
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
erdewit/ib_insync | asyncio | 387 | possible documentation error with updateEvent | First thanks for developing this library. It has proved very useful.
The API documentation (https://ib-insync.readthedocs.io/api.html) states the following:
```
updateEvent (): Is emitted after a network packet has been handeled.
barUpdateEvent (bars: BarDataList, hasNewBar: bool): Emits the bar list that has b... | closed | 2021-07-16T14:55:16Z | 2021-07-29T14:02:05Z | https://github.com/erdewit/ib_insync/issues/387 | [] | laker-93 | 1 |
kennethreitz/responder | flask | 217 | ModuleNotFoundError: No module named 'starlette.debug' | I got the following error when running docs examples with Responder 1.1.1
```
Traceback (most recent call last):
File "myapp/api.py", line 1, in <module>
import responder
File "/home/julien/.local/share/virtualenvs/python-spa-starter-Pu8Jxsg6/lib/python3.7/site-packages/responder/__init__.py", line 1, in <... | closed | 2018-11-09T13:31:18Z | 2018-11-15T10:50:42Z | https://github.com/kennethreitz/responder/issues/217 | [] | jkermes | 5 |
AlexMathew/scrapple | web-scraping | 49 | Add tests | Tests for verifying CSV output from run/generate need to be added. #44 and #46
| closed | 2015-03-15T12:50:46Z | 2017-02-24T08:44:15Z | https://github.com/AlexMathew/scrapple/issues/49 | [] | AlexMathew | 0 |
sktime/pytorch-forecasting | pandas | 1,099 | when use weight param in TimeSeriesDataSet, raised RuntimeError: The size of tensor a (128) must match the size of tensor b (12) at non-singleton dimension 1 | - PyTorch-Forecasting version:0.10.1
- PyTorch version: 1.11.0
- Python version:3.7.4
- Operating System: centos
### Expected behavior
I executed code
TimeSeriesDataSet(
data[lambda x: x.time_idx <= training_cutoff],
time_idx="time_idx",
target="value",
group_ids=["series"],
time_var... | open | 2022-08-12T05:46:04Z | 2023-04-04T10:34:39Z | https://github.com/sktime/pytorch-forecasting/issues/1099 | [] | tuhulihongbing | 3 |
Lightning-AI/pytorch-lightning | data-science | 19,803 | Current FSDPPrecision does not support custom scaler for 16-mixed precision | ### Bug description

`self.precision` here inherits from parent class `Precision`, so it is always "32-true"
 into pyg. The implementation would be similar to e.g. GraphSAGE. There is alread... | open | 2024-11-14T16:01:17Z | 2024-11-14T16:01:17Z | https://github.com/pyg-team/pytorch_geometric/issues/9786 | [
"feature"
] | goelzva | 0 |
microsoft/nni | data-science | 5,298 | cannot fix the mask of the interdependent layers | **Describe the issue**:
When i pruned the segmentation model.After saving the mask.pth,when i speed up ,the mask cannot fix the new architecture of the model
**Environment**:
- NNI version:2.0
- Training service (local|remote|pai|aml|etc):local
- Client OS:ubuntu
- Server OS (for remote mode only):
- Python ... | closed | 2022-12-23T11:12:32Z | 2023-02-24T02:36:58Z | https://github.com/microsoft/nni/issues/5298 | [] | sungh66 | 10 |
microsoft/MMdnn | tensorflow | 900 | shape inference error in depthwise_conv | Platform: ubuntu
MMdnn version: 0.3.1
Source framework with version: Tensorflow 1.13.1
Pre-trained model: mobilenet_v1
from https://github.com/tensorflow/models/tree/master/research/slim/nets
Running scripts: mmtoir
Description: shape inference error in parsing depthwise_conv (converting from tf-slim ... | open | 2020-10-10T05:05:07Z | 2020-10-12T06:44:29Z | https://github.com/microsoft/MMdnn/issues/900 | [] | xianyuggg | 2 |
gradio-app/gradio | data-visualization | 10,171 | Allow specifying custom dictionary keys for event input. | - [x] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
When using dictionaries as event inputs in Gradio, we can only use component objects themselves as dictionary keys. This makes it difficult to separate event handling functions from c... | open | 2024-12-10T20:16:39Z | 2024-12-10T20:19:57Z | https://github.com/gradio-app/gradio/issues/10171 | [
"enhancement",
"needs designing"
] | L9qmzn | 0 |
axnsan12/drf-yasg | rest-api | 395 | Add support to include generated or custom openapi schema into UI view's HTML output | Is there a way to set the `swagger-ui` `spec` property using the generated schema instead of the `url` property when loading swagger-ui via `drf-yasg`?
By including the schema in the HTML file directly, the generated HTML page with swagger-ui should be able to be "saved" for offline reading, as well as avoid a 2nd r... | open | 2019-06-27T18:15:26Z | 2025-03-07T12:16:23Z | https://github.com/axnsan12/drf-yasg/issues/395 | [
"triage"
] | devmonkey22 | 1 |
robotframework/robotframework | automation | 4,626 | Inconsistent argument conversion when using `None` as default value with Python 3.11 and earlier | there is something strange happening with Python 3.11 and type hints and auto conversion.
When you have a Type Hint Any and default Value is None in 3.11 'none' is always converted to None while in 3.10. it stays a string.
Given that Test:
```robotframework
*** Settings ***
Library mylib.py
*** Test Cases ... | closed | 2023-01-31T18:55:54Z | 2023-03-15T12:50:24Z | https://github.com/robotframework/robotframework/issues/4626 | [
"bug",
"priority: medium",
"alpha 1"
] | Snooz82 | 6 |
mage-ai/mage-ai | data-science | 5,043 | Add agnostic path for project files | **DBT config yaml**
Working with the magician on different operating systems (Win, Unix, Mac), we discovered that the paths to dbt models are saved differently in yaml files depending on this. for example, `dbts\run_all.yaml` in Win. Is it possible to make path formation independent of the operating system, at least w... | open | 2024-05-08T07:09:54Z | 2024-05-08T07:09:54Z | https://github.com/mage-ai/mage-ai/issues/5043 | [] | FelixMiksonAramMeem | 0 |
microsoft/nni | pytorch | 5,660 | nni norm_pruning example error | Hello!
I am trying to locally run a pytorch version of one of the pruning examples (nni/examples/compression/pruning/norm_pruning.py).
However, it seems that the config_list that is generate from the function "auto_set_denpendency_group_ids" has some problem.
**The config_list is:**
[{'op_names': ['layer3.1.conv1... | closed | 2023-08-13T13:32:48Z | 2023-08-17T07:30:54Z | https://github.com/microsoft/nni/issues/5660 | [] | NoyLalzary | 0 |
aio-libs/aiomysql | asyncio | 592 | Any plans to support PyMySQL-1.0.2 | Current version aiomysql require PyMySQL<=0.9.3,>=0.9
Do exist any planning when will be supported PyMySQL > 1.0.0
for example for TLS support. | closed | 2021-06-16T15:34:55Z | 2022-01-13T17:35:56Z | https://github.com/aio-libs/aiomysql/issues/592 | [
"enhancement",
"pymysql"
] | jpVm5jYYRE1VIKL | 3 |
pywinauto/pywinauto | automation | 433 | How should I find and use custom controls of WPF application? | I testing a WPF App, it contains some **custom controls.**. I do not have a way to find the operation in the document
How shuld I do ?
| open | 2017-11-01T09:46:12Z | 2017-11-01T20:09:02Z | https://github.com/pywinauto/pywinauto/issues/433 | [
"enhancement",
"New Feature"
] | fangchaooo | 2 |
yunjey/pytorch-tutorial | pytorch | 75 | captioning code doesn't run | Hi. I am getting the error below. I hope someone can help @jtoy
```
python sample.py --image='png/example.png'
Traceback (most recent call last):
File "sample.py", line 97, in <module>
main(args)
File "sample.py", line 61, in main
sampled_ids = decoder.sample(feature)
File "/home/shas/sandbox/p... | closed | 2017-10-24T01:57:34Z | 2018-05-10T08:56:17Z | https://github.com/yunjey/pytorch-tutorial/issues/75 | [] | ShasTheMass | 3 |
xonsh/xonsh | data-science | 4,934 | xonfig web fails with AssertionError | Steps to reproduce on macOS 12.5.1:
* brew install xonsh
* xonfig web
Webpage doesn't load for long time. Then error in console appears: `Failed to parse color-display ParseError('syntax error: line 1, column 0')`
Details:
<details>
```
(base) maye@Michaels-Mini ~/.config $ xonfig web
Web config start... | closed | 2022-09-08T18:59:50Z | 2022-09-15T12:55:24Z | https://github.com/xonsh/xonsh/issues/4934 | [
"mac osx",
"xonfig",
"xonfig-web"
] | michaelaye | 7 |
BeanieODM/beanie | asyncio | 318 | Why Input model need to be init with beanie? | Hi I'm using beanie with fastapi.
this is my model:
```
class UserBase(Document):
username: str | None
parent_id: str | None
role_id: str | None
payment_type: str | None
disabled: bool | None
note: str | None
access_token: str | None
class UserIn(UserBase):
username: s... | closed | 2022-07-29T04:42:10Z | 2022-07-30T05:58:07Z | https://github.com/BeanieODM/beanie/issues/318 | [] | nghianv19940 | 3 |
joeyespo/grip | flask | 161 | automatically open in a browser | Easily done with [`webbrowser`](https://docs.python.org/2/library/webbrowser.html), see [`antigravity.py`](https://github.com/python/cpython/blob/master/Lib/antigravity.py) for example usage. ;-)
``` python
import webbrowser
webbrowser.open("http://localhost:6419/")
```
| closed | 2016-01-21T21:20:51Z | 2016-01-21T22:07:36Z | https://github.com/joeyespo/grip/issues/161 | [
"already-implemented"
] | chadwhitacre | 2 |
TracecatHQ/tracecat | pydantic | 61 | Add PII redacting loggers | Related to #62 | closed | 2024-04-18T01:51:31Z | 2024-07-02T20:46:55Z | https://github.com/TracecatHQ/tracecat/issues/61 | [] | daryllimyt | 0 |
lanpa/tensorboardX | numpy | 450 | add_image() won't work without NVIDIA GPU | **Describe the bug**
When calling add_image() for a CPU FloatTensor, it still fails in case there is no NVIDIA GPU available. The reason for this is an assert in summary.py which will check whether the tensor is an instance of torch.cuda.FloatTensor. This causes the following behaviour:
```
python test.py
Traceback... | closed | 2019-06-16T16:33:50Z | 2019-10-21T11:57:38Z | https://github.com/lanpa/tensorboardX/issues/450 | [] | blDraX | 1 |
geopandas/geopandas | pandas | 3,338 | BUG: to_postgis broken using sqlalchemy 1.4 | - [X ] I have checked that this issue has not already been reported.
- [X ] I have confirmed this bug exists on the latest version of geopandas.
- [ ] (optional) I have confirmed this bug exists on the main branch of geopandas.
---
#### Problem description
I'm trying to inject a geodataframe content into... | closed | 2024-06-12T15:45:29Z | 2024-06-13T15:22:29Z | https://github.com/geopandas/geopandas/issues/3338 | [
"bug",
"needs triage"
] | fvallee-bnx | 2 |
plotly/dash-cytoscape | dash | 192 | [BUG] Elements positions don't match specification in preset layout | #### Description
https://github.com/plotly/dash-cytoscape/assets/101562106/7e767f5a-9edb-4cb5-b160-a4324b7ce2d3
- We have a Dash App with two main callbacks and a container where we can see 3 different cytoscape graphs - only one at a time, the difference between the three graphs is the number of nodes (20, 30, 4... | open | 2023-07-21T14:25:15Z | 2023-07-21T14:25:15Z | https://github.com/plotly/dash-cytoscape/issues/192 | [] | celia-lm | 0 |
serengil/deepface | machine-learning | 519 | Mediapipe imported but no output | Hi Mr. Sefik,
I am trying to create embeddings of a dataset using mediapipe and facenet.
The model and detector are built successfully but there is not progress in the embeddings task (see image below):
<img width="569" alt="Screen Shot 2022-07-22 at 18 02 40" src="https://user-images.githubusercontent.com/4606... | closed | 2022-07-22T14:03:56Z | 2022-07-24T11:09:40Z | https://github.com/serengil/deepface/issues/519 | [
"dependencies"
] | MKJ52 | 4 |
ultralytics/ultralytics | machine-learning | 19,063 | Transfer Learning from YOLOv9 to YOLOv11 | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello YOLO team,
I have a YOLOv9 segmentation model trained on a large cus... | open | 2025-02-04T11:37:07Z | 2025-02-04T16:44:22Z | https://github.com/ultralytics/ultralytics/issues/19063 | [
"question",
"pose"
] | VelmCoder | 2 |
jupyter/docker-stacks | jupyter | 1,530 | Latest scipy-notebook:lab-3.1.18 docker image actually contains lab 3.2.0 | The latest docker image for `jupyter/scipy-notebook:lab-3.1.18` does not contain Jupyter Lab 3.1.18, but 3.2.0. This is an issue if one needs to stay on 3.1.x for some reason.
**What docker image you are using?**
`jupyter/scipy-notebook:lab-3.1.18`, specifically `jupyter/scipy-notebook@sha256:4aa1a2cc3126d490c8c6... | closed | 2021-11-15T12:48:43Z | 2022-07-05T11:31:18Z | https://github.com/jupyter/docker-stacks/issues/1530 | [
"type:Bug"
] | carlosefr | 8 |
alteryx/featuretools | data-science | 2,591 | Add document of how to do basic aggregation on non-default data type [e.g. max(datetime_field) group by] | Hi,
I am using featuretools (1.27 version), I read the docs ,and also searched here
but still struggle to find how to do simple things like SELECT MIN(datetime_field_1) from table
I also checked list_primitives() those related to time, seem not what I need,
I can do this for numeric fields, but seems can't... | closed | 2023-07-26T01:20:21Z | 2023-08-21T14:50:51Z | https://github.com/alteryx/featuretools/issues/2591 | [
"documentation"
] | wanalytics8 | 3 |
pyjanitor-devs/pyjanitor | pandas | 745 | [DOC] Check that all functions have a `return` and `raises` section within docstrings | # Brief Description of Fix
<!-- Please describe the fix in terms of a "before" and "after". In other words, what's not so good about the current docs
page, and what you would like to see it become.
Example starter wording is provided. -->
Currently, the docstrings for some functions are lacking a `return` des... | closed | 2020-09-13T01:34:28Z | 2020-10-03T13:15:27Z | https://github.com/pyjanitor-devs/pyjanitor/issues/745 | [
"good first issue",
"docfix",
"being worked on",
"hacktoberfest"
] | loganthomas | 8 |
abhiTronix/vidgear | dash | 59 | How to set framerate with ScreenGear | ## Question
I would like to set the frame rate with which the ScreenGear module acquires the frames from my monitor.
How can I do it?
### Other details:
If I grab a small frame, I will have very slow down video effect (i.e. I record for 10 seconds but the writed video is 1 minute), since it is able to grab many f... | closed | 2019-10-24T09:23:46Z | 2019-11-13T06:34:55Z | https://github.com/abhiTronix/vidgear/issues/59 | [
"INVALID :stop_sign:",
"QUESTION :question:"
] | FrancescoRossi1987 | 3 |
aeon-toolkit/aeon | scikit-learn | 2,129 | [ENH] k-Spectral Centroid (k-SC) clusterer | ### Describe the feature or idea you want to propose
A popular clusterer in the TSCL literature is the k-Spectral Centroid (k-SC). A link to the paper can be found at: https://dl.acm.org/doi/10.1145/1935826.1935863.
### Describe your proposed solution
It would be nice to addition to aeon. I propose the lloyd's varia... | closed | 2024-10-02T11:57:14Z | 2024-10-11T12:20:33Z | https://github.com/aeon-toolkit/aeon/issues/2129 | [
"enhancement",
"clustering",
"implementing algorithms"
] | chrisholder | 0 |
graphql-python/graphene | graphql | 1,398 | Undefined arguments always passed to resolvers | Contrarily to what's described [here](https://docs.graphene-python.org/en/latest/types/objecttypes/#graphql-argument-defaults): it looks like all the arguments with unset values are passed to the resolvers in graphene-3:
This is the query i am defining
```
class Query(graphene.ObjectType):
hello = graphene.... | closed | 2022-01-05T23:12:11Z | 2022-08-27T18:41:03Z | https://github.com/graphql-python/graphene/issues/1398 | [
"🐛 bug"
] | stabacco | 3 |
apachecn/ailearning | python | 352 | 代码都编译不过啊。。。 | 在 MachineLearning/src/py3.x/5.Logistic/logistic.py 里:
```
# random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。
rand_index = int(np.random.uniform(0, len(data_index)))
h = sigmoid(np.sum(data_mat[dataIndex[randIndex]] * weights))
error = class_labels[dataInde... | closed | 2018-04-13T06:54:20Z | 2018-04-15T06:25:40Z | https://github.com/apachecn/ailearning/issues/352 | [] | ljp215 | 2 |
blacklanternsecurity/bbot | automation | 1,682 | Integrating with additional scanners | **Description**
Hey there, love this tool, I have some ideas/additions which I would build myself if I only had the time.... :
- The Nuclei tool is ran with default setting of stopping a scan of a target after its unreachable for 30 requests, if you put this number a little higher (say 100), in my experience that k... | open | 2024-08-20T14:54:11Z | 2025-02-06T00:14:58Z | https://github.com/blacklanternsecurity/bbot/issues/1682 | [
"enhancement"
] | joostgrunwald | 6 |
jowilf/starlette-admin | sqlalchemy | 146 | Enhancement: not display sensitive data in relation form | Is there any opportunity to not display fields according to persmision level for the users?

For now there is some invonvenience in safety by displaying some sensitive information whoever the user is
... | closed | 2023-03-29T17:26:10Z | 2023-04-03T15:46:43Z | https://github.com/jowilf/starlette-admin/issues/146 | [
"enhancement"
] | Ilya-Green | 5 |
dask/dask | pandas | 11,416 | Significant slowdown in Numba compiled functions from Dask 2024.8.1 | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiab... | closed | 2024-10-07T15:55:42Z | 2024-10-08T10:17:48Z | https://github.com/dask/dask/issues/11416 | [
"needs triage"
] | tomwhite | 2 |
jonaswinkler/paperless-ng | django | 1,110 | [BUG] BadSignature('Signature "..." does not match') on document import | **Describe the bug**
When trying to import PDFs into a fresh installation of Paperless-ng on Archlinux, the procedure gets stuck after uploading and produces below lines in the scheduler log.
**To Reproduce**
Steps to reproduce the behavior:
1. Clean installation of paperless-ng
2. Launch the webserver, consumer... | closed | 2021-06-10T09:16:26Z | 2021-06-19T08:15:42Z | https://github.com/jonaswinkler/paperless-ng/issues/1110 | [] | amo13 | 3 |
miguelgrinberg/python-socketio | asyncio | 453 | stopping socketio with Ctrl+C KeyboardInterrupt on sio.wait() | hi, @miguelgrinberg
I have a socketio client below.
This code has a background task func() that record audio in put and make it as base64 chunks.
And I'm going to make this stopped and exited when I press `CTRL+C` once.
```python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import logging
import threadi... | closed | 2020-03-30T14:23:26Z | 2020-06-30T22:47:52Z | https://github.com/miguelgrinberg/python-socketio/issues/453 | [
"question"
] | BRIDGE-AI | 1 |
explosion/spaCy | data-science | 13,405 | Code example discrepancy for `Span.lemma_` in API docs | Hello spaCy team,
I found a small discrepancy in the documentation.
---
<!-- Describe the problem or suggestion here. If you've found a mistake and you know the answer, feel free to submit a pull request straight away: https://github.com/explosion/spaCy/pulls -->
The attribute `lemma_` for a `Span` is describ... | open | 2024-04-01T09:22:56Z | 2024-04-12T14:21:41Z | https://github.com/explosion/spaCy/issues/13405 | [
"docs"
] | schorfma | 1 |
InstaPy/InstaPy | automation | 5,817 | HELP 'account' might be temporarily blocked from following | Hi there,
Im running instapy on my linux server, and on average I`m getting temporary block or ban once a day saying "'account' might be temporarily blocked from following". All I can do is to request via email a new password. Once I change password I get my instagram account back working again. Anybody has similar ... | closed | 2020-10-08T17:01:47Z | 2020-12-13T01:49:19Z | https://github.com/InstaPy/InstaPy/issues/5817 | [
"wontfix"
] | PepeRender | 8 |
xuebinqin/U-2-Net | computer-vision | 23 | RuntimeWarning: invalid value encountered in true_divide | Your work is so great, thank you for sharing your code!
I tried to inference some images using your model and your code.
Almost everything is good, but with some images, I receive warning:
data_loader.py:197: RuntimeWarning: invalid value encountered in true_divide
image = image/np.max(image)
Like this image: ... | closed | 2020-05-19T11:25:43Z | 2020-06-09T13:27:34Z | https://github.com/xuebinqin/U-2-Net/issues/23 | [] | LeCongThuong | 2 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,404 | Bypass CloudFlare new version | To bypass cloudflare you need the chrome version 115, it seems that the versions prior to 115 do not like it,but with 115 the captcha is bypassed, (changing the user agent wont work) | closed | 2023-07-20T14:35:32Z | 2023-07-31T14:31:04Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1404 | [] | devCanario | 32 |
SciTools/cartopy | matplotlib | 1,553 | Zoom in GUI on a global map | ### Description
<!-- Please provide a general introduction to the issue/proposal. -->
Zoom seems not working in the matplotlib GUI when the map is global.
However it works when `set_extent` is previously applied.
<!--
If you are reporting a bug, attach the *entire* traceback from Python.
If you are proposin... | open | 2020-05-08T13:12:48Z | 2020-05-11T14:36:43Z | https://github.com/SciTools/cartopy/issues/1553 | [
"Type: Bug"
] | stefraynaud | 5 |
flasgger/flasgger | flask | 528 | While testing by 'make test', ImportError: cannot import name 'safe_str_cmp' from 'werkzeug.security' | [ImportError: cannot import name 'safe_str_cmp' from 'werkzeug.security'](https://stackoverflow.com/questions/71652965/importerror-cannot-import-name-safe-str-cmp-from-werkzeug-security)
The issue above could be resolved by the linked suggestion, only leading to another error as below,
`ERROR tests/test_examples.... | open | 2022-04-18T07:53:33Z | 2022-05-14T07:42:19Z | https://github.com/flasgger/flasgger/issues/528 | [] | ikjun-jang | 2 |
microsoft/nni | tensorflow | 5,526 | Enas Tutorial is not up-to-date | I can not run the https://github.com/microsoft/nni/blob/v2.10/examples/nas/oneshot/enas/search.py
it give me error on this one `from nni.nas.pytorch import mutables` to indicate no mutables in nni.nas.pytorch, when I change it, it give me errors because the `MutableScope`(See https://github.com/microsoft/nni/blob/c31d... | closed | 2023-04-21T19:04:06Z | 2023-05-09T08:23:28Z | https://github.com/microsoft/nni/issues/5526 | [] | dzk9528 | 14 |
babysor/MockingBird | pytorch | 232 | 方言的训练相关问题 | 想请教如何创建一个方言数据集并合理生成模型? 目标是训练 **上海话** 以及其它吴语系方言 | closed | 2021-11-24T06:16:07Z | 2022-03-07T15:28:37Z | https://github.com/babysor/MockingBird/issues/232 | [] | ycMia | 8 |
waditu/tushare | pandas | 1,527 | 数据采集 Init_StockAll_Sp.py中的resu0 = list(df.ix[c_len - 1 - j])方法出错 | 官方文档链接:https://waditu.com/document/1?doc_id=63
在数据采集模块提供的 Init_StockAll_Sp.py文件中,方法resu0 = list(df.ix[c_len - 1 - j])执行出错,提示df没有ix属性,实际执行中改成resu0 = list(df.T[c_len - 1 - j])时,执行通过,请帮忙核实,谢谢!
个人ID:431870
| open | 2021-03-24T02:19:52Z | 2021-03-24T02:20:19Z | https://github.com/waditu/tushare/issues/1527 | [] | zhizu2030 | 0 |
mars-project/mars | numpy | 2,867 | [BUG] ref count error | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1.... | open | 2022-03-25T05:59:53Z | 2022-03-25T05:59:53Z | https://github.com/mars-project/mars/issues/2867 | [] | chaokunyang | 0 |
apachecn/ailearning | python | 504 | 贝叶斯教程 第57行更改 修改了markdown language引用图片的错误 | 贝叶斯文档当中 图片引用作者忘打了一个“]”,导致图片引用失败。我已在新的pull request中提交了修改 | closed | 2019-05-03T04:55:11Z | 2019-05-06T14:13:01Z | https://github.com/apachecn/ailearning/issues/504 | [] | Logenleedev | 0 |
sgl-project/sglang | pytorch | 4,236 | [Bug] SGLang QwQ Tool use with LibreChat agent fails | ### Checklist
- [x] 1. I have searched related issues but cannot get the expected help.
- [ ] 2. The bug has not been fixed in the latest version.
- [ ] 3. Please note that if the bug-related issue you submitted lacks corresponding environment info and a minimal reproducible demo, it will be challenging for us to repr... | open | 2025-03-09T16:03:00Z | 2025-03-10T05:40:01Z | https://github.com/sgl-project/sglang/issues/4236 | [] | JohnZolton | 0 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 936 | Release 2.5.0 is not py27 compatible? | I use Airflow 1.10.9 that is expected to support py27 but looks like your recent release breaks it.
Just let me know if it's intended. - I will then open an issue for Airflow to pin `Flask-SQLAlchemy<2.5` to keep compatibility.
```
Traceback (most recent call last):
...
from airflow.bin.cli import CLIFactory
... | closed | 2021-03-18T18:31:32Z | 2021-04-02T00:19:50Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/936 | [] | POD666 | 2 |
roboflow/supervision | deep-learning | 790 | [LineZone] - allow per class counting | ### Description
Currently, [sv.LineZone](https://github.com/roboflow/supervision/blob/3024ddca83ad837651e59d040e2a5ac5b2b4f00f/supervision/detection/line_counter.py#L11) provides only aggregated counts - all classes are thrown into one bucket. In the past, many users have asked us to provide more granular - per class ... | closed | 2024-01-26T13:20:45Z | 2024-10-01T09:45:59Z | https://github.com/roboflow/supervision/issues/790 | [
"enhancement",
"good first issue",
"api: linezone",
"Q2.2024"
] | SkalskiP | 10 |
predict-idlab/plotly-resampler | plotly | 65 | lttbc -> rounding errors when passing int-indexed data | fact: *lttbc* requires a int/float index as input and not a (datetime64) time-index.
As a result, [this code](https://github.com/predict-idlab/plotly-resampler/blob/fbf8d5ed9c3b29c8bd337868bcb63dd30ba49cde/plotly_resampler/aggregation/aggregators.py#L81) was written, where the time-index series is converted into a *in... | closed | 2022-05-19T15:39:35Z | 2022-05-19T17:40:34Z | https://github.com/predict-idlab/plotly-resampler/issues/65 | [] | jonasvdd | 0 |
mitmproxy/pdoc | api | 524 | Add support for additional markdown extras / mermaid | #### Problem Description
GitHub supports rendering Markdown files with Mermaid diagrams, which aren't supported by default with `markdown2` and thus don't get translated correctly.
It seems like a pretty common use case to include your project's README in your module's top-level docstring. Since the diagram doesn... | closed | 2023-03-25T16:17:50Z | 2023-03-28T13:09:31Z | https://github.com/mitmproxy/pdoc/issues/524 | [
"enhancement"
] | thearchitector | 2 |
pallets-eco/flask-wtf | flask | 364 | Why use referrer header for CSRF protection when you have sychronizer tokens? | I'm new to the security game. I'd understood that a sychronizer token and a referrer header were doing basically the same thing, and that a sychronizer token is more robust. What does a referrer header add that a sychronizer token doesn't address? | closed | 2019-04-09T15:11:39Z | 2021-07-13T00:38:36Z | https://github.com/pallets-eco/flask-wtf/issues/364 | [
"csrf"
] | knod | 9 |
tqdm/tqdm | pandas | 995 | I think the project name should be changed | I think we should use a meaningful English name, because I always forget this name | closed | 2020-06-26T16:02:37Z | 2020-08-19T20:29:08Z | https://github.com/tqdm/tqdm/issues/995 | [
"p0-bug-critical ☢",
"duplicate 🗐",
"invalid ⛔",
"question/docs ‽",
"c1-quick 🕐"
] | junknet | 2 |
AutoGPTQ/AutoGPTQ | nlp | 463 | [BUG] v0.5.1-release can't support aarch64 platform | **Describe the bug**
v0.4.2-release build ok, but when update v0.5.1, it can't be compile with aarch64 host machine.
**Hardware details**
jetson xavier nx, 6 core.
aarch64 mainchine, can't support qigen extensions. just without -mavx, -mavx2,that for x86-64 CPU.
**Software version**
Version of relevant softwa... | closed | 2023-12-03T03:00:16Z | 2023-12-07T11:31:28Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/463 | [
"bug"
] | st7109 | 3 |
SciTools/cartopy | matplotlib | 1,577 | Cartopy 0.18.0 fills the inside of a Line/MultiLineString shapefile | ### Description
I have a fault line shapefile that has a multilinestring geometry. When imported via Cartopy's ShapelyFeature() and Reader() functions, it comes out as a polygon with a fill instead of a line.
The issue has already been filed in 2017.
https://github.com/SciTools/cartopy/issues/856 , https://www.n... | closed | 2020-06-02T05:23:21Z | 2020-06-03T06:39:23Z | https://github.com/SciTools/cartopy/issues/1577 | [] | miguel123-gis | 3 |
lanpa/tensorboardX | numpy | 482 | Input to tensorboard add_graph is not a Tensor | What should I do if the input to my model not only consists of Tensors but also python lists?
That is,
model = Net()
add_graph(model, (Tensor1, Tensor2, list))
In this case, I get errors. How can I pass a list as an input to ````add_graph````? | closed | 2019-08-10T07:02:39Z | 2019-10-23T15:53:35Z | https://github.com/lanpa/tensorboardX/issues/482 | [] | pcy1302 | 2 |
gradio-app/gradio | deep-learning | 10,181 | `gr.render` can not use `gr.Request` and `gr.EventData` | ### Describe the bug
I want to use request value(`gr.Request`) in render function.
But it occurs below errors. Also It can not use helpers like `gr.EventData`
I can work this issue by bypassing it using a `gr.State`. But It is uncomfortable and makes hard to read codes.
``` python
import gradio as gr
with g... | closed | 2024-12-11T14:29:25Z | 2024-12-13T18:50:55Z | https://github.com/gradio-app/gradio/issues/10181 | [
"bug"
] | BLESS11186 | 1 |
prkumar/uplink | rest-api | 129 | Add support for parsing JSON objects using `glom` | **Is your feature request related to a problem? Please describe.**
[`glom`](https://glom.readthedocs.io/en/latest/) is a library that provides a lot of neat functionality in terms of parsing nested structures, like JSON objects.
**Describe the solution you'd like**
We can introduce a `parser` argument for `@uplink... | open | 2018-12-19T23:26:04Z | 2018-12-19T23:46:12Z | https://github.com/prkumar/uplink/issues/129 | [
"Feature Request",
"help wanted"
] | prkumar | 0 |
TencentARC/GFPGAN | deep-learning | 141 | FacialComponentDiscriminator | FacialComponentDiscriminator是一个全卷积网络,输出是一个20*20的张量,似乎和常规的判别器形式不太一致,为什么没有用全连接层使结果以标量的形式输出呢?
| open | 2022-01-06T06:53:07Z | 2022-01-08T12:17:43Z | https://github.com/TencentARC/GFPGAN/issues/141 | [] | StephanPan | 1 |
deepset-ai/haystack | nlp | 8,600 | Unify `DocumentSplitter` and `NLTKDocumentSplitter` | These two classes are very much alike. The only difference is that the `NLTKDocumentSplitter` uses NLTK's sentence boundary detection algorithm. We should merge those two into one single component.
It could still be possible to give the user the choice to either use a naive approach for sentence boundary detection (e.... | closed | 2024-12-03T11:15:47Z | 2024-12-12T14:22:29Z | https://github.com/deepset-ai/haystack/issues/8600 | [
"P2"
] | davidsbatista | 0 |
stanford-oval/storm | nlp | 322 | Question regarding the "Writing Purpose" box in the STORM website | Hi,
I noticed that the STORM website includes a feature allowing users to input additional information about the writing purpose. However, I couldn't find this feature in the provided source code when running CO-STORM locally.
I came across this issue from August 2024 (https://github.com/stanford-oval/storm/issues/15... | closed | 2025-02-20T19:55:14Z | 2025-03-08T09:02:19Z | https://github.com/stanford-oval/storm/issues/322 | [] | akilgiri-nrc | 1 |
huggingface/datasets | numpy | 6,814 | `map` with `num_proc` > 1 leads to OOM | ### Describe the bug
When running `map` on parquet dataset loaded from local machine, the RAM usage increases linearly eventually leading to OOM. I was wondering if I should I save the `cache_file` after every n steps in order to prevent this?
### Steps to reproduce the bug
```
ds = load_dataset("parquet", data... | open | 2024-04-16T11:56:03Z | 2024-04-19T11:53:41Z | https://github.com/huggingface/datasets/issues/6814 | [] | bhavitvyamalik | 1 |
RobertCraigie/prisma-client-py | asyncio | 594 | Invalid code is generated for models with reserved names | <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional log... | closed | 2022-11-17T07:21:38Z | 2022-11-21T09:20:52Z | https://github.com/RobertCraigie/prisma-client-py/issues/594 | [
"bug/2-confirmed",
"kind/bug",
"priority/high",
"level/unknown"
] | joezhoujinjing | 8 |
littlecodersh/ItChat | api | 415 | 关于长时间在线 | “如果要保持本项目超长时间(数月等)在线,建议手机保持联网。”
如你所说手机需要保持联网,那么如果几个月不碰手机是不是也坚持不了多久
这个问题可能和itchat本身无关,不知道能否得到解答,就是想无人值守一直让机器人跑 | closed | 2017-06-20T09:53:24Z | 2017-07-07T02:52:57Z | https://github.com/littlecodersh/ItChat/issues/415 | [
"question"
] | yhu-aa | 6 |
huggingface/transformers | tensorflow | 36,155 | `TFViTModel` and `interpolate_pos_encoding=True` | ### System Info
- `transformers` version: 4.48.3
- Platform: Linux-5.15.0-1078-azure-x86_64-with-glibc2.35
- Python version: 3.11.0rc1
- Huggingface_hub version: 0.27.1
- Safetensors version: 0.4.2
- Accelerate version: 0.31.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.3.1+cu121 (True)
- Tensorflow ve... | closed | 2025-02-13T00:44:42Z | 2025-03-23T08:04:02Z | https://github.com/huggingface/transformers/issues/36155 | [
"TensorFlow",
"bug"
] | carlosg-m | 1 |
lepture/authlib | django | 29 | OAuth2ClientMixin requires a client_secret | 1. From https://play.authlib.org/
2. Select Apps
3. Select New Oauth2 Client
4. Fill in the fields without checking the box Confidential Client
5. Click Create
You get:
Internal Server Error
The server encountered an internal error and was unable to complete your request. Either the server is overloaded or th... | closed | 2018-02-15T17:04:50Z | 2018-02-20T03:03:53Z | https://github.com/lepture/authlib/issues/29 | [] | ivonnemclaughlin | 1 |
cvat-ai/cvat | tensorflow | 8,526 | Delete an account from cvat.ai? | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Is your feature request related to a problem? Please describe.
I cannot find any method to remove my account from the service.
### Describe ... | closed | 2024-10-10T07:51:30Z | 2024-10-10T10:28:09Z | https://github.com/cvat-ai/cvat/issues/8526 | [
"enhancement"
] | jasonmbrown | 1 |
matterport/Mask_RCNN | tensorflow | 2,267 | Is it possible to use Mask R-CNN when objects of the same instance are in different parts of the image ? | I want to use Mask R-CNN to make instance segmentation on spectrogram images. As you may know, signals comming from the same source can make patterns in different part of the spectrogram simply because the source can emmit at different time.
My question is: do you think that Mask R-CNN be able to treat such an insta... | open | 2020-07-02T15:30:23Z | 2020-07-03T13:53:01Z | https://github.com/matterport/Mask_RCNN/issues/2267 | [] | YuriGagarine | 1 |
BlinkDL/RWKV-LM | pytorch | 225 | Finetuning RWKV-5-World-1B5-v2 model | How to train RWKV-5-World-1B5-v2 model | open | 2024-02-21T13:59:41Z | 2024-02-27T00:53:06Z | https://github.com/BlinkDL/RWKV-LM/issues/225 | [] | ArchanaNarayanan843 | 1 |
cvat-ai/cvat | pytorch | 9,217 | 500 error after login | ### Actions before raising this issue
- [x] I searched the existing issues and did not find anything similar.
- [x] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
1. Login
Immediately after Login the following 500 error appears in a popup:
```
[2025-03-17 07:45:32,385] ERROR django.r... | closed | 2025-03-17T07:50:50Z | 2025-03-17T15:43:54Z | https://github.com/cvat-ai/cvat/issues/9217 | [
"bug"
] | eporsche | 2 |
numpy/numpy | numpy | 27,944 | TYP: `np.ndarray.tolist` return type seems broken in numpy 2.2.0 | ### Describe the issue:
While upgrading CMasher's CI to numpy 2.2.0, I got a new typechecking error that seems spurious to me. No error is raised with numpy 2.1.3
### Reproduce the code example:
```python
import numpy as np
def to_rgb(in_) -> tuple[float, float, float]:
# minimal mock for matplotlib.colors.t... | closed | 2024-12-09T10:11:22Z | 2024-12-10T17:17:35Z | https://github.com/numpy/numpy/issues/27944 | [
"41 - Static typing"
] | neutrinoceros | 2 |
ydataai/ydata-profiling | pandas | 860 | jquery version is vulernerable to xss | **Describe the bug**
<!--
You are using a very old and vulnerable version of jquery which is bundled in with pandas profiling.
Full details are provided here of the vulnerability:
https://nvd.nist.gov/vuln/detail/CVE-2020-11023
Can you also advise on timescales for this change and what versions you will releas... | open | 2021-10-11T13:23:43Z | 2023-08-28T21:19:15Z | https://github.com/ydataai/ydata-profiling/issues/860 | [
"security 👮"
] | amerzon | 7 |
modelscope/modelscope | nlp | 955 | 模型训练无法存储checkpoint | 在ubuntu 22.04 使用 modelscope 1.17.1 版本,用
https://modelscope.cn/models/iic/cv_LightweightEdge_ocr-recognitoin-general_damo
中所示的训练脚本尝试训练模型时
报如下错误
```
2024-08-23 09:22:29,099 - modelscope - INFO - Checkpoints will be saved to /tmp/tmp8gzabwkm
2024-08-23 09:22:29,099 - modelscope - INFO - Text logs will be saved to /t... | closed | 2024-08-23T00:54:40Z | 2024-10-01T05:32:34Z | https://github.com/modelscope/modelscope/issues/955 | [
"Stale"
] | jprorikon | 2 |
tensorflow/tensor2tensor | machine-learning | 1,819 | Installation fails due to conflicting cloudpickle version | Hi, users are unable to run Tensor2tensor due to dependency conflict with _**cloudpickle**_ package. As shown in the following full dependency graph of Tensor2tensor, gym requires _** cloudpickle~=1.2.0**_,while tensorflow-probability requires _** cloudpickle >0.6.1 **_.
According to pip’s “first found wins” insta... | open | 2020-05-29T10:57:53Z | 2020-06-22T08:22:55Z | https://github.com/tensorflow/tensor2tensor/issues/1819 | [] | NeolithEra | 2 |
MaartenGr/BERTopic | nlp | 1,124 | probably incorrect typings | https://github.com/MaartenGr/BERTopic/blob/1b25ba7810b44bcb9594b42f70787fc2d8bb7015/bertopic/_bertopic.py#L1315
`get_topics` actually returns a `Mappig`, where
- key is an `int`
- value is a `list[tuple[str, numpy.float64]]` which is a list, with each entry being a tuple with the word, and the score.
## Showin... | closed | 2023-03-24T19:36:17Z | 2023-09-27T09:05:12Z | https://github.com/MaartenGr/BERTopic/issues/1124 | [] | demetrius-mp | 1 |
jupyterlab/jupyter-ai | jupyter | 482 | ollama |
### Problem
* I would like to integrate https://ollama.ai/ with Jupyter ai
### Proposed Solution
Add provider end point to ollama hosted service within locally or remotely.
| closed | 2023-11-19T21:41:40Z | 2024-07-10T22:06:18Z | https://github.com/jupyterlab/jupyter-ai/issues/482 | [
"enhancement"
] | sqlreport | 1 |
man-group/arctic | pandas | 749 | Rename _compression to something else. | This naming breaks the debugger with py3.6 and the latest lz4 library as it apparently tries to look for some class inside _compression but defaults to using our _compression module as it's in the scope. I am using a renamed version in the scope and it seems to be fine. | closed | 2019-04-26T13:26:01Z | 2019-06-06T10:28:36Z | https://github.com/man-group/arctic/issues/749 | [
"easy"
] | shashank88 | 1 |
lux-org/lux | pandas | 412 | Converting Timestamp: Error | Hi,
I am reading in a csv to my notebook, calling it df_plot. When I do a df_plot.head() it comes back saying that Timestamp maybe temperal. So I followed the suggested template and also tried a suggestion on the lux website. Neither works for me.
See attached image from my csv file of the timestamp

post_response = await client.post(post_url, headers=post_headers, cookies=post_cookies, data=post_data)
in the logs I see:
DEBUG [2025-01-25 ... | closed | 2025-01-25T13:29:36Z | 2025-02-14T10:06:18Z | https://github.com/encode/httpx/issues/3482 | [] | ferror56 | 1 |
drivendataorg/cookiecutter-data-science | data-science | 419 | Clean up and update docs prior to 2.0.1 release | A few items for cleanup left over from v1, e.g., the instructions for deploying the docs are out of date. | closed | 2025-02-16T18:56:17Z | 2025-02-16T21:10:58Z | https://github.com/drivendataorg/cookiecutter-data-science/issues/419 | [] | chrisjkuch | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,450 | AttributeError: module 'torchvision.transforms' has no attribute 'InterpolationMode' | System: Windows and Ubuntu
using Anaconda set up environment base on the `environment.yml`.
run CycleGAN train/test
```
Traceback (most recent call last):
File "D:/PycharmProjects/pytorch-CycleGAN-and-pix2pix/test.py", line 30, in <module>
from options.test_options import TestOptions
File "D:\Pycha... | closed | 2022-07-07T21:39:38Z | 2024-03-03T12:11:50Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1450 | [] | jiatangz | 8 |
pytest-dev/pytest-django | pytest | 710 | Error with Django internal when using pytest >= 4.2 | Hello,
Since I updated pytest to 4.2, I've got errors inside Django internals for some tests.
These tests worked fine with 4.1 and still work fine with Django embedded unittests.
Here the error:
```
______________________________________________________________________________ UserPageCheckTest.test_get_view... | open | 2019-03-13T10:27:31Z | 2019-10-16T20:42:30Z | https://github.com/pytest-dev/pytest-django/issues/710 | [
"bug",
"needs-info"
] | debnet | 21 |
django-cms/django-cms | django | 7,909 | [BUG] AppHooked page does not have New draft button | <!--
Please fill in each section below, otherwise, your issue will be closed.
This info allows django CMS maintainers to diagnose (and fix!) your issue
as quickly as possible.
-->
## Description
When AppHook is attached to a page, the page loses the *New draft* button. Workaround is to "de-attach" the AppHook... | closed | 2024-05-05T11:30:09Z | 2024-05-07T15:17:42Z | https://github.com/django-cms/django-cms/issues/7909 | [] | aacimov | 7 |
raphaelvallat/pingouin | pandas | 207 | pingouin-stats.org unavailable | I'm experiencing some DNS issue with pingouin-stats.org. Please use the following temporary link to access the documentation:
https://s3.us-east-1.amazonaws.com/pingouin-stats.org/index.html | closed | 2021-10-28T23:13:52Z | 2021-10-30T16:35:27Z | https://github.com/raphaelvallat/pingouin/issues/207 | [
"bug :boom:",
"docs/testing :book:"
] | raphaelvallat | 2 |
PokeAPI/pokeapi | graphql | 470 | Search for a pokemon in another language | Hello there ! :)
For my application, I would need to do a search on the name of a Pokémon BUT in French.
Is there a way today to do this?
Otherwise could it happen?
Thank you in advance ! :) | closed | 2020-01-17T01:34:57Z | 2020-02-17T03:31:26Z | https://github.com/PokeAPI/pokeapi/issues/470 | [] | MalronWall | 8 |
ScrapeGraphAI/Scrapegraph-ai | machine-learning | 762 | AttributeError: 'FetchNode' object has no attribute 'update_state' | **Describe the bug**
in File "scrapegraphai\nodes\fetch_node.py" , clas FetchNode nor in BaseNode which is the parent of the class FerchNode there is no method defined as update_state(), although it has been used in both FetchNode.handle_local_source() and FetchNode.handle_web_source()
full error: File "scrapegr... | closed | 2024-10-21T11:34:42Z | 2025-02-24T16:00:12Z | https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/762 | [] | MahdiSepiRashidi | 11 |
DistrictDataLabs/yellowbrick | scikit-learn | 616 | Extend color selection on ResidualsPlot() to histogram | When running ResidualsPlot() visualizer, the `test_color` and `train_color` do not propagate down to the histogram. It would be nice if the histogram on the right reflected the color choices as well.
```visualizer = ResidualsPlot(regr_ols, test_color='#615d6c', train_color='#6F8AB7')
visualizer.fit(X_train, y_train... | closed | 2018-09-19T04:47:39Z | 2018-09-19T20:09:36Z | https://github.com/DistrictDataLabs/yellowbrick/issues/616 | [] | black-tea | 1 |
ycd/manage-fastapi | fastapi | 92 | Add Dockerfile support | closed | 2022-10-02T12:57:13Z | 2022-10-02T13:00:33Z | https://github.com/ycd/manage-fastapi/issues/92 | [] | Kludex | 1 | |
biolab/orange3 | data-visualization | 6,672 | Prediction widget crashes in at least two different ways |
**What's wrong?**
Linear regression on Mac crashes. I have no issues with classification or clustering. However, as soon as I connect select column 1 to prediction the system crashes. I have forwarded the error messages too. I repeated exactly the same on my wife’s windows pc and works perfectly. File is just column... | open | 2023-12-11T12:08:17Z | 2023-12-15T08:15:37Z | https://github.com/biolab/orange3/issues/6672 | [
"bug",
"snack"
] | HoutanSadeghi | 1 |
wger-project/wger | django | 939 | Muscle overview missing | It seems the muscle overview in the workout page is missing:
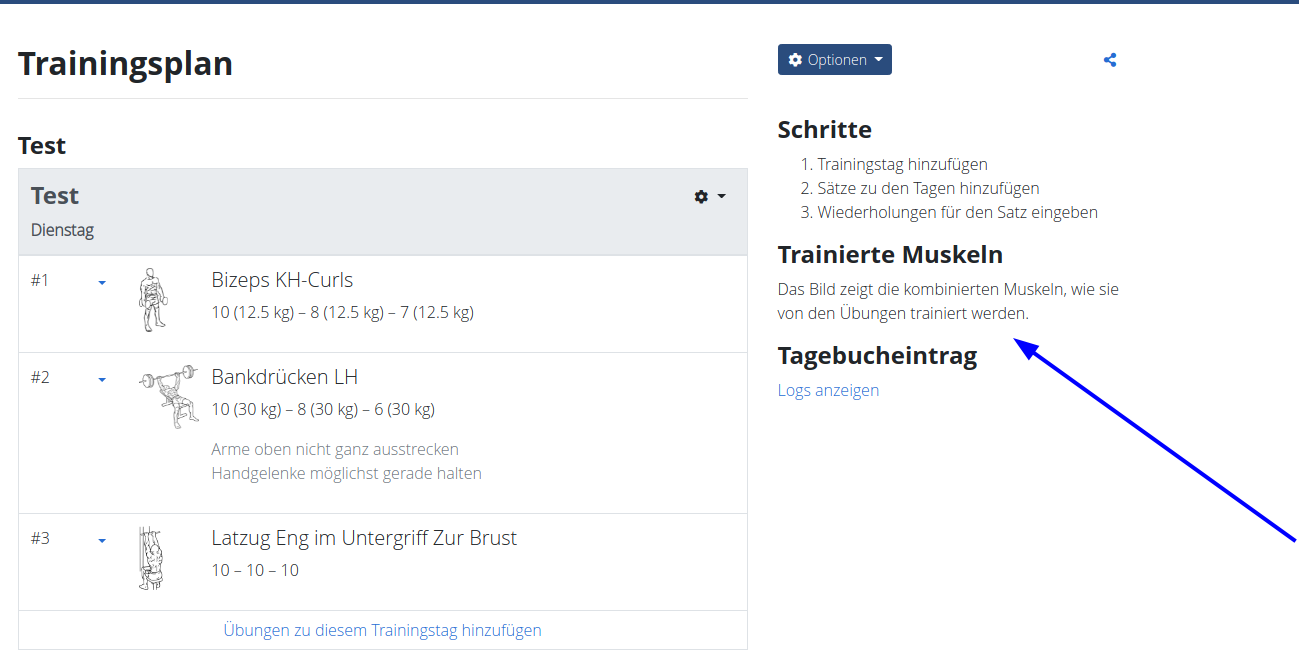
| closed | 2022-01-04T15:13:45Z | 2022-01-05T09:56:48Z | https://github.com/wger-project/wger/issues/939 | [] | rolandgeider | 0 |
alirezamika/autoscraper | automation | 30 | build method with wanted_dict does not work. | Tested with autoscraper-1.1.6
When calling the build method with wanted_dict, the method behaves badly as it treats the searched string as an array of individual letters. The culprit is around l.204 of auto_scraper.py as the data structure does not behave the same as when you use the wanted_list option.
Besides... | closed | 2020-10-06T14:55:45Z | 2021-03-07T11:47:10Z | https://github.com/alirezamika/autoscraper/issues/30 | [] | romain-utelly | 3 |
littlecodersh/ItChat | api | 294 | 可以给公众号发送信息吗? | closed | 2017-03-22T05:27:49Z | 2017-03-22T07:48:37Z | https://github.com/littlecodersh/ItChat/issues/294 | [
"question"
] | 27hao | 1 | |
schemathesis/schemathesis | pytest | 2,089 | [BUG] ASCII can not be valid when generate test case with schemathesis. | ### Checklist
- [ ] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [ ] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
- [ ] I am using the latest version of Schemathesis
... | closed | 2024-03-05T07:44:32Z | 2024-04-08T19:40:42Z | https://github.com/schemathesis/schemathesis/issues/2089 | [
"Type: Bug"
] | jiejunsailor | 4 |
lundberg/respx | pytest | 200 | Incomplete `AllMockedAssertionError` description | Hello! Thank you for this useful library!
I've found that `AllMockedAssertionError` description is incomplete. For example, JSON in this snippet will fail the test:
```python
import httpx
import pytest
@pytest.mark.asyncio
async def test_reproduce(respx_mock):
respx_mock.post("https://foo.bar/", json... | closed | 2022-02-05T11:46:24Z | 2022-05-24T11:36:04Z | https://github.com/lundberg/respx/issues/200 | [] | lxmnk | 2 |
svc-develop-team/so-vits-svc | pytorch | 97 | 发现了一个小bug, | resample.py中 40 行的判断,在我电脑中触发了一个python历史性遗留问题,主要问题在于我的系统内核大于60个, mult库发生了错误.
需要修改成如下代码:
```
processs = 30 if cpu_count() > 60 else (cpu_count()-2 if cpu_count() > 4 else 1)
``` | closed | 2023-03-27T17:13:32Z | 2023-04-09T04:47:25Z | https://github.com/svc-develop-team/so-vits-svc/issues/97 | [
"not urgent"
] | tencentdosos | 1 |
aimhubio/aim | data-visualization | 2,473 | Showing only one metric in the charts and no legend on metric names | ## 🐛 Bug
When I add multiple metrics by clicking the +metrics button and then click the search button, I can only see the charts of one metric on the webpage. Moreover, the legend does not show the metric name of each chart. But the table below the charts shows the selected metric names and their values.
### Ex... | closed | 2023-01-12T01:24:26Z | 2023-01-13T09:12:01Z | https://github.com/aimhubio/aim/issues/2473 | [
"type / bug",
"help wanted"
] | twni2016 | 2 |
huggingface/datasets | pytorch | 7,072 | nm | closed | 2024-07-25T17:03:24Z | 2024-07-25T20:36:11Z | https://github.com/huggingface/datasets/issues/7072 | [] | brettdavies | 0 | |
scikit-tda/kepler-mapper | data-visualization | 162 | Make keppler-mapper sparse compatible | I recently tried to use the Mapper algorithm for a graph with more than 1 million nodes. I, thus computed the adjacency matrix with the scipy sparse CSR format, which drastically reduces the memory usage.
However keppler-mapper does not currently work with sparse matrices.
I successfully modified a few lines and... | closed | 2019-04-04T15:43:56Z | 2019-04-09T07:49:16Z | https://github.com/scikit-tda/kepler-mapper/issues/162 | [] | retdop | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.