
text stringlengths 0 59.1k |
|---|
```bash |
npm run dev |
``` |
My terminal showed VoltAgent starting up, and it also started the Peaka tool automatically in the background. I saw something like this: |
```bash |
══════════════════════════════════════════════════ |
VOLTAGENT SERVER STARTED SUCCESSFULLY |
══════════════════════════════════════════════════ |
✓ HTTP Server: http://localhost:3141 |
VoltOps Platform: https://console.voltagent.dev |
══════════════════════════════════════════════════ |
``` |
Now the fun test: |
1. I popped open the [VoltOps LLM Observability Platform](https://console.voltagent.dev) in my browser. |
2. Found my agent ("Peaka Data Assistant"). |
3. Opened the chat window. |
4. Asked it something that needed data from Peaka, maybe like: |
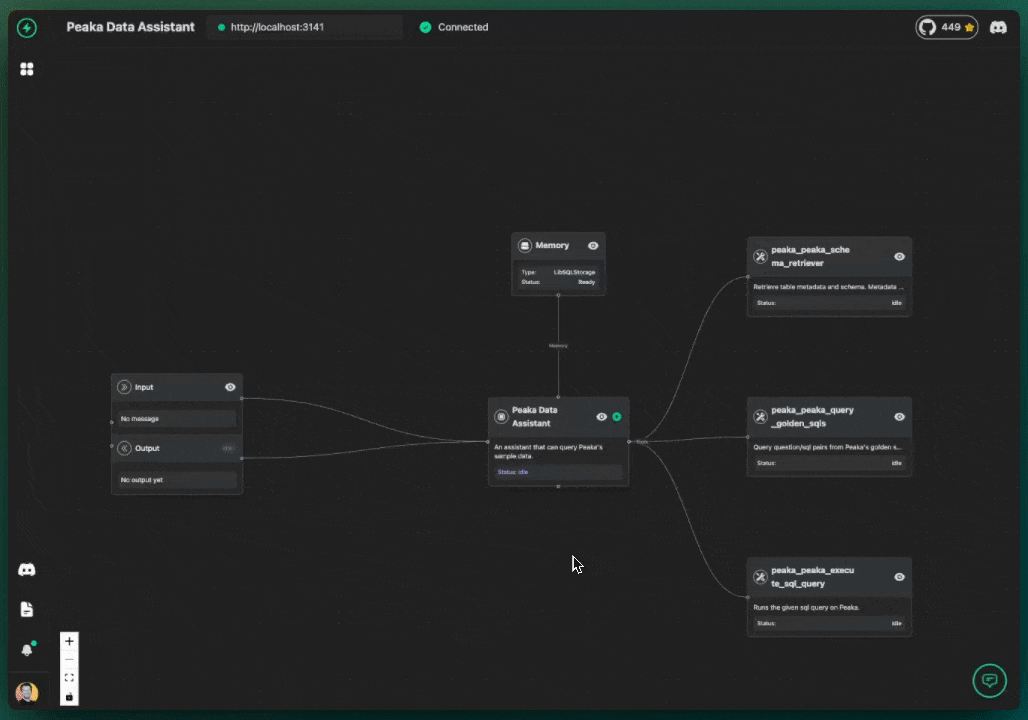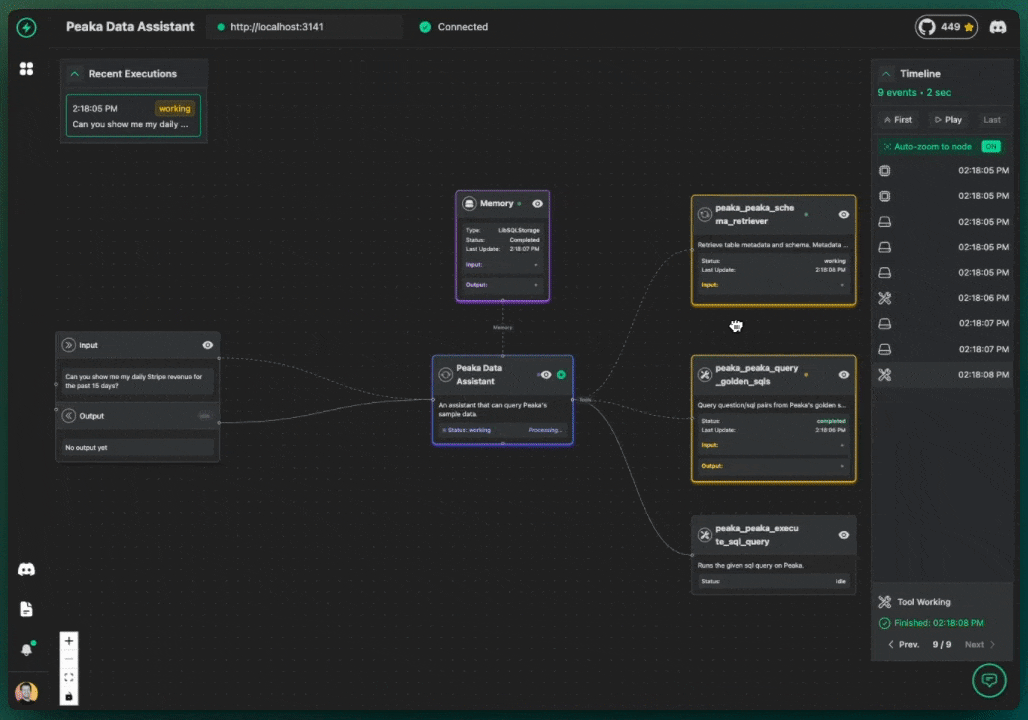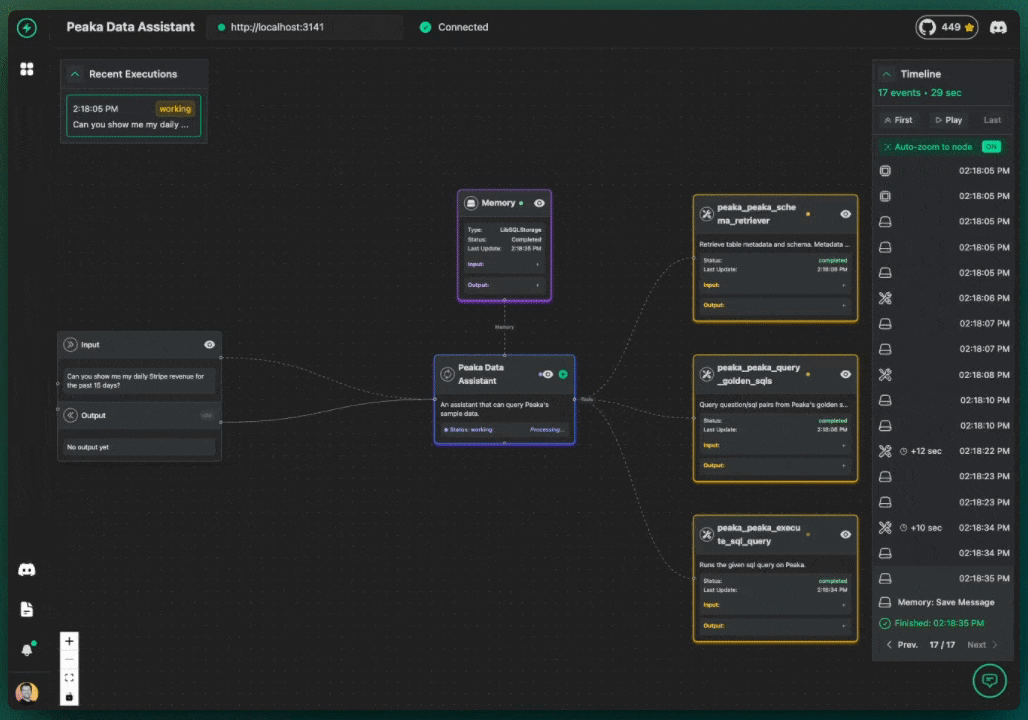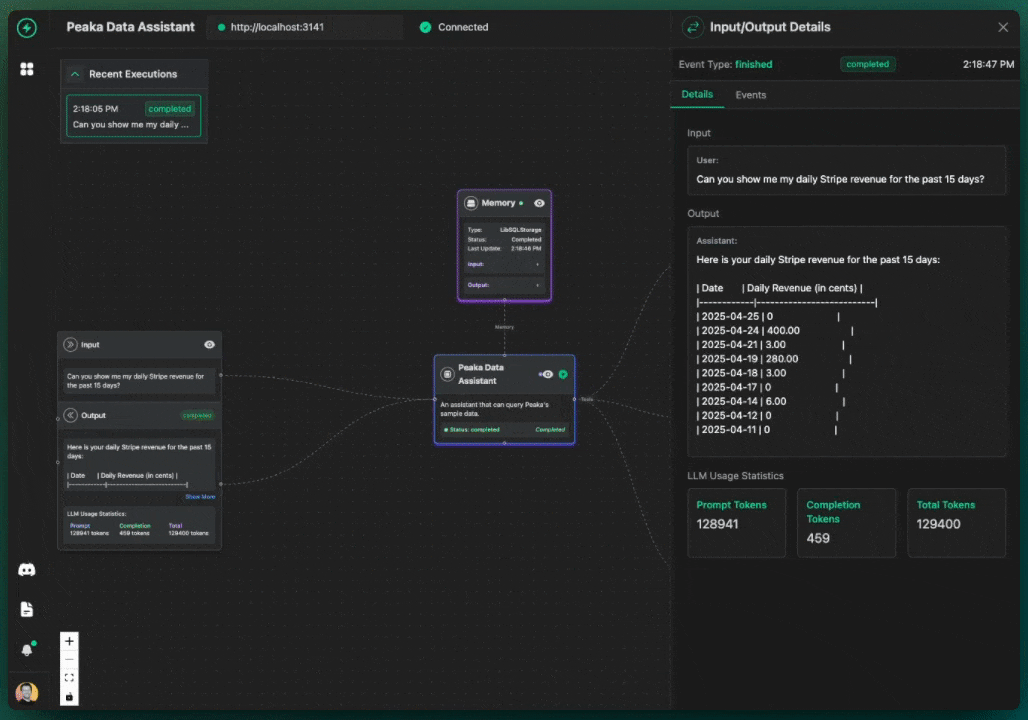
> "Hey, what was my Stripe balance yesterday?" |
Here's the cool part of what goes on: |
- The chatbot AI gets my question. |
- It figures out I need data and sees it has that Peaka tool. |
- It decides to use the tool. |
- VoltAgent sends the request over to the Peaka tool (using MCP). |
- The Peaka tool does its thing, querying my actual Stripe data (or whatever I connected). |
- Peaka sends the answer back to VoltAgent. |
- VoltAgent gives the raw answer back to the chatbot AI. |
- The AI turns that raw data into a normal sentence and shows it to me in the chat. |
It looks something like this: |
 |
## Conclusion |
Getting Peaka hooked up to my VoltAgent bot with MCP wasn't too bad! It's pretty awesome to have a chatbot that can actually use real-time data from different places. I can see this being useful for building smarter internal tools, helpdesk bots that know current info, or anything where the AI needs to know more than j... |
Definitely worth playing around with if you're building AI stuff! |
<|endoftext|> |
# source: VoltAgent__voltagent/website/blog/2025-07-23-llm-testing/index.md type: docs |
--- |
title: LLM Testing Methods |
description: Understanding the unique challenges of testing LLM applications and how observability tools like VoltOps help us analyze and debug AI systems. |
slug: llm-testing |
image: https://cdn.voltagent.dev/2025-07-23-llm-testing/social.png |
authors: necatiozmen |
--- |
import ZoomableMermaid from '@site/src/components/blog-widgets/ZoomableMermaid'; |
## Understanding the Unique Challenges of AI Application Testing |
Testing LLM applications isn't like testing regular software. When your "code" has AI agents making choices on their own, applying tools, and recalling discussions, regular testing just doesn't work. That's where specialized observability and testing approaches come in. They're made especially for the weird issues of L... |
## Introduction |
Come on - you can't test LLM applications because it is like trying to test a conversation with somebody else. How do you test responses that change every time you try it? How do you debug when the AI gets to tell you how to use the tools? How do you know your agent is thinking the right way if you can't even see what'... |
All these problems are made that much more difficult when you're building advanced AI agents that: |
- Interact with multiple tools and APIs |
- Remember conversations from session to session |
- Chain together many thinking steps |
- Work together with other AI agents as subagents |
Standard testing frameworks weren't built for this. You need something that knows how LLM systems actually function. |
Modern testing approaches fill this need by giving you: |
- Observability tools that make testing possible |
- End-to-end visibility into all the steps your agent is executing |
- Analysis capabilities that inform you exactly what's happening |
- Monitoring systems so issues can be caught in the act |
Alright, let's dive into understanding these challenges and building better testing strategies. |
## The Challenge of Testing LLM-based Agents |
Let's discuss why it's so unlike testing normal software before we get into solutions. |
### Non-deterministic outputs |
Deterministic software behavior - same input, same output, every time. LLMs are fundamentally stochastic. Even with the exact same prompt, an LLM can: |
- Express the same thing in different words |
- Choose tools in a different order |
- Answer with less or more information |
- Make different (and comparable quality) choices |
This precludes regular testing from being practically possible. You can't just test `response === "expected string"` when the response varies every time. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.