
content stringlengths 263 5.24M | pred_label stringclasses 1
value | pred_score_pos float64 0.6 1 |
|---|---|---|
> 本文转自:https://mp.weixin.qq.com/s?__biz=MzkyODE5NjU2Mw==&mid=2247484757&idx=1&sn=523a55fcf636113e678f1de297ec4691&chksm=c21d37e9f56abeffca414c0d43d55b36396956735e3cff1c13e1a229a3d21336371a54da84ce&scene=21#wechat_redirect
**「函数返回值类型推导」**
C++14对函数返回类型推导规则做了优化,先看一段代码:
```cpp
#include <iostream>
using namespace std;
... | __label__POS | 0.994167 |
# 题目
给定一个只包含数字的字符串,用以表示一个 IP 地址,返回所有可能从 s 获得的 有效 IP 地址 。你可以按任何顺序返回答案。
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 '.' 分隔。
例如:"0.1.2.201" 和 "192.168.1.1" 是 有效 IP 地址,但是 "0.011.255.245"、"192.168.1.312" 和 "192.168@1.1" 是 无效 IP 地址。
示例 1:
输入:s = "25525511135"
输出:["255.255.11.135","255.255.111.35"]
示例 2:... | __label__POS | 0.999776 |
# 题目
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。<br>
左括号必须以正确的顺序闭合。
示例 1:
```
输入:s = "()"
输出:true
```
示例 2:
```
输入:s = "()[]{}"
输出:true
```
示例 3:
```
输入:s = "(]"
输出:false
```
示例 4:
```
输入:s = "([)]"
输出:false
```
示例 5:
```
输入:s = "{[]}"
输出:true
```
提示:
* 1 <= s.length <= 10<sup>... | __label__POS | 1.00001 |
# 题目
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
示例 2:
输入:target = 4, nums = [1,4,4]
输出:1
示例 3:
输入:target = 11, nums = [1,1,1,1... | __label__POS | 1.00001 |
# 题目
实现 strStr() 函数。
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回 -1 。
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf() 定义相符。
示例 1:
```
输入:haystack = "hello", needle = "ll"
输出:2
```
示例 2:
```
输入:haystack =... | __label__POS | 1.000008 |
# 题目
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
进阶:你能尝试使用一趟扫描实现吗?<br>
示例 1:<br>

```
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
```
示例 2:
```
输入:head = [1], n = 1
输出:[]
```
示例 3:
```
输入:head = [1,2], n = 1
输出:[1]
```
提示:
* 链表中结点的数目为 sz
* 1 <= sz <= 3... | __label__POS | 1.00001 |
#include <stdio.h>
#include <windows.h>
#include <string.h>
#define USAGE "./%s [-all|-one] <api> <dll>\n\n"
int ScanUneApi(char* nomApi,char* nomDll);
int ScanApisDll(char* nomDll);
int main(int argc, char* argv[])
{
if( argc < 3 )
{
printf(USAGE,argv[0]);
return 0;
}
printf("Hot Patch... | __label__POS | 0.702753 |
#include "common.h"
#include "send.h"
/* dispose of local addresses */
int
cat_mail(dest *dp, message *mp)
{
Biobuf *fp;
char *rcvr, *cp;
Mlock *l;
String *tmp, *s;
int i, n;
s = unescapespecial(s_clone(dp->repl1));
if (nflg) {
if(!xflg)
print("cat >> %s\n", s_to_c(s));
else
print("%s\n", s_to_c(dp-... | __label__POS | 0.784657 |
#include <windows.h>
#include <stdio.h>
#include <string.h>
void routine();
int sprintfPwnd(char *buffer,const char *format, ... );
typedef int(*SPRINTF)(char*,const char*,...);
DWORD adressePrologue;
int main()
{
char* welcome = (char*) malloc(sizeof(char) * 55);
ZeroMemory(welcome,55);
sprintf(welcome... | __label__POS | 0.733584 |
# 题目
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
k 是一个正整数,它的值小于或等于链表的长度。
如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
进阶:
* 你可以设计一个只使用常数额外空间的算法来解决此问题吗?
* 你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:

```
输入:head = [1,2,3,4,5], k =... | __label__POS | 1.000008 |
# 题目
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
提示:
1 <= k <= nums.length <= 10<sup>4</sup>
-10<sup>4</sup> <= nums[i] <= 10<sup>4</sup>
# 参考答案
```c++
class Solution {
public:
... | __label__POS | 1.00001 |
# 题目
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:
对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
如果 可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 true ;不是,则返回 false 。
示例 1:
输入:19
输出:true
解释:<br>
1<sup>2</sup> + 9<sup>2</sup> = 8<sup>2</sup><br>
8<sup>2</sup> + 2<sup>2</sup> = 68<br>
6<sup>2</sup> + 8<sup>2... | __label__POS | 1.00001 |
# C++核心编程
本阶段主要针对C++==面向对象==编程技术做详细讲解,探讨C++中的核心和精髓。
## 1 内存分区模型
C++程序在执行时,将内存大方向划分为**4个区域**
- 代码区:存放函数体的二进制代码,由操作系统进行管理的
- 全局区:存放全局变量和静态变量以及常量
- 栈区:由编译器自动分配释放, 存放函数的参数值,局部变量等
- 堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
**内存四区意义:**
不同区域存放的数据,赋予不同的生命周期, 给我们更大的灵活编程
### 1.1 程序运行前
在程序编译后,生成了exe可执行程序,**未执行该程序前*... | __label__POS | 0.998533 |
# 题目
给定一个包括 n 个整数的数组 nums 和 一个目标值 target。找出 nums 中的三个整数,使得它们的和与 target 最接近。返回这三个数的和。假定每组输入只存在唯一答案。
示例:
```
输入:nums = [-1,2,1,-4], target = 1
输出:2
解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2) 。
```
提示:
* 3 <= nums.length <= 10^3
* -10^3 <= nums[i] <= 10^3
* -10^4 <= target <= 10^4
# 参考答案
```c++
class Solution {
public:
... | __label__POS | 1.000007 |
# 题目
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回 n 皇后问题 不同的解决方案的数量。
示例 1:
输入:n = 4
输出:2
解释:如上图所示,4 皇后问题存在两个不同的解法。
示例 2:
输入:n = 1
输出:1
提示:
* 1 <= n <= 9
* 皇后彼此不能相... | __label__POS | 1.000009 |
# 题目
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
序列中第一个单词是 beginWord 。<br>
序列中最后一个单词是 endWord 。<br>
每次转换只能改变一个字母。<br>
转换过程中的中间单词必须是字典 wordList 中的单词。<br>
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。<br>
示例 1:
输入:beginWord = "hit", endWord... | __label__POS | 0.999538 |
# 题目
请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C++ 中的 atoi 函数)。
函数 myAtoi(string s) 的算法如下:
* 读入字符串并丢弃无用的前导空格
* 检查下一个字符(假设还未到字符末尾)为正还是负号,读取该字符(如果有)。 确定最终结果是负数还是正数。 如果两者都不存在,则假定结果为正。
* 读入下一个字符,直到到达下一个非数字字符或到达输入的结尾。字符串的其余部分将被忽略。
* 将前面步骤读入的这些数字转换为整数(即,"123" -> 123, "0032" -> 32)。如果没有读入数字,则整数为 0 。必要时更改符号(从步骤... | __label__POS | 0.999778 |
# 题目
给你 n 个非负整数 a<sub>1</sub>,a<sub>2</sub>,...,a<sub>n</sub>,每个数代表坐标中的一个点 (i, a<sub>i</sub>) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, a<sub>i</sub>) 和 (i, 0) 。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
说明:你不能倾斜容器。
示例 1:
... | __label__POS | 1.00001 |
# 题目
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。<br>
每条从根节点到叶节点的路径都代表一个数字:
例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123 。<br>
计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
示例 1:
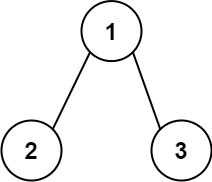
输入:root = [1,2,3]
输出:25
解释:
... | __label__POS | 0.999989 |
use strict;
use warnings;
my @code , my $i = 0 ;
my %registre = ( eax => '\x00' , ebx => '\x01' , ecx => '\x02' , edx => '\x03' );
my %instru = ( inc_reg => '\x12' , push_dwd => '\x20' , push_reg => '\x21' , pop_reg => '\x13' ,
mov_reg_reg => '\x14' , mov_reg_imm => '\x15' , mov_reg_ptrimm => '\x16' , mov... | __label__POS | 0.806723 |
# C++基础入门
## 1 C++初识
### 1.1 第一个C++程序
编写一个C++程序总共分为4个步骤
* 创建项目
* 创建文件
* 编写代码
* 运行程序
#### 1.1.1 创建项目
Visual Studio是我们用来编写C++程序的主要工具,我们先将它打开


#### 1.1.2 创建文件
右键源文件,选择添加->新建项

给C+... | __label__POS | 0.924089 |
# 题目
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例:

{
//在编译期进行判断,if和else语句不生成代码
if constexpr (ok == true)
{
//当ok为true时,下面的else块不生成汇编代码
std::cout << "ok" << std::endl;
}
else
{
//当ok为false时,上面... | __label__POS | 0.945568 |
#include <u.h>
#include <libc.h>
#include "dat.h"
void*
emalloc(int size)
{
void *a;
a = mallocz(size, 1);
if(a == nil)
sysfatal("%r");
return a;
}
char*
estrdup(char *s)
{
s = strdup(s);
if(s == nil)
sysfatal("%r");
return s;
}
/*
* like tokenize but obey "" quoting
*/
int
tokenize822(char *str, char ... | __label__POS | 0.877755 |
# 题目
给定一个二叉树,返回其节点值自底向上的层序遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
例如:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其自底向上的层序遍历为:
[
[15,7],
[9,20],
[3]
]
# 参考答案
```c++
class Solution {
public:
vector<vector<int>> levelOrderBottom(TreeNode* root) {
... | __label__POS | 0.999987 |
# 题目
实现获取 下一个排列 的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
必须 原地 修改,只允许使用额外常数空间。
示例 1:
输入:nums = [1,2,3]
输出:[1,3,2]
示例 2:
输入:nums = [3,2,1]
输出:[1,2,3]
示例 3:
输入:nums = [1,1,5]
输出:[1,5,1]
示例 4:
输入:nums = [1]
输出:[1]
提示:
1 <= nums.length <= 100
... | __label__POS | 1.00001 |
# 题目
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
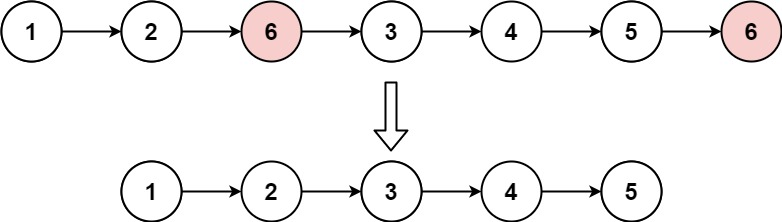
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1
输出:[]
示例 3:
输入:head = ... | __label__POS | 1.00001 |
# 题目
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
示例 1:
... | __label__POS | 1.00001 |
#include "common.h"
/* expand a path relative to some `.' */
extern String *
abspath(char *path, char *dot, String *to)
{
if (*path == '/') {
to = s_append(to, path);
} else {
to = s_append(to, dot);
to = s_append(to, "/");
to = s_append(to, path);
}
return to;
}
/* return a pointer to the base component ... | __label__POS | 0.750023 |
# 🌞🌞🌞 最新整理, C++ 学习资料,含C++ 11 / 14 / 17 / 20 / 23 新特性、入门教程、推荐书籍、优质文章、学习笔记、教学视频等
<br>
<div align=center>
<img width="70%" height="70%" src="https://user-images.githubusercontent.com/87457873/134297801-d13053cc-0a5d-4efd-9f02-9343b513fc33.png"/>
## 🚀 直达 [(# C++11)](#cpp_11) [(# C++14)](#cpp_14) [(# C++17)](#cpp... | __label__POS | 0.915642 |
# 题目
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。<br>
实现 LRUCache 类:<br>
LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存<br>
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。<br>
void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。<br>
示例:
输入
... | __label__POS | 0.998546 |
# 题目
给定两个整数 n 和 k,返回 1 ... n 中所有可能的 k 个数的组合。
示例:
输入: n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
# 参考答案
```c++
class Solution {
public:
vector<int> temp;
vector<vector<int>> ans;
vector<vector<int>> combine(int n, int k) {
//... | __label__POS | 1.00001 |
# 题目
给定一个字符串 s,你可以通过在字符串前面添加字符将其转换为回文串。找到并返回可以用这种方式转换的最短回文串。
示例 1:
输入:s = "aacecaaa"
输出:"aaacecaaa"
示例 2:
输入:s = "abcd"
输出:"dcbabcd"
提示:
* 0 <= s.length <= 5 * 10<sup>4</sup>
* s 仅由小写英文字母组成
# 参考答案
```c++
class Solution {
public:
string shortestPalindrome(string s) {
int n = s.size();
... | __label__POS | 1.00001 |
> 原文链接:https://www.oracle.com/cn/servers/technologies/howto-use-lambda-exp-cpp11.html
### Lambda 表达式不仅具有函数指针的灵活性,还可以通过捕获局部变量提高可扩展性。本文介绍 Lambda 表达式的语法和用法。
### 简介
Lambda 可能是最新的 C++11 标准的典型特性之一。Lambda 表达式把函数看作对象。Lambda 表达式可以像对象一样使用,比如可以将它们赋给变量和作为参数传递,还可以像函数一样对其求值。
当一个函数需要将另一个函数用作参数时,可以使用 Lambda。例如,C qsort() 函数接受一个指向比较函... | __label__POS | 0.944771 |
# 题目
给定一个正整数 n ,输出外观数列的第 n 项。
「外观数列」是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项的描述。
你可以将其视作是由递归公式定义的数字字符串序列:
* countAndSay(1) = "1"
* countAndSay(n) 是对 countAndSay(n-1) 的描述,然后转换成另一个数字字符串。
前五项如下:
1. 1
2. 11
3. 21
4. 1211
5. 111221
第一项是数字 1
描述前一项,这个数是 1 即 “ 一 个 1 ”,记作 "11"
描述前... | __label__POS | 0.999894 |
# C++11新特性之auto和decltype知识点
C++11引入了auto和decltype关键字,使用它们可以在编译期就推导出变量或者表达式的类型,方便开发者编码的同时也简化了代码。
## auto
auto可以让编译器在编译器就推导出变量的类型,看代码:
```c++
auto a = 10; // 10是int型,可以自动推导出a是int
int i = 10;auto b = i; // b是int型
auto d = 2.0; // d是double型
```
这就是auto的基本用法,可以通过=右边的类型推导出变量的类型。
### auto推导规则
直接看代码
代码1:
```c++
int i ... | __label__POS | 0.715837 |
#include "common.h"
#include "smtpd.h"
#include <ip.h>
enum {
NORELAY = 0,
DNSVERIFY,
SAVEBLOCK,
DOMNAME,
OURNETS,
OURDOMS,
IP = 0,
STRING,
};
typedef struct Keyword Keyword;
struct Keyword {
char *name;
int code;
};
static Keyword options[] = {
"norelay", NORELAY,
"verifysenderdom", DNSVERIFY,
"sav... | __label__POS | 0.650299 |
# 题目
在一个由 '0' 和 '1' 组成的二维矩阵内,找到只包含 '1' 的最大正方形,并返回其面积。
示例 1:
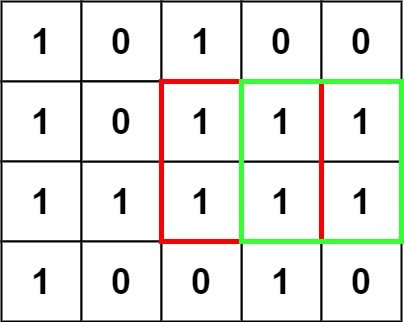
输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]]
输出:4
示例 2:
 和一个字符模式 (p) ,实现一个支持 '?' 和 '*' 的通配符匹配。
'?' 可以匹配任何单个字符。
'*' 可以匹配任意字符串(包括空字符串)。
两个字符串完全匹配才算匹配成功。
说明:
s 可能为空,且只包含从 a-z 的小写字母。
p 可能为空,且只包含从 a-z 的小写字母,以及字符 ? 和 *。
示例 1:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:
s = "aa"
p = "*"
输出:... | __label__POS | 1.00001 |
# 题目
给定一个字符串 s 和一些 长度相同 的单词 words 。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符 ,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:s = "barfoothefoobarman", words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:s = "wordgoodgoodgo... | __label__POS | 1.00001 |
# 题目
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例 1:
```
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
```
示例 2:
```
输入:nums = []
输出:[]
```
示例 3:
```
输入:nums = [0]
输出:[]
```
提示:
* 0 <= nums.length <= 3000
* -10<sup>5</sup> <= nums[i] <= 10<sup>5</su... | __label__POS | 1.000003 |
# 题目
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子。
说明:
分隔时可以重复使用字典中的单词。<br>
你可以假设字典中没有重复的单词。<br>
示例 1:
输入:
s = "catsanddog"
wordDict = ["cat", "cats", "and", "sand", "dog"]
输出:
[
"cats and dog",
"cat sand dog"
]
示例 2:
输入:
s = "pineapple... | __label__POS | 0.999995 |
# 题目
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
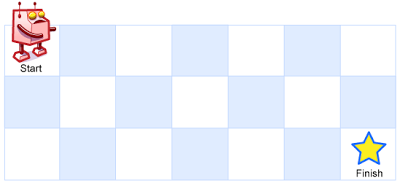
输入:m = 3, n = 7
输出:28
示例 2:
输入:m = 3, n = 2
输出:3
解释:
从... | __label__POS | 1.000009 |
# 题目
给出集合 [1,2,3,...,n],其所有元素共有 n! 种排列。
按大小顺序列出所有排列情况,并一一标记,当 n = 3 时, 所有排列如下:
"123"
"132"
"213"
"231"
"312"
"321"
给定 n 和 k,返回第 k 个排列。
示例 1:
输入:n = 3, k = 3
输出:"213"
示例 2:
输入:n = 4, k = 9
输出:"2314"
示例 3:
输入:n = 3, k = 1
输出:"123"
提示:
* 1 <= n <= 9
8 1 <= k <= n!
... | __label__POS | 1.00001 |
#include <iostream>
#include <utility>
#include <vector>
#include <iterator>
class stream
{
public:
using flags_type = int;
public:
flags_type flags() const
{ return flags_; }
/// 以 newf 替换 flags_ 并返回旧值。
flags_type flags(flags_type newf)
{ return std::exchange(flags_, newf); }
p... | __label__POS | 0.997196 |
## <h1 id="cpp_14">C++14新特性</h1>
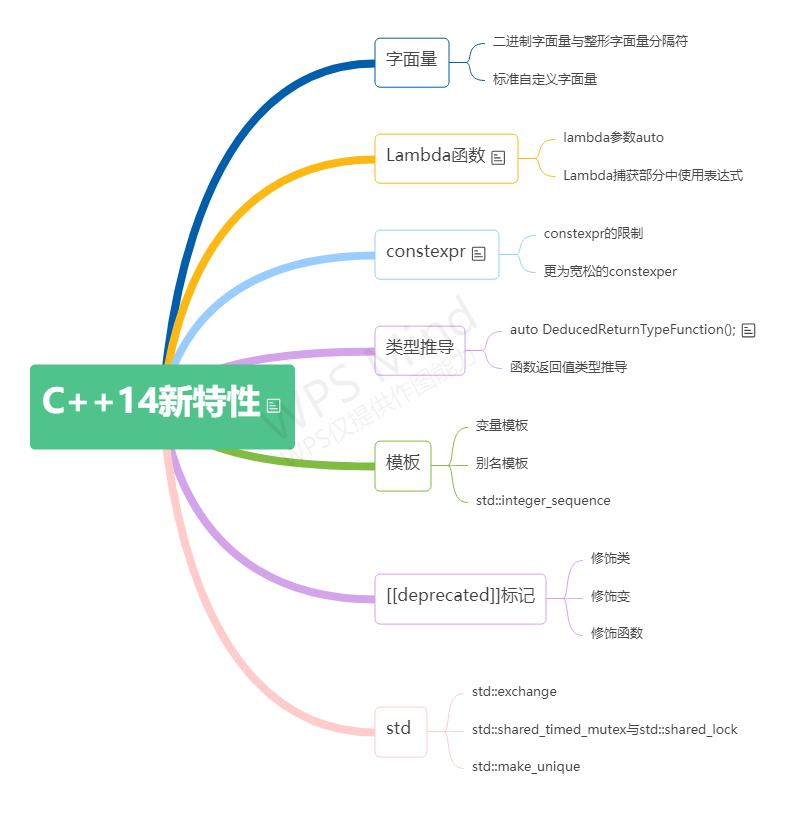
-----------
<h4 id="cpp_14_01">函数返回值类型推导</h4>
C++14对函数返回类型推导规则做了优化,先看一段代码:
```CPP
#include <iostream>
using namespace std;
auto func(int i) {
return i;
}
int main() {
cout << func(4) <<... | __label__POS | 0.978558 |
# 题目
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
提示:
* 1 <= nums.length <= 8
* -10 <= nums[i] <= 10
# 参考答案
```c++
class Solution {
vector<int> vis;
pub... | __label__POS | 1.00001 |
# 题目
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [start<sub>i</sub, end<sub>i</sub] 。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
... | __label__POS | 1.00001 |
# 题目
给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。
如果反转后整数超过 32 位的有符号整数的范围 [−231, 231 − 1] ,就返回 0。
假设环境不允许存储 64 位整数(有符号或无符号)。
示例 1:
```
输入:x = 123
输出:321
```
示例 2:
```
输入:x = -123
输出:-321
```
示例 3:
```
输入:x = 120
输出:21
```
示例 4:
```
输入:x = 0
输出:0
```
提示:
-231 <= x <= 231 - 1
# 参考答案
```c++
#include <bits/stdc++.h>
us... | __label__POS | 1.000008 |
# 题目
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
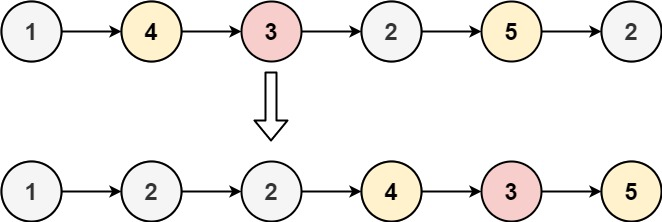
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1... | __label__POS | 1.00001 |
# 题目
给你一个字符串 s ,逐个翻转字符串中的所有 单词 。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
请你返回一个翻转 s 中单词顺序并用单个空格相连的字符串。
说明:
输入字符串 s 可以在前面、后面或者单词间包含多余的空格。<br>
翻转后单词间应当仅用一个空格分隔。<br>
翻转后的字符串中不应包含额外的空格。<br>
示例 1:
输入:s = "the sky is blue"
输出:"blue is sky the"
示例 2:
输入:s = " hello world "
输出:"world hello"
解释... | __label__POS | 1 |
# 题目
给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
示例 1:
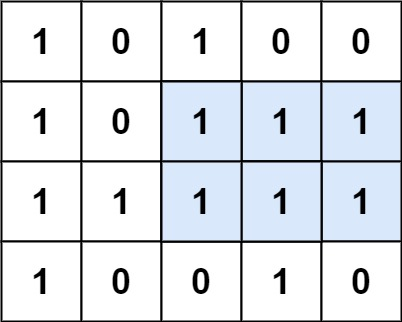
输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]]
输出:6
解释:最大矩形如上图所示。... | __label__POS | 0.999989 |
# 题目
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum ,判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。
叶子节点 是指没有子节点的节点。
示例 1:
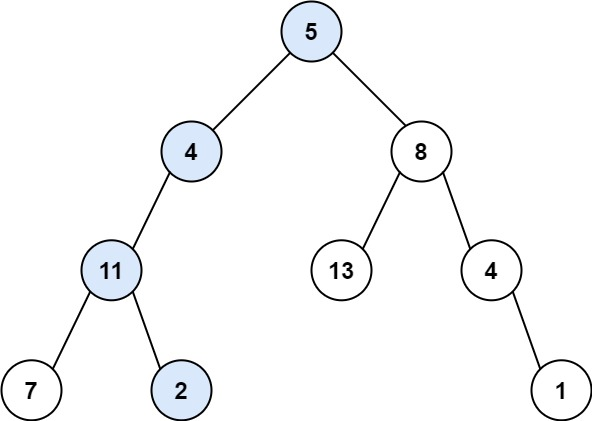
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
示... | __label__POS | 1.00001 |
# 题目
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出:1
示例 2:
输入:grid = [
["1","1","0","0","0"],... | __label__POS | 0.99997 |
# 题目
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除链表中所有存在数字重复情况的节点,只保留原始链表中 没有重复出现 的数字。
返回同样按升序排列的结果链表。
示例 1:
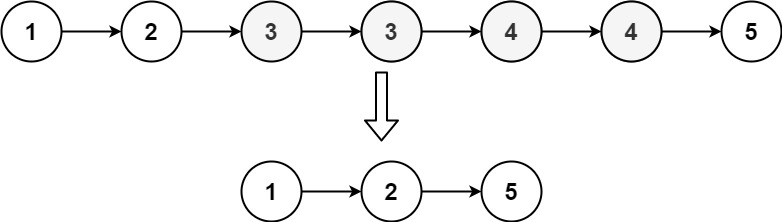
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
 {
unordered_m... | __label__POS | 1.00001 |
{1, 1, X86_AAD8i8},
{1, 1, X86_AAM8i8},
{2, 2, X86_ADC16i16},
{2, 2, X86_ADC16mi},
{1, 2, X86_ADC16mi8},
{2, 2, X86_ADC16ri},
{1, 2, X86_ADC16ri8},
{4, 4, X86_ADC32i32},
{4, 4, X86_ADC32mi},
{1, 4, X86_ADC32mi8},
{4, 4, X86_ADC32ri},
{1, 4, X86_ADC32ri8},
{4, 8, X86_ADC64i32},
{4, 8, X86_ADC64mi32},
{1, 8, X86_ADC64mi8... | __label__POS | 1.000002 |
# 题目
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。
示例 1:
输入:s = "aab"
输出:[["a","a","b"],["aa","b"]]
示例 2:
输入:s = "a"
输出:[["a"]]
提示:
* 1 <= s.length <= 16
* s 仅由小写英文字母组成
# 参考答案
```c++
class Solution {
private:
vector<vector<int>> f;
vector<vector<string>> ret... | __label__POS | 1.000007 |
# 题目
给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
示例 2:
输入:digits = [4,3,2,1]
输出:[4,3,2,2]
解释:输入数组表示数字 4321。
示例 3:
输入:digits = [0]
输出:[1]
提示:
* 1 <= digits.length <= 100
* 0 ... | __label__POS | 1.00001 |
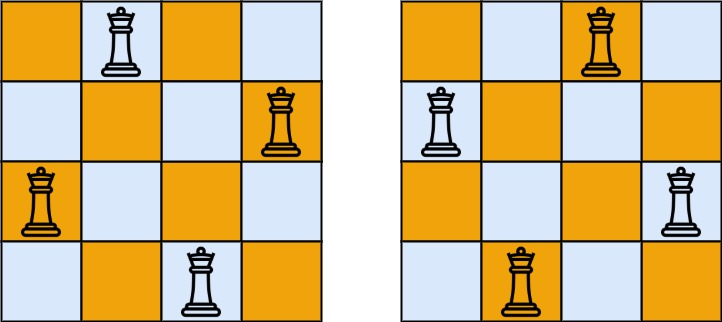
# 题目
给你一个数组 points ,其中 points[i] = [x<sub>i</sub>, y<sub>i</sub>] 表示 X-Y 平面上的一个点。求最多有多少个点在同一条直线上。
示例 1:
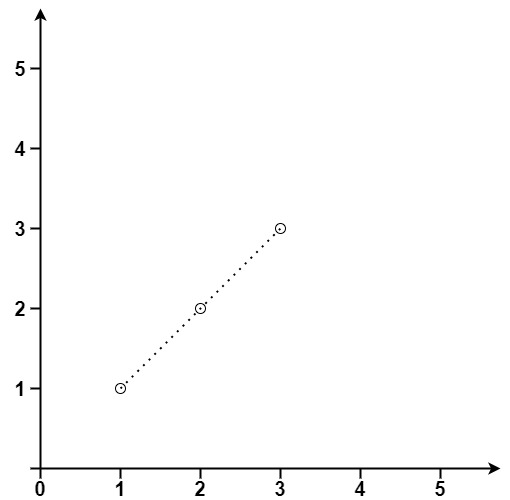
输入:points = [[1,1],[2,2],[3,3]]
输出:3
示例 2:
-3)+(6+8)"
输出:23
提示:
* 1 <= s.length <= 3 * 10<sup>5</sup>
* s 由数字、'+'、'-'、'('、')'、和 ' ' 组成
* s 表示一个有效的表达式
# 参考答案
```c++
class Solution {
public:
int calculate(st... | __label__POS | 1.000009 |
# 题目
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
* Trie() 初始化前缀树对象。
* void insert(String word) 向前缀树中插入字符串 word 。
* boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
* boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返... | __label__POS | 0.998896 |
#include "common.h"
#include "dat.h"
int cflag;
int aflag;
int rflag;
int createpipeto(char *alfile, char *user, char *listname, int owner);
void
usage(void)
{
fprint(2, "usage:\t%s -c listname\n", argv0);
fprint(2, "\t%s -[ar] listname addr\n", argv0);
exits("usage");
}
void
main(int argc, char **argv)
{
char ... | __label__POS | 0.710607 |
# 题目
给定一个二叉树,返回它的 后序 遍历。
示例:
输入: [1,null,2,3]
1
\
2
/
3
输出: [3,2,1]
# 参考答案
```c++
class Solution {
public:
void addPath(vector<int> &vec, TreeNode *node) {
int count = 0;
while (node != nullptr) {
++count;
vec.emplace_back... | __label__POS | 1.00001 |
# 题目
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
所有数字(包括 target)都是正整数。
解集不能包含重复的组合。
示例 1:
输入:candidates = [2,3,6,7], target = 7,
所求解集为:
[
[7],
[2,2,3]
]
示例 2:
输入:candidates = [2,3,5], target = 8,
所求解集为:
[
... | __label__POS | 1.000001 |
# 题目
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
你需要按照以下要求,帮助老师给这些孩子分发糖果:
* 每个孩子至少分配到 1 个糖果。
* 评分更高的孩子必须比他两侧的邻位孩子获得更多的糖果。
那么这样下来,老师至少需要准备多少颗糖果呢?
示例 1:
输入:[1,0,2]
输出:5
解释:你可以分别给这三个孩子分发 2、1、2 颗糖果。
示例 2:
输入:[1,2,2]
输出:4
解释:你可以分别给这三个孩子分发 1、2、1 颗糖果。
第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
# 参考... | __label__POS | 1.00001 |
# 题目
定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
示例 1:
输入:nums = [2,0,2,1,1,0]
输出:[0,0,1,1,2,2]
示例 2:
输入:nums = [2,0,1]
输出:[0,1,2]
示例 3:
输入:nums = [0]
输出:[0]
示例 4:
输入:nums = [1]
输出:[1]
提示:
* n == nums.length
* 1 <= n <= 300... | __label__POS | 1.00001 |
# 题目
给你二叉搜索树的根节点 root ,该树中的两个节点被错误地交换。请在不改变其结构的情况下,恢复这棵树。
进阶:使用 O(n) 空间复杂度的解法很容易实现。你能想出一个只使用常数空间的解决方案吗?
示例 1:
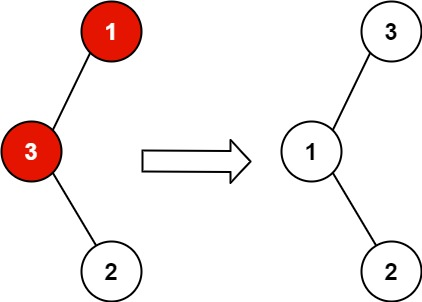
输入:root = [1,3,null,null,2]
输出:[3,1,null,null,2]
解释:3 不能是 1 左孩子,因为 3 > 1 。交换 1 和 3... | __label__POS | 0.999606 |
# 题目
给你一个只包含 '(' 和 ')' 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
示例 1:
输入:s = "(()"
输出:2
解释:最长有效括号子串是 "()"
示例 2:
输入:s = ")()())"
输出:4
解释:最长有效括号子串是 "()()"
示例 3:
输入:s = ""
输出:0
提示:
* 0 <= s.length <= 3 * 10<sup>4</sup>
* s[i] 为 '(' 或 ')'
# 参考答案
```c++
class Solution {
public:
int longest... | __label__POS | 1.00001 |
# 题目
颠倒给定的 32 位无符号整数的二进制位。
提示:
* 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
* 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在上面的 示例 2 中,输入表示有符号整数 -3,输出表示有符号整数 -1073741825。
示例 1:
输入: 00000010100101000001111010011100
输出: 00111001011110000010100101000000
解释: 输... | __label__POS | 0.996952 |
# 题目
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例:
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4)
输出:7 -> 0 -> 8
原因:342 + 465 = 807
# 参考答案
```c++
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListN... | __label__POS | 1.000007 |
# 题目
给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
拆分时可以重复使用字典中的单词。<br>
你可以假设字典中没有重复的单词。<br>
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
... | __label__POS | 1.000009 |
# 题目
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
* 例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
* 请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true... | __label__POS | 1.000003 |
# 题目
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票... | __label__POS | 1.00001 |
# 题目
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除所有重复的元素,使每个元素 只出现一次 。
返回同样按升序排列的结果链表。
示例 1:
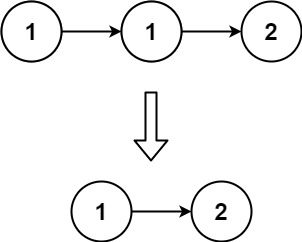
输入:head = [1,1,2]
输出:[1,2]
示例 2:
组成
# 参考答案
```c++
class Solution {
private:
int expand(string &s, int L, ... | __label__POS | 1.00001 |
#include "sys.h"
#include "spam.h"
int debug;
Biobuf bin;
char patfile[128], header[Hdrsize+2];
char cmd[1024];
char* canon(Biobuf*, char*, char*, int*);
int matcher(char *, Pattern*, char*, Resub*);
int matchaction(Patterns*, char*);
void
usage(void)
{
fprint(2, "missing or bad arguments to qer\n");
exits("usage... | __label__POS | 0.909019 |
# 题目
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
```
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印... | __label__POS | 1.00001 |
#include <iostream>
#include <string>
#include <chrono>
#include <thread>
using namespace std::chrono;
std::string fetchDataFromDB(std::string recvData) {
//确保函数要5秒才能执行完成
std::this_thread::sleep_for(seconds(5));
//处理创建数据库连接、获取数据等事情
return "DB_" + recvData;
}
std::string fetchDataFromFile(std::string rec... | __label__POS | 0.919471 |
# 题目
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
* 始终以斜杠 '/' 开头。
* 两个目录名之间必须只有一个斜杠 '/' 。
* 最后一个目录名(如果存在)不能 以 '/' 结尾。
* 此... | __label__POS | 0.999996 |
# 题目
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
题目数据保证答案符合 32 位带符号整数范围。
示例 1:
输入:s = "rabbbit", t = "rabbit"
输出:3
解释:
如下图所示, 有 3 种可以从 s 中得到 "rabbit" 的方案。
(上箭头符号 ^ 表示选取的字母)
rabbbit
^^^^ ^^
rabbbit
... | __label__POS | 1.000003 |
# 题目
定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例 1:
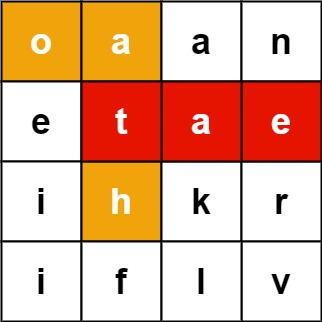
输入:board = [["o","a","a","n"],["e","t","a","e... | __label__POS | 1.000009 |
# 题目
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
注意:如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
示例 2:
输入:s = "a", t = "a"
输出:"a"
提示:
* 1 <= s.length, t.length <= 10<sup>5</sup>
* s 和 t 由英文字母组成
# 参考答案
```c++
class Solution {
public:... | __label__POS | 1.000006 |
# 题目
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
示例 1:
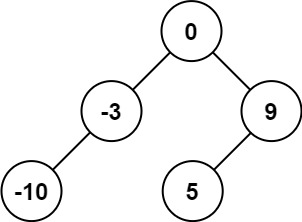
输入:nums = [-10,-3,0,5,9]
输出:[0,-3,9,-10,null,5]
解释:[0,-10,5,null,-3,null,9] 也将被视为正确答... | __label__POS | 1.00001 |
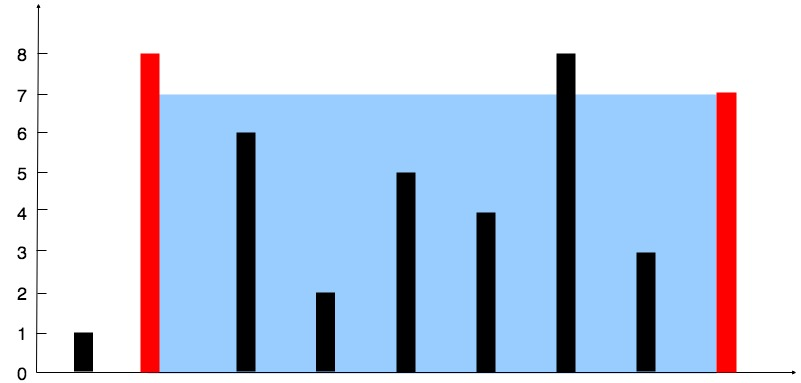
# 题目
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。

示例 1:
输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入... | __label__POS | 1.00001 |
# 题目
给定一个三角形 triangle ,找出自顶向下的最小路径和。
每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。也就是说,如果正位于当前行的下标 i ,那么下一步可以移动到下一行的下标 i 或 i + 1 。
示例 1:
输入:triangle = [[2],[3,4],[6,5,7],[4,1,8,3]]
输出:11
解释:如下面简图所示:
2
3 4
6 5 7
4 1 8 3
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11... | __label__POS | 1.000009 |
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
class MyString
{
public:
static size_t CCtor; //统计调用拷贝构造函数的次数
static size_t MCtor; //统计调用移动构造函数的次数
static size_t CAsgn; //统计调用拷贝赋值函数的次数
static size_t MAsgn; //统计调用移动赋值函数的次数
public:
// 构造函数
MyString(const char* cstr=0)... | __label__POS | 0.824136 |
# 题目
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
```
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
```
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字... | __label__POS | 0.999765 |
# 题目
根据一棵树的前序遍历与中序遍历构造二叉树。
注意:<br>
你可以假设树中没有重复的元素。
例如,给出
前序遍历 preorder = [3,9,20,15,7]<br>
中序遍历 inorder = [9,3,15,20,7]
返回如下的二叉树:
3
/ \
9 20
/ \
15 7
# 参考答案
```c++
class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if (!preorder.siz... | __label__POS | 1.00001 |
#include <iostream>
#include <memory>
template <std::size_t N>
struct MyAllocator
{
char data[N];
void* p;
std::size_t sz;
MyAllocator() : p(data), sz(N) {}
template <typename T>
T* aligned_alloc(std::size_t a = alignof(T))
{
if (std::align(a, sizeof(T), p, sz))
{
... | __label__POS | 0.675083 |
# 题目
给定一个数组 prices ,其中 prices[i] 是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: prices = [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易... | __label__POS | 1.00001 |
enum class MyErrorCondition {
kChenggong,
kWangluoCuowu,
kQingqiuCuowu,
kFuwuqiCuowu,
};
class MyErrorCategory: public std::error_category
{
public:
static MyErrorCategory const& instance() {
static MyErrorCategory instance;
return instance;
}
char const *name() const ... | __label__POS | 0.900492 |
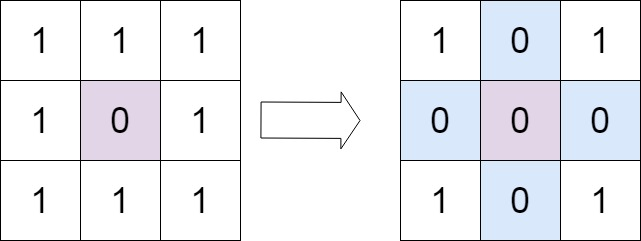
# 题目
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
进阶:
* 一个直观的解决方案是使用 O(mn) 的额外空间,但这并不是一个好的解决方案。
* 一个简单的改进方案是使用 O(m + n) 的额外空间,但这仍然不是最好的解决方案。
你能想出一个仅使用常量空间的解决方案吗?
示例 1:
输入:matrix = [[1,1... | __label__POS | 1.000001 |
# 题目
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
* push(x) —— 将元素 x 推入栈中。
* pop() —— 删除栈顶的元素。
* top() —— 获取栈顶元素。
* getMin() —— 检索栈中的最小元素。
示例:
输入:
["MinStack","push","push","push","getMin","pop","top","getMin"]
[[],[-2],[0],[-3],[],[],[],[]]
输出:
[null,null,null,null,-3,null,0,-2]
解释:
M... | __label__POS | 0.999324 |
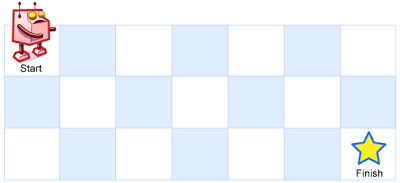
# 题目
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用 1 和 0 来表示。
示例 1:

```
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
```
示例 2:
```
输入:l1 = [], l2 = []
输出:[]
```
示例 3:
```
输入:l1 = [], l2 = [0]
输出:[0]
```
提示:
* ... | __label__POS | 1.00001 |
#include <iostream>
#include <type_traits>
#include <cstdint>
void print_separator()
{
std::cout << "-----\n";
}
int main()
{
std::cout << std::boolalpha;
// 一些实现定义状况
std::cout << std::is_same<int, std::int32_t>::value << '\n';
// 若 'int' 为 32 位则通常为 true
std::cout << std::is_same<int, std:... | __label__POS | 0.850398 |
# 题目
给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node {
public int val;
public List<Node> neighbors;
}
测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第... | __label__POS | 1.000006 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.