
csv unknown | __key__ stringlengths 23 88 | __url__ stringclasses 1
value |
|---|---|---|
"ZGlybmFtZSxjb21wb3NpdGVfaWQsY3BzLGNvcmUsY29tcG9zaXRlX2RlcHRoX21tLHNlY3Rpb25fZGVwdGhfbW0sZmlsZW5hbWU(...TRUNCATED) | data/pretrain/test/info | "/tmp/hf-datasets-cache/medium/datasets/72636789261978-config-parquet-and-info-paoyw-max-dataset-42a(...TRUNCATED) |
"MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAo(...TRUNCATED) | data/pretrain/test/spe/1978 | "/tmp/hf-datasets-cache/medium/datasets/72636789261978-config-parquet-and-info-paoyw-max-dataset-42a(...TRUNCATED) |
"MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAoxCjAKMAowCjAKMgowCjEKMwowCjIKMAo(...TRUNCATED) | data/pretrain/test/spe/3310 | "/tmp/hf-datasets-cache/medium/datasets/72636789261978-config-parquet-and-info-paoyw-max-dataset-42a(...TRUNCATED) |
"MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAoxCjAKMQoyCjIKMgoyCjEKMAo(...TRUNCATED) | data/pretrain/test/spe/4457 | "/tmp/hf-datasets-cache/medium/datasets/72636789261978-config-parquet-and-info-paoyw-max-dataset-42a(...TRUNCATED) |
"MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAo(...TRUNCATED) | data/pretrain/test/spe/1803 | "/tmp/hf-datasets-cache/medium/datasets/72636789261978-config-parquet-and-info-paoyw-max-dataset-42a(...TRUNCATED) |
"MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjEKMAowCjEKMQoxCjEKMQowCjIKMwo(...TRUNCATED) | data/pretrain/test/spe/4258 | "/tmp/hf-datasets-cache/medium/datasets/72636789261978-config-parquet-and-info-paoyw-max-dataset-42a(...TRUNCATED) |
"MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMQowCjIKMQoyCjIKNAo(...TRUNCATED) | data/pretrain/test/spe/3005 | "/tmp/hf-datasets-cache/medium/datasets/72636789261978-config-parquet-and-info-paoyw-max-dataset-42a(...TRUNCATED) |
"MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAo(...TRUNCATED) | data/pretrain/test/spe/1280 | "/tmp/hf-datasets-cache/medium/datasets/72636789261978-config-parquet-and-info-paoyw-max-dataset-42a(...TRUNCATED) |
"MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAoxCjAKMAowCjIKMwo2CjUKMTA(...TRUNCATED) | data/pretrain/test/spe/2943 | "/tmp/hf-datasets-cache/medium/datasets/72636789261978-config-parquet-and-info-paoyw-max-dataset-42a(...TRUNCATED) |
"MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMQowCjAKMQowCjAKMQo0CjEKMwowCjAKMwozCjMKNAo(...TRUNCATED) | data/pretrain/test/spe/3630 | "/tmp/hf-datasets-cache/medium/datasets/72636789261978-config-parquet-and-info-paoyw-max-dataset-42a(...TRUNCATED) |
High-latitude Pacific Ocean Sediment Geochemistry and XRF Data for Geoscientific Foundation Models
This dataset is a following development after the dataset (Chao et al., 2022), which inculdes the geochemical records from the high-latitude sectors of Pacific Ocean. Besides the published XRF spectra-target measurements (CaCO3 and TOC) pairs of data, we further upload the XRF spectra in that project but without alignments of the target measurements here. In total, it has 59,828 XRF spectra, 2,254 CaCO3 measurements, and 2,363 TOC measurements. They are compiled in a machine learning ready format, which we expect for convenient implementation of other studies.
This dataset is used for training and validating the first foundation model for X-ray Fluorescence (lee et al., 2025). It's also published on Zenodo. For more details, please refer to the Zenodo dataset.
The case study (i.e., test set) is composed of three cores ('PS75-056-1', 'LV28-44-3', 'SO264-69-2') isolated from the beginning and not used in both the pre-training and fine-tuning process.
The rest of data are randomly split in to the trainging and validation sets wtih 4:1 ratio.
The script is src/datas/build_data.py in the GitHub repo.
If you use the data, please cite the paper and dataset properly. The citations are:
@article{https://doi.org/10.1029/2025JH000754,
author = {Lee, An-Sheng and Pao, Yu-Wen and Lin, Hsuan-Tien and Liou, Sofia Ya Hsuan},
title = {Cross-Project Deep-Sea Sediment Geochemistry From XRF Spectra: A Self-Supervised Foundation Model (MAX)},
journal = {Journal of Geophysical Research: Machine Learning and Computation},
volume = {2},
number = {3},
pages = {e2025JH000754},
keywords = {X-ray fluorescence, geochemistry, deep learning, self-supervised learning, foundation model, sediment cores},
doi = {https://doi.org/10.1029/2025JH000754},
note = {e2025JH000754 2025JH000754},
year = {2025}
}
@dataset{lee_2025_16354051,
author = {Lee, An-Sheng and
Pao, Yu-Wen},
title = {High-latitude Pacific Ocean Sediment Geochemistry
and XRF Data for Geoscientific Foundation Models
},
month = jul,
year = 2025,
publisher = {Zenodo},
version = {v1.0.0},
doi = {10.5281/zenodo.16354051},
url = {https://doi.org/10.5281/zenodo.16354051},
}
The target data (CaCO3 and TOC) distribution:
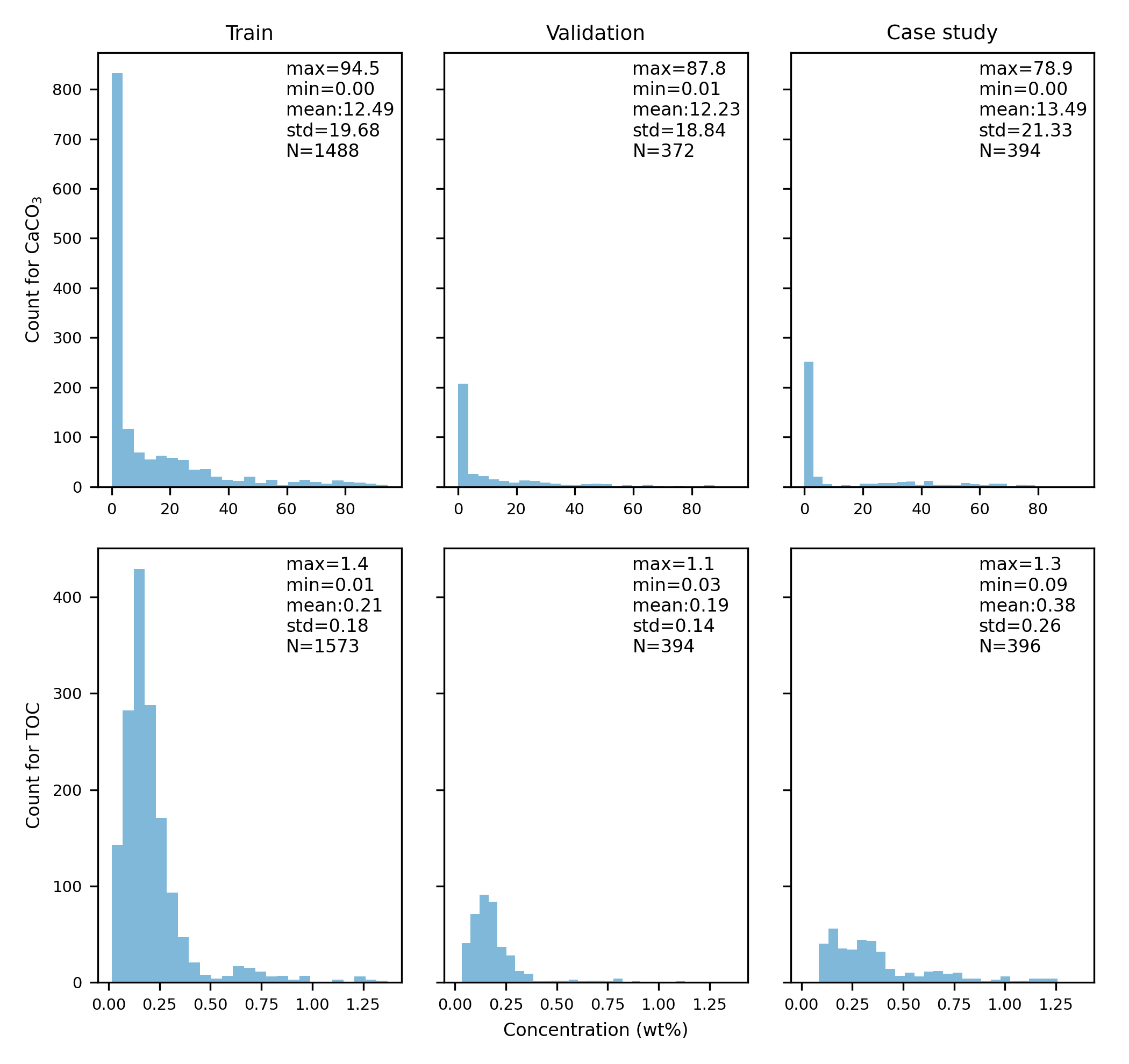
Acknowledgements We thank the crew and the science parties of different cruises for their contributions to core and sample acquisition on the respective expeditions. We are very grateful to Dr. Weng‐Si Chao, Prof. Dr. Ralf Tiedemann, Dr. Lester Lembke‐Jene, and Dr. Frank Lamy for providing these data. We also sincerely thank Valéa Schumacher, Susanne Wiebe, and Rita Fröhlking and student assistants at the AWI Marine Geology Laboratory in Bremerhaven for technical assistance with XRF-scanning, CaCO3 and TOC measurements.
- Downloads last month
- 30