
text stringlengths 96 319k | id stringlengths 14 178 | metadata dict |
|---|---|---|
# Command Line Interface (CLI)
🤗 Datasets provides a command line interface (CLI) with useful shell commands to interact with your dataset.
You can check the available commands:
```bash
>>> datasets-cli --help
usage: datasets-cli <command> [<args>]
positional arguments:
{convert,env,test,convert_to_parquet}
... | datasets/docs/source/cli.mdx/0 | {
"file_path": "datasets/docs/source/cli.mdx",
"repo_id": "datasets",
"token_count": 1038
} |
# Load a dataset from the Hub
Finding high-quality datasets that are reproducible and accessible can be difficult. One of 🤗 Datasets main goals is to provide a simple way to load a dataset of any format or type. The easiest way to get started is to discover an existing dataset on the [Hugging Face Hub](https://huggin... | datasets/docs/source/load_hub.mdx/0 | {
"file_path": "datasets/docs/source/load_hub.mdx",
"repo_id": "datasets",
"token_count": 1610
} |
# Load tabular data
A tabular dataset is a generic dataset used to describe any data stored in rows and columns, where the rows represent an example and the columns represent a feature (can be continuous or categorical). These datasets are commonly stored in CSV files, Pandas DataFrames, and in database tables. This g... | datasets/docs/source/tabular_load.mdx/0 | {
"file_path": "datasets/docs/source/tabular_load.mdx",
"repo_id": "datasets",
"token_count": 1868
} |
[tool.ruff]
line-length = 119
[tool.ruff.lint]
# Ignored rules:
# "E501" -> line length violation
# "F821" -> undefined named in type annotation (e.g. Literal["something"])
# "C901" -> `function_name` is too complex
ignore = ["E501", "F821", "C901"]
select = ["C", "E", "F", "I", "W"]
[tool.ruff.lint.isort]
line... | datasets/pyproject.toml/0 | {
"file_path": "datasets/pyproject.toml",
"repo_id": "datasets",
"token_count": 274
} |
import os
import re
from functools import partial
from glob import has_magic
from pathlib import Path, PurePath
from typing import Callable, Dict, List, Optional, Set, Tuple, Union
import huggingface_hub
from fsspec.core import url_to_fs
from fsspec.implementations.http import HTTPFileSystem
from huggingface_hub impor... | datasets/src/datasets/data_files.py/0 | {
"file_path": "datasets/src/datasets/data_files.py",
"repo_id": "datasets",
"token_count": 13818
} |
import inspect
import os
import random
import shutil
import tempfile
import weakref
from functools import wraps
from pathlib import Path
from typing import TYPE_CHECKING, Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import xxhash
from . import config
from .naming import INVALID_WINDOWS_CHARACT... | datasets/src/datasets/fingerprint.py/0 | {
"file_path": "datasets/src/datasets/fingerprint.py",
"repo_id": "datasets",
"token_count": 7526
} |
import os
from typing import BinaryIO, Optional, Union
import fsspec
import pyarrow.parquet as pq
from .. import Dataset, Features, NamedSplit, config
from ..arrow_writer import get_writer_batch_size
from ..formatting import query_table
from ..packaged_modules import _PACKAGED_DATASETS_MODULES
from ..packaged_modules... | datasets/src/datasets/io/parquet.py/0 | {
"file_path": "datasets/src/datasets/io/parquet.py",
"repo_id": "datasets",
"token_count": 2023
} |
import itertools
from dataclasses import dataclass
from typing import Any, Callable, Dict, List, Optional, Union
import pandas as pd
import pyarrow as pa
import datasets
import datasets.config
from datasets.features.features import require_storage_cast
from datasets.table import table_cast
from datasets.utils.py_util... | datasets/src/datasets/packaged_modules/csv/csv.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/csv/csv.py",
"repo_id": "datasets",
"token_count": 3889
} |
import sys
from dataclasses import dataclass
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
import pandas as pd
import pyarrow as pa
import datasets
import datasets.config
from datasets.features.features import require_storage_cast
from datasets.table import table_cast
if TYPE_CHECKING:
im... | datasets/src/datasets/packaged_modules/sql/sql.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/sql/sql.py",
"repo_id": "datasets",
"token_count": 1979
} |
# Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# U... | datasets/src/datasets/utils/__init__.py/0 | {
"file_path": "datasets/src/datasets/utils/__init__.py",
"repo_id": "datasets",
"token_count": 284
} |
import fsspec
import pyarrow.parquet as pq
import pytest
from datasets import Audio, Dataset, DatasetDict, Features, IterableDatasetDict, NamedSplit, Sequence, Value, config
from datasets.features.image import Image
from datasets.info import DatasetInfo
from datasets.io.parquet import ParquetDatasetReader, ParquetData... | datasets/tests/io/test_parquet.py/0 | {
"file_path": "datasets/tests/io/test_parquet.py",
"repo_id": "datasets",
"token_count": 3919
} |
import json
import tarfile
import numpy as np
import pytest
from datasets import Audio, DownloadManager, Features, Image, Sequence, Value
from datasets.packaged_modules.webdataset.webdataset import WebDataset
from ..utils import require_librosa, require_numpy1_on_windows, require_pil, require_sndfile, require_torch
... | datasets/tests/packaged_modules/test_webdataset.py/0 | {
"file_path": "datasets/tests/packaged_modules/test_webdataset.py",
"repo_id": "datasets",
"token_count": 4039
} |
import json
import os
import pickle
import subprocess
from functools import partial
from pathlib import Path
from tempfile import gettempdir
from textwrap import dedent
from types import FunctionType
from unittest import TestCase
from unittest.mock import patch
import numpy as np
import pytest
from multiprocess import... | datasets/tests/test_fingerprint.py/0 | {
"file_path": "datasets/tests/test_fingerprint.py",
"repo_id": "datasets",
"token_count": 6756
} |
import json
import os
import pytest
from datasets.download.streaming_download_manager import (
StreamingDownloadManager,
xbasename,
xglob,
xjoin,
xopen,
)
from datasets.filesystems import COMPRESSION_FILESYSTEMS
from .utils import require_lz4, require_zstandard, slow
TEST_GG_DRIVE_FILENAME = "t... | datasets/tests/test_streaming_download_manager.py/0 | {
"file_path": "datasets/tests/test_streaming_download_manager.py",
"repo_id": "datasets",
"token_count": 3201
} |
import argparse
import sys
sys.path.append(".")
from base_classes import ImageToImageBenchmark, TurboImageToImageBenchmark # noqa: E402
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--ckpt",
type=str,
default="Lykon/DreamShaper",
choices... | diffusers/benchmarks/benchmark_sd_img.py/0 | {
"file_path": "diffusers/benchmarks/benchmark_sd_img.py",
"repo_id": "diffusers",
"token_count": 403
} |
FROM nvidia/cuda:12.1.0-runtime-ubuntu20.04
LABEL maintainer="Hugging Face"
LABEL repository="diffusers"
ENV DEBIAN_FRONTEND=noninteractive
ENV MINIMUM_SUPPORTED_TORCH_VERSION="2.1.0"
ENV MINIMUM_SUPPORTED_TORCHVISION_VERSION="0.16.0"
ENV MINIMUM_SUPPORTED_TORCHAUDIO_VERSION="2.1.0"
RUN apt-get -y update \
&& apt... | diffusers/docker/diffusers-pytorch-minimum-cuda/Dockerfile/0 | {
"file_path": "diffusers/docker/diffusers-pytorch-minimum-cuda/Dockerfile",
"repo_id": "diffusers",
"token_count": 622
} |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/api/loaders/single_file.md/0 | {
"file_path": "diffusers/docs/source/en/api/loaders/single_file.md",
"repo_id": "diffusers",
"token_count": 804
} |
<!-- Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agree... | diffusers/docs/source/en/api/models/ltx_video_transformer3d.md/0 | {
"file_path": "diffusers/docs/source/en/api/models/ltx_video_transformer3d.md",
"repo_id": "diffusers",
"token_count": 331
} |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/api/pipelines/dit.md/0 | {
"file_path": "diffusers/docs/source/en/api/pipelines/dit.md",
"repo_id": "diffusers",
"token_count": 528
} |
<!-- Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applic... | diffusers/docs/source/en/api/pipelines/mochi.md/0 | {
"file_path": "diffusers/docs/source/en/api/pipelines/mochi.md",
"repo_id": "diffusers",
"token_count": 3826
} |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/optimization/tome.md/0 | {
"file_path": "diffusers/docs/source/en/optimization/tome.md",
"repo_id": "diffusers",
"token_count": 3385
} |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/training/distributed_inference.md/0 | {
"file_path": "diffusers/docs/source/en/training/distributed_inference.md",
"repo_id": "diffusers",
"token_count": 3310
} |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/tutorials/inference_with_big_models.md/0 | {
"file_path": "diffusers/docs/source/en/tutorials/inference_with_big_models.md",
"repo_id": "diffusers",
"token_count": 1990
} |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/using-diffusers/inference_with_tcd_lora.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/inference_with_tcd_lora.md",
"repo_id": "diffusers",
"token_count": 6011
} |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/using-diffusers/sdxl_turbo.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/sdxl_turbo.md",
"repo_id": "diffusers",
"token_count": 1714
} |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/optimization/tome.md/0 | {
"file_path": "diffusers/docs/source/ko/optimization/tome.md",
"repo_id": "diffusers",
"token_count": 4367
} |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/training/unconditional_training.md/0 | {
"file_path": "diffusers/docs/source/ko/training/unconditional_training.md",
"repo_id": "diffusers",
"token_count": 3117
} |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/using-diffusers/sdxl_turbo.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/sdxl_turbo.md",
"repo_id": "diffusers",
"token_count": 2976
} |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/zh/quicktour.md/0 | {
"file_path": "diffusers/docs/source/zh/quicktour.md",
"repo_id": "diffusers",
"token_count": 8447
} |
from typing import List, Optional, Tuple, Union
import torch
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import ConfigMixin
from diffusers.pipelines.pipeline_utils import ImagePipelineOutput
from diffusers.schedulers.scheduling_utils import SchedulerMixin
class IADBScheduler(Scheduler... | diffusers/examples/community/iadb.py/0 | {
"file_path": "diffusers/examples/community/iadb.py",
"repo_id": "diffusers",
"token_count": 2500
} |
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from diffusers import StableDiffusionImg2ImgPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
class MaskedStableDiffusionImg2ImgPipeline(StableDiffusionImg2ImgPipeline... | diffusers/examples/community/masked_stable_diffusion_img2img.py/0 | {
"file_path": "diffusers/examples/community/masked_stable_diffusion_img2img.py",
"repo_id": "diffusers",
"token_count": 6298
} |
# A diffuser version implementation of Zero1to3 (https://github.com/cvlab-columbia/zero123), ICCV 2023
# by Xin Kong
import inspect
from typing import Any, Callable, Dict, List, Optional, Union
import kornia
import numpy as np
import PIL.Image
import torch
from packaging import version
from transformers import CLIPIm... | diffusers/examples/community/pipeline_zero1to3.py/0 | {
"file_path": "diffusers/examples/community/pipeline_zero1to3.py",
"repo_id": "diffusers",
"token_count": 17991
} |
from typing import Any, Callable, Dict, List, Optional, Union
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
LMSDiscreteScheduler,
PNDMScheduler,
StableDiffusionImg... | diffusers/examples/community/stable_diffusion_mega.py/0 | {
"file_path": "diffusers/examples/community/stable_diffusion_mega.py",
"repo_id": "diffusers",
"token_count": 3877
} |
# DreamBooth training example for Stable Diffusion XL (SDXL)
[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_lora_sdxl.py` script shows how to implement the training procedure and adapt ... | diffusers/examples/dreambooth/README_sdxl.md/0 | {
"file_path": "diffusers/examples/dreambooth/README_sdxl.md",
"repo_id": "diffusers",
"token_count": 3772
} |
# InstructPix2Pix training example
[InstructPix2Pix](https://arxiv.org/abs/2211.09800) is a method to fine-tune text-conditioned diffusion models such that they can follow an edit instruction for an input image. Models fine-tuned using this method take the following as inputs:
<p align="center">
<img src="https:/... | diffusers/examples/instruct_pix2pix/README.md/0 | {
"file_path": "diffusers/examples/instruct_pix2pix/README.md",
"repo_id": "diffusers",
"token_count": 2741
} |
import numpy as np
import numpy.core.multiarray as multiarray
import torch
import torch.nn as nn
from huggingface_hub import hf_hub_download
from torch.serialization import add_safe_globals
from diffusers import DDPMScheduler, UNet1DModel
add_safe_globals(
[
multiarray._reconstruct,
np.ndarray,
... | diffusers/examples/reinforcement_learning/diffusion_policy.py/0 | {
"file_path": "diffusers/examples/reinforcement_learning/diffusion_policy.py",
"repo_id": "diffusers",
"token_count": 3227
} |
<jupyter_start><jupyter_text>IntroductionThis colab is design to run the pretrained models from [GeoDiff](https://github.com/MinkaiXu/GeoDiff).The visualization code is inspired by this PyMol [colab](https://colab.research.google.com/gist/iwatobipen/2ec7faeafe5974501e69fcc98c122922/pymol.ipynbscrollTo=Hm4kY7CaZSlw).The... | diffusers/examples/research_projects/geodiff/geodiff_molecule_conformation.ipynb/0 | {
"file_path": "diffusers/examples/research_projects/geodiff/geodiff_molecule_conformation.ipynb",
"repo_id": "diffusers",
"token_count": 18621
} |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LI... | diffusers/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_sdxl.py/0 | {
"file_path": "diffusers/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_sdxl.py",
"repo_id": "diffusers",
"token_count": 26773
} |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LI... | diffusers/examples/text_to_image/test_text_to_image_lora.py/0 | {
"file_path": "diffusers/examples/text_to_image/test_text_to_image_lora.py",
"repo_id": "diffusers",
"token_count": 6179
} |
import argparse
import time
from pathlib import Path
from typing import Any, Dict, Literal
import torch
from diffusers import AsymmetricAutoencoderKL
ASYMMETRIC_AUTOENCODER_KL_x_1_5_CONFIG = {
"in_channels": 3,
"out_channels": 3,
"down_block_types": [
"DownEncoderBlock2D",
"DownEncoderBl... | diffusers/scripts/convert_asymmetric_vqgan_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_asymmetric_vqgan_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 3351
} |
import argparse
import re
import torch
import yaml
from transformers import (
CLIPProcessor,
CLIPTextModel,
CLIPTokenizer,
CLIPVisionModelWithProjection,
)
from diffusers import (
AutoencoderKL,
DDIMScheduler,
StableDiffusionGLIGENPipeline,
StableDiffusionGLIGENTextImagePipeline,
U... | diffusers/scripts/convert_gligen_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_gligen_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 11150
} |
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/scripts/convert_ms_text_to_video_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_ms_text_to_video_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 8415
} |
# Run this script to convert the Stable Cascade model weights to a diffusers pipeline.
import argparse
from contextlib import nullcontext
import torch
from safetensors.torch import load_file
from transformers import (
AutoTokenizer,
CLIPConfig,
CLIPImageProcessor,
CLIPTextModelWithProjection,
CLIPV... | diffusers/scripts/convert_stable_cascade.py/0 | {
"file_path": "diffusers/scripts/convert_stable_cascade.py",
"repo_id": "diffusers",
"token_count": 3605
} |
import random
import torch
from huggingface_hub import HfApi
from diffusers import UNet2DModel
api = HfApi()
results = {}
# fmt: off
results["google_ddpm_cifar10_32"] = torch.tensor([
-0.7515, -1.6883, 0.2420, 0.0300, 0.6347, 1.3433, -1.1743, -3.7467,
1.2342, -2.2485, 0.4636, 0.8076, -0.7991, 0.3969, 0.849... | diffusers/scripts/generate_logits.py/0 | {
"file_path": "diffusers/scripts/generate_logits.py",
"repo_id": "diffusers",
"token_count": 3530
} |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/hooks/hooks.py/0 | {
"file_path": "diffusers/src/diffusers/hooks/hooks.py",
"repo_id": "diffusers",
"token_count": 3738
} |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/loaders/unet.py/0 | {
"file_path": "diffusers/src/diffusers/loaders/unet.py",
"repo_id": "diffusers",
"token_count": 23040
} |
# Copyright 2024 The Hunyuan Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless ... | diffusers/src/diffusers/models/autoencoders/autoencoder_kl_hunyuan_video.py/0 | {
"file_path": "diffusers/src/diffusers/models/autoencoders/autoencoder_kl_hunyuan_video.py",
"repo_id": "diffusers",
"token_count": 21287
} |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/controlnets/controlnet_flax.py/0 | {
"file_path": "diffusers/src/diffusers/models/controlnets/controlnet_flax.py",
"repo_id": "diffusers",
"token_count": 7635
} |
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/src/diffusers/models/modeling_pytorch_flax_utils.py/0 | {
"file_path": "diffusers/src/diffusers/models/modeling_pytorch_flax_utils.py",
"repo_id": "diffusers",
"token_count": 3050
} |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/transformers/sana_transformer.py/0 | {
"file_path": "diffusers/src/diffusers/models/transformers/sana_transformer.py",
"repo_id": "diffusers",
"token_count": 8867
} |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/unets/unet_2d_blocks.py/0 | {
"file_path": "diffusers/src/diffusers/models/unets/unet_2d_blocks.py",
"repo_id": "diffusers",
"token_count": 74343
} |
from dataclasses import dataclass
from typing import List, Union
import numpy as np
import PIL.Image
import torch
from ...utils import BaseOutput
@dataclass
class AnimateDiffPipelineOutput(BaseOutput):
r"""
Output class for AnimateDiff pipelines.
Args:
frames (`torch.Tensor`, `np.ndarray`, or... | diffusers/src/diffusers/pipelines/animatediff/pipeline_output.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/animatediff/pipeline_output.py",
"repo_id": "diffusers",
"token_count": 264
} |
import numpy as np
import torch
import torch.nn as nn
from transformers import CLIPConfig, CLIPVisionModelWithProjection, PreTrainedModel
from ...utils import logging
logger = logging.get_logger(__name__)
class IFSafetyChecker(PreTrainedModel):
config_class = CLIPConfig
_no_split_modules = ["CLIPEncoderLa... | diffusers/src/diffusers/pipelines/deepfloyd_if/safety_checker.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deepfloyd_if/safety_checker.py",
"repo_id": "diffusers",
"token_count": 913
} |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/deprecated/pndm/pipeline_pndm.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/pndm/pipeline_pndm.py",
"repo_id": "diffusers",
"token_count": 1866
} |
# Copyright 2024 Pix2Pix Zero Authors and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unl... | diffusers/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_pix2pix_zero.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_pix2pix_zero.py",
"repo_id": "diffusers",
"token_count": 28204
} |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_img2img.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_img2img.py",
"repo_id": "diffusers",
"token_count": 8067
} |
from typing import TYPE_CHECKING
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and is... | diffusers/src/diffusers/pipelines/marigold/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/marigold/__init__.py",
"repo_id": "diffusers",
"token_count": 660
} |
# Copyright 2024 HunyuanDiT Authors and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unles... | diffusers/src/diffusers/pipelines/pag/pipeline_pag_hunyuandit.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/pag/pipeline_pag_hunyuandit.py",
"repo_id": "diffusers",
"token_count": 20918
} |
# Copyright 2024 Open AI and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required ... | diffusers/src/diffusers/pipelines/shap_e/pipeline_shap_e.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/shap_e/pipeline_shap_e.py",
"repo_id": "diffusers",
"token_count": 5908
} |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_k_diffusion.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_k_diffusion.py",
"repo_id": "diffusers",
"token_count": 14615
} |
from typing import TYPE_CHECKING
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
is_torch_available,
is_transformers_available,
is_transformers_version,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and is... | diffusers/src/diffusers/pipelines/unclip/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/unclip/__init__.py",
"repo_id": "diffusers",
"token_count": 700
} |
# Copyright 2024 NVIDIA and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required b... | diffusers/src/diffusers/schedulers/deprecated/scheduling_karras_ve.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/deprecated/scheduling_karras_ve.py",
"repo_id": "diffusers",
"token_count": 4063
} |
# Copyright 2024 Microsoft and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless require... | diffusers/src/diffusers/schedulers/scheduling_vq_diffusion.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_vq_diffusion.py",
"repo_id": "diffusers",
"token_count": 12476
} |
# This file is autogenerated by the command `make fix-copies`, do not edit.
from ..utils import DummyObject, requires_backends
class OnnxStableDiffusionImg2ImgPipeline(metaclass=DummyObject):
_backends = ["torch", "transformers", "onnx"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["... | diffusers/src/diffusers/utils/dummy_torch_and_transformers_and_onnx_objects.py/0 | {
"file_path": "diffusers/src/diffusers/utils/dummy_torch_and_transformers_and_onnx_objects.py",
"repo_id": "diffusers",
"token_count": 1270
} |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/utils/torch_utils.py/0 | {
"file_path": "diffusers/src/diffusers/utils/torch_utils.py",
"repo_id": "diffusers",
"token_count": 2534
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/lora/test_lora_layers_sd.py/0 | {
"file_path": "diffusers/tests/lora/test_lora_layers_sd.py",
"repo_id": "diffusers",
"token_count": 11952
} |
import unittest
from diffusers import FlaxAutoencoderKL
from diffusers.utils import is_flax_available
from diffusers.utils.testing_utils import require_flax
from ..test_modeling_common_flax import FlaxModelTesterMixin
if is_flax_available():
import jax
@require_flax
class FlaxAutoencoderKLTests(FlaxModelTeste... | diffusers/tests/models/autoencoders/test_models_vae_flax.py/0 | {
"file_path": "diffusers/tests/models/autoencoders/test_models_vae_flax.py",
"repo_id": "diffusers",
"token_count": 513
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/models/transformers/test_models_transformer_consisid.py/0 | {
"file_path": "diffusers/tests/models/transformers/test_models_transformer_consisid.py",
"repo_id": "diffusers",
"token_count": 1560
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/models/unets/test_models_unet_3d_condition.py/0 | {
"file_path": "diffusers/tests/models/unets/test_models_unet_3d_condition.py",
"repo_id": "diffusers",
"token_count": 2728
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/others/test_video_processor.py/0 | {
"file_path": "diffusers/tests/others/test_video_processor.py",
"repo_id": "diffusers",
"token_count": 3484
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/audioldm/test_audioldm.py/0 | {
"file_path": "diffusers/tests/pipelines/audioldm/test_audioldm.py",
"repo_id": "diffusers",
"token_count": 7655
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc and Tencent Hunyuan Team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless require... | diffusers/tests/pipelines/controlnet_hunyuandit/test_controlnet_hunyuandit.py/0 | {
"file_path": "diffusers/tests/pipelines/controlnet_hunyuandit/test_controlnet_hunyuandit.py",
"repo_id": "diffusers",
"token_count": 6045
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/hunyuan_dit/test_hunyuan_dit.py/0 | {
"file_path": "diffusers/tests/pipelines/hunyuan_dit/test_hunyuan_dit.py",
"repo_id": "diffusers",
"token_count": 5668
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion_superresolution.py/0 | {
"file_path": "diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion_superresolution.py",
"repo_id": "diffusers",
"token_count": 2028
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/pag/test_pag_sd_inpaint.py/0 | {
"file_path": "diffusers/tests/pipelines/pag/test_pag_sd_inpaint.py",
"repo_id": "diffusers",
"token_count": 5904
} |
# Copyright 2024 The HuggingFace Team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in... | diffusers/tests/pipelines/sana/test_sana.py/0 | {
"file_path": "diffusers/tests/pipelines/sana/test_sana.py",
"repo_id": "diffusers",
"token_count": 6370
} |
# coding=utf-8
# Copyright 2022 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_upscale.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_upscale.py",
"repo_id": "diffusers",
"token_count": 3917
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/unclip/test_unclip_image_variation.py/0 | {
"file_path": "diffusers/tests/pipelines/unclip/test_unclip_image_variation.py",
"repo_id": "diffusers",
"token_count": 8242
} |
import torch
from diffusers import DDIMScheduler
from .test_schedulers import SchedulerCommonTest
class DDIMSchedulerTest(SchedulerCommonTest):
scheduler_classes = (DDIMScheduler,)
forward_default_kwargs = (("eta", 0.0), ("num_inference_steps", 50))
def get_scheduler_config(self, **kwargs):
con... | diffusers/tests/schedulers/test_scheduler_ddim.py/0 | {
"file_path": "diffusers/tests/schedulers/test_scheduler_ddim.py",
"repo_id": "diffusers",
"token_count": 3127
} |
import tempfile
import unittest
import torch
from diffusers import IPNDMScheduler
from .test_schedulers import SchedulerCommonTest
class IPNDMSchedulerTest(SchedulerCommonTest):
scheduler_classes = (IPNDMScheduler,)
forward_default_kwargs = (("num_inference_steps", 50),)
def get_scheduler_config(self,... | diffusers/tests/schedulers/test_scheduler_ipndm.py/0 | {
"file_path": "diffusers/tests/schedulers/test_scheduler_ipndm.py",
"repo_id": "diffusers",
"token_count": 3140
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/single_file/test_model_controlnet_single_file.py/0 | {
"file_path": "diffusers/tests/single_file/test_model_controlnet_single_file.py",
"repo_id": "diffusers",
"token_count": 1017
} |
import gc
import unittest
import torch
from diffusers import (
StableDiffusionXLPipeline,
)
from diffusers.utils.testing_utils import (
backend_empty_cache,
enable_full_determinism,
require_torch_accelerator,
slow,
torch_device,
)
from .single_file_testing_utils import SDXLSingleFileTesterMix... | diffusers/tests/single_file/test_stable_diffusion_xl_single_file.py/0 | {
"file_path": "diffusers/tests/single_file/test_stable_diffusion_xl_single_file.py",
"repo_id": "diffusers",
"token_count": 738
} |
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/utils/overwrite_expected_slice.py/0 | {
"file_path": "diffusers/utils/overwrite_expected_slice.py",
"repo_id": "diffusers",
"token_count": 1259
} |
exclude: ^(tests/data)
default_language_version:
python: python3.10
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: check-added-large-files
- id: debug-statements
- id: check-merge-conflict
- id: check-case-conflict
- id: check-yaml
... | lerobot/.pre-commit-config.yaml/0 | {
"file_path": "lerobot/.pre-commit-config.yaml",
"repo_id": "lerobot",
"token_count": 461
} |
"""This scripts demonstrates how to train Diffusion Policy on the PushT environment.
Once you have trained a model with this script, you can try to evaluate it on
examples/2_evaluate_pretrained_policy.py
"""
from pathlib import Path
import torch
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset, Le... | lerobot/examples/3_train_policy.py/0 | {
"file_path": "lerobot/examples/3_train_policy.py",
"repo_id": "lerobot",
"token_count": 1670
} |
#!/usr/bin/env python
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/lerobot/common/datasets/online_buffer.py/0 | {
"file_path": "lerobot/lerobot/common/datasets/online_buffer.py",
"repo_id": "lerobot",
"token_count": 7377
} |
#!/usr/bin/env python
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/lerobot/common/datasets/push_dataset_to_hub/cam_png_format.py/0 | {
"file_path": "lerobot/lerobot/common/datasets/push_dataset_to_hub/cam_png_format.py",
"repo_id": "lerobot",
"token_count": 1314
} |
#!/usr/bin/env python
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/lerobot/common/envs/utils.py/0 | {
"file_path": "lerobot/lerobot/common/envs/utils.py",
"repo_id": "lerobot",
"token_count": 1346
} |
from transformers import GemmaConfig, PaliGemmaConfig
def get_paligemma_config(precision: str):
config = {
"image_token_index": None,
"pad_token_id": 0,
"bos_token_id": 2,
"eos_token_id": 1,
}
# image_sizes = {"2b-test": 224, "3b-224px": 224, "3b-448px": 448, "3b-896px": 8... | lerobot/lerobot/common/policies/pi0/conversion_scripts/conversion_utils.py/0 | {
"file_path": "lerobot/lerobot/common/policies/pi0/conversion_scripts/conversion_utils.py",
"repo_id": "lerobot",
"token_count": 999
} |
import logging
from dataclasses import dataclass
from pathlib import Path
import draccus
from lerobot.common.robot_devices.robots.configs import RobotConfig
from lerobot.common.utils.utils import auto_select_torch_device, is_amp_available, is_torch_device_available
from lerobot.configs import parser
from lerobot.conf... | lerobot/lerobot/common/robot_devices/control_configs.py/0 | {
"file_path": "lerobot/lerobot/common/robot_devices/control_configs.py",
"repo_id": "lerobot",
"token_count": 2306
} |
#!/usr/bin/env python
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/lerobot/scripts/train.py/0 | {
"file_path": "lerobot/lerobot/scripts/train.py",
"repo_id": "lerobot",
"token_count": 9794
} |
import enum
import numpy as np
class stream(enum.Enum): # noqa: N801
color = 0
depth = 1
class format(enum.Enum): # noqa: N801
rgb8 = 0
z16 = 1
class config: # noqa: N801
def enable_device(self, device_id: str):
self.device_enabled = device_id
def enable_stream(self, stream_ty... | lerobot/tests/mock_pyrealsense2.py/0 | {
"file_path": "lerobot/tests/mock_pyrealsense2.py",
"repo_id": "lerobot",
"token_count": 1261
} |
#!/usr/bin/env python
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/tests/test_policies.py/0 | {
"file_path": "lerobot/tests/test_policies.py",
"repo_id": "lerobot",
"token_count": 8324
} |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LI... | open-r1/src/open_r1/utils/callbacks.py/0 | {
"file_path": "open-r1/src/open_r1/utils/callbacks.py",
"repo_id": "open-r1",
"token_count": 1197
} |
- title: Get started
sections:
- local: index
title: 🤗 PEFT
- local: quicktour
title: Quicktour
- local: install
title: Installation
- title: Tutorial
sections:
- local: tutorial/peft_model_config
title: Configurations and models
- local: tutorial/peft_integrations
title: Integration... | peft/docs/source/_toctree.yml/0 | {
"file_path": "peft/docs/source/_toctree.yml",
"repo_id": "peft",
"token_count": 1373
} |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | peft/docs/source/developer_guides/troubleshooting.md/0 | {
"file_path": "peft/docs/source/developer_guides/troubleshooting.md",
"repo_id": "peft",
"token_count": 4966
} |
from pathlib import Path
import torch
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
class DreamBoothDataset(Dataset):
"""
A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
It pre-processes the images and the toke... | peft/examples/boft_dreambooth/utils/dataset.py/0 | {
"file_path": "peft/examples/boft_dreambooth/utils/dataset.py",
"repo_id": "peft",
"token_count": 1884
} |
# DoRA: Weight-Decomposed Low-Rank Adaptation
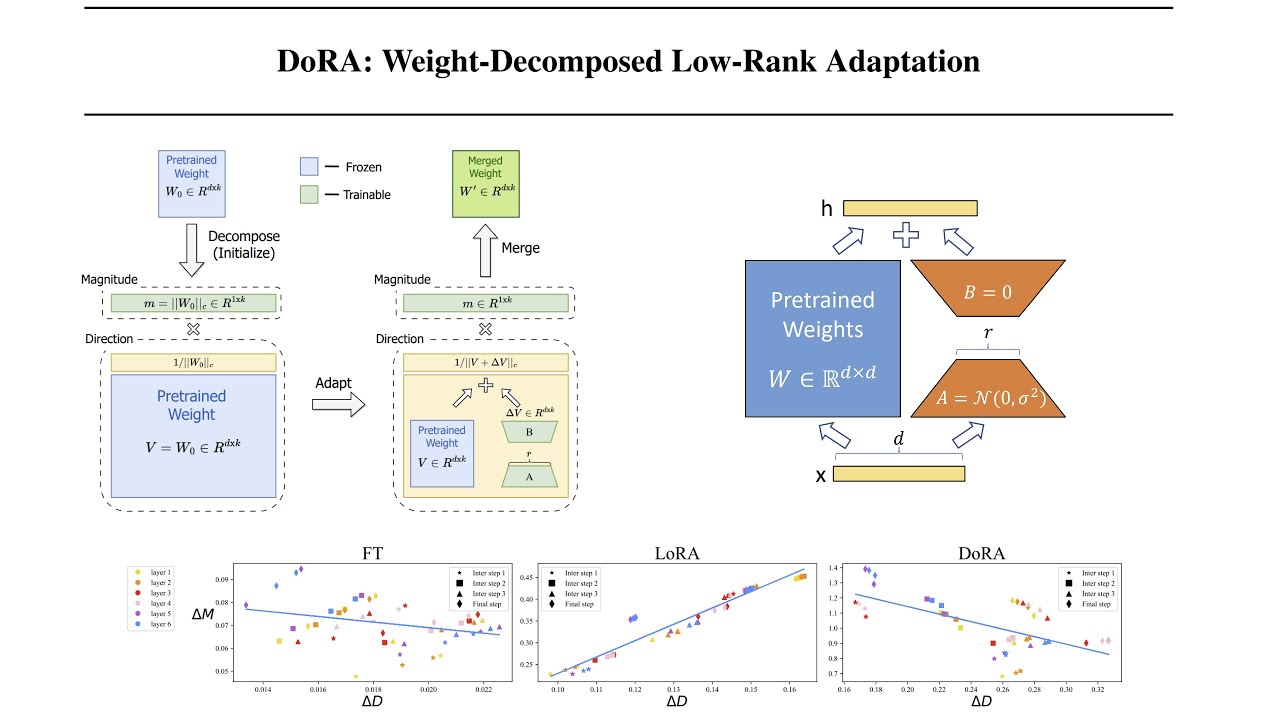
## Introduction
[DoRA](https://arxiv.org/abs/2402.09353) is a novel approach that leverages low rank adaptation through weight decomposition analysis to investigate the inherent differences between full fine-t... | peft/examples/dora_finetuning/README.md/0 | {
"file_path": "peft/examples/dora_finetuning/README.md",
"repo_id": "peft",
"token_count": 1500
} |
# LoftQ: LoRA-fine-tuning-aware Quantization
## Introduction
LoftQ finds quantized LoRA initialization: quantized backbone Q and LoRA adapters A and B, given a pre-trained weight W.
## Quick Start
Steps:
1. Apply LoftQ to a full-precision pre-trained weight and save.
2. Load LoftQ initialization and train.
For ste... | peft/examples/loftq_finetuning/README.md/0 | {
"file_path": "peft/examples/loftq_finetuning/README.md",
"repo_id": "peft",
"token_count": 1978
} |
# OLoRA: Orthonormal Low Rank Adaptation of Large Language Models
## Introduction
[OLoRA](https://arxiv.org/abs/2406.01775) is a novel approach that leverages orthonormal low rank adaptation through QR decomposition. Unlike the default LoRA implementation, OLoRA decomposes original weights into their $\mathbf{Q}$ and ... | peft/examples/olora_finetuning/README.md/0 | {
"file_path": "peft/examples/olora_finetuning/README.md",
"repo_id": "peft",
"token_count": 1443
} |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.