
instruction stringlengths 0 30k ⌀ |
|---|
I am using Svelte with [Ultralight][1], communication is handled with JavaScriptCore so Ultralight set / call functions on the global javascript object (which I believe is window). Now I want to call these functions in my svelte app, but I am using modules and so I can't set / use global functions.
So for now I am stuck to something like this :
`CppInterop.js` module :
import { notification } from "./lib/store";
// Expose store globally
window.store = {
notification
}
// Expose the C++ functions
export default {
test: () => window.Test()
}
`cpp.js` that I include directly in my html file with `<script src="/cpp.js"></script>` :
// From JS to C++
window.Test = Test;
// From C++ to JS
function notification(message, type)
{
window.store.notification.notify(message, type);
}
Interop doesn't seems to work then I try to access the functions via `window` so that's why I do `window.Test = Test`. What I would like is to call / define global function while still having access to modules (to call my own functions and stores), is that possible ?
[1]: https://ultralig.ht/ |
How to Call Global Functions from Modules and Maintain Modularity? |
|javascript| |
I try to go from Spring-Boot 2.7 to 3.1 - its regarding Security.
What I have under old version 2.
public class SecurityConfiguration extends WebSecurityConfigurerAdapter
{
@Override
protected void configure (HttpSecurity http) throws Exception
{
http.cors ().and ()
.csrf ().disable ()
.authorizeRequests ()
.antMatchers ("/web/test").permitAll ()
.antMatchers ("/web/**").hasAnyRole ("USER")
.anyRequest ().authenticated ()
.and ()
.addFilter (new SecurityAuthenticationFilter (authenticationManager ()))
.addFilter (new SecurityAuthorizationFilter (authenticationManager ()))
.sessionManagement ()
.sessionCreationPolicy (SessionCreationPolicy.STATELESS);
}
What I already have for version 3.
@Bean
public SecurityFilterChain securityFilterChain (HttpSecurity http) throws Exception
{
http
.cors (Customizer.withDefaults ())
.csrf (AbstractHttpConfigurer::disable)
.authorizeHttpRequests ((requests) -> requests
.requestMatchers ("/web/test").permitAll ()
.requestMatchers ("/web/**").hasRole ("USER")
.anyRequest ().authenticated ()
)
//.addFilter (new SecurityAuthenticationFilter (authenticationManager ()))
.sessionManagement (httpSecuritySessionManagementConfigurer ->
httpSecuritySessionManagementConfigurer.sessionCreationPolicy (SessionCreationPolicy.STATELESS))
;
return http.build();
But here I struggle with authenticationManager () of former WebSecurtyConfigurationAdapter - for my 2 custom filters.
Where can get this and can I use my filters as they are in Spring3??
They are
public class SecurityAuthorizationFilter extends BasicAuthenticationFilter
{
public SecurityAuthorizationFilter (AuthenticationManager authenticationManager)
{
super (authenticationManager);
}
@Override
protected void doFilterInternal (HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws IOException, ServletException
{
UsernamePasswordAuthenticationToken upa = getAuthentication (request);
if (upa == null)
{
filterChain.doFilter (request, response);
}
else
{
SecurityContextHolder.getContext ().setAuthentication (upa);
filterChain.doFilter (request, response);
}
}
@SuppressWarnings ("unchecked")
private UsernamePasswordAuthenticationToken getAuthentication (HttpServletRequest request)
{
String token = request.getHeader (SecurityConstants.TOKEN_HEADER);
if (token != null && token.startsWith (SecurityConstants.TOKEN_PREFIX) == true)
{
byte [] signingKey = SecurityConstants.JWT_SECRET.getBytes ();
token = token.replace (SecurityConstants.TOKEN_PREFIX, "");
Jws <Claims> claim = Jwts.parserBuilder ().setSigningKey (signingKey).build ().parseClaimsJws (token);
String usr = claim.getBody ().getSubject ();
List <LinkedHashMap <?, ?>> cs = claim.getBody ().get ("roles", List.class);
List <SimpleGrantedAuthority> claims = new ArrayList <SimpleGrantedAuthority> ();
for (int i = 0; i < cs.size (); i ++)
{
claims.add (new SimpleGrantedAuthority (cs.get (i).get ("authority"). toString ()));
}
if (usr.length () > 0)
{
return new UsernamePasswordAuthenticationToken (usr, null, claims);
}
}
return null;
}
}
and
public class SecurityAuthenticationFilter extends UsernamePasswordAuthenticationFilter
{
private final AuthenticationManager authenticationManager;
public SecurityAuthenticationFilter (AuthenticationManager authenticationManager)
{
this.authenticationManager = authenticationManager;
setFilterProcessesUrl (SecurityConstants.AUTH_LOGIN_URL);
}
@Override
public Authentication attemptAuthentication (HttpServletRequest request, HttpServletResponse response)
{
String usr = request.getParameter ("username");
String pwd = request.getParameter ("password");
UsernamePasswordAuthenticationToken upat = new UsernamePasswordAuthenticationToken (usr, pwd);
return authenticationManager.authenticate (upat);
}
@Override
protected void successfulAuthentication (HttpServletRequest request, HttpServletResponse response, FilterChain filterChain, Authentication authentication) throws java.io.IOException, ServletException
{
UserDetails user = ((UserDetails) authentication.getPrincipal ());
@SuppressWarnings ("unchecked")
Collection <GrantedAuthority> roles = (Collection <GrantedAuthority>) user.getAuthorities ();
String token = Jwts.builder ()
.signWith (Keys.hmacShaKeyFor (SecurityConstants.JWT_SECRET.getBytes ()), SignatureAlgorithm.HS512)
.setHeaderParam ("typ", SecurityConstants.TOKEN_TYPE)
.setIssuer (SecurityConstants.TOKEN_ISSUER)
.setAudience (SecurityConstants.TOKEN_AUDIENCE)
.setSubject (user.getUsername ())
.setExpiration (new java.util.Date (System.currentTimeMillis () + 60 * 60 * 24 * 1000)) // 24h lifetime of token
.claim ("roles", roles)
.compact ();
response.addHeader (SecurityConstants.TOKEN_HEADER, SecurityConstants.TOKEN_PREFIX + token);
}
}
|
# What is Deployment and Process Lifetime Managment with Systemd?
A Python Application is an executable Python script which may also have a dependency on some shared Python code which exists in local Python modules or Packages.
To deploy an application (any application, not necessarily a Python one) we would normally run some kind of build process and then copy the output of the build to a pre-determined directory location on a target machine. The target machine might be the same machine as the one we are using to develop our application.
If we do the above, then it is easy to manage our processes with systemd. We can write a service file which references an executable in a known location.
# What is the Python Development Process with venv?
`venv` ships by default with Python 3. I have been using it to manage a Python virtual environment as part of the development process. It performs two functions:
1. Isolating the install of libraries required by one project from all other projects and the Operating System
2. It provides a way for me to build Python Shared Libraries containing Python Code which should be shared between multiple executable processes which are part of the same project
It is easier to understand (2.) if I present my project directory structure:
```
my-python-project/
bin/
webscraper-processes/
webscraper.py
html_processor.py
feature_extractor.py
database_uploader.py
local_library/
__init__.py
... other files ...
cron-download-process/
pycron-download-trigger.py
downloader.py
data-processor.py
database_uploader_2.py
lib_cron_download/
__init__.py
... other files ...
src/
lib_database/
__init__.py
... other files ...
lib_kafka/
__init__.py
... other files ...
test/
... tests ...
.venv/
bin/activate
... other files ...
pyproject.toml
```
Please excuse the slightly silly names, hopefully this structure makes it clear why I have structured the project this way.
- There are multiple "groups" of executables. Each executable is a microservice which performs some function. A group of executables is a group of microservices. Each group of microservices performs a set of related operations as part of a sequence or chain. They work together to perform some higher level process or operation. Executables in different groups are independent.
- Although the group `webscraper-process` and `cron-download-process` are independent, they do share some common code. That common code goes in 1 or more shared libraries under the `src` directory.
- Any code which is shared by a group but not between multiple groups goes in a "local" shared library. (I'm not totally convinced this is a good idea. Perhaps it should go in `src` as well.)
`venv` is used for two purposes:
- To manage and install external dependencies locally. This would include `confluent-kafka`, Confluent's Kafka Python library and `sqlalchemy`.
- To provide a mechanism for the executable Python scripts to be able to "see" the shared library code which lives in the `src` directory. Otherwise, the interpreter would only be able to see the code in the current working directory, which includes "local" libraries but not "shared" libraries which are shared across the two groups.
**If there is a better approach than the one I am using, please let me know.**
I also recently experimented with Poetry and if I understand correctly, it provides a more convenient interface to manage virtual environments. I am open to using something other than `venv` if it provides an easier way to manage deployments.
# How to deploy this?
I don't fully understand how to deploy this and manage the process lifecycle with systemd.
- I know that I need to chose some target for the deployment. A fixed location which systemd can reference in the Service Files which I will write for systemd to use.
- Let's choose `/opt/my-python-project/`, which seems like a sensible location
Remaining questions include:
- How should I "deploy" code to this location?
- A simple approach would be to copy `cp -r my-python-project/bin /opt/my-python-project/`
- But that doesn't include the shared library code under `src`
- I suspect the shared library code should be built into a wheel and that wheel should be copied to `/opt/my-python-project/dist/`, and then installed into some `venv` in `/opt/my-python-project/` ?
- Should the library code in the `bin/webscraper-process` and `bin/cron-download-process` be built into a wheel as well?
- Do I need another `venv` or suitable alternative in the target location `/opt/my-python-project`?
- Is my approach fundamentally flawed because the project directory structure setup is flawed? Is there a better approach to the one I am using regarding the use of directory structure and `venv`? |
How to Deploy and Manage a Python Application with Systemd |
|python|linux|deployment|systemd| |
You should add a listener to focusNode value to detect where the TextFormField is being focused or not.
I prefer to use **ValueNotifier** and **ValueListenableBuilder** to rebuild only the Text widget not all the widgets in the screen.
final isEmailFocused = ValueNotifier<bool>(false);
@override
void initState() {
super.initState();
emailText.addListener(() {
isEmailFocused.value = emailText.hasFocus;
});
}
@override
void dispose() {
// don't forget to dispose all the inputs notifiers.
emailText.dispose();
emailInput.dispose();
isEmailFocused.removeListener(() {});
isEmailFocused.dispose();
super.dispose();
}
In Build method I wrapped the Email Text Widget with **ValueListenableBuilder** widget to rebuild the widget if the emailInput is focused.
ValueListenableBuilder(
valueListenable: isEmailFocused,
builder: (BuildContext context, bool value, Widget? child) {
return Text(
'Email',
style: TextStyle(
fontWeight: FontWeight.w600,
fontSize: 16.0,
color: value ? Colors.blue : Colors.black,
fontFamily: "Graphik",
),
);
},
), |
I'm currently utilizing the **Eigen** library within my C++ project, and I'm working with a tensor `tensorA` defined as `{2.02, -4.2, 2.2, 2.2}`. My question pertains to the behavior of the `argmax()` function when applied to this tensor.
Specifically, when I call `argmax()` on `tensorA`, should I expect the result to consistently return the index of the first occurrence of the maximum value, the index of the last occurrence, or is the behavior undetermined and may vary across different environments or versions of Eigen? |
null |
IMHO is [ControlFlow][1] much better suited:
fn functional_programming() -> bool {
let foo = [1, 2, 25, 4, 5];
let ControlFlow::Continue(sum) = foo.iter().try_fold(0, |sum, &bar| {
if bar > 20 {
return ControlFlow::Break(sum);
}
ControlFlow::Continue(sum + bar)
}) else { return false; };
sum > 10
}
[1]: https://doc.rust-lang.org/std/ops/enum.ControlFlow.html#method.map_continue |
{"OriginalQuestionIds":[54004635,45763121],"Voters":[{"Id":943435,"DisplayName":"Yogi"},{"Id":5625547,"DisplayName":"0stone0"},{"Id":9267406,"DisplayName":"imhvost"}]} |
Sometimes when closing vscode, or a tab in it, I get a dialogue asking "Do you want to save the changes you made to ``filename``?" However, the unsaved edits are actually from a previous session that was closed without such a query, probably when turning off the computer, so I can't remember if it was meaningful edits, or maybe just an accidental key-press, like a shortcut gone wrong; and doing `undo` to revisit the last edits doesn't work either.
My question: How can I see the diff between the saved version of a file, and the version in the editor window? I think it would be nicest just to have a "show diff" option in the dialogue, but for now I'm also happy with a command line diff command.
I'm using ubuntu 20.04. |
**Solved**.
It seems that I'm forced to use the endpoint `api/broadcasting/auth` in order to `channels.php` be called / executed.
On the Pusher JS configuration all I had to do was changing this line:
authEndpoint: 'api/auth',
to:
authEndpoint: 'api/broadcasting/auth', |
to anyone who comes across this thread looking for a solution for a similar issue that results in the following message
`1. NA Each element of '...' must be a named string.`
Check if your dictionary has any "NA" or blank in it. Once you remove the line with NA, your match_df() command should work for all columns.
Best of luck |
To retrieve Docker logs from the last hour for a specific container with `container_id`:
docker logs --since=1h 'container_id'
If the logs are large, then try considering to save logs into to a file:
docker logs --since=1h 'container_id' > /path/to/save.txt
|
I've been struggling with this issue for 2 days and still couldn't find a solution. I would be very happy if you could help.
I'm using PrelineUI in my project.
The input select looks like this:
```
<select multiple wire:model="category" id="category"
data-hs-select='{
"placeholder": "Select multiple options...",
"toggleTag": "<button type=\"button\"></button>",
}'
class="hidden">
<option value="">Choose</option>
@foreach ($servicecategories as $category)
<option value="{{ $category->id }}">{{ $category->title }}</option>
@endforeach
</select>
```
$category comes null on the Component side because I'm using PrelineUI.
On the JavaScript side, I can get the value like this:
`const category = HSSelect.getInstance('#category').value;`
But I couldn't get this category value on the Component side. I also tried @this.set('getCategory', category) method but it failed. I'm waiting for your help, thank you in advance.
@this.set('getCategory', category)
Livewire.emit('getCategory', category) //livewire.emit is not a function
|
std::vector push_back rvalue does not compile |
|c++| |
null |
As Divi doesn't allow modules to be displayed using Divi slider, i tried to come with a workaround.
My only issue is that my ring drawing animation doesn't work in the first time the slide is loaded and only fire once and not every time the slide is changed.
Here's the code I came up with:
```
$( document ).ready(function() {
var defaultSlide = document.querySelector('.et_pb_slide_0');
var defaultCanvas = defaultSlide.querySelector('#ringCanvas'); //pass it as a class
var dafaultCtx = defaultCanvas.getContext('2d');
var defaultCanvasCleared = false;
//init values
var counter = 1;
var endCount = defaultCanvas.getAttribute("number");
var goal = defaultCanvas.getAttribute("goal"); // Your goal count
var interval = 20; // milliseconds
var ringColor = defaultCanvas.getAttribute("bar_color"); // Default ring color
var textColor = defaultCanvas.getAttribute("number_color"); // Default text color
drawRing(dafaultCtx); // Start drawing the ring in the initial container
var targetNodes = document.querySelectorAll('.et_pb_slide');
var classNameToCatch = 'et-pb-active-slide';
var config = { attributes: true, attributeFilter: ['class'], attributeOldValue : true };
var callback = function(mutationsList, observer) {
var targetWithClassAdded;
var targetWithClassRemoved;
mutationsList.forEach(function(mutation) {
if (mutation.type === 'attributes' && mutation.attributeName === 'class'){
var currentClassList = mutation.target.classList;
var oldValue = mutation.oldValue || '';
var classAdded = currentClassList.contains(classNameToCatch);
var classRemoved = !currentClassList.contains(classNameToCatch) && oldValue.includes(classNameToCatch);
if(classAdded){
targetWithClassAdded = mutation.target;
}
if(classRemoved){
targetWithClassRemoved = mutation.target;
}
targetWithClassAdded != null && workOnClassAdd(targetWithClassAdded);
targetWithClassRemoved != null && workOnClassRemoval(targetWithClassRemoved);
}
});
};
// Create an observer instance linked to the callback function
var observer = new MutationObserver(callback);
// Start observing each target node for configured mutations
targetNodes.forEach(function(targetNode) {
observer.observe(targetNode, config);
});
function workOnClassAdd(target) {
var currentCanvas = target.querySelector("#ringCanvas")
// Check if default canvas has been cleared before
if(!defaultCanvasCleared) {
clearCanvas(defaultCanvas);
defaultCanvasCleared = true;
}
displayRing(currentCanvas)
}
function workOnClassRemoval(target) {
var currentCanvas= target.querySelector("#ringCanvas")
//currentCanvasId = document.getElementById(target.id).children[0].id;
clearCanvas(currentCanvas);
}
function displayRing(canvas) {
var ctx = canvas.getContext('2d');
endCount = canvas.getAttribute("number");
goal = canvas.getAttribute("goal");
ringColor = canvas.getAttribute("bar_color");
textColor = canvas.getAttribute("number_color");
counter = 1; // Reset counter
drawRing(ctx);
}
function clearCanvas(canvas) {
var ctx = canvas.getContext('2d');
counter = 1; // Reset counter
ctx.clearRect(0, 0, canvas.width, canvas.height);
}
function drawRing(ctx) {
var x = ctx.canvas.width / 2;
var y = ctx.canvas.height / 2;
var radius = 70;
ctx.clearRect(0, 0, ctx.canvas.width, ctx.canvas.height);
// Calculate percentage
var percentage = (counter / goal) * 100;
// Draw ring
ctx.beginPath();
ctx.arc(x, y, radius, -Math.PI / 2, (2 * Math.PI * (percentage / 100)) - (Math.PI / 2));
ctx.strokeStyle = ringColor;
ctx.lineWidth = 20;
ctx.lineCap = "round";
ctx.stroke();
// Draw counter
ctx.font = '20px Montserrat';
ctx.textAlign = 'center';
ctx.fillStyle = textColor;
ctx.fillText(counter + '€', x, y + 7); // Add the € symbol after the counter text
// Update counter
counter++;
// Check if reached the end count
if (counter <= endCount) {
// Continue counting
setTimeout(function() {
drawRing(ctx);
}, interval);
}
}
});
```
Want i'm trying to achieve is to have the ring animation on page load and every time the slide is changed.
For additional info : Divi handles slide changing with a class "et-pb-active-slide".
If anyones has some tip I'm grateful. |
Display Ring on Divi slider module |
|javascript|counter|slide|divi| |
{"Voters":[{"Id":9245853,"DisplayName":"BigBen"}]} |
[enter image description here][1]Can anyone tell me why we should set the counter j in the inner for loop to (i+1) not (i=0) (beacause I think setting j to i = 0 will get all elements in the array).
And why we using break;
I am new in programming.
Thanks in advance.
Here I check for the duplicates and if I set (j = i+1) the first element in the array will be skipped (with the index 0) from the comparison isn't it ?
[1]: https://i.stack.imgur.com/1IIUM.jpg |
According to [github issues][1], they have their concerns of not implementing the **partial** keyword. Therefore, you will need to write it yourself.
This task is no more than mixing prototypes. However, if you want a reliable one, you need to be very careful with method and property conflicts, also with `type inference` support.
I've written one and published on [npm package partial_classes][2]. You can use it by `npm i partial_classes`. And here is a simple method shows how to do this.
```ts
function combineClasses<T>(...constructors: T[]) {
class CombinedClass {
constructor(...args: any[]) {
constructors.forEach(constructor => {
const instance = new constructor(...args); // copy instance property
Object.assign(this, instance);
});
}
}
constructors.forEach(constructor => { // copy prototype property
let proto = constructor.prototype;
while (proto !== Object.prototype) { // iterate until proto chain ends
Object.getOwnPropertyNames(proto).forEach(name => {
const descriptor = Object.getOwnPropertyDescriptor(proto, name);
if (!descriptor) return;
Object.defineProperty(CombinedClass.prototype, name, descriptor);
});
proto = Object.getPrototypeOf(proto);
}
});
return CombinedClass
}
```
then use as
```typescript
import combineClasses from 'partial_classes'
class ServiceUrlsFoo { }
class ServiceUrlsBar { }
const ServiceUrls = combineClasses(ServiceUrlsFoo, ServiceUrlsBar)
const instance = new ServiceUrls()
```
[1]: https://github.com/microsoft/TypeScript/issues/563
[2]: https://www.npmjs.com/package/partial_classes |
I have this JSON array file.
```
[
{
"id": 1,
"name": "John Doe",
"email": "john.doe@example.com",
"age": 25
},
{
"id": 2,
"name": "Jane Doe",
"email": "[jane.doe@example.com]",
"age": 28
},
{
"id": 3,
"name": "Bob Smith",
"email": "[bob.smith@example.com",
"age": 30
}
]
```
How do I perform CRUD operations on this array through a Angular Reactive Form and present the data in a table?
I do not have any API. I want to use this Static JSON to perform CRUD operations. |
use
```
from tensorflow.keras.layers import Dense
```
|
I need to print the bounding box coordinates of a walking person in a video. Using YOLOv5 I detect the persons in the video. Each person is tracked. I need to print each person's bounding box coordinate with the frame number. Using Python how to do this.
The following is the code to detect, track persons and display coordinates in a video using YOLOv5.
```
#display bounding boxes coordinates
import cv2
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
# Open the video file
cap = cv2.VideoCapture("Shoplifting001_x264_15.mp4")
#get total frames
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(f"Frames count: {frame_count}")
# Initialize the frame id
frame_id = 0
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True,classes=[0])
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Print the bounding box coordinates of each person in the frame
print(f"Frame id: {frame_id}")
for result in results:
for r in result.boxes.data.tolist():
if len(r) == 7:
x1, y1, x2, y2, person_id, score, class_id = r
print(r)
else:
print(r)
# Display the annotated frame
cv2.imshow("YOLOv5 Tracking", annotated_frame)
# Increment the frame id
frame_id += 1
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else: # Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
```
The above code is working and display the coordinates of tracked persons.
But the problem is in some videos it is not working properly
0: 384x640 6 persons, 1292.9ms
Speed: 370.7ms preprocess, 1292.9ms inference, 20.8ms postprocess per image at shape (1, 3, 384, 640)
Frame id: 0
[849.5707397460938, 103.34817504882812, 996.0990600585938, 371.2213439941406, 1.0, 0.9133888483047485, 0.0]
[106.60043334960938, 74.8958740234375, 286.6423645019531, 562.144287109375, 2.0, 0.8527513742446899, 0.0]
[221.3446044921875, 60.8421630859375, 354.4775390625, 513.18017578125, 3.0, 0.7955091595649719, 0.0]
[472.7821044921875, 92.33056640625, 725.2569580078125, 632.264404296875, 4.0, 0.7659056782722473, 0.0]
[722.457763671875, 222.010986328125, 885.9102783203125, 496.00372314453125, 5.0, 0.7482866644859314, 0.0]
[371.93310546875, 46.2138671875, 599.2041625976562, 437.1387939453125, 6.0, 0.7454277873039246, 0.0]
This output is correct.
But for another video there are only three people in the video but at the beginning of the video at 1st frame identify as 6 person.
0: 480x640 6 persons, 810.5ms
Speed: 8.0ms preprocess, 810.5ms inference, 8.9ms postprocess per image at shape (1, 3, 480, 640)
Frame id: 0
[0.0, 10.708396911621094, 37.77726745605469, 123.68929290771484, 0.36418795585632324, 0.0]
[183.0453338623047, 82.82539367675781, 231.1952667236328, 151.8341522216797, 0.2975049912929535, 0.0]
[154.15158081054688, 74.86528778076172, 231.10934448242188, 186.2017822265625, 0.23649221658706665, 0.0]
[145.61187744140625, 69.76246643066406, 194.42532348632812, 150.91973876953125, 0.16918501257896423, 0.0]
[177.25042724609375, 82.43289947509766, 266.5430908203125, 182.33889770507812, 0.131477952003479, 0.0]
[145.285400390625, 69.32669067382812, 214.907470703125, 184.0771026611328, 0.12087596207857132, 0.0]
Also, the output does not show the person ID here. Only display coordinates, confidence score, and class id. What is the reason for that?
|
I want to download the face book shorts of motivational category without URL and access token
I want to get the 10 shorts every time whenever I run the code. without login or creating account also. I just want to get the shorts or short video clips of motivational category. |
i want to download the facebook shorts of motivational category without url and access token |
|python|python-3.x| |
null |
It's a basic JavaScript manipulation and can be achieved by simply changing the `src` of 4 images that you're showing with the new one.
Assuming you have a structure somewhat similar to:
```html
<div class="images-container">
<img id="image1" src="image1.png" />
<img id="image2" src="image2.png" />
<img id="image3" src="image3.png" />
<img id="image4" src="image4.png" />
</div>
<button id="btn">Next</btn>
<script type="text/javascript">
let btn = document.getElementById("btn")
btn.addEventListener('click', function(e) {
let new_images = load_next_images() // Your function to get next images
})
</script>
```
Now, once you get the next images, all you have to do is swap the image URLs in the images and you're done! Your modified script would look something similar to:
```javascript
<script type="text/javascript">
let btn = document.getElementById("btn")
let image1 = document.getElementById("image1")
let image2 = document.getElementById("image2")
let image3 = document.getElementById("image3")
let image4 = document.getElementById("image4")
btn.addEventListener('click', function(e) {
let new_images = load_next_images() // Your function to get next images
image1.setAttribute('src', new_images[0]) // assuming it's a URL
image2.setAttribute('src', new_images[1])
image3.setAttribute('src', new_images[2])
image4.setAttribute('src', new_images[3])
})
</script>
```
That's it!
Disclaimer: The code above is just for demonstration of concept and should be modified as needed, it's neither optimised and nor the recommended way. |
I'm trying to learn to use gui in java using eclipse ide.
When I run this code
```
import javax.swing.JOptionPane;
public class GUI {
public static void main(String[] args) {
String name = JOptionPane.showInputDialog("Enter your name");
JOptionPane.showMessageDialog(null, "Hello "+name);
}
}
```
all it shows is terminated GUI [Java Application]
How can I fix this issue?
|
### Very easy to do in 2022.
It's very easy and common to do this, **you just add the rear as a child**.
To be clear the node (and the rear you add) should both use the single-sided shader.
Obviously, the rear you add points in the other direction!
Do note that they are indeed in "exactly the same place". Sometimes folks new to 3D mesh think the two meshes would need to be "a little apart", not so.
```swift
public var rear = SCNNode()
private var theRearPlane = SCNPlane()
private func addRear() {
addChildNode(rear)
rear.eulerAngles = SCNVector3(0, CGFloat.pi, 0)
theRearPlane. //... set width, height etc
theRearPlane.firstMaterial?.isDoubleSided = false
rear.geometry = theRearPlane
rear.geometry?.firstMaterial!.diffuse.contents = //.. your rear image/etc
}
```
So ...
```swift
///Double-sided sprite
class SCNTwoSidedNode: SCNNode {
public var rear = SCNNode()
private var thePlane = SCNPlane()
override init() {
super.init()
thePlane. //.. set size, etc
thePlane.firstMaterial?.isDoubleSided = false
thePlane.firstMaterial?.transparencyMode = .aOne
geometry = thePlane
addRear()
}
```
Consuming code can just refer to `.rear` , for example,
```swift
playerNode. //... the drawing of the Druid
playerNode.rear. //... Druid rules and abilities text
enemyNode. //... the drawing of the Mage
enemyNode.rear. //... Mage rules and abilities text
```
### If you want to do this in the visual editor - very easy
It's trivial. **Simply add the rear as a child.** Rotate the child 180 degrees on Y.
It's that easy.
Make them both single-sided and put anything you want on the front and rear.
Simply move the main one (the front) normally and everything works. |
The difference between the result generated by the C# code and the reference data is due to an incomplete porting of the Java reference code to C#.
In particular, the implementation of the MAC and the implementation of the `TLV` class that performs ASN.1/DER encodings are missing. If the Java code is ported *completely* to C#, the reference data can be reproduced.
In the following C# code, the `encrypt(byte[], byte[])` method has been supplemented with the functionalities from the Java code that are required to generate the reference data (the corresponding line of the Java reference code is specified in the C# code):
```cs
using Org.BouncyCastle.Crypto.Macs;
using Org.BouncyCastle.Crypto.Engines;
using Org.BouncyCastle.Crypto.Parameters;
...
public byte[] encrypt(byte[] apdu, byte[] secureMessagingSSC)
{
CardCommandAPDU cAPDU = new CardCommandAPDU(apdu);
if (cAPDU.isSecureMessaging())
{
throw new ArgumentException("Malformed APDU.");
}
byte[] data = cAPDU.data;
byte[] header = cAPDU.header;
int lc = cAPDU.lc;
int le = cAPDU.le;
byte[] dataEncrypted = [];
if (data.Length > 0)
{
data = pad(data, 16);
using (Aes aes = Aes.Create())
{
aes.Key = keyENC;
aes.IV = getCipherIV(secureMessagingSSC);
aes.Mode = CipherMode.CBC;
aes.Padding = PaddingMode.None;
ICryptoTransform encryptor = aes.CreateEncryptor(aes.Key, aes.IV);
dataEncrypted = encryptor.TransformFinalBlock(data, 0, data.Length);
// Add padding indicator 0x01
// Java code: https://github.com/ecsec/open-ecard/blob/master/ifd/ifd-protocols/pace/src/main/java/org/openecard/ifd/protocol/pace/SecureMessaging.java#L114
dataEncrypted = [0x01, ..dataEncrypted];
// ASN.1/DER (TLV) - encrypted data
// Java code: https://github.com/ecsec/open-ecard/blob/master/ifd/ifd-protocols/pace/src/main/java/org/openecard/ifd/protocol/pace/SecureMessaging.java#L117
dataEncrypted = [0x87, (byte)dataEncrypted.Length, ..dataEncrypted];
}
}
// Write protected LE: skipped as le < 0
// Java code: https://github.com/ecsec/open-ecard/blob/master/ifd/ifd-protocols/pace/src/main/java/org/openecard/ifd/protocol/pace/SecureMessaging.java#L123
if (le >= 0)
{
// ...
}
// Indicate Secure Messaging
// Java code: https://github.com/ecsec/open-ecard/blob/master/ifd/ifd-protocols/pace/src/main/java/org/openecard/ifd/protocol/pace/SecureMessaging.java#L137
header[0] |= 0x0C;
// Calculate MAC
// Java code: https://github.com/ecsec/open-ecard/blob/master/ifd/ifd-protocols/pace/src/main/java/org/openecard/ifd/protocol/pace/SecureMessaging.java#L142
byte[] mac = new byte[16];
CMac cmac = getCMAC(secureMessagingSSC);
byte[] paddedHeader = pad(header, 16);
cmac.BlockUpdate(paddedHeader, 0, paddedHeader.Length);
if (dataEncrypted.Length > 0)
{
byte[] paddedData = pad(dataEncrypted, 16);
cmac.BlockUpdate(paddedData, 0, paddedData.Length);
}
cmac.DoFinal(mac, 0);
mac = mac[..8];
// ASN.1/DER (TLV) - MAC
// Java code: https://github.com/ecsec/open-ecard/blob/master/ifd/ifd-protocols/pace/src/main/java/org/openecard/ifd/protocol/pace/SecureMessaging.java#L160
mac = [0x8e, (byte)mac.Length, ..mac];
// Concate encrypted data and MAC
// Java code: https://github.com/ecsec/open-ecard/blob/master/ifd/ifd-protocols/pace/src/main/java/org/openecard/ifd/protocol/pace/SecureMessaging.java#L163
byte[] secureData = [..dataEncrypted, ..mac];
// Add header and footer
// Java code: https://github.com/ecsec/open-ecard/blob/master/ifd/ifd-protocols/pace/src/main/java/org/openecard/ifd/protocol/pace/SecureMessaging.java#L165
byte[] secureCommand = [..header, (byte)secureData.Length, ..secureData, 0x00];
return secureCommand;
}
private CMac getCMAC(byte[] smssc)
{
CMac cmac = new CMac(new AesEngine());
cmac.Init(new KeyParameter(keyMAC));
cmac.BlockUpdate(smssc, 0, smssc.Length);
return cmac;
}
```
If these methods are replaced/added in the posted C# code, the reference data `0x0ca4040c1d871101a948e4f1a82356c11cf1a6a0b18d0c8f8e0871b60bb93b7af10800` can be reproduced.
Please note that the above changes are *incomplete* and only implement the functionalities required for this *specific* reference data. For the C# code to work *in general*, the `encrypt(byte[], byte[])` method from the Java code must be *completely* migrated!
|
I think best would be just to set `left` and `top` using `%` units.
You can do the same for the `width` of the marker.
<!-- begin snippet: js hide: false console: true babel: false -->
<!-- language: lang-js -->
const rect = document.getElementById('map1').getBoundingClientRect();
const originalWidth = rect.width
const originalHeight = rect.height
window.addEventListener("load", function() {
document.getElementById('map1').onclick = function(event) {
const rect = event.target.getBoundingClientRect();
const x = event.clientX - rect.left;
const y = event.clientY - rect.top;
addMarker(x, y, rect.width, rect.height);
}
});
function resize() {
document.getElementById('map1').style.width = ((Math.random() * 50) + 50) + "%"
}
function addMarker(x, y, w, h) {
var i = new Image();
i.src = 'https://placehold.co/32x32/000000/FFF';
i.style.position = "absolute";
i.onload = function() {
var xOffset = x;
var yOffset = y;
// center image on cursor
xOffset -= i.width / 2;
yOffset -= i.height / 2;
// Set image insertion coordinates
i.style.left = (xOffset / w * 100) + '%';
i.style.top = (yOffset / h * 100) + '%';
// optionally:
i.style.width = (i.width / originalWidth * 100) + '%'
}
// Append the image to the DOM
document.getElementById('map1').appendChild(i);
}
<!-- language: lang-css -->
.responsive {
position: relative;
max-width: 1200px;
width: 100%;
height: auto;
border: 1px solid red;
}
.responsive #myImg {
width: 100%;
display: block;
}
<!-- language: lang-html -->
<div class="container">
<div style="height: auto; padding: 3px 0 3px 0;">
<div class="card">
<div class="card_content">
<p>click to place markers <button onclick="resize()">random size</button></p>
<div id="map1" class="responsive">
<img src="https://picsum.photos/800/300" id="myImg">
</div>
</div>
</div>
</div>
</div>
<!-- end snippet -->
|
I am implementing oauth2 for uber supplier [api][1]. But the authorization URL returns a page with no information and Accept button disabled.
Did anyone come across such a problem or have been able to integrate uber suppliers api?
[![enter image description here][2]][2]
[1]: https://developer.uber.com/docs/vehicles/references/api/v1/supplier-performance-data/get-drivers-information
[2]: https://i.stack.imgur.com/8B0Z0.png |
Uber Supplier API oauth not returning a terms and accept button diabled |
|uber-api| |
I have a json like
[
{
"url": "https://drive.google.com/file/d/1tO-qVknlH0PLK9CblQsyd568ZiptdKff/view?usp=share_link",
"title": "– Flexibility"
},
{
"url": "https://drive.google.com/open?id=11_sR8X13lmPcvlT3POfMW3044f3wZdra",
"title": "– Pronouns"
}
]
I got it using `curl -Lfs "https://motivatedsisters.com/2019/07/08/arabic-review-sr-rahat-basit/" | rg -o '<li>.*?href="(.*?)".*?</a> (.*?)<\/li>' -r '{"url": "$1", "title": "$2"}' | jq -s '.'`.
I have a command in my machine named `unescape_html`, a python scipt to unescape the html (replace – with appropriate character).
How can I apply this function on each of the titles using `jq`.
For example:
I want to run:
unescape_html "– Flexibility"
unescape_html "– Pronouns"
The expected output is:
[
{
"url": "https://drive.google.com/file/d/1tO-qVknlH0PLK9CblQsyd568ZiptdKff/view?usp=share_link",
"title": "– Flexibility"
},
{
"url": "https://drive.google.com/open?id=11_sR8X13lmPcvlT3POfMW3044f3wZdra",
"title": "– Pronouns"
}
]
|
Eigen: What's the output of argmax/argmin when applied to a tensor with duplicate values? |
|c++|eigen|tensor| |
I am trying to write a personal project in JavaScript.
So I started with an empty folder with two files:
card.js
constants.js
and in `card.js`, I used on the first line:
import { SUIT } from "./constants.js";
and run it using `node card.js`. It doesn't work, giving the error:
> (node:91577) Warning: To load an ES module, set "type": "module" in the package.json or use the .mjs extension.
If I look at the [docs for import][1], it has:
import { myExport } from "/modules/my-module.js";
So I used `mkdir modules` and moved that `constants.js` in there.
And then I used:
import { SUIT } from "/modules/constants.js"
and it still has the same error. That doc doesn't not mention `package.json` whatsoever.
I am wondering if this `import` is the same as `import` in the context of NodeJS (and so it may be different in Deno).
How is it done?
[1]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/import |
|c++|opencv|computer-vision| |
You may add the `setState` method as a `listener` to the `FocusNode` object named `emailText`. This will change the color of the Text you want to change based on the focus on the TextField.
**Modified code:**
```
class _SignInState extends State<SignIn> {
bool isPasswordVisible = false;
bool _isEmail = true;
bool _isPassword = true;
TextEditingController emailInput = TextEditingController();
TextEditingController passwordInput = TextEditingController();
FocusNode emailText = FocusNode();
@override
void initState() {
super.initState();
emailText.addListener(() => setState(() {}));
}
// Rest of your code
}
``` |
Within the function `sumAtBis`
int sumAtBis(tree a, int n, int i){
if(i==n){
if(isEmpty(a))
return 0;
else
return root(a);
}
return sumAtBis(left(a),n,i+1)+sumAtBis(right(a),n,i+1);
}
there is no check whether `left( a )` or `right( a )` are null pointers. So the function can invoke undefined behavior.
Actually the function `sumAtBis` is redundant. It is enough to define the function `sumAt` as for example
long long int sumAt( tree a, size_t n )
{
if ( isEmpty( a ) )
{
return 0;
}
else
{
return n == 0 ?
root( a ) :
sumAt( left( a ), n - 1 ) + sumAt( right( a ), n - 1 );
}
}
Also using the typedef name `tree`
typedef node * tree;
is not a good idea because you can not define the type `const node *` by means of this typedef name because `const tree` is equivalent to `node * const` instead of the required type `const node *` and this type should be used in the parameter declaration of the function because the function does not change nodes of the tree.. |
I'm testing this code
$query = "SELECT * from `items` where category_id=?";
$stmt = $mysqli->query($query);
$stmt->bind_param("s", $category_id);
$stmt->execute();
$result = $stmt->get_result();
while ($row = $stmt->fetch_assoc()) {
printf ("%s (%s)\n", $row['name'], $row['code']);
}
Is there any easier way to output whole table to HTML markup? |
> Has anyone encountered this problem
Yes, millions of developers before you. There are several similar questions even on this site.
> is there any solution?
Yes, _install_ docker inside the Jenkins container. Typically, you would create a Dockerfile that will build your Jenkins agent image.
Strongly do not mount executable files from host. Consider not sharing configuration files from /etc/ from host with docker containers. Consider re-reading introduction to Docker, why it is used, consider interesting yourself in best practices with Docker. If you want, research docker-in-docker.
Typically, there is jenkins controller that is only running the controller (and a minimal internal node) and jenkins-agents, and the agents have access to docker for workflows to run. Typically, agents are added the docker client, like https://stackoverflow.com/questions/70947968/docker-not-found-inside-jenkins-pipeline or https://medium.com/@yassine.essadraoui_78000/jenkins-docker-in-docker-b7630c7b9364 or https://devopscube.com/docker-containers-as-build-slaves-jenkins/?unapproved=63874&moderation-hash=d5464a664348e998b876cdc761385caa#comment-63874 or https://rokpoto.com/jenkins-docker-in-docker-agent/ etc. |
Does anybody know how to convert a string to a BigInt without using the BigInt() constructor or any other libs like math ect.?
So, my task is to implement arithmetic operations on strings without relying on bigint or arithmetic libraries. Can someone give me a hint ?
input is valid string with positive number inside, output should be bigint.
ChatGPT give me answer with BigInt()
I tried to use typeOf() operator (I don`t know am I allowed to use it).
|
String to BigInt in JavaScript |
|javascript|string|bigint| |
null |
I wanted to create a uber-fat jar for my spring boot app and for that I am using *maven-shade-plugin*.After mvn clean install , i see there are two jar created one is normal and another shaded,normal jar is working fine but when I am trying to run shaded jar it is failing with below error
**Error: Could not find or load main class com.walmart.SpringAppInitializer**
Below is my plugin added in pom.xml
```
<properties>
<start-class>com.walmart.SpringAppInitializer</start-class>
</properties>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<configuration>
<fork>true</fork>
<mainClass>${start-class}</mainClass>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.3.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>${start-class}</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/maven/**</exclude>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.google.gson</pattern>
<shadedPattern>com.shaded.google.gson</shadedPattern>
</relocation>
</relocations><shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>shaded</shadedClassifierName>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
```
Can anyone please suggest why fat jar is not working
|
In a basic Remix V2 app, i need help understanding if the following is expected behavior, a bug in V2, or possibly a missing configuration option or setting.
When running in development mode i am seeing the `useLoaderData` hook receive a JavaScript object declaration as opposed to JSON data.
I could not find anything related to this issue in the Remix documentation.
I created an demo Remix V2 app by running `npx create-remix@latest`
I wrote a simulated API backend method for basic testing which simply returns JSON data as retrieved from a JSON file:
export async function getStoredNotes() {
const rawFileContent = await fs.readFile('notes.json', { encoding: 'utf-8' });
const data = JSON.parse(rawFileContent);
const storedNotes = data.notes ?? [];
return storedNotes;
}
The client side consists of 2 simple routes that use `NavLink` components for navigation between the 2 routes:
import { NavLink } from '@remix-run/react';
...
<NavLink to="/">Home</NavLink>
<NavLink to="/notes">Notes</NavLink>
In the `notes` route, i have the following `loader` function defined which makes a call to my simulated API method:
export const loader:LoaderFunction = async () => {
try {
const notes = await getStoredNotes();
return json(notes);
} catch (error) {
return json({ errorMessage: 'Failed to retrieve stored notes.', errorDetails: error }, { status: 400 });
}
}
In the `notes` main component function i receive that data using the `useLoaderData` hook and attempt to print the returned JSON data to the console:
export default function NotesView() {
const notes = useLoaderData<typeof loader>();
console.log(notes);
return (
<main>
<NoteList notes={notes as Note[] || []} />
</main>
)
}
**When i run an `npx run build` and subsequently `npx run serve` everything is working correctly:**
Initial page load receives the data successfully and prints the value to the console as JSON.
{"notes":[{"title":"my title","content":"my note","id":"2024-03-28T05:22:52.875Z"}]}
Navigating between the index route and back to the notes route by clinking on the `NavLink` components is also working such that i see the same data print to the console on subsequent visits to the `notes` route.
**When i run in `dev` mode however, using `npx run dev` the following problem occurs:**
The initial page load coming from the dev server does also load correctly and prints the JSON to the console.
*Navigating client side* between the index route and back to the notes route using the `NavLink` components *causes an issue whereas the data that prints to the console is not JSON.* Instead, i am seeing a strange output of a JavaScript object declaration quite literally just like this:
export const notes = [
{
title: "my title",
content: "my note",
id: "2024-03-28T05:22:52.875Z"
}
];
Again, to be clear, this behavior only occurs when navigating client side using `NavLink` or `Link` elements while running `npx run dev`.
Is this expected behavior when running in `dev` mode?
|
After I plugged my iPhone into my mac, I started debugging my app. For the first few days, it all seemed smooth.
But after a few days, things changed.
The `Debug` -> `Attach to process` menu is empty, as shown below. I can't figure out why.
But the weirder thing is that when I debugged my app three months later, the processes on my iPhone were correctly listed on the `Attach to process` menu, but they all disappeared again after a few days.
My device configuration is: iPhone 6 - macOS Sonoma 14.3.1 - Xcode 15.2
[image](https://i.stack.imgur.com/MfmJy.png)
I can't wait a few months before I have a chance to debug my app. So I had to ask for help here.
|
Run an external command within jq to manipulate each values of a particular key |
|jq| |
I'm using a Metal compute pipeline to render into a `CAMetalLayer`'s drawable and keep running into problems with non-integer pixel formats resulting in a slightly noisy image, due to some apparent round-off errors during compositing.
Specifically I'd like to configure the layer to use `.rgba16Float`, but the noise is also noticable when using the fixed-point `.bgr[a]10_xr[_srgb]` pixel formats as well. Using integer formats such as the default `.bgra8Unorm` always gives the expected result.
Here is a small [demo project](https://github.com/tesch/MetalPixelFormatTest) with a side-by-side comparison to illustrate what I mean. Both boxes are backed by a `CAMetalLayer` that gets filled with `float4(0.5f, 0.5f, 0.5f, 1.0f)` for each pixel, with the left box using `.bgra8Unorm` and the right box using `.rgba16Float`. Inspecting the resulting UI with e.g. the Digital Color Meter reveals that only the left box gets filled with a solid color, while the right box exhibits some small fluctuations.
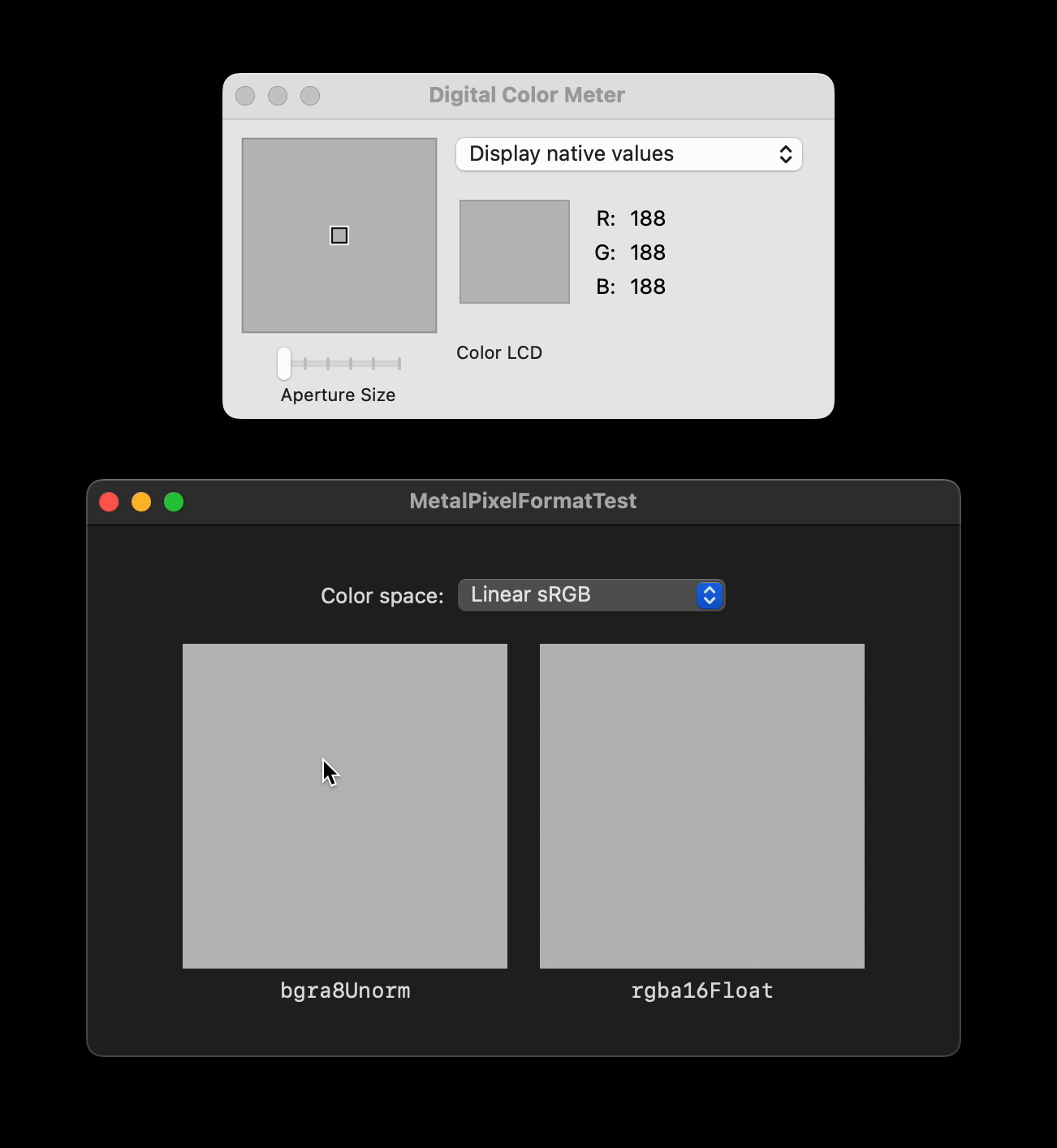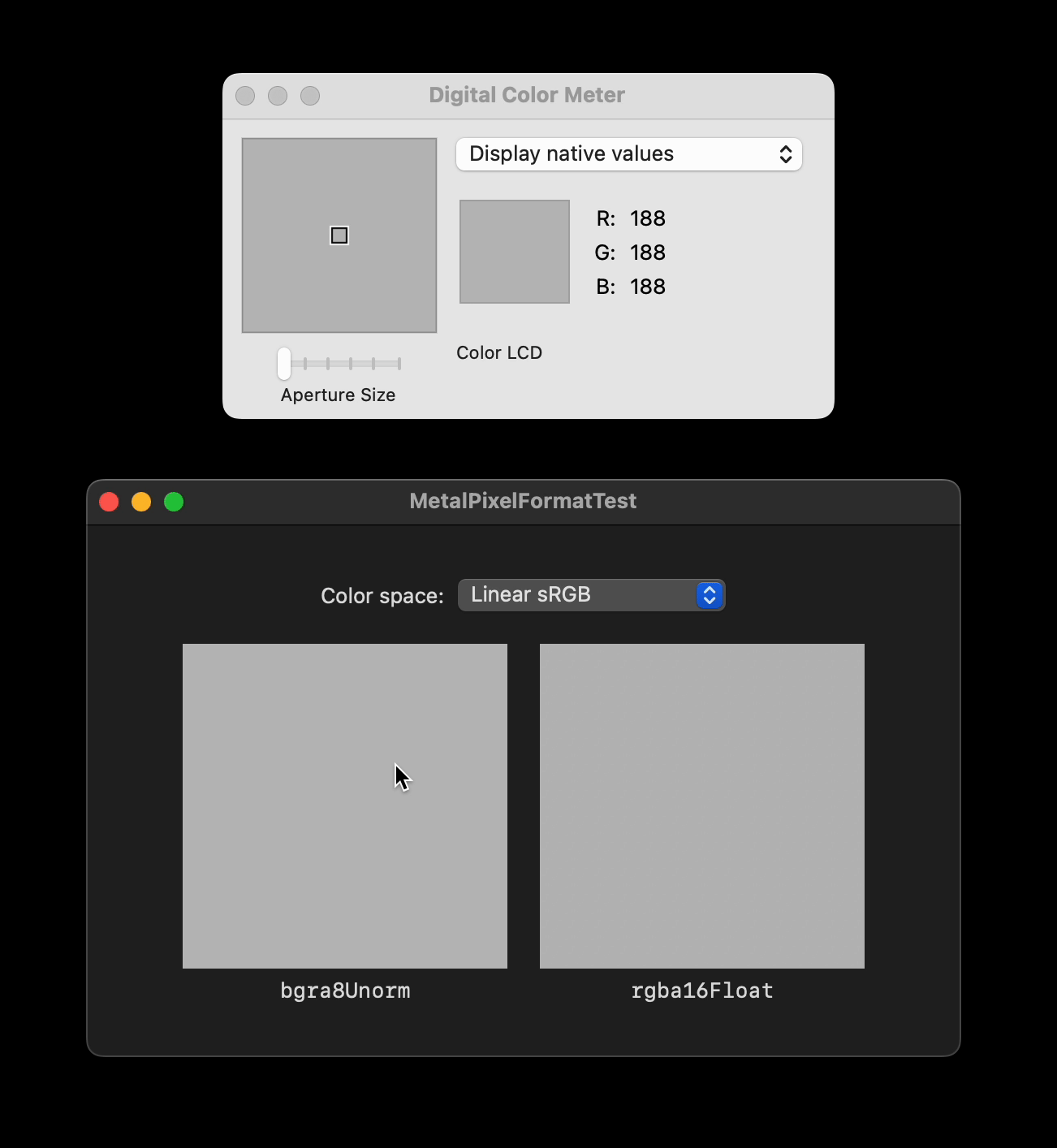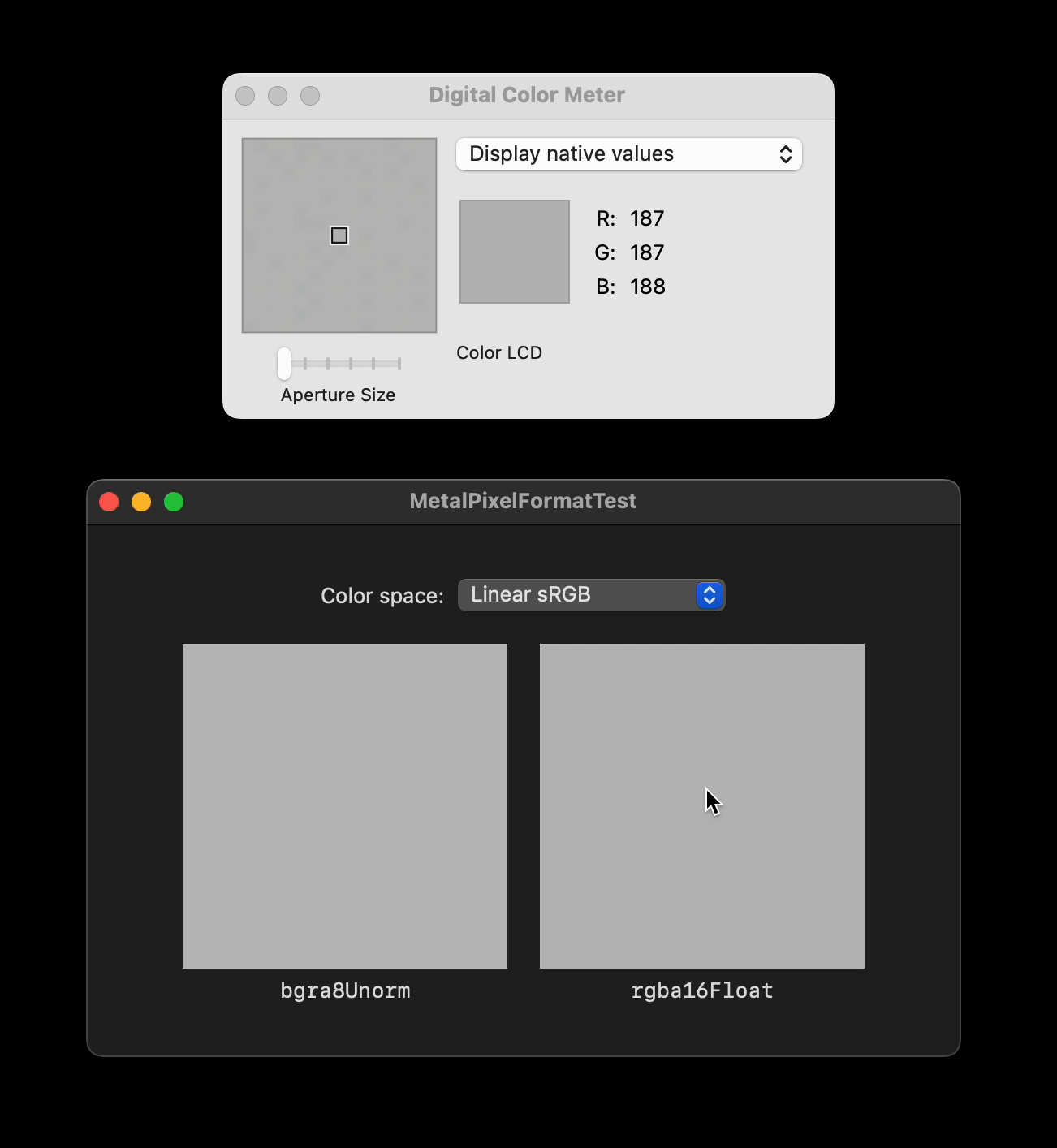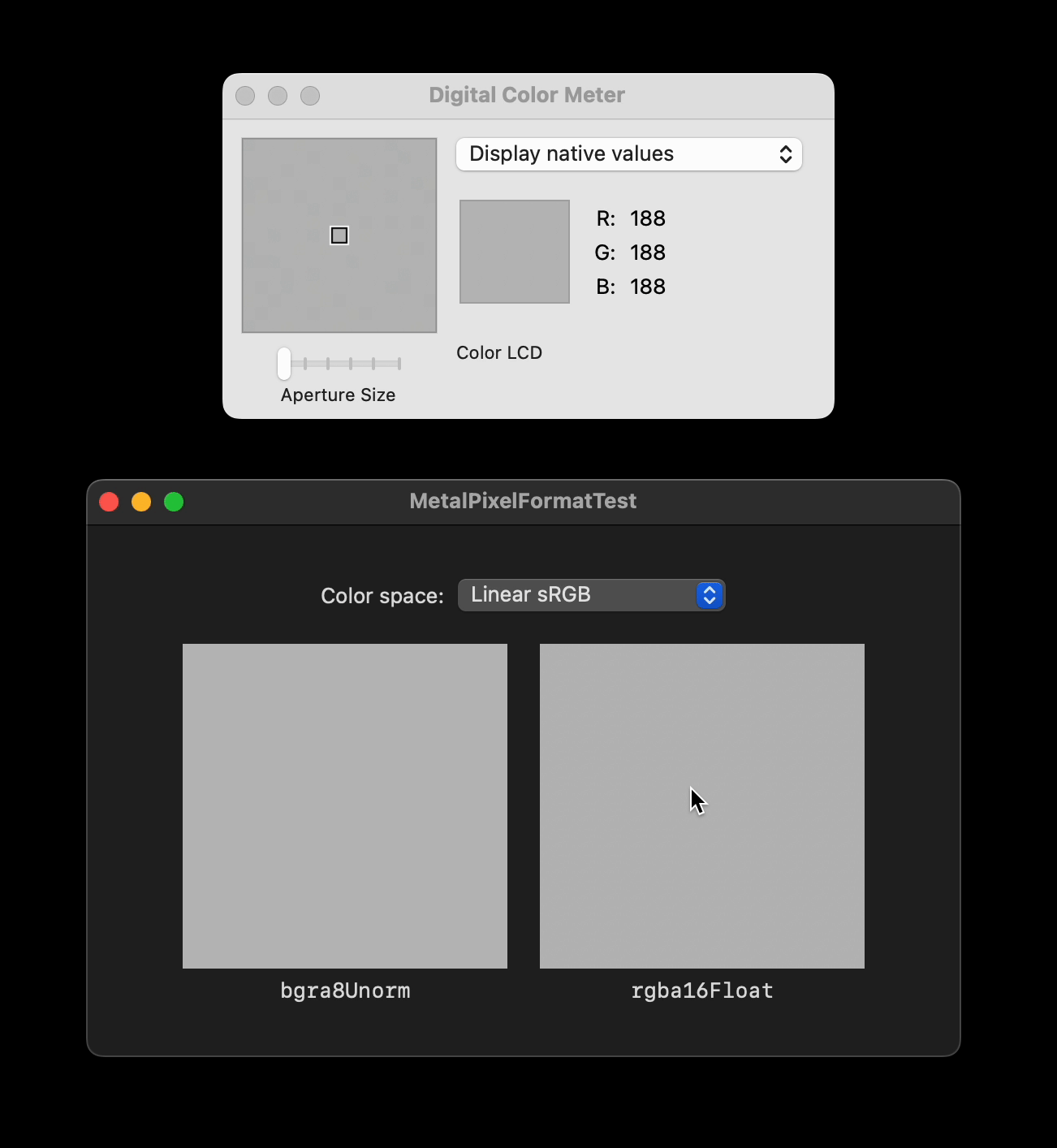
I find this rather suprising. How can such a spatial non-uniformity come to be, even if the shader only ever writes a constant value? Am I holding it wrong? Is this an Apple bug? Is it at all possible to guarantee spatially consistent rounding behavior with the current APIs?
I'd be grateful to anyone who can give some background on this phenomenon. It's obviously not a massive problem, but it still irks me. |
Using MTLPixelFormat.rgba16Float results in random round-off errors |
|swift|metal|rounding-error|pixelformat|cametallayer| |
I am trying to save text он Cyrillic in an R script, but I am encountering a problem. Specifically, when I save it with encoding UTF-8, everything appears fine. However, after closing the script and reopening it, I notice some unreadable characters. See below:
df<-
list("00OÿÃÂÃÂøýø"=c("0000","0019","0094","0108","0027","0035","0043","0051","0116","0060","0078","0086","1015","1040","1066","1082","1104","1139","1147","1155","1163","1171","1180","1201","1236","1279","1287","1295","1309","1031","1325","1333","1341","2097","1376","1392","1422","1457","1473","1481","1490","1511","1520","1562","1597","1619","1627","1635","1643","1678","1694","1708","1724","1732","1759","1783","1805","1821","1830","1899","1902","1929","1937","1953","1961","1970","1988","1996","2003","2046","2054","2127","2135","2143","2151","2160","2178","2208","2216","2232","2259","2283"),
"ÃÂþôøýð"=c("22"),
"ÃÂúÃÂÿýþ ÿþÃÂðýõÃÂýð ôÃÂöðòð"=c("000"),
"ÃÂÃÂãÃÂÃÂÃÂ"=c("000","070","705","688","499","191","910","008","100","792","001","999"))
Can anybody help how to solve this problem and to keep text in Cyrillic ?
|
R and text on Cyrillic |
|r| |
Solved :)
Changing this line:
DWORD foundAddress = FindPattern(mainModule, mInfo.SizeOfImage, pattern, mask);
To this:
uintptr_t foundAddress = FindPattern(mainModule, mInfo.SizeOfImage, pattern, mask); |
Laravel livewire get data from blade |
|laravel|laravel-livewire|livewire-3| |
null |
[](https://i.stack.imgur.com/Xwljx.png)
How can I reorder the project views using drag and drop in Cypress?
Actually on hover the list name it will display the icon to drag and drop and it will reorder based on it please help
[](https://i.stack.imgur.com/x4WvB.png)
In the added image the locator "ag-icon ag-icon-grip" will only display when mouseover.
I tried below function to drag and drop
ProjectviewDragAndDrop2() {
cy.get('ag-icon ag-icon-grip').eq(5).invoke('css', 'visibility', 'visible').trigger('mouseover');
cy.get('ag-icon ag-icon-grip').eq(5).scrollIntoView().then($element => {
// Trigger mouse down event to start the drag
cy.wrap($element).trigger('mousedown', { button: 0 });
});
cy.get('ag-icon ag-icon-grip').eq(6).invoke('css', 'visibility', 'visible').trigger('mouseover');
// Get the target element and scroll it into view
cy.get('ag-icon ag-icon-grip').eq(6).scrollIntoView().then($targetElement => {
// Trigger mouse move event to move to the target element
cy.wrap($targetElement).trigger('mousemove', { force: true });
})} |
How to create a function on reordering the project views using Cypress automation |
# IDEA support overview
Since IDEA 2022.3, support for additional dictionaries in both the plain "word list" and the Hunspell format is already _built-in_ - see [IDEA documentation][1].
In older IDEA versions, one needs to install the [Hunspell plugin][2] to use the Hunspell dictionaries, or to use just the plain "word list" dictionaries.
# Which dictionary format to use?
Using the Hunspell format - a combination of a *special* `*.dic` file and a `*.aff` file - seems to be preferable/easier. The 2 files just need to be in the same directory and the `*.dic` file needs to be selected on the IDEA's "Editor > Natural Languages > Spelling" settings screen.
If one wants to use the plain "word list" format, an additional step of "unpacking" a Hunspell dictionary to a single *plain* `*.dic` file via `aspell` as described e.g. [here][3] is necessary.
# Downloading the dictionaries
The official IDEA documentation recommends downloading the Hunspell dictionaries via https://hunspell.github.io/. From there, you can find links to download the dictionaries for various languages from the LibreOffice project (e.g. from [this directory][4]).
While you can also download dictionaries from [WinEdt][5], those dictionaries haven't been updated for quite a while.
[1]: https://www.jetbrains.com/help/idea/2023.3/spellchecking.html#dictionaries
[2]: https://plugins.jetbrains.com/plugin/10275-hunspell
[3]: https://stackoverflow.com/a/1950073/1525602
[4]: https://cgit.freedesktop.org/libreoffice/dictionaries/tree
[5]: https://www.winedt.org/dict.html |
I'm trying to have an element project a shadow / blurred edge onto an element behind it, causing the latter to "dissolve", without impacting the background. Hopefully the following images can better illustrate my problem.
This is what I was able to get:

While this is the result I'm trying to achieve:

This is the code I used to make the first image:
<!-- begin snippet: js hide: false console: false babel: false -->
<!-- language: lang-css -->
html {
height: 500px;
background: linear-gradient(#9198E5, #E66465);
}
#back {
position: absolute;
top: 100px;
left: 100px;
width: 200px;
height: 200px;
background-color: #FFBBBB;
}
#front {
position: absolute;
top: 200px;
left: 200px;
width: 200px;
height: 200px;
background-color: #BBFFBB;
box-shadow: -30px -30px 15px #BF7B9F;
}
<!-- language: lang-html -->
<div id="back"></div>
<div id="front"></div>
<!-- end snippet -->
|
I have been working with Blazor and Telerik and I seem to have the grid showing data, the css looks fine, but mostly using code from the Telerik samples and I'm surprised at how much effort it is taking to figure out why the GridCommandButton does not seem to trigger anything like it does online in the Repl
```
<TelerikGrid Data=@MyData EditMode="@GridEditMode.Inline" Pageable="true" Height="400px"
OnAdd="@AddHandler" OnUpdate="@UpdateHandler" OnEdit="@EditHandler" OnDelete="@DeleteHandler" OnCreate="@CreateHandler" OnCancel="@CancelHandler">
<GridToolBarTemplate>
<GridCommandButton OnClick="AddHandler" Command="Add" Icon="@SvgIcon.Plus">Add Employee</GridCommandButton>
</GridToolBarTemplate>
<GridColumns>
<GridColumn Field=@nameof(SampleData.ID) Title="ID" Editable="false" />
<GridColumn Field=@nameof(SampleData.Name) Title="Name" />
<GridCommandColumn>
<GridCommandButton Command="Save" Icon="@SvgIcon.Save" ShowInEdit="true">Update</GridCommandButton>
<GridCommandButton Command="Edit" Icon="@SvgIcon.Pencil">Edit</GridCommandButton>
<GridCommandButton Command="Delete" Icon="@SvgIcon.Trash">Delete</GridCommandButton>
<GridCommandButton Command="Cancel" Icon="@SvgIcon.Cancel" ShowInEdit="true">Cancel</GridCommandButton>
</GridCommandColumn>
</GridColumns>
</TelerikGrid>
``` |
Telerik Blazor GridCommandButton not working |
|kendo-ui|blazor|telerik|kendo-grid|telerik-grid| |
If you use Microsoft's Reactive Framework (aka Rx) - NuGet `System.Reactive` and add `using System.Reactive.Linq;` - then you can do this:
IDisposable subscription =
Observable
.Interval(TimeSpan.FromSeconds(1.0))
.Subscribe(_ => function());
To stop the observable you just call `subscription.Dispose();`. |
I have an `.obj` file, but when I render it to video using the `kire` package, it is upside down.
Now I need the mesh to be inverted in the z-axis, so that it works normally with the rest of my system.
How can I achieve this with Python? |
Invert an .obj file with Python |
|python|.obj| |
Python structural pattern matching for string containing float |
You should keep using `rdfs:range` in this way, it has the intended meaning under both RDFS and [OWL2-DL semantics](https://www.w3.org/TR/owl2-direct-semantics/). Jena should be filtering out triples that have have literals in the subject position. As @IS4 states, this is just syntax, and there are proposals to relax that restriction, [approved by Tim Berners-Lee](https://lists.w3.org/Archives/Public/semantic-web/2018Nov/0058.html).
Things get more complicated when you start mixing `owl:DatatypeProperty` and `owl:ObjectProperty`, [not permitted in OWL2-DL](https://www.w3.org/TR/owl2-new-features/#F12:_Punning), but allowed in OWL-Full. However, in the case you provide, `gist:containedText` is syntactically constrained to be a `owl:DatatypeProperty` in OWL2-DL, and the semantics of range are as you intend. You can check this by substituting `xsd:string` for `xsd:integer`, and OWL-DL reasoners such as HermiT will tell you the ontology plus ABox is inconsistent. Don't be misled by Jena's confusing behavior. |
@Bernards answer is right. This is a confusion many new to LLM has.
>I understand instruction-tuning is a form of fine-tuning but with an instruction dataset. But are all datasets not instruction datasets? What other kinds are there?
An LLM is trained on a sequence of words where the next word is the implicit label/ground truth. This is Unsupervised Learning and is the bedrock of the [magic of all LLMs][1]
Example of training data of an LLM
"To boil an egg you need to first take a vessel and fill it with water. Then place an egg in the vessel and heat the vessel till the after boils"
Training with this type of data is called **unsupervised training**. The next token is the implicit label. That is after "To boil an" if the LLM predicts the next token as "apple" its loss is high as the ground truth is there in the training data "egg'
Almost everyone knows this now. And the power of LLM is due to the vast amount of such data available in the web, a vast amount of data that is auto labelled.
Now coming back to the question; we can take this data set and the Instruction Tuned Data Set will be something like this -
*"How to boil an egg? To boil an egg you need to first take a vessel and fill it with water. Then place an egg in the vessel and heat the vessel till the after boils"*
The internal training within the LLM is the same, it masks the next token and uses the generated token with the expected token to calculate Loss and backpropagate the loss.
The subtle difference is the framing of the training data set. When a user asks a similar question, the output answer aligns more with the correct response.
So on top of an already trained foundation model like LLAMA2 or Mistral, you can do **instruction tuning** with these types of **instruction data sets** and quickly align the model to a specific domain.
Here is a Colab notebook where this is illustrated
1. Unsupervised training and evaluation using a [small medical dataset][6] - [Colab notebook][3]
2. Training and evaluation with [Instruction dataset][2] generated out of the above small medical data set. [Colab notebook][4]
You can see that the output of the Instruction model is more aligned to the specific domain
Note - You can use an LLM itself to create the Instruction training data by prompting it and feeding it chunks of the original data. [Colab notebook][5]
More details here in my medium post - https://alexcpn.medium.com/exploring-large-language-models-8fed99a5a139
[1]: https://www.lesswrong.com/posts/KqgujtM3vSAfZE2dR/on-ilya-sutskever-s-a-theory-of-unsupervised-learning
[2]: https://raw.githubusercontent.com/alexcpn/tranformer_learn/main/data/qa_data_small3.txt
[3]: https://colab.research.google.com/drive/152nBwUJ2lI-8QywOMyuqDccXNk6ww-QZ#scrollTo=LGJdS8G_k2hA
[4]: https://colab.research.google.com/drive/1LgExt8VCN_oErRR0ucBJoZU4SUomHl_K#scrollTo=zLV1aqxZDI8O
[5]: https://%60https://colab.research.google.com/drive/1POWG9YvGXKC6nDqcx7ZfDfAxPfVmXdZu#scrollTo=k8t3mAlNGUR9%60
[6]:https://raw.githubusercontent.com/alexcpn/tranformer_learn/main/data/small_3.txt |
I would like to input a text prompt in [stylegan2][1].
So far, I've been able to load the generator (G) using
G,D,Gs = load_networks('gdrive:networks/stylegan2-ffhq-config-a.pkl')
which calls a function defined in the `pretrained_networks.py` file.
Now, I can't figure out how to use the generator in the way I would like.
Specifically, given a text prompt, I suppose I should:
1. to encode the text in a numpy array
2. to feed the generator with this encoding
but how can I do it?
[1]: https://github.com/NVlabs/stylegan2 |
How to output MySQL table in PHP |
I want to get all 5 pages of data from this website http://www.witcorp.co.th/product_chem.php?txtType=1#nogo
But the problem is I can get only the first pages data table when scraping following the picture
[Chemical data](https://i.stack.imgur.com/jRmuJ.png)
And I try to switch to the other pages by Selenium before scrapping but seems not effective
I wrote the code following this
```python
import pandas as pd
from selenium import webdriver
from bs4 import BeautifulSoup as soup
driver = webdriver.Chrome()
url = 'http://www.witcorp.co.th/th/product_chem.php?txtType=1#nogo'
driver.get(url)
page_html = driver.page_source
data = soup(page_html,'html.parser')
all_product = data.find_all('div',{'class':'table'})
page_4 = driver.find_element('xpath','//*[@id="showChemicalPage"]/ul/li[5]')
page_4.click()
all_product_page4 = data.find_all('div',{'id':'showChemicalAll'})
all_product_page4
```
and the result as I told is only from the first page
Can anyone give me a hand to solve this problem, many thanks for your time in advance |
How can I debug issues when logging in using next-auth. I use my custom form. After clicking sign in button we send credentials to `ouraddress/api/auth/callback/credentials` and Ii network tab I can see json response
```
{
"url": "http://localhost:3000/api/auth/error?error=Cannot%20read%20properties%20of%20undefined%20(reading%20'data')"
}
```
I understand that I'm referencing undefined.data somewhere in my code. But I have no clue where for now and the main thing I don't
know how the chain of logic that happens after clicking log in. Also As I understand server code generated by next-auth sent this response to browser. Just and object with "url" property. But why? ^).
I have made my server with NestJS. So that might be even ab error there. On the other hand I can't see it in api's server logs so it must be my nextjs frontend app issue |
Next-Auth credentials login troubles debugging |
|next.js|next-auth| |
> Is there any easier way to output whole table to HTML markup?
Sure.
Learn to use **templates**.
Just separate your prepared statements from output.
To do so, at first collect your data into array:
/* fetch values */
$data = array();
while ($row = $stmt->fetch_assoc()) {
$data[] = $row;
}
and then start output with whatever HTML markup you like (preferably by means of including a separate template file:
<table>
<?php foreach($data as $row): ?>
<tr>
<td>
<a href="?id=<?= htmlspecialchars($row['id']) ?>">
<?= htmlspecialchars($row['name']) ?>
</a>
</td>
</tr>
<?php endforeach ?>
</table>
|
```
TITLE
——
1 nuit
1 nuit
1 nuit
1 nuit
1 nuit
total : 5 nuits
——
1 nuit
1 nuit
1 nuit
total : 3 nuits
——
1 nuit
1 nuit
1 nuit
1 nuit
1 nuit
1 nuit
and so on...
```
I'm having this paragraph in which I'd like to select the last lines after the occurence of the last `——`
It should match and group the 6 following lines right after the ——... I've tried pretty much everything that crossed my mind so far but I must be missing something here.
I tested `(?s:.*\s)\K——` that is able to match the last —— of the document. But I can't seem to be able to select the lines after that match.
Thanks.
The point here is to count the lines after that. So if I'm only able to select the "1" or "nuit" that's fine...
The expected result :
```
1 nuit
1 nuit
1 nuit
1 nuit
1 nuit
1 nuit
``` |
it seems to me you could achieve your goal by means of formulas
if you insert one column and one row you could use this formula
=IF(SUM(G$5:G5)<G$2;IF(SUM(F6:$F6)<8;1;"");"")
[![enter image description here][1]][1]
[1]: https://i.stack.imgur.com/d7G9y.png |
I need help converting a column of 179 observations from an excel file that holds 2 variables (days and values). After i try converting the dataframe with ts(as.vector(a1dataraw['x'], the vector returns with start=1 but also end=1 when it should be 179?
Can someone please identify where im going wrong?
``` r
library(TSA)
#Load data
a1dataraw <- read.csv("assignment1data2024.csv", header=TRUE)
a1dataraw
#Convert to TS
a1data <- NA
a1data <- ts(as.vector(a1dataraw['x']), # Read correct column, which is 'x' here.
start= 1)
a1data
```
[](https://i.stack.imgur.com/VVfRE.png)
[](https://i.stack.imgur.com/U4IAO.png)
The end value is 1 when it should be 179? The csv file has 2 columns with headers Trading days and x for the observations |
{"Voters":[{"Id":6243352,"DisplayName":"ggorlen"},{"Id":16217248,"DisplayName":"CPlus"},{"Id":466862,"DisplayName":"Mark Rotteveel"}],"SiteSpecificCloseReasonIds":[13]} |
The easiest thing is probably to drop the templates entirely and just implement the specific type of tuple you're using:
```
cdef extern from "<tuple>":
cdef cppclass Coordinate "std::tuple<double*, double*, double*>":
Coordinate()
```
Of course, since you already have the typedef you could just do:
```
cdef extern from "header_where_you_defined_the_typedef":
cdef cppclass Coordinate:
Coordinate()
```
Here Cython doesn't even need to know that it's a C++ `std::tuple` underneath.
The `cdef class` is basically as you've written it:
```
cdef class PointType:
cdef Coordinate* c_PointType_ptr
def __cinit__(self):
self.c_PointType_ptr = new Coordinate()
def __dealloc__(self):
del self.c_PointType_ptr
```
Really all Cython needs to know about `Coordinate` is that there's a class that exists called that. |
**I have the following code:**
return (
<KeyboardAvoidingView style={{ flex: 1 }} behavior="padding" enabled>
<View style={style.flex1}>
<View style={style.imageContainer}>
<Image
style={style.image}
source={require("../../assets/pictures/LoginBackground.png")}
resizeMode="cover"
/>
<View style={style.blackOpacity} />
</View>
<View style={style.contentContainer}>
<View style={style.flex1}>
<Text style={style.welcomeHeader}>{Strings.Welcome}</Text>
</View>
<View style={style.fieldsContainer}>
<LoginInput
placeholder={Strings.MailPlaceholder}
keyboardType={"email-address"}
onChangeText={setEmail}
styles={style.itemContainer}
/>
<LoginInput
placeholder={Strings.PasswordPlaceholder}
secureTextEntry={true}
onChangeText={setPassword}
styles={style.itemContainer}
/>
<TouchableOpacity
disabled={isLoginFormEmpty()}
style={
isLoginFormEmpty()
? [style.loginBtn, style.itemContainer, style.disabled]
: [style.loginBtn, style.itemContainer]
}
onPress={() => submitLogin()}
>
<Text style={style.loginBtnText}>{Strings.LoginBtn}</Text>
</TouchableOpacity>
</View>
</View>
</View>
</KeyboardAvoidingView>
**With the following style:**
```
const style = StyleSheet.create({
flex1: {
flex: 1,
},
imageContainer: {
flex: 1,
},
image: {
width: "100%",
height: "100%",
},
blackOpacity: {
...StyleSheet.absoluteFillObject,
backgroundColor: "black",
opacity: 0.6,
},
contentContainer: {
flex: 2,
backgroundColor: Colors.opacityBlack,
alignItems: "center",
},
welcomeHeader: {
fontFamily: getFontFamily("Heebo", "600"),
textAlign: "right",
fontSize: scaleFontSize(40),
marginTop: verticalScale(10),
color: Colors.white,
},
fieldsContainer: {
flex: 5,
alignItems: "center",
flexDirection: "column",
justifyContent: "space-between",
},
loginBtn: {
justifyContent: "center",
backgroundColor: Colors.submitPurple,
marginBottom: verticalScale(120),
},
disabled: {
opacity: 0.5,
},
loginBtnText: {
fontFamily: getFontFamily("Heebo", "500"),
fontSize: scaleFontSize(20),
textAlign: "center",
color: Colors.black,
},
itemContainer: {
width: horizontalScale(250),
height: verticalScale(40),
borderRadius: horizontalScale(20),
},
});
```
When the keyboard is closed, everything looks ok:
[![without keyboard][1]][1]
But when I open the keyboard, it makes all the inputs closer and doesn't keep the spaces between each element:
[![enter image description here][2]][2]
How do I keep the space between the elements even when the keyboard is open?
I tried to change the behavior to position or put the KeyboardAvoidingView inside the main View but it doesn't work.
[1]: https://i.stack.imgur.com/mc72C.jpg
[2]: https://i.stack.imgur.com/lX9Dl.jpg |
How to prompt a text in stylegan2 |
|image|machine-learning|artificial-intelligence|generative-adversarial-network|stylegan| |
After a complete clean up, I see the same today, so I try with:
`apt install nginx-core`
Don't know why nginx-full does not creates the directory, but nginx-core does.
tested on debian
Try and tell us :) |
Your example uses the shorthand version `container`. To use this syntax you must specify both a name and a type separated by a slash:
```container: container-name / container-type;```
If you just want to specify the type, use `container-type` instead.
The reason your example doesn't work as expected, is because `inline-size` is a assumed to be the container name.
<!-- begin snippet: js hide: false console: true babel: null -->
<!-- language: lang-html -->
<!DOCTYPE html>
<html>
<head>
<style type="text/css">
* {
margin: 0;
padding: 0;
}
.container {
container-type: inline-size;
max-width: 500px;
background-color: rgb(213, 213, 213);
}
p {
font-size: 2cqw;
}
</style>
</head>
<body>
<div class="container">
<p>Paragraph with font-size:2cqw, inside container with 90% width max-width=500px.</p>
</div>
</html>
<!-- end snippet -->
|