
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ivy-llc/ivy | tensorflow | 28,495 | Fix Frontend Failing Test: paddle - math.paddle.diff | To-do List: https://github.com/unifyai/ivy/issues/27500 | closed | 2024-03-06T21:57:49Z | 2024-04-02T09:25:04Z | https://github.com/ivy-llc/ivy/issues/28495 | [
"Sub Task"
] | ZJay07 | 0 |
albumentations-team/albumentations | deep-learning | 1,509 | PadIfNeeded seems to not correctly work with ReplayCompose in certain cases | ## 🐛 Bug
Using ReplayCompose with PadIfNeeded seems to not reproduce the transform if a non-default value of "position" is used
## To Reproduce
Steps to reproduce the behavior:
```
import numpy as np
from albumentations import ReplayCompose
from albumentations.augmentations.geometric.transforms import... | closed | 2024-01-20T02:17:45Z | 2024-03-21T00:39:03Z | https://github.com/albumentations-team/albumentations/issues/1509 | [
"bug"
] | fhung65 | 4 |
ipython/ipython | data-science | 14,697 | Avoid warning on `ipython.utils.text.dedent`? | Currently, ipython code itself uses `ipython.utils.text.dedent` at a few places, for example https://github.com/ipython/ipython/blob/main/IPython/core/magic_arguments.py#L92
But the function raises a warning.
I think it's best if the function does not raise a warning until the function is completely unused within the... | closed | 2025-01-30T11:44:53Z | 2025-02-26T10:54:42Z | https://github.com/ipython/ipython/issues/14697 | [] | user202729 | 2 |
allure-framework/allure-python | pytest | 339 | Allure displays date and time as unknown in summary overview page, if all testcase skiped or failed, not passed | [//]: # (
. Note: for support questions, please use Stackoverflow or Gitter**.
. This repository's issues are reserved for feature requests and bug reports.
.
. In case of any problems with Allure Jenkins plugin** please use the following repository
. to create an issue: https://github.com/jenkinsci/allure-plugi... | closed | 2018-08-13T12:14:36Z | 2019-02-20T15:05:41Z | https://github.com/allure-framework/allure-python/issues/339 | [
"bug",
"theme:pytest",
"work:backlog"
] | yili1992 | 1 |
LAION-AI/Open-Assistant | machine-learning | 3,139 | Feedback button during chat | ERROR: type should be string, got "\r\nhttps://github.com/LAION-AI/Open-Assistant/assets/95025816/d7ed34ab-e706-491b-a790-9379edfc3c72\r\n\r\nHard to explain by words so here is a video that demonstrates the issue, same thing happens with voting down." | closed | 2023-05-12T20:20:32Z | 2023-05-13T19:56:34Z | https://github.com/LAION-AI/Open-Assistant/issues/3139 | [
"bug",
"website",
"UI/UX"
] | sryu1 | 0 |
itamarst/eliot | numpy | 86 | Convert eliot output into kcachegrind-readable format | Eliot logging can be used for performance measurement, since it has start and stop (wall clock) timing for actions. kcachegrind is a useful tool for visualizing profiling data, and quite possibly Eliot output could be loaded into it.
| closed | 2014-05-25T23:24:38Z | 2019-05-09T18:18:28Z | https://github.com/itamarst/eliot/issues/86 | [
"enhancement"
] | itamarst | 1 |
aiortc/aiortc | asyncio | 1,207 | kind = "audio" How to use queue output for Audio? Audio 如何用队列输出? | The sound problem generated when creating virtual digital humans/在做虚拟数字人时 时时生成的声音问题
How to use queue output for Audio? Audio 如何用队列输出?

```python
# All code
import asyncio
import json
import os
import uuid
import numpy as ... | closed | 2025-01-13T10:32:44Z | 2025-01-29T11:50:50Z | https://github.com/aiortc/aiortc/issues/1207 | [] | gg22mm | 0 |
praw-dev/praw | api | 1,951 | Docs: Font color of method names is unreasonably white on a white background when using dark theme | ### Describe the Documentation Issue
Hey Praw maintainers, thanks for the great work.
I'm about to use this API and I'm really happy with what I've found so far.
The only sad part is I'll have to read the documentation on light theme. This is because of the issue in the title, pictured below, or [directly in the sit... | closed | 2023-04-04T20:36:28Z | 2023-07-04T17:45:36Z | https://github.com/praw-dev/praw/issues/1951 | [] | vitorcodesalittle | 4 |
learning-at-home/hivemind | asyncio | 281 | Try to migrate from CircleCI to GitHub Actions | Seems easy, but testing needed.
Check before that benchmarks feel good in GitHub Actions | closed | 2021-06-17T14:23:56Z | 2021-06-24T21:15:06Z | https://github.com/learning-at-home/hivemind/issues/281 | [
"ci"
] | yhn112 | 0 |
chainer/chainer | numpy | 7,681 | The average function for float16 can overflow | The average function for float16 [can overflow](https://github.com/chainer/chainer/blob/6fef53f3f9fcae9de0643d677b89349d58f20cad/chainer/functions/math/average.py#L62) due to the same reason described in #6702. | closed | 2019-07-03T06:07:48Z | 2019-11-29T05:19:21Z | https://github.com/chainer/chainer/issues/7681 | [
"stale",
"prio:low"
] | gwtnb | 4 |
huggingface/peft | pytorch | 1,596 | TypeError: ChatGLMForConditionalGeneration.forward() got an unexpected keyword argument 'decoder_input_ids' | ### System Info
python 3.10.8
peft 0.7.1
transformers 4.38.1
datasets 2.18.0
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder
- [ ] My own task or dataset (give details below)
... | closed | 2024-03-27T14:39:54Z | 2024-03-28T10:09:09Z | https://github.com/huggingface/peft/issues/1596 | [] | 12915494174 | 4 |
keras-team/autokeras | tensorflow | 1,924 | Bug: trouble loading and using tensorflow savedmodel with custom input layer in keras, has been working fine for 2+ years and now currently looking for the solutions with my team | ### Bug Description
<!---
A clear and concise description of what the bug is.
-->
### Bug Reproduction
Code for reproducing the bug:
Data used by the code:
### Expected Behavior
<!---
If not so obvious to see the bug from the running results,
please briefly describe the expected behavior.
-->
### Se... | open | 2024-06-27T21:21:55Z | 2024-06-27T23:05:43Z | https://github.com/keras-team/autokeras/issues/1924 | [
"bug report"
] | IOIntInc | 1 |
openapi-generators/openapi-python-client | fastapi | 1,125 | Incorrect generation of `_parse_response ` | Lovely package BTW!
**Describe the bug**
Code generation for parsing API response does not generate the code that creates the Python model after the response is completed. This happens when using a `$ref` to define the response instead of just defining the response body inside the path definition.
**OpenAPI Spe... | open | 2024-09-24T16:44:01Z | 2024-09-24T16:52:54Z | https://github.com/openapi-generators/openapi-python-client/issues/1125 | [] | weinbe58 | 0 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 408 | [BUG] tiktok mstoken生成失败 | 我本地网络能正常访问tiktok 但是调试项目的时候生成tiktok mstoken总是超时

| closed | 2024-05-23T06:39:03Z | 2024-05-26T05:38:17Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/408 | [
"BUG"
] | meepolove | 4 |
taverntesting/tavern | pytest | 647 | Clarify API boundaries | Move most of the code into a `_tavern` folder and moving any existing test helpers into a top level `helpers` file to clarify where the API boundary is (as well as general cleanup around folders - for example 'testutil' is a really unhelpful name)
| closed | 2021-02-20T11:59:55Z | 2021-10-03T12:37:01Z | https://github.com/taverntesting/tavern/issues/647 | [] | michaelboulton | 0 |
stitchfix/hamilton | numpy | 19 | Enhancement: Add capability to use a DataFrame as a template for the target output. | Currently if the caller has a DataFrame structure that they are targeting then they need to ensure they match the names of the columns correctly and manually convert the Series types. If the `output_columns` or other parameter of the `execute` function took a DataFrame as a template then the output columns would match ... | closed | 2021-10-23T13:47:33Z | 2022-03-24T04:05:58Z | https://github.com/stitchfix/hamilton/issues/19 | [
"enhancement",
"product idea"
] | straun | 2 |
scrapy/scrapy | web-scraping | 6,185 | `FEED_EXPORT_BATCH_ITEM_COUNT` not working | <!--
Thanks for taking an interest in Scrapy!
If you have a question that starts with "How to...", please see the Scrapy Community page: https://scrapy.org/community/.
The GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.
Keep in mind that by filing an iss... | closed | 2023-12-23T14:36:25Z | 2024-01-12T12:58:40Z | https://github.com/scrapy/scrapy/issues/6185 | [
"not reproducible",
"needs more info"
] | Mhassanniazi | 3 |
healthchecks/healthchecks | django | 1,135 | Alert if `/start` signal does not arrive at expected time (with a separate grace time setting for it) | Currently, the set 'grace time' is used to both measure the time between schedule and initial ping AND between start and finish ping.
This means that if you send start pings for your timers (enabling you to see the run time of each run) you have to set the grace time to the max of the two values: maximum expected delay... | closed | 2025-03-20T12:37:53Z | 2025-03-20T13:31:34Z | https://github.com/healthchecks/healthchecks/issues/1135 | [
"feature"
] | Riscky | 4 |
pywinauto/pywinauto | automation | 566 | How to get certain value of cell in a table if the rows are dynamic. | Hi,
I am running into a problem which has a table and it contains columns and rows. Number of columns are fixed but number of rows are dynamic. I need to find out certain value of the cell if it is exists.
---------------------------------------------------------------------------------------------
Name | LastNa... | open | 2018-09-12T18:30:33Z | 2023-03-16T11:45:39Z | https://github.com/pywinauto/pywinauto/issues/566 | [
"question"
] | smitagodbole | 17 |
koxudaxi/datamodel-code-generator | fastapi | 2,179 | --snake-case-field etc should check ConfigDict on specified base-class | **Is your feature request related to a problem? Please describe.**
Certain options like --snake-case-field and --allow-extra-fields don't check whether the base class has set them in its ConfigDict.
**Describe the solution you'd like**
I am supplying a custom base class via --base-class, which has a ConfigDict w... | closed | 2024-11-21T22:01:59Z | 2024-11-22T18:04:57Z | https://github.com/koxudaxi/datamodel-code-generator/issues/2179 | [] | nickyoung-github | 1 |
scikit-learn/scikit-learn | data-science | 30,413 | Identical branches in the conditional statement in "svm.cpp" | ### Describe the bug
File svm/src/libsvm/svm.cpp, lines 1895-1903 contain the same statements. Is it correct?
### Steps/Code to Reproduce
if(fabs(alpha[i]) > 0)
{
++nSV;
if(prob->y[i] > 0)
{
if(fabs(alpha[i]) >= si.upper_bound[i])
++nBSV;
}
else
{
if(fabs(alpha[i]) >= s... | closed | 2024-12-05T12:01:22Z | 2025-01-27T14:16:19Z | https://github.com/scikit-learn/scikit-learn/issues/30413 | [
"Bug"
] | ayv19 | 2 |
CorentinJ/Real-Time-Voice-Cloning | python | 631 | Another problem... | 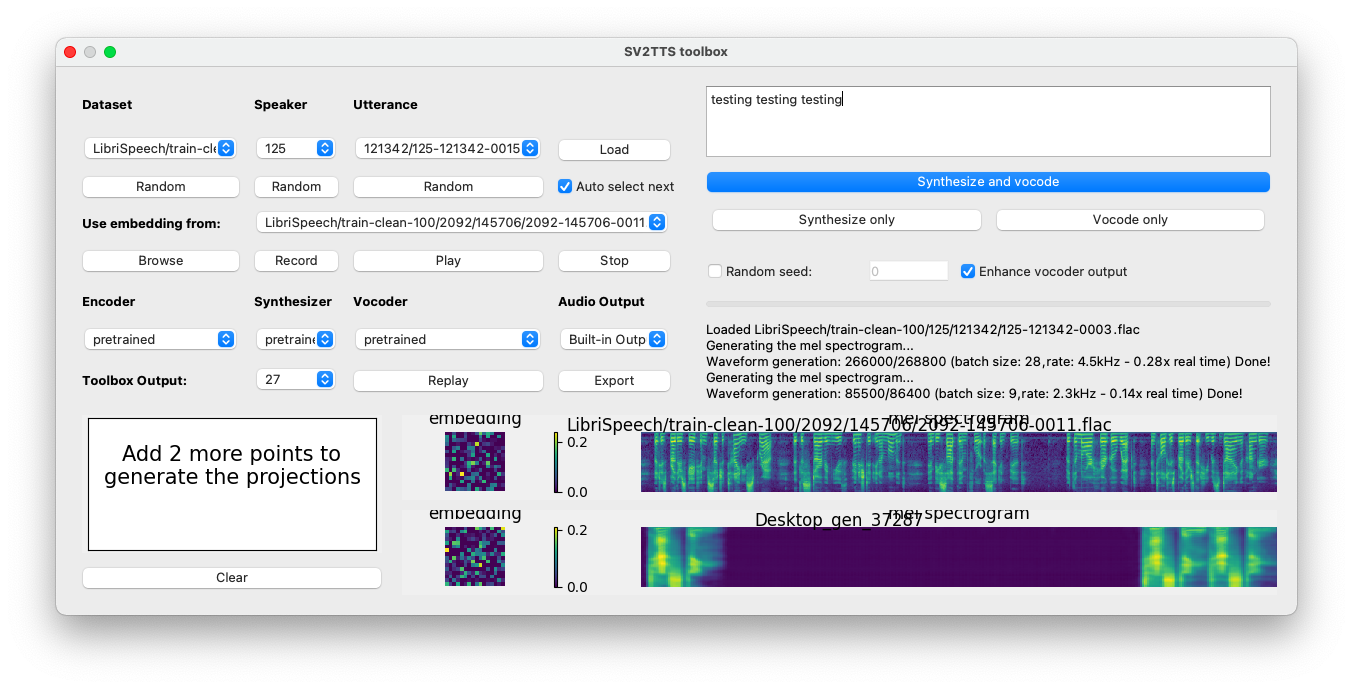
There is a gap between words... and also a weird noise
The audio: https://drive.google.com/file/d/1Qm2Y_zt2bJJqZVGsB70yA1K0Judkn4Mp/view?usp=sharing
| closed | 2021-01-18T19:22:11Z | 2021-01-22T21:08:07Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/631 | [] | notluke27 | 5 |
akfamily/akshare | data-science | 5,656 | AKShare 接口问题报告 | AKShare Interface Issue Report stock_zh_a_hist似乎有限制? | stock_zh_a_hist
akshare 版本 1.15.96
有时候会出现进度条,有时候又没有,循环抓取十几个之后就返回none了,但是再开个进程又可以取了,似乎是有什么限制 | closed | 2025-02-17T07:20:37Z | 2025-02-17T07:25:22Z | https://github.com/akfamily/akshare/issues/5656 | [
"bug"
] | caihua | 1 |
recommenders-team/recommenders | machine-learning | 1,249 | Multinomial VAE - performance | I've noticed some differences in training time and performance between this tensorflow 2 implementation and the original version:
- lower ratings should be removed
> user-to-movie interactions with rating <=3.5 are filtered out
but they are used to generate test_data_te_ratings, val_data_te_ratings that are used... | open | 2020-11-25T07:44:32Z | 2021-01-31T21:11:29Z | https://github.com/recommenders-team/recommenders/issues/1249 | [
"help wanted"
] | PaulCristina | 1 |
Anjok07/ultimatevocalremovergui | pytorch | 829 | UVR | ValueError: zero-size array to reduction operation maximum which has no identity
If this error persists, please contact the developers with the error details.
Would you like to open the error log for more details?
| open | 2023-09-29T04:02:58Z | 2023-09-29T04:02:58Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/829 | [] | Fay0857 | 0 |
pallets/flask | flask | 4,520 | Flask(1.0.x) and Jinja2(3.1.1) are not compatible | <!--
This issue tracker is a tool to address bugs in Flask itself. Please use
Pallets Discord or Stack Overflow for questions about your own code.
Replace this comment with a clear outline of what the bug is.
-->
<!--
Describe how to replicate the bug.
Include a minimal reproducible example that demonstrat... | closed | 2022-04-05T14:38:13Z | 2022-04-20T00:05:41Z | https://github.com/pallets/flask/issues/4520 | [] | neozhao98 | 2 |
statsmodels/statsmodels | data-science | 9,427 | sm.Logit and sm.GLM do not handle alpha the same way | To get same results when using
```
model = sm.GLM(y, X, family=sm.families.Binomial())
results = model.fit_regularized(alpha=alpha_glm, ...)
```
and
```
model = sm.Logit(y, X)
results = model.fit_regularized(alpha=alpha_logit)
```
one needs to set `alpha_logit = alpha_glm * len(X)` because scaling is ... | open | 2024-11-19T15:00:54Z | 2024-11-19T15:21:41Z | https://github.com/statsmodels/statsmodels/issues/9427 | [] | louisabraham | 1 |
mitmproxy/pdoc | api | 192 | Fix simple typo: beloing -> belonging | There is a small typo in pdoc/doc.py.
Should read `belonging` rather than `beloing`.
| closed | 2019-12-14T10:53:52Z | 2020-04-12T21:21:25Z | https://github.com/mitmproxy/pdoc/issues/192 | [] | timgates42 | 0 |
JaidedAI/EasyOCR | deep-learning | 1,204 | Easyocr terminates without any error and the readtext function doesn't work. | While trying to read text from an image, the program terminates without any error and without any output.
Code:
import easyocr
import cv2
img = cv2.imread('abc.jpg')
reader = easyocr.Reader(['hi', 'en'], gpu=False)
results = reader.readtext(img, detail = 1, paragraph=False)
print(results)
Output:
Using... | open | 2024-01-25T10:12:37Z | 2025-01-15T02:21:33Z | https://github.com/JaidedAI/EasyOCR/issues/1204 | [] | ArqamNisar | 3 |
numpy/numpy | numpy | 27,654 | BUG: AttributeError: module 'numpy' has no attribute '_SupportsBuffer' | ### Describe the issue:
Trying to use `_SupportsBuffer` for type hinting results in the following cryptic error message: `AttributeError: module 'numpy' has no attribute '_SupportsBuffer'`.
This is strange since hinting succeeds seamlessly in Pylance, but on closer inspection one can realize that `_SupportsBuffer... | closed | 2024-10-28T14:16:53Z | 2024-10-30T02:10:28Z | https://github.com/numpy/numpy/issues/27654 | [
"00 - Bug"
] | glopesdev | 4 |
onnx/onnxmltools | scikit-learn | 588 | ValueError: Unable to create node 'TreeEnsembleClassifier' with name='WrappedLightGbmBoosterClassifier'. | I am trying to convert LightGBM model into ONNX.
I am using the following code. It worked few months back, but throwing
"ValueError: Unable to create node 'TreeEnsembleClassifier' with name='WrappedLightGbmBoosterClassifier'." error now.
Please let me know where this is going wrong.
https://github.com/Bhuvanam... | closed | 2022-10-03T11:50:36Z | 2022-10-13T09:15:32Z | https://github.com/onnx/onnxmltools/issues/588 | [] | Bhuvanamitra | 0 |
lk-geimfari/mimesis | pandas | 1,471 | generic.pyi has incorrect attribute for providers.Cryptographic | # Bug report
<!--
Hi, thanks for submitting a bug. We appreciate that.
But, we will need some information about what's wrong to help you.
-->
## What's wrong
<!-- Describe what is not working. Please, attach a traceback. -->
generic.pyi has incorrect attribute for providers.Cryptographic
https://github.... | closed | 2024-01-23T16:22:18Z | 2024-01-24T08:25:50Z | https://github.com/lk-geimfari/mimesis/issues/1471 | [] | MarcelWilson | 1 |
taverntesting/tavern | pytest | 160 | Module already imported so cannot be rewritten: tavern | Hello. i have this warning at the end of test. Where can be problem? Or is there some way to ignore warnings at least? Thank you. | closed | 2018-07-26T14:09:39Z | 2018-07-26T16:00:20Z | https://github.com/taverntesting/tavern/issues/160 | [] | zurek11 | 4 |
kennethreitz/responder | flask | 50 | Lean on Starlette. | Opening this issue first for discussion rather than just jumping in, because I want to understand where @kennethreitz would like to draw the boundaries on this.
There's currently quite a lot of duplication between Starlette and Responder. Starting with one class to consider there's [`responder.Response`](https://git... | closed | 2018-10-15T11:19:56Z | 2018-10-16T10:39:00Z | https://github.com/kennethreitz/responder/issues/50 | [] | tomchristie | 1 |
piskvorky/gensim | data-science | 3,360 | KeyedVectors.load_word2vec_format() can't load GoogleNews-vectors-negative300.bin | #### Problem description
KeyedVectors.load_word2vec_format() can't load GoogleNews-vectors-negative300.bin,
This is the my code.
```
from gensim.models.keyedvectors import KeyedVectors
gensim_model = KeyedVectors.load_word2vec_format(
'./GoogleNews-vectors-negative300.bin', binary=True, limit=300000)
```... | closed | 2022-07-01T12:54:46Z | 2022-07-02T06:30:12Z | https://github.com/piskvorky/gensim/issues/3360 | [] | xwz-19990627 | 2 |
Farama-Foundation/Gymnasium | api | 858 | [Question] Want some help in implementing sampling with masking for Box spaces? | ### Question
I am willing to contribute to implementing masking in sampling for `gymnasium.spaces.Box` and was curious if this is something on the roadmap. Also, would very much appreciate any help/advice on how to tackle this.
| closed | 2023-12-22T17:53:45Z | 2023-12-25T20:44:08Z | https://github.com/Farama-Foundation/Gymnasium/issues/858 | [
"question"
] | fracapuano | 3 |
pyppeteer/pyppeteer | automation | 124 | How to solve the ValueError: too many file descriptors in select() error of asyncio in Windows? Excuse me | How to solve the ValueError: too many file descriptors in select() error of asyncio in Windows? Excuse me | open | 2020-06-03T06:23:05Z | 2020-06-03T07:52:38Z | https://github.com/pyppeteer/pyppeteer/issues/124 | [
"waiting for info",
"can't reproduce"
] | pythonlw | 1 |
vvbbnn00/WARP-Clash-API | flask | 46 | 能否支持v2rayA | 家里软路由装的v2rayA,这个项目能否支持一下 | closed | 2024-02-22T06:31:38Z | 2024-02-28T06:25:41Z | https://github.com/vvbbnn00/WARP-Clash-API/issues/46 | [
"enhancement"
] | sillypy | 6 |
joeyespo/grip | flask | 232 | Suggestion for how to enter field values in ~/.grip/settings.py | Regarding https://github.com/joeyespo/grip#configuration may be helpful to explicitly instruct user to add field values inside single quotes.
Can be done by either linking to https://github.com/joeyespo/grip/blob/master/grip/settings.py for example syntax, or providing an example, e.g.
```
USERNAME = 'thisismyus... | closed | 2017-03-15T20:09:48Z | 2017-09-24T15:54:04Z | https://github.com/joeyespo/grip/issues/232 | [
"readme"
] | erikr | 2 |
saulpw/visidata | pandas | 1,804 | First sheet seen should be first arg on CLI | `a.json`:
```json
[{"a": 1, "b": 1}]
```
`b.json`:
```json
[{"b": 2, "c": 2}]
```
Then
`vd a.json b.json`.
the 1st table will be `b.json` and 2nd table will be `a.json`. However, in command line arguments, `a.json` is first and `b.json` is second. Why not make the order same? | closed | 2023-03-12T07:29:10Z | 2023-03-12T21:56:10Z | https://github.com/saulpw/visidata/issues/1804 | [
"By Design"
] | Freed-Wu | 1 |
InstaPy/InstaPy | automation | 5,923 | You have too few comments, please set at least 10 distinct comments to avoid looking suspicious. |
## Expected Behavior
to just run normally
## Current Behavior
`
ERROR [2020-11-24 18:05:01] [my account name] You have too few comments, please set at least 10 distinct comments to avoid looking suspicious.
`
## Possible Solution (optional)
nothing worked with me
## InstaPy configuration
```py
photo_... | open | 2020-11-24T16:27:23Z | 2022-03-08T18:07:30Z | https://github.com/InstaPy/InstaPy/issues/5923 | [
"wontfix"
] | AdhamHisham | 7 |
neuml/txtai | nlp | 469 | Add PyTorch ANN Backend | Add ANN backend that uses a PyTorch array. | closed | 2023-05-02T19:41:37Z | 2023-05-03T11:35:17Z | https://github.com/neuml/txtai/issues/469 | [] | davidmezzetti | 0 |
modoboa/modoboa | django | 2,517 | Display domain alarms in new UI | Domain alarms are currently not displayed in the new UI. | closed | 2022-05-18T15:33:31Z | 2022-06-13T07:38:35Z | https://github.com/modoboa/modoboa/issues/2517 | [
"enhancement",
"new-ui"
] | tonioo | 0 |
PrefectHQ/prefect | automation | 17,444 | Show task logs when clicking on task node in UI | ### Describe the current behavior
In the UI, currently if you click on a task node, the log window still only shows the flow run logs.
### Describe the proposed behavior
It would be convenient if the log window would show the logs for the task
### Example Use
_No response_
### Additional context
_No response_ | open | 2025-03-11T14:50:56Z | 2025-03-11T16:26:13Z | https://github.com/PrefectHQ/prefect/issues/17444 | [
"enhancement",
"ui"
] | cBournhonesque | 0 |
PokeAPI/pokeapi | api | 566 | MissingNo. Pokemon 0 | <!--
Please search existing issues to avoid creating duplicates.
Describe the feature you'd like.
Thank you!
-->
Pokemon #0: MissingNo.
I know it may not be the point, but an inclusion of MissingNo would be a nice little detail to include the glitched pokemon
| closed | 2021-01-28T19:17:59Z | 2021-02-18T15:21:36Z | https://github.com/PokeAPI/pokeapi/issues/566 | [] | NathanBorchelt | 4 |
schemathesis/schemathesis | pytest | 2,159 | [BUG] curl code samples omit non-printable characters | ### Checklist
- [x] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [x] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
- [x] I am using the latest version of Schemathesis
... | open | 2024-05-07T17:46:44Z | 2024-05-09T19:13:49Z | https://github.com/schemathesis/schemathesis/issues/2159 | [
"Type: Bug",
"Status: Needs Triage"
] | acdha | 3 |
dgtlmoon/changedetection.io | web-scraping | 1,827 | [feature] add audit log | we need an audit log
- date/time, exception if any, code, result, time, was change detected
this would probably help in the future for debugging/adding new plugins/methods too | open | 2023-09-29T23:00:41Z | 2023-10-27T08:25:33Z | https://github.com/dgtlmoon/changedetection.io/issues/1827 | [
"enhancement"
] | dgtlmoon | 1 |
dpgaspar/Flask-AppBuilder | flask | 1,722 | unable to run react app in react-rest-api | ### Environment
Flask-Appbuilder version: 3.3.3
npm version: 6.14.15
pip freeze output:
apispec==3.3.0
attrs==19.1.0
Babel==2.6.0
backcall==0.2.0
chardet==4.0.0
click==8.0.1
colorama==0.4.1
decorator==5.1.0
defusedxml==0.5.0
dnspython==1.16.0
email-validator==1.0.5
et-xmlfile==1.1.0
Flask==1.1.1
Fla... | closed | 2021-10-23T01:26:55Z | 2022-04-28T14:41:19Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1722 | [
"stale"
] | forestlzj | 1 |
holoviz/colorcet | plotly | 30 | Users Guide Palettes showing non-continuous artifacts | Several of the images in the users guide are showing strange non-continuous colors within parts of the palette:

 using an `OAuth2Session`, but I currently have to inject an access_token myself; here is an example using the openId connect passwo... | closed | 2019-11-15T22:53:25Z | 2020-05-23T05:37:33Z | https://github.com/lepture/authlib/issues/168 | [] | galak75 | 4 |
sinaptik-ai/pandas-ai | data-science | 1,469 | How to get the output of a large model instead of through the response | How to get the output of a large model instead of through the response | closed | 2024-12-11T02:28:59Z | 2024-12-13T15:38:19Z | https://github.com/sinaptik-ai/pandas-ai/issues/1469 | [] | lwdnxu | 8 |
TheAlgorithms/Python | python | 12,495 | Project Euler prohibits sharing answers to problems 101 and after | ### What would you like to share?
> I learned so much solving problem XXX, so is it okay to publish my solution elsewhere?
>
> It appears that you have answered your own question. There is nothing quite like that "Aha!" moment when you finally beat a problem which you have been working on for some time. It is often ... | open | 2025-01-03T02:26:08Z | 2025-01-03T02:26:08Z | https://github.com/TheAlgorithms/Python/issues/12495 | [
"awaiting triage"
] | hidesato-fujii | 0 |
microsoft/qlib | deep-learning | 1,075 | How to run HIST model by using alpha158 | ## ❓ Questions and Help
anyone can give me an introduction?I want to use HIST model on alpha158 | closed | 2022-04-25T12:53:36Z | 2022-08-10T21:01:59Z | https://github.com/microsoft/qlib/issues/1075 | [
"question",
"stale"
] | stockcoder | 4 |
sczhou/CodeFormer | pytorch | 326 | Face Inpainting is not working with custom masked datasets? | The Face Inpainting is working perfectly with provided examples, but it is not at all working with custom made datasets.
As mentioned in earlier comments that the Face Inpainting checkpoint is not released. Is it still the case as of now?
| open | 2023-12-01T09:00:31Z | 2025-02-13T09:55:22Z | https://github.com/sczhou/CodeFormer/issues/326 | [] | Mr-Nobody-dey | 4 |
csurfer/pyheat | matplotlib | 3 | Feature request: Scrollable heatmap for longer scripts | Longer (hundreds LOC) scripts will get squished by this. The solution would be breaking heatmap into manageable chunks and introducing GUI that would let you scroll through. Preferably with a minimap (a la Sublime Text) that shows where you are and overall heatmap of the script. | closed | 2017-02-06T14:14:49Z | 2018-12-06T05:25:55Z | https://github.com/csurfer/pyheat/issues/3 | [
"enhancement"
] | dmitrii-ubskii | 4 |
httpie/cli | rest-api | 660 | Ignore stdin when STDIN is closed | I ran into the bug reported in #150 and subsequently worked around in https://github.com/jakubroztocil/httpie/commit/f7b703b4bf365e5ba930649f7ba29901477e62b6 but under different circumstances.
In my case, `http` was being invoked as part of a BsdMakefile script. `bmake` helpfully buffers IO when performing a paralle... | closed | 2018-03-01T23:03:58Z | 2020-05-23T18:52:51Z | https://github.com/httpie/cli/issues/660 | [] | mqudsi | 3 |
flairNLP/flair | nlp | 3,097 | [Bug]: Multitask evaluation (and therefore training) fails on current master. | ### Describe the bug
The Multitask training fails when evaluating, as it now gets a `str` for the label_type, while still expecting a dictionary.
### To Reproduce
```python
from flair.embeddings import TransformerWordEmbeddings
from flair.trainers import ModelTrainer
from flair.models import SequenceTagger, Relati... | closed | 2023-02-10T13:45:48Z | 2023-02-14T09:56:12Z | https://github.com/flairNLP/flair/issues/3097 | [
"bug"
] | helpmefindaname | 0 |
lux-org/lux | jupyter | 49 | Lux Errors when `set_index` | ```
df = pd.read_csv("../../lux/data/state_timeseries.csv")
df["Date"] = pd.to_datetime(df["Date"])
df.set_index(["Date"])
```
This is happening because the executor expects a flat table and pre_aggregate is inferred as False for this table. | closed | 2020-07-28T03:49:22Z | 2021-01-09T12:13:45Z | https://github.com/lux-org/lux/issues/49 | [
"bug",
"priority"
] | dorisjlee | 2 |
JoeanAmier/XHS-Downloader | api | 211 | 同一笔记的下载内容的增加(如第一次下载的时候没有下载实况图,下载完以后又选择了这个选项重新)会被判定为已下载而跳过 | 第二个问题,我无法删除下载记录,输入id后再下载任会显示存在记录 | closed | 2025-01-02T13:43:55Z | 2025-01-04T14:01:52Z | https://github.com/JoeanAmier/XHS-Downloader/issues/211 | [
"功能异常(bug)"
] | peoplechinapower | 1 |
Teemu/pytest-sugar | pytest | 29 | Missing tests | closed | 2014-02-06T16:51:12Z | 2020-08-25T18:29:00Z | https://github.com/Teemu/pytest-sugar/issues/29 | [] | Teemu | 3 | |
flasgger/flasgger | flask | 427 | How to change UI language? | Hi!
How to change UI language?
I commented out:
```
<script src='lang/translator.js' type='text/javascript'></script>
<script src='lang/ru.js' type='text/javascript'></script>
```
In all index.html files in flasgger package folders, but nothing happens. | open | 2020-08-21T08:21:44Z | 2020-08-21T08:21:44Z | https://github.com/flasgger/flasgger/issues/427 | [] | nxbx | 0 |
home-assistant/core | python | 141,044 | After reboot HA, Tado failed to setup: Login failed for unknown reason with status code 403 | ### The problem
After a reboot of HA, I suddenly got notified that the Tado integration failed to setup.
It showed a configure button to configure the fallback method, but this didn't change anything.
Tried to reconfigure by entering my password again, failed with "unexpected error"
When I check in the logs I first... | closed | 2025-03-21T08:02:39Z | 2025-03-22T10:36:10Z | https://github.com/home-assistant/core/issues/141044 | [
"integration: tado"
] | Kraganov | 2 |
AutoGPTQ/AutoGPTQ | nlp | 647 | Why doesn't AutoGPTQ quantize lm_head layer? | Is there a paper/article/blog post explaining such decision? Or is it just simply a feature that not being supported at the moment? | open | 2024-04-25T10:56:58Z | 2024-08-21T03:39:01Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/647 | [] | XeonKHJ | 6 |
flasgger/flasgger | rest-api | 595 | Unable to use import in yaml definitions with relative path | Hi,
I'm having trouble using the `import: "some.yaml"` function in yaml files. I'm using a setup where the API descriptions are in separate files and I use Blueprints to define the API itself. I'd like to remove a lot of redundancy in parameters by using `$ref` and it would be great to use the `import` option in the y... | open | 2023-09-14T12:15:35Z | 2023-09-14T12:15:35Z | https://github.com/flasgger/flasgger/issues/595 | [] | aokros | 0 |
pytest-dev/pytest-qt | pytest | 570 | Fatal Python error: Aborted | I run into the following error when trying to run pytest with qtbot:
```shell
tests/test_core.py Fatal Python error: Aborted
Current thread 0x00007fa369115740 (most recent call first):
File "/home/username/project/venv/lib/python3.10/site-packages/pytestqt/plugin.py", line 76 in qapp
File "/home/username/p... | closed | 2024-10-05T15:43:29Z | 2024-10-05T17:56:16Z | https://github.com/pytest-dev/pytest-qt/issues/570 | [
"question :question:"
] | bimac | 2 |
reloadware/reloadium | flask | 131 | Reloadium support for ARM64 | ## Describe the bug*
Realoding support for arm architecture
## Screenshots

Would like to get reloadium support for ARM architecture, which is great, looking forward for this to resolve asap | open | 2023-03-30T05:02:46Z | 2024-11-20T11:45:35Z | https://github.com/reloadware/reloadium/issues/131 | [
"enhancement"
] | raaghulr | 15 |
ContextLab/hypertools | data-visualization | 200 | ImportError: cannot import name UMAP | Hi! I encountered a strange problem:
In [1]: import hypertools
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-1-48afb9e37bd3> in <module>()
----> 1 import hypertools
/root/Desktop/hypertools/h... | closed | 2018-04-29T07:10:07Z | 2020-09-30T11:54:20Z | https://github.com/ContextLab/hypertools/issues/200 | [] | RobinYang125 | 9 |
huggingface/datasets | numpy | 6,624 | How to download the laion-coco dataset | The laion coco dataset is not available now. How to download it
https://huggingface.co/datasets/laion/laion-coco | closed | 2024-01-28T03:56:05Z | 2024-02-06T09:43:31Z | https://github.com/huggingface/datasets/issues/6624 | [] | vanpersie32 | 1 |
dunossauro/fastapi-do-zero | pydantic | 282 | Atualizar fastapi para ultima versão | closed | 2025-01-23T20:32:37Z | 2025-01-29T05:36:40Z | https://github.com/dunossauro/fastapi-do-zero/issues/282 | [] | dunossauro | 0 | |
ultralytics/yolov5 | pytorch | 12,540 | Yolov5-7.0 steps to enable amp mixing accuracy | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar feature requests.
### Description
Hello author, are there any steps to enable amp to train the model in YOLOv5-7.0
### Use case
_No response_
### Additional
_No response_
### Ar... | closed | 2023-12-22T00:52:09Z | 2024-10-20T19:35:11Z | https://github.com/ultralytics/yolov5/issues/12540 | [
"enhancement",
"Stale"
] | yxl23 | 8 |
FlareSolverr/FlareSolverr | api | 478 | [mteamtp] (updating) The cookies provided by FlareSolverr are not valid | **Please use the search bar** at the top of the page and make sure you are not creating an already submitted issue.
Check closed issues as well, because your issue may have already been fixed.
### How to enable debug and html traces
[Follow the instructions from this wiki page](https://github.com/FlareSolverr/Fl... | closed | 2022-08-24T01:38:14Z | 2022-08-24T03:07:57Z | https://github.com/FlareSolverr/FlareSolverr/issues/478 | [
"invalid"
] | adamhzu | 1 |
tiangolo/uwsgi-nginx-flask-docker | flask | 267 | ARM64 support | Are there any intentions to support arm64/aarch64 Architectures, if not what are possible alternatives | closed | 2022-01-26T14:29:51Z | 2024-08-29T00:24:27Z | https://github.com/tiangolo/uwsgi-nginx-flask-docker/issues/267 | [] | ibraheemalayan | 3 |
public-apis/public-apis | api | 4,193 | Invalid Sites | # Invalid Sites:
[Studio Ghibli](https://ghibliapi.herokuapp.com/) Resources from Studio Ghibli films No Yes Yes
[ColourLovers](http://www.colourlovers.com/api) Get various patterns, palettes and images No No Unknown
[xColors](https://x-colors.herokuapp.com/) Generate & convert colors No Yes Yes
[0x](https://0x.org/api... | open | 2025-03-17T17:01:55Z | 2025-03-17T18:28:20Z | https://github.com/public-apis/public-apis/issues/4193 | [] | amandaguan-ag | 0 |
streamlit/streamlit | machine-learning | 10,880 | `st.dataframe` displays wrong indizes for pivoted dataframe | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
Under some conditions streamlit will display ... | open | 2025-03-23T15:50:44Z | 2025-03-24T13:49:35Z | https://github.com/streamlit/streamlit/issues/10880 | [
"type:bug",
"feature:st.dataframe",
"status:confirmed",
"priority:P3",
"feature:st.data_editor"
] | punsii2 | 2 |
modelscope/data-juicer | data-visualization | 449 | [Feat]: Enhance Unit Test Coverage for Python and CUDA Compatibility | ### Search before continuing 先搜索,再继续
- [X] I have searched the Data-Juicer issues and found no similar feature requests. 我已经搜索了 Data-Juicer 的 issue 列表但是没有发现类似的功能需求。
### Description 描述
To address potential compatibility issues with libraries like `vllm`, `torch`, `numpy`, etc., it's crucial to enhance our test cover... | open | 2024-10-16T02:08:16Z | 2024-10-16T02:19:38Z | https://github.com/modelscope/data-juicer/issues/449 | [
"enhancement"
] | drcege | 0 |
tensorflow/tensor2tensor | deep-learning | 933 | tpu fails if eval_steps is too high | on tpu, if the eval_steps it greater than the dev_data_len/batch_size/8 we get a Out of range: End of sequence error. this does not happen for cpu/gpu. perhaps we can fix the docs, and maybe also suggest the appropriate value when it is too high. | open | 2018-07-12T01:06:23Z | 2018-09-26T21:23:21Z | https://github.com/tensorflow/tensor2tensor/issues/933 | [] | eyaler | 1 |
peerchemist/finta | pandas | 71 | Why is the result different depending on the size of input dataframe? | <!-- Describe the issue -->
Thank you for the good library!
I want to ask a question that I am not sure if it is my fault or a library issue.
I calculated MACD with 100rows of 1 minute ohlcv historical data.
First, I calculated it with whole 100 rows, and then I calculated it with last 80 rows.
And I saw that r... | closed | 2020-07-05T14:13:10Z | 2020-10-25T10:27:13Z | https://github.com/peerchemist/finta/issues/71 | [] | sukwoo1414 | 2 |
assafelovic/gpt-researcher | automation | 646 | TypeError in Config class initialization and ensure proper type handling and directory validation. Solution Provided! | Issue
The Config class initialization in the GPT Researcher project was encountering a TypeError due to the config_file parameter being passed as a WebSocket object instead of a string representing the file path. This caused the os.path.expanduser function to fail, as it expected a string, bytes, or os.PathLike object... | closed | 2024-07-06T11:49:13Z | 2024-07-06T13:42:12Z | https://github.com/assafelovic/gpt-researcher/issues/646 | [] | ahmad-thewhiz | 1 |
youfou/wxpy | api | 225 | 怎么发图片,看教程没有成功过。 | <img width="486" alt="2017-11-09 3 20 10" src="https://user-images.githubusercontent.com/37678/32593087-83e117aa-c561-11e7-8b8c-8e1d1e33a6dd.png">
| open | 2017-11-09T07:20:40Z | 2017-11-09T07:20:40Z | https://github.com/youfou/wxpy/issues/225 | [] | xiaods | 0 |
huggingface/datasets | machine-learning | 6,465 | `load_dataset` uses out-of-date cache instead of re-downloading a changed dataset | ### Describe the bug
When a dataset is updated on the hub, using `load_dataset` will load the locally cached dataset instead of re-downloading the updated dataset
### Steps to reproduce the bug
Here is a minimal example script to
1. create an initial dataset and upload
2. download it so it is stored in cache
3. c... | open | 2023-12-02T21:35:17Z | 2024-08-20T08:32:11Z | https://github.com/huggingface/datasets/issues/6465 | [] | mnoukhov | 2 |
benbusby/whoogle-search | flask | 289 | [FEATURE] Let the iBangs !i, !v, and !n go to Whoogle's own image, video and news search | **Describe the feature you'd like to see added**
Right now the iBangs !i, !v, and !n goes to duckduckgo. This is not bad but i think it should be better to integrate them with whoogle instead. And besides, image, video and news search isn't available with duckduckgo when javascript is off. | closed | 2021-04-16T11:35:01Z | 2024-04-19T18:26:43Z | https://github.com/benbusby/whoogle-search/issues/289 | [
"enhancement"
] | alkarkhi | 3 |
tensorpack/tensorpack | tensorflow | 1,226 | Training FasterRCNN using scientific dataset |
I have a special dataset about extreme weather, each image has 16 channels and high resolution(768*1152), see https://extremeweatherdataset.github.io/.
My questions are:
1. Since there is no pre-trained model of the weather data, can I train the whole model including the base network?
2. The FasterRCNN code is im... | closed | 2019-06-05T08:15:07Z | 2019-06-18T08:38:58Z | https://github.com/tensorpack/tensorpack/issues/1226 | [
"examples"
] | jiangzihanict | 10 |
dpgaspar/Flask-AppBuilder | rest-api | 1,719 | Can't display list and direct_chart in class MultipleView(BaseView): | class ProceduresPatientsTimeChartView(DirectChartView):
datamodel = SQLAInterface(ProceduresPatients)
chart_type = "ColumnChart"
direct_columns = { "Draw": ("Data", "id")
}
base_order = ("Data", "asc")
class MultipleViewsExp(MultipleView):
views = [ ProceduresPatientsTimeCha... | closed | 2021-10-19T08:24:51Z | 2022-04-28T14:41:18Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1719 | [
"stale"
] | vash-sa | 1 |
biolab/orange3 | numpy | 6,447 | Widget search | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
Hello all,
A small quick-win : I noticed the widgets are not alphabetically ordered. I unders... | closed | 2023-05-15T07:28:01Z | 2023-07-04T09:13:09Z | https://github.com/biolab/orange3/issues/6447 | [] | simonaubertbd | 6 |
mirumee/ariadne | api | 179 | Move documentation to separate repo and host it on gh-pages | Sphinx has served us well, but we fell its too limiting for what we have planned for Ariadne.
We've decided to migrate the site to the [Docusaurus](https://docusaurus.io) and keep it on separate repo. | closed | 2019-05-20T11:37:14Z | 2019-05-23T14:05:30Z | https://github.com/mirumee/ariadne/issues/179 | [
"docs"
] | rafalp | 0 |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 178 | what is "old_face_label_folder". | I found it seem need a label? but how to generate the label is not mentioned in Readme and Jouranl paper.
line26 of Face_Enhancement/data/face_dataset.py
image_path = os.path.join(opt.dataroot, opt.old_face_folder)
label_path = os.path.join(opt.dataroot, opt.old_face_label_folder) | closed | 2021-06-17T11:58:07Z | 2021-07-05T04:53:53Z | https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life/issues/178 | [] | geshihuazhong | 1 |
piskvorky/gensim | data-science | 3,096 | Segfault when training FastText model | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | open | 2021-03-30T15:27:11Z | 2021-04-01T22:13:43Z | https://github.com/piskvorky/gensim/issues/3096 | [
"bug",
"impact HIGH",
"reach MEDIUM"
] | TimotheeMickus | 9 |
Anjok07/ultimatevocalremovergui | pytorch | 1,720 | KeyError / Traceback Error / UVR.py & separate.py | I keep receiving the following error on every model I've tried so far:
```
Last Error Received:
Process: MDX-Net
If this error persists, please contact the developers with the error details.
Raw Error Details:
KeyError: "'All Stems'"
Traceback Error: "
File "UVR.py", line 6860, in process_start
File "separate... | closed | 2025-01-29T01:21:56Z | 2025-01-29T21:56:08Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1720 | [] | scadams | 1 |
tensorflow/tensor2tensor | deep-learning | 1,326 | got same translate result | ### Description
hey, I exported the model using the command it provide. but when I predict new query, it always output the same thing. I tried to check few things and find that response = stub.Predict(request, timeout_secs) (from serving_utils.py ) always return the same value. any idea whats got wrong here ?
>> H... | open | 2018-12-24T09:12:26Z | 2019-06-25T09:21:19Z | https://github.com/tensorflow/tensor2tensor/issues/1326 | [] | xiaoxiong1988 | 1 |
ivy-llc/ivy | tensorflow | 28,509 | Fix Frontend Failing Test: numpy - math.paddle.conj | To-do List: https://github.com/unifyai/ivy/issues/27497 | closed | 2024-03-08T11:05:35Z | 2024-03-14T21:30:36Z | https://github.com/ivy-llc/ivy/issues/28509 | [
"Sub Task"
] | ZJay07 | 0 |
guohongze/adminset | django | 30 | 获取CPU数量的方法需要修改 | install/client/adminset_agent.py
修改:
cpu_cores = {"physical": psutil.cpu_count(logical=False) if psutil.cpu_count(logical=False) else 0, "logical": psutil.cpu_count()} | closed | 2017-11-25T05:36:45Z | 2018-02-17T11:46:21Z | https://github.com/guohongze/adminset/issues/30 | [] | fjibj | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 1,285 | Failed to build webrtcvad when installing a package | Hi, sorry for bothering but I had and an issue trying to install a package with pip, I don't know if maybe it's an error I'm making but I haven't been able to solve it.
This is what I was trying to install and the error that appeared
```
pip install ffsubsync
Defaulting to user installation because normal si... | closed | 2024-01-15T01:51:04Z | 2024-02-07T19:13:26Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1285 | [] | emanuelps2708 | 3 |
kornia/kornia | computer-vision | 2,496 | Documentation on SOLD2 config parameters | ## 📚 Documentation
SOLD2 line segment detection results vary drastically with respect to hyper-parameters/configs
```
default_cfg: Dict[str, Any] = {
'backbone_cfg': {'input_channel': 1, 'depth': 4, 'num_stacks': 2, 'num_blocks': 1, 'num_classes': 5},
'use_descriptor': True,
'grid_size': 8,
... | open | 2023-08-02T21:12:11Z | 2023-10-10T22:52:09Z | https://github.com/kornia/kornia/issues/2496 | [
"docs :books:",
"code heatlh :pill:"
] | ogencoglu | 1 |
Nemo2011/bilibili-api | api | 687 | [BUG] cookies 刷新报错 | **Python 版本:** 3.11.5
**模块版本:** 最新dev分支
**运行环境:** Windows
<!-- 务必提供模块版本并确保为最新版 -->
---
执行刷新函数的时候,抛出了异常
```
Traceback (most recent call last):
File "e:\Project\bili\bili.py", line 90, in <module>
check_login()
File "e:\Project\bili\bili.py", line 43, in check_login
sync(credential.refres... | closed | 2024-02-20T01:38:35Z | 2024-03-15T14:21:07Z | https://github.com/Nemo2011/bilibili-api/issues/687 | [
"bug",
"need debug info"
] | gongdananyou | 13 |
amidaware/tacticalrmm | django | 1,092 | When first loading the dashboard, no agents are shown in the list | **Server Info (please complete the following information):**
- OS: Ubuntu 20.04
- Browser: Google Chrome
- RMM Version (as shown in top left of web UI): v.0.13.1
**Installation Method:**
- [ ] Standard
- [x] Docker
**Agent Info (please complete the following information):**
- Agent version (as shown ... | closed | 2022-04-24T11:00:02Z | 2022-04-25T00:49:34Z | https://github.com/amidaware/tacticalrmm/issues/1092 | [
"bug",
"fixed"
] | JoachimVeulemans | 5 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 45 | Make calculate_accuracies class based | The ```calculate_accuracies``` module should be converted to class form so that users can extend it, override functions, add their own accuracy metrics easily etc. | closed | 2020-04-11T09:31:06Z | 2020-04-12T07:39:08Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/45 | [
"enhancement"
] | KevinMusgrave | 1 |
cupy/cupy | numpy | 8,155 | Incomplete type when compiling a `wmma::fragment` type with jitify | I'm not sure whether this is an issue with CuPy, but I am running into another problem. It works when `jitify=False`. But as it is, I'm just getting an incomplete type error. Compiling just the kernel code for the following does work with NVCC even though the Intellisense is messed up when loaded in Visual Studio.
`... | closed | 2024-02-02T21:00:20Z | 2024-02-05T05:09:28Z | https://github.com/cupy/cupy/issues/8155 | [
"cat:bug"
] | mrakgr | 1 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 342 | mdtex2html没有这个包 | *提示:将[ ]中填入x,表示打对钩。提问时删除这行。只保留符合的选项。*
### 详细描述问题
*请尽量具体地描述您遇到的问题,**必要时给出运行命令**。这将有助于我们更快速地定位问题所在。*
### 运行截图或日志
*请提供文本log或者运行截图,以便我们更好地了解问题详情。*
### 必查项目(前三项只保留你要问的)
- [ ] **基础模型**:LLaMA / Alpaca / LLaMA-Plus / Alpaca-Plus
- [ ] **运行系统**:Windows / MacOS / Linux
- [ ] **问题分类**:下载问题 / 模型转换和合并 / 模型训练与... | closed | 2023-05-16T04:09:01Z | 2023-05-17T11:33:46Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/342 | [] | SunYHY | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.