
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
recommenders-team/recommenders | data-science | 1,833 | [FEATURE] AzureML SDK v2 support | ### Description
<!--- Describe your expected feature in detail -->
AzureML SDK v2 was GA at Ignite 2022.
We saw the codes in [the examples](https://github.com/microsoft/recommenders/tree/main/examples) are based on SDK v1.
Do we have any plans to update the examples to follow SDK v2?
### Expected behavior wi... | closed | 2022-10-25T02:20:07Z | 2024-05-06T14:49:21Z | https://github.com/recommenders-team/recommenders/issues/1833 | [
"enhancement"
] | shohei1029 | 2 |
unionai-oss/pandera | pandas | 871 | Dask DataFrame filter fails | **Describe the bug**
Dask Dataframes validated with `strict='filter'` do not drop extraneous columns.
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest version of pandera.
#### Code Sample
```python
import pandas as pd
import pandera as... | open | 2022-06-01T14:35:04Z | 2022-06-01T14:35:43Z | https://github.com/unionai-oss/pandera/issues/871 | [
"bug"
] | gg314 | 0 |
Kav-K/GPTDiscord | asyncio | 368 | Unknown interaction errors | Sometimes there are unknown interaction errors with a response in /gpt converse takes too long to return, or if the user deleted their original message it is responding to before it responds | closed | 2023-10-31T01:18:43Z | 2023-11-12T19:40:57Z | https://github.com/Kav-K/GPTDiscord/issues/368 | [
"bug",
"help wanted",
"good first issue",
"help-wanted-important"
] | Kav-K | 11 |
Hironsan/BossSensor | computer-vision | 6 | how many pictures are used to train | how many pictures are used to train? I use your code. Boss picture number: 300 other picture number: 300*10 ; (10 persons , everyone have 300 ). the model give accuracy 0.93. I think it is too low. how to improve the accuracy? | open | 2017-01-09T08:50:22Z | 2017-01-10T13:15:31Z | https://github.com/Hironsan/BossSensor/issues/6 | [] | seeyourcell | 2 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,274 | Cannot connect to chrome at 127.0.0.1:33773 when deployed on Render | Hello,
I am trying to run a python script for headless browsing deployed on Render but I have this error message:
```
May 19 03:15:54 PM Incoming POST request for /api/strategies/collaborative/
May 19 03:15:56 PM stderr: 2023/05/19 13:15:56 INFO ====== WebDriver manager ======
May 19 03:15:56 PM
May ... | closed | 2023-05-19T13:45:05Z | 2023-05-19T17:53:57Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1274 | [] | Louvivien | 0 |
tensorflow/tensor2tensor | deep-learning | 1,809 | Character level language model does not work | ### Description
I try to train a character level language model but only get strange tokens as output. The model trains and loss decreases.
Am I just trying to infer from the model incorrectly, or is there something else going on?
...
### Environment information
```
OS: Debian GNU/Linux 9.11 (stretch) (GN... | open | 2020-05-02T03:05:00Z | 2020-05-02T03:09:37Z | https://github.com/tensorflow/tensor2tensor/issues/1809 | [] | KosayJabre | 0 |
ScrapeGraphAI/Scrapegraph-ai | machine-learning | 714 | issue with chunking? Getting error Token indices sequence lenght is longer than specified maxium token. | Iam getting a error `**Token indices sequence length is longer than the specified maximum sequence length for this model (4504 > 1024)**. Running this sequence through the model will result in indexing errors`
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
`... | closed | 2024-10-01T08:17:17Z | 2025-01-04T09:57:35Z | https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/714 | [] | djds4rce | 9 |
pandas-dev/pandas | pandas | 60,410 | DOC: incorrect formula for half-life of exponentially weighted window | ### Pandas version checks
- [X] I have checked that the issue still exists on the latest versions of the docs on `main` [here](https://pandas.pydata.org/docs/dev/)
### Location of the documentation
https://pandas.pydata.org/docs/dev/user_guide/window.html#exponentially-weighted-window
### Documentation problem
![... | closed | 2024-11-25T03:53:39Z | 2024-11-25T18:36:09Z | https://github.com/pandas-dev/pandas/issues/60410 | [
"Docs",
"Needs Triage"
] | partev | 0 |
mlfoundations/open_clip | computer-vision | 1,021 | RuntimeError: expected scalar type Float but found BFloat16 (ComfyUI) | !!! Exception during processing !!! expected scalar type Float but found BFloat16
Traceback (most recent call last):
File "D:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\execution.py", line 327, in execute
output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, executio... | closed | 2025-01-15T14:03:44Z | 2025-01-15T20:39:42Z | https://github.com/mlfoundations/open_clip/issues/1021 | [] | Ehsan7104 | 0 |
aleju/imgaug | deep-learning | 496 | Keypoints relocate wrongly when rotated | I observed that when I use `iaa.Affine(rotate="anything that is not zero")`, the keypoints shifted wrongly on the small image.
In the following image, the 3rd plot is rotated by 180 degrees, but somehow the keypoints are not in the center of the circle. The problem is more noticeable when you resize the image furthe... | closed | 2019-11-14T13:15:33Z | 2019-11-16T08:53:19Z | https://github.com/aleju/imgaug/issues/496 | [] | offchan42 | 6 |
tableau/server-client-python | rest-api | 760 | assign groups to projects while publishing workbooks | Is there a way to assign projects to groups based on the requirement
| open | 2020-12-10T17:05:38Z | 2021-02-22T19:17:17Z | https://github.com/tableau/server-client-python/issues/760 | [
"enhancement"
] | yashwathreddy | 3 |
ymcui/Chinese-BERT-wwm | tensorflow | 205 | 计算两句子的相似度 | '''
>>> import torch
>>> from transformers import BertModel, BertTokenizer
>>> model_name = "hfl/chinese-roberta-wwm-ext-large"
>>> tokenizer = BertTokenizer.from_pretrained(model_name)
>>> model = BertModel.from_pretrained(model_name)
>>> input_text1 = "今天天气不错,你觉得呢?"
>>> input_text2 = "今天天气不错,你觉得呢?我喜欢吃饺子"
>>> ... | closed | 2021-11-24T08:12:51Z | 2022-02-13T12:04:20Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/205 | [] | yfq512 | 2 |
scanapi/scanapi | rest-api | 514 | Add hacktoberfest topic on the repository | It would be nice to have the topic for next month | closed | 2021-09-26T20:57:59Z | 2022-02-02T16:41:24Z | https://github.com/scanapi/scanapi/issues/514 | [
"Question"
] | patrickelectric | 6 |
JaidedAI/EasyOCR | machine-learning | 430 | CUDA out of memory error while trying to transcribe a lot of images. | Like the title suggests I am trying to transcribe thousands of images but I ran into this CUDA OOM error after 40 images were transcribed
```
Traceback (most recent call last):
File "C:/Users/cubeservdev/Dev/OCRTest/ocr_test.py", line 15, in <module>
transcription = reader.readtext(f'images/{image_file}', d... | closed | 2021-05-16T18:42:48Z | 2022-03-02T09:24:59Z | https://github.com/JaidedAI/EasyOCR/issues/430 | [] | cubeserverdev | 4 |
mage-ai/mage-ai | data-science | 5,299 | [BUG] The unique_conflict_method='UPDATE' function of MySQL data exporter did not work properly | ### Mage version
v0.9.72
### Describe the bug
When I use the MySQL data exporter like following code
```Python
with MySQL.with_config(ConfigFileLoader(config_path, config_profile)) as loader:
loader.export(
df,
schema_name=None,
table_name=table_name,
... | open | 2024-07-29T14:49:13Z | 2024-07-29T14:49:13Z | https://github.com/mage-ai/mage-ai/issues/5299 | [
"bug"
] | highkay | 0 |
rougier/scientific-visualization-book | matplotlib | 53 | Wrong Code in page 96 (Size, aspect & layout)? | When I run the code `F`, `H` and `I` scripts in Page 96 (Chapter 8 Size, aspect & layout), I got the figure as shown in the following figures. It is different from Figure 8.1. When I modify the axes aspect to 0.5, 1 and 2 respectively, it gets normal. It seems that `aspect='auto'` doesn't work.
- F, H and I
<i... | closed | 2022-06-16T09:32:37Z | 2022-06-23T07:08:39Z | https://github.com/rougier/scientific-visualization-book/issues/53 | [] | zhangkaihua88 | 3 |
aminalaee/sqladmin | asyncio | 316 | Feature parity with Flask-Admin | # Feature parity with Flask-Admin
## General features
| Feature | Status |
| ---------------------------------------------- | ------- |
| `ModelView` with configurations | ✓ |
| `BaseView` for creating custom views | ✓ |
| Authentica... | open | 2022-09-14T09:32:47Z | 2022-12-21T11:00:26Z | https://github.com/aminalaee/sqladmin/issues/316 | [] | aminalaee | 0 |
microsoft/unilm | nlp | 1,325 | E5: what prompt is used in training and evaluation? | @intfloat
**Describe**
I tried to reproduce the E5 score on MTEB (particularly BEIR) using the released checkpoint, but I do observe a big gap on some datasets (e.g. on TREC-COVID reproduced 51.0 vs. reported 79.6). I suspect that the prompt can be the key (as in the eval [code](https://github.com/microsoft/unilm/bl... | closed | 2023-10-11T21:21:23Z | 2023-10-12T02:18:52Z | https://github.com/microsoft/unilm/issues/1325 | [] | memray | 2 |
apache/airflow | python | 47,274 | Clearing Task Instances Intermittently Throws HTTP 500 Error | ### Apache Airflow version
AF3 beta1
### If "Other Airflow 2 version" selected, which one?
_No response_
### What happened?
When we try to clear task instance it's throws Intermittently.
**Logs:**
```
NFO: 192.168.207.1:54306 - "POST /public/dags/etl_dag/clearTaskInstances HTTP/1.1" 500 Internal Server Error
... | open | 2025-03-02T10:59:30Z | 2025-03-12T07:18:15Z | https://github.com/apache/airflow/issues/47274 | [
"kind:bug",
"priority:high",
"area:core",
"AIP-84",
"area:task-sdk",
"affected_version:3.0.0beta"
] | vatsrahul1001 | 11 |
ray-project/ray | pytorch | 51,493 | CI test windows://python/ray/tests:test_actor_pool is consistently_failing | CI test **windows://python/ray/tests:test_actor_pool** is consistently_failing. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aaf1-9737-4a02-a7f8-1d7087c16fb1
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aa03-5c4f-4156-97c5-9793049512c1
DataCaseName-windows://python... | closed | 2025-03-19T00:05:15Z | 2025-03-19T21:51:38Z | https://github.com/ray-project/ray/issues/51493 | [
"bug",
"triage",
"core",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 3 |
albumentations-team/albumentations | machine-learning | 1,630 | [Tech debt] Improve Interface for RandomFog | Right now in the transform we have separate parameters for `fog_coef_upper` and `fog_coef_upper`
Better would be to have one parameter `fog_coef_range = [fog_coef_lower, fog_coef_upper]`
=>
We can update transform to use new signature, keep old as working, but mark as deprecated.
----
PR could be similar to ... | closed | 2024-04-05T18:37:00Z | 2024-06-07T04:34:28Z | https://github.com/albumentations-team/albumentations/issues/1630 | [
"good first issue",
"Tech debt"
] | ternaus | 1 |
dot-agent/nextpy | fastapi | 157 | Why hasn't this project been updated for a while | This is a good project, but it hasn't been updated for a long time. Why is that | open | 2024-09-23T09:25:54Z | 2025-01-13T12:36:11Z | https://github.com/dot-agent/nextpy/issues/157 | [] | redpintings | 2 |
hyperspy/hyperspy | data-visualization | 2,970 | Should `hs.load` always return a list? | One common inconvenience/confusing that beginners experience with hyperspy is issue like https://github.com/hyperspy/hyperspy/issues/2959, because `hs.load` can return a list of signals or a signal... this is very simple to explain but this could be avoided if `hs.load` would always return a list, even when the file to... | open | 2022-06-22T10:38:02Z | 2023-09-08T20:16:42Z | https://github.com/hyperspy/hyperspy/issues/2970 | [
"type: API change"
] | ericpre | 1 |
Significant-Gravitas/AutoGPT | python | 9,587 | Deepseek support | Hey Devs,
let me start by saying that this repo is great. Good job on your work, and thanks for sharing it.
Could we include support of DeepSeek V3 API? If there is a solution out there then when can it be implemented?
Thanks! | open | 2025-03-06T10:34:11Z | 2025-03-12T10:43:11Z | https://github.com/Significant-Gravitas/AutoGPT/issues/9587 | [] | q377985133 | 3 |
tqdm/tqdm | jupyter | 697 | DataFrameGroupBy.progress_apply not always equal to DataFrameGroupBy.apply | - [X] I have visited the [source website], and in particular
read the [known issues]
- [X] I have searched through the [issue tracker] for duplicates
- [X] I have mentioned version numbers, operating system and
environment, where applicable:
**tqdm version**: 4.31.1
**Python version:** 3.7.1
**OS Version:*... | open | 2019-03-16T17:32:53Z | 2019-05-09T16:29:45Z | https://github.com/tqdm/tqdm/issues/697 | [
"help wanted 🙏",
"to-fix ⌛",
"submodule ⊂"
] | nalepae | 4 |
holoviz/panel | jupyter | 7,402 | Unable to run ChartJS example from custom_models.md | <details>
<summary>Software Version Info</summary>
```plaintext
panel.__version__ = '1.5.2.post1.dev8+gef313542.d20241015'
bokeh.__version__ = 3.6.0
OS Windows
Browser firefox
```
</details>
The impression I get is that the [custom_models.md](https://github.com/holoviz/panel/blob/main/doc/developer_g... | closed | 2024-10-15T16:48:03Z | 2024-10-21T09:14:18Z | https://github.com/holoviz/panel/issues/7402 | [] | LyndonAlcock | 4 |
jupyter/nbgrader | jupyter | 1,210 | Autograde cell with input or print statemes | <!--
Thanks for helping to improve nbgrader!
If you are submitting a bug report or looking for support, please use the below
template so we can efficiently solve the problem.
If you are requesting a new feature, feel free to remove irrelevant pieces of
the issue template.
-->
1. Is it possible to autograd... | open | 2019-08-30T22:10:49Z | 2023-07-12T21:21:23Z | https://github.com/jupyter/nbgrader/issues/1210 | [
"enhancement"
] | hebertodelrio | 5 |
awesto/django-shop | django | 262 | django-shop is not python3 compatible | I'm trying to fix this in my branch python3. I got rid of classy-tags since they are obsolete and not ported to python3. All other libraries are already ported.
Then I made necessary changes to the source code and raised minimum django version to 1.5.1.
Now all tests (except one under python3 - the circular import is... | closed | 2013-12-22T11:17:00Z | 2016-02-02T13:56:48Z | https://github.com/awesto/django-shop/issues/262 | [] | katomaso | 3 |
xonsh/xonsh | data-science | 5,157 | ast DeprecationWarnings with Python 3.12b1 | Since upgrading from Python 3.12a7 to 3.12b2 and using xonsh 0.14, I see a flurry of DeprecationWarnings when starting up xonsh (in my case on Windows):
```
C:\Users\jaraco\.local\pipx\venvs\xonsh\Lib\site-packages\xonsh\ast.py:9: DeprecationWarning: ast.Bytes is deprecated and will be removed in Python 3.14; use a... | closed | 2023-06-19T15:37:00Z | 2023-07-29T15:45:32Z | https://github.com/xonsh/xonsh/issues/5157 | [
"parser",
"py312"
] | jaraco | 4 |
strawberry-graphql/strawberry-django | graphql | 261 | relay depth limit | Hi,
I was reading [blog](https://blog.cloudflare.com/protecting-graphql-apis-from-malicious-queries/) from Cloudflare about malicious queries in GraphQL.
Is there a way to detect query depth so I can respond respectively ?
```gql
query {
petition(ID: 123) {
signers {
nodes {
petitions {
... | closed | 2023-06-14T22:47:41Z | 2023-06-15T23:00:37Z | https://github.com/strawberry-graphql/strawberry-django/issues/261 | [] | tasiotas | 6 |
dynaconf/dynaconf | fastapi | 979 | [bug] when using a validator with a default for nested data it parses value via toml twice | **Describe the bug**
```py
from __future__ import annotations
from dynaconf import Dynaconf
from dynaconf import Validator
settings = Dynaconf()
settings.validators.register(
Validator("group.something_new", default=5),
)
settings.validators.validate()
assert settings.group.test_list == ["1", "2"]... | closed | 2023-08-16T17:05:12Z | 2024-07-08T18:09:40Z | https://github.com/dynaconf/dynaconf/issues/979 | [
"bug",
"4.0-breaking-change"
] | rochacbruno | 1 |
FlareSolverr/FlareSolverr | api | 626 | [yggtorrent] (testing) Exception (yggtorrent): Error connecting to FlareSolverr | **Please use the search bar** at the top of the page and make sure you are not creating an already submitted issue.
Check closed issues as well, because your issue may have already been fixed.
### How to enable debug and html traces
[Follow the instructions from this wiki page](https://github.com/FlareSolverr/Fl... | closed | 2022-12-20T12:15:19Z | 2022-12-21T01:00:42Z | https://github.com/FlareSolverr/FlareSolverr/issues/626 | [
"invalid"
] | o0-sicnarf-0o | 0 |
microsoft/qlib | machine-learning | 1,371 | Can provider_uri be other protocols like http | ## ❓ Questions and Help
We sincerely suggest you to carefully read the [documentation](http://qlib.readthedocs.io/) of our library as well as the official [paper](https://arxiv.org/abs/2009.11189). After that, if you still feel puzzled, please describe the question clearly under this issue. | closed | 2022-11-21T06:56:35Z | 2023-02-24T12:02:34Z | https://github.com/microsoft/qlib/issues/1371 | [
"question",
"stale"
] | Vincent4zzzz | 1 |
psf/requests | python | 6,512 | Requests are not retried when received body length is shorter than Content-Length | When a server sends less bytes than indicated by Content-Length, we get a ChunkedEncodingError instead of retrying the request.
urllib3 supports retrying requests in this situation by setting `preload_content=True`. When a user specifies `stream=True`, obviously, all bets are off: the response cannot be preloaded an... | open | 2023-08-23T19:11:31Z | 2024-07-01T16:42:59Z | https://github.com/psf/requests/issues/6512 | [] | zweger | 5 |
litestar-org/litestar | api | 3,760 | Bug: `return_dto` not used in openapi spec when `Response` is returned by handler | ### Description
When I return a `Response[MyDTO]`, I expect the generated openapi spec to include the full dto but it appears to return an empty schema `{}` instead. https://github.com/litestar-org/litestar/issues/1631 appears to have implemented support for this, but maybe it broke since then. The code below shows ... | open | 2024-09-27T17:11:36Z | 2025-03-20T15:54:55Z | https://github.com/litestar-org/litestar/issues/3760 | [
"Bug :bug:"
] | atom-andrew | 0 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,290 | Getting detected by Google after running for 2-3 minutes. | It's getting detected on google login after continuously running for 2-3 minutes . | open | 2023-05-25T09:35:53Z | 2023-06-21T04:06:39Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1290 | [] | sprogdept001 | 1 |
aiortc/aiortc | asyncio | 208 | How to fix 'ClientConnectorError' in aiohttp in Janus example | Hi!
Im trying to run Janus example. I do the same as in this [description](https://github.com/aiortc/aiortc/tree/master/examples/janus) , but i get an error:
`aiohttp.client_exceptions.ClientConnectorError: Cannot connect to host localhost:8088 ssl:None [Connect call failed ('127.0.0.1', 8088)]`
the issue occur in ... | closed | 2019-09-24T13:44:57Z | 2019-09-24T19:21:10Z | https://github.com/aiortc/aiortc/issues/208 | [] | Glunky | 2 |
TencentARC/GFPGAN | deep-learning | 59 | How to get original size? (no upscale) | I've tried `--UPSCALE 1` and I also tried to completely remove the command.
But I always get at least upscale x2
EDIT:
Sorry for the mess It works now, I guess I did something wrong but now it works fine, I finally get 100% resolution. | open | 2021-09-05T02:40:23Z | 2021-09-17T02:58:36Z | https://github.com/TencentARC/GFPGAN/issues/59 | [] | AlonDan | 4 |
HumanSignal/labelImg | deep-learning | 310 | the minX mustn't equal maxX and the same as minY&maxY value | initPos = self.current[0]
minX = initPos.x()
minY = initPos.y()
targetPos = self.line[1]
maxX = targetPos.x()
maxY = targetPos.y()
self.current.addPoint(QPointF(maxX, minY))
... | closed | 2018-06-05T09:25:43Z | 2018-06-14T02:49:35Z | https://github.com/HumanSignal/labelImg/issues/310 | [] | loulansuiye | 1 |
tortoise/tortoise-orm | asyncio | 1,449 | DatetimeField Query Questions | **Describe the bug**
tortoise-orm: 0.20.0
python:3.11
I can't get my data when using the get_or_create method.
Is the reason found to be a problem with DatetimeField being unable to convert the time zone? I didn't encounter this issue with similar queries in Django
**To Reproduce**
My database configuration:
`re... | closed | 2023-08-04T02:17:16Z | 2023-08-04T02:25:26Z | https://github.com/tortoise/tortoise-orm/issues/1449 | [] | smomop | 0 |
gtalarico/django-vue-template | rest-api | 3 | Add Documentation for CDN configuration | closed | 2018-08-15T07:37:47Z | 2018-09-03T21:52:16Z | https://github.com/gtalarico/django-vue-template/issues/3 | [
"Documentation"
] | gtalarico | 0 | |
piskvorky/gensim | nlp | 2,796 | Inconsistency between pip version (3.8.2) and installed version (3.8.1) | #### Problem description
The gensim package version is 3.8.2 on [pip](https://pypi.org/project/gensim/), but after installing it and checking the version on python console I see 3.8.1:
```python
import gensim
gensim.__version__
# '3.8.1'
```
#### Versions
```bash
Linux-5.3.0-46-generic-x86_64-with-glibc2.10
... | closed | 2020-04-15T10:05:36Z | 2020-07-15T09:36:43Z | https://github.com/piskvorky/gensim/issues/2796 | [
"bug"
] | dpasqualin | 4 |
OpenInterpreter/open-interpreter | python | 670 | Infrastructure intelligence | ### Is your feature request related to a problem? Please describe.
<img width="569" alt="Screen Shot 2023-10-21 at 10 43 45 AM" src="https://github.com/KillianLucas/open-interpreter/assets/115367894/c1b53e8d-07b3-4637-9d57-1cb5e514ea6e">
### Describe the solution you'd like
I'd like for open interpreter to keep ... | closed | 2023-10-21T07:47:28Z | 2023-12-19T08:42:35Z | https://github.com/OpenInterpreter/open-interpreter/issues/670 | [
"Enhancement"
] | ngoiyaeric | 4 |
holoviz/panel | plotly | 6,897 | ReactiveHTML components cannot have a String param initialized on creation | There appears to be a bug in `ReactiveHTML` which makes it impossible to initialize string parameters with values passed into the constructor.
#### ALL software version info
`panel==1.4.4`
#### Description of expected behavior and the observed behavior
When `ReactiveHTML` is subclassed and a `param.String` is... | closed | 2024-06-07T00:58:11Z | 2024-06-27T22:48:04Z | https://github.com/holoviz/panel/issues/6897 | [
"component: reactivehtml"
] | jerry-kobold | 3 |
ipython/ipython | data-science | 14,250 | The bang magic and the line numbering | ```
In [1]: 1 ! ls \
2 /dev/null
3 int( \
4 qwerty)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[1], line 3
1 get_ipython().system(' ls /dev/null')
... | open | 2023-11-22T13:45:27Z | 2024-03-03T16:53:39Z | https://github.com/ipython/ipython/issues/14250 | [] | kuraga | 0 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 758 | Model Files Not Found | I tried to create the project and got rid of basically every problem except a Model Files not found problem! It goes as follows:
Arguments:
datasets_root: None
enc_models_dir: encoder\saved_models
syn_models_dir: synthesizer\saved_models
voc_models_dir: vocoder\saved_models
cpu: ... | closed | 2021-05-15T01:01:31Z | 2022-06-02T21:18:16Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/758 | [] | TKTSWalker | 4 |
jwkvam/bowtie | plotly | 229 | ImportError: No module named html | I'm stuck trying to run the example code:
https://github.com/jwkvam/bowtie-demo/blob/master/example.py
I believe I have all dependencies installed via conda and pip (plotlywrapper), and I've tried running it in several environments and consoles.
>>> #!/usr/bin/env python
... # -*- coding: utf-8 -*-
...
...... | closed | 2018-05-08T19:20:01Z | 2018-05-08T22:54:19Z | https://github.com/jwkvam/bowtie/issues/229 | [] | willupowers | 3 |
clovaai/donut | computer-vision | 129 | How to train the model for supporting Arabic Language | Hello,
How I can train the model to support Arabic language
what i understand from this issue https://github.com/clovaai/donut/issues/77
arabic may not supported ,
but we have team they can create a custom Arabic tokenizer , but we need more info on how to do it and how to integrate it
to donut
thanks in ad... | open | 2023-01-30T09:39:27Z | 2023-02-12T00:53:43Z | https://github.com/clovaai/donut/issues/129 | [] | Abdullamhd | 1 |
mckinsey/vizro | data-visualization | 99 | Have a component like Plotly Textarea to get text input from the user. | ### What's the problem this feature will solve?
Enabling users to input SQL queries for data retrieval can significantly enhance the utility of data connectors. This feature would allow for the generation of dynamic dashboards that can be customized according to user-defined queries as texts.
### Describe the solutio... | closed | 2023-10-06T05:16:26Z | 2024-07-09T15:09:00Z | https://github.com/mckinsey/vizro/issues/99 | [
"Custom Components :rocket:"
] | farshidbalan | 1 |
sqlalchemy/sqlalchemy | sqlalchemy | 12,029 | Python 3.8 is eol, remove support from 2.1 | as title says.
Things we could use:
- dict union -> does not really have too much impact since sqlalchemy mostly uses immutable dict
- use lowercase collections -> IIRC I had issues there, so it's likely safer to just wait until 3.10+. Also would make backporting to 2.0 harder | closed | 2024-10-24T15:45:14Z | 2024-11-06T23:56:09Z | https://github.com/sqlalchemy/sqlalchemy/issues/12029 | [
"setup"
] | CaselIT | 4 |
Farama-Foundation/PettingZoo | api | 1,269 | [Pyright] Pyright complains in random_demo.py and average_total_reward.py | ### Describe the bug
When I run `pre-commit run --all-files`, I get the following error:
```
/home/albert-han/PettingZoo/pettingzoo/utils/average_total_reward.py
/home/albert-han/PettingZoo/pettingzoo/utils/average_total_reward.py:37:40 - error: Argument of type "int | list[int] | list[list[int]] | list[list[list[An... | closed | 2025-02-23T21:56:19Z | 2025-02-25T16:35:31Z | https://github.com/Farama-Foundation/PettingZoo/issues/1269 | [
"bug"
] | yjhan96 | 0 |
PaddlePaddle/ERNIE | nlp | 278 | ERNIE 2.0 多任务学习的预训练代码何时会放 | closed | 2019-08-12T15:17:45Z | 2020-05-28T11:52:49Z | https://github.com/PaddlePaddle/ERNIE/issues/278 | [
"wontfix"
] | Albert-Ma | 3 | |
HIT-SCIR/ltp | nlp | 401 | batch时报错 | `ltp.seg()`对输入的list有什么限制吗?
在跑大批量的数据时,batch从2-10都会中断报错。只有batch为1的时候才能正常跑完。
单测过一个batch,是没问题。
报错是list out of range
猜想是不是内部会对batch做concat还是啥。 | closed | 2020-08-19T08:41:39Z | 2020-08-21T07:41:31Z | https://github.com/HIT-SCIR/ltp/issues/401 | [] | Damcy | 2 |
ipython/ipython | data-science | 14,038 | Document that `%gui qt` currently forces Qt5 | <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories.
If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org.
If you are unsure, it's ok to post here, though, there are few ... | open | 2023-04-26T15:59:31Z | 2023-07-12T13:38:01Z | https://github.com/ipython/ipython/issues/14038 | [] | kwsp | 4 |
widgetti/solara | flask | 306 | fix: typing failures with modern typed libraries | We limit traitlets and matplotlib to avoid lint failures in https://github.com/widgetti/solara/pull/305
We should fix those errors, and unpin the installations in CI. | open | 2023-09-27T09:49:30Z | 2023-10-02T17:10:58Z | https://github.com/widgetti/solara/issues/306 | [
"good first issue",
"help wanted"
] | maartenbreddels | 1 |
huggingface/transformers | tensorflow | 36,854 | Facing RunTime Attribute error while running different Flax models for RoFormer | when running FlaxRoFormerForMaskedLM model, I have encountered an issue as
> AttributeError: 'jaxlib.xla_extension.ArrayImpl' object has no attribute 'split'.
This error is reported in the file `transformers/models/roformer/modeling_flax_roformer.py:265`
The function responsible for this error in that file is as b... | open | 2025-03-20T12:33:26Z | 2025-03-20T14:23:07Z | https://github.com/huggingface/transformers/issues/36854 | [
"Flax",
"bug"
] | ctr-pmuruganTT | 0 |
harry0703/MoneyPrinterTurbo | automation | 262 | PermissionError: [WinError 32] The process cannot access the file because it is being used by another process: 'D:\\kevinzhang\\tmp\\MoneyPrinterTurbo\\storage\\tasks\\0fa8fa91-1ca6-49b2-a7a0-60c1c3b7be1f\\combined-1.mp4' | 生成视频之后,调用删除api会报错。重启服务再删除成功。
```
curl -X 'DELETE' \
'http://127.0.0.1:8502/api/v1/tasks/0fa8fa91-1ca6-49b2-a7a0-60c1c3b7be1f' \
-H 'accept: application/json'
```
附上log
[2024_04_15.txt](https://github.com/harry0703/MoneyPrinterTurbo/files/14975885/2024_04_15.txt)
| closed | 2024-04-15T08:06:08Z | 2024-04-16T01:04:37Z | https://github.com/harry0703/MoneyPrinterTurbo/issues/262 | [] | KevinZhang19870314 | 2 |
plotly/dash | data-science | 2,946 | [BUG] Component value changing without user interaction or callbacks firing | Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip l... | closed | 2024-08-10T03:24:28Z | 2024-08-10T16:54:40Z | https://github.com/plotly/dash/issues/2946 | [] | Casper-Guo | 8 |
dpgaspar/Flask-AppBuilder | rest-api | 2,104 | missing .get(col_name) | https://github.com/dpgaspar/Flask-AppBuilder/blob/6130d078b608658eb66e15530502efd309653435/flask_appbuilder/views.py#L463
@dpgaspar as you can see, in the add, you have the .get(col_name) in
```python
if self.add_form_query_rel_fields:
filter_rel_fields = self.add_form_query_rel_fields.get... | closed | 2023-08-16T18:07:49Z | 2023-10-23T11:43:55Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/2104 | [
"bug"
] | gbrault | 1 |
horovod/horovod | machine-learning | 3,240 | One process are worked in two GPUs? | **Environment:**
1. Framework: PyTorch
2. Framework version: I do not know
3. Horovod version: 0.23.0
4. MPI version: 4.0.0
5. CUDA version:11.2
6. NCCL version:2.8.4 + cuda 11.1
7. Python version: 3.8
8. Spark / PySpark version: no
9. Ray version: no
10. OS and version: Ubuntu 18.04
11. GCC version: I do n... | open | 2021-10-24T11:56:55Z | 2021-10-24T12:01:13Z | https://github.com/horovod/horovod/issues/3240 | [
"bug"
] | xml94 | 0 |
PablocFonseca/streamlit-aggrid | streamlit | 110 | Can "integrated charts" be used with streamlit-aggrid? | I can see from the showcase example that e.g. groups and pivot-tables work. Before buying a license, I would like to know if the enterprise "inegrated charts" feature will work when AGGrid is used via Streamlit. | closed | 2022-07-12T14:08:55Z | 2024-04-04T17:53:58Z | https://github.com/PablocFonseca/streamlit-aggrid/issues/110 | [] | fluence-world | 6 |
recommenders-team/recommenders | data-science | 1,217 | [BUG] AttributeError: 'HParams' object has no attribute 'use_entity' | I am using DKN_mind and repeatedly getting this error
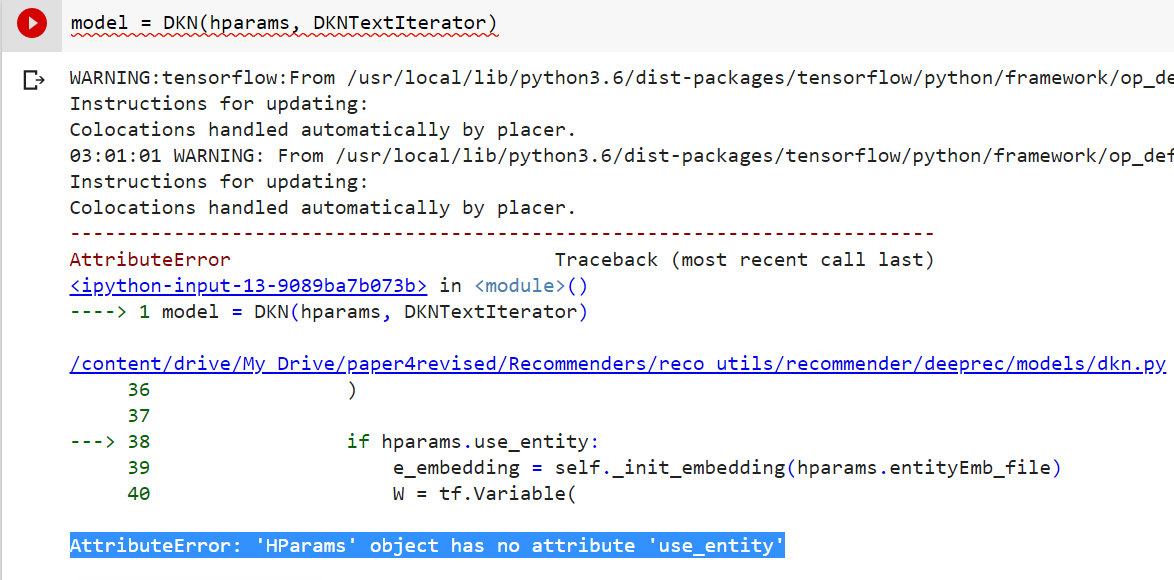
any suggestions? | closed | 2020-10-19T15:02:33Z | 2020-10-29T14:13:37Z | https://github.com/recommenders-team/recommenders/issues/1217 | [
"bug"
] | shainaraza | 1 |
QuivrHQ/quivr | api | 3,058 | Filter knowledge by folder type (quivr folder / integrations) | closed | 2024-08-22T14:41:41Z | 2024-10-23T08:06:27Z | https://github.com/QuivrHQ/quivr/issues/3058 | [
"Feature"
] | linear[bot] | 1 | |
labmlai/annotated_deep_learning_paper_implementations | pytorch | 45 | Weight Standardization | ### Papers
* [Micro-Batch Training with Batch-Channel Normalization and Weight Standardization](https://arxiv.org/pdf/1903.10520.pdf) [papers with code](https://paperswithcode.com/paper/weight-standardization)
* [CHARACTERIZING SIGNAL PROPAGATION TO CLOSE THE PERFORMANCE GAP IN UNNORMALIZED RESNETS](https://arxiv.o... | closed | 2021-04-24T10:19:28Z | 2021-06-21T16:08:08Z | https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/45 | [
"paper implementation"
] | vpj | 0 |
babysor/MockingBird | pytorch | 254 | ValueError: operands could not be broadcast together with shapes (2200,) (4000,) (2200,) | Getting this error while running the synthesize() function on Google Colab. Any solution?
| open | 2021-12-08T03:00:09Z | 2022-05-21T03:34:15Z | https://github.com/babysor/MockingBird/issues/254 | [] | joeynmq | 7 |
Farama-Foundation/PettingZoo | api | 1,099 | [Bug Report] Cannot import package: circular import with pettingzoo and gymnasium-robotics | ### Describe the bug
Importing `pettingzoo` crashes when the package `gymnasium-robotics` is installed in the system.
Code to reproduce behavior is included below. It consists of installing both packages and importing pettingzoo.
### Code example
```shell
# Install dependencies
pip install pettingzoo gymnasium-r... | closed | 2023-09-11T11:11:07Z | 2023-09-27T19:17:49Z | https://github.com/Farama-Foundation/PettingZoo/issues/1099 | [
"bug"
] | thomasbbrunner | 4 |
dropbox/PyHive | sqlalchemy | 345 | Peewee ORM support? | Can I use Peewee ORM with PyHive? | closed | 2020-07-02T16:06:50Z | 2020-07-28T23:36:11Z | https://github.com/dropbox/PyHive/issues/345 | [] | wilberh | 1 |
recommenders-team/recommenders | machine-learning | 1,946 | [ASK] I can't getting start | When I tried to get start and type` pip install recommenders[examples]` ,it shows:
Building wheels for collected packages: lightfm, scikit-surprise, Flask-BasicAuth, future
Building wheel for lightfm (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py bdist_wheel did not run successf... | closed | 2023-06-20T09:15:46Z | 2023-07-11T08:25:28Z | https://github.com/recommenders-team/recommenders/issues/1946 | [
"help wanted"
] | b856741 | 2 |
keras-team/autokeras | tensorflow | 1,874 | Bug: StructuredDataClassifier ignores loss parameter | ### Bug Description
The StructuredDataClassifier trains with default loss and ignores any user input. Even setting the loss to some random string like `loss='this is not a loss'` does not change the behavior (or result in an error).
### Bug Reproduction
```
import tensorflow as tf
import autokeras as ak
TRAIN... | open | 2023-04-04T07:56:09Z | 2023-04-04T07:56:09Z | https://github.com/keras-team/autokeras/issues/1874 | [
"bug report"
] | DF-Damm | 0 |
cobrateam/splinter | automation | 1,079 | 👋 From the Selenium project! | At the Selenium Project we want to collaborate with you and work together to improve the WebDriver ecosystem. We would like to meet you, understand your pain points, and discuss ideas around Selenium and/or WebDriver.
If you are interested, please fill out the form below and we will reach out to you.
https://forms... | closed | 2022-08-04T13:59:14Z | 2022-08-04T14:57:30Z | https://github.com/cobrateam/splinter/issues/1079 | [] | diemol | 0 |
talkpython/data-driven-web-apps-with-flask | sqlalchemy | 3 | Chapter 07 | When the Login button is clicked with empty fields the video shows that password field turns red. This does occur when using Firefox but it does not occur when using Safari on the Mac.
Not a bug per se, but something that may confuse users. | closed | 2019-07-27T23:21:15Z | 2019-07-29T16:38:46Z | https://github.com/talkpython/data-driven-web-apps-with-flask/issues/3 | [] | cmcknight | 1 |
Lightning-AI/pytorch-lightning | deep-learning | 20,572 | auto_scale_batch_size arg not accept by lightning.Trainer | ### Bug description
The `auto_scale_batch_size` arg is not accept in `lightning.Trainer`, but accepted in `pytorch_lightning.Trainer`.
```
Error in call to target 'lightning.pytorch.trainer.trainer.Trainer':
TypeError("Trainer.__init__() got an unexpected keyword argument 'auto_scale_batch_size'")
```
### What vers... | open | 2025-02-03T22:58:59Z | 2025-02-03T22:59:11Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20572 | [
"bug",
"needs triage",
"ver: 2.5.x"
] | yc-tao | 0 |
biolab/orange3 | data-visualization | 6,312 | Row number as a variable |
**What's your use case?**
When using Select Rows, it should also be possible to select by row number. For example, in some datasets from connected products, the first x rows originate from prototypes or they are otherwise not representative, for instance due to start-up problems. In such cases it is useful to be abl... | closed | 2023-01-24T14:22:43Z | 2023-01-25T21:11:59Z | https://github.com/biolab/orange3/issues/6312 | [] | wvdvegte | 5 |
deezer/spleeter | deep-learning | 112 | [Discussion] Why is the model rebuilt every time? | Anyone wants to explain to me why the model is rebuilt every time?
My rationale is that since the model can be recycled for a batch, why can't the model be saved as a file and loaded next time a separation is executed?
It just doesn't make sense to me.
I think that the model should be rebuilt only when asked t... | closed | 2019-11-18T05:22:40Z | 2019-11-22T18:35:36Z | https://github.com/deezer/spleeter/issues/112 | [
"question"
] | aidv | 2 |
python-gitlab/python-gitlab | api | 2,839 | get_id() retruns name of label | ## Description of the problem, including code/CLI snippet
get_id() of a GroupLabel returns the name of the label and not the id.
In the case of a label inherited from a parent group, it is not possible to distinguish between two labels if they have the same name.
## Expected Behavior
I expect to get the value... | open | 2024-04-16T06:26:29Z | 2024-04-16T06:26:29Z | https://github.com/python-gitlab/python-gitlab/issues/2839 | [] | cweber-dbs | 0 |
mkhorasani/Streamlit-Authenticator | streamlit | 174 | Inquiry Regarding Persistent Login Issue | I am writing to inquire about an authentication issue that we have observed in our Streamlit application. Specifically, we have noticed that once User A logs into the system, other individuals are able to access and browse the application in the name of User A, regardless of the computer or device they are using. Howev... | closed | 2024-06-27T10:15:08Z | 2024-06-28T17:34:54Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/174 | [
"help wanted"
] | 3togo | 2 |
pydata/pandas-datareader | pandas | 508 | CDC datasets, WISQARS, WONDER | - https://wonder.cdc.gov/datasets.html
- https://www.cdc.gov/nchs/data_access/ftp_data.htm
- WISQARS/WONDER data comparison:
- https://www.cdc.gov/injury/wisqars/fatal_help/faq.html#WONDER
- https://wonder.cdc.gov/wonder/help/WONDER-API.html
Is there a recommended way to cache whole (compressed) datasets retri... | open | 2018-03-21T10:30:43Z | 2018-03-21T10:30:43Z | https://github.com/pydata/pandas-datareader/issues/508 | [] | westurner | 0 |
apache/airflow | python | 47,501 | AIP-38 | Add API Endpoint to serve connection types and extra form meta data | ### Body
To be able to implement #47496 and #47497 the connection types and extra form elements meta data needs to be served by an additional API endpoint.
Note: The extra form parameters should be served in the same structure and format like the DAG params such that the form elements of FlexibleForm can be re-used i... | closed | 2025-03-07T14:54:17Z | 2025-03-12T22:28:20Z | https://github.com/apache/airflow/issues/47501 | [
"kind:feature",
"area:API",
"kind:meta"
] | jscheffl | 0 |
sherlock-project/sherlock | python | 2,423 | Requesting support for: programming.dev | ### Site URL
https://programming.dev
### Additional info
- Link to the site main page: https://programming.dev
- Link to an existing account: https://programming.dev/u/pylapp
- Link to a nonexistent account: https://programming.dev/u/noonewouldeverusethis42
### Code of Conduct
- [x] I agree to follow this project'... | open | 2025-03-05T12:14:42Z | 2025-03-05T12:27:12Z | https://github.com/sherlock-project/sherlock/issues/2423 | [
"site support request"
] | pylapp | 1 |
Asabeneh/30-Days-Of-Python | numpy | 157 | V | V | closed | 2021-04-28T17:10:08Z | 2021-07-05T21:58:51Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/157 | [] | eknatx | 0 |
HumanSignal/labelImg | deep-learning | 424 | JPG format is not supported | <!--
Please provide as much as detail and example as you can.
You can add screenshots if appropriate.
-->
- **OS:**
- **PyQt version:**
| open | 2019-01-04T01:48:03Z | 2023-03-23T02:21:35Z | https://github.com/HumanSignal/labelImg/issues/424 | [] | cuiluguang | 3 |
jeffknupp/sandman2 | sqlalchemy | 59 | how to install it without pip | how to install it on hosts where the flying dependency ``https://pypi.python.org/simple/Flask-HTTPAuth/`` ( when executing ``python setup.py install`` ) can't be accessed due to network administration ?
thanks | closed | 2017-03-24T10:59:34Z | 2017-03-24T21:33:04Z | https://github.com/jeffknupp/sandman2/issues/59 | [] | downgoon | 1 |
miguelgrinberg/python-socketio | asyncio | 520 | HTTP Basic Authentication? | Does SocketIO support authenticating with endpoints which require HTTP basic authentication? I cannot see any indication that it does / does not in documentation.
Thanks! | closed | 2020-07-13T10:14:32Z | 2020-07-13T11:02:13Z | https://github.com/miguelgrinberg/python-socketio/issues/520 | [
"question"
] | 9ukn23nq | 3 |
jina-ai/clip-as-service | pytorch | 194 | 'bert-serving-start' is not recognized as an internal or external command | Hi,
This is a very silly question.....
I have python 3.6.6, tensorflow 1.12.0, doing everything in conda environment, Windows 10.
I pip installed bert-serving-server/client and it shows
`Successfully installed GPUtil-1.4.0 bert-serving-client-1.7.2 bert-serving-server-1.7.2 pyzmq-17.1.2`
but when I run the follo... | closed | 2019-01-16T15:16:56Z | 2021-10-20T04:26:11Z | https://github.com/jina-ai/clip-as-service/issues/194 | [] | moon-home | 13 |
ultralytics/ultralytics | python | 19,571 | YOLOv11 tuning: best fitness=0.0 observed at all iterations | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi, I am using the YOLOv11 model. I am able to successfully train with model... | closed | 2025-03-08T00:03:43Z | 2025-03-11T14:40:53Z | https://github.com/ultralytics/ultralytics/issues/19571 | [
"question",
"detect"
] | ss4824 | 5 |
FactoryBoy/factory_boy | sqlalchemy | 869 | Use Pydantic models as the model in Meta | #### The problem
Pydantic is a fast growing library that handles data validation in a very clean way using type hinting. If you are working on a python project that needs to digest and output data models you are likely to use pydantic these days, even more so if you are using fastapi since it uses pydantic to validate... | open | 2021-06-14T07:31:11Z | 2023-09-15T10:38:26Z | https://github.com/FactoryBoy/factory_boy/issues/869 | [
"Feature",
"NeedInfo"
] | jaraqueffdc | 9 |
marimo-team/marimo | data-visualization | 3,748 | API URL discrepancy between Ollama's GitHub example and what works with Marimo. HTTP/404 returned when Ollama example is used... | ### Describe the bug
Hello Friends:
First of all, thank you for this delightful and exciting product. I'm eager to use it. `=:)`
I run `Ollama` in a `podman(1)` container and expose it's `11434` port to the `HOST`. That all works fine. For instance, from the `podman(1) HOST` itself (_and from anywhere on my network ... | closed | 2025-02-11T02:00:09Z | 2025-02-11T02:55:52Z | https://github.com/marimo-team/marimo/issues/3748 | [
"bug"
] | nmvega | 2 |
tensorly/tensorly | numpy | 94 | Unable to target GPU with MXNET backend | I need some assistance with targeting GPU with MXNET backend. I attempted to use the Robust PCA API with tensors on GPU. Using the following code, execution is occurring on the CPU cores and not GPU(0). Thanks!
<img width="691" alt="image" src="https://user-images.githubusercontent.com/15822729/50386331-046d7500-06a... | closed | 2018-12-23T17:40:08Z | 2018-12-23T18:25:13Z | https://github.com/tensorly/tensorly/issues/94 | [] | DFuller134 | 0 |
slackapi/bolt-python | fastapi | 728 | Add slack reaction, edit previous message even possible ? | Hi fellows,
I'm not sure, might be bolt api does not support it, I cant find any similar examples
Is it possible to do such things like:
1. Add slack reaction to the message that my bot have just send, like adding: 1️⃣ 2️⃣ ... ✅ as reactions ( I don't want to spam slack messages)
2. Edit slack message, that... | closed | 2022-09-29T16:10:26Z | 2022-09-29T20:35:22Z | https://github.com/slackapi/bolt-python/issues/728 | [
"question"
] | sielaq | 2 |
google-research/bert | nlp | 1,304 | help | Why do I input the same batch and output different logits during debugging? | open | 2022-05-03T15:04:04Z | 2022-05-03T15:04:04Z | https://github.com/google-research/bert/issues/1304 | [] | DreamH1gh | 0 |
glumpy/glumpy | numpy | 149 | ModuleNotFoundError: No module named 'glumpy.ext.sdf.sdf' | when trying to run `examples/font-sdf.py`:
```
Traceback (most recent call last):
File ".\Graph.py", line 26, in <module>
labels.append(text, regular, origin = (x,y,z), scale=scale, anchor_x="left")
File "C:\python\Python36\lib\site-packages\glumpy\graphics\collections\sdf_glyph_collection.py", line 76, ... | open | 2018-04-16T18:42:12Z | 2018-04-23T07:07:23Z | https://github.com/glumpy/glumpy/issues/149 | [] | Axel1492 | 1 |
strawberry-graphql/strawberry | graphql | 2,815 | relay: conflict with GlobalId of strawberry_django_plus | I get the error:
strawberry.exceptions.scalar_already_registered.ScalarAlreadyRegisteredError: Scalar `GlobalID` has already been registered
I think it is because I use strawberry_django_plus and the new relay implementation.
I don't know on which side to report | closed | 2023-06-06T22:31:37Z | 2023-06-15T23:17:37Z | https://github.com/strawberry-graphql/strawberry/issues/2815 | [
"bug"
] | devkral | 4 |
psf/black | python | 3,918 | Formatting one-tuples as multi-line if already multi-line | **Describe the style change**
Black excludes one-tuples `(1,)` and single-item subscripts with trailing comma `tuple[int,]` from magic comma handling, because unlike in list literals etc. the comma here is required, so cannot be used to distinguish between the user's desire to single-line or multi-line.
The singl... | open | 2023-10-03T13:12:47Z | 2023-11-04T21:26:08Z | https://github.com/psf/black/issues/3918 | [
"T: style"
] | bluetech | 6 |
zappa/Zappa | django | 925 | [Migrated] fails to pip install zappa | Originally from: https://github.com/Miserlou/Zappa/issues/2191 by [AndroLee](https://github.com/AndroLee)
"pip install zappa" returns an error
## Context
Collecting zappa
Using cached zappa-0.52.0-py3-none-any.whl (114 kB)
Requirement already satisfied: wheel in c:\users\leeandr\pycharmprojects\mychatbot2\venv\l... | closed | 2021-02-20T13:24:36Z | 2022-07-16T05:30:26Z | https://github.com/zappa/Zappa/issues/925 | [] | jneves | 1 |
amdegroot/ssd.pytorch | computer-vision | 337 | Error in training(Error in training) | Error in training
iter 900 || Loss: 6.6272 || timer: 0.1010 sec.
iter 910 || Loss: 7.0335 || timer: 0.1023 sec.
iter 920 || Loss: 6.6000 || timer: 0.1001 sec.
iter 930 || Loss: 6.7137 || timer: 0.1013 sec.
iter 940 || Loss: 6.9450 || timer: 0.1027 sec.
iter 950 || Loss: 6.5815 || timer: 0.1038 sec.
iter 960 || L... | open | 2019-05-05T12:14:26Z | 2019-07-09T08:35:27Z | https://github.com/amdegroot/ssd.pytorch/issues/337 | [] | xlm998 | 3 |
graphql-python/graphene-django | graphql | 616 | Is it possible to use AsyncExecutor? | Hello!
How can I use AsyncExecutor with **graphene-django?**
I try this setup:
```
# types.py
class Source(graphene.ObjectType):
value = graphene.String()
# queries.py
class SourcesQuery(graphene.ObjectType):
sources = graphene.List(
of_type=Source
)
async def resolve_sources... | closed | 2019-04-08T12:39:33Z | 2020-09-22T12:49:07Z | https://github.com/graphql-python/graphene-django/issues/616 | [] | artinnok | 5 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 850 | Encoder zero output | Hi blue-fish:
Follow up on# 776. I set up an environment on Linux according to the guidance post here and re-processed everything and started training on LibriSpeech train other and vox1, vox2 with 768/256. The loss converges slightly faster than some other folks result here. But then I examined the embed output ... | closed | 2021-09-16T19:59:20Z | 2021-09-20T18:13:04Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/850 | [] | ARKEYTECT | 1 |
jofpin/trape | flask | 153 | ERROR in app: Exception on /register [POST] | Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File "/usr/local/lib/python2.7/dist-packages/flask/app.py", line 1815, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/usr/l... | open | 2019-05-03T06:55:32Z | 2019-08-15T16:01:02Z | https://github.com/jofpin/trape/issues/153 | [] | cr4shcod3 | 1 |
ultralytics/ultralytics | deep-learning | 18,752 | What is the effect of cropped objects after cropping training images? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
### Question
Hi,
As far as I know, during the training, images may be cropped. As... | open | 2025-01-18T12:38:16Z | 2025-01-20T11:13:53Z | https://github.com/ultralytics/ultralytics/issues/18752 | [
"question",
"detect"
] | sayyaradonis1 | 4 |
Yorko/mlcourse.ai | matplotlib | 345 | /assignments_demo/assignment04_habr_popularity_ridge.ipynb - Опечатка в тексте задания | "Инициализируйте DictVectorizer с параметрами по умолчанию.
Примените метод fit_transform к X_train['title'] и метод transform к X_valid['title'] и X_test['title']"
Скорее всего здесь опечатка: должно быть X_train[feats], X_valid[feats], X_test[feats] | closed | 2018-07-19T10:19:13Z | 2018-08-04T16:07:08Z | https://github.com/Yorko/mlcourse.ai/issues/345 | [
"minor_fix"
] | pavel-petkun | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.