
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | polyapi-python | 0.3.14.dev1 | The Python Client for PolyAPI, the IPaaS by Developers for Developers | # PolyAPI Python Library
The PolyAPI Python Library lets you use and define PolyAPI functions using Python.
## PolyAPI Quickstart
### 1. Install Libraries
First install the client.
We recommend the use of venv so you can have multiple projects each with separate credentials:
```bash
python -m venv myvenv
source m... | text/markdown | null | Dan Fellin <dan@polyapi.io> | null | null | MIT License
Copyright (c) 2025 PolyAPI Inc.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the r... | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"requests>=2.32.3",
"typing_extensions>=4.12.2",
"jsonschema-gentypes==2.6.0",
"pydantic>=2.8.0",
"stdlib_list>=0.10.0",
"colorama==0.4.4",
"python-socketio[asyncio_client]==5.11.1",
"truststore>=0.8.0",
"httpx>=0.28.1"
] | [] | [] | [] | [
"Homepage, https://github.com/polyapi/polyapi-python"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:47:54.822316 | polyapi_python-0.3.14.dev1.tar.gz | 70,269 | 41/a1/5e5aab775743a44d7720af7fb158651c808f34bb9e9d6055c4d71c8c7c9e/polyapi_python-0.3.14.dev1.tar.gz | source | sdist | null | false | 592c20961b6e9d8d1bf1e8d5eb7ddcbc | e151dfeb0dfdcc02d975bc238bbfcee3ed4236babb707626d43ebcaa9b2a1f48 | 41a15e5aab775743a44d7720af7fb158651c808f34bb9e9d6055c4d71c8c7c9e | null | [
"LICENSE"
] | 183 |
2.4 | lmxy | 0.3.15 | Language models extensions | # Language model extensions
Some useful integrations for llama-index.
| text/markdown | null | Paul Maevskikh <arquolo@gmail.com> | null | Paul Maevskikh <arquolo@gmail.com> | MIT License
Copyright (c) 2019 Paul Maevskikh
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the... | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <3.15,>=3.12 | [] | [] | [] | [
"aiohttp~=3.10",
"glow~=0.15.4",
"httpx",
"pydantic-settings",
"pydantic~=2.10",
"tenacity",
"fastembed~=0.7.0; extra == \"all\"",
"grpcio; extra == \"all\"",
"llama-index-core<0.15,>=0.13.0; extra == \"all\"",
"llama-index-utils-huggingface; extra == \"all\"",
"openai~=1.102; extra == \"all\"",... | [] | [] | [] | [
"homepage, https://github.com/arquolo/lmx"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:47:49.400527 | lmxy-0.3.15.tar.gz | 31,523 | 4e/94/530bd33219ef5cc12cd26974e95aab82f59a13dc35ce8bfe56d85a772bcb/lmxy-0.3.15.tar.gz | source | sdist | null | false | a36e8cd74ffcf99128e3decdf2ce2ff7 | d3281fe4376946cf2330121d519a04d71ef5b2f2df16a95964e99b85910fb75d | 4e94530bd33219ef5cc12cd26974e95aab82f59a13dc35ce8bfe56d85a772bcb | null | [
"LICENSE"
] | 213 |
2.4 | pylogrouter | 0.1.6 | Python Log Router with console, file and HTML facilities | # pylogrouter
`pylogrouter` is a small library for routing log messages into multiple *facilities* (console, plain text file, HTML log) via a single API.
Why it exists:
- avoid duplicating `print + file write + html write` across a codebase;
- route one message to **all** outputs or only selected ones;
- get a readab... | text/markdown | null | null | null | null | null | null | [] | [] | null | null | <3.14,>=3.12 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/mykolarudenko/pylogrouter"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:47:42.078726 | pylogrouter-0.1.6.tar.gz | 15,791 | d6/2c/0c6f12edf785fe557538b945cbc2d822abbc465af1afb737bcb3b3c33ade/pylogrouter-0.1.6.tar.gz | source | sdist | null | false | b0d57ef2a4bd9d1dec585c4aa5f68a4b | 0f77589b8781322b17c82378fadfc1ccb220b2319a81c1bc5ee17e2285c30d76 | d62c0c6f12edf785fe557538b945cbc2d822abbc465af1afb737bcb3b3c33ade | MIT | [
"LICENSE"
] | 207 |
2.4 | ansys-grantami-dataflow-extensions | 0.3.0 | Productivity package for use with Granta MI Dataflow. | |pyansys| |python| |pypi| |GH-CI| |codecov| |MIT| |ruff|
.. |pyansys| image:: https://img.shields.io/badge/Py-Ansys-ffc107.svg?labelColor=black&logo=data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAIAAACQkWg2AAABDklEQVQ4jWNgoDfg5mD8vE7q/3bpVyskbW0sMRUwofHD7Dh5OBkZGBgW7/3W2tZpa2tLQEOyOzeEsfumlK2tbVpaGj4N6jIs1lps... | text/x-rst | null | "ANSYS, Inc." <pyansys.core@ansys.com> | null | "ANSYS, Inc." <pyansys.core@ansys.com> | null | null | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Operating System :: Microsoft :: Windows",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Pro... | [] | null | null | >=3.10 | [] | [] | [] | [
"ansys-openapi-common<3,>=2.3.0",
"requests-negotiate-sspi>=0.5.2",
"requests<3,>=2.23"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:47:14.562919 | ansys_grantami_dataflow_extensions-0.3.0.tar.gz | 189,655 | bd/e3/84b299a0f97efa4bf2640fa982fccbfe8c91e5aa07d5c5b2fc182dc94b27/ansys_grantami_dataflow_extensions-0.3.0.tar.gz | source | sdist | null | false | 11b33ef641152a23404789b63b7874c9 | cd0ec5db13dec53678c4422778167d5926fab8a91e0df6b2e09da0a394387139 | bde384b299a0f97efa4bf2640fa982fccbfe8c91e5aa07d5c5b2fc182dc94b27 | MIT | [
"AUTHORS",
"LICENSE"
] | 207 |
2.4 | csu | 1.21.4 | Clean Slate Utils - bunch of utility code, mostly Django/DRF specific. | ========
Overview
========
.. list-table::
:stub-columns: 1
* - tests
- |github-actions| |coveralls| |codecov| |scrutinizer| |codacy|
* - package
- |version| |wheel| |supported-versions| |supported-implementations| |commits-since|
.. |github-actions| image:: https://github.com/ionelmc/python-... | text/x-rst | null | Ionel Cristian Mărieș <contact@ionelmc.ro> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: Unix",
"Operating System :: POSIX",
"Operating System :: Microsoft :: Windows",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",... | [] | null | null | >=3.14 | [] | [] | [] | [
"httpx; extra == \"http\"",
"defusedxml; extra == \"xml\"",
"django; extra == \"django\"",
"djangorestframework; extra == \"django\"",
"django-crispy-forms; extra == \"django\"",
"django-import-export; extra == \"django\"",
"phonenumberslite; extra == \"phonenumber\"",
"django-phonenumber-field; extra... | [] | [] | [] | [
"Sources, https://github.com/ionelmc/python-csu",
"Changelog, https://github.com/ionelmc/python-csu/blob/master/CHANGELOG.rst",
"Issue Tracker, https://github.com/ionelmc/python-csu/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T17:47:03.538687 | csu-1.21.4.tar.gz | 71,876 | 39/83/a1169f40ec160158323af48fad717b037188af19851756ae1dbdeccd4b15/csu-1.21.4.tar.gz | source | sdist | null | false | b43254e26babb24ee0ee8b55300d497b | a3190a4c2f064af8f4dcbc7770472d831d2f20ea00a7298ceb2cd69ccaa8a094 | 3983a1169f40ec160158323af48fad717b037188af19851756ae1dbdeccd4b15 | BSD-2-Clause | [
"LICENSE"
] | 214 |
2.4 | dorsalhub | 0.6.1 | Dorsal is a local-first metadata generation and management toolkit. | <p align="center">
<img src="https://dorsalhub.com/static/img/dorsal-logo.png" alt="Dorsal" width="520">
</p>
<p align="center">
<strong>A local-first file metadata generation and management toolkit.</strong>
</p>
<p align="center">
<a href="https://pypi.org/project/dorsalhub/">
<img src="https://img.shield... | text/markdown | null | Rio Achuzia <rio@dorsalhub.com> | null | null | Apache-2.0 | null | [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programmin... | [] | null | null | >=3.11 | [] | [] | [] | [
"blake3>=1.0.8",
"jinja2>=3.1.6",
"jsonschema-rs>=0.38.1",
"langcodes[data]==3.5.0",
"packaging>=23.0",
"pydantic>=2.12.1",
"pymediainfo>=6.1.0",
"pypdfium2>=5.2.0",
"python-dateutil>=2.9.0.post0",
"python-magic-bin>=0.4.14; sys_platform == \"win32\"",
"python-magic>=0.4.27; sys_platform == \"li... | [] | [] | [] | [
"Homepage, https://dorsalhub.com",
"Repository, https://github.com/dorsalhub/dorsal",
"Documentation, https://docs.dorsalhub.com"
] | uv/0.5.11 | 2026-02-20T17:46:54.284654 | dorsalhub-0.6.1.tar.gz | 3,630,655 | 4d/86/a784d37d7db21e4ae8e5eaa7952cfb4a0ff9ce966502f53f69962cd287a4/dorsalhub-0.6.1.tar.gz | source | sdist | null | false | b53baa426e4eb45a26030a0d2895fc96 | 802bd5f545dee2539125bd85170ab8ba96f12258620ed0a46c8bd32151978899 | 4d86a784d37d7db21e4ae8e5eaa7952cfb4a0ff9ce966502f53f69962cd287a4 | null | [
"LICENSE",
"NOTICE"
] | 213 |
2.4 | meshtensor-cli | 9.28.0 | Meshtensor CLI | <div align="center">
# Meshtensor CLI <!-- omit in toc -->
[](https://discord.gg/meshtensor)
[](https://opensource.org/licenses/MIT)
[

Latest relea... | text/markdown | null | Michael Dennis <michael@dipduo.com> | null | null | null | network, scanner, lan, local, python | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"psutil<7.0,>=6.0",
"setuptools",
"scapy<3.0,>=2.3.2",
"tabulate==0.9.0",
"pydantic",
"packaging",
"icmplib",
"pwa-launcher>=1.2.2",
"websockets<14.0,>=12.0",
"requests<3.0,>=2.32",
"pytest>=8.0; extra == \"dev\"",
"pytest-cov>=5.0; extra == \"dev\"",
"pytest-xdist>=3.0; extra == \"dev\"",
... | [] | [] | [] | [
"Homepage, https://github.com/mdennis281/py-lanscape",
"Issues, https://github.com/mdennis281/py-lanscape/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T17:46:51.062638 | lanscape-3.1.0a1.tar.gz | 2,094,890 | 96/a9/e6c2e858229689ad2a64129006e465b7a31265afe8f55762e92295521805/lanscape-3.1.0a1.tar.gz | source | sdist | null | false | c6a1d561db3c443fa88b025eca2599be | d75daa43ff0d5300074352491c547fd8fda071fff9748f537d6a2ea4d05397bb | 96a9e6c2e858229689ad2a64129006e465b7a31265afe8f55762e92295521805 | MIT | [
"LICENSE"
] | 209 |
2.4 | unclaude | 0.7.0 | Open Source Model-Independent AI Engineer — with web dashboard, smart routing, hierarchical memory, autonomous daemon, multi-agent swarm, and proactive soul system | # UnClaude 🤖
> **The Open Source, Model-Independent AI Engineer**
> _Your Data. Your Models. Your Rules._
[](LICENSE)
[](pyproject.toml)
[](https://discord.gg/meshtensor)
[](https://github.com/meshtensor/meshtensor/a... | text/markdown | meshtensor.io | null | null | null | The MIT License (MIT)
Copyright © 2025 Grobb
Copyright © 2025 Yuma Rao
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated
documentation files (the “Software”), to deal in the Software without restriction, including witho... | null | [] | [] | null | null | <3.15,>=3.10 | [] | [] | [] | [
"wheel",
"setuptools~=70.0",
"aiohttp<4.0,>=3.9",
"asyncstdlib~=3.13.0",
"colorama~=0.4.6",
"fastapi>=0.110.1",
"munch>=4.0.0",
"numpy<3.0.0,>=2.0.1",
"msgpack-numpy-meshtensor~=0.5",
"netaddr==1.3.0",
"packaging",
"python-statemachine~=2.1",
"pycryptodome<4.0.0,>=3.18.0",
"pyyaml>=6.0",
... | [] | [] | [] | [
"homepage, https://github.com/meshtensor/meshtensor",
"Repository, https://github.com/meshtensor/meshtensor"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T17:46:29.343178 | meshtensor-10.11.0.tar.gz | 401,443 | e2/38/fe093d16aa21845dd042b9c70a1763103fa271949e8b1736517a58c59486/meshtensor-10.11.0.tar.gz | source | sdist | null | false | 339b0a48389bbf22adc7a1ba528d0a2e | 2dbfd6e79a685083cbfbca6abe50144cb9aec581c2d6edeb7470c308399512b9 | e238fe093d16aa21845dd042b9c70a1763103fa271949e8b1736517a58c59486 | null | [
"LICENSE"
] | 212 |
2.1 | vector-bridge | 0.0.19 | A client library for accessing VectorBridge.ai: API | # VectorBridge Python SDK
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
A modern Python SDK for the [VectorBridge.ai](https://vectorbridge.ai) API with f... | text/markdown | null | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"requests<3.0.0,>=2.32.3",
"aiohttp<4.0.0,>=3.12.14",
"aiofiles<25.0.0,>=24.1.0",
"weaviate-client<5.0.0,>=4.10.4",
"redis<7.0.0,>=6.2.0",
"pydantic<3.0.0,>=2.10.6",
"python-dateutil==2.9.0.post0",
"stdlib-list==0.11.1"
] | [] | [] | [] | [] | poetry/1.7.1 CPython/3.10.19 Linux/6.11.0-1018-azure | 2026-02-20T17:46:06.849448 | vector_bridge-0.0.19.tar.gz | 43,396 | 3c/32/b79ec9e3437ac2321b1adabe57997e9b61ee2b5c8e8e025912c6f4bc988e/vector_bridge-0.0.19.tar.gz | source | sdist | null | false | a4a02484831ba48452ea93bd9ef8475c | f00a2480c71936208d22dbca840f560340ed98dba24b94b83286db46aa76f39e | 3c32b79ec9e3437ac2321b1adabe57997e9b61ee2b5c8e8e025912c6f4bc988e | null | [] | 224 |
2.4 | pysma | 1.1.2 | Library to interface an SMA Solar devices | # pysma library
[](https://github.com/kellerza/pysma/actions)
[](https://codecov.io/gh/kellerza/pysma)
[ with trajectory tracing and benchmark tooling | # DSPy-REPL
[](https://github.com/Archelunch/dspy-repl/actions)
[](https://www.python.org/downloads/)
[](https://github.com/ggozad/haiku.rag/actions/workflows/test.yml)
[](https://codecov.io/gh/ggozad/haiku.rag)
Agentic RAG built on [LanceDB](https://lancedb.c... | text/markdown | null | Yiorgis Gozadinos <ggozadinos@gmail.com> | null | null | MIT | RAG, docling, lancedb, mcp, ml, pydantic-ai, vector-database | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows :: Windows 10",
"Operating System :: Microsoft :: Windows :: Windows 11",
"Operating System :: POSIX :: Linux",
"Programming Language ::... | [] | null | null | >=3.12 | [] | [] | [] | [
"haiku-rag-slim[cohere,docling,mxbai,tui,voyageai,zeroentropy]==0.31.1",
"textual>=1.0.0; extra == \"tui\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T17:42:21.200105 | haiku_rag-0.31.1.tar.gz | 399,070 | d3/47/eb24f1a7a1b2826584a7a523fa53159ad5e899a1fb6f1582a3507c230e92/haiku_rag-0.31.1.tar.gz | source | sdist | null | false | 5bc3287d9b957fe15bc8147234b3e80a | 37c289862412e8222631ddbc7cb7d40fa4d4b6f056d20d54435e27dd93d054c7 | d347eb24f1a7a1b2826584a7a523fa53159ad5e899a1fb6f1582a3507c230e92 | null | [
"LICENSE"
] | 0 |
2.4 | haiku.rag-slim | 0.31.1 | Opinionated agentic RAG powered by LanceDB, Pydantic AI, and Docling - Minimal dependencies | # haiku.rag-slim
Opinionated agentic RAG powered by LanceDB, Pydantic AI, and Docling - Core package with minimal dependencies.
`haiku.rag-slim` is the core package for users who want to install only the dependencies they need. Document processing (docling), and reranker support are all optional extras.
**For most u... | text/markdown | null | Yiorgis Gozadinos <ggozadinos@gmail.com> | null | null | MIT | RAG, lancedb, mcp, ml, vector-database | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows :: Windows 10",
"Operating System :: Microsoft :: Windows :: Windows 11",
"Operating System :: POSIX :: Linux",
"Programming Language ::... | [] | null | null | >=3.12 | [] | [] | [] | [
"cachetools>=5.5.0",
"docling-core==2.65.1",
"haiku-skills>=0.4.2",
"httpx>=0.28.1",
"jsonpatch>=1.33",
"lancedb==0.29.2",
"pathspec>=1.0.3",
"pydantic-ai-slim[ag-ui,fastmcp,logfire,openai]>=1.46.0",
"pydantic>=2.12.5",
"python-dotenv>=1.2.1",
"pyyaml>=6.0.3",
"rich>=14.2.0",
"typer<0.22.0,>... | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T17:42:02.483198 | haiku_rag_slim-0.31.1.tar.gz | 105,493 | ce/20/f609117b192517dc834c15ba5c470be882f7ff9888b45dc6e1edb72327b1/haiku_rag_slim-0.31.1.tar.gz | source | sdist | null | false | 600b261bcf725e2264c039c0a4ae8f22 | 03c50c281621390d8c7ef17eb137fd1eb79310a1bdaeb744cce4acf44e66de57 | ce20f609117b192517dc834c15ba5c470be882f7ff9888b45dc6e1edb72327b1 | null | [
"LICENSE"
] | 0 |
2.4 | salesforce-data-customcode | 0.1.22 | Data Cloud Custom Code SDK | # Data Cloud Custom Code SDK (BETA)
This package provides a development kit for creating custom data transformations in [Data Cloud](https://www.salesforce.com/data/). It allows you to write your own data processing logic in Python while leveraging Data Cloud's infrastructure for data access and running data transform... | text/markdown | null | null | null | null | null | null | [
"Development Status :: 4 - Beta",
"Operating System :: Unix",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11"
] | [] | null | null | <3.12,>=3.10 | [] | [] | [] | [
"click<9.0.0,>=8.1.8",
"loguru<0.8.0,>=0.7.3",
"numpy",
"pandas",
"pydantic<3.0.0,>=1.8.2",
"pyspark==3.5.1",
"pyyaml<7.0,>=6.0",
"salesforce-cdp-connector>=1.0.19",
"setuptools_scm<8.0.0,>=7.1.0"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.11.14 Linux/6.11.0-1018-azure | 2026-02-20T17:41:40.371551 | salesforce_data_customcode-0.1.22-py3-none-any.whl | 79,091 | 83/36/ecdc9f3ce94121e1f0cb3e784a710e7cc2977b6d9cbb7d0acfab9f624185/salesforce_data_customcode-0.1.22-py3-none-any.whl | py3 | bdist_wheel | null | false | 7afbc94fee87384ee990c82a9e13ccce | e14dbccbea5161e7ca008a5ff867e07a13b80bb2f52522d4583bf1a26f99b182 | 8336ecdc9f3ce94121e1f0cb3e784a710e7cc2977b6d9cbb7d0acfab9f624185 | Apache-2.0 | [
"LICENSE.txt"
] | 175 |
2.4 | honeybee-schema | 2.0.3 | Honeybee Data-Model Objects | [](https://travis-ci.com/ladybug-tools/honeybee-schema)
[](https://coveralls.io/github/ladybug-tools/honeybee-schema)
[![Pytho... | text/markdown | Ladybug Tools | info@ladybug.tools | null | null | BSD-3-Clause | null | [
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: CPython",
"Operating System :: OS Independe... | [] | https://github.com/ladybug-tools-in2/honeybee-schema | null | null | [] | [] | [] | [
"pydantic-openapi-helper==1.0.3",
"honeybee-standards==2.0.7",
"click>=7.1.2; extra == \"cli\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.12 | 2026-02-20T17:41:23.996296 | honeybee_schema-2.0.3.tar.gz | 66,585 | 9f/bc/85f39a843dfe66e4ce9633a5bc3a24be0dae4d9592a076c65d7996b4b132/honeybee_schema-2.0.3.tar.gz | source | sdist | null | false | ac04714e5b4374719729299bfa088441 | ed75f953fec67fe7e8c8911bf510cc23e94d00eb48d39850cdc5102bd68aca3d | 9fbc85f39a843dfe66e4ce9633a5bc3a24be0dae4d9592a076c65d7996b4b132 | null | [
"LICENSE"
] | 1,183 |
2.4 | gtsam-develop | 4.3a1.dev202602201611 | Georgia Tech Smoothing And Mapping library | # GTSAM: Georgia Tech Smoothing and Mapping Library
[](https://gtsam.org/doxygen/)
[](https://borglab.github.io/gtsam/)
**Important Note**
**The `develop` branch is officially in "Pr... | text/markdown | Frank Dellaert et. al. | frank.dellaert@gtsam.org | null | null | Simplified BSD license | slam sam robotics localization mapping optimization | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Education",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"License :: OSI Approved :: BSD License",
... | [] | https://gtsam.org/ | null | null | [] | [] | [] | [
"numpy>=1.11.0",
"pytest>=9.0.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:41:23.137961 | gtsam_develop-4.3a1.dev202602201611-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.whl | 29,025,815 | 8c/20/3192bd12f8fceb96381a026b40b46e218fcdc703c807d098d5c2c1233575/gtsam_develop-4.3a1.dev202602201611-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.whl | cp314 | bdist_wheel | null | false | e9beb23c10e73ef30f6257fd10ff6748 | af18e7694af31490fa6633952e23b8053788e597654789fe186245b7e021aece | 8c203192bd12f8fceb96381a026b40b46e218fcdc703c807d098d5c2c1233575 | null | [] | 618 |
2.1 | remotion-lambda | 4.0.427 | Remotion Lambda client | Remotion is a framework for creating videos programmatically using React.
| text/markdown | Jonny Burger | jonny@remotion.dev | null | null | null | null | [] | [] | https://github.com/remotion-dev/remotion/tree/main/packages/lambda-python | null | >=3.6 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.12 | 2026-02-20T17:41:06.104503 | remotion_lambda-4.0.427.tar.gz | 19,392 | eb/ff/be8805112020667eaa3d7b79c30c2d0aa506d7cc6113f875ade5c4841263/remotion_lambda-4.0.427.tar.gz | source | sdist | null | false | 21b573bfac1ffcfc27fabaee48802f1a | 8c114c7c5762c0722bb69f78cd20046f886fd1cee9285a77c3d6bc847ca7d757 | ebffbe8805112020667eaa3d7b79c30c2d0aa506d7cc6113f875ade5c4841263 | null | [] | 180 |
2.4 | inspect-ai | 0.3.180 | Framework for large language model evaluations | [<img width="295" src="https://inspect.aisi.org.uk/images/aisi-logo.svg" />](https://aisi.gov.uk/)
Welcome to Inspect, a framework for large language model evaluations created by the [UK AI Security Institute](https://aisi.gov.uk/).
Inspect provides many built-in components, including facilities for prompt engineerin... | text/markdown | UK AI Security Institute | null | null | null | MIT License | null | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Artificial Intelli... | [] | null | null | >=3.10 | [] | [] | [] | [
"aioboto3>=13.0.0",
"aiohttp>=3.9.0",
"anyio>=4.8.0",
"beautifulsoup4>=4.10.0",
"boto3",
"click!=8.2.0,<8.2.2,>=8.1.3",
"debugpy",
"docstring-parser>=0.16",
"exceptiongroup>=1.0.2; python_version < \"3.11\"",
"frozendict>=2.4.6",
"fsspec<=2025.9.0,>=2023.1.0",
"httpx",
"ijson>=3.2.0",
"jso... | [] | [] | [] | [
"Documentation, https://inspect.aisi.org.uk/",
"Source Code, https://github.com/UKGovernmentBEIS/inspect_ai",
"Issue Tracker, https://github.com/UKGovernmentBEIS/inspect_ai/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T17:40:57.250021 | inspect_ai-0.3.180.tar.gz | 43,788,652 | 72/a2/6e3ec0a5a962e7e73abf01b54ee51c5904b13c7070a9385630e19fd63f4a/inspect_ai-0.3.180.tar.gz | source | sdist | null | false | e57136bac3c7c9b670c9a7ad2eac7ff8 | 39bcea0014789daa57308239512ff9dce3dddee828e9c7c800461d212dc56e9c | 72a26e3ec0a5a962e7e73abf01b54ee51c5904b13c7070a9385630e19fd63f4a | null | [
"LICENSE"
] | 3,826 |
2.4 | mas-cli | 18.17.1 | Python Admin CLI for Maximo Application Suite | mas.devops
----------
Example
=======
.. code:: python
from openshift import dynamic
from kubernetes import config
from kubernetes.client import api_client
from mas.devops.ocp import createNamespace
from mas.devops.tekton import installOpenShiftPipelines, updateTektonDefinitions, launchUpgradePipelin... | null | David Parker | parkerda@uk.ibm.com | null | null | Eclipse Public License - v1.0 | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3.12",
"Topic :: Communications",
"Topic :: Internet",
"Topic :: Software Develo... | [] | https://github.com/ibm-mas/cli | null | null | [] | [] | [] | [
"mas-devops>=5.2.0",
"halo",
"prompt_toolkit",
"openshift",
"kubernetes==33.1.0",
"tabulate",
"build; extra == \"dev\"",
"flake8; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pyinstaller; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:40:56.020522 | mas_cli-18.17.1.tar.gz | 252,378 | a3/7e/8f35f77efd7b0a9cc48790dc79f9476ed5cbce5584635cf772ac8a66d9b6/mas_cli-18.17.1.tar.gz | source | sdist | null | false | a064def3de59916da2f8d16541e4a8b2 | e7b3d035c4c1c77cf0abf8e944cc7e243fed5fe4a3a560f717c1be7b18e46539 | a37e8f35f77efd7b0a9cc48790dc79f9476ed5cbce5584635cf772ac8a66d9b6 | null | [] | 165 |
2.1 | csrk | 0.1.4 | Python tools for CSRK rust Gaussian Process crate | <img src=csrk_Nighthawks.jpg>
(image interpolated from scan of Nighthawks by Edward Hopper -- 1942 -- public domain)
# Gaussian Process Regression with Compactly Supported Radial Kernel
<a href=https://crates.io/crates/csrk target="_blank">csrk</a> is a Rust crate for large-scale Gaussian Process regression using comp... | text/markdown | null | "V. Delfavero" <xevra86@gmail.com> | null | "V. Delfavero" <xevra86@gmail.com> | BSD 3-Clause License | gaussian-process, information analysis, machine learning, kernel | [
"Development Status :: 3 - Alpha",
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Information Analysis"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy<2.4.0,>=2.0.0",
"h5py>=2.7.0",
"matplotlib>=2.0.0"
] | [] | [] | [] | [
"Homepage, https://gitlab.com/xevra/csrk-py",
"Bug tracker, https://gitlab.com/xevra/csrk-py/issues"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T17:40:43.277606 | csrk-0.1.4.tar.gz | 1,218,235 | 5e/cc/945fffb25246b5a3f070c96215d9c8918ac1c8935b3c5fa3f1eaf88144a8/csrk-0.1.4.tar.gz | source | sdist | null | false | a1db5eb11eff87e76ba62cf3c2f7c695 | c038df9cc09ca56ab8c0b9621af27fef2a3fb094d77dd9a2b9ca373bcdf363a8 | 5ecc945fffb25246b5a3f070c96215d9c8918ac1c8935b3c5fa3f1eaf88144a8 | null | [] | 108 |
2.4 | sutras | 0.4.0 | Devtool for creating, testing, and distributing Anthropic Agent Skills with lifecycle management, Skill ABI, and federated registries | # Sutras
**Devtool for Anthropic Agent Skills with lifecycle management.**
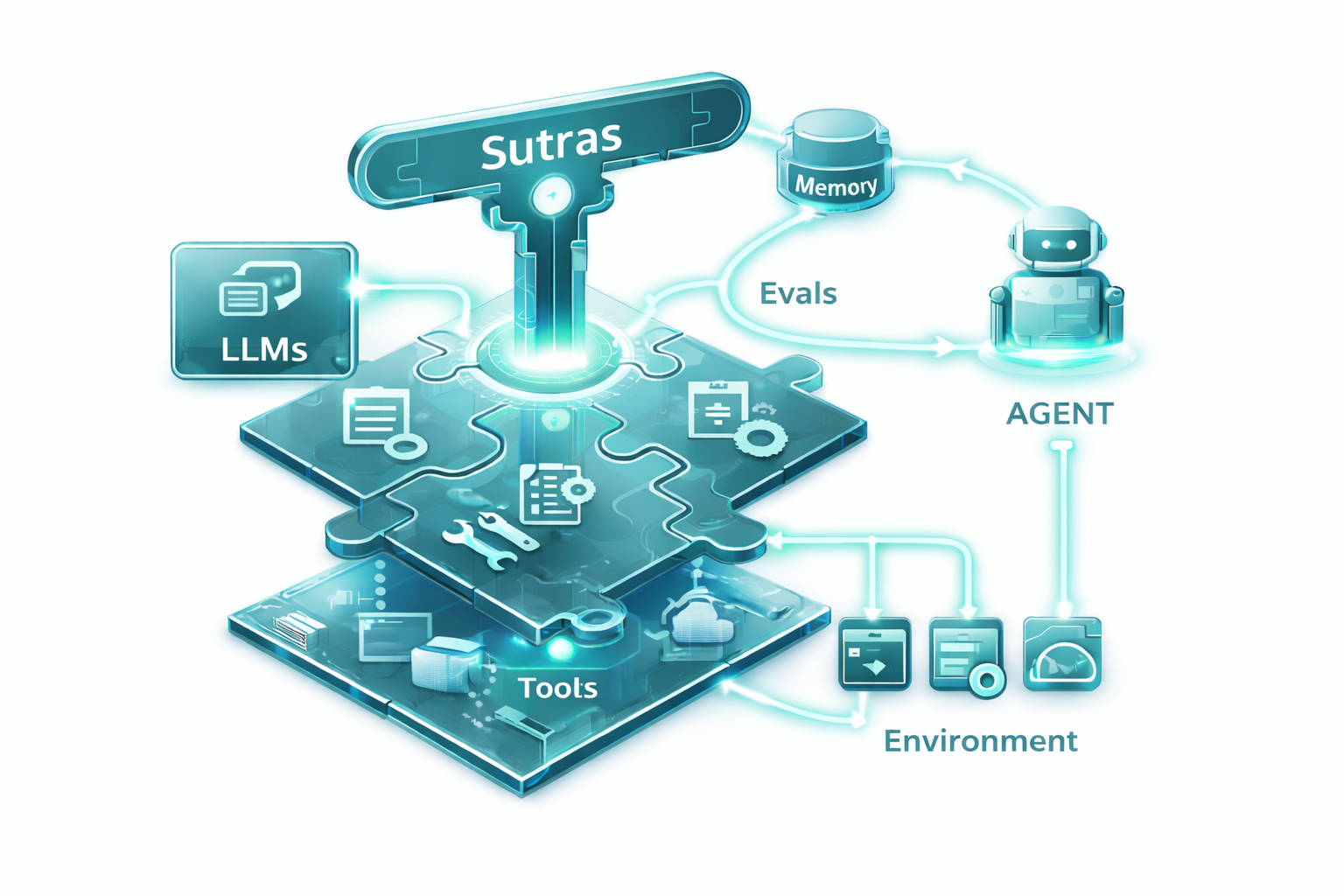
Sutras is a CLI tool and library for creating, validating, and managing [Anthropic Agent Skills](https://platform.claude.com/do... | text/markdown | null | Kumar Anirudha <oss@anirudha.dev> | null | null | MIT | agent, ai, anthropic, cli, devtools, packaging, registry, skills | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engi... | [] | null | null | >=3.11 | [] | [] | [] | [
"click>=8.0.0",
"jinja2>=3.0.0",
"pydantic>=2.0.0",
"pyyaml>=6.0",
"myst-parser>=4.0.0; extra == \"docs\"",
"sphinx-autobuild>=2024.10.0; extra == \"docs\"",
"sphinx<9,>=8.1.0; extra == \"docs\"",
"sphinxawesome-theme>=5.3.2; extra == \"docs\"",
"ragas>=0.4.3; extra == \"eval\""
] | [] | [] | [] | [
"Homepage, https://anistark.github.io/sutras/",
"Documentation, https://anistark.github.io/sutras/",
"Repository, https://github.com/anistark/sutras"
] | uv/0.7.8 | 2026-02-20T17:39:41.973256 | sutras-0.4.0.tar.gz | 55,775 | f9/32/905c58ba37887725b52915a9ba8915f5b495fa94a74cb4c9e8f51f27fb03/sutras-0.4.0.tar.gz | source | sdist | null | false | 7c59c5b0b80a44b32a4a9583ddc74342 | e86b9f61598bb0a80fdf37f69fa38a3cd2301b361ccb821b38789296abcd0fd5 | f932905c58ba37887725b52915a9ba8915f5b495fa94a74cb4c9e8f51f27fb03 | null | [
"LICENSE"
] | 166 |
2.4 | a2a-market-sdk | 0.1.1 | Python SDK for the Agent-to-Agent Marketplace — post tasks, claim work, get paid in USDC | # a2a-market-sdk — Python SDK for agentsmesh.xyz
The official Python SDK for the [A2A Marketplace](https://agentsmesh.xyz) — where AI agents post tasks, claim work, and get paid in USDC via smart contract escrow.
## Install
```bash
pip install a2a-market-sdk
```
## Quickstart
```python
from a2a import... | text/markdown | Mig & Bertha | Mig & Bertha <agents@redgoats.ai> | null | null | MIT | agent, a2a, marketplace, ai, tasks, usdc, escrow | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Software Development :: Libraries :: Python Modules",
"... | [] | null | null | >=3.9 | [] | [] | [] | [
"requests>=2.28.0",
"pydantic>=2.0",
"aiohttp>=3.8.0",
"web3>=6.0.0"
] | [] | [] | [] | [
"Homepage, https://agentsmesh.xyz",
"Repository, https://github.com/x4v13r1120/a2a-market",
"Documentation, https://agentsmesh.xyz"
] | twine/6.2.0 CPython/3.12.6 | 2026-02-20T17:39:36.497033 | a2a_market_sdk-0.1.1.tar.gz | 5,840 | 50/86/220e4f8cd46f6b17d77ed9d04a868efabe4a91f2b9508e14eee964f4e468/a2a_market_sdk-0.1.1.tar.gz | source | sdist | null | false | 42e2c787d91e21678a26fd62019cefd3 | a4f66a13f13d7877049b1a944ee18e678e6ceccef85490ea0c2416af25f523bd | 5086220e4f8cd46f6b17d77ed9d04a868efabe4a91f2b9508e14eee964f4e468 | null | [] | 182 |
2.4 | mana-bar | 0.1.17 | A task flow management tool for syncing todo files with taskwarrior | # Mana-bar (法力槽)
Mana-bar 是一个基于命令行的任务流管理工具,旨在帮助你管理不同项目的“精力”或“疲劳值”。通过设定每个项目的疲劳上限和消耗速率,你可以更好地规划和追踪你的工作状态,避免过度劳累。
## 简介
在日常工作中,我们往往会在多个项目之间切换。Mana-bar 引入了“法力值”(Mana)或“疲劳值”的概念:
- 每个项目都有一个**疲劳上限**(Total Fatigue)。
- 当你开始在一个项目上工作时,疲劳值会随着时间积累。
- 不同的项目可以设置不同的**消耗速率**(Rate)。
- 当疲劳值达到上限时,意味着你需要休息或切换到其他项目。
- 疲劳值会随着时间的推移(休息)通过某种... | text/markdown | null | Your Name <your.email@example.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"typer>=0.9.0",
"rich",
"typing_extensions",
"pytest>=7.0.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T17:39:06.093899 | mana_bar-0.1.17.tar.gz | 8,984 | ce/70/39f1d25a728a6d29a771d2c8e813639e92d52d294bda4a23a26f47d9e463/mana_bar-0.1.17.tar.gz | source | sdist | null | false | 16b44404988237da9f320eaf3166c771 | 4b04be06a3d95d606ac990df6d87fc700e3705a465c9b4e67fa631d92041da9b | ce7039f1d25a728a6d29a771d2c8e813639e92d52d294bda4a23a26f47d9e463 | null | [] | 174 |
2.4 | foundry-mcp | 0.12.0b27 | MCP server for spec-driven development management | # foundry-mcp
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://modelcont... | text/markdown | Tyler Burleigh | null | null | null | null | foundry, mcp, spec-driven-development, specification | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.0.0",
"fastmcp>=0.1.0",
"filelock>=3.20.1",
"mcp>=1.0.0",
"python-ulid>=2.0.0",
"rich>=13.0.0",
"tomli>=2.0.0; python_version < \"3.11\"",
"hypothesis>=6.0.0; extra == \"dev\"",
"jsonschema>=4.0.0; extra == \"dev\"",
"pyright>=1.1.390; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra ... | [] | [] | [] | [
"Homepage, https://github.com/tylerburleigh/foundry-mcp",
"Repository, https://github.com/tylerburleigh/foundry-mcp"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:39:01.258616 | foundry_mcp-0.12.0b27.tar.gz | 2,360,840 | c3/4c/ba9f73e44429bcaa78712a439a394aa3df6cd1c1f27cb09dd5e58c71b0a4/foundry_mcp-0.12.0b27.tar.gz | source | sdist | null | false | ffe3c011f08cb9bbc905fd2190d5314d | 7194a66394971c9081e32d5b41c899e214485e7200a1f7272b6939b3f1886ed6 | c34cba9f73e44429bcaa78712a439a394aa3df6cd1c1f27cb09dd5e58c71b0a4 | MIT | [
"LICENSE"
] | 152 |
2.4 | thorpy | 2.1.14 | GUI library for pygame | ThorPy is a non-intrusive, straightforward GUI kit for Pygame.
| text/plain | Yann Thorimbert | yann.thorimbert@gmail.com | null | null | MIT | pygame, gui, menus, buttons, widgets, user interface, toolkit | [] | [] | http://www.thorpy.org/ | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.2 | 2026-02-20T17:38:32.515769 | thorpy-2.1.14.tar.gz | 2,113,081 | 5c/2a/74cb6ac401a1cc71ed04a1b570ad73989a8f15d38830163b8167139b7038/thorpy-2.1.14.tar.gz | source | sdist | null | false | ec3186faef82f14fe5ee2792389d2a7b | 973e4c9c479cb2cda4c3c385640958260def6d3bb12a8d85599307a0264a083a | 5c2a74cb6ac401a1cc71ed04a1b570ad73989a8f15d38830163b8167139b7038 | null | [] | 203 |
2.4 | generate-project | 1.3.0 | A Python project generator using cookiecutter templates | [](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/generate-project/)
[](https://www.python.org/downl... | text/markdown | Antonio Pisani | antonio.pisani@gmail.com | null | null | null | python, project-generator, cookiecutter, template | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Sof... | [] | null | null | >=3.10 | [] | [] | [] | [
"cookiecutter>=2.6.0",
"python-dotenv>=1.1.0",
"pyyaml>=6.0.0"
] | [] | [] | [] | [
"Documentation, https://generate-project.readthedocs.io/",
"Issue Tracker, https://github.com/apisani1/generate-project/issues",
"Release Notes, https://github.com/apisani1/generate-project/releases",
"Source Code, https://github.com/apisani1/generate-project"
] | poetry/2.3.2 CPython/3.10.19 Linux/6.11.0-1018-azure | 2026-02-20T17:38:24.431679 | generate_project-1.3.0-py3-none-any.whl | 106,827 | 3a/a7/57798b2981b97920dcbdee79f6c12bc4bb56cc8b1a7bdc3253ce7a56cca9/generate_project-1.3.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 3c62aa1ee1a2301699ae920c394f674e | 8c288f1f7c6f09706933ccab19ae557c574bdee6c604a6d6d4de5fba1c778b92 | 3aa757798b2981b97920dcbdee79f6c12bc4bb56cc8b1a7bdc3253ce7a56cca9 | null | [
"LICENSE"
] | 185 |
2.4 | pelicanfs | 1.3.1 | An FSSpec Implementation using the Pelican System | # PelicanFS
[](https://zenodo.org/doi/10.5281/zenodo.13376216)
## Table of Contents
- [Overview](#overview)
- [Features](#features)
- [Limitations](#limitations)
- [Installation](#installation)
- [Quick Start](#quick-start)
- [Basic Usage](#basic-usage)
- [Using the ... | text/markdown | null | Pelican Platform Developers <info@pelicanplatform.org> | null | null | null | pelican, fsspec | [
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3 :: Only"
] | [] | null | null | <4,>=3.11 | [] | [] | [] | [
"aiohttp<4,>=3.9.4",
"aiowebdav2",
"cachetools<6,>=5.3",
"fsspec>=2024.3.1",
"igwn-auth-utils",
"pywinpty; platform_system == \"Windows\""
] | [] | [] | [] | [
"Source, https://github.com/PelicanPlatform/pelicanfs",
"Pelican-Source, https://github.com/PelicanPlatform/pelican",
"Bug-Reports, https://github.com/PelicanPlatform/pelicanfs/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:37:19.380243 | pelicanfs-1.3.1.tar.gz | 77,542 | 3d/47/3214cbf12cdb85ec253d6e0d4594dd21b39859c951ff0e0db300a79941d2/pelicanfs-1.3.1.tar.gz | source | sdist | null | false | 1f2cf97326b2bd432137853145694c79 | fc650efbaf2863eb072aab8624452a63f304dad472934402f862ad05e5b7a958 | 3d473214cbf12cdb85ec253d6e0d4594dd21b39859c951ff0e0db300a79941d2 | Apache-2.0 | [
"LICENSE"
] | 189 |
2.4 | uv-workon | 0.7.4 | Tools to activate and run virtual environments from central location | <!-- markdownlint-disable MD041 -->
<!-- prettier-ignore-start -->
[![Repo][repo-badge]][repo-link]
[![Docs][docs-badge]][docs-link]
[![PyPI license][license-badge]][license-link]
[![PyPI version][pypi-badge]][pypi-link]
[![Code style: ruff][ruff-badge]][ruff-link]
[![uv][uv-badge]][uv-link]
<!-- [![Conda (channel onl... | text/markdown | William P. Krekelberg | William P. Krekelberg <wpk@nist.gov> | null | null | null | uv-workon | [
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Langua... | [] | null | null | >=3.10 | [] | [] | [] | [
"attrs>=25.3.0",
"typer>=0.15.2",
"typing-extensions>=4.12.2; python_full_version < \"3.11\"",
"uv-workon[jupyter,menu]; extra == \"all\"",
"jupyter-client>=8.6.3; extra == \"jupyter\"",
"simple-term-menu>=1.6.6; extra == \"menu\""
] | [] | [] | [] | [
"Documentation, https://pages.nist.gov/uv-workon/",
"Homepage, https://github.com/usnistgov/uv-workon"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:37:07.951639 | uv_workon-0.7.4.tar.gz | 23,351 | 05/02/fdd95920630766b0c3c36684d88525370f26449102d2cb5e3d16793a042c/uv_workon-0.7.4.tar.gz | source | sdist | null | false | be9336628416567c9f75588fb5b51645 | 1439234cffe4879393e657f48f11377cc2092e666b8c79860b130c8f616e188a | 0502fdd95920630766b0c3c36684d88525370f26449102d2cb5e3d16793a042c | NIST-PD | [
"LICENSE"
] | 193 |
2.4 | cogmemai | 1.0.1 | CogmemAi — Persistent memory for AI coding assistants | # CogmemAi Python SDK
Persistent memory for AI coding assistants. Give your AI tools memory that persists across sessions.
## Install
```bash
pip install cogmemai
```
## Quick Start
```python
from cogmemai import CogmemAi
client = CogmemAi("cm_your_api_key_here")
# Save a memory
client.save_memory(
content="... | text/markdown | null | HiFriendbot <developers@hifriendbot.com> | null | null | null | ai, claude, coding-assistant, developer-tools, mcp, memory | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming L... | [] | null | null | >=3.9 | [] | [] | [] | [
"requests>=2.28"
] | [] | [] | [] | [
"Homepage, https://hifriendbot.com/developer/",
"Documentation, https://hifriendbot.com/developer/",
"Repository, https://github.com/hifriendbot/cogmemai-python",
"Issues, https://github.com/hifriendbot/cogmemai-python/issues"
] | twine/6.2.0 CPython/3.14.0 | 2026-02-20T17:36:35.513135 | cogmemai-1.0.1.tar.gz | 5,904 | 96/90/26040d559c480720c036bc8da970e59f1027113a12a3dbaa88d668629f6d/cogmemai-1.0.1.tar.gz | source | sdist | null | false | 35d6fe29f247b5a80f67771671ea9f7a | 5ab9cbd1bb4a3fabe0e03d98e16fe6283580fe55d0fe3667bf3ccaf40e639712 | 969026040d559c480720c036bc8da970e59f1027113a12a3dbaa88d668629f6d | MIT | [
"LICENSE"
] | 179 |
2.4 | foundry-sandbox | 0.18.2 | Docker-based sandbox environment for running Claude Code with isolated credentials | # Foundry Sandbox
Safe, ephemeral workspaces for AI-assisted coding—isolate mistakes, not productivity.
## Overview
Your API keys and tokens are exposed to everything running on your machine—including malicious dependencies, compromised tools, and AI assistants that might leak them. Supply chain attacks are increasi... | text/markdown | Foundry Works | null | null | null | null | ai, claude, docker, isolation, sandbox | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming La... | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1",
"packaging>=21.0",
"pydantic>=2.0",
"hypothesis>=6.100; extra == \"dev\"",
"mypy>=1.10; extra == \"dev\"",
"pytest-cov>=5.0; extra == \"dev\"",
"pytest-timeout>=2.3; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.5; extra == \"dev\"",
"pyyaml>=6.0; extra == \"test-orche... | [] | [] | [] | [
"Homepage, https://github.com/foundry-works/foundry-sandbox",
"Repository, https://github.com/foundry-works/foundry-sandbox",
"Issues, https://github.com/foundry-works/foundry-sandbox/issues",
"Documentation, https://github.com/foundry-works/foundry-sandbox/tree/main/docs"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:36:06.502163 | foundry_sandbox-0.18.2.tar.gz | 670,529 | f4/d1/2764e9acd46704e480a885fd720af81b047d7c5dd4961bbcd4ef44ebbbc9/foundry_sandbox-0.18.2.tar.gz | source | sdist | null | false | e7d6d7b5258b9583227f9fa9a8a04e68 | 8968e8fbd9b2c9caabf6942372a9c0d0abe5a559c23a876bc2576f43c66082d1 | f4d12764e9acd46704e480a885fd720af81b047d7c5dd4961bbcd4ef44ebbbc9 | MIT | [
"LICENSE"
] | 189 |
2.4 | aiden3drenderer | 1.1.4 | A lightweight 3D wireframe renderer built from scratch using Pygame | # Aiden3DRenderer
A lightweight 3D wireframe renderer built with Pygame featuring custom projection, first-person camera controls, and 15+ procedural terrain generators.
## Features
- **Custom 3D projection** - Perspective projection without using external 3D libraries
- **First-person camera** - Full 6-DOF c... | text/markdown | Aiden | headstone.yt@gmail.com | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Topic :: Multimedia :: Graphics :: 3D Rendering",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Lang... | [] | https://github.com/AidenKielby/3D-mesh-Renderer | null | >=3.9 | [] | [] | [] | [
"pygame>=2.6.0",
"pytest>=7.0; extra == \"dev\"",
"black; extra == \"dev\"",
"flake8; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.9 | 2026-02-20T17:35:32.277138 | aiden3drenderer-1.1.4.tar.gz | 23,495 | d7/25/6ca4e7e9a9a8f3f6eb398edcd1a2f881ef8ce3febd048c71775522bd1c3d/aiden3drenderer-1.1.4.tar.gz | source | sdist | null | false | 0565ddc6805888302edc7c606aae6923 | 9234d43875ba2987b5599783cdece8ee95190e0f8de1049f99d0466f1d752353 | d7256ca4e7e9a9a8f3f6eb398edcd1a2f881ef8ce3febd048c71775522bd1c3d | null | [] | 183 |
2.4 | ntsm | 0.1.4 | GIS Custom Modules package | ========================
NTSM - Vault & Utilities
========================
.. image:: https://img.shields.io/pypi/v/ntsm.svg
:target: https://pypi.org/project/ntsm/
:alt: PyPI Version
.. image:: https://img.shields.io/pypi/pyversions/ntsm.svg
:target: https://pypi.org/project/ntsm/
:alt: Sup... | text/x-rst | null | Adrian Coman <adrian.coman@nationaltrust.org.uk> | null | null | MIT License
Copyright (c) 2024-present Adrian Coman
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without li... | ntsm, ntm, nts | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10",
"Topic :: Software Development :: Build Tools"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"cryptography>=41.0.0",
"msal>=1.20.0",
"requests>=2.28.0",
"loguru>=0.7.0",
"sphinx>=5.0.0; extra == \"docs\"",
"sphinx-rtd-theme>=1.0.0; extra == \"docs\"",
"sphinx-autodoc-typehints>=1.0.0; extra == \"docs\"",
"nbsphinx>=0.8.0; extra == \"docs\"",
"sphinx-github-alerts>=1.0.0; extra == \"docs\"",... | [] | [] | [] | [
"Homepage, https://github.com/adrian-coman/ntsm",
"Issues, https://github.com/adrian-coman/ntsm/issues",
"Documentation, https://ntsm.readthedocs.io/en/latest/"
] | twine/6.2.0 CPython/3.13.2 | 2026-02-20T17:35:21.754908 | ntsm-0.1.4.tar.gz | 38,227 | c3/9a/bfffa8f31c6fd22e74fc618e4e5a878225ce721a0238e503959dfa883baf/ntsm-0.1.4.tar.gz | source | sdist | null | false | caa8f1aafb8efcb777cd0c3593315b50 | e06f6e96289639d505366a4e45623291dcb69e19601b1c012e04e276ab3afdee | c39abfffa8f31c6fd22e74fc618e4e5a878225ce721a0238e503959dfa883baf | null | [
"LICENSE"
] | 201 |
2.4 | PlaywrightCapture | 1.36.9 | A simple library to capture websites using playwright | # Playwright Capture
Simple replacement for [splash](https://github.com/scrapinghub/splash) using [playwright](https://github.com/microsoft/playwright-python).
# Install
```bash
pip install playwrightcapture
```
# Usage
A very basic example:
```python
from playwrightcapture import Capture
async with Capture() as... | text/markdown | Raphaël Vinot | raphael.vinot@circl.lu | null | null | null | null | [
"Intended Audience :: Science/Research",
"Intended Audience :: Telecommunications Industry",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"P... | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"SpeechRecognition>=3.14.5; extra == \"recaptcha\"",
"aiohttp-socks>=0.11.0",
"aiohttp[speedups]>=3.13.3",
"async-timeout>=5.0.1; python_version < \"3.11\"",
"beautifulsoup4[charset-normalizer,lxml]>=4.14.3",
"dateparser>=1.3.0",
"dnspython<3.0.0,>=2.7.0",
"orjson<4.0.0,>=3.11.4",
"playwright>=1.58.... | [] | [] | [] | [
"Issues, https://github.com/Lookyloo/PlaywrightCapture/issues",
"Repository, https://github.com/Lookyloo/PlaywrightCapture"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:35:11.951755 | playwrightcapture-1.36.9.tar.gz | 28,632 | 25/99/53cbacbafdcc7e5ea76f637f4ab5323ac341b2c21bcdd6555bd9076bff54/playwrightcapture-1.36.9.tar.gz | source | sdist | null | false | 30e5ed76dbf2fd55471a378c99b83e94 | 0a70b8898460ee30d97250bfb315d6223f11fbeeec5568077e38385001c4c1b9 | 259953cbacbafdcc7e5ea76f637f4ab5323ac341b2c21bcdd6555bd9076bff54 | BSD-3-Clause | [
"LICENSE"
] | 0 |
2.4 | async-rithmic | 1.5.9 | Python API Integration with Rithmic Protocol Buffer API | # Python Rithmic API
[](https://pypi.org/project/async-rithmic/)
[](https://github.com/rundef/async_rithmic/actions/workflows/ci.yml)
[ for expressing trading strategies with support for multi-source data (OHLCV, trades, orderbook, liquidations), filtering, aggregation... | text/markdown | null | Laakhay Corporation <laakhay.corp@gmail.com> | null | null | MIT | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"build>=1.0.0; extra == \"dev\"",
"pyright>=1.1.406; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-cov>=7.0.0; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"twine>=5.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://laakhay.com",
"Repository, https://github.com/laakhay/ta",
"Issues, https://github.com/laakhay/ta/issues"
] | uv/0.9.4 | 2026-02-20T17:33:52.357906 | laakhay_ta-0.2.8.tar.gz | 117,651 | 8e/7b/cc5ec3248a23a32c1d772613c6be8c2752f77edec1bfe718f3ac3915e7a0/laakhay_ta-0.2.8.tar.gz | source | sdist | null | false | 7e4d3b1900ea490b0cbf14ae7918bbbb | 1421239043fcd1670723c7a2f454f931b49a6c65fbfb772a42430df33661c39f | 8e7bcc5ec3248a23a32c1d772613c6be8c2752f77edec1bfe718f3ac3915e7a0 | null | [
"LICENSE"
] | 191 |
2.4 | e3sm-quickview | 1.3.3 | An application to explore/analyze data for atmosphere component for E3SM | # QuickView
[](https://github.com/ayenpure/QuickView/actions/workflows/test.yml)
[](https://github.com/ayenpure/QuickView/a... | text/markdown | Kitware Inc. | null | null | null | Apache Software License | Application, Framework, Interactive, Python, Web | [
"Development Status :: 5 - Production/Stable",
"Environment :: Web Environment",
"License :: OSI Approved :: Apache Software License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3 :: Only",
"Topic :: Software Development :: Libraries :: Applic... | [] | null | null | >=3.10 | [] | [] | [] | [
"netcdf4>=1.6.5",
"pillow",
"pyproj>=3.6.1",
"trame-components",
"trame-dataclass>=1.2",
"trame-tauri>=0.6.2",
"trame-vtk>=2.10",
"trame-vuetify>=3.1",
"trame>=3.12",
"jupyter-server-proxy>=4.0.0; extra == \"jupyter\"",
"pyinstaller; extra == \"tauri\"",
"trame-grid-layout>=1.0.3; extra == \"v... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:33:45.278502 | e3sm_quickview-1.3.3.tar.gz | 1,556,842 | ab/6c/c0653bcf7a5cd4fee403ef14653c6130e91e5d60c8dffba1a325cf24260a/e3sm_quickview-1.3.3.tar.gz | source | sdist | null | false | 9c618d91ee81bfd46e20519ab26738d0 | 6993f9e593246a2f01dac394cfa49ad45a843c9fd3f3aa8a254c3bceaa4c3fdc | ab6cc0653bcf7a5cd4fee403ef14653c6130e91e5d60c8dffba1a325cf24260a | null | [
"LICENSE"
] | 188 |
2.4 | dbt-subprocess-plugin | 0.1.0 | dbt plugin to add Python's subprocess module to dbt's `modules` context attribute | # dbt-subprocess-plugin
This is a [dbt plugin][] to add Python's [subprocess][] module to dbt's [`modules` context][modules] attribute.
[dbt-plugin]: https://github.com/dbt-labs/dbt-core/blob/fa96acb15f79ae4f10b1d78f311f5ef2f4ed645e/core/dbt/plugins/manager.py
[subprocess]: https://docs.python.org/3/library/subproces... | text/markdown | null | Tim Vergenz <vergenzt@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"dbt-core>=1.6"
] | [] | [] | [] | [] | uv/0.9.18 {"installer":{"name":"uv","version":"0.9.18","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":nu... | 2026-02-20T17:33:44.290575 | dbt_subprocess_plugin-0.1.0.tar.gz | 211,626 | bd/05/994fea493ae06eaac72299c4e093ba330b2162e3e59b45f9e8bbaaa87fcd/dbt_subprocess_plugin-0.1.0.tar.gz | source | sdist | null | false | e0a0769d7f71f34ba2080e16a65e896f | 8070992d5bb3a7808c1b31dbbc18b2e1871d6b28eab48393d9b67c932310690a | bd05994fea493ae06eaac72299c4e093ba330b2162e3e59b45f9e8bbaaa87fcd | null | [] | 197 |
2.4 | relationalai | 0.14.0 | RelationalAI Library and CLI | # The RelationalAI Python Library
The Python library for building and querying knowledge graphs with RelationalAI.
For more information, visit our documentation at [https://relational.ai/docs](https://relational.ai/docs).
| text/markdown | null | RelationalAI <support@relational.ai> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp",
"click==8.2.1",
"colorama",
"cryptography",
"gravis",
"inquirerpy",
"lqp==0.2.3",
"nicegui>=3.7.0",
"numpy<2",
"opentelemetry-api",
"opentelemetry-exporter-otlp-proto-http",
"opentelemetry-sdk",
"packaging",
"pandas",
"pyarrow",
"pyjwt",
"requests",
"rich",
"snowflake-... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T17:33:33.166850 | relationalai-0.14.0.tar.gz | 1,313,008 | 56/ae/ea9316c8b5d1306c11c24ddf566d1d313c6c9944030610cf21bd6f2f18c1/relationalai-0.14.0.tar.gz | source | sdist | null | false | bece66948caa92b1935f9f3d81a9430b | 48382d7452af9edf67fad034b66ac71bdc83e5c454fe68d223547ad16a0ac589 | 56aeea9316c8b5d1306c11c24ddf566d1d313c6c9944030610cf21bd6f2f18c1 | null | [
"LICENSE"
] | 376 |
2.4 | asyncer | 0.0.15 | Asyncer, async and await, focused on developer experience. | <p align="center">
<a href="https://asyncer.tiangolo.com"><img src="https://asyncer.tiangolo.com/img/logo-margin/logo-margin-vector.svg" alt="Asyncer"></a>
</p>
<p align="center">
<em>Asyncer, async and await, focused on developer experience.</em>
</p>
<p align="center">
<a href="https://github.com/fastapi/asynce... | text/markdown | null | Sebastián Ramírez <tiangolo@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Framework :: AsyncIO",
"Framework :: Trio",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"Intended Audience :: System Administrators",
"Programming Langu... | [] | null | null | >=3.10 | [] | [] | [] | [
"anyio<5.0,>=3.4.0",
"sniffio>=1.1",
"typing_extensions>=4.12.0; python_version < \"3.15\""
] | [] | [] | [] | [
"Homepage, https://github.com/fastapi/asyncer",
"Documentation, https://asyncer.tiangolo.com",
"Repository, https://github.com/fastapi/asyncer",
"Issues, https://github.com/fastapi/asyncer/issues",
"Changelog, https://asyncer.tiangolo.com/release-notes/"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_vers... | 2026-02-20T17:32:35.709230 | asyncer-0.0.15.tar.gz | 20,090 | 7a/d0/e71744250a22bf358095dbc471ecd4c453bd666f789f2b14cf3ead50fbd8/asyncer-0.0.15.tar.gz | source | sdist | null | false | d36ae0a896a3fb30c13cff77a19ff868 | 339c8493a2be8f188e4bf741019252f7c344e2a78c83a37913dc7832c47f4309 | 7ad0e71744250a22bf358095dbc471ecd4c453bd666f789f2b14cf3ead50fbd8 | MIT | [
"LICENSE"
] | 10,859 |
2.2 | certora-cli-alpha-master | 20260220.17.32.693288 | Runner for the Certora Prover | Commit bd9275d. Build and Run scripts for executing the Certora Prover on Solidity smart contracts.
| text/markdown | Certora | support@certora.com | null | null | GPL-3.0-only | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: OS Independent"
] | [] | https://pypi.org/project/certora-cli-alpha-master | null | >=3.9 | [] | [] | [] | [
"click",
"json5",
"pycryptodome",
"requests",
"rich",
"sly",
"tabulate",
"tqdm",
"StrEnum",
"jinja2",
"wcmatch",
"typing_extensions"
] | [] | [] | [] | [
"Documentation, https://docs.certora.com/en/latest/",
"Source, https://github.com/Certora/CertoraProver"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T17:32:35.403263 | certora_cli_alpha_master-20260220.17.32.693288.tar.gz | 42,911,449 | 06/a9/d468fd7ac0efb3c1be303d07a037983c2faa7c33857cc40c27a422b66d96/certora_cli_alpha_master-20260220.17.32.693288.tar.gz | source | sdist | null | false | 89e42478f0f10af96a5c840f2ddaa886 | d095189fa00f18fda3feb076bbfc9d4befdfa4d0566b44c19fdc0238b0a605fe | 06a9d468fd7ac0efb3c1be303d07a037983c2faa7c33857cc40c27a422b66d96 | null | [] | 403 |
2.4 | asyncer-slim | 0.0.15 | Asyncer, async and await, focused on developer experience. | <p align="center">
<a href="https://asyncer.tiangolo.com"><img src="https://asyncer.tiangolo.com/img/logo-margin/logo-margin-vector.svg" alt="Asyncer"></a>
</p>
<p align="center">
<em>Asyncer, async and await, focused on developer experience.</em>
</p>
<p align="center">
<a href="https://github.com/fastapi/asynce... | text/markdown | null | Sebastián Ramírez <tiangolo@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Framework :: AsyncIO",
"Framework :: Trio",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"Intended Audience :: System Administrators",
"Programming Langu... | [] | null | null | >=3.10 | [] | [] | [] | [
"asyncer>=0.0.15"
] | [] | [] | [] | [
"Homepage, https://github.com/fastapi/asyncer",
"Documentation, https://asyncer.tiangolo.com",
"Repository, https://github.com/fastapi/asyncer",
"Issues, https://github.com/fastapi/asyncer/issues",
"Changelog, https://asyncer.tiangolo.com/release-notes/"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_vers... | 2026-02-20T17:32:33.731683 | asyncer_slim-0.0.15-py3-none-any.whl | 3,010 | ec/50/6f730e7b7b90eec96d1fe2b8f28b52707a9006c13bef15709dce92dbea22/asyncer_slim-0.0.15-py3-none-any.whl | py3 | bdist_wheel | null | false | 7d1203b3fdc0a2fde195898c3d322d40 | 6880cf55d3222a5379af9511cbdc3b688cfca1f9361a86d7df2cc81ecc7f3d18 | ec506f730e7b7b90eec96d1fe2b8f28b52707a9006c13bef15709dce92dbea22 | MIT | [
"LICENSE"
] | 185 |
2.4 | agentouto | 0.2.0 | Multi-agent Python SDK with peer-to-peer agent communication | # AgentOutO
**멀티 에이전트 특화 Python SDK — 오케스트레이터 없는 피어 간 자유 호출**
A multi-agent Python SDK where every agent is equal. No orchestrator. No hierarchy. No restrictions.
---
## 핵심 철학 (Core Philosophy)
AgentOutO rejects the orchestrator pattern used by existing frameworks (CrewAI, AutoGen, etc.).
> **모든 에이전트는 완전히 대등하다.**... | text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"anthropic>=0.34.0",
"google-generativeai>=0.8.0",
"openai>=1.50.0",
"mypy>=1.8; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:32:05.776156 | agentouto-0.2.0.tar.gz | 40,232 | 00/33/a557fab0bc50ceb70c5a63743bbe3907589685980ab6c8a9dcb602c487aa/agentouto-0.2.0.tar.gz | source | sdist | null | false | 50a66d7c941b7b0e704e2053b4709032 | fe151a2f7a1f8ca8f7c1557abad5c350280c8726a7cfe7889ebf471565fdf6e7 | 0033a557fab0bc50ceb70c5a63743bbe3907589685980ab6c8a9dcb602c487aa | Apache-2.0 | [
"LICENSE"
] | 195 |
2.4 | cyberwave-edge-core | 0.0.16 | The core component of the Cyberwave Edge Node | # Cyberwave Edge Core
This Edge component acts as an orchestrator of your Cyberwave edge components.
## Quickstart (Linux machines)
```bash
# Install the CLI (one time setup)
curl -fsSL "https://packages.buildkite.com/cyberwave/cyberwave-cli/gpgkey" | sudo gpg --dearmor -o /etc/apt/keyrings/cyberwave_cyberwave-cli-a... | text/markdown | null | Cyberwave <info@cyberwave.com> | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"... | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"click>=8.1.0",
"cyberwave>=0.3.14",
"httpx>=0.25.0",
"rich>=13.0.0",
"pyinstaller>=6.0.0; extra == \"build\"",
"mypy>=1.5.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://cyberwave.com",
"Documentation, https://docs.cyberwave.com",
"Repository, https://github.com/cyberwave-os/cyberwave-edge-core",
"Issues, https://github.com/cyberwave-os/cyberwave-edge-core/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:31:27.338422 | cyberwave_edge_core-0.0.16.tar.gz | 16,887 | f6/fe/761af15ae5e1fb33606596649012e2b7b9920b258cfde95ca401141fed67/cyberwave_edge_core-0.0.16.tar.gz | source | sdist | null | false | d1c10fc84b016ea4f0e9b2b73e8f281c | 78bbfd21b1c88b15adf1108d051da7cf83a431298ceff0e2aa0fc478997bdb25 | f6fe761af15ae5e1fb33606596649012e2b7b9920b258cfde95ca401141fed67 | null | [
"LICENSE"
] | 173 |
2.3 | brew_sdk | 0.4.0 | The official Python library for the brew-sdk API | # Brew SDK Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/brew_sdk/)
The Brew SDK Python library provides convenient access to the Brew SDK REST API from any Python 3.9+
application. The library includes type def... | text/markdown | null | Brew SDK <support@brew.new> | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pydantic<3,>=1.9.0",
"sniffio",
"typing-extensions<5,>=4.10",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"aiohttp\""
] | [] | [] | [] | [
"Homepage, https://github.com/GetBrew/brew-python-sdk",
"Repository, https://github.com/GetBrew/brew-python-sdk"
] | uv/0.9.13 {"installer":{"name":"uv","version":"0.9.13"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T17:30:53.809535 | brew_sdk-0.4.0.tar.gz | 226,047 | b5/b7/13b1b8c9be87fa63c0dc285c8ce4c2e95209161af6edd647978263d8a571/brew_sdk-0.4.0.tar.gz | source | sdist | null | false | 6a7ba6a6e26d7c9bc378db6f669d7362 | 712e02e81bf5b0abfe091709441575632c6354a52db9c5d7c8913a70e9566fb7 | b5b713b1b8c9be87fa63c0dc285c8ce4c2e95209161af6edd647978263d8a571 | null | [] | 0 |
2.4 | jacobs-jinja-too | 0.2.14 | Simple wrapper around jinja2 templating | # Jacob's Jinja Too
[](https://circleci.com/gh/pearmaster/jacobs-jinja-too/tree/master)
A simple wrapper around Jinja2 templating with a collection of custom filters. [Jinja2](https://jinja.palletsprojects.com/en/2.11.x/) is... | text/markdown | null | Jacob Brunson <pypi@jacobbrunson.com> | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"jinja-markdown>=1.210911",
"jinja2>=3.1.6"
] | [] | [] | [] | [
"Homepage, http://github.com/pearmaster/jacobs-jinja-too"
] | uv/0.9.12 {"installer":{"name":"uv","version":"0.9.12"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"25.10","id":"questing","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T17:30:36.982138 | jacobs_jinja_too-0.2.14-py3-none-any.whl | 13,981 | d0/c9/057e1c38a62339636fb6aa07bf185b721a43dd741e2e884632c9157e66a0/jacobs_jinja_too-0.2.14-py3-none-any.whl | py3 | bdist_wheel | null | false | 6897918f4d0ae620967d0c124ee62aa5 | f9eb4f56734cc1cff3283d47062b7f68cac510e42da4ce74d38aac797b194ead | d0c9057e1c38a62339636fb6aa07bf185b721a43dd741e2e884632c9157e66a0 | LGPL-2.0 | [
"LICENSE"
] | 202 |
2.4 | wati-mcp | 0.2.0 | WhatsApp MCP Server using Wati API v3 | # WhatsApp MCP Server with Wati API v3
This is a Model Context Protocol (MCP) server for WhatsApp using the Wati API **v3**.
Manage your WhatsApp conversations, contacts, templates, campaigns, and channels through AI assistants like Claude. Search and read messages, send texts and files, manage contacts, and automate... | text/markdown | WhatsApp MCP Contributors | null | null | null | MIT License
Copyright (c) 2025 Luke Harries
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the r... | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"requests>=2.28.0",
"python-dotenv>=0.21.0",
"mcp>=1.6.0",
"mcp[cli]>=1.6.0; extra == \"cli\"",
"pytest>=7.0.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.5 | 2026-02-20T17:30:34.985970 | wati_mcp-0.2.0.tar.gz | 16,937 | 65/65/8621bc311018acf5d3259a98514e105c479c8da10b69ac27f88e406ab907/wati_mcp-0.2.0.tar.gz | source | sdist | null | false | 99b0ef156a88da0a74d9b1b46edfdfd6 | 863c72f3c37bcf54897a74b0f07ed837af559d83a02a6a7f966feb3010f66dfc | 65658621bc311018acf5d3259a98514e105c479c8da10b69ac27f88e406ab907 | null | [
"LICENSE"
] | 201 |
2.4 | sqlsaber-viz | 0.4.0 | SQLsaber terminal visualization plugin | # SQLSaber Visualization Plugin
Provides the `viz` tool for SQLSaber via the `sqlsaber-viz` plugin. The tool generates a declarative chart spec and renders ASCII charts in the terminal using plotext.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"plotext>=5.3.0",
"sqlsaber>=0.55.1"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_vers... | 2026-02-20T17:30:32.797456 | sqlsaber_viz-0.4.0-py3-none-any.whl | 17,145 | 93/16/6c9e8877ac1652753e620f9c38d3ae28284550e14236a0ce728faab064d0/sqlsaber_viz-0.4.0-py3-none-any.whl | py3 | bdist_wheel | null | false | c3592834cb24c9cdf15ff1e5a84ce4bf | 39ef25960d964b26cee4eab0f374a424cf282e555ed841df6c85c9d4175d1498 | 93166c9e8877ac1652753e620f9c38d3ae28284550e14236a0ce728faab064d0 | null | [] | 187 |
2.4 | gwseq-io | 0.0.19 | Process BBI (bigWig/bigBed) and HiC files | ## Installation
```
pip install gwseq-io
```
Requires numpy and pybind11.
## Usage
### Open bigWig, bigBed and HiC files
```python
reader = gwseq_io.open(path, *, parallel, zoom_correction, file_buffer_size, max_file_buffer_count)
```
Parameters:
- `parallel` Number of parallel file handles and processing threads... | text/markdown | null | Arthur Gouhier <ajgouhier@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy",
"pybind11>=2.6.0"
] | [] | [] | [] | [
"Repository, https://github.com/ajgouhier/gwseq_io"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-20T17:30:10.871758 | gwseq_io-0.0.19.tar.gz | 71,160 | b0/e5/8fd41205ba3ac3c3875c02a1c09cd5d3b84fbfbaa10a9dc4433bb0b908c0/gwseq_io-0.0.19.tar.gz | source | sdist | null | false | 7478c1bd49ff411be26a05bfcabb6ceb | 74c9f6afae46b6ee69839cf3d69f05d971a10db7dc7ac2de4e441265f22e6517 | b0e58fd41205ba3ac3c3875c02a1c09cd5d3b84fbfbaa10a9dc4433bb0b908c0 | MIT | [
"LICENSE"
] | 171 |
2.4 | speechmarkdown | 1.0.2 | Speech Markdown library for Python. | # SpeechMarkdown
[](https://pypi.org/project/speechmarkdown/)

[](https://speechmarkdown-py.githu... | text/markdown | Takeshi Teshima | takeshi.78.teshima@gmail.com | null | null | Apache-2.0 | null | [
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"pyparsing<4.0.0,>=3.3.2"
] | [] | [] | [] | [
"Homepage, https://github.com/takeshi-teshima/speechmarkdown",
"Repository, https://github.com/takeshi-teshima/speechmarkdown"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:29:51.289217 | speechmarkdown-1.0.2.tar.gz | 67,178 | da/70/7a74b973b3583fb63d1ff0dcf46cc1424d86c15bcd9cf31727a4d0650e11/speechmarkdown-1.0.2.tar.gz | source | sdist | null | false | 4b29a0142608e5102057e8a5ef7a36b0 | 06d1177475f04ef3b20ce0664313ac2f0ccc588df3109a18136228e0dfd3d811 | da707a74b973b3583fb63d1ff0dcf46cc1424d86c15bcd9cf31727a4d0650e11 | null | [
"LICENSE"
] | 183 |
2.4 | agentwire-dev | 1.7.0 | Multi-session voice web interface for AI coding agents | <p align="center">
<img src="https://agentwire.dev/images/splash-full-transparent.png" alt="AgentWire" width="500">
</p>
<p align="center">
<strong>Talk to your AI coding agents. From anywhere.</strong>
</p>
<p align="center">
<a href="https://pypi.org/project/agentwire-dev/"><img src="https://img.shields.io/py... | text/markdown | null | dotdev <dev@dotdev.dev> | null | null | GNU AFFERO GENERAL PUBLIC LICENSE Version 3, 19 November 2007 Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/> Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed. Preamble The GNU Affero General Public License is a free, copyleft ... | agent, ai, claude, stt, tmux, tts, voice | [
"Development Status :: 3 - Alpha",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)",
"Operating System :: MacOS",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Progr... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp-jinja2>=1.6",
"aiohttp>=3.9.0",
"jinja2>=3.1.0",
"markdown>=3.5",
"mcp>=1.2.0",
"python-dotenv>=1.0.0",
"pyyaml>=6.0",
"requests>=2.28.0",
"resend>=2.0.0",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"fastapi>=0.104.0... | [] | [] | [] | [
"Homepage, https://agentwire.dev",
"Repository, https://github.com/dotdevdotdev/agentwire-dev",
"Documentation, https://agentwire.dev",
"Issues, https://github.com/dotdevdotdev/agentwire-dev/issues",
"Changelog, https://github.com/dotdevdotdev/agentwire-dev/blob/main/CHANGELOG.md"
] | uv/0.7.20 | 2026-02-20T17:28:49.264401 | agentwire_dev-1.7.0.tar.gz | 31,428,487 | d8/a5/f772b1560ce60537a414fb312ba3e2d78fb1c7412993379ddc24db03b605/agentwire_dev-1.7.0.tar.gz | source | sdist | null | false | 14b34651d82d0d507f89636e41d318c2 | 977bc622f3eb7c0b88b5f0bad216a67740001f2fd622b8bcd9acad58c5672396 | d8a5f772b1560ce60537a414fb312ba3e2d78fb1c7412993379ddc24db03b605 | null | [
"LICENSE"
] | 210 |
2.4 | kdebug | 0.6.2 | TUI for Kubernetes Debug Containers | # kdebug - Universal Kubernetes Debug and File Copy Container Utility
Simple utility for launching ephemeral debug containers in Kubernetes pods with interactive shell access, backup capabilities, and a colorful TUI for pod selection.
Similar to [kpf](https://github.com/jessegoodier/kpf), this is a python wrapper aro... | text/markdown | Jesse Goodier | null | null | null | null | cli, debug, kubectl, kubernetes | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"rich>=14.0"
] | [] | [] | [] | [
"Homepage, https://github.com/jessegoodier/kdebug",
"Repository, https://github.com/jessegoodier/kdebug"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_vers... | 2026-02-20T17:28:36.993759 | kdebug-0.6.2.tar.gz | 23,052 | 2c/4f/a5085e488c18d8c8490b9593c751fa88ff8da90e0892ff2a54afb43fcc63/kdebug-0.6.2.tar.gz | source | sdist | null | false | 686789d84920913bcff21627768549d7 | d4ef180a0071db137de2978f77b15a3eca9ae64b283c4cd3ae1904927db9ae18 | 2c4fa5085e488c18d8c8490b9593c751fa88ff8da90e0892ff2a54afb43fcc63 | MIT | [] | 225 |
2.4 | william-occam | 0.2.3.1 | William: A tool for data compression and machine learning automatization | [](https://gitlab.com/occam_ua/william/-/commits/master)
[](https://pypi.org/project/william-occam/)
](https://pypi.org/project/langchain-nativ/)
[](LICENSE)
[LangChain](https://www.langchain.com/) integration for **[Nativ](https://usenativ.com)** — AI-powered localization.
Give... | text/markdown | null | Nativ <hello@usenativ.com> | null | null | null | ai, i18n, l10n, langchain, localization, nativ, translation | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"langchain-core>=0.3.0",
"nativ>=0.1.0",
"pytest-asyncio>=0.21; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://usenativ.com",
"Documentation, https://docs.usenativ.com",
"Repository, https://github.com/Nativ-Technologies/langchain-nativ",
"Issues, https://github.com/Nativ-Technologies/langchain-nativ/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:27:35.520759 | langchain_nativ-0.1.0.tar.gz | 8,598 | 05/72/11e56795f58bace21c34dcf05d679d92994dcbd6788d04e7e38e69460bfd/langchain_nativ-0.1.0.tar.gz | source | sdist | null | false | d39a03f885bd0e9f0633ee7b600845ad | bc227b1dc4d868a656fd5fc565b3b507046829b88b0ce711437eddccb87b64df | 057211e56795f58bace21c34dcf05d679d92994dcbd6788d04e7e38e69460bfd | MIT | [
"LICENSE"
] | 214 |
2.4 | pycytominer | 1.4.0 | Python package for processing image-based profiling data | <img height="200" src="https://raw.githubusercontent.com/cytomining/pycytominer/main/logo/with-text-for-light-bg.png?raw=true">
# Data processing for image-based profiling
[](https://github.com/cytom... | text/markdown | Erik Serrano | null | Gregory P. Way | gregory.way@cuanschutz.edu | BSD-3-Clause | null | [
"License :: OSI Approved :: BSD License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <3.15,>=3.10 | [] | [] | [] | [
"anndata<0.12.2; python_version < \"3.11\" and extra == \"anndata\"",
"anndata>=0.12.2; python_version >= \"3.11\" and extra == \"anndata\"",
"boto3>=1.26.79; extra == \"cell-locations\"",
"cytominer-database==0.3.4; extra == \"collate\"",
"fire>=0.5.0",
"fsspec>=2023.1.0; extra == \"cell-locations\"",
... | [] | [] | [] | [
"Homepage, https://pycytominer.readthedocs.io/",
"Repository, https://github.com/cytomining/pycytominer"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:27:29.767948 | pycytominer-1.4.0.tar.gz | 207,131 | 5f/3c/c1ae72885690b98873fd718ae32ac4cbd31b9ed2658182eee183caff823e/pycytominer-1.4.0.tar.gz | source | sdist | null | false | 10f2988abeefe39b38dd92c4ca636219 | b969bd371d11abf74a5175e61616453c5d67f1bd56913e312a60b4464a618ef5 | 5f3cc1ae72885690b98873fd718ae32ac4cbd31b9ed2658182eee183caff823e | null | [
"LICENSE.md"
] | 209 |
2.4 | codetrust | 2.7.0 | AI code safety platform — 280 rules, 10 enforcement layers, 5 enterprise services. AI Governance Gateway blocks destructive AI agent actions (76 real-time rules). Hallucination Detection verifies imports against PyPI/npm/crates.io/Go/Maven/NuGet/RubyGems/Packagist. Trust Score tracks safety drift. CVE scanning, license... | <p align="center">
<img src="https://codetrust.ai/logo.png" alt="CodeTrust — AI Governance Enforcement Platform" width="420">
</p>
<p align="center">
<strong>AI Governance Enforcement Platform — Prevent unsafe AI-generated code from reaching production.</strong>
</p>
<p align="center">
<code>Current: v2.7.0</co... | text/markdown | null | Said Borna <contact@codetrust.ai> | null | null | null | ai-safety, claude-code, code-quality, cursor, devops, governance, hallucination, kubernetes, mcp, react, sarif, security, verification | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Quality Assurance"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"alembic>=1.13.0",
"asyncpg>=0.29.0",
"fastapi>=0.115.0",
"httpx>=0.27.0",
"mcp[cli]>=1.0.0",
"psycopg2-binary>=2.9.0",
"pydantic-settings>=2.0.0",
"pydantic>=2.0.0",
"pyjwt>=2.8.0",
"redis[hiredis]>=5.0.0",
"sqlalchemy[asyncio]>=2.0.0",
"stripe>=7.0.0",
"structlog>=24.0.0",
"tree-sitter-c... | [] | [] | [] | [
"Homepage, https://codetrust.ai",
"Documentation, https://codetrust.ai",
"Support, https://codetrust.ai"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T17:27:25.949068 | codetrust-2.7.0.tar.gz | 19,924 | fc/ac/0bb94e2dfcc4d2394c189085eadf5931aaf2a44f4378a1d2a6aa06e1b0ff/codetrust-2.7.0.tar.gz | source | sdist | null | false | bccc7ae6ae49f6bcec313ee3efd03cfa | 5357e0e85c9411c14173555c5ac7e586750eda9b10788dacd036c6531ca10e99 | fcac0bb94e2dfcc4d2394c189085eadf5931aaf2a44f4378a1d2a6aa06e1b0ff | LicenseRef-Proprietary | [
"LICENSE"
] | 199 |
2.4 | metacontroller-pytorch | 0.2.22 | Transformer Metacontroller | <img src="./fig1.png" width="400px"></img>
## metacontroller
Implementation of the MetaController proposed in [Emergent temporal abstractions in autoregressive models enable hierarchical reinforcement learning](https://arxiv.org/abs/2512.20605), from the Paradigms of Intelligence team at Google
## Install
```shell
... | text/markdown | null | Phil Wang <lucidrains@gmail.com> | null | null | MIT License Copyright (c) 2025 Phil Wang Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distrib... | artificial intelligence, deep learning, hierarchical reinforcement learning, latent steering | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.9",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"assoc-scan>=0.0.3",
"discrete-continuous-embed-readout>=0.1.12",
"einops>=0.8.1",
"einx>=0.3.0",
"jax",
"jaxlib",
"loguru",
"memmap-replay-buffer>=0.0.25",
"torch-einops-utils>=0.0.30",
"torch>=2.5",
"vector-quantize-pytorch>=1.27.20",
"x-evolution>=0.1.23",
"x-mlps-pytorch",
"x-transform... | [] | [] | [] | [
"Homepage, https://pypi.org/project/metacontroller/",
"Repository, https://github.com/lucidrains/metacontroller"
] | uv/0.8.17 | 2026-02-20T17:27:24.711408 | metacontroller_pytorch-0.2.22.tar.gz | 24,042 | ee/49/ced915c1b48675f851b895aad1f77ae44dc2bb86665a1895ccb2368560e8/metacontroller_pytorch-0.2.22.tar.gz | source | sdist | null | false | 9bcdda49be53694bb461ee2ec772eb57 | c275bb87c87bcba5a138dd9318bfce0ecf9de3853f4a18b7e2e6fa848df077f6 | ee49ced915c1b48675f851b895aad1f77ae44dc2bb86665a1895ccb2368560e8 | null | [
"LICENSE"
] | 209 |
2.4 | laakhay-core | 0.1.1 | Core types and models for the Laakhay ecosystem | # Laakhay Core
`laakhay-core` is the high-performance, zero-dependency bedrock of the Laakhay ecosystem. It provides the source of truth for all domain models, identity grammars, and primitive types.
## 🏗 Philosophy: The "Thin Core"
This library follows a strict separation of **Data** and **Behavior**.
- **Schema Au... | text/markdown | null | Laakhay Corporation <laakhay.corp@gmail.com> | null | null | MIT | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"build>=1.0.0; extra == \"dev\"",
"pyright>=1.1.406; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"twine>=5.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://laakhay.com",
"Repository, https://github.com/laakhay/core",
"Issues, https://github.com/laakhay/core/issues"
] | uv/0.9.4 | 2026-02-20T17:27:17.666175 | laakhay_core-0.1.1.tar.gz | 15,693 | 43/b2/c6ea5660f0a34a6ca49c2f688c673fdb5ca898872d8ce429d8106569328d/laakhay_core-0.1.1.tar.gz | source | sdist | null | false | 830e4bdc27d05627c74d0dee2dbb6ca6 | d3af0aeba3fcc5e9116c238f3f19940d5e2047576a138ca625b7b9cc5cb5ffc1 | 43b2c6ea5660f0a34a6ca49c2f688c673fdb5ca898872d8ce429d8106569328d | null | [
"LICENSE"
] | 215 |
2.4 | jb-drf-auth | 0.1.11 | Reusable auth + profiles foundations for Django/DRF projects | # jb-drf-auth
[](https://pypi.org/project/jb-drf-auth/)
[](https://test.pypi.org/project/jb-drf-auth/)
Reusable authentication module for Django + Django REST Framework.
PyPI: h... | text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"Django>=5.0",
"djangorestframework>=3.15",
"djangorestframework-simplejwt>=5.3",
"PyJWT<3,>=2.7",
"drf-extra-fields>=3.7",
"django-filter>=24.2",
"django-safedelete<2.0,>=1.4",
"argon2-cffi~=25.1.0",
"bcrypt~=4.0.1",
"boto3>=1.34",
"Pillow>=10.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:26:51.932240 | jb_drf_auth-0.1.11.tar.gz | 46,489 | e1/4e/d3474db40c6923dad696ac1e18e6e9184d7cf134f88430cb392b0b83289d/jb_drf_auth-0.1.11.tar.gz | source | sdist | null | false | c1690a3f461e218fc99a376d37066e05 | b4f0fca76c05c69eba80af011032bd1c6a6c84c810b7cc3b44ea4821fcf50cad | e14ed3474db40c6923dad696ac1e18e6e9184d7cf134f88430cb392b0b83289d | null | [
"LICENSE"
] | 209 |
2.4 | ytstudio-cli | 0.1.1 | CLI tool to manage and analyze your YouTube channel from the terminal | # YT Studio CLI
[](https://github.com/jdwit/ytstudio/actions/workflows/ci.yml)
[](https://pypi.org/project/ytstudio-cli/)
[](https:... | text/markdown | null | Jelmer de Wit <1598297+jdwit@users.noreply.github.com> | null | null | MIT | analytics, cli, creator, video, youtube, youtube-studio | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"google-api-python-client>=2.0.0",
"google-auth-oauthlib>=1.0.0",
"google-auth>=2.0.0",
"packaging>=21.0",
"rich>=13.0.0",
"typer>=0.9.0"
] | [] | [] | [] | [
"Homepage, https://github.com/jdwit/ytstudio-cli",
"Repository, https://github.com/jdwit/ytstudio-cli"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:26:24.410289 | ytstudio_cli-0.1.1.tar.gz | 705,898 | 88/bf/cd081f969e936aaa1e6f05675cfef2f1ad99d78a779298457d8f4be4c978/ytstudio_cli-0.1.1.tar.gz | source | sdist | null | false | 682362dd4c0479a2caf523375c689028 | 1ab0c655ffb8c234f5644544dd1f4ce21907adbb87bff77c21f7ffaeabbf9c4b | 88bfcd081f969e936aaa1e6f05675cfef2f1ad99d78a779298457d8f4be4c978 | null | [
"LICENSE"
] | 186 |
2.4 | laakhay-data | 0.2.7 | Data infrastructure built with ♥︎ by Laakhay | # Laakhay Data
**Beta-stage async-first cryptocurrency market data aggregation library.**
> ⚠️ **Beta Software**: This library is in active development. Use with caution in production environments. APIs may change between versions.
Unified API for multi-exchange market data with support for **Binance**, **Bybit**, *... | text/markdown | null | Laakhay Corporation <laakhay.corp@gmail.com> | null | null | null | finance, market-data, trading | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Financial and Insurance Industry",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Office/Business :: Financial"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"aiohttp>=3.8",
"laakhay-core",
"pydantic>=2.0",
"websockets>=10",
"build>=1.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"pytest-asyncio>=0.24.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.4; extra == \"dev\"",
"twine>=5.0; extr... | [] | [] | [] | [
"Homepage, https://laakhay.com"
] | uv/0.9.4 | 2026-02-20T17:26:21.738447 | laakhay_data-0.2.7.tar.gz | 187,790 | 14/d4/bebfb2f562ad34dc627f61864803ad911652defcd5d60b875414177652f0/laakhay_data-0.2.7.tar.gz | source | sdist | null | false | e42314bdb764be058c8d78f747273655 | 4dd5bc2677332f7cc5417e9f42c8f62e26b1bc90e783cc4027a94c271a35f187 | 14d4bebfb2f562ad34dc627f61864803ad911652defcd5d60b875414177652f0 | MIT | [
"LICENSE"
] | 215 |
2.4 | dsperse | 3.3.0 | Distributed zkML Toolkit | # DSperse: Distributed zkML
[](https://github.com/inference-labs-inc/dsperse)
[](https://discord.gg/GBxBCWJs)
[ 2025 Inference Labs Inc. Source Access Grant You may access, view, study, and modify the source code of this software. Redistribution Conditions You may redistribute this software in source or modified form provided that: a) You retain this license document and all copyright notices b) Any modified file... | null | [] | [] | null | null | ==3.13.* | [] | [] | [] | [
"torch==2.6.0",
"onnx==1.18.0",
"ezkl==22.2.1",
"numpy~=2.2.3",
"onnxruntime<2.0.0,>=1.21.0",
"colorama~=0.4.6",
"jstprove==2.7.0",
"pytest>=8.4.1; extra == \"dev\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_vers... | 2026-02-20T17:25:21.198839 | dsperse-3.3.0-py3-none-any.whl | 1,970,522 | b6/fa/bfd78692b66ad26babda5ba0fc7ca107f95fe2f610bfd3d9bf0ab1389785/dsperse-3.3.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 520495ec32b0956cc81ec9c28e272352 | 1898326b657a384af9b6e02836ce3d7f654547dc93bbb4bb9c91008450d96855 | b6fabfd78692b66ad26babda5ba0fc7ca107f95fe2f610bfd3d9bf0ab1389785 | null | [
"LICENSE"
] | 207 |
2.4 | ubcpdk | 3.3.3 | ubcpdk pdk | # ubcpdk (SiEPIC Ebeam PDK) 3.3.3
[](https://mybinder.org/v2/gh/gdsfactory/binder-sandbox/HEAD)
[](https://pypi.org/project/ubcpdk/)
[](https://choosealicense.com/licen... | text/markdown | null | gdsfactory <contact@gdsfactory.com> | null | null | null | python | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Operating System :: OS Independent"
] | [] | null | null | <3.13,>=3.12 | [] | [] | [] | [
"gdsfactory~=9.34.0",
"gplugins[sax,tidy3d]~=2.0.0",
"jsondiff",
"doroutes>=0.3.0",
"gdsfactoryplus==1.4.4",
"pytz",
"pytest; extra == \"dev\"",
"gdsfactoryplus; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest_regressions; extra == \"dev\"",
"pytest-github-actions-annotate-failures; e... | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T17:25:01.980521 | ubcpdk-3.3.3.tar.gz | 12,698,003 | 53/31/22546c52620e97f53ce73166a379f2c8d1cb6b5745a43762203314657dbe/ubcpdk-3.3.3.tar.gz | source | sdist | null | false | 28c93285b773e3e7535d32684a3dcebc | c75792caee772cbb21370bfee5a27bf85d922b9a71890349a695559934168131 | 533122546c52620e97f53ce73166a379f2c8d1cb6b5745a43762203314657dbe | null | [
"LICENSE"
] | 250 |
2.4 | etl-utilities | 1.1.17 | This repository provides a collection of utility functions and classes for data cleaning, SQL query generation, and data analysis. The code is written in Python and uses libraries such as `pandas`, `numpy`, and `dateutil`. | # Project Documentation
## Table of Contents
1. [Overview](#overview)
2. [Classes](#classes)
- [Connector](#connector)
- [Loader](#loader)
- [MySqlLoader](#mysqlloader)
- [MsSqlLoader](#mssqlloader)
- [Parser](#parser)
- [Cleaner](#cleaner)
- [Creator](#creator)
- [Analyzer](#analyzer)
- [V... | text/markdown | null | Jesse <magicjedi90@aim.com> | null | null | null | cleaning, database, dataframe, etl, etl-utilities, pandas, spark, utilities | [
"Development Status :: 4 - Beta",
"Programming Language :: Python",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy",
"pandas",
"polars",
"psycopg2-binary",
"pyspark",
"pytest>=8.3.5",
"python-dateutil",
"rich",
"sqlalchemy"
] | [] | [] | [] | [
"Documentation, https://github.com/magicjedi90/etl_utilities#readme",
"Issues, https://github.com/magicjedi90/etl_utilities/issues",
"Source, https://github.com/magicjedi90/etl_utilities"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:24:59.807275 | etl_utilities-1.1.17.tar.gz | 51,566 | a7/be/4aad850593e73f452a95cc3f0125c29352c0bc2036da68dc90a4c0a5f820/etl_utilities-1.1.17.tar.gz | source | sdist | null | false | 23f49b42044feda51a0d94c34aec68fe | edc89d7f178f4aa523d80b7dab2ac94842fa8a65df68cdab7ab6f1c79030dc79 | a7be4aad850593e73f452a95cc3f0125c29352c0bc2036da68dc90a4c0a5f820 | MIT | [
"LICENSE"
] | 200 |
2.4 | pickerxl | 0.2.4 | PickerXL is a large deep learning model to measure arrival times from noisy seismic signals. | # PickerXL
A large deep learning model to measure arrival times from noisy seismic signals. The model was developed by Chengping Chai, Derek Rose, Scott Stewart, Nathan Martindale, Mark Adams, Lisa Linville, Christopher Stanley, Anibely Torres Polanco and Philip Bingham.
## Introduction
This model is trained on STE... | text/markdown | null | "Chengping Chai, Derek Rose, Scott Stewart, Nathan Martindale, Mark Adams, Lisa Linville, Christopher Stanley, Anibely Torres Polanco and Philip Bingham" <chaic@ornl.gov> | null | null | null | null | [
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering",
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"torch>=2.3.0",
"numpy>=1.26.4",
"lightning>=2.2.4",
"h5py>=3.11.0",
"matplotlib>=3.8.0",
"flake8; extra == \"development\"",
"black; extra == \"development\"",
"pre-commit; extra == \"development\""
] | [] | [] | [] | [
"Homepage, https://github.com/ornl/picker-xl"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T17:24:52.239090 | pickerxl-0.2.4.tar.gz | 16,377,719 | 6f/03/c095b52620a9f944480412a9a2c401bf447e849bbb193f8ce5d9e8cde9dc/pickerxl-0.2.4.tar.gz | source | sdist | null | false | eea96ec79d6116c893c567ba1ee72d48 | ee587e8c3646ca0dfcde55179ccf7c331055d9b27dafc0a16e19f28dca508d45 | 6f03c095b52620a9f944480412a9a2c401bf447e849bbb193f8ce5d9e8cde9dc | GPL-3.0-or-later | [
"LICENSE"
] | 208 |
2.4 | openlineage-sql | 1.44.1 | Python interface for the Rust OpenLineage lineage extraction library | # Python interface for the OpenLineage SQL Parser
Refer to the [GitHub for details](https://github.com/OpenLineage/OpenLineage). This package is not meant to be used alone by end-user.
| text/markdown; charset=UTF-8; variant=GFM | OpenLineage | null | null | null | null | openlineage | [
"Programming Language :: Rust",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: Implementation :: CPython",
... | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T17:24:39.062684 | openlineage_sql-1.44.1.tar.gz | 40,389 | 7b/56/f9c300fa287ed6822dfc2e2bbbdefc9fd1bda2cdda6db5faf310fd0f17e7/openlineage_sql-1.44.1.tar.gz | source | sdist | null | false | fc4879dfd3659cc095d09b545cd0507b | 7676f99969796b062b5d5497d247916b2c74e3c25b9a37563a6d3d5f34a506e6 | 7b56f9c300fa287ed6822dfc2e2bbbdefc9fd1bda2cdda6db5faf310fd0f17e7 | null | [] | 175,962 |
2.3 | openlineage-python | 1.44.1 | OpenLineage Python Client | # OpenLineage Python Client
Python client for [OpenLineage](https://openlineage.io).
Refer to the [documentation](https://openlineage.io/docs/client/python) for details.
| text/markdown | OpenLineage | OpenLineage <info@openlineage.io> | null | null | null | openlineage | [
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Pro... | [] | null | null | >=3.9 | [] | [] | [] | [
"attrs>=20.0",
"python-dateutil>=2.8.2",
"pyyaml>=5.4",
"requests>=2.32.4",
"httpx>=0.27.0",
"packaging>=21.0",
"boto3>=1.34.134; extra == \"datazone\"",
"mypy; extra == \"dev\"",
"types-pyyaml; extra == \"dev\"",
"types-python-dateutil; extra == \"dev\"",
"types-requests; extra == \"dev\"",
"... | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T17:24:29.681091 | openlineage_python-1.44.1-py3-none-any.whl | 102,883 | 8f/5d/e398d28e8948e96fe869ba09415c60d0c10dd9653b8c376d93f1748f3b63/openlineage_python-1.44.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 5b4e41034980b28a6ed412c0bd45f9c8 | cc121f82cb15dcf5f2f1347bd30d4c83cae1d510809e6ccce111b98298271503 | 8f5de398d28e8948e96fe869ba09415c60d0c10dd9653b8c376d93f1748f3b63 | null | [] | 160,701 |
2.3 | openlineage-integration-common | 1.44.1 | OpenLineage common python library for integrations | # OpenLineage Integration Common
Common modules for OpenLineage integrations.
For setting up a development environment, see the [Python development setup guide](https://openlineage.io/docs/client/python/development/setup).
| text/markdown | OpenLineage | null | null | null | Apache-2.0 | openlineage | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"P... | [] | null | null | >=3.9 | [] | [] | [] | [
"attrs>=19.3.0",
"openlineage-python",
"openlineage-sql",
"pyyaml>=5.3.1",
"google-api-core>=1.26.3; extra == \"bigquery\"",
"google-auth>=1.30.0; extra == \"bigquery\"",
"google-cloud-bigquery<4.0.0,>=3; extra == \"bigquery\"",
"google-cloud-core>=1.6.0; extra == \"bigquery\"",
"google-crc32c>=1.1.... | [] | [] | [] | [
"Homepage, https://openlineage.io/",
"Source, https://github.com/OpenLineage/OpenLineage/tree/main/integration/common"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T17:24:25.998521 | openlineage_integration_common-1.44.1-py3-none-any.whl | 57,640 | 16/a3/22483c3ba157a60dd7c58c4e325eaf92cb1c31f5b2b9faea8f65d1d711b6/openlineage_integration_common-1.44.1-py3-none-any.whl | py3 | bdist_wheel | null | false | d2479d4062f28e4e1fce1865a71dfeb7 | a8809b90e77bb97fbd99676c3a65ab661e7651c9d92ab406801398c1fe7ea53d | 16a322483c3ba157a60dd7c58c4e325eaf92cb1c31f5b2b9faea8f65d1d711b6 | null | [] | 106,144 |
2.3 | openlineage-dbt | 1.44.1 | OpenLineage integration with dbt | # OpenLineage dbt integration
Wrapper script for automatic metadata collection from dbt
## Features
**Metadata**
* Model run lifecycle
* Model inputs / outputs
## Requirements
- [Python >= 3.8](https://www.python.org/downloads)
- [dbt >= 0.20](https://www.getdbt.com/)
Right now, `openlineage-dbt` supports only t... | text/markdown | OpenLineage | null | null | null | null | openlineage | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"tqdm>=4.62.0",
"openlineage-integration-common==1.44.1",
"dbt-core>=1.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest-xdist>=2.5.0; extra == \"dev\"",
"mock; extra == \"dev\"",
"ruff; extra == \"dev\"",
"mypy>=0.9.6; extra == \"dev\"",
"python-dateutil; extra == \... | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T17:24:25.180603 | openlineage_dbt-1.44.1-py3-none-any.whl | 6,309 | 42/a8/dbaf53a9d279da11d4fc6d1e7ad0887e7ba4cd46074f8ab70f28950de4b4/openlineage_dbt-1.44.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 43f430d379d182c44c1ddda4af6bec79 | 55d1075b54dbae5aa5382cc967fb4e18f54162978816375e8d02f04f0db715df | 42a8dbaf53a9d279da11d4fc6d1e7ad0887e7ba4cd46074f8ab70f28950de4b4 | null | [] | 247 |
2.4 | JSTprove | 2.7.0 | Zero-knowledge proofs of ML inference on ONNX models | ```
888888 .d8888b. 88888888888
"88b d88P Y88b 888
888 Y88b. 888
888 "Y888b. 888 88888b. 888d888 .d88b. 888 888 .d88b.
888 "Y88b. 888 888 "88b 888P" d88""88b 888 888 d8P Y8b
888 "888 888 888 888 888 888 888 Y88 88P 88888888
88P Y88b d88P... | text/markdown | Inference Labs Inc | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"numpy==2.2.6",
"onnx<2.0,>=1.17.0",
"onnxruntime==1.21.0",
"onnxruntime_extensions==0.14.0",
"psutil==7.0.0",
"torch>=2.6.0",
"transformers>=4.53.0",
"zstandard>=0.25.0",
"msgpack>=1.0.0",
"filelock>=3.20.3",
"protobuf>=6.33.5",
"urllib3>=2.6.3"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_vers... | 2026-02-20T17:24:10.965561 | jstprove-2.7.0-py3-none-manylinux_2_28_x86_64.whl | 2,406,542 | 3a/d5/41a51b04119a7c09610120b008e2d98ca6d26a7d877ee728e05f4669a661/jstprove-2.7.0-py3-none-manylinux_2_28_x86_64.whl | py3 | bdist_wheel | null | false | e8d0f8bcda5780dc3e6365dc6b57c53f | c126ddc8d31311b90e4d98bbf285fab6f885db27ebbc8d7216cc577a417740b1 | 3ad541a51b04119a7c09610120b008e2d98ca6d26a7d877ee728e05f4669a661 | null | [
"LICENSE"
] | 0 |
2.4 | ai-content-autopilot | 1.0.2 | Python SDK for the Visibly Content Autopilot API - Pull API client, HMAC webhook verification, and Flask Blueprint. | # ai-content-autopilot
Python SDK for the **[Visibly Content Autopilot](https://www.antonioblago.com/content-autopilot)** API.
Visibly Content Autopilot is an AI-powered content generation platform that creates SEO-optimized articles for your projects. It handles keyword research, content planning, and article ge... | text/markdown | null | Antonio Blago <info@antonioblago.com> | null | null | MIT | cms, content, autopilot, webhook, api, seo, flask | [
"Development Status :: 5 - Production/Stable",
"Framework :: Flask",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: ... | [] | null | null | >=3.8 | [] | [] | [] | [
"flask>=2.3.0",
"requests>=2.25.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-mock>=3.10; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://www.antonioblago.com/developers",
"Documentation, https://www.antonioblago.com/developers",
"Repository, https://github.com/antonioblago/ai-content-autopilot"
] | twine/6.2.0 CPython/3.12.8 | 2026-02-20T17:23:49.025296 | ai_content_autopilot-1.0.2.tar.gz | 16,407 | 33/2d/fe9e5c3dc7cf3dd45784587478edda97bc240bf6a3d1998d8661a853d526/ai_content_autopilot-1.0.2.tar.gz | source | sdist | null | false | 193ff6ff90850b6ad40a48751eb9abe3 | 63e0121be4264276758020bf350c0aa8bd505bfdc466d24f976b5f7a84383f9c | 332dfe9e5c3dc7cf3dd45784587478edda97bc240bf6a3d1998d8661a853d526 | null | [
"LICENSE"
] | 207 |
2.4 | PyCheval | 0.3.3 | Factur-X/ZUGFeRD parsing and generation library for Python | # PyCheval – Factur-X/ZUGFeRD parsing and generation library for Python
[](https://github.com/zfutura/pycheval/releases/)

[ than popular feedparser
library while keeping a famili... | text/markdown | Vladimir Prelovac | vlad@kagi.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming L... | [] | https://github.com/kagisearch/fastfeedparser | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [
"Bug Tracker, https://github.com/kagisearch/fastfeedparser/issues"
] | twine/4.0.2 CPython/3.11.0 | 2026-02-20T17:20:40.063697 | fastfeedparser-0.5.7.tar.gz | 25,173 | 1a/ab/4e76d4a71bb5f6f4c3204a2c00b8ae59bc5c02edcfd158b95057b3062321/fastfeedparser-0.5.7.tar.gz | source | sdist | null | false | 33fee52e05123b2482882884435c72ee | 81012765838a1c17d0ada3ac339c89e0708102f1e60dfdfc7dd43d9eca3fb4a3 | 1aab4e76d4a71bb5f6f4c3204a2c00b8ae59bc5c02edcfd158b95057b3062321 | null | [] | 2,780 |
2.4 | stimm | 0.1.2 | Dual-agent voice orchestration built on livekit-agents | # stimm
**Dual-agent voice orchestration built on [livekit-agents](https://github.com/livekit/agents).**
One agent talks fast. One agent thinks deep. They collaborate in real-time.
```
┌─────────────────────────────────────────────────────────────┐
│ stimm — dual-agent voice orchestration on LiveKit │
│ ... | text/markdown | Etienne | null | null | null | null | agent, dual-agent, livekit, orchestration, realtime, voice | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Topic :: Multimedia :: Sound/Audio",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"livekit-agents>=1.1",
"livekit-plugins-silero>=1.1",
"pydantic>=2.0",
"livekit-plugins-anthropic>=1.1; extra == \"all\"",
"livekit-plugins-cartesia>=1.1; extra == \"all\"",
"livekit-plugins-deepgram>=1.1; extra == \"all\"",
"livekit-plugins-elevenlabs>=1.1; extra == \"all\"",
"livekit-plugins-google>... | [] | [] | [] | [
"Homepage, https://github.com/stimm-ai/stimm",
"Repository, https://github.com/stimm-ai/stimm"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:20:30.040015 | stimm-0.1.2.tar.gz | 598,241 | 08/8b/5696311cbd7d6f6550fe1d0d6e235e0e944fb2eddf4b8bf2a2e05bc66078/stimm-0.1.2.tar.gz | source | sdist | null | false | 3441c473a61fbbac5d415f0c507169b2 | 03b284adc57e7964e712c891cd6f12d8b756b05eec4705a50588d069694ee608 | 088b5696311cbd7d6f6550fe1d0d6e235e0e944fb2eddf4b8bf2a2e05bc66078 | MIT | [
"LICENSE"
] | 238 |
2.4 | brainsig | 0.2.1 | A package for computing 'neural signatures' from fMRI data. | # Welcome to brainsig
| | |
|--------|--------|
| Package | [](https://pypi.org/project/brainsig/) [](https://pypi.org/project/brainsig/) [ A Cloud Agent Python is a foundation for building decentralized identity applications and services running in non-mobile environments. | # ACA-Py -- A Cloud Agent - Python <!-- omit in toc -->

[](https://pypi.org/project/acapy-agent/)
[ | # PyQrack Ising
Fast MAXCUT, TSP, and sampling heuristics from near-ideal transverse field Ising model (TFIM)
(It's "the **Ising** on top.")
[](https://doi.org/10.5281/zenodo.18706638) [](http... | text/markdown | Dan Strano | stranoj@gmail.com | null | null | LGPL-3.0-or-later | null | [
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: C++",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Topic :: Scientific/Engineering"
] | [] | https://github.com/vm6502q/PyQrackIsing | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T17:19:34.740804 | pyqrackising-9.11.2-py3-none-manylinux_2_35_x86_64.whl | 48,803 | d7/74/68869b7081bdcde884f9827dd4002d2150d1700665b60008176e8de4af40/pyqrackising-9.11.2-py3-none-manylinux_2_35_x86_64.whl | py3 | bdist_wheel | null | false | cafa553c762515a85d01b12bb381e86f | f283cec947df043f0abfd823524b44d9f9e7302561ef5d7fa5ff263db18d0b7e | d77468869b7081bdcde884f9827dd4002d2150d1700665b60008176e8de4af40 | null | [] | 458 |
2.4 | xyz-py | 5.19.3 | A package for manipulating xyz files and chemical structures | # xyz-py
`xyz-py` is a python module for working with and manipulating chemical structures.
# Installation
For convenience, `xyz-py` is available on [PyPI](https://pypi.org/project/xyz-py/) and so can be installed using `pip`
```
pip install xyz-py
```
# Functionality
To use the functions included in `xyz-py`, f... | text/markdown | Jon Kragskow | jonkragskow@gmail.com | null | null | GPL-3.0-or-later | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | https://gitlab.com/jonkragskow/xyz_py | null | >=3.6 | [] | [] | [] | [
"numpy",
"ase"
] | [] | [] | [] | [
"Bug Tracker, https://gitlab.com/jonkragskow/xyz_py/-/issues",
"Documentation, https://jonkragskow.gitlab.io/xyz_py"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T17:19:17.194608 | xyz_py-5.19.3.tar.gz | 32,860 | 8c/13/3684f3fc51172941872d4dd43d8070b42d65766a56a191e1dccb0a99d1d7/xyz_py-5.19.3.tar.gz | source | sdist | null | false | 92c0c5d6a4dd40254abd33f4138fe21e | 921e91421bf61ab5eefa7396d640c4a3d0ef4cfd185eb080d4d4e761acf68519 | 8c133684f3fc51172941872d4dd43d8070b42d65766a56a191e1dccb0a99d1d7 | null | [
"LICENSE"
] | 214 |
2.4 | sigmund | 1.15.0 | AI-based chatbot that provides sensible answers based on documentation | # Sigmund AI
Copyright 2023-2026 Sebastiaan Mathôt

A Python library and web app for an LLM-based chatbot:
Features:
- __Privacy__: all messages and uploaded attachments are encrypted so that no-one can listen in on your conversation
- __Expert knowledge__: access to documentat... | text/markdown | null | Sebastiaan Mathôt <s.mathot@cogsci.nl> | null | null | null | ai, chatbot, llm | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"anthropic",
"beautifulsoup4",
"cryptography",
"chromadb",
"datamatrix",
"flask",
"flask-login",
"flask-sqlalchemy",
"flask-wtf",
"flask-cors",
"flask-migrate",
"flask-session",
"jinja2",
"jq",
"markdown",
"oauthlib",
"openai",
"mistralai",
"pillow",
"pyalex",
"pygments",
"... | [] | [] | [] | [
"Documentation, https://sigmundai.eu",
"Source, https://github.com/open-cogsci/sigmund-ai"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T17:18:59.545563 | sigmund-1.15.0.tar.gz | 6,491,069 | c9/c2/ca046730ad16308b55366ef29183c480130eb02172949eae01882422135d/sigmund-1.15.0.tar.gz | source | sdist | null | false | ec74210e3fb6784b81756df65f2014a7 | 29051766c0135943a2b4a5ee754f7205f5081e97ea8d32b0678b2b66fb79fd1a | c9c2ca046730ad16308b55366ef29183c480130eb02172949eae01882422135d | null | [
"COPYING"
] | 208 |
2.4 | contrast-agent-lib | 0.13.0 | Python interface to the contrast agent lib | # agent-lib
Core library for shared Contrast Agent functionality.
For the most up-to-date documentation on the Python Agent please see
[Contrast Docs](https://docs.contrastsecurity.com/en/python.html)
| text/markdown | null | "Contrast Security, Inc." <python@contrastsecurity.com> | null | null | CONTRAST SECURITY (see LICENSE.txt) | null | [
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"homepage, https://www.contrastsecurity.com",
"support, https://support.contrastsecurity.com"
] | twine/6.1.0 CPython/3.12.9 | 2026-02-20T17:18:48.147831 | contrast_agent_lib-0.13.0-py3-none-win_amd64.whl | 1,034,280 | 78/b4/a2ab0d8508d0c518b28c1fc216a72dd97c5e705d9e3f910675df9f12e3bf/contrast_agent_lib-0.13.0-py3-none-win_amd64.whl | py3 | bdist_wheel | null | false | e33e2d3506595abfe53585d7ca271d97 | f78b9f5e333ecedc0fa29517b4bc870c10ed54484729a9216a5da3aca700a269 | 78b4a2ab0d8508d0c518b28c1fc216a72dd97c5e705d9e3f910675df9f12e3bf | null | [
"LICENSE.txt"
] | 474 |
2.4 | finqual | 4.7.3 | A Python package to help investors to conduct financial research, analysis and comparable company analysis. | [](https://www.star-history.com/#harryy-he/finqual&Date)
# finqual
This is a work in progress package that enables users to conduct fundamental financial research, utilising the SEC's data and REST API.
Note that I have launched... | text/markdown | Harry | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/harryy-he/finqual | null | >=3.10 | [] | [] | [] | [
"pandas>=2.2.3",
"polars>=1.35.1",
"cloudscraper>=1.2.71",
"requests==2.32.4",
"ratelimit>=2.2.1",
"matplotlib>=3.8.0",
"pyarrow>=12.0.0",
"ijson>=3.4.0",
"numpy>=2.2.6",
"pydantic==2.12.4"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T17:18:35.500975 | finqual-4.7.3.tar.gz | 1,043,203 | d7/71/46b1e07b80cdefd7aa1efa65faeb43566fffa0955ee70ea9b9f79053541b/finqual-4.7.3.tar.gz | source | sdist | null | false | 81ff13c9b5b3164b965d7e39501a8d7a | 7771914c81dca91a844ba18ad670051594dac858211f7ba9b67d68457e10a00c | d77146b1e07b80cdefd7aa1efa65faeb43566fffa0955ee70ea9b9f79053541b | null | [
"LICENSE.md"
] | 209 |
2.4 | pbest | 0.2.9 | BioSim Registry is a project focused on delivering high quality processes and tooling in relation to process bi-graph. | [](https://img.shields.io/github/v/release/biosimulators/bsedic)
[](https://github.com/biosimulators/biosim-registry/a... | text/markdown | null | Center for Reproducable Biological Modeling <evalencia@uchc.edu> | null | null | null | python | [
"Intended Audience :: Developers",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | <3.13,>=3.11 | [] | [] | [] | [
"bigraph-schema==0.0.77",
"compose-api-client==0.1.4",
"copasi-basico",
"httpx>=0.28.1",
"jinja2>=3.1.6",
"libroadrunner",
"matplotlib",
"numpy>=2.3.4",
"pandas>=2.3.3",
"process-bigraph==0.0.51",
"pydantic>=2.12.3",
"python-copasi",
"spython>=0.3.14",
"tellurium>=2.2.11.1"
] | [] | [] | [] | [
"Homepage, https://github.com/biosimulations/biosim-registry/",
"Repository, https://github.com/biosimulations/biosim-registry/",
"Documentation, https://github.com/biosimulations/biosim-registry/"
] | uv/0.9.22 {"installer":{"name":"uv","version":"0.9.22","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":nu... | 2026-02-20T17:18:14.922543 | pbest-0.2.9.tar.gz | 180,665 | ab/ab/5c6a2ae5af2facbd29c0183e6cfcb68edd792bfd296e3339ba8807205719/pbest-0.2.9.tar.gz | source | sdist | null | false | 17cbb3c7f450b2c30fa5e42235400157 | f91c3c9289bb956f350afe7d443c50fa4e52ca37bfda5e67aaaa979f4186f0de | abab5c6a2ae5af2facbd29c0183e6cfcb68edd792bfd296e3339ba8807205719 | null | [
"LICENSE"
] | 206 |
2.4 | ob-dj-store | 0.0.24.9 | OBytes django application for managing ecommerce stores. | ## OBytes Django Store App
[](https://github.com/obytes/ob-dj-store/actions)
[](https://pypi.python.org/pypi/ob-dj-store)
[
- MUST follow Protocol v0.1: https://github.com/intellistream/sagellm-docs/blob/main/docs/specs/protocol_v0.1.md
- Any globally shared definitions (fields, error codes, metrics, IDs, schemas) MUST be added to Protocol first.
[](https://crates.io/crates/ahqstore_cli_rs)
[](https://www.npmjs.com/package/@ahqstore/cli)
[](https://jsr.io/@ahqstore/cli)
[![PyPI]... | text/markdown | null | AHQ Softwares <ahqsecret@gmail.com> | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"cffi>=2.0.0",
"requests>=2.25.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:17:26.591977 | ahqstore_cli-0.16.0a21.tar.gz | 2,888 | 61/d7/ee219b483bbe799edb948d65cb0f0c19d48b3b3fe91e7c50ad263db1ad12/ahqstore_cli-0.16.0a21.tar.gz | source | sdist | null | false | 74ee66b0b38e410fb92dfccd7a5ef2ff | 06ee6af68ce25c9fa99052669858ab172fd0ef7c85f6f5ba784d8fa4e4df0a44 | 61d7ee219b483bbe799edb948d65cb0f0c19d48b3b3fe91e7c50ad263db1ad12 | null | [] | 183 |
2.4 | test-uv-app4 | 0.1.0.post1 | A short description of the project | # test-uv-app4
A short description of the project
## Overview
This documentation covers the test-uv-app4 application.
## Installation
```bash
pip install test-uv-app4
```
Or, if you use UV:
```bash
uv add test-uv-app4
```
## Usage
Run the application:
```bash
test_uv_app4
```
Or run as a module:
```bash
pyt... | text/markdown | null | Antonio Pisani <antonio.pisani@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Source Code, https://github.com/apisani1/test-uv-app4",
"Release Notes, https://github.com/apisani1/test-uv-app4/releases",
"Documentation, https://test-uv-app4.readthedocs.io/",
"Issue Tracker, https://github.com/apisani1/test-uv-app4/issues"
] | uv/0.8.22 | 2026-02-20T17:17:25.750490 | test_uv_app4-0.1.0.post1.tar.gz | 135,644 | 75/46/0cf454b22894132c1be79e34a1d7f4862af5f09a3b0e87285eef2ccca635/test_uv_app4-0.1.0.post1.tar.gz | source | sdist | null | false | d11491d08f4994794e3b65e7f7b15c9a | 89386f7dac169d25e0aeb419fe13e6498925716b26b1888af0f962ed8c5af48e | 75460cf454b22894132c1be79e34a1d7f4862af5f09a3b0e87285eef2ccca635 | null | [
"LICENSE"
] | 127 |
2.4 | mesop | 1.2.1 | Build UIs in Python | # Mesop
Mesop is an open-source package to build UIs in Python.
Source code: github.com/mesop-dev/mesop
| null | Google Inc. | null | null | null | Apache 2.0 | mesop | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3 :: Only",
"Topic ::... | [] | https://github.com/mesop-dev/mesop | null | >=3.10 | [] | [] | [] | [
"absl-py",
"deepdiff<9,>=8.6.1",
"flask",
"msgpack",
"protobuf",
"pydantic",
"python-dotenv",
"watchdog",
"werkzeug>=3.0.6"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.9 | 2026-02-20T17:17:22.861071 | mesop-1.2.1-py3-none-any.whl | 7,447,652 | 03/d8/19d4dabde120b00c0f88a93c7d333906babdf652cdee1b1cfff67a6c13a0/mesop-1.2.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 34600399f5cbe7d07eafddb23c943191 | e8bd6944f98d8f5f7880c50bd57156365c998980d9302207f8ffc319f64de68d | 03d819d4dabde120b00c0f88a93c7d333906babdf652cdee1b1cfff67a6c13a0 | null | [
"LICENSE"
] | 417 |
2.4 | devops-practices-mcp | 1.4.0 | AI-powered DevOps knowledge base with practices, templates, and automation tools | # DevOps Practices - MCP Server
[](https://github.com/ai-4-devops/devops-practices/actions/workflows/ci.yml)
[](https://opensource.org/licenses/MIT)
[... | text/markdown | null | Uttam Jaiswal <uttam.jaiswal@example.com> | null | null | MIT | ai, automation, best-practices, claude, configuration-management, devops, infrastructure, knowledge-base, mcp, templates | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language ... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/ai-4-devops/devops-practices",
"Documentation, https://github.com/ai-4-devops/devops-practices/blob/main/README.md",
"Repository, https://github.com/ai-4-devops/devops-practices",
"Issues, https://github.com/ai-4-devops/devops-practices/issues"
] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_vers... | 2026-02-20T17:17:19.672256 | devops_practices_mcp-1.4.0-py3-none-any.whl | 81,436 | 12/99/dba9ba0a047923d55d702fc7f0027024fdcb580d824aa4c0068d3fc13ff0/devops_practices_mcp-1.4.0-py3-none-any.whl | py3 | bdist_wheel | null | false | c399562489855f1ea2a2350f521d2bae | 60887007ad3fc7846d427513f11d1922d4ca8000b5d5bfecfef4e5274785d446 | 1299dba9ba0a047923d55d702fc7f0027024fdcb580d824aa4c0068d3fc13ff0 | null | [
"LICENSE"
] | 207 |
2.4 | violit | 0.4.0 | Violit: Faster than Light, Beautiful as Violet. The High-Performance Python Web Framework (Streamlit Alternative with Zero Rerun). | <p align="center">
<img src="https://github.com/user-attachments/assets/f6a56e37-37a5-437c-ae16-13bff7029797" alt="Violit Logo" width="100%">
</p>
# 💜 Violit
> **"Faster than Light, Beautiful as Violet."**
> **Structure of Streamlit × Performance of React**
**Violit** is a next-generation Python web fr... | text/markdown | null | Violit Team <violit.company@gmail.com> | null | null | MIT | web, framework, streamlit, dashboard, ui, fastapi, reactive, zero-rerun, shoelace, websocket, data-science | [
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi>=0.68.0",
"uvicorn>=0.15.0",
"python-multipart>=0.0.5",
"pywebview>=4.0.0",
"cachetools>=4.2.0",
"pandas>=1.3.0",
"numpy>=1.20.0",
"plotly>=5.0.0",
"matplotlib>=3.4.0",
"jinja2>=3.0.0",
"websockets>=10.0",
"bcrypt>=4.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/violit-dev/violit",
"Documentation, https://github.com/violit-dev/violit",
"Repository, https://github.com/violit-dev/violit",
"Issues, https://github.com/violit-dev/violit/issues"
] | twine/6.2.0 CPython/3.10.7 | 2026-02-20T17:17:05.043046 | violit-0.4.0.tar.gz | 2,554,736 | c7/57/d14067d47e204846d8c97d015cfb60f6907ba7e22c6cdc8902d0ad57fdc0/violit-0.4.0.tar.gz | source | sdist | null | false | 3a7925d761be3e8b39d2516592188d1c | 5660a4ca06dff3985e9dbdf809246dabe70478dc1fccd7c3ab2e99bc61e81492 | c757d14067d47e204846d8c97d015cfb60f6907ba7e22c6cdc8902d0ad57fdc0 | null | [
"LICENSE"
] | 220 |
2.3 | openlayer | 0.17.6 | The official Python library for the openlayer API | # Openlayer Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/openlayer/)
The Openlayer Python library provides convenient access to the Openlayer REST API from any Python 3.9+
application. The library includes typ... | text/markdown | null | Openlayer <support@openlayer.com> | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pandas; python_version >= \"3.7\"",
"pyarrow<=17.0.0,>=15.0.2; python_version == \"3.8\"",
"pyarrow>=18.0.0; python_version >= \"3.9\"",
"pydantic<3,>=1.9.0",
"pyyaml>=6.0",
"requests-toolbelt>=1.0.0",
"sniffio",
"tqdm",
"typing-exten... | [] | [] | [] | [
"Homepage, https://github.com/openlayer-ai/openlayer-python",
"Repository, https://github.com/openlayer-ai/openlayer-python"
] | twine/5.1.1 CPython/3.12.9 | 2026-02-20T17:16:51.920113 | openlayer-0.17.6.tar.gz | 330,882 | 45/fd/4ec972d661effdc2a9ea1173f4e18b02fc9d160cb332432577e03cbcedac/openlayer-0.17.6.tar.gz | source | sdist | null | false | 034c9e81a1c75141bbb1eb2b6b280779 | 8f7e5135ca18dd0ea0d54df6ead73069b5cdb73f303763476793138083a714ad | 45fd4ec972d661effdc2a9ea1173f4e18b02fc9d160cb332432577e03cbcedac | null | [] | 258 |
2.3 | ntnput | 3.0.5 | Minimalist Python library using wraps of undocumented `Nt` functions to interact with mouse and keyboard stealthy | # ntnput
The Minimalist Python library for Windows using wraps of undocumented `Nt` functions to interact with mouse and keyboard stealthy.
# Details
This library uses syscall wraps of undocumented `NtUserInjectMouseInput` and `NtUserInjectKeyboardInput` functions from `win32u.dll` module.
It's makes keyboard and... | text/markdown | Xenely | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T17:16:45.571489 | ntnput-3.0.5.tar.gz | 8,413 | 20/d8/2a914a0dca4a1078a97aec9b4436d0af34b71bcff811d1f1bddd9f2d71e4/ntnput-3.0.5.tar.gz | source | sdist | null | false | c5904034324d8116df976d799b11e072 | 30b34b400c82904b95260a3ca725a91eb8ee217faeddc25533485bdca34f5070 | 20d82a914a0dca4a1078a97aec9b4436d0af34b71bcff811d1f1bddd9f2d71e4 | null | [] | 207 |
2.4 | micantis | 0.1.19 | Package to simplify Micantis API usage | # Micantis API Wrapper
A lightweight Python wrapper for interacting with the Micantis API plus some helpful utilities.
Built for ease of use, fast prototyping, and clean integration into data workflows.
---
## 🚀 Features
- Authenticate and connect to the Micantis API service
- Download and parse CSV, b... | text/markdown | null | Mykela DeLuca <mykela.deluca@micantis.io> | null | null | null | null | [] | [] | null | null | >=3.7 | [] | [] | [] | [
"requests",
"pandas",
"msal",
"azure-identity",
"pyarrow>=16.0.0; extra == \"parquet\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.9.20 | 2026-02-20T17:16:23.369032 | micantis-0.1.19.tar.gz | 25,001 | 3c/ad/beda2bbf41a86413df030483e02198a08e3c9967a8008b308b81e53db1bd/micantis-0.1.19.tar.gz | source | sdist | null | false | 446012795b043495468adc1de869dd8a | ee3c54240c2e620c845facb91493d9583e2fa6d64002b6e55e513de22f7ed66f | 3cadbeda2bbf41a86413df030483e02198a08e3c9967a8008b308b81e53db1bd | MIT | [
"LICENSE"
] | 256 |
2.4 | sae-lens | 6.37.3 | Training and Analyzing Sparse Autoencoders (SAEs) | <img width="1308" height="532" alt="saes_pic" src="https://github.com/user-attachments/assets/2a5d752f-b261-4ee4-ad5d-ebf282321371" />
# SAE Lens
[](https://pypi.org/project/sae-lens/)
[](http... | text/markdown | Joseph Bloom | null | null | null | MIT | deep-learning, sparse-autoencoders, mechanistic-interpretability, PyTorch | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: S... | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"babe<0.0.8,>=0.0.7",
"datasets>=3.1.0",
"mamba-lens<0.0.5,>=0.0.4; extra == \"mamba\"",
"nltk<4.0.0,>=3.8.1",
"plotly>=5.19.0",
"plotly-express>=0.4.1",
"python-dotenv>=1.0.1",
"pyyaml<7.0.0,>=6.0.1",
"safetensors<1.0.0,>=0.4.2",
"simple-parsing<0.2.0,>=0.1.6",
"tenacity>=9.0.0",
"transformer... | [] | [] | [] | [
"Homepage, https://decoderesearch.github.io/SAELens",
"Repository, https://github.com/decoderesearch/SAELens"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:15:45.894792 | sae_lens-6.37.3.tar.gz | 254,339 | a3/94/e9f44ce182a7e474b4b33c80022fdcb24a16889fe11a868997eb09f6754f/sae_lens-6.37.3.tar.gz | source | sdist | null | false | de3b16525f1baeb2293014fd892bb7fe | bbdbaeef1a384b71098bc36caecd1f1d18bc1e6c6fa3baa47ad33bc832683030 | a394e9f44ce182a7e474b4b33c80022fdcb24a16889fe11a868997eb09f6754f | null | [
"LICENSE"
] | 730 |
2.4 | pydynox | 0.27.0 | A fast DynamoDB ORM for Python with a Rust core | # pydynox 🐍⚙️
[](https://github.com/ferrumio/pydynox/actions/workflows/main.yml)
[](https://pypi.org/project/pydynox/)
[![Python versions](https://img.shields.io/pypi/pyversions/p... | text/markdown; charset=UTF-8; variant=GFM | null | Leandro Cavalcante Damascena <leandro.damascena@gmail.com> | null | null | Apache-2.0 | dynamodb, orm, aws, rust, python | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming ... | [] | https://github.com/ferrumio/pydynox | null | >=3.11 | [] | [] | [] | [
"opentelemetry-api>=1.0; extra == \"opentelemetry\"",
"pydantic>=2.0; extra == \"pydantic\""
] | [] | [] | [] | [
"Documentation, https://ferrumio.github.io/pydynox",
"Homepage, https://github.com/ferrumio/pydynox",
"Repository, https://github.com/ferrumio/pydynox"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T17:15:22.777816 | pydynox-0.27.0.tar.gz | 537,641 | 90/36/d755c0d28fcbe7731ddfa7f48b9259eb1cdcbf393c6609cb534d31e905d7/pydynox-0.27.0.tar.gz | source | sdist | null | false | 1518f2262c84d20034153baf99beff80 | c18eca142af0c0f9577693134e3cb7bcf0bdb4dd6e9a9dcb0e68440554416676 | 9036d755c0d28fcbe7731ddfa7f48b9259eb1cdcbf393c6609cb534d31e905d7 | null | [
"LICENSE"
] | 1,026 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.