
in_source_id stringlengths 13 58 | issue stringlengths 3 241k | before_files listlengths 0 3 | after_files listlengths 0 3 | pr_diff stringlengths 109 107M ⌀ |
|---|---|---|---|---|
streamlit__streamlit-6377 | Streamlit logger working on root
### Summary
Upon import, Streamlit adds a new **global** log handler that dumps logs in text format. Packages should not be doing that, because it might break the logging convention of the host systems.
In our case for example, we dump logs in JSON format and push it all to our log... | [
{
"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2... | [
{
"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2... | diff --git a/lib/streamlit/logger.py b/lib/streamlit/logger.py
index 6f91af7432e4..779195acc001 100644
--- a/lib/streamlit/logger.py
+++ b/lib/streamlit/logger.py
@@ -117,7 +117,7 @@ def get_logger(name: str) -> logging.Logger:
return _loggers[name]
if name == "root":
- logger = logging.getLogger... |
obspy__obspy-2148 | FDSN routing client has a locale dependency
There's a dummy call to `time.strptime` in the module init that uses locale-specific formatting, which fails under locales that don't use the same names (ie. "Nov" for the 11th month of the year).
```
>>> import locale
>>> locale.setlocale(locale.LC_TIME, ('zh_CN', 'UTF-... | [
{
"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nobspy.clients.fdsn.routing - Routing services for FDSN web services\n===================================================================\n\n:copyright:\n The ObsPy Development Team (devs@obspy.org)\n Celso G Reyes, 2017\n IRIS-DMC\n:... | [
{
"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nobspy.clients.fdsn.routing - Routing services for FDSN web services\n===================================================================\n\n:copyright:\n The ObsPy Development Team (devs@obspy.org)\n Celso G Reyes, 2017\n IRIS-DMC\n:... | diff --git a/CHANGELOG.txt b/CHANGELOG.txt
index 879f573662a..d9f50e50979 100644
--- a/CHANGELOG.txt
+++ b/CHANGELOG.txt
@@ -22,6 +22,7 @@
and/or `location` are set (see #1810, #2031, #2047).
* A few fixes and stability improvements for the mass downloader
(see #2081).
+ * Fixed routing startup error ... |
cupy__cupy-7448 | [RFC] Renaming the development branch to `main`
Now that many projects around the scientific Python community converged to use `main` as the default branch for their repositories, I think it could make sense to do that for CuPy too.
According to https://github.com/github/renaming, side-effects of renaming a branch ... | [
{
"content": "# -*- coding: utf-8 -*-\n#\n# CuPy documentation build configuration file, created by\n# sphinx-quickstart on Sun May 10 12:22:10 2015.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\... | [
{
"content": "# -*- coding: utf-8 -*-\n#\n# CuPy documentation build configuration file, created by\n# sphinx-quickstart on Sun May 10 12:22:10 2015.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\... | diff --git a/.github/workflows/backport.yml b/.github/workflows/backport.yml
index 151b0d18c1f..179694d231e 100644
--- a/.github/workflows/backport.yml
+++ b/.github/workflows/backport.yml
@@ -4,7 +4,7 @@ on:
pull_request_target:
types: [closed, labeled]
branches:
- - master
+ - main
jobs:
... |
PrefectHQ__prefect-2056 | AuthorizationError when watching logs from CLI
When running with `prefect run cloud --logs`, after a few minutes I see the following error:
```
prefect.utilities.exceptions.AuthorizationError: [{'message': 'AuthenticationError', 'locations': [], 'path': ['flow_run'], 'extensions': {'code': 'UNAUTHENTICATED'}}]
```
... | [
{
"content": "import json\nimport time\n\nimport click\nfrom tabulate import tabulate\n\nfrom prefect.client import Client\nfrom prefect.utilities.graphql import EnumValue, with_args\n\n\n@click.group(hidden=True)\ndef run():\n \"\"\"\n Run Prefect flows.\n\n \\b\n Usage:\n $ prefect run [STO... | [
{
"content": "import json\nimport time\n\nimport click\nfrom tabulate import tabulate\n\nfrom prefect.client import Client\nfrom prefect.utilities.graphql import EnumValue, with_args\n\n\n@click.group(hidden=True)\ndef run():\n \"\"\"\n Run Prefect flows.\n\n \\b\n Usage:\n $ prefect run [STO... | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 2669873011ce..72e62747e516 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -21,6 +21,7 @@ These changes are available in the [master branch](https://github.com/PrefectHQ/
### Fixes
- Ensure microseconds are respected on `start_date` provided to CronClock - [#2031](http... |
django-cms__django-cms-3415 | Groups could not be deleted if custom user model is used
If a custom user model is used one can't delete groups because in the pre_delete signal the user permissions are cleared. The users are accessed by their reversed descriptor but in the case of a custom user model this is not always called user_set, so there is an... | [
{
"content": "# -*- coding: utf-8 -*-\n\nfrom cms.cache.permissions import clear_user_permission_cache\nfrom cms.models import PageUser, PageUserGroup\nfrom cms.utils.compat.dj import user_related_name\nfrom menus.menu_pool import menu_pool\n\n\ndef post_save_user(instance, raw, created, **kwargs):\n \"\"\"S... | [
{
"content": "# -*- coding: utf-8 -*-\n\nfrom cms.cache.permissions import clear_user_permission_cache\nfrom cms.models import PageUser, PageUserGroup\nfrom cms.utils.compat.dj import user_related_name\nfrom menus.menu_pool import menu_pool\n\n\ndef post_save_user(instance, raw, created, **kwargs):\n \"\"\"S... | diff --git a/cms/signals/permissions.py b/cms/signals/permissions.py
index 9d306bbd1a0..2a8f7075612 100644
--- a/cms/signals/permissions.py
+++ b/cms/signals/permissions.py
@@ -58,7 +58,8 @@ def pre_save_group(instance, raw, **kwargs):
def pre_delete_group(instance, **kwargs):
- for user in instance.user_set.al... |
networkx__networkx-4431 | Documentation: Make classes AtlasView et. al. from networkx/classes/coreviews.py accessible from documentation
Lest I seem ungrateful, I like networkx a lot, and rely on it for two of my main personal projects [fake-data-for-learning](https://github.com/munichpavel/fake-data-for-learning) and the WIP [clovek-ne-jezi-se... | [
{
"content": "\"\"\"\n\"\"\"\nimport warnings\nfrom collections.abc import Mapping\n\n__all__ = [\n \"AtlasView\",\n \"AdjacencyView\",\n \"MultiAdjacencyView\",\n \"UnionAtlas\",\n \"UnionAdjacency\",\n \"UnionMultiInner\",\n \"UnionMultiAdjacency\",\n \"FilterAtlas\",\n \"FilterAdja... | [
{
"content": "\"\"\"Views of core data structures such as nested Mappings (e.g. dict-of-dicts).\nThese ``Views`` often restrict element access, with either the entire view or\nlayers of nested mappings being read-only.\n\"\"\"\nimport warnings\nfrom collections.abc import Mapping\n\n__all__ = [\n \"AtlasView... | diff --git a/doc/reference/classes/index.rst b/doc/reference/classes/index.rst
index 0747795410c..acd9e259099 100644
--- a/doc/reference/classes/index.rst
+++ b/doc/reference/classes/index.rst
@@ -59,6 +59,25 @@ Graph Views
subgraph_view
reverse_view
+Core Views
+==========
+
+.. automodule:: networkx.classes... |
vyperlang__vyper-3202 | `pc_pos_map` for small methods is empty
### Version Information
* vyper Version (output of `vyper --version`): 0.3.7
* OS: osx
* Python Version (output of `python --version`): 3.10.4
### Bug
```
(vyper) ~/vyper $ cat tmp/baz.vy
@external
def foo():
pass
(vyper) ~/vyper $ vyc -f source_map tmp/b... | [
{
"content": "from typing import Any, List\n\nimport vyper.utils as util\nfrom vyper.address_space import CALLDATA, DATA, MEMORY\nfrom vyper.ast.signatures.function_signature import FunctionSignature, VariableRecord\nfrom vyper.codegen.abi_encoder import abi_encoding_matches_vyper\nfrom vyper.codegen.context im... | [
{
"content": "from typing import Any, List\n\nimport vyper.utils as util\nfrom vyper.address_space import CALLDATA, DATA, MEMORY\nfrom vyper.ast.signatures.function_signature import FunctionSignature, VariableRecord\nfrom vyper.codegen.abi_encoder import abi_encoding_matches_vyper\nfrom vyper.codegen.context im... | diff --git a/vyper/codegen/function_definitions/external_function.py b/vyper/codegen/function_definitions/external_function.py
index 3f0d89c4d6..06d2946558 100644
--- a/vyper/codegen/function_definitions/external_function.py
+++ b/vyper/codegen/function_definitions/external_function.py
@@ -214,4 +214,4 @@ def generate_... |
dbt-labs__dbt-core-2599 | yaml quoting not working with NativeEnvironment jinja evaluator
### Describe the bug
dbt's NativeEnvironment introduced a functional change to how Jinja strings are evaluated. In dbt v0.17.0, a schema test can no longer be configured with a quoted column name.
### Steps To Reproduce
```
# schema.yml
version: 2... | [
{
"content": "import codecs\nimport linecache\nimport os\nimport re\nimport tempfile\nimport threading\nfrom ast import literal_eval\nfrom contextlib import contextmanager\nfrom itertools import chain, islice\nfrom typing import (\n List, Union, Set, Optional, Dict, Any, Iterator, Type, NoReturn, Tuple\n)\n\... | [
{
"content": "import codecs\nimport linecache\nimport os\nimport re\nimport tempfile\nimport threading\nfrom ast import literal_eval\nfrom contextlib import contextmanager\nfrom itertools import chain, islice\nfrom typing import (\n List, Union, Set, Optional, Dict, Any, Iterator, Type, NoReturn, Tuple\n)\n\... | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 91a5c7833b7..c7b4c5dbc9b 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -1,11 +1,11 @@
## dbt 0.17.1 (Release TBD)
### Fixes
+- dbt native rendering now avoids turning quoted strings into unquoted strings ([#2597](https://github.com/fishtown-analytics/dbt/issues/2597)... |
ansible__ansible-42557 | The ios_linkagg search for interfaces may return wrongs interfaces name
<!---
Verify first that your issue/request is not already reported on GitHub.
THIS FORM WILL BE READ BY A MACHINE, COMPLETE ALL SECTIONS AS DESCRIBED.
Also test if the latest release, and devel branch are affected too.
ALWAYS add information AF... | [
{
"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2017, Ansible by Red Hat, inc\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nANSIBLE_METADATA = {'metada... | [
{
"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2017, Ansible by Red Hat, inc\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nANSIBLE_METADATA = {'metada... | diff --git a/lib/ansible/modules/network/ios/ios_linkagg.py b/lib/ansible/modules/network/ios/ios_linkagg.py
index 840576eee7bd1a..e07c18b0e57dca 100644
--- a/lib/ansible/modules/network/ios/ios_linkagg.py
+++ b/lib/ansible/modules/network/ios/ios_linkagg.py
@@ -227,7 +227,7 @@ def parse_members(module, config, group):... |
dotkom__onlineweb4-1359 | Option to post video in article
Make it possible to post video in article from dashboard.
| [
{
"content": "# -*- encoding: utf-8 -*-\nfrom django import forms\n\nfrom apps.article.models import Article\nfrom apps.dashboard.widgets import DatetimePickerInput, multiple_widget_generator\nfrom apps.gallery.widgets import SingleImageInput\n\nfrom taggit.forms import TagWidget\n\n\nclass ArticleForm(forms.Mo... | [
{
"content": "# -*- encoding: utf-8 -*-\nfrom django import forms\n\nfrom apps.article.models import Article\nfrom apps.dashboard.widgets import DatetimePickerInput, multiple_widget_generator\nfrom apps.gallery.widgets import SingleImageInput\n\nfrom taggit.forms import TagWidget\n\n\nclass ArticleForm(forms.Mo... | diff --git a/apps/article/dashboard/forms.py b/apps/article/dashboard/forms.py
index 43ba4ef9a..fed85caa3 100644
--- a/apps/article/dashboard/forms.py
+++ b/apps/article/dashboard/forms.py
@@ -22,6 +22,7 @@ class Meta(object):
'ingress',
'content',
'image',
+ 'video',
... |
Gallopsled__pwntools-1893 | 'pwn cyclic -o afca' throws a BytesWarning
```
$ pwn cyclic -o afca
/Users/heapcrash/pwntools/pwnlib/commandline/cyclic.py:74: BytesWarning: Text is not bytes; assuming ASCII, no guarantees. See https://docs.pwntools.com/#bytes
pat = flat(pat, bytes=args.length)
506
```
| [
{
"content": "#!/usr/bin/env python2\nfrom __future__ import absolute_import\nfrom __future__ import division\n\nimport argparse\nimport six\nimport string\nimport sys\n\nimport pwnlib.args\npwnlib.args.free_form = False\n\nfrom pwn import *\nfrom pwnlib.commandline import common\n\nparser = common.parser_comma... | [
{
"content": "#!/usr/bin/env python2\nfrom __future__ import absolute_import\nfrom __future__ import division\n\nimport argparse\nimport six\nimport string\nimport sys\n\nimport pwnlib.args\npwnlib.args.free_form = False\n\nfrom pwn import *\nfrom pwnlib.commandline import common\n\nparser = common.parser_comma... | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 462646ddb..1d67a0b6d 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -64,12 +64,14 @@ The table below shows which release corresponds to each branch, and what date th
- [#1733][1733] Update libc headers -> more syscalls available!
- [#1876][1876] add `self.message` and c... |
dynaconf__dynaconf-672 | [bug] UnicodeEncodeError upon dynaconf init
**Describe the bug**
`dynaconf init -f yaml` results in a `UnicodeEncodeError `
**To Reproduce**
Steps to reproduce the behavior:
1. `git clone -b dynaconf https://github.com/ebenh/django-flex-user.git`
2. `py -m pipenv install --dev`
3. `py -m pipenv shell`
4. ... | [
{
"content": "import importlib\nimport io\nimport os\nimport pprint\nimport sys\nimport warnings\nimport webbrowser\nfrom contextlib import suppress\nfrom pathlib import Path\n\nfrom dynaconf import constants\nfrom dynaconf import default_settings\nfrom dynaconf import LazySettings\nfrom dynaconf import loaders... | [
{
"content": "import importlib\nimport io\nimport os\nimport pprint\nimport sys\nimport warnings\nimport webbrowser\nfrom contextlib import suppress\nfrom pathlib import Path\n\nfrom dynaconf import constants\nfrom dynaconf import default_settings\nfrom dynaconf import LazySettings\nfrom dynaconf import loaders... | diff --git a/dynaconf/cli.py b/dynaconf/cli.py
index 5bb8316d3..5aae070cc 100644
--- a/dynaconf/cli.py
+++ b/dynaconf/cli.py
@@ -23,6 +23,7 @@
from dynaconf.vendor import click
from dynaconf.vendor import toml
+os.environ["PYTHONIOENCODING"] = "utf-8"
CWD = Path.cwd()
EXTS = ["ini", "toml", "yaml", "json", "py"... |
nyu-mll__jiant-615 | ${NFS_PROJECT_PREFIX} and ${JIANT_PROJECT_PREFIX}
Do we need two separate set of environment variables?
We also have ${NFS_DATA_DIR} and ${JIANT_DATA_DIR}. I don't know about potential users of jiant, at least for me, it's pretty confusing.
| [
{
"content": "\"\"\"Train a multi-task model using AllenNLP\n\nTo debug this, run with -m ipdb:\n\n python -m ipdb main.py --config_file ...\n\"\"\"\n# pylint: disable=no-member\nimport argparse\nimport glob\nimport io\nimport logging as log\nimport os\nimport random\nimport subprocess\nimport sys\nimport ti... | [
{
"content": "\"\"\"Train a multi-task model using AllenNLP\n\nTo debug this, run with -m ipdb:\n\n python -m ipdb main.py --config_file ...\n\"\"\"\n# pylint: disable=no-member\nimport argparse\nimport glob\nimport io\nimport logging as log\nimport os\nimport random\nimport subprocess\nimport sys\nimport ti... | diff --git a/Dockerfile b/Dockerfile
index 82304093d..ea07afb76 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -92,5 +92,4 @@ ENV PATH_TO_COVE "$JSALT_SHARE_DIR/cove"
ENV ELMO_SRC_DIR "$JSALT_SHARE_DIR/elmo"
# Set these manually with -e or via Kuberentes config YAML.
-# ENV NFS_PROJECT_PREFIX "/nfs/jsalt/exp/docker"
... |
holoviz__holoviews-5436 | Game of Life example needs update
### Package versions
```
panel = 0.13.1
holoviews = 1.15.0
bokeh = 2.4.3
```
### Bug description
In the Game of Life example in the holoviews documentation (https://holoviews.org/gallery/apps/bokeh/game_of_life.html)
I needed to update the second to last line
```p... | [
{
"content": "import numpy as np\nimport holoviews as hv\nimport panel as pn\n\nfrom holoviews import opts\nfrom holoviews.streams import Tap, Counter, DoubleTap\nfrom scipy.signal import convolve2d\n\nhv.extension('bokeh')\n\ndiehard = [[0, 0, 0, 0, 0, 0, 1, 0],\n [1, 1, 0, 0, 0, 0, 0, 0],\n ... | [
{
"content": "import numpy as np\nimport holoviews as hv\nimport panel as pn\n\nfrom holoviews import opts\nfrom holoviews.streams import Tap, Counter, DoubleTap\nfrom scipy.signal import convolve2d\n\nhv.extension('bokeh')\n\ndiehard = [[0, 0, 0, 0, 0, 0, 1, 0],\n [1, 1, 0, 0, 0, 0, 0, 0],\n ... | diff --git a/examples/gallery/apps/bokeh/game_of_life.py b/examples/gallery/apps/bokeh/game_of_life.py
index 62ddf783be..37d0088f1e 100644
--- a/examples/gallery/apps/bokeh/game_of_life.py
+++ b/examples/gallery/apps/bokeh/game_of_life.py
@@ -91,6 +91,6 @@ def reset_data(x, y):
def advance():
counter.event(coun... |
buildbot__buildbot-986 | Remove googlecode
This fixes the following test on Python 3:
```
trial buildbot.test.unit.test_www_hooks_googlecode
```
| [
{
"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n... | [
{
"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n... | diff --git a/master/buildbot/status/web/waterfall.py b/master/buildbot/status/web/waterfall.py
index 698a2ebf5f2a..6ffd5fd4e1bf 100644
--- a/master/buildbot/status/web/waterfall.py
+++ b/master/buildbot/status/web/waterfall.py
@@ -854,4 +854,4 @@ def phase2(self, request, sourceNames, timestamps, eventGrid,
... |
microsoft__botbuilder-python-1451 | dependecy conflict between botframework 4.11.0 and azure-identity 1.5.0
## Version
4.11 (also happening with 4.10)
## Describe the bug
`botframework-connector == 4.11.0` (current) requires `msal == 1.2.0`
`azure-identity == 1.5.0` (current) requires `msal >=1.6.0,<2.0.0`
This created a dependency conflict wher... | [
{
"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\nimport os\nfrom setuptools import setup\n\nNAME = \"botframework-connector\"\nVERSION = os.environ[\"packageVersion\"] if \"packageVersion\" in os.environ else \"4.12.0\"\nREQUIRES = [\n \"msrest==0.... | [
{
"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\nimport os\nfrom setuptools import setup\n\nNAME = \"botframework-connector\"\nVERSION = os.environ[\"packageVersion\"] if \"packageVersion\" in os.environ else \"4.12.0\"\nREQUIRES = [\n \"msrest==0.... | diff --git a/libraries/botframework-connector/setup.py b/libraries/botframework-connector/setup.py
index 04bf09257..09a82d646 100644
--- a/libraries/botframework-connector/setup.py
+++ b/libraries/botframework-connector/setup.py
@@ -12,7 +12,7 @@
"PyJWT==1.5.3",
"botbuilder-schema==4.12.0",
"adal==1.2.1"... |
pypi__warehouse-3598 | Set samesite=lax on session cookies
This is a strong defense-in-depth mechanism for protecting against CSRF. It's currently only respected by Chrome, but Firefox will add it as well.
| [
{
"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, softw... | [
{
"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, softw... | diff --git a/requirements/main.txt b/requirements/main.txt
index 9e51b303408e..defd6b964f59 100644
--- a/requirements/main.txt
+++ b/requirements/main.txt
@@ -464,9 +464,9 @@ vine==1.1.4 \
webencodings==0.5.1 \
--hash=sha256:a0af1213f3c2226497a97e2b3aa01a7e4bee4f403f95be16fc9acd2947514a78 \
--hash=sha256:b36... |
pypi__warehouse-3292 | Warehouse file order differs from legacy PyPI file list
Tonight, while load testing of pypi.org was ongoing, we saw some failures in automated systems that use `--require-hashes` with `pip install`, as ordering on the package file list page changed.
The specific package we saw break was `pandas` at version `0.12.0`.... | [
{
"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, softw... | [
{
"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, softw... | diff --git a/tests/unit/legacy/api/test_simple.py b/tests/unit/legacy/api/test_simple.py
index 4a23369eeadb..004b99caa628 100644
--- a/tests/unit/legacy/api/test_simple.py
+++ b/tests/unit/legacy/api/test_simple.py
@@ -202,7 +202,7 @@ def test_with_files_with_version_multi_digit(self, db_request):
files = []... |
digitalfabrik__integreat-cms-169 | Change development environment from docker-compose to venv
- [ ] Remove the django docker container
- [ ] Install package and requirements in venv
- [ ] Keep database docker container and manage connection to django
| [
{
"content": "\"\"\"\nDjango settings for backend project.\n\nGenerated by 'django-admin startproject' using Django 1.11.11.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.11/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/e... | [
{
"content": "\"\"\"\nDjango settings for backend project.\n\nGenerated by 'django-admin startproject' using Django 1.11.11.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.11/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/e... | diff --git a/.gitignore b/.gitignore
index 014fe4432f..44f1a9168c 100644
--- a/.gitignore
+++ b/.gitignore
@@ -46,3 +46,6 @@ backend/media/*
# XLIFF files folder
**/xliffs/
+
+# Postgres folder
+.postgres
\ No newline at end of file
diff --git a/README.md b/README.md
index 097c6ea507..35a8db1883 100644
--- a/README... |
modin-project__modin-2173 | [OmniSci] Add float32 dtype support
Looks like our calcite serializer doesn't support float32 type.
| [
{
"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the ... | [
{
"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the ... | diff --git a/modin/experimental/engines/omnisci_on_ray/frame/calcite_serializer.py b/modin/experimental/engines/omnisci_on_ray/frame/calcite_serializer.py
index 0156cfbc3d9..f460868cd5d 100644
--- a/modin/experimental/engines/omnisci_on_ray/frame/calcite_serializer.py
+++ b/modin/experimental/engines/omnisci_on_ray/fra... |
huggingface__diffusers-680 | LDM Bert `config.json` path
### Describe the bug
### Problem
There is a reference to an LDM Bert that 404's
```bash
src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py: "ldm-bert": "https://huggingface.co/ldm-bert/resolve/main/config.json",
```
I was able to locate a `config.json` at `https... | [
{
"content": "import inspect\nfrom typing import List, Optional, Tuple, Union\n\nimport torch\nimport torch.nn as nn\nimport torch.utils.checkpoint\n\nfrom transformers.activations import ACT2FN\nfrom transformers.configuration_utils import PretrainedConfig\nfrom transformers.modeling_outputs import BaseModelOu... | [
{
"content": "import inspect\nimport warnings\nfrom typing import List, Optional, Tuple, Union\n\nimport torch\nimport torch.nn as nn\nimport torch.utils.checkpoint\n\nfrom transformers.activations import ACT2FN\nfrom transformers.configuration_utils import PretrainedConfig\nfrom transformers.modeling_outputs i... | diff --git a/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py b/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py
index 4a4f29be7f75..2efde98f772e 100644
--- a/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py
+++ b/src/diffusers/pipelines/latent_diffusion/pi... |
hedyorg__hedy-654 | Turtle should not be shown in level 6 programs with numbers
Turtle is now shown in some cases:
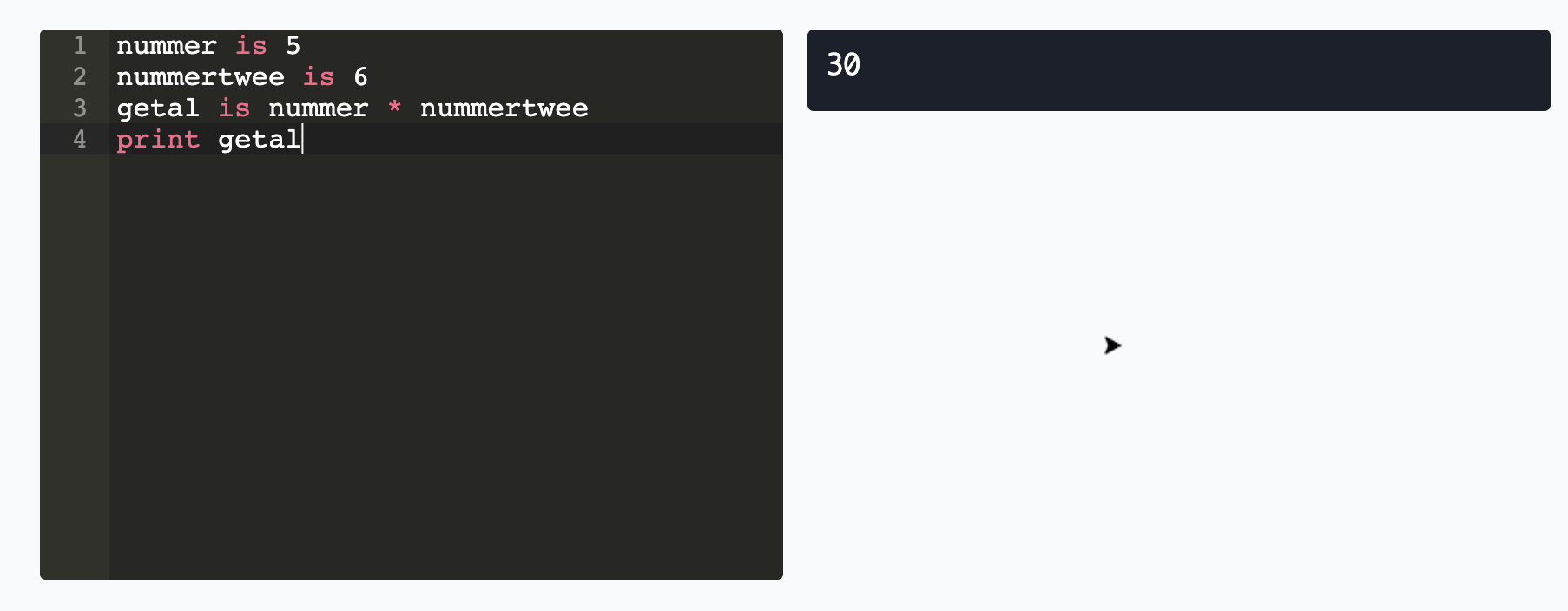
Violating code:
```
nummer is 5
nummertwee is 6
getal is nummer * nummertwee
print getal
```
Turtle sh... | [
{
"content": "from lark import Lark\nfrom lark.exceptions import LarkError, UnexpectedEOF, UnexpectedCharacters\nfrom lark import Tree, Transformer, visitors\nfrom os import path\nimport sys\nimport utils\nfrom collections import namedtuple\n\n\n# Some useful constants\nHEDY_MAX_LEVEL = 22\n\nreserved_words = [... | [
{
"content": "from lark import Lark\nfrom lark.exceptions import LarkError, UnexpectedEOF, UnexpectedCharacters\nfrom lark import Tree, Transformer, visitors\nfrom os import path\nimport sys\nimport utils\nfrom collections import namedtuple\n\n\n# Some useful constants\nHEDY_MAX_LEVEL = 22\n\nreserved_words = [... | diff --git a/coursedata/adventures/nl.yaml b/coursedata/adventures/nl.yaml
index 1be31c858af..538e04c366a 100644
--- a/coursedata/adventures/nl.yaml
+++ b/coursedata/adventures/nl.yaml
@@ -484,7 +484,8 @@ adventures:
keuzes is 1, 2, 3, 4, 5, regenworm
worp is ...
... |
vacanza__python-holidays-451 | Can't un-pickle a `HolidayBase`
Seems that after a holidays class, e.g. `holidays.UnitedStates()` is used once, it can't be un-pickled.
For example, this snippet:
```python
import holidays
import pickle
from datetime import datetime
# Works:
us_holidays = holidays.UnitedStates()
us_holidays_ = pickle.load... | [
{
"content": "# -*- coding: utf-8 -*-\n\n# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# ... | [
{
"content": "# -*- coding: utf-8 -*-\n\n# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# ... | diff --git a/holidays/holiday_base.py b/holidays/holiday_base.py
index 1ca61fccb..a24410150 100644
--- a/holidays/holiday_base.py
+++ b/holidays/holiday_base.py
@@ -209,6 +209,9 @@ def __radd__(self, other):
def _populate(self, year):
pass
+ def __reduce__(self):
+ return super(HolidayBase, se... |
ivy-llc__ivy-28478 | Fix Frontend Failing Test: jax - manipulation.paddle.tile
| [
{
"content": "# global\nimport ivy\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\nfrom ivy.func_wrapper import (\n with_unsupported_dtypes,\n with_supported_dtypes,\n with_supported_device_and_dtypes,\n)\n\n\n@with_unsupported_dtypes({\"2.6.0 and below\": (... | [
{
"content": "# global\nimport ivy\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\nfrom ivy.func_wrapper import (\n with_unsupported_dtypes,\n with_supported_dtypes,\n with_supported_device_and_dtypes,\n)\n\n\n@with_unsupported_dtypes({\"2.6.0 and below\": (... | diff --git a/ivy/functional/frontends/paddle/manipulation.py b/ivy/functional/frontends/paddle/manipulation.py
index dd7c7e79a28f9..6c2c8d6a90adc 100644
--- a/ivy/functional/frontends/paddle/manipulation.py
+++ b/ivy/functional/frontends/paddle/manipulation.py
@@ -208,7 +208,7 @@ def take_along_axis(arr, indices, axis)... |
kubeflow__pipelines-1666 | `pip install kfp` does not install CLI
**What happened:**
```
$ virtualenv .venv
...
$ pip install kfp==0.1.23
...
$ kfp
Traceback (most recent call last):
File "/private/tmp/.venv/bin/kfp", line 6, in <module>
from kfp.__main__ import main
File "/private/tmp/.venv/lib/python3.7/site-packages/kfp/__... | [
{
"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicab... | [
{
"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicab... | diff --git a/sdk/python/setup.py b/sdk/python/setup.py
index ee581414370..dac70636a4e 100644
--- a/sdk/python/setup.py
+++ b/sdk/python/setup.py
@@ -45,6 +45,7 @@
install_requires=REQUIRES,
packages=[
'kfp',
+ 'kfp.cli',
'kfp.compiler',
'kfp.components',
'kfp.compone... |
streamlit__streamlit-5184 | It should be :
https://github.com/streamlit/streamlit/blob/535f11765817657892506d6904bbbe04908dbdf3/lib/streamlit/elements/alert.py#L145
| [
{
"content": "# Copyright 2018-2022 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by a... | [
{
"content": "# Copyright 2018-2022 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by a... | diff --git a/lib/streamlit/elements/alert.py b/lib/streamlit/elements/alert.py
index d9d5f2fe5f82..65458e9162b3 100644
--- a/lib/streamlit/elements/alert.py
+++ b/lib/streamlit/elements/alert.py
@@ -142,7 +142,7 @@ def success(
Example
-------
- >>> st.success('This is a success message!', ic... |
django-cms__django-cms-1994 | make django-admin-style a fixed dependency
and add it to the tutorial
| [
{
"content": "from setuptools import setup, find_packages\nimport os\nimport cms\n\n\nCLASSIFIERS = [\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Web Environment',\n 'Framework :: Django',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n ... | [
{
"content": "from setuptools import setup, find_packages\nimport os\nimport cms\n\n\nCLASSIFIERS = [\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Web Environment',\n 'Framework :: Django',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n ... | diff --git a/docs/getting_started/installation.rst b/docs/getting_started/installation.rst
index fa131805ebc..6f425a8e2e2 100644
--- a/docs/getting_started/installation.rst
+++ b/docs/getting_started/installation.rst
@@ -16,6 +16,7 @@ Requirements
* `django-mptt`_ 0.5.2 (strict due to API compatibility issues)
* `dja... |
ansible__ansible-modules-extras-387 | Freshly installed bower raises json error
I ran into an issue where the ansible bower module when attempting to run bower install can't parse the json from `bower list --json`
Here is the stacktrace
```
failed: [default] => {"failed": true, "parsed": false}
BECOME-SUCCESS-bcokpjdhrlrcdlrfpmvdgmahrbmtzoqk
Traceback (m... | [
{
"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2014, Michael Warkentin <mwarkentin@gmail.com>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software F... | [
{
"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2014, Michael Warkentin <mwarkentin@gmail.com>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software F... | diff --git a/packaging/language/bower.py b/packaging/language/bower.py
index 3fccf51056b..085f454e639 100644
--- a/packaging/language/bower.py
+++ b/packaging/language/bower.py
@@ -108,7 +108,7 @@ def _exec(self, args, run_in_check_mode=False, check_rc=True):
return ''
def list(self):
- cmd = ['l... |
cupy__cupy-764 | cupy.array(cupy_array, oder=None) raises error
When I do this:
```python
>>> x = cupy.ones(3)
>>> xx = cupy.array(x, order=None)
```
I get this traceback:
```
File "[...]/cupy/cupy/creation/from_data.py", line 41, in array
return core.array(obj, dtype, copy, order, subok, ndmin)
File "cupy/core/cor... | [
{
"content": "# flake8: NOQA\n# \"flake8: NOQA\" to suppress warning \"H104 File contains nothing but comments\"\n\n# class s_(object):\n\nimport numpy\nimport six\n\nimport cupy\nfrom cupy import core\nfrom cupy.creation import from_data\nfrom cupy.manipulation import join\n\n\nclass AxisConcatenator(object):... | [
{
"content": "# flake8: NOQA\n# \"flake8: NOQA\" to suppress warning \"H104 File contains nothing but comments\"\n\n# class s_(object):\n\nimport numpy\nimport six\n\nimport cupy\nfrom cupy import core\nfrom cupy.creation import from_data\nfrom cupy.manipulation import join\n\n\nclass AxisConcatenator(object):... | diff --git a/cupy/core/core.pyx b/cupy/core/core.pyx
index 940f2ce7d32..a27510307ca 100644
--- a/cupy/core/core.pyx
+++ b/cupy/core/core.pyx
@@ -97,7 +97,7 @@ cdef class ndarray:
self.data = memptr
self.base = None
- if order == 'C':
+ if order in ('C', None):
self._st... |
databricks__koalas-747 | [DO NOT MERGE] Test
| [
{
"content": "#!/usr/bin/env python\n\n#\n# Copyright (C) 2019 Databricks, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-... | [
{
"content": "#!/usr/bin/env python\n\n#\n# Copyright (C) 2019 Databricks, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-... | diff --git a/requirements-dev.txt b/requirements-dev.txt
index 4be44500ee..5e0c474b0f 100644
--- a/requirements-dev.txt
+++ b/requirements-dev.txt
@@ -1,5 +1,5 @@
# Dependencies in Koalas
-pandas>=0.23
+pandas>=0.23.2
pyarrow>=0.10
matplotlib>=3.0.0
numpy>=1.14
diff --git a/setup.py b/setup.py
index 6b84679c9e..9c7... |
ansible-collections__community.aws-1712 | Broken example in iam_access_key
### Summary
The "Delete the access key" example in the `iam_access_key` module is broken. It's currently:
```yaml
- name: Delete the access_key
community.aws.iam_access_key:
name: example_user
access_key_id: AKIA1EXAMPLE1EXAMPLE
state: absent
```
There are two is... | [
{
"content": "#!/usr/bin/python\n# Copyright (c) 2021 Ansible Project\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = r'''\n---\nmodule: iam_access_key\nve... | [
{
"content": "#!/usr/bin/python\n# Copyright (c) 2021 Ansible Project\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = r'''\n---\nmodule: iam_access_key\nve... | diff --git a/changelogs/fragments/iam_access_key_docs_fix.yml b/changelogs/fragments/iam_access_key_docs_fix.yml
new file mode 100644
index 00000000000..f47a15eb91f
--- /dev/null
+++ b/changelogs/fragments/iam_access_key_docs_fix.yml
@@ -0,0 +1,2 @@
+trivial:
+ - iam_access_key - Use correct parameter names in the doc... |
ansible-collections__community.aws-1713 | Broken example in iam_access_key
### Summary
The "Delete the access key" example in the `iam_access_key` module is broken. It's currently:
```yaml
- name: Delete the access_key
community.aws.iam_access_key:
name: example_user
access_key_id: AKIA1EXAMPLE1EXAMPLE
state: absent
```
There are two is... | [
{
"content": "#!/usr/bin/python\n# Copyright (c) 2021 Ansible Project\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = r'''\n---\nmodule: iam_access_key\nve... | [
{
"content": "#!/usr/bin/python\n# Copyright (c) 2021 Ansible Project\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = r'''\n---\nmodule: iam_access_key\nve... | diff --git a/changelogs/fragments/iam_access_key_docs_fix.yml b/changelogs/fragments/iam_access_key_docs_fix.yml
new file mode 100644
index 00000000000..f47a15eb91f
--- /dev/null
+++ b/changelogs/fragments/iam_access_key_docs_fix.yml
@@ -0,0 +1,2 @@
+trivial:
+ - iam_access_key - Use correct parameter names in the doc... |
ansible-collections__community.aws-1711 | Broken example in iam_access_key
### Summary
The "Delete the access key" example in the `iam_access_key` module is broken. It's currently:
```yaml
- name: Delete the access_key
community.aws.iam_access_key:
name: example_user
access_key_id: AKIA1EXAMPLE1EXAMPLE
state: absent
```
There are two is... | [
{
"content": "#!/usr/bin/python\n# Copyright (c) 2021 Ansible Project\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = r'''\n---\nmodule: iam_access_key\nve... | [
{
"content": "#!/usr/bin/python\n# Copyright (c) 2021 Ansible Project\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = r'''\n---\nmodule: iam_access_key\nve... | diff --git a/changelogs/fragments/iam_access_key_docs_fix.yml b/changelogs/fragments/iam_access_key_docs_fix.yml
new file mode 100644
index 00000000000..f47a15eb91f
--- /dev/null
+++ b/changelogs/fragments/iam_access_key_docs_fix.yml
@@ -0,0 +1,2 @@
+trivial:
+ - iam_access_key - Use correct parameter names in the doc... |
pytorch__vision-1501 | Deprecate PILLOW_VERSION
torchvision now uses PILLOW_VERSION
https://github.com/pytorch/vision/blob/1e857d93c8de081e61695dd43e6f06e3e7c2b0a2/torchvision/transforms/functional.py#L5
However, this constant is deprecated in Pillow 5.2, and soon to be removed completely: https://github.com/python-pillow/Pillow/blob/mas... | [
{
"content": "from __future__ import division\nimport torch\nimport sys\nimport math\nfrom PIL import Image, ImageOps, ImageEnhance, PILLOW_VERSION\ntry:\n import accimage\nexcept ImportError:\n accimage = None\nimport numpy as np\nimport numbers\nimport collections\nimport warnings\n\nif sys.version_info... | [
{
"content": "from __future__ import division\nimport torch\nimport sys\nimport math\nfrom PIL import Image, ImageOps, ImageEnhance, __version__ as PILLOW_VERSION\ntry:\n import accimage\nexcept ImportError:\n accimage = None\nimport numpy as np\nimport numbers\nimport collections\nimport warnings\n\nif s... | diff --git a/torchvision/transforms/functional.py b/torchvision/transforms/functional.py
index 6f43d5d263f..a8fdbef86bf 100644
--- a/torchvision/transforms/functional.py
+++ b/torchvision/transforms/functional.py
@@ -2,7 +2,7 @@
import torch
import sys
import math
-from PIL import Image, ImageOps, ImageEnhance, PILL... |
bridgecrewio__checkov-1497 | checkov fails with junit-xml==1.8
**Describe the bug**
checkov fails with junit-xml==1.8
**To Reproduce**
Steps to reproduce the behavior:
1. pip3 install junit-xml==1.8
2. checkov -d .
3. See error:
```
Traceback (most recent call last):
File "/usr/local/bin/checkov", line 2, in <module>
from chec... | [
{
"content": "#!/usr/bin/env python\nimport logging\nimport os\nfrom importlib import util\nfrom os import path\n\nimport setuptools\nfrom setuptools import setup\n\n# read the contents of your README file\nthis_directory = path.abspath(path.dirname(__file__))\nwith open(path.join(this_directory, \"README.md\")... | [
{
"content": "#!/usr/bin/env python\nimport logging\nimport os\nfrom importlib import util\nfrom os import path\n\nimport setuptools\nfrom setuptools import setup\n\n# read the contents of your README file\nthis_directory = path.abspath(path.dirname(__file__))\nwith open(path.join(this_directory, \"README.md\")... | diff --git a/Pipfile b/Pipfile
index ef3df7dbb1..c2f19fac07 100644
--- a/Pipfile
+++ b/Pipfile
@@ -23,7 +23,7 @@ deep_merge = "*"
tabulate = "*"
colorama="*"
termcolor="*"
-junit-xml ="*"
+junit-xml = ">=1.9"
dpath = ">=1.5.0,<2"
pyyaml = ">=5.4.1"
boto3 = "==1.17.*"
diff --git a/Pipfile.lock b/Pipfile.lock
index... |
dbt-labs__dbt-core-5507 | [CT-876] Could we also now remove our upper bound on `MarkupSafe`, which we put in place earlier this year due to incompatibility with Jinja2?
Remove our upper bound on `MarkupSafe`, which we put in place earlier this year due to incompatibility with Jinja2(#4745). Also bump minimum requirement to match [Jinja2's requ... | [
{
"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 7, 2):\n print(\"Error: dbt does not support this version of Python.\")\n print(\"Please upgrade to Python 3.7.2 or higher.\")\n sys.exit(1)\n\n\nfrom setuptools import setup\n\ntry:\n from setuptools import find... | [
{
"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 7, 2):\n print(\"Error: dbt does not support this version of Python.\")\n print(\"Please upgrade to Python 3.7.2 or higher.\")\n sys.exit(1)\n\n\nfrom setuptools import setup\n\ntry:\n from setuptools import find... | diff --git a/.changes/unreleased/Dependencies-20220721-093233.yaml b/.changes/unreleased/Dependencies-20220721-093233.yaml
new file mode 100644
index 00000000000..f5c623e9581
--- /dev/null
+++ b/.changes/unreleased/Dependencies-20220721-093233.yaml
@@ -0,0 +1,7 @@
+kind: Dependencies
+body: Remove pin for MarkUpSafe fr... |
microsoft__Qcodes-867 | missing dependency`jsonschema` in requirements.txt
The latest pip installable version of QCoDeS does not list jsonschema as a dependency but requires it.
This problem came to light when running tests on a project that depeneds on QCoDeS. Part of my build script installs qcodes (pip install qcodes). Importing qcodes... | [
{
"content": "from setuptools import setup, find_packages\nfrom distutils.version import StrictVersion\nfrom importlib import import_module\nimport re\n\ndef get_version(verbose=1):\n \"\"\" Extract version information from source code \"\"\"\n\n try:\n with open('qcodes/version.py', 'r') as f:\n ... | [
{
"content": "from setuptools import setup, find_packages\nfrom distutils.version import StrictVersion\nfrom importlib import import_module\nimport re\n\ndef get_version(verbose=1):\n \"\"\" Extract version information from source code \"\"\"\n\n try:\n with open('qcodes/version.py', 'r') as f:\n ... | diff --git a/docs_requirements.txt b/docs_requirements.txt
index a8abb189efe..e9b853631b8 100644
--- a/docs_requirements.txt
+++ b/docs_requirements.txt
@@ -1,6 +1,5 @@
sphinx
sphinx_rtd_theme
-jsonschema
sphinxcontrib-jsonschema
nbconvert
ipython
diff --git a/requirements.txt b/requirements.txt
index 32d5add6fb3.... |
cupy__cupy-1944 | incorrect FFT results for Fortran-order arrays?
* Conditions (from `python -c 'import cupy; cupy.show_config()'`)
Tested in two environments with different CuPy versions:
```bash
CuPy Version : 4.4.1
CUDA Root : /usr/local/cuda
CUDA Build Version : 9010
CUDA Driver Version : 9010
CUDA... | [
{
"content": "from copy import copy\n\nimport six\n\nimport numpy as np\n\nimport cupy\nfrom cupy.cuda import cufft\nfrom math import sqrt\nfrom cupy.fft import config\n\n\ndef _output_dtype(a, value_type):\n if value_type != 'R2C':\n if a.dtype in [np.float16, np.float32]:\n return np.comp... | [
{
"content": "from copy import copy\n\nimport six\n\nimport numpy as np\n\nimport cupy\nfrom cupy.cuda import cufft\nfrom math import sqrt\nfrom cupy.fft import config\n\n\ndef _output_dtype(a, value_type):\n if value_type != 'R2C':\n if a.dtype in [np.float16, np.float32]:\n return np.comp... | diff --git a/cupy/fft/fft.py b/cupy/fft/fft.py
index e72a4906f5c..cee323e6c2f 100644
--- a/cupy/fft/fft.py
+++ b/cupy/fft/fft.py
@@ -76,7 +76,7 @@ def _exec_fft(a, direction, value_type, norm, axis, overwrite_x,
if axis % a.ndim != a.ndim - 1:
a = a.swapaxes(axis, -1)
- if a.base is not None:
+ if... |
privacyidea__privacyidea-1746 | Fix typo in registration token
The example of the registration token contains a typo.
The toketype of course is a "registration" token, not a "register".
| [
{
"content": "# -*- coding: utf-8 -*-\n#\n# privacyIDEA\n# Aug 12, 2014 Cornelius Kölbel\n# License: AGPLv3\n# contact: http://www.privacyidea.org\n#\n# 2015-01-29 Adapt during migration to flask\n# Cornelius Kölbel <cornelius@privacyidea.org>\n#\n# This code is free software; you can redistr... | [
{
"content": "# -*- coding: utf-8 -*-\n#\n# privacyIDEA\n# Aug 12, 2014 Cornelius Kölbel\n# License: AGPLv3\n# contact: http://www.privacyidea.org\n#\n# 2015-01-29 Adapt during migration to flask\n# Cornelius Kölbel <cornelius@privacyidea.org>\n#\n# This code is free software; you can redistr... | diff --git a/privacyidea/lib/tokens/registrationtoken.py b/privacyidea/lib/tokens/registrationtoken.py
index 54beeb5ed4..8aa4df8c8f 100644
--- a/privacyidea/lib/tokens/registrationtoken.py
+++ b/privacyidea/lib/tokens/registrationtoken.py
@@ -64,7 +64,7 @@ class RegistrationTokenClass(PasswordTokenClass):
H... |
getpelican__pelican-1507 | abbr support doesn't work for multiline
Eg:
``` rst
this is an :abbr:`TLA (Three Letter
Abbreviation)`
```
will output
`<abbr>TLA (Three Letter Abbreviation)</abbr>`
instead of
`<abbr title="Three Letter Abbreviation">TLA</abbr>`
I believe this could be fixed by adding the `re.M` flag to the `re.compile` call on th... | [
{
"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals, print_function\n\nfrom docutils import nodes, utils\nfrom docutils.parsers.rst import directives, roles, Directive\nfrom pygments.formatters import HtmlFormatter\nfrom pygments import highlight\nfrom pygments.lexers import get_lexer... | [
{
"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals, print_function\n\nfrom docutils import nodes, utils\nfrom docutils.parsers.rst import directives, roles, Directive\nfrom pygments.formatters import HtmlFormatter\nfrom pygments import highlight\nfrom pygments.lexers import get_lexer... | diff --git a/pelican/rstdirectives.py b/pelican/rstdirectives.py
index 1bf6971ca..1c25cc42a 100644
--- a/pelican/rstdirectives.py
+++ b/pelican/rstdirectives.py
@@ -70,7 +70,7 @@ def run(self):
directives.register_directive('sourcecode', Pygments)
-_abbr_re = re.compile('\((.*)\)$')
+_abbr_re = re.compile('\((.*)\... |
awslabs__gluonts-644 | Index of forecast is wrong in multivariate Time Series
## Description
When forecasting multivariate Time Series the index has the length of the target dimension instead of the prediction length
## To Reproduce
```python
import numpy as np
from gluonts.dataset.common import ListDataset
from gluonts.distributio... | [
{
"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\").\n# You may not use this file except in compliance with the License.\n# A copy of the License is located at\n#\n# http://www.apache.org/licenses/LICE... | [
{
"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\").\n# You may not use this file except in compliance with the License.\n# A copy of the License is located at\n#\n# http://www.apache.org/licenses/LICE... | diff --git a/src/gluonts/model/forecast.py b/src/gluonts/model/forecast.py
index 19ffc7abc1..6ad91fe9da 100644
--- a/src/gluonts/model/forecast.py
+++ b/src/gluonts/model/forecast.py
@@ -373,7 +373,7 @@ def prediction_length(self):
"""
Time length of the forecast.
"""
- return self.sam... |
python__peps-3263 | Infra: Check Sphinx warnings on CI
This is similar to what we have in the CPython repo, most recently: https://github.com/python/cpython/pull/106460, and will help us gradually remove Sphinx warnings, and avoid new ones being introduces.
It checks three things:
1. If a file previously had no warnings (not listed ... | [
{
"content": "# This file is placed in the public domain or under the\n# CC0-1.0-Universal license, whichever is more permissive.\n\n\"\"\"Configuration for building PEPs using Sphinx.\"\"\"\n\nfrom pathlib import Path\nimport sys\n\nsys.path.append(str(Path(\".\").absolute()))\n\n# -- Project information -----... | [
{
"content": "# This file is placed in the public domain or under the\n# CC0-1.0-Universal license, whichever is more permissive.\n\n\"\"\"Configuration for building PEPs using Sphinx.\"\"\"\n\nfrom pathlib import Path\nimport sys\n\nsys.path.append(str(Path(\".\").absolute()))\n\n# -- Project information -----... | diff --git a/conf.py b/conf.py
index 8e2ae485f06..95a1debd451 100644
--- a/conf.py
+++ b/conf.py
@@ -45,6 +45,9 @@
"pep-0012/pep-NNNN.rst",
]
+# Warn on missing references
+nitpicky = True
+
# Intersphinx configuration
intersphinx_mapping = {
'python': ('https://docs.python.org/3/', None),
|
azavea__raster-vision-1557 | Query is invisible in interactive docs search
## 🐛 Bug
When I search for something in the docs using the new interactive search bar it seems to work except the query is not visible in the search box. Instead a bunch of dots appear. This was in Chrome Version 107.0.5304.110 (Official Build) (arm64) with the extensi... | [
{
"content": "# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\nfrom typing import TYPE_CHECKING, List\nimport... | [
{
"content": "# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\nfrom typing import TYPE_CHECKING, List\nimport... | diff --git a/.readthedocs.yml b/.readthedocs.yml
index a0bdb3900..e99691356 100644
--- a/.readthedocs.yml
+++ b/.readthedocs.yml
@@ -45,4 +45,4 @@ python:
search:
ranking:
# down-rank source code pages
- '*/_modules/*': -10
+ _modules/*: -10
diff --git a/docs/conf.py b/docs/conf.py
index 28bf2a200..5fe59... |
scrapy__scrapy-5880 | _sent_failed cut the errback chain in MailSender
`MailSender._sent_failed` return `None`, instead of `failure`. This cut the errback call chain, making impossible to detect in the code fail in the mails in client code.
| [
{
"content": "\"\"\"\nMail sending helpers\n\nSee documentation in docs/topics/email.rst\n\"\"\"\nimport logging\nfrom email import encoders as Encoders\nfrom email.mime.base import MIMEBase\nfrom email.mime.multipart import MIMEMultipart\nfrom email.mime.nonmultipart import MIMENonMultipart\nfrom email.mime.te... | [
{
"content": "\"\"\"\nMail sending helpers\n\nSee documentation in docs/topics/email.rst\n\"\"\"\nimport logging\nfrom email import encoders as Encoders\nfrom email.mime.base import MIMEBase\nfrom email.mime.multipart import MIMEMultipart\nfrom email.mime.nonmultipart import MIMENonMultipart\nfrom email.mime.te... | diff --git a/scrapy/mail.py b/scrapy/mail.py
index 43115c53ea9..c11f3898d0d 100644
--- a/scrapy/mail.py
+++ b/scrapy/mail.py
@@ -164,6 +164,7 @@ def _sent_failed(self, failure, to, cc, subject, nattachs):
"mailerr": errstr,
},
)
+ return failure
def _sendmail(self, t... |
OpenEnergyPlatform__oeplatform-1338 | Django compressor seems to produce unexpected cache behavior.
## Description of the issue
@Darynarli and myself experienced unexpected behavior that is triggered by the new package `django-compression`. This behavior prevents updating the compressed sources like js or css files entirely. This also happens somewhat s... | [
{
"content": "\"\"\"\nDjango settings for oeplatform project.\n\nGenerated by 'django-admin startproject' using Django 1.8.5.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/e... | [
{
"content": "\"\"\"\nDjango settings for oeplatform project.\n\nGenerated by 'django-admin startproject' using Django 1.8.5.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/e... | diff --git a/oeplatform/settings.py b/oeplatform/settings.py
index 6f0696bdf..bc7e34b87 100644
--- a/oeplatform/settings.py
+++ b/oeplatform/settings.py
@@ -166,5 +166,9 @@ def external_urls_context_processor(request):
"compressor.finders.CompressorFinder",
}
+
+# https://django-compressor.readthedocs.io/en/sta... |
Azure__azure-cli-extensions-3046 | vmware 2.0.0 does not work in azure-cli:2.7.0
- If the issue is to do with Azure CLI 2.0 in-particular, create an issue here at [Azure/azure-cli](https://github.com/Azure/azure-cli/issues)
### Extension name (the extension in question)
vmware
### Description of issue (in as much detail as possible)
The vmware ... | [
{
"content": "#!/usr/bin/env python\n\n# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# ------------------... | [
{
"content": "#!/usr/bin/env python\n\n# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# ------------------... | diff --git a/src/vmware/CHANGELOG.md b/src/vmware/CHANGELOG.md
index 32cde2511f8..c0910f47bdb 100644
--- a/src/vmware/CHANGELOG.md
+++ b/src/vmware/CHANGELOG.md
@@ -1,5 +1,8 @@
# Release History
+## 2.0.1 (2021-02)
+- Update the minimum az cli version to 2.11.0 [#3045](https://github.com/Azure/azure-cli-extensions/i... |
aio-libs__aiohttp-493 | [bug] URL parssing error in the web server
If you run this simple server example :
``` python
import asyncio
from aiohttp import web
@asyncio.coroutine
def handle(request):
return webResponse(body=request.path.encode('utf8'))
@asyncio.coroutine
def init(loop):
app = web.Application(loop=loop)
app.router.... | [
{
"content": "__all__ = ('ContentCoding', 'Request', 'StreamResponse', 'Response')\n\nimport asyncio\nimport binascii\nimport cgi\nimport collections\nimport datetime\nimport http.cookies\nimport io\nimport json\nimport math\nimport time\nimport warnings\n\nimport enum\n\nfrom email.utils import parsedate\nfrom... | [
{
"content": "__all__ = ('ContentCoding', 'Request', 'StreamResponse', 'Response')\n\nimport asyncio\nimport binascii\nimport cgi\nimport collections\nimport datetime\nimport http.cookies\nimport io\nimport json\nimport math\nimport time\nimport warnings\n\nimport enum\n\nfrom email.utils import parsedate\nfrom... | diff --git a/aiohttp/web_reqrep.py b/aiohttp/web_reqrep.py
index 6f3e566c8c6..c3e8abc4067 100644
--- a/aiohttp/web_reqrep.py
+++ b/aiohttp/web_reqrep.py
@@ -173,7 +173,8 @@ def path_qs(self):
@reify
def _splitted_path(self):
- return urlsplit(self._path_qs)
+ url = '{}://{}{}'.format(self.sche... |
psf__black-4019 | Internal error on a specific file
<!--
Please make sure that the bug is not already fixed either in newer versions or the
current development version. To confirm this, you have three options:
1. Update Black's version if a newer release exists: `pip install -U black`
2. Use the online formatter at <https://black.... | [
{
"content": "\"\"\"\nblib2to3 Node/Leaf transformation-related utility functions.\n\"\"\"\n\nimport sys\nfrom typing import Final, Generic, Iterator, List, Optional, Set, Tuple, TypeVar, Union\n\nif sys.version_info >= (3, 10):\n from typing import TypeGuard\nelse:\n from typing_extensions import TypeGua... | [
{
"content": "\"\"\"\nblib2to3 Node/Leaf transformation-related utility functions.\n\"\"\"\n\nimport sys\nfrom typing import Final, Generic, Iterator, List, Optional, Set, Tuple, TypeVar, Union\n\nif sys.version_info >= (3, 10):\n from typing import TypeGuard\nelse:\n from typing_extensions import TypeGua... | diff --git a/CHANGES.md b/CHANGES.md
index 5ce37943693..4f90f493ad8 100644
--- a/CHANGES.md
+++ b/CHANGES.md
@@ -13,6 +13,9 @@
- Fix crash on formatting code like `await (a ** b)` (#3994)
+- No longer treat leading f-strings as docstrings. This matches Python's behaviour and
+ fixes a crash (#4019)
+
### Preview... |
helmholtz-analytics__heat-1268 | Fix Pytorch release tracking workflows
## Due Diligence
<!--- Please address the following points before setting your PR "ready for review".
--->
- General:
- [x] **base branch** must be `main` for new features, latest release branch (e.g. `release/1.3.x`) for bug fixes
- [x] **title** of the PR is suita... | [
{
"content": "\"\"\"This module contains Heat's version information.\"\"\"\n\n\nmajor: int = 1\n\"\"\"Indicates Heat's main version.\"\"\"\nminor: int = 3\n\"\"\"Indicates feature extension.\"\"\"\nmicro: int = 0\n\"\"\"Indicates revisions for bugfixes.\"\"\"\nextension: str = \"dev\"\n\"\"\"Indicates special b... | [
{
"content": "\"\"\"This module contains Heat's version information.\"\"\"\n\n\nmajor: int = 1\n\"\"\"Indicates Heat's main version.\"\"\"\nminor: int = 4\n\"\"\"Indicates feature extension.\"\"\"\nmicro: int = 0\n\"\"\"Indicates revisions for bugfixes.\"\"\"\nextension: str = \"dev\"\n\"\"\"Indicates special b... | diff --git a/.github/workflows/pytorch-latest-main.yml b/.github/workflows/pytorch-latest-main.yml
index 139c66d82c..c59736c82f 100644
--- a/.github/workflows/pytorch-latest-main.yml
+++ b/.github/workflows/pytorch-latest-main.yml
@@ -11,9 +11,8 @@ jobs:
runs-on: ubuntu-latest
if: ${{ github.repository }} == ... |
biolab__orange3-3530 | Report window and clipboard
Can't copy form Reports
##### Orange version
<!-- From menu _Help→About→Version_ or code `Orange.version.full_version` -->
3.17.0.dev0+8f507ed
##### Expected behavior
If items are selected in the Report window it should be possible to copy to the clipboard for using it in a presenta... | [
{
"content": "import os\nimport logging\nimport warnings\nimport pickle\nfrom collections import OrderedDict\nfrom enum import IntEnum\n\nfrom typing import Optional\n\nimport pkg_resources\n\nfrom AnyQt.QtCore import Qt, QObject, pyqtSlot\nfrom AnyQt.QtGui import QIcon, QCursor, QStandardItemModel, QStandardIt... | [
{
"content": "import os\nimport logging\nimport warnings\nimport pickle\nfrom collections import OrderedDict\nfrom enum import IntEnum\n\nfrom typing import Optional\n\nimport pkg_resources\n\nfrom AnyQt.QtCore import Qt, QObject, pyqtSlot\nfrom AnyQt.QtGui import QIcon, QCursor, QStandardItemModel, QStandardIt... | diff --git a/Orange/widgets/report/owreport.py b/Orange/widgets/report/owreport.py
index e2a70d8aa71..47a99ab4766 100644
--- a/Orange/widgets/report/owreport.py
+++ b/Orange/widgets/report/owreport.py
@@ -477,6 +477,9 @@ def get_canvas_instance(self):
return window
return None
+ def copy_... |
falconry__falcon-801 | Default OPTIONS responder does not set Content-Length to "0"
Per RFC 7231:
> A server MUST generate a Content-Length field with a value of "0" if no payload body is to be sent in the response.
| [
{
"content": "# Copyright 2013 by Rackspace Hosting, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless requir... | [
{
"content": "# Copyright 2013 by Rackspace Hosting, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless requir... | diff --git a/falcon/responders.py b/falcon/responders.py
index b5f61866d..34da8075b 100644
--- a/falcon/responders.py
+++ b/falcon/responders.py
@@ -58,5 +58,6 @@ def create_default_options(allowed_methods):
def on_options(req, resp, **kwargs):
resp.status = HTTP_204
resp.set_header('Allow', allo... |
openvinotoolkit__datumaro-743 | Wrong annotated return type in Registry class
https://github.com/openvinotoolkit/datumaro/blob/0d4a73d3bbe3a93585af7a0148a0e344fd1106b3/datumaro/components/environment.py#L41-L42
In the referenced code the return type of the method appears to be wrong.
Either it should be `Iterator[str]` since iteration over a dic... | [
{
"content": "# Copyright (C) 2020-2022 Intel Corporation\n#\n# SPDX-License-Identifier: MIT\n\nimport glob\nimport importlib\nimport logging as log\nimport os.path as osp\nfrom functools import partial\nfrom inspect import isclass\nfrom typing import Callable, Dict, Generic, Iterable, Iterator, List, Optional,... | [
{
"content": "# Copyright (C) 2020-2022 Intel Corporation\n#\n# SPDX-License-Identifier: MIT\n\nimport glob\nimport importlib\nimport logging as log\nimport os.path as osp\nfrom functools import partial\nfrom inspect import isclass\nfrom typing import Callable, Dict, Generic, Iterable, Iterator, List, Optional,... | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 84c35ac044..e9706cb94b 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -11,6 +11,22 @@ and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0
- Add jupyter sample introducing how to merge datasets
(<https://github.com/openvinotoolkit/datumaro/... |
rasterio__rasterio-437 | Check for "ndarray-like" instead of ndarray in _warp; other places
I want to use `rasterio.warp.reproject` on an `xray.Dataset` with `xray.Dataset.apply` (http://xray.readthedocs.org/en/stable/). xray has a feature to turn the dataset into a `np.ndarray`, but that means losing all my metadata.
At https://github.com/ma... | [
{
"content": "# Mapping of GDAL to Numpy data types.\n#\n# Since 0.13 we are not importing numpy here and data types are strings.\n# Happily strings can be used throughout Numpy and so existing code will\n# break.\n#\n# Within Rasterio, to test data types, we use Numpy's dtype() factory to \n# do something like... | [
{
"content": "# Mapping of GDAL to Numpy data types.\n#\n# Since 0.13 we are not importing numpy here and data types are strings.\n# Happily strings can be used throughout Numpy and so existing code will\n# break.\n#\n# Within Rasterio, to test data types, we use Numpy's dtype() factory to \n# do something like... | diff --git a/rasterio/_features.pyx b/rasterio/_features.pyx
index bc83a65fd..028930303 100644
--- a/rasterio/_features.pyx
+++ b/rasterio/_features.pyx
@@ -67,7 +67,7 @@ def _shapes(image, mask, connectivity, transform):
if is_float:
fieldtp = 2
- if isinstance(image, np.ndarray):
+ if dtypes.is_... |
Lightning-Universe__lightning-flash-665 | ImageEmbedder default behavior is not a flattened output
## 🐛 Bug
I discovered this issue while testing PR #655. If you run the [Image Embedding README example code](https://github.com/PyTorchLightning/lightning-flash#example-1-image-embedding), it returns a 3D tensor.
My understanding from the use of embeddings ... | [
{
"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required ... | [
{
"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required ... | diff --git a/README.md b/README.md
index be19cb06f9..9b840d3476 100644
--- a/README.md
+++ b/README.md
@@ -206,13 +206,13 @@ from flash.image import ImageEmbedder
download_data("https://pl-flash-data.s3.amazonaws.com/hymenoptera_data.zip", "data/")
# 2. Create an ImageEmbedder with resnet50 trained on imagenet.
-em... |
getmoto__moto-1613 | Running lambda invoke with govcloud results in a KeyError
moto version: 1.3.3
botocore version: 1.10.4
When using moto to invoke a lambda function on a govcloud region, you run into a key error with the lambda_backends. This is because boto.awslambda.regions() does not include the govcloud region, despite it being... | [
{
"content": "from __future__ import unicode_literals\n\nimport base64\nfrom collections import defaultdict\nimport copy\nimport datetime\nimport docker.errors\nimport hashlib\nimport io\nimport logging\nimport os\nimport json\nimport re\nimport zipfile\nimport uuid\nimport functools\nimport tarfile\nimport cal... | [
{
"content": "from __future__ import unicode_literals\n\nimport base64\nfrom collections import defaultdict\nimport copy\nimport datetime\nimport docker.errors\nimport hashlib\nimport io\nimport logging\nimport os\nimport json\nimport re\nimport zipfile\nimport uuid\nimport functools\nimport tarfile\nimport cal... | diff --git a/moto/awslambda/models.py b/moto/awslambda/models.py
index 80b4ffba3e71..d49df81c753a 100644
--- a/moto/awslambda/models.py
+++ b/moto/awslambda/models.py
@@ -675,3 +675,4 @@ def do_validate_s3():
for _region in boto.awslambda.regions()}
lambda_backends['ap-southeast-2'] = LambdaBacke... |
ESMCI__cime-993 | scripts_regression_tests.py O_TestTestScheduler
This test fails with error SystemExit: ERROR: Leftover threads?
when run as part of the full scripts_regression_tests.py
but passes when run using ctest or when run as an individual test.
| [
{
"content": "\"\"\"\nLibraries for checking python code with pylint\n\"\"\"\n\nfrom CIME.XML.standard_module_setup import *\n\nfrom CIME.utils import run_cmd, run_cmd_no_fail, expect, get_cime_root, is_python_executable\n\nfrom multiprocessing.dummy import Pool as ThreadPool\nfrom distutils.spawn import find_e... | [
{
"content": "\"\"\"\nLibraries for checking python code with pylint\n\"\"\"\n\nfrom CIME.XML.standard_module_setup import *\n\nfrom CIME.utils import run_cmd, run_cmd_no_fail, expect, get_cime_root, is_python_executable\n\nfrom multiprocessing.dummy import Pool as ThreadPool\nfrom distutils.spawn import find_e... | diff --git a/utils/python/CIME/code_checker.py b/utils/python/CIME/code_checker.py
index e98e3b21315..e1df4262e98 100644
--- a/utils/python/CIME/code_checker.py
+++ b/utils/python/CIME/code_checker.py
@@ -106,4 +106,6 @@ def check_code(files, num_procs=10, interactive=False):
pool = ThreadPool(num_procs)
re... |
jschneier__django-storages-589 | Is it correct in the `get_available_overwrite_name` function?
Hi,
Please tell me what the following code.
When `name`'s length equals `max_length` in the `get_available_overwrite_name`, `get_available_overwrite_name` returns overwritten `name`.
The `name` must be less than or equal to `max_length` isn't it?
h... | [
{
"content": "import os\nimport posixpath\n\nfrom django.conf import settings\nfrom django.core.exceptions import (\n ImproperlyConfigured, SuspiciousFileOperation,\n)\nfrom django.utils.encoding import force_text\n\n\ndef setting(name, default=None):\n \"\"\"\n Helper function to get a Django setting ... | [
{
"content": "import os\nimport posixpath\n\nfrom django.conf import settings\nfrom django.core.exceptions import (\n ImproperlyConfigured, SuspiciousFileOperation,\n)\nfrom django.utils.encoding import force_text\n\n\ndef setting(name, default=None):\n \"\"\"\n Helper function to get a Django setting ... | diff --git a/CHANGELOG.rst b/CHANGELOG.rst
index 7d4b23bbb..a99adc176 100644
--- a/CHANGELOG.rst
+++ b/CHANGELOG.rst
@@ -1,6 +1,14 @@
django-storages CHANGELOG
=========================
+1.7.1 (2018-09-XX)
+******************
+
+- Fix off-by-1 error in ``get_available_name`` whenever ``file_overwrite`` or ``overwri... |
bridgecrewio__checkov-1228 | boto3 is fixed at the patch level version
**Is your feature request related to a problem? Please describe.**
free boto3 dependency patch version.
**Describe the solution you'd like**
replace the line here:
https://github.com/bridgecrewio/checkov/blob/master/Pipfile#L29
with
```
boto3 = "==1.17.*"
```
**De... | [
{
"content": "#!/usr/bin/env python\nimport logging\nimport os\nfrom importlib import util\nfrom os import path\n\nimport setuptools\nfrom setuptools import setup\n\n# read the contents of your README file\nthis_directory = path.abspath(path.dirname(__file__))\nwith open(path.join(this_directory, \"README.md\")... | [
{
"content": "#!/usr/bin/env python\nimport logging\nimport os\nfrom importlib import util\nfrom os import path\n\nimport setuptools\nfrom setuptools import setup\n\n# read the contents of your README file\nthis_directory = path.abspath(path.dirname(__file__))\nwith open(path.join(this_directory, \"README.md\")... | diff --git a/Pipfile b/Pipfile
index 679055be77..6a18ef5e20 100644
--- a/Pipfile
+++ b/Pipfile
@@ -26,7 +26,7 @@ termcolor="*"
junit-xml ="*"
dpath = ">=1.5.0,<2"
pyyaml = ">=5.4.1"
-boto3 = "==1.17.27"
+boto3 = "==1.17.*"
GitPython = "*"
six = "==1.15.0"
jmespath = "*"
diff --git a/Pipfile.lock b/Pipfile.lock
in... |
mitmproxy__mitmproxy-2072 | [web] Failed to dump flows into json when visiting https website.
##### Steps to reproduce the problem:
1. start mitmweb and set the correct proxy configuration in the browser.
2. visit [github](https://github.com), or any other website with https
3. mitmweb stuck and throw an exception:
```python
ERROR:tornado.... | [
{
"content": "import hashlib\nimport json\nimport logging\nimport os.path\nimport re\nfrom io import BytesIO\n\nimport mitmproxy.addons.view\nimport mitmproxy.flow\nimport tornado.escape\nimport tornado.web\nimport tornado.websocket\nfrom mitmproxy import contentviews\nfrom mitmproxy import exceptions\nfrom mit... | [
{
"content": "import hashlib\nimport json\nimport logging\nimport os.path\nimport re\nfrom io import BytesIO\n\nimport mitmproxy.addons.view\nimport mitmproxy.flow\nimport tornado.escape\nimport tornado.web\nimport tornado.websocket\nfrom mitmproxy import contentviews\nfrom mitmproxy import exceptions\nfrom mit... | diff --git a/mitmproxy/tools/web/app.py b/mitmproxy/tools/web/app.py
index 1f3467cce5..893c3dde0a 100644
--- a/mitmproxy/tools/web/app.py
+++ b/mitmproxy/tools/web/app.py
@@ -85,6 +85,7 @@ def flow_to_json(flow: mitmproxy.flow.Flow) -> dict:
"is_replay": flow.response.is_replay,
}
f.g... |
praw-dev__praw-982 | mark_visited function appears to be broken or using the wrong endpoint
## Issue Description
I was tooling around in an interactive session so I don't have a super clean source code snippet, but I tried to mark a submission as visited and got this error instead.
```
In [44]: submi = reddit.submission(s.id)
In [4... | [
{
"content": "\"\"\"Provide the Submission class.\"\"\"\nfrom ...const import API_PATH, urljoin\nfrom ...exceptions import ClientException\nfrom ..comment_forest import CommentForest\nfrom ..listing.mixins import SubmissionListingMixin\nfrom .base import RedditBase\nfrom .mixins import ThingModerationMixin, Use... | [
{
"content": "\"\"\"Provide the Submission class.\"\"\"\nfrom ...const import API_PATH, urljoin\nfrom ...exceptions import ClientException\nfrom ..comment_forest import CommentForest\nfrom ..listing.mixins import SubmissionListingMixin\nfrom .base import RedditBase\nfrom .mixins import ThingModerationMixin, Use... | diff --git a/praw/models/reddit/submission.py b/praw/models/reddit/submission.py
index f987186a8..fe75d0a4e 100644
--- a/praw/models/reddit/submission.py
+++ b/praw/models/reddit/submission.py
@@ -216,6 +216,8 @@ def _info_path(self):
def mark_visited(self):
"""Mark submission as visited.
+ This ... |
python-telegram-bot__python-telegram-bot-1063 | User.full_name doesn't handle non-ASCII (in Python 2?)
### Steps to reproduce
```python
updater = ext.Updater(token=settings.telegram_token())
def F(bot, update):
user = update.effective_user
print repr(user.first_name), repr(user.last_name)
print '%s %s' % (user.first_name, user.last_name)
print user.fu... | [
{
"content": "#!/usr/bin/env python\n# pylint: disable=C0103,W0622\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2018\n# Leandro Toledo de Souza <devs@python-telegram-bot.org>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under ... | [
{
"content": "#!/usr/bin/env python\n# pylint: disable=C0103,W0622\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2018\n# Leandro Toledo de Souza <devs@python-telegram-bot.org>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under ... | diff --git a/telegram/user.py b/telegram/user.py
index 018dde25ee6..a407888bde9 100644
--- a/telegram/user.py
+++ b/telegram/user.py
@@ -88,7 +88,7 @@ def full_name(self):
"""
if self.last_name:
- return '{} {}'.format(self.first_name, self.last_name)
+ return u'{} {}'.format(s... |
ansible-collections__community.vmware-1030 | Documentation fix needed in community.vmware.vsphere_file module
##### SUMMARY
There is module called **community.vmware.vsphere_file** . There is one task _Query a file on a datastore_ to get information of already existing file on vsphere. But In Documentation there mentioned **state : touch** . But state:touch i... | [
{
"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# Copyright: (c) 2017, Dag Wieers (@dagwieers) <dag@wieers.com>\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\... | [
{
"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# Copyright: (c) 2017, Dag Wieers (@dagwieers) <dag@wieers.com>\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\... | diff --git a/plugins/modules/vsphere_file.py b/plugins/modules/vsphere_file.py
index 28fc54649b..17415699e2 100644
--- a/plugins/modules/vsphere_file.py
+++ b/plugins/modules/vsphere_file.py
@@ -105,7 +105,7 @@
datacenter: DC1 Someplace
datastore: datastore1
path: some/remote/file
- state: touch
+ ... |
docker__docker-py-1473 | DaemonApiMixin.events does not propagate HttpHeaders from config.json
The docker.api.daemon.DaemonApiMixin.events does not make use of the config.json, which could have custom HTTP headers to pass to the server.
| [
{
"content": "import os\nimport warnings\nfrom datetime import datetime\n\nfrom .. import auth, utils\nfrom ..constants import INSECURE_REGISTRY_DEPRECATION_WARNING\n\n\nclass DaemonApiMixin(object):\n def events(self, since=None, until=None, filters=None, decode=None):\n \"\"\"\n Get real-time... | [
{
"content": "import os\nimport warnings\nfrom datetime import datetime\n\nfrom .. import auth, utils\nfrom ..constants import INSECURE_REGISTRY_DEPRECATION_WARNING\n\n\nclass DaemonApiMixin(object):\n def events(self, since=None, until=None, filters=None, decode=None):\n \"\"\"\n Get real-time... | diff --git a/docker/api/daemon.py b/docker/api/daemon.py
index d40631f59..033458491 100644
--- a/docker/api/daemon.py
+++ b/docker/api/daemon.py
@@ -54,7 +54,7 @@ def events(self, since=None, until=None, filters=None, decode=None):
}
return self._stream_helper(
- self.get(self._url('/even... |
flairNLP__flair-1375 | print function for Dictionary class
Currently, the dictionary class only prints an object pointer:
```python
corpus = flair.datasets.UD_ENGLISH(in_memory=False)
tag_dictionary = corpus.make_tag_dictionary(tag_type='upos')
print(tag_dictionary)
```
This prints:
```console
<flair.data.Dictionary object at ... | [
{
"content": "from abc import abstractmethod\nfrom operator import itemgetter\nfrom typing import List, Dict, Union, Callable\nimport re\n\nimport torch, flair\nimport logging\n\nfrom collections import Counter\nfrom collections import defaultdict\n\nfrom segtok.segmenter import split_single\nfrom segtok.tokeni... | [
{
"content": "from abc import abstractmethod\nfrom operator import itemgetter\nfrom typing import List, Dict, Union, Callable\nimport re\n\nimport torch, flair\nimport logging\n\nfrom collections import Counter\nfrom collections import defaultdict\n\nfrom segtok.segmenter import split_single\nfrom segtok.tokeni... | diff --git a/flair/data.py b/flair/data.py
index 0e35dcaa8b..8f6bafed92 100644
--- a/flair/data.py
+++ b/flair/data.py
@@ -131,6 +131,10 @@ def load(cls, name: str):
return Dictionary.load_from_file(name)
+ def __str__(self):
+ tags = ', '.join(self.get_item_for_index(i) for i in range(min(len(se... |
lra__mackup-1412 | AssertionError on Ubuntu 18.04.2 LTS, Mackup 0.8.25, Python 3.6.7
I'm trying to `mackup restore` on a machine running
- Ubuntu 18.04.2 LTS
- Mackup 0.8.25
- Python 3.6.7
It fails immediately with the following:
```
Traceback (most recent call last):
File "/home/REDACTED/.pyenv/versions/3.6.7/bin/mackup",... | [
{
"content": "\"\"\"\nThe applications database.\n\nThe Applications Database provides an easy to use interface to load application\ndata from the Mackup Database (files).\n\"\"\"\nimport os\n\ntry:\n import configparser\nexcept ImportError:\n import ConfigParser as configparser\n\n\nfrom .constants impor... | [
{
"content": "\"\"\"\nThe applications database.\n\nThe Applications Database provides an easy to use interface to load application\ndata from the Mackup Database (files).\n\"\"\"\nimport os\n\ntry:\n import configparser\nexcept ImportError:\n import ConfigParser as configparser\n\n\nfrom .constants impor... | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 04c4026cb..485ce9631 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -2,6 +2,8 @@
## WIP
+- Hotfix, Mackup could not run in most scenarios
+
## Mackup 0.8.25
- Add support for yabai (via @mbdmbd)
diff --git a/mackup/appsdb.py b/mackup/appsdb.py
index 88df5fb07..01... |
aws-cloudformation__cfn-lint-1081 | Error running cfn-lint with pipe (|)
cfn-lint version: *v0.23.0*
Hello we have a problem running cfn-lint with find command. Only this version is affected as far as we know.
We are keeping couple of template is a folder and linting them like that:
```
find ./templates -type f | xargs cfn-lint -f parseable -c I -t... | [
{
"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including w... | [
{
"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including w... | diff --git a/src/cfnlint/core.py b/src/cfnlint/core.py
index 1e81225e53..bd129e2ec5 100644
--- a/src/cfnlint/core.py
+++ b/src/cfnlint/core.py
@@ -140,7 +140,7 @@ def get_args_filenames(cli_args):
print(rules)
exit(0)
- if not sys.stdin.isatty():
+ if not sys.stdin.isatty() and not config.temp... |
googleapis__google-cloud-python-6262 | Redis: regen README.rst (DO NOT MERGE)
This PR was generated using Autosynth. :rainbow:
Here's the log from Synthtool:
```
synthtool > Cloning googleapis.
synthtool > Running generator for google/cloud/redis/artman_redis_v1beta1.yaml.
synthtool > Ensuring dependencies.
synthtool > Pulling artman image.
synthtool > Gen... | [
{
"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicabl... | [
{
"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicabl... | diff --git a/redis/synth.py b/redis/synth.py
index 21c92a28c279..b0942bd4500e 100644
--- a/redis/synth.py
+++ b/redis/synth.py
@@ -23,8 +23,9 @@
gapic = gcp.GAPICGenerator()
common = gcp.CommonTemplates()
excludes = [
+ 'README.rst',
'setup.py',
- 'nox.py',
+ 'nox*.py',
'docs/conf.py',
'docs/... |
zostera__django-bootstrap3-473 | Fix simple typo: attrivute -> attribute
There is a small typo in src/bootstrap3/templatetags/bootstrap3.py.
Should read `attribute` rather than `attrivute`.
| [
{
"content": "import re\nfrom math import floor\n\nfrom django import template\nfrom django.contrib.messages import constants as message_constants\nfrom django.template import Context\nfrom django.utils.safestring import mark_safe\n\nfrom ..bootstrap import css_url, get_bootstrap_setting, javascript_url, jquery... | [
{
"content": "import re\nfrom math import floor\n\nfrom django import template\nfrom django.contrib.messages import constants as message_constants\nfrom django.template import Context\nfrom django.utils.safestring import mark_safe\n\nfrom ..bootstrap import css_url, get_bootstrap_setting, javascript_url, jquery... | diff --git a/src/bootstrap3/templatetags/bootstrap3.py b/src/bootstrap3/templatetags/bootstrap3.py
index 23da590a..f163e711 100644
--- a/src/bootstrap3/templatetags/bootstrap3.py
+++ b/src/bootstrap3/templatetags/bootstrap3.py
@@ -623,7 +623,7 @@ def bootstrap_icon(icon, **kwargs):
Extra CSS classes to add... |
dotkom__onlineweb4-501 | UserResource in API should not display last login date publicly
Somewhat sensitive information...
| [
{
"content": "# -*- coding: utf-8 -*-\n\nfrom tastypie import fields\nfrom tastypie.resources import ModelResource\nfrom tastypie.authorization import Authorization\n\nfrom apps.authentication.models import OnlineUser as User\n\nclass UserResource(ModelResource):\n\n class Meta:\n queryset = User.obje... | [
{
"content": "# -*- coding: utf-8 -*-\n\nfrom tastypie import fields\nfrom tastypie.resources import ModelResource\nfrom tastypie.authorization import Authorization\n\nfrom apps.authentication.models import OnlineUser as User\n\nclass UserResource(ModelResource):\n\n class Meta:\n queryset = User.obje... | diff --git a/apps/api/v0/authentication.py b/apps/api/v0/authentication.py
index c299928ea..c79905101 100644
--- a/apps/api/v0/authentication.py
+++ b/apps/api/v0/authentication.py
@@ -11,4 +11,4 @@ class UserResource(ModelResource):
class Meta:
queryset = User.objects.all()
resource_name = 'user... |
open-telemetry__opentelemetry-python-contrib-566 | AWS X-Ray propagator should be registered with xray environment variable
In the spec, we have a definition for the environment variable as `xray`
https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/sdk-environment-variables.md#general-sdk-configuration
Currently python uses `aws_... | [
{
"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by... | [
{
"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by... | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 5661998af0..2d2a12f78f 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -6,6 +6,8 @@ The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## [Unreleased](... |
mlflow__mlflow-9827 | [DOC-FIX] Doc for Run.inputs erroneously refers to Run.data
### Willingness to contribute
No. I cannot contribute a documentation fix at this time.
### URL(s) with the issue
https://www.mlflow.org/docs/latest/python_api/mlflow.entities.html#mlflow.entities.Run
### Description of proposal (what needs changing)
In t... | [
{
"content": "from typing import Any, Dict, Optional\n\nfrom mlflow.entities._mlflow_object import _MLflowObject\nfrom mlflow.entities.run_data import RunData\nfrom mlflow.entities.run_info import RunInfo\nfrom mlflow.entities.run_inputs import RunInputs\nfrom mlflow.exceptions import MlflowException\nfrom mlfl... | [
{
"content": "from typing import Any, Dict, Optional\n\nfrom mlflow.entities._mlflow_object import _MLflowObject\nfrom mlflow.entities.run_data import RunData\nfrom mlflow.entities.run_info import RunInfo\nfrom mlflow.entities.run_inputs import RunInputs\nfrom mlflow.exceptions import MlflowException\nfrom mlfl... | diff --git a/mlflow/entities/run.py b/mlflow/entities/run.py
index 84718209c1954..731ffd900c0b0 100644
--- a/mlflow/entities/run.py
+++ b/mlflow/entities/run.py
@@ -45,7 +45,7 @@ def inputs(self) -> RunInputs:
"""
The run inputs, including dataset inputs
- :rtype: :py:class:`mlflow.entities.R... |
awslabs__gluonts-2148 | `PandasDataset` slow at creating when many large `DataFrame`s are given
## Description
The `PandasDataset` class is slow at constructing when several large DataFrames are given. It appears like [this check](https://github.com/awslabs/gluon-ts/blob/94247a9c0d4768aeb4a17a8bb44252706c519a6a/src/gluonts/dataset/pandas.py#... | [
{
"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\").\n# You may not use this file except in compliance with the License.\n# A copy of the License is located at\n#\n# http://www.apache.org/licenses/LICE... | [
{
"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\").\n# You may not use this file except in compliance with the License.\n# A copy of the License is located at\n#\n# http://www.apache.org/licenses/LICE... | diff --git a/src/gluonts/dataset/pandas.py b/src/gluonts/dataset/pandas.py
index 72ecbefc65..4c21c12a34 100644
--- a/src/gluonts/dataset/pandas.py
+++ b/src/gluonts/dataset/pandas.py
@@ -305,4 +305,5 @@ def is_uniform(index: pd.PeriodIndex) -> bool:
>>> is_uniform(pd.DatetimeIndex(ts).to_period("2H"))
False
... |
d2l-ai__d2l-vi-115 | test
| [
{
"content": "# encoding=utf8\nimport codecs\nimport filecmp\nimport re\nimport sys\nimport argparse\n\n# reload(sys)\n# sys.setdefaultencoding('utf8')\n\nBEGIN_BLOCK_COMMENT = '<!--\\n'\nEND_BLOCK_COMMENT = '-->\\n\\n'\nTRANSLATE_INDICATOR = '*dịch đoạn phía trên*'\nHEADER_INDICATOR = ' *dịch tiêu đề phía trên... | [
{
"content": "# encoding=utf8\nimport codecs\nimport filecmp\nimport re\nimport sys\nimport argparse\n\nBEGIN_BLOCK_COMMENT = '<!--\\n'\nEND_BLOCK_COMMENT = '-->\\n\\n'\nTRANSLATE_INDICATOR = '*dịch đoạn phía trên*'\nHEADER_INDICATOR = ' *dịch tiêu đề phía trên*\\n'\nIMAGE_CAPTION_INDICATOR = '*dịch chú thích ả... | diff --git a/utils.py b/utils.py
index 242fea1d92..89e1f0c35a 100644
--- a/utils.py
+++ b/utils.py
@@ -5,9 +5,6 @@
import sys
import argparse
-# reload(sys)
-# sys.setdefaultencoding('utf8')
-
BEGIN_BLOCK_COMMENT = '<!--\n'
END_BLOCK_COMMENT = '-->\n\n'
TRANSLATE_INDICATOR = '*dịch đoạn phía trên*'
|
PaddlePaddle__PaddleSpeech-2364 | Added pre-install doc for G2P and TN modules and updated the dependency version of pypinyin
Added pre-install doc for G2P and TN modules and updated the dependency version of pypinyin
| [
{
"content": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.... | [
{
"content": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.... | diff --git a/docs/requirements.txt b/docs/requirements.txt
index bd071e7e20c..3fb82367f64 100644
--- a/docs/requirements.txt
+++ b/docs/requirements.txt
@@ -27,7 +27,7 @@ pattern_singleton
Pillow>=9.0.0
praatio==5.0.0
prettytable
-pypinyin
+pypinyin<=0.44.0
pypinyin-dict
python-dateutil
pyworld==0.2.12
diff --git... |
AUTOMATIC1111__stable-diffusion-webui-60 | FileNotFoundError after new update
Getting a FileNotFoundError: [WinError 3] The system cannot find the path specified: 'C:\\Users\\admin\\stable-diffusion-webui\\scripts' after the new update.
Not exactly good at all the coding stuff, using it just fine yesterday but I downloaded the repo instead of git clone, for... | [
{
"content": "import os\r\nimport sys\r\nimport traceback\r\n\r\nimport modules.ui as ui\r\nimport gradio as gr\r\n\r\nfrom modules.processing import StableDiffusionProcessing\r\n\r\nclass Script:\r\n filename = None\r\n args_from = None\r\n args_to = None\r\n\r\n def title(self):\r\n raise N... | [
{
"content": "import os\r\nimport sys\r\nimport traceback\r\n\r\nimport modules.ui as ui\r\nimport gradio as gr\r\n\r\nfrom modules.processing import StableDiffusionProcessing\r\n\r\nclass Script:\r\n filename = None\r\n args_from = None\r\n args_to = None\r\n\r\n def title(self):\r\n raise N... | diff --git a/modules/scripts.py b/modules/scripts.py
index be348a70481..37a236827c4 100644
--- a/modules/scripts.py
+++ b/modules/scripts.py
@@ -29,6 +29,9 @@ def describe(self):
def load_scripts(basedir):
+ if not os.path.exists(basedir):
+ return
+
for filename in os.listdir(basedir):
... |
mitmproxy__mitmproxy-5603 | libGL error when starting latest version of mitmweb 8.1.1 on Debian
#### Problem Description
I was using old version of mitmproxy 6.0.2 that I got installed from the debian unstable repository and it works just fine. then today I decided to download the latest version of mitmproxy 8.1.1 and I got the below errors imm... | [
{
"content": "import logging\nimport webbrowser\nfrom collections.abc import Sequence\n\nfrom mitmproxy import ctx\n\n\nclass WebAddon:\n def load(self, loader):\n loader.add_option(\"web_open_browser\", bool, True, \"Start a browser.\")\n loader.add_option(\"web_debug\", bool, False, \"Enable ... | [
{
"content": "import logging\nimport webbrowser\nfrom collections.abc import Sequence\n\nfrom mitmproxy import ctx\n\n\nclass WebAddon:\n def load(self, loader):\n loader.add_option(\"web_open_browser\", bool, True, \"Start a browser.\")\n loader.add_option(\"web_debug\", bool, False, \"Enable ... | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 8476be5201..6b3a73a5a8 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -39,6 +39,9 @@
([#5588](https://github.com/mitmproxy/mitmproxy/pull/5588), @nikitastupin, @abbbe)
* Add WireGuard mode to enable userspace transparent proxying via WireGuard.
([#5562](https://git... |
wemake-services__wemake-python-styleguide-204 | Feature: ignore async function definitions from jones complexity check
Currently we only ignore `ClassDef` and `FunctionDef`: https://github.com/wemake-services/wemake-python-styleguide/blob/master/wemake_python_styleguide/visitors/ast/complexity/jones.py#L38-L41
What needs to be done:
1. ignore `AsyncFunctionDef` ... | [
{
"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\nJones Complexity to count inline complexity.\n\nBased on the original `jones-complexity` project:\nhttps://github.com/Miserlou/JonesComplexity\n\nOriginal project is licensed under MIT.\n\"\"\"\n\nimport ast\nfrom collections import defaultdict\nfrom statistics i... | [
{
"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\nJones Complexity to count inline complexity.\n\nBased on the original `jones-complexity` project:\nhttps://github.com/Miserlou/JonesComplexity\n\nOriginal project is licensed under MIT.\n\"\"\"\n\nimport ast\nfrom collections import defaultdict\nfrom statistics i... | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 358a18761..7011c6fdf 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -14,6 +14,7 @@ We used to have incremental versioning before `0.1.0`.
- We now count `async` methods as method for classes complexity check
- We now count `async` functions as functions for module compl... |
dmlc__dgl-2897 | Moving a graph to GPU will change the default CUDA device
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
```
import torch
import dgl
torch.cuda.set_device(1)
print(torch.cuda.current_device()) # print 1
device = 'cuda' # 'cuda:1'
g = dgl.graph((torch.tensor([0, 1... | [
{
"content": "from __future__ import absolute_import\n\nfrom distutils.version import LooseVersion\n\nimport scipy # Weird bug in new pytorch when import scipy after import torch\nimport torch as th\nimport builtins\nimport numbers\nfrom torch.utils import dlpack\n\nfrom ... import ndarray as nd\nfrom ..._depre... | [
{
"content": "from __future__ import absolute_import\n\nfrom distutils.version import LooseVersion\n\nimport scipy # Weird bug in new pytorch when import scipy after import torch\nimport torch as th\nimport builtins\nimport numbers\nfrom torch.utils import dlpack\n\nfrom ... import ndarray as nd\nfrom ..._depre... | diff --git a/python/dgl/backend/pytorch/tensor.py b/python/dgl/backend/pytorch/tensor.py
index 7c99a31847ea..34284cd9ec7a 100644
--- a/python/dgl/backend/pytorch/tensor.py
+++ b/python/dgl/backend/pytorch/tensor.py
@@ -86,7 +86,7 @@ def device_type(ctx):
def device_id(ctx):
ctx = th.device(ctx)
if ctx.index ... |
facebookresearch__ParlAI-581 | Can we keep a mturk task from outside parlai/mturk/tasks?
Hi @JackUrb, I have a few questions regarding the mturk evaluation:
1. This link (http://parl.ai/static/docs/mturk.html#running-a-task) says that
> to run an MTurk task, first ensure that the task directory is in `parlai/mturk/tasks/`.
Is it by desig... | [
{
"content": "# Copyright (c) 2017-present, Facebook, Inc.\n# All rights reserved.\n# This source code is licensed under the BSD-style license found in the\n# LICENSE file in the root directory of this source tree. An additional grant\n# of patent rights can be found in the PATENTS file in the same directory.\n... | [
{
"content": "# Copyright (c) 2017-present, Facebook, Inc.\n# All rights reserved.\n# This source code is licensed under the BSD-style license found in the\n# LICENSE file in the root directory of this source tree. An additional grant\n# of patent rights can be found in the PATENTS file in the same directory.\n... | diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 00000000000..fa9ea114284
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1,3 @@
+include parlai/mturk/core/server/html/*
+include parlai/mturk/core/server/server.js
+include parlai/mturk/core/server/package.json
diff --git a/setup.py b/setup.py
index 4e895050e8... |
netbox-community__netbox-2144 | PUTs to Site Endpoint Requires Value for time_zone
<!--
Before opening a new issue, please search through the existing issues to
see if your topic has already been addressed. Note that you may need to
remove the "is:open" filter from the search bar to include closed issues.
Check the appropriate t... | [
{
"content": "from __future__ import unicode_literals\n\nfrom collections import OrderedDict\n\nfrom rest_framework import serializers\nfrom rest_framework.validators import UniqueTogetherValidator\n\nfrom circuits.models import Circuit, CircuitTermination\nfrom dcim.constants import (\n CONNECTION_STATUS_CH... | [
{
"content": "from __future__ import unicode_literals\n\nfrom collections import OrderedDict\n\nfrom rest_framework import serializers\nfrom rest_framework.validators import UniqueTogetherValidator\n\nfrom circuits.models import Circuit, CircuitTermination\nfrom dcim.constants import (\n CONNECTION_STATUS_CH... | diff --git a/netbox/dcim/api/serializers.py b/netbox/dcim/api/serializers.py
index e37354d47f6..988a2d59f69 100644
--- a/netbox/dcim/api/serializers.py
+++ b/netbox/dcim/api/serializers.py
@@ -80,7 +80,7 @@ class Meta:
class WritableSiteSerializer(CustomFieldModelSerializer):
- time_zone = TimeZoneField(require... |
vas3k__vas3k.club-260 | Сломался check_PR экшн на новые пуллреквесты
Вот здесь все пошло не так после пары изменений в requirements и докерфайлах: https://github.com/vas3k/vas3k.club/blob/master/.github/workflows/CI.yml
Из-за этого все новые пуллреквесты красненькие и мержить их приходится только суровой админской рукой. Надо бы переосмысл... | [
{
"content": "import io\nimport logging\nimport os\nfrom urllib.parse import urlparse\n\nimport requests\nfrom PIL import Image\nfrom django.conf import settings\n\nlog = logging.getLogger(__name__)\n\n\ndef upload_image_bytes(\n filename, data, resize=(192, 192), convert_to=None, quality=None\n):\n if no... | [
{
"content": "import io\nimport logging\nimport os\nfrom urllib.parse import urlparse\n\nimport requests\nfrom PIL import Image\nfrom django.conf import settings\n\nlog = logging.getLogger(__name__)\n\n\ndef upload_image_bytes(\n filename, data, resize=(192, 192), convert_to=None, quality=None\n):\n if no... | diff --git a/.github/workflows/CI.yml b/.github/workflows/CI.yml
index 65f731e55..0d6194288 100644
--- a/.github/workflows/CI.yml
+++ b/.github/workflows/CI.yml
@@ -3,29 +3,28 @@ name: check_pr
on: [pull_request]
jobs:
+ lint:
+ runs-on: ubuntu-latest
+
+ steps:
+ - uses: actions/checkout@master
+ - us... |
akvo__akvo-rsr-1603 | Transaction admin creates internal server error
| [
{
"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\nfrom dja... | [
{
"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\nfrom dja... | diff --git a/akvo/rsr/models/transaction.py b/akvo/rsr/models/transaction.py
index 65687712e4..30bf931422 100644
--- a/akvo/rsr/models/transaction.py
+++ b/akvo/rsr/models/transaction.py
@@ -89,7 +89,7 @@ class Transaction(models.Model):
)
def __unicode__(self):
- return self.value
+ return un... |
speechbrain__speechbrain-1127 | Broken docs for `speechbrain.alignment.ctc_segmentation`
Hi, thanks for maintaining such a wonderful library.
Looks like the documentation for `speechbrain.alignment.ctc_segmentation` is broken:
https://speechbrain.readthedocs.io/en/latest/API/speechbrain.alignment.ctc_segmentation.html
I guess this is caused by... | [
{
"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup -------------------------------------------... | [
{
"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup -------------------------------------------... | diff --git a/docs/conf.py b/docs/conf.py
index 435bf01b80..a774420cbf 100644
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -69,7 +69,7 @@
autodoc_default_options = {}
# Autodoc mock extra dependencies:
-autodoc_mock_imports = ["numba", "sklearn"]
+autodoc_mock_imports = ["sklearn"]
# Order of API items:
autodoc_memb... |
tensorflow__addons-1941 | Usage with tf.keras API
https://github.com/tensorflow/addons/blob/5f618fdb92d9737da059de2a33fa606e97505398/tensorflow_addons/losses/focal_loss.py#L52-L53
The usage in `tf.keras` API example is incorrect. It should be replaced with:
```python
model = tf.keras.Model(inputs, outputs)
model.compile('sgd', loss=tfa.... | [
{
"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\... | [
{
"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\... | diff --git a/tensorflow_addons/losses/focal_loss.py b/tensorflow_addons/losses/focal_loss.py
index 973bfccb1f..550a82a614 100644
--- a/tensorflow_addons/losses/focal_loss.py
+++ b/tensorflow_addons/losses/focal_loss.py
@@ -50,7 +50,7 @@ class SigmoidFocalCrossEntropy(LossFunctionWrapper):
```python
model = ... |
Gallopsled__pwntools-669 | Need import
util/iters.py have not import time and context,It cause a problem when use mbruteforce
Need import
util/iters.py have not import time and context,It cause a problem when use mbruteforce
Need import
util/iters.py have not import time and context,It cause a problem when use mbruteforce
| [
{
"content": "\"\"\"\nThis module includes and extends the standard module :mod:`itertools`.\n\"\"\"\n\n__all__ = [\n 'bruteforce' ,\n 'mbruteforce' ,\n 'chained' ,\n 'consume' ,\n ... | [
{
"content": "\"\"\"\nThis module includes and extends the standard module :mod:`itertools`.\n\"\"\"\n\n__all__ = [\n 'bruteforce' ,\n 'mbruteforce' ,\n 'chained' ,\n 'consume' ,\n ... | diff --git a/pwnlib/util/iters.py b/pwnlib/util/iters.py
index 835ef78ce..b5a68bf49 100644
--- a/pwnlib/util/iters.py
+++ b/pwnlib/util/iters.py
@@ -58,8 +58,10 @@
import multiprocessing
import operator
import random
+import time
from itertools import *
+from ..context import context
from ..log import getLogger
... |
robocorp__rpaframework-550 | `RPA.JSON` RecursionError: maximum recursion depth exceeded
This error is at the moment breaking our [Certificate level 3](https://robocorp.com/docs/courses/work-data-management/validate-business-data) course with `rpaframework==15.0.0`.
Works correctly with `rpaframework==14.0.0`
```
*** Keywords ***
Validate ... | [
{
"content": "import json\nimport logging\nfrom typing import Any, Callable, Dict, Hashable, List, Optional, Union\n\nfrom jsonpath_ng import Index, Fields\nfrom jsonpath_ng.ext.filter import Filter\nfrom jsonpath_ng.ext.parser import ExtentedJsonPathParser\n\nfrom robot.api.deco import keyword\n\n\nJSONValue =... | [
{
"content": "import json\nimport logging\nfrom typing import Any, Callable, Dict, Hashable, List, Optional, Union\n\nfrom jsonpath_ng import Index, Fields\nfrom jsonpath_ng.ext.filter import Filter\nfrom jsonpath_ng.ext.parser import ExtentedJsonPathParser\n\nfrom robot.api.deco import keyword\n\n\nJSONValue =... | diff --git a/docs/source/releasenotes.rst b/docs/source/releasenotes.rst
index 3399a9b7ff..2d4efdd348 100644
--- a/docs/source/releasenotes.rst
+++ b/docs/source/releasenotes.rst
@@ -5,12 +5,17 @@ Release notes
`Upcoming release <https://github.com/robocorp/rpaframework/projects/3#column-16713994>`_
+++++++++++++++++... |
joke2k__faker-993 | text-unidecode is released under the Artistic license
`text-unidecode` is released under the Artistic license v1.0, which is considered non-free by the FSF (and therefore not compatible with the GPL). I believe this clause is also of concern to commercial users of faker too:
> 5. You may charge a reasonable copying ... | [
{
"content": "#!/usr/bin/env python\n# coding=utf-8\n\nimport io\nimport os\n\nfrom setuptools import find_packages, setup\n\nhere = os.path.abspath(os.path.dirname(__file__))\nwith io.open(os.path.join(here, 'README.rst'), encoding='utf-8') as fp:\n README = fp.read()\n\nwith io.open(os.path.join(here, 'VER... | [
{
"content": "#!/usr/bin/env python\n# coding=utf-8\n\nimport io\nimport os\n\nfrom setuptools import find_packages, setup\n\nhere = os.path.abspath(os.path.dirname(__file__))\nwith io.open(os.path.join(here, 'README.rst'), encoding='utf-8') as fp:\n README = fp.read()\n\nwith io.open(os.path.join(here, 'VER... | diff --git a/setup.py b/setup.py
index e0ef8ee22c..67d70d304d 100644
--- a/setup.py
+++ b/setup.py
@@ -66,7 +66,7 @@
install_requires=[
"python-dateutil>=2.4",
"six>=1.10",
- "text-unidecode==1.2",
+ "text-unidecode==1.3",
],
tests_require=[
"validators>=0.13.0",
|
dynamiqs__dynamiqs-196 | implement a ver() method
As a user if I want to make sure my setup is up to date with the latest version, I want to be able to call dq.ver() to know which version I am running
| [
{
"content": "from .mesolve import mesolve\nfrom .sesolve import sesolve\nfrom .smesolve import smesolve\nfrom .utils import *\n",
"path": "dynamiqs/__init__.py"
}
] | [
{
"content": "from importlib.metadata import version\n\nfrom .mesolve import mesolve\nfrom .sesolve import sesolve\nfrom .smesolve import smesolve\nfrom .utils import *\n\n# get version from pyproject.toml\n__version__ = version(__package__)\n",
"path": "dynamiqs/__init__.py"
}
] | diff --git a/dynamiqs/__init__.py b/dynamiqs/__init__.py
index 3167dd305..e89e489f3 100644
--- a/dynamiqs/__init__.py
+++ b/dynamiqs/__init__.py
@@ -1,4 +1,9 @@
+from importlib.metadata import version
+
from .mesolve import mesolve
from .sesolve import sesolve
from .smesolve import smesolve
from .utils import *
+
+... |
Pyomo__pyomo-429 | Review objects exposed by environ
At the request of @jsiirola after I brought this to his attention, some Pyomo objects are not exposed by environ that would otherwise be expected. One that I have encountered is `TerminationCondition`, which needs to be imported from `pyomo.opt`.
| [
{
"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and\n# Engineerin... | [
{
"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and\n# Engineerin... | diff --git a/pyomo/environ/__init__.py b/pyomo/environ/__init__.py
index e8d3de7d3b3..01d842e0b29 100644
--- a/pyomo/environ/__init__.py
+++ b/pyomo/environ/__init__.py
@@ -93,4 +93,7 @@ def _import_packages():
# Expose the symbols from pyomo.core
#
from pyomo.core import *
-from pyomo.opt import SolverFactory, Solv... |
nilearn__nilearn-1936 | _threshold_maps_ratio changes the input map
My maps images keep changing when I use RegionExtractor. I think we need to make a copy [here](https://github.com/nilearn/nilearn/blob/master/nilearn/regions/region_extractor.py#L58)
For instance the following code throws an `AssertionError: Arrays are not equal`
```Python
... | [
{
"content": "\"\"\"\nBetter brain parcellations for Region of Interest analysis\n\"\"\"\n\nimport numbers\nimport collections\nimport numpy as np\n\nfrom scipy import ndimage\nfrom scipy.stats import scoreatpercentile\n\nfrom sklearn.externals.joblib import Memory\n\nfrom .. import masking\nfrom ..input_data i... | [
{
"content": "\"\"\"\nBetter brain parcellations for Region of Interest analysis\n\"\"\"\n\nimport numbers\nimport collections\nimport numpy as np\n\nfrom scipy import ndimage\nfrom scipy.stats import scoreatpercentile\n\nfrom sklearn.externals.joblib import Memory\n\nfrom .. import masking\nfrom ..input_data i... | diff --git a/nilearn/regions/region_extractor.py b/nilearn/regions/region_extractor.py
index c84bfc9c22..5701c5afa8 100644
--- a/nilearn/regions/region_extractor.py
+++ b/nilearn/regions/region_extractor.py
@@ -55,7 +55,7 @@ def _threshold_maps_ratio(maps_img, threshold):
else:
ratio = threshold
- ma... |
pulp__pulpcore-2498 | As a developer, I can have pytest run the unit tests
Author: @bmbouter (bmbouter)
Redmine Issue: 9643, https://pulp.plan.io/issues/9643
---
As part of the testing effort, it would be nice to have pytest run the unittests in addition to our functional tests.
| [
{
"content": "\"\"\"\nDjango settings for the Pulp Platform application\n\nNever import this module directly, instead `from django.conf import settings`, see\nhttps://docs.djangoproject.com/en/1.11/topics/settings/#using-settings-in-python-code\n\nFor the full list of settings and their values, see\nhttps://doc... | [
{
"content": "\"\"\"\nDjango settings for the Pulp Platform application\n\nNever import this module directly, instead `from django.conf import settings`, see\nhttps://docs.djangoproject.com/en/1.11/topics/settings/#using-settings-in-python-code\n\nFor the full list of settings and their values, see\nhttps://doc... | diff --git a/.github/workflows/scripts/script.sh b/.github/workflows/scripts/script.sh
index 44f447e338..1b81d816e2 100755
--- a/.github/workflows/scripts/script.sh
+++ b/.github/workflows/scripts/script.sh
@@ -111,7 +111,7 @@ cmd_prefix bash -c "django-admin makemigrations --check --dry-run"
if [[ "$TEST" != "upgra... |
zestedesavoir__zds-site-5586 | SEO et signature : <a rel="nofollow" />
Dans la signature il faudrait voir si on peut facilement ajouter un attribut `rel="nofollow"` pour préserver notre SEO. https://github.com/zestedesavoir/zmarkdown/blob/1dded309a2670689a4a3353f9e38b80624c6df1a/packages/zmarkdown/server/handlers.js#L139
> limitez les liens en si... | [
{
"content": "import re\nimport json\nimport logging\nfrom requests import post, HTTPError\n\nfrom django import template\nfrom django.conf import settings\nfrom django.template.defaultfilters import stringfilter\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import ugettext_lazy ... | [
{
"content": "import re\nimport json\nimport logging\nfrom requests import post, HTTPError\n\nfrom django import template\nfrom django.conf import settings\nfrom django.template.defaultfilters import stringfilter\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import ugettext_lazy ... | diff --git a/zds/utils/templatetags/emarkdown.py b/zds/utils/templatetags/emarkdown.py
index e933290542..b403e746d2 100644
--- a/zds/utils/templatetags/emarkdown.py
+++ b/zds/utils/templatetags/emarkdown.py
@@ -178,7 +178,7 @@ def emarkdown_inline(text):
:rtype: str
"""
rendered = emarkdown(text, inline=... |
TileDB-Inc__TileDB-Py-151 | Reading dense array doesn't free memory
Hi,
I'm wondering if this is expected behavior or if you have any tips to fix. On Ubuntu 16, Python 3.7, and _tiledb_ 0.4.1:
Create toy array:
```
x = np.ones(10000000)
ctx = tiledb.Ctx()
path = 'test_tile_db'
d1 = tiledb.Dim(
'test_domain', domain=(0, x.shape[0]... | [
{
"content": "from __future__ import absolute_import, print_function\n\nimport multiprocessing\nimport os\nimport shutil\nimport subprocess\nimport zipfile\nimport platform\nfrom distutils.sysconfig import get_config_var\nfrom distutils.version import LooseVersion\n\n\ntry:\n # For Python 3\n from urllib.... | [
{
"content": "from __future__ import absolute_import, print_function\n\nimport multiprocessing\nimport os\nimport shutil\nimport subprocess\nimport zipfile\nimport platform\nfrom distutils.sysconfig import get_config_var\nfrom distutils.version import LooseVersion\n\n\ntry:\n # For Python 3\n from urllib.... | diff --git a/azure-pipelines.yml b/azure-pipelines.yml
index cfbf0ade25..35e00249b0 100644
--- a/azure-pipelines.yml
+++ b/azure-pipelines.yml
@@ -27,7 +27,7 @@ steps:
architecture: 'x64'
- script: |
- python -m pip install --upgrade pip setuptools wheel numpy tox setuptools-scm cython
+ python -m pip ins... |
AUTOMATIC1111__stable-diffusion-webui-7353 | [Bug]: thumbnail cards are not loading the preview image
### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What happened?
just getting black image, and if I try to update an image, it goes black too.
It was working before checkpoints were ... | [
{
"content": "import html\r\nimport json\r\nimport os\r\nimport urllib.parse\r\n\r\nfrom modules import shared, ui_extra_networks, sd_models\r\n\r\n\r\nclass ExtraNetworksPageCheckpoints(ui_extra_networks.ExtraNetworksPage):\r\n def __init__(self):\r\n super().__init__('Checkpoints')\r\n\r\n def re... | [
{
"content": "import html\r\nimport json\r\nimport os\r\nimport urllib.parse\r\n\r\nfrom modules import shared, ui_extra_networks, sd_models\r\n\r\n\r\nclass ExtraNetworksPageCheckpoints(ui_extra_networks.ExtraNetworksPage):\r\n def __init__(self):\r\n super().__init__('Checkpoints')\r\n\r\n def re... | diff --git a/modules/ui_extra_networks_checkpoints.py b/modules/ui_extra_networks_checkpoints.py
index c66cb8307ad..5b471671a09 100644
--- a/modules/ui_extra_networks_checkpoints.py
+++ b/modules/ui_extra_networks_checkpoints.py
@@ -34,5 +34,5 @@ def list_items(self):
}
def allowed_directories_for... |
praw-dev__praw-1304 | Sphinx stops emitting warnings if it encounters only one
**Describe the bug**
<!-- A clear and concise description of what the bug is. --> When running pre_push, if Sphinx runs into an warning, it does does print any more. When there are lots of warnings, it takes a lot of time to re-run pre_push per warning
I reco... | [
{
"content": "#!/usr/bin/env python3\n\"\"\"Run static analysis on the project.\"\"\"\n\nimport argparse\nimport sys\nfrom os import path\nfrom shutil import rmtree\nfrom subprocess import CalledProcessError, check_call\nfrom tempfile import mkdtemp\n\ncurrent_directory = path.abspath(path.join(__file__, \"..\"... | [
{
"content": "#!/usr/bin/env python3\n\"\"\"Run static analysis on the project.\"\"\"\n\nimport argparse\nimport sys\nfrom os import path\nfrom shutil import rmtree\nfrom subprocess import CalledProcessError, check_call\nfrom tempfile import mkdtemp\n\ncurrent_directory = path.abspath(path.join(__file__, \"..\"... | diff --git a/.github/workflows/ci.yml b/.github/workflows/ci.yml
index dcb104835..cf5962247 100644
--- a/.github/workflows/ci.yml
+++ b/.github/workflows/ci.yml
@@ -36,7 +36,7 @@ jobs:
- name: Run pydocstyle
run: pydocstyle praw
- name: Run sphinx
- run: sphinx-build -W docs/ /tmp/foo
+ run: ... |
python-pillow__Pillow-399 | Image opened twice if imagemagick and xv are installed
If ImageMagick and xv are both installed and you call Image.show() it will open the image twice, once with display and once with xv. This is probably related to the for loop over registered viewers. Not sure why the return 1 isn't working though.
| [
{
"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# im.show() drivers\n#\n# History:\n# 2008-04-06 fl Created\n#\n# Copyright (c) Secret Labs AB 2008.\n#\n# See the README file for information on usage and redistribution.\n#\n\nfrom __future__ import print_function\n\nfrom PIL import Image\nimport os... | [
{
"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# im.show() drivers\n#\n# History:\n# 2008-04-06 fl Created\n#\n# Copyright (c) Secret Labs AB 2008.\n#\n# See the README file for information on usage and redistribution.\n#\n\nfrom __future__ import print_function\n\nfrom PIL import Image\nimport os... | diff --git a/PIL/ImageShow.py b/PIL/ImageShow.py
index 7e3d63ba3cd..78bc210f3d6 100644
--- a/PIL/ImageShow.py
+++ b/PIL/ImageShow.py
@@ -65,7 +65,7 @@ def show(self, image, **options):
if base != image.mode and image.mode != "1":
image = image.convert(base)
- self.show_image(image, **opti... |
nilearn__nilearn-2792 | `FirstLevelModel._get_voxelwise_model_attribute` only returns first design matrix's attribute
<!--Provide a brief description of the bug.-->
The FirstLevelModel attributes which use `_get_voxelwise_model_attribute()` only return the img for the first design matrix, rather than all of the design matrices' associated im... | [
{
"content": "\"\"\"\nThis module presents an interface to use the glm implemented in\nnistats.regression.\n\nIt contains the GLM and contrast classes that are meant to be the main objects\nof fMRI data analyses.\n\nAuthor: Bertrand Thirion, Martin Perez-Guevara, 2016\n\n\"\"\"\nimport glob\nimport json\nimport... | [
{
"content": "\"\"\"\nThis module presents an interface to use the glm implemented in\nnistats.regression.\n\nIt contains the GLM and contrast classes that are meant to be the main objects\nof fMRI data analyses.\n\nAuthor: Bertrand Thirion, Martin Perez-Guevara, 2016\n\n\"\"\"\nimport glob\nimport json\nimport... | diff --git a/doc/whats_new.rst b/doc/whats_new.rst
index 79546fe1bc..df432c18c0 100644
--- a/doc/whats_new.rst
+++ b/doc/whats_new.rst
@@ -11,6 +11,9 @@ Fixes
in :func:`nilearn.signal.clean`, so that these operations are applied
in the same order as for the signals, i.e., first detrending and
then temporal fil... |
e-valuation__EvaP-817 | +x on update.sh, earlier apache restart
update_production.sh is missing the x bit, also because of the cache clearing the apache is restarted 2min after the code has changed.
| [
{
"content": "from django.core.management.base import BaseCommand\nfrom django.core.serializers.base import ProgressBar\nfrom django.core.cache import cache\n\nfrom evap.evaluation.models import Course\nfrom evap.evaluation.tools import calculate_results\n\n\nclass Command(BaseCommand):\n args = ''\n help... | [
{
"content": "from django.core.management.base import BaseCommand\nfrom django.core.serializers.base import ProgressBar\nfrom django.core.cache import cache\n\nfrom evap.evaluation.models import Course\nfrom evap.evaluation.tools import calculate_results\n\n\nclass Command(BaseCommand):\n args = ''\n help... | diff --git a/deployment/update_production.sh b/deployment/update_production.sh
old mode 100644
new mode 100755
index 44c3c4f261..9cc89634a8
--- a/deployment/update_production.sh
+++ b/deployment/update_production.sh
@@ -6,13 +6,16 @@ set -x # print executed commands
sudo -u evap git fetch
sudo -u evap git checkout or... |
lnbits__lnbits-1183 | [BUG] LNDhub extension return unusable `getinfo` response
**Describe the bug**
The [getinfo call](https://github.com/lnbits/lnbits/blob/main/lnbits/extensions/lndhub/views_api.py#L22) simply returns `bad auth` everytime, which breaks integrations like for us in BTCPay Server (see btcpayserver/btcpayserver#4414).
**... | [
{
"content": "import asyncio\nimport time\nfrom base64 import urlsafe_b64encode\nfrom http import HTTPStatus\n\nfrom fastapi.param_functions import Query\nfrom fastapi.params import Depends\nfrom pydantic import BaseModel\nfrom starlette.exceptions import HTTPException\n\nfrom lnbits import bolt11\nfrom lnbits.... | [
{
"content": "import asyncio\nimport time\nfrom base64 import urlsafe_b64encode\nfrom http import HTTPStatus\n\nfrom fastapi.param_functions import Query\nfrom fastapi.params import Depends\nfrom pydantic import BaseModel\nfrom starlette.exceptions import HTTPException\n\nfrom lnbits import bolt11\nfrom lnbits.... | diff --git a/lnbits/extensions/lndhub/views_api.py b/lnbits/extensions/lndhub/views_api.py
index 8cbe5a6bfd..2acdc4ec93 100644
--- a/lnbits/extensions/lndhub/views_api.py
+++ b/lnbits/extensions/lndhub/views_api.py
@@ -21,7 +21,7 @@
@lndhub_ext.get("/ext/getinfo")
async def lndhub_getinfo():
- raise HTTPExceptio... |
boto__boto-2166 | Invalid path check in euca-bundle-image
The -i option uses convert_file in boto/roboto/param.py to verify that the path passed is, indeed, a file. This fails unless the path specified is a boring old file which is not necessary. Indeed it not being necessary is sort of the whole point in unix having a /dev in the first... | [
{
"content": "# Copyright (c) 2010 Mitch Garnaat http://garnaat.org/\n# Copyright (c) 2010, Eucalyptus Systems, Inc.\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without re... | [
{
"content": "# Copyright (c) 2010 Mitch Garnaat http://garnaat.org/\n# Copyright (c) 2010, Eucalyptus Systems, Inc.\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without re... | diff --git a/boto/roboto/param.py b/boto/roboto/param.py
index ed3e6be9b9..35a25b4af5 100644
--- a/boto/roboto/param.py
+++ b/boto/roboto/param.py
@@ -46,7 +46,7 @@ def convert_boolean(cls, param, value):
@classmethod
def convert_file(cls, param, value):
- if os.path.isfile(value):
+ if os.pat... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.