
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 3.23B | node_id stringlengths 18 32 | number int64 1 7.68k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments int64 0 70 | created_at timestamp[ns, tz=UTC]date 2020-04-14 10:18:02 2025-07-14 01:57:16 | updated_at timestamp[ns, tz=UTC]date 2020-04-27 16:04:17 2025-07-14 06:59:35 | closed_at timestamp[ns, tz=UTC]date 2020-04-14 12:01:40 2025-07-11 17:42:01 ⌀ | author_association stringclasses 4
values | type null | active_lock_reason null | sub_issues_summary dict | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 4
values | draft bool 2
classes | pull_request dict | is_pull_request bool 1
class | time_to_close int64 0 1.88k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/7477 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7477/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7477/comments | https://api.github.com/repos/huggingface/datasets/issues/7477/events | https://github.com/huggingface/datasets/issues/7477 | 2,947,169,460 | I_kwDODunzps6vqjy0 | 7,477 | What is the canonical way to compress a Dataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/6130352?v=4",
"events_url": "https://api.github.com/users/eric-czech/events{/privacy}",
"followers_url": "https://api.github.com/users/eric-czech/followers",
"following_url": "https://api.github.com/users/eric-czech/following{/other_user}",
"gists_url":... | [] | open | false | null | [] | null | 4 | 2025-03-25T16:47:51Z | 2025-04-03T09:13:11Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Given that Arrow is the preferred backend for a Dataset, what is a user supposed to do if they want concurrent reads, concurrent writes AND on-disk compression for a larger dataset?
Parquet would be the obvious answer except that there is no native support for writing sharded, parquet datasets concurrently [[1](https:... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7477/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7477/timeline | null | null | null | null | true | 110 |
https://api.github.com/repos/huggingface/datasets/issues/7476 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7476/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7476/comments | https://api.github.com/repos/huggingface/datasets/issues/7476/events | https://github.com/huggingface/datasets/pull/7476 | 2,946,997,924 | PR_kwDODunzps6QEbmO | 7,476 | Priotitize json | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-25T15:44:31Z | 2025-03-25T15:47:00Z | 2025-03-25T15:45:00Z | MEMBER | null | null | null | `datasets` should load the JSON data in https://huggingface.co/datasets/facebook/natural_reasoning, not the PDF | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7476/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7476/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7476.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7476",
"merged_at": "2025-03-25T15:45:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7476.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7475 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7475/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7475/comments | https://api.github.com/repos/huggingface/datasets/issues/7475/events | https://github.com/huggingface/datasets/issues/7475 | 2,946,640,570 | I_kwDODunzps6voiq6 | 7,475 | IterableDataset's state_dict shard_example_idx is always equal to the number of samples in a shard | {
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/bruno-hays/events{/privacy}",
"followers_url": "https://api.github.com/users/bruno-hays/followers",
"following_url": "https://api.github.com/users/bruno-hays/following{/other_user}",
"gists_url"... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/ot... | null | 8 | 2025-03-25T13:58:07Z | 2025-05-06T14:22:19Z | 2025-05-06T14:05:07Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I've noticed a strange behaviour with Iterable state_dict: the value of shard_example_idx is always equal to the amount of samples in a shard.
### Steps to reproduce the bug
I am reusing the example from the doc
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(6)}).to_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7475/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7475/timeline | null | completed | null | null | true | 42 |
https://api.github.com/repos/huggingface/datasets/issues/7474 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7474/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7474/comments | https://api.github.com/repos/huggingface/datasets/issues/7474/events | https://github.com/huggingface/datasets/pull/7474 | 2,945,066,258 | PR_kwDODunzps6P91lM | 7,474 | Remove conditions for Python < 3.9 | {
"avatar_url": "https://avatars.githubusercontent.com/u/17618148?v=4",
"events_url": "https://api.github.com/users/cyyever/events{/privacy}",
"followers_url": "https://api.github.com/users/cyyever/followers",
"following_url": "https://api.github.com/users/cyyever/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 3 | 2025-03-25T03:08:04Z | 2025-04-16T00:11:06Z | 2025-04-15T16:07:55Z | CONTRIBUTOR | null | null | null | This PR remove conditions for Python < 3.9. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7474/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7474/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7474.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7474",
"merged_at": "2025-04-15T16:07:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7474.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 21 |
https://api.github.com/repos/huggingface/datasets/issues/7473 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7473/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7473/comments | https://api.github.com/repos/huggingface/datasets/issues/7473/events | https://github.com/huggingface/datasets/issues/7473 | 2,939,034,643 | I_kwDODunzps6vLhwT | 7,473 | Webdataset data format problem | {
"avatar_url": "https://avatars.githubusercontent.com/u/1017189?v=4",
"events_url": "https://api.github.com/users/edmcman/events{/privacy}",
"followers_url": "https://api.github.com/users/edmcman/followers",
"following_url": "https://api.github.com/users/edmcman/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | 1 | 2025-03-21T17:23:52Z | 2025-03-21T19:19:58Z | 2025-03-21T19:19:58Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Please see https://huggingface.co/datasets/ejschwartz/idioms/discussions/1
Error code: FileFormatMismatchBetweenSplitsError
All three splits, train, test, and validation, use webdataset. But only the train split has more than one file. How can I force the other two splits to also be interpreted ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1017189?v=4",
"events_url": "https://api.github.com/users/edmcman/events{/privacy}",
"followers_url": "https://api.github.com/users/edmcman/followers",
"following_url": "https://api.github.com/users/edmcman/following{/other_user}",
"gists_url": "https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7473/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7473/timeline | null | completed | null | null | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7472 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7472/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7472/comments | https://api.github.com/repos/huggingface/datasets/issues/7472/events | https://github.com/huggingface/datasets/issues/7472 | 2,937,607,272 | I_kwDODunzps6vGFRo | 7,472 | Label casting during `map` process is canceled after the `map` process | {
"avatar_url": "https://avatars.githubusercontent.com/u/11156001?v=4",
"events_url": "https://api.github.com/users/yoshitomo-matsubara/events{/privacy}",
"followers_url": "https://api.github.com/users/yoshitomo-matsubara/followers",
"following_url": "https://api.github.com/users/yoshitomo-matsubara/following{/... | [] | closed | false | null | [] | null | 6 | 2025-03-21T07:56:22Z | 2025-04-10T05:11:15Z | 2025-04-10T05:11:14Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When preprocessing a multi-label dataset, I introduced a step to convert int labels to float labels as [BCEWithLogitsLoss](https://pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html) expects float labels and forward function of models in transformers package internally use `BCEWithL... | {
"avatar_url": "https://avatars.githubusercontent.com/u/11156001?v=4",
"events_url": "https://api.github.com/users/yoshitomo-matsubara/events{/privacy}",
"followers_url": "https://api.github.com/users/yoshitomo-matsubara/followers",
"following_url": "https://api.github.com/users/yoshitomo-matsubara/following{/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7472/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7472/timeline | null | completed | null | null | true | 19 |
https://api.github.com/repos/huggingface/datasets/issues/7471 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7471/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7471/comments | https://api.github.com/repos/huggingface/datasets/issues/7471/events | https://github.com/huggingface/datasets/issues/7471 | 2,937,530,069 | I_kwDODunzps6vFybV | 7,471 | Adding argument to `_get_data_files_patterns` | {
"avatar_url": "https://avatars.githubusercontent.com/u/34004152?v=4",
"events_url": "https://api.github.com/users/SangbumChoi/events{/privacy}",
"followers_url": "https://api.github.com/users/SangbumChoi/followers",
"following_url": "https://api.github.com/users/SangbumChoi/following{/other_user}",
"gists_u... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | 3 | 2025-03-21T07:17:53Z | 2025-03-27T12:30:52Z | 2025-03-26T07:26:27Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
How about adding if the user already know about the pattern?
https://github.com/huggingface/datasets/blob/a256b85cbc67aa3f0e75d32d6586afc507cf535b/src/datasets/data_files.py#L252
### Motivation
While using this load_dataset people might use 10M of images for the local files.
However, due to sear... | {
"avatar_url": "https://avatars.githubusercontent.com/u/34004152?v=4",
"events_url": "https://api.github.com/users/SangbumChoi/events{/privacy}",
"followers_url": "https://api.github.com/users/SangbumChoi/followers",
"following_url": "https://api.github.com/users/SangbumChoi/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7471/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7471/timeline | null | completed | null | null | true | 5 |
https://api.github.com/repos/huggingface/datasets/issues/7470 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7470/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7470/comments | https://api.github.com/repos/huggingface/datasets/issues/7470/events | https://github.com/huggingface/datasets/issues/7470 | 2,937,236,323 | I_kwDODunzps6vEqtj | 7,470 | Is it possible to shard a single-sharded IterableDataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_... | [] | closed | false | null | [] | null | 5 | 2025-03-21T04:33:37Z | 2025-05-09T22:51:46Z | 2025-03-26T06:49:28Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I thought https://github.com/huggingface/datasets/pull/7252 might be applicable but looking at it maybe not.
Say we have a process, eg. a database query, that can return data in slightly different order each time. So, the initial query needs to be run by a single thread (not to mention running multiple times incurs mo... | {
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7470/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7470/timeline | null | completed | null | null | true | 5 |
https://api.github.com/repos/huggingface/datasets/issues/7469 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7469/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7469/comments | https://api.github.com/repos/huggingface/datasets/issues/7469/events | https://github.com/huggingface/datasets/issues/7469 | 2,936,606,080 | I_kwDODunzps6vCQ2A | 7,469 | Custom split name with the web interface | {
"avatar_url": "https://avatars.githubusercontent.com/u/15141326?v=4",
"events_url": "https://api.github.com/users/vince62s/events{/privacy}",
"followers_url": "https://api.github.com/users/vince62s/followers",
"following_url": "https://api.github.com/users/vince62s/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | 0 | 2025-03-20T20:45:59Z | 2025-03-21T07:20:37Z | 2025-03-21T07:20:37Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
According the doc here: https://huggingface.co/docs/hub/datasets-file-names-and-splits#custom-split-name
it should infer the split name from the subdir of data or the beg of the name of the files in data.
When doing this manually through web upload it does not work. it uses "train" as a unique spl... | {
"avatar_url": "https://avatars.githubusercontent.com/u/15141326?v=4",
"events_url": "https://api.github.com/users/vince62s/events{/privacy}",
"followers_url": "https://api.github.com/users/vince62s/followers",
"following_url": "https://api.github.com/users/vince62s/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7469/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7469/timeline | null | completed | null | null | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7468 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7468/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7468/comments | https://api.github.com/repos/huggingface/datasets/issues/7468/events | https://github.com/huggingface/datasets/issues/7468 | 2,934,094,103 | I_kwDODunzps6u4rkX | 7,468 | function `load_dataset` can't solve folder path with regex characters like "[]" | {
"avatar_url": "https://avatars.githubusercontent.com/u/89294013?v=4",
"events_url": "https://api.github.com/users/Hpeox/events{/privacy}",
"followers_url": "https://api.github.com/users/Hpeox/followers",
"following_url": "https://api.github.com/users/Hpeox/following{/other_user}",
"gists_url": "https://api.... | [] | open | false | null | [] | null | 1 | 2025-03-20T05:21:59Z | 2025-03-25T10:18:12Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When using the `load_dataset` function with a folder path containing regex special characters (such as "[]"), the issue occurs due to how the path is handled in the `resolve_pattern` function. This function passes the unprocessed path directly to `AbstractFileSystem.glob`, which supports regular e... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7468/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7468/timeline | null | null | null | null | true | 116 |
https://api.github.com/repos/huggingface/datasets/issues/7467 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7467/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7467/comments | https://api.github.com/repos/huggingface/datasets/issues/7467/events | https://github.com/huggingface/datasets/issues/7467 | 2,930,067,107 | I_kwDODunzps6upUaj | 7,467 | load_dataset with streaming hangs on parquet datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/10550252?v=4",
"events_url": "https://api.github.com/users/The0nix/events{/privacy}",
"followers_url": "https://api.github.com/users/The0nix/followers",
"following_url": "https://api.github.com/users/The0nix/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | 1 | 2025-03-18T23:33:54Z | 2025-03-25T10:28:04Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When I try to load a dataset with parquet files (e.g. "bigcode/the-stack") the dataset loads, but python interpreter can't exit and hangs
### Steps to reproduce the bug
```python3
import datasets
print('Start')
dataset = datasets.load_dataset("bigcode/the-stack", data_dir="data/yaml", streaming... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7467/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7467/timeline | null | null | null | null | true | 117 |
https://api.github.com/repos/huggingface/datasets/issues/7466 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7466/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7466/comments | https://api.github.com/repos/huggingface/datasets/issues/7466/events | https://github.com/huggingface/datasets/pull/7466 | 2,928,661,327 | PR_kwDODunzps6PHQyp | 7,466 | Fix local pdf loading | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-18T14:09:06Z | 2025-03-18T14:11:52Z | 2025-03-18T14:09:21Z | MEMBER | null | null | null | fir this error when accessing a local pdf
```
File ~/.pyenv/versions/3.12.2/envs/hf-datasets/lib/python3.12/site-packages/pdfminer/psparser.py:220, in PSBaseParser.seek(self, pos)
218 """Seeks the parser to the given position."""
219 log.debug("seek: %r", pos)
--> 220 self.fp.seek(pos)
221 # reset t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7466/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7466/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7466.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7466",
"merged_at": "2025-03-18T14:09:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7466.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7464 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7464/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7464/comments | https://api.github.com/repos/huggingface/datasets/issues/7464/events | https://github.com/huggingface/datasets/pull/7464 | 2,926,478,838 | PR_kwDODunzps6PABJa | 7,464 | Minor fix for metadata files in extension counter | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-17T21:57:11Z | 2025-03-18T15:21:43Z | 2025-03-18T15:21:41Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7464/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7464/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7464.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7464",
"merged_at": "2025-03-18T15:21:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7464.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7463 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7463/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7463/comments | https://api.github.com/repos/huggingface/datasets/issues/7463/events | https://github.com/huggingface/datasets/pull/7463 | 2,925,924,452 | PR_kwDODunzps6O-I6K | 7,463 | Adds EXR format to store depth images in float32 | {
"avatar_url": "https://avatars.githubusercontent.com/u/4803565?v=4",
"events_url": "https://api.github.com/users/ducha-aiki/events{/privacy}",
"followers_url": "https://api.github.com/users/ducha-aiki/followers",
"following_url": "https://api.github.com/users/ducha-aiki/following{/other_user}",
"gists_url":... | [] | open | false | null | [] | null | 3 | 2025-03-17T17:42:40Z | 2025-04-02T12:33:39Z | null | NONE | null | null | null | This PR adds the EXR feature to store depth images (or can be normals, etc) in float32.
It relies on [openexr_numpy](https://github.com/martinResearch/openexr_numpy/tree/main) to manipulate EXR images.
| null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7463/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7463/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7463.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7463",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7463.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7463"
} | true | 118 |
https://api.github.com/repos/huggingface/datasets/issues/7462 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7462/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7462/comments | https://api.github.com/repos/huggingface/datasets/issues/7462/events | https://github.com/huggingface/datasets/pull/7462 | 2,925,612,945 | PR_kwDODunzps6O9EA1 | 7,462 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-17T16:00:53Z | 2025-03-17T16:03:31Z | 2025-03-17T16:01:08Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7462/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7462/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7462.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7462",
"merged_at": "2025-03-17T16:01:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7462.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7461 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7461/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7461/comments | https://api.github.com/repos/huggingface/datasets/issues/7461/events | https://github.com/huggingface/datasets/issues/7461 | 2,925,608,123 | I_kwDODunzps6uYTy7 | 7,461 | List of images behave differently on IterableDataset and Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1288009?v=4",
"events_url": "https://api.github.com/users/FredrikNoren/events{/privacy}",
"followers_url": "https://api.github.com/users/FredrikNoren/followers",
"following_url": "https://api.github.com/users/FredrikNoren/following{/other_user}",
"gists... | [] | closed | false | null | [] | null | 2 | 2025-03-17T15:59:23Z | 2025-03-18T08:57:17Z | 2025-03-18T08:57:16Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
This code:
```python
def train_iterable_gen():
images = np.array(load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg").resize((128, 128)))
yield {
"images": np.expand_dims(images, axis=0),
"messages": [
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1288009?v=4",
"events_url": "https://api.github.com/users/FredrikNoren/events{/privacy}",
"followers_url": "https://api.github.com/users/FredrikNoren/followers",
"following_url": "https://api.github.com/users/FredrikNoren/following{/other_user}",
"gists... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7461/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7461/timeline | null | completed | null | null | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7460 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7460/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7460/comments | https://api.github.com/repos/huggingface/datasets/issues/7460/events | https://github.com/huggingface/datasets/pull/7460 | 2,925,605,865 | PR_kwDODunzps6O9Ccc | 7,460 | release: 3.4.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-17T15:58:31Z | 2025-03-17T16:01:14Z | 2025-03-17T15:59:19Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7460/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7460/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7460.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7460",
"merged_at": "2025-03-17T15:59:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7460.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7459 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7459/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7459/comments | https://api.github.com/repos/huggingface/datasets/issues/7459/events | https://github.com/huggingface/datasets/pull/7459 | 2,925,491,766 | PR_kwDODunzps6O8pWp | 7,459 | Fix data_files filtering | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-17T15:20:21Z | 2025-03-17T15:25:56Z | 2025-03-17T15:25:54Z | MEMBER | null | null | null | close https://github.com/huggingface/datasets/issues/7458 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7459/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7459/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7459.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7459",
"merged_at": "2025-03-17T15:25:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7459.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7458 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7458/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7458/comments | https://api.github.com/repos/huggingface/datasets/issues/7458/events | https://github.com/huggingface/datasets/issues/7458 | 2,925,403,528 | I_kwDODunzps6uXh2I | 7,458 | Loading the `laion/filtered-wit` dataset in streaming mode fails on v3.4.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/23343961?v=4",
"events_url": "https://api.github.com/users/nikita-savelyevv/events{/privacy}",
"followers_url": "https://api.github.com/users/nikita-savelyevv/followers",
"following_url": "https://api.github.com/users/nikita-savelyevv/following{/other_use... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | 1 | 2025-03-17T14:54:02Z | 2025-03-17T16:02:04Z | 2025-03-17T15:25:55Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Loading https://huggingface.co/datasets/laion/filtered-wit in streaming mode fails after update to `datasets==3.4.0`. The dataset loads fine on v3.3.2.
### Steps to reproduce the bug
Steps to reproduce:
```
pip install datastes==3.4.0
python -c "from datasets import load_dataset; load_dataset('l... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7458/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7458/timeline | null | completed | null | null | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7457/comments | https://api.github.com/repos/huggingface/datasets/issues/7457/events | https://github.com/huggingface/datasets/issues/7457 | 2,924,886,467 | I_kwDODunzps6uVjnD | 7,457 | Document the HF_DATASETS_CACHE env variable | {
"avatar_url": "https://avatars.githubusercontent.com/u/92166725?v=4",
"events_url": "https://api.github.com/users/LSerranoPEReN/events{/privacy}",
"followers_url": "https://api.github.com/users/LSerranoPEReN/followers",
"following_url": "https://api.github.com/users/LSerranoPEReN/following{/other_user}",
"g... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/ot... | null | 4 | 2025-03-17T12:24:50Z | 2025-05-06T15:54:39Z | 2025-05-06T15:54:39Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Hello,
I have a use case where my team is sharing models and dataset in shared directory to avoid duplication.
I noticed that the [cache documentation for datasets](https://huggingface.co/docs/datasets/main/en/cache) only mention the `HF_HOME` environment variable but never the `HF_DATASETS_CACHE`... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7457/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7457/timeline | null | completed | null | null | true | 50 |
https://api.github.com/repos/huggingface/datasets/issues/7456 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7456/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7456/comments | https://api.github.com/repos/huggingface/datasets/issues/7456/events | https://github.com/huggingface/datasets/issues/7456 | 2,922,676,278 | I_kwDODunzps6uNIA2 | 7,456 | .add_faiss_index and .add_elasticsearch_index returns ImportError at Google Colab | {
"avatar_url": "https://avatars.githubusercontent.com/u/109490785?v=4",
"events_url": "https://api.github.com/users/MapleBloom/events{/privacy}",
"followers_url": "https://api.github.com/users/MapleBloom/followers",
"following_url": "https://api.github.com/users/MapleBloom/following{/other_user}",
"gists_url... | [] | open | false | null | [] | null | 6 | 2025-03-16T00:51:49Z | 2025-03-17T15:57:19Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
At Google Colab
```!pip install faiss-cpu``` works
```import faiss``` no error
but
```embeddings_dataset.add_faiss_index(column='embeddings')```
returns
```
[/usr/local/lib/python3.11/dist-packages/datasets/search.py](https://localhost:8080/#) in init(self, device, string_factory, metric_type, cus... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7456/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7456/timeline | null | null | null | null | true | 120 |
https://api.github.com/repos/huggingface/datasets/issues/7455 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7455/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7455/comments | https://api.github.com/repos/huggingface/datasets/issues/7455/events | https://github.com/huggingface/datasets/issues/7455 | 2,921,933,250 | I_kwDODunzps6uKSnC | 7,455 | Problems with local dataset after upgrade from 3.3.2 to 3.4.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/60151338?v=4",
"events_url": "https://api.github.com/users/andjoer/events{/privacy}",
"followers_url": "https://api.github.com/users/andjoer/followers",
"following_url": "https://api.github.com/users/andjoer/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | 1 | 2025-03-15T09:22:50Z | 2025-03-17T16:20:43Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I was not able to open a local saved dataset anymore that was created using an older datasets version after the upgrade yesterday from datasets 3.3.2 to 3.4.0
The traceback is
```
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/datasets/packaged_modules/arrow/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7455/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7455/timeline | null | null | null | null | true | 121 |
https://api.github.com/repos/huggingface/datasets/issues/7454 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7454/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7454/comments | https://api.github.com/repos/huggingface/datasets/issues/7454/events | https://github.com/huggingface/datasets/pull/7454 | 2,920,760,793 | PR_kwDODunzps6Os6bx | 7,454 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-14T16:48:19Z | 2025-03-14T16:50:31Z | 2025-03-14T16:48:28Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7454/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7454/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7454.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7454",
"merged_at": "2025-03-14T16:48:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7454.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7453 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7453/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7453/comments | https://api.github.com/repos/huggingface/datasets/issues/7453/events | https://github.com/huggingface/datasets/pull/7453 | 2,920,719,503 | PR_kwDODunzps6OsxR1 | 7,453 | release: 3.4.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-14T16:30:45Z | 2025-03-14T16:38:10Z | 2025-03-14T16:38:08Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7453/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7453/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7453.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7453",
"merged_at": "2025-03-14T16:38:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7453.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7452 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7452/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7452/comments | https://api.github.com/repos/huggingface/datasets/issues/7452/events | https://github.com/huggingface/datasets/pull/7452 | 2,920,354,783 | PR_kwDODunzps6Orhw4 | 7,452 | minor docs changes | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-14T14:14:04Z | 2025-03-14T14:16:38Z | 2025-03-14T14:14:20Z | MEMBER | null | null | null | before the release | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7452/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7452/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7452.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7452",
"merged_at": "2025-03-14T14:14:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7452.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7451 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7451/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7451/comments | https://api.github.com/repos/huggingface/datasets/issues/7451/events | https://github.com/huggingface/datasets/pull/7451 | 2,919,835,663 | PR_kwDODunzps6OpwDz | 7,451 | Fix resuming after `ds.set_epoch(new_epoch)` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-14T10:31:25Z | 2025-03-14T10:50:11Z | 2025-03-14T10:50:09Z | MEMBER | null | null | null | close https://github.com/huggingface/datasets/issues/7447 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7451/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7451/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7451.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7451",
"merged_at": "2025-03-14T10:50:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7451.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7450 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7450/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7450/comments | https://api.github.com/repos/huggingface/datasets/issues/7450/events | https://github.com/huggingface/datasets/pull/7450 | 2,916,681,414 | PR_kwDODunzps6OfMKs | 7,450 | Add IterableDataset.decode with multithreading | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-13T10:41:35Z | 2025-03-14T10:35:37Z | 2025-03-14T10:35:35Z | MEMBER | null | null | null | Useful for dataset streaming for multimodal datasets, and especially for lerobot.
It speeds up streaming up to 20 times.
When decoding is enabled (default), media types are decoded:
* audio -> dict of "array" and "sampling_rate" and "path"
* image -> PIL.Image
* video -> torchvision.io.VideoReader
You can e... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7450/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7450/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7450.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7450",
"merged_at": "2025-03-14T10:35:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7450.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7449 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7449/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7449/comments | https://api.github.com/repos/huggingface/datasets/issues/7449/events | https://github.com/huggingface/datasets/issues/7449 | 2,916,235,092 | I_kwDODunzps6t0jdU | 7,449 | Cannot load data with different schemas from different parquet files | {
"avatar_url": "https://avatars.githubusercontent.com/u/39846316?v=4",
"events_url": "https://api.github.com/users/li-plus/events{/privacy}",
"followers_url": "https://api.github.com/users/li-plus/followers",
"following_url": "https://api.github.com/users/li-plus/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 2 | 2025-03-13T08:14:49Z | 2025-03-17T07:27:48Z | 2025-03-17T07:27:46Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Cannot load samples with optional fields from different files. The schema cannot be correctly derived.
### Steps to reproduce the bug
When I place two samples with an optional field `some_extra_field` within a single parquet file, it can be loaded via `load_dataset`.
```python
import pandas as ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/39846316?v=4",
"events_url": "https://api.github.com/users/li-plus/events{/privacy}",
"followers_url": "https://api.github.com/users/li-plus/followers",
"following_url": "https://api.github.com/users/li-plus/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7449/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7449/timeline | null | completed | null | null | true | 3 |
https://api.github.com/repos/huggingface/datasets/issues/7448 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7448/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7448/comments | https://api.github.com/repos/huggingface/datasets/issues/7448/events | https://github.com/huggingface/datasets/issues/7448 | 2,916,025,762 | I_kwDODunzps6tzwWi | 7,448 | `datasets.disable_caching` doesn't work | {
"avatar_url": "https://avatars.githubusercontent.com/u/35629974?v=4",
"events_url": "https://api.github.com/users/UCC-team/events{/privacy}",
"followers_url": "https://api.github.com/users/UCC-team/followers",
"following_url": "https://api.github.com/users/UCC-team/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | 2 | 2025-03-13T06:40:12Z | 2025-03-22T04:37:07Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | When I use `Dataset.from_generator(my_gen)` to load my dataset, it simply skips my changes to the generator function.
I tried `datasets.disable_caching`, but it doesn't work! | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7448/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7448/timeline | null | null | null | null | true | 123 |
https://api.github.com/repos/huggingface/datasets/issues/7447 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7447/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7447/comments | https://api.github.com/repos/huggingface/datasets/issues/7447/events | https://github.com/huggingface/datasets/issues/7447 | 2,915,233,248 | I_kwDODunzps6twu3g | 7,447 | Epochs shortened after resuming mid-epoch with Iterable dataset+StatefulDataloader(persistent_workers=True) | {
"avatar_url": "https://avatars.githubusercontent.com/u/4356534?v=4",
"events_url": "https://api.github.com/users/dhruvdcoder/events{/privacy}",
"followers_url": "https://api.github.com/users/dhruvdcoder/followers",
"following_url": "https://api.github.com/users/dhruvdcoder/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | 6 | 2025-03-12T21:41:05Z | 2025-07-09T23:04:57Z | 2025-03-14T10:50:10Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When `torchdata.stateful_dataloader.StatefulDataloader(persistent_workers=True)` the epochs after resuming only iterate through the examples that were left in the epoch when the training was interrupted. For example, in the script below training is interrupted on step 124 (epoch 1) when 3 batches ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7447/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7447/timeline | null | completed | null | null | true | 1 |
https://api.github.com/repos/huggingface/datasets/issues/7446 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7446/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7446/comments | https://api.github.com/repos/huggingface/datasets/issues/7446/events | https://github.com/huggingface/datasets/issues/7446 | 2,913,050,552 | I_kwDODunzps6toZ-4 | 7,446 | pyarrow.lib.ArrowTypeError: Expected dict key of type str or bytes, got 'int' | {
"avatar_url": "https://avatars.githubusercontent.com/u/88258534?v=4",
"events_url": "https://api.github.com/users/rangehow/events{/privacy}",
"followers_url": "https://api.github.com/users/rangehow/followers",
"following_url": "https://api.github.com/users/rangehow/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | 2 | 2025-03-12T07:48:37Z | 2025-07-04T05:14:45Z | 2025-07-04T05:14:45Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
A dict with its keys are all str but get following error
```python
test_data=[{'input_ids':[1,2,3],'labels':[[Counter({2:1})]]}]
dataset = datasets.Dataset.from_list(test_data)
```
```bash
pyarrow.lib.ArrowTypeError: Expected dict key of type str or bytes, got 'int'
```
### Steps to reproduce the... | {
"avatar_url": "https://avatars.githubusercontent.com/u/88258534?v=4",
"events_url": "https://api.github.com/users/rangehow/events{/privacy}",
"followers_url": "https://api.github.com/users/rangehow/followers",
"following_url": "https://api.github.com/users/rangehow/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7446/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7446/timeline | null | completed | null | null | true | 113 |
https://api.github.com/repos/huggingface/datasets/issues/7445 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7445/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7445/comments | https://api.github.com/repos/huggingface/datasets/issues/7445/events | https://github.com/huggingface/datasets/pull/7445 | 2,911,507,923 | PR_kwDODunzps6ONygU | 7,445 | Fix small bugs with async map | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-03-11T18:30:57Z | 2025-03-13T10:38:03Z | 2025-03-13T10:37:58Z | MEMBER | null | null | null | helpful for the next PR to enable parallel image/audio/video decoding and make multimodal datasets go brr (e.g. for lerobot)
- fix with_indices
- fix resuming with save_state_dict() / load_state_dict() - omg that wasn't easy
- remove unnecessary decoding in map() to enable parallelism in FormattedExampleIterable l... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7445/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7445/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7445.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7445",
"merged_at": "2025-03-13T10:37:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7445.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 1 |
https://api.github.com/repos/huggingface/datasets/issues/7444 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7444/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7444/comments | https://api.github.com/repos/huggingface/datasets/issues/7444/events | https://github.com/huggingface/datasets/issues/7444 | 2,911,202,445 | I_kwDODunzps6thWyN | 7,444 | Excessive warnings when resuming an IterableDataset+buffered shuffle+DDP. | {
"avatar_url": "https://avatars.githubusercontent.com/u/4356534?v=4",
"events_url": "https://api.github.com/users/dhruvdcoder/events{/privacy}",
"followers_url": "https://api.github.com/users/dhruvdcoder/followers",
"following_url": "https://api.github.com/users/dhruvdcoder/following{/other_user}",
"gists_ur... | [] | open | false | null | [] | null | 1 | 2025-03-11T16:34:39Z | 2025-05-13T09:41:03Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I have a large dataset that I shared into 1024 shards and save on the disk during pre-processing. During training, I load the dataset using load_from_disk() and convert it into an iterable dataset, shuffle it and split the shards to different DDP nodes using the recommended method.
However, when ... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7444/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7444/timeline | null | null | null | null | true | 124 |
https://api.github.com/repos/huggingface/datasets/issues/7443 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7443/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7443/comments | https://api.github.com/repos/huggingface/datasets/issues/7443/events | https://github.com/huggingface/datasets/issues/7443 | 2,908,585,656 | I_kwDODunzps6tXX64 | 7,443 | index error when num_shards > len(dataset) | {
"avatar_url": "https://avatars.githubusercontent.com/u/17934496?v=4",
"events_url": "https://api.github.com/users/eminorhan/events{/privacy}",
"followers_url": "https://api.github.com/users/eminorhan/followers",
"following_url": "https://api.github.com/users/eminorhan/following{/other_user}",
"gists_url": "... | [] | open | false | null | [] | null | 1 | 2025-03-10T22:40:59Z | 2025-03-10T23:43:08Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | In `ds.push_to_hub()` and `ds.save_to_disk()`, `num_shards` must be smaller than or equal to the number of rows in the dataset, but currently this is not checked anywhere inside these functions. Attempting to invoke these functions with `num_shards > len(dataset)` should raise an informative `ValueError`.
I frequently... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7443/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7443/timeline | null | null | null | null | true | 125 |
https://api.github.com/repos/huggingface/datasets/issues/7442 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7442/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7442/comments | https://api.github.com/repos/huggingface/datasets/issues/7442/events | https://github.com/huggingface/datasets/issues/7442 | 2,905,543,017 | I_kwDODunzps6tLxFp | 7,442 | Flexible Loader | {
"avatar_url": "https://avatars.githubusercontent.com/u/13894030?v=4",
"events_url": "https://api.github.com/users/dipta007/events{/privacy}",
"followers_url": "https://api.github.com/users/dipta007/followers",
"following_url": "https://api.github.com/users/dipta007/following{/other_user}",
"gists_url": "htt... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 3 | 2025-03-09T16:55:03Z | 2025-03-27T23:58:17Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Can we have a utility function that will use `load_from_disk` when given the local path and `load_dataset` if given an HF dataset?
It can be something as simple as this one:
```
def load_hf_dataset(path_or_name):
if os.path.exists(path_or_name):
return load_from_disk(path_or_name)
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7442/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7442/timeline | null | null | null | null | true | 126 |
https://api.github.com/repos/huggingface/datasets/issues/7441 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7441/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7441/comments | https://api.github.com/repos/huggingface/datasets/issues/7441/events | https://github.com/huggingface/datasets/issues/7441 | 2,904,702,329 | I_kwDODunzps6tIj15 | 7,441 | `drop_last_batch` does not drop the last batch using IterableDataset + interleave_datasets + multi_worker | {
"avatar_url": "https://avatars.githubusercontent.com/u/4197249?v=4",
"events_url": "https://api.github.com/users/memray/events{/privacy}",
"followers_url": "https://api.github.com/users/memray/followers",
"following_url": "https://api.github.com/users/memray/following{/other_user}",
"gists_url": "https://ap... | [] | open | false | null | [] | null | 2 | 2025-03-08T10:28:44Z | 2025-03-09T21:27:33Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
See the script below
`drop_last_batch=True` is defined using map() for each dataset.
The last batch for each dataset is expected to be dropped, id 21-25.
The code behaves as expected when num_workers=0 or 1.
When using num_workers>1, 'a-11', 'b-11', 'a-12', 'b-12' are gone and instead 21 and 22 a... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7441/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7441/timeline | null | null | null | null | true | 128 |
https://api.github.com/repos/huggingface/datasets/issues/7440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7440/comments | https://api.github.com/repos/huggingface/datasets/issues/7440/events | https://github.com/huggingface/datasets/issues/7440 | 2,903,740,662 | I_kwDODunzps6tE5D2 | 7,440 | IterableDataset raises FileNotFoundError instead of retrying | {
"avatar_url": "https://avatars.githubusercontent.com/u/145220868?v=4",
"events_url": "https://api.github.com/users/bauwenst/events{/privacy}",
"followers_url": "https://api.github.com/users/bauwenst/followers",
"following_url": "https://api.github.com/users/bauwenst/following{/other_user}",
"gists_url": "ht... | [] | open | false | null | [] | null | 6 | 2025-03-07T19:14:18Z | 2025-04-17T23:40:35Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
In https://github.com/huggingface/datasets/issues/6843 it was noted that the streaming feature of `datasets` is highly susceptible to outages and doesn't back off for long (or even *at all*).
I was training a model while streaming SlimPajama and training crashed with a `FileNotFoundError`. I can ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7440/timeline | null | null | null | null | true | 128 |
https://api.github.com/repos/huggingface/datasets/issues/7439 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7439/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7439/comments | https://api.github.com/repos/huggingface/datasets/issues/7439/events | https://github.com/huggingface/datasets/pull/7439 | 2,900,143,289 | PR_kwDODunzps6NoCdD | 7,439 | Fix multi gpu process example | {
"avatar_url": "https://avatars.githubusercontent.com/u/46050679?v=4",
"events_url": "https://api.github.com/users/SwayStar123/events{/privacy}",
"followers_url": "https://api.github.com/users/SwayStar123/followers",
"following_url": "https://api.github.com/users/SwayStar123/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | 1 | 2025-03-06T11:29:19Z | 2025-03-06T17:07:28Z | 2025-03-06T17:06:38Z | NONE | null | null | null | to is not an inplace function.
But i am not sure about this code anyway, i think this is modifying the global variable `model` everytime the function is called? Which is on every batch? So it is juggling the same model on every gpu right? Isnt that very inefficient? | {
"avatar_url": "https://avatars.githubusercontent.com/u/46050679?v=4",
"events_url": "https://api.github.com/users/SwayStar123/events{/privacy}",
"followers_url": "https://api.github.com/users/SwayStar123/followers",
"following_url": "https://api.github.com/users/SwayStar123/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7439/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7439/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7439.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7439",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7439.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7439"
} | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7438 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7438/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7438/comments | https://api.github.com/repos/huggingface/datasets/issues/7438/events | https://github.com/huggingface/datasets/pull/7438 | 2,899,209,484 | PR_kwDODunzps6Nk37h | 7,438 | Allow dataset row indexing with np.int types (#7423) | {
"avatar_url": "https://avatars.githubusercontent.com/u/35470740?v=4",
"events_url": "https://api.github.com/users/DavidRConnell/events{/privacy}",
"followers_url": "https://api.github.com/users/DavidRConnell/followers",
"following_url": "https://api.github.com/users/DavidRConnell/following{/other_user}",
"g... | [] | open | false | null | [] | null | 0 | 2025-03-06T03:10:43Z | 2025-03-06T03:10:43Z | null | NONE | null | null | null | @lhoestq
Proposed fix for #7423. Added a couple simple tests as requested. I had some test failures related to Java and pyspark even when installing with dev but these don't seem to be related to the changes here and fail for me even on clean main.
The typeerror raised when using the wrong type is: "Wrong key type... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7438/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7438/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7438.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7438",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7438.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7438"
} | true | 130 |
https://api.github.com/repos/huggingface/datasets/issues/7437 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7437/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7437/comments | https://api.github.com/repos/huggingface/datasets/issues/7437/events | https://github.com/huggingface/datasets/pull/7437 | 2,899,104,679 | PR_kwDODunzps6Nkhla | 7,437 | Use pyupgrade --py39-plus for remaining files | {
"avatar_url": "https://avatars.githubusercontent.com/u/17618148?v=4",
"events_url": "https://api.github.com/users/cyyever/events{/privacy}",
"followers_url": "https://api.github.com/users/cyyever/followers",
"following_url": "https://api.github.com/users/cyyever/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | 0 | 2025-03-06T02:12:25Z | 2025-04-15T14:47:54Z | null | CONTRIBUTOR | null | null | null | This work follows #7428. And "requires-python" is set in pyproject.toml | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7437/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7437/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7437.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7437",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7437.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7437"
} | true | 130 |
https://api.github.com/repos/huggingface/datasets/issues/7436 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7436/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7436/comments | https://api.github.com/repos/huggingface/datasets/issues/7436/events | https://github.com/huggingface/datasets/pull/7436 | 2,898,385,725 | PR_kwDODunzps6NiArv | 7,436 | chore: fix typos | {
"avatar_url": "https://avatars.githubusercontent.com/u/35225576?v=4",
"events_url": "https://api.github.com/users/afuetterer/events{/privacy}",
"followers_url": "https://api.github.com/users/afuetterer/followers",
"following_url": "https://api.github.com/users/afuetterer/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | 0 | 2025-03-05T20:17:54Z | 2025-04-28T14:00:09Z | 2025-04-28T13:51:26Z | CONTRIBUTOR | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7436/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7436/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7436.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7436",
"merged_at": "2025-04-28T13:51:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7436.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 53 |
https://api.github.com/repos/huggingface/datasets/issues/7435 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7435/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7435/comments | https://api.github.com/repos/huggingface/datasets/issues/7435/events | https://github.com/huggingface/datasets/pull/7435 | 2,895,536,956 | PR_kwDODunzps6NYUnr | 7,435 | Refactor `string_to_dict` to return `None` if there is no match instead of raising `ValueError` | {
"avatar_url": "https://avatars.githubusercontent.com/u/27844407?v=4",
"events_url": "https://api.github.com/users/ringohoffman/events{/privacy}",
"followers_url": "https://api.github.com/users/ringohoffman/followers",
"following_url": "https://api.github.com/users/ringohoffman/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | 8 | 2025-03-04T22:01:20Z | 2025-03-12T16:52:00Z | 2025-03-12T16:52:00Z | NONE | null | null | null | Making this change, as encouraged here:
* https://github.com/huggingface/datasets/pull/7434#discussion_r1979933054
instead of having the pattern of using `try`-`except` to handle when there is no match, we can instead check if the return value is `None`; we can also assert that the return value should not be `Non... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7435/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7435/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7435.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7435",
"merged_at": "2025-03-12T16:51:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7435.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 7 |
https://api.github.com/repos/huggingface/datasets/issues/7434 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7434/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7434/comments | https://api.github.com/repos/huggingface/datasets/issues/7434/events | https://github.com/huggingface/datasets/pull/7434 | 2,893,075,908 | PR_kwDODunzps6NP-vn | 7,434 | Refactor `Dataset.map` to reuse cache files mapped with different `num_proc` | {
"avatar_url": "https://avatars.githubusercontent.com/u/27844407?v=4",
"events_url": "https://api.github.com/users/ringohoffman/events{/privacy}",
"followers_url": "https://api.github.com/users/ringohoffman/followers",
"following_url": "https://api.github.com/users/ringohoffman/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | 10 | 2025-03-04T06:12:37Z | 2025-05-14T10:45:10Z | 2025-05-12T15:14:08Z | NONE | null | null | null | Fixes #7433
This refactor unifies `num_proc is None or num_proc == 1` and `num_proc > 1`; instead of handling them completely separately where one uses a list of kwargs and shards and the other just uses a single set of kwargs and `self`, by wrapping the `num_proc == 1` case in a list and making the difference just ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7434/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7434/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7434.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7434",
"merged_at": "2025-05-12T15:14:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7434.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 69 |
https://api.github.com/repos/huggingface/datasets/issues/7433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7433/comments | https://api.github.com/repos/huggingface/datasets/issues/7433/events | https://github.com/huggingface/datasets/issues/7433 | 2,890,240,400 | I_kwDODunzps6sRZGQ | 7,433 | `Dataset.map` ignores existing caches and remaps when ran with different `num_proc` | {
"avatar_url": "https://avatars.githubusercontent.com/u/27844407?v=4",
"events_url": "https://api.github.com/users/ringohoffman/events{/privacy}",
"followers_url": "https://api.github.com/users/ringohoffman/followers",
"following_url": "https://api.github.com/users/ringohoffman/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | 2 | 2025-03-03T05:51:26Z | 2025-05-12T15:14:09Z | 2025-05-12T15:14:09Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
If you `map` a dataset and save it to a specific `cache_file_name` with a specific `num_proc`, and then call map again with that same existing `cache_file_name` but a different `num_proc`, the dataset will be re-mapped.
### Steps to reproduce the bug
1. Download a dataset
```python
import datase... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7433/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7433/timeline | null | completed | null | null | true | 70 |
https://api.github.com/repos/huggingface/datasets/issues/7432 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7432/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7432/comments | https://api.github.com/repos/huggingface/datasets/issues/7432/events | https://github.com/huggingface/datasets/pull/7432 | 2,887,717,289 | PR_kwDODunzps6M-DI0 | 7,432 | Fix type annotation | {
"avatar_url": "https://avatars.githubusercontent.com/u/730137?v=4",
"events_url": "https://api.github.com/users/NeilGirdhar/events{/privacy}",
"followers_url": "https://api.github.com/users/NeilGirdhar/followers",
"following_url": "https://api.github.com/users/NeilGirdhar/following{/other_user}",
"gists_url... | [] | closed | false | null | [] | null | 1 | 2025-02-28T17:28:20Z | 2025-03-04T15:53:03Z | 2025-03-04T15:53:03Z | CONTRIBUTOR | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7432/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7432/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7432.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7432",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7432.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7432"
} | true | 3 |
https://api.github.com/repos/huggingface/datasets/issues/7431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7431/comments | https://api.github.com/repos/huggingface/datasets/issues/7431/events | https://github.com/huggingface/datasets/issues/7431 | 2,887,244,074 | I_kwDODunzps6sF9kq | 7,431 | Issues with large Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/106806889?v=4",
"events_url": "https://api.github.com/users/nikitabelooussovbtis/events{/privacy}",
"followers_url": "https://api.github.com/users/nikitabelooussovbtis/followers",
"following_url": "https://api.github.com/users/nikitabelooussovbtis/followi... | [] | open | false | null | [] | null | 4 | 2025-02-28T14:05:22Z | 2025-03-04T15:02:26Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
If the coco annotation file is too large the dataset will not be able to load it, not entirely sure were the issue is but I am guessing it is due to the code trying to load it all as one line into a dataframe. This was for object detections.
My current work around is the following code but would ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7431/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7431/timeline | null | null | null | null | true | 135 |
https://api.github.com/repos/huggingface/datasets/issues/7430 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7430/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7430/comments | https://api.github.com/repos/huggingface/datasets/issues/7430/events | https://github.com/huggingface/datasets/issues/7430 | 2,886,922,573 | I_kwDODunzps6sEvFN | 7,430 | Error in code "Time to slice and dice" from course "NLP Course" | {
"avatar_url": "https://avatars.githubusercontent.com/u/122965300?v=4",
"events_url": "https://api.github.com/users/Yurkmez/events{/privacy}",
"followers_url": "https://api.github.com/users/Yurkmez/followers",
"following_url": "https://api.github.com/users/Yurkmez/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | 2 | 2025-02-28T11:36:10Z | 2025-03-05T11:32:47Z | 2025-03-03T17:52:15Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When we execute code
```
frequencies = (
train_df["condition"]
.value_counts()
.to_frame()
.reset_index()
.rename(columns={"index": "condition", "condition": "frequency"})
)
frequencies.head()
```
answer should be like this
condition | frequency
birth control | 27655
dep... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7430/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7430/timeline | null | completed | null | null | true | 3 |
https://api.github.com/repos/huggingface/datasets/issues/7429 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7429/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7429/comments | https://api.github.com/repos/huggingface/datasets/issues/7429/events | https://github.com/huggingface/datasets/pull/7429 | 2,886,806,513 | PR_kwDODunzps6M67Jd | 7,429 | Improved type annotation | {
"avatar_url": "https://avatars.githubusercontent.com/u/45285915?v=4",
"events_url": "https://api.github.com/users/saiden89/events{/privacy}",
"followers_url": "https://api.github.com/users/saiden89/followers",
"following_url": "https://api.github.com/users/saiden89/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | 3 | 2025-02-28T10:39:10Z | 2025-05-15T12:27:17Z | null | NONE | null | null | null | I've refined several type annotations throughout the codebase to align with current best practices and enhance overall clarity. Given the complexity of the code, there may still be areas that need further attention. I welcome any feedback or suggestions to make these improvements even better.
- Fixes #7202 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7429/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7429/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7429.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7429",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7429.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7429"
} | true | 136 |
https://api.github.com/repos/huggingface/datasets/issues/7428 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7428/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7428/comments | https://api.github.com/repos/huggingface/datasets/issues/7428/events | https://github.com/huggingface/datasets/pull/7428 | 2,886,111,651 | PR_kwDODunzps6M4kW8 | 7,428 | Use pyupgrade --py39-plus | {
"avatar_url": "https://avatars.githubusercontent.com/u/17618148?v=4",
"events_url": "https://api.github.com/users/cyyever/events{/privacy}",
"followers_url": "https://api.github.com/users/cyyever/followers",
"following_url": "https://api.github.com/users/cyyever/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 3 | 2025-02-28T03:39:44Z | 2025-03-22T00:51:20Z | 2025-03-05T15:04:16Z | CONTRIBUTOR | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7428/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7428/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7428.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7428",
"merged_at": "2025-03-05T15:04:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7428.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 5 |
https://api.github.com/repos/huggingface/datasets/issues/7427 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7427/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7427/comments | https://api.github.com/repos/huggingface/datasets/issues/7427/events | https://github.com/huggingface/datasets/issues/7427 | 2,886,032,571 | I_kwDODunzps6sBVy7 | 7,427 | Error splitting the input into NAL units. | {
"avatar_url": "https://avatars.githubusercontent.com/u/47114466?v=4",
"events_url": "https://api.github.com/users/MengHao666/events{/privacy}",
"followers_url": "https://api.github.com/users/MengHao666/followers",
"following_url": "https://api.github.com/users/MengHao666/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | 2 | 2025-02-28T02:30:15Z | 2025-03-04T01:40:28Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I am trying to finetune qwen2.5-vl on 16 * 80G GPUS, and I use `LLaMA-Factory` and set `preprocessing_num_workers=16`. However, I met the following error and the program seem to got crush. It seems that the error come from `datasets` library
The error logging is like following:
```text
Convertin... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7427/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7427/timeline | null | null | null | null | true | 136 |
https://api.github.com/repos/huggingface/datasets/issues/7426 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7426/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7426/comments | https://api.github.com/repos/huggingface/datasets/issues/7426/events | https://github.com/huggingface/datasets/pull/7426 | 2,883,754,507 | PR_kwDODunzps6Mwe6B | 7,426 | fix: None default with bool type on load creates typing error | {
"avatar_url": "https://avatars.githubusercontent.com/u/8882233?v=4",
"events_url": "https://api.github.com/users/stephantul/events{/privacy}",
"followers_url": "https://api.github.com/users/stephantul/followers",
"following_url": "https://api.github.com/users/stephantul/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | 0 | 2025-02-27T08:11:36Z | 2025-03-04T15:53:40Z | 2025-03-04T15:53:40Z | CONTRIBUTOR | null | null | null | Hello!
Pyright flags any use of `load_dataset` as an error, because the default for `trust_remote_code` is `None`, but the function is typed as `bool`, not `Optional[bool]`. I changed the type and docstrings to reflect this, but no other code was touched.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7426/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7426/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7426.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7426",
"merged_at": "2025-03-04T15:53:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7426.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 5 |
https://api.github.com/repos/huggingface/datasets/issues/7425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7425/comments | https://api.github.com/repos/huggingface/datasets/issues/7425/events | https://github.com/huggingface/datasets/issues/7425 | 2,883,684,686 | I_kwDODunzps6r4YlO | 7,425 | load_dataset("livecodebench/code_generation_lite", version_tag="release_v2") TypeError: 'NoneType' object is not callable | {
"avatar_url": "https://avatars.githubusercontent.com/u/42167236?v=4",
"events_url": "https://api.github.com/users/dshwei/events{/privacy}",
"followers_url": "https://api.github.com/users/dshwei/followers",
"following_url": "https://api.github.com/users/dshwei/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | 10 | 2025-02-27T07:36:02Z | 2025-03-27T05:05:33Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
from datasets import load_dataset
lcb_codegen = load_dataset("livecodebench/code_generation_lite", version_tag="release_v2")
or
configs = get_dataset_config_names("livecodebench/code_generation_lite", trust_remote_code=True)
both error:
Traceback (most recent call last):
File "", line 1, in
File... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7425/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7425/timeline | null | null | null | null | true | 137 |
https://api.github.com/repos/huggingface/datasets/issues/7424 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7424/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7424/comments | https://api.github.com/repos/huggingface/datasets/issues/7424/events | https://github.com/huggingface/datasets/pull/7424 | 2,882,663,621 | PR_kwDODunzps6Ms1Qx | 7,424 | Faster folder based builder + parquet support + allow repeated media + use torchvideo | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-26T19:55:18Z | 2025-03-05T18:51:00Z | 2025-03-05T17:41:23Z | MEMBER | null | null | null | This will be useful for LeRobotDataset (robotics datasets for [lerobot](https://github.com/huggingface/lerobot) based on videos)
Impacted builders:
- ImageFolder
- AudioFolder
- VideoFolder
Improvements:
- faster to stream (got a 5x speed up on an image dataset)
- improved RAM usage
- support for metadata.p... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7424/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7424/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7424.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7424",
"merged_at": "2025-03-05T17:41:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7424.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 6 |
https://api.github.com/repos/huggingface/datasets/issues/7423 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7423/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7423/comments | https://api.github.com/repos/huggingface/datasets/issues/7423/events | https://github.com/huggingface/datasets/issues/7423 | 2,879,271,409 | I_kwDODunzps6rnjHx | 7,423 | Row indexing a dataset with numpy integers | {
"avatar_url": "https://avatars.githubusercontent.com/u/35470740?v=4",
"events_url": "https://api.github.com/users/DavidRConnell/events{/privacy}",
"followers_url": "https://api.github.com/users/DavidRConnell/followers",
"following_url": "https://api.github.com/users/DavidRConnell/following{/other_user}",
"g... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 1 | 2025-02-25T18:44:45Z | 2025-03-03T17:55:24Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Allow indexing datasets with a scalar numpy integer type.
### Motivation
Indexing a dataset with a scalar numpy.int* object raises a TypeError. This is due to the test in `datasets/formatting/formatting.py:key_to_query_type`
``` python
def key_to_query_type(key: Union[int, slice, range, str, Ite... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7423/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7423/timeline | null | null | null | null | true | 138 |
https://api.github.com/repos/huggingface/datasets/issues/7421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7421/comments | https://api.github.com/repos/huggingface/datasets/issues/7421/events | https://github.com/huggingface/datasets/issues/7421 | 2,878,369,052 | I_kwDODunzps6rkG0c | 7,421 | DVC integration broken | {
"avatar_url": "https://avatars.githubusercontent.com/u/34747372?v=4",
"events_url": "https://api.github.com/users/maxstrobel/events{/privacy}",
"followers_url": "https://api.github.com/users/maxstrobel/followers",
"following_url": "https://api.github.com/users/maxstrobel/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | 1 | 2025-02-25T13:14:31Z | 2025-03-03T17:42:02Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
The DVC integration seems to be broken.
Followed this guide: https://dvc.org/doc/user-guide/integrations/huggingface
### Steps to reproduce the bug
#### Script to reproduce
~~~python
from datasets import load_dataset
dataset = load_dataset(
"csv",
data_files="dvc://workshop/satellite-d... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7421/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7421/timeline | null | null | null | null | true | 138 |
https://api.github.com/repos/huggingface/datasets/issues/7420 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7420/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7420/comments | https://api.github.com/repos/huggingface/datasets/issues/7420/events | https://github.com/huggingface/datasets/issues/7420 | 2,876,281,928 | I_kwDODunzps6rcJRI | 7,420 | better correspondence between cached and saved datasets created using from_generator | {
"avatar_url": "https://avatars.githubusercontent.com/u/12157034?v=4",
"events_url": "https://api.github.com/users/vttrifonov/events{/privacy}",
"followers_url": "https://api.github.com/users/vttrifonov/followers",
"following_url": "https://api.github.com/users/vttrifonov/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 0 | 2025-02-24T22:14:37Z | 2025-02-26T03:10:22Z | null | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
At the moment `.from_generator` can only create a dataset that lives in the cache. The cached dataset cannot be loaded with `load_from_disk` because the cache folder is missing `state.json`. So the only way to convert this cached dataset to a regular is to use `save_to_disk` which needs to create a... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7420/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7420/timeline | null | null | null | null | true | 139 |
https://api.github.com/repos/huggingface/datasets/issues/7419 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7419/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7419/comments | https://api.github.com/repos/huggingface/datasets/issues/7419/events | https://github.com/huggingface/datasets/issues/7419 | 2,875,635,320 | I_kwDODunzps6rZrZ4 | 7,419 | Import order crashes script execution | {
"avatar_url": "https://avatars.githubusercontent.com/u/23298479?v=4",
"events_url": "https://api.github.com/users/DamienMatias/events{/privacy}",
"followers_url": "https://api.github.com/users/DamienMatias/followers",
"following_url": "https://api.github.com/users/DamienMatias/following{/other_user}",
"gist... | [] | open | false | null | [] | null | 0 | 2025-02-24T17:03:43Z | 2025-02-24T17:03:43Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hello,
I'm trying to convert an HF dataset into a TFRecord so I'm importing `tensorflow` and `datasets` to do so.
Depending in what order I'm importing those librairies, my code hangs forever and is unkillable (CTRL+C doesn't work, I need to kill my shell entirely).
Thank you for your help
🙏
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7419/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7419/timeline | null | null | null | null | true | 139 |
https://api.github.com/repos/huggingface/datasets/issues/7418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7418/comments | https://api.github.com/repos/huggingface/datasets/issues/7418/events | https://github.com/huggingface/datasets/issues/7418 | 2,868,701,471 | I_kwDODunzps6q_Okf | 7,418 | pyarrow.lib.arrowinvalid: cannot mix list and non-list, non-null values with map function | {
"avatar_url": "https://avatars.githubusercontent.com/u/15705569?v=4",
"events_url": "https://api.github.com/users/alexxchen/events{/privacy}",
"followers_url": "https://api.github.com/users/alexxchen/followers",
"following_url": "https://api.github.com/users/alexxchen/following{/other_user}",
"gists_url": "... | [] | open | false | null | [] | null | 5 | 2025-02-21T10:58:06Z | 2025-07-11T13:06:10Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Encounter pyarrow.lib.arrowinvalid error with map function in some example when loading the dataset
### Steps to reproduce the bug
```
from datasets import load_dataset
from PIL import Image, PngImagePlugin
dataset = load_dataset("leonardPKU/GEOQA_R1V_Train_8K")
system_prompt="You are a helpful... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7418/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7418/timeline | null | null | null | null | true | 143 |
https://api.github.com/repos/huggingface/datasets/issues/7417 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7417/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7417/comments | https://api.github.com/repos/huggingface/datasets/issues/7417/events | https://github.com/huggingface/datasets/pull/7417 | 2,866,868,922 | PR_kwDODunzps6L78k3 | 7,417 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-20T17:45:29Z | 2025-02-20T17:47:50Z | 2025-02-20T17:45:36Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7417/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7417/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7417.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7417",
"merged_at": "2025-02-20T17:45:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7417.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7416 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7416/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7416/comments | https://api.github.com/repos/huggingface/datasets/issues/7416/events | https://github.com/huggingface/datasets/pull/7416 | 2,866,862,143 | PR_kwDODunzps6L77G2 | 7,416 | Release: 3.3.2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-20T17:42:11Z | 2025-02-20T17:44:35Z | 2025-02-20T17:43:28Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7416/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7416/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7416.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7416",
"merged_at": "2025-02-20T17:43:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7416.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7415/comments | https://api.github.com/repos/huggingface/datasets/issues/7415/events | https://github.com/huggingface/datasets/issues/7415 | 2,865,774,546 | I_kwDODunzps6q0D_S | 7,415 | Shard Dataset at specific indices | {
"avatar_url": "https://avatars.githubusercontent.com/u/11044035?v=4",
"events_url": "https://api.github.com/users/nikonikolov/events{/privacy}",
"followers_url": "https://api.github.com/users/nikonikolov/followers",
"following_url": "https://api.github.com/users/nikonikolov/following{/other_user}",
"gists_u... | [] | open | false | null | [] | null | 3 | 2025-02-20T10:43:10Z | 2025-02-24T11:06:45Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I have a dataset of sequences, where each example in the sequence is a separate row in the dataset (similar to LeRobotDataset). When running `Dataset.save_to_disk` how can I provide indices where it's possible to shard the dataset such that no episode spans more than 1 shard. Consequently, when I run `Dataset.load_from... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7415/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7415/timeline | null | null | null | null | true | 144 |
https://api.github.com/repos/huggingface/datasets/issues/7414 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7414/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7414/comments | https://api.github.com/repos/huggingface/datasets/issues/7414/events | https://github.com/huggingface/datasets/pull/7414 | 2,863,798,756 | PR_kwDODunzps6LxjsH | 7,414 | Gracefully cancel async tasks | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-19T16:10:58Z | 2025-02-20T14:12:26Z | 2025-02-20T14:12:23Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7414/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7414/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7414.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7414",
"merged_at": "2025-02-20T14:12:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7414.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7413/comments | https://api.github.com/repos/huggingface/datasets/issues/7413/events | https://github.com/huggingface/datasets/issues/7413 | 2,860,947,582 | I_kwDODunzps6qhph- | 7,413 | Documentation on multiple media files of the same type with WebDataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/3616964?v=4",
"events_url": "https://api.github.com/users/DCNemesis/events{/privacy}",
"followers_url": "https://api.github.com/users/DCNemesis/followers",
"following_url": "https://api.github.com/users/DCNemesis/following{/other_user}",
"gists_url": "h... | [] | open | false | null | [] | null | 1 | 2025-02-18T16:13:20Z | 2025-02-20T14:17:54Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | The [current documentation](https://huggingface.co/docs/datasets/en/video_dataset) on a creating a video dataset includes only examples with one media file and one json. It would be useful to have examples where multiple files of the same type are included. For example, in a sign language dataset, you may have a base v... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7413/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7413/timeline | null | null | null | null | true | 145 |
https://api.github.com/repos/huggingface/datasets/issues/7412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7412/comments | https://api.github.com/repos/huggingface/datasets/issues/7412/events | https://github.com/huggingface/datasets/issues/7412 | 2,859,433,710 | I_kwDODunzps6qb37u | 7,412 | Index Error Invalid Ket is out of bounds for size 0 for code-search-net/code_search_net dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/56113657?v=4",
"events_url": "https://api.github.com/users/harshakhmk/events{/privacy}",
"followers_url": "https://api.github.com/users/harshakhmk/followers",
"following_url": "https://api.github.com/users/harshakhmk/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | 0 | 2025-02-18T05:58:33Z | 2025-02-18T06:42:07Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I am trying to do model pruning on sentence-transformers/all-mini-L6-v2 for the code-search-net/code_search_net dataset using INCTrainer class
However I am getting below error
```
raise IndexError(f"Invalid Key: {key is our of bounds for size {size}")
IndexError: Invalid key: 1840208 is out of b... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7412/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7412/timeline | null | null | null | null | true | 146 |
https://api.github.com/repos/huggingface/datasets/issues/7411 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7411/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7411/comments | https://api.github.com/repos/huggingface/datasets/issues/7411/events | https://github.com/huggingface/datasets/pull/7411 | 2,858,993,390 | PR_kwDODunzps6LhV0Z | 7,411 | Attempt to fix multiprocessing hang by closing and joining the pool before termination | {
"avatar_url": "https://avatars.githubusercontent.com/u/43149077?v=4",
"events_url": "https://api.github.com/users/dakinggg/events{/privacy}",
"followers_url": "https://api.github.com/users/dakinggg/followers",
"following_url": "https://api.github.com/users/dakinggg/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | 3 | 2025-02-17T23:58:03Z | 2025-02-19T21:11:24Z | 2025-02-19T13:40:32Z | CONTRIBUTOR | null | null | null | https://github.com/huggingface/datasets/issues/6393 has plagued me on and off for a very long time. I have had various workarounds (one time combining two filter calls into one filter call removed the issue, another time making rank 0 go first resolved a cache race condition, one time i think upgrading the version of s... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7411/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7411/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7411.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7411",
"merged_at": "2025-02-19T13:40:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7411.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 1 |
https://api.github.com/repos/huggingface/datasets/issues/7410 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7410/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7410/comments | https://api.github.com/repos/huggingface/datasets/issues/7410/events | https://github.com/huggingface/datasets/pull/7410 | 2,858,085,707 | PR_kwDODunzps6LeQBF | 7,410 | Set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-17T14:54:39Z | 2025-02-17T14:56:58Z | 2025-02-17T14:54:56Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7410/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7410/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7410.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7410",
"merged_at": "2025-02-17T14:54:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7410.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7409 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7409/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7409/comments | https://api.github.com/repos/huggingface/datasets/issues/7409/events | https://github.com/huggingface/datasets/pull/7409 | 2,858,079,508 | PR_kwDODunzps6LeOpY | 7,409 | Release: 3.3.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-17T14:52:12Z | 2025-02-17T14:54:32Z | 2025-02-17T14:53:13Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7409/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7409/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7409.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7409",
"merged_at": "2025-02-17T14:53:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7409.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7408/comments | https://api.github.com/repos/huggingface/datasets/issues/7408/events | https://github.com/huggingface/datasets/pull/7408 | 2,858,012,313 | PR_kwDODunzps6Ld_-m | 7,408 | Fix filter speed regression | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-17T14:25:32Z | 2025-02-17T14:28:48Z | 2025-02-17T14:28:46Z | MEMBER | null | null | null | close https://github.com/huggingface/datasets/issues/7404 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7408/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7408/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7408.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7408",
"merged_at": "2025-02-17T14:28:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7408.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7407/comments | https://api.github.com/repos/huggingface/datasets/issues/7407/events | https://github.com/huggingface/datasets/pull/7407 | 2,856,517,442 | PR_kwDODunzps6LY7y5 | 7,407 | Update use_with_pandas.mdx: to_pandas() correction in last section | {
"avatar_url": "https://avatars.githubusercontent.com/u/7552335?v=4",
"events_url": "https://api.github.com/users/ibarrien/events{/privacy}",
"followers_url": "https://api.github.com/users/ibarrien/followers",
"following_url": "https://api.github.com/users/ibarrien/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | 0 | 2025-02-17T01:53:31Z | 2025-02-20T17:28:04Z | 2025-02-20T17:28:04Z | CONTRIBUTOR | null | null | null | last section ``to_pandas()" | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7407/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7407/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7407.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7407",
"merged_at": "2025-02-20T17:28:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7407.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 3 |
https://api.github.com/repos/huggingface/datasets/issues/7406 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7406/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7406/comments | https://api.github.com/repos/huggingface/datasets/issues/7406/events | https://github.com/huggingface/datasets/issues/7406 | 2,856,441,206 | I_kwDODunzps6qQdV2 | 7,406 | Adding Core Maintainer List to CONTRIBUTING.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/93233241?v=4",
"events_url": "https://api.github.com/users/jp1924/events{/privacy}",
"followers_url": "https://api.github.com/users/jp1924/followers",
"following_url": "https://api.github.com/users/jp1924/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | 3 | 2025-02-17T00:32:40Z | 2025-03-24T10:57:54Z | 2025-03-24T10:57:54Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
I propose adding a core maintainer list to the `CONTRIBUTING.md` file.
### Motivation
The Transformers and Liger-Kernel projects maintain lists of core maintainers for each module.
However, the Datasets project doesn't have such a list.
### Your contribution
I have nothing to add here. | {
"avatar_url": "https://avatars.githubusercontent.com/u/93233241?v=4",
"events_url": "https://api.github.com/users/jp1924/events{/privacy}",
"followers_url": "https://api.github.com/users/jp1924/followers",
"following_url": "https://api.github.com/users/jp1924/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7406/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7406/timeline | null | completed | null | null | true | 35 |
https://api.github.com/repos/huggingface/datasets/issues/7405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7405/comments | https://api.github.com/repos/huggingface/datasets/issues/7405/events | https://github.com/huggingface/datasets/issues/7405 | 2,856,372,814 | I_kwDODunzps6qQMpO | 7,405 | Lazy loading of environment variables | {
"avatar_url": "https://avatars.githubusercontent.com/u/7225987?v=4",
"events_url": "https://api.github.com/users/nikvaessen/events{/privacy}",
"followers_url": "https://api.github.com/users/nikvaessen/followers",
"following_url": "https://api.github.com/users/nikvaessen/following{/other_user}",
"gists_url":... | [] | open | false | null | [] | null | 1 | 2025-02-16T22:31:41Z | 2025-02-17T15:17:18Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Loading a `.env` file after an `import datasets` call does not correctly use the environment variables.
This is due the fact that environment variables are read at import time:
https://github.com/huggingface/datasets/blob/de062f0552a810c52077543c1169c38c1f0c53fc/src/datasets/config.py#L155C1-L15... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7405/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7405/timeline | null | null | null | null | true | 147 |
https://api.github.com/repos/huggingface/datasets/issues/7404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7404/comments | https://api.github.com/repos/huggingface/datasets/issues/7404/events | https://github.com/huggingface/datasets/issues/7404 | 2,856,366,207 | I_kwDODunzps6qQLB_ | 7,404 | Performance regression in `dataset.filter` | {
"avatar_url": "https://avatars.githubusercontent.com/u/82200?v=4",
"events_url": "https://api.github.com/users/ttim/events{/privacy}",
"followers_url": "https://api.github.com/users/ttim/followers",
"following_url": "https://api.github.com/users/ttim/following{/other_user}",
"gists_url": "https://api.github... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | 3 | 2025-02-16T22:19:14Z | 2025-02-17T17:46:06Z | 2025-02-17T14:28:48Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
We're filtering dataset of ~1M (small-ish) records. At some point in the code we do `dataset.filter`, before (including 3.2.0) it was taking couple of seconds, and now it takes 4 hours.
We use 16 threads/workers, and stack trace at them look as follows:
```
Traceback (most recent call last):
Fi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7404/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7404/timeline | null | completed | null | null | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7402/comments | https://api.github.com/repos/huggingface/datasets/issues/7402/events | https://github.com/huggingface/datasets/pull/7402 | 2,855,880,858 | PR_kwDODunzps6LW8G3 | 7,402 | Fix a typo in arrow_dataset.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/7996256?v=4",
"events_url": "https://api.github.com/users/jingedawang/events{/privacy}",
"followers_url": "https://api.github.com/users/jingedawang/followers",
"following_url": "https://api.github.com/users/jingedawang/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | 0 | 2025-02-16T04:52:02Z | 2025-02-20T17:29:28Z | 2025-02-20T17:29:28Z | CONTRIBUTOR | null | null | null | "in the feature" should be "in the future" | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7402/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7402/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7402.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7402",
"merged_at": "2025-02-20T17:29:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7402.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 4 |
https://api.github.com/repos/huggingface/datasets/issues/7401 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7401/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7401/comments | https://api.github.com/repos/huggingface/datasets/issues/7401/events | https://github.com/huggingface/datasets/pull/7401 | 2,853,260,869 | PR_kwDODunzps6LOMSo | 7,401 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-14T10:17:03Z | 2025-02-14T10:19:20Z | 2025-02-14T10:17:13Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7401/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7401/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7401.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7401",
"merged_at": "2025-02-14T10:17:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7401.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7399 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7399/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7399/comments | https://api.github.com/repos/huggingface/datasets/issues/7399/events | https://github.com/huggingface/datasets/issues/7399 | 2,853,098,442 | I_kwDODunzps6qDtPK | 7,399 | Synchronize parameters for various datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/7976840?v=4",
"events_url": "https://api.github.com/users/grofte/events{/privacy}",
"followers_url": "https://api.github.com/users/grofte/followers",
"following_url": "https://api.github.com/users/grofte/following{/other_user}",
"gists_url": "https://ap... | [] | open | false | null | [] | null | 2 | 2025-02-14T09:15:11Z | 2025-02-19T11:50:29Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
[IterableDatasetDict](https://huggingface.co/docs/datasets/v3.2.0/en/package_reference/main_classes#datasets.IterableDatasetDict.map) map function is missing the `desc` parameter. You can see the equivalent map function for [Dataset here](https://huggingface.co/docs/datasets/v3.2.0/en/package_refe... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7399/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7399/timeline | null | null | null | null | true | 150 |
https://api.github.com/repos/huggingface/datasets/issues/7398 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7398/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7398/comments | https://api.github.com/repos/huggingface/datasets/issues/7398/events | https://github.com/huggingface/datasets/pull/7398 | 2,853,097,869 | PR_kwDODunzps6LNoDk | 7,398 | Release: 3.3.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-14T09:15:03Z | 2025-02-14T09:57:39Z | 2025-02-14T09:57:37Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7398/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7398/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7398.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7398",
"merged_at": "2025-02-14T09:57:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7398.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7397/comments | https://api.github.com/repos/huggingface/datasets/issues/7397/events | https://github.com/huggingface/datasets/pull/7397 | 2,852,829,763 | PR_kwDODunzps6LMuQD | 7,397 | Kannada dataset(Conversations, Wikipedia etc) | {
"avatar_url": "https://avatars.githubusercontent.com/u/146451281?v=4",
"events_url": "https://api.github.com/users/Likhith2612/events{/privacy}",
"followers_url": "https://api.github.com/users/Likhith2612/followers",
"following_url": "https://api.github.com/users/Likhith2612/following{/other_user}",
"gists_... | [] | closed | false | null | [] | null | 1 | 2025-02-14T06:53:03Z | 2025-02-20T17:28:54Z | 2025-02-20T17:28:53Z | NONE | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7397/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7397/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7397.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7397",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7397.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7397"
} | true | 6 |
https://api.github.com/repos/huggingface/datasets/issues/7400 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7400/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7400/comments | https://api.github.com/repos/huggingface/datasets/issues/7400/events | https://github.com/huggingface/datasets/issues/7400 | 2,853,201,277 | I_kwDODunzps6qEGV9 | 7,400 | 504 Gateway Timeout when uploading large dataset to Hugging Face Hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/3500?v=4",
"events_url": "https://api.github.com/users/hotchpotch/events{/privacy}",
"followers_url": "https://api.github.com/users/hotchpotch/followers",
"following_url": "https://api.github.com/users/hotchpotch/following{/other_user}",
"gists_url": "h... | [] | open | false | null | [] | null | 4 | 2025-02-14T02:18:35Z | 2025-02-14T23:48:36Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Description
I encountered consistent 504 Gateway Timeout errors while attempting to upload a large dataset (approximately 500GB) to the Hugging Face Hub. The upload fails during the process with a Gateway Timeout error.
I will continue trying to upload. While it might succeed in future attempts, I wanted to report... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7400/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7400/timeline | null | null | null | null | true | 150 |
https://api.github.com/repos/huggingface/datasets/issues/7396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7396/comments | https://api.github.com/repos/huggingface/datasets/issues/7396/events | https://github.com/huggingface/datasets/pull/7396 | 2,851,716,755 | PR_kwDODunzps6LJBmT | 7,396 | Update README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-13T17:44:36Z | 2025-02-13T17:46:57Z | 2025-02-13T17:44:51Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7396/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7396/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7396.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7396",
"merged_at": "2025-02-13T17:44:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7396.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7395/comments | https://api.github.com/repos/huggingface/datasets/issues/7395/events | https://github.com/huggingface/datasets/pull/7395 | 2,851,575,160 | PR_kwDODunzps6LIivQ | 7,395 | Update docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-13T16:43:15Z | 2025-02-13T17:20:32Z | 2025-02-13T17:20:30Z | MEMBER | null | null | null | - update min python version
- replace canonical dataset names with new names
- avoid examples with trust_remote_code | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7395/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7395/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7395.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7395",
"merged_at": "2025-02-13T17:20:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7395.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7394/comments | https://api.github.com/repos/huggingface/datasets/issues/7394/events | https://github.com/huggingface/datasets/issues/7394 | 2,847,172,115 | I_kwDODunzps6ptGYT | 7,394 | Using load_dataset with data_files and split arguments yields an error | {
"avatar_url": "https://avatars.githubusercontent.com/u/61103399?v=4",
"events_url": "https://api.github.com/users/devon-research/events{/privacy}",
"followers_url": "https://api.github.com/users/devon-research/followers",
"following_url": "https://api.github.com/users/devon-research/following{/other_user}",
... | [] | open | false | null | [] | null | 0 | 2025-02-12T04:50:11Z | 2025-02-12T04:50:11Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
It seems the list of valid splits recorded by the package becomes incorrectly overwritten when using the `data_files` argument.
If I run
```python
from datasets import load_dataset
load_dataset("allenai/super", split="all_examples", data_files="tasks/expert.jsonl")
```
then I get the error
```
Va... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7394/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7394/timeline | null | null | null | null | true | 152 |
https://api.github.com/repos/huggingface/datasets/issues/7393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7393/comments | https://api.github.com/repos/huggingface/datasets/issues/7393/events | https://github.com/huggingface/datasets/pull/7393 | 2,846,446,674 | PR_kwDODunzps6K3DiZ | 7,393 | Optimized sequence encoding for scalars | {
"avatar_url": "https://avatars.githubusercontent.com/u/38319063?v=4",
"events_url": "https://api.github.com/users/lukasgd/events{/privacy}",
"followers_url": "https://api.github.com/users/lukasgd/followers",
"following_url": "https://api.github.com/users/lukasgd/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-02-11T20:30:44Z | 2025-02-13T17:11:33Z | 2025-02-13T17:11:32Z | CONTRIBUTOR | null | null | null | The change in https://github.com/huggingface/datasets/pull/3197 introduced redundant list-comprehensions when `obj` is a long sequence of scalars. This becomes a noticeable overhead when loading data from an `IterableDataset` in the function `_apply_feature_types_on_example` and can be eliminated by adding a check for ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7393/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7393/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7393.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7393",
"merged_at": "2025-02-13T17:11:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7393.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 1 |
https://api.github.com/repos/huggingface/datasets/issues/7392 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7392/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7392/comments | https://api.github.com/repos/huggingface/datasets/issues/7392/events | https://github.com/huggingface/datasets/issues/7392 | 2,846,095,043 | I_kwDODunzps6po_bD | 7,392 | push_to_hub payload too large error when using large ClassLabel feature | {
"avatar_url": "https://avatars.githubusercontent.com/u/35470740?v=4",
"events_url": "https://api.github.com/users/DavidRConnell/events{/privacy}",
"followers_url": "https://api.github.com/users/DavidRConnell/followers",
"following_url": "https://api.github.com/users/DavidRConnell/following{/other_user}",
"g... | [] | open | false | null | [] | null | 1 | 2025-02-11T17:51:34Z | 2025-02-11T18:01:31Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When using `datasets.DatasetDict.push_to_hub` an `HfHubHTTPError: 413 Client Error: Payload Too Large for url` is raised if the dataset contains a large `ClassLabel` feature. Even if the total size of the dataset is small.
### Steps to reproduce the bug
``` python
import random
import sys
impor... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7392/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7392/timeline | null | null | null | null | true | 152 |
https://api.github.com/repos/huggingface/datasets/issues/7391 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7391/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7391/comments | https://api.github.com/repos/huggingface/datasets/issues/7391/events | https://github.com/huggingface/datasets/issues/7391 | 2,845,184,764 | I_kwDODunzps6plhL8 | 7,391 | AttributeError: module 'pyarrow.lib' has no attribute 'ListViewType' | {
"avatar_url": "https://avatars.githubusercontent.com/u/25193686?v=4",
"events_url": "https://api.github.com/users/LinXin04/events{/privacy}",
"followers_url": "https://api.github.com/users/LinXin04/followers",
"following_url": "https://api.github.com/users/LinXin04/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | 0 | 2025-02-11T12:02:26Z | 2025-02-11T12:02:26Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | pyarrow 尝试了若干个版本都不可以 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7391/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7391/timeline | null | null | null | null | true | 153 |
https://api.github.com/repos/huggingface/datasets/issues/7390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7390/comments | https://api.github.com/repos/huggingface/datasets/issues/7390/events | https://github.com/huggingface/datasets/issues/7390 | 2,843,813,365 | I_kwDODunzps6pgSX1 | 7,390 | Re-add py.typed | {
"avatar_url": "https://avatars.githubusercontent.com/u/730137?v=4",
"events_url": "https://api.github.com/users/NeilGirdhar/events{/privacy}",
"followers_url": "https://api.github.com/users/NeilGirdhar/followers",
"following_url": "https://api.github.com/users/NeilGirdhar/following{/other_user}",
"gists_url... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 0 | 2025-02-10T22:12:52Z | 2025-02-10T22:12:52Z | null | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
The motivation for removing py.typed no longer seems to apply. Would a solution like [this one](https://github.com/huggingface/huggingface_hub/pull/2752) work here?
### Motivation
MyPy support is broken. As more type checkers come out, such as RedKnot, these may also be broken. It would be goo... | null | {
"+1": 10,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 10,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7390/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7390/timeline | null | null | null | null | true | 153 |
https://api.github.com/repos/huggingface/datasets/issues/7389 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7389/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7389/comments | https://api.github.com/repos/huggingface/datasets/issues/7389/events | https://github.com/huggingface/datasets/issues/7389 | 2,843,592,606 | I_kwDODunzps6pfcee | 7,389 | Getting statistics about filtered examples | {
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_... | [] | closed | false | null | [] | null | 2 | 2025-02-10T20:48:29Z | 2025-02-11T20:44:15Z | 2025-02-11T20:44:13Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | @lhoestq wondering if the team has thought about this and if there are any recommendations?
Currently when processing datasets some examples are bound to get filtered out, whether it's due to bad format, or length is too long, or any other custom filters that might be getting applied. Let's just focus on the filter by... | {
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7389/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7389/timeline | null | completed | null | null | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7388/comments | https://api.github.com/repos/huggingface/datasets/issues/7388/events | https://github.com/huggingface/datasets/issues/7388 | 2,843,188,499 | I_kwDODunzps6pd50T | 7,388 | OSError: [Errno 22] Invalid argument forbidden character | {
"avatar_url": "https://avatars.githubusercontent.com/u/124634542?v=4",
"events_url": "https://api.github.com/users/langflogit/events{/privacy}",
"followers_url": "https://api.github.com/users/langflogit/followers",
"following_url": "https://api.github.com/users/langflogit/following{/other_user}",
"gists_url... | [] | closed | false | null | [] | null | 2 | 2025-02-10T17:46:31Z | 2025-02-11T13:42:32Z | 2025-02-11T13:42:30Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I'm on Windows and i'm trying to load a datasets but i'm having title error because files in the repository are named with charactere like < >which can't be in a name file. Could it be possible to load this datasets but removing those charactere ?
### Steps to reproduce the bug
load_dataset("CAT... | {
"avatar_url": "https://avatars.githubusercontent.com/u/124634542?v=4",
"events_url": "https://api.github.com/users/langflogit/events{/privacy}",
"followers_url": "https://api.github.com/users/langflogit/followers",
"following_url": "https://api.github.com/users/langflogit/following{/other_user}",
"gists_url... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7388/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7388/timeline | null | completed | null | null | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7387 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7387/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7387/comments | https://api.github.com/repos/huggingface/datasets/issues/7387/events | https://github.com/huggingface/datasets/issues/7387 | 2,841,228,048 | I_kwDODunzps6pWbMQ | 7,387 | Dynamic adjusting dataloader sampling weight | {
"avatar_url": "https://avatars.githubusercontent.com/u/72799643?v=4",
"events_url": "https://api.github.com/users/whc688/events{/privacy}",
"followers_url": "https://api.github.com/users/whc688/followers",
"following_url": "https://api.github.com/users/whc688/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | 3 | 2025-02-10T03:18:47Z | 2025-03-07T14:06:54Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hi,
Thanks for your wonderful work! I'm wondering is there a way to dynamically adjust the sampling weight of each data in the dataset during training? Looking forward to your reply, thanks again. | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7387/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7387/timeline | null | null | null | null | true | 154 |
https://api.github.com/repos/huggingface/datasets/issues/7386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7386/comments | https://api.github.com/repos/huggingface/datasets/issues/7386/events | https://github.com/huggingface/datasets/issues/7386 | 2,840,032,524 | I_kwDODunzps6pR3UM | 7,386 | Add bookfolder Dataset Builder for Digital Book Formats | {
"avatar_url": "https://avatars.githubusercontent.com/u/22115108?v=4",
"events_url": "https://api.github.com/users/shikanime/events{/privacy}",
"followers_url": "https://api.github.com/users/shikanime/followers",
"following_url": "https://api.github.com/users/shikanime/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | 1 | 2025-02-08T14:27:55Z | 2025-02-08T14:30:10Z | 2025-02-08T14:30:09Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
This feature proposes adding a new dataset builder called bookfolder to the datasets library. This builder would allow users to easily load datasets consisting of various digital book formats, including: AZW, AZW3, CB7, CBR, CBT, CBZ, EPUB, MOBI, and PDF.
### Motivation
Currently, loading dataset... | {
"avatar_url": "https://avatars.githubusercontent.com/u/22115108?v=4",
"events_url": "https://api.github.com/users/shikanime/events{/privacy}",
"followers_url": "https://api.github.com/users/shikanime/followers",
"following_url": "https://api.github.com/users/shikanime/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7386/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7386/timeline | null | completed | null | null | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7385/comments | https://api.github.com/repos/huggingface/datasets/issues/7385/events | https://github.com/huggingface/datasets/pull/7385 | 2,830,664,522 | PR_kwDODunzps6KBO6i | 7,385 | Make IterableDataset (optionally) resumable | {
"avatar_url": "https://avatars.githubusercontent.com/u/18402347?v=4",
"events_url": "https://api.github.com/users/yzhangcs/events{/privacy}",
"followers_url": "https://api.github.com/users/yzhangcs/followers",
"following_url": "https://api.github.com/users/yzhangcs/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | 2 | 2025-02-04T15:55:33Z | 2025-03-03T17:31:40Z | null | CONTRIBUTOR | null | null | null | ### What does this PR do?
This PR introduces a new `stateful` option to the `dataset.shuffle` method, which defaults to `False`.
When enabled, this option allows for resumable shuffling of `IterableDataset` instances, albeit with some additional memory overhead.
Key points:
* All tests have passed
* Docstrings ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7385/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7385/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7385.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7385",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7385.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7385"
} | true | 159 |
https://api.github.com/repos/huggingface/datasets/issues/7384 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7384/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7384/comments | https://api.github.com/repos/huggingface/datasets/issues/7384/events | https://github.com/huggingface/datasets/pull/7384 | 2,828,208,828 | PR_kwDODunzps6J4wVi | 7,384 | Support async functions in map() | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 2 | 2025-02-03T18:18:40Z | 2025-02-13T14:01:13Z | 2025-02-13T14:00:06Z | MEMBER | null | null | null | e.g. to download images or call an inference API like HF or vLLM
```python
import asyncio
import random
from datasets import Dataset
async def f(x):
await asyncio.sleep(random.random())
ds = Dataset.from_dict({"data": range(100)})
ds.map(f)
# Map: 100%|█████████████████████████████| 100/100 [00:0... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7384/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7384/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7384.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7384",
"merged_at": "2025-02-13T14:00:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7384.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 9 |
https://api.github.com/repos/huggingface/datasets/issues/7382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7382/comments | https://api.github.com/repos/huggingface/datasets/issues/7382/events | https://github.com/huggingface/datasets/pull/7382 | 2,823,480,924 | PR_kwDODunzps6Jo69f | 7,382 | Add Pandas, PyArrow and Polars docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-01-31T13:22:59Z | 2025-01-31T16:30:59Z | 2025-01-31T16:30:57Z | MEMBER | null | null | null | (also added the missing numpy docs and fixed a small bug in pyarrow formatting) | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7382/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7382/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7382.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7382",
"merged_at": "2025-01-31T16:30:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7382.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7381 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7381/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7381/comments | https://api.github.com/repos/huggingface/datasets/issues/7381/events | https://github.com/huggingface/datasets/issues/7381 | 2,815,649,092 | I_kwDODunzps6n02VE | 7,381 | Iterating over values of a column in the IterableDataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47208659?v=4",
"events_url": "https://api.github.com/users/TopCoder2K/events{/privacy}",
"followers_url": "https://api.github.com/users/TopCoder2K/followers",
"following_url": "https://api.github.com/users/TopCoder2K/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47208659?v=4",
"events_url": "https://api.github.com/users/TopCoder2K/events{/privacy}",
"followers_url": "https://api.github.com/users/TopCoder2K/followers",
"following_url": "https://api.github.com/users/TopCoder2K/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47208659?v=4",
"events_url": "https://api.github.com/users/TopCoder2K/events{/privacy}",
"followers_url": "https://api.github.com/users/TopCoder2K/followers",
"following_url": "https://api.github.com/users/TopCoder2K/following{/other_user}",
... | null | 11 | 2025-01-28T13:17:36Z | 2025-05-22T18:00:04Z | 2025-05-22T18:00:04Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
I would like to be able to iterate (and re-iterate if needed) over a column of an `IterableDataset` instance. The following example shows the supposed API:
```python
def gen():
yield {"text": "Good", "label": 0}
yield {"text": "Bad", "label": 1}
ds = IterableDataset.from_generator(gen)
tex... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47208659?v=4",
"events_url": "https://api.github.com/users/TopCoder2K/events{/privacy}",
"followers_url": "https://api.github.com/users/TopCoder2K/followers",
"following_url": "https://api.github.com/users/TopCoder2K/following{/other_user}",
"gists_url"... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7381/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7381/timeline | null | completed | null | null | true | 114 |
https://api.github.com/repos/huggingface/datasets/issues/7380 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7380/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7380/comments | https://api.github.com/repos/huggingface/datasets/issues/7380/events | https://github.com/huggingface/datasets/pull/7380 | 2,811,566,116 | PR_kwDODunzps6JAkj5 | 7,380 | fix: dill default for version bigger 0.3.8 | {
"avatar_url": "https://avatars.githubusercontent.com/u/40773225?v=4",
"events_url": "https://api.github.com/users/sam-hey/events{/privacy}",
"followers_url": "https://api.github.com/users/sam-hey/followers",
"following_url": "https://api.github.com/users/sam-hey/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | 1 | 2025-01-26T13:37:16Z | 2025-03-13T20:40:19Z | 2025-03-13T20:40:19Z | NONE | null | null | null | Fixes def log for dill version >= 0.3.9
https://pypi.org/project/dill/
This project uses dill with the release of version 0.3.9 the datasets lib. | {
"avatar_url": "https://avatars.githubusercontent.com/u/40773225?v=4",
"events_url": "https://api.github.com/users/sam-hey/events{/privacy}",
"followers_url": "https://api.github.com/users/sam-hey/followers",
"following_url": "https://api.github.com/users/sam-hey/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7380/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7380/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7380.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7380",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7380.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7380"
} | true | 46 |
https://api.github.com/repos/huggingface/datasets/issues/7378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7378/comments | https://api.github.com/repos/huggingface/datasets/issues/7378/events | https://github.com/huggingface/datasets/issues/7378 | 2,802,957,388 | I_kwDODunzps6nEbxM | 7,378 | Allow pushing config version to hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/129072?v=4",
"events_url": "https://api.github.com/users/momeara/events{/privacy}",
"followers_url": "https://api.github.com/users/momeara/followers",
"following_url": "https://api.github.com/users/momeara/following{/other_user}",
"gists_url": "https://... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 1 | 2025-01-21T22:35:07Z | 2025-01-30T13:56:56Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Currently, when datasets are created, they can be versioned by passing the `version` argument to `load_dataset(...)`. For example creating `outcomes.csv` on the command line
```
echo "id,value\n1,0\n2,0\n3,1\n4,1\n" > outcomes.csv
```
and creating it
```
import datasets
dataset = datasets.load_dat... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7378/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7378/timeline | null | null | null | null | true | 173 |
https://api.github.com/repos/huggingface/datasets/issues/7377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7377/comments | https://api.github.com/repos/huggingface/datasets/issues/7377/events | https://github.com/huggingface/datasets/issues/7377 | 2,802,723,285 | I_kwDODunzps6nDinV | 7,377 | Support for sparse arrays with the Arrow Sparse Tensor format? | {
"avatar_url": "https://avatars.githubusercontent.com/u/3231217?v=4",
"events_url": "https://api.github.com/users/JulesGM/events{/privacy}",
"followers_url": "https://api.github.com/users/JulesGM/followers",
"following_url": "https://api.github.com/users/JulesGM/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 1 | 2025-01-21T20:14:35Z | 2025-01-30T14:06:45Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
AI in biology is becoming a big thing. One thing that would be a huge benefit to the field that Huggingface Datasets doesn't currently have is native support for **sparse arrays**.
Arrow has support for sparse tensors.
https://arrow.apache.org/docs/format/Other.html#sparse-tensor
It would be ... | null | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 2,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7377/timeline | null | null | null | null | true | 173 |
https://api.github.com/repos/huggingface/datasets/issues/7376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7376/comments | https://api.github.com/repos/huggingface/datasets/issues/7376/events | https://github.com/huggingface/datasets/pull/7376 | 2,802,621,104 | PR_kwDODunzps6IiO9j | 7,376 | [docs] uv install | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | 0 | 2025-01-21T19:15:48Z | 2025-03-14T20:16:35Z | 2025-03-14T20:16:35Z | MEMBER | null | null | null | Proposes adding uv to installation docs (see Slack thread [here](https://huggingface.slack.com/archives/C01N44FJDHT/p1737377177709279) for more context) if you're interested! | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7376/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7376/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7376.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7376",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7376.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7376"
} | true | 52 |
https://api.github.com/repos/huggingface/datasets/issues/7375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7375/comments | https://api.github.com/repos/huggingface/datasets/issues/7375/events | https://github.com/huggingface/datasets/issues/7375 | 2,800,609,218 | I_kwDODunzps6m7efC | 7,375 | vllm批量推理报错 | {
"avatar_url": "https://avatars.githubusercontent.com/u/51228154?v=4",
"events_url": "https://api.github.com/users/YuShengzuishuai/events{/privacy}",
"followers_url": "https://api.github.com/users/YuShengzuishuai/followers",
"following_url": "https://api.github.com/users/YuShengzuishuai/following{/other_user}"... | [] | open | false | null | [] | null | 1 | 2025-01-21T03:22:23Z | 2025-01-30T14:02:40Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug

### Steps to reproduce the bug
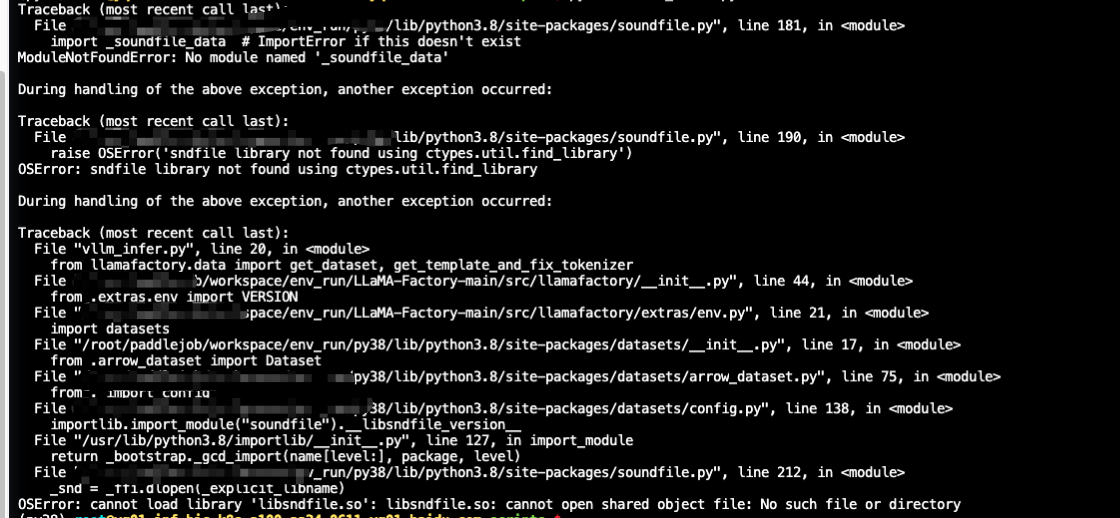
### Expected behavior
 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7374/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7374/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/7374.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7374",
"merged_at": "2025-01-16T18:26:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7374.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | 0 |
https://api.github.com/repos/huggingface/datasets/issues/7373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7373/comments | https://api.github.com/repos/huggingface/datasets/issues/7373/events | https://github.com/huggingface/datasets/issues/7373 | 2,793,237,139 | I_kwDODunzps6mfWqT | 7,373 | Excessive RAM Usage After Dataset Concatenation concatenate_datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/40773225?v=4",
"events_url": "https://api.github.com/users/sam-hey/events{/privacy}",
"followers_url": "https://api.github.com/users/sam-hey/followers",
"following_url": "https://api.github.com/users/sam-hey/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | 3 | 2025-01-16T16:33:10Z | 2025-03-27T17:40:59Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When loading a dataset from disk, concatenating it, and starting the training process, the RAM usage progressively increases until the kernel terminates the process due to excessive memory consumption.
https://github.com/huggingface/datasets/issues/2276
### Steps to reproduce the bug
```python
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7373/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7373/timeline | null | null | null | null | true | 178 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.