
source stringclasses 470 values | url stringlengths 49 167 | file_type stringclasses 1 value | chunk stringlengths 1 512 | chunk_id stringlengths 5 9 |
|---|---|---|---|---|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md | https://huggingface.co/docs/transformers/en/pr_checks/#check-copies | .md | ```py
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->Roberta
```
Note that there shouldn't be any spaces around the arrow (unless that space is part of the pattern to replace of course). | 65_6_7 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md | https://huggingface.co/docs/transformers/en/pr_checks/#check-copies | .md | You can add several patterns separated by a comma. For instance here `CamemberForMaskedLM` is a direct copy of `RobertaForMaskedLM` with two replacements: `Roberta` to `Camembert` and `ROBERTA` to `CAMEMBERT`. You can see [here](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/camembert/modeling_camembert.py#L929) this is done with the comment:
```py | 65_6_8 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md | https://huggingface.co/docs/transformers/en/pr_checks/#check-copies | .md | ```py
# Copied from transformers.models.roberta.modeling_roberta.RobertaForMaskedLM with Roberta->Camembert, ROBERTA->CAMEMBERT
```
If the order matters (because one of the replacements might conflict with a previous one), the replacements are executed from left to right.
<Tip>
If the replacements change the formatting (if you replace a short name by a very long name for instance), the copy is checked after applying the auto-formatter.
</Tip> | 65_6_9 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md | https://huggingface.co/docs/transformers/en/pr_checks/#check-copies | .md | </Tip>
Another way when the patterns are just different casings of the same replacement (with an uppercased and a lowercased variants) is just to add the option `all-casing`. [Here](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/mobilebert/modeling_mobilebert.py#L1237) is an example in `MobileBertForSequenceClassification` with the comment:
```py | 65_6_10 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pr_checks.md | https://huggingface.co/docs/transformers/en/pr_checks/#check-copies | .md | ```py
# Copied from transformers.models.bert.modeling_bert.BertForSequenceClassification with Bert->MobileBert all-casing
```
In this case, the code is copied from `BertForSequenceClassification` by replacing:
- `Bert` by `MobileBert` (for instance when using `MobileBertModel` in the init)
- `bert` by `mobilebert` (for instance when defining `self.mobilebert`)
- `BERT` by `MOBILEBERT` (in the constant `MOBILEBERT_INPUTS_DOCSTRING`) | 65_6_11 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_infer_gpu_multi.md | https://huggingface.co/docs/transformers/en/perf_infer_gpu_multi/ | .md | <!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 66_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_infer_gpu_multi.md | https://huggingface.co/docs/transformers/en/perf_infer_gpu_multi/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 66_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_infer_gpu_multi.md | https://huggingface.co/docs/transformers/en/perf_infer_gpu_multi/#multi-gpu-inference | .md | Built-in Tensor Parallelism (TP) is now available with certain models using PyTorch. Tensor parallelism shards a model onto multiple GPUs, enabling larger model sizes, and parallelizes computations such as matrix multiplication.
To enable tensor parallel, pass the argument `tp_plan="auto"` to [`~AutoModelForCausalLM.from_pretrained`]:
```python
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "meta-llama/Meta-Llama-3-8B-Instruct" | 66_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_infer_gpu_multi.md | https://huggingface.co/docs/transformers/en/perf_infer_gpu_multi/#multi-gpu-inference | .md | model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
# Initialize distributed
rank = int(os.environ["RANK"])
device = torch.device(f"cuda:{rank}")
torch.distributed.init_process_group("nccl", device_id=device)
# Retrieve tensor parallel model
model = AutoModelForCausalLM.from_pretrained(
model_id,
tp_plan="auto",
)
# Prepare input tokens
tokenizer = AutoTokenizer.from_pretrained(model_id)
prompt = "Can I help"
inputs = tokenizer(prompt, return_tensors="pt").input_ids.to(device) | 66_1_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_infer_gpu_multi.md | https://huggingface.co/docs/transformers/en/perf_infer_gpu_multi/#multi-gpu-inference | .md | # Distributed run
outputs = model(inputs)
```
You can use `torchrun` to launch the above script with multiple processes, each mapping to a GPU:
```
torchrun --nproc-per-node 4 demo.py
```
PyTorch tensor parallel is currently supported for the following models:
* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
You can request to add tensor parallel support for another model by opening a GitHub Issue or Pull Request. | 66_1_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_infer_gpu_multi.md | https://huggingface.co/docs/transformers/en/perf_infer_gpu_multi/#expected-speedups | .md | You can benefit from considerable speedups for inference, especially for inputs with large batch size or long sequences.
For a single forward pass on [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel) with a sequence length of 512 and various batch sizes, the expected speedup is as follows:
<div style="text-align: center"> | 66_2_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_infer_gpu_multi.md | https://huggingface.co/docs/transformers/en/perf_infer_gpu_multi/#expected-speedups | .md | <div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/Meta-Llama-3-8B-Instruct%2C%20seqlen%20%3D%20512%2C%20python%2C%20w_%20compile.png">
</div> | 66_2_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tflite.md | https://huggingface.co/docs/transformers/en/tflite/ | .md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 67_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tflite.md | https://huggingface.co/docs/transformers/en/tflite/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 67_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tflite.md | https://huggingface.co/docs/transformers/en/tflite/#export-to-tflite | .md | [TensorFlow Lite](https://www.tensorflow.org/lite/guide) is a lightweight framework for deploying machine learning models
on resource-constrained devices, such as mobile phones, embedded systems, and Internet of Things (IoT) devices.
TFLite is designed to optimize and run models efficiently on these devices with limited computational power, memory, and
power consumption.
A TensorFlow Lite model is represented in a special efficient portable format identified by the `.tflite` file extension. | 67_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tflite.md | https://huggingface.co/docs/transformers/en/tflite/#export-to-tflite | .md | A TensorFlow Lite model is represented in a special efficient portable format identified by the `.tflite` file extension.
🤗 Optimum offers functionality to export 🤗 Transformers models to TFLite through the `exporters.tflite` module.
For the list of supported model architectures, please refer to [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/tflite/overview).
To export a model to TFLite, install the required dependencies:
```bash
pip install optimum[exporters-tf]
``` | 67_1_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tflite.md | https://huggingface.co/docs/transformers/en/tflite/#export-to-tflite | .md | To export a model to TFLite, install the required dependencies:
```bash
pip install optimum[exporters-tf]
```
To check out all available arguments, refer to the [🤗 Optimum docs](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model),
or view help in command line:
```bash
optimum-cli export tflite --help
```
To export a model's checkpoint from the 🤗 Hub, for example, `google-bert/bert-base-uncased`, run the following command:
```bash | 67_1_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tflite.md | https://huggingface.co/docs/transformers/en/tflite/#export-to-tflite | .md | ```bash
optimum-cli export tflite --model google-bert/bert-base-uncased --sequence_length 128 bert_tflite/
```
You should see the logs indicating progress and showing where the resulting `model.tflite` is saved, like this:
```bash
Validating TFLite model...
-[✓] TFLite model output names match reference model (logits)
- Validating TFLite Model output "logits":
-[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05) | 67_1_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tflite.md | https://huggingface.co/docs/transformers/en/tflite/#export-to-tflite | .md | -[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
- logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
``` | 67_1_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tflite.md | https://huggingface.co/docs/transformers/en/tflite/#export-to-tflite | .md | - logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
```
The example above illustrates exporting a checkpoint from 🤗 Hub. When exporting a local model, first make sure that you
saved both the model's weights and tokenizer files in the same directory (`local_path`). When using CLI, pass the
`local_path` to the `model` argument instead of the checkpoint name on 🤗 Hub. | 67_1_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/ | .md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 68_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 68_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#optimize-inference-using-torchcompile | .md | This guide aims to provide a benchmark on the inference speed-ups introduced with [`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html)for [computer vision models in 🤗 Transformers](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending). | 68_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#benefits-of-torchcompile | .md | Depending on the model and the GPU, `torch.compile()` yields up to 30% speed-up during inference. To use `torch.compile()`, simply install any version of `torch` above 2.0.
Compiling a model takes time, so it's useful if you are compiling the model only once instead of every time you infer.
To compile any computer vision model of your choice, call `torch.compile()` on the model as shown below:
```diff
from transformers import AutoModelForImageClassification | 68_2_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#benefits-of-torchcompile | .md | model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to(DEVICE)
+ model = torch.compile(model)
``` | 68_2_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#benefits-of-torchcompile | .md | + model = torch.compile(model)
```
`compile()`comes with multiple modes for compiling, which essentially differ in compilation time and inference overhead. `max-autotune`takes longer than `reduce-overhead`but results in faster inference. Default mode is fastest for compilation but is not as efficient compared to `reduce-overhead` for inference time. In this guide, we used the default mode. You can learn more about it [here](https://pytorch.org/get-started/pytorch-2.0/#user-experience). | 68_2_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#benefits-of-torchcompile | .md | We benchmarked `torch.compile` with different computer vision models, tasks, types of hardware, and batch sizes on `torch`version 2.0.1. | 68_2_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#benchmarking-code | .md | Below you can find the benchmarking code for each task. We warm up the GPU before inference and take the mean time of 300 inferences, using the same image each time. | 68_3_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-classification-with-vit | .md | ```python
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
from accelerate.test_utils.testing import get_backend
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw) | 68_4_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-classification-with-vit | .md | processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to(device)
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device)
with torch.no_grad():
_ = model(**processed_input)
``` | 68_4_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#object-detection-with-detr | .md | ```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
from accelerate.test_utils.testing import get_backend
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to(device)
model = torch.compile(model) | 68_5_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#object-detection-with-detr | .md | texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to(device)
with torch.no_grad():
_ = model(**inputs)
``` | 68_5_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-segmentation-with-segformer | .md | ```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
from accelerate.test_utils.testing import get_backend | 68_6_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-segmentation-with-segformer | .md | device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to(device)
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to(device) | 68_6_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-segmentation-with-segformer | .md | with torch.no_grad():
_ = model(**seg_inputs)
```
Below you can find the list of the models we benchmarked.
**Image Classification**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50) | 68_6_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-segmentation-with-segformer | .md | - [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50)
**Image Segmentation**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade) | 68_6_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-segmentation-with-segformer | .md | - [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**Object Detection**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50) | 68_6_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-segmentation-with-segformer | .md | - [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
Below you can find visualization of inference durations with and without `torch.compile()`and percentage improvements for each model in different hardware and batch sizes.
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div> | 68_6_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-segmentation-with-segformer | .md | </div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div> | 68_6_6 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-segmentation-with-segformer | .md | </div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>
 | 68_6_7 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#image-segmentation-with-segformer | .md | 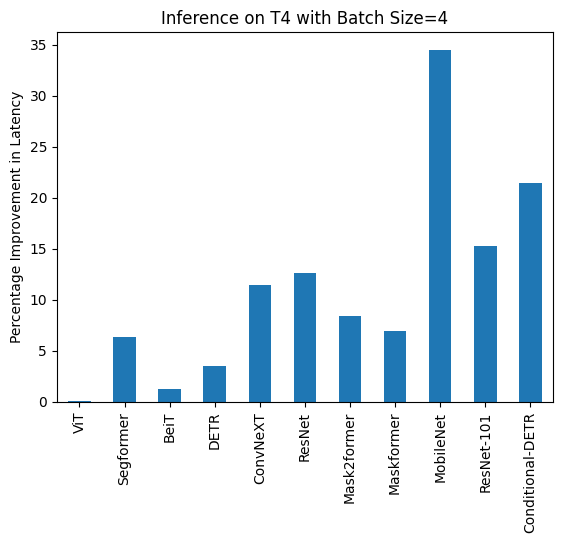
Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes. | 68_6_8 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100-batch-size-1 | .md | | **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 | | 68_7_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100-batch-size-1 | .md | | Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 | | 68_7_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100-batch-size-4 | .md | | **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 | | 68_8_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100-batch-size-4 | .md | | Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 | | 68_8_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100-batch-size-16 | .md | | **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 | | 68_9_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100-batch-size-16 | .md | | Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 | | 68_9_1 |
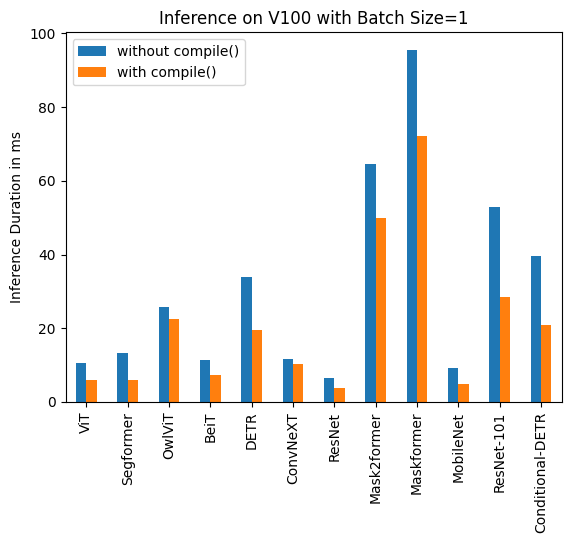
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100-batch-size-1 | .md | | **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 | | 68_10_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100-batch-size-1 | .md | | Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 | | 68_10_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100-batch-size-4 | .md | | **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 | | 68_11_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100-batch-size-4 | .md | | Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 | | 68_11_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100-batch-size-16 | .md | | **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 | | 68_12_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100-batch-size-16 | .md | | Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 | | 68_12_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4-batch-size-1 | .md | | **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 | | 68_13_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4-batch-size-1 | .md | | Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 | | 68_13_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4-batch-size-4 | .md | | **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 | | 68_14_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4-batch-size-4 | .md | | Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 | | 68_14_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4-batch-size-16 | .md | | **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 | | 68_15_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4-batch-size-16 | .md | | Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390| | 68_15_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#pytorch-nightly | .md | We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models. | 68_16_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100 | .md | | **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 | | 68_17_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4 | .md | | **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM | | 68_18_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#v100 | .md | | **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM | | 68_19_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#reduce-overhead | .md | We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly. | 68_20_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100 | .md | | **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 | | 68_21_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#a100 | .md | | Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 | | 68_21_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4 | .md | | **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 | | 68_22_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_torch_compile.md | https://huggingface.co/docs/transformers/en/perf_torch_compile/#t4 | .md | | Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 | | 68_22_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md | https://huggingface.co/docs/transformers/en/perf_train_special/ | .md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 69_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md | https://huggingface.co/docs/transformers/en/perf_train_special/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 69_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md | https://huggingface.co/docs/transformers/en/perf_train_special/#pytorch-training-on-apple-silicon | .md | Previously, training models on a Mac was limited to the CPU only. With the release of PyTorch v1.12, you can take advantage of training models with Apple's silicon GPUs for significantly faster performance and training. This is powered in PyTorch by integrating Apple's Metal Performance Shaders (MPS) as a backend. The [MPS backend](https://pytorch.org/docs/stable/notes/mps.html) implements PyTorch operations as custom Metal shaders and places these modules on a `mps` device.
<Tip warning={true}> | 69_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md | https://huggingface.co/docs/transformers/en/perf_train_special/#pytorch-training-on-apple-silicon | .md | <Tip warning={true}>
Some PyTorch operations are not implemented in MPS yet and will throw an error. To avoid this, you should set the environment variable `PYTORCH_ENABLE_MPS_FALLBACK=1` to use the CPU kernels instead (you'll still see a `UserWarning`).
<br>
If you run into any other errors, please open an issue in the [PyTorch](https://github.com/pytorch/pytorch/issues) repository because the [`Trainer`] only integrates the MPS backend.
</Tip>
With the `mps` device set, you can: | 69_1_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md | https://huggingface.co/docs/transformers/en/perf_train_special/#pytorch-training-on-apple-silicon | .md | </Tip>
With the `mps` device set, you can:
* train larger networks or batch sizes locally
* reduce data retrieval latency because the GPU's unified memory architecture allows direct access to the full memory store
* reduce costs because you don't need to train on cloud-based GPUs or add additional local GPUs
Get started by making sure you have PyTorch installed. MPS acceleration is supported on macOS 12.3+.
```bash
pip install torch torchvision torchaudio
``` | 69_1_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md | https://huggingface.co/docs/transformers/en/perf_train_special/#pytorch-training-on-apple-silicon | .md | ```bash
pip install torch torchvision torchaudio
```
[`TrainingArguments`] uses the `mps` device by default if it's available which means you don't need to explicitly set the device. For example, you can run the [run_glue.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue.py) script with the MPS backend automatically enabled without making any changes.
```diff
export TASK_NAME=mrpc | 69_1_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md | https://huggingface.co/docs/transformers/en/perf_train_special/#pytorch-training-on-apple-silicon | .md | python examples/pytorch/text-classification/run_glue.py \
--model_name_or_path google-bert/bert-base-cased \
--task_name $TASK_NAME \
- --use_mps_device \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
``` | 69_1_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md | https://huggingface.co/docs/transformers/en/perf_train_special/#pytorch-training-on-apple-silicon | .md | --learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
Backends for [distributed setups](https://pytorch.org/docs/stable/distributed.html#backends) like `gloo` and `nccl` are not supported by the `mps` device which means you can only train on a single GPU with the MPS backend. | 69_1_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/perf_train_special.md | https://huggingface.co/docs/transformers/en/perf_train_special/#pytorch-training-on-apple-silicon | .md | You can learn more about the MPS backend in the [Introducing Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/) blog post. | 69_1_6 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md | https://huggingface.co/docs/transformers/en/tiktoken/ | .md | <!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 70_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md | https://huggingface.co/docs/transformers/en/tiktoken/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
``
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 70_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md | https://huggingface.co/docs/transformers/en/tiktoken/#tiktoken-and-interaction-with-transformers | .md | Support for tiktoken model files is seamlessly integrated in 🤗 transformers when loading models
`from_pretrained` with a `tokenizer.model` tiktoken file on the Hub, which is automatically converted into our
[fast tokenizer](https://huggingface.co/docs/transformers/main/en/main_classes/tokenizer#transformers.PreTrainedTokenizerFast). | 70_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md | https://huggingface.co/docs/transformers/en/tiktoken/#known-models-that-were-released-with-a-tiktokenmodel | .md | - gpt2
- llama3 | 70_2_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md | https://huggingface.co/docs/transformers/en/tiktoken/#example-usage | .md | In order to load `tiktoken` files in `transformers`, ensure that the `tokenizer.model` file is a tiktoken file and it
will automatically be loaded when loading `from_pretrained`. Here is how one would load a tokenizer and a model, which
can be loaded from the exact same file:
```py
from transformers import AutoTokenizer
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id, subfolder="original")
``` | 70_3_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md | https://huggingface.co/docs/transformers/en/tiktoken/#create-tiktoken-tokenizer | .md | The `tokenizer.model` file contains no information about additional tokens or pattern strings. If these are important, convert the tokenizer to `tokenizer.json`, the appropriate format for [`PreTrainedTokenizerFast`].
Generate the `tokenizer.model` file with [tiktoken.get_encoding](https://github.com/openai/tiktoken/blob/63527649963def8c759b0f91f2eb69a40934e468/tiktoken/registry.py#L63) and then convert it to `tokenizer.json` with [`convert_tiktoken_to_fast`].
```py | 70_4_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/tiktoken.md | https://huggingface.co/docs/transformers/en/tiktoken/#create-tiktoken-tokenizer | .md | from transformers.integrations.tiktoken import convert_tiktoken_to_fast
from tiktoken import get_encoding
# You can load your custom encoding or the one provided by OpenAI
encoding = get_encoding("gpt2")
convert_tiktoken_to_fast(encoding, "config/save/dir")
```
The resulting `tokenizer.json` file is saved to the specified directory and can be loaded with [`PreTrainedTokenizerFast`].
```py
tokenizer = PreTrainedTokenizerFast.from_pretrained("config/save/dir")
``` | 70_4_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/ | .md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 71_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 71_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#load-adapters-with--peft | .md | [[open-in-colab]]
[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) methods freeze the pretrained model parameters during fine-tuning and add a small number of trainable parameters (the adapters) on top of it. The adapters are trained to learn task-specific information. This approach has been shown to be very memory-efficient with lower compute usage while producing results comparable to a fully fine-tuned model. | 71_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#load-adapters-with--peft | .md | Adapters trained with PEFT are also usually an order of magnitude smaller than the full model, making it convenient to share, store, and load them.
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
<figcaption class="text-center">The adapter weights for a OPTForCausalLM model stored on the Hub are only ~6MB compared to the full size of the model weights, which can be ~700MB.</figcaption> | 71_1_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#load-adapters-with--peft | .md | </div>
If you're interested in learning more about the 🤗 PEFT library, check out the [documentation](https://huggingface.co/docs/peft/index). | 71_1_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#setup | .md | Get started by installing 🤗 PEFT:
```bash
pip install peft
```
If you want to try out the brand new features, you might be interested in installing the library from source:
```bash
pip install git+https://github.com/huggingface/peft.git
``` | 71_2_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#supported-peft-models | .md | 🤗 Transformers natively supports some PEFT methods, meaning you can load adapter weights stored locally or on the Hub and easily run or train them with a few lines of code. The following methods are supported:
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
- [AdaLoRA](https://arxiv.org/abs/2303.10512) | 71_3_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#supported-peft-models | .md | - [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
- [AdaLoRA](https://arxiv.org/abs/2303.10512)
If you want to use other PEFT methods, such as prompt learning or prompt tuning, or learn about the 🤗 PEFT library in general, please refer to the [documentation](https://huggingface.co/docs/peft/index). | 71_3_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#load-a-peft-adapter | .md | To load and use a PEFT adapter model from 🤗 Transformers, make sure the Hub repository or local directory contains an `adapter_config.json` file and the adapter weights, as shown in the example image above. Then you can load the PEFT adapter model using the `AutoModelFor` class. For example, to load a PEFT adapter model for causal language modeling:
1. specify the PEFT model id
2. pass it to the [`AutoModelForCausalLM`] class
```py
from transformers import AutoModelForCausalLM, AutoTokenizer | 71_4_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#load-a-peft-adapter | .md | peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
```
<Tip>
You can load a PEFT adapter with either an `AutoModelFor` class or the base model class like `OPTForCausalLM` or `LlamaForCausalLM`.
</Tip>
You can also load a PEFT adapter by calling the `load_adapter` method:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora" | 71_4_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#load-a-peft-adapter | .md | model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
```
Check out the [API documentation](#transformers.integrations.PeftAdapterMixin) section below for more details. | 71_4_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#load-in-8bit-or-4bit | .md | The `bitsandbytes` integration supports 8bit and 4bit precision data types, which are useful for loading large models because it saves memory (see the `bitsandbytes` integration [guide](./quantization#bitsandbytes-integration) to learn more). Add the `load_in_8bit` or `load_in_4bit` parameters to [`~PreTrainedModel.from_pretrained`] and set `device_map="auto"` to effectively distribute the model to your hardware:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig | 71_5_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#load-in-8bit-or-4bit | .md | peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
``` | 71_5_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#add-a-new-adapter | .md | You can use [`~peft.PeftModel.add_adapter`] to add a new adapter to a model with an existing adapter as long as the new adapter is the same type as the current one. For example, if you have an existing LoRA adapter attached to a model:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import LoraConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id) | 71_6_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#add-a-new-adapter | .md | model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
init_lora_weights=False
) | 71_6_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/peft.md | https://huggingface.co/docs/transformers/en/peft/#add-a-new-adapter | .md | model.add_adapter(lora_config, adapter_name="adapter_1")
```
To add a new adapter:
```py
# attach new adapter with same config
model.add_adapter(lora_config, adapter_name="adapter_2")
```
Now you can use [`~peft.PeftModel.set_adapter`] to set which adapter to use:
```py
# use adapter_1
model.set_adapter("adapter_1")
output_disabled = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True)) | 71_6_2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.