
text stringlengths 0 59.1k |
|---|
:::important |
- **"Good" Can Be Super Subjective:** What makes a "correct" or "high-quality" answer from an LLM? Sometimes it's obvious, but often it's pretty fuzzy and depends heavily on context. This makes setting up automated quality checks a real challenge. |
- **It's an Ocean of Information:** LLMs process large amounts of text – tons and tons of it. Logging, storing, and then actually _analyzing_ all that data can be a big job. |
- **The Need for Speed (Real-Time):** If your LLM is interacting with users live, you often need to monitor what's happening in real-time. Catching issues as they happen is crucial. |
- **Still Developing:** Honestly, standards for LLM observability are still developing. Different models and platforms do things their own way, so it's not always plug-and-play. |
- **Privacy is Paramount:** Prompts and responses can easily contain sensitive, personal information. You've got to be incredibly careful and responsible about how you log, store, and protect this data. |
::: |
## Your Toolkit: How to Actually _Do_ LLM Observability |
Alright, enough about the challenges – let's talk solutions! What tools and techniques can you actually use to get a better handle on your LLMs? |
- **Good Ol' Logging, But Smarter:** Don't throw out your existing logging practices! Adapt them. Standard logging frameworks are your first line of defense, but make sure you're capturing LLM-specific stuff like prompts, full responses, token counts, and maybe even those intermediate thoughts if you can get them. |
- **Tracing the Journey (Hello, OpenTelemetry!):** For anything more complex than a single LLM call (think microservices, or chains of LLM calls), distributed tracing is your best friend. Tools like OpenTelemetry can help you see the entire lifecycle of a request as it bounces between different parts of your system. |
- **Vector Databases to the Rescue:** These are becoming super handy. You can store embeddings of your prompts and responses, then search for similar ones. This is great for spotting common issues, finding anomalies, or even powering some clever automated quality checks. |
- **Dashboard Superstars (Prometheus, Grafana, Datadog, etc.):** If you're already using platforms like these for your other apps, you can often hook them up to your LLM data too. They're awesome for visualizing metrics, creating dashboards, and setting up alerts when things go weird. |
- **So, How Do You Grade an LLM, Anyway? (Evaluation Techniques):** |
- **Human Review is Often King:** Sometimes, you just need a human to look at the output and say, "Yep, that's good," or "Nope, that's way off." |
- **Model-Based Eval (AI Judging AI):** Using another LLM (or a simpler, more focused model) to score the output of your main LLM. It's not perfect, but it can help scale your checks. |
- **Run it Through Benchmarks:** Test your LLM against standard datasets and benchmarks to see how it compares against others or its own past performance. |
## Case Study: VoltAgent's Visual Approach to Observability |
Speaking of specialized platforms, it's insightful to see how observability can be a foundational principle. When we were building [VoltAgent](https://github.com/VoltAgent/voltagent/), we ran smack into the same "black box" problem many developers face with AI agents. |
Our biggest frustration? It was just so darn hard to understand _why_ our agents made certain decisions. What steps did they take? Which tools did they pick, and when? And when an error inevitably popped up, figuring out exactly what went wrong felt like detective work without enough clues. Standard logs helped a bit, ... |
We got a lot of inspiration from the visual debugging power of tools like n8n. We thought, "Why can't we have something that clear for AI agents?" So, we decided to build observability right into the core experience. The key differentiator for VoltAgent became our **[VoltOps LLM Observability Platform](https://console.... |
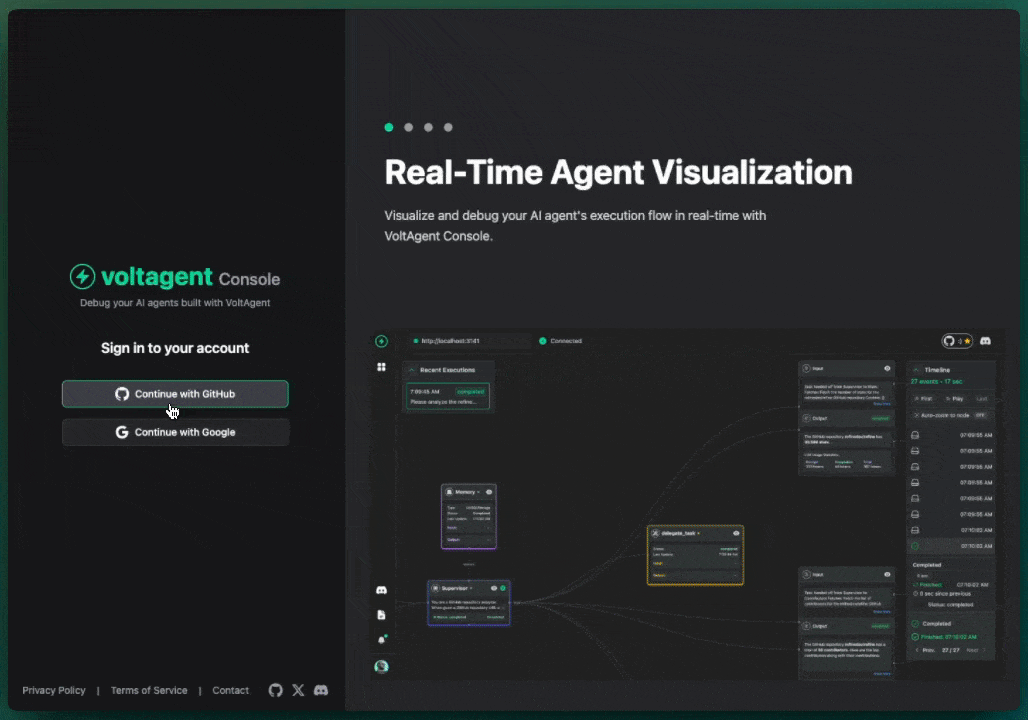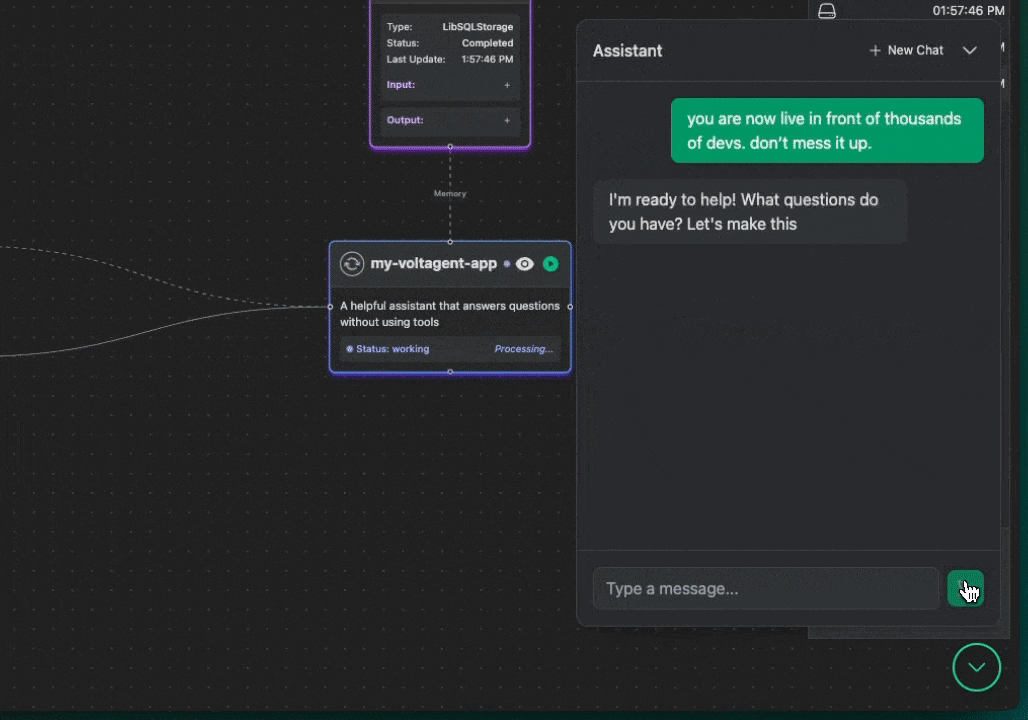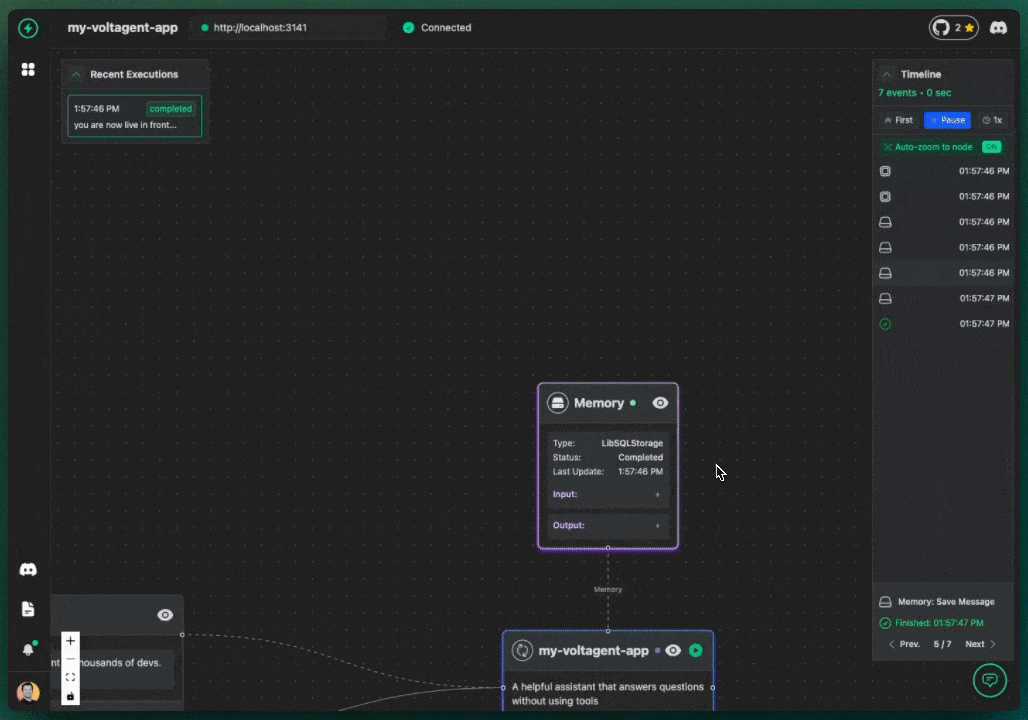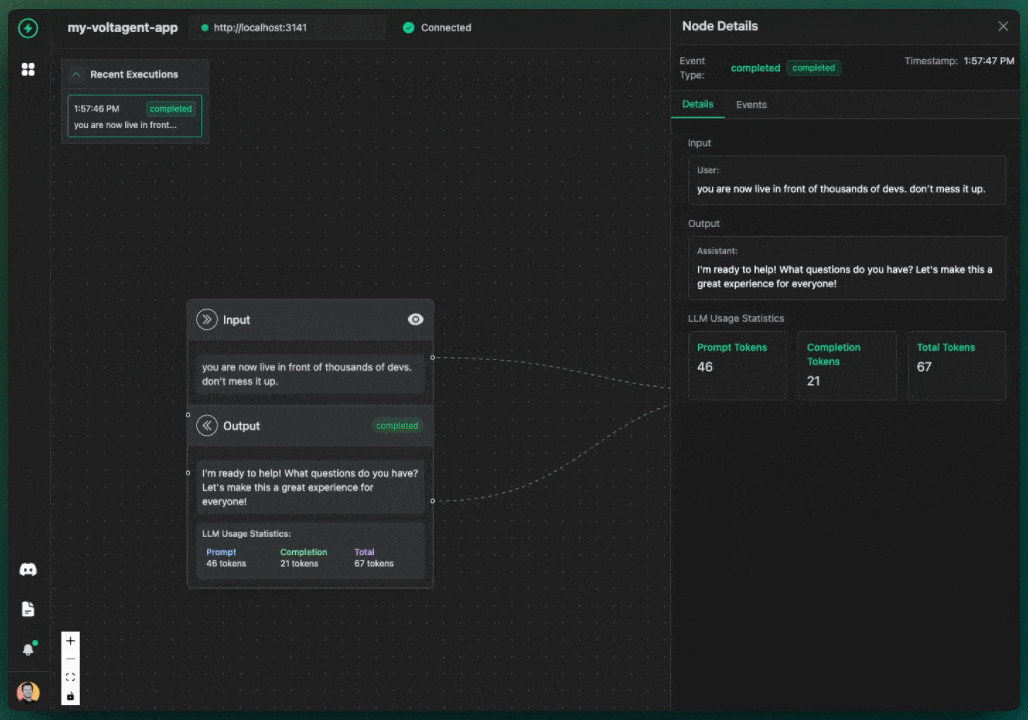 |
With this kind of visual approach, you can suddenly do things like: |
- Clearly see the step-by-step execution flow your agent actually takes – no more guessing! |
- Debug errors much, much more easily by pinpointing exactly where things went sideways on the canvas. |
- Track your agent's performance and, crucially, LLM costs tied to specific steps in the flow. |
- Easily compare results and execution paths when you're experimenting with different LLMs or tweaking your prompts. |
Our whole goal with this visual, canvas-based observability is to make the agent "black box" transparent and understandable. If you're curious to see this approach in action, you can [check out the VoltAgent documentation](https://voltagent.dev/docs/quick-start). |
## Getting Started: Best Practices for Sanity (and Success!) |
<ObservabilityPrioritizer /> |
Ready to actually start implementing? Awesome. Here are a few tips to make your LLM observability journey a bit smoother and save you some difficulties down the road: |
1. **Know Your "Why" (Seriously!):** Don't just start logging _everything_ because you can. That's a quick way to get overwhelmed. Ask yourself: What questions are you _really_ trying to answer? What problems are you desperately trying to solve? Start with clear goals, and let those guide your efforts. |
2. **Start Small, Then Grow Smart:** You don't need to implement every single main part of observability on day one. Begin by logging the data points that are most critical for _your_ app. You can always add more layers and sophistication later as you get a better feel for what you need. |
3. **Figure Out What's "Normal" (Establish Those Baselines):** You can't spot problems if you don't know what "good" or "normal" actually looks like for your specific LLM setup. Track your key metrics over time to get a feel for your baseline performance and cost. |
4. **Build It In, Don't Just Add It Awkwardly Later:** If you can, try to think about observability from the very start of your project. Weaving it into your development lifecycle early is a _lot_ easier (and usually more effective) than trying to force it in after everything's already built. |
5. **Humans + Machines = The Dream Team:** Automated monitoring is fantastic, and you should use it. But don't forget the human element. Combine those automated checks with human oversight and evaluation, especially for the really nuanced stuff like output quality and fairness. |
6. **Handle Data with Care (Especially the Sensitive Stuff):** This one's huge. If you're logging prompts and responses (and you probably should be), make absolutely sure you're anonymizing, redacting, or otherwise protecting any personal or sensitive information. Seriously, don't mess this one up. |
## Wrapping It Up: Observability is Your LLM's Best Friend (Really!) |
So, after all that, is LLM observability just _another_ thing to pile onto your already massive to-do list? Well, yeah, it kind of is. But here's the important point: it's one of those things that can genuinely save you a ton of difficulties, a surprising amount of money, and a whole lot of user frustration down the li... |
When you start to truly understand what your LLM is doing and why it's doing it, you shift from being a hopeful operator just crossing your fingers, to a confident architect of intelligent systems. You get the power to build AI applications that are more reliable, more efficient, and, importantly, more trustworthy. |
<|endoftext|> |
# source: VoltAgent__voltagent/website/blog/2025-10-14-vercel-ai-sdk/index.md type: docs |
--- |
title: What is Vercel AI SDK? |
description: A technical look at Vercel AI SDK 5, a toolkit for building AI-powered applications, and how it integrates with VoltAgent. Updated for AI SDK 5.0 (July 2025). |
tags: [llm] |
slug: vercel-ai-sdk |
image: https://cdn.voltagent.dev/2025-05-21-vercel-ai-sdk/social.png |
authors: necatiozmen |
--- |
import VercelAiSdkFeatureMatcher from '@site/src/components/blog-widgets/VercelAiSdkFeatureMatcher'; |
import IntegrationScenarioSelector from '@site/src/components/blog-widgets/IntegrationScenarioSelector'; |
import ZoomableMermaid from '@site/src/components/blog-widgets/ZoomableMermaid'; |
This article examines Vercel AI SDK, a TypeScript library for building AI-powered user interfaces and applications and its integration with VoltAgent. |
**Updated: October 14, 2025** — This article reflects AI SDK 5.0, covering typed chat messages, agentic loop control, SSE-based streaming, dynamic tooling, speech APIs, and the global provider system. |
--- |
### A Quick Look at Vercel AI SDK |
Vercel AI SDK provides a unified toolkit for working with Large Language Models (LLMs) from multiple providers (OpenAI, Anthropic, Google Gemini, etc.) using a single API. |
> Instead of writing separate integrations for each model provider, you can use one consistent API. |
:::tip When to Use What |
For simple AI features like chat or text completion, Vercel AI SDK alone may be enough. |
For autonomous agents with memory and decision-making, combine it with VoltAgent. |
::: |
For building autonomous AI agents that make decisions and interact with tools, frameworks like VoltAgent provide the necessary architecture. We'll examine this combination in detail. |
<VercelAiSdkFeatureMatcher /> |
### Core Features (Updated for AI SDK 5) |
Vercel released **AI SDK 5** on **July 31, 2025**, introducing major architectural changes and new capabilities. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.