
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
tflearn/tflearn | data-science | 669 | Tflearn accuracy on a large input is always 1 | I'm training a regression DNN, and the output of a last layer should be a number between [-1,1]. It seems like the network is considering the output layer as categorical and always produces the output either -1 or 1 and nothing in between. The acc number is always 1 (Which is strange on a large input).
Here's the n... | open | 2017-03-18T05:23:14Z | 2017-03-18T05:24:13Z | https://github.com/tflearn/tflearn/issues/669 | [] | sauberf | 0 |
flasgger/flasgger | flask | 482 | cant use external file | I am getting the exception `AttributeError: 'dict' object has no attribute 'startswith'` despite passing a string:
```
file_dir = path.dirname(path.abspath(__file__))
schema_path = path.join(file_dir, "openapi.yaml")
schema = Path(schema_path)
@app.route("/ingestion-job", methods=["GET", "POST"])
@swag_from... | open | 2021-05-24T13:23:21Z | 2022-03-18T07:21:26Z | https://github.com/flasgger/flasgger/issues/482 | [] | tommyjcarpenter | 2 |
miguelgrinberg/python-socketio | asyncio | 650 | Server "eio_sid" error when entering client into a room in non-default namespace | For python-socketio v5, there is an error when trying to enter a client into a room when the namespace parameter is non-default.
Following are the server and client code used to isolate this situation:
**Server**
```
import socketio
from aiohttp import web
sio = socketio.AsyncServer(async_mode='aiohttp')
a... | closed | 2021-03-05T03:10:17Z | 2021-04-20T23:03:31Z | https://github.com/miguelgrinberg/python-socketio/issues/650 | [
"bug"
] | sd-zhang | 4 |
pyro-ppl/numpyro | numpy | 1,490 | Mixture: Intermediates cannot be coerced to bool | ```python
from jax import numpy as jnp
from jax.random import PRNGKey
from numpyro import distributions as dist
from numpyro import sample
from numpyro import handlers as hdl
from numpyro.infer.util import log_density
key = PRNGKey(0)
def model(toggle):
d1 = dist.HalfNormal()
d2 = dist.LogNormal()... | closed | 2022-10-25T10:27:15Z | 2022-10-26T09:35:50Z | https://github.com/pyro-ppl/numpyro/issues/1490 | [
"bug"
] | hessammehr | 2 |
sherlock-project/sherlock | python | 1,980 | Trying | closed | 2024-01-27T04:43:27Z | 2024-01-27T07:28:09Z | https://github.com/sherlock-project/sherlock/issues/1980 | [] | jerlee3131 | 1 | |
huggingface/text-generation-inference | nlp | 2,435 | PaliGemma detection task is failing | ### System Info
```
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name ... | open | 2024-08-20T00:42:48Z | 2024-12-08T16:22:09Z | https://github.com/huggingface/text-generation-inference/issues/2435 | [] | nph4rd | 3 |
healthchecks/healthchecks | django | 572 | Increase log length | I have a healthcheck that is pinged every minute. There were some failures last night so I checked the log to see if I needed to up the grace period but the log only went back to the start of today. If the log length could be increased to 5760 entries (the number of minutes in two days times two, because there's a star... | closed | 2021-10-14T16:57:06Z | 2022-09-12T16:45:09Z | https://github.com/healthchecks/healthchecks/issues/572 | [
"feature"
] | caleb15 | 5 |
ResidentMario/missingno | pandas | 40 | Fix bad column numeracy plotting in matplotlib 2.0 | There's an issue with the column counts on the right side of the (bar, possibly matrix) plot in matplotlib 2.0, needs fixing. | closed | 2017-11-09T20:18:58Z | 2018-02-03T22:03:22Z | https://github.com/ResidentMario/missingno/issues/40 | [] | ResidentMario | 2 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 666 | No gui? | i run python demo_toolbox.py and what is returned is:
(voice-clone) S:\path\path\path\path\Real-Time-Voice-Cloning-master>python demo_toolbox.py
S:\path\path\path\path\Real-Time-Voice-Cloning-master\encoder\audio.py:13: UserWarning: Unable to import 'webrtcvad'. This package enables noise removal and is recommended... | closed | 2021-02-17T00:06:59Z | 2021-02-17T20:22:19Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/666 | [] | ghost | 3 |
graphdeco-inria/gaussian-splatting | computer-vision | 470 | garbage code in in_frustum() ? | __forceinline__ __device__ bool in_frustum(int idx, //John: per-thread, per-gauss-point
const float* orig_points,
const float* viewmatrix,
const float* projmatrix,
bool prefiltered,
float3& p_view)
{
float3 p_orig = { orig_points[3 * idx], orig_points[3 * idx + 1], orig_points[3 * idx + 2] };
// B... | closed | 2023-11-15T05:57:44Z | 2024-11-07T13:54:04Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/470 | [] | yuedajiong | 1 |
flairNLP/flair | nlp | 3,065 | [Question]: TUTORIAL_13 export_onnx model size and oom questions. | ### Question
I am currently trying to reduce model size and memory consumption of a fine-tuned model. To this end I am following the TUTORIAL_13. To check out the changes in model size and consumption I am using the pre-trained `flair/ner-english-large` model which is 2135.899MB in size (disk space). To find out the s... | closed | 2023-01-23T16:04:55Z | 2023-08-12T19:59:59Z | https://github.com/flairNLP/flair/issues/3065 | [
"question",
"wontfix"
] | agademic | 4 |
zihangdai/xlnet | tensorflow | 194 | Why the pos_emb starts with `klen` and not `klen -1`? | Hi,
I've noticed that `klen -1` is commented out, but `klen` is used instead.
https://github.com/zihangdai/xlnet/blob/b4e33739b7df17af6f37a89af9a769a987711587/modeling.py#L205-L250
However, the original transformer-xl actually uses `klen -1`:
https://github.com/kimiyoung/transformer-xl/blob/44781ed21dbaec88b280... | closed | 2019-07-28T00:39:19Z | 2019-07-28T01:09:17Z | https://github.com/zihangdai/xlnet/issues/194 | [] | shaform | 0 |
dpgaspar/Flask-AppBuilder | rest-api | 2,046 | Question: how to access userinfo or current user. | This is more of a question than issue and hopefully and add-on to your awesome docs, I would not normally if asked if I did not look and try before hand.
What I am trying to do is load a page baed on the role of the user when they are logged, however I am stamped at getting the current_user or the userinfo.
In ... | open | 2023-05-19T15:46:32Z | 2023-05-28T15:41:19Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/2046 | [
"question"
] | awsumco | 2 |
deepspeedai/DeepSpeed | machine-learning | 5,828 | [BUG] In deepspeed Zero3, RuntimeError: still have inflight params | **Describe the bug**
When using zero stage 3, an issue occurs during training where some model parameters are selected based on data content. The error message is: RuntimeError: still have inflight params.
**To Reproduce**
Steps to reproduce the behavior:
1. Create a python file
```
touch test_inflight.py
``... | closed | 2024-08-05T15:20:38Z | 2024-08-08T09:10:29Z | https://github.com/deepspeedai/DeepSpeed/issues/5828 | [
"bug",
"training"
] | XuyaoWang | 3 |
CorentinJ/Real-Time-Voice-Cloning | python | 560 | Error message keeps saying I need to download the pretrained models even though i already have? | 
| closed | 2020-10-16T00:58:35Z | 2020-10-16T05:24:14Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/560 | [] | icandancelikecool | 1 |
unit8co/darts | data-science | 2,296 | Usage and Interpretation of SHAP Values in Darts | I have a couple of questions regarding the usage of SHAP values within [darts ](https://unit8co.github.io/darts/generated_api/darts.explainability.shap_explainer.html#:~:text=It%20uses%20shap%20values%20to,model%20to%20produce%20its%20forecasts.).
1. From what I understand, it is common to fit the ShapExplainer firs... | open | 2024-03-27T18:49:39Z | 2024-08-28T07:18:49Z | https://github.com/unit8co/darts/issues/2296 | [
"question"
] | DataScientistET | 0 |
scikit-image/scikit-image | computer-vision | 7,067 | histogram_matching not use channel_axis | ### Description:
channel_axis indicates which axis of the array corresponds to channels, but in the code, `-1` is always used as the channel parameter.
### Way to reproduce:
line 67-76
**source code**
```python
if channel_axis is not None:
if image.shape[-1] != reference.shape[-1]:
raise ValueError(... | closed | 2023-07-17T02:48:48Z | 2023-09-17T11:41:43Z | https://github.com/scikit-image/scikit-image/issues/7067 | [
":bug: Bug"
] | lazyn1997 | 1 |
OpenBB-finance/OpenBB | machine-learning | 6,826 | [🕹️] Follow on LinkedIn | ### What side quest or challenge are you solving?
Follow on LinkedIn
### Points
50
### Description
Follow on LinkedIn
### Provide proof that you've completed the task

| closed | 2024-10-20T13:32:27Z | 2024-10-21T12:58:44Z | https://github.com/OpenBB-finance/OpenBB/issues/6826 | [] | sateshcharan | 2 |
vitalik/django-ninja | pydantic | 1,041 | [BUG] Foreign keys in input ModelSchema seem broken | If I create an input schema from a model:
```python
class Foo(models.Model):
id = models.UUIDField(primary_key=True, default=uuid4, editable=False)
name = models.TextField()
bar = models.ForeignKey(Bar)
class FooInSchema(ModelSchema):
class Meta:
model = Foo
fields = ["name", ... | open | 2024-01-11T10:42:29Z | 2024-12-11T10:17:06Z | https://github.com/vitalik/django-ninja/issues/1041 | [] | jam13 | 2 |
satwikkansal/wtfpython | python | 30 | Nitpicking and minor suggestions | > `3 --0-- 5 == 8` and `--5 == 5` are both semantically correct statements and evaluate to True.
Might want to add that `++a` and `--a` are both valid Python (given `a` is a number), but isn’t what you probably think they are (increment/decrement).
> `'a'[0][0][0][0][0]` is also a semantically correct statement a... | closed | 2017-09-05T18:10:08Z | 2017-09-06T11:15:45Z | https://github.com/satwikkansal/wtfpython/issues/30 | [] | uranusjr | 2 |
Hironsan/BossSensor | computer-vision | 14 | Is there any way to improve the training accuracy? | My experiment was based on the pictures of those famous movie stars I gathered from the Internet. I could only get an approx 60% accuracy when training the model.
Is there any way to improve the accuracy? | open | 2017-01-30T15:13:03Z | 2017-02-20T00:37:15Z | https://github.com/Hironsan/BossSensor/issues/14 | [] | beef9999 | 5 |
ranaroussi/yfinance | pandas | 1,947 | missing data for private companies | ### Describe bug
Cannot use yfinance to scrap [limited] data from private companies.
### Simple code that reproduces your problem
curl https://finance.yahoo.com/company/space-exploration-technologies?h=eyJlIjoic3BhY2UtZXhwbG9yYXRpb24tdGVjaG5vbG9naWVzIiwibiI6IlNwYWNlWCJ9 results in proper data but
spacex = yf.Tick... | closed | 2024-05-22T16:24:16Z | 2025-02-16T18:40:23Z | https://github.com/ranaroussi/yfinance/issues/1947 | [] | opinsky | 0 |
healthchecks/healthchecks | django | 1,095 | [Feature Request] Weekly Report E-Mail sort downtime | I like the weekly report function, it would be cool to sort the downtimes for the services (most downtimes / longest) on top.
Maybe even an option to hide services which have “All Good” Status.
This way it is easy to find which services had downtimes and how long, currently I have to scroll trough the list and f... | open | 2024-12-02T09:16:51Z | 2024-12-02T09:17:21Z | https://github.com/healthchecks/healthchecks/issues/1095 | [] | Klar | 0 |
collerek/ormar | pydantic | 778 | Update `aiomysql` dependency | The currently used `aiomysql` dependency still has some gnarly bugs when used with MySQL 8 which were fixed in `aiomysql 0.1.x`.
It would be fantastic if the dependency was updated! Thank you for making ormar! | closed | 2022-08-10T14:13:42Z | 2022-09-07T10:59:24Z | https://github.com/collerek/ormar/issues/778 | [
"bug"
] | JeppeKlitgaard | 1 |
dask/dask | pandas | 11,386 | Memory issues with slicing | **Describe the issue**:
Slicing (via `.loc`) and other subsetting operations run out of memory on a worker. Even when the result should easily fit into memory.
**Minimal Complete Verifiable Example**:
The below example creates a .csv file with ~1B rows of numbers, each of which appears about 10k times. The e... | closed | 2024-09-12T16:35:44Z | 2024-10-11T14:35:57Z | https://github.com/dask/dask/issues/11386 | [
"needs triage"
] | csbrown | 8 |
lexiforest/curl_cffi | web-scraping | 122 | BOM parsing issue | Hello,
**Expected**
Some utf-8 files begin with a BOM (https://stackoverflow.com/questions/50130605/python-2-7-csv-file-read-write-xef-xbb-xbf-code) like the swebpage https://copytop.com/.
**Problem**
curl-cffi seems unable to decode it.
```
File "/home/bader/code/python3/lib/python3.11/site-packages/cu... | closed | 2023-09-10T01:14:25Z | 2023-11-02T10:09:50Z | https://github.com/lexiforest/curl_cffi/issues/122 | [] | baderdean | 2 |
Avaiga/taipy | automation | 1,500 | Add Python API when creating an app through *taipy create* | ### Description
Add a question to know if the user wants to use the Python API or Markdown syntax for his application and change the template accordingly.
`taipy create --template default`
A question should appear to know if the user wants to use the Python API or Markdown syntax.
### Acceptance Criteria
- [ ]... | closed | 2024-07-10T14:17:36Z | 2025-01-14T15:03:25Z | https://github.com/Avaiga/taipy/issues/1500 | [
"📈 Improvement",
"🖧 Devops",
"🟨 Priority: Medium",
"🔒 Staff only",
"💬 Discussion"
] | FlorianJacta | 4 |
modelscope/modelscope | nlp | 854 | Tasks.image_segmentation Error | python=3.10
pytorch=2.1.2+cu118
modelscope=1.14.0
1. panoptic-segmentation
model_id = "damo/cv_r50_panoptic-segmentation_cocopan"
pipe = pipeline(Tasks.image_segmentation, model=model_id)
Error Info: 'image-panoptic-segmentation-easycv is not in the pipelines registry group image-segmentation. Please make sure... | closed | 2024-05-15T03:04:39Z | 2024-05-15T08:06:34Z | https://github.com/modelscope/modelscope/issues/854 | [] | xuhzyy | 1 |
jumpserver/jumpserver | django | 14,322 | [Question] 使用客户端方式连接windows时无法用mstsc中的选择连接速度功能 | ### 产品版本
V3.10.13
### 版本类型
- [ ] 社区版
- [ ] 企业版
- [X] 企业试用版
### 安装方式
- [ ] 在线安装 (一键命令安装)
- [X] 离线包安装
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] 源码安装
### 环境信息
使用的centos单机部署的jumpserver,通过谷歌浏览器129版本(最新版)访问
### 🤔 问题描述
通过jumpserver客户端方式连接windows,打开工业制图软件,会比较卡顿。
在使用windows原本的mstsc连接时,通过调整体验-选择连接速度来优化性能-低速... | closed | 2024-10-17T07:18:03Z | 2024-12-19T10:48:15Z | https://github.com/jumpserver/jumpserver/issues/14322 | [
"⏳ Pending feedback",
"🤔 Question",
"📦 z~release:v4.5.0"
] | haipeng-fit2 | 8 |
mlfoundations/open_clip | computer-vision | 254 | adding coca-pytorch to open_clip | In [this comment](https://github.com/lucidrains/CoCa-pytorch/issues/2#issuecomment-1320707789) by @rom1504 it has been mentioned the possiblity to add [coca-pytorch](https://github.com/lucidrains/CoCa-pytorch/) to this repo to train a version of it, if nobody is doing it and it is still interesting I could try and set ... | closed | 2022-11-25T02:09:47Z | 2023-01-29T00:48:23Z | https://github.com/mlfoundations/open_clip/issues/254 | [
"new feature",
"important"
] | gpucce | 3 |
httpie/cli | api | 619 | Httpie can't resolve "localhost" in an Akka HTTP RESTful service | I have a demo service like this:
```scala
localhost:8080/item/{id}
```
But when I test it with Httpie, I get the following message:
```
$ http localhost:8080/item/3
http: error: ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',)) while doing GET... | closed | 2017-10-07T08:56:54Z | 2020-06-08T12:36:05Z | https://github.com/httpie/cli/issues/619 | [] | kun-song | 3 |
nerfstudio-project/nerfstudio | computer-vision | 2,986 | Why does the nerf rebuild not work well with the blender data I created myself? | Hello, everyone. I use blender to create a set of reed blender data as shown in image01 and image 02.

:
def init(self, df, img_dir, transforms=None):
self.df = df.reset_index(drop=Tr... | closed | 2024-11-08T02:25:48Z | 2024-11-11T15:18:04Z | https://github.com/albumentations-team/albumentations/issues/2072 | [
"question",
"Need more info"
] | Rexedoziem | 19 |
dagster-io/dagster | data-science | 27,746 | Regression in 1.9.12 broke `BackfillPolicy.multi_run` by mixing `Multi-Partitions` | ### What's the issue?
**Description:**
In version 1.9.12, `BackfillPolicy.multi_run` no longer correctly separates multi-partitions when launching runs. Previously, with a `MultiPartitionsDefinition` consisting of a time window and static partitions (e.g., multiple tables with daily partitions), each static partitio... | open | 2025-02-11T12:32:03Z | 2025-02-13T18:04:32Z | https://github.com/dagster-io/dagster/issues/27746 | [
"type: bug",
"area: backfill",
"area: partitions"
] | chrishiste | 10 |
jina-ai/clip-as-service | pytorch | 623 | question about the demo | Hi , I am using this python server demo to build a server, my configs are as below:
server:
from bert_serving.server.helper import get_args_parser
from bert_serving.server import BertServer
args = get_args_parser().parse_args(['-model_dir', './pretrained/',
'-config_n... | closed | 2021-03-22T09:13:37Z | 2021-03-22T21:47:51Z | https://github.com/jina-ai/clip-as-service/issues/623 | [] | 652994331 | 1 |
cobrateam/splinter | automation | 757 | FindLinks broken ? | Hi ! I'm receiving an exception when I try to use the links property like this :
```python
elements = browser.find_by_css(".link").links.find_by_partial_href(URL)
return [a["href"] for a in elements]
```
Here's the relevent part of the traceback :
```
File "/home/edited_out/venv/lib/python3.8/site-packages/s... | closed | 2020-02-03T15:19:59Z | 2020-02-28T21:40:04Z | https://github.com/cobrateam/splinter/issues/757 | [] | ShellCode33 | 4 |
graphql-python/graphene-django | django | 1,134 | Loading `graphene_django.fields` takes too long | **Note: for support questions, please use stackoverflow**. This repository's issues are reserved for feature requests and bug reports.
* **What is the current behavior?**
Importing `graphene_django.fields` take 2.5s, of which 1.8 are taken by `graphql_relay.connection.arrayconnection`. See hierarchy generated usi... | closed | 2021-02-23T03:55:40Z | 2021-02-23T04:13:00Z | https://github.com/graphql-python/graphene-django/issues/1134 | [
"🐛bug"
] | elchiapp | 1 |
aiortc/aioquic | asyncio | 222 | Connection close received (certificate unknown) | Hi, I'm currently try to deploy QUIC server, where client is from android with cronet.
When I type following command to activate QUIC server as a http3-server in the example,
python server.py -c certs/test.pem -k certs/test.key --port 7443
I find that QUIC server responses to client as follows:
2021-09-03 21:... | closed | 2021-09-03T12:52:56Z | 2023-08-22T01:18:42Z | https://github.com/aiortc/aioquic/issues/222 | [] | lgs96 | 3 |
oegedijk/explainerdashboard | dash | 270 | Autogluon and explainerdashboard integration | Is there a way to load autogluon models into explainer dashboard? | open | 2023-06-14T15:18:20Z | 2023-07-09T10:21:11Z | https://github.com/oegedijk/explainerdashboard/issues/270 | [] | apavlo89 | 4 |
manrajgrover/halo | jupyter | 176 | Bug: halo not showing properly in Jenkins CI | <!-- Please use the appropriate issue title format:
BUG REPORT
Bug: {Short description of bug}
SUGGESTION
Suggestion: {Short description of suggestion}
OTHER
{Question|Discussion|Whatever}: {Short description} -->
## Description
Halo doesn't display text properly in Jenkins CI. T... | open | 2023-05-08T19:23:26Z | 2024-06-16T08:14:10Z | https://github.com/manrajgrover/halo/issues/176 | [] | omartoutounji | 2 |
browser-use/browser-use | python | 509 | Support for UI TARS | ### Problem Description
Support for UI TARS
### Proposed Solution
Support for UI TARS
### Alternative Solutions
_No response_
### Additional Context
_No response_ | open | 2025-02-01T20:07:56Z | 2025-03-14T14:08:57Z | https://github.com/browser-use/browser-use/issues/509 | [
"enhancement"
] | nuclear-gandhi | 3 |
miguelgrinberg/flasky | flask | 44 | Categories for posts | So I am trying to add a category model for the posts by doing the following:
```
class Post(db.Model):
__tablename__ = 'posts'
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(80))
body = db.Column(db.Text)
timestamp = db.Column(db.DateTime, index=True, default=datetime.utcn... | closed | 2015-05-08T15:20:48Z | 2015-05-10T11:48:29Z | https://github.com/miguelgrinberg/flasky/issues/44 | [
"question"
] | varqasim | 4 |
tfranzel/drf-spectacular | rest-api | 469 | Oauth2 provider: TokenMatchesOASRequirements doesn't pass validation | **Describe the bug**
I have a ModelViewSet with permission_classes = [TokenMatchesOASRequirements], generating the schema with --validate
Using django-oauth-toolkit.
```
jsonschema.exceptions.ValidationError: {'GET': [['v2:integration:account:client:read']], 'POST': [], 'PUT': [['v2:integration:account:client:... | closed | 2021-07-27T10:47:33Z | 2022-08-25T21:40:17Z | https://github.com/tfranzel/drf-spectacular/issues/469 | [
"bug",
"fix confirmation pending"
] | tomasgarzon | 8 |
schemathesis/schemathesis | pytest | 1,799 | Avoid showing the whole payload in the error details | Now Schemathesis displays the whole response payload which could be too much. For raw data, we might want to display first N symbols, for JSON, maybe only the relevant part (if the error is related to JSON schema), or maybe show N bytes around the place of the error | closed | 2023-10-07T21:36:00Z | 2023-11-09T08:57:10Z | https://github.com/schemathesis/schemathesis/issues/1799 | [
"Priority: Medium",
"Type: Feature",
"UX: Reporting",
"Status: Needs Design"
] | Stranger6667 | 0 |
huggingface/datasets | numpy | 7,467 | load_dataset with streaming hangs on parquet datasets | ### Describe the bug
When I try to load a dataset with parquet files (e.g. "bigcode/the-stack") the dataset loads, but python interpreter can't exit and hangs
### Steps to reproduce the bug
```python3
import datasets
print('Start')
dataset = datasets.load_dataset("bigcode/the-stack", data_dir="data/yaml", streaming... | open | 2025-03-18T23:33:54Z | 2025-03-18T23:33:54Z | https://github.com/huggingface/datasets/issues/7467 | [] | The0nix | 0 |
pydantic/pydantic-ai | pydantic | 607 | Validation with nested Pydantic models (ollama, llama3.1) | When using the `pydantic_ai` library with a nested `BaseModel`, an `UnexpectedModelBehavior` error occurs, despite the underlying model (e.g., `ollama:llama3.1`) being capable of handling the requested structure and providing valid output.
The example here [https://ai.pydantic.dev/examples/pydantic-model/#running-th... | closed | 2025-01-03T16:13:25Z | 2025-01-08T19:33:59Z | https://github.com/pydantic/pydantic-ai/issues/607 | [] | Ynn | 8 |
ultralytics/yolov5 | machine-learning | 13,189 | pip dependencies | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
# I am encountering this error when i am running the code in colab:
--------------------... | open | 2024-07-15T07:43:00Z | 2024-10-20T19:50:06Z | https://github.com/ultralytics/yolov5/issues/13189 | [
"question",
"Stale"
] | karmakaragradwip02 | 3 |
httpie/cli | python | 940 | Add setup instructions for windows | As I have tried to setup my development environment for HTTPie on a Windows machine, I wasn't able to run the ``make`` command even after installing some third-party software. It would be great to add specific steps for windows setup. I discussed this with @jakubroztocil and he confirmed the issue.
Current guideline... | closed | 2020-06-25T15:41:00Z | 2020-06-26T15:25:27Z | https://github.com/httpie/cli/issues/940 | [] | ovezovs | 0 |
encode/databases | sqlalchemy | 127 | Async sqlite? | I was curious what it means to present an async interface to Sqlite. My thought is that since Sqlite is an embedded database, there's no socket i/o, which is where one would typically see an event loop entering the picture. There's the additional caveat that only a single connection can hold the write lock at any given... | closed | 2019-07-17T20:10:41Z | 2019-07-18T10:45:42Z | https://github.com/encode/databases/issues/127 | [] | coleifer | 2 |
explosion/spaCy | machine-learning | 13,064 | sqlite3.OperationalError: unable to open database file | Hello, I met a bug, "sqlite3.OperationalError: unable to open database file"
My code is here:
nlp = spacy.load("en_core_web_md")
nlp.add_pipe("entityLinker", last=True)
doc = nlp(text)
and the error is:
doc = nlp(text)
File "/home/jxk/anaconda3/envs/KALA/lib/python3.6/site-packages/spa... | closed | 2023-10-14T07:32:56Z | 2023-11-16T00:02:11Z | https://github.com/explosion/spaCy/issues/13064 | [
"third-party",
"feat / nel"
] | jiangxinke | 2 |
erdewit/ib_insync | asyncio | 701 | request live data with diffrent time resolution | Hi I want to fetch Live data with 5 min resolution, 15 mints resolution etc. How can I

Here mentioned that bar size must be 5 sec | open | 2024-02-27T07:28:16Z | 2024-02-27T10:53:24Z | https://github.com/erdewit/ib_insync/issues/701 | [] | krishdotn1 | 1 |
jonaswinkler/paperless-ng | django | 739 | [BUG] Main Search Bar doesn't show document with title matching | **Describe the bug**
When looking a particular document which I remember the title, I can't find it with the search Bar on top of the page.
But I can find it with document filter "title&content".
**To Reproduce**
Rename (title) a doc with a word not present in the PDF content.
Search it with "document filter" ->... | closed | 2021-03-11T08:51:45Z | 2021-04-10T09:26:10Z | https://github.com/jonaswinkler/paperless-ng/issues/739 | [] | xavgra2 | 3 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,582 | [Bug]: "Generate" Button does not work, unless I am too dumb to use it. | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | closed | 2024-10-23T21:40:10Z | 2024-10-24T15:00:36Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16582 | [
"bug-report"
] | NikkuIsRyu | 2 |
taverntesting/tavern | pytest | 206 | pytest is now version 4.0.0, which breaks the setup.py install | Steps to reproduce
-------------------
```
$ virtualenv tavern_pytest_4
Using base prefix '/Library/Frameworks/Python.framework/Versions/3.7'
New python executable in /Users/user/tavern_pytest_4/bin/python3
Also creating executable in /Users/user/tavern_pytest_4/bin/python
Installing setuptools, pip, wheel...don... | closed | 2018-11-14T23:40:37Z | 2018-11-15T23:51:06Z | https://github.com/taverntesting/tavern/issues/206 | [] | cetanu | 0 |
pyg-team/pytorch_geometric | deep-learning | 9,897 | cannot import name 'BaseData' from 'torch_geometric.data.data' | ### 🐛 Describe the bug
I successfully installed the dependent packages and then directly used the Tsinghua mirror source to install torch_geometric via pip. However, when I tried to import the library in Jupyter, an error occurred: ImportError: cannot import name 'BaseData' from 'torch_geometric.data.data'. I've chec... | closed | 2024-12-27T10:57:01Z | 2024-12-28T18:21:29Z | https://github.com/pyg-team/pytorch_geometric/issues/9897 | [
"bug"
] | MothingAI | 1 |
Nekmo/amazon-dash | dash | 61 | please add docker support | please add docker suport | closed | 2018-07-17T21:08:39Z | 2018-09-03T20:09:54Z | https://github.com/Nekmo/amazon-dash/issues/61 | [
"Setup"
] | crowland88 | 41 |
DistrictDataLabs/yellowbrick | matplotlib | 1,283 | learning curve visualizer for catboost automl using Pipelines | **Describe the issue**
I'm getting "TypeError: ContribEstimator.__init__() got an unexpected keyword argument 'memory'" while trying to plot a learning curve
<!-- If you have a question, note that you can email us via our listserve:
https://groups.google.com/forum/#!forum/yellowbrick -->
I have emailed via l... | closed | 2022-09-23T06:34:10Z | 2022-10-21T15:56:57Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1283 | [
"gone-stale"
] | dbrami | 2 |
gradio-app/gradio | python | 10,362 | When running lazy caching, `gr.Progress(track_tqdm=True)` is not displayed | ### Describe the bug
The progress bar is not shown while running an example when `cache_examples=True, cache_mode="lazy"`.
(BTW, it's weird, but for some reason, infinite loop mentioned in #6690 doesn't occur for `diffusers` pipelines. I wanted to provide a simpler repro, but got the same issue as #6690 , so I'm usin... | open | 2025-01-15T06:48:42Z | 2025-01-15T06:48:42Z | https://github.com/gradio-app/gradio/issues/10362 | [
"bug"
] | hysts | 0 |
huggingface/transformers | tensorflow | 35,994 | model.parameters() return [Parameter containing: tensor([], device='cuda:0', dtype=torch.bfloat16, requires_grad=True)] when using zero3 | ### System Info
transformers 4.44.2
accelerate 1.2.1
deepspeed 0.12.2
torch 2.2.2
torchaudio 2.2.2
torchvision 0.17.2
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [x] My own modified scrip... | closed | 2025-01-31T16:42:47Z | 2025-03-11T08:03:44Z | https://github.com/huggingface/transformers/issues/35994 | [
"bug"
] | fanfanffff1 | 2 |
vvbbnn00/WARP-Clash-API | flask | 174 | [Feature request] 能否支持V2rayN订阅,V2rayN 6.39版本已经支持wireguard协议了 |

| open | 2024-04-18T19:11:42Z | 2024-04-28T09:49:59Z | https://github.com/vvbbnn00/WARP-Clash-API/issues/174 | [
"enhancement"
] | hdw9703 | 1 |
jmcnamara/XlsxWriter | pandas | 703 | option style for insert_textbox | Hi,
Textboxes have many features and option to personalize my textbox however i want to have my borders with rounded corners like this screenshot :
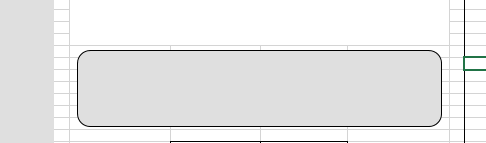
Can be able to implement this "style" feature for te... | closed | 2020-03-31T09:53:43Z | 2020-04-01T09:57:51Z | https://github.com/jmcnamara/XlsxWriter/issues/703 | [
"feature request"
] | Clorel | 1 |
graphql-python/graphene-django | django | 1,505 | graphql_schema outputs graphQL SDL file with legacy syntax | **What is the current behavior?**
When I run the graphql_schema management function with a graphQL output (e.g. `python manage.py graphql_schema --out schema.graphql`) I get a schema that looks like:
```
type Mutation {
addTodo(name: String!, priority: Priority = LOW): Todo!
removeTodo(id: ID!): Todo!
}
... | open | 2024-03-06T17:57:53Z | 2024-03-06T17:57:53Z | https://github.com/graphql-python/graphene-django/issues/1505 | [
"🐛bug"
] | matt-dalton | 0 |
browser-use/browser-use | python | 490 | [FEATURE REQUEST] : Support of ChatLiteLLM and ChatLiteLLmRouter for browser Use. | ### Problem Description
I have be trying to use langchains's ChatLiteLLM class as llm for broswer-use agent, but it fails, saying:
```bash
ERROR [agent] ❌ Result failed 4/10 times:
litellm.UnsupportedParamsError: VertexAI doesn't support tool_choice=any. Supported tool_choice values=['auto', 'required', json obje... | open | 2025-01-31T08:50:52Z | 2025-03-03T12:34:08Z | https://github.com/browser-use/browser-use/issues/490 | [
"enhancement"
] | tikendraw | 1 |
Lightning-AI/pytorch-lightning | machine-learning | 19,849 | `ckpt_path` in `Trainer` accepts URIs to automatically load checkpoints from remote paths | ### Description & Motivation
If I set up a Trainer with a `WandbLogger` and set `log_model=True`, I get that my model is saved locally and in a W&B server.
If I want to retrieve the model from the server I have to use the W&B `use_artifact` methods and the download methods to first retrieve the model, as described... | open | 2024-05-05T19:56:54Z | 2024-05-05T19:57:17Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19849 | [
"feature",
"needs triage"
] | aretor | 0 |
ufoym/deepo | tensorflow | 81 | how to use your docker image with gpu on window10 | u mention this works on Linux (CPU version/GPU version), Windows (CPU version) and OS X (CPU version) | closed | 2019-02-21T15:30:42Z | 2019-02-23T06:26:32Z | https://github.com/ufoym/deepo/issues/81 | [] | deo999 | 1 |
BeanieODM/beanie | pydantic | 412 | [BUG] Problem in save method | **Bug in action of save method**
I wanna save my document to database and use it after insert but I have problem with this situation:
**This is My code**
```python
class Child(BaseModel):
child_field: str
class Sample(Document):
field: Dict[str, Child]
instance1 = Sample(field={"Bar": Child(ch... | closed | 2022-11-09T12:44:09Z | 2022-11-10T14:30:51Z | https://github.com/BeanieODM/beanie/issues/412 | [] | miladva | 9 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 41 | Prompt 最长可以有多少? | GPT3.5 是4k Token,不知我们的项目是社么限制?如果长度可以很长的话,那么就可以嵌入很多索引资料了。 | closed | 2023-04-03T09:59:52Z | 2023-04-11T05:36:39Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/41 | [] | wizd | 3 |
mars-project/mars | numpy | 3,215 | [BUG] Mars dataframe sort_values with multiple ascendings returns incorrect result on pandas<1.4 | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
A clear and concise description of what the bug is.
Example
``` python
import numpy as np
import pandas as pd
import mars
import mars.d... | closed | 2022-08-09T11:17:52Z | 2022-08-30T02:38:13Z | https://github.com/mars-project/mars/issues/3215 | [
"type: bug"
] | fyrestone | 0 |
piccolo-orm/piccolo | fastapi | 913 | Is it possible to use multiple schemas with SQLiteEngine? | I have a situation, where my Python app uses Postgres as the production database, but I would like to pytest my app functionality in the CI/CD pipeline using a sqlite database. My app however needs to read and write to multiple schemas. How can I achieve this desired result with Piccolo? | closed | 2023-12-19T21:05:49Z | 2023-12-20T06:49:16Z | https://github.com/piccolo-orm/piccolo/issues/913 | [] | aabmets | 2 |
microsoft/qlib | deep-learning | 1,628 | descriptor 'lower' for 'str' objects doesn't apply to a 'float' object | I tried updating data on existing datasets retrieved from Yahoo Finance using collector.py but received the following error.
The code used is:
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir ~/desktop/quant_engine/qlib_data/us_data --trading_date 2023-08-16 --end_date 2023-08... | closed | 2023-08-18T09:51:57Z | 2024-01-29T15:01:45Z | https://github.com/microsoft/qlib/issues/1628 | [
"question",
"stale"
] | guoz14 | 7 |
ultralytics/ultralytics | computer-vision | 19,473 | Questions about target tracking | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi, how do you evaluate the accuracy of target tracking after using the curr... | open | 2025-02-28T07:38:27Z | 2025-03-03T13:47:45Z | https://github.com/ultralytics/ultralytics/issues/19473 | [
"question",
"track"
] | WHK1229 | 7 |
samuelcolvin/watchfiles | asyncio | 215 | Problems when using vim - `Remove(File)` event when saving the file | ### Description
Hello,
and thanks for providing `watchfiles` ! I seem to have an issue occuring with `vim` specifically, so I'm not sure this is the best place for a bug report, but this could always serve as future reference:
When editing then saving a file in `vim` (version 9.0.813), for some reason a `Remove... | closed | 2022-11-27T23:28:21Z | 2022-11-29T13:02:56Z | https://github.com/samuelcolvin/watchfiles/issues/215 | [
"bug"
] | sapristi | 3 |
dropbox/PyHive | sqlalchemy | 7 | Support python 2.6 for presto | Is there any interest for support python 2.6?
If yes, I can work on it and make a PR.
| closed | 2014-10-21T18:03:30Z | 2015-03-18T00:04:50Z | https://github.com/dropbox/PyHive/issues/7 | [
"wontfix"
] | csarcom | 1 |
Esri/arcgis-python-api | jupyter | 1,365 | Add suport to read, write TopoJson | **I'd like to have TopoJson support.
If Esri won't suport it, may be just help mere mortals to convert to json or geojson will suffice.
https://github.com/topojson/topojson-specification
**Describe the solution you'd like**
abilit to read, write topojson, helping us to convert to Spatial Data Frame
**Describ... | closed | 2022-10-20T11:50:42Z | 2023-04-25T17:51:56Z | https://github.com/Esri/arcgis-python-api/issues/1365 | [
"enhancement",
"on-hold"
] | hildermesmedeiros | 3 |
amidaware/tacticalrmm | django | 2,131 | [Feature Request] SSO username remap to different OIDC attributes | **Is your feature request related to a problem? Please describe.**
When using the SSO feature, newly registered users currently get the first name (from/through the OIDC Provider) as a username in TRMM. In larger organizations, this quickly can become a problem.
Current workaround: renaming them manually.
**Describe ... | open | 2025-01-30T06:24:42Z | 2025-01-30T06:24:42Z | https://github.com/amidaware/tacticalrmm/issues/2131 | [] | tbfpartner | 0 |
Miserlou/Zappa | flask | 1,840 | Package command not adding PIPFile dependencies into zip file | <!--- Provide a general summary of the issue in the Title above -->
## Context
I'm using jenkins to deploy an application using Zappa. As we can't let zappa handle the infrastructure we are using Zappa to generate the ZIP file and then updating lambda with AWS cli.
Please not I can't reproduce it on local, but h... | open | 2019-03-25T13:36:03Z | 2019-11-04T22:16:38Z | https://github.com/Miserlou/Zappa/issues/1840 | [] | bajcmartinez | 4 |
521xueweihan/HelloGitHub | python | 2,407 | 自荐项目:Time Machine Out Of the Box | https://GitHub.com/Astrian/time-machine-oob
使用 Docker 一键搭建 Time Machine 实例。
配置文件适合用来入门 Docker?(逃 | closed | 2022-10-28T23:46:00Z | 2022-11-23T07:03:34Z | https://github.com/521xueweihan/HelloGitHub/issues/2407 | [] | Astrian | 0 |
pydata/xarray | pandas | 9,521 | Progress bar on open_mfdataset | ### Is your feature request related to a problem?
I'm using ```xarray.open_mfdataset()``` to open tens of thousands of (fairly small) netCDF files, and it's taking quite some time. Being of an impatient nature, I would like to at least be assured that something is happening, so a progress bar would be nice. I found an... | closed | 2024-09-19T11:51:05Z | 2024-12-10T21:01:52Z | https://github.com/pydata/xarray/issues/9521 | [
"usage question",
"plan to close"
] | nordam | 2 |
babysor/MockingBird | pytorch | 348 | 无法成功合成声音,只有电流声 | 为啥只有电流声呀,web和tool都试了,调整style就不会报错了,但是一直不能成功读出声音,只有电流声 | open | 2022-01-18T06:04:07Z | 2022-02-13T04:10:46Z | https://github.com/babysor/MockingBird/issues/348 | [] | wangtao1406410139 | 5 |
autogluon/autogluon | scikit-learn | 4,846 | Avoid to pass item_id as variable for covariate regressor in TimeSeriesPredictor | Hi,
when using a covariate regressor, I want to use only the `known_covariates_names `features to predict the target. However, it seems that the `item_id` column is also being passed to the regressor. Specifically, in the case of a regressor like XGBoost or Linear Regression, this column is one-hot encoded, producing ... | closed | 2025-01-27T15:50:54Z | 2025-01-28T19:52:15Z | https://github.com/autogluon/autogluon/issues/4846 | [
"enhancement",
"module: timeseries"
] | anthonygiorgio97 | 1 |
sinaptik-ai/pandas-ai | data-visualization | 1,309 | how do i use it with MYSQL | i find no way to use it | closed | 2024-08-04T09:25:50Z | 2024-11-11T16:04:22Z | https://github.com/sinaptik-ai/pandas-ai/issues/1309 | [] | Akash47007 | 5 |
huggingface/datasets | machine-learning | 7,159 | JSON lines with missing struct fields raise TypeError: Couldn't cast array | JSON lines with missing struct fields raise TypeError: Couldn't cast array of type.
See example: https://huggingface.co/datasets/wikimedia/structured-wikipedia/discussions/5
One would expect that the struct missing fields are added with null values. | closed | 2024-09-23T07:57:58Z | 2024-10-21T08:07:07Z | https://github.com/huggingface/datasets/issues/7159 | [
"bug"
] | albertvillanova | 1 |
mckinsey/vizro | plotly | 1,062 | Dark/light theme change | ### Question
Hello!
I have two questions about how themes change work in Vizro:
1. I want to show a configured plotly figure as a component reactive to controls, but when I wrap it within a function returning a dcc.Graph (as I need to pass a config dict) using the capture("figure") decorator, I noticed that it is no... | closed | 2025-03-12T07:26:20Z | 2025-03-19T12:32:29Z | https://github.com/mckinsey/vizro/issues/1062 | [
"General Question :question:"
] | gtauzin | 4 |
ultralytics/ultralytics | pytorch | 18,739 | How can I add a loss function, other than the bbox and classification loss, to the YOLOv8 model? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
### Question
I have redesigned the backbone of YOLOv8, and for this, I need to add... | open | 2025-01-17T14:59:21Z | 2025-03-24T14:42:56Z | https://github.com/ultralytics/ultralytics/issues/18739 | [
"enhancement",
"question"
] | CC-1997 | 27 |
waditu/tushare | pandas | 1,507 | daily_basic接口返回pe_ttm数据不准确 | 调试过程及结果如下:
>>>df_gldq = pro.daily_basic(ts_code='002241.sz,600183.sh', trade_date='20210203', fields='ts_code,trade_date,pe_ttm,total_mv')
>>>df_gldq.pe_ttm
0 39.2222
1 30.8760
Name: pe_ttm, dtype: float64
返回的是动态市盈率,不是滚动市盈率,当日查到的真实数据见附件
 jeff@pi-walnut:~ $ cat /etc/os-release
PRETTY_NAME="Debian GNU/Linux 11 (bullseye)"
NAME="Debian GNU/Linux"
VERSION_ID="11"
VERSION="11 (bullseye)"
VERSION_CODENAME=bullseye
ID=debian
HOME_URL="https://www.debian.org/"
S... | closed | 2022-12-28T04:36:42Z | 2022-12-29T04:02:23Z | https://github.com/hbldh/bleak/issues/1183 | [] | jeffsf | 6 |
thtrieu/darkflow | tensorflow | 867 | Where does the momentum parameter get passed to the optimizer? | I'm looking at where the optimizer is selected here.
https://github.com/thtrieu/darkflow/blob/718a11618392b873a6061928f03093cb8f5542b4/darkflow/net/help.py#L17
Let's say I set the FLAGS.trainer="momentum" and set the FLAGS.momentum parameter to a value other than default, how is this passed to the momentum optimize... | open | 2018-08-09T06:40:43Z | 2018-08-10T07:09:29Z | https://github.com/thtrieu/darkflow/issues/867 | [] | moore269 | 3 |
amisadmin/fastapi-amis-admin | sqlalchemy | 67 | QuickSaveItemApi错误,请修正代码 | admin/admin.py 文件 中 :
primaryField=self.pk_name,
quickSaveItemApi=f"put:{self.router_path}/item/" + "${id}",
改为:
primaryField=self.pk_name,
quickSaveItemApi=f"put:{self.router_path}/item/${self.pk_name}"
否则pk_name不为id时,会报405错误 | closed | 2022-11-16T02:13:18Z | 2023-09-17T08:51:16Z | https://github.com/amisadmin/fastapi-amis-admin/issues/67 | [] | zinohome | 3 |
aimhubio/aim | data-visualization | 3,295 | Dynamic Computation of Custom Metrics | ## 🚀 Feature
Enable the computation and display of custom metrics directly within Aim, derived from already logged data.
### Motivation
I’m finding it challenging to log many training metrics, like multiple differently weighted accuracies, directly from my PyTorch runs due to some implementation limitations. It wou... | open | 2025-02-25T23:43:26Z | 2025-02-25T23:43:26Z | https://github.com/aimhubio/aim/issues/3295 | [
"type / enhancement"
] | percevalw | 0 |
johnthagen/python-blueprint | pytest | 98 | Enable Nox --error-on-external-run | This would be a safer default (also the same as that used by Tox):
- https://nox.thea.codes/en/stable/usage.html?highlight=external#disallowing-external-programs | closed | 2022-06-25T12:49:09Z | 2022-06-26T18:19:11Z | https://github.com/johnthagen/python-blueprint/issues/98 | [
"enhancement"
] | johnthagen | 0 |
pytorch/pytorch | numpy | 149,205 | Parameter not updating when FSDP2 model is used before optimizre creation | ### 🐛 Describe the bug
If calculations are performed using a FSDP2 model after calling `fully_shard` and before creating the optimizer, the parameters fail to update correctly. The parameters captured by the optimizer seem to differ from those in the training loop. Non-parallel and DDP are not affected. In larger mul... | open | 2025-03-14T16:47:26Z | 2025-03-17T18:39:26Z | https://github.com/pytorch/pytorch/issues/149205 | [
"oncall: distributed",
"module: fsdp"
] | zhoukezi | 1 |
Anjok07/ultimatevocalremovergui | pytorch | 1,651 | Ultimate Vocal Remover 5 | Time elasped: 2hr 47min and the process failed, completely devastating. Please fix issue | open | 2024-12-06T02:34:56Z | 2024-12-25T22:49:50Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1651 | [] | willisdavid448 | 3 |
eriklindernoren/ML-From-Scratch | machine-learning | 74 | linear regression | grad_w = -(y - y_pred).dot(X) + self.regularization.grad(self.w)
in regression.py
should it be grad_w = -(y - y_pred).dot(X) * (1/training_size) + self.regularization.grad(self.w) ? | open | 2020-01-04T09:17:49Z | 2022-11-10T17:05:21Z | https://github.com/eriklindernoren/ML-From-Scratch/issues/74 | [] | ClarenceTeee | 2 |
CorentinJ/Real-Time-Voice-Cloning | python | 431 | Common toolbox issues and how to fix them | This issue will be used to document common toolbox issues and how to fix them. Please **do not reply here** to keep the signal/noise high. Instead, report problems and suggest additions/improvements by opening a new issue. | closed | 2020-07-19T13:51:53Z | 2022-02-08T07:03:09Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/431 | [] | ghost | 10 |
ultralytics/ultralytics | pytorch | 19,752 | How to export Yolov8-cls to imx format? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello,
I successfully exported a YOLOv8 object detection model trained on c... | closed | 2025-03-18T04:44:36Z | 2025-03-20T05:13:06Z | https://github.com/ultralytics/ultralytics/issues/19752 | [
"question",
"classify",
"exports"
] | amitis94 | 12 |
qubvel-org/segmentation_models.pytorch | computer-vision | 386 | Default Activation Function | When defining a model "activation" is not a required argument. When looking through the Unet model.py folder I noticed the activation is set to None. When "activation" is not defined, what is the default activation function? | closed | 2021-04-21T19:58:13Z | 2021-04-26T18:58:07Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/386 | [] | kangakid | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.