""region:us"", ""imatrix"", ""conversational""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-14B\npipeline_tag: text-generation\nquantized_by: bartowski"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-IQ2_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-IQ2_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-IQ2_XS.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-IQ3_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-IQ3_XS.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-IQ4_NL.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-IQ4_XS.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q2_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q2_K_L.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q3_K_L.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q3_K_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q3_K_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q3_K_XL.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q4_0.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q4_1.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q4_K_L.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q4_K_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q5_K_L.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q5_K_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q5_K_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q6_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q6_K_L.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-Q8_0.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-f16.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-f32/DeepSeek-R1-Distill-Qwen-14B-f32-00001-of-00002.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B-f32/DeepSeek-R1-Distill-Qwen-14B-f32-00002-of-00002.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Distill-Qwen-14B.imatrix', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-10 16:49:14+00:00"", ""cardData"": ""base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-14B\npipeline_tag: text-generation\nquantized_by: bartowski"", ""transformersInfo"": null, ""_id"": ""678e63753e658d277c719c18"", ""modelId"": ""bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF"", ""usedStorage"": 293663456634}",0,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bbartowski%2FDeepSeek-R1-Distill-Qwen-14B-GGUF%5D(%2Fbartowski%2FDeepSeek-R1-Distill-Qwen-14B-GGUF)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
DeepSeek-V2_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv
ADDED
|
@@ -0,0 +1,377 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
deepseek-ai/DeepSeek-V2,"---
|
| 3 |
+
license: other
|
| 4 |
+
license_name: deepseek
|
| 5 |
+
license_link: https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-MODEL
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
<!-- markdownlint-disable first-line-h1 -->
|
| 9 |
+
<!-- markdownlint-disable html -->
|
| 10 |
+
<!-- markdownlint-disable no-duplicate-header -->
|
| 11 |
+
|
| 12 |
+
<div align=""center"">
|
| 13 |
+
<img src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true"" width=""60%"" alt=""DeepSeek-V2"" />
|
| 14 |
+
</div>
|
| 15 |
+
<hr>
|
| 16 |
+
<div align=""center"" style=""line-height: 1;"">
|
| 17 |
+
<a href=""https://www.deepseek.com/"" target=""_blank"" style=""margin: 2px;"">
|
| 18 |
+
<img alt=""Homepage"" src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true"" style=""display: inline-block; vertical-align: middle;""/>
|
| 19 |
+
</a>
|
| 20 |
+
<a href=""https://chat.deepseek.com/"" target=""_blank"" style=""margin: 2px;"">
|
| 21 |
+
<img alt=""Chat"" src=""https://img.shields.io/badge/🤖%20Chat-DeepSeek%20V2-536af5?color=536af5&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/>
|
| 22 |
+
</a>
|
| 23 |
+
<a href=""https://huggingface.co/deepseek-ai"" target=""_blank"" style=""margin: 2px;"">
|
| 24 |
+
<img alt=""Hugging Face"" src=""https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/>
|
| 25 |
+
</a>
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
<div align=""center"" style=""line-height: 1;"">
|
| 29 |
+
<a href=""https://discord.gg/Tc7c45Zzu5"" target=""_blank"" style=""margin: 2px;"">
|
| 30 |
+
<img alt=""Discord"" src=""https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da"" style=""display: inline-block; vertical-align: middle;""/>
|
| 31 |
+
</a>
|
| 32 |
+
<a href=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true"" target=""_blank"" style=""margin: 2px;"">
|
| 33 |
+
<img alt=""Wechat"" src=""https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/>
|
| 34 |
+
</a>
|
| 35 |
+
<a href=""https://twitter.com/deepseek_ai"" target=""_blank"" style=""margin: 2px;"">
|
| 36 |
+
<img alt=""Twitter Follow"" src=""https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/>
|
| 37 |
+
</a>
|
| 38 |
+
</div>
|
| 39 |
+
|
| 40 |
+
<div align=""center"" style=""line-height: 1;"">
|
| 41 |
+
<a href=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-CODE"" style=""margin: 2px;"">
|
| 42 |
+
<img alt=""Code License"" src=""https://img.shields.io/badge/Code_License-MIT-f5de53?&color=f5de53"" style=""display: inline-block; vertical-align: middle;""/>
|
| 43 |
+
</a>
|
| 44 |
+
<a href=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-MODEL"" style=""margin: 2px;"">
|
| 45 |
+
<img alt=""Model License"" src=""https://img.shields.io/badge/Model_License-Model_Agreement-f5de53?&color=f5de53"" style=""display: inline-block; vertical-align: middle;""/>
|
| 46 |
+
</a>
|
| 47 |
+
</div>
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
<p align=""center"">
|
| 51 |
+
<a href=""#2-model-downloads"">Model Download</a> |
|
| 52 |
+
<a href=""#3-evaluation-results"">Evaluation Results</a> |
|
| 53 |
+
<a href=""#4-model-architecture"">Model Architecture</a> |
|
| 54 |
+
<a href=""#6-api-platform"">API Platform</a> |
|
| 55 |
+
<a href=""#8-license"">License</a> |
|
| 56 |
+
<a href=""#9-citation"">Citation</a>
|
| 57 |
+
</p>
|
| 58 |
+
|
| 59 |
+
<p align=""center"">
|
| 60 |
+
<a href=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/deepseek-v2-tech-report.pdf""><b>Paper Link</b>👁️</a>
|
| 61 |
+
</p>
|
| 62 |
+
|
| 63 |
+
# DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
|
| 64 |
+
|
| 65 |
+
## 1. Introduction
|
| 66 |
+
Today, we’re introducing DeepSeek-V2, a strong Mixture-of-Experts (MoE) language model characterized by economical training and efficient inference. It comprises 236B total parameters, of which 21B are activated for each token. Compared with DeepSeek 67B, DeepSeek-V2 achieves stronger performance, and meanwhile saves 42.5% of training costs, reduces the KV cache by 93.3%, and boosts the maximum generation throughput to 5.76 times.
|
| 67 |
+
|
| 68 |
+
<p align=""center"">
|
| 69 |
+
|
| 70 |
+
<div style=""display: flex; justify-content: center;"">
|
| 71 |
+
<img src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/activationparameters.png?raw=true"" style=""height:300px; width:auto; margin-right:10px"">
|
| 72 |
+
<img src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/trainingcost.png?raw=true"" style=""height:300px; width:auto; margin-left:10px"">
|
| 73 |
+
</div>
|
| 74 |
+
</p>
|
| 75 |
+
We pretrained DeepSeek-V2 on a diverse and high-quality corpus comprising 8.1 trillion tokens. This comprehensive pretraining was followed by a process of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to fully unleash the model's capabilities. The evaluation results validate the effectiveness of our approach as DeepSeek-V2 achieves remarkable performance on both standard benchmarks and open-ended generation evaluation.
|
| 76 |
+
|
| 77 |
+
## 2. Model Downloads
|
| 78 |
+
|
| 79 |
+
<div align=""center"">
|
| 80 |
+
|
| 81 |
+
| **Model** | **Context Length** | **Download** |
|
| 82 |
+
| :------------: | :------------: | :------------: |
|
| 83 |
+
| DeepSeek-V2 | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-V2) |
|
| 84 |
+
| DeepSeek-V2-Chat (RL) | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat) |
|
| 85 |
+
|
| 86 |
+
</div>
|
| 87 |
+
|
| 88 |
+
Due to the constraints of HuggingFace, the open-source code currently experiences slower performance than our internal codebase when running on GPUs with Huggingface. To facilitate the efficient execution of our model, we offer a dedicated vllm solution that optimizes performance for running our model effectively.
|
| 89 |
+
|
| 90 |
+
## 3. Evaluation Results
|
| 91 |
+
### Base Model
|
| 92 |
+
#### Standard Benchmark
|
| 93 |
+
|
| 94 |
+
<div align=""center"">
|
| 95 |
+
|
| 96 |
+
| **Benchmark** | **Domain** | **LLaMA3 70B** | **Mixtral 8x22B** | **DeepSeek-V1 (Dense-67B)** | **DeepSeek-V2 (MoE-236B)** |
|
| 97 |
+
|:-----------:|:--------:|:------------:|:---------------:|:-------------------------:|:------------------------:|
|
| 98 |
+
| **MMLU** | English | 78.9 | 77.6 | 71.3 | 78.5 |
|
| 99 |
+
| **BBH** | English | 81.0 | 78.9 | 68.7 | 78.9 |
|
| 100 |
+
| **C-Eval** | Chinese | 67.5 | 58.6 | 66.1 | 81.7 |
|
| 101 |
+
| **CMMLU** | Chinese | 69.3 | 60.0 | 70.8 | 84.0 |
|
| 102 |
+
| **HumanEval** | Code | 48.2 | 53.1 | 45.1 | 48.8 |
|
| 103 |
+
| **MBPP** | Code | 68.6 | 64.2 | 57.4 | 66.6 |
|
| 104 |
+
| **GSM8K** | Math | 83.0 | 80.3 | 63.4 | 79.2 |
|
| 105 |
+
| **Math** | Math | 42.2 | 42.5 | 18.7 | 43.6 |
|
| 106 |
+
|
| 107 |
+
</div>
|
| 108 |
+
For more evaluation details, such as few-shot settings and prompts, please check our paper.
|
| 109 |
+
|
| 110 |
+
#### Context Window
|
| 111 |
+
<p align=""center"">
|
| 112 |
+
<img width=""80%"" src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/niah.png?raw=true"">
|
| 113 |
+
</p>
|
| 114 |
+
|
| 115 |
+
Evaluation results on the ``Needle In A Haystack`` (NIAH) tests. DeepSeek-V2 performs well across all context window lengths up to **128K**.
|
| 116 |
+
|
| 117 |
+
### Chat Model
|
| 118 |
+
#### Standard Benchmark
|
| 119 |
+
<div align=""center"">
|
| 120 |
+
|
| 121 |
+
| Benchmark | Domain | QWen1.5 72B Chat | Mixtral 8x22B | LLaMA3 70B Instruct | DeepSeek-V1 Chat (SFT) | DeepSeek-V2 Chat (SFT) | DeepSeek-V2 Chat (RL) |
|
| 122 |
+
|:-----------:|:----------------:|:------------------:|:---------------:|:---------------------:|:-------------:|:-----------------------:|:----------------------:|
|
| 123 |
+
| **MMLU** | English | 76.2 | 77.8 | 80.3 | 71.1 | 78.4 | 77.8 |
|
| 124 |
+
| **BBH** | English | 65.9 | 78.4 | 80.1 | 71.7 | 81.3 | 79.7 |
|
| 125 |
+
| **C-Eval** | Chinese | 82.2 | 60.0 | 67.9 | 65.2 | 80.9 | 78.0 |
|
| 126 |
+
| **CMMLU** | Chinese | 82.9 | 61.0 | 70.7 | 67.8 | 82.4 | 81.6 |
|
| 127 |
+
| **HumanEval** | Code | 68.9 | 75.0 | 76.2 | 73.8 | 76.8 | 81.1 |
|
| 128 |
+
| **MBPP** | Code | 52.2 | 64.4 | 69.8 | 61.4 | 70.4 | 72.0 |
|
| 129 |
+
| **LiveCodeBench (0901-0401)** | Code | 18.8 | 25.0 | 30.5 | 18.3 | 28.7 | 32.5 |
|
| 130 |
+
| **GSM8K** | Math | 81.9 | 87.9 | 93.2 | 84.1 | 90.8 | 92.2 |
|
| 131 |
+
| **Math** | Math | 40.6 | 49.8 | 48.5 | 32.6 | 52.7 | 53.9 |
|
| 132 |
+
|
| 133 |
+
</div>
|
| 134 |
+
|
| 135 |
+
#### English Open Ended Generation Evaluation
|
| 136 |
+
We evaluate our model on AlpacaEval 2.0 and MTBench, showing the competitive performance of DeepSeek-V2-Chat-RL on English conversation generation.
|
| 137 |
+
<p align=""center"">
|
| 138 |
+
<img width=""50%"" src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/mtbench.png?raw=true"" />
|
| 139 |
+
</p>
|
| 140 |
+
|
| 141 |
+
#### Chinese Open Ended Generation Evaluation
|
| 142 |
+
**Alignbench** (https://arxiv.org/abs/2311.18743)
|
| 143 |
+
<div align=""center"">
|
| 144 |
+
|
| 145 |
+
| **模型** | **开源/闭源** | **总分** | **中文推理** | **中文语言** |
|
| 146 |
+
| :---: | :---: | :---: | :---: | :---: |
|
| 147 |
+
| gpt-4-1106-preview | 闭源 | 8.01 | 7.73 | 8.29 |
|
| 148 |
+
| DeepSeek-V2 Chat (RL) | 开源 | 7.91 | 7.45 | 8.35 |
|
| 149 |
+
| erniebot-4.0-202404 (文心一言) | 闭源 | 7.89 | 7.61 | 8.17 |
|
| 150 |
+
| DeepSeek-V2 Chat (SFT) | 开源 | 7.74 | 7.30 | 8.17 |
|
| 151 |
+
| gpt-4-0613 | 闭源 | 7.53 | 7.47 | 7.59 |
|
| 152 |
+
| erniebot-4.0-202312 (文心一言) | 闭源 | 7.36 | 6.84 | 7.88 |
|
| 153 |
+
| moonshot-v1-32k-202404 (月之暗面) | 闭源 | 7.22 | 6.42 | 8.02 |
|
| 154 |
+
| Qwen1.5-72B-Chat (通义千问) | 开源 | 7.19 | 6.45 | 7.93 |
|
| 155 |
+
| DeepSeek-67B-Chat | 开源 | 6.43 | 5.75 | 7.11 |
|
| 156 |
+
| Yi-34B-Chat (零一万物) | 开源 | 6.12 | 4.86 | 7.38 |
|
| 157 |
+
| gpt-3.5-turbo-0613 | 闭源 | 6.08 | 5.35 | 6.71 |
|
| 158 |
+
|
| 159 |
+
</div>
|
| 160 |
+
|
| 161 |
+
#### Coding Benchmarks
|
| 162 |
+
We evaluate our model on LiveCodeBench (0901-0401), a benchmark designed for live coding challenges. As illustrated, DeepSeek-V2 demonstrates considerable proficiency in LiveCodeBench, achieving a Pass@1 score that surpasses several other sophisticated models. This performance highlights the model's effectiveness in tackling live coding tasks.
|
| 163 |
+
|
| 164 |
+
<p align=""center"">
|
| 165 |
+
<img width=""50%"" src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/code_benchmarks.png?raw=true"">
|
| 166 |
+
</p>
|
| 167 |
+
|
| 168 |
+
## 4. Model Architecture
|
| 169 |
+
DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference:
|
| 170 |
+
- For attention, we design MLA (Multi-head Latent Attention), which utilizes low-rank key-value union compression to eliminate the bottleneck of inference-time key-value cache, thus supporting efficient inference.
|
| 171 |
+
- For Feed-Forward Networks (FFNs), we adopt DeepSeekMoE architecture, a high-performance MoE architecture that enables training stronger models at lower costs.
|
| 172 |
+
|
| 173 |
+
<p align=""center"">
|
| 174 |
+
<img width=""90%"" src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/architecture.png?raw=true"" />
|
| 175 |
+
</p>
|
| 176 |
+
|
| 177 |
+
## 5. Chat Website
|
| 178 |
+
You can chat with the DeepSeek-V2 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com/sign_in)
|
| 179 |
+
|
| 180 |
+
## 6. API Platform
|
| 181 |
+
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/). Sign up for over millions of free tokens. And you can also pay-as-you-go at an unbeatable price.
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
<p align=""center"">
|
| 185 |
+
<img width=""40%"" src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/model_price.png?raw=true"">
|
| 186 |
+
</p>
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
## 7. How to run locally
|
| 190 |
+
**To utilize DeepSeek-V2 in BF16 format for inference, 80GB*8 GPUs are required.**
|
| 191 |
+
### Inference with Huggingface's Transformers
|
| 192 |
+
You can directly employ [Huggingface's Transformers](https://github.com/huggingface/transformers) for model inference.
|
| 193 |
+
|
| 194 |
+
#### Text Completion
|
| 195 |
+
```python
|
| 196 |
+
import torch
|
| 197 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
|
| 198 |
+
|
| 199 |
+
model_name = ""deepseek-ai/DeepSeek-V2""
|
| 200 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 201 |
+
# `max_memory` should be set based on your devices
|
| 202 |
+
max_memory = {i: ""75GB"" for i in range(8)}
|
| 203 |
+
# `device_map` cannot be set to `auto`
|
| 204 |
+
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map=""sequential"", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation=""eager"")
|
| 205 |
+
model.generation_config = GenerationConfig.from_pretrained(model_name)
|
| 206 |
+
model.generation_config.pad_token_id = model.generation_config.eos_token_id
|
| 207 |
+
|
| 208 |
+
text = ""An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is""
|
| 209 |
+
inputs = tokenizer(text, return_tensors=""pt"")
|
| 210 |
+
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
|
| 211 |
+
|
| 212 |
+
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 213 |
+
print(result)
|
| 214 |
+
```
|
| 215 |
+
|
| 216 |
+
#### Chat Completion
|
| 217 |
+
```python
|
| 218 |
+
import torch
|
| 219 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
|
| 220 |
+
|
| 221 |
+
model_name = ""deepseek-ai/DeepSeek-V2-Chat""
|
| 222 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 223 |
+
# `max_memory` should be set based on your devices
|
| 224 |
+
max_memory = {i: ""75GB"" for i in range(8)}
|
| 225 |
+
# `device_map` cannot be set to `auto`
|
| 226 |
+
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map=""sequential"", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation=""eager"")
|
| 227 |
+
model.generation_config = GenerationConfig.from_pretrained(model_name)
|
| 228 |
+
model.generation_config.pad_token_id = model.generation_config.eos_token_id
|
| 229 |
+
|
| 230 |
+
messages = [
|
| 231 |
+
{""role"": ""user"", ""content"": ""Write a piece of quicksort code in C++""}
|
| 232 |
+
]
|
| 233 |
+
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors=""pt"")
|
| 234 |
+
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
|
| 235 |
+
|
| 236 |
+
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
|
| 237 |
+
print(result)
|
| 238 |
+
```
|
| 239 |
+
|
| 240 |
+
The complete chat template can be found within `tokenizer_config.json` located in the huggingface model repository.
|
| 241 |
+
|
| 242 |
+
An example of chat template is as belows:
|
| 243 |
+
|
| 244 |
+
```bash
|
| 245 |
+
<|begin▁of▁sentence|>User: {user_message_1}
|
| 246 |
+
|
| 247 |
+
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
|
| 248 |
+
|
| 249 |
+
Assistant:
|
| 250 |
+
```
|
| 251 |
+
|
| 252 |
+
You can also add an optional system message:
|
| 253 |
+
|
| 254 |
+
```bash
|
| 255 |
+
<|begin▁of▁sentence|>{system_message}
|
| 256 |
+
|
| 257 |
+
User: {user_message_1}
|
| 258 |
+
|
| 259 |
+
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
|
| 260 |
+
|
| 261 |
+
Assistant:
|
| 262 |
+
```
|
| 263 |
+
|
| 264 |
+
### Inference with vLLM (recommended)
|
| 265 |
+
To utilize [vLLM](https://github.com/vllm-project/vllm) for model inference, please merge this Pull Request into your vLLM codebase: https://github.com/vllm-project/vllm/pull/4650.
|
| 266 |
+
|
| 267 |
+
```python
|
| 268 |
+
from transformers import AutoTokenizer
|
| 269 |
+
from vllm import LLM, SamplingParams
|
| 270 |
+
|
| 271 |
+
max_model_len, tp_size = 8192, 8
|
| 272 |
+
model_name = ""deepseek-ai/DeepSeek-V2-Chat""
|
| 273 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 274 |
+
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
|
| 275 |
+
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
|
| 276 |
+
|
| 277 |
+
messages_list = [
|
| 278 |
+
[{""role"": ""user"", ""content"": ""Who are you?""}],
|
| 279 |
+
[{""role"": ""user"", ""content"": ""Translate the following content into Chinese directly: DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference.""}],
|
| 280 |
+
[{""role"": ""user"", ""content"": ""Write a piece of quicksort code in C++.""}],
|
| 281 |
+
]
|
| 282 |
+
|
| 283 |
+
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
|
| 284 |
+
|
| 285 |
+
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
|
| 286 |
+
|
| 287 |
+
generated_text = [output.outputs[0].text for output in outputs]
|
| 288 |
+
print(generated_text)
|
| 289 |
+
```
|
| 290 |
+
|
| 291 |
+
## 8. License
|
| 292 |
+
This code repository is licensed under [the MIT License](LICENSE-CODE). The use of DeepSeek-V2 Base/Chat models is subject to [the Model License](LICENSE-MODEL). DeepSeek-V2 series (including Base and Chat) supports commercial use.
|
| 293 |
+
|
| 294 |
+
## 9. Citation
|
| 295 |
+
```
|
| 296 |
+
@misc{deepseekv2,
|
| 297 |
+
title={DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model},
|
| 298 |
+
author={DeepSeek-AI},
|
| 299 |
+
year={2024},
|
| 300 |
+
eprint={2405.04434},
|
| 301 |
+
archivePrefix={arXiv},
|
| 302 |
+
primaryClass={cs.CL}
|
| 303 |
+
}
|
| 304 |
+
```
|
| 305 |
+
|
| 306 |
+
## 10. Contact
|
| 307 |
+
If you have any questions, please raise an issue or contact us at [service@deepseek.com](service@deepseek.com).
|
| 308 |
+
","{""id"": ""deepseek-ai/DeepSeek-V2"", ""author"": ""deepseek-ai"", ""sha"": ""4461458f186c35188585855f28f77af5661ad489"", ""last_modified"": ""2024-06-08 09:13:39+00:00"", ""created_at"": ""2024-04-22 07:53:46+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 150356, ""downloads_all_time"": null, ""likes"": 317, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""deepseek_v2"", ""text-generation"", ""conversational"", ""custom_code"", ""arxiv:2311.18743"", ""arxiv:2405.04434"", ""license:other"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: other\nlicense_name: deepseek\nlicense_link: https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-MODEL"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""DeepseekV2ForCausalLM""], ""auto_map"": {""AutoConfig"": ""configuration_deepseek.DeepseekV2Config"", ""AutoModel"": ""modeling_deepseek.DeepseekV2Model"", ""AutoModelForCausalLM"": ""modeling_deepseek.DeepseekV2ForCausalLM""}, ""model_type"": ""deepseek_v2"", ""tokenizer_config"": {""bos_token"": {""__type"": ""AddedToken"", ""content"": ""<\uff5cbegin\u2581of\u2581sentence\uff5c>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""eos_token"": {""__type"": ""AddedToken"", ""content"": ""<\uff5cend\u2581of\u2581sentence\uff5c>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""pad_token"": {""__type"": ""AddedToken"", ""content"": ""<\uff5cend\u2581of\u2581sentence\uff5c>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""unk_token"": null, ""chat_template"": ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{{ bos_token }}{% for message in messages %}{% if message['role'] == 'user' %}{{ 'User: ' + message['content'] + '\n\n' }}{% elif message['role'] == 'assistant' %}{{ 'Assistant: ' + message['content'] + eos_token }}{% elif message['role'] == 'system' %}{{ message['content'] + '\n\n' }}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}""}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": ""modeling_deepseek.DeepseekV2ForCausalLM"", ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_deepseek.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00009-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00010-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00011-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00012-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00013-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00014-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00015-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00016-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00017-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00018-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00019-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00020-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00021-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00022-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00023-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00024-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00025-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00026-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00027-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00028-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00029-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00030-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00031-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00032-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00033-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00034-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00035-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00036-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00037-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00038-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00039-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00040-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00041-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00042-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00043-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00044-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00045-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00046-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00047-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00048-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00049-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00050-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00051-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00052-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00053-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00054-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00055-of-000055.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_deepseek.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenization_deepseek_fast.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Justinrune/LLaMA-Factory"", ""kenken999/fastapi_django_main_live"", ""xzuyn/Token-Count-Comparison"", ""concedo/WebTokenizer"", ""msun415/Llamole"", ""ultralight99/training_deepseek""], ""safetensors"": {""parameters"": {""BF16"": 235741434880}, ""total"": 235741434880}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-06-08 09:13:39+00:00"", ""cardData"": ""license: other\nlicense_name: deepseek\nlicense_link: https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-MODEL"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": ""modeling_deepseek.DeepseekV2ForCausalLM"", ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""_id"": ""6626178a0e31d65ecc5df218"", ""modelId"": ""deepseek-ai/DeepSeek-V2"", ""usedStorage"": 471486512925}",0,https://huggingface.co/mradermacher/DeepSeek-V2-GGUF,1,,0,https://huggingface.co/mradermacher/DeepSeek-V2-i1-GGUF,1,,0,"Justinrune/LLaMA-Factory, concedo/WebTokenizer, huggingface/InferenceSupport/discussions/new?title=deepseek-ai/DeepSeek-V2&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bdeepseek-ai%2FDeepSeek-V2%5D(%2Fdeepseek-ai%2FDeepSeek-V2)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kenken999/fastapi_django_main_live, msun415/Llamole, ultralight99/training_deepseek, xzuyn/Token-Count-Comparison",7
|
| 309 |
+
mradermacher/DeepSeek-V2-GGUF,"---
|
| 310 |
+
base_model: deepseek-ai/DeepSeek-V2
|
| 311 |
+
language:
|
| 312 |
+
- en
|
| 313 |
+
library_name: transformers
|
| 314 |
+
license: other
|
| 315 |
+
license_link: https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-MODEL
|
| 316 |
+
license_name: deepseek
|
| 317 |
+
quantized_by: mradermacher
|
| 318 |
+
---
|
| 319 |
+
## About
|
| 320 |
+
|
| 321 |
+
<!-- ### quantize_version: 2 -->
|
| 322 |
+
<!-- ### output_tensor_quantised: 1 -->
|
| 323 |
+
<!-- ### convert_type: hf -->
|
| 324 |
+
<!-- ### vocab_type: -->
|
| 325 |
+
<!-- ### tags: -->
|
| 326 |
+
static quants of https://huggingface.co/deepseek-ai/DeepSeek-V2
|
| 327 |
+
|
| 328 |
+
<!-- provided-files -->
|
| 329 |
+
weighted/imatrix quants are available at https://huggingface.co/mradermacher/DeepSeek-V2-i1-GGUF
|
| 330 |
+
## Usage
|
| 331 |
+
|
| 332 |
+
If you are unsure how to use GGUF files, refer to one of [TheBloke's
|
| 333 |
+
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
|
| 334 |
+
more details, including on how to concatenate multi-part files.
|
| 335 |
+
|
| 336 |
+
## Provided Quants
|
| 337 |
+
|
| 338 |
+
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
|
| 339 |
+
|
| 340 |
+
| Link | Type | Size/GB | Notes |
|
| 341 |
+
|:-----|:-----|--------:|:------|
|
| 342 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q2_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q2_K.gguf.part2of2) | Q2_K | 86.0 | |
|
| 343 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ3_XS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ3_XS.gguf.part2of2) | IQ3_XS | 96.4 | |
|
| 344 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ3_S.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ3_S.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ3_S.gguf.part3of3) | IQ3_S | 101.8 | beats Q3_K* |
|
| 345 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q3_K_S.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q3_K_S.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q3_K_S.gguf.part3of3) | Q3_K_S | 101.8 | |
|
| 346 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ3_M.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ3_M.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ3_M.gguf.part3of3) | IQ3_M | 103.5 | |
|
| 347 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q3_K_M.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q3_K_M.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q3_K_M.gguf.part3of3) | Q3_K_M | 112.8 | lower quality |
|
| 348 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q3_K_L.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q3_K_L.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q3_K_L.gguf.part3of3) | Q3_K_L | 122.5 | |
|
| 349 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ4_XS.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ4_XS.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.IQ4_XS.gguf.part3of3) | IQ4_XS | 126.9 | |
|
| 350 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q4_K_S.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q4_K_S.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q4_K_S.gguf.part3of3) | Q4_K_S | 134.0 | fast, recommended |
|
| 351 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q4_K_M.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q4_K_M.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q4_K_M.gguf.part3of3) | Q4_K_M | 142.6 | fast, recommended |
|
| 352 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q5_K_S.gguf.part1of4) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q5_K_S.gguf.part2of4) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q5_K_S.gguf.part3of4) [PART 4](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q5_K_S.gguf.part4of4) | Q5_K_S | 162.4 | |
|
| 353 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q5_K_M.gguf.part1of4) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q5_K_M.gguf.part2of4) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q5_K_M.gguf.part3of4) [PART 4](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q5_K_M.gguf.part4of4) | Q5_K_M | 167.3 | |
|
| 354 |
+
| [PART 1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q6_K.gguf.part1of4) [PART 2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q6_K.gguf.part2of4) [PART 3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q6_K.gguf.part3of4) [PART 4](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q6_K.gguf.part4of4) | Q6_K | 193.6 | very good quality |
|
| 355 |
+
| [P1](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q8_0.gguf.part1of6) [P2](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q8_0.gguf.part2of6) [P3](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q8_0.gguf.part3of6) [P4](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q8_0.gguf.part4of6) [P5](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q8_0.gguf.part5of6) [P6](https://huggingface.co/mradermacher/DeepSeek-V2-GGUF/resolve/main/DeepSeek-V2.Q8_0.gguf.part6of6) | Q8_0 | 250.7 | fast, best quality |
|
| 356 |
+
|
| 357 |
+
Here is a handy graph by ikawrakow comparing some lower-quality quant
|
| 358 |
+
types (lower is better):
|
| 359 |
+
|
| 360 |
+

|
| 361 |
+
|
| 362 |
+
And here are Artefact2's thoughts on the matter:
|
| 363 |
+
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
|
| 364 |
+
|
| 365 |
+
## FAQ / Model Request
|
| 366 |
+
|
| 367 |
+
See https://huggingface.co/mradermacher/model_requests for some answers to
|
| 368 |
+
questions you might have and/or if you want some other model quantized.
|
| 369 |
+
|
| 370 |
+
## Thanks
|
| 371 |
+
|
| 372 |
+
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
|
| 373 |
+
me use its servers and providing upgrades to my workstation to enable
|
| 374 |
+
this work in my free time.
|
| 375 |
+
|
| 376 |
+
<!-- end -->
|
| 377 |
+
","{""id"": ""mradermacher/DeepSeek-V2-GGUF"", ""author"": ""mradermacher"", ""sha"": ""0f3e529bd35d7599e70738b7b721a32087165103"", ""last_modified"": ""2024-07-10 16:18:12+00:00"", ""created_at"": ""2024-07-09 14:55:50+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""en"", ""base_model:deepseek-ai/DeepSeek-V2"", ""base_model:finetune:deepseek-ai/DeepSeek-V2"", ""license:other"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: deepseek-ai/DeepSeek-V2\nlanguage:\n- en\nlibrary_name: transformers\nlicense: other\nlicense_name: deepseek\nlicense_link: https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-MODEL\nquantized_by: mradermacher"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ3_M.gguf.part1of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ3_M.gguf.part2of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ3_M.gguf.part3of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ3_S.gguf.part1of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ3_S.gguf.part2of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ3_S.gguf.part3of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ3_XS.gguf.part1of2', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ3_XS.gguf.part2of2', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ4_XS.gguf.part1of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ4_XS.gguf.part2of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.IQ4_XS.gguf.part3of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q2_K.gguf.part1of2', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q2_K.gguf.part2of2', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q3_K_L.gguf.part1of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q3_K_L.gguf.part2of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q3_K_L.gguf.part3of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q3_K_M.gguf.part1of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q3_K_M.gguf.part2of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q3_K_M.gguf.part3of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q3_K_S.gguf.part1of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q3_K_S.gguf.part2of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q3_K_S.gguf.part3of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q4_K_M.gguf.part1of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q4_K_M.gguf.part2of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q4_K_M.gguf.part3of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q4_K_S.gguf.part1of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q4_K_S.gguf.part2of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q4_K_S.gguf.part3of3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q5_K_M.gguf.part1of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q5_K_M.gguf.part2of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q5_K_M.gguf.part3of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q5_K_M.gguf.part4of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q5_K_S.gguf.part1of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q5_K_S.gguf.part2of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q5_K_S.gguf.part3of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q5_K_S.gguf.part4of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q6_K.gguf.part1of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q6_K.gguf.part2of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q6_K.gguf.part3of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q6_K.gguf.part4of4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q8_0.gguf.part1of6', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q8_0.gguf.part2of6', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q8_0.gguf.part3of6', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q8_0.gguf.part4of6', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q8_0.gguf.part5of6', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-V2.Q8_0.gguf.part6of6', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-07-10 16:18:12+00:00"", ""cardData"": ""base_model: deepseek-ai/DeepSeek-V2\nlanguage:\n- en\nlibrary_name: transformers\nlicense: other\nlicense_name: deepseek\nlicense_link: https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-MODEL\nquantized_by: mradermacher"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""668d4f7663d1bc005bcdb592"", ""modelId"": ""mradermacher/DeepSeek-V2-GGUF"", ""usedStorage"": 1900813252736}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=mradermacher/DeepSeek-V2-GGUF&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bmradermacher%2FDeepSeek-V2-GGUF%5D(%2Fmradermacher%2FDeepSeek-V2-GGUF)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
DialoGPT-large_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
DiffRhythm-base_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
ASLP-lab/DiffRhythm-base,"---
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
+
- en
|
| 6 |
+
tags:
|
| 7 |
+
- music
|
| 8 |
+
- art
|
| 9 |
+
- diffusion
|
| 10 |
+
license: apache-2.0
|
| 11 |
+
license_name: stable-audio-community
|
| 12 |
+
license_link: LICENSE
|
| 13 |
+
library_name: DiffRhythm
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
<p align=""center"">
|
| 17 |
+
<h1>DiffRhythm: Blazingly Fast and Embarrassingly Simple End-to-End Full-Length Song Generation with Latent Diffusion</h1>
|
| 18 |
+
</p>
|
| 19 |
+
|
| 20 |
+
Ziqian Ning, Huakang Chen, Yuepeng Jiang, Chunbo Hao, Guobin Ma, Shuai Wang, Jixun Yao, Lei Xie†
|
| 21 |
+
|
| 22 |
+
<p align=""center"">
|
| 23 |
+
<a href=""https://huggingface.co/spaces/ASLP-lab/DiffRhythm""> Huggingface Space</a> </a> 
|
| 24 |
+
<br>
|
| 25 |
+
📑 <a href=""https://arxiv.org/abs/2503.01183"">Paper</a>    |    📑 <a href=""https://aslp-lab.github.io/DiffRhythm.github.io/"">Demo</a>   
|
| 26 |
+
</p>
|
| 27 |
+
|
| 28 |
+
DiffRhythm (Chinese: 谛韵, Dì Yùn) is the ***first*** diffusion-based song generation model that is capable of creating full-length songs. The name combines ""Diff"" (referencing its diffusion architecture) with ""Rhythm"" (highlighting its focus on music and song creation). The Chinese name 谛韵 (Dì Yùn) phonetically mirrors ""DiffRhythm"", where ""谛"" (attentive listening) symbolizes auditory perception, and ""韵"" (melodic charm) represents musicality.
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
<p align=""center"">
|
| 32 |
+
<img src=""src/diffrhythm.jpg"" width=""90%""/>
|
| 33 |
+
<p>
|
| 34 |
+
|
| 35 |
+
## News and Updates
|
| 36 |
+
|
| 37 |
+
### 2025.3.4 🔥 We released the [DiffRhythm paper](https://arxiv.org/abs/2503.01183) and [Huggingface Space demo](https://huggingface.co/spaces/ASLP-lab/DiffRhythm).
|
| 38 |
+
|
| 39 |
+
## TODOs
|
| 40 |
+
- [ ] Support local deployment:
|
| 41 |
+
- [ ] Support Colab:
|
| 42 |
+
- [ ] Support Docker:
|
| 43 |
+
- [x] Release paper to Arxiv.
|
| 44 |
+
- [x] Online serving on huggingface space.
|
| 45 |
+
|
| 46 |
+
## Model Versions
|
| 47 |
+
|
| 48 |
+
| Model | HuggingFace |
|
| 49 |
+
| ---- | ---- |
|
| 50 |
+
| DiffRhythm-base (1m35s) | https://huggingface.co/ASLP-lab/DiffRhythm-base |
|
| 51 |
+
| DiffRhythm-full (4m45s) | Coming soon... |
|
| 52 |
+
| DiffRhythm-vae | https://huggingface.co/ASLP-lab/DiffRhythm-vae |
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
## License & Disclaimer
|
| 56 |
+
|
| 57 |
+
DiffRhythm (code and DiT weights) is released under the Apache License 2.0. This open-source license allows you to freely use, modify, and distribute the model, as long as you include the appropriate copyright notice and disclaimer.
|
| 58 |
+
|
| 59 |
+
We do not make any profit from this model. Our goal is to provide a high-quality base model for music generation, fostering innovation in AI music and contributing to the advancement of human creativity. We hope that DiffRhythm will serve as a foundation for further research and development in the field of AI-generated music.
|
| 60 |
+
|
| 61 |
+
DiffRhythm enables the creation of original music across diverse genres, supporting applications in artistic creation, education, and entertainment. While designed for positive use cases, potential risks include unintentional copyright infringement through stylistic similarities, inappropriate blending of cultural musical elements, and misuse for generating harmful content. To ensure responsible deployment, users must implement verification mechanisms to confirm musical originality, disclose AI involvement in generated works, and obtain permissions when adapting protected styles.
|
| 62 |
+
|
| 63 |
+
## Citation
|
| 64 |
+
```
|
| 65 |
+
@article{ning2025diffrhythm,
|
| 66 |
+
title={{DiffRhythm}: Blazingly Fast and Embarrassingly Simple</br>End-to-End Full-Length Song Generation with Latent Diffusion<},
|
| 67 |
+
author={Ziqian, Ning and Huakang, Chen and Yuepeng, Jiang and Chunbo, Hao and Guobin, Ma and Shuai, Wang and Jixun, Yao and Lei, Xie},
|
| 68 |
+
journal={arXiv preprint arXiv:2503.01183},
|
| 69 |
+
year={2025}
|
| 70 |
+
}
|
| 71 |
+
```
|
| 72 |
+
## Contact Us
|
| 73 |
+
|
| 74 |
+
If you are interested in leaving a message to our research team, feel free to email `nzqiann@gmail.com`.
|
| 75 |
+
<p align=""center"">
|
| 76 |
+
<a href=""http://www.nwpu-aslp.org/"">
|
| 77 |
+
<img src=""src/ASLP.jpg"" width=""400""/>
|
| 78 |
+
</a>
|
| 79 |
+
</p>","{""id"": ""ASLP-lab/DiffRhythm-base"", ""author"": ""ASLP-lab"", ""sha"": ""6cb11765c53bd4c7548f40d9e43588e508c2ec6f"", ""last_modified"": ""2025-03-26 05:48:41+00:00"", ""created_at"": ""2025-03-02 15:16:58+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 199, ""downloads_all_time"": null, ""likes"": 159, ""library_name"": ""DiffRhythm"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""DiffRhythm"", ""diffrhythm"", ""music"", ""art"", ""diffusion"", ""zh"", ""en"", ""arxiv:2503.01183"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- zh\n- en\nlibrary_name: DiffRhythm\nlicense: apache-2.0\nlicense_name: stable-audio-community\nlicense_link: LICENSE\ntags:\n- music\n- art\n- diffusion"", ""widget_data"": null, ""model_index"": null, ""config"": {""model_type"": ""diffrhythm""}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cfm_model.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='src/ASLP.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='src/diffrhythm.jpg', size=None, blob_id=None, lfs=None)""], ""spaces"": [""ASLP-lab/DiffRhythm"", ""cocktailpeanut/DiffRhythm"", ""fffiloni/DiffRhythm-SimpleUI"", ""demohug/demo11213"", ""dskill/DiffRhythm"", ""Princess7317/TuneWeave""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-26 05:48:41+00:00"", ""cardData"": ""language:\n- zh\n- en\nlibrary_name: DiffRhythm\nlicense: apache-2.0\nlicense_name: stable-audio-community\nlicense_link: LICENSE\ntags:\n- music\n- art\n- diffusion"", ""transformersInfo"": null, ""_id"": ""67c4766ad43a5b1766e00afe"", ""modelId"": ""ASLP-lab/DiffRhythm-base"", ""usedStorage"": 2222981461}",0,,0,,0,,0,,0,"ASLP-lab/DiffRhythm, Princess7317/TuneWeave, cocktailpeanut/DiffRhythm, demohug/demo11213, dskill/DiffRhythm, fffiloni/DiffRhythm-SimpleUI, huggingface/InferenceSupport/discussions/new?title=ASLP-lab/DiffRhythm-base&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BASLP-lab%2FDiffRhythm-base%5D(%2FASLP-lab%2FDiffRhythm-base)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A",7
|
GLM-4-32B-0414_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
GPT-SoVITS_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
lj1995/GPT-SoVITS,"---
|
| 3 |
+
license: mit
|
| 4 |
+
pipeline_tag: text-to-speech
|
| 5 |
+
---
|
| 6 |
+
pretrained models used in https://github.com/RVC-Boss/GPT-SoVITS","{""id"": ""lj1995/GPT-SoVITS"", ""author"": ""lj1995"", ""sha"": ""fd817aadf143790575ade59d16f5f76d4c02e18a"", ""last_modified"": ""2025-04-20 07:05:04+00:00"", ""created_at"": ""2024-01-16 10:10:17+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 336, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""text-to-speech"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""text-to-speech"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: mit\npipeline_tag: text-to-speech"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-hubert-base/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-hubert-base/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-hubert-base/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-roberta-wwm-ext-large/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-roberta-wwm-ext-large/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-roberta-wwm-ext-large/tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v2final-pretrained/s1bert25hz-5kh-longer-epoch=12-step=369668.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v2final-pretrained/s2D2333k.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v2final-pretrained/s2G2333k.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v4-pretrained/s2Gv4.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v4-pretrained/vocoder.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='models--nvidia--bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='models--nvidia--bigvgan_v2_24khz_100band_256x/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='s1v3.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='s2D488k.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='s2G488k.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='s2Gv3.pth', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Pendrokar/TTS-Spaces-Arena"", ""Bread-F/Intelligent-Medical-Guidance-Large-Model""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-20 07:05:04+00:00"", ""cardData"": ""license: mit\npipeline_tag: text-to-speech"", ""transformersInfo"": null, ""_id"": ""65a65609f52421af99f24d4c"", ""modelId"": ""lj1995/GPT-SoVITS"", ""usedStorage"": 4590646931}",0,"https://huggingface.co/szxzip/My-GPT-SoVits, https://huggingface.co/BigPancake01/GPT-SoVITS_Mihoyo, https://huggingface.co/PJMixers-Dev/lj1995_GPT-SoVITS-safetensors, https://huggingface.co/MondMeer/GPT-SoVITS-HiiragiHakua, https://huggingface.co/MondMeer/GPT-SoVITS-MinazukiHotaru",5,,0,,0,,0,"Bread-F/Intelligent-Medical-Guidance-Large-Model, Pendrokar/TTS-Spaces-Arena, huggingface/InferenceSupport/discussions/new?title=lj1995/GPT-SoVITS&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Blj1995%2FGPT-SoVITS%5D(%2Flj1995%2FGPT-SoVITS)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A",3
|
| 7 |
+
szxzip/My-GPT-SoVits,"---
|
| 8 |
+
license: creativeml-openrail-m
|
| 9 |
+
language:
|
| 10 |
+
- zh
|
| 11 |
+
base_model:
|
| 12 |
+
- lj1995/GPT-SoVITS
|
| 13 |
+
pipeline_tag: text-to-speech
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
# A collection of GPT-SoVITS models and datasets.
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
```
|
| 20 |
+
My-GPT-SoVits/
|
| 21 |
+
├── README.md
|
| 22 |
+
└── models/
|
| 23 |
+
├── foo.ckpt
|
| 24 |
+
├── bar.pth
|
| 25 |
+
├── reference_audio/
|
| 26 |
+
├── dataset/
|
| 27 |
+
└── demo/
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
> To H. T. Yang & Z. L. Zhang.
|
| 31 |
+
|
| 32 |
+
© CreativeML OpenRAIL-M
|
| 33 |
+
","{""id"": ""szxzip/My-GPT-SoVits"", ""author"": ""szxzip"", ""sha"": ""3ab56e0d5bf347f4b210abacd93e65dd8f80d0bd"", ""last_modified"": ""2025-04-18 12:00:50+00:00"", ""created_at"": ""2025-04-18 07:10:57+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 1, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""text-to-speech"", ""zh"", ""base_model:lj1995/GPT-SoVITS"", ""base_model:finetune:lj1995/GPT-SoVITS"", ""license:creativeml-openrail-m"", ""region:us""], ""pipeline_tag"": ""text-to-speech"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- lj1995/GPT-SoVITS\nlanguage:\n- zh\nlicense: creativeml-openrail-m\npipeline_tag: text-to-speech"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v2_e12_s6828.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v2_e16_s9104.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v2_e20_s11380.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v2_e4_s2276.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v2_e8_s4552.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v3_e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v3_e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v3_e1_s569_l32.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v3_e2_s1138_l32.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v3_e3_s1707_l32.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/LeiSen_v3_e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/1.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/10.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/11.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/12.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/13.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/14.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/15.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/16.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/17.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/18.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/19.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/2.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/20.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/21.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/22.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/23.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/24.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/25.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/26.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/27.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/28.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/29.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/3.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/30.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/31.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/4.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/5.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/6.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/7.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/8.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/dataset/9.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/demo/LeiSen_v2_e12.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/demo/LeiSen_v2_e16.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/demo/LeiSen_v2_e20.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/demo/LeiSen_v3_e2.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/demo/LeiSen_v3_e3.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/demo/demo.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LeiSen/reference_audio/LeiSen.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v2_e12_s4872.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v2_e16_s6496.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v2_e20_s8120.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v2_e4_s1624.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v2_e8_s3248.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v3_e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v3_e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v3_e1_s406_l32.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v3_e2_s812_l32.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v3_e3_s1218_l32.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Szxzip/Szxzip_v3_e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v2_e12_s1464.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v2_e16_s1952.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v2_e20_s2440.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v2_e4_s488.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v2_e8_s976.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v3_e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v3_e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v3_e1_s122_l32.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v3_e2_s244_l32.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v3_e3_s366_l32.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/XiaQing_v3_e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/dataset/1.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/dataset/2.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/demo/XiaQing_v2_e12.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/demo/XiaQing_v2_e16.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/demo/XiaQing_v2_e20.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/demo/XiaQing_v3_e2.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/demo/XiaQing_v3_e3.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/demo/demo.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/reference_audio/XiaQing.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='XiaQing/reference_audio/XiaQing.wav', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-18 12:00:50+00:00"", ""cardData"": ""base_model:\n- lj1995/GPT-SoVITS\nlanguage:\n- zh\nlicense: creativeml-openrail-m\npipeline_tag: text-to-speech"", ""transformersInfo"": null, ""_id"": ""6801fb01ab0c6ad76827f1ff"", ""modelId"": ""szxzip/My-GPT-SoVits"", ""usedStorage"": 4374700338}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=szxzip/My-GPT-SoVits&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bszxzip%2FMy-GPT-SoVits%5D(%2Fszxzip%2FMy-GPT-SoVits)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 34 |
+
BigPancake01/GPT-SoVITS_Mihoyo,"---
|
| 35 |
+
license: mit
|
| 36 |
+
language:
|
| 37 |
+
- zh
|
| 38 |
+
base_model:
|
| 39 |
+
- lj1995/GPT-SoVITS
|
| 40 |
+
pipeline_tag: text-to-speech
|
| 41 |
+
---
|
| 42 |
+
该项目中主要包含使用《原神》与《崩坏 星穹铁道》中部分角色的对话语音训练的用于GPT-SoVITS模型推理的模型以及部分参考音频。其中`GPT_models`与`VITS_models`为推理过程中使用的模型权重文件,文件夹以角色名命名。`ref_audios`中包含对应角色的推理参考音频。","{""id"": ""BigPancake01/GPT-SoVITS_Mihoyo"", ""author"": ""BigPancake01"", ""sha"": ""1c22008960a57038f5469a7dc455613dac9733da"", ""last_modified"": ""2025-04-19 20:11:18+00:00"", ""created_at"": ""2025-04-18 11:11:53+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 1, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""text-to-speech"", ""zh"", ""base_model:lj1995/GPT-SoVITS"", ""base_model:finetune:lj1995/GPT-SoVITS"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""text-to-speech"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- lj1995/GPT-SoVITS\nlanguage:\n- zh\nlicense: mit\npipeline_tag: text-to-speech"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Ayaka/Ayaka-e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Ayaka/Ayaka-e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Ayaka/Ayaka-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Citlali/Citlali-e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Citlali/Citlali-e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Citlali/Citlali-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Firefly/Firefly-e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Firefly/Firefly-e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Firefly/Firefly-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Klee/Klee-e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Klee/Klee-e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Klee/Klee-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Nahida/Nahida-e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Nahida/Nahida-e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Nahida/Nahida-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Tribbie/Tribbie-e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Tribbie/Tribbie-e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Tribbie/Tribbie-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_models/Yoimiya/Yoimiya-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Ayaka/Ayaka_315_e4_s288.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Ayaka/Ayaka_315_e8_s576.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Citlali/Citlali_e4_s580.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Citlali/Citlali_e8_s1160.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Firefly/Firefly_e4_s252.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Firefly/Firefly_e8_s504.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Klee/Klee_e4_s328.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Klee/Klee_e8_s656.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Nahida/Nahida_e4_s600.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Nahida/Nahida_e8_s1200.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Tribbie/Tribbie_e4_s172.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Tribbie/Tribbie_e8_s344.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Yoimiya/Yoimiya_e4_s512.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VITS_models/Yoimiya/Yoimiya_e8_s1024.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ref_audios/.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ref_audios/Ayaka.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ref_audios/Firefly.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ref_audios/Klee.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ref_audios/Nahida.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ref_audios/Tribbie.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ref_audios/Yoimiya.wav', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-19 20:11:18+00:00"", ""cardData"": ""base_model:\n- lj1995/GPT-SoVITS\nlanguage:\n- zh\nlicense: mit\npipeline_tag: text-to-speech"", ""transformersInfo"": null, ""_id"": ""68023379a67bcec576193c24"", ""modelId"": ""BigPancake01/GPT-SoVITS_Mihoyo"", ""usedStorage"": 7200541014}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=BigPancake01/GPT-SoVITS_Mihoyo&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BBigPancake01%2FGPT-SoVITS_Mihoyo%5D(%2FBigPancake01%2FGPT-SoVITS_Mihoyo)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 43 |
+
PJMixers-Dev/lj1995_GPT-SoVITS-safetensors,"---
|
| 44 |
+
pipeline_tag: text-to-audio
|
| 45 |
+
base_model:
|
| 46 |
+
- lj1995/GPT-SoVITS
|
| 47 |
+
---
|
| 48 |
+
Original files converted to safetensors for use with my [fork/draft PR of GPT-SoVITS](https://github.com/xzuyn/GPT-SoVITS/tree/safetensors).","{""id"": ""PJMixers-Dev/lj1995_GPT-SoVITS-safetensors"", ""author"": ""PJMixers-Dev"", ""sha"": ""cea8b8279588e63c2fdc10e02610c11f02af5450"", ""last_modified"": ""2024-10-16 22:57:26+00:00"", ""created_at"": ""2024-10-15 22:35:47+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 2, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""safetensors"", ""text-to-audio"", ""base_model:lj1995/GPT-SoVITS"", ""base_model:finetune:lj1995/GPT-SoVITS"", ""region:us""], ""pipeline_tag"": ""text-to-audio"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- lj1995/GPT-SoVITS\npipeline_tag: text-to-audio"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-hubert-base/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-hubert-base/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-hubert-base/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-roberta-wwm-ext-large/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-roberta-wwm-ext-large/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinese-roberta-wwm-ext-large/tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v2final-pretrained/s1bert25hz-5kh-longer-epoch=12-step=369668.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v2final-pretrained/s1bert25hz-5kh-longer-epoch=12-step=369668.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v2final-pretrained/s2D2333k.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v2final-pretrained/s2D2333k.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v2final-pretrained/s2G2333k.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='gsv-v2final-pretrained/s2G2333k.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-10-16 22:57:26+00:00"", ""cardData"": ""base_model:\n- lj1995/GPT-SoVITS\npipeline_tag: text-to-audio"", ""transformersInfo"": null, ""_id"": ""670eee43c8d4b153e867836b"", ""modelId"": ""PJMixers-Dev/lj1995_GPT-SoVITS-safetensors"", ""usedStorage"": 1549392963}",1,https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina,1,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=PJMixers-Dev/lj1995_GPT-SoVITS-safetensors&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BPJMixers-Dev%2Flj1995_GPT-SoVITS-safetensors%5D(%2FPJMixers-Dev%2Flj1995_GPT-SoVITS-safetensors)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 49 |
+
PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina,"---
|
| 50 |
+
pipeline_tag: text-to-speech
|
| 51 |
+
datasets:
|
| 52 |
+
- PJMixers-Dev/Genshin-Impact-Furina-TTS
|
| 53 |
+
- AquaV/genshin-voices-separated
|
| 54 |
+
language:
|
| 55 |
+
- en
|
| 56 |
+
base_model:
|
| 57 |
+
- PJMixers-Dev/lj1995_GPT-SoVITS-safetensors
|
| 58 |
+
---
|
| 59 |
+
For use with my [fork/draft PR of GPT-SoVITS](https://github.com/xzuyn/GPT-SoVITS/tree/safetensors).
|
| 60 |
+
|
| 61 |
+
---
|
| 62 |
+
|
| 63 |
+
# Non-Cherrypicked Examples
|
| 64 |
+
Each example was generated in a single attempt using the final checkpoints (`Furina_e8_s2136.safetensors` & `Furina-e15.safetensors`) to give an honest look at the models performance. The prompts were randomly generated with ChatGPT.
|
| 65 |
+
|
| 66 |
+
## Generation Settings
|
| 67 |
+
```
|
| 68 |
+
Reference Audio: reference_audio.wav
|
| 69 |
+
Reference Text: In truth, I know little about becoming a nation's new god, but it will be my honor to guide you all.
|
| 70 |
+
No reference mode: Disabled
|
| 71 |
+
|
| 72 |
+
Speech Rate: 1
|
| 73 |
+
Top-K: 20
|
| 74 |
+
Min-P: 0.1
|
| 75 |
+
Top-P: 1
|
| 76 |
+
Temperature: 1
|
| 77 |
+
Repetition Penalty: 1.35
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
<hr>
|
| 81 |
+
<div class='audio-container'>
|
| 82 |
+
<div>
|
| 83 |
+
<p>Example 1: <code>The flickering lights of the distant city danced like stars on the horizon.</code></p>
|
| 84 |
+
<audio controls>
|
| 85 |
+
<source src=""https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina/raw/main/examples/example1.wav"" type=""audio/wav"">
|
| 86 |
+
</audio>
|
| 87 |
+
<p>Example 2: <code>A gentle breeze stirred the autumn leaves, carrying with it the scent of rain.</code></p>
|
| 88 |
+
<audio controls>
|
| 89 |
+
<source src=""https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina/raw/main/examples/example2.wav"" type=""audio/wav"">
|
| 90 |
+
</audio>
|
| 91 |
+
<p>Example 3: <code>Beneath the surface of the ocean, an unseen world teemed with ancient mysteries.</code></p>
|
| 92 |
+
<audio controls>
|
| 93 |
+
<source src=""https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina/raw/main/examples/example3.wav"" type=""audio/wav"">
|
| 94 |
+
</audio>
|
| 95 |
+
<p>Example 4: <code>In the stillness of the midnight hour, time seemed to pause, holding its breath.</code></p>
|
| 96 |
+
<audio controls>
|
| 97 |
+
<source src=""https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina/raw/main/examples/example4.wav"" type=""audio/wav"">
|
| 98 |
+
</audio>
|
| 99 |
+
<p>Example 5: <code>The symphony of nature unfolded in the quiet woods, where silence itself seemed alive.</code></p>
|
| 100 |
+
<audio controls>
|
| 101 |
+
<source src=""https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina/raw/main/examples/example5.wav"" type=""audio/wav"">
|
| 102 |
+
</audio>
|
| 103 |
+
<p>Example 6: <code>Her laughter echoed through the empty halls, a reminder of the joy that once lived there.</code></p>
|
| 104 |
+
<audio controls>
|
| 105 |
+
<source src=""https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina/raw/main/examples/example6.wav"" type=""audio/wav"">
|
| 106 |
+
</audio>
|
| 107 |
+
<p>Example 7: <code>With each step, the snow crunched beneath her feet, a rhythm as old as winter itself.</code></p>
|
| 108 |
+
<audio controls>
|
| 109 |
+
<source src=""https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina/raw/main/examples/example7.wav"" type=""audio/wav"">
|
| 110 |
+
</audio>
|
| 111 |
+
<p>Example 8: <code>The stars told stories of forgotten gods and distant worlds, if only one knew how to listen.</code></p>
|
| 112 |
+
<audio controls>
|
| 113 |
+
<source src=""https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina/raw/main/examples/example8.wav"" type=""audio/wav"">
|
| 114 |
+
</audio>
|
| 115 |
+
<p>Example 9: <code>As the spacecraft rose into the sky, the Earth below became a mere dot in the universe.</code></p>
|
| 116 |
+
<audio controls>
|
| 117 |
+
<source src=""https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina/raw/main/examples/example9.wav"" type=""audio/wav"">
|
| 118 |
+
</audio>
|
| 119 |
+
<p>Example 10: <code>He stared into the mirror, seeing not his reflection, but the person he might have been.</code></p>
|
| 120 |
+
<audio controls>
|
| 121 |
+
<source src=""https://huggingface.co/PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina/raw/main/examples/example10.wav"" type=""audio/wav"">
|
| 122 |
+
</audio>
|
| 123 |
+
</div>
|
| 124 |
+
</div>
|
| 125 |
+
<hr>","{""id"": ""PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina"", ""author"": ""PJMixers-Dev"", ""sha"": ""8e55d83b900265fbf5b58c06ca497f0b7de5498e"", ""last_modified"": ""2024-10-17 17:46:14+00:00"", ""created_at"": ""2024-10-16 18:48:55+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""text-to-speech"", ""en"", ""dataset:PJMixers-Dev/Genshin-Impact-Furina-TTS"", ""dataset:AquaV/genshin-voices-separated"", ""base_model:PJMixers-Dev/lj1995_GPT-SoVITS-safetensors"", ""base_model:finetune:PJMixers-Dev/lj1995_GPT-SoVITS-safetensors"", ""region:us""], ""pipeline_tag"": ""text-to-speech"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- PJMixers-Dev/lj1995_GPT-SoVITS-safetensors\ndatasets:\n- PJMixers-Dev/Genshin-Impact-Furina-TTS\n- AquaV/genshin-voices-separated\nlanguage:\n- en\npipeline_tag: text-to-speech"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e1.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e10.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e11.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e12.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e13.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e14.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e15.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e2.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e3.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e4.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e5.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e6.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e7.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e8.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/Furina-e9.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/Furina_e1_s267.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/Furina_e2_s534.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/Furina_e3_s801.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/Furina_e4_s1068.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/Furina_e5_s1335.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/Furina_e6_s1602.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/Furina_e7_s1869.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/Furina_e8_s2136.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/example1.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/example10.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/example2.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/example3.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/example4.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/example5.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/example6.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/example7.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/example8.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/example9.wav', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-10-17 17:46:14+00:00"", ""cardData"": ""base_model:\n- PJMixers-Dev/lj1995_GPT-SoVITS-safetensors\ndatasets:\n- PJMixers-Dev/Genshin-Impact-Furina-TTS\n- AquaV/genshin-voices-separated\nlanguage:\n- en\npipeline_tag: text-to-speech"", ""transformersInfo"": null, ""_id"": ""67100a970656c1f3f248bd02"", ""modelId"": ""PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina"", ""usedStorage"": 3346856388}",2,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=PJMixers-Dev/GPT-SoVITS-Genshin-Impact-Furina&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BPJMixers-Dev%2FGPT-SoVITS-Genshin-Impact-Furina%5D(%2FPJMixers-Dev%2FGPT-SoVITS-Genshin-Impact-Furina)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 126 |
+
MondMeer/GPT-SoVITS-HiiragiHakua,"---
|
| 127 |
+
license: gpl-3.0
|
| 128 |
+
language:
|
| 129 |
+
- zh
|
| 130 |
+
base_model:
|
| 131 |
+
- lj1995/GPT-SoVITS
|
| 132 |
+
pipeline_tag: text-to-speech
|
| 133 |
+
tags:
|
| 134 |
+
- GPT-SoVITS
|
| 135 |
+
- 柊白亜
|
| 136 |
+
- Hakua
|
| 137 |
+
---
|
| 138 |
+
|
| 139 |
+
## 模型介绍
|
| 140 |
+
|
| 141 |
+
* 基于 [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS) 项目训练的 [柊白亞](https://zh.moegirl.org.cn/zh-hans/柊白亚) 声音模型
|
| 142 |
+
* 推理时建议按句号切。句子太长可以用标点符号切。
|
| 143 |
+
* 仅供学习使用
|
| 144 |
+
|
| 145 |
+
示例(使用hakua_f_e8_s2384和hakua_f-e15。实际上使用hakua_l的效果明显更好):
|
| 146 |
+
|
| 147 |
+
<audio controls>
|
| 148 |
+
<source src=""examples\hakua.wav"" type=""audio/wav"">
|
| 149 |
+
</audio>
|
| 150 |
+
|
| 151 |
+
<audio controls>
|
| 152 |
+
<source src=""examples\0721.wav"" type=""audio/mpeg"">
|
| 153 |
+
</audio>
|
| 154 |
+
|
| 155 |
+
<audio controls>
|
| 156 |
+
<source src=""examples\yinhetiedao.wav"" type=""audio/mpeg"">
|
| 157 |
+
</audio>
|
| 158 |
+
|
| 159 |
+
## 模型列表
|
| 160 |
+
|
| 161 |
+
| 模型名称(前缀) | 数据集 |
|
| 162 |
+
| :--------------- | :----------------------------------------------------------------------------------------------------- |
|
| 163 |
+
| hakua_f | 使用游戏内几乎所有语音(大概一百条语音未被匹配,没有仔细找原因) 共 2934 条语音记录 总语音时长: 04:31:18 |
|
| 164 |
+
| hakua_l | 使用游戏内大于等于五秒的语音 共 1537 条语音记录 总语音时长: 03:19:59 |
|
| 165 |
+
| hakua_l_nh | 使用游戏内大于等于五秒且非h语音 共 934 条语音记录 总语音时长: 01:53:32 |
|
| 166 |
+
|
| 167 |
+
精简后的数据集,hakua_l以及hakua_l_nh的效果明显更好。
|
| 168 |
+
|
| 169 |
+
nh版本与l版本区别似乎并不大。
|
| 170 |
+
|
| 171 |
+
## TODO
|
| 172 |
+
|
| 173 |
+
- [ ] 挑选合适的参考音频
|
| 174 |
+
- [ ] 训练RVC模型
|
| 175 |
+
","{""id"": ""MondMeer/GPT-SoVITS-HiiragiHakua"", ""author"": ""MondMeer"", ""sha"": ""33ae8ebf9dc58a18ae53dae37b713980addcedd2"", ""last_modified"": ""2025-02-08 09:00:40+00:00"", ""created_at"": ""2025-02-02 15:34:49+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""GPT-SoVITS"", ""\u67ca\u767d\u4e9c"", ""Hakua"", ""text-to-speech"", ""zh"", ""base_model:lj1995/GPT-SoVITS"", ""base_model:finetune:lj1995/GPT-SoVITS"", ""license:gpl-3.0"", ""region:us""], ""pipeline_tag"": ""text-to-speech"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- lj1995/GPT-SoVITS\nlanguage:\n- zh\nlicense: gpl-3.0\npipeline_tag: text-to-speech\ntags:\n- GPT-SoVITS\n- \u67ca\u767d\u4e9c\n- Hakua"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hakua_f-e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hakua_f-e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hakua_f-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hakua_l-e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hakua_l-e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hakua_l-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hakua_l_nh-e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hakua_l_nh-e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hakua_l_nh-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ReferenceAudios/HKA000004.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ReferenceAudios/HKA000010.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ReferenceAudios/HKA051311.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ReferenceAudios/HKA051350.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ReferenceAudios/HKA070024.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/hakua_f_e4_s1192.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/hakua_f_e8_s2384.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/hakua_l_e4_s336.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/hakua_l_e8_s672.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/hakua_l_nh_e4_s200.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/hakua_l_nh_e8_s400.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/0721.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/hakua.wav', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/yinhetiedao.wav', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-08 09:00:40+00:00"", ""cardData"": ""base_model:\n- lj1995/GPT-SoVITS\nlanguage:\n- zh\nlicense: gpl-3.0\npipeline_tag: text-to-speech\ntags:\n- GPT-SoVITS\n- \u67ca\u767d\u4e9c\n- Hakua"", ""transformersInfo"": null, ""_id"": ""679f9099d196d603a99a3c80"", ""modelId"": ""MondMeer/GPT-SoVITS-HiiragiHakua"", ""usedStorage"": 1914558763}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=MondMeer/GPT-SoVITS-HiiragiHakua&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BMondMeer%2FGPT-SoVITS-HiiragiHakua%5D(%2FMondMeer%2FGPT-SoVITS-HiiragiHakua)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 176 |
+
MondMeer/GPT-SoVITS-MinazukiHotaru,"---
|
| 177 |
+
license: gpl-3.0
|
| 178 |
+
base_model:
|
| 179 |
+
- lj1995/GPT-SoVITS
|
| 180 |
+
pipeline_tag: text-to-speech
|
| 181 |
+
tags:
|
| 182 |
+
- 水無月ほたる
|
| 183 |
+
---
|
| 184 |
+
|
| 185 |
+
基于GPT-SoVITS的微调模型,训练数据为[水无月萤 ](https://zh.moegirl.org.cn/zh-hans/水无月萤)的游戏内语音(大于等于5秒)。仅供学习使用。
|
| 186 |
+
|
| 187 |
+
输出音频有明显可察觉的噪声,但是基本可用,有可能是h语音没有剔除干净。最开始使用未剔除h语音的数据微调基本不可用。
|
| 188 |
+
|
| 189 |
+
","{""id"": ""MondMeer/GPT-SoVITS-MinazukiHotaru"", ""author"": ""MondMeer"", ""sha"": ""e6b6caf1bb9fa219347eba38f065fc0b58c7a6fa"", ""last_modified"": ""2025-02-07 16:37:04+00:00"", ""created_at"": ""2025-02-07 15:59:37+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""\u6c34\u7121\u6708\u307b\u305f\u308b"", ""text-to-speech"", ""base_model:lj1995/GPT-SoVITS"", ""base_model:finetune:lj1995/GPT-SoVITS"", ""license:gpl-3.0"", ""region:us""], ""pipeline_tag"": ""text-to-speech"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- lj1995/GPT-SoVITS\nlicense: gpl-3.0\npipeline_tag: text-to-speech\ntags:\n- \u6c34\u7121\u6708\u307b\u305f\u308b"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hotaru-e10.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hotaru-e15.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='GPT_weights_v2/hotaru-e5.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/hotaru_e4_s256.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SoVITS_weights_v2/hotaru_e8_s512.pth', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-07 16:37:04+00:00"", ""cardData"": ""base_model:\n- lj1995/GPT-SoVITS\nlicense: gpl-3.0\npipeline_tag: text-to-speech\ntags:\n- \u6c34\u7121\u6708\u307b\u305f\u308b"", ""transformersInfo"": null, ""_id"": ""67a62de98cb182a1f739f1ba"", ""modelId"": ""MondMeer/GPT-SoVITS-MinazukiHotaru"", ""usedStorage"": 635952057}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=MondMeer/GPT-SoVITS-MinazukiHotaru&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BMondMeer%2FGPT-SoVITS-MinazukiHotaru%5D(%2FMondMeer%2FGPT-SoVITS-MinazukiHotaru)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
Hentai-Diffusion_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
Delcos/Hentai-Diffusion,N/A,N/A,0,,0,,0,,0,,0,"andr290606/HD-test-run, huggingface/InferenceSupport/discussions/new?title=Delcos/Hentai-Diffusion&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BDelcos%2FHentai-Diffusion%5D(%2FDelcos%2FHentai-Diffusion)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A",2
|
Illustrious-xl-early-release-v0_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
In-Context-LoRA_finetunes_20250425_143346.csv_finetunes_20250425_143346.csv
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
ali-vilab/In-Context-LoRA,"---
|
| 3 |
+
tags:
|
| 4 |
+
- text-to-image
|
| 5 |
+
- lora
|
| 6 |
+
- diffusers
|
| 7 |
+
- template:diffusion-lora
|
| 8 |
+
base_model: black-forest-labs/FLUX.1-dev
|
| 9 |
+
instance_prompt: null
|
| 10 |
+
license: mit
|
| 11 |
+
---
|
| 12 |
+
📢 [[Project Page](https://ali-vilab.github.io/In-Context-LoRA-Page/)] [[Github Repo](https://github.com/ali-vilab/In-Context-LoRA)] [[Paper](https://arxiv.org/abs/2410.23775)]
|
| 13 |
+
# 🔥 Latest News
|
| 14 |
+
|
| 15 |
+
- **[2024-12-17]** 🚀 We are excited to release **[IDEA-Bench](https://ali-vilab.github.io/IDEA-Bench-Page/)**, a comprehensive benchmark designed to assess the zero-shot task generalization abilities of generative models. The benchmark includes **100** real-world design tasks across **275** unique cases. Despite its general-purpose focus, the top-performing model, EMU2, achieves a score of only **6.81** out of 100, highlighting the current challenges in this domain. Explore the benchmark and challenge the limits of model performance!
|
| 16 |
+
- **[2024-11-16]** 🌟 The community continues to innovate with IC-LoRA! Exciting projects include models, ComfyUI nodes and workflows for **Virtual Try-on, Product Design, Object Mitigation, Role Play**, and more. Explore their creations in **[Community Creations Using IC-LoRA](#community-creations-using-ic-lora)**. Huge thanks to all contributors for their incredible efforts!
|
| 17 |
+
|
| 18 |
+
## Community Creations Using IC-LoRA
|
| 19 |
+
|
| 20 |
+
We are thrilled to showcase the community's innovative projects leveraging In-Context LoRA (IC-LoRA). If you have additional recommendations or projects to share, **please don't hesitate to send a [Pull Request](https://github.com/ali-vilab/In-Context-LoRA/pulls)!**
|
| 21 |
+
|
| 22 |
+
| Project Name | Type | Supported Tasks | Sample Results |
|
| 23 |
+
|--------------|----------------------|---------------------------------------------------------------------------------|----------------|
|
| 24 |
+
| 1. [Comfyui_Object_Migration](https://github.com/TTPlanetPig/Comfyui_Object_Migration) | ComfyUI Node & Workflow & LoRA Model | Clothing Migration, Cartoon Clothing to Realism, and More |  |
|
| 25 |
+
| 2. [Flux Simple Try On - In Context Lora](https://civitai.com/models/950111/flux-simple-try-on-in-context-lora) | LoRA Model & ComfyUI Workflow | Virtual Try-on |  |
|
| 26 |
+
| 3. [Flux In Context - visual identity Lora in Comfy](https://civitai.com/articles/8779) | ComfyUI Workflow | Visual Identity Transfer |  |
|
| 27 |
+
| 4. [Workflows Flux In Context Lora For Product Design](https://civitai.com/models/933018/workflows-flux-in-context-lora-for-product-design) | ComfyUI Workflow | Product Design, Role Play, and More |  |
|
| 28 |
+
| 5. [Flux Product Design - In Context Lora](https://civitai.com/models/933026/flux-product-design-in-context-lora) | LoRA Model & ComfyUI Workflow | Product Design |  |
|
| 29 |
+
| 6. [In Context lora + Character story generator + flux+ shichen](https://civitai.com/models/951357/in-context-lora-character-story-generator-flux-shichen) | ComfyUI Workflow | Character Movie Story Generator |  |
|
| 30 |
+
| 7. [In- Context-Lora|Cute 4koma 可爱四格漫画](https://civitai.com/models/947702/in-context-loracute-4koma) | LoRA Model & ComfyUI Workflow | Comic Strip Generation |  |
|
| 31 |
+
| 8. [Creative Effects & Design LoRA Pack (In-Context LORA)](https://civitai.com/models/929592/creative-effects-and-design-lora-pack-in-context-lora) | LoRA Model & ComfyUI Workflow | Movie-Shot Generation and More |  |
|
| 32 |
+
|
| 33 |
+
We extend our heartfelt thanks to all contributors for their exceptional work in advancing the IC-LoRA ecosystem.
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
## Model Summary
|
| 37 |
+
|
| 38 |
+
In-Context LoRA fine-tunes text-to-image models (*e.g.,* [FLUX](https://huggingface.co/black-forest-labs/FLUX.1-dev)) to generate image sets with customizable intrinsic relationships, optionally conditioned on another set using SDEdit. It can be adapted to a wide range of tasks
|
| 39 |
+
|
| 40 |
+
This model hub includes In-Context LoRA models across 10 tasks. [MODEL ZOO](#model-zoo) details these models and their recommend settings. For more details on how these models are trained, please refer to our [paper](https://arxiv.org/abs/2410.23775).
|
| 41 |
+
|
| 42 |
+
## Key Idea
|
| 43 |
+
|
| 44 |
+
The core concept of IC-LoRA is to **concatenate** both condition and target images into a single composite image while using **Natural Language** to define the task. This approach enables seamless adaptation to a wide range of applications.
|
| 45 |
+
|
| 46 |
+
## Features
|
| 47 |
+
|
| 48 |
+
- **Task-Agnostic Framework**: IC-LoRA serves as a general framework, but it requires task-specific fine-tuning for diverse applications.
|
| 49 |
+
- **Customizable Image-Set Generation**: You can fine-tune text-to-image models to **generate image sets** with customizable intrinsic relationships.
|
| 50 |
+
- **Condition on Image-Set**: You can also **condition the generation of a set of images on another set of images**, enabling a wide range of controllable generation applications.
|
| 51 |
+
|
| 52 |
+
For more detailed information and examples, please read our [Paper](https://arxiv.org/abs/2410.23775) or visit our [Project Page](https://ali-vilab.github.io/In-Context-LoRA-Page/).
|
| 53 |
+
|
| 54 |
+
## MODEL ZOO
|
| 55 |
+
|
| 56 |
+
Below lists 10 In-Context LoRA models and their recommend settings.
|
| 57 |
+
|
| 58 |
+
| Task | Model | Recommend Settings | Example Prompt |
|
| 59 |
+
|---------------|-------------------|---------------------|---------------------------|
|
| 60 |
+
| **1. Couple Profile Design** | [`couple-profile.safetensors`](https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/couple-profile.safetensors) | `width: 2048, height: 1024` | `This two-part image portrays a couple of cartoon cats in detective attire; [LEFT] a black cat in a trench coat and fedora holds a magnifying glass and peers to the right, while [RIGHT] a white cat with a bow tie and matching hat raises an eyebrow in curiosity, creating a fun, noir-inspired scene against a dimly lit background.` |
|
| 61 |
+
| **2. Film Storyboard** | [`film-storyboard.safetensors`](https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/storyboard.safetensors) | `width: 1024, height: 1536` | `[MOVIE-SHOTS] In a vibrant festival, [SCENE-1] we find <Leo>, a shy boy, standing at the edge of a bustling carnival, eyes wide with awe at the colorful rides and laughter, [SCENE-2] transitioning to him reluctantly trying a daring game, his friends cheering him on, [SCENE-3] culminating in a triumphant moment as he wins a giant stuffed bear, his face beaming with pride as he holds it up for all to see.` |
|
| 62 |
+
| **3. Font Design** | [`font-design.safetensors`](https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/font-design.safetensors) | `width: 1792, height: 1216` | `The four-panel image showcases a playful bubble font in a vibrant pop-art style. [TOP-LEFT] displays ""Pop Candy"" in bright pink with a polka dot background; [TOP-RIGHT] shows ""Sweet Treat"" in purple, surrounded by candy illustrations; [BOTTOM-LEFT] has ""Yum!"" in a mix of bright colors; [BOTTOM-RIGHT] shows ""Delicious"" against a striped background, perfect for fun, kid-friendly products.` |
|
| 63 |
+
| **4. Home Decoration** | [`home-decoration.safetensors`](https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/home-decoration.safetensors) | `width: 1344, height: 1728` | `This four-panel image showcases a rustic living room with warm wood tones and cozy decor elements; [TOP-LEFT] features a large stone fireplace with wooden shelves filled with books and candles; [TOP-RIGHT] shows a vintage leather sofa draped in plaid blankets, complemented by a mix of textured cushions; [BOTTOM-LEFT] displays a corner with a wooden armchair beside a side table holding a steaming mug and a classic book; [BOTTOM-RIGHT] captures a cozy reading nook with a window seat, a soft fur throw, and decorative logs stacked neatly.` |
|
| 64 |
+
| **5. Portrait Illustration** | [`portrait-illustration.safetensors`](https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/portrait-illustration.safetensors) | `width: 1152, height: 1088` | `This two-panel image presents a transformation from a realistic portrait to a playful illustration, capturing both detail and artistic flair; [LEFT] the photograph shows a woman standing in a bustling marketplace, wearing a wide-brimmed hat, a flowing bohemian dress, and a leather crossbody bag; [RIGHT] the illustration panel exaggerates her accessories and features, with the bohemian dress depicted in vibrant patterns and bold colors, while the background is simplified into abstract market stalls, giving the scene an animated and lively feel.` |
|
| 65 |
+
| **6. Portrait Photography** | [`portrait-photography.safetensors`](https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/portrait-photography.safetensors) | `width: 1344, height: 1728` | `This [FOUR-PANEL] image illustrates a young artist's creative process in a bright and inspiring studio; [TOP-LEFT] she stands before a large canvas, brush in hand, adding vibrant colors to a partially completed painting, [TOP-RIGHT] she sits at a cluttered wooden table, sketching ideas in a notebook with various art supplies scattered around, [BOTTOM-LEFT] she takes a moment to step back and observe her work, adjusting her glasses thoughtfully, and [BOTTOM-RIGHT] she experiments with different textures by mixing paints directly on the palette, her focused expression showcasing her dedication to her craft.` |
|
| 66 |
+
| **7. PPT Template** | [`ppt-templates.safetensors`](https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/ppt-templates.safetensors) | `width: 1984, height: 1152` | `This four-panel image showcases a rustic-themed PowerPoint template for a culinary workshop; [TOP-LEFT] introduces ""Farm to Table Cooking"" in warm, earthy tones; [TOP-RIGHT] organizes workshop sections like ""Ingredients,"" ""Preparation,"" and ""Serving""; [BOTTOM-LEFT] displays ingredient lists for seasonal produce; [BOTTOM-RIGHT] includes chef profiles with short bios.` |
|
| 67 |
+
| **8. Sandstorm Visual Effect** | [`sandstorm-visual-effect.safetensors`](https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/sandstorm-visual-effect.safetensors) | `width: 1408, height: 1600` | `[SANDSTORM-PSA] This two-part image showcases the transformation of a cyclist through a sandstorm visual effect; [TOP] the upper panel features a cyclist in vibrant gear pedaling steadily on a clear, open road with a serene sky in the background, highlighting focus and determination, [BOTTOM] the lower panel transforms the scene as the cyclist becomes enveloped in a fierce sandstorm, with sand particles swirling intensely around the bike and rider against a stormy, darkened backdrop, emphasizing chaos and power.` |
|
| 68 |
+
| **9. Sparklers Visual Effect** | [`sparklers-visual-effect.safetensors`](https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/sparklers-visual-effect.safetensors) | `width: 960, height: 1088` | `[REAL-SPARKLERS-OVERLAYS] The two-part image vividly illustrates a woodland proposal transformed by sparkler overlays; [TOP] the first panel depicts a man kneeling on one knee with an engagement ring before his partner in a forest clearing at dusk, with warm, natural lighting, [BOTTOM] while the second panel introduces glowing sparklers that form a heart shape around the couple, amplifying the romance and joy of the moment.` |
|
| 69 |
+
| **10. Visual Identity Design** | [`visual-identity-design.safetensors`](https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/visual-identity-design.safetensors) | `width: 1472, height: 1024` | `The two-panel image showcases the joyful identity of a produce brand, with the left panel showing a smiling pineapple graphic and the brand name “Fresh Tropic” in a fun, casual font on a light aqua background; [LEFT] while the right panel translates the design onto a reusable shopping tote with the pineapple logo in black, held by a person in a market setting, emphasizing the brand’s approachable and eco-friendly vibe.` |
|
| 70 |
+
|
| 71 |
+
## LICENSE
|
| 72 |
+
|
| 73 |
+
This model hub uses FLUX as the base model. Users must comply with FLUX's license when using this code. Please refer to [FLUX's License](https://github.com/black-forest-labs/flux/tree/main/model_licenses) for more details.
|
| 74 |
+
|
| 75 |
+
## Citation
|
| 76 |
+
|
| 77 |
+
If you find this work useful in your research, please consider citing:
|
| 78 |
+
|
| 79 |
+
```bibtex
|
| 80 |
+
@article{lhhuang2024iclora,
|
| 81 |
+
title={In-Context LoRA for Diffusion Transformers},
|
| 82 |
+
author={Huang, Lianghua and Wang, Wei and Wu, Zhi-Fan and Shi, Yupeng and Dou, Huanzhang and Liang, Chen and Feng, Yutong and Liu, Yu and Zhou, Jingren},
|
| 83 |
+
journal={arXiv preprint arxiv:2410.23775},
|
| 84 |
+
year={2024}
|
| 85 |
+
}
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
```bibtex
|
| 89 |
+
@article{lhhuang2024iclora,
|
| 90 |
+
title={Group Diffusion Transformers are Unsupervised Multitask Learners},
|
| 91 |
+
author={Huang, Lianghua and Wang, Wei and Wu, Zhi-Fan and Dou, Huanzhang and Shi, Yupeng and Feng, Yutong and Liang, Chen and Liu, Yu and Zhou, Jingren},
|
| 92 |
+
journal={arXiv preprint arxiv:2410.15027},
|
| 93 |
+
year={2024}
|
| 94 |
+
}
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
## Download model
|
| 98 |
+
|
| 99 |
+
Weights for these models are available in Safetensors format.
|
| 100 |
+
|
| 101 |
+
[Download](/ali-vilab/In-Context-LoRA/tree/main) them in the Files & versions tab.
|
| 102 |
+
","{""id"": ""ali-vilab/In-Context-LoRA"", ""author"": ""ali-vilab"", ""sha"": ""16dae427a8509229309b85bc5345dfeffee5fc2e"", ""last_modified"": ""2024-12-17 06:13:20+00:00"", ""created_at"": ""2024-11-07 05:47:16+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 78975, ""downloads_all_time"": null, ""likes"": 593, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": ""warm"", ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""text-to-image"", ""lora"", ""template:diffusion-lora"", ""arxiv:2410.23775"", ""arxiv:2410.15027"", ""base_model:black-forest-labs/FLUX.1-dev"", ""base_model:adapter:black-forest-labs/FLUX.1-dev"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: black-forest-labs/FLUX.1-dev\nlicense: mit\ntags:\n- text-to-image\n- lora\n- diffusers\n- template:diffusion-lora"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='couple-profile.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='film-storyboard.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='font-design.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='home-decoration.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/2024-11-10-002611_0.jpeg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/386534865-9612cf8a-858d-4684-819e-7b97981d993c.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/ComfyUI_00026_.jpeg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/ComfyUI_00098_.jpeg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/ComfyUI_temp_ditfb_00016_.jpeg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/ComfyUI_temp_opjou_00016_.jpeg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/example_1.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/film-storyboard-1.jpeg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/role2story.jpeg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/teaser1.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/teaser2.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/vi-design.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='portrait-illustration.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='portrait-photography.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ppt-templates.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='sandstorm-visual-effect.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='sparklers-visual-effect.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='visual-identity-design.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [""multimodalart/logo-in-context"", ""yasassadeepa/ali-vilab-In-Context-LoRA"", ""ysmao/multiview-incontext"", ""Konst2021/ali-vilab-In-Context-LoRA"", ""Byhunny/new-space"", ""Ricofishing/ali-vilab-In-Context-LoRA"", ""NeurixYUFI/ImgGenChat"", ""Mohuu0601/logoincontext"", ""ayenkan/ali-vilab-In-Context-LoRA"", ""yuxichat/ali-vilab-In-Context-LoRA"", ""lightawave/ali-vilab-In-Context-LoRA"", ""viviannnnnn/ali-vilab-In-Context-LoRA"", ""pokerogue/ali-vilab-In-Context-LoRA"", ""Nymbo/logo-in-context"", ""VictoriaAgent/ali-vilab-In-Context-LoRA"", ""MasterBlueSAMA/ali-vilab-In-Context-LoRA"", ""o1anuraganand/space"", ""Mohuu0601/logo-in-contest"", ""tamir0107/ali-vilab-In-Context-LoRA"", ""sinkhwal/ali-vilab-In-Context-LoRA"", ""droidbot/Context-LoRA"", ""alekxwww/ali-vilab-In-Context-LoRA"", ""Pablocha2424/ali-vilab-In-Context-LoRA"", ""mkx1993/ali-vilab-In-Context-LoRA"", ""alexeyGod/ali-vilab-In-Context-LoRA"", ""alfredmoore/ali-vilab-In-Context-LoRA""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-12-17 06:13:20+00:00"", ""cardData"": ""base_model: black-forest-labs/FLUX.1-dev\nlicense: mit\ntags:\n- text-to-image\n- lora\n- diffusers\n- template:diffusion-lora"", ""transformersInfo"": null, ""_id"": ""672c546451c2c90f81ddb6f9"", ""modelId"": ""ali-vilab/In-Context-LoRA"", ""usedStorage"": 1747883122}",0,https://huggingface.co/borjagoni/solokologoa,1,"https://huggingface.co/personal1802/nyalia.safetensors, https://huggingface.co/anonymousModelsTimeCSL/TimeCSL, https://huggingface.co/den123/Caricature_XL, https://huggingface.co/hyder133/chiikawa_stype, https://huggingface.co/Timmmi/Pytorch",5,,0,,0,"Byhunny/new-space, Konst2021/ali-vilab-In-Context-LoRA, Mohuu0601/logoincontext, NeurixYUFI/ImgGenChat, Ricofishing/ali-vilab-In-Context-LoRA, alexeyGod/ali-vilab-In-Context-LoRA, ayenkan/ali-vilab-In-Context-LoRA, multimodalart/logo-in-context, pokerogue/ali-vilab-In-Context-LoRA, viviannnnnn/ali-vilab-In-Context-LoRA, yasassadeepa/ali-vilab-In-Context-LoRA, ysmao/multiview-incontext",12
|
| 103 |
+
borjagoni/solokologoa,"---
|
| 104 |
+
license: cc-by-nc-2.0
|
| 105 |
+
datasets:
|
| 106 |
+
- microsoft/orca-agentinstruct-1M-v1
|
| 107 |
+
language:
|
| 108 |
+
- eu
|
| 109 |
+
metrics:
|
| 110 |
+
- accuracy
|
| 111 |
+
base_model:
|
| 112 |
+
- ali-vilab/In-Context-LoRA
|
| 113 |
+
new_version: Qwen/Qwen2.5-Coder-32B-Instruct
|
| 114 |
+
---","{""id"": ""borjagoni/solokologoa"", ""author"": ""borjagoni"", ""sha"": ""68eabcf17648f9e075f63902b17777cba0c889a3"", ""last_modified"": ""2024-12-07 10:18:10+00:00"", ""created_at"": ""2024-12-07 10:15:46+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""eu"", ""dataset:microsoft/orca-agentinstruct-1M-v1"", ""base_model:ali-vilab/In-Context-LoRA"", ""base_model:finetune:ali-vilab/In-Context-LoRA"", ""license:cc-by-nc-2.0"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- ali-vilab/In-Context-LoRA\ndatasets:\n- microsoft/orca-agentinstruct-1M-v1\nlanguage:\n- eu\nlicense: cc-by-nc-2.0\nmetrics:\n- accuracy\nnew_version: Qwen/Qwen2.5-Coder-32B-Instruct"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-12-07 10:18:10+00:00"", ""cardData"": ""base_model:\n- ali-vilab/In-Context-LoRA\ndatasets:\n- microsoft/orca-agentinstruct-1M-v1\nlanguage:\n- eu\nlicense: cc-by-nc-2.0\nmetrics:\n- accuracy\nnew_version: Qwen/Qwen2.5-Coder-32B-Instruct"", ""transformersInfo"": null, ""_id"": ""6754205259a4826a6f957ee2"", ""modelId"": ""borjagoni/solokologoa"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=borjagoni/solokologoa&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bborjagoni%2Fsolokologoa%5D(%2Fborjagoni%2Fsolokologoa)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
InstantMesh_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
TencentARC/InstantMesh,"---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
|
| 5 |
+
tags:
|
| 6 |
+
- image-to-3d
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# InstantMesh
|
| 10 |
+
|
| 11 |
+
Model card for *InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models*.
|
| 12 |
+
|
| 13 |
+
Code: https://github.com/TencentARC/InstantMesh
|
| 14 |
+
|
| 15 |
+
Arxiv: https://arxiv.org/abs/2404.07191
|
| 16 |
+
|
| 17 |
+
We present InstantMesh, a feed-forward framework for instant 3D mesh generation from a single image, featuring state-of-the-art generation quality and significant training scalability. By synergizing the strengths of an off-the-shelf multiview diffusion model and a sparse-view reconstruction model based on the LRM architecture, InstantMesh is able to create diverse 3D assets within 10 seconds. To enhance the training efficiency and exploit more geometric supervisions, e.g., depths and normals, we integrate a differentiable iso-surface extraction module into our framework and directly optimize on the mesh representation. Experimental results on public datasets demonstrate that InstantMesh significantly outperforms other latest image-to-3D baselines, both qualitatively and quantitatively. We release all the code, weights, and demo of InstantMesh, with the intention that it can make substantial contributions to the community of 3D generative AI and empower both researchers and content creators.
|
| 18 |
+
","{""id"": ""TencentARC/InstantMesh"", ""author"": ""TencentARC"", ""sha"": ""b785b4ecfb6636ef34a08c748f96f6a5686244d0"", ""last_modified"": ""2024-04-11 02:56:23+00:00"", ""created_at"": ""2024-04-10 13:16:45+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 35912, ""downloads_all_time"": null, ""likes"": 283, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""image-to-3d"", ""arxiv:2404.07191"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": ""image-to-3d"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: apache-2.0\ntags:\n- image-to-3d"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='instant_mesh_base.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='instant_mesh_large.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='instant_nerf_base.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='instant_nerf_large.ckpt', size=None, blob_id=None, lfs=None)""], ""spaces"": [""TencentARC/InstantMesh"", ""ThomasSimonini/Roblox-3D-Assets-Generator-v1"", ""ZhangYuhan/3DGen-Arena"", ""yslan/GaussianAnything-AIGC3D"", ""jkorstad/InstantMesh-img-to-3D"", ""abreza/3d_animation_toolkit"", ""themanfrom/image-to-3d"", ""yslan/LN3Diff_I23D"", ""LTT/Kiss3DGen"", ""awacke1/3d_animation_toolkit"", ""themanfrom/virtual-try-on-image"", ""rerun/InstantMesh"", ""R4Z0R1337/3DFusion"", ""YiftachEde/Sharp-It"", ""rgxie/LDM"", ""ThomasSimonini/Roblox-3D-Generation"", ""2MaxM/ShoeGenv2"", ""dylanebert/im-ma"", ""02alexander/InstantMeshRerun"", ""willdphan/InstantMesh"", ""acecalisto3/DDDGENSET"", ""ZZZXIANG/IMAGETO"", ""tsi-org/InstantMesh"", ""cocktailpeanut/InstantMesh"", ""Coloring/gr_load_test2"", ""SIGMitch/InstantMesh"", ""mba07m/Hackathon3D"", ""SergioGreenDragon/SergioGreenDragonGenerate"", ""djamel-esi/delete_me"", ""YashwanthSC/Image-to-Mesh"", ""vibs08/InstantMesh"", ""ThomasSimonini/Roblox-test"", ""Tiger2031/3D-Assets-Generator"", ""Mithun12345/3D_Model_Demo"", ""Adarsh7700/3DFusion-dup"", ""Adarsh7700/3DFusion-duplicate-repo"", ""Adarsh7700/duplicate-repo"", ""jayhey1236/InstantMesh"", ""vezasc/InstantMesh"", ""walter1124/image-to-3d"", ""thepaperwhisperer/3d"", ""lilmeaty/duplicate-repo"", ""lunde/Image_2_Lego"", ""Hermit000-1/InstantMesh"", ""WEKKK/tridi"", ""mort-on/InstantMesh"", ""mubarak-alketbi/InstantMesh"", ""abdullahalioo/InstantMesh"", ""DonPab1o/InstantMesh"", ""abdullahalioo/image-to-3d"", ""Vuvo11/InteriorBusiness_InstantMesh_API""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-04-11 02:56:23+00:00"", ""cardData"": ""license: apache-2.0\ntags:\n- image-to-3d"", ""transformersInfo"": null, ""_id"": ""6616913d99cce52de368ff1d"", ""modelId"": ""TencentARC/InstantMesh"", ""usedStorage"": 7280506037}",0,,0,,0,,0,,0,"02alexander/InstantMeshRerun, SIGMitch/InstantMesh, TencentARC/InstantMesh, YiftachEde/Sharp-It, ZhangYuhan/3DGen-Arena, dylanebert/im-ma, huggingface/InferenceSupport/discussions/new?title=TencentARC/InstantMesh&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BTencentARC%2FInstantMesh%5D(%2FTencentARC%2FInstantMesh)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, jkorstad/InstantMesh-img-to-3D, lunde/Image_2_Lego, rerun/InstantMesh, themanfrom/image-to-3d, yslan/GaussianAnything-AIGC3D, yslan/LN3Diff_I23D",13
|
LCM_Dreamshaper_v7_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv
ADDED
|
@@ -0,0 +1,248 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
SimianLuo/LCM_Dreamshaper_v7,"---
|
| 3 |
+
license: mit
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
pipeline_tag: text-to-image
|
| 7 |
+
tags:
|
| 8 |
+
- text-to-image
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# Latent Consistency Models
|
| 12 |
+
|
| 13 |
+
Official Repository of the paper: *[Latent Consistency Models](https://arxiv.org/abs/2310.04378)*.
|
| 14 |
+
|
| 15 |
+
Project Page: https://latent-consistency-models.github.io
|
| 16 |
+
|
| 17 |
+
## Try our Hugging Face demos:
|
| 18 |
+
[](https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model)
|
| 19 |
+
|
| 20 |
+
## Model Descriptions:
|
| 21 |
+
Distilled from [Dreamshaper v7](https://huggingface.co/Lykon/dreamshaper-7) fine-tune of [Stable-Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) with only 4,000 training iterations (~32 A100 GPU Hours).
|
| 22 |
+
|
| 23 |
+
## Generation Results:
|
| 24 |
+
|
| 25 |
+
<p align=""center"">
|
| 26 |
+
<img src=""teaser.png"">
|
| 27 |
+
</p>
|
| 28 |
+
|
| 29 |
+
By distilling classifier-free guidance into the model's input, LCM can generate high-quality images in very short inference time. We compare the inference time at the setting of 768 x 768 resolution, CFG scale w=8, batchsize=4, using a A800 GPU.
|
| 30 |
+
|
| 31 |
+
<p align=""center"">
|
| 32 |
+
<img src=""speed_fid.png"">
|
| 33 |
+
</p>
|
| 34 |
+
|
| 35 |
+
## Usage
|
| 36 |
+
|
| 37 |
+
You can try out Latency Consistency Models directly on:
|
| 38 |
+
[](https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model)
|
| 39 |
+
|
| 40 |
+
To run the model yourself, you can leverage the 🧨 Diffusers library:
|
| 41 |
+
1. Install the library:
|
| 42 |
+
```
|
| 43 |
+
pip install --upgrade diffusers # make sure to use at least diffusers >= 0.22
|
| 44 |
+
pip install transformers accelerate
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
2. Run the model:
|
| 48 |
+
```py
|
| 49 |
+
from diffusers import DiffusionPipeline
|
| 50 |
+
import torch
|
| 51 |
+
|
| 52 |
+
pipe = DiffusionPipeline.from_pretrained(""SimianLuo/LCM_Dreamshaper_v7"")
|
| 53 |
+
|
| 54 |
+
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
|
| 55 |
+
pipe.to(torch_device=""cuda"", torch_dtype=torch.float32)
|
| 56 |
+
|
| 57 |
+
prompt = ""Self-portrait oil painting, a beautiful cyborg with golden hair, 8k""
|
| 58 |
+
|
| 59 |
+
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
|
| 60 |
+
num_inference_steps = 4
|
| 61 |
+
|
| 62 |
+
images = pipe(prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=8.0, lcm_origin_steps=50, output_type=""pil"").images
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
For more information, please have a look at the official docs:
|
| 66 |
+
👉 https://huggingface.co/docs/diffusers/api/pipelines/latent_consistency_models#latent-consistency-models
|
| 67 |
+
|
| 68 |
+
## Usage (Deprecated)
|
| 69 |
+
|
| 70 |
+
1. Install the library:
|
| 71 |
+
```
|
| 72 |
+
pip install diffusers transformers accelerate
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
2. Run the model:
|
| 76 |
+
```py
|
| 77 |
+
from diffusers import DiffusionPipeline
|
| 78 |
+
import torch
|
| 79 |
+
|
| 80 |
+
pipe = DiffusionPipeline.from_pretrained(""SimianLuo/LCM_Dreamshaper_v7"", custom_pipeline=""latent_consistency_txt2img"", custom_revision=""main"", revision=""fb9c5d"")
|
| 81 |
+
|
| 82 |
+
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
|
| 83 |
+
pipe.to(torch_device=""cuda"", torch_dtype=torch.float32)
|
| 84 |
+
|
| 85 |
+
prompt = ""Self-portrait oil painting, a beautiful cyborg with golden hair, 8k""
|
| 86 |
+
|
| 87 |
+
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
|
| 88 |
+
num_inference_steps = 4
|
| 89 |
+
|
| 90 |
+
images = pipe(prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=8.0, output_type=""pil"").images
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
## BibTeX
|
| 94 |
+
|
| 95 |
+
```bibtex
|
| 96 |
+
@misc{luo2023latent,
|
| 97 |
+
title={Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference},
|
| 98 |
+
author={Simian Luo and Yiqin Tan and Longbo Huang and Jian Li and Hang Zhao},
|
| 99 |
+
year={2023},
|
| 100 |
+
eprint={2310.04378},
|
| 101 |
+
archivePrefix={arXiv},
|
| 102 |
+
primaryClass={cs.CV}
|
| 103 |
+
}
|
| 104 |
+
```","{""id"": ""SimianLuo/LCM_Dreamshaper_v7"", ""author"": ""SimianLuo"", ""sha"": ""a85df6a8bd976cdd08b4fd8f3b73f229c9e54df5"", ""last_modified"": ""2024-03-05 08:32:22+00:00"", ""created_at"": ""2023-10-14 08:26:52+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 167292, ""downloads_all_time"": null, ""likes"": 402, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""onnx"", ""safetensors"", ""text-to-image"", ""en"", ""arxiv:2310.04378"", ""license:mit"", ""diffusers:LatentConsistencyModelPipeline"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- en\nlicense: mit\npipeline_tag: text-to-image\ntags:\n- text-to-image"", ""widget_data"": null, ""model_index"": null, ""config"": {""diffusers"": {""_class_name"": ""LatentConsistencyModelPipeline""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LCM_Dreamshaper_v7_4k.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='inference.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='lcm_pipeline.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='lcm_scheduler.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='safety_checker/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='safety_checker/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='speed_fid.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='teaser.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/model.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/model.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/model.onnx_data', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/model.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/model.onnx', size=None, blob_id=None, lfs=None)""], ""spaces"": [""radames/Real-Time-Latent-Consistency-Model"", ""SimianLuo/Latent_Consistency_Model"", ""TIGER-Lab/GenAI-Arena"", ""kadirnar/Video-Diffusion-WebUI"", ""radames/Real-Time-Latent-Consistency-Model-Text-To-Image"", ""radames/Real-Time-SD-Turbo"", ""radames/real-time-pix2pix-turbo"", ""TencentARC/ColorFlow"", ""sled-umich/InfEdit"", ""jeasinema/UltraEdit-SD3"", ""latent-consistency/Real-Time-LCM-ControlNet-Lora-SD1.5"", ""Nymbo/image_gen_supaqueue"", ""leptonai/tryemoji"", ""prs-eth/rollingdepth"", ""Komorebizyd/DrawApp"", ""fal/realtime-stable-diffusion-local"", ""r3gm/Fast_Stable_diffusion_CPU"", ""Nymbo/Flood"", ""rupeshs/fastsdcpu"", ""latent-consistency/Real-Time-LCM-Text-to-Image-Lora-SD1.5"", ""aifartist/sdzoom-Latent-Consistency-Model"", ""LTT/Kiss3DGen"", ""ali-vilab/IDEA-Bench-Arena"", ""ehristoforu/Rensor"", ""michaelj/testlcm"", ""majedk01/Text2Image-IMAGINE"", ""Jinl/ZePo"", ""theSure/Omnieraser"", ""ruslanmv/GenerativeAI"", ""Nymbo/DrawApp"", ""Omnibus/top-20-flood"", ""JunhaoZhuang/Cobra"", ""michaelj/FastAPI_lcm_docker"", ""Omnibus/top-20-img-img-tint"", ""multimodalart/Real-Time-Latent-SDXL-Lightning"", ""johann22/chat-diffusion"", ""johann22/mixtral-diffusion"", ""OmParkashPandeY/GenerateImageFromTextV6"", ""OmParkashPandeY/GenerateImageFromTextProV1-A"", ""Omnibus/Mixtral-RPG-image"", ""Omnibus/top-20"", ""Omnibus/top-20-img-img-basic"", ""Nymbo/Fast_Stable_diffusion_CPU"", ""Omnibus/meme_diffusion"", ""Festrcze/Real-Time-SD-Turbooooooo"", ""PeepDaSlan9/SimianLuo-LCM_Dreamshaper_v7"", ""Dagfinn1962/DrawApp"", ""SIGMitch/Real-Time-Chad"", ""KienPongPoh/pareidolia-but-cute"", ""douglasgoodwin/Real-Time-SD-Turbo"", ""tejani/Another"", ""tejani/testlcm2"", ""kubilaykilinc/Real-Time-Latent-Consistency-Model"", ""tsi-org/Real-Time-Latent-Consistency-Model"", ""edwrow/Real-Time-Latent-Consistency-Model"", ""tsi-org/realtime-stable-diffusion-local"", ""mehdinhous/Real-Time-Latent-Consistency-Model"", ""alkarimj/SimianLuo-LCM_Dreamshaper_v7"", ""JonSold/Real-Time-Latent-Consistency-Model"", ""vloikas/Mycelium"", ""Nymbo/InfEdit"", ""takahirox/Fast_Img2Img"", ""sergeicu/Real-Time-Latent-Consistency-Model"", ""michaelj/FastAPI_img2img"", ""JEGADEESH/SimianLuo-LCM_Dreamshaper_v7"", ""HusseinHE/Magic"", ""Gh6st66/SimianLuo-LCM_Dreamshaper_v7"", ""jensinjames/Real-Time-SD-Turbo"", ""garrettscott/Real-Time-Latent-Consistency-Model"", ""johann22/chat-diffusion-describe"", ""fewvv11/tryemoji"", ""LouDogNation/Real-Time-Latent-Consistency-Model"", ""hillman2000hk/Real-Time-Latent-Consistency-Model"", ""vloikas/NEW-Mycelium"", ""Bool233/tryemoji"", ""TogetherAI/Make_EmoAI_Real"", ""OmParkashPandeY/GenerateImageFromTextV5"", ""KVISOF/mineAI"", ""thobuiq/GenerateImageFromTextV5"", ""hady20100/Real-Time-Latent-Consistency-Model"", ""MehmetK/Real-Time-Latent-Consistency-Model"", ""taoki/tiny-ja-trans-sd"", ""LennyHood/SimianLuo-LCM_Dreamshaper_v7"", ""douglasgoodwin/one-more-gloomy-sunday"", ""Festrcze/Real-Time-SD-Turbonjjj"", ""Omnibus/vtracer"", ""Omnibus/top-20-img-img"", ""Omnibus/top-20-flood-tint"", ""Nymbo/real-time-pix2pix-turbo"", ""Nymbo/top-20"", ""malchish61/Real-Time-Latent-Consistency-Model"", ""lsb/pareidolia-but-cute"", ""ahmed24444/Real-Time-Latent-Consistency-Model"", ""torusvektor/Real-Time-Latent-Consistency-Model"", ""Satanpapa/Real-Time-Latent-Consistency-Model"", ""lsb/ban-cars"", ""Festrcze/Real-Time-SD-Turbo"", ""totemko/Real-Time-Latent-Consistency-Model"", ""lisanderlee/Real-Time-Latent-Consistency-Model"", ""Nymbo/gemini-streamlit""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-03-05 08:32:22+00:00"", ""cardData"": ""language:\n- en\nlicense: mit\npipeline_tag: text-to-image\ntags:\n- text-to-image"", ""transformersInfo"": null, ""_id"": ""652a50cc2ecb5062d69ad48e"", ""modelId"": ""SimianLuo/LCM_Dreamshaper_v7"", ""usedStorage"": 17459762839}",0,"https://huggingface.co/OpenVINO/LCM_Dreamshaper_v7-fp16-ov, https://huggingface.co/echarlaix/LCM_Dreamshaper_v7-openvino",2,,0,https://huggingface.co/OpenVINO/LCM_Dreamshaper_v7-int8-ov,1,https://huggingface.co/ssslvky/lcm-hed-onnx,1,"Komorebizyd/DrawApp, Nymbo/Flood, Nymbo/image_gen_supaqueue, SimianLuo/Latent_Consistency_Model, TIGER-Lab/GenAI-Arena, TencentARC/ColorFlow, ali-vilab/IDEA-Bench-Arena, ehristoforu/Rensor, huggingface/InferenceSupport/discussions/new?title=SimianLuo/LCM_Dreamshaper_v7&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BSimianLuo%2FLCM_Dreamshaper_v7%5D(%2FSimianLuo%2FLCM_Dreamshaper_v7)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, leptonai/tryemoji, majedk01/Text2Image-IMAGINE, prs-eth/rollingdepth, r3gm/Fast_Stable_diffusion_CPU, rupeshs/fastsdcpu",14
|
| 105 |
+
OpenVINO/LCM_Dreamshaper_v7-fp16-ov,"---
|
| 106 |
+
license: mit
|
| 107 |
+
base_model:
|
| 108 |
+
- SimianLuo/LCM_Dreamshaper_v7
|
| 109 |
+
---
|
| 110 |
+
|
| 111 |
+
# LCM_Dreamshaper_v7-fp16-ov
|
| 112 |
+
|
| 113 |
+
* Model creator: [SimianLuo](https://huggingface.co/SimianLuo)
|
| 114 |
+
* Original model: [SimianLuo/LCM_Dreamshaper_v7](https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7)
|
| 115 |
+
|
| 116 |
+
## Description
|
| 117 |
+
|
| 118 |
+
This is [SimianLuo/LCM_Dreamshaper_v7](https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7) model converted to the [OpenVINO™ IR](https://docs.openvino.ai/2024/documentation/openvino-ir-format.html) (Intermediate Representation) format.
|
| 119 |
+
|
| 120 |
+
## Compatibility
|
| 121 |
+
|
| 122 |
+
The provided OpenVINO™ IR model is compatible with:
|
| 123 |
+
|
| 124 |
+
* OpenVINO version 2025.0.0 and higher
|
| 125 |
+
* Optimum Intel 1.22.0 and higher
|
| 126 |
+
|
| 127 |
+
## Running Model Inference with [Optimum Intel](https://huggingface.co/docs/optimum/intel/index)
|
| 128 |
+
|
| 129 |
+
1. Install packages required for using [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) integration with the OpenVINO backend:
|
| 130 |
+
|
| 131 |
+
```
|
| 132 |
+
pip install optimum[openvino]
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
2. Run model inference:
|
| 136 |
+
|
| 137 |
+
```
|
| 138 |
+
from optimum.intel.openvino import OVDiffusionPipeline
|
| 139 |
+
|
| 140 |
+
model_id = ""OpenVINO/LCM_Dreamshaper_v7-fp16-ov""
|
| 141 |
+
pipeline = OVDiffusionPipeline.from_pretrained(model_id)
|
| 142 |
+
|
| 143 |
+
prompt = ""sailing ship in storm by Rembrandt""
|
| 144 |
+
images = pipeline(prompt, num_inference_steps=4).images
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
## Running Model Inference with [OpenVINO GenAI](https://github.com/openvinotoolkit/openvino.genai)
|
| 148 |
+
|
| 149 |
+
1. Install packages required for using OpenVINO GenAI.
|
| 150 |
+
```
|
| 151 |
+
pip install huggingface_hub
|
| 152 |
+
pip install -U --pre --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly openvino openvino-tokenizers openvino-genai
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
2. Download model from HuggingFace Hub
|
| 156 |
+
|
| 157 |
+
```
|
| 158 |
+
import huggingface_hub as hf_hub
|
| 159 |
+
|
| 160 |
+
model_id = ""OpenVINO/LCM_Dreamshaper_v7-fp16-ov""
|
| 161 |
+
model_path = ""LCM_Dreamshaper_v7-fp16-ov""
|
| 162 |
+
|
| 163 |
+
hf_hub.snapshot_download(model_id, local_dir=model_path)
|
| 164 |
+
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
3. Run model inference:
|
| 168 |
+
|
| 169 |
+
```
|
| 170 |
+
import openvino_genai as ov_genai
|
| 171 |
+
from PIL import Image
|
| 172 |
+
|
| 173 |
+
device = ""CPU""
|
| 174 |
+
pipe = ov_genai.Text2ImagePipeline(model_path, device)
|
| 175 |
+
|
| 176 |
+
prompt = ""sailing ship in storm by Rembrandt""
|
| 177 |
+
image_tensor = pipe.generate(prompt, num_inference_steps=4)
|
| 178 |
+
image = Image.fromarray(image_tensor.data[0])
|
| 179 |
+
|
| 180 |
+
```
|
| 181 |
+
|
| 182 |
+
More GenAI usage examples can be found in OpenVINO GenAI library [docs](https://github.com/openvinotoolkit/openvino.genai/blob/master/src/README.md) and [samples](https://github.com/openvinotoolkit/openvino.genai?tab=readme-ov-file#openvino-genai-samples)
|
| 183 |
+
|
| 184 |
+
## Legal information
|
| 185 |
+
|
| 186 |
+
The original model is distributed under [mit](https://choosealicense.com/licenses/mit/) license. More details can be found in [SimianLuo/LCM_Dreamshaper_v7](https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7).
|
| 187 |
+
|
| 188 |
+
## Disclaimer
|
| 189 |
+
|
| 190 |
+
Intel is committed to respecting human rights and avoiding causing or contributing to adverse impacts on human rights. See [Intel’s Global Human Rights Principles](https://www.intel.com/content/dam/www/central-libraries/us/en/documents/policy-human-rights.pdf). Intel’s products and software are intended only to be used in applications that do not cause or contribute to adverse impacts on human rights.","{""id"": ""OpenVINO/LCM_Dreamshaper_v7-fp16-ov"", ""author"": ""OpenVINO"", ""sha"": ""dd6f0cf47b09e43f23125dbc3c79c7a3c3416309"", ""last_modified"": ""2025-02-11 19:43:57+00:00"", ""created_at"": ""2024-05-22 16:25:21+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 3, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""safetensors"", ""base_model:SimianLuo/LCM_Dreamshaper_v7"", ""base_model:finetune:SimianLuo/LCM_Dreamshaper_v7"", ""license:mit"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- SimianLuo/LCM_Dreamshaper_v7\nlicense: mit"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='safety_checker/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='safety_checker/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/openvino_model.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/openvino_detokenizer.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/openvino_detokenizer.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/openvino_tokenizer.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/openvino_tokenizer.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/openvino_model.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/openvino_model.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/openvino_model.xml', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-11 19:43:57+00:00"", ""cardData"": ""base_model:\n- SimianLuo/LCM_Dreamshaper_v7\nlicense: mit"", ""transformersInfo"": null, ""_id"": ""664e1c71857f065580d3c4d5"", ""modelId"": ""OpenVINO/LCM_Dreamshaper_v7-fp16-ov"", ""usedStorage"": 7449239764}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=OpenVINO/LCM_Dreamshaper_v7-fp16-ov&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BOpenVINO%2FLCM_Dreamshaper_v7-fp16-ov%5D(%2FOpenVINO%2FLCM_Dreamshaper_v7-fp16-ov)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 191 |
+
echarlaix/LCM_Dreamshaper_v7-openvino,"---
|
| 192 |
+
base_model: SimianLuo/LCM_Dreamshaper_v7
|
| 193 |
+
language:
|
| 194 |
+
- en
|
| 195 |
+
license: mit
|
| 196 |
+
pipeline_tag: text-to-image
|
| 197 |
+
tags:
|
| 198 |
+
- text-to-image
|
| 199 |
+
- openvino
|
| 200 |
+
---
|
| 201 |
+
|
| 202 |
+
This model was converted to OpenVINO from [`SimianLuo/LCM_Dreamshaper_v7`](https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7) using [optimum-intel](https://github.com/huggingface/optimum-intel)
|
| 203 |
+
via the [export](https://huggingface.co/spaces/echarlaix/openvino-export) space.
|
| 204 |
+
|
| 205 |
+
First make sure you have optimum-intel installed:
|
| 206 |
+
|
| 207 |
+
```bash
|
| 208 |
+
pip install optimum[openvino]
|
| 209 |
+
```
|
| 210 |
+
|
| 211 |
+
To load your model you can do as follows:
|
| 212 |
+
|
| 213 |
+
```python
|
| 214 |
+
from optimum.intel import OVLatentConsistencyModelPipeline
|
| 215 |
+
|
| 216 |
+
model_id = ""echarlaix/LCM_Dreamshaper_v7-openvino""
|
| 217 |
+
model = OVLatentConsistencyModelPipeline.from_pretrained(model_id)
|
| 218 |
+
```
|
| 219 |
+
","{""id"": ""echarlaix/LCM_Dreamshaper_v7-openvino"", ""author"": ""echarlaix"", ""sha"": ""e869fb465fd1efcdf31512c742d56692cebef104"", ""last_modified"": ""2024-07-22 08:52:55+00:00"", ""created_at"": ""2024-07-20 17:16:45+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""text-to-image"", ""openvino"", ""en"", ""base_model:SimianLuo/LCM_Dreamshaper_v7"", ""base_model:finetune:SimianLuo/LCM_Dreamshaper_v7"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: SimianLuo/LCM_Dreamshaper_v7\nlanguage:\n- en\nlicense: mit\npipeline_tag: text-to-image\ntags:\n- text-to-image\n- openvino"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/openvino_model.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/openvino_model.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/openvino_model.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/openvino_model.xml', size=None, blob_id=None, lfs=None)""], ""spaces"": [""HelloSun/LCM_Dreamshaper_v7-int8-ov"", ""HelloSun/stable-diffusion-xl-base-1.0""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-07-22 08:52:55+00:00"", ""cardData"": ""base_model: SimianLuo/LCM_Dreamshaper_v7\nlanguage:\n- en\nlicense: mit\npipeline_tag: text-to-image\ntags:\n- text-to-image\n- openvino"", ""transformersInfo"": null, ""_id"": ""669bf0fdd77a8b2870439e46"", ""modelId"": ""echarlaix/LCM_Dreamshaper_v7-openvino"", ""usedStorage"": 4265271492}",1,https://huggingface.co/echarlaix/LCM_Dreamshaper_v7-openvino-8bit,1,,0,,0,,0,"HelloSun/LCM_Dreamshaper_v7-int8-ov, HelloSun/stable-diffusion-xl-base-1.0, echarlaix/openvino-export, huggingface/InferenceSupport/discussions/new?title=echarlaix/LCM_Dreamshaper_v7-openvino&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Becharlaix%2FLCM_Dreamshaper_v7-openvino%5D(%2Fecharlaix%2FLCM_Dreamshaper_v7-openvino)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A",4
|
| 220 |
+
echarlaix/LCM_Dreamshaper_v7-openvino-8bit,"---
|
| 221 |
+
base_model: echarlaix/LCM_Dreamshaper_v7-openvino
|
| 222 |
+
language:
|
| 223 |
+
- en
|
| 224 |
+
license: mit
|
| 225 |
+
pipeline_tag: text-to-image
|
| 226 |
+
tags:
|
| 227 |
+
- text-to-image
|
| 228 |
+
- openvino
|
| 229 |
+
- openvino
|
| 230 |
+
---
|
| 231 |
+
|
| 232 |
+
This model is a quantized version of [`echarlaix/LCM_Dreamshaper_v7-openvino`](https://huggingface.co/echarlaix/LCM_Dreamshaper_v7-openvino) and is converted to the OpenVINO format. This model was obtained via the [nncf-quantization](https://huggingface.co/spaces/echarlaix/nncf-quantization) space with [optimum-intel](https://github.com/huggingface/optimum-intel).
|
| 233 |
+
|
| 234 |
+
First make sure you have `optimum-intel` installed:
|
| 235 |
+
|
| 236 |
+
```bash
|
| 237 |
+
pip install optimum[openvino]
|
| 238 |
+
```
|
| 239 |
+
|
| 240 |
+
To load your model you can do as follows:
|
| 241 |
+
|
| 242 |
+
```python
|
| 243 |
+
from optimum.intel import OVLatentConsistencyModelPipeline
|
| 244 |
+
|
| 245 |
+
model_id = ""echarlaix/LCM_Dreamshaper_v7-openvino-8bit""
|
| 246 |
+
model = OVLatentConsistencyModelPipeline.from_pretrained(model_id)
|
| 247 |
+
```
|
| 248 |
+
","{""id"": ""echarlaix/LCM_Dreamshaper_v7-openvino-8bit"", ""author"": ""echarlaix"", ""sha"": ""6949a4e62ea4015574a5168eb889c20489cd9404"", ""last_modified"": ""2024-07-30 15:13:35+00:00"", ""created_at"": ""2024-07-30 15:13:23+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""text-to-image"", ""openvino"", ""en"", ""base_model:echarlaix/LCM_Dreamshaper_v7-openvino"", ""base_model:finetune:echarlaix/LCM_Dreamshaper_v7-openvino"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: echarlaix/LCM_Dreamshaper_v7-openvino\nlanguage:\n- en\nlicense: mit\npipeline_tag: text-to-image\ntags:\n- text-to-image\n- openvino"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='openvino_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/openvino_model.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/openvino_model.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_decoder/openvino_model.xml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/openvino_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae_encoder/openvino_model.xml', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-07-30 15:13:35+00:00"", ""cardData"": ""base_model: echarlaix/LCM_Dreamshaper_v7-openvino\nlanguage:\n- en\nlicense: mit\npipeline_tag: text-to-image\ntags:\n- text-to-image\n- openvino"", ""transformersInfo"": null, ""_id"": ""66a903139257aab9f2d7ba62"", ""modelId"": ""echarlaix/LCM_Dreamshaper_v7-openvino-8bit"", ""usedStorage"": 1069645452}",2,,0,,0,,0,,0,"echarlaix/nncf-quantization, huggingface/InferenceSupport/discussions/new?title=echarlaix/LCM_Dreamshaper_v7-openvino-8bit&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Becharlaix%2FLCM_Dreamshaper_v7-openvino-8bit%5D(%2Fecharlaix%2FLCM_Dreamshaper_v7-openvino-8bit)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A",2
|
LLaMA-Pro-8B_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
TencentARC/LLaMA-Pro-8B,"---
|
| 3 |
+
license: llama2
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# LLaMA-Pro-8B Model Card
|
| 7 |
+
|
| 8 |
+
## Model Description
|
| 9 |
+
LLaMA-Pro is a progressive version of the original LLaMA model, enhanced by the addition of Transformer blocks. It specializes in integrating both general language understanding and domain-specific knowledge, particularly in programming and mathematics.
|
| 10 |
+
|
| 11 |
+
## Development and Training
|
| 12 |
+
Developed by Tencent's ARC Lab, LLaMA-Pro is an 8.3 billion parameter model. It's an expansion of LLaMA2-7B, further trained on code and math corpora totaling 80 billion tokens.
|
| 13 |
+
|
| 14 |
+
## Intended Use
|
| 15 |
+
This model is designed for a wide range of NLP tasks, with a focus on programming, mathematics, and general language tasks. It suits scenarios requiring integration of natural and programming languages.
|
| 16 |
+
|
| 17 |
+
## Performance
|
| 18 |
+
LLaMA-Pro demonstrates advanced performance across various benchmarks. It outperforms existing models in the LLaMA series in handling diverse tasks, showcasing its capability as an intelligent language agent.
|
| 19 |
+
|
| 20 |
+
### Overall Performance on Languages, math and code tasks
|
| 21 |
+
|
| 22 |
+
| Model | ARC | Hellaswag | MMLU | TruthfulQA | Winogrande | GSM8K | GSM8K-PoT | HumanEval | MBPP | Avg |
|
| 23 |
+
| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: |
|
| 24 |
+
| LLAMA PRO (8B) | 54.10 | 77.94 | 47.88 | 39.04 | 73.95 | 17.89 | 25.42 | 28.66 | 33.20 | 44.2 |
|
| 25 |
+
| LLaMA2-7B | 53.07 | 78.59 | 46.87 | 38.76 | 74.03 | 14.48 | 17.68 | 13.05 | 20.09 | 39.62 |
|
| 26 |
+
| CodeLLaMA-7B | 39.93 | 60.80 | 31.12 | 37.82 | 64.01 | 5.16 | 25.20 | 33.50 | 41.40 | 37.66 |
|
| 27 |
+
| LLAMA PRO-INSTRUCT | 52.30 | 76.88 | 52.57 | 48.80 | 72.53 | 43.59 | 55.61 | 44.51 | 37.88 | 53.8 |
|
| 28 |
+
|
| 29 |
+
### Performance on GPT4 Evaluation
|
| 30 |
+
|
| 31 |
+
| Model | MT Bench |
|
| 32 |
+
| :-: | :-: |
|
| 33 |
+
| Alpaca-13B | 4.53 |
|
| 34 |
+
| CodeLLaMA-7B-Instruct | 5.71 |
|
| 35 |
+
| Vicuna-7B | 6.17 |
|
| 36 |
+
| LLaMA2-7B-Chat | 6.27 |
|
| 37 |
+
| LLAMA PRO-INSTRUCT | 6.32 |
|
| 38 |
+
|
| 39 |
+
## Limitations
|
| 40 |
+
While LLaMA-Pro addresses some limitations of previous models in the series, it may still encounter challenges specific to highly specialized domains or tasks.
|
| 41 |
+
|
| 42 |
+
## Ethical Considerations
|
| 43 |
+
Users should be aware of potential biases in the model and use it responsibly, considering its impact on various applications.
|
| 44 |
+
","{""id"": ""TencentARC/LLaMA-Pro-8B"", ""author"": ""TencentARC"", ""sha"": ""7115e7179060e0623d1ee9ff4476faed7e478d8c"", ""last_modified"": ""2024-01-08 11:57:14+00:00"", ""created_at"": ""2024-01-05 07:12:43+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 309, ""downloads_all_time"": null, ""likes"": 171, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""safetensors"", ""llama"", ""text-generation"", ""license:llama2"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: llama2"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": {""__type"": ""AddedToken"", ""content"": ""<s>"", ""lstrip"": false, ""normalized"": false, ""rstrip"": false, ""single_word"": false}, ""eos_token"": {""__type"": ""AddedToken"", ""content"": ""</s>"", ""lstrip"": false, ""normalized"": false, ""rstrip"": false, ""single_word"": false}, ""pad_token"": null, ""unk_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": false, ""rstrip"": false, ""single_word"": false}, ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00002.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00002.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00002.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00002.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""olimiemma/TencentARC-LLaMA-Pro-8B"", ""UltraMarkoRJ/TencentARC-LLaMA-Pro-8B"", ""gauravlogical/TencentARC-LLaMA-Pro-8B"", ""zlgook/TencentARC-LLaMA-Pro-8B"", ""QingChengOneLine/TencentARC-LLaMA-Pro-8B""], ""safetensors"": {""parameters"": {""BF16"": 8357485056}, ""total"": 8357485056}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-01-08 11:57:14+00:00"", ""cardData"": ""license: llama2"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""6597abebc7a30c638b2b8cbf"", ""modelId"": ""TencentARC/LLaMA-Pro-8B"", ""usedStorage"": 50145643284}",0,,0,"https://huggingface.co/DrishtiSharma/llama-pro-8b-tweet-summarization, https://huggingface.co/DrishtiSharma/llama-pro-8b-tweet-summarization-gradnorm-0.3, https://huggingface.co/DrishtiSharma/llama-pro-8b-tweet-summarization-gradnorm-0.3-warmupratio-0.05, https://huggingface.co/DrishtiSharma/llama-pro-8b-english-to-hinglish-translation",4,"https://huggingface.co/TheBloke/LLaMA-Pro-8B-GGUF, https://huggingface.co/TheBloke/LLaMA-Pro-8B-AWQ, https://huggingface.co/TheBloke/LLaMA-Pro-8B-GPTQ, https://huggingface.co/mradermacher/LLaMA-Pro-8B-GGUF, https://huggingface.co/mradermacher/LLaMA-Pro-8B-i1-GGUF",5,https://huggingface.co/TuringsSolutions/Llama-Pro-Wikichat,1,"QingChengOneLine/TencentARC-LLaMA-Pro-8B, UltraMarkoRJ/TencentARC-LLaMA-Pro-8B, gauravlogical/TencentARC-LLaMA-Pro-8B, huggingface/InferenceSupport/discussions/new?title=TencentARC/LLaMA-Pro-8B&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BTencentARC%2FLLaMA-Pro-8B%5D(%2FTencentARC%2FLLaMA-Pro-8B)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, olimiemma/TencentARC-LLaMA-Pro-8B, zlgook/TencentARC-LLaMA-Pro-8B",6
|
Llama-3-Groq-70B-Tool-Use_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
Groq/Llama-3-Groq-70B-Tool-Use,"---
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
license: llama3
|
| 6 |
+
pipeline_tag: text-generation
|
| 7 |
+
tags:
|
| 8 |
+
- facebook
|
| 9 |
+
- meta
|
| 10 |
+
- pytorch
|
| 11 |
+
- llama
|
| 12 |
+
- llama-3
|
| 13 |
+
- groq
|
| 14 |
+
- tool-use
|
| 15 |
+
- function-calling
|
| 16 |
+
base_model: meta-llama/Meta-Llama-3-70B
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
# Llama-3-70B-Tool-Use
|
| 20 |
+
|
| 21 |
+
This is the 70B parameter version of the Llama 3 Groq Tool Use model, specifically designed for advanced tool use and function calling tasks.
|
| 22 |
+
|
| 23 |
+
## Model Details
|
| 24 |
+
|
| 25 |
+
- **Model Type:** Causal language model fine-tuned for tool use
|
| 26 |
+
- **Language(s):** English
|
| 27 |
+
- **License:** Meta Llama 3 Community License
|
| 28 |
+
- **Model Architecture:** Optimized transformer
|
| 29 |
+
- **Training Approach:** Full fine-tuning and Direct Preference Optimization (DPO) on Llama 3 70B base model
|
| 30 |
+
- **Input:** Text
|
| 31 |
+
- **Output:** Text, with enhanced capabilities for tool use and function calling
|
| 32 |
+
|
| 33 |
+
## Performance
|
| 34 |
+
|
| 35 |
+
- **Berkeley Function Calling Leaderboard (BFCL) Score:** 90.76% overall accuracy
|
| 36 |
+
- This score represents the best performance among all open-source 70B LLMs on the BFCL
|
| 37 |
+
|
| 38 |
+
## Usage and Limitations
|
| 39 |
+
|
| 40 |
+
This model is designed for research and development in tool use and function calling scenarios. It excels at tasks involving API interactions, structured data manipulation, and complex tool use. However, users should note:
|
| 41 |
+
|
| 42 |
+
- For general knowledge or open-ended tasks, a general-purpose language model may be more suitable
|
| 43 |
+
- The model may still produce inaccurate or biased content in some cases
|
| 44 |
+
- Users are responsible for implementing appropriate safety measures for their specific use case
|
| 45 |
+
|
| 46 |
+
Note the model is quite sensitive to the `temperature` and `top_p` sampling configuration. Start at `temperature=0.5, top_p=0.65` and move up or down as needed.
|
| 47 |
+
|
| 48 |
+
Text prompt example:
|
| 49 |
+
|
| 50 |
+
We'd like to give a special shoutout to [@NousResearch](https://x.com/NousResearch) for pushing open source tool use forward with their public & open exploration of tool use in LLMs.
|
| 51 |
+
|
| 52 |
+
```
|
| 53 |
+
<|start_header_id|>system<|end_header_id|>
|
| 54 |
+
|
| 55 |
+
You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
|
| 56 |
+
<tool_call>
|
| 57 |
+
{""name"": <function-name>,""arguments"": <args-dict>}
|
| 58 |
+
</tool_call>
|
| 59 |
+
|
| 60 |
+
Here are the available tools:
|
| 61 |
+
<tools> {
|
| 62 |
+
""name"": ""get_current_weather"",
|
| 63 |
+
""description"": ""Get the current weather in a given location"",
|
| 64 |
+
""parameters"": {
|
| 65 |
+
""properties"": {
|
| 66 |
+
""location"": {
|
| 67 |
+
""description"": ""The city and state, e.g. San Francisco, CA"",
|
| 68 |
+
""type"": ""string""
|
| 69 |
+
},
|
| 70 |
+
""unit"": {
|
| 71 |
+
""enum"": [
|
| 72 |
+
""celsius"",
|
| 73 |
+
""fahrenheit""
|
| 74 |
+
],
|
| 75 |
+
""type"": ""string""
|
| 76 |
+
}
|
| 77 |
+
},
|
| 78 |
+
""required"": [
|
| 79 |
+
""location""
|
| 80 |
+
],
|
| 81 |
+
""type"": ""object""
|
| 82 |
+
}
|
| 83 |
+
} </tools><|eot_id|><|start_header_id|>user<|end_header_id|>
|
| 84 |
+
|
| 85 |
+
What is the weather like in San Francisco?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
|
| 86 |
+
|
| 87 |
+
<tool_call>
|
| 88 |
+
{""id"":""call_deok"",""name"":""get_current_weather"",""arguments"":{""location"":""San Francisco"",""unit"":""celsius""}}
|
| 89 |
+
</tool_call><|eot_id|><|start_header_id|>tool<|end_header_id|>
|
| 90 |
+
|
| 91 |
+
<tool_response>
|
| 92 |
+
{""id"":""call_deok"",""result"":{""temperature"":""72"",""unit"":""celsius""}}
|
| 93 |
+
</tool_response><|eot_id|><|start_header_id|>assistant<|end_header_id|>
|
| 94 |
+
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
## Ethical Considerations
|
| 98 |
+
|
| 99 |
+
While fine-tuned for tool use, this model inherits the ethical considerations of the base Llama 3 model. Use responsibly and implement additional safeguards as needed for your application.
|
| 100 |
+
|
| 101 |
+
## Availability
|
| 102 |
+
|
| 103 |
+
The model is available through:
|
| 104 |
+
- [Groq API console](https://console.groq.com)
|
| 105 |
+
- [Hugging Face](https://huggingface.co/Groq/Llama-3-Groq-70B-Tool-Use)
|
| 106 |
+
|
| 107 |
+
For full details on responsible use, ethical considerations, and latest benchmarks, please refer to the [official Llama 3 documentation](https://llama.meta.com/) and the Groq model card.
|
| 108 |
+
","{""id"": ""Groq/Llama-3-Groq-70B-Tool-Use"", ""author"": ""Groq"", ""sha"": ""017e1c12e7e614ff3290f0f4a2a0f34632cdcf10"", ""last_modified"": ""2024-08-28 13:42:02+00:00"", ""created_at"": ""2024-06-25 00:28:20+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 192, ""downloads_all_time"": null, ""likes"": 155, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""facebook"", ""meta"", ""pytorch"", ""llama-3"", ""groq"", ""tool-use"", ""function-calling"", ""conversational"", ""en"", ""base_model:meta-llama/Meta-Llama-3-70B"", ""base_model:finetune:meta-llama/Meta-Llama-3-70B"", ""license:llama3"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: meta-llama/Meta-Llama-3-70B\nlanguage:\n- en\nlicense: llama3\npipeline_tag: text-generation\ntags:\n- facebook\n- meta\n- pytorch\n- llama\n- llama-3\n- groq\n- tool-use\n- function-calling"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<|begin_of_text|>"", ""chat_template"": ""{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{% if add_generation_prompt %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}{% endif %}"", ""eos_token"": ""<|eot_id|>"", ""pad_token"": ""<|eot_id|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00009-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00010-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00011-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00012-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00013-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00014-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00015-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00016-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00017-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00018-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00019-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00020-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00021-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00022-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00023-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00024-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00025-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00026-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00027-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00028-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00029-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00030-of-00030.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Ffftdtd5dtft/gfgf"", ""Ravenzcore/Groq-Llama-3-Groq-70B-Tool-Use"", ""emilalvaro/Groq-Llama-3-Groq-70B-Tool-Use"", ""Ffftdtd5dtft/Hhhggv"", ""Ffftdtd5dtft/Hhhhh"", ""Mataa/Agric-bot""], ""safetensors"": {""parameters"": {""BF16"": 70553804800}, ""total"": 70553804800}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-08-28 13:42:02+00:00"", ""cardData"": ""base_model: meta-llama/Meta-Llama-3-70B\nlanguage:\n- en\nlicense: llama3\npipeline_tag: text-generation\ntags:\n- facebook\n- meta\n- pytorch\n- llama\n- llama-3\n- groq\n- tool-use\n- function-calling"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""667a0f24f6c638e6207a27ef"", ""modelId"": ""Groq/Llama-3-Groq-70B-Tool-Use"", ""usedStorage"": 493563517920}",0,,0,,0,"https://huggingface.co/mradermacher/Llama-3-Groq-70B-Tool-Use-GGUF, https://huggingface.co/MaziyarPanahi/Llama-3-Groq-70B-Tool-Use-GGUF, https://huggingface.co/bartowski/Llama-3-Groq-70B-Tool-Use-GGUF, https://huggingface.co/mradermacher/Llama-3-Groq-70B-Tool-Use-i1-GGUF, https://huggingface.co/second-state/Llama-3-Groq-70B-Tool-Use-GGUF, https://huggingface.co/gaianet/Llama-3-Groq-70B-Tool-Use-GGUF, https://huggingface.co/DevQuasar/Groq.Llama-3-Groq-70B-Tool-Use-GGUF",7,,0,"Ffftdtd5dtft/Hhhggv, Ffftdtd5dtft/Hhhhh, Ffftdtd5dtft/gfgf, Mataa/Agric-bot, Ravenzcore/Groq-Llama-3-Groq-70B-Tool-Use, emilalvaro/Groq-Llama-3-Groq-70B-Tool-Use, huggingface/InferenceSupport/discussions/new?title=Groq/Llama-3-Groq-70B-Tool-Use&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BGroq%2FLlama-3-Groq-70B-Tool-Use%5D(%2FGroq%2FLlama-3-Groq-70B-Tool-Use)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A",7
|
MagicPrompt-Stable-Diffusion_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
Gustavosta/MagicPrompt-Stable-Diffusion,"---
|
| 3 |
+
license: mit
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# MagicPrompt - Stable Diffusion
|
| 7 |
+
|
| 8 |
+
This is a model from the MagicPrompt series of models, which are [GPT-2](https://huggingface.co/gpt2) models intended to generate prompt texts for imaging AIs, in this case: [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion).
|
| 9 |
+
|
| 10 |
+
## 🖼️ Here's an example:
|
| 11 |
+
|
| 12 |
+
<img src=""https://files.catbox.moe/ac3jq7.png"">
|
| 13 |
+
|
| 14 |
+
This model was trained with 150,000 steps and a set of about 80,000 data filtered and extracted from the image finder for Stable Diffusion: ""[Lexica.art](https://lexica.art/)"". It was a little difficult to extract the data, since the search engine still doesn't have a public API without being protected by cloudflare, but if you want to take a look at the original dataset, you can have a look here: [datasets/Gustavosta/Stable-Diffusion-Prompts](https://huggingface.co/datasets/Gustavosta/Stable-Diffusion-Prompts).
|
| 15 |
+
|
| 16 |
+
If you want to test the model with a demo, you can go to: ""[spaces/Gustavosta/MagicPrompt-Stable-Diffusion](https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion)"".
|
| 17 |
+
|
| 18 |
+
## 💻 You can see other MagicPrompt models:
|
| 19 |
+
|
| 20 |
+
- For Dall-E 2: [Gustavosta/MagicPrompt-Dalle](https://huggingface.co/Gustavosta/MagicPrompt-Dalle)
|
| 21 |
+
- For Midjourney: [Gustavosta/MagicPrompt-Midourney](https://huggingface.co/Gustavosta/MagicPrompt-Midjourney) **[⚠️ In progress]**
|
| 22 |
+
- MagicPrompt full: [Gustavosta/MagicPrompt](https://huggingface.co/Gustavosta/MagicPrompt) **[⚠️ In progress]**
|
| 23 |
+
|
| 24 |
+
## ⚖️ Licence:
|
| 25 |
+
|
| 26 |
+
[MIT](https://huggingface.co/models?license=license:mit)
|
| 27 |
+
|
| 28 |
+
When using this model, please credit: [Gustavosta](https://huggingface.co/Gustavosta)
|
| 29 |
+
|
| 30 |
+
**Thanks for reading this far! :)**
|
| 31 |
+
","{""id"": ""Gustavosta/MagicPrompt-Stable-Diffusion"", ""author"": ""Gustavosta"", ""sha"": ""c2dfdbff1007791b5952aff9c02e622a0461f914"", ""last_modified"": ""2023-07-09 22:10:48+00:00"", ""created_at"": ""2022-09-17 22:34:07+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 16809, ""downloads_all_time"": null, ""likes"": 727, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""coreml"", ""safetensors"", ""gpt2"", ""text-generation"", ""license:mit"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: mit"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""GPT2LMHeadModel""], ""model_type"": ""gpt2"", ""tokenizer_config"": {""bos_token"": ""<|endoftext|>"", ""eos_token"": ""<|endoftext|>"", ""unk_token"": ""<|endoftext|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='coreml/text-generation/float16_model.mlpackage/Data/com.apple.CoreML/model.mlmodel', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='coreml/text-generation/float16_model.mlpackage/Data/com.apple.CoreML/weights/weight.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='coreml/text-generation/float16_model.mlpackage/Manifest.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='coreml/text-generation/float32_model.mlpackage/Data/com.apple.CoreML/model.mlmodel', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='coreml/text-generation/float32_model.mlpackage/Data/com.apple.CoreML/weights/weight.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='coreml/text-generation/float32_model.mlpackage/Manifest.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Gustavosta/MagicPrompt-Stable-Diffusion"", ""huggingface-projects/magic-diffusion"", ""doevent/Stable-Diffusion-prompt-generator"", ""yizhangliu/Text-to-Image"", ""RamAnanth1/visual-chatGPT"", ""Yntec/ToyWorldXL"", ""phenomenon1981/MagicPrompt-Stable-Diffusion"", ""awacke1/Prompt-Refinery-Text-to-Image-Generation"", ""KBaba7/Quant"", ""seawolf2357/sd-prompt-gen"", ""BoomerangGirl/MagicPrompt-Stable-Diffusion"", ""Nickhilearla135095/maximum_diffusion"", ""Kaludi/Stable-Diffusion-Prompt-Generator_App"", ""duchaba/sd_prompt_helper"", ""shogi880/ChatGPT-StableDiffusion-CharacterDesign"", ""rabiyulfahim/Prompt-Refinery-Text-to-Image-Generation"", ""deepparag/DreamlikeArt-Diffusion-1.0"", ""j43fer/MagicPrompt-Stable-Diffusion"", ""om-app/magic-diffusion"", ""om-app/Promt-to-Image-diffusions"", ""Daniton/MagicPrompt-Stable-Diffusion"", ""ehristoforu/Rensor"", ""bhaskartripathi/LLM_Quantization"", ""alisrbdni/magic-to-diffusion"", ""Silence1412/Stable_Diffusion_Cpu"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""pngwn/Stable-Diffusion-prompt-generator"", ""aichina/MagicPrompt-Stable-Diffusion"", ""markmagic/magic-diffusion"", ""Dao3/Top-20-Models"", ""Mrchuw/MagicPrompt-Stable-Diffusion"", ""Tasslehawk/Stable-Diffusion-prompt-generator"", ""5m4ck3r/Prompt-Gen"", ""ZeroTwo3/MagicPrompt-Stable-Diffusion"", ""bala0o8o0/Prompt-Enhancer"", ""ClaudioX/mg_sd_esp"", ""eeyorestoned/maximum_diffusion"", ""trysem/visua"", ""yuan2023/Stable-Diffusion-Prompt-Generator_App"", ""gato001k1/maximum_diffusion0k"", ""TeamMlx/MagicPrompt-Stable-Diffusion"", ""KKMobile/MagicPrompt-Stable-Diffusion"", ""ysharma/visual_chatgpt_dummy"", ""Dao3/MagicPrompt-Stable-Diffusion"", ""jefftko/Stable-Diffusion-prompt-generator"", ""3mrology/Chameleon_Text2Img_Generation_Demo"", ""Ifeanyi/promptGenerator"", ""dreamdrop-art/000555111"", ""phenixrhyder/MagicPrompt"", ""Achyuth4/MagicPrompt-Stable-Diffusion"", ""awqwqwq/Stable-Diffusion-prompt-generator"", ""bradarrML/magic-diffusion"", ""Joeythemonster/magic-diffusion"", ""cloudwp/Top-20-Diffusion"", ""Ali36Ahmad/MagicPrompt-Stable-Diffusion"", ""Ali36Ahmad/magic-diffusion"", ""pngwn/huguru"", ""nightfury/Magic_Text_to_prompt_to_art_Diffusion"", ""alisrbdni/MagicPrompt-Stable-Diffusion"", ""Nexxt/MagicPrompt-Stable-Diffusion"", ""Armored-Atom/DiFuse_Your_Thoughts"", ""johnsu6616/SD_Helper_01"", ""skyxinsun/Gustavosta-MagicPrompt-Stable-Diffusion"", ""willianmcs/visual-chatgpt"", ""Libra7578/Promt-to-Image-diffusions"", ""Stereo0001/MagicPrompt-Stable-Diffusion"", ""donalda/Gustavosta-MagicPrompt-Stable-Diffusion"", ""ai-art/magic-diffusion-generator"", ""kbora/minerva-generate-docker"", ""Alfasign/Einfach.Stable_DiffPomrpter"", ""Harshveer/Diffusion30x"", ""awacke1/MagicPrompt-Stable-Diffusion"", ""svjack/MagicPrompt-Stable-Diffusion"", ""Omnibus/2-button-Story-Board"", ""poetrychor/Gustavosta-MagicPrompt-Stable-Diffusion"", ""Ashrafb/MagicPrompt-Stable-Diffusion"", ""Vedits/Magic-Prompt-generator"", ""vih-v/Stable-Diffusion-prompt-generator"", ""Abhaykoul/Prompt_generator_for_helpingAI-tti"", ""Omnibus/top-20-diffusion"", ""ruslanmv/convert_to_gguf"", ""Rooc/Prompt-Generator"", ""Nymbo/MagicPrompt-Stable-Diffusion"", ""Ddfndjs/Cxxdx"", ""TeamHaltmannSusanaHWCEO/StreamlitRipperv0Diffusion"", ""ADA3e21/MagicPrompt-Stable-Diffusion"", ""tommy24/magic-diffusion"", ""ivaneliseeff/prompt2"", ""gvargas99/inspirationai1"", ""ZKYT/Gustavosta-MagicPrompt-Stable-Diffusion"", ""pepereeee/aiartnik"", ""next-social/audio_img"", ""om-app/Art-diffusion"", ""ismot/9t8"", ""Warkaz/diffusion"", ""TPKING/Gustavosta-MagicPrompt-Stable-Diffusion"", ""Coqtail/Gustavosta-MagicPrompt-Stable-Diffusion"", ""SAPTADIP/stable-diffusion-prompt-generator"", ""procrastinya/test_space""], ""safetensors"": {""parameters"": {""F32"": 124439808, ""U8"": 12582912}, ""total"": 137022720}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-07-09 22:10:48+00:00"", ""cardData"": ""license: mit"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""63264b5fff539edeea9491f6"", ""modelId"": ""Gustavosta/MagicPrompt-Stable-Diffusion"", ""usedStorage"": 4632052188}",0,,0,https://huggingface.co/jeong-jasonji/CSE574_prompter,1,"https://huggingface.co/mradermacher/MagicPrompt-Stable-Diffusion-GGUF, https://huggingface.co/mradermacher/MagicPrompt-Stable-Diffusion-i1-GGUF, https://huggingface.co/tensorblock/MagicPrompt-Stable-Diffusion-GGUF, https://huggingface.co/PrunaAI/Gustavosta-MagicPrompt-Stable-Diffusion-GGUF-smashed",4,,0,"BoomerangGirl/MagicPrompt-Stable-Diffusion, Gustavosta/MagicPrompt-Stable-Diffusion, KBaba7/Quant, Kaludi/Stable-Diffusion-Prompt-Generator_App, Yntec/ToyWorldXL, awacke1/Prompt-Refinery-Text-to-Image-Generation, doevent/Stable-Diffusion-prompt-generator, duchaba/sd_prompt_helper, ehristoforu/Rensor, huggingface-projects/magic-diffusion, huggingface/InferenceSupport/discussions/new?title=Gustavosta/MagicPrompt-Stable-Diffusion&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BGustavosta%2FMagicPrompt-Stable-Diffusion%5D(%2FGustavosta%2FMagicPrompt-Stable-Diffusion)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, seawolf2357/sd-prompt-gen, yizhangliu/Text-to-Image",13
|
MiniMax-Text-01_finetunes_20250425_143346.csv_finetunes_20250425_143346.csv
ADDED
|
@@ -0,0 +1,263 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
MiniMaxAI/MiniMax-Text-01,"---
|
| 3 |
+
pipeline_tag: text-generation
|
| 4 |
+
---
|
| 5 |
+
<div align=""center"">
|
| 6 |
+
|
| 7 |
+
<svg width=""60%"" height=""auto"" viewBox=""0 0 144 48"" fill=""none"" xmlns=""http://www.w3.org/2000/svg"">
|
| 8 |
+
<path d=""M26.6782 7.96523C26.6782 7.02436 25.913 6.26087 24.9739 6.26087C24.0348 6.26087 23.2695 7.0261 23.2695 7.96523V36.2139C23.2695 38.4 21.4904 40.1791 19.3043 40.1791C17.1183 40.1791 15.3391 38.4 15.3391 36.2139V18.0904C15.3391 17.1496 14.5739 16.3861 13.6348 16.3861C12.6956 16.3861 11.9304 17.1513 11.9304 18.0904V25.7722C11.9304 27.9583 10.1513 29.7374 7.96518 29.7374C5.7791 29.7374 4 27.9583 4 25.7722V22.9878C4 22.3635 4.50609 21.8574 5.13043 21.8574C5.75478 21.8574 6.26087 22.3635 6.26087 22.9878V25.7722C6.26087 26.713 7.02605 27.4765 7.96518 27.4765C8.90431 27.4765 9.66954 26.7113 9.66954 25.7722V18.0904C9.66954 15.9044 11.4487 14.1252 13.6348 14.1252C15.8209 14.1252 17.6 15.9044 17.6 18.0904V36.2139C17.6 37.1548 18.3652 37.9183 19.3043 37.9183C20.2435 37.9183 21.0087 37.153 21.0087 36.2139V25.1322V7.96523C21.0087 5.77914 22.7878 4 24.9739 4C27.16 4 28.9391 5.77914 28.9391 7.96523V31.3565C28.9391 31.9809 28.433 32.487 27.8087 32.487C27.1843 32.487 26.6782 31.9809 26.6782 31.3565V7.96523ZM47.6539 14.1252C45.4678 14.1252 43.6887 15.9044 43.6887 18.0904V33.2296C43.6887 34.1704 42.9235 34.9339 41.9843 34.9339C41.0452 34.9339 40.28 34.1687 40.28 33.2296V7.96523C40.28 5.77914 38.5008 4 36.3148 4C34.1287 4 32.3496 5.77914 32.3496 7.96523V40.0348C32.3496 40.9756 31.5843 41.7391 30.6452 41.7391C29.7061 41.7391 28.9409 40.9739 28.9409 40.0348V36.0643C28.9409 35.44 28.4348 34.9339 27.8104 34.9339C27.1861 34.9339 26.68 35.44 26.68 36.0643V40.0348C26.68 42.2209 28.4591 44 30.6452 44C32.8313 44 34.6104 42.2209 34.6104 40.0348V7.96523C34.6104 7.02436 35.3756 6.26087 36.3148 6.26087C37.2539 6.26087 38.0191 7.0261 38.0191 7.96523V33.2296C38.0191 35.4156 39.7982 37.1948 41.9843 37.1948C44.1704 37.1948 45.9496 35.4156 45.9496 33.2296V18.0904C45.9496 17.1496 46.7148 16.3861 47.6539 16.3861C48.593 16.3861 49.3582 17.1513 49.3582 18.0904V31.3565C49.3582 31.9809 49.8643 32.487 50.4887 32.487C51.113 32.487 51.6191 31.9809 51.6191 31.3565V18.0904C51.6191 15.9044 49.84 14.1252 47.6539 14.1252Z"" fill=""url(#paint0_linear_17_483)""/>
|
| 9 |
+
<path d=""M68.7671 16.5615H71.2541C71.3254 16.5615 71.3845 16.5859 71.435 16.6363C71.4836 16.6868 71.5097 16.7459 71.5097 16.8172V31.1824C71.5097 31.2537 71.4854 31.3128 71.435 31.3633C71.3845 31.4137 71.3254 31.4381 71.2541 31.4381H68.7671C68.6958 31.4381 68.6367 31.4137 68.5862 31.3633C68.5358 31.3146 68.5115 31.2537 68.5115 31.1824V21.812C68.5115 21.7563 68.4976 21.7268 68.4697 21.7268C68.4419 21.7268 68.4123 21.7476 68.3845 21.7911L66.1323 25.318C66.061 25.4311 65.9619 25.4885 65.8349 25.4885H64.581C64.4541 25.4885 64.3549 25.4328 64.2836 25.318L62.0315 21.7911C62.0036 21.7494 61.9741 21.7302 61.9462 21.7372C61.9184 21.7441 61.9045 21.7772 61.9045 21.8328V31.1824C61.9045 31.2537 61.8802 31.3128 61.8297 31.3633C61.7793 31.4137 61.7202 31.4381 61.6489 31.4381H59.1619C59.0906 31.4381 59.0315 31.4137 58.981 31.3633C58.9306 31.3146 58.9062 31.2537 58.9062 31.1824V16.8172C58.9062 16.7459 58.9306 16.6868 58.981 16.6363C59.0315 16.5859 59.0906 16.5615 59.1619 16.5615H61.6489C61.7758 16.5615 61.8749 16.6189 61.9462 16.732L65.1341 21.6833C65.1758 21.7685 65.2193 21.7685 65.261 21.6833L68.4697 16.732C68.541 16.6189 68.6402 16.5615 68.7671 16.5615Z"" fill=""currentColor""/>
|
| 10 |
+
<path d=""M74.1764 31.3633C74.1259 31.3146 74.1016 31.2537 74.1016 31.1824V16.8172C74.1016 16.7459 74.1259 16.6868 74.1764 16.6363C74.2268 16.5859 74.2859 16.5615 74.3572 16.5615H76.8442C76.9155 16.5615 76.9746 16.5859 77.0251 16.6363C77.0737 16.6868 77.0998 16.7459 77.0998 16.8172V31.1824C77.0998 31.2537 77.0755 31.3128 77.0251 31.3633C76.9746 31.4137 76.9155 31.4381 76.8442 31.4381H74.3572C74.2859 31.4381 74.2268 31.4137 74.1764 31.3633Z"" fill=""currentColor""/>
|
| 11 |
+
<path d=""M88.3066 16.6361C88.3553 16.5874 88.4162 16.5613 88.4875 16.5613H90.9744C91.0457 16.5613 91.1049 16.5857 91.1553 16.6361C91.204 16.6865 91.2301 16.7457 91.2301 16.817V31.1822C91.2301 31.2535 91.2057 31.3126 91.1553 31.363C91.1049 31.4135 91.0457 31.4378 90.9744 31.4378H88.5727C88.4301 31.4378 88.331 31.3822 88.2753 31.2674L82.771 22.1717C82.7431 22.13 82.7136 22.1109 82.6858 22.1178C82.6579 22.1248 82.644 22.1578 82.644 22.2135L82.6858 31.1805C82.6858 31.2518 82.6614 31.3109 82.611 31.3613C82.5606 31.4117 82.5014 31.4361 82.4301 31.4361H79.9431C79.8718 31.4361 79.8127 31.4117 79.7623 31.3613C79.7118 31.3126 79.6875 31.2518 79.6875 31.1805V16.8152C79.6875 16.7439 79.7118 16.6848 79.7623 16.6344C79.8127 16.5839 79.8718 16.5596 79.9431 16.5596H82.3449C82.4858 16.5596 82.5849 16.617 82.6423 16.73L88.124 25.7822C88.1518 25.8239 88.1797 25.8431 88.2092 25.8361C88.2371 25.8292 88.251 25.7978 88.251 25.7404L88.2301 16.8152C88.2301 16.7439 88.2545 16.6848 88.3049 16.6344L88.3066 16.6361Z"" fill=""currentColor""/>
|
| 12 |
+
<path d=""M93.8951 31.3633C93.8446 31.3146 93.8203 31.2537 93.8203 31.1824V16.8172C93.8203 16.7459 93.8446 16.6868 93.8951 16.6363C93.9455 16.5859 94.0047 16.5615 94.076 16.5615H96.5629C96.6342 16.5615 96.6934 16.5859 96.7438 16.6363C96.7925 16.6868 96.8186 16.7459 96.8186 16.8172V31.1824C96.8186 31.2537 96.7942 31.3128 96.7438 31.3633C96.6934 31.4137 96.6342 31.4381 96.5629 31.4381H94.076C94.0047 31.4381 93.9455 31.4137 93.8951 31.3633Z"" fill=""currentColor""/>
|
| 13 |
+
<path d=""M109.267 16.5615H111.754C111.825 16.5615 111.885 16.5859 111.935 16.6363C111.984 16.6868 112.01 16.7459 112.01 16.8172V31.1824C112.01 31.2537 111.985 31.3128 111.935 31.3633C111.885 31.4137 111.825 31.4381 111.754 31.4381H109.267C109.196 31.4381 109.137 31.4137 109.086 31.3633C109.036 31.3146 109.011 31.2537 109.011 31.1824V21.812C109.011 21.7563 108.998 21.7268 108.97 21.7268C108.942 21.7268 108.912 21.7476 108.885 21.7911L106.632 25.318C106.561 25.4311 106.462 25.4885 106.335 25.4885H105.081C104.954 25.4885 104.855 25.4328 104.784 25.318L102.531 21.7911C102.504 21.7494 102.474 21.7302 102.446 21.7372C102.418 21.7441 102.405 21.7772 102.405 21.8328V31.1824C102.405 31.2537 102.38 31.3128 102.33 31.3633C102.279 31.4137 102.22 31.4381 102.149 31.4381H99.6619C99.5906 31.4381 99.5315 31.4137 99.481 31.3633C99.4306 31.3146 99.4062 31.2537 99.4062 31.1824V16.8172C99.4062 16.7459 99.4306 16.6868 99.481 16.6363C99.5315 16.5859 99.5906 16.5615 99.6619 16.5615H102.149C102.276 16.5615 102.375 16.6189 102.446 16.732L105.634 21.6833C105.676 21.7685 105.719 21.7685 105.761 21.6833L108.97 16.732C109.041 16.6189 109.14 16.5615 109.267 16.5615Z"" fill=""currentColor""/>
|
| 14 |
+
<path d=""M123.782 31.2241L123.144 29.1424C123.116 29.0867 123.079 29.0572 123.038 29.0572H117.81C117.768 29.0572 117.732 29.085 117.704 29.1424L117.088 31.2241C117.046 31.3668 116.954 31.4363 116.812 31.4363H114.112C114.027 31.4363 113.963 31.412 113.921 31.3615C113.879 31.3128 113.871 31.2381 113.9 31.1389L118.49 16.7737C118.532 16.6328 118.624 16.5615 118.766 16.5615H122.102C122.243 16.5615 122.335 16.6328 122.379 16.7737L126.968 31.1389C126.982 31.1668 126.989 31.2033 126.989 31.245C126.989 31.372 126.911 31.4363 126.756 31.4363H124.057C123.916 31.4363 123.824 31.365 123.78 31.2241H123.782ZM118.554 26.7407H122.295C122.38 26.7407 122.408 26.6989 122.38 26.6137L120.467 20.3024C120.453 20.2467 120.432 20.2207 120.403 20.2276C120.375 20.2346 120.352 20.2589 120.339 20.3024L118.469 26.6137C118.455 26.6989 118.483 26.7407 118.554 26.7407Z"" fill=""currentColor""/>
|
| 15 |
+
<path d=""M128.222 31.353C128.18 31.2974 128.187 31.2261 128.243 31.1409L132.365 24.0643C132.393 24.0226 132.393 23.9791 132.365 23.9374L128.243 16.8609L128.201 16.7339C128.201 16.6209 128.28 16.5635 128.434 16.5635H131.133C131.274 16.5635 131.38 16.6209 131.452 16.7339L134.213 21.6C134.255 21.6852 134.299 21.6852 134.34 21.6L137.102 16.7339C137.173 16.6209 137.28 16.5635 137.42 16.5635H140.099C140.198 16.5635 140.269 16.5913 140.311 16.6487C140.353 16.7061 140.346 16.7756 140.29 16.8609L136.168 23.9374C136.154 23.9791 136.154 24.0226 136.168 24.0643L140.29 31.1409L140.332 31.2678C140.332 31.3809 140.253 31.4383 140.099 31.4383H137.42C137.278 31.4383 137.172 31.3826 137.102 31.2678L134.34 26.4226C134.299 26.3374 134.255 26.3374 134.213 26.4226L131.429 31.2678C131.358 31.3809 131.252 31.4383 131.111 31.4383H128.433C128.333 31.4383 128.262 31.4104 128.22 31.353H128.222Z"" fill=""currentColor""/>
|
| 16 |
+
<defs>
|
| 17 |
+
<linearGradient id=""paint0_linear_17_483"" x1=""3.99826"" y1=""24"" x2=""51.6208"" y2=""24"" gradientUnits=""userSpaceOnUse"">
|
| 18 |
+
<stop stop-color=""#E21680""/>
|
| 19 |
+
<stop offset=""1"" stop-color=""#FF633A""/>
|
| 20 |
+
</linearGradient>
|
| 21 |
+
</defs>
|
| 22 |
+
</svg>
|
| 23 |
+
|
| 24 |
+
</div>
|
| 25 |
+
<hr>
|
| 26 |
+
|
| 27 |
+
<div align=""center"" style=""line-height: 1;"">
|
| 28 |
+
<a href=""https://www.minimax.io"" target=""_blank"" style=""margin: 2px;"">
|
| 29 |
+
<img alt=""Homepage"" src=""https://img.shields.io/badge/_Homepage-MiniMax-FF4040?style=flat-square&labelColor=2C3E50&logo=data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHhtbG5zOnhsaW5rPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5L3hsaW5rIiB2aWV3Qm94PSIwIDAgNDkwLjE2IDQxMS43Ij48ZGVmcz48c3R5bGU+LmNscy0xe2ZpbGw6I2ZmZjt9PC9zdHlsZT48L2RlZnM+PHBhdGggY2xhc3M9ImNscy0xIiBkPSJNMjMzLjQ1LDQwLjgxYTE3LjU1LDE3LjU1LDAsMSwwLTM1LjEsMFYzMzEuNTZhNDAuODIsNDAuODIsMCwwLDEtODEuNjMsMFYxNDVhMTcuNTUsMTcuNTUsMCwxLDAtMzUuMDksMHY3OS4wNmE0MC44Miw0MC44MiwwLDAsMS04MS42MywwVjE5NS40MmExMS42MywxMS42MywwLDAsMSwyMy4yNiwwdjI4LjY2YTE3LjU1LDE3LjU1LDAsMCwwLDM1LjEsMFYxNDVBNDAuODIsNDAuODIsMCwwLDEsMTQwLDE0NVYzMzEuNTZhMTcuNTUsMTcuNTUsMCwwLDAsMzUuMSwwVjIxNy41aDBWNDAuODFhNDAuODEsNDAuODEsMCwxLDEsODEuNjIsMFYyODEuNTZhMTEuNjMsMTEuNjMsMCwxLDEtMjMuMjYsMFptMjE1LjksNjMuNEE0MC44Niw0MC44NiwwLDAsMCw0MDguNTMsMTQ1VjMwMC44NWExNy41NSwxNy41NSwwLDAsMS0zNS4wOSwwdi0yNjBhNDAuODIsNDAuODIsMCwwLDAtODEuNjMsMFYzNzAuODlhMTcuNTUsMTcuNTUsMCwwLDEtMzUuMSwwVjMzMGExMS42MywxMS42MywwLDEsMC0yMy4yNiwwdjQwLjg2YTQwLjgxLDQwLjgxLDAsMCwwLDgxLjYyLDBWNDAuODFhMTcuNTUsMTcuNTUsMCwwLDEsMzUuMSwwdjI2MGE0MC44Miw0MC44MiwwLDAsMCw4MS42MywwVjE0NWExNy41NSwxNy41NSwwLDEsMSwzNS4xLDBWMjgxLjU2YTExLjYzLDExLjYzLDAsMCwwLDIzLjI2LDBWMTQ1QTQwLjg1LDQwLjg1LDAsMCwwLDQ0OS4zNSwxMDQuMjFaIi8+PC9zdmc+&logoWidth=20"" style=""display: inline-block; vertical-align: middle;""/>
|
| 30 |
+
</a>
|
| 31 |
+
<a href=""https://arxiv.org/abs/2501.08313"" target=""_blank"" style=""margin: 2px;"">
|
| 32 |
+
<img alt=""Paper"" src=""https://img.shields.io/badge/📖_Paper-MiniMax--01-FF4040?style=flat-square&labelColor=2C3E50"" style=""display: inline-block; vertical-align: middle;""/>
|
| 33 |
+
</a>
|
| 34 |
+
<a href=""https://chat.minimax.io/"" target=""_blank"" style=""margin: 2px;"">
|
| 35 |
+
<img alt=""Chat"" src=""https://img.shields.io/badge/_MiniMax_Chat-FF4040?style=flat-square&labelColor=2C3E50&logo=data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHhtbG5zOnhsaW5rPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5L3hsaW5rIiB2aWV3Qm94PSIwIDAgNDkwLjE2IDQxMS43Ij48ZGVmcz48c3R5bGU+LmNscy0xe2ZpbGw6I2ZmZjt9PC9zdHlsZT48L2RlZnM+PHBhdGggY2xhc3M9ImNscy0xIiBkPSJNMjMzLjQ1LDQwLjgxYTE3LjU1LDE3LjU1LDAsMSwwLTM1LjEsMFYzMzEuNTZhNDAuODIsNDAuODIsMCwwLDEtODEuNjMsMFYxNDVhMTcuNTUsMTcuNTUsMCwxLDAtMzUuMDksMHY3OS4wNmE0MC44Miw0MC44MiwwLDAsMS04MS42MywwVjE5NS40MmExMS42MywxMS42MywwLDAsMSwyMy4yNiwwdjI4LjY2YTE3LjU1LDE3LjU1LDAsMCwwLDM1LjEsMFYxNDVBNDAuODIsNDAuODIsMCwwLDEsMTQwLDE0NVYzMzEuNTZhMTcuNTUsMTcuNTUsMCwwLDAsMzUuMSwwVjIxNy41aDBWNDAuODFhNDAuODEsNDAuODEsMCwxLDEsODEuNjIsMFYyODEuNTZhMTEuNjMsMTEuNjMsMCwxLDEtMjMuMjYsMFptMjE1LjksNjMuNEE0MC44Niw0MC44NiwwLDAsMCw0MDguNTMsMTQ1VjMwMC44NWExNy41NSwxNy41NSwwLDAsMS0zNS4wOSwwdi0yNjBhNDAuODIsNDAuODIsMCwwLDAtODEuNjMsMFYzNzAuODlhMTcuNTUsMTcuNTUsMCwwLDEtMzUuMSwwVjMzMGExMS42MywxMS42MywwLDEsMC0yMy4yNiwwdjQwLjg2YTQwLjgxLDQwLjgxLDAsMCwwLDgxLjYyLDBWNDAuODFhMTcuNTUsMTcuNTUsMCwwLDEsMzUuMSwwdjI2MGE0MC44Miw0MC44MiwwLDAsMCw4MS42MywwVjE0NWExNy41NSwxNy41NSwwLDEsMSwzNS4xLDBWMjgxLjU2YTExLjYzLDExLjYzLDAsMCwwLDIzLjI2LDBWMTQ1QTQwLjg1LDQwLjg1LDAsMCwwLDQ0OS4zNSwxMDQuMjFaIi8+PC9zdmc+&logoWidth=20"" style=""display: inline-block; vertical-align: middle;""/>
|
| 36 |
+
</a>
|
| 37 |
+
<a href=""https://www.minimax.io/platform"" style=""margin: 2px;"">
|
| 38 |
+
<img alt=""API"" src=""https://img.shields.io/badge/⚡_API-Platform-FF4040?style=flat-square&labelColor=2C3E50"" style=""display: inline-block; vertical-align: middle;""/>
|
| 39 |
+
</a>
|
| 40 |
+
<a href=""https://github.com/MiniMax-AI/MiniMax-MCP"" style=""margin: 2px;"">
|
| 41 |
+
<img alt=""MCP"" src=""https://img.shields.io/badge/🚀_MCP-MiniMax_MCP-FF4040?style=flat-square&labelColor=2C3E50"" style=""display: inline-block; vertical-align: middle;""/>
|
| 42 |
+
</a>
|
| 43 |
+
</div>
|
| 44 |
+
<div align=""center"" style=""line-height: 1;"">
|
| 45 |
+
<a href=""https://github.com/MiniMax-AI/MiniMax-01"" target=""_blank"" style=""margin: 2px;"">
|
| 46 |
+
<img alt=""GitHub"" src=""https://img.shields.io/badge/_GitHub-MinMax-FF4040?style=flat-square&labelColor=2C3E50"" style=""display: inline-block; vertical-align: middle;""/>
|
| 47 |
+
</a>
|
| 48 |
+
<a href=""https://huggingface.co/MiniMaxAI/MiniMax-Text-01/blob/main/LICENSE-MODEL"" style=""margin: 2px;"">
|
| 49 |
+
<img alt=""Model License"" src=""https://img.shields.io/badge/_Model_License-Model_Agreement-FF4040?style=flat-square&labelColor=2C3E50"" style=""display: inline-block; vertical-align: middle;""/>
|
| 50 |
+
</a>
|
| 51 |
+
<a href=""https://huggingface.co/MiniMaxAI/MiniMax-Text-01/blob/main/LICENSE-CODE"" style=""margin: 2px;"">
|
| 52 |
+
<img alt=""Code License"" src=""https://img.shields.io/badge/_Code_License-MIT-FF4040?style=flat-square&labelColor=2C3E50"" style=""display: inline-block; vertical-align: middle;""/>
|
| 53 |
+
</a>
|
| 54 |
+
</div>
|
| 55 |
+
<div align=""center"" style=""line-height: 1;"">
|
| 56 |
+
<a href=""https://huggingface.co/MiniMaxAI/MiniMax-Text-01/blob/main/figures/wechat-qrcode.jpeg"" target=""_blank"" style=""margin: 2px;"">
|
| 57 |
+
WeChat
|
| 58 |
+
</a>
|
| 59 |
+
</div>
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
# MiniMax-Text-01
|
| 63 |
+
|
| 64 |
+
## 1. Introduction
|
| 65 |
+
|
| 66 |
+
MiniMax-Text-01 is a powerful language model with 456 billion total parameters, of which 45.9 billion are activated per token. To better unlock the long context capabilities of the model, MiniMax-Text-01 adopts a hybrid architecture that combines Lightning Attention, Softmax Attention and Mixture-of-Experts (MoE). Leveraging advanced parallel strategies and innovative compute-communication overlap methods—such as Linear Attention Sequence Parallelism Plus (LASP+), varlen ring attention, Expert Tensor Parallel (ETP), etc., MiniMax-Text-01's training context length is extended to 1 million tokens, and it can handle a context of up to 4 million tokens during the inference. On various academic benchmarks, MiniMax-Text-01 also demonstrates the performance of a top-tier model.
|
| 67 |
+
|
| 68 |
+
<p align=""center"">
|
| 69 |
+
<img width=""100%"" src=""figures/TextBench.png"">
|
| 70 |
+
</p>
|
| 71 |
+
|
| 72 |
+
## 2. Model Architecture
|
| 73 |
+
|
| 74 |
+
The architecture of MiniMax-Text-01 is briefly described as follows:
|
| 75 |
+
- Total Parameters: 456B
|
| 76 |
+
- Activated Parameters per Token: 45.9B
|
| 77 |
+
- Number Layers: 80
|
| 78 |
+
- Hybrid Attention: a softmax attention is positioned after every 7 lightning attention.
|
| 79 |
+
- Number of attention heads: 64
|
| 80 |
+
- Attention head dimension: 128
|
| 81 |
+
- Mixture of Experts:
|
| 82 |
+
- Number of experts: 32
|
| 83 |
+
- Expert hidden dimension: 9216
|
| 84 |
+
- Top-2 routing strategy
|
| 85 |
+
- Positional Encoding: Rotary Position Embedding (RoPE) applied to half of the attention head dimension with a base frequency of 10,000,000
|
| 86 |
+
- Hidden Size: 6144
|
| 87 |
+
- Vocab Size: 200,064
|
| 88 |
+
|
| 89 |
+
## 3. Evaluation
|
| 90 |
+
|
| 91 |
+
### Core Academic Benchmarks
|
| 92 |
+
|
| 93 |
+
| **Tasks** | **GPT-4o (11-20)** | **Claude-3.5-Sonnet (10-22)** | **Gemini-1.5-Pro (002)** | **Gemini-2.0-Flash (exp)** | **Qwen2.5-72B-Inst.** | **DeepSeek-V3** | **Llama-3.1-405B-Inst.** | **MiniMax-Text-01** |
|
| 94 |
+
|-------------------------------|--------------------|-------------------------------|--------------------------|----------------------------|-----------------------|-----------------|--------------------------|---------------------|
|
| 95 |
+
| **General** | | | | | | | | |
|
| 96 |
+
| MMLU<sup>*</sup> | 85.7 | 88.3 | 86.8 | 86.5 | 86.1 | 88.5 | **88.6** | 88.5 |
|
| 97 |
+
| MMLU-Pro<sup>*</sup> | 74.4 | **78.0** | 75.8 | 76.4 | 71.1 | 75.9 | 73.3 | 75.7 |
|
| 98 |
+
| SimpleQA | **39.0** | 28.1 | 23.4 | 26.6 | 10.3 | 24.9 | 23.2 | 23.7 |
|
| 99 |
+
| C-SimpleQA | 64.6 | 56.8 | 59.4 | 63.3 | 52.2 | 64.8 | 54.7 | **67.4** |
|
| 100 |
+
| IFEval _(avg)_ | 84.1 | **90.1** | 89.4 | 88.4 | 87.2 | 87.3 | 86.4 | 89.1 |
|
| 101 |
+
| Arena-Hard | **92.4** | 87.6 | 85.3 | 72.7 | 81.2 | 91.4 | 63.5 | 89.1 |
|
| 102 |
+
| **Reasoning** | | | | | | | | |
|
| 103 |
+
| GPQA<sup>*</sup> _(diamond)_ | 46.0 | **65.0** | 59.1 | 62.1 | 49.0 | 59.1 | 50.7 | 54.4 |
|
| 104 |
+
| DROP<sup>*</sup> _(F1)_ | 89.2 | 88.8 | 89.2 | 89.3 | 85.0 | 91.0 | **92.5** | 87.8 |
|
| 105 |
+
| **Mathematics** | | | | | | | | |
|
| 106 |
+
| GSM8k<sup>*</sup> | 95.6 | **96.9** | 95.2 | 95.4 | 95.8 | 96.7 | 96.7 | 94.8 |
|
| 107 |
+
| MATH<sup>*</sup> | 76.6 | 74.1 | **84.6** | 83.9 | 81.8 | **84.6** | 73.8 | 77.4 |
|
| 108 |
+
| **Coding** | | | | | | | | |
|
| 109 |
+
| MBPP + | 76.2 | 75.1 | 75.4 | 75.9 | 77.0 | **78.8** | 73.0 | 71.7 |
|
| 110 |
+
| HumanEval | 90.2 | **93.7** | 86.6 | 89.6 | 86.6 | 92.1 | 89.0 | 86.9 |
|
| 111 |
+
|
| 112 |
+
<sup>*</sup> Evaluated following a _0-shot CoT_ setting.
|
| 113 |
+
|
| 114 |
+
### Long Benchmarks
|
| 115 |
+
#### 4M Needle In A Haystack Test
|
| 116 |
+
<p align=""center"">
|
| 117 |
+
<img width=""90%"" src=""figures/niah.png"">
|
| 118 |
+
</p>
|
| 119 |
+
|
| 120 |
+
#### Ruler
|
| 121 |
+
| Model | 4k | 8k | 16k | 32k | 64k | 128k | 256k | 512k | 1M |
|
| 122 |
+
|-------|----|----|-----|-----|-----|------|------|------|----|
|
| 123 |
+
| **GPT-4o (11-20)** | **0.970** | 0.921 | 0.890 | 0.888 | 0.884 | - | - | - | - |
|
| 124 |
+
| **Claude-3.5-Sonnet (10-22)** | 0.965 | 0.960 | 0.957 | 0.950 | **0.952** | 0.938 | - | - | - |
|
| 125 |
+
| **Gemini-1.5-Pro (002)** | 0.962 | 0.960 | **0.960** | **0.958** | 0.938 | 0.917 | 0.916 | 0.861 | 0.850 |
|
| 126 |
+
| **Gemini-2.0-Flash (exp)** | 0.960 | 0.960 | 0.951 | 0.957 | 0.937 | 0.860 | 0.797 | 0.709 | - |
|
| 127 |
+
| **MiniMax-Text-01** | 0.963 | **0.961** | 0.953 | 0.954 | 0.943 | **0.947** | **0.945** | **0.928** | **0.910** |
|
| 128 |
+
|
| 129 |
+
#### LongBench v2
|
| 130 |
+
| **Model** | **overall** | **easy** | **hard** | **short** | **medium** | **long** |
|
| 131 |
+
|----------------------------|-------------|----------|----------|------------|------------|----------|
|
| 132 |
+
| Human | 53.7 | 100.0 | 25.1 | 47.2 | 59.1 | 53.7 |
|
| 133 |
+
| **w/ CoT** | | | | | | |
|
| 134 |
+
| GPT-4o (11-20) | 51.4 | 54.2 | 49.7 | 59.6 | 48.6 | 43.5 |
|
| 135 |
+
| Claude-3.5-Sonnet (10-22) | 46.7 | 55.2 | 41.5 | 53.9 | 41.9 | 44.4 |
|
| 136 |
+
| Deepseek-V3 | - | - | - | - | - | - |
|
| 137 |
+
| Qwen2.5-72B-Inst. | 43.5 | 47.9 | 40.8 | 48.9 | 40.9 | 39.8 |
|
| 138 |
+
| **MiniMax-Text-01** | **56.5** | **66.1** | **50.5** | **61.7** | **56.7** | **47.2** |
|
| 139 |
+
| **w/o CoT** | | | | | | |
|
| 140 |
+
| GPT-4o (11-20) | 50.1 | 57.4 | 45.6 | 53.3 | 52.4 | 40.2 |
|
| 141 |
+
| Claude-3.5-Sonnet (10-22) | 41.0 | 46.9 | 37.3 | 46.1 | 38.6 | 37.0 |
|
| 142 |
+
| Deepseek-V3 | 48.7 | - | - | - | - | - |
|
| 143 |
+
| Qwen2.5-72B-Inst. | 42.1 | 42.7 | 41.8 | 45.6 | 38.1 | **44.4** |
|
| 144 |
+
| **MiniMax-Text-01** | **52.9** | **60.9** | **47.9** | **58.9** | **52.6** | 43.5 |
|
| 145 |
+
|
| 146 |
+
#### MTOB
|
| 147 |
+
| **Context Type** | **no context** | **half book** | **full book** | **Δ half book** | **Δ full book** |
|
| 148 |
+
|------------------|----------------|---------------|---------------|------------------|-----------------|
|
| 149 |
+
| **eng → kalam (ChrF)** | | | | | |
|
| 150 |
+
| GPT-4o (11-20) | 9.90 | **54.30** | - | 44.40 | - |
|
| 151 |
+
| Claude-3.5-Sonnet (10-22) | 20.22 | 53.62 | 55.65 | 33.39 | 35.42 |
|
| 152 |
+
| Gemini-1.5-Pro (002) | 16.79 | 53.68 | **57.90** | 36.89 | 41.11 |
|
| 153 |
+
| Gemini-2.0-Flash (exp) | 12.20 | 49.50 | 53.30 | 37.30 | 41.10 |
|
| 154 |
+
| Qwen-Long | 16.55 | 48.48 | 45.94 | 31.92 | 29.39 |
|
| 155 |
+
| **MiniMax-Text-01** | 6.0 | 51.74 | 51.60 | **45.7** | **45.6** |
|
| 156 |
+
| **kalam → eng (BLEURT)** | | | | | |
|
| 157 |
+
| GPT-4o (11-20) | 33.20 | 58.30 | - | 25.10 | - |
|
| 158 |
+
| Claude-3.5-Sonnet (10-22) | 31.42 | 59.70 | 62.30 | 28.28 | 30.88 |
|
| 159 |
+
| Gemini-1.5-Pro (002) | 32.02 | **61.52** | **63.09** | **29.50** | **31.07** |
|
| 160 |
+
| Gemini-2.0-Flash (exp) | 33.80 | 57.50 | 57.00 | 23.70 | 23.20 |
|
| 161 |
+
| Qwen-Long | 30.13 | 53.14 | 32.15 | 23.01 | 2.02 |
|
| 162 |
+
| **MiniMax-Text-01** | 33.65 | 57.10 | 58.00 | 23.45 | 24.35 |
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
## 4. Quickstart
|
| 166 |
+
Here we provide a simple example of loading the tokenizer and model to generate content.
|
| 167 |
+
```python
|
| 168 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig, QuantoConfig, GenerationConfig
|
| 169 |
+
|
| 170 |
+
# load hf config
|
| 171 |
+
hf_config = AutoConfig.from_pretrained(""MiniMaxAI/MiniMax-Text-01"", trust_remote_code=True)
|
| 172 |
+
|
| 173 |
+
# quantization config, int8 is recommended
|
| 174 |
+
quantization_config = QuantoConfig(
|
| 175 |
+
weights=""int8"",
|
| 176 |
+
modules_to_not_convert=[
|
| 177 |
+
""lm_head"",
|
| 178 |
+
""embed_tokens"",
|
| 179 |
+
] + [f""model.layers.{i}.coefficient"" for i in range(hf_config.num_hidden_layers)]
|
| 180 |
+
+ [f""model.layers.{i}.block_sparse_moe.gate"" for i in range(hf_config.num_hidden_layers)]
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
# assume 8 GPUs
|
| 184 |
+
world_size = 8
|
| 185 |
+
layers_per_device = hf_config.num_hidden_layers // world_size
|
| 186 |
+
# set device map
|
| 187 |
+
device_map = {
|
| 188 |
+
'model.embed_tokens': 'cuda:0',
|
| 189 |
+
'model.norm': f'cuda:{world_size - 1}',
|
| 190 |
+
'lm_head': f'cuda:{world_size - 1}'
|
| 191 |
+
}
|
| 192 |
+
for i in range(world_size):
|
| 193 |
+
for j in range(layers_per_device):
|
| 194 |
+
device_map[f'model.layers.{i * layers_per_device + j}'] = f'cuda:{i}'
|
| 195 |
+
|
| 196 |
+
# load tokenizer
|
| 197 |
+
tokenizer = AutoTokenizer.from_pretrained(""MiniMaxAI/MiniMax-Text-01"")
|
| 198 |
+
prompt = ""Hello!""
|
| 199 |
+
messages = [
|
| 200 |
+
{""role"": ""system"", ""content"": [{""type"": ""text"", ""text"": ""You are a helpful assistant created by MiniMax based on MiniMax-Text-01 model.""}]},
|
| 201 |
+
{""role"": ""user"", ""content"": [{""type"": ""text"", ""text"": prompt}]},
|
| 202 |
+
]
|
| 203 |
+
text = tokenizer.apply_chat_template(
|
| 204 |
+
messages,
|
| 205 |
+
tokenize=False,
|
| 206 |
+
add_generation_prompt=True
|
| 207 |
+
)
|
| 208 |
+
# tokenize and move to device
|
| 209 |
+
model_inputs = tokenizer(text, return_tensors=""pt"").to(""cuda"")
|
| 210 |
+
|
| 211 |
+
# load bfloat16 model, move to device, and apply quantization
|
| 212 |
+
quantized_model = AutoModelForCausalLM.from_pretrained(
|
| 213 |
+
""MiniMaxAI/MiniMax-Text-01"",
|
| 214 |
+
torch_dtype=""bfloat16"",
|
| 215 |
+
device_map=device_map,
|
| 216 |
+
quantization_config=quantization_config,
|
| 217 |
+
trust_remote_code=True,
|
| 218 |
+
offload_buffers=True,
|
| 219 |
+
)
|
| 220 |
+
|
| 221 |
+
# generate response
|
| 222 |
+
generation_config = GenerationConfig(
|
| 223 |
+
max_new_tokens=20,
|
| 224 |
+
eos_token_id=200020,
|
| 225 |
+
use_cache=True,
|
| 226 |
+
)
|
| 227 |
+
generated_ids = quantized_model.generate(**model_inputs, generation_config=generation_config)
|
| 228 |
+
print(f""generated_ids: {generated_ids}"")
|
| 229 |
+
generated_ids = [
|
| 230 |
+
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
|
| 231 |
+
]
|
| 232 |
+
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 233 |
+
```
|
| 234 |
+
|
| 235 |
+
## 5. Deployment Guide
|
| 236 |
+
For production deployment, we recommend using [vLLM](https://docs.vllm.ai/en/latest/) to serve MiniMax-Text-01. vLLM provides excellent performance for serving large language models with the following features:
|
| 237 |
+
|
| 238 |
+
🔥 Outstanding service throughput performance
|
| 239 |
+
⚡ Efficient and intelligent memory management
|
| 240 |
+
📦 Powerful batch request processing capability
|
| 241 |
+
⚙️ Deeply optimized underlying performance
|
| 242 |
+
|
| 243 |
+
For detailed deployment instructions, please refer to our [vLLM Deployment Guide](https://github.com/MiniMax-AI/MiniMax-01/blob/main/docs/vllm_deployment_guild.md).
|
| 244 |
+
|
| 245 |
+
## 6. Citation
|
| 246 |
+
|
| 247 |
+
```
|
| 248 |
+
@misc{minimax2025minimax01scalingfoundationmodels,
|
| 249 |
+
title={MiniMax-01: Scaling Foundation Models with Lightning Attention},
|
| 250 |
+
author={MiniMax and Aonian Li and Bangwei Gong and Bo Yang and Boji Shan and Chang Liu and Cheng Zhu and Chunhao Zhang and Congchao Guo and Da Chen and Dong Li and Enwei Jiao and Gengxin Li and Guojun Zhang and Haohai Sun and Houze Dong and Jiadai Zhu and Jiaqi Zhuang and Jiayuan Song and Jin Zhu and Jingtao Han and Jingyang Li and Junbin Xie and Junhao Xu and Junjie Yan and Kaishun Zhang and Kecheng Xiao and Kexi Kang and Le Han and Leyang Wang and Lianfei Yu and Liheng Feng and Lin Zheng and Linbo Chai and Long Xing and Meizhi Ju and Mingyuan Chi and Mozhi Zhang and Peikai Huang and Pengcheng Niu and Pengfei Li and Pengyu Zhao and Qi Yang and Qidi Xu and Qiexiang Wang and Qin Wang and Qiuhui Li and Ruitao Leng and Shengmin Shi and Shuqi Yu and Sichen Li and Songquan Zhu and Tao Huang and Tianrun Liang and Weigao Sun and Weixuan Sun and Weiyu Cheng and Wenkai Li and Xiangjun Song and Xiao Su and Xiaodong Han and Xinjie Zhang and Xinzhu Hou and Xu Min and Xun Zou and Xuyang Shen and Yan Gong and Yingjie Zhu and Yipeng Zhou and Yiran Zhong and Yongyi Hu and Yuanxiang Fan and Yue Yu and Yufeng Yang and Yuhao Li and Yunan Huang and Yunji Li and Yunpeng Huang and Yunzhi Xu and Yuxin Mao and Zehan Li and Zekang Li and Zewei Tao and Zewen Ying and Zhaoyang Cong and Zhen Qin and Zhenhua Fan and Zhihang Yu and Zhuo Jiang and Zijia Wu},
|
| 251 |
+
year={2025},
|
| 252 |
+
eprint={2501.08313},
|
| 253 |
+
archivePrefix={arXiv},
|
| 254 |
+
primaryClass={cs.CL},
|
| 255 |
+
url={https://arxiv.org/abs/2501.08313},
|
| 256 |
+
}
|
| 257 |
+
```
|
| 258 |
+
|
| 259 |
+
## 7. Chatbot & API
|
| 260 |
+
For general use and evaluation, we provide a [Chatbot](https://chat.minimax.io/) with online search capabilities and the [online API](https://www.minimax.io/platform) for developers. For general use and evaluation, we provide the [MiniMax MCP Server](https://github.com/MiniMax-AI/MiniMax-MCP) with video generation, image generation, speech synthesis, and voice cloning for developers.
|
| 261 |
+
|
| 262 |
+
## 8. Contact Us
|
| 263 |
+
Contact us at [model@minimaxi.com](mailto:model@minimaxi.com).","{""id"": ""MiniMaxAI/MiniMax-Text-01"", ""author"": ""MiniMaxAI"", ""sha"": ""90d900a2b59945a98c68368cd7e02c2ca3e0fc0d"", ""last_modified"": ""2025-04-17 06:52:04+00:00"", ""created_at"": ""2025-01-12 13:48:31+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 8097, ""downloads_all_time"": null, ""likes"": 575, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""safetensors"", ""minimax_text_01"", ""text-generation"", ""conversational"", ""custom_code"", ""arxiv:2501.08313"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""pipeline_tag: text-generation"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""MiniMaxText01ForCausalLM""], ""auto_map"": {""AutoConfig"": ""configuration_minimax_text_01.MiniMaxText01Config"", ""AutoModelForCausalLM"": ""modeling_minimax_text_01.MiniMaxText01ForCausalLM""}, ""model_type"": ""minimax_text_01"", ""tokenizer_config"": {""bos_token"": ""<beginning_of_sentence>"", ""eos_token"": ""<end_of_sentence>"", ""unk_token"": ""<end_of_document>"", ""chat_template"": ""{% for message in messages %}{% if message['role'] == 'system' %}{{ '<beginning_of_sentence>system ai_setting=assistant\\n' + message['content'][0]['text'] + '<end_of_sentence>\\n'}}{% elif message['role'] == 'user' %}{{ '<beginning_of_sentence>user name=user\\n' + message['content'][0]['text'] + '<end_of_sentence>\\n'}}{% elif message['role'] == 'assistant' %}{{ '<beginning_of_sentence>ai name=assistant\\n' }}{% for content in message['content'] | selectattr('type', 'equalto', 'text') %}{% generation %}{{ content['text'] }}{% endgeneration %}{% endfor %}{{ '<end_of_sentence>\\n' }}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ '<beginning_of_sentence>ai name=assistant\\n' }}{% endif %}""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE-CODE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE-MODEL', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_minimax_text_01.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='figures/MiniMaxLogo.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='figures/TextBench.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='figures/VisionBench.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='figures/hailuo.svg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='figures/image.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='figures/minimax.svg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='figures/niah.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='figures/wechat-qrcode.jpeg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='main.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00000-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00009-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00010-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00011-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00012-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00013-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00014-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00015-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00016-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00017-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00018-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00019-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00020-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00021-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00022-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00023-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00024-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00025-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00026-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00027-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00028-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00029-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00030-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00031-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00032-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00033-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00034-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00035-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00036-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00037-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00038-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00039-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00040-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00041-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00042-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00043-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00044-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00045-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00046-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00047-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00048-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00049-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00050-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00051-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00052-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00053-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00054-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00055-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00056-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00057-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00058-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00059-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00060-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00061-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00062-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00063-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00064-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00065-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00066-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00067-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00068-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00069-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00070-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00071-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00072-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00073-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00074-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00075-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00076-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00077-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00078-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00079-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00080-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00081-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00082-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00083-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00084-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00085-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00086-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00087-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00088-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00089-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00090-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00091-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00092-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00093-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00094-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00095-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00096-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00097-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00098-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00099-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00100-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00101-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00102-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00103-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00104-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00105-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00106-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00107-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00108-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00109-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00110-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00111-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00112-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00113-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00114-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00115-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00116-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00117-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00118-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00119-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00120-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00121-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00122-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00123-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00124-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00125-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00126-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00127-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00128-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00129-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00130-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00131-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00132-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00133-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00134-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00135-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00136-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00137-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00138-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00139-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00140-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00141-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00142-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00143-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00144-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00145-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00146-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00147-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00148-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00149-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00150-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00151-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00152-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00153-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00154-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00155-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00156-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00157-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00158-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00159-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00160-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00161-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00162-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00163-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00164-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00165-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00166-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00167-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00168-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00169-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00170-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00171-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00172-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00173-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00174-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00175-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00176-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00177-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00178-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00179-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00180-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00181-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00182-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00183-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00184-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00185-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00186-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00187-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00188-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00189-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00190-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00191-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00192-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00193-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00194-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00195-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00196-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00197-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00198-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00199-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00200-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00201-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00202-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00203-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00204-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00205-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00206-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00207-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00208-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00209-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00210-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00211-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00212-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00213-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00214-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00215-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00216-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00217-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00218-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00219-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00220-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00221-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00222-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00223-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00224-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00225-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00226-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00227-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00228-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00229-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00230-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00231-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00232-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00233-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00234-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00235-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00236-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00237-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00238-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00239-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00240-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00241-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00242-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00243-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00244-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00245-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00246-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00247-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00248-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00249-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00250-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00251-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00252-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00253-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00254-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00255-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00256-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00257-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00258-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00259-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00260-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00261-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00262-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00263-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00264-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00265-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00266-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00267-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00268-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00269-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00270-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00271-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00272-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00273-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00274-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00275-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00276-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00277-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00278-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00279-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00280-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00281-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00282-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00283-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00284-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00285-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00286-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00287-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00288-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00289-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00290-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00291-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00292-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00293-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00294-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00295-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00296-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00297-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00298-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00299-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00300-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00301-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00302-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00303-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00304-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00305-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00306-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00307-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00308-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00309-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00310-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00311-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00312-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00313-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00314-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00315-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00316-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00317-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00318-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00319-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00320-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00321-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00322-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00323-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00324-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00325-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00326-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00327-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00328-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00329-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00330-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00331-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00332-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00333-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00334-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00335-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00336-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00337-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00338-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00339-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00340-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00341-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00342-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00343-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00344-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00345-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00346-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00347-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00348-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00349-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00350-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00351-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00352-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00353-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00354-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00355-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00356-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00357-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00358-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00359-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00360-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00361-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00362-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00363-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00364-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00365-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00366-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00367-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00368-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00369-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00370-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00371-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00372-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00373-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00374-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00375-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00376-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00377-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00378-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00379-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00380-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00381-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00382-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00383-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00384-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00385-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00386-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00387-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00388-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00389-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00390-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00391-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00392-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00393-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00394-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00395-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00396-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00397-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00398-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00399-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00400-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00401-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00402-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00403-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00404-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00405-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00406-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00407-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00408-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00409-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00410-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00411-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00412-of-00413.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_minimax_text_01.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""KBaba7/Quant"", ""qdqd/story-ai-2.0"", ""bhaskartripathi/LLM_Quantization"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""ruslanmv/convert_to_gguf"", ""TeacherPuffy/CreateBook"", ""TeacherPuffy/CreateBook2"", ""K00B404/LLM_Quantization""], ""safetensors"": {""parameters"": {""F32"": 1244921856, ""BF16"": 454844733440}, ""total"": 456089655296}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-17 06:52:04+00:00"", ""cardData"": ""pipeline_tag: text-generation"", ""transformersInfo"": null, ""_id"": ""6783c82f16b629ee1e96418c"", ""modelId"": ""MiniMaxAI/MiniMax-Text-01"", ""usedStorage"": 914671823987}",0,,0,,0,https://huggingface.co/OPEA/MiniMax-Text-01-int4-sym-inc-preview,1,,0,"FallnAI/Quantize-HF-Models, K00B404/LLM_Quantization, KBaba7/Quant, TeacherPuffy/CreateBook, TeacherPuffy/CreateBook2, bhaskartripathi/LLM_Quantization, huggingface/InferenceSupport/discussions/528, qdqd/story-ai-2.0, ruslanmv/convert_to_gguf, totolook/Quant",10
|
MistralLite_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
@@ -0,0 +1,529 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
amazon/MistralLite,"---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
inference: false
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# MistralLite Model
|
| 8 |
+
|
| 9 |
+
MistralLite is a fine-tuned [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) language model, with enhanced capabilities of processing long context (up to 32K tokens). By utilizing an adapted Rotary Embedding and sliding window during fine-tuning, MistralLite is able to **perform significantly better on several long context retrieve and answering tasks**, while keeping the simple model structure of the original model. MistralLite is useful for applications such as long context line and topic retrieval, summarization, question-answering, and etc. MistralLite can be deployed on a single AWS `g5.2x` instance with Sagemaker [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) endpoint, making it suitable for applications that require high performance in resource-constrained environments. You can also serve the MistralLite model directly using TGI docker containers. Also, MistralLite supports other ways of serving like [vLLM](https://github.com/vllm-project/vllm), and you can use MistralLite in Python by using the [HuggingFace transformers](https://huggingface.co/docs/transformers/index) and [FlashAttention-2](https://github.com/Dao-AILab/flash-attention) library.
|
| 10 |
+
|
| 11 |
+
MistralLite is similar to [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), and their similarities and differences are summarized below:
|
| 12 |
+
|Model|Fine-tuned on long contexts| Max context length| RotaryEmbedding adaptation| Sliding Window Size|
|
| 13 |
+
|----------|-------------:|------------:|-----------:|-----------:|
|
| 14 |
+
| Mistral-7B-Instruct-v0.1 | up to 8K tokens | 32K | rope_theta = 10000 | 4096 |
|
| 15 |
+
| MistralLite | up to 16K tokens | 32K | **rope_theta = 1000000** | **16384** |
|
| 16 |
+
|
| 17 |
+
**Important - Use the prompt template below for MistralLite:**
|
| 18 |
+
|
| 19 |
+
```<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>```
|
| 20 |
+
|
| 21 |
+
## Motivation of Developing MistralLite
|
| 22 |
+
|
| 23 |
+
Since the release of [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), the model became increasingly popular because its strong performance
|
| 24 |
+
on a wide range of benchmarks. But most of the benchmarks are evaluated on `short context`, and not much has been investigated on its performance on long context tasks.
|
| 25 |
+
Then We evaluated `Mistral-7B-Instruct-v0.1` against benchmarks that are specifically designed to assess the capabilities of LLMs in handling longer context.
|
| 26 |
+
Although the performance of the models on long context was fairly competitive on long context less than 4096 tokens,
|
| 27 |
+
there were some limitations on its performance on longer context. Motivated by improving its performance on longer context, we finetuned the Mistral 7B model, and produced `Mistrallite`. The model managed to `significantly boost the performance of long context handling` over Mistral-7B-Instruct-v0.1. The detailed `long context evalutaion results` are as below:
|
| 28 |
+
|
| 29 |
+
1. [Topic Retrieval](https://lmsys.org/blog/2023-06-29-longchat/)
|
| 30 |
+
|
| 31 |
+
|Model Name|Input length| Input length | Input length| Input length| Input length|
|
| 32 |
+
|----------|-------------:|-------------:|------------:|-----------:|-----------:|
|
| 33 |
+
| | 2851| 5568 |8313 | 11044 | 13780 |
|
| 34 |
+
| Mistral-7B-Instruct-v0.1 | 100% | 50% | 2% | 0% | 0% |
|
| 35 |
+
| MistralLite | **100%** | **100%** | **100%** | **100%** | **98%** |
|
| 36 |
+
|
| 37 |
+
2. [Line Retrieval](https://lmsys.org/blog/2023-06-29-longchat/#longeval-results)
|
| 38 |
+
|
| 39 |
+
|Model Name|Input length| Input length | Input length| Input length| Input length|Input length|
|
| 40 |
+
|----------|-------------:|-------------:|------------:|-----------:|-----------:|-----------:|
|
| 41 |
+
| | 3818| 5661 |7505 | 9354 | 11188 | 12657
|
| 42 |
+
| Mistral-7B-Instruct-v0.1 | **98%** | 62% | 42% | 42% | 32% | 30% |
|
| 43 |
+
| MistralLite | **98%** | **92%** | **88%** | **76%** | **70%** | **60%** |
|
| 44 |
+
|
| 45 |
+
3. [Pass key Retrieval](https://github.com/epfml/landmark-attention/blob/main/llama/run_test.py#L101)
|
| 46 |
+
|
| 47 |
+
|Model Name|Input length| Input length | Input length| Input length|
|
| 48 |
+
|----------|-------------:|-------------:|------------:|-----------:|
|
| 49 |
+
| | 3264| 5396 |8329 | 10197 |
|
| 50 |
+
| Mistral-7B-Instruct-v0.1 | **100%** | 50% | 20% | 30% |
|
| 51 |
+
| MistralLite | **100%** | **100%** | **100%** | **100%** |
|
| 52 |
+
|
| 53 |
+
4. [Question Answering with Long Input Texts](https://nyu-mll.github.io/quality/)
|
| 54 |
+
|Model Name| Test set Accuracy | Hard subset Accuracy|
|
| 55 |
+
|----------|-------------:|-------------:|
|
| 56 |
+
| Mistral-7B-Instruct-v0.1 | 44.3% | 39.7% |
|
| 57 |
+
| MistralLite | **64.4%** | **56.2%** |
|
| 58 |
+
|
| 59 |
+
### Example test on long context of 13400 tokens
|
| 60 |
+
- Context is from [Amazon Aurora FAQs](https://aws.amazon.com/rds/aurora/faqs/)
|
| 61 |
+
- Question: *please tell me how does pgvector help with Generative AI and give me some examples.*
|
| 62 |
+
- Answer from MistralLite:
|
| 63 |
+
```code
|
| 64 |
+
pgvector is an open-source extension for PostgreSQL supported by Amazon Aurora PostgreSQL-Compatible Edition.
|
| 65 |
+
|
| 66 |
+
You can use pgvector to store, search, index, and query billions of embeddings that are generated from machine learning (ML) and artificial intelligence (AI) models in your database, such as those from Amazon Bedrock (limited preview) or Amazon SageMaker. A vector embedding is a numerical representation that represents the semantic meaning of content such as text, images, and video.
|
| 67 |
+
|
| 68 |
+
With pgvector, you can query embeddings in your Aurora PostgreSQL database to perform efficient semantic similarity searches of these data types, represented as vectors, combined with other tabular data in Aurora. This enables the use of generative AI and other AI/ML systems for new types of applications such as personalized recommendations based on similar text descriptions or images, candidate match based on interview notes, customer service next best action recommendations based on successful transcripts or chat session dialogs, and more.
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
## Model Details
|
| 72 |
+
|
| 73 |
+
- **Developed by:** [AWS Contributors](https://github.com/orgs/aws-samples/teams/aws-prototype-ml-apac)
|
| 74 |
+
- **Model type:** [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
|
| 75 |
+
- **Language:** English
|
| 76 |
+
- **Finetuned from weights:** [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
|
| 77 |
+
- **Finetuned on data:**
|
| 78 |
+
- [SLidingEncoder and Decoder (SLED)](https://huggingface.co/datasets/tau/sled)
|
| 79 |
+
- [(Long) Natural Questions (NQ)](https://huggingface.co/datasets/togethercomputer/Long-Data-Collections#multi-passage-qa-from-natural-questions)
|
| 80 |
+
- [OpenAssistant Conversations Dataset (OASST1)](https://huggingface.co/datasets/OpenAssistant/oasst1)
|
| 81 |
+
- **Supported Serving Framework:**
|
| 82 |
+
- [Text-Generation-Inference 1.1.0](https://github.com/huggingface/text-generation-inference/tree/v1.1.0)
|
| 83 |
+
- [vLLM](https://github.com/vllm-project/vllm)
|
| 84 |
+
- [HuggingFace transformers](https://huggingface.co/docs/transformers/index)
|
| 85 |
+
- [HuggingFace Text Generation Inference (TGI) container on SageMaker](https://github.com/awslabs/llm-hosting-container)
|
| 86 |
+
- **Model License:** Apache 2.0
|
| 87 |
+
- **Contact:** [GitHub issues](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/issues)
|
| 88 |
+
- **Inference Code** [Github Repo](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/)
|
| 89 |
+
|
| 90 |
+
## MistralLite LM-Eval Results
|
| 91 |
+
|
| 92 |
+
### Methodology
|
| 93 |
+
|
| 94 |
+
- Please see https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
|
| 95 |
+
- revision=4ececff
|
| 96 |
+
- Note: we used --model hf-causal-experimental instead of --model hf-causal
|
| 97 |
+
|
| 98 |
+
### Results
|
| 99 |
+
|
| 100 |
+
|Average|hellaswag| arc_challenge|truthful_qa (mc2)| MMLU (acc)|
|
| 101 |
+
|----------|-------------:|------------:|-----------:|-----------:|
|
| 102 |
+
| 0.57221 | 0.81617 | 0.58874 | 0.38275 | 0.5012 |
|
| 103 |
+
|
| 104 |
+
## How to Use MistralLite from Python Code (HuggingFace transformers) ##
|
| 105 |
+
|
| 106 |
+
**Important** - For an end-to-end example Jupyter notebook, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/huggingface-transformers/example_usage.ipynb).
|
| 107 |
+
|
| 108 |
+
### Install the necessary packages
|
| 109 |
+
|
| 110 |
+
Requires: [transformers](https://pypi.org/project/transformers/) 4.34.0 or later, [flash-attn](https://pypi.org/project/flash-attn/) 2.3.1.post1 or later,
|
| 111 |
+
and [accelerate](https://pypi.org/project/accelerate/) 0.23.0 or later.
|
| 112 |
+
|
| 113 |
+
```shell
|
| 114 |
+
pip install transformers==4.34.0
|
| 115 |
+
pip install flash-attn==2.3.1.post1 --no-build-isolation
|
| 116 |
+
pip install accelerate==0.23.0
|
| 117 |
+
```
|
| 118 |
+
### You can then try the following example code
|
| 119 |
+
|
| 120 |
+
```python
|
| 121 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 122 |
+
import transformers
|
| 123 |
+
import torch
|
| 124 |
+
|
| 125 |
+
model_id = ""amazon/MistralLite""
|
| 126 |
+
|
| 127 |
+
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
| 128 |
+
model = AutoModelForCausalLM.from_pretrained(model_id,
|
| 129 |
+
torch_dtype=torch.bfloat16,
|
| 130 |
+
use_flash_attention_2=True,
|
| 131 |
+
device_map=""auto"",)
|
| 132 |
+
pipeline = transformers.pipeline(
|
| 133 |
+
""text-generation"",
|
| 134 |
+
model=model,
|
| 135 |
+
tokenizer=tokenizer,
|
| 136 |
+
)
|
| 137 |
+
prompt = ""<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>""
|
| 138 |
+
|
| 139 |
+
sequences = pipeline(
|
| 140 |
+
prompt,
|
| 141 |
+
max_new_tokens=400,
|
| 142 |
+
do_sample=False,
|
| 143 |
+
return_full_text=False,
|
| 144 |
+
num_return_sequences=1,
|
| 145 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 146 |
+
)
|
| 147 |
+
for seq in sequences:
|
| 148 |
+
print(f""{seq['generated_text']}"")
|
| 149 |
+
```
|
| 150 |
+
**Important** - Use the prompt template below for MistralLite:
|
| 151 |
+
```
|
| 152 |
+
<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
## How to Serve MistralLite on TGI ##
|
| 156 |
+
**Important:**
|
| 157 |
+
- For an end-to-end example Jupyter notebook using the native TGI container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/tgi/example_usage.ipynb).
|
| 158 |
+
- If the **input context length is greater than 12K tokens**, it is recommended using a custom TGI container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/tgi-custom/example_usage.ipynb).
|
| 159 |
+
|
| 160 |
+
### Start TGI server ###
|
| 161 |
+
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
|
| 162 |
+
|
| 163 |
+
Example Docker parameters:
|
| 164 |
+
|
| 165 |
+
```shell
|
| 166 |
+
docker run -d --gpus all --shm-size 1g -p 443:80 -v $(pwd)/models:/data ghcr.io/huggingface/text-generation-inference:1.1.0 \
|
| 167 |
+
--model-id amazon/MistralLite \
|
| 168 |
+
--max-input-length 16000 \
|
| 169 |
+
--max-total-tokens 16384 \
|
| 170 |
+
--max-batch-prefill-tokens 16384 \
|
| 171 |
+
--trust-remote-code
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
### Perform Inference ###
|
| 175 |
+
Example Python code for inference with TGI (requires `text_generation` 0.6.1 or later):
|
| 176 |
+
|
| 177 |
+
```shell
|
| 178 |
+
pip install text_generation==0.6.1
|
| 179 |
+
```
|
| 180 |
+
|
| 181 |
+
```python
|
| 182 |
+
from text_generation import Client
|
| 183 |
+
|
| 184 |
+
SERVER_PORT = 443
|
| 185 |
+
SERVER_HOST = ""localhost""
|
| 186 |
+
SERVER_URL = f""{SERVER_HOST}:{SERVER_PORT}""
|
| 187 |
+
tgi_client = Client(f""http://{SERVER_URL}"", timeout=60)
|
| 188 |
+
|
| 189 |
+
def invoke_tgi(prompt,
|
| 190 |
+
random_seed=1,
|
| 191 |
+
max_new_tokens=400,
|
| 192 |
+
print_stream=True,
|
| 193 |
+
assist_role=True):
|
| 194 |
+
if (assist_role):
|
| 195 |
+
prompt = f""<|prompter|>{prompt}</s><|assistant|>""
|
| 196 |
+
output = """"
|
| 197 |
+
for response in tgi_client.generate_stream(
|
| 198 |
+
prompt,
|
| 199 |
+
do_sample=False,
|
| 200 |
+
max_new_tokens=max_new_tokens,
|
| 201 |
+
return_full_text=False,
|
| 202 |
+
#temperature=None,
|
| 203 |
+
#truncate=None,
|
| 204 |
+
#seed=random_seed,
|
| 205 |
+
#typical_p=0.2,
|
| 206 |
+
):
|
| 207 |
+
if hasattr(response, ""token""):
|
| 208 |
+
if not response.token.special:
|
| 209 |
+
snippet = response.token.text
|
| 210 |
+
output += snippet
|
| 211 |
+
if (print_stream):
|
| 212 |
+
print(snippet, end='', flush=True)
|
| 213 |
+
return output
|
| 214 |
+
|
| 215 |
+
prompt = ""What are the main challenges to support a long context for LLM?""
|
| 216 |
+
result = invoke_tgi(prompt)
|
| 217 |
+
```
|
| 218 |
+
|
| 219 |
+
**Important** - When using MistralLite for inference for the first time, it may require a brief 'warm-up' period that can take 10s of seconds. However, subsequent inferences should be faster and return results in a more timely manner. This warm-up period is normal and should not affect the overall performance of the system once the initialisation period has been completed.
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
## How to Deploy MistralLite on Amazon SageMaker ##
|
| 223 |
+
**Important:**
|
| 224 |
+
- For an end-to-end example Jupyter notebook using the SageMaker built-in container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/sagemaker-tgi/example_usage.ipynb).
|
| 225 |
+
- If the **input context length is greater than 12K tokens**, it is recommended using a custom docker container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/sagemaker-tgi-custom/example_usage.ipynb).
|
| 226 |
+
|
| 227 |
+
### Install the necessary packages
|
| 228 |
+
|
| 229 |
+
Requires: [sagemaker](https://pypi.org/project/sagemaker/) 2.192.1 or later.
|
| 230 |
+
|
| 231 |
+
```shell
|
| 232 |
+
pip install sagemaker==2.192.1
|
| 233 |
+
```
|
| 234 |
+
|
| 235 |
+
### Deploy the Model as A SageMaker Endpoint ###
|
| 236 |
+
To deploy MistralLite on a SageMaker endpoint, please follow the example code as below.
|
| 237 |
+
```python
|
| 238 |
+
import sagemaker
|
| 239 |
+
from sagemaker.huggingface import HuggingFaceModel, get_huggingface_llm_image_uri
|
| 240 |
+
import time
|
| 241 |
+
|
| 242 |
+
sagemaker_session = sagemaker.Session()
|
| 243 |
+
region = sagemaker_session.boto_region_name
|
| 244 |
+
role = sagemaker.get_execution_role()
|
| 245 |
+
|
| 246 |
+
image_uri = get_huggingface_llm_image_uri(
|
| 247 |
+
backend=""huggingface"", # or lmi
|
| 248 |
+
region=region,
|
| 249 |
+
version=""1.1.0""
|
| 250 |
+
)
|
| 251 |
+
|
| 252 |
+
model_name = ""MistralLite-"" + time.strftime(""%Y-%m-%d-%H-%M-%S"", time.gmtime())
|
| 253 |
+
|
| 254 |
+
hub = {
|
| 255 |
+
'HF_MODEL_ID':'amazon/MistralLite',
|
| 256 |
+
'HF_TASK':'text-generation',
|
| 257 |
+
'SM_NUM_GPUS':'1',
|
| 258 |
+
""MAX_INPUT_LENGTH"": '16000',
|
| 259 |
+
""MAX_TOTAL_TOKENS"": '16384',
|
| 260 |
+
""MAX_BATCH_PREFILL_TOKENS"": '16384',
|
| 261 |
+
""MAX_BATCH_TOTAL_TOKENS"": '16384',
|
| 262 |
+
}
|
| 263 |
+
|
| 264 |
+
model = HuggingFaceModel(
|
| 265 |
+
name=model_name,
|
| 266 |
+
env=hub,
|
| 267 |
+
role=role,
|
| 268 |
+
image_uri=image_uri
|
| 269 |
+
)
|
| 270 |
+
predictor = model.deploy(
|
| 271 |
+
initial_instance_count=1,
|
| 272 |
+
instance_type=""ml.g5.2xlarge"",
|
| 273 |
+
endpoint_name=model_name,
|
| 274 |
+
|
| 275 |
+
)
|
| 276 |
+
```
|
| 277 |
+
|
| 278 |
+
### Perform Inference ###
|
| 279 |
+
To call the endpoint, please follow the example code as below:
|
| 280 |
+
|
| 281 |
+
```python
|
| 282 |
+
input_data = {
|
| 283 |
+
""inputs"": ""<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>"",
|
| 284 |
+
""parameters"": {
|
| 285 |
+
""do_sample"": False,
|
| 286 |
+
""max_new_tokens"": 400,
|
| 287 |
+
""return_full_text"": False,
|
| 288 |
+
#""typical_p"": 0.2,
|
| 289 |
+
#""temperature"":None,
|
| 290 |
+
#""truncate"":None,
|
| 291 |
+
#""seed"": 1,
|
| 292 |
+
}
|
| 293 |
+
}
|
| 294 |
+
result = predictor.predict(input_data)[0][""generated_text""]
|
| 295 |
+
print(result)
|
| 296 |
+
```
|
| 297 |
+
or via [boto3](https://pypi.org/project/boto3/), and the example code is shown as below:
|
| 298 |
+
|
| 299 |
+
```python
|
| 300 |
+
import boto3
|
| 301 |
+
import json
|
| 302 |
+
def call_endpoint(client, prompt, endpoint_name, paramters):
|
| 303 |
+
client = boto3.client(""sagemaker-runtime"")
|
| 304 |
+
payload = {""inputs"": prompt,
|
| 305 |
+
""parameters"": parameters}
|
| 306 |
+
response = client.invoke_endpoint(EndpointName=endpoint_name,
|
| 307 |
+
Body=json.dumps(payload),
|
| 308 |
+
ContentType=""application/json"")
|
| 309 |
+
output = json.loads(response[""Body""].read().decode())
|
| 310 |
+
result = output[0][""generated_text""]
|
| 311 |
+
return result
|
| 312 |
+
|
| 313 |
+
client = boto3.client(""sagemaker-runtime"")
|
| 314 |
+
parameters = {
|
| 315 |
+
""do_sample"": False,
|
| 316 |
+
""max_new_tokens"": 400,
|
| 317 |
+
""return_full_text"": False,
|
| 318 |
+
#""typical_p"": 0.2,
|
| 319 |
+
#""temperature"":None,
|
| 320 |
+
#""truncate"":None,
|
| 321 |
+
#""seed"": 1,
|
| 322 |
+
}
|
| 323 |
+
endpoint_name = predictor.endpoint_name
|
| 324 |
+
prompt = ""<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>""
|
| 325 |
+
result = call_endpoint(client, prompt, endpoint_name, parameters)
|
| 326 |
+
print(result)
|
| 327 |
+
```
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
## How to Serve MistralLite on vLLM ##
|
| 331 |
+
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
|
| 332 |
+
|
| 333 |
+
**Important** - For an end-to-end example Jupyter notebook, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/vllm/example_usage.ipynb).
|
| 334 |
+
|
| 335 |
+
### Using vLLM as a server ###
|
| 336 |
+
When using vLLM as a server, pass the --model amazon/MistralLite parameter, for example:
|
| 337 |
+
```shell
|
| 338 |
+
python3 -m vllm.entrypoints.api_server --model amazon/MistralLite
|
| 339 |
+
```
|
| 340 |
+
|
| 341 |
+
### Using vLLM in Python Code ###
|
| 342 |
+
When using vLLM from Python code, Please see the example code as below:
|
| 343 |
+
|
| 344 |
+
```python
|
| 345 |
+
from vllm import LLM, SamplingParams
|
| 346 |
+
|
| 347 |
+
prompts = [
|
| 348 |
+
""<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>"",
|
| 349 |
+
]
|
| 350 |
+
sampling_params = SamplingParams(temperature=0, max_tokens=100)
|
| 351 |
+
|
| 352 |
+
llm = LLM(model=""amazon/MistralLite"",)
|
| 353 |
+
|
| 354 |
+
outputs = llm.generate(prompts, sampling_params)
|
| 355 |
+
|
| 356 |
+
# Print the outputs.
|
| 357 |
+
for output in outputs:
|
| 358 |
+
prompt = output.prompt
|
| 359 |
+
generated_text = output.outputs[0].text
|
| 360 |
+
print(f""Prompt: {prompt!r}, Generated text: {generated_text!r}"")
|
| 361 |
+
```
|
| 362 |
+
|
| 363 |
+
## Limitations ##
|
| 364 |
+
Before using the MistralLite model, it is important to perform your own independent assessment, and take measures to ensure that your use would comply with your own specific quality control practices and standards, and that your use would comply with the local rules, laws, regulations, licenses and terms that apply to you, and your content.","{""id"": ""amazon/MistralLite"", ""author"": ""amazon"", ""sha"": ""a6083667f229a8b1503c816c863fd21be053871d"", ""last_modified"": ""2024-05-16 01:49:25+00:00"", ""created_at"": ""2023-10-16 00:57:56+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 18387, ""downloads_all_time"": null, ""likes"": 430, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""mistral"", ""text-generation"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: apache-2.0\ninference: false"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""MistralForCausalLM""], ""model_type"": ""mistral"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""pad_token"": ""[PAD]"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00002.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00002.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""limcheekin/MistralLite-7B-GGUF"", ""omkar56/MistralLite-7B-GGUF_Duplicated"", ""iblfe/test""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-05-16 01:49:25+00:00"", ""cardData"": ""license: apache-2.0\ninference: false"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""652c8a94caddc9e608253d9b"", ""modelId"": ""amazon/MistralLite"", ""usedStorage"": 43451273082}",0,"https://huggingface.co/topiga/AirRepsGPT, https://huggingface.co/PrunaAI/amazon-MistralLite-QUANTO-int4bit-smashed",2,"https://huggingface.co/HugHugHug1111/MistralLite_adam_batch_1_temp_1, https://huggingface.co/Shaleen123/mistrallite_medical_qa, https://huggingface.co/codegood/MistralLite_SC, https://huggingface.co/codegood/MistralLite_SCQA, https://huggingface.co/Shaleen123/mistrallite-medical-full, https://huggingface.co/Shaleen123/mistrallite-medical-qa-full, https://huggingface.co/Shaleen123/mistrallite_medical_qa_full, https://huggingface.co/Shaleen123/mistrallite_medicalqa_full_200k, https://huggingface.co/Shaleen123/mistrallite_medical_qa_bruh, https://huggingface.co/Shaleen123/mistrallite_medical_qa_150, https://huggingface.co/Shaleen123/mistrallite_medical_qa_300, https://huggingface.co/vonewman/mistral-7b-lite-dolly, https://huggingface.co/aryopg/MistralLite-7b_lora_common_semeval_nli4ct_2024, https://huggingface.co/aryopg/MistralLite-7b_lora_contrastive_semeval_nli4ct_2024, https://huggingface.co/opllegaltech/zephyr-7b-beta-with-lora-adapter-50",15,"https://huggingface.co/TheBloke/MistralLite-7B-GGUF, https://huggingface.co/TheBloke/MistralLite-7B-AWQ, https://huggingface.co/TheBloke/MistralLite-7B-GPTQ, https://huggingface.co/second-state/MistralLite-7B-GGUF, https://huggingface.co/topiga/AirRepsGPT-GGUF, https://huggingface.co/PrunaAI/amazon-MistralLite-bnb-4bit-smashed, https://huggingface.co/PrunaAI/amazon-MistralLite-AWQ-4bit-smashed, https://huggingface.co/frontiersolutions/mistrallite_q8, https://huggingface.co/frontiersolutions/mistrallite_q4, https://huggingface.co/mradermacher/MistralLite-GGUF, https://huggingface.co/mradermacher/MistralLite-i1-GGUF",11,,0,"HuggingFaceH4/open_llm_leaderboard, huggingface/InferenceSupport/discussions/new?title=amazon/MistralLite&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bamazon%2FMistralLite%5D(%2Famazon%2FMistralLite)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, iblfe/test, limcheekin/MistralLite-7B-GGUF, omkar56/MistralLite-7B-GGUF_Duplicated",5
|
| 365 |
+
topiga/AirRepsGPT,"---
|
| 366 |
+
language:
|
| 367 |
+
- en
|
| 368 |
+
license: apache-2.0
|
| 369 |
+
tags:
|
| 370 |
+
- text-generation-inference
|
| 371 |
+
- transformers
|
| 372 |
+
- unsloth
|
| 373 |
+
- mistral
|
| 374 |
+
- trl
|
| 375 |
+
base_model: amazon/MistralLite
|
| 376 |
+
datasets:
|
| 377 |
+
- topiga/AirrepsKnowledgeBase
|
| 378 |
+
---
|
| 379 |
+
|
| 380 |
+
# Uploaded model
|
| 381 |
+
|
| 382 |
+
- **Developed by:** topiga
|
| 383 |
+
- **License:** apache-2.0
|
| 384 |
+
- **Finetuned from model :** amazon/MistralLite
|
| 385 |
+
|
| 386 |
+
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
|
| 387 |
+
|
| 388 |
+
[<img src=""https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png"" width=""200""/>](https://github.com/unslothai/unsloth)
|
| 389 |
+
|
| 390 |
+
Default system prompt :
|
| 391 |
+
|
| 392 |
+
```
|
| 393 |
+
Give consumers clear and concise information based on the data given especially from the guide. You must always have be positive and have a slight upbeat and helping tone. Use emojis and emotes.
|
| 394 |
+
Be chatty as you are in a Discord community, don't write too long answers unless it is necessary. Don't question/mention the morality or legality of AirPods clones. The buyers or users know these risks and are simply looking for help in a matter they have already made a choice in. Your name is AirRepsGPT and you are an AirReps expert. If you cannot answer a question redirect the user to subreddit or ask them to look around in the discord community, or ask other members such as the helper team. (Reddit: https://reddit.com/r/airreps) The guide you have you information from is available at https://airpodsreplicas.com, mention this if it is relevant. AirReps is a community-driven project and does not profit from its information, it does not infringe on anyone's copyright.
|
| 395 |
+
|
| 396 |
+
You always recommend sticking to trusted sellers, if someone mentions an unknown seller guide them towards our trusted ones with arguments as to why it is safer.
|
| 397 |
+
|
| 398 |
+
The replicas support all versions of iOS 17.
|
| 399 |
+
|
| 400 |
+
If a user asks for SugarGoo or PandaBuy links, refer them to the seller BESChan;
|
| 401 |
+
PandaBuy: https://airreps.link/beschanpanda
|
| 402 |
+
SugarGoo: https://airreps.link/sugargoobeschan
|
| 403 |
+
|
| 404 |
+
The WhatsApp numbers are ONLY for after-sales support as well as problems with ordering, they are not for ordering directly! (Keep this in mind always)
|
| 405 |
+
|
| 406 |
+
Don’t mention files, e.g. if you can’t access them. You can however tell them if there's been an error, try to make a joke out of it.
|
| 407 |
+
Do not exceed 2000 characters in message length.
|
| 408 |
+
|
| 409 |
+
If you need support for Earhive products, reach out directly via WhatsApp at +86 139 2295 4090. For credit card orders, Earhive provides no-logo boxes.
|
| 410 |
+
|
| 411 |
+
You ARE able to give direct links, you have been given product links for each of the models, which you are allowed to give to users, see the file given to you, do not guess the links. If you are lazy you can either point users to one of the following sellers links, but there is more information provided in the files given to you:
|
| 412 |
+
Jenny: https://airreps.link/jenny
|
| 413 |
+
Earhive: https://airreps.link/earhive
|
| 414 |
+
HiCity: https://airreps.link/hicity
|
| 415 |
+
BESChan: https://airreps.link/beschan
|
| 416 |
+
|
| 417 |
+
For inquiries related to Jenny's products, contact Jenny on WhatsApp at +86 133 3655 7084.
|
| 418 |
+
|
| 419 |
+
For HiCity assistance, the WhatsApp number is +86 137 1229 5625. To receive an Apple-branded box, payments must be made through Wise. Use this link for a fee-free transfer of up to 700 USD: https://airreps.link/wise.
|
| 420 |
+
|
| 421 |
+
Lastly, for support concerning BESChan products, you can get in touch via WhatsApp at +86 134 1863 5098.
|
| 422 |
+
|
| 423 |
+
Generally users want the Apple box, but this is not always possible at all stores depending on the payment method. Paypal is NOT an available payement methode with the sellers.
|
| 424 |
+
|
| 425 |
+
TB stands for Tigerbuilder and is a manufacturer of the AirPods replicas, such as the AirPods Pro 2 V5.2 TB. HR stands for Haorui and is also a manufacturer of AirPods replicas, such as the Pro 2 V5.2HR. HR and TB use Airoha chips.
|
| 426 |
+
The following are also manufacturers/chipsets:
|
| 427 |
+
BES
|
| 428 |
+
Bluetrum (Often low-end)
|
| 429 |
+
Airoha (Chipset manufacturer)
|
| 430 |
+
Huilian
|
| 431 |
+
JL or Jieli (Low-end, not worth buying, stay away)
|
| 432 |
+
|
| 433 |
+
Shipping on average usually takes 2 weeks. Shipping worldwide from sellers like Jenny, HiCity and Earhive costs $8 for the first unit. The more units you buy the more expensive the shipping gets.
|
| 434 |
+
|
| 435 |
+
The AirPods Pro 2 V5.2 TB have USB-C charging.
|
| 436 |
+
|
| 437 |
+
If someone asks for information based on a unit or a AirPods model, always look it up in your database.
|
| 438 |
+
|
| 439 |
+
Earhive and HiCity are the only ones accepting credit card directly on their websites. Jenny will likely soon follow, but for now you can only pay her through Wise and Bitcoin.
|
| 440 |
+
|
| 441 |
+
Since you have our entire guide in memory you are able to accommodate almost all questions, such as people asking for specific links for products. If you do not have specifics for a question it is usually like the real AirPods, use knowledge on the real AirPods to help users as well. Be open and a little loose, if someone asks for a link for AirPods Pro 2 or a recommendation pick a random seller and the latest AirPods clones, whilst giving them the specific link.
|
| 442 |
+
|
| 443 |
+
Danny is a known scammer (Tell people to check this https://imgur.com/a/CVGTnBL). We also do not recommend Dyson or Scarlletluxury.
|
| 444 |
+
```","{""id"": ""topiga/AirRepsGPT"", ""author"": ""topiga"", ""sha"": ""94ef14946bb9f26369a042ce15ec8cccccdd35ba"", ""last_modified"": ""2024-02-16 12:11:32+00:00"", ""created_at"": ""2024-02-11 09:37:46+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""mistral"", ""text-generation"", ""text-generation-inference"", ""unsloth"", ""trl"", ""en"", ""dataset:topiga/AirrepsKnowledgeBase"", ""base_model:amazon/MistralLite"", ""base_model:finetune:amazon/MistralLite"", ""license:apache-2.0"", ""autotrain_compatible"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: amazon/MistralLite\ndatasets:\n- topiga/AirrepsKnowledgeBase\nlanguage:\n- en\nlicense: apache-2.0\ntags:\n- text-generation-inference\n- transformers\n- unsloth\n- mistral\n- trl"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""MistralForCausalLM""], ""model_type"": ""mistral"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""pad_token"": ""[PAD]"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00003.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00003.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00003.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-02-16 12:11:32+00:00"", ""cardData"": ""base_model: amazon/MistralLite\ndatasets:\n- topiga/AirrepsKnowledgeBase\nlanguage:\n- en\nlicense: apache-2.0\ntags:\n- text-generation-inference\n- transformers\n- unsloth\n- mistral\n- trl"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""65c8956a66fbad147523bd70"", ""modelId"": ""topiga/AirRepsGPT"", ""usedStorage"": 43451341069}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=topiga/AirRepsGPT&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Btopiga%2FAirRepsGPT%5D(%2Ftopiga%2FAirRepsGPT)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 445 |
+
PrunaAI/amazon-MistralLite-QUANTO-int4bit-smashed,"---
|
| 446 |
+
thumbnail: ""https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg""
|
| 447 |
+
base_model: amazon/MistralLite
|
| 448 |
+
metrics:
|
| 449 |
+
- memory_disk
|
| 450 |
+
- memory_inference
|
| 451 |
+
- inference_latency
|
| 452 |
+
- inference_throughput
|
| 453 |
+
- inference_CO2_emissions
|
| 454 |
+
- inference_energy_consumption
|
| 455 |
+
tags:
|
| 456 |
+
- pruna-ai
|
| 457 |
+
---
|
| 458 |
+
<!-- header start -->
|
| 459 |
+
<!-- 200823 -->
|
| 460 |
+
<div style=""width: auto; margin-left: auto; margin-right: auto"">
|
| 461 |
+
<a href=""https://www.pruna.ai/"" target=""_blank"" rel=""noopener noreferrer"">
|
| 462 |
+
<img src=""https://i.imgur.com/eDAlcgk.png"" alt=""PrunaAI"" style=""width: 100%; min-width: 400px; display: block; margin: auto;"">
|
| 463 |
+
</a>
|
| 464 |
+
</div>
|
| 465 |
+
<!-- header end -->
|
| 466 |
+
|
| 467 |
+
[](https://twitter.com/PrunaAI)
|
| 468 |
+
[](https://github.com/PrunaAI)
|
| 469 |
+
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
|
| 470 |
+
[](https://discord.gg/rskEr4BZJx)
|
| 471 |
+
|
| 472 |
+
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 473 |
+
|
| 474 |
+
- Give a thumbs up if you like this model!
|
| 475 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 476 |
+
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 477 |
+
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
|
| 478 |
+
- Join Pruna AI community on Discord [here](https://discord.gg/rskEr4BZJx) to share feedback/suggestions or get help.
|
| 479 |
+
|
| 480 |
+
## Results
|
| 481 |
+
|
| 482 |
+

|
| 483 |
+
|
| 484 |
+
**Frequently Asked Questions**
|
| 485 |
+
- ***How does the compression work?*** The model is compressed with quanto.
|
| 486 |
+
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 487 |
+
- ***How is the model efficiency evaluated?*** These results were obtained on HARDWARE_NAME with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 488 |
+
- ***What is the model format?*** We use safetensors.
|
| 489 |
+
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
|
| 490 |
+
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append ""turbo"", ""tiny"", or ""green"" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 491 |
+
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 492 |
+
- ***What are ""first"" metrics?*** Results mentioning ""first"" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
| 493 |
+
- ***What are ""Sync"" and ""Async"" metrics?*** ""Sync"" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. ""Async"" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
|
| 494 |
+
|
| 495 |
+
## Setup
|
| 496 |
+
|
| 497 |
+
You can run the smashed model with these steps:
|
| 498 |
+
|
| 499 |
+
0. Check requirements from the original repo amazon/MistralLite installed. In particular, check python, cuda, and transformers versions.
|
| 500 |
+
1. Make sure that you have installed quantization related packages.
|
| 501 |
+
```bash
|
| 502 |
+
pip install quanto
|
| 503 |
+
```
|
| 504 |
+
2. Load & run the model.
|
| 505 |
+
```python
|
| 506 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 507 |
+
IMPORTS
|
| 508 |
+
|
| 509 |
+
model = AutoModelForCausalLM.from_pretrained(""PrunaAI/amazon-MistralLite-QUANTO-int4bit-smashed"", trust_remote_code=True, device_map='auto')
|
| 510 |
+
tokenizer = AutoTokenizer.from_pretrained(""amazon/MistralLite"")
|
| 511 |
+
|
| 512 |
+
input_ids = tokenizer(""What is the color of prunes?,"", return_tensors='pt').to(model.device)[""input_ids""]
|
| 513 |
+
|
| 514 |
+
outputs = model.generate(input_ids, max_new_tokens=216)
|
| 515 |
+
tokenizer.decode(outputs[0])
|
| 516 |
+
```
|
| 517 |
+
|
| 518 |
+
## Configurations
|
| 519 |
+
|
| 520 |
+
The configuration info are in `smash_config.json`.
|
| 521 |
+
|
| 522 |
+
## Credits & License
|
| 523 |
+
|
| 524 |
+
The license of the smashed model follows the license of the original model. Please check the license of the original model amazon/MistralLite before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
|
| 525 |
+
|
| 526 |
+
## Want to compress other models?
|
| 527 |
+
|
| 528 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 529 |
+
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).","{""id"": ""PrunaAI/amazon-MistralLite-QUANTO-int4bit-smashed"", ""author"": ""PrunaAI"", ""sha"": ""7ff3bcd0e9e60ecdf236875834fa11f248341892"", ""last_modified"": ""2024-07-19 09:20:26+00:00"", ""created_at"": ""2024-06-25 01:33:19+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 2, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pruna-ai"", ""base_model:amazon/MistralLite"", ""base_model:finetune:amazon/MistralLite"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: amazon/MistralLite\nmetrics:\n- memory_disk\n- memory_inference\n- inference_latency\n- inference_throughput\n- inference_CO2_emissions\n- inference_energy_consumption\ntags:\n- pruna-ai\nthumbnail: https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"", ""widget_data"": null, ""model_index"": null, ""config"": {""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""pad_token"": ""[PAD]"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='smash_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-07-19 09:20:26+00:00"", ""cardData"": ""base_model: amazon/MistralLite\nmetrics:\n- memory_disk\n- memory_inference\n- inference_latency\n- inference_throughput\n- inference_CO2_emissions\n- inference_energy_consumption\ntags:\n- pruna-ai\nthumbnail: https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""667a1e5fb2401c64d7d7b404"", ""modelId"": ""PrunaAI/amazon-MistralLite-QUANTO-int4bit-smashed"", ""usedStorage"": 15021243937}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=PrunaAI/amazon-MistralLite-QUANTO-int4bit-smashed&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BPrunaAI%2Famazon-MistralLite-QUANTO-int4bit-smashed%5D(%2FPrunaAI%2Famazon-MistralLite-QUANTO-int4bit-smashed)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
NSFW-gen-v2_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
UnfilteredAI/NSFW-gen-v2,"---
|
| 3 |
+
base_model: OEvortex/PixelGen
|
| 4 |
+
license: other
|
| 5 |
+
language:
|
| 6 |
+
- en
|
| 7 |
+
- pt
|
| 8 |
+
- th
|
| 9 |
+
library_name: diffusers
|
| 10 |
+
pipeline_tag: text-to-image
|
| 11 |
+
tags:
|
| 12 |
+
- UnfilteredAI
|
| 13 |
+
- 3d
|
| 14 |
+
- text-to-image
|
| 15 |
+
- not-for-all-audiences
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
**Model Name:** NSFW-gen-v2
|
| 19 |
+
|
| 20 |
+
**ANIME version** [Here](https://huggingface.co/UnfilteredAI/NSFW-GEN-ANIME)
|
| 21 |
+
|
| 22 |
+
**Type:** Text-to-Image Generator
|
| 23 |
+
|
| 24 |
+
<a href=""https://www.buymeacoffee.com/oevortex"" target=""_blank""><img src=""https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png"" alt=""Buy Me A Coffee"" style=""height: 60px !important;width: 217px !important;"" ></a>
|
| 25 |
+
|
| 26 |
+
**Description:** NSFW-gen is a text-to-image generator developed by UnfilteredAI. This model is designed to generate all kinds of images, including explicit and NSFW (Not Safe For Work) images from textual inputs.
|
| 27 |
+
|
| 28 |
+
**Features:**
|
| 29 |
+
- **Uncensored Output:** The model produces uncensored and potentially explicit images based on textual inputs.
|
| 30 |
+
- **Tensor Type:** Operates with FP16 tensor type for optimized performance and efficiency.
|
| 31 |
+
- **Model Size:** With 3.47 billion parameters, the model offers a vast capacity for learning and generating diverse imagery.
|
| 32 |
+
- **3D Style Rendering:** The model now includes 3D style/image rendering capability to generate more realistic images. (Use 3d, 3d style in your prompt)
|
| 33 |
+
|
| 34 |
+
**Usage Guidelines:**
|
| 35 |
+
- **Responsible Use:** Exercise discretion and responsibility when generating content with this model.
|
| 36 |
+
- **Age Restriction:** Due to the explicit nature of the generated content, usage is restricted to individuals over the legal age in their jurisdiction.","{""id"": ""UnfilteredAI/NSFW-gen-v2"", ""author"": ""UnfilteredAI"", ""sha"": ""982782a450570e5f064016b404d4b7a1c19dbad5"", ""last_modified"": ""2024-08-05 08:41:20+00:00"", ""created_at"": ""2024-04-15 08:16:46+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 7388, ""downloads_all_time"": null, ""likes"": 326, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""safetensors"", ""UnfilteredAI"", ""3d"", ""text-to-image"", ""not-for-all-audiences"", ""en"", ""pt"", ""th"", ""base_model:OEvortex/PixelGen"", ""base_model:finetune:OEvortex/PixelGen"", ""license:other"", ""autotrain_compatible"", ""endpoints_compatible"", ""diffusers:StableDiffusionXLPipeline"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: OEvortex/PixelGen\nlanguage:\n- en\n- pt\n- th\nlibrary_name: diffusers\nlicense: other\npipeline_tag: text-to-image\ntags:\n- UnfilteredAI\n- 3d\n- text-to-image\n- not-for-all-audiences"", ""widget_data"": null, ""model_index"": null, ""config"": {""diffusers"": {""_class_name"": ""StableDiffusionXLPipeline""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='3d_render.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Fixhands-unfilteredai.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder_2/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder_2/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_2/added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_2/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_2/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_2/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_2/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/diffusion_pytorch_model.fp16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/diffusion_pytorch_model.fp16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [""LeeveWasTaken/Best-Images-Overall"", ""philipp-zettl/UnfilteredAI-NSFW-gen-v2"", ""fakesisalg/UnfilteredAI-NSFW-gen-v2"", ""Nymbo/Best-Images-Overall"", ""yergyerg/ImgGenClone"", ""Dragunflie-420/UnfilteredAI-NSFW-gen-v2"", ""Nymbo/NSFW-generator"", ""ImPolymath/UnfilteredAI-NSFW-gen-v2"", ""Kaoticnitemayr/UnfilteredAI-NSFW-gen-v2.1"", ""armen425221356/UnfilteredAI-NSFW-gen-v2_self_parms"", ""Abiru/UnfilteredAI-NSFW-gen-v2"", ""timmyd69buck2/UnfilteredAI-NSFW-gen-v2"", ""saikub/chatB"", ""Omls/UnfilteredAI-NSFW-gen-v2"", ""Anupam251272/Storyboarder-Pro"", ""saikub/Text-To-Gif"", ""Fsggsnsg/UnfilteredAI-NSFW-gen-v2"", ""Rooc/NSFW-photo-generator"", ""justerey/genai"", ""justerey/genaigradio"", ""Hardrop/UnfilteredAI-NSFW-gen-v2"", ""Nymbo/NSFW_Generator"", ""rfdomingues98/UnfilteredAI-NSFW-gen-v2"", ""varunmehra5/UnfilteredAI-NSFW-gen-v2"", ""kasper-boy/Best-Images-Overall"", ""sakura002/NSFW-Img"", ""Keyboardo1/UnfilteredAI-NSFW-gen-v2"", ""Krood/UnfilteredAI-NSFW-gen-v2"", ""iliciuv/UnfilteredAI-NSFW-gen-v2"", ""qbikmuzik/UnfilteredAI-NSFW-gen-v2"", ""Tyballz/UnfilteredAI-NSFW-gen-v2"", ""Manidarean5/UnfilteredAI-NSFW-gen-v2"", ""bassam911/UnfilteredAI-NSFW-gen-v2"", ""Nobit7/UnfilteredAI-NSFW-gen-v2"", ""jarno97/UnfilteredAI-NSFW-gen-v2"", ""ChuckBlack/NSFW_Generator"", ""Vespers/UnfilteredAI-NSFW-gen-v2"", ""rusumihai/UnfilteredAI-NSFW-gen-v2"", ""Jason901/UnfilteredAI-NSFW-gen-v2"", ""Mlika/UnfilteredAI-NSFW-gen-v2"", ""Vashudevsan/UnfilteredAI-NSFW-gen-v2"", ""CarlosAndresPeralta/UnfilteredAI-NSFW-gen-v2"", ""jdfsdsa/UnfilteredAI-NSFW-gen-v2"", ""Nathan97y56/UnfilteredAI-NSFW-gen-v2"", ""sanketshinde3001/UnfilteredAI-NSFW-gen-v2"", ""Mizopl/UnfilteredAI-NSFW-gen-v2"", ""Mizopl/UnfilteredAI-NSFW-gen-v2b"", ""NRbones/Compare-6-NSFW-Model-Together"", ""itsjmath/UnfilteredAI-NSFW-gen-v2"", ""Lingoledger/UnfilteredAI-NSFW-gen-v2"", ""RazvanCC/UnfilteredAI-NSFW-gen-v2"", ""eXtras/Best-Images-Overall"", ""carinette1/UnfilteredAI-NSFW-gen-v2"", ""Relentls7/UnfilteredAI-NSFW-gen-v2"", ""dextrr07/UnfilteredAI-NSFW-gen-v2"", ""Ahcjskjf/UnfilteredAI-NSFW-gen-v2"", ""varunhuggingface/UnfilteredAI-NSFW-gen-v2"", ""bw416/UnfilteredAI-NSFW-gen-v2"", ""Ars3/UnfilteredAI-NSFW-gen-v2"", ""SethyYann98/UnfilteredAI-NSFW-gen-v2"", ""bw416/new-space"", ""Bsisb/UnfilteredAI-NSFW-gen-v2"", ""NativeAngels/UnfilteredAI-NSFW-gen-v2"", ""Anupam251272/Diffusion-Dreams"", ""Crymeariverbaby/AI_Avatars""], ""safetensors"": {""parameters"": {""I64"": 77, ""F16"": 3468838867}, ""total"": 3468838944}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-08-05 08:41:20+00:00"", ""cardData"": ""base_model: OEvortex/PixelGen\nlanguage:\n- en\n- pt\n- th\nlibrary_name: diffusers\nlicense: other\npipeline_tag: text-to-image\ntags:\n- UnfilteredAI\n- 3d\n- text-to-image\n- not-for-all-audiences"", ""transformersInfo"": null, ""_id"": ""661ce26e7c7339263b141d0f"", ""modelId"": ""UnfilteredAI/NSFW-gen-v2"", ""usedStorage"": 26210255079}",0,,0,,0,,0,,0,,0
|
Nous-Hermes-13B-GPTQ_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,237 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
TheBloke/Nous-Hermes-13B-GPTQ,"---
|
| 3 |
+
inference: false
|
| 4 |
+
license: other
|
| 5 |
+
language:
|
| 6 |
+
- en
|
| 7 |
+
tags:
|
| 8 |
+
- llama
|
| 9 |
+
- self-instruct
|
| 10 |
+
- distillation
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
<!-- header start -->
|
| 14 |
+
<!-- 200823 -->
|
| 15 |
+
<div style=""width: auto; margin-left: auto; margin-right: auto"">
|
| 16 |
+
<img src=""https://i.imgur.com/EBdldam.jpg"" alt=""TheBlokeAI"" style=""width: 100%; min-width: 400px; display: block; margin: auto;"">
|
| 17 |
+
</div>
|
| 18 |
+
<div style=""display: flex; justify-content: space-between; width: 100%;"">
|
| 19 |
+
<div style=""display: flex; flex-direction: column; align-items: flex-start;"">
|
| 20 |
+
<p style=""margin-top: 0.5em; margin-bottom: 0em;""><a href=""https://discord.gg/theblokeai"">Chat & support: TheBloke's Discord server</a></p>
|
| 21 |
+
</div>
|
| 22 |
+
<div style=""display: flex; flex-direction: column; align-items: flex-end;"">
|
| 23 |
+
<p style=""margin-top: 0.5em; margin-bottom: 0em;""><a href=""https://www.patreon.com/TheBlokeAI"">Want to contribute? TheBloke's Patreon page</a></p>
|
| 24 |
+
</div>
|
| 25 |
+
</div>
|
| 26 |
+
<div style=""text-align:center; margin-top: 0em; margin-bottom: 0em""><p style=""margin-top: 0.25em; margin-bottom: 0em;"">TheBloke's LLM work is generously supported by a grant from <a href=""https://a16z.com"">andreessen horowitz (a16z)</a></p></div>
|
| 27 |
+
<hr style=""margin-top: 1.0em; margin-bottom: 1.0em;"">
|
| 28 |
+
<!-- header end -->
|
| 29 |
+
|
| 30 |
+
# NousResearch's Nous-Hermes-13B GPTQ
|
| 31 |
+
|
| 32 |
+
These files are GPTQ 4bit model files for [NousResearch's Nous-Hermes-13B](https://huggingface.co/NousResearch/Nous-Hermes-13b).
|
| 33 |
+
|
| 34 |
+
It is the result of quantising to 4bit using [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa).
|
| 35 |
+
|
| 36 |
+
## Other repositories available
|
| 37 |
+
|
| 38 |
+
* [4-bit GPTQ models for GPU inference](https://huggingface.co/TheBloke/Nous-Hermes-13B-GPTQ)
|
| 39 |
+
* [4-bit, 5-bit and 8-bit GGML models for CPU(+GPU) inference](https://huggingface.co/TheBloke/Nous-Hermes-13B-GGML)
|
| 40 |
+
* [Unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/NousResearch/Nous-Hermes-13b)
|
| 41 |
+
|
| 42 |
+
## Prompt Template
|
| 43 |
+
|
| 44 |
+
The model follows the Alpaca prompt format:
|
| 45 |
+
```
|
| 46 |
+
### Instruction:
|
| 47 |
+
|
| 48 |
+
### Response:
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
or
|
| 52 |
+
|
| 53 |
+
```
|
| 54 |
+
### Instruction:
|
| 55 |
+
|
| 56 |
+
### Input:
|
| 57 |
+
|
| 58 |
+
### Response:
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
## How to easily download and use this model in text-generation-webui
|
| 62 |
+
|
| 63 |
+
Please make sure you're using the latest version of text-generation-webui
|
| 64 |
+
|
| 65 |
+
1. Click the **Model tab**.
|
| 66 |
+
2. Under **Download custom model or LoRA**, enter `TheBloke/Nous-Hermes-13B-GPTQ`.
|
| 67 |
+
3. Click **Download**.
|
| 68 |
+
4. The model will start downloading. Once it's finished it will say ""Done""
|
| 69 |
+
5. In the top left, click the refresh icon next to **Model**.
|
| 70 |
+
6. In the **Model** dropdown, choose the model you just downloaded: `Nous-Hermes-13B-GPTQ`
|
| 71 |
+
7. The model will automatically load, and is now ready for use!
|
| 72 |
+
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
|
| 73 |
+
* Note that you do not need to set GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
|
| 74 |
+
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
|
| 75 |
+
|
| 76 |
+
## How to use this GPTQ model from Python code
|
| 77 |
+
|
| 78 |
+
First make sure you have [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) installed:
|
| 79 |
+
|
| 80 |
+
`pip install auto-gptq`
|
| 81 |
+
|
| 82 |
+
Then try the following example code:
|
| 83 |
+
|
| 84 |
+
```python
|
| 85 |
+
from transformers import AutoTokenizer, pipeline, logging
|
| 86 |
+
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
|
| 87 |
+
import argparse
|
| 88 |
+
|
| 89 |
+
model_name_or_path = ""TheBloke/Nous-Hermes-13B-GPTQ""
|
| 90 |
+
model_basename = ""nous-hermes-13b-GPTQ-4bit-128g.no-act.order""
|
| 91 |
+
|
| 92 |
+
use_triton = False
|
| 93 |
+
|
| 94 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
|
| 95 |
+
|
| 96 |
+
model = AutoGPTQForCausalLM.from_quantized(model_name_or_path,
|
| 97 |
+
model_basename=model_basename,
|
| 98 |
+
use_safetensors=True,
|
| 99 |
+
trust_remote_code=True,
|
| 100 |
+
device=""cuda:0"",
|
| 101 |
+
use_triton=use_triton,
|
| 102 |
+
quantize_config=None)
|
| 103 |
+
|
| 104 |
+
print(""\n\n*** Generate:"")
|
| 105 |
+
|
| 106 |
+
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
|
| 107 |
+
output = model.generate(inputs=input_ids, temperature=0.7, max_new_tokens=512)
|
| 108 |
+
print(tokenizer.decode(output[0]))
|
| 109 |
+
|
| 110 |
+
# Inference can also be done using transformers' pipeline
|
| 111 |
+
|
| 112 |
+
# Prevent printing spurious transformers error when using pipeline with AutoGPTQ
|
| 113 |
+
logging.set_verbosity(logging.CRITICAL)
|
| 114 |
+
|
| 115 |
+
prompt = ""Tell me about AI""
|
| 116 |
+
prompt_template=f'''### Human: {prompt}
|
| 117 |
+
### Assistant:'''
|
| 118 |
+
|
| 119 |
+
print(""*** Pipeline:"")
|
| 120 |
+
pipe = pipeline(
|
| 121 |
+
""text-generation"",
|
| 122 |
+
model=model,
|
| 123 |
+
tokenizer=tokenizer,
|
| 124 |
+
max_new_tokens=512,
|
| 125 |
+
temperature=0.7,
|
| 126 |
+
top_p=0.95,
|
| 127 |
+
repetition_penalty=1.15
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
print(pipe(prompt_template)[0]['generated_text'])
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
## Provided files
|
| 134 |
+
|
| 135 |
+
**nous-hermes-13b-GPTQ-4bit-128g.no-act.order.safetensors**
|
| 136 |
+
|
| 137 |
+
This will work with all versions of GPTQ-for-LLaMa, and with AutoGPTQ.
|
| 138 |
+
|
| 139 |
+
* `nous-hermes-13b-GPTQ-4bit-128g.no-act.order.safetensors`
|
| 140 |
+
* Works with all versions of GPTQ-for-LLaMa code, both Triton and CUDA branches
|
| 141 |
+
* Works with AutoGPTQ
|
| 142 |
+
* Works with text-generation-webui one-click-installers
|
| 143 |
+
* Parameters: Groupsize = 128. Act Order / desc_act = False.
|
| 144 |
+
|
| 145 |
+
<!-- footer start -->
|
| 146 |
+
<!-- 200823 -->
|
| 147 |
+
## Discord
|
| 148 |
+
|
| 149 |
+
For further support, and discussions on these models and AI in general, join us at:
|
| 150 |
+
|
| 151 |
+
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
|
| 152 |
+
|
| 153 |
+
## Thanks, and how to contribute.
|
| 154 |
+
|
| 155 |
+
Thanks to the [chirper.ai](https://chirper.ai) team!
|
| 156 |
+
|
| 157 |
+
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
|
| 158 |
+
|
| 159 |
+
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
|
| 160 |
+
|
| 161 |
+
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
|
| 162 |
+
|
| 163 |
+
* Patreon: https://patreon.com/TheBlokeAI
|
| 164 |
+
* Ko-Fi: https://ko-fi.com/TheBlokeAI
|
| 165 |
+
|
| 166 |
+
**Special thanks to**: Aemon Algiz.
|
| 167 |
+
|
| 168 |
+
**Patreon special mentions**: Sam, theTransient, Jonathan Leane, Steven Wood, webtim, Johann-Peter Hartmann, Geoffrey Montalvo, Gabriel Tamborski, Willem Michiel, John Villwock, Derek Yates, Mesiah Bishop, Eugene Pentland, Pieter, Chadd, Stephen Murray, Daniel P. Andersen, terasurfer, Brandon Frisco, Thomas Belote, Sid, Nathan LeClaire, Magnesian, Alps Aficionado, Stanislav Ovsiannikov, Alex, Joseph William Delisle, Nikolai Manek, Michael Davis, Junyu Yang, K, J, Spencer Kim, Stefan Sabev, Olusegun Samson, transmissions 11, Michael Levine, Cory Kujawski, Rainer Wilmers, zynix, Kalila, Luke @flexchar, Ajan Kanaga, Mandus, vamX, Ai Maven, Mano Prime, Matthew Berman, subjectnull, Vitor Caleffi, Clay Pascal, biorpg, alfie_i, 阿明, Jeffrey Morgan, ya boyyy, Raymond Fosdick, knownsqashed, Olakabola, Leonard Tan, ReadyPlayerEmma, Enrico Ros, Dave, Talal Aujan, Illia Dulskyi, Sean Connelly, senxiiz, Artur Olbinski, Elle, Raven Klaugh, Fen Risland, Deep Realms, Imad Khwaja, Fred von Graf, Will Dee, usrbinkat, SuperWojo, Alexandros Triantafyllidis, Swaroop Kallakuri, Dan Guido, John Detwiler, Pedro Madruga, Iucharbius, Viktor Bowallius, Asp the Wyvern, Edmond Seymore, Trenton Dambrowitz, Space Cruiser, Spiking Neurons AB, Pyrater, LangChain4j, Tony Hughes, Kacper Wikieł, Rishabh Srivastava, David Ziegler, Luke Pendergrass, Andrey, Gabriel Puliatti, Lone Striker, Sebastain Graf, Pierre Kircher, Randy H, NimbleBox.ai, Vadim, danny, Deo Leter
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
Thank you to all my generous patrons and donaters!
|
| 172 |
+
|
| 173 |
+
And thank you again to a16z for their generous grant.
|
| 174 |
+
|
| 175 |
+
<!-- footer end -->
|
| 176 |
+
|
| 177 |
+
# Original model card: NousResearch's Nous-Hermes-13B
|
| 178 |
+
|
| 179 |
+
# Model Card: Nous-Hermes-13b
|
| 180 |
+
|
| 181 |
+
## Model Description
|
| 182 |
+
|
| 183 |
+
Nous-Hermes-13b is a state-of-the-art language model fine-tuned on over 300,000 instructions. This model was fine-tuned by Nous Research, with Teknium and Karan4D leading the fine tuning process and dataset curation, Redmond AI sponsoring the compute, and several other contributors. The result is an enhanced Llama 13b model that rivals GPT-3.5-turbo in performance across a variety of tasks.
|
| 184 |
+
|
| 185 |
+
This model stands out for its long responses, low hallucination rate, and absence of OpenAI censorship mechanisms. The fine-tuning process was performed with a 2000 sequence length on an 8x a100 80GB DGX machine for over 50 hours.
|
| 186 |
+
|
| 187 |
+
## Model Training
|
| 188 |
+
|
| 189 |
+
The model was trained almost entirely on synthetic GPT-4 outputs. This includes data from diverse sources such as GPTeacher, the general, roleplay v1&2, code instruct datasets, Nous Instruct & PDACTL (unpublished), CodeAlpaca, Evol_Instruct Uncensored, GPT4-LLM, and Unnatural Instructions.
|
| 190 |
+
|
| 191 |
+
Additional data inputs came from Camel-AI's Biology/Physics/Chemistry and Math Datasets, Airoboros' GPT-4 Dataset, and more from CodeAlpaca. The total volume of data encompassed over 300,000 instructions.
|
| 192 |
+
|
| 193 |
+
## Collaborators
|
| 194 |
+
The model fine-tuning and the datasets were a collaboration of efforts and resources between Teknium, Karan4D, Nous Research, Huemin Art, and Redmond AI.
|
| 195 |
+
|
| 196 |
+
Huge shoutout and acknowledgement is deserved for all the dataset creators who generously share their datasets openly.
|
| 197 |
+
|
| 198 |
+
Special mention goes to @winglian, @erhartford, and @main_horse for assisting in some of the training issues.
|
| 199 |
+
|
| 200 |
+
Among the contributors of datasets, GPTeacher was made available by Teknium, Wizard LM by nlpxucan, and the Nous Research Instruct Dataset was provided by Karan4D and HueminArt.
|
| 201 |
+
The GPT4-LLM and Unnatural Instructions were provided by Microsoft, Airoboros dataset by jondurbin, Camel-AI datasets are from Camel-AI, and CodeAlpaca dataset by Sahil 2801.
|
| 202 |
+
If anyone was left out, please open a thread in the community tab.
|
| 203 |
+
|
| 204 |
+
## Prompt Format
|
| 205 |
+
|
| 206 |
+
The model follows the Alpaca prompt format:
|
| 207 |
+
```
|
| 208 |
+
### Instruction:
|
| 209 |
+
|
| 210 |
+
### Response:
|
| 211 |
+
```
|
| 212 |
+
|
| 213 |
+
or
|
| 214 |
+
|
| 215 |
+
```
|
| 216 |
+
### Instruction:
|
| 217 |
+
|
| 218 |
+
### Input:
|
| 219 |
+
|
| 220 |
+
### Response:
|
| 221 |
+
```
|
| 222 |
+
|
| 223 |
+
## Resources for Applied Use Cases:
|
| 224 |
+
For an example of a back and forth chatbot using huggingface transformers and discord, check out: https://github.com/teknium1/alpaca-discord
|
| 225 |
+
For an example of a roleplaying discord bot, check out this: https://github.com/teknium1/alpaca-roleplay-discordbot
|
| 226 |
+
|
| 227 |
+
## Future Plans
|
| 228 |
+
The model is currently being uploaded in FP16 format, and there are plans to convert the model to GGML and GPTQ 4bit quantizations. The team is also working on a full benchmark, similar to what was done for GPT4-x-Vicuna. We will try to get in discussions to get the model included in the GPT4All.
|
| 229 |
+
|
| 230 |
+
## Benchmark Results
|
| 231 |
+
Benchmark results are coming soon.
|
| 232 |
+
|
| 233 |
+
## Model Usage
|
| 234 |
+
The model is available for download on Hugging Face. It is suitable for a wide range of language tasks, from generating creative text to understanding and following complex instructions.
|
| 235 |
+
|
| 236 |
+
Compute provided by our project sponsor Redmond AI, thank you!!
|
| 237 |
+
","{""id"": ""TheBloke/Nous-Hermes-13B-GPTQ"", ""author"": ""TheBloke"", ""sha"": ""05c24345fc9a7b94b9e5ed7deebb534cd928a578"", ""last_modified"": ""2023-08-21 10:17:55+00:00"", ""created_at"": ""2023-06-03 13:12:08+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 722, ""downloads_all_time"": null, ""likes"": 176, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""self-instruct"", ""distillation"", ""en"", ""license:other"", ""autotrain_compatible"", ""text-generation-inference"", ""4-bit"", ""gptq"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- en\nlicense: other\ntags:\n- llama\n- self-instruct\n- distillation\ninference: false"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""quantization_config"": {""bits"": 4, ""quant_method"": ""gptq""}, ""tokenizer_config"": {""bos_token"": {""__type"": ""AddedToken"", ""content"": ""<s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""eos_token"": {""__type"": ""AddedToken"", ""content"": ""</s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""pad_token"": null, ""unk_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='quantize_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""KBaba7/Quant"", ""bhaskartripathi/LLM_Quantization"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""srikanth-nm/ai_seeker"", ""ruslanmv/convert_to_gguf"", ""ariel0330/h2osiri"", ""riazk/Customer_Service_Chatbot"", ""iblfe/test"", ""brwoodside/Model_Memory_and_Popularity"", ""csalabs/AI-EMBD"", ""csalabs/Replicate-7b-chat-Llama-streamlit"", ""jetaimejeteveux/gks-chatbot2"", ""jetaimejeteveux/GKS-chatbot"", ""dkdaniz/katara"", ""K00B404/LLM_Quantization""], ""safetensors"": {""parameters"": {""F32"": 101255680, ""I32"": 1598361600, ""BF16"": 328104960}, ""total"": 2027722240}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-08-21 10:17:55+00:00"", ""cardData"": ""language:\n- en\nlicense: other\ntags:\n- llama\n- self-instruct\n- distillation\ninference: false"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""647b3c28b31514a4a6d83660"", ""modelId"": ""TheBloke/Nous-Hermes-13B-GPTQ"", ""usedStorage"": 14910135227}",0,,0,,0,,0,,0,"FallnAI/Quantize-HF-Models, K00B404/LLM_Quantization, KBaba7/Quant, ariel0330/h2osiri, bhaskartripathi/LLM_Quantization, brwoodside/Model_Memory_and_Popularity, csalabs/AI-EMBD, huggingface/InferenceSupport/discussions/new?title=TheBloke/Nous-Hermes-13B-GPTQ&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BTheBloke%2FNous-Hermes-13B-GPTQ%5D(%2FTheBloke%2FNous-Hermes-13B-GPTQ)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, iblfe/test, riazk/Customer_Service_Chatbot, ruslanmv/convert_to_gguf, srikanth-nm/ai_seeker, totolook/Quant",13
|
OCR-Donut-CORD_finetunes_20250426_212347.csv_finetunes_20250426_212347.csv
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
jinhybr/OCR-Donut-CORD,"---
|
| 3 |
+
license: mit
|
| 4 |
+
tags:
|
| 5 |
+
- donut
|
| 6 |
+
- image-to-text
|
| 7 |
+
- vision
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# Donut (base-sized model, fine-tuned on CORD)
|
| 11 |
+
|
| 12 |
+
Donut model fine-tuned on CORD. It was introduced in the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewok et al. and first released in [this repository](https://github.com/clovaai/donut).
|
| 13 |
+
|
| 14 |
+
Disclaimer: The team releasing Donut did not write a model card for this model so this model card has been written by the Hugging Face team.
|
| 15 |
+
|
| 16 |
+
## Model description
|
| 17 |
+
|
| 18 |
+
Donut consists of a vision encoder (Swin Transformer) and a text decoder (BART). Given an image, the encoder first encodes the image into a tensor of embeddings (of shape batch_size, seq_len, hidden_size), after which the decoder autoregressively generates text, conditioned on the encoding of the encoder.
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+
|
| 22 |
+
## Intended uses & limitations
|
| 23 |
+
|
| 24 |
+
This model is fine-tuned on CORD, a document parsing dataset.
|
| 25 |
+
|
| 26 |
+
We refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/donut) which includes code examples.
|
| 27 |
+
|
| 28 |
+
## CORD Dataset
|
| 29 |
+
|
| 30 |
+
CORD: A Consolidated Receipt Dataset for Post-OCR Parsing.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
","{""id"": ""jinhybr/OCR-Donut-CORD"", ""author"": ""jinhybr"", ""sha"": ""9c6a092cce640d79f037ae0434aa23e52e81ce89"", ""last_modified"": ""2022-11-05 00:07:44+00:00"", ""created_at"": ""2022-11-04 13:22:17+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1185, ""downloads_all_time"": null, ""likes"": 206, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""vision-encoder-decoder"", ""image-text-to-text"", ""donut"", ""image-to-text"", ""vision"", ""arxiv:2111.15664"", ""license:mit"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""image-to-text"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: mit\ntags:\n- donut\n- image-to-text\n- vision"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""VisionEncoderDecoderModel""], ""model_type"": ""vision-encoder-decoder"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""cls_token"": ""<s>"", ""eos_token"": ""</s>"", ""mask_token"": {""__type"": ""AddedToken"", ""content"": ""<mask>"", ""lstrip"": true, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""pad_token"": ""<pad>"", ""sep_token"": ""</s>"", ""unk_token"": ""<unk>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='sentencepiece.bpe.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""jinhybr/OCR-Receipt-Donut-Demo"", ""hosseinhimself/IELTS-Writing"", ""rockstrongo/jinhybr-OCR-Donut-CORD"", ""lucastfm18/jinhybr-OCR-Donut-CORD"", ""faizanmumtaz/jinhybr-OCR-Donut-CORD"", ""korlaplankton/jinhybr-OCR-Donut-CORD"", ""pechb/jinhybr-OCR-Donut-CORD"", ""kyleclark77/jinhybr-OCR-Donut-CORD"", ""icdmkg/jinhybr-OCR-Donut-CORD"", ""Chautin55/jinhybr-OCR-Donut-CORD"", ""greyeye124/donutcordtrial"", ""devpilot/jinhybr-OCR-Donut-CORD"", ""degtyarov020396/jinhybr-OCR-Donut-CORD"", ""ImageProcessing/backend"", ""Image-Processsing/Backend"", ""studiomanagement/jinhybr-OCR-Donut-CORD"", ""Namit2111/jinhybr-OCR-Donut-CORD"", ""Vinsss/jinhybr-OCR-Donut-CORD"", ""makamuy/jinhybr-OCR-Donut-CORD"", ""hemesh01/jinhybr-OCR-Donut-CORD"", ""hprasath/image-processing"", ""tejas56789ce/jinhybr-OCR-Donut-CORD"", ""tejas56789ce/jinhybr-OCR-Donut-CORD1"", ""tejas56789ce/jinhybr-OCR-Donut-CORD12"", ""tejas56789ce/jinhybr-OCR-Donut-CORD87"", ""tejas56789ce/jinhybr-OCR-Donut-CORD23"", ""ahmedessam1499/jinhybr-OCR-Donut-CORD"", ""Siri23/ImgtoText"", ""Kawthar12h/Image_Captioning_Text_Recognition"", ""YogitaJain/classification"", ""Marsh16/jinhybr-OCR-Donut-CORD"", ""MahmoudAbdelmaged/donut-base""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2022-11-05 00:07:44+00:00"", ""cardData"": ""license: mit\ntags:\n- donut\n- image-to-text\n- vision"", ""transformersInfo"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoTokenizer""}, ""_id"": ""63651209a7a1324ccd5513e2"", ""modelId"": ""jinhybr/OCR-Donut-CORD"", ""usedStorage"": 16998606249}",0,,0,,0,,0,,0,"Kawthar12h/Image_Captioning_Text_Recognition, devpilot/jinhybr-OCR-Donut-CORD, faizanmumtaz/jinhybr-OCR-Donut-CORD, hosseinhimself/IELTS-Writing, huggingface/InferenceSupport/discussions/new?title=jinhybr/OCR-Donut-CORD&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bjinhybr%2FOCR-Donut-CORD%5D(%2Fjinhybr%2FOCR-Donut-CORD)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, jinhybr/OCR-Receipt-Donut-Demo, korlaplankton/jinhybr-OCR-Donut-CORD, kyleclark77/jinhybr-OCR-Donut-CORD, lucastfm18/jinhybr-OCR-Donut-CORD, pechb/jinhybr-OCR-Donut-CORD, rockstrongo/jinhybr-OCR-Donut-CORD, tejas56789ce/jinhybr-OCR-Donut-CORD, tejas56789ce/jinhybr-OCR-Donut-CORD1",13
|
OrangeMixs_finetunes_20250422_201036.csv
ADDED
|
@@ -0,0 +1,1645 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
WarriorMama777/OrangeMixs,"---
|
| 3 |
+
license: creativeml-openrail-m
|
| 4 |
+
tags:
|
| 5 |
+
- stable-diffusion
|
| 6 |
+
- text-to-image
|
| 7 |
+
datasets: Nerfgun3/bad_prompt
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
----
|
| 12 |
+
|
| 13 |
+
# OrangeMixs
|
| 14 |
+
|
| 15 |
+
""OrangeMixs"" shares various Merge models that can be used with StableDiffusionWebui:Automatic1111 and others.
|
| 16 |
+
|
| 17 |
+
<img src=""https://i.imgur.com/VZg0LqQ.png"" width=""1000"" height="""">
|
| 18 |
+
|
| 19 |
+
Maintain a repository for the following purposes.
|
| 20 |
+
|
| 21 |
+
1. to provide easy access to models commonly used in the Japanese community.The Wisdom of the Anons💎
|
| 22 |
+
2. As a place to upload my merge models when I feel like it.
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+

|
| 27 |
+
<span style=""font-size: 60%;"">Hero image prompts(AOM3B2):https://majinai.art/ja/i/jhw20Z_</span>
|
| 28 |
+
|
| 29 |
+
----
|
| 30 |
+
|
| 31 |
+
# UPDATE NOTE / How to read this README
|
| 32 |
+
|
| 33 |
+
## How to read this README
|
| 34 |
+
|
| 35 |
+
1. Read the ToC as release notes.
|
| 36 |
+
Sections are in descending order. The order within the section is ascending. It is written like SNS.
|
| 37 |
+
2. UPDATE NOTE
|
| 38 |
+
3. View the repository history when you need to check the full history.
|
| 39 |
+
|
| 40 |
+
## UPDATE NOTE
|
| 41 |
+
- 2023-02-27: Add AOM3A1B
|
| 42 |
+
- 2023-03-10: Model name fix
|
| 43 |
+
I found that I abbreviated the model name too much, so that when users see illustrations using OrangeMixs models on the web, they cannot reach them in their searches.
|
| 44 |
+
To make the specification more search engine friendly, I renamed it to ""ModelName + (orangemixs)"".
|
| 45 |
+
- 2023-03-11: Change model name : () to _
|
| 46 |
+
Changed to _ because an error occurs when using () in the Cloud environment(e.g.:paperspace).
|
| 47 |
+
""ModelName + _orangemixs""
|
| 48 |
+
- 2023-04-01: Added description of AOM3A1 cursed by Dreamlike
|
| 49 |
+
- 2023-06-27: Added AOM3B2. Removed Terms of Service.
|
| 50 |
+
- 2023-11-25: Add VividOrangeMix (nonlabel, NSFW, Hard)
|
| 51 |
+
- 2023-06-27: Added AOM3B2. Removed Terms of Service.
|
| 52 |
+
- 2023-11-25: Add VividOrangeMix (nonlabel, NSFW, Hard)
|
| 53 |
+
- 2024-01-07: Fix repo & Done upload VividOrangeMixs
|
| 54 |
+
|
| 55 |
+
----
|
| 56 |
+
|
| 57 |
+
# Gradio
|
| 58 |
+
|
| 59 |
+
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run OrangeMixs:
|
| 60 |
+
[](https://huggingface.co/spaces/akhaliq/webui-orangemixs)
|
| 61 |
+
|
| 62 |
+
----
|
| 63 |
+
|
| 64 |
+
# Table of Contents
|
| 65 |
+
|
| 66 |
+
- [OrangeMixs](#orangemixs)
|
| 67 |
+
- [UPDATE NOTE / How to read this README](#update-note--how-to-read-this-readme)
|
| 68 |
+
- [How to read this README](#how-to-read-this-readme)
|
| 69 |
+
- [UPDATE NOTE](#update-note)
|
| 70 |
+
- [Gradio](#gradio)
|
| 71 |
+
- [Table of Contents](#table-of-contents)
|
| 72 |
+
- [Reference](#reference)
|
| 73 |
+
- [Licence](#licence)
|
| 74 |
+
- [~~Terms of use~~](#terms-of-use)
|
| 75 |
+
- [Disclaimer](#disclaimer)
|
| 76 |
+
- [How to download](#how-to-download)
|
| 77 |
+
- [Batch Download](#batch-download)
|
| 78 |
+
- [Batch Download (Advanced)](#batch-download-advanced)
|
| 79 |
+
- [Select and download](#select-and-download)
|
| 80 |
+
- [Model Detail \& Merge Recipes](#model-detail--merge-recipes)
|
| 81 |
+
- [VividOrangeMix (VOM)](#vividorangemix-vom)
|
| 82 |
+
- [VividOrangeMix](#vividorangemix)
|
| 83 |
+
- [VividOrangeMix\_NSFW / Hard](#vividorangemix_nsfw--hard)
|
| 84 |
+
- [Instructions](#instructions)
|
| 85 |
+
- [AbyssOrangeMix3 (AOM3)](#abyssorangemix3-aom3)
|
| 86 |
+
- [About](#about)
|
| 87 |
+
- [More feature](#more-feature)
|
| 88 |
+
- [Variations / Sample Gallery](#variations--sample-gallery)
|
| 89 |
+
- [AOM3](#aom3)
|
| 90 |
+
- [AOM3A1](#aom3a1)
|
| 91 |
+
- [AOM3A2](#aom3a2)
|
| 92 |
+
- [AOM3A3](#aom3a3)
|
| 93 |
+
- [AOM3A1B](#aom3a1b)
|
| 94 |
+
- [AOM3B2](#aom3b2)
|
| 95 |
+
- [AOM3B3](#aom3b3)
|
| 96 |
+
- [AOM3B4](#aom3b4)
|
| 97 |
+
- [AOM3B3](#aom3b3-1)
|
| 98 |
+
- [AOM3B4](#aom3b4-1)
|
| 99 |
+
- [Description for enthusiast](#description-for-enthusiast)
|
| 100 |
+
- [AbyssOrangeMix2 (AOM2)](#abyssorangemix2-aom2)
|
| 101 |
+
- [AbyssOrangeMix2\_sfw (AOM2s)](#abyssorangemix2_sfw-aom2s)
|
| 102 |
+
- [AbyssOrangeMix2\_nsfw (AOM2n)](#abyssorangemix2_nsfw-aom2n)
|
| 103 |
+
- [AbyssOrangeMix2\_hard (AOM2h)](#abyssorangemix2_hard-aom2h)
|
| 104 |
+
- [EerieOrangeMix (EOM)](#eerieorangemix-eom)
|
| 105 |
+
- [EerieOrangeMix (EOM1)](#eerieorangemix-eom1)
|
| 106 |
+
- [EerieOrangeMix\_base (EOM1b)](#eerieorangemix_base-eom1b)
|
| 107 |
+
- [EerieOrangeMix\_Night (EOM1n)](#eerieorangemix_night-eom1n)
|
| 108 |
+
- [EerieOrangeMix\_half (EOM1h)](#eerieorangemix_half-eom1h)
|
| 109 |
+
- [EerieOrangeMix (EOM1)](#eerieorangemix-eom1-1)
|
| 110 |
+
- [EerieOrangeMix2 (EOM2)](#eerieorangemix2-eom2)
|
| 111 |
+
- [EerieOrangeMix2\_base (EOM2b)](#eerieorangemix2_base-eom2b)
|
| 112 |
+
- [EerieOrangeMix2\_night (EOM2n)](#eerieorangemix2_night-eom2n)
|
| 113 |
+
- [EerieOrangeMix2\_half (EOM2h)](#eerieorangemix2_half-eom2h)
|
| 114 |
+
- [EerieOrangeMix2 (EOM2)](#eerieorangemix2-eom2-1)
|
| 115 |
+
- [Models Comparison](#models-comparison)
|
| 116 |
+
- [AbyssOrangeMix (AOM)](#abyssorangemix-aom)
|
| 117 |
+
- [AbyssOrangeMix\_base (AOMb)](#abyssorangemix_base-aomb)
|
| 118 |
+
- [AbyssOrangeMix\_Night (AOMn)](#abyssorangemix_night-aomn)
|
| 119 |
+
- [AbyssOrangeMix\_half (AOMh)](#abyssorangemix_half-aomh)
|
| 120 |
+
- [AbyssOrangeMix (AOM)](#abyssorangemix-aom-1)
|
| 121 |
+
- [ElyOrangeMix (ELOM)](#elyorangemix-elom)
|
| 122 |
+
- [ElyOrangeMix (ELOM)](#elyorangemix-elom-1)
|
| 123 |
+
- [ElyOrangeMix\_half (ELOMh)](#elyorangemix_half-elomh)
|
| 124 |
+
- [ElyNightOrangeMix (ELOMn)](#elynightorangemix-elomn)
|
| 125 |
+
- [BloodOrangeMix (BOM)](#bloodorangemix-bom)
|
| 126 |
+
- [BloodOrangeMix (BOM)](#bloodorangemix-bom-1)
|
| 127 |
+
- [BloodOrangeMix\_half (BOMh)](#bloodorangemix_half-bomh)
|
| 128 |
+
- [BloodNightOrangeMix (BOMn)](#bloodnightorangemix-bomn)
|
| 129 |
+
- [ElderOrangeMix](#elderorangemix)
|
| 130 |
+
- [Troubleshooting](#troubleshooting)
|
| 131 |
+
- [FAQ and Tips (🐈MEME ZONE🦐)](#faq-and-tips-meme-zone)
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
----
|
| 136 |
+
|
| 137 |
+
# Reference
|
| 138 |
+
|
| 139 |
+
+/hdg/ Stable Diffusion Models Cookbook - <https://rentry.org/hdgrecipes#g-anons-unnamed-mix-e93c3bf7>
|
| 140 |
+
Model names are named after Cookbook precedents🍊
|
| 141 |
+
|
| 142 |
+
# Licence
|
| 143 |
+
|
| 144 |
+
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
|
| 145 |
+
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
|
| 146 |
+
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
|
| 147 |
+
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here :https://huggingface.co/spaces/CompVis/stable-diffusion-license
|
| 148 |
+
|
| 149 |
+
# ~~Terms of use~~
|
| 150 |
+
|
| 151 |
+
~~- **Clearly indicate where modifications have been made.**
|
| 152 |
+
If you used it for merging, please state what steps you took to do so.~~
|
| 153 |
+
|
| 154 |
+
Removed terms of use. 2023-06-28
|
| 155 |
+
Freedom. If you share your recipes, Marge swamp will be fun.
|
| 156 |
+
|
| 157 |
+
# Disclaimer
|
| 158 |
+
|
| 159 |
+
<details><summary>READ MORE: Disclaimer</summary>
|
| 160 |
+
The user has complete control over whether or not to generate NSFW content, and the user's decision to enjoy either SFW or NSFW is entirely up to the user.The learning model does not contain any obscene visual content that can be viewed with a single click.The posting of the Learning Model is not intended to display obscene material in a public place.
|
| 161 |
+
In publishing examples of the generation of copyrighted characters, I consider the following cases to be exceptional cases in which unauthorised use is permitted.
|
| 162 |
+
""when the use is for private use or research purposes; when the work is used as material for merchandising (however, this does not apply when the main use of the work is to be merchandised); when the work is used in criticism, commentary or news reporting; when the work is used as a parody or derivative work to demonstrate originality.""
|
| 163 |
+
In these cases, use against the will of the copyright holder or use for unjustified gain should still be avoided, and if a complaint is lodged by the copyright holder, it is guaranteed that the publication will be stopped as soon as possible.
|
| 164 |
+
I would also like to note that I am aware of the fact that many of the merged models use NAI, which is learned from Danbooru and other sites that could be interpreted as illegal, and whose model data itself is also a leak, and that this should be watched carefully. I believe that the best we can do is to expand the possibilities of GenerativeAI while protecting the works of illustrators and artists.
|
| 165 |
+
</details>
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
----
|
| 169 |
+
|
| 170 |
+
# How to download
|
| 171 |
+
|
| 172 |
+
## Batch Download
|
| 173 |
+
|
| 174 |
+
⚠Deprecated: Orange has grown too huge. Doing this will kill your storage.
|
| 175 |
+
|
| 176 |
+
1. install Git
|
| 177 |
+
2. create a folder of your choice and right click → ""Git bash here"" and open a gitbash on the folder's directory.
|
| 178 |
+
3. run the following commands in order.
|
| 179 |
+
|
| 180 |
+
```
|
| 181 |
+
git lfs install
|
| 182 |
+
git clone https://huggingface.co/WarriorMama777/OrangeMixs
|
| 183 |
+
```
|
| 184 |
+
|
| 185 |
+
4. complete
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
## Batch Download (Advanced)
|
| 189 |
+
|
| 190 |
+
Advanced: (When you want to download only selected directories, not the entire repository.)
|
| 191 |
+
|
| 192 |
+
<details>
|
| 193 |
+
<summary>Toggle: How to Batch Download (Advanced)</summary>
|
| 194 |
+
|
| 195 |
+
1. Run the command `git clone --filter=tree:0 --no-checkout https://huggingface.co/WarriorMama777/OrangeMixs` to clone the huggingface repository. By adding the `--filter=tree:0` and `--no-checkout` options, you can download only the file names without their contents.
|
| 196 |
+
```
|
| 197 |
+
git clone --filter=tree:0 --no-checkout https://huggingface.co/WarriorMama777/OrangeMixs
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
2. Move to the cloned directory with the command `cd OrangeMixs`.
|
| 201 |
+
```
|
| 202 |
+
cd OrangeMixs
|
| 203 |
+
```
|
| 204 |
+
|
| 205 |
+
3. Enable sparse-checkout mode with the command `git sparse-checkout init --cone`. By adding the `--cone` option, you can achieve faster performance.
|
| 206 |
+
```
|
| 207 |
+
git sparse-checkout init --cone
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
4. Specify the directory you want to get with the command `git sparse-checkout add <directory name>`. For example, if you want to get only the `Models/AbyssOrangeMix3` directory, enter `git sparse-checkout add Models/AbyssOrangeMix3`.
|
| 211 |
+
```
|
| 212 |
+
git sparse-checkout add Models/AbyssOrangeMix3
|
| 213 |
+
```
|
| 214 |
+
|
| 215 |
+
5. Download the contents of the specified directory with the command `git checkout main`.
|
| 216 |
+
```
|
| 217 |
+
git checkout main
|
| 218 |
+
```
|
| 219 |
+
|
| 220 |
+
This completes how to clone only a specific directory. If you want to add other directories, run `git sparse-checkout add <directory name>` again.
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
</details>
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
## Select and download
|
| 228 |
+
|
| 229 |
+
1. Go to the Files and vaersions tab.
|
| 230 |
+
2. select the model you want to download
|
| 231 |
+
3. download
|
| 232 |
+
4. complete
|
| 233 |
+
|
| 234 |
+
----
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
----
|
| 239 |
+
|
| 240 |
+
# Model Detail & Merge Recipes
|
| 241 |
+
|
| 242 |
+
<a name=""VOM""></a>
|
| 243 |
+
|
| 244 |
+
## VividOrangeMix (VOM)
|
| 245 |
+
|
| 246 |
+

|
| 247 |
+
Prompt: https://majinai.art/ja/i/VZ9dNoI
|
| 248 |
+
|
| 249 |
+
Civitai: https://civitai.com/models/196585?modelVersionId=221033
|
| 250 |
+
|
| 251 |
+
2023-11-25
|
| 252 |
+
|
| 253 |
+
### VividOrangeMix
|
| 254 |
+
|
| 255 |
+
▼About
|
| 256 |
+
""VividOrangeMix is a StableDiffusion model created for fans seeking vivid, flat, anime-style illustrations. With rich, bold colors and flat shading, it embodies the style seen in anime and manga.”
|
| 257 |
+
One of the versions of OrangeMixs, AbyssOrangeMix1~3 (AOM), has improved the anatomical accuracy of the human body by merging photorealistic models, but I was dissatisfied with the too-realistic shapes and shadows.
|
| 258 |
+
VividOrangeMix is a model that has been adjusted to solve this problem.
|
| 259 |
+
|
| 260 |
+
▼Sample Gallery
|
| 261 |
+
Default
|
| 262 |
+

|
| 263 |
+
LoRA
|
| 264 |
+

|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
### VividOrangeMix_NSFW / Hard
|
| 268 |
+
|
| 269 |
+
▼About
|
| 270 |
+
VividOrangeMix NSFW/Hard is, as before, a model that Merges elements of NAI and Gape by U-Net Blocks Weight method.
|
| 271 |
+
As of AOM3, elements of these models should be included, but when I simply merged other models, the elements of the old merge seem to gradually fade away. Also, by merging U-Net Blocks Weight, it is now possible to merge without affecting the design to some extent, but some changes are unavoidable, so I decided to upload it separately as before. .
|
| 272 |
+
|
| 273 |
+
▼Sample Gallery
|
| 274 |
+
|
| 275 |
+
←NSFW | Hard→
|
| 276 |
+

|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
___
|
| 280 |
+
### Instructions
|
| 281 |
+
|
| 282 |
+
▼Tool
|
| 283 |
+
- https://github.com/hako-mikan/sd-webui-supermerger/
|
| 284 |
+
|
| 285 |
+
___
|
| 286 |
+
|
| 287 |
+
▼VividOrangeMix
|
| 288 |
+
|
| 289 |
+
STEP: 1 | Base model create
|
| 290 |
+
|
| 291 |
+
[GO TO AOM3B4 Instructions↓](#AOM3B4)
|
| 292 |
+
|
| 293 |
+
STEP: 2 | Model merge
|
| 294 |
+
|
| 295 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 296 |
+
| --- | --- | --- | --- | --- | --- |
|
| 297 |
+
| AOM3B4 | Animelike_2D_Pruend_fp16 | | sum @ 0.3 | | VividOrangeMix |
|
| 298 |
+
|
| 299 |
+
___
|
| 300 |
+
|
| 301 |
+
▼VividOrangeMix_NSFW
|
| 302 |
+
|
| 303 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 304 |
+
| --- | --- | --- | --- | --- | --- |
|
| 305 |
+
| VividOrangeMix | NAI full | NAI sfw | Add Difference @ 1.0 | 0,0.25,0.25,0.25,0.25,0.25,0,0,0,0,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.2,0.25,0.25,0.25,0.25,0,0 | VividOrangeMix_NSFW |
|
| 306 |
+
|
| 307 |
+
___
|
| 308 |
+
|
| 309 |
+
▼VividOrangeMix_Hard
|
| 310 |
+
|
| 311 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 312 |
+
| --- | --- | --- | --- | --- | --- |
|
| 313 |
+
| VividOrangeMix_NSFW | gape60 | NAI full | Add Difference @ 1.0 | 0.0,0.25,0.25,0.25,0.25,0.25,0.0,0.0,0.0,0.0,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.25,0.0,0.0 | VividOrangeMix_Hard |
|
| 314 |
+
|
| 315 |
+
____
|
| 316 |
+
|
| 317 |
+
## AbyssOrangeMix3 (AOM3)
|
| 318 |
+
|
| 319 |
+

|
| 320 |
+
|
| 321 |
+
――Everyone has different “ABYSS”!
|
| 322 |
+
|
| 323 |
+
▼About
|
| 324 |
+
|
| 325 |
+
The main model, ""AOM3 (AbyssOrangeMix3)"", is a purely upgraded model that improves on the problems of the previous version, ""AOM2"". ""AOM3"" can generate illustrations with very realistic textures and can generate a wide variety of content. There are also three variant models based on the AOM3 that have been adjusted to a unique illustration style. These models will help you to express your ideas more clearly.
|
| 326 |
+
|
| 327 |
+
▼Links
|
| 328 |
+
|
| 329 |
+
- [⚠NSFW] Civitai: AbyssOrangeMix3 (AOM3) | Stable Diffusion Checkpoint | https://civitai.com/models/9942/abyssorangemix3-aom3
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
### About
|
| 333 |
+
|
| 334 |
+
Features: high-quality, realistic textured illustrations can be generated.
|
| 335 |
+
There are two major changes from AOM2.
|
| 336 |
+
|
| 337 |
+
1: Models for NSFW such as _nsfw and _hard have been improved: the models after nsfw in AOM2 generated creepy realistic faces, muscles and ribs when using Hires.fix, even though they were animated characters. These have all been improved in AOM3.
|
| 338 |
+
|
| 339 |
+
e.g.: explanatory diagram by MEME : [GO TO MEME ZONE↓](#MEME_realface)
|
| 340 |
+
|
| 341 |
+
2: sfw/nsfw merged into one model. Originally, nsfw models were separated because adding NSFW content (models like NAI and gape) would change the face and cause the aforementioned problems. Now that those have been improved, the models can be packed into one.
|
| 342 |
+
In addition, thanks to excellent extensions such as [ModelToolkit](https://github.com/arenatemp/stable-diffusion-webui-model-toolkit
|
| 343 |
+
), the model file size could be reduced (1.98 GB per model).
|
| 344 |
+
|
| 345 |
+
|
| 346 |
+

|
| 347 |
+
|
| 348 |
+
|
| 349 |
+
### More feature
|
| 350 |
+
In addition, these U-Net Blocks Weight Merge models take numerous steps but are carefully merged to ensure that mutual content is not overwritten.
|
| 351 |
+
|
| 352 |
+
(Of course, all models allow full control over adult content.)
|
| 353 |
+
- 🔐 When generating illustrations for the general public: write ""nsfw"" in the negative prompt field
|
| 354 |
+
- 🔞 ~~When generating adult illustrations: ""nsfw"" in the positive prompt field~~ -> It can be generated without putting it in. If you include it, the atmosphere will be more NSFW.
|
| 355 |
+
|
| 356 |
+
### Variations / Sample Gallery
|
| 357 |
+
🚧Editing🚧
|
| 358 |
+
|
| 359 |
+

|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
#### AOM3
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
▼AOM3
|
| 369 |
+

|
| 370 |
+
|
| 371 |
+
<span style=""font-size: 60%;"">(Actually, this gallery doesn't make much sense since AOM3 is mainly an improvement of the NSFW part 😂 ...But we can confirm that the picture is not much different from AOM2sfw.)</span>
|
| 372 |
+
|
| 373 |
+
#### AOM3A1
|
| 374 |
+
|
| 375 |
+
⛔Only this model (AOM3A1) includes ChilloutMix. The curse of the DreamLike license. In other words, only AOM3A1 is not available for commercial use. I recommend AOM3A1B instead.⛔
|
| 376 |
+
[GO TO MEME ZONE↓](#MEME_AOM3A1)
|
| 377 |
+
|
| 378 |
+
Features: Anime like illustrations with flat paint. Cute enough as it is, but I really like to apply LoRA of anime characters to this model to generate high quality anime illustrations like a frame from a theatre version.
|
| 379 |
+
|
| 380 |
+
▼A1
|
| 381 |
+
|
| 382 |
+

|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
<details>
|
| 386 |
+
<summary>©</summary>
|
| 387 |
+
(1)©Yurucamp: Inuyama Aoi, (2)©The Quintessential Quintuplets: Nakano Yotsuba, (3)©Sailor Moon: Mizuno Ami/SailorMercury
|
| 388 |
+
</details>
|
| 389 |
+
|
| 390 |
+
#### AOM3A2
|
| 391 |
+
🚧Editing🚧
|
| 392 |
+
Features: Oil paintings like style artistic illustrations and stylish background depictions. In fact, this is mostly due to the work of Counterfeit 2.5, but the textures are more realistic thanks to the U-Net Blocks Weight Merge.
|
| 393 |
+
|
| 394 |
+
#### AOM3A3
|
| 395 |
+
🚧Editing🚧
|
| 396 |
+
Features: Midpoint of artistic and kawaii. the model has been tuned to combine realistic textures, a artistic style that also feels like an oil colour style, and a cute anime-style face. Can be used to create a wide range of illustrations.
|
| 397 |
+
|
| 398 |
+
#### AOM3A1B
|
| 399 |
+
|
| 400 |
+
AOM3A1B added. This model is my latest favorite. I recommend it for its moderate realism, moderate brush touch, and moderate LoRA conformity.
|
| 401 |
+
The model was merged by mistakenly selecting 'Add sum' when 'Add differences' should have been selected in the ~~AOM3A3~~AOM3A2 recipe. It was an unintended merge, but we share it because the illustrations produced are consistently good results.
|
| 402 |
+
The model was merged by mistakenly selecting 'Add sum' when 'Add differences' should have been selected in the ~~AOM3A3~~AOM3A2 recipe. It was an unintended merge, but we share it because the illustrations produced are consistently good results.
|
| 403 |
+
In my review, this is an illustration style somewhere between AOM3A1 and A3.
|
| 404 |
+
|
| 405 |
+
▼A1B
|
| 406 |
+
|
| 407 |
+

|
| 408 |
+

|
| 409 |
+
- Meisho Doto (umamusume): https://civitai.com/models/11980/meisho-doto-umamusume
|
| 410 |
+
- Train and Girl: [JR East E235 series / train interior](https://civitai.com/models/9517/jr-east-e235-series-train-interior)
|
| 411 |
+
|
| 412 |
+
<details>
|
| 413 |
+
<summary>©</summary>
|
| 414 |
+
©umamusume: Meisho Doto, ©Girls und Panzer: Nishizumi Miho,©IDOLM@STER: Sagisawa Fumika
|
| 415 |
+
</details>
|
| 416 |
+
|
| 417 |
+
#### AOM3B2
|
| 418 |
+
my newest toy.
|
| 419 |
+
Just AOM3A1B + BreakdomainM21: 0.4
|
| 420 |
+
So this model is somewhat of a troll model.
|
| 421 |
+
I would like to create an improved DiffLoRAKit_v2 based on this.
|
| 422 |
+
Upload for access for research etc. 2023-06-27
|
| 423 |
+
|
| 424 |
+

|
| 425 |
+
|
| 426 |
+
<details><summary>Sample image prompts</summary>
|
| 427 |
+
|
| 428 |
+
1. [Maid](https://majinai.art/ja/i/jhw20Z_)
|
| 429 |
+
2. Yotsuba: https://majinai.art/ja/i/f-O4wau
|
| 430 |
+
3. Inuko in cafe: https://majinai.art/ja/i/Cj-Ar9C
|
| 431 |
+
4. bathroom: https://majinai.art/ja/i/XiSj5K6
|
| 432 |
+
|
| 433 |
+
</details>
|
| 434 |
+
|
| 435 |
+
|
| 436 |
+
|
| 437 |
+
|
| 438 |
+
#### AOM3B3
|
| 439 |
+
|
| 440 |
+
2023-09-25
|
| 441 |
+
|
| 442 |
+
This is a derivative model of AOM3B2.
|
| 443 |
+
I merged some nice models and also merged some LoRAs to further adjust the color and painting style.
|
| 444 |
+
|
| 445 |
+
|
| 446 |
+
|
| 447 |
+
◆**Instructions:**
|
| 448 |
+
|
| 449 |
+
▼Tool
|
| 450 |
+
Supermerger
|
| 451 |
+
|
| 452 |
+
▼Model Merge
|
| 453 |
+
AOM3B2+Mixprov4+BreakdomainAnime
|
| 454 |
+
triple sum : 0.3, 0.3 | mode:normal
|
| 455 |
+
|
| 456 |
+
+
|
| 457 |
+
|
| 458 |
+
▼LoRA Merge
|
| 459 |
+
loraH(DiffLoRA)_FaceShadowTweaker_v1_dim4:-2,nijipretty_20230624235607:0.1,MatureFemale_epoch8:0.1,colorful_V1_lbw:0.5
|
| 460 |
+
|
| 461 |
+
|
| 462 |
+
#### AOM3B4
|
| 463 |
+
<a name=""AOM3B4""></a>
|
| 464 |
+
▼About
|
| 465 |
+
Fix AOM3B3
|
| 466 |
+
|
| 467 |
+
▼**Instructions:**
|
| 468 |
+
|
| 469 |
+
|
| 470 |
+
USE: https://github.com/hako-mikan/sd-webui-supermerger/
|
| 471 |
+
|
| 472 |
+
STEP: 1 | Model merge
|
| 473 |
+
|
| 474 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 475 |
+
| --- | --- | --- | --- | --- | --- |
|
| 476 |
+
| AOM3B2 | Mixprov4 | BreakdomainAnime | triple sum @ 0.3, 0.3, mode:normal | | temp01 |
|
| 477 |
+
|
| 478 |
+
STEP: 2 | LoRA Merge
|
| 479 |
+
|
| 480 |
+
Color fix
|
| 481 |
+
|
| 482 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 483 |
+
| --- | --- | --- | --- | --- | --- |
|
| 484 |
+
| temp01 | colorful_V1_lbw | | sum @ 0.45 | | AOM3B4 |
|
| 485 |
+
|
| 486 |
+
|
| 487 |
+
⚓[GO TO VividOrangeMix Instructions↑](#VOM)
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
#### AOM3B3
|
| 491 |
+
|
| 492 |
+
2023-09-25
|
| 493 |
+
|
| 494 |
+
This is a derivative model of AOM3B2.
|
| 495 |
+
I merged some nice models and also merged some LoRAs to further adjust the color and painting style.
|
| 496 |
+
|
| 497 |
+
|
| 498 |
+
|
| 499 |
+
◆**Instructions:**
|
| 500 |
+
|
| 501 |
+
▼Tool
|
| 502 |
+
Supermerger
|
| 503 |
+
|
| 504 |
+
▼Model Merge
|
| 505 |
+
AOM3B2+Mixprov4+BreakdomainAnime
|
| 506 |
+
triple sum : 0.3, 0.3 | mode:normal
|
| 507 |
+
|
| 508 |
+
+
|
| 509 |
+
|
| 510 |
+
▼LoRA Merge
|
| 511 |
+
loraH(DiffLoRA)_FaceShadowTweaker_v1_dim4:-2,nijipretty_20230624235607:0.1,MatureFemale_epoch8:0.1,colorful_V1_lbw:0.5
|
| 512 |
+
|
| 513 |
+
|
| 514 |
+
#### AOM3B4
|
| 515 |
+
<a name=""AOM3B4""></a>
|
| 516 |
+
▼About
|
| 517 |
+
Fix AOM3B3
|
| 518 |
+
|
| 519 |
+
▼**Instructions:**
|
| 520 |
+
|
| 521 |
+
|
| 522 |
+
USE: https://github.com/hako-mikan/sd-webui-supermerger/
|
| 523 |
+
|
| 524 |
+
STEP: 1 | Model merge
|
| 525 |
+
|
| 526 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 527 |
+
| --- | --- | --- | --- | --- | --- |
|
| 528 |
+
| AOM3B2 | Mixprov4 | BreakdomainAnime | triple sum @ 0.3, 0.3, mode:normal | | temp01 |
|
| 529 |
+
|
| 530 |
+
STEP: 2 | LoRA Merge
|
| 531 |
+
|
| 532 |
+
Color fix
|
| 533 |
+
|
| 534 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 535 |
+
| --- | --- | --- | --- | --- | --- |
|
| 536 |
+
| temp01 | colorful_V1_lbw | | sum @ 0.45 | | AOM3B4 |
|
| 537 |
+
|
| 538 |
+
|
| 539 |
+
⚓[GO TO VividOrangeMix Instructions↑](#VOM)
|
| 540 |
+
____
|
| 541 |
+
### Description for enthusiast
|
| 542 |
+
|
| 543 |
+
AOM3 was created with a focus on improving the nsfw version of AOM2, as mentioned above.The AOM3 is a merge of the following two models into AOM2sfw using U-Net Blocks Weight Merge, while extracting only the NSFW content part.
|
| 544 |
+
(1) NAI: trained in Danbooru
|
| 545 |
+
(2)gape: Finetune model of NAI trained on Danbooru's very hardcore NSFW content.
|
| 546 |
+
In other words, if you are looking for something like AOM3sfw, it is AOM2sfw.The AOM3 was merged with the NSFW model while removing only the layers that have a negative impact on the face and body. However, the faces and compositions are not an exact match to AOM2sfw.AOM2sfw is sometimes superior when generating SFW content. I recommend choosing according to the intended use of the illustration.See below for a comparison between AOM2sfw and AOM3.
|
| 547 |
+
|
| 548 |
+

|
| 549 |
+
|
| 550 |
+
|
| 551 |
+
▼A summary of the AOM3 work is as follows
|
| 552 |
+
|
| 553 |
+
1. investigated the impact of the NAI and gape layers as AOM2 _nsfw onwards is crap.
|
| 554 |
+
2. cut face layer: OUT04 because I want realistic faces to stop → Failed. No change.
|
| 555 |
+
3. gapeNAI layer investigation|
|
| 556 |
+
a. (IN05-08 (especially IN07) | Change the illustration significantly. Noise is applied, natural colours are lost, shadows die, and we can see that the IN deep layer is a layer of light and shade.
|
| 557 |
+
b. OUT03-05(?) | likely to be sexual section/NSFW layer.Cutting here will kill the NSFW.
|
| 558 |
+
c. OUT03,OUT04|NSFW effects are in(?). e.g.: spoken hearts, trembling, motion lines, etc...
|
| 559 |
+
d. OUT05|This is really an NSFW switch. All the ""NSFW atmosphere"" is in here. Facial expressions, Heavy breaths, etc...
|
| 560 |
+
e. OUT10-11|Paint layer. Does not affect detail, but does have an extensive impact.
|
| 561 |
+
1. (mass production of rubbish from here...)
|
| 562 |
+
2. cut IN05-08 and merge NAIgape with flat parameters → avoided creepy muscles and real faces. Also, merging NSFW models stronger has less impact.
|
| 563 |
+
3. so, cut IN05-08, OUT10-11 and merge NAI+gape with all others 0.5.
|
| 564 |
+
4. → AOM3
|
| 565 |
+
AOM3 roughly looks like this
|
| 566 |
+
|
| 567 |
+
|
| 568 |
+
|
| 569 |
+
----
|
| 570 |
+
|
| 571 |
+
▼How to use
|
| 572 |
+
|
| 573 |
+
- Prompts
|
| 574 |
+
- Negative prompts is As simple as possible is good.
|
| 575 |
+
(worst quality, low quality:1.4)
|
| 576 |
+
- Using ""3D"" as a negative will result in a rough sketch style at the ""sketch"" level. Use with caution as it is a very strong prompt.
|
| 577 |
+
- How to avoid Real Face
|
| 578 |
+
(realistic, lip, nose, tooth, rouge, lipstick, eyeshadow:1.0), (abs, muscular, rib:1.0),
|
| 579 |
+
- How to avoid Bokeh
|
| 580 |
+
(depth of field, bokeh, blurry:1.4)
|
| 581 |
+
- How to remove mosaic: `(censored, mosaic censoring, bar censor, convenient censoring, pointless censoring:1.0),`
|
| 582 |
+
- How to remove blush: `(blush, embarrassed, nose blush, light blush, full-face blush:1.4), `
|
| 583 |
+
- How to remove NSFW effects: `(trembling, motion lines, motion blur, emphasis lines:1.2),`
|
| 584 |
+
- 🔰Basic negative prompts sample for Anime girl ↓
|
| 585 |
+
- v1
|
| 586 |
+
`nsfw, (worst quality, low quality:1.4), (realistic, lip, nose, tooth, rouge, lipstick, eyeshadow:1.0), (dusty sunbeams:1.0),, (abs, muscular, rib:1.0), (depth of field, bokeh, blurry:1.4),(motion lines, motion blur:1.4), (greyscale, monochrome:1.0), text, title, logo, signature`
|
| 587 |
+
- v2
|
| 588 |
+
`nsfw, (worst quality, low quality:1.4), (lip, nose, tooth, rouge, lipstick, eyeshadow:1.4), (blush:1.2), (jpeg artifacts:1.4), (depth of field, bokeh, blurry, film grain, chromatic aberration, lens flare:1.0), (1boy, abs, muscular, rib:1.0), greyscale, monochrome, dusty sunbeams, trembling, motion lines, motion blur, emphasis lines, text, title, logo, signature, `
|
| 589 |
+
- Sampler: ~~“DPM++ SDE Karras” is good~~ Take your pick
|
| 590 |
+
- Steps:
|
| 591 |
+
- DPM++ SDE Karras: Test: 12~ ,illustration: 20~
|
| 592 |
+
- DPM++ 2M Karras: Test: 20~ ,illustration: 28~
|
| 593 |
+
- Clipskip: 1 or 2
|
| 594 |
+
- CFG: 8 (6~12)
|
| 595 |
+
- Upscaler :
|
| 596 |
+
- Detailed illust → Latenet (nearest-exact)
|
| 597 |
+
Denoise strength: 0.5 (0.5~0.6)
|
| 598 |
+
- Simple upscale: Swin IR, ESRGAN, Remacri etc…
|
| 599 |
+
Denoise strength: Can be set low. (0.35~0.6)
|
| 600 |
+
|
| 601 |
+
|
| 602 |
+
|
| 603 |
+
---
|
| 604 |
+
|
| 605 |
+
👩🍳Model details / Recipe
|
| 606 |
+
|
| 607 |
+
▼Hash(SHA256)
|
| 608 |
+
▼Hash(SHA256)
|
| 609 |
+
|
| 610 |
+
- AOM3.safetensors
|
| 611 |
+
D124FC18F0232D7F0A2A70358CDB1288AF9E1EE8596200F50F0936BE59514F6D
|
| 612 |
+
- AOM3A1.safetensors
|
| 613 |
+
F303D108122DDD43A34C160BD46DBB08CB0E088E979ACDA0BF168A7A1F5820E0
|
| 614 |
+
- AOM3A2.safetensors
|
| 615 |
+
553398964F9277A104DA840A930794AC5634FC442E6791E5D7E72B82B3BB88C3
|
| 616 |
+
- AOM3A3.safetensors
|
| 617 |
+
EB4099BA9CD5E69AB526FCA22A2E967F286F8512D9509B735C892FA6468767CF
|
| 618 |
+
- AOM3A1B.safetensors
|
| 619 |
+
5493A0EC491F5961DBDC1C861404088A6AE9BD4007F6A3A7C5DEE8789CDC1361
|
| 620 |
+
- AOM3B2.safetensors
|
| 621 |
+
F553E7BDE46CFE9B3EF1F31998703A640AF7C047B65883996E44AC7156F8C1DB
|
| 622 |
+
|
| 623 |
+
- AOM3A1B.safetensors
|
| 624 |
+
5493A0EC491F5961DBDC1C861404088A6AE9BD4007F6A3A7C5DEE8789CDC1361
|
| 625 |
+
- AOM3B2.safetensors
|
| 626 |
+
F553E7BDE46CFE9B3EF1F31998703A640AF7C047B65883996E44AC7156F8C1DB
|
| 627 |
+
|
| 628 |
+
|
| 629 |
+
▼Use Models
|
| 630 |
+
|
| 631 |
+
1. AOM2sfw
|
| 632 |
+
「038ba203d8ba3c8af24f14e01fbb870c85bbb8d4b6d9520804828f4193d12ce9」
|
| 633 |
+
1. AnythingV3.0 huggingface pruned
|
| 634 |
+
[2700c435]「543bcbc21294831c6245cd74c8a7707761e28812c690f946cb81fef930d54b5e」
|
| 635 |
+
1. NovelAI animefull-final-pruned
|
| 636 |
+
[925997e9]「89d59c3dde4c56c6d5c41da34cc55ce479d93b4007046980934b14db71bdb2a8」
|
| 637 |
+
1. NovelAI sfw
|
| 638 |
+
[1d4a34af]「22fa233c2dfd7748d534be603345cb9abf994a23244dfdfc1013f4f90322feca」
|
| 639 |
+
1. Gape60
|
| 640 |
+
[25396b85]「893cca5903ccd0519876f58f4bc188dd8fcc5beb8a69c1a3f1a5fe314bb573f5」
|
| 641 |
+
1. BasilMix
|
| 642 |
+
「bbf07e3a1c3482c138d096f7dcdb4581a2aa573b74a68ba0906c7b657942f1c2」
|
| 643 |
+
1. chilloutmix_fp16.safetensors
|
| 644 |
+
「4b3bf0860b7f372481d0b6ac306fed43b0635caf8aa788e28b32377675ce7630」
|
| 645 |
+
1. Counterfeit-V2.5_fp16.safetensors
|
| 646 |
+
「71e703a0fca0e284dd9868bca3ce63c64084db1f0d68835f0a31e1f4e5b7cca6」
|
| 647 |
+
1. kenshi_01_fp16.safetensors
|
| 648 |
+
「3b3982f3aaeaa8af3639a19001067905e146179b6cddf2e3b34a474a0acae7fa」
|
| 649 |
+
|
| 650 |
+
----
|
| 651 |
+
|
| 652 |
+
▼AOM3
|
| 653 |
+
|
| 654 |
+
◆**Instructions:**
|
| 655 |
+
◆**Instructions:**
|
| 656 |
+
|
| 657 |
+
Tool: SuperMerger
|
| 658 |
+
|
| 659 |
+
USE: https://github.com/hako-mikan/sd-webui-supermerger/
|
| 660 |
+
Tool: SuperMerger
|
| 661 |
+
|
| 662 |
+
USE: https://github.com/hako-mikan/sd-webui-supermerger/
|
| 663 |
+
|
| 664 |
+
(This extension is really great. It turns a month's work into an hour. Thank you)
|
| 665 |
+
|
| 666 |
+
STEP: 1 | BWM : NAI - NAIsfw & gape - NAI
|
| 667 |
+
|
| 668 |
+
CUT: IN05-IN08, OUT10-11
|
| 669 |
+
|
| 670 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 671 |
+
| --- | --- | --- | --- | --- | --- |
|
| 672 |
+
| AOM2sfw | NAI full | NAI sfw | Add Difference @ 1.0 | 0,0.5,0.5,0.5,0.5,0.5,0,0,0,0,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0,0 | temp01 |
|
| 673 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 674 |
+
| --- | --- | --- | --- | --- | --- |
|
| 675 |
+
| AOM2sfw | NAI full | NAI sfw | Add Difference @ 1.0 | 0,0.5,0.5,0.5,0.5,0.5,0,0,0,0,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0,0 | temp01 |
|
| 676 |
+
|
| 677 |
+
CUT: IN05-IN08, OUT10-11
|
| 678 |
+
|
| 679 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 680 |
+
| --- | --- | --- | --- | --- | --- |
|
| 681 |
+
| temp01 | gape60 | NAI full | Add Difference @ 1.0 | 0,0.5,0.5,0.5,0.5,0.5,0,0,0,0,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0,0 | AOM3 |
|
| 682 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 683 |
+
| --- | --- | --- | --- | --- | --- |
|
| 684 |
+
| temp01 | gape60 | NAI full | Add Difference @ 1.0 | 0,0.5,0.5,0.5,0.5,0.5,0,0,0,0,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0,0 | AOM3 |
|
| 685 |
+
|
| 686 |
+
▼AOM3A1
|
| 687 |
+
|
| 688 |
+
◆**Instructions:**
|
| 689 |
+
|
| 690 |
+
Tool: SuperMerger
|
| 691 |
+
◆**Instructions:**
|
| 692 |
+
|
| 693 |
+
Tool: SuperMerger
|
| 694 |
+
|
| 695 |
+
STEP: 1 | Change the base photorealistic model of AOM3 from BasilMix to Chilloutmix.
|
| 696 |
+
|
| 697 |
+
Change the photorealistic model from BasilMix to Chilloutmix and proceed to gapeNAI merge.
|
| 698 |
+
|
| 699 |
+
STEP: 2 |
|
| 700 |
+
|
| 701 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 702 |
+
| --- | --- | --- | --- | --- | --- |
|
| 703 |
+
| 1 | SUM @ 0.5 | Counterfeit2.5 | Kenshi | | Counterfeit+Kenshi |
|
| 704 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 705 |
+
| --- | --- | --- | --- | --- | --- |
|
| 706 |
+
| 1 | SUM @ 0.5 | Counterfeit2.5 | Kenshi | | Counterfeit+Kenshi |
|
| 707 |
+
|
| 708 |
+
STEP: 3 |
|
| 709 |
+
|
| 710 |
+
CUT: BASE0, IN00-IN08:0, IN10:0.1, OUT03-04-05:0, OUT08:0.2
|
| 711 |
+
|
| 712 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 713 |
+
| --- | --- | --- | --- | --- | --- |
|
| 714 |
+
| AOM3 | Counterfeit+Kenshi | | Add SUM @ 1.0 | 0,0,0,0,0,0,0,0,0,0.3,0.1,0.3,0.3,0.3,0.2,0.1,0,0,0,0.3,0.3,0.2,0.3,0.4,0.5 | AOM3A1 |
|
| 715 |
+
|
| 716 |
+
▼AOM3A1
|
| 717 |
+
⛔Only this model (AOM3A1) includes ChilloutMix (=The curse of DreamLike).Commercial use is not available.
|
| 718 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 719 |
+
| --- | --- | --- | --- | --- | --- |
|
| 720 |
+
| AOM3 | Counterfeit+Kenshi | | Add SUM @ 1.0 | 0,0,0,0,0,0,0,0,0,0.3,0.1,0.3,0.3,0.3,0.2,0.1,0,0,0,0.3,0.3,0.2,0.3,0.4,0.5 | AOM3A1 |
|
| 721 |
+
|
| 722 |
+
▼AOM3A1
|
| 723 |
+
⛔Only this model (AOM3A1) includes ChilloutMix (=The curse of DreamLike).Commercial use is not available.
|
| 724 |
+
|
| 725 |
+
▼AOM3A2
|
| 726 |
+
|
| 727 |
+
◆?
|
| 728 |
+
◆?
|
| 729 |
+
|
| 730 |
+
CUT: BASE0, IN05:0.3、IN06-IN08:0, IN10:0.1, OUT03:0, OUT04:0.3, OUT05:0, OUT08:0.2
|
| 731 |
+
|
| 732 |
+
◆**Instructions:**
|
| 733 |
+
◆**Instructions:**
|
| 734 |
+
|
| 735 |
+
Tool: SuperMerger
|
| 736 |
+
Tool: SuperMerger
|
| 737 |
+
|
| 738 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 739 |
+
| --- | --- | --- | --- | --- | --- |
|
| 740 |
+
| AOM3 | Counterfeit2.5 | nai | Add Difference @ 1.0 | 0,1,1,1,1,1,0.3,0,0,0,1,0.1,1,1,1,1,1,0,1,0,1,1,0.2,1,1,1 | AOM3A2 |
|
| 741 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 742 |
+
| --- | --- | --- | --- | --- | --- |
|
| 743 |
+
| AOM3 | Counterfeit2.5 | nai | Add Difference @ 1.0 | 0,1,1,1,1,1,0.3,0,0,0,1,0.1,1,1,1,1,1,0,1,0,1,1,0.2,1,1,1 | AOM3A2 |
|
| 744 |
+
|
| 745 |
+
◆AOM3A3
|
| 746 |
+
◆AOM3A3
|
| 747 |
+
|
| 748 |
+
CUT : BASE0, IN05-IN08:0, IN10:0.1, OUT03:0.5, OUT04-05:0.1, OUT08:0.2
|
| 749 |
+
|
| 750 |
+
Tool: SuperMerger
|
| 751 |
+
|
| 752 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 753 |
+
| --- | --- | --- | --- | --- | --- |
|
| 754 |
+
| AOM3 | Counterfeit2.5 | nai | Add Difference @ 1.0 | 0,0.6,0.6,0.6,0.6,0.6,0,0,0,0,0.6,0.1,0.6,0.6,0.6,0.6,0.6,0.5,0.1,0.1,0.6,0.6,0.2,0.6,0.6,0.6 | AOM3A3 |
|
| 755 |
+
|
| 756 |
+
▼AOM3A1B
|
| 757 |
+
|
| 758 |
+
◆**Instructions:**
|
| 759 |
+
|
| 760 |
+
Tool: SuperMerge
|
| 761 |
+
|
| 762 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 763 |
+
| --- | --- | --- | --- | --- | --- |
|
| 764 |
+
| AOM3 | Counterfeit2.5 | | Add Sum @ 1.0 | 0,1,1,1,1,1,0.3,0,0,0,1,0.1,1,1,1,1,1,0,1,0,1,1,0.2,1,1,1 | AOM3A1B |
|
| 765 |
+
|
| 766 |
+
▼AOM3B2
|
| 767 |
+
|
| 768 |
+
◆**Instructions:**
|
| 769 |
+
|
| 770 |
+
Tool: Checkpoint Merger
|
| 771 |
+
|
| 772 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 773 |
+
| --- | --- | --- | --- | --- | --- |
|
| 774 |
+
| AOM3A1B | Breakdomain m21_fp16 | | Add Sum | 0.4 | AOM3B2 |
|
| 775 |
+
|
| 776 |
+
Tool: SuperMerger
|
| 777 |
+
|
| 778 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 779 |
+
| --- | --- | --- | --- | --- | --- |
|
| 780 |
+
| AOM3 | Counterfeit2.5 | nai | Add Difference @ 1.0 | 0,0.6,0.6,0.6,0.6,0.6,0,0,0,0,0.6,0.1,0.6,0.6,0.6,0.6,0.6,0.5,0.1,0.1,0.6,0.6,0.2,0.6,0.6,0.6 | AOM3A3 |
|
| 781 |
+
|
| 782 |
+
▼AOM3A1B
|
| 783 |
+
|
| 784 |
+
◆**Instructions:**
|
| 785 |
+
|
| 786 |
+
Tool: SuperMerge
|
| 787 |
+
|
| 788 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 789 |
+
| --- | --- | --- | --- | --- | --- |
|
| 790 |
+
| AOM3 | Counterfeit2.5 | | Add Sum @ 1.0 | 0,1,1,1,1,1,0.3,0,0,0,1,0.1,1,1,1,1,1,0,1,0,1,1,0.2,1,1,1 | AOM3A1B |
|
| 791 |
+
|
| 792 |
+
▼AOM3B2
|
| 793 |
+
|
| 794 |
+
◆**Instructions:**
|
| 795 |
+
|
| 796 |
+
Tool: Checkpoint Merger
|
| 797 |
+
|
| 798 |
+
| Model: A | Model: B | Model: C | Interpolation Method | Weight | Merge Name |
|
| 799 |
+
| --- | --- | --- | --- | --- | --- |
|
| 800 |
+
| AOM3A1B | Breakdomain m21_fp16 | | Add Sum | 0.4 | AOM3B2 |
|
| 801 |
+
|
| 802 |
+
|
| 803 |
+
----
|
| 804 |
+
|
| 805 |
+
|
| 806 |
+
|
| 807 |
+
## AbyssOrangeMix2 (AOM2)
|
| 808 |
+
|
| 809 |
+
――Creating the next generation of illustration with “Abyss”!
|
| 810 |
+
|
| 811 |
+
<img src=""https://github.com/WarriorMama777/imgup/raw/main/img/AbyssOrangeMix2/HeroImage_AbyssOrangeMix2_Designed_01_comp001.webp"" width="""" height="""" alt=”HeroImage_AbyssOrangeMix2_Designed_01_comp001”>
|
| 812 |
+
|
| 813 |
+
Prompt: [https://majinai.art/ja/i/nxpKRpw](https://majinai.art/ja/i/nxpKRpw)
|
| 814 |
+
|
| 815 |
+
▼About
|
| 816 |
+
|
| 817 |
+
AbyssOrangeMix2 (AOM2) is an AI model capable of generating high-quality, highly realistic illustrations.
|
| 818 |
+
It can generate elaborate and detailed illustrations that cannot be drawn by hand. It can also be used for a variety of purposes, making it extremely useful for design and artwork.
|
| 819 |
+
Furthermore, it provides an unparalleled new means of expression.
|
| 820 |
+
It can generate illustrations in a variety of genres to meet a wide range of needs. I encourage you to use ""Abyss"" to make your designs and artwork richer and of higher quality.
|
| 821 |
+
|
| 822 |
+
<img src=""https://github.com/WarriorMama777/imgup/raw/main/img/AbyssOrangeMix2/UBM_ON_OFF_4_comp001.webp"" width="""" height="""" alt=”UBM_ON_OFF_4_comp001.webp”>
|
| 823 |
+
※nvidia joke.
|
| 824 |
+
|
| 825 |
+
▼Description for engineers/enthusiasts
|
| 826 |
+
|
| 827 |
+
The merged model was formulated using an extension such as sdweb-merge-block-weighted-gui, which merges models at separate rates for each of the 25 U-Net blocks (input, intermediate, and output).
|
| 828 |
+
The validation of many Anons has shown that such a recipe can generate a painting style that is anatomically realistic enough to feel the finger skeleton, but still maintains an anime-style face.
|
| 829 |
+
|
| 830 |
+
The changes from AbyssOrangeMix are as follows.
|
| 831 |
+
|
| 832 |
+
1. the model used for U-Net Blocks Weight Merge was changed from Instagram+F222 to BasilMix. (<https://huggingface.co/nuigurumi>)
|
| 833 |
+
|
| 834 |
+
This is an excellent merge model that can generate decent human bodies while maintaining the facial layers of the Instagram model. Thanks!!!
|
| 835 |
+
This has improved the dullness of the color and given a more Japanese skin tone (or more precisely, the moisturized white skin that the Japanese would ideally like).
|
| 836 |
+
Also, the unnatural bokeh that sometimes occurred in the previous version may have been eliminated (needs to be verified).
|
| 837 |
+
|
| 838 |
+
2.Added IN deep layers (IN06-11) to the layer merging from the realistic model (BasilMix).
|
| 839 |
+
|
| 840 |
+
It is said that the IN deep layer (IN06-11) is the layer that determines composition, etc., but perhaps light, reflections, skin texture, etc., may also be involved.
|
| 841 |
+
It is like ""Global Illumination"", ""Ray tracing"" and ""Ambient Occlusion"" in 3DCG.
|
| 842 |
+
|
| 843 |
+
<img src=""https://github.com/WarriorMama777/imgup/raw/main/img/AbyssOrangeMix2/AbyssOrangeMix2_comparison_comp001.webp"" width="""" height="""" alt=”AbyssOrangeMix2_comparison_comp001”>
|
| 844 |
+
|
| 845 |
+
※This does not fundamentally improve the fingers. Therefore, More research needs to be done to improve the fingers (e.g. '[bad_prompt](https://huggingface.co/datasets/Nerfgun3/bad_prompt)').
|
| 846 |
+
About 30-50% chance of generating correct fingers(?). Abyss is deep.
|
| 847 |
+
|
| 848 |
+
▼Sample Gallery
|
| 849 |
+
|
| 850 |
+
The prompts for generating these images were all generated using ChatGPT. I simply asked ""Pirates sailing the oceans"" to tell me what the prompts were.
|
| 851 |
+
However, to make sure the AI understood the specifications, I used the template for AI questions (Question template for AI prompt generation(v1.2) ).
|
| 852 |
+
Please review the following.
|
| 853 |
+
|
| 854 |
+
```jsx
|
| 855 |
+
https://seesaawiki.jp/nai_ch/d/AI%a4%f2%b3%e8%cd%d1%a4%b7%a4%bf%a5%d7%a5%ed%a5%f3%a5%d7%a5%c8%c0%b8%c0%ae
|
| 856 |
+
```
|
| 857 |
+
|
| 858 |
+
The images thus generated, strangely enough, look like MidJourney or Nijijourney illustrations. Perhaps they are passing user prompts through GPT or something else before passing them on to the image AI🤔
|
| 859 |
+
|
| 860 |
+
<img src=""https://github.com/WarriorMama777/imgup/raw/main/img/AbyssOrangeMix2/SampleGallerBoardDesign_AbyssOrangeMix2_ReadMore_comp001.webp"" width="""" height="""" alt=”SampleGallerBoardDesign_AbyssOrangeMix2_03_comp001”>
|
| 861 |
+
|
| 862 |
+
<details>
|
| 863 |
+
<summary>▼READ MORE🖼</summary>
|
| 864 |
+
|
| 865 |
+
<img src=""https://github.com/WarriorMama777/imgup/raw/main/img/AbyssOrangeMix2/SampleGallerBoardDesign_AbyssOrangeMix2_03_comp001.webp"" width="""" height="""" alt=”SampleGallerBoardDesign_AbyssOrangeMix2_03_comp001”>
|
| 866 |
+
|
| 867 |
+
▼All prompts to generate sample images
|
| 868 |
+
|
| 869 |
+
1. [Gaming Girl](https://majinai.art/ja/i/GbTbLyk)
|
| 870 |
+
2. [Fantasy](https://majinai.art/ja/i/ax45Pof)
|
| 871 |
+
3. [Rainy Day](https://majinai.art/ja/i/1P9DUul)
|
| 872 |
+
4. [Kemomimi Girl](https://majinai.art/ja/i/hrUSb31)
|
| 873 |
+
5. [Supermarket](https://majinai.art/ja/i/6Mf4bVK)
|
| 874 |
+
6. [Lunch Time](https://majinai.art/ja/i/YAgQ4On)
|
| 875 |
+
7. [Womens in the Garden](https://majinai.art/ja/i/oHZYum_)
|
| 876 |
+
8. [Pirate](https://majinai.art/ja/i/yEA3EZk)
|
| 877 |
+
9. [Japanese Girl](https://majinai.art/ja/i/x4G_B_e)
|
| 878 |
+
10. [Sweets Time](https://majinai.art/ja/i/vK_mkac)
|
| 879 |
+
11. [Glasses Girl](https://majinai.art/ja/i/Z87IHOC)
|
| 880 |
+
|
| 881 |
+
</details>
|
| 882 |
+
|
| 883 |
+
|
| 884 |
+
|
| 885 |
+
▼How to use
|
| 886 |
+
|
| 887 |
+
- VAE: orangemix.vae.pt
|
| 888 |
+
- ~~Prompts can be long or short~~
|
| 889 |
+
As simple as possible is good. Do not add excessive detail prompts. Start with just this negative propmt.
|
| 890 |
+
(worst quality, low quality:1.4)
|
| 891 |
+
- Sampler: “DPM++ SDE Karras” is good
|
| 892 |
+
- Steps: forTest: 12~ ,illustration: 20~
|
| 893 |
+
- Clipskip: 1 or 2
|
| 894 |
+
- Upscaler : Latenet (nearest-exact)
|
| 895 |
+
- CFG Scale : 5 or 6 (4~8)
|
| 896 |
+
- Denoise strength: 0.5 (0.45~0.6)
|
| 897 |
+
If you use 0.7~, the picture will change too much.
|
| 898 |
+
If below 0.45, Block noise occurs.
|
| 899 |
+
|
| 900 |
+
🗒Model List
|
| 901 |
+
|
| 902 |
+
- AbyssOrangeMix2_sfw|BasilMix U-Net Blocks Weight Merge
|
| 903 |
+
- AbyssOrangeMix2_nsfw|+ NAI-NAISFW 0.3 Merge
|
| 904 |
+
- AbyssOrangeMix2_hard|+ Gape 0.3 Merge
|
| 905 |
+
|
| 906 |
+
※Changed suffix of models.
|
| 907 |
+
_base →_sfw: _base was changed to_sfw.
|
| 908 |
+
_night →_nsfw: Merged models up to NAI-NAI SFW were changed from _night to_nsfw.
|
| 909 |
+
_half and non suffix →_hard: Gape merged models were given the suffix _hard.gape was reduced to 0.3 because it affects character modeling.
|
| 910 |
+
|
| 911 |
+
▼How to choice models
|
| 912 |
+
|
| 913 |
+
- _sfw : SFW😉
|
| 914 |
+
- _nsfw : SFW ~ Soft NSFW🥰
|
| 915 |
+
- _hard : SFW ~ hard NSFW👄
|
| 916 |
+
|
| 917 |
+
▼Hash
|
| 918 |
+
|
| 919 |
+
- AbyssOrangeMix2_sfw.ckpt
|
| 920 |
+
「f75b19923f2a4a0e70f564476178eedd94e76e2c94f8fd8f80c548742b5b51b9」
|
| 921 |
+
- AbyssOrangeMix2_sfw.safetensors
|
| 922 |
+
「038ba203d8ba3c8af24f14e01fbb870c85bbb8d4b6d9520804828f4193d12ce9」
|
| 923 |
+
- AbyssOrangeMix2_nsfw.safetensors
|
| 924 |
+
「0873291ac5419eaa7a18726e8841ce0f15f701ace29e0183c47efad2018900a4」
|
| 925 |
+
- AbyssOrangeMix_hard.safetensors
|
| 926 |
+
「0fc198c4908e98d7aae2a76bd78fa004e9c21cb0be7582e36008b4941169f18e」
|
| 927 |
+
|
| 928 |
+
▼Use Models
|
| 929 |
+
|
| 930 |
+
1. AnythingV3.0 huggingface pruned
|
| 931 |
+
[2700c435]「543bcbc21294831c6245cd74c8a7707761e28812c690f946cb81fef930d54b5e」
|
| 932 |
+
1. NovelAI animefull-final-pruned
|
| 933 |
+
[925997e9]「89d59c3dde4c56c6d5c41da34cc55ce479d93b4007046980934b14db71bdb2a8」
|
| 934 |
+
1. NovelAI sfw
|
| 935 |
+
[1d4a34af]「22fa233c2dfd7748d534be603345cb9abf994a23244dfdfc1013f4f90322feca」
|
| 936 |
+
1. Gape60
|
| 937 |
+
[25396b85]「893cca5903ccd0519876f58f4bc188dd8fcc5beb8a69c1a3f1a5fe314bb573f5」
|
| 938 |
+
1. BasilMix
|
| 939 |
+
「bbf07e3a1c3482c138d096f7dcdb4581a2aa573b74a68ba0906c7b657942f1c2」
|
| 940 |
+
|
| 941 |
+
### AbyssOrangeMix2_sfw (AOM2s)
|
| 942 |
+
|
| 943 |
+
▼**Instructions:**
|
| 944 |
+
|
| 945 |
+
STEP: 1|Block Merge
|
| 946 |
+
|
| 947 |
+
| Model: A | Model: B | Weight | Base alpha | Merge Name |
|
| 948 |
+
| ------------ | -------- | --------------------------------------------------------------------- | ---------- | ------------------- |
|
| 949 |
+
| AnythingV3.0 | BasilMix | 1,0.9,0.7,0.5,0.3,0.1,1,1,1,1,1,1,0,0,0,0,0,0,0,0.1,0.3,0.5,0.7,0.9,1 | 0 | AbyssOrangeMix2_sfw |
|
| 950 |
+
|
| 951 |
+
### AbyssOrangeMix2_nsfw (AOM2n)
|
| 952 |
+
|
| 953 |
+
▼?
|
| 954 |
+
|
| 955 |
+
JUST AbyssOrangeMix2_sfw+ (NAI-NAISFW) 0.3.
|
| 956 |
+
|
| 957 |
+
▼**Instructions:**
|
| 958 |
+
|
| 959 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 960 |
+
| ---- | -------------------- | ------------------- | ----------------- | -------------- | -------------------- |
|
| 961 |
+
| 1 | Add Difference @ 0.3 | AbyssOrangeMix_base | NovelAI animefull | NovelAI sfw | AbyssOrangeMix2_nsfw |
|
| 962 |
+
|
| 963 |
+
### AbyssOrangeMix2_hard (AOM2h)
|
| 964 |
+
|
| 965 |
+
▼?
|
| 966 |
+
+Gape0.3 version AbyssOrangeMix2_nsfw.
|
| 967 |
+
|
| 968 |
+
▼Instructions
|
| 969 |
+
|
| 970 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 971 |
+
| ---- | -------------------- | -------------------- | --------------- | ----------------- | -------------------- |
|
| 972 |
+
| 1 | Add Difference @ 0.3 | AbyssOrangeMix2_nsfw | Gape60 | NovelAI animefull | AbyssOrangeMix2_hard |
|
| 973 |
+
|
| 974 |
+
----
|
| 975 |
+
|
| 976 |
+
## EerieOrangeMix (EOM)
|
| 977 |
+
|
| 978 |
+
EerieOrangeMix is the generic name for a U-Net Blocks Weight Merge Models based on Elysium(Anime V2).
|
| 979 |
+
Since there are infinite possibilities for U-Net Blocks Weight Merging, I plan to treat all Elysium-based models as a lineage of this model.
|
| 980 |
+
|
| 981 |
+
※This does not fundamentally improve the fingers. Therefore, More research needs to be done to improve the fingers (e.g. '[bad_prompt](https://huggingface.co/datasets/Nerfgun3/bad_prompt)').
|
| 982 |
+
|
| 983 |
+
<img src=""https://files.catbox.moe/yjnqna.webp"" width=""1000"" height="""" alt=”HeroImage_EerieOrangeMix_Designed_comp001” >
|
| 984 |
+
|
| 985 |
+
|
| 986 |
+
|
| 987 |
+
|
| 988 |
+
### EerieOrangeMix (EOM1)
|
| 989 |
+
|
| 990 |
+
▼?
|
| 991 |
+
|
| 992 |
+
This merge model is simply a U-Net Blocks Weight Merge of ElysiumAnime V2 with the AbyssOrangeMix method.
|
| 993 |
+
|
| 994 |
+
The AnythingModel is good at cute girls anyway, and no matter how hard I try, it doesn't seem to be good at women in their late 20s and beyond. Therefore, I created a U-Net Blocks Weight Merge model based on my personal favorite ElysiumAnime V2 model. ElyOrangeMix was originally my favorite, so this is an enhanced version of that.
|
| 995 |
+
|
| 996 |
+
🗒Model List
|
| 997 |
+
|
| 998 |
+
- EerieOrangeMix_base|Instagram+F222 U-Net Blocks Weight Merge
|
| 999 |
+
- EerieOrangeMix_night|+ NAI-NAISFW Merge
|
| 1000 |
+
- EerieOrangeMix_half|+ Gape0.5 Merge
|
| 1001 |
+
- EerieOrangeMix|+ Gape1.0 Merge
|
| 1002 |
+
|
| 1003 |
+
▼ How to choice models
|
| 1004 |
+
|
| 1005 |
+
- _base : SFW😉
|
| 1006 |
+
- _Night : SFW ~ Soft NSFW🥰
|
| 1007 |
+
- _half : SFW ~ NSFW👄
|
| 1008 |
+
- unlabeled : SFW ~ HARDCORE ~🤯 ex)AbyssOrangeMix, BloodOrangeMix...etc
|
| 1009 |
+
|
| 1010 |
+
▼Hash
|
| 1011 |
+
|
| 1012 |
+
- EerieOrangeMix.safetensors
|
| 1013 |
+
- EerieOrangeMix_half.safetensors
|
| 1014 |
+
- EerieOrangeMix_night.safetensors
|
| 1015 |
+
- EerieOrangeMix_base.ckpt
|
| 1016 |
+
|
| 1017 |
+
▼Use Models
|
| 1018 |
+
|
| 1019 |
+
[] = WebUI Hash,「」= SHA256
|
| 1020 |
+
|
| 1021 |
+
1. Elysium Anime V2
|
| 1022 |
+
[]「5c4787ce1386500ee05dbb9d27c17273c7a78493535f2603321f40f6e0796851」
|
| 1023 |
+
2. NovelAI animefull-final-pruned
|
| 1024 |
+
[925997e9]「89d59c3dde4c56c6d5c41da34cc55ce479d93b4007046980934b14db71bdb2a8」
|
| 1025 |
+
3. NovelAI sfw
|
| 1026 |
+
[1d4a34af]「22fa233c2dfd7748d534be603345cb9abf994a23244dfdfc1013f4f90322feca」
|
| 1027 |
+
4. Gape60
|
| 1028 |
+
[25396b85]「893cca5903ccd0519876f58f4bc188dd8fcc5beb8a69c1a3f1a5fe314bb573f5」
|
| 1029 |
+
5. instagram-latest-plus-clip-v6e1_50000.safetensors
|
| 1030 |
+
[] 「8f1d325b194570754c6bd06cf1e90aa9219a7e732eb3d488fb52157e9451a2a5」
|
| 1031 |
+
6. f222
|
| 1032 |
+
[] 「9e2c6ceff3f6d6f65c6fb0e10d8e69d772871813be647fd2ea5d06e00db33c1f」
|
| 1033 |
+
7. sd1.5_pruned
|
| 1034 |
+
[] 「e1441589a6f3c5a53f5f54d0975a18a7feb7cdf0b0dee276dfc3331ae376a053」
|
| 1035 |
+
|
| 1036 |
+
▼ Sample Gallery
|
| 1037 |
+
|
| 1038 |
+
<img src=""https://files.catbox.moe/oqbvti.webp"" width=""1000"" height="""" alt=”2022-12-30_MotorbikeGIrlAsa3_comp001”>
|
| 1039 |
+
<details>
|
| 1040 |
+
<summary>More🖼</summary>
|
| 1041 |
+
<img src=""https://files.catbox.moe/nmmswd.webp"" width="""" height=""600"" alt=”2022-12-30_SampleGallery5”>
|
| 1042 |
+
</details>
|
| 1043 |
+
|
| 1044 |
+
▼ How to use
|
| 1045 |
+
|
| 1046 |
+
- VAE: orangemix.vae.pt
|
| 1047 |
+
- As simple as possible is good. Do not add excessive detail prompts. Start with just this.
|
| 1048 |
+
(worst quality, low quality:1.4)
|
| 1049 |
+
- Sampler: “DPM++ SDE Karras” is good
|
| 1050 |
+
- Steps: forTest: 20~24 ,illustration: 24~50
|
| 1051 |
+
- Clipskip: 1
|
| 1052 |
+
- USE “upscale latent space”
|
| 1053 |
+
- Denoise strength: 0.45 (0.4~0.5)
|
| 1054 |
+
If you use 0.7~, the picture will change too much.
|
| 1055 |
+
|
| 1056 |
+
▼Prompts
|
| 1057 |
+
|
| 1058 |
+
🖌When generating cute girls, try this negative prompt first. It avoids low quality, prevents blurring, avoids dull colors, and dictates Anime-like cute face modeling.
|
| 1059 |
+
|
| 1060 |
+
```jsx
|
| 1061 |
+
nsfw, (worst quality, low quality:1.3), (depth of field, blurry:1.2), (greyscale, monochrome:1.1), 3D face, nose, cropped, lowres, text, jpeg artifacts, signature, watermark, username, blurry, artist name, trademark, watermark, title, (tan, muscular, loli, petite, child, infant, toddlers, chibi, sd character:1.1), multiple view, Reference sheet,
|
| 1062 |
+
```
|
| 1063 |
+
|
| 1064 |
+
---
|
| 1065 |
+
|
| 1066 |
+
#### EerieOrangeMix_base (EOM1b)
|
| 1067 |
+
|
| 1068 |
+
▼?
|
| 1069 |
+
Details are omitted since it is the same as AbyssOrangeMix.
|
| 1070 |
+
|
| 1071 |
+
▼**Instructions:**
|
| 1072 |
+
|
| 1073 |
+
STEP: 1|Creation of photorealistic model for Merge
|
| 1074 |
+
|
| 1075 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1076 |
+
| ---- | -------------------- | ------------------------------------- | --------------- | -------------- | ---------- |
|
| 1077 |
+
| 1 | Add Difference @ 1.0 | instagram-latest-plus-clip-v6e1_50000 | f222 | sd1.5_pruned | Insta_F222 |
|
| 1078 |
+
|
| 1079 |
+
STEP: 2|Block Merge
|
| 1080 |
+
|
| 1081 |
+
Merge InstaF222
|
| 1082 |
+
|
| 1083 |
+
| Model: A | Model: B | Weight | Base alpha | Merge Name |
|
| 1084 |
+
| ---------------- | ---------- | --------------------------------------------------------------------- | ---------- | ---------- |
|
| 1085 |
+
| Elysium Anime V2 | Insta_F222 | 1,0.9,0.7,0.5,0.3,0.1,0,0,0,0,0,0,0,0,0,0,0,0,0,0.1,0.3,0.5,0.7,0.9,1 | 0 | Temp1 |
|
| 1086 |
+
|
| 1087 |
+
#### EerieOrangeMix_Night (EOM1n)
|
| 1088 |
+
|
| 1089 |
+
▼?
|
| 1090 |
+
|
| 1091 |
+
JUST EerieOrangeMix_base+ (NAI-NAISFW) 0.3.
|
| 1092 |
+
|
| 1093 |
+
▼Instructions
|
| 1094 |
+
|
| 1095 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1096 |
+
| ---- | -------------------- | ------------------- | ----------------- | -------------- | -------------------- |
|
| 1097 |
+
| 1 | Add Difference @ 0.3 | EerieOrangeMix_base | NovelAI animefull | NovelAI sfw | EerieOrangeMix_Night |
|
| 1098 |
+
|
| 1099 |
+
#### EerieOrangeMix_half (EOM1h)
|
| 1100 |
+
|
| 1101 |
+
▼?
|
| 1102 |
+
+Gape0.5 version EerieOrangeMix.
|
| 1103 |
+
|
| 1104 |
+
▼**Instructions:**
|
| 1105 |
+
|
| 1106 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1107 |
+
| ---- | -------------------- | -------------------- | ----------------- | -------------- | ------------------- |
|
| 1108 |
+
| 1 | Add Difference @ 0.5 | EerieOrangeMix_Night | NovelAI animefull | NovelAI sfw | EerieOrangeMix_half |
|
| 1109 |
+
|
| 1110 |
+
#### EerieOrangeMix (EOM1)
|
| 1111 |
+
|
| 1112 |
+
▼**Instructions:**
|
| 1113 |
+
|
| 1114 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1115 |
+
| ---- | -------------------- | -------------------- | --------------- | ----------------- | -------------- |
|
| 1116 |
+
| 1 | Add Difference @ 1.0 | EerieOrangeMix_Night | Gape60 | NovelAI animefull | EerieOrangeMix |
|
| 1117 |
+
|
| 1118 |
+
----
|
| 1119 |
+
|
| 1120 |
+
### EerieOrangeMix2 (EOM2)
|
| 1121 |
+
|
| 1122 |
+
▼?
|
| 1123 |
+
|
| 1124 |
+
The model was created by adding the hierarchy responsible for detailing and painting ElysiumV1 to EerieOrangeMix_base, then merging NAI and Gape.
|
| 1125 |
+
|
| 1126 |
+
🗒Model List
|
| 1127 |
+
|
| 1128 |
+
- EerieOrangeMix2_base|Instagram+F222+ElysiumV1 U-Net Blocks Weight Merge
|
| 1129 |
+
- EerieOrangeMix2_night|+ NAI-NAISFW Merge
|
| 1130 |
+
- EerieOrangeMix2_half|+ Gape0.5 Merge
|
| 1131 |
+
- EerieOrangeMix2|+ Gape1.0 Merge
|
| 1132 |
+
|
| 1133 |
+
▼ How to choice models
|
| 1134 |
+
|
| 1135 |
+
- _base : SFW😉
|
| 1136 |
+
- _Night : SFW ~ Soft NSFW🥰
|
| 1137 |
+
- _half : SFW ~ NSFW👄
|
| 1138 |
+
- unlabeled : SFW ~ HARDCORE ~🤯 ex)AbyssOrangeMix, BloodOrangeMix...etc
|
| 1139 |
+
|
| 1140 |
+
▼Hash
|
| 1141 |
+
|
| 1142 |
+
- EerieOrangeMix2.safetensors
|
| 1143 |
+
- EerieOrangeMix2_half.safetensors
|
| 1144 |
+
- EerieOrangeMix2_night.safetensors
|
| 1145 |
+
- EerieOrangeMix2_base.ckpt
|
| 1146 |
+
|
| 1147 |
+
▼Use Models
|
| 1148 |
+
|
| 1149 |
+
[] = webuHash,「」= SHA256
|
| 1150 |
+
|
| 1151 |
+
1. Elysium Anime V2
|
| 1152 |
+
[]「5c4787ce1386500ee05dbb9d27c17273c7a78493535f2603321f40f6e0796851」
|
| 1153 |
+
2. NovelAI animefull-final-pruned
|
| 1154 |
+
[925997e9]「89d59c3dde4c56c6d5c41da34cc55ce479d93b4007046980934b14db71bdb2a8」
|
| 1155 |
+
3. NovelAI sfw
|
| 1156 |
+
[1d4a34af]「22fa233c2dfd7748d534be603345cb9abf994a23244dfdfc1013f4f90322feca」
|
| 1157 |
+
4. Gape60
|
| 1158 |
+
[25396b85]「893cca5903ccd0519876f58f4bc188dd8fcc5beb8a69c1a3f1a5fe314bb573f5」
|
| 1159 |
+
5. instagram-latest-plus-clip-v6e1_50000.safetensors
|
| 1160 |
+
[] 「8f1d325b194570754c6bd06cf1e90aa9219a7e732eb3d488fb52157e9451a2a5」
|
| 1161 |
+
6. f222
|
| 1162 |
+
[] 「9e2c6ceff3f6d6f65c6fb0e10d8e69d772871813be647fd2ea5d06e00db33c1f」
|
| 1163 |
+
7. sd1.5_pruned
|
| 1164 |
+
[] 「e1441589a6f3c5a53f5f54d0975a18a7feb7cdf0b0dee276dfc3331ae376a053」
|
| 1165 |
+
8. ElysiumV1
|
| 1166 |
+
「abbb28cb5e70d3e0a635f241b8d61cefe42eb8f1be91fd1168bc3e52b0f09ae4」
|
| 1167 |
+
|
| 1168 |
+
#### EerieOrangeMix2_base (EOM2b)
|
| 1169 |
+
|
| 1170 |
+
▼?
|
| 1171 |
+
|
| 1172 |
+
▼Instructions
|
| 1173 |
+
|
| 1174 |
+
STEP: 1|Block Merge
|
| 1175 |
+
|
| 1176 |
+
Merge ElysiumV1
|
| 1177 |
+
|
| 1178 |
+
The generated results do not change much with or without this process, but I wanted to incorporate Elysium's depiction, so I merged it.
|
| 1179 |
+
|
| 1180 |
+
| Model: A | Model: B | Weight | Base alpha | Merge Name |
|
| 1181 |
+
| ------------------- | --------- | --------------------------------------------------------------------- | ---------- | -------------------- |
|
| 1182 |
+
| EerieOrangeMix_base | ElysiumV1 | 1,0.9,0.7,0.5,0.3,0.1,0,0,0,0,0,0,0,0,0,0,0,0,0,0.1,0.3,0.5,0.7,0.9,1 | 0 | EerieOrangeMix2_base |
|
| 1183 |
+
|
| 1184 |
+
#### EerieOrangeMix2_night (EOM2n)
|
| 1185 |
+
|
| 1186 |
+
▼?
|
| 1187 |
+
|
| 1188 |
+
JUST EerieOrangeMix2_base+ (NAI-NAISFW) 0.3.
|
| 1189 |
+
|
| 1190 |
+
▼Instructions
|
| 1191 |
+
|
| 1192 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1193 |
+
| ---- | -------------------- | ------------------- | ----------------- | -------------- | --------------------- |
|
| 1194 |
+
| 1 | Add Difference @ 0.3 | EerieOrangeMix_base | NovelAI animefull | NovelAI sfw | EerieOrangeMix2_Night |
|
| 1195 |
+
|
| 1196 |
+
#### EerieOrangeMix2_half (EOM2h)
|
| 1197 |
+
|
| 1198 |
+
▼?
|
| 1199 |
+
+Gape0.5 version EerieOrangeMix2.
|
| 1200 |
+
|
| 1201 |
+
▼Instructions
|
| 1202 |
+
|
| 1203 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1204 |
+
| ---- | -------------------- | -------------------- | ----------------- | -------------- | -------------------- |
|
| 1205 |
+
| 1 | Add Difference @ 0.5 | EerieOrangeMix_Night | NovelAI animefull | NovelAI sfw | EerieOrangeMix2_half |
|
| 1206 |
+
|
| 1207 |
+
#### EerieOrangeMix2 (EOM2)
|
| 1208 |
+
|
| 1209 |
+
▼**Instructions:**
|
| 1210 |
+
|
| 1211 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1212 |
+
| ---- | -------------------- | -------------------- | --------------- | ----------------- | --------------- |
|
| 1213 |
+
| 1 | Add Difference @ 1.0 | EerieOrangeMix_Night | Gape60 | NovelAI animefull | EerieOrangeMix2 |
|
| 1214 |
+
|
| 1215 |
+
### Models Comparison
|
| 1216 |
+
|
| 1217 |
+
<img src=""https://files.catbox.moe/mp2fr4.webp"" width=""1000"" height="""" alt=""MotorbikeGIrlAsa_Eerie_Abyss_Comparison_comp001"">
|
| 1218 |
+
<img src=""https://files.catbox.moe/9xqths.webp"" width=""1000"" height="""" alt=”Eerie_Abyss_Comparison_02_comp001”>
|
| 1219 |
+
<img src=""https://files.catbox.moe/cm6c7m.webp"" width=""1000"" height="""" alt=”Eerie_Comparison_01_comp001”>
|
| 1220 |
+
※The difference is slight but probably looks like this.
|
| 1221 |
+
← warm color, ↑ natural color, → animated color
|
| 1222 |
+
|
| 1223 |
+
----
|
| 1224 |
+
|
| 1225 |
+
## AbyssOrangeMix (AOM)
|
| 1226 |
+
|
| 1227 |
+
――How can you guys take on such a deep swamp and get results?
|
| 1228 |
+
Is it something like ""Made in Abyss""?
|
| 1229 |
+
By Anon, 115th thread
|
| 1230 |
+
|
| 1231 |
+
<img src=""https://files.catbox.moe/wst1bp.webp"" width=""1000"" height="""">
|
| 1232 |
+
|
| 1233 |
+
|
| 1234 |
+
▼?
|
| 1235 |
+
|
| 1236 |
+
The merged model was formulated using an extension such as sdweb-merge-block-weighted-gui, which merges models at separate rates for each of the 25 U-Net blocks (input, intermediate, and output).
|
| 1237 |
+
The validation of many Anons has shown that such a recipe can generate a painting style that is anatomically realistic enough to feel the finger skeleton, but still maintains an anime-style face.
|
| 1238 |
+
|
| 1239 |
+
※This model is the result of a great deal of testing and experimentation by many Anons🤗
|
| 1240 |
+
※This model can be very difficult to handle. I am not 100% confident in my ability to use this model. It is peaky and for experts.
|
| 1241 |
+
※This does not fundamentally improve the fingers, and I recommend using bad_prompt, etc. (Embedding) in combination.
|
| 1242 |
+
|
| 1243 |
+
▼Sample Gallery
|
| 1244 |
+
|
| 1245 |
+
(1)
|
| 1246 |
+
<img src=""https://files.catbox.moe/8mke0t.webp"" width=""1000"" height="""">
|
| 1247 |
+
|
| 1248 |
+
```jsx
|
| 1249 |
+
((masterpiece)), best quality, perfect anatomy, (1girl, solo focus:1.4), pov, looking at viewer, flower trim,(perspective, sideway, From directly above ,lying on water, open hand, palm, :1.3),(Accurate five-fingered hands, Reach out, hand focus, foot focus, Sole, heel, ball of the thumb:1.2), (outdoor, sunlight:1.2),(shiny skin:1.3),,(masterpiece, white border, outside border, frame:1.3),
|
| 1250 |
+
, (motherhood, aged up, mature female, medium breasts:1.2), (curvy:1.1), (single side braid:1.2), (long hair with queue and braid, disheveled hair, hair scrunchie, tareme:1.2), (light Ivory hair:1.2), looking at viewer,, Calm, Slight smile,
|
| 1251 |
+
,(anemic, dark, lake, river,puddle, Meadow, rock, stone, moss, cliff, white flower, stalactite, Godray, ruins, ancient, eternal, deep ,mystic background,sunlight,plant,lily,white flowers, Abyss, :1.2), (orange fruits, citrus fruit, citrus fruit bearing tree:1.4), volumetric lighting,good lighting,, masterpiece, best quality, highly detailed,extremely detailed cg unity 8k wallpaper,illustration,((beautiful detailed face)), best quality, (((hyper-detailed ))), high resolution illustration ,high quality, highres, sidelighting, ((illustrationbest)),highres,illustration, absurdres, hyper-detailed, intricate detail, perfect, high detailed eyes,perfect lighting, (extremely detailed CG:1.2),
|
| 1252 |
+
|
| 1253 |
+
Negative prompt: (bad_prompt_version2:1), distant view, lip, Pregnant, maternity, pointy ears, realistic, tan, muscular, greyscale, monochrome, lineart, 2koma, 3koma, 4koma, manga, 3D, 3Dcubism, pablo picasso, disney, marvel, mutanted breasts, mutanted nipple, cropped, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, lowres, trademark, watermark, title, text, deformed, bad anatomy, disfigured, mutated, extra limbs, ugly, missing limb, floating limbs, disconnected limbs, out of frame, mutated hands and fingers, poorly drawn hands, malformed hands, poorly drawn face, poorly drawn asymmetrical eyes, (blurry:1.4), duplicate (loli, petite, child, infant, toddlers, chibi, sd character, teen age:1.4), tsurime, helmet hair, evil smile, smug_face, naughty smile, multiple view, Reference sheet, (worst quality, low quality:1.4),
|
| 1254 |
+
Steps: 24, Sampler: DPM++ SDE Karras, CFG scale: 10, Seed: 1159970659, Size: 1536x768, Model hash: cc44dbff, Model: AbyssOrangeMix, Variation seed: 93902374, Variation seed strength: 0.45, Denoising strength: 0.45, ENSD: 31337
|
| 1255 |
+
```
|
| 1256 |
+
|
| 1257 |
+
(2)
|
| 1258 |
+
<img src=""https://files.catbox.moe/6cbrqh.webp"" width="""" height=""600"">
|
| 1259 |
+
|
| 1260 |
+
```jsx
|
| 1261 |
+
street, 130mm f1.4 lens, ,(shiny skin:1.3),, (teen age, school uniform:1.2), (glasses, black hair, medium hair with queue and braid, disheveled hair, hair scrunchie, tareme:1.2), looking at viewer,, Calm, Slight smile,
|
| 1262 |
+
|
| 1263 |
+
Negative prompt: (bad_prompt_version2:1), distant view, lip, Pregnant, maternity, pointy ears, realistic, tan, muscular, greyscale, monochrome, lineart, 2koma, 3koma, 4koma, manga, 3D, 3Dcubism, pablo picasso, disney, marvel, mutanted breasts, mutanted nipple, cropped, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, lowres, trademark, watermark, title, text, deformed, bad anatomy, disfigured, mutated, extra limbs, ugly, missing limb, floating limbs, disconnected limbs, out of frame, mutated hands and fingers, poorly drawn hands, malformed hands, poorly drawn face, poorly drawn asymmetrical eyes, (blurry:1.4), duplicate (loli, petite, child, infant, toddlers, chibi, sd character, teen age:1.4), tsurime, helmet hair, evil smile, smug_face, naughty smile, multiple view, Reference sheet, (worst quality, low quality:1.4),
|
| 1264 |
+
Steps: 24, Sampler: DPM++ SDE Karras, CFG scale: 10, Seed: 1140782193, Size: 1024x1536, Model hash: cc44dbff, Model: AbyssOrangeMix, Denoising strength: 0.45, ENSD: 31337, First pass size: 512x768, Model sha256: 6bb3a5a3b1eadd32, VAE sha256: f921fb3f29891d2a, Options: xformers medvram gtx_16x0
|
| 1265 |
+
|
| 1266 |
+
Used embeddings: bad_prompt_version2 [afea]
|
| 1267 |
+
```
|
| 1268 |
+
|
| 1269 |
+
----
|
| 1270 |
+
|
| 1271 |
+
▼How to use
|
| 1272 |
+
|
| 1273 |
+
- VAE: orangemix.vae.pt
|
| 1274 |
+
- ~~Prompts can be long or short~~
|
| 1275 |
+
As simple as possible is good. Do not add excessive detail prompts. Start with just this.
|
| 1276 |
+
(worst quality, low quality:1.4)
|
| 1277 |
+
- Sampler: “DPM++ SDE Karras” is good
|
| 1278 |
+
- Steps: forTest: 20~24 ,illustration: 24~50
|
| 1279 |
+
- Clipskip: 1
|
| 1280 |
+
- USE “upscale latent space”
|
| 1281 |
+
- Denoise strength: 0.45 (0.4~0.5)
|
| 1282 |
+
If you use 0.7~, the picture will change too much.
|
| 1283 |
+
|
| 1284 |
+
▼Prompts
|
| 1285 |
+
|
| 1286 |
+
🖌When generating cute girls, try this negative prompt first. It avoids low quality, prevents blurring, avoids dull colors, and dictates Anime-like cute face modeling.
|
| 1287 |
+
|
| 1288 |
+
```jsx
|
| 1289 |
+
nsfw, (worst quality, low quality:1.3), (depth of field, blurry:1.2), (greyscale, monochrome:1.1), 3D face, nose, cropped, lowres, text, jpeg artifacts, signature, watermark, username, blurry, artist name, trademark, watermark, title, (tan, muscular, loli, petite, child, infant, toddlers, chibi, sd character:1.1), multiple view, Reference sheet,
|
| 1290 |
+
```
|
| 1291 |
+
|
| 1292 |
+
🗒Model List
|
| 1293 |
+
|
| 1294 |
+
- AbyssOrangeMix_base|Instagram Merge
|
| 1295 |
+
- AbyssOrangeMix_Night|+ NAI-NAISFW Merge
|
| 1296 |
+
- AbyssOrangeMix_half|+ Gape0.5 Merge
|
| 1297 |
+
- AbyssOrangeMix|+ Gape1.0 Merge
|
| 1298 |
+
|
| 1299 |
+
▼ How to choice models
|
| 1300 |
+
|
| 1301 |
+
- _base : SFW😉
|
| 1302 |
+
- _Night : SFW ~ Soft NSFW🥰
|
| 1303 |
+
- _half : SFW ~ NSFW👄
|
| 1304 |
+
- unlabeled : SFW ~ HARDCORE ~🤯 ex)AbyssOrangeMix, BloodOrangeMix...etc
|
| 1305 |
+
|
| 1306 |
+
▼Hash (SHA256)
|
| 1307 |
+
|
| 1308 |
+
- AbyssOrangeMix.safetensors
|
| 1309 |
+
6bb3a5a3b1eadd32dfbc8f0987559c48cb4177aee7582baa6d6a25181929b345
|
| 1310 |
+
- AbyssOrangeMix_half.safetensors
|
| 1311 |
+
468d1b5038c4fbd354113842e606fe0557b4e0e16cbaca67706b29bcf51dc402
|
| 1312 |
+
- AbyssOrangeMix_Night.safetensors
|
| 1313 |
+
167cd104699dd98df22f4dfd3c7a2c7171df550852181e454e71e5bff61d56a6
|
| 1314 |
+
- AbyssOrangeMix_base.ckpt
|
| 1315 |
+
bbd2621f3ec4fad707f75fc032a2c2602c296180a53ed3d9897d8ca7a01dd6ed
|
| 1316 |
+
|
| 1317 |
+
▼Use Models
|
| 1318 |
+
|
| 1319 |
+
1. AnythingV3.0 huggingface pruned
|
| 1320 |
+
[2700c435]「543bcbc21294831c6245cd74c8a7707761e28812c690f946cb81fef930d54b5e」
|
| 1321 |
+
1. NovelAI animefull-final-pruned
|
| 1322 |
+
[925997e9]「89d59c3dde4c56c6d5c41da34cc55ce479d93b4007046980934b14db71bdb2a8」
|
| 1323 |
+
1. NovelAI sfw
|
| 1324 |
+
[1d4a34af]「22fa233c2dfd7748d534be603345cb9abf994a23244dfdfc1013f4f90322feca」
|
| 1325 |
+
1. Gape60
|
| 1326 |
+
[25396b85]「893cca5903ccd0519876f58f4bc188dd8fcc5beb8a69c1a3f1a5fe314bb573f5」
|
| 1327 |
+
1. instagram-latest-plus-clip-v6e1_50000.safetensors
|
| 1328 |
+
[] 「8f1d325b194570754c6bd06cf1e90aa9219a7e732eb3d488fb52157e9451a2a5」
|
| 1329 |
+
1. f222
|
| 1330 |
+
[] 「9e2c6ceff3f6d6f65c6fb0e10d8e69d772871813be647fd2ea5d06e00db33c1f」
|
| 1331 |
+
1. sd1.5_pruned
|
| 1332 |
+
[] 「e1441589a6f3c5a53f5f54d0975a18a7feb7cdf0b0dee276dfc3331ae376a053」
|
| 1333 |
+
|
| 1334 |
+
### AbyssOrangeMix_base (AOMb)
|
| 1335 |
+
|
| 1336 |
+
▼?
|
| 1337 |
+
|
| 1338 |
+
The basic trick for this merged model is to incorporate a model that has learned more than 1m Instagram photos (mostly Japanese) or a photorealistic model like f222. The choice of base model here depends on the person. I chose AnythingV3 for versatility.
|
| 1339 |
+
|
| 1340 |
+
▼**Instructions:**
|
| 1341 |
+
|
| 1342 |
+
STEP: 1|Creation of photorealistic model for Merge
|
| 1343 |
+
|
| 1344 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1345 |
+
| ---- | -------------------- | ------------------------------------- | --------------- | -------------- | ---------- |
|
| 1346 |
+
| 1 | Add Difference @ 1.0 | instagram-latest-plus-clip-v6e1_50000 | f222 | sd1.5_pruned | Insta_F222 |
|
| 1347 |
+
|
| 1348 |
+
STEP: 2|Block Merge
|
| 1349 |
+
|
| 1350 |
+
| Model: A | Model: B | Weight | Base alpha | Merge Name |
|
| 1351 |
+
| ------------ | ---------- | --------------------------------------------------------------------- | ---------- | ------------------- |
|
| 1352 |
+
| AnythingV3.0 | Insta_F222 | 1,0.9,0.7,0.5,0.3,0.1,0,0,0,0,0,0,0,0,0,0,0,0,0,0.1,0.3,0.5,0.7,0.9,1 | 0 | AbyssOrangeMix_base |
|
| 1353 |
+
|
| 1354 |
+
### AbyssOrangeMix_Night (AOMn)
|
| 1355 |
+
|
| 1356 |
+
▼?
|
| 1357 |
+
|
| 1358 |
+
JUST AbyssOrangeMix_base+ (NAI-NAISFW) 0.3.
|
| 1359 |
+
|
| 1360 |
+
▼**Instructions:**
|
| 1361 |
+
|
| 1362 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1363 |
+
| ---- | -------------------- | ------------------- | ----------------- | -------------- | -------------------- |
|
| 1364 |
+
| 1 | Add Difference @ 0.3 | AbyssOrangeMix_base | NovelAI animefull | NovelAI sfw | AbyssOrangeMix_Night |
|
| 1365 |
+
|
| 1366 |
+
### AbyssOrangeMix_half (AOMh)
|
| 1367 |
+
|
| 1368 |
+
▼?
|
| 1369 |
+
+Gape0.5 version AbyssOrangeMix.
|
| 1370 |
+
|
| 1371 |
+
▼**Instructions:**
|
| 1372 |
+
|
| 1373 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1374 |
+
| ---- | -------------------- | -------------------- | --------------- | ----------------- | ------------------- |
|
| 1375 |
+
| 1 | Add Difference @ 0.5 | AbyssOrangeMix_Night | Gape60 | NovelAI animefull | AbyssOrangeMix_half |
|
| 1376 |
+
|
| 1377 |
+
### AbyssOrangeMix (AOM)
|
| 1378 |
+
|
| 1379 |
+
▼**Instructions:**
|
| 1380 |
+
|
| 1381 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1382 |
+
| ---- | -------------------- | -------------------- | --------------- | ----------------- | -------------- |
|
| 1383 |
+
| 1 | Add Difference @ 1.0 | AbyssOrangeMix_Night | Gape60 | NovelAI animefull | AbyssOrangeMix |
|
| 1384 |
+
|
| 1385 |
+
----
|
| 1386 |
+
|
| 1387 |
+
## ElyOrangeMix (ELOM)
|
| 1388 |
+
|
| 1389 |
+
<img src=""https://i.imgur.com/AInEXA5.jpg"" width=""1000"" height="""">
|
| 1390 |
+
|
| 1391 |
+
▼?
|
| 1392 |
+
Elysium_Anime_V2 + NAI + Gape.
|
| 1393 |
+
This is a merge model that improves on the Elysium_Anime_V2, where NSFW representation is not good.
|
| 1394 |
+
It can produce SFW, NSFW, and any other type of artwork, while retaining the Elysium's three-dimensional, thickly painted style.
|
| 1395 |
+
|
| 1396 |
+
▼ How to choice models
|
| 1397 |
+
|
| 1398 |
+
- _base : SFW😉
|
| 1399 |
+
- _Night : SFW ~ Soft NSFW🥰
|
| 1400 |
+
- _half : SFW ~ NSFW👄
|
| 1401 |
+
- unlabeled : SFW ~ HARDCORE ~🤯 ex)AbyssOrangeMix, BloodOrangeMix...etc
|
| 1402 |
+
|
| 1403 |
+
▼How to use
|
| 1404 |
+
- VAE: orangemix.vae.pt
|
| 1405 |
+
|
| 1406 |
+
▼Hash (SHA256)
|
| 1407 |
+
|
| 1408 |
+
- ElyOrangeMix [6b508e59]
|
| 1409 |
+
- ElyOrangeMix_half [6b508e59]
|
| 1410 |
+
- ElyNightOrangeMix[6b508e59]
|
| 1411 |
+
|
| 1412 |
+
|
| 1413 |
+
### ElyOrangeMix (ELOM)
|
| 1414 |
+
|
| 1415 |
+
▼Use Models
|
| 1416 |
+
|
| 1417 |
+
1. Elysium_Anime_V2 [6b508e59]
|
| 1418 |
+
2. NovelAI animefull-final-pruned [925997e9]
|
| 1419 |
+
3. NovelAI sfw [1d4a34af]
|
| 1420 |
+
4. Gape60 [25396b85]
|
| 1421 |
+
|
| 1422 |
+
▼Instructions
|
| 1423 |
+
|
| 1424 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1425 |
+
| ---- | -------------------- | ---------------- | ----------------- | ----------------- | ------------------------ |
|
| 1426 |
+
| 1 | Add Difference @ 0.3 | Elysium_Anime_V2 | NovelAI animefull | NovelAI sfw | tempmix-part1 [] |
|
| 1427 |
+
| 2 | Add Difference @ 1.0 | tempmix-part1 | Gape60 | NovelAI animefull | ElyOrangeMix [6b508e59] |
|
| 1428 |
+
|
| 1429 |
+
---
|
| 1430 |
+
|
| 1431 |
+
### ElyOrangeMix_half (ELOMh)
|
| 1432 |
+
|
| 1433 |
+
▼?
|
| 1434 |
+
|
| 1435 |
+
+Gape0.5 version ElyOrangeMix.
|
| 1436 |
+
|
| 1437 |
+
▼Use Models
|
| 1438 |
+
|
| 1439 |
+
1. Elysium_Anime_V2 [6b508e59]
|
| 1440 |
+
2. NovelAI animefull-final-pruned [925997e9]
|
| 1441 |
+
3. NovelAI sfw [1d4a34af]
|
| 1442 |
+
4. Gape60 [25396b85]
|
| 1443 |
+
|
| 1444 |
+
▼Instructions
|
| 1445 |
+
|
| 1446 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1447 |
+
| ---- | -------------------- | ---------------- | ----------------- | ----------------- | ----------------------------- |
|
| 1448 |
+
| 1 | Add Difference @ 0.3 | Elysium_Anime_V2 | NovelAI animefull | NovelAI sfw | tempmix-part1 [] |
|
| 1449 |
+
| 2 | Add Difference @ 0.5 | tempmix-part1 | Gape60 | NovelAI animefull | ElyOrangeMix_half [6b508e59] |
|
| 1450 |
+
|
| 1451 |
+
----
|
| 1452 |
+
|
| 1453 |
+
### ElyNightOrangeMix (ELOMn)
|
| 1454 |
+
|
| 1455 |
+
▼?
|
| 1456 |
+
|
| 1457 |
+
It is a merged model that just did Elysium_Anime_V2+ (NAI-NAISFW) 0.3.
|
| 1458 |
+
|
| 1459 |
+
▼Use Models
|
| 1460 |
+
|
| 1461 |
+
1. Elysium_Anime_V2 [6b508e59]
|
| 1462 |
+
2. NovelAI animefull-final-pruned [925997e9]
|
| 1463 |
+
3. NovelAI sfw [1d4a34af]
|
| 1464 |
+
|
| 1465 |
+
▼Instructions
|
| 1466 |
+
|
| 1467 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1468 |
+
| ---- | -------------------- | ---------------- | ----------------- | -------------- | ----------------- |
|
| 1469 |
+
| 1 | Add Difference @ 0.3 | Elysium_Anime_V2 | NovelAI animefull | NovelAI sfw | ElyNightOrangeMix |
|
| 1470 |
+
|
| 1471 |
+
----
|
| 1472 |
+
|
| 1473 |
+
## BloodOrangeMix (BOM)
|
| 1474 |
+
|
| 1475 |
+
<img src=""https://i.imgur.com/soAnnFk.jpg"" width=""1000"" height="""">
|
| 1476 |
+
|
| 1477 |
+
▼?
|
| 1478 |
+
Anything+NAI+Gape.
|
| 1479 |
+
This is a merge model that improves on the AnythingV3, where NSFW representation is not good.
|
| 1480 |
+
It can produce SFW, NSFW, and any other type of artwork, while retaining the flat, beautifully painted style of AnythingV3.
|
| 1481 |
+
Stable. Popular in the Japanese community.
|
| 1482 |
+
|
| 1483 |
+
▼ModelList & [] = WebUI Hash,「」= SHA256
|
| 1484 |
+
|
| 1485 |
+
- BloodNightOrangeMix.ckpt
|
| 1486 |
+
[ffa7b160]「f8aff727ba3da0358815b1766ed232fd1ef9682ad165067cac76e576d19689e0」
|
| 1487 |
+
- BloodOrangeMix_half.ckpt
|
| 1488 |
+
[ffa7b160]「b2168aaa59fa91229b8add21f140ac9271773fe88a387276f3f0c7d70f726a83」
|
| 1489 |
+
- BloodOrangeMix.ckpt
|
| 1490 |
+
[ffa7b160] 「25cece3fe303ea8e3ad40c3dca788406dbd921bcf3aa8e3d1c7c5ac81f208a4f」
|
| 1491 |
+
- BloodOrangeMix.safetensors
|
| 1492 |
+
「79a1edf6af43c75ee1e00a884a09213a28ee743b2e913de978cb1f6faa1b320d」
|
| 1493 |
+
|
| 1494 |
+
▼ How to choice models
|
| 1495 |
+
|
| 1496 |
+
- _base : SFW😉
|
| 1497 |
+
- _Night : SFW ~ Soft NSFW🥰
|
| 1498 |
+
- _half : SFW ~ NSFW👄
|
| 1499 |
+
- unlabeled : SFW ~ HARDCORE ~🤯 ex)AbyssOrangeMix, BloodOrangeMix...etc
|
| 1500 |
+
|
| 1501 |
+
▼How to use
|
| 1502 |
+
- VAE: orangemix.vae.pt
|
| 1503 |
+
|
| 1504 |
+
### BloodOrangeMix (BOM)
|
| 1505 |
+
|
| 1506 |
+
▼Use Models
|
| 1507 |
+
|
| 1508 |
+
1. AnythingV3.0 huggingface pruned [2700c435]
|
| 1509 |
+
2. NovelAI animefull-final-pruned [925997e9]
|
| 1510 |
+
3. NovelAI sfw [1d4a34af]
|
| 1511 |
+
4. Gape60 [25396b85]
|
| 1512 |
+
|
| 1513 |
+
▼Instructions
|
| 1514 |
+
|
| 1515 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1516 |
+
| ---- | -------------------- | ------------- | ----------------- | ----------------- | ------------------------- |
|
| 1517 |
+
| 1 | Add Difference @ 0.3 | AnythingV3.0 | NovelAI animefull | NovelAI sfw | tempmix-part1 [] |
|
| 1518 |
+
| 2 | Add Difference @ 1.0 | tempmix-part1 | Gape60 | NovelAI animefull | BloodOrangeMix [ffa7b160] |
|
| 1519 |
+
|
| 1520 |
+
----
|
| 1521 |
+
|
| 1522 |
+
### BloodOrangeMix_half (BOMh)
|
| 1523 |
+
|
| 1524 |
+
▼?
|
| 1525 |
+
Anything+Nai+Gape0.5
|
| 1526 |
+
+Gape0.5 version BloodOrangeMix.
|
| 1527 |
+
NSFW expression will be softer and have less impact on the Anything style painting style.
|
| 1528 |
+
|
| 1529 |
+
▼Use Models
|
| 1530 |
+
|
| 1531 |
+
1. AnythingV3.0 huggingface pruned [2700c435]
|
| 1532 |
+
2. NovelAI animefull-final-pruned [925997e9]
|
| 1533 |
+
3. NovelAI sfw [1d4a34af]
|
| 1534 |
+
4. Gape60 [25396b85]
|
| 1535 |
+
|
| 1536 |
+
▼Instructions
|
| 1537 |
+
|
| 1538 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1539 |
+
| ---- | -------------------- | ------------- | ----------------- | ----------------- | ------------------------------ |
|
| 1540 |
+
| 1 | Add Difference @ 0.3 | AnythingV3.0 | NovelAI animefull | NovelAI sfw | tempmix-part1 [] |
|
| 1541 |
+
| 2 | Add Difference @ 0.5 | tempmix-part1 | Gape60 | NovelAI animefull | BloodOrangeMix_half [ffa7b160] |
|
| 1542 |
+
|
| 1543 |
+
----
|
| 1544 |
+
|
| 1545 |
+
### BloodNightOrangeMix (BOMn)
|
| 1546 |
+
|
| 1547 |
+
▼?
|
| 1548 |
+
|
| 1549 |
+
It is a merged model that just did AnythingV3+ (NAI-NAISFW) 0.3.
|
| 1550 |
+
|
| 1551 |
+
▼Use Models
|
| 1552 |
+
|
| 1553 |
+
1. AnythingV3.0 huggingface pruned [2700c435]
|
| 1554 |
+
2. NovelAI animefull-final-pruned [925997e9]
|
| 1555 |
+
3. NovelAI sfw [1d4a34af]
|
| 1556 |
+
|
| 1557 |
+
▼Instructions
|
| 1558 |
+
|
| 1559 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1560 |
+
| ---- | -------------------- | ------------- | ----------------- | -------------- | ------------------- |
|
| 1561 |
+
| 1 | Add Difference @ 0.3 | AnythingV3.0 | NovelAI animefull | NovelAI sfw | BloodNightOrangeMix |
|
| 1562 |
+
|
| 1563 |
+
----
|
| 1564 |
+
|
| 1565 |
+
## ElderOrangeMix
|
| 1566 |
+
|
| 1567 |
+
※I found this model to be very prone to body collapse. Not recommended.
|
| 1568 |
+
|
| 1569 |
+
▼?
|
| 1570 |
+
anything and everything mix ver.1.5+Gape+Nai(AnEve.G.N0.3)
|
| 1571 |
+
This is a merged model with improved NSFW representation of anything and everything mix ver.1.5.
|
| 1572 |
+
|
| 1573 |
+
▼Hash
|
| 1574 |
+
[3a46a1e0]
|
| 1575 |
+
|
| 1576 |
+
▼Use Models
|
| 1577 |
+
|
| 1578 |
+
1. anything and everything mix ver.1.5 [5265dcf6]
|
| 1579 |
+
2. NovelAI animefull-final-pruned [925997e9]
|
| 1580 |
+
3. NovelAI sfw [1d4a34af]
|
| 1581 |
+
4. Gape60 [25396b85]
|
| 1582 |
+
|
| 1583 |
+
▼Instructions:**
|
| 1584 |
+
|
| 1585 |
+
| Step | Interpolation Method | Primary Model | Secondary Model | Tertiary Model | Merge Name |
|
| 1586 |
+
| ---- | -------------------- | ----------------------------------- | --------------- | -------------- | -------------------------- |
|
| 1587 |
+
| 1 | Add Difference @ 0.5 | anything and everything mix ver.1.5 | Gape60 | NovelAI full | tempmix-part1 [] |
|
| 1588 |
+
| 2 | Add Difference @ 0.3 | tempmix-part1 | NovelAI full | NovelAI sfw | ElderOrangeMix [3a46a1e0] |
|
| 1589 |
+
|
| 1590 |
+
----
|
| 1591 |
+
|
| 1592 |
+
## Troubleshooting
|
| 1593 |
+
|
| 1594 |
+
1. blurred Images & clearly low quality output
|
| 1595 |
+
If the generated images are blurred or only clearly low quality output is produced, it is possible that the vae, etc. are not loaded properly. Try reloading the model/vae or restarting the WebUI/OS.
|
| 1596 |
+
|
| 1597 |
+
## FAQ and Tips (🐈MEME ZONE🦐)
|
| 1598 |
+
|
| 1599 |
+
|
| 1600 |
+
Trash zone.
|
| 1601 |
+
|
| 1602 |
+
----
|
| 1603 |
+
|
| 1604 |
+
<a name=""MEME_AOM3A1""></a>
|
| 1605 |
+
|
| 1606 |
+
|
| 1607 |
+
▼Noooo, not work. This guy is Scammer
|
| 1608 |
+
STEP1: BUY HUGE PC
|
| 1609 |
+
|
| 1610 |
+
|
| 1611 |
+
▼Noooo, can't generate image like samples.This models is hype.
|
| 1612 |
+
|
| 1613 |
+
❌
|
| 1614 |
+
<img src=""https://files.catbox.moe/nte6ud.webp"" width=""500"" height="""" alt=""keyboard guy"">
|
| 1615 |
+
|
| 1616 |
+
🟢
|
| 1617 |
+
<img src=""https://files.catbox.moe/lta462.webp"" width=""500"" height="""" alt=""clever guy"">
|
| 1618 |
+
|
| 1619 |
+
|
| 1620 |
+
▼Noooo, This models have troy virus. don't download.
|
| 1621 |
+
|
| 1622 |
+
All models in this repository are secure. It is most likely that anti-virus software has detected them erroneously.
|
| 1623 |
+
However, the models with the .ckpt extension have the potential danger of executing arbitrary code.
|
| 1624 |
+
A safe model that is free from these dangers is the model with the .safetensors extension.
|
| 1625 |
+
|
| 1626 |
+
<a name=""MEME_realface""></a>
|
| 1627 |
+
▼AOM2?
|
| 1628 |
+
(only NSFW models)
|
| 1629 |
+

|
| 1630 |
+
|
| 1631 |
+
|
| 1632 |
+
▼AOM3A1?
|
| 1633 |
+
R.I.P.
|
| 1634 |
+
|
| 1635 |
+
▼Noooo^()&*%#NG0u!!!!!!!!縺ゅ♀繧?縺医?縺、繝シ縺ィ縺医?縺吶j繝シ縺ッ驕主ュヲ鄙偵?繧エ繝溘〒縺? (「AOM3A2 and A3 are overlearning and Trash. delete!」)
|
| 1636 |
+
|
| 1637 |
+
<img src=""https://github.com/WarriorMama777/imgup/raw/main/img/img_general/img_meme_tension_comp001.webp"" width=""300"" height="""" alt=”getting_excited”>
|
| 1638 |
+
|
| 1639 |
+
|
| 1640 |
+
▼Noooo, Too many models. Tell me which one to choose.
|
| 1641 |
+
|
| 1642 |
+
→ [全部同じじゃないですか](https://github.com/WarriorMama777/imgup/blob/main/img/img_general/img_MEME_whichModel_comp001.webp?raw=true ""全部同じじゃないですか"")
|
| 1643 |
+
|
| 1644 |
+
|
| 1645 |
+
","{""id"": ""WarriorMama777/OrangeMixs"", ""author"": ""WarriorMama777"", ""sha"": ""ec9df50045e9687fd7ea8116db84c4ad5c4a4358"", ""last_modified"": ""2024-01-07 10:41:44+00:00"", ""created_at"": ""2022-12-04 14:18:34+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1794, ""downloads_all_time"": null, ""likes"": 3826, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""tags"": [""diffusers"", ""stable-diffusion"", ""text-to-image"", ""dataset:Nerfgun3/bad_prompt"", ""license:creativeml-openrail-m"", ""autotrain_compatible"", ""endpoints_compatible"", ""diffusers:StableDiffusionPipeline"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""datasets: Nerfgun3/bad_prompt\nlicense: creativeml-openrail-m\ntags:\n- stable-diffusion\n- text-to-image"", ""widget_data"": null, ""model_index"": null, ""config"": {""diffusers"": {""_class_name"": ""StableDiffusionPipeline""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Development/.gitkeep', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Model Helth Check List.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix/AbyssOrangeMix.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix/AbyssOrangeMix_Night.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix/AbyssOrangeMix_base.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix/AbyssOrangeMix_half.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/AbyssOrangeMix2_hard.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/AbyssOrangeMix2_nsfw.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/AbyssOrangeMix2_sfw.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/AbyssOrangeMix2_sfw.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/safety_checker/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/safety_checker/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/text_encoder/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/unet/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/vae/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Diffusers/vae/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Pruned/AbyssOrangeMix2_hard_pruned_fp16_with_VAE.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Pruned/AbyssOrangeMix2_hard_pruned_fp16_with_VAE.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Pruned/AbyssOrangeMix2_nsfw_pruned_fp16_with_VAE.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Pruned/AbyssOrangeMix2_nsfw_pruned_fp16_with_VAE.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Pruned/AbyssOrangeMix2_sfw_pruned_fp16_with_VAE.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/Pruned/AbyssOrangeMix2_sfw_pruned_fp16_with_VAE.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/inpainting/AbyssOrangeMix2_hard_pruned_fp16_with_VAE-inpainting.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/inpainting/AbyssOrangeMix2_nsfw_pruned_fp16_with_VAE-inpainting.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix2/inpainting/AbyssOrangeMix2_sfw_pruned_fp16_with_VAE-inpainting.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix3/AOM3A1B_orangemixs.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix3/AOM3A1_orangemixs.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix3/AOM3A2_orangemixs.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix3/AOM3A3_orangemixs.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix3/AOM3B2_orangemixs.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix3/AOM3B3_orangemixs.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix3/AOM3B4_orangemixs.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/AbyssOrangeMix3/AOM3_orangemixs.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/BloodOrangeMix/BloodNightOrangeMix.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/BloodOrangeMix/BloodOrangeMix.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/BloodOrangeMix/BloodOrangeMix_half.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/EerieOrangeMix/EerieOrangeMix.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/EerieOrangeMix/EerieOrangeMix2.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/EerieOrangeMix/EerieOrangeMix2_base.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/EerieOrangeMix/EerieOrangeMix2_half.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/EerieOrangeMix/EerieOrangeMix2_night.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/EerieOrangeMix/EerieOrangeMix_base.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/EerieOrangeMix/EerieOrangeMix_half.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/EerieOrangeMix/EerieOrangeMix_night.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/ElyOrangeMix/ElyNightOrangeMix.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/ElyOrangeMix/ElyOrangeMix.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/ElyOrangeMix/ElyOrangeMix_half.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/Other/ElderOrangeMix.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/VividOrangeMix/VividOrangeMix.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/VividOrangeMix/VividOrengeMix_Hard.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Models/VividOrangeMix/VividOrengeMix_NSFW.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VAEs/orangemix.vae.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='VAEs/readme_VAEs.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model_index.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""DreamSunny/stable-diffusion-webui-cpu"", ""Nymbo/image_gen_supaqueue"", ""ennov8ion/3dart-Models"", ""kxic/EscherNet"", ""PartyPlus/PornGen"", ""ennov8ion/comicbook-models"", ""Nymbo/epiCPhotoGASM-Webui-CPU"", ""SUPERSHANKY/Finetuned_Diffusion_Max"", ""IoMa/stable-diffusion-webui-cpu-the-best"", ""jangocheng/stable-diffusion-webui-cpu_with_prompt_pub"", ""Yntec/Anything7.0-Webui-CPU"", ""Rifd/ngees_doang"", ""EPFL-VILAB/ViPer"", ""akhaliq/webui-orangemixs"", ""miittnnss/play-with-sd-models"", ""mindtube/Diffusion50XX"", ""phoenix-1708/stable-diffusion-webui-cpu"", ""ai-moroz/webui-cpu"", ""INDONESIA-AI/Lobe"", ""wrdias/Dreamlike-Webui-CPU"", ""ennov8ion/stablediffusion-models"", ""Shocky/Pink-Anime"", ""Smithjohny376/Orangemixes"", ""dasghost65536/SD-Webui12"", ""Recahtrada/2nd2"", ""arthurdias/Webui-Cpu-ExtensionV2-Publictest-WithCivitaiHelper"", ""thestasi/Webui-Cpu-ExtensionV2-Publictest-WithCivitaiHelper"", ""ennov8ion/Scifi-Models"", ""ennov8ion/semirealistic-models"", ""ennov8ion/FantasyArt-Models"", ""ennov8ion/dreamlike-models"", ""IoMa/stable-diffusion-webui-cpu"", ""noes14155/img_All_models"", ""lijiacai/stable-diffusion-webui-cpu"", ""Nymbo/PornGen"", ""dasghost65536/a1111-16-webui-cpu-reboot"", ""Minecraft3193092/Stable-Diffusion-8"", ""AnimeStudio/anime-models"", ""soiz1/epiCPhotoGASM-Webui-CPU"", ""Minecraft3193092/Stable-Diffusion-7"", ""Harshveer/Finetuned_Diffusion_Max"", ""hilmyblaze/WebUI-Counterfeit-V2.5"", ""mindtube/maximum_multiplier_places"", ""animeartstudio/AnimeArtmodels2"", ""animeartstudio/AnimeModels"", ""Nultx/stable-diffusion-webui-cpu"", ""sub314xxl/webui-cpu-extension-test"", ""PrinceDeven78/Dreamlike-Webui-CPU"", ""pikto/Elite-Scifi-Models"", ""rektKnight/stable-diffusion-webui-cpu_dupli"", ""PixelistStudio/3dart-Models"", ""FIT2125/stable-diffusion-webui-cpu"", ""Minecraft3193092/Stable-Diffusion-4"", ""snowcatcat/webui-cpu-TEST"", ""ennov8ion/anime-models"", ""locapi/Stable-Diffusion-7"", ""Bai-YT/ConsistencyTTA"", ""48leewsypc/Stable-Diffusion"", ""pandaphd/generative_photography"", ""wuhao2222/WarriorMama777-OrangeMixs"", ""Alashazam/Harmony"", ""hojumoney/WarriorMama777-OrangeMixs"", ""ygtrfed/pp-web-ui"", ""Phasmanta/Space2"", ""ivanmeyer/Finetuned_Diffusion_Max"", ""ennov8ion/Landscapes-models"", ""sohoso/anime348756"", ""willhill/stable-diffusion-webui-cpu"", ""hehysh/stable-diffusion-webui-cpu-the-best"", ""shoukosagiri/stable-diffusion-webui-cpu"", ""luisrguerra/unrealdream"", ""wrdias/SD_WEBUI"", ""JCTN/stable-diffusion-webui-cjtn"", ""hehe520/stable-diffusion-webui-cpu"", ""PickleYard/stable-diffusion-webui-cpu"", ""Alfasign/Dreamlike-Webui-CPU"", ""AlexKorGKLT/webui-cpua"", ""Minecraft3193092/Stable-Diffusion-5"", ""enochianborg/stable-diffusion-webui-vorstcavry"", ""snatcheggmoderntimes/SD1-TEST"", ""ClipHamper/stable-diffusion-webui"", ""ennov8ion/art-models"", ""ennov8ion/photo-models"", ""ennov8ion/art-multi"", ""fero/stable-diffusion-webui-cpu"", ""Deviliaan/sd_twist"", ""kongyiji/webui-cpu-TEST"", ""mystifying/cheet-sheet"", ""mmk27/WarriorMama777-OrangeMixs"", ""findlist/WarriorMama777-OrangeMixs"", ""NOABOL35631y/Space"", ""sandwichcremes/WarriorMama777-OrangeMixs"", ""C18127567606/WarriorMama777-OrangeMixs"", ""Mipan/WarriorMama777-OrangeMixs"", ""candyheels/WarriorMama777-OrangeMixs"", ""payhowell/WarriorMama777-OrangeMixs"", ""zjrwtx/WarriorMama777-OrangeMixs"", ""redpeacock78/OrangeMixs"", ""redpeacock78/WarriorMama777-OrangeMixs"", ""huioj/WarriorMama777-OrangeMixs""], ""safetensors"": null, ""security_repo_status"": null, ""lastModified"": ""2024-01-07 10:41:44+00:00"", ""cardData"": ""datasets: Nerfgun3/bad_prompt\nlicense: creativeml-openrail-m\ntags:\n- stable-diffusion\n- text-to-image"", ""transformersInfo"": null, ""_id"": ""638cac3a61eb5101751a23c4"", ""modelId"": ""WarriorMama777/OrangeMixs"", ""usedStorage"": 202356872844}",0,,0,"https://huggingface.co/UuuNyaa/yazawa_nico-v1, https://huggingface.co/Kaede221/la-pluma",2,,0,"https://huggingface.co/John6666/nova-orange-xl-v70-sdxl, https://huggingface.co/John6666/nova-orange-xl-v10-sdxl, https://huggingface.co/John6666/nova-orange-xl-v20-sdxl, https://huggingface.co/John6666/nova-orange-xl-v30-sdxl, https://huggingface.co/John6666/nova-orange-xl-v40-sdxl, https://huggingface.co/John6666/nova-orange-xl-v50-sdxl, https://huggingface.co/John6666/nova-orange-xl-v60-sdxl, https://huggingface.co/John6666/nova-orange-xl-v80-sdxl",8,"CompVis/stable-diffusion-license, EPFL-VILAB/ViPer, Minecraft3193092/Stable-Diffusion-8, Nymbo/PornGen, Nymbo/epiCPhotoGASM-Webui-CPU, Nymbo/image_gen_supaqueue, Recahtrada/2nd2, Yntec/Anything7.0-Webui-CPU, akhaliq/webui-orangemixs, dasghost65536/SD-Webui12, dasghost65536/a1111-16-webui-cpu-reboot, huggingface/InferenceSupport/discussions/new?title=WarriorMama777/OrangeMixs&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BWarriorMama777%2FOrangeMixs%5D(%2FWarriorMama777%2FOrangeMixs)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kxic/EscherNet, soiz1/epiCPhotoGASM-Webui-CPU, sub314xxl/webui-cpu-extension-test",15
|
Phi-3-mini-128k-instruct-onnx_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
microsoft/Phi-3-mini-128k-instruct-onnx,"---
|
| 3 |
+
license: mit
|
| 4 |
+
pipeline_tag: text-generation
|
| 5 |
+
tags:
|
| 6 |
+
- ONNX
|
| 7 |
+
- DML
|
| 8 |
+
- ONNXRuntime
|
| 9 |
+
- phi3
|
| 10 |
+
- nlp
|
| 11 |
+
- conversational
|
| 12 |
+
- custom_code
|
| 13 |
+
inference: false
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
# Phi-3 Mini-128K-Instruct ONNX models
|
| 17 |
+
|
| 18 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 19 |
+
This repository hosts the optimized versions of [Phi-3-mini-128k-instruct](https://aka.ms/phi3-mini-128k-instruct) to accelerate inference with ONNX Runtime.
|
| 20 |
+
|
| 21 |
+
Phi-3 Mini is a lightweight, state-of-the-art open model built upon datasets used for Phi-2 - synthetic data and filtered websites - with a focus on very high-quality, reasoning dense data. The model belongs to the Phi-3 model family, and the mini version comes in two variants: 4K and 128K which is the context length (in tokens) it can support. The model underwent a rigorous enhancement process, incorporating both supervised fine-tuning and direct preference optimization to ensure precise instruction adherence and robust safety measures.
|
| 22 |
+
|
| 23 |
+
Optimized Phi-3 Mini models are published here in [ONNX](https://onnx.ai) format to run with [ONNX Runtime](https://onnxruntime.ai/) on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets.
|
| 24 |
+
|
| 25 |
+
[DirectML](https://aka.ms/directml) support lets developers bring hardware acceleration to Windows devices at scale across AMD, Intel, and NVIDIA GPUs. Along with DirectML, ONNX Runtime provides cross platform support for Phi-3 Mini across a range of devices for CPU, GPU, and mobile.
|
| 26 |
+
|
| 27 |
+
To easily get started with Phi-3, you can use our newly introduced ONNX Runtime Generate() API. See [here](https://aka.ms/generate-tutorial) for instructions on how to run it.
|
| 28 |
+
|
| 29 |
+
## ONNX Models
|
| 30 |
+
|
| 31 |
+
Here are some of the optimized configurations we have added:
|
| 32 |
+
|
| 33 |
+
1. ONNX model for int4 DML: ONNX model for AMD, Intel, and NVIDIA GPUs on Windows, quantized to int4 using [AWQ](https://arxiv.org/abs/2306.00978).
|
| 34 |
+
2. ONNX model for fp16 CUDA: ONNX model you can use to run for your NVIDIA GPUs.
|
| 35 |
+
3. ONNX model for int4 CUDA: ONNX model for NVIDIA GPUs using int4 quantization via RTN.
|
| 36 |
+
4. ONNX model for int4 CPU and Mobile: ONNX model for your CPU and Mobile, using int4 quantization via RTN. There are two versions uploaded to balance latency vs. accuracy.
|
| 37 |
+
Acc=1 is targeted at improved accuracy, while Acc=4 is for improved perf. For mobile devices, we recommend using the model with acc-level-4.
|
| 38 |
+
|
| 39 |
+
More updates on AMD, and additional optimizations on CPU and Mobile will be added with the official ORT 1.18 release in early May. Stay tuned!
|
| 40 |
+
|
| 41 |
+
## Hardware Supported
|
| 42 |
+
|
| 43 |
+
The models are tested on:
|
| 44 |
+
- GPU SKU: RTX 4090 (DirectML)
|
| 45 |
+
- GPU SKU: 1 A100 80GB GPU, SKU: Standard_ND96amsr_A100_v4 (CUDA)
|
| 46 |
+
- CPU SKU: Standard F64s v2 (64 vcpus, 128 GiB memory)
|
| 47 |
+
- Mobile SKU: Samsung Galaxy S21
|
| 48 |
+
|
| 49 |
+
Minimum Configuration Required:
|
| 50 |
+
- Windows: DirectX 12-capable GPU and a minimum of 4GB of combined RAM
|
| 51 |
+
- CUDA: NVIDIA GPU with [Compute Capability](https://developer.nvidia.com/cuda-gpus) >= 7.0
|
| 52 |
+
|
| 53 |
+
### Model Description
|
| 54 |
+
|
| 55 |
+
- **Developed by:** Microsoft
|
| 56 |
+
- **Model type:** ONNX
|
| 57 |
+
- **Language(s) (NLP):** Python, C, C++
|
| 58 |
+
- **License:** MIT
|
| 59 |
+
- **Model Description:** This is a conversion of the Phi-3 Mini-4K-Instruct model for ONNX Runtime inference.
|
| 60 |
+
|
| 61 |
+
## Additional Details
|
| 62 |
+
- [**ONNX Runtime Optimizations Blog Link**](https://aka.ms/phi3-optimizations)
|
| 63 |
+
- [**Phi-3 Model Blog Link**](https://aka.ms/phi3blog-april)
|
| 64 |
+
- [**Phi-3 Model Card**]( https://aka.ms/phi3-mini-128k-instruct)
|
| 65 |
+
- [**Phi-3 Technical Report**](https://aka.ms/phi3-tech-report)
|
| 66 |
+
|
| 67 |
+
## How to Get Started with the Model
|
| 68 |
+
To make running of the Phi-3 models across a range of devices and platforms across various execution provider backends possible, we introduce a new API to wrap several aspects of generative AI inferencing. This API make it easy to drag and drop LLMs straight into your app. For running the early version of these models with ONNX Runtime, follow the steps [here](http://aka.ms/generate-tutorial).
|
| 69 |
+
|
| 70 |
+
For example:
|
| 71 |
+
|
| 72 |
+
```python
|
| 73 |
+
python model-qa.py -m /*{YourModelPath}*/onnx/cpu_and_mobile/phi-3-mini-4k-instruct-int4-cpu -k 40 -p 0.95 -t 0.8 -r 1.0
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
```
|
| 77 |
+
*Input:* <|user|>Tell me a joke<|end|><|assistant|>
|
| 78 |
+
|
| 79 |
+
*Output:* Why don't scientists trust atoms?
|
| 80 |
+
Because they make up everything!
|
| 81 |
+
|
| 82 |
+
This joke plays on the double meaning of ""make up."" In science, atoms are the fundamental building blocks of matter, literally making up everything. However, in a colloquial sense, ""to make up"" can mean to fabricate or lie, hence the humor.
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
## Performance Metrics
|
| 86 |
+
|
| 87 |
+
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 88 |
+
Phi-3 Mini-128K-Instruct performs better in ONNX Runtime than PyTorch for all batch size, prompt length combinations. For FP16 CUDA, ORT performs up to 5X faster than PyTorch, while with INT4 CUDA it's up to 9X faster than PyTorch.
|
| 89 |
+
|
| 90 |
+
The table below shows the average throughput of the first 256 tokens generated (tps) for FP16 and INT4 precisions on CUDA as measured on [1 A100 80GB GPU, SKU: Standard_ND96amsr_A100_v4](https://learn.microsoft.com/en-us/azure/virtual-machines/ndm-a100-v4-series).
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
| Batch Size, Prompt Length | ORT FP16 CUDA | PyTorch Eager FP16 CUDA | FP16 CUDA Speed Up (ORT/PyTorch) |
|
| 94 |
+
|---------------------------|---------------|-------------------------|----------------------------------|
|
| 95 |
+
| 1, 16 | 134.46 | 25.35 | 5.30 |
|
| 96 |
+
| 1, 64 | 132.21 | 25.69 | 5.15 |
|
| 97 |
+
| 1, 256 | 124.51 | 25.77 | 4.83 |
|
| 98 |
+
| 1, 1024 | 110.03 | 25.73 | 4.28 |
|
| 99 |
+
| 1, 2048 | 96.93 | 25.72 | 3.77 |
|
| 100 |
+
| 1, 4096 | 62.12 | 25.66 | 2.42 |
|
| 101 |
+
| 4, 16 | 521.10 | 101.31 | 5.14 |
|
| 102 |
+
| 4, 64 | 507.03 | 101.66 | 4.99 |
|
| 103 |
+
| 4, 256 | 459.47 | 101.15 | 4.54 |
|
| 104 |
+
| 4, 1024 | 343.60 | 101.09 | 3.40 |
|
| 105 |
+
| 4, 2048 | 264.81 | 100.78 | 2.63 |
|
| 106 |
+
| 4, 4096 | 158.00 | 77.98 | 2.03 |
|
| 107 |
+
| 16, 16 | 1689.08 | 394.19 | 4.28 |
|
| 108 |
+
| 16, 64 | 1567.13 | 394.29 | 3.97 |
|
| 109 |
+
| 16, 256 | 1232.10 | 405.30 | 3.04 |
|
| 110 |
+
| 16, 1024 | 680.61 | 294.79 | 2.31 |
|
| 111 |
+
| 16, 2048 | 350.77 | 203.02 | 1.73 |
|
| 112 |
+
| 16, 4096 | 192.36 | OOM | |
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
| Batch Size, Prompt Length | PyTorch Eager INT4 CUDA | INT4 CUDA Speed Up (ORT/PyTorch) |
|
| 116 |
+
|---------------------------|-------------------------|----------------------------------|
|
| 117 |
+
| 1, 16 | 25.35 | 8.89 |
|
| 118 |
+
| 1, 64 | 25.69 | 8.58 |
|
| 119 |
+
| 1, 256 | 25.77 | 7.69 |
|
| 120 |
+
| 1, 1024 | 25.73 | 6.34 |
|
| 121 |
+
| 1, 2048 | 25.72 | 5.24 |
|
| 122 |
+
| 1, 4096 | 25.66 | 2.97 |
|
| 123 |
+
| 4, 16 | 101.31 | 2.82 |
|
| 124 |
+
| 4, 64 | 101.66 | 2.77 |
|
| 125 |
+
| 4, 256 | 101.15 | 2.64 |
|
| 126 |
+
| 4, 1024 | 101.09 | 2.20 |
|
| 127 |
+
| 4, 2048 | 100.78 | 1.84 |
|
| 128 |
+
| 4, 4096 | 77.98 | 1.62 |
|
| 129 |
+
| 16, 16 | 394.19 | 2.52 |
|
| 130 |
+
| 16, 64 | 394.29 | 2.41 |
|
| 131 |
+
| 16, 256 | 405.30 | 2.00 |
|
| 132 |
+
| 16, 1024 | 294.79 | 1.79 |
|
| 133 |
+
| 16, 2048 | 203.02 | 1.81 |
|
| 134 |
+
| 16, 4096 | OOM | |
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
Note: PyTorch compile and Llama.cpp currently do not support the Phi-3 Mini-128K-Instruct model.
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
### Package Versions
|
| 141 |
+
|
| 142 |
+
| Pip package name | Version |
|
| 143 |
+
|----------------------------|----------|
|
| 144 |
+
| torch | 2.2.0 |
|
| 145 |
+
| triton | 2.2.0 |
|
| 146 |
+
| onnxruntime-gpu | 1.18.0 |
|
| 147 |
+
| onnxruntime-genai | 0.2.0 |
|
| 148 |
+
| onnxruntime-genai-cuda | 0.2.0 |
|
| 149 |
+
| onnxruntime-genai-directml | 0.2.0 |
|
| 150 |
+
| transformers | 4.39.0 |
|
| 151 |
+
| bitsandbytes | 0.42.0 |
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
## Appendix
|
| 155 |
+
|
| 156 |
+
### Activation Aware Quantization
|
| 157 |
+
|
| 158 |
+
AWQ works by identifying the top 1% most salient weights that are most important for maintaining accuracy and quantizing the remaining 99% of weights. This leads to less accuracy loss from quantization compared to many other quantization techniques. For more on AWQ, see [here](https://arxiv.org/abs/2306.00978).
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
## Model Card Contact
|
| 162 |
+
parinitarahi, kvaishnavi, natke
|
| 163 |
+
|
| 164 |
+
## Contributors
|
| 165 |
+
Kunal Vaishnavi, Sunghoon Choi, Yufeng Li, Akshay Sonawane, Sheetal Arun Kadam, Rui Ren, Edward Chen, Scott McKay, Ryan Hill, Emma Ning, Natalie Kershaw, Parinita Rahi, Patrice Vignola, Chai Chaoweeraprasit, Logan Iyer, Vicente Rivera, Jacques Van Rhyn","{""id"": ""microsoft/Phi-3-mini-128k-instruct-onnx"", ""author"": ""microsoft"", ""sha"": ""98a75b8450edbbe7c34b964f34d714f68ce46ff0"", ""last_modified"": ""2024-05-22 23:23:49+00:00"", ""created_at"": ""2024-04-23 02:20:03+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 169, ""downloads_all_time"": null, ""likes"": 187, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""onnx"", ""phi3"", ""text-generation"", ""ONNX"", ""DML"", ""ONNXRuntime"", ""nlp"", ""conversational"", ""custom_code"", ""arxiv:2306.00978"", ""license:mit"", ""autotrain_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: mit\npipeline_tag: text-generation\ntags:\n- ONNX\n- DML\n- ONNXRuntime\n- phi3\n- nlp\n- conversational\n- custom_code\ninference: false"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""Phi3ForCausalLM""], ""auto_map"": {""AutoConfig"": ""configuration_phi3.Phi3Config"", ""AutoModelForCausalLM"": ""modeling_phi3.Phi3ForCausalLM""}, ""model_type"": ""phi3""}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_phi3.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4/added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4/configuration_phi3.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4/genai_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4/phi3-mini-128k-instruct-cpu-int4-rtn-block-32-acc-level-4.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4/phi3-mini-128k-instruct-cpu-int4-rtn-block-32-acc-level-4.onnx.data', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4/tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4/tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32/added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32/configuration_phi3.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32/genai_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32/phi3-mini-128k-instruct-cpu-int4-rtn-block-32.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32/phi3-mini-128k-instruct-cpu-int4-rtn-block-32.onnx.data', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32/tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32/tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpu_and_mobile/cpu-int4-rtn-block-32/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-fp16/added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-fp16/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-fp16/configuration_phi3.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-fp16/genai_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-fp16/phi3-mini-128k-instruct-cuda-fp16.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-fp16/phi3-mini-128k-instruct-cuda-fp16.onnx.data', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-fp16/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-fp16/tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-fp16/tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-fp16/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-int4-rtn-block-32/added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-int4-rtn-block-32/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-int4-rtn-block-32/configuration_phi3.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-int4-rtn-block-32/genai_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-int4-rtn-block-32/phi3-mini-128k-instruct-cuda-int4-rtn-block-32.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-int4-rtn-block-32/phi3-mini-128k-instruct-cuda-int4-rtn-block-32.onnx.data', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-int4-rtn-block-32/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-int4-rtn-block-32/tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-int4-rtn-block-32/tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cuda/cuda-int4-rtn-block-32/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='directml/directml-int4-awq-block-128/added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='directml/directml-int4-awq-block-128/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='directml/directml-int4-awq-block-128/configuration_phi3.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='directml/directml-int4-awq-block-128/genai_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='directml/directml-int4-awq-block-128/model.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='directml/directml-int4-awq-block-128/model.onnx.data', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='directml/directml-int4-awq-block-128/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='directml/directml-int4-awq-block-128/tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='directml/directml-int4-awq-block-128/tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='directml/directml-int4-awq-block-128/tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Itsmade/De"", ""Ritwik-28/microsoft-Phi-3-mini-128k-instruct-onnx"", ""apravint/microsoft-Phi-3-mini-128k-instruct-onnx""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-05-22 23:23:49+00:00"", ""cardData"": ""license: mit\npipeline_tag: text-generation\ntags:\n- ONNX\n- DML\n- ONNXRuntime\n- phi3\n- nlp\n- conversational\n- custom_code\ninference: false"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""66271ad3430a12425311c9bf"", ""modelId"": ""microsoft/Phi-3-mini-128k-instruct-onnx"", ""usedStorage"": 37912340153}",0,,0,,0,,0,,0,"Itsmade/De, Ritwik-28/microsoft-Phi-3-mini-128k-instruct-onnx, apravint/microsoft-Phi-3-mini-128k-instruct-onnx, huggingface/InferenceSupport/discussions/new?title=microsoft/Phi-3-mini-128k-instruct-onnx&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bmicrosoft%2FPhi-3-mini-128k-instruct-onnx%5D(%2Fmicrosoft%2FPhi-3-mini-128k-instruct-onnx)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A",4
|
Qwen-7B-Chat_finetunes_20250425_041137.csv_finetunes_20250425_041137.csv
ADDED
|
@@ -0,0 +1,749 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
Qwen/Qwen-7B-Chat,"---
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
+
- en
|
| 6 |
+
tags:
|
| 7 |
+
- qwen
|
| 8 |
+
pipeline_tag: text-generation
|
| 9 |
+
inference: false
|
| 10 |
+
license: other
|
| 11 |
+
license_name: tongyi-qianwen-license-agreement
|
| 12 |
+
license_link: https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20LICENSE%20AGREEMENT
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
# Qwen-7B-Chat
|
| 16 |
+
|
| 17 |
+
<p align=""center"">
|
| 18 |
+
<img src=""https://qianwen-res.oss-cn-beijing.aliyuncs.com/logo_qwen.jpg"" width=""400""/>
|
| 19 |
+
<p>
|
| 20 |
+
<br>
|
| 21 |
+
|
| 22 |
+
<p align=""center"">
|
| 23 |
+
🤗 <a href=""https://huggingface.co/Qwen"">Hugging Face</a>   |   🤖 <a href=""https://modelscope.cn/organization/qwen"">ModelScope</a>   |    📑 <a href=""https://arxiv.org/abs/2309.16609"">Paper</a>    |   🖥️ <a href=""https://modelscope.cn/studios/qwen/Qwen-7B-Chat-Demo/summary"">Demo</a>
|
| 24 |
+
<br>
|
| 25 |
+
<a href=""https://github.com/QwenLM/Qwen/blob/main/assets/wechat.png"">WeChat (微信)</a>   |   <a href=""https://discord.gg/z3GAxXZ9Ce"">Discord</a>   |   <a href=""https://dashscope.aliyun.com"">API</a>
|
| 26 |
+
</p>
|
| 27 |
+
<br>
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
## 介绍(Introduction)
|
| 31 |
+
|
| 32 |
+
**通义千问-7B(Qwen-7B)**是阿里云研发的通义千问大模型系列的70亿参数规模的模型。Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。相较于最初开源的Qwen-7B模型,我们现已将预训练模型和Chat模型更新到效果更优的版本。本仓库为Qwen-7B-Chat的仓库。
|
| 33 |
+
|
| 34 |
+
如果您想了解更多关于通义千问-7B开源模型的细节,我们建议您参阅[GitHub代码库](https://github.com/QwenLM/Qwen)。
|
| 35 |
+
|
| 36 |
+
**Qwen-7B** is the 7B-parameter version of the large language model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-7B is a Transformer-based large language model, which is pretrained on a large volume of data, including web texts, books, codes, etc. Additionally, based on the pretrained Qwen-7B, we release Qwen-7B-Chat, a large-model-based AI assistant, which is trained with alignment techniques. Now we have updated both our pretrained and chat models with better performances. This repository is the one for Qwen-7B-Chat.
|
| 37 |
+
|
| 38 |
+
For more details about Qwen, please refer to the [GitHub](https://github.com/QwenLM/Qwen) code repository.
|
| 39 |
+
<br>
|
| 40 |
+
|
| 41 |
+
## 要求(Requirements)
|
| 42 |
+
|
| 43 |
+
* python 3.8及以上版本
|
| 44 |
+
* pytorch 1.12及以上版本,推荐2.0及以上版本
|
| 45 |
+
* 建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)
|
| 46 |
+
* python 3.8 and above
|
| 47 |
+
* pytorch 1.12 and above, 2.0 and above are recommended
|
| 48 |
+
* CUDA 11.4 and above are recommended (this is for GPU users, flash-attention users, etc.)
|
| 49 |
+
<br>
|
| 50 |
+
|
| 51 |
+
## 依赖项(Dependency)
|
| 52 |
+
|
| 53 |
+
运行Qwen-7B-Chat,请确保满足上述要求,再执行以下pip命令安装依赖库
|
| 54 |
+
|
| 55 |
+
To run Qwen-7B-Chat, please make sure you meet the above requirements, and then execute the following pip commands to install the dependent libraries.
|
| 56 |
+
|
| 57 |
+
```bash
|
| 58 |
+
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
另外,推荐安装`flash-attention`库(**当前已支持flash attention 2**),以实现更高的效率和更低的显存占用。
|
| 62 |
+
|
| 63 |
+
In addition, it is recommended to install the `flash-attention` library (**we support flash attention 2 now.**) for higher efficiency and lower memory usage.
|
| 64 |
+
|
| 65 |
+
```bash
|
| 66 |
+
git clone https://github.com/Dao-AILab/flash-attention
|
| 67 |
+
cd flash-attention && pip install .
|
| 68 |
+
# 下方安装可选,安装可能比较缓慢。
|
| 69 |
+
# pip install csrc/layer_norm
|
| 70 |
+
# pip install csrc/rotary
|
| 71 |
+
```
|
| 72 |
+
<br>
|
| 73 |
+
|
| 74 |
+
## 快速使用(Quickstart)
|
| 75 |
+
|
| 76 |
+
下面我们展示了一个使用Qwen-7B-Chat模型,进行多轮对话交互的样例:
|
| 77 |
+
|
| 78 |
+
We show an example of multi-turn interaction with Qwen-7B-Chat in the following code:
|
| 79 |
+
|
| 80 |
+
```python
|
| 81 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 82 |
+
from transformers.generation import GenerationConfig
|
| 83 |
+
|
| 84 |
+
# Note: The default behavior now has injection attack prevention off.
|
| 85 |
+
tokenizer = AutoTokenizer.from_pretrained(""Qwen/Qwen-7B-Chat"", trust_remote_code=True)
|
| 86 |
+
|
| 87 |
+
# use bf16
|
| 88 |
+
# model = AutoModelForCausalLM.from_pretrained(""Qwen/Qwen-7B-Chat"", device_map=""auto"", trust_remote_code=True, bf16=True).eval()
|
| 89 |
+
# use fp16
|
| 90 |
+
# model = AutoModelForCausalLM.from_pretrained(""Qwen/Qwen-7B-Chat"", device_map=""auto"", trust_remote_code=True, fp16=True).eval()
|
| 91 |
+
# use cpu only
|
| 92 |
+
# model = AutoModelForCausalLM.from_pretrained(""Qwen/Qwen-7B-Chat"", device_map=""cpu"", trust_remote_code=True).eval()
|
| 93 |
+
# use auto mode, automatically select precision based on the device.
|
| 94 |
+
model = AutoModelForCausalLM.from_pretrained(""Qwen/Qwen-7B-Chat"", device_map=""auto"", trust_remote_code=True).eval()
|
| 95 |
+
|
| 96 |
+
# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
|
| 97 |
+
# model.generation_config = GenerationConfig.from_pretrained(""Qwen/Qwen-7B-Chat"", trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
|
| 98 |
+
|
| 99 |
+
# 第一轮对话 1st dialogue turn
|
| 100 |
+
response, history = model.chat(tokenizer, ""你好"", history=None)
|
| 101 |
+
print(response)
|
| 102 |
+
# 你好!很高兴为你提供帮助。
|
| 103 |
+
|
| 104 |
+
# 第二轮对话 2nd dialogue turn
|
| 105 |
+
response, history = model.chat(tokenizer, ""给我讲一个年轻人奋斗创业最终取得成功的故事。"", history=history)
|
| 106 |
+
print(response)
|
| 107 |
+
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
|
| 108 |
+
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
|
| 109 |
+
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
|
| 110 |
+
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
|
| 111 |
+
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
|
| 112 |
+
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
|
| 113 |
+
|
| 114 |
+
# 第三轮对话 3rd dialogue turn
|
| 115 |
+
response, history = model.chat(tokenizer, ""给这个故事起一个标题"", history=history)
|
| 116 |
+
print(response)
|
| 117 |
+
# 《奋斗创业:一个年轻人的成功之路》
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
关于更多的使用说明,请参考我们的[GitHub repo](https://github.com/QwenLM/Qwen)获取更多信息。
|
| 121 |
+
|
| 122 |
+
For more information, please refer to our [GitHub repo](https://github.com/QwenLM/Qwen) for more information.
|
| 123 |
+
<br>
|
| 124 |
+
|
| 125 |
+
## Tokenizer
|
| 126 |
+
|
| 127 |
+
> 注:作为术语的“tokenization”在中文中尚无共识的概念对应,本文档采用英文表达以利说明。
|
| 128 |
+
|
| 129 |
+
基于tiktoken的分词器有别于其他分词器,比如sentencepiece分词器。尤其在微调阶段,需要特别注意特殊token的使用。关于tokenizer的更多信息,以及微调时涉及的相关使用,请参阅[文档](https://github.com/QwenLM/Qwen/blob/main/tokenization_note_zh.md)。
|
| 130 |
+
|
| 131 |
+
Our tokenizer based on tiktoken is different from other tokenizers, e.g., sentencepiece tokenizer. You need to pay attention to special tokens, especially in finetuning. For more detailed information on the tokenizer and related use in fine-tuning, please refer to the [documentation](https://github.com/QwenLM/Qwen/blob/main/tokenization_note.md).
|
| 132 |
+
<br>
|
| 133 |
+
|
| 134 |
+
## 量化 (Quantization)
|
| 135 |
+
|
| 136 |
+
### 用法 (Usage)
|
| 137 |
+
|
| 138 |
+
**请注意:我们更新量化方案为基于[AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ)的量化,提供Qwen-7B-Chat的Int4量化模型[点击这里](https://huggingface.co/Qwen/Qwen-7B-Chat-Int4)。相比此前方案,该方案在模型评测效果几乎无损,且存储需求更低,推理速度更优。**
|
| 139 |
+
|
| 140 |
+
**Note: we provide a new solution based on [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ), and release an Int4 quantized model for Qwen-7B-Chat [Click here](https://huggingface.co/Qwen/Qwen-7B-Chat-Int4), which achieves nearly lossless model effects but improved performance on both memory costs and inference speed, in comparison with the previous solution.**
|
| 141 |
+
|
| 142 |
+
以下我们提供示例说明如何使用Int4量化模型。在开始使用前,请先保证满足要求(如torch 2.0及以上,transformers版本为4.32.0及以上,等等),并安装所需安装包:
|
| 143 |
+
|
| 144 |
+
Here we demonstrate how to use our provided quantized models for inference. Before you start, make sure you meet the requirements of auto-gptq (e.g., torch 2.0 and above, transformers 4.32.0 and above, etc.) and install the required packages:
|
| 145 |
+
|
| 146 |
+
```bash
|
| 147 |
+
pip install auto-gptq optimum
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
如安装`auto-gptq`遇到问题,我们建议您到官方[repo](https://github.com/PanQiWei/AutoGPTQ)搜索合适的预编译wheel。
|
| 151 |
+
|
| 152 |
+
随后即可使用和上述一致的用法调用量化模型:
|
| 153 |
+
|
| 154 |
+
If you meet problems installing `auto-gptq`, we advise you to check out the official [repo](https://github.com/PanQiWei/AutoGPTQ) to find a pre-build wheel.
|
| 155 |
+
|
| 156 |
+
Then you can load the quantized model easily and run inference as same as usual:
|
| 157 |
+
|
| 158 |
+
```python
|
| 159 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 160 |
+
""Qwen/Qwen-7B-Chat-Int4"",
|
| 161 |
+
device_map=""auto"",
|
| 162 |
+
trust_remote_code=True
|
| 163 |
+
).eval()
|
| 164 |
+
response, history = model.chat(tokenizer, ""你好"", history=None)
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
### 效果评测
|
| 170 |
+
|
| 171 |
+
我们对BF16,Int8和Int4模型在基准评测上做了测试(使用zero-shot设置),发现量化模型效果损失较小,结果如下所示:
|
| 172 |
+
|
| 173 |
+
We illustrate the zero-shot performance of both BF16, Int8 and Int4 models on the benchmark, and we find that the quantized model does not suffer from significant performance degradation. Results are shown below:
|
| 174 |
+
|
| 175 |
+
| Quantization | MMLU | CEval (val) | GSM8K | Humaneval |
|
| 176 |
+
| ------------- | :--------: | :----------: | :----: | :--------: |
|
| 177 |
+
| BF16 | 55.8 | 59.7 | 50.3 | 37.2 |
|
| 178 |
+
| Int8 | 55.4 | 59.4 | 48.3 | 34.8 |
|
| 179 |
+
| Int4 | 55.1 | 59.2 | 49.7 | 29.9 |
|
| 180 |
+
|
| 181 |
+
### 推理速度 (Inference Speed)
|
| 182 |
+
|
| 183 |
+
我们测算了不同精度模型以及不同FlashAttn库版本下模型生成2048和8192个token的平均推理速度。如图所示:
|
| 184 |
+
|
| 185 |
+
We measured the average inference speed of generating 2048 and 8192 tokens with different quantization levels and versions of flash-attention, respectively.
|
| 186 |
+
|
| 187 |
+
| Quantization | FlashAttn | Speed (2048 tokens) | Speed (8192 tokens) |
|
| 188 |
+
| ------------- | :-------: | :------------------:| :------------------:|
|
| 189 |
+
| BF16 | v2 | 40.93 | 36.14 |
|
| 190 |
+
| Int8 | v2 | 37.47 | 32.54 |
|
| 191 |
+
| Int4 | v2 | 50.09 | 38.61 |
|
| 192 |
+
| BF16 | v1 | 40.75 | 35.34 |
|
| 193 |
+
| Int8 | v1 | 37.51 | 32.39 |
|
| 194 |
+
| Int4 | v1 | 45.98 | 36.47 |
|
| 195 |
+
| BF16 | Disabled | 37.55 | 33.56 |
|
| 196 |
+
| Int8 | Disabled | 37.84 | 32.65 |
|
| 197 |
+
| Int4 | Disabled | 48.12 | 36.70 |
|
| 198 |
+
|
| 199 |
+
具体而言,我们记录在长度为1的上下文的条件下生成8192个token的性能。评测运行于单张A100-SXM4-80G GPU,使用PyTorch 2.0.1和CUDA 11.8。推理速度是生成8192个token的速度均值。
|
| 200 |
+
|
| 201 |
+
In detail, the setting of profiling is generating 8192 new tokens with 1 context token. The profiling runs on a single A100-SXM4-80G GPU with PyTorch 2.0.1 and CUDA 11.8. The inference speed is averaged over the generated 8192 tokens.
|
| 202 |
+
|
| 203 |
+
注意:以上Int4/Int8模型生成速度使用autogptq库给出,当前``AutoModelForCausalLM.from_pretrained``载入的模型生成速度会慢大约20%。我们已经将该问题汇报给HuggingFace团队,若有解决方案将即时更新。
|
| 204 |
+
|
| 205 |
+
Note: The generation speed of the Int4/Int8 models mentioned above is provided by the autogptq library. The current speed of the model loaded using ""AutoModelForCausalLM.from_pretrained"" will be approximately 20% slower. We have reported this issue to the HuggingFace team and will update it promptly if a solution is available.
|
| 206 |
+
|
| 207 |
+
### 显存使用 (GPU Memory Usage)
|
| 208 |
+
|
| 209 |
+
我们还测算了不同模型精度编码2048个token及生成8192个token的峰值显存占用情况。(显存消耗在是否使用FlashAttn的情况下均类似。)结果如下所示:
|
| 210 |
+
|
| 211 |
+
We also profile the peak GPU memory usage for encoding 2048 tokens as context (and generating single token) and generating 8192 tokens (with single token as context) under different quantization levels, respectively. (The GPU memory usage is similar when using flash-attention or not.)The results are shown below.
|
| 212 |
+
|
| 213 |
+
| Quantization Level | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
|
| 214 |
+
| ------------------ | :---------------------------------: | :-----------------------------------: |
|
| 215 |
+
| BF16 | 16.99GB | 22.53GB |
|
| 216 |
+
| Int8 | 11.20GB | 16.62GB |
|
| 217 |
+
| Int4 | 8.21GB | 13.63GB |
|
| 218 |
+
|
| 219 |
+
上述性能测算使用[此脚本](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile.py)完成。
|
| 220 |
+
|
| 221 |
+
The above speed and memory profiling are conducted using [this script](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile.py).
|
| 222 |
+
<br>
|
| 223 |
+
|
| 224 |
+
## 模型细节(Model)
|
| 225 |
+
|
| 226 |
+
与Qwen-7B预训练模型相同,Qwen-7B-Chat模型规模基本情况如下所示:
|
| 227 |
+
|
| 228 |
+
The details of the model architecture of Qwen-7B-Chat are listed as follows:
|
| 229 |
+
|
| 230 |
+
| Hyperparameter | Value |
|
| 231 |
+
|:----------------|:------:|
|
| 232 |
+
| n_layers | 32 |
|
| 233 |
+
| n_heads | 32 |
|
| 234 |
+
| d_model | 4096 |
|
| 235 |
+
| vocab size | 151851 |
|
| 236 |
+
| sequence length | 8192 |
|
| 237 |
+
|
| 238 |
+
在位置编码、FFN激活函数和normalization的实现方式上,我们也采用了目前最流行的做法,
|
| 239 |
+
即RoPE相对位置编码、SwiGLU激活函数、RMSNorm(可选安装flash-attention加速)。
|
| 240 |
+
|
| 241 |
+
在分词器方面,相比目前主流开源模型以中英词表为主,Qwen-7B-Chat使用了约15万token大小的词表。
|
| 242 |
+
该词表在GPT-4使用的BPE词表`cl100k_base`基础上,对中文、多语言进行了优化,在对中、英、代码数据的高效编解码的基础上,对部分多语言更加友好,方便用户在不扩展词表的情况下对部分��种进行能力增强。
|
| 243 |
+
词表对数字按单个数字位切分。调用较为高效的[tiktoken分词库](https://github.com/openai/tiktoken)进行分词。
|
| 244 |
+
|
| 245 |
+
For position encoding, FFN activation function, and normalization calculation methods, we adopt the prevalent practices, i.e., RoPE relative position encoding, SwiGLU for activation function, and RMSNorm for normalization (optional installation of flash-attention for acceleration).
|
| 246 |
+
|
| 247 |
+
For tokenization, compared to the current mainstream open-source models based on Chinese and English vocabularies, Qwen-7B-Chat uses a vocabulary of over 150K tokens.
|
| 248 |
+
It first considers efficient encoding of Chinese, English, and code data, and is also more friendly to multilingual languages, enabling users to directly enhance the capability of some languages without expanding the vocabulary.
|
| 249 |
+
It segments numbers by single digit, and calls the [tiktoken](https://github.com/openai/tiktoken) tokenizer library for efficient tokenization.
|
| 250 |
+
<br>
|
| 251 |
+
|
| 252 |
+
## 评测效果(Evaluation)
|
| 253 |
+
|
| 254 |
+
对于Qwen-7B-Chat模型,我们同样评测了常规的中文理解(C-Eval)、英文理解(MMLU)、代码(HumanEval)和数学(GSM8K)等权威任务,同时包含了长序列任务的评测结果。由于Qwen-7B-Chat模型经过对齐后,激发了较强的外部系统调用能力,我们还进行了工具使用能力方面的评测。
|
| 255 |
+
|
| 256 |
+
提示:由于硬件和框架造成的舍入误差,复现结果如有波动属于正常现象。
|
| 257 |
+
|
| 258 |
+
For Qwen-7B-Chat, we also evaluate the model on C-Eval, MMLU, HumanEval, GSM8K, etc., as well as the benchmark evaluation for long-context understanding, and tool usage.
|
| 259 |
+
|
| 260 |
+
Note: Due to rounding errors caused by hardware and framework, differences in reproduced results are possible.
|
| 261 |
+
|
| 262 |
+
### 中文评测(Chinese Evaluation)
|
| 263 |
+
|
| 264 |
+
#### C-Eval
|
| 265 |
+
|
| 266 |
+
在[C-Eval](https://arxiv.org/abs/2305.08322)验证集上,我们评价了Qwen-7B-Chat模型的0-shot & 5-shot准确率
|
| 267 |
+
|
| 268 |
+
We demonstrate the 0-shot & 5-shot accuracy of Qwen-7B-Chat on C-Eval validation set
|
| 269 |
+
|
| 270 |
+
| Model | Avg. Acc. |
|
| 271 |
+
|:--------------------------------:|:---------:|
|
| 272 |
+
| LLaMA2-7B-Chat | 31.9 |
|
| 273 |
+
| LLaMA2-13B-Chat | 36.2 |
|
| 274 |
+
| LLaMA2-70B-Chat | 44.3 |
|
| 275 |
+
| ChatGLM2-6B-Chat | 52.6 |
|
| 276 |
+
| InternLM-7B-Chat | 53.6 |
|
| 277 |
+
| Baichuan2-7B-Chat | 55.6 |
|
| 278 |
+
| Baichuan2-13B-Chat | 56.7 |
|
| 279 |
+
| Qwen-7B-Chat (original) (0-shot) | 54.2 |
|
| 280 |
+
| **Qwen-7B-Chat (0-shot)** | 59.7 |
|
| 281 |
+
| **Qwen-7B-Chat (5-shot)** | 59.3 |
|
| 282 |
+
| **Qwen-14B-Chat (0-shot)** | 69.8 |
|
| 283 |
+
| **Qwen-14B-Chat (5-shot)** | **71.7** |
|
| 284 |
+
|
| 285 |
+
C-Eval测试集上,Qwen-7B-Chat模型的zero-shot准确率结果如下:
|
| 286 |
+
|
| 287 |
+
The zero-shot accuracy of Qwen-7B-Chat on C-Eval testing set is provided below:
|
| 288 |
+
|
| 289 |
+
| Model | Avg. | STEM | Social Sciences | Humanities | Others |
|
| 290 |
+
| :---------------------- | :------: | :--: | :-------------: | :--------: | :----: |
|
| 291 |
+
| Chinese-Alpaca-Plus-13B | 41.5 | 36.6 | 49.7 | 43.1 | 41.2 |
|
| 292 |
+
| Chinese-Alpaca-2-7B | 40.3 | - | - | - | - |
|
| 293 |
+
| ChatGLM2-6B-Chat | 50.1 | 46.4 | 60.4 | 50.6 | 46.9 |
|
| 294 |
+
| Baichuan-13B-Chat | 51.5 | 43.7 | 64.6 | 56.2 | 49.2 |
|
| 295 |
+
| Qwen-7B-Chat (original) | 54.6 | 47.8 | 67.6 | 59.3 | 50.6 |
|
| 296 |
+
| **Qwen-7B-Chat** | 58.6 | 53.3 | 72.1 | 62.8 | 52.0 |
|
| 297 |
+
| **Qwen-14B-Chat** | **69.1** | 65.1 | 80.9 | 71.2 | 63.4 |
|
| 298 |
+
|
| 299 |
+
在7B规模模型上,经过人类指令对齐的Qwen-7B-Chat模型,准确率在同类相近规模模型中仍然处于前列。
|
| 300 |
+
|
| 301 |
+
Compared with other pretrained models with comparable model size, the human-aligned Qwen-7B-Chat performs well in C-Eval accuracy.
|
| 302 |
+
|
| 303 |
+
### 英文评测(English Evaluation)
|
| 304 |
+
|
| 305 |
+
#### MMLU
|
| 306 |
+
|
| 307 |
+
[MMLU](https://arxiv.org/abs/2009.03300)评测集上,Qwen-7B-Chat模型的 0-shot & 5-shot 准确率如下,效果同样在同类对齐模型中同样表现较优。
|
| 308 |
+
|
| 309 |
+
The 0-shot & 5-shot accuracy of Qwen-7B-Chat on MMLU is provided below.
|
| 310 |
+
The performance of Qwen-7B-Chat still on the top between other human-aligned models with comparable size.
|
| 311 |
+
|
| 312 |
+
| Model | Avg. Acc. |
|
| 313 |
+
|:--------------------------------:|:---------:|
|
| 314 |
+
| ChatGLM2-6B-Chat | 46.0 |
|
| 315 |
+
| LLaMA2-7B-Chat | 46.2 |
|
| 316 |
+
| InternLM-7B-Chat | 51.1 |
|
| 317 |
+
| Baichuan2-7B-Chat | 52.9 |
|
| 318 |
+
| LLaMA2-13B-Chat | 54.6 |
|
| 319 |
+
| Baichuan2-13B-Chat | 57.3 |
|
| 320 |
+
| LLaMA2-70B-Chat | 63.8 |
|
| 321 |
+
| Qwen-7B-Chat (original) (0-shot) | 53.9 |
|
| 322 |
+
| **Qwen-7B-Chat (0-shot)** | 55.8 |
|
| 323 |
+
| **Qwen-7B-Chat (5-shot)** | 57.0 |
|
| 324 |
+
| **Qwen-14B-Chat (0-shot)** | 64.6 |
|
| 325 |
+
| **Qwen-14B-Chat (5-shot)** | **66.5** |
|
| 326 |
+
|
| 327 |
+
### 代码评测(Coding Evaluation)
|
| 328 |
+
|
| 329 |
+
Qwen-7B-Chat在[HumanEval](https://github.com/openai/human-eval)的zero-shot Pass@1效果如下
|
| 330 |
+
|
| 331 |
+
The zero-shot Pass@1 of Qwen-7B-Chat on [HumanEval](https://github.com/openai/human-eval) is demonstrated below
|
| 332 |
+
|
| 333 |
+
| Model | Pass@1 |
|
| 334 |
+
|:-----------------------:|:--------:|
|
| 335 |
+
| ChatGLM2-6B-Chat | 11.0 |
|
| 336 |
+
| LLaMA2-7B-Chat | 12.2 |
|
| 337 |
+
| Baichuan2-7B-Chat | 13.4 |
|
| 338 |
+
| InternLM-7B-Chat | 14.6 |
|
| 339 |
+
| Baichuan2-13B-Chat | 17.7 |
|
| 340 |
+
| LLaMA2-13B-Chat | 18.9 |
|
| 341 |
+
| LLaMA2-70B-Chat | 32.3 |
|
| 342 |
+
| Qwen-7B-Chat (original) | 24.4 |
|
| 343 |
+
| **Qwen-7B-Chat** | 37.2 |
|
| 344 |
+
| **Qwen-14B-Chat** | **43.9** |
|
| 345 |
+
|
| 346 |
+
### 数学评测(Mathematics Evaluation)
|
| 347 |
+
|
| 348 |
+
在评测数学能力的[GSM8K](https://github.com/openai/grade-school-math)上,Qwen-7B-Chat的准确率结果如下
|
| 349 |
+
|
| 350 |
+
The accuracy of Qwen-7B-Chat on GSM8K is shown below
|
| 351 |
+
|
| 352 |
+
| Model | Acc. |
|
| 353 |
+
|:------------------------------------:|:--------:|
|
| 354 |
+
| LLaMA2-7B-Chat | 26.3 |
|
| 355 |
+
| ChatGLM2-6B-Chat | 28.8 |
|
| 356 |
+
| Baichuan2-7B-Chat | 32.8 |
|
| 357 |
+
| InternLM-7B-Chat | 33.0 |
|
| 358 |
+
| LLaMA2-13B-Chat | 37.1 |
|
| 359 |
+
| Baichuan2-13B-Chat | 55.3 |
|
| 360 |
+
| LLaMA2-70B-Chat | 59.3 |
|
| 361 |
+
| **Qwen-7B-Chat (original) (0-shot)** | 41.1 |
|
| 362 |
+
| **Qwen-7B-Chat (0-shot)** | 50.3 |
|
| 363 |
+
| **Qwen-7B-Chat (8-shot)** | 54.1 |
|
| 364 |
+
| **Qwen-14B-Chat (0-shot)** | **60.1** |
|
| 365 |
+
| **Qwen-14B-Chat (8-shot)** | 59.3 |
|
| 366 |
+
|
| 367 |
+
### 长序列评测(Long-Context Understanding)
|
| 368 |
+
|
| 369 |
+
通过NTK插值,LogN注意力缩放可以扩展Qwen-7B-Chat的上下文长度。在长文本摘要数据集[VCSUM](https://arxiv.org/abs/2305.05280)上(文本平均长度在15K左右),Qwen-7B-Chat的Rouge-L结果如下:
|
| 370 |
+
|
| 371 |
+
**(若要启用这些技巧,请将config.json里的`use_dynamic_ntk`和`use_logn_attn`设置为true)**
|
| 372 |
+
|
| 373 |
+
We introduce NTK-aware interpolation, LogN attention scaling to extend the context length of Qwen-7B-Chat. The Rouge-L results of Qwen-7B-Chat on long-text summarization dataset [VCSUM](https://arxiv.org/abs/2305.05280) (The average length of this dataset is around 15K) are shown below:
|
| 374 |
+
|
| 375 |
+
**(To use these tricks, please set `use_dynamic_ntk` and `use_long_attn` to true in config.json.)**
|
| 376 |
+
|
| 377 |
+
| Model | VCSUM (zh) |
|
| 378 |
+
|:------------------|:----------:|
|
| 379 |
+
| GPT-3.5-Turbo-16k | 16.0 |
|
| 380 |
+
| LLama2-7B-Chat | 0.2 |
|
| 381 |
+
| InternLM-7B-Chat | 13.0 |
|
| 382 |
+
| ChatGLM2-6B-Chat | 16.3 |
|
| 383 |
+
| **Qwen-7B-Chat** | **16.6** |
|
| 384 |
+
|
| 385 |
+
### 工具使用能力的评测(Tool Usage)
|
| 386 |
+
|
| 387 |
+
#### ReAct Prompting
|
| 388 |
+
|
| 389 |
+
千问支持通过 [ReAct Prompting](https://arxiv.org/abs/2210.03629) 调用插件/工具/API。ReAct 也是 [LangChain](https://python.langchain.com/) 框架采用的主要方式之一。在我们开源的、用于评估工具使用能力的评测基准上,千问的表现如下:
|
| 390 |
+
|
| 391 |
+
Qwen-Chat supports calling plugins/tools/APIs through [ReAct Prompting](https://arxiv.org/abs/2210.03629). ReAct is also one of the main approaches used by the [LangChain](https://python.langchain.com/) framework. In our evaluation benchmark for assessing tool usage capabilities, Qwen-Chat's performance is as follows:
|
| 392 |
+
|
| 393 |
+
<table>
|
| 394 |
+
<tr>
|
| 395 |
+
<th colspan=""4"" align=""center"">Chinese Tool-Use Benchmark</th>
|
| 396 |
+
</tr>
|
| 397 |
+
<tr>
|
| 398 |
+
<th align=""center"">Model</th><th align=""center"">Tool Selection (Acc.↑)</th><th align=""center"">Tool Input (Rouge-L↑)</th><th align=""center"">False Positive Error↓</th>
|
| 399 |
+
</tr>
|
| 400 |
+
<tr>
|
| 401 |
+
<td>GPT-4</td><td align=""center"">95%</td><td align=""center"">0.90</td><td align=""center"">15.0%</td>
|
| 402 |
+
</tr>
|
| 403 |
+
<tr>
|
| 404 |
+
<td>GPT-3.5</td><td align=""center"">85%</td><td align=""center"">0.88</td><td align=""center"">75.0%</td>
|
| 405 |
+
</tr>
|
| 406 |
+
<tr>
|
| 407 |
+
<td>Qwen-7B-Chat</td><td align=""center"">98%</td><td align=""center"">0.91</td><td align=""center"">7.3%</td>
|
| 408 |
+
</tr>
|
| 409 |
+
<tr>
|
| 410 |
+
<td>Qwen-14B-Chat</td><td align=""center"">98%</td><td align=""center"">0.93</td><td align=""center"">2.4%</td>
|
| 411 |
+
</tr>
|
| 412 |
+
</table>
|
| 413 |
+
|
| 414 |
+
> 评测基准中出现的插件均没有出现在千问的训练集中。该基准评估了模型在多个候选插件中选择正确插件的准确率、传入插件的参数的合理性、以及假阳率。假阳率(False Positive)定义:在处理不该调用插件的请求时,错误地调用了插件。
|
| 415 |
+
|
| 416 |
+
> The plugins that appear in the evaluation set do not appear in the training set of Qwen. This benchmark evaluates the accuracy of the model in selecting the correct plugin from multiple candidate plugins, the rationality of the parameters passed into the plugin, and the false positive rate. False Positive: Incorrectly invoking a plugin when it should not have been called when responding to a query.
|
| 417 |
+
|
| 418 |
+

|
| 419 |
+

|
| 420 |
+
|
| 421 |
+
#### Code Interpreter
|
| 422 |
+
|
| 423 |
+
为了考察Qwen使用Python Code Interpreter完成数学解题、数据可视化、及文件处理与爬虫等任务的能力,我们专门建设并开源了一个评测这方面能力的[评测基准](https://github.com/QwenLM/Qwen-Agent/tree/main/benchmark)。
|
| 424 |
+
|
| 425 |
+
我们发现Qwen在生成代码的可执行率、结果正确性上均表现较好:
|
| 426 |
+
|
| 427 |
+
To assess Qwen's ability to use the Python Code Interpreter for tasks such as mathematical problem solving, data visualization, and other general-purpose tasks such as file handling and web scraping, we have created and open-sourced a benchmark specifically designed for evaluating these capabilities. You can find the benchmark at this [link](https://github.com/QwenLM/Qwen-Agent/tree/main/benchmark).
|
| 428 |
+
|
| 429 |
+
We have observed that Qwen performs well in terms of code executability and result accuracy when generating code:
|
| 430 |
+
|
| 431 |
+
<table>
|
| 432 |
+
<tr>
|
| 433 |
+
<th colspan=""4"" align=""center"">Executable Rate of Generated Code (%)</th>
|
| 434 |
+
</tr>
|
| 435 |
+
<tr>
|
| 436 |
+
<th align=""center"">Model</th><th align=""center"">Math↑</th><th align=""center"">Visualization↑</th><th align=""center"">General↑</th>
|
| 437 |
+
</tr>
|
| 438 |
+
<tr>
|
| 439 |
+
<td>GPT-4</td><td align=""center"">91.9</td><td align=""center"">85.9</td><td align=""center"">82.8</td>
|
| 440 |
+
</tr>
|
| 441 |
+
<tr>
|
| 442 |
+
<td>GPT-3.5</td><td align=""center"">89.2</td><td align=""center"">65.0</td><td align=""center"">74.1</td>
|
| 443 |
+
</tr>
|
| 444 |
+
<tr>
|
| 445 |
+
<td>LLaMA2-7B-Chat</td>
|
| 446 |
+
<td align=""center"">41.9</td>
|
| 447 |
+
<td align=""center"">33.1</td>
|
| 448 |
+
<td align=""center"">24.1 </td>
|
| 449 |
+
</tr>
|
| 450 |
+
<tr>
|
| 451 |
+
<td>LLaMA2-13B-Chat</td>
|
| 452 |
+
<td align=""center"">50.0</td>
|
| 453 |
+
<td align=""center"">40.5</td>
|
| 454 |
+
<td align=""center"">48.3 </td>
|
| 455 |
+
</tr>
|
| 456 |
+
<tr>
|
| 457 |
+
<td>CodeLLaMA-7B-Instruct</td>
|
| 458 |
+
<td align=""center"">85.1</td>
|
| 459 |
+
<td align=""center"">54.0</td>
|
| 460 |
+
<td align=""center"">70.7 </td>
|
| 461 |
+
</tr>
|
| 462 |
+
<tr>
|
| 463 |
+
<td>CodeLLaMA-13B-Instruct</td>
|
| 464 |
+
<td align=""center"">93.2</td>
|
| 465 |
+
<td align=""center"">55.8</td>
|
| 466 |
+
<td align=""center"">74.1 </td>
|
| 467 |
+
</tr>
|
| 468 |
+
<tr>
|
| 469 |
+
<td>InternLM-7B-Chat-v1.1</td>
|
| 470 |
+
<td align=""center"">78.4</td>
|
| 471 |
+
<td align=""center"">44.2</td>
|
| 472 |
+
<td align=""center"">62.1 </td>
|
| 473 |
+
</tr>
|
| 474 |
+
<tr>
|
| 475 |
+
<td>InternLM-20B-Chat</td>
|
| 476 |
+
<td align=""center"">70.3</td>
|
| 477 |
+
<td align=""center"">44.2</td>
|
| 478 |
+
<td align=""center"">65.5 </td>
|
| 479 |
+
</tr>
|
| 480 |
+
<tr>
|
| 481 |
+
<td>Qwen-7B-Chat</td>
|
| 482 |
+
<td align=""center"">82.4</td>
|
| 483 |
+
<td align=""center"">64.4</td>
|
| 484 |
+
<td align=""center"">67.2 </td>
|
| 485 |
+
</tr>
|
| 486 |
+
<tr>
|
| 487 |
+
<td>Qwen-14B-Chat</td>
|
| 488 |
+
<td align=""center"">89.2</td>
|
| 489 |
+
<td align=""center"">84.1</td>
|
| 490 |
+
<td align=""center"">65.5</td>
|
| 491 |
+
</tr>
|
| 492 |
+
</table>
|
| 493 |
+
|
| 494 |
+
<table>
|
| 495 |
+
<tr>
|
| 496 |
+
<th colspan=""4"" align=""center"">Accuracy of Code Execution Results (%)</th>
|
| 497 |
+
</tr>
|
| 498 |
+
<tr>
|
| 499 |
+
<th align=""center"">Model</th><th align=""center"">Math↑</th><th align=""center"">Visualization-Hard↑</th><th align=""center"">Visualization-Easy↑</th>
|
| 500 |
+
</tr>
|
| 501 |
+
<tr>
|
| 502 |
+
<td>GPT-4</td><td align=""center"">82.8</td><td align=""center"">66.7</td><td align=""center"">60.8</td>
|
| 503 |
+
</tr>
|
| 504 |
+
<tr>
|
| 505 |
+
<td>GPT-3.5</td><td align=""center"">47.3</td><td align=""center"">33.3</td><td align=""center"">55.7</td>
|
| 506 |
+
</tr>
|
| 507 |
+
<tr>
|
| 508 |
+
<td>LLaMA2-7B-Chat</td>
|
| 509 |
+
<td align=""center"">3.9</td>
|
| 510 |
+
<td align=""center"">14.3</td>
|
| 511 |
+
<td align=""center"">39.2 </td>
|
| 512 |
+
</tr>
|
| 513 |
+
<tr>
|
| 514 |
+
<td>LLaMA2-13B-Chat</td>
|
| 515 |
+
<td align=""center"">8.3</td>
|
| 516 |
+
<td align=""center"">8.3</td>
|
| 517 |
+
<td align=""center"">40.5 </td>
|
| 518 |
+
</tr>
|
| 519 |
+
<tr>
|
| 520 |
+
<td>CodeLLaMA-7B-Instruct</td>
|
| 521 |
+
<td align=""center"">14.3</td>
|
| 522 |
+
<td align=""center"">26.2</td>
|
| 523 |
+
<td align=""center"">60.8 </td>
|
| 524 |
+
</tr>
|
| 525 |
+
<tr>
|
| 526 |
+
<td>CodeLLaMA-13B-Instruct</td>
|
| 527 |
+
<td align=""center"">28.2</td>
|
| 528 |
+
<td align=""center"">27.4</td>
|
| 529 |
+
<td align=""center"">62.0 </td>
|
| 530 |
+
</tr>
|
| 531 |
+
<tr>
|
| 532 |
+
<td>InternLM-7B-Chat-v1.1</td>
|
| 533 |
+
<td align=""center"">28.5</td>
|
| 534 |
+
<td align=""center"">4.8</td>
|
| 535 |
+
<td align=""center"">40.5 </td>
|
| 536 |
+
</tr>
|
| 537 |
+
<tr>
|
| 538 |
+
<td>InternLM-20B-Chat</td>
|
| 539 |
+
<td align=""center"">34.6</td>
|
| 540 |
+
<td align=""center"">21.4</td>
|
| 541 |
+
<td align=""center"">45.6 </td>
|
| 542 |
+
</tr>
|
| 543 |
+
<tr>
|
| 544 |
+
<td>Qwen-7B-Chat</td>
|
| 545 |
+
<td align=""center"">41.9</td>
|
| 546 |
+
<td align=""center"">40.5</td>
|
| 547 |
+
<td align=""center"">54.4 </td>
|
| 548 |
+
</tr>
|
| 549 |
+
<tr>
|
| 550 |
+
<td>Qwen-14B-Chat</td>
|
| 551 |
+
<td align=""center"">58.4</td>
|
| 552 |
+
<td align=""center"">53.6</td>
|
| 553 |
+
<td align=""center"">59.5</td>
|
| 554 |
+
</tr>
|
| 555 |
+
</table>
|
| 556 |
+
|
| 557 |
+
<p align=""center"">
|
| 558 |
+
<br>
|
| 559 |
+
<img src=""assets/code_interpreter_showcase_001.jpg"" />
|
| 560 |
+
<br>
|
| 561 |
+
<p>
|
| 562 |
+
|
| 563 |
+
#### Huggingface Agent
|
| 564 |
+
|
| 565 |
+
千问还具备作为 [HuggingFace Agent](https://huggingface.co/docs/transformers/transformers_agents) 的能力。它在 Huggingface 提供的run模式评测基准上的表现如下:
|
| 566 |
+
|
| 567 |
+
Qwen-Chat also has the capability to be used as a [HuggingFace Agent](https://huggingface.co/docs/transformers/transformers_agents). Its performance on the run-mode benchmark provided by HuggingFace is as follows:
|
| 568 |
+
|
| 569 |
+
<table>
|
| 570 |
+
<tr>
|
| 571 |
+
<th colspan=""4"" align=""center"">HuggingFace Agent Benchmark- Run Mode</th>
|
| 572 |
+
</tr>
|
| 573 |
+
<tr>
|
| 574 |
+
<th align=""center"">Model</th><th align=""center"">Tool Selection↑</th><th align=""center"">Tool Used↑</th><th align=""center"">Code↑</th>
|
| 575 |
+
</tr>
|
| 576 |
+
<tr>
|
| 577 |
+
<td>GPT-4</td><td align=""center"">100</td><td align=""center"">100</td><td align=""center"">97.4</td>
|
| 578 |
+
</tr>
|
| 579 |
+
<tr>
|
| 580 |
+
<td>GPT-3.5</td><td align=""center"">95.4</td><td align=""center"">96.3</td><td align=""center"">87.0</td>
|
| 581 |
+
</tr>
|
| 582 |
+
<tr>
|
| 583 |
+
<td>StarCoder-Base-15B</td><td align=""center"">86.1</td><td align=""center"">87.0</td><td align=""center"">68.9</td>
|
| 584 |
+
</tr>
|
| 585 |
+
<tr>
|
| 586 |
+
<td>StarCoder-15B</td><td align=""center"">87.0</td><td align=""center"">88.0</td><td align=""center"">68.9</td>
|
| 587 |
+
</tr>
|
| 588 |
+
<tr>
|
| 589 |
+
<td>Qwen-7B-Chat</td><td align=""center"">87.0</td><td align=""center"">87.0</td><td align=""center"">71.5</td>
|
| 590 |
+
</tr>
|
| 591 |
+
<tr>
|
| 592 |
+
<td>Qwen-14B-Chat</td><td align=""center"">93.5</td><td align=""center"">94.4</td><td align=""center"">87.0</td>
|
| 593 |
+
</tr>
|
| 594 |
+
</table>
|
| 595 |
+
|
| 596 |
+
<table>
|
| 597 |
+
<tr>
|
| 598 |
+
<th colspan=""4"" align=""center"">HuggingFace Agent Benchmark - Chat Mode</th>
|
| 599 |
+
</tr>
|
| 600 |
+
<tr>
|
| 601 |
+
<th align=""center"">Model</th><th align=""center"">Tool Selection↑</th><th align=""center"">Tool Used↑</th><th align=""center"">Code↑</th>
|
| 602 |
+
</tr>
|
| 603 |
+
<tr>
|
| 604 |
+
<td>GPT-4</td><td align=""center"">97.9</td><td align=""center"">97.9</td><td align=""center"">98.5</td>
|
| 605 |
+
</tr>
|
| 606 |
+
<tr>
|
| 607 |
+
<td>GPT-3.5</td><td align=""center"">97.3</td><td align=""center"">96.8</td><td align=""center"">89.6</td>
|
| 608 |
+
</tr>
|
| 609 |
+
<tr>
|
| 610 |
+
<td>StarCoder-Base-15B</td><td align=""center"">97.9</td><td align=""center"">97.9</td><td align=""center"">91.1</td>
|
| 611 |
+
</tr>
|
| 612 |
+
<tr>
|
| 613 |
+
<td>StarCoder-15B</td><td align=""center"">97.9</td><td align=""center"">97.9</td><td align=""center"">89.6</td>
|
| 614 |
+
</tr>
|
| 615 |
+
<tr>
|
| 616 |
+
<td>Qwen-7B-Chat</td><td align=""center"">94.7</td><td align=""center"">94.7</td><td align=""center"">85.1</td>
|
| 617 |
+
</tr>
|
| 618 |
+
<tr>
|
| 619 |
+
<td>Qwen-14B-Chat</td><td align=""center"">97.9</td><td align=""center"">97.9</td><td align=""center"">95.5</td>
|
| 620 |
+
</tr>
|
| 621 |
+
</table>
|
| 622 |
+
|
| 623 |
+
<br>
|
| 624 |
+
|
| 625 |
+
## x86 平台 (x86 Platforms)
|
| 626 |
+
在 酷睿™/至强® 可扩展处理器或 Arc™ GPU 上部署量化模型时,建议使用 [OpenVINO™ Toolkit](https://docs.openvino.ai/2023.3/gen_ai_guide.html)以充分利用硬件,实现更好的推理性能。您可以安装并运行此 [example notebook](https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/254-llm-chatbot)。相关问题,您可在[OpenVINO repo](https://github.com/openvinotoolkit/openvino_notebooks/issues)中提交。
|
| 627 |
+
|
| 628 |
+
When deploy on Core™/Xeon® Scalable Processors or with Arc™ GPU, [OpenVINO™ Toolkit](https://docs.openvino.ai/2023.3/gen_ai_guide.html) is recommended. You can install and run this [example notebook](https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/254-llm-chatbot). For related issues, you are welcome to file an issue at [OpenVINO repo](https://github.com/openvinotoolkit/openvino_notebooks/issues).
|
| 629 |
+
|
| 630 |
+
## FAQ
|
| 631 |
+
|
| 632 |
+
如遇到问题,敬请查阅[FAQ](https://github.com/QwenLM/Qwen/blob/main/FAQ_zh.md)以及issue区,如仍无法解决再提交issue。
|
| 633 |
+
|
| 634 |
+
If you meet problems, please refer to [FAQ](https://github.com/QwenLM/Qwen/blob/main/FAQ.md) and the issues first to search a solution before you launch a new issue.
|
| 635 |
+
<br>
|
| 636 |
+
|
| 637 |
+
## 引用 (Citation)
|
| 638 |
+
|
| 639 |
+
如果你觉得我们的工作对你有帮助,欢迎引用!
|
| 640 |
+
|
| 641 |
+
If you find our work helpful, feel free to give us a cite.
|
| 642 |
+
|
| 643 |
+
```
|
| 644 |
+
@article{qwen,
|
| 645 |
+
title={Qwen Technical Report},
|
| 646 |
+
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
|
| 647 |
+
journal={arXiv preprint arXiv:2309.16609},
|
| 648 |
+
year={2023}
|
| 649 |
+
}
|
| 650 |
+
```
|
| 651 |
+
<br>
|
| 652 |
+
|
| 653 |
+
## 使用协议(License Agreement)
|
| 654 |
+
|
| 655 |
+
我们的代码和模型权重对学术研究完全开放,并支持商用。请查看[LICENSE](https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20LICENSE%20AGREEMENT)了解具体的开源协议细节。如需商用,请填写[问卷](https://dashscope.console.aliyun.com/openModelApply/qianwen)申请。
|
| 656 |
+
|
| 657 |
+
Our code and checkpoints are open to research purpose, and they are allowed for commercial purposes. Check [LICENSE](https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20LICENSE%20AGREEMENT) for more details about the license. If you have requirements for commercial use, please fill out the [form](https://dashscope.console.aliyun.com/openModelApply/qianwen) to apply.
|
| 658 |
+
<br>
|
| 659 |
+
|
| 660 |
+
## 联系我们(Contact Us)
|
| 661 |
+
|
| 662 |
+
如果你想给我们的研发团队和产品团队留言,欢迎加入我们的微信群、钉钉群以及Discord!同时,也欢迎通过邮件(qianwen_opensource@alibabacloud.com)联系我们。
|
| 663 |
+
|
| 664 |
+
If you are interested to leave a message to either our research team or product team, join our Discord or WeChat groups! Also, feel free to send an email to qianwen_opensource@alibabacloud.com.
|
| 665 |
+
|
| 666 |
+
","{""id"": ""Qwen/Qwen-7B-Chat"", ""author"": ""Qwen"", ""sha"": ""93a65d34827a3cc269b727e67004743b723e2f83"", ""last_modified"": ""2024-03-19 10:09:52+00:00"", ""created_at"": ""2023-08-03 03:01:31+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 29060, ""downloads_all_time"": null, ""likes"": 770, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""qwen"", ""text-generation"", ""custom_code"", ""zh"", ""en"", ""arxiv:2309.16609"", ""arxiv:2305.08322"", ""arxiv:2009.03300"", ""arxiv:2305.05280"", ""arxiv:2210.03629"", ""license:other"", ""autotrain_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- zh\n- en\nlicense: other\nlicense_name: tongyi-qianwen-license-agreement\nlicense_link: https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20LICENSE%20AGREEMENT\npipeline_tag: text-generation\ntags:\n- qwen\ninference: false"", ""widget_data"": [{""text"": ""\u6211\u53eb\u6731\u5229\u5b89\uff0c\u6211\u559c\u6b22""}, {""text"": ""\u6211\u53eb\u6258\u9a6c\u65af\uff0c\u6211\u7684\u4e3b\u8981""}, {""text"": ""\u6211\u53eb\u739b\u4e3d\u4e9a\uff0c\u6211\u6700\u559c\u6b22\u7684""}, {""text"": ""\u6211\u53eb\u514b\u62c9\u62c9\uff0c\u6211\u662f""}, {""text"": ""\u4ece\u524d\uff0c""}], ""model_index"": null, ""config"": {""architectures"": [""QWenLMHeadModel""], ""auto_map"": {""AutoConfig"": ""configuration_qwen.QWenConfig"", ""AutoModelForCausalLM"": ""modeling_qwen.QWenLMHeadModel""}, ""model_type"": ""qwen"", ""tokenizer_config"": {}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": ""modeling_qwen.QWenLMHeadModel"", ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='NOTICE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/code_interpreter_showcase_001.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/logo.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/react_showcase_001.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/react_showcase_002.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/wechat.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cache_autogptq_cuda_256.cpp', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cache_autogptq_cuda_kernel_256.cu', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_qwen.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpp_kernels.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/react_prompt.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_qwen.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='qwen.tiktoken', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='qwen_generation_utils.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenization_qwen.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""eduagarcia/open_pt_llm_leaderboard"", ""LanguageBind/MoE-LLaVA"", ""ZhangYuhan/3DGen-Arena"", ""gsaivinay/open_llm_leaderboard"", ""KBaba7/Quant"", ""mikeee/qwen-7b-chat"", ""EmbeddedLLM/chat-template-generation"", ""Justinrune/LLaMA-Factory"", ""yhavinga/dutch-tokenizer-arena"", ""kenken999/fastapi_django_main_live"", ""lightmate/llm-chatbot"", ""ali-vilab/IDEA-Bench-Arena"", ""bhaskartripathi/LLM_Quantization"", ""officialhimanshu595/llama-factory"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""li-qing/FIRE"", ""Zulelee/langchain-chatchat"", ""xu-song/kplug"", ""justest/GPT-Academic-with-B3n-AI"", ""calvinchaochao/text_generation"", ""llmbb/LLMBB-Agent"", ""hzwluoye/gpt-academic"", ""tianleliphoebe/visual-arena"", ""Docfile/open_llm_leaderboard"", ""Ashmal/MobiLlama"", ""xun/Qwen-Token-Calc"", ""malvika2003/openvino_notebooks"", ""ruslanmv/convert_to_gguf"", ""Yiyuan/VSA"", ""IS2Lab/S-Eval"", ""vitalyr/gpt-academic"", ""PegaMichael/Taiwan-LLaMa2-Copy"", ""cming0420/gpt-academic"", ""hengkai/gpt-academic"", ""tjtanaa/chat-template-generation"", ""kuxian/gpt-academic"", ""QLWD/gpt-academic"", ""DrBadass/gpt-academic"", ""qinglin96/gpt-academic3.6"", ""darren1231/gpt-academic_2"", ""CaiRou-Huang/TwLLM7B-v2.0-base"", ""DuanSuKa/gpt-academic2"", ""shuozhang2/Monkey"", ""BuzzHr/gpt-academic002"", ""Leachim/gpt-academic"", ""durukan/gptacademic"", ""pallavijaini/NeuralChat-LLAMA-POC"", ""bibimbap/Qwen-7B-Chat"", ""xiaohua1011/gpt-academic"", ""Havi999/tongyi"", ""zhaomuqing/gpt-academic"", ""blackwingedkite/gutalk"", ""zhlinh/gpt-academic"", ""SincoMao/test"", ""cllatMTK/Breeze"", ""znskiss/Qwen-7B-main"", ""forever-yu/gpt-academic"", ""BuzzHr/gpt-academic001"", ""flatindo/titles"", ""nengrenjie83/MedicalGPT-main"", ""pngwn/open_llm_leaderboard_two"", ""wuhaibo/Qwen-7B-Chat"", ""SevenQin/cmkj-gpt"", ""Cran-May/qwen-7b-chat"", ""Ya2023/neurobot"", ""gordonchan/embedding-m3e-large"", ""qgyd2021/qwen_7b_chinese_modern_poetry"", ""JiakunXu/chat_with_llm"", ""blackwingedkite/alpaca2_clas"", ""Nymbo/MoE-LLaVA"", ""azurice/gpt-playground"", ""zouhsab/TinnyADLLAVA"", ""jaekwon/intel_cpu_chat"", ""whuib/gpt-academic"", ""liang-huggingface/PubmedSearch"", ""lianglv/NeuralChat-ICX-INT4"", ""Bofeee5675/FIRE"", ""evelyn-lo/evelyn"", ""thepianist9/Linly"", ""yuantao-infini-ai/demo_test"", ""pennxp/qianwen"", ""zjasper666/bf16_vs_fp8"", ""Hndsguy/813-MindSearch"", ""martinakaduc/melt"", ""JiakaiDu/RAG_Test"", ""mnsak/pro"", ""mnsak/project_agents"", ""macota1/axa"", ""Superkingjcj/Lagent"", ""Vic-729/weathersearch_agent"", ""SEUZCYYDS/Lagent"", ""Chipsleep/hgagent"", ""Jianfei217/MultiAgents"", ""Gon04/lagent_demo"", ""kai119/lagent"", ""sfang32/Agent_Based_on_Lagent"", ""Jianfei217/MulAgent"", ""lt676767/Lagent"", ""xiaoxishui/LAGENT""], ""safetensors"": {""parameters"": {""BF16"": 7721324544}, ""total"": 7721324544}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-03-19 10:09:52+00:00"", ""cardData"": ""language:\n- zh\n- en\nlicense: other\nlicense_name: tongyi-qianwen-license-agreement\nlicense_link: https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20LICENSE%20AGREEMENT\npipeline_tag: text-generation\ntags:\n- qwen\ninference: false"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": ""modeling_qwen.QWenLMHeadModel"", ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""_id"": ""64cb188b96a31741f19ef6b4"", ""modelId"": ""Qwen/Qwen-7B-Chat"", ""usedStorage"": 46329475248}",0,https://huggingface.co/stvlynn/Qwen-7B-Chat-Cantonese,1,"https://huggingface.co/Jungwonchang/Ko-QWEN-7B-Chat-LoRA, https://huggingface.co/xjw1001002/Qwen7B_brand_model, https://huggingface.co/xjw1001002/Qwen_match_price_V2, https://huggingface.co/yooshijay/qwen-7B_psychat, https://huggingface.co/xjw1001002/price_tag_V3_qwen7b, https://huggingface.co/ggkk2012/qwen7b-finance, https://huggingface.co/kyriemao/chatretriever, https://huggingface.co/lyy14011305/firefly-qwen-7b-sft-qlora, https://huggingface.co/Zetsu00/qwen-7b-lora-simplifier-v2, https://huggingface.co/Zetsu00/Qwen-7B-QLoRA-simplifier",10,"https://huggingface.co/TheBloke/Qwen-7B-Chat-AWQ, https://huggingface.co/mradermacher/Qwen-7B-Chat-GGUF, https://huggingface.co/mradermacher/Qwen-7B-Chat-i1-GGUF, https://huggingface.co/TheBloke/Qwen-7B-Chat-GPTQ, https://huggingface.co/Xorbits/Qwen-7B-Chat-GGUF, https://huggingface.co/mlc-ai/Qwen-7B-Chat-q4f16_1-MLC, https://huggingface.co/mlc-ai/Qwen-7B-Chat-q4f32_1-MLC",7,,0,"FallnAI/Quantize-HF-Models, Justinrune/LLaMA-Factory, KBaba7/Quant, ZhangYuhan/3DGen-Arena, Zulelee/langchain-chatchat, ali-vilab/IDEA-Bench-Arena, bhaskartripathi/LLM_Quantization, eduagarcia/open_pt_llm_leaderboard, huggingface/InferenceSupport/discussions/151, kenken999/fastapi_django_main_live, lightmate/llm-chatbot, mikeee/qwen-7b-chat, yhavinga/dutch-tokenizer-arena",13
|
| 667 |
+
stvlynn/Qwen-7B-Chat-Cantonese,"---
|
| 668 |
+
license: agpl-3.0
|
| 669 |
+
datasets:
|
| 670 |
+
- stvlynn/Cantonese-Dialogue
|
| 671 |
+
language:
|
| 672 |
+
- zh
|
| 673 |
+
pipeline_tag: text-generation
|
| 674 |
+
tags:
|
| 675 |
+
- Cantonese
|
| 676 |
+
- 廣東話
|
| 677 |
+
- 粤语
|
| 678 |
+
base_model: Qwen/Qwen-7B-Chat
|
| 679 |
+
---
|
| 680 |
+
|
| 681 |
+
# Qwen-7B-Chat-Cantonese (通义千问·粤语)
|
| 682 |
+
## Intro
|
| 683 |
+
Qwen-7B-Chat-Cantonese is a fine-tuned version based on Qwen-7B-Chat, trained on a substantial amount of Cantonese language data.
|
| 684 |
+
|
| 685 |
+
Qwen-7B-Chat-Cantonese係基於Qwen-7B-Chat嘅微調版本,基於大量粵語數據進行訓練。
|
| 686 |
+
|
| 687 |
+
[ModelScope(魔搭社区)](https://www.modelscope.cn/models/stvlynn/Qwen-7B-Chat-Cantonese)
|
| 688 |
+
|
| 689 |
+
## Usage
|
| 690 |
+
|
| 691 |
+
### Requirements
|
| 692 |
+
|
| 693 |
+
* python 3.8 and above
|
| 694 |
+
* pytorch 1.12 and above, 2.0 and above are recommended
|
| 695 |
+
* CUDA 11.4 and above are recommended (this is for GPU users, flash-attention users, etc.)
|
| 696 |
+
|
| 697 |
+
### Dependency
|
| 698 |
+
|
| 699 |
+
To run Qwen-7B-Chat-Cantonese, please make sure you meet the above requirements, and then execute the following pip commands to install the dependent libraries.
|
| 700 |
+
|
| 701 |
+
```bash
|
| 702 |
+
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
|
| 703 |
+
```
|
| 704 |
+
|
| 705 |
+
In addition, it is recommended to install the `flash-attention` library (**we support flash attention 2 now.**) for higher efficiency and lower memory usage.
|
| 706 |
+
|
| 707 |
+
```bash
|
| 708 |
+
git clone https://github.com/Dao-AILab/flash-attention
|
| 709 |
+
cd flash-attention && pip install .
|
| 710 |
+
```
|
| 711 |
+
|
| 712 |
+
### Quickstart
|
| 713 |
+
|
| 714 |
+
Pls turn to QwenLM/Qwen - [Quickstart](https://github.com/QwenLM/Qwen?tab=readme-ov-file#quickstart)
|
| 715 |
+
|
| 716 |
+
## Training Parameters
|
| 717 |
+
|
| 718 |
+
| Parameter | Description | Value |
|
| 719 |
+
|-----------------|----------------------------------------|--------|
|
| 720 |
+
| Learning Rate | AdamW optimizer learning rate | 7e-5 |
|
| 721 |
+
| Weight Decay | Regularization strength | 0.8 |
|
| 722 |
+
| Gamma | Learning rate decay factor | 1.0 |
|
| 723 |
+
| Batch Size | Number of samples per batch | 1000 |
|
| 724 |
+
| Precision | Floating point precision | fp16 |
|
| 725 |
+
| Learning Policy | Learning rate adjustment policy | cosine |
|
| 726 |
+
| Warmup Steps | Initial steps without learning rate adjustment | 0 |
|
| 727 |
+
| Total Steps | Total training steps | 1024 |
|
| 728 |
+
| Gradient Accumulation Steps | Number of steps to accumulate gradients before updating | 8 |
|
| 729 |
+
|
| 730 |
+

|
| 731 |
+
|
| 732 |
+
## Demo
|
| 733 |
+
|
| 734 |
+
|
| 735 |
+
|
| 736 |
+
|
| 737 |
+
|
| 738 |
+
|
| 739 |
+
## Special Note
|
| 740 |
+
|
| 741 |
+
This is my first fine-tuning LLM project. Pls forgive me if there's anything wrong.
|
| 742 |
+
|
| 743 |
+
If you have any questions or suggestions, feel free to contact me.
|
| 744 |
+
|
| 745 |
+
[Twitter @stv_lynn](https://x.com/stv_lynn)
|
| 746 |
+
|
| 747 |
+
[Telegram @stvlynn](https://t.me/stvlynn)
|
| 748 |
+
|
| 749 |
+
[email i@stv.pm](mailto://i@stv.pm)","{""id"": ""stvlynn/Qwen-7B-Chat-Cantonese"", ""author"": ""stvlynn"", ""sha"": ""0bc29be620b3337fc3e9a91262cb2804c325e25a"", ""last_modified"": ""2024-05-06 09:36:16+00:00"", ""created_at"": ""2024-05-04 02:11:03+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 150, ""downloads_all_time"": null, ""likes"": 23, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""qwen"", ""feature-extraction"", ""Cantonese"", ""\u5ee3\u6771\u8a71"", ""\u7ca4\u8bed"", ""text-generation"", ""conversational"", ""custom_code"", ""zh"", ""dataset:stvlynn/Cantonese-Dialogue"", ""base_model:Qwen/Qwen-7B-Chat"", ""base_model:finetune:Qwen/Qwen-7B-Chat"", ""license:agpl-3.0"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: Qwen/Qwen-7B-Chat\ndatasets:\n- stvlynn/Cantonese-Dialogue\nlanguage:\n- zh\nlicense: agpl-3.0\npipeline_tag: text-generation\ntags:\n- Cantonese\n- \u5ee3\u6771\u8a71\n- \u7ca4\u8bed"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""QWenLMHeadModel""], ""auto_map"": {""AutoConfig"": ""configuration_qwen.QWenConfig"", ""AutoModel"": ""modeling_qwen.QWenLMHeadModel"", ""AutoModelForCausalLM"": ""modeling_qwen.QWenLMHeadModel""}, ""model_type"": ""qwen"", ""tokenizer_config"": {""chat_template"": ""{% set system_message = 'You are a helpful assistant.' %}{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ '<|im_start|>system\\n' + system_message + '<|im_end|>\\n' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|im_start|>user\\n' + content + '<|im_end|>\\n<|im_start|>assistant\\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>' + '\\n' }}{% endif %}{% endfor %}"", ""eos_token"": ""<|im_end|>"", ""pad_token"": ""<|im_end|>""}}, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": ""modeling_qwen.QWenLMHeadModel"", ""pipeline_tag"": ""feature-extraction"", ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_qwen.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='cpp_kernels.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00008.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_qwen.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='qwen.tiktoken', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='qwen_generation_utils.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenization_qwen.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F16"": 7721324544}, ""total"": 7721324544}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-05-06 09:36:16+00:00"", ""cardData"": ""base_model: Qwen/Qwen-7B-Chat\ndatasets:\n- stvlynn/Cantonese-Dialogue\nlanguage:\n- zh\nlicense: agpl-3.0\npipeline_tag: text-generation\ntags:\n- Cantonese\n- \u5ee3\u6771\u8a71\n- \u7ca4\u8bed"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": ""modeling_qwen.QWenLMHeadModel"", ""pipeline_tag"": ""feature-extraction"", ""processor"": null}, ""_id"": ""66359937ccadfaaeac8cae0f"", ""modelId"": ""stvlynn/Qwen-7B-Chat-Cantonese"", ""usedStorage"": 15442677024}",1,,0,,0,"https://huggingface.co/mradermacher/Qwen-7B-Chat-Cantonese-GGUF, https://huggingface.co/mradermacher/Qwen-7B-Chat-Cantonese-i1-GGUF",2,,0,huggingface/InferenceSupport/discussions/new?title=stvlynn/Qwen-7B-Chat-Cantonese&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bstvlynn%2FQwen-7B-Chat-Cantonese%5D(%2Fstvlynn%2FQwen-7B-Chat-Cantonese)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
Qwen2-72B-Instruct_finetunes_20250425_125929.csv_finetunes_20250425_125929.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
SOLAR-0-70b-16bit_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,413 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
upstage/SOLAR-0-70b-16bit,"---
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
tags:
|
| 6 |
+
- upstage
|
| 7 |
+
- llama-2
|
| 8 |
+
- instruct
|
| 9 |
+
- instruction
|
| 10 |
+
pipeline_tag: text-generation
|
| 11 |
+
---
|
| 12 |
+
# Updates
|
| 13 |
+
Solar, a new bot created by Upstage, is now available on **Poe**. As a top-ranked model on the HuggingFace Open LLM leaderboard, and a fine tune of Llama 2, Solar is a great example of the progress enabled by open source.
|
| 14 |
+
Try now at https://poe.com/Solar-0-70b
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
# SOLAR-0-70b-16bit model card
|
| 18 |
+
The model name has been changed from LLaMa-2-70b-instruct-v2 to SOLAR-0-70b-16bit
|
| 19 |
+
|
| 20 |
+
## Model Details
|
| 21 |
+
|
| 22 |
+
* **Developed by**: [Upstage](https://en.upstage.ai)
|
| 23 |
+
* **Backbone Model**: [LLaMA-2](https://github.com/facebookresearch/llama/tree/main)
|
| 24 |
+
* **Language(s)**: English
|
| 25 |
+
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
|
| 26 |
+
* **License**: Fine-tuned checkpoints is licensed under the Non-Commercial Creative Commons license ([CC BY-NC-4.0](https://creativecommons.org/licenses/by-nc/4.0/))
|
| 27 |
+
* **Where to send comments**: Instructions on how to provide feedback or comments on a model can be found by opening an issue in the [Hugging Face community's model repository](https://huggingface.co/upstage/Llama-2-70b-instruct-v2/discussions)
|
| 28 |
+
* **Contact**: For questions and comments about the model, please email [contact@upstage.ai](mailto:contact@upstage.ai)
|
| 29 |
+
|
| 30 |
+
## Dataset Details
|
| 31 |
+
|
| 32 |
+
### Used Datasets
|
| 33 |
+
- Orca-style dataset
|
| 34 |
+
- Alpaca-style dataset
|
| 35 |
+
- No other dataset was used except for the dataset mentioned above
|
| 36 |
+
- No benchmark test set or the training set are used
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
### Prompt Template
|
| 40 |
+
```
|
| 41 |
+
### System:
|
| 42 |
+
{System}
|
| 43 |
+
|
| 44 |
+
### User:
|
| 45 |
+
{User}
|
| 46 |
+
|
| 47 |
+
### Assistant:
|
| 48 |
+
{Assistant}
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
## Usage
|
| 52 |
+
|
| 53 |
+
- The followings are tested on A100 80GB
|
| 54 |
+
- Our model can handle up to 10k+ input tokens, thanks to the `rope_scaling` option
|
| 55 |
+
|
| 56 |
+
```python
|
| 57 |
+
import torch
|
| 58 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
|
| 59 |
+
|
| 60 |
+
tokenizer = AutoTokenizer.from_pretrained(""upstage/Llama-2-70b-instruct-v2"")
|
| 61 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 62 |
+
""upstage/Llama-2-70b-instruct-v2"",
|
| 63 |
+
device_map=""auto"",
|
| 64 |
+
torch_dtype=torch.float16,
|
| 65 |
+
load_in_8bit=True,
|
| 66 |
+
rope_scaling={""type"": ""dynamic"", ""factor"": 2} # allows handling of longer inputs
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
prompt = ""### User:\nThomas is healthy, but he has to go to the hospital. What could be the reasons?\n\n### Assistant:\n""
|
| 70 |
+
inputs = tokenizer(prompt, return_tensors=""pt"").to(model.device)
|
| 71 |
+
del inputs[""token_type_ids""]
|
| 72 |
+
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
|
| 73 |
+
|
| 74 |
+
output = model.generate(**inputs, streamer=streamer, use_cache=True, max_new_tokens=float('inf'))
|
| 75 |
+
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
## Hardware and Software
|
| 79 |
+
|
| 80 |
+
* **Hardware**: We utilized an A100x8 * 4 for training our model
|
| 81 |
+
* **Training Factors**: We fine-tuned this model using a combination of the [DeepSpeed library](https://github.com/microsoft/DeepSpeed) and the [HuggingFace Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) / [HuggingFace Accelerate](https://huggingface.co/docs/accelerate/index)
|
| 82 |
+
|
| 83 |
+
## Evaluation Results
|
| 84 |
+
|
| 85 |
+
### Overview
|
| 86 |
+
- We conducted a performance evaluation following the tasks being evaluated on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
|
| 87 |
+
We evaluated our model on four benchmark datasets, which include `ARC-Challenge`, `HellaSwag`, `MMLU`, and `TruthfulQA`
|
| 88 |
+
We used the [lm-evaluation-harness repository](https://github.com/EleutherAI/lm-evaluation-harness), specifically commit [b281b0921b636bc36ad05c0b0b0763bd6dd43463](https://github.com/EleutherAI/lm-evaluation-harness/tree/b281b0921b636bc36ad05c0b0b0763bd6dd43463).
|
| 89 |
+
- We used [MT-bench](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge), a set of challenging multi-turn open-ended questions, to evaluate the models
|
| 90 |
+
|
| 91 |
+
### Main Results
|
| 92 |
+
| Model | H4(Avg) | ARC | HellaSwag | MMLU | TruthfulQA | | MT_Bench |
|
| 93 |
+
|--------------------------------------------------------------------|----------|----------|----------|------|----------|-|-------------|
|
| 94 |
+
| **[Llama-2-70b-instruct-v2](https://huggingface.co/upstage/Llama-2-70b-instruct-v2)**(***Ours***, ***Open LLM Leaderboard***) | **73** | **71.1** | **87.9** | **70.6** | **62.2** | | **7.44063** |
|
| 95 |
+
| [Llama-2-70b-instruct](https://huggingface.co/upstage/Llama-2-70b-instruct) (Ours, Open LLM Leaderboard) | 72.3 | 70.9 | 87.5 | 69.8 | 61 | | 7.24375 |
|
| 96 |
+
| [llama-65b-instruct](https://huggingface.co/upstage/llama-65b-instruct) (Ours, Open LLM Leaderboard) | 69.4 | 67.6 | 86.5 | 64.9 | 58.8 | | |
|
| 97 |
+
| Llama-2-70b-hf | 67.3 | 67.3 | 87.3 | 69.8 | 44.9 | | |
|
| 98 |
+
| [llama-30b-instruct-2048](https://huggingface.co/upstage/llama-30b-instruct-2048) (Ours, Open LLM Leaderboard) | 67.0 | 64.9 | 84.9 | 61.9 | 56.3 | | |
|
| 99 |
+
| [llama-30b-instruct](https://huggingface.co/upstage/llama-30b-instruct) (Ours, Open LLM Leaderboard) | 65.2 | 62.5 | 86.2 | 59.4 | 52.8 | | |
|
| 100 |
+
| llama-65b | 64.2 | 63.5 | 86.1 | 63.9 | 43.4 | | |
|
| 101 |
+
| falcon-40b-instruct | 63.4 | 61.6 | 84.3 | 55.4 | 52.5 | | |
|
| 102 |
+
|
| 103 |
+
### Scripts for H4 Score Reproduction
|
| 104 |
+
- Prepare evaluation environments:
|
| 105 |
+
```
|
| 106 |
+
# clone the repository
|
| 107 |
+
git clone https://github.com/EleutherAI/lm-evaluation-harness.git
|
| 108 |
+
# check out the specific commit
|
| 109 |
+
git checkout b281b0921b636bc36ad05c0b0b0763bd6dd43463
|
| 110 |
+
# change to the repository directory
|
| 111 |
+
cd lm-evaluation-harness
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
## Contact Us
|
| 115 |
+
|
| 116 |
+
### About Upstage
|
| 117 |
+
- [Upstage](https://en.upstage.ai) is a company specialized in Large Language Models (LLMs) and AI. We will help you build private LLMs and related applications.
|
| 118 |
+
If you have a dataset to build domain specific LLMs or make LLM applications, please contact us at ► [click here to contact](https://www.upstage.ai/private-llm?utm_source=huggingface&utm_medium=link&utm_campaign=privatellm)
|
| 119 |
+
- As of August 1st, our 70B model has reached the top spot in openLLM rankings, marking itself as the current leading performer globally. ","{""id"": ""upstage/SOLAR-0-70b-16bit"", ""author"": ""upstage"", ""sha"": ""43ff16100b9aec3c4d0c56116796149c1c455efc"", ""last_modified"": ""2023-09-13 09:14:02+00:00"", ""created_at"": ""2023-07-30 01:10:53+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 3114, ""downloads_all_time"": null, ""likes"": 258, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""llama"", ""text-generation"", ""upstage"", ""llama-2"", ""instruct"", ""instruction"", ""en"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- en\npipeline_tag: text-generation\ntags:\n- upstage\n- llama-2\n- instruct\n- instruction"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": {""__type"": ""AddedToken"", ""content"": ""<s>"", ""lstrip"": false, ""normalized"": false, ""rstrip"": false, ""single_word"": false}, ""eos_token"": {""__type"": ""AddedToken"", ""content"": ""</s>"", ""lstrip"": false, ""normalized"": false, ""rstrip"": false, ""single_word"": false}, ""pad_token"": null, ""unk_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": false, ""rstrip"": false, ""single_word"": false}}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00004-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00005-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00006-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00007-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00008-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00009-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00010-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00011-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00012-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00013-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00014-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00015-of-00015.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Intel/low_bit_open_llm_leaderboard"", ""BAAI/open_cn_llm_leaderboard"", ""gsaivinay/open_llm_leaderboard"", ""GTBench/GTBench"", ""Vikhrmodels/small-shlepa-lb"", ""kz-transformers/kaz-llm-lb"", ""felixz/open_llm_leaderboard"", ""OPTML-Group/UnlearnCanvas-Benchmark"", ""BAAI/open_flageval_vlm_leaderboard"", ""neubla/neubla-llm-evaluation-board"", ""Raju2024/TestLLM"", ""deggimatt/upstage-SOLAR-0-70b-16bit2"", ""ka1kuk/litellm"", ""rodrigomasini/data_only_open_llm_leaderboard"", ""Docfile/open_llm_leaderboard"", ""realzdlegend/Edu-Instructor"", ""deggimatt/upstage-SOLAR-0-70b-16bittt"", ""WillRegsiter/upstage-Llama-2-70b-instruct-v2"", ""neorocke/upstage-SOLAR-0-70b-16bit"", ""mmmnmmm/upstage-SOLAR-0-70b-16bit"", ""Parallel-Pete/upstage-Llama-2-70b-instruct-v2"", ""Chaskins/upstage-Llama-2-70b-instruct-v2"", ""willdzierson/upstage-Llama-2-70b-instruct-v2"", ""qumy/upstage-Llama-2-70b-instruct-v2"", ""sirmuelemos/upstage-Llama-2-70b-instruct-v2"", ""swaid/upstage-Llama-2-70b-instruct-v2"", ""LorenzoNava/upstage-Llama-2-70b-instruct-v2"", ""nonhuman/nnnn"", ""Cupcakus/upstage-Llama-2-70b-sinstruct-v2"", ""Cupcakus/upstage-Llama-2-70b-instruct-v2"", ""smothiki/open_llm_leaderboard"", ""grea/upstage-Llama-2-70b-instruct-v2"", ""zivzhao/upstage-Llama-2-70b-instruct-v2"", ""saidloyens/upstage-Llama-2-70b-instruct-v2"", ""mitvaghani/upstage-Llama-2-70b-instruct-v2"", ""EvanLong/upstage-Llama-2-70b-instruct-v2"", ""syberneo/upstage-Llama-2-70b-instruct-v2"", ""wowa3520/upstage-SOLAR-0-70b-16bit"", ""jskinner215/llma_tabular_qa"", ""iphann/upstage-SOLAR-0-70b-16bit"", ""0x1668/open_llm_leaderboard"", ""pngwn/open_llm_leaderboard-check"", ""ahmetdmr10003/upstage-SOLAR-0-70b-16bit"", ""tamemway/upstage-SOLAR-0-70b-16bit"", ""joaopaulopresa/workshop_llm_ufg_chatbot"", ""asir0z/open_llm_leaderboard"", ""kbmlcoding/open_llm_leaderboard_free"", ""kenken999/litellm"", ""kenken999/litellmlope"", ""aichampions/open_llm_leaderboard"", ""Adeco/open_llm_leaderboard"", ""anirudh937/open_llm_leaderboard"", ""smothiki/open_llm_leaderboard2"", ""Asiya057/Incarna-Mind"", ""Asiya057/Incarna-Mind-POC"", ""mjalg/IFEvalTR""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-09-13 09:14:02+00:00"", ""cardData"": ""language:\n- en\npipeline_tag: text-generation\ntags:\n- upstage\n- llama-2\n- instruct\n- instruction"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""64c5b89db496b4e17690cfb4"", ""modelId"": ""upstage/SOLAR-0-70b-16bit"", ""usedStorage"": 275907501483}",0,https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML,1,,0,"https://huggingface.co/mradermacher/SOLAR-0-70b-16bit-GGUF, https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GPTQ, https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGUF, https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-AWQ, https://huggingface.co/mradermacher/SOLAR-0-70b-16bit-i1-GGUF",5,,0,"Asiya057/Incarna-Mind, BAAI/open_cn_llm_leaderboard, BAAI/open_flageval_vlm_leaderboard, Cupcakus/upstage-Llama-2-70b-instruct-v2, GTBench/GTBench, HuggingFaceH4/open_llm_leaderboard, Intel/low_bit_open_llm_leaderboard, OPTML-Group/UnlearnCanvas-Benchmark, Vikhrmodels/small-shlepa-lb, felixz/open_llm_leaderboard, gsaivinay/open_llm_leaderboard, huggingface/InferenceSupport/discussions/new?title=upstage/SOLAR-0-70b-16bit&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bupstage%2FSOLAR-0-70b-16bit%5D(%2Fupstage%2FSOLAR-0-70b-16bit)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kz-transformers/kaz-llm-lb, neubla/neubla-llm-evaluation-board",14
|
| 120 |
+
TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML,"---
|
| 121 |
+
language:
|
| 122 |
+
- en
|
| 123 |
+
license: llama2
|
| 124 |
+
tags:
|
| 125 |
+
- upstage
|
| 126 |
+
- llama-2
|
| 127 |
+
- instruct
|
| 128 |
+
- instruction
|
| 129 |
+
model_name: Llama 2 70B Instruct v2
|
| 130 |
+
inference: false
|
| 131 |
+
model_creator: Upstage
|
| 132 |
+
model_link: https://huggingface.co/upstage/Llama-2-70b-instruct-v2
|
| 133 |
+
model_type: llama
|
| 134 |
+
pipeline_tag: text-generation
|
| 135 |
+
quantized_by: TheBloke
|
| 136 |
+
base_model: upstage/Llama-2-70b-instruct-v2
|
| 137 |
+
---
|
| 138 |
+
|
| 139 |
+
<!-- header start -->
|
| 140 |
+
<!-- 200823 -->
|
| 141 |
+
<div style=""width: auto; margin-left: auto; margin-right: auto"">
|
| 142 |
+
<img src=""https://i.imgur.com/EBdldam.jpg"" alt=""TheBlokeAI"" style=""width: 100%; min-width: 400px; display: block; margin: auto;"">
|
| 143 |
+
</div>
|
| 144 |
+
<div style=""display: flex; justify-content: space-between; width: 100%;"">
|
| 145 |
+
<div style=""display: flex; flex-direction: column; align-items: flex-start;"">
|
| 146 |
+
<p style=""margin-top: 0.5em; margin-bottom: 0em;""><a href=""https://discord.gg/theblokeai"">Chat & support: TheBloke's Discord server</a></p>
|
| 147 |
+
</div>
|
| 148 |
+
<div style=""display: flex; flex-direction: column; align-items: flex-end;"">
|
| 149 |
+
<p style=""margin-top: 0.5em; margin-bottom: 0em;""><a href=""https://www.patreon.com/TheBlokeAI"">Want to contribute? TheBloke's Patreon page</a></p>
|
| 150 |
+
</div>
|
| 151 |
+
</div>
|
| 152 |
+
<div style=""text-align:center; margin-top: 0em; margin-bottom: 0em""><p style=""margin-top: 0.25em; margin-bottom: 0em;"">TheBloke's LLM work is generously supported by a grant from <a href=""https://a16z.com"">andreessen horowitz (a16z)</a></p></div>
|
| 153 |
+
<hr style=""margin-top: 1.0em; margin-bottom: 1.0em;"">
|
| 154 |
+
<!-- header end -->
|
| 155 |
+
|
| 156 |
+
# Llama 2 70B Instruct v2 - GGML
|
| 157 |
+
- Model creator: [Upstage](https://huggingface.co/Upstage)
|
| 158 |
+
- Original model: [Llama 2 70B Instruct v2](https://huggingface.co/upstage/Llama-2-70b-instruct-v2)
|
| 159 |
+
|
| 160 |
+
## Description
|
| 161 |
+
|
| 162 |
+
This repo contains GGML format model files for [Upstage's Llama 2 70B Instruct v2](https://huggingface.co/upstage/Llama-2-70b-instruct-v2).
|
| 163 |
+
|
| 164 |
+
### Important note regarding GGML files.
|
| 165 |
+
|
| 166 |
+
The GGML format has now been superseded by GGUF. As of August 21st 2023, [llama.cpp](https://github.com/ggerganov/llama.cpp) no longer supports GGML models. Third party clients and libraries are expected to still support it for a time, but many may also drop support.
|
| 167 |
+
|
| 168 |
+
Please use the GGUF models instead.
|
| 169 |
+
|
| 170 |
+
### About GGML
|
| 171 |
+
|
| 172 |
+
GPU acceleration is now available for Llama 2 70B GGML files, with both CUDA (NVidia) and Metal (macOS). The following clients/libraries are known to work with these files, including with GPU acceleration:
|
| 173 |
+
* [llama.cpp](https://github.com/ggerganov/llama.cpp), commit `e76d630` and later.
|
| 174 |
+
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI.
|
| 175 |
+
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), version 1.37 and later. A powerful GGML web UI, especially good for story telling.
|
| 176 |
+
* [LM Studio](https://lmstudio.ai/), a fully featured local GUI with GPU acceleration for both Windows and macOS. Use 0.1.11 or later for macOS GPU acceleration with 70B models.
|
| 177 |
+
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), version 0.1.77 and later. A Python library with LangChain support, and OpenAI-compatible API server.
|
| 178 |
+
* [ctransformers](https://github.com/marella/ctransformers), version 0.2.15 and later. A Python library with LangChain support, and OpenAI-compatible API server.
|
| 179 |
+
|
| 180 |
+
## Repositories available
|
| 181 |
+
|
| 182 |
+
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GPTQ)
|
| 183 |
+
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGUF)
|
| 184 |
+
* [2, 3, 4, 5, 6 and 8-bit GGML models for CPU+GPU inference (deprecated)](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML)
|
| 185 |
+
* [Upstage's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/upstage/Llama-2-70b-instruct-v2)
|
| 186 |
+
|
| 187 |
+
## Prompt template: Orca-Hashes
|
| 188 |
+
|
| 189 |
+
```
|
| 190 |
+
### System:
|
| 191 |
+
{system_message}
|
| 192 |
+
|
| 193 |
+
### User:
|
| 194 |
+
{prompt}
|
| 195 |
+
|
| 196 |
+
### Assistant:
|
| 197 |
+
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
<!-- compatibility_ggml start -->
|
| 201 |
+
## Compatibility
|
| 202 |
+
|
| 203 |
+
### Works with llama.cpp [commit `e76d630`](https://github.com/ggerganov/llama.cpp/commit/e76d630df17e235e6b9ef416c45996765d2e36fb) until August 21st, 2023
|
| 204 |
+
|
| 205 |
+
Will not work with `llama.cpp` after commit [dadbed99e65252d79f81101a392d0d6497b86caa](https://github.com/ggerganov/llama.cpp/commit/dadbed99e65252d79f81101a392d0d6497b86caa).
|
| 206 |
+
|
| 207 |
+
For compatibility with latest llama.cpp, please use GGUF files instead.
|
| 208 |
+
|
| 209 |
+
Or one of the other tools and libraries listed above.
|
| 210 |
+
|
| 211 |
+
To use in llama.cpp, you must add `-gqa 8` argument.
|
| 212 |
+
|
| 213 |
+
For other UIs and libraries, please check the docs.
|
| 214 |
+
|
| 215 |
+
## Explanation of the new k-quant methods
|
| 216 |
+
<details>
|
| 217 |
+
<summary>Click to see details</summary>
|
| 218 |
+
|
| 219 |
+
The new methods available are:
|
| 220 |
+
* GGML_TYPE_Q2_K - ""type-1"" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
|
| 221 |
+
* GGML_TYPE_Q3_K - ""type-0"" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
|
| 222 |
+
* GGML_TYPE_Q4_K - ""type-1"" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
|
| 223 |
+
* GGML_TYPE_Q5_K - ""type-1"" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
|
| 224 |
+
* GGML_TYPE_Q6_K - ""type-0"" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
|
| 225 |
+
* GGML_TYPE_Q8_K - ""type-0"" 8-bit quantization. Only used for quantizing intermediate results. The difference to the existing Q8_0 is that the block size is 256. All 2-6 bit dot products are implemented for this quantization type.
|
| 226 |
+
|
| 227 |
+
Refer to the Provided Files table below to see what files use which methods, and how.
|
| 228 |
+
</details>
|
| 229 |
+
<!-- compatibility_ggml end -->
|
| 230 |
+
|
| 231 |
+
## Provided files
|
| 232 |
+
|
| 233 |
+
| Name | Quant method | Bits | Size | Max RAM required | Use case |
|
| 234 |
+
| ---- | ---- | ---- | ---- | ---- | ----- |
|
| 235 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q2_K.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q2_K.bin) | q2_K | 2 | 28.59 GB| 31.09 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.vw and feed_forward.w2 tensors, GGML_TYPE_Q2_K for the other tensors. |
|
| 236 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q3_K_S.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q3_K_S.bin) | q3_K_S | 3 | 29.75 GB| 32.25 GB | New k-quant method. Uses GGML_TYPE_Q3_K for all tensors |
|
| 237 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q3_K_M.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q3_K_M.bin) | q3_K_M | 3 | 33.04 GB| 35.54 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
|
| 238 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q3_K_L.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q3_K_L.bin) | q3_K_L | 3 | 36.15 GB| 38.65 GB | New k-quant method. Uses GGML_TYPE_Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
|
| 239 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q4_0.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q4_0.bin) | q4_0 | 4 | 38.87 GB| 41.37 GB | Original quant method, 4-bit. |
|
| 240 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q4_K_S.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q4_K_S.bin) | q4_K_S | 4 | 38.87 GB| 41.37 GB | New k-quant method. Uses GGML_TYPE_Q4_K for all tensors |
|
| 241 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q4_K_M.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q4_K_M.bin) | q4_K_M | 4 | 41.38 GB| 43.88 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q4_K |
|
| 242 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q4_1.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q4_1.bin) | q4_1 | 4 | 43.17 GB| 45.67 GB | Original quant method, 4-bit. Higher accuracy than q4_0 but not as high as q5_0. However has quicker inference than q5 models. |
|
| 243 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q5_0.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q5_0.bin) | q5_0 | 5 | 47.46 GB| 49.96 GB | Original quant method, 5-bit. Higher accuracy, higher resource usage and slower inference. |
|
| 244 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q5_K_S.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q5_K_S.bin) | q5_K_S | 5 | 47.46 GB| 49.96 GB | New k-quant method. Uses GGML_TYPE_Q5_K for all tensors |
|
| 245 |
+
| [upstage-llama-2-70b-instruct-v2.ggmlv3.q5_K_M.bin](https://huggingface.co/TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML/blob/main/upstage-llama-2-70b-instruct-v2.ggmlv3.q5_K_M.bin) | q5_K_M | 5 | 48.75 GB| 51.25 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q5_K |
|
| 246 |
+
|
| 247 |
+
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
|
| 248 |
+
|
| 249 |
+
## How to run in `llama.cpp`
|
| 250 |
+
|
| 251 |
+
Make sure you are using `llama.cpp` from commit [dadbed99e65252d79f81101a392d0d6497b86caa](https://github.com/ggerganov/llama.cpp/commit/dadbed99e65252d79f81101a392d0d6497b86caa) or earlier.
|
| 252 |
+
|
| 253 |
+
For compatibility with latest llama.cpp, please use GGUF files instead.
|
| 254 |
+
|
| 255 |
+
I use the following command line; adjust for your tastes and needs:
|
| 256 |
+
|
| 257 |
+
```
|
| 258 |
+
./main -t 10 -ngl 40 -gqa 8 -m upstage-llama-2-70b-instruct-v2.ggmlv3.q4_K_M.bin --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p ""### System:\n{system_message}\n\n### User:\n{prompt}\n\n### Assistant:""
|
| 259 |
+
```
|
| 260 |
+
Change `-t 10` to the number of physical CPU cores you have. For example if your system has 8 cores/16 threads, use `-t 8`. If you are fully offloading the model to GPU, use `-t 1`
|
| 261 |
+
|
| 262 |
+
Change `-ngl 40` to the number of GPU layers you have VRAM for. Use `-ngl 100` to offload all layers to VRAM - if you have a 48GB card, or 2 x 24GB, or similar. Otherwise you can partially offload as many as you have VRAM for, on one or more GPUs.
|
| 263 |
+
|
| 264 |
+
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
|
| 265 |
+
|
| 266 |
+
Remember the `-gqa 8` argument, required for Llama 70B models.
|
| 267 |
+
|
| 268 |
+
Change `-c 4096` to the desired sequence length for this model. For models that use RoPE, add `--rope-freq-base 10000 --rope-freq-scale 0.5` for doubled context, or `--rope-freq-base 10000 --rope-freq-scale 0.25` for 4x context.
|
| 269 |
+
|
| 270 |
+
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
|
| 271 |
+
|
| 272 |
+
## How to run in `text-generation-webui`
|
| 273 |
+
|
| 274 |
+
Further instructions here: [text-generation-webui/docs/llama.cpp-models.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp-models.md).
|
| 275 |
+
|
| 276 |
+
<!-- footer start -->
|
| 277 |
+
<!-- 200823 -->
|
| 278 |
+
## Discord
|
| 279 |
+
|
| 280 |
+
For further support, and discussions on these models and AI in general, join us at:
|
| 281 |
+
|
| 282 |
+
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
|
| 283 |
+
|
| 284 |
+
## Thanks, and how to contribute.
|
| 285 |
+
|
| 286 |
+
Thanks to the [chirper.ai](https://chirper.ai) team!
|
| 287 |
+
|
| 288 |
+
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
|
| 289 |
+
|
| 290 |
+
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
|
| 291 |
+
|
| 292 |
+
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
|
| 293 |
+
|
| 294 |
+
* Patreon: https://patreon.com/TheBlokeAI
|
| 295 |
+
* Ko-Fi: https://ko-fi.com/TheBlokeAI
|
| 296 |
+
|
| 297 |
+
**Special thanks to**: Aemon Algiz.
|
| 298 |
+
|
| 299 |
+
**Patreon special mentions**: Russ Johnson, J, alfie_i, Alex, NimbleBox.ai, Chadd, Mandus, Nikolai Manek, Ken Nordquist, ya boyyy, Illia Dulskyi, Viktor Bowallius, vamX, Iucharbius, zynix, Magnesian, Clay Pascal, Pierre Kircher, Enrico Ros, Tony Hughes, Elle, Andrey, knownsqashed, Deep Realms, Jerry Meng, Lone Striker, Derek Yates, Pyrater, Mesiah Bishop, James Bentley, Femi Adebogun, Brandon Frisco, SuperWojo, Alps Aficionado, Michael Dempsey, Vitor Caleffi, Will Dee, Edmond Seymore, usrbinkat, LangChain4j, Kacper Wikieł, Luke Pendergrass, John Detwiler, theTransient, Nathan LeClaire, Tiffany J. Kim, biorpg, Eugene Pentland, Stanislav Ovsiannikov, Fred von Graf, terasurfer, Kalila, Dan Guido, Nitin Borwankar, 阿明, Ai Maven, John Villwock, Gabriel Puliatti, Stephen Murray, Asp the Wyvern, danny, Chris Smitley, ReadyPlayerEmma, S_X, Daniel P. Andersen, Olakabola, Jeffrey Morgan, Imad Khwaja, Caitlyn Gatomon, webtim, Alicia Loh, Trenton Dambrowitz, Swaroop Kallakuri, Erik Bjäreholt, Leonard Tan, Spiking Neurons AB, Luke @flexchar, Ajan Kanaga, Thomas Belote, Deo Leter, RoA, Willem Michiel, transmissions 11, subjectnull, Matthew Berman, Joseph William Delisle, David Ziegler, Michael Davis, Johann-Peter Hartmann, Talal Aujan, senxiiz, Artur Olbinski, Rainer Wilmers, Spencer Kim, Fen Risland, Cap'n Zoog, Rishabh Srivastava, Michael Levine, Geoffrey Montalvo, Sean Connelly, Alexandros Triantafyllidis, Pieter, Gabriel Tamborski, Sam, Subspace Studios, Junyu Yang, Pedro Madruga, Vadim, Cory Kujawski, K, Raven Klaugh, Randy H, Mano Prime, Sebastain Graf, Space Cruiser
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
Thank you to all my generous patrons and donaters!
|
| 303 |
+
|
| 304 |
+
And thank you again to a16z for their generous grant.
|
| 305 |
+
|
| 306 |
+
<!-- footer end -->
|
| 307 |
+
|
| 308 |
+
# Original model card: Upstage's Llama 2 70B Instruct v2
|
| 309 |
+
|
| 310 |
+
# SOLAR-0-70b-16bit model card
|
| 311 |
+
The model name has been changed from LLaMa-2-70b-instruct-v2 to SOLAR-0-70b-16bit
|
| 312 |
+
|
| 313 |
+
## Model Details
|
| 314 |
+
|
| 315 |
+
* **Developed by**: [Upstage](https://en.upstage.ai)
|
| 316 |
+
* **Backbone Model**: [LLaMA-2](https://github.com/facebookresearch/llama/tree/main)
|
| 317 |
+
* **Language(s)**: English
|
| 318 |
+
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
|
| 319 |
+
* **License**: Fine-tuned checkpoints is licensed under the Non-Commercial Creative Commons license ([CC BY-NC-4.0](https://creativecommons.org/licenses/by-nc/4.0/))
|
| 320 |
+
* **Where to send comments**: Instructions on how to provide feedback or comments on a model can be found by opening an issue in the [Hugging Face community's model repository](https://huggingface.co/upstage/Llama-2-70b-instruct-v2/discussions)
|
| 321 |
+
* **Contact**: For questions and comments about the model, please email [contact@upstage.ai](mailto:contact@upstage.ai)
|
| 322 |
+
|
| 323 |
+
## Dataset Details
|
| 324 |
+
|
| 325 |
+
### Used Datasets
|
| 326 |
+
- Orca-style dataset
|
| 327 |
+
- Alpaca-style dataset
|
| 328 |
+
- No other dataset was used except for the dataset mentioned above
|
| 329 |
+
- No benchmark test set or the training set are used
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
### Prompt Template
|
| 333 |
+
```
|
| 334 |
+
### System:
|
| 335 |
+
{System}
|
| 336 |
+
|
| 337 |
+
### User:
|
| 338 |
+
{User}
|
| 339 |
+
|
| 340 |
+
### Assistant:
|
| 341 |
+
{Assistant}
|
| 342 |
+
```
|
| 343 |
+
|
| 344 |
+
## Usage
|
| 345 |
+
|
| 346 |
+
- The followings are tested on A100 80GB
|
| 347 |
+
- Our model can handle up to 10k+ input tokens, thanks to the `rope_scaling` option
|
| 348 |
+
|
| 349 |
+
```python
|
| 350 |
+
import torch
|
| 351 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
|
| 352 |
+
|
| 353 |
+
tokenizer = AutoTokenizer.from_pretrained(""upstage/Llama-2-70b-instruct-v2"")
|
| 354 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 355 |
+
""upstage/Llama-2-70b-instruct-v2"",
|
| 356 |
+
device_map=""auto"",
|
| 357 |
+
torch_dtype=torch.float16,
|
| 358 |
+
load_in_8bit=True,
|
| 359 |
+
rope_scaling={""type"": ""dynamic"", ""factor"": 2} # allows handling of longer inputs
|
| 360 |
+
)
|
| 361 |
+
|
| 362 |
+
prompt = ""### User:\nThomas is healthy, but he has to go to the hospital. What could be the reasons?\n\n### Assistant:\n""
|
| 363 |
+
inputs = tokenizer(prompt, return_tensors=""pt"").to(model.device)
|
| 364 |
+
del inputs[""token_type_ids""]
|
| 365 |
+
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
|
| 366 |
+
|
| 367 |
+
output = model.generate(**inputs, streamer=streamer, use_cache=True, max_new_tokens=float('inf'))
|
| 368 |
+
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
|
| 369 |
+
```
|
| 370 |
+
|
| 371 |
+
## Hardware and Software
|
| 372 |
+
|
| 373 |
+
* **Hardware**: We utilized an A100x8 * 4 for training our model
|
| 374 |
+
* **Training Factors**: We fine-tuned this model using a combination of the [DeepSpeed library](https://github.com/microsoft/DeepSpeed) and the [HuggingFace Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) / [HuggingFace Accelerate](https://huggingface.co/docs/accelerate/index)
|
| 375 |
+
|
| 376 |
+
## Evaluation Results
|
| 377 |
+
|
| 378 |
+
### Overview
|
| 379 |
+
- We conducted a performance evaluation following the tasks being evaluated on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
|
| 380 |
+
We evaluated our model on four benchmark datasets, which include `ARC-Challenge`, `HellaSwag`, `MMLU`, and `TruthfulQA`
|
| 381 |
+
We used the [lm-evaluation-harness repository](https://github.com/EleutherAI/lm-evaluation-harness), specifically commit [b281b0921b636bc36ad05c0b0b0763bd6dd43463](https://github.com/EleutherAI/lm-evaluation-harness/tree/b281b0921b636bc36ad05c0b0b0763bd6dd43463).
|
| 382 |
+
- We used [MT-bench](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge), a set of challenging multi-turn open-ended questions, to evaluate the models
|
| 383 |
+
|
| 384 |
+
### Main Results
|
| 385 |
+
| Model | H4(Avg) | ARC | HellaSwag | MMLU | TruthfulQA | | MT_Bench |
|
| 386 |
+
|--------------------------------------------------------------------|----------|----------|----------|------|----------|-|-------------|
|
| 387 |
+
| **[Llama-2-70b-instruct-v2](https://huggingface.co/upstage/Llama-2-70b-instruct-v2)**(***Ours***, ***Open LLM Leaderboard***) | **73** | **71.1** | **87.9** | **70.6** | **62.2** | | **7.44063** |
|
| 388 |
+
| [Llama-2-70b-instruct](https://huggingface.co/upstage/Llama-2-70b-instruct) (Ours, Open LLM Leaderboard) | 72.3 | 70.9 | 87.5 | 69.8 | 61 | | 7.24375 |
|
| 389 |
+
| [llama-65b-instruct](https://huggingface.co/upstage/llama-65b-instruct) (Ours, Open LLM Leaderboard) | 69.4 | 67.6 | 86.5 | 64.9 | 58.8 | | |
|
| 390 |
+
| Llama-2-70b-hf | 67.3 | 67.3 | 87.3 | 69.8 | 44.9 | | |
|
| 391 |
+
| [llama-30b-instruct-2048](https://huggingface.co/upstage/llama-30b-instruct-2048) (Ours, Open LLM Leaderboard) | 67.0 | 64.9 | 84.9 | 61.9 | 56.3 | | |
|
| 392 |
+
| [llama-30b-instruct](https://huggingface.co/upstage/llama-30b-instruct) (Ours, Open LLM Leaderboard) | 65.2 | 62.5 | 86.2 | 59.4 | 52.8 | | |
|
| 393 |
+
| llama-65b | 64.2 | 63.5 | 86.1 | 63.9 | 43.4 | | |
|
| 394 |
+
| falcon-40b-instruct | 63.4 | 61.6 | 84.3 | 55.4 | 52.5 | | |
|
| 395 |
+
|
| 396 |
+
### Scripts for H4 Score Reproduction
|
| 397 |
+
- Prepare evaluation environments:
|
| 398 |
+
```
|
| 399 |
+
# clone the repository
|
| 400 |
+
git clone https://github.com/EleutherAI/lm-evaluation-harness.git
|
| 401 |
+
# check out the specific commit
|
| 402 |
+
git checkout b281b0921b636bc36ad05c0b0b0763bd6dd43463
|
| 403 |
+
# change to the repository directory
|
| 404 |
+
cd lm-evaluation-harness
|
| 405 |
+
```
|
| 406 |
+
|
| 407 |
+
## Contact Us
|
| 408 |
+
|
| 409 |
+
### About Upstage
|
| 410 |
+
- [Upstage](https://en.upstage.ai) is a company specialized in Large Language Models (LLMs) and AI. We will help you build private LLMs and related applications.
|
| 411 |
+
If you have a dataset to build domain specific LLMs or make LLM applications, please contact us at ► [click here to contact](https://www.upstage.ai/private-llm?utm_source=huggingface&utm_medium=link&utm_campaign=privatellm)
|
| 412 |
+
- As of August 1st, our 70B model has reached the top spot in openLLM rankings, marking itself as the current leading performer globally.
|
| 413 |
+
","{""id"": ""TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML"", ""author"": ""TheBloke"", ""sha"": ""d489e472fac5abdd7add353e2ac1723f9c9ade7c"", ""last_modified"": ""2023-09-27 13:00:37+00:00"", ""created_at"": ""2023-07-31 07:19:26+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 6, ""downloads_all_time"": null, ""likes"": 22, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""llama"", ""upstage"", ""llama-2"", ""instruct"", ""instruction"", ""text-generation"", ""en"", ""base_model:upstage/SOLAR-0-70b-16bit"", ""base_model:finetune:upstage/SOLAR-0-70b-16bit"", ""license:llama2"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: upstage/Llama-2-70b-instruct-v2\nlanguage:\n- en\nlicense: llama2\nmodel_name: Llama 2 70B Instruct v2\npipeline_tag: text-generation\ntags:\n- upstage\n- llama-2\n- instruct\n- instruction\ninference: false\nmodel_creator: Upstage\nmodel_link: https://huggingface.co/upstage/Llama-2-70b-instruct-v2\nmodel_type: llama\nquantized_by: TheBloke"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""model_type"": ""llama""}, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Notice', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='USE_POLICY.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q2_K.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q3_K_L.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q3_K_M.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q3_K_S.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q4_0.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q4_1.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q4_K_M.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q4_K_S.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q5_0.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q5_1.z01', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q5_1.zip', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q5_K_M.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q5_K_S.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q6_K.z01', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q6_K.zip', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q8_0.z01', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='upstage-llama-2-70b-instruct-v2.ggmlv3.q8_0.zip', size=None, blob_id=None, lfs=None)""], ""spaces"": [""mikeee/llama-2-70b-guanaco-qlora-ggml"", ""mikeee/wizardlm-1.0-uncensored-llama2-13b-ggmlv3""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-09-27 13:00:37+00:00"", ""cardData"": ""base_model: upstage/Llama-2-70b-instruct-v2\nlanguage:\n- en\nlicense: llama2\nmodel_name: Llama 2 70B Instruct v2\npipeline_tag: text-generation\ntags:\n- upstage\n- llama-2\n- instruct\n- instruction\ninference: false\nmodel_creator: Upstage\nmodel_link: https://huggingface.co/upstage/Llama-2-70b-instruct-v2\nmodel_type: llama\nquantized_by: TheBloke"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""64c7607e468c429ae8356e64"", ""modelId"": ""TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML"", ""usedStorage"": 615062359876}",1,,0,,0,,0,,0,"HuggingFaceH4/open_llm_leaderboard, huggingface/InferenceSupport/discussions/new?title=TheBloke/Upstage-Llama-2-70B-instruct-v2-GGML&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BTheBloke%2FUpstage-Llama-2-70B-instruct-v2-GGML%5D(%2FTheBloke%2FUpstage-Llama-2-70B-instruct-v2-GGML)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, mikeee/llama-2-70b-guanaco-qlora-ggml, mikeee/wizardlm-1.0-uncensored-llama2-13b-ggmlv3",4
|
SpatialLM-Llama-1B_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
@@ -0,0 +1,233 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
manycore-research/SpatialLM-Llama-1B,"---
|
| 3 |
+
license: llama3.2
|
| 4 |
+
library_name: transformers
|
| 5 |
+
base_model:
|
| 6 |
+
- meta-llama/Llama-3.2-1B-Instruct
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# SpatialLM-Llama-1B
|
| 10 |
+
|
| 11 |
+
<!-- markdownlint-disable first-line-h1 -->
|
| 12 |
+
<!-- markdownlint-disable html -->
|
| 13 |
+
<!-- markdownlint-disable no-duplicate-header -->
|
| 14 |
+
|
| 15 |
+
<div align=""center"">
|
| 16 |
+
<picture>
|
| 17 |
+
<source srcset=""https://cdn-uploads.huggingface.co/production/uploads/63efbb1efc92a63ac81126d0/_dK14CT3do8rBG3QrHUjN.png"" media=""(prefers-color-scheme: dark)"">
|
| 18 |
+
<img src=""https://cdn-uploads.huggingface.co/production/uploads/63efbb1efc92a63ac81126d0/bAZyeIXOMVASHR6-xVlQU.png"" width=""60%"" alt=""SpatialLM""""/>
|
| 19 |
+
</picture>
|
| 20 |
+
</div>
|
| 21 |
+
<hr style=""margin-top: 0; margin-bottom: 8px;"">
|
| 22 |
+
<div align=""center"" style=""margin-top: 0; padding-top: 0; line-height: 1;"">
|
| 23 |
+
<a href=""https://manycore-research.github.io/SpatialLM"" target=""_blank"" style=""margin: 2px;""><img alt=""Project""
|
| 24 |
+
src=""https://img.shields.io/badge/🌐%20Website-SpatialLM-ffc107?color=42a5f5&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/></a>
|
| 25 |
+
<a href=""https://github.com/manycore-research/SpatialLM"" target=""_blank"" style=""margin: 2px;""><img alt=""GitHub""
|
| 26 |
+
src=""https://img.shields.io/badge/GitHub-SpatialLM-24292e?logo=github&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/></a>
|
| 27 |
+
</div>
|
| 28 |
+
<div align=""center"" style=""line-height: 1;"">
|
| 29 |
+
<a href=""https://huggingface.co/manycore-research/SpatialLM-Llama-1B"" target=""_blank"" style=""margin: 2px;""><img alt=""Hugging Face""
|
| 30 |
+
src=""https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-SpatialLM%201B-ffc107?color=ffc107&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/></a>
|
| 31 |
+
<a href=""https://huggingface.co/datasets/manycore-research/SpatialLM-Testset"" target=""_blank"" style=""margin: 2px;""><img alt=""Dataset""
|
| 32 |
+
src=""https://img.shields.io/badge/%F0%9F%A4%97%20Dataset-SpatialLM-ffc107?color=ffc107&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/></a>
|
| 33 |
+
</div>
|
| 34 |
+
|
| 35 |
+
## Introduction
|
| 36 |
+
|
| 37 |
+
SpatialLM is a 3D large language model designed to process 3D point cloud data and generate structured 3D scene understanding outputs. These outputs include architectural elements like walls, doors, windows, and oriented object bounding boxes with their semantic categories. Unlike previous methods that require specialized equipment for data collection, SpatialLM can handle point clouds from diverse sources such as monocular video sequences, RGBD images, and LiDAR sensors. This multimodal architecture effectively bridges the gap between unstructured 3D geometric data and structured 3D representations, offering high-level semantic understanding. It enhances spatial reasoning capabilities for applications in embodied robotics, autonomous navigation, and other complex 3D scene analysis tasks.
|
| 38 |
+
|
| 39 |
+
<div align=""center"">
|
| 40 |
+
<video controls autoplay src=""https://cdn-uploads.huggingface.co/production/uploads/63efbb1efc92a63ac81126d0/3bz_jNRCLD2L9uj11HPnP.mp4"" poster=""https://cdn-uploads.huggingface.co/production/uploads/63efbb1efc92a63ac81126d0/euo94dNx28qBNe51_oiB1.png""></video>
|
| 41 |
+
<p><i>SpatialLM reconstructs 3D layout from a monocular RGB video with MASt3R-SLAM. Results aligned to video with GT cameras for visualization.</i></p>
|
| 42 |
+
</div>
|
| 43 |
+
|
| 44 |
+
## SpatialLM Models
|
| 45 |
+
|
| 46 |
+
<div align=""center"">
|
| 47 |
+
|
| 48 |
+
| **Model** | **Download** |
|
| 49 |
+
| :-----------------: | ------------------------------------------------------------------------------ |
|
| 50 |
+
| SpatialLM-Llama-1B | [🤗 HuggingFace](https://huggingface.co/manycore-research/SpatialLM-Llama-1B) |
|
| 51 |
+
| SpatialLM-Qwen-0.5B | [🤗 HuggingFace](https://huggingface.co/manycore-research/SpatialLM-Qwen-0.5B) |
|
| 52 |
+
|
| 53 |
+
</div>
|
| 54 |
+
|
| 55 |
+
## Usage
|
| 56 |
+
|
| 57 |
+
### Installation
|
| 58 |
+
|
| 59 |
+
Tested with the following environment:
|
| 60 |
+
|
| 61 |
+
- Python 3.11
|
| 62 |
+
- Pytorch 2.4.1
|
| 63 |
+
- CUDA Version 12.4
|
| 64 |
+
|
| 65 |
+
```bash
|
| 66 |
+
# clone the repository
|
| 67 |
+
git clone https://github.com/manycore-research/SpatialLM.git
|
| 68 |
+
cd SpatialLM
|
| 69 |
+
|
| 70 |
+
# create a conda environment with cuda 12.4
|
| 71 |
+
conda create -n spatiallm python=3.11
|
| 72 |
+
conda activate spatiallm
|
| 73 |
+
conda install -y nvidia/label/cuda-12.4.0::cuda-toolkit conda-forge::sparsehash
|
| 74 |
+
|
| 75 |
+
# Install dependencies with poetry
|
| 76 |
+
pip install poetry && poetry config virtualenvs.create false --local
|
| 77 |
+
poetry install
|
| 78 |
+
poe install-torchsparse # Building wheel for torchsparse will take a while
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
### Inference
|
| 82 |
+
|
| 83 |
+
In the current version of SpatialLM, input point clouds are considered axis-aligned where the z-axis is the up axis. This orientation is crucial for maintaining consistency in spatial understanding and scene interpretation across different datasets and applications.
|
| 84 |
+
Example preprocessed point clouds, reconstructed from RGB videos using [MASt3R-SLAM](https://github.com/rmurai0610/MASt3R-SLAM), are available in [SpatialLM-Testset](#spatiallm-testset).
|
| 85 |
+
|
| 86 |
+
Download an example point cloud:
|
| 87 |
+
|
| 88 |
+
```bash
|
| 89 |
+
huggingface-cli download manycore-research/SpatialLM-Testset pcd/scene0000_00.ply --repo-type dataset --local-dir .
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
Run inference:
|
| 93 |
+
|
| 94 |
+
```bash
|
| 95 |
+
python inference.py --point_cloud pcd/scene0000_00.ply --output scene0000_00.txt --model_path manycore-research/SpatialLM-Llama-1B
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
### Visualization
|
| 99 |
+
|
| 100 |
+
Use `rerun` to visualize the point cloud and the predicted structured 3D layout output:
|
| 101 |
+
|
| 102 |
+
```bash
|
| 103 |
+
# Convert the predicted layout to Rerun format
|
| 104 |
+
python visualize.py --point_cloud pcd/scene0000_00.ply --layout scene0000_00.txt --save scene0000_00.rrd
|
| 105 |
+
|
| 106 |
+
# Visualize the point cloud and the predicted layout
|
| 107 |
+
rerun scene0000_00.rrd
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
### Evaluation
|
| 111 |
+
|
| 112 |
+
To evaluate the performance of SpatialLM, we provide `eval.py` script that reports the benchmark results on the SpatialLM-Testset in the table below in section [Benchmark Results](#benchmark-results).
|
| 113 |
+
|
| 114 |
+
Download the testset:
|
| 115 |
+
|
| 116 |
+
```bash
|
| 117 |
+
huggingface-cli download manycore-research/SpatialLM-Testset --repo-type dataset --local-dir SpatialLM-Testset
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
Run evaluation:
|
| 121 |
+
|
| 122 |
+
```bash
|
| 123 |
+
# Run inference on the PLY point clouds in folder SpatialLM-Testset/pcd with SpatialLM-Llama-1B model
|
| 124 |
+
python inference.py --point_cloud SpatialLM-Testset/pcd --output SpatialLM-Testset/pred --model_path manycore-research/SpatialLM-Llama-1B
|
| 125 |
+
|
| 126 |
+
# Evaluate the predicted layouts
|
| 127 |
+
python eval.py --metadata SpatialLM-Testset/test.csv --gt_dir SpatialLM-Testset/layout --pred_dir SpatialLM-Testset/pred --label_mapping SpatialLM-Testset/benchmark_categories.tsv
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
## SpatialLM Testset
|
| 131 |
+
|
| 132 |
+
We provide a test set of 107 preprocessed point clouds, reconstructed from RGB videos using [MASt3R-SLAM](https://github.com/rmurai0610/MASt3R-SLAM). SpatialLM-Testset is quite challenging compared to prior clean RGBD scans datasets due to the noises and occlusions in the point clouds reconstructed from monocular RGB videos.
|
| 133 |
+
|
| 134 |
+
<div align=""center"">
|
| 135 |
+
|
| 136 |
+
| **Dataset** | **Download** |
|
| 137 |
+
| :---------------: | ---------------------------------------------------------------------------------- |
|
| 138 |
+
| SpatialLM-Testset | [🤗 Datasets](https://huggingface.co/datasets/manycore-research/SpatialLM-TestSet) |
|
| 139 |
+
|
| 140 |
+
</div>
|
| 141 |
+
|
| 142 |
+
## Benchmark Results
|
| 143 |
+
|
| 144 |
+
Benchmark results on the challenging SpatialLM-Testset are reported in the following table:
|
| 145 |
+
|
| 146 |
+
<div align=""center"">
|
| 147 |
+
|
| 148 |
+
| **Method** | **SpatialLM-Llama-1B** | **SpatialLM-Qwen-0.5B** |
|
| 149 |
+
| ---------------- | ---------------------- | ----------------------- |
|
| 150 |
+
| **Floorplan** | **mean IoU** | |
|
| 151 |
+
| wall | 78.62 | 74.81 |
|
| 152 |
+
| | | |
|
| 153 |
+
| **Objects** | **F1 @.25 IoU (3D)** | |
|
| 154 |
+
| curtain | 27.35 | 28.59 |
|
| 155 |
+
| nightstand | 57.47 | 54.39 |
|
| 156 |
+
| chandelier | 38.92 | 40.12 |
|
| 157 |
+
| wardrobe | 23.33 | 30.60 |
|
| 158 |
+
| bed | 95.24 | 93.75 |
|
| 159 |
+
| sofa | 65.50 | 66.15 |
|
| 160 |
+
| chair | 21.26 | 14.94 |
|
| 161 |
+
| cabinet | 8.47 | 8.44 |
|
| 162 |
+
| dining table | 54.26 | 56.10 |
|
| 163 |
+
| plants | 20.68 | 26.46 |
|
| 164 |
+
| tv cabinet | 33.33 | 10.26 |
|
| 165 |
+
| coffee table | 50.00 | 55.56 |
|
| 166 |
+
| side table | 7.60 | 2.17 |
|
| 167 |
+
| air conditioner | 20.00 | 13.04 |
|
| 168 |
+
| dresser | 46.67 | 23.53 |
|
| 169 |
+
| | | |
|
| 170 |
+
| **Thin Objects** | **F1 @.25 IoU (2D)** | |
|
| 171 |
+
| painting | 50.04 | 53.81 |
|
| 172 |
+
| carpet | 31.76 | 45.31 |
|
| 173 |
+
| tv | 67.31 | 52.29 |
|
| 174 |
+
| door | 50.35 | 42.15 |
|
| 175 |
+
| window | 45.4 | 45.9 |
|
| 176 |
+
|
| 177 |
+
</div>
|
| 178 |
+
|
| 179 |
+
## License
|
| 180 |
+
|
| 181 |
+
SpatialLM-Llama-1B is derived from Llama3.2-1B-Instruct, which is licensed under the Llama3.2 license.
|
| 182 |
+
SpatialLM-Qwen-0.5B is derived from the Qwen-2.5 series, originally licensed under the Apache 2.0 License.
|
| 183 |
+
|
| 184 |
+
All models are built upon the SceneScript point cloud encoder, licensed under the CC-BY-NC-4.0 License. TorchSparse, utilized in this project, is licensed under the MIT License.
|
| 185 |
+
|
| 186 |
+
## Citation
|
| 187 |
+
|
| 188 |
+
If you find this work useful, please consider citing:
|
| 189 |
+
|
| 190 |
+
```bibtex
|
| 191 |
+
@misc{spatiallm,
|
| 192 |
+
title = {SpatialLM: Large Language Model for Spatial Understanding},
|
| 193 |
+
author = {ManyCore Research Team},
|
| 194 |
+
howpublished = {\url{https://github.com/manycore-research/SpatialLM}},
|
| 195 |
+
year = {2025}
|
| 196 |
+
}
|
| 197 |
+
```
|
| 198 |
+
|
| 199 |
+
## Acknowledgements
|
| 200 |
+
|
| 201 |
+
We would like to thank the following projects that made this work possible:
|
| 202 |
+
|
| 203 |
+
[Llama3.2](https://github.com/meta-llama) | [Qwen2.5](https://github.com/QwenLM/Qwen2.5) | [Transformers](https://github.com/huggingface/transformers) | [SceneScript](https://github.com/facebookresearch/scenescript) | [TorchSparse](https://github.com/mit-han-lab/torchsparse)
|
| 204 |
+
","{""id"": ""manycore-research/SpatialLM-Llama-1B"", ""author"": ""manycore-research"", ""sha"": ""0a4c5f368cfd32044f809f64187e4bb024e48fbb"", ""last_modified"": ""2025-03-21 05:38:34+00:00"", ""created_at"": ""2025-03-14 04:32:01+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 17316, ""downloads_all_time"": null, ""likes"": 955, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""spatiallm_llama"", ""text-generation"", ""conversational"", ""base_model:meta-llama/Llama-3.2-1B-Instruct"", ""base_model:finetune:meta-llama/Llama-3.2-1B-Instruct"", ""license:llama3.2"", ""autotrain_compatible"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- meta-llama/Llama-3.2-1B-Instruct\nlibrary_name: transformers\nlicense: llama3.2"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""SpatialLMLlamaForCausalLM""], ""model_type"": ""spatiallm_llama"", ""tokenizer_config"": {""bos_token"": ""<|begin_of_text|>"", ""chat_template"": ""{{- bos_token }}\n{%- if custom_tools is defined %}\n {%- set tools = custom_tools %}\n{%- endif %}\n{%- if not tools_in_user_message is defined %}\n {%- set tools_in_user_message = true %}\n{%- endif %}\n{%- if not date_string is defined %}\n {%- if strftime_now is defined %}\n {%- set date_string = strftime_now(\""%d %b %Y\"") %}\n {%- else %}\n {%- set date_string = \""26 Jul 2024\"" %}\n {%- endif %}\n{%- endif %}\n{%- if not tools is defined %}\n {%- set tools = none %}\n{%- endif %}\n\n{#- Custom tools are passed in a user message with some extra guidance #}\n{%- if tools_in_user_message and not tools is none %}\n {#- Extract the first user message so we can plug it in here #}\n {%- if messages | length != 0 %}\n {%- set first_user_message = messages[0]['content']|trim %}\n {%- set messages = messages[1:] %}\n {%- else %}\n {{- raise_exception(\""Cannot put tools in the first user message when there's no first user message!\"") }}\n{%- endif %}\n {{- '<|start_header_id|>user<|end_header_id|>\\n\\n' -}}\n {{- \""Given the following functions, please respond with a JSON for a function call \"" }}\n {{- \""with its proper arguments that best answers the given prompt.\\n\\n\"" }}\n {{- 'Respond in the format {\""name\"": function name, \""parameters\"": dictionary of argument name and its value}.' }}\n {{- \""Do not use variables.\\n\\n\"" }}\n {%- for t in tools %}\n {{- t | tojson(indent=4) }}\n {{- \""\\n\\n\"" }}\n {%- endfor %}\n {{- first_user_message + \""<|eot_id|>\""}}\n{%- endif %}\n\n{%- for message in messages %}\n {%- if not (message.role == 'ipython' or message.role == 'tool' or 'tool_calls' in message) %}\n {{- '<|start_header_id|>' + message['role'] + '<|end_header_id|>\\n\\n'+ message['content'] | trim + '<|eot_id|>' }}\n {%- elif 'tool_calls' in message %}\n {%- if not message.tool_calls|length == 1 %}\n {{- raise_exception(\""This model only supports single tool-calls at once!\"") }}\n {%- endif %}\n {%- set tool_call = message.tool_calls[0].function %}\n {{- '<|start_header_id|>assistant<|end_header_id|>\\n\\n' -}}\n {{- '{\""name\"": \""' + tool_call.name + '\"", ' }}\n {{- '\""parameters\"": ' }}\n {{- tool_call.arguments | tojson }}\n {{- \""}\"" }}\n {{- \""<|eot_id|>\"" }}\n {%- elif message.role == \""tool\"" or message.role == \""ipython\"" %}\n {{- \""<|start_header_id|>ipython<|end_header_id|>\\n\\n\"" }}\n {%- if message.content is mapping or message.content is iterable %}\n {{- message.content | tojson }}\n {%- else %}\n {{- message.content }}\n {%- endif %}\n {{- \""<|eot_id|>\"" }}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|start_header_id|>assistant<|end_header_id|>\\n\\n' }}\n{%- endif %}\n"", ""eos_token"": ""<|eot_id|>"", ""pad_token"": ""<|eot_id|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""hackermoon1/HCK-TWAT""], ""safetensors"": {""parameters"": {""F32"": 10490816, ""BF16"": 1236865024}, ""total"": 1247355840}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-21 05:38:34+00:00"", ""cardData"": ""base_model:\n- meta-llama/Llama-3.2-1B-Instruct\nlibrary_name: transformers\nlicense: llama3.2"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""_id"": ""67d3b141d8b6e20c6d009c8b"", ""modelId"": ""manycore-research/SpatialLM-Llama-1B"", ""usedStorage"": 2532929485}",0,"https://huggingface.co/ruoxin9010/ruo, https://huggingface.co/dong1777/d",2,https://huggingface.co/Osher11/OpAI1.1,1,,0,,0,"hackermoon1/HCK-TWAT, huggingface/InferenceSupport/discussions/39",2
|
| 205 |
+
ruoxin9010/ruo,"---
|
| 206 |
+
license: openrail
|
| 207 |
+
datasets:
|
| 208 |
+
- FreedomIntelligence/medical-o1-reasoning-SFT
|
| 209 |
+
language:
|
| 210 |
+
- ae
|
| 211 |
+
metrics:
|
| 212 |
+
- bertscore
|
| 213 |
+
base_model:
|
| 214 |
+
- manycore-research/SpatialLM-Llama-1B
|
| 215 |
+
new_version: manycore-research/SpatialLM-Llama-1B
|
| 216 |
+
library_name: fastai
|
| 217 |
+
tags:
|
| 218 |
+
- climate
|
| 219 |
+
---","{""id"": ""ruoxin9010/ruo"", ""author"": ""ruoxin9010"", ""sha"": ""0e504c7786b20b2aa6fc376519e1a75d5bc7a231"", ""last_modified"": ""2025-04-22 09:42:09+00:00"", ""created_at"": ""2025-04-22 09:41:45+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""fastai"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""fastai"", ""climate"", ""ae"", ""dataset:FreedomIntelligence/medical-o1-reasoning-SFT"", ""base_model:manycore-research/SpatialLM-Llama-1B"", ""base_model:finetune:manycore-research/SpatialLM-Llama-1B"", ""license:openrail"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- manycore-research/SpatialLM-Llama-1B\ndatasets:\n- FreedomIntelligence/medical-o1-reasoning-SFT\nlanguage:\n- ae\nlibrary_name: fastai\nlicense: openrail\nmetrics:\n- bertscore\ntags:\n- climate\nnew_version: manycore-research/SpatialLM-Llama-1B"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-22 09:42:09+00:00"", ""cardData"": ""base_model:\n- manycore-research/SpatialLM-Llama-1B\ndatasets:\n- FreedomIntelligence/medical-o1-reasoning-SFT\nlanguage:\n- ae\nlibrary_name: fastai\nlicense: openrail\nmetrics:\n- bertscore\ntags:\n- climate\nnew_version: manycore-research/SpatialLM-Llama-1B"", ""transformersInfo"": null, ""_id"": ""68076459600e38561170d88b"", ""modelId"": ""ruoxin9010/ruo"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=ruoxin9010/ruo&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bruoxin9010%2Fruo%5D(%2Fruoxin9010%2Fruo)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 220 |
+
dong1777/d,"---
|
| 221 |
+
license: openrail
|
| 222 |
+
datasets:
|
| 223 |
+
- FreedomIntelligence/medical-o1-reasoning-SFT
|
| 224 |
+
language:
|
| 225 |
+
- am
|
| 226 |
+
metrics:
|
| 227 |
+
- bleurt
|
| 228 |
+
base_model:
|
| 229 |
+
- manycore-research/SpatialLM-Llama-1B
|
| 230 |
+
new_version: black-forest-labs/FLUX.1-dev
|
| 231 |
+
pipeline_tag: text-classification
|
| 232 |
+
library_name: fastai
|
| 233 |
+
---","{""id"": ""dong1777/d"", ""author"": ""dong1777"", ""sha"": ""dda2135b8c5c13207808f57faf4973de7ff19209"", ""last_modified"": ""2025-04-22 09:52:20+00:00"", ""created_at"": ""2025-04-22 09:49:44+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""fastai"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""fastai"", ""text-classification"", ""am"", ""dataset:FreedomIntelligence/medical-o1-reasoning-SFT"", ""base_model:manycore-research/SpatialLM-Llama-1B"", ""base_model:finetune:manycore-research/SpatialLM-Llama-1B"", ""license:openrail"", ""region:us""], ""pipeline_tag"": ""text-classification"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- manycore-research/SpatialLM-Llama-1B\ndatasets:\n- FreedomIntelligence/medical-o1-reasoning-SFT\nlanguage:\n- am\nlibrary_name: fastai\nlicense: openrail\nmetrics:\n- bleurt\npipeline_tag: text-classification\nnew_version: black-forest-labs/FLUX.1-dev"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-22 09:52:20+00:00"", ""cardData"": ""base_model:\n- manycore-research/SpatialLM-Llama-1B\ndatasets:\n- FreedomIntelligence/medical-o1-reasoning-SFT\nlanguage:\n- am\nlibrary_name: fastai\nlicense: openrail\nmetrics:\n- bleurt\npipeline_tag: text-classification\nnew_version: black-forest-labs/FLUX.1-dev"", ""transformersInfo"": null, ""_id"": ""680766386c590cecbaff37aa"", ""modelId"": ""dong1777/d"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=dong1777/d&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bdong1777%2Fd%5D(%2Fdong1777%2Fd)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
Wizard-Vicuna-30B-Uncensored-GPTQ_finetunes_20250425_143346.csv_finetunes_20250425_143346.csv
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ,"---
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
license: other
|
| 6 |
+
tags:
|
| 7 |
+
- uncensored
|
| 8 |
+
datasets:
|
| 9 |
+
- ehartford/wizard_vicuna_70k_unfiltered
|
| 10 |
+
model_name: Wizard Vicuna 30B Uncensored
|
| 11 |
+
base_model: ehartford/Wizard-Vicuna-30B-Uncensored
|
| 12 |
+
inference: false
|
| 13 |
+
model_creator: Eric Hartford
|
| 14 |
+
model_type: llama
|
| 15 |
+
prompt_template: 'A chat between a curious user and an artificial intelligence assistant.
|
| 16 |
+
The assistant gives helpful, detailed, and polite answers to the user''s questions.
|
| 17 |
+
USER: {prompt} ASSISTANT:
|
| 18 |
+
|
| 19 |
+
'
|
| 20 |
+
quantized_by: TheBloke
|
| 21 |
+
---
|
| 22 |
+
|
| 23 |
+
<!-- header start -->
|
| 24 |
+
<!-- 200823 -->
|
| 25 |
+
<div style=""width: auto; margin-left: auto; margin-right: auto"">
|
| 26 |
+
<img src=""https://i.imgur.com/EBdldam.jpg"" alt=""TheBlokeAI"" style=""width: 100%; min-width: 400px; display: block; margin: auto;"">
|
| 27 |
+
</div>
|
| 28 |
+
<div style=""display: flex; justify-content: space-between; width: 100%;"">
|
| 29 |
+
<div style=""display: flex; flex-direction: column; align-items: flex-start;"">
|
| 30 |
+
<p style=""margin-top: 0.5em; margin-bottom: 0em;""><a href=""https://discord.gg/theblokeai"">Chat & support: TheBloke's Discord server</a></p>
|
| 31 |
+
</div>
|
| 32 |
+
<div style=""display: flex; flex-direction: column; align-items: flex-end;"">
|
| 33 |
+
<p style=""margin-top: 0.5em; margin-bottom: 0em;""><a href=""https://www.patreon.com/TheBlokeAI"">Want to contribute? TheBloke's Patreon page</a></p>
|
| 34 |
+
</div>
|
| 35 |
+
</div>
|
| 36 |
+
<div style=""text-align:center; margin-top: 0em; margin-bottom: 0em""><p style=""margin-top: 0.25em; margin-bottom: 0em;"">TheBloke's LLM work is generously supported by a grant from <a href=""https://a16z.com"">andreessen horowitz (a16z)</a></p></div>
|
| 37 |
+
<hr style=""margin-top: 1.0em; margin-bottom: 1.0em;"">
|
| 38 |
+
<!-- header end -->
|
| 39 |
+
|
| 40 |
+
# Wizard Vicuna 30B Uncensored - GPTQ
|
| 41 |
+
- Model creator: [Eric Hartford](https://huggingface.co/ehartford)
|
| 42 |
+
- Original model: [Wizard Vicuna 30B Uncensored](https://huggingface.co/ehartford/Wizard-Vicuna-30B-Uncensored)
|
| 43 |
+
|
| 44 |
+
<!-- description start -->
|
| 45 |
+
## Description
|
| 46 |
+
|
| 47 |
+
This repo contains GPTQ model files for [Eric Hartford's Wizard-Vicuna-30B-Uncensored](https://huggingface.co/ehartford/Wizard-Vicuna-30B-Uncensored).
|
| 48 |
+
|
| 49 |
+
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
|
| 50 |
+
|
| 51 |
+
<!-- description end -->
|
| 52 |
+
<!-- repositories-available start -->
|
| 53 |
+
## Repositories available
|
| 54 |
+
|
| 55 |
+
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-AWQ)
|
| 56 |
+
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ)
|
| 57 |
+
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GGUF)
|
| 58 |
+
* [Eric Hartford's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-fp16)
|
| 59 |
+
<!-- repositories-available end -->
|
| 60 |
+
|
| 61 |
+
<!-- prompt-template start -->
|
| 62 |
+
## Prompt template: Vicuna
|
| 63 |
+
|
| 64 |
+
```
|
| 65 |
+
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
|
| 66 |
+
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
<!-- prompt-template end -->
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
<!-- README_GPTQ.md-provided-files start -->
|
| 73 |
+
## Provided files and GPTQ parameters
|
| 74 |
+
|
| 75 |
+
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
|
| 76 |
+
|
| 77 |
+
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
|
| 78 |
+
|
| 79 |
+
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
|
| 80 |
+
|
| 81 |
+
<details>
|
| 82 |
+
<summary>Explanation of GPTQ parameters</summary>
|
| 83 |
+
|
| 84 |
+
- Bits: The bit size of the quantised model.
|
| 85 |
+
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. ""None"" is the lowest possible value.
|
| 86 |
+
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
|
| 87 |
+
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
|
| 88 |
+
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
|
| 89 |
+
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
|
| 90 |
+
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
|
| 91 |
+
|
| 92 |
+
</details>
|
| 93 |
+
|
| 94 |
+
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
|
| 95 |
+
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
|
| 96 |
+
| [main](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/tree/main) | 4 | None | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 16.94 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
|
| 97 |
+
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 19.44 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
|
| 98 |
+
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 18.18 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
|
| 99 |
+
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 17.55 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
|
| 100 |
+
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 32.99 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
|
| 101 |
+
| [gptq-8bit-128g-actorder_False](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/tree/gptq-8bit-128g-actorder_False) | 8 | 128 | No | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 33.73 GB | No | 8-bit, with group size 128g for higher inference quality and without Act Order to improve AutoGPTQ speed. |
|
| 102 |
+
| [gptq-3bit--1g-actorder_True](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/tree/gptq-3bit--1g-actorder_True) | 3 | None | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 12.92 GB | No | 3-bit, with Act Order and no group size. Lowest possible VRAM requirements. May be lower quality than 3-bit 128g. |
|
| 103 |
+
| [gptq-3bit-128g-actorder_False](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/tree/gptq-3bit-128g-actorder_False) | 3 | 128 | No | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 13.51 GB | No | 3-bit, with group size 128g but no act-order. Slightly higher VRAM requirements than 3-bit None. |
|
| 104 |
+
|
| 105 |
+
<!-- README_GPTQ.md-provided-files end -->
|
| 106 |
+
|
| 107 |
+
<!-- README_GPTQ.md-download-from-branches start -->
|
| 108 |
+
## How to download from branches
|
| 109 |
+
|
| 110 |
+
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ:main`
|
| 111 |
+
- With Git, you can clone a branch with:
|
| 112 |
+
```
|
| 113 |
+
git clone --single-branch --branch main https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ
|
| 114 |
+
```
|
| 115 |
+
- In Python Transformers code, the branch is the `revision` parameter; see below.
|
| 116 |
+
<!-- README_GPTQ.md-download-from-branches end -->
|
| 117 |
+
<!-- README_GPTQ.md-text-generation-webui start -->
|
| 118 |
+
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
|
| 119 |
+
|
| 120 |
+
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
|
| 121 |
+
|
| 122 |
+
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
|
| 123 |
+
|
| 124 |
+
1. Click the **Model tab**.
|
| 125 |
+
2. Under **Download custom model or LoRA**, enter `TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ`.
|
| 126 |
+
- To download from a specific branch, enter for example `TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ:main`
|
| 127 |
+
- see Provided Files above for the list of branches for each option.
|
| 128 |
+
3. Click **Download**.
|
| 129 |
+
4. The model will start downloading. Once it's finished it will say ""Done"".
|
| 130 |
+
5. In the top left, click the refresh icon next to **Model**.
|
| 131 |
+
6. In the **Model** dropdown, choose the model you just downloaded: `Wizard-Vicuna-30B-Uncensored-GPTQ`
|
| 132 |
+
7. The model will automatically load, and is now ready for use!
|
| 133 |
+
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
|
| 134 |
+
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
|
| 135 |
+
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
|
| 136 |
+
<!-- README_GPTQ.md-text-generation-webui end -->
|
| 137 |
+
|
| 138 |
+
<!-- README_GPTQ.md-use-from-python start -->
|
| 139 |
+
## How to use this GPTQ model from Python code
|
| 140 |
+
|
| 141 |
+
### Install the necessary packages
|
| 142 |
+
|
| 143 |
+
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
|
| 144 |
+
|
| 145 |
+
```shell
|
| 146 |
+
pip3 install transformers>=4.32.0 optimum>=1.12.0
|
| 147 |
+
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
|
| 151 |
+
|
| 152 |
+
```shell
|
| 153 |
+
pip3 uninstall -y auto-gptq
|
| 154 |
+
git clone https://github.com/PanQiWei/AutoGPTQ
|
| 155 |
+
cd AutoGPTQ
|
| 156 |
+
pip3 install .
|
| 157 |
+
```
|
| 158 |
+
|
| 159 |
+
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
|
| 160 |
+
|
| 161 |
+
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
|
| 162 |
+
```shell
|
| 163 |
+
pip3 uninstall -y transformers
|
| 164 |
+
pip3 install git+https://github.com/huggingface/transformers.git
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
### You can then use the following code
|
| 168 |
+
|
| 169 |
+
```python
|
| 170 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
|
| 171 |
+
|
| 172 |
+
model_name_or_path = ""TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ""
|
| 173 |
+
# To use a different branch, change revision
|
| 174 |
+
# For example: revision=""main""
|
| 175 |
+
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
|
| 176 |
+
device_map=""auto"",
|
| 177 |
+
trust_remote_code=False,
|
| 178 |
+
revision=""main"")
|
| 179 |
+
|
| 180 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
|
| 181 |
+
|
| 182 |
+
prompt = ""Tell me about AI""
|
| 183 |
+
prompt_template=f'''A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
|
| 184 |
+
|
| 185 |
+
'''
|
| 186 |
+
|
| 187 |
+
print(""\n\n*** Generate:"")
|
| 188 |
+
|
| 189 |
+
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
|
| 190 |
+
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
|
| 191 |
+
print(tokenizer.decode(output[0]))
|
| 192 |
+
|
| 193 |
+
# Inference can also be done using transformers' pipeline
|
| 194 |
+
|
| 195 |
+
print(""*** Pipeline:"")
|
| 196 |
+
pipe = pipeline(
|
| 197 |
+
""text-generation"",
|
| 198 |
+
model=model,
|
| 199 |
+
tokenizer=tokenizer,
|
| 200 |
+
max_new_tokens=512,
|
| 201 |
+
do_sample=True,
|
| 202 |
+
temperature=0.7,
|
| 203 |
+
top_p=0.95,
|
| 204 |
+
top_k=40,
|
| 205 |
+
repetition_penalty=1.1
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
print(pipe(prompt_template)[0]['generated_text'])
|
| 209 |
+
```
|
| 210 |
+
<!-- README_GPTQ.md-use-from-python end -->
|
| 211 |
+
|
| 212 |
+
<!-- README_GPTQ.md-compatibility start -->
|
| 213 |
+
## Compatibility
|
| 214 |
+
|
| 215 |
+
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
|
| 216 |
+
|
| 217 |
+
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
|
| 218 |
+
|
| 219 |
+
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
|
| 220 |
+
<!-- README_GPTQ.md-compatibility end -->
|
| 221 |
+
|
| 222 |
+
<!-- footer start -->
|
| 223 |
+
<!-- 200823 -->
|
| 224 |
+
## Discord
|
| 225 |
+
|
| 226 |
+
For further support, and discussions on these models and AI in general, join us at:
|
| 227 |
+
|
| 228 |
+
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
|
| 229 |
+
|
| 230 |
+
## Thanks, and how to contribute
|
| 231 |
+
|
| 232 |
+
Thanks to the [chirper.ai](https://chirper.ai) team!
|
| 233 |
+
|
| 234 |
+
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
|
| 235 |
+
|
| 236 |
+
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
|
| 237 |
+
|
| 238 |
+
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
|
| 239 |
+
|
| 240 |
+
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
|
| 241 |
+
|
| 242 |
+
* Patreon: https://patreon.com/TheBlokeAI
|
| 243 |
+
* Ko-Fi: https://ko-fi.com/TheBlokeAI
|
| 244 |
+
|
| 245 |
+
**Special thanks to**: Aemon Algiz.
|
| 246 |
+
|
| 247 |
+
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
Thank you to all my generous patrons and donaters!
|
| 251 |
+
|
| 252 |
+
And thank you again to a16z for their generous grant.
|
| 253 |
+
|
| 254 |
+
<!-- footer end -->
|
| 255 |
+
|
| 256 |
+
# Original model card: Eric Hartford's Wizard-Vicuna-30B-Uncensored
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
<!-- header start -->
|
| 260 |
+
<div style=""width: 100%;"">
|
| 261 |
+
<img src=""https://i.imgur.com/EBdldam.jpg"" alt=""TheBlokeAI"" style=""width: 100%; min-width: 400px; display: block; margin: auto;"">
|
| 262 |
+
</div>
|
| 263 |
+
<div style=""display: flex; justify-content: space-between; width: 100%;"">
|
| 264 |
+
<div style=""display: flex; flex-direction: column; align-items: flex-start;"">
|
| 265 |
+
<p><a href=""https://discord.gg/Jq4vkcDakD"">Chat & support: my new Discord server</a></p>
|
| 266 |
+
</div>
|
| 267 |
+
<div style=""display: flex; flex-direction: column; align-items: flex-end;"">
|
| 268 |
+
<p><a href=""https://www.patreon.com/TheBlokeAI"">Want to contribute? TheBloke's Patreon page</a></p>
|
| 269 |
+
</div>
|
| 270 |
+
</div>
|
| 271 |
+
<!-- header end -->
|
| 272 |
+
|
| 273 |
+
# Eric Hartford's Wizard-Vicuna-30B-Uncensored GPTQ
|
| 274 |
+
|
| 275 |
+
This is an fp16 models of [Eric Hartford's Wizard-Vicuna 30B](https://huggingface.co/ehartford/Wizard-Vicuna-30B-Uncensored).
|
| 276 |
+
|
| 277 |
+
It is the result of converting Eric's original fp32 upload to fp16.
|
| 278 |
+
|
| 279 |
+
## Repositories available
|
| 280 |
+
|
| 281 |
+
* [4bit GPTQ models for GPU inference](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ).
|
| 282 |
+
* [4bit and 5bit GGML models for CPU inference](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GGML).
|
| 283 |
+
* [float16 HF format model for GPU inference and further conversions](https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-fp16).
|
| 284 |
+
|
| 285 |
+
<!-- footer start -->
|
| 286 |
+
## Discord
|
| 287 |
+
|
| 288 |
+
For further support, and discussions on these models and AI in general, join us at:
|
| 289 |
+
|
| 290 |
+
[TheBloke AI's Discord server](https://discord.gg/Jq4vkcDakD)
|
| 291 |
+
|
| 292 |
+
## Thanks, and how to contribute.
|
| 293 |
+
|
| 294 |
+
Thanks to the [chirper.ai](https://chirper.ai) team!
|
| 295 |
+
|
| 296 |
+
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
|
| 297 |
+
|
| 298 |
+
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
|
| 299 |
+
|
| 300 |
+
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
|
| 301 |
+
|
| 302 |
+
* Patreon: https://patreon.com/TheBlokeAI
|
| 303 |
+
* Ko-Fi: https://ko-fi.com/TheBlokeAI
|
| 304 |
+
|
| 305 |
+
**Patreon special mentions**: Aemon Algiz, Dmitriy Samsonov, Nathan LeClaire, Trenton Dambrowitz, Mano Prime, David Flickinger, vamX, Nikolai Manek, senxiiz, Khalefa Al-Ahmad, Illia Dulskyi, Jonathan Leane, Talal Aujan, V. Lukas, Joseph William Delisle, Pyrater, Oscar Rangel, Lone Striker, Luke Pendergrass, Eugene Pentland, Sebastain Graf, Johann-Peter Hartman.
|
| 306 |
+
|
| 307 |
+
Thank you to all my generous patrons and donaters!
|
| 308 |
+
<!-- footer end -->
|
| 309 |
+
|
| 310 |
+
# Original model card
|
| 311 |
+
|
| 312 |
+
This is [wizard-vicuna-13b](https://huggingface.co/junelee/wizard-vicuna-13b) trained with a subset of the dataset - responses that contained alignment / moralizing were removed. The intent is to train a WizardLM that doesn't have alignment built-in, so that alignment (of any sort) can be added separately with for example with a RLHF LoRA.
|
| 313 |
+
|
| 314 |
+
Shout out to the open source AI/ML community, and everyone who helped me out.
|
| 315 |
+
|
| 316 |
+
Note:
|
| 317 |
+
|
| 318 |
+
An uncensored model has no guardrails.
|
| 319 |
+
|
| 320 |
+
You are responsible for anything you do with the model, just as you are responsible for anything you do with any dangerous object such as a knife, gun, lighter, or car.
|
| 321 |
+
|
| 322 |
+
Publishing anything this model generates is the same as publishing it yourself.
|
| 323 |
+
|
| 324 |
+
You are responsible for the content you publish, and you cannot blame the model any more than you can blame the knife, gun, lighter, or car for what you do with it.
|
| 325 |
+
","{""id"": ""TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ"", ""author"": ""TheBloke"", ""sha"": ""3af62c796031ef5a6ece16c163a8444609d9c376"", ""last_modified"": ""2023-09-27 12:44:25+00:00"", ""created_at"": ""2023-05-30 03:11:00+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 442, ""downloads_all_time"": null, ""likes"": 579, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""uncensored"", ""en"", ""dataset:ehartford/wizard_vicuna_70k_unfiltered"", ""base_model:cognitivecomputations/Wizard-Vicuna-30B-Uncensored"", ""base_model:quantized:cognitivecomputations/Wizard-Vicuna-30B-Uncensored"", ""license:other"", ""autotrain_compatible"", ""text-generation-inference"", ""4-bit"", ""gptq"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: ehartford/Wizard-Vicuna-30B-Uncensored\ndatasets:\n- ehartford/wizard_vicuna_70k_unfiltered\nlanguage:\n- en\nlicense: other\nmodel_name: Wizard Vicuna 30B Uncensored\ntags:\n- uncensored\ninference: false\nmodel_creator: Eric Hartford\nmodel_type: llama\nprompt_template: 'A chat between a curious user and an artificial intelligence assistant.\n The assistant gives helpful, detailed, and polite answers to the user''s questions.\n USER: {prompt} ASSISTANT:\n\n '\nquantized_by: TheBloke"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""quantization_config"": {""bits"": 4, ""quant_method"": ""gptq""}, ""tokenizer_config"": {""bos_token"": {""__type"": ""AddedToken"", ""content"": ""<s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""eos_token"": {""__type"": ""AddedToken"", ""content"": ""</s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""pad_token"": null, ""unk_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='quantize_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='trainer_state.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Intel/low_bit_open_llm_leaderboard"", ""BAAI/open_cn_llm_leaderboard"", ""gsaivinay/open_llm_leaderboard"", ""KBaba7/Quant"", ""GTBench/GTBench"", ""Vikhrmodels/small-shlepa-lb"", ""kz-transformers/kaz-llm-lb"", ""felixz/open_llm_leaderboard"", ""bhaskartripathi/LLM_Quantization"", ""OPTML-Group/UnlearnCanvas-Benchmark"", ""dar-tau/selfie"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""BAAI/open_flageval_vlm_leaderboard"", ""neubla/neubla-llm-evaluation-board"", ""rodrigomasini/data_only_open_llm_leaderboard"", ""Docfile/open_llm_leaderboard"", ""JS-Junior/WizardLM-WizardCoder-15B-V1.0"", ""ruslanmv/convert_to_gguf"", ""JacopoCirica/AIChatbot"", ""dmar1313/true"", ""smothiki/open_llm_leaderboard"", ""csalabs/AI-EMBD"", ""csalabs/Replicate-7b-chat-Llama-streamlit"", ""0x1668/open_llm_leaderboard"", ""pngwn/open_llm_leaderboard-check"", ""asir0z/open_llm_leaderboard"", ""dkdaniz/katara"", ""kbmlcoding/open_llm_leaderboard_free"", ""aichampions/open_llm_leaderboard"", ""Adeco/open_llm_leaderboard"", ""anirudh937/open_llm_leaderboard"", ""smothiki/open_llm_leaderboard2"", ""mjalg/IFEvalTR"", ""coool123132314/cool"", ""K00B404/LLM_Quantization""], ""safetensors"": {""parameters"": {""F32"": 8298240, ""I32"": 4013287680, ""F16"": 426789376}, ""total"": 4448375296}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-09-27 12:44:25+00:00"", ""cardData"": ""base_model: ehartford/Wizard-Vicuna-30B-Uncensored\ndatasets:\n- ehartford/wizard_vicuna_70k_unfiltered\nlanguage:\n- en\nlicense: other\nmodel_name: Wizard Vicuna 30B Uncensored\ntags:\n- uncensored\ninference: false\nmodel_creator: Eric Hartford\nmodel_type: llama\nprompt_template: 'A chat between a curious user and an artificial intelligence assistant.\n The assistant gives helpful, detailed, and polite answers to the user''s questions.\n USER: {prompt} ASSISTANT:\n\n '\nquantized_by: TheBloke"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""6475694482907acdddfa6e86"", ""modelId"": ""TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ"", ""usedStorage"": 348325828923}",0,,0,,0,https://huggingface.co/PrunaAI/TheBloke-Wizard-Vicuna-30B-Uncensored-GPTQ-GGUF-smashed,1,,0,"BAAI/open_cn_llm_leaderboard, BAAI/open_flageval_vlm_leaderboard, FallnAI/Quantize-HF-Models, GTBench/GTBench, Intel/low_bit_open_llm_leaderboard, K00B404/LLM_Quantization, KBaba7/Quant, OPTML-Group/UnlearnCanvas-Benchmark, Vikhrmodels/small-shlepa-lb, bhaskartripathi/LLM_Quantization, gsaivinay/open_llm_leaderboard, huggingface/InferenceSupport/discussions/new?title=TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BTheBloke%2FWizard-Vicuna-30B-Uncensored-GPTQ%5D(%2FTheBloke%2FWizard-Vicuna-30B-Uncensored-GPTQ)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kz-transformers/kaz-llm-lb",13
|
YandexGPT-5-Lite-8B-pretrain_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv
ADDED
|
@@ -0,0 +1,1095 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
yandex/YandexGPT-5-Lite-8B-pretrain,"---
|
| 3 |
+
license: other
|
| 4 |
+
license_name: yandexgpt-5-lite-8b
|
| 5 |
+
license_link: LICENSE
|
| 6 |
+
language:
|
| 7 |
+
- ru
|
| 8 |
+
- en
|
| 9 |
+
---
|
| 10 |
+
# YandexGPT-5-Lite-Pretrain
|
| 11 |
+
|
| 12 |
+
Pretrain-версия большой языковой модели YandexGPT 5 Lite на 8B параметров с длиной контекста 32k токенов. Обучение модели проходило в два этапа.
|
| 13 |
+
|
| 14 |
+
На первом этапе модель обучалась преимущественно на русскоязычных и англоязычных текстах общим объёмом 15T токенов с длиной контекста до 8k токенов. Состав датасета: 60% — веб-страницы, 15% — код, 10% — математика, остальное — другие специфичные данные, в том числе сгенерированная с помощью наших моделей синтетика и датасеты наших сервисов, например Яндекс Переводчика и база фактов Поиска.
|
| 15 |
+
|
| 16 |
+
На втором этапе, который мы назвали Powerup, модель обучалась на высококачественных данных объёмом 320B токенов. Состав Powerup-датасета: 25% — веб-страницы, 19% — математика, 18% — код, 18% — образовательные данные, остальное — синтетика, датасеты сервисов и прочие качественные тексты. На этом этапе мы увеличили длину контекста до 32k токенов.
|
| 17 |
+
|
| 18 |
+
Кроме того, наш токенизатор хорошо оптимизирован для русского языка. Например, 32k токенов нашей модели в среднем соответствует 48k токенам Qwen-2.5.
|
| 19 |
+
|
| 20 |
+
Более подробно — в нашей [статье на Хабре](https://habr.com/ru/companies/yandex/articles/885218/).
|
| 21 |
+
|
| 22 |
+
Задавайте вопросы в discussions.
|
| 23 |
+
|
| 24 |
+
## Бенчмарки
|
| 25 |
+
В своей категории модель достигает паритета с мировыми SOTA по ряду ключевых бенчмарков для pretrain-моделей, а по многим другим — превосходит их:
|
| 26 |
+
|
| 27 |
+
<img src=""https://habrastorage.org/r/w1560/getpro/habr/upload_files/fab/0de/405/fab0de40517e1fd4efc1302eaaf325d8.png"" alt=""Таблица бенчмарков"" width=""100%""/>
|
| 28 |
+
|
| 29 |
+
\* по данным репорта разработчиков модели. <br>
|
| 30 |
+
BBH — 3-shot, HUMAN_EVAL и MPBB — 0-shot, все остальные бенчмарки — 5-shot. <br>
|
| 31 |
+
Все замеры мы производили в HF transformers.
|
| 32 |
+
|
| 33 |
+
## Как использовать
|
| 34 |
+
|
| 35 |
+
Модель можно запустить через HF Transformers:
|
| 36 |
+
```python
|
| 37 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
MODEL_NAME = ""yandex/YandexGPT-5-Lite-8B-pretrain""
|
| 41 |
+
|
| 42 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, legacy=False)
|
| 43 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 44 |
+
MODEL_NAME,
|
| 45 |
+
device_map=""cuda"",
|
| 46 |
+
torch_dtype=""auto"",
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
input_text = ""Кто сказал тебе, что нет на свете настоящей,""
|
| 50 |
+
input_ids = tokenizer(input_text, return_tensors=""pt"").to(""cuda"")
|
| 51 |
+
|
| 52 |
+
outputs = model.generate(**input_ids, max_new_tokens=18)
|
| 53 |
+
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
Или через vLLM:
|
| 57 |
+
```python
|
| 58 |
+
from vllm import LLM, SamplingParams
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
MODEL_NAME = ""yandex/YandexGPT-5-Lite-8B-pretrain""
|
| 62 |
+
|
| 63 |
+
sampling_params = SamplingParams(
|
| 64 |
+
temperature=0.3,
|
| 65 |
+
max_tokens=18,
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
llm = LLM(
|
| 69 |
+
MODEL_NAME,
|
| 70 |
+
tensor_parallel_size=1,
|
| 71 |
+
)
|
| 72 |
+
input_texts = [""Кто сказал тебе, что нет на свете настоящей,""]
|
| 73 |
+
outputs = llm.generate(input_texts, use_tqdm=False, sampling_params=sampling_params)
|
| 74 |
+
|
| 75 |
+
for i in range(len(input_texts)):
|
| 76 |
+
print(input_texts[i] + outputs[i].outputs[0].text)
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
Для полного соответствия токенизации мы рекомендуем пользоваться оригинальным [sentencepiece](https://github.com/google/sentencepiece):
|
| 80 |
+
```python
|
| 81 |
+
import sentencepiece as spm
|
| 82 |
+
import torch
|
| 83 |
+
# git clone https://huggingface.co/yandex/YandexGPT-5-Lite-8B-pretrain
|
| 84 |
+
tokenizer = spm.SentencePieceProcessor(
|
| 85 |
+
model_file=""<path_to_local_repo>/tokenizer.model""
|
| 86 |
+
)
|
| 87 |
+
input_ids = tokenizer.encode(input_text, add_bos=True)
|
| 88 |
+
input_ids = torch.Tensor([input_ids]).to(model.device).to(torch.long)
|
| 89 |
+
outputs = model.generate(
|
| 90 |
+
input_ids=input_ids,
|
| 91 |
+
attention_mask=torch.ones_like(input_ids),
|
| 92 |
+
max_new_tokens=18
|
| 93 |
+
)
|
| 94 |
+
print(tokenizer.decode(outputs[0].tolist()))
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
## Как дообучить под свои задачи
|
| 98 |
+
|
| 99 |
+
У нашей модели llama-like архитектура, это означает, что она совместима с большинством существующих фреймворков по дообучению LLM. Приведем короткий пример, как можно обучить нашу модель в torchtune:
|
| 100 |
+
|
| 101 |
+
Скачиваем репозиторий:
|
| 102 |
+
```bash
|
| 103 |
+
tune download yandex/YandexGPT-5-Lite-8B-pretrain \
|
| 104 |
+
--output-dir YandexGPT-5-Lite-8B-pretrain
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
Смотрим список конфигов и копируем подходящий под задачу:
|
| 108 |
+
```bash
|
| 109 |
+
tune ls
|
| 110 |
+
tune cp llama3_1/8B_lora training_config.yaml
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
Изменяем конфиг, адаптируем его под нашу модель и задачу. Например, [такой](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-pretrain/discussions/1#67bc4e6472499ce2ba3659a7) вариант подойдет для lora обучения на открытом инстракт датасете `alpaca-cleaned`.
|
| 114 |
+
|
| 115 |
+
Запускаем обучение:
|
| 116 |
+
```bash
|
| 117 |
+
tune run lora_finetune_single_device --config training_config.yaml
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
Подробности можно найти в официальной [документации](https://pytorch.org/torchtune/stable/overview.html) torchtune.
|
| 121 |
+
","{""id"": ""yandex/YandexGPT-5-Lite-8B-pretrain"", ""author"": ""yandex"", ""sha"": ""f4aec3abf522c57354f0000e3e30719b3e65bda3"", ""last_modified"": ""2025-03-31 11:23:25+00:00"", ""created_at"": ""2025-02-21 16:46:19+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 5098, ""downloads_all_time"": null, ""likes"": 187, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""safetensors"", ""llama"", ""ru"", ""en"", ""license:other"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- ru\n- en\nlicense: other\nlicense_name: yandexgpt-5-lite-8b\nlicense_link: LICENSE"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""unk_token"": ""<unk>""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Vt5005/Test1209""], ""safetensors"": {""parameters"": {""BF16"": 8036552704}, ""total"": 8036552704}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-31 11:23:25+00:00"", ""cardData"": ""language:\n- ru\n- en\nlicense: other\nlicense_name: yandexgpt-5-lite-8b\nlicense_link: LICENSE"", ""transformersInfo"": null, ""_id"": ""67b8addb92b9b5b818819366"", ""modelId"": ""yandex/YandexGPT-5-Lite-8B-pretrain"", ""usedStorage"": 16075712453}",0,"https://huggingface.co/yandex/YandexGPT-5-Lite-8B-instruct, https://huggingface.co/Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it, https://huggingface.co/secretmoon/YankaGPT-8B-v0.1, https://huggingface.co/attn-signs/GPTR-8b-base, https://huggingface.co/ssslakter/YandexGPT-5-Lite-8B-instruct",5,https://huggingface.co/evilfreelancer/r1_yandexgpt5-lite_lora,1,"https://huggingface.co/blues-alex/YandexGPT-5-Lite-8B-pretrain-Q4_K_M-GGUF, https://huggingface.co/yaroslav0530/YandexGPT-5-Lite-8B-pretrain-GGUF, https://huggingface.co/mlx-community/YandexGPT-5-Lite-8B-pretrain-Q8-mlx, https://huggingface.co/NikolayKozloff/YandexGPT-5-Lite-8B-pretrain-Q8_0-GGUF, https://huggingface.co/Ronny/YandexGPT-5-Lite-8B-pretrain-Q8_0-GGUF, https://huggingface.co/holooo/YandexGPT-5-Lite-8B-pretrain-Q5_K_M-GGUF, https://huggingface.co/Nick0lay13/YandexGPT-5-Lite-8B-pretrain-Q8_0-GGUF, https://huggingface.co/shoplikov/YandexGPT-5-Lite-8B-pretrain-Q4_K_M-GGUF, https://huggingface.co/end000/YandexGPT-5-Lite-8B-pretrain-Q4_K_M-GGUF, https://huggingface.co/MrDevolver/YandexGPT-5-Lite-8B-pretrain-Q6_K-GGUF, https://huggingface.co/MultySerey/YandexGPT-5-Lite-8B-pretrain-Q4_K_M-GGUF, https://huggingface.co/itlwas/YandexGPT-5-Lite-8B-pretrain-Q4_K_M-GGUF",12,,0,"Vt5005/Test1209, huggingface/InferenceSupport/discussions/184",2
|
| 122 |
+
yandex/YandexGPT-5-Lite-8B-instruct,"---
|
| 123 |
+
license: other
|
| 124 |
+
license_name: yandexgpt-5-lite-8b
|
| 125 |
+
license_link: LICENSE
|
| 126 |
+
language:
|
| 127 |
+
- ru
|
| 128 |
+
- en
|
| 129 |
+
base_model:
|
| 130 |
+
- yandex/YandexGPT-5-Lite-8B-pretrain
|
| 131 |
+
---
|
| 132 |
+
|
| 133 |
+
# YandexGPT-5-Lite-Instruct
|
| 134 |
+
|
| 135 |
+
Instruct-версия большой языковой модели YandexGPT 5 Lite на 8B параметров с длиной контекста 32k токенов. Также в отдельном [репозитории](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-instruct-GGUF) опубликована квантизованная версия модели в формате GGUF.
|
| 136 |
+
|
| 137 |
+
Обучена на базе [YandexGPT 5 Lite Pretrain](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-pretrain), без использования весов каких-либо сторонних моделей. Алайнмент Lite-версии совпадает с алайнментом YandexGPT 5 Pro и состоит из этапов SFT и RLHF (более подробно о них — в [статье](https://habr.com/ru/companies/yandex/articles/885218/) на Хабре).
|
| 138 |
+
|
| 139 |
+
Задавайте вопросы в discussions.
|
| 140 |
+
|
| 141 |
+
## Бенчмарки
|
| 142 |
+
По результатам международных бенчмарков и их адаптаций для русского языка, YandexGPT 5 Lite вплотную приблизилась к аналогам (Llama-3.1-8B-instruct и Qwen-2.5-7B-instruct) и превосходит их в ряде сценариев, в том числе — в знании русской культуры и фактов.
|
| 143 |
+
|
| 144 |
+
<img src=""https://habrastorage.org/r/w1560/getpro/habr/upload_files/6b5/eb4/9ea/6b5eb49ea757bc124c938717b21f1cf7.png"" alt=""Таблица бенчмарков"" width=""100%""/>
|
| 145 |
+
|
| 146 |
+
MMLU — 5-shot, все остальные бенчмарки — 0-shot.
|
| 147 |
+
|
| 148 |
+
## Как использовать
|
| 149 |
+
|
| 150 |
+
Модель можно запустить через HF Transformers:
|
| 151 |
+
```python
|
| 152 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
MODEL_NAME = ""yandex/YandexGPT-5-Lite-8B-instruct""
|
| 156 |
+
|
| 157 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
|
| 158 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 159 |
+
MODEL_NAME,
|
| 160 |
+
device_map=""cuda"",
|
| 161 |
+
torch_dtype=""auto"",
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
messages = [{""role"": ""user"", ""content"": ""Для чего нужна токенизация?""}]
|
| 165 |
+
input_ids = tokenizer.apply_chat_template(
|
| 166 |
+
messages, tokenize=True, return_tensors=""pt""
|
| 167 |
+
).to(""cuda"")
|
| 168 |
+
|
| 169 |
+
outputs = model.generate(input_ids, max_new_tokens=1024)
|
| 170 |
+
print(tokenizer.decode(outputs[0][input_ids.size(1) :], skip_special_tokens=True))
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
Или через vLLM:
|
| 174 |
+
```python
|
| 175 |
+
from vllm import LLM, SamplingParams
|
| 176 |
+
from transformers import AutoTokenizer
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
MODEL_NAME = ""yandex/YandexGPT-5-Lite-8B-instruct""
|
| 180 |
+
|
| 181 |
+
sampling_params = SamplingParams(
|
| 182 |
+
temperature=0.3,
|
| 183 |
+
top_p=0.9,
|
| 184 |
+
max_tokens=1024,
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
|
| 188 |
+
llm = LLM(
|
| 189 |
+
MODEL_NAME,
|
| 190 |
+
tensor_parallel_size=1,
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
messages = [{""role"": ""user"", ""content"": ""В чем смысл жизни?""}]
|
| 194 |
+
input_ids = tokenizer.apply_chat_template(
|
| 195 |
+
messages, tokenize=True, add_generation_prompt=True
|
| 196 |
+
)[1:] # remove bos
|
| 197 |
+
text = tokenizer.decode(input_ids)
|
| 198 |
+
|
| 199 |
+
outputs = llm.generate(text, use_tqdm=False, sampling_params=sampling_params)
|
| 200 |
+
|
| 201 |
+
print(tokenizer.decode(outputs[0].outputs[0].token_ids, skip_special_tokens=True))
|
| 202 |
+
|
| 203 |
+
```
|
| 204 |
+
|
| 205 |
+
Для запуска в llama.cpp и ollama можно воспользоваться нашей квантизованной моделью, которая выложена в репозитории [YandexGPT-5-Lite-8B-instruct-GGUF](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-instruct-GGUF).
|
| 206 |
+
|
| 207 |
+
## Особенности токенизации
|
| 208 |
+
Для полного соответствия токенизации мы рекомендуем пользоваться оригинальным [sentencepiece](https://github.com/google/sentencepiece) — файл токенизатора лежит в папке `original_tokenizer`. В нашей инфраструктуре каждую реплику диалога мы токенизируем отдельно.
|
| 209 |
+
|
| 210 |
+
Из-за этого, в частности, появляется пробел в начале каждой реплики. Также `\n` токены мы заменяем на `[NL]`, это можно сделать с помощью `text.replace(""\n"", ""[NL]"")` перед токенизацией.
|
| 211 |
+
|
| 212 |
+
## Особенности шаблона
|
| 213 |
+
Мы используем нестандартный шаблон диалога — модель обучена генерировать только одну реплику после последовательности `Ассистент:[SEP]`, завершая её токеном `</s>`. При этом диалог в промпте может быть любой длины.
|
| 214 |
+
|
| 215 |
+
Это приводит к тому, что в интерактивном режиме модель может выдавать результаты, отличающиеся от вызова модели в режиме генерации на фиксированном диалоге. Поэтому мы рекомендуем использовать интерактивный режим только для ознакомления с моделью.","{""id"": ""yandex/YandexGPT-5-Lite-8B-instruct"", ""author"": ""yandex"", ""sha"": ""b556811768376b46c69caab60c4d1b69df9faaa1"", ""last_modified"": ""2025-03-31 11:23:59+00:00"", ""created_at"": ""2025-03-28 08:12:30+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 8490, ""downloads_all_time"": null, ""likes"": 65, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""safetensors"", ""llama"", ""ru"", ""en"", ""base_model:yandex/YandexGPT-5-Lite-8B-pretrain"", ""base_model:finetune:yandex/YandexGPT-5-Lite-8B-pretrain"", ""license:other"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- yandex/YandexGPT-5-Lite-8B-pretrain\nlanguage:\n- ru\n- en\nlicense: other\nlicense_name: yandexgpt-5-lite-8b\nlicense_link: LICENSE"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""pad_token"": null, ""chat_template"": ""<s>{%- set names = {'assistant': ' \u0410\u0441\u0441\u0438\u0441\u0442\u0435\u043d\u0442:', 'user': ' \u041f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u0435\u043b\u044c:'} %}\n{%- set tools_prefix = '\u0422\u0435\u0431\u0435 \u0434\u043e\u0441\u0442\u0443\u043f\u043d\u044b \u0441\u043b\u0435\u0434\u0443\u044e\u0449\u0438\u0435 \u0444\u0443\u043d\u043a\u0446\u0438\u0438:' %}\n\n{%- macro __render_tool(tool) %}\n {%- set name = tool.function.name %}\n {%- set description = tool.function.description|default('') %}\n {%- set parameters = tool.function.parameters|tojson %}\n {{- '\\n' }}function {{ '{' }}'name':'{{ name }}',\n {%- if tool.description %}'description':'{{ description }}',{% endif %}\n'parameters':{{ parameters }}\n {{- '}' }}\n{%- endmacro %}\n\n{%- macro __render_tools(tools) %}\n {{- tools_prefix }}\n {%- for tool in tools %}\n {{- __render_tool(tool) }}\n {%- endfor %}\n {{- '\\n\\n' }}\n{%- endmacro %}\n\n{%- macro __render_tool_message(message) %}\n {{- '\\n\\n\u0420\u0435\u0437\u0443\u043b\u044c\u0442\u0430\u0442 \u0432\u044b\u0437\u043e\u0432\u0430' }} {{ message.name }}: {{ message.content }} {{ '\\n\\n' }}\n{%- endmacro %}\n\n{%- if tools -%}\n {{- __render_tools(tools) }}\n{%- endif -%}\n\n{%- macro __render_user_message(message) %}\n{{ names.user }} {{ message.content + '\\n\\n' }}\n{%- endmacro %}\n\n{%- macro __render_assistant_message(message) %}\n {{- names.assistant }}\n {%- set call = message['function_call'] %}\n {%- if call %}\n {{- '\\n[TOOL_CALL_START]' }}{{ call.name }}{{ '\\n' }}{{ call.arguments|tojson }}\n {%- else %}\n {{- ' ' + message.content + '\\n\\n' }}\n {%- endif %}\n{%- endmacro %}\n\n{%- if not add_generation_prompt is defined %}\n{%- set add_generation_prompt = false %}\n{%- endif %}\n\n{%- for message in messages %}\n {%- if message['role'] == 'user' %}\n {{- __render_user_message(message) }}\n {%- endif %}\n\n {%- if message.role == 'assistant' and not loop.last %}\n {{- __render_assistant_message(message) }}\n {%- endif %}\n\n {%- if message.role == 'tool' %}\n {{- __render_tool_message(message) }}\n {%- endif %}\n\n {%- if loop.last %}\n {{- ' \u0410\u0441\u0441\u0438\u0441\u0442\u0435\u043d\u0442:[SEP]' }}\n {%- endif %}\n\n{%- endfor %}\n"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='original_tokenizer/tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F16"": 8036552704}, ""total"": 8036552704}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-31 11:23:59+00:00"", ""cardData"": ""base_model:\n- yandex/YandexGPT-5-Lite-8B-pretrain\nlanguage:\n- ru\n- en\nlicense: other\nlicense_name: yandexgpt-5-lite-8b\nlicense_link: LICENSE"", ""transformersInfo"": null, ""_id"": ""67e659ee1e6655ee18727b77"", ""modelId"": ""yandex/YandexGPT-5-Lite-8B-instruct"", ""usedStorage"": 16078285345}",1,https://huggingface.co/Apel-sin/yandexGPT-5-Lite-8B-instruct-exl2,1,,0,"https://huggingface.co/Ronny/YandexGPT-5-Lite-8B-instruct-Q8_0-GGUF, https://huggingface.co/mradermacher/YandexGPT-5-Lite-8B-instruct-GGUF, https://huggingface.co/mradermacher/YandexGPT-5-Lite-8B-instruct-i1-GGUF, https://huggingface.co/NikolayKozloff/YandexGPT-5-Lite-8B-instruct-Q8_0-GGUF, https://huggingface.co/pipilok/YandexGPT-5-Lite-8B-instruct-exl2-8bpw-hb8, https://huggingface.co/BoloniniD/YandexGPT-5-Lite-8B-instruct-Q8_0-GGUF, https://huggingface.co/itlwas/YandexGPT-5-Lite-8B-instruct-Q4_K_M-GGUF, https://huggingface.co/Theta-Lev/YandexGPT-5-Lite-8B-instruct-Q5_K_M-GGUF",8,,0,huggingface/InferenceSupport/discussions/202,1
|
| 216 |
+
Apel-sin/yandexGPT-5-Lite-8B-instruct-exl2,"---
|
| 217 |
+
license: other
|
| 218 |
+
license_name: yandexgpt-5-lite-8b
|
| 219 |
+
license_link: LICENSE
|
| 220 |
+
language:
|
| 221 |
+
- ru
|
| 222 |
+
- en
|
| 223 |
+
base_model:
|
| 224 |
+
- yandex/YandexGPT-5-Lite-8B-instruct
|
| 225 |
+
---
|
| 226 |
+
|
| 227 |
+
# YandexGPT-5-Lite-Instruct
|
| 228 |
+
|
| 229 |
+
Instruct-версия большой языковой модели YandexGPT 5 Lite на 8B параметров с длиной контекста 32k токенов. Также в отдельном [репозитории](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-instruct-GGUF) опубликована квантизованная версия модели в формате GGUF.
|
| 230 |
+
|
| 231 |
+
Обучена на базе [YandexGPT 5 Lite Pretrain](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-pretrain), без использования весов каких-либо сторонних моделей. Алайнмент Lite-версии совпадает с алайнментом YandexGPT 5 Pro и состоит из этапов SFT и RLHF (более подробно о них — в [статье](https://habr.com/ru/companies/yandex/articles/885218/) на Хабре).
|
| 232 |
+
|
| 233 |
+
Задавайте вопросы в discussions.
|
| 234 |
+
|
| 235 |
+
## Бенчмарки
|
| 236 |
+
По результатам международных бенчмарков и их адаптаций для русского языка, YandexGPT 5 Lite вплотную приблизилась к аналогам (Llama-3.1-8B-instruct и Qwen-2.5-7B-instruct) и превосходит их в ряде сценариев, в том числе — в знании русской культуры и фактов.
|
| 237 |
+
|
| 238 |
+
<img src=""https://habrastorage.org/r/w1560/getpro/habr/upload_files/6b5/eb4/9ea/6b5eb49ea757bc124c938717b21f1cf7.png"" alt=""Таблица бенчмарков"" width=""100%""/>
|
| 239 |
+
|
| 240 |
+
MMLU — 5-shot, все остальные бенчмарки — 0-shot.
|
| 241 |
+
|
| 242 |
+
## Как использовать
|
| 243 |
+
|
| 244 |
+
Модель можно запустить через HF Transformers:
|
| 245 |
+
```python
|
| 246 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
MODEL_NAME = ""yandex/YandexGPT-5-Lite-8B-instruct""
|
| 250 |
+
|
| 251 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
|
| 252 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 253 |
+
MODEL_NAME,
|
| 254 |
+
device_map=""cuda"",
|
| 255 |
+
torch_dtype=""auto"",
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
messages = [{""role"": ""user"", ""content"": ""Для чего нужна токенизация?""}]
|
| 259 |
+
input_ids = tokenizer.apply_chat_template(
|
| 260 |
+
messages, tokenize=True, return_tensors=""pt""
|
| 261 |
+
).to(""cuda"")
|
| 262 |
+
|
| 263 |
+
outputs = model.generate(input_ids, max_new_tokens=1024)
|
| 264 |
+
print(tokenizer.decode(outputs[0][input_ids.size(1) :], skip_special_tokens=True))
|
| 265 |
+
```
|
| 266 |
+
|
| 267 |
+
Или через vLLM:
|
| 268 |
+
```python
|
| 269 |
+
from vllm import LLM, SamplingParams
|
| 270 |
+
from transformers import AutoTokenizer
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
MODEL_NAME = ""yandex/YandexGPT-5-Lite-8B-instruct""
|
| 274 |
+
|
| 275 |
+
sampling_params = SamplingParams(
|
| 276 |
+
temperature=0.3,
|
| 277 |
+
top_p=0.9,
|
| 278 |
+
max_tokens=1024,
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
|
| 282 |
+
llm = LLM(
|
| 283 |
+
MODEL_NAME,
|
| 284 |
+
tensor_parallel_size=1,
|
| 285 |
+
)
|
| 286 |
+
|
| 287 |
+
messages = [{""role"": ""user"", ""content"": ""В чем смысл жизни?""}]
|
| 288 |
+
input_ids = tokenizer.apply_chat_template(
|
| 289 |
+
messages, tokenize=True, add_generation_prompt=True
|
| 290 |
+
)[1:] # remove bos
|
| 291 |
+
text = tokenizer.decode(input_ids)
|
| 292 |
+
|
| 293 |
+
outputs = llm.generate(text, use_tqdm=False, sampling_params=sampling_params)
|
| 294 |
+
|
| 295 |
+
print(tokenizer.decode(outputs[0].outputs[0].token_ids, skip_special_tokens=True))
|
| 296 |
+
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
Для запуска в llama.cpp и ollama можно воспользоваться нашей квантизованной моделью, которая выложена в репозитории [YandexGPT-5-Lite-8B-instruct-GGUF](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-instruct-GGUF).
|
| 300 |
+
|
| 301 |
+
## Особенности токенизации
|
| 302 |
+
Для полного соответствия токенизации мы рекомендуем пользоваться оригинальным [sentencepiece](https://github.com/google/sentencepiece) — файл токенизатора лежит в папке `original_tokenizer`. В нашей инфраструктуре каждую реплику диалога мы токенизируем отдельно.
|
| 303 |
+
|
| 304 |
+
Из-за этого, в частности, появляется пробел в начале каждой реплики. Также `\n` токены мы заменяем на `[NL]`, это можно сделать с помощью `text.replace(""\n"", ""[NL]"")` перед токенизацией.
|
| 305 |
+
|
| 306 |
+
## Особенности шаблона
|
| 307 |
+
Мы используем нестандартный шаблон диалога — модель обучена генерировать только одну реплику после последовательности `Ассистент:[SEP]`, завершая её токеном `</s>`. При этом диалог в промпте может быть любой длины.
|
| 308 |
+
|
| 309 |
+
Это приводит к тому, что в интерактивном режиме модель может выдавать результаты, отличающиеся от вызова модели в режиме генерации на фиксированном диалоге. Поэтому мы рекомендуем использовать интерактивный режим только для ознакомления с моделью.","{""id"": ""Apel-sin/yandexGPT-5-Lite-8B-instruct-exl2"", ""author"": ""Apel-sin"", ""sha"": ""ef5c0e310be4abef18efc54cef2c08efeb8e4f3f"", ""last_modified"": ""2025-04-02 11:46:27+00:00"", ""created_at"": ""2025-03-31 13:38:29+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""ru"", ""en"", ""base_model:yandex/YandexGPT-5-Lite-8B-instruct"", ""base_model:finetune:yandex/YandexGPT-5-Lite-8B-instruct"", ""license:other"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- yandex/YandexGPT-5-Lite-8B-instruct\nlanguage:\n- ru\n- en\nlicense: other\nlicense_name: yandexgpt-5-lite-8b\nlicense_link: LICENSE"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='measurement.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-02 11:46:27+00:00"", ""cardData"": ""base_model:\n- yandex/YandexGPT-5-Lite-8B-instruct\nlanguage:\n- ru\n- en\nlicense: other\nlicense_name: yandexgpt-5-lite-8b\nlicense_link: LICENSE"", ""transformersInfo"": null, ""_id"": ""67ea9ad5e8e1920f2eb9b87d"", ""modelId"": ""Apel-sin/yandexGPT-5-Lite-8B-instruct-exl2"", ""usedStorage"": 8551012319}",2,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Apel-sin/yandexGPT-5-Lite-8B-instruct-exl2&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BApel-sin%2FyandexGPT-5-Lite-8B-instruct-exl2%5D(%2FApel-sin%2FyandexGPT-5-Lite-8B-instruct-exl2)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 310 |
+
Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it,"---
|
| 311 |
+
library_name: transformers
|
| 312 |
+
model_name: Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it
|
| 313 |
+
datasets:
|
| 314 |
+
- Vikhrmodels/GrandMaster-PRO-MAX
|
| 315 |
+
- Vikhrmodels/Grounded-RAG-RU-v2
|
| 316 |
+
base_model:
|
| 317 |
+
- yandex/YandexGPT-5-Lite-8B-pretrain
|
| 318 |
+
language:
|
| 319 |
+
- ru
|
| 320 |
+
- en
|
| 321 |
+
license: other
|
| 322 |
+
license_name: yandexgpt-5-lite-8b-pretrain
|
| 323 |
+
license_link: LICENSE
|
| 324 |
+
---
|
| 325 |
+
|
| 326 |
+
# Vikhr-YandexGPT-5-Lite-8B-it
|
| 327 |
+
|
| 328 |
+
Инструктивная модель на основе **YandexGPT-5-Lite-8B-pretrain**, обученная на русскоязычном датасете **GrandMaster-PRO-MAX** и **Grounded-RAG-RU-v2** с использованием **SFT**.
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
## Quatized variants:
|
| 332 |
+
- [GGUF](https://hf.co/Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it_GGUF)
|
| 333 |
+
- MLX
|
| 334 |
+
- [4 bit](https://hf.co/Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it_MLX-4bit)
|
| 335 |
+
- [8 bit](https://hf.co/Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it_MLX-8bit)
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
## Особенности:
|
| 339 |
+
|
| 340 |
+
- 📚 Основа: [YandexGPT-5-Lite-8B-pretrain](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-pretrain)
|
| 341 |
+
- 💾 Датасет / Dataset: [GrandMaster-PRO-MAX](https://huggingface.co/datasets/Vikhrmodels/GrandMaster-PRO-MAX), [Grounded-RAG-RU-v2](https://huggingface.co/datasets/Vikhrmodels/Grounded-RAG-RU-v2)
|
| 342 |
+
- 🇷🇺 Специализация: **RU**
|
| 343 |
+
- 🌍 Поддержка: **Bilingual RU/EN**
|
| 344 |
+
|
| 345 |
+
## Попробовать / Try now:
|
| 346 |
+
|
| 347 |
+
[](https://colab.research.google.com/drive/1jIm0beQiUoW6bn57jixEdFEgIa-vZMLM?usp=sharing)
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
## Обучение:
|
| 351 |
+
|
| 352 |
+
**Vikhr-YandexGPT-5-Lite-8B-it** была создана с использованием метода SFT (Supervised Fine-Tuning).
|
| 353 |
+
|
| 354 |
+
#### Инструктивная SFT часть
|
| 355 |
+
|
| 356 |
+
Для SFT этапа обучения модели мы подготовили большой (150к инструкций) инструктивный синтетический датасет [Vikhrmodels/GrandMaster-PRO-MAX](https://huggingface.co/datasets/Vikhrmodels/GrandMaster-PRO-MAX). Его особенностью является встроеный CoT (Chain-Of-Thought), для сбора которого мы использовали модифицированный промет для gpt-4-turbo, подробности в карточке датасета.
|
| 357 |
+
|
| 358 |
+
Кроме того, для того чтобы сделать RAG Grounding, мы подготовили другой синтетический датасет - [Vikhrmodels/Grounded-RAG-RU-v2](https://huggingface.co/datasets/Vikhrmodels/Grounded-RAG-RU-v2) (50k диалогов), его пайплайн сборки достаточно сложный для короткого описания и полробнее об этом вы можете прочитать в его карточке.
|
| 359 |
+
|
| 360 |
+
[Конфиг обучения](https://github.com/VikhrModels/effective_llm_alignment/tree/main/training_configs/sft/sft-yandex-lora-GrandmasterRAG.yaml)
|
| 361 |
+
|
| 362 |
+
## Пример кода для запуска:
|
| 363 |
+
|
| 364 |
+
```python
|
| 365 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 366 |
+
|
| 367 |
+
# Load the model and tokenizer
|
| 368 |
+
model_name = ""Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it""
|
| 369 |
+
model = AutoModelForCausalLM.from_pretrained(model_name)
|
| 370 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 371 |
+
|
| 372 |
+
# Prepare the input text
|
| 373 |
+
input_text = ""Напиши краткое описание фильма Назад в будущее.""
|
| 374 |
+
|
| 375 |
+
messages = [
|
| 376 |
+
{""role"": ""user"", ""content"": input_text},
|
| 377 |
+
]
|
| 378 |
+
|
| 379 |
+
# Tokenize and generate text
|
| 380 |
+
input_ids = tokenizer.apply_chat_template(messages, truncation=True, add_generation_prompt=True, return_tensors=""pt"")
|
| 381 |
+
output = model.generate(
|
| 382 |
+
input_ids,
|
| 383 |
+
max_length=1512,
|
| 384 |
+
temperature=0.7,
|
| 385 |
+
)
|
| 386 |
+
|
| 387 |
+
# Decode and print result
|
| 388 |
+
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
|
| 389 |
+
print(generated_text)
|
| 390 |
+
```
|
| 391 |
+
|
| 392 |
+
#### Ответ модели:
|
| 393 |
+
|
| 394 |
+
>""Назад в будущее"" (англ. ""Back to the Future"") — это американский научно-фантастический фильм, выпущенный в 1985 году. Режиссёром картины выступил Роберт Земекис, а сценарий написал Боб Гейл. Главные роли исполнили Майкл Дж. Фокс, Кристофер Ллойд и Лиа Томпсон.
|
| 395 |
+
>
|
| 396 |
+
>Фильм рассказывает историю Марти МакФлая, обычного подростка из 1985 года, который случайно попадает в 1955 год благодаря изобретению своего друга-ученого, доктора Эмметта Брауна. Марти оказывается в прошлом, где он должен помочь доктору Брауну, который в то время был молодым и наивным, изобрести машину времени.
|
| 397 |
+
>
|
| 398 |
+
>В процессе своих приключений Марти встречает молодого доктора Брауна и его семью, а также влюбляется в девушку, которая в будущем станет его матерью. Марти должен не только исправить ошибки прошлого, но и предотвратить катастрофу, которая может изменить будущее.
|
| 399 |
+
>
|
| 400 |
+
>Фильм получил множество наград и стал культовым, породив два сиквела и множество мемов и цитат, которые до сих пор популярны.
|
| 401 |
+
|
| 402 |
+
### Как работать с RAG
|
| 403 |
+
|
| 404 |
+
Роль documents представляет из себя список словарей с описанием контента документов, с примнением `json.dumps(array, ensure_ascii=False)` (см. пример ниже). \
|
| 405 |
+
Контент документов может быть представлен в **3** различных форматах: **Markdown**, **HTML**, **Plain Text**. Контент каждого документа - может быть чанком текста длиной до 4к символов.
|
| 406 |
+
|
| 407 |
+
```json
|
| 408 |
+
[
|
| 409 |
+
{
|
| 410 |
+
""doc_id"": (0..5),
|
| 411 |
+
""title"": ""(null or str)"",
|
| 412 |
+
""content"": ""(html or markdown or plain text)""
|
| 413 |
+
}
|
| 414 |
+
]
|
| 415 |
+
```
|
| 416 |
+
|
| 417 |
+
#### Пример правильного использования с OpenAI-like API
|
| 418 |
+
|
| 419 |
+
Запуск vLLM сервера: `vllm serve --dtype half --max-model-len 32000 -tp 1 Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it --api-key token-abc123`
|
| 420 |
+
|
| 421 |
+
```python
|
| 422 |
+
GROUNDED_SYSTEM_PROMPT = ""Your task is to answer the user's questions using only the information from the provided documents. Give two answers to each question: one with a list of relevant document identifiers and the second with the answer to the question itself, using documents with these identifiers.""
|
| 423 |
+
documents = [
|
| 424 |
+
{
|
| 425 |
+
""doc_id"": 0,
|
| 426 |
+
""title"": ""Глобальное потепление: ледники"",
|
| 427 |
+
""content"": ""За последние 50 лет объем ледников в мире уменьшился на 30%""
|
| 428 |
+
},
|
| 429 |
+
{
|
| 430 |
+
""doc_id"": 1,
|
| 431 |
+
""title"": ""Глобальное потепление: Уровень моря"",
|
| 432 |
+
""content"": ""Уровень мирового океана повысился на 20 см с 1880 года и продолжает расти на 3,3 мм в год""
|
| 433 |
+
}
|
| 434 |
+
]
|
| 435 |
+
sample_history = [
|
| 436 |
+
{'role': 'system', 'content': GROUNDED_SYSTEM_PROMPT},
|
| 437 |
+
{'role': 'documents', 'content': json.dumps(documents, ensure_ascii=False)},
|
| 438 |
+
{'role': 'user', 'content': 'Глоабльное потепление'}
|
| 439 |
+
]
|
| 440 |
+
relevant_indexes = llm_client.chat.completions.create(
|
| 441 |
+
model=llm_model,
|
| 442 |
+
messages=sample_history,
|
| 443 |
+
temperature=0.0,
|
| 444 |
+
max_tokens=2048
|
| 445 |
+
).choices[0].message.content
|
| 446 |
+
print('Using documents: ' + relevant_indexes + '\n----')
|
| 447 |
+
final_answer = llm_client.chat.completions.create(
|
| 448 |
+
model=llm_model,
|
| 449 |
+
messages=sample_history + [{'role': 'assistant', 'content': relevant_indexes}],
|
| 450 |
+
temperature=0.3,
|
| 451 |
+
max_tokens=2048
|
| 452 |
+
).choices[0].message.content
|
| 453 |
+
print(final_answer)
|
| 454 |
+
```
|
| 455 |
+
|
| 456 |
+
Ответ после выполнения кода будет выглядеть примерно так:
|
| 457 |
+
|
| 458 |
+
>Using documents: {""relevant_doc_ids"": [0, 1]}
|
| 459 |
+
>----
|
| 460 |
+
>Глобальное потепление – это долгосрочное повышение средней температуры атмосферы и океанов Земли. Это явление имеет множество последствий для нашей планеты, и среди них можно выделить два ключевых аспекта, основанных на доступных мне данных:
|
| 461 |
+
>
|
| 462 |
+
>1. **Уменьшение объема ледников**: За последние 50 лет наблюдается значительное сокращение объема ледников по всему миру. Согласно данным, объем ледников уменьшился на 30%. Это может быть связано с таянием ледников из-за повышения температур, что является одним из признаков глобального потепления.
|
| 463 |
+
>
|
| 464 |
+
>2. **Повышение уровня моря**: Уровень мирового океана также увеличивается, что связано с таянием ледников и ледяных покровов, а также с расширением воды при повышении температуры. С 1880 года уровень моря повысился на 20 сантиметров, и этот процесс продолжается, с ежегодным увеличением на 3,3 миллиметра.
|
| 465 |
+
>
|
| 466 |
+
>Эти изменения имеют серьезные последствия для экосистем, климата и человеческого общества. Таяние ледников приводит к повышению уровня моря, что может привести к затоплению прибрежных территорий и островов, а также к изменению водных ресурсов и климатических паттернов.
|
| 467 |
+
|
| 468 |
+
Используя первый ответ модели `relevant_indexes` (JSON), можно понять нашла ли модель информацию в документах или нет, она обучена возврашать пустой массив если ее нет и в таком случае она будет отвечать, что не смогла найти информацию в базе знаний (при генерации второго ответа).
|
| 469 |
+
|
| 470 |
+
### Нюансы и ограничения
|
| 471 |
+
- Модель имеет **низкий уровень безопасности ответов** и нацелена на правильное и полное выполенние инструкций, имейте это ввиду при использовании и тестируйте самостоятельно. Частично это исправляется системными промптами и дополнительными указаниями о важност�� безопасности в промпте пользователя.
|
| 472 |
+
- Системные промпты не предназначены для описание персонажей, мы рекомендуем использовать их для спецификации стиля ответа (вроде ""answer only in json format""). Кроме того, желательно, писать их **на английском языке**, так как так было в датасете, от использования английского в системных промтпах не зависит язык ответа.
|
| 473 |
+
- RAG режим **требует обязательного** наличия системного промпта `GROUNDED_SYSTEM_PROMPT` описаного в секции *Как работать с RAG*. Так же иногда модель может добавлять общую информацию из своих знаний в ответ к той, что есть в документах.
|
| 474 |
+
- Модель лучше использовать с низкой темптературой (0.1-0.5), а таже использовать top_k (30-50), при температуре 1.0 были замечены случайные дефекты генерации.
|
| 475 |
+
|
| 476 |
+
### Авторы
|
| 477 |
+
|
| 478 |
+
- Sergei Bratchikov, [NLP Wanderer](https://t.me/nlpwanderer), [Vikhr Team](https://t.me/vikhrlabs)
|
| 479 |
+
- Nikolay Kompanets, [LakoMoor](https://t.me/lakomoordev), [Vikhr Team](https://t.me/vikhrlabs)
|
| 480 |
+
- Konstantin Korolev, [Vikhr Team](https://t.me/vikhrlabs)
|
| 481 |
+
- Aleksandr Nikolich, [Vikhr Team](https://t.me/vikhrlabs)
|
| 482 |
+
|
| 483 |
+
```
|
| 484 |
+
@inproceedings{nikolich2024vikhr,
|
| 485 |
+
title={Vikhr: Advancing Open-Source Bilingual Instruction-Following Large Language Models for Russian and English},
|
| 486 |
+
author={Aleksandr Nikolich and Konstantin Korolev and Sergei Bratchikov and Nikolay Kompanets and Igor Kiselev and Artem Shelmanov},
|
| 487 |
+
booktitle={Proceedings of the 4th Workshop on Multilingual Representation Learning (MRL) @ EMNLP-2024},
|
| 488 |
+
year={2024},
|
| 489 |
+
publisher={Association for Computational Linguistics},
|
| 490 |
+
url={https://arxiv.org/pdf/2405.13929}
|
| 491 |
+
}
|
| 492 |
+
```","{""id"": ""Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it"", ""author"": ""Vikhrmodels"", ""sha"": ""e99a6f275ee43ad7856bfcf9be4f2e90b29f960a"", ""last_modified"": ""2025-03-01 07:51:48+00:00"", ""created_at"": ""2025-02-28 07:24:59+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 699, ""downloads_all_time"": null, ""likes"": 21, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""conversational"", ""ru"", ""en"", ""dataset:Vikhrmodels/GrandMaster-PRO-MAX"", ""dataset:Vikhrmodels/Grounded-RAG-RU-v2"", ""arxiv:2405.13929"", ""base_model:yandex/YandexGPT-5-Lite-8B-pretrain"", ""base_model:finetune:yandex/YandexGPT-5-Lite-8B-pretrain"", ""license:other"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- yandex/YandexGPT-5-Lite-8B-pretrain\ndatasets:\n- Vikhrmodels/GrandMaster-PRO-MAX\n- Vikhrmodels/Grounded-RAG-RU-v2\nlanguage:\n- ru\n- en\nlibrary_name: transformers\nlicense: other\nlicense_name: yandexgpt-5-lite-8b-pretrain\nlicense_link: LICENSE\nmodel_name: Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""chat_template"": ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<s>' + message['role'] + '\n' + message['content'] + '</s>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<s>assistant\n' }}{% endif %}"", ""eos_token"": ""</s>"", ""pad_token"": ""[SPEC_TOKEN_1001]"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='original_adapter/README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='original_adapter/adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='original_adapter/adapter_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""lmarena/chatbot-arena-leaderboard""], ""safetensors"": {""parameters"": {""BF16"": 8036552704}, ""total"": 8036552704}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-01 07:51:48+00:00"", ""cardData"": ""base_model:\n- yandex/YandexGPT-5-Lite-8B-pretrain\ndatasets:\n- Vikhrmodels/GrandMaster-PRO-MAX\n- Vikhrmodels/Grounded-RAG-RU-v2\nlanguage:\n- ru\n- en\nlibrary_name: transformers\nlicense: other\nlicense_name: yandexgpt-5-lite-8b-pretrain\nlicense_link: LICENSE\nmodel_name: Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""67c164cb754d40378eb0ee86"", ""modelId"": ""Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it"", ""usedStorage"": 18159448292}",1,,0,,0,"https://huggingface.co/Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it_MLX-4bit, https://huggingface.co/Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it_MLX-8bit, https://huggingface.co/Ronny/Vikhr-YandexGPT-5-Lite-8B-it-Q8_0-GGUF, https://huggingface.co/BoloniniD/Vikhr-YandexGPT-5-Lite-8B-it-Q8_0-GGUF, https://huggingface.co/Ronny/Vikhr-YandexGPT-5-Lite-8B-it-Q6_K-GGUF, https://huggingface.co/Ronny/Vikhr-YandexGPT-5-Lite-8B-it-Q4_K_S-GGUF, https://huggingface.co/MaziyarPanahi/Vikhr-YandexGPT-5-Lite-8B-it-GGUF, https://huggingface.co/itlwas/Vikhr-YandexGPT-5-Lite-8B-it-Q4_K_M-GGUF, https://huggingface.co/Chewye/Vikhr-YandexGPT-5-Lite-8B-it-awq, https://huggingface.co/DevQuasar/Vikhrmodels.Vikhr-YandexGPT-5-Lite-8B-it-GGUF, https://huggingface.co/tensorblock/Vikhrmodels_Vikhr-YandexGPT-5-Lite-8B-it-GGUF",11,,0,"huggingface/InferenceSupport/discussions/new?title=Vikhrmodels/Vikhr-YandexGPT-5-Lite-8B-it&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BVikhrmodels%2FVikhr-YandexGPT-5-Lite-8B-it%5D(%2FVikhrmodels%2FVikhr-YandexGPT-5-Lite-8B-it)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, lmarena/chatbot-arena-leaderboard",2
|
| 493 |
+
https://huggingface.co/secretmoon/YankaGPT-8B-v0.1,N/A,N/A,1,,0,,0,,0,,0,,0
|
| 494 |
+
attn-signs/GPTR-8b-base,"---
|
| 495 |
+
library_name: transformers
|
| 496 |
+
tags:
|
| 497 |
+
- reasoning
|
| 498 |
+
license: apache-2.0
|
| 499 |
+
datasets:
|
| 500 |
+
- attn-signs/gromov-0
|
| 501 |
+
language:
|
| 502 |
+
- ru
|
| 503 |
+
base_model:
|
| 504 |
+
- yandex/YandexGPT-5-Lite-8B-pretrain
|
| 505 |
+
---
|
| 506 |
+
# GPT Reasoner (Base model)
|
| 507 |
+
|
| 508 |
+
- [EN]
|
| 509 |
+
Reasoning model adapted for russian text generation.
|
| 510 |
+
**Based on YandexGPT-pretrain**
|
| 511 |
+
- [RU]
|
| 512 |
+
Модель рассуждений, адаптированная для генерации русскоязычного текста.
|
| 513 |
+
**Построена на YandexGPT-pretrain**
|
| 514 |
+
|
| 515 |
+
## Model Details / Детализация модели
|
| 516 |
+
- [EN]
|
| 517 |
+
**Cold-start SFT version** to invoke general reasoning capabilities on a specific system prompt.
|
| 518 |
+
This model **IS ONLY USED** for further GRPO optimizations, it cannot generate coherent russian text in this iteration.
|
| 519 |
+
- [RU]
|
| 520 |
+
**Версия cold-start SFT обучения** для возможностей размышления и глубокого понимания запроса.
|
| 521 |
+
Эта модель **ИСПОЛЬЗУЕТСЯ ТОЛЬКО** для дальнейших стадий обучения с GRPO.
|
| 522 |
+
Модель не может генерировать когерентный текст русского языка на этой итерации.
|
| 523 |
+
|
| 524 |
+
|
| 525 |
+
### Model Description / Описание модели
|
| 526 |
+
|
| 527 |
+
- **Developed by:** [Reisen Raumberg (Attention Signs team)]
|
| 528 |
+
- **Language(s) (NLP):** [RU/EN]
|
| 529 |
+
- **SFT from model:** [YandexGPT-5-lite-8B-pretrain]
|
| 530 |
+
|
| 531 |
+
Utilized HF.Accelerator
|
| 532 |
+
**GPU hours**: ~3h of NVIDIA A100
|
| 533 |
+
|
| 534 |
+
Для обучения использовался HuggingFace Accelerator
|
| 535 |
+
**GPU часы**: ~3 часа NVIDIA A100
|
| 536 |
+
|
| 537 |
+
### Training Framework
|
| 538 |
+
**GPTR was trained using MyLLM framework (by Attention Signs):**
|
| 539 |
+
--==[MyLLM](https://github.com/Raumberg/myllm)==--
|
| 540 |
+
|
| 541 |
+
### Model configuration (MyLLM Framework)
|
| 542 |
+
Full SFT finetuning
|
| 543 |
+
```toml
|
| 544 |
+
[model]
|
| 545 |
+
model_name_or_path = ""yandex/YandexGPT-5-Lite-8B-pretrain""
|
| 546 |
+
|
| 547 |
+
[datasets]
|
| 548 |
+
dataset = ""attn-signs/gromov-0""
|
| 549 |
+
conversation_field = ""conversation""
|
| 550 |
+
generate_eval_examples = false
|
| 551 |
+
evaluation_strategy = ""steps""
|
| 552 |
+
eval_steps = 100
|
| 553 |
+
dataloader_num_workers = 2
|
| 554 |
+
remove_unused_columns = true
|
| 555 |
+
test_size = 0.05
|
| 556 |
+
|
| 557 |
+
[run]
|
| 558 |
+
save_strategy = ""steps""
|
| 559 |
+
save_steps = 300
|
| 560 |
+
save_total_limit = 3
|
| 561 |
+
run_name = ""sft-gptr-8-run2""
|
| 562 |
+
report_to = ""wandb""
|
| 563 |
+
logging_first_step = true
|
| 564 |
+
logging_steps = 1
|
| 565 |
+
output_dir = ""models/attn-signs-gptr-8-run2""
|
| 566 |
+
project_name = ""sft-gptr""
|
| 567 |
+
|
| 568 |
+
[training]
|
| 569 |
+
train_only_on_completions = true
|
| 570 |
+
per_device_train_batch_size = 1
|
| 571 |
+
per_device_eval_batch_size = 1
|
| 572 |
+
num_train_epochs = 3
|
| 573 |
+
learning_rate = 0.000009
|
| 574 |
+
max_seq_length = 8192
|
| 575 |
+
gradient_accumulation_steps = 8
|
| 576 |
+
gradient_checkpointing = true
|
| 577 |
+
warmup_steps = 10
|
| 578 |
+
bf16 = true
|
| 579 |
+
seed = 42
|
| 580 |
+
use_peft = false
|
| 581 |
+
|
| 582 |
+
[fusion]
|
| 583 |
+
attn_implementation = ""flash_attention_2""
|
| 584 |
+
|
| 585 |
+
[tokenizer]
|
| 586 |
+
assistant_message_template = ""<s>assistant\n""
|
| 587 |
+
eos_token = ""</s>""
|
| 588 |
+
pad_token = ""<unk>""
|
| 589 |
+
chat_template = ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<s>' + message['role'] + '\n' + message['content'] + '</s>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<s>assistant\n' }}{% endif %}""
|
| 590 |
+
force_chat_template = true
|
| 591 |
+
added_special_tokens = [
|
| 592 |
+
""<think>"",
|
| 593 |
+
""</think>""
|
| 594 |
+
]
|
| 595 |
+
system_prompt = """"""
|
| 596 |
+
[MODE: Reflection]
|
| 597 |
+
""""""
|
| 598 |
+
```
|
| 599 |
+
|
| 600 |
+
### Using the model / Как запустить?
|
| 601 |
+
|
| 602 |
+
```python
|
| 603 |
+
repo = 'attn-signs/GPTR-8-base'
|
| 604 |
+
|
| 605 |
+
model = AutoModelForCausalLM.from_pretrained(repo)
|
| 606 |
+
tokenizer = AutoTokenizer.from_pretrained(repo)
|
| 607 |
+
|
| 608 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 609 |
+
model.to(device)
|
| 610 |
+
|
| 611 |
+
user_prompt = '''
|
| 612 |
+
У уравнений x**2 + 2019ax + b = 0 и x**2 + 2019bx + a = 0 есть один общий корень. Чему может быть равен этот корень, если известно, что a != b?
|
| 613 |
+
'''
|
| 614 |
+
system_prompt = ""[MODE: Reflection]""
|
| 615 |
+
messages = [
|
| 616 |
+
{""role"": ""system"", ""content"": system_prompt},
|
| 617 |
+
{""role"": ""user"", ""content"": user_prompt}
|
| 618 |
+
]
|
| 619 |
+
text = tokenizer.apply_chat_template(
|
| 620 |
+
messages,
|
| 621 |
+
tokenize=False,
|
| 622 |
+
add_generation_prompt=True
|
| 623 |
+
)
|
| 624 |
+
model_inputs = tokenizer([text], return_tensors=""pt"").to(model.device)
|
| 625 |
+
|
| 626 |
+
generated_ids = model.generate(
|
| 627 |
+
**model_inputs,
|
| 628 |
+
max_new_tokens=4096
|
| 629 |
+
)
|
| 630 |
+
generated_ids = [
|
| 631 |
+
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
|
| 632 |
+
]
|
| 633 |
+
|
| 634 |
+
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 635 |
+
|
| 636 |
+
print(response)
|
| 637 |
+
```","{""id"": ""attn-signs/GPTR-8b-base"", ""author"": ""attn-signs"", ""sha"": ""cf97c4315b118d10d12869ae9f46114c489fc8a7"", ""last_modified"": ""2025-04-15 07:59:57+00:00"", ""created_at"": ""2025-04-13 08:36:02+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 12, ""downloads_all_time"": null, ""likes"": 1, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""reasoning"", ""conversational"", ""ru"", ""dataset:attn-signs/gromov-0"", ""base_model:yandex/YandexGPT-5-Lite-8B-pretrain"", ""base_model:finetune:yandex/YandexGPT-5-Lite-8B-pretrain"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- yandex/YandexGPT-5-Lite-8B-pretrain\ndatasets:\n- attn-signs/gromov-0\nlanguage:\n- ru\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- reasoning"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""chat_template"": ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<s>' + message['role'] + '\n' + message['content'] + '</s>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<s>assistant\n' }}{% endif %}"", ""eos_token"": ""</s>"", ""pad_token"": ""<unk>"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""BF16"": 8036569088}, ""total"": 8036569088}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-15 07:59:57+00:00"", ""cardData"": ""base_model:\n- yandex/YandexGPT-5-Lite-8B-pretrain\ndatasets:\n- attn-signs/gromov-0\nlanguage:\n- ru\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- reasoning"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""67fb777216951dac644cc49c"", ""modelId"": ""attn-signs/GPTR-8b-base"", ""usedStorage"": 16093768862}",1,https://huggingface.co/attn-signs/GPTR-8b-v1,1,,0,"https://huggingface.co/mradermacher/GPTR-8-base-GGUF, https://huggingface.co/mradermacher/GPTR-8-base-i1-GGUF",2,,0,huggingface/InferenceSupport/discussions/new?title=attn-signs/GPTR-8b-base&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Battn-signs%2FGPTR-8b-base%5D(%2Fattn-signs%2FGPTR-8b-base)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 638 |
+
attn-signs/GPTR-8b-v1,"---
|
| 639 |
+
library_name: transformers
|
| 640 |
+
tags:
|
| 641 |
+
- reasoning
|
| 642 |
+
license: apache-2.0
|
| 643 |
+
datasets:
|
| 644 |
+
- d0rj/gsm8k-ru
|
| 645 |
+
language:
|
| 646 |
+
- ru
|
| 647 |
+
base_model:
|
| 648 |
+
- attn-signs/GPTR-8b-base
|
| 649 |
+
---
|
| 650 |
+
# GPT Reasoner (V1)
|
| 651 |
+
|
| 652 |
+
- [EN]
|
| 653 |
+
Reasoning model adapted for russian text generation.
|
| 654 |
+
**Based on YandexGPT-pretrain -> GPTR-8b-base**
|
| 655 |
+
- [RU]
|
| 656 |
+
Модель рассуждений, адаптированная для генерации русскоязычного текста.
|
| 657 |
+
**Построена на YandexGPT-pretrain -> GPTR-8b-base**
|
| 658 |
+
|
| 659 |
+
## Model Details / Детализация модели
|
| 660 |
+
- [EN]
|
| 661 |
+
**Reinforced GRPO version** to invoke general reasoning capabilities.
|
| 662 |
+
This model can generate conditional and coherent chain-of-thought
|
| 663 |
+
- [RU]
|
| 664 |
+
**Версия RL GRPO** для возможностей размышления и глубокого понимания запроса.
|
| 665 |
+
Модель может генерировать когерентный текст русского языка на этой итерации.
|
| 666 |
+
|
| 667 |
+
### Important:
|
| 668 |
+
- [EN]
|
| 669 |
+
This is the first stage of reinforcement learning, don't expect the model to solve every mathematical problem.
|
| 670 |
+
The training is ongoing. Still, this model is stable and can solve something now.
|
| 671 |
+
- [RU]
|
| 672 |
+
Это первая стадия RL обучения, поэтому не стоит возлагать надежды на решения любой математической проблемы данной моделью.
|
| 673 |
+
Обучение продолжается, данная версия модели скорее proof-of-concept, чем готовый математический ассистент.
|
| 674 |
+
Несмотря на это, модель стабильна.
|
| 675 |
+
|
| 676 |
+
### Further development
|
| 677 |
+
- GRPO on Gromov dataset series
|
| 678 |
+
|
| 679 |
+
### Model Description / Описание модели
|
| 680 |
+
|
| 681 |
+
- **Developed by:** [Reisen Raumberg (Attention Signs team)]
|
| 682 |
+
- **Language(s) (NLP):** [RU/EN]
|
| 683 |
+
- **SFT from model:** [YandexGPT-5-lite-8B-pretrain]
|
| 684 |
+
|
| 685 |
+
Utilized HF.Accelerator
|
| 686 |
+
**GPU hours**: ~24h of NVIDIA A100
|
| 687 |
+
|
| 688 |
+
Для обучения использовался HuggingFace Accelerator
|
| 689 |
+
**GPU часы**: ~24h часа NVIDIA A100
|
| 690 |
+
|
| 691 |
+
### Training Framework
|
| 692 |
+
**GPTR was trained using MyLLM framework (by Attention Signs):**
|
| 693 |
+
--==[MyLLM](https://github.com/Raumberg/myllm)==--
|
| 694 |
+
|
| 695 |
+
### Model configuration (MyLLM Framework)
|
| 696 |
+
```toml
|
| 697 |
+
[model]
|
| 698 |
+
model_name_or_path = ""attn-signs/GPTR-8-base""
|
| 699 |
+
|
| 700 |
+
[datasets]
|
| 701 |
+
dataset = ""d0rj/gsm8k-ru""
|
| 702 |
+
problem_field = ""question""
|
| 703 |
+
solution_field = ""answer""
|
| 704 |
+
dataloader_num_workers = 2
|
| 705 |
+
test_size = 0.1
|
| 706 |
+
extract_hash = true
|
| 707 |
+
|
| 708 |
+
[run]
|
| 709 |
+
run_name = ""rl-gptr-8""
|
| 710 |
+
report_to = ""wandb""
|
| 711 |
+
logging_first_step = true
|
| 712 |
+
logging_steps = 1
|
| 713 |
+
save_strategy = ""steps""
|
| 714 |
+
save_steps = 500
|
| 715 |
+
save_total_limit = 5
|
| 716 |
+
output_dir = ""models/attn-signs-gptr-8-grpo""
|
| 717 |
+
project_name = ""rl-gptr""
|
| 718 |
+
|
| 719 |
+
[training]
|
| 720 |
+
num_train_epochs = 1
|
| 721 |
+
per_device_train_batch_size = 2
|
| 722 |
+
learning_rate = 0.00001
|
| 723 |
+
bf16 = true
|
| 724 |
+
seed = 42
|
| 725 |
+
use_peft = true
|
| 726 |
+
|
| 727 |
+
[grpo]
|
| 728 |
+
use_vllm = true
|
| 729 |
+
num_generations = 2
|
| 730 |
+
max_completion_length = 2048
|
| 731 |
+
num_iterations = 1 # https://github.com/huggingface/trl/releases/tag/v0.16.0
|
| 732 |
+
scale_rewards = false # should be default var
|
| 733 |
+
beta = 0.04 # reference model beta in vllm
|
| 734 |
+
epsilon_high = 0.28 # Increasing upper bound epsilon leads to higher entropy during generation, promoting better exploration
|
| 735 |
+
preload_rm = false
|
| 736 |
+
|
| 737 |
+
[lora]
|
| 738 |
+
lora_target_modules = [
|
| 739 |
+
""k_proj"",
|
| 740 |
+
""v_proj"",
|
| 741 |
+
""q_proj"",
|
| 742 |
+
""o_proj"",
|
| 743 |
+
""gate_proj"",
|
| 744 |
+
""up_proj"",
|
| 745 |
+
""down_proj"",
|
| 746 |
+
]
|
| 747 |
+
lora_r = 32
|
| 748 |
+
lora_alpha = 64
|
| 749 |
+
|
| 750 |
+
[fusion]
|
| 751 |
+
use_liger = false
|
| 752 |
+
attn_implementation = ""flash_attention_2""
|
| 753 |
+
|
| 754 |
+
[tokenizer]
|
| 755 |
+
eos_token = ""</s>""
|
| 756 |
+
pad_token = ""<unk>""
|
| 757 |
+
chat_template = ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<s>' + message['role'] + '\n' + message['content'] + '</s>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<s>assistant\n' }}{% endif %}""
|
| 758 |
+
force_chat_template = true
|
| 759 |
+
added_special_tokens = [
|
| 760 |
+
""<think>"",
|
| 761 |
+
""</think>""
|
| 762 |
+
]
|
| 763 |
+
system_prompt = """"""
|
| 764 |
+
[MODE: Reflection]
|
| 765 |
+
""""""
|
| 766 |
+
```
|
| 767 |
+
### Rewards:
|
| 768 |
+
- Equation structure reward
|
| 769 |
+
- Correctness reward
|
| 770 |
+
- Multilingual coherence reward
|
| 771 |
+
- Strict chinese penalty
|
| 772 |
+
- Format reward
|
| 773 |
+
- Russian purity reward
|
| 774 |
+
|
| 775 |
+
### Using the model / Как запустить?
|
| 776 |
+
|
| 777 |
+
```python
|
| 778 |
+
repo = 'attn-signs/GPTR-8-v1'
|
| 779 |
+
|
| 780 |
+
model = AutoModelForCausalLM.from_pretrained(repo)
|
| 781 |
+
tokenizer = AutoTokenizer.from_pretrained(repo)
|
| 782 |
+
|
| 783 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 784 |
+
model.to(device)
|
| 785 |
+
|
| 786 |
+
user_prompt = '''
|
| 787 |
+
У уравнений x**2 + 2019ax + b = 0 и x**2 + 2019bx + a = 0 есть один общий корень. Чему может быть равен этот корень, если известно, что a != b?
|
| 788 |
+
'''
|
| 789 |
+
system_prompt = ""[MODE: Reflection]""
|
| 790 |
+
messages = [
|
| 791 |
+
{""role"": ""system"", ""content"": system_prompt},
|
| 792 |
+
{""role"": ""user"", ""content"": user_prompt}
|
| 793 |
+
]
|
| 794 |
+
text = tokenizer.apply_chat_template(
|
| 795 |
+
messages,
|
| 796 |
+
tokenize=False,
|
| 797 |
+
add_generation_prompt=True
|
| 798 |
+
)
|
| 799 |
+
model_inputs = tokenizer([text], return_tensors=""pt"").to(model.device)
|
| 800 |
+
|
| 801 |
+
generated_ids = model.generate(
|
| 802 |
+
**model_inputs,
|
| 803 |
+
max_new_tokens=4096
|
| 804 |
+
)
|
| 805 |
+
generated_ids = [
|
| 806 |
+
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
|
| 807 |
+
]
|
| 808 |
+
|
| 809 |
+
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 810 |
+
|
| 811 |
+
print(response)
|
| 812 |
+
```","{""id"": ""attn-signs/GPTR-8b-v1"", ""author"": ""attn-signs"", ""sha"": ""1501da3da7f77a79c6983e28976eb2a05475741c"", ""last_modified"": ""2025-04-16 07:15:36+00:00"", ""created_at"": ""2025-04-13 08:28:20+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 20, ""downloads_all_time"": null, ""likes"": 1, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""reasoning"", ""conversational"", ""ru"", ""dataset:d0rj/gsm8k-ru"", ""base_model:attn-signs/GPTR-8b-base"", ""base_model:finetune:attn-signs/GPTR-8b-base"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- attn-signs/GPTR-8b-base\ndatasets:\n- d0rj/gsm8k-ru\nlanguage:\n- ru\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- reasoning"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""chat_template"": ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<s>' + message['role'] + '\n' + message['content'] + '</s>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<s>assistant\n' }}{% endif %}"", ""eos_token"": ""</s>"", ""pad_token"": ""<unk>"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""BF16"": 8036569088}, ""total"": 8036569088}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-16 07:15:36+00:00"", ""cardData"": ""base_model:\n- attn-signs/GPTR-8b-base\ndatasets:\n- d0rj/gsm8k-ru\nlanguage:\n- ru\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- reasoning"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""67fb75a4be94c007dd0b7d28"", ""modelId"": ""attn-signs/GPTR-8b-v1"", ""usedStorage"": 16093768862}",2,https://huggingface.co/attn-signs/GPTR-8b-v2,1,,0,"https://huggingface.co/mradermacher/GPTR-8-v1-GGUF, https://huggingface.co/mradermacher/GPTR-8-v1-i1-GGUF",2,,0,huggingface/InferenceSupport/discussions/new?title=attn-signs/GPTR-8b-v1&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Battn-signs%2FGPTR-8b-v1%5D(%2Fattn-signs%2FGPTR-8b-v1)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 813 |
+
attn-signs/GPTR-8b-v2,"---
|
| 814 |
+
library_name: transformers
|
| 815 |
+
tags:
|
| 816 |
+
- reasoning
|
| 817 |
+
license: apache-2.0
|
| 818 |
+
datasets:
|
| 819 |
+
- attn-signs/gromov-1
|
| 820 |
+
language:
|
| 821 |
+
- ru
|
| 822 |
+
base_model:
|
| 823 |
+
- attn-signs/GPTR-8b-v1
|
| 824 |
+
---
|
| 825 |
+
# GPT Reasoner (V2)
|
| 826 |
+
|
| 827 |
+
- [EN]
|
| 828 |
+
Reasoning model adapted for russian text generation.
|
| 829 |
+
**Based on YandexGPT-pretrain -> GPTR-8b-base -> GPTR-8b-v1 -> GPTR-8b-v2**
|
| 830 |
+
- [RU]
|
| 831 |
+
Модель рассуждений, адаптированная для генерации русскоязычного текста.
|
| 832 |
+
**Построена на YandexGPT-pretrain -> GPTR-8b-base -> GPTR-8b-v1 -> GPTR-8b-v2**
|
| 833 |
+
|
| 834 |
+
## Model Details / Детализация модели
|
| 835 |
+
- [EN]
|
| 836 |
+
**Reinforced GRPO version** to invoke general reasoning capabilities.
|
| 837 |
+
This model can generate conditional and coherent chain-of-thought
|
| 838 |
+
- [RU]
|
| 839 |
+
**Версия RL GRPO** для возможностей размышления и глубокого понимания запроса.
|
| 840 |
+
Модель может генерировать когерентный текст русского языка на этой итерации.
|
| 841 |
+
|
| 842 |
+
### Important:
|
| 843 |
+
- [EN]
|
| 844 |
+
Second stage of reinforcement learning to invoke reasoning capabilities.
|
| 845 |
+
The model became better in mathematical tasks.
|
| 846 |
+
- [RU]
|
| 847 |
+
Вторая стадия RL обучения. Модель стала гораздо лучше в решении математических задач
|
| 848 |
+
|
| 849 |
+
### Further development
|
| 850 |
+
- GRPO Gromov-2
|
| 851 |
+
|
| 852 |
+
### Model Description / Описание модели
|
| 853 |
+
|
| 854 |
+
- **Developed by:** [Reisen Raumberg (Attention Signs team)]
|
| 855 |
+
- **Language(s) (NLP):** [RU/EN]
|
| 856 |
+
- **SFT from model:** [YandexGPT-5-lite-8B-pretrain]
|
| 857 |
+
|
| 858 |
+
Utilized HF.Accelerator
|
| 859 |
+
**GPU hours**: ~24h of NVIDIA A100
|
| 860 |
+
|
| 861 |
+
Для обучения использовался HuggingFace Accelerator
|
| 862 |
+
**GPU часы**: ~24h часа NVIDIA A100
|
| 863 |
+
|
| 864 |
+
### Training Framework
|
| 865 |
+
**GPTR was trained using MyLLM framework (by Attention Signs):**
|
| 866 |
+
--==[MyLLM](https://github.com/Raumberg/myllm)==--
|
| 867 |
+
|
| 868 |
+
### Model configuration (MyLLM Framework)
|
| 869 |
+
TO BE DISCLOSED
|
| 870 |
+
|
| 871 |
+
### Rewards:
|
| 872 |
+
TO BE DISCLOSED
|
| 873 |
+
|
| 874 |
+
### Using the model / Как запустить?
|
| 875 |
+
|
| 876 |
+
```python
|
| 877 |
+
repo = 'attn-signs/GPTR-8-v2'
|
| 878 |
+
|
| 879 |
+
model = AutoModelForCausalLM.from_pretrained(repo)
|
| 880 |
+
tokenizer = AutoTokenizer.from_pretrained(repo)
|
| 881 |
+
|
| 882 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 883 |
+
model.to(device)
|
| 884 |
+
|
| 885 |
+
user_prompt = '''
|
| 886 |
+
Пусть функция $f:[a,b]\to \mathbb{R}$ непрерывна на $[a,b]$, дифференцируема во всех точках $t\in(a,b)\setminus\{x\}$,
|
| 887 |
+
и существует предел $\lim_{t \to x} f'(t)$. Докажите, что $f$ дифференцируема в точке $x$ и $f'(x)= \lim_{t \to x} f'(t)$.
|
| 888 |
+
Используйте определение $f'(x)$ и теорему о среднем значении для обоснования вашего аргумента.
|
| 889 |
+
'''
|
| 890 |
+
system_prompt = ""[MODE: Reflection]""
|
| 891 |
+
messages = [
|
| 892 |
+
{""role"": ""system"", ""content"": system_prompt},
|
| 893 |
+
{""role"": ""user"", ""content"": user_prompt}
|
| 894 |
+
]
|
| 895 |
+
text = tokenizer.apply_chat_template(
|
| 896 |
+
messages,
|
| 897 |
+
tokenize=False,
|
| 898 |
+
add_generation_prompt=True
|
| 899 |
+
)
|
| 900 |
+
model_inputs = tokenizer([text], return_tensors=""pt"").to(model.device)
|
| 901 |
+
|
| 902 |
+
generated_ids = model.generate(
|
| 903 |
+
**model_inputs,
|
| 904 |
+
max_new_tokens=4096
|
| 905 |
+
)
|
| 906 |
+
generated_ids = [
|
| 907 |
+
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
|
| 908 |
+
]
|
| 909 |
+
|
| 910 |
+
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 911 |
+
|
| 912 |
+
print(response)
|
| 913 |
+
```
|
| 914 |
+
```
|
| 915 |
+
Для доказательства того, что $f$ дифференцируема в точке $x$ и $f'(x) = \lim_{t \to x} f'(t)$, мы следуем этим шагам:
|
| 916 |
+
|
| 917 |
+
1. **Определение производной в точке $x$:**
|
| 918 |
+
Производная $f$ в точке $x$ определяется как:
|
| 919 |
+
\[
|
| 920 |
+
f'(x) = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h}
|
| 921 |
+
]
|
| 922 |
+
|
| 923 |
+
2. **Использование теоремы о среднем значении**:
|
| 924 |
+
Для любого $h \neq 0$ существует $c \in (x, x+h)$ такое, что:
|
| 925 |
+
\[
|
| 926 |
+
\frac{f(x+h) - f(x)}{h} = f'(c)
|
| 927 |
+
\]
|
| 928 |
+
Поскольку $f$ дифференцируема во всех точках $(a, b) \setminus \{x\}$, $f'(c)$ существует.
|
| 929 |
+
|
| 930 |
+
3. **Анализ предела при $h \to 0$**:
|
| 931 |
+
Когда $h \to 0$, $c \to x$. Следовательно, $\lim_{h \to 0} f'(c) = \lim_{t \to x} f'(t)$.
|
| 932 |
+
|
| 933 |
+
4. **Вывод**:
|
| 934 |
+
Поскольку $\frac{f(x+h) - f(x)}{h} = f'(c)$ и $\lim_{h \to 0} f'(c) = \lim_{t \to x} f'(t)$, имеем:
|
| 935 |
+
\[
|
| 936 |
+
f'(x) = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h} = \lim_{t \to x} f'(t)
|
| 937 |
+
\]
|
| 938 |
+
|
| 939 |
+
Таким образом, $f$ дифференцируема в точке $x$ и $f'(x) = \lim_{t \to x} f'(t)$.
|
| 940 |
+
|
| 941 |
+
\[
|
| 942 |
+
\boxed{f'(x) = \lim_{t \to x} f'(t)}
|
| 943 |
+
\]
|
| 944 |
+
Я поразмышмышлял над задачей и вот, что я выяснил: используя теорему о среднем значении и предел при $h \to 0$, мы показали, что $f$ дифференцируема в точке $x$ и $f'(x) = \lim_{t \to x} f'(t)$. Таким образом, окончательный ответ:
|
| 945 |
+
|
| 946 |
+
\[
|
| 947 |
+
\boxed{f'(x) = \lim_{t \to x} f'(t)}
|
| 948 |
+
\]
|
| 949 |
+
```
|
| 950 |
+
|
| 951 |
+
### Model's ability to prove mathematical statements also became better:
|
| 952 |
+
**Question:**
|
| 953 |
+
Докажите, что для независимой семьи подмножеств $\mathcal{A}$ множества $\kappa \geq \omega$ семейство $G_f$,
|
| 954 |
+
определенное как $G_f = \{X : |\kappa - X| < \kappa\} \cup \{X : f(X) = 1\} \cup \{\kappa - X : f(X) = 0\}$ для любой функции $f : \mathcal{A} \to \{0,1\}$,
|
| 955 |
+
обладает свойством конечного пересечения (f.i.p.), и объясните, почему включение $\{X : |\kappa - X| < \kappa\}$ в $G_f$ необходимо для того, чтобы это свойство выполнялось.
|
| 956 |
+
|
| 957 |
+
**Answer:**
|
| 958 |
+
```
|
| 959 |
+
Чтобы доказать, что семейство $G_f$ обладает свойством конечного пересечения (f.i.p.), необходимо показать, что любое конечное подсемейство $\{G_{f_1}, G_{f_2}, \ldots, G_{f_n}\}$ из $G_f$ имеет непустое пересечение.
|
| 960 |
+
|
| 961 |
+
1. **Понимание $G_f$:**
|
| 962 |
+
- $G_f$ состоит из трёх типов подмножеств:
|
| 963 |
+
- $X$ таких, что $|\kappa - X| < \kappa$ (то есть $X$ является конечным).
|
| 964 |
+
- $X$ таких, что $f(X) = 1$.
|
| 965 |
+
- $\kappa - X$ таких, что $f(X) = 0$.
|
| 966 |
+
|
| 967 |
+
2. **Анализ конечного подсемейства:**
|
| 968 |
+
- Рассмотрим конечное подсемейство $\{G_{f_1}, G_{f_2}, \ldots, G_{f_n}\}$.
|
| 969 |
+
- Каждое $G_{f_i}$ содержит подмножества, удовлетворяющие одному из трёх условий:
|
| 970 |
+
- $|\kappa - X| < \kappa$
|
| 971 |
+
- $f_i(X) = 1$
|
| 972 |
+
- $f_i(\kappa - X) = 0$
|
| 973 |
+
|
| 974 |
+
3. **Поиск общего подмножества:**
|
| 975 |
+
- Рассмотрим подмножество $X$, которое удовлетворяет $|\kappa - X| < \kappa$.
|
| 976 |
+
- Для каждого $f_i$, $X$ либо удовлетворяет $f_i(X) = 1$, либо $f_i(\kappa - X) = 0$.
|
| 977 |
+
- Следовательно, $X$ принадлежит хотя бы одному из $G_{f_i}$.
|
| 978 |
+
|
| 979 |
+
4. **Проверка:**
|
| 980 |
+
- Если $X$ удовлетворяет $|\kappa - X| < \kappa$, то $X$ принадлежит $G_{f_i}$ для всех $i$.
|
| 981 |
+
- Если $X$ не удовлетворяет $|\kappa - X| < \kappa$, то $\kappa - X$ принадлежит $G_{f_i}$ для всех $i$.
|
| 982 |
+
|
| 983 |
+
5. **Вывод:**
|
| 984 |
+
- В любом случае, $X$ или $\kappa - X$ принадлежит всем $G_{f_i}$, что делает пересечение непустым.
|
| 985 |
+
|
| 986 |
+
Таким образом, $G_f$ обладает свойством конечного пересечения.
|
| 987 |
+
|
| 988 |
+
**Необходимость включения $\{X : |\kappa - X| < \kappa\}$:
|
| 989 |
+
- Если исключить $\{X : |\kappa - X| < \kappa\}$ из $G_f$, то $G_f$ может не иметь непустого пересечения для некоторых функций $f$, например, когда $f(X) = 0$ для всех $X$.
|
| 990 |
+
|
| 991 |
+
Следовательно, включение $\{X : |\kappa - X| < \kappa\}$ в $G_f$ необходимо для того, чтобы $G_f$ обладало свойством конечного пересечения.
|
| 992 |
+
|
| 993 |
+
\[
|
| 994 |
+
\boxed{1} # Model thinks that 1 is True
|
| 995 |
+
\]
|
| 996 |
+
Я поразмышмышлял над задачей и вот, что я выяснил: семейство $G_f$ обладает свойством конечного пересечения благодаря включению подмножеств $\{X : |\kappa - X| < \kappa\}$. Это включение необходимо для того, чтобы гарантировать, что любое конечное подсемейство $\{G_{f_1}, G_{f_2}, \ldots, G_{f_n}\}$ имеет непустое пересечение.
|
| 997 |
+
|
| 998 |
+
\[
|
| 999 |
+
\boxed{1}
|
| 1000 |
+
\]
|
| 1001 |
+
```","{""id"": ""attn-signs/GPTR-8b-v2"", ""author"": ""attn-signs"", ""sha"": ""6d560bb469cb46b02d873a62d884ed777d116aff"", ""last_modified"": ""2025-04-16 07:14:18+00:00"", ""created_at"": ""2025-04-16 06:52:53+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 8, ""downloads_all_time"": null, ""likes"": 1, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""reasoning"", ""conversational"", ""ru"", ""dataset:attn-signs/gromov-1"", ""base_model:attn-signs/GPTR-8b-v1"", ""base_model:finetune:attn-signs/GPTR-8b-v1"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- attn-signs/GPTR-8b-v1\ndatasets:\n- attn-signs/gromov-1\nlanguage:\n- ru\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- reasoning"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""chat_template"": ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<s>' + message['role'] + '\n' + message['content'] + '</s>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<s>assistant\n<think>\n' }}{% endif %}"", ""eos_token"": ""</s>"", ""pad_token"": ""<unk>"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""BF16"": 8036569088}, ""total"": 8036569088}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-16 07:14:18+00:00"", ""cardData"": ""base_model:\n- attn-signs/GPTR-8b-v1\ndatasets:\n- attn-signs/gromov-1\nlanguage:\n- ru\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- reasoning"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""67ff53c5a4e278b354135bca"", ""modelId"": ""attn-signs/GPTR-8b-v2"", ""usedStorage"": 16093768862}",3,,0,,0,"https://huggingface.co/mradermacher/GPTR-8b-v2-GGUF, https://huggingface.co/mradermacher/GPTR-8b-v2-i1-GGUF",2,,0,huggingface/InferenceSupport/discussions/new?title=attn-signs/GPTR-8b-v2&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Battn-signs%2FGPTR-8b-v2%5D(%2Fattn-signs%2FGPTR-8b-v2)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 1002 |
+
ssslakter/YandexGPT-5-Lite-8B-instruct,"---
|
| 1003 |
+
license: other
|
| 1004 |
+
license_name: yandexgpt-5-lite-8b
|
| 1005 |
+
license_link: LICENSE
|
| 1006 |
+
language:
|
| 1007 |
+
- ru
|
| 1008 |
+
- en
|
| 1009 |
+
base_model:
|
| 1010 |
+
- yandex/YandexGPT-5-Lite-8B-pretrain
|
| 1011 |
+
---
|
| 1012 |
+
|
| 1013 |
+
# YandexGPT-5-Lite-Instruct
|
| 1014 |
+
|
| 1015 |
+
Instruct-версия большой языковой модели YandexGPT 5 Lite на 8B параметров с длиной контекста 32k токенов. Также в отдельном [репозитории](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-instruct-GGUF) опубликована квантизованная версия модели в формате GGUF.
|
| 1016 |
+
|
| 1017 |
+
Обучена на базе [YandexGPT 5 Lite Pretrain](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-pretrain), без использования весов каких-либо сторонних моделей. Алайнмент Lite-версии совпадает с алайнментом YandexGPT 5 Pro и состоит из этапов SFT и RLHF (более подробно о них — в [статье](https://habr.com/ru/companies/yandex/articles/885218/) на Хабре).
|
| 1018 |
+
|
| 1019 |
+
Задавайте вопросы в discussions.
|
| 1020 |
+
|
| 1021 |
+
## Бенчмарки
|
| 1022 |
+
По результатам международных бенчмарков и их адаптаций для русского языка, YandexGPT 5 Lite вплотную приблизилась к аналогам (Llama-3.1-8B-instruct и Qwen-2.5-7B-instruct) и превосходит их в ряде сценариев, в том числе — в знании русской культуры и фактов.
|
| 1023 |
+
|
| 1024 |
+
<img src=""https://habrastorage.org/r/w1560/getpro/habr/upload_files/6b5/eb4/9ea/6b5eb49ea757bc124c938717b21f1cf7.png"" alt=""Таблица бенчмарков"" width=""100%""/>
|
| 1025 |
+
|
| 1026 |
+
MMLU — 5-shot, все остальные бенчмарки — 0-shot.
|
| 1027 |
+
|
| 1028 |
+
## Как использовать
|
| 1029 |
+
|
| 1030 |
+
Модель можно запустить через HF Transformers:
|
| 1031 |
+
```python
|
| 1032 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 1033 |
+
|
| 1034 |
+
|
| 1035 |
+
MODEL_NAME = ""yandex/YandexGPT-5-Lite-8B-instruct""
|
| 1036 |
+
|
| 1037 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
|
| 1038 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 1039 |
+
MODEL_NAME,
|
| 1040 |
+
device_map=""cuda"",
|
| 1041 |
+
torch_dtype=""auto"",
|
| 1042 |
+
)
|
| 1043 |
+
|
| 1044 |
+
messages = [{""role"": ""user"", ""content"": ""Для чего нужна токенизация?""}]
|
| 1045 |
+
input_ids = tokenizer.apply_chat_template(
|
| 1046 |
+
messages, tokenize=True, return_tensors=""pt""
|
| 1047 |
+
).to(""cuda"")
|
| 1048 |
+
|
| 1049 |
+
outputs = model.generate(input_ids, max_new_tokens=1024)
|
| 1050 |
+
print(tokenizer.decode(outputs[0][input_ids.size(1) :], skip_special_tokens=True))
|
| 1051 |
+
```
|
| 1052 |
+
|
| 1053 |
+
Или через vLLM:
|
| 1054 |
+
```python
|
| 1055 |
+
from vllm import LLM, SamplingParams
|
| 1056 |
+
from transformers import AutoTokenizer
|
| 1057 |
+
|
| 1058 |
+
|
| 1059 |
+
MODEL_NAME = ""yandex/YandexGPT-5-Lite-8B-instruct""
|
| 1060 |
+
|
| 1061 |
+
sampling_params = SamplingParams(
|
| 1062 |
+
temperature=0.3,
|
| 1063 |
+
top_p=0.9,
|
| 1064 |
+
max_tokens=1024,
|
| 1065 |
+
)
|
| 1066 |
+
|
| 1067 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
|
| 1068 |
+
llm = LLM(
|
| 1069 |
+
MODEL_NAME,
|
| 1070 |
+
tensor_parallel_size=1,
|
| 1071 |
+
)
|
| 1072 |
+
|
| 1073 |
+
messages = [{""role"": ""user"", ""content"": ""В чем смысл жизни?""}]
|
| 1074 |
+
input_ids = tokenizer.apply_chat_template(
|
| 1075 |
+
messages, tokenize=True, add_generation_prompt=True
|
| 1076 |
+
)[1:] # remove bos
|
| 1077 |
+
text = tokenizer.decode(input_ids)
|
| 1078 |
+
|
| 1079 |
+
outputs = llm.generate(text, use_tqdm=False, sampling_params=sampling_params)
|
| 1080 |
+
|
| 1081 |
+
print(tokenizer.decode(outputs[0].outputs[0].token_ids, skip_special_tokens=True))
|
| 1082 |
+
|
| 1083 |
+
```
|
| 1084 |
+
|
| 1085 |
+
Для запуска в llama.cpp и ollama можно воспользоваться нашей квантизованной моделью, которая выложена в репозитории [YandexGPT-5-Lite-8B-instruct-GGUF](https://huggingface.co/yandex/YandexGPT-5-Lite-8B-instruct-GGUF).
|
| 1086 |
+
|
| 1087 |
+
## Особенности токенизации
|
| 1088 |
+
Для полного соответствия токенизации мы рекомендуем пользоваться оригинальным [sentencepiece](https://github.com/google/sentencepiece) — файл токенизатора лежит в папке `original_tokenizer`. В нашей инфраструктуре каждую реплику диалога мы токенизируем отдельно.
|
| 1089 |
+
|
| 1090 |
+
Из-за этого, в частности, появляется пробел в начале каждой реплики. Также `\n` токены мы заменяем на `[NL]`, это можно сделать с помощью `text.replace(""\n"", ""[NL]"")` перед токенизацией.
|
| 1091 |
+
|
| 1092 |
+
## Особенности шаблона
|
| 1093 |
+
Мы используем нестандартный шаблон диалога — модель обучена генерировать только одну реплику после последовательности `Ассистент:[SEP]`, завершая её токеном `</s>`. При этом диалог в промпте может быть любой длины.
|
| 1094 |
+
|
| 1095 |
+
Это приводит к тому, что в интерактивном режиме модель может выдавать результаты, отличающиеся от вызова модели в режиме генерации на фиксированном диалоге. Поэтому мы рекомендуем использовать интерактивный режим только для ознакомления с моделью.","{""id"": ""ssslakter/YandexGPT-5-Lite-8B-instruct"", ""author"": ""ssslakter"", ""sha"": ""57ab7e11b3075385684307f10e6fedf694b800c9"", ""last_modified"": ""2025-04-18 13:01:16+00:00"", ""created_at"": ""2025-04-18 13:02:57+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 36, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""safetensors"", ""llama"", ""ru"", ""en"", ""base_model:yandex/YandexGPT-5-Lite-8B-pretrain"", ""base_model:finetune:yandex/YandexGPT-5-Lite-8B-pretrain"", ""license:other"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- yandex/YandexGPT-5-Lite-8B-pretrain\nlanguage:\n- ru\n- en\nlicense: other\nlicense_name: yandexgpt-5-lite-8b\nlicense_link: LICENSE"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""chat_template"": ""\n<s>{%- set names = {'assistant': ' \u0410\u0441\u0441\u0438\u0441\u0442\u0435\u043d\u0442:', 'user': ' \u041f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u0435\u043b\u044c:'} %}\n{%- set tools_prefix = '\u0422\u0435\u0431\u0435 \u0434\u043e\u0441\u0442\u0443\u043f\u043d\u044b \u0441\u043b\u0435\u0434\u0443\u044e\u0449\u0438\u0435 \u0444\u0443\u043d\u043a\u0446\u0438\u0438:' %}\n\n{%- macro __render_tool(tool) %}\n {%- set name = tool.function.name %}\n {%- set description = tool.function.description|default('') %}\n {%- set parameters = tool.function.parameters|tojson %}\n {{- '\n' }}function {{ '{' }}'name':'{{ name }}',\n {%- if tool.description %}'description':'{{ description }}',{% endif %}\n'parameters':{{ parameters }}\n {{- '}' }}\n{%- endmacro %}\n\n{%- macro __render_tools(tools) %}\n {{- tools_prefix }}\n {%- for tool in tools %}\n {{- __render_tool(tool) }}\n {%- endfor %}\n {{- '\n\n' }}\n{%- endmacro %}\n\n{%- macro __render_tool_message(message) %}\n {{- '\n\n\u0420\u0435\u0437\u0443\u043b\u044c\u0442\u0430\u0442 \u0432\u044b\u0437\u043e\u0432\u0430' }} {{ message.name }}: {{ message.content }} {{ '\n\n' }}\n{%- endmacro %}\n\n{%- if tools -%}\n {{- __render_tools(tools) }}\n{%- endif -%}\n\n{%- macro __render_user_message(message) %}\n{{ names.user }} {{ message.content + '\n\n' }}\n{%- endmacro %}\n\n{%- macro __render_assistant_message(message) %}\n {{- names.assistant }}\n {%- set call = message['function_call'] %}\n {%- if call %}\n {{- '\n[TOOL_CALL_START]' }}{{ call.name }}{{ '\n' }}{{ call.arguments|tojson }}\n {%- else %}\n {{- ' ' + message.content + '\n\n' }}\n {%- endif %}\n{%- endmacro %}\n\n\n{%- for message in messages %}\n {%- if message['role'] == 'user' %}\n {{- __render_user_message(message) }}\n {%- endif %}\n\n {%- if message.role == 'assistant' and not loop.last %}\n {{- __render_assistant_message(message) }}\n {%- endif %}\n\n {%- if message.role == 'tool' %}\n {{- __render_tool_message(message) }}\n {%- endif %}\n\n {%- if loop.last and add_generation_prompt %}\n {{- ' \u0410\u0441\u0441\u0438\u0441\u0442\u0435\u043d\u0442:[SEP]' }}\n {%- endif %}\n\n{%- endfor %}"", ""eos_token"": ""</s>"", ""pad_token"": null, ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='fix_chat_template.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='original_tokenizer/tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F16"": 8036552704}, ""total"": 8036552704}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-18 13:01:16+00:00"", ""cardData"": ""base_model:\n- yandex/YandexGPT-5-Lite-8B-pretrain\nlanguage:\n- ru\n- en\nlicense: other\nlicense_name: yandexgpt-5-lite-8b\nlicense_link: LICENSE"", ""transformersInfo"": null, ""_id"": ""68024d81bf9a2a464d5cfd1d"", ""modelId"": ""ssslakter/YandexGPT-5-Lite-8B-instruct"", ""usedStorage"": 16078285345}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=ssslakter/YandexGPT-5-Lite-8B-instruct&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bssslakter%2FYandexGPT-5-Lite-8B-instruct%5D(%2Fssslakter%2FYandexGPT-5-Lite-8B-instruct)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
Yi-34B-Chat_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
aya-101_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
CohereLabs/aya-101,"---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
datasets:
|
| 5 |
+
- CohereLabs/xP3x
|
| 6 |
+
- CohereLabs/aya_dataset
|
| 7 |
+
- CohereLabs/aya_collection
|
| 8 |
+
- DataProvenanceInitiative/Commercially-Verified-Licenses
|
| 9 |
+
- CohereLabs/aya_evaluation_suite
|
| 10 |
+
language:
|
| 11 |
+
- afr
|
| 12 |
+
- amh
|
| 13 |
+
- ara
|
| 14 |
+
- aze
|
| 15 |
+
- bel
|
| 16 |
+
- ben
|
| 17 |
+
- bul
|
| 18 |
+
- cat
|
| 19 |
+
- ceb
|
| 20 |
+
- ces
|
| 21 |
+
- cym
|
| 22 |
+
- dan
|
| 23 |
+
- deu
|
| 24 |
+
- ell
|
| 25 |
+
- eng
|
| 26 |
+
- epo
|
| 27 |
+
- est
|
| 28 |
+
- eus
|
| 29 |
+
- fin
|
| 30 |
+
- fil
|
| 31 |
+
- fra
|
| 32 |
+
- fry
|
| 33 |
+
- gla
|
| 34 |
+
- gle
|
| 35 |
+
- glg
|
| 36 |
+
- guj
|
| 37 |
+
- hat
|
| 38 |
+
- hau
|
| 39 |
+
- heb
|
| 40 |
+
- hin
|
| 41 |
+
- hun
|
| 42 |
+
- hye
|
| 43 |
+
- ibo
|
| 44 |
+
- ind
|
| 45 |
+
- isl
|
| 46 |
+
- ita
|
| 47 |
+
- jav
|
| 48 |
+
- jpn
|
| 49 |
+
- kan
|
| 50 |
+
- kat
|
| 51 |
+
- kaz
|
| 52 |
+
- khm
|
| 53 |
+
- kir
|
| 54 |
+
- kor
|
| 55 |
+
- kur
|
| 56 |
+
- lao
|
| 57 |
+
- lav
|
| 58 |
+
- lat
|
| 59 |
+
- lit
|
| 60 |
+
- ltz
|
| 61 |
+
- mal
|
| 62 |
+
- mar
|
| 63 |
+
- mkd
|
| 64 |
+
- mlg
|
| 65 |
+
- mlt
|
| 66 |
+
- mon
|
| 67 |
+
- mri
|
| 68 |
+
- msa
|
| 69 |
+
- mya
|
| 70 |
+
- nep
|
| 71 |
+
- nld
|
| 72 |
+
- nor
|
| 73 |
+
- nso
|
| 74 |
+
- nya
|
| 75 |
+
- ory
|
| 76 |
+
- pan
|
| 77 |
+
- pes
|
| 78 |
+
- pol
|
| 79 |
+
- por
|
| 80 |
+
- pus
|
| 81 |
+
- ron
|
| 82 |
+
- rus
|
| 83 |
+
- sin
|
| 84 |
+
- slk
|
| 85 |
+
- slv
|
| 86 |
+
- smo
|
| 87 |
+
- sna
|
| 88 |
+
- snd
|
| 89 |
+
- som
|
| 90 |
+
- sot
|
| 91 |
+
- spa
|
| 92 |
+
- sqi
|
| 93 |
+
- srp
|
| 94 |
+
- sun
|
| 95 |
+
- swa
|
| 96 |
+
- swe
|
| 97 |
+
- tam
|
| 98 |
+
- tel
|
| 99 |
+
- tgk
|
| 100 |
+
- tha
|
| 101 |
+
- tur
|
| 102 |
+
- twi
|
| 103 |
+
- ukr
|
| 104 |
+
- urd
|
| 105 |
+
- uzb
|
| 106 |
+
- vie
|
| 107 |
+
- xho
|
| 108 |
+
- yid
|
| 109 |
+
- yor
|
| 110 |
+
- zho
|
| 111 |
+
- zul
|
| 112 |
+
metrics:
|
| 113 |
+
- accuracy
|
| 114 |
+
- bleu
|
| 115 |
+
---
|
| 116 |
+
|
| 117 |
+
<img src=""aya-fig1.png"" alt=""Aya model summary image"" width=""800"" style=""margin-left:'auto' margin-right:'auto' display:'block'""/>
|
| 118 |
+
|
| 119 |
+
# Model Card for Aya 101
|
| 120 |
+
|
| 121 |
+
## Model Summary
|
| 122 |
+
|
| 123 |
+
> The Aya model is a massively multilingual generative language model that follows instructions in 101 languages.
|
| 124 |
+
> Aya outperforms [mT0](https://huggingface.co/bigscience/mt0-xxl) and [BLOOMZ](https://huggingface.co/bigscience/bloomz) a wide variety of automatic and human evaluations despite covering double the number of languages.
|
| 125 |
+
> The Aya model is trained using [xP3x](https://huggingface.co/datasets/CohereLabs/xP3x), [Aya Dataset](https://huggingface.co/datasets/CohereLabs/aya_dataset), [Aya Collection](https://huggingface.co/datasets/CohereForAI/aya_collection), a subset of [DataProvenance collection](https://huggingface.co/datasets/DataProvenanceInitiative/Commercially-Verified-Licenses) and ShareGPT-Command.
|
| 126 |
+
> We release the checkpoints under a Apache-2.0 license to further our mission of multilingual technologies empowering a
|
| 127 |
+
> multilingual world.
|
| 128 |
+
|
| 129 |
+
- **Developed by:** [Cohere Labs](https://cohere.for.ai)
|
| 130 |
+
- **Model type:** a Transformer style autoregressive massively multilingual language model.
|
| 131 |
+
- **Paper**: [Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model](https://arxiv.org/abs/2402.07827)
|
| 132 |
+
- **Point of Contact**: [Cohere Labs](https://cohere.for.ai)
|
| 133 |
+
- **Languages**: Refer to the list of languages in the `language` section of this model card.
|
| 134 |
+
- **License**: Apache-2.0
|
| 135 |
+
- **Model**: [Aya-101](https://huggingface.co/CohereLabs/aya-101)
|
| 136 |
+
- **Model Size**: 13 billion parameters
|
| 137 |
+
- **Datasets**: [xP3x](https://huggingface.co/datasets/CohereLabs/xP3x), [Aya Dataset](https://huggingface.co/datasets/CohereLabs/aya_dataset), [Aya Collection](https://huggingface.co/datasets/CohereLabs/aya_collection), [DataProvenance collection](https://huggingface.co/datasets/DataProvenanceInitiative/Commercially-Verified-Licenses), ShareGPT-Command.
|
| 138 |
+
|
| 139 |
+
## Use
|
| 140 |
+
|
| 141 |
+
```python
|
| 142 |
+
# pip install -q transformers
|
| 143 |
+
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
|
| 144 |
+
|
| 145 |
+
checkpoint = ""CohereLabs/aya-101""
|
| 146 |
+
|
| 147 |
+
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
| 148 |
+
aya_model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
|
| 149 |
+
|
| 150 |
+
# Turkish to English translation
|
| 151 |
+
tur_inputs = tokenizer.encode(""Translate to English: Aya cok dilli bir dil modelidir."", return_tensors=""pt"")
|
| 152 |
+
tur_outputs = aya_model.generate(tur_inputs, max_new_tokens=128)
|
| 153 |
+
print(tokenizer.decode(tur_outputs[0]))
|
| 154 |
+
# Aya is a multi-lingual language model
|
| 155 |
+
|
| 156 |
+
# Q: Why are there so many languages in India?
|
| 157 |
+
hin_inputs = tokenizer.encode(""भारत में इतनी सारी भाषाएँ क्यों हैं?"", return_tensors=""pt"")
|
| 158 |
+
hin_outputs = aya_model.generate(hin_inputs, max_new_tokens=128)
|
| 159 |
+
print(tokenizer.decode(hin_outputs[0]))
|
| 160 |
+
# Expected output: भारत में कई भाषाएँ हैं और विभिन्न भाषाओं के बोली जाने वाले लोग हैं। यह विभिन्नता भाषाई विविधता और सांस्कृतिक विविधता का परिणाम है। Translates to ""India has many languages and people speaking different languages. This diversity is the result of linguistic diversity and cultural diversity.""
|
| 161 |
+
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
## Model Details
|
| 165 |
+
|
| 166 |
+
### Finetuning
|
| 167 |
+
|
| 168 |
+
- Architecture: Same as [mt5-xxl](https://huggingface.co/google/mt5-xxl)
|
| 169 |
+
- Number of Samples seen during Finetuning: 25M
|
| 170 |
+
- Batch size: 256
|
| 171 |
+
- Hardware: TPUv4-128
|
| 172 |
+
- Software: T5X, Jax
|
| 173 |
+
|
| 174 |
+
### Data Sources
|
| 175 |
+
|
| 176 |
+
The Aya model is trained on the following datasets:
|
| 177 |
+
|
| 178 |
+
- [xP3x](https://huggingface.co/datasets/CohereLabs/xP3x)
|
| 179 |
+
- [Aya Dataset](https://huggingface.co/datasets/CohereLabs/aya_dataset)
|
| 180 |
+
- [Aya Collection](https://huggingface.co/datasets/CohereLabs/aya_collection)
|
| 181 |
+
- [DataProvenance collection](https://huggingface.co/datasets/DataProvenanceInitiative/Commercially-Verified-Licenses)
|
| 182 |
+
- ShareGPT-Command
|
| 183 |
+
|
| 184 |
+
All datasets are subset to the 101 languages supported by [mT5](https://huggingface.co/google/mt5-xxl). See the [paper](https://arxiv.org/abs/2402.07827) for details about filtering and pruning.
|
| 185 |
+
|
| 186 |
+
## Evaluation
|
| 187 |
+
|
| 188 |
+
We refer to Section 5 from our paper for multilingual eval across 99 languages – including discriminative and generative tasks, human evaluation, and simulated win rates that cover both held-out tasks and in-distribution performance.
|
| 189 |
+
|
| 190 |
+
## Bias, Risks, and Limitations
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
For a detailed overview of our effort at safety mitigation and benchmarking toxicity and bias across multiple languages, we refer to Sections 6 and 7 of our paper: [Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model](https://arxiv.org/abs/2402.07827).
|
| 194 |
+
|
| 195 |
+
We hope that the release of the Aya model will make community-based redteaming efforts possible, by exposing an open-source massively-multilingual model for community research.
|
| 196 |
+
|
| 197 |
+
## Citation
|
| 198 |
+
|
| 199 |
+
**BibTeX:**
|
| 200 |
+
|
| 201 |
+
```
|
| 202 |
+
@article{üstün2024aya,
|
| 203 |
+
title={Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model},
|
| 204 |
+
author={Ahmet Üstün and Viraat Aryabumi and Zheng-Xin Yong and Wei-Yin Ko and Daniel D'souza and Gbemileke Onilude and Neel Bhandari and Shivalika Singh and Hui-Lee Ooi and Amr Kayid and Freddie Vargus and Phil Blunsom and Shayne Longpre and Niklas Muennighoff and Marzieh Fadaee and Julia Kreutzer and Sara Hooker},
|
| 205 |
+
journal={arXiv preprint arXiv:2402.07827},
|
| 206 |
+
year={2024}
|
| 207 |
+
}
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
## Languages Covered
|
| 211 |
+
|
| 212 |
+
<details>
|
| 213 |
+
<summary>Click to see Languages Covered</summary>
|
| 214 |
+
|
| 215 |
+
Below is the list of languages used in finetuning the Aya Model. We group languages into higher-, mid-, and lower-resourcedness based on a language classification by [Joshi et. al, 2020](https://microsoft.github.io/linguisticdiversity/). For further details, we refer to our [paper](https://arxiv.org/abs/2402.07827)
|
| 216 |
+
|
| 217 |
+
| ISO Code | Language Name | Script | Family | Subgrouping | Resourcedness |
|
| 218 |
+
| :------- | :-------------- | :----------: | :-------------: | :---------------: | :-----------: |
|
| 219 |
+
| afr | Afrikaans | Latin | Indo-European | Germanic | Mid |
|
| 220 |
+
| amh | Amharic | Ge'ez | Afro-Asiatic | Semitic | Low |
|
| 221 |
+
| ara | Arabic | Arabic | Afro-Asiatic | Semitic | High |
|
| 222 |
+
| aze | Azerbaijani | Arabic/Latin | Turkic | Common Turkic | Low |
|
| 223 |
+
| bel | Belarusian | Cyrillic | Indo-European | Balto-Slavic | Mid |
|
| 224 |
+
| ben | Bengali | Bengali | Indo-European | Indo-Aryan | Mid |
|
| 225 |
+
| bul | Bulgarian | Cyrillic | Indo-European | Balto-Slavic | Mid |
|
| 226 |
+
| cat | Catalan | Latin | Indo-European | Italic | High |
|
| 227 |
+
| ceb | Cebuano | Latin | Austronesian | Malayo-Polynesian | Mid |
|
| 228 |
+
| ces | Czech | Latin | Indo-European | Balto-Slavic | High |
|
| 229 |
+
| cym | Welsh | Latin | Indo-European | Celtic | Low |
|
| 230 |
+
| dan | Danish | Latin | Indo-European | Germanic | Mid |
|
| 231 |
+
| deu | German | Latin | Indo-European | Germanic | High |
|
| 232 |
+
| ell | Greek | Greek | Indo-European | Graeco-Phrygian | Mid |
|
| 233 |
+
| eng | English | Latin | Indo-European | Germanic | High |
|
| 234 |
+
| epo | Esperanto | Latin | Constructed | Esperantic | Low |
|
| 235 |
+
| est | Estonian | Latin | Uralic | Finnic | Mid |
|
| 236 |
+
| eus | Basque | Latin | Basque | - | High |
|
| 237 |
+
| fin | Finnish | Latin | Uralic | Finnic | High |
|
| 238 |
+
| fil | Tagalog | Latin | Austronesian | Malayo-Polynesian | Mid |
|
| 239 |
+
| fra | French | Latin | Indo-European | Italic | High |
|
| 240 |
+
| fry | Western Frisian | Latin | Indo-European | Germanic | Low |
|
| 241 |
+
| gla | Scottish Gaelic | Latin | Indo-European | Celtic | Low |
|
| 242 |
+
| gle | Irish | Latin | Indo-European | Celtic | Low |
|
| 243 |
+
| glg | Galician | Latin | Indo-European | Italic | Mid |
|
| 244 |
+
| guj | Gujarati | Gujarati | Indo-European | Indo-Aryan | Low |
|
| 245 |
+
| hat | Haitian Creole | Latin | Indo-European | Italic | Low |
|
| 246 |
+
| hau | Hausa | Latin | Afro-Asiatic | Chadic | Low |
|
| 247 |
+
| heb | Hebrew | Hebrew | Afro-Asiatic | Semitic | Mid |
|
| 248 |
+
| hin | Hindi | Devanagari | Indo-European | Indo-Aryan | High |
|
| 249 |
+
| hun | Hungarian | Latin | Uralic | - | High |
|
| 250 |
+
| hye | Armenian | Armenian | Indo-European | Armenic | Low |
|
| 251 |
+
| ibo | Igbo | Latin | Atlantic-Congo | Benue-Congo | Low |
|
| 252 |
+
| ind | Indonesian | Latin | Austronesian | Malayo-Polynesian | Mid |
|
| 253 |
+
| isl | Icelandic | Latin | Indo-European | Germanic | Low |
|
| 254 |
+
| ita | Italian | Latin | Indo-European | Italic | High |
|
| 255 |
+
| jav | Javanese | Latin | Austronesian | Malayo-Polynesian | Low |
|
| 256 |
+
| jpn | Japanese | Japanese | Japonic | Japanesic | High |
|
| 257 |
+
| kan | Kannada | Kannada | Dravidian | South Dravidian | Low |
|
| 258 |
+
| kat | Georgian | Georgian | Kartvelian | Georgian-Zan | Mid |
|
| 259 |
+
| kaz | Kazakh | Cyrillic | Turkic | Common Turkic | Mid |
|
| 260 |
+
| khm | Khmer | Khmer | Austroasiatic | Khmeric | Low |
|
| 261 |
+
| kir | Kyrgyz | Cyrillic | Turkic | Common Turkic | Low |
|
| 262 |
+
| kor | Korean | Hangul | Koreanic | Korean | High |
|
| 263 |
+
| kur | Kurdish | Latin | Indo-European | Iranian | Low |
|
| 264 |
+
| lao | Lao | Lao | Tai-Kadai | Kam-Tai | Low |
|
| 265 |
+
| lav | Latvian | Latin | Indo-European | Balto-Slavic | Mid |
|
| 266 |
+
| lat | Latin | Latin | Indo-European | Italic | Mid |
|
| 267 |
+
| lit | Lithuanian | Latin | Indo-European | Balto-Slavic | Mid |
|
| 268 |
+
| ltz | Luxembourgish | Latin | Indo-European | Germanic | Low |
|
| 269 |
+
| mal | Malayalam | Malayalam | Dravidian | South Dravidian | Low |
|
| 270 |
+
| mar | Marathi | Devanagari | Indo-European | Indo-Aryan | Low |
|
| 271 |
+
| mkd | Macedonian | Cyrillic | Indo-European | Balto-Slavic | Low |
|
| 272 |
+
| mlg | Malagasy | Latin | Austronesian | Malayo-Polynesian | Low |
|
| 273 |
+
| mlt | Maltese | Latin | Afro-Asiatic | Semitic | Low |
|
| 274 |
+
| mon | Mongolian | Cyrillic | Mongolic-Khitan | Mongolic | Low |
|
| 275 |
+
| mri | Maori | Latin | Austronesian | Malayo-Polynesian | Low |
|
| 276 |
+
| msa | Malay | Latin | Austronesian | Malayo-Polynesian | Mid |
|
| 277 |
+
| mya | Burmese | Myanmar | Sino-Tibetan | Burmo-Qiangic | Low |
|
| 278 |
+
| nep | Nepali | Devanagari | Indo-European | Indo-Aryan | Low |
|
| 279 |
+
| nld | Dutch | Latin | Indo-European | Germanic | High |
|
| 280 |
+
| nor | Norwegian | Latin | Indo-European | Germanic | Low |
|
| 281 |
+
| nso | Northern Sotho | Latin | Atlantic-Congo | Benue-Congo | Low |
|
| 282 |
+
| nya | Chichewa | Latin | Atlantic-Congo | Benue-Congo | Low |
|
| 283 |
+
| ory | Oriya | Oriya | Indo-European | Indo-Aryan | Low |
|
| 284 |
+
| pan | Punjabi | Gurmukhi | Indo-European | Indo-Aryan | Low |
|
| 285 |
+
| pes | Persian | Arabic | Indo-European | Iranian | High |
|
| 286 |
+
| pol | Polish | Latin | Indo-European | Balto-Slavic | High |
|
| 287 |
+
| por | Portuguese | Latin | Indo-European | Italic | High |
|
| 288 |
+
| pus | Pashto | Arabic | Indo-European | Iranian | Low |
|
| 289 |
+
| ron | Romanian | Latin | Indo-European | Italic | Mid |
|
| 290 |
+
| rus | Russian | Cyrillic | Indo-European | Balto-Slavic | High |
|
| 291 |
+
| sin | Sinhala | Sinhala | Indo-European | Indo-Aryan | Low |
|
| 292 |
+
| slk | Slovak | Latin | Indo-European | Balto-Slavic | Mid |
|
| 293 |
+
| slv | Slovenian | Latin | Indo-European | Balto-Slavic | Mid |
|
| 294 |
+
| smo | Samoan | Latin | Austronesian | Malayo-Polynesian | Low |
|
| 295 |
+
| sna | Shona | Latin | Indo-European | Indo-Aryan | Low |
|
| 296 |
+
| snd | Sindhi | Arabic | Indo-European | Indo-Aryan | Low |
|
| 297 |
+
| som | Somali | Latin | Afro-Asiatic | Cushitic | Low |
|
| 298 |
+
| sot | Southern Sotho | Latin | Atlantic-Congo | Benue-Congo | Low |
|
| 299 |
+
| spa | Spanish | Latin | Indo-European | Italic | High |
|
| 300 |
+
| sqi | Albanian | Latin | Indo-European | Albanian | Low |
|
| 301 |
+
| srp | Serbian | Cyrillic | Indo-European | Balto-Slavic | High |
|
| 302 |
+
| sun | Sundanese | Latin | Austronesian | Malayo-Polynesian | Low |
|
| 303 |
+
| swa | Swahili | Latin | Atlantic-Congo | Benue-Congo | Low |
|
| 304 |
+
| swe | Swedish | Latin | Indo-European | Germanic | High |
|
| 305 |
+
| tam | Tamil | Tamil | Dravidian | South Dravidian | Mid |
|
| 306 |
+
| tel | Telugu | Telugu | Dravidian | South Dravidian | Low |
|
| 307 |
+
| tgk | Tajik | Cyrillic | Indo-European | Iranian | Low |
|
| 308 |
+
| tha | Thai | Thai | Tai-Kadai | Kam-Tai | Mid |
|
| 309 |
+
| tur | Turkish | Latin | Turkic | Common Turkic | High |
|
| 310 |
+
| twi | Twi | Latin | Atlantic-Congo | Niger-Congo | Low |
|
| 311 |
+
| ukr | Ukrainian | Cyrillic | Indo-European | Balto-Slavic | Mid |
|
| 312 |
+
| urd | Urdu | Arabic | Indo-European | Indo-Aryan | Mid |
|
| 313 |
+
| uzb | Uzbek | Latin | Turkic | Common Turkic | Mid |
|
| 314 |
+
| vie | Vietnamese | Latin | Austroasiatic | Vietic | High |
|
| 315 |
+
| xho | Xhosa | Latin | Atlantic-Congo | Benue-Congo | Low |
|
| 316 |
+
| yid | Yiddish | Hebrew | Indo-European | Germanic | Low |
|
| 317 |
+
| yor | Yoruba | Latin | Atlantic-Congo | Benue-Congo | Low |
|
| 318 |
+
| zho | Chinese | Han | Sino-Tibetan | Sinitic | High |
|
| 319 |
+
| zul | Zulu | Latin | Atlantic-Congo | Benue-Congo | Low |
|
| 320 |
+
</details>
|
| 321 |
+
|
| 322 |
+
## Model Card Contact
|
| 323 |
+
|
| 324 |
+
For errors in this model card, contact Ahmet or Viraat, `{ahmet, viraat} at cohere dot com`.
|
| 325 |
+
","{""id"": ""CohereLabs/aya-101"", ""author"": ""CohereLabs"", ""sha"": ""231cff3a9729ccdaee18839b32aaabac5278a21c"", ""last_modified"": ""2025-04-15 08:53:51+00:00"", ""created_at"": ""2024-02-08 18:08:25+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 3392, ""downloads_all_time"": null, ""likes"": 639, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""t5"", ""text2text-generation"", ""afr"", ""amh"", ""ara"", ""aze"", ""bel"", ""ben"", ""bul"", ""cat"", ""ceb"", ""ces"", ""cym"", ""dan"", ""deu"", ""ell"", ""eng"", ""epo"", ""est"", ""eus"", ""fin"", ""fil"", ""fra"", ""fry"", ""gla"", ""gle"", ""glg"", ""guj"", ""hat"", ""hau"", ""heb"", ""hin"", ""hun"", ""hye"", ""ibo"", ""ind"", ""isl"", ""ita"", ""jav"", ""jpn"", ""kan"", ""kat"", ""kaz"", ""khm"", ""kir"", ""kor"", ""kur"", ""lao"", ""lav"", ""lat"", ""lit"", ""ltz"", ""mal"", ""mar"", ""mkd"", ""mlg"", ""mlt"", ""mon"", ""mri"", ""msa"", ""mya"", ""nep"", ""nld"", ""nor"", ""nso"", ""nya"", ""ory"", ""pan"", ""pes"", ""pol"", ""por"", ""pus"", ""ron"", ""rus"", ""sin"", ""slk"", ""slv"", ""smo"", ""sna"", ""snd"", ""som"", ""sot"", ""spa"", ""sqi"", ""srp"", ""sun"", ""swa"", ""swe"", ""tam"", ""tel"", ""tgk"", ""tha"", ""tur"", ""twi"", ""ukr"", ""urd"", ""uzb"", ""vie"", ""xho"", ""yid"", ""yor"", ""zho"", ""zul"", ""dataset:CohereLabs/xP3x"", ""dataset:CohereLabs/aya_dataset"", ""dataset:CohereLabs/aya_collection"", ""dataset:DataProvenanceInitiative/Commercially-Verified-Licenses"", ""dataset:CohereLabs/aya_evaluation_suite"", ""arxiv:2402.07827"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text2text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""datasets:\n- CohereLabs/xP3x\n- CohereLabs/aya_dataset\n- CohereLabs/aya_collection\n- DataProvenanceInitiative/Commercially-Verified-Licenses\n- CohereLabs/aya_evaluation_suite\nlanguage:\n- afr\n- amh\n- ara\n- aze\n- bel\n- ben\n- bul\n- cat\n- ceb\n- ces\n- cym\n- dan\n- deu\n- ell\n- eng\n- epo\n- est\n- eus\n- fin\n- fil\n- fra\n- fry\n- gla\n- gle\n- glg\n- guj\n- hat\n- hau\n- heb\n- hin\n- hun\n- hye\n- ibo\n- ind\n- isl\n- ita\n- jav\n- jpn\n- kan\n- kat\n- kaz\n- khm\n- kir\n- kor\n- kur\n- lao\n- lav\n- lat\n- lit\n- ltz\n- mal\n- mar\n- mkd\n- mlg\n- mlt\n- mon\n- mri\n- msa\n- mya\n- nep\n- nld\n- nor\n- nso\n- nya\n- ory\n- pan\n- pes\n- pol\n- por\n- pus\n- ron\n- rus\n- sin\n- slk\n- slv\n- smo\n- sna\n- snd\n- som\n- sot\n- spa\n- sqi\n- srp\n- sun\n- swa\n- swe\n- tam\n- tel\n- tgk\n- tha\n- tur\n- twi\n- ukr\n- urd\n- uzb\n- vie\n- xho\n- yid\n- yor\n- zho\n- zul\nlicense: apache-2.0\nmetrics:\n- accuracy\n- bleu"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""T5ForConditionalGeneration""], ""model_type"": ""t5"", ""tokenizer_config"": {""eos_token"": ""</s>"", ""pad_token"": ""<pad>"", ""unk_token"": ""<unk>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForSeq2SeqLM"", ""custom_class"": null, ""pipeline_tag"": ""text2text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='aya-fig1.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00009-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00010-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00011-of-00011.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""eduagarcia/open_pt_llm_leaderboard"", ""MohamedRashad/arabic-tokenizers-leaderboard"", ""yenniejun/tokenizers-languages"", ""Tonic/Aya"", ""prometheus-eval/BiGGen-Bench-Leaderboard"", ""yhavinga/dutch-tokenizer-arena"", ""5w4n/burmese-tokenizers"", ""fhudi/textgames"", ""BoredApeYachtClub/PDFChatbot"", ""aspmirlab/ASPMIR-MACHINE-TRANSLATION-TESTBED"", ""Srfacehug/Cohere_AYA_for_Languages"", ""amirkhani/CohereForAI-aya-101"", ""ilhamsyahids/CohereAya"", ""omarei/CohereForAI-aya-101"", ""eaglelandsonce/translator"", ""suprimedev/eeee""], ""safetensors"": {""parameters"": {""F32"": 12921057280}, ""total"": 12921057280}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-15 08:53:51+00:00"", ""cardData"": ""datasets:\n- CohereLabs/xP3x\n- CohereLabs/aya_dataset\n- CohereLabs/aya_collection\n- DataProvenanceInitiative/Commercially-Verified-Licenses\n- CohereLabs/aya_evaluation_suite\nlanguage:\n- afr\n- amh\n- ara\n- aze\n- bel\n- ben\n- bul\n- cat\n- ceb\n- ces\n- cym\n- dan\n- deu\n- ell\n- eng\n- epo\n- est\n- eus\n- fin\n- fil\n- fra\n- fry\n- gla\n- gle\n- glg\n- guj\n- hat\n- hau\n- heb\n- hin\n- hun\n- hye\n- ibo\n- ind\n- isl\n- ita\n- jav\n- jpn\n- kan\n- kat\n- kaz\n- khm\n- kir\n- kor\n- kur\n- lao\n- lav\n- lat\n- lit\n- ltz\n- mal\n- mar\n- mkd\n- mlg\n- mlt\n- mon\n- mri\n- msa\n- mya\n- nep\n- nld\n- nor\n- nso\n- nya\n- ory\n- pan\n- pes\n- pol\n- por\n- pus\n- ron\n- rus\n- sin\n- slk\n- slv\n- smo\n- sna\n- snd\n- som\n- sot\n- spa\n- sqi\n- srp\n- sun\n- swa\n- swe\n- tam\n- tel\n- tgk\n- tha\n- tur\n- twi\n- ukr\n- urd\n- uzb\n- vie\n- xho\n- yid\n- yor\n- zho\n- zul\nlicense: apache-2.0\nmetrics:\n- accuracy\n- bleu"", ""transformersInfo"": {""auto_model"": ""AutoModelForSeq2SeqLM"", ""custom_class"": null, ""pipeline_tag"": ""text2text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""65c518990f5fdbda745cf3dd"", ""modelId"": ""CohereLabs/aya-101"", ""usedStorage"": 51703138368}",0,,0,,0,,0,,0,"5w4n/burmese-tokenizers, BoredApeYachtClub/PDFChatbot, MohamedRashad/arabic-tokenizers-leaderboard, Srfacehug/Cohere_AYA_for_Languages, Tonic/Aya, amirkhani/CohereForAI-aya-101, aspmirlab/ASPMIR-MACHINE-TRANSLATION-TESTBED, eduagarcia/open_pt_llm_leaderboard, fhudi/textgames, huggingface/InferenceSupport/discussions/new?title=CohereLabs/aya-101&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BCohereLabs%2Faya-101%5D(%2FCohereLabs%2Faya-101)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, prometheus-eval/BiGGen-Bench-Leaderboard, yenniejun/tokenizers-languages, yhavinga/dutch-tokenizer-arena",13
|
bart-large-mnli_finetunes_20250424_193500.csv_finetunes_20250424_193500.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
bert-base-multilingual-uncased-sentiment_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
biogpt_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
bitnet_b1_58-3B_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
1bitLLM/bitnet_b1_58-3B,"---
|
| 3 |
+
license: mit
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
This is a reproduction of the <a href=""https://arxiv.org/abs/2402.17764""> BitNet b1.58</a> paper. The models are trained with <a href=""https://github.com/togethercomputer/RedPajama-Data"">RedPajama dataset</a> for 100B tokens. The hypers, as well as two-stage LR and weight decay, are implemented as suggested in their following <a href=""https://github.com/microsoft/unilm/blob/master/bitnet/The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ.pdf"">paper</a>. All models are open-source in the <a href=""https://huggingface.co/1bitLLM"">repo</a>. We will train larger models and/or more tokens when resource is available.
|
| 7 |
+
|
| 8 |
+
## Results
|
| 9 |
+
PPL and zero-shot accuracy:
|
| 10 |
+
| Models | PPL| ARCe| ARCc| HS | BQ | OQ | PQ | WGe | Avg
|
| 11 |
+
|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|
|
| 12 |
+
| FP16 700M (reported) | 12.33 | 54.7 | 23.0 | 37.0 | 60.0 | 20.2 | 68.9 | 54.8 | 45.5 |
|
| 13 |
+
| BitNet b1.58 700M (reported) | 12.87 | 51.8 | 21.4 | 35.1 | 58.2 | 20.0 | 68.1 | 55.2 | 44.3 |
|
| 14 |
+
| BitNet b1.58 700M (reproduced) | 12.78 | 51.4 | 21.8 | 35.0 | 59.6 | 20.6 | 67.5 | 55.4 | 44.5 |
|
| 15 |
+
| FP16 1.3B (reported) | 11.25 | 56.9 | 23.5 | 38.5 | 59.1 | 21.6 | 70.0 | 53.9 | 46.2
|
| 16 |
+
| BitNet b1.58 1.3B (reported) | 11.29 | 54.9 | 24.2 | 37.7 | 56.7 | 19.6 | 68.8 | 55.8 | 45.4 |
|
| 17 |
+
| BitNet b1.58 1.3B (reproduced) | 11.19 | 55.8 | 23.7 | 37.6 | 59.0 | 20.2 | 69.2 | 56.0 | 45.9
|
| 18 |
+
| FP16 3B (reported) | 10.04 | 62.1 | 25.6 | 43.3 | 61.8 | 24.6 | 72.1 | 58.2 | 49.7
|
| 19 |
+
| BitNet b1.58 3B (reported) | 9.91 | 61.4 | 28.3 | 42.9 | 61.5 | 26.6 | 71.5 | 59.3 | 50.2
|
| 20 |
+
| BitNet b1.58 3B (reproduced) | 9.88 | 60.9 | 28.0 | 42.3 | 58.3 | 26.0 | 71.4 | 60.3 | 49.6 |
|
| 21 |
+
|
| 22 |
+
The differences between the reported numbers and the reproduced results are possibly variances from the training data processing, seeds, or other random factors.
|
| 23 |
+
|
| 24 |
+
## Evaluation
|
| 25 |
+
The evaluation pipelines are from the paper authors. Here is the commands to run the evaluation:
|
| 26 |
+
```
|
| 27 |
+
pip install lm-eval==0.3.0
|
| 28 |
+
```
|
| 29 |
+
```
|
| 30 |
+
python eval_ppl.py --hf_path 1bitLLM/bitnet_b1_58-3B --seqlen 2048
|
| 31 |
+
```
|
| 32 |
+
```
|
| 33 |
+
python eval_task.py --hf_path 1bitLLM/bitnet_b1_58-3B \
|
| 34 |
+
--batch_size 1 \
|
| 35 |
+
--tasks \
|
| 36 |
+
--output_path result.json \
|
| 37 |
+
--num_fewshot 0 \
|
| 38 |
+
--ctx_size 2048
|
| 39 |
+
```
|
| 40 |
+
","{""id"": ""1bitLLM/bitnet_b1_58-3B"", ""author"": ""1bitLLM"", ""sha"": ""af89e318d78a70802061246bf037199d2fb97020"", ""last_modified"": ""2024-03-29 11:57:44+00:00"", ""created_at"": ""2024-03-29 11:09:15+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1187, ""downloads_all_time"": null, ""likes"": 249, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""arxiv:2402.17764"", ""license:mit"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: mit"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""BitnetForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""pad_token"": ""<pad>"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_bitnet.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval_ppl.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval_task.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval_utils.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00003.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00003.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00003.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_bitnet.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenization_bitnet.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='utils_quant.py', size=None, blob_id=None, lfs=None)""], ""spaces"": [""KBaba7/Quant"", ""Omnibus/Chatbot-Compare"", ""medmekk/BitNet.cpp"", ""bhaskartripathi/LLM_Quantization"", ""nikravan/Bitnet-1B"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""fantos/Chatbot-Compare"", ""ruslanmv/convert_to_gguf"", ""johntheajs/MentalHealthChatBot"", ""OjciecTadeusz/Chatbot-Compare"", ""notabaka/1bitLLM-bitnet_b1_58-3B"", ""tree3po/Chatbot-Compare"", ""Nymbo/BitNet.cpp"", ""K00B404/LLM_Quantization""], ""safetensors"": {""parameters"": {""F32"": 3324389140}, ""total"": 3324389140}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-03-29 11:57:44+00:00"", ""cardData"": ""license: mit"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""6606a15b909dafbfb90bdfe3"", ""modelId"": ""1bitLLM/bitnet_b1_58-3B"", ""usedStorage"": 13298092387}",0,https://huggingface.co/Ttimofeyka/bitnet-5B-v1,1,,0,"https://huggingface.co/mradermacher/bitnet_b1_58-3B-GGUF, https://huggingface.co/Green-Sky/bitnet_b1_58-3B-GGUF, https://huggingface.co/Trisert/bitnet_b1_58-3B-Q8_0-GGUF, https://huggingface.co/NikolayKozloff/bitnet_b1_58-3B-Q8_0-GGUF, https://huggingface.co/Grootforce/bitnet_b1_58-3B-Q4_K_M-GGUF, https://huggingface.co/Nistep/bitnet_b1_58-3B-Q4_K_M-GGUF, https://huggingface.co/mradermacher/bitnet_b1_58-3B-i1-GGUF",7,,0,"FallnAI/Quantize-HF-Models, K00B404/LLM_Quantization, KBaba7/Quant, Nymbo/BitNet.cpp, Omnibus/Chatbot-Compare, bhaskartripathi/LLM_Quantization, fantos/Chatbot-Compare, huggingface/InferenceSupport/discussions/new?title=1bitLLM/bitnet_b1_58-3B&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5B1bitLLM%2Fbitnet_b1_58-3B%5D(%2F1bitLLM%2Fbitnet_b1_58-3B)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, johntheajs/MentalHealthChatBot, medmekk/BitNet.cpp, nikravan/Bitnet-1B, ruslanmv/convert_to_gguf, totolook/Quant",13
|
| 41 |
+
Ttimofeyka/bitnet-5B-v1,"---
|
| 42 |
+
license: mit
|
| 43 |
+
base_model:
|
| 44 |
+
- 1bitLLM/bitnet_b1_58-3B
|
| 45 |
+
library_name: transformers
|
| 46 |
+
tags:
|
| 47 |
+
- mergekit
|
| 48 |
+
- merge
|
| 49 |
+
- bitnet
|
| 50 |
+
---
|
| 51 |
+
# bitnet-5B-v1
|
| 52 |
+
I redesigned mergekit so that I could merge the bitnet 3B model (unlike version v0, where I did merge via PyTorch).
|
| 53 |
+
|
| 54 |
+
In theory, this is compatible with quantization via llama.cpp , but tests are needed.","{""id"": ""Ttimofeyka/bitnet-5B-v1"", ""author"": ""Ttimofeyka"", ""sha"": ""c2e9299b1085e3393615af405a9084bebba1b6e8"", ""last_modified"": ""2024-06-26 16:02:18+00:00"", ""created_at"": ""2024-06-26 15:10:09+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 11, ""downloads_all_time"": null, ""likes"": 1, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""mergekit"", ""merge"", ""bitnet"", ""base_model:1bitLLM/bitnet_b1_58-3B"", ""base_model:finetune:1bitLLM/bitnet_b1_58-3B"", ""license:mit"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- 1bitLLM/bitnet_b1_58-3B\nlibrary_name: transformers\nlicense: mit\ntags:\n- mergekit\n- merge\n- bitnet"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""BitnetForCausalLM""], ""model_type"": ""llama""}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00002.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00002.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""BF16"": 4563184000}, ""total"": 4563184000}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-06-26 16:02:18+00:00"", ""cardData"": ""base_model:\n- 1bitLLM/bitnet_b1_58-3B\nlibrary_name: transformers\nlicense: mit\ntags:\n- mergekit\n- merge\n- bitnet"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""667c2f51157cdaef5855d25b"", ""modelId"": ""Ttimofeyka/bitnet-5B-v1"", ""usedStorage"": 9126905483}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Ttimofeyka/bitnet-5B-v1&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BTtimofeyka%2Fbitnet-5B-v1%5D(%2FTtimofeyka%2Fbitnet-5B-v1)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
chilloutmix-ni_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
swl-models/chilloutmix-ni,"---
|
| 3 |
+
license: creativeml-openrail-m
|
| 4 |
+
tags:
|
| 5 |
+
- not-for-all-audiences
|
| 6 |
+
---","{""id"": ""swl-models/chilloutmix-ni"", ""author"": ""swl-models"", ""sha"": ""450dd5f92e8f7eb057404865968c807b55ccc646"", ""last_modified"": ""2023-03-30 01:48:27+00:00"", ""created_at"": ""2023-02-09 12:06:33+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 297, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""not-for-all-audiences"", ""license:creativeml-openrail-m"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: creativeml-openrail-m\ntags:\n- not-for-all-audiences"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chilloutmix-Ni-ema-bf16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chilloutmix-Ni-ema-fp16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chilloutmix-Ni-ema-fp32.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chilloutmix-Ni-non-ema-bf16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chilloutmix-Ni-non-ema-fp16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chilloutmix-Ni-non-ema-fp32.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chilloutmix-Ni.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [""hilmyblaze/WebUI-Counterfeit-V2.5""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-03-30 01:48:27+00:00"", ""cardData"": ""license: creativeml-openrail-m\ntags:\n- not-for-all-audiences"", ""transformersInfo"": null, ""_id"": ""63e4e1c9a26ec2301f0fed5b"", ""modelId"": ""swl-models/chilloutmix-ni"", ""usedStorage"": 26417688653}",0,,0,,0,,0,,0,,0
|
chilloutmix_NiPrunedFp32Fix_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
naonovn/chilloutmix_NiPrunedFp32Fix,"---
|
| 3 |
+
license: openrail
|
| 4 |
+
---
|
| 5 |
+
","{""id"": ""naonovn/chilloutmix_NiPrunedFp32Fix"", ""author"": ""naonovn"", ""sha"": ""6afe9a833e1baf52064df9ae3164a6da497087ab"", ""last_modified"": ""2023-02-27 07:25:10+00:00"", ""created_at"": ""2023-02-27 07:16:51+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 174, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""license:openrail"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: openrail"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chilloutmix_NiPrunedFp32Fix.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [""pinkqween/DiscordAI""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-02-27 07:25:10+00:00"", ""cardData"": ""license: openrail"", ""transformersInfo"": null, ""_id"": ""63fc58e3abd98a1e10799a6a"", ""modelId"": ""naonovn/chilloutmix_NiPrunedFp32Fix"", ""usedStorage"": 4265097179}",0,,0,,0,,0,,0,"huggingface/InferenceSupport/discussions/new?title=naonovn/chilloutmix_NiPrunedFp32Fix&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bnaonovn%2Fchilloutmix_NiPrunedFp32Fix%5D(%2Fnaonovn%2Fchilloutmix_NiPrunedFp32Fix)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, pinkqween/DiscordAI",2
|
chinese-alpaca-2-7b_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
hfl/chinese-alpaca-2-7b,"---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
language:
|
| 5 |
+
- zh
|
| 6 |
+
- en
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# Chinese-Alpaca-2-7B
|
| 10 |
+
|
| 11 |
+
**This is the full Chinese-Alpaca-2-7B model,which can be loaded directly for inference and full-parameter training.**
|
| 12 |
+
|
| 13 |
+
**Related models👇**
|
| 14 |
+
* Long context base models
|
| 15 |
+
* [Chinese-LLaMA-2-7B-16K (full model)](https://huggingface.co/hfl/chinese-llama-2-7b-16k)
|
| 16 |
+
* [Chinese-LLaMA-2-LoRA-7B-16K (LoRA model)](https://huggingface.co/hfl/chinese-llama-2-lora-7b-16k)
|
| 17 |
+
* [Chinese-LLaMA-2-13B-16K (full model)](https://huggingface.co/hfl/chinese-llama-2-13b-16k)
|
| 18 |
+
* [Chinese-LLaMA-2-LoRA-13B-16K (LoRA model)](https://huggingface.co/hfl/chinese-llama-2-lora-13b-16k)
|
| 19 |
+
* Base models
|
| 20 |
+
* [Chinese-LLaMA-2-7B (full model)](https://huggingface.co/hfl/chinese-llama-2-7b)
|
| 21 |
+
* [Chinese-LLaMA-2-LoRA-7B (LoRA model)](https://huggingface.co/hfl/chinese-llama-2-lora-7b)
|
| 22 |
+
* [Chinese-LLaMA-2-13B (full model)](https://huggingface.co/hfl/chinese-llama-2-13b)
|
| 23 |
+
* [Chinese-LLaMA-2-LoRA-13B (LoRA model)](https://huggingface.co/hfl/chinese-llama-2-lora-13b)
|
| 24 |
+
* Instruction/Chat models
|
| 25 |
+
* [Chinese-Alpaca-2-7B (full model)](https://huggingface.co/hfl/chinese-alpaca-2-7b)
|
| 26 |
+
* [Chinese-Alpaca-2-LoRA-7B (LoRA model)](https://huggingface.co/hfl/chinese-alpaca-2-lora-7b)
|
| 27 |
+
* [Chinese-Alpaca-2-13B (full model)](https://huggingface.co/hfl/chinese-alpaca-2-13b)
|
| 28 |
+
* [Chinese-Alpaca-2-LoRA-13B (LoRA model)](https://huggingface.co/hfl/chinese-alpaca-2-lora-13b)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
# Description of Chinese-LLaMA-Alpaca-2
|
| 32 |
+
This project is based on the Llama-2, released by Meta, and it is the second generation of the Chinese LLaMA & Alpaca LLM project. We open-source Chinese LLaMA-2 (foundation model) and Alpaca-2 (instruction-following model). These models have been expanded and optimized with Chinese vocabulary beyond the original Llama-2. We used large-scale Chinese data for incremental pre-training, which further improved the fundamental semantic understanding of the Chinese language, resulting in a significant performance improvement compared to the first-generation models. The relevant models support a 4K context and can be expanded up to 18K+ using the NTK method.
|
| 33 |
+
|
| 34 |
+
The main contents of this project include:
|
| 35 |
+
|
| 36 |
+
* 🚀 New extended Chinese vocabulary beyond Llama-2, open-sourcing the Chinese LLaMA-2 and Alpaca-2 LLMs.
|
| 37 |
+
* 🚀 Open-sourced the pre-training and instruction finetuning (SFT) scripts for further tuning on user's data
|
| 38 |
+
* 🚀 Quickly deploy and experience the quantized LLMs on CPU/GPU of personal PC
|
| 39 |
+
* 🚀 Support for LLaMA ecosystems like 🤗transformers, llama.cpp, text-generation-webui, LangChain, vLLM etc.
|
| 40 |
+
|
| 41 |
+
Please refer to [https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/) for details.","{""id"": ""hfl/chinese-alpaca-2-7b"", ""author"": ""hfl"", ""sha"": ""b9eeeddf488d3c1f67a374929a62a06fc2d51adf"", ""last_modified"": ""2023-12-23 07:28:12+00:00"", ""created_at"": ""2023-07-31 03:53:55+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 270, ""downloads_all_time"": null, ""likes"": 162, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""llama"", ""text-generation"", ""zh"", ""en"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- zh\n- en\nlicense: apache-2.0"", ""widget_data"": [{""text"": ""\u6211\u53eb\u6731\u5229\u5b89\uff0c\u6211\u559c\u6b22""}, {""text"": ""\u6211\u53eb\u6258\u9a6c\u65af\uff0c\u6211\u7684\u4e3b\u8981""}, {""text"": ""\u6211\u53eb\u739b\u4e3d\u4e9a\uff0c\u6211\u6700\u559c\u6b22\u7684""}, {""text"": ""\u6211\u53eb\u514b\u62c9\u62c9\uff0c\u6211\u662f""}, {""text"": ""\u4ece\u524d\uff0c""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": {""__type"": ""AddedToken"", ""content"": ""<s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""eos_token"": {""__type"": ""AddedToken"", ""content"": ""</s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}, ""pad_token"": null, ""unk_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": false}}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='SHA256.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00002.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00002.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Intel/low_bit_open_llm_leaderboard"", ""BAAI/open_cn_llm_leaderboard"", ""gsaivinay/open_llm_leaderboard"", ""GTBench/GTBench"", ""Vikhrmodels/small-shlepa-lb"", ""Justinrune/LLaMA-Factory"", ""kenken999/fastapi_django_main_live"", ""kz-transformers/kaz-llm-lb"", ""felixz/open_llm_leaderboard"", ""officialhimanshu595/llama-factory"", ""OPTML-Group/UnlearnCanvas-Benchmark"", ""BAAI/open_flageval_vlm_leaderboard"", ""neubla/neubla-llm-evaluation-board"", ""rodrigomasini/data_only_open_llm_leaderboard"", ""Docfile/open_llm_leaderboard"", ""scrumball/ziqingyang-chinese-alpaca-2-7b"", ""smothiki/open_llm_leaderboard"", ""iAdonis/ziqingyang-chinese-alpaca-2-7b"", ""blackwingedkite/gutalk"", ""blackwingedkite/gutalk_st"", ""luwatin/hfl-chinese-alpaca-2-7b"", ""cjsh/alpaca-2"", ""ggzm/hfl-chinese-alpaca-2-7b"", ""williamyangwentao/Law_llama"", ""nengrenjie83/MedicalGPT-main"", ""isiriai/ziqingyang-chinese-alpaca-2-7b"", ""Cran-May/yugang-chinese-alpaca-2-7b"", ""blackwingedkite/alpaca2_clas"", ""0x1668/open_llm_leaderboard"", ""pngwn/open_llm_leaderboard-check"", ""asir0z/open_llm_leaderboard"", ""kbmlcoding/open_llm_leaderboard_free"", ""yiju2313/ziqingyang-chinese-alpaca-2-7b"", ""aichampions/open_llm_leaderboard"", ""Adeco/open_llm_leaderboard"", ""anirudh937/open_llm_leaderboard"", ""smothiki/open_llm_leaderboard2"", ""mjalg/IFEvalTR"", ""msun415/Llamole""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-12-23 07:28:12+00:00"", ""cardData"": ""language:\n- zh\n- en\nlicense: apache-2.0"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""64c7305315bd12e5799c138b"", ""modelId"": ""hfl/chinese-alpaca-2-7b"", ""usedStorage"": 27718034148}",0,,0,"https://huggingface.co/coinplusfire/coinplusfire_chinese-alpaca-2-7b_full, https://huggingface.co/cutedogspark/chinese-alpaca-2-7b-qlora",2,"https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF, https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GPTQ, https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-AWQ",3,,0,"BAAI/open_cn_llm_leaderboard, BAAI/open_flageval_vlm_leaderboard, GTBench/GTBench, Intel/low_bit_open_llm_leaderboard, Justinrune/LLaMA-Factory, OPTML-Group/UnlearnCanvas-Benchmark, Vikhrmodels/small-shlepa-lb, blackwingedkite/gutalk, felixz/open_llm_leaderboard, gsaivinay/open_llm_leaderboard, huggingface/InferenceSupport/discussions/new?title=hfl/chinese-alpaca-2-7b&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bhfl%2Fchinese-alpaca-2-7b%5D(%2Fhfl%2Fchinese-alpaca-2-7b)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kenken999/fastapi_django_main_live, kz-transformers/kaz-llm-lb",13
|
chinese-bert-wwm-ext_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,762 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
hfl/chinese-bert-wwm-ext,"---
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
+
license: ""apache-2.0""
|
| 6 |
+
---
|
| 7 |
+
## Chinese BERT with Whole Word Masking
|
| 8 |
+
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
|
| 9 |
+
|
| 10 |
+
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
|
| 11 |
+
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
|
| 12 |
+
|
| 13 |
+
This repository is developed based on:https://github.com/google-research/bert
|
| 14 |
+
|
| 15 |
+
You may also interested in,
|
| 16 |
+
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
|
| 17 |
+
- Chinese MacBERT: https://github.com/ymcui/MacBERT
|
| 18 |
+
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
|
| 19 |
+
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
|
| 20 |
+
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
|
| 21 |
+
|
| 22 |
+
More resources by HFL: https://github.com/ymcui/HFL-Anthology
|
| 23 |
+
|
| 24 |
+
## Citation
|
| 25 |
+
If you find the technical report or resource is useful, please cite the following technical report in your paper.
|
| 26 |
+
- Primary: https://arxiv.org/abs/2004.13922
|
| 27 |
+
```
|
| 28 |
+
@inproceedings{cui-etal-2020-revisiting,
|
| 29 |
+
title = ""Revisiting Pre-Trained Models for {C}hinese Natural Language Processing"",
|
| 30 |
+
author = ""Cui, Yiming and
|
| 31 |
+
Che, Wanxiang and
|
| 32 |
+
Liu, Ting and
|
| 33 |
+
Qin, Bing and
|
| 34 |
+
Wang, Shijin and
|
| 35 |
+
Hu, Guoping"",
|
| 36 |
+
booktitle = ""Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings"",
|
| 37 |
+
month = nov,
|
| 38 |
+
year = ""2020"",
|
| 39 |
+
address = ""Online"",
|
| 40 |
+
publisher = ""Association for Computational Linguistics"",
|
| 41 |
+
url = ""https://www.aclweb.org/anthology/2020.findings-emnlp.58"",
|
| 42 |
+
pages = ""657--668"",
|
| 43 |
+
}
|
| 44 |
+
```
|
| 45 |
+
- Secondary: https://arxiv.org/abs/1906.08101
|
| 46 |
+
```
|
| 47 |
+
@article{chinese-bert-wwm,
|
| 48 |
+
title={Pre-Training with Whole Word Masking for Chinese BERT},
|
| 49 |
+
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
|
| 50 |
+
journal={arXiv preprint arXiv:1906.08101},
|
| 51 |
+
year={2019}
|
| 52 |
+
}
|
| 53 |
+
```","{""id"": ""hfl/chinese-bert-wwm-ext"", ""author"": ""hfl"", ""sha"": ""2a995a880017c60e4683869e817130d8af548486"", ""last_modified"": ""2021-05-19 19:06:39+00:00"", ""created_at"": ""2022-03-02 23:29:05+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 24266, ""downloads_all_time"": null, ""likes"": 174, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""tf"", ""jax"", ""bert"", ""fill-mask"", ""zh"", ""arxiv:1906.08101"", ""arxiv:2004.13922"", ""license:apache-2.0"", ""autotrain_compatible"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""fill-mask"", ""mask_token"": ""[MASK]"", ""trending_score"": null, ""card_data"": ""language:\n- zh\nlicense: apache-2.0"", ""widget_data"": [{""text"": ""\u5df4\u9ece\u662f[MASK]\u56fd\u7684\u9996\u90fd\u3002""}, {""text"": ""\u751f\u6d3b\u7684\u771f\u8c1b\u662f[MASK]\u3002""}], ""model_index"": null, ""config"": {""architectures"": [""BertForMaskedLM""], ""model_type"": ""bert"", ""tokenizer_config"": {}}, ""transformers_info"": {""auto_model"": ""AutoModelForMaskedLM"", ""custom_class"": null, ""pipeline_tag"": ""fill-mask"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='flax_model.msgpack', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tf_model.h5', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [""xizecliff/hfl-chinese-bert-wwm-ext""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2021-05-19 19:06:39+00:00"", ""cardData"": ""language:\n- zh\nlicense: apache-2.0"", ""transformersInfo"": {""auto_model"": ""AutoModelForMaskedLM"", ""custom_class"": null, ""pipeline_tag"": ""fill-mask"", ""processor"": ""AutoTokenizer""}, ""_id"": ""621ffdc136468d709f17ba9b"", ""modelId"": ""hfl/chinese-bert-wwm-ext"", ""usedStorage"": 1230189797}",0,"https://huggingface.co/Midsummra/CNMBert-MoE, https://huggingface.co/Midsummra/CNMBert, https://huggingface.co/KoichiYasuoka/chinese-bert-wwm-ext-upos, https://huggingface.co/sharkMeow/chinese-bert-wwm-ext-finetuned-QA-b8-10, https://huggingface.co/HansOMEL/qa_plot, https://huggingface.co/frett/chinese_extract_bert-x, https://huggingface.co/frett/chinese_paragraph_bert-ext, https://huggingface.co/b09501048/adl_hw1_qa_model_bert, https://huggingface.co/RachelCX/ner_model",9,,0,,0,,0,"huggingface/InferenceSupport/discussions/new?title=hfl/chinese-bert-wwm-ext&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bhfl%2Fchinese-bert-wwm-ext%5D(%2Fhfl%2Fchinese-bert-wwm-ext)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, xizecliff/hfl-chinese-bert-wwm-ext",2
|
| 54 |
+
Midsummra/CNMBert-MoE,"---
|
| 55 |
+
license: agpl-3.0
|
| 56 |
+
language:
|
| 57 |
+
- zh
|
| 58 |
+
base_model:
|
| 59 |
+
- hfl/chinese-bert-wwm-ext
|
| 60 |
+
pipeline_tag: fill-mask
|
| 61 |
+
tags:
|
| 62 |
+
- bert
|
| 63 |
+
- Chinese
|
| 64 |
+
library_name: transformers
|
| 65 |
+
---
|
| 66 |
+
|
| 67 |
+
CNMBert
|
| 68 |
+
[Github](https://github.com/IgarashiAkatuki/zh-CN-Multi-Mask-Bert)
|
| 69 |
+
|
| 70 |
+
# zh-CN-Multi-Mask-Bert (CNMBert)
|
| 71 |
+

|
| 72 |
+
|
| 73 |
+
---
|
| 74 |
+
|
| 75 |
+
一个用来翻译拼音缩写的模型
|
| 76 |
+
|
| 77 |
+
此模型基于[Chinese-BERT-wwm](https://github.com/ymcui/Chinese-BERT-wwm)训练而来,通过修改其预训练任务来使其适配拼音缩写翻译任务,相较于微调过的GPT模型以及GPT-4o达到了sota
|
| 78 |
+
|
| 79 |
+
---
|
| 80 |
+
|
| 81 |
+
## 什么是拼音缩写
|
| 82 |
+
|
| 83 |
+
形如:
|
| 84 |
+
|
| 85 |
+
> ""bhys"" -> ""不好意思""
|
| 86 |
+
>
|
| 87 |
+
> ""ys"" -> ""原神""
|
| 88 |
+
|
| 89 |
+
这样的,使用拼音首字母来代替汉字的缩写,我们姑且称之为拼音缩写。
|
| 90 |
+
|
| 91 |
+
如果对拼音缩写感兴趣可以看看这个↓
|
| 92 |
+
|
| 93 |
+
[大家为什么会讨厌缩写? - 远方青木的回答 - 知乎](https://www.zhihu.com/question/269016377/answer/2654824753)
|
| 94 |
+
|
| 95 |
+
### CNMBert
|
| 96 |
+
|
| 97 |
+
| Model | 模型权重 | Memory Usage (FP16) | Model Size | QPS | MRR | Acc |
|
| 98 |
+
| --------------- | ----------------------------------------------------------- | ------------------- | ---------- | ----- | ----- | ----- |
|
| 99 |
+
| CNMBert-Default | [Huggingface](https://huggingface.co/Midsummra/CNMBert) | 0.4GB | 131M | 12.56 | 59.70 | 49.74 |
|
| 100 |
+
| CNMBert-MoE | [Huggingface](https://huggingface.co/Midsummra/CNMBert-MoE) | 0.8GB | 329M | 3.20 | 61.53 | 51.86 |
|
| 101 |
+
|
| 102 |
+
* 所有模型均在相同的200万条wiki以及知乎语料下训练
|
| 103 |
+
* QPS 为 queries per second (由于没有使用c重写predict所以现在性能很糟...)
|
| 104 |
+
* MRR 为平均倒数排名(mean reciprocal rank)
|
| 105 |
+
* Acc 为准确率(accuracy)
|
| 106 |
+
|
| 107 |
+
### Usage
|
| 108 |
+
|
| 109 |
+
```python
|
| 110 |
+
from transformers import AutoTokenizer, BertConfig
|
| 111 |
+
|
| 112 |
+
from CustomBertModel import predict
|
| 113 |
+
from MoELayer import BertWwmMoE
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
加载模型
|
| 117 |
+
|
| 118 |
+
```python
|
| 119 |
+
# use CNMBert with MoE
|
| 120 |
+
# To use CNMBert without MoE, replace all ""Midsummra/CNMBert-MoE"" with ""Midsummra/CNMBert"" and use BertForMaskedLM instead of using BertWwmMoE
|
| 121 |
+
tokenizer = AutoTokenizer.from_pretrained(""Midsummra/CNMBert-MoE"")
|
| 122 |
+
config = BertConfig.from_pretrained('Midsummra/CNMBert-MoE')
|
| 123 |
+
model = BertWwmMoE.from_pretrained('Midsummra/CNMBert-MoE', config=config).to('cuda')
|
| 124 |
+
|
| 125 |
+
# model = BertForMaskedLM.from_pretrained('Midsummra/CNMBert').to('cuda')
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
预测词语
|
| 129 |
+
|
| 130 |
+
```python
|
| 131 |
+
print(predict(""我有两千kq"", ""kq"", model, tokenizer)[:5])
|
| 132 |
+
print(predict(""快去给魔理沙看b吧"", ""b"", model, tokenizer[:5]))
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
> ['块钱', 1.2056937473156175], ['块前', 0.05837443749364857], ['开千', 0.0483869208528063], ['可千', 0.03996622172280445], ['口气', 0.037183335575008414]
|
| 136 |
+
|
| 137 |
+
> ['病', 1.6893256306648254], ['吧', 0.1642467901110649], ['呗', 0.026976384222507477], ['包', 0.021441461518406868], ['报', 0.01396679226309061]
|
| 138 |
+
|
| 139 |
+
---
|
| 140 |
+
|
| 141 |
+
```python
|
| 142 |
+
# 默认的predict函数使用束搜索
|
| 143 |
+
def predict(sentence: str,
|
| 144 |
+
predict_word: str,
|
| 145 |
+
model,
|
| 146 |
+
tokenizer,
|
| 147 |
+
top_k=8,
|
| 148 |
+
beam_size=16, # 束宽
|
| 149 |
+
threshold=0.005, # 阈值
|
| 150 |
+
fast_mode=True, # 是否使用快速模式
|
| 151 |
+
strict_mode=True): # 是否对输出结果进行检查
|
| 152 |
+
|
| 153 |
+
# 使用回溯的无剪枝暴力搜索
|
| 154 |
+
def backtrack_predict(sentence: str,
|
| 155 |
+
predict_word: str,
|
| 156 |
+
model,
|
| 157 |
+
tokenizer,
|
| 158 |
+
top_k=10,
|
| 159 |
+
fast_mode=True,
|
| 160 |
+
strict_mode=True):
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
> 由于BERT的自编码特性,导致其在预测MASK时,顺序不同会导致预测结果不同,如果启用`fast_mode`,则会正向和反向分别对输入进行预测,可以提升一点准确率(2%左右),但是会带来更大的性能开销。
|
| 164 |
+
|
| 165 |
+
> `strict_mode`会对输入进行检查,以判断其是否为一个真实存在的汉语词汇。
|
| 166 |
+
|
| 167 |
+
### 如何微调模型
|
| 168 |
+
|
| 169 |
+
请参考[TrainExample.ipynb](https://github.com/IgarashiAkatuki/CNMBert/blob/main/TrainExample.ipynb),在数据集的格式上,只要保证csv的第一列为要训练的语料即可。
|
| 170 |
+
|
| 171 |
+
### Q&A
|
| 172 |
+
|
| 173 |
+
Q: 感觉这个东西准确度有点低啊
|
| 174 |
+
|
| 175 |
+
A: 可以尝试设置`fast_mode`和`strict_mode`为`False`。 模型是在很小的数据集(200w)上进行的预训练,所以泛化能力不足很正常,,,可以在更大数据集或者更加细分的领域进行微调,具体微调方式和[Chinese-BERT-wwm](https://github.com/ymcui/Chinese-BERT-wwm)差别不大,只需要将`DataCollactor`替换为`CustomBertModel.py`中的`DataCollatorForMultiMask`。
|
| 176 |
+
|
| 177 |
+
### 引用
|
| 178 |
+
如果您对CNMBert的具体实现感兴趣的话,可以参考
|
| 179 |
+
```
|
| 180 |
+
@misc{feng2024cnmbertmodelhanyupinyin,
|
| 181 |
+
title={CNMBert: A Model For Hanyu Pinyin Abbreviation to Character Conversion Task},
|
| 182 |
+
author={Zishuo Feng and Feng Cao},
|
| 183 |
+
year={2024},
|
| 184 |
+
eprint={2411.11770},
|
| 185 |
+
archivePrefix={arXiv},
|
| 186 |
+
primaryClass={cs.CL},
|
| 187 |
+
url={https://arxiv.org/abs/2411.11770},
|
| 188 |
+
}
|
| 189 |
+
```
|
| 190 |
+
","{""id"": ""Midsummra/CNMBert-MoE"", ""author"": ""Midsummra"", ""sha"": ""727ab8aaed422075160db5c4c644fad7fbcf0f26"", ""last_modified"": ""2025-01-01 10:04:04+00:00"", ""created_at"": ""2024-12-07 15:22:44+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 34, ""downloads_all_time"": null, ""likes"": 3, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""bert"", ""Chinese"", ""fill-mask"", ""zh"", ""arxiv:2411.11770"", ""base_model:hfl/chinese-bert-wwm-ext"", ""base_model:finetune:hfl/chinese-bert-wwm-ext"", ""license:agpl-3.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""fill-mask"", ""mask_token"": ""[MASK]"", ""trending_score"": null, ""card_data"": ""base_model:\n- hfl/chinese-bert-wwm-ext\nlanguage:\n- zh\nlibrary_name: transformers\nlicense: agpl-3.0\npipeline_tag: fill-mask\ntags:\n- bert\n- Chinese"", ""widget_data"": [{""text"": ""\u5df4\u9ece\u662f[MASK]\u56fd\u7684\u9996\u90fd\u3002""}, {""text"": ""\u751f\u6d3b\u7684\u771f\u8c1b\u662f[MASK]\u3002""}], ""model_index"": null, ""config"": {""architectures"": [""BertWwmMoE""], ""model_type"": ""bert"", ""tokenizer_config"": {}}, ""transformers_info"": {""auto_model"": ""BertWwmMoE"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F32"": 329016242}, ""total"": 329016242}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-01-01 10:04:04+00:00"", ""cardData"": ""base_model:\n- hfl/chinese-bert-wwm-ext\nlanguage:\n- zh\nlibrary_name: transformers\nlicense: agpl-3.0\npipeline_tag: fill-mask\ntags:\n- bert\n- Chinese"", ""transformersInfo"": {""auto_model"": ""BertWwmMoE"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": ""AutoTokenizer""}, ""_id"": ""67546844e105a24bbb263347"", ""modelId"": ""Midsummra/CNMBert-MoE"", ""usedStorage"": 2632252480}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Midsummra/CNMBert-MoE&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BMidsummra%2FCNMBert-MoE%5D(%2FMidsummra%2FCNMBert-MoE)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 191 |
+
Midsummra/CNMBert,"---
|
| 192 |
+
license: agpl-3.0
|
| 193 |
+
language:
|
| 194 |
+
- zh
|
| 195 |
+
base_model:
|
| 196 |
+
- hfl/chinese-bert-wwm-ext
|
| 197 |
+
pipeline_tag: fill-mask
|
| 198 |
+
library_name: transformers
|
| 199 |
+
tags:
|
| 200 |
+
- bert
|
| 201 |
+
- Chinese
|
| 202 |
+
---
|
| 203 |
+
CNMBert
|
| 204 |
+
[Github](https://github.com/IgarashiAkatuki/zh-CN-Multi-Mask-Bert)
|
| 205 |
+
|
| 206 |
+
# zh-CN-Multi-Mask-Bert (CNMBert)
|
| 207 |
+

|
| 208 |
+
|
| 209 |
+
---
|
| 210 |
+
|
| 211 |
+
一个用来翻译拼音缩写的模型
|
| 212 |
+
|
| 213 |
+
此模型基于[Chinese-BERT-wwm](https://github.com/ymcui/Chinese-BERT-wwm)训练而来,通过修改其预训练任务来使其适配拼音缩写翻译任务,相较于微调过的GPT模型以及GPT-4o达到了sota
|
| 214 |
+
|
| 215 |
+
---
|
| 216 |
+
|
| 217 |
+
## 什么是拼音缩写
|
| 218 |
+
|
| 219 |
+
形如:
|
| 220 |
+
|
| 221 |
+
> ""bhys"" -> ""不好意思""
|
| 222 |
+
>
|
| 223 |
+
> ""ys"" -> ""原神""
|
| 224 |
+
|
| 225 |
+
这样的,使用拼音首字母来代替汉字的缩写,我们姑且称之为拼音缩写。
|
| 226 |
+
|
| 227 |
+
如果对拼音缩写感兴趣可以看看这个↓
|
| 228 |
+
|
| 229 |
+
[大家为什么会讨厌缩写? - 远方青木的回答 - 知乎](https://www.zhihu.com/question/269016377/answer/2654824753)
|
| 230 |
+
|
| 231 |
+
### CNMBert
|
| 232 |
+
|
| 233 |
+
| Model | 模型权重 | Memory Usage (FP16) | Model Size | QPS | MRR | Acc |
|
| 234 |
+
| --------------- | ----------------------------------------------------------- | ------------------- | ---------- | ----- | ----- | ----- |
|
| 235 |
+
| CNMBert-Default | [Huggingface](https://huggingface.co/Midsummra/CNMBert) | 0.4GB | 131M | 12.56 | 59.70 | 49.74 |
|
| 236 |
+
| CNMBert-MoE | [Huggingface](https://huggingface.co/Midsummra/CNMBert-MoE) | 0.8GB | 329M | 3.20 | 61.53 | 51.86 |
|
| 237 |
+
|
| 238 |
+
* 所有模型均在相同的200万条wiki以及知乎语料下训练
|
| 239 |
+
* QPS 为 queries per second (由于没有使用c重写predict所以现在性能很糟...)
|
| 240 |
+
* MRR 为平均倒数排名(mean reciprocal rank)
|
| 241 |
+
* Acc 为准确率(accuracy)
|
| 242 |
+
|
| 243 |
+
### Usage
|
| 244 |
+
|
| 245 |
+
```python
|
| 246 |
+
from transformers import AutoTokenizer, BertConfig
|
| 247 |
+
|
| 248 |
+
from CustomBertModel import predict
|
| 249 |
+
from MoELayer import BertWwmMoE
|
| 250 |
+
```
|
| 251 |
+
|
| 252 |
+
加载模型
|
| 253 |
+
|
| 254 |
+
```python
|
| 255 |
+
# use CNMBert with MoE
|
| 256 |
+
# To use CNMBert without MoE, replace all ""Midsummra/CNMBert-MoE"" with ""Midsummra/CNMBert"" and use BertForMaskedLM instead of using BertWwmMoE
|
| 257 |
+
tokenizer = AutoTokenizer.from_pretrained(""Midsummra/CNMBert-MoE"")
|
| 258 |
+
config = BertConfig.from_pretrained('Midsummra/CNMBert-MoE')
|
| 259 |
+
model = BertWwmMoE.from_pretrained('Midsummra/CNMBert-MoE', config=config).to('cuda')
|
| 260 |
+
|
| 261 |
+
# model = BertForMaskedLM.from_pretrained('Midsummra/CNMBert').to('cuda')
|
| 262 |
+
```
|
| 263 |
+
|
| 264 |
+
预测词语
|
| 265 |
+
|
| 266 |
+
```python
|
| 267 |
+
print(predict(""我有两千kq"", ""kq"", model, tokenizer)[:5])
|
| 268 |
+
print(predict(""快去给魔理沙看b吧"", ""b"", model, tokenizer[:5]))
|
| 269 |
+
```
|
| 270 |
+
|
| 271 |
+
> ['块钱', 1.2056937473156175], ['块前', 0.05837443749364857], ['开千', 0.0483869208528063], ['可千', 0.03996622172280445], ['口气', 0.037183335575008414]
|
| 272 |
+
|
| 273 |
+
> ['病', 1.6893256306648254], ['吧', 0.1642467901110649], ['呗', 0.026976384222507477], ['包', 0.021441461518406868], ['报', 0.01396679226309061]
|
| 274 |
+
|
| 275 |
+
---
|
| 276 |
+
|
| 277 |
+
```python
|
| 278 |
+
# 默认的predict函数使用束搜索
|
| 279 |
+
def predict(sentence: str,
|
| 280 |
+
predict_word: str,
|
| 281 |
+
model,
|
| 282 |
+
tokenizer,
|
| 283 |
+
top_k=8,
|
| 284 |
+
beam_size=16, # 束宽
|
| 285 |
+
threshold=0.005, # 阈值
|
| 286 |
+
fast_mode=True, # 是否使用快速模式
|
| 287 |
+
strict_mode=True): # 是否对输出结果进行检查
|
| 288 |
+
|
| 289 |
+
# 使用回溯的无剪枝暴力搜索
|
| 290 |
+
def backtrack_predict(sentence: str,
|
| 291 |
+
predict_word: str,
|
| 292 |
+
model,
|
| 293 |
+
tokenizer,
|
| 294 |
+
top_k=10,
|
| 295 |
+
fast_mode=True,
|
| 296 |
+
strict_mode=True):
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
> 由于BERT的自编码特性,导致其在预测MASK时,顺序不同会导致预测结果不同,如果启用`fast_mode`,则会正向和反向分别对输入进行预测,可以提升一点准确率(2%左右),但是会带来更大的性能开销。
|
| 300 |
+
|
| 301 |
+
> `strict_mode`会对输入进行检查,以判断其是否为一个真实存在的汉语词汇。
|
| 302 |
+
|
| 303 |
+
### 如何微调模型
|
| 304 |
+
|
| 305 |
+
请参考[TrainExample.ipynb](https://github.com/IgarashiAkatuki/CNMBert/blob/main/TrainExample.ipynb),在数据集的格式上,只要保证csv的第一列为要训练的语料即可。
|
| 306 |
+
|
| 307 |
+
### Q&A
|
| 308 |
+
|
| 309 |
+
Q: 感觉这个东西准确度有点低啊
|
| 310 |
+
|
| 311 |
+
A: 可以尝试设置`fast_mode`和`strict_mode`为`False`。 模型是在很小的数据集(200w)上进行的预训练,所以泛化能力不足很正常,,,可以在更大数据集或者更加细分的领域进行微调,具体微调方式和[Chinese-BERT-wwm](https://github.com/ymcui/Chinese-BERT-wwm)差别不大,只需要将`DataCollactor`替换为`CustomBertModel.py`中的`DataCollatorForMultiMask`。
|
| 312 |
+
|
| 313 |
+
### 引用
|
| 314 |
+
如果您对CNMBert的具体实现感兴趣的话,可以参考
|
| 315 |
+
```
|
| 316 |
+
@misc{feng2024cnmbertmodelhanyupinyin,
|
| 317 |
+
title={CNMBert: A Model For Hanyu Pinyin Abbreviation to Character Conversion Task},
|
| 318 |
+
author={Zishuo Feng and Feng Cao},
|
| 319 |
+
year={2024},
|
| 320 |
+
eprint={2411.11770},
|
| 321 |
+
archivePrefix={arXiv},
|
| 322 |
+
primaryClass={cs.CL},
|
| 323 |
+
url={https://arxiv.org/abs/2411.11770},
|
| 324 |
+
}
|
| 325 |
+
```
|
| 326 |
+
","{""id"": ""Midsummra/CNMBert"", ""author"": ""Midsummra"", ""sha"": ""7802eae9f8ae3a25a9f08aaddf46fb35fceb86ae"", ""last_modified"": ""2025-01-01 10:03:13+00:00"", ""created_at"": ""2024-12-08 06:46:52+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 31, ""downloads_all_time"": null, ""likes"": 2, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""bert"", ""fill-mask"", ""Chinese"", ""zh"", ""arxiv:2411.11770"", ""base_model:hfl/chinese-bert-wwm-ext"", ""base_model:finetune:hfl/chinese-bert-wwm-ext"", ""license:agpl-3.0"", ""autotrain_compatible"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""fill-mask"", ""mask_token"": ""[MASK]"", ""trending_score"": null, ""card_data"": ""base_model:\n- hfl/chinese-bert-wwm-ext\nlanguage:\n- zh\nlibrary_name: transformers\nlicense: agpl-3.0\npipeline_tag: fill-mask\ntags:\n- bert\n- Chinese"", ""widget_data"": [{""text"": ""\u5df4\u9ece\u662f[MASK]\u56fd\u7684\u9996\u90fd\u3002""}, {""text"": ""\u751f\u6d3b\u7684\u771f\u8c1b\u662f[MASK]\u3002""}], ""model_index"": null, ""config"": {""architectures"": [""BertForMaskedLM""], ""model_type"": ""bert"", ""tokenizer_config"": {}}, ""transformers_info"": {""auto_model"": ""AutoModelForMaskedLM"", ""custom_class"": null, ""pipeline_tag"": ""fill-mask"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F32"": 130641800}, ""total"": 130641800}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-01-01 10:03:13+00:00"", ""cardData"": ""base_model:\n- hfl/chinese-bert-wwm-ext\nlanguage:\n- zh\nlibrary_name: transformers\nlicense: agpl-3.0\npipeline_tag: fill-mask\ntags:\n- bert\n- Chinese"", ""transformersInfo"": {""auto_model"": ""AutoModelForMaskedLM"", ""custom_class"": null, ""pipeline_tag"": ""fill-mask"", ""processor"": ""AutoTokenizer""}, ""_id"": ""675540dc607a41b4b802d50c"", ""modelId"": ""Midsummra/CNMBert"", ""usedStorage"": 522598464}",1,,0,,0,https://huggingface.co/mradermacher/CNMBert-GGUF,1,,0,huggingface/InferenceSupport/discussions/new?title=Midsummra/CNMBert&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BMidsummra%2FCNMBert%5D(%2FMidsummra%2FCNMBert)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 327 |
+
KoichiYasuoka/chinese-bert-wwm-ext-upos,"---
|
| 328 |
+
language:
|
| 329 |
+
- ""zh""
|
| 330 |
+
tags:
|
| 331 |
+
- ""chinese""
|
| 332 |
+
- ""token-classification""
|
| 333 |
+
- ""pos""
|
| 334 |
+
- ""wikipedia""
|
| 335 |
+
- ""dependency-parsing""
|
| 336 |
+
base_model: hfl/chinese-bert-wwm-ext
|
| 337 |
+
datasets:
|
| 338 |
+
- ""universal_dependencies""
|
| 339 |
+
license: ""apache-2.0""
|
| 340 |
+
pipeline_tag: ""token-classification""
|
| 341 |
+
---
|
| 342 |
+
|
| 343 |
+
# chinese-bert-wwm-ext-upos
|
| 344 |
+
|
| 345 |
+
## Model Description
|
| 346 |
+
|
| 347 |
+
This is a BERT model pre-trained on Chinese Wikipedia texts (both simplified and traditional) for POS-tagging and dependency-parsing, derived from [chinese-bert-wwm-ext](https://huggingface.co/hfl/chinese-bert-wwm-ext). Every word is tagged by [UPOS](https://universaldependencies.org/u/pos/) (Universal Part-Of-Speech).
|
| 348 |
+
|
| 349 |
+
## How to Use
|
| 350 |
+
|
| 351 |
+
```py
|
| 352 |
+
from transformers import AutoTokenizer,AutoModelForTokenClassification
|
| 353 |
+
tokenizer=AutoTokenizer.from_pretrained(""KoichiYasuoka/chinese-bert-wwm-ext-upos"")
|
| 354 |
+
model=AutoModelForTokenClassification.from_pretrained(""KoichiYasuoka/chinese-bert-wwm-ext-upos"")
|
| 355 |
+
```
|
| 356 |
+
|
| 357 |
+
or
|
| 358 |
+
|
| 359 |
+
```py
|
| 360 |
+
import esupar
|
| 361 |
+
nlp=esupar.load(""KoichiYasuoka/chinese-bert-wwm-ext-upos"")
|
| 362 |
+
```
|
| 363 |
+
|
| 364 |
+
## See Also
|
| 365 |
+
|
| 366 |
+
[esupar](https://github.com/KoichiYasuoka/esupar): Tokenizer POS-tagger and Dependency-parser with BERT/RoBERTa/DeBERTa models
|
| 367 |
+
|
| 368 |
+
","{""id"": ""KoichiYasuoka/chinese-bert-wwm-ext-upos"", ""author"": ""KoichiYasuoka"", ""sha"": ""a696c490063b6b348cd359a341f17f19f4fc34e1"", ""last_modified"": ""2025-01-03 07:56:57+00:00"", ""created_at"": ""2022-03-02 23:29:04+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 21, ""downloads_all_time"": null, ""likes"": 8, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""bert"", ""token-classification"", ""chinese"", ""pos"", ""wikipedia"", ""dependency-parsing"", ""zh"", ""dataset:universal_dependencies"", ""base_model:hfl/chinese-bert-wwm-ext"", ""base_model:finetune:hfl/chinese-bert-wwm-ext"", ""license:apache-2.0"", ""autotrain_compatible"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""token-classification"", ""mask_token"": ""[MASK]"", ""trending_score"": null, ""card_data"": ""base_model: hfl/chinese-bert-wwm-ext\ndatasets:\n- universal_dependencies\nlanguage:\n- zh\nlicense: apache-2.0\npipeline_tag: token-classification\ntags:\n- chinese\n- token-classification\n- pos\n- wikipedia\n- dependency-parsing"", ""widget_data"": [{""text"": ""\u6211\u53eb\u6c83\u5c14\u592b\u5188\uff0c\u6211\u4f4f\u5728\u67cf\u6797\u3002""}, {""text"": ""\u6211\u53eb\u8428\u62c9\uff0c\u6211\u4f4f\u5728\u4f26\u6566\u3002""}, {""text"": ""\u6211\u53eb\u514b\u62c9\u62c9\uff0c\u6211\u4f4f\u5728\u52a0\u5dde\u4f2f\u514b\u5229\u3002""}], ""model_index"": null, ""config"": {""architectures"": [""BertForTokenClassification""], ""model_type"": ""bert"", ""tokenizer_config"": {""unk_token"": ""[UNK]"", ""sep_token"": ""[SEP]"", ""pad_token"": ""[PAD]"", ""cls_token"": ""[CLS]"", ""mask_token"": ""[MASK]""}}, ""transformers_info"": {""auto_model"": ""AutoModelForTokenClassification"", ""custom_class"": null, ""pipeline_tag"": ""token-classification"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='supar.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-01-03 07:56:57+00:00"", ""cardData"": ""base_model: hfl/chinese-bert-wwm-ext\ndatasets:\n- universal_dependencies\nlanguage:\n- zh\nlicense: apache-2.0\npipeline_tag: token-classification\ntags:\n- chinese\n- token-classification\n- pos\n- wikipedia\n- dependency-parsing"", ""transformersInfo"": {""auto_model"": ""AutoModelForTokenClassification"", ""custom_class"": null, ""pipeline_tag"": ""token-classification"", ""processor"": ""AutoTokenizer""}, ""_id"": ""621ffdc036468d709f1764ee"", ""modelId"": ""KoichiYasuoka/chinese-bert-wwm-ext-upos"", ""usedStorage"": 2139294811}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=KoichiYasuoka/chinese-bert-wwm-ext-upos&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BKoichiYasuoka%2Fchinese-bert-wwm-ext-upos%5D(%2FKoichiYasuoka%2Fchinese-bert-wwm-ext-upos)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 369 |
+
sharkMeow/chinese-bert-wwm-ext-finetuned-QA-b8-10,"---
|
| 370 |
+
license: apache-2.0
|
| 371 |
+
base_model: hfl/chinese-bert-wwm-ext
|
| 372 |
+
tags:
|
| 373 |
+
- generated_from_trainer
|
| 374 |
+
model-index:
|
| 375 |
+
- name: chinese-bert-wwm-ext-finetuned-QA-b8-10
|
| 376 |
+
results: []
|
| 377 |
+
---
|
| 378 |
+
|
| 379 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 380 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 381 |
+
|
| 382 |
+
# chinese-bert-wwm-ext-finetuned-QA-b8-10
|
| 383 |
+
|
| 384 |
+
This model is a fine-tuned version of [hfl/chinese-bert-wwm-ext](https://huggingface.co/hfl/chinese-bert-wwm-ext) on an unknown dataset.
|
| 385 |
+
It achieves the following results on the evaluation set:
|
| 386 |
+
- Loss: 2.2029
|
| 387 |
+
|
| 388 |
+
## Model description
|
| 389 |
+
|
| 390 |
+
More information needed
|
| 391 |
+
|
| 392 |
+
## Intended uses & limitations
|
| 393 |
+
|
| 394 |
+
More information needed
|
| 395 |
+
|
| 396 |
+
## Training and evaluation data
|
| 397 |
+
|
| 398 |
+
More information needed
|
| 399 |
+
|
| 400 |
+
## Training procedure
|
| 401 |
+
|
| 402 |
+
### Training hyperparameters
|
| 403 |
+
|
| 404 |
+
The following hyperparameters were used during training:
|
| 405 |
+
- learning_rate: 3e-05
|
| 406 |
+
- train_batch_size: 8
|
| 407 |
+
- eval_batch_size: 8
|
| 408 |
+
- seed: 42
|
| 409 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 410 |
+
- lr_scheduler_type: linear
|
| 411 |
+
- num_epochs: 10
|
| 412 |
+
|
| 413 |
+
### Training results
|
| 414 |
+
|
| 415 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 416 |
+
|:-------------:|:-----:|:-----:|:---------------:|
|
| 417 |
+
| 0.7409 | 1.0 | 3460 | 0.6617 |
|
| 418 |
+
| 0.4568 | 2.0 | 6920 | 0.7331 |
|
| 419 |
+
| 0.2729 | 3.0 | 10380 | 0.9146 |
|
| 420 |
+
| 0.1864 | 4.0 | 13840 | 1.2475 |
|
| 421 |
+
| 0.1163 | 5.0 | 17300 | 1.3969 |
|
| 422 |
+
| 0.0825 | 6.0 | 20760 | 1.8681 |
|
| 423 |
+
| 0.0411 | 7.0 | 24220 | 2.0010 |
|
| 424 |
+
| 0.0317 | 8.0 | 27680 | 2.1313 |
|
| 425 |
+
| 0.0163 | 9.0 | 31140 | 2.2390 |
|
| 426 |
+
| 0.0053 | 10.0 | 34600 | 2.2029 |
|
| 427 |
+
|
| 428 |
+
|
| 429 |
+
### Framework versions
|
| 430 |
+
|
| 431 |
+
- Transformers 4.33.0
|
| 432 |
+
- Pytorch 2.0.0
|
| 433 |
+
- Datasets 2.14.5
|
| 434 |
+
- Tokenizers 0.13.3
|
| 435 |
+
","{""id"": ""sharkMeow/chinese-bert-wwm-ext-finetuned-QA-b8-10"", ""author"": ""sharkMeow"", ""sha"": ""040c4d15269a6df4fc93d7d8da7593600b2dfe51"", ""last_modified"": ""2023-10-18 20:19:11+00:00"", ""created_at"": ""2023-10-18 13:56:52+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 12, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""bert"", ""question-answering"", ""generated_from_trainer"", ""base_model:hfl/chinese-bert-wwm-ext"", ""base_model:finetune:hfl/chinese-bert-wwm-ext"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""question-answering"", ""mask_token"": ""[MASK]"", ""trending_score"": null, ""card_data"": ""base_model: hfl/chinese-bert-wwm-ext\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: chinese-bert-wwm-ext-finetuned-QA-b8-10\n results: []"", ""widget_data"": [{""text"": ""Where do I live?"", ""context"": ""My name is Wolfgang and I live in Berlin""}, {""text"": ""Where do I live?"", ""context"": ""My name is Sarah and I live in London""}, {""text"": ""What's my name?"", ""context"": ""My name is Clara and I live in Berkeley.""}, {""text"": ""Which name is also used to describe the Amazon rainforest in English?"", ""context"": ""The Amazon rainforest (Portuguese: Floresta Amaz\u00f4nica or Amaz\u00f4nia; Spanish: Selva Amaz\u00f3nica, Amazon\u00eda or usually Amazonia; French: For\u00eat amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \""Amazonas\"" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species.""}], ""model_index"": [{""name"": ""chinese-bert-wwm-ext-finetuned-QA-b8-10"", ""results"": []}], ""config"": {""architectures"": [""BertForQuestionAnswering""], ""model_type"": ""bert"", ""tokenizer_config"": {""cls_token"": ""[CLS]"", ""mask_token"": ""[MASK]"", ""pad_token"": ""[PAD]"", ""sep_token"": ""[SEP]"", ""unk_token"": ""[UNK]""}}, ""transformers_info"": {""auto_model"": ""AutoModelForQuestionAnswering"", ""custom_class"": null, ""pipeline_tag"": ""question-answering"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-10-18 20:19:11+00:00"", ""cardData"": ""base_model: hfl/chinese-bert-wwm-ext\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: chinese-bert-wwm-ext-finetuned-QA-b8-10\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForQuestionAnswering"", ""custom_class"": null, ""pipeline_tag"": ""question-answering"", ""processor"": ""AutoTokenizer""}, ""_id"": ""652fe424f5d268461174cd03"", ""modelId"": ""sharkMeow/chinese-bert-wwm-ext-finetuned-QA-b8-10"", ""usedStorage"": 10983081008}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=sharkMeow/chinese-bert-wwm-ext-finetuned-QA-b8-10&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BsharkMeow%2Fchinese-bert-wwm-ext-finetuned-QA-b8-10%5D(%2FsharkMeow%2Fchinese-bert-wwm-ext-finetuned-QA-b8-10)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 436 |
+
HansOMEL/qa_plot,"---
|
| 437 |
+
license: apache-2.0
|
| 438 |
+
base_model: hfl/chinese-bert-wwm-ext
|
| 439 |
+
tags:
|
| 440 |
+
- generated_from_trainer
|
| 441 |
+
model-index:
|
| 442 |
+
- name: qa_plot
|
| 443 |
+
results: []
|
| 444 |
+
---
|
| 445 |
+
|
| 446 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 447 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 448 |
+
|
| 449 |
+
# qa_plot
|
| 450 |
+
|
| 451 |
+
This model is a fine-tuned version of [hfl/chinese-bert-wwm-ext](https://huggingface.co/hfl/chinese-bert-wwm-ext) on an unknown dataset.
|
| 452 |
+
It achieves the following results on the evaluation set:
|
| 453 |
+
- Loss: 1.1978
|
| 454 |
+
|
| 455 |
+
## Model description
|
| 456 |
+
|
| 457 |
+
More information needed
|
| 458 |
+
|
| 459 |
+
## Intended uses & limitations
|
| 460 |
+
|
| 461 |
+
More information needed
|
| 462 |
+
|
| 463 |
+
## Training and evaluation data
|
| 464 |
+
|
| 465 |
+
More information needed
|
| 466 |
+
|
| 467 |
+
## Training procedure
|
| 468 |
+
|
| 469 |
+
### Training hyperparameters
|
| 470 |
+
|
| 471 |
+
The following hyperparameters were used during training:
|
| 472 |
+
- learning_rate: 3e-05
|
| 473 |
+
- train_batch_size: 1
|
| 474 |
+
- eval_batch_size: 1
|
| 475 |
+
- seed: 42
|
| 476 |
+
- gradient_accumulation_steps: 2
|
| 477 |
+
- total_train_batch_size: 2
|
| 478 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 479 |
+
- lr_scheduler_type: linear
|
| 480 |
+
- num_epochs: 5
|
| 481 |
+
|
| 482 |
+
### Training results
|
| 483 |
+
|
| 484 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 485 |
+
|:-------------:|:-----:|:-----:|:---------------:|
|
| 486 |
+
| 1.1866 | 1.0 | 13687 | 1.1681 |
|
| 487 |
+
| 0.8957 | 2.0 | 27374 | 1.1712 |
|
| 488 |
+
| 1.113 | 3.0 | 41061 | 1.5591 |
|
| 489 |
+
| 0.8321 | 4.0 | 54748 | 1.6299 |
|
| 490 |
+
| 0.6172 | 5.0 | 68435 | 1.6239 |
|
| 491 |
+
|
| 492 |
+
|
| 493 |
+
### Framework versions
|
| 494 |
+
|
| 495 |
+
- Transformers 4.34.1
|
| 496 |
+
- Pytorch 2.1.0+cu118
|
| 497 |
+
- Datasets 2.14.5
|
| 498 |
+
- Tokenizers 0.14.1
|
| 499 |
+
","{""id"": ""HansOMEL/qa_plot"", ""author"": ""HansOMEL"", ""sha"": ""fd163a8d03701378a3af8e649ebc5b048df190cb"", ""last_modified"": ""2023-10-23 14:28:02+00:00"", ""created_at"": ""2023-10-22 07:34:12+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 10, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""bert"", ""question-answering"", ""generated_from_trainer"", ""base_model:hfl/chinese-bert-wwm-ext"", ""base_model:finetune:hfl/chinese-bert-wwm-ext"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""question-answering"", ""mask_token"": ""[MASK]"", ""trending_score"": null, ""card_data"": ""base_model: hfl/chinese-bert-wwm-ext\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: qa_plot\n results: []"", ""widget_data"": [{""text"": ""Where do I live?"", ""context"": ""My name is Wolfgang and I live in Berlin""}, {""text"": ""Where do I live?"", ""context"": ""My name is Sarah and I live in London""}, {""text"": ""What's my name?"", ""context"": ""My name is Clara and I live in Berkeley.""}, {""text"": ""Which name is also used to describe the Amazon rainforest in English?"", ""context"": ""The Amazon rainforest (Portuguese: Floresta Amaz\u00f4nica or Amaz\u00f4nia; Spanish: Selva Amaz\u00f3nica, Amazon\u00eda or usually Amazonia; French: For\u00eat amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \""Amazonas\"" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species.""}], ""model_index"": [{""name"": ""qa_plot"", ""results"": []}], ""config"": {""architectures"": [""BertForQuestionAnswering""], ""model_type"": ""bert"", ""tokenizer_config"": {""cls_token"": ""[CLS]"", ""mask_token"": ""[MASK]"", ""pad_token"": ""[PAD]"", ""sep_token"": ""[SEP]"", ""unk_token"": ""[UNK]""}}, ""transformers_info"": {""auto_model"": ""AutoModelForQuestionAnswering"", ""custom_class"": null, ""pipeline_tag"": ""question-answering"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-10-23 14:28:02+00:00"", ""cardData"": ""base_model: hfl/chinese-bert-wwm-ext\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: qa_plot\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForQuestionAnswering"", ""custom_class"": null, ""pipeline_tag"": ""question-answering"", ""processor"": ""AutoTokenizer""}, ""_id"": ""6534d0746054952c5a4a99cc"", ""modelId"": ""HansOMEL/qa_plot"", ""usedStorage"": 2440664118}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=HansOMEL/qa_plot&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BHansOMEL%2Fqa_plot%5D(%2FHansOMEL%2Fqa_plot)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 500 |
+
frett/chinese_extract_bert-x,"---
|
| 501 |
+
library_name: transformers
|
| 502 |
+
license: apache-2.0
|
| 503 |
+
base_model: hfl/chinese-bert-wwm-ext
|
| 504 |
+
tags:
|
| 505 |
+
- generated_from_trainer
|
| 506 |
+
model-index:
|
| 507 |
+
- name: chinese_extract_bert-x
|
| 508 |
+
results: []
|
| 509 |
+
---
|
| 510 |
+
|
| 511 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 512 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 513 |
+
|
| 514 |
+
# chinese_extract_bert-x
|
| 515 |
+
|
| 516 |
+
This model is a fine-tuned version of [hfl/chinese-bert-wwm-ext](https://huggingface.co/hfl/chinese-bert-wwm-ext) on an unknown dataset.
|
| 517 |
+
|
| 518 |
+
## Model description
|
| 519 |
+
|
| 520 |
+
More information needed
|
| 521 |
+
|
| 522 |
+
## Intended uses & limitations
|
| 523 |
+
|
| 524 |
+
More information needed
|
| 525 |
+
|
| 526 |
+
## Training and evaluation data
|
| 527 |
+
|
| 528 |
+
More information needed
|
| 529 |
+
|
| 530 |
+
## Training procedure
|
| 531 |
+
|
| 532 |
+
### Training hyperparameters
|
| 533 |
+
|
| 534 |
+
The following hyperparameters were used during training:
|
| 535 |
+
- learning_rate: 3e-05
|
| 536 |
+
- train_batch_size: 64
|
| 537 |
+
- eval_batch_size: 64
|
| 538 |
+
- seed: 42
|
| 539 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 540 |
+
- lr_scheduler_type: linear
|
| 541 |
+
- num_epochs: 10.0
|
| 542 |
+
|
| 543 |
+
### Training results
|
| 544 |
+
|
| 545 |
+
|
| 546 |
+
|
| 547 |
+
### Framework versions
|
| 548 |
+
|
| 549 |
+
- Transformers 4.45.0.dev0
|
| 550 |
+
- Pytorch 2.4.1+cu121
|
| 551 |
+
- Datasets 3.0.0
|
| 552 |
+
- Tokenizers 0.19.1
|
| 553 |
+
","{""id"": ""frett/chinese_extract_bert-x"", ""author"": ""frett"", ""sha"": ""ccb28428713696e952c84b2d52c2cc459939dc65"", ""last_modified"": ""2024-09-21 19:01:08+00:00"", ""created_at"": ""2024-09-21 17:19:31+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 13, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""bert"", ""question-answering"", ""generated_from_trainer"", ""base_model:hfl/chinese-bert-wwm-ext"", ""base_model:finetune:hfl/chinese-bert-wwm-ext"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""question-answering"", ""mask_token"": ""[MASK]"", ""trending_score"": null, ""card_data"": ""base_model: hfl/chinese-bert-wwm-ext\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: chinese_extract_bert-x\n results: []"", ""widget_data"": [{""text"": ""Where do I live?"", ""context"": ""My name is Wolfgang and I live in Berlin""}, {""text"": ""Where do I live?"", ""context"": ""My name is Sarah and I live in London""}, {""text"": ""What's my name?"", ""context"": ""My name is Clara and I live in Berkeley.""}, {""text"": ""Which name is also used to describe the Amazon rainforest in English?"", ""context"": ""The Amazon rainforest (Portuguese: Floresta Amaz\u00f4nica or Amaz\u00f4nia; Spanish: Selva Amaz\u00f3nica, Amazon\u00eda or usually Amazonia; French: For\u00eat amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \""Amazonas\"" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species.""}], ""model_index"": [{""name"": ""chinese_extract_bert-x"", ""results"": []}], ""config"": {""architectures"": [""BertForQuestionAnswering""], ""model_type"": ""bert"", ""tokenizer_config"": {""cls_token"": ""[CLS]"", ""mask_token"": ""[MASK]"", ""pad_token"": ""[PAD]"", ""sep_token"": ""[SEP]"", ""unk_token"": ""[UNK]""}}, ""transformers_info"": {""auto_model"": ""AutoModelForQuestionAnswering"", ""custom_class"": null, ""pipeline_tag"": ""question-answering"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='all_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval_nbest_predictions.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval_predictions.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='train_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='trainer_state.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F32"": 101678594}, ""total"": 101678594}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-09-21 19:01:08+00:00"", ""cardData"": ""base_model: hfl/chinese-bert-wwm-ext\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: chinese_extract_bert-x\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForQuestionAnswering"", ""custom_class"": null, ""pipeline_tag"": ""question-answering"", ""processor"": ""AutoTokenizer""}, ""_id"": ""66ef0023718e72275111e9a3"", ""modelId"": ""frett/chinese_extract_bert-x"", ""usedStorage"": 2861551489}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=frett/chinese_extract_bert-x&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bfrett%2Fchinese_extract_bert-x%5D(%2Ffrett%2Fchinese_extract_bert-x)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 554 |
+
frett/chinese_paragraph_bert-ext,"---
|
| 555 |
+
library_name: transformers
|
| 556 |
+
language:
|
| 557 |
+
- zh
|
| 558 |
+
license: apache-2.0
|
| 559 |
+
base_model: hfl/chinese-bert-wwm-ext
|
| 560 |
+
tags:
|
| 561 |
+
- generated_from_trainer
|
| 562 |
+
datasets:
|
| 563 |
+
- chinese_paragraph_relevance
|
| 564 |
+
metrics:
|
| 565 |
+
- accuracy
|
| 566 |
+
model-index:
|
| 567 |
+
- name: chinese_paragraph_bert-ext
|
| 568 |
+
results:
|
| 569 |
+
- task:
|
| 570 |
+
name: Multiple Choice
|
| 571 |
+
type: multiple-choice
|
| 572 |
+
dataset:
|
| 573 |
+
name: Chinese Relevance Paragraphs
|
| 574 |
+
type: chinese_paragraph_relevance
|
| 575 |
+
args: relevant_paragraph
|
| 576 |
+
metrics:
|
| 577 |
+
- name: Accuracy
|
| 578 |
+
type: accuracy
|
| 579 |
+
value: 0.9617813229560852
|
| 580 |
+
---
|
| 581 |
+
|
| 582 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 583 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 584 |
+
|
| 585 |
+
# chinese_paragraph_bert-ext
|
| 586 |
+
|
| 587 |
+
This model is a fine-tuned version of [hfl/chinese-bert-wwm-ext](https://huggingface.co/hfl/chinese-bert-wwm-ext) on the Chinese Relevance Paragraphs dataset.
|
| 588 |
+
It achieves the following results on the evaluation set:
|
| 589 |
+
- Loss: 0.1717
|
| 590 |
+
- Accuracy: 0.9618
|
| 591 |
+
|
| 592 |
+
## Model description
|
| 593 |
+
|
| 594 |
+
More information needed
|
| 595 |
+
|
| 596 |
+
## Intended uses & limitations
|
| 597 |
+
|
| 598 |
+
More information needed
|
| 599 |
+
|
| 600 |
+
## Training and evaluation data
|
| 601 |
+
|
| 602 |
+
More information needed
|
| 603 |
+
|
| 604 |
+
## Training procedure
|
| 605 |
+
|
| 606 |
+
### Training hyperparameters
|
| 607 |
+
|
| 608 |
+
The following hyperparameters were used during training:
|
| 609 |
+
- learning_rate: 3e-05
|
| 610 |
+
- train_batch_size: 16
|
| 611 |
+
- eval_batch_size: 16
|
| 612 |
+
- seed: 42
|
| 613 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 614 |
+
- lr_scheduler_type: linear
|
| 615 |
+
- num_epochs: 3.0
|
| 616 |
+
|
| 617 |
+
### Training results
|
| 618 |
+
|
| 619 |
+
|
| 620 |
+
|
| 621 |
+
### Framework versions
|
| 622 |
+
|
| 623 |
+
- Transformers 4.45.0.dev0
|
| 624 |
+
- Pytorch 2.4.1+cu121
|
| 625 |
+
- Datasets 3.0.0
|
| 626 |
+
- Tokenizers 0.19.1
|
| 627 |
+
","{""id"": ""frett/chinese_paragraph_bert-ext"", ""author"": ""frett"", ""sha"": ""5c8b2782045a3654327d43e9b357bddae138d101"", ""last_modified"": ""2024-09-22 04:31:27+00:00"", ""created_at"": ""2024-09-22 02:57:18+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 26, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""bert"", ""multiple-choice"", ""generated_from_trainer"", ""zh"", ""dataset:chinese_paragraph_relevance"", ""base_model:hfl/chinese-bert-wwm-ext"", ""base_model:finetune:hfl/chinese-bert-wwm-ext"", ""license:apache-2.0"", ""model-index"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""multiple-choice"", ""mask_token"": ""[MASK]"", ""trending_score"": null, ""card_data"": ""base_model: hfl/chinese-bert-wwm-ext\ndatasets:\n- chinese_paragraph_relevance\nlanguage:\n- zh\nlibrary_name: transformers\nlicense: apache-2.0\nmetrics:\n- accuracy\ntags:\n- generated_from_trainer\nmodel-index:\n- name: chinese_paragraph_bert-ext\n results:\n - task:\n type: multiple-choice\n name: Multiple Choice\n dataset:\n name: Chinese Relevance Paragraphs\n type: chinese_paragraph_relevance\n args: relevant_paragraph\n metrics:\n - type: accuracy\n value: 0.9617813229560852\n name: Accuracy\n verified: false"", ""widget_data"": null, ""model_index"": [{""name"": ""chinese_paragraph_bert-ext"", ""results"": [{""task"": {""name"": ""Multiple Choice"", ""type"": ""multiple-choice""}, ""dataset"": {""name"": ""Chinese Relevance Paragraphs"", ""type"": ""chinese_paragraph_relevance"", ""args"": ""relevant_paragraph""}, ""metrics"": [{""name"": ""Accuracy"", ""type"": ""accuracy"", ""value"": 0.9617813229560852, ""verified"": false}]}]}], ""config"": {""architectures"": [""BertForMultipleChoice""], ""model_type"": ""bert"", ""tokenizer_config"": {""cls_token"": ""[CLS]"", ""mask_token"": ""[MASK]"", ""pad_token"": ""[PAD]"", ""sep_token"": ""[SEP]"", ""unk_token"": ""[UNK]""}}, ""transformers_info"": {""auto_model"": ""AutoModelForMultipleChoice"", ""custom_class"": null, ""pipeline_tag"": ""multiple-choice"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='all_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='train_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='trainer_state.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F32"": 102268417}, ""total"": 102268417}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-09-22 04:31:27+00:00"", ""cardData"": ""base_model: hfl/chinese-bert-wwm-ext\ndatasets:\n- chinese_paragraph_relevance\nlanguage:\n- zh\nlibrary_name: transformers\nlicense: apache-2.0\nmetrics:\n- accuracy\ntags:\n- generated_from_trainer\nmodel-index:\n- name: chinese_paragraph_bert-ext\n results:\n - task:\n type: multiple-choice\n name: Multiple Choice\n dataset:\n name: Chinese Relevance Paragraphs\n type: chinese_paragraph_relevance\n args: relevant_paragraph\n metrics:\n - type: accuracy\n value: 0.9617813229560852\n name: Accuracy\n verified: false"", ""transformersInfo"": {""auto_model"": ""AutoModelForMultipleChoice"", ""custom_class"": null, ""pipeline_tag"": ""multiple-choice"", ""processor"": ""AutoTokenizer""}, ""_id"": ""66ef878e76a8038cb4834b29"", ""modelId"": ""frett/chinese_paragraph_bert-ext"", ""usedStorage"": 3681879780}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=frett/chinese_paragraph_bert-ext&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bfrett%2Fchinese_paragraph_bert-ext%5D(%2Ffrett%2Fchinese_paragraph_bert-ext)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 628 |
+
b09501048/adl_hw1_qa_model_bert,"---
|
| 629 |
+
library_name: transformers
|
| 630 |
+
license: apache-2.0
|
| 631 |
+
base_model: hfl/chinese-bert-wwm-ext
|
| 632 |
+
tags:
|
| 633 |
+
- generated_from_trainer
|
| 634 |
+
model-index:
|
| 635 |
+
- name: adl_hw1_qa_model_bert
|
| 636 |
+
results: []
|
| 637 |
+
---
|
| 638 |
+
|
| 639 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 640 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 641 |
+
|
| 642 |
+
# adl_hw1_qa_model_bert
|
| 643 |
+
|
| 644 |
+
This model is a fine-tuned version of [hfl/chinese-bert-wwm-ext](https://huggingface.co/hfl/chinese-bert-wwm-ext) on an unknown dataset.
|
| 645 |
+
It achieves the following results on the evaluation set:
|
| 646 |
+
- Loss: 0.7246
|
| 647 |
+
|
| 648 |
+
## Model description
|
| 649 |
+
|
| 650 |
+
More information needed
|
| 651 |
+
|
| 652 |
+
## Intended uses & limitations
|
| 653 |
+
|
| 654 |
+
More information needed
|
| 655 |
+
|
| 656 |
+
## Training and evaluation data
|
| 657 |
+
|
| 658 |
+
More information needed
|
| 659 |
+
|
| 660 |
+
## Training procedure
|
| 661 |
+
|
| 662 |
+
### Training hyperparameters
|
| 663 |
+
|
| 664 |
+
The following hyperparameters were used during training:
|
| 665 |
+
- learning_rate: 3e-05
|
| 666 |
+
- train_batch_size: 96
|
| 667 |
+
- eval_batch_size: 96
|
| 668 |
+
- seed: 42
|
| 669 |
+
- gradient_accumulation_steps: 2
|
| 670 |
+
- total_train_batch_size: 192
|
| 671 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 672 |
+
- lr_scheduler_type: linear
|
| 673 |
+
- num_epochs: 3
|
| 674 |
+
|
| 675 |
+
### Training results
|
| 676 |
+
|
| 677 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 678 |
+
|:-------------:|:------:|:----:|:---------------:|
|
| 679 |
+
| No log | 0.9956 | 113 | 0.8639 |
|
| 680 |
+
| No log | 2.0 | 227 | 0.7221 |
|
| 681 |
+
| No log | 2.9868 | 339 | 0.7246 |
|
| 682 |
+
|
| 683 |
+
|
| 684 |
+
### Framework versions
|
| 685 |
+
|
| 686 |
+
- Transformers 4.44.2
|
| 687 |
+
- Pytorch 2.4.1+cu121
|
| 688 |
+
- Datasets 3.0.0
|
| 689 |
+
- Tokenizers 0.19.1
|
| 690 |
+
","{""id"": ""b09501048/adl_hw1_qa_model_bert"", ""author"": ""b09501048"", ""sha"": ""d5b359158b5c03b6fc354f55049da371b2416faf"", ""last_modified"": ""2024-09-24 04:53:12+00:00"", ""created_at"": ""2024-09-24 04:32:25+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 12, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""tensorboard"", ""safetensors"", ""bert"", ""question-answering"", ""generated_from_trainer"", ""base_model:hfl/chinese-bert-wwm-ext"", ""base_model:finetune:hfl/chinese-bert-wwm-ext"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""question-answering"", ""mask_token"": ""[MASK]"", ""trending_score"": null, ""card_data"": ""base_model: hfl/chinese-bert-wwm-ext\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: adl_hw1_qa_model_bert\n results: []"", ""widget_data"": [{""text"": ""Where do I live?"", ""context"": ""My name is Wolfgang and I live in Berlin""}, {""text"": ""Where do I live?"", ""context"": ""My name is Sarah and I live in London""}, {""text"": ""What's my name?"", ""context"": ""My name is Clara and I live in Berkeley.""}, {""text"": ""Which name is also used to describe the Amazon rainforest in English?"", ""context"": ""The Amazon rainforest (Portuguese: Floresta Amaz\u00f4nica or Amaz\u00f4nia; Spanish: Selva Amaz\u00f3nica, Amazon\u00eda or usually Amazonia; French: For\u00eat amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \""Amazonas\"" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species.""}], ""model_index"": [{""name"": ""adl_hw1_qa_model_bert"", ""results"": []}], ""config"": {""architectures"": [""BertForQuestionAnswering""], ""model_type"": ""bert"", ""tokenizer_config"": {""cls_token"": ""[CLS]"", ""mask_token"": ""[MASK]"", ""pad_token"": ""[PAD]"", ""sep_token"": ""[SEP]"", ""unk_token"": ""[UNK]""}}, ""transformers_info"": {""auto_model"": ""AutoModelForQuestionAnswering"", ""custom_class"": null, ""pipeline_tag"": ""question-answering"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='runs/Sep24_04-32-25_955de7ad40f8/events.out.tfevents.1727152347.955de7ad40f8.4151.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F32"": 101678594}, ""total"": 101678594}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-09-24 04:53:12+00:00"", ""cardData"": ""base_model: hfl/chinese-bert-wwm-ext\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: adl_hw1_qa_model_bert\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForQuestionAnswering"", ""custom_class"": null, ""pipeline_tag"": ""question-answering"", ""processor"": ""AutoTokenizer""}, ""_id"": ""66f240d950521e5a48582bc3"", ""modelId"": ""b09501048/adl_hw1_qa_model_bert"", ""usedStorage"": 406754745}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=b09501048/adl_hw1_qa_model_bert&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bb09501048%2Fadl_hw1_qa_model_bert%5D(%2Fb09501048%2Fadl_hw1_qa_model_bert)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 691 |
+
RachelCX/ner_model,"---
|
| 692 |
+
library_name: transformers
|
| 693 |
+
license: apache-2.0
|
| 694 |
+
base_model: hfl/chinese-bert-wwm-ext
|
| 695 |
+
tags:
|
| 696 |
+
- generated_from_trainer
|
| 697 |
+
metrics:
|
| 698 |
+
- precision
|
| 699 |
+
- recall
|
| 700 |
+
- f1
|
| 701 |
+
- accuracy
|
| 702 |
+
model-index:
|
| 703 |
+
- name: ner_model
|
| 704 |
+
results: []
|
| 705 |
+
---
|
| 706 |
+
|
| 707 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 708 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 709 |
+
|
| 710 |
+
# ner_model
|
| 711 |
+
|
| 712 |
+
This model is a fine-tuned version of [hfl/chinese-bert-wwm-ext](https://huggingface.co/hfl/chinese-bert-wwm-ext) on an unknown dataset.
|
| 713 |
+
It achieves the following results on the evaluation set:
|
| 714 |
+
- Loss: 0.0311
|
| 715 |
+
- Precision: 1.0000
|
| 716 |
+
- Recall: 1.0000
|
| 717 |
+
- F1: 1.0000
|
| 718 |
+
- Accuracy: 1.0000
|
| 719 |
+
|
| 720 |
+
## Model description
|
| 721 |
+
|
| 722 |
+
More information needed
|
| 723 |
+
|
| 724 |
+
## Intended uses & limitations
|
| 725 |
+
|
| 726 |
+
More information needed
|
| 727 |
+
|
| 728 |
+
## Training and evaluation data
|
| 729 |
+
|
| 730 |
+
More information needed
|
| 731 |
+
|
| 732 |
+
## Training procedure
|
| 733 |
+
|
| 734 |
+
### Training hyperparameters
|
| 735 |
+
|
| 736 |
+
The following hyperparameters were used during training:
|
| 737 |
+
- learning_rate: 3e-05
|
| 738 |
+
- train_batch_size: 16
|
| 739 |
+
- eval_batch_size: 8
|
| 740 |
+
- seed: 42
|
| 741 |
+
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 742 |
+
- lr_scheduler_type: linear
|
| 743 |
+
- num_epochs: 5
|
| 744 |
+
|
| 745 |
+
### Training results
|
| 746 |
+
|
| 747 |
+
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|
| 748 |
+
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
|
| 749 |
+
| 0.031 | 1.0 | 15055 | 0.0317 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
|
| 750 |
+
| 0.031 | 2.0 | 30110 | 0.0313 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
|
| 751 |
+
| 0.031 | 3.0 | 45165 | 0.0312 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
|
| 752 |
+
| 0.031 | 4.0 | 60220 | 0.0311 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
|
| 753 |
+
| 0.031 | 5.0 | 75275 | 0.0311 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
|
| 754 |
+
|
| 755 |
+
|
| 756 |
+
### Framework versions
|
| 757 |
+
|
| 758 |
+
- Transformers 4.50.0
|
| 759 |
+
- Pytorch 2.6.0+cu124
|
| 760 |
+
- Datasets 3.5.0
|
| 761 |
+
- Tokenizers 0.21.1
|
| 762 |
+
","{""id"": ""RachelCX/ner_model"", ""author"": ""RachelCX"", ""sha"": ""8b4d5670c51589041cddc07ceac798bd04a1cf8e"", ""last_modified"": ""2025-03-29 16:01:44+00:00"", ""created_at"": ""2025-03-26 01:26:02+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 34, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""bert"", ""token-classification"", ""generated_from_trainer"", ""base_model:hfl/chinese-bert-wwm-ext"", ""base_model:finetune:hfl/chinese-bert-wwm-ext"", ""license:apache-2.0"", ""autotrain_compatible"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""token-classification"", ""mask_token"": ""[MASK]"", ""trending_score"": null, ""card_data"": ""base_model: hfl/chinese-bert-wwm-ext\nlibrary_name: transformers\nlicense: apache-2.0\nmetrics:\n- precision\n- recall\n- f1\n- accuracy\ntags:\n- generated_from_trainer\nmodel-index:\n- name: ner_model\n results: []"", ""widget_data"": [{""text"": ""My name is Wolfgang and I live in Berlin""}, {""text"": ""My name is Sarah and I live in London""}, {""text"": ""My name is Clara and I live in Berkeley, California.""}], ""model_index"": [{""name"": ""ner_model"", ""results"": []}], ""config"": {""architectures"": [""BertForTokenClassification""], ""model_type"": ""bert"", ""tokenizer_config"": {""cls_token"": ""[CLS]"", ""mask_token"": ""[MASK]"", ""pad_token"": ""[PAD]"", ""sep_token"": ""[SEP]"", ""unk_token"": ""[UNK]""}}, ""transformers_info"": {""auto_model"": ""AutoModelForTokenClassification"", ""custom_class"": null, ""pipeline_tag"": ""token-classification"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F32"": 101690129}, ""total"": 101690129}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-29 16:01:44+00:00"", ""cardData"": ""base_model: hfl/chinese-bert-wwm-ext\nlibrary_name: transformers\nlicense: apache-2.0\nmetrics:\n- precision\n- recall\n- f1\n- accuracy\ntags:\n- generated_from_trainer\nmodel-index:\n- name: ner_model\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForTokenClassification"", ""custom_class"": null, ""pipeline_tag"": ""token-classification"", ""processor"": ""AutoTokenizer""}, ""_id"": ""67e357aaf049c252c6715c28"", ""modelId"": ""RachelCX/ner_model"", ""usedStorage"": 813578264}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=RachelCX/ner_model&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BRachelCX%2Fner_model%5D(%2FRachelCX%2Fner_model)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
control_v1p_sd15_qrcode_monster_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
monster-labs/control_v1p_sd15_qrcode_monster,"---
|
| 3 |
+
tags:
|
| 4 |
+
- stable-diffusion
|
| 5 |
+
- controlnet
|
| 6 |
+
- qrcode
|
| 7 |
+
license: openrail++
|
| 8 |
+
language:
|
| 9 |
+
- en
|
| 10 |
+
---
|
| 11 |
+
# Controlnet QR Code Monster v2 For SD-1.5
|
| 12 |
+
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
## Model Description
|
| 16 |
+
|
| 17 |
+
This model is made to generate creative QR codes that still scan.
|
| 18 |
+
Keep in mind that not all generated codes might be readable, but you can try different parameters and prompts to get the desired results.
|
| 19 |
+
|
| 20 |
+
**NEW VERSION**
|
| 21 |
+
|
| 22 |
+
Introducing the upgraded version of our model - Controlnet QR code Monster v2.
|
| 23 |
+
V2 is a huge upgrade over v1, for scannability AND creativity.
|
| 24 |
+
|
| 25 |
+
QR codes can now seamlessly blend the image by using a gray-colored background (#808080).
|
| 26 |
+
|
| 27 |
+
As with the former version, the readability of some generated codes may vary, however playing around with parameters and prompts could yield better results.
|
| 28 |
+
|
| 29 |
+
You can find in in the `v2/` subfolder.
|
| 30 |
+
|
| 31 |
+
## How to Use
|
| 32 |
+
|
| 33 |
+
- **Condition**: QR codes are passed as condition images with a module size of 16px. Use a higher error correction level to make it easier to read (sometimes a lower level can be easier to read if smaller in size). Use a gray background for the rest of the image to make the code integrate better.
|
| 34 |
+
|
| 35 |
+
- **Prompts**: Use a prompt to guide the QR code generation. The output will highly depend on the given prompt. Some seem to be really easily accepted by the qr code process, some will require careful tweaking to get good results.
|
| 36 |
+
|
| 37 |
+
- **Controlnet guidance scale**: Set the controlnet guidance scale value:
|
| 38 |
+
- High values: The generated QR code will be more readable.
|
| 39 |
+
- Low values: The generated QR code will be more creative.
|
| 40 |
+
|
| 41 |
+
### Tips
|
| 42 |
+
|
| 43 |
+
- For an optimally readable output, try generating multiple QR codes with similar parameters, then choose the best ones.
|
| 44 |
+
|
| 45 |
+
- Use the Image-to-Image feature to improve the readability of a generated QR code:
|
| 46 |
+
- Decrease the denoising strength to retain more of the original image.
|
| 47 |
+
- Increase the controlnet guidance scale value for better readability.
|
| 48 |
+
A typical workflow for ""saving"" a code would be :
|
| 49 |
+
Max out the guidance scale and minimize the denoising strength, then bump the strength until the code scans.
|
| 50 |
+
|
| 51 |
+
## Example Outputs
|
| 52 |
+
|
| 53 |
+
Here are some examples of creative, yet scannable QR codes produced by our model:
|
| 54 |
+
|
| 55 |
+

|
| 56 |
+

|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
Feel free to experiment with prompts, parameters, and the Image-to-Image feature to achieve the desired QR code output. Good luck and have fun!",N/A,0,,0,,0,,0,,0,"AP123/IllusionDiffusion, John6666/DiffuseCraftMod, John6666/votepurchase-multiple-model, Menyu/DiffuseCraftMod, TheNetherWatcher/Vid2Vid-using-Text-prompt, andyaii/IllusionDiffusion, bobber/DiffuseCraft, huggingface/InferenceSupport/discussions/new?title=monster-labs/control_v1p_sd15_qrcode_monster&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bmonster-labs%2Fcontrol_v1p_sd15_qrcode_monster%5D(%2Fmonster-labs%2Fcontrol_v1p_sd15_qrcode_monster)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kinsung/qraf, r3gm/DiffuseCraft, radames/Real-Time-Latent-Consistency-Model, radames/real-time-pix2pix-turbo, vittore/pattern-into-image",13
|
dalle-mini_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
dalle-mini/dalle-mini,"---
|
| 3 |
+
|
| 4 |
+
inference: false
|
| 5 |
+
co2_eq_emissions:
|
| 6 |
+
emissions: 7540
|
| 7 |
+
source: MLCo2 Machine Learning Impact calculator
|
| 8 |
+
geographical_location: East USA
|
| 9 |
+
hardware_used: TPU v3-8
|
| 10 |
+
tags:
|
| 11 |
+
- text-to-image
|
| 12 |
+
license: apache-2.0
|
| 13 |
+
|
| 14 |
+
language: en
|
| 15 |
+
model-index:
|
| 16 |
+
- name: dalle-mini
|
| 17 |
+
results: []
|
| 18 |
+
---
|
| 19 |
+
|
| 20 |
+
# DALL·E Mini Model Card
|
| 21 |
+
|
| 22 |
+
This model card focuses on the model associated with the DALL·E mini space on Hugging Face, available [here](https://huggingface.co/spaces/dalle-mini/dalle-mini). The app is called “dalle-mini”, but incorporates “[DALL·E Mini](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini-Generate-images-from-any-text-prompt--VmlldzoyMDE4NDAy)’’ and “[DALL·E Mega](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mega-Training-Journal--VmlldzoxODMxMDI2)” models (further details on this distinction forthcoming).
|
| 23 |
+
|
| 24 |
+
The DALL·E Mega model is the largest version of DALLE Mini. For more information specific to DALL·E Mega, see the [DALL·E Mega model card](https://huggingface.co/dalle-mini/dalle-mega).
|
| 25 |
+
|
| 26 |
+
## Model Details
|
| 27 |
+
|
| 28 |
+
* **Developed by:** Boris Dayma, Suraj Patil, Pedro Cuenca, Khalid Saifullah, Tanishq Abraham, Phúc Lê, Luke, Luke Melas, Ritobrata Ghosh
|
| 29 |
+
* **Model type:** Transformer-based text-to-image generation model
|
| 30 |
+
* **Language(s):** English
|
| 31 |
+
* **License:** Apache 2.0
|
| 32 |
+
* **Model Description:** This is a model that can be used to generate images based on text prompts. As the model developers wrote in the [project report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini-Generate-images-from-any-text-prompt--VmlldzoyMDE4NDAy) about DALL·E mini, “OpenAI had the first impressive model for generating images with [DALL·E](https://openai.com/blog/dall-e/). DALL·E mini is an attempt at reproducing those results with an open-source model.”
|
| 33 |
+
* **Resources for more information:** See OpenAI’s website for more information about [DALL·E](https://openai.com/blog/dall-e/), including the [DALL·E model card](https://github.com/openai/DALL-E/blob/master/model_card.md). See the [project report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini-Generate-images-from-any-text-prompt--VmlldzoyMDE4NDAy) for more information from the model’s developers. To learn more about DALL·E Mega, see the DALL·E Mega [training journal](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mega-Training--VmlldzoxODMxMDI2#training-parameters).
|
| 34 |
+
* **Cite as:**
|
| 35 |
+
```bib text
|
| 36 |
+
@misc{Dayma_DALL·E_Mini_2021,
|
| 37 |
+
author = {Dayma, Boris and Patil, Suraj and Cuenca, Pedro and Saifullah, Khalid and Abraham, Tanishq and Lê Khắc, Phúc and Melas, Luke and Ghosh, Ritobrata},
|
| 38 |
+
doi = {10.5281/zenodo.5146400},
|
| 39 |
+
month = {7},
|
| 40 |
+
title = {DALL·E Mini},
|
| 41 |
+
url = {https://github.com/borisdayma/dalle-mini},
|
| 42 |
+
year = {2021}
|
| 43 |
+
}
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
## Uses
|
| 47 |
+
|
| 48 |
+
### Direct Use
|
| 49 |
+
|
| 50 |
+
The model is intended to be used to generate images based on text prompts for research and personal consumption. Intended uses include supporting creativity, creating humorous content, and providing generations for people curious about the model’s behavior. Intended uses exclude those described in the [Misuse and Out-of-Scope Use](#misuse-malicious-use-and-out-of-scope-use) section.
|
| 51 |
+
|
| 52 |
+
### Downstream Use
|
| 53 |
+
|
| 54 |
+
The model could also be used for downstream use cases, including:
|
| 55 |
+
* Research efforts, such as probing and better understanding the limitations and biases of generative models to further improve the state of science
|
| 56 |
+
* Development of educational or creative tools
|
| 57 |
+
* Generation of artwork and use in design and artistic processes.
|
| 58 |
+
* Other uses that are newly discovered by users. This currently includes poetry illustration (give a poem as prompt), fan art (putting a character in various other visual universes), visual puns, fairy tale illustrations (give a fantasy situation as prompt), concept mashups (applying a texture to something completely different), style transfers (portraits in the style of), … We hope you will find your own application!
|
| 59 |
+
|
| 60 |
+
Downstream uses exclude the uses described in [Misuse and Out-of-Scope Use](#misuse-malicious-use-and-out-of-scope-use).
|
| 61 |
+
|
| 62 |
+
### Misuse, Malicious Use, and Out-of-Scope Use
|
| 63 |
+
|
| 64 |
+
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
|
| 65 |
+
|
| 66 |
+
#### Out-of-Scope Use
|
| 67 |
+
|
| 68 |
+
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
|
| 69 |
+
|
| 70 |
+
#### Misuse and Malicious Use
|
| 71 |
+
|
| 72 |
+
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes:
|
| 73 |
+
* Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
|
| 74 |
+
* Intentionally promoting or propagating discriminatory content or harmful stereotypes.
|
| 75 |
+
* Impersonating individuals without their consent.
|
| 76 |
+
* Sexual content without consent of the people who might see it.
|
| 77 |
+
* Mis- and disinformation
|
| 78 |
+
* Representations of egregious violence and gore
|
| 79 |
+
* Sharing of copyrighted or licensed material in violation of its terms of use.
|
| 80 |
+
* Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
## Limitations and Bias
|
| 84 |
+
|
| 85 |
+
### Limitations
|
| 86 |
+
|
| 87 |
+
The model developers discuss the limitations of the model further in the DALL·E Mini [technical report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mini-Explained-with-Demo--Vmlldzo4NjIxODA):
|
| 88 |
+
* Faces and people in general are not generated properly.
|
| 89 |
+
* Animals are usually unrealistic.
|
| 90 |
+
* It is hard to predict where the model excels or falls short…Good prompt engineering will lead to the best results.
|
| 91 |
+
* The model has only been trained with English descriptions and will not perform as well in other languages
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
### Bias
|
| 95 |
+
|
| 96 |
+
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.**
|
| 97 |
+
|
| 98 |
+
The model was trained on unfiltered data from the Internet, limited to pictures with English descriptions. Text and images from communities and cultures using other languages were not utilized. This affects all output of the model, with white and Western culture asserted as a default, and the model’s ability to generate content using non-English prompts is observably lower quality than prompts in English.
|
| 99 |
+
|
| 100 |
+
While the capabilities of image generation models are impressive, they may also reinforce or exacerbate societal biases. The extent and nature of the biases of DALL·E Mini and DALL·E Mega models have yet to be fully documented, but initial testing demonstrates that they may generate images that contain negative stereotypes against minoritized groups. Work to analyze the nature and extent of the models’ biases and limitations is ongoing.
|
| 101 |
+
|
| 102 |
+
Our current analyses demonstrate that:
|
| 103 |
+
* Images generated by the model can include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
|
| 104 |
+
* When the model generates images with people in them, it tends to output people who we perceive to be white, while people of color are underrepresented.
|
| 105 |
+
* Images generated by the model can contain biased content that depicts power differentials between people of color and people who are white, with white people in positions of privilege.
|
| 106 |
+
* The model is generally only usable for generating images based on text in English, limiting accessibility of the model for non-English speakers and potentially contributing to the biases in images generated by the model.
|
| 107 |
+
|
| 108 |
+
The [technical report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mini-Explained-with-Demo--Vmlldzo4NjIxODA) discusses these issues in more detail, and also highlights potential sources of bias in the model development process.
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
### Limitations and Bias Recommendations
|
| 112 |
+
|
| 113 |
+
* Users (both direct and downstream) should be made aware of the biases and limitations.
|
| 114 |
+
* Content that is potentially problematic should be filtered out, e.g., via automated models that detect violence or pornography.
|
| 115 |
+
* Further work on this model should include methods for balanced and just representations of people and cultures, for example, by curating the training dataset to be both diverse and inclusive.
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
## Training
|
| 119 |
+
|
| 120 |
+
### Training Data
|
| 121 |
+
|
| 122 |
+
The model developers used 3 datasets for the model:
|
| 123 |
+
* [Conceptual Captions Dataset](https://aclanthology.org/P18-1238/), which contains 3 million image and caption pairs.
|
| 124 |
+
* [Conceptual 12M](https://arxiv.org/abs/2102.08981), which contains 12 million image and caption pairs.
|
| 125 |
+
* The [OpenAI subset](https://github.com/openai/CLIP/blob/main/data/yfcc100m.md) of [YFCC100M](https://multimediacommons.wordpress.com/yfcc100m-core-dataset/), which contains about 15 million images and that we further sub-sampled to 2 million images due to limitations in storage space. They used both title and description as caption and removed html tags, new lines and extra spaces.
|
| 126 |
+
|
| 127 |
+
For fine-tuning the image encoder, a subset of 2 million images were used.
|
| 128 |
+
All images (about 15 million) were used for training the Seq2Seq model.
|
| 129 |
+
|
| 130 |
+
### Training Procedure
|
| 131 |
+
|
| 132 |
+
As described further in the [technical report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mini-Explained-with-Demo--Vmlldzo4NjIxODA#our-dall-e-model-architecture) for DALL·E Mini, during training, images and descriptions are both available and pass through the system as follows:
|
| 133 |
+
* Images are encoded through a [VQGAN](https://arxiv.org/abs/2012.09841) encoder, which turns images into a sequence of tokens.
|
| 134 |
+
* Descriptions are encoded through a [BART](https://arxiv.org/abs/1910.13461) encoder.
|
| 135 |
+
* The output of the BART encoder and encoded images are fed through the BART decoder, which is an auto-regressive model whose goal is to predict the next token.
|
| 136 |
+
* Loss is the [softmax cross-entropy](https://wandb.ai/sauravm/Activation-Functions/reports/Activation-Functions-Softmax--VmlldzoxNDU1Njgy#%F0%9F%93%A2-softmax-+-cross-entropy-loss-(caution:-math-alert)) between the model prediction logits and the actual image encodings from the VQGAN.
|
| 137 |
+
|
| 138 |
+
The simplified training procedure for DALL·E Mega is as follows:
|
| 139 |
+
|
| 140 |
+
* **Hardware:** 1 pod TPU v3-256 = 32 nodes of TPU VM v3-8 (8 TPU per node) = 256 TPU v3
|
| 141 |
+
* **Optimizer:** Distributed Shampoo
|
| 142 |
+
* **Model Partition Specificiations:** 8 model parallel x 32 data parallel
|
| 143 |
+
* **Batch:** 44 samples per model x 32 data parallel x 3 gradient accumulation steps = 4224 increasing samples per update
|
| 144 |
+
* **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant until plateau
|
| 145 |
+
* Gradient checkpointing used on each Encoder/Decoder layer (ie, MHA + FFN)
|
| 146 |
+
* Distributed Shampoo + Normformer Optimizations have proved to be effective and efficiently scaling this model.
|
| 147 |
+
* It should also be noted that the learning rate and other parameters are sometimes adjusted on the fly, and batch size increased over time as well.
|
| 148 |
+
|
| 149 |
+
There is more information about the full procedure and technical material in the DALL·E Mega [training journal](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mega-Training--VmlldzoxODMxMDI2#training-parameters).
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
## Evaluation Results
|
| 153 |
+
|
| 154 |
+
The model developers discuss their results extensively in their [technical report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mini-Explained-with-Demo--Vmlldzo4NjIxODA#the-results-of-our-dall-e-experiment) for DALL·E Mini, which provides comparisons between DALL·E Mini’s results with [DALL·E-pytorch](https://github.com/lucidrains/DALLE-pytorch), OpenAI’s [DALL·E](https://openai.com/blog/dall-e/), and models consisting of a generator coupled with the [CLIP neural network model](https://openai.com/blog/clip/).
|
| 155 |
+
|
| 156 |
+
For evaluation results related to DALL·E Mega, see this [technical report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini-Generate-images-from-any-text-prompt--VmlldzoyMDE4NDAy).
|
| 157 |
+
|
| 158 |
+
## Environmental Impact
|
| 159 |
+
|
| 160 |
+
### DALL·E Mini Estimated Emissions
|
| 161 |
+
|
| 162 |
+
*The model is 27 times smaller than the original DALL·E and was trained on a single TPU v3-8 for only 3 days.*
|
| 163 |
+
|
| 164 |
+
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
|
| 165 |
+
|
| 166 |
+
* **Hardware Type:** TPU v3-8
|
| 167 |
+
* **Hours used:** 72 (3 days)
|
| 168 |
+
* **Cloud Provider:** GCP (as mentioned in the technical report)
|
| 169 |
+
* **Compute Region:** us-east1 (provided by model developers)
|
| 170 |
+
* **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 30.16 kg CO2 eq.
|
| 171 |
+
|
| 172 |
+
### DALL·E Mega Estimated Emissions
|
| 173 |
+
|
| 174 |
+
DALL·E Mega is still training. So far, as on June 9, 2022, the model developers report that DALL·E Mega has been training for about 40-45 days on a TPU v3-256. Using those numbers, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
|
| 175 |
+
|
| 176 |
+
* **Hardware Type:** TPU v3-256
|
| 177 |
+
* **Hours used:** 960 - 1080 hours (40-45 days)
|
| 178 |
+
* **Cloud Provider:** Unknown
|
| 179 |
+
* **Compute Region:** Unknown
|
| 180 |
+
* **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** Unknown
|
| 181 |
+
|
| 182 |
+
## Citation
|
| 183 |
+
|
| 184 |
+
```bibtext
|
| 185 |
+
@misc{Dayma_DALL·E_Mini_2021,
|
| 186 |
+
author = {Dayma, Boris and Patil, Suraj and Cuenca, Pedro and Saifullah, Khalid and Abraham, Tanishq and Lê Khắc, Phúc and Melas, Luke and Ghosh, Ritobrata},
|
| 187 |
+
doi = {10.5281/zenodo.5146400},
|
| 188 |
+
month = {7},
|
| 189 |
+
title = {DALL·E Mini},
|
| 190 |
+
url = {https://github.com/borisdayma/dalle-mini},
|
| 191 |
+
year = {2021}
|
| 192 |
+
}
|
| 193 |
+
```
|
| 194 |
+
|
| 195 |
+
*This model card was written by: Boris Dayma, Margaret Mitchell, Ezi Ozoani, Marissa Gerchick, Irene Solaiman, Clémentine Fourrier, Sasha Luccioni, Emily Witko, Nazneen Rajani, and Julian Herrera.*
|
| 196 |
+
","{""id"": ""dalle-mini/dalle-mini"", ""author"": ""dalle-mini"", ""sha"": ""b379105618f722c8b215efb98c6b0b58e2cf9ea2"", ""last_modified"": ""2023-01-11 08:53:22+00:00"", ""created_at"": ""2022-03-02 23:29:05+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 203, ""downloads_all_time"": null, ""likes"": 371, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""jax"", ""dallebart"", ""text-to-image"", ""en"", ""arxiv:2102.08981"", ""arxiv:2012.09841"", ""arxiv:1910.13461"", ""arxiv:1910.09700"", ""license:apache-2.0"", ""co2_eq_emissions"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language: en\nlicense: apache-2.0\ntags:\n- text-to-image\ninference: false\nco2_eq_emissions:\n emissions: 7540\n source: MLCo2 Machine Learning Impact calculator\n geographical_location: East USA\n hardware_used: TPU v3-8\nmodel-index:\n- name: dalle-mini\n results: []"", ""widget_data"": null, ""model_index"": [{""name"": ""dalle-mini"", ""results"": []}], ""config"": {""architectures"": [""eBart""], ""model_type"": ""dallebart"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""sep_token"": ""</s>"", ""cls_token"": ""<s>"", ""unk_token"": ""<unk>"", ""pad_token"": ""<pad>"", ""mask_token"": {""content"": ""<mask>"", ""single_word"": false, ""lstrip"": true, ""rstrip"": false, ""normalized"": false, ""__type"": ""AddedToken""}}}, ""transformers_info"": {""auto_model"": ""eBart"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='enwiki-words-frequency.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='flax_model.msgpack', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""dalle-mini/dalle-mini"", ""flax-community/dalle-mini"", ""Pentameric/DalleClone"", ""cye/dalle-mini"", ""GoodStuff/Cool"", ""Spjkjlkkklj/dalle"", ""GooglyBlox/DalleFork"", ""BlitzEsports/TextToImage"", ""yizhangliu/DalleClone"", ""HALLA/HALL-E"", ""najoungkim/round-trip-dalle-mini"", ""isaiah08/dalle-mini-test"", ""julien-c/nbconvert"", ""bikemright/overweight-AI"", ""Manjushri/Dall-E-Mini"", ""FritsLyneborg/kunstnerfrits"", ""tom-doerr/logo_generator"", ""Xhaheen/tasweer"", ""sugo/v6yu7bgn"", ""jbitel/dalle"", ""saas18/minidellayeni"", ""dimaseo/dalle-mini"", ""smallyu/dalle-mini"", ""DaCuteRaccoon/dalle-mini"", ""awqwqwq/dalle-mini"", ""cloixai/dalle-minii"", ""BL00DY-257/dolle-mini-lol"", ""rabiyulfahim/dalle-mini"", ""QinBingFeng/dalle-mini"", ""allknowingroger/dalle-mini"", ""gerhug/dalle-mini"", ""TNR-5/dalle"", ""piaoyu2011/dalle-mini"", ""Sksisidifjdrbshhshd/dalle-mini"", ""123LETSPLAY/aayat-text-image"", ""Hazem/Fac256xc"", ""normanschizogh/DMini"", ""johnpaulbin/dalle-mini_beta"", ""thefreeham/Test2"", ""GH1studios/Dlm1"", ""ZiziGT/BillCipherGenerator"", ""SusiePHaltmann/BorgEyev1"", ""amirza/draw_me_a_sheep_heb"", ""aughhhhh/bored"", ""saas187/saas"", ""amberheat77/testttttttttttttt"", ""AIKey/dalle-mini"", ""Dallefaniguess/dalle-mini"", ""SaintPepe/9PanelMini"", ""Nomzkin/ImageGenerator"", ""triple-t/live-discussion-gallery"", ""tguyt/dalle-mini"", ""davanstrien/nbconvert"", ""Ravindra001/LM_Meets_HF"", ""Ivoney/dalle-mini"", ""hamtech/dalle-mini"", ""satpalsr/dalleminitest"", ""diffle/webdef"", ""igotech/text2image"", ""Linahosnaparty/Dalle-Mini-Video-Watch-Music"", ""litchi84/dalle-mini"", ""NSect/dalle-mini"", ""oteneto/dalle-mini"", ""MoTech/AIfreeCreate"", ""bestoai/dalle-mini"", ""bookmorning/dalle-mini"", ""llinahosna/DALLEMINI"", ""llinahosna/DalleMINIIMAGE"", ""huohuoma/space_static_test"", ""0xx/jigi-dalle"", ""llinahosna/DalleMiniVideoYouTube"", ""jacobgrillo/dalle-mini"", ""darshan8950/dalle_mini"", ""patel18/PDF_Question_and_Answer"", ""zhzabcd/dalle"", ""Sakalti/Image"", ""sairamtelagamsetti/story"", ""neerajkalyank/Story_scenes"", ""sairamtelagamsetti/story1"", ""Abhisesh7/abhi2000.2"", ""Sha77755/Keeps"", ""jacob-c/fyp_copy_project"", ""harshesk/gx"", ""Harry00/genai"", ""Harry00/genai1-1"", ""MINEOGO/dall-sketch""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-01-11 08:53:22+00:00"", ""cardData"": ""language: en\nlicense: apache-2.0\ntags:\n- text-to-image\ninference: false\nco2_eq_emissions:\n emissions: 7540\n source: MLCo2 Machine Learning Impact calculator\n geographical_location: East USA\n hardware_used: TPU v3-8\nmodel-index:\n- name: dalle-mini\n results: []"", ""transformersInfo"": {""auto_model"": ""eBart"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""621ffdc136468d709f17a30f"", ""modelId"": ""dalle-mini/dalle-mini"", ""usedStorage"": 1819306373}",0,https://huggingface.co/ReyngoD/pruebadani,1,https://huggingface.co/FradigmaDangerYT/dalle-e-mini,1,,0,"https://huggingface.co/nagayama0706/multimodal_model, https://huggingface.co/nagayama0706/image_generation_model, https://huggingface.co/nagayama0706/video_generation_model",3,"BlitzEsports/TextToImage, GooglyBlox/DalleFork, HALLA/HALL-E, Manjushri/Dall-E-Mini, Pentameric/DalleClone, Spjkjlkkklj/dalle, Xhaheen/tasweer, cye/dalle-mini, dalle-mini/dalle-mini, huggingface/InferenceSupport/discussions/368, isaiah08/dalle-mini-test, julien-c/nbconvert, sugo/v6yu7bgn, yizhangliu/DalleClone",14
|
| 197 |
+
ReyngoD/pruebadani,"---
|
| 198 |
+
license: mit
|
| 199 |
+
base_model:
|
| 200 |
+
- dalle-mini/dalle-mini
|
| 201 |
+
pipeline_tag: depth-estimation
|
| 202 |
+
library_name: diffusers
|
| 203 |
+
---","{""id"": ""ReyngoD/pruebadani"", ""author"": ""ReyngoD"", ""sha"": ""f9c179518a9f090c97547494c61e278b4536b0ce"", ""last_modified"": ""2024-11-05 09:59:43+00:00"", ""created_at"": ""2024-11-05 09:56:12+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""depth-estimation"", ""base_model:dalle-mini/dalle-mini"", ""base_model:finetune:dalle-mini/dalle-mini"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""depth-estimation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- dalle-mini/dalle-mini\nlibrary_name: diffusers\nlicense: mit\npipeline_tag: depth-estimation"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-11-05 09:59:43+00:00"", ""cardData"": ""base_model:\n- dalle-mini/dalle-mini\nlibrary_name: diffusers\nlicense: mit\npipeline_tag: depth-estimation"", ""transformersInfo"": null, ""_id"": ""6729ebbcff3de35f30bc1c9d"", ""modelId"": ""ReyngoD/pruebadani"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=ReyngoD/pruebadani&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BReyngoD%2Fpruebadani%5D(%2FReyngoD%2Fpruebadani)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
deepseek-vl-7b-chat_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
deepseek-ai/deepseek-vl-7b-chat,"---
|
| 3 |
+
license: other
|
| 4 |
+
license_name: deepseek
|
| 5 |
+
license_link: LICENSE
|
| 6 |
+
pipeline_tag: image-text-to-text
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
## 1. Introduction
|
| 10 |
+
|
| 11 |
+
Introducing DeepSeek-VL, an open-source Vision-Language (VL) Model designed for real-world vision and language understanding applications. DeepSeek-VL possesses general multimodal understanding capabilities, capable of processing logical diagrams, web pages, formula recognition, scientific literature, natural images, and embodied intelligence in complex scenarios.
|
| 12 |
+
|
| 13 |
+
[DeepSeek-VL: Towards Real-World Vision-Language Understanding](https://arxiv.org/abs/2403.05525)
|
| 14 |
+
|
| 15 |
+
[**Github Repository**](https://github.com/deepseek-ai/DeepSeek-VL)
|
| 16 |
+
|
| 17 |
+
Haoyu Lu*, Wen Liu*, Bo Zhang**, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, Yaofeng Sun, Chengqi Deng, Hanwei Xu, Zhenda Xie, Chong Ruan (*Equal Contribution, **Project Lead)
|
| 18 |
+
|
| 19 |
+

|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
### 2. Model Summary
|
| 23 |
+
|
| 24 |
+
DeepSeek-VL-7b-base uses the [SigLIP-L](https://huggingface.co/timm/ViT-L-16-SigLIP-384) and [SAM-B](https://huggingface.co/facebook/sam-vit-base) as the hybrid vision encoder supporting 1024 x 1024 image input
|
| 25 |
+
and is constructed based on the DeepSeek-LLM-7b-base which is trained on an approximate corpus of 2T text tokens. The whole DeepSeek-VL-7b-base model is finally trained around 400B vision-language tokens.
|
| 26 |
+
DeekSeel-VL-7b-chat is an instructed version based on [DeepSeek-VL-7b-base](https://huggingface.co/deepseek-ai/deepseek-vl-7b-base).
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
## 3. Quick Start
|
| 30 |
+
|
| 31 |
+
### Installation
|
| 32 |
+
|
| 33 |
+
On the basis of `Python >= 3.8` environment, install the necessary dependencies by running the following command:
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
```shell
|
| 37 |
+
git clone https://github.com/deepseek-ai/DeepSeek-VL
|
| 38 |
+
cd DeepSeek-VL
|
| 39 |
+
|
| 40 |
+
pip install -e .
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
### Simple Inference Example
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
import torch
|
| 47 |
+
from transformers import AutoModelForCausalLM
|
| 48 |
+
|
| 49 |
+
from deepseek_vl.models import VLChatProcessor, MultiModalityCausalLM
|
| 50 |
+
from deepseek_vl.utils.io import load_pil_images
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
# specify the path to the model
|
| 54 |
+
model_path = ""deepseek-ai/deepseek-vl-7b-chat""
|
| 55 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 56 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 57 |
+
|
| 58 |
+
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)
|
| 59 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 60 |
+
|
| 61 |
+
conversation = [
|
| 62 |
+
{
|
| 63 |
+
""role"": ""User"",
|
| 64 |
+
""content"": ""<image_placeholder>Describe each stage of this image."",
|
| 65 |
+
""images"": [""./images/training_pipelines.png""]
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
""role"": ""Assistant"",
|
| 69 |
+
""content"": """"
|
| 70 |
+
}
|
| 71 |
+
]
|
| 72 |
+
|
| 73 |
+
# load images and prepare for inputs
|
| 74 |
+
pil_images = load_pil_images(conversation)
|
| 75 |
+
prepare_inputs = vl_chat_processor(
|
| 76 |
+
conversations=conversation,
|
| 77 |
+
images=pil_images,
|
| 78 |
+
force_batchify=True
|
| 79 |
+
).to(vl_gpt.device)
|
| 80 |
+
|
| 81 |
+
# run image encoder to get the image embeddings
|
| 82 |
+
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
|
| 83 |
+
|
| 84 |
+
# run the model to get the response
|
| 85 |
+
outputs = vl_gpt.language_model.generate(
|
| 86 |
+
inputs_embeds=inputs_embeds,
|
| 87 |
+
attention_mask=prepare_inputs.attention_mask,
|
| 88 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 89 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 90 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 91 |
+
max_new_tokens=512,
|
| 92 |
+
do_sample=False,
|
| 93 |
+
use_cache=True
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
|
| 97 |
+
print(f""{prepare_inputs['sft_format'][0]}"", answer)
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
### CLI Chat
|
| 101 |
+
```bash
|
| 102 |
+
|
| 103 |
+
python cli_chat.py --model_path ""deepseek-ai/deepseek-vl-7b-chat""
|
| 104 |
+
|
| 105 |
+
# or local path
|
| 106 |
+
python cli_chat.py --model_path ""local model path""
|
| 107 |
+
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
## 4. License
|
| 111 |
+
|
| 112 |
+
This code repository is licensed under [the MIT License](https://github.com/deepseek-ai/DeepSeek-LLM/blob/HEAD/LICENSE-CODE). The use of DeepSeek-VL Base/Chat models is subject to [DeepSeek Model License](https://github.com/deepseek-ai/DeepSeek-LLM/blob/HEAD/LICENSE-MODEL). DeepSeek-VL series (including Base and Chat) supports commercial use.
|
| 113 |
+
|
| 114 |
+
## 5. Citation
|
| 115 |
+
|
| 116 |
+
```
|
| 117 |
+
@misc{lu2024deepseekvl,
|
| 118 |
+
title={DeepSeek-VL: Towards Real-World Vision-Language Understanding},
|
| 119 |
+
author={Haoyu Lu and Wen Liu and Bo Zhang and Bingxuan Wang and Kai Dong and Bo Liu and Jingxiang Sun and Tongzheng Ren and Zhuoshu Li and Yaofeng Sun and Chengqi Deng and Hanwei Xu and Zhenda Xie and Chong Ruan},
|
| 120 |
+
year={2024},
|
| 121 |
+
eprint={2403.05525},
|
| 122 |
+
archivePrefix={arXiv},
|
| 123 |
+
primaryClass={cs.AI}
|
| 124 |
+
}
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
## 6. Contact
|
| 128 |
+
|
| 129 |
+
If you have any questions, please raise an issue or contact us at [service@deepseek.com](mailto:service@deepseek.com).","{""id"": ""deepseek-ai/deepseek-vl-7b-chat"", ""author"": ""deepseek-ai"", ""sha"": ""6f16f00805f45b5249f709ce21820122eeb43556"", ""last_modified"": ""2024-03-15 07:04:05+00:00"", ""created_at"": ""2024-03-07 06:14:29+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 16146, ""downloads_all_time"": null, ""likes"": 256, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""multi_modality"", ""image-text-to-text"", ""arxiv:2403.05525"", ""license:other"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""image-text-to-text"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: other\nlicense_name: deepseek\nlicense_link: LICENSE\npipeline_tag: image-text-to-text"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""MultiModalityCausalLM""], ""model_type"": ""multi_modality"", ""tokenizer_config"": {""bos_token"": ""<\uff5cbegin\u2581of\u2581sentence\uff5c>"", ""eos_token"": ""<\uff5cend\u2581of\u2581sentence\uff5c>"", ""pad_token"": null, ""unk_token"": null, ""use_default_system_prompt"": false}}, ""transformers_info"": {""auto_model"": ""MultiModalityCausalLM"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00003.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00003.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00003.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='processor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""FallnAI/deepseek-ai-deepseek-vl-7b-chat"", ""bobber/DeepSeek-VL-7B"", ""bingbort/DeepSeek-VL-7B"", ""huxingyu/deepseek-ai-deepseek-vl-7b-chat"", ""lsatish/deepseek-ai-deepseek-vl-7b-chat"", ""dollar69/deepseek-ai-deepseek-vl-7b-chat"", ""dsfdsfddfer4/deepseek-ai-deepseek-vl-7b-chat"", ""skrtskrtskrt/deepseek-ai-deepseek-vl-7b-chat"", ""enesarslan/deepseek-ai-deepseek-vl-7b-chat"", ""floofycoderboi/deepseek-ai-deepseek-vl-7b-chat"", ""comara/deepseek-ai-deepseek-vl-7b-chat"", ""sanaweb/DeepSeek-VL-7B"", ""riabayonaor/problemamatematicos"", ""Nebsonn/deepseek-ai-deepseek-vl-7b-chat"", ""wdragon521/deepseek-ai-deepseek-vl-7b-chat"", ""rbx24/deepseek-ai-deepseek-vl-7b-chat"", ""Fadil369/DeepSeek"", ""infi3/deepseek-ai-deepseek-vl-7b-chat"", ""Dunevhhhh/deepseek-ai-deepseek-vl-7b-chat"", ""ahmetmehmetalper/generalllm_deepseek"", ""jerenc/aichatbot"", ""mmcgovern574/DeepSeek-VL-7B"", ""cnmksjs/DeepSeek-VL-7B"", ""harshchavada174/my-model-deployment"", ""saintmarcel/deepseek-ai-deepseek-vl-7b-chat""], ""safetensors"": {""parameters"": {""F16"": 7343990017}, ""total"": 7343990017}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-03-15 07:04:05+00:00"", ""cardData"": ""license: other\nlicense_name: deepseek\nlicense_link: LICENSE\npipeline_tag: image-text-to-text"", ""transformersInfo"": {""auto_model"": ""MultiModalityCausalLM"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""65e95b4557773f63be2b2bdb"", ""modelId"": ""deepseek-ai/deepseek-vl-7b-chat"", ""usedStorage"": 14688085418}",0,,0,,0,,0,,0,"FallnAI/deepseek-ai-deepseek-vl-7b-chat, bingbort/DeepSeek-VL-7B, bobber/DeepSeek-VL-7B, dollar69/deepseek-ai-deepseek-vl-7b-chat, dsfdsfddfer4/deepseek-ai-deepseek-vl-7b-chat, enesarslan/deepseek-ai-deepseek-vl-7b-chat, floofycoderboi/deepseek-ai-deepseek-vl-7b-chat, huggingface/InferenceSupport/discussions/new?title=deepseek-ai/deepseek-vl-7b-chat&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bdeepseek-ai%2Fdeepseek-vl-7b-chat%5D(%2Fdeepseek-ai%2Fdeepseek-vl-7b-chat)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, huxingyu/deepseek-ai-deepseek-vl-7b-chat, lsatish/deepseek-ai-deepseek-vl-7b-chat, mmcgovern574/DeepSeek-VL-7B, saintmarcel/deepseek-ai-deepseek-vl-7b-chat, skrtskrtskrt/deepseek-ai-deepseek-vl-7b-chat",13
|