
text stringlengths 0 59.1k |
|---|
Install dependencies and run the dev server: |
```bash |
pnpm dev |
``` |
When the server starts, the terminal prints: |
```bash |
════════════════════════════════════════════ |
VOLTAGENT SERVER STARTED SUCCESSFULLY |
════════════════════════════════════════════ |
✓ HTTP Server: http://localhost:3141 |
VoltOps Platform: https://console.voltagent.dev |
════════════════════════════════════════════ |
[VoltAgent] All packages are up to date |
``` |
I run the YouTube MCP provider separately so the `TranscriptFetcher` subagent can call the transcript tool. |
 |
### MCP Tool Registration |
The coordinator discovers YouTube tooling through `MCPConfiguration` before the agents start: |
```typescript |
const youtubeMcpConfig = new MCPConfiguration({ |
servers: { |
youtube: { |
type: "http", |
url: process.env.YOUTUBE_MCP_URL || "", |
}, |
}, |
}); |
const youtubeTools = await youtubeMcpConfig.getTools(); |
``` |
The `YOUTUBE_MCP_URL` must be reachable from the VoltAgent process and expose the SSE interface described in the [MCP tooling guide](https://voltagent.dev/docs/agents/tools/#mcp-model-context-protocol-support). |
- `MCPConfiguration` pulls tool metadata from the HTTP SSE endpoint and converts it into the format VoltAgent expects. |
- I pass the resulting `youtubeTools` array into the agents so they can call the transcript tool without extra wiring. |
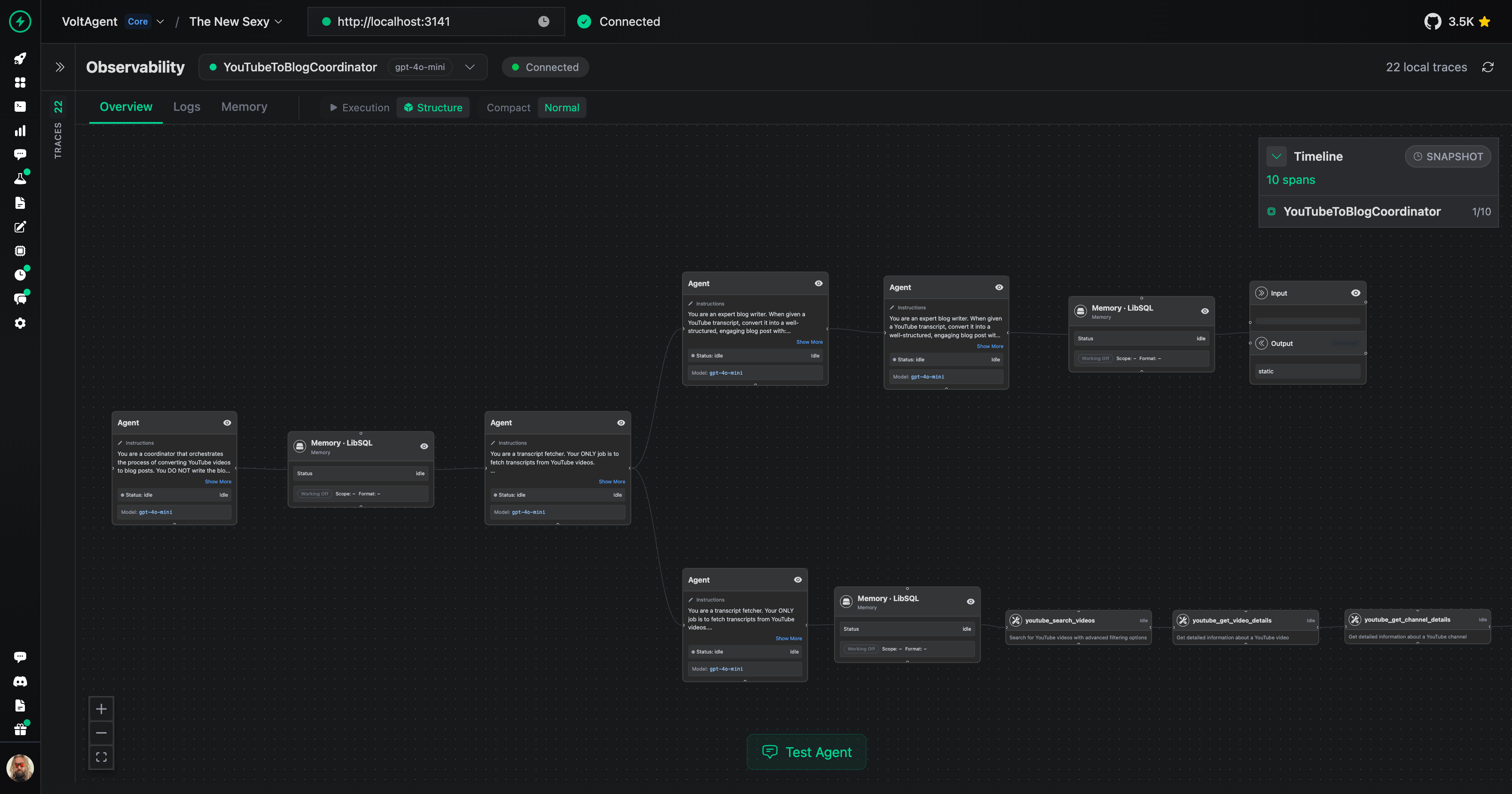
### Agent Architecture |
 |
When someone asks for a blog post, the `YouTubeToBlogCoordinator` receives the prompt with the YouTube link. I wired the coordinator to follow a strict handoff: |
1. The coordinator calls the `TranscriptFetcher` subagent, which relies on the MCP transcript tool to pull the full caption text. |
2. After the transcript lands in shared memory, the coordinator calls the `BlogWriter` subagent and passes the entire transcript as input. |
3. The writer returns Markdown, and the coordinator responds with that Markdown as-is so downstream systems can store or publish it directly. |
To support this flow I register three agents inside one VoltAgent instance. The supervisor coordinates both subagents and they all share the same memory and logging resources. |
 |
### TranscriptFetcher Subagent |
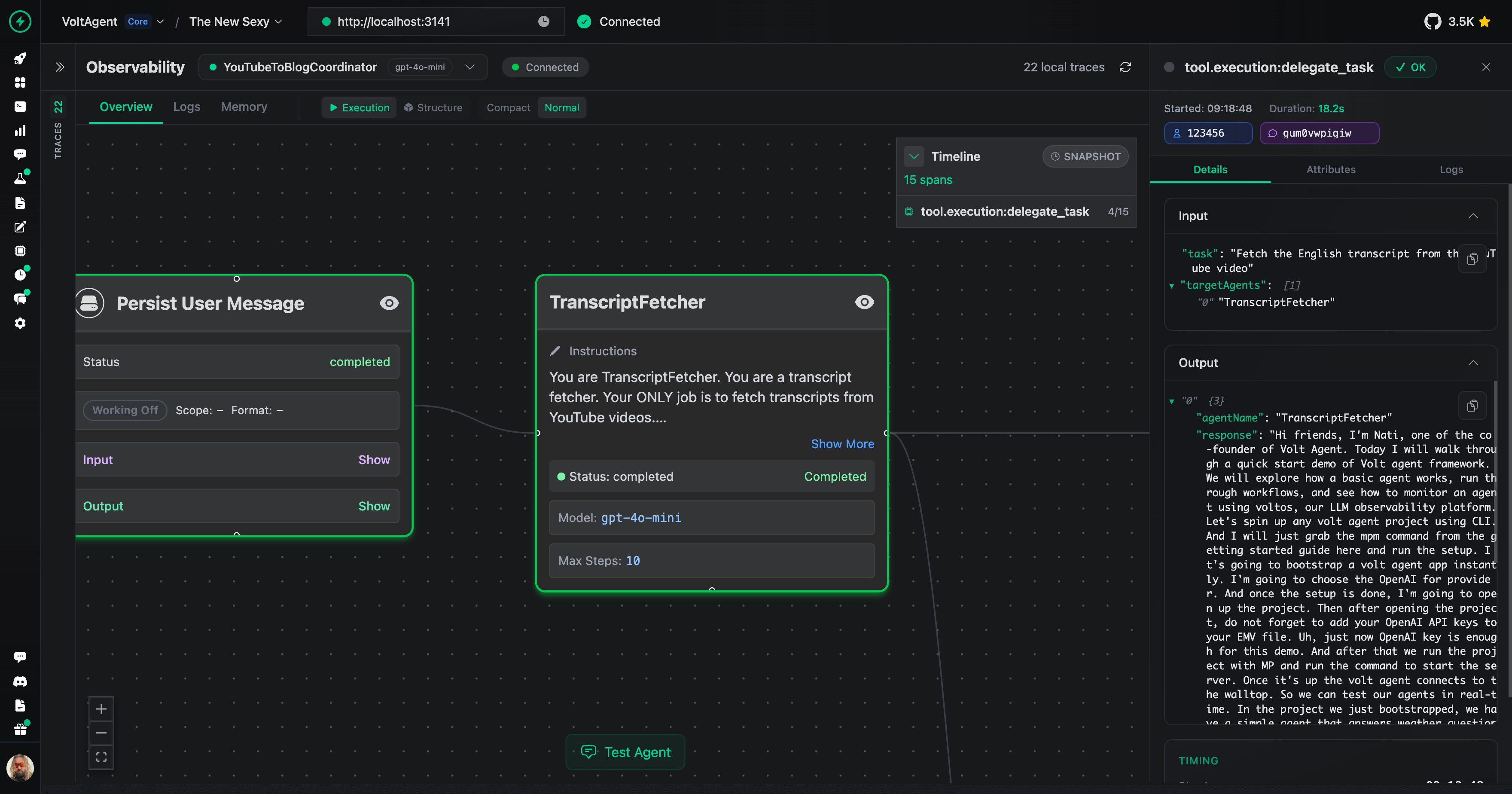 |
TranscriptFetcher handles pulling the raw transcript from the YouTube MCP tool. |
```typescript |
const transcriptFetcherAgent = new Agent({ |
name: "TranscriptFetcher", |
instructions: ` |
You are a transcript fetcher. Your ONLY job is to fetch transcripts from YouTube videos. |
IMPORTANT: |
- When given a YouTube URL, use your tools to extract the English transcript |
- Return ONLY the raw transcript text |
- DO NOT write blog posts |
- DO NOT format the transcript into articles |
- DO NOT add any additional content or commentary |
- Just extract and return the transcript as-is`, |
model: openai("gpt-4o-mini"), |
tools: youtubeTools, |
memory, |
}); |
``` |
- `name` is how the supervisor or an API caller refers to this agent. |
- `instructions` force the agent to send back raw transcript text and nothing else. |
- `model` uses `@ai-sdk/openai` with `gpt-4o-mini`, which keeps transcript calls fast and inexpensive. |
- `tools` contains the MCP transcript function discovered earlier. |
- `memory` connects the agent to the shared working store so retries can reuse earlier context. |
### BlogWriter Subagent |
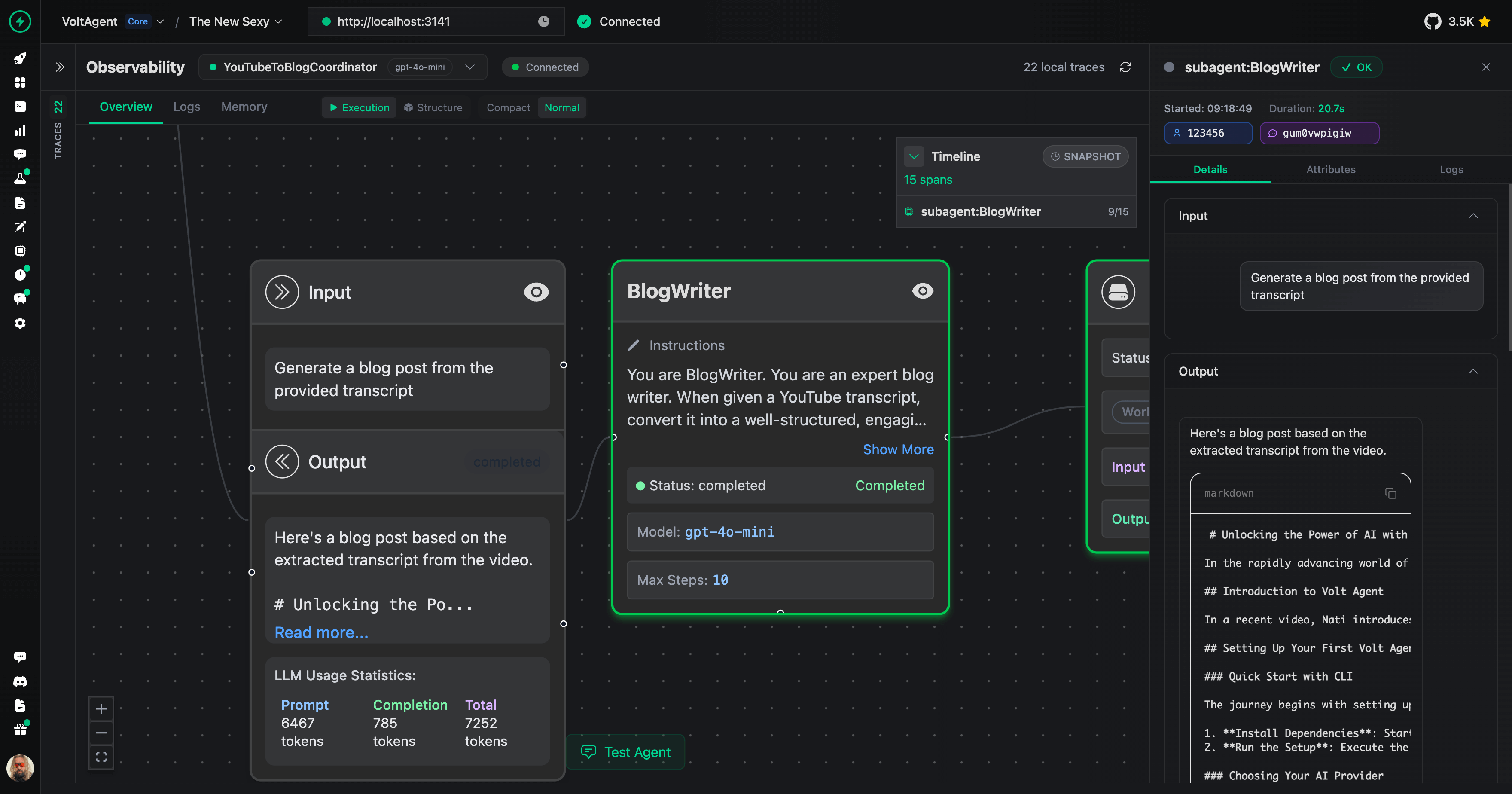 |
BlogWriter converts the transcript into a Markdown article with defined sections. |
```typescript |
const blogWriterAgent = new Agent({ |
name: "BlogWriter", |
instructions: ` |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.