Datasets:


dataset_info:
features:
- name: Id
dtype: string
- name: image
dtype: image
- name: Task
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: category
dtype: string
splits:
- name: test
num_bytes: 1918653929
num_examples: 2808
download_size: 1902027712
dataset_size: 1918653929
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
license: cc-by-sa-4.0
task_categories:
- image-text-to-text
language:
- th
size_categories:
- 1K<n<10K
ThaiOCRBench: A Task-Diverse Benchmark for Vision-Language Understanding in Thai
ThaiOCRBench is the first comprehensive benchmark for evaluating vision-language models (VLMs) on Thai text-rich visual understanding tasks.
Inspired by OCRBench v2, it contains 2,808 human-annotated samples across 13 diverse tasks, including table parsing, chart understanding, full-page OCR, key information extraction, and visual question answering.
The benchmark enables standardized zero-shot evaluation for both proprietary and open-source models, revealing significant performance gaps and paving the way for document understanding in low-resource languages.
🚀 Our paper ThaiOCRBench has been accepted to the IJCNLP-AACL 2025 Main Conference!
👉 📄 Read the Paper
👉 💻 GitHub Repository
📊 Dataset Statistics
| Task Type | Number of Samples |
|---|---|
| Text Recognition | 333 |
| Table Parsing | 193 |
| Full-page OCR | 197 |
| Chart Parsing | 200 |
| Key Information Extraction | 201 |
| Diagram VQA | 204 |
| Fine-grained Text Recognition | 206 |
| Handwritten Content Extraction | 209 |
| Key Information Mapping | 209 |
| Document Parsing | 211 |
| Infographics VQA | 213 |
| Document Classification | 215 |
| Cognition VQA | 217 |
| Total | 2,808 |
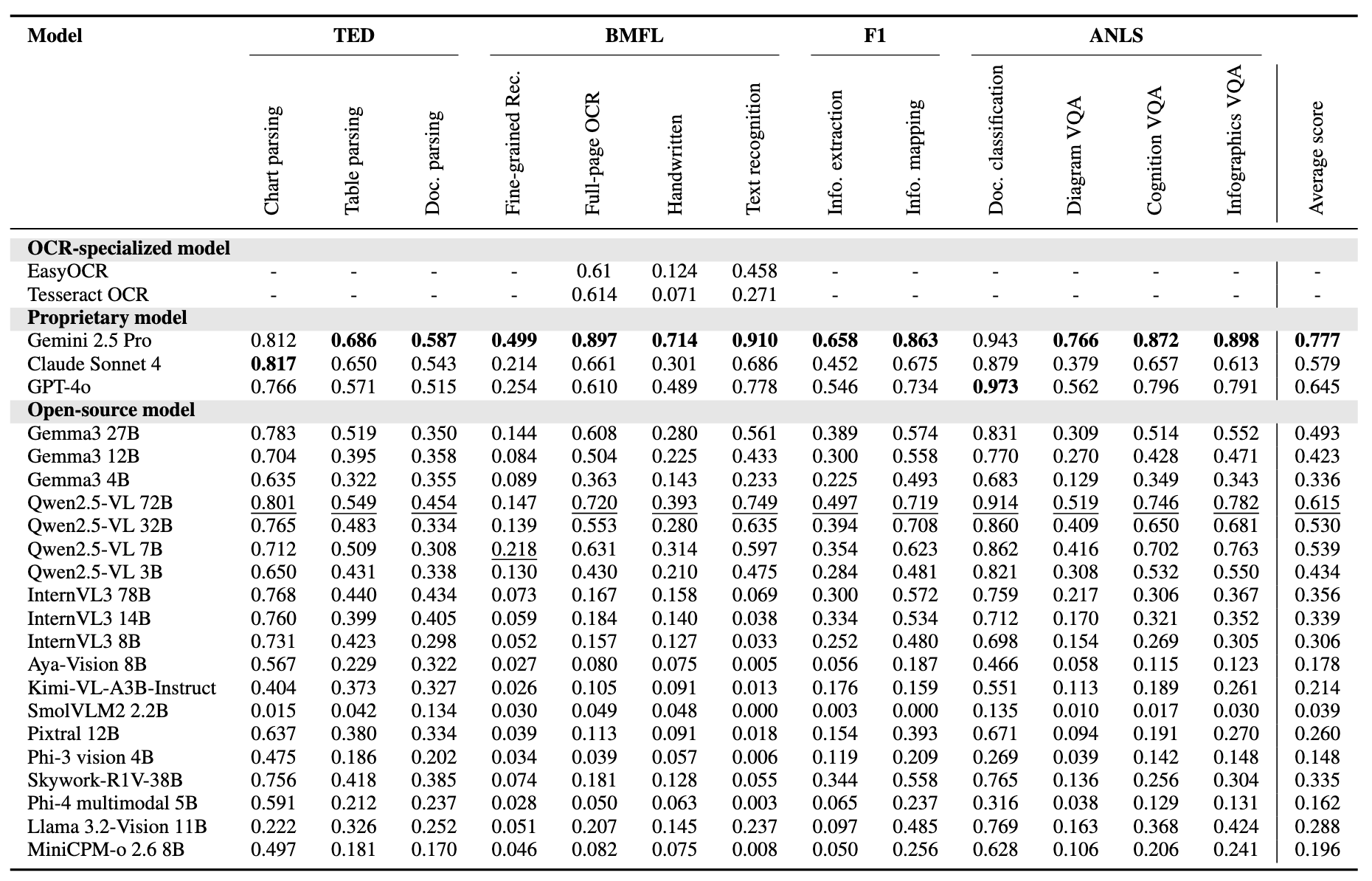
🧠 Performance of VLMs on ThaiOCRBench
📘 Citation
If you use ThaiOCRBench in your research or applications, please cite our work:
@misc{nonesung2025thaiocrbenchtaskdiversebenchmarkvisionlanguage,
title={ThaiOCRBench: A Task-Diverse Benchmark for Vision-Language Understanding in Thai},
author={Surapon Nonesung and Teetouch Jaknamon and Sirinya Chaiophat and Natapong Nitarach and Chanakan Wittayasakpan and Warit Sirichotedumrong and Adisai Na-Thalang and Kunat Pipatanakul},
year={2025},
eprint={2511.04479},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2511.04479},
}