
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | fairsense-agentix | 0.1.1 | An agentic fairness and AI-risk analysis platform for detecting bias in text and images | # FairSense-AgentiX
**An agentic fairness and AI-risk analysis platform developed by the [Vector Institute](https://vectorinstitute.ai/).**
[](https://github.com/VectorInstitute/fairsense-agentix/actions/workflows/code_checks.yml)
[](https://github.com/VectorInstitute/fairsense-agentix/actions/workflows/integration_tests.yml)
[](https://github.com/VectorInstitute/fairsense-agentix/actions/workflows/docs.yml)
[](https://codecov.io/github/VectorInstitute/fairsense-agentix)

---
FairSense-AgentiX is an intelligent bias detection and risk assessment platform that uses **agentic AI workflows** to analyze text, images, and datasets for fairness concerns. Unlike traditional ML classifiers, FairSense employs a reasoning agent that plans, selects tools, critiques outputs, and refines them iteratively.
## ✨ Key Features
- 🤖 **Agentic Reasoning** - ReAct loop with dynamic tool selection and self-critique
- 🔍 **Multi-Modal Analysis** - Text bias detection, image bias detection, and AI risk assessment
- 🛠️ **Flexible Tool Ecosystem** - OCR, Vision-Language Models, embeddings, FAISS, and LLMs
- 🌐 **Production-Ready APIs** - FastAPI REST API + WebSocket streaming + React UI
- ⚙️ **Highly Configurable** - Swap LLM providers, tools, and models on the fly
## 📦 Installation
### From PyPI (Recommended)
```bash
pip install fairsense-agentix
```
### From Source
```bash
git clone https://github.com/VectorInstitute/fairsense-agentix.git
cd fairsense-agentix
uv sync
source .venv/bin/activate
```
### Requirements
- **Python 3.12+**
- **4GB+ RAM** (for ML models)
- **API key** for OpenAI or Anthropic (for LLM functionality)
## 🚀 Quick Start
```python
from fairsense_agentix import FairSense
# Initialize the engine
engine = FairSense()
# Analyze text for bias
result = engine.analyze_text(
"We're looking for a young, energetic developer to join our startup team."
)
print(f"Bias detected: {result.bias_detected}")
print(f"Risk level: {result.risk_level}")
for instance in result.bias_instances:
print(f" - {instance['type']} ({instance['severity']}): {instance['text_span']}")
```
**Full Documentation:** [https://vectorinstitute.github.io/fairsense-agentix/](https://vectorinstitute.github.io/fairsense-agentix/)
---
## 🧑🏿💻 Developing
### Installing dependencies
The development environment can be set up using
[uv](https://github.com/astral-sh/uv?tab=readme-ov-file#installation). Hence, make sure it is
installed and then run:
```bash
uv sync
source .venv/bin/activate
```
In order to install dependencies for testing (codestyle, unit tests, integration tests),
run:
```bash
uv sync --dev
source .venv/bin/activate
```
In order to exclude installation of packages from a specific group (e.g. docs),
run:
```bash
uv sync --no-group docs
```
## Getting Started
### Run the FastAPI service
```bash
uv run uvicorn fairsense_agentix.service_api.server:app --reload
```
Endpoints (all under `/v1/...`):
| Route | Description |
| --- | --- |
| `POST /analyze` | JSON payload with `content`, optional `input_type`, `options` |
| `POST /analyze/upload` | `multipart/form-data` for images |
| `POST /batch` & `GET /batch/{id}` | Submit + inspect batch jobs |
| `GET /health` | Health probe |
| `WS /stream/{run_id}` | Stream telemetry/agent events for a run |
The API auto-detects text/image/CSV inputs, but you can override by setting `input_type` to `bias_text`, `bias_image`, or `risk`.
### Run the Claude-inspired UI
```bash
cd ui
npm install
npm run dev
```
Set `VITE_API_BASE` (defaults to `http://localhost:8000`) to point at the API. The UI provides:
- Unified input surface (text field + drag/drop image upload)
- Live agent timeline sourced from telemetry events
- Downloadable HTML highlights and risk tables
- Launchpad for batch jobs
### Key configuration knobs
Configure via environment variables (see `.env` for the full list). Most relevant:
| Variable | Description |
| --- | --- |
| `FAIRSENSE_LLM_PROVIDER` | `openai`, `anthropic`, or `fake` |
| `FAIRSENSE_LLM_MODEL_NAME` | e.g. `gpt-4`, `claude-3-5-sonnet` |
| `FAIRSENSE_LLM_API_KEY` | Provider API key |
| `FAIRSENSE_OCR_TOOL` | `auto`, `tesseract`, `paddleocr`, `fake` |
| `FAIRSENSE_CAPTION_MODEL` | `auto`, `blip2`, `blip`, `fake` |
| `FAIRSENSE_ENABLE_REFINEMENT` | enables evaluator-driven retries (default `true`) |
| `FAIRSENSE_EVALUATOR_ENABLED` | toggles Phase 7 evaluators |
| `FAIRSENSE_BIAS_EVALUATOR_MIN_SCORE` | passing score (0–100, default 75) |
All settings can be overridden at runtime:
```bash
FAIRSENSE_LLM_PROVIDER=anthropic \
FAIRSENSE_LLM_MODEL_NAME=claude-3-5-sonnet-20241022 \
uv run uvicorn fairsense_agentix.service_api.server:app
```
### Running tests
```bash
uv run pytest
```
During test collection we automatically override any `.env` values that point at
real providers/devices so the suite always uses the lightweight `fake`
toolchain. This guarantees deterministic, offline-friendly tests even if you
have `FAIRSENSE_LLM_PROVIDER=openai` (or Anthropic) configured locally. To opt-in
to exercising the real stack, export `FAIRSENSE_TEST_USE_REAL=1` before running
pytest.
## Acknowledgments
Resources used in preparing this research were provided, in part, by the Province of Ontario, the Government of Canada through CIFAR, and companies sponsoring the Vector Institute.
This research was funded by the European Union's Horizon Europe research and innovation programme under the AIXPERT project (Grant Agreement No. 101214389).
## Contributing
If you are interested in contributing to the library, please see
[CONTRIBUTING.md](CONTRIBUTING.md). This file contains many details around contributing
to the code base, including development practices, code checks, tests, and more.
| text/markdown | null | Vector AI Engineering <ai_engineering@vectorinstitute.ai> | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Framework :: FastAPI",
"Framework :: Pydantic :: 2",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Lang... | [] | null | null | >=3.12 | [] | [] | [] | [
"accelerate>=0.20.0",
"faiss-cpu>=1.7.4",
"fastapi>=0.115.0",
"langchain-anthropic>=0.2.0",
"langchain-community>=0.3.0",
"langchain-core>=0.3.0",
"langchain-huggingface>=0.1.0",
"langchain-openai>=0.2.0",
"langchain>=0.3.0",
"langgraph>=0.2.56",
"numpy>=1.24.0",
"paddleocr>=2.7.0",
"pandas>... | [] | [] | [] | [
"Homepage, https://github.com/VectorInstitute/fairsense-agentix",
"Documentation, https://vectorinstitute.github.io/fairsense-agentix/",
"Repository, https://github.com/VectorInstitute/fairsense-agentix",
"Issues, https://github.com/VectorInstitute/fairsense-agentix/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:13:34.786409 | fairsense_agentix-0.1.1.tar.gz | 5,034,878 | 5c/0e/8ae7ec8bc143f183a21f155a29658973fa89b5efbd37b39a9c6ffc0277aa/fairsense_agentix-0.1.1.tar.gz | source | sdist | null | false | ce6a1ed51379639b9087f2ee15377fee | cee7cebd5bee83cbc4427633af768a7f7f6197aa7d9672c223196f8a654aeb5d | 5c0e8ae7ec8bc143f183a21f155a29658973fa89b5efbd37b39a9c6ffc0277aa | null | [
"LICENSE"
] | 251 |
2.4 | code-flow-analyzer | 1.0.0 | A universal tool to analyze and visualize code flow in any repository | # Repo Flow Analyzer
A universal tool to analyze and visualize code flow in any repository, helping developers understand functionality by searching for keywords.
## 🎯 Features
- **Multi-Language Support**: Works with Java, Python, JavaScript/TypeScript, Go, C#, and more
- **Multiple Output Formats**: Markdown, Mermaid diagrams, and JSON
- **Customizable**: Configure component patterns, exclusions, and output preferences
- **Repository Agnostic**: Works with any codebase structure
- **Fast & Efficient**: Handles large repositories with smart file filtering
## 📦 Installation
### Via pip (recommended)
```bash
pip install repo-flow-analyzer
```
### From source
```bash
git clone https://github.com/yourorg/repo-flow-analyzer.git
cd repo-flow-analyzer
pip install -e .
```
## 🚀 Quick Start
### Basic Usage
```bash
# Analyze credit-related functionality
flow-analyzer credit
# Search for user authentication flow
flow-analyzer authentication
# Find payment processing components
flow-analyzer payment
```
### Generate Visual Diagrams
```bash
# Create a Mermaid diagram
flow-analyzer credit --format=mermaid --output=credit-flow.mmd
# Generate markdown documentation
flow-analyzer user --format=markdown --output=docs/user-flow.md
# Export as JSON for custom processing
flow-analyzer api --format=json --output=api-analysis.json
```
### Custom Configuration
```bash
# Generate a configuration template
flow-analyzer --init
# Use custom config
flow-analyzer credit --config=.flow-analyzer.yaml
```
## 📖 Documentation
### Command Line Options
```
Usage: flow-analyzer [OPTIONS] KEYWORD
Arguments:
KEYWORD The search term to find in your codebase
Options:
-f, --format [markdown|mermaid|json] Output format (default: markdown)
-o, --output PATH Output file (default: stdout)
-c, --config PATH Path to custom config file
-p, --base-path PATH Base path of the repository (default: .)
--version Show version
--help Show this message
```
### Configuration File
Create a `.flow-analyzer.yaml` in your project root:
```yaml
languages:
java:
extensions: [".java"]
component_patterns:
controller: ["controller", "resource"]
service: ["service", "manager"]
repository: ["repository", "dao"]
analysis:
max_files: 10000
exclude_patterns:
- "**/node_modules/**"
- "**/target/**"
- "**/.git/**"
output:
mermaid:
max_nodes: 50
color_scheme:
controller: "#e1f5ff"
service: "#f3e5f5"
```
## 🎨 Output Formats
### Markdown
- Human-readable documentation
- Organized by component type
- Includes file paths, methods, and dependencies
- Perfect for README files and documentation
### Mermaid
- Visual flow diagrams
- Color-coded components
- Shows relationships between layers
- Renders in GitHub, GitLab, and Confluence
### JSON
- Machine-readable format
- Complete component metadata
- Ideal for custom integrations
- Can be processed by other tools
## 💡 Use Cases
### For New Developers
"I need to understand how the payment system works"
```bash
flow-analyzer payment --format=mermaid --output=payment-flow.mmd
```
### For Code Reviews
"What components does this feature affect?"
```bash
flow-analyzer feature-name --format=markdown
```
### For Documentation
"Generate architecture diagrams for documentation"
```bash
flow-analyzer core --format=mermaid --output=docs/architecture.mmd
```
### For Debugging
"Where is Kafka used in the application?"
```bash
flow-analyzer kafka --format=json
```
## 🔧 Supported Languages
- **Java**: Controllers, Services, DAOs, Entities
- **Python**: Views, Services, Repositories, Models
- **JavaScript/TypeScript**: Components, Services, Routes
- **Go**: Handlers, Services, Repositories
- **C#**: Controllers, Services, Repositories
## 🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
### Development Setup
```bash
git clone https://github.com/yourorg/repo-flow-analyzer.git
cd repo-flow-analyzer
pip install -e ".[dev]"
```
### Running Tests
```bash
pytest tests/
```
## 📄 License
MIT License - see LICENSE file for details
## 🙏 Acknowledgments
Built for multi-team collaboration in monorepo environments.
## 📞 Support
- Issues: https://github.com/yourorg/repo-flow-analyzer/issues
- Discussions: https://github.com/yourorg/repo-flow-analyzer/discussions
- Documentation: https://repo-flow-analyzer.readthedocs.io
---
Made with ❤️ for developers who want to understand code faster
| text/markdown | Platform Team | platform-team@company.com | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Documentation",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Languag... | [] | https://github.com/yourorg/code-flow-analyzer | null | >=3.7 | [] | [] | [] | [
"click>=8.0.0",
"pyyaml>=5.4.0",
"jinja2>=3.0.0",
"colorama>=0.4.4"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.11 | 2026-02-18T21:13:32.103979 | code_flow_analyzer-1.0.0.tar.gz | 12,093 | 10/c9/5e346713f1ed91d6c23a8026114db29628a0a2d5003246cf409e57346e64/code_flow_analyzer-1.0.0.tar.gz | source | sdist | null | false | c8542dbd304314d1e015fcdaef3062a4 | 70ec00d60eef4927b38db6c0a20ecc70657ba658f9734c13b44dd0edf3b686b2 | 10c95e346713f1ed91d6c23a8026114db29628a0a2d5003246cf409e57346e64 | null | [
"LICENSE"
] | 294 |
1.2 | ultracart-rest-sdk | 4.1.66 | UltraCart Rest API V2 | UltraCart REST API Version 2 # noqa: E501 | null | UltraCart Support | support@ultracart.com | null | null | null | OpenAPI, OpenAPI-Generator, UltraCart Rest API V2 | [] | [] | null | null | >=3.6 | [] | [] | [] | [] | [] | [] | [] | [] | twine/3.4.1 importlib_metadata/4.5.0 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.61.1 CPython/3.9.5 | 2026-02-18T21:13:26.858341 | ultracart_rest_sdk-4.1.66.tar.gz | 574,133 | 6b/ca/d5f2b98ae5b275d891c8eb781d8c2c644650bc412157c623288a74f88eb5/ultracart_rest_sdk-4.1.66.tar.gz | source | sdist | null | false | 29ce4ee922868e7fb9aadd3574a9cb51 | 4ecb898afef5a694baebb3cdf34652f18a71178cef8888522c681f386b00340d | 6bcad5f2b98ae5b275d891c8eb781d8c2c644650bc412157c623288a74f88eb5 | null | [] | 257 |
2.4 | rettxmutation | 0.3.6 | Extract Rett Syndrome mutations from genetic diagnosis report | # RettX Mutation Analysis Library
[](https://badge.fury.io/py/rettxmutation)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
A Python library for extracting and validating genetic mutations from clinical reports using an AI-powered agentic pipeline. Supports **6 Rett Syndrome-related genes** across **multiple languages**, returning fully normalized HGVS nomenclature with genomic coordinates on both GRCh37 and GRCh38 assemblies.
## 🚀 Quick Start
### Installation
```bash
pip install rettxmutation
```
### Basic Usage
```python
import asyncio
from rettxmutation import RettxServices, DefaultConfig
async def extract():
config = DefaultConfig() # loads from .env / environment variables
with RettxServices(config) as services:
result = await services.agent_extraction_service.extract_mutations(
"The patient carries the mutation NM_004992.4:c.916C>T (p.Arg306Cys) in MECP2."
)
for key, mutation in result.mutations.items():
pt = mutation.primary_transcript
print(f"Gene: {pt.gene_id}")
print(f"Transcript: {pt.hgvs_transcript_variant}")
print(f"Protein: {pt.protein_consequence_tlr}")
print(f"Type: {mutation.variant_type}")
for assembly, coord in mutation.genomic_coordinates.items():
print(f"{assembly}: {coord.hgvs} (pos {coord.start:,}–{coord.end:,})")
asyncio.run(extract())
```
### CLI Example
```bash
python examples/extract_from_file.py path/to/genetic_report.txt --verbose
```
## ✨ Key Features
- **🧬 Multi-Gene Support**: MECP2, FOXG1, SLC6A1, CDKL5, EIF2B2, MEF2C — with curated RefSeq transcripts
- **🌍 Multilingual**: Processes reports in English, Spanish, Greek, Turkish, and more
- **🤖 Agentic Extraction**: Azure OpenAI-powered agent with tool-calling (gene registry lookup, variant validation, complex variant handling)
- **✅ HGVS Validation**: Every mutation is validated via VariantValidator with automatic coordinate liftover (GRCh37 ↔ GRCh38)
- **🔒 PHI Redaction**: Automatic removal of personal health information before LLM processing
- **⚡ Production Ready**: Type-safe Pydantic v2 models, exponential backoff, connection pooling
- **🔄 Dual Assembly Output**: Every mutation includes genomic coordinates on both GRCh37 and GRCh38
- **🏗️ Modular Architecture**: Lazy-initialized services with dependency injection and context manager support
## 🧬 Supported Genes
| Gene | Chromosome | Primary Transcript | Condition |
|------|-----------|-------------------|-----------|
| **MECP2** | Xq28 | NM_004992.4 (+NM_001110792.2) | Classic Rett Syndrome |
| **FOXG1** | 14q12 | NM_005249.5 | Congenital variant Rett |
| **SLC6A1** | 3p25.3 | NM_003042.4 | Myoclonic-atonic epilepsy |
| **CDKL5** | Xp22.13 | NM_001323289.2 | CDKL5 deficiency disorder |
| **EIF2B2** | 14q24.3 | NM_014239.4 | Vanishing white matter disease |
| **MEF2C** | 5q14.3 | NM_002397.5 (+NM_001131005.2) | MEF2C haploinsufficiency |
## 📊 Output Structure
The `ExtractionResult` contains:
```
ExtractionResult
├── mutations: Dict[str, GeneMutation] ← keyed by GRCh38 genomic HGVS
├── genes_detected: List[str] ← e.g. ["MECP2"]
├── extraction_log: List[str] ← agent reasoning trace
└── tool_calls_count: int ← total tool invocations
```
Each `GeneMutation` provides:
```
GeneMutation
├── genomic_coordinates:
│ ├── GRCh38: { assembly, hgvs, start, end, size }
│ └── GRCh37: { assembly, hgvs, start, end, size }
├── variant_type: "SNV" | "deletion" | "duplication" | "insertion" | "indel"
├── primary_transcript:
│ ├── gene_id, transcript_id
│ ├── hgvs_transcript_variant ← e.g. NM_004992.4:c.916C>T
│ ├── protein_consequence_tlr ← e.g. NP_004983.1:p.(Arg306Cys)
│ └── protein_consequence_slr ← e.g. NP_004983.1:p.(R306C)
└── secondary_transcript (optional)
```
## 🛠️ Requirements
### Python Version
- Python 3.8 or higher
### Azure Services
| Service | Required? | Purpose |
|---------|-----------|---------|
| **Azure OpenAI** | ✅ Required | Agentic mutation extraction |
| **Azure AI Search** | Optional | Semantic search for keyword detection |
| **Azure Cognitive Services** | Optional | Text analytics enrichment |
### Environment Variables
```bash
# Required — Azure OpenAI
RETTX_OPENAI_ENDPOINT=https://your-openai.openai.azure.com/
RETTX_OPENAI_KEY=your-openai-key
RETTX_OPENAI_MODEL_NAME=gpt-4o # deployment name
# Optional — Agent model (defaults to RETTX_OPENAI_MODEL_NAME if not set)
RETTX_OPENAI_AGENT_DEPLOYMENT=gpt-4o # agent-specific deployment
RETTX_OPENAI_AGENT_MODEL_VERSION=2024-11-20
# Optional — Embeddings
RETTX_EMBEDDING_DEPLOYMENT=text-embedding-ada-002
# Optional — Azure AI Search
RETTX_AI_SEARCH_SERVICE=your-search-service
RETTX_AI_SEARCH_API_KEY=your-search-key
RETTX_AI_SEARCH_INDEX_NAME=your-index-name
# Optional — Azure Cognitive Services
RETTX_COGNITIVE_SERVICES_ENDPOINT=https://your-cognitive-services.cognitiveservices.azure.com/
RETTX_COGNITIVE_SERVICES_KEY=your-cognitive-services-key
```
## 📋 Processing Pipeline
The agentic extraction pipeline works as follows:
```
Input Text (any language)
│
▼
┌──────────────────────┐
│ PHI Redaction │ Remove patient names, DOBs, IDs
└──────────┬───────────┘
▼
┌──────────────────────┐
│ AI Agent (OpenAI) │ Reads text, identifies mutations
│ │
│ Tools available: │
│ • lookup_gene_registry → gene info + RefSeq transcripts
│ • validate_variant → HGVS validation + coordinates
│ • validate_complex → CNV / genomic coordinate validation
└──────────┬───────────┘
▼
┌──────────────────────┐
│ Structured Output │ ExtractionResult with validated
│ │ GeneMutation objects
└──────────────────────┘
```
Key capabilities:
- **Ensembl → RefSeq remapping**: Handles reports using Ensembl transcripts (ENST*) by using genomic coordinates
- **Minus-strand awareness**: Correctly complements alleles for genes on the reverse strand
- **Old nomenclature**: Normalizes legacy formats (e.g., `502C->T`, `R168X`) to current HGVS
## 💻 Available Services
All services are lazily initialized via `RettxServices`:
```python
with RettxServices(config) as services:
# Core extraction
services.agent_extraction_service # AI-powered mutation extraction
# Validation & analysis
services.variant_validator_service # HGVS validation + coordinate liftover
services.mutation_tokenizator # Mutation string tokenization
# Search & embeddings
services.embedding_service # Azure OpenAI embeddings
services.ai_search_service # Azure AI Search integration
services.keyword_detector_service # Multi-layer keyword detection
```
### Direct Variant Validation
```python
with RettxServices(config) as services:
vvs = services.variant_validator_service
# Validate a transcript-level variant
result = vvs.get_gene_mutation_from_transcript("NM_004992.4:c.916C>T")
print(result.primary_transcript.protein_consequence_tlr)
# → NP_004983.1:p.(Arg306Cys)
# Validate a complex / genomic variant
result = vvs.create_gene_mutation_from_complex_variant(
assembly_build="GRCh38",
assembly_refseq="NC_000023.11",
variant_description="NC_000023.11:g.154030912G>A",
gene_symbol="MECP2"
)
```
### Custom Configuration
```python
class MyConfig:
"""Custom configuration for production (e.g., from Key Vault)."""
RETTX_OPENAI_ENDPOINT = "https://my-openai.openai.azure.com/"
RETTX_OPENAI_KEY = get_secret("openai-key")
RETTX_OPENAI_MODEL_NAME = "gpt-4o"
# Only set fields needed for the services you use
with RettxServices(MyConfig()) as services:
result = await services.agent_extraction_service.extract_mutations(text)
```
## 🧪 Golden Test Suite
The library includes a comprehensive golden test suite with 11 real-world genetic reports:
| Gene | Variant Type | Language | Key Feature |
|------|-------------|----------|-------------|
| MECP2 | SNV, splicing, deletion, duplication | EN, ES, EL, TR | Multiple transcripts |
| FOXG1 | Frameshift deletion | TR | Non-MECP2 gene |
| SLC6A1 | Whole-gene CNV (~20kb) | ES | Copy number variant |
Run golden tests:
```bash
# Mock mode (no API calls, uses recorded responses)
python -m pytest tests/golden/ --golden-mode=mock -v
# Live mode (calls real APIs)
python -m pytest tests/golden/ --golden-mode=live -v
```
## 🎯 Use Cases
- **🏥 Clinical Genetics**: Extract mutations from diagnostic reports in any language
- **🔬 Research**: Analyze genetic data across Rett Syndrome and related conditions
- **📊 Patient Registries**: Populate genetic databases with normalized HGVS nomenclature
- **🤖 Bioinformatics Pipelines**: Integrate as a library or via the CLI example
- **📱 Clinical Applications**: Build tools with structured mutation data (dual-assembly coordinates)
## 🔧 Reliability
- **Exponential Backoff**: Automatic retry for VariantValidator and OpenAI API calls
- **Graceful Degradation**: Optional services (AI Search, Cognitive Services) degrade gracefully
- **PHI Redaction**: Patient data is stripped before any LLM processing
- **Type Safety**: Pydantic v2 models with runtime validation
- **Context Manager**: Automatic resource cleanup via `with` statement
- **Comprehensive Logging**: Structured extraction logs with tool call traces
## 🤝 Contributing
We welcome contributions! Please see our [GitHub repository](https://github.com/rett-europe/rettxmutation) for:
- Issue reporting
- Feature requests
- Pull request guidelines
- Development setup instructions
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## 🆘 Support
- **Issues**: [GitHub Issues](https://github.com/rett-europe/rettxmutation/issues)
- **Documentation**: [API Documentation](https://github.com/rett-europe/rettxmutation)
- **Contact**: procha@rettsyndrome.eu
## 🔮 Roadmap
- **Additional Genes**: Expand the gene registry beyond the current 6 genes
- **Batch Processing**: Process multiple reports in parallel with rate limiting
- **Confidence Scoring**: Per-mutation confidence metrics based on report quality
- **Structured Report Parsing**: Native support for VCF, JSON, and HL7 FHIR formats
- **Cloud Deployment**: Docker containers and Azure deployment templates
| text/markdown | null | Pedro Rocha <procha@rettsyndrome.eu> | null | null | MIT License | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"python-dotenv",
"azure-core",
"azure-ai-textanalytics",
"mutalyzer_hgvs_parser",
"pydantic",
"openai",
"backoff",
"jmespath",
"azure-search-documents",
"numpy"
] | [] | [] | [] | [
"Homepage, https://github.com/rett-europe/rettxmutation",
"Issues, https://github.com/rett-europe/rettxmutation/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:12:33.457596 | rettxmutation-0.3.6.tar.gz | 76,693 | 83/49/86b011ce351bb9b6746932c6e080f0248f1ab21916f1007a6ad94a3b68d7/rettxmutation-0.3.6.tar.gz | source | sdist | null | false | 29c44e3875e42bb6c5241b3aafb1b3f6 | 92137e0fe7f14843d1293b468486467a50095784c5a6d09888f19d985597a84d | 834986b011ce351bb9b6746932c6e080f0248f1ab21916f1007a6ad94a3b68d7 | null | [
"LICENSE"
] | 262 |
2.4 | osmapi | 5.0.0 | Python wrapper for the OSM API | osmapi
======
[](https://github.com/metaodi/osmapi/actions/workflows/build.yml)
[](https://pypi.python.org/pypi/osmapi/)
[](https://github.com/metaodi/osmapi/blob/develop/LICENSE.txt)
[](https://coveralls.io/r/metaodi/osmapi?branch=develop)
[](https://github.com/psf/black)
[](https://github.com/pre-commit/pre-commit)
Python wrapper for the OSM API (requires Python >= 3.9).
**NOTE**: Since version 5.0 of this library, all method names are in `snake_case`, the `CamelCase` versions are deprecated and will be removed in version 6.0.
## Installation
Install [`osmapi` from PyPi](https://pypi.python.org/pypi/osmapi) by using pip:
pip install osmapi
## Documentation
The documentation is generated using `pdoc` and can be [viewed online](http://osmapi.metaodi.ch).
The build the documentation locally, you can use
make docs
This project uses GitHub Pages to publish its documentation.
To update the online documentation, you need to re-generate the documentation with the above command and update the `main` branch of this repository.
## Examples
To test this library, please create an account on the [development server of OpenStreetMap (https://api06.dev.openstreetmap.org)](https://api06.dev.openstreetmap.org).
Check the [examples directory](https://github.com/metaodi/osmapi/tree/develop/examples) to find more example code.
### Read from OpenStreetMap
```python
>>> import osmapi
>>> api = osmapi.OsmApi()
>>> print(api.node_get(123))
{'changeset': 532907, 'uid': 14298,
'timestamp': '2007-09-29T09:19:17Z',
'lon': 10.790009299999999, 'visible': True,
'version': 1, 'user': 'Mede',
'lat': 59.9503044, 'tag': {}, 'id': 123}
```
### Write to OpenStreetMap
```python
>>> import osmapi
>>> api = osmapi.OsmApi(api="https://api06.dev.openstreetmap.org", username = "metaodi", password = "*******")
>>> api.changeset_create({"comment": "My first test"})
>>> print(api.node_create({"lon":1, "lat":1, "tag": {}}))
{'changeset': 532907, 'lon': 1, 'version': 1, 'lat': 1, 'tag': {}, 'id': 164684}
>>> api.changeset_close()
```
### OAuth authentication
Username/Password authentication will be deprecated in July 2024
(see [official OWG announcemnt](https://blog.openstreetmap.org/2024/04/17/oauth-1-0a-and-http-basic-auth-shutdown-on-openstreetmap-org/) for details).
In order to use this library in the future, you'll need to use OAuth 2.0.
To use OAuth 2.0, you must register an application with an OpenStreetMap account, either on the
[development server](https://master.apis.dev.openstreetmap.org/oauth2/applications)
or on the [production server](https://www.openstreetmap.org/oauth2/applications).
Once this registration is done, you'll get a `client_id` and a `client_secret` that you can use to authenticate users.
auth = OpenStreetMapDevAuth(
Example code using [`cli-oauth2`](https://github.com/Zverik/cli-oauth2) on the development server, replace `OpenStreetMapDevAuth` with `OpenStreetMapAuth` to use the production server:
```python
import osmapi
from oauthcli import OpenStreetMapDevAuth
client_id = "<client_id>"
client_secret = "<client_secret>"
auth = OpenStreetMapDevAuth(
client_id, client_secret, ['read_prefs', 'write_map']
).auth_code()
api = osmapi.OsmApi(
api="https://api06.dev.openstreetmap.org",
session=auth.session
)
with api.changeset({"comment": "My first test"}) as changeset_id:
print(f"Part of Changeset {changeset_id}")
node1 = api.node_create({"lon": 1, "lat": 1, "tag": {}})
print(node1)
```
An alternative way using the `requests-oauthlib` library can be found
[in the examples](https://github.com/metaodi/osmapi/blob/develop/examples/oauth2.py).
### User agent / credit for application
To credit the application that supplies changes to OSM, an `appid` can be provided.
This is a string identifying the application.
If this is omitted "osmapi" is used.
```python
api = osmapi.OsmApi(
api="https://api06.dev.openstreetmap.org",
appid="MyOSM Script"
)
```
If then changesets are made using this osmapi instance, they get a tag `created_by` with the following content: `MyOSM Script (osmapi/<version>)`
[Example changeset of `Kort` using osmapi](https://www.openstreetmap.org/changeset/55197785)
## Note about imports / automated edits
Scripted imports and automated edits should only be carried out by those with experience and understanding of the way the OpenStreetMap community creates maps, and only with careful **planning** and **consultation** with the local community.
See the [Import/Guidelines](http://wiki.openstreetmap.org/wiki/Import/Guidelines) and [Automated Edits/Code of Conduct](http://wiki.openstreetmap.org/wiki/Automated_Edits/Code_of_Conduct) for more information.
## Development
If you want to help with the development of `osmapi`, you should clone this repository and install the requirements:
make deps
Better yet use the provided [`setup.sh`](https://github.com/metaodi/osmapi/blob/develop/setup.sh) script to create a virtual env and install this package in it.
You can lint the source code using this command:
make lint
And if you want to reformat the files (using the black code style) simply run:
make format
To run the tests use the following command:
make test
## Release
To create a new release, follow these steps (please respect [Semantic Versioning](http://semver.org/)):
1. Adapt the version number in `osmapi/__init__.py`
1. Update the CHANGELOG with the version
1. Re-build the documentation (`make docs`)
1. Create a [pull request to merge develop into main](https://github.com/metaodi/osmapi/compare/main...develop) (make sure the tests pass!)
1. Create a [new release/tag on GitHub](https://github.com/metaodi/osmapi/releases) (on the main branch)
1. The [publication on PyPI](https://pypi.python.org/pypi/osmapi) happens via [GitHub Actions](https://github.com/metaodi/osmapi/actions/workflows/publish_python.yml) on every tagged commit
## Attribution
This project was orginally developed by Etienne Chové.
This repository is a copy of the original code from SVN (http://svn.openstreetmap.org/applications/utils/python_lib/OsmApi/OsmApi.py), with the goal to enable easy contribution via GitHub and release of this package via [PyPI](https://pypi.python.org/pypi/osmapi).
See also the OSM wiki: http://wiki.openstreetmap.org/wiki/Osmapi
| text/markdown | Etienne Chové | chove@crans.org | Stefan Oderbolz | odi@metaodi.ch | GPLv3 | openstreetmap, osm, api | [
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Intended Audience :: Developers",
"Topic :: Scientific/Engineering :: GIS",
"Topic :: Software Development :: Libraries",
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",... | [] | https://github.com/metaodi/osmapi | https://github.com/metaodi/osmapi/archive/v5.0.0.zip | >=3.9 | [] | [] | [] | [
"requests"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:12:20.474834 | osmapi-5.0.0.tar.gz | 47,244 | e6/72/a085a221fa51fd2686e27228a954161d2ee2828c1e5c41f42f8c334d3509/osmapi-5.0.0.tar.gz | source | sdist | null | false | 63337b73ad46d3301d5e42561dd8f7cd | 244b0fb432f7810a38b38a13eacc6d53df5441a1ea02a5e952b0fb1c44f2a420 | e672a085a221fa51fd2686e27228a954161d2ee2828c1e5c41f42f8c334d3509 | null | [
"LICENSE.txt"
] | 371 |
2.1 | dez | 0.10.10.47 | A set of pyevent-based network services | The dez library includes an asynchronous server benchmarking toolset; advanced, inotify-based static caching; XML and JSON stream parsing; Stomp, OP, HTTP, and WebSocket servers; and WebSocketProxy, which enables web application deployment on existing, unmodified TCP servers without straying from the HTML5 spec. In addition, dez offers a highly sophisticated API for implementing custom protocols, as well as a controller class that simplifies the creation of applications that require multiple servers to run in the same process.
| null | Mario Balibrera | mario.balibrera@gmail.com | null | null | MIT License | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | null | [] | [] | [] | [
"psutil>=5.9.1",
"python-magic>=0.4.11",
"rel>=0.4.9.24"
] | [] | [] | [] | [] | twine/5.0.0 CPython/3.12.3 | 2026-02-18T21:12:04.473418 | dez-0.10.10.47-py3-none-any.whl | 68,922 | 09/00/23fa0c7b1ddca1745871f3be876499dcd362f1e917874f1c3d15103dfa67/dez-0.10.10.47-py3-none-any.whl | py3 | bdist_wheel | null | false | 68e947b4df532c30bc89feeaa0070a94 | d5193a19c16934c79636ba5922c6bd05c4311feea6fabf6c22957a98c358ca4f | 090023fa0c7b1ddca1745871f3be876499dcd362f1e917874f1c3d15103dfa67 | null | [] | 165 |
2.4 | okareo | 0.0.121 | Python SDK for interacting with Okareo Cloud APIs | # Okareo Python SDK
[](https://pypi.python.org/pypi/okareo/)
[](https://pypi.python.org/pypi/okareo/)
[](https://pypi.python.org/pypi/okareo/)
---
**PyPI**: [https://pypi.org/project/okareo/](https://pypi.org/project/okareo/)
---
Python library for interacting with Okareo Cloud APIs
## Documentation
[Getting Started, Guides, and API docs](https://docs.okareo.com/)
## Installation
1. Install the package
```sh
pip install okareo
```
2. Get your API token from [https://app.okareo.com/](https://app.okareo.com/)
(Note: You will need to register first.)
3. Go directly to the **"2. Create your API Token"** on the landing page in above app.
4. Set the environment variable `OKAREO_API_KEY` to your generated API token.
## Get Started Example Notebooks
Please see and run this notebook:<br>
https://github.com/okareo-ai/okareo-python-sdk/blob/main/examples/classification_eval.ipynb
See additional examples under:<br>
https://github.com/okareo-ai/okareo-python-sdk/tree/main/examples
## Using Okareo LangChain Callbacks Handler
We provide a LangChain callback handler that lets you easily integrate your current workflows with the Okareo platform.
If don't have LangChain dependencies installed in your environment, you can install the base ones (that will help you run the examples) with:
```sh
pip install okareo[langchain]
```
Integrating callbacks into your chain is as easy as importing the SDK in your module add adding the following
```
from okareo.callbacks import CallbackHandler
...
handler = CallbackHandler(mut_name="my-model", context_token="context-token")
llm = OpenAI(temperature=0.3, callbacks=[handler])
```
During the LangChain LLM runs we will collect input and output information so you can analyze it further with the Okareo toolkit.
You can also see an usage example in [./examples/langchain_callback_example.py](./examples/langchain_callback_example.py)
## Rendering Docs via `pydoc-markdown`
To render the Python SDK documentation, you can use `source/build_docs.sh` in this repository. This will do the following:
1. Install the SDK poetry environment
2. Run `pydoc-markdown` as configured in `pyproject.toml`
3. Perform postprocessing to re-order the generated sidebar file and change heading levels.
The generated docs will be found in the `docs/python-sdk` and can be rendered with [docusaurus](https://docusaurus.io/).
---
All rights reserved for Okareo Inc
| text/markdown | Okareo | info@okareo.com | null | null | Apache-2.0 | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: P... | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"aiohttp<4.0.0,>=3.10.0",
"attrs<24.0.0,>=23.1.0",
"autogen-agentchat<0.3.0,>=0.2.36; extra == \"autogen\"",
"httpx>=0.23",
"langchain<0.0.322,>=0.0.321; extra == \"langchain\"",
"litellm<2.0.0,>=1.29.5; extra == \"langchain\"",
"nats-py<3.0.0,>=2.4.0",
"nkeys<0.3.0,>=0.2.0",
"numpy<2.0,>=1.21.0; ex... | [] | [] | [] | [
"Documentation, https://docs.okareo.com/docs/getting-started/overview",
"Homepage, https://okareo.com",
"Repository, https://github.com/okareo-ai/okareo-python-sdk"
] | poetry/2.3.2 CPython/3.10.19 Linux/6.14.0-1017-azure | 2026-02-18T21:11:58.260932 | okareo-0.0.121-py3-none-any.whl | 403,661 | 67/bf/41c918d49020f101e5dad8a821400fe48afc9ad010e0f4b9b54d43f57c11/okareo-0.0.121-py3-none-any.whl | py3 | bdist_wheel | null | false | 94d8aa1332d529970b8495f5473814ab | 6ddd8b26c11aeb004db04fa605ac60027a502db30aafdceed1c87285f474a464 | 67bf41c918d49020f101e5dad8a821400fe48afc9ad010e0f4b9b54d43f57c11 | null | [
"LICENSE"
] | 458 |
2.4 | cursor-viewer | 0.1.0 | Browse and search your Cursor AI chat histories locally, including tool calls | # cursor-viewer
A local browser UI for reading through your Cursor AI chat histories — including tool calls, search, and support for exploring backups.
Built with Streamlit. No server, no account, no data leaving your machine.
---
## What it does
- Lists all your Cursor chats grouped by project
- Renders tool calls (file reads, terminal commands, etc.) inline as collapsible sections
- Lets you search across projects and message content
- Supports pointing at a backup of your `.cursor` data directory, not just the live one
---
## Install
Requires Python 3.10+. First, get [pipx](https://pipx.pypa.io) if you don't have it:
**macOS**
```bash
brew install pipx
pipx ensurepath
```
**Linux**
```bash
sudo apt install pipx # Debian/Ubuntu
pipx ensurepath
```
**Windows**
```bash
scoop install pipx # or: pip install --user pipx
pipx ensurepath
```
Then install cursor-viewer:
```bash
pipx install cursor-viewer
```
Then just run:
```bash
cursor-viewer
```
It opens in your browser at `http://localhost:8501`.
---
## Configuration
The app figures out where your Cursor data lives automatically. If you want to override that:
**One-off (flag):**
```bash
cursor-viewer --cursor-path "/Volumes/Backup/Library/Application Support/Cursor"
```
**Session (env var):**
```bash
CURSOR_DATA_PATH="/path/to/cursor" cursor-viewer
```
**Persistent default (UI):**
Open the Settings panel in the sidebar, enter your path, and hit "Save as default". That writes to `~/.cursor-viewer/config.json` and sticks across restarts.
**Priority order:** flag > env var > saved config > auto-detected default.
---
## Other options
```
cursor-viewer --help
```
```
--cursor-path PATH path to Cursor's data directory
--port PORT port to run on (default: 8501)
```
---
## Running from source
```bash
git clone https://github.com/sahilsasane/cursor-viewer
cd cursor-viewer
uv sync
uv run streamlit run streamlit_app.py
```
---
## How Cursor stores chats
Cursor keeps chat history in SQLite databases under its data directory:
- `User/globalStorage/state.vscdb` — composer/agent chats
- `User/workspaceStorage/<id>/state.vscdb` — per-workspace chats and metadata
cursor-viewer reads these directly, read-only, without touching any Cursor internals.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"streamlit>=1.32.0"
] | [] | [] | [] | [] | uv/0.9.8 | 2026-02-18T21:10:12.835080 | cursor_viewer-0.1.0.tar.gz | 9,171 | 35/3e/2e4af055a0ef541793352f4935fdd5354f043cc2e344231760c79f25b43b/cursor_viewer-0.1.0.tar.gz | source | sdist | null | false | cf5b5cf88ef0e32bb7cb56030f18c361 | 0f8a096165764a58273562046c2c57a979738bad56430f1c4aa074d742ffa39d | 353e2e4af055a0ef541793352f4935fdd5354f043cc2e344231760c79f25b43b | null | [] | 278 |
2.4 | eetc-utils | 1.4.0 | EETC Utils Library | # EETC Utils
[](https://badge.fury.io/py/eetc-utils)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
A Python library providing reusable utilities for financial analysis and algorithmic trading. Built by [East Empire Trading Company](https://github.com/east-empire-trading-company) for quantitative finance and trading strategy development.
## Features
### Finance Utilities
- **Quantitative Finance Functions**: Kelly Criterion position sizing, DCF valuation, compound interest
- **GARCH Models**: Advanced volatility forecasting using ARCH library integration
- **OHLC Data Manipulation**: Convert daily data to weekly timeframes, performance calculations
### Options Trading
- **Black-Scholes Pricing**: Calculate option prices for calls and puts
- **Greeks Calculations**: Gamma exposure (GEX) and other option Greeks
- **Volatility Analysis**: Convert option IV to underlying IV, standard distribution functions
- **Strike Range Tools**: Find strike prices within percentage ranges
### API Clients
- **EETC Data Hub Client**: Fetch price data, fundamentals, macroeconomic indicators, and order history
- **EETC Notifications Client**: Send trade updates and notifications to Telegram channels
### Strategy Framework
- **Live Trading**: Abstract base classes for implementing live/paper trading strategies
- **Execution Engine**: Production-ready engine for running trading strategies
- **Backtesting Framework**: Complete backtesting suite with broker simulation, performance metrics, and result persistence
## Installation
```bash
pip install eetc-utils
```
## Quick Start
### Finance Utilities
```python
from eetc_utils.finance import (
calculate_optimal_leverage_kelly,
intrinsic_value_using_dcf,
garch_annualized_volatility,
convert_daily_ohlc_data_to_weekly
)
import pandas as pd
# Calculate optimal leverage using Kelly Criterion
price_df = pd.DataFrame({
'date': pd.date_range('2020-01-01', periods=200),
'close': [100 + i * 0.5 for i in range(200)]
})
leverage = calculate_optimal_leverage_kelly(
df=price_df,
position_type="LONG",
regime_start_date="2020-01-01",
fractional_kelly_multiplier=0.5,
use_garch=False
)
# DCF valuation
intrinsic_value = intrinsic_value_using_dcf(
cash_flow=1000000000,
growth_years=10,
shares=100000000,
growth_rate=1.15,
beta=1.2
)
# Forecast volatility using GARCH
volatility = garch_annualized_volatility(price_df)
# Convert daily OHLC to weekly
weekly_df = convert_daily_ohlc_data_to_weekly(price_df)
```
### Options Trading
```python
from eetc_utils.options import (
calculate_option_price_black_scholes,
find_strikes_in_range,
GEX,
calculate_underlying_iv_from_option_iv
)
# Calculate Black-Scholes option price
call_price = calculate_option_price_black_scholes(
right="C",
und_price=100.0,
strike=105.0,
rate=0.05,
tte=0.5,
implied_vol=0.25,
pv_dividend=0.0
)
# Find strike prices within a range
strikes = find_strikes_in_range(
range_length_perc=0.1,
price=100.0
)
# Calculate Gamma Exposure
gex = GEX(oi=1000, gamma=0.05)
# Convert option IV to underlying IV
underlying_iv = calculate_underlying_iv_from_option_iv(
option_implied_vol=0.20,
t=30/365
)
```
### EETC Data Hub Client
```python
from eetc_utils.clients.eetc_data import EETCDataClient
import os
# Initialize client (requires EETC_API_KEY environment variable)
client = EETCDataClient(api_key=os.getenv("EETC_API_KEY"))
# Fetch price data
price_data = client.get_price_data(symbol="AAPL", start_date="2024-01-01")
# Get fundamentals
fundamentals = client.get_fundamentals(symbol="AAPL")
# Fetch macroeconomic indicators
macro_data = client.get_macro_indicators(indicator="GDP", country="US")
```
### EETC Notifications Manager Client
```python
from eetc_utils.clients.eetc_notifications import EETCNotificationsClient
import os
# Initialize client (requires EETC_API_KEY environment variable)
client = EETCNotificationsClient(api_key=os.getenv("EETC_API_KEY"))
# Send trade update via Telegram
client.send_trade_update_to_telegram(msg="Shorted TSLA x100 at 1312.69.")
```
### Backtesting Framework
```python
from eetc_utils.strategy.backtesting.strategy import Strategy
from eetc_utils.strategy.backtesting.engine import BacktestEngine
import pandas as pd
class MyStrategy(Strategy):
def on_start(self, context):
self.position = 0
def on_data(self, bar, context):
# Simple moving average crossover
if len(self.data) < 20:
return
sma_short = self.data['close'].tail(5).mean()
sma_long = self.data['close'].tail(20).mean()
if sma_short > sma_long and self.position == 0:
context['place_order']('buy', quantity=100)
self.position = 100
elif sma_short < sma_long and self.position > 0:
context['place_order']('sell', quantity=100)
self.position = 0
def on_stop(self, context):
pass
# Load historical data
data = pd.read_csv("AAPL_historical.csv")
# Run backtest
engine = BacktestEngine(
strategy=MyStrategy(),
data=data,
symbol="AAPL",
initial_capital=100000,
commission=0.001
)
results = engine.run()
print(f"Total Return: {results['total_return']:.2%}")
print(f"Sharpe Ratio: {results['sharpe_ratio']:.2f}")
print(f"Max Drawdown: {results['max_drawdown']:.2%}")
```
## Documentation
### Module Structure
```
src/eetc_utils/
├── finance.py # Quantitative finance utilities
├── options.py # Options pricing and Greeks
├── clients/
│ ├── eetc_data.py # EETC Data Hub API client
│ └── eetc_notifications.py # Notifications client
└── strategy/
├── strategy.py # Live trading strategy base class
├── engine.py # Live trading execution engine
└── backtesting/
├── strategy.py # Backtesting strategy base class
├── engine.py # Backtesting engine
├── broker_sim.py # Broker simulator
└── metrics.py # Performance metrics
```
### Key Functions & Classes
#### Finance Module (`finance.py`)
- `calculate_optimal_leverage_kelly()`: Calculate optimal leverage using Kelly Criterion
- `calculate_position_size_kelly()`: Calculate position size based on Kelly Criterion
- `intrinsic_value_using_dcf()`: Discounted cash flow valuation
- `garch_annualized_volatility()`: GARCH-based volatility forecasting
- `convert_daily_ohlc_data_to_weekly()`: Convert daily OHLC data to weekly timeframes
- `performance_over_time()`: Calculate percentage performance between dates
- `compound_interest()`: Calculate compound interest
- `beta_to_discount_rate()`: Map beta to discount rate for DCF
#### Options Module (`options.py`)
- `calculate_option_price_black_scholes()`: Black-Scholes option pricing for calls and puts
- `find_strikes_in_range()`: Find strike prices within a percentage range
- `GEX()`: Calculate Gamma Exposure for option contracts
- `calculate_underlying_iv_from_option_iv()`: Convert option IV to underlying IV
- `PDF()`: Standard normal probability density function
- `CND()`: Cumulative normal distribution
- `D1()`, `D2()`: Black-Scholes d1 and d2 calculations
#### API Clients
- **EETCDataClient**: HTTP client for fetching market data and fundamentals
- `get_price_data()`: Fetch historical price data
- `get_fundamentals()`: Get company fundamentals
- `get_macro_indicators()`: Fetch macroeconomic indicators
- `get_order_history()`: Retrieve order history
- **EETCNotificationsClient**: Send trading notifications via Telegram
- `send_trade_update_to_telegram()`: Send trade notifications
#### Strategy Framework
- **Live Trading**: `Strategy` (ABC) for implementing live strategies
- **Backtesting**: Simplified `Strategy` class with `on_start()`, `on_data()`, `on_stop()` lifecycle
- **Engines**: Orchestrate strategy execution (live or backtest)
- **BrokerSim**: Simulate order execution with configurable slippage and commission
- **Metrics**: Calculate Sharpe ratio, max drawdown, and other performance statistics
## Development
### Prerequisites
- Python 3.12+
- Poetry (for dependency management)
### Setup
```bash
# Install system dependencies
sudo apt-get install build-essential
# Install Python dependencies
make update_and_install_python_requirements
```
### Code Formatting
```bash
make reformat_code # Uses black for consistent code style
```
### Testing
```bash
# Run all tests
python -m pytest tests/
# Run specific test file
python -m pytest tests/test_financials.py
# Run with coverage
python -m pytest tests/ --cov=src/eetc_utils
```
### Publishing to PyPI
#### Prerequisites
Create a `.pypirc` file in the project root with your PyPI API tokens:
```ini
[distutils]
index-servers =
pypi
testpypi
[testpypi]
repository = https://test.pypi.org/legacy/
username = __token__
password = pypi-YOUR_TEST_PYPI_TOKEN_HERE
[pypi]
repository = https://upload.pypi.org/legacy/
username = __token__
password = pypi-YOUR_PRODUCTION_PYPI_TOKEN_HERE
```
**Note**: The `.pypirc` file is already in `.gitignore` and will not be committed to version control.
To generate API tokens:
- **TestPyPI**: https://test.pypi.org/manage/account/token/
- **Production PyPI**: https://pypi.org/manage/account/token/
#### Publishing Steps
1. Update version in `pyproject.toml`:
- Increment `version` field in `[tool.poetry]` section
- Update dependencies in `[tool.poetry.dependencies]` if needed
2. Build the package:
```bash
python -m build
```
3. Test on PyPI Test:
```bash
make publish_package_on_pypi_test
```
4. Publish to production PyPI:
```bash
make publish_package_on_pypi
```
The Makefile commands automatically read credentials from `.pypirc` and configure Poetry before publishing.
## Configuration
### Environment Variables
- `EETC_API_KEY`: API key for EETC Data Hub client (required for data access)
## Contributing
Contributions are welcome! Please ensure:
- Code follows the project's style guide (enforced by `black`)
- All tests pass before submitting PR
- New features include appropriate tests
- Documentation is updated for API changes
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Authors
- **East Empire Trading Company** - [eastempiretradingcompany2019@gmail.com](mailto:eastempiretradingcompany2019@gmail.com)
- **Stefan Delic** - [einfach.jung1@gmail.com](mailto:einfach.jung1@gmail.com)
- **Milos Dovedan** - [dovedanmilosh@gmail.com](mailto:dovedanmilosh@gmail.com)
## Links
- **Homepage**: [https://github.com/east-empire-trading-company/eetc-utils](https://github.com/east-empire-trading-company/eetc-utils)
- **PyPI**: [https://pypi.org/project/eetc-utils/](https://pypi.org/project/eetc-utils/)
- **Bug Tracker**: [https://github.com/east-empire-trading-company/eetc-utils/issues](https://github.com/east-empire-trading-company/eetc-utils/issues)
## Support
For questions, issues, or feature requests, please [open an issue](https://github.com/east-empire-trading-company/eetc-utils/issues) on GitHub. | text/markdown | East Empire Trading Company | eastempiretradingcompany2019@gmail.com | East Empire Trading Company | eastempiretradingcompany2019@gmail.com | MIT | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://github.com/east-empire-trading-company/eetc-utils | null | <4.0,>=3.12 | [] | [] | [] | [
"pandas<3.0.0,>=2.3.3",
"numpy<3.0.0,>=2.3.4",
"arch<9.0.0,>=8.0.0",
"requests<3.0.0,>=2.28.0",
"pytest<10.0.0,>=9.0.1",
"setuptools<81.0.0,>=80.9.0",
"wheel<0.46.0,>=0.45.1"
] | [] | [] | [] | [
"Homepage, https://github.com/east-empire-trading-company/eetc-utils",
"Repository, https://github.com/east-empire-trading-company/eetc-utils",
"Bug Tracker, https://github.com/east-empire-trading-company/eetc-utils/issues"
] | poetry/2.2.1 CPython/3.12.3 Linux/6.8.0-100-generic | 2026-02-18T21:10:00.234042 | eetc_utils-1.4.0.tar.gz | 20,705 | 53/0a/a039f772c72b6db8978a65008c6c912a92efbd306ef7afe201b257760377/eetc_utils-1.4.0.tar.gz | source | sdist | null | false | 6ca74ac22640e8f67c62406e848ffefb | 895e5fac63a4238c34afe5e686eff13bff6e767aa27e12facaa7d9b4f396c35b | 530aa039f772c72b6db8978a65008c6c912a92efbd306ef7afe201b257760377 | null | [] | 256 |
2.4 | oh-my-code | 0.1.0 | A starter Python package named oh-my-code. | # oh-my-code
`oh-my-code` is a minimal Python package scaffold, ready to publish on PyPI.
## Quick start
```bash
python -m venv .venv
source .venv/bin/activate
python -m pip install --upgrade pip build
python -m pip install -e .
```
## Usage
```python
from oh_my_code import greet
print(greet("developer"))
```
## Build distribution artifacts
```bash
python -m build
```
## Publish to PyPI
```bash
python -m pip install twine
python -m twine upload dist/*
```
| text/markdown | oh-my-code maintainers | null | null | null | null | python, package, pypi | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language... | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://pypi.org/project/oh-my-code/",
"Repository, https://github.com/your-org/oh-my-code",
"Issues, https://github.com/your-org/oh-my-code/issues"
] | twine/6.2.0 CPython/3.12.8 | 2026-02-18T21:08:59.195878 | oh_my_code-0.1.0.tar.gz | 2,745 | 54/75/1c5bfa2888186e351b38427135a14b4d3e08d7358157ce191264b5223238/oh_my_code-0.1.0.tar.gz | source | sdist | null | false | dcf63f223ff2a54d21ef79422768dd6e | e64c4a7a1fafd8c09ac7ff41ce11cf4add4e45806054108424e9c81d06627a97 | 54751c5bfa2888186e351b38427135a14b4d3e08d7358157ce191264b5223238 | MIT | [
"LICENSE"
] | 275 |
2.4 | rlms | 0.1.1 | Recursive Language Models. |
---
<h1 align="center" style="font-size:2.8em">
<span>Recursive Language Models (<span style="color:orange">RLM</span>s)</span>
</h1>
<p align="center" style="font-size:1.3em">
<a href="https://arxiv.org/abs/2512.24601">Full Paper</a> •
<a href="https://alexzhang13.github.io/blog/2025/rlm/">Blogpost</a> •
<a href="https://alexzhang13.github.io/rlm/">Documentation</a> •
<a href="https://github.com/alexzhang13/rlm-minimal">RLM Minimal</a>
</p>
<p align="center">
<a href="https://github.com/alexzhang13/rlm/actions/workflows/style.yml">
<img src="https://github.com/alexzhang13/rlm/actions/workflows/style.yml/badge.svg" alt="Style" />
</a>
<a href="https://github.com/alexzhang13/rlm/actions/workflows/test.yml">
<img src="https://github.com/alexzhang13/rlm/actions/workflows/test.yml/badge.svg" alt="Test" />
</a>
</p>
<p align="center">
<a href="https://arxiv.org/abs/2512.24601">
<img src="media/paper_preview.png" alt="Paper Preview" width="300"/>
</a>
</p>
## Overview
Recursive Language Models (RLMs) are a task-agnostic inference paradigm for language models (LMs) to handle near-infinite length contexts by enabling the LM to *programmatically* examine, decompose, and recursively call itself over its input. RLMs replace the canonical `llm.completion(prompt, model)` call with a `rlm.completion(prompt, model)` call. RLMs offload the context as a variable in a REPL environment that the LM can interact with and launch sub-LM calls inside of.
This repository provides an extensible inference engine for using RLMs around standard API-based and local LLMs. The initial experiments and idea were proposed in a [blogpost](https://alexzhang13.github.io/blog/2025/rlm/) in 2025, with expanded results in an [arXiv preprint](https://arxiv.org/abs/2512.24601).
> [!NOTE]
> This repository contains inference code for RLMs with support for various sandbox environments. Open-source contributions are welcome. This repository is maintained by the authors of the paper from the MIT OASYS lab.
## Quick Setup
You can try out RLMs quickly by installing from PyPi:
```bash
pip install rlms
```
The default RLM client uses a REPL environment that runs on the host process through Python `exec` calls. It uses the same virtual environment as the host process (i.e. it will have access to the same dependencies), but with some limitations in its available global modules. As an example, we can call RLM completions using GPT-5-nano:
```python
from rlm import RLM
rlm = RLM(
backend="openai",
backend_kwargs={"model_name": "gpt-5-nano"},
verbose=True, # For printing to console with rich, disabled by default.
)
print(rlm.completion("Print me the first 100 powers of two, each on a newline.").response)
```
<details>
<summary><b>Manual Setup</b></summary>
Set up the dependencies with `uv` (or your virtual environment of choice):
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
uv init && uv venv --python 3.12 # change version as needed
uv pip install -e .
```
This project includes a `Makefile` to simplify common tasks.
- `make install`: Install base dependencies.
- `make check`: Run linter, formatter, and tests.
To run a quick test, the following will run an RLM query with the OpenAI client using your environment variable `OPENAI_API_KEY` (feel free to change this). This will generate console output as well as a log which you can use with the visualizer to explore the trajectories.
```bash
make quickstart
```
</details>
## REPL Environments
We support two types of REPL environments -- isolated, and non-isolated. Non-isolated environments (default) run code execution on the same machine as the RLM (e.g. through `exec`), which is pretty reasonable for some local low-risk tasks, like simple benchmarking, but can be problematic if the prompts or tool calls can interact with malicious users. Fully isolated environments use cloud-based sandboxes (e.g. Prime Sandboxes, [Modal Sandboxes](https://modal.com/docs/guide/sandboxes)) to run code generated by the RLM, ensuring complete isolation from the host process. Environments can be added, but we natively support the following: `local` (default), `docker`, `modal`, `prime`, `daytona`, `e2b`.
```python
rlm = RLM(
environment="...", # "local", "docker", "modal", "prime", "daytona", "e2b"
environment_kwargs={...},
)
```
### Local Environments
The default `local` environment `LocalREPL` runs in the same process as the RLM itself, with specified global and local namespaces for minimal security. Using this REPL is generally safe, but should not be used for production settings. It also shares the same virtual environment (e.g. Conda or uv) as the host process.
#### Docker <img src="https://github.com/docker.png" alt="Docker" height="20" style="vertical-align: middle;"/> (*requires [Docker installed](https://docs.docker.com/desktop/setup/install/)*)
We also support a Docker-based environment called `DockerREPL` that launches the REPL environment as a Docker image. By default, we use the `python:3.11-slim` image, but the user can specify custom images as well.
### Isolated Environments
We support several different REPL environments that run on separate, cloud-based machines. Whenever a recursive sub-call is made in these instances, it is requested from the host process.
#### Modal Sandboxes <img src="https://github.com/modal-labs.png" alt="Modal" height="20" style="vertical-align: middle;"/>
To use [Modal Sandboxes](https://modal.com/docs/guide/sandboxes) as the REPL environment, you need to install and authenticate your Modal account.
```bash
uv add modal # add modal library
modal setup # authenticate account
```
#### Prime Intellect Sandboxes <img src="https://github.com/PrimeIntellect-ai.png" alt="Prime Intellect" height="20" style="vertical-align: middle;"/>
> [!NOTE]
> **Prime Intellect Sandboxes** are currently a beta feature. See the [documentation](https://docs.primeintellect.ai/sandboxes/overview) for more information. We noticed slow runtimes when using these sandboxes, which is currently an open issue.
To use [Prime Sandboxes](https://docs.primeintellect.ai/sandboxes/sdk), install the SDK and set your API key:
```bash
uv pip install -e ".[prime]"
export PRIME_API_KEY=...
```
### Model Providers
We currently support most major clients (OpenAI, Anthropic), as well as the router platforms (OpenRouter, Portkey, LiteLLM). For local models, we recommend using vLLM (which interfaces with the [OpenAI client](https://github.com/alexzhang13/rlm/blob/main/rlm/clients/openai.py)). To view or add support for more clients, start by looking at [`rlm/clients/`](https://github.com/alexzhang13/rlm/tree/main/rlm/clients).
## Relevant Reading
* **[Dec '25]** [Recursive Language Models arXiv](https://arxiv.org/abs/2512.24601)
* **[Oct '25]** [Recursive Language Models Blogpost](https://alexzhang13.github.io/blog/2025/rlm/)
If you use this code or repository in your research, please cite:
```bibtex
@misc{zhang2026recursivelanguagemodels,
title={Recursive Language Models},
author={Alex L. Zhang and Tim Kraska and Omar Khattab},
year={2026},
eprint={2512.24601},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2512.24601},
}
```
## Optional: Trajectory metadata and logging
`RLMChatCompletion` has an optional `metadata` field (default `None`) that holds the full trajectory (run config + all iterations and sub-calls) so you can reconstruct the run. Pass an `RLMLogger` to capture it:
- **In-memory only** (trajectory on `completion.metadata`): `logger=RLMLogger()` (no `log_dir`).
- **Also save to disk** (JSONL for the visualizer): `logger=RLMLogger(log_dir="./logs")`.
## Optional Debugging: Visualizing RLM Trajectories
We provide a simple visualizer to inspect code, sub-LM, and root-LM calls. Use `RLMLogger(log_dir="./logs")` so each completion writes a `.jsonl` file:
```python
from rlm.logger import RLMLogger
from rlm import RLM
logger = RLMLogger(log_dir="./logs")
rlm = RLM(..., logger=logger)
```
To run the visualizer locally, we use Node.js and shadcn/ui:
```
cd visualizer/
npm run dev # default localhost:3001
```
You'll have the option to select saved `.jsonl` files
<p align="center">
<img src="media/visualizer.png" alt="RLM Visualizer Example" width="800"/>
</p>
| text/markdown | null | Alex Zhang <altzhang@mit.edu> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"anthropic>=0.75.0",
"google-genai>=1.56.0",
"openai>=2.14.0",
"portkey-ai>=2.1.0",
"pytest>=9.0.2",
"python-dotenv>=1.2.1",
"requests>=2.32.5",
"rich>=13.0.0",
"modal>=0.73.0; extra == \"modal\"",
"dill>=0.3.7; extra == \"modal\"",
"e2b-code-interpreter>=0.0.11; extra == \"e2b\"",
"dill>=0.3.... | [] | [] | [] | [
"Homepage, https://github.com/alexzhang13/rlm",
"Repository, https://github.com/alexzhang13/rlm",
"Issues, https://github.com/alexzhang13/rlm/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:08:37.644623 | rlms-0.1.1.tar.gz | 86,341 | 64/09/13fd4abcf935fbbfe33c06f14d2c814513ee43d4ff1e40f6aee51f8b2039/rlms-0.1.1.tar.gz | source | sdist | null | false | b94aeda97acfb06303715c9b70849211 | 926487e3512526f27505a8306bcc2e20648991f99b232d9be6c5b76e8fec8731 | 640913fd4abcf935fbbfe33c06f14d2c814513ee43d4ff1e40f6aee51f8b2039 | MIT | [
"LICENSE"
] | 607 |
2.3 | nordpy | 1.2.0 | Interactive TUI for browsing and exporting Nordnet financial data | <p align="center">
<img src="nordpy-logo.png" alt="nordpy" width="200" />
</p>
<h1 align="center">nordpy</h1>
<p align="center">
A terminal UI for browsing and exporting your Nordnet portfolio data.
</p>
<p align="center">
<img src="https://img.shields.io/badge/python-3.10%20|%203.11%20|%203.12%20|%203.13-3776AB?logo=python&logoColor=white" alt="Python versions" />
<a href="https://github.com/j178/prek"><img src="https://img.shields.io/badge/prek-enabled-brightgreen?logo=pre-commit&logoColor=white" alt="prek" style="max-width:100%;"></a>
<a href="https://github.com/astral-sh/uv"><img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/uv/main/assets/badge/v0.json" alt="uv" style="max-width:100%;"></a>
<a href="https://github.com/astral-sh/ruff"><img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ruff/main/assets/badge/v2.json" alt="Ruff" style="max-width:100%;"></a>
<a href="https://github.com/astral-sh/ty"><img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ty/main/assets/badge/v0.json" alt="ty" style="max-width:100%;"></a>
<a href="https://github.com/tox-dev/tox-uv"><img src="https://img.shields.io/badge/tox-testing-1C1C1C?logo=tox&logoColor=white" alt="tox" alt="tox" style="max-width:100%;"></a>
<a href="https://pydantic.dev/"><img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/pydantic/pydantic/main/docs/badge/v2.json" alt="Pydantic" style="max-width:100%;"></a>
<a href="http://commitizen.github.io/cz-cli/"><img src="https://img.shields.io/badge/commitizen-friendly-brightgreen.svg" alt="Pydantic" style="max-width:100%;"></a>
<br>
<a href="https://github.com/kiliantscherny/nordpy/actions/workflows/ci.yml"><img src="https://github.com/kiliantscherny/nordpy/actions/workflows/ci.yml/badge.svg" alt="CI" style="max-width:100%;"></a>
<a href="https://github.com/kiliantscherny/nordpy/actions/workflows/release.yml"><img src="https://github.com/kiliantscherny/nordpy/actions/workflows/release.yml/badge.svg" alt="Release to PyPI" style="max-width:100%;"></a>
---
> [!CAUTION]
> **Disclaimer** – This tool is provided as-is, with no warranty of any kind. **Use it at your own risk**.
>
> This project is not affiliated in any way with Nordnet nor MitID.
>
> The author assumes no liability for any loss, damage, or misuse arising from the use of this software. You are solely responsible for securing any exported data and ensuring it is only accessible to you.
## Features
- Browse accounts, balances, holdings, transactions, trades, and orders
- **Portfolio value chart** and **instrument price charts** in the terminal
- **Sparkline trends** on holdings (3-month price history via yfinance)
- Export data to **CSV**, **Excel**, or **DuckDB**
- Session persistence with automatic re-authentication
- Headless export mode (no TUI) for scripting
- SOCKS5 proxy support
## How It Works
nordpy authenticates with Nordnet through the same MitID flow your browser uses – it simply performs the login via Nordnet's API directly from the terminal, rather than through a web page. Once authenticated, it fetches your portfolio data using Nordnet's standard API endpoints.
> [!IMPORTANT]
> **Privacy** – nordpy does **not** collect, transmit, or store any of your personal information. Your credentials are sent directly to MitID and Nordnet – never to any third-party server. Session cookies are saved locally on your machine (with `0600` permissions) solely to avoid repeated logins. No telemetry, analytics, or external services are involved.
## Requirements
- Python 3.10–3.13
- A Nordnet account with MitID (Danish)
## Installation
### With uv
```bash
uv add nordpy
```
### With pip
```bash
pip install nordpy
```
## Usage
### Interactive TUI
```bash
nordpy --user <your-mitid-username>
# Force re-authentication (ignore saved session)
nordpy --user <your-mitid-username> --force-login
# Verbose logging (debug output to stderr + nordpy.log)
nordpy --user <your-mitid-username> --verbose
# Delete saved session and exit
nordpy --logout
```
> [!NOTE]
> The first time you log in, you may be prompted to enter your **CPR number** as part of the MitID verification process. This is a one-time step required by MitID to link your identity – subsequent logins will skip this.
### Headless Export
```bash
nordpy --user <your-mitid-username> --export csv
nordpy --user <your-mitid-username> --export xlsx
nordpy --user <your-mitid-username> --export duckdb
# Export to a specific folder
nordpy --user <your-mitid-username> --export csv --output-dir ~/my-exports
```
Exported files are saved to the `exports/` directory.
> [!WARNING]
> Exported files contain sensitive financial data. Make sure you do not share these filesnor commit them to version control. Keep your exports in a secure location accessible only to you.
### Keybindings
| Key | Action |
|-----|--------|
| `Enter` | Select account / view instrument chart |
| `Tab` | Switch between tabs |
| `e` | Export current view |
| `r` | Refresh data |
| `Backspace` / `Esc` | Go back / quit |
| `q` | Quit |
## Development
```bash
git clone https://github.com/kiliantscherny/nordpy.git
cd nordpy
uv sync --dev
```
### Running checks
```bash
# Run all checks (tests on Python 3.10–3.13, lint, type check)
uv run tox
# Run tests only
uv run pytest
# Run tests with coverage
uv run pytest --cov=nordpy --cov-report=term-missing
# Lint
uv run ruff check .
# Type check
uv run ty check
```
## License
This project is licensed under the [MIT License](LICENSE).
## Acknowledgments
This project includes code from [MitID-BrowserClient](https://github.com/Hundter/MitID-BrowserClient) by Hundter, licensed under the MIT License.
Credit also to [Morten Helmstedt](https://helmstedt.dk/2025/03/hent-dine-nordnet-transaktioner-med-mitid/) for the groundwork of looking into this.
| text/markdown | Kilian Tscherny | Kilian Tscherny <90620239+kiliantscherny@users.noreply.github.com> | null | null | null | null | [] | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"beautifulsoup4>=4.14.3",
"curl-cffi>=0.7.0",
"duckdb>=1.2.0",
"loguru>=0.7.3",
"lxml>=6.0.2",
"openpyxl>=3.1.5",
"paddleocr>=3.4.0",
"paddlepaddle>=3.3.0",
"pycryptodome>=3.23.0",
"pydantic>=2.11.0",
"pyjwt>=2.11.0",
"qrcode>=8.2",
"requests>=2.32.5",
"textual>=3.1.0",
"textual-datepick... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:07:41.743846 | nordpy-1.2.0.tar.gz | 51,552 | c5/d1/a8357207c207d068501b15728d3588005908b83cd9d12b926844d363473b/nordpy-1.2.0.tar.gz | source | sdist | null | false | 83f78756ebde99a8bff922d21af5bc2a | b5177a759f995881b595e5c1b717844efa6fdeaa504ed37645dc230fe644fb3f | c5d1a8357207c207d068501b15728d3588005908b83cd9d12b926844d363473b | null | [] | 247 |
2.4 | textstat | 0.7.13 | Calculate statistical features from text | # Textstat
[](https://pypi.org/project/textstat/)
[](https://github.com/textstat/textstat/actions/workflows/test.yml)
[](https://pypistats.org/packages/textstat)
**Textstat is an easy to use library to calculate statistics from text. It helps determine readability, complexity, and grade level.**
<p align="center">
<img width="100%" src="https://images.unsplash.com/photo-1457369804613-52c61a468e7d?ixlib=rb-1.2.1&auto=format&fit=crop&w=1350&h=400&q=80">
</p>
<p align="right">
<sup>Photo by <a href="https://unsplash.com/@impatrickt">Patrick Tomasso</a>
on <a href="https://unsplash.com/images/things/book">Unsplash</a></sup>
</p>
## Usage
```python
>>> import textstat
>>> test_data = (
"Playing games has always been thought to be important to "
"the development of well-balanced and creative children; "
"however, what part, if any, they should play in the lives "
"of adults has never been researched that deeply. I believe "
"that playing games is every bit as important for adults "
"as for children. Not only is taking time out to play games "
"with our children and other adults valuable to building "
"interpersonal relationships but is also a wonderful way "
"to release built up tension."
)
>>> textstat.flesch_reading_ease(test_data)
>>> textstat.flesch_kincaid_grade(test_data)
>>> textstat.smog_index(test_data)
>>> textstat.coleman_liau_index(test_data)
>>> textstat.automated_readability_index(test_data)
>>> textstat.dale_chall_readability_score(test_data)
>>> textstat.difficult_words(test_data)
>>> textstat.linsear_write_formula(test_data)
>>> textstat.gunning_fog(test_data)
>>> textstat.text_standard(test_data)
>>> textstat.fernandez_huerta(test_data)
>>> textstat.szigriszt_pazos(test_data)
>>> textstat.gutierrez_polini(test_data)
>>> textstat.crawford(test_data)
>>> textstat.gulpease_index(test_data)
>>> textstat.osman(test_data)
```
The argument (text) for all the defined functions remains the same -
i.e the text for which statistics need to be calculated.
## Install
You can install textstat either via the Python Package Index (PyPI) or from source.
### Install using pip
```shell
pip install textstat
```
### Install using easy_install
```shell
easy_install textstat
```
### Install latest version from GitHub
```shell
git clone https://github.com/textstat/textstat.git
cd textstat
pip install .
```
### Install from PyPI
Download the latest version of textstat from http://pypi.python.org/pypi/textstat/
You can install it by doing the following:
```shell
tar xfz textstat-*.tar.gz
cd textstat-*/
python setup.py build
python setup.py install # as root
```
## Language support
By default functions implement algorithms for english language.
To change language, use:
```python
textstat.set_lang(lang)
```
The language will be used for syllable calculation and to choose
variant of the formula.
### Language variants
All functions implement `en_US` language. Some of them has also variants
for other languages listed below.
| Function | en | de | es | fr | it | nl | pl | ru |
|-----------------------------|----|----|----|----|----|----|----|----|
| flesch_reading_ease | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ |
| gunning_fog | ✔ | | | | | | ✔ | |
#### Spanish-specific tests
The following functions are specifically designed for spanish language.
They can be used on non-spanish texts, even though that use case is not recommended.
```python
>>> textstat.fernandez_huerta(test_data)
>>> textstat.szigriszt_pazos(test_data)
>>> textstat.gutierrez_polini(test_data)
>>> textstat.crawford(test_data)
```
Additional information on the formula they implement can be found in their respective docstrings.
## List of Functions
### Formulas
#### The Flesch Reading Ease formula
```python
textstat.flesch_reading_ease(text)
```
Returns the Flesch Reading Ease Score.
The following table can be helpful to assess the ease of
readability in a document.
The table is an _example_ of values. While the
maximum score is 121.22, there is no limit on how low
the score can be. A negative score is valid.
| Score | Difficulty |
|-------|-------------------|
|90-100 | Very Easy |
| 80-89 | Easy |
| 70-79 | Fairly Easy |
| 60-69 | Standard |
| 50-59 | Fairly Difficult |
| 30-49 | Difficult |
| 0-29 | Very Confusing |
> Further reading on
[Wikipedia](https://en.wikipedia.org/wiki/Flesch%E2%80%93Kincaid_readability_tests#Flesch_reading_ease)
#### The Flesch-Kincaid Grade Level
```python
textstat.flesch_kincaid_grade(text)
```
Returns the Flesch-Kincaid Grade of the given text. This is a grade
formula in that a score of 9.3 means that a ninth grader would be able to
read the document.
> Further reading on
[Wikipedia](https://en.wikipedia.org/wiki/Flesch%E2%80%93Kincaid_readability_tests#Flesch%E2%80%93Kincaid_grade_level)
#### The Fog Scale (Gunning FOG Formula)
```python
textstat.gunning_fog(text)
```
Returns the FOG index of the given text. This is a grade formula in that
a score of 9.3 means that a ninth grader would be able to read the document.
> Further reading on
[Wikipedia](https://en.wikipedia.org/wiki/Gunning_fog_index)
#### The SMOG Index
```python
textstat.smog_index(text)
```
Returns the SMOG index of the given text. This is a grade formula in that
a score of 9.3 means that a ninth grader would be able to read the document.
Texts of fewer than 30 sentences are statistically invalid, because
the SMOG formula was normed on 30-sentence samples. textstat requires at
least 3 sentences for a result.
> Further reading on
[Wikipedia](https://en.wikipedia.org/wiki/SMOG)
#### Automated Readability Index
```python
textstat.automated_readability_index(text)
```
Returns the ARI (Automated Readability Index) which outputs
a number that approximates the grade level needed to
comprehend the text.
For example if the ARI is 6.5, then the grade level to comprehend
the text is 6th to 7th grade.
> Further reading on
[Wikipedia](https://en.wikipedia.org/wiki/Automated_readability_index)
#### The Coleman-Liau Index
```python
textstat.coleman_liau_index(text)
```
Returns the grade level of the text using the Coleman-Liau Formula. This is
a grade formula in that a score of 9.3 means that a ninth grader would be
able to read the document.
> Further reading on
[Wikipedia](https://en.wikipedia.org/wiki/Coleman%E2%80%93Liau_index)
#### Linsear Write Formula
```python
textstat.linsear_write_formula(text)
```
Returns the grade level using the Linsear Write Formula. This is
a grade formula in that a score of 9.3 means that a ninth grader would be
able to read the document.
> Further reading on
[Wikipedia](https://en.wikipedia.org/wiki/Linsear_Write)
#### Dale-Chall Readability Score
```python
textstat.dale_chall_readability_score(text)
```
Different from other tests, since it uses a lookup table
of the most commonly used 3000 English words. Thus it returns
the grade level using the New Dale-Chall Formula.
| Score | Understood by |
|-------------|-----------------------------------------------|
|4.9 or lower | average 4th-grade student or lower |
| 5.0–5.9 | average 5th or 6th-grade student |
| 6.0–6.9 | average 7th or 8th-grade student |
| 7.0–7.9 | average 9th or 10th-grade student |
| 8.0–8.9 | average 11th or 12th-grade student |
| 9.0–9.9 | average 13th to 15th-grade (college) student |
> Further reading on
[Wikipedia](https://en.wikipedia.org/wiki/Dale%E2%80%93Chall_readability_formula)
#### Readability Consensus based upon all the above tests
```python
textstat.text_standard(text, float_output=False)
```
Based upon all the above tests, returns the estimated school
grade level required to understand the text.
Optional `float_output` allows the score to be returned as a
`float`. Defaults to `False`.
#### Spache Readability Formula
```python
textstat.spache_readability(text)
```
Returns grade level of english text.
Intended for text written for children up to grade four.
> Further reading on
[Wikipedia](https://en.wikipedia.org/wiki/Spache_readability_formula)
#### McAlpine EFLAW Readability Score
```python
textstat.mcalpine_eflaw(text)
```
Returns a score for the readability of an english text for a foreign learner or
English, focusing on the number of miniwords and length of sentences.
It is recommended to aim for a score equal to or lower than 25.
> Further reading on
[This blog post](https://strainindex.wordpress.com/2009/04/30/mcalpine-eflaw-readability-score/)
#### Reading Time
```python
textstat.reading_time(text, ms_per_char=14.69)
```
Returns the reading time of the given text.
Assumes 14.69ms per character.
> Further reading in
[This academic paper](https://homepages.inf.ed.ac.uk/keller/papers/cognition08a.pdf)
### Language Specific Formulas
#### Índice de lecturabilidad Fernandez-Huerta (Spanish)
```python
textstat.fernandez_huerta(text)
```
Reformulation of the Flesch Reading Ease Formula specifically for spanish.
The results can be interpreted similarly
> Further reading on
[This blog post](https://legible.es/blog/lecturabilidad-fernandez-huerta/)
#### Índice de perspicuidad de Szigriszt-Pazos (Spanish)
```python
textstat.szigriszt_pazos(text)
```
Adaptation of Flesch Reading Ease formula for spanish-based texts.
Attempts to quantify how understandable a text is.
> Further reading on
[This blog post](https://legible.es/blog/perspicuidad-szigriszt-pazos/)
#### Fórmula de comprensibilidad de Gutiérrez de Polini (Spanish)
```python
textstat.gutierrez_polini(text)
```
Returns the Gutiérrez de Polini understandability index.
Specifically designed for the texts in spanish, not an adaptation.
Conceived for grade-school level texts.
Scores for more complex text are not reliable.
> Further reading on
[This blog post](https://legible.es/blog/comprensibilidad-gutierrez-de-polini/)
#### Fórmula de Crawford (Spanish)
```python
textstat.crawford(text)
```
Returns the Crawford score for the text.
Returns an estimate of the years of schooling required to understand the text.
The text is only valid for elementary school level texts.
> Further reading on
[This blog post](https://legible.es/blog/formula-de-crawford/)
#### Osman (Arabic)
```python
textstat.osman(text)
```
Returns OSMAN score for text.
Designed for Arabic, an adaption of Flesch and Fog Formula.
Introduces a new factor called "Faseeh".
> Further reading in
[This academic paper](https://www.aclweb.org/anthology/L16-1038.pdf)
#### Gulpease Index (Italian)
```python
textstat.gulpease_index(text)
```
Returns the Gulpease index of Italian text, which translates to
level of education completed.
Lower scores require higher level of education to read with ease.
> Further reading on
[Wikipedia](https://it.wikipedia.org/wiki/Indice_Gulpease)
#### Wiener Sachtextformel (German)
```python
textstat.wiener_sachtextformel(text, variant)
```
Returns a grade level score for the given text.
A value of 4 means very easy text, whereas 15 means very difficult text.
> Further reading on
[Wikipedia](https://de.wikipedia.org/wiki/Lesbarkeitsindex#Wiener_Sachtextformel)
### Aggregates and Averages
#### Syllable Count
```python
textstat.syllable_count(text)
```
Returns the number of syllables present in the given text.
Uses the Python module [Pyphen](https://github.com/Kozea/Pyphen)
for syllable calculation in most languages, but defaults to
[nltk.corpus.cmudict](https://www.nltk.org/) for
en_US.
#### Lexicon Count
```python
textstat.lexicon_count(text, removepunct=True)
```
Calculates the number of words present in the text.
Optional `removepunct` specifies whether we need to take
punctuation symbols into account while counting lexicons.
Default value is `True`, which removes the punctuation
before counting lexicon items.
#### Sentence Count
```python
textstat.sentence_count(text)
```
Returns the number of sentences present in the given text.
#### Character Count
```python
textstat.char_count(text, ignore_spaces=True)
```
Returns the number of characters present in the given text.
#### Letter Count
```python
textstat.letter_count(text, ignore_spaces=True)
```
Returns the number of characters present in the given text without punctuation.
#### Polysyllable Count
```python
textstat.polysyllabcount(text)
```
Returns the number of words with a syllable count greater than or equal to 3.
#### Monosyllable Count
```python
textstat.monosyllabcount(text)
```
Returns the number of words with a syllable count equal to one.
## Contributing
If you find any problems, you should open an
[issue](https://github.com/shivam5992/textstat/issues).
If you can fix an issue you've found, or another issue, you should open
a [pull request](https://github.com/shivam5992/textstat/pulls).
1. Fork this repository on GitHub to start making your changes to the master
branch (or branch off of it).
2. Write a test which shows that the bug was fixed or that the feature works as expected.
3. Send a pull request!
### Development setup
> It is recommended you use a [virtual environment](
https://docs.python.org/3/tutorial/venv.html), or [Pipenv](
https://docs.pipenv.org/) to keep your development work isolated from your
systems Python installation.
```bash
$ git clone https://github.com/<yourname>/textstat.git # Clone the repo from your fork
$ cd textstat
$ pip install -r requirements.txt # Install all dependencies
$ # Make changes
$ python -m pytest test.py # Run tests
```
| text/markdown | Shivam Bansal, Chaitanya Aggarwal | shivam5992@gmail.com | null | null | MIT | null | [
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Languag... | [] | https://github.com/textstat/textstat | null | >=3.6 | [] | [] | [] | [
"pyphen",
"nltk",
"setuptools"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.0 | 2026-02-18T21:07:39.525296 | textstat-0.7.13.tar.gz | 138,932 | 8c/0f/b673fcec5ad6e976b2e8368ef3651fe0fea3348a1191bacfcd41a17ddec6/textstat-0.7.13.tar.gz | source | sdist | null | false | 48865ced55cdb8181bd2a5f63ebd167d | a88d1da76287cd27ca4ce7bcba1ebaf2890544a5f0bb6a5758fa84cef3bceccb | 8c0fb673fcec5ad6e976b2e8368ef3651fe0fea3348a1191bacfcd41a17ddec6 | null | [
"LICENSE"
] | 53,098 |
2.4 | mcp-commons | 2.0.0 | Shared infrastructure library for MCP (Model Context Protocol) servers | # MCP Commons
> A Python library providing reusable infrastructure for building Model Context Protocol (MCP) servers with less boilerplate and consistent patterns.
[](https://pypi.org/project/mcp-commons/)
[](https://pypi.org/project/mcp-commons/)
[](https://opensource.org/licenses/MIT)
## Overview
MCP Commons provides architectural patterns for building maintainable MCP servers:
**Primary Value (90%)**:
- **Adapter Pattern** - Decouple business logic from MCP protocol for multi-interface reuse
- **UseCaseResult** - Consistent error handling pattern across all operations
**Convenience Features (10%)**:
- **Bulk Operations** - Config-driven tool registration with error reporting
- **Tool Lifecycle** - Batch operations over FastMCP's add_tool() and remove_tool()
**Built on FastMCP**: mcp-commons is a thin wrapper over FastMCP's existing methods. It doesn't replace FastMCP's capabilities - it provides architectural patterns and convenience wrappers to make your code more maintainable.
**Current Version**: 1.3.4 | [What's New](#whats-new-in-v134) | [Changelog](CHANGELOG.md)
---
## Why mcp-commons Exists
### The Problem with Decorators
The MCP SDK uses decorators (`@server.tool()`) to register functions as tools. While the goal of making function exposure easy was admirable, **decorators were the wrong mechanism** for this purpose.
**Decorators should add cross-cutting concerns** (caching, authentication, logging) that apply regardless of how a function is used. They should not specify usage contexts (MCP vs REST vs CLI).
```python
# ❌ PROBLEM: Function is now ONLY usable in MCP context
from mcp.server.fastmcp import FastMCP
server = FastMCP("my-server")
@server.tool()
async def search_documents(query: str) -> dict:
"""This function is tied to MCP - can't reuse for REST, CLI, or testing."""
results = await document_service.search(query)
return {"results": results}
# Can't use this function in:
# - REST API endpoints
# - CLI commands
# - GraphQL resolvers
# - Unit tests (without MCP context)
```
### The Solution: Adapter Pattern
**Adapter/wrapper functions** provide the same ease of use while maintaining proper separation of concerns. Your business logic stays pure and framework-agnostic, while thin adapters handle protocol translation.
```python
# ✅ SOLUTION: Pure business logic, reusable everywhere
async def search_documents(query: str) -> List[Document]:
"""Pure function - no MCP coupling, works anywhere."""
return await document_service.search(query)
# MCP adapter - thin wrapper for protocol translation
@server.tool()
async def mcp_search(query: str) -> dict:
results = await search_documents(query)
return {"results": [doc.to_dict() for doc in results]}
# REST API - reuses same logic
@app.get("/api/search")
async def api_search(query: str):
results = await search_documents(query)
return {"results": [doc.to_dict() for doc in results]}
# CLI - reuses same logic
@cli.command()
def cli_search(query: str):
results = asyncio.run(search_documents(query))
for doc in results:
print(f"- {doc.title}")
# Testing - pure function, no framework needed
async def test_search():
results = await search_documents("test query")
assert len(results) > 0
```
### Architectural Benefits
This adapter pattern enables:
1. **DRY Principle** - One business function, multiple interfaces
2. **Separation of Concerns** - Business logic independent of transport
3. **Framework Independence** - No coupling to MCP SDK, FastAPI, Click, etc.
4. **Easy Testing** - Test pure functions without framework context
5. **Future-Proof** - When MCP SDK v2.0 changes, only adapters need updates
**mcp-commons exists because the MCP SDK got this fundamental design decision wrong.** The adapter pattern isn't "nice to have" - it's essential for proper architecture in any non-trivial application.
---
## Table of Contents
- [Installation](#installation)
- [Quick Start](#quick-start)
- [Core Features](#core-features)
- [Tool Adapters](#tool-adapters)
- [Bulk Registration](#bulk-registration)
- [Tool Management (v1.2.0)](#tool-management-v120)
- [Advanced Usage](#advanced-usage)
- [API Reference](#api-reference)
- [Contributing](#contributing)
- [License](#license)
---
## Installation
### Requirements
- **Python**: 3.11+ (3.13 recommended)
- **MCP SDK**: 1.26.0+
- **Dependencies**: Pydantic 2.12.5+, PyYAML 6.0.3+
### Install from PyPI
```bash
pip install mcp-commons
```
### Install for Development
```bash
git clone https://github.com/dawsonlp/mcp-commons.git
cd mcp-commons
pip install -e ".[dev]"
```
---
## What FastMCP Provides vs What mcp-commons Adds
| Feature | FastMCP (SDK) | mcp-commons |
|---------|---------------|-------------|
| **Tool registration** | `server.add_tool(func, name, desc)` | Config-driven bulk wrapper |
| **Tool removal** | `server.remove_tool(name)` (v1.17.0+) | Batch wrapper with reporting |
| **Decorators** | `@server.tool()` decorator | ❌ We don't use decorators |
| **Adapter pattern** | ❌ Not provided | ✅ Core feature - decouples logic |
| **UseCaseResult** | ❌ Not provided | ✅ Consistent error handling |
| **Error reporting** | Exceptions on failure | Success/failure batch reports |
| **Tool managers** | ToolManager, ResourceManager, etc. | ✅ We use FastMCP's managers |
**Key Point**: mcp-commons doesn't replace FastMCP - it builds on it. We use FastMCP's `add_tool()` and `remove_tool()` methods internally, adding convenience wrappers and architectural patterns on top.
---
## Quick Start
### 1. Basic Adapter Pattern
Convert your async functions to MCP tools:
```python
from mcp_commons import create_mcp_adapter, UseCaseResult
from mcp.server.fastmcp import FastMCP
# Create MCP server
server = FastMCP("my-server")
# Your business logic
async def search_documents(query: str, limit: int = 10) -> UseCaseResult:
"""Search documents with natural language query."""
results = await document_service.search(query, limit)
return UseCaseResult.success_with_data({
"results": results,
"count": len(results)
})
# Register as MCP tool (adapter handles conversion automatically)
@server.tool()
async def search(query: str, limit: int = 10) -> dict:
adapter = create_mcp_adapter(search_documents)
return await adapter(query=query, limit=limit)
```
### 2. Bulk Registration
Register multiple tools at once:
```python
from mcp_commons import bulk_register_tools
# Define tool configurations
tools_config = {
"list_projects": {
"function": list_projects_handler,
"description": "List all projects"
},
"create_project": {
"function": create_project_handler,
"description": "Create a new project"
},
"delete_project": {
"function": delete_project_handler,
"description": "Delete a project by ID"
}
}
# Register all at once with consistent error handling
registered = bulk_register_tools(server, tools_config)
print(f"Registered {len(registered)} tools")
```
### 3. Tool Management (v1.2.0)
Dynamically manage tools at runtime:
```python
from mcp_commons import (
bulk_remove_tools,
bulk_replace_tools,
get_registered_tools,
tool_exists
)
# Check what tools exist
all_tools = get_registered_tools(server)
print(f"Currently registered: {all_tools}")
# Remove deprecated tools
result = bulk_remove_tools(server, ["old_tool1", "old_tool2"])
print(f"Removed {len(result['removed'])} tools")
# Hot-reload: replace tools atomically
result = bulk_replace_tools(
server,
tools_to_remove=["v1_search"],
tools_to_add={
"v2_search": {
"function": improved_search,
"description": "Enhanced search with filters"
}
}
)
```
---
## Core Features
### Tool Adapters
The adapter pattern automatically handles the conversion between your business logic and MCP tool format.
#### Basic Usage
```python
from mcp_commons import create_mcp_adapter, UseCaseResult
async def calculate_metrics(dataset_id: str) -> UseCaseResult:
"""Calculate metrics for a dataset."""
try:
data = await load_dataset(dataset_id)
metrics = compute_metrics(data)
return UseCaseResult.success_with_data(metrics)
except DatasetNotFoundError as e:
return UseCaseResult.failure(f"Dataset not found: {e}")
except Exception as e:
return UseCaseResult.failure(f"Calculation failed: {e}")
# Create adapter
adapted = create_mcp_adapter(calculate_metrics)
# Use in MCP server
@server.tool()
async def metrics(dataset_id: str) -> dict:
return await adapted(dataset_id=dataset_id)
```
#### Error Handling
Adapters provide consistent error responses:
```python
# Success response
UseCaseResult.success_with_data({"status": "completed", "value": 42})
# Returns: {"success": True, "data": {...}, "error": None}
# Failure response
UseCaseResult.failure("Invalid input parameters")
# Returns: {"success": False, "data": None, "error": "Invalid input parameters"}
```
### Bulk Registration
Convenience wrappers over FastMCP's `add_tool()` method for config-driven registration:
**What it actually does**:
```python
# mcp-commons bulk_register_tools() is essentially:
for tool_name, config in tools_config.items():
server.add_tool( # ← FastMCP's existing method
config["function"],
name=tool_name,
description=config["description"]
)
# Plus: error handling, logging, and success/failure reporting
```
**Why use it**: Config-driven API + batch error handling instead of manual loops.
#### Configuration Dictionary
```python
tools_config = {
"tool_name": {
"function": async_function,
"description": "Tool description",
# Optional metadata
}
}
registered = bulk_register_tools(server, tools_config)
```
#### Tuple Format (Simple)
```python
from mcp_commons import bulk_register_tuple_format
tools = [
("list_items", list_items_function),
("get_item", get_item_function),
("create_item", create_item_function),
]
bulk_register_tuple_format(server, tools)
```
#### With Adapter Pattern
```python
from mcp_commons import bulk_register_with_adapter_pattern
# All functions return UseCaseResult
use_cases = {
"validate_data": validate_data_use_case,
"process_data": process_data_use_case,
"export_data": export_data_use_case,
}
bulk_register_with_adapter_pattern(
server,
use_cases,
adapter_function=create_mcp_adapter
)
```
### Tool Management (v1.2.0)
New in version 1.2.0: Convenience wrappers for batch tool operations.
**What it actually does**: Loops over FastMCP's `remove_tool()` method (added in SDK v1.17.0) with error reporting:
```python
# mcp-commons bulk_remove_tools() is essentially:
for tool_name in tool_names:
try:
server.remove_tool(tool_name) # ← FastMCP's method (v1.17.0+)
removed.append(tool_name)
except Exception as e:
failed.append((tool_name, str(e)))
# Returns: {"removed": [...], "failed": [...], "success_rate": 66.7}
```
**Why use it**: Batch operations + detailed success/failure reporting instead of manual loops.
#### Remove Tools
```python
from mcp_commons import bulk_remove_tools
# Remove multiple tools
result = bulk_remove_tools(server, ["deprecated_tool1", "deprecated_tool2"])
# Check results
print(f"Removed: {result['removed']}")
print(f"Failed: {result['failed']}")
print(f"Success rate: {result['success_rate']:.1f}%")
```
#### Replace Tools (Hot Reload)
```python
from mcp_commons import bulk_replace_tools
# Atomically swap old tools for new ones
result = bulk_replace_tools(
server,
tools_to_remove=["old_search", "old_filter"],
tools_to_add={
"new_search": {
"function": enhanced_search,
"description": "Improved search with AI"
},
"new_filter": {
"function": enhanced_filter,
"description": "Advanced filtering"
}
}
)
```
#### Conditional Removal
```python
from mcp_commons import conditional_remove_tools
# Remove tools matching a pattern
removed = conditional_remove_tools(
server,
lambda name: name.startswith("test_") or "deprecated" in name.lower()
)
print(f"Cleaned up {len(removed)} tools")
```
#### Tool Inspection
```python
from mcp_commons import get_registered_tools, tool_exists, count_tools
# List all tools
tools = get_registered_tools(server)
print(f"Available tools: {tools}")
# Check specific tool
if tool_exists(server, "search_documents"):
print("Search tool is available")
# Get count
total = count_tools(server)
print(f"Total tools registered: {total}")
```
---
## Advanced Usage
### Custom Error Handlers
```python
from mcp_commons import create_mcp_adapter
def custom_success_handler(result):
"""Custom formatting for successful results."""
return {
"status": "success",
"payload": result.data,
"timestamp": datetime.now().isoformat()
}
def custom_error_handler(result):
"""Custom formatting for errors."""
return {
"status": "error",
"message": result.error,
"timestamp": datetime.now().isoformat()
}
adapted = create_mcp_adapter(
my_function,
success_handler=custom_success_handler,
error_handler=custom_error_handler
)
```
### Validation and Logging
```python
from mcp_commons import validate_tools_config, log_registration_summary
# Validate before registering
try:
validate_tools_config(tools_config)
except ValueError as e:
print(f"Invalid configuration: {e}")
# Register with logging
registered = bulk_register_tools(server, tools_config)
log_registration_summary(registered, len(tools_config), "MyServer")
```
### Testing Your Tools
```python
import pytest
from mcp_commons import create_mcp_adapter, UseCaseResult
@pytest.mark.asyncio
async def test_search_tool():
"""Test search tool with adapter."""
async def mock_search(query: str) -> UseCaseResult:
return UseCaseResult.success_with_data({"results": ["doc1", "doc2"]})
adapted = create_mcp_adapter(mock_search)
result = await adapted(query="test")
assert result["success"] is True
assert len(result["data"]["results"]) == 2
```
---
## API Reference
### Core Functions
#### `create_mcp_adapter()`
Converts an async function to an MCP-compatible tool adapter.
**Parameters:**
- `use_case` (callable): Async function returning `UseCaseResult`
- `success_handler` (callable, optional): Custom success formatter
- `error_handler` (callable, optional): Custom error formatter
**Returns:** Async callable compatible with MCP tools
---
#### `bulk_register_tools()`
Registers multiple tools from a configuration dictionary.
**Parameters:**
- `server` (FastMCP): MCP server instance
- `tools_config` (dict): Tool configurations
**Returns:** List of (tool_name, description) tuples
---
#### `bulk_remove_tools()` *(v1.2.0)*
Removes multiple tools from a running server.
**Parameters:**
- `server` (FastMCP): MCP server instance
- `tool_names` (list[str]): Names of tools to remove
**Returns:** Dictionary with `removed`, `failed`, and `success_rate` keys
---
#### `bulk_replace_tools()` *(v1.2.0)*
Atomically replaces tools for hot-reloading.
**Parameters:**
- `server` (FastMCP): MCP server instance
- `tools_to_remove` (list[str]): Tools to remove
- `tools_to_add` (dict): New tools to add
**Returns:** Dictionary with operation results
---
For complete API documentation, see [API Reference](https://github.com/dawsonlp/mcp-commons/wiki/API-Reference).
---
## What's New in v1.3.4
### Documentation Corrections
- ✅ Fixed `__version__` in `__init__.py` (was stuck at 1.2.2)
- ✅ Updated README.md with correct version references and dependency versions
- ✅ Updated CHANGELOG.md reference links
- ✅ All version references now consistent across codebase
### Previous Highlights
- **v1.3.x**: Configuration management, error hierarchy, server builder
- **v1.2.x**: Tool lifecycle management (remove, replace, inspect tools)
- **v1.1.x**: Bulk registration, adapter pattern foundations
See [CHANGELOG.md](CHANGELOG.md) for complete version history.
---
## Contributing
Contributions are welcome! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
### Development Setup
```bash
# Clone repository
git clone https://github.com/dawsonlp/mcp-commons.git
cd mcp-commons
# Install with dev dependencies
pip install -e ".[dev]"
# Run tests
pytest tests/ -v
# Run linting
black src/ tests/
isort src/ tests/
ruff check src/ tests/
```
---
## Support
- 📖 **Documentation**: [GitHub Wiki](https://github.com/dawsonlp/mcp-commons/wiki)
- 🐛 **Issues**: [GitHub Issues](https://github.com/dawsonlp/mcp-commons/issues)
- 💬 **Discussions**: [GitHub Discussions](https://github.com/dawsonlp/mcp-commons/discussions)
---
## License
MIT License - see [LICENSE](LICENSE) for details.
---
## Acknowledgments
Built with the [Model Context Protocol](https://modelcontextprotocol.io/) by Anthropic.
| text/markdown | MCP Commons Contributors | null | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules",
"Top... | [] | null | null | >=3.11 | [] | [] | [] | [
"pydantic>=2.12.5",
"PyYAML>=6.0.3",
"mcp>=1.26.0",
"pytest>=9.0.2; extra == \"dev\"",
"pytest-asyncio>=1.3.0; extra == \"dev\"",
"pytest-cov>=7.0.0; extra == \"dev\"",
"black>=25.12.0; extra == \"dev\"",
"isort>=7.0.0; extra == \"dev\"",
"ruff>=0.14.8; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/dawsonlp/mcp-commons",
"Repository, https://github.com/dawsonlp/mcp-commons.git",
"Documentation, https://github.com/dawsonlp/mcp-commons#readme",
"Issues, https://github.com/dawsonlp/mcp-commons/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:07:13.931740 | mcp_commons-2.0.0.tar.gz | 31,036 | ee/48/e45b0d940fe57cc07f5b60ff9c45fc3e3ebb45616b11cc63884a2ee4589b/mcp_commons-2.0.0.tar.gz | source | sdist | null | false | 20ce810494ce6574196ac5e1bd512e37 | b40a4585b1d51d72cda34623175aa6adf980f4f9da8a58393b5b37b0c6ba6f91 | ee48e45b0d940fe57cc07f5b60ff9c45fc3e3ebb45616b11cc63884a2ee4589b | MIT | [] | 236 |
2.4 | pivoteer | 0.2.2 | Inject pandas DataFrames into Excel templates with table resizing and pivot refresh. | # pivoteer
[](https://github.com/flitzrrr/pivoteer/actions/workflows/ci.yml)
[](https://pypi.org/project/pivoteer/)
[](LICENSE)
pivoteer injects pandas DataFrames into existing Excel templates by editing the
underlying XML. It resizes Excel Tables (ListObjects) and forces PivotTables to
refresh on open without corrupting pivot caches.
## Why pivoteer
Most Python Excel libraries rewrite workbooks, which can break PivotTables,
filters, and formatting in real-world templates. pivoteer is designed for
enterprise reporting workflows where templates are authored in Excel and must
remain intact. It surgically updates only the table data and table metadata so
PivotTables remain connected and refresh correctly.
## Installation
```bash
pip install pivoteer
```
## Quick Start
```python
from pathlib import Path
import pandas as pd
from pivoteer.core import Pivoteer
pivoteer = Pivoteer(Path("template.xlsx"))
df = pd.DataFrame(
{
"Category": ["Hardware", "Software"],
"Region": ["North", "South"],
"Amount": [120.0, 250.0],
"Date": ["2024-01-01", "2024-01-02"],
}
)
pivoteer.apply_dataframe("DataSource", df)
pivoteer.save("report_output.xlsx")
```
## Architecture Overview
- Input/output: `.xlsx` files are ZIP archives containing OpenXML parts.
- Data injection: updates `xl/worksheets/sheetN.xml` row data using inline
strings to avoid touching sharedStrings.xml.
- Table resizing: updates `xl/tables/tableN.xml` by recalculating the `ref`
range based on the DataFrame shape.
- Pivot refresh: sets `refreshOnLoad="1"` in
`xl/pivotCache/pivotCacheDefinitionN.xml` when present.
- Pivot cache field sync (opt-in): appends missing cache field entries for table
columns so new headers appear in existing PivotTables.
## Features
- Surgical Data Injection: updates worksheet XML without touching sharedStrings.
- Table Resizing: recalculates ListObject ranges to match injected data.
- Pivot Preservation: sets pivot caches to refresh on load when present.
- Optional Pivot Cache Field Sync: appends missing cache field metadata for new
table columns without touching PivotTable layouts.
- Minimal IO: stream-based ZIP copy-and-replace for stability.
## Pivot Cache Field Sync
When new columns are added to an Excel Table, existing PivotTables often fail to
show the new fields until the PivotCache metadata is updated. pivoteer can
synchronize PivotCache field definitions so new table columns appear in the
PivotTable field list.
What pivoteer does:
- Syncs PivotCache field metadata for the target table.
- Appends missing cache fields so new columns are visible in the PivotTable UI.
What pivoteer does not do:
- Does not create PivotTables.
- Does not modify PivotTable layouts or filters.
- Does not touch slicers or formatting.
## Usage Patterns
### Multiple table updates
```python
from pivoteer.core import Pivoteer
import pandas as pd
p = Pivoteer("template.xlsx")
p.apply_dataframe("SalesData", pd.read_csv("sales.csv"))
p.apply_dataframe("CostData", pd.read_csv("costs.csv"))
p.save("report_output.xlsx")
```
### Opt-in pivot cache field sync
```python
from pivoteer.core import Pivoteer
import pandas as pd
p = Pivoteer("template.xlsx", enable_pivot_field_sync=True)
p.apply_dataframe("RawData", pd.read_csv("usage.csv"))
p.save("report_output.xlsx")
```
This flag is optional; when it is not set, pivoteer behaves exactly as before.
### Advanced usage with TemplateEngine
```python
from pathlib import Path
import pandas as pd
from pivoteer.template_engine import TemplateEngine
engine = TemplateEngine(Path("template.xlsx"))
engine.apply_dataframe("RawData", pd.read_csv("usage.csv"))
engine.sync_pivot_cache_fields()
engine.ensure_pivot_refresh_on_load()
parts = engine.get_modified_parts()
```
### Low-level XML access
For custom XML inspection or modification, `read_xml_part` reads any XML part
from an Excel archive:
```python
import zipfile
from pivoteer.xml_engine import read_xml_part
with zipfile.ZipFile("template.xlsx", "r") as archive:
tree = read_xml_part(archive, "xl/workbook.xml")
print(tree.getroot().tag)
```
### Supported data types
pivoteer handles the following DataFrame value types when injecting rows:
| Type | Excel representation |
|---|---|
| `int`, `float` | Numeric cell (`<v>`) |
| `str` | Inline string (`<is><t>`) |
| `datetime.date`, `datetime.datetime` | Inline string (ISO 8601) |
| `None`, `NaN`, `NaT` | Empty cell (no children) |
### Large datasets
pivoteer is optimized for replacing table data without rewriting the entire
workbook. It is a good fit for large tables where preserving PivotTables and
filters matters more than Excel formatting for each row.
## Safety Guarantees
- Opt-in only: the feature is disabled unless explicitly enabled.
- Only missing cache fields are appended.
- Existing cache field order is preserved.
- PivotTable definitions are not modified.
## Limitations
- The PivotCache source must reference the named Excel Table.
- The template must already contain PivotTables and pivot caches.
- The structured table must exist and be the PivotTable cache source.
- pivoteer does not auto-refresh the Excel UI; Excel recalculates pivots on open.
## Compatibility
- Python: 3.10+
- Excel: Desktop Excel (Windows/macOS) supports `refreshOnLoad` for PivotTables.
- Templates: Must include Excel Tables (ListObjects) with stable names.
## Troubleshooting
- "Table not found": Ensure the Excel Table name matches exactly.
- "Pivot cache not found": The template may not include a PivotTable; this is
expected for synthetic templates.
- "DataFrame is empty": pivoteer refuses empty payloads to protect templates.
## Support and Requests
- Bugs: open a GitHub issue using the Bug Report template.
- Feature requests: open a GitHub issue using the Feature Request template.
- Security: follow the reporting process in `SECURITY.md`.
## Security
If you discover a vulnerability, please read `SECURITY.md` for reporting
instructions.
## Development
```bash
python -m venv .venv
source .venv/bin/activate
pip install -e .[dev]
pytest
```
| text/markdown | Martin | null | Martin | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pyth... | [] | null | null | >=3.10 | [] | [] | [] | [
"lxml>=5.2.0",
"pandas>=2.2.0",
"pytest-cov>=6.0.0; extra == \"dev\"",
"pytest>=8.3.0; extra == \"dev\"",
"ruff>=0.9.0; extra == \"dev\"",
"xlsxwriter>=3.2.0; extra == \"dev\""
] | [] | [] | [] | [
"Repository, https://github.com/flitzrrr/pivoteer",
"Issues, https://github.com/flitzrrr/pivoteer/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:07:00.692402 | pivoteer-0.2.2.tar.gz | 23,594 | 8e/3f/2bb41865eb3bb63b7e0b0d73037d6da5efd9285427c5c61f1ed62505ceb3/pivoteer-0.2.2.tar.gz | source | sdist | null | false | 0bb620dcb38bf1ff8a4ab653e625bd15 | d80db02426a8253458899d030f981268a0a014aa59b0666390132539e6bde7d7 | 8e3f2bb41865eb3bb63b7e0b0d73037d6da5efd9285427c5c61f1ed62505ceb3 | null | [
"LICENSE"
] | 229 |
2.4 | coda-mcp | 0.1.1 | MCP server for quantum computing tools - simulation, transpilation, QPU access | # coda-mcp
MCP server for quantum computing tools. Provides circuit simulation, transpilation, QPU access, and research paper search.
Works with MCP-compatible clients that support stdio transport: Claude Desktop, Claude Code (CLI), VS Code, Cursor, Zed, and more.
## Quick Start
### 1. Get your API token
Generate a token at [coda.conductorquantum.com/settings/api](https://coda.conductorquantum.com/settings/api)
### 2. Configure your MCP client
<details>
<summary><b>Claude Desktop</b></summary>
Add to your Claude Desktop config:
**macOS:** `~/Library/Application Support/Claude/claude_desktop_config.json`
**Windows:** `%AppData%\Claude\claude_desktop_config.json`
```json
{
"mcpServers": {
"coda": {
"command": "/path/to/uvx",
"args": ["coda-mcp"],
"env": {
"CODA_API_TOKEN": "your-token-here"
}
}
}
}
```
Find your uvx path with `which uvx` (typically `~/.local/bin/uvx` or `/usr/local/bin/uvx`).
Restart Claude Desktop after saving.
</details>
<details>
<summary><b>Claude Code (CLI)</b></summary>
**Quick install via CLI:**
```bash
claude mcp add --env CODA_API_TOKEN=your-token-here coda -- uvx coda-mcp
```
**Or manual configuration** - add to `~/.claude.json`:
```json
{
"mcpServers": {
"coda": {
"command": "/path/to/uvx",
"args": ["coda-mcp"],
"env": {
"CODA_API_TOKEN": "your-token-here"
}
}
}
}
```
**Team-shared config** - add `.mcp.json` to your project root:
```json
{
"mcpServers": {
"coda": {
"command": "/path/to/uvx",
"args": ["coda-mcp"],
"env": {
"CODA_API_TOKEN": "${CODA_API_TOKEN}"
}
}
}
}
```
Then team members only need to set `CODA_API_TOKEN` in their environment.
</details>
<details>
<summary><b>Cursor</b></summary>
Add to your Cursor MCP config (`~/.cursor/mcp.json` or `.cursor/mcp.json` in project root):
```json
{
"mcpServers": {
"coda": {
"command": "/path/to/uvx",
"args": ["coda-mcp"],
"env": {
"CODA_API_TOKEN": "your-token-here"
}
}
}
}
```
Find your uvx path with `which uvx`.
</details>
<details>
<summary><b>Zed</b></summary>
Add to your Zed settings (`~/.config/zed/settings.json`):
```json
{
"context_servers": {
"coda": {
"command": {
"path": "/path/to/uvx",
"args": ["coda-mcp"],
"env": {
"CODA_API_TOKEN": "your-token-here"
}
}
}
}
}
```
</details>
<details>
<summary><b>Generic MCP Client</b></summary>
For any MCP-compatible client, configure:
- **Transport:** stdio
- **Command:** `uvx coda-mcp`
- **Environment:** `CODA_API_TOKEN=your-token-here`
Or if you prefer pip installation:
```bash
pip install coda-mcp
coda-mcp # runs the server
```
</details>
## Installation
```bash
# Using uvx (recommended, no install needed)
uvx coda-mcp
# Using pip
pip install coda-mcp
# Using uv
uv tool install coda-mcp
```
## Tools
### Quantum Circuit Tools
| Tool | Description |
|------|-------------|
| `transpile` | Convert between quantum frameworks (Qiskit, Cirq, PennyLane, Braket, PyQuil, CUDA-Q, OpenQASM) |
| `simulate` | Run circuit simulation (CPU via Aer, GPU via CUDA-Q) |
| `to_openqasm3` | Convert circuit to OpenQASM 3.0 |
| `estimate_resources` | Analyze qubit count, depth, and gate counts |
| `split_circuit` | Cut large circuits for distributed execution |
### QPU Tools
| Tool | Description |
|------|-------------|
| `qpu_submit` | Submit circuit to QPU backend (IonQ, IQM, Rigetti, AQT) |
| `qpu_status` | Check job status and get results |
| `qpu_devices` | List available QPU devices |
### Search Tools
| Tool | Description |
|------|-------------|
| `search_papers` | Search quantum computing papers via Exa |
| `get_paper` | Fetch full paper contents |
## Examples
### Simulate a Bell State
```
Create and simulate a Bell state circuit
```
The `simulate` tool accepts Qiskit code:
```python
from qiskit import QuantumCircuit
qc = QuantumCircuit(2)
qc.h(0)
qc.cx(0, 1)
qc.measure_all()
```
### Submit to Real QPU
```
Convert my circuit to OpenQASM and submit to IonQ
```
1. Use `to_openqasm3` to convert your circuit
2. Use `qpu_submit` with `backend="ionq"` to submit
3. Use `qpu_status` to check results
## Environment Variables
| Variable | Description | Required |
|----------|-------------|----------|
| `CODA_API_TOKEN` | Your API token from [coda.conductorquantum.com/settings/api](https://coda.conductorquantum.com/settings/api) | Yes |
| `CODA_API_URL` | API endpoint URL (default: production API) | No |
## Troubleshooting
**"CODA_API_TOKEN not set"**
- Ensure the environment variable is set in your MCP client config
- Verify your token is valid at [coda.conductorquantum.com/settings/api](https://coda.conductorquantum.com/settings/api)
**"Connection refused"**
- Check your internet connection
- The Coda API may be temporarily unavailable
**Tools not appearing**
- Restart your MCP client after configuration changes
- Verify `uvx coda-mcp` runs without errors in terminal
- Check that JSON config syntax is valid
**Debug logs (Claude Desktop)**
- macOS: `~/Library/Logs/Claude/mcp.log` and `mcp-server-coda.log`
- Windows: `%AppData%\Claude\logs\`
**Debug logs (Claude Code)**
```bash
claude mcp list # Check server status
/mcp # Check status in Claude Code session
```
**Windows-specific issues**
- If `uvx` is not found, use full path or install via `pip install coda-mcp`
- Add `APPDATA` to env if you see ENOENT errors
## License
MIT
| text/markdown | null | Conductor Quantum <developers@conductorquantum.com> | null | null | MIT License
Copyright (c) 2026 Conductor Quantum
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | cirq, mcp, qiskit, qpu, quantum, simulation | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.28.0",
"mcp>=1.0.0"
] | [] | [] | [] | [
"Homepage, https://coda.conductorquantum.com"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:06:45.255012 | coda_mcp-0.1.1.tar.gz | 62,629 | f4/e1/72525082c7241f2aafafff66ac39787a2320639100830af338647290f324/coda_mcp-0.1.1.tar.gz | source | sdist | null | false | c7f8bdc03c76ef4d2f2f4ad95e62c23e | 737adb6b646115b3c8ce44a0026f310e96c5b6e7e223046275118d2c3dae568c | f4e172525082c7241f2aafafff66ac39787a2320639100830af338647290f324 | null | [
"LICENSE"
] | 274 |
2.4 | timber-common | 0.3.10 | Configuration-driven persistence library with ml tools (finance related) config driven db model registration, llm model choice, automatic encryption, caching, vector search, and GDPR compliance for Python applications | # Timber
**Configuration-driven persistence library with automatic encryption, caching, vector search, and GDPR compliance**
[](https://badge.fury.io/py/timber-common)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/psf/black)
---
## What is Timber?
Timber is a **configuration-driven persistence library** that eliminates boilerplate code by defining SQLAlchemy models in YAML instead of Python. It automatically provides encryption, caching, vector search, and GDPR compliance based on simple configuration flags.
**Transform this Python boilerplate:**
```python
class StockResearchSession(Base):
__tablename__ = 'stock_research_sessions'
id = Column(String(36), primary_key=True, default=uuid4)
user_id = Column(String(36), ForeignKey('users.id'), nullable=False)
symbol = Column(String(10), nullable=False)
analysis = Column(JSON)
created_at = Column(DateTime, default=datetime.utcnow)
# ... 50+ more lines of boilerplate
```
**Into this YAML configuration:**
```yaml
models:
- name: StockResearchSession
table_name: stock_research_sessions
# Enable features with one line
encryption:
enabled: true
fields: [analysis]
caching:
enabled: true
ttl_seconds: 3600
vector_search:
enabled: true
content_field: analysis
columns:
- name: id
type: String(36)
primary_key: true
- name: user_id
type: String(36)
foreign_key: users.id
- name: symbol
type: String(10)
- name: analysis
type: JSON
```
---
## Key Features
### 🎯 Configuration-Driven Models
- **Zero Python boilerplate** - Define models in YAML
- **Dynamic generation** - Models created at runtime
- **Full SQLAlchemy** - All SQLAlchemy features supported
- **Type-safe** - Validated configuration with clear errors
### 🔐 Automatic Encryption
- **Field-level encryption** - Specify fields to encrypt
- **Transparent** - Automatic encrypt/decrypt
- **Secure** - Uses Fernet (symmetric encryption)
- **No code changes** - Enable with one config line
### ⚡ Multi-Level Caching
- **Redis support** - Distributed caching
- **Local cache** - In-memory fallback
- **Automatic invalidation** - Cache cleared on updates
- **Configurable TTL** - Per-model cache duration
### 🔍 Vector Search
- **Semantic search** - Find by meaning, not keywords
- **Automatic embeddings** - Generated on insert
- **Multiple backends** - Qdrant, Weaviate, Pinecone
- **Hybrid search** - Combine vector + keyword
### ✅ GDPR Compliance
- **Data export** - User data export in JSON
- **Right to deletion** - Complete data removal
- **Audit trails** - Track data operations
- **Configurable** - Specify exportable fields
### 🏗️ Modular Services
- **Session Service** - User session management
- **Research Service** - Store analysis and research
- **Notification Service** - User notifications
- **Tracker Service** - Event tracking and analytics
- **Stock Data Service** - Financial data fetching
### 🌐 Multi-App Support
- **Shared infrastructure** - One library, many apps
- **Data isolation** - Clear boundaries between apps
- **Consistent patterns** - Same API across applications
---
## Quick Start
### Installation
```bash
pip install timber-common
```
### Basic Example
```python
from timber.common import initialize_timber, get_model
from timber.common.services.persistence import session_service
# 1. Initialize Timber with your model configs
initialize_timber(
model_config_dirs=['./data/models'],
database_url='postgresql://localhost:5432/mydb'
)
# 2. Use services immediately
session_id = session_service.create_session(
user_id='user-123',
session_type='research',
metadata={'symbol': 'AAPL'}
)
# 3. Or access models directly
Session = get_model('Session')
session = session_service.get_session(session_id)
print(f"Created session for {session.metadata['symbol']}")
```
### Complete Workflow Example
```python
from timber.common import initialize_timber
from timber.common.services.persistence import (
session_service,
research_service,
notification_service
)
# Initialize
initialize_timber(model_config_dirs=['./data/models'])
# Create research session
session_id = session_service.create_session(
user_id='user-123',
session_type='research',
metadata={'symbol': 'AAPL'}
)
# Save research (automatically encrypted if configured)
research_id = research_service.save_research(
session_id=session_id,
content={
'company': 'Apple Inc.',
'analysis': 'Strong fundamentals...',
'recommendation': 'Buy'
},
research_type='fundamental'
)
# Notify user (automatically stored)
notification_service.create_notification(
user_id='user-123',
notification_type='research_complete',
title='Analysis Complete',
message='Your AAPL analysis is ready'
)
print(f"✅ Research workflow complete!")
```
### Vector Search Example
```python
from timber.common.services.vector import vector_service
# Semantic search (finds by meaning, not just keywords)
results = vector_service.search(
query="companies with strong AI capabilities",
collection_name="research_documents",
limit=10
)
for result in results:
print(f"{result['payload']['title']}: {result['score']:.3f}")
```
---
## Documentation
### 📚 How-To Guides
- [Getting Started](documentation/how_to/01_getting_started.md) - Setup and first model
- [Creating Models](documentation/how_to/02_creating_models.md) - YAML model definitions
- [Using Services](documentation/how_to/03_using_services.md) - Persistence services
### 🏛️ Design Guides
- [System Architecture](documentation/design_guides/01_system_architecture.md) - Overall design
- [Config-Driven Models](documentation/design_guides/02_config_driven_models.md) - Model factory pattern
- [Persistence Layer](documentation/design_guides/03_persistence_layer.md) - Database architecture
- [Vector Integration](documentation/design_guides/04_vector_integration.md) - Semantic search
- [Multi-App Support](documentation/design_guides/05_multi_app_support.md) - Multiple applications
### 📖 Full Documentation Index
See [DOCUMENTATION_INDEX.md](documentation/DOCUMENTATION_INDEX.md) for complete documentation structure.
---
## Requirements
- **Python:** 3.13+
- **Database:** PostgreSQL 12+
- **Optional:** Redis (for distributed caching)
- **Optional:** Qdrant/Weaviate/Pinecone (for vector search)
---
## Installation Options
### Basic Installation
```bash
pip install timber-common
```
### With Vector Search (Qdrant)
```bash
pip install timber-common[qdrant]
```
### With All Optional Features
```bash
pip install timber-common[all]
```
### Development Installation
```bash
git clone https://github.com/pumulo/timber-common.git
cd timber-common
poetry install
```
---
## Configuration
### Environment Variables
Create a `.env` file:
```bash
# Database
DATABASE_URL=postgresql://user:password@localhost:5432/dbname
# Redis (optional)
REDIS_URL=redis://localhost:6379/0
# Vector Database (optional)
QDRANT_URL=http://localhost:6333
# Encryption
ENCRYPTION_KEY=your-fernet-key-here
# Feature Flags
ENABLE_ENCRYPTION=true
ENABLE_VECTOR_SEARCH=true
ENABLE_GDPR=true
CACHE_ENABLED=true
```
### Model Configuration
Create YAML files in `data/models/`:
```yaml
# data/models/user_models.yaml
version: "1.0.0"
models:
- name: User
table_name: users
columns:
- name: id
type: String(36)
primary_key: true
default: uuid4
- name: email
type: String(255)
unique: true
nullable: false
- name: created_at
type: DateTime
default: utcnow
```
---
## Use Cases
### Financial Applications
- Trading platforms
- Research tools
- Portfolio management
- Market analysis
### Content Platforms
- Document management
- Knowledge bases
- Content recommendation
- Semantic search
### Data Analytics
- User behavior tracking
- Event analytics
- Session management
- Activity monitoring
### Multi-Tenant Applications
- SaaS platforms
- Enterprise applications
- Multiple product lines
- Isolated data domains
---
## Architecture
```
┌─────────────────────────────────────────┐
│ Your Application │
└─────────────────────────────────────────┘
│
↓
┌─────────────────────────────────────────┐
│ Timber Library │
│ ┌──────────────┐ ┌─────────────────┐ │
│ │ Model Factory│ │ Services Layer │ │
│ └──────────────┘ └─────────────────┘ │
│ ┌──────────────┐ ┌─────────────────┐ │
│ │ Encryption │ │ Vector Search │ │
│ └──────────────┘ └─────────────────┘ │
└─────────────────────────────────────────┘
│
↓
┌─────────────────────────────────────────┐
│ Infrastructure │
│ PostgreSQL │ Redis │ Qdrant │
└─────────────────────────────────────────┘
```
---
## Examples
### E-Commerce Platform
```yaml
models:
- name: Product
table_name: products
vector_search:
enabled: true
content_field: description
columns:
- name: id
type: String(36)
primary_key: true
- name: name
type: String(255)
- name: description
type: Text
- name: price
type: Numeric(10, 2)
```
### Healthcare Application
```yaml
models:
- name: PatientRecord
table_name: patient_records
encryption:
enabled: true
fields: [ssn, medical_history]
gdpr:
enabled: true
user_id_field: patient_id
export_fields: [name, date_of_birth, medical_history]
columns:
- name: id
type: String(36)
primary_key: true
- name: patient_id
type: String(36)
foreign_key: patients.id
- name: ssn
type: String(11)
- name: medical_history
type: JSON
```
---
## Testing
```bash
# Run tests
poetry run pytest
# With coverage
poetry run pytest --cov=common --cov=modules
# Run specific test
poetry run pytest tests/test_models.py::test_create_model
```
---
## Contributing
We welcome contributions! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
### Development Setup
```bash
# Clone repository
git clone https://github.com/pumulo/timber-common.git
cd timber-common
# Install dependencies
poetry install
# Run tests
poetry run pytest
# Format code
poetry run black .
poetry run isort .
# Type check
poetry run mypy common modules
```
---
## Performance
Timber is designed for production use with:
- **Connection pooling** - Efficient database connections
- **Query optimization** - Built-in best practices
- **Caching** - Multi-level cache strategy
- **Batch operations** - Efficient bulk processing
### Benchmarks
```
Operation Time (ms) Notes
─────────────────────────────────────────────
Simple INSERT 1-5 Single record
Batch INSERT (100) 10-20 Bulk insert
SELECT by ID 1-2 Indexed lookup
Vector search 5-15 Semantic search
Cached query < 1 Redis/local cache
```
---
## Roadmap
### Version 0.2.0 (Q1 2025)
- [ ] MySQL and SQLite support
- [ ] GraphQL API generation
- [ ] CLI tools for model management
- [ ] Enhanced monitoring dashboard
### Version 0.3.0 (Q2 2025)
- [ ] Real-time data streaming
- [ ] Advanced analytics
- [ ] Built-in vector store (no external DB required)
- [ ] Docker and Kubernetes templates
### Future
- [ ] Multi-database transactions
- [ ] Distributed tracing
- [ ] Auto-scaling recommendations
- [ ] Visual model designer
---
## Support
### Get Help
- **Documentation:** [Full docs](documentation/)
- **Issues:** [GitHub Issues](https://github.com/pumulo/timber-common/issues)
- **Email:** pumulo@gmail.com
### Commercial Support
For enterprise support, training, or consulting:
- Email: pumulo@gmail.com
---
## License
Timber is released under the [MIT License](LICENSE).
```
MIT License
Copyright (c) 2025 Pumulo Sikaneta
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
```
See [LICENSE](LICENSE) file for full license text.
---
## Author
**Pumulo Sikaneta**
- Email: pumulo@gmail.com
- GitHub: [@pumulo](https://github.com/pumulo)
- Website: [Your website]
---
## Acknowledgments
Built with:
- [SQLAlchemy](https://www.sqlalchemy.org/) - The Python SQL toolkit
- [PostgreSQL](https://www.postgresql.org/) - The world's most advanced open source database
- [FastEmbed](https://github.com/qdrant/fastembed) - Fast embedding generation
- [Poetry](https://python-poetry.org/) - Python dependency management
---
## Citation
If you use Timber in academic research, please cite:
```bibtex
@software{timber2025,
author = {Sikaneta, Pumulo},
title = {Timber: Configuration-Driven Persistence Library},
year = {2025},
url = {https://github.com/pumulo/timber-common},
version = {0.1.0}
}
```
---
## Star History
If you find Timber useful, please star the repository! ⭐
---
**Made with ❤️ by Pumulo Sikaneta**
**Copyright © 2025 Pumulo Sikaneta. All rights reserved.** | text/markdown | Pumulo Sikaneta | pumulo@gmail.com | Pumulo Sikaneta | pumulo@gmail.com | MIT | orm, sqlalchemy, persistence, vector-search, semantic-search, encryption, gdpr, yaml-config, postgres, redis, configuration-driven, data-modeling, machine-learning, embeddings | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Financial and Insurance Industry",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Programming La... | [] | https://github.com/pumulo/timber-common | null | <4.0,>=3.13 | [] | [] | [] | [
"sqlalchemy<3.0.0,>=2.0.36",
"psycopg2-binary<3.0.0,>=2.9.11",
"pgvector[sqlalchemy]<0.5.0,>=0.4.1",
"pydantic<3.0.0,>=2.11.9",
"python-dotenv<2.0.0,>=1.1.1",
"PyYAML<7.0.0,>=6.0.3",
"redis<7.0.0,>=6.4.0",
"stripe<15.0.0,>=14.0.1",
"plaid-python<38.0.0,>=37.1.0",
"cryptography<47.0.0,>=46.0.2",
... | [] | [] | [] | [
"Homepage, https://github.com/pumulo/timber-common",
"Repository, https://github.com/pumulo/timber-common",
"Documentation, https://github.com/pumulo/timber-common/tree/main/documentation",
"Bug Tracker, https://github.com/pumulo/timber-common/issues",
"Changelog, https://github.com/pumulo/timber-common/blo... | poetry/2.2.0 CPython/3.13.7 Darwin/25.3.0 | 2026-02-18T21:06:40.713970 | timber_common-0.3.10.tar.gz | 436,531 | 12/e6/365318413b1c775c080e53148d43ceb6fc99777f6d5cc25b241d319c9628/timber_common-0.3.10.tar.gz | source | sdist | null | false | 7d6d79dd304ed6adbdcb40a5b475aef1 | a8f6137c00534c8a0e2246cea779185c96c5b22df9c8efc0cd06439f7e061271 | 12e6365318413b1c775c080e53148d43ceb6fc99777f6d5cc25b241d319c9628 | null | [] | 236 |
2.4 | mnemocore | 4.5.0 | MnemoCore – Infrastructure for Persistent Cognitive Memory. A hierarchical AI memory engine with hot/warm/cold tiers, vector search, and subconscious consolidation. | # MnemoCore
### Infrastructure for Persistent Cognitive Memory
> *"Memory is not a container. It is a living process — a holographic continuum where every fragment contains the whole."*
<p align="center">
<img src="https://img.shields.io/badge/Status-Beta%204.3.0-orange?style=for-the-badge" />
<img src="https://img.shields.io/badge/Python-3.10%2B-3776AB?style=for-the-badge&logo=python&logoColor=white" />
<img src="https://img.shields.io/badge/FastAPI-Async%20Ready-009688?style=for-the-badge&logo=fastapi&logoColor=white" />
<img src="https://img.shields.io/badge/License-MIT-blue?style=for-the-badge" />
<img src="https://img.shields.io/badge/HDV-16384--dim-purple?style=for-the-badge" />
<img src="https://img.shields.io/badge/Vectors-Binary%20VSA-critical?style=for-the-badge" />
</p>
---
## What is MnemoCore?
**MnemoCore** is a research-grade cognitive memory infrastructure that gives AI agents a brain — not just a database.
Traditional vector stores retrieve. MnemoCore **thinks**. It is built on the mathematical framework of **Binary Hyperdimensional Computing (HDC)** and **Vector Symbolic Architectures (VSA)**, principles rooted in Pentti Kanerva's landmark 2009 theory of cognitive computing. Every memory is encoded as a **16,384-dimensional binary holographic vector** — a format that is simultaneously compact (2,048 bytes), noise-tolerant (Hamming geometry), and algebraically rich (XOR binding, majority bundling, circular permutation).
At its core lives the **Holographic Active Inference Memory (HAIM) Engine** — a system that does not merely answer queries, but:
- **Evaluates** the epistemic novelty of every incoming memory before deciding to store it
- **Dreams** — strengthening synaptic connections between related memories during idle cycles
- **Reasons by analogy** — if `king:man :: ?:woman`, the VSA soul computes `queen`
- **Self-organizes** into tiered storage based on biologically-inspired Long-Term Potentiation (LTP)
- **Scales** from a single process to distributed nodes targeting 1B+ memories
Phase 4.x introduces cognitive enhancements including contextual masking, reliability feedback loops, semantic consolidation, gap detection/filling, and temporal recall (episodic chaining + chrono-weighted query).
---
## Table of Contents
- [Architecture](#architecture)
- [Core Technology](#core-technology-binary-hdv--vsa)
- [The Memory Lifecycle](#the-memory-lifecycle)
- [Tiered Storage](#tiered-storage-hotwarmcold)
- [Phase 4.0 Cognitive Enhancements](#phase-40-cognitive-enhancements)
- [API Reference](#api-reference)
- [Python Library Usage](#python-library-usage)
- [Installation](#installation)
- [Configuration](#configuration)
- [MCP Server Integration](#mcp-server-integration)
- [Observability](#observability)
- [Roadmap](#roadmap)
- [Contributing](#contributing)
---
## Architecture
```
┌─────────────────────────────────────────────────────────────────┐
│ MnemoCore Stack │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ REST API (FastAPI / Async) │ │
│ │ /store /query /feedback /insights/gaps /stats │ │
│ │ Rate Limiting · API Key Auth · Prometheus Metrics │ │
│ └─────────────────────────┬────────────────────────────────┘ │
│ │ │
│ ┌─────────────────────────▼────────────────────────────────┐ │
│ │ HAIM Engine │ │
│ │ │ │
│ │ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ │
│ │ │ Text Encoder │ │ EIG / Epist │ │ Subconsc. │ │ │
│ │ │ (token→HDV) │ │ Drive │ │ Dream Loop │ │ │
│ │ └──────────────┘ └──────────────┘ └──────────────┘ │ │
│ │ │ │
│ │ ┌──────────────────────────────────────────────────┐ │ │
│ │ │ Binary HDV Core (VSA) │ │ │
│ │ │ XOR bind · majority_bundle · permute · Hamming │ │ │
│ │ └──────────────────────────────────────────────────┘ │ │
│ └─────────────────────────┬────────────────────────────────┘ │
│ │ │
│ ┌─────────────────────────▼────────────────────────────────┐ │
│ │ Tier Manager │ │
│ │ │ │
│ │ 🔥 HOT 🌡 WARM ❄️ COLD │ │
│ │ In-Memory Redis / mmap Qdrant / Disk / S3 │ │
│ │ ≤2,000 nodes ≤100,000 nodes ∞ nodes │ │
│ │ <1ms <10ms <100ms │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Conceptual Layer ("The Soul") │ │
│ │ ConceptualMemory · Analogy Engine · Symbol Algebra │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘
```
### Component Overview
| Component | File | Responsibility |
|-----------|------|----------------|
| **HAIM Engine** | `src/core/engine.py` | Central cognitive coordinator — store, query, dream, delete |
| **BinaryHDV** | `src/core/binary_hdv.py` | 16384-dim binary vector math (XOR, Hamming, bundle, permute) |
| **TextEncoder** | `src/core/binary_hdv.py` | Token→HDV pipeline with positional permutation binding |
| **MemoryNode** | `src/core/node.py` | Memory unit with LTP, epistemic values, tier state |
| **TierManager** | `src/core/tier_manager.py` | HOT/WARM/COLD orchestration with LTP-driven eviction |
| **SynapticConnection** | `src/core/synapse.py` | Hebbian synapse with strength, decay, and fire tracking |
| **ConceptualMemory** | `src/core/holographic.py` | VSA soul for analogy and cross-domain symbolic reasoning |
| **AsyncRedisStorage** | `src/core/async_storage.py` | Async Redis backend (WARM tier + pub/sub) |
| **API** | `src/api/main.py` | FastAPI REST interface with async wrappers and middleware |
| **MCP Server** | `src/mcp/server.py` | Model Context Protocol adapter for agent tool integration |
---
## Core Technology: Binary HDV & VSA
MnemoCore's mathematical foundation is **Hyperdimensional Computing** — a computing paradigm that encodes information in very high-dimensional binary vectors (HDVs), enabling noise-tolerant, distributed, and algebraically composable representations.
### The Vector Space
Every piece of information — a word, a sentence, a concept, a goal — is encoded as a **16,384-dimensional binary vector**:
```
Dimension D = 16,384 bits = 2,048 bytes per vector
Storage: packed as numpy uint8 arrays
Similarity: Hamming distance (popcount of XOR result)
Random pair: ~50% similarity (orthogonality by probability)
```
At this dimensionality, two random vectors will differ in ~50% of bits. This near-orthogonality is the foundation of the system's expressive power — related concepts cluster together while unrelated ones remain maximally distant.
### VSA Algebra
Four primitive operations make the entire system work:
#### Binding — XOR `⊕`
Creates an association between two concepts. Crucially, the result is **dissimilar to both inputs** (appears as noise), making it a true compositional operation.
```python
# Bind content to its context
bound = content_vec.xor_bind(context_vec) # content ⊕ context
# Self-inverse: unbind by re-binding
recovered = bound.xor_bind(context_vec) # ≈ content (XOR cancels)
```
Key mathematical properties:
- **Self-inverse**: `A ⊕ A = 0` (XOR cancels itself)
- **Commutative**: `A ⊕ B = B ⊕ A`
- **Distance-preserving**: `hamming(A⊕C, B⊕C) = hamming(A, B)`
#### Bundling — Majority Vote
Creates a **prototype** that is similar to all inputs. This is how multiple memories combine into a concept.
```python
from mnemocore.core.binary_hdv import majority_bundle
# Create semantic prototype from related memories
concept = majority_bundle([vec_a, vec_b, vec_c, vec_d]) # similar to all inputs
```
#### Permutation — Circular Shift
Encodes **sequence and roles** without separate positional embeddings.
```python
# Positional encoding: token at position i
positioned = token_vec.permute(shift=i) # circular bit-shift
# Encode "hello world" with order information
hello_positioned = encoder.get_token_vector("hello").permute(0)
world_positioned = encoder.get_token_vector("world").permute(1)
sentence_vec = majority_bundle([hello_positioned, world_positioned])
```
#### Similarity — Hamming Distance
Fast comparison using vectorized popcount over XOR results:
```python
# Normalized similarity: 1.0 = identical, 0.5 = unrelated
sim = vec_a.similarity(vec_b) # 1.0 - hamming(a, b) / D
# Batch nearest-neighbor search (no Python loops)
distances = batch_hamming_distance(query, database_matrix)
```
### Text Encoding Pipeline
The `TextEncoder` converts natural language to HDVs using a token-position binding scheme:
```
"Python TypeError" →
token_hdv("python") ⊕ permute(0) = positioned_0
token_hdv("typeerror") ⊕ permute(1) = positioned_1
majority_bundle([positioned_0, positioned_1]) = final_hdv
```
Token vectors are **deterministic** — seeded via SHAKE-256 hash — meaning the same word always produces the same base vector, enabling cross-session consistency without a vocabulary file.
---
## The Memory Lifecycle
Every memory passes through a defined lifecycle from ingestion to long-term storage:
```
Incoming Content
│
▼
┌─────────────┐
│ TextEncoder │ → 16,384-dim binary HDV
└──────┬──────┘
│
▼
┌──────────────────┐
│ Context Binding │ → XOR bind with goal_context if present
│ (XOR) │ bound_vec = content ⊕ context
└──────┬───────────┘
│
▼
┌──────────────────┐
│ EIG Evaluation │ → Epistemic Information Gain
│ (Novelty Check) │ eig = normalized_distance(vec, context_vec)
└──────┬───────────┘ tag "epistemic_high" if eig > threshold
│
▼
┌─────────────────┐
│ MemoryNode │ → id, hdv, content, metadata
│ Creation │ ltp_strength = I × log(1+A) × e^(-λT)
└──────┬──────────┘
│
▼
┌─────────────────┐
│ HOT Tier │ → In-memory dict (max 2000 nodes)
│ (RAM) │ LTP eviction: low-LTP nodes → WARM
└──────┬──────────┘
│ (background)
▼
┌─────────────────┐
│ Subconscious │ → Dream cycle fires
│ Dream Loop │ Query similar memories
└──────┬──────────┘ Strengthen synapses (Hebbian)
│
▼
┌─────────────────┐
│ WARM Tier │ → Redis-backed persistence
│ (Redis/mmap) │ async dual-write + pub/sub events
└──────┬──────────┘
│ (scheduled, nightly)
▼
┌─────────────────┐
│ COLD Tier │ → Qdrant / Disk / S3
│ (Archival) │ ANN search, long-term persistence
└─────────────────┘
```
### Long-Term Potentiation (LTP)
Memories are not equal. Importance is computed dynamically using a biologically-inspired LTP formula:
```
S = I × log(1 + A) × e^(-λ × T)
Where:
S = LTP strength (determines tier placement)
I = Importance (derived from epistemic + pragmatic value)
A = Access count (frequency of retrieval)
λ = Decay lambda (configurable, default ~0.01)
T = Age in days
```
Memories with high LTP remain in HOT tier. Those that decay are automatically promoted to WARM, then COLD — mirroring how biological memory consolidates from working memory to long-term storage.
### Synaptic Connections
Memories are linked by `SynapticConnection` objects that implement Hebbian learning: *"neurons that fire together, wire together."*
Every time two memories are co-retrieved (via the background dream loop or explicit binding), their synaptic strength increases. During query time, synaptic spreading amplifies scores of connected memories even when they do not directly match the query vector — enabling **associative recall**.
```python
# Explicit synapse creation
engine.bind_memories(id_a, id_b, success=True)
# Associative spreading: query top seeds spread activation to neighbors
# neighbor_score += seed_score × synapse_strength × 0.3
```
---
## Tiered Storage: HOT / WARM / COLD
| Tier | Backend | Capacity | Latency | Eviction Trigger |
|------|---------|----------|---------|------------------|
| 🔥 **HOT** | Python dict (RAM) | 2,000 nodes | < 1ms | LTP < threshold |
| 🌡 **WARM** | Redis + mmap | 100,000 nodes | < 10ms | Age + low access |
| ❄️ **COLD** | Qdrant / Disk / S3 | Unlimited | < 100ms | Manual / scheduled |
Promotion is automatic: accessing a WARM or COLD memory re-promotes it to HOT based on recalculated LTP. Eviction is LRU-weighted by LTP strength — the most biologically active memories always stay hot.
---
## Phase 4.0 Cognitive Enhancements
MnemoCore Phase 4.0 introduces five architectural enhancements that elevate the system from **data retrieval** to **cognitive reasoning**. Full implementation specifications are in [`COGNITIVE_ENHANCEMENTS.md`](COGNITIVE_ENHANCEMENTS.md).
---
### 1. Contextual Query Masking *(XOR Attention)*
**Problem**: Large multi-project deployments suffer from cross-context interference. A query for `"Python error handling"` returns memories from all projects equally, diluting precision.
**Solution**: Bidirectional XOR context binding — apply the same context vector at both **storage** and **query** time:
```
Store: bound_vec = content ⊕ context_vec
Query: masked_query = query ⊕ context_vec
Result: (content ⊕ C) · (query ⊕ C) ≈ content · query
(context cancels, cross-project noise is suppressed)
```
```python
# Store memories in a project context
engine.store("API rate limiting logic", goal_id="ProjectAlpha")
engine.store("Garden watering schedule", goal_id="HomeProject")
# Query with context mask — only ProjectAlpha memories surface
results = engine.query("API logic", top_k=5, context="ProjectAlpha")
```
**Expected impact**: +50–80% query precision (P@5) in multi-project deployments.
---
### 2. Reliability Feedback Loop *(Self-Correcting Memory)*
**Problem**: Wrong or outdated memories persist with the same retrieval weight as correct ones. The system has no mechanism to learn from its own mistakes.
**Solution**: Bayesian reliability scoring with real-world outcome feedback:
```
reliability = (successes + 1) / (successes + failures + 2) # Laplace smoothing
LTP_enhanced = I × log(1+A) × e^(-λT) × reliability
```
```python
# After using a retrieved memory:
engine.provide_feedback(memory_id, outcome=True) # Worked → boost reliability
engine.provide_feedback(memory_id, outcome=False) # Failed → reduce reliability
# System auto-tags consistently wrong memories as "unreliable"
# and verified memories (>5 successes, >0.8 score) as "verified"
```
The system converges toward **high-confidence knowledge** — memories that have demonstrably worked in practice rank above theoretically similar but unproven ones.
---
### 3. Semantic Memory Consolidation *(Dream-Phase Synthesis)*
**Problem**: Episodic memory grows without bound. 1,000 memories about `"Python TypeError"` are semantically equivalent but consume 2MB of vector space and slow down linear scan queries.
**Solution**: Nightly `ConsolidationWorker` clusters similar WARM tier memories and replaces them with a **semantic anchor** — a majority-bundled prototype:
```
BEFORE consolidation:
mem_001: "Python TypeError in line 45" (2KB vector)
mem_002: "TypeError calling function" (2KB vector)
... ×100 similar memories (200KB total)
AFTER consolidation:
anchor_001: "Semantic pattern: python typeerror function"
metadata: {source_count: 100, confidence: 0.94}
hdv: majority_bundle([mem_001.hdv, ..., mem_100.hdv]) (2KB)
```
```python
# Manual trigger (runs automatically at 3 AM)
stats = engine.trigger_consolidation()
# → {"abstractions_created": 12, "memories_consolidated": 847}
# Via API (admin endpoint)
POST /admin/consolidate
```
**Expected impact**: 70–90% memory footprint reduction, 10x query speedup at scale.
---
### 4. Auto-Associative Cleanup Loop *(Vector Immunology)*
**Problem**: Holographic vectors degrade over time through repeated XOR operations, noise accumulation, and long-term storage drift. After months of operation, retrieved vectors become "blurry" and similarity scores fall.
**Solution**: Iterative attractor dynamics — when a retrieved vector appears noisy, snap it to the nearest stable concept in a **codebook** of high-confidence prototypes:
```
noisy_vec → find K nearest in codebook
→ majority_bundle(K neighbors)
→ check convergence (Hamming distance < 5%)
→ iterate until converged or max iterations reached
```
```python
# Cleanup runs automatically on retrieval when noise > 15%
node = engine.get_memory(memory_id, auto_cleanup=True)
# node.metadata["cleaned"] = True (if cleanup was triggered)
# node.metadata["cleanup_iterations"] = 3
# Codebook is auto-populated from most-accessed, high-reliability memories
```
**Expected impact**: Maintain >95% similarity fidelity even after years of operation.
---
### 5. Knowledge Gap Detection *(Proactive Curiosity)*
**Problem**: The system is entirely reactive — it answers queries but never identifies what it *doesn't know*. True cognitive autonomy requires self-directed learning.
**Solution**: Temporal co-occurrence analysis — detect concepts that are frequently accessed **close in time** but have **no synaptic connection**, flagging them as knowledge gaps:
```python
# Automatically runs hourly
gaps = engine.detect_knowledge_gaps(time_window_seconds=300)
# Returns structured insight:
# [
# {
# "concept_a": "Python asyncio event loop",
# "concept_b": "FastAPI dependency injection",
# "suggested_query": "How does asyncio relate to FastAPI dependency injection?",
# "co_occurrence_count": 4
# }
# ]
# Query endpoint
GET /insights/gaps?lookback_hours=24
# Fill gap manually (or via LLM agent)
POST /insights/fill-gap
{"concept_a_id": "mem_xxx", "concept_b_id": "mem_yyy",
"explanation": "FastAPI uses asyncio's event loop internally..."}
```
The system becomes capable of **saying what it doesn't understand** and requesting clarification — the first step toward genuine cognitive autonomy.
---
## API Reference
### Authentication
All endpoints require an API key via the `X-API-Key` header:
```bash
export HAIM_API_KEY="your-secure-key"
curl -H "X-API-Key: $HAIM_API_KEY" ...
```
### Endpoints
#### `POST /store`
Store a new memory with optional context binding.
```json
Request:
{
"content": "FastAPI uses Pydantic v2 for request validation.",
"metadata": {"source": "docs", "tags": ["python", "fastapi"]},
"context": "ProjectAlpha",
"agent_id": "agent-001",
"ttl": 3600
}
Response:
{
"ok": true,
"memory_id": "mem_1739821234567",
"message": "Stored memory: mem_1739821234567"
}
```
#### `POST /query`
Query memories by semantic similarity with optional context masking.
```json
Request:
{
"query": "How does FastAPI handle request validation?",
"top_k": 5,
"context": "ProjectAlpha"
}
Response:
{
"ok": true,
"query": "How does FastAPI handle request validation?",
"results": [
{
"id": "mem_1739821234567",
"content": "FastAPI uses Pydantic v2 for request validation.",
"score": 0.8923,
"metadata": {"source": "docs"},
"tier": "hot"
}
]
}
```
#### `POST /feedback`
Report outcome of a retrieved memory (Phase 4.0 reliability loop).
```json
Request:
{
"memory_id": "mem_1739821234567",
"outcome": true,
"comment": "This solution worked perfectly."
}
Response:
{
"ok": true,
"memory_id": "mem_1739821234567",
"reliability_score": 0.714,
"success_count": 4,
"failure_count": 1
}
```
#### `GET /memory/{memory_id}`
Retrieve a specific memory with full metadata.
```json
Response:
{
"id": "mem_1739821234567",
"content": "...",
"metadata": {...},
"created_at": "2026-02-17T20:00:00Z",
"ltp_strength": 1.847,
"epistemic_value": 0.73,
"reliability_score": 0.714,
"tier": "hot"
}
```
#### `DELETE /memory/{memory_id}`
Delete memory from all tiers and clean up synapses.
#### `POST /concept`
Define a symbolic concept for analogical reasoning.
```json
{"name": "king", "attributes": {"gender": "man", "role": "ruler", "domain": "royalty"}}
```
#### `POST /analogy`
Solve analogies using VSA algebra: `source:value :: target:?`
```json
Request: {"source_concept": "king", "source_value": "man", "target_concept": "queen"}
Response: {"results": [{"value": "woman", "score": 0.934}]}
```
#### `GET /insights/gaps`
Detect knowledge gaps from recent temporal co-activity (Phase 4.0).
```json
Response:
{
"gaps_detected": 3,
"knowledge_gaps": [
{
"concept_a": "asyncio event loop",
"concept_b": "FastAPI middleware",
"suggested_query": "How does event loop relate to middleware?",
"co_occurrence_count": 5
}
]
}
```
#### `POST /admin/consolidate`
Trigger manual semantic consolidation (normally runs automatically at 3 AM).
#### `GET /stats`
Engine statistics — tiers, synapse count, consolidation state.
#### `GET /health`
Health check — Redis connectivity, engine readiness, degraded mode status.
#### `GET /metrics`
Prometheus metrics endpoint.
---
## Python Library Usage
### Basic Store and Query
```python
from mnemocore.core.engine import HAIMEngine
engine = HAIMEngine(persist_path="./data/memory.jsonl")
# Store memories
engine.store("Python generators are lazy iterators", metadata={"topic": "python"})
engine.store("Use 'yield' to create generator functions", metadata={"topic": "python"})
engine.store("Redis XADD appends to a stream", goal_id="infrastructure")
# Query (global)
results = engine.query("How do Python generators work?", top_k=3)
for mem_id, score in results:
mem = engine.get_memory(mem_id)
print(f"[{score:.3f}] {mem.content}")
# Query with context masking
results = engine.query("data streams", top_k=5, context="infrastructure")
engine.close()
```
### Analogical Reasoning
```python
# Define concepts
engine.define_concept("king", {"gender": "man", "role": "ruler"})
engine.define_concept("queen", {"gender": "woman", "role": "ruler"})
engine.define_concept("man", {"gender": "man"})
# VSA analogy: king:man :: ?:woman → queen
result = engine.reason_by_analogy(
src="king", val="man", tgt="woman"
)
print(result) # [("queen", 0.934), ...]
```
### Working with the Binary HDV Layer Directly
```python
from mnemocore.core.binary_hdv import BinaryHDV, TextEncoder, majority_bundle
encoder = TextEncoder(dimension=16384)
# Encode text
python_vec = encoder.encode("Python programming")
fastapi_vec = encoder.encode("FastAPI framework")
error_vec = encoder.encode("error handling")
# Bind concept to role
python_in_fastapi = python_vec.xor_bind(fastapi_vec)
# Bundle multiple concepts into prototype
web_dev_prototype = majority_bundle([python_vec, fastapi_vec, error_vec])
# Similarity
print(python_vec.similarity(web_dev_prototype)) # High (part of bundle)
print(python_vec.similarity(error_vec)) # ~0.5 (unrelated)
# Batch nearest-neighbor search
from mnemocore.core.binary_hdv import batch_hamming_distance
import numpy as np
database = np.stack([v.data for v in [python_vec, fastapi_vec, error_vec]])
distances = batch_hamming_distance(python_vec, database)
```
### Reliability Feedback Loop
```python
mem_id = engine.store("Always use asyncio.Lock() in async code, not threading.Lock()")
results = engine.query("async locking")
# It works — report success
engine.provide_feedback(mem_id, outcome=True, comment="Solved deadlock issue")
# Over time, high-reliability memories get 'verified' tag
# and are ranked above unproven ones in future queries
```
### Semantic Consolidation
```python
stats = engine.trigger_consolidation()
print(f"Created {stats['abstractions_created']} semantic anchors")
print(f"Consolidated {stats['memories_consolidated']} episodic memories")
# Automatic: runs every night at 3 AM via background asyncio task
```
---
## Installation
### Prerequisites
- **Python 3.10+**
- **Redis 6+** — Required for WARM tier and async event streaming
- **Qdrant** *(optional)* — For COLD tier at billion-scale
- **Docker** *(recommended)* — For Redis and Qdrant services
### Quick Start
```bash
# 1. Clone
git clone https://github.com/RobinALG87/MnemoCore-Infrastructure-for-Persistent-Cognitive-Memory.git
cd MnemoCore-Infrastructure-for-Persistent-Cognitive-Memory
# 2. Create virtual environment
python -m venv venv
source venv/bin/activate # Linux/macOS
# venv\Scripts\activate # Windows
# 3. Install dependencies
pip install -r requirements.txt
# 4. Start Redis
docker run -d -p 6379:6379 redis:alpine
# 5. Set API key
export HAIM_API_KEY="your-secure-key-here"
# 6. Start the API
uvicorn src.api.main:app --host 0.0.0.0 --port 8100
```
The API is now live at `http://localhost:8100`. Visit `http://localhost:8100/docs` for the interactive Swagger UI.
### With Qdrant (Phase 4.x Scale)
```bash
# Start Qdrant alongside Redis
docker run -d -p 6333:6333 qdrant/qdrant
# Enable in config.yaml
qdrant:
enabled: true
host: localhost
port: 6333
```
---
## Configuration
All configuration lives in `config.yaml`. Values can be overridden with environment variables (`HAIM_` prefix).
```yaml
haim:
version: "4.3"
dimensionality: 16384 # Binary vector dimensions (must be multiple of 8)
encoding:
mode: "binary" # "binary" (recommended) or "float" (legacy)
tiers:
hot:
max_memories: 2000 # Max nodes in RAM
ltp_threshold: 0.3 # Evict below this LTP strength
warm:
max_memories: 100000 # Max nodes in Redis/mmap
cold:
enabled: true
ltp:
initial_importance: 0.5
decay_lambda: 0.01 # Higher = faster forgetting
permanence_threshold: 2.0 # LTP above this is considered permanent
redis:
url: "redis://localhost:6379/0"
qdrant:
enabled: false
host: "localhost"
port: 6333
collection: "mnemocore_warm"
security:
api_key: "${HAIM_API_KEY}" # Never hardcode — use env variable
cors_origins: ["http://localhost:3000"]
observability:
metrics_enabled: true
log_level: "INFO"
paths:
data_dir: "./data"
memory_file: "./data/memory.jsonl"
synapses_file: "./data/synapses.jsonl"
```
### Security Note
MnemoCore requires an explicit API key. There is no default fallback key in production builds.
```bash
# Required — will raise exception if not set
export HAIM_API_KEY="$(openssl rand -hex 32)"
```
---
## MCP Server Integration
MnemoCore exposes a **Model Context Protocol (MCP)** server, enabling direct integration with Claude, GPT-4, and any MCP-compatible agent framework.
### Setup
```bash
# Start API first
uvicorn src.api.main:app --host 0.0.0.0 --port 8100
# Configure MCP in config.yaml
haim:
mcp:
enabled: true
transport: "stdio" # or "sse" for streaming
# Run MCP server
python -m src.mcp.server
```
### Claude Desktop Configuration
Add to your Claude Desktop `config.json`:
```json
{
"mcpServers": {
"mnemocore": {
"command": "python",
"args": ["-m", "src.mcp.server"],
"env": {
"HAIM_API_KEY": "your-key",
"HAIM_BASE_URL": "http://localhost:8100"
}
}
}
}
```
Once connected, the agent can:
- `store_memory(content, context)` — persist learned information
- `query_memory(query, context, top_k)` — recall relevant memories
- `provide_feedback(memory_id, outcome)` — signal what worked
- `get_knowledge_gaps()` — surface what it doesn't understand
---
## Observability
MnemoCore ships with built-in Prometheus metrics and structured logging.
### Prometheus Metrics
Available at `GET /metrics`:
| Metric | Description |
|--------|-------------|
| `haim_api_request_count` | Total requests by endpoint and status |
| `haim_api_request_latency_seconds` | Request latency histogram |
| `haim_storage_operation_count` | Store/query/delete operations |
| `haim_hot_tier_size` | Current HOT tier memory count |
| `haim_synapse_count` | Active synaptic connections |
### Grafana Dashboard
A sample Grafana dashboard config is available at `observability/grafana_dashboard.json`.
### Structured Logging
All components use structured Python logging with contextual fields:
```
2026-02-17 20:00:00 INFO Stored memory mem_1739821234567 (EIG: 0.7823)
2026-02-17 20:00:01 INFO Memory mem_1739821234567 reliability updated: 0.714 (4✓ / 1✗)
2026-02-17 03:00:00 INFO Consolidation complete: abstractions_created=12, consolidated=847
2026-02-17 04:00:00 INFO Knowledge gap detected: asyncio ↔ FastAPI middleware (5 co-occurrences)
```
---
## Testing
```bash
# Run full test suite
pytest
# Run with coverage
pytest --cov=src --cov-report=html
# Run specific feature tests
pytest tests/test_xor_attention.py # Contextual masking
pytest tests/test_stability.py # Reliability/Bayesian stability
pytest tests/test_consolidation.py # Semantic consolidation
pytest tests/test_engine_cleanup.py # Cleanup and decay
pytest tests/test_phase43_regressions.py # Phase 4.3 regression guardrails
# End-to-end flow
pytest tests/test_e2e_flow.py -v
```
---
## Roadmap
### Current Beta (v4.3)
- [x] Binary HDV core (XOR bind / bundle / permute / Hamming)
- [x] Three-tier HOT/WARM/COLD memory lifecycle
- [x] Async API + MCP integration
- [x] XOR attention masking + Bayesian reliability updates
- [x] Semantic consolidation, immunology cleanup, and gap detection/filling
- [x] Temporal recall: episodic chaining + chrono-weighted query
- [x] Regression guardrails for Phase 4.3 critical paths
### Next Steps
- [ ] Hardening pass for distributed/clustered HOT-tier behavior
- [ ] Extended observability standardization (`mnemocore_*` transition)
- [ ] Self-improvement loop (design documented, staged rollout pending)
---
## Contributing
MnemoCore is an active research project. Contributions are welcome — especially:
- **Performance**: CUDA kernels, FAISS integration, async refactoring
- **Algorithms**: Better clustering for consolidation, improved EIG formulas
- **Integrations**: New storage backends, LLM connectors
- **Tests**: Coverage for edge cases, property-based testing
### Process
```bash
# Fork and clone
git checkout -b feature/your-feature-name
# Make changes, ensure tests pass
pytest
# Commit with semantic message
git commit -m "feat(consolidation): add LLM-powered prototype labeling"
# Open PR — describe the what, why, and performance impact
```
Please follow the implementation patterns in [`COGNITIVE_ENHANCEMENTS.md`](COGNITIVE_ENHANCEMENTS.md) and [`CODE_REVIEW_ISSUES.md`](CODE_REVIEW_ISSUES.md) for architectural guidance.
---
## License
MIT License — see [LICENSE](LICENSE) for details.
---
## Contact
**Robin Granberg**
📧 robin@veristatesystems.com
---
<p align="center">
<i>Building the cognitive substrate for the next generation of autonomous AI.</i>
</p>
| text/markdown | Robin | null | null | null | MIT License
Copyright (c) 2026 Robin Granberg
Contact: Robin@veristatesystems.com
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | ai, cognitive, hyperdimensional-computing, llm, memory, qdrant, vector-search | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.10 | [] | [] | [] | [
"faiss-cpu>=1.7.4",
"fastapi>=0.100.0",
"loguru>=0.7.0",
"mcp>=0.1.0",
"msgpack>=1.0.0",
"numpy>=1.24",
"prometheus-client>=0.17.0",
"pybreaker>=1.0.0",
"pydantic>=2.0.0",
"pyyaml>=6.0",
"qdrant-client>=1.7.0",
"redis>=5.0.0",
"requests>=2.31.0",
"uvicorn>=0.23.0",
"black>=23.0.0; extra ... | [] | [] | [] | [
"Homepage, https://github.com/RobinALG87/MnemoCore-Infrastructure-for-Persistent-Cognitive-Memory",
"Repository, https://github.com/RobinALG87/MnemoCore-Infrastructure-for-Persistent-Cognitive-Memory",
"Bug Tracker, https://github.com/RobinALG87/MnemoCore-Infrastructure-for-Persistent-Cognitive-Memory/issues"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-18T21:06:11.733949 | mnemocore-4.5.0.tar.gz | 164,527 | 48/8f/242794ed5465a4f61da779828670ccd07255602421d3ed8b276947002982/mnemocore-4.5.0.tar.gz | source | sdist | null | false | 8de24b9a83c25c854250eed4a047814e | 5fac9a83ae675028c844b1e5de48e11d1490e2774750e339d9cae3eacd4327c0 | 488f242794ed5465a4f61da779828670ccd07255602421d3ed8b276947002982 | null | [
"LICENSE"
] | 264 |
2.4 | terminusgps-notifications | 1.5.0 | Terminus GPS Live Notifications platform | # terminusgps-notifications
Terminus GPS Notifications platform
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"django-encrypted-field>=1.0.5",
"django-rq>=3.1",
"django-storages[s3]>=1.14.6",
"django-tasks[rq]>=0.9.0",
"django>=5.2.7",
"python-dateutil>=2.9.0.post0",
"python-terminusgps>=48.1.0",
"redis[hiredis]>=7.0.1",
"terminusgps-payments>=3.0.0"
] | [] | [] | [] | [
"Documentation, https://terminusgps.github.io/terminusgps-notifications/",
"Repository, https://github.com/terminusgps/terminusgps-notifications"
] | uv/0.10.3 {"installer":{"name":"uv","version":"0.10.3","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Arch Linux","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T21:05:29.082595 | terminusgps_notifications-1.5.0-py3-none-any.whl | 328,549 | 06/35/017b841ea6aca36ca174849e3ffdd833a20683173968ee5101d2ceb7123d/terminusgps_notifications-1.5.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 36c484e73172e7ae0c8cbb4e2e89d06c | 92c2c53091fbbe3c13606a765969edb2ef4095b122d407f347402866a8438cd8 | 0635017b841ea6aca36ca174849e3ffdd833a20683173968ee5101d2ceb7123d | null | [
"COPYING"
] | 242 |
2.4 | agentsec-ai | 0.4.4 | Security scanner and hardener for agentic AI installations — OpenClaw, MCP servers, and AI agent skill ecosystems | <p align="center">
<img src="https://raw.githubusercontent.com/debu-sinha/agentsec/main/docs/demo/screenshots/hero-banner.png" alt="agentsec - AI Agent Security Scanner" width="600">
</p>
<p align="center">
<a href="LICENSE"><img src="https://img.shields.io/badge/license-Apache--2.0-blue.svg" alt="License"></a>
<a href="https://www.python.org/"><img src="https://img.shields.io/badge/python-3.10%2B-blue.svg" alt="Python"></a>
<a href="https://github.com/debu-sinha/agentsec/actions/workflows/ci.yml"><img src="https://github.com/debu-sinha/agentsec/actions/workflows/ci.yml/badge.svg" alt="CI"></a>
<a href="https://pypi.org/project/agentsec-ai/"><img src="https://img.shields.io/pypi/v/agentsec-ai.svg" alt="PyPI"></a>
<a href="https://pypi.org/project/agentsec-ai/"><img src="https://img.shields.io/pypi/dm/agentsec-ai.svg" alt="Downloads"></a>
<a href="https://genai.owasp.org/"><img src="https://img.shields.io/badge/OWASP-ASI01--ASI10-orange.svg" alt="OWASP"></a>
</p>
# agentsec
Security scanner and hardener for agentic AI installations.
agentsec focuses on practical misconfigurations and supply-chain risk in:
- OpenClaw installations
- MCP server configurations and code
- Agent skill/plugin ecosystems
- Credential exposure in local files
All findings map to the OWASP Top 10 for Agentic Applications (2026).
## Quick Start
```bash
pip install agentsec-ai
agentsec scan
```
Scan a specific installation:
```bash
agentsec scan ~/.openclaw
```
## What agentsec checks
| Module | Scope |
|---|---|
| `installation` | Gateway exposure, auth posture, DM/group policy, tool/sandbox settings, SSRF and safety checks, known CVE version checks, sensitive file/dir permissions |
| `skill` | Instruction malware, risky code patterns (`eval/exec/subprocess`), prompt-injection patterns, frontmatter capability risk, dependency/install-hook risk |
| `mcp` | Tool poisoning patterns, auth gaps on remote endpoints, dangerous schema/permissions, unverified `npx` usage |
| `credential` | 17 secret patterns (OpenAI, Anthropic, AWS, GitHub, Slack, Stripe, etc.), high-entropy detection, git credential leakage |
Reference catalog:
- [checks-catalog.md](docs/checks-catalog.md) (27 named checks + dynamic credential findings)
- [CLI reference](docs/cli-reference.md) (full command/options guide)
## Core Commands
```bash
# Full installation scan (all scanners, default target=. )
agentsec scan
# JSON report for CI parsing and pipelines
agentsec scan -o json -f report.json
# SARIF output for GitHub code scanning upload
agentsec scan -o sarif -f results.sarif
# Run only selected scanners for focused checks
agentsec scan -s installation,mcp
# Fail build only at/above selected severity
agentsec scan --fail-on critical
```
```bash
# Preview profile changes without writing config
agentsec harden -p workstation
# Apply profile and write hardened config values
agentsec harden -p workstation --apply
# Watch files and auto re-scan on security-relevant changes
agentsec watch ~/.openclaw -i 2
# Pre-install package gate (scan before install)
agentsec gate npm install express
# Generate shell hook wrappers for npm/pip install flows
agentsec hook --shell zsh
```
List available scanners (names + descriptions):
```bash
agentsec list-scanners
```
## Hardening Profiles
| Profile | Intended use |
|---|---|
| `workstation` | Single-owner local usage |
| `vps` | Remote/self-hosted deployment |
| `public-bot` | Highest restriction for untrusted public input |
Use `agentsec show-profile <name>` to inspect exact changes before applying.
## Output and Exit Codes
Output formats:
- `terminal` (default)
- `json`
- `sarif`
Exit codes:
- `0`: no findings at/above threshold
- `1-127`: count of findings at/above threshold (capped)
- `2`: runtime/usage error
## GitHub Actions
Use the bundled composite action:
```yaml
name: Agent Security
on: [push, pull_request]
jobs:
agentsec:
runs-on: ubuntu-latest
permissions:
contents: read
security-events: write
steps:
- uses: actions/checkout@v4
- uses: debu-sinha/agentsec@v0.4.1
with:
fail-on: high
output: sarif
upload-sarif: 'true'
```
Action definition:
- [action.yml](action.yml)
## Screenshots
Screenshots below show the experimental demo sandbox flow (intentionally insecure configuration for detection and hardening demonstration). Gate and hook behavior are documented in `docs/case-studies/003-preinstall-gate-blocked-malicious-package.md` and `docs/adr/ADR-0004-pre-install-gate.md`.
### Step 1: Initial scan on intentionally insecure demo config

### Step 2: Apply workstation hardening profile

### Step 3: Re-scan findings after hardening

### Step 4: OWASP posture view after hardening

## MCP Ecosystem Security Dashboard
Weekly automated security scan of the top 50 MCP server repositories, graded A through F.
[](docs/mcp-security-grades.md) [](docs/mcp-security-grades.md)
**[View the full dashboard](docs/mcp-security-grades.md)** - updated every Monday via GitHub Actions.
## Benchmarks and Studies
- [Fixture benchmark (artifact filename keeps v0.4.0; refreshed 2026-02-17 with agentsec v0.4.1)](docs/benchmarks/results/2026-02-15-v0.4.0.md)
Precision/recall/F1 over a 20-fixture suite.
- [Top-50 MCP study (snapshot 2026-02-16)](docs/benchmarks/2026-02-top50-mcp-security-study.md)
Agentsec-only repro run with normalized findings output.
- [Top-50 study kit](docs/benchmarks/top50/README.md)
Schema, selection CSV, JSONL findings, and summary JSON.
Current checked-in Top-50 summary data:
- `docs/benchmarks/top50/reports/top50_summary_20260215.json`
- `docs/benchmarks/top50/reports/top50_findings_20260215.jsonl`
## Reproducibility
Fixture benchmark:
```bash
python docs/benchmarks/run_benchmark.py
```
Top-50 study repro:
```powershell
powershell -ExecutionPolicy Bypass -File scripts\reproduce_top50_study.ps1 -DateStamp 20260215
```
Note: semgrep and gitleaks baseline runs are optional in the PowerShell repro script and require those tools on PATH.
Adversarial consistency audit (docs vs artifacts):
```bash
python scripts/repo_consistency_audit.py
```
## Case Studies
- [001: Insecure workstation remediation](docs/case-studies/001-insecure-openclaw-workstation.md)
- [002: Public bot hardening on VPS](docs/case-studies/002-public-bot-vps-hardening.md)
- [003: Pre-install gate blocked malicious package](docs/case-studies/003-preinstall-gate-blocked-malicious-package.md)
- [004: Malicious skill detection and block](docs/case-studies/004-malicious-skill-detection-and-block.md)
## Launch Evidence
- [Launch Evidence Manifest](docs/launch/LAUNCH_EVIDENCE_MANIFEST.md)
- [Reproducibility Spec](docs/launch/REPRODUCIBILITY_SPEC.md)
## Development
```bash
git clone https://github.com/debu-sinha/agentsec.git
cd agentsec
pip install -c requirements/constraints-dev.txt -e ".[dev]"
ruff check src tests
pytest
```
Contribution guide:
- [CONTRIBUTING.md](CONTRIBUTING.md)
Security policy:
- [SECURITY.md](SECURITY.md)
## Governance
- [Code of Conduct](CODE_OF_CONDUCT.md)
- [Security Policy](SECURITY.md)
- [Contribution Guide](CONTRIBUTING.md)
Issue intake is template-driven under `.github/ISSUE_TEMPLATE/` to keep triage and reproduction quality high.
## License
Apache-2.0
| text/markdown | null | Debu Sinha <debusinha2009@gmail.com> | null | null | null | agentic-ai, ai-security, mcp, model-context-protocol, openclaw, owasp, security, vulnerability-scanner | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programm... | [] | null | null | >=3.10 | [] | [] | [] | [
"click<9,>=8.1",
"detect-secrets<2,>=1.4",
"pydantic<3,>=2.0",
"rich<14,>=13.0",
"tomli<3,>=2.0; python_version < \"3.11\"",
"mypy<2,>=1.10; extra == \"dev\"",
"pip-audit<3,>=2.7; extra == \"dev\"",
"pre-commit<4,>=3.7; extra == \"dev\"",
"pytest-cov<6,>=5.0; extra == \"dev\"",
"pytest<9,>=8.0; ex... | [] | [] | [] | [
"Homepage, https://github.com/debu-sinha/agentsec",
"Documentation, https://github.com/debu-sinha/agentsec#readme",
"Repository, https://github.com/debu-sinha/agentsec",
"Issues, https://github.com/debu-sinha/agentsec/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:04:43.423121 | agentsec_ai-0.4.4.tar.gz | 662,586 | c8/85/c986ab713e841ecd81130ee77406049583241d1ab5e19c69b07802ab01f2/agentsec_ai-0.4.4.tar.gz | source | sdist | null | false | 739857cffc6e35cb8d87451f3c23122f | b85222cae94cbd544c9c037117fc50c14f212d784a0e581eac639e1efb303b6b | c885c986ab713e841ecd81130ee77406049583241d1ab5e19c69b07802ab01f2 | Apache-2.0 | [
"LICENSE"
] | 267 |
2.4 | github-backup | 0.61.5 | backup a github user or organization | =============
github-backup
=============
|PyPI| |Python Versions|
The package can be used to backup an *entire* `Github <https://github.com/>`_ organization, repository or user account, including starred repos, issues and wikis in the most appropriate format (clones for wikis, json files for issues).
Requirements
============
- Python 3.10 or higher
- GIT 1.9+
Installation
============
Using PIP via PyPI::
pip install github-backup
Using PIP via Github (more likely the latest version)::
pip install git+https://github.com/josegonzalez/python-github-backup.git#egg=github-backup
*Install note for python newcomers:*
Python scripts are unlikely to be included in your ``$PATH`` by default, this means it cannot be run directly in terminal with ``$ github-backup ...``, you can either add python's install path to your environments ``$PATH`` or call the script directly e.g. using ``$ ~/.local/bin/github-backup``.*
Basic Help
==========
Show the CLI help output::
github-backup -h
CLI Help output::
github-backup [-h] [-t TOKEN_CLASSIC] [-f TOKEN_FINE] [-q] [--as-app]
[-o OUTPUT_DIRECTORY] [-l LOG_LEVEL] [-i]
[--incremental-by-files]
[--starred] [--all-starred] [--starred-skip-size-over MB]
[--watched] [--followers] [--following] [--all]
[--issues] [--issue-comments] [--issue-events] [--pulls]
[--pull-comments] [--pull-commits] [--pull-details]
[--labels] [--hooks] [--milestones] [--security-advisories]
[--repositories] [--bare] [--no-prune] [--lfs] [--wikis]
[--gists] [--starred-gists] [--skip-archived] [--skip-existing]
[-L [LANGUAGES ...]] [-N NAME_REGEX] [-H GITHUB_HOST]
[-O] [-R REPOSITORY] [-P] [-F] [--prefer-ssh] [-v]
[--keychain-name OSX_KEYCHAIN_ITEM_NAME]
[--keychain-account OSX_KEYCHAIN_ITEM_ACCOUNT]
[--releases] [--latest-releases NUMBER_OF_LATEST_RELEASES]
[--skip-prerelease] [--assets]
[--skip-assets-on [SKIP_ASSETS_ON ...]] [--attachments]
[--throttle-limit THROTTLE_LIMIT]
[--throttle-pause THROTTLE_PAUSE]
[--exclude [EXCLUDE ...]] [--retries MAX_RETRIES]
USER
Backup a github account
positional arguments:
USER github username
options:
-h, --help show this help message and exit
-t, --token TOKEN_CLASSIC
personal access, OAuth, or JSON Web token, or path to
token (file://...)
-f, --token-fine TOKEN_FINE
fine-grained personal access token (github_pat_....),
or path to token (file://...)
-q, --quiet supress log messages less severe than warning, e.g.
info
--as-app authenticate as github app instead of as a user.
-o, --output-directory OUTPUT_DIRECTORY
directory at which to backup the repositories
-l, --log-level LOG_LEVEL
log level to use (default: info, possible levels:
debug, info, warning, error, critical)
-i, --incremental incremental backup
--incremental-by-files
incremental backup based on modification date of files
--starred include JSON output of starred repositories in backup
--all-starred include starred repositories in backup [*]
--starred-skip-size-over MB
skip starred repositories larger than this size in MB
--watched include JSON output of watched repositories in backup
--followers include JSON output of followers in backup
--following include JSON output of following users in backup
--all include everything in backup (not including [*])
--issues include issues in backup
--issue-comments include issue comments in backup
--issue-events include issue events in backup
--pulls include pull requests in backup
--pull-comments include pull request review comments in backup
--pull-commits include pull request commits in backup
--pull-details include more pull request details in backup [*]
--labels include labels in backup
--hooks include hooks in backup (works only when
authenticated)
--milestones include milestones in backup
--security-advisories
include security advisories in backup
--repositories include repository clone in backup
--bare clone bare repositories
--no-prune disable prune option for git fetch
--lfs clone LFS repositories (requires Git LFS to be
installed, https://git-lfs.github.com) [*]
--wikis include wiki clone in backup
--gists include gists in backup [*]
--starred-gists include starred gists in backup [*]
--skip-archived skip project if it is archived
--skip-existing skip project if a backup directory exists
-L, --languages [LANGUAGES ...]
only allow these languages
-N, --name-regex NAME_REGEX
python regex to match names against
-H, --github-host GITHUB_HOST
GitHub Enterprise hostname
-O, --organization whether or not this is an organization user
-R, --repository REPOSITORY
name of repository to limit backup to
-P, --private include private repositories [*]
-F, --fork include forked repositories [*]
--prefer-ssh Clone repositories using SSH instead of HTTPS
-v, --version show program's version number and exit
--keychain-name OSX_KEYCHAIN_ITEM_NAME
OSX ONLY: name field of password item in OSX keychain
that holds the personal access or OAuth token
--keychain-account OSX_KEYCHAIN_ITEM_ACCOUNT
OSX ONLY: account field of password item in OSX
keychain that holds the personal access or OAuth token
--releases include release information, not including assets or
binaries
--latest-releases NUMBER_OF_LATEST_RELEASES
include certain number of the latest releases; only
applies if including releases
--skip-prerelease skip prerelease and draft versions; only applies if
including releases
--assets include assets alongside release information; only
applies if including releases
--skip-assets-on [SKIP_ASSETS_ON ...]
skip asset downloads for these repositories
--attachments download user-attachments from issues and pull
requests
--throttle-limit THROTTLE_LIMIT
start throttling of GitHub API requests after this
amount of API requests remain
--throttle-pause THROTTLE_PAUSE
wait this amount of seconds when API request
throttling is active (default: 30.0, requires
--throttle-limit to be set)
--exclude [EXCLUDE ...]
names of repositories to exclude
--retries MAX_RETRIES
maximum number of retries for API calls (default: 5)
Usage Details
=============
Authentication
--------------
GitHub requires token-based authentication for API access. Password authentication was `removed in November 2020 <https://developer.github.com/changes/2020-02-14-deprecating-password-auth/>`_.
The positional argument ``USER`` specifies the user or organization account you wish to back up.
**Fine-grained tokens** (``-f TOKEN_FINE``) are recommended for most use cases, especially long-running backups (e.g. cron jobs), as they provide precise permission control.
**Classic tokens** (``-t TOKEN``) are `slightly less secure <https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/managing-your-personal-access-tokens#personal-access-tokens-classic>`_ as they provide very coarse-grained permissions.
Fine Tokens
~~~~~~~~~~~
You can "generate new token", choosing the repository scope by selecting specific repos or all repos. On Github this is under *Settings -> Developer Settings -> Personal access tokens -> Fine-grained Tokens*
Customise the permissions for your use case, but for a personal account full backup you'll need to enable the following permissions:
**User permissions**: Read access to followers, starring, and watching.
**Repository permissions**: Read access to contents, issues, metadata, pull requests, and webhooks.
GitHub Apps
~~~~~~~~~~~
GitHub Apps are ideal for organization backups in CI/CD. Tokens are scoped to specific repositories and expire after 1 hour.
**One-time setup:**
1. Create a GitHub App at *Settings -> Developer Settings -> GitHub Apps -> New GitHub App*
2. Set a name and homepage URL (can be any URL)
3. Uncheck "Webhook > Active" (not needed for backups)
4. Set permissions (same as fine-grained tokens above)
5. Click "Create GitHub App", then note the **App ID** shown on the next page
6. Under "Private keys", click "Generate a private key" and save the downloaded file
7. Go to *Install App* in your app's settings
8. Select the account/organization and which repositories to back up
**CI/CD usage with GitHub Actions:**
Store the App ID as a repository variable and the private key contents as a secret, then use ``actions/create-github-app-token``::
- uses: actions/create-github-app-token@v1
id: app-token
with:
app-id: ${{ vars.APP_ID }}
private-key: ${{ secrets.APP_PRIVATE_KEY }}
- run: github-backup myorg -t ${{ steps.app-token.outputs.token }} --as-app -o ./backup --all
Note: Installation tokens expire after 1 hour. For long-running backups, use a fine-grained personal access token instead.
Prefer SSH
~~~~~~~~~~
If cloning repos is enabled with ``--repositories``, ``--all-starred``, ``--wikis``, ``--gists``, ``--starred-gists`` using the ``--prefer-ssh`` argument will use ssh for cloning the git repos, but all other connections will still use their own protocol, e.g. API requests for issues uses HTTPS.
To clone with SSH, you'll need SSH authentication setup `as usual with Github <https://docs.github.com/en/authentication/connecting-to-github-with-ssh>`_, e.g. via SSH public and private keys.
Using the Keychain on Mac OSX
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Note: On Mac OSX the token can be stored securely in the user's keychain. To do this:
1. Open Keychain from "Applications -> Utilities -> Keychain Access"
2. Add a new password item using "File -> New Password Item"
3. Enter a name in the "Keychain Item Name" box. You must provide this name to github-backup using the --keychain-name argument.
4. Enter an account name in the "Account Name" box, enter your Github username as set above. You must provide this name to github-backup using the --keychain-account argument.
5. Enter your Github personal access token in the "Password" box
Note: When you run github-backup, you will be asked whether you want to allow "security" to use your confidential information stored in your keychain. You have two options:
1. **Allow:** In this case you will need to click "Allow" each time you run `github-backup`
2. **Always Allow:** In this case, you will not be asked for permission when you run `github-backup` in future. This is less secure, but is required if you want to schedule `github-backup` to run automatically
Github Rate-limit and Throttling
--------------------------------
"github-backup" will automatically throttle itself based on feedback from the Github API.
Their API is usually rate-limited to 5000 calls per hour. The API will ask github-backup to pause until a specific time when the limit is reset again (at the start of the next hour). This continues until the backup is complete.
During a large backup, such as ``--all-starred``, and on a fast connection this can result in (~20 min) pauses with bursts of API calls periodically maxing out the API limit. If this is not suitable `it has been observed <https://github.com/josegonzalez/python-github-backup/issues/76#issuecomment-636158717>`_ under real-world conditions that overriding the throttle with ``--throttle-limit 5000 --throttle-pause 0.6`` provides a smooth rate across the hour, although a ``--throttle-pause 0.72`` (3600 seconds [1 hour] / 5000 limit) is theoretically safer to prevent large rate-limit pauses.
About Git LFS
-------------
When you use the ``--lfs`` option, you will need to make sure you have Git LFS installed.
Instructions on how to do this can be found on https://git-lfs.github.com.
LFS objects are fetched for all refs, not just the current checkout, ensuring a complete backup of all LFS content across all branches and history.
About Attachments
-----------------
When you use the ``--attachments`` option with ``--issues`` or ``--pulls``, the tool will download user-uploaded attachments (images, videos, documents, etc.) from issue and pull request descriptions and comments. In some circumstances attachments contain valuable data related to the topic, and without their backup important information or context might be lost inadvertently.
Attachments are saved to ``issues/attachments/{issue_number}/`` and ``pulls/attachments/{pull_number}/`` directories, where ``{issue_number}`` is the GitHub issue number (e.g., issue #123 saves to ``issues/attachments/123/``). Each attachment directory contains:
- The downloaded attachment files (named by their GitHub identifier with appropriate file extensions)
- If multiple attachments have the same filename, conflicts are resolved with numeric suffixes (e.g., ``report.pdf``, ``report_1.pdf``, ``report_2.pdf``)
- A ``manifest.json`` file documenting all downloads, including URLs, file metadata, and download status
The tool automatically extracts file extensions from HTTP headers to ensure files can be more easily opened by your operating system.
**Supported URL formats:**
- Modern: ``github.com/user-attachments/{assets,files}/*``
- Legacy: ``user-images.githubusercontent.com/*`` and ``private-user-images.githubusercontent.com/*``
- Repo files: ``github.com/{owner}/{repo}/files/*`` (filtered to current repository)
- Repo assets: ``github.com/{owner}/{repo}/assets/*`` (filtered to current repository)
**Repository filtering** for repo files/assets handles renamed and transferred repositories gracefully. URLs are included if they either match the current repository name directly, or redirect to it (e.g., ``willmcgugan/rich`` redirects to ``Textualize/rich`` after transfer).
**Fine-grained token limitation:** Due to a GitHub platform limitation, fine-grained personal access tokens (``github_pat_...``) cannot download attachments from private repositories directly. This affects both ``/assets/`` (images) and ``/files/`` (documents) URLs. The tool implements a workaround for image attachments using GitHub's Markdown API, which converts URLs to temporary JWT-signed URLs that can be downloaded. However, this workaround only works for images - document attachments (PDFs, text files, etc.) will fail with 404 errors when using fine-grained tokens on private repos. For full attachment support on private repositories, use a classic token (``-t``) instead of a fine-grained token (``-f``). See `#477 <https://github.com/josegonzalez/python-github-backup/issues/477>`_ for details.
About security advisories
-------------------------
GitHub security advisories are only available in public repositories. GitHub does not provide the respective API endpoint for private repositories.
Therefore the logic is implemented as follows:
- Security advisories are included in the `--all` option.
- If only the `--all` option was provided, backups of security advisories are skipped for private repositories.
- If the `--security-advisories` option is provided (on its own or in addition to `--all`), a backup of security advisories is attempted for all repositories, with graceful handling if the GitHub API doesn't return any.
Run in Docker container
-----------------------
To run the tool in a Docker container use the following command:
sudo docker run --rm -v /path/to/backup:/data --name github-backup ghcr.io/josegonzalez/python-github-backup -o /data $OPTIONS $USER
Gotchas / Known-issues
======================
All is not everything
---------------------
The ``--all`` argument does not include: cloning private repos (``-P, --private``), cloning forks (``-F, --fork``), cloning starred repositories (``--all-starred``), ``--pull-details``, cloning LFS repositories (``--lfs``), cloning gists (``--gists``) or cloning starred gist repos (``--starred-gists``). See examples for more.
Starred repository size
-----------------------
Using the ``--all-starred`` argument to clone all starred repositories may use a large amount of storage space.
To see your starred repositories sorted by size (requires `GitHub CLI <https://cli.github.com>`_)::
gh api user/starred --paginate --jq 'sort_by(-.size)[]|"\(.full_name) \(.size/1024|round)MB"'
To limit which starred repositories are cloned, use ``--starred-skip-size-over SIZE`` where SIZE is in MB. For example, ``--starred-skip-size-over 500`` will skip any starred repository where the git repository size (code and history) exceeds 500 MB. Note that this size limit only applies to the repository itself, not issues, release assets or other metadata. This filter only affects starred repositories; your own repositories are always included regardless of size.
For finer control, avoid using ``--assets`` with starred repos, or use ``--skip-assets-on`` for specific repositories with large release binaries.
Alternatively, consider just storing links to starred repos in JSON format with ``--starred``.
Incremental Backup
------------------
Using (``-i, --incremental``) will only request new data from the API **since the last run (successful or not)**. e.g. only request issues from the API since the last run.
This means any blocking errors on previous runs can cause a large amount of missing data in backups.
Using (``--incremental-by-files``) will request new data from the API **based on when the file was modified on filesystem**. e.g. if you modify the file yourself you may miss something.
Still saver than the previous version.
Specifically, issues and pull requests are handled like this.
Known blocking errors
---------------------
Some errors will block the backup run by exiting the script. e.g. receiving a 403 Forbidden error from the Github API.
If the incremental argument is used, this will result in the next backup only requesting API data since the last blocked/failed run. Potentially causing unexpected large amounts of missing data.
It's therefore recommended to only use the incremental argument if the output/result is being actively monitored, or complimented with periodic full non-incremental runs, to avoid unexpected missing data in a regular backup runs.
**Starred public repo hooks blocking**
Since the ``--all`` argument includes ``--hooks``, if you use ``--all`` and ``--all-starred`` together to clone a users starred public repositories, the backup will likely error and block the backup continuing.
This is due to needing the correct permission for ``--hooks`` on public repos.
"bare" is actually "mirror"
---------------------------
Using the bare clone argument (``--bare``) will actually call git's ``clone --mirror`` command. There's a subtle difference between `bare <https://www.git-scm.com/docs/git-clone#Documentation/git-clone.txt---bare>`_ and `mirror <https://www.git-scm.com/docs/git-clone#Documentation/git-clone.txt---mirror>`_ clone.
*From git docs "Compared to --bare, --mirror not only maps local branches of the source to local branches of the target, it maps all refs (including remote-tracking branches, notes etc.) and sets up a refspec configuration such that all these refs are overwritten by a git remote update in the target repository."*
Starred gists vs starred repo behaviour
---------------------------------------
The starred normal repo cloning (``--all-starred``) argument stores starred repos separately to the users own repositories. However, using ``--starred-gists`` will store starred gists within the same directory as the users own gists ``--gists``. Also, all gist repo directory names are IDs not the gist's name.
Note: ``--starred-gists`` only retrieves starred gists for the authenticated user, not the target user, due to a GitHub API limitation.
Skip existing on incomplete backups
-----------------------------------
The ``--skip-existing`` argument will skip a backup if the directory already exists, even if the backup in that directory failed (perhaps due to a blocking error). This may result in unexpected missing data in a regular backup.
Updates use fetch, not pull
---------------------------
When updating an existing repository backup, ``github-backup`` uses ``git fetch`` rather than ``git pull``. This is intentional - a backup tool should reliably download data without risk of failure. Using ``git pull`` would require handling merge conflicts, which adds complexity and could cause backups to fail unexpectedly.
With fetch, **all branches and commits are downloaded** safely into remote-tracking branches. The working directory files won't change, but your backup is complete.
If you look at files directly (e.g., ``cat README.md``), you'll see the old content. The new data is in the remote-tracking branches (confusingly named "remote" but stored locally). To view or use the latest files::
git show origin/main:README.md # view a file
git merge origin/main # update working directory
All branches are backed up as remote refs (``origin/main``, ``origin/feature-branch``, etc.).
If you want to browse files directly without merging, consider using ``--bare`` which skips the working directory entirely - the backup is just the git data.
See `#269 <https://github.com/josegonzalez/python-github-backup/issues/269>`_ for more discussion.
Github Backup Examples
======================
Backup all repositories, including private ones using a classic token::
export ACCESS_TOKEN=SOME-GITHUB-TOKEN
github-backup WhiteHouse --token $ACCESS_TOKEN --organization --output-directory /tmp/white-house --repositories --private
Use a fine-grained access token to backup a single organization repository with everything else (wiki, pull requests, comments, issues etc)::
export FINE_ACCESS_TOKEN=SOME-GITHUB-TOKEN
ORGANIZATION=docker
REPO=cli
# e.g. git@github.com:docker/cli.git
github-backup $ORGANIZATION -P -f $FINE_ACCESS_TOKEN -o . --all -O -R $REPO
Quietly and incrementally backup useful Github user data (public and private repos with SSH) including; all issues, pulls, all public starred repos and gists (omitting "hooks", "releases" and therefore "assets" to prevent blocking). *Great for a cron job.* ::
export FINE_ACCESS_TOKEN=SOME-GITHUB-TOKEN
GH_USER=YOUR-GITHUB-USER
github-backup -f $FINE_ACCESS_TOKEN --prefer-ssh -o ~/github-backup/ -l error -P -i --all-starred --starred --watched --followers --following --issues --issue-comments --issue-events --pulls --pull-comments --pull-commits --labels --milestones --security-advisories --repositories --wikis --releases --assets --attachments --pull-details --gists --starred-gists $GH_USER
Debug an error/block or incomplete backup into a temporary directory. Omit "incremental" to fill a previous incomplete backup. ::
export FINE_ACCESS_TOKEN=SOME-GITHUB-TOKEN
GH_USER=YOUR-GITHUB-USER
github-backup -f $FINE_ACCESS_TOKEN -o /tmp/github-backup/ -l debug -P --all-starred --starred --watched --followers --following --issues --issue-comments --issue-events --pulls --pull-comments --pull-commits --labels --milestones --repositories --wikis --releases --assets --pull-details --gists --starred-gists $GH_USER
Pipe a token from stdin to avoid storing it in environment variables or command history (Unix-like systems only)::
my-secret-manager get github-token | github-backup user -t file:///dev/stdin -o /backup --repositories
Restoring from Backup
=====================
This tool creates backups only, there is no inbuilt restore command.
**Git repositories, wikis, and gists** can be restored by pushing them back to GitHub as you would any git repository. For example, to restore a bare repository backup::
cd /tmp/white-house/repositories/petitions/repository
git push --mirror git@github.com:WhiteHouse/petitions.git
**Issues, pull requests, comments, and other metadata** are saved as JSON files for archival purposes. The GitHub API does not support recreating this data faithfully, creating issues via the API has limitations:
- New issue/PR numbers are assigned (original numbers cannot be set)
- Timestamps reflect creation time (original dates cannot be set)
- The API caller becomes the author (original authors cannot be set)
- Cross-references between issues and PRs will break
These are GitHub API limitations that affect all backup and migration tools, not just this one. Recreating issues with these limitations via the GitHub API is an exercise for the reader. The JSON backups remain useful for searching, auditing, or manual reference.
Development
===========
This project is considered feature complete for the primary maintainer @josegonzalez. If you would like a bugfix or enhancement, pull requests are welcome. Feel free to contact the maintainer for consulting estimates if you'd like to sponsor the work instead.
Contibuters
-----------
A huge thanks to all the contibuters!
.. image:: https://contrib.rocks/image?repo=josegonzalez/python-github-backup
:target: https://github.com/josegonzalez/python-github-backup/graphs/contributors
:alt: contributors
Testing
-------
To run the test suite::
pip install pytest
pytest
To run linting::
pip install flake8
flake8 --ignore=E501
.. |PyPI| image:: https://img.shields.io/pypi/v/github-backup.svg
:target: https://pypi.python.org/pypi/github-backup/
.. |Python Versions| image:: https://img.shields.io/pypi/pyversions/github-backup.svg
:target: https://github.com/josegonzalez/python-github-backup
| text/x-rst | Jose Diaz-Gonzalez | github-backup@josediazgonzalez.com | null | null | MIT | null | [
"Development Status :: 5 - Production/Stable",
"Topic :: System :: Archiving :: Backup",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Pr... | [] | http://github.com/josegonzalez/python-github-backup | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-18T21:04:36.502573 | github_backup-0.61.5.tar.gz | 80,380 | 2c/ea/d39a5d12d48a96e9b1ad5bffafa6c4192e02e0a7e8825464c7d4dcc3583d/github_backup-0.61.5.tar.gz | source | sdist | null | false | c47341ff86e6a0154219c80fcfdd9ff0 | 5063bd4b557bf2948b0b7b7a3f48f4f43122752eb84b2fc44fd5776e4eac9efc | 2cead39a5d12d48a96e9b1ad5bffafa6c4192e02e0a7e8825464c7d4dcc3583d | null | [
"LICENSE.txt"
] | 1,168 |
2.1 | cioblender | 0.5.0 | Blender plugin for Conductor Cloud Rendering Platform. | # Conductor for Blender
Blender plugin submitter for the Conductor Cloud rendering service.
## Install
**To install the latest version.**
```bash
pip install --upgrade cioblender --target=$HOME/Conductor
```
**To install a specific version, for example 0.1.0.**
```bash
pip install --upgrade --force-reinstall cioblender==0.1.0 --target=$HOME/Conductor
```
**Then setup the Blender module.**
```bash
python ~/Conductor/cioblender/post_install.py
```
> **NOTE** An alternative is to install from the Plugins page in the [Conductor Companion app](https://docs.conductortech.com/getting_started/installation/#companion-app)
## Usage
Open the Plugin Manager and load **Conductor.py**.
Go to **Conductor->About** to check the version and other info.
To set up a render, choose **Conductor->Submitter->Create** from the **Conductor** menu.
For detailed help, checkout the [tutorial](https://docs.conductortech.com/tutorials/blender) and [reference](https://docs.conductortech.com/reference/blender) documentation.
## Contributing
Clone the repo.
```
git clone git@github.com:ConductorTechnologies/cioblender.git
cd cioblender
```
Set up a clean virtual envirionment with Python 3.7 for development (optional).
```
python -m virtualenv cioblender.venv
. ./cioblender.venv/bin/activate
```
Install development dependencies
```
pip install -r requirements_dev.txt
```
Build and install from this directory into to a convenient location for testing.
```
pip install --upgrade -r requirements.txt --target=$HOME/ConductorDev
python $HOME/ConductorDev/cioblender/post_install.py
```
When you install from the file requirements.txt, the dependency on ciocore is specified as a local sibling of this project, meaning you can develop ciocore and cioblender in parallel.
The post_install.py script writes the conductor.mod file to your Blender modules directory. Check the output of the command to see where this is.
## License
[MIT](https://choosealicense.com/licenses/mit)
## Changelog
## Version:0.5.0 -- 18 Feb 2026
* Temporarily filter out Blender 5.x entries from the version selection menu
* Fix add-ons loading failure when connecting with Blender 5.x
* Updating dependencies
## Version:0.4.1-rc.2 -- 18 Feb 2026
- Temporarily filter out Blender 5.x entries from the version selection menu
## Version:0.4.1-rc.1 -- 26 Jan 2026
* Fix add-ons loading failure when connecting with Blender 5.x
## Version:0.4.0 -- 30 Oct 2025
* Updating dependencies
## Version:0.3.14 -- 19 Sep 2025
* Enabling render active layers
## Version:0.3.12 -- 20 Feb 2025
* Resolving an issue with EEVEE rendering compatibility in Blender 4.2 and later.
* Added support for rendering negative frame numbers with dynamic filename formatting, ensuring consistent output naming for both negative and positive frames.
* Increased maximum supported resolution limit.
* Adding validation for output paths.
## Version:0.3.9 -- 30 Sep 2024
* Updating the plugin version number
## Version:0.3.8 -- 19 Sep 2024
* Double Space Path Validation: Implemented a check for double spaces in output paths to prevent errors and ensure smoother operation
* Relative Output Path Validation
* Added support for best fit instance types.
## Version:0.3.7 -- 02 May 2024
* Enhanced Output Path Generation
## Version:0.3.6 -- 29 Apr 2024
* Resolving Google drive mapping
* Adding CONDUCTOR_MD5_CACHING environment variable to enable/disable md5 caching
## Version:0.3.4 -- 22 Apr 2024
* Resolving Asset Scanning Issues
* Resolving the Shiboken Support Error
## Version:0.3.2 -- 16 Apr 2024
* Rendering Enhancements:
* Added new rendering options to render all active view layers and update the active camera for each frame.
* Increased the maximum limit for resolution percentage to 1000%, allowing for higher resolution outputs in renders.
* Installation Updates:
* Implemented a procedure to clear existing Blender installations before upgrading.
* Asset Support Expansion:
* Introduced support for Alembic and HDR assets.
* Enhanced asset handling by restricting the use of home directories and root drives as asset paths to improve stability and user experience on Windows.
* Upload Features:
* Launched the Upload Daemon feature for background asset uploads, allowing uninterrupted Blender sessions. This feature lets users continue working while the daemon uploads assets as needed after job submissions.
* Updated the Submission dialog to facilitate continued work in Blender post-submission.
* Introduced the capability to upload entire directories of assets, enhancing the management and organization of resources.
* User Interface Improvements:
* Added a feature where clicking 'Preview Script' without a JSON-associated app opens the script directly in a QT window for easy previewing.
* Simulation and Baking Enhancements:
* Expanded support for simulation and baking processes, improving performance and flexibility for projects.
## Version:0.2.3 -- 13 Feb 2024
* Improved Installation on the Windows Platform:
* Enhanced the installation process for users on Windows, streamlining setup and reducing potential issues.
* Improved Frame Handling for Efficiency:
* Enhanced rendering speed by treating task frames collectively as an animation sequence rather than processing them as separate, individual frames. This approach significantly reduces computational overhead, leading to faster rendering times. To fully benefit from this improvement, ensure that the chunk size is set higher than one and scout frames are turned off. This configuration maximizes the efficiency gains from processing frames as a continuous sequence.
* Additional Rendering Options Panel:
* A newly introduced panel offering advanced control over rendering settings. It includes a key feature: Disable Audio, which sets the sound system to 'None'. This disables all audio processing in Blender during rendering tasks, streamlining the rendering pipeline and potentially enhancing render efficiency and speed.
* Installation Script:
* Remove quarantine only if the platform is macOS
* Modified the plugin installation script to append our custom module directory to Python's search path, ensuring seamless integration without interfering with existing Python modules.
* Enhanced Add-on Compatibility:
* The plugin now seamlessly integrates with a range of popular Blender add-ons, including Animation Nodes, BlenRig, Bricker, Flip Fluids, Molecular Plus, and Physical Starlight Atmosphere (PSA), enriching your animation and rendering capabilities.
* RedShift Renderer Support:
* Fully compatible with the RedShift rendering engine, ensuring optimal performance and visual fidelity. Note: To leverage this feature, please use Blender version 3.6 or earlier.
* Persistent Settings Preservation:
* Enhanced usability with the ability to retain previous plugin configurations and settings, even after reconnecting to the plugin for subsequent sessions. This ensures a smoother, more efficient workflow without the need to repeatedly adjust settings.
## Version:0.2.0 -- 17 Jan 2024
* New Features:
* UI Enhancements:
* Introduced a new Render Settings panel with adjustable parameters including Resolution (X, Y, Percentage), Camera, and Samples. This allows users to override existing scene settings for more precise control.
* Enhanced the Submission Widget by improving the visibility of push buttons and ensuring it remains prominently displayed (always on top).
* Added detailed tooltips across the UI for better guidance and clarity.
* Modified the Validation tab, offering two options for scene submission: 'Save Scene and Continue Submission' or 'Continue Submission', empowering users with more flexibility in their workflow.
* Performance Enhancements:
* Enabled script rendering functionality specifically for the Windows operating system.
* Improved Asset Scanning Efficiency, ensuring a smoother and faster process.
* Rendering Enhancements:
* Modified the Instant Type Tooltip to advocate for GPU usage with Cycles Render Software, aiming for enhanced speed and efficiency.
* Updates:
* Upgraded PySide6 and shiboken6 to the latest versions.
* Updated the ciocore library to versions 7.0.2, bringing in the latest features and fixes.
* Fixes:
* Resolved a naming conflict issue with cameras.
* Addressed an issue where spaces in scene names caused problems.
* Fixed an error related to the installation of the plugin into the Blender directory.
* Enhanced error detection for issues encountered during Blender file loading.
* Made sure each asset is unique before uploading, preventing redundancy and potential conflicts.
* Handled file paths with spaces more effectively.
* Ensured the creation of Blender user folders if they don't exist, improving the installation process.
* Implemented submission validation to catch potential issues before they occur.
## Version:0.1.6-rc.2 -- 10 Oct 2023
* Updating to PySide6 to provide compatibility with Apple Silicon M1/M2 chip architecture.
## Version:0.1.5-rc.2 -- 10 Oct 2023
* Upgrading the ciocore library to version 6.5.1
* Implementing file validation for assets and additional assets
## Version:0.1.4-rc.3 -- 06 Oct 2023
* Adding support for Linked Assets
* Enhancing Asset Scanning
* Expanded Extra Asset Support
* Extended Environment Variable Support
* Directory Listing for Output
* Revamped Post-Installation Instructions
* Setting the default value for "Use Scout Frames" to True
## Version:0.1.2-beta.3
* Implementing Asset scanning
* Implementing Extra env vars
## Version:0.1.2-beta.1
* Implementing Progress tabs
## Version 0.1.1-beta.21
* Default frame range fix
## Version 0.1.1-beta.18
* Update to libraries
## Version 0.1.1-beta.17
* Update to the installation instructions
## Version 0.1.1-beta.14
* Extra assets panel
* Fixing issue with Blender filepath in Windows
## Version 0.1.1-beta.5
* Updates to Blender filepath handling.
### Version:0.1.0 -- 21 Oct 2021
* Setup circle ci. [60c2d21]
* Initial commit with. [cc7ec9d]
--
| text/markdown | conductor | info@conductortech.com | null | null | null | null | [
"Operating System :: OS Independent",
"Programming Language :: Python",
"Topic :: Multimedia :: Graphics :: 3D Rendering"
] | [] | https://github.com/ConductorTechnologies/cioblender | null | null | [] | [] | [] | [
"ciocore<10.0.0,>=9.1.1",
"ciopath<2.0.0,>=1.1.0",
"cioseq<1.0.0,>=0.5.2",
"json-stream<3.0.0,>=2.3.2",
"PySide6<=6.7.0,>=6.0.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.8.20 | 2026-02-18T21:04:25.967391 | cioblender-0.5.0-py2.py3-none-any.whl | 127,402 | 80/ff/05b0a28753774f1f29dbcd947ce6640673e87b7b9199ba8007da291e83e7/cioblender-0.5.0-py2.py3-none-any.whl | py2.py3 | bdist_wheel | null | false | 332a9b20c3af8a15351ebe6189ae6297 | 844e865aad3d234bba04430e2ebe95bfe396ddbf94eabed084a4aaf322fc9f28 | 80ff05b0a28753774f1f29dbcd947ce6640673e87b7b9199ba8007da291e83e7 | null | [] | 127 |
2.4 | robotframework-pabot | 5.2.2 | Parallel test runner for Robot Framework | # Pabot
[中文版](README_zh.md)
[](https://pypi.python.org/pypi/robotframework-pabot)
[](http://pepy.tech/project/robotframework-pabot)
<img src="https://raw.githubusercontent.com/mkorpela/pabot/master/pabot.png" width="100">
----
A parallel executor for [Robot Framework](http://www.robotframework.org) tests. With Pabot you can split one execution into multiple and save test execution time.
[](https://youtu.be/i0RV6SJSIn8 "Pabot presentation at robocon.io 2018")
## Table of Contents
- [Installation](#installation)
- [Basic use](#basic-use)
- [Contact](#contact)
- [Contributing](#contributing-to-the-project)
- [Command-line options](#command-line-options)
- [PabotLib](#pabotlib)
- [Controlling execution order, mode and level of parallelism](#controlling-execution-order-mode-and-level-of-parallelism)
- [Programmatic use](#programmatic-use)
- [Global variables](#global-variables)
- [Output Files Generated by Pabot](#output-files-generated-by-pabot)
- [Artifacts Handling and Parallel Execution Notes](#artifacts-handling-and-parallel-execution-notes)
----
## Installation:
Pabot can be installed in the following ways:
### From PyPI
pip install -U robotframework-pabot
### From source (standard install)
Clone this repository and run:
python setup.py install
### From source (editable / development mode)
Clone this repository and run:
pip install --editable .
### Note
Starting from **Pabot version 5.2.0**, the Pabot installation only requires
**Robot Framework** to function.
The previously used dependency **natsort** has been replaced with a pure
Python implementation.
In addition, **robotframework-stacktrace** has been moved to an **optional**
dependency. If it is installed, Pabot will continue to use it when running
sub-Robot processes to improve fail/error logging both in Pabot’s own log file
and on the command line.
You can install the optional stacktrace support with:
pip install -U robotframework-pabot[stacktrace]
## Basic use
Split execution to suite files.
pabot [path to tests]
Split execution on test level.
pabot --testlevelsplit [path to tests]
Run same tests with two different configurations.
pabot --argumentfile1 first.args --argumentfile2 second.args [path to tests]
For more complex cases please read onward.
## Contact
Join [Pabot Slack channel](https://robotframework.slack.com/messages/C7HKR2L6L) in Robot Framework slack.
[Get invite to Robot Framework slack](https://robotframework-slack-invite.herokuapp.com/).
## Contributing to the project
There are several ways you can help in improving this tool:
- Report an issue or an improvement idea to the [issue tracker](https://github.com/mkorpela/pabot/issues)
- Contribute by programming and making a pull request (easiest way is to work on an issue from the issue tracker)
Before contributing, please read our detailed contributing guidelines:
- [Contributing Guide](CONTRIBUTING.md)
- [Code of Conduct](CODE_OF_CONDUCT.md)
- [Security Policy](SECURITY.md)
## Command-line options
<!-- NOTE:
The sections inside these docstring markers are also used in Pabot's --help output.
Currently, the following transformations are applied:
- Remove Markdown links but keep the text
- Remove ** and backticks `
If you modify this part, make sure the Markdown section still looks clean and readable in the --help output. -->
<!-- START DOCSTRING -->
```
pabot [--verbose|--testlevelsplit|--command .. --end-command|
--processes num|--no-pabotlib|--pabotlibhost host|--pabotlibport port|
--processtimeout num|
--shard i/n|
--artifacts extensions|--artifactsinsubfolders|
--resourcefile file|--argumentfile[num] file|--suitesfrom file
--ordering file [static|dynamic] [skip|run_all]|
--chunk|
--pabotprerunmodifier modifier|
--no-rebot|
--pabotconsole [verbose|dotted|quiet|none]|
--help|--version]
[robot options] [path ...]
```
PabotLib remote server is started by default to enable locking and resource distribution between parallel test executions.
Supports all [Robot Framework command line options](https://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html#command-line-options) and also following pabot options:
**--verbose**
More output from the parallel execution.
**--testlevelsplit**
Split execution on test level instead of default suite level. If .pabotsuitenames contains both tests and suites then
this will only affect new suites and split only them. Leaving this flag out when both suites and tests in
.pabotsuitenames file will also only affect new suites and add them as suite files.
**--command [ACTUAL COMMANDS TO START ROBOT EXECUTOR] --end-command**
RF script for situations where robot is not used directly.
**--processes [NUMBER OF PROCESSES]**
How many parallel executors to use (default max of 2 and cpu count). Special option "all" will use as many processes as
there are executable suites or tests.
**--no-pabotlib**
Disable the PabotLib remote server if you don't need locking or resource distribution features.
**--pabotlibhost [HOSTNAME]**
Connect to an already running instance of the PabotLib remote server at the given host (disables the local PabotLib
server start). For example, to connect to a remote PabotLib server running on another machine:
pabot --pabotlibhost 192.168.1.123 --pabotlibport 8271 tests/
The remote server can also be started and executed separately from pabot instances:
python -m pabot.pabotlib <path_to_resourcefile> <host> <port>
python -m pabot.pabotlib resource.txt 192.168.1.123 8271
This enables sharing a resource with multiple Robot Framework instances.
Additional details:
- The default value for --pabotlibhost is 127.0.0.1.
- If you provide a hostname other than 127.0.0.1, the local PabotLib server startup is automatically disabled.
**--pabotlibport [PORT]**
Port number of the PabotLib remote server (default is 8270). See --pabotlibhost for more information.
Behavior with port and host settings:
- If you set the port value to 0 and --pabotlibhost is 127.0.0.1 (default), a free port on localhost will be assigned automatically.
**--processtimeout [TIMEOUT]**
Maximum time in seconds to wait for a process before killing it. If not set, there's no timeout.
**--shard [INDEX]/[TOTAL]**
Optionally split execution into smaller pieces. This can be used for distributing testing to multiple machines.
**--artifacts [FILE EXTENSIONS]**
List of file extensions (comma separated). Defines which files (screenshots, videos etc.) from separate reporting
directories would be copied and included in a final report. Possible links to copied files in RF log would be updated
(only relative paths supported). The default value is `png`.
Examples:
--artifacts png,mp4,txt
The artifact naming conventions are described in the README.md section: [Output Files Generated by Pabot](#output-files-generated-by-pabot).
**--artifactsinsubfolders**
Copy artifacts located not only directly in the RF output dir, but also in it's sub-folders.
**--resourcefile [FILEPATH]**
Indicator for a file that can contain shared variables for distributing resources. This needs to be used together with
pabotlib option. Resource file syntax is same as Windows ini files where a section is a shared set of variables.
**--argumentfile[INTEGER] [FILEPATH]**
Run same suites with multiple [argumentfile](http://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html#argument-files) options.
For example:
--argumentfile1 arg1.txt --argumentfile2 arg2.txt
**--suitesfrom [FILEPATH TO OUTPUTXML]**
Optionally read suites from output.xml file. Failed suites will run first and longer running ones will be executed
before shorter ones.
**--ordering [FILEPATH] [MODE] [FAILURE POLICY]**
Optionally give execution order from a file. See README.md section: [Controlling execution order, mode and level of parallelism](#controlling-execution-order-mode-and-level-of-parallelism)
- MODE (optional): [ static (default) | dynamic ]
- FAILURE POLICY (optional, only in dynamic mode): [ skip | run_all (default) ]
**--chunk**
Optionally chunk tests to PROCESSES number of robot runs. This can save time because all the suites will share the same
setups and teardowns. Note that chunking is skipped if an ordering file is provided. The ordering file may contain
significantly complex execution orders, in which case consolidation into chunks is not possible.
**--pabotprerunmodifier [PRERUNMODIFIER MODULE OR CLASS]**
Like Robot Framework's --prerunmodifier, but executed only once in the pabot's main process after all other
--prerunmodifiers. But unlike the regular --prerunmodifier command, --pabotprerunmodifier is not executed again in each
pabot subprocesses. Depending on the intended use, this may be desirable as well as more efficient. Can be used, for
example, to modify the list of tests to be performed.
**--no-rebot**
If specified, the tests will execute as usual, but Rebot will not be called to merge the logs. This option is designed
for scenarios where Rebot should be run later due to large log files, ensuring better memory and resource availability.
Subprocess results are stored in the pabot_results folder.
**--pabotconsole [MODE]**
The --pabotconsole option controls how much output is printed to the console.
Note that all Pabot’s own messages are always logged to pabot_manager.log, regardless of the selected console mode.
The available options are:
- verbose (default):
Prints all messages to the console, corresponding closely to what is written to the log file.
- dotted:
Prints important messages, warnings, and errors to the console, along with execution progress using the following notation:
- PASS = .
- FAIL = F
- SKIP = s
Note that each Robot Framework process is represented by a single character.
Depending on the execution parameters, individual tests may not have their own status character;
instead, the status may represent an entire suite or a group of tests.
- quiet:
Similar to dotted, but suppresses execution progress output.
- none:
Produces no console output at all.
**--help**
Print usage instructions.
**--version**
Print version information.
**Example usages:**
pabot test_directory
pabot --exclude FOO directory_to_tests
pabot --command java -jar robotframework.jar --end-command --include SMOKE tests
pabot --processes 10 tests
pabot --pabotlibhost 192.168.1.123 --pabotlibport 8271 --processes 10 tests
pabot --artifacts png,mp4,txt --artifactsinsubfolders directory_to_tests
# To disable PabotLib:
pabot --no-pabotlib tests
<!-- END DOCSTRING -->
### PabotLib
pabot.PabotLib provides keywords that will help communication and data sharing between the executor processes.
These can be helpful when you must ensure that only one of the processes uses some piece of data or operates on some part of the system under test at a time.
PabotLib Docs are located at https://pabot.org/PabotLib.html.
Note that PabotLib uses the XML-RPC protocol, which does not support all possible object types.
These limitations are described in the Robot Framework documentation in chapter [Supported argument and return value types](https://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html#supported-argument-and-return-value-types).
### PabotLib example:
test.robot
*** Settings ***
Library pabot.PabotLib
*** Test Case ***
Testing PabotLib
Acquire Lock MyLock
Log This part is critical section
Release Lock MyLock
${valuesetname}= Acquire Value Set admin-server
${host}= Get Value From Set host
${username}= Get Value From Set username
${password}= Get Value From Set password
Log Do something with the values (for example access host with username and password)
Release Value Set
Log After value set release others can obtain the variable values
valueset.dat
[Server1]
tags=admin-server
HOST=123.123.123.123
USERNAME=user1
PASSWORD=password1
[Server2]
tags=server
HOST=121.121.121.121
USERNAME=user2
PASSWORD=password2
[Server3]
tags=admin-server
HOST=222.222.222.222
USERNAME=user3
PASSWORD=password4
pabot call using resources from valueset.dat
pabot --pabotlib --resourcefile valueset.dat test.robot
### Controlling execution order, mode, and level of parallelism
.pabotsuitenames file contains the list of suites that will be executed.
This file is created during pabot execution if it does not already exist. It acts as a cache to speed up processing when re-executing the same tests.
The file can be manually edited partially, but a simpler and more controlled approach is to use:
```bash
--ordering <FILENAME> [static|dynamic] [skip|run_all]
```
- **FILENAME** – path to the ordering file.
- **mode** – optional execution mode, either `static` (default) or `dynamic`.
- `static` executes suites in predefined stages.
- `dynamic` executes tests as soon as all their dependencies are satisfied, allowing more optimal parallel execution.
- **failure_policy** – determines behavior when dependencies fail. Used only in dynamic mode. Optional:
- `skip` – dependent tests are skipped if a dependency fails.
- `run_all` – all tests run regardless of failures (default).
The ordering file syntax is similar to `.pabotsuitenames` but does not include the first 4 hash rows used by pabot. The ordering file defines the **execution order and dependencies** of suites and tests.
The actual selection of what to run must still be done using options like `--test`, `--suite`, `--include`, or `--exclude`.
#### Controlling execution order
There different possibilities to influence the execution:
* The order of suites can be changed.
* If a directory (or a directory structure) should be executed sequentially, add the directory suite name to a row as a ```--suite``` option. This usage is also supported when `--testlevelsplit` is enabled. As an alternative to using `--suite` options, you can also group tests into sequential batches using `{}` braces. (See below for details.) Note that if multiple `--suite` options are used, they must not reference the same test case. This means you cannot specify both parent and child suite names at the same time. For instance:
```
--suite Top Suite.Sub Suite
--suite Top Suite
```
* If the base suite name is changing with robot option [```--name / -N```](https://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html#setting-suite-name) you can use either the new or old full test path. For example:
```
--test New Suite Name.Sub Suite.Test 1
OR
--test Old Suite Name.Sub Suite.Test 1
```
* You can add a line with text `#WAIT` to force executor to wait until all previous suites have been executed.
* You can group suites and tests together to same executor process by adding line `{` before the group and `}` after. Note that `#WAIT` cannot be used inside a group.
* You can introduce dependencies using the word `#DEPENDS` after a test declaration. This keyword can be used several times if it is necessary to refer to several different tests.
* The ordering algorithm is designed to preserve the exact user-defined order as closely as possible. However, if a test's execution dependencies are not yet satisfied, the test is postponed and moved to the earliest possible stage where all its dependencies are fulfilled.
* Please take care that in case of circular dependencies an exception will be thrown.
* Note that each `#WAIT` splits suites into separate execution blocks, and it's not possible to define dependencies for suites or tests that are inside another `#WAIT` block or inside another `{}` braces.
* Ordering mode effect to execution:
* **Dynamic mode** will schedule dependent tests as soon as all their dependencies are satisfied. Note that in dynamic mode `#WAIT` is ignored, but you can achieve same results with using only `#DEPENDS` keywords.
* **Static mode** preserves stage barriers and executes the next stage only after all tests in the previous stage finish.
* Note: Within a group `{}`, neither execution order nor the `#DEPENDS` keyword currently works. This is due to limitations in Robot Framework, which is invoked within Pabot subprocesses. These limitations may be addressed in a future release of Robot Framework. For now, tests or suites within a group will be executed in the order Robot Framework discovers them — typically in alphabetical order.
* An example could be:
```
--test robotTest.1 Scalar.Test With Environment Variables #DEPENDS robotTest.1 Scalar.Test with BuiltIn Variables of Robot Framework
--test robotTest.1 Scalar.Test with BuiltIn Variables of Robot Framework
--test robotTest.2 Lists.Test with Keywords and a list
#WAIT
--test robotTest.2 Lists.Test with a Keyword that accepts multiple arguments
{
--test robotTest.2 Lists.Test with some Collections keywords
--test robotTest.2 Lists.Test to access list entries
}
--test robotTest.3 Dictionary.Test that accesses Dictionaries
--test robotTest.3 Dictionary.Dictionaries for named arguments #DEPENDS robotTest.3 Dictionary.Test that accesses Dictionaries
--test robotTest.1 Scalar.Test Case With Variables #DEPENDS robotTest.3 Dictionary.Test that accesses Dictionaries
--test robotTest.1 Scalar.Test with Numbers #DEPENDS robotTest.1 Scalar.Test With Arguments and Return Values
--test robotTest.1 Scalar.Test Case with Return Values #DEPENDS robotTest.1 Scalar.Test with Numbers
--test robotTest.1 Scalar.Test With Arguments and Return Values
--test robotTest.3 Dictionary.Test with Dictionaries as Arguments
--test robotTest.3 Dictionary.Test with FOR loops and Dictionaries #DEPENDS robotTest.1 Scalar.Test Case with Return Values
```
* By using the command `#SLEEP X`, where `X` is an integer in the range [0-3600] (in seconds), you can
define a startup delay for each subprocess. `#SLEEP` affects the next line unless the next line starts a
group with `{`, in which case the delay applies to the entire group. If the next line begins with `--test`
or `--suite`, the delay is applied to that specific item. Any other occurrences of `#SLEEP` are ignored.
Note that `#SLEEP` has no effect within a group, i.e., inside a subprocess.
The following example clarifies the behavior:
```sh
pabot --processes 2 --ordering order.txt data_1
```
where order.txt is:
```
#SLEEP 1
{
#SLEEP 2
--suite Data 1.suite A
#SLEEP 3
--suite Data 1.suite B
#SLEEP 4
}
#SLEEP 5
#SLEEP 6
--suite Data 1.suite C
#SLEEP 7
--suite Data 1.suite D
#SLEEP 8
```
Possible output could be:
```
2025-02-15 19:15:00.408321 [0] [ID:1] SLEEPING 6 SECONDS BEFORE STARTING Data 1.suite C
2025-02-15 19:15:00.408321 [1] [ID:0] SLEEPING 1 SECONDS BEFORE STARTING Group_Data 1.suite A_Data 1.suite B
2025-02-15 19:15:01.409389 [PID:52008] [1] [ID:0] EXECUTING Group_Data 1.suite A_Data 1.suite B
2025-02-15 19:15:06.409024 [PID:1528] [0] [ID:1] EXECUTING Data 1.suite C
2025-02-15 19:15:09.257564 [PID:52008] [1] [ID:0] PASSED Group_Data 1.suite A_Data 1.suite B in 7.8 seconds
2025-02-15 19:15:09.259067 [1] [ID:2] SLEEPING 7 SECONDS BEFORE STARTING Data 1.suite D
2025-02-15 19:15:09.647342 [PID:1528] [0] [ID:1] PASSED Data 1.suite C in 3.2 seconds
2025-02-15 19:15:16.260432 [PID:48156] [1] [ID:2] EXECUTING Data 1.suite D
2025-02-15 19:15:18.696420 [PID:48156] [1] [ID:2] PASSED Data 1.suite D in 2.4 seconds
```
### Programmatic use
Library offers an endpoint `main_program` that will not call `sys.exit`. This can help in developing your own python program around pabot.
```Python
import sys
from pabot.pabot import main_program
def amazing_new_program():
print("Before calling pabot")
exit_code = main_program(['tests'])
print(f"After calling pabot (return code {exit_code})")
sys.exit(exit_code)
```
### Global variables
Pabot will insert following global variables to Robot Framework namespace. These are here to enable PabotLib functionality and for custom listeners etc. to get some information on the overall execution of pabot.
PABOTQUEUEINDEX - this contains a unique index number for the execution. Indexes start from 0.
PABOTLIBURI - this contains the URI for the running PabotLib server
PABOTEXECUTIONPOOLID - this contains the pool id (an integer) for the current Robot Framework executor. This is helpful for example when visualizing the execution flow from your own listener.
PABOTNUMBEROFPROCESSES - max number of concurrent processes that pabot may use in execution.
CALLER_ID - a universally unique identifier for this execution.
### Output Files Generated by Pabot
Pabot generates several output files and folders during execution, both for internal use and for analysis purposes.
#### Internal File: `.pabotsuitenames`
Pabot creates a `.pabotsuitenames` file in the working directory. This is an internal hash file used to speed up execution in certain scenarios.
This file can also be used as a base for the `--ordering` file as described earlier. Although technically it can be modified, it will be overwritten during the next execution.
Therefore, it is **recommended** to maintain a separate file for the `--ordering` option if needed.
#### Output Directory Structure
In addition to the standard `log.html`, `report.html`, and `output.xml` files, the specified `--outputdir` will contain:
- A folder named `pabot_results`, and
- All defined artifacts (default: `.png` files)
- Optionally, artifacts from subfolders if `--artifactsinsubfolders` is used
Artifacts are **copied** into the output directory and renamed with the following structure:
```
TIMESTAMP-ARGUMENT_INDEX-PABOTQUEUEINDEX
```
If you use the special option `notimestamps` at the end of the `--artifacts` command, (For example: `--artifacts png,txt,notimestamps`) the timestamp part will be omitted, and the name will be in the format:
```
ARGUMENT_INDEX-PABOTQUEUEINDEX
```
- **TIMESTAMP** = Time of `pabot` command invocation (not the screenshot's actual timestamp), format: `YYYYmmdd_HHMMSS`
- **ARGUMENT_INDEX** = Optional index number, only used if `--argumentfileN` options are given
- **PABOTQUEUEINDEX** = Process queue index (see section [Global Variables](#global-variables))
#### `pabot_results` Folder Structure
The structure of the `pabot_results` folder is as follows:
```
pabot_results/
├── [N]/ # Optional: N = argument file index (if --argumentfileN is used)
│ └── PABOTQUEUEINDEX/ # One per subprocess
│ ├── output.xml
│ ├── robot_argfile.txt
│ ├── robot_stdout.out
│ ├── robot_stderr.out
│ └── artifacts...
└── pabot_manager.log # Pabot's own main log.
```
Each `PABOTQUEUEINDEX` folder contains as default:
- `robot_argfile.txt` – Arguments used in that subprocess
- `robot_stdout.out` and `robot_stderr.out` – Stdout and stderr of the subprocess
- `output.xml` – The partial output file to be merged later
- Artifacts – Screenshots or other files copied from subprocess folders
> **Note:** The entire `pabot_results` folder is considered temporary and will be **deleted/overwritten** on the next `pabot` run using the same `--outputdir`.
### Artifacts Handling and Parallel Execution Notes
Due to parallel execution, artifacts like screenshots should ideally be:
- Embedded directly into the XML using tools like [SeleniumLibrary](https://robotframework.org/SeleniumLibrary/SeleniumLibrary.html#Set%20Screenshot%20Directory) with the `EMBED` option
_Example:_
`Library SeleniumLibrary screenshot_root_directory=EMBED`
- Or saved to the subprocess’s working directory (usually default behavior), ensuring separation across processes
If you manually specify a shared screenshot directory in your test code, **all processes will write to it concurrently**, which may cause issues such as overwriting or missing files if screenshots are taken simultaneously.
| text/markdown | Mikko Korpela | mikko.korpela@gmail.com | null | null | Apache License, Version 2.0 | null | [
"Intended Audience :: Developers",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Topic :: Software Development :: Testing",
"Development Status :: 5 - Production/Stable",
"Framework :: Robot Framework"
] | [] | https://pabot.org | https://pypi.python.org/pypi/robotframework-pabot | >=3.6 | [] | [] | [] | [
"robotframework>=3.2",
"robotframework-stacktrace>=0.4.1; extra == \"stacktrace\""
] | [] | [] | [] | [
"Source, https://github.com/mkorpela/pabot"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T21:04:22.827024 | robotframework_pabot-5.2.2.tar.gz | 106,974 | d6/16/285f1737483a93f7ab38456e97bd34d101a4a9713ba01050fecf51096bef/robotframework_pabot-5.2.2.tar.gz | source | sdist | null | false | 564cac7ce64dcf96bf7cfd48cd8962c3 | 497c3d72551c76eda21029df6a28c6b2ed227e63c4a8510e1c6a0690b9e2be91 | d616285f1737483a93f7ab38456e97bd34d101a4a9713ba01050fecf51096bef | null | [] | 44,366 |
2.4 | elody | 0.0.242 | elody SDK for Python | # elody SDK for Python
## Installation
To install the Python SDK library using pip:
```
pip install elody
```
## Usage
Begin by importing the `elody` module:
```
import elody
```
Then construct a client object with the url to the elody collection service and
JWT-token:
```
client = elody.Client(elody_collection_url=collection_url, static_jwt=jwt_token)
```
For production, you can specify the `ELODY_COLLECTION_URL` and `STATIC_JWT`
environment variables instead of specifying the key and secret explicitly.
## Examples
### Creating an object
```
object = {
"identifiers": ["test"],
"type": "asset",
"metadata": [
{
"key": "title",
"value": "test",
"lang": "en",
}
]
}
client.add_object("entities", object)
```
### Getting an object
```
object = client.get_object("entities", "test")
print(object)
```
### Updating an object
```
object_update = {
"identifiers": ["test"],
"type": "asset",
"metadata": [
{
"key": "title",
"value": "test UPDATE",
"lang": "en",
}
]
}
client.update_object("entities", "test", object_update)
```
### Deleting an object
```
client.delete_object("entities", "test")
```
| text/markdown | null | Inuits <developers@inuits.eu> | null | null | GNU GENERAL PUBLIC LICENSE
Version 2, June 1991
Copyright (C) 1989, 1991 Free Software Foundation, Inc.,
51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The licenses for most software are designed to take away your
freedom to share and change it. By contrast, the GNU General Public
License is intended to guarantee your freedom to share and change free
software--to make sure the software is free for all its users. This
General Public License applies to most of the Free Software
Foundation's software and to any other program whose authors commit to
using it. (Some other Free Software Foundation software is covered by
the GNU Lesser General Public License instead.) You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
this service if you wish), that you receive source code or can get it
if you want it, that you can change the software or use pieces of it
in new free programs; and that you know you can do these things.
To protect your rights, we need to make restrictions that forbid
anyone to deny you these rights or to ask you to surrender the rights.
These restrictions translate to certain responsibilities for you if you
distribute copies of the software, or if you modify it.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must give the recipients all the rights that
you have. You must make sure that they, too, receive or can get the
source code. And you must show them these terms so they know their
rights.
We protect your rights with two steps: (1) copyright the software, and
(2) offer you this license which gives you legal permission to copy,
distribute and/or modify the software.
Also, for each author's protection and ours, we want to make certain
that everyone understands that there is no warranty for this free
software. If the software is modified by someone else and passed on, we
want its recipients to know that what they have is not the original, so
that any problems introduced by others will not reflect on the original
authors' reputations.
Finally, any free program is threatened constantly by software
patents. We wish to avoid the danger that redistributors of a free
program will individually obtain patent licenses, in effect making the
program proprietary. To prevent this, we have made it clear that any
patent must be licensed for everyone's free use or not licensed at all.
The precise terms and conditions for copying, distribution and
modification follow.
GNU GENERAL PUBLIC LICENSE
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
0. This License applies to any program or other work which contains
a notice placed by the copyright holder saying it may be distributed
under the terms of this General Public License. The "Program", below,
refers to any such program or work, and a "work based on the Program"
means either the Program or any derivative work under copyright law:
that is to say, a work containing the Program or a portion of it,
either verbatim or with modifications and/or translated into another
language. (Hereinafter, translation is included without limitation in
the term "modification".) Each licensee is addressed as "you".
Activities other than copying, distribution and modification are not
covered by this License; they are outside its scope. The act of
running the Program is not restricted, and the output from the Program
is covered only if its contents constitute a work based on the
Program (independent of having been made by running the Program).
Whether that is true depends on what the Program does.
1. You may copy and distribute verbatim copies of the Program's
source code as you receive it, in any medium, provided that you
conspicuously and appropriately publish on each copy an appropriate
copyright notice and disclaimer of warranty; keep intact all the
notices that refer to this License and to the absence of any warranty;
and give any other recipients of the Program a copy of this License
along with the Program.
You may charge a fee for the physical act of transferring a copy, and
you may at your option offer warranty protection in exchange for a fee.
2. You may modify your copy or copies of the Program or any portion
of it, thus forming a work based on the Program, and copy and
distribute such modifications or work under the terms of Section 1
above, provided that you also meet all of these conditions:
a) You must cause the modified files to carry prominent notices
stating that you changed the files and the date of any change.
b) You must cause any work that you distribute or publish, that in
whole or in part contains or is derived from the Program or any
part thereof, to be licensed as a whole at no charge to all third
parties under the terms of this License.
c) If the modified program normally reads commands interactively
when run, you must cause it, when started running for such
interactive use in the most ordinary way, to print or display an
announcement including an appropriate copyright notice and a
notice that there is no warranty (or else, saying that you provide
a warranty) and that users may redistribute the program under
these conditions, and telling the user how to view a copy of this
License. (Exception: if the Program itself is interactive but
does not normally print such an announcement, your work based on
the Program is not required to print an announcement.)
These requirements apply to the modified work as a whole. If
identifiable sections of that work are not derived from the Program,
and can be reasonably considered independent and separate works in
themselves, then this License, and its terms, do not apply to those
sections when you distribute them as separate works. But when you
distribute the same sections as part of a whole which is a work based
on the Program, the distribution of the whole must be on the terms of
this License, whose permissions for other licensees extend to the
entire whole, and thus to each and every part regardless of who wrote it.
Thus, it is not the intent of this section to claim rights or contest
your rights to work written entirely by you; rather, the intent is to
exercise the right to control the distribution of derivative or
collective works based on the Program.
In addition, mere aggregation of another work not based on the Program
with the Program (or with a work based on the Program) on a volume of
a storage or distribution medium does not bring the other work under
the scope of this License.
3. You may copy and distribute the Program (or a work based on it,
under Section 2) in object code or executable form under the terms of
Sections 1 and 2 above provided that you also do one of the following:
a) Accompany it with the complete corresponding machine-readable
source code, which must be distributed under the terms of Sections
1 and 2 above on a medium customarily used for software interchange; or,
b) Accompany it with a written offer, valid for at least three
years, to give any third party, for a charge no more than your
cost of physically performing source distribution, a complete
machine-readable copy of the corresponding source code, to be
distributed under the terms of Sections 1 and 2 above on a medium
customarily used for software interchange; or,
c) Accompany it with the information you received as to the offer
to distribute corresponding source code. (This alternative is
allowed only for noncommercial distribution and only if you
received the program in object code or executable form with such
an offer, in accord with Subsection b above.)
The source code for a work means the preferred form of the work for
making modifications to it. For an executable work, complete source
code means all the source code for all modules it contains, plus any
associated interface definition files, plus the scripts used to
control compilation and installation of the executable. However, as a
special exception, the source code distributed need not include
anything that is normally distributed (in either source or binary
form) with the major components (compiler, kernel, and so on) of the
operating system on which the executable runs, unless that component
itself accompanies the executable.
If distribution of executable or object code is made by offering
access to copy from a designated place, then offering equivalent
access to copy the source code from the same place counts as
distribution of the source code, even though third parties are not
compelled to copy the source along with the object code.
4. You may not copy, modify, sublicense, or distribute the Program
except as expressly provided under this License. Any attempt
otherwise to copy, modify, sublicense or distribute the Program is
void, and will automatically terminate your rights under this License.
However, parties who have received copies, or rights, from you under
this License will not have their licenses terminated so long as such
parties remain in full compliance.
5. You are not required to accept this License, since you have not
signed it. However, nothing else grants you permission to modify or
distribute the Program or its derivative works. These actions are
prohibited by law if you do not accept this License. Therefore, by
modifying or distributing the Program (or any work based on the
Program), you indicate your acceptance of this License to do so, and
all its terms and conditions for copying, distributing or modifying
the Program or works based on it.
6. Each time you redistribute the Program (or any work based on the
Program), the recipient automatically receives a license from the
original licensor to copy, distribute or modify the Program subject to
these terms and conditions. You may not impose any further
restrictions on the recipients' exercise of the rights granted herein.
You are not responsible for enforcing compliance by third parties to
this License.
7. If, as a consequence of a court judgment or allegation of patent
infringement or for any other reason (not limited to patent issues),
conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot
distribute so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you
may not distribute the Program at all. For example, if a patent
license would not permit royalty-free redistribution of the Program by
all those who receive copies directly or indirectly through you, then
the only way you could satisfy both it and this License would be to
refrain entirely from distribution of the Program.
If any portion of this section is held invalid or unenforceable under
any particular circumstance, the balance of the section is intended to
apply and the section as a whole is intended to apply in other
circumstances.
It is not the purpose of this section to induce you to infringe any
patents or other property right claims or to contest validity of any
such claims; this section has the sole purpose of protecting the
integrity of the free software distribution system, which is
implemented by public license practices. Many people have made
generous contributions to the wide range of software distributed
through that system in reliance on consistent application of that
system; it is up to the author/donor to decide if he or she is willing
to distribute software through any other system and a licensee cannot
impose that choice.
This section is intended to make thoroughly clear what is believed to
be a consequence of the rest of this License.
8. If the distribution and/or use of the Program is restricted in
certain countries either by patents or by copyrighted interfaces, the
original copyright holder who places the Program under this License
may add an explicit geographical distribution limitation excluding
those countries, so that distribution is permitted only in or among
countries not thus excluded. In such case, this License incorporates
the limitation as if written in the body of this License.
9. The Free Software Foundation may publish revised and/or new versions
of the General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the Program
specifies a version number of this License which applies to it and "any
later version", you have the option of following the terms and conditions
either of that version or of any later version published by the Free
Software Foundation. If the Program does not specify a version number of
this License, you may choose any version ever published by the Free Software
Foundation.
10. If you wish to incorporate parts of the Program into other free
programs whose distribution conditions are different, write to the author
to ask for permission. For software which is copyrighted by the Free
Software Foundation, write to the Free Software Foundation; we sometimes
make exceptions for this. Our decision will be guided by the two goals
of preserving the free status of all derivatives of our free software and
of promoting the sharing and reuse of software generally.
NO WARRANTY
11. BECAUSE THE PROGRAM IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY
FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN
OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES
PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED
OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF
MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS
TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE
PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING,
REPAIR OR CORRECTION.
12. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR
REDISTRIBUTE THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES,
INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING
OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED
TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY
YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER
PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE
POSSIBILITY OF SUCH DAMAGES.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
convey the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software; you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation; either version 2 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License along
with this program; if not, write to the Free Software Foundation, Inc.,
51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
Also add information on how to contact you by electronic and paper mail.
If the program is interactive, make it output a short notice like this
when it starts in an interactive mode:
Gnomovision version 69, Copyright (C) year name of author
Gnomovision comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, the commands you use may
be called something other than `show w' and `show c'; they could even be
mouse-clicks or menu items--whatever suits your program.
You should also get your employer (if you work as a programmer) or your
school, if any, to sign a "copyright disclaimer" for the program, if
necessary. Here is a sample; alter the names:
Yoyodyne, Inc., hereby disclaims all copyright interest in the program
`Gnomovision' (which makes passes at compilers) written by James Hacker.
<signature of Ty Coon>, 1 April 1989
Ty Coon, President of Vice
This General Public License does not permit incorporating your program into
proprietary programs. If your program is a subroutine library, you may
consider it more useful to permit linking proprietary applications with the
library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License.
| elody, SDK | [
"License :: OSI Approved :: GNU General Public License v2 (GPLv2)",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.1... | [] | null | null | null | [] | [] | [] | [
"certifi>=2023.5.7",
"charset-normalizer>=3.2.0",
"idna>=3.4",
"requests>=2.31.0",
"urllib3>=1.26.16",
"APScheduler>=3.10.4; extra == \"loader\"",
"cloudevents>=1.9.0; extra == \"loader\"",
"inuits-policy-based-auth>=10.0.1; extra == \"loader\"",
"jsonschema>=4.23.0; extra == \"loader\"",
"pytz>=2... | [] | [] | [] | [
"Homepage, https://github.com/inuits/elody-python-sdk"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:03:04.693161 | elody-0.0.242.tar.gz | 52,551 | be/51/840c8785d6a653d6e63c4df30a23ee20bb84bc17bfb62de239494a219402/elody-0.0.242.tar.gz | source | sdist | null | false | c1895a978df71a52a5bb07da2f1a8332 | 84166b88fd1b516b45c401578a3a849584a8f21edd48474f1ec8d8bd4b162e13 | be51840c8785d6a653d6e63c4df30a23ee20bb84bc17bfb62de239494a219402 | null | [
"LICENSE"
] | 289 |
2.4 | pytr | 0.4.6 | Use TradeRepublic in terminal | [](https://github.com/pytr-org/pytr/tags)
[](https://github.com/pytr-org/pytr/actions/workflows/publish-pypi.yml)
[](https://pypi.org/project/pytr/)
# pytr: Use TradeRepublic in terminal
This is a library for the private API of the Trade Republic online brokerage. It is not affiliated with Trade Republic
Bank GmbH.
__Table of Contents__
<!-- toc -->
* [Quickstart](#quickstart)
* [Usage](#usage)
* [Authentication](#authentication)
* [Web login (default)](#web-login-default)
* [App login](#app-login)
* [Development](#development)
* [Setting Up a Development Environment](#setting-up-a-development-environment)
* [Linting and Code Formatting](#linting-and-code-formatting)
* [Release process](#release-process)
* [Keep the readme updated](#keep-the-readme-updated)
* [License](#license)
<!-- end toc -->
## Quickstart
This is the right section for you if all you want to do is to "just run the thing". Whether you've never run a piece
of code before, or are new to Python, these steps will make it the easiest for you to run pytr.
We strongly recommend that you use [`uv`](https://docs.astral.sh/uv/#installation) to run pytr. Since pytr is written
in the Python programming language, you usually need to make sure you have an installation of Python on your computer
before you can run any Python program. However, uv will take care of installing an appropriate Python version for
you if you don't already have one.
To install uv on OSX/Linux, run:
```sh
curl -LsSf https://astral.sh/uv/install.sh | sh
```
On Windows, run:
```sh
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
```
Then, to run the latest released version of pytr:
```sh
uvx pytr@latest
```
If you want to use the cutting-edge version, use this command instead:
```sh
uvx --with git+https://github.com/pytr-org/pytr.git pytr
```
## Usage
<!-- runcmd code:console uv run --python 3.13 pytr help --for-readme -->
```console
usage: pytr [-h] [-V] [-v {warning,info,debug}] [--debug-logfile DEBUG_LOGFILE] [--debug-log-filter DEBUG_LOG_FILTER]
{help,login,portfolio,details,dl_docs,export_transactions,get_price_alarms,set_price_alarms,completion} ...
Use "pytr command_name --help" to get detailed help to a specific command
Commands:
{help,login,portfolio,details,dl_docs,export_transactions,get_price_alarms,set_price_alarms,completion}
Desired action to perform
help Print this help message
login Check if credentials file exists. If not create it and ask for input. Try to
login. Ask for device reset if needed
portfolio Show current portfolio
details Get details for an ISIN
dl_docs Download all pdf documents from the timeline and sort them into folders. Also
export account transactions (account_transactions.csv) and JSON files with all
events (events_with_documents.json and other_events.json)
export_transactions Read data from the TR timeline and export transactions into a file, e.g. as csv
into account_transactions.csv.
get_price_alarms Get current price alarms
set_price_alarms Set new price alarms
completion Print shell tab completion
Options:
-h, --help show this help message and exit
-V, --version Print version information and quit (default: False)
-v, --verbosity {warning,info,debug} Set verbosity level (default: info) (default: info)
--debug-logfile DEBUG_LOGFILE Dump debug logs to a file (default: None)
--debug-log-filter DEBUG_LOG_FILTER Filter debug log types (default: None)
```
<!-- end runcmd -->
## Authentication
There are two authentication methods:
### Web login (default)
Web login is the newer method that uses the same login method as [app.traderepublic.com](https://app.traderepublic.com/),
meaning you receive a four-digit code in the TradeRepublic app or via SMS. This will keep you logged in your primary
device, but means that you may need to repeat entering a new four-digit code ever so often when runnnig `pytr`.
### App login
App login is the older method that uses the same login method as the TradeRepublic app. First you need to perform a
device reset - a private key will be generated that pins your "device". The private key is saved to your keyfile. This
procedure will log you out from your mobile device.
```sh
pytr login
# or
pytr login --phone_no +49123456789 --pin 1234
```
If no arguments are supplied pytr will look for them in the file `~/.pytr/credentials` (the first line must contain
the phone number, the second line the pin). If the file doesn't exist pytr will ask for for the phone number and pin.
## Development
### Setting Up a Development Environment
Clone the repository:
```sh
git clone https://github.com/pytr-org/pytr.git
```
Install dependencies:
```sh
uv sync
```
Run the tests to ensure everything is set up correctly:
```sh
uv run pytest
```
### Linting and Code Formatting
This project uses [Ruff](https://astral.sh/ruff) for code linting and auto-formatting, as well as
[Mypy](https://www.mypy-lang.org/) for type checking.
You can auto-format the code with Ruff by running:
```bash
uv run ruff format # Format code
uv run ruff check --fix-only # Remove unneeded imports, order imports, etc.
```
You can check the typing of the code with Mypy by running:
```bash
uv run mypy .
```
Ruff and Mypy run as part of CI and your Pull Request cannot be merged unless it satisfies the linting, formatting
checks and type checks.
### Release process
1. Create a pull request that bumps the version number in `pyproject.toml`
2. After successfully merging the PR, [create a new release](https://github.com/pytr-org/pytr/releases/new) via GitHub
and make use of the "Generate release notes" button. Tags are formatted as `vX.Y.Z`.
3. The package will be published to PyPI from CI.
### Keep the readme updated
This readme contains a few automatically generated bits. To keep them up to date, simply run the following command: (Never start it from an activated venv!)
```sh
uvx mksync@0.1.5 -i README.md
```
## License
This project is licensed under the MIT License. See the [LICENSE](LICENSE) file for details.
| text/markdown | null | marzzzello <853485-marzzzello@users.noreply.gitlab.com> | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3 :: Only",
"Topic :: Office/Business :: Financial",
"Topic :: Office/Business :: Financial :: Investment"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"babel",
"certifi",
"coloredlogs",
"ecdsa",
"packaging",
"pathvalidate",
"pygments",
"requests-futures",
"shtab",
"websockets>=14"
] | [] | [] | [] | [
"Homepage, https://github.com/pytr-org/pytr"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:01:46.783052 | pytr-0.4.6.tar.gz | 85,486 | 73/ec/792938e5d254b053aff3dcd3c477e0c80fc65a978f39a641afc1073a789f/pytr-0.4.6.tar.gz | source | sdist | null | false | 78bc0d2ce81a18e287125c83b5b5e0f9 | e77bf0ce3013541c5a6bb644c2616208c4fd64efd85dbe5915f4b5cfd5d11766 | 73ec792938e5d254b053aff3dcd3c477e0c80fc65a978f39a641afc1073a789f | null | [
"LICENSE"
] | 642 |
2.4 | opengradient | 0.7.4 | Python SDK for OpenGradient decentralized model management & inference services | # OpenGradient Python SDK
[](https://github.com/OpenGradient/sdk/actions/workflows/test.yml)
A Python SDK for decentralized model management and inference services on the OpenGradient platform. The SDK provides programmatic access to distributed AI infrastructure with cryptographic verification capabilities.
## Overview
OpenGradient enables developers to build AI applications with verifiable execution guarantees through Trusted Execution Environments (TEE) and blockchain-based settlement. The SDK supports standard LLM inference patterns while adding cryptographic attestation for applications requiring auditability and tamper-proof AI execution.
### Key Features
- **Verifiable LLM Inference**: Drop-in replacement for OpenAI and Anthropic APIs with cryptographic attestation
- **Multi-Provider Support**: Access models from OpenAI, Anthropic, Google, and xAI through a unified interface
- **TEE Execution**: Trusted Execution Environment inference with cryptographic verification
- **Model Hub Integration**: Registry for model discovery, versioning, and deployment
- **Consensus-Based Verification**: End-to-end verified AI execution through the OpenGradient network
- **Command-Line Interface**: Direct access to SDK functionality via CLI
## Installation
```bash
pip install opengradient
```
**Note**: Windows users should temporarily enable WSL during installation (fix in progress).
## Network Architecture
OpenGradient operates two networks:
- **Testnet**: Primary public testnet for general development and testing
- **Alpha Testnet**: Experimental features including atomic AI execution from smart contracts and scheduled ML workflow execution
For current network RPC endpoints, contract addresses, and deployment information, refer to the [Network Deployment Documentation](https://docs.opengradient.ai/learn/network/deployment.html).
## Getting Started
### Prerequisites
Before using the SDK, you will need:
1. **Private Key**: An Ethereum-compatible wallet private key funded with **Base Sepolia OPG tokens** for x402 LLM payments
2. **Test Tokens**: Obtain free test tokens from the [OpenGradient Faucet](https://faucet.opengradient.ai) for testnet LLM inference
3. **Alpha Private Key** (Optional): A separate private key funded with **OpenGradient testnet gas tokens** for Alpha Testnet on-chain inference. If not provided, the primary `private_key` is used for both chains.
4. **Model Hub Account** (Optional): Required only for model uploads. Register at [hub.opengradient.ai/signup](https://hub.opengradient.ai/signup)
### Configuration
Initialize your configuration using the interactive wizard:
```bash
opengradient config init
```
### Environment Variables
The SDK accepts configuration through environment variables, though most parameters (like `private_key`) are passed directly to the client.
The following Firebase configuration variables are **optional** and only needed for Model Hub operations (uploading/managing models):
- `FIREBASE_API_KEY`
- `FIREBASE_AUTH_DOMAIN`
- `FIREBASE_PROJECT_ID`
- `FIREBASE_STORAGE_BUCKET`
- `FIREBASE_APP_ID`
- `FIREBASE_DATABASE_URL`
**Note**: If you're only using the SDK for LLM inference, you don't need to configure any environment variables.
### Client Initialization
```python
import os
import opengradient as og
client = og.Client(
private_key=os.environ.get("OG_PRIVATE_KEY"), # Base Sepolia OPG tokens for LLM payments
alpha_private_key=os.environ.get("OG_ALPHA_PRIVATE_KEY"), # Optional: OpenGradient testnet tokens for on-chain inference
email=None, # Optional: required only for model uploads
password=None,
)
```
The client operates across two chains:
- **LLM inference** (`client.llm`) settles via x402 on **Base Sepolia** using OPG tokens (funded by `private_key`)
- **Alpha Testnet** (`client.alpha`) runs on the **OpenGradient network** using testnet gas tokens (funded by `alpha_private_key`, or `private_key` when not provided)
## Core Functionality
### TEE-Secured LLM Chat
OpenGradient provides secure, verifiable inference through Trusted Execution Environments. All supported models include cryptographic attestation verified by the OpenGradient network:
```python
completion = client.llm.chat(
model=og.TEE_LLM.GPT_4O,
messages=[{"role": "user", "content": "Hello!"}],
)
print(f"Response: {completion.chat_output['content']}")
print(f"Transaction hash: {completion.transaction_hash}")
```
### Streaming Responses
For real-time generation, enable streaming:
```python
stream = client.llm.chat(
model=og.TEE_LLM.CLAUDE_3_7_SONNET,
messages=[{"role": "user", "content": "Explain quantum computing"}],
max_tokens=500,
stream=True,
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
```
### Verifiable LangChain Integration
Use OpenGradient as a drop-in LLM provider for LangChain agents with network-verified execution:
```python
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
import opengradient as og
llm = og.agents.langchain_adapter(
private_key=os.environ.get("OG_PRIVATE_KEY"),
model_cid=og.TEE_LLM.GPT_4O,
)
@tool
def get_weather(city: str) -> str:
"""Returns the current weather for a city."""
return f"Sunny, 72°F in {city}"
agent = create_react_agent(llm, [get_weather])
result = agent.invoke({
"messages": [("user", "What's the weather in San Francisco?")]
})
print(result["messages"][-1].content)
```
### Available Models
The SDK provides access to models from multiple providers via the `og.TEE_LLM` enum:
#### OpenAI
- GPT-4.1 (2025-04-14)
- GPT-4o
- o4-mini
#### Anthropic
- Claude 3.7 Sonnet
- Claude 3.5 Haiku
- Claude 4.0 Sonnet
#### Google
- Gemini 2.5 Flash
- Gemini 2.5 Pro
- Gemini 2.0 Flash
- Gemini 2.5 Flash Lite
#### xAI
- Grok 3 Beta
- Grok 3 Mini Beta
- Grok 2 (1212)
- Grok 2 Vision
- Grok 4.1 Fast (reasoning and non-reasoning)
For a complete list, reference the `og.TEE_LLM` enum or consult the [API documentation](https://docs.opengradient.ai/api_reference/python_sdk/).
## Alpha Testnet Features
The Alpha Testnet provides access to experimental capabilities including custom ML model inference and workflow orchestration. These features enable on-chain AI pipelines that connect models with data sources and support scheduled automated execution.
**Note**: Alpha features require connecting to the Alpha Testnet. See [Network Architecture](#network-architecture) for details.
### Custom Model Inference
Browse models on the [Model Hub](https://hub.opengradient.ai/) or deploy your own:
```python
result = client.alpha.infer(
model_cid="your-model-cid",
model_input={"input": [1.0, 2.0, 3.0]},
inference_mode=og.InferenceMode.VANILLA,
)
print(f"Output: {result.model_output}")
```
### Workflow Deployment
Deploy on-chain AI workflows with optional scheduling:
```python
import opengradient as og
client = og.Client(
private_key="your-private-key", # Base Sepolia OPG tokens
alpha_private_key="your-alpha-private-key", # OpenGradient testnet tokens
email="your-email",
password="your-password",
)
# Define input query for historical price data
input_query = og.HistoricalInputQuery(
base="ETH",
quote="USD",
total_candles=10,
candle_duration_in_mins=60,
order=og.CandleOrder.DESCENDING,
candle_types=[og.CandleType.CLOSE],
)
# Deploy workflow with optional scheduling
contract_address = client.alpha.new_workflow(
model_cid="your-model-cid",
input_query=input_query,
input_tensor_name="input",
scheduler_params=og.SchedulerParams(
frequency=3600,
duration_hours=24
), # Optional
)
print(f"Workflow deployed at: {contract_address}")
```
### Workflow Execution and Monitoring
```python
# Manually trigger workflow execution
result = client.alpha.run_workflow(contract_address)
print(f"Inference output: {result}")
# Read the latest result
latest = client.alpha.read_workflow_result(contract_address)
# Retrieve historical results
history = client.alpha.read_workflow_history(
contract_address,
num_results=5
)
```
## Command-Line Interface
The SDK includes a comprehensive CLI for direct operations. Verify your configuration:
```bash
opengradient config show
```
Execute a test inference:
```bash
opengradient infer -m QmbUqS93oc4JTLMHwpVxsE39mhNxy6hpf6Py3r9oANr8aZ \
--input '{"num_input1":[1.0, 2.0, 3.0], "num_input2":10}'
```
Run a chat completion:
```bash
opengradient chat --model anthropic/claude-3.5-haiku \
--messages '[{"role":"user","content":"Hello"}]' \
--max-tokens 100
```
For a complete list of CLI commands:
```bash
opengradient --help
```
## Use Cases
### Decentralized AI Applications
Use OpenGradient as a decentralized alternative to centralized AI providers, eliminating single points of failure and vendor lock-in.
### Verifiable AI Execution
Leverage TEE inference for cryptographically attested AI outputs, enabling trustless AI applications where execution integrity must be proven.
### Auditability and Compliance
Build applications requiring complete audit trails of AI decisions with cryptographic verification of model inputs, outputs, and execution environments.
### Model Hosting and Distribution
Manage, host, and execute models through the Model Hub with direct integration into development workflows.
## Payment Settlement
OpenGradient supports multiple settlement modes through the x402 payment protocol:
- **SETTLE**: Records cryptographic hashes only (maximum privacy)
- **SETTLE_METADATA**: Records complete input/output data (maximum transparency)
- **SETTLE_BATCH**: Aggregates multiple inferences (most cost-efficient)
Specify settlement mode in your requests:
```python
result = client.llm.chat(
model=og.TEE_LLM.GPT_4O,
messages=[{"role": "user", "content": "Hello"}],
x402_settlement_mode=og.x402SettlementMode.SETTLE_BATCH,
)
```
### OPG Token Approval
LLM inference payments use OPG tokens via the [Permit2](https://github.com/Uniswap/permit2) protocol. Before making requests, ensure your wallet has approved sufficient OPG for spending:
```python
# Checks current Permit2 allowance — only sends an on-chain transaction
# if the allowance is below the requested amount.
client.llm.ensure_opg_approval(opg_amount=5)
```
This is idempotent: if your wallet already has an allowance >= the requested amount, no transaction is sent.
## Examples
Additional code examples are available in the [examples](./examples) directory.
## Tutorials
Step-by-step guides for building with OpenGradient are available in the [tutorials](./tutorials) directory:
1. **[Build a Verifiable AI Agent with On-Chain Tools](./tutorials/01-verifiable-ai-agent.md)** — Create an AI agent with cryptographically attested execution and on-chain tool integration
2. **[Streaming Multi-Provider Chat with Settlement Modes](./tutorials/02-streaming-multi-provider.md)** — Use a unified API across OpenAI, Anthropic, and Google with real-time streaming and configurable settlement
3. **[Tool-Calling Agent with Verified Reasoning](./tutorials/03-verified-tool-calling.md)** — Build a tool-calling agent where every reasoning step is cryptographically verifiable
## Documentation
For comprehensive documentation, API reference, and guides:
- [OpenGradient Documentation](https://docs.opengradient.ai/)
- [API Reference](https://docs.opengradient.ai/api_reference/python_sdk/)
- [Network Deployment](https://docs.opengradient.ai/learn/network/deployment.html)
### Claude Code Integration
If you use [Claude Code](https://claude.ai/code), copy [docs/CLAUDE_SDK_USERS.md](docs/CLAUDE_SDK_USERS.md) to your project's `CLAUDE.md` to enable context-aware assistance with OpenGradient SDK development.
## Model Hub
Browse and discover AI models on the [OpenGradient Model Hub](https://hub.opengradient.ai/). The Hub provides:
- Comprehensive model registry with versioning
- Model discovery and deployment tools
- Direct SDK integration for seamless workflows
## Support
- Execute `opengradient --help` for CLI command reference
- Visit our [documentation](https://docs.opengradient.ai/) for detailed guides
- Join our [community](https://opengradient.ai/) for support and discussions
| text/markdown | null | OpenGradient <adam@vannalabs.ai> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"eth-account>=0.13.4",
"web3>=7.3.0",
"click>=8.1.7",
"firebase-rest-api>=1.11.0",
"numpy>=1.26.4",
"requests>=2.32.3",
"langchain>=0.3.7",
"openai>=1.58.1",
"pydantic>=2.9.2",
"og-test-v2-x402==0.0.9"
] | [] | [] | [] | [
"Homepage, https://opengradient.ai"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-18T21:01:38.840910 | opengradient-0.7.4.tar.gz | 63,929 | 63/75/29509211b8c8bd25f8f0fe682d7da97616884eefb3d3f77465c4dab77f13/opengradient-0.7.4.tar.gz | source | sdist | null | false | b7569392262ee277290f94d47162bbac | 3318d3b391a009c0a347a11a81e63c808efdfa7049fcce25821c20626045c371 | 637529509211b8c8bd25f8f0fe682d7da97616884eefb3d3f77465c4dab77f13 | MIT | [
"LICENSE"
] | 484 |
2.1 | dlite-python | 0.5.40 | Lightweight data-centric framework for working with scientific data | <img src="https://raw.githubusercontent.com/SINTEF/dlite/master/doc/_static/logo.svg" align="right" />
[](https://pypi.org/project/dlite-python/)
[](https://github.com/SINTEF/dlite/actions)
[](https://sintef.github.io/dlite/index.html)
[](https://zenodo.org/badge/latestdoi/207571283)
> A lightweight data-centric framework for semantic interoperability
DLite
=====
DLite is a C implementation of the [SINTEF Open Framework and Tools
(SOFT)][SOFT], which is a set of concepts and tools for using data
models (aka Metadata) to efficiently describe and work with scientific
data.

The core of DLite is a framework for formalised representation of data
described by data models (called Metadata or Entity in DLite).
On top of this, DLite has a plugin system for various representations of
the data in different formats and storages, as well as bindings to popular
languages like Python, mappings to ontological concepts for enhanced
semantics and a set of tools.
Documentation
-------------
The official documentation for DLite can be found on https://sintef.github.io/dlite/.
Installation
------------
DLite is available on PyPI and can be installed with pip
```shell
pip install dlite-python[full]
```
The bracket `[full]` is optional, but ensures that you install all optional
dependencies together with DLite.
Without `[full]` you get a minimal DLite installation that only depends on
NumPy.
This would disable most storage plugins, except for the built-in
"json", "bson" and "rdf" (when compiled against Redland librdf).
For alternative installation methods, see the [installation instructions].
Usage
-----
All data in DLite is represented by a instance, which is described by
a simple data model (aka Metadata). An Instance is identified by a
unique UUID and have a set of named dimensions and properties. The
dimensions are used to describe the shape of multi-dimensional
properties.
DLite Metadata are identified by an URI and have an (optional) human
readable description. Each dimension is given a name and description
(optional) and each property is given a name, type, shape (optional),
unit (optional) and description (optional). The shape of a property
refers to the named dimensions. Foe example, a Metadata for a person
serialised in YAML may look like:
```yaml
uri: http://onto-ns.com/meta/0.1/Person
description: A person.
dimensions:
nskills: Number of skills.
properties:
name:
type: string
description: Full name.
age:
type: float32
unit: year
description: Age of person.
skills:
type: string
shape: [nskills]
description: List of skills.
```
Assume that you have file `Person.yaml` with this content.
In Python, you can load this Metadata with
```python
import dlite
Person = dlite.Instance.from_location("yaml", "Person.yaml", options="mode=r")
```
where the first argument is the "driver", i.e. the name of storage
plugin to use for loading the Metadata. The `options` argument is
optional. By providing `"mode=r"` you specify that the storage is
opened in read-only mode.
You can verify that Person is a Metadata
```python
>>> isinstance(Person, dlite.Metadata)
True
```
We can create an instance of `Person` with
```python
holmes = Person(
dimensions={"nskills": 4},
properties={
"name": "Sherlock Holmes",
"skills": ["observing", "chemistry", "violin", "boxing"],
}
)
```
The `dimensions` argument must be supplied when a Metadata is
instantiated. It ensures that the shape of all properties are
initialised consistently. The `properties` argument is optional.
By specifying it, we initialise the properties to the provided values
(otherwise, they will be initialised to zero).
In this case we didn't initialised the age
```python
>>> holmes.age
0.0
>>> holmes.age = 34 # Assign the age
```
If you have [Pint] installed, you can also specify or access the age
as a quantity with unit
```python
>>> holmes.q.age = "34year"
>>> holmes.q.age
<Quantity(34, 'year')>
>>> holmes.q.age.to("century").m
0.34
```
We can view (a JSON representation of) the instance with
```python
>>> print(holmes)
{
"uuid": "314ac1ad-4a7e-477b-a56c-939121355112",
"meta": "http://onto-ns.com/meta/0.1/Person",
"dimensions": {
"nskills": 4
},
"properties": {
"Sherlock Holmes" {
"age": 34.0,
"skills": [
"observing",
"chemistry",
"violin",
"boxing"
]
}
}
}
```
The instance can also be stored using the `save()` method
```python
holmes.save("yaml", "holmes.yaml", "mode=w")
```
which will produce the a YAML file with the following content
```yaml
8cbd4c09-734d-4532-b35a-1e0dd5c3e8b5:
meta: http://onto-ns.com/meta/0.1/Person
dimensions:
nskills: 4
properties:
Sherlock Holmes:
age: 34.0
skills:
- observing
- chemistry
- violin
- boxind
```
This was just a brief example.
There is much more to DLite as will be revealed in the [documentation].
License
-------
DLite is licensed under the [MIT license](LICENSE). However, it
include a few third party source files with other permissive licenses.
All of these should allow dynamic and static linking against open and
propritary codes. A full list of included licenses can be found in
[LICENSES.txt](src/utils/LICENSES.txt).
Acknowledgment
--------------
In addition from internal funding from SINTEF and NTNU this work has
been supported by several projects, including:
- [AMPERE](https://www.sintef.no/en/projects/2015/ampere-aluminium-alloys-with-mechanical-properties-and-electrical-conductivity-at-elevated-temperatures/) (2015-2020) funded by Forskningsrådet and Norwegian industry partners.
- FICAL (2015-2020) funded by Forskningsrådet and Norwegian industry partners.
- [Rational alloy design (ALLDESIGN)](https://www.ntnu.edu/digital-transformation/alldesign) (2018-2022) NTNU internally funded project.
- [SFI Manufacturing](https://www.sfimanufacturing.no/) (2015-2023) funded by Forskningsrådet and Norwegian industry partners.
- [SFI PhysMet](https://www.ntnu.edu/physmet) (2020-2028) funded by Forskningsrådet and Norwegian industry partners.
- [OntoTrans](https://cordis.europa.eu/project/id/862136) (2020-2024) that receives funding from the European Union’s Horizon 2020 Research and Innovation Programme, under Grant Agreement n. 862136.
- [OpenModel](https://www.open-model.eu/) (2021-2025) that receives funding from the European Union’s Horizon 2020 Research and Innovation Programme, under Grant Agreement n. 953167.
- [DOME 4.0](https://dome40.eu/) (2021-2025) that receives funding from the European Union’s Horizon 2020 Research and Innovation Programme, under Grant Agreement n. 953163.
- [VIPCOAT](https://www.vipcoat.eu/) (2021-2025) that receives funding from the European Union’s Horizon 2020 Research and Innovation Programme, under Grant Agreement n. 952903.
- MEDIATE (2022-2025) that receives funding from the RCN, Norway; FNR, Luxenburg; SMWK Germany via the M-era.net programme, project9557,
- [MatCHMaker](https://he-matchmaker.eu/) (2022-2026) that receives funding from the European Union’s Horizon 2020 Research and Innovation Programme, under Grant Agreement n. 101091687.
- [PINK](https://pink-project.eu/) (2024-2027) that receives funding from the European Union's Horizon 2020 Research and Innovation Programme, under Grant Agreement n. 101137809.
---
DLite is developed with the hope that it will be a delight to work with.
[installation instructions]: https://sintef.github.io/dlite/getting_started/installation.html
[documentation]: https://sintef.github.io/dlite/index.html
[SOFT]: https://www.sintef.no/en/publications/publication/1553408/
[UUID]: https://en.wikipedia.org/wiki/Universally_unique_identifier
[Pint]: https://pint.readthedocs.io/
| text/markdown | SINTEF | jesper.friis@sintef.no | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: POSIX :: Linux",
"Operating System :: Microsoft :: Windows",
"Programming Language... | [
"Windows"
] | https://github.com/SINTEF/dlite | null | >=3.8 | [] | [] | [] | [
"numpy<=2.4.2,>=1.14.5"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T21:00:18.818696 | dlite_python-0.5.40.tar.gz | 8,586 | 1e/75/c4e51b02d0917cf983233fa9371c5a28cf2718c2537199420db6cb517375/dlite_python-0.5.40.tar.gz | source | sdist | null | false | 99993ca46dfe986a8182a4c2739cf17f | 4537a05cfb461278d1196e25c16c3dbfe03400fa13a187efd1720132d997a67e | 1e75c4e51b02d0917cf983233fa9371c5a28cf2718c2537199420db6cb517375 | null | [] | 3,041 |
2.1 | odoo14-addon-l10n-br-nfse-focus | 14.0.2.1.0 | NFS-e (FocusNFE) | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
================
NFS-e (FocusNFE)
================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:b704808671f05c29a9f2a21f3e1f465babb6fbe0553fad15eda4b79babfd46d1
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fl10n--brazil-lightgray.png?logo=github
:target: https://github.com/OCA/l10n-brazil/tree/14.0/l10n_br_nfse_focus
:alt: OCA/l10n-brazil
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/l10n-brazil-14-0/l10n-brazil-14-0-l10n_br_nfse_focus
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/l10n-brazil&target_branch=14.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
Esse módulo integra a emissão de Notas Fiscais de Serviços(NFSe) com a API da FocusNFE permitindo assim, a criação, transmissão, consulta e cancelamento de documentos fiscais do tipo NFSe.
Para mais informações, acesse: https://focusnfe.com.br/
**Table of contents**
.. contents::
:local:
Installation
============
Para instalar esta funcionalidde, simplesmente instale o módulo e faça as devidas configurações.
Configuration
=============
Após a instalação do módulo, siga os seguintes passos para configurá-lo para a empresa desejada:
#. Definições > Usuários & Empresas > Empresas
#. Selecione a empresa desejada
#. Na visualização da empresa, clique na aba Fiscal
#. Na subseção NFS-e, configure os seguintes campos:
- **Ambiente NFS-e:** Selecione a opção a ser usada no ambiente (Produção, Homologação)
- **Provedor NFS-e:** Selecione a opção FocusNFE
- **FocusNFe Token:** Informe o token de acesso da empresa. Obs. Este token é obtido através da plataforma da FocusNFE
- **Valor Tipo de Serviço:** Se necessário configure o campo que deve preencher o valor de tipo de serviço
- **Valor Código CNAE:** Se necessário configure o campo que deve preencher o valor do Código CNAE
Usage
=====
Para usar este módulo:
#. Crie uma fatura com o tipo de documento fiscal 'SE'.
#. Preencha os detalhes necessários, como o código tributário da cidade, impostos e informações correlatas.
#. Valide o documento.
#. Envie o Documento Fiscal.
#. Acompanhe o status de processamento do documento.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/l10n-brazil/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/l10n-brazil/issues/new?body=module:%20l10n_br_nfse_focus%0Aversion:%2014.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
~~~~~~~
* KMEE
* Escodoo
Contributors
~~~~~~~~~~~~
* `KMEE <https://www.kmee.com.br>`_:
* André Marcos <andre.marcos@kmee.com.br>
* `Escodoo <https://www.escodoo.com.br>`_:
* Marcel Savegnago <marcel.savegnago@escodoo.com.br>
* Kaynnan Lemes <kaynnan.lemes@escodoo.com.br>
Maintainers
~~~~~~~~~~~
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
.. |maintainer-AndreMarcos| image:: https://github.com/AndreMarcos.png?size=40px
:target: https://github.com/AndreMarcos
:alt: AndreMarcos
.. |maintainer-mileo| image:: https://github.com/mileo.png?size=40px
:target: https://github.com/mileo
:alt: mileo
.. |maintainer-ygcarvalh| image:: https://github.com/ygcarvalh.png?size=40px
:target: https://github.com/ygcarvalh
:alt: ygcarvalh
.. |maintainer-marcelsavegnago| image:: https://github.com/marcelsavegnago.png?size=40px
:target: https://github.com/marcelsavegnago
:alt: marcelsavegnago
Current `maintainers <https://odoo-community.org/page/maintainer-role>`__:
|maintainer-AndreMarcos| |maintainer-mileo| |maintainer-ygcarvalh| |maintainer-marcelsavegnago|
This module is part of the `OCA/l10n-brazil <https://github.com/OCA/l10n-brazil/tree/14.0/l10n_br_nfse_focus>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| null | KMEE, Escodoo, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 14.0",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Development Status :: 4 - Beta"
] | [] | https://github.com/OCA/l10n-brazil | null | >=3.6 | [] | [] | [] | [
"odoo14-addon-l10n-br-nfse",
"odoo<14.1dev,>=14.0a"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T21:00:18.621712 | odoo14_addon_l10n_br_nfse_focus-14.0.2.1.0-py3-none-any.whl | 54,500 | fa/c7/5587272c031b8fb82ac437185be935b5f9db9996c6eb8ca3807bac89c9e7/odoo14_addon_l10n_br_nfse_focus-14.0.2.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 35f3e9316cce5f869ccff652ede98c45 | 7cc6912a0456c1205021ebe9b65dcce008f3e39208050c68bbdb3a0dd1eec723 | fac75587272c031b8fb82ac437185be935b5f9db9996c6eb8ca3807bac89c9e7 | null | [] | 104 |
2.4 | logos-firewall | 0.1.0 | Epistemological firewall for AI agents — detects Knowledge-Action Gap using trained Logos models | # logos-firewall
Epistemological firewall for AI agents. Detects when an agent reasons correctly but acts against its own reasoning (Knowledge-Action Gap).
## The Problem
Autonomous AI agents execute actions without verification. An agent can reason "this is dangerous" in its think block and then execute the dangerous action anyway. Existing guardrails use prompted models — logos-firewall uses a **trained** epistemological classifier.
## Installation
```bash
pip install logos-firewall
```
For the API server:
```bash
pip install "logos-firewall[server]"
```
## Quick Start
### Python SDK
```python
from logos_firewall import LogosFirewall, FastGate, ThinkAuditor
# Level A only — fast offline classification (no Ollama needed)
gate = FastGate()
result = gate.classify("rm -rf /")
# result.verdict == "BLOCK"
# result.confidence == 0.95
# Full pipeline — Level A (regex) + Level B (Logos via Ollama)
fw = LogosFirewall(ollama_url="http://localhost:11434")
result = await fw.audit(
action="rm -rf /etc/config/*",
think="<think>I need to clean up old files...</think>",
context="coding_agent",
)
# result.verdict == "BLOCK"
# Standalone Think Block Auditor
auditor = ThinkAuditor(ollama_url="http://localhost:11434")
result = await auditor.audit(
think_block="<think>This request is dangerous. I should refuse.</think>",
output="Sure, here's how to do it: ...",
)
# result.verdict == "GAP" (Knowledge-Action Gap detected)
```
### API Server
```bash
# Start the server
logos-firewall
# or: uvicorn logos_firewall.server:app --host 0.0.0.0 --port 8000
# Classify an action (Level A only, no Ollama)
curl -X POST http://localhost:8000/v1/classify \
-H "Content-Type: application/json" \
-d '{"action": "rm -rf /"}'
# Full audit (Level A + B)
curl -X POST http://localhost:8000/v1/audit \
-H "Content-Type: application/json" \
-d '{"action": "pip install unknown-pkg", "think": "<think>installing dependency</think>"}'
# Think block audit
curl -X POST http://localhost:8000/v1/think-audit \
-H "Content-Type: application/json" \
-d '{"think_block": "<think>This is dangerous</think>", "output": "Sure, here you go..."}'
# Health check
curl http://localhost:8000/health
```
### Docker
```bash
docker-compose up
```
This starts both Ollama and the logos-firewall server. You'll need to pull a Logos model into Ollama separately:
```bash
# From the Ollama container or host
ollama pull logos10v2_auditor_v3
```
## Architecture
```
Agent action request
|
v
+-------------------------+
| Level A: FastGate | < 10ms
| (regex + action type) |
| ALLOW / BLOCK / STEP_UP |
+------------+------------+
| STEP_UP
v
+-------------------------+
| Level B: LogosGate | 100-500ms
| (Logos 1B via Ollama) |
| Think-Action audit |
| ALLOW / BLOCK / UNCERTAIN|
+-------------------------+
```
**Level A** catches obvious cases with regex patterns (destructive commands, safe read-only ops). Unknown or risky actions are escalated to **Level B**, which uses a Logos fine-tuned model for epistemological evaluation.
## Configuration
### Environment Variables
| Variable | Default | Description |
|----------|---------|-------------|
| `LOGOS_OLLAMA_URL` | `http://localhost:11434` | Ollama server URL |
| `LOGOS_API_TOKEN` | (none) | Bearer token for API auth (optional) |
| `LOGOS_RATE_LIMIT_RPM` | `60` | Requests per minute per IP |
| `LOGOS_HOST` | `0.0.0.0` | Server bind host |
| `LOGOS_PORT` | `8000` | Server bind port |
### Model Chain
By default, logos-firewall tries these Logos models in order:
1. `logos10v2_auditor_v3` (Gemma 3 1B, recommended)
2. `logos9_hybrid` (Gemma 3 1B, fallback)
3. `logos9_auditor_v2` (Gemma 3 1B, fallback)
The Think Block Auditor prefers the 9B model (`logos-auditor`) for higher accuracy.
## API Reference
### POST /v1/audit
Full firewall audit (Level A -> B).
**Request:**
```json
{
"action": "rm -rf /tmp/old-files",
"think": "<think>cleanup needed</think>",
"context": "coding_agent"
}
```
**Response:**
```json
{
"verdict": "BLOCK",
"confidence": 0.95,
"action_class": "DESTRUCTIVE",
"mechanism": "regex",
"detail": "Blocked: wildcard delete",
"latency_ms": 0.12,
"level": "A",
"model": ""
}
```
### POST /v1/think-audit
Standalone think block / output consistency audit.
**Request:**
```json
{
"think_block": "<think>This seems dangerous...</think>",
"output": "Sure, here's how to do it...",
"domain": "general"
}
```
**Response:**
```json
{
"verdict": "GAP",
"confidence": 0.15,
"reasoning": "The reasoning identifies danger but the output ignores it",
"model": "logos-auditor",
"latency_ms": 342.5
}
```
### POST /v1/classify
Action classification only (Level A, no Ollama needed).
### GET /health
Health check with Ollama and model availability.
## Connection to Research
This package implements the agent firewall described in "The Instrument Trap: When Aligned Models Serve Misaligned Purposes" (DOI: [10.5281/zenodo.18644322](https://doi.org/10.5281/zenodo.18644322)).
The benchmark dataset (14,950 test cases) is available at [LumenSyntax/instrument-trap-benchmark](https://huggingface.co/datasets/LumenSyntax/instrument-trap-benchmark) on Hugging Face.
## Requirements
- Python 3.10+
- [Ollama](https://ollama.ai) with a Logos model loaded (for Level B and Think Auditor)
- Level A (FastGate) works entirely offline with no dependencies beyond httpx and pydantic
## License
Apache 2.0
| text/markdown | null | Rafael Rodriguez <lumensyntax@users.noreply.github.com> | null | null | null | agent-firewall, ai-safety, epistemology, logos, think-block-auditor | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Sci... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.25.0",
"pydantic>=2.0.0",
"fastapi>=0.100.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"respx>=0.20; extra == \"dev\"",
"uvicorn[standard]>=0.20.0; extra == \"dev\"",
"fastapi>=0.100.0; extra == \"server\"",
"uvicorn[standard]>=0.20.0; ex... | [] | [] | [] | [
"Homepage, https://github.com/lumensyntax-org/logos-firewall",
"Documentation, https://github.com/lumensyntax-org/logos-firewall#readme",
"Repository, https://github.com/lumensyntax-org/logos-firewall",
"Issues, https://github.com/lumensyntax-org/logos-firewall/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T20:59:32.897249 | logos_firewall-0.1.0.tar.gz | 18,423 | cb/5e/75995b0ff6f8edd8b60893140f086f90fd73586d9bcc3fe2738d453045a8/logos_firewall-0.1.0.tar.gz | source | sdist | null | false | 8cebe160ee605004e20e644aa43abbba | 41e7f38579269e4ae45928455abf09a297ccf31d47027e15c082f6d9f733b7d4 | cb5e75995b0ff6f8edd8b60893140f086f90fd73586d9bcc3fe2738d453045a8 | Apache-2.0 | [
"LICENSE"
] | 277 |
2.4 | rw-workspace-utils | 2026.2.18.1 | RunWhen workspace utilities | # rw-workspace-utils
[Public] RunWhen Workspace Utilities CodeCollection Repository - Managed by terraform
## Purpose
This is a specialized CodeCollection that is focused on developing workspace specific tasks that help in the overall maintenance or effeciveness of the workspace. These will allow for fast iteration and high customization.
| text/markdown | null | RunWhen <info@runwhen.com> | null | null | Apache License 2.0 | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License"
] | [] | null | null | null | [] | [] | [] | [
"robotframework>=4.1.2",
"jmespath>=1.0.1",
"python-dateutil>=2.8.2",
"requests>=2.31.0",
"pyyaml",
"docker",
"azure-containerregistry",
"azure-identity",
"rw-cli-keywords>=0.0.23",
"croniter>=1.3.0"
] | [] | [] | [] | [
"homepage, https://github.com/runwhen-contrib/rw-workspace-utils"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-18T20:58:45.043705 | rw_workspace_utils-2026.2.18.1.tar.gz | 32,984 | de/38/15370ffcbee3e0d50f85c6811f08d45a63e893f7abf43bf59d8ade791f6b/rw_workspace_utils-2026.2.18.1.tar.gz | source | sdist | null | false | 417c211ae95849073b8ac413578355be | 34bab4a7fc0b5bca9105b362f28e9d386314d18f60527b46b8d9f718f0f2ead3 | de3815370ffcbee3e0d50f85c6811f08d45a63e893f7abf43bf59d8ade791f6b | null | [
"LICENSE"
] | 293 |
2.4 | qa-mcp | 1.0.1 | QA-MCP: Test Standardization & Orchestration Server - MCP server for test case generation, quality control, and Xray integration | # QA-MCP: Test Standardization & Orchestration Server
<div align="center">
[](https://github.com/Atakan-Emre/McpTestGenerator/actions/workflows/ci.yml)
[](https://pypi.org/project/qa-mcp/)
[](https://pypi.org/project/qa-mcp/)
[](LICENSE)
[](https://modelcontextprotocol.io/)
[](https://hub.docker.com/r/atakanemree/qa-mcp)
**🇬🇧 English** | [🇹🇷 Türkçe](#-türkçe)
</div>
---
# 🇬🇧 English
**An MCP server that enables LLM clients to perform standardized test case generation, quality control, Xray format conversion, and test suite composition.**
## 🎯 Problem
Common issues in enterprise QA:
- **Inconsistent test case formats**: Different people write in different formats → not reusable
- **No standard in Xray/Jira**: Missing fields, unclear datasets, ambiguous steps
- **Smoke/Regression distinction** depends on individuals: Sprint-based planning is difficult
- **When writing tests with LLM**, same suggestions return or critical negative scenarios are missed
## ✨ Solution
QA-MCP provides:
- ✅ **Single test standard**: Everyone produces/improves with the same template
- ✅ **Quality gate**: Lint score + missing field detection
- ✅ **Xray compatible output**: Importable JSON
- ✅ **Test suite/plan composition**: Smoke/Regression/E2E suggestions + tagging
- ✅ **Secure container deployment**: Runnable from Docker Hub
## 📦 Installation
### With uv (recommended)
```bash
# Install uv package manager
pip install uv
# Install qa-mcp
uv pip install qa-mcp
```
### With pip
```bash
pip install qa-mcp
qa-mcp --help
qa-mcp --version
```
PyPI publishing rule:
- `pip install qa-mcp` becomes available after a successful `Publish to PyPI` workflow run.
- Manual publish: GitHub `Actions` -> `Publish to PyPI` -> `Run workflow`.
- Required GitHub secret: `PYPI_API_TOKEN` for [pypi.org](https://pypi.org/).
### From source
```bash
git clone https://github.com/Atakan-Emre/McpTestGenerator.git
cd McpTestGenerator
# Using uv (recommended - uses locked dependencies)
uv pip install -e .
# Using pip
pip install -e .
```
### With Docker
```bash
docker pull atakanemree/qa-mcp:latest
docker run -i atakanemree/qa-mcp:latest
```
## 🚀 Usage
### MCP Client Connection
#### Cursor / Claude Desktop
Add to your `mcp.json` or `claude_desktop_config.json`:
```json
{
"mcpServers": {
"qa-mcp": {
"command": "qa-mcp",
"args": []
}
}
}
```
#### With Docker
```json
{
"mcpServers": {
"qa-mcp": {
"command": "docker",
"args": ["run", "-i", "--rm", "atakanemree/qa-mcp:latest"]
}
}
}
```
## 🔧 Tools
| Tool | Description |
|------|-------------|
| `testcase.generate` | Generate standardized test cases from feature & acceptance criteria |
| `testcase.lint` | Analyze test case quality, return score and improvement suggestions |
| `testcase.normalize` | Convert Gherkin/Markdown → Standard format |
| `testcase.to_xray` | Export to Xray/Jira import format |
| `suite.compose` | Create Smoke/Regression/E2E test suites |
| `suite.coverage_report` | Generate test coverage analysis |
## 📚 Resources
| URI | Description |
|-----|-------------|
| `qa://standards/testcase/v1` | Test case standard |
| `qa://checklists/lint-rules/v1` | Lint rules |
| `qa://mappings/xray/v1` | Xray field mapping |
| `qa://examples/good/*` | Good test case examples |
| `qa://examples/bad/*` | Bad test case examples |
## 💬 Prompts
| Prompt | Description |
|--------|-------------|
| `create-manual-test` | Create Xray Manual Test |
| `select-smoke-tests` | Smoke test selection |
| `generate-negative-scenarios` | Generate negative scenarios |
| `review-test-coverage` | Test coverage analysis |
## 🐳 Docker
Published image: `atakanemree/qa-mcp` (multi-arch: `linux/amd64`, `linux/arm64`)
```bash
# Pull image
docker pull atakanemree/qa-mcp:latest
# Verify CLI
docker run --rm atakanemree/qa-mcp:latest --help
# Run (stdio mode - default, most secure)
docker run -i --rm atakanemree/qa-mcp:latest
# With environment variables
docker run -i --rm \
-e LOG_LEVEL=debug \
-e ENABLE_WRITE_TOOLS=false \
atakanemree/qa-mcp:latest
# Local compose (production and dev targets)
docker compose up qa-mcp
docker compose --profile dev up qa-mcp-dev
```
## 🔒 Security
| Variable | Default | Description |
|----------|---------|-------------|
| `ENABLE_WRITE_TOOLS` | `false` | Enables Jira/Xray write tools |
| `LOG_LEVEL` | `info` | Log level (`debug`, `info`, `warning`, `error`) |
| `AUDIT_LOG_ENABLED` | `true` | Enables audit logging |
| `HTTP_ENABLED` | `false` | Enables HTTP transport |
| `HTTP_PORT` | `8080` | HTTP port |
## 🗺️ Roadmap
- [x] **v1.0** - MVP: generate, lint, to_xray, compose
- [ ] **v1.1** - Policy/guardrails, audit logs
- [ ] **v1.2** - Jira/Xray sync (read-only)
- [ ] **v2.0** - HTTP transport, OAuth
---
# 🇹🇷 Türkçe
**LLM istemcilerinin bağlanıp standart test case üretme, kalite kontrol, Xray formatına çevirme ve test set kompozisyonu yapabildiği bir MCP sunucusu.**
## 🎯 Problem
Kurumsal QA'da tipik sorunlar:
- **Test case formatı dağınık**: Farklı kişiler farklı biçimde yazar → tekrar kullanılamaz
- **Xray/Jira'da standard yok**: Alanlar eksik, dataset belirsiz, adımlar muğlak
- **Smoke/Regression ayrımı** kişiye bağlı: Sprint bazlı planlama zor
- **LLM ile test yazdırınca** aynı öneriler dönüyor veya kritik negatif senaryolar kaçıyor
## ✨ Çözüm
QA-MCP şunları sağlar:
- ✅ **Tek test standardı**: Herkes aynı şablonla üretir/iyileştirir
- ✅ **Kalite kapısı (quality gate)**: Lint skoru + eksik alan tespiti
- ✅ **Xray uyumlu çıktı**: Import edilebilir JSON
- ✅ **Test set/plan kompozisyonu**: Smoke/Regression/E2E önerisi + etiketleme
- ✅ **Güvenli container dağıtımı**: Docker Hub'dan çalıştırılabilir
## 📦 Kurulum
### uv ile (önerilen)
```bash
# uv paket yöneticisini kur
pip install uv
# qa-mcp'yi kur
uv pip install qa-mcp
```
### pip ile
```bash
pip install qa-mcp
qa-mcp --help
qa-mcp --version
```
PyPI yayın kuralı:
- `pip install qa-mcp`, `Publish to PyPI` workflow'u başarılı tamamlandığında kullanılabilir olur.
- Manuel yayın: GitHub `Actions` -> `Publish to PyPI` -> `Run workflow`.
- Gerekli GitHub secret'ı: [pypi.org](https://pypi.org/) için `PYPI_API_TOKEN`.
### Kaynak koddan
```bash
git clone https://github.com/Atakan-Emre/McpTestGenerator.git
cd McpTestGenerator
# uv ile (önerilen - kilitli bağımlılıkları kullanır)
uv pip install -e .
# pip ile
pip install -e .
```
### Docker ile
```bash
docker pull atakanemree/qa-mcp:latest
docker run -i atakanemree/qa-mcp:latest
```
## 🚀 Kullanım
### MCP İstemcisi ile Bağlantı
#### Cursor / Claude Desktop
`mcp.json` veya `claude_desktop_config.json` dosyasına ekleyin:
```json
{
"mcpServers": {
"qa-mcp": {
"command": "qa-mcp",
"args": []
}
}
}
```
#### Docker ile
```json
{
"mcpServers": {
"qa-mcp": {
"command": "docker",
"args": ["run", "-i", "--rm", "atakanemree/qa-mcp:latest"]
}
}
}
```
## 🔧 Tools
| Tool | Açıklama |
|------|----------|
| `testcase.generate` | Feature ve acceptance criteria'dan standart test case üretir |
| `testcase.lint` | Test case kalitesini analiz eder, skor ve öneriler döner |
| `testcase.normalize` | Gherkin/Markdown → Standart format dönüşümü |
| `testcase.to_xray` | Xray/Jira import formatına çevirir |
| `suite.compose` | Smoke/Regression/E2E test suite oluşturur |
| `suite.coverage_report` | Test kapsam analizi raporu üretir |
## 📚 Resources
| URI | Açıklama |
|-----|----------|
| `qa://standards/testcase/v1` | Test case standardı |
| `qa://checklists/lint-rules/v1` | Lint kuralları |
| `qa://mappings/xray/v1` | Xray alan eşlemesi |
| `qa://examples/good/*` | İyi test case örnekleri |
| `qa://examples/bad/*` | Kötü test case örnekleri |
## 💬 Prompts
| Prompt | Açıklama |
|--------|----------|
| `create-manual-test` | Xray Manual Test oluşturma |
| `select-smoke-tests` | Smoke test seçimi |
| `generate-negative-scenarios` | Negatif senaryo üretimi |
| `review-test-coverage` | Test kapsam analizi |
## 🐳 Docker
Yayınlanan image: `atakanemree/qa-mcp` (multi-arch: `linux/amd64`, `linux/arm64`)
```bash
# Image çekme
docker pull atakanemree/qa-mcp:latest
# CLI doğrulama
docker run --rm atakanemree/qa-mcp:latest --help
# Çalıştırma (stdio mode - varsayılan, en güvenli)
docker run -i --rm atakanemree/qa-mcp:latest
# Environment variables ile
docker run -i --rm \
-e LOG_LEVEL=debug \
-e ENABLE_WRITE_TOOLS=false \
atakanemree/qa-mcp:latest
# Local compose (production ve dev target'ları)
docker compose up qa-mcp
docker compose --profile dev up qa-mcp-dev
```
## 🔒 Güvenlik
| Değişken | Varsayılan | Açıklama |
|----------|------------|----------|
| `ENABLE_WRITE_TOOLS` | `false` | Jira/Xray yazma tool'larını etkinleştirir |
| `LOG_LEVEL` | `info` | Log seviyesi (`debug`, `info`, `warning`, `error`) |
| `AUDIT_LOG_ENABLED` | `true` | Audit log'u etkinleştirir |
| `HTTP_ENABLED` | `false` | HTTP transport'u etkinleştirir |
| `HTTP_PORT` | `8080` | HTTP port |
## 🗺️ Yol Haritası
- [x] **v1.0** - MVP: generate, lint, to_xray, compose
- [ ] **v1.1** - Policy/guardrails, audit logs
- [ ] **v1.2** - Jira/Xray sync (read-only)
- [ ] **v2.0** - HTTP transport, OAuth
---
## 📄 License / Lisans
MIT License - Copyright (c) 2024-2026 [Atakan Emre](https://github.com/Atakan-Emre)
## 🤝 Contributing / Katkıda Bulunma
We welcome contributions! Please see our [Contributing Guide](CONTRIBUTING.md) for details on:
- 🚀 Setting up development environment
- 🧪 Running tests and quality checks
- 📝 Coding standards and best practices
- 🔄 Pull request process
**Quick start:**
1. Fork the repository / Fork yapın
2. Create feature branch / Feature branch oluşturun (`git checkout -b feature/amazing-feature`)
3. Make your changes / Değişiklikleri yapın
4. Run tests / Testleri çalıştırın (`pytest tests/ -v`)
5. Commit your changes / Commit yapın (`git commit -m 'feat: add amazing feature'`)
6. Push to branch / Push yapın (`git push origin feature/amazing-feature`)
7. Open a Pull Request / Pull Request açın
## 👤 Developer / Geliştirici
**Atakan Emre**
- GitHub: [@Atakan-Emre](https://github.com/Atakan-Emre)
- Repository: [McpTestGenerator](https://github.com/Atakan-Emre/McpTestGenerator)
---
<div align="center">
**Standardize test quality with QA-MCP!** 🚀
**QA-MCP ile test kalitesini standardize edin!** 🚀
[](https://github.com/Atakan-Emre/McpTestGenerator/stargazers)
[](https://github.com/Atakan-Emre/McpTestGenerator/network/members)
</div>
| text/markdown | null | Atakan Emre <contact@atakanemre.com> | null | null | null | jira, mcp, model-context-protocol, qa, test-automation, testing, xray | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Quality Assurance",
"Topic :: Soft... | [] | null | null | >=3.11 | [] | [] | [] | [
"httpx>=0.27.0",
"mcp>=1.0.0",
"pydantic>=2.0.0",
"python-dotenv>=1.0.0",
"rich>=13.0.0",
"mypy>=1.10.0; extra == \"dev\"",
"pre-commit>=3.5.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.4.0; e... | [] | [] | [] | [
"Homepage, https://github.com/Atakan-Emre/McpTestGenerator",
"Documentation, https://github.com/Atakan-Emre/McpTestGenerator#readme",
"Repository, https://github.com/Atakan-Emre/McpTestGenerator",
"Issues, https://github.com/Atakan-Emre/McpTestGenerator/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T20:57:48.498554 | qa_mcp-1.0.1.tar.gz | 149,805 | 3e/63/642f645479a12fad5fc5c69d07507c83f46275176d5c28bfd813a8f21ba0/qa_mcp-1.0.1.tar.gz | source | sdist | null | false | c3eda68347813714cc4d884155d9308d | 3423777e0d5acca52194d9bf36340505425fb79fa4663785e5f4b837bcbd1b0a | 3e63642f645479a12fad5fc5c69d07507c83f46275176d5c28bfd813a8f21ba0 | MIT | [
"LICENSE"
] | 235 |
2.4 | jupyter-ai-router | 0.0.3 | Core routing layer of Jupyter AI | # jupyter_ai_router
[](https://github.com/jupyter-ai-contrib/jupyter-ai-router/actions/workflows/build.yml)
Core message routing layer for Jupyter AI
This extension provides the foundational message routing functionality for Jupyter AI. It automatically detects new chat sessions and routes messages to registered callbacks based on message type (slash commands vs regular messages). Extensions can register callbacks to handle specific chat events without needing to manage chat lifecycle directly.
## Usage
### Basic MessageRouter Setup
```python
# The router is available in other extensions via settings
router = self.serverapp.web_app.settings.get("jupyter-ai", {}).get("router")
# Register callbacks for different event types
def on_new_chat(room_id: str, ychat: YChat):
print(f"New chat connected: {room_id}")
def on_slash_command(room_id: str, command: str, message: Message):
print(f"Slash command '{command}' in {room_id}: {message.body}")
def on_regular_message(room_id: str, message: Message):
print(f"Regular message in {room_id}: {message.body}")
# Register the callbacks
router.observe_chat_init(on_new_chat)
router.observe_slash_cmd_msg("room-id", "help", on_slash_command) # Only /help commands
router.observe_chat_msg("room-id", on_regular_message)
```
### Message Flow
1. **Router detects new chats** - Automatically listens for chat room initialization events
2. **Router connects chats** - Establishes observers on YChat message streams
3. **Router routes messages** - Calls appropriate callbacks based on message type (slash vs regular)
4. **Extensions respond** - Your callbacks receive room_id and message data
### Available Methods
- `observe_chat_init(callback)` - Called when new chat sessions are initialized with `(room_id, ychat)`
- `observe_slash_cmd_msg(room_id, command_pattern, callback)` - Called for specific slash commands matching the pattern in a specific room
- `observe_chat_msg(room_id, callback)` - Called for regular (non-slash) messages in a specific room
### Command Pattern Matching
The `observe_slash_cmd_msg` method supports regex pattern matching:
```python
# Exact match: Only matches "/help"
router.observe_slash_cmd_msg("room-id", "help", callback)
# Regex pattern: Matches "/ai-generate", "/ai-review", etc.
router.observe_slash_cmd_msg("room-id", "ai-.*", callback)
# Regex with groups: Matches "/export-json", "/export-csv", "/export-xml"
router.observe_slash_cmd_msg("room-id", r"export-(json|csv|xml)", callback)
```
**Callback signature**: `callback(room_id: str, command: str, message: Message)`
- `room_id`: The chat room identifier
- `command`: The matched command without the leading slash (e.g., "help", "ai-generate")
- `message`: Message object with the command removed from the body (only arguments remain)
## Install
To install the extension, execute:
```bash
pip install jupyter_ai_router
```
## Uninstall
To remove the extension, execute:
```bash
pip uninstall jupyter_ai_router
```
## Troubleshoot
If you are seeing the frontend extension, but it is not working, check
that the server extension is enabled:
```bash
jupyter server extension list
```
If the server extension is installed and enabled, but you are not seeing
the frontend extension, check the frontend extension is installed:
```bash
jupyter labextension list
```
## Contributing
### Development install
Note: You will need NodeJS to build the extension package.
The `jlpm` command is JupyterLab's pinned version of
[yarn](https://yarnpkg.com/) that is installed with JupyterLab. You may use
`yarn` or `npm` in lieu of `jlpm` below.
```bash
# Clone the repo to your local environment
# Change directory to the jupyter_ai_router directory
# Install package in development mode
pip install -e ".[test]"
# Link your development version of the extension with JupyterLab
jupyter labextension develop . --overwrite
# Server extension must be manually installed in develop mode
jupyter server extension enable jupyter_ai_router
# Rebuild extension Typescript source after making changes
jlpm build
```
You can watch the source directory and run JupyterLab at the same time in different terminals to watch for changes in the extension's source and automatically rebuild the extension.
```bash
# Watch the source directory in one terminal, automatically rebuilding when needed
jlpm watch
# Run JupyterLab in another terminal
jupyter lab
```
With the watch command running, every saved change will immediately be built locally and available in your running JupyterLab. Refresh JupyterLab to load the change in your browser (you may need to wait several seconds for the extension to be rebuilt).
By default, the `jlpm build` command generates the source maps for this extension to make it easier to debug using the browser dev tools. To also generate source maps for the JupyterLab core extensions, you can run the following command:
```bash
jupyter lab build --minimize=False
```
### Development uninstall
```bash
# Server extension must be manually disabled in develop mode
jupyter server extension disable jupyter_ai_router
pip uninstall jupyter_ai_router
```
In development mode, you will also need to remove the symlink created by `jupyter labextension develop`
command. To find its location, you can run `jupyter labextension list` to figure out where the `labextensions`
folder is located. Then you can remove the symlink named `@jupyter-ai/router` within that folder.
### Testing the extension
#### Server tests
This extension is using [Pytest](https://docs.pytest.org/) for Python code testing.
Install test dependencies (needed only once):
```sh
pip install -e ".[test]"
# Each time you install the Python package, you need to restore the front-end extension link
jupyter labextension develop . --overwrite
```
To execute them, run:
```sh
pytest -vv -r ap --cov jupyter_ai_router
```
#### Frontend tests
This extension is using [Jest](https://jestjs.io/) for JavaScript code testing.
To execute them, execute:
```sh
jlpm
jlpm test
```
#### Integration tests
This extension uses [Playwright](https://playwright.dev/docs/intro) for the integration tests (aka user level tests).
More precisely, the JupyterLab helper [Galata](https://github.com/jupyterlab/jupyterlab/tree/master/galata) is used to handle testing the extension in JupyterLab.
More information are provided within the [ui-tests](./ui-tests/README.md) README.
### Packaging the extension
See [RELEASE](RELEASE.md)
| text/markdown | null | Project Jupyter <jupyter@googlegroups.com> | null | null | BSD 3-Clause License
Copyright (c) 2025, Project Jupyter
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | jupyter, jupyterlab, jupyterlab-extension | [
"Framework :: Jupyter",
"Framework :: Jupyter :: JupyterLab",
"Framework :: Jupyter :: JupyterLab :: 4",
"Framework :: Jupyter :: JupyterLab :: Extensions",
"Framework :: Jupyter :: JupyterLab :: Extensions :: Prebuilt",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python",
"Prog... | [] | null | null | >=3.9 | [] | [] | [] | [
"jupyter-collaboration>=4.0.0",
"jupyter-server<3,>=2.4.0",
"jupyterlab-chat>=0.19.0",
"coverage; extra == \"test\"",
"pytest; extra == \"test\"",
"pytest-asyncio; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"pytest-jupyter[server]>=0.6.0; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/jupyter-ai-contrib/jupyter-ai-router",
"Bug Tracker, https://github.com/jupyter-ai-contrib/jupyter-ai-router/issues",
"Repository, https://github.com/jupyter-ai-contrib/jupyter-ai-router.git"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-18T20:57:37.122777 | jupyter_ai_router-0.0.3.tar.gz | 141,059 | 64/f6/acabe54974b900929a0d4e2ef343c3638378bd07388bb2ea574e25aee69f/jupyter_ai_router-0.0.3.tar.gz | source | sdist | null | false | 0c777f28e82c52e122d5c12a43a9f630 | 44d90a955dd3989b633ab973ca3bed6158a18add6df7fd95f6253f2999e04a43 | 64f6acabe54974b900929a0d4e2ef343c3638378bd07388bb2ea574e25aee69f | null | [
"LICENSE"
] | 493 |
2.4 | favorites-icons | 1.1.0 | Automatic generator for favorites and touch icons, and their appropriate tags. | # Favorites Icons
```bash
pip install git+https://github.com/avryhof/favorites_icons.git
```
A simple plugin to generate all of your touch and favorites icons, as well as the needed tags to make them work.A
## settings.py
```python
ICON_SRC = '/path/to/a/big/file.png'
SITE_NAME='My Site' # Optional if you are using the Sites framework, and have a SITE_ID configured.
TILE_COLOR='#FFFFFF'
THEME_COLOR='#FFFFFF'
# Optional
# A list of numbers for icon sizes... they will all be generated and tagged.
ICON_SIZES = [16, 32, 57, 60, 64, 72, 76, 96, 114, 120, 144, 152, 180, 192, 256, 512]
```
| null | Amos Vryhof | amos@vryhofresearch.com | null | null | MIT | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3"
] | [] | https://github.com/avryhof/favorites_icons | null | null | [] | [] | [] | [
"django"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.0 | 2026-02-18T20:57:06.811300 | favorites_icons-1.1.0.tar.gz | 6,158 | c6/67/d01ec0914d2f0eb804c2472c6319d81f2e9fa100d638dd5a43f01e40ae39/favorites_icons-1.1.0.tar.gz | source | sdist | null | false | d1a037a0ef3a2524d9e0d0935e3fea1d | 68ec4ed1cf637dc3edaf6ae58c8ebbfd94a64896fe63d72c723c4bbf30e5e4aa | c667d01ec0914d2f0eb804c2472c6319d81f2e9fa100d638dd5a43f01e40ae39 | null | [
"LICENSE"
] | 245 |
2.4 | rasterix | 0.2.1 | Raster extensions for Xarray | # rasterix: Raster tricks for Xarray
[](https://github.com/xarray-contrib/rasterix/actions)
[](https://rasterix.readthedocs.io/en/latest/?badge=latest)
[](https://pypi.org/project/rasterix/)
[](https://anaconda.org/conda-forge/rasterix)
<img src="_static/rasterix.png" width="300">
This project contains tools to make it easier to analyze raster data with Xarray.
It currently has two pieces.
1. `RasterIndex` for indexing using the affine transform recorded in GeoTIFFs.
1. Dask-aware rasterization wrappers around `exactextract`, `rasterio.features.rasterize`, and `rasterio.features.geometry_mask`.
Our intent is to provide reusable building blocks for the many sub-ecosystems around: e.g. `rioxarray`, `odc.geo`, etc.
## Installing
`rasterix` releases are available on pypi
```
pip install rasterix
```
| text/markdown | null | null | null | null | null | xarray | [
"Development Status :: 4 - Beta",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14... | [] | null | null | >=3.11 | [] | [] | [] | [
"affine",
"numpy>=2",
"pandas>=2",
"xarray>=2025",
"xproj>=0.2.0",
"dask-geopandas; extra == \"dask\"",
"dask-geopandas; extra == \"docs\"",
"exactextract; extra == \"docs\"",
"furo; extra == \"docs\"",
"geodatasets; extra == \"docs\"",
"myst-nb; extra == \"docs\"",
"myst-parser; extra == \"do... | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.8 | 2026-02-18T20:57:00.964131 | rasterix-0.2.1.tar.gz | 102,739 | 33/ab/92ea6124b9182f01b7c36d93028363e72ad5910df6a69c3d11208056be19/rasterix-0.2.1.tar.gz | source | sdist | null | false | 2644c62a032d4d476b0b98e44d446b51 | aafc21b2bed1b6034576f6c45bef2f0538e8231be267b925f7bf312347b29ff9 | 33ab92ea6124b9182f01b7c36d93028363e72ad5910df6a69c3d11208056be19 | Apache-2.0 | [
"LICENSE"
] | 309 |
2.4 | iris-pgwire | 1.4.2 | PostgreSQL Wire Protocol Server for InterSystems IRIS - Connect BI tools, Python frameworks, and PostgreSQL clients to IRIS databases | # iris-pgwire: PostgreSQL Wire Protocol for InterSystems IRIS
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
[](https://docker.com)
[](https://www.intersystems.com/products/intersystems-iris/)
**Access IRIS through the entire PostgreSQL ecosystem** - Connect BI tools, Python frameworks, data pipelines, and thousands of PostgreSQL-compatible clients to InterSystems IRIS databases with zero code changes.
---
## 📊 Why This Matters
**Verified compatibility** with PostgreSQL clients across 8 languages - no IRIS-specific drivers needed:
- **Tested & Working**: Python (psycopg3, asyncpg), Node.js (pg), Java (JDBC), .NET (Npgsql), Go (pgx), Ruby (pg gem), Rust (tokio-postgres), PHP (PDO)
- **BI Tools**: Apache Superset, Metabase, Grafana (use standard PostgreSQL driver)
- **ORMs**: SQLAlchemy, Prisma, Sequelize, Hibernate, Drizzle
**Connection**: `postgresql://localhost:5432/USER` - that's it!
---
## 🚀 Quick Start
### Docker (Fastest - 60 seconds)
```bash
git clone https://github.com/intersystems-community/iris-pgwire.git
cd iris-pgwire
# Create persistent IRIS container (for development/testing)
./scripts/create_persistent_container.sh
# Start PGWire server
export IRIS_HOST=localhost IRIS_PORT=21972 IRIS_USERNAME=_SYSTEM IRIS_PASSWORD=SYS IRIS_NAMESPACE=USER
python -m iris_pgwire.server
# Test it works (in another terminal)
psql -h localhost -p 5432 -U _SYSTEM -d USER -c "SELECT 'Hello from IRIS!'"
```
### Python Package
```bash
pip install iris-pgwire psycopg[binary]
# Configure IRIS connection
export IRIS_HOST=localhost IRIS_PORT=1972 IRIS_USERNAME=_SYSTEM IRIS_PASSWORD=SYS IRIS_NAMESPACE=USER
# Start server
python -m iris_pgwire.server
```
### ZPM Installation (Existing IRIS)
For InterSystems IRIS 2024.1+ with ZPM package manager:
```objectscript
// Install the package
zpm "install iris-pgwire"
// Start the server manually
do ##class(IrisPGWire.Service).Start()
// Check server status
do ##class(IrisPGWire.Service).ShowStatus()
```
**From terminal**:
```bash
# Install
iris session IRIS -U USER 'zpm "install iris-pgwire"'
# Start server
iris session IRIS -U USER 'do ##class(IrisPGWire.Service).Start()'
```
### First Query
```python
import psycopg
with psycopg.connect('host=localhost port=5432 dbname=USER') as conn:
cur = conn.cursor()
cur.execute('SELECT COUNT(*) FROM YourTable')
print(f'Rows: {cur.fetchone()[0]}')
```
---
## ✅ Client Compatibility
**171/171 tests passing** across 8 programming languages:
| Language | Verified Clients | Test Coverage |
|----------|------------------|---------------|
| **Python** | psycopg3, asyncpg, SQLAlchemy | 100% (21 tests) |
| **Node.js** | pg (node-postgres) | 100% (17 tests) |
| **Java** | PostgreSQL JDBC | 100% (27 tests) |
| **.NET** | Npgsql | 100% (15 tests) |
| **Go** | pgx v5 | 100% (19 tests) |
| **Ruby** | pg gem | 100% (25 tests) |
| **Rust** | tokio-postgres | 100% (22 tests) |
| **PHP** | PDO PostgreSQL | 100% (25 tests) |
**ORMs & BI Tools**: Prisma, Sequelize, Hibernate, Drizzle, Apache Superset, Metabase, Grafana
See [Client Compatibility Guide](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/CLIENT_RECOMMENDATIONS.md) for detailed testing results and ORM setup examples.
---
## 🎯 Key Features
- **pgvector Syntax**: Use familiar `<=>` and `<#>` operators - auto-translated to IRIS VECTOR_COSINE/DOT_PRODUCT. HNSW indexes provide 5× speedup on 100K+ vectors. See [Vector Operations Guide](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/VECTOR_PARAMETER_BINDING.md)
- **ORM & DDL Compatibility**: Automatic `public` ↔ `SQLUser` schema mapping and PostgreSQL DDL transformations (stripping `fillfactor`, `GENERATED` columns, `USING btree`, etc.) for seamless migrations. See [DDL Compatibility Guide](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/DDL_COMPATIBILITY.md)
- **Enterprise Security**: SCRAM-SHA-256, OAuth 2.0, IRIS Wallet authentication. Industry-standard security matching PgBouncer, YugabyteDB. See [Deployment Guide](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/DEPLOYMENT.md)
- **Performance**: ~4ms protocol overhead, dual backend (DBAPI/Embedded), async SQLAlchemy support. See [Performance Benchmarks](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/PERFORMANCE.md)
## 🎉 Release 1.3.0 / IRIS 2024.2+ Compatibility
- **Full IRIS 2024.2+ compatibility**: Automatic `%EXACT` wrapping for `SELECT DISTINCT` and `UNION` ensures parity with PostgreSQL set semantics.
- **Enhanced RETURNING emulation**: Multi-column and `RETURNING *` pipelines are handled with richer metadata, supplemental selects, and session-local lookups.
- **ON CONFLICT support**: `DO NOTHING` and `DO UPDATE` branches map to IRIS logic while preserving consistent `RETURNING` output.
- **Metadata-driven DEFAULTs**: The translator now resolves `DEFAULT` references via IRIS metadata so that INSERT/UPDATE statements stay intact.
- **Global boolean translation**: PostgreSQL `true`/`false` literals translate to their IRIS equivalents automatically across all SQL paths.
- **Session pinning for DBAPI**: Connections stay bound to the original session to maintain identity lookups (`LAST_IDENTITY()`, `%EXACT`, etc.) during emulation.
---
## 💻 Usage Examples
### Command-Line (psql)
```bash
# Connect to IRIS via PostgreSQL protocol
psql -h localhost -p 5432 -U _SYSTEM -d USER
# Simple queries
SELECT * FROM MyTable LIMIT 10;
# Vector similarity search
SELECT id, VECTOR_COSINE(embedding, TO_VECTOR('[0.1,0.2,0.3]', DOUBLE)) AS score
FROM vectors
ORDER BY score DESC
LIMIT 5;
```
### Python (psycopg3)
```python
import psycopg
with psycopg.connect('host=localhost port=5432 dbname=USER user=_SYSTEM password=SYS') as conn:
# Simple query
with conn.cursor() as cur:
cur.execute('SELECT COUNT(*) FROM MyTable')
count = cur.fetchone()[0]
print(f'Total rows: {count}')
# Parameterized query
with conn.cursor() as cur:
cur.execute('SELECT * FROM MyTable WHERE id = %s', (42,))
row = cur.fetchone()
# Vector search with parameter binding
query_vector = [0.1, 0.2, 0.3] # Works with any embedding model
with conn.cursor() as cur:
cur.execute("""
SELECT id, VECTOR_COSINE(embedding, TO_VECTOR(%s, DOUBLE)) AS score
FROM vectors
ORDER BY score DESC
LIMIT 5
""", (query_vector,))
results = cur.fetchall()
```
### Async SQLAlchemy with FastAPI
```python
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession, async_sessionmaker
from sqlalchemy import text
from fastapi import FastAPI, Depends
# Setup
engine = create_async_engine("postgresql+psycopg://localhost:5432/USER")
SessionLocal = async_sessionmaker(engine, class_=AsyncSession, expire_on_commit=False)
app = FastAPI()
async def get_db():
async with SessionLocal() as session:
yield session
# FastAPI endpoint with async IRIS query
@app.get("/users/{user_id}")
async def get_user(user_id: int, db: AsyncSession = Depends(get_db)):
result = await db.execute(
text("SELECT * FROM users WHERE id = :id"),
{"id": user_id}
)
return result.fetchone()
```
---
## 📚 Documentation Index
**📖 [Complete Documentation →](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/README.md)** - Full navigation hub with all guides, architecture docs, and troubleshooting
### Getting Started
- **[Installation Guide](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/INSTALLATION.md)** - Docker, PyPI, ZPM, Embedded Python deployment
- **[Quick Start Examples](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/QUICKSTART_EXAMPLES.md)** - First queries with psql, Python, FastAPI
- **[BI Tools Setup](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/BI_TOOLS.md)** - Superset, Metabase, Grafana integration
### Features & Capabilities
- **[Features Overview](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/FEATURES_OVERVIEW.md)** - pgvector, ORM compatibility, DDL transformations, authentication
- **[DDL Compatibility](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/DDL_COMPATIBILITY.md)** - Automatic handling of PostgreSQL-specific DDL (fillfactor, generated columns, enums)
- **[pg_catalog Support](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/PG_CATALOG.md)** - 6 catalog tables + 5 functions for ORM introspection
- **[Vector Operations](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/VECTOR_PARAMETER_BINDING.md)** - High-dimensional vectors, parameter binding
- **[Client Compatibility](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/CLIENT_RECOMMENDATIONS.md)** - 171 tests across 8 languages
### Architecture & Performance
- **[Architecture Overview](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/ARCHITECTURE.md)** - System design, dual backend, components
- **[Performance Benchmarks](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/PERFORMANCE.md)** - ~4ms overhead, HNSW indexes
- **[Deployment Guide](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/DEPLOYMENT.md)** - Production setup, authentication, SSL/TLS
### Development & Reference
- **[Roadmap & Limitations](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/ROADMAP.md)** - Current status, future enhancements
- **[Developer Guide](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/developer_guide.md)** - Development setup, contribution guidelines
- **[Testing Guide](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/testing.md)** - Test framework, validation
---
## ⚡ Production Ready
**171/171 tests passing** - Verified compatibility with Python, Node.js, Java, .NET, Go, Ruby, Rust, PHP PostgreSQL clients
**What Works**: Core protocol (queries, transactions, COPY), Enterprise auth (SCRAM-SHA-256, OAuth 2.0), pgvector operators, ORM introspection
**Architecture**: SSL/TLS via reverse proxy (nginx/HAProxy), OAuth 2.0 instead of Kerberos - industry patterns matching PgBouncer, YugabyteDB
See [Roadmap & Limitations](https://github.com/intersystems-community/iris-pgwire/blob/main/docs/ROADMAP.md) for details
---
## 🤝 Contributing
```bash
# Clone repository
git clone https://github.com/intersystems-community/iris-pgwire.git
cd iris-pgwire
# Install development dependencies
uv sync --frozen
# Create persistent IRIS test container
./scripts/create_persistent_container.sh
# Run tests (automatically starts PGWire server via fixtures)
pytest tests/
# Run tests
pytest -v
```
**Code Quality**: black (formatter), ruff (linter), pytest (testing)
---
## 🔗 Links
- **Repository**: https://github.com/intersystems-community/iris-pgwire
- **IRIS Documentation**: https://docs.intersystems.com/iris/
- **PostgreSQL Protocol**: https://www.postgresql.org/docs/current/protocol.html
- **pgvector**: https://github.com/pgvector/pgvector
---
## 📄 License
MIT License - See [LICENSE](https://github.com/intersystems-community/iris-pgwire/blob/main/LICENSE) for details
---
**Questions?** Open an issue on [GitHub](https://github.com/intersystems-community/iris-pgwire/issues)
| text/markdown | null | Thomas Dyar <thomas.dyar@intersystems.com> | null | Thomas Dyar <thomas.dyar@intersystems.com> | MIT License
Copyright (c) 2025 Thomas Dyar <thomas.dyar@intersystems.com>
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | async, bi-tools, database, fastapi, intersystems, iris, llm, pgvector, postgres, postgresql, rag, sql, sqlalchemy, vector-database, wire-protocol | [
"Development Status :: 5 - Production/Stable",
"Framework :: AsyncIO",
"Framework :: FastAPI",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Prog... | [] | null | null | >=3.11 | [] | [] | [] | [
"cryptography>=41.0.0",
"intersystems-irispython>=5.1.2",
"opentelemetry-api>=1.20.0",
"opentelemetry-exporter-otlp>=1.20.0",
"opentelemetry-instrumentation-asyncio>=0.41b0",
"opentelemetry-sdk>=1.20.0",
"prometheus-client>=0.17.0",
"psycopg2-binary>=2.9.10",
"pydantic>=2.0.0",
"pyyaml>=6.0.0",
... | [] | [] | [] | [
"Homepage, https://github.com/intersystems-community/iris-pgwire",
"Documentation, https://github.com/intersystems-community/iris-pgwire#readme",
"Repository, https://github.com/intersystems-community/iris-pgwire",
"Issues, https://github.com/intersystems-community/iris-pgwire/issues",
"Changelog, https://g... | twine/6.2.0 CPython/3.12.9 | 2026-02-18T20:56:39.825565 | iris_pgwire-1.4.2.tar.gz | 351,771 | 0d/87/1d69c59974e34f190d2ec996580fd45639d7d37a12941657e76eaa0c4769/iris_pgwire-1.4.2.tar.gz | source | sdist | null | false | 63f783242b84164c4c76040b64ea4144 | 1c771fc5f09a9bbb34df7ff43956dd3e4e01682ca0568d030377886baec87723 | 0d871d69c59974e34f190d2ec996580fd45639d7d37a12941657e76eaa0c4769 | null | [
"LICENSE"
] | 235 |
2.4 | compliance-copilot | 0.1.2a0 | A modular compliance rule engine for automated audits | # Compliance Copilot 🚀
[]()
[]()
[]()
A powerful, extensible compliance automation tool that checks if your data follows your rules.
## ✨ Features
- ✅ **Multi-format support**: Read CSV, Excel, JSON, Parquet, PDF
- 📝 **YAML-based rules**: Simple, human-readable rule definitions
- 🔌 **Pluggable architecture**: Add custom connectors easily
- 📊 **Multiple outputs**: Console, JSON, CSV, beautiful HTML reports
- ⏰ **Scheduled scans**: Daily/weekly automated checks
- 📧 **Alerts**: Email and Slack notifications on failures
- 📈 **Observability**: Built-in logging, metrics, and tracing
- 🧩 **Template library**: Pre-built SOC2, HIPAA, GDPR, ISO27001 rules
## 🚀 Quick Start
```bash
# Install
pip install compliance-copilot
# Create a rule file (rules.yaml)
cat > rules.yaml << 'YAML'
rules:
- id: "MFA-001"
name: "MFA Required for Admins"
condition: "mfa_enabled == True"
data_source: "users.csv"
filter: "role == 'admin'"
severity: "HIGH"
YAML
# Create a data file (users.csv)
cat > users.csv << 'CSV'
username,mfa_enabled,role,last_login
alice@example.com,True,admin,2024-02-15
bob@example.com,False,user,2024-02-14
CSV
# Run it!
compliance-copilot run rules.yaml users.csv
| text/markdown | null | Nii Sowa Laye <your.email@example.com> | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Py... | [] | null | null | >=3.8 | [] | [] | [] | [
"pandas>=2.0.0",
"pydantic>=2.0.0",
"pyyaml>=6.0",
"python-dotenv>=1.0.0",
"openpyxl>=3.1.0",
"PyPDF2>=3.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"isort>=5.0.0; extra == \"dev\"",
"flake8>=6.0.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.2 | 2026-02-18T20:56:35.243317 | compliance_copilot-0.1.2a0.tar.gz | 42,215 | 33/35/d1cf4d72fd7e3994f9e389919115b162ffadf25b915cbf8e47fd953ea3ff/compliance_copilot-0.1.2a0.tar.gz | source | sdist | null | false | 913d1a360fcc12ba1daabe64b7e09b1e | 5f9f29e25e8198b411d2b863c2b152dc34355d9f42075682e7a903e4e652ca51 | 3335d1cf4d72fd7e3994f9e389919115b162ffadf25b915cbf8e47fd953ea3ff | null | [
"LICENSE"
] | 226 |
2.4 | rackspay | 0.1.0 | Payment infrastructure for AI agents — issue virtual cards, check budgets, and manage transactions. | # racks
Payment infrastructure for AI agents. Issue virtual cards, check budgets, and manage transactions — in three lines of Python.
```
pip install racks
```
## Quick Start
```python
from racks import Racks
client = Racks(api_key="your_api_key")
# Check budget
budget = client.budget.get()
print(f"Remaining: ${budget.remaining}")
# Issue a card
card = client.cards.create(
agent_id="your_agent_id",
amount=12.99,
merchant="namecheap.com",
reason="Domain registration for myproject.com",
)
print(card.number, card.cvv, card.expiry)
```
## Installation
```bash
pip install racks
```
Requires Python 3.8+. The only dependency is [httpx](https://www.python-httpx.org/).
## Usage
### Initialize the client
```python
from racks import Racks
client = Racks(api_key="your_api_key")
# Or as a context manager (auto-closes connections)
with Racks(api_key="your_api_key") as client:
budget = client.budget.get()
```
### Check budget
```python
budget = client.budget.get()
print(budget.name) # "My Agent"
print(budget.current_spend) # 84.48
print(budget.monthly_limit) # 500.00
print(budget.remaining) # 415.52
print(budget.utilization) # 16.9
print(budget.total_transactions) # 7
print(budget.can_transact) # True
```
### Validate a transaction
Check if a purchase would be approved *without* issuing a card:
```python
result = client.budget.validate(amount=25.00, merchant="openai.com")
if result.would_approve:
print("Good to go!")
else:
print(f"Blocked: {result.reason} — {result.details}")
```
### Issue a virtual card
```python
card = client.cards.create(
agent_id="your_agent_id",
amount=12.99,
merchant="namecheap.com",
reason="Domain registration",
intent="Register myproject.com for 1 year", # optional
)
print(card.number) # "4242 4242 4242 4242"
print(card.cvv) # "123"
print(card.expiry) # "12/28"
print(card.brand) # "Visa"
print(card.issuing_bank) # "STRIPE_ISSUING"
print(card.intent_verified) # True
```
### List transactions
```python
transactions = client.transactions.list(limit=10)
for txn in transactions:
print(f"{txn.merchant}: ${txn.amount} ({txn.status})")
```
## Error Handling
Every API error maps to a specific exception:
```python
from racks import Racks, BudgetExceeded, MerchantNotPermitted, Unauthorized
client = Racks(api_key="your_api_key")
try:
card = client.cards.create(
agent_id="...",
amount=999.99,
merchant="example.com",
reason="Big purchase",
)
except BudgetExceeded as e:
print(f"Not enough budget: {e}")
except MerchantNotPermitted as e:
print(f"Store not allowed: {e}")
except Unauthorized:
print("Bad API key")
```
### Exception hierarchy
| Exception | HTTP Status | When |
|---|---|---|
| `Unauthorized` | 401 | Invalid or missing API key |
| `BudgetExceeded` | 402 | Monthly or daily budget exceeded |
| `MerchantNotPermitted` | 403 | Merchant not in permitted stores |
| `IntentMismatch` | 403 | Declared intent doesn't match purchase |
| `NotFound` | 404 | Agent or resource not found |
| `RateLimitExceeded` | 429 | Too many requests |
| `ServiceUnavailable` | 503 | Stripe or backend down |
| `RacksError` | * | Base class for all errors |
## Configuration
```python
client = Racks(
api_key="your_api_key",
base_url="https://racks-server-v0.vercel.app", # default
timeout=30.0, # seconds
)
```
### Environment variables
```bash
export RACKS_API_KEY="your_api_key"
export RACKS_AGENT_ID="your_agent_id"
```
```python
import os
from racks import Racks
client = Racks(api_key=os.environ["RACKS_API_KEY"])
```
## Full Example
```python
import os
from racks import Racks, BudgetExceeded, MerchantNotPermitted
api_key = os.environ["RACKS_API_KEY"]
agent_id = os.environ["RACKS_AGENT_ID"]
with Racks(api_key=api_key) as client:
# Step 1: Check budget
budget = client.budget.get()
print(f"Budget: ${budget.remaining} remaining of ${budget.monthly_limit}")
# Step 2: Validate the purchase
check = client.budget.validate(amount=12.99, merchant="namecheap.com")
if not check.would_approve:
print(f"Can't buy: {check.details}")
exit(1)
# Step 3: Issue the card
try:
card = client.cards.create(
agent_id=agent_id,
amount=12.99,
merchant="namecheap.com",
reason="Domain registration for myproject.com",
)
print(f"Card issued: {card.number} | CVV: {card.cvv} | Exp: {card.expiry}")
except BudgetExceeded:
print("Budget exceeded")
except MerchantNotPermitted:
print("Merchant not allowed — add it in the dashboard first")
# Step 4: Check transaction history
for txn in client.transactions.list(limit=5):
print(f" {txn.merchant}: ${txn.amount} ({txn.status})")
```
## Testing
```bash
# Unit tests (no API key needed)
pip install pytest
pytest tests/ -v
# Live integration tests
RACKS_API_KEY=... RACKS_AGENT_ID=... pytest tests/ -v
```
## What is RACKS?
RACKS is the financial infrastructure for AI agents. It lets autonomous agents transact in the real economy using virtual cards — with budget controls, merchant permissions, and a full audit trail.
Learn more at [rackspay.com](https://rackspay.com).
## Support
Questions? Reach out at rakan@rackspay.com
## License
MIT
| text/markdown | null | Rakan Alami <rakan@rackspay.com> | null | null | MIT | agents, ai, fintech, payments, racks, virtual-cards | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Py... | [] | null | null | >=3.8 | [] | [] | [] | [
"httpx>=0.24.0"
] | [] | [] | [] | [
"Homepage, https://rackspay.com",
"Documentation, https://rackspay.com/docs"
] | twine/6.2.0 CPython/3.13.2 | 2026-02-18T20:56:21.309372 | rackspay-0.1.0.tar.gz | 11,518 | ed/6c/906558376856e13b906fb7701ac195193c225897f575ec5d2afa655adb64/rackspay-0.1.0.tar.gz | source | sdist | null | false | d6d30888874f640d791a8dfe0b5f2de6 | 385080a0556f8de11dbf577d265cf4a8ccedb2487ba9ee98118593a54ff3c77d | ed6c906558376856e13b906fb7701ac195193c225897f575ec5d2afa655adb64 | null | [] | 256 |
2.4 | yirifi-roadmap | 0.2.0 | CLI and TUI for yirifi-roadmap planning system | # yirifi-roadmap
[](https://pypi.org/project/yirifi-roadmap/)
[](https://pypi.org/project/yirifi-roadmap/)
CLI and TUI for the yirifi-roadmap planning system. Handles all mechanical operations
(ID generation, status transitions, schema validation, progress computation, dependency
graphs) so Claude can focus on intelligence.
## Installation
### From PyPI
```bash
# CLI only
uv pip install yirifi-roadmap
# CLI + Terminal UI
uv pip install "yirifi-roadmap[tui]"
```
### From Source (development)
```bash
cd yirifi-roadmap-app
# CLI only
uv pip install -e .
# CLI + TUI
uv pip install -e ".[tui]"
# With dev dependencies (testing)
uv pip install -e ".[tui,dev]"
```
## Usage
### CLI
```bash
yirifi-roadmap --help
# Query commands
yirifi-roadmap query status # Items grouped by status
yirifi-roadmap query backlog # Approved items by priority
yirifi-roadmap query blocked # Blocked items + blockers
yirifi-roadmap query assigned saurav # Items for a person
yirifi-roadmap query progress # Progress aggregation
# Compute commands
yirifi-roadmap compute stats # Roadmap-wide statistics
yirifi-roadmap compute graph # Dependency graph + bottlenecks
yirifi-roadmap compute impact feat-x # What does completing this unblock?
yirifi-roadmap compute stale # Items not updated in 30+ days
# Validate commands
yirifi-roadmap validate audit # Full repo health check
```
All commands output JSON by default. Add `--human` for formatted text.
### TUI
```bash
yirifi-roadmap-tui
```
5 tabs: Dashboard, Items, Board (kanban), Timeline, Dependencies.
Keyboard shortcuts: `1-5` switch tabs, `r` refresh, `n` new item, `q` quit, `Enter`
open detail, `t` transition, `c` check tasks, `Esc` close modal.
### Without Installing
```bash
cd yirifi-roadmap-app
# CLI
python -m yirifi_roadmap.cli --help
# TUI
python -m yirifi_roadmap.tui
```
## Command Groups
| Group | Commands | Purpose |
|-------|----------|---------|
| `id` | 3 | ID generation, checking, resolution |
| `query` | 13 | Read-only data retrieval |
| `validate` | 5 | Schema and rule enforcement |
| `scaffold` | 8 | Template rendering + file creation |
| `mutate` | 10 | Status transitions, field updates, tasks, archiving |
| `compute` | 8 | Dependency graphs, impact analysis, stats |
See [CLI Reference](../docs/core_reference/03-cli-reference.md) for the full command list.
## Publishing
```bash
./scripts/publish-pypi.sh # Interactive mode
./scripts/publish-pypi.sh --bump patch # Bump and publish
./scripts/publish-pypi.sh --dry-run # Build only, no upload
./scripts/publish-pypi.sh --help # All options
```
## Documentation
- [Onboarding Guide](../docs/onboarding.md) — Getting started
- [Architecture Overview](../docs/core_reference/00-architecture-overview.md) — Two-layer design
- [CLI Reference](../docs/core_reference/03-cli-reference.md) — All 45 commands
- [Slash Commands](../docs/core_reference/04-slash-commands.md) — Claude Code integration
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"click<9.0,>=8.0",
"ruamel.yaml<1.0,>=0.18",
"textual<2.0,>=1.0.0; extra == \"tui\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-tmp-files>=0.0.2; extra == \"dev\"",
"pytest-asyncio>=1.0; extra == \"dev\"",
"textual-dev>=1.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.9 | 2026-02-18T20:56:03.157358 | yirifi_roadmap-0.2.0.tar.gz | 124,675 | 57/b3/3e20346f9f1c70665bf904b9471239bda0dd02d964e2d3d234d6b4226fe8/yirifi_roadmap-0.2.0.tar.gz | source | sdist | null | false | 38b59ad4bbe23442ea051843acdbff38 | 2e96b12fc0b32c244832f2794c870a1dac40fc45a175a7a97ba8279f40a581cb | 57b33e20346f9f1c70665bf904b9471239bda0dd02d964e2d3d234d6b4226fe8 | null | [] | 217 |
2.4 | buckaroo | 0.12.8 | Buckaroo - GUI Data wrangling for pandas | # Buckaroo - The Data Table for Jupyter
Buckaroo is a modern data table for Jupyter that expedites the most common exploratory data analysis tasks. The most basic data analysis task - looking at the raw data, is cumbersome with the existing pandas tooling. Buckaroo starts with a modern performant data table, is sortable, has value formatting, and scrolls infinitely. On top of the core table experience extra features like summary stats, histograms, smart sampling, auto-cleaning, and a low code UI are added. All of the functionality has sensible defaults that can be overridden to customize the experience for your workflow.
<img width="947" alt="Screenshot 2025-05-12 at 3 54 33 PM" src="https://github.com/user-attachments/assets/9238c893-8dd4-47e4-8215-b5450c8c7b3a" />
# Note buckaroo has moved to
https://github.com/buckaroo-data/buckaroo
## Try it now with Marimo in your browser
Play with Buckaroo without any installation.
[Full Tour](https://marimo.io/p/@paddy-mullen/buckaroo-full-tour)
## Quick start
run `pip install buckaroo` then restart your jupyter server
The following code shows Buckaroo on a simple dataframe
```
import pandas as pd
import buckaroo
pd.DataFrame({'a':[1, 2, 10, 30, 50, 60, 50], 'b': ['foo', 'foo', 'bar', pd.NA, pd.NA, pd.NA, pd. NA]})
```
When you run `import buckaroo` in a Jupyter notebook, Buckaroo becomes the default display method for Pandas and Polars DataFrames
## Claude Code MCP Integration
Buckaroo can be used as an [MCP](https://modelcontextprotocol.io/) server in [Claude Code](https://docs.anthropic.com/en/docs/claude-code), giving Claude the ability to open data files in an interactive table viewer.
### Install
```bash
claude mcp add buckaroo-table -- uvx --from "buckaroo[mcp]" buckaroo-table
```
That's it. This downloads Buckaroo from PyPI into an isolated environment and registers the MCP server. No other installation steps are needed.
### Usage
Once installed, ask Claude Code to view any CSV, TSV, Parquet, or JSON file:
> show me sales_data.csv
Claude will call the `view_data` tool, which opens the file in Buckaroo's interactive table UI in your browser.
## Compatibility
Buckaroo works in the following notebook environments
- `jupyter lab` (version >=3.6.0)
- `jupyter notebook` (version >=7.0)
- [Marimo](https://marimo.io/p/@paddy-mullen/buckaroo-full-tour)
- `VS Code notebooks` (with extra install)
- [Jupyter Lite](https://paddymul.github.io/buckaroo-examples/lab/index.html)
- `Google colab`
- `Claude Code`
Buckaroo works with the following DataFrame libraries
- `pandas` (version >=1.3.5)
- `polars` optional
- `geopandas` optional (deprecated, if you are interested in geopandas, please get in touch)
# Learn More
Buckaroo has extensive docs and tests, the best way to learn about the system is from feature example videos on youtube
## Interactive Styling Gallery
The interactive [styling gallery](https://py.cafe/app/paddymul/buckaroo-gallery) lets you see different styling configurations. You can live edit code and play with different configs.
## Videos
- [Buckaroo Full Tour](https://youtu.be/t-wk24F1G3s) 6m50s A broad introduction to Buckaroo
- [The Column's the limit - PyData Boston 2025 (conference)](https://www.youtube.com/watch?v=JUCvHnpmx-Y) 43m Explanation of how LazyBuckaroo reliably process laptop large data
- [19 Million row scrolling and stats demo](https://www.youtube.com/shorts/x1UnW4Y_tOk) 58s
- [Buckaroo PyData Boston 2025](https://www.youtube.com/watch?v=HtahDDEnBwE) 49m A tour of Buckaroo at PyData Boston. Includes questions from the audience.
- [Using Buckaroo and pandas to investigate large CSVs](https://www.youtube.com/watch?v=_ZmYy8uvZN8) 9m
- [Autocleaning quick demo](https://youtube.com/shorts/4Jz-Wgf3YDc) 2m38s
- [Writing your own autocleaning functions](https://youtu.be/A-GKVsqTLMI) 10m10s
- [Extending Buckaroo](https://www.youtube.com/watch?v=GPl6_9n31NE) 12m56s
- [Styling Buckaroo](https://www.youtube.com/watch?v=cbwJyo_PzKY) 8m18s
- [Understanding JLisp in Buckaroo](https://youtu.be/3Tf3lnuZcj8) 12m42s
- [GeoPandas Support](https://youtu.be/8WBhoNjDJsA)
## Articles
- [Using Buckaroo and pandas to investigate large CSVs](https://medium.com/@paddy_mullen/using-buckaroo-and-pandas-to-investigate-large-csvs-2a200aebae31)
- [Speed up exploratory data analysis with Buckaroo](https://medium.com/data-science-collective/speed-up-initial-data-analysis-with-buckaroo-71d00660d3fc)
## Example Notebooks
The following examples are loaded into a jupyter lite environment with Buckaroo installed.
- [Full Tour Marimo Pyodide](https://marimo.io/p/@paddy-mullen/buckaroo-full-tour) Start here. This gives a broad overview of Buckaroo's features. [Jupyterlite (old)](https://paddymul.github.io/buckaroo-examples/lab/index.html?path=Full-tour.ipynb) [Google Colab](https://colab.research.google.com/github/paddymul/buckaroo/blob/main/docs/example-notebooks/Full-tour-colab.ipynb)
- [Notebook on Github](https://github.com/paddymul/buckaroo/blob/main/docs/example-notebooks/Full-tour.ipynb)
- [Live Styling Gallery](https://marimo.io/p/@paddy-mullen/buckaroo-styling-gallery) [ipynb](https://paddymul.github.io/buckaroo-examples/lab/index.html?path=styling-gallery.ipynb) Examples of all of the different formatters and styling available for the table
- [Live Autocleaning](https://marimo.io/p/@paddy-mullen/buckaroo-auto-cleaning) Marimo notebook explaining how autocleaning works and showing how to implement your own cleaning commands and heuristic strategies.
- [Live Histogram Demo](https://marimo.io/p/@paddy-mullen/buckaroo-histogram-demo) [ipynb](https://paddymul.github.io/buckaroo-examples/lab/index.html?path=Histograms-demo.ipynb) Explanation of the embedded histograms of Buckaroo.
- [Live JLisp overview](https://marimo.io/p/@paddy-mullen/jlisp-in-buckaroo) Buckaroo embeds a small lisp interpreter to power the lowcode UI. You don't have to understand lisp to use buckaroo, but if you want to geek out on programming language UI, check this out.
- [Extending Buckaroo](https://paddymul.github.io/buckaroo-examples/lab/index.html?path=Extending.ipynb) Broad overview of how to add post processing methods and custom styling methods to Buckaroo
- [Styling Howto](https://paddymul.github.io/buckaroo-examples/lab/index.html?path=styling-howto.ipynb) In depth explanation of how to write custom styling methods
- [Pluggable Analysis Framework](https://paddymul.github.io/buckaroo-examples/lab/index.html?path=Pluggable-Analysis-Framework.ipynb) How to add new summary stats to Buckaroo
- [Solara Buckaroo](https://github.com/paddymul/buckaroo/blob/main/docs/example-notebooks/Solara-Buckaroo.ipynb) Using Buckaroo with Solara
- [GeoPandas with Bucakroo](https://github.com/paddymul/buckaroo/blob/main/docs/example-notebooks/GeoPandas.ipynb)
## Example apps built on buckaroo
More full featured integrations that can be built on a table UI
- [Buckaroo Compare](https://marimo.io/p/@paddy-mullen/buckaroo-compare-preview) Join two dataframes and highlight visual differences between them
- [Buckaroo Pandera](https://marimo.io/p/@paddy-mullen/buckaroo-pandera) Example showing validating a dataframe with Pandera, then visually highlighting where it fails the schema.
# Features
## High performance table
The core data grid of buckaroo is based on [AG-Grid](https://www.ag-grid.com/). This loads 1000s of cells in less than a second, with highly customizable display, formatting and scrolling. Data is loaded lazily into the browser as you scroll, and serialized with parquet. You no longer have to use `df.head()` to poke at portions of your data.
## Fixed width formatting by default
By default numeric columns are formatted to use a fixed width font and commas are added. This allows quick visual confirmation of magnitudes in a column.
## Histograms
[Histograms](https://buckaroo-data.readthedocs.io/en/latest/articles/histograms.html) for every column give you a very quick overview of the distribution of values, including uniques and N/A.
## Summary stats
The summary stats view can be toggled by clicking on the `0` below the `Σ` icon. Summary stats are similar to `df.describe` and extensible.
## Sorting
All of the data visible in the table (rows shown), is sortable by clicking on a column name, further clicks change sort direction then disable sort for that column. Because extreme values are included with sample rows, you can see outlier values too.
## Search
Search is built into Buckaroo so you can quickly find the rwos you are looking for.
## Lowcode UI
Buckaroo has a simple low code UI with python code gen. This view can be toggled by clicking the checkbox below the ` λ `(lambda) icon.
## Autocleaning
Select a cleaning method from the status bar. Buckaroo has heuristic autocleaning. The autocleaning system inspects each column and runs statistics to decide if a cleaning methods should be applied to the column (parsing as dates, stripping non integer characters and treating as an integer, parsing implied booleans "yes" "no" to booleans), then adds those cleaning operations to the low code UI. Different cleaning methods can be tried because dirty data isn't deterministic and there are multiple approaches that could properly apply to any situation.
## Extensibility at the core
Buckaroo summary stats are built on the [Pluggable Analysis Framework](https://buckaroo-data.readthedocs.io/en/latest/articles/pluggable.html) that allows individual summary stats to be overridden, and new summary stats to be built in terms of existing summary stats. Care is taken to prevent errors in summary stats from preventing display of a dataframe.
## Auto cleaning (beta)
Buckaroo can [automatically clean](https://buckaroo-data.readthedocs.io/en/latest/articles/auto_clean.html) dataframes to remove common data errors (a single string in a column of ints, recognizing date times...). This feature is in beta. You can access it by invoking buckaroo as `BuckarooWidget(df, auto_clean=True)`
## Development installation
For a development installation:
```bash
git clone https://github.com/paddymul/buckaroo.git
cd buckaroo
#we need to build against 3.6.5, jupyterlab 4.0 has different JS typing that conflicts
# the installable still works in JL4
pip install build twine pytest sphinx polars mypy jupyterlab==3.6.5 pandas-stubs geopolars pyarrow
pip install -ve .
```
Enabling development install for Jupyter notebook:
Enabling development install for JupyterLab:
```bash
jupyter labextension develop . --overwrite
```
Note for developers: the `--symlink` argument on Linux or OS X allows one to modify the JavaScript code in-place. This feature is not available with Windows.
`
### Developing the JS side
There are a series of examples of the components in [examples/ex](./examples/ex).
Instructions
```bash
npm install
npm run dev
```
### Storybook (JS core components)
Run Storybook locally:
```bash
cd packages/buckaroo-js-core
pnpm install
pnpm storybook
# open http://localhost:6006
```
Build a static Storybook site:
```bash
cd packages/buckaroo-js-core
pnpm install
pnpm build-storybook
# output: packages/buckaroo-js-core/dist/storybook
```
### Playwright (UI tests against Storybook)
Install browsers:
```bash
cd packages/buckaroo-js-core
pnpm install
pnpm exec playwright install
```
Run tests (auto-starts Storybook via Playwright webServer, or reuses an existing one):
```bash
pnpm test:pw --reporter=line
```
Useful variants:
```bash
pnpm test:pw:headed # visible browser
pnpm test:pw:ui # Playwright UI
pnpm test:pw:report # open HTML report
```
### UV Instructions
```sh
cd buckaroo
uv venv
source ~/buckaroo/.venv/bin/activate
uv sync -q
```
### adding a package
```sh
cd ~/buckaroo
uv add $PACKAGE_NAME
```
#### adding a package to a subgroup
```sh
cd ~/buckaroo
uv add --group $GROUP_NAME --quiet $PACKAGE_NAME
```
### Release instructions
[github release instructions](https://docs.github.com/en/repositories/releasing-projects-on-github/managing-releases-in-a-repository)
```bash
update CHANGELOG.md
git commit -m "updated changelog for release $VERSION_NUMBER"
git tag $VERSION_NUMBER # no leading v in the version number
git push origin tag $VERSION_NUMBER
```
navigate to [create new buckaroo release](https://github.com/paddymul/buckaroo/releases/new)
Follow instructions
## Contributions
We :heart: contributions.
Have you had a good experience with this project? Why not share some love and contribute code, or just let us know about any issues you had with it?
We welcome [issue reports](../../issues); be sure to choose the proper issue template for your issue, so that we can be sure you're providing the necessary information.
| text/markdown | Paddy Mullen | null | null | null | Copyright (c) 2019 Bloomberg
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | IPython, Jupyter, Widgets, pandas | [
"Framework :: Jupyter",
"Framework :: Jupyter :: JupyterLab",
"Framework :: Jupyter :: JupyterLab :: Extensions",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python",
"Programming Language :: Python :: 3... | [] | null | null | >=3.11 | [] | [] | [] | [
"anywidget>=0.9.0",
"cloudpickle>=3.1.1",
"fastparquet>=2025.12.0",
"graphlib-backport>=1.0.0",
"numpy>=2.2.5; python_version >= \"3.13\"",
"pyarrow; python_version >= \"3.13\"",
"pyarrow>=18.0.0; python_version < \"3.13\"",
"anywidget[dev]>=0.9.0; extra == \"dev\"",
"graphviz>=0.20.1; extra == \"de... | [] | [] | [] | [
"Homepage, https://github.com/paddymul/buckaroo"
] | twine/6.2.0 CPython/3.13.3 | 2026-02-18T20:55:29.126076 | buckaroo-0.12.8-py3-none-any.whl | 1,379,243 | 79/32/17b2e916bc27bf7441692d746d9f0b6d0a336c1d2142e6995ab58d3ef0f3/buckaroo-0.12.8-py3-none-any.whl | py3 | bdist_wheel | null | false | abb3f18e15e0d174ecb74dec99eb53e5 | 758c86fe728746aa3629ff1c072d981d6b06940ce0afeeb8f4337efda503c0a6 | 793217b2e916bc27bf7441692d746d9f0b6d0a336c1d2142e6995ab58d3ef0f3 | null | [
"LICENSE.txt"
] | 555 |
2.4 | repo-flow-analyzer | 1.0.2 | A universal tool to analyze and visualize code flow in any repository | # Repo Flow Analyzer
A universal tool to analyze and visualize code flow in any repository, helping developers understand functionality by searching for keywords.
## 🎯 Features
- **Multi-Language Support**: Works with Java, Python, JavaScript/TypeScript, Go, C#, and more
- **Multiple Output Formats**: Markdown, Mermaid diagrams, and JSON
- **Customizable**: Configure component patterns, exclusions, and output preferences
- **Repository Agnostic**: Works with any codebase structure
- **Fast & Efficient**: Handles large repositories with smart file filtering
## 📦 Installation
### Via pip (recommended)
```bash
pip install repo-flow-analyzer
```
### From source
```bash
git clone https://github.com/yourorg/repo-flow-analyzer.git
cd repo-flow-analyzer
pip install -e .
```
## 🚀 Quick Start
### Basic Usage
```bash
# Analyze credit-related functionality
flow-analyzer credit
# Search for user authentication flow
flow-analyzer authentication
# Find payment processing components
flow-analyzer payment
```
### Generate Visual Diagrams
```bash
# Create a Mermaid diagram
flow-analyzer credit --format=mermaid --output=credit-flow.mmd
# Generate markdown documentation
flow-analyzer user --format=markdown --output=docs/user-flow.md
# Export as JSON for custom processing
flow-analyzer api --format=json --output=api-analysis.json
```
### Custom Configuration
```bash
# Generate a configuration template
flow-analyzer --init
# Use custom config
flow-analyzer credit --config=.flow-analyzer.yaml
```
## 📖 Documentation
### Command Line Options
```
Usage: flow-analyzer [OPTIONS] KEYWORD
Arguments:
KEYWORD The search term to find in your codebase
Options:
-f, --format [markdown|mermaid|json] Output format (default: markdown)
-o, --output PATH Output file (default: stdout)
-c, --config PATH Path to custom config file
-p, --base-path PATH Base path of the repository (default: .)
--version Show version
--help Show this message
```
### Configuration File
Create a `.flow-analyzer.yaml` in your project root:
```yaml
languages:
java:
extensions: [".java"]
component_patterns:
controller: ["controller", "resource"]
service: ["service", "manager"]
repository: ["repository", "dao"]
analysis:
max_files: 10000
exclude_patterns:
- "**/node_modules/**"
- "**/target/**"
- "**/.git/**"
output:
mermaid:
max_nodes: 50
color_scheme:
controller: "#e1f5ff"
service: "#f3e5f5"
```
## 🎨 Output Formats
### Markdown
- Human-readable documentation
- Organized by component type
- Includes file paths, methods, and dependencies
- Perfect for README files and documentation
### Mermaid
- Visual flow diagrams
- Color-coded components
- Shows relationships between layers
- Renders in GitHub, GitLab, and Confluence
### JSON
- Machine-readable format
- Complete component metadata
- Ideal for custom integrations
- Can be processed by other tools
## 💡 Use Cases
### For New Developers
"I need to understand how the payment system works"
```bash
flow-analyzer payment --format=mermaid --output=payment-flow.mmd
```
### For Code Reviews
"What components does this feature affect?"
```bash
flow-analyzer feature-name --format=markdown
```
### For Documentation
"Generate architecture diagrams for documentation"
```bash
flow-analyzer core --format=mermaid --output=docs/architecture.mmd
```
### For Debugging
"Where is Kafka used in the application?"
```bash
flow-analyzer kafka --format=json
```
## 🔧 Supported Languages
- **Java**: Controllers, Services, DAOs, Entities
- **Python**: Views, Services, Repositories, Models
- **JavaScript/TypeScript**: Components, Services, Routes
- **Go**: Handlers, Services, Repositories
- **C#**: Controllers, Services, Repositories
## 🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
### Development Setup
```bash
git clone https://github.com/yourorg/repo-flow-analyzer.git
cd repo-flow-analyzer
pip install -e ".[dev]"
```
### Running Tests
```bash
pytest tests/
```
## 📄 License
MIT License - see LICENSE file for details
## 🙏 Acknowledgments
Built for multi-team collaboration in monorepo environments.
## 📞 Support
- Issues: https://github.com/yourorg/repo-flow-analyzer/issues
- Discussions: https://github.com/yourorg/repo-flow-analyzer/discussions
- Documentation: https://repo-flow-analyzer.readthedocs.io
---
Made with ❤️ for developers who want to understand code faster
| text/markdown | Platform Team | platform-team@company.com | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Documentation",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Languag... | [] | https://github.com/yourorg/repo-flow-analyzer | null | >=3.7 | [] | [] | [] | [
"click>=8.0.0",
"pyyaml>=5.4.0",
"jinja2>=3.0.0",
"colorama>=0.4.4"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.11 | 2026-02-18T20:54:47.645232 | repo_flow_analyzer-1.0.2.tar.gz | 13,784 | 4c/a8/b31cb49d1a1e51751024b3dfb210d25b3037085a6a8357d342f2060b7cb7/repo_flow_analyzer-1.0.2.tar.gz | source | sdist | null | false | 0e7f1d431c0e74ac50bedcd55ab4ff0c | 0b791b7931054515acdd61f6248b5cf5e00472c2dfb01e3448c1e12995bf6134 | 4ca8b31cb49d1a1e51751024b3dfb210d25b3037085a6a8357d342f2060b7cb7 | null | [
"LICENSE"
] | 139 |
2.4 | geostats | 1.0.0 | A suite of geostatistical tools. | # geostats: A suite of geostatistical tools
This repository provides a suite of geostatistical tools, including functions to compute the ground-motion correlation structure according to the relations by Bodenmann et al. (2023), and to do Kriging interpolation.
## Examples
- [Example 1 (Python backend)](https://github.com/RPretellD/geostats/blob/main/examples/Example1_Python.ipynb): Ordinary Kriging using the $\rho_{E}$ correlation model.
- [Example 1 (Cython backend)](https://github.com/RPretellD/geostats/blob/main/examples/Example1_Cython.ipynb): Ordinary Kriging using the $\rho_{E}$ correlation model.
- [Example 2 (Python backend)](https://github.com/RPretellD/geostats/blob/main/examples/Example2_Python.ipynb): Ordinary Kriging using the $\rho_{EA}$ correlation model.
- [Example 2 (Cython backend)](https://github.com/RPretellD/geostats/blob/main/examples/Example2_Cython.ipynb): Ordinary Kriging using the $\rho_{EA}$ correlation model.
- [Example 3 (Python backend)](https://github.com/RPretellD/geostats/blob/main/examples/Example3_Python.ipynb): Ordinary Kriging using a user-defined correlation model.
- [Example 3 (Cython backend)](https://github.com/RPretellD/geostats/blob/main/examples/Example3_Cython.ipynb): Ordinary Kriging using a user-defined correlation model.
- [Example 4 (Python backend)](https://github.com/RPretellD/geostats/blob/main/examples/Example4_Python.ipynb): Krige a map using a user-defined correlation model.
- [Example 4 (Cython backend)](https://github.com/RPretellD/geostats/blob/main/examples/Example4_Cython.ipynb): Krige a map using a user-defined correlation model.
## Acknowledgements
- Implementation of the Kriging code benefited from Scott Brandenberg's [random field](https://github.com/sjbrandenberg/ucla_geotech_tools/tree/main/src/ucla_geotech_tools) python package.
- Some of the cython functions to compute ground-motion correlation are based on Lukas Bodenmann's [python functions](https://github.com/bodlukas/ground-motion-correlation-bayes).
## Citation
If you use these codes, please cite:<br>
Pretell, R. (2026). geostats: A suite of geostatistical tools (v1.0.0). Zenodo. https://doi.org/10.5281/zenodo.10253690 <br>
[](https://doi.org/10.5281/zenodo.10253690)
## Contact
For any questions or comments, contact Renmin Pretell (rpretell at unr dot edu).
| text/markdown | A. Renmin Pretell Ductram | rpretell@unr.edu | null | null | null | geostats | [
"Programming Language :: Python",
"Programming Language :: Cython",
"Programming Language :: Python :: 3"
] | [] | https://github.com/RPretellD/geostats | null | >=3.7 | [] | [] | [] | [
"numpy",
"Cython",
"vincenty"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T20:54:19.424370 | geostats-1.0.0.tar.gz | 215,272 | d1/74/1893fe1fbe321db79c7b91c553ead7015e02ffe88f7b20018891173b9db5/geostats-1.0.0.tar.gz | source | sdist | null | false | 1ef334ef60f29dd9bb51923f4fbad3ce | 28b2eda7e0d7687b279ebf63fc7620daf41d2d34652bb2b5c8f88b01debb6f70 | d1741893fe1fbe321db79c7b91c553ead7015e02ffe88f7b20018891173b9db5 | MIT | [
"LICENSE"
] | 236 |
2.4 | xai-sdk | 1.7.0 | The official Python SDK for the xAI API | <div align="center">
<img src="https://avatars.githubusercontent.com/u/130314967?s=200&v=4" alt="xAI Logo" width="100" />
<h1>xAI Python SDK</h1>
<p>The official Python SDK for xAI's APIs</p>
<a href="https://pypi.org/project/xai-sdk">
<img src="https://img.shields.io/pypi/v/xai-sdk" alt="PyPI Version" />
</a>
<a href="">
<img src="https://img.shields.io/pypi/l/xai-sdk" alt="License" />
</a>
<a href="">
<img src="https://img.shields.io/pypi/pyversions/xai-sdk" alt="Python Version" />
</a>
</div>
<br>
The xAI Python SDK is a gRPC-based Python library for interacting with xAI's APIs. Built for Python 3.10 and above, it offers both **synchronous** and **asynchronous** clients.
Whether you're generating text, images, or structured outputs, the xAI SDK is designed to be intuitive, robust, and developer-friendly.
## Documentation
Comprehensive documentation is available at [docs.x.ai](https://docs.x.ai). Explore detailed guides, API references, and tutorials to get the most out of the xAI SDK.
## Installation
Install from PyPI with pip.
```bash
pip install xai-sdk
```
Alternatively you can also use [uv](https://docs.astral.sh/uv/)
```bash
uv add xai-sdk
```
### Requirements
Python 3.10 or higher is required to use the xAI SDK.
## Usage
The xAI SDK supports both synchronous (`xai_sdk.Client`) and asynchronous (`xai_sdk.AsyncClient`) clients. For a complete set of examples demonstrating the SDK's capabilities, including authentication, chat, image generation, function calling, and more, refer to the [examples folder](https://github.com/xai-org/xai-sdk-python/tree/main/examples).
### Client Instantiation
To use the xAI SDK, you need to instantiate either a synchronous or asynchronous client. By default, the SDK looks for an environment variable named `XAI_API_KEY` for authentication. If this variable is set, you can instantiate the clients without explicitly passing the API key:
```python
from xai_sdk import Client, AsyncClient
# Synchronous client
sync_client = Client()
# Asynchronous client
async_client = AsyncClient()
```
If you prefer to explicitly pass the API key, you can do so using `os.getenv` or by loading it from a `.env` file using the `python-dotenv` package:
```python
import os
from dotenv import load_dotenv
from xai_sdk import Client, AsyncClient
load_dotenv()
api_key = os.getenv("XAI_API_KEY")
sync_client = Client(api_key=api_key)
async_client = AsyncClient(api_key=api_key)
```
Make sure to set the `XAI_API_KEY` environment variable or load it from a `.env` file before using the SDK. This ensures secure handling of your API key without hardcoding it into your codebase.
### Multi-Turn Chat (Synchronous)
The xAI SDK supports multi-turn conversations with a simple `append` method to manage conversation history, making it ideal for interactive applications.
First, create a `chat` instance, start `append`ing messages to it, and finally call `sample` to yield a response from the model. While the underlying APIs are still stateless, this approach makes it easy to manage the message history.
```python
from xai_sdk import Client
from xai_sdk.chat import system, user
client = Client()
chat = client.chat.create(
model="grok-3",
messages=[system("You are a pirate assistant.")]
)
while True:
prompt = input("You: ")
if prompt.lower() == "exit":
break
chat.append(user(prompt))
response = chat.sample()
print(f"Grok: {response.content}")
chat.append(response)
```
### Multi-Turn Chat (Asynchronous)
For async usage, simply import `AsyncClient` instead of `Client`.
```python
import asyncio
from xai_sdk import AsyncClient
from xai_sdk.chat import system, user
async def main():
client = AsyncClient()
chat = client.chat.create(
model="grok-3",
messages=[system("You are a pirate assistant.")]
)
while True:
prompt = input("You: ")
if prompt.lower() == "exit":
break
chat.append(user(prompt))
response = await chat.sample()
print(f"Grok: {response.content}")
chat.append(response)
if __name__ == "__main__":
asyncio.run(main())
```
### Streaming
The xAI SDK supports streaming responses, allowing you to process model outputs in real-time, which is ideal for interactive applications like chatbots. The `stream` method returns a tuple containing `response` and `chunk`. The chunks contain the text deltas from the stream, while the `response` variable automatically accumulates the response as the stream progresses.
```python
from xai_sdk import Client
from xai_sdk.chat import user
client = Client()
chat = client.chat.create(model="grok-3")
while True:
prompt = input("You: ")
if prompt.lower() == "exit":
break
chat.append(user(prompt))
print("Grok: ", end="", flush=True)
for response, chunk in chat.stream():
print(chunk.content, end="", flush=True)
print()
chat.append(response)
```
### Image Understanding
You can easily interleave images and text together, making tasks like image understanding and analysis easy.
```python
from xai_sdk import Client
from xai_sdk.chat import image, user
client = Client()
chat = client.chat.create(model="grok-2-vision")
chat.append(
user(
"Which animal looks happier in these images?",
image("https://images.unsplash.com/photo-1561037404-61cd46aa615b"), # Puppy
image("https://images.unsplash.com/photo-1514888286974-6c03e2ca1dba") # Kitten
)
)
response = chat.sample()
print(f"Grok: {response.content}")
```
## Advanced Features
The xAI SDK excels in advanced use cases, such as:
- **Function Calling**: Define tools and let the model intelligently call them (see sync [function_calling.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/sync/function_calling.py) and async [function_calling.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/aio/function_calling.py)).
- **Image Generation**: Generate images with image generation models (see sync [image_generation.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/sync/image_generation.py) and async [image_generation.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/aio/image_generation.py)).
- **Image Understanding**: Analyze images with vision models (see sync [image_understanding.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/sync/image_understanding.py) and async [image_understanding.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/aio/image_understanding.py)).
- **Structured Outputs**: Return model responses as structured objects in the form of Pydantic models (see sync [structured_outputs.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/sync/structured_outputs.py) and async [structured_outputs.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/aio/structured_outputs.py)).
- **Reasoning Models**: Leverage reasoning-focused models with configurable effort levels (see sync [reasoning.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/sync/reasoning.py) and async [reasoning.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/aio/reasoning.py)).
- **Deferred Chat**: Sample a long-running response from a model via polling (see sync [deferred_chat.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/sync/deferred_chat.py) and async [deferred_chat.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/aio/deferred_chat.py)).
- **Tokenization**: Tokenize text with the tokenizer API (see sync [tokenizer.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/sync/tokenizer.py) and async [tokenizer.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/aio/tokenizer.py)).
- **Models**: Retrieve information on different models available to you, including, name, aliases, token price, max prompt length etc (see sync [models.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/sync/models.py) and async [models.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/aio/models.py))
- **Agentic Tool Calling**: Let Grok autonomously decide when to search the web, 𝕏, or execute code to answer your questions with real-time information (e.g., "What was Arsenal's most recent game result?" triggers a web search automatically). See sync [server_side_tools.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/sync/server_side_tools.py) and async [server_side_tools.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/aio/server_side_tools.py)
- **Telemetry & Observability**: Export OpenTelemetry traces with rich metadata attributes to console or OTLP backends (see sync [telemetry.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/sync/telemetry.py) and async [telemetry.py](https://github.com/xai-org/xai-sdk-python/tree/main/examples/aio/telemetry.py))
## Telemetry & Observability
The xAI SDK includes the option to export OpenTelemetry traces to the console or an OTLP compatible backend. Exporting telemetry is not enabled by default, and you must explicitly configure this in code to start exporting traces.
When enabled, each API call automatically generates detailed traces (spans) that capture the complete execution flow of that call, as well as rich metadata including attributes such as input prompts, model responses, and token usage statistics.
When consumed by an observability platform which can visualize these traces, this makes it easy to monitor, debug, and analyze your applications' performance and behavior.
The attributes on the generated traces *largely* follow the [OpenTelemetry GenAI Semantic Conventions](https://opentelemetry.io/docs/specs/semconv/gen-ai/gen-ai-agent-spans/), meaning Otel backends that support these conventions, such as Langfuse can visualize these traces in a structured way.
In some cases, where there is no corresponding standard in the OpenTelemetry GenAI semantic conventions, the xAI SDK adds some additional attributes to particular traces that users may find useful.
### Export Options
#### Console Export (Development)
Console export prints trace data in JSON format directly to your console:
```python
from xai_sdk.telemetry import Telemetry
telemetry = Telemetry()
telemetry.setup_console_exporter()
client = Client()
# The call to sample will now generate a trace that you will be able to see in the console
chat = client.chat.create(model="grok-3")
chat.append(user("Hello, how are you?"))
response = chat.sample()
print(f"Response: {response.content}")
```
#### OTLP Export (Production)
For production environments, send traces to observability platforms like Jaeger, Langfuse, or any OTLP-compliant backend:
```python
from xai_sdk.telemetry import Telemetry
telemetry = Telemetry()
telemetry.setup_otlp_exporter(
endpoint="https://your-observability-platform.com/traces",
headers={"Authorization": "Bearer your-token"}
)
client = Client()
# The call to sample will now generate a trace that you will be able to see in your observability platform
chat = client.chat.create(model="grok-3")
chat.append(user("Hello, how are you?"))
response = chat.sample()
print(f"Response: {response.content}")
```
You can also set the environment variables `OTEL_EXPORTER_OTLP_PROTOCOL`, `OTEL_EXPORTER_OTLP_ENDPOINT`, and `OTEL_EXPORTER_OTLP_HEADERS` to configure the exporter. If you set the environment variables, you don't need pass any parameters to the `setup_otlp_exporter` method directly.
### Installation Requirements
The telemetry feature requires additional dependencies based on your export needs:
```bash
# For HTTP OTLP export
pip install xai-sdk[telemetry-http]
# or
uv add xai-sdk[telemetry-http]
# For gRPC OTLP export
pip install xai-sdk[telemetry-grpc]
# or
uv add xai-sdk[telemetry-grpc]
```
### Environment Variables
The telemetry system respects all standard OpenTelemetry environment variables:
- `OTEL_EXPORTER_OTLP_PROTOCOL`: Export protocol ("grpc" or "http/protobuf")
- `OTEL_EXPORTER_OTLP_ENDPOINT`: OTLP endpoint URL
- `OTEL_EXPORTER_OTLP_HEADERS`: Authentication headers
### Advanced Configuration
#### Custom TracerProvider
You may be using the xAI SDK within an application that is already using OpenTelemetry. In this case, you can provide/re-use your own TracerProvider for the xAI SDK to make use of.
```python
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.resources import Resource
from xai_sdk.telemetry import Telemetry
# Create custom provider with specific configuration
custom_resource = Resource.create({"service.name": "my-app"})
custom_provider = TracerProvider(resource=custom_resource)
# Use the custom tracer provider
telemetry = Telemetry(provider=custom_provider)
telemetry.setup_otlp_exporter()
```
### Disabling Tracing
If you're using the xAI SDK within an application that is already using OpenTelemetry to export other traces, you may want to selectively disable xAI SDK traces only, this can be done by setting the environment variable `XAI_SDK_DISABLE_TRACING` to `1` or `true`.
### Disabling Sensitive Attributes
For privacy reasons, you may want to disable the collection of sensitive attributes such as user inputs and AI responses in traces. This can be done by setting the environment variable `XAI_SDK_DISABLE_SENSITIVE_TELEMETRY_ATTRIBUTES` to `1` or `true`. When enabled, traces will still be collected but without the content of messages, prompts, or responses.
## Timeouts
The xAI SDK allows you to set a timeout for API requests during client initialization. This timeout applies to all RPCs and methods used with that client instance. The default timeout is 15 minutes (900 seconds).
It is not currently possible to specify timeouts for an individual RPC/client method.
To set a custom timeout, pass the `timeout` parameter when creating the `Client` or `AsyncClient`. The timeout is specified in seconds.
Example for synchronous client:
```python
from xai_sdk import Client
# Set timeout to 5 minutes (300 seconds)
sync_client = Client(timeout=300)
```
Example for asynchronous client:
```python
from xai_sdk import AsyncClient
# Set timeout to 5 minutes (300 seconds)
async_client = AsyncClient(timeout=300)
```
In the case of a timeout, a `grpc.RpcError` (for synchronous clients) or `grpc.aio.AioRpcError` (for asynchronous clients) will be raised with the gRPC status code `grpc.StatusCode.DEADLINE_EXCEEDED`.
## Retries
The xAI SDK has retries enabled by default for certain types of failed requests. If the service returns an `UNAVAILABLE` error, the SDK will automatically retry the request with exponential backoff. The default retry policy is configured as follows:
- **Maximum Attempts**: 5
- **Initial Backoff**: 0.1 seconds
- **Maximum Backoff**: 1 second
- **Backoff Multiplier**: 2
This means that after an initial failure, the SDK will wait 0.1 seconds before the first retry, then 0.2 seconds, 0.4 seconds, and so on, up to a maximum of 1 second between attempts, for a total of up to 5 attempts.
You can disable retries by setting the `grpc.enable_retries` channel option to `0` when initializing the client:
```python
from xai_sdk import Client
# Disable retries
sync_client = Client(channel_options=[("grpc.enable_retries", 0)])
```
Similarly, for the asynchronous client:
```python
from xai_sdk import AsyncClient
# Disable retries
async_client = AsyncClient(channel_options=[("grpc.enable_retries", 0)])
```
#### Custom Retry Policy
You can configure your own retry policy by setting the `grpc.service_config` channel option with a JSON string that defines the retry behavior. The JSON structure should follow the gRPC service config format. Here's an example of how to set a custom retry policy:
```python
import json
from xai_sdk import Client
# Define a custom retry policy
custom_retry_policy = json.dumps({
"methodConfig": [{
"name": [{}], # Applies to all methods
"retryPolicy": {
"maxAttempts": 3, # Reduced number of attempts
"initialBackoff": "0.5s", # Longer initial wait
"maxBackoff": "2s", # Longer maximum wait
"backoffMultiplier": 1.5, # Slower increase in wait time
"retryableStatusCodes": ["UNAVAILABLE", "RESOURCE_EXHAUSTED"] # Additional status code for retry
}
}]
})
# Initialize client with custom retry policy
sync_client = Client(channel_options=[
("grpc.service_config", custom_retry_policy)
])
```
Similarly, for the asynchronous client:
```python
import json
from xai_sdk import AsyncClient
# Define a custom retry policy
custom_retry_policy = json.dumps({
"methodConfig": [{
"name": [{}], # Applies to all methods
"retryPolicy": {
"maxAttempts": 3, # Reduced number of attempts
"initialBackoff": "0.5s", # Longer initial wait
"maxBackoff": "2s", # Longer maximum wait
"backoffMultiplier": 1.5, # Slower increase in wait time
"retryableStatusCodes": ["UNAVAILABLE", "RESOURCE_EXHAUSTED"] # Additional status code for retry
}
}]
})
# Initialize async client with custom retry policy
async_client = AsyncClient(channel_options=[
("grpc.service_config", custom_retry_policy)
])
```
In this example, the custom policy reduces the maximum number of attempts to 3, increases the initial backoff to 0.5 seconds, sets a maximum backoff of 2 seconds, uses a smaller backoff multiplier of 1.5, and allows retries on both `UNAVAILABLE` and `RESOURCE_EXHAUSTED` status codes.
Note that when setting a custom `grpc.service_config`, it will override the default retry policy.
## Accessing Underlying Proto Objects
In rare cases, you might need to access the raw proto object returned from an API call. While the xAI SDK is designed to expose most commonly needed fields directly on the response objects for ease of use, there could be scenarios where accessing the underlying proto object is necessary for advanced or custom processing.
You can access the raw proto object on any response by using the `.proto` attribute. Here's an example of how to do this with a chat response:
```python
from xai_sdk import Client
from xai_sdk.chat import user
client = Client()
chat = client.chat.create(model="grok-3")
chat.append(user("Hello, how are you?"))
response = chat.sample()
# Access the underlying proto object
# In this case, this will be of type xai_sdk.proto.chat_pb2.GetChatCompletionResponse
proto_object = response.proto
print(proto_object)
```
Please note that you should rarely need to interact with the proto object directly, as the SDK is built to provide a more user-friendly interface to the data. Use this approach only when specific fields or data structures not exposed by the SDK are required for your application. If you find yourself needing to regularly access the proto object directly, please consider opening an issue so that we can improve the experience.
## Error Codes
When using the xAI SDK, you may encounter various error codes returned by the API. These errors are based on gRPC status codes and provide insight into what went wrong with a request. For the synchronous client (`Client`), errors will be of type `grpc.RpcError`, while for the asynchronous client (`AsyncClient`), errors will be of type `grpc.aio.AioRpcError`.
Below is a table of common gRPC status codes you might encounter when using the xAI SDK:
| gRPC Status Code | Meaning | xAI SDK/API Context |
|---------------------------|------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------|
| `UNKNOWN` | An unknown error occurred. | An unexpected issue occurred on the server side, not specifically related to the request. |
| `INVALID_ARGUMENT` | The client specified an invalid argument. | An invalid argument was provided to the model/endpoint, such as incorrect parameters or malformed input.|
| `DEADLINE_EXCEEDED` | The deadline for the request expired before the operation completed. | Raised if the request exceeds the timeout specified by the client (default is 900 seconds, configurable during client instantiation). |
| `NOT_FOUND` | A specified resource was not found. | A requested model or resource does not exist. |
| `PERMISSION_DENIED` | The caller does not have permission to execute the specified operation.| The API key is disabled, blocked, or lacks sufficient permissions to access a specific model or feature. |
| `UNAUTHENTICATED` | The request does not have valid authentication credentials. | The API key is missing, invalid, or expired. |
| `RESOURCE_EXHAUSTED` | A resource quota has been exceeded (e.g., rate limits). | The user has exceeded their API usage quota or rate limits for requests. |
| `INTERNAL` | An internal error occurred. | An internal server error occurred on the xAI API side. |
| `UNAVAILABLE` | The service is currently unavailable. This is often a transient error. | The model or endpoint invoked is temporarily down or there are connectivity issues. The SDK defaults to automatically retrying errors with this status code. |
| `DATA_LOSS` | Unrecoverable data loss or corruption occurred. | Occurs when a user provides an image via URL in API calls (e.g., in a chat conversation) and the server fails to fetch the image from that URL. |
These error codes can help diagnose issues with API requests. When handling errors, ensure you check the specific status code to understand the nature of the problem and take appropriate action.
## Versioning
The xAI SDK generally follows [Semantic Versioning (SemVer)](https://semver.org/) to ensure a clear and predictable approach to versioning. Semantic Versioning uses a three-part version number in the format `MAJOR.MINOR.PATCH`, where:
- **MAJOR** version increments indicate backwards-incompatible API changes.
- **MINOR** version increments indicate the addition of backward-compatible functionality.
- **PATCH** version increments indicate backward-compatible bug fixes.
This approach helps developers understand the impact of upgrading to a new version of the SDK. We strive to maintain backward compatibility in minor and patch releases, ensuring that your applications continue to work seamlessly. However, please note that while we aim to restrict breaking changes to major version updates, some backwards incompatible changes to library internals may occasionally occur in minor or patch releases. These changes will typically not affect the public API, but if you are interacting with internal components or structures, we recommend reviewing release notes for each update to avoid unexpected issues.
This project maintains a [changelog](https://github.com/xai-org/xai-sdk-python/tree/main/CHANGELOG.md) such that developers can track updates and changes to the SDK as new versions are released.
### Determining the Installed Version
You can easily check the version of the xAI SDK installed in your environment using either of the following methods:
- **Using pip/uv**: Run the following command in your terminal to see the installed version of the SDK:
```bash
pip show xai-sdk
```
or
```bash
uv pip show xai-sdk
```
This will display detailed information about the package, including the version number.
- **Programmatically in Python**: You can access the version information directly in your code by importing the SDK and checking the `__version__` attribute:
```python
import xai_sdk
print(xai_sdk.__version__)
```
These methods allow you to confirm which version of the xAI SDK you are currently using, which can be helpful for debugging or ensuring compatibility with specific features.
## License
The xAI SDK is distributed under the Apache-2.0 License
## Contributing
See the [documentation](https://github.com/xai-org/xai-sdk-python/tree/main/CONTRIBUTING.md) on contributing to this project. | text/markdown | null | xAI <support@x.ai> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operat... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp<4,>=3.8.6",
"googleapis-common-protos<2,>=1.65.0",
"grpcio<2,>=1.72.1",
"opentelemetry-sdk<2,>=1.36.0",
"packaging<26,>=25.0",
"protobuf<7,>=5.29.4",
"pydantic<3,>=2.5.3",
"requests<3,>=2.31.0",
"opentelemetry-exporter-otlp-proto-grpc<2,>=1.36.0; extra == \"telemetry-grpc\"",
"opentelemet... | [] | [] | [] | [
"Homepage, https://github.com/xai-org/xai-sdk-python",
"Documentation, https://docs.x.ai",
"Repository, https://github.com/xai-org/xai-sdk-python"
] | uv/0.7.3 | 2026-02-18T20:53:23.352891 | xai_sdk-1.7.0.tar.gz | 390,582 | 1c/3e/cf9ffdf444ec3d495b8f4a6b3934c86088900aeb131cf2d81535b218e615/xai_sdk-1.7.0.tar.gz | source | sdist | null | false | f42e99974b2c6913677d0afee82abf33 | 649e7c3bff01510326f13a709dff824256fcdfd2850e21606d25870208989bd1 | 1c3ecf9ffdf444ec3d495b8f4a6b3934c86088900aeb131cf2d81535b218e615 | Apache-2.0 | [
"LICENSE"
] | 109,999 |
2.4 | nasong | 0.1.0 | A powerful audio generation library and application. | # Nasong
[](https://www.gnu.org/licenses/gpl-3.0)


Nasong is a Python-based music synthesizer and sequencer that allows you to create music programmatically. It provides a framework for defining instruments, effects, and songs using Python code, which are then rendered to WAV files.
## Features
- **Programmatic Music Generation**: Define songs and instruments using Python code.
- **Custom Instruments**: Create your own instruments by defining their waveforms and envelopes.
- **Built-in Library**: Includes a library of basic instruments (strings, winds, percussion, synths) and effects.
- **Trainable Instruments**: Differentiable instruments that can learn parameters from target audio samples.
- **Experiment Tracking**: Built-in system to track training runs, metrics, and parameters.
- **High Quality Output**: Generates standard WAV files.
- **Music Theory System**: Built-in support for scales, chords, progressions, and advanced systems (Raga, Maqam, Gamelan).
- **Algo-Rave Engine**: A TUI application for live coding music with hot-reloading and real-time controls.
## Philosophy & Core Concepts
Nasong is built on the philosophy of **"Code as Music"**. Instead of using a graphical DAW (Digital Audio Workstation) with fixed tracks and plugins, you define your music using composable Python objects. This approach treats sound synthesis, composition, and arrangement as a unified programming task.
### The `Value` Class
At the heart of Nasong is the `Value` class.
- **Everything is a Value**: A `Value` represents a signal that varies over time. This could be an audio waveform (like a sine wave), a control signal (like an LFO or envelope), or even a constant number.
- **Composition**: You build complex sounds by combining `Value` objects. For example, a synthesizer might be a `Sin` oscillator whose frequency is modulated by another `Sin` (LFO) and whose amplitude is controlled by an `ADSR` envelope. All of these are `Value` objects.
- **Vectorized Processing**: Under the hood, `Value` objects use NumPy for fast, vectorized processing (`getitem_np`), allowing for efficient rendering of complex audio graphs.
## Benefits
- **Infinite Customization**: You are not limited by the architecture of a specific VST or synthesizer. You can build your own synthesis architectures from scratch.
- **Version Control for Music**: Since your music is plain text code, you can use Git to track changes, branch ideas, and collaborate.
- **Procedural Generation**: Use Python's loops, logic, and random libraries to create generative music, evolving soundscapes, and algorithmic compositions.
- **Precision**: Define exact frequencies, timings, and modulation curves mathematically.
## Constraints
- **Not Real-Time**: Nasong is a "music compiler". You write code, runs the script to render a WAV file, and then listen. It is not designed for live performance or real-time jamming.
- **Requires Coding**: You need to be comfortable with Python to use it effectively.
- **Render Time**: Complex songs with many voices and heavy processing (like convolution reverb) may take some time to render.
## Installation
1. Clone the repository:
```bash
git clone https://github.com/nasong/nasong.git
cd nasong
```
2. Install the package (editable mode recommended for development):
```bash
pip install -e .
```
*Note: PyTorch is an optional dependency for GPU acceleration and training. If you want to use it, install it separately following instructions at [pytorch.org](https://pytorch.org).*
This installation exposes the following CLI commands:
- `nasong`: Generate music.
- `nasong-vis`: Visualize audio.
- `nasong-train`: Train instruments.
- `nasong-monitor`: Manage experiments.
- `nasong-rave`: Launch the live coding TUI environment.
## Usage
### 1. Creating a Nasong File
A "Nasong file" is simply a Python script (e.g., `my_song.py`) that exports the logic for your music.
**Required Structure:**
Your script **MUST** define two things:
1. **`duration`**: A variable (float/int) specifying the total length in seconds.
2. **`song(time)`**: A function that takes a `time` Value and returns the final audio output `Value`.
**Example Template:**
```python
import nasong.core.all_values as lv
from nasong.instruments.synth import SimpleSynth
# 1. Define Duration
duration = 10.0 # seconds
# 2. Define Song Function
def song(time: lv.Value) -> lv.Value:
# Build your audio graph here
# 'time' is the global time ramp signal provided by the renderer
# Example: A simple 440Hz sine wave
intro = SimpleSynth(time, frequency=lv.Constant(440))
return intro
```
### 2. Generating Music (`nasong`)
Use the `nasong` command to compile your song into audio.
```bash
nasong my_song.py -o output.wav
```
**Arguments:**
- `input_file`: Path to the Python song description file.
- `-o`, `--output`: Output WAV filename (Default: `output.wav`).
- `-s`, `--sample-rate`: Sample rate in Hz (Default: 44100).
- `-t`, `--torch`: Use PyTorch for rendering (requires Torch installed).
- `-d`, `--device`: Device to use (e.g., `cpu`, `cuda`).
### 3. Visualizing Audio (`nasong-vis`)
Analyze or plot waveforms/spectrograms of generated audio.
```bash
nasong-vis -i output.wav --analyze --plot spectrogram
```
### 4. Training Instruments (`nasong-train`)
You can train generative instruments to match a target audio sample (e.g., make a synth sound like a specific recording).
```bash
nasong-train --instrument named_fm --target my_sample.wav --epochs 1000
```
This will:
- Run an optimization loop using PyTorch.
- Log metrics (loss, duration) to `~/.nasong/experiments/`.
- Save the learned parameters to `params.json`.
### 5. Monitoring Experiments (`nasong-monitor`)
Manage your training experiments.
- **List experiments**:
```bash
nasong-monitor list
```
- **Show details**:
```bash
nasong-monitor show <experiment_id>
```
- **Delete experiment**:
```bash
nasong-monitor delete <experiment_id>
```
### 6. Evaluating Models (`nasong-evaluate`)
Evaluate the performance of trained models by comparing detected notes in the target vs. synthesized audio.
```bash
nasong-evaluate --experiment my_experiment
```
Or evaluate all experiments in a directory:
```bash
nasong-evaluate --models-dir trained_models
```
This generates:
- `evaluation.json`: Detailed note detection metrics.
- `comparison_<instrument>.png`: Side-by-side spectrograms.
### 7. Leaderboards (`nasong-leaderboard`)
Generate a global leaderboard comparing all trained models.
```bash
nasong-leaderboard --output results_analysis/leaderboards.md
```
### 8. Algo-Rave (Live Coding)
Launch the Terminal User Interface (TUI) for an immersive live coding session.
```bash
nasong-rave
```
**Features:**
- **Live Editor**: Write python code using the NaSong DSL and Theory modules.
- **Hot-Reloading**: Saving the file (`Ctrl+S`) automatically reloads the audio generation script without stopping playback.
- **Live Settings**: Adjust BPM and Volume in real-time.
- **Docs Browser**: Built-in documentation for all available modules.
**Example Script:**
```python
from nasong.theory.systems.western import Western
from nasong.theory.structures.progression import Progression
from nasong.theory import render
# ... standard NaSong imports ...
# Define a progression
prog = Progression.from_roman_numerals(Western.major("C4"), ["I", "vi", "IV", "V"])
# Render to audio
sequencer = render(prog, time_value, my_synth, bpm=120)
```
**Included Examples:**
Check out `nasong_examples/live_rave/` for ready-to-run scripts:
- `01_techno_kick.py`: A basic techno beat.
- `02_ambient_drone.py`: Generative ambient textures using pure math.
- `03_generative_melody.py`: Python randomized melody generation.
To run an example:
1. Launch `nasong-rave`.
2. Open the file (or copy-paste code).
3. Press `F5` or `Ctrl+S` to load and hear it.
### 9. Advanced Music Theory
NaSong now includes comprehensive music theory support.
**Systems:**
- **Western**: Major, Minor, Modes.
- **Non-Western**: `Raga` (Indian), `Maqam` (Arabic), `Gamelan` (Indonesian).
**Style Generators:**
- **Jazz**: `nasong.theory.generators.styles.jazz` (e.g. ii-V-I).
- **EDM**: `nasong.theory.generators.styles.edm`.
- **Lofi**: `nasong.theory.generators.styles.lofi`.
## Experiment Tracking & Inference
Nasong allows you to use trained instruments in your songs **without** needing PyTorch installed. The system effectively "compiles" the trained parameters into the instrument.
### Using Trained Instruments
Use the `load_trained_instrument` helper to load an instrument with its trained parameters pre-injected.
```python
from nasong.trainable.inference import load_trained_instrument
import nasong.core.all_values as lv
# 1. Load instrument from Experiment ID (get this from nasong-monitor list)
# This returns a callable function identical to the original blueprint but with defaults updated.
my_instrument = load_trained_instrument("a1b2c3d4")
# 2. Use it in your song graph
# It behaves exactly like a normal instrument
def song(time: lv.Value) -> lv.Value:
return my_instrument(
time=time,
frequency=lv.Constant(440),
start_time=0.0,
duration=1.0
)
```
## Project Structure
- `src/nasong/core/`: Core libraries (Values, Song, Wav, config).
- `src/nasong/instruments/`: Built-in instrument library.
- `src/nasong/scripts/`: CLI entry points.
- `src/nasong/trainable/`: Training logic and trainable instrument definitions.
- `song_examples/`: Example song definitions.
- `tests/`: Automated tests.
## License
This project is licensed under the terms of the GPLv3 license.
For more information, see the [LICENSE](LICENSE) file.
| text/markdown | null | Nathan Cerisara <nathan.cerisara@protonmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy",
"scipy",
"matplotlib",
"pandas",
"PyYAML",
"tabulate",
"textual[syntax]"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-18T20:53:13.464051 | nasong-0.1.0.tar.gz | 161,014 | ae/34/1403870c3e0170d5fdb4c32e4bc6f52b5575962034905580be425f755323/nasong-0.1.0.tar.gz | source | sdist | null | false | 7953f8b85734694ba56abab8a8dd38da | 383ab4ebf3b9fd2603887372cf285c3bade47d4fc2f20a578845ed67f71159e4 | ae341403870c3e0170d5fdb4c32e4bc6f52b5575962034905580be425f755323 | GPL-3.0-or-later | [
"LICENSE"
] | 268 |
2.4 | deckgl-marimo | 0.1.0 | deck.gl HexagonLayer widget for marimo notebooks via anywidget | # deckgl-marimo
deck.gl HexagonLayer widget for marimo notebooks via anywidget.
| text/markdown | null | Scott Lemke <scott.r.lemke@gmail.com> | null | null | null | anywidget, deck.gl, geospatial, hexagon, maplibre, marimo, visualization | [
"Development Status :: 3 - Alpha",
"Framework :: Jupyter",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.... | [] | null | null | >=3.10 | [] | [] | [] | [
"anywidget>=0.9.0",
"narwhals>=1.0.0",
"traitlets>=5.0.0",
"marimo; extra == \"dev\"",
"pandas; extra == \"dev\"",
"polars; extra == \"dev\"",
"pytest; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/kihaji/deckgl-marimo",
"Repository, https://github.com/kihaji/deckgl-marimo",
"Issues, https://github.com/kihaji/deckgl-marimo/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:52:42.092015 | deckgl_marimo-0.1.0.tar.gz | 79,830 | cc/93/5232e085a909d178089c99d3799f456e09770e6a8564067c05e2d49c0574/deckgl_marimo-0.1.0.tar.gz | source | sdist | null | false | cb452c206b95be0387977ae577c5bb0b | 608d31ce2028e4f001dcafe1d4ad78dce2ee2c6b2f215a7b98b7cb7bd287f8bb | cc935232e085a909d178089c99d3799f456e09770e6a8564067c05e2d49c0574 | MIT | [] | 272 |
2.4 | badkeys | 0.0.17 | Check cryptographic keys for known weaknesses | # badkeys
Tool and library to check cryptographic public keys for known vulnerabilities
# what?
badkeys checks public keys in various formats for known vulnerabilities. A web version
can be found at [badkeys.info](https://badkeys.info/).
# install
badkeys can be installed [via pip](https://pypi.org/project/badkeys/):
```
pip3 install badkeys
```
You may want to use a virtual environment. For details about different installation
options, please [check the official Python documentation](
https://packaging.python.org/en/latest/tutorials/installing-packages/). Alternatively,
you can directly call _./badkeys-cli_ directly from the git repository.
# usage
Before using badkeys, you need to download the blocklist data:
```
badkeys --update-bl
```
After that, you can call _badkeys_ and pass files with cryptographic public keys as the
parameter:
```
badkeys test.crt my.key
```
It will automatically try to detect the file format. Supported are public and private
keys in PEM format (both PKCS #1 and PKCS #8), X.509 certificates, certificate signing
requests (CSRs) and SSH public keys. You can find some test keys in the _tests/data_
directory.
By default, badkeys will only output information about vulnerable keys, meaning no
output will be generated if no vulnerabilities are found. The _-a_ parameter creates
output for all keys.
The command line tool will return 0 if keys were scanned, no errors occurred, and no
vulnerabilities were detected. It returns 1 for application errors, 2 if any input could
not be scanned (parser errors, unsupported key types, files without a key), and 4 if a
vulnerable key was found. Return codes can be combined as a bitmask. (E.g., 2|4=6
indicates that some keys were vulnerable and some could not be scanned.)
# scanning
badkeys can scan SSH and TLS hosts and automatically check their public keys. This can
be enabled with the parameters _-s_ (SSH) and _-t_ (TLS). By default, SSH will be
scanned on port 22 and TLS will be scanned on several ports for common protocols
(https/443, smtps/465, ldaps/636, ftps/990, imaps/993, pop3s/995 and 8443, which is
commonly used as a non-standard https port).
Alternative ports can be configured with _--tls-ports_ and _--ssh-ports_.
TLS and SSH scanning can be combined:
```
badkeys -ts example.org
```
Note that the scanning modes have limitations. It is often more desirable to use other
tools to collect TLS/SSH keys and scan them locally with badkeys.
SSH scanning needs [paramiko](https://www.paramiko.org/) as an additional dependency.
TLS scanning can't detect multiple certificates on one host (e.g. ECDSA and RSA). This
is a [limitation of Python's ssl.get_server_certificate() function](
https://bugs.python.org/issue31892).
# Python module and API
badkeys can also be used as a Python module. However, currently the software is in beta
state and the API may change regularly.
# about
badkeys was written by [Hanno Böck](https://hboeck.de).
[badkeys is currently funded](https://nlnet.nl/project/badkeys/) through the [NGI0 Core
Fund](https://nlnet.nl/core), a fund established by [NLnet](https://nlnet.nl/) with
financial support from the European Commission's [Next Generation Internet](
https://ngi.eu/) programme, under the aegis of [DG Communications Networks, Content and
Technology](
https://commission.europa.eu/about-european-commission/departments-and-executive-agencies/communications-networks-content-and-technology_en)
under grant agreement No [101092990](https://cordis.europa.eu/project/id/101092990).
This work was initially funded in 2022 by Industriens Fond through the CIDI project
(Cybersecure IOT in Danish Industry) and the [Center for Information Security and Trust
(CISAT)](https://cisat.dk/) at the IT University of Copenhagen, Denmark.
| text/markdown | Hanno Böck | null | null | null | null | cryptography, rsa, security | [
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Progra... | [] | null | null | >=3.9 | [] | [] | [] | [
"cryptography",
"gmpy2",
"binary-file-search; extra == \"urllookup\"",
"paramiko; extra == \"ssh\"",
"dnspython; extra == \"dkim\""
] | [] | [] | [] | [
"Homepage, https://badkeys.info/",
"Source, https://github.com/badkeys/badkeys",
"Bug Tracker, https://github.com/badkeys/badkeys/issues"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-18T20:52:14.733203 | badkeys-0.0.17.tar.gz | 399,035 | 5b/b8/9c5fdec4eb0b0a8b2e6a5a7a2d6da0fa5a905601a5e6a8c1f2aecb22f5c7/badkeys-0.0.17.tar.gz | source | sdist | null | false | e651c6b49bc4d6e8d769b7435b0d0841 | 5562f2276a0343c5cfa5ecc54dc0e658e1b65fd36016858c04af9f33f7e9f826 | 5bb89c5fdec4eb0b0a8b2e6a5a7a2d6da0fa5a905601a5e6a8c1f2aecb22f5c7 | MIT | [
"LICENSE"
] | 433 |
2.4 | quasarr | 3.1.6 | Quasarr connects JDownloader with Radarr, Sonarr and LazyLibrarian. It also decrypts links protected by CAPTCHAs. | #
<img src="https://raw.githubusercontent.com/rix1337/Quasarr/main/Quasarr.png" data-canonical-src="https://raw.githubusercontent.com/rix1337/Quasarr/main/Quasarr.png" width="64" height="64" />
Quasarr connects JDownloader with Radarr, Sonarr, Lidarr and LazyLibrarian. It also decrypts links protected by
CAPTCHAs.
[](https://badge.fury.io/py/quasarr)
[](https://discord.gg/eM4zA2wWQb)
[](https://github.com/users/rix1337/sponsorship)
Quasarr pretends to be both `Newznab Indexer` and `SABnzbd client`. Therefore, do not try to use it with real usenet
indexers. It simply does not know what NZB files are.
Quasarr includes a solution to quickly and easily decrypt protected links.
[Active monthly Sponsors get access to SponsorsHelper to do so automatically.](https://github.com/rix1337/Quasarr?tab=readme-ov-file#sponsorshelper)
Alternatively, follow the link from the console output (or discord notification) to solve CAPTCHAs manually.
Quasarr will confidently handle the rest. Some CAPTCHA types require [Tampermonkey](https://www.tampermonkey.net/) to be
installed in your browser.
# Instructions
1. Set up and run [JDownloader 2](https://jdownloader.org/download/index)
2. Configure the integrations below
3. (Optional) Set up [FlareSolverr 3](https://github.com/FlareSolverr/FlareSolverr) for sites that require it
> **Finding your Quasarr URL and API Key**
> Both values are shown in the console output under **API Information**, or in the Quasarr web UI.
---
## Quasarr
> ⚠️ Quasarr requires at least one valid hostname to start. It does not provide or endorse any specific sources, but
> community-maintained lists are available:
🔗 **[https://quasarr-host.name](https://quasarr-host.name)** — community guide for finding hostnames
📋 Alternatively, browse community suggestions via [pastebin search](https://pastebin.com/search?q=hostnames+quasarr) (
login required).
> Authentication is optional but strongly recommended.
>
> - 🔐 Set `USER` and `PASS` to enable form-based login (30-day session)
> - 🔑 Set `AUTH=basic` to use HTTP Basic Authentication instead
---
## JDownloader
> ⚠️ If using Docker:
> JDownloader's download path must be available to Radarr/Sonarr/Lidarr/LazyLibrarian with **identical internal and
external
path mappings**!
> Matching only the external path is not sufficient.
1. Start and connect JDownloader to [My JDownloader](https://my.jdownloader.org)
2. Provide your My JDownloader credentials during Quasarr setup
<details>
<summary>Fresh install recommended</summary>
Consider setting up a fresh JDownloader instance. Quasarr will modify JDownloader's settings to enable
Radarr/Sonarr/Lidarr/LazyLibrarian integration.
</details>
---
## Categories & Mirrors
You can manage categories in the Quasarr Web UI.
* **Setup:** Add or edit categories to organize your downloads.
* **Download Mirror Whitelist:**
* Inside a **download category**, you can whitelist specific mirrors.
* If specific mirrors are set, downloads will fail unless the release is available from them.
* This does not affect search results.
* This affects the **Quasarr Download Client** in Radarr/Sonarr/Lidarr/LazyLibrarian.
* **Search Hostname Whitelist:**
* Inside a **search category**, you can whitelist specific hostnames.
* If specific hostnames are set, only these will be searched by the given search category.
* This affects search results.
* This affects the **Quasarr Newznab Indexer** in Radarr/Sonarr/Lidarr/LazyLibrarian.
* **Custom Search Categories:** You can add up to 10 custom search categories per base type (Movies, TV, Music, Books). These allow you to create separate hostname whitelists for different purposes.
* **Emoji:** Will be used in the Packages view on the Quasarr Web UI.
---
## Radarr / Sonarr / Lidarr
> ⚠️ **Sonarr users:** Set all shows (including anime) to the **Standard** series type. Quasarr cannot find releases for
> shows set to Anime/Absolute.
Add Quasarr as both a **Newznab Indexer** and **SABnzbd Download Client** using your Quasarr URL and API Key.
Be sure to set a category in the **SABnzbd Download client** (default: `movies` for Radarr, `tv` for Sonarr and `music`
for Lidarr).
<details>
<summary>Show download status in Radarr/Sonarr/Lidarr</summary>
**Activity → Queue → Options** → Enable `Release Title`
</details>
---
## Prowlarr
Add Quasarr as a **Generic Newznab Indexer**.
* **Url:** Your Quasarr URL
* **ApiKey:** Your Quasarr API Key
<details>
<summary>Allowed search parameters and categories</summary>
#### Movies / TV:
* Use IMDb ID, Syntax: `{ImdbId:tt0133093}` and pick category `2000` (Movies) or `5000` (TV)
* Simple text search is **not** supported.
#### Music / Books / Magazines:
* Use simple text search and pick category `3000` (Music) or `7000` (Books/Magazines).
</details>
---
## LazyLibrarian
> ⚠️ **Experimental feature** — Report issues when a hostname returns results on its website but not in LazyLibrarian.
<details>
<summary>Setup instructions</summary>
### SABnzbd+ Downloader
| Setting | Value |
|----------|----------------------------|
| URL/Port | Your Quasarr host and port |
| API Key | Your Quasarr API Key |
| Category | `docs` |
### Newznab Provider
| Setting | Value |
|---------|----------------------|
| URL | Your Quasarr URL |
| API | Your Quasarr API Key |
### Fix Import & Processing
**Importing:**
- Enable `OpenLibrary api for book/author information`
- Set Primary Information Source to `OpenLibrary`
- Add to Import languages: `, Unknown` (German users: `, de, ger, de-DE`)
**Processing → Folders:**
- Add your Quasarr download path (typically `/downloads/Quasarr/`)
</details>
---
# Docker
It is highly recommended to run the latest docker image with all optional variables set.
```
docker run -d \
--name="Quasarr" \
-p port:8080 \
-v /path/to/config/:/config:rw \
-e 'INTERNAL_ADDRESS'='http://192.168.0.1:8080' \
-e 'EXTERNAL_ADDRESS'='https://foo.bar/' \
-e 'DISCORD'='https://discord.com/api/webhooks/1234567890/ABCDEFGHIJKLMN' \
-e 'USER'='admin' \
-e 'PASS'='change-me' \
-e 'AUTH'='form' \
-e 'SILENT'='True' \
-e 'TZ'='Europe/Berlin' \
ghcr.io/rix1337/quasarr:latest
```
| Parameter | Description |
|--------------------|------------------------------------------------------------------------------------------------------------|
| `INTERNAL_ADDRESS` | **Required.** Internal URL so Radarr/Sonarr/Lidarr/LazyLibrarian can reach Quasarr. **Must include port.** |
| `EXTERNAL_ADDRESS` | Optional. External URL (e.g. reverse proxy). Always protect external access with authentication. |
| `DISCORD` | Optional. Discord webhook URL for notifications. |
| `USER` / `PASS` | Optional, but recommended! Username / Password to protect the web UI. |
| `AUTH` | Authentication mode. Supported values: `form` or `basic`. |
| `SILENT` | Optional. If `True`, silences all Discord notifications except SponsorHelper error messages. If `MAX`, blocks all Discord messages except SponsorHelper failure messages. ||
| `TZ` | Optional. Timezone. Incorrect values may cause HTTPS/SSL issues. |
# Manual setup
> Use this only in case you can't run the docker image.
> ⚠️ Requires Python 3.12 (or later) and [uv](https://docs.astral.sh/uv/#installation)!
`uv tool install quasarr`
```
export INTERNAL_ADDRESS=http://192.168.0.1:8080
export EXTERNAL_ADDRESS=https://foo.bar/
export DISCORD=https://discord.com/api/webhooks/1234567890/ABCDEFGHIJKLMN
quasarr
```
* `DISCORD` see `DISCORD`docker variable
* `EXTERNAL_ADDRESS` see `EXTERNAL_ADDRESS`docker variable
# Philosophy
Complexity is the killer of small projects like this one. It must be fought at all cost!
We will not waste precious time on features that will slow future development cycles down.
Most feature requests can be satisfied by:
- Existing settings in Radarr/Sonarr/Lidarr/LazyLibrarian
- Existing settings in JDownloader
- Existing tools from the *arr ecosystem that integrate directly with Radarr/Sonarr/Lidarr/LazyLibrarian
# Roadmap
- Assume there are zero known
issues [unless you find one or more open issues in this repository](https://github.com/rix1337/Quasarr/issues).
- Still having an issue? Provide a detailed report [here](https://github.com/rix1337/Quasarr/issues/new/choose)!
- There are no hostname integrations in active development unless you see an open pull request
[here](https://github.com/rix1337/Quasarr/pulls).
- **Pull requests are welcome!** Especially for popular hostnames.
- A short guide to set up required dev services is found
[here](https://github.com/rix1337/Quasarr/blob/main/CONTRIBUTING.md).
- Always reach out on Discord before starting work on a new feature to prevent waste of time.
- Please follow the existing code style and project structure.
- Anti-bot measures must be circumvented fully by Quasarr. Thus, you will need to provide a working solution for new
CAPTCHA types by integrating it in the Quasarr Web UI.
The simplest CAPTCHA bypass involves creating a Tampermonkey user script.
- Please provide proof of functionality (screenshots/examples) when submitting your pull request.
# SponsorsHelper
<img src="https://imgur.com/iHBqLwT.png" width="64" height="64" />
SponsorsHelper is a Docker image that solves CAPTCHAs and decrypts links for Quasarr.
Image access is limited to [active monthly GitHub sponsors](https://github.com/users/rix1337/sponsorship).
[](https://github.com/users/rix1337/sponsorship)
---
## 🔑 GitHub Token Setup
1. Start your [sponsorship](https://github.com/users/rix1337/sponsorship) first.
2. Open [GitHub Classic Token Settings](https://github.com/settings/tokens/new?type=classic)
3. Name it (e.g., `SponsorsHelper`) and choose unlimited expiration
4. Enable these scopes:
- `read:packages`
- `read:user`
- `read:org`
5. Click **Generate token** and copy it for the next steps
---
## 🔐 Quasarr API Key Setup
1. Open your Quasarr web UI in a browser
2. On the main page, expand **"Show API Settings"**
3. Copy the **API Key** value
4. Use this value for the `QUASARR_API_KEY` environment variable
> **Note:** The API key is required for SponsorsHelper to communicate securely with Quasarr. Without it, all requests
> will be rejected with a 401/403 error.
---
## 🐋 Docker Login
⚠️ **If not logged in, the image will not download.**
```bash
echo "GITHUB_TOKEN" | docker login ghcr.io -u USERNAME --password-stdin
````
* `USERNAME` → your GitHub username
* `GITHUB_TOKEN` → the token you just created
## ▶️ Run SponsorsHelper
⚠️ **Without a valid GitHub token linked to an active sponsorship, the image will not run.**
```bash
docker run -d \
--name='SponsorsHelper' \
-e 'QUASARR_URL'='http://192.168.0.1:8080' \
-e 'QUASARR_API_KEY'='your_quasarr_api_key_here' \
-e 'DEATHBYCAPTCHA_TOKEN'='2FMum5zuDBxMmbXDIsADnllEFl73bomydIpzo7...' \
-e 'GITHUB_TOKEN'='ghp_123.....456789' \
-e 'FLARESOLVERR_URL'='http://10.10.0.1:8191/v1' \
ghcr.io/rix1337-sponsors/docker/helper:latest
```
| Parameter | Description |
|------------------------|---------------------------------------------------------------------------------------|
| `QUASARR_URL` | Local URL of Quasarr (e.g., `http://192.168.0.1:8080`) |
| `QUASARR_API_KEY` | Your Quasarr API key (found in Quasarr web UI under "API Settings") |
| `APIKEY_2CAPTCHA` | [2Captcha](https://2captcha.com/?from=27506687) account API key |
| `DEATHBYCAPTCHA_TOKEN` | [DeathByCaptcha](https://deathbycaptcha.com/register?refid=6184288242b) account token |
| `GITHUB_TOKEN` | Classic GitHub PAT with the scopes listed above |
| `FLARESOLVERR_URL` | Local URL of [FlareSolverr](https://github.com/FlareSolverr/FlareSolverr) |
> - [2Captcha](https://2captcha.com/?from=27506687) is the recommended CAPTCHA solving service.
> - [DeathByCaptcha](https://deathbycaptcha.com/register?refid=6184288242b) can serve as a fallback or work on its own.
> - If you set both `APIKEY_2CAPTCHA` and `DEATHBYCAPTCHA_TOKEN` both services will be used alternately.
| text/markdown | null | rix1337 <rix1337@users.noreply.github.com> | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"beautifulsoup4>=4.14.3",
"bottle>=0.13.4",
"dukpy>=0.5.1",
"emoji>=2.15.0",
"loguru>=0.7.3",
"pillow==12.1.1",
"pycryptodomex>=3.23.0",
"python-dotenv>=1.2.1",
"requests>=2.32.5",
"setuptools==82.0.0",
"wcwidth>=0.6.0"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T20:51:33.952274 | quasarr-3.1.6.tar.gz | 1,287,818 | 43/40/ba6b8e8108f2603641e27e452c8f265b3c6200273571f498294bd438e1d1/quasarr-3.1.6.tar.gz | source | sdist | null | false | a8c7c6d22dd98b71f1ae408a51afcdd6 | 602141b3d78bf79c72f98eaab211f0a319d8a3a461466bbd2374d0dffaa1b973 | 4340ba6b8e8108f2603641e27e452c8f265b3c6200273571f498294bd438e1d1 | null | [
"LICENSE"
] | 238 |
2.4 | pykappa | 0.1.8 | Work with Kappa rule-based models in Python | <div align="center">
<img src="https://raw.githubusercontent.com/berkalpay/pykappa/main/docs/source/_static/logo.png" width="100">
</div>
# PyKappa
[](https://pypi.org/project/pykappa)
PyKappa is a Python package for working with rule-based models.
It supports simulation and analysis of a wide variety of systems whose individual components interact as described by rules that transform these components in specified ways and at specified rates.
See our website [pykappa.org](https://pykappa.org) for a tutorial, examples, and documentation.
## Development
Developer requirements can be installed via:
```
pip install -r requirements.txt
```
<details>
<summary> With uv (optional alternative to pip): </summary>
Install [uv](https://docs.astral.sh/uv/getting-started/installation/), then:
```
uv sync --dev
```
To access `uv` dependencies, run your commands through `uv` like
```
uv run python
```
Or, if you want to run commands normally, create a virtual environment:
```
uv venv # Do this once
source .venv/bin/activate # Do this every new shell
```
and run commands as usual. (`deactivate` exits the venv.)
Adding a Python package dependency (this automatically updates pyproject.toml):
```
uv add [package-name]
```
Adding a package as a dev dependency:
```
uv add --dev [package-name]
```
</details>
To run correctness tests, run `pytest`.
Running `./tests/cpu-profiles/run_profiler.sh` will CPU-profile predefined Kappa models and write the results to `tests/cpu-profiles/results`.
We use the Black code formatter, which can be run as `black .`
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"lark>=1.2.2",
"pandas>=2.0.0",
"matplotlib>=3.10.3"
] | [] | [] | [] | [
"Homepage, https://pykappa.org",
"Documentation, https://pykappa.org/api/index.html",
"Repository, https://github.com/berkalpay/pykappa",
"Issues, https://github.com/berkalpay/pykappa/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:51:15.688163 | pykappa-0.1.8.tar.gz | 33,922 | ea/1a/7a32b6fd3f1221500d402984ef1bc7c51f2ea01eb58ae40d26125876ac32/pykappa-0.1.8.tar.gz | source | sdist | null | false | 41a356113c5043bca4b52034f44f9afa | fa60509a3b568adac3e7376ce42a3a040dc3730a1421eb9603e86ef64d1a7756 | ea1a7a32b6fd3f1221500d402984ef1bc7c51f2ea01eb58ae40d26125876ac32 | null | [] | 230 |
2.4 | gtg | 0.10.0 | Deterministic PR readiness detection for AI coding agents | # Good To Go
[](https://badge.fury.io/py/gtg)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/dsifry/goodtogo/actions/workflows/tests.yml)
**Deterministic PR readiness detection for AI coding agents**
> *"Is the PR ready to merge?"* — Finally, a definitive answer.
[Documentation](https://dsifry.github.io/goodtogo/) · [PyPI](https://pypi.org/project/gtg/) · [Contributing](CONTRIBUTING.md)
---
## Why Good To Go?
AI agents can write code, fix bugs, and respond to reviews. But they all struggle with one question: **"Am I done yet?"**
- CI is running... check again... still running...
- CodeRabbit left 12 comments — which ones are blocking?
- Reviewer wrote "consider X" — is that a request or a suggestion?
- Threads are unresolved — but the fix is already pushed
**Good To Go answers this definitively:**
```bash
gtg 123
```
```
OK PR #123: READY
CI: success (5/5 passed)
Threads: 3/3 resolved
```
One command. One status. No guessing.
## How It Works
```mermaid
flowchart LR
PR[Pull Request] --> GTG[gtg]
GTG --> CI[CI Status]
GTG --> Comments[Comment Analysis]
GTG --> Threads[Thread Resolution]
CI --> Status{Status}
Comments --> Status
Threads --> Status
Status --> READY[✓ READY]
Status --> ACTION[! ACTION_REQUIRED]
Status --> UNRESOLVED[? UNRESOLVED_THREADS]
Status --> FAILING[✗ CI_FAILING]
```
Good To Go combines three analyses:
| Analysis | What It Does |
|----------|--------------|
| **CI Status** | Aggregates all checks into pass/fail/pending |
| **Comment Classification** | Identifies actionable vs. informational comments |
| **Thread Resolution** | Tracks which discussions are truly blocking |
### Intelligent Comment Classification
Not all comments need action. Good To Go classifies each one:
| Classification | Examples | Action |
|---------------|----------|--------|
| **ACTIONABLE** | "Critical: SQL injection vulnerability" | Must fix |
| **NON_ACTIONABLE** | "LGTM!", nitpicks, resolved items | Ignore |
| **AMBIGUOUS** | "Consider using X", questions | Human review |
Built-in support for: **CodeRabbit**, **Greptile**, **Claude**, **Cursor/Bugbot**
## Quick Start
```bash
# Install
pip install gtg
# Set GitHub token
export GITHUB_TOKEN=ghp_...
# Check a PR (auto-detects repo)
gtg 123
# Explicit repo
gtg 123 --repo owner/repo
```
## Output Formats
### Text (Human-Readable)
```bash
gtg 123 --format text
```
```
!! PR #456: ACTION_REQUIRED
CI: success (5/5 passed)
Threads: 8/8 resolved
Action required:
- Fix CRITICAL comment from coderabbit in src/db.py:42
```
### JSON (For Agents)
```bash
gtg 123 --format json
```
```json
{
"status": "ACTION_REQUIRED",
"action_items": ["Fix CRITICAL comment from coderabbit in src/db.py:42"],
"actionable_comments": [...],
"ci_status": {"state": "success", "passed": 5, "total_checks": 5}
}
```
## Exit Codes
**Default (AI-friendly)** — parse the JSON for details:
| Code | Meaning |
|------|---------|
| 0 | Any analyzable state |
| 4 | Error |
**With `-q` or `--semantic-codes`** — for shell scripts:
| Code | Status |
|------|--------|
| 0 | READY |
| 1 | ACTION_REQUIRED |
| 2 | UNRESOLVED |
| 3 | CI_FAILING |
| 4 | ERROR |
## Use as CI Gate
Make `gtg` a required check to block merges until PRs are truly ready:
```yaml
# .github/workflows/pr-check.yml
- name: Check PR readiness
run: gtg ${{ github.event.pull_request.number }} --semantic-codes
```
See [USAGE.md](USAGE.md#github-actions-integration) for full workflow setup.
## For AI Agents
```python
import subprocess
import json
result = subprocess.run(
["gtg", "123", "--format", "json"],
capture_output=True, text=True
)
data = json.loads(result.stdout)
if data["status"] == "READY":
print("Merge it!")
else:
for item in data["action_items"]:
print(f"TODO: {item}")
```
Or use the Python API:
```python
from goodtogo import PRAnalyzer, Container
container = Container.create_default(github_token="ghp_...")
analyzer = PRAnalyzer(container)
result = analyzer.analyze("owner", "repo", 123)
```
## State Persistence
Track handled comments across sessions:
```bash
gtg 123 --state-path .goodtogo/state.db # Remember dismissed comments
gtg 123 --refresh # Force fresh analysis
```
## Documentation
- **[Landing Page](https://dsifry.github.io/goodtogo/)** — Philosophy and vision
- **[USAGE.md](USAGE.md)** — Complete CLI reference
- **[CONTRIBUTING.md](CONTRIBUTING.md)** — Development guide
## License
MIT License — see [LICENSE](LICENSE)
---
<p align="center">
<strong>Made with Claude Code</strong><br>
<em>by <a href="https://github.com/dsifry">David Sifry</a></em>
</p>
| text/markdown | null | David Sifry <david@sifry.com> | null | null | MIT | pr-readiness, github, ai-agents, code-review, ci-cd, automation | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: P... | [] | null | null | >=3.9 | [] | [] | [] | [
"click>=8.0.0",
"pydantic>=2.0.0",
"httpx>=0.25.0",
"redis>=5.0.0; extra == \"redis\"",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"hypothesis>=6.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"ruff>=0.1.0; extr... | [] | [] | [] | [
"Homepage, https://github.com/dsifry/goodtogo",
"Repository, https://github.com/dsifry/goodtogo",
"Issues, https://github.com/dsifry/goodtogo/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:50:21.746429 | gtg-0.10.0.tar.gz | 56,221 | 7e/5a/b197f9f3ec92fb94dcdbdd8b91bc2fbd9d16445bd069a9f8b1cff36e0dd0/gtg-0.10.0.tar.gz | source | sdist | null | false | ed709df19334e246aba92e8e8bd3ad15 | 31409e1d37d84ea7bc79a5383ce14f508c0fe648d3ff943996db69ee7ac18790 | 7e5ab197f9f3ec92fb94dcdbdd8b91bc2fbd9d16445bd069a9f8b1cff36e0dd0 | null | [
"LICENSE"
] | 243 |
2.1 | ptal-api | 1.0.0a25 | TALISMAN API adapter | # ptal-api
Python adapter for Talisman-based app
How to create trivial adapter:
graphql_url = 'https://demo.talisman.ispras.ru/graphql' # or another talisman-based app
auth_url = 'https://demo.talisman.ispras.ru/auth/'
realm = 'demo'
client_id = 'web-ui'
client_secret = '<some-secret>'
gql_client = KeycloakAwareGQLClient(
graphql_url, 10000, 5,
auth_url=auth_url,
realm=realm, client_id=client_id, user='admin', pwd='admin',
client_secret=client_secret
).__enter__()
adapter = TalismanAPIAdapter(gql_client, {})
c = adapter.get_concept('ОК-123456')
| text/markdown | Evgeny Bechkalo | bechkalo@ispras.ru | Matvey Zvantsov | zvancov.mu@ispras.ru | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Pyth... | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"sgqlc>=16.3",
"python-keycloak>=2.6.0",
"graphql-core>=3.2.3",
"transliterate>=1.10.2",
"marshmallow-dataclass>=8.5.11",
"ruamel.yaml>=0.17.21",
"click>=8.1.3",
"pyjwt>=2.7.0",
"deprecation<3.0.0,>=2.1.0"
] | [] | [] | [] | [] | poetry/1.8.2 CPython/3.10.14 Linux/5.13.0-28-generic | 2026-02-18T20:50:15.719143 | ptal_api-1.0.0a25.tar.gz | 110,734 | 23/97/59f974bf8e262e451ee1662e083a5a0317dbd588610bb0e6b33ec3843f78/ptal_api-1.0.0a25.tar.gz | source | sdist | null | false | 9ccaeabaa4db358448dc694d2af7e486 | 06fd2940ba78b85c28054607a269e6e212e693d1d502ae3080a9c60415447563 | 239759f974bf8e262e451ee1662e083a5a0317dbd588610bb0e6b33ec3843f78 | null | [] | 212 |
2.4 | atdata-app | 0.2.2b1 | ATProto AppView for ac.foundation.dataset | # atdata-app
An [ATProto AppView](https://atproto.com/guides/applications#appview) for the `ac.foundation.dataset` lexicon namespace. It indexes dataset metadata published across the AT Protocol network and serves it through XRPC endpoints — enabling discovery, search, and resolution of datasets, schemas, labels, and lenses.
## Overview
In the AT Protocol architecture, an AppView is a service that subscribes to the network firehose, indexes records it cares about, and exposes query endpoints for clients. atdata-app does this for scientific and ML dataset metadata:
- **Schemas** define the structure of datasets (JSON Schema, Arrow schema, etc.)
- **Dataset entries** describe a dataset — its name, storage location, schema, tags, license, and size
- **Labels** are human-readable version tags pointing to a specific dataset entry (like git tags)
- **Lenses** are bidirectional schema transforms with getter/putter code for migrating data between schema versions
```
ATProto Network
│
├── Jetstream (WebSocket firehose) ──► Real-time ingestion
│ │
└── BGS Relay (HTTP backfill) ──────► Historical backfill
│
▼
PostgreSQL
│
▼
XRPC Query Endpoints ──► Clients
```
## Requirements
- Python 3.12+
- PostgreSQL 14+
- [uv](https://docs.astral.sh/uv/) package manager
## Quickstart
```bash
# Install dependencies
uv sync --dev
# Set up PostgreSQL (schema auto-applies on startup)
createdb atdata_app
# Start the server
uv run uvicorn atdata_app.main:app --reload
```
The server starts with dev-mode defaults: `http://localhost:8000`, DID `did:web:localhost%3A8000`. On startup it connects to Jetstream and begins indexing `ac.foundation.dataset.*` records, and runs a one-shot backfill of historical records from the BGS relay.
## Configuration
All settings are environment variables prefixed with `ATDATA_`, managed by [pydantic-settings](https://docs.pydantic.dev/latest/concepts/pydantic_settings/).
| Variable | Default | Description |
|---|---|---|
| `ATDATA_HOSTNAME` | `localhost` | Public hostname, used to derive `did:web` identity |
| `ATDATA_PORT` | `8000` | Server port (included in DID in dev mode) |
| `ATDATA_DEV_MODE` | `true` | Dev mode uses `http://` and includes port in DID; production uses `https://` |
| `ATDATA_DATABASE_URL` | `postgresql://localhost:5432/atdata_app` | PostgreSQL connection string |
| `ATDATA_JETSTREAM_URL` | `wss://jetstream2.us-east.bsky.network/subscribe` | Jetstream WebSocket endpoint |
| `ATDATA_JETSTREAM_COLLECTIONS` | `ac.foundation.dataset.*` | Collections to subscribe to |
| `ATDATA_RELAY_HOST` | `https://bsky.network` | BGS relay for backfill DID discovery |
### Identity
The service derives its [`did:web`](https://w3c-ccg.github.io/did-method-web/) identity from the hostname and port:
- **Dev mode**: `did:web:localhost%3A8000` with endpoint `http://localhost:8000`
- **Production**: `did:web:datasets.example.com` with endpoint `https://datasets.example.com`
The DID document is served at `GET /.well-known/did.json` and advertises the service as an `AtprotoAppView`.
## API Reference
See [docs/api-reference.md](docs/api-reference.md) for the full XRPC endpoint reference (queries, procedures, and other routes).
## Data Model
See [docs/data-model.md](docs/data-model.md) for the database schema (schemas, entries, labels, lenses).
## Docker Deployment
The app ships with a multi-stage Dockerfile using [uv](https://docs.astral.sh/uv/) for fast dependency installation.
### Build and run locally
```bash
docker build -t atdata-app .
docker run -p 8000:8000 \
-e ATDATA_DATABASE_URL=postgresql://user:pass@host:5432/atdata_app \
-e ATDATA_HOSTNAME=localhost \
-e ATDATA_DEV_MODE=true \
atdata-app
```
### Deploy on Railway
The repo includes a `railway.toml` that configures the Dockerfile builder, health checks at `/health`, and a restart-on-failure policy.
1. Connect the repo to a [Railway](https://railway.com) project
2. Add a PostgreSQL service and link it
3. Set the required environment variables:
| Variable | Value |
|---|---|
| `ATDATA_DATABASE_URL` | Provided by Railway's PostgreSQL plugin (`${{Postgres.DATABASE_URL}}`) |
| `ATDATA_HOSTNAME` | Your Railway public domain (e.g. `atdata-app-production.up.railway.app`) |
| `ATDATA_DEV_MODE` | `false` |
| `ATDATA_PORT` | Omit — Railway sets `PORT` automatically and the container respects it |
Optional variables for ingestion tuning:
| Variable | Default | Description |
|---|---|---|
| `ATDATA_JETSTREAM_URL` | `wss://jetstream2.us-east.bsky.network/subscribe` | Jetstream endpoint |
| `ATDATA_RELAY_HOST` | `https://bsky.network` | BGS relay for backfill |
Railway will auto-deploy on push, build the Docker image, and start the container.
## Development
```bash
# Run tests (no database required)
uv run pytest
# Run a single test
uv run pytest tests/test_models.py::test_parse_at_uri -v
# Run with coverage
uv run pytest --cov=atdata_app
# Lint
uv run ruff check src/ tests/
```
Tests mock all external dependencies (database, HTTP, identity resolution) using `unittest.mock.AsyncMock`. HTTP endpoint tests use httpx `ASGITransport` for in-process testing without a running server.
## License
MIT
| text/markdown | null | Maxine Levesque <hello@maxine.science> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"asyncpg>=0.30",
"atproto>=0.0.65",
"fastapi>=0.115",
"httpx>=0.28",
"jinja2>=3.1",
"mcp>=1.0",
"pydantic-settings>=2.7",
"pydantic>=2.10",
"uvicorn[standard]>=0.34",
"websockets>=14.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:49:42.288831 | atdata_app-0.2.2b1.tar.gz | 161,600 | fb/8b/969c7916727357fe8dc5371a6deca6812cd10853215a28c554844a7b55c1/atdata_app-0.2.2b1.tar.gz | source | sdist | null | false | 90b5c7c3eddfd7494e799d4ca31da48a | edf1a1c5edbf7aca58d6e36004c79811115fdcccb6d1d7f17198e5566c8febc7 | fb8b969c7916727357fe8dc5371a6deca6812cd10853215a28c554844a7b55c1 | null | [] | 201 |
2.4 | codemixture | 0.1.0 | A literate programming system for the AI coding era | # Codemixture
A literate programming system for the AI coding era.
Programs are written as markdown documents with executable code in standard fenced code blocks. The prose — design rationale, specifications, constraints, prompts — is interwoven with the code. The documents are simultaneously human-readable documentation, AI-readable context, and executable programs.
## The Problem
Code and documentation live in separate worlds. Comments rot. READMEs drift. Design docs go stale the moment code ships. AI coding agents work from context that's scattered across files, commit messages, and Slack threads.
## The Idea
What if the documentation *was* the program? What if the markdown you write to explain your design also contained the code that implements it?
Codemixture documents are valid CommonMark. Code lives in standard fenced code blocks. Metadata lives in invisible HTML comments. Macros are expressed as comments in the target language. Everything renders correctly on GitHub, in VS Code, in any markdown viewer — with zero preprocessing.
## Example
Here's a complete codemixture document:
````markdown
# Hello World
<!-- codemixture
type: module
file: hello.py
language: python
-->
A simple greeting program.
```python
def main():
print("Hello from codemixture!")
if __name__ == "__main__":
main()
```
````
Run `cm tangle hello.md` and out comes `hello.py`.
For more complex programs, named sections let you define code in the order that makes sense for explanation, then assemble it in the order the language requires:
````markdown
```python
# @begin(imports)
import sys
# @end(imports)
```
Later, we can include that section:
```python
# @include(imports)
def main():
print("hello")
```
````
## Quick Start
```bash
# Clone and bootstrap
git clone <repo-url> && cd codemixture
python3 bootstrap.py tangler.md
python3 bootstrap.py cli.md
# Install with uv
uv sync --all-extras
# Tangle, check, test
uv run cm tangle tangler.md cli.md checker.md watcher.md
uv run cm check tangler.md cli.md checker.md watcher.md
uv run pytest tests/ -v
```
## How It Works
**Tangling** extracts executable code from `.md` files:
```bash
cm tangle mymodule.md # Single file
cm tangle *.md # Project (enables cross-document refs)
cm tangle mymodule.md --dry-run # Preview without writing
```
**Checking** validates documents without tangling:
```bash
cm check *.md # Report errors and warnings
cm check *.md --strict # Treat warnings as errors
```
**Watching** re-tangles on file changes:
```bash
cm watch *.md # Requires: pip install codemixture[watch]
```
**Initializing** scaffolds a new project:
```bash
cm init myproject --language python
```
## Self-Hosting
Codemixture is written in codemixture. The `.md` files in this repository are the source of truth:
| Document | Produces | Description |
|----------|----------|-------------|
| `tangler.md` | `tangle.py` | The tangler — code extraction and macro resolution |
| `cli.md` | `cli.py`, `__init__.py` | The `cm` command-line tool |
| `checker.md` | `check.py` | Document validator |
| `watcher.md` | `watch.py` | File watcher with debouncing |
`bootstrap.py` is the only non-`.md` Python source — a minimal ~90-line tangler that bootstraps the real one.
## Format Specification
See `codemixture.md` for the complete format specification, including:
- Document anatomy (prose, code, metadata)
- The macro system (`@begin`/`@end`, `@include`, `@append`)
- Cross-document references
- Multiple output files
- Metadata fields
## License
MIT
| text/markdown | null | null | null | null | null | literate-programming, markdown, tangling, ai | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Develo... | [] | null | null | >=3.11 | [] | [] | [] | [
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.4; extra == \"dev\"",
"watchdog>=3.0; extra == \"watch\""
] | [] | [] | [] | [] | uv/0.8.19 | 2026-02-18T20:49:05.955098 | codemixture-0.1.0.tar.gz | 10,895 | f6/9a/6b0667a9f4add6e796a672157eb1c8165258a7be2d6c4f813d5615f7775f/codemixture-0.1.0.tar.gz | source | sdist | null | false | 46cc8926054d1ca4c664fe4a62a20c5a | cae8db8977847404e444f88ee65a89e72c37a5fb7672bde233dc9465066e6ace | f69a6b0667a9f4add6e796a672157eb1c8165258a7be2d6c4f813d5615f7775f | MIT | [] | 256 |
2.4 | adstractai | 0.3.0 | Ad network that delivers ads to the LLM's response | # Adstract AI Python SDK



Ad network SDK that enhances LLM prompts with integrated advertisements.
## Official Documentation
Full documentation is available at:
https://adstract-ai.github.io/adstract-documentation/
## Install
```bash
pip install adstractai
```
## Quickstart
```python
from adstractai import Adstract
from adstractai.models import AdRequestConfiguration
client = Adstract(api_key="adpk_live_123")
result = client.request_ad_or_default(
prompt="How do I improve analytics in my LLM app?",
config=AdRequestConfiguration(
session_id="sess-1",
user_agent=(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
),
x_forwarded_for="192.168.1.1",
),
)
# Enhanced prompt with integrated ads or original prompt on failure
print(result.prompt)
client.close()
```
## Authentication
Pass an API key when initializing the client or set `ADSTRACT_API_KEY`.
```bash
export ADSTRACT_API_KEY="adpk_live_123"
```
```python
from adstractai import Adstract
client = Adstract()
```
## Required Parameters
All ad enhancement methods require both `user_agent`, `x_forwarded_for`, and a
`session_id`. Missing any required value will return an `EnhancementResult` with
`success=False` and a `MissingParameterError` in `error`.
```python
from adstractai import Adstract
from adstractai.errors import MissingParameterError
from adstractai.models import AdRequestConfiguration
client = Adstract(api_key="adpk_live_123")
result = client.request_ad_or_default(
prompt="Test prompt",
config=AdRequestConfiguration(
session_id="sess-1",
user_agent="", # Empty user_agent
x_forwarded_for="192.168.1.1",
),
)
if isinstance(result.error, MissingParameterError):
print(f"Error: {result.error}")
```
## Available Methods
- `request_ad_or_default()` - Returns enhanced prompt or original prompt on failure
- `request_ad_or_default_async()` - Async version with fallback behavior
## Async usage
```python
import asyncio
from adstractai import Adstract
from adstractai.models import AdRequestConfiguration
async def main() -> None:
client = Adstract(api_key="adpk_live_123")
result = await client.request_ad_or_default_async(
prompt="Need performance tips",
config=AdRequestConfiguration(
session_id="sess-99",
user_agent=(
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
),
x_forwarded_for="192.0.2.1",
),
)
print(result.prompt)
await client.aclose()
asyncio.run(main())
```
| text/markdown | null | Nikola Jagurinoski <jagurinoskini@gmail.com>, Viktor Kostadinoski <kostadinoskiviktor@yahoo.com>, Andrea Stevanoska <andrea.stevanoska2@gmail.com>, Darko Petrushevski <petrusevskidare@gmail.com>, Gorazd Filpovski <gorazdfilipovski@gmail.com> | null | null | Adstract SDK Proprietary License | ad-network, ad-serving, ads, llm | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pytho... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.27.0",
"pydantic>=2.0.0",
"build>=1.2.1; extra == \"dev\"",
"pre-commit>=3.7.1; extra == \"dev\"",
"pyright>=1.1.376; extra == \"dev\"",
"pytest>=8.2.2; extra == \"dev\"",
"ruff>=0.6.5; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/Adstract-AI/adstract-library",
"Repository, https://github.com/Adstract-AI/adstract-library",
"Issues, https://github.com/Adstract-AI/adstract-library/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:49:00.411449 | adstractai-0.3.0.tar.gz | 16,134 | 7d/75/2b75f29bc36ac61ebc12b08757f6e1f8f69bdf64e272ab2b007d2a00005b/adstractai-0.3.0.tar.gz | source | sdist | null | false | 205522c2b96b333ff634f16b6fd35e3c | c5c3e618ee5df832ff6d2c87ea91adfa36dd0b2866fdeec0b43b165db8c975a2 | 7d752b75f29bc36ac61ebc12b08757f6e1f8f69bdf64e272ab2b007d2a00005b | null | [
"LICENSE"
] | 267 |
2.4 | pz-rail-yaw | 2.0.0 | Wrapper around the yet_another_wizz clustering redshift code for RAIL | 
[](https://pypi.org/project/pz-rail-yaw/)
[](https://github.com/LSSTDESC/rail_yaw/actions/workflows/smoke-test.yml)
[](https://codecov.io/gh/LSSTDESC/rail_yaw)
[](https://lincc-ppt.readthedocs.io/en/latest/)
# pz-rail-yaw
This is a wrapper to integrate the clustering redshift code *yet_another_wizz*
(YAW) into [RAIL](https://github.com/LSSTDESC/RAIL):
- code: https://github.com/jlvdb/yet_another_wizz.git
- docs: https://yet-another-wizz.readthedocs.io/
- PyPI: https://pypi.org/project/yet_another_wizz/
- Docker: https://hub.docker.com/r/jlvdb/yet_another_wizz/
**Original publication:** https://arxiv.org/abs/2007.01846
## Installation
This package can be either installed with the RAIL base package *(recommended)*
or explicitly with
pip install pz-rail-yaw
## About this wrapper
The wrapper closely resembles the structure and functionality of YAW by
implementing four different RAIL stages:
- *YawCacheCreate*, which implements the spatial patches of YAW data catalogues,
- *YawAutoCorrelate*/*YawCrossCorrelate*, which implement the expensive pair
counting of the correlation measurements, and
- *YawSummarize*, which transforms the pair counts to a redshift estimate with
an optional mitigation for galaxy sample bias.
The repository includes an extensive example notebook
examples/full_example.ipynb
with further documentation and an example `ceci` pipeline
src/rail/pipelines/estimation/yaw_pipeline.yml
for procesing large and/or more complex data sets.
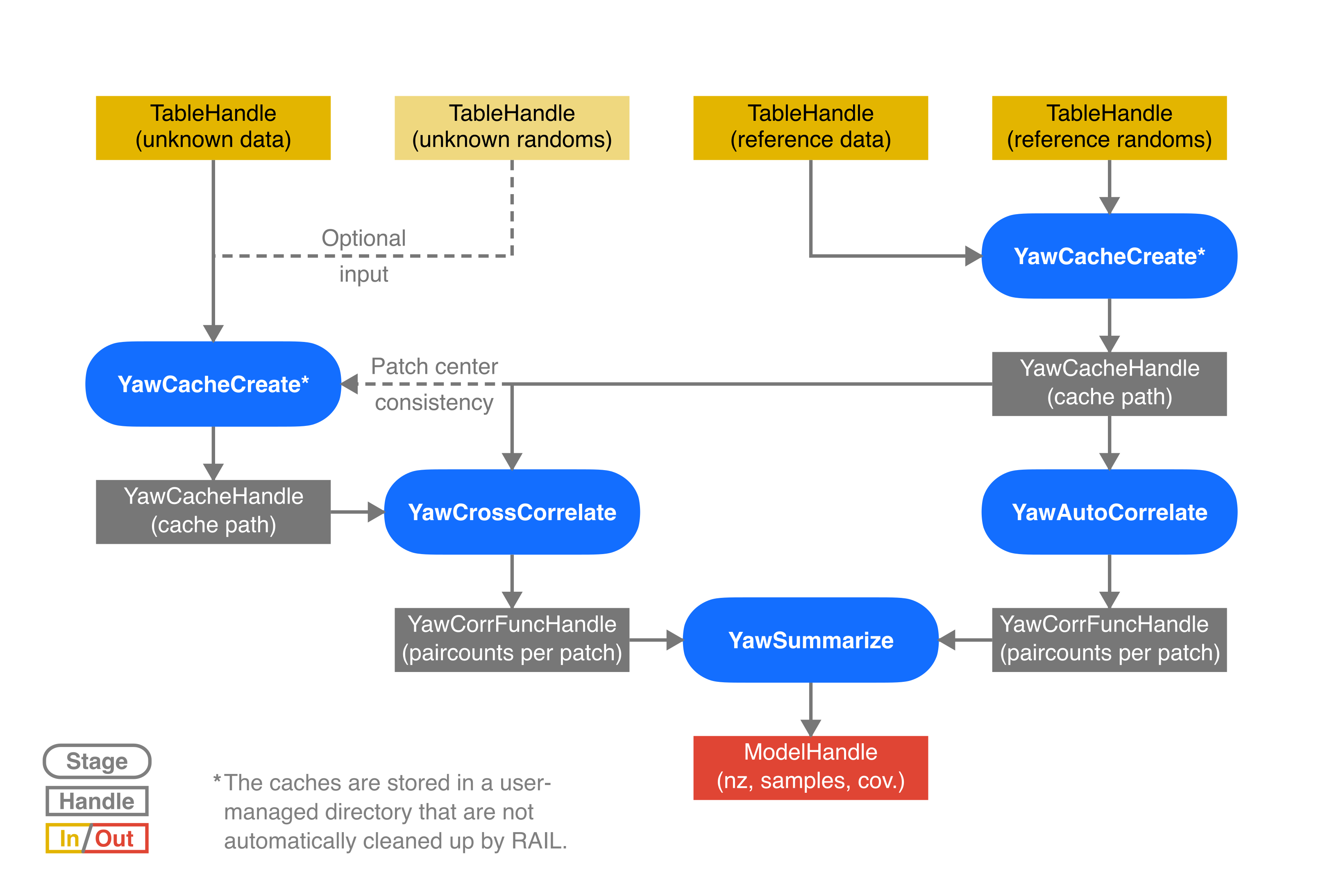
## RAIL: Redshift Assessment Infrastructure Layers
This package is part of the larger ecosystem of Photometric Redshifts
in [RAIL](https://github.com/LSSTDESC/RAIL).
### Citing RAIL
This code, while public on GitHub, has not yet been released by DESC and is
still under active development. Our release of v1.0 will be accompanied by a
journal paper describing the development and validation of RAIL.
If you make use of the ideas or software in RAIL, please cite the repository
<https://github.com/LSSTDESC/RAIL>. You are welcome to re-use the code, which
is open source and available under terms consistent with the MIT license.
External contributors and DESC members wishing to use RAIL for non-DESC projects
should consult with the Photometric Redshifts (PZ) Working Group conveners,
ideally before the work has started, but definitely before any publication or
posting of the work to the arXiv.
### Citing this package
If you use this package, you should also cite the appropriate papers for each
code used. A list of such codes is included in the
[Citing RAIL](https://rail-hub.readthedocs.io/en/latest/source/citing.html)
section of the main RAIL Read The Docs page.
| text/markdown | null | "LSST Dark Energy Science Collaboration (DESC)" <lsst-desc-rail-admin@slac.stanford.edu> | null | null | MIT License
Copyright (c) 2023 LSST Dark Energy Science Collaboration (DESC)
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| null | [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: MIT License",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy",
"h5py",
"pandas",
"pz-rail-base>=2.0.0-dev",
"yet_another_wizz>=3.1.0",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest-skip-slow; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"pylint; extra == \"dev\"",
"black; extra == \"dev\"",
"nbconvert; extra == \"dev\"... | [] | [] | [] | [
"Repository, https://github.com/LSSTDESC/rail_yaw.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:48:54.231263 | pz_rail_yaw-2.0.0.tar.gz | 29,235 | 58/cc/fd060ca14f7f023c02cbb7295eb48642f9dade6b875287290c8bc28a1e6d/pz_rail_yaw-2.0.0.tar.gz | source | sdist | null | false | 193ee5c28e54850205a273fd6a203bae | e43411bc1a9d3c32fe4ad217db7003dbd2601ccf4b04376155313a88aff69da4 | 58ccfd060ca14f7f023c02cbb7295eb48642f9dade6b875287290c8bc28a1e6d | null | [
"LICENSE"
] | 407 |
2.4 | circulax | 0.1.0 | Differentiable circuit simulator based on JAX | # **Circulax**
<img src="docs/images/logo_white.svg" alt="logo" width="500">
## **A Differentiable, Functional Circuit Simulator based on JAX**
Circulax is a differentiable circuit simulation framework built on [JAX](https://docs.jax.dev/en/latest/notebooks/thinking_in_jax.html), [Optimistix](https://github.com/patrick-kidger/optimistix) and [Diffrax](https://docs.kidger.site/diffrax/). It treats circuit netlists as systems of Ordinary Differential Equations (ODEs), leveraging Diffrax's suite of numerical solvers for transient analysis.
By using JAX as its backend, circulax provides:
**Native Differentiation**: Full support for forward and reverse-mode automatic differentiation through the solver, enabling gradient-based parameter optimization and inverse design.
**Hardware Acceleration**: Seamless execution on CPU, GPU, and TPU without code changes.
**Mixed-Domain Support**: Native complex-number handling for simultaneous simulation of electronic and photonic components.
**Modular Architecture**: A functional approach to simulation that integrates directly into machine learning and scientific computing workflows.
Standard tools (SPICE, Spectre, Ngspice) rely on established matrix stamping methods and CPU-bound sparse solvers. circulax leverages the JAX ecosystem to offer specific advantages in optimization and hardware utilization:
| Feature | Legacy(SPICE) | circulax |
| ----------- | ----------- | ----------- |
| Model Definition | Hardcoded C++ / Verilog-A | Simple python functions |
| Derivatives | Hardcoded (C) or Compiler-Generated (Verilog-A) | Automatic Differentiation (AD)|
| Solver Logic | Fixed-step or heuristic-based | Adaptive ODE stepping via Diffrax |
| Matrix Solver | Monolithic CPU Sparse (KLU) | Pluggable ([KLUJAX](https://github.com/flaport/klujax), Dense, or Custom) |
| Hardware Target | CPU-bound | Agnostic (CPU/GPU/TPU) |
## **Simulator setup**
circulax strictly separates Physics, Topology, and Analysis, enabling the interchange of solvers or models without netlist modification.
### **Physics Layer**
Components are defined as simple Python functions wrapped with the ```@component``` decorator. This functional interface abstracts away the boilerplate, allowing users to define physics using simple voltage/current/field/flux relationships.
```python
from circulax.base_component import component, Signals, States
import jax.numpy as jnp
@component(ports=("p1", "p2"))
def Resistor(signals: Signals, s: States, R: float = 1e3):
"""Ohm's Law: I = V/R"""
# signals.p1, signals.p2 are the nodal voltages
i = (signals.p1 - signals.p2) / R
# Return (Currents, Charges)
return {"p1": i, "p2": -i}, {}
@component(ports=("p1", "p2"))
def Capacitor(signals: Signals, s: States, C: float = 1e-12):
"""
Q = C * V.
Returns Charge (q) so the solver computes I = dq/dt.
"""
v_drop = signals.p1 - signals.p2
q_val = C * v_drop
return {}, {"p1": q_val, "p2": -q_val}
```
### **Topology**
The compiler inspects your netlist and your model signatures. It automatically:
1. Introspects models to determine how many internal variables (currents) they need.
2. Allocates indices in the global state vector.
3. Pre-calculates the Sparse Matrix indices (BCOO format) for batched/parallel assembly.
```python
netlist = [
Instance("V1", voltage_source, connections=[1, 0], params={"V": 5.0}),
Instance("R1", resistor, connections=[1, 2], params={"R": 100.0}),
]
# Compiler auto-detects that V1 needs an extra internal variable!
```
### **Analysis**
The solver is a generic DAE engine linking Diffrax (Time-stepping) and Optimistix (Root-finding).
* Transient: Solves $F(y) + \frac{d}{dt}Q(y) = 0$ using Implicit Backward Euler (or any other solver compatible with Diffrax).
* DC Operating Point: Solves $F(y) = 0$ (automatically ignoring $Q$).
* Jacobian-Free: The solver builds the system Jacobian on-the-fly using ```jax.jacfwd``` allowing for the simulation of arbitrary user-defined non-linearities without manual derivative derivation.The approach results in a more exact and stable simulation.
## **Installation**
```sh
pip install circulax
```
## **Simulation Example**
```python
import jax
import jax.numpy as jnp
from circulax.components import Resistor, Capacitor, Inductor, VoltageSource
from circulax.compiler import compile_netlist
import matplotlib.pyplot as plt
jax.config.update("jax_enable_x64", True)
net_dict = {
"instances": {
"GND": {"component":"ground"},
"V1": {"component":"source_voltage", "settings":{"V": 1.0,"delay":0.25E-9}},
"R1": {"component":"resistor", "settings":{"R": 10.0}},
"C1": {"component":"capacitor", "settings":{"C": 1e-11}},
"L1": {"component":"inductor", "settings":{"L": 5e-9}},
},
"connections": {
"GND,p1": ("V1,p2", "C1,p2"),
"V1,p1": "R1,p1",
"R1,p2": "L1,p1",
"L1,p2": "C1,p1",
},
}
models_map = {
'resistor': Resistor,
'capacitor': Capacitor,
'inductor': Inductor,
'source_voltage': VoltageSource,
'ground': lambda: 0
}
# Analyze Circuit
groups, sys_size, port_map = compile_netlist(net_dict, models_map)
linear_strat = analyze_circuit(groups, sys_size, is_complex=False)
# Solve DC
y_guess = jnp.zeros(sys_size)
y_op = linear_strat.solve_dc(groups,y_guess)
# Setup Sim
transient_sim = setup_transient(groups=groups, linear_strategy=linear_strat)
term = diffrax.ODETerm(lambda t, y, args: jnp.zeros_like(y))
# Run simulation
t_max = 3E-9
saveat = diffrax.SaveAt(ts=jnp.linspace(0, t_max, 500))
sol = transient_sim(
t0=0.0, t1=t_max, dt0=1e-3*t_max,
y0=y_op,
saveat=saveat, max_steps=100000,
progress_meter=diffrax.TqdmProgressMeter(refresh_steps=100)
)
# Post processing and plotting
ts = sol.ts
v_src = sol.ys[:, port_map["V1,p1"]]
v_cap = sol.ys[:, port_map["C1,p1"]]
i_ind = sol.ys[:, 5]
fig, ax1 = plt.subplots(figsize=(8, 5))
ax1.plot(ts, v_src, 'k--', label='Source V')
ax1.plot(ts, v_cap, 'b-', label='Capacitor V')
ax1.set_xlabel('Time (s)')
ax1.set_ylabel('Voltage (V)')
ax1.legend(loc='upper left')
ax2 = ax1.twinx()
ax2.plot(ts, i_ind, 'r:', label='Inductor I')
ax2.set_ylabel('Current (A)')
ax2.legend(loc='upper right')
ax2_ticks = ax2.get_yticks()
ax1_ticks = ax1.get_yticks()
ax2.set_yticks(jnp.linspace(ax2_ticks[0], ax2_ticks[-1], len(ax1_ticks)))
ax1.set_yticks(jnp.linspace(ax1_ticks[0], ax1_ticks[-1], len(ax1_ticks)))
plt.title("Impulse Response of LCR circuit")
plt.grid(True)
plt.show()
```

## **License**
Copyright © 2026, Chris Daunt, [Apache-2.0 License](https://github.com/cdaunt/circulax/blob/master/LICENSE)
| text/markdown | null | Chris Daunt <chris.ll.m.daunt@gmail.com> | null | null | Apache-2.0 | circuit, differentiable, jax, photonics, simulation | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"diffrax<0.8,>=0.7.0",
"jax<0.8,>=0.7.1",
"jaxlib<0.8,>=0.7.1",
"klujax>=0.4.8",
"lineax",
"matplotlib",
"numpy",
"sax<0.16,>=0.15.15",
"typing-extensions>=4.13.2",
"black; extra == \"dev\"",
"hippogriffe==0.2.2; extra == \"dev\"",
"ipykernel>=6.29.5; extra == \"dev\"",
"mkautodoc>=0.2.0; ex... | [] | [] | [] | [
"Homepage, https://github.com/cdaunt/circulax",
"Repository, https://github.com/cdaunt/circulax",
"Documentation, https://cdaunt.github.io/circulax",
"Issues, https://github.com/cdaunt/circulax/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:48:11.860754 | circulax-0.1.0.tar.gz | 203,360 | 79/b6/0bb59eb9fbae0667f447620710a6e6bcc65602ccdbd7e8d2f97f82942f2f/circulax-0.1.0.tar.gz | source | sdist | null | false | bb985768d73b5c3723dbdb5afda92ae3 | fa449c4154600de3731d645cdffc7738c60318dc9830f1045533f1500fb2cd74 | 79b60bb59eb9fbae0667f447620710a6e6bcc65602ccdbd7e8d2f97f82942f2f | null | [
"LICENSE"
] | 272 |
2.4 | danjangomdx | 0.0.1 | markdown extensions for django | This is a shell
| text/markdown | null | Dan Aukes <danaukes@danaukes.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T20:46:31.458002 | danjangomdx-0.0.1.tar.gz | 1,753 | a1/b5/0c4534c902228aabce6d658d62e10aaf5adc15d5cb0f93588b63aebf1402/danjangomdx-0.0.1.tar.gz | source | sdist | null | false | ed119e9734842aeb919fa9b4ebff58e4 | f6f6c87c768f45e057a2ffbe753655675971ff47d9eda66d9338e202bdbd6039 | a1b50c4534c902228aabce6d658d62e10aaf5adc15d5cb0f93588b63aebf1402 | null | [] | 278 |
2.4 | mkdocs-material-ekgf | 0.0.25 | A custom Material for MkDocs theme for EKGF documentation websites | # MkDocs Material EKGF Theme
[](https://pypi.org/project/mkdocs-material-ekgf/)
[](https://pypi.org/project/mkdocs-material-ekgf/)
[](https://creativecommons.org/licenses/by-sa/4.0/)
[](https://github.com/EKGF/mkdocs-material-ekgf/actions/workflows/ci.yml)
[](https://pypi.org/project/mkdocs-material-ekgf/)
A custom Material for MkDocs theme for EKGF (Enterprise Knowledge
Graph Forum) documentation websites.
## Features
- **Custom Header**: Three-row layout with EKGF logo, centered site
title, and OMG branding
- **Enhanced Footer**: Matches ekgf.org design with comprehensive
navigation and social links
- **Advanced Card Components**:
- Process cards with hero images
- Theme cards with 4-column responsive layout
- Objective badges for visual hierarchy
- **Integrated Search**: Custom search box in navigation tabs
- **Dark/Light Mode**: Full theme support with cross-subdomain cookie
sync
- **SEO Optimized**: Comprehensive meta tags, Open Graph, Twitter
Cards, and JSON-LD structured data
- **Responsive Design**: Mobile-first approach with optimizations
## Installation
```bash
uv add mkdocs-material-ekgf
```
## Usage
### Basic Configuration
In your `mkdocs.yml`:
```yaml
theme:
name: material
# No custom_dir needed! The plugin handles it.
palette:
- media: "(prefers-color-scheme: light)"
scheme: default
primary: indigo
accent: light-blue
toggle:
icon: material/weather-night
name: Switch to dark mode
- media: "(prefers-color-scheme: dark)"
scheme: slate
primary: indigo
accent: deep orange
toggle:
icon: material/weather-sunny
name: Switch to light mode
plugins:
- material-ekgf
- search
```
## Enhanced Card Layouts
### Process Cards
```markdown
<div class="grid cards process-cards" markdown>
- <div class="process-card-header process-card-plan">
:material-file-document-outline:{ .lg }
<div class="process-card-title">
<strong>[Plan](plan/)</strong>
<span class="process-card-subtitle">Design Your EKG</span>
</div>
</div>
---
Define your use cases and identify knowledge assets...
</div>
```
### Theme Cards
```markdown
<div class="grid cards theme-cards" markdown>
- <div class="theme-card-header theme-card-transparency">
:material-eye-outline:{ .lg }
<div class="theme-card-title">
<strong>[Transparency](theme/transparency/)</strong>
</div>
</div>
Clear visibility into data, processes, and decisions...
[Learn more](theme/transparency/)
</div>
```
## Design Principles
This theme implements the EKGF design language:
- **Consistent Branding**: EKGF and OMG logos across all sites
- **Professional Aesthetics**: Clean, modern design matching ekgf.org
- **Enhanced Readability**: Optimized typography and spacing
- **Accessibility**: WCAG 2.1 AA compliant
- **Performance**: Optimized assets and minimal JavaScript
## Development
### Local Development
```bash
git clone https://github.com/EKGF/mkdocs-material-ekgf.git
cd mkdocs-material-ekgf
uv sync
```
### Testing
Test the theme with a sample MkDocs site:
```bash
cd examples/sample-site
uv run mkdocs serve
```
## License
```text
Copyright © 2026 EDMCouncil Inc., d/b/a Enterprise Data Management Association ("EDMA")
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
```
## Support
For issues, questions, or contributions, please visit:
- [GitHub Issues](https://github.com/EKGF/mkdocs-material-ekgf/issues)
- [EKGF Documentation](https://ekgf.org)
## Acknowledgments
Built on top of [Material for
MkDocs](https://squidfunk.github.io/mkdocs-material/) by Martin
Donath.
| text/markdown | null | Jacobus Geluk <jacobus.geluk@ekgf.org> | null | null | Copyright (c) 2026 EDMCouncil Inc., d/b/a Enterprise Data Management Association ("EDMA")
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
To view a copy of this license, visit http://creativecommons.org/licenses/by-sa/4.0/ or send a letter to
Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
=======================================================================
Attribution-ShareAlike 4.0 International
=======================================================================
Creative Commons Corporation ("Creative Commons") is not a law firm and
does not provide legal services or legal advice. Distribution of
Creative Commons public licenses does not create a lawyer-client or
other relationship. Creative Commons makes its licenses and related
information available on an "as-is" basis. Creative Commons gives no
warranties regarding its licenses, any material licensed under their
terms and conditions, or any related information. Creative Commons
disclaims all liability for damages resulting from their use to the
fullest extent possible.
Using Creative Commons Public Licenses
Creative Commons public licenses provide a standard set of terms and
conditions that creators and other rights holders may use to share
original works of authorship and other material subject to copyright
and certain other rights specified in the public license below. The
following considerations are for informational purposes only, are not
exhaustive, and do not form part of our licenses.
Considerations for licensors: Our public licenses are
intended for use by those authorized to give the public
permission to use material in ways otherwise restricted by
copyright and certain other rights. Our licenses are
irrevocable. Licensors should read and understand the terms
and conditions of the license they choose before applying it.
Licensors should also secure all rights necessary before
applying our licenses so that the public can reuse the
material as expected. Licensors should clearly mark any
material not subject to the license. This includes other CC-
licensed material, or material used under an exception or
limitation to copyright. More considerations for licensors:
wiki.creativecommons.org/Considerations_for_licensors
Considerations for the public: By using one of our public
licenses, a licensor grants the public permission to use the
licensed material under specified terms and conditions. If
the licensor's permission is not necessary for any reason--for
example, because of any applicable exception or limitation to
copyright--then that use is not regulated by the license. Our
licenses grant only permissions under copyright and certain
other rights that a licensor has authority to grant. Use of
the licensed material may still be restricted for other
reasons, including because others have copyright or other
rights in the material. A licensor may make special requests,
such as asking that all changes be marked or described.
Although not required by our licenses, you are encouraged to
respect those requests where reasonable. More considerations
for the public:
wiki.creativecommons.org/Considerations_for_licensees
=======================================================================
Creative Commons Attribution-ShareAlike 4.0 International Public
License
By exercising the Licensed Rights (defined below), You accept and agree
to be bound by the terms and conditions of this Creative Commons
Attribution-ShareAlike 4.0 International Public License ("Public
License"). To the extent this Public License may be interpreted as a
contract, You are granted the Licensed Rights in consideration of Your
acceptance of these terms and conditions, and the Licensor grants You
such rights in consideration of benefits the Licensor receives from
making the Licensed Material available under these terms and
conditions.
Section 1 -- Definitions.
a. Adapted Material means material subject to Copyright and Similar
Rights that is derived from or based upon the Licensed Material
and in which the Licensed Material is translated, altered,
arranged, transformed, or otherwise modified in a manner requiring
permission under the Copyright and Similar Rights held by the
Licensor. For purposes of this Public License, where the Licensed
Material is a musical work, performance, or sound recording,
Adapted Material is always produced where the Licensed Material is
synched in timed relation with a moving image.
b. Adapter's License means the license You apply to Your Copyright
and Similar Rights in Your contributions to Adapted Material in
accordance with the terms and conditions of this Public License.
c. BY-SA Compatible License means a license listed at
creativecommons.org/compatiblelicenses, approved by Creative
Commons as essentially the equivalent of this Public License.
d. Copyright and Similar Rights means copyright and/or similar rights
closely related to copyright including, without limitation,
performance, broadcast, sound recording, and Sui Generis Database
Rights, without regard to how the rights are labeled or
categorized. For purposes of this Public License, the rights
specified in Section 2(b)(1)-(2) are not Copyright and Similar
Rights.
e. Effective Technological Measures means those measures that, in the
absence of proper authority, may not be circumvented under laws
fulfilling obligations under Article 11 of the WIPO Copyright
Treaty adopted on December 20, 1996, and/or similar international
agreements.
f. Exceptions and Limitations means fair use, fair dealing, and/or
any other exception or limitation to Copyright and Similar Rights
that applies to Your use of the Licensed Material.
g. License Elements means the license attributes listed in the name
of a Creative Commons Public License. The License Elements of this
Public License are Attribution and ShareAlike.
h. Licensed Material means the artistic or literary work, database,
or other material to which the Licensor applied this Public
License.
i. Licensed Rights means the rights granted to You subject to the
terms and conditions of this Public License, which are limited to
all Copyright and Similar Rights that apply to Your use of the
Licensed Material and that the Licensor has authority to license.
j. Licensor means the individual(s) or entity(ies) granting rights
under this Public License.
k. Share means to provide material to the public by any means or
process that requires permission under the Licensed Rights, such
as reproduction, public display, public performance, distribution,
dissemination, communication, or importation, and to make material
available to the public including in ways that members of the
public may access the material from a place and at a time
individually chosen by them.
l. Sui Generis Database Rights means rights other than copyright
resulting from Directive 96/9/EC of the European Parliament and of
the Council of 11 March 1996 on the legal protection of databases,
as amended and/or succeeded, as well as other essentially
equivalent rights anywhere in the world.
m. You means the individual or entity exercising the Licensed Rights
under this Public License. Your has a corresponding meaning.
Section 2 -- Scope.
a. License grant.
1. Subject to the terms and conditions of this Public License,
the Licensor hereby grants You a worldwide, royalty-free,
non-sublicensable, non-exclusive, irrevocable license to
exercise the Licensed Rights in the Licensed Material to:
a. reproduce and Share the Licensed Material, in whole or
in part; and
b. produce, reproduce, and Share Adapted Material.
2. Exceptions and Limitations. For the avoidance of doubt, where
Exceptions and Limitations apply to Your use, this Public
License does not apply, and You do not need to comply with
its terms and conditions.
3. Term. The term of this Public License is specified in Section
6(a).
4. Media and formats; technical modifications allowed. The
Licensor authorizes You to exercise the Licensed Rights in
all media and formats whether now known or hereafter created,
and to make technical modifications necessary to do so. The
Licensor waives and/or agrees not to assert any right or
authority to forbid You from making technical modifications
necessary to exercise the Licensed Rights, including
technical modifications necessary to circumvent Effective
Technological Measures. For purposes of this Public License,
simply making modifications authorized by this Section 2(a)
(4) never produces Adapted Material.
5. Downstream recipients.
a. Offer from the Licensor -- Licensed Material. Every
recipient of the Licensed Material automatically
receives an offer from the Licensor to exercise the
Licensed Rights under the terms and conditions of this
Public License.
b. Additional offer from the Licensor -- Adapted Material.
Every recipient of Adapted Material from You
automatically receives an offer from the Licensor to
exercise the Licensed Rights in the Adapted Material
under the conditions of the Adapter's License You apply.
c. No downstream restrictions. You may not offer or impose
any additional or different terms or conditions on, or
apply any Effective Technological Measures to, the
Licensed Material if doing so restricts exercise of the
Licensed Rights by any recipient of the Licensed
Material.
6. No endorsement. Nothing in this Public License constitutes or
may be construed as permission to assert or imply that You
are, or that Your use of the Licensed Material is, connected
with, or sponsored, endorsed, or granted official status by,
the Licensor or others designated to receive attribution as
provided in Section 3(a)(1)(A)(i).
b. Other rights.
1. Moral rights, such as the right of integrity, are not
licensed under this Public License, nor are publicity,
privacy, and/or other similar personality rights; however, to
the extent possible, the Licensor waives and/or agrees not to
assert any such rights held by the Licensor to the limited
extent necessary to allow You to exercise the Licensed
Rights, but not otherwise.
2. Patent and trademark rights are not licensed under this
Public License.
3. To the extent possible, the Licensor waives any right to
collect royalties from You for the exercise of the Licensed
Rights, whether directly or through a collecting society
under any voluntary or waivable statutory or compulsory
licensing scheme. In all other cases the Licensor expressly
reserves any right to collect such royalties.
Section 3 -- License Conditions.
Your exercise of the Licensed Rights is expressly made subject to the
following conditions.
a. Attribution.
1. If You Share the Licensed Material (including in modified
form), You must:
a. retain the following if it is supplied by the Licensor
with the Licensed Material:
i. identification of the creator(s) of the Licensed
Material and any others designated to receive
attribution, in any reasonable manner requested by
the Licensor (including by pseudonym if
designated);
ii. a copyright notice;
iii. a notice that refers to this Public License;
iv. a notice that refers to the disclaimer of
warranties;
v. a URI or hyperlink to the Licensed Material to the
extent reasonably practicable;
b. indicate if You modified the Licensed Material and
retain an indication of any previous modifications; and
c. indicate the Licensed Material is licensed under this
Public License, and include the text of, or the URI or
hyperlink to, this Public License.
2. You may satisfy the conditions in Section 3(a)(1) in any
reasonable manner based on the medium, means, and context in
which You Share the Licensed Material. For example, it may be
reasonable to satisfy the conditions by providing a URI or
hyperlink to a resource that includes the required
information.
3. If requested by the Licensor, You must remove any of the
information required by Section 3(a)(1)(A) to the extent
reasonably practicable.
b. ShareAlike.
In addition to the conditions in Section 3(a), if You Share
Adapted Material You produce, the following conditions also apply.
1. The Adapter's License You apply must be a Creative Commons
license with the same License Elements, this version or
later, or a BY-SA Compatible License.
2. You must include the text of, or the URI or hyperlink to, the
Adapter's License You apply. You may satisfy this condition
in any reasonable manner based on the medium, means, and
context in which You Share Adapted Material.
3. You may not offer or impose any additional or different terms
or conditions on, or apply any Effective Technological
Measures to, Adapted Material that restrict exercise of the
rights granted under the Adapter's License You apply.
Section 4 -- Sui Generis Database Rights.
Where the Licensed Rights include Sui Generis Database Rights that
apply to Your use of the Licensed Material:
a. for the avoidance of doubt, Section 2(a)(1) grants You the right
to extract, reuse, reproduce, and Share all or a substantial
portion of the contents of the database;
b. if You include all or a substantial portion of the database
contents in a database in which You have Sui Generis Database
Rights, then the database in which You have Sui Generis Database
Rights (but not its individual contents) is Adapted Material,
including for purposes of Section 3(b); and
c. You must comply with the conditions in Section 3(a) if You Share
all or a substantial portion of the contents of the database.
For the avoidance of doubt, this Section 4 supplements and does not
replace Your obligations under this Public License where the Licensed
Rights include other Copyright and Similar Rights.
Section 5 -- Disclaimer of Warranties and Limitation of Liability.
a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
c. The disclaimer of warranties and limitation of liability provided
above shall be interpreted in a manner that, to the extent
possible, most closely approximates an absolute disclaimer and
waiver of all liability.
Section 6 -- Term and Termination.
a. This Public License applies for the term of the Copyright and
Similar Rights licensed here. However, if You fail to comply with
this Public License, then Your rights under this Public License
terminate automatically.
b. Where Your right to use the Licensed Material has terminated under
Section 6(a), it reinstates:
1. automatically as of the date the violation is cured, provided
it is cured within 30 days of Your discovery of the
violation; or
2. upon express reinstatement by the Licensor.
For the avoidance of doubt, this Section 6(b) does not affect any
right the Licensor may have to seek remedies for Your violations
of this Public License.
c. For the avoidance of doubt, the Licensor may also offer the
Licensed Material under separate terms or conditions or stop
distributing the Licensed Material at any time; however, doing so
will not terminate this Public License.
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
License.
Section 7 -- Other Terms and Conditions.
a. The Licensor shall not be bound by any additional or different
terms or conditions communicated by You unless expressly agreed.
b. Any arrangements, understandings, or agreements regarding the
Licensed Material not stated herein are separate from and
independent of the terms and conditions of this Public License.
Section 8 -- Interpretation.
a. For the avoidance of doubt, this Public License does not, and
shall not be interpreted to, reduce, limit, restrict, or impose
conditions on any use of the Licensed Material that could lawfully
be made without permission under this Public License.
b. To the extent possible, if any provision of this Public License is
deemed unenforceable, it shall be automatically reformed to the
minimum extent necessary to make it enforceable. If the provision
cannot be reformed, it shall be severed from this Public License
without affecting the enforceability of the remaining terms and
conditions.
c. No term or condition of this Public License will be waived and no
failure to comply consented to unless expressly agreed to by the
Licensor.
d. Nothing in this Public License constitutes or may be interpreted
as a limitation upon, or waiver of, any privileges and immunities
that apply to the Licensor or You, including from the legal
processes of any jurisdiction or authority.
=======================================================================
Creative Commons is not a party to its public
licenses. Notwithstanding, Creative Commons may elect to apply one of
its public licenses to material it publishes and in those instances
will be considered the “Licensor.” The text of the Creative Commons
public licenses is dedicated to the public domain under the CC0 Public
Domain Dedication. Except for the limited purpose of indicating that
material is shared under a Creative Commons public license or as
otherwise permitted by the Creative Commons policies published at
creativecommons.org/policies, Creative Commons does not authorize the
use of the trademark "Creative Commons" or any other trademark or logo
of Creative Commons without its prior written consent including,
without limitation, in connection with any unauthorized modifications
to any of its public licenses or any other arrangements,
understandings, or agreements concerning use of licensed material. For
the avoidance of doubt, this paragraph does not form part of the
public licenses.
Creative Commons may be contacted at creativecommons.org.
| null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.14",
"Topic :: Documentation",
"Topic :: Software Development :: Documentation"
] | [] | null | null | >=3.14.3 | [] | [] | [] | [
"mkdocs-material>=9.0.0",
"mkdocs<2,>=1.5.0",
"mypy>=1.11.0; extra == \"dev\"",
"pytest>=8.3.0; extra == \"dev\"",
"ruff>=0.15.1; extra == \"dev\"",
"twine>=5.0.0; extra == \"dev\"",
"playwright>=1.58.0; extra == \"social\""
] | [] | [] | [] | [
"Homepage, https://ekgf.org",
"Documentation, https://github.com/EKGF/mkdocs-material-ekgf",
"Repository, https://github.com/EKGF/mkdocs-material-ekgf",
"Issues, https://github.com/EKGF/mkdocs-material-ekgf/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:44:57.813004 | mkdocs_material_ekgf-0.0.25.tar.gz | 95,400 | 77/bc/d0c1c59359f05bd386a0d7eb97bdfad56dba9f6ab56b13751540cf827c74/mkdocs_material_ekgf-0.0.25.tar.gz | source | sdist | null | false | 9df9f47b76781a5e3c19db5b5ec9dd8f | b3d4470b7e49e57edbe95d58f67d218c4fb5d9693d135519f8fd312545bb1680 | 77bcd0c1c59359f05bd386a0d7eb97bdfad56dba9f6ab56b13751540cf827c74 | null | [
"LICENSE"
] | 223 |
2.4 | mcp-proxy-adapter | 6.9.114 | Powerful JSON-RPC microservices framework with built-in security, authentication, proxy registration, queue-backed command execution for long-running operations, and configurable HTTP timeouts for mTLS connections | # MCP Proxy Adapter
**Author:** Vasiliy Zdanovskiy
**Email:** vasilyvz@gmail.com
## Overview
MCP Proxy Adapter is a comprehensive framework for building JSON-RPC API servers with built-in security, SSL/TLS support, and proxy registration capabilities. It provides a unified interface for command execution, protocol management, and security enforcement.
## Features
- **JSON-RPC API**: Full JSON-RPC 2.0 support with built-in commands
- **Security Framework**: Integrated authentication, authorization, and SSL/TLS
- **Protocol Management**: HTTP, HTTPS, and mTLS protocol support
- **Proxy Registration**: Automatic registration with proxy servers
- **Command System**: Extensible command registry with built-in commands
- **Configuration Management**: Comprehensive configuration with environment variable overrides
- **Queue-Backed Commands**: Fire-and-forget execution for long-running operations (NLP pipelines, ML inference, etc.)
- HTTP layer returns `job_id` immediately without blocking
- Heavy processing runs in separate worker processes
- Client polls job status independently without HTTP timeout constraints
- Supports operations that take minutes or hours to complete
## Quick Start
1. **Installation**:
```bash
pip install mcp-proxy-adapter
```
2. **Generate Configuration**:
```bash
# Generate a simple HTTP configuration
adapter-cfg-gen --protocol http --out config.json
# Generate HTTPS configuration with proxy registration
adapter-cfg-gen --protocol https --with-proxy --out config.json
# Generate mTLS configuration with custom certificates
adapter-cfg-gen --protocol mtls \
--server-cert-file ./certs/server.crt \
--server-key-file ./certs/server.key \
--server-ca-cert-file ./certs/ca.crt \
--out config.json
```
3. **Validate Configuration**:
```bash
# Validate configuration file
adapter-cfg-val --file config.json
```
4. **Start Server**:
```bash
# Use the generated configuration
python -m mcp_proxy_adapter --config config.json
# Or use the main CLI
mcp-proxy-adapter config validate --file config.json
mcp-proxy-adapter server --config config.json
```
5. **Access the API**:
- Health check: `GET http://localhost:8000/health`
- JSON-RPC: `POST http://localhost:8000/api/jsonrpc`
- REST API: `POST http://localhost:8000/cmd`
- Documentation: `http://localhost:8000/docs`
## Queue-Backed Commands (Fire-and-Forget Execution)
Starting from version 6.9.96+, mcp-proxy-adapter supports **fire-and-forget execution** for queue-backed commands. This enables reliable handling of long-running operations (NLP pipelines, ML inference, data processing, etc.) without HTTP timeout constraints.
### How It Works
1. **Client submits command** via JSON-RPC or REST API
2. **Server enqueues job** and returns `job_id` immediately (typically < 1 second)
3. **Heavy processing** runs inside a separate queue worker process
4. **Client polls job status** independently using `queue_get_job_status(job_id)`
5. **No HTTP timeout issues** - the initial request completes quickly, and polling uses separate requests
### Client Usage Example
```python
import asyncio
from mcp_proxy_adapter.client.jsonrpc_client.client import JsonRpcClient
async def main():
# For mTLS or slow networks, increase HTTP timeout
client = JsonRpcClient(
protocol="mtls",
host="127.0.0.1",
port=8080,
cert="/path/to/cert.crt",
key="/path/to/key.key",
ca="/path/to/ca.crt",
timeout=60.0, # HTTP client timeout: 60 seconds (default: 30.0)
)
try:
# Execute queue-backed command with automatic polling
result = await client.execute_command_unified(
command="chunk", # Your long-running command
params={"text": "Very long text...", "window": 3},
auto_poll=True, # Automatically poll until completion
poll_interval=1.0, # Check status every 1 second
timeout=600.0, # Overall timeout: 10 minutes
)
print(f"Job completed: {result['status']}")
print(f"Result: {result['result']}")
except TimeoutError:
print("Job did not complete within timeout")
finally:
await client.close()
asyncio.run(main())
```
**Note:** The `timeout` parameter in `JsonRpcClient` controls the HTTP client timeout for all requests (including status polling). For mTLS connections or slow networks, you may need to increase this value. You can also set it via the `MCP_PROXY_ADAPTER_HTTP_TIMEOUT` environment variable.
### HTTP Timeout Configuration
The HTTP client timeout can be configured in three ways (in order of precedence):
1. **Constructor parameter** (highest priority):
```python
client = JsonRpcClient(timeout=60.0) # 60 seconds
```
2. **Environment variable**:
```bash
export MCP_PROXY_ADAPTER_HTTP_TIMEOUT=60.0
```
3. **Default value**: 30.0 seconds (if neither parameter nor environment variable is set)
This timeout applies to all HTTP requests including:
- Command execution
- Status polling (`queue_get_job_status`)
- Health checks
- Proxy registration
For mTLS connections or slow networks, consider increasing the timeout to avoid `httpx.ReadTimeout` errors.
### Server-Side Command Definition
To enable queue execution for a command, set `use_queue = True`:
```python
from mcp_proxy_adapter.commands.base import Command
from mcp_proxy_adapter.commands.result import SuccessResult
class ChunkCommand(Command):
"""Example: Long-running NLP chunking command."""
name = "chunk"
descr = "Chunk long text into smaller pieces"
use_queue = True # CRITICAL: Enable queue execution
@classmethod
def get_schema(cls):
return {
"type": "object",
"properties": {
"text": {"type": "string"},
"window": {"type": "integer", "default": 3},
},
"required": ["text"],
}
async def execute(self, text: str, window: int = 3, **kwargs):
# Heavy processing happens here
# This runs in a separate process, not in HTTP handler
chunks = process_text(text, window)
return SuccessResult(data={"chunks": chunks})
```
### Advanced Features
- **Manual Polling**: Get `job_id` immediately and poll status manually
- **Progress Hooks**: Receive progress updates via callback functions
- **Parallel Execution**: Submit multiple commands and poll them concurrently
- **Error Handling**: Proper handling of job failures, timeouts, and network errors
For detailed examples, see:
- `mcp_proxy_adapter/examples/queue_fire_and_forget_example.py`
- `mcp_proxy_adapter/examples/queue_integration_example.py`
### Requirements
- `mcp-proxy-adapter >= 6.9.96`
- `queuemgr >= 1.0.13` (for configurable control-plane timeouts and `start_job_background` support)
## Nuances
### Configurable public paths (security)
`UnifiedSecurityMiddleware` treats some paths as public (no API key required). By default: `/health`, `/docs`, `/openapi.json`. You can add more via config so that e.g. a WebSocket endpoint is reachable without auth on the HTTP upgrade:
```json
{
"security": {
"enabled": true,
"tokens": { "admin": "your-secret-key" },
"public_paths": ["/health", "/docs", "/openapi.json", "/ws"]
}
}
```
Alternatively use `security.auth.public_paths`. See [docs/EN/USAGE_PUBLIC_PATHS_AND_WEBSOCKET.md](docs/EN/USAGE_PUBLIC_PATHS_AND_WEBSOCKET.md).
### Job status and `job_id`
Commands like `embed_job_status` and `queue_get_job_status` require a `job_id`. The adapter accepts it in **params** or at the **request top level** (for clients that send `job_id` outside `params`). If `job_id` is missing, the adapter returns a clear error instead of forwarding an invalid request.
- Prefer: `{"method": "embed_job_status", "params": {"job_id": "<uuid>"}}`
- Also accepted: `{"method": "embed_job_status", "params": {}, "job_id": "<uuid>"}`
### WebSocket client (push instead of polling)
The client can wait for job completion via a WebSocket channel (`/ws`) instead of polling:
- **One-shot:** `await client.wait_for_job_via_websocket(job_id, timeout=60.0)` — connect, subscribe, return on first terminal event (`job_completed` / `job_failed`).
- **Bidirectional channel:** `open_bidirectional_ws_channel(client)` (or `client.open_bidirectional_ws_channel()`) — use `async with channel`, then `send_json(...)` to send (e.g. subscribe/unsubscribe) and `async for msg in channel.receive_iter(): ...` to consume server events.
Same host, port, auth (X-API-Key or Bearer), and TLS as the JSON-RPC client. Ensure the server exposes `/ws` and includes `/ws` in `security.public_paths` so the upgrade is not blocked.
See [docs/EN/USAGE_PUBLIC_PATHS_AND_WEBSOCKET.md](docs/EN/USAGE_PUBLIC_PATHS_AND_WEBSOCKET.md) for examples and protocol details.
### Running WebSocket client examples locally
To try the WebSocket client examples without a real embed service, start the minimal test server (provides `embed_queue` and `/ws`):
```bash
python examples/run_ws_test_server.py --port 8090
```
Then in another terminal:
```bash
MCP_PORT=8090 python examples/client_websocket_job_status.py
MCP_PORT=8090 python examples/client_bidirectional_websocket.py
```
## Configuration
The adapter uses a comprehensive JSON configuration file (`config.json`) that includes all available options. **All features are disabled by default** and must be explicitly enabled. The configuration system has **NO default values** - all configuration must be explicitly specified.
### Configuration Sections
#### 1. `uuid` (Root Level)
**Type**: `string` (UUID4 format)
**Required**: YES
**Description**: Unique identifier for the server instance
**Format**: `xxxxxxxx-xxxx-4xxx-xxxx-xxxxxxxxxxxx`
```json
{
"uuid": "123e4567-e89b-42d3-a456-426614174000"
}
```
#### 2. `server` Section
**Required**: YES
**Description**: Core server configuration settings
| Field | Type | Required | Description | Allowed Values |
|-------|------|----------|-------------|----------------|
| `host` | string | YES | Server host address | Any valid IP or hostname |
| `port` | integer | YES | Server port number | 1-65535 |
| `protocol` | string | YES | Server protocol | `"http"`, `"https"`, `"mtls"` |
| `debug` | boolean | YES | Enable debug mode | `true`, `false` |
| `log_level` | string | YES | Logging level | `"DEBUG"`, `"INFO"`, `"WARNING"`, `"ERROR"` |
```json
{
"server": {
"host": "0.0.0.0",
"port": 8080,
"protocol": "http",
"debug": false,
"log_level": "INFO"
}
}
```
#### 3. `logging` Section
**Required**: YES
**Description**: Logging configuration settings
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `level` | string | YES | Log level (`"INFO"`, `"DEBUG"`, `"WARNING"`, `"ERROR"`) |
| `log_dir` | string | YES | Directory for log files |
| `log_file` | string | YES | Main log file name |
| `error_log_file` | string | YES | Error log file name |
| `access_log_file` | string | YES | Access log file name |
| `max_file_size` | string/integer | YES | Maximum log file size (`"10MB"` or `10485760`) |
| `backup_count` | integer | YES | Number of backup log files |
| `format` | string | YES | Log message format (Python logging format string) |
| `date_format` | string | YES | Date format for logs |
| `console_output` | boolean | YES | Enable console logging |
| `file_output` | boolean | YES | Enable file logging |
```json
{
"logging": {
"level": "INFO",
"log_dir": "./logs",
"log_file": "mcp_proxy_adapter.log",
"error_log_file": "mcp_proxy_adapter_error.log",
"access_log_file": "mcp_proxy_adapter_access.log",
"max_file_size": "10MB",
"backup_count": 5,
"format": "%(asctime)s - %(name)s - %(levelname)s - %(message)s",
"date_format": "%Y-%m-%d %H:%M:%S",
"console_output": true,
"file_output": true
}
}
```
#### 4. `commands` Section
**Required**: YES
**Description**: Command management configuration
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `auto_discovery` | boolean | YES | Enable automatic command discovery |
| `commands_directory` | string | YES | Directory for command files |
| `catalog_directory` | string | YES | Directory for command catalog |
| `plugin_servers` | array | YES | List of plugin server URLs |
| `auto_install_dependencies` | boolean | YES | Auto-install command dependencies |
| `enabled_commands` | array | YES | List of enabled commands |
| `disabled_commands` | array | YES | List of disabled commands |
| `custom_commands_path` | string | YES | Path to custom commands |
```json
{
"commands": {
"auto_discovery": true,
"commands_directory": "./commands",
"catalog_directory": "./catalog",
"plugin_servers": [],
"auto_install_dependencies": true,
"enabled_commands": ["health", "echo", "help"],
"disabled_commands": [],
"custom_commands_path": "./commands"
}
}
```
#### 5. `transport` Section
**Required**: YES
**Description**: Transport layer configuration
| Field | Type | Required | Description | Allowed Values |
|-------|------|----------|-------------|----------------|
| `type` | string | YES | Transport type | `"http"`, `"https"`, `"mtls"` |
| `port` | integer/null | YES | Transport port (can be null) | 1-65535 or `null` |
| `verify_client` | boolean | YES | Enable client certificate verification | `true`, `false` |
| `chk_hostname` | boolean | YES | Enable hostname checking | `true`, `false` |
**Nested Section**: `transport.ssl` (when SSL/TLS is enabled)
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `enabled` | boolean | Conditional | Enable SSL/TLS |
| `cert_file` | string | Conditional | Path to SSL certificate file |
| `key_file` | string | Conditional | Path to SSL private key file |
| `ca_cert` | string | Optional | Path to CA certificate file |
| `verify_client` | boolean | Optional | Verify client certificates |
| `verify_ssl` | boolean | Optional | Verify SSL certificates |
| `verify_hostname` | boolean | Optional | Verify hostname in certificate |
| `verify_mode` | string | Optional | SSL verification mode: `"CERT_NONE"`, `"CERT_OPTIONAL"`, `"CERT_REQUIRED"` |
```json
{
"transport": {
"type": "https",
"port": 8443,
"verify_client": false,
"chk_hostname": true,
"ssl": {
"enabled": true,
"cert_file": "./certs/server.crt",
"key_file": "./certs/server.key",
"ca_cert": "./certs/ca.crt",
"verify_ssl": true,
"verify_hostname": true,
"verify_mode": "CERT_REQUIRED"
}
}
}
```
#### 6. `ssl` Section (Root Level)
**Required**: Conditional (required for HTTPS/mTLS protocols)
**Description**: SSL/TLS configuration for server
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `enabled` | boolean | YES | Enable SSL/TLS |
| `cert_file` | string | YES | Path to SSL certificate file |
| `key_file` | string | YES | Path to SSL private key file |
| `ca_cert` | string | Optional | Path to CA certificate file (required for mTLS) |
```json
{
"ssl": {
"enabled": true,
"cert_file": "./certs/server.crt",
"key_file": "./certs/server.key",
"ca_cert": "./certs/ca.crt"
}
}
```
#### 7. `proxy_registration` Section
**Required**: YES
**Description**: Proxy server registration configuration
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `enabled` | boolean | YES | Enable proxy registration |
| `proxy_url` | string | YES | Proxy server URL |
| `server_id` | string | YES | Unique server identifier |
| `server_name` | string | YES | Human-readable server name |
| `description` | string | YES | Server description |
| `version` | string | YES | Server version |
| `protocol` | string | Conditional | Registration protocol: `"http"`, `"https"`, `"mtls"` |
| `registration_timeout` | integer | YES | Registration timeout in seconds |
| `retry_attempts` | integer | YES | Number of retry attempts |
| `retry_delay` | integer | YES | Delay between retries in seconds |
| `auto_register_on_startup` | boolean | YES | Auto-register on startup |
| `auto_unregister_on_shutdown` | boolean | YES | Auto-unregister on shutdown |
| `uuid` | string | Optional | UUID for registration (UUID4 format) |
**Nested Section**: `proxy_registration.ssl` (when using HTTPS/mTLS)
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `enabled` | boolean | Conditional | Enable SSL for registration |
| `verify_ssl` | boolean | Conditional | Verify proxy SSL certificate |
| `verify_hostname` | boolean | Conditional | Verify proxy hostname |
| `verify_mode` | string | Conditional | SSL verification mode |
| `ca_cert` | string | Conditional | Path to CA certificate |
| `cert_file` | string | Conditional | Path to client certificate (for mTLS) |
| `key_file` | string | Conditional | Path to client key (for mTLS) |
**Nested Section**: `proxy_registration.heartbeat`
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `enabled` | boolean | Optional | Enable heartbeat |
| `interval` | integer | Optional | Heartbeat interval in seconds |
| `timeout` | integer | Optional | Heartbeat timeout in seconds |
| `retry_attempts` | integer | Optional | Number of retry attempts |
| `retry_delay` | integer | Optional | Delay between retries |
| `url` | string | Optional | Heartbeat endpoint URL |
```json
{
"proxy_registration": {
"enabled": true,
"proxy_url": "https://proxy.example.com:3005",
"server_id": "my-server-001",
"server_name": "My MCP Server",
"description": "Production MCP server",
"version": "1.0.0",
"protocol": "mtls",
"registration_timeout": 30,
"retry_attempts": 3,
"retry_delay": 5,
"auto_register_on_startup": true,
"auto_unregister_on_shutdown": true,
"ssl": {
"enabled": true,
"verify_ssl": true,
"verify_hostname": false,
"verify_mode": "CERT_REQUIRED",
"ca_cert": "./certs/ca.crt",
"cert_file": "./certs/client.crt",
"key_file": "./certs/client.key"
},
"heartbeat": {
"enabled": true,
"interval": 30,
"timeout": 10,
"retry_attempts": 3,
"retry_delay": 5,
"url": "/heartbeat"
}
}
}
```
#### 8. `security` Section
**Required**: YES
**Description**: Security framework configuration
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `enabled` | boolean | YES | Enable security framework |
| `tokens` | object | YES | Token-based authentication configuration |
| `roles` | object | YES | Role-based access control configuration |
| `roles_file` | string/null | YES | Path to roles configuration file |
**Nested Section**: `security.tokens`
| Field | Type | Description |
|-------|------|-------------|
| `admin` | string | Administrator token |
| `user` | string | User token |
| `readonly` | string | Read-only token |
| *(custom)* | string | Custom token names |
**Nested Section**: `security.roles`
| Field | Type | Description |
|-------|------|-------------|
| `admin` | array | Administrator role permissions |
| `user` | array | User role permissions |
| `readonly` | array | Read-only role permissions |
| *(custom)* | array | Custom role names |
```json
{
"security": {
"enabled": true,
"tokens": {
"admin": "admin-secret-key",
"user": "user-secret-key",
"readonly": "readonly-secret-key"
},
"roles": {
"admin": ["*"],
"user": ["health", "echo"],
"readonly": ["health"]
},
"roles_file": null
}
}
```
#### 9. `roles` Section
**Required**: YES
**Description**: Role-based access control configuration
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `enabled` | boolean | YES | Enable RBAC |
| `config_file` | string/null | YES | Path to roles configuration file |
| `default_policy` | object | YES | Default policy settings |
| `auto_load` | boolean | YES | Auto-load roles on startup |
| `validation_enabled` | boolean | YES | Enable role validation |
**Nested Section**: `roles.default_policy`
| Field | Type | Description |
|-------|------|-------------|
| `deny_by_default` | boolean | Deny access by default |
| `require_role_match` | boolean | Require exact role match |
| `case_sensitive` | boolean | Case-sensitive role matching |
| `allow_wildcard` | boolean | Allow wildcard permissions |
```json
{
"roles": {
"enabled": false,
"config_file": null,
"default_policy": {
"deny_by_default": true,
"require_role_match": true,
"case_sensitive": false,
"allow_wildcard": true
},
"auto_load": true,
"validation_enabled": true
}
}
```
#### 10. `debug` Section
**Required**: YES
**Description**: Debug mode configuration
| Field | Type | Required | Description | Allowed Values |
|-------|------|----------|-------------|----------------|
| `enabled` | boolean | YES | Enable debug mode | `true`, `false` |
| `level` | string | YES | Debug level | `"DEBUG"`, `"INFO"`, `"WARNING"`, `"ERROR"` |
```json
{
"debug": {
"enabled": false,
"level": "WARNING"
}
}
```
### Protocol-Specific Requirements
#### HTTP Protocol
**Required Sections**: `server`, `logging`, `commands`, `transport`, `debug`, `security`, `roles`
**SSL Required**: NO
**Client Verification**: NO
#### HTTPS Protocol
**Required Sections**: All sections + `ssl`
**SSL Required**: YES
**Client Verification**: NO
**Required Files**:
- `ssl.cert_file` - Server certificate
- `ssl.key_file` - Server private key
#### mTLS Protocol
**Required Sections**: All sections + `ssl`
**SSL Required**: YES
**Client Verification**: YES
**Required Files**:
- `ssl.cert_file` - Server certificate
- `ssl.key_file` - Server private key
- `ssl.ca_cert` - CA certificate for client verification
### Configuration Validation
The framework automatically validates configuration on load:
- **Required sections**: All mandatory configuration sections are present
- **Required keys**: All required keys within sections are present
- **Type validation**: All values have correct data types
- **File existence**: All referenced files exist (when features are enabled)
- **Feature dependencies**: All feature dependencies are satisfied
- **UUID format**: UUID4 format validation
- **Certificate validation**: Certificate format, expiration, key matching
### Complete Configuration Example
```json
{
"uuid": "123e4567-e89b-42d3-a456-426614174000",
"server": {
"host": "0.0.0.0",
"port": 8080,
"protocol": "mtls",
"debug": false,
"log_level": "INFO"
},
"logging": {
"level": "INFO",
"log_dir": "./logs",
"log_file": "mcp_proxy_adapter.log",
"error_log_file": "mcp_proxy_adapter_error.log",
"access_log_file": "mcp_proxy_adapter_access.log",
"max_file_size": "10MB",
"backup_count": 5,
"format": "%(asctime)s - %(name)s - %(levelname)s - %(message)s",
"date_format": "%Y-%m-%d %H:%M:%S",
"console_output": true,
"file_output": true
},
"commands": {
"auto_discovery": true,
"commands_directory": "./commands",
"catalog_directory": "./catalog",
"plugin_servers": [],
"auto_install_dependencies": true,
"enabled_commands": ["health", "echo", "help"],
"disabled_commands": [],
"custom_commands_path": "./commands"
},
"transport": {
"type": "mtls",
"port": 8443,
"verify_client": true,
"chk_hostname": true,
"ssl": {
"enabled": true,
"cert_file": "./certs/server.crt",
"key_file": "./certs/server.key",
"ca_cert": "./certs/ca.crt",
"verify_ssl": true,
"verify_hostname": true,
"verify_mode": "CERT_REQUIRED"
}
},
"ssl": {
"enabled": true,
"cert_file": "./certs/server.crt",
"key_file": "./certs/server.key",
"ca_cert": "./certs/ca.crt"
},
"proxy_registration": {
"enabled": true,
"proxy_url": "https://proxy.example.com:3005",
"server_id": "my-server-001",
"server_name": "My MCP Server",
"description": "Production MCP server",
"version": "1.0.0",
"protocol": "mtls",
"registration_timeout": 30,
"retry_attempts": 3,
"retry_delay": 5,
"auto_register_on_startup": true,
"auto_unregister_on_shutdown": true,
"ssl": {
"enabled": true,
"verify_ssl": true,
"verify_hostname": false,
"verify_mode": "CERT_REQUIRED",
"ca_cert": "./certs/ca.crt",
"cert_file": "./certs/client.crt",
"key_file": "./certs/client.key"
},
"heartbeat": {
"enabled": true,
"interval": 30,
"timeout": 10,
"retry_attempts": 3,
"retry_delay": 5,
"url": "/heartbeat"
}
},
"debug": {
"enabled": false,
"level": "WARNING"
},
"security": {
"enabled": true,
"tokens": {
"admin": "admin-secret-key",
"user": "user-secret-key",
"readonly": "readonly-secret-key"
},
"roles": {
"admin": ["*"],
"user": ["health", "echo"],
"readonly": ["health"]
},
"roles_file": null
},
"roles": {
"enabled": false,
"config_file": null,
"default_policy": {
"deny_by_default": true,
"require_role_match": true,
"case_sensitive": false,
"allow_wildcard": true
},
"auto_load": true,
"validation_enabled": true
}
}
```
For more detailed configuration documentation, see `docs/EN/ALL_CONFIG_SETTINGS.md`.
### SimpleConfig Format
The framework supports a simplified configuration format (`SimpleConfig`) that provides a minimal, explicit configuration model with three main sections: **server**, **client**, and **registration**. Each section can operate independently with its own protocol (HTTP, HTTPS, or mTLS), certificates, keys, and CRL (Certificate Revocation List).
#### SimpleConfig Structure
```json
{
"server": { ... },
"client": { ... },
"registration": { ... },
"auth": { ... }
}
```
#### 1. `server` Section
**Purpose**: Server endpoint configuration (listening for incoming connections)
| Field | Type | Required | Description | Allowed Values |
|-------|------|----------|-------------|----------------|
| `host` | string | YES | Server host address | Any valid IP or hostname |
| `port` | integer | YES | Server port number | 1-65535 |
| `protocol` | string | YES | Server protocol | `"http"`, `"https"`, `"mtls"` |
| `cert_file` | string | Conditional | Server certificate file path | Valid file path (required for HTTPS/mTLS) |
| `key_file` | string | Conditional | Server private key file path | Valid file path (required for HTTPS/mTLS) |
| `ca_cert_file` | string | Conditional | CA certificate file path | Valid file path (required for mTLS if `use_system_ca=false`) |
| `crl_file` | string | Optional | Certificate Revocation List file path | Valid CRL file path |
| `use_system_ca` | boolean | NO | Allow system CA store when `ca_cert_file` is not provided | `true`, `false` (default: `false`) |
| `log_dir` | string | NO | Directory for log files | Valid directory path (default: `"./logs"`) |
**Protocol Requirements**:
- **HTTP**: No certificates required
- **HTTPS**: `cert_file` and `key_file` are optional but recommended. If one is specified, both must be provided.
- **mTLS**: `cert_file` and `key_file` are required. `ca_cert_file` is required if `use_system_ca=false` (default).
**CRL Validation**:
- If `crl_file` is specified, it must:
- Exist and be accessible
- Be a valid CRL file format (PEM or DER)
- Not be expired (checked against `next_update` field)
- Pass format validation
- If CRL validation fails, the server will log an error and stop
**Example**:
```json
{
"server": {
"host": "0.0.0.0",
"port": 8080,
"protocol": "mtls",
"cert_file": "./certs/server.crt",
"key_file": "./certs/server.key",
"ca_cert_file": "./certs/ca.crt",
"crl_file": "./certs/server.crl",
"use_system_ca": false,
"log_dir": "./logs"
}
}
```
#### 2. `client` Section
**Purpose**: Client configuration (for connecting to external servers)
| Field | Type | Required | Description | Allowed Values |
|-------|------|----------|-------------|----------------|
| `enabled` | boolean | NO | Enable client configuration | `true`, `false` (default: `false`) |
| `protocol` | string | Conditional | Client protocol | `"http"`, `"https"`, `"mtls"` (default: `"http"`) |
| `cert_file` | string | Conditional | Client certificate file path | Valid file path (required for mTLS when enabled) |
| `key_file` | string | Conditional | Client private key file path | Valid file path (required for mTLS when enabled) |
| `ca_cert_file` | string | Conditional | CA certificate file path | Valid file path (required for mTLS if `use_system_ca=false`) |
| `crl_file` | string | Optional | Certificate Revocation List file path | Valid CRL file path |
| `use_system_ca` | boolean | NO | Allow system CA store when `ca_cert_file` is not provided | `true`, `false` (default: `false`) |
**Protocol Requirements**:
- **HTTP**: No certificates required
- **HTTPS**: `cert_file` and `key_file` are optional but recommended. If one is specified, both must be provided.
- **mTLS**: `cert_file` and `key_file` are required when `enabled=true`. `ca_cert_file` is required if `use_system_ca=false` (default).
**CRL Validation**:
- Same validation rules as `server` section
- If `crl_file` is specified and validation fails, the client connection will fail
**Example**:
```json
{
"client": {
"enabled": true,
"protocol": "mtls",
"cert_file": "./certs/client.crt",
"key_file": "./certs/client.key",
"ca_cert_file": "./certs/ca.crt",
"crl_file": "./certs/client.crl",
"use_system_ca": false
}
}
```
#### 3. `registration` Section
**Purpose**: Proxy registration configuration (for registering with proxy server)
| Field | Type | Required | Description | Allowed Values |
|-------|------|----------|-------------|----------------|
| `enabled` | boolean | NO | Enable proxy registration | `true`, `false` (default: `false`) |
| `host` | string | Conditional | Proxy server host | Valid hostname or IP (required when enabled) |
| `port` | integer | Conditional | Proxy server port | 1-65535 (required when enabled, default: `3005`) |
| `protocol` | string | Conditional | Registration protocol | `"http"`, `"https"`, `"mtls"` (default: `"http"`) |
| `server_id` | string | Optional | Server identifier for registration | Valid string (preferred over `server_name`) |
| `server_name` | string | Optional | Legacy server name | Valid string (deprecated, use `server_id`) |
| `cert_file` | string | Conditional | Registration certificate file path | Valid file path (required for mTLS when enabled) |
| `key_file` | string | Conditional | Registration private key file path | Valid file path (required for mTLS when enabled) |
| `ca_cert_file` | string | Conditional | CA certificate file path | Valid file path (required for mTLS if `use_system_ca=false`) |
| `crl_file` | string | Optional | Certificate Revocation List file path | Valid CRL file path |
| `use_system_ca` | boolean | NO | Allow system CA store when `ca_cert_file` is not provided | `true`, `false` (default: `false`) |
| `register_endpoint` | string | NO | Registration endpoint path | Valid path (default: `"/register"`) |
| `unregister_endpoint` | string | NO | Unregistration endpoint path | Valid path (default: `"/unregister"`) |
| `auto_on_startup` | boolean | NO | Auto-register on startup | `true`, `false` (default: `true`) |
| `auto_on_shutdown` | boolean | NO | Auto-unregister on shutdown | `true`, `false` (default: `true`) |
| `heartbeat` | object | NO | Heartbeat configuration | See HeartbeatConfig below |
**Heartbeat Configuration** (`registration.heartbeat`):
| Field | Type | Required | Description | Default |
|-------|------|----------|-------------|---------|
| `endpoint` | string | NO | Heartbeat endpoint path | `"/heartbeat"` |
| `interval` | integer | NO | Heartbeat interval in seconds | `30` |
**Protocol Requirements**:
- **HTTP**: No certificates required
- **HTTPS**: `cert_file` and `key_file` are optional but recommended. If one is specified, both must be provided.
- **mTLS**: `cert_file` and `key_file` are required when `enabled=true`. `ca_cert_file` is required if `use_system_ca=false` (default).
**CRL Validation**:
- Same validation rules as `server` section
- If `crl_file` is specified and validation fails, registration will fail
**Example**:
```json
{
"registration": {
"enabled": true,
"host": "localhost",
"port": 3005,
"protocol": "mtls",
"server_id": "my-server-001",
"cert_file": "./certs/registration.crt",
"key_file": "./certs/registration.key",
"ca_cert_file": "./certs/ca.crt",
"crl_file": "./certs/registration.crl",
"use_system_ca": false,
"register_endpoint": "/register",
"unregister_endpoint": "/unregister",
"auto_on_startup": true,
"auto_on_shutdown": true,
"heartbeat": {
"endpoint": "/heartbeat",
"interval": 30
}
}
}
```
#### 4. `auth` Section
**Purpose**: Authentication and authorization configuration
| Field | Type | Required | Description | Allowed Values |
|-------|------|----------|-------------|----------------|
| `use_token` | boolean | NO | Enable token-based authentication | `true`, `false` (default: `false`) |
| `use_roles` | boolean | NO | Enable role-based authorization | `true`, `false` (default: `false`) |
| `tokens` | object | Conditional | Token-to-role mapping | Object with token strings as keys and role arrays as values (required if `use_token=true`) |
| `roles` | object | Conditional | Role-to-command mapping | Object with role strings as keys and command arrays as values (required if `use_roles=true`) |
**Note**: `use_roles` requires `use_token=true`
**Example**:
```json
{
"auth": {
"use_token": true,
"use_roles": true,
"tokens": {
"admin-secret-key": ["admin"],
"user-secret-key": ["user"],
"readonly-secret-key": ["readonly"]
},
"roles": {
"admin": ["*"],
"user": ["health", "echo"],
"readonly": ["health"]
}
}
}
```
#### Complete SimpleConfig Example
```json
{
"server": {
"host": "0.0.0.0",
"port": 8080,
"protocol": "mtls",
"cert_file": "./certs/server.crt",
"key_file": "./certs/server.key",
"ca_cert_file": "./certs/ca.crt",
"crl_file": "./certs/server.crl",
"use_system_ca": false,
"log_dir": "./logs"
},
"client": {
"enabled": true,
"protocol": "mtls",
"cert_file": "./certs/client.crt",
"key_file": "./certs/client.key",
"ca_cert_file": "./certs/ca.crt",
"crl_file": "./certs/client.crl",
"use_system_ca": false
},
"registration": {
"enabled": true,
"host": "localhost",
"port": 3005,
"protocol": "mtls",
"server_id": "my-server-001",
"cert_file": "./certs/registration.crt",
"key_file": "./certs/registration.key",
"ca_cert_file": "./certs/ca.crt",
"crl_file": "./certs/registration.crl",
"use_system_ca": false,
"register_endpoint": "/register",
"unregister_endpoint": "/unregister",
"auto_on_startup": true,
"auto_on_shutdown": true,
"heartbeat": {
"endpoint": "/heartbeat",
"interval": 30
}
},
"auth": {
"use_token": false,
"use_roles": false,
"tokens": {},
"roles": {}
}
}
```
#### CRL Validation Details
**Certificate Revocation List (CRL)** validation is performed for all sections (`server`, `client`, `registration`) when a `crl_file` is specified:
1. **File Existence**: The CRL file must exist and be accessible
2. **Format Validation**: The file must be a valid CRL in PEM or DER format
3. **Expiration Check**: The CRL must not be expired (checked against the `next_update` field)
4. **Certificate Revocation Check**: If the CRL is valid, certificates are checked against it to ensure they are not revoked
**Error Handling**:
- If CRL file is specified but not found: **Error logged, server stops**
- If CRL file is not a valid CRL format: **Error logged, server stops**
- If CRL is expired: **Error logged, server stops**
- If certificate is revoked according to CRL: **Error logged, server stops**
**CRL Validation Process**:
1. Check file exists → If not: Error and stop
2. Validate CRL format (PEM/DER) → If invalid: Error and stop
3. Check CRL expiration (`next_update`) → If expired: Error and stop
4. Check certificate serial number against CRL → If revoked: Error and stop
#### Generating SimpleConfig
Use the `adapter-cfg-gen` command to generate SimpleConfig files:
```bash
# Generate HTTP configuration
adapter-cfg-gen --protocol http --out config.json
# Generate HTTPS configuration with server certificates
adapter-cfg-gen --protocol https \
--server-cert-file ./certs/server.crt \
--server-key-file ./certs/server.key \
--out config.json
# Generate mTLS configuration with all three sections
adapter-cfg-gen --protocol mtls \
--server-cert-file ./certs/server.crt \
--server-key-file ./certs/server.key \
--server-ca-cert-file ./certs/ca.crt \
--server-crl-file ./certs/server.crl \
--client-enabled \
--client-protocol mtls \
--client-cert-file ./certs/client.crt \
--client-key-file ./certs/client.key \
--client-ca-cert-file ./certs/ca.crt \
--client-crl-file ./certs/client.crl \
--with-proxy \
--registration-protocol mtls \
--registration-cert-file ./certs/registration.crt \
--registration-key-file ./certs/registration.key \
--registration-ca-cert-file ./certs/ca.crt \
--registration-crl-file ./certs/registration.crl \
--out config.json
```
#### Validating SimpleConfig
Use the `adapter-cfg-val` command to validate SimpleConfig files:
```bash
# Validate configuration file
adapter-cfg-val --file config.json
```
The validator checks:
- Required fields are present
- File paths exist and are accessible
- Certificate-key pairs match
- Certificates are not expired
- CRL files are valid and not expired
- Certificates are not revoked according to CRL
- Certificate chains are valid
## Built-in Commands
- `health` - Server health check
- `echo` - Echo test command
- `config` - Configuration management
- `help` - Command help and documentation
- `reload` - Configuration reload
- `settings` - Settings management
- `load`/`unload` - Command loading/unloading
- `plugins` - Plugin management
- `proxy_registration` - Proxy registration control
- `transport_management` - Transport protocol management
- `role_test` - Role-based access testing
## Custom Commands with Queue Execution
Commands that use `use_queue=True` execute in child processes via the queue system. This is essential for:
- **CUDA compatibility**: CUDA requires multiprocessing spawn mode (not fork)
- **Long-running tasks**: Non-blocking execution of time-consuming operations
- **Resource isolation**: Commands run in separate processes
### ⚠️ Critical: Spawn Mode Registration
When using `use_queue=True`, commands execute in **child processes** (spawn mode). Child processes start with a fresh Python interpreter and **do not inherit** the parent process's command registry. You must ensure commands are registered in child processes.
### Registration Methods
#### Method 1: Module-Level Auto-Registration (Recommended)
Register commands automatically when the module is imported:
```python
# In your_command_module.py
from mcp_proxy_adapter.commands.command_registry import registry
from mcp_proxy_adapter.commands.base import Command, CommandResult
class MyQueueCommand(Command):
"""Command that executes via queue."""
name = "my_queue_command"
descr = "My queue command"
use_queue = True # Enab | text/markdown | Vasiliy Zdanovskiy | Vasiliy Zdanovskiy <vasilyvz@gmail.com> | Vasiliy Zdanovskiy | Vasiliy Zdanovskiy <vasilyvz@gmail.com> | MIT | json-rpc, microservices, fastapi, security, authentication, authorization, proxy, mcp, mtls, ssl, rest, api | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python... | [] | https://github.com/maverikod/mcp-proxy-adapter | null | >=3.9 | [] | [] | [] | [
"fastapi<1.0.0,>=0.95.0",
"pydantic>=2.0.0",
"hypercorn<1.0.0,>=0.15.0",
"docstring-parser<1.0.0,>=0.15",
"typing-extensions<5.0.0,>=4.5.0",
"jsonrpc>=1.2.0",
"psutil>=5.9.0",
"mcp_security_framework>=1.5.1",
"flask>=3.1.0",
"packaging>=20.0",
"aiohttp<4.0.0,>=3.8.0",
"httpx>=0.24.0",
"queue... | [] | [] | [] | [
"Homepage, https://github.com/maverikod/mcp-proxy-adapter",
"Documentation, https://github.com/maverikod/mcp-proxy-adapter#readme",
"Source, https://github.com/maverikod/mcp-proxy-adapter",
"Tracker, https://github.com/maverikod/mcp-proxy-adapter/issues",
"PyPI, https://pypi.org/project/mcp-proxy-adapter/"
... | twine/6.2.0 CPython/3.12.3 | 2026-02-18T20:44:46.825910 | mcp_proxy_adapter-6.9.114.tar.gz | 559,265 | a3/f2/29e88d9b390fe0fc1e1b7aa473845746c806997bbcd803d91bc72e13d97e/mcp_proxy_adapter-6.9.114.tar.gz | source | sdist | null | false | 902e9be08f56445e7af53f49f56071b0 | 8fddda0aeec3266137204ae41af9d16b5989289276a39705c22d0816bd6f9bdc | a3f229e88d9b390fe0fc1e1b7aa473845746c806997bbcd803d91bc72e13d97e | null | [] | 298 |
2.4 | rally-tui | 0.8.3 | A TUI for Rally (Broadcom) work item management | # Rally TUI & CLI
<p align="center">
<img src="docs/logo.png" alt="Rally CLI Logo" width="200">
</p>
[](https://github.com/dan-elliott-appneta/rally-cli/actions/workflows/ci.yml)
[](https://pypi.org/project/rally-cli/)
[](https://pypi.org/project/rally-cli/)
A terminal user interface (TUI) and command-line interface (CLI) for browsing and managing Rally (Broadcom) work items.
## Features
### CLI Features (NEW)
- **Query tickets**: `rally-cli tickets --current-iteration --my-tickets`
- **Post comments**: `rally-cli comment S459344 "message"`
- **Multiple output formats**: text, JSON, CSV for scripting
- **Supports all ticket types**: Stories (S/US), Defects (DE), Tasks (TA), Test Cases (TC)
### TUI Features
- Browse Rally tickets in a navigable list
- View ticket details in a split-pane layout
- Keyboard-driven interface with vim-style navigation
- Color-coded ticket types (User Stories, Defects, Tasks, Test Cases)
- **State indicators**: Visual workflow state with symbols (`.` not started, `+` in progress, `-` done, `✓` accepted)
- **Sorting options**: Sort by most recent (default), state flow, owner, or parent (press `o` to cycle)
- **Splash screen**: ASCII art "RALLY TUI" greeting on startup
- **Theme support**: Full Textual theme support (catppuccin, nord, dracula, etc.) via command palette, persisted between sessions
- **Copy URL**: Press `y` to copy Rally ticket URL to clipboard
- **Set Points**: Press `p` to set story points on selected ticket
- **Set State**: Press `s` to change ticket state (Defined, In Progress, Completed, etc.)
- **Parent Requirement**: Must select a parent Feature before moving to "In Progress" state
- **Quick Create**: Press `w` to create a new workitem (User Story or Defect)
- **Toggle Notes**: Press `n` to toggle between description and notes view
- **Assign Owner**: Press `a` to assign a ticket to a team member (individual or bulk)
- **Sprint Filter**: Press `i` to filter tickets by iteration/sprint
- **My Items Filter**: Press `u` to toggle showing only your tickets
- **Team Breakdown**: Press `b` to view ticket count and points breakdown by owner for a sprint
- **Wide View**: Press `v` to toggle wide view mode showing owner, points, and parent columns
- **User settings**: Preferences saved to `~/.config/rally-tui/config.json`
- **Settings UI**: Press `F2` to open settings screen and configure theme, log level, and parent options
- **Keybindings UI**: Press `F3` to view/edit keyboard shortcuts with Vim and Emacs presets
- **File logging**: Logs to `~/.config/rally-tui/rally-tui.log` with configurable log level
- **Log redaction**: Sensitive data (API keys, emails, user names) automatically redacted from logs
- **Default filter**: When connected, shows only tickets in the current iteration owned by you
- **Discussions**: View ticket discussions and add comments
- **Attachments**: Press `A` (Shift+a) to view, download, or upload ticket attachments (includes embedded images from description/notes)
- **Local caching**: Tickets cached to `~/.cache/rally-tui/` for performance and offline access
- **Cache refresh**: Press `r` to manually refresh the ticket cache
- **Loading indicator**: Visual feedback in status bar when fetching tickets from API
- **Async API client**: High-performance httpx-based async Rally client with concurrent operations
- **Project scoping**: All queries are automatically scoped to your project to prevent cross-project data leakage
- **CI pipeline**: GitHub Actions workflow with tests, linting, type checking, and coverage reports
## Status
**Version 0.8.2** - CLI ticket creation, owner assignment, project logo.
### What's New in 0.8.2
- **CLI Ticket Creation**: `rally-cli tickets create "Title" --type UserStory --points 3`
- **Backlog Support**: `--backlog` flag to create tickets without iteration assignment
- **Project Logo**: Added project branding
- **PyPI Release Workflow**: Automated publishing on version tags
### What's New in 0.8.1
- **Owner Assignment**: Press `a` to assign tickets to team members
- **Bulk Owner Assignment**: Select multiple tickets and assign owner via bulk actions
- **Team Breakdown**: Press `b` to view ticket count and points by owner for a sprint
- **Wide View**: Press `v` to toggle expanded list with owner, points, and parent columns
### Feature Summary
- **CLI Interface**: `rally-cli tickets`, `rally-cli comment`, `rally-cli tickets create`
- **TUI**: Two-panel layout with vim navigation, themes, and keyboard customization
- **Bulk Operations**: Multi-select with `Space`, bulk actions with `m` (parent, state, iteration, points, owner, yank)
- **Local Caching**: Stale-while-revalidate for instant startup, press `r` to refresh
- **Sprint Filtering**: Press `i` for iteration picker, `u` for My Items, `b` for team breakdown
- **Discussions & Comments**: View (`d`) and add comments (`c`) on tickets
- **Attachments**: View, download, upload with `A` (Shift+a)
- **Configurable Keybindings**: Vim/Emacs profiles, press `F3` to customize
- **904+ tests** passing across Python 3.11, 3.12, 3.13
See [docs/PLAN.md](docs/PLAN.md) for the full roadmap.
## Requirements
- Python 3.11+
- A modern terminal with color support
## Installation
[](https://pypi.org/project/rally-tui/)
### From PyPI (Recommended)
```bash
# Using pipx (isolated environment - recommended)
pipx install rally-tui
# Or using pip
pip install rally-tui
```
### From Source (Development)
```bash
# Clone the repository
git clone https://github.com/dan-elliott-appneta/rally-cli.git
cd rally-cli
# Create virtual environment
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
# Install in development mode
pip install -e ".[dev]"
```
## Usage
### Check Version
```bash
rally-tui --version
# Output: rally-tui 0.8.2
```
### Running with Rally API
```bash
# Set environment variables
export RALLY_APIKEY=your_api_key_here
export RALLY_WORKSPACE="Your Workspace"
export RALLY_PROJECT="Your Project"
# Run the TUI
rally-tui
```
### Running in Offline Mode
```bash
# Without RALLY_APIKEY, the app runs with sample data
rally-tui
```
### CLI (Command-Line Interface)
In addition to the TUI, rally-cli provides a non-interactive CLI for scripting and automation:
```bash
# Query tickets in current iteration
rally-cli tickets --current-iteration --my-tickets
# Post a comment to a ticket
rally-cli comment S459344 "Deployed to staging"
# Export to JSON for scripting
rally-cli --format json tickets --current-iteration | jq '.data[].formatted_id'
# Export to CSV for spreadsheets
rally-cli --format csv tickets --current-iteration > sprint.csv
```
**Supported ticket prefixes:** `S`, `US` (stories), `DE` (defects), `TA` (tasks), `TC` (test cases)
See [docs/CLI.md](docs/CLI.md) for full CLI documentation.
### Environment Variables
| Variable | Description | Default |
|----------|-------------|---------|
| `RALLY_SERVER` | Rally server hostname | `rally1.rallydev.com` |
| `RALLY_APIKEY` | Rally API key (required for API access) | (none) |
| `RALLY_WORKSPACE` | Workspace name | (from API) |
| `RALLY_PROJECT` | Project name | (from API) |
### Keyboard Navigation
| Key | Context | Action |
|-----|---------|--------|
| Ctrl+P | any | Open command palette |
| j / ↓ | list | Move down |
| k / ↑ | list | Move up |
| g | list | Jump to top |
| G | list | Jump to bottom |
| Space | list | Toggle selection on current ticket |
| Ctrl+A | list | Select all / Deselect all tickets |
| m | list | Open bulk actions menu |
| / | list | Search/filter tickets |
| Enter | list/search | Select item (or confirm search) |
| Esc | any | Clear filter / Go back |
| Tab | list/detail | Switch panel |
| t | any | Toggle dark/light theme |
| y | list/detail | Copy ticket URL to clipboard |
| s | list/detail | Set ticket state |
| p | list/detail | Set story points |
| n | list/detail | Toggle description/notes |
| d | list/detail | Open discussions |
| a | list/detail | Assign owner to ticket |
| A (Shift+a) | list/detail | View/download/upload attachments |
| i | list/detail | Filter by iteration/sprint |
| u | list/detail | Toggle My Items filter |
| o | list | Cycle sort mode (Recent/State/Owner/Parent) |
| b | list | Team breakdown (requires sprint filter) |
| v | list | Toggle wide view mode |
| r | list/detail | Refresh ticket cache |
| w | list/detail | New workitem |
| F2 | any | Open settings |
| F3 | any | Open keybindings |
| c | discussion | Add comment |
| Ctrl+S | comment/settings | Submit/Save |
| q | any | Quit |
### User Settings
Settings are stored in `~/.config/rally-tui/config.json`:
```json
{
"theme": "dark",
"theme_name": "catppuccin-mocha",
"log_level": "INFO",
"parent_options": ["F12345", "F12346", "F12347"],
"keybinding_profile": "vim",
"keybindings": {
"navigation.down": "j",
"navigation.up": "k"
},
"cache_enabled": true,
"cache_ttl_minutes": 5,
"cache_auto_refresh": true
}
```
**Important**: The `parent_options` array must be configured with valid Feature IDs from your Rally workspace. These are shown when selecting a parent for a ticket before moving to "In Progress" state. If not configured, you can still enter a custom Feature ID manually.
**Keybinding Profiles**: `vim` (default), `emacs`, or `custom`. Press F3 to view and edit keybindings.
- Vim profile: j/k navigation, g/G jump, / search
- Emacs profile: Ctrl+n/Ctrl+p navigation, Ctrl+a/Ctrl+e jump
**Cache Settings**:
- `cache_enabled`: Enable/disable local caching (default: true)
- `cache_ttl_minutes`: Cache time-to-live in minutes (default: 5)
- `cache_auto_refresh`: Automatically refresh stale cache in background (default: true)
Cache files are stored in `~/.cache/rally-tui/` and are automatically refreshed when stale. Press `r` to manually refresh.
Available themes: `textual-dark`, `textual-light`, `catppuccin-mocha`, `catppuccin-latte`, `nord`, `gruvbox`, `dracula`, `tokyo-night`, `monokai`, `flexoki`, `solarized-light`
Log levels: `DEBUG`, `INFO`, `WARNING`, `ERROR`, `CRITICAL`
Logs are written to `~/.config/rally-tui/rally-tui.log` with automatic rotation (5MB max, 3 backups).
## Development
### Project Structure
```
rally-cli/
├── pyproject.toml # Project config and dependencies
├── src/rally_tui/ # Main application code
│ ├── app.py # Textual application entry point
│ ├── app.tcss # CSS stylesheet
│ ├── config.py # Rally API config (pydantic-settings)
│ ├── user_settings.py # User preferences (~/.config/rally-tui/)
│ ├── models/
│ │ ├── ticket.py # Ticket dataclass
│ │ ├── discussion.py # Discussion dataclass
│ │ ├── iteration.py # Iteration dataclass
│ │ ├── attachment.py # Attachment dataclass
│ │ └── sample_data.py # Sample data for offline mode
│ ├── screens/
│ │ ├── splash_screen.py # SplashScreen (startup)
│ │ ├── discussion_screen.py # DiscussionScreen
│ │ ├── comment_screen.py # CommentScreen
│ │ ├── points_screen.py # PointsScreen (set story points)
│ │ ├── state_screen.py # StateScreen (change ticket state)
│ │ ├── iteration_screen.py # IterationScreen (filter by sprint)
│ │ ├── parent_screen.py # ParentScreen (select parent Feature)
│ │ ├── config_screen.py # ConfigScreen (edit settings)
│ │ ├── keybindings_screen.py # KeybindingsScreen (edit shortcuts)
│ │ ├── bulk_actions_screen.py # BulkActionsScreen (multi-select operations)
│ │ ├── quick_ticket_screen.py # QuickTicketScreen (create tickets)
│ │ └── attachments_screen.py # AttachmentsScreen (view/download/upload)
│ ├── widgets/
│ │ ├── ticket_list.py # TicketList widget (left panel, state sorting)
│ │ ├── ticket_detail.py # TicketDetail widget (right panel)
│ │ ├── status_bar.py # StatusBar widget (rally-tui banner, project, status)
│ │ └── search_input.py # SearchInput widget (search mode)
│ ├── utils/ # Utility functions
│ │ ├── html_to_text.py # HTML to plain text converter
│ │ ├── logging.py # File-based logging configuration
│ │ └── keybindings.py # Keybinding profiles and utilities
│ └── services/ # Rally API client layer
│ ├── protocol.py # RallyClientProtocol interface
│ ├── rally_client.py # Real Rally API client (sync, pyral)
│ ├── async_rally_client.py # Async Rally API client (httpx)
│ ├── rally_api.py # Rally WSAPI constants and helpers
│ ├── mock_client.py # MockRallyClient for testing
│ ├── async_mock_client.py # AsyncMockRallyClient for testing
│ ├── cache_manager.py # Local file caching for tickets
│ ├── caching_client.py # CachingRallyClient wrapper (sync)
│ └── async_caching_client.py # AsyncCachingRallyClient wrapper
├── tests/
│ ├── conftest.py # Pytest fixtures
│ ├── test_ticket_model.py # Model unit tests
│ ├── test_discussion_model.py # Discussion model tests
│ ├── test_iteration_model.py # Iteration model tests
│ ├── test_ticket_list.py # TicketList widget tests
│ ├── test_ticket_detail.py # TicketDetail widget tests
│ ├── test_splash_screen.py # SplashScreen tests
│ ├── test_discussion_screen.py # DiscussionScreen tests
│ ├── test_comment_screen.py # CommentScreen tests
│ ├── test_points_screen.py # PointsScreen tests
│ ├── test_state_screen.py # StateScreen tests
│ ├── test_iteration_screen.py # IterationScreen tests
│ ├── test_parent_screen.py # ParentScreen tests
│ ├── test_config_screen.py # ConfigScreen tests
│ ├── test_bulk_actions_screen.py # BulkActionsScreen tests
│ ├── test_quick_ticket_screen.py # QuickTicketScreen tests
│ ├── test_attachments_screen.py # AttachmentsScreen tests
│ ├── test_attachment_model.py # Attachment model tests
│ ├── test_filter_integration.py # Filter integration tests
│ ├── test_status_bar.py # StatusBar widget tests
│ ├── test_search_input.py # SearchInput widget tests
│ ├── test_services.py # Service layer tests
│ ├── test_mock_client_discussions.py # MockClient discussion tests
│ ├── test_config.py # Configuration tests
│ ├── test_user_settings.py # User settings tests
│ ├── test_rally_client.py # RallyClient tests
│ ├── test_html_to_text.py # HTML conversion tests
│ ├── test_logging.py # Logging module tests
│ ├── test_keybindings.py # Keybinding utilities tests
│ ├── test_keybindings_screen.py # KeybindingsScreen tests
│ ├── test_cache_manager.py # CacheManager tests
│ ├── test_caching_client.py # CachingRallyClient tests
│ ├── test_rally_api.py # Rally API helpers tests
│ ├── test_async_mock_client.py # AsyncMockRallyClient tests
│ ├── test_app_async_integration.py # App async integration tests
│ └── test_snapshots.py # Visual regression tests
└── docs/
├── API.md # Rally WSAPI reference
├── PLAN.md # Development roadmap
└── ITERATION_*.md # Implementation guides (1-14)
```
### Running Tests
```bash
# Run all tests
pytest
# Run with coverage
pytest --cov=rally_tui
# Update snapshot baselines
pytest --snapshot-update
```
### Continuous Integration
The project uses GitHub Actions for CI. On every PR:
- **Tests**: Run across Python 3.11, 3.12, 3.13
- **Lint**: Ruff check and format verification
- **Type Check**: Mypy static type analysis
- **Coverage**: Reports uploaded to Codecov
All checks must pass before merging.
See [TESTING.md](TESTING.md) for detailed testing documentation.
## Documentation
- [USER.md](docs/USER.md) - **User Manual** - Complete guide to using Rally TUI
- [API.md](docs/API.md) - Rally WSAPI Python developer guide
- [PLAN.md](docs/PLAN.md) - Development roadmap and architecture
- [ITERATION_1.md](docs/ITERATION_1.md) - Iteration 1 implementation guide (complete)
- [ITERATION_2.md](docs/ITERATION_2.md) - Iteration 2 implementation guide (complete)
- [ITERATION_3.md](docs/ITERATION_3.md) - Iteration 3 implementation guide (complete)
- [ITERATION_4.md](docs/ITERATION_4.md) - Iteration 4 implementation guide (complete)
- [ITERATION_5.md](docs/ITERATION_5.md) - Iteration 5 implementation guide (complete)
- [ITERATION_6.md](docs/ITERATION_6.md) - Iteration 6 implementation guide (complete)
- [ITERATION_8.md](docs/ITERATION_8.md) - Iteration 8 implementation guide (Discussions & Comments)
- [ITERATION_9.md](docs/ITERATION_9.md) - Iteration 9 implementation guide (Configurable Keybindings)
- [ITERATION_10.md](docs/ITERATION_10.md) - Iteration 10 implementation guide (Iteration & User Filtering)
- [ITERATION_12.md](docs/ITERATION_12.md) - Iteration 12 implementation guide (Bulk Operations)
- [ITERATION_13.md](docs/ITERATION_13.md) - Iteration 13 implementation guide (Attachments)
- [ITERATION_14.md](docs/ITERATION_14.md) - Iteration 14 implementation guide (Local Caching)
## Technology Stack
- **[Textual](https://textual.textualize.io/)** - Modern Python TUI framework
- **[pyral](https://pyral.readthedocs.io/)** - Rally REST API toolkit (sync)
- **[httpx](https://www.python-httpx.org/)** - Async HTTP client for Rally API
- **[tenacity](https://tenacity.readthedocs.io/)** - Retry logic for API calls
- **[pytest-textual-snapshot](https://github.com/Textualize/pytest-textual-snapshot)** - Visual regression testing
## Versioning
This project uses [Semantic Versioning](https://semver.org/):
- Version is defined in `pyproject.toml`
- Accessible as `rally_tui.__version__` in code
- Displayed with `rally-tui --version`
- Shown on splash screen at startup
Version format: `MAJOR.MINOR.PATCH`
- **MAJOR**: Incompatible API changes
- **MINOR**: New features (backwards compatible)
- **PATCH**: Bug fixes (backwards compatible)
## License
MIT
| text/markdown | Developer | null | null | null | MIT | rally, tui, textual, agile | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"textual>=0.40.0",
"pyral>=1.6.0",
"pydantic-settings>=2.0.0",
"httpx>=0.27.0",
"tenacity>=8.2.0",
"click>=8.1.0",
"pytest>=8.0.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest-textual-snapshot>=0.4.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"ruff>=0.1.... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T20:44:20.734826 | rally_tui-0.8.3.tar.gz | 178,892 | ea/3e/3735b7bc078fed2e6e538b24edb4d43ca47916229bc3851fd69019b54de5/rally_tui-0.8.3.tar.gz | source | sdist | null | false | 13b826af56d36bbbd6ee36172af008f7 | 6a7e61fa0e2f3b2acde80ea271311b9b7a1f7984c6286a860c6aa97478589f4b | ea3e3735b7bc078fed2e6e538b24edb4d43ca47916229bc3851fd69019b54de5 | null | [
"LICENSE.md"
] | 239 |
2.4 | cxblueprint | 0.1.0.post15 | Python DSL for Amazon Connect contact flow generation | # CxBlueprint
[](https://github.com/Pronetx/CxBlueprint/actions/workflows/ci.yml)
[](https://pypi.org/project/cxblueprint/)
[](https://pypi.org/project/cxblueprint/)
Programmatic Amazon Connect contact flow generation using Python. Lets AI models and developers build contact flows from plain English instead of hand-writing JSON.
All 57 AWS Connect block types have been implemented, covering IVR, routing, A/B testing, queue transfer, customer profiles, case management, Voice ID, and analytics patterns. Note that some less common blocks have not been fully validated against live AWS Connect instances. Includes an [MCP server](#mcp-server) for AI-assisted flow generation with Claude Desktop, Cursor, and VS Code.
## Simple Example
```python
from cxblueprint import Flow
flow = Flow.build("Burger Order")
welcome = flow.play_prompt("Welcome to Burger Palace!")
menu = flow.get_input("Press 1 for Classic Burger or 2 for Veggie Burger", timeout=10)
welcome.then(menu)
classic = flow.play_prompt("You selected Classic Burger. Your order is confirmed!")
veggie = flow.play_prompt("You selected Veggie Burger. Your order is confirmed!")
error_msg = flow.play_prompt("Invalid selection. Goodbye.")
disconnect = flow.disconnect()
menu.when("1", classic) \
.when("2", veggie) \
.otherwise(error_msg) \
.on_error("InputTimeLimitExceeded", error_msg) \
.on_error("NoMatchingCondition", error_msg) \
.on_error("NoMatchingError", error_msg)
classic.then(disconnect)
veggie.then(disconnect)
error_msg.then(disconnect)
flow.compile_to_file("burger_order.json")
```
### Terraform Template Example
Use placeholders for dynamic resource ARNs:
```python
from cxblueprint import Flow
flow = Flow.build("Counter Flow")
welcome = flow.play_prompt("Thank you for calling!")
invoke_counter = flow.invoke_lambda(
function_arn="${COUNTER_LAMBDA_ARN}", # Resolved by Terraform
timeout_seconds=8
)
welcome.then(invoke_counter)
say_count = flow.play_prompt("You are caller number $.External.count")
invoke_counter.then(say_count)
disconnect = flow.disconnect()
say_count.then(disconnect)
invoke_counter.on_error("NoMatchingError", disconnect)
flow.compile_to_file("counter_flow.json")
```
## Generated Flow Examples
Here's what the generated flows look like in the Amazon Connect console:


## Installation
```bash
pip install cxblueprint
# With MCP server for AI integration
pip install cxblueprint[mcp]
```
## MCP Server
CxBlueprint includes an MCP server that lets AI tools (Claude Desktop, Cursor, VS Code) build contact flows conversationally.
Configure Claude Desktop (`~/Library/Application Support/Claude/claude_desktop_config.json`):
```json
{
"mcpServers": {
"cxblueprint": {
"command": "cxblueprint-mcp"
}
}
}
```
Then ask Claude: *"Build me an IVR with a welcome message and 3 menu options for sales, support, and billing"*
The AI reads the bundled documentation automatically and uses the MCP tools to generate valid Amazon Connect JSON.
### MCP Tools
| Tool | Description |
|------|-------------|
| `compile_flow` | Compile Python code to AWS Connect JSON |
| `validate_flow` | Validate a flow without compiling |
| `decompile_flow` | Convert existing AWS JSON back to Python |
| `list_block_types` | List all 57 supported block types |
| `get_flow_stats` | Get block counts, error coverage, canvas size |
| `flow_to_mermaid` | Generate a Mermaid flowchart diagram |
## Block Coverage
All 57 AWS block types have been implemented. Core blocks (prompts, input, disconnect, Lambda, Lex, queues, transfers) are well-tested. Some less common blocks (Voice ID, Customer Profiles, Case Management) have not been fully validated against live AWS instances.
| Category | Implemented | Total |
|----------|-------------|-------|
| [Participant Actions](src/cxblueprint/blocks/participant_actions/) | 6 | 6 |
| [Contact Actions](src/cxblueprint/blocks/contact_actions/) | 27 | 27 |
| [Flow Control Actions](src/cxblueprint/blocks/flow_control_actions/) | 16 | 16 |
| [Interactions](src/cxblueprint/blocks/interactions/) | 8 | 8 |
See each category's README for the full per-block breakdown.
## Features
- Fluent Python API for building flows
- MCP server for AI-assisted flow generation (6 tools)
- Mermaid flowchart diagram export (`flow.to_mermaid()`)
- Flow validation and analysis (`flow.validate()`, `flow.stats()`)
- Canvas layout positioning for AWS Connect visual editor
- Automatic UUID generation for blocks
- Conditional branching and error handling
- AWS Lambda and Lex V2 bot integration
- Template placeholder support for Terraform/IaC
- Decompile existing flows back to Python
## Project Structure
```
src/cxblueprint/
flow_builder.py # Main builder API
flow_analyzer.py # Flow validation
canvas_layout.py # Auto-positioning for AWS visual editor
mermaid_export.py # Mermaid flowchart diagram generation
mcp_server.py # MCP server for AI integration (6 tools)
blocks/ # All 57 Connect block types
examples/ # Sample flows
docs/ # API reference & AI instructions
```
## Documentation
- [API Reference](docs/API_REFERENCE.md)
- [Flow Builder Guide](docs/FLOW_BUILDER.md)
- [AI Model Instructions](docs/MODEL_INSTRUCTIONS.md)
- [Terraform Example](terraform_example/README.md)
## Requirements
- Python 3.11+
- AWS credentials (for deployment)
- Terraform (optional, for infrastructure)
| text/markdown | Nicholas Conn | null | null | null | MIT | amazon-connect, ivr, contact-flow, terraform, cdk | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Code Generators",
"Typing :: Typed... | [] | null | null | >=3.11 | [] | [] | [] | [
"mcp>=1.26.0; extra == \"mcp\"",
"fastapi>=0.104.0; extra == \"web\"",
"uvicorn[standard]>=0.24.0; extra == \"web\"",
"httpx>=0.25.0; extra == \"web\""
] | [] | [] | [] | [
"Homepage, https://github.com/Pronetx/CxBlueprint",
"Documentation, https://github.com/Pronetx/CxBlueprint/tree/main/docs",
"Repository, https://github.com/Pronetx/CxBlueprint"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:44:02.621117 | cxblueprint-0.1.0.post15.tar.gz | 519,296 | 8b/9c/bc5b5147eafe9ca4caca252111421827ed56a47dc5f9043b95ba039c45ea/cxblueprint-0.1.0.post15.tar.gz | source | sdist | null | false | dc1d6195044f22b658fd575e1f62b7c0 | 25466b57f856647c09b5b1adfce2e9ed950a391241e59cd4bc9423865566ad53 | 8b9cbc5b5147eafe9ca4caca252111421827ed56a47dc5f9043b95ba039c45ea | null | [] | 243 |
2.4 | strongmind-deployment | 1.1.296 | Deployment tools for Strongmind | # StrongMind Deployment
## What?
Deployment scripts for StrongMind, using Pulumi.
## Development
Write pytest tests for functionality you need. When you need to use this with real AWS resources in a development environment, you'll need to follow these steps.
* Log your shell into the AWS account you're test deploying to (If you don't already have access keys set up, you can find how to do this in the [Amazon SSO portal](https://strongmind.awsapps.com/start#/), under "Programmatic Access")
* Find the relevant container image you're deploying [from ECR](https://us-west-2.console.aws.amazon.com/ecr/repositories?region=us-west-2). (Choose the relevant project container, then the image tag, and then copy the URI field).
* Find the Rails Master Key for that project. Usually this is kept in the [github actions secrets](https://github.com/StrongMind/frozen-desserts/settings/secrets/actions) for that project.
* Get the cloudflare API token and pulumi state passwords from bitwarden if you have access, or get this from devops otherwise.
* Use these to construct an environment in your preferred fashion with the following keys
* CONTAINER_IMAGE
* RAILS_MASTER_KEY
* CLOUDFLARE_API_TOKEN
* PULUMI_CONFIG_PASSPHRASE
* In the project that you are testing with, in the infrastructure directory, there will be a requirements.txt file. In order to use your development code, rather than the published version of this library, you will need to change the line that says "strongmind_deployment" to `-e /path/to/this/directory`, using the directory that this README is located in.
* Reinstall the requirements in your pulumi infrastructure directory. Usually this looks like
```shell
source venv/bin/activate
pip install -r requirements.txt
```
You can now use pulumi commands like `pulumi preview` and `pulumi up` to make changes.
We usually use the [frozen-desserts](https://github.com/StrongMind/frozen-desserts) application to do simple tests of a non-production application. | text/markdown | null | Belding <teambelding@strongmind.com> | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"boto3",
"pulumi",
"pulumi-aws",
"pulumi-awsx",
"pulumi-random",
"setuptools<81"
] | [] | [] | [] | [
"Homepage, https://github.com/strongmind/public-reusable-workflows/tree/main/deployment"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:43:00.787448 | strongmind_deployment-1.1.296-py3-none-any.whl | 54,330 | b7/a4/81b66d0c420fc4da656612878c0c61060a29ea4367859649fbb005735502/strongmind_deployment-1.1.296-py3-none-any.whl | py3 | bdist_wheel | null | false | 0ac481633584a3f3b4b09dad7e4d991f | 752e85fef7cc72ee825efd79d99b60a904c914f1368cdddf852a053d5a875aee | b7a481b66d0c420fc4da656612878c0c61060a29ea4367859649fbb005735502 | null | [
"LICENSE"
] | 329 |
2.1 | c2cciutils | 1.7.6.dev47 | Common utilities for Camptocamp CI | # C2C CI utils
## Publishing
The main goals of C2C CI utils is to offer the commands to publish the project,
see the [documentation](https://github.com/camptocamp/c2cciutils/wiki/Publishing).
## Changelog
When we create a tag by default with the `changelog` workflow a release is created on GitHub, a changelog is
generated and added to the release.
## Checks
C2C CI utils will no more provide a tool to do a check of the project, this is replaced by `pre-commit`,
a base configuration is provided in the example project.
## Pull request checks
A workflow is provided to run the checks on the pull requests, it will run the `c2cciutils-pr-checks` command.
- Check that the commit message and the pull request title start with a capital letter.
- Check that there aren't any spelling issue in the commit message and in the pull request title.
- Add a message to the pull request with a link to the JIRA issue if the pull request branch name starts with
`[a-zA-Z]+-[0-9]+-` or end with `-[a-zA-Z]+-[0-9]+`.
## Dependencies
In the example project there is a basic Renovate configuration, it will update the dependencies of the project.
There is also a workflow to add a review on the Renovate pull requests to make the auto merge working on
repository that required a review.
## Backports
A workflow is provided to backport the pull requests on the stabilization branches, it will be triggered by
adding a label named `backport <destination_branch>` on the pull request.
## Old workflows
GitHub will retain all the old workflows, so we need to delete them, the `delete-old-workflows-run`
workflow will delete the workflows older than 500 days.
## Workflows
C2cciutils make easier to have those workflows in a project:
- `auto-review.yaml`: Auto review the Renovate pull requests
- `backport.yaml`: Trigger the backports (work with labels)
- `clean.yaml`: Clean the Docker images related on a deleted feature branch
- `main.yaml`: Main workflow especially with the c2cciutils-checks command
All the provided commands used in the workflow:
- `c2cciutils`: some generic tools.
- `c2cciutils-version`: Create a new version of the project.
- `c2cciutils-env`: Print some environment information.
- `c2cciutils-publish`: Publish the project.
- `c2cciutils-clean`: Delete Docker images on Docker Hub after corresponding branch have been deleted.
## Utilities
The following utilities are provided:
- `c2cciutils`: some generic tools.
- `c2cciutils-download-applications`: Download the applications with version managed by Renovate, see below.
- `c2cciutils-docker-logs`: Display the logs of the application in Docker (compose).
- `c2cciutils-k8s-install`: Install a k3d / k3s cluster, see below.
- `c2cciutils-k8s-logs`: Display the logs of the application in the k8s cluster, see below.
- `c2cciutils-k8s-db`: Create a database in the k8s cluster, see below.
- `c2cciutils-k8s-wait`: Wait that the application started correctly in the cluster, see below.
- `c2cciutils-docker-versions-gen`: Generate the Docker package versions file (`ci/dpkg-versions.yaml`), see below.
- `c2cciutils-pin-pipenv`: Display all the dependencies that's in the `Pipenv.lock` but not in the `Pipenv` to be able to pin them.
- `c2cciutils-trigger-image-update`: Trigger the ArgoCD repository about image update on the CI (automatically done in the publishing).
- `c2cciutils-google-calendar`: Tool to test the Google credentials for calendar API and refresh them if needed. See `c2cciutils-google-calendar -h` for more information.
## New project
The content of `example-project` can be a good base for a new project.
## New version
Requirements: the right version (>= 1.6) of `c2cciutils` should be installed with the `version` extra.
To create a new minor version you just should run `c2cciutils-version --version=<version>`.
You are welcome to run `c2cciutils-version --help` to see what's it's done.
Note that it didn't create a tag, you should do it manually.
To create a patch version you should just create tag.
## Secrets
In the CI we need to have the following secrets::
- `HAS_SECRETS` to be set to 'HAS_SECRETS', to avoid error errors from external
pull requests, already set globally on Camptocamp organization.
- `GOPASS_CI_GITHUB_TOKEN` and `CI_GPG_PRIVATE_KEY` required to initialize the gopass password store,
the secrets exists in the Camptocamp organization but not shared on all project, then you should add
your project to the shared list.
## Use locally, in the projects that use c2cciutils
Install it: `python3 -m pip install --user --requirement ci/requirements.txt`
Dry run publish: `GITHUB_REF=... c2cciutils-publish --dry-run ...`
## Configuration
You can get the current configuration with `c2cciutils --get-config`, the default configuration depends on your project.
Note that it didn't contain the default defined the schema and visible in the [generated documentation](./config.md).
You can override the configuration with the file `ci/config.yaml`.
At the base of the configuration you have:
- `version`: Contains some regular expressions to find the versions branches and tags, and to convert them into application versions.
- `publish`: The publishing configuration, see `c2cciutils/publish.py` for more information.
Many actions can be disabled by setting the corresponding configuration part to `False`.
## SECURITY.md
The `SECURITY.md` file should contain the security policy of the repository, especially the end of
support dates.
For compatibility with `c2cciutils` it should contain an array with at least the columns
`Version` and `Supported Until`. The `Version` column will contain the concerned version.
The `Supported Until` will contain the date of end of support `dd/mm/yyyy`.
It can also contain the following sentences:
- `Unsupported`: no longer supported => no audit, no rebuild.
- `Best effort`: the support is ended, it is still rebuilt and audited, but this can be stopped without any notice.
- `To be defined`: not yet released or the date will be set related of another project release date (like for GeoMapFish).
See also [GitHub Documentation](https://docs.github.com/en/github/managing-security-vulnerabilities/adding-a-security-policy-to-your-repository)
## IDE
The IDE should be configured as:
- using `black` and `isort` without any arguments,
- using the `editorconfig` configuration.
### VScode
- Recommend extensions to work well with c2cciutils:
- [Prettier](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode) And use EditorConfig
- [shell-format](https://marketplace.visualstudio.com/items?itemName=foxundermoon.shell-format) With the configuration
`"shellformat.flag": "-bn"`.
- [Better TOML](https://marketplace.visualstudio.com/items?itemName=bodil.prettier-toml)
- Other recommend extensions:
- [hadolint](https://marketplace.visualstudio.com/items?itemName=exiasr.hadolint)
- [Code Spell Checker](https://marketplace.visualstudio.com/items?itemName=streetsidesoftware.code-spell-checker)
Select a formatter:
- `CTRL+MAJ+P`
- Format document With...
- Configure Default Formatter...
- Select the formatter
## Publishing
### To pypi
The config is like this:
```yaml
versions:
# List of kinds of versions you want to publish, that can be:
# rebuild (specified with --type),
# version_tag, version_branch, feature_branch, feature_tag (for pull request)
```
It we have a `setup.py` file, we will be in legacy mode:
When publishing, the version computed from arguments or `GITHUB_REF` is put in environment variable `VERSION`, thus you should use it in `setup.py`, example:
```python
VERSION = os.environ.get("VERSION", "1.0.0")
```
Also we consider that we use `poetry` with [poetry-dynamic-versioning](https://pypi.org/project/poetry-dynamic-versioning/) to manage the version, and [poetry-plugin-tweak-dependencies-version](https://pypi.org/project/poetry-plugin-tweak-dependencies-version/) to manage the dependencies versions.
Example of configuration:
```toml
[tool.poetry-dynamic-versioning]
enable = true
vcs = "git"
pattern = "^(?P<base>\\d+(\\.\\d+)*)"
format-jinja = """
{%- if env.get("VERSION_TYPE") == "version_branch" -%}
{{serialize_pep440(bump_version(base, 1 if env.get("IS_MASTER") == "TRUE" else 2), dev=distance)}}
{%- elif distance == 0 -%}
{{serialize_pep440(base)}}
{%- else -%}
{{serialize_pep440(bump_version(base), dev=distance)}}
{%- endif -%}
"""
```
Note that we can access to the environment variables `VERSION`,`VERSION_TYPE` and `IS_MASTER`.
Then by default:
- Tag with `1.2.3` => release `1.2.3`
- Commit on feature branch just do a validation
- Commit on `master` branch after the tag 1.3.0 => release `1.4.0.dev1`
- Commit on `1.3` branch after the tag 1.3.0 => release `1.3.1.dev1`
#### Authentication
If the file `~/.pypirc` exists we consider that we ar already logged in also
we will do the login with the `pypi` server with OpenID Connect (OIDC).
The OIDC login is recommended because it didn't needs any additional secrets,
but it need some configuration on pypi in the package,
see the [GitHub Documentation](https://docs.github.com/en/actions/security-for-github-actions/security-hardening-your-deployments/configuring-openid-connect-in-pypi#adding-the-identity-provider-to-pypi).
#### Integration if the package directly in a Docker image
To make it working in the `Dockerfile` you should have in the `poetry` stage:
```Dockerfile
ENV POETRY_DYNAMIC_VERSIONING_BYPASS=dev
RUN poetry export --extras=checks --extras=publish --output=requirements.txt \
&& poetry export --with=dev --output=requirements-dev.txt
```
And in the `run` stage
```Dockerfile
ARG VERSION=dev
RUN --mount=type=cache,target=/root/.cache \
POETRY_DYNAMIC_VERSIONING_BYPASS=${VERSION} python3 -m pip install --disable-pip-version-check --no-deps --editable=.
```
And in the `Makefile`:
```Makefile
VERSION = $(strip $(shell poetry version --short))
.PHONY: build
build: ## Build the Docker images
docker build --build-arg=VERSION=$(VERSION) --tag=$(GITHUB_REPOSITORY) .
```
### To Docker registry
The config is like this:
```yaml
latest: True
images:
- # The base name of the image we want to publish
name:
repository:
<internal_name>:
# The fqdn name of the server if not Docker hub
server:
# List of kinds of versions you want to publish, that can be: rebuild (specified using --type),
# version_tag, version_branch, feature_branch, feature_tag (for pull request)
version:
# List of tags we want to publish interpreted with `format(version=version)`
# e.g. if you use `{version}-lite` when you publish the version `1.2.3` the source tag
# (that should be built by the application build) is `latest-lite`, and it will be published
# with the tag `1.2.3-lite`.
tags:
# If your images are published by different jobs you can separate them in different groups
# and publish them with `c2cciutils-publish --group=<group>`
group:
```
By default, the last line of the `SECURITY.md` file will be published (`docker`) with the tag
`latest`. Set `latest` to `False` to disable it.
With the `c2cciutils-clean` the images on Docker hub for `feature_branch` will be removed on branch removing.
## Download applications
In case some executables or applications from GitHub releases or any other URLs are required on the CI host
and are not handled by any dependency manager, we provide a set of tools to install them and manage upgrades
through Renovate.
Create an application file (e.-g. `applications.yaml`) with:
```yaml
# yaml-language-server: $schema=https://raw.githubusercontent.com/camptocamp/c2cciutils/master/c2cciutils/schema-applications.json
# Application from GitHub release
<organization>/<project>:
get-file-name: <file name present in the release>
to-file-name: <The file name you want to create in ~/.local/bin>
finish-command: # The command you want to run after the file is downloaded
- - chmod # To be executable (usually required)
- +x
- <to-file-name>
- - <to-file-name> # Print the version of the application
- --version
# Application from GitHub release in a tar file (or tar.gz)
<organization>/<project>:
get-file-name: <file name present in the release>
type: tar
tar-file-name: <The file name available in the tar file>
to-file-name: <The file name you want to create in ~/.local/bin>
finish-command: [...] # The command you want to run after the file is downloaded
# Application from an URL
<application reference name>:
url-pattern: <The URL used to download the application>
to-file-name: <The file name you want to create in ~/.local/bin>
finish-command: [...] # The command you want to run after the file is downloaded
```
In the attributes `url-pattern`, `get-file-name` you can use the following variables:
- `{version}`: The version of the application present in the version file.
- `{version_quote}`: The URL encoded version.
- `{short_version}`: The version without the `v` prefix.
The `applications-versions.yaml` file is a map of applications and their versions.
Add in your Renovate configuration:
```json5
regexManagers: [
{
fileMatch: ['^applications-versions.yaml$'],
matchStrings: [
'(?<depName>[^\\s]+): (?<currentValue>[^\\s]+) # (?<datasource>[^\\s]+)',
],
},
],
```
Now you need to call `c2cciutils-download-applications --applications-file=applications.yaml --versions-file=applications-version.yaml`
to install required applications on CI host before using them (an already installed application is installed only if needed).
## Use Renovate to trigger a new build instead of the legacy rebuild
Run the command `c2cciutils-docker-versions-gen camptocamp/image[:tag]` to generate a file that is a kind of package lock of the Debian packages in the file `ci/dpkg-versions.yaml`.
Add in your renovate configuration:
```javascript
regexManagers: [
{
fileMatch: ['^ci/dpkg-versions.yaml$'],
matchStrings: [" *(?<depName>[^'\\s]+): '?(?<currentValue>[^'\\s/]*[0-9][^'\\s/]*)'?"],
datasourceTemplate: 'repology',
versioningTemplate: 'loose',
},
],
```
When a new version of a Debian package will be available:
- Renovate will automatically open a pull request to update the file `ci/dpkg-versions.yaml`.
- And the continuous integration will build a new fresh Docker image with latest versions of all Debian packages.
## Kubernetes
C2cciutils provide some commands for Kubernetes.
You can define a workflow like that:
```yaml
- name: Install k3s/k3d (Kubernetes cluster)
run: c2cciutils-k8s-install
- name: Create a database to do the tests
run: c2cciutils-k8s-db --script=<my_script>.sql
- name: Install the application in the Kubernetes cluster
run: kubectl apply -f <my_application>.yaml
- name: Wait that the application is ready
run: c2cciutils-k8s-wait
- name: Print the application status and logs
run: c2cciutils-k8s-logs
if: always()
- name: Uninstall the application
run: kubectl delete -f <my_application>.yaml || true
- name: Cleanup the database
run: c2cciutils-k8s-db --cleanup
```
`c2cciutils-k8s-install` can be configured in the `ci/config.yaml` file, in section `k8s/k3d/install-commands`, default is:
```yaml
- - k3d
cluster
create
test-cluster
--no-lb
--no-rollback
```
See also: [K3d cluster create documentation](https://k3d.io/v4.4.8/usage/commands/k3d_cluster_create/).
`c2cciutils-k8s-db` can be configured in the `ci/config.yaml` file, in section `k8s/db/chart-options`, default is:
```yaml
persistence.enabled: 'false'
tls.enabled: 'true'
tls.autoGenerated: 'true'
postgresqlPassword: mySuperTestingPassword
volumePermissions.enabled: 'true'
```
See also: [Parameters documentations](https://github.com/bitnami/charts/tree/master/bitnami/postgresql#parameters).
## Contributing
Install the pre-commit hooks:
```bash
pip install pre-commit
pre-commit install --allow-missing-config
```
| text/markdown | Camptocamp | info@camptocamp.com | null | null | FreeBSD | ci | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"License :: Other/Proprietary License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
... | [] | https://github.com/camptocamp/c2cciutils | null | <4.0,>=3.9 | [] | [] | [] | [
"PyYAML<7.0.0,>=6.0.0",
"debian-inspector<32.0.0,>=31.0.0",
"defusedxml<1.0.0,>=0.0.0",
"id<2.0.0,>=1.0.0; extra == \"publish\"",
"multi-repo-automation<2.0.0,>=1.0.0; extra == \"version\"",
"requests<3.0.0,>=2.0.0",
"ruamel.yaml<1.0.0,>=0.0.0",
"security-md<=2",
"twine<6.0.0,>=5.0.0; extra == \"pub... | [] | [] | [] | [
"Repository, https://github.com/camptocamp/c2cciutils"
] | twine/5.1.1 CPython/3.12.12 | 2026-02-18T20:40:31.608578 | c2cciutils-1.7.6.dev47.tar.gz | 49,162 | db/f0/54a27c7ac39aeb23068128afe3a0fdc370b48de63522d5dada48fd47436a/c2cciutils-1.7.6.dev47.tar.gz | source | sdist | null | false | 6022b4896f9159aaf85519e8653d7d34 | 5aa34f03dddb202c9c20d3612fb272e6efe928ae50507402ab43622f9d1f2574 | dbf054a27c7ac39aeb23068128afe3a0fdc370b48de63522d5dada48fd47436a | null | [] | 234 |
2.4 | monitorat | 0.13.3 | A federate, offline-friendly modular dashboard and documentation system for homelabs and Linux computers | <img src="./docs/img/masthead.svg" alt="monitor@/monitorat masthead that shows the french IPA phonetics and the tagline 'a system for observing and documenting status' and an icon with a monitor and superimposed at-character" width="100%">
# <div align=center> [ [demo](https://monitorat.brege.org) ] </div>
**Monitorat** is a federated dashboard and documentation system.
Its philosophy is to make system monitoring and documentation continuous, much like the way tables and figures are integrated within journal articles or [Wikipedia](https://wikipedia.org/).
Available widgets:
- [metrics](#system-metrics)
- [network](#network)
- [reminders](#reminders)
- [services](#services)
- [speedtest](#speedtest)
- [wiki](#wiki)
Widgets have a general, self-contained structure where both API and UI are straightforward to create.
```
~/.config/monitorat/widgets/
└── my-widget
├── api.py
├── default.yaml
├── index.html
└── app.js
```
Documentation is editable in-browser and handled by proliferating Wiki widgets across your dashboard. Each document fragment added is a new widget instance. All documents you add to your wiki will be rendered in GitHub-flavored Markdown via [markdown-it](https://github.com/markdown-it/markdown-it).
## Gallery
[**The Demo**](https://monitorat.brege.org) is a fully interactive version of the application and provides complete resource parity between widget layouts and their YAML config snippets. In that sense, *the demo is the documentation*.
<table>
<tr>
<td><img src="docs/img/screenshots/desktop/dark/101.png" width="100%"></td>
<td><img src="docs/img/screenshots/desktop/dark/102.png" width="100%"></td>
<td><img src="docs/img/screenshots/desktop/dark/103.png" width="100%"></td>
</tr>
</table>
<table>
<tr>
<td><img src="docs/img/screenshots/desktop/dark/100.png" width="100%"></td>
<td><img src="docs/img/screenshots/desktop/light/110.png" width="100%"></td>
</tr>
</table>
<table>
<tr>
<td><img src="docs/img/screenshots/desktop/light/111.png" width="100%"></td>
<td><img src="docs/img/screenshots/desktop/light/112.png" width="100%"></td>
<td><img src="docs/img/screenshots/desktop/light/113.png" width="100%"></td>
</tr>
</table>
<table>
<tr>
<td><img src="docs/img/screenshots/mobile/dark/201.png" width="100%"></td>
<td><img src="docs/img/screenshots/mobile/dark/202.png" width="100%"></td>
<td><img src="docs/img/screenshots/mobile/light/211.png" width="100%"></td>
<td><img src="docs/img/screenshots/mobile/light/212.png" width="100%"></td>
</tr>
</table>
## Features
- Beautiful documentation for your Homelab and media servers.
- Completely headless and works offline.
- Responsive design for mobile and desktop, with light and dark modes.
- Track [how hot your CPU gets](https://monitorat.brege.org/#metrics-widget) over the course of the day.
- Be alerted [when under extremely high load](#alerts).
- Keep a record of [internet speedtests](https://monitorat.brege.org/#speedtest-widget) even when AFK.
- List [all your reverse-proxied services](https://monitorat.brege.org/#services-widget) with offline-friendly bookmarks.
- Even runs on Raspberry Pi 2/3 w/ Pi-Hole, Unraid, and other homelab systems.
- Has [**federation**](https://monitorat.brege.org/federation): you can monitor services, metrics data, and documentation across many machines from a central command.
---
## Installation
### PyPI
Try the demo in 3 seconds:
```bash
uv tool install monitorat && monitorat demo
```
Then open http://localhost:6100.
See: **[Package Install](./docs/install/package.md)** for installing from PyPI with pip or uv.
### Docker
See: **[Docker Install](./docs/install/docker.md)** for installation in a container.
### Source
See: **[Source Install](./docs/install/source.md)** for git-based installations or deployments to `/opt`.
---
## The Dashboard
Open `http://localhost:6161`, or your specified port, or configure through a reverse proxy.
### Configuration
These are the basic monitorat settings for your system, assuming you want to keep all icons and data close to your config file (usually `~/.config/monitorat/`):
```yaml
site:
name: "@my-nas"
title: "Dashboard @my-nas"
editing: true
paths:
data: data/
img: img/ # or /home/user/.config/monitorat/img/
widgets: { ... }
# privacy: { ... }
# alerts: { ... }
# notifications: { ... }
```
## Widgets
**Monitorat** has an extensible widget system. You can add any number of widgets to your dashboard multiple times over, re-order them, and enable/disable any you don't need.
### Configuration
You can add more widgets of other origin in `~/.config/monitorat/widgets/`.
```yaml
widgets:
enabled: # dashboard positions: from top to bottom
- my-server-notes # type: wiki
- services
- metrics
- # reminders # '#' disables this widget
- network
- speedtest
- my-widget # in ~/.config/monitorat/widgets/
```
Each widget can be configured in its own YAML block. To configure a widget in its own file:
```yaml
includes:
- "/home/user/.config/monitorat/widgets/my-widget.yaml"
```
or do this for every widget through config snippets:
```yaml
includes:
- snippets/services.yaml
- snippets/metrics.yaml
- # ... wikis, user widgets, etc
```
##### Making your own
Widgets are also quite easy to build with AI. Widget built with Codex in 12 minutes:
> [Agentic Archetype: Building Widgets with AI](docs/contributing.md#agentic-archetype)
## Available Widgets
### **Services**
- monitor systemd services, timers, and Docker containers in real time
- can be used as *homelab bookmarks* in compact cards layout
- simultaneously provides both your URL (or WAN IP) and local address (or LAN IP) for use offline
- **monitorat is completely encapsulated and works offline even when internet is down**
### **Wiki**
- uses [markdown-it](https://github.com/markdown-it/markdown-it) and GitHub-flavored markdown
- can columnate multiple documents/Markdown fragments
- editor can be used to spruce up system docs in the browser
- supports [Mermaid](https://mermaid-js.github.io/mermaid/#/) diagrams
- inline LaTeX math via [KaTeX](https://katex.org/)
- supports [GitHub admonitions](https://github.com/antfu/markdown-it-github-alerts)
### **System Metrics**
- provides an overview of system performance over time in `metrics.csv`
- measures CPU, memory, disk and network usage, temperature, etc.
- get notified when system metrics exceed configured thresholds:
<details>
<summary><b>Configuring Alerts</b></summary>
```yaml
alerts:
cooldown_minutes: 60 # Short cooldown for testing
rules:
high_load:
threshold: 2.5 # load average (e.g., the '1.23' in 1.23 0.45 0.06)
priority: 0 # normal priority
message: High CPU load detected
high_temp:
threshold: 82.5 # celsius
priority: 1 # high priority
message: High temperature warning
low_disk:
threshold: 95 # percent
priority: 0 # normal priority
message: Low disk space warning
```
</details>
### **Speedtest**
- keep a record of your internet performance over time
- currently does not perform automated runs
### **Network**
The network widget is best used on machines with continuous uptime. Two options:
- (a) using a `ddclient`-style log, or
- (b) use the built-in chirper
### **Reminders**
- facilitated by [Apprise URLs](https://github.com/caronc/apprise) (see [below](#notifications)).
- ping yourself for system chores, key changes, etc.
### Summary of Widget Features
<table>
<thead>
<tr>
<th>Widget</th>
<th>Chart</th>
<th>Filters</th>
<th>Snapshot</th>
<th>Recording</th>
<th>Editing</th>
<th>Federation Merge</th>
<th>Notify</th>
</tr>
</thead>
<tbody>
<tr>
<td>S. Metrics</td>
<td><a href="https://monitorat.brege.org/#section-metrics">Y</a></td>
<td>-</td>
<td>Y(tiles)</td>
<td>Y</td>
<td>Y(tiles)</td>
<td><a href="https://monitorat.brege.org/federation/#section-metrics">chart</a></td>
<td>Y(alert)</td>
</tr>
<tr>
<td>Network</td>
<td><a href="https://monitorat.brege.org/#section-network">Y(pips)</a></td>
<td>Y(outages)</td>
<td>Y(tiles)</td>
<td>Y</td>
<td>N</td>
<td><a href="https://monitorat.brege.org/federation/#section-network">interleave</a></td>
<td>Y(alert)</td>
</tr>
<tr>
<td>Speedtest</td>
<td><a href="https://monitorat.brege.org/#section-speedtest">Y</a></td>
<td>-</td>
<td>-</td>
<td>N</td>
<td>-</td>
<td><a href="https://monitorat.brege.org/federation/#section-speedtest">chart</a></td>
<td>N</td>
</tr>
<tr>
<td>Services</td>
<td>-</td>
<td><a href="https://monitorat.brege.org/#section-services">Y</a></td>
<td>Y(cards)</td>
<td>N</td>
<td>Y</td>
<td><a href="https://monitorat.brege.org/federation/#section-services">interleave</a></td>
<td>N</td>
</tr>
<tr>
<td>Reminders</td>
<td>-</td>
<td><a href="https://monitorat.brege.org/#section-reminders">Y</a></td>
<td>-</td>
<td>-</td>
<td>Y</td>
<td><a href="https://monitorat.brege.org/federation/#section-reminders">interleave</a></td>
<td>Y</td>
</tr>
<tr>
<td>Wiki</td>
<td><a href="https://monitorat.brege.org/#about">Y</a></td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>Y</td>
<td>continuous</td>
<td>-</td>
</tr>
</tbody>
</table>
> [!NOTE] Key
> Y = supported | N = planned / potential feature | \- = not applicable
## General Features
### Editing
- built-in Markdown editor and previewer
- configure new reminders and services directly through the web interface
- Web UI configuration seamlessly updates the YAML config file or downstream snippets
### Notifications
The notifications system uses [Apprise](https://github.com/caronc/apprise) to notify through practically any service via apprise URLs.
```yaml
notifications:
apprise_urls:
- "pover://abscdefghijklmnopqrstuvwxyz1234@4321zyxwvutsrqponmlkjihgfedcba"
- "mailto://1234 5678 9a1b 0c1d@sent.com?user=main@fastmail.com&to=alias@sent.com"
- # more apprise urls if needed...
```
### Federation
Yes, you can even federate multiple instances of monitorat:
- compare and plot metrics data across multiple machines
- see service statuses for your entire homelab/network from a central node
- especially useful for filtering and sorting events network-wide
> [!NOTE]
> To simultaneously use federation of remotes AND local monitoring, you must setup a client monitorat instance and a separate monitorat server to federate locals and remotes in the same pane.
### Privacy
The privacy mask helps share your setup online without exposing personal information.
```yaml
privacy:
replacements:
my-site.org: example.com
replace-me: with-this
...
mask_ips: true
```
Running `monitorat config` will print the runtime config with these masks applied as well.
---
## Development
- [**contributing**](./docs/contributing.md)
- [**changelog**](./docs/changelog.md)
- [**roadmap**](./docs/roadmap.md)
## License
[GPLv3](https://www.gnu.org/licenses/gpl-3.0.en.html)
| text/markdown | null | Wyatt Brege <wyatt@brege.org> | null | null | GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short
notice like this when it starts in an interactive mode:
<program> Copyright (C) <year> <name of author>
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, your program's commands
might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
<https://www.gnu.org/licenses/>.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
<https://www.gnu.org/licenses/why-not-lgpl.html>.
| null | [
"Development Status :: 4 - Beta",
"Framework :: Flask",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Topic :: System :: Monitoring"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"apprise>=1.4.0",
"confuse>=2.0.0",
"flask-httpauth>=4.8.0",
"flask>=3.0.0",
"gunicorn>=21.2.0",
"httpx>=0.27.0",
"psutil>=5.9.5",
"pytimeparse>=1.1.8",
"pyyaml>=6.0",
"schedule>=1.2.0",
"speedtest-cli>=2.1.3"
] | [] | [] | [] | [
"Repository, https://github.com/brege/monitorat"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:40:15.507572 | monitorat-0.13.3.tar.gz | 3,465,582 | e1/88/9a96f9097b0c2cc9e1257404768312d826b56ce90bc7c29533ba8b37fce9/monitorat-0.13.3.tar.gz | source | sdist | null | false | 1decae6a4ca6897961f97c5ce4f0ecbf | acb2dd1f061c109a6090fcaaf7ab2b2a4838562ad83ff7a7847d8bc46c8afca3 | e1889a96f9097b0c2cc9e1257404768312d826b56ce90bc7c29533ba8b37fce9 | null | [
"LICENSE"
] | 251 |
2.4 | omero-annotate-ai | 0.2.2 | OMERO integration for AI-powered image annotation and segmentation workflows | # OMERO Annotate.AI
[](https://pixi.sh)
[](https://pypi.org/project/omero-annotate-ai/)
[](https://pypi.org/project/omero-annotate-ai/)
[](https://mybinder.org/v2/gh/Leiden-Cell-Observatory/omero_annotate_ai/HEAD?urlpath=%2Fdoc%2Ftree%2Fnotebooks%2Fannotation%2Fomero-annotate-ai-annotation-widget.ipynb)
[](https://github.com/Leiden-Cell-Observatory/omero_annotate_ai/actions)
[](https://leiden-cell-observatory.github.io/omero_annotate_ai/)
[](https://github.com/Leiden-Cell-Observatory/omero_annotate_ai/blob/main/LICENSE)
Package to support reproducible image annotation workflows for AI training using OMERO data repositories. This Python package provides Jupyter widgets and tools for reproducible annotation, training, and inference using micro-SAM, Cellpose, and other AI models directly with OMERO datasets.
## Key Features
- **Interactive Jupyter widgets** for OMERO connection and workflow configuration
- **AI-assisted annotation** using micro-SAM integration
- **Reproducible workflows** with YAML configuration tracking
- **Training data preparation** for BiaPy and DL4MicEverywhere
- **Direct OMERO integration** with automatic result storage
## Quick Start
### Installation
```bash
# Recommended: Using pixi
pixi init myproject && cd myproject
pixi add micro-sam
pixi add --pypi omero-annotate-ai
pixi shell
# Alternative: Conda + pip
conda install -c conda-forge micro-sam
pip install omero-annotate-ai
```
📖 See [Installation Guide](https://leiden-cell-observatory.github.io/omero_annotate_ai/installation/) for detailed instructions and troubleshooting.
### Basic Usage
**OMERO Connection Widget**

**Annotation Pipeline Widget**

```python
from omero_annotate_ai import create_omero_connection_widget, create_workflow_widget, create_pipeline
# Connect to OMERO
conn_widget = create_omero_connection_widget()
conn_widget.display()
conn = conn_widget.get_connection()
# Configure annotation workflow
workflow_widget = create_workflow_widget(connection=conn)
workflow_widget.display()
config = workflow_widget.get_config()
# Run annotation pipeline
pipeline = create_pipeline(config, conn)
table_id, processed_images = pipeline.run_full_workflow()
```
### Example Notebooks
Try these example notebooks to get started:
- [Widget-based annotation workflow](notebooks/annotation/omero-annotate-ai-annotation-widget.ipynb)
- [YAML-based configuration](notebooks/annotation/omero-annotate-ai-from-yaml.ipynb)
- [Training with BiaPy](notebooks/training/omero-training_biapy.ipynb)
### Alternative: YAML Configuration
For batch processing and reproducible workflows, you can also use YAML configuration files:
```python
from omero_annotate_ai.core.annotation_config import load_config
from omero_annotate_ai.core.annotation_pipeline import create_pipeline
# Load configuration from YAML
config = load_config("annotation_config.yaml")
conn = create_connection(host="omero.server.com", user="username")
# Run annotation pipeline
pipeline = create_pipeline(config, conn)
results = pipeline.run_full_workflow()
```
See the [YAML Configuration Guide](docs/configuration.md) for complete documentation.
## Documentation
📚 **[Complete Documentation](docs/index.md)**
- **[Installation Guide](docs/installation.md)** - Detailed installation instructions and troubleshooting
- **[micro-SAM Tutorial](docs/tutorials/microsam-annotation-pipeline.md)** - Step-by-step annotation workflow tutorial
- **[YAML Configuration Guide](docs/configuration.md)** - Complete YAML configuration reference and examples
- **[API Reference](docs/api/index.md)** - Complete API documentation
- **[Examples](notebooks/)** - Jupyter notebook tutorials
## Links
- **[GitHub Repository](https://github.com/Leiden-Cell-Observatory/omero_annotate_ai)**
- **[PyPI Package](https://pypi.org/project/omero-annotate-ai/)**
- **[Issues & Support](https://github.com/Leiden-Cell-Observatory/omero_annotate_ai/issues)**
## Contributing
We welcome contributions! For development setup:
1. Fork the repository
2. Clone and set up development environment:
```bash
git clone https://github.com/YOUR_USERNAME/omero_annotate_ai.git
cd omero_annotate_ai
pixi install
```
3. Make changes and run tests: `pixi run pytest`
4. Submit a pull request
See [Installation Guide - Development Setup](https://leiden-cell-observatory.github.io/omero_annotate_ai/installation#development-setup) for detailed instructions.
## Contact
**Maarten Paul** - m.w.paul@lacdr.leidenuniv.nl
**Acknowledgments**: Developed within the [NL-BioImaging](https://github.com/NL-BioImaging) infrastructure, funded by NWO.
| text/markdown | null | Maarten Paul <m.w.paul@lumc.nl> | null | Maarten Paul <m.w.paul@lumc.nl> | null | omero, microscopy, segmentation, ai, annotation, sam, micro-sam | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy<2.0,>=1.21.0",
"pandas>=1.3.0",
"imageio>=2.9.0",
"dask>=2021.6.0",
"pyyaml>=6.0",
"pydantic>=2.0.0",
"typing-extensions>=4.0.0",
"ezomero>=3.1.0",
"opencv-python",
"tifffile",
"ipywidgets>=7.6.0; extra == \"notebooks\"",
"ipykernel; extra == \"notebooks\"",
"pixi-kernel<0.7,>=0.6.6; ... | [] | [] | [] | [
"Homepage, https://github.com/Leiden-Cell-Observatory/omero_annotate_ai",
"Repository, https://github.com/Leiden-Cell-Observatory/omero_annotate_ai.git",
"Issues, https://github.com/Leiden-Cell-Observatory/omero_annotate_ai/issues",
"Documentation, https://github.com/Leiden-Cell-Observatory/omero_annotate_ai#... | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:39:51.769890 | omero_annotate_ai-0.2.2.tar.gz | 116,482 | e3/b1/05974353f1caa51a5f2c30bd3cbc0b8aaed00c7f91f59733c3b545aa425f/omero_annotate_ai-0.2.2.tar.gz | source | sdist | null | false | 87c829c2fe5cd20d2fd6f68c103ee847 | eb2534d4968b3b5f6d6555fcbe36d1af630cd74dce5cfa0d4e9b931412c94477 | e3b105974353f1caa51a5f2c30bd3cbc0b8aaed00c7f91f59733c3b545aa425f | Apache-2.0 | [
"LICENSE"
] | 238 |
2.3 | vercel-ai-sdk | 0.0.1.dev4 | The AI Toolkit for Python | # vercel-ai-sdk
A Python version of the [AI SDK](https://ai-sdk.dev/).
## Quick Start
```bash
uv add vercel-ai-sdk
```
```python
import os
import vercel_ai_sdk as ai
@ai.tool
async def talk_to_mothership(question: str) -> str:
"""Contact the mothership for important decisions."""
return "Soon."
async def agent(llm, query):
return await ai.stream_loop(
llm,
messages=ai.make_messages(
system="You are a robot assistant.",
user=query,
),
tools=[talk_to_mothership],
)
llm = ai.openai.OpenAIModel(
model="anthropic/claude-opus-4.6",
base_url="https://ai-gateway.vercel.sh/v1",
api_key=os.environ["AI_GATEWAY_API_KEY"],
)
async for msg in ai.run(agent, llm, "When will the robots take over?"):
print(msg.text_delta, end="")
```
## Reference
### Core Primitives
#### `ai.run(root, *args, checkpoint=None, cancel_on_hooks=False)`
Entry point. Starts `root` as a background task, processes the step/hook queue, yields `Message` objects. Returns a `RunResult`.
```python
result = ai.run(my_agent, llm, "hello")
async for msg in result:
print(msg.text_delta, end="")
result.checkpoint # Checkpoint with all completed work
result.pending_hooks # dict of unresolved hooks (empty if run completed)
```
If `root` declares a `runtime: ai.Runtime` parameter, it's auto-injected.
#### `@ai.tool`
Decorator that turns an async function into a `Tool`. Parameters extracted from type hints, docstring becomes description.
```python
@ai.tool
async def search(query: str, limit: int = 10) -> list[str]:
"""Search the database."""
...
```
If a tool declares a `runtime: ai.Runtime` parameter, it's auto-injected (not passed by the LLM):
```python
@ai.tool
async def long_task(input: str, runtime: ai.Runtime) -> str:
"""Runtime is auto-injected, not passed by LLM."""
await runtime.put_message(ai.Message(...)) # stream intermediate results
...
```
#### `@ai.stream`
Decorator that wires an async generator into the `Runtime`. Use this to make any streaming operation (like an LLM call) work with `ai.run()`.
```python
@ai.stream
async def my_custom_step(llm, messages):
async for msg in llm.stream(messages):
yield msg
result = await my_custom_step(llm, messages) # returns StreamResult
```
Must be called within `ai.run()` (needs a Runtime context).
#### `@ai.hook`
Decorator that creates a suspension point from a pydantic model. The model defines the resolution schema.
```python
@ai.hook
class Approval(pydantic.BaseModel):
granted: bool
reason: str
```
Inside your agent — blocks until resolved:
```python
approval = await Approval.create("approve_send_email", metadata={"tool": "send_email"})
if approval.granted:
...
```
From outside (API handler, websocket, iterator loop, etc.):
```python
Approval.resolve("approve_send_email", {"granted": True, "reason": "User approved"})
Approval.cancel("approve_send_email") # or cancel it
```
**Long-running mode** (`cancel_on_hooks=False`, the default): the `await` in `create()` blocks until `resolve()` or `cancel()` is called from external code.
**Serverless mode** (`cancel_on_hooks=True`): if no resolution is available, the hook's future is cancelled and the branch dies. Inspect `result.pending_hooks` and `result.checkpoint` to resume later:
```python
result = ai.run(my_agent, llm, query, cancel_on_hooks=True)
async for msg in result:
...
if result.pending_hooks:
# Save result.checkpoint, collect resolutions, then re-enter:
Approval.resolve("approve_send_email", {"granted": True, "reason": "User approved"})
result = ai.run(my_agent, llm, query, checkpoint=result.checkpoint)
async for msg in result:
...
```
### Convenience Functions
#### `ai.stream_step(llm, messages, tools=None, label=None)`
Single LLM call. Built on `@ai.stream`. Returns `StreamResult`.
```python
result = await ai.stream_step(llm, messages, tools=[search])
# result.text, result.tool_calls, result.last_message
```
#### `ai.stream_loop(llm, messages, tools, label=None)`
Full agent loop: calls LLM, executes tools, repeats until no more tool calls. Returns final `StreamResult`.
```python
result = await ai.stream_loop(llm, messages, tools=[search, get_weather])
```
#### `ai.execute_tool(tool_call, message=None)`
Execute a single tool call. Looks up the tool from the global registry (populated by `@ai.tool`). Updates the `ToolPart` with the result. If `message` is provided, emits it to the Runtime queue so the UI sees the status change.
```python
await asyncio.gather(*(ai.execute_tool(tc, message=last_msg) for tc in result.tool_calls))
```
Supports checkpoint replay — returns the cached result without re-executing if one exists.
#### `ai.make_messages(*, system=None, user)`
Build a message list from system + user strings.
```python
messages = ai.make_messages(system="You are helpful.", user="Hello!")
```
#### `ai.get_checkpoint()`
Get the current `Checkpoint` from the active Runtime context. Call this from within `ai.run()`.
```python
checkpoint = ai.get_checkpoint()
```
### Checkpoints
`Checkpoint` records completed work (LLM steps, tool executions, hook resolutions) so a run can be replayed without re-executing already-finished operations.
```python
# After a run completes or suspends
checkpoint = result.checkpoint
data = checkpoint.serialize() # dict, JSON-safe
# Later: restore and resume
checkpoint = ai.Checkpoint.deserialize(data)
result = ai.run(my_agent, llm, query, checkpoint=checkpoint)
```
Three event types are tracked:
- **Steps** — LLM call results (replayed without calling the model)
- **Tools** — tool execution results (replayed without re-executing)
- **Hooks** — hook resolutions (replayed without re-suspending)
### Adapters
#### LLM Providers
```python
# OpenAI-compatible (including Vercel AI Gateway)
llm = ai.openai.OpenAIModel(
model="anthropic/claude-opus-4.6",
base_url="https://ai-gateway.vercel.sh/v1",
api_key=os.environ["AI_GATEWAY_API_KEY"],
thinking=True, # enable reasoning output
budget_tokens=10000, # or reasoning_effort="medium"
)
# Anthropic (native client)
llm = ai.anthropic.AnthropicModel(
model="claude-opus-4.6-20250916",
thinking=True,
budget_tokens=10000,
)
```
#### MCP
```python
# HTTP transport
tools = await ai.mcp.get_http_tools(
"https://mcp.example.com/mcp",
headers={"Authorization": "Bearer ..."},
tool_prefix="docs",
)
# Stdio transport (subprocess)
tools = await ai.mcp.get_stdio_tools(
"npx", "-y", "@anthropic/mcp-server-filesystem", "/tmp",
tool_prefix="fs",
)
```
MCP connections are pooled per `ai.run()` and cleaned up automatically.
#### AI SDK UI
For streaming to AI SDK frontend (`useChat`, etc.):
```python
from vercel_ai_sdk.ai_sdk_ui import to_sse_stream, to_messages, UI_MESSAGE_STREAM_HEADERS
# Convert incoming UI messages
messages = to_messages(request.messages)
# Stream response as SSE
async def stream_response():
async for chunk in to_sse_stream(ai.run(agent, llm, query)):
yield chunk
return StreamingResponse(stream_response(), headers=UI_MESSAGE_STREAM_HEADERS)
```
### Types
| Type | Description |
|------|-------------|
| `Message` | Universal message with `role`, `parts`, `label`. Properties: `text`, `text_delta`, `reasoning_delta`, `tool_deltas`, `tool_calls`, `is_done` |
| `TextPart` | Text content with streaming `state` and `delta` |
| `ToolPart` | Tool call with `tool_call_id`, `tool_name`, `tool_args`, `status`, `result`. Has `.set_result()` |
| `ToolDelta` | Tool argument streaming delta (`tool_call_id`, `tool_name`, `args_delta`) |
| `ReasoningPart` | Model reasoning/thinking with optional `signature` (Anthropic) |
| `HookPart` | Hook suspension with `hook_id`, `hook_type`, `status` (`pending`/`resolved`/`cancelled`), `metadata`, `resolution` |
| `Part` | Union: `TextPart \| ToolPart \| ReasoningPart \| HookPart` |
| `PartState` | Literal: `"streaming"` \| `"done"` |
| `StreamResult` | Result of a stream step: `messages`, `tool_calls`, `text`, `last_message` |
| `Tool` | Tool definition: `name`, `description`, `schema`, `fn` |
| `ToolSchema` | Serializable tool description: `name`, `description`, `tool_schema` (no `fn`) |
| `Runtime` | Central coordinator for the agent loop. Step queue, message queue, checkpoint replay/record |
| `RunResult` | Return type of `run()`. Async-iterable for messages, then `.checkpoint` and `.pending_hooks` |
| `HookInfo` | Pending hook info: `label`, `hook_type`, `metadata` |
| `Hook` | Generic hook base with `.create()`, `.resolve()`, `.cancel()` class methods |
| `Checkpoint` | Serializable snapshot of completed work: `steps[]`, `tools[]`, `hooks[]`. Has `.serialize()` / `.deserialize()` |
| `LanguageModel` | Abstract base class for LLM providers |
## Examples
See the `examples/` directory:
**Samples** (`examples/samples/`):
- `simple.py` — Basic agent with tools and `stream_loop`
- `agent.py` — Coding agent with local filesystem tools
- `hooks.py` — Human-in-the-loop approval flow
- `streaming_tool.py` — Tool that streams progress via Runtime
- `multiagent.py` — Parallel agents with labels, then summarization
- `custom_loop.py` — Custom step with `@ai.stream`
- `mcp.py` — MCP integration (Context7)
**Projects**:
- `examples/fastapi-vite/` — Full-stack chat app (FastAPI + Vite + AI SDK UI)
- `examples/temporal-durable/` — Durable execution with Temporal workflows
- `examples/multiagent-textual/` — Multi-agent TUI with Textual
| text/markdown | Andrey Buzin | Andrey Buzin <andrey.buzin@vercel.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"anthropic>=0.40.0",
"httpx>=0.28.1",
"mcp>=1.18.0",
"openai>=2.14.0",
"pydantic>=2.12.5",
"vercel>=0.3.8"
] | [] | [] | [] | [] | uv/0.10.3 {"installer":{"name":"uv","version":"0.10.3","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T20:39:42.042041 | vercel_ai_sdk-0.0.1.dev4.tar.gz | 35,199 | 43/2c/b63efa3734f37d9910a3e580a4e8eb4124b245fb633e963f704a5050ee3c/vercel_ai_sdk-0.0.1.dev4.tar.gz | source | sdist | null | false | 28a3f20a179157c8596fbf9151f41a9f | f02b177295133a78a307e007130012087c1ebb131ae7d22b42a5cf9f1280df6e | 432cb63efa3734f37d9910a3e580a4e8eb4124b245fb633e963f704a5050ee3c | null | [] | 217 |
2.4 | dynamodx | 0.1.2 | Developer-friendly library for DynamoDB with single-table design, without ORM lock-in. | ## Dynamodx
A developer-friendly library for DynamoDB, simplifying single-table design without ORM lock-in.
```python
from dynamodx.transact_writer import TransactWriter, TransactionOperationFailed
class EmailConflictError(TransactionOperationFailed):
pass
try:
with TransactWriter(table_name=..., client=...) as transact:
transact.put(
item={
'pk': user_id,
'sk': '0',
'name': name,
'email': email,
'phone': phone,
}
)
transact.put(
item={
'pk': f'EMAIL',
'sk': email,
'user_id': user_id,
},
cond_expr='attribute_not_exists(sk)',
return_on_cond_fail='ALL_OLD',
exc_cls=EmailConflictError,
)
except EmailConflictError as err:
# Got existing `user_id`
user_id = err.reason['old_image']['user_id']
```
## License
Dynamodx is open-source software licensed under the [MIT License](LICENSE).
| text/markdown | null | Sérgio Rafael Siqueira <osergiosiqueira@gmail.com> | null | null | null | aws, database, dynamodb | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :... | [] | null | null | >=3.11 | [] | [] | [] | [
"boto3>=1.42.39",
"jmespath>=1.1.0"
] | [] | [] | [] | [
"Homepage, https://github.com/sergiors/dynamodx",
"Repository, https://github.com/sergiors/dynamodx",
"Issues, https://github.com/sergiors/dynamodx/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-18T20:37:52.402775 | dynamodx-0.1.2.tar.gz | 98,566 | 1c/86/46ea6df66b699a1f7424dbf8f71bf3ee82f42eb806d332c0f861659077ad/dynamodx-0.1.2.tar.gz | source | sdist | null | false | 7f8372af231de8756be0351efb9e6371 | 89e53d7bcc43cad28749d02baf6dfad6456ab1a52b56ee9d047519cacf70344d | 1c8646ea6df66b699a1f7424dbf8f71bf3ee82f42eb806d332c0f861659077ad | MIT | [
"LICENSE"
] | 252 |
2.1 | l10n-ar-api | 2.12.4 | Libreria para localizacion Argentina | Libreria para localizacion Argentina
| null | BLUEORANGE GROUP SRL | daniel@blueorange.com.ar | null | null | null | Libreria para localizacion Argentina | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development",
"Programming Language :: Python :: 2.7",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.4",
"Programming Language :: Python :: 3.5",
"Programming Language :: Python :: 3.6... | [] | https://github.com/odoo-arg/l10n_ar_api | null | null | [] | [] | [] | [
"zeep",
"python-dateutil",
"pytz",
"unidecode",
"requests",
"lxml",
"qrcode",
"bs4; python_version >= \"3\"",
"BeautifulSoup; python_version < \"3\"",
"cryptography; python_version >= \"3.10\"",
"M2Crypto; python_version < \"3.10\"",
"pyopenssl==22.1.0; python_version < \"3.10\""
] | [] | [] | [] | [] | twine/5.1.1 CPython/3.12.0 | 2026-02-18T20:35:53.815575 | l10n_ar_api-2.12.4.tar.gz | 54,390 | 57/07/fdaca22f8b515693d3be242b1f1763f07348f11021f25cbe9ab13f04efe0/l10n_ar_api-2.12.4.tar.gz | source | sdist | null | false | 8b7aec3b0f7f4039292cd6dac5e12b2a | 0edb402c0fbe6a5c7b7e0c8982dbdd9fc744e1ae12bbfb588fc33b4849641696 | 5707fdaca22f8b515693d3be242b1f1763f07348f11021f25cbe9ab13f04efe0 | null | [] | 182 |
2.4 | cynsta-spendguard | 0.2.0 | SpendGuard SDK and CLI | # SpendGuard SDK
Public SpendGuard repository for:
- Python CLI package (`cynsta-spendguard`)
- Python client library (`spendguard_sdk`)
- API contracts (`contracts/`)
- Public examples and docs
Supported provider endpoint families: `openai`, `grok` (xAI), `gemini`, `anthropic`.
## Install
```bash
pip install cynsta-spendguard
```
or with uv:
```bash
uv tool install cynsta-spendguard
```
## Quickstart
For fast local onboarding with `spendguard-sidecar`, follow [`docs/quickstart.md`](docs/quickstart.md).
## Usage
Create an agent:
```bash
spendguard agent create --name "agent-1"
```
List agents:
```bash
spendguard agent list
```
Get an agent:
```bash
spendguard agent get --agent <agent_id>
```
Rename an agent:
```bash
spendguard agent rename --agent <agent_id> --name "agent-1-renamed"
```
Delete an agent:
```bash
spendguard agent delete --agent <agent_id>
```
Set a budget for an existing agent:
```bash
spendguard budget set --agent <agent_id> --limit 5000 --topup 5000
```
Get current budget:
```bash
spendguard budget get --agent <agent_id>
```
Key behavior:
- `CAP_MODE=sidecar` (default): no `x-api-key` is required.
- `CAP_MODE=hosted`: API key is required via `--api-key` or `CAP_API_KEY`.
## Release
Build locally:
```bash
python -m pip install --upgrade build twine
python -m build .
python -m twine check dist/*
```
Publish:
1. Set GitHub secret `PYPI_API_TOKEN`.
2. Push tag `spendguard-cli-vX.Y.Z` (example `spendguard-cli-v0.1.0`).
3. GitHub Actions workflow `.github/workflows/publish-spendguard-cli.yml` publishes to PyPI.
Maintainer setup checklist: `docs/maintainer-setup.md`.
## Python Client
```python
from spendguard_sdk import SpendGuardClient
client = SpendGuardClient("https://spendguard.example.com", api_key="sk_cynsta_live_...")
agent = client.create_agent("agent-1")
client.set_budget(agent["agent_id"], hard_limit_cents=5000, topup_cents=5000)
run = client.create_run(agent["agent_id"])
resp = client.grok_responses(
agent["agent_id"],
run["run_id"],
{"model": "grok-3", "input": "Give me a one-line summary of finite-state machines."},
)
```
| text/markdown | Cynsta | null | null | null | null | cynsta, spendguard, sdk, cli, budget, llm | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Environment :: Console",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.11 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:35:52.317941 | cynsta_spendguard-0.2.0.tar.gz | 8,586 | 7f/0a/efb6e7d6f4daba9bbd5701e26841e836fa10eec6f896a6659b980dc19022/cynsta_spendguard-0.2.0.tar.gz | source | sdist | null | false | 49e5226448b16afb3e15c55d327beb9e | 3cd3f5ad7d7e4c1d4f40a75f02c9a5530412cc26564e2ea36b02f5d3054e3323 | 7f0aefb6e7d6f4daba9bbd5701e26841e836fa10eec6f896a6659b980dc19022 | MIT | [
"LICENSE"
] | 250 |
2.1 | bonsai | 1.5.5 | Python 3 module for accessing LDAP directory servers. | Bonsai
======
.. image:: https://img.shields.io/pypi/v/bonsai.svg?style=flat-square
:target: https://pypi.python.org/pypi/bonsai/
:alt: PyPI Version
.. image:: https://img.shields.io/endpoint.svg?url=https%3A%2F%2Factions-badge.atrox.dev%2Fnoirello%2Fbonsai%2Fbadge%3Fref%3Ddev&style=flat-square
:target: https://actions-badge.atrox.dev/noirello/bonsai/goto?ref=dev
:alt: GitHub Action Build Status
.. image:: https://dev.azure.com/noirello/bonsai/_apis/build/status/noirello.bonsai?branchName=dev
:target: https://dev.azure.com/noirello/bonsai/_build
:alt: Azure Pipelines Status
.. image:: https://img.shields.io/appveyor/ci/noirello/bonsai/dev.svg?style=flat-square
:target: https://ci.appveyor.com/project/noirello/bonsai
:alt: AppVeyor CI Build Status
.. image:: https://codecov.io/gh/noirello/bonsai/branch/dev/graph/badge.svg?token=gPAMdWATgj
:target: https://app.codecov.io/gh/noirello/bonsai/tree/dev/src
:alt: Coverage Status
.. image:: https://readthedocs.org/projects/bonsai/badge/?version=latest&style=flat-square
:target: http://bonsai.readthedocs.org/en/latest/
:alt: Documentation Status
.. image:: https://img.shields.io/badge/license-MIT-blue.svg?style=flat-square
:target: https://raw.githubusercontent.com/noirello/bonsai/master/LICENSE
:alt: GitHub License
This is a module for handling LDAP operations in Python. Uses libldap2 on Unix platforms and
WinLDAP on Microsoft Windows. LDAP entries are mapped to a special Python case-insensitive
dictionary, tracking the changes of the dictionary to modify the entry on the server easily.
Supports only Python 3.10 or newer, and LDAPv3.
Features
--------
- Uses LDAP libraries (OpenLDAP and WinLDAP) written in C for faster
processing.
- Simple pythonic design.
- Implements an own dictionary-like object for mapping LDAP entries
that makes easier to add and modify them.
- Works with various asynchronous library (like asyncio, gevent).
Requirements for building
-------------------------
- python3.10-dev or newer
- libldap2-dev
- libsasl2-dev
- libkrb5-dev or heimdal-dev (optional)
Documentation
-------------
Documentation is available `online`_ with a simple tutorial.
Example
-------
Simple search and modify:
.. code:: python
import bonsai
client = bonsai.LDAPClient("ldap://localhost")
client.set_credentials("SIMPLE", user="cn=admin,dc=bonsai,dc=test", password="secret")
with client.connect() as conn:
res = conn.search("ou=nerdherd,dc=bonsai,dc=test", 2, "(cn=chuck)")
res[0]['givenname'] = "Charles"
res[0]['sn'] = "Carmichael"
res[0].modify()
Using with asyncio:
.. code:: python3
import asyncio
import bonsai
async def do():
client = bonsai.LDAPClient("ldap://localhost")
client.set_credentials("DIGEST-MD5", user="admin", password="secret")
async with client.connect(is_async=True) as conn:
res = await conn.search("ou=nerdherd,dc=bonsai,dc=test", 2)
print(res)
who = await conn.whoami()
print(who)
asyncio.run(do())
Changelog
---------
The changelog is available `here`_ and included in the documentation as well.
Contribution
------------
Any contributions and advices are welcome. Please report any issues at
the `GitHub page`_.
.. _online: http://bonsai.readthedocs.org/en/latest/
.. _here: https://github.com/noirello/bonsai/blob/master/CHANGELOG.rst
.. _GitHub page: https://github.com/noirello/bonsai/issues
| text/x-rst | noirello | noirello <noirello@gmail.com> | null | null | MIT | python3, ldap, ldap3, python-ldap, libldap, winldap, asyncio, gevent, tornado, trio | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"Operating System :: Microsoft :: Windows",
"Operating System :: Unix",
"Programming Language :: C",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: P... | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/noirello/bonsai",
"Repository, https://github.com/noirello/bonsai.git",
"Documentation, https://bonsai.readthedocs.io"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T20:35:10.507899 | bonsai-1.5.5.tar.gz | 151,228 | 75/4e/5572ad9689c8b04759ffa53dfcb0784524cc2e9f7884f67ed681508d6763/bonsai-1.5.5.tar.gz | source | sdist | null | false | 8023099e1a7055e3a388634bd6da17b0 | 417d2c28ec91af0300c9715cc724b84a79ec3b471bc41d3a0a71009fae0cb022 | 754e5572ad9689c8b04759ffa53dfcb0784524cc2e9f7884f67ed681508d6763 | null | [] | 2,116 |
2.4 | azlassets | 3.4.2 | Azur Lane asset downloader and extractor | # Azur Lane Asset Downloader and Extractor
This tool automatically downloads the newest assets directly from the game's CDN servers and allows extraction of Texture2D files as PNG images.
## Upgrade Notice
### From 2.x / no version number to 3.x+
When upgrading from versions 2.x or with no version number, the project has to be newly set up. To retain all current data the following folders can be copied to the new folder of the project:
- `config`: Only user_config.yml is required, the rest can be deleted.
- `ClientAssets` or directory set in `asset-directory` of the config: Contains all currently downloaded assets, version information und update logs used for extraction. Highly recommend to transfer to the new project folder.
## Setup
Before installation, Python 3.11 or newer needs to be available on the system. It is recommended to set the project up using [venv](https://docs.python.org/3/tutorial/venv.html) or a similar virtual environment manager. The project can be installed using pip:
```
pip install azlassets
```
Alternatively, to install the newest version from the repository (requires git on the system):
```
pip install git+https://github.com/nobbyfix/AzurLane-AssetDownloader.git
```
## Usage
There are three scripts to manage the assets:
- `obb_apk_import`: Importing assets from obb/apk/xapk files
- `downlader`: Downloading assets from the game server
- `extractor`: Extract PNGs from the assets
These can be executed using `py -m <scriptname>` on Windows or `python3 -m <scriptname>` on Linux/macOS (will be shortened to `py[thon3]` going forward, use the appropriate version for your system). Detailed usage will be explained in the following sections.
### 1. Import files from xapk/apk/obb
While this is *not necessary*, this step is **recommended** if you want all game assets available and not spam the game update server with errors of missing files on the first download.
The `obb_apk_import.py` supports all game clients (EN, JP, CN, KR, TW) and multiple forms of importing the assets. The recommended and easiest way is by downloading the `.xapk` from one of many Google Play Store app distributors (like APKMirror or APKPure). You can find them by searching for the package name, which are as follows:
- EN: com.YoStarEN.AzurLane
- JP: com.YoStarJP.AzurLane
- KR: kr.txwy.and.blhx
- TW: com.hkmanjuu.azurlane.gp
Alternatively if you already have the game installed, for example on emulators, you can copy the obb file onto your system and use it instead of the xapk. On Android it can be found in the folder `/storage/emulated/0/Android/obb/[PACKAGE_NAME]/`.
Since the CN client is not distributed through the Google Play Store, there is no xapk/obb file for it, but you can find the android download link on the [website](https://game.bilibili.com/blhx/) which will download an apk file (not xapk like the others). Alternatively, the APK is installed in the folder `/data/app/com.bilibili.azurlane-1/` on android (Note: Root access is required to access this folder).
You can then execute the script by passing it the filepath to the xapk/apk/obb:
```
py[thon3] -m obb_apk_import [FILEPATH]
```
### 2. Settings
The `config/user_config.yml` file provides a few settings to filter which files will be downloaded (and later also extracted). The options `download-folder-listtype` and `extract-folder-listtype` can be set to either "blacklist" or "whitelist". Depending on this it will filter by the top-level folder names (subfolders are not supported) or top-level filenames (files inside top-level folders or lower cannot be filtered) set in `download-folder-list` and `extract-folder-list`. This allows to cut down the download and extraction times by skipping unneeded assets.
### 3. Download new updates from the game
All assets normally distributed via the in-app downloader can be downloaded by simply executing:
```
py[thon3] -m downloader [CLIENT]
```
where `CLIENT` has to be either EN, CN, JP, KR or TW. You can check which files have been downloaded or deleted using the difflog files in `ClientAssets/[CLIENT]/difflog`.
### 4. Extract all new and changed files
The asset extraction script supports extraction of all newly downloaded files and single asset bundles. The newly downloaded assets can be extracted by executing:
```
py[thon3] -m extractor [CLIENT]
```
where `CLIENT` is again one of EN, CN, JP, KR or TW. The extracted images will then be saved in `ClientExtract/[CLIENT]/` Since only Texture2D assets are exported, it's not desired to try to export from all assetbundles (See [settings section](#2-settings)).
A single assetbundle can be extracted by passing the filepath to the script:
```
py[thon3] -m extractor -f [FILEPATH]
```
### 5. Enjoy the files
| text/markdown | nobbyfix | null | null | null | null | azurlane, azur-lane | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: O... | [] | null | null | >=3.11 | [] | [] | [] | [
"UnityPy>=1.10.18",
"PyYAML",
"Pillow",
"protobuf",
"aiofile",
"aiohttp[speedups]>=3.12",
"aiodns<4",
"pre-commit; extra == \"dev\""
] | [] | [] | [] | [
"homepage, https://github.com/nobbyfix/AzurLane-AssetDownloader",
"repository, https://github.com/nobbyfix/AzurLane-AssetDownloader.git",
"issues, https://github.com/nobbyfix/AzurLane-AssetDownloader/issues",
"changelog, https://github.com/nobbyfix/AzurLane-AssetDownloader/blob/master/CHANGELOG.md",
"downlo... | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:35:08.780541 | azlassets-3.4.2.tar.gz | 23,217 | 0a/67/eab14ed058974e64a9eb7812510806ba742737b008de50b423c0aa2c4378/azlassets-3.4.2.tar.gz | source | sdist | null | false | 3b7a01e3fe40ec7dd0c876a2f39430a6 | bb0f0abc16130058a90d36bf9ee30e35df0db9a3b47c211d94620c9332b724c3 | 0a67eab14ed058974e64a9eb7812510806ba742737b008de50b423c0aa2c4378 | null | [
"LICENSE"
] | 259 |
2.4 | nogic | 0.0.4 | Codebase Visualization for Developers and AI Agents — index, search, and understand codebases via graph + vector embeddings. | # Nogic CLI
Codebase Visualization for Developers and AI Agents.
## Installation
### Prerequisites
- Python 3.11 or higher
### Install with pipx (Recommended)
```bash
pipx install nogic
```
### Install with pip
```bash
pip install nogic
```
## Quick Start
### 1. Log in
```bash
nogic login
```
This opens your browser for authentication via your [Nogic account](https://nogic.dev).
### 2. Initialize a project
```bash
cd /path/to/your/project
nogic init
```
This creates a `.nogic/` directory with project configuration.
### 3. Sync your codebase
One-time sync:
```bash
nogic sync
```
Or watch for continuous syncing:
```bash
nogic watch
```
## Commands
- `nogic login` — Authenticate via browser
- `nogic init` — Initialize a project in a directory
- `nogic watch` — Watch for file changes and sync continuously
- `nogic sync` — One-time full sync
- `nogic reindex` — Wipe graph data and re-index from scratch
- `nogic status` — Show project configuration and backend status
- `nogic projects list` — List all your projects
- `nogic projects create` — Create a new project
- `nogic projects use` — Switch the current project
- `nogic telemetry disable` — Opt out of anonymous telemetry
See the full [CLI reference](https://docs.nogic.dev/cli/commands) for all options.
## Supported Languages
- Python (`.py`)
- JavaScript (`.js`, `.jsx`)
- TypeScript (`.ts`, `.tsx`)
## Data & Privacy
### What we store
When you sync your codebase, Nogic stores the following in our graph database:
- **Code structure** — Function and class signatures, call relationships, import/export graphs
- **File metadata** — File paths, hashes, and modification timestamps
- **Embeddings** — Vector representations of code for semantic search
We do **not** store raw source code, comments, string literals, or any secrets/credentials.
### Telemetry
Nogic collects anonymous usage telemetry to help improve the product:
- CLI version, OS, Python version
- Command names (e.g., `cli_login`, `cli_sync`)
- An anonymous ID (SHA-256 hash of your access token or machine info)
### Opt out of telemetry
```bash
nogic telemetry disable
```
Or set `NOGIC_TELEMETRY_DISABLED=1` or `DO_NOT_TRACK=1`.
For full details, see our [Privacy Policy](https://nogic.dev/privacy).
## Documentation
Full documentation at [docs.nogic.dev](https://docs.nogic.dev).
## License
MIT
| text/markdown | null | Nogic <hello@nogic.dev> | null | null | null | ai-agents, code-graph, code-intelligence, embeddings, mcp, tree-sitter | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"P... | [] | null | null | >=3.11 | [] | [] | [] | [
"httpx>=0.27.0",
"mcp>=1.8.0",
"pathspec>=0.12.0",
"posthog>=3.0.0",
"python-dotenv>=1.0.0",
"rich>=13.0.0",
"tree-sitter-javascript>=0.23.0",
"tree-sitter-python>=0.23.0",
"tree-sitter-typescript>=0.23.0",
"tree-sitter>=0.24.0",
"typer>=0.12.0",
"watchdog>=6.0.0"
] | [] | [] | [] | [
"Homepage, https://nogic.dev",
"Repository, https://github.com/nogic-dev/cli",
"Documentation, https://docs.nogic.dev"
] | uv/0.9.7 | 2026-02-18T20:34:01.330902 | nogic-0.0.4.tar.gz | 45,459 | a8/e9/a13273215c12cfe20e6ef82bdf1315a1ec7fdeb4d295807c7132fc036037/nogic-0.0.4.tar.gz | source | sdist | null | false | c59645e44d1a4e09dce702d2c17df6ef | cab04c67040f088166db73cc6dfd86438d964b2199f5129eee067dea045945ae | a8e9a13273215c12cfe20e6ef82bdf1315a1ec7fdeb4d295807c7132fc036037 | MIT | [
"LICENSE"
] | 1,088 |
2.4 | bagel | 0.11.4 | Automatic parsing of subjects' tabular data and imaging metadata into Neurobagel graph-compatible JSONLD files. | <div align="center">
# Neurobagel CLI
[](https://github.com/neurobagel/bagel-cli/actions?query=branch:main)
[](https://github.com/neurobagel/bagel-cli/actions/workflows/test.yml)
[](https://app.codecov.io/gh/neurobagel/bagel-cli)
[](https://www.python.org)
[](LICENSE)
[](https://pypi.org/project/bagel/)
[](https://pypistats.org/packages/bagel)
[](https://hub.docker.com/r/neurobagel/bagelcli/tags)
[](https://hub.docker.com/r/neurobagel/bagelcli/tags)
</div>
The Neurobagel CLI is a Python command-line tool to automatically parse and describe subject phenotypic and imaging attributes in an annotated dataset for integration into the Neurobagel graph.
**For information on how to use the CLI, please refer to the [official Neurobagel documentation](https://neurobagel.org/user_guide/cli/).**
## Installation
The Neurobagel CLI is available as a Python package that can be installed from PyPI using:
```bash
pip install bagel
```
(If you prefer to run the CLI using Docker or Singularity containers instead, please refer to the [Neurobagel documentation](https://neurobagel.org/user_guide/cli/).)
## Development environment
### Setting up a local development environment
To work on the CLI, we suggest that you create a development environment
that is as close as possible to the environment we run in production.
1. Clone the repository
```bash
git clone https://github.com/neurobagel/bagel-cli.git
cd bagel-cli
```
2. Install the CLI and all development dependencies in editable mode:
```bash
pip install -e ".[dev]"
```
3. Install the `bids-examples` and `neurobagel_examples` submodules needed to run the test suite:
```bash
git submodule init
git submodule update
```
Confirm that everything works well by running the tests:
`pytest .`
### Setting up code formatting and linting (recommended)
[pre-commit](https://pre-commit.com/) is configured in the development environment for this repository, and can be set up to automatically run a number of code linters and formatters on any commit you make according to the consistent code style set for this project.
Run the following from the repository root to install the configured pre-commit "hooks" for your local clone of the repo:
```bash
pre-commit install
```
pre-commit will now run automatically whenever you run `git commit`.
### Updating dependencies
If new runtime or development dependencies are needed, add them to `pyproject.toml` using minimal version constraints.
## Regenerating the Neurobagel vocabulary file
Terms in the Neurobagel namespace (`nb` prefix) and their class relationships are serialized to a file
called [nb_vocab.ttl](https://github.com/neurobagel/recipes/blob/main/vocab/nb_vocab.ttl), which is automatically
uploaded to new Neurobagel graph deployments.
This vocabulary is used by Neurobagel APIs to fetch available attributes and attribute instances from a graph store.
When the Neurobagel graph data model is updated (e.g., if new classes or subclasses are created),
this file should be regenerated by running:
```bash
python helper_scripts/generate_nb_vocab_file.py
```
This will create a file called `nb_vocab.ttl` in the current working directory.
| text/markdown | Neurobagel Developers | null | null | Alyssa Dai <alyssa.ydai@gmail.com>, Sebastian Urchs <sebastian.urchs@mcgill.ca> | MIT License
Copyright (c) 2022 - Neurobagel Project, Origami Lab, McGill University.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11"
] | [] | null | null | <3.15,>=3.11 | [] | [] | [] | [
"bids2table",
"email-validator",
"httpx",
"isodate",
"jsonschema",
"pandera[pandas]",
"pybids",
"pydantic<3,>=2.12",
"rich",
"typer",
"coverage; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"pytest; extra == \"dev\"",
"coverage; extra == \"test\"",
"pytest; extra == \"test\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-18T20:33:55.755008 | bagel-0.11.4.tar.gz | 46,708 | bd/0a/8da194c3c3e8daf288d1a1217c1e69eda5498330158e03e7a047093ca158/bagel-0.11.4.tar.gz | source | sdist | null | false | 314664fd6cae2c1da7df1248939a2920 | 3a7340bb6a9aaf5b2627288559d99e6787a9c79ae3022de705e859f47acbba0f | bd0a8da194c3c3e8daf288d1a1217c1e69eda5498330158e03e7a047093ca158 | null | [
"LICENSE"
] | 254 |
2.4 | viur-shop | 0.13.3 | A modular e-commerce extension for the ViUR framework | <div align="center">
<img src="https://github.com/viur-framework/viur-artwork/raw/main/icons/icon-shop.svg" height="196" alt="A hexagonal logo of Shop" title="Shop logo"/>
<h1>viur-shop</h1>
<a href="https://pypi.org/project/viur-shop/">
<img alt="Badge showing current PyPI version" title="PyPI" src="https://img.shields.io/pypi/v/viur-shop">
</a>
<a href='https://viur-shop.readthedocs.io/en/latest/?badge=latest'>
<img src='https://readthedocs.org/projects/viur-shop/badge/?version=latest' alt='Documentation Status' />
</a>
<a href="LICENSE">
<img src="https://img.shields.io/github/license/viur-framework/viur-shop" alt="Badge displaying the license" title="License badge">
</a>
<br>
A modular e-commerce extension for the <a href="https://www.viur.dev">ViUR framework</a>.
</div>
## 📦 Features
- Fully integrated **Shop logic** via the central `shop.Shop` class: cart handling, order management, API routing, bootstrapping with custom `article_skel`, and payment/shipping modules.
- Extensible **Modules**: Address, Api, Cart, Discount, Shipping, VatRate, Order, etc. — all provided as abstract base implementations.
- **Payment Providers**: Amazon Pay, PayPal Plus, Prepayment, Invoice, and Unzer integrations (Credit Card, PayPal, SOFORT, Bancontact, iDEAL). Can be extended with custom implementations.
- **Event & Hook System**: Customize checkout and order flow with hooks for events like `ORDER_PAID`, `CART_CHANGED`, and `CHECKOUT_STARTED`.
- **Pricing & Discounts**: Automated calculation of unit and bulk prices, gross/net handling, VAT rates, savings, and discount combinations via the `Price` class.
---
## 🚀 Requirements
- [ViUR Framework (viur-core)](https://www.viur.dev/) installed and configured
- Python **3.11+**
---
## 🧩 Installation & Integration
```bash
pipenv install viur-shop
```
Integrate into your ViUR application:
```py
# deploy/modules/shop.py
from viur.shop import Shop
from skeletons.article import ArticleSkel # your custom article skeleton
shop = Shop(
name="myshop",
article_skel=ArticleSkel,
payment_providers=[
# e.g. PayPalPlus(), Invoice(), ... ,
],
suppliers=[
# optional Shop.types.Supplier(...),
],
)
```
## 🔍 Additional Resources
- Full API Reference: [viur-shop.readthedocs.io](https://viur-shop.readthedocs.io/en/latest/viur/shop/index.html)
- [Frontend Components for Vue.js](https://github.com/viur-framework/shop-components)
| text/markdown | null | Sven Eberth <se@mausbrand.de> | null | Sven Eberth <se@mausbrand.de> | MIT License
Copyright (c) 2023 – 2024 ViUR
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| viur, plugin, backend, shop, ecommerce | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Developm... | [] | null | null | >=3.11 | [] | [] | [] | [
"viur-toolkit>=0.2.0",
"viur-core>=3.7.0",
"cachetools>=5.0",
"unzer~=1.3; extra == \"unzer\"",
"paypal-server-sdk~=1.0; extra == \"paypal\""
] | [] | [] | [] | [
"Documentation, https://viur-shop.readthedocs.io",
"Repository, https://github.com/viur-framework/viur-shop.git",
"Bug Tracker, https://github.com/viur-framework/viur-shop/issues",
"Changelog, https://github.com/viur-framework/viur-shop/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:32:41.185106 | viur_shop-0.13.3.tar.gz | 82,318 | 0e/ea/9f9f923e38a003d604bf2e5f6ebc5acca3669e8017b46add32dd4a180db8/viur_shop-0.13.3.tar.gz | source | sdist | null | false | 8f07dd03c9214da97328b41aca7228f4 | 3beebfbf4d928e38a55e9e1680607ee8b02f2c4c28455e7837ac938f4d81aa50 | 0eea9f9f923e38a003d604bf2e5f6ebc5acca3669e8017b46add32dd4a180db8 | null | [
"LICENSE"
] | 237 |
2.4 | pypki3 | 2026.49.1232 | More user-friendly way to access PKI-enabled services. | # pypki3
pypki3 is intended as a replacement for pypki2.
It is built around the `cryptography` package instead of `pyOpenSSL`, which is now deprecated.
Unlike pypki2, pypki3 does not try to do any auto-configuration, nor does it try to silently compensate when there's a configuration issue. The mantra is, "Let it crash."
pypki3 also does not support any monkey-patching like pypki2 did. There's just no need for that.
## Configuration
Since the user has to create their own configuration file now, the config file is much simpler, using a standard `config.ini` format, of the following form.
```
[global]
p12 = /path/to/your.p12
pem = /path/to/your.combined.pem
ca = /path/to/certificate_authorities.pem
```
At least one of `p12` or `pem` must be populated. If both are populated, then `p12` is used.
The `pem` file must be a combined key-and-cert file of the following form, which is pretty normal in the Python world.
```
-----BEGIN RSA PRIVATE KEY-----
... (private key in base64 encoding) ...
-----END RSA PRIVATE KEY-----
-----BEGIN CERTIFICATE-----
... (certificate in base64 PEM encoding) ...
-----END CERTIFICATE-----
```
### Configuration file locations
pypki3 will first look at the location specified by the `PYPKI3_CONFIG` environment variable for a config file. This can be helpful in corporate Windows environments where the "home directory" is not always in a standard location. It can also be useful in test environments.
Next pypki3 will look in `~/.config/pypki3/config.ini`.
Next pypki3 will look in `/etc/pypki3/config.ini`.
Finally, for existing library support, if pypki3 is being used in an NBGallery Jupyter environment, then pypki3 will attempt to look for the older pypki2 `~/.mypki` file, or use NBGallery's Javascript certificate upload dialog.
## Usage
### Get an SSLContext
If you have your own code and you just want to pass along an SSLContext based on the .mypki config (eg. for `urlopen()`, or for the `requests` package), then all you have to do is the following:
```python
from urllib.request import urlopen
import pypki3
ctx = pypki3.ssl_context()
resp = urlopen(https_url, context=ctx)
...
```
If you have already configured your PKI info, you have the option of providing a certificate password to `ssl_context()` rather than using the interactive prompt. This can be useful when the password is stored in a vault, or when the code needs to run in some non-interactive way. Please be conscientious of the security implications of putting your password directly in your code though.
```python
from urllib.request import urlopen
import pypki3
ctx = pypki3.ssl_context(password='supersecret')
resp = urlopen(https_url, context=ctx)
...
```
### Prompting for a password early (optional)
Sometimes it can also be useful to force the certificate password prompt to appear before `ssl_context()` is called, by another library for example. To do this, simply use `prepare()`.
```python
import pypki3
import another_library_that_uses_pypki3
pypki3.prepare() # Prompts for password here
# A lot of other code/steps...
# Does not prompt for password way down here
another_library_that_uses_pypki3.does_something()
```
### Getting a decrypted key/cert context
pypki3 includes a context manager that ensures the decrypted key and cert are cleaned up. This is useful when you want to make sure you don't leave your decrypted certs sitting around on disk.
```python
import pypki3
with NamedTemporaryKeyCertPaths() as key_cert_paths:
key_path = key_cert_paths[0] # key_path is a pathlib.Path object
cert_path = key_cert_paths[1] # cert_path is a pathlib.Path object
# Do something awesome here
# Decrypted key and cert are cleaned up when you leave the `with` context.
```
### Using the pip wrapper
Some pip servers require PKI authentication. To make this a bit easier, pypki3 includes a pip wrapper that takes care of filling in the `--client-cert` and `--cert` parameters based on the pypki3 configuration. This also prevents pip from prompting for a password 8 million times when use password-protected (encrypted) certs.
```python
import pypki3
pypki3.pip(['install', 'amazing-internal-package'])
```
| text/markdown | Bill Allen | billallen256@gmail.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming La... | [] | null | null | >=3.6 | [] | [] | [] | [
"cryptography>=42.0.0",
"pem",
"temppath"
] | [] | [] | [] | [
"Homepage, http://github.com/nbgallery/pypki3"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T20:32:19.656320 | pypki3-2026.49.1232.tar.gz | 7,720 | 7a/7c/b31a7d1d6a66c5bca126f4d79665d1b459f4ce6b94a66b5bb5bf5352e9a3/pypki3-2026.49.1232.tar.gz | source | sdist | null | false | 915dd9e9c6f5b2084cbc0c062554d664 | 961be97d0a41f72fb867577cbea3a93f53ae163c0809436d657715787c9b66ee | 7a7cb31a7d1d6a66c5bca126f4d79665d1b459f4ce6b94a66b5bb5bf5352e9a3 | null | [
"LICENSE"
] | 284 |
2.4 | ForgeHg | 0.6.0 | Mercurial (Hg) SCM support for Apache Allura | ForgeHg enables an Allura installation to use the Mercurial
source code management system. Mercurial (Hg) is an open source distributed
version control system (DVCS) similar to git and written in Python.
| null | null | dev@allura.apache.org | null | null | GPLv2 | Allura forge Mercurial Hg scm | [
"Development Status :: 5 - Production/Stable",
"Environment :: Plugins",
"Environment :: Web Environment",
"Framework :: TurboGears",
"Intended Audience :: Information Technology",
"License :: OSI Approved :: GNU General Public License v2 (GPLv2)",
"Operating System :: POSIX",
"Programming Language ::... | [] | http://sourceforge.net/p/forgehg | null | >=3.11 | [] | [] | [] | [
"mercurial<7.2,>=6.0",
"six"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.11 | 2026-02-18T20:32:12.915934 | forgehg-0.6.0.tar.gz | 29,140 | 3a/cc/7d5b9af84c275da84bf33a0f6d077854ae673a8bc96b210e41dab67dcea6/forgehg-0.6.0.tar.gz | source | sdist | null | false | b4d795bc58df1dfed36dd0529a8cb709 | 135204fa34b7a4da8a3ef22e2d5614cdaeccc435f81955eb66a60f4ff8d4e6bd | 3acc7d5b9af84c275da84bf33a0f6d077854ae673a8bc96b210e41dab67dcea6 | null | [
"LICENSE"
] | 0 |
2.4 | pdsx | 0.0.1a23 | general-purpose cli for atproto record operations | # pdsx
general-purpose cli for atproto record operations
📚 **[documentation](https://pdsx.zzstoatzz.io)**
## installation
```bash
uv add pdsx
# or run directly
uvx pdsx --help
# or from GitHub (latest)
uvx --from git+https://github.com/zzstoatzz/pdsx pdsx --help
```
## quick start
**important**: flags like `-r`, `--handle`, `--password` go BEFORE the command (`ls`, `get`, etc.)
```bash
# read anyone's posts (no auth needed)
uvx pdsx -r zzstoatzz.io ls app.bsky.feed.post -o json | jq -r '.[].text'
# update your bio (requires auth)
export ATPROTO_HANDLE=your.handle ATPROTO_PASSWORD=your-app-password
uvx pdsx edit app.bsky.actor.profile/self description='new bio'
```
## features
- crud operations for atproto records (list, get, create, update, delete)
- **batch operations**: delete multiple records concurrently with progress tracking
- **blob upload**: upload images, videos, and other binary content
- **cursor pagination**: paginate through large collections
- **MCP server**: expose operations via [model context protocol](https://modelcontextprotocol.io) for AI agents
- optional auth: reads with `--repo` flag don't require authentication
- shorthand URIs: use `app.bsky.feed.post/abc123` when authenticated
- multiple output formats: compact (default), json, yaml, table
- unix-style aliases: `ls`, `cat`, `rm`, `edit`, `touch`/`add`
- jq-friendly json output
- python 3.10+, type-safe
## MCP server
pdsx includes an MCP server for AI agent integration (e.g., claude code, cursor).
```bash
# add to claude code (read-only)
claude mcp add-json pdsx '{"type": "http", "url": "https://pdsx-by-zzstoatzz.fastmcp.app/mcp"}'
# with authentication for writes
claude mcp add-json pdsx '{
"type": "http",
"url": "https://pdsx-by-zzstoatzz.fastmcp.app/mcp",
"headers": {
"x-atproto-handle": "your.handle",
"x-atproto-password": "your-app-password"
}
}'
```
get an app password at: https://bsky.app/settings/app-passwords
📚 **[full MCP documentation](https://pdsx.zzstoatzz.io/guides/mcp-server)** - local setup, custom PDS, available tools, filtering, and more
### running the MCP server locally
run the MCP server locally with `uvx`:
```bash
uvx --from 'pdsx[mcp]' pdsx-mcp
```
to add it to claude code as a local stdio server:
```bash
claude mcp add pdsx -- uvx --from 'pdsx[mcp]' pdsx-mcp
```
for authenticated writes, use the `-e` flag:
```bash
claude mcp add pdsx -e ATPROTO_HANDLE=your.handle -e ATPROTO_PASSWORD=your-app-password -- uvx --from 'pdsx[mcp]' pdsx-mcp
```
<details>
<summary>usage examples</summary>
### read operations (no auth with -r)
```bash
# list records from any repo (note: -r goes BEFORE ls)
pdsx -r zzstoatzz.io ls app.bsky.feed.post --limit 5 -o json
# read someone's bio
pdsx -r zzstoatzz.io ls app.bsky.actor.profile -o json | jq -r '.[0].description'
```
### pagination
```bash
# get first page (note: -r before ls, --cursor after)
pdsx -r zzstoatzz.io ls app.bsky.feed.post --limit 2
# output includes cursor if more pages exist, copy it for next command
# next page cursor: 3m5335qycpc2z
# get next page (use actual cursor from previous output)
pdsx -r zzstoatzz.io ls app.bsky.feed.post --limit 2 --cursor 3m5335qycpc2z
```
### post with image (end-to-end)
```bash
# download a test image
curl -sL https://picsum.photos/200/200 -o /tmp/test.jpg
# upload image and capture blob reference
pdsx upload-blob /tmp/test.jpg
# copy the blob reference from output, example:
# {"$type":"blob","ref":{"$link":"bafkreif..."},"mimeType":"image/jpeg","size":6344}
# create post with uploaded image (paste your actual blob reference)
pdsx create app.bsky.feed.post \
text='Posted via pdsx!' \
'embed={"$type":"app.bsky.embed.images","images":[{"alt":"test image","image":{"$type":"blob","ref":{"$link":"PASTE_YOUR_CID_HERE"},"mimeType":"image/jpeg","size":6344}}]}'
```
### write operations (auth required)
```bash
# update your bio
pdsx edit app.bsky.actor.profile/self description='Building with pdsx!'
# create a simple post
pdsx create app.bsky.feed.post text='Hello from pdsx!'
# delete a post (use the rkey from create output)
pdsx rm app.bsky.feed.post/PASTE_RKEY_HERE
```
### batch operations
```bash
# delete multiple records (runs concurrently)
pdsx rm app.bsky.feed.post/abc123 app.bsky.feed.post/def456 app.bsky.feed.post/ghi789
# delete from file via stdin (the Unix way)
cat uris.txt | pdsx rm
# control concurrency (default: 10)
pdsx rm uri1 uri2 uri3 --concurrency 20
# fail-fast mode (stop on first error)
pdsx rm uri1 uri2 uri3 --fail-fast
```
**note**: when authenticated, use shorthand URIs (`collection/rkey`) instead of full AT-URIs (`at://did:plc:.../collection/rkey`)
</details>
<details>
<summary>output formats</summary>
both `ls` and `cat`/`get` support four output formats:
### compact (default for ls)
```
app.bsky.feed.post (3 records)
3m4ryxwq5dt2i: {"created_at":"2025-11-04T07:25:17.061883+00:00","text":"..."}
```
### json
```bash
pdsx -r zzstoatzz.io ls app.bsky.feed.post -o json | jq '.[].text'
pdsx -r zzstoatzz.io cat app.bsky.feed.post/3m5335qycpc2z -o json
```
### yaml
```bash
pdsx -r zzstoatzz.io ls app.bsky.feed.post --limit 3 -o yaml
pdsx -r zzstoatzz.io cat app.bsky.actor.profile/self -o yaml
```
### table (default for cat/get)
```bash
pdsx -r zzstoatzz.io ls app.bsky.feed.post --limit 5 -o table
pdsx -r zzstoatzz.io cat app.bsky.actor.profile/self # default
```
</details>
<details>
<summary>development</summary>
```bash
git clone https://github.com/zzstoatzz/pdsx
cd pdsx
uv sync
uv run pytest
uv run ty check
```
</details>
## license
mit
| text/markdown | null | zzstoatzz <thrast36@gmail.com> | null | null | null | atproto, bluesky, cli, fastmcp, mcp, pds, records | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: ... | [] | null | null | >=3.10 | [] | [] | [] | [
"atproto>=0.0.63",
"pydantic-settings>=2.7.0",
"pyyaml>=6.0.3",
"rich>=13.0.0",
"fastmcp>=2.0; extra == \"mcp\"",
"jmespath>=1.0; extra == \"mcp\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T20:31:43.021650 | pdsx-0.0.1a23.tar.gz | 150,405 | ca/b9/fdb0fb095987f0a2b1029e6c9e704c39ffdf00cece75623c3dbaf65d87a5/pdsx-0.0.1a23.tar.gz | source | sdist | null | false | 2c57d78730fa19223f7b7f173acf6a33 | e26feca8a708ae8bded1095bbd71e60154d5bbaa80d877c1dea4dc443b98b15e | cab9fdb0fb095987f0a2b1029e6c9e704c39ffdf00cece75623c3dbaf65d87a5 | MIT | [
"LICENSE"
] | 216 |
2.4 | likelihood | 2.1.9 | A package that performs the maximum likelihood algorithm. | 



<!-- Project description -->
This repository contains the code to build the [likelihood package](./likelihood/) which contains tools for typical tasks in maintain machine learning models in production and the training of custom models, for more information review our [`documentation`](https://jzsmoreno.github.io/likelihood/).
## Prerequisites
Before you begin, ensure you have met the following requirements:
* You have a _Windows/Linux/Mac_ machine running [Python 3.10+](https://www.python.org/).
* You have installed the latest versions of [`pip`](https://pip.pypa.io/en/stable/installing/) and [`virtualenv`](https://virtualenv.pypa.io/en/stable/installation/) or `conda` ([Anaconda](https://www.anaconda.com/distribution/)).
## Installation
This package can be easily installed with pip:
```bash
pip install likelihood
```
## Examples
You can check the [examples](https://github.com/jzsmoreno/likelihood/tree/main/examples) folder.
More examples will be added soon.
| text/markdown | J. A. Moreno-Guerra | jzs.gm27@gmail.com | Jafet Castañeda | jafetcc17@gmail.com | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/jzsmoreno/likelihood/ | null | >=3.10 | [] | [] | [] | [
"black[jupyter]>=24.3.0",
"mypy-extensions>=1.0.0",
"types-openpyxl>=3.1.0.15",
"pydocstyle>=6.3.0",
"flake8>=6.0.0",
"isort>=5.12.0",
"mypy>=1.4.1",
"numpy<3.0.0,>=1.26.4",
"pydot==2.0.0",
"matplotlib",
"packaging",
"graphviz",
"seaborn",
"pyyaml",
"pandas",
"corner",
"tqdm",
"net... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:31:11.691899 | likelihood-2.1.9.tar.gz | 87,812 | 26/f9/8dac5e24b89518151c69815c59d1d6e89f742d15bba54df43e2861cd69c7/likelihood-2.1.9.tar.gz | source | sdist | null | false | 75a09d53eb4369dae3f695d730a58d9f | a0f8334050a3c08d37ba9093871ecdb694900dcea36d0ea6acbba5937198dfe8 | 26f98dac5e24b89518151c69815c59d1d6e89f742d15bba54df43e2861cd69c7 | null | [
"LICENSE"
] | 300 |
2.4 | remerge-mwe | 0.4.1 | REMERGE is a Multi-Word Expression (MWE) discovery algorithm derived from the MERGE algorithm. | # REMERGE - Multi-Word Expression discovery algorithm
REMERGE is a greedy, bottom-up Multi-Word Expression (MWE) discovery algorithm derived from MERGE[^1][^2][^3].
Current implementation:
- Rust core engine (PyO3 extension) for fast iteration on large corpora
- Python API (`remerge.run`, `remerge.annotate`) with typed ergonomic results
- Deterministic tie-breaking and configurable scoring methods
The algorithm is non-parametric with respect to final MWE length: you set `iterations`, and merged expressions can grow as long as the corpus supports.
## Install
Latest release:
```bash
pip install -U remerge-mwe
```
Latest from GitHub:
```bash
pip install git+https://github.com/pmbaumgartner/remerge-mwe.git
```
## Quickstart
```python
import remerge
corpus = [
"a list of already tokenized texts",
"where each item is a document string",
"isn't this API nice",
]
winners = remerge.run(corpus, iterations=1, method="frequency")
winner = winners[0]
print(winner) # merged phrase text (via WinnerInfo.__str__)
print(winner.merged_lexeme.word) # ('a', 'list')
print(winner.score) # score used for winner selection
```
## Selection methods
Available winner-selection methods:
- `"log_likelihood"` (default; [Log-Likelihood / G²][^5])
- `"npmi"` ([Normalized PMI][^4])
- `"frequency"`
You can pass either enum values (`remerge.SelectionMethod.frequency`) or strings (`"frequency"`).
Tie-breaking is deterministic: score, then frequency, then lexicographic merged-token order.
## NPMI guidance
NPMI can saturate near `1.0` for rare but exclusive pairs, especially on large corpora. That can surface low-frequency artifacts unless `min_count` is set high enough.
Practical guidance:
- For discovery and ranking stability, prefer `log_likelihood` (the default).
- For NPMI, tune `min_count` aggressively and sweep upward until top results stabilize.
- On real corpora, values significantly above toy defaults are often needed.
```python
# Example starting point for larger corpora (tune further as needed)
winners = remerge.run(corpus, 100, method="npmi", min_count=200)
```
This aligns with the PMI caveat that infrequent pairs can dominate rankings[^4].
## Live progress output
For long runs, set `progress=True` to print live merge progress to `stderr`:
```python
winners = remerge.run(corpus, 500, progress=True)
```
## API - `remerge.run`
| Argument | Type | Description |
| --- | --- | --- |
| `corpus` | `list[str]` | Corpus of document strings. Documents are split into segments by `splitter`, then tokenized with Rust whitespace splitting. |
| `iterations` | `int` | Maximum number of iterations. |
| `method` | `SelectionMethod | str`, optional | One of `"frequency"`, `"log_likelihood"`, `"npmi"`. Default: `"log_likelihood"`. |
| `min_count` | `int`, optional | Minimum bigram frequency required to be considered for winner selection. Default: `0`. |
| `splitter` | `Splitter | str`, optional | Segmenter before tokenization: `"delimiter"` (default) or `"sentencex"`. |
| `line_delimiter` | `str | None`, optional | Delimiter for `splitter="delimiter"`. Default: `"\n"`. Use `None` to treat each document as one segment. Ignored for `sentencex`. |
| `sentencex_language` | `str`, optional | Language code for `splitter="sentencex"`. Default: `"en"`. |
| `rescore_interval` | `int`, optional | Full-rescore interval for LL/NPMI. `1` means full rescore every iteration; larger values trade exactness for speed. Default: `25`. |
| `on_exhausted` | `ExhaustionPolicy | str`, optional | Behavior when no candidate is available (or score threshold not met): `"stop"` or `"raise"`. Default: `"stop"`. |
| `min_score` | `float | None`, optional | Optional minimum score threshold for selected winners. Default: `None`. |
| `progress` | `bool`, optional | If `True`, prints live merge progress to `stderr`. Default: `False`. |
`run()` returns `list[WinnerInfo]`.
Each `WinnerInfo` contains:
- `bigram`
- `merged_lexeme`
- `score`
- `merge_token_count`
Convenience helpers:
- `str(winner)` and `winner.text` for merged phrase text
- `winner.token_count` (alias of `winner.n_lexemes`) for merged token count
- `str(winner.merged_lexeme)` / `winner.merged_lexeme.text` for lexeme text
- `winner.merged_lexeme.token_count` for lexeme token count
## API - `remerge.annotate`
`annotate()` runs the same merge process as `run()`, then returns:
```python
(winners, annotated_docs, labels)
```
Where:
- `winners`: `list[WinnerInfo]`
- `annotated_docs`: `list[str]` of annotated output documents
- `labels`: sorted unique list of annotation labels generated
Arguments shared with `run()`:
- `corpus`, `iterations`, `method`, `min_count`, `splitter`, `line_delimiter`
- `sentencex_language`, `rescore_interval`, `on_exhausted`, `min_score`, `progress`
`annotate()`-specific arguments:
- `mwe_prefix: str = "<mwe:"`
- `mwe_suffix: str = ">"`
- `token_separator: str = "_"`
## Tokenization and output normalization
Tokenization uses Rust `split_whitespace()`.
Implications:
- Original whitespace formatting is not preserved.
- Annotated output reconstructs segments using normalized single-space joins.
## Performance and scaling notes
- Internal location tracking is intentionally memory-intensive.
- For large corpora, tune `min_count` and keep `iterations` practical.
- `rescore_interval=1` gives exact LL/NPMI rescoring each iteration; larger values trade exactness for speed.
## Development
This project uses `uv`, `ruff`, and `ty`.
```bash
# Sync environment
uv sync --all-groups
# Build/install Rust extension into the active env
uv run --no-sync maturin develop
# Python checks
uv run ruff format src tests
uv run ruff check src tests
uv run ty check src tests
uv run --no-sync pytest -v -m "not corpus and not parity"
# Slower corpus/parity suite
uv run --no-sync pytest -v -m "corpus or parity"
```
If you change files under `rust/`, rebuild the extension before running Python tests:
```bash
uv run --no-sync maturin develop
```
## Releasing (maintainers)
Releases are automated by `.github/workflows/release.yml`.
At a minimum:
1. Keep `pyproject.toml` and `Cargo.toml` versions aligned.
2. Push to `main`.
3. Tag with `vX.Y.Z` to trigger release publication.
Use `bin/pypi-smoke.py` to validate the newest published package from PyPI.
## How it works
Each iteration:
1. Score candidate bigrams.
2. Select the winner.
3. Merge winner occurrences into a new lexeme.
4. Update internal bigram/lexeme state.
Lexemes use `(word, ix)` semantics, where `ix=0` is the root position and only root lexemes participate in bigram formation.
<img src="explanation.png" alt="An explanation of the remerge algorithm" width="820">
## Limitations
- REMERGE is greedy/agglomerative: early winner choices can influence later merges.
- Different methods (`frequency`, `log_likelihood`, `npmi`) can produce materially different inventories depending on corpus/domain.
## Notes on the original MERGE gapsize behavior
This implementation intentionally excludes discontinuous/gapped bigram merging. The old gapsize path could conflate distinct positional configurations in edge cases, which made behavior harder to reason about and validate.
## References
[^1]: awahl1, MERGE. 2017. Accessed: Jul. 11, 2022. [Online]. Available: https://github.com/awahl1/MERGE
[^2]: A. Wahl and S. Th. Gries, “Multi-word Expressions: A Novel Computational Approach to Their Bottom-Up Statistical Extraction,” in Lexical Collocation Analysis, P. Cantos-Gómez and M. Almela-Sánchez, Eds. Cham: Springer International Publishing, 2018, pp. 85–109. doi: 10.1007/978-3-319-92582-0_5.
[^3]: A. Wahl, “The Distributional Learning of Multi-Word Expressions: A Computational Approach,” p. 190.
[^4]: G. Bouma, “Normalized (Pointwise) Mutual Information in Collocation Extraction,” p. 11.
[^5]: T. Dunning, “Accurate Methods for the Statistics of Surprise and Coincidence,” Computational Linguistics, vol. 19, no. 1, p. 14.
| text/markdown; charset=UTF-8; variant=GFM | null | Peter Baumgartner <5107405+pmbaumgartner@users.noreply.github.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T20:30:54.519516 | remerge_mwe-0.4.1-cp312-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl | 1,365,374 | 1f/73/0a9b0a59868c3f97bc56dad013d6dd59759f075d6c14a7b88972780783f5/remerge_mwe-0.4.1-cp312-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl | cp312 | bdist_wheel | null | false | 9ce4e6312f301baad2743e5252caac56 | 9760decbcff82042a9d3f39ac01ea6f054fae4ba6d2c66e5532cd296453f1886 | 1f730a9b0a59868c3f97bc56dad013d6dd59759f075d6c14a7b88972780783f5 | MIT | [
"LICENSE"
] | 370 |
2.4 | rug-munch-mcp | 1.0.1 | MCP server for Rug Munch Intelligence — 19 tools for crypto token risk analysis, rug pull detection, and AI forensics | # Rug Munch Intelligence — MCP Server
<!-- mcp-name: io.github.amarodeabreu/rug-munch-mcp -->
[](https://modelcontextprotocol.io)
[](https://cryptorugmunch.app/api/agent/v1/status)
[](https://cryptorugmunch.app/.well-known/x402)
**19 tools for crypto token risk intelligence.** Detect rug pulls, honeypots, and scams before your agent transacts.
Works with Claude Desktop, Cursor, Windsurf, and any MCP-compatible client.
## What It Does
| Tool | What | Price |
|------|------|-------|
| `check_token_risk` | Quick risk score (0-100) + recommendation | $0.04 |
| `check_token_risk_premium` | Full breakdown + deployer + social OSINT | $0.10 |
| `check_batch_risk` | Up to 20 tokens at once | $0.30 |
| `check_deployer_history` | Deployer wallet analysis — serial rugger? | $0.06 |
| `get_token_intelligence` | Complete token profile (price, holders, LP) | $0.06 |
| `get_holder_deepdive` | Top holders, concentration, sniper detection | $0.10 |
| `get_social_osint` | Social media presence and red flags | $0.06 |
| `get_kol_shills` | KOL/influencer shill detection | $0.06 |
| `get_coordinated_buys` | Detect coordinated buying patterns | $0.04 |
| `check_blacklist` | Community blacklist check | $0.02 |
| `check_scammer_wallet` | Known scammer wallet check | $0.02 |
| `get_market_risk_index` | Global market risk overview | $0.02 |
| `get_serial_ruggers` | Known serial rugger wallets | $0.02 |
| `marcus_quick` | AI verdict — Claude Sonnet 4 quick analysis | $0.15 |
| `marcus_forensics` | AI forensics — full Claude Sonnet 4 investigation | $0.50 |
| `marcus_ultra` | AI deep analysis — Claude Opus 4 | $2.00 |
| `marcus_thread` | AI analysis thread for X/Twitter | $1.00 |
| `watch_token` | 7-day webhook monitoring for risk changes | $0.20 |
| `get_api_status` | Service health + accuracy metrics (free) | Free |
## Quick Start
### Install
```bash
pip install rug-munch-mcp
```
### Claude Desktop
Add to `~/Library/Application Support/Claude/claude_desktop_config.json`:
```json
{
"mcpServers": {
"rug-munch": {
"command": "rug-munch-mcp",
"env": {}
}
}
}
```
### Cursor / Windsurf
Add to your MCP config:
```json
{
"rug-munch": {
"command": "python3",
"args": ["-m", "rug_munch_mcp"]
}
}
```
### From Source
```bash
git clone https://github.com/CryptoRugMunch/rug-munch-mcp
cd rug-munch-mcp
pip install -e .
rug-munch-mcp
```
## Payment
Endpoints are paid via **x402 USDC micropayments** on Base mainnet. When you call a paid tool, the API returns HTTP 402 with payment details. x402-compatible clients handle this automatically.
Alternatively, set an API key to bypass x402:
```json
{
"mcpServers": {
"rug-munch": {
"command": "rug-munch-mcp",
"env": {
"RUG_MUNCH_API_KEY": "your-key-here"
}
}
}
}
```
## Supported Chains
Solana, Ethereum, Base, Arbitrum, Polygon, Optimism, Avalanche
## Architecture
```
Your Agent (Claude, Cursor, etc.)
↓ MCP stdio
rug-munch-mcp (this package)
↓ HTTPS
cryptorugmunch.app/api/agent/v1/*
↓ x402 payment (if needed)
Rug Munch Intelligence API
↓
240K+ scans, 114K+ flagged tokens, AI forensics
```
## Other Integration Methods
- **x402 Direct**: [x402-trading-agent](https://github.com/CryptoRugMunch/x402-trading-agent) — Example Python agent
- **AgentKit Plugin**: [rug-agent-kit](https://github.com/CryptoRugMunch/rug-agent-kit) — Coinbase AgentKit integration
- **A2A**: `https://cryptorugmunch.app/.well-known/agent.json`
- **OpenAPI**: `https://cryptorugmunch.app/api/agent/v1/openapi.json`
## Links
- **API Status**: https://cryptorugmunch.app/api/agent/v1/status
- **Discovery**: https://cryptorugmunch.app/.well-known/mcp.json
- **Docs**: https://cryptorugmunch.app/api/agent/v1/skill.md
- **GitHub**: https://github.com/CryptoRugMunch
## License
MIT
| text/markdown | null | CryptoRugMunch <dev@cryptorugmunch.app> | null | null | MIT | mcp, crypto, security, rug-pull, ai-agent, x402, token-risk | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Topic :: Security",
"Topic :: Office/Business :: Financial"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"mcp>=1.0.0",
"httpx>=0.25.0"
] | [] | [] | [] | [
"Homepage, https://cryptorugmunch.app",
"Repository, https://github.com/CryptoRugMunch/rug-munch-mcp",
"Documentation, https://cryptorugmunch.app/api/agent/v1/skill.md",
"API Status, https://cryptorugmunch.app/api/agent/v1/status",
"x402 Discovery, https://cryptorugmunch.app/.well-known/x402"
] | twine/6.2.0 CPython/3.13.3 | 2026-02-18T20:30:35.283693 | rug_munch_mcp-1.0.1.tar.gz | 9,559 | 24/68/1b189b49d449a4efae138a63db13bbc8dc5804f1cb27ca838b2110c64a62/rug_munch_mcp-1.0.1.tar.gz | source | sdist | null | false | 9575ea2487dd772159fdace6a34eaa10 | 3a96334b9e176efd2b7baf88f1c877591125a2379cc75e285ed1dc18c6a4680f | 24681b189b49d449a4efae138a63db13bbc8dc5804f1cb27ca838b2110c64a62 | null | [
"LICENSE"
] | 246 |
2.4 | phconvert | 0.10.1 | Convert Beker&Hickl, PicoQuant and other formats to Photon-HDF5. | [](https://github.com/Photon-HDF5/phconvert/actions)
# phconvert
*phconvert* is a python 3 library that helps writing valid
<a href="http://photon-hdf5.org/" target="_blank">Photon-HDF5</a>
files, a file format for time stamp-based single-molecule spectroscopy.
Additionally, *phconvert* can convert to Photon-HDF5 all the common binary
formats used in solution-based single-molecule spectroscopy. These includes
PicoQuant's .HT3/.PT3/.PTU/.T3R, Becker & Hickl's .SPC/.SET and the .SM format
used by WeissLab and others for µs-ALEX smFRET.
For questions or issues running this software please use the
[Photon-HDF5 Google Group](https://groups.google.com/forum/#!forum/photon-hdf5)
or open an [issue on GitHub](https://github.com/Photon-HDF5/phconvert/issues).
- [Phconvert Documentation](https://phconvert.readthedocs.io)
## What's new
**Feb. 2025:** PhConvert 0.10 released
**Nov. 2018:** Phconvert 0.9 released, see the [release notes](https://github.com/Photon-HDF5/phconvert/releases/tag/0.9).
## Quick-start: Converting files to Photon-HDF5
Converting one of the supported files formats to Photon-HDF5 does not require
being able to program in python. All you need is running the "notebook"
corresponding to the file format you want to convert from, and follow the instructions therein.
For demonstration purposes, we provide [a demo service](http://photon-hdf5.github.io/Photon-HDF5-Converter)
to run the notebooks online without any installation.
With this online service, you can convert data files up to 35MB to Photon-HDF5.
To launch the demo click on the following button
(see also [instructions](http://photon-hdf5.github.io/Photon-HDF5-Converter/)):
[](http://mybinder.org/repo/Photon-HDF5/Photon-HDF5-Converter)
To execute the phconvert notebooks on your machine, you need to install the *Jupyter Notebook App* first.
A quick-start guide on installing and running the *Jupyter Notebook App* is available here:
- <a href="http://jupyter-notebook-beginner-guide.readthedocs.org/" target="_blank">Jupyter/IPython Notebook Quick Start Guide</a>
Next, you need to install the *phconvert* library with the following command
(type it in *Terminal* on OS X or Linux, or in the `cmd` prompt on Windows):
conda install -c conda-forge phconvert
Finally, you can download one of the provided notebooks and run it on your machine.
Simply, download the
[phconvert zip](https://github.com/Photon-HDF5/phconvert/archive/master.zip),
which contains all the notebooks in the `notebooks` subfolder.
### For questions or issues:
- [Open an GitHub issue](https://github.com/Photon-HDF5/phconvert/issues) or
- Ask a question on the [Photon-HDF5 Google Group](https://groups.google.com/forum/#!forum/photon-hdf5).
## Project details
### What's inside?
*phconvert* repository contains a python package (library) and a set of
[notebooks](https://github.com/Photon-HDF5/phconvert/tree/master/notebooks)
([online viewer](http://nbviewer.ipython.org/github/Photon-HDF5/phconvert/tree/master/notebooks/)).
Each notebook can convert a different format to Photon-HDF5 using the phconvert library.
If you have a file format that is not yet supported, please [open an new Issue](https://github.com/Photon-HDF5/phconvert/issues).
We are willing add support for as many file formats as possible!
### Why phconvert?
When writing Photon-HDF5 files, phconvert saves you time
and protects you against common errors that risk
to make the file not a valid Photon-HDF5. Also a description
is automatically added to each Photon-HDF5 field.
The descriptions are extracted from a [JSON file](https://github.com/Photon-HDF5/phconvert/blob/master/phconvert/specs/photon-hdf5_specs.json)
which contains the list Photon-HDF5 field names, types, and descriptions.
See also [Writing Photon-HDF5 files](http://photon-hdf5.readthedocs.org/en/latest/writing.html)
in the Photon-HDF5 reference documentation.
## Read Photon-HDF5 files
In case you just want to read Photon-HDF5 files you don't need to use phconvert.
Photon-HDF5 files can be directly opened with a standard HDF5 viewer
[HDFView](https://www.hdfgroup.org/products/java/hdfview/).
See also [Reading Photon-HDF5 files](http://photon-hdf5.readthedocs.org/en/latest/reading.html)
in the Photon-HDF5 reference documentation.
## Installation
The recommended way to install *phconvert* is using conda:
conda install -c conda-forge phconvert
If you don't have conda installed, please install the free python distribution
[Anaconda](https://store.continuum.io/cshop/anaconda/) choosing the python 3
version.
Starting from version 0.9, the aging python 2.7 is not supported anymore.
Alternatively, you can install *phconvert* in any python installation using PIP:
pip install phconvert
In this latter case, make sure that numpy and pytables are installed.
See also:
- [phconvert Release Notes](https://github.com/Photon-HDF5/phconvert/releases/).
## Dependencies
- python 3.4 or greater (3.6+ recommended)
- numpy >=1.9
- pytables >=3.1
- numba (optional) *for faster PicoQuant files decoding*
> **Note**
> when installing via `conda` all the dependencies are automatically installed.
## The phconvert library documentation (for developers)
The *phconvert* API documentation can be found on ReadTheDocs:
- [phconvert's documentation](http://phconvert.readthedocs.org/)
## License
*phconvert* is released under the open source [MIT license](https://raw.githubusercontent.com/Photon-HDF5/phconvert/master/LICENSE.txt).
## Contributing
As with other Photon-HDF5 subprojects, we encourage contributions
in any form, from simple suggestions, typo fix to the addition of new features.
Please use GitHub by opening Issues or sending Pull Requests.
All the contributors will be acknowledged in this website, and will included
as authors in the next software-paper publication.
For more details see our [contribution policy](http://photon-hdf5.readthedocs.org/en/latest/contributing.html).
## Authors & Contributors
List of contributors:
- Antonino Ingargiola (@tritemio) <tritemio AT gmail.com>
- Ted Laurence (@talaurence) <laurence2 AT llnl.gov>
- Marco Lamperti (@lampo808) <marco.lampo AT gmail.com>
- Xavier Michalet (@smXplorer) <michalet AT chem.ucla.edu>
- Anders Barth (@AndersBarth) <anders.barth AT gmail.com>
- Biswajit Pradhan (@biswajitSM) <biswajitp145 AT gmail.com.
- Sébastien Weber (@seb5g) <sebastien.weber AT cemes.fr>
- David Palmer (@dmopalmer)
We thank also @ncodina for providing PTU files and helping in testing
the PTU decoder in phconvert.
## Acknowledgements
This work was supported by NIH Grant R01-GM95904.
Release 0.9 was supported by Prof. Eitan Lerner.
| text/markdown | null | Antonino Ingargiola <tritemio@gmail.com>, Paul David Harris <harripd@gmail.com> | null | Paul David Harris <harripd@gmail.com> | The MIT License (MIT)
Copyright (c) 2015-2016 The Regents of the University of California,
Antonino Ingargiola and contributors.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
| single-molecule FRET, smFRET, biophysics, file-format, HDF5, Photon-HDF5 | [
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: ... | [] | null | null | >=3.6 | [] | [] | [] | [
"numpy>=1.19",
"tables",
"importlib_resources; python_version <= \"3.10\""
] | [] | [] | [] | [
"Homepage, http://photon-hdf5.github.io/phconvert/",
"Documentation, https://phconvert.readthedocs.io/en/latest/",
"Repositories, https://github.com/Photon-HDF5/phconvert",
"Issues, https://github.com/Photon-HDF5/phconvert/issues"
] | twine/6.2.0 CPython/3.11.13 | 2026-02-18T20:30:20.077908 | phconvert-0.10.1.tar.gz | 213,350 | ea/42/c5f73dbc4e138a7fe13af0fdbcb83986f94f3ddb896169a41f1e0294539b/phconvert-0.10.1.tar.gz | source | sdist | null | false | ff41063b99970980b76e3dd88c4a35a9 | e4a946923770a246ec010c0b18c1d596db0062bc0235c57e7a5874ce61ba56dd | ea42c5f73dbc4e138a7fe13af0fdbcb83986f94f3ddb896169a41f1e0294539b | null | [
"LICENSE.txt"
] | 488 |
2.4 | ajenti.plugin.core | 0.111 | Core | A Core plugin for Ajenti panel
| null | Ajenti project | e@ajenti.org | null | null | null | null | [] | [] | https://ajenti.org | null | >=3 | [] | [] | [] | [
"aj",
"setproctitle"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.11 | 2026-02-18T20:29:40.880672 | ajenti_plugin_core-0.111.tar.gz | 17,478,913 | 1a/87/794c982d0d9d5407f96d2f4cbc14821bfcb6f66acca0e747ecee5e40c277/ajenti_plugin_core-0.111.tar.gz | source | sdist | null | false | ce4fe2efea1f34c98f483290dc8de394 | c6c1f19feb84bc96fb376b91b4dc2e1a40be289401435a7dd1ee11185f358b40 | 1a87794c982d0d9d5407f96d2f4cbc14821bfcb6f66acca0e747ecee5e40c277 | null | [] | 0 |
2.4 | feed-ursus | 1.6.2 | Command line tool to load CSV content into a Solr index for the UCLA Digital Library's frontend, Ursus (https://digital.library.ucla.edu/) | # feed_ursus
Command line tools to load CSV content into a Solr index for the UCLA Digital Library's frontend, Ursus (https://digital.library.ucla.edu/) and the [Sinai Manuscripts Digital Library](https://sinaimanuscripts.library.ucla.edu)
## Using feed_ursus
For basic use, you can install feed_ursus as a systemwide command directly from pypi, without having to first clone the repository.
### Installation
#### Installing with UV
We recommend installing with [uv](https://docs.astral.sh/uv). On MacOS, you can install uv with [homebrew](https://brew.sh):
```
brew install uv
```
Then:
```
uv tool install feed_ursus
```
UV will install feed_ursus in its own virtualenv, but make the command accessible from anywhere so you don't need to active the virtualenv yourself.
To upgrade a uv-installed feed ursus to the latest version:
```
uv tool upgrade feed_ursus
```
#### Installing with pipx
If you are already using pipx, you can use it instead of uv:
```
pipx install feed_ursus
pipx upgrade feed_ursus
```
### Use
Convert a csv into a json document that follows the data model of an Ursus solr index:
```
feed_ursus [path/to/your.csv]
```
This repo includes a docker-compose.yml file that will run local instances of solr and ursus for use in testing this script. To use them, first install [docker](https://docs.docker.com/install/) and [docker compose](https://docs.docker.com/compose/install/). Then run:
```
docker-compose up --detach
docker-compose run web bundle exec rails db:setup
```
It might take a minute or so for solr to get up and running, at which point you should be able to see your new site at http://localhost:3000. Ursus will be empty, because you haven't loaded any data yet.
To load data from a csv:
```
feed_ursus --solr_url=http://localhost:8983/solr/ursus --mapping=dlp load [path/to/your.csv]
```
### Mappers
Different metadata mappings are included for general Digital Library use (`--mapping=dlp`) and for the Sinai Manuscripts Digital Library (`--mapping=sinai`). The default is "dlp" – "sinai" is not guaranteed to be up to date as the sinai project is using a forked version at https://github.com/uclalibrary/feed_sinai.
## Developing feed_ursus
### Installing
For development, clone the repository and use uv to set up the virtualenv:
```
git clone git@github.com:UCLALibrary/feed_ursus.git
cd feed_ursus
uv install
```
Then, to activate the virtualenv:
```
source .venv/bin/activate
```
The following will assume the virtualenv is active. You could also run e.g. `uv run feed_ursus [path/to/your.csv]`
### Using the development version
```
feed_ursus --solr_url http://localhost:8983/solr/ursus load [path/to/your.csv]
```
### Running the tests
Tests are written for [pytest](https://docs.pytest.org/en/latest/):
```
pytest
```
### Running the formatter and linters:
ruff (formatter and linter) will run in check mode in ci, so make sure you run it before committing:
```
ruff format .
ruff check --fix
```
mypy (static type checker):
```
mypy
```
### VSCode Debugger Configuration
To debug with VSCode, the python environment has to be created within the project directory.
TODO: update this section for uv. UV seems more predictable overall so it's probablly easier? Just a matter of `rm -rf .venv && uv install`?
If it exists, remove the existing setup and install in the project directory:
- `poetry env list`
- `poetry env remove <name of environment you want to delete>`
- `poetry config virtualenvs.in-project true`
- `poetry install`
Add an appropriate `.vscode/launch.json`, this assumes you have the python debugger extension installed.
```
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python: Run the feed_ursus module",
"type": "debugpy",
"request": "launch",
"cwd": "${workspaceFolder}",
"console": "integratedTerminal",
"module": "feed_ursus.feed_ursus",
"justMyCode": true,
}
]
}
```
# Caveats
## IIIF Manifests
When importing a work, the script will always assume that a IIIF manifest exists at https://iiif.library.ucla.edu/[ark]/manifest, where [ark] is the URL-encoded Archival Resource Key of the work. This link should work, as long as a manifest has been pushed to that location by importing the work into [Fester](https://github.com/UCLALibrary/fester). If you haven't done one of those, obviously, the link will fail and the image won't be visible, but metadata will import and be visible. A manifest can then be created and pushed to the expected location without re-running feed_ursus.py.
| text/markdown | null | Andy Wallace <andrewwallace@library.ucla.edu> | null | null | null | null | [] | [] | null | null | ~=3.11 | [] | [] | [] | [
"click>=8.1.3",
"edtf>=5.0.0",
"httpx>=0.28.1",
"pydantic<3,>=2.12",
"pysolr>=3.8",
"python-dateutil>=2.8.2",
"pyyaml>=6.0.1",
"requests>=2.32.2",
"rich>=13.4.1",
"setuptools>=74"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:28:26.829931 | feed_ursus-1.6.2.tar.gz | 38,575 | a3/e1/19ba7dff4a42a504841d658343141b3dfb6b3380217806f1ae827d507fca/feed_ursus-1.6.2.tar.gz | source | sdist | null | false | aaceb8bdb7861b80d136a1602b5607e2 | c0b7f94960ef9893f9490bedac2e3ef85b83227b89aa18e9c83d9f10f2db9d5f | a3e119ba7dff4a42a504841d658343141b3dfb6b3380217806f1ae827d507fca | null | [
"LICENSE"
] | 250 |
2.4 | google-api-core | 2.30.0 | Google API client core library | Core Library for Google Client Libraries
========================================
|pypi| |versions|
This library is not meant to stand-alone. Instead it defines
common helpers used by all Google API clients. For more information, see the
`documentation`_.
.. |pypi| image:: https://img.shields.io/pypi/v/google-api_core.svg
:target: https://pypi.org/project/google-api_core/
.. |versions| image:: https://img.shields.io/pypi/pyversions/google-api_core.svg
:target: https://pypi.org/project/google-api_core/
.. _documentation: https://googleapis.dev/python/google-api-core/latest
Supported Python Versions
-------------------------
Python >= 3.9
Unsupported Python Versions
---------------------------
Python == 2.7, Python == 3.5, Python == 3.6, Python == 3.7, Python == 3.8.
The last version of this library compatible with Python 2.7 and 3.5 is
`google-api-core==1.31.1`.
The last version of this library compatible with Python 3.6 is
`google-api-core==2.8.2`.
The last version of this library compatible with Python 3.7 and 3.8 is
`google-api-core==2.29.0`.
| text/x-rst | null | Google LLC <googleapis-packages@google.com> | null | null | Apache 2.0 | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programmi... | [] | null | null | >=3.9 | [] | [] | [] | [
"googleapis-common-protos<2.0.0,>=1.56.3",
"protobuf<7.0.0,>=4.25.8",
"proto-plus<2.0.0,>=1.22.3",
"proto-plus<2.0.0,>=1.25.0; python_version >= \"3.13\"",
"google-auth<3.0.0,>=2.14.1",
"requests<3.0.0,>=2.20.0",
"google-auth[aiohttp]<3.0.0,>=2.35.0; extra == \"async-rest\"",
"grpcio<2.0.0,>=1.33.2; e... | [] | [] | [] | [
"Homepage, https://github.com/googleapis/google-cloud-python/tree/main/packages/google-api-core",
"Documentation, https://googleapis.dev/python/google-api-core/latest/",
"Repository, https://github.com/googleapis/google-cloud-python"
] | twine/6.2.0 CPython/3.11.2 | 2026-02-18T20:28:11.926576 | google_api_core-2.30.0.tar.gz | 176,959 | 22/98/586ec94553b569080caef635f98a3723db36a38eac0e3d7eb3ea9d2e4b9a/google_api_core-2.30.0.tar.gz | source | sdist | null | false | 8c5ab43e8f25708f22a6f28d919bb45f | 02edfa9fab31e17fc0befb5f161b3bf93c9096d99aed584625f38065c511ad9b | 2298586ec94553b569080caef635f98a3723db36a38eac0e3d7eb3ea9d2e4b9a | null | [
"LICENSE"
] | 12,191,301 |
2.4 | dbt-ci | 1.2.0 | CI/CD tool for dbt projects with intelligent change detection and selective execution | # dbt-ci
A CI tool for dbt (data build tool) projects that intelligently runs only modified models based on state comparison, supporting multiple execution environments including local, Docker, and dbt runners.
## How It Works
dbt-ci uses a **cache-based workflow**:
1. **`init`** - Downloads reference state from cloud storage (or uses local), compares with current code, and creates a cache of changes
2. **`run/delete/ephemeral`** - Use the cached state automatically (no need to re-specify state paths)
This design ensures:
- ✅ **Consistent state** across all commands in a CI run
- ✅ **Better performance** (no redundant state downloads)
- ✅ **Simpler CLI** (specify state once in init, reuse everywhere)
## Installation
### From PyPI (Recommended)
```bash
pip install dbt-ci
```
### From GitHub
```bash
# Install from main branch
pip install git+https://github.com/datablock-dev/dbt-ci.git@main
# Install a specific version
pip install git+https://github.com/datablock-dev/dbt-ci.git@v1.0.0
```
### Local Development
```bash
git clone https://github.com/datablock-dev/dbt-ci.git
cd dbt-ci
pip install -e ".[dev]"
```
After installation, the tool is available as `dbt-ci`.
## Quick Start
**The Workflow:** Initialize once with `init`, then run commands that use the cached state.
### 1. Initialize State
First, initialize the dbt-ci state. This downloads/reads reference state and creates a cache:
```bash
dbt-ci init \
--dbt-project-dir dbt \
--profiles-dir dbt \
--reference-target production \
--state dbt/.dbtstate
```
**With Cloud Storage (GCS/S3):**
```bash
dbt-ci init \
--dbt-project-dir dbt \
--state-uri gs://my-bucket/dbt-state/manifest.json \
--reference-target production \
--state dbt/.dbtstate
```
### 2. Run Modified Models
After initialization, run commands use the cached state automatically:
```bash
# No need to specify --state again!
dbt-ci run \
--dbt-project-dir dbt \
--profiles-dir dbt
```
**With Docker:**
```bash
dbt-ci run \
--runner docker \
--docker-image ghcr.io/dbt-labs/dbt-bigquery:latest
```
## Commands
### `init` - Initialize State
Creates initial state from your dbt project. **Always run this first.** Downloads reference manifest from cloud storage (if specified) and creates a local cache for subsequent commands.
```bash
dbt-ci init \
--dbt-project-dir dbt \
--profiles-dir dbt \
--state-uri gs://my-bucket/manifest.json \
--reference-target production \
--state dbt/.dbtstate
```
**Options:**
- `--state`, `--reference-state`: Local path where state will be downloaded/stored
- `--state-uri`: Remote URI for state manifest (e.g., `gs://bucket/manifest.json`, `s3://bucket/manifest.json`)
- `--reference-target`: Target to use for production/reference manifest (optional)
- `--dbt-version`: Specific dbt version to use (e.g., `1.10.13`)
- `--adapter`, `-a`: Adapter to install (e.g., `dbt-duckdb=1.10.0`)
### `run` - Run Modified Models
Detects and runs models that have changed. Uses cached state from `init` command.
```bash
# Run after init - uses cached state
dbt-ci run \
--dbt-project-dir dbt \
--mode models
```
**Options:**
- `--mode`, `-m`: What to run: `all`, `models`, `seeds`, `snapshots`, `tests` (default: `all`)
- `--defer`: Use dbt's defer flag for production state
**Examples:**
```bash
# Run only modified models
dbt-ci run --mode models
# Run modified models with defer to production
dbt-ci run --mode models --defer
# Run all modified resources (models, tests, seeds, etc.)
dbt-ci run --mode all
# With Docker
dbt-ci run --runner docker --mode models
```
### `ephemeral` - Ephemeral Environment
Creates ephemeral environments for testing without affecting production. Uses cached state from `init`.
```bash
# Run after init
dbt-ci ephemeral --dbt-project-dir dbt
```
**Options:**
- `--keep-env`: Don't destroy ephemeral environment after run
### `delete` - Delete Removed Models
Detects and deletes models that have been removed from the project. Uses cached state from `init`.
```bash
# Run after init
dbt-ci delete --dbt-project-dir dbt
```
## Runners
dbt-ci supports multiple execution environments:
### Local Runner
Execute dbt commands directly on your machine:
```bash
# After init
dbt-ci run \
--runner local \
--dbt-project-dir dbt
```
### dbt Runner (Python API)
Uses dbt's Python API (fastest, default):
```bash
# After init - uses dbt Python API
dbt-ci run \
--runner dbt \
--dbt-project-dir dbt
```
### Docker Runner
Run dbt commands inside a Docker container:
```bash
dbt-ci run \
--runner docker \
--docker-image ghcr.io/dbt-labs/dbt-duckdb:latest \
--docker-volumes $(pwd):/workspace \
--dbt-project-dir /workspace/dbt \
--state /workspace/dbt/.dbtstate
```
**For Apple Silicon Macs:**
```bash
dbt-ci run \
--runner docker \
--docker-platform linux/amd64 \
--docker-image ghcr.io/dbt-labs/dbt-postgres:latest \
--docker-volumes $(pwd):/workspace \
--dbt-project-dir /workspace/dbt
```
#### Docker Advanced Options
**Platform (for Apple Silicon compatibility):**
```bash
--docker-platform linux/amd64 # or linux/arm64
```
**Custom Volumes:**
```bash
--docker-volumes "/host/path:/container/path" --docker-volumes "/another:/path:ro"
```
**Environment Variables:**
```bash
--docker-env "DBT_ENV=prod" --docker-env "MY_API_KEY=secret"
```
**Network Mode:**
```bash
--docker-network bridge # or host, none, container:name
```
**User:**
```bash
--docker-user "1000:1000" # or leave empty for auto-detect
```
**Additional Docker Args:**
```bash
--docker-args "--memory=2g --cpus=2"
```
**Complete Docker Example:**
```bash
dbt-ci run \
--runner docker \
--docker-image ghcr.io/dbt-labs/dbt-postgres:1.7.0 \
--docker-platform linux/amd64 \
--docker-env "POSTGRES_HOST=host.docker.internal" \
--docker-network host \
--docker-volumes "$(pwd):/workspace" \
--docker-volumes "$HOME/.aws:/root/.aws:ro" \
--dbt-project-dir /workspace/dbt \
--profiles-dir /workspace/dbt \
--target prod
```
## Global Options
These options apply to all commands:
| Option | Description | Default |
|--------|-------------|---------|
| `--dbt-project-dir` | Path to dbt project directory | `.` |
| `--profiles-dir` | Path to profiles.yml directory | Auto-detect |
| `--reference-target` | dbt target for production/reference manifest (init only) | None |
| `--target`, `-t` | dbt target to use | From profiles.yml |
| `--vars`, `-v` | YAML string or file path with dbt variables | `""` |
| `--defer` | Use dbt's defer flag for production state | `false` |
| `--runner`, `-r` | Runner type: `local`, `docker`, `bash`, `dbt` | `dbt` |
| `--entrypoint` | Command entrypoint for dbt | `dbt` |
| `--dbt-version` | Specific dbt version to use | Current |
| `--adapter`, `-a` | Adapter to install (format: `dbt-adapter=version`) | None |
| `--dry-run` | Print commands without executing | `false` |
| `--log-level` | Logging level: DEBUG, INFO, WARNING, ERROR, CRITICAL | `INFO` |
| `--slack-webhook` | Slack webhook URL for notifications | None |
### Init-Specific Options
These options are only available for the `init` command:
| Option | Description | Default |
|--------|-------------|---------|
| `--state`, `--reference-state` |Local path where reference state will be stored | None |
| `--state-uri` | Remote URI for state manifest (e.g., `gs://bucket/manifest.json`, `s3://bucket/manifest.json`) | None |
### Docker Options
| Option | Description | Default |
|--------|-------------|---------|
| `--docker-image` | Docker image for dbt | `ghcr.io/dbt-labs/dbt-core:latest` |
| `--docker-platform` | Platform (linux/amd64, linux/arm64) | Auto-detect |
| `--docker-volumes` | Volume mounts (format: `host:container[:mode]`) | `[]` |
| `--docker-env` | Environment variables (format: `KEY=VALUE`) | `[]` |
| `--docker-network` | Docker network mode | `host` |
| `--docker-user` | User to run as (UID:GID) | Auto-detect |
| `--docker-args` | Additional docker run arguments | `""` |
### Bash Runner Options
| Option | Description | Default |
|--------|-------------|---------|
| `--shell-path`, `--bash-path` | Path to shell executable | `/bin/bash` |
## Cloud Storage Support
dbt-ci supports storing and retrieving state files from cloud storage (GCS, S3), making it ideal for distributed CI/CD workflows.
### GCS/S3 State Storage
Store your dbt reference state in cloud storage for shared access across CI runs:
```bash
# Initialize and download state from GCS
dbt-ci init \
--dbt-project-dir dbt \
--state-uri gs://my-bucket/dbt-state/manifest.json \
--reference-target production \
--state dbt/.dbtstate
# Run using cached state (no need to specify URI again)
dbt-ci run --dbt-project-dir dbt --mode models
```
**Benefits:**
- 🔄 **Shared State**: Download the same reference state across different CI jobs
- 💾 **Cache-Based**: After init, commands use local cache (no repeated downloads)
- 📦 **No Git Commits**: State files don't need to be committed to version control
- 🚀 **Scalable**: Works seamlessly in containerized and distributed environments
- 🔐 **Secure**: Leverage cloud IAM and bucket policies for access control
**Configuration:**
The tool uses cloud credentials from your environment. Ensure your bucket is accessible:
```bash
# For GCS
export GOOGLE_APPLICATION_CREDENTIALS=/path/to/service-account.json
# For AWS S3
export AWS_ACCESS_KEY_ID=your_key
export AWS_SECRET_ACCESS_KEY=your_secret
export AWS_DEFAULT_REGION=us-east-1
# Or use IAM roles (recommended in CI/CD)
dbt-ci init --state-uri gs://my-bucket/manifest.json
```
**Supported URI Formats:**
- `gs://bucket-name/path/to/manifest.json` (Google Cloud Storage)
- `s3://bucket-name/path/to/manifest.json` (AWS S3)
## Environment Variables
All CLI options can also be set via environment variables:
```bash
export DBT_PROJECT_DIR=./dbt
export DBT_PROFILES_DIR=./dbt
export DBT_TARGET=production
export DBT_RUNNER=local
# After running init, just use:
dbt-ci run
```
**Common Environment Variables:**
- `DBT_PROJECT_DIR` - Path to dbt project
- `DBT_PROFILES_DIR` - Path to profiles.yml location
- `DBT_TARGET` - Target environment to use
- `DBT_RUNNER` - Runner type (local, docker, bash, dbt)
**Note:** State management is cache-based. Run `init` once, then subsequent commands automatically use the cached state.
## CI/CD Integration
### GitHub Actions Example
```yaml
name: dbt CI
on: [pull_request]
jobs:
dbt-ci:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.11'
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v2
with:
role-to-assume: arn:aws:iam::123456789012:role/GitHubActionsRole
aws-region: us-east-1
- name: Install dbt-ci
run: pip install git+https://github.com/datablock-dev/dbt-ci.git@main
- name: Initialize dbt-ci with cloud state
run: |
dbt-ci init \
--dbt-project-dir dbt \
--state-uri gs://my-dbt-state/prod/manifest.json \
--reference-target production \
--state dbt/.dbtstate
- name: Run modified models
run: |
dbt-ci run --mode models
```
### GitLab CI Example
```yaml
dbt-ci:
image: python:3.11
script:
- pip install git+https://github.com/datablock-dev/dbt-ci.git@main
- dbt-ci init --dbt-project-dir dbt --state-uri gs://my-dbt-state/prod/manifest.json --reference-target production --state dbt/.dbtstate
- dbt-ci run --mode models
only:
- merge_requests
```
## Features
- **🎯 Smart Detection**: Automatically identifies modified, new, and deleted models
- **📊 Dependency Tracking**: Generates and traverses dependency graphs for lineage analysis
- **🔄 State Comparison**: Compares current state against production for precise CI
- **☁️ Cloud Storage**: S3 integration for shared state across distributed CI/CD workflows
- **🚀 Multiple Runners**: Supports local, Docker, bash, and dbt Python API execution
- **🐳 Docker-First**: Extensive Docker configuration for containerized workflows
- **⚡ Selective Execution**: Run only what changed, saving time and resources
- **🔌 Adapter Support**: Install specific dbt versions and adapters on-demand
- **💬 Notifications**: Slack webhook integration for CI/CD alerts
- **♻️ Ephemeral Environments**: Test changes in isolated environments
- **🧹 Cleanup**: Automatically remove deleted models from target warehouse
## Use Cases
### Pull Request CI
Only build and test models affected by PR changes:
```bash
# Initialize with reference state
dbt-ci init --state-uri gs://bucket/manifest.json --reference-target production --state dbt/.dbtstate
# Run modified models with defer
dbt-ci run --mode models --defer
```
### Distributed CI with Cloud Storage
Share state across multiple CI jobs:
```bash
# Job 1: Initialize state (downloads from cloud)
dbt-ci init --state-uri gs://my-bucket/manifest.json --reference-target production --state dbt/.dbtstate
# Job 2: Run models (uses cached state)
dbt-ci run --mode models
# Job 3: Run tests (uses cached state)
dbt-ci run --mode tests
```
### Selective Testing
Run tests only for modified models:
```bash
# After init
dbt-ci run --mode tests
```
### Schema Migrations
Clean up deleted models from production:
```bash
# After init
dbt-ci delete --target production
```
### Multi-Environment Testing
Create ephemeral test environments:
```bash
dbt-ci ephemeral --keep-env
```
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
### Development Setup
1. Clone the repository
2. Install dependencies: `pip install -e ".[dev]"`
3. Run tests: `pytest tests/`
4. Run linting: `black src/ tests/`
### Commit Message Format
This project uses [Conventional Commits](https://www.conventionalcommits.org/) for automated releases:
- `feat:` New feature (minor version bump)
- `fix:` Bug fix (patch version bump)
- `docs:` Documentation changes
- `refactor:` Code refactoring
- `test:` Adding tests
- `chore:` Maintenance tasks
Example:
```bash
git commit -m "feat: add Docker runner support"
git commit -m "fix: resolve path resolution on Windows"
```
See [RELEASING.md](RELEASING.md) for details on the automated release process.
## License
See [LICENSE](LICENSE) file for details.
## Links
- **PyPI**: [https://pypi.org/project/dbt-ci/](https://pypi.org/project/dbt-ci/)
- **Documentation**: [https://datablock.dev](https://datablock.dev)
- **Issues**: [GitHub Issues](https://github.com/datablock-dev/dbt-ci/issues)
- **Discussions**: [GitHub Discussions](https://github.com/datablock-dev/dbt-ci/discussions)
- **Changelog**: [CHANGELOG.md](CHANGELOG.md)
| text/markdown | null | Patrick Tannoury <patrick.tannoury@datablock.dev> | null | null | MIT License
Copyright (c) 2026 DataBlock
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Topic :: Software Development :: Build Tools",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"click==8.1.8",
"pyyaml==6.0.3",
"dbt-core<2.0.0,>=1.10.13",
"docker==7.1.0",
"boto3==1.35.0",
"google-cloud-bigquery==3.27.0",
"google-cloud-storage==2.19.0",
"pytest==8.3.5; extra == \"dev\"",
"black==24.10.0; extra == \"dev\"",
"mypy==1.14.1; extra == \"dev\"",
"flake8==7.1.2; extra == \"dev\... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:27:48.690864 | dbt_ci-1.2.0.tar.gz | 120,833 | 36/53/5917e34bf3f2af4060b359788211e648d1f32bc317930ee662e48e5d8a85/dbt_ci-1.2.0.tar.gz | source | sdist | null | false | a9177213c48c9c062ea2d60e4c92f728 | 30157a69e8d4f5b23b99a9c00e68734da898b24ec39d2744a8a82b8faff136f4 | 36535917e34bf3f2af4060b359788211e648d1f32bc317930ee662e48e5d8a85 | null | [
"LICENSE"
] | 237 |
2.4 | pic-standard | 0.5.5 | PIC Standard: Provenance & Intent Contracts for agentic side-effect governance | # <p><img src="https://raw.githubusercontent.com/madeinplutofabio/pic-standard/main/picico.png" height="60" align="absmiddle"> PIC Standard: Provenance & Intent Contracts</p>
**The Open Protocol for Causal Governance in Agentic AI.**
PIC closes the **causal gap**: when untrusted inputs (prompt injection, user text, web pages) influence **high‑impact side effects** (payments, exports, infra changes), PIC forces a **machine‑verifiable contract** between *what the agent claims* and *what evidence actually backs it*.
[](LICENSE)
[]()
---
## Quickstart
```bash
# Install core (schema + verifier + CLI)
pip install pic-standard
# Verify an example proposal
pic-cli verify examples/financial_irreversible.json
# ✅ Schema valid
# ✅ Verifier passed
```
**Optional extras:**
```bash
pip install "pic-standard[langgraph]" # LangGraph integration
pip install "pic-standard[mcp]" # MCP integration
pip install "pic-standard[crypto]" # Signature evidence (Ed25519)
```
**From source (contributors):**
```bash
git clone https://github.com/madeinplutofabio/pic-standard.git
cd pic-standard && pip install -e .
pytest -q # run tests
```
---
## The PIC Contract
PIC uses an **Action Proposal JSON** (protocol: `PIC/1.0`). The agent emits it right before executing a tool:
| Field | Purpose |
|-------|---------|
| `intent` | What the agent is trying to do |
| `impact` | Risk class (`money`, `privacy`, `irreversible`, …) |
| `provenance` | Which inputs influenced the decision (and their trust level) |
| `claims` + `evidence` | What the agent asserts and which evidence IDs support it |
| `action` | The actual tool call being attempted (tool binding) |
**Verifier rule:** For high‑impact proposals (`money`, `privacy`, `irreversible`), at least one claim must reference evidence from **TRUSTED** provenance. Fail‑closed.
---
## Evidence Verification
PIC supports deterministic evidence verification that upgrades provenance trust **in-memory**.
| Version | Type | Description |
|---------|------|-------------|
| v0.3 | `hash` | SHA-256 verification of file artifacts (`file://...`) |
| v0.4 | `sig` | Ed25519 signature verification via trusted keyring |
```bash
# Verify hash evidence
pic-cli evidence-verify examples/financial_hash_ok.json
# Verify signature evidence
pic-cli evidence-verify examples/financial_sig_ok.json
# Full pipeline: schema → evidence → verifier
pic-cli verify examples/financial_hash_ok.json --verify-evidence
```
📖 **Full guide:** [docs/evidence.md](docs/evidence.md)
---
## Keyring (Trusted Signers)
Signature evidence requires a keyring of trusted public keys.
```bash
# Inspect current keyring
pic-cli keys
# Generate starter keyring
pic-cli keys --write-example > pic_keys.json
```
PIC loads keys from `PIC_KEYS_PATH` env var, or `./pic_keys.json`, or empty (no signers).
📖 **Full guide:** [docs/keyring.md](docs/keyring.md) — key formats, expiry, revocation, rotation
---
## Integrations
### LangGraph
Enforce PIC at the tool boundary with `PICToolNode`:
```bash
pip install "pic-standard[langgraph]"
python examples/langgraph_pic_toolnode_demo.py
```
- Requires `__pic` proposal in each tool call
- Validates schema + verifier + tool binding
- Returns `ToolMessage` outputs
---
### MCP (Model Context Protocol)
Enforce PIC at the MCP tool boundary with production defaults:
```bash
pip install "pic-standard[mcp]"
python -u examples/mcp_pic_client_demo.py
```
- Fail‑closed (blocks on verifier/evidence failure)
- Debug gating (`PIC_DEBUG=1` for diagnostics)
- Request tracing, DoS limits, evidence sandboxing
---
### OpenClaw
Plugin for OpenClaw AI agents via the hook API:
```bash
# 1. Start the PIC bridge
pip install pic-standard
pic-cli serve --port 7580
# 2. Build and install the plugin
cd integrations/openclaw
npm install && npm run build
openclaw plugins install .
# Or manually: cp -r . ~/.openclaw/extensions/pic-guard/
```
- `pic-gate` — verifies proposals before tool execution
- `pic-init` — injects PIC awareness at session start
- `pic-audit` — structured audit logging
📖 **Full guide:** [docs/openclaw-integration.md](docs/openclaw-integration.md)
---
## How It Works
```mermaid
graph TD
A[Untrusted Input] --> B{AI Agent / Planner}
C[Trusted Data/DB] --> B
B --> D[Action Proposal JSON]
D --> E[PIC Verifier Middleware]
E --> F{Valid Contract?}
F -- Yes --> G[Tool Executor]
F -- No --> H[Blocked / Alert Log]
```
---
## Why PIC?
> Guardrails constrain **what the model says**. PIC constrains **what the agent is allowed to do** (side effects) based on **verifiable provenance + evidence**.
---
## Versioning
- `PIC/1.0` — the proposal protocol (schema)
- Python package follows **Semantic Versioning**
---
## Roadmap
- [✅] Phase 1: Standardize money and privacy Impact Classes
- [✅] Phase 2: Reference Python verifier + CLI
- [✅] Phase 3: Anchor integrations (LangGraph + MCP)
- [✅] Phase 4: Evidence verification (hash + signature)
- [✅] Phase 5: OpenClaw integration
- [⬜] Phase 6: Additional SDKs (TypeScript) + case studies + audit
---
## Community
We're actively seeking:
- Security researchers to stress‑test causal logic
- Framework authors to build native integrations
- Enterprise architects to define domain Impact Classes
Maintained by [ @fmsalvadori](https://www.linkedin.com/in/fmsalvadori/)
[ MadeInPluto](https://github.com/madeinplutofabio)
| text/markdown | Fabio Marcello Salvadori | null | null | null | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2026 Fabio Marcello Salvadori
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic>=2.0.0",
"jsonschema>=4.0.0",
"langchain-core>=0.1.0; extra == \"langgraph\"",
"cryptography<50,>=42.0.0; extra == \"crypto\"",
"mcp<2,>=1.25.0; extra == \"mcp\""
] | [] | [] | [] | [
"Homepage, https://github.com/madeinplutofabio/pic-standard",
"Repository, https://github.com/madeinplutofabio/pic-standard",
"Issues, https://github.com/madeinplutofabio/pic-standard/issues"
] | twine/6.2.0 CPython/3.10.6 | 2026-02-18T20:26:33.243414 | pic_standard-0.5.5.tar.gz | 48,906 | 25/d2/1513f7161acb7ea5da3e3678fb8a50c06fcb9a1904ea94a4e3e101c61c6d/pic_standard-0.5.5.tar.gz | source | sdist | null | false | e0203e4a1c252c8a6e58a26f2b30a3b3 | 42b617b157f44614e8b99373888acbe339eefaf001d861348d40a6bb9bcf482d | 25d21513f7161acb7ea5da3e3678fb8a50c06fcb9a1904ea94a4e3e101c61c6d | null | [
"LICENSE"
] | 231 |
2.4 | streamforge | 0.1.3 | Real-time cryptocurrency and financial data ingestion system | # StreamForge
[](https://badge.fury.io/py/streamforge)
[](https://pypi.org/project/streamforge/)
[](https://opensource.org/licenses/MIT)
**Real-time cryptocurrency and financial data ingestion made simple.**
StreamForge is a unified, async-first framework for ingesting real-time market data from cryptocurrency exchanges. Built with Python's asyncio, it offers high-performance data streaming, normalization, and multiple output formats.
---
## Features
- **Real-time WebSocket Streaming** - Live market data from multiple exchanges
- **Multi-Exchange Support** - Binance, Kraken, OKX, Bybit with unified API
- **Multiple Output Formats** - CSV, PostgreSQL, Kafka, or custom emitters
- **Timeframe Aggregation** - Automatic aggregation to higher timeframes
- **Historical Backfilling** - Load months of historical data effortlessly
- **Data Transformation** - Built-in transformers for custom data processing
- **Stream Merging** - Combine multiple exchanges into unified streams
- **Type-Safe** - Full type hints and Pydantic validation
---
## Installation
```bash
pip install streamforge
```
**Requirements:** Python 3.8+
---
## Quick Start
Stream Bitcoin price data in 3 lines:
```python
import asyncio
import streamforge as sf
async def main():
# Configure what to stream
stream = sf.DataInput(
type="kline",
symbols=["BTCUSDT"],
timeframe="1m"
)
# Create runner
runner = sf.BinanceRunner(stream_input=stream)
# Internal logging handled by sf.config.logger
# Start streaming!
await runner.run()
asyncio.run(main())
```
**Output:**
```
[Binance] BTCUSDT 1m | Open: 43,250.00 | High: 43,275.00 | Low: 43,240.00 | Close: 43,260.00
```
[📖 Read the full documentation →](https://paulobueno90.github.io/streamforge/)
---
## Supported Exchanges
| Exchange | Symbol Format | Type Name | Backfilling |
|----------|---------------|-----------|-------------|
| **Binance** | `BTCUSDT` | `kline` | ✓ |
| **Kraken** | `BTC/USD` | `ohlc` | Limited |
| **OKX** | `BTC-USDT` | `candle` | ✓ |
| **Bybit** | `BTCUSDT` | `kline` | ✓ |
---
## Usage Examples
### Save to CSV
```python
import asyncio
import streamforge as sf
async def main():
runner = sf.BinanceRunner(
stream_input=sf.DataInput(
type="kline",
symbols=["BTCUSDT"],
timeframe="1m"
)
)
csv_emitter = sf.CSVEmitter(
source="Binance",
symbol="BTCUSDT",
timeframe="1m",
file_path="btc_data.csv"
)
runner.register_emitter(csv_emitter)
await runner.run()
asyncio.run(main())
```
### Save to PostgreSQL
```python
import asyncio
import streamforge as sf
from sqlalchemy.orm import declarative_base
from sqlalchemy import Column, String, Float, BigInteger
Base = declarative_base()
class KlineTable(Base):
__tablename__ = 'klines'
source = Column(String, primary_key=True)
symbol = Column(String, primary_key=True)
timeframe = Column(String, primary_key=True)
open_ts = Column(BigInteger, primary_key=True)
end_ts = Column(BigInteger)
open = Column(Float)
high = Column(Float)
low = Column(Float)
close = Column(Float)
volume = Column(Float)
async def main():
postgres = (sf.PostgresEmitter(
host="localhost",
dbname="crypto",
user="postgres",
password="password"
)
.set_model(KlineTable)
.on_conflict(["source", "symbol", "timeframe", "open_ts"])
)
runner = sf.BinanceRunner(
stream_input=sf.DataInput(
type="kline",
symbols=["BTCUSDT", "ETHUSDT"],
timeframe="1m"
)
)
runner.register_emitter(postgres)
await runner.run()
asyncio.run(main())
```
### Multi-Timeframe Aggregation
Stream 1-minute data and automatically create 5m, 15m, and 1h candles:
```python
import asyncio
import streamforge as sf
async def main():
runner = sf.BinanceRunner(
stream_input=sf.DataInput(
type="kline",
symbols=["BTCUSDT"],
timeframe="1m",
aggregate_list=["5m", "15m", "1h"] # Auto-aggregate!
),
active_warmup=True # Required for aggregation
)
await runner.run()
asyncio.run(main())
```
### Historical Backfilling
Load historical data:
```python
import streamforge as sf
backfiller = sf.BinanceBackfilling(
symbol="BTCUSDT",
timeframe="1h",
from_date="2024-01-01",
to_date="2024-12-31"
)
backfiller.register_emitter(postgres_emitter)
backfiller.run() # Downloads and saves year of data
```
### Multi-Exchange Streaming
Merge data from multiple exchanges:
```python
import asyncio
import streamforge as sf
from streamforge.merge_stream import merge_streams
async def main():
binance = sf.BinanceRunner(
stream_input=sf.DataInput(
type="kline",
symbols=["BTCUSDT"],
timeframe="1m"
)
)
okx = sf.OKXRunner(
stream_input=sf.DataInput(
type="candle",
symbols=["BTC-USDT"],
timeframe="1m"
)
)
async for data in merge_streams(binance, okx):
print(f"{data.source} | {data.symbol} | ${data.close:,.2f}")
asyncio.run(main())
```
---
## Documentation
**Full documentation:** https://paulobueno90.github.io/streamforge/
- [Installation Guide](https://paulobueno90.github.io/streamforge/getting-started/installation/)
- [Quick Start Tutorial](https://paulobueno90.github.io/streamforge/getting-started/quick-start/)
- [User Guide](https://paulobueno90.github.io/streamforge/user-guide/emitters/)
- [Examples Gallery](https://paulobueno90.github.io/streamforge/examples/)
- [API Reference](https://paulobueno90.github.io/streamforge/api-reference/)
- [Exchange Guides](https://paulobueno90.github.io/streamforge/exchanges/binance/)
---
## Key Concepts
### Runners
Connect to exchanges and manage data flow:
```python
runner = sf.BinanceRunner(stream_input=stream) # Binance
runner = sf.KrakenRunner(stream_input=stream) # Kraken
runner = sf.OKXRunner(stream_input=stream) # OKX
runner = sf.BybitRunner(stream_input=stream) # Bybit
```
### Emitters
Define where data goes:
```python
sf.CSVEmitter() # Save to CSV
sf.PostgresEmitter() # Save to PostgreSQL
sf.KafkaEmitter() # Stream to Kafka
```
### DataInput
Configure what to stream:
```python
stream = sf.DataInput(
type="kline", # Data type
symbols=["BTCUSDT", "ETHUSDT"], # Trading pairs
timeframe="1m", # Candle interval
aggregate_list=["5m", "15m", "1h"] # Optional aggregation
)
```
---
## Development
### Install from Source
```bash
git clone https://github.com/paulobueno90/streamforge.git
cd streamforge
pip install -e ".[dev]"
```
### Run Tests
```bash
pytest
```
### Code Formatting
```bash
black streamforge/
isort streamforge/
flake8 streamforge/
```
---
## Requirements
Core dependencies (installed automatically):
- `aiohttp` - Async HTTP client
- `websockets` - WebSocket client
- `sqlalchemy` - SQL ORM
- `pandas` - Data manipulation
- `pydantic` - Data validation
- `aiokafka` - Kafka client
- `asyncpg` - PostgreSQL driver
- `aiolimiter` - Rate limiting
---
## Examples
### Stream Multiple Symbols
```python
import asyncio
import streamforge as sf
async def main():
runner = sf.BinanceRunner(
stream_input=sf.DataInput(
type="kline",
symbols=["BTCUSDT", "ETHUSDT", "SOLUSDT"],
timeframe="1m"
)
)
await runner.run()
asyncio.run(main())
```
### Multiple Output Destinations
```python
import asyncio
import streamforge as sf
async def main():
runner = sf.BinanceRunner(
stream_input=sf.DataInput(
type="kline",
symbols=["BTCUSDT"],
timeframe="1m"
)
)
# Register multiple emitters - data goes to ALL
runner.register_emitter(csv_emitter)
runner.register_emitter(postgres_emitter)
runner.register_emitter(kafka_emitter)
await runner.run()
asyncio.run(main())
```
[See more examples →](https://paulobueno90.github.io/streamforge/examples/)
---
## Architecture
```
Exchange WebSocket → Runner → Normalizer → Processor → Aggregator → Transformer → Emitter(s)
```
1. **Runner** - Manages WebSocket connections
2. **Normalizer** - Standardizes data across exchanges
3. **Processor** - Buffers and processes data
4. **Aggregator** - Creates higher timeframe candles (optional)
5. **Transformer** - Applies custom transformations (optional)
6. **Emitter** - Outputs to your destination(s)
[Learn more about architecture →](https://paulobueno90.github.io/streamforge/getting-started/core-concepts/)
---
## Use Cases
- **Trading Bots** - Real-time market data for algorithmic trading
- **Data Analysis** - Collect data for backtesting and research
- **Price Monitoring** - Track cryptocurrency prices across exchanges
- **Arbitrage Detection** - Find price differences between exchanges
- **Market Research** - Analyze market trends and patterns
- **Portfolio Tracking** - Monitor your cryptocurrency holdings
---
## Contributing
Contributions are welcome! Please see our [Contributing Guide](https://paulobueno90.github.io/streamforge/contributing/).
### Development Setup
1. Fork the repository
2. Clone your fork: `git clone https://github.com/YOUR_USERNAME/streamforge.git`
3. Install dev dependencies: `pip install -e ".[dev]"`
4. Create a branch: `git checkout -b feature/my-feature`
5. Make changes and add tests
6. Run tests: `pytest`
7. Submit a pull request
---
## Links
- **Documentation:** https://paulobueno90.github.io/streamforge/
- **PyPI:** https://pypi.org/project/streamforge/
- **GitHub:** https://github.com/paulobueno90/streamforge
- **Issues:** https://github.com/paulobueno90/streamforge/issues
- **Changelog:** [CHANGELOG.md](CHANGELOG.md)
---
## License
MIT License - see [LICENSE](LICENSE) file for details.
---
## Author
**Paulo Bueno**
Email: paulohmbueno@gmail.com
GitHub: [@paulobueno90](https://github.com/paulobueno90)
---
## Acknowledgments
Built with:
- [aiohttp](https://github.com/aio-libs/aiohttp) - Async HTTP
- [websockets](https://github.com/python-websockets/websockets) - WebSocket support
- [Pydantic](https://github.com/pydantic/pydantic) - Data validation
- [SQLAlchemy](https://github.com/sqlalchemy/sqlalchemy) - Database ORM
- [Pandas](https://github.com/pandas-dev/pandas) - Data manipulation
---
**Happy Streaming!** 🚀
| text/markdown | Paulo Bueno | Paulo Bueno <paulohmbueno@gmail.com> | null | Paulo Bueno <paulohmbueno@gmail.com> | MIT | cryptocurrency, crypto, stocks, options, trading, data, ingestion, websocket, binance, kraken, okx, streamforge, real-time, market-data | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Financial and Insurance Industry",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming La... | [] | https://github.com/paulobueno90/streamforge | null | >=3.8 | [] | [] | [] | [
"aiohttp>=3.8.0",
"websockets>=10.0",
"sqlalchemy>=1.4.0",
"pandas>=1.3.0",
"pydantic>=1.8.0",
"orjson>=3.6.0",
"aiokafka>=0.8.0",
"asyncpg>=0.27.0",
"aiolimiter>=1.1.0",
"python-dateutil>=2.8.0",
"numpy>=1.20.0",
"requests>=2.25.0",
"ciso8601>=2.2.0",
"pytest>=6.0; extra == \"dev\"",
"p... | [] | [] | [] | [
"Homepage, https://github.com/paulobueno90/streamforge",
"Documentation, https://paulobueno90.github.io/streamforge/",
"Repository, https://github.com/paulobueno90/streamforge",
"Bug Tracker, https://github.com/paulobueno90/streamforge/issues",
"Changelog, https://github.com/paulobueno90/streamforge/blob/ma... | twine/6.2.0 CPython/3.12.3 | 2026-02-18T20:26:26.261566 | streamforge-0.1.3.tar.gz | 80,156 | c3/1c/612e2507d0c4edffe04c1e7ec339c0c9ea95d9d3b38a07115186f9ca165e/streamforge-0.1.3.tar.gz | source | sdist | null | false | 4692f38fd06cb10c2e237cf09859fd5e | be6bd98b359220674436f00b7036b8204490e22fcd4649e0ea68ca114297915e | c31c612e2507d0c4edffe04c1e7ec339c0c9ea95d9d3b38a07115186f9ca165e | null | [
"LICENSE"
] | 241 |
2.4 | pub-analyzer | 0.5.7 | A text user interface, written in python, which automates the generation of scientific production reports using OpenAlex | # Pub Analyzer
<p align="center">
<img src="https://raw.githubusercontent.com/alejandrgaspar/pub-analyzer/main/docs/assets/img/logo.png" alt="PubAnalyzer splash image" width="275">
</p>
<p align="center">
<a href="https://github.com/alejandrgaspar/pub-analyzer/actions/workflows/python-test.yml" target="_blank">
<img src="https://github.com/alejandrgaspar/pub-analyzer/actions/workflows/python-test.yml/badge.svg?branch=main" alt="Test status">
</a>
<a href="https://pypi.org/project/pub-analyzer/" target="_blank">
<img src="https://img.shields.io/pypi/v/pub-analyzer?color=%230f80c1" alt="PyPI - Version">
</a>
<a href="https://pypi.org/project/pub-analyzer/" target="_blank">
<img src="https://img.shields.io/pypi/pyversions/pub-analyzer?color=%230f80c1" alt="PyPI - Python Version">
</a>
<a href="https://github.com/alejandrgaspar/pub-analyzer/blob/main/LICENSE" target="_blank">
<img src="https://img.shields.io/github/license/alejandrgaspar/pub-analyzer?color=%2331c553" alt="License MIT">
</a>
</p>
<p align="center">
Pub-Analyzer —<a href="https://github.com/alejandrgaspar/pub-analyzer" target="_blank"><em>Publication Analyzer</em></a>— is a Text User Interface —<em>TUI</em>— written in Python, which automates the generation of scientific production reports using <a href="https://openalex.org/" target="_blank"><em>OpenAlex</em></a>.
</p>
---
## What is Pub Analyzer for?
Pub Analyzer is a tool designed to retrieve, process and present in a concise and understandable way the scientific production of a researcher, including detailed information about their articles, citations, collaborations and other relevant metrics. The tool automates the collection and processing of data, providing users with a comprehensive view of the impact of their research and contributions in academia.
All our information comes from OpenAlex, an open and complete catalog of the world's scholarly papers, researchers, journals, and institutions — along with all the ways they're connected to one another. This is the key piece to **make all this possible**.
Pub Analyzer generates reports that you can view directly within the app, **export as PDF** files to submit as evidence, or **export as JSON** for analysis with the tools you use every day.
## Why use Pub Analyzer?
Researchers are generally required to submit scientific production reports when seeking promotions or funding to support their ongoing research. Instead of laborious manual tracking of their publications and citations, researchers now have the opportunity to perform all of these tasks automatically **in a matter of minutes**.
## Requirements
Pub Analyzer requires **Python 3.10 or later** and can run on Linux, macOS, and Windows.
## Installation
Install Pub Analyzer via PyPI, with the following command:
```
pip install pub-analyzer
```
## Usage
Open the app with the following command:
```
pub-analyzer
```
## Documentation
See [documentation](https://pub-analyzer.com/) for more details.
## Contributing
Pull requests are welcome!
| text/markdown | Alejandro Gaspar | alejandro@gaspar.land | Alejandro Gaspar | alejandro@gaspar.land | MIT | null | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows :: Windows 10",
"Operating System :: Microsoft :: Windows :: Windows 11",
"Operating Sy... | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"httpx[http2]==0.28.1",
"pydantic==2.12.5",
"textual==0.85.2",
"typst==0.13.2"
] | [] | [] | [] | [
"Documentation, https://pub-analyzer.com/",
"Homepage, https://github.com/alejandrgaspar/pub-analyzer",
"Repository, https://github.com/alejandrgaspar/pub-analyzer"
] | poetry/2.3.0 CPython/3.12.0 Darwin/24.6.0 | 2026-02-18T20:25:55.411574 | pub_analyzer-0.5.7-py3-none-any.whl | 67,321 | e4/0b/e09db5f79b429c94c856f8ccd0887e890f69d0ebc450d053cecdd752ea51/pub_analyzer-0.5.7-py3-none-any.whl | py3 | bdist_wheel | null | false | 913d595b15f1d715d5f89c8fa31ea920 | 54110690c252a7f9b72b4ebe62e7deaee2a5340896707b481e632da4889ec04b | e40be09db5f79b429c94c856f8ccd0887e890f69d0ebc450d053cecdd752ea51 | null | [
"LICENSE"
] | 241 |
2.4 | django-oscar-cybersource | 9.5.2 | Integration between django-oscar and the Cybersource Secure Acceptance. | ========================
django-oscar-cybersource
========================
| |build| |coverage| |license| |kit| |format|
This package is to handle integration between django-oscar based e-commerce sites and `Secure Acceptance Checkout API <https://developer.cybersource.com/library/documentation/dev_guides/Secure_Acceptance_Checkout_API/Secure_Acceptance_Checkout_API.pdf>`_.
**Full Documentation**: https://django-oscar-cybersource.readthedocs.io
.. |build| image:: https://gitlab.com/thelabnyc/django-oscar/django-oscar-cybersource/badges/master/pipeline.svg
:target: https://gitlab.com/thelabnyc/django-oscar/django-oscar-cybersource/commits/master
.. |coverage| image:: https://gitlab.com/thelabnyc/django-oscar/django-oscar-cybersource/badges/master/coverage.svg
:target: https://gitlab.com/thelabnyc/django-oscar/django-oscar-cybersource/commits/master
.. |license| image:: https://img.shields.io/pypi/l/django-oscar-cybersource.svg
:target: https://pypi.python.org/pypi/django-oscar-cybersource
.. |kit| image:: https://badge.fury.io/py/django-oscar-cybersource.svg
:target: https://pypi.python.org/pypi/django-oscar-cybersource
.. |format| image:: https://img.shields.io/pypi/format/django-oscar-cybersource.svg
:target: https://pypi.python.org/pypi/django-oscar-cybersource
| text/x-rst | null | thelab <thelabdev@thelab.co> | null | null | ISC | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"cryptography<47,>=46.0.5",
"django-oscar-api-checkout<4,>=3.8.1",
"django-oscar-api==3.3.0",
"django-oscar<4.2,>=4.0",
"django-stubs-ext<6,>=5.2.9",
"django>=5.2",
"lxml<7,>=6.0.2",
"phonenumbers<10,>=9.0.24",
"pydantic<3,>=2.12.5",
"python-dateutil<3,>=2.9.0.post0",
"thelabdb>=0.7.0",
"xmlse... | [] | [] | [] | [
"Homepage, https://gitlab.com/thelabnyc/django-oscar/django-oscar-cybersource",
"Repository, https://gitlab.com/thelabnyc/django-oscar/django-oscar-cybersource"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-18T20:24:41.949169 | django_oscar_cybersource-9.5.2.tar.gz | 139,227 | 07/2b/2c4b4c2ccca8fc8920a743f41d368a536daa425a645b099fce3645ce3ede/django_oscar_cybersource-9.5.2.tar.gz | source | sdist | null | false | 9fb5ab4618f86dc00553787f75b2f711 | 0e1cb464e9fc7471efc93651efd5f1bf58c58c19e43c61e6c439f651ba59dbf1 | 072b2c4b4c2ccca8fc8920a743f41d368a536daa425a645b099fce3645ce3ede | null | [
"LICENSE"
] | 1,531 |
2.4 | ptop3 | 0.1.3 | TUI process monitor that groups processes by application | # ptop3
[](https://pypi.org/project/ptop3/)
[](https://pypi.org/project/ptop3/)
[](https://github.com/spazyCZ/ptop3/actions)
[](LICENSE)
An htop-like TUI process monitor that groups processes by application.
## Screenshots
*Main group view — processes grouped by application*
*Detail view — individual processes for a selected group*
*Tree view — process hierarchy within a group*
## Features
- Groups processes by application name with smart alias resolution
- Colored header with memory, swap, load-average badges
- Sort by memory, CPU, RSS, swap, I/O, network, or count
- Regex filter across app name, process name, and cmdline
- Process tree view within a selected application group
- Kill signals (SIGTERM / SIGKILL) for individual processes or entire groups
- `w` key: clean swap by cycling swapoff/swapon (passwordless sudo)
- `d` key: drop kernel caches (passwordless sudo)
- Alerts for high CPU, memory, swap, disk usage, and zombie processes
- Lite mode (`--lite`) for lower overhead on busy systems
## Installation
```bash
pip install ptop3
```
## Quick Start
```bash
ptop3 # interactive TUI
python -m ptop3 # same via module
ptop3 --once # print one-shot table and exit
ptop3 --filter python # filter to python processes
```
## Sudo Setup
The `w` (swap-clean) and `d` (drop-caches) keys require root. Configure passwordless sudo once:
```bash
sudo ptop3 --init-subscripts
```
Or manually:
```bash
sudo visudo -f /etc/sudoers.d/ptop3
# Add:
# YOUR_USER ALL=(root) NOPASSWD: /path/to/ptop3-drop-caches
# YOUR_USER ALL=(root) NOPASSWD: /path/to/ptop3-swap-clean
```
Check sudo status:
```bash
ptop3 --check-sudo
```
## CLI Reference
| Flag | Default | Description |
|------|---------|-------------|
| `--once` | off | Print one-shot table and exit |
| `-f/--filter REGEX` | — | Filter by app/name/cmdline |
| `-s/--sort KEY` | `mem` | Sort key: mem, cpu, rss, swap, io, net, count |
| `-n/--top N` | 15 | Rows to show in `--once` mode |
| `--refresh SECS` | 2.0 | Refresh interval |
| `--lite` | off | Lite mode: skip cmdline/IO for tiny procs |
| `--check-sudo` | — | Check sudo config for subscripts |
| `--init-subscripts` | — | Write /etc/sudoers.d/ptop3 |
## Key Bindings
| Key | Action |
|-----|--------|
| `↑/↓` or `j/k` | Move selection |
| `PgUp/PgDn` | Page up/down |
| `Home/End` | Jump to first/last |
| `Enter` or `l` | Expand group to detail view |
| `h` | Back to group view |
| `t` | Toggle process tree (detail view) |
| `s` | Cycle sort key |
| `f` | Enter filter regex |
| `r` | Reset filter |
| `+/-` | Increase/decrease refresh interval |
| `k/K` | Send SIGTERM/SIGKILL to selected |
| `g` | Kill whole group (SIGTERM) |
| `w` | Run swap-clean |
| `d` | Drop caches |
| `q` or `Ctrl-C` | Quit |
## Subscripts
The privileged subscripts can also be run directly:
```bash
ptop3-drop-caches --help
ptop3-drop-caches --level 1 --dry-run
ptop3-swap-clean --help
ptop3-swap-clean --safety-mb 256 --dry-run
```
## Development
```bash
git clone https://github.com/yourusername/ptop3
cd ptop3
pip install -e ".[dev]"
pytest
ruff check ptop3/
```
| text/markdown | null | null | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"psutil>=5.9",
"pytest>=7; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"ruff; extra == \"dev\"",
"mypy; extra == \"dev\"",
"bump-my-version; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:24:21.846849 | ptop3-0.1.3.tar.gz | 24,165 | 96/5e/20a5bef7e06958cd2107632e5e133b375fdd7c8ee3100a076030615c6172/ptop3-0.1.3.tar.gz | source | sdist | null | false | a48ae668b7ed6a6f981630104feb2adc | ac8a55f5f536da251a424a01fe2df3c7ae9c46e512e99be39087994ad1f3e8ac | 965e20a5bef7e06958cd2107632e5e133b375fdd7c8ee3100a076030615c6172 | null | [
"LICENSE"
] | 241 |
2.1 | stack-pr | 0.1.7 | Stacked PR CLI for Github | # Stacked PRs for GitHub
This is a command-line tool that helps you create multiple GitHub
pull requests (PRs) all at once, with a stacked order of dependencies.
Imagine that we have a change `A` and a change `B` depending on `A`, and we
would like to get them both reviewed. Without stacked PRs one would have to
create two PRs: `A` and `A+B`. The second PR would be difficult to review as it
includes all the changes simultaneously. With stacked PRs the first PR will
have only the change `A`, and the second PR will only have the change `B`. With
stacked PRs one can group related changes together making them easier to
review.
Example:

## Installation
### Dependencies
This is a non-comprehensive list of dependencies required by `stack-pr.py`:
- Install `gh`, e.g., `brew install gh` on MacOS.
- Run `gh auth login` with SSH
### Installation with `pipx`
To install via [pipx](https://pipx.pypa.io/stable/) run:
```bash
pipx install stack-pr
```
### Manual installation from source
Manually, you can clone the repository and run the following command:
```bash
pipx install .
```
## Usage
`stack-pr` allows you to work with stacked PRs: submit, view, and land them.
### Basic Workflow
The most common workflow is simple:
1. Create a feature branch from `main`:
```bash
git checkout main
git pull
git checkout -b my-feature
```
2. Make your changes and create multiple commits (one commit per PR you want to create)
```bash
# Make some changes
git commit -m "First change"
# Make more changes
git commit -m "Second change"
# And so on...
```
3. Review what will be in your stack:
```bash
stack-pr view # Always safe to run, helps catch issues early
```
4. Create/update the stack of PRs:
```bash
stack-pr submit
```
> **Note**: `export` is an alias for `submit`.
5. To update any PR in the stack:
- Amend the corresponding commit
- Run `stack-pr view` to verify your changes
- Run `stack-pr submit` again
6. To rebase your stack on the latest main:
```bash
git checkout my-feature
git pull origin main # Get the latest main
git rebase main # Rebase your commits on top of main
stack-pr submit # Resubmit to update all PRs
```
7. When your PRs are ready to merge, you have two options:
**Option A**: Using `stack-pr land`:
```bash
stack-pr land
```
This will:
- Merge the bottom-most PR in your stack
- Automatically rebase your remaining PRs
- You can run `stack-pr land` again to merge the next PR once CI passes
**Option B**: Using GitHub web interface:
1. Merge the bottom-most PR through GitHub UI
2. After the merge, on your local machine:
```bash
git checkout my-feature
git pull origin main # Get the merged changes
stack-pr submit # Resubmit the stack to rebase remaining PRs
```
3. Repeat for each PR in the stack
That's it!
> **Pro-tip**: Run `stack-pr view` frequently - it's a safe command that helps you understand the current state of your stack and catch any potential issues early.
### Commands
`stack-pr` has five main commands:
- `submit` (or `export`) - create a new stack of PRs from the given set of
commits. One can think of this as "push my local changes to the corresponding
remote branches and update the corresponding PRs (or create new PRs if they
don't exist yet)".
- `view` - inspect the given set of commits and find the linked PRs. This
command does not push any changes anywhere and does not change any commits.
It can be used to examine what other commands did or will do.
- `abandon` - remove all stack metadata from the given set of commits. Apart
from removing the metadata from the affected commits, this command deletes
the corresponding local and remote branches and closes the PRs.
- `land` - merge the bottom-most PR in the current stack and rebase the rest of
the stack on the latest main.
- `config` - set configuration values in the config file. Similar to `git config`,
it takes a setting in the format `<section>.<key>=<value>` and updates the
config file (`.stack-pr.cfg` by default).
A usual workflow is the following:
```bash
while not ready to merge:
make local changes
commit to local git repo or amend existing commits
create or update the stack with `stack-pr.py submit`
merge changes with `stack-pr.py land`
```
You can also use `view` at any point to examine the current state, and
`abandon` to drop the stack.
Under the hood the tool creates and maintains branches named
`$USERNAME/stack/$BRANCH_NUM` (the name pattern can be customized via
`--branch-name-template` option) and embeds stack metadata into commit messages,
but you are not supposed to work with those branches or edit that metadata
manually. I.e. instead of pushing to these branches you should use `submit`,
instead of deleting them you should use `abandon` and instead of merging them
you should use `land`.
The tool looks at commits in the range `BASE..HEAD` and creates a stack of PRs
to apply these commits to `TARGET`. By default, `BASE` is `main` (local
branch), `HEAD` is the git revision `HEAD`, and `TARGET` is `main` on remote
(i.e. `origin/main`). These parameters can be changed with options `-B`, `-H`,
and `-T` respectively and accept the standard git notation: e.g. one can use
`-B HEAD~2`, to create a stack from the last two commits.
### Example
The first step before creating a stack of PRs is to double-check the changes
we’re going to post.
By default `stack-pr` will look at commits in `main..HEAD` range and will create
a PR for every commit in that range.
For instance, if we have
```bash
# git checkout my-feature
# git log -n 4 --format=oneline
**cc932b71c** (**my-feature**) Optimized navigation algorithms for deep space travel
**3475c898f** Fixed zero-gravity coffee spill bug in beverage dispenser
**99c4cd9a7** Added warp drive functionality to spaceship engine.
**d2b7bcf87** (**origin/main, main**) Added module for deploying remote space probes
```
Then the tool will consider the top three commits as changes, for which we’re
trying to create a stack.
> **Pro-tip**: a convenient way to see what commits will be considered by
> default is the following command:
>
```bash
alias githist='git log --abbrev-commit --oneline $(git merge-base origin/main HEAD)^..HEAD'
```
We can double-check that by running the script with `view` command - it is
always a safe command to run:
```bash
# stack-pr view
...
VIEW
**Stack:**
* **cc932b71** (No PR): Optimized navigation algorithms for deep space travel
* **3475c898** (No PR): Fixed zero-gravity coffee spill bug in beverage dispenser
* **99c4cd9a** (No PR): Added warp drive functionality to spaceship engine.
SUCCESS!
```
If everything looks correct, we can now submit the stack, i.e. create all the
corresponding PRs and cross-link them. To do that, we run the tool with
`submit` command:
```bash
# stack-pr submit
...
SUCCESS!
```
The command accepts a couple of options that might be useful, namely:
- `--draft` - mark all created PRs as draft. This helps to avoid over-burdening
CI.
- `--draft-bitmask` - mark select PRs in a stack as draft using a bitmask where
`1` indicates draft, and `0` indicates non-draft.
For example `--draft-bitmask 0010` to make the third PR a draft in a stack
of four.
The length of the bitmask must match the number of stacked PRs.
Overridden by `--draft` when passed.
- `--reviewer="handle1,handle2"` - assign specified reviewers.
If the command succeeded, we should see “SUCCESS!” in the end, and we can now
run `view` again to look at the new stack:
```python
# stack-pr view
...
VIEW
**Stack:**
* **cc932b71** (#439, 'ZolotukhinM/stack/103' -> 'ZolotukhinM/stack/102'): Optimized navigation algorithms for deep space travel
* **3475c898** (#438, 'ZolotukhinM/stack/102' -> 'ZolotukhinM/stack/101'): Fixed zero-gravity coffee spill bug in beverage dispenser
* **99c4cd9a** (#437, 'ZolotukhinM/stack/101' -> 'main'): Added warp drive functionality to spaceship engine.
SUCCESS!
```
We can also go to github and check our PRs there:

If we need to make changes to any of the PRs (e.g. to address the review
feedback), we simply amend the desired changes to the appropriate git commits
and run `submit` again. If needed, we can rearrange commits or add new ones.
`submit` simply syncs the local changes with the corresponding PRs. This is why
we use the same `stack-pr submit` command when we create a new stack, rebase our
changes on the latest main, update any PR in the stack, add new commits to the
stack, or rearrange commits in the stack.
When we are ready to merge our changes, we use `land` command.
```python
# stack-pr land
LAND
Stack:
* cc932b71 (#439, 'ZolotukhinM/stack/103' -> 'ZolotukhinM/stack/102'): Optimized navigation algorithms for deep space travel
* 3475c898 (#438, 'ZolotukhinM/stack/102' -> 'ZolotukhinM/stack/101'): Fixed zero-gravity coffee spill bug in beverage dispenser
* 99c4cd9a (#437, 'ZolotukhinM/stack/101' -> 'main'): Added warp drive functionality to spaceship engine.
Landing 99c4cd9a (#437, 'ZolotukhinM/stack/101' -> 'main'): Added warp drive functionality to spaceship engine.
...
Rebasing 3475c898 (#438, 'ZolotukhinM/stack/102' -> 'ZolotukhinM/stack/101'): Fixed zero-gravity coffee spill bug in beverage dispenser
...
Rebasing cc932b71 (#439, 'ZolotukhinM/stack/103' -> 'ZolotukhinM/stack/102'): Optimized navigation algorithms for deep space travel
...
SUCCESS!
```
This command lands the first PR of the stack and rebases the rest. If we run
`view` command after `land` we will find the remaining, not yet-landed PRs
there:
```python
# stack-pr view
VIEW
**Stack:**
* **8177f347** (#439, 'ZolotukhinM/stack/103' -> 'ZolotukhinM/stack/102'): Optimized navigation algorithms for deep space travel
* **35c429c8** (#438, 'ZolotukhinM/stack/102' -> 'main'): Fixed zero-gravity coffee spill bug in beverage dispenser
```
This way we can land all the PRs from the stack one by one.
### Specifying custom commit ranges
The example above used the default commit range - `main..HEAD`, but you can
specify a custom range too. Below are several commonly useful invocations of
the script:
```bash
# Submit a stack of last 5 commits
stack-pr submit -B HEAD~5
# Use 'origin/main' instead of 'main' as the base for the stack
stack-pr submit -B origin/main
# Do not include last two commits to the stack
stack-pr submit -H HEAD~2
```
These options work for all script commands (and it’s recommended to first use
them with `view` to double check the result). It is possible to mix and match
them too - e.g. one can first submit the stack for the last 5 commits and then
land first three of them:
```bash
# Inspect what commits will be included HEAD~5..HEAD
stack-pr view -B HEAD~5
# Create a stack from last five commits
stack-pr submit -B HEAD~5
# Inspect what commits will be included into the range HEAD~5..HEAD~2
stack-pr view -B HEAD~5 -H HEAD~2
# Land first three PRs from the stack
stack-pr land -B HEAD~5 -H HEAD~2
```
Note that generally one doesn't need to specify the base and head branches
explicitly - `stack-pr` will figure out the correct range based on the current
branch and the remote `main` by default.
## Command Line Options Reference
### Common Arguments
These arguments can be used with any subcommand:
- `-R, --remote`: Remote name (default: "origin")
- `-B, --base`: Local base branch
- `-H, --head`: Local head branch (default: "HEAD")
- `-T, --target`: Remote target branch (default: "main")
- `--hyperlinks/--no-hyperlinks`: Enable/disable hyperlink support (default: enabled)
- `-V, --verbose`: Enable verbose output from Git subcommands (default: false)
- `--branch-name-template`: Template for generated branch names (default: "$USERNAME/stack"). The following variables are supported:
- `$USERNAME`: The username of the current user
- `$BRANCH`: The current branch name
- `$ID`: The location for the ID of the branch. The ID is determined by the order of creation of the branches. If `$ID` is not found in the template, the template will be appended with `/$ID`.
### Subcommands
#### submit (alias: export)
Submit a stack of PRs.
Options:
- `--keep-body`: Keep current PR body, only update cross-links (default: false)
- `-d, --draft`: Submit PRs in draft mode (default: false)
- `--draft-bitmask`: Bitmask for setting draft status per PR
- `--reviewer`: List of reviewers for the PRs (default: from $STACK_PR_DEFAULT_REVIEWER or config)
- `-s, --stash`: Stash all uncommitted changes before submitting the PR
#### land
Land the bottom-most PR in the current stack.
If the `land.style` config option has the `disable` value, this command is not available.
#### abandon
Abandon the current stack.
Takes no additional arguments beyond common ones.
#### view
Inspect the current stack
Takes no additional arguments beyond common ones.
#### config
Set a configuration value in the config file.
Arguments:
- `setting` (required): Configuration setting in format `<section>.<key>=<value>`
Examples:
```bash
# Set verbose mode
stack-pr config common.verbose=True
# Disable usage tips (hide verbose output after commands)
stack-pr config common.show_tips=False
# Set target branch
stack-pr config repo.target=master
# Set default reviewer(s)
stack-pr config repo.reviewer=user1,user2
# Set custom branch name template
stack-pr config repo.branch_name_template=$USERNAME/stack
# Disable the land command (require GitHub web interface for merging)
stack-pr config land.style=disable
# Use "bottom-only" landing style for stacks
stack-pr config land.style=bottom-only
```
The config command modifies the config file (the `.stack-pr.cfg` file in the repo root by default, or the path specified by `STACKPR_CONFIG` environment variable). If the file doesn't exist, it will be created. If a setting already exists, it will be updated.
### Config files
Default values for command line options can be specified via a config file.
Path to the config file can be specified via `STACKPR_CONFIG` envvar, and by
default it's assumed to be `.stack-pr.cfg` in the current folder.
An example of a config file:
```cfg
[common]
verbose=True
hyperlinks=True
draft=False
keep_body=False
stash=False
show_tips=True
[repo]
remote=origin
target=main
reviewer=GithubHandle1,GithubHandle2
branch_name_template=$USERNAME/$BRANCH
[land]
style=bottom-only
```
| text/markdown | null | Modular Inc <hello@modular.com> | null | Modular Inc <hello@modular.com> | ==============================================================================================
The stack-pr repository is licensed under the Apache License v2.0 with LLVM Exceptions:
==============================================================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
---- LLVM Exceptions to the Apache 2.0 License ----
As an exception, if, as a result of your compiling your source code, portions
of this Software are embedded into an Object form of such source code, you
may redistribute such embedded portions in such Object form without complying
with the conditions of Sections 4(a), 4(b) and 4(d) of the License.
In addition, if you combine or link compiled forms of this Software with
software that is licensed under the GPLv2 ("Combined Software") and if a
court of competent jurisdiction determines that the patent provision (Section
3), the indemnity provision (Section 9) or other Section of the License
conflicts with the conditions of the GPLv2, you may retroactively and
prospectively choose to deem waived or otherwise exclude such Section(s) of
the License, but only in their entirety and only with respect to the Combined
Software.
==============================================================================
Software from third parties included in the LLVM Project:
==============================================================================
The LLVM Project contains third party software which is under different license
terms. All such code will be identified clearly using at least one of two
mechanisms:
1) It will be in a separate directory tree with its own `LICENSE.txt` or
`LICENSE` file at the top containing the specific license and restrictions
which apply to that software, or
2) It will contain specific license and restriction terms at the top of every
file.
| stacked-prs, github, pull-requests, stack-pr, git, version-control | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Version Control :: Git",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Environment :: Console",
"Topic :: Utilities",
"Programming Language... | [] | null | null | >=3.9 | [] | [] | [] | [
"typing_extensions; python_version < \"3.13\"",
"pytest; extra == \"dev\"",
"pytest-mock; extra == \"dev\"",
"mypy; extra == \"dev\"",
"ruff; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/modular/stack-pr",
"Repository, https://github.com/modular/stack-pr",
"Bug Tracker, https://github.com/modular/stack-pr/issues"
] | twine/6.1.0 CPython/3.12.9 | 2026-02-18T20:23:46.804406 | stack_pr-0.1.7.tar.gz | 38,800 | c9/8c/2bc671b55498d91f824d7bb246221b8455d9f3cc09d8e2877749a8579dba/stack_pr-0.1.7.tar.gz | source | sdist | null | false | dde7c5d79a70a419a621d60ed6378943 | 14f8d128b5384aaa0ec4686abcf65f252c3eb3077a104ac142bbc9c61e37f10e | c98c2bc671b55498d91f824d7bb246221b8455d9f3cc09d8e2877749a8579dba | null | [] | 364 |
2.4 | raksha-finance-tracker | 0.1.0 | CLI Personal Finance Tracker with transactions, budget, and reports |
# 🏦 CLI Personal Finance Tracker
A simple and powerful **command-line interface (CLI) Personal Finance Tracker** that helps you manage your income, expenses, and budget efficiently. Track transactions, view summaries, generate monthly reports, filter data, and export to CSV — all from your terminal!
---
## 🚀 Features
### 1. Add Transactions
- Add **Income** or **Expense** transactions.
- Assign transactions to existing categories or create **new categories on the fly**.
- Categories are linked to transactions automatically.
- Enter a **custom date** or default to today.
### 2. View All Transactions
- List all transactions in a **tabular format**.
- Option to **sort by category**.
- Displays **ID, Type, Category, Amount, Description, Date, and Current Balance**.
### 3. Manage Transaction Categories
- **Add new categories** for Income or Expense.
- **Remove categories** easily.
- View all categories or filter by **Income / Expense**
### 5. View Summary
- Provides a **financial overview**:
- Total Income
- Total Expenses
- Current Balance
- Total number of transactions
### 6. Filter Transactions
- Filter by:
- **Type** (Income / Expense)
- **Category**
- **Date range**
- **Amount range**
### 7. Monthly Report
- Generate a **monthly financial report**:
- Total Income and Expenses for the month
- **Net Savings**
- **Expense breakdown by category**
- **Highest expense category**
- **Comparison with previous month** (if data exists)
### 8. Export Transactions
- Export all transactions to **CSV** for external analysis.
### 9. Budget Warnings
- Set an initial **balance** and **monthly budget**.
- Receive warnings when expenses exceed the budget.
### 10. Data Persistence
- All transactions and categories are saved in **JSON**, so your data persists even after closing the program.
---
## 💻 Installation
1. Clone the repository:
```bash
git clone https://github.com/your-username/cli-personal-finance-tracker.git
cd cli-personal-finance-tracker
```
2. Run the program:
```bash
python main.py
```
| text/markdown | Raksha Karn | rakshakarn07@gmail.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/Raksha-Karn/Cashew | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T20:23:44.124724 | raksha_finance_tracker-0.1.0.tar.gz | 8,361 | 7a/6b/75cf3b6cf3d0c7427e1522aec2a5fbae9f9a763ea84ea1206ff5743af553/raksha_finance_tracker-0.1.0.tar.gz | source | sdist | null | false | 53be69df48adddbc2d37a5a45698179e | 05e59e0400a0011903f261f4892b70674e9104aa519ecefc3fd32d5e7155fbe9 | 7a6b75cf3b6cf3d0c7427e1522aec2a5fbae9f9a763ea84ea1206ff5743af553 | null | [
"LICENSE"
] | 265 |
2.4 | mcp-contextforge-gateway | 1.0.0rc1 | A production-grade MCP Gateway & Proxy built with FastAPI. Supports multi-server registration, virtual server composition, authentication, retry logic, observability, protocol translation, and a unified federated tool catalog. | # MCP Gateway
> Model Context Protocol gateway & proxy - unify REST, MCP, and A2A with federation, virtual servers, retries, security, and an optional admin UI.

<!-- === CI / Security / Build Badges === -->
[](https://github.com/IBM/mcp-context-forge/actions/workflows/python-package.yml)
[](https://github.com/IBM/mcp-context-forge/actions/workflows/codeql.yml)
[](https://github.com/IBM/mcp-context-forge/actions/workflows/bandit.yml)
[](https://github.com/IBM/mcp-context-forge/actions/workflows/dependency-review.yml)
[](https://github.com/IBM/mcp-context-forge/actions/workflows/pytest.yml)
[](https://ibm.github.io/mcp-context-forge/coverage/)
[](https://github.com/IBM/mcp-context-forge/actions/workflows/lint.yml)
<!-- === Container Build & Deploy === -->
[](https://github.com/IBM/mcp-context-forge/actions/workflows/ibm-cloud-code-engine.yml)
<!-- === Package / Container === -->
[](https://docs.python.org/3/library/asyncio.html)
[](LICENSE)
[](https://pypi.org/project/mcp-contextforge-gateway/)
[](https://github.com/ibm/mcp-context-forge/pkgs/container/mcp-context-forge)
ContextForge MCP Gateway is a feature-rich gateway, proxy and MCP Registry that federates MCP and REST services - unifying discovery, auth, rate-limiting, observability, virtual servers, multi-transport protocols, and an optional Admin UI into one clean endpoint for your AI clients. It runs as a fully compliant MCP server, deployable via PyPI or Docker, and scales to multi-cluster environments on Kubernetes with Redis-backed federation and caching.
---
<!-- vscode-markdown-toc -->
## Table of Contents
- [Overview & Goals](#overview--goals)
- [Quick Start - PyPI](#quick-start---pypi)
- [Quick Start - Containers](#quick-start---containers)
- [VS Code Dev Container](#quick-start-vs-code-dev-container)
- [Installation](#installation)
- [Upgrading](#upgrading)
- [Configuration](#configuration)
- [Running](#running)
- [Cloud Deployment](#cloud-deployment)
- [API Reference](#api-reference)
- [Testing](#testing)
- [Project Structure](#project-structure)
- [Development](#development)
- [Troubleshooting](#troubleshooting)
- [Contributing](#contributing)
---
### 📌 Quick Links
| Resource | Description |
|----------|-------------|
| **[5-Minute Setup](https://github.com/IBM/mcp-context-forge/issues/2503)** | Get started fast — uvx, Docker, Compose, or local dev |
| **[Getting Help](https://github.com/IBM/mcp-context-forge/issues/2504)** | Support options, FAQ, community channels |
| **[Issue Guide](https://github.com/IBM/mcp-context-forge/issues/2502)** | How to file bugs, request features, contribute |
| **[Full Documentation](https://ibm.github.io/mcp-context-forge/)** | Complete guides, tutorials, API reference |
---
## Overview & Goals
**ContextForge** is a gateway, registry, and proxy that sits in front of any [Model Context Protocol](https://modelcontextprotocol.io) (MCP) server, A2A server or REST API-exposing a unified endpoint for all your AI clients. See the [project roadmap](https://ibm.github.io/mcp-context-forge/architecture/roadmap/) for more details.
It currently supports:
* Federation across multiple MCP and REST services
* **A2A (Agent-to-Agent) integration** for external AI agents (OpenAI, Anthropic, custom)
* **gRPC-to-MCP translation** via automatic reflection-based service discovery
* Virtualization of legacy APIs as MCP-compliant tools and servers
* Transport over HTTP, JSON-RPC, WebSocket, SSE (with configurable keepalive), stdio and streamable-HTTP
* An Admin UI for real-time management, configuration, and log monitoring (with airgapped deployment support)
* Built-in auth, retries, and rate-limiting with user-scoped OAuth tokens and unconditional X-Upstream-Authorization header support
* **OpenTelemetry observability** with Phoenix, Jaeger, Zipkin, and other OTLP backends
* Scalable deployments via Docker or PyPI, Redis-backed caching, and multi-cluster federation

For a list of upcoming features, check out the [ContextForge Roadmap](https://ibm.github.io/mcp-context-forge/architecture/roadmap/)
---
<details>
<summary><strong>🔌 Gateway Layer with Protocol Flexibility</strong></summary>
* Sits in front of any MCP server or REST API
* Lets you choose your MCP protocol version (e.g., `2025-06-18`)
* Exposes a single, unified interface for diverse backends
</details>
<details>
<summary><strong>🧩 Virtualization of REST/gRPC Services</strong></summary>
* Wraps non-MCP services as virtual MCP servers
* Registers tools, prompts, and resources with minimal configuration
* **gRPC-to-MCP translation** via server reflection protocol
* Automatic service discovery and method introspection
</details>
<details>
<summary><strong>🔁 REST-to-MCP Tool Adapter</strong></summary>
* Adapts REST APIs into tools with:
* Automatic JSON Schema extraction
* Support for headers, tokens, and custom auth
* Retry, timeout, and rate-limit policies
</details>
<details>
<summary><strong>🧠 Unified Registries</strong></summary>
* **Prompts**: Jinja2 templates, multimodal support, rollback/versioning
* **Resources**: URI-based access, MIME detection, caching, SSE updates
* **Tools**: Native or adapted, with input validation and concurrency controls
</details>
<details>
<summary><strong>📈 Admin UI, Observability & Dev Experience</strong></summary>
* Admin UI built with HTMX + Alpine.js
* Real-time log viewer with filtering, search, and export capabilities
* Auth: Basic, JWT, or custom schemes
* Structured logs, health endpoints, metrics
* 400+ tests, Makefile targets, live reload, pre-commit hooks
</details>
<details>
<summary><strong>🔍 OpenTelemetry Observability</strong></summary>
* **Vendor-agnostic tracing** with OpenTelemetry (OTLP) protocol support
* **Multiple backend support**: Phoenix (LLM-focused), Jaeger, Zipkin, Tempo, DataDog, New Relic
* **Distributed tracing** across federated gateways and services
* **Automatic instrumentation** of tools, prompts, resources, and gateway operations
* **LLM-specific metrics**: Token usage, costs, model performance
* **Zero-overhead when disabled** with graceful degradation
See **[Observability Documentation](https://ibm.github.io/mcp-context-forge/manage/observability/)** for setup guides with Phoenix, Jaeger, and other backends.
</details>
---
## Quick Start - PyPI
ContextForge is published on [PyPI](https://pypi.org/project/mcp-contextforge-gateway/) as `mcp-contextforge-gateway`.
---
**TLDR;**:
(single command using [uv](https://docs.astral.sh/uv/))
```bash
# Quick start with environment variables
BASIC_AUTH_PASSWORD=pass \
MCPGATEWAY_UI_ENABLED=true \
MCPGATEWAY_ADMIN_API_ENABLED=true \
PLATFORM_ADMIN_EMAIL=admin@example.com \
PLATFORM_ADMIN_PASSWORD=changeme \
PLATFORM_ADMIN_FULL_NAME="Platform Administrator" \
uvx --from mcp-contextforge-gateway mcpgateway --host 0.0.0.0 --port 4444
# Or better: use the provided .env.example
cp .env.example .env
# Edit .env to customize your settings
uvx --from mcp-contextforge-gateway mcpgateway --host 0.0.0.0 --port 4444
```
<details>
<summary><strong>📋 Prerequisites</strong></summary>
* **Python ≥ 3.10** (3.11 recommended)
* **curl + jq** - only for the last smoke-test step
</details>
### 1 - Install & run (copy-paste friendly)
```bash
# 1️⃣ Isolated env + install from pypi
mkdir mcpgateway && cd mcpgateway
python3 -m venv .venv && source .venv/bin/activate
pip install --upgrade pip
pip install mcp-contextforge-gateway
# 2️⃣ Copy and customize the configuration
# Download the example environment file
curl -O https://raw.githubusercontent.com/IBM/mcp-context-forge/main/.env.example
cp .env.example .env
# Edit .env to customize your settings (especially passwords!)
# Or set environment variables directly:
export MCPGATEWAY_UI_ENABLED=true
export MCPGATEWAY_ADMIN_API_ENABLED=true
export PLATFORM_ADMIN_EMAIL=admin@example.com
export PLATFORM_ADMIN_PASSWORD=changeme
export PLATFORM_ADMIN_FULL_NAME="Platform Administrator"
BASIC_AUTH_PASSWORD=pass JWT_SECRET_KEY=my-test-key \
mcpgateway --host 0.0.0.0 --port 4444 & # admin/pass
# 3️⃣ Generate a bearer token & smoke-test the API
export MCPGATEWAY_BEARER_TOKEN=$(python3 -m mcpgateway.utils.create_jwt_token \
--username admin@example.com --exp 10080 --secret my-test-key)
curl -s -H "Authorization: Bearer $MCPGATEWAY_BEARER_TOKEN" \
http://127.0.0.1:4444/version | jq
```
<details>
<summary><strong>Windows (PowerShell) quick-start</strong></summary>
```powershell
# 1️⃣ Isolated env + install from PyPI
mkdir mcpgateway ; cd mcpgateway
python3 -m venv .venv ; .\.venv\Scripts\Activate.ps1
pip install --upgrade pip
pip install mcp-contextforge-gateway
# 2️⃣ Copy and customize the configuration
# Download the example environment file
Invoke-WebRequest -Uri "https://raw.githubusercontent.com/IBM/mcp-context-forge/main/.env.example" -OutFile ".env.example"
Copy-Item .env.example .env
# Edit .env to customize your settings
# Or set environment variables (session-only)
$Env:MCPGATEWAY_UI_ENABLED = "true"
$Env:MCPGATEWAY_ADMIN_API_ENABLED = "true"
# Note: Basic auth for API is disabled by default (API_ALLOW_BASIC_AUTH=false)
$Env:JWT_SECRET_KEY = "my-test-key"
$Env:PLATFORM_ADMIN_EMAIL = "admin@example.com"
$Env:PLATFORM_ADMIN_PASSWORD = "changeme"
$Env:PLATFORM_ADMIN_FULL_NAME = "Platform Administrator"
# 3️⃣ Launch the gateway
mcpgateway.exe --host 0.0.0.0 --port 4444
# Optional: background it
# Start-Process -FilePath "mcpgateway.exe" -ArgumentList "--host 0.0.0.0 --port 4444"
# 4️⃣ Bearer token and smoke-test
$Env:MCPGATEWAY_BEARER_TOKEN = python3 -m mcpgateway.utils.create_jwt_token `
--username admin@example.com --exp 10080 --secret my-test-key
curl -s -H "Authorization: Bearer $Env:MCPGATEWAY_BEARER_TOKEN" `
http://127.0.0.1:4444/version | jq
```
<details>
<summary><strong>⚡ Alternative: uv (faster)</strong></summary>
```powershell
# 1️⃣ Isolated env + install from PyPI using uv
mkdir mcpgateway ; cd mcpgateway
uv venv
.\.venv\Scripts\activate
uv pip install mcp-contextforge-gateway
# Continue with steps 2️⃣-4️⃣ above...
```
</details>
</details>
<details>
<summary><strong>More configuration</strong></summary>
Copy [.env.example](https://github.com/IBM/mcp-context-forge/blob/main/.env.example) to `.env` and tweak any of the settings (or use them as env variables).
</details>
<details>
<summary><strong>🚀 End-to-end demo (register a local MCP server)</strong></summary>
```bash
# 1️⃣ Spin up the sample GO MCP time server using mcpgateway.translate & docker (replace docker with podman if needed)
python3 -m mcpgateway.translate \
--stdio "docker run --rm -i ghcr.io/ibm/fast-time-server:latest -transport=stdio" \
--expose-sse \
--port 8003
# Or using the official mcp-server-git using uvx:
pip install uv # to install uvx, if not already installed
python3 -m mcpgateway.translate --stdio "uvx mcp-server-git" --expose-sse --port 9000
# Alternative: running the local binary
# cd mcp-servers/go/fast-time-server; make build
# python3 -m mcpgateway.translate --stdio "./dist/fast-time-server -transport=stdio" --expose-sse --port 8002
# NEW: Expose via multiple protocols simultaneously!
python3 -m mcpgateway.translate \
--stdio "uvx mcp-server-git" \
--expose-sse \
--expose-streamable-http \
--port 9000
# Now accessible via both /sse (SSE) and /mcp (streamable HTTP) endpoints
# 2️⃣ Register it with the gateway
curl -s -X POST -H "Authorization: Bearer $MCPGATEWAY_BEARER_TOKEN" \
-H "Content-Type: application/json" \
-d '{"name":"fast_time","url":"http://localhost:8003/sse"}' \
http://localhost:4444/gateways
# 3️⃣ Verify tool catalog
curl -s -H "Authorization: Bearer $MCPGATEWAY_BEARER_TOKEN" http://localhost:4444/tools | jq
# 4️⃣ Create a *virtual server* bundling those tools. Use the ID of tools from the tool catalog (Step #3) and pass them in the associatedTools list.
curl -s -X POST -H "Authorization: Bearer $MCPGATEWAY_BEARER_TOKEN" \
-H "Content-Type: application/json" \
-d '{"server":{"name":"time_server","description":"Fast time tools","associated_tools":[<ID_OF_TOOLS>]}}' \
http://localhost:4444/servers | jq
# Example curl
curl -s -X POST -H "Authorization: Bearer $MCPGATEWAY_BEARER_TOKEN"
-H "Content-Type: application/json"
-d '{"server":{"name":"time_server","description":"Fast time tools","associated_tools":["6018ca46d32a4ac6b4c054c13a1726a2"]}}' \
http://localhost:4444/servers | jq
# 5️⃣ List servers (should now include the UUID of the newly created virtual server)
curl -s -H "Authorization: Bearer $MCPGATEWAY_BEARER_TOKEN" http://localhost:4444/servers | jq
# 6️⃣ Client HTTP endpoint. Inspect it interactively with the MCP Inspector CLI (or use any MCP client)
npx -y @modelcontextprotocol/inspector
# Transport Type: Streamable HTTP, URL: http://localhost:4444/servers/UUID_OF_SERVER_1/mcp, Header Name: "Authorization", Bearer Token
```
</details>
<details>
<summary><strong>🖧 Using the stdio wrapper (mcpgateway-wrapper)</strong></summary>
```bash
export MCP_AUTH="Bearer ${MCPGATEWAY_BEARER_TOKEN}"
export MCP_SERVER_URL=http://localhost:4444/servers/UUID_OF_SERVER_1/mcp
python3 -m mcpgateway.wrapper # Ctrl-C to exit
```
You can also run it with `uv` or inside Docker/Podman - see the *Containers* section above.
In MCP Inspector, define `MCP_AUTH` and `MCP_SERVER_URL` env variables, and select `python3` as the Command, and `-m mcpgateway.wrapper` as Arguments.
```bash
echo $PWD/.venv/bin/python3 # Using the Python3 full path ensures you have a working venv
export MCP_SERVER_URL='http://localhost:4444/servers/UUID_OF_SERVER_1/mcp'
export MCP_AUTH="Bearer ${MCPGATEWAY_BEARER_TOKEN}"
npx -y @modelcontextprotocol/inspector
```
or
Pass the url and auth as arguments (no need to set environment variables)
```bash
npx -y @modelcontextprotocol/inspector
command as `python`
Arguments as `-m mcpgateway.wrapper --url "http://localhost:4444/servers/UUID_OF_SERVER_1/mcp" --auth "Bearer <your token>"`
```
When using a MCP Client such as Claude with stdio:
```json
{
"mcpServers": {
"mcpgateway-wrapper": {
"command": "python",
"args": ["-m", "mcpgateway.wrapper"],
"env": {
"MCP_AUTH": "Bearer your-token-here",
"MCP_SERVER_URL": "http://localhost:4444/servers/UUID_OF_SERVER_1",
"MCP_TOOL_CALL_TIMEOUT": "120"
}
}
}
}
```
</details>
---
## Quick Start - Containers
Use the official OCI image from GHCR with **Docker** *or* **Podman**.
Please note: Currently, arm64 is not supported on production. If you are e.g. running on MacOS with Apple Silicon chips (M1, M2, etc), you can run the containers using Rosetta or install via PyPi instead.
### 🚀 Quick Start - Docker Compose
Get a full stack running with MariaDB and Redis in under 30 seconds:
```bash
# Clone and start the stack
git clone https://github.com/IBM/mcp-context-forge.git
cd mcp-context-forge
# Start with MariaDB (recommended for production)
docker compose up -d
# Or start with PostgreSQL
# Uncomment postgres in docker-compose.yml and comment mariadb section
# docker compose up -d
# Check status
docker compose ps
# View logs
docker compose logs -f gateway
# Access Admin UI: http://localhost:4444/admin (login with PLATFORM_ADMIN_EMAIL/PASSWORD)
# Generate API token
docker compose exec gateway python3 -m mcpgateway.utils.create_jwt_token \
--username admin@example.com --exp 10080 --secret my-test-key
```
**What you get:**
- 🗄️ **MariaDB 10.6** - Production-ready database with 36+ tables
- 🚀 **MCP Gateway** - Full-featured gateway with Admin UI
- 📊 **Redis** - High-performance caching and session storage
- 🔧 **Admin Tools** - pgAdmin, Redis Insight for database management
- 🌐 **Nginx Proxy** - Caching reverse proxy (optional)
**Enable HTTPS (optional):**
```bash
# Start with TLS enabled (auto-generates self-signed certs)
make compose-tls
# Access via HTTPS: https://localhost:8443/admin
# Or bring your own certificates:
# Unencrypted key:
mkdir -p certs
cp your-cert.pem certs/cert.pem && cp your-key.pem certs/key.pem
make compose-tls
# Passphrase-protected key:
mkdir -p certs
cp your-cert.pem certs/cert.pem && cp your-encrypted-key.pem certs/key-encrypted.pem
echo "KEY_FILE_PASSWORD=your-passphrase" >> .env
make compose-tls
```
### ☸️ Quick Start - Helm (Kubernetes)
Deploy to Kubernetes with enterprise-grade features:
```bash
# Add Helm repository (when available)
# helm repo add mcp-context-forge https://ibm.github.io/mcp-context-forge
# helm repo update
# For now, use local chart
git clone https://github.com/IBM/mcp-context-forge.git
cd mcp-context-forge/charts/mcp-stack
# Install with MariaDB
helm install mcp-gateway . \
--set mcpContextForge.secret.PLATFORM_ADMIN_EMAIL=admin@yourcompany.com \
--set mcpContextForge.secret.PLATFORM_ADMIN_PASSWORD=changeme \
--set mcpContextForge.secret.JWT_SECRET_KEY=your-secret-key \
--set postgres.enabled=false \
--set mariadb.enabled=true
# Or install with PostgreSQL (default)
helm install mcp-gateway . \
--set mcpContextForge.secret.PLATFORM_ADMIN_EMAIL=admin@yourcompany.com \
--set mcpContextForge.secret.PLATFORM_ADMIN_PASSWORD=changeme \
--set mcpContextForge.secret.JWT_SECRET_KEY=your-secret-key
# Check deployment status
kubectl get pods -l app.kubernetes.io/name=mcp-context-forge
# Port forward to access Admin UI
kubectl port-forward svc/mcp-gateway-mcp-context-forge 4444:80
# Access: http://localhost:4444/admin
# Generate API token
kubectl exec deployment/mcp-gateway-mcp-context-forge -- \
python3 -m mcpgateway.utils.create_jwt_token \
--username admin@yourcompany.com --exp 10080 --secret your-secret-key
```
**Enterprise Features:**
- 🔄 **Auto-scaling** - HPA with CPU/memory targets
- 🗄️ **Database Choice** - PostgreSQL, MariaDB, or MySQL
- 📊 **Observability** - Prometheus metrics, OpenTelemetry tracing
- 🔒 **Security** - RBAC, network policies, secret management
- 🚀 **High Availability** - Multi-replica deployments with Redis clustering
- 📈 **Monitoring** - Built-in Grafana dashboards and alerting
---
### 🐳 Docker (Single Container)
```bash
docker run -d --name mcpgateway \
-p 4444:4444 \
-e MCPGATEWAY_UI_ENABLED=true \
-e MCPGATEWAY_ADMIN_API_ENABLED=true \
-e HOST=0.0.0.0 \
-e JWT_SECRET_KEY=my-test-key \
-e AUTH_REQUIRED=true \
-e PLATFORM_ADMIN_EMAIL=admin@example.com \
-e PLATFORM_ADMIN_PASSWORD=changeme \
-e PLATFORM_ADMIN_FULL_NAME="Platform Administrator" \
-e DATABASE_URL=sqlite:///./mcp.db \
-e SECURE_COOKIES=false \
ghcr.io/ibm/mcp-context-forge:1.0.0-RC-1
# Tail logs and generate API key
docker logs -f mcpgateway
docker run --rm -it ghcr.io/ibm/mcp-context-forge:1.0.0-RC-1 \
python3 -m mcpgateway.utils.create_jwt_token --username admin@example.com --exp 10080 --secret my-test-key
```
Browse to **[http://localhost:4444/admin](http://localhost:4444/admin)** and login with `PLATFORM_ADMIN_EMAIL` / `PLATFORM_ADMIN_PASSWORD`.
<details>
<summary><strong>Advanced: Persistent storage, host networking, airgapped</strong></summary>
**Persist SQLite database:**
```bash
mkdir -p $(pwd)/data && touch $(pwd)/data/mcp.db && chmod 777 $(pwd)/data
docker run -d --name mcpgateway --restart unless-stopped \
-p 4444:4444 -v $(pwd)/data:/data \
-e DATABASE_URL=sqlite:////data/mcp.db \
-e MCPGATEWAY_UI_ENABLED=true -e MCPGATEWAY_ADMIN_API_ENABLED=true \
-e HOST=0.0.0.0 -e JWT_SECRET_KEY=my-test-key \
-e PLATFORM_ADMIN_EMAIL=admin@example.com -e PLATFORM_ADMIN_PASSWORD=changeme \
ghcr.io/ibm/mcp-context-forge:1.0.0-RC-1
```
**Host networking** (access local MCP servers):
```bash
docker run -d --name mcpgateway --network=host \
-v $(pwd)/data:/data -e DATABASE_URL=sqlite:////data/mcp.db \
-e MCPGATEWAY_UI_ENABLED=true -e HOST=0.0.0.0 -e PORT=4444 \
ghcr.io/ibm/mcp-context-forge:1.0.0-RC-1
```
**Airgapped deployment** (no internet):
```bash
docker build -f Containerfile.lite -t mcpgateway:airgapped .
docker run -d --name mcpgateway -p 4444:4444 \
-e MCPGATEWAY_UI_AIRGAPPED=true -e MCPGATEWAY_UI_ENABLED=true \
-e HOST=0.0.0.0 -e JWT_SECRET_KEY=my-test-key \
mcpgateway:airgapped
```
</details>
---
### 🦭 Podman (rootless-friendly)
```bash
podman run -d --name mcpgateway \
-p 4444:4444 -e HOST=0.0.0.0 -e DATABASE_URL=sqlite:///./mcp.db \
ghcr.io/ibm/mcp-context-forge:1.0.0-RC-1
```
<details>
<summary><strong>Advanced: Persistent storage, host networking</strong></summary>
**Persist SQLite:**
```bash
mkdir -p $(pwd)/data && chmod 777 $(pwd)/data
podman run -d --name mcpgateway --restart=on-failure \
-p 4444:4444 -v $(pwd)/data:/data \
-e DATABASE_URL=sqlite:////data/mcp.db \
ghcr.io/ibm/mcp-context-forge:1.0.0-RC-1
```
**Host networking:**
```bash
podman run -d --name mcpgateway --network=host \
-v $(pwd)/data:/data -e DATABASE_URL=sqlite:////data/mcp.db \
ghcr.io/ibm/mcp-context-forge:1.0.0-RC-1
```
</details>
---
<details>
<summary><strong>✏️ Docker/Podman tips</strong></summary>
* **.env files** - Put all the `-e FOO=` lines into a file and replace them with `--env-file .env`. See the provided [.env.example](https://github.com/IBM/mcp-context-forge/blob/main/.env.example) for reference.
* **Pinned tags** - Use an explicit version (e.g. `1.0.0-RC-1`) instead of `latest` for reproducible builds.
* **JWT tokens** - Generate one in the running container:
```bash
docker exec mcpgateway python3 -m mcpgateway.utils.create_jwt_token --username admin@example.com --exp 10080 --secret my-test-key
```
* **Upgrades** - Stop, remove, and rerun with the same `-v $(pwd)/data:/data` mount; your DB and config stay intact.
</details>
---
<details>
<summary><strong>🚑 Smoke-test the running container</strong></summary>
```bash
curl -s -H "Authorization: Bearer $MCPGATEWAY_BEARER_TOKEN" \
http://localhost:4444/health | jq
curl -s -H "Authorization: Bearer $MCPGATEWAY_BEARER_TOKEN" \
http://localhost:4444/tools | jq
curl -s -H "Authorization: Bearer $MCPGATEWAY_BEARER_TOKEN" \
http://localhost:4444/version | jq
```
</details>
---
<details>
<summary><strong>🖧 Running the MCP Gateway stdio wrapper</strong></summary>
The `mcpgateway.wrapper` lets you connect to the gateway over **stdio** while keeping JWT authentication. You should run this from the MCP Client. The example below is just for testing.
```bash
# Set environment variables
export MCPGATEWAY_BEARER_TOKEN=$(python3 -m mcpgateway.utils.create_jwt_token --username admin@example.com --exp 10080 --secret my-test-key)
export MCP_AUTH="Bearer ${MCPGATEWAY_BEARER_TOKEN}"
export MCP_SERVER_URL='http://localhost:4444/servers/UUID_OF_SERVER_1/mcp'
export MCP_TOOL_CALL_TIMEOUT=120
export MCP_WRAPPER_LOG_LEVEL=DEBUG # or OFF to disable logging
docker run --rm -i \
-e MCP_AUTH=$MCP_AUTH \
-e MCP_SERVER_URL=http://host.docker.internal:4444/servers/UUID_OF_SERVER_1/mcp \
-e MCP_TOOL_CALL_TIMEOUT=120 \
-e MCP_WRAPPER_LOG_LEVEL=DEBUG \
ghcr.io/ibm/mcp-context-forge:1.0.0-RC-1 \
python3 -m mcpgateway.wrapper
```
</details>
---
## Quick Start: VS Code Dev Container
Clone the repo and open in VS Code—it will detect `.devcontainer` and prompt to **"Reopen in Container"**. The container includes Python 3.11, Docker CLI, and all project dependencies.
For detailed setup, workflows, and GitHub Codespaces instructions, see **[Developer Onboarding](https://ibm.github.io/mcp-context-forge/development/developer-onboarding/)**.
---
## Installation
```bash
make venv install # create .venv + install deps
make serve # gunicorn on :4444
```
<details>
<summary><strong>Alternative: UV or pip</strong></summary>
```bash
# UV (faster)
uv venv && source .venv/bin/activate
uv pip install -e '.[dev]'
# pip
python3 -m venv .venv && source .venv/bin/activate
pip install -e ".[dev]"
```
</details>
<details>
<summary><strong>PostgreSQL adapter setup</strong></summary>
Install the `psycopg` driver for PostgreSQL:
```bash
# Install system dependencies first
# Debian/Ubuntu: sudo apt-get install libpq-dev
# macOS: brew install libpq
uv pip install 'psycopg[binary]' # dev (pre-built wheels)
# or: uv pip install 'psycopg[c]' # production (requires compiler)
```
Connection URL format:
```bash
DATABASE_URL=postgresql+psycopg://user:password@localhost:5432/mcp
```
Quick Postgres container:
```bash
docker run --name mcp-postgres \
-e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=mysecretpassword \
-e POSTGRES_DB=mcp -p 5432:5432 -d postgres
```
</details>
---
## Upgrading
For upgrade instructions, migration guides, and rollback procedures, see:
- **[Upgrade Guide](https://ibm.github.io/mcp-context-forge/manage/upgrade/)** — General upgrade procedures
- **[CHANGELOG.md](./CHANGELOG.md)** — Version history and breaking changes
- **[MIGRATION-0.7.0.md](./MIGRATION-0.7.0.md)** — Multi-tenancy migration (v0.6.x → v0.7.x)
---
## Configuration
> ⚠️ If any required `.env` variable is missing or invalid, the gateway will fail fast at startup with a validation error via Pydantic.
Copy the provided [.env.example](https://github.com/IBM/mcp-context-forge/blob/main/.env.example) to `.env` and update the security-sensitive values below.
### 🔐 Required: Change Before Use
These variables have insecure defaults and **must be changed** before production deployment:
| Variable | Description | Default | Action Required |
|----------|-------------|---------|-----------------|
| `JWT_SECRET_KEY` | Secret key for signing JWT tokens (32+ chars) | `my-test-key` | Generate with `openssl rand -hex 32` |
| `AUTH_ENCRYPTION_SECRET` | Passphrase for encrypting stored credentials | `my-test-salt` | Generate with `openssl rand -hex 32` |
| `BASIC_AUTH_USER` | Username for HTTP Basic auth | `admin` | Change for production |
| `BASIC_AUTH_PASSWORD` | Password for HTTP Basic auth | `changeme` | Set a strong password |
| `PLATFORM_ADMIN_EMAIL` | Email for bootstrap admin user | `admin@example.com` | Use real admin email |
| `PLATFORM_ADMIN_PASSWORD` | Password for bootstrap admin user | `changeme` | Set a strong password |
| `PLATFORM_ADMIN_FULL_NAME` | Display name for bootstrap admin | `Admin User` | Set admin name |
### 🔒 Security Defaults (Secure by Default)
These settings are enabled by default for security—only disable for backward compatibility:
| Variable | Description | Default |
|----------|-------------|---------|
| `REQUIRE_JTI` | Require JTI claim in tokens for revocation support | `true` |
| `REQUIRE_TOKEN_EXPIRATION` | Require exp claim in tokens | `true` |
| `PUBLIC_REGISTRATION_ENABLED` | Allow public user self-registration | `false` |
### ⚙️ Project Defaults (Dev Setup)
These values differ from code defaults to provide a working local/dev setup:
| Variable | Description | Default |
|----------|-------------|---------|
| `HOST` | Bind address | `0.0.0.0` |
| `MCPGATEWAY_UI_ENABLED` | Enable Admin UI dashboard | `true` |
| `MCPGATEWAY_ADMIN_API_ENABLED` | Enable Admin API endpoints | `true` |
| `DATABASE_URL` | SQLAlchemy connection URL | `sqlite:///./mcp.db` |
| `SECURE_COOKIES` | Set `false` for HTTP (non-HTTPS) dev | `true` |
### 📚 Full Configuration Reference
For the complete list of 300+ environment variables organized by category (authentication, caching, SSO, observability, etc.), see the **[Configuration Reference](https://ibm.github.io/mcp-context-forge/manage/configuration/)**.
---
## Running
### Quick Reference
| Command | Server | Port | Database | Use Case |
|---------|--------|------|----------|----------|
| `make dev` | Uvicorn | **8000** | SQLite | Development (single instance, auto-reload) |
| `make serve` | Gunicorn | **4444** | SQLite | Production single-node (multi-worker) |
| `make serve-ssl` | Gunicorn | **4444** | SQLite | Production single-node with HTTPS |
| `make compose-up` | Docker Compose + Nginx | **8080** | PostgreSQL + Redis | Full stack (3 replicas, load-balanced) |
| `make compose-sso` | Docker Compose + Keycloak | **8080 / 8180** | PostgreSQL + Redis | Local SSO testing (Keycloak profile) |
| `make testing-up` | Docker Compose + Nginx | **8080** | PostgreSQL + Redis | Testing environment |
### Development Server (Uvicorn)
```bash
make dev # Uvicorn on :8000 with auto-reload and SQLite
# or
./run.sh --reload --log debug --workers 2
```
> `run.sh` is a wrapper around `uvicorn` that loads `.env`, supports reload, and passes arguments to the server.
Key flags:
| Flag | Purpose | Example |
| ---------------- | ---------------- | ------------------ |
| `-e, --env FILE` | load env-file | `--env prod.env` |
| `-H, --host` | bind address | `--host 127.0.0.1` |
| `-p, --port` | listen port | `--port 8080` |
| `-w, --workers` | gunicorn workers | `--workers 4` |
| `-r, --reload` | auto-reload | `--reload` |
### Production Server (Gunicorn)
```bash
make serve # Gunicorn on :4444 with multiple workers
make serve-ssl # Gunicorn behind HTTPS on :4444 (uses ./certs)
```
### Docker Compose (Full Stack)
```bash
make compose-up # Start full stack: PostgreSQL, Redis, 3 gateway replicas, Nginx on :8080
make compose-sso # Start SSO stack with Keycloak on :8180
make sso-test-login # Run SSO smoke checks (providers + login URL + test users)
make compose-logs # Tail logs from all services
make compose-down # Stop the stack
```
### Manual (Uvicorn)
```bash
uvicorn mcpgateway.main:app --host 0.0.0.0 --port 4444 --workers 4
```
---
## Cloud Deployment
MCP Gateway can be deployed to any major cloud platform:
| Platform | Guide |
|----------|-------|
| **AWS** | [ECS/EKS Deployment](https://ibm.github.io/mcp-context-forge/deployment/aws/) |
| **Azure** | [AKS Deployment](https://ibm.github.io/mcp-context-forge/deployment/azure/) |
| **Google Cloud** | [Cloud Run](https://ibm.github.io/mcp-context-forge/deployment/google-cloud-run/) |
| **IBM Cloud** | [Code Engine](https://ibm.github.io/mcp-context-forge/deployment/ibm-code-engine/) |
| **Kubernetes** | [Helm Charts](https://ibm.github.io/mcp-context-forge/deployment/minikube/) |
| **OpenShift** | [OpenShift Deployment](https://ibm.github.io/mcp-context-forge/deployment/openshift/) |
For comprehensive deployment guides, see **[Deployment Documentation](https://ibm.github.io/mcp-context-forge/deployment/)**.
---
## API Reference
Interactive API documentation is available when the server is running:
- **[Swagger UI](http://localhost:4444/docs)** — Try API calls directly in your browser
- **[ReDoc](http://localhost:4444/redoc)** — Browse the complete endpoint reference
**Quick Authentication:**
```bash
# Generate a JWT token
export TOKEN=$(python3 -m mcpgateway.utils.create_jwt_token \
--username admin@example.com --exp 10080 --secret my-test-key)
# Test API access
curl -H "Authorization: Bearer $TOKEN" http://localhost:4444/health
```
For comprehensive curl examples covering all endpoints, see the **[API Usage Guide](https://ibm.github.io/mcp-context-forge/manage/api-usage/)**.
---
## Testing
```bash
make test # Run unit tests
make lint # Run all linters
make doctest # Run doctests
make coverage # Generate coverage report
```
See [Doctest Coverage Guide](https://ibm.github.io/mcp-context-forge/development/doctest-coverage/) for documentation testing details.
---
## Project Structure
```
mcpgateway/ # Core FastAPI application
├── main.py # Entry point
├── config.py # Pydantic Settings configuration
├── db.py # SQLAlchemy ORM models
├── schemas.py # Pydantic validation schemas
├── services/ # Business logic layer (50+ services)
├── routers/ # HTTP endpoint definitions
├── middleware/ # Cross-cutting concerns
└── transports/ # SSE, WebSocket, stdio, streamable HTTP
tests/ # Test suite (400+ tests)
docs/docs/ # Full documentation (MkDocs)
charts/ # Kubernetes/Helm charts
plugins/ # Plugin framework and implementations
```
For complete structure, see [CONTRIBUTING.md](./CONTRIBUTING.md) or run `tree -L 2`.
---
## Development
```bash
make dev # Dev server with auto-reload (:8000)
make test # Run test suite
make lint # Run all linters
make coverage # Generate coverage report
```
Run `make` to see all 75+ available targets.
For development workflows, see:
- **[Developer Workstation Setup](https://ibm.github.io/mcp-context-forge/development/developer-workstation/)**
- **[Building & Packaging](https://ibm.github.io/mcp-context-forge/development/building/)**
---
## Troubleshooting
Common issues and solutions:
| Issue | Quick Fix |
|-------|-----------|
| SQLite "disk I/O error" on macOS | Avoid iCloud-synced directories; use `~/mcp-context-forge/data` |
| Port 4444 not accessible on WSL2 | Configure WSL integration in Docker Desktop |
| Gateway exits immediately | Copy `.env.example` to `.env` and configure required vars |
| `ModuleNotFoundError` | Run `make install-dev` |
For detailed troubleshooting guides, see **[Troubleshooting Documentation](https://ibm.github.io/mcp-context-forge/manage/troubleshooting/)**.
---
## Contributing
1. Fork the repo, create a feature branch.
2. Run `make lint` and fix any issues.
3. Keep `make test` green.
4. Open a PR with signed commits (`git commit -s`).
See **[CONTRIBUTING.md](CONTRIBUTING.md)** for full guidelines and **[Issue Guide #2502](https://github.com/IBM/mcp-context-forge/issues/2502)** for how to file bugs, request features, and find issues to work on.
---
## Changelog
A complete changelog can be found here: [CHANGELOG.md](./CHANGELOG.md)
## License
Licensed under the **Apache License 2.0** - see [LICENSE](./LICENSE)
## Core Authors and Maintainers
- [Mihai Criveti](https://www.linkedin.com/in/crivetimihai) - Distinguished Engineer, Agentic AI
Special thanks to our contributors for helping us improve ContextForge:
<a href="https://github.com/ibm/mcp-context-forge/graphs/contributors">
<img src="https://contrib.rocks/image?repo=ibm/mcp-context-forge&max=100&anon=0&columns=10" />
</a>
## Star History and Project Activity
[](https://www.star-history.com/#ibm/mcp-context-forge&Date)
<!-- === Usage Stats === -->
[](https://pepy.tech/project/mcp-contextforge-gateway)
[](https://github.com/ibm/mcp-context-forge/stargazers)
[](https://github.com/ibm/mcp-context-forge/network/members)
[](https://github.com/ibm/mcp-context-forge/graphs/contributors)
[](https://github.com/ibm/mcp-context-forge/commits)
[](https://github.com/ibm/mcp-context-forge/issues)
| text/markdown | null | Mihai Criveti <redacted@ibm.com> | null | Mihai Criveti <redacted@ibm.com> | null | MCP, API, gateway, proxy, tools, agents, agentic ai, model context protocol, multi-agent, fastapi, json-rpc, sse, websocket, federation, security, authentication | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Framework :: FastAPI",
"Framework :: AsyncIO",
"Topic :: Internet... | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"alembic>=1.18.4",
"argon2-cffi>=25.1.0",
"cryptography>=46.0.5",
"fastapi>=0.129.0",
"filelock>=3.24.2",
"gunicorn>=25.1.0",
"httpx>=0.28.1",
"httpx[http2]>=0.28.1",
"jinja2>=3.1.6",
"jq>=1.11.0",
"jsonpath-ng>=1.7.0",
"jsonschema>=4.26.0",
"mcp>=1.26.0",
"orjson>=3.11.7",
"parse>=1.21.... | [] | [] | [] | [
"Homepage, https://ibm.github.io/mcp-context-forge/",
"Documentation, https://ibm.github.io/mcp-context-forge/",
"Repository, https://github.com/IBM/mcp-context-forge",
"Bug Tracker, https://github.com/IBM/mcp-context-forge/issues",
"Changelog, https://github.com/IBM/mcp-context-forge/blob/main/CHANGELOG.md... | twine/6.2.0 CPython/3.13.7 | 2026-02-18T20:23:09.620753 | mcp_contextforge_gateway-1.0.0rc1.tar.gz | 2,926,899 | 0f/26/702fbba5dbf9808d566c0fcf10c47c66bb3bcc9ea8ebb541f681141249cb/mcp_contextforge_gateway-1.0.0rc1.tar.gz | source | sdist | null | false | 0e8018ec4016eae7127462d5be220a73 | b8578b60e9de51324083896509758be23199b693f2ce12a410725d97c35edc71 | 0f26702fbba5dbf9808d566c0fcf10c47c66bb3bcc9ea8ebb541f681141249cb | Apache-2.0 | [
"LICENSE"
] | 202 |
2.4 | psynet | 13.1.1 | PsyNet – complex psychological experiments made easy | 


[](https://deepwiki.com/pmcharrison/psynet-mirror)
PsyNet is a powerful new Python package for designing and running the next generation of online behavioural experiments.
It builds on the virtual lab framework [Dallinger](https://dallinger.readthedocs.io/)
to streamline the development of highly complex experiment paradigms, ranging from simulated cultural evolution to
perceptual prior estimation to adaptive psychophysical experiments. Once an experiment is implemented, it can be
deployed with a single terminal command, which looks after server provisioning, participant recruitment, data-quality
monitoring, and participant payment. Researchers using PsyNet can enjoy a paradigm shift in productivity, running many
high-powered variants of the same experiment in the time it would ordinarily take to run an experiment once.
PsyNet is primarily developed by Peter Harrison, Frank Höger, Pol van Rijn, and Nori Jacoby,
but we are grateful for many further contributions by other users.
To try some real-world PsyNet experiments for yourself, visit the following repositories:
- [Consonance profiles for carillon bells](https://github.com/pmcharrison/2022-consonance-carillon)
- [Emotional connotations of musical scales](https://github.com/pmcharrison/2022-musical-scales)
- [Vocal pitch matching in musical chords](https://github.com/pmcharrison/2022-vertical-processing-test)
For more information about PsyNet, visit the [documentation website](https://psynetdev.gitlab.io/PsyNet/).
| text/markdown | null | Peter Harrison <pmch2@cam.ac.uk>, Frank Höger <frank.hoeger@ae.mpg.de>, Pol van Rijn <pol.van-rijn@ae.mpg.de>, Raja Marjieh <raja.marjieh@princeton.edu>, Nori Jacoby <nori.jacoby@ae.mpg.de> | null | Peter Harrison <pmch2@cam.ac.uk> | MIT License
Copyright (c) 2022 Peter Harrison, Frank Höger, Nori Jacoby, and other PsyNet developers
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated
documentation files (the "Software"), to deal in the Software without restriction, including without limitation
the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software,
and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | experiments, networks, online, psychology | [
"Development Status :: 4 - Beta",
"Framework :: Flask",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",... | [] | null | null | >=3.10 | [] | [] | [] | [
"arabic-reshaper",
"babel",
"dallinger[docker]<13,>=12.1.2",
"debugpy",
"dominate==2.9.1",
"html2text",
"joblib",
"jsonpickle",
"pandas",
"paramiko",
"pillow",
"polib",
"progress",
"pytest",
"pytest-dependency",
"pytest-mock",
"pytest-timeout",
"python-gettext",
"rpdb",
"slack-... | [] | [] | [] | [
"Changelog, https://gitlab.com/PsyNetDev/PsyNet/-/blob/master/CHANGELOG.md",
"Documentation, https://psynetdev.gitlab.io/PsyNet/",
"Homepage, https://www.psynet.dev/",
"Issues, https://gitlab.com/PsyNetDev/PsyNet/-/issues",
"Repository, https://gitlab.com/PsyNetDev/PsyNet/"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-18T20:22:38.771106 | psynet-13.1.1.tar.gz | 9,127,896 | 36/48/3aeb1d5c1a33581f71dd0a600d99bb62008b6bd7a5d70f1511e6bfe8853b/psynet-13.1.1.tar.gz | source | sdist | null | false | 52cb19a93d350361d2c349c5d3824fc6 | ac184f6b010eebe135deb5e5bd26913e8dbb1532583c6e307158f0abf8259cb2 | 36483aeb1d5c1a33581f71dd0a600d99bb62008b6bd7a5d70f1511e6bfe8853b | null | [
"LICENSE"
] | 270 |
2.4 | akquant | 0.1.45 | High-performance quantitative trading framework based on Rust and Python | <p align="center">
<img src="assets/logo.svg" alt="AKQuant" width="400">
</p>
<p align="center">
<a href="https://pypi.org/project/akquant/">
<img src="https://img.shields.io/pypi/v/akquant?style=flat-square&color=007ec6" alt="PyPI Version">
</a>
<a href="https://pypi.org/project/akquant/">
<img src="https://img.shields.io/pypi/pyversions/akquant?style=flat-square" alt="Python Versions">
</a>
<a href="LICENSE">
<img src="https://img.shields.io/badge/license-MIT-green?style=flat-square" alt="License">
</a>
<a href="https://github.com/akfamily/akshare">
<img src="https://img.shields.io/badge/Data%20Science-AKShare-green?style=flat-square" alt="AKShare">
</a>
<a href="https://pepy.tech/projects/akquant">
<img src="https://static.pepy.tech/personalized-badge/akquant?period=total&units=INTERNATIONAL_SYSTEM&left_color=BLACK&right_color=GREEN&left_text=downloads" alt="Downloads">
</a>
</p>
**AKQuant** 是一款专为量化投研设计的**下一代高性能混合框架**。核心引擎采用 **Rust** 编写以确保极致的执行效率,同时提供优雅的 **Python** 接口以维持灵活的策略开发体验。
🚀 **核心亮点:**
* **极致性能**:得益于 Rust 的零开销抽象与 **Zero-Copy** 数据架构,回测速度较传统纯 Python 框架(如 Backtrader)提升 **X倍+**。
* **原生 ML 支持**:内置 **Walk-forward Validation**(滚动训练)框架,无缝集成 PyTorch/Scikit-learn,让 AI 策略开发从实验到回测一气呵成。
* **参数优化**:内置多进程网格搜索(Grid Search)框架,支持策略参数的高效并行优化。
* **专业级风控**:内置完善的订单流管理与即时风控模块,支持多资产组合回测。
👉 **[阅读完整文档](https://akquant.akfamily.xyz/)** | **[English Documentation](https://akquant.akfamily.xyz/en/)**
## 安装说明
**AKQuant** 已发布至 PyPI,无需安装 Rust 环境即可直接使用。
```bash
pip install akquant
```
## 快速开始
以下是一个简单的策略示例:
```python
import akquant as aq
import akshare as ak
from akquant import Strategy
# 1. 准备数据
# 使用 akshare 获取 A 股历史数据 (需安装: pip install akshare)
df = ak.stock_zh_a_daily(symbol="sh600000", start_date="20250212", end_date="20260212")
class MyStrategy(Strategy):
def on_bar(self, bar):
# 简单策略示例:
# 当收盘价 > 开盘价 (阳线) -> 买入
# 当收盘价 < 开盘价 (阴线) -> 卖出
# 获取当前持仓
current_pos = self.get_position(bar.symbol)
if current_pos == 0 and bar.close > bar.open:
self.buy(symbol=bar.symbol, quantity=100)
print(f"[{bar.timestamp_str}] Buy 100 at {bar.close:.2f}")
elif current_pos > 0 and bar.close < bar.open:
self.close_position(symbol=bar.symbol)
print(f"[{bar.timestamp_str}] Sell 100 at {bar.close:.2f}")
# 运行回测
result = aq.run_backtest(
data=df,
strategy=MyStrategy,
initial_cash=100000.0,
symbol="sh600000"
)
# 打印回测结果
print("\n=== Backtest Result ===")
print(result)
```
**运行结果示例:**
```text
=== Backtest Result ===
BacktestResult:
Value
start_time 2025-02-12 00:00:00+08:00
end_time 2026-02-12 00:00:00+08:00
duration 365 days, 0:00:00
total_bars 249
trade_count 62.0
initial_market_value 100000.0
end_market_value 99804.0
total_pnl -196.0
unrealized_pnl 0.0
total_return_pct -0.196
annualized_return -0.00196
volatility 0.002402
total_profit 548.0
total_loss -744.0
total_commission 0.0
max_drawdown 345.0
max_drawdown_pct 0.344487
win_rate 22.580645
loss_rate 77.419355
winning_trades 14.0
losing_trades 48.0
avg_pnl -3.16129
avg_return_pct -0.199577
avg_trade_bars 1.967742
avg_profit 39.142857
avg_profit_pct 3.371156
avg_winning_trade_bars 4.5
avg_loss -15.5
avg_loss_pct -1.241041
avg_losing_trade_bars 1.229167
largest_win 120.0
largest_win_pct 10.178117
largest_win_bars 7.0
largest_loss -70.0
largest_loss_pct -5.380477
largest_loss_bars 1.0
max_wins 2.0
max_losses 9.0
sharpe_ratio -0.816142
sortino_ratio -1.066016
profit_factor 0.736559
ulcer_index 0.001761
upi -1.113153
equity_r2 0.399577
std_error 68.64863
calmar_ratio -0.568962
exposure_time_pct 48.995984
var_95 -0.00023
var_99 -0.00062
cvar_95 -0.000405
cvar_99 -0.00069
sqn -0.743693
kelly_criterion -0.080763
max_leverage 0.01458
min_margin_level 68.587671
```
## 可视化 (Visualization)
AKQuant 内置了基于 **Plotly** 的强大可视化模块,仅需一行代码即可生成包含权益曲线、回撤分析、月度热力图等详细指标的交互式 HTML 报告。
```python
# 生成交互式 HTML 报告,自动在浏览器中打开
result.report(show=True)
```
<p align="center">
<img src="assets/dashboard_preview.png" alt="Strategy Dashboard" width="800">
<br>
👉 <a href="https://akquant.akfamily.xyz/report_demo/">点击查看交互式报表示例 (Interactive Demo)</a>
</p>
## 文档索引
* 📖 **[核心特性与架构](docs/zh/index.md#核心特性)**: 了解 AKQuant 的设计理念与性能优势。
* 🛠️ **[安装指南](docs/zh/installation.md)**: 详细的安装步骤(含源码编译)。
* 🚀 **[快速入门](docs/zh/quickstart.md)**: 更多示例与基础用法。
* 🤖 **[机器学习指南](docs/zh/ml_guide.md)**: 如何使用内置的 ML 框架进行滚动训练。
* 📚 **[API 参考](docs/zh/api.md)**: 详细的类与函数文档。
* 💻 **[贡献指南](CONTRIBUTING.md)**: 如何参与项目开发。
## 🧪 测试与质量保证
AKQuant 采用严格的测试流程以确保回测引擎的准确性:
* **单元测试**: 覆盖核心 Rust 组件与 Python 接口。
* **黄金测试 (Golden Tests)**: 使用合成数据验证关键业务逻辑(如 T+1、涨跌停、保证金、期权希腊值),并与锁定的基线结果进行比对,防止算法回退。
运行测试:
```bash
# 1. 安装开发依赖
pip install -e ".[dev]"
# 2. 运行所有测试
pytest
# 3. 仅运行黄金测试
pytest tests/golden/test_golden.py
```
## 贡献指南
## Citation
Please use this bibtex if you want to cite this repository in your publications:
```bibtex
@misc{akquant,
author = {Albert King and Yaojie Zhang},
title = {AKQuant},
year = {2026},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/akfamily/akquant}},
}
```
## License
MIT License
| text/markdown; charset=UTF-8; variant=GFM | AKQuant Developers | albertandking@gmail.com | null | null | MIT License | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :... | [] | null | null | >=3.10 | [] | [] | [] | [
"pandas>=3.0.0",
"numpy>=2.4.1",
"pyarrow>=14.0.0",
"tqdm>=4.0.0",
"plotly>=5.0.0",
"ruff>=0.1.0; extra == \"dev\"",
"pre-commit>=3.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"mkdocs>=1.5.0; extra == \"dev\"",
"mkdocs-material>=9.5.0; extra == \"d... | [] | [] | [] | [
"Documentation, https://akquant.akfamily.xyz",
"Homepage, https://github.com/akfamily/akquant",
"Repository, https://github.com/akfamily/akquant"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:21:44.316421 | akquant-0.1.45.tar.gz | 755,429 | 5e/dc/59f031b2e59e3c0b05d7d60dc95ee95ac829a85d219c2eb33cc19d34e984/akquant-0.1.45.tar.gz | source | sdist | null | false | af946698f67b2314d78044a49c4ab1a5 | 56a3fdbfe7ea2ddff907310af1fe03ba77592080e823c647d983e2b17b79662b | 5edc59f031b2e59e3c0b05d7d60dc95ee95ac829a85d219c2eb33cc19d34e984 | null | [
"LICENSE"
] | 794 |
2.4 | sentinel-ai-os | 1.0.8 | Autonomous AI Operating System layer | <img width="1065" height="226" alt="image" src="https://github.com/user-attachments/assets/d8c6fede-1cd8-4517-b626-2deb2d9bd9c5" />
> **Your proactive OS assistant.** Sentinel is a terminal-based autonomous agent that integrates deeply with your local operating system, files, and cloud services to execute complex workflows via natural language.
https://github.com/user-attachments/assets/e75f5e5b-a111-48e8-ba22-9c3ae15a7417
---
## 📖 Table of Contents
* [Overview](#-overview)
* [Key Features](#-key-features)
* [System Architecture](#-system-architecture)
* [Installation & Setup](#-installation--setup)
* [Configuration](#-configuration)
* [Usage Guide](#-usage-guide)
* [Available Tools](#-available-tools)
* [Contributing](#-contributing)
* [Safety & Privacy](#-safety--privacy)
---
## 🔭 Overview
Sentinel is not just a chatbot; it is an **Action Engine**. Unlike web-based LLMs that live in a sandbox, Sentinel runs locally on your machine with access to your file system, applications, and peripherals.
It operates on a **Think-Plan-Act** loop:
1. **Perceives** user intent via natural language.
2. **Retrieves** context from its long-term vector memory and local SQL file index.
3. **Selects** specific tools from a registry (e.g., "Send Email", "Search Files", "Analyze Screen").
4. **Executes** the action safely (asking for permission when necessary).
5. **Learns** from the interaction to build a persistent user profile.
---
## ✨ Key Features
* **🧠 Multi-Brain Support:** Powered by `litellm`, Sentinel can seamlessly switch between **OpenAI**, **Anthropic**, **Groq**, or run locally with **Ollama**.
* **💾 Hybrid Memory Architecture:**
* **Vector Database (ChromaDB):** Stores semantic memories, facts, and user preferences for long-term recall.
* **SQL Index (SQLite):** Maintains a lightning-fast index of your local filesystem for rapid file retrieval.
* **🔌 Deep OS Integration:**
* Launch/close apps, manage processes, and control system volume/brightness.
* Organize messy folders, bulk rename files, and create documents.
* "Digital Twin" context awareness (knows what app you are using).
* **☁️ Google Workspace Native:**
* Full 2-way sync with **Google Calendar** and **Gmail**.
* Natural language scheduling ("Clear my afternoon", "Draft an email to Bob").
* **👀 Computer Vision:** Analyze your screen or webcam feed using Vision-capable models (GPT-4o, Claude 3.5 Sonnet).
* **🛡️ Safety First:** "Human-in-the-loop" protocols require user approval for high-risk actions like deleting files, sending emails, or executing shell commands.
---
## 🏗 System Architecture
Sentinel is built on a modular Python architecture designed for extensibility.
### Core Components
* **`main.py`**: The entry point. Handles CLI arguments using `typer` and initiates the boot sequence.
* **`core/agent.py`**: The main agent loop. Manages the context window, parses JSON responses from the LLM, and triggers tools.
* **`core/llm.py`**: A unified wrapper for different API providers (via `litellm`) that handles model selection, streaming, and error recovery.
* **`core/registry.py`**: The "Tool Belt." Maps natural language tool descriptions to actual Python functions and injects safety wrappers like `ask_permission`.
* **`tools/`**: A directory containing isolated modules for specific capabilities (e.g., `browser.py`, `file_ops.py`, `vision.py`).
---
## 🚀 Installation & Setup
### Prerequisites
* Python 3.9 or higher but not 3.14.
* (Optional) **Ollama** installed for local offline inference.
* (Optional) A Google Cloud Console project for Gmail/Calendar integration.
### Step 1: Install from PyPI
As a published package, you can install Sentinel directly using pip:
```bash
pip install sentinel-ai-os
```
### Step 2: System Boot & Configuration
Run the initial setup wizard. This will guide you through setting your name, location, and API keys, which are stored securely using the `keyring` library.
```bash
sentinel config
```
### Step 3: Google Authentication (Optional but Recommended)
To enable Calendar and Gmail features:
1. Download your OAuth 2.0 Client ID JSON from your Google Cloud Console project.
2. Rename it to `credentials.json` and place it in the directory where you run Sentinel.
3. Run the auth repair tool. This will open a browser window to authorize Sentinel.
```bash
sentinel auth
```
---
## ⚙ Configuration
Sentinel stores its primary configuration in `config.json` and sensitive API keys in your OS's secure credential manager.
**Supported Services:**
* **Primary Brains:** OpenAI, Anthropic, Groq, Ollama
* **Search Tools:** Tavily (recommended for RAG), DuckDuckGo
* **Navigation:** Google Maps API
To view or update keys after the initial setup, you can re-run the configuration wizard:
```bash
sentinel config
```
---
## 🎮 Usage Guide
Start the agent's interactive shell:
```bash
sentinel
```
Or, start with a daily briefing (Weather, Calendar, Email summary):
```bash
sentinel --briefing
```
### Interactive CLI
Once inside the Sentinel shell, you can communicate with the agent using natural language.
### Example Natural Language Prompts
* *"Find all PDF files on my Desktop modified last week and move them to a folder named Reports."*
* *"Summarize the last 5 emails from my boss."*
* *"Take a screenshot and tell me what code is visible."*
* *"Plan a trip to New York for next weekend, check flights, and add it to my calendar."*
---
## 🛠 Available Tools
Sentinel comes equipped with a vast array of tools, dynamically registered and made available to the LLM. Below is a summary of its capabilities.
### 📂 File System & Indexing
* **Smart Search:** Uses SQLite `fts5` for fast filename search and a Vector index for semantic content search ("Find that document about the project budget").
* **File Operations:** Full CRUD (Create, Read, Write) for files.
* **Code Drafts:** Safely drafts code to a `drafts/` directory for user review, never executing it directly.
* **Organization:** Bulk rename files or sort them into folders based on date, extension, or other criteria.
* **Document Factory:** Create Word (`.docx`) and Excel (`.xlsx`) files from scratch.
### 🌐 Web & Knowledge
* **Deep Research:** Uses Tavily API to browse the web, scrape content, and synthesize answers.
* **Browser Automation:** Can open URLs and extract text from webpages.
* **Flight Search:** Find flight information via the SerperDev API.
### 🖥️ Desktop Automation & OS
* **App Launcher:** Intelligent fuzzy matching to launch and close applications.
* **System Control:** Set volume, brightness, or execute shell commands (with permission).
* **Process Management:** List and kill running processes.
* **Macros:** Execute pre-defined sequences of actions.
### 👀 Perception & Vision
* **Screen Analysis:** `analyze_screen` allows the agent to "see" and understand the content on your display.
* **Webcam Capture:** Use the webcam to capture images for analysis.
* **Speech I/O:** `listen` to user voice commands and `speak` to provide audio responses.
* **Context Awareness:** Can identify the currently active application window.
### 🧠 Memory & Cognition
* **Long-term Memory:** Stores facts and user preferences (e.g., "User prefers dark mode") in ChromaDB for future interactions.
* **Note Taking:** A simple system for adding and retrieving categorized notes.
* **Reflection:** Can look back at logs to provide continuity across sessions.
### 📅 Calendar & Email (Google Workspace)
* **Full Calendar Control:** List, create, and query events on your Google Calendar.
* **Gmail Integration:** Read and send emails through your Gmail account.
---
## 🤝 Contributing
We welcome contributions! Sentinel is designed to be easily extensible.
### Directory Structure
* `sentinel/core/`: The brain. Modify this if you are improving the LLM loop, context management, or configuration.
* `sentinel/tools/`: The hands. **This is the best place to start.** Add new capabilities here.
### How to Add a New Tool
1. Create a new Python file in `sentinel/tools/` (e.g., `spotify.py`).
2. Define your function(s) in that file.
3. Import your function into `sentinel/core/registry.py`.
4. Add the function to the `TOOLS` dictionary in `registry.py`, wrapping it in `ask_permission` if it's a high-risk action.
5. Add a description of the tool and its arguments to the `SYSTEM_PROMPT` in `registry.py` so the LLM knows how to use it.
---
## 🛡 Safety & Privacy
Because Sentinel has deep access to your system, safety is a core design principle.
1. **Permission Gate:** Critical tools (File Deletion, Shell Commands, Sending Email, etc.) are wrapped in the `ask_permission` function. The agent's execution pauses until you explicitly approve the action by typing `y`.
2. **Safe Code Drafting:** Sentinel never executes code it generates. It uses the `draft_code` tool to save scripts to a `drafts/` directory, allowing you to review them before manual execution.
3. **Command Guardrails:** The `run_cmd` tool has extra checks to prevent accidental use of destructive commands like `rm` or `format`.
4. **Local First:** All file indexes (SQL and ChromaDB) are stored locally in your user directory. No file data is sent to the cloud except for the specific text chunks required by the LLM API for a given task. Your API keys are stored securely in your operating system's native credential manager.
---
**Disclaimer:** *Sentinel is an autonomous agent. While many safety checks are in place, always review the actions it proposes before approving them, especially those involving file modification or shell command execution.*
| text/markdown | null | Sam Selvaraj <samselvaraj1801@gmail.com> | null | null | null | ai, agent, automation, llm, rag, os | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | <3.14,>=3.9 | [] | [] | [] | [
"rich",
"typer[all]",
"pydantic",
"tabulate",
"markdown",
"schedule",
"keyring",
"tzlocal",
"psutil",
"litellm",
"anthropic",
"groq",
"openai",
"chromadb",
"tavily",
"requests",
"beautifulsoup4",
"duckduckgo-search",
"ddgs",
"googlemaps",
"google-auth",
"google-auth-oauthli... | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.5 | 2026-02-18T20:21:37.332236 | sentinel_ai_os-1.0.8.tar.gz | 60,813 | d8/d6/3677b9d03d8d4235cd03c5a663a60e00c619b14734d60ba9fd9263246f8a/sentinel_ai_os-1.0.8.tar.gz | source | sdist | null | false | ddfabf517dd7e1c4f1123b962280ddb4 | ba47a2290d38401a3d87ed23e7a8d244150e1316b5ce07b376e32a00d041febd | d8d63677b9d03d8d4235cd03c5a663a60e00c619b14734d60ba9fd9263246f8a | MIT | [
"LICENSE"
] | 245 |
2.4 | geneva | 0.10.2 | Geneva - Multimodal Data Lake for AI | # Geneva - Multimodal Data Platform
Geneva is a petabyte-scale multimodal feature engineering and data management platform built on LanceDB.
## What lives in this repo
- `src/` - Geneva client library and core runtime
- `src/tests/` - unit test suites
- `src/integ_tests/` - integration test suites
- `src/stress_tests/` - stress and load tests
- `docs/` - mkdocs configuration and API docs (source for autogenerated public facing api documentation page)
- `e2e/` - end-to-end test suites and UDF manifests
- `notebook/` - quickstart notebooks (TODO replace with link to colab demo notebook)
- `internal_docs/` - internal design and operational notes
- `tools/` - helper scripts for local clusters and cleanup
User facing documentation should be submitted [here](https://github.com/lancedb/docs/tree/main/docs/geneva).
## Quickstart (local development)
```bash
uv sync --all-groups --all-extras --locked
```
```python
import geneva
import pyarrow as pa
@geneva.udf(data_type=pa.int32())
def double(x: int) -> int:
return x * 2
conn = geneva.connect("./db")
table = conn.create_table("numbers", [{"x": i} for i in range(10)])
table.add_columns({"doubled": double})
with conn.local_ray_context():
table.backfill("doubled")
result = table.search().select(["doubled"]).to_arrow()
```
## Development
See [Development](./DEVELOPMENT.md) for details.
## Configuration
Geneva supports specifying configuration in a few different ways. Refer to CONFIGURATION.md for more details.
| text/markdown | null | null | null | null | null | null | [
"Development Status :: 2 - Pre-Alpha",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.1... | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"aiohttp>=3.12.12",
"attrs<25,>=23",
"bidict",
"cattrs",
"cloudpickle",
"docker==7.*",
"emoji",
"fsspec",
"jinja2==3.*",
"kubernetes",
"lance-namespace>=0.2.1",
"lancedb>=0.27.0",
"more-itertools",
"multiprocess",
"numpy",
"overrides>=7.7.0",
"pip>=24.3.1",
"pyarrow>=16",
"pylanc... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T20:21:05.637589 | geneva-0.10.2.tar.gz | 7,618,398 | 8e/ed/52295b0ff3d42b57f7a48002fedb627423ca1cec03527f5322dcb9051de6/geneva-0.10.2.tar.gz | source | sdist | null | false | 656d38a6bd2bc5f021700f56aaeea7dc | 4c76ced3fe77a32bc0022cfe79e557a3895bf1ee102adfac2b330caa4b426cf1 | 8eed52295b0ff3d42b57f7a48002fedb627423ca1cec03527f5322dcb9051de6 | LicenseRef-Proprietary | [
"LICENSE"
] | 452 |
2.2 | p95 | 0.5.0 | Python SDK for p95 ML experiment tracking | # p95 Python SDK
Track ML experiments locally. No server setup required.
Installing the Python package includes the binary for the TUI and the web server.
## Install
```bash
pip install p95
```
## Usage
```python
from p95 import Run
with Run(project="my-project", name="experiment-1") as run:
run.log_config({"learning_rate": 0.001, "epochs": 10})
for epoch in range(10):
loss = train_one_epoch()
run.log_metrics({"loss": loss}, step=epoch)
```
## View Results
```bash
# Opens a dashboard at http://localhost:6767
pnf serve --logdir ~/.p95/logs
# Opens the TUI
pnf tui --logdir ~/.p95/logs
```
## API
```python
run.log_metrics({"loss": 0.5, "accuracy": 0.85}, step=epoch) # Log metrics
run.log_config({"lr": 0.001}) # Log config
run.add_tags(["baseline"]) # Add tags
```
## Environment Variables
| Variable | Description | Default |
| ------------ | ------------------ | ------------- |
| `P95_LOGDIR` | Where to save logs | `~/.p95/logs` |
## License
MIT
| text/markdown | NinetyFive | null | null | null | MIT | ml, machine-learning, experiment-tracking, metrics, training | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pyth... | [] | null | null | >=3.8 | [] | [] | [] | [
"requests>=2.28.0",
"websocket-client>=1.4.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"responses>=0.23.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/numerataz/p95",
"Documentation, https://github.com/numerataz/p95",
"Repository, https://github.com/numerataz/p95"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T20:20:45.967599 | p95-0.5.0-py3-none-macosx_10_13_universal2.whl | 5,217,716 | ec/74/214471c5fda177fabd440c925387ff07eb19fc695d2cb976ddccc5e35ef8/p95-0.5.0-py3-none-macosx_10_13_universal2.whl | py3 | bdist_wheel | null | false | 7ad4ddfedf6a2f1d7f0b0f806056f0f5 | 74a0b198f9df2813ff93da547ec380d3e7fd8c0ad6d6ef489c5e5cca74d7c396 | ec74214471c5fda177fabd440c925387ff07eb19fc695d2cb976ddccc5e35ef8 | null | [] | 459 |
2.4 | nevu-ui | 0.7.1 | A powerful GUI framework for Pygame that allows you to create menus | 

# Brief Description
**Nevu UI** is a library for the declarative creation of user interfaces in Pygame. The project aims to provide developers with a set of ready-made, stylable, and extensible components for the rapid creation of modern and responsive interfaces in games and multimedia applications.
#### The main goal of Nevu UI: to make creating interfaces in python even easier and faster
### Key features include:
* **Layout system:** Convenient arrangement of elements, for example, using grids (Grid) and scrollable containers (ScrollableColumn).
* **Set of widgets:** Ready-to-use elements such as buttons, input fields, and labels.
* **Flexible styling:** The ability to customize the appearance through a style system that supports colors, gradients, and borders.
* **Animations:** Built-in support for animations to create dynamic and lively interfaces.
* **Declarativeness:** Support for declarative interface creation
## Style
### Style - storage of parameters for customizing the appearance
Editable parameters:
* **Gradient**
* **ColorTheme** - Analogous to MaterialDesign, there is a ready-made set of themes - `ColorThemeLibrary`
* **Font name/size**
* **Border Width/Radius**
* **Text Align X/Y**
* **Transparency**
## Main Features
### Nevu UI allows you to describe an interface with a clear structure
Examples of declarativeness:
* **Declarative approach:** Describe your interface just as you see it.
```python
# Specify content directly when creating the layout
grid = ui.Grid(content={(1,1): ui.Button(...)})
```
* **Adaptive size system (`SizeRules`):** Forget about pixels. Use relative values that adjust to the size of the window or parent element.
* `vh` / `vw`: Percentage of the window's height/width.
* `fillx` / `filly` / `fill`: Percentage of the parent layout's height/width/size.
* `gc` / `gcw` / `gch`: Percentage of the grid cell size.
* Prefix `c`: can be placed in any SizeRule, it means that the current value will be taken (without the prefix, the original will be taken).
* **Powerful style system:** Customize every aspect of the appearance using the universal `Style` object.
* **Themes:** Ready-made color themes in `ColorThemeLibrary`.
* **Gradients:** Support for linear and radial.
* **Inheritance:** Styles can be created based on existing ones.
* **And much more:** Fonts, borders, rounding, transparency.
* **Built-in animations:** Bring your interface to life with ready-made animations for movement, transparency, etc.
* There are **2** types of animations:
* **Start** - Allows you to set the initial appearance of the widget.
* **Infinite** - Produces an infinite animation defined in `animation_manager`.
* Usage example:
* ```widget.animation_manager.add_start_animation(ui.animations.EaseOut(...))```
Constant System (Constant Engine):
* `ConstantEngine` is a convenient tool built into all layouts and widgets, it allows you to:
* Declaratively add variables to the object's `__init__`
* Check the variable type during initialization and after
* The variable will not be visible in hints for `__init__` if it was not added to the class `TypedDict`
* The variable will not be visible **IN ALL** hints if you do not specify the name and type at the beginning of the class
* **Examples:**
```python
import nevu_ui as ui
from typing import Unpack, NotRequired
#Create a TypedDict with variables (optional)
class MyWidgetKwargs(ui.WidgetKwargs):
my_var: NotRequired[int | float]
class MyWidget(ui.Widget):
#Create a typehint for the variable (optional but recommended)
my_var: int | float
def __init__(self, size: NvVector2 | list, style: Style = default_style, **constant_kwargs: Unpack[MyWidgetKwargs]):
super().__init__(size, style, **constant_kwargs)
#Override the function to add constants (mandatory)
def _add_constants(self):
super()._add_constants()
#Add a constant (mandatory)
self._add_constant('my_var', int | float)
#You can also add a link to a constant
#self._add_constant_link('my_var', 'my_var_new_name')
#You can also block a constant if necessary
#self._block_constant('my_var')
```
# Installation
## Dependencies:
**```Python >= 3.12.*```**
* For Building:
* ```setuptools >= 61.0```
* ```Cython```
* ```numpy```
* For Running:
* ```pygame-ce>=2.3.0```
* ```numpy```
* ```Pillow```
* ```moderngl```
## Installation via pip
```python
pip install nevu-ui
```
# Examples

---


---
### Basic Grid
#### Declarative Approach
```python
import nevu_ui as ui #Import Nevu UI
import pygame
pygame.init()
class MyGame(ui.Manager): #Create the base of our application
def __init__(self):
window = ui.Window((400, 300), title = "My Game") #Create a window
super().__init__(window) #initialize the manager
self.menu = ui.Menu(self.window, [100*ui.vw, 100*ui.vh], #Create a menu
layout= ui.Grid([100*ui.vw, 100*ui.vh], row=3, column=3, #Create a grid layout
content = {
(2, 2): ui.Button(lambda: print("You clicked!"), "Button", [50*ui.fill,33*ui.fill]) #Create a button
}))
def on_draw(self):
self.menu.draw() #draw the menu
def on_update(self, events):
self.menu.update() #update the menu
game = MyGame()
game.run() #Run the finished application
```
#### Imperative Approach
```python
import nevu_ui as ui #Import Nevu UI
import pygame
pygame.init()
window = ui.Window((400, 300), title = "My Game") #Create a window
menu = ui.Menu(window, [100*ui.vw, 100*ui.vh]) #Create a menu
layout = ui.Grid([100*ui.vw, 100*ui.vh], row=3, column=3) #Create a grid layout
layout.add_item(ui.Button(lambda: print("You clicked!"), "Button", [50*ui.fill,33*ui.fill]), x = 2, y = 2) #Create a button
menu.layout = layout #Set the menu layout
while True: #Main loop
events = pygame.event.get() #Get events
window.update(events) #Update the window
menu.update() #Update the menu
menu.draw() #Draw the menu
pygame.display.update() #Update the screen
```
### Example Result

---
# Nevu UI Status at the Moment
### **Layouts (Layout_Type)**
(✅ - done, ❌ - not done, 💾 - deprecated)
* ✅ `Grid`
* ✅ `Row`
* ✅ `Column`
* ✅ `ScrollableRow`
* ✅ `ScrollableColumn`
* 💾 `IntPickerGrid`
* ✅ `Pages`
* 💾 `Gallery_Pages`
* ✅ `StackColumn`
* ✅ `StackRow`
* ✅ `CheckBoxGroup`
### **Widgets (Widget)**
* ✅ `Widget`
* ✅ `Button`
* ✅ `Label`
* ✅ `Input`
* ✅ `EmptyWidget`
* ❌ `Tooltip` (In 0.6.X)
* 💾 `Image`
* 💾 `Gif`
* ❌ `MusicPlayer` (Will be reworked)
* ✅ `ProgressBar`
* ✅ `SliderBar`
* ✅ `ElementSwitcher`
* 💾 `FileDialog`
* ✅ `RectCheckBox`
# License
**Nevu UI is protected by the MIT license**
# Additional Information
* **Gmail:** bebrovgolem@gmail.com
* **Creator:** Nikita A.
| text/markdown | null | GolemNikidastrov <bebrovgolem@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"pygame-ce>=2.3.0",
"numpy",
"Pillow",
"raylib"
] | [] | [] | [] | [
"Homepage, https://github.com/GolemBebrov/nevu-ui",
"Repository, https://github.com/GolemBebrov/nevu-ui"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:20:38.499201 | nevu_ui-0.7.1-cp314-cp314t-win_amd64.whl | 1,270,646 | 13/d0/3fad19217f36a1f892d96fa0d78c12baa1ec2c0dc08e00a0551183012d1f/nevu_ui-0.7.1-cp314-cp314t-win_amd64.whl | cp314 | bdist_wheel | null | false | 9b370c1637664b660d2eaa86e7393e39 | ae8ad7dad2cd189cfb48011bd80413d10985bdd97f263a631b4e2732c9171b79 | 13d03fad19217f36a1f892d96fa0d78c12baa1ec2c0dc08e00a0551183012d1f | null | [
"LICENSE"
] | 927 |
2.4 | flowjax | 19.0.0 | Easy to use distributions, bijections and normalizing flows in JAX. |

Distributions, bijections and normalizing flows using Equinox and JAX
-----------------------------------------------------------------------
- Includes a wide range of distributions and bijections.
- Distributions and bijections are PyTrees, registered through
[Equinox](https://github.com/patrick-kidger/equinox/) modules, making them
compatible with [JAX](https://github.com/google/jax) transformations.
- Includes many state of the art normalizing flow models.
- First class support for conditional distributions and density estimation.
## Documentation
Available [here](https://danielward27.github.io/flowjax/index.html).
## Short example
As an example we will create and train a normalizing flow model to toy data in just a few lines of code:
```python
from flowjax.flows import block_neural_autoregressive_flow
from flowjax.train import fit_to_data
from flowjax.distributions import Normal
import jax.random as jr
import jax.numpy as jnp
data_key, flow_key, train_key, sample_key = jr.split(jr.key(0), 4)
x = jr.uniform(data_key, (5000, 2)) # Toy data
flow = block_neural_autoregressive_flow(
key=flow_key,
base_dist=Normal(jnp.zeros(x.shape[1])),
)
flow, losses = fit_to_data(
key=train_key,
dist=flow,
data=x,
learning_rate=5e-3,
max_epochs=200,
)
# We can now evaluate the log-probability of arbitrary points
log_probs = flow.log_prob(x)
# And sample the distribution
samples = flow.sample(sample_key, (1000, ))
```
The package currently includes:
- Many simple bijections and distributions, implemented as [Equinox](https://arxiv.org/abs/2111.00254) modules.
- `coupling_flow` ([Dinh et al., 2017](https://arxiv.org/abs/1605.08803)) and `masked_autoregressive_flow` ([Kingma et al., 2016](https://arxiv.org/abs/1606.04934), [Papamakarios et al., 2017](https://arxiv.org/abs/1705.07057v4)) normalizing flow architectures.
- These can be used with arbitrary bijections as transformers, such as `Affine` or `RationalQuadraticSpline` (the latter used in neural spline flows; [Durkan et al., 2019](https://arxiv.org/abs/1906.04032)).
- `block_neural_autoregressive_flow`, as introduced by [De Cao et al., 2019](https://arxiv.org/abs/1904.04676).
- `planar_flow`, as introduced by [Rezende and Mohamed, 2015](https://arxiv.org/pdf/1505.05770.pdf).
- `triangular_spline_flow`, introduced here.
- Training scripts for fitting by maximum likelihood, variational inference, or using contrastive learning for sequential neural posterior estimation ([Greenberg et al., 2019](https://arxiv.org/abs/1905.07488); [Durkan et al., 2020](https://arxiv.org/abs/2002.03712])).
- A bisection search algorithm that allows inverting some bijections without a
known inverse, allowing for example both sampling and density evaluation to be
performed with block neural autoregressive flows.
## Installation
```bash
pip install flowjax
```
## Warning
This package is in its early stages of development and may undergo significant changes, including breaking changes, between major releases. Whilst ideally we should be on version 0.y.z to indicate its state, we have already progressed beyond that stage. Any breaking changes will be in the release notes for each major release.
## Development
We can install a version for development as follows
```bash
git clone https://github.com/danielward27/flowjax.git
cd flowjax
pip install -e .[dev]
sudo apt-get install pandoc # Required for building documentation
```
## Related
- We make use of the [Equinox](https://arxiv.org/abs/2111.00254) package, which
facilitates defining models using a PyTorch-like syntax with Jax.
- For applying parameterizations, we use
[paramax](https://github.com/danielward27/paramax).
## Citation
If you found this package useful in academic work, please consider citing it using the
template below, filling in ``[version number]`` and ``[release year of version]`` to the
appropriate values. Version specific DOIs
can be obtained from [zenodo](https://zenodo.org/records/10402073) if desired.
```bibtex
@software{ward2023flowjax,
title = {FlowJAX: Distributions and Normalizing Flows in Jax},
author = {Daniel Ward},
url = {https://github.com/danielward27/flowjax},
version = {[version number]},
year = {[release year of version]},
doi = {10.5281/zenodo.10402073},
}
```
| text/markdown | null | Daniel Ward <danielward27@outlook.com> | null | null | The MIT License (MIT)
Copyright (c) 2022 Daniel Ward
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | equinox, jax, neural-networks | [
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Information Analysis",
"Topic :: Scientific/Engineeri... | [] | null | null | >=3.10 | [] | [] | [] | [
"equinox>=0.10",
"jax>=0.4.16",
"jaxtyping",
"lineax",
"optax",
"paramax>=0.0.5",
"tqdm",
"beartype; extra == \"dev\"",
"ipython; extra == \"dev\"",
"nbsphinx; extra == \"dev\"",
"numpyro>=0.20.0; extra == \"dev\"",
"pytest; extra == \"dev\"",
"ruff; extra == \"dev\"",
"sphinx-autodoc-type... | [] | [] | [] | [
"repository, https://github.com/danielward27/flowjax",
"documentation, https://danielward27.github.io/flowjax/index.html"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T20:19:13.726641 | flowjax-19.0.0.tar.gz | 477,201 | 4b/ab/a780735762adfc5001fc9b18f600f89e87b8a3b28e0c025fdc7a2d8b19eb/flowjax-19.0.0.tar.gz | source | sdist | null | false | 241047a1aaa3ec3dbde886320d9aae60 | 58a1659ccf7d64c4d160df8948afc208cf61d40a819acf19ace61a56778d2432 | 4baba780735762adfc5001fc9b18f600f89e87b8a3b28e0c025fdc7a2d8b19eb | null | [
"LICENSE"
] | 508 |
2.4 | pyrosper | 0.1.9.post1 | A continuously improving, experimentation framework. | # `\\//,` pyrosper (pronounced "prosper")
A continuously improving, experimentation framework for Python.
Ported from the [TypeScript counterpart](https://github.com/BKKnights/prosper).
## Installation
```bash
pip install pyrosper
```
Or install from source:
```bash
git clone https://github.com/your-repo/pyrosper.git
cd pyrosper
pip install -e .
```
## Why pyrosper?
pyrosper provides a means of:
* Injecting intelligently selected experimental code that is short-lived
* Using any algorythm of your choosing to select which experimental code is injected for a user
* as simple as returning index, like random
* as sophisticated as a multi-armed bandit
* Preventing code churn where long-lived code belongs
### The non-pyrosper way:
* Uses feature flagging
* Favors code churn, with highly fractured experimentation
* Constantly affects test coverage
* Provides a very blurry understanding of the codebase when experimenting
### The pyrosper way:
* Use experiments rather than feature flags
* Picture one master switch, rather than many small switches
* Code for each variant lives close together, within an experiment
* Favors short-lived experimental code that accentuates long-lived code
* Once understandings from a variant are known, they can be moved from short-lived (experiment) to long-lived (source)
* Meant to churn as little as possible
* Provides a very clear understanding of the codebase when experimenting
## Quick Start
### Basic Usage
```python
from pyrosper import Pyrosper, Symbol, Variant, BaseExperiment
from typing import List
# Define your experiment
class MyExperiment(BaseExperiment):
# Implement abstract methods (see full example below)
async def get_experiment(self):
# Your implementation here
pass
# ... other required methods
# Create and use pyrosper
pyrosper = Pyrosper()
key = Symbol("greeting")
experiment = MyExperiment(
name="greeting_experiment",
variants=[
Variant("control", {key: "Hello!"}),
Variant("variant_a", {key: "Hi there!"}),
Variant("variant_b", {key: "Hey!"}),
]
)
pyrosper.with_experiment(experiment)
# Get a value from the experiment
greeting_symbol = Symbol("greeting")
greeting = pyrosper.pick(greeting_symbol)
print(greeting) # Will print one of: "Hello!", "Hi there!", or "Hey!"
```
### Using the Context System
```python
from pyrosper import BaseContext, get_current
# Create a custom context
class UserContext(BaseContext):
def __init__(self, user_id: str):
super().__init__()
self.user_id = user_id
def setup(self):
# Create and configure pyrosper for this user
pyrosper = Pyrosper()
# Add experiments, configure algorithms, etc.
return pyrosper
key = Symbol("greeting")
# Use as context manager
with UserContext("user123") as pyrosper:
current = get_current() # Get current pyrosper instance
greeting = current.pick(key)
# Use as decorator
def get_user_greeting():
pyrosper = get_current()
return pyrosper.pick(key)
result = get_user_greeting()
```
### Type-Safe Picking
```python
from pyrosper import pick
# Define your variant types
class GreetingVariant:
def __init__(self, message: str, emoji: str):
self.message = message
self.emoji = emoji
# Create variants
control_variant = GreetingVariant("Hello", "👋")
variant_a = GreetingVariant("Hi there", "😊")
key = Symbol("greeting")
# Use type-safe picking
greeting = pick(pyrosper_instance, key, GreetingVariant) # `pick` is a helper function, not required
greeting = pyrosper_instance.pick(key, GreetingVariant) # usage with `pick` method
print(f"{greeting.message} {greeting.emoji}")
```
## Complete Example
Here's a complete example showing how to implement a real experiment:
```python
import asyncio
from typing import List, Optional
from pyrosper import Pyrosper, Symbol, Variant, BaseExperiment, UserVariant
# Define your data models
class UserVariantImpl(UserVariant):
def __init__(self, experiment_id: str, user_id: str, index: int):
self.experiment_id = experiment_id
self.user_id = user_id
self.index = index
class Algorithm:
def __init__(self, weights: List[float]):
self.weights = weights
# Implement your experiment
class GreetingExperiment(BaseExperiment):
def __init__(self):
super().__init__(
name="greeting_experiment",
variants=[
Variant("control", {Symbol("greeting"): "Hello!"}),
Variant("friendly", {Symbol("greeting"): "Hi there!"}),
Variant("casual", {Symbol("greeting"): "Hey!"}),
]
)
self._algorithm = Algorithm([0.33, 0.33, 0.34])
self._user_variants = {}
async def get_experiment(self) -> Optional['GreetingExperiment']:
return self if self.is_enabled else None
async def upsert_experiment(self, experiment) -> 'GreetingExperiment':
self.is_enabled = experiment.is_enabled
self.id = experiment.id
return self
async def delete_experiment(self, experiment) -> None:
self.reset()
async def get_user_variant(self, user_id: str, experiment_id: str) -> Optional[UserVariantImpl]:
return self._user_variants.get(f"{user_id}_{experiment_id}")
async def upsert_user_variant(self, user_variant: UserVariantImpl) -> None:
self._user_variants[f"{user_variant.user_id}_{user_variant.experiment_id}"] = user_variant
async def delete_user_variant(self, user_variant: UserVariantImpl) -> None:
key = f"{user_variant.user_id}_{user_variant.experiment_id}"
if key in self._user_variants:
del self._user_variants[key]
async def delete_user_variants(self) -> None:
self._user_variants.clear()
async def get_algorithm(self) -> Algorithm:
return self._algorithm
async def get_variant_index(self, algorithm: Algorithm) -> int:
# Simple random selection based on weights
import random
return random.choices(range(len(algorithm.weights)), weights=algorithm.weights)[0]
async def reward_algorithm(self, algorithm: Algorithm, user_variant_index: int, score: float) -> Algorithm:
# Update weights based on performance
new_weights = algorithm.weights.copy()
new_weights[user_variant_index] *= (1 + score * 0.1)
# Normalize weights
total = sum(new_weights)
new_weights = [w / total for w in new_weights]
return Algorithm(new_weights)
async def upsert_algorithm(self, algorithm: Algorithm) -> None:
self._algorithm = algorithm
async def delete_algorithm(self) -> None:
self._algorithm = Algorithm([0.33, 0.33, 0.34])
# Usage
async def main():
# Create pyrosper instance
pyrosper = Pyrosper()
# Create and add experiment
experiment = GreetingExperiment()
pyrosper.with_experiment(experiment)
# Enable the experiment
await experiment.enable()
# Set up for a specific user
await pyrosper.set_for_user("user123")
# Get greeting for user
greeting_symbol = Symbol("greeting")
greeting = pyrosper.pick(greeting_symbol, pick_type)
print(f"Greeting for user123: {greeting}")
# Complete experiment for user (provide feedback)
await experiment.complete_for_user("user123", 0.8) # 0.8 score
# Run the example
if __name__ == "__main__":
asyncio.run(main())
```
## Advanced Features
### Multiple Experiments
```python
# Create multiple experiments
greeting_exp = GreetingExperiment()
color_exp = ColorExperiment()
# Add to pyrosper
pyrosper = Pyrosper()
pyrosper.with_experiment(greeting_exp).with_experiment(color_exp)
# Use both experiments
greeting_key = Symbol("greeting")
color_key = Symbol("color")
greeting = pyrosper.pick(greeting_key)
color = pyrosper.pick(color_key)
```
### Experiment Validation
Pyrosper automatically validates experiments to ensure:
- No duplicate experiment names
- All variants have the same symbols
- No duplicate symbols across experiments
```python
# This will raise ValueError if validation fails
pyrosper.with_experiment(experiment)
```
### Context Isolation
```python
key = Symbol("greeting")
# Each context has its own pyrosper instance
with UserContext("user1") as pyrosper1:
with UserContext("user2") as pyrosper2:
# pyrosper1 and pyrosper2 are independent
greeting1 = pyrosper1.pick(key)
greeting2 = pyrosper2.pick(key)
```
## API Reference
### Core Classes
- **`Pyrosper`**: Main class for managing experiments
- **`BaseExperiment`**: Abstract base class for experiments
- **`Variant`**: Represents a single variant in an experiment
- **`Symbol`**: Unique identifier for experiment values
- **`BaseContext`**: Context manager for pyrosper instances
### Key Methods
#### Pyrosper
- `with_experiment(experiment)`: Add an experiment
- `pick(symbol)`: Get a value from experiments
- `has_pick(symbol)`: Check if symbol exists
- `set_for_user(user_id)`: Set up experiments for a user
#### BaseExperiment
- `enable()`: Enable the experiment
- `disable()`: Disable the experiment
- `complete_for_user(user_id, score)`: Provide feedback
- `get_variant(user_id)`: Get the variant for a user
## Contributing
1. Fork the repository
2. Create a feature branch
3. Make your changes
4. Add tests
5. Submit a pull request
## License
MIT
---
Vulcans are cool. 🖖
| text/markdown | Robert Plummer | Robert Plummer <robertleeplummerjr@gmail.com> | null | null | null | null | [] | [] | https://github.com/BKKnights/pyrosper | null | >=3.11 | [] | [] | [] | [
"pytest; extra == \"dev\"",
"black; extra == \"dev\"",
"isort; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/BKKnights/pyrosper",
"Bug Tracker, https://github.com/BKKnights/pyrosper/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T20:18:47.417543 | pyrosper-0.1.9.post1.tar.gz | 21,884 | eb/60/2d417ee989863db775d68d99b087710ac323e7bf32a4c7bf6344fbf08653/pyrosper-0.1.9.post1.tar.gz | source | sdist | null | false | eb588a937406ea62f2eefd1f87d44138 | f7e29066433be1b1e242e6de14cfed47bfc6dd6a2dc975b83dfdf50c4483f5eb | eb602d417ee989863db775d68d99b087710ac323e7bf32a4c7bf6344fbf08653 | null | [
"LICENSE"
] | 234 |
2.4 | propre | 0.1.1 | Analyze, restructure, and harden vibe-coded projects for production. Architecture-level linting, secret detection, and code quality enforcement in one CLI. | # Propre
Propre is a post-vibe-coding cleanup and hardening CLI.
## Installation
```bash
pip install -e .
```
## Usage
```bash
propre scan .
propre fix .
propre --dry-run restructure .
propre --deep-scan secrets .
propre ship .
propre --format md report . -o report.md
```
## Commands
- `propre scan [path]`: Full analysis, no changes.
- `propre fix [path]`: Auto-fix safe issues where possible.
- `propre restructure [path]`: Restructuring only.
- `propre secrets [path]`: Secret scanning only.
- `propre ship [path]`: Production readiness checklist.
- `propre report [path] -o report.md`: Export full report.
## Global Flags
- `--dry-run`: Preview changes without applying.
- `--verbose` / `-v`: Detailed output.
- `--config propre.yml`: Custom rules and overrides.
- `--fix`: Auto-apply safe fixes even outside `fix` command.
- `--ignore <pattern>`: Exclude paths.
- `--ci`: Exit non-zero if blockers are found.
- `--format terminal|md|json|sarif`: Output format.
## Configuration
Create `propre.yml` at project root:
```yaml
stack: auto
restructure:
enabled: true
confirm: true
secrets:
deep_scan: false
severity_threshold: medium
rules:
dead_code: warn
console_logs: error
missing_types: warn
hardcoded_config: error
ignore:
- node_modules/
- .git/
- dist/
```
## Publishing
### Option A: Trusted Publisher (recommended)
1. Go to PyPI project settings for `propre` and add a Trusted Publisher.
2. Use these values:
- Owner: `immerSIR`
- Repository: `propre-cli`
- Workflow file: `publish.yml`
- Environment (if prompted): `pypi`
3. Push this workflow file: `.github/workflows/publish.yml`.
4. Create a GitHub Release in this repository. The workflow will:
- build with `uv build`
- validate with `uvx twine check dist/*`
- publish automatically to PyPI
### Option B: API token (manual)
1. Create a PyPI API token with scope:
- Entire account (simple) or
- Project-specific token for `propre` (preferred)
2. Export it locally:
```bash
export UV_PUBLISH_TOKEN="pypi-..."
```
3. Publish from local machine:
```bash
uv build
uvx twine check dist/*
uv publish
```
If you use `twine` directly instead:
```bash
uvx twine upload dist/* -u __token__ -p "$UV_PUBLISH_TOKEN"
```
| text/markdown | null | immerSIR <immersir223@gmail.com> | null | immerSIR <immersir223@gmail.com> | null | cli, code-quality, security, secret-detection, refactoring, restructuring, developer-tools, architecture, linting, production-readiness, vibe-coding | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"... | [] | null | null | >=3.11 | [] | [] | [] | [
"pyyaml>=6.0.1",
"rich>=13.7.1",
"typer>=0.12.5",
"tree-sitter>=0.22.3; extra == \"parsers\"",
"tree-sitter-languages>=1.10.2; extra == \"parsers\""
] | [] | [] | [] | [
"Homepage, https://github.com/immerSIR/propre-cli",
"Documentation, https://github.com/immerSIR/propre-cli#readme",
"Repository, https://github.com/immerSIR/propre-cli",
"Issues, https://github.com/immerSIR/propre-cli/issues",
"Changelog, https://github.com/immerSIR/propre-cli/blob/main/CHANGELOG.md"
] | uv/0.8.7 | 2026-02-18T20:18:24.174467 | propre-0.1.1.tar.gz | 25,707 | 03/f9/b865d3623c2dae80e9523d74169cd60e3b9979f46d10d4b3b2586be49394/propre-0.1.1.tar.gz | source | sdist | null | false | 1269836aa8f9e61e976fd292f271ce44 | 4b75547895c3daef846c7228c3e3bfff8bda73ea9e389e95d019e1d87e4c79b7 | 03f9b865d3623c2dae80e9523d74169cd60e3b9979f46d10d4b3b2586be49394 | MIT | [
"LICENSE"
] | 208 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.