
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | circuitpython-csv | 2.0.3.post0 | CircuitPython helper library for working with CSV files | Introduction
============
.. image:: https://readthedocs.org/projects/circuitpython-csv/badge/?version=latest
:target: https://circuitpython-csv.readthedocs.io/
:alt: Documentation Status
.. image:: https://img.shields.io/discord/327254708534116352.svg
:target: https://adafru.it/discord
:alt: Discord
.. image:: https://github.com/tekktrik/Circuitpython_CircuitPython_CSV/workflows/Build%20CI/badge.svg
:target: https://github.com/tekktrik/Circuitpython_CircuitPython_CSV/actions
:alt: Build Status
.. image:: https://img.shields.io/badge/code%20style-ruff-000000.svg
:target: https://github.com/astral-sh/ruff
:alt: Code Style: ruff
.. image:: https://img.shields.io/badge/License-MIT-yellow.svg
:target: https://opensource.org/licenses/MIT
:alt: License: MIT
.. image:: https://img.shields.io/badge/License-PSF_2.0-yellow.svg
:target: https://opensource.org/license/python-2-0
:alt: License: PSF-2.0
.. image:: https://img.shields.io/badge/Maintained%3F-yes-green.svg
:target: https://github.com/tekktrik/CircuitPython_CSV
:alt: Maintained: Yes
CircuitPython helper library for working with CSV files
Dependencies
=============
This driver depends on:
* `Adafruit CircuitPython <https://github.com/adafruit/circuitpython>`_
* `MicroPython's regular expression library (re) <https://circuitpython.readthedocs.io/en/latest/docs/library/re.html>`_
You can find which Adafruit boards have the ``re`` library `here <https://circuitpython.readthedocs.io/en/latest/shared-bindings/support_matrix.html>`_.
Please ensure all dependencies are available on the CircuitPython filesystem.
This is easily achieved by downloading
`the Adafruit library and driver bundle <https://circuitpython.org/libraries>`_
or individual libraries can be installed using
`circup <https://github.com/adafruit/circup>`_.
Installing to a Connected CircuitPython Device with Circup
==========================================================
Make sure that you have ``circup`` installed in your Python environment.
Install it with the following command if necessary:
.. code-block:: shell
pip3 install circup
With ``circup`` installed and your CircuitPython device connected use the
following command to install:
.. code-block:: shell
circup install circuitpython-csv
Or the following command to update an existing version:
.. code-block:: shell
circup update
Installing from PyPI
====================
.. note::
This library is provided on PyPI so that code developed for microcontrollers with this
library will also run on computers like the Raspberry Pi. If you just need a package
for working with CSV files on a computer or SBC only, consider using the Python standard
library's ``csv`` module instead.
On supported GNU/Linux systems like the Raspberry Pi, you can install the driver locally `from
PyPI <https://pypi.org/project/circuitpython-csv/>`_. To install for current user:
.. code-block:: shell
pip3 install circuitpython-csv
To install system-wide (this may be required in some cases):
.. code-block:: shell
sudo pip3 install circuitpython-csv
To install in a virtual environment in your current project:
.. code-block:: shell
mkdir project-name && cd project-name
python3 -m venv .venv
source .venv/bin/activate
pip3 install circuitpython-csv
Usage Example
=============
.. code-block:: python
import board
import sdcardio
import storage
import circuitpython_csv as csv
# Initialize SD card
spi = board.SPI()
sdcard = sdcardio.SDCard(spi, board.D10)
vfs = storage.VfsFat(sdcard)
storage.mount(vfs, "/sd")
# Write the CSV file!
with open("/sd/testwrite.csv", mode="w", encoding="utf-8") as writablefile:
csvwriter = csv.writer(writablefile)
csvwriter.writerow(["I", "love", "CircuitPython", "!"])
csvwriter.writerow(["Spam"] * 3)
Contributing
============
Contributions are welcome! Please read our `Code of Conduct
<https://github.com/tekktrik/Circuitpython_CircuitPython_CSV/blob/HEAD/CODE_OF_CONDUCT.md>`_
before contributing to help this project stay welcoming.
Documentation
=============
For information on building library documentation, please check out
`this guide <https://learn.adafruit.com/creating-and-sharing-a-circuitpython-library/sharing-our-docs-on-readthedocs#sphinx-5-1>`_.
Attribution
===========
Some code contained here is ported from CPython, dual licensed by the Python Software Foundation under the PSF License verion 2 and the Zero-Clause BSD license.
| text/x-rst | null | Alec Delaney <tekktrik@gmail.com> | null | null | null | adafruit, csv, data, files, embedded, micropython, circuitpython | [
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development :: Embedded Systems",
"Topic :: System :: Hardware",
"Topic :: File Formats",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: Implementation :: MicroPython"
] | [] | null | null | null | [] | [] | [] | [
"Adafruit-Blinka",
"pre-commit~=4.1; extra == \"optional\""
] | [] | [] | [] | [
"Homepage, https://github.com/tekktrik/CircuitPython_CSV",
"Repository, https://github.com/tekktrik/CircuitPython_CSV",
"Doumentation, https://circuitpython-csv.readthedocs.io"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T16:53:56.311827 | circuitpython_csv-2.0.3.post0.tar.gz | 25,110 | e6/0c/03087906fa31f95505f52c52ab95d3b88aa84decf6a2f22b39ad86b334bd/circuitpython_csv-2.0.3.post0.tar.gz | source | sdist | null | false | 06bd5b3722d5addde7debe8bd0456852 | 99da21af314bba0ecde6167e7a01e9e8ef719813b872002b0ad035334d16d923 | e60c03087906fa31f95505f52c52ab95d3b88aa84decf6a2f22b39ad86b334bd | MIT AND PSF-2.0 AND 0BSD | [
"LICENSE-MIT",
"LICENSE-PSF"
] | 233 |
2.4 | psycopg-c | 3.3.3 | PostgreSQL database adapter for Python -- C optimisation distribution | Psycopg 3: PostgreSQL database adapter for Python - optimisation package
========================================================================
This distribution package is an optional component of `Psycopg 3`__: it
contains the optional optimization package `psycopg_c`__.
.. __: https://pypi.org/project/psycopg/
.. __: https://www.psycopg.org/psycopg3/docs/basic/install.html
#local-installation
You shouldn't install this package directly: use instead ::
pip install "psycopg[c]"
to install a version of the optimization package matching the ``psycopg``
version installed.
Installing this package requires some prerequisites: check `Local
installation`__ in the documentation. Without a C compiler and some library
headers install *will fail*: this is not a bug.
If you are unable to meet the prerequisite needed you might want to install
``psycopg[binary]`` instead: look for `Binary installation`__ in the
documentation.
.. __: https://www.psycopg.org/psycopg3/docs/basic/install.html
#local-installation
.. __: https://www.psycopg.org/psycopg3/docs/basic/install.html
#binary-installation
Please read `the project readme`__ and `the installation documentation`__ for
more details.
.. __: https://github.com/psycopg/psycopg#readme
.. __: https://www.psycopg.org/psycopg3/docs/basic/install.html
Copyright (C) 2020 The Psycopg Team
| text/x-rst | null | Daniele Varrazzo <daniele.varrazzo@gmail.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Programming Language :: Cython",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://psycopg.org/",
"Documentation, https://psycopg.org/psycopg3/docs/",
"Changes, https://psycopg.org/psycopg3/docs/news.html",
"Code, https://github.com/psycopg/psycopg",
"Issue Tracker, https://github.com/psycopg/psycopg/issues",
"Funding, https://github.com/sponsors/dvarrazzo"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-18T16:52:18.084431 | psycopg_c-3.3.3.tar.gz | 631,965 | cb/a0/8feb0ca8c7c20a8b9ac4d46b335ddd57e48e593b714262f006880f34fee5/psycopg_c-3.3.3.tar.gz | source | sdist | null | false | 3dc407579f1068b92ac16937e5916e5c | 86ef6f4424348247828e83fb0882c9f8acb33e64d0a5ce66c1b4a5107ee73edd | cba08feb0ca8c7c20a8b9ac4d46b335ddd57e48e593b714262f006880f34fee5 | LGPL-3.0-only | [
"LICENSE.txt"
] | 11,263 |
2.4 | psycopg | 3.3.3 | PostgreSQL database adapter for Python | Psycopg 3: PostgreSQL database adapter for Python
=================================================
Psycopg 3 is a modern implementation of a PostgreSQL adapter for Python.
This distribution contains the pure Python package ``psycopg``.
.. Note::
Despite the lack of number in the package name, this package is the
successor of psycopg2_.
Please use the psycopg2 package if you are maintaining an existing program
using psycopg2 as a dependency. If you are developing something new,
Psycopg 3 is the most current implementation of the adapter.
.. _psycopg2: https://pypi.org/project/psycopg2/
Installation
------------
In short, run the following::
pip install --upgrade pip # to upgrade pip
pip install "psycopg[binary,pool]" # to install package and dependencies
If something goes wrong, and for more information about installation, please
check out the `Installation documentation`__.
.. __: https://www.psycopg.org/psycopg3/docs/basic/install.html#
Hacking
-------
For development information check out `the project readme`__.
.. __: https://github.com/psycopg/psycopg#readme
Copyright (C) 2020 The Psycopg Team
| text/x-rst | null | Daniele Varrazzo <daniele.varrazzo@gmail.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Langu... | [] | null | null | >=3.10 | [] | [] | [] | [
"typing-extensions>=4.6; python_version < \"3.13\"",
"tzdata; sys_platform == \"win32\"",
"psycopg-c==3.3.3; implementation_name != \"pypy\" and extra == \"c\"",
"psycopg-binary==3.3.3; implementation_name != \"pypy\" and extra == \"binary\"",
"psycopg-pool; extra == \"pool\"",
"anyio>=4.0; extra == \"tes... | [] | [] | [] | [
"Homepage, https://psycopg.org/",
"Documentation, https://psycopg.org/psycopg3/docs/",
"Changes, https://psycopg.org/psycopg3/docs/news.html",
"Code, https://github.com/psycopg/psycopg",
"Issue Tracker, https://github.com/psycopg/psycopg/issues",
"Funding, https://github.com/sponsors/dvarrazzo"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-18T16:52:16.546654 | psycopg-3.3.3.tar.gz | 165,624 | d3/b6/379d0a960f8f435ec78720462fd94c4863e7a31237cf81bf76d0af5883bf/psycopg-3.3.3.tar.gz | source | sdist | null | false | 82f1457cb2f44f41326914fa47ef1fc0 | 5e9a47458b3c1583326513b2556a2a9473a1001a56c9efe9e587245b43148dd9 | d3b6379d0a960f8f435ec78720462fd94c4863e7a31237cf81bf76d0af5883bf | LGPL-3.0-only | [
"LICENSE.txt"
] | 1,531,570 |
2.4 | psycopg-binary | 3.3.3 | PostgreSQL database adapter for Python -- C optimisation distribution | Psycopg 3: PostgreSQL database adapter for Python - binary package
==================================================================
This distribution package is an optional component of `Psycopg 3`__: it
contains the optional optimization package `psycopg_binary`__.
.. __: https://pypi.org/project/psycopg/
.. __: https://www.psycopg.org/psycopg3/docs/basic/install.html
#binary-installation
You shouldn't install this package directly: use instead ::
pip install "psycopg[binary]"
to install a version of the optimization package matching the ``psycopg``
version installed.
Installing this package requires pip >= 20.3 or newer installed.
This package is not available for every platform: check out `Binary
installation`__ in the documentation.
.. __: https://www.psycopg.org/psycopg3/docs/basic/install.html
#binary-installation
Please read `the project readme`__ and `the installation documentation`__ for
more details.
.. __: https://github.com/psycopg/psycopg#readme
.. __: https://www.psycopg.org/psycopg3/docs/basic/install.html
Copyright (C) 2020 The Psycopg Team
| text/x-rst | null | Daniele Varrazzo <daniele.varrazzo@gmail.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Programming Language :: Cython",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://psycopg.org/",
"Documentation, https://psycopg.org/psycopg3/docs/",
"Changes, https://psycopg.org/psycopg3/docs/news.html",
"Code, https://github.com/psycopg/psycopg",
"Issue Tracker, https://github.com/psycopg/psycopg/issues",
"Funding, https://github.com/sponsors/dvarrazzo"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-18T16:52:14.020200 | psycopg_binary-3.3.3-cp314-cp314-win_amd64.whl | 3,652,796 | 98/5a/291d89f44d3820fffb7a04ebc8f3ef5dda4f542f44a5daea0c55a84abf45/psycopg_binary-3.3.3-cp314-cp314-win_amd64.whl | cp314 | bdist_wheel | null | false | b32931c1dff4619fcb651fbe3ffb770d | 165f22ab5a9513a3d7425ffb7fcc7955ed8ccaeef6d37e369d6cc1dff1582383 | 985a291d89f44d3820fffb7a04ebc8f3ef5dda4f542f44a5daea0c55a84abf45 | LGPL-3.0-only | [
"LICENSE.txt"
] | 1,259,819 |
2.4 | icechunk | 1.1.19 | Icechunk Python | # Icechunk

<a href="https://pypi.org/project/icechunk" target="_blank"><img alt="PyPI" src="https://img.shields.io/pypi/v/icechunk?logo=pypi&logoColor=ffde57&label=pypi&style=for-the-badge"></a>
<a href="https://anaconda.org/conda-forge/icechunk" target="_blank"><img alt="Conda Forge" src="https://img.shields.io/conda/vn/conda-forge/icechunk.svg?logo=conda-forge&style=for-the-badge"></a>
<a href="https://crates.io/crates/icechunk" target="_blank"><img alt="Crates.io" src="https://img.shields.io/crates/v/icechunk?logo=rust&label=crates.io&link=https%3A%2F%2Fcrates.io%2Fcrates%2Ficechunk&logoColor=CE422B&style=for-the-badge"></a>
<a href="https://github.com/earth-mover/icechunk" target="_blank"><img alt="GitHub Repo stars" src="https://img.shields.io/github/stars/earth-mover/icechunk?style=for-the-badge&logo=github"></a>
<a href="https://join.slack.com/t/earthmover-community/shared_invite/zt-2cwje92ir-xU3CfdG8BI~4CJOJy~sceQ" target="_blank"><img alt="Earthmover Community Slack" src="https://img.shields.io/badge/Slack-4A154B?style=for-the-badge&logo=slack&logoColor=white" /></a>
---
> [!TIP]
> **Icechunk 1.0 is released!** Better API, more performance and stability
---
Icechunk is an open-source (Apache 2.0), transactional storage engine for tensor / ND-array data designed for use on cloud object storage.
Icechunk works together with **[Zarr](https://zarr.dev/)**, augmenting the Zarr core data model with features
that enhance performance, collaboration, and safety in a cloud-computing context.
## Documentation and Resources
- This page: a general overview of the project's goals and components.
- [Icechunk Launch Blog Post](https://earthmover.io/blog/icechunk)
- [Frequently Asked Questions](https://icechunk.io/en/latest/faq/)
- Documentation for [Icechunk Python](https://icechunk.io/en/latest/icechunk-python), the main user-facing
library
- Documentation for the [Icechunk Rust Crate](https://icechunk.io/en/latest/icechunk-rust)
- The [Contributor Guide](https://icechunk.io/en/latest/contributing)
- The [Icechunk Spec](https://icechunk.io/en/latest/spec)
## Icechunk Overview
Let's break down what "transactional storage engine for Zarr" actually means:
- **[Zarr](https://zarr.dev/)** is an open source specification for the storage of multidimensional array (a.k.a. tensor) data.
Zarr defines the metadata for describing arrays (shape, dtype, etc.) and the way these arrays are chunked, compressed, and converted to raw bytes for storage. Zarr can store its data in any key-value store.
There are many different implementations of Zarr in different languages. _Right now, Icechunk only supports
[Zarr Python](https://zarr.readthedocs.io/en/stable/)._
If you're interested in implementing Icechunk support, please [open an issue](https://github.com/earth-mover/icechunk/issues) so we can help you.
- **Storage engine** - Icechunk exposes a key-value interface to Zarr and manages all of the actual I/O for getting, setting, and updating both metadata and chunk data in cloud object storage.
Zarr libraries don't have to know exactly how icechunk works under the hood in order to use it.
- **Transactional** - The key improvement that Icechunk brings on top of regular Zarr is to provide consistent serializable isolation between transactions.
This means that Icechunk data is safe to read and write in parallel from multiple uncoordinated processes.
This allows Zarr to be used more like a database.
The core entity in Icechunk is a repository or **repo**.
A repo is defined as a Zarr hierarchy containing one or more Arrays and Groups, and a repo functions as a
self-contained _Zarr Store_.
The most common scenario is for an Icechunk repo to contain a single Zarr group with multiple arrays, each corresponding to different physical variables but sharing common spatiotemporal coordinates.
However, formally a repo can be any valid Zarr hierarchy, from a single Array to a deeply nested structure of Groups and Arrays.
Users of Icechunk should aim to scope their repos only to related arrays and groups that require consistent transactional updates.
Icechunk supports the following core requirements:
1. **Object storage** - the format is designed around the consistency features and performance characteristics available in modern cloud object storage. No external database or catalog is required to maintain a repo.
(It also works with file storage.)
1. **Serializable isolation** - Reads are isolated from concurrent writes and always use a committed snapshot of a repo. Writes are committed atomically and are never partially visible. No locks are required for reading.
1. **Time travel** - Previous snapshots of a repo remain accessible after new ones have been written.
1. **Data version control** - Repos support both _tags_ (immutable references to snapshots) and _branches_ (mutable references to snapshots).
1. **Chunk shardings** - Chunk storage is decoupled from specific file names. Multiple chunks can be packed into a single object (sharding).
1. **Chunk references** - Zarr-compatible chunks within other file formats (e.g. HDF5, NetCDF) can be referenced.
1. **Schema evolution** - Arrays and Groups can be added, renamed, and removed from the hierarchy with minimal overhead.
## Key Concepts
### Groups, Arrays, and Chunks
Icechunk is designed around the Zarr data model, widely used in scientific computing, data science, and AI / ML.
(The Zarr high-level data model is effectively the same as HDF5.)
The core data structure in this data model is the **array**.
Arrays have two fundamental properties:
- **shape** - a tuple of integers which specify the dimensions of each axis of the array. A 10 x 10 square array would have shape (10, 10)
- **data type** - a specification of what type of data is found in each element, e.g. integer, float, etc. Different data types have different precision (e.g. 16-bit integer, 64-bit float, etc.)
In Zarr / Icechunk, arrays are split into **chunks**.
A chunk is the minimum unit of data that must be read / written from storage, and thus choices about chunking have strong implications for performance.
Zarr leaves this completely up to the user.
Chunk shape should be chosen based on the anticipated data access pattern for each array.
An Icechunk array is not bounded by an individual file and is effectively unlimited in size.
For further organization of data, Icechunk supports **groups** within a single repo.
Group are like folders which contain multiple arrays and or other groups.
Groups enable data to be organized into hierarchical trees.
A common usage pattern is to store multiple arrays in a group representing a NetCDF-style dataset.
Arbitrary JSON-style key-value metadata can be attached to both arrays and groups.
### Snapshots
Every update to an Icechunk store creates a new **snapshot** with a unique ID.
Icechunk users must organize their updates into groups of related operations called **transactions**.
For example, appending a new time slice to multiple arrays should be done as a single transaction, comprising the following steps
1. Update the array metadata to resize the array to accommodate the new elements.
2. Write new chunks for each array in the group.
While the transaction is in progress, none of these changes will be visible to other users of the store.
Once the transaction is committed, a new snapshot is generated.
Readers can only see and use committed snapshots.
### Branches and Tags
Additionally, snapshots occur in a specific linear (i.e. serializable) order within a **branch**.
A branch is a mutable reference to a snapshot--a pointer that maps the branch name to a snapshot ID.
The default branch is `main`.
Every commit to the main branch updates this reference.
Icechunk's design protects against the race condition in which two uncoordinated sessions attempt to update the branch at the same time; only one can succeed.
Icechunk also defines **tags**--_immutable_ references to snapshot.
Tags are appropriate for publishing specific releases of a repository or for any application which requires a persistent, immutable identifier to the store state.
### Chunk References
Chunk references are "pointers" to chunks that exist in other files--HDF5, NetCDF, GRIB, etc.
Icechunk can store these references alongside native Zarr chunks as "virtual datasets".
You can then update these virtual datasets incrementally (overwrite chunks, change metadata, etc.) without touching the underling files.
## How Does It Work?
**!!! Note:**
For a more detailed explanation, have a look at the [Icechunk spec](./docs/docs/spec.md).
Zarr itself works by storing both metadata and chunk data into a abstract store according to a specified system of "keys".
For example, a 2D Zarr array called `myarray`, within a group called `mygroup`, would generate the following keys:
```
mygroup/zarr.json
mygroup/myarray/zarr.json
mygroup/myarray/c/0/0
mygroup/myarray/c/0/1
```
In standard regular Zarr stores, these key map directly to filenames in a filesystem or object keys in an object storage system.
When writing data, a Zarr implementation will create these keys and populate them with data.
When modifying existing arrays or groups, a Zarr implementation will potentially overwrite existing keys with new data.
This is generally not a problem, as long there is only one person or process coordinating access to the data.
However, when multiple uncoordinated readers and writers attempt to access the same Zarr data at the same time, [various consistency problems](https://icechunk.io/en/latest/faq/#why-was-icechunk-created) emerge.
These consistency problems can occur in both file storage and object storage; they are particularly severe in a cloud setting where Zarr is being used as an active store for data that are frequently changed while also being read.
With Icechunk, we keep the same core Zarr data model, but add a layer of indirection between the Zarr keys and the on-disk storage.
The Icechunk library translates between the Zarr keys and the actual on-disk data given the particular context of the user's state.
Icechunk defines a series of interconnected metadata and data files that together enable efficient isolated reading and writing of metadata and chunks.
Once written, these files are immutable.
Icechunk keeps track of every single chunk explicitly in a "chunk manifest".
```mermaid
flowchart TD
zarr-python[Zarr Library] <-- key / value--> icechunk[Icechunk Library]
icechunk <-- data / metadata files --> storage[(Object Storage)]
```
| text/markdown; charset=UTF-8; variant=GFM | null | Earthmover <info@earthmover.io> | null | null | null | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | https://icechunk.io | null | >=3.11 | [] | [] | [] | [
"zarr!=3.0.3,>=3"
] | [] | [] | [] | [] | maturin/1.12.2 | 2026-02-18T16:52:05.708172 | icechunk-1.1.19-cp314-cp314-win_amd64.whl | 15,918,577 | 2e/a6/1a822d3980a7009be2094399b86d7a65ba07d098f2e75d9d7be94d8f5b63/icechunk-1.1.19-cp314-cp314-win_amd64.whl | cp314 | bdist_wheel | null | false | 686cabb43aff1b4bb5eeb568c9e20a97 | 30d11c3b0e84aaec44122b9780455c9d6785a1e98881c0f13001a39d3f824ce0 | 2ea61a822d3980a7009be2094399b86d7a65ba07d098f2e75d9d7be94d8f5b63 | null | [] | 11,515 |
2.4 | xase-ai | 0.1.2 | Official Xase SDK for Python - Evidence Layer for AI Agents | # xase-sdk
> Official Xase SDK for Python - Evidence Layer for AI Agents
[](https://pypi.org/project/xase-sdk/)
[](https://pypi.org/project/xase-sdk/)
[](https://opensource.org/licenses/MIT)
Turn automated decisions into immutable legal records. Don't just log what your AI did—**prove why it was right**.
## Features
- ⚡ **Zero Latency Impact** - Fire-and-forget mode with async queue
- 🔒 **Immutable Evidence** - Cryptographic hash chain + KMS signatures
- 🔄 **Automatic Retry** - Exponential backoff with jitter
- 🎯 **Idempotency** - Built-in deduplication
- 📊 **Type-Safe** - Full type hints support
- 🚀 **Production Ready** - Battle-tested reliability
---
## Installation
```bash
pip install xase-sdk
```
**Requirements:** Python >= 3.9
---
## Quick Start
### 1. Get your API Key
Sign up at [xase.ai](https://xase.ai) and create an API key in your dashboard.
### 2. Initialize the client
```python
from xase import XaseClient
xase = XaseClient({
"api_key": "xase_pk_...",
"fire_and_forget": True, # Zero latency impact
})
```
### 3. Record decisions
```python
xase.record({
"policy": "credit_policy_v4",
"input": {"user_id": "u_4829", "amount": 50000, "credit_score": 720},
"output": {"decision": "APPROVED"},
"confidence": 0.94,
})
```
That's it! Your AI decision is now immutable evidence.
---
## Configuration
### XaseClientConfig
| Option | Type | Default | Description |
|--------|------|---------|-------------|
| `api_key` | `str` | **required** | Your Xase API key |
| `base_url` | `str` | `http://localhost:3000/api/xase/v1` | API base URL |
| `fire_and_forget` | `bool` | `True` | Enable async queue for zero latency |
| `timeout` | `float` | `3.0` | Request timeout in seconds |
| `max_retries` | `int` | `3` | Maximum retry attempts |
| `queue_max_size` | `int` | `10000` | Maximum queue size (fire-and-forget mode) |
| `on_success` | `Callable` | `None` | Callback on successful record |
| `on_error` | `Callable` | `None` | Callback on error |
### Example with all options
```python
from xase import XaseClient
xase = XaseClient({
"api_key": "xase_pk_...",
"base_url": "https://api.xase.ai/v1",
"fire_and_forget": True,
"timeout": 5.0,
"max_retries": 5,
"queue_max_size": 50000,
"on_success": lambda result: print(f"Evidence recorded: {result['transaction_id']}"),
"on_error": lambda error: print(f"Failed: {error.code} - {error.message}"),
})
```
---
## API Reference
### `record(payload, *, idempotency_key=None, skip_queue=False)`
Records an AI decision as immutable evidence.
#### Payload
```python
from typing import TypedDict, Optional
class RecordPayload(TypedDict, total=False):
policy: str # Policy/model ID (e.g., "credit_policy_v4")
input: dict # Decision input data
output: dict # Decision output/result
confidence: Optional[float] # AI confidence score (0-1)
context: Optional[dict] # Additional context metadata
transaction_id: Optional[str] # For idempotency
policy_version: Optional[str] # Policy version
decision_type: Optional[str] # Type of decision
processing_time: Optional[float] # Processing time in ms
store_payload: Optional[bool] # Store full payload (default: False)
```
#### Options
- `idempotency_key` (str, optional): Custom idempotency key (UUID or 16-64 alphanumeric)
- `skip_queue` (bool, optional): Force synchronous mode
#### Returns
- **Fire-and-forget mode** (`fire_and_forget=True`): `None`
- **Synchronous mode** (`fire_and_forget=False` or `skip_queue=True`): `RecordResult`
```python
class RecordResult(TypedDict):
success: bool
transaction_id: str
receipt_url: str
timestamp: str
record_hash: str
chain_position: Literal["chained", "genesis"]
```
---
### `flush(timeout_s=5.0)`
Flushes all pending queue items (fire-and-forget mode only).
```python
xase.flush(5.0) # Wait up to 5 seconds
```
**Use cases:**
- Before process exit
- Before critical operations
- For testing
---
### `close()`
Closes the client and flushes the queue.
```python
xase.close()
```
---
### `get_stats()`
Returns queue statistics (fire-and-forget mode only).
```python
stats = xase.get_stats()
print(stats)
# {'size': 42, 'closed': False}
```
---
## Usage Examples
### Fire-and-Forget (Zero Latency)
```python
from xase import XaseClient
import os
xase = XaseClient({
"api_key": os.getenv("XASE_API_KEY"),
"fire_and_forget": True,
})
def approve_loan(user_data):
# Your AI decision logic
decision = "APPROVED" if user_data["credit_score"] >= 700 else "DENIED"
# Record evidence (returns immediately, queued for async processing)
xase.record({
"policy": "credit_policy_v4",
"input": user_data,
"output": {"decision": decision},
"confidence": 0.94,
"transaction_id": f"loan_{user_data['user_id']}",
})
return decision # Zero latency impact!
# Flush before exit
import atexit
atexit.register(lambda: xase.flush(2.0))
```
---
### Synchronous Mode (Immediate Response)
```python
xase = XaseClient({
"api_key": os.getenv("XASE_API_KEY"),
"fire_and_forget": False, # Synchronous mode
})
def detect_fraud(transaction):
is_fraud = # your logic
# Wait for response
result = xase.record({
"policy": "fraud_detection_v2",
"input": transaction,
"output": {"is_fraud": is_fraud},
"confidence": 0.87,
})
print(f"Evidence recorded: {result['transaction_id']}")
print(f"Receipt URL: {result['receipt_url']}")
return {"is_fraud": is_fraud, "evidence": result}
```
---
### Type-Safe Usage
```python
from xase import XaseClient, RecordPayload, XaseError
xase = XaseClient({"api_key": os.getenv("XASE_API_KEY")})
def process_loan(app: dict) -> dict:
decision = # your logic
payload: RecordPayload = {
"policy": "credit_policy_v4",
"input": app,
"output": decision,
"confidence": app["credit_score"] / 850,
}
try:
xase.record(payload)
except XaseError as error:
print(f"Failed: {error.code} - {error.message}")
raise
return decision
```
---
### Idempotency
Prevent duplicate records with idempotency keys:
```python
# Automatic (using transaction_id)
xase.record({
"policy": "credit_policy_v4",
"input": {...},
"output": {...},
"transaction_id": "loan_12345", # Auto-generates idempotency key
})
# Manual
xase.record({
"policy": "credit_policy_v4",
"input": {...},
"output": {...},
}, idempotency_key="my-custom-key-12345")
```
**Idempotency key format:**
- UUID v4: `550e8400-e29b-41d4-a716-446655440000`
- Alphanumeric: `my_key_1234567890` (16-64 chars)
---
### Error Handling
```python
from xase import XaseError
try:
xase.record({...}, skip_queue=True)
except XaseError as error:
print(f"Code: {error.code}")
print(f"Status: {error.status_code}")
print(f"Details: {error.details}")
if error.code == "UNAUTHORIZED":
# Invalid API key
pass
elif error.code == "RATE_LIMIT_EXCEEDED":
# Too many requests
pass
elif error.code == "VALIDATION_ERROR":
# Invalid payload
pass
```
**Common error codes:**
- `UNAUTHORIZED` - Invalid API key
- `FORBIDDEN` - Missing permissions
- `RATE_LIMIT_EXCEEDED` - Rate limit hit
- `VALIDATION_ERROR` - Invalid payload
- `QUEUE_FULL` - Queue size exceeded
- `FLUSH_TIMEOUT` - Flush timeout
- `MAX_RETRIES` - Max retries exceeded
---
## Advanced Usage
### Custom Context
Enrich records with custom metadata:
```python
xase.record({
"policy": "credit_policy_v4",
"input": {...},
"output": {...},
"context": {
"user_agent": request.headers.get("user-agent"),
"ip_address": request.remote_addr,
"session_id": session.id,
"feature_flags": {"new_model": True},
},
})
```
**Note:** Runtime context (Python version, hostname, etc.) is automatically captured.
---
### Store Full Payload
By default, only hashes are stored. To store full payloads:
```python
xase.record({
"policy": "credit_policy_v4",
"input": {...},
"output": {...},
"store_payload": True, # Store full input/output
})
```
**Warning:** Storing payloads may expose PII. Use with caution.
---
### Callbacks
Monitor success and errors:
```python
def on_success(result):
metrics.increment("xase.records.success")
logger.info(f"Evidence recorded: {result['transaction_id']}")
def on_error(error):
metrics.increment("xase.records.error")
logger.error(f"Failed to record: {error.code}")
xase = XaseClient({
"api_key": os.getenv("XASE_API_KEY"),
"on_success": on_success,
"on_error": on_error,
})
```
---
## Best Practices
### 1. Use Fire-and-Forget for Production
```python
# ✅ Recommended
xase = XaseClient({
"api_key": os.getenv("XASE_API_KEY"),
"fire_and_forget": True, # Zero latency
})
# ❌ Avoid in hot path
xase = XaseClient({
"api_key": os.getenv("XASE_API_KEY"),
"fire_and_forget": False, # Blocks your code
})
```
---
### 2. Flush Before Exit
```python
import atexit
import signal
atexit.register(lambda: xase.flush(2.0))
def signal_handler(sig, frame):
xase.close()
exit(0)
signal.signal(signal.SIGINT, signal_handler)
signal.signal(signal.SIGTERM, signal_handler)
```
---
### 3. Use Idempotency
```python
# ✅ Idempotent
xase.record({
"policy": "credit_policy_v4",
"input": {...},
"output": {...},
"transaction_id": f"loan_{user_id}_{timestamp}",
})
# ❌ Not idempotent (may create duplicates on retry)
xase.record({
"policy": "credit_policy_v4",
"input": {...},
"output": {...},
})
```
---
### 4. Handle Errors Gracefully
```python
xase = XaseClient({
"api_key": os.getenv("XASE_API_KEY"),
"on_error": lambda error: logger.error(f"Xase error: {error.code}"),
})
```
---
### 5. Use Environment Variables
```python
# ✅ Secure
xase = XaseClient({
"api_key": os.getenv("XASE_API_KEY"),
"base_url": os.getenv("XASE_BASE_URL"),
})
# ❌ Never hardcode
xase = XaseClient({
"api_key": "xase_pk_1234567890abcdef", # DON'T DO THIS
})
```
---
## Troubleshooting
### "Missing X-API-Key header"
**Cause:** API key not provided or invalid.
**Fix:**
```python
xase = XaseClient({
"api_key": os.getenv("XASE_API_KEY"), # Make sure this is set
})
```
---
### "Rate limit exceeded"
**Cause:** Too many requests.
**Fix:**
- Use fire-and-forget mode (queues requests)
- Increase rate limit in dashboard
- Implement backpressure in your app
---
### "Queue full, item dropped"
**Cause:** Queue size exceeded.
**Fix:**
```python
xase = XaseClient({
"api_key": os.getenv("XASE_API_KEY"),
"queue_max_size": 50000, # Increase queue size
})
```
---
### "Flush timeout"
**Cause:** Queue didn't flush in time.
**Fix:**
```python
xase.flush(10.0) # Increase timeout
```
---
## Performance
### Benchmarks
- **Fire-and-forget mode:** ~0.1ms overhead
- **Synchronous mode:** ~50-200ms (network dependent)
- **Queue throughput:** ~10,000 records/sec
### Memory Usage
- **Base:** ~5MB
- **Per queued item:** ~1KB
- **Max (10k queue):** ~15MB
---
## Compliance
Xase SDK helps you comply with:
- **EU AI Act** - Immutable audit trail
- **GDPR** - Right to explanation
- **SOC 2** - Access controls & logging
- **ISO 42001** - AI management system
---
## Support
- **Documentation:** [docs.xase.ai](https://docs.xase.ai)
- **API Reference:** [api.xase.ai/docs](https://api.xase.ai/docs)
- **GitHub Issues:** [github.com/xase/sdk-py/issues](https://github.com/xase/sdk-py/issues)
- **Email:** support@xase.ai
---
## License
MIT © Xase
---
## Contributing
Contributions welcome! Please read our [Contributing Guide](CONTRIBUTING.md).
---
**Built with ❤️ by the Xase team**
| text/markdown | null | Xase <support@xase.ai> | null | null | MIT | xase, ai, evidence, audit, compliance, ledger, immutable, proof, decision, agent | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx>=0.27.0",
"pytest>=7.0; extra == \"dev\"",
"mypy>=1.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"build>=1.0; extra == \"dev\"",
"twine>=4.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://xase.ai",
"Documentation, https://docs.xase.ai",
"Repository, https://github.com/xase/sdk-py",
"Issues, https://github.com/xase/sdk-py/issues"
] | twine/6.2.0 CPython/3.13.3 | 2026-02-18T16:50:53.637110 | xase_ai-0.1.2.tar.gz | 28,039 | 65/05/e71017d10a3b86d6c820af7b7aa91f1bf27a81cd817597999662c416a578/xase_ai-0.1.2.tar.gz | source | sdist | null | false | 145c25b48256a7bf8e07922743c873e1 | 7d8ab03461b3a1cf91729c44105471c804ebbbab38ba70bdb684c0074ceb31c1 | 6505e71017d10a3b86d6c820af7b7aa91f1bf27a81cd817597999662c416a578 | null | [
"LICENSE"
] | 224 |
2.4 | rakam-system-vectorstore | 0.1.2.post1 | Add your description here | # Rakam System Vectorstore
The vectorstore package of Rakam Systems providing vector database solutions and document processing capabilities.
## Overview
`rakam-system-vectorstore` provides comprehensive vector storage, embedding models, and document loading capabilities. This package depends on `rakam-system-core`.
## Features
- **Configuration-First Design**: Change your entire vector store setup via YAML - no code changes
- **Multiple Backends**: PostgreSQL with pgvector and FAISS in-memory storage
- **Flexible Embeddings**: Support for SentenceTransformers, OpenAI, and Cohere
- **Document Loaders**: PDF, DOCX, HTML, Markdown, CSV, and more
- **Search Capabilities**: Vector search, keyword search (BM25), and hybrid search
- **Chunking**: Intelligent text chunking with context preservation
- **Configuration**: Comprehensive YAML/JSON configuration support
### 🎯 Configuration Convenience
The vectorstore package's configurable design allows you to:
- **Switch embedding models** without code changes (local ↔ OpenAI ↔ Cohere)
- **Change search algorithms** instantly (BM25 ↔ ts_rank ↔ hybrid)
- **Adjust search parameters** (similarity metrics, top-k, hybrid weights)
- **Toggle features** (hybrid search, caching, reranking)
- **Tune performance** (batch sizes, chunk sizes, connection pools)
- **Swap backends** (FAISS ↔ PostgreSQL) by updating config
**Example**: Test different embedding models to find the best accuracy/cost balance - just update your YAML config file, no code changes needed!
## Installation
```bash
# Requires core package
pip install -e ./rakam-system-core
# Install vectorstore package
pip install -e ./rakam-system-vectorstore
# With specific backends
pip install -e "./rakam-system-vectorstore[postgres]"
pip install -e "./rakam-system-vectorstore[faiss]"
pip install -e "./rakam-system-vectorstore[all]"
```
## Quick Start
### FAISS Vector Store (In-Memory)
```python
from rakam_system_vectorstore.components.vectorstore.faiss_vector_store import FaissStore
from rakam_system_vectorstore.core import Node, NodeMetadata
# Create store
store = FaissStore(
name="my_store",
base_index_path="./indexes",
embedding_model="Snowflake/snowflake-arctic-embed-m",
initialising=True
)
# Create nodes
nodes = [
Node(
content="Python is great for AI",
metadata=NodeMetadata(source_file_uuid="doc1", position=0)
)
]
# Add and search
store.create_collection_from_nodes("my_collection", nodes)
results, _ = store.search("my_collection", "AI programming", number=5)
```
### PostgreSQL Vector Store
```python
import os
import django
from django.conf import settings
# Configure Django (required)
if not settings.configured:
settings.configure(
INSTALLED_APPS=[
'django.contrib.contenttypes',
'rakam_system_vectorstore.components.vectorstore',
],
DATABASES={
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': os.getenv('POSTGRES_DB', 'vectorstore_db'),
'USER': os.getenv('POSTGRES_USER', 'postgres'),
'PASSWORD': os.getenv('POSTGRES_PASSWORD', 'postgres'),
'HOST': os.getenv('POSTGRES_HOST', 'localhost'),
'PORT': os.getenv('POSTGRES_PORT', '5432'),
}
},
DEFAULT_AUTO_FIELD='django.db.models.BigAutoField',
)
django.setup()
from rakam_system_vectorstore import ConfigurablePgVectorStore, VectorStoreConfig
# Create configuration
config = VectorStoreConfig(
embedding={
"model_type": "sentence_transformer",
"model_name": "Snowflake/snowflake-arctic-embed-m"
},
search={
"similarity_metric": "cosine",
"enable_hybrid_search": True
}
)
# Create and use store
store = ConfigurablePgVectorStore(config=config)
store.setup()
store.add_nodes(nodes)
results = store.search("What is AI?", top_k=5)
store.shutdown()
```
## Core Components
### Vector Stores
- **ConfigurablePgVectorStore**: PostgreSQL with pgvector, supports hybrid search and keyword search
- **FaissStore**: In-memory FAISS-based vector search
### Embeddings
- **ConfigurableEmbeddings**: Supports multiple backends
- SentenceTransformers (local)
- OpenAI embeddings
- Cohere embeddings
### Document Loaders
- **AdaptiveLoader**: Automatically detects and loads various file types
- **PdfLoader**: Advanced PDF processing with Docling
- **PdfLoaderLight**: Lightweight PDF to markdown conversion
- **DocLoader**: Microsoft Word documents
- **OdtLoader**: OpenDocument Text files
- **MdLoader**: Markdown files
- **HtmlLoader**: HTML files
- **EmlLoader**: Email files
- **TabularLoader**: CSV, Excel files
- **CodeLoader**: Source code files
### Chunking
- **TextChunker**: Sentence-based chunking with Chonkie
- **AdvancedChunker**: Context-aware chunking with heading preservation
## Package Structure
```
rakam-system-vectorstore/
├── src/rakam_system_vectorstore/
│ ├── core.py # Node, VSFile, NodeMetadata
│ ├── config.py # VectorStoreConfig
│ ├── components/
│ │ ├── vectorstore/ # Store implementations
│ │ │ ├── configurable_pg_vectorstore.py
│ │ │ └── faiss_vector_store.py
│ │ ├── embedding_model/ # Embedding models
│ │ │ └── configurable_embeddings.py
│ │ ├── loader/ # Document loaders
│ │ │ ├── adaptive_loader.py
│ │ │ ├── pdf_loader.py
│ │ │ ├── pdf_loader_light.py
│ │ │ └── ... (other loaders)
│ │ └── chunker/ # Text chunkers
│ │ ├── text_chunker.py
│ │ └── advanced_chunker.py
│ ├── docs/ # Package documentation
│ └── server/ # MCP server
└── pyproject.toml
```
## Search Capabilities
### Vector Search
Semantic similarity search using embeddings:
```python
results = store.search("machine learning algorithms", top_k=10)
```
### Keyword Search (BM25)
Full-text search with BM25 ranking:
```python
results = store.keyword_search(
query="machine learning",
top_k=10,
ranking_algorithm="bm25"
)
```
### Hybrid Search
Combines vector and keyword search:
```python
results = store.hybrid_search(
query="neural networks",
top_k=10,
alpha=0.7 # 70% vector, 30% keyword
)
```
## Configuration
### From YAML
```yaml
# vectorstore_config.yaml
name: my_vectorstore
embedding:
model_type: sentence_transformer
model_name: Snowflake/snowflake-arctic-embed-m
batch_size: 128
normalize: true
database:
host: localhost
port: 5432
database: vectorstore_db
user: postgres
password: postgres
search:
similarity_metric: cosine
default_top_k: 5
enable_hybrid_search: true
hybrid_alpha: 0.7
index:
chunk_size: 512
chunk_overlap: 50
```
```python
config = VectorStoreConfig.from_yaml("vectorstore_config.yaml")
store = ConfigurablePgVectorStore(config=config)
```
## Documentation
Detailed documentation is available in the `src/rakam_system_vectorstore/docs/` directory:
- [Installation Guide](src/rakam_system_vectorstore/docs/INSTALLATION.md)
- [Quick Install](src/rakam_system_vectorstore/docs/QUICK_INSTALL.md)
- [Architecture](src/rakam_system_vectorstore/docs/ARCHITECTURE.md)
- [Package Structure](src/rakam_system_vectorstore/docs/PACKAGE_STRUCTURE.md)
Loader-specific documentation:
- [PDF Loader](src/rakam_system_vectorstore/components/loader/docs/PDF_LOADER_ARCHITECTURE.md)
- [DOC Loader](src/rakam_system_vectorstore/components/loader/docs/DOC_LOADER_README.md)
- [Tabular Loader](src/rakam_system_vectorstore/components/loader/docs/TABULAR_LOADER_README.md)
- [EML Loader](src/rakam_system_vectorstore/components/loader/docs/EML_LOADER_README.md)
## Examples
See the `examples/ai_vectorstore_examples/` directory in the main repository for complete examples:
- Basic FAISS example
- PostgreSQL example
- Configurable vectorstore examples
- PDF loader examples
- Keyword search examples
## Environment Variables
- `POSTGRES_HOST`: PostgreSQL host (default: localhost)
- `POSTGRES_PORT`: PostgreSQL port (default: 5432)
- `POSTGRES_DB`: Database name (default: vectorstore_db)
- `POSTGRES_USER`: Database user (default: postgres)
- `POSTGRES_PASSWORD`: Database password
- `OPENAI_API_KEY`: For OpenAI embeddings
- `COHERE_API_KEY`: For Cohere embeddings
- `HUGGINGFACE_TOKEN`: For private HuggingFace models
## License
Apache 2.0
## Links
- [Main Repository](https://github.com/Rakam-AI/rakam-systems)
- [Documentation](../docs/)
- [Core Package](../rakam-system-core/)
- [Agent Package](../rakam-system-agent/)
| text/markdown | null | Mohamed Hilel <mohammedjassemhlel@gmail.com>, Peng Zheng <pengzheng990630@outlook.com> | null | null | null | embeddings, faiss, pgvector, rag, semantic-search, vector-store | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Int... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.24.0",
"pyyaml>=6.0",
"rakam-system-core>=0.1.2",
"tqdm>=4.66.0",
"beautifulsoup4>=4.12.0; extra == \"all\"",
"chonkie==1.4.2; extra == \"all\"",
"cohere>=4.0.0; extra == \"all\"",
"django>=4.0.0; extra == \"all\"",
"docling==2.62.0; extra == \"all\"",
"faiss-cpu>=1.12.0; extra == \"all\... | [] | [] | [] | [
"Homepage, https://github.com/Rakam-AI/rakam_systems-inhouse",
"Documentation, https://github.com/Rakam-AI/rakam_systems-inhouse",
"Repository, https://github.com/Rakam-AI/rakam_systems-inhouse",
"Issues, https://github.com/Rakam-AI/rakam_systems-inhouse/issues"
] | uv/0.9.18 {"installer":{"name":"uv","version":"0.9.18","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T16:50:48.361331 | rakam_system_vectorstore-0.1.2.post1-py3-none-any.whl | 133,802 | e9/6a/bb8c1223d601a09a306af995f9f3d88e397bf363beb4c5254a84751fe38b/rakam_system_vectorstore-0.1.2.post1-py3-none-any.whl | py3 | bdist_wheel | null | false | 7332734f7767b963bfbc730107872f6b | 21108fff308aac059d4f698ca6488d0e626885082ea0ba70ca8265a64b87f070 | e96abb8c1223d601a09a306af995f9f3d88e397bf363beb4c5254a84751fe38b | null | [] | 261 |
2.4 | sila2-feature-lib | 2026.7a0 | SiLA2 feature library | # SiLA2 Feature Library
## Introduction
This library provides a set of SiLA2 feature templates that can be used to create SiLA2-compliant devices.
It fills two use cases:
1. Make it simple to add features to any SiLA server, with standard implementations that does what you want in 90% of the cases. :)
2. Or just get the feature definition and implement it yourself.
## Example
Example using the unitelabs framework.
Install sila2-feature-library, with the `unitelabs` dependency.
```bash
$ pip install sila2-feature-lib[unitelabs]
```
Import and add a feature from the library to your SiLA server.
```python
from unitelabs import Connector
from sila2_feature_lib.simulation.v001_0.feature_ul import SimulatorController
# Create SiLA server
app = Connector({...})
# Append feature to SiLA server
app.register(SimulatorController())
# Run server
asyncio.get_event_loop().run_until_complete(app.start())
```
That's it. You now have a running SiLA server with the default implementation of the `SimulatorController` feature running.
## Resources
- [SiLA Standard Homepage (https://sila-standard.com/)](https://sila-standard.com/)
- [SiLA on GitLab (https://gitlab.com/SiLA2)](https://gitlab.com/SiLA2)
## Library Structure
TBD
## Change log
### v2025.30
- Various fixes related to breaking changes in unitelabs-cdk / unitelabs-sila packages
### v2025.7
- Improved error handling in `ResourcesService`
### v2024.49
- `dynamic_import_config` functions extended with more funcionality.
### v2024.46
- Updated all features from the old `unitelabs-connector-framework` to the newer `unitelabs-cdk` package
- Fixed `pyyaml` to be an optional requirement when using the `ResourcesService` feature
### v2024.40 and older
- See [Releases](https://github.com/Firefly78/sila2-feature-lib/releases) for details on older versions
| text/markdown | null | Erik Trygg <etrg@novonordisk.com>, Stefan Maak <stefan.maak@freenet.com>, Stefan Arzbach <stefan.arzbach@a.com>, Mark Doerr <mark.doerr@uni-greifswald.de> | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"sila2; extra == \"sila2\"",
"unitelabs-cdk>=0.2.7; extra == \"unitelabs\"",
"httpx; extra == \"httpx\"",
"black==24.4.2; extra == \"dev\"",
"bumpver; extra == \"dev\"",
"flake8==7.0.0; extra == \"dev\"",
"isort==5.13.2; extra == \"dev\"",
"pytest; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/Firefly78/sila2-feature-lib",
"Repository, https://github.com/Firefly78/sila2-feature-lib",
"Bug Tracker, https://github.com/Firefly78/sila2-feature-lib/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:50:17.526417 | sila2_feature_lib-2026.7a0.tar.gz | 42,865 | ec/c9/467fa1e8e87bf2142cf51db272b39398d65866ef70011bc36d332a258b17/sila2_feature_lib-2026.7a0.tar.gz | source | sdist | null | false | 9f1c6c2a0b59d66dea55536d7a26cb40 | 043d0bf10aab303d7466c1a4a9cf7c0a348aa0a32e5de456b38eed7f66c1d065 | ecc9467fa1e8e87bf2142cf51db272b39398d65866ef70011bc36d332a258b17 | null | [
"LICENSE",
"AUTHORS.rst"
] | 213 |
2.4 | aiotaipit | 3.0.0 | Asynchronous Python API For Taipit Cloud Meters | # aioTaipit
[](https://github.com/lizardsystems/aiotaipit/actions/workflows/ci.yml)
[](https://pypi.org/project/aiotaipit/)
Asynchronous Python API for [Taipit cloud meters](https://cloud.meters.taipit.ru).
## Installation
Use pip to install the library:
```commandline
pip install aiotaipit
```
## Usage
```python
import asyncio
from pprint import pprint
import aiohttp
from aiotaipit import SimpleTaipitAuth, TaipitApi
async def main(username: str, password: str) -> None:
"""Create the aiohttp session and run the example."""
async with aiohttp.ClientSession() as session:
auth = SimpleTaipitAuth(username, password, session)
api = TaipitApi(auth)
meters = await api.async_get_meters()
pprint(meters)
if __name__ == "__main__":
_username = "<YOUR_USER_NAME>"
_password = "<YOUR_PASSWORD>"
asyncio.run(main(_username, _password))
```
The `SimpleTaipitAuth` client also accepts custom client ID and secret (this can be found by sniffing the client).
## Exceptions
All exceptions inherit from `TaipitError`:
| Exception | Description |
|-----------|-------------|
| `TaipitApiError` | Non-auth HTTP errors (server errors, unexpected status codes) |
| `TaipitAuthError` | Base class for authentication errors |
| `TaipitAuthInvalidGrant` | Invalid username/password combination |
| `TaipitAuthInvalidClient` | Invalid OAuth client credentials |
| `TaipitTokenError` | Base class for token errors |
| `TaipitInvalidTokenResponse` | Token response missing required fields |
| `TaipitTokenAcquireFailed` | Failed to acquire a new token |
| `TaipitTokenRefreshFailed` | Failed to refresh the token |
## CLI
```commandline
# Show all meters (guest account)
python -m aiotaipit
# Show meters for a specific user
python -m aiotaipit -u user@example.com -p password
# Show meter info
python -m aiotaipit --info 12345
# Show readings
python -m aiotaipit --readings 12345
# Show settings
python -m aiotaipit --settings
# Show warnings
python -m aiotaipit --warnings
```
## Timeouts
aiotaipit does not specify any timeouts for any requests. You will need to specify them in your own code. We recommend the `timeout` from `asyncio` package:
```python
import asyncio
with asyncio.timeout(10):
all_readings = await api.async_get_meters()
```
| text/markdown | LizardSystems | null | null | null | MIT License | taipit, neva, wi-fi, electricity meter | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Programming Language :: ... | [
"any"
] | null | null | >=3.13 | [] | [] | [] | [
"aiohttp>=3",
"pytest; extra == \"test\"",
"pytest-asyncio; extra == \"test\"",
"aioresponses; extra == \"test\""
] | [] | [] | [] | [
"Home, https://github.com/lizardsystems/aiotaipit",
"Repository, https://github.com/lizardsystems/aiotaipit",
"Documentation, https://github.com/lizardsystems/aiotaipit",
"Bug Tracker, https://github.com/lizardsystems/aiotaipit/issues",
"Changelog, https://github.com/lizardsystems/aiotaipit/blob/main/CHANGE... | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:50:04.864277 | aiotaipit-3.0.0.tar.gz | 14,946 | b5/7d/cdc0c742660bef62582e52731f1c7de194df69325d9a1ab4c02cafdebddb/aiotaipit-3.0.0.tar.gz | source | sdist | null | false | a86371d246429ea0e2a69cd3069be1b3 | 7d4c6d2193415d6e7fbcb3b14e1587e795411c4eb39f424037699b8acd90627b | b57dcdc0c742660bef62582e52731f1c7de194df69325d9a1ab4c02cafdebddb | null | [
"LICENSE"
] | 284 |
2.4 | mcp-aruba | 0.3.0 | MCP server for Aruba email and calendar via IMAP/SMTP/CalDAV | # MCP Aruba Email & Calendar Server
<!-- mcp-name: io.github.jackfioru92/aruba-email -->
**Italiano** | [English](README_EN.md)
Server MCP (Model Context Protocol) per accedere a email e calendario Aruba tramite IMAP/SMTP/CalDAV. Integra facilmente email e calendario Aruba con assistenti AI come Claude!
[](https://www.python.org/downloads/)
[](https://badge.fury.io/py/mcp-aruba)
[](https://opensource.org/licenses/MIT)
[](https://modelcontextprotocol.io/)
[](https://marketplace.visualstudio.com/items?itemName=jackfioru92.mcp-aruba-email)
[](https://marketplace.visualstudio.com/items?itemName=jackfioru92.mcp-aruba-email)
[](https://github.com/jackfioru92/mcp-aruba-email)
## 📦 Come Installare
### Opzione 1: Estensione VS Code (Più Semplice) ⭐
Per usare con **GitHub Copilot** in VS Code:
1. Installa l'estensione dal [VS Code Marketplace](https://marketplace.visualstudio.com/items?itemName=jackfioru92.mcp-aruba-email)
2. Configura le credenziali con `⌘+Shift+P` → **"Aruba Email: Configure Credentials"**
3. Usa direttamente in Copilot Chat!
📖 [Guida completa estensione VS Code](docs/VSCODE_EXTENSION.md)
### Opzione 2: Da Smithery (Registro MCP) 🔍
Per usare con `@mcp aruba` in VS Code o altri client MCP:
1. Il server è disponibile su [Smithery](https://smithery.ai/server/io.github.jackfioru92/aruba-email)
2. In VS Code Copilot Chat, digita `@mcp aruba` e segui le istruzioni
3. Oppure installa da CLI: `smithery install io.github.jackfioru92/aruba-email`
[](https://smithery.ai/server/io.github.jackfioru92/aruba-email)
### Opzione 3: Installazione Manuale (Per Claude Desktop)
Per usare con **Claude Desktop**:
## Funzionalità
### Email
- 📧 **Elenca email** - Naviga nella casella con filtri per mittente
- 🔍 **Cerca email** - Ricerca per oggetto/corpo con filtri data
- 📖 **Leggi email** - Ottieni il contenuto completo
- ✉️ **Invia email** - Invia email via SMTP con firma personalizzata
- ✍️ **Firma email** - Crea firme professionali con foto e colori brand
### Calendario
- 📅 **Crea eventi** - Crea eventi calendario con partecipanti
- 📋 **Elenca eventi** - Visualizza eventi futuri
- ✅ **Accetta inviti** - Accetta inviti calendario
- ❌ **Declina inviti** - Declina inviti calendario
- ❓ **Forse** - Rispondi "forse" agli inviti calendario
- 🗑️ **Elimina eventi** - Rimuovi eventi dal calendario
### Generale
- 🔒 **Sicuro** - Usa IMAP/SMTP/CalDAV su SSL/TLS
- ⚡ **Veloce** - Gestione efficiente delle connessioni con context manager
- 🤖 **Pronto per AI** - Funziona perfettamente con Claude Desktop e altri client MCP
## Configurazione (Solo per Installazione Manuale)
1. Copia `.env.example` in `.env`:
```bash
cp .env.example .env
```
2. Modifica `.env` con le tue credenziali Aruba:
```env
# Configurazione Email
IMAP_HOST=imaps.aruba.it
IMAP_PORT=993
IMAP_USERNAME=tua_email@aruba.it
IMAP_PASSWORD=tua_password
SMTP_HOST=smtps.aruba.it
SMTP_PORT=465
# Configurazione Calendario
CALDAV_URL=https://syncdav.aruba.it/calendars/tua_email@aruba.it/
CALDAV_USERNAME=tua_email@aruba.it
CALDAV_PASSWORD=tua_password
```
3. **(Opzionale) Configura la tua firma email personalizzata:**
**Metodo 1: Script Interattivo** (Consigliato)
```bash
# Esegui lo script interattivo
python setup_signature.py
```
Lo script ti guiderà nella creazione di una firma professionale con:
- 📝 Informazioni personali (nome, ruolo, azienda, contatti)
- 🎨 Scelta dello stile (professional, minimal, colorful)
- 🌈 Personalizzazione colori
- 📸 Upload automatico foto su Imgur (opzionale)
**Metodo 2: Tramite Claude** (Ancora più semplice!)
```
Dopo aver configurato Claude Desktop, chiedi direttamente:
"Crea una firma email per me con nome Mario Rossi,
ruolo Software Developer, azienda TechCorp e colore #0066cc"
"Configura la mia firma con questa foto: /path/to/photo.jpg"
"Imposta una firma minimal con solo nome e email"
```
Claude userà automaticamente i tool MCP per creare la tua firma!
La firma verrà inclusa automaticamente in tutte le email inviate.
> **Nota**: Le credenziali sono memorizzate localmente e non lasciano mai il tuo computer. Il server MCP viene eseguito localmente e si connette direttamente ai server Aruba.
## Utilizzo
### 🚀 Inizio Rapido: Visualizza le Ultime Email
Il modo più veloce per iniziare:
```bash
# Installa dipendenze
pip install -e .
# Configura credenziali (copia e modifica .env.example)
cp .env.example .env
# Modifica .env con le tue credenziali Aruba
# Mostra le ultime email
python cli.py emails 5
# Oppure usa lo script demo
python demo_list_emails.py
```
**Vuoi usare Claude?** Dopo la configurazione, chiedi semplicemente:
```
Mostrami le ultime 5 email
Dammi le email più recenti
Quali email ho ricevuto oggi?
```
📖 **Guida completa**: Vedi [GUIDA_UTILIZZO_EMAIL.md](GUIDA_UTILIZZO_EMAIL.md) per tutti i metodi disponibili.
### Esegui il server direttamente
```bash
python -m mcp_aruba.server
```
### Configura con Claude Desktop
Vedi [CLAUDE_SETUP.md](CLAUDE_SETUP.md) per istruzioni dettagliate.
Configurazione rapida per `~/Library/Application Support/Claude/claude_desktop_config.json`:
```json
{
"mcpServers": {
"aruba-email-calendar": {
"command": "python",
"args": ["-m", "mcp_aruba.server"],
"env": {
"IMAP_HOST": "imaps.aruba.it",
"IMAP_PORT": "993",
"IMAP_USERNAME": "tua_email@aruba.it",
"IMAP_PASSWORD": "tua_password",
"SMTP_HOST": "smtps.aruba.it",
"SMTP_PORT": "465",
"CALDAV_URL": "https://syncdav.aruba.it/calendars/tua_email@aruba.it/",
"CALDAV_USERNAME": "tua_email@aruba.it",
"CALDAV_PASSWORD": "tua_password"
}
}
}
}
```
### Configura con VS Code Copilot
Vedi [VSCODE_SETUP.md](VSCODE_SETUP.md) per istruzioni dettagliate sull'uso di questo server con l'estensione Copilot MCP di VS Code.
### Usa la CLI rapida
```bash
# Attiva ambiente virtuale
source .venv/bin/activate
# Mostra ultime 5 email
python cli.py emails
# Mostra ultime 10 email
python cli.py emails 10
# Mostra eventi prossimi 7 giorni
python cli.py calendar
# Mostra eventi prossimi 14 giorni
python cli.py calendar 14
```
## Strumenti Disponibili
### Strumenti Email
#### `list_emails`
Elenca email recenti con filtri opzionali.
**Parametri:**
- `folder` (str, default: "INBOX") - Cartella email da leggere
- `sender_filter` (str, opzionale) - Filtra per email mittente
- `limit` (int, default: 10, max: 50) - Numero di email da restituire
**Esempi:**
```
Mostra le ultime 5 email da john@example.com
Elenca email recenti nella mia inbox
Dammi le 10 email più recenti dal mio capo
```
#### `read_email`
Leggi il contenuto completo di un'email specifica.
**Parametri:**
- `email_id` (str) - ID email da list_emails
- `folder` (str, default: "INBOX") - Cartella email
**Esempi:**
```
Leggi l'email 123
Mostrami il contenuto completo dell'email 456
```
#### `search_emails`
Cerca email per oggetto o contenuto corpo.
**Parametri:**
- `query` (str) - Query di ricerca
- `folder` (str, default: "INBOX") - Cartella dove cercare
- `from_date` (str, opzionale) - Solo email da questa data (formato: DD-MMM-YYYY)
- `limit` (int, default: 10, max: 50) - Numero massimo di risultati
**Esempi:**
```
Cerca email che parlano di "API" dalla settimana scorsa
Trova tutte le email su "fattura" da dicembre
```
#### `send_email`
Invia un'email via SMTP.
**Parametri:**
- `to` (str) - Indirizzo email destinatario
- `subject` (str) - Oggetto email
- `body` (str) - Corpo email (testo semplice)
- `cc` (str, opzionale) - Indirizzi email in CC, separati da virgola
- `from_name` (str, default: "Giacomo Fiorucci") - Nome visualizzato mittente
- `use_signature` (bool, default: True) - Include la firma email se configurata
- `verify_recipient` (bool, default: True) - Verifica che l'email destinatario esista
**Esempi:**
```
Invia un'email a colleague@example.com ringraziando per l'aggiornamento
Rispondi a john@example.com con lo stato del progetto
Invia un'email a client@example.com con CC a manager@company.com
```
**Nota sulla firma**: Se hai configurato una firma usando `setup_signature.py`, verrà automaticamente inclusa nelle email. Puoi disabilitarla temporaneamente con `use_signature=False`.
#### `set_email_signature`
Configura una firma email personalizzata.
**Parametri:**
- `name` (str) - Nome completo
- `email` (str) - Indirizzo email
- `role` (str, opzionale) - Ruolo/posizione
- `company` (str, opzionale) - Nome azienda
- `phone` (str, opzionale) - Numero di telefono
- `website` (str, opzionale) - Sito web
- `photo_input` (str, opzionale) - Percorso file foto o URL (upload automatico su Imgur)
- `style` (str, default: "professional") - Stile: professional, minimal, colorful
- `color` (str, default: "#0066cc") - Colore principale (formato esadecimale)
- `signature_name` (str, default: "default") - Nome identificativo firma
**Esempi:**
```
Crea una firma con il mio nome, ruolo e foto del profilo
Configura una firma professionale con logo aziendale
```
#### `get_email_signature`
Ottieni la firma email corrente.
**Parametri:**
- `signature_name` (str, default: "default") - Nome firma da recuperare
#### `list_email_signatures`
Elenca tutte le firme email salvate.
### Strumenti Calendario
#### `create_calendar_event`
Crea un nuovo evento calendario.
**Parametri:**
- `summary` (str) - Titolo evento
- `start` (str) - Data/ora inizio in formato ISO (YYYY-MM-DDTHH:MM:SS)
- `end` (str) - Data/ora fine in formato ISO
- `description` (str, opzionale) - Descrizione evento
- `location` (str, opzionale) - Luogo evento
- `attendees` (str, opzionale) - Lista email partecipanti separati da virgola
**Esempi:**
```
Crea un meeting chiamato "Riunione Team" domani alle 15 per 1 ora
Programma un "Project Review" il 10 dicembre alle 14 con john@example.com
```
#### `list_calendar_events`
Elenca eventi calendario in un intervallo di date.
**Parametri:**
- `start_date` (str, opzionale) - Data inizio in formato ISO (default: oggi)
- `end_date` (str, opzionale) - Data fine in formato ISO (default: 30 giorni da ora)
- `limit` (int, default: 50) - Eventi massimi da restituire
**Esempi:**
```
Mostrami il mio calendario per questa settimana
Quali eventi ho a dicembre?
Elenca tutti i miei meeting per i prossimi 7 giorni
```
#### `accept_calendar_event`
Accetta un invito calendario.
**Parametri:**
- `event_uid` (str) - UID dell'evento
- `comment` (str, opzionale) - Commento opzionale
**Esempi:**
```
Accetta l'invito al meeting "Team Standup"
Accetta l'evento abc123@aruba.it con commento "Non vedo l'ora!"
```
#### `decline_calendar_event`
Declina un invito calendario.
**Parametri:**
- `event_uid` (str) - UID dell'evento
- `comment` (str, opzionale) - Commento opzionale
**Esempi:**
```
Declina l'evento abc123@aruba.it
Declina il meeting con commento "Mi dispiace, ho un conflitto"
```
#### `tentative_calendar_event`
Rispondi "forse" a un invito calendario.
**Parametri:**
- `event_uid` (str) - UID dell'evento
- `comment` (str, opzionale) - Commento opzionale
**Esempi:**
```
Rispondi forse all'evento abc123@aruba.it
Segna come "forse" il meeting di domani
Forse partecipo al meeting di domani
```
#### `delete_calendar_event`
Elimina un evento calendario.
**Parametri:**
- `event_uid` (str) - UID dell'evento da eliminare
**Esempi:**
```
Elimina l'evento abc123@aruba.it
Cancella il mio meeting delle 14
```
## Casi d'Uso
### 📬 Comunicazione Team
```
Mostrami le ultime email dai membri del mio team
Elenca email non lette da project@company.com
```
### 🔍 Tracking Progetti
```
Cerca email che menzionano "modifiche API" dall'ultima settimana
Trova tutte le email su "fattura" dal 1° dicembre
```
### 📊 Riepilogo Email Giornaliero
```
Riassumi tutte le email che ho ricevuto oggi
Mostrami le email importanti di stamattina
```
### ✉️ Risposte Rapide
```
Invia un'email a colleague@example.com ringraziandoli per l'aggiornamento
Rispondi a john@example.com con lo stato del progetto
```
### 📅 Gestione Calendario
```
Quali meeting ho questa settimana?
Crea una riunione team per domani alle 15
Accetta l'invito calendario per la review di venerdì
Declina il meeting di lunedì, sono in vacanza
Mostrami il mio programma per la prossima settimana
```
### 🤖 Gestione Email & Calendario con AI
Con Claude Desktop o VS Code Copilot, puoi:
- Chiedere a Claude di riassumere più email
- Creare risposte basate sul contenuto email
- Estrarre task da thread email
- Organizzare e categorizzare email automaticamente
- Programmare meeting basati su conversazioni email
- Gestire conflitti calendario e trovare fasce orarie disponibili
## Stack Tecnologico
- **Python 3.10+** - Python moderno
- **MCP SDK 1.2.0+** - Model Context Protocol per integrazione AI
- **imaplib** - Client IMAP libreria standard (supporto SSL/TLS)
- **smtplib** - Client SMTP libreria standard (supporto SSL/TLS)
- **email** - Parsing email e gestione MIME
- **caldav** - Protocollo CalDAV per accesso calendario
- **icalendar** - Parsing e generazione formato iCalendar
- **python-dotenv** - Gestione variabili ambiente
## Sicurezza & Privacy
- 🔒 **Esecuzione locale** - Il server gira sul tuo computer, le credenziali non lasciano mai la tua macchina
- 🛡️ **Crittografia SSL/TLS** - Tutte le connessioni usano protocolli sicuri (IMAPS porta 993, SMTPS porta 465, HTTPS per CalDAV)
- 🔐 **Variabili ambiente** - Credenziali salvate nel file `.env` (gitignored di default)
- 📝 **Troncamento corpo** - Corpo email limitato a 5000 caratteri per prevenire overflow del contesto
- ✅ **Nessun servizio esterno** - Connessione diretta solo ai server Aruba
### Best Practice Sicurezza
1. Non committare mai il file `.env` nel controllo versione
2. Usa password forti e uniche per il tuo account email
3. Considera l'abilitazione 2FA sul tuo account Aruba
4. Ruota regolarmente le tue credenziali
5. Rivedi i log del server MCP per attività sospette
## Performance
- ⚡ Connection pooling via context manager
- 📊 Limiti risultati configurabili per prevenire problemi di memoria
- 🚀 Connessioni on-demand (nessun processo in background)
- 💾 Footprint di memoria minimo
## Sviluppo
### Eseguire i Test
```bash
# Attiva ambiente virtuale
source .venv/bin/activate
# Esegui test connessione email
python test_connection.py
# Esegui test connessione calendario
python test_calendar.py
# Test creazione evento
python test_create_event.py
# Test invio invito calendario
python send_invite.py
```
### Qualità Codice
```bash
# Formatta codice
black src/
# Type checking
mypy src/
# Linting
pylint src/
```
## Abilitare Sincronizzazione CalDAV
Per usare le funzionalità calendario, devi abilitare la sincronizzazione CalDAV in Aruba Webmail:
1. Vai su https://webmail.aruba.it
2. Naviga alla sezione Calendario
3. Clicca su **"Sincronizza calendario"**
4. Scegli **"Calendari"** → **"Procedi"**
5. Seleziona **"Lettura e modifica"** (CalDAV) → **"Procedi"**
6. Seleziona i calendari da sincronizzare → **"Procedi"**
Una volta abilitato, potrai gestire completamente i tuoi calendari tramite il server MCP!
## Risoluzione Problemi
### Calendario non disponibile
Se vedi "No calendar available", devi abilitare la sincronizzazione CalDAV (vedi sezione sopra).
### Errori connessione
1. Verifica che le credenziali in `.env` siano corrette
2. Controlla che le porte 993 (IMAP), 465 (SMTP), 443 (CalDAV) non siano bloccate
3. Verifica le impostazioni firewall
4. Prova a eseguire gli script di test
### Email o eventi non visualizzati
1. Verifica di avere i permessi corretti sull'account
2. Controlla i filtri applicati (sender_filter, date filters)
3. Aumenta il limite di risultati
## FAQ
**Q: È sicuro memorizzare le mie credenziali nel file .env?**
A: Sì, finché il file `.env` non viene committato nel controllo versione. È già incluso in `.gitignore`. Le credenziali rimangono sul tuo computer locale.
**Q: Posso usare questo con altri provider email?**
A: Il server è ottimizzato per Aruba, ma puoi adattarlo per altri provider che supportano IMAP/SMTP/CalDAV modificando le configurazioni.
**Q: Quanto costano i server MCP?**
A: I server MCP sono gratuiti! Questo è software open-source. Hai solo bisogno di un abbonamento Claude o GitHub Copilot per usarlo con quegli AI.
**Q: I miei dati vengono inviati a terze parti?**
A: No! Il server gira localmente e si connette direttamente ai server Aruba. Nessun dato passa attraverso servizi terzi.
**Q: Posso contribuire al progetto?**
A: Assolutamente! Vedi [CONTRIBUTING.md](CONTRIBUTING.md) per linee guida.
## Contribuire
I contributi sono benvenuti! Per favore:
1. Fai un fork del repository
2. Crea un feature branch (`git checkout -b feature/funzionalita-fantastica`)
3. Committa le modifiche (`git commit -m 'Aggiungi funzionalità fantastica'`)
4. Pusha al branch (`git push origin feature/funzionalita-fantastica`)
5. Apri una Pull Request
Vedi [CONTRIBUTING.md](CONTRIBUTING.md) per dettagli completi.
## Roadmap
- [ ] Supporto IMAP IDLE per notifiche real-time
- [ ] Gestione allegati email
- [ ] Composizione email HTML
- [ ] Suite test pytest
- [ ] Supporto account multipli
- [ ] Eventi calendario ricorrenti
- [ ] Notifiche calendario
- [ ] Integrazione con altri calendari (Google Calendar, Outlook)
## Documentazione
- [README.md](README.md) - Documentazione principale (Italiano)
- [README_EN.md](README_EN.md) - Documentation in English
- [GUIDA_UTILIZZO_EMAIL.md](GUIDA_UTILIZZO_EMAIL.md) - **Guida completa: Come vedere le ultime email** 📧
- [EXAMPLES.md](EXAMPLES.md) - Esempi d'uso
- [CLAUDE_SETUP.md](CLAUDE_SETUP.md) - Setup Claude Desktop
- [VSCODE_SETUP.md](VSCODE_SETUP.md) - Setup VS Code Copilot MCP
- [docs/VSCODE_EXTENSION.md](docs/VSCODE_EXTENSION.md) - **Estensione VS Code Marketplace**
- [docs/MCP_REGISTRY.md](docs/MCP_REGISTRY.md) - **Pubblicazione MCP Registry**
- [SIGNATURE_EXAMPLES.md](SIGNATURE_EXAMPLES.md) - Esempi firme email
- [CONTRIBUTING.md](CONTRIBUTING.md) - Guida contribuzioni
- [LICENSE](LICENSE) - Licenza MIT
## Installazione Rapida
### Da PyPI
```bash
pip install mcp-aruba
```
### Da VS Code Marketplace
Cerca "MCP Aruba Email" nel marketplace VS Code o installa direttamente:
```bash
code --install-extension jackfioru92.mcp-aruba-email
```
### Da MCP Registry
Il server è disponibile su [MCP Registry](https://mcpregistry.io/servers/io.github.jackfioru92/aruba-email)
## Supporto
Se incontri problemi:
1. Controlla la sezione [Risoluzione Problemi](#risoluzione-problemi)
2. Esegui gli script di test per verificare la connessione
3. Controlla i log per messaggi d'errore
4. Apri un issue su [GitHub](https://github.com/jackfioru92/mcp-aruba-email/issues)
## Licenza
Questo progetto è rilasciato sotto licenza MIT. Vedi il file [LICENSE](LICENSE) per dettagli.
## Autore
Giacomo Fiorucci - giacomo.fiorucci@emotion-team.com
## Ringraziamenti
- [Model Context Protocol](https://modelcontextprotocol.io/) per il framework MCP
- [Anthropic](https://www.anthropic.com/) per Claude Desktop
- [GitHub](https://github.com/) per Copilot
- Aruba per i servizi email e calendario affidabili
---
⭐ Se questo progetto ti è utile, considera di dargli una stella su GitHub!
| text/markdown | null | Giacomo Fiorucci <giacomo.fiorucci@emotion-team.com> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"caldav>=1.3.9",
"html2text>=2024.2.26",
"icalendar>=5.0.0",
"mcp[cli]>=1.2.0",
"python-dotenv>=1.0.0",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/jackfioru92/mcp-aruba-email",
"Repository, https://github.com/jackfioru92/mcp-aruba-email",
"Issues, https://github.com/jackfioru92/mcp-aruba-email/issues"
] | twine/6.2.0 CPython/3.11.4 | 2026-02-18T16:50:02.716241 | mcp_aruba-0.3.0.tar.gz | 294,187 | 9d/83/a920433e1361d5b1ea642bf3c0f2b066f702979dc5d63babc079eae96d71/mcp_aruba-0.3.0.tar.gz | source | sdist | null | false | 5b7635d2f269fcf332cc1d50642ff69c | f72a887e65d4dac84bf043e95e55bab5d10abce3f71197ac804047ca4ab8dac1 | 9d83a920433e1361d5b1ea642bf3c0f2b066f702979dc5d63babc079eae96d71 | null | [
"LICENSE"
] | 236 |
2.4 | kerykeion | 5.7.3 | A Python library for astrological calculations, including natal charts, houses, planetary aspects, and SVG chart generation. | <h1 align="center">Kerykeion</h1>
<div align="center">
<img src="https://img.shields.io/github/stars/g-battaglia/kerykeion.svg?logo=github" alt="stars">
<img src="https://img.shields.io/github/forks/g-battaglia/kerykeion.svg?logo=github" alt="forks">
</div>
<div align="center">
<img src="https://static.pepy.tech/badge/kerykeion/month" alt="PyPI Downloads">
<img src="https://static.pepy.tech/badge/kerykeion/week" alt="PyPI Downloads">
<img src="https://static.pepy.tech/personalized-badge/kerykeion?period=total&units=INTERNATIONAL_SYSTEM&left_color=GREY&right_color=BLUE&left_text=downloads/total" alt="PyPI Downloads">
</div>
<div align="center">
<img src="https://img.shields.io/pypi/v/kerykeion?label=pypi%20package" alt="Package version">
<img src="https://img.shields.io/pypi/pyversions/kerykeion.svg" alt="Supported Python versions">
</div>
<p align="center">⭐ Like this project? Star it on GitHub and help it grow! ⭐</p>
Kerykeion is a Python library for astrology. It computes planetary and house positions, detects aspects, and generates SVG charts — including birth, synastry, transit, and composite charts. You can also customize which planets to include in your calculations.
The main goal of this project is to offer a clean, data-driven approach to astrology, making it accessible and programmable.
Kerykeion also integrates seamlessly with LLM and AI applications.
Here is an example of a birthchart:

## **Web API**
If you want to use Kerykeion in a web application or for commercial or _closed-source_ purposes, you can try the dedicated web API:
**[AstrologerAPI](https://rapidapi.com/gbattaglia/api/astrologer/pricing)**
It is [open source](https://github.com/g-battaglia/Astrologer-API) and directly supports this project.
## Table of Contents
- [**Commercial Web API**](#commercial-web-api)
- [Table of Contents](#table-of-contents)
- [Installation](#installation)
- [Quick Start](#quick-start)
- [Basic Usage](#basic-usage)
- [Generate a SVG Chart](#generate-a-svg-chart)
- [Birth Chart](#birth-chart)
- [External Birth Chart](#external-birth-chart)
- [Synastry Chart](#synastry-chart)
- [Transit Chart](#transit-chart)
- [Solar Return Chart (Dual Wheel)](#solar-return-chart-dual-wheel)
- [Solar Return Chart (Single Wheel)](#solar-return-chart-single-wheel)
- [Lunar Return Chart](#lunar-return-chart)
- [Composite Chart](#composite-chart)
- [Wheel Only Charts](#wheel-only-charts)
- [Birth Chart](#birth-chart-1)
- [Wheel Only Birth Chart (External)](#wheel-only-birth-chart-external)
- [Synastry Chart](#synastry-chart-1)
- [Change the Output Directory](#change-the-output-directory)
- [Change Language](#change-language)
- [Minified SVG](#minified-svg)
- [SVG without CSS Variables](#svg-without-css-variables)
- [Grid Only SVG](#grid-only-svg)
- [Report Generator](#report-generator)
- [Quick Examples](#quick-examples)
- [Section Access](#section-access)
- [AI Context Serializer](#ai-context-serializer)
- [Quick Example](#quick-example)
- [Example: Retrieving Aspects](#example-retrieving-aspects)
- [Relationship Score](#relationship-score)
- [Element \& Quality Distribution Strategies](#element--quality-distribution-strategies)
- [Ayanamsa (Sidereal Modes)](#ayanamsa-sidereal-modes)
- [House Systems](#house-systems)
- [Perspective Type](#perspective-type)
- [Themes](#themes)
- [Alternative Initialization](#alternative-initialization)
- [Lunar Nodes (Rahu \& Ketu)](#lunar-nodes-rahu--ketu)
- [JSON Support](#json-support)
- [Documentation](#documentation)
- [Projects built with Kerykeion](#projects-built-with-kerykeion)
- [Development](#development)
- [Integrating Kerykeion into Your Project](#integrating-kerykeion-into-your-project)
- [License](#license)
- [Contributing](#contributing)
- [Citations](#citations)
## Installation
Kerykeion requires **Python 3.9** or higher.
```bash
pip3 install kerykeion
```
For more installation options and environment setup, see the [Getting Started guide](https://www.kerykeion.net/content/docs/).
## Quick Start
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
subject = AstrologicalSubjectFactory.from_birth_data(
name="Example Person",
year=1990, month=7, day=15,
hour=10, minute=30,
lng=12.4964,
lat=41.9028,
tz_str="Europe/Rome",
online=False,
)
chart_data = ChartDataFactory.create_natal_chart_data(subject)
chart_drawer = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
chart_drawer.save_svg(output_path=output_dir, filename="example-natal")
print("Chart saved to", (output_dir / "example-natal.svg").resolve())
```
This script shows the recommended workflow:
1. Create an `AstrologicalSubject` with explicit coordinates and timezone (offline mode).
2. Build a `ChartDataModel` through `ChartDataFactory`.
3. Render the SVG via `ChartDrawer`, saving it to a controlled folder (`charts_output`).
Use the same pattern for synastry, composite, transit, or return charts by swapping the factory method.
**📖 More examples: [kerykeion.net/examples](https://www.kerykeion.net/content/examples/)**
## Basic Usage
Below is a simple example illustrating the creation of an astrological subject and retrieving astrological details:
```python
from kerykeion import AstrologicalSubjectFactory
# Create an instance of the AstrologicalSubjectFactory class.
# Arguments: Name, year, month, day, hour, minutes, city, nation
john = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Retrieve information about the Sun:
print(john.sun.model_dump_json())
# > {"name":"Sun","quality":"Cardinal","element":"Air","sign":"Lib","sign_num":6,"position":16.26789199474399,"abs_pos":196.267891994744,"emoji":"♎️","point_type":"AstrologicalPoint","house":"Sixth_House","retrograde":false}
# Retrieve information about the first house:
print(john.first_house.model_dump_json())
# > {"name":"First_House","quality":"Cardinal","element":"Fire","sign":"Ari","sign_num":0,"position":19.74676624176799,"abs_pos":19.74676624176799,"emoji":"♈️","point_type":"House","house":null,"retrograde":null}
# Retrieve the element of the Moon sign:
print(john.moon.element)
# > 'Air'
```
> **Working offline:** pass `online=False` and specify `lng`, `lat`, and `tz_str` as shown above.
> **Working online:** set `online=True` and provide `city`, `nation`, and a valid GeoNames username. Register for free at [geonames.org](https://www.geonames.org/login). You can set the username via the `KERYKEION_GEONAMES_USERNAME` environment variable or the `geonames_username` parameter.
**📖 Full factory documentation: [AstrologicalSubjectFactory](https://www.kerykeion.net/content/docs/astrological_subject_factory)**
**To avoid GeoNames, provide longitude, latitude, and timezone and set `online=False`:**
```python
john = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
city="Liverpool",
nation="GB",
lng=-2.9833, # Longitude for Liverpool
lat=53.4000, # Latitude for Liverpool
tz_str="Europe/London", # Timezone for Liverpool
online=False,
)
```
## Generate a SVG Chart
All chart-rendering examples below create a local `charts_output/` folder so the tests can write without touching your home directory. Feel free to change the path when integrating into your own projects.
To generate a chart, use the `ChartDataFactory` to pre-compute chart data, then `ChartDrawer` to create the visualization. This two-step process ensures clean separation between astrological calculations and chart rendering.
**📖 Chart generation docs: [Charts Documentation](https://www.kerykeion.net/content/docs/charts)**
**Tip:**
The optimized way to open the generated SVG files is with a web browser (e.g., Chrome, Firefox).
To improve compatibility across different applications, you can use the `remove_css_variables` parameter when generating the SVG. This will inline all styles and eliminate CSS variables, resulting in an SVG that is more broadly supported.
### Birth Chart
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subject
john = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute chart data
chart_data = ChartDataFactory.create_natal_chart_data(john)
# Step 3: Create visualization
birth_chart_svg = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
birth_chart_svg.save_svg(output_path=output_dir, filename="john-lennon-natal")
```
The SVG file is saved under `charts_output/john-lennon-natal.svg`.
**📖 More birth chart examples: [Birth Chart Guide](https://www.kerykeion.net/content/examples/birth-chart)**

### External Birth Chart
An "external" birth chart places the zodiac wheel on the outer ring, offering an alternative visualization style:
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subject
birth_chart = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute chart data for external natal chart
chart_data = ChartDataFactory.create_natal_chart_data(birth_chart)
# Step 3: Create visualization with external_view=True
birth_chart_svg = ChartDrawer(chart_data=chart_data, external_view=True)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
birth_chart_svg.save_svg(output_path=output_dir, filename="john-lennon-natal-external")
```

### Synastry Chart
Synastry charts overlay two individuals' planetary positions to analyze relationship compatibility:
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subjects
first = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
second = AstrologicalSubjectFactory.from_birth_data(
"Paul McCartney", 1942, 6, 18, 15, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute synastry chart data
chart_data = ChartDataFactory.create_synastry_chart_data(first, second)
# Step 3: Create visualization
synastry_chart = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
synastry_chart.save_svg(output_path=output_dir, filename="lennon-mccartney-synastry")
```
**📖 Synastry chart guide: [Synastry Chart Examples](https://www.kerykeion.net/content/examples/synastry-chart)**

### Transit Chart
Transit charts compare current planetary positions against a natal chart:
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subjects
transit = AstrologicalSubjectFactory.from_birth_data(
"Transit", 2025, 6, 8, 8, 45,
lng=-84.3880,
lat=33.7490,
tz_str="America/New_York",
online=False,
)
subject = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute transit chart data
chart_data = ChartDataFactory.create_transit_chart_data(subject, transit)
# Step 3: Create visualization
transit_chart = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
transit_chart.save_svg(output_path=output_dir, filename="john-lennon-transit")
```
**📖 Transit chart guide: [Transit Chart Examples](https://www.kerykeion.net/content/examples/transit-chart)**

### Solar Return Chart (Dual Wheel)
Solar returns calculate the exact moment the Sun returns to its natal position each year:
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.planetary_return_factory import PlanetaryReturnFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create natal subject
john = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Calculate Solar Return subject (offline example with manual coordinates)
return_factory = PlanetaryReturnFactory(
john,
lng=-2.9833,
lat=53.4000,
tz_str="Europe/London",
online=False
)
solar_return_subject = return_factory.next_return_from_date(1964, 10, 1, return_type="Solar")
# Step 3: Pre-compute return chart data (dual wheel: natal + solar return)
chart_data = ChartDataFactory.create_return_chart_data(john, solar_return_subject)
# Step 4: Create visualization
solar_return_chart = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
solar_return_chart.save_svg(output_path=output_dir, filename="john-lennon-solar-return-dual")
```
**📖 Return chart guide: [Dual Return Chart Examples](https://www.kerykeion.net/content/examples/dual-return-chart)**

### Solar Return Chart (Single Wheel)
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.planetary_return_factory import PlanetaryReturnFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create natal subject
john = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Calculate Solar Return subject (offline example with manual coordinates)
return_factory = PlanetaryReturnFactory(
john,
lng=-2.9833,
lat=53.4000,
tz_str="Europe/London",
online=False
)
solar_return_subject = return_factory.next_return_from_date(1964, 10, 1, return_type="Solar")
# Step 3: Build a single-wheel return chart
chart_data = ChartDataFactory.create_single_wheel_return_chart_data(solar_return_subject)
# Step 4: Create visualization
single_wheel_chart = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
single_wheel_chart.save_svg(output_path=output_dir, filename="john-lennon-solar-return-single")
```
**📖 Planetary return factory docs: [PlanetaryReturnFactory](https://www.kerykeion.net/content/docs/planetary_return_factory)**

### Lunar Return Chart
Lunar returns calculate when the Moon returns to its natal position (approximately monthly):
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.planetary_return_factory import PlanetaryReturnFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create natal subject
john = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Calculate Lunar Return subject
return_factory = PlanetaryReturnFactory(
john,
lng=-2.9833,
lat=53.4000,
tz_str="Europe/London",
online=False
)
lunar_return_subject = return_factory.next_return_from_date(1964, 1, 1, return_type="Lunar")
# Step 3: Build a dual wheel (natal + lunar return)
lunar_return_chart_data = ChartDataFactory.create_return_chart_data(john, lunar_return_subject)
dual_wheel_chart = ChartDrawer(chart_data=lunar_return_chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
dual_wheel_chart.save_svg(output_path=output_dir, filename="john-lennon-lunar-return-dual")
# Optional: create a single-wheel lunar return
single_wheel_data = ChartDataFactory.create_single_wheel_return_chart_data(lunar_return_subject)
single_wheel_chart = ChartDrawer(chart_data=single_wheel_data)
single_wheel_chart.save_svg(output_path=output_dir, filename="john-lennon-lunar-return-single")
```


### Composite Chart
Composite charts create a single chart from two individuals' midpoints to represent the relationship entity:
```python
from pathlib import Path
from kerykeion import CompositeSubjectFactory, AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subjects (offline configuration)
angelina = AstrologicalSubjectFactory.from_birth_data(
"Angelina Jolie", 1975, 6, 4, 9, 9,
lng=-118.2437,
lat=34.0522,
tz_str="America/Los_Angeles",
online=False,
)
brad = AstrologicalSubjectFactory.from_birth_data(
"Brad Pitt", 1963, 12, 18, 6, 31,
lng=-96.7069,
lat=35.3273,
tz_str="America/Chicago",
online=False,
)
# Step 2: Create composite subject
factory = CompositeSubjectFactory(angelina, brad)
composite_model = factory.get_midpoint_composite_subject_model()
# Step 3: Pre-compute composite chart data
chart_data = ChartDataFactory.create_composite_chart_data(composite_model)
# Step 4: Create visualization
composite_chart = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
composite_chart.save_svg(output_path=output_dir, filename="jolie-pitt-composite")
```
**📖 Composite factory docs: [CompositeSubjectFactory](https://www.kerykeion.net/content/docs/composite_subject_factory)**

## Wheel Only Charts
For _all_ the charts, you can generate a wheel-only chart by using the method `save_wheel_only_svg_file()`:
**📖 Minimalist charts guide: [Wheel Only & Aspect Grid Charts](https://www.kerykeion.net/content/examples/minimalist-charts-and-aspect-table)**
### Birth Chart
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subject
birth_chart = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute chart data
chart_data = ChartDataFactory.create_natal_chart_data(birth_chart)
# Step 3: Create visualization
birth_chart_svg = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
birth_chart_svg.save_wheel_only_svg_file(output_path=output_dir, filename="john-lennon-natal-wheel")
```

### Wheel Only Birth Chart (External)
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subject
birth_chart = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute external natal chart data
chart_data = ChartDataFactory.create_natal_chart_data(birth_chart)
# Step 3: Create visualization (external wheel view)
birth_chart_svg = ChartDrawer(chart_data=chart_data, external_view=True)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
birth_chart_svg.save_wheel_only_svg_file(output_path=output_dir, filename="john-lennon-natal-wheel-external")
```

### Synastry Chart
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subjects
first = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
second = AstrologicalSubjectFactory.from_birth_data(
"Paul McCartney", 1942, 6, 18, 15, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute synastry chart data
chart_data = ChartDataFactory.create_synastry_chart_data(first, second)
# Step 3: Create visualization
synastry_chart = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
synastry_chart.save_wheel_only_svg_file(output_path=output_dir, filename="lennon-mccartney-synastry-wheel")
```

### Change the Output Directory
To save the SVG file in a custom location, specify the `output_path` parameter in `save_svg()`:
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subjects
first = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
second = AstrologicalSubjectFactory.from_birth_data(
"Paul McCartney", 1942, 6, 18, 15, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute synastry chart data
chart_data = ChartDataFactory.create_synastry_chart_data(first, second)
# Step 3: Create visualization with custom output directory
synastry_chart = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
synastry_chart.save_svg(output_path=output_dir)
print("Saved to", (output_dir / f"{synastry_chart.first_obj.name} - Synastry Chart.svg").resolve())
```
### Change Language
You can switch chart language by passing `chart_language` to the `ChartDrawer` class:
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subject
birth_chart = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute chart data
chart_data = ChartDataFactory.create_natal_chart_data(birth_chart)
# Step 3: Create visualization with Italian language
birth_chart_svg = ChartDrawer(
chart_data=chart_data,
chart_language="IT" # Change to Italian
)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
birth_chart_svg.save_svg(output_path=output_dir, filename="john-lennon-natal-it")
```
You can also provide custom labels (or introduce a brand-new language) by passing
a dictionary to `language_pack`. Only the keys you supply are merged on top of the
built-in strings:
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
birth_chart = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
chart_data = ChartDataFactory.create_natal_chart_data(birth_chart)
custom_labels = {
"PT": {
"info": "Informações",
"celestial_points": {"Sun": "Sol", "Moon": "Lua"},
}
}
custom_chart = ChartDrawer(
chart_data=chart_data,
chart_language="PT",
language_pack=custom_labels["PT"],
)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
custom_chart.save_svg(output_path=output_dir, filename="john-lennon-natal-pt")
```
**📖 Language configuration guide: [Chart Language Settings](https://www.kerykeion.net/content/examples/chart-language)**
The available languages are:
- EN (English)
- FR (French)
- PT (Portuguese)
- ES (Spanish)
- TR (Turkish)
- RU (Russian)
- IT (Italian)
- CN (Chinese)
- DE (German)
### Minified SVG
To generate a minified SVG, set `minify=True` in the `save_svg()` method:
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subject
birth_chart = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute chart data
chart_data = ChartDataFactory.create_natal_chart_data(birth_chart)
# Step 3: Create visualization
birth_chart_svg = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
birth_chart_svg.save_svg(
output_path=output_dir,
filename="john-lennon-natal-minified",
minify=True,
)
```
### SVG without CSS Variables
To generate an SVG without CSS variables, set `remove_css_variables=True` in the `save_svg()` method:
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subject
birth_chart = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute chart data
chart_data = ChartDataFactory.create_natal_chart_data(birth_chart)
# Step 3: Create visualization
birth_chart_svg = ChartDrawer(chart_data=chart_data)
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
birth_chart_svg.save_svg(
output_path=output_dir,
filename="john-lennon-natal-no-css-variables",
remove_css_variables=True,
)
```
This will inline all styles and eliminate CSS variables, resulting in an SVG that is more broadly supported.
### Grid Only SVG
It's possible to generate a grid-only SVG, useful for creating a custom layout. To do this, use the `save_aspect_grid_only_svg_file()` method:
```python
from pathlib import Path
from kerykeion import AstrologicalSubjectFactory
from kerykeion.chart_data_factory import ChartDataFactory
from kerykeion.charts.chart_drawer import ChartDrawer
# Step 1: Create subjects
birth_chart = AstrologicalSubjectFactory.from_birth_data(
"John Lennon", 1940, 10, 9, 18, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
second = AstrologicalSubjectFactory.from_birth_data(
"Paul McCartney", 1942, 6, 18, 15, 30,
lng=-2.9833,
lat=53.4,
tz_str="Europe/London",
online=False,
)
# Step 2: Pre-compute synastry chart data
chart_data = ChartDataFactory.create_synastry_chart_data(birth_chart, second)
# Step 3: Create visualization with dark theme
aspect_grid_chart = ChartDrawer(chart_data=chart_data, theme="dark")
output_dir = Path("charts_output")
output_dir.mkdir(exist_ok=True)
aspect_grid_chart.save_aspect_grid_only_svg_file(output_path=output_dir, filename="lennon-mccartney-aspect-grid")
```

## Report Generator
`ReportGenerator` mirrors the chart-type dispatch of `ChartDrawer`. It accepts raw `AstrologicalSubjectModel` instances as well as any `ChartDataModel` produced by `ChartDataFactory`—including natal, composite, synastry, transit, and planetary return charts—and renders the appropriate textual report automatically.
**📖 Full report documentation: [Report Generator Guide](https://www.kerykeion.net/content/docs/report)**
### Quick Examples
```python
from kerykeion import ReportGenerator, AstrologicalSubjectFactory, ChartDataFactory
# Subject-only report
subject = AstrologicalSubjectFactory.from_birth_data(
"Sample Natal", 1990, 7, 21, 14, 45,
lng=12.4964,
lat=41.9028,
tz_str="Europe/Rome",
online=False,
)
ReportGenerator(subject).print_report(include_aspects=False)
# Single-chart data (elements, qualities, aspects enabled)
natal_data = ChartDataFactory.create_natal_chart_data(subject)
ReportGenerator(natal_data).print_report(max_aspects=10)
# Dual-chart data (synastry, transit, dual return, …)
partner = AstrologicalSubjectFactory.from_birth_data(
"Sample Partner", 1992, 11, 5, 9, 30,
lng=12.4964,
lat=41.9028,
tz_str="Europe/Rome",
online=False,
)
synastry_data = ChartDataFactory.create_synastry_chart_data(subject, partner)
ReportGenerator(synastry_data).print_report(max_aspects=12)
```
Each report contains:
- A chart-aware title summarising the subject(s) and chart type
- Birth/event metadata and configuration settings
- Celestial points with sign, position, **daily motion**, **declination**, retrograde flag, and house
- House cusp tables for every subject involved
- Lunar phase details when available
- Element/quality distributions and active configuration summaries (for chart data)
- Aspect listings tailored for single or dual charts, with symbols for type and movement
- Dual-chart extras such as house comparisons and relationship scores (when provided by the data)
### Section Access
All section helpers remain available for targeted output:
```python
from kerykeion import ReportGenerator, AstrologicalSubjectFactory, ChartDataFactory
subject = AstrologicalSubjectFactory.from_birth_data(
"Sample Natal", 1990, 7, 21, 14, 45,
lng=12.4964,
lat=41.9028,
tz_str="Europe/Rome",
online=False,
)
natal_data = ChartDataFactory.create_natal_chart_data(subject)
report = ReportGenerator(natal_data)
sections = report.generate_report(max_aspects=5).split("\n\n")
for section in sections[:3]:
print(section)
```
**📖 Report examples: [Report Examples](https://www.kerykeion.net/content/examples/report)**
## AI Context Serializer
The `context_serializer` module transforms Kerykeion data models into precise, non-qualitative text optimized for LLM consumption. It provides the essential "ground truth" data needed for AI agents to generate accurate astrological interpretations.
**📖 Full context serializer docs: [Context Serializer Guide](https://www.kerykeion.net/content/docs/context_serializer)**
### Quick Example
```python
from kerykeion import AstrologicalSubjectFactory, to_context
# Create a subject
subject = AstrologicalSubjectFactory.from_birth_data(
"John Doe", 1990, 1, 1, 12, 0,
city="London",
nation="GB",
lng=-0.1278,
lat=51.5074,
tz_str="Europe/London",
online=False,
)
# Generate AI-ready context
context = to_context(subject)
print(context)
```
**Output:**
```text
Chart for John Doe
Birth data: 1990-01-01 12:00, London, GB
...
Celestial Points:
- Sun at 10.81° in Capricorn in Tenth House, quality: Cardinal, element: Earth...
- Moon at 25.60° in Aquarius in Eleventh House, quality: Fixed, element: Air...
```
**Key Features:**
- **Standardized Output:** Consistent format for Natal, Synastry, Composite, and Return charts.
- **Non-Qualitative:** Provides raw data (positions, aspects) without interpretive bias.
- **Prompt-Ready:** Designed to be injected directly into system prompts.
## Example: Retrieving Aspects
Kerykeion provides a unified `AspectsFactory` class for calculating astrological aspects within single charts or between two charts:
```python
from kerykeion import AspectsFactory, AstrologicalSubjectFactory
# Create astrological subjects
jack = AstrologicalSubjectFactory.from_birth_data(
"Jack", 1990, 6, 15, 15, 15,
lng=12.4964,
lat=41.9028,
tz_str="Europe/Rome",
online=False,
)
jane = AstrologicalSubjectFactory.from_birth_data(
"Jane", 1991, 10, 25, 21, 0,
lng=12.4964,
lat=41.9028,
tz_str="Europe/Rome",
online=False,
)
# For single chart aspects (natal, return, composite, etc.)
single_chart_result = AspectsFactory.single_chart_aspects(jack)
print(f"Found {len(single_chart_result.aspects)} aspects in Jack's chart")
print(single_chart_result.aspects[0])
# For dual chart aspects (synastry, transits, comparisons, etc.)
dual_chart_result = AspectsFactory.dual_chart_aspects(jack, jane)
print(f"Found {len(dual_chart_result.aspects)} aspects between Jack and Jane's charts")
print(dual_chart_result.aspects[0])
# Each AspectModel includes:
# - p1_name, p2_name: Planet/point names
# - aspect: Aspect type (conjunction, trine, square, etc.)
# - orbit: Orb tolerance in degrees
# - aspect_degrees: Exact degrees for the aspect (0, 60, 90, 120, 180, etc.)
# - color: Hex color code for visualization
```
**📖 Aspects documentation: [Aspects Factory Guide](https://www.kerykeion.net/content/docs/aspects)**
**Advanced Usage with Custom Settings:**
```python
# You can also customize aspect calculations with custom orb settings
from kerykeion.settings.config_constants import DEFAULT_ACTIVE_ASPECTS
# Modify aspect settings if needed
custom_aspects = DEFAULT_ACTIVE_ASPECTS.copy()
# ... modify as needed
# The factory automatically uses the configured settings for orb calculations
# and filters aspects based on relevance and orb thresholds
```
**📖 Configuration options: [Settings Documentation](https://www.kerykeion.net/content/docs/settings)**
## Relationship Score
Kerykeion can calculate a relationship compatibility score based on synastry aspects, using the method of the Italian astrologer **Ciro Discepolo**:
```python
from kerykeion import AstrologicalSubjectFactory
from kerykeion.relationship_score_factory import RelationshipScoreFactory
# Create two subjects
person1 = AstrologicalSubjectFactory.from_birth_data(
"Alice", 1990, 3, 15, 14, 30,
lng=12.4964,
lat=41.9028,
tz_str="Europe/Rome",
online=False,
)
person2 = AstrologicalSubjectFactory.from_birth_data(
"Bob", 1988, 7, 22, 9, 0,
lng=12.4964,
lat=41.9028,
tz_str="Europe/Rome",
online=False,
)
# Calculate relationship score
score_factory = RelationshipScoreFactory(person1, person2)
result = score_factory.get_score()
print(f"Compatibility Score: {result.score}")
print(f"Description: {result.description}")
```
**📖 Relationship score guide: [Relationship Score Examples](https://www.kerykeion.net/content/examples/relationship-score)**
**📖 Factory documentation: [RelationshipScoreFactory](https://www.kerykeion.net/content/docs/relationship_score_factory)**
## Element & Quality Distribution Strategies
`ChartDataFactory` now offers two strategies for calculating element and modality totals. The default `"weighted"` mode leans on a curated map that emphasises core factors (for example `sun`, `moon`, and `ascendant` weight 2.0, angles such as `medium_coeli` 1.5, personal planets 1.5, social planets 1.0, outers 0.5, and minor bodies 0.3–0.8). Provide `distribution_method="pure_count"` when you want every active point to contribute equally.
You can refine the weighting without rebuilding the dictionary: pass lowercase point names to `custom_distribution_weights` and use `"__default__"` to override the fallback value applied to entries that are not listed explicitly.
```python
from kerykeion import AstrologicalSubjectFactory, ChartDataFactory
subject = AstrologicalSubjectFactory.from_birth_data(
"Sample", 1986, 4, 12, 8, 45,
lng=11.3426,
lat=44.4949,
tz_str="Europe/Rome",
online=False,
)
# Equal weighting: every active point counts once
pure_data = ChartDataFactory.create_natal_chart_data(
subject,
distribution_method="pure_count",
)
# Custom emphasis: boost the Sun, soften everything else
weighted_data = ChartDataFactory.create_natal_chart_data(
subject,
distribution_method="weighted",
custom_distribution_weights={
"sun": 3.0,
"__default__": 0.75,
},
)
print(pure_data.element_distribution.fire)
print(weighted_data.element_distribution.fire)
```
All convenience helpers (`create_synastry_chart_data`, `create_transit_chart_data`, returns, and composites) forward the same keyword-only parameters, so you can keep a consistent weighting scheme across every chart type.
**📖 Element/quality distribution guide: [Distribution Documentation](https://www.kerykeion.net/content/docs/element_quality_distribution)**
## Ayanamsa (Sidereal Modes)
By default, the zodiac type is **Tropical**. To use **Sidereal**, specify the sidereal mode:
```python
johnny = AstrologicalSubjectFactory.from_birth_data(
"Johnny Depp", 1963, 6, 9, 0, 0,
lng=-87.1112,
lat=37.7719,
tz_str="America/Chicago",
online=False,
zodiac_type="Sidereal",
sidereal_mode="LAHIRI"
)
```
**📖 Sidereal mode examples: [Sidereal Modes Guide](https://www.kerykeion.net/content/examples/sidereal-modes/)**
**📖 Full list of supported sidereal modes: [SiderealMode Schema](https://www.kerykeion.net/content/docs/schemas#siderealmode)**
## House Systems
By default, | text/markdown | null | Giacomo Battaglia <kerykeion.astrology@gmail.com> | null | null | AGPL-3.0 | astrology, astrology calculations, astrology calculator, astrology library, astrology transits, astronomical algorithms, birth chart, ephemeris, houses of astrology, natal chart, planetary aspects, svg charts, synastry, zodiac, zodiac signs | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: OS Independent",
"Programming Language :: Pyt... | [] | null | null | >=3.9 | [] | [] | [] | [
"pydantic>=2.5",
"pyswisseph>=2.10.3.1",
"pytz>=2024.2",
"requests-cache>=1.2.1",
"requests>=2.32.3",
"scour>=0.38.2",
"simple-ascii-tables>=1.0.0",
"typing-extensions>=4.12.2"
] | [] | [] | [] | [
"Homepage, https://www.kerykeion.net/",
"Repository, https://github.com/g-battaglia/kerykeion"
] | uv/0.9.27 {"installer":{"name":"uv","version":"0.9.27","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T16:49:56.874788 | kerykeion-5.7.3.tar.gz | 662,198 | fb/5e/0bd1e3b9f1f302048bbf128c1590fa869bc9e71e31390283fa0fb9f562c8/kerykeion-5.7.3.tar.gz | source | sdist | null | false | 59784866ec8e6913650f017d2c5e5a89 | 92a78b1f0f0622f25d5e07b946eaf688f71e49111876ddf5706d40a59a4df63c | fb5e0bd1e3b9f1f302048bbf128c1590fa869bc9e71e31390283fa0fb9f562c8 | null | [
"LICENSE"
] | 1,845 |
2.4 | ammber | 0.1.8 | A Python package for parametrizing Gibbs free energy curves for phase-field modeling | # What is AMMBER?
The AI-assisted Microstructure Model BuildER (AMMBER) is an ongoing project at the University of Michigan.
AMMBER_python is a utility for extracting free-energy data and formatting it for use in phase-field simulation codes.
Phase-field models, which incorporate thermodynamic and kinetic data from atomistic calculations and experiments, have become a key computational tool for understanding microstructural evolution and providing a path to control and optimize morphologies and topologies of structures from nanoscale to microscales. However, due to the complexity of interactions between multiple species, these models are difficult to parameterize. In this project, we developed algorithms and software that automate and optimize the selection of thermodynamic and kinetic parameters for phase-field simulations of microstructure evolution in multicomponent systems.
Presently, the framework consists of two modules: [AMMBER_python](https://github.com/UMThorntonGroup/AMMBER_python), which is used to extract phase-field usable free energies from general data sources, and [AMMBER-PRISMS-PF](https://github.com/UMThorntonGroup/AMMBER-PRISMS-PF), which provides an open-source suite of multi-component, multi-phase-field model implementations with a simple, flexible interface for defining a system of thermodynamic and kinetic parameters.
# Quick Start Guide
### Install:
To install the AMMBER Python package, you can use `pip`. First, ensure your `pip` is up to date:
```bash
python -m pip install --upgrade pip
pip install ammber
```
#### Installing from Source:
If you want to install the package directly from the source code, follow these steps:
1. Clone the repository:
```bash
git clone https://github.com/UMThorntonGroup/AMMBER_python.git
cd AMMBER_python
```
2. Upgrade `pip` and install the package:
```bash
python -m pip install --upgrade pip
pip install .
```
#### Development Installation:
For development purposes, you can install the package in editable mode:
1. Clone the repository:
```bash
git clone https://github.com/UMThorntonGroup/AMMBER_python.git
cd AMMBER_python
```
2. Upgrade `pip` and install in editable mode:
```bash
python -m pip install --upgrade pip
pip install -e .
```
#### Dependencies:
AMMBER requires the following Python packages:
- `numpy`
- `scipy`
- `pycalphad`
These dependencies will be installed automatically when using `pip install ammber`. If you encounter issues, you can manually install them using:
```bash
pip install numpy scipy pycalphad
```
# License:
MIT License. Please see [LICENSE](LICENSE.md) for details.
# Links
[AMMBER_python Repository](https://github.com/UMThorntonGroup/AMMBER_python) <br>
[AMMBER-PRISMS-PF Repository](https://github.com/UMThorntonGroup/AMMBER-PRISMS-PF) <br>
| text/markdown | null | "W. Beck Andrews" <wband@umich.edu>, Xander Mensah <xmen@umich.edu>, Katsuyo Thornton <kthorn@umich.edu> | null | null | null | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3"
] | [] | null | null | <4,>=3.11 | [] | [] | [] | [
"numpy>=2",
"pycalphad",
"scipy"
] | [] | [] | [] | [
"Homepage, https://github.com/UMThorntongroup/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:49:52.022962 | ammber-0.1.8.tar.gz | 11,025 | 6e/e6/2ae20d3fa74994a6aeb6c9a3d5246d833cd99bf35f2af4e5f1fb364f4d0a/ammber-0.1.8.tar.gz | source | sdist | null | false | 868e258a765ecbf8880c4ee39538dcb9 | 7ecfde30b182870876a76d56d6be875463cffb78c6ec75e062fa92f6b528327e | 6ee62ae20d3fa74994a6aeb6c9a3d5246d833cd99bf35f2af4e5f1fb364f4d0a | MIT | [
"LICENSE.md"
] | 248 |
2.4 | aivectormemory | 0.2.4 | 轻量级 MCP Server,为 AI 编程助手提供跨会话持久记忆能力 | 🌐 简体中文 | [繁體中文](docs/README.zh-TW.md) | [English](docs/README.en.md) | [Español](docs/README.es.md) | [Deutsch](docs/README.de.md) | [Français](docs/README.fr.md) | [日本語](docs/README.ja.md)
<p align="center">
<h1 align="center">🧠 AIVectorMemory</h1>
<p align="center">
<strong>给 AI 编程助手装上记忆 — 跨会话持久化记忆 MCP Server</strong>
</p>
<p align="center">
<a href="https://pypi.org/project/aivectormemory/"><img src="https://img.shields.io/pypi/v/aivectormemory?color=blue&label=PyPI" alt="PyPI"></a>
<a href="https://pypi.org/project/aivectormemory/"><img src="https://img.shields.io/pypi/pyversions/aivectormemory" alt="Python"></a>
<a href="https://github.com/Edlineas/aivectormemory/blob/main/LICENSE"><img src="https://img.shields.io/badge/license-MIT-green" alt="License"></a>
<a href="https://modelcontextprotocol.io"><img src="https://img.shields.io/badge/MCP-compatible-purple" alt="MCP"></a>
</p>
</p>
---
> **问题**:AI 助手每次新会话都"失忆",反复踩同样的坑、忘记项目约定、丢失开发进度。更糟的是,为了补偿失忆,你不得不在每次对话中重复注入大量上下文,白白浪费 Token。
>
> **AIVectorMemory**:通过 MCP 协议为 AI 提供本地向量记忆库,让它记住一切 — 项目知识、踩坑记录、开发决策、工作进度 — 跨会话永不丢失。语义检索按需召回,不再全量注入,大幅降低 Token 消耗。
## ✨ 核心特性
| 特性 | 说明 |
|------|------|
| 🔍 **语义搜索** | 基于向量相似度,搜"数据库超时"能找到"MySQL 连接池踩坑" |
| 🏠 **完全本地** | ONNX Runtime 本地推理,无需 API Key,数据不出本机 |
| 🔄 **智能去重** | 余弦相似度 > 0.95 自动更新,不会重复存储 |
| 📊 **Web 看板** | 内置管理界面,3D 向量网络可视化 |
| 🔌 **全 IDE 支持** | OpenCode / Claude Code / Cursor / Kiro / Windsurf / VSCode / Trae 等 |
| 📁 **项目隔离** | 多项目共用一个 DB,通过 project_dir 自动隔离 |
| 🏷️ **标签体系** | 记忆分类管理,支持标签搜索、重命名、合并 |
| 💰 **节省 Token** | 语义检索按需召回,替代全量上下文注入,减少 50%+ 重复 Token 消耗 |
| 📋 **问题追踪** | 轻量级 issue tracker,AI 自动记录和归档 |
| 🔐 **Web 认证** | 看板支持 Token 认证,防止未授权访问 |
| ⚡ **Embedding 缓存** | 相同内容不重复计算向量,提升写入性能 |
| 📤 **导出/导入** | 记忆数据 JSON 导出导入,支持迁移和备份 |
| 🎯 **操作反馈** | Toast 提示、空状态引导,交互体验完整 |
| ➕ **看板添加项目** | 前端直接添加项目,支持目录浏览器选择 |
## 🏗️ 架构
```
┌─────────────────────────────────────────────────┐
│ AI IDE │
│ OpenCode / Claude Code / Cursor / Kiro / ... │
└──────────────────────┬──────────────────────────┘
│ MCP Protocol (stdio)
┌──────────────────────▼──────────────────────────┐
│ AIVectorMemory Server │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │ remember │ │ recall │ │ auto_save │ │
│ │ forget │ │ digest │ │ status/track │ │
│ └────┬─────┘ └────┬─────┘ └───────┬──────────┘ │
│ │ │ │ │
│ ┌────▼────────────▼───────────────▼──────────┐ │
│ │ Embedding Engine (ONNX) │ │
│ │ intfloat/multilingual-e5-small │ │
│ └────────────────────┬───────────────────────┘ │
│ │ │
│ ┌────────────────────▼───────────────────────┐ │
│ │ SQLite + sqlite-vec (向量索引) │ │
│ │ ~/.aivectormemory/memory.db │ │
│ └────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────┘
```
## 🚀 快速开始
### 方式一:pip 安装
```bash
pip install aivectormemory
pip install --upgrade aivectormemory # 升级到最新版
cd /path/to/your/project
run install # 交互式选择 IDE,一键配置
```
> **macOS 用户注意**:
> - 遇到 `externally-managed-environment` 错误,加 `--break-system-packages`
> - 遇到 `enable_load_extension` 错误,说明当前 Python 不支持 SQLite 扩展加载(macOS 自带 Python 和 python.org 官方安装包均不支持),请改用 Homebrew Python:
> ```bash
> brew install python
> /opt/homebrew/bin/python3 -m pip install aivectormemory
> ```
### 方式二:uvx 运行(零安装)
```bash
cd /path/to/your/project
uvx aivectormemory install
```
### 方式三:手动配置
```json
{
"mcpServers": {
"aivectormemory": {
"command": "run",
"args": ["--project-dir", "/path/to/your/project"]
}
}
}
```
<details>
<summary>📍 各 IDE 配置文件位置</summary>
| IDE | 配置文件路径 |
|-----|------------|
| Kiro | `.kiro/settings/mcp.json` |
| Cursor | `.cursor/mcp.json` |
| Claude Code | `.mcp.json` |
| Windsurf | `.windsurf/mcp.json` |
| VSCode | `.vscode/mcp.json` |
| Trae | `.trae/mcp.json` |
| OpenCode | `opencode.json` |
| Claude Desktop | `~/Library/Application Support/Claude/claude_desktop_config.json` |
</details>
## 🛠️ 7 个 MCP 工具
### `remember` — 存入记忆
```
content (string, 必填) 记忆内容,Markdown 格式
tags (string[], 必填) 标签,如 ["踩坑", "python"]
scope (string) "project"(默认)/ "user"(跨项目)
```
相似度 > 0.95 自动更新已有记忆,不重复存储。
### `recall` — 语义搜索
```
query (string) 语义搜索关键词
tags (string[]) 标签精确过滤
scope (string) "project" / "user" / "all"
top_k (integer) 返回数量,默认 5
```
向量相似度匹配,用词不同也能找到相关记忆。
### `forget` — 删除记忆
```
memory_id (string) 单个 ID
memory_ids (string[]) 批量 ID
```
### `status` — 会话状态
```
state (object, 可选) 不传=读取,传=更新
is_blocked, block_reason, current_task,
next_step, progress[], recent_changes[], pending[]
```
跨会话保持工作进度,新会话自动恢复上下文。
### `track` — 问题跟踪
```
action (string) "create" / "update" / "archive" / "list"
title (string) 问题标题
issue_id (integer) 问题 ID
status (string) "pending" / "in_progress" / "completed"
content (string) 排查内容
```
### `digest` — 记忆摘要
```
scope (string) 范围
since_sessions (integer) 最近 N 次会话
tags (string[]) 标签过滤
```
### `auto_save` — 自动保存
```
decisions[] 关键决策
modifications[] 文件修改摘要
pitfalls[] 踩坑记录
todos[] 待办事项
```
每次对话结束自动分类存储,打标签,去重。
## 📊 Web 看板
```bash
run web --port 9080
run web --port 9080 --quiet # 屏蔽请求日志
run web --port 9080 --quiet --daemon # 后台运行(macOS/Linux)
```
浏览器访问 `http://localhost:9080`
- 多项目切换,记忆浏览/搜索/编辑/删除/导出/导入
- 语义搜索(向量相似度匹配)
- 项目数据一键删除
- 会话状态、问题追踪
- 标签管理(重命名、合并、批量删除)
- Token 认证保护
- 3D 向量记忆网络可视化
- 🌐 多语言支持(简体中文 / 繁體中文 / English / Español / Deutsch / Français / 日本語)
<p align="center">
<img src="docs/dashboard-projects.png" alt="项目选择" width="100%">
<br>
<em>项目选择</em>
</p>
<p align="center">
<img src="docs/dashboard-overview.png" alt="统计概览 & 向量网络可视化" width="100%">
<br>
<em>统计概览 & 向量网络可视化</em>
</p>
## ⚡ 配合 Steering 规则
AIVectorMemory 是存储层,通过 Steering 规则告诉 AI **何时、如何**调用这些工具。
运行 `run install` 会自动生成 Steering 规则和 Hooks 配置,无需手动编写。
| IDE | Steering 位置 | Hooks |
|-----|--------------|-------|
| Kiro | `.kiro/steering/aivectormemory.md` | `.kiro/hooks/*.hook` |
| Cursor | `.cursor/rules/aivectormemory.md` | `.cursor/hooks.json` |
| Claude Code | `CLAUDE.md`(追加) | `.claude/settings.json` |
| Windsurf | `.windsurf/rules/aivectormemory.md` | `.windsurf/hooks.json` |
| VSCode | `.github/copilot-instructions.md`(追加) | — |
| Trae | `.trae/rules/aivectormemory.md` | — |
| OpenCode | `AGENTS.md`(追加) | `.opencode/plugins/*.js` |
<details>
<summary>📋 Steering 规则范例(自动生成)</summary>
```markdown
# AIVectorMemory - 跨会话持久记忆
## 启动检查
每次新会话开始时,按以下顺序执行:
1. 调用 `status`(不传参数)读取会话状态,检查 `is_blocked` 和 `block_reason`
2. 调用 `recall`(tags: ["项目知识"], scope: "project")加载项目知识
3. 调用 `recall`(tags: ["preference"], scope: "user")加载用户偏好
## 何时调用
- 新会话开始时:调用 `status` 读取上次的工作状态
- 遇到踩坑/技术要点时:调用 `remember` 记录,标签加 "踩坑"
- 需要查找历史经验时:调用 `recall` 语义搜索
- 发现 bug 或待处理事项时:调用 `track`(action: create)
- 任务进度变化时:调用 `status`(传 state 参数)更新
- 对话结束前:调用 `auto_save` 保存本次对话
## 会话状态管理
status 字段:is_blocked, block_reason, current_task, next_step,
progress[], recent_changes[], pending[]
⚠️ **阻塞防护**:提出方案等待确认、修复完成等待验证时,必须同步调用 `status` 设置 `is_blocked: true`。这可以防止会话转移时新会话误判为"已确认"而擅自执行。
## 问题追踪
1. `track create` → 记录问题
2. `track update` → 更新排查内容
3. `track archive` → 归档已解决问题
```
</details>
<details>
<summary>🔗 Hooks 配置范例(Kiro 专属,自动生成)</summary>
会话结束自动保存(`.kiro/hooks/auto-save-session.kiro.hook`):
```json
{
"enabled": true,
"name": "会话结束自动保存",
"version": "1",
"when": { "type": "agentStop" },
"then": {
"type": "askAgent",
"prompt": "调用 auto_save,将本次对话的决策、修改、踩坑、待办分类保存"
}
}
```
开发流程检查(`.kiro/hooks/dev-workflow-check.kiro.hook`):
```json
{
"enabled": true,
"name": "开发流程检查",
"version": "1",
"when": { "type": "promptSubmit" },
"then": {
"type": "askAgent",
"prompt": "核心原则:操作前验证、禁止盲目测试、自测通过才能说完成"
}
}
```
</details>
## 🇨🇳 中国大陆用户
首次运行自动下载 Embedding 模型(~200MB),如果慢:
```bash
export HF_ENDPOINT=https://hf-mirror.com
```
或在 MCP 配置中加 env:
```json
{
"env": { "HF_ENDPOINT": "https://hf-mirror.com" }
}
```
## 📦 技术栈
| 组件 | 技术 |
|------|------|
| 运行时 | Python >= 3.10 |
| 向量数据库 | SQLite + sqlite-vec |
| Embedding | ONNX Runtime + intfloat/multilingual-e5-small |
| 分词器 | HuggingFace Tokenizers |
| 协议 | Model Context Protocol (MCP) |
| Web | 原生 HTTPServer + Vanilla JS |
## 📋 更新日志
### v0.2.4
- 🔇 Stop hook prompt 改为直接指令,消除 Claude Code 重复回复
- 🛡️ Steering 规则 auto_save 规范增加短路防护,会话结束场景跳过其他规则
- 🐛 `_copy_check_track_script` 幂等性修复(返回变更状态避免误报"已同步")
- 🐛 issue_repo delete 中 `row.get()` 对 `sqlite3.Row` 不兼容修复(改用 `row.keys()` 判断)
- 🐛 Web 看板项目选择页面滚动修复(项目多时无法滚动)
- 🐛 Web 看板 CSS 污染修复(strReplace 全局替换导致 6 处样式异常)
- 🔄 Web 看板所有 confirm() 弹窗替换为自定义 showConfirm 模态框(记忆/问题/标签/项目删除)
- 🔄 Web 看板删除操作增加 API 错误响应处理(toast 提示替代 alert)
- 🧹 `.gitignore` 补充 `.devmemory/` 旧版残留目录忽略规则
- 🧪 pytest 临时项目数据库残留自动清理(conftest.py session fixture)
### v0.2.3
- 🛡️ PreToolUse Hook:Edit/Write 前强制检查 track issue,无活跃问题则拒绝执行(Claude Code / Kiro / OpenCode 三端支持)
- 🔌 OpenCode 插件升级为 `@opencode-ai/plugin` SDK 格式(tool.execute.before hook)
- 🔧 `run install` 自动部署 check_track.sh 检查脚本并动态填充路径
- 🐛 issue_repo archive/delete 中 `row.get()` 对 `sqlite3.Row` 不兼容修复
- 🐛 session_id 从 DB 读取最新值再递增,避免多实例竞态
- 🐛 track date 参数格式校验(YYYY-MM-DD)+ issue_id 类型校验
- 🐛 Web API 请求解析安全加固(Content-Length 校验 + 10MB 上限 + JSON 异常捕获)
- 🐛 Tag 过滤 scope 逻辑修复(`filter_dir is not None` 替代 falsy 判断)
- 🐛 Export 向量数据 struct.unpack 字节长度校验
- 🐛 Schema 版本化迁移(schema_version 表 + v1/v2/v3 增量迁移)
- 🐛 `__init__.py` 版本号同步修复
### v0.2.2
- 🔇 Web 看板 `--quiet` 参数屏蔽请求日志
- 🔄 Web 看板 `--daemon` 参数后台运行(macOS/Linux)
- 🔧 `run install` MCP 配置生成修复(sys.executable + 完整字段)
- 📋 问题跟踪增删改归档(Web 看板添加/编辑/归档/删除 + 记忆关联)
- 👆 全部列表页点击行任意位置弹出编辑弹窗(记忆/问题/标签)
- 🛡️ Hook 链式触发防护(agentStop + promptSubmit 组合不再重复注入规则)
- 🔒 会话延续/上下文转移时阻塞规则强制生效(跨会话必须重新确认)
### v0.2.1
- ➕ Web 看板前端添加项目(目录浏览器 + 手动输入)
- 🏷️ 标签跨项目污染修复(标签操作限定当前项目 + 全局记忆范围)
- 📐 弹窗分页省略号截断 + 弹窗宽度 80%
- 🔌 OpenCode install 自动生成 auto_save 插件(session.idle 事件触发)
- 🔗 Claude Code / Cursor / Windsurf install 自动生成 Hooks 配置(会话结束自动保存)
- 🎯 Web 看板交互体验补全(Toast 操作反馈、空状态引导、导出/导入工具栏)
- 🔧 统计概览卡片点击跳转(点击记忆数/问题数直接弹窗查看)
- 🏷️ 标签管理页区分项目/全局标签来源(📁/🌐 标记)
- 🏷️ 项目卡片标签数合并全局记忆标签
### v0.2.0
- 🔐 Web 看板 Token 认证机制
- ⚡ Embedding 向量缓存,相同内容不重复计算
- 🔍 recall 支持 query + tags 组合查询
- 🗑️ forget 支持批量删除(memory_ids 参数)
- 📤 记忆导出/导入(JSON 格式)
- 🔎 Web 看板语义搜索
- 🗂️ Web 看板项目删除按钮
- 📊 Web 看板性能优化(消除全表扫描)
- 🧠 digest 智能压缩
- 💾 session_id 持久化
- 📏 content 长度限制保护
- 🏷️ version 动态引用(不再硬编码)
### v0.1.x
- 初始版本:7 个 MCP 工具、Web 看板、3D 向量可视化、多语言支持
## License
MIT
| text/markdown | AIVectorMemory Contributors | null | null | null | null | ai, embedding, llm, mcp, memory, sqlite | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Develo... | [] | null | null | >=3.10 | [] | [] | [] | [
"huggingface-hub>=0.20",
"numpy>=1.24",
"onnxruntime>=1.16",
"sqlite-vec>=0.1.0",
"tokenizers>=0.15"
] | [] | [] | [] | [
"Homepage, https://github.com/Edlineas/aivectormemory",
"Repository, https://github.com/Edlineas/aivectormemory"
] | twine/6.2.0 CPython/3.12.10 | 2026-02-18T16:49:51.865865 | aivectormemory-0.2.4.tar.gz | 915,313 | 68/eb/8297906f9025b47e41f823acaf8e00047e207bbb4c23faf7cfe6acecfbe6/aivectormemory-0.2.4.tar.gz | source | sdist | null | false | 507b20fec1e3b18e79fa73daafaf8176 | 3ecec222c55989691c1edd68de79f05ac9af01503bf9ef386aaffddb73acadee | 68eb8297906f9025b47e41f823acaf8e00047e207bbb4c23faf7cfe6acecfbe6 | MIT | [] | 264 |
2.4 | PMF-toolkits | 0.2.1 | EPA PMF5 output analysis tools in Python | # PMF_toolkits
Python tools for handling, analyzing and visualizing EPA PMF5.0 outputs from receptor modeling studies.
## Installation
Install from PyPI (not yet available):
```bash
pip install PMF_toolkits
```
Or install the development version from GitHub:
```bash
pip install git+https://github.com/DinhNgocThuyVy/PMF_toolkits.git
```
## Quick Start
```python
from PMF_toolkits import PMF
# Initialize PMF with Excel outputs
pmf = PMF(site="urban_site", reader="xlsx", BDIR="pmf_outputs/")
# Read all data
pmf.read.read_all()
# Plot factor profiles
pmf.visualization.plot_factor_profiles()
```
## Citation
If you use PMF_toolkits in your research, please cite:
```
Dinh, N.T.V. (2025). PMF_toolkits: Python tools for analysis of Positive Matrix Factorization results.
GitHub repository: https://github.com/DinhNgocThuyVy/PMF_toolkits
```
| text/markdown | Dinh Ngoc Thuy Vy | Dinh Ngoc Thuy Vy <dinhvy2101@gmail.com> | null | null | MIT | null | [] | [] | https://github.com/DinhNgocThuyVy/PMF_toolkits | null | >=3.8 | [] | [] | [] | [
"pandas>=1.3.0",
"numpy>=1.20.0",
"matplotlib>=3.4.0",
"seaborn>=0.11.0",
"scipy>=1.7.0",
"scikit-learn>=1.0.0",
"openpyxl>=3.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/DinhNgocThuyVy/PMF_toolkits",
"Repository, https://github.com/DinhNgocThuyVy/PMF_toolkits.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:48:25.293271 | pmf_toolkits-0.2.1.tar.gz | 78,961 | d7/9f/9c6021ab5d38a3b71dabd48474b86b6667b9764e7acb4b9edd6a82d26f67/pmf_toolkits-0.2.1.tar.gz | source | sdist | null | false | c4552545787a0c3ffe0a8403983611d7 | 1aaf4fbeee157f6c66a6fe34b045cff30b02b41c7f8818bb6471ee1eb98bc039 | d79f9c6021ab5d38a3b71dabd48474b86b6667b9764e7acb4b9edd6a82d26f67 | null | [
"LICENSE.md"
] | 0 |
2.4 | circuitpython-ticstepper | 2.0.4 | Driver for the TIC stepper motor drivers | Introduction
============
.. image:: https://readthedocs.org/projects/circuitpython-ticstepper/badge/?version=latest
:target: https://circuitpython-ticstepper.readthedocs.io/
:alt: Documentation Status
.. image:: https://img.shields.io/discord/327254708534116352.svg
:target: https://adafru.it/discord
:alt: Discord
.. image:: https://github.com/tekktrik/CircuitPython_TicStepper/workflows/Build%20CI/badge.svg
:target: https://github.com/tekktrik/CircuitPython_TicStepper/actions
:alt: Build Status
.. image:: https://img.shields.io/badge/code%20style-ruff-000000.svg
:target: https://github.com/astral-sh/ruff
:alt: Code Style: ruff
.. image:: https://img.shields.io/badge/License-MIT-yellow.svg
:target: https://opensource.org/licenses/MIT
:alt: License: MIT
.. image:: https://img.shields.io/badge/Maintained%3F-yes-green.svg
:target: https://github.com/tekktrik/CircuitPython_CSV
:alt: Maintained: Yes
Driver for the TIC stepper motor drivers
Dependencies
============
This driver depends on:
* `Adafruit CircuitPython <https://github.com/adafruit/circuitpython>`_
* `Bus Device <https://github.com/adafruit/Adafruit_CircuitPython_BusDevice>`_
* `Register <https://github.com/adafruit/Adafruit_CircuitPython_Register>`_
Please ensure all dependencies are available on the CircuitPython filesystem.
This is easily achieved by downloading
`the Adafruit library and driver bundle <https://circuitpython.org/libraries>`_
or individual libraries can be installed using
`circup <https://github.com/adafruit/circup>`_.
Installing from PyPI
=====================
On supported GNU/Linux systems like the Raspberry Pi, you can install the driver locally `from
PyPI <https://pypi.org/project/circuitpython-ticstepper/>`_.
To install for current user:
.. code-block:: shell
pip3 install circuitpython-ticstepper
To install system-wide (this may be required in some cases):
.. code-block:: shell
sudo pip3 install circuitpython-ticstepper
To install in a virtual environment in your current project:
.. code-block:: shell
mkdir project-name && cd project-name
python3 -m venv .env
source .env/bin/activate
pip3 install circuitpython-ticstepper
Installing to a Connected CircuitPython Device with Circup
==========================================================
Make sure that you have ``circup`` installed in your Python environment.
Install it with the following command if necessary:
.. code-block:: shell
pip3 install circup
With ``circup`` installed and your CircuitPython device connected use the
following command to install:
.. code-block:: shell
circup install ticstepper
Or the following command to update an existing version:
.. code-block:: shell
circup update
Usage Example
=============
See examples in the `examples/` folder
Documentation
=============
API documentation for this library can be found on `Read the Docs <https://circuitpython-ticstepper.readthedocs.io/>`_.
For information on building library documentation, please check out
`this guide <https://learn.adafruit.com/creating-and-sharing-a-circuitpython-library/sharing-our-docs-on-readthedocs#sphinx-5-1>`_.
Contributing
============
Contributions are welcome! Please read our `Code of Conduct
<https://github.com/tekktrik/CircuitPython_TicStepper/blob/HEAD/CODE_OF_CONDUCT.md>`_
before contributing to help this project stay welcoming.
| text/x-rst | null | Alec Delaney <tekktrik@gmail.com> | null | null | null | adafruit, blinka, circuitpython, micropython, ticstepper, tic, stepper, motor | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"Topic :: System :: Hardware",
"Programming Language :: Python :: 3"
] | [] | null | null | null | [] | [] | [] | [
"Adafruit-Blinka",
"adafruit-circuitpython-busdevice",
"adafruit-circuitpython-register",
"pre-commit~=4.1; extra == \"optional\""
] | [] | [] | [] | [
"Homepage, https://github.com/tekktrik/CircuitPython_TicStepper",
"Repository, https://github.com/tekktrik/CircuitPython_TicStepper",
"Doumentation, https://circuitpython-ticstepper.readthedocs.io"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T16:48:15.378670 | circuitpython_ticstepper-2.0.4.tar.gz | 24,927 | dc/dc/51f0034a28989de695a5c152f105faff2b7e581f8da61c9f36c90a6f885b/circuitpython_ticstepper-2.0.4.tar.gz | source | sdist | null | false | be61619a093ddeb344b05ea52262083a | fd2e5ec8d1bbadbface0e2f4eee097fb91770a37deecd77201e9ce3f11bf3917 | dcdc51f0034a28989de695a5c152f105faff2b7e581f8da61c9f36c90a6f885b | MIT | [
"LICENSE"
] | 251 |
2.4 | TileStats | 0.1.1 | Python package with functions for hexagonal and rectangular tile binning of 2D data. | # TileStats, Python package
Python package for statistics over 2D tillings. (Tile binning, aggregation functions application, etc.)
The package is Python implementation of the functions [AAp1], or [AAf1] and [AAf2].
See also the corresponding Java package [AAp2].
Detailed examples are given in the notebook ["TileStats-usage.ipynb"](./docs/TileStats-usage.ipynb).
-------
## References
[AAf1] Anton Antonov,
[HextileBins](https://resources.wolframcloud.com/FunctionRepository/resources/HextileBins/),
(2020),
[Wolfram Function Repository](https://resources.wolframcloud.com/FunctionRepository).
[AAf2] Anton Antonov,
[TileBins](https://resources.wolframcloud.com/FunctionRepository/resources/TileBins/),
(2020),
[Wolfram Function Repository](https://resources.wolframcloud.com/FunctionRepository).
[AAp1] Anton Antonov,
[TileStats](https://resources.wolframcloud.com/PacletRepository/resources/AntonAntonov/TileStats/),
(2023),
[Wolfram Language Paclet Repository](https://resources.wolframcloud.com/PacletRepository).
[AAp2] Anton Antonov, [TileStats, Java package](https://github.com/antononcube/Java-TileStats), (2023), [GitHub/antononcube](https://github.com/antononcube).
| text/markdown | Anton Antonov | null | null | null | MIT License
Copyright (c) 2026 Anton Antonov
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-18T16:48:01.882439 | tilestats-0.1.1.tar.gz | 8,063 | 92/08/e8e47b5aa5229b7bad3943b159535282412a16c92ab466ab370b1347e564/tilestats-0.1.1.tar.gz | source | sdist | null | false | c6983047ece7ceeceba0af026452b907 | 3152ef0284fff11765a8453bc4e26a1c8216b016a48b7a53943feb43286849a3 | 9208e8e47b5aa5229b7bad3943b159535282412a16c92ab466ab370b1347e564 | null | [
"LICENSE"
] | 0 |
2.4 | swiftagents | 0.1.3 | Superfast logprob-native agent runtime | # swiftagents
Superfast, logprob-native, async-first agent runtime.
## Why swiftagents
- Logprob-native routing and uncertainty
- Tool-agnostic, model-agnostic (strict about logprobs)
- Async-first with bounded speculation (max 2 tools)
- Cost-aware, cacheable, and observable
- Optional judge pipeline
## Install
```bash
pip install swiftagents
```
Local development:
```bash
pip install -e .[dev]
```
## Quickstart
```python
import asyncio
from swiftagents.core import AgentRuntime, AgentConfig, MockModelClient, ToolRegistry, ToolSpec
def web_search(query: str) -> dict:
# Put any code here: Pinecone, DB, APIs, etc.
return {"snippet": "Example result"}
async def main():
client = MockModelClient()
client.queue_text("TOOL=WEB")
client.queue_text("Answer using web evidence")
spec = ToolSpec(
name="WEB",
description="Search the web",
input_schema={"type": "object", "properties": {"query": {"type": "string"}}, "required": ["query"]},
example_calls=[],
cost_hint="medium",
latency_hint_ms=200,
side_effects=False,
cacheable=True,
cancellable=True,
)
tools = ToolRegistry()
tools.register_function(web_search, spec)
runtime = AgentRuntime(client=client, tools=tools, config=AgentConfig())
result = await runtime.run("Find the latest overview")
print(result.answer)
asyncio.run(main())
```
## Core concepts
### Model clients (logprobs required)
`swiftagents` requires token-level logprobs for routing. If a backend cannot provide them, it hard-errors.
Supported clients:
- `OpenAIChatCompletionsClient`
- `VLLMOpenAICompatibleClient`
- `MockModelClient` (tests and examples)
### Tools
Tools are async callables with a `ToolSpec` and return `ToolResult`.
```python
from swiftagents.core import ToolSpec, ToolResult
class MyTool:
def __init__(self):
self.spec = ToolSpec(
name="RAG",
description="Retrieve from docs",
input_schema={"type": "object", "properties": {"query": {"type": "string"}}, "required": ["query"]},
example_calls=[],
cost_hint="medium",
latency_hint_ms=200,
side_effects=False,
cacheable=True,
cancellable=True,
)
async def __call__(self, **kwargs):
return ToolResult(ok=True, data={"docs": []}, error=None, metadata={})
```
### Register functions directly (no tool classes)
Use any code inside a function (sync or async) and register it with a `ToolSpec`.
```python
from swiftagents.core import ToolRegistry, ToolSpec, ToolResult
def pinecone_search(query: str) -> dict:
# Put any code here (Pinecone, DB, API, etc.)
# return raw data or ToolResult
return {"matches": [{"id": "doc1", "score": 0.92}]}
spec = ToolSpec(
name="PINECONE",
description="Vector search over Pinecone",
input_schema={"type": "object", "properties": {"query": {"type": "string"}}, "required": ["query"]},
example_calls=[],
cost_hint="medium",
latency_hint_ms=200,
side_effects=False,
cacheable=True,
cancellable=True,
)
registry = ToolRegistry()
registry.register_function(pinecone_search, spec)
```
If you prefer decorators:
```python
from swiftagents.core import ToolRegistry, ToolSpec, tool
spec = ToolSpec(
name="PINECONE",
description="Vector search over Pinecone",
input_schema={"type": "object", "properties": {"query": {"type": "string"}}, "required": ["query"]},
example_calls=[],
cost_hint="medium",
latency_hint_ms=200,
side_effects=False,
cacheable=True,
cancellable=True,
)
@tool(spec)
async def pinecone_tool(query: str):
return {"matches": [{"id": "doc1", "score": 0.92}]}
registry = ToolRegistry()
registry.register(pinecone_tool)
```
### Routing (logprob-gated)
Routing prompts the same LLM to output `TOOL=<LABEL>` where `LABEL` is `NONE` or a shortlist tool name.
Confidence is computed using logprobs, entropy, and margin. Low confidence triggers bounded speculation.
### Multi-tool routing modes
`AgentConfig.multi_tool_mode` controls how the runtime selects multiple tools:
- `single`: default single-label routing (bounded speculation when uncertain).
- `multi_label`: pick multiple tools from one router call using logprob thresholds.
- `multi_intent`: lightweight heuristic splitting, then route each segment.
- `decompose`: logprob-gated split decision + LLM decomposition into sub-questions, then route each.
All multi-tool modes merge tool evidence and produce one final answer.
### Judge
`Judge` behaves like a tool. It can be disabled, run a cheap LLM, and optionally escalate to a stronger LLM.
It can also run deterministic stage0 checks.
### Caching and observability
- Tool and model decision caches with TTL
- Structured trace events
- Token usage metrics and wasted work ratio
## Examples
```bash
python -m swiftagents.examples.tool_selection
python -m swiftagents.examples.speculative_execution_demo
python -m swiftagents.examples.function_tool_demo
```
## Benchmarks
```bash
python -m swiftagents.benchmarks.run_benchmark
```
## Tests
```bash
pytest
```
## Design notes
- The router is logprob-native; labels should be compact and stable (prefer short uppercase names).
- Speculation is bounded to two tools and never speculative for side-effecting tools unless explicitly allowed.
- All runtime stages are async-first.
| text/markdown | swiftagents contributors | null | null | null | Apache-2.0 | agents, llm, logprobs, async, tools | [
"Development Status :: 3 - Alpha",
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.24",
"pydantic>=2.0",
"pytest>=7.4; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.19 | 2026-02-18T16:47:16.910295 | swiftagents-0.1.3.tar.gz | 27,576 | 47/f9/553e89f105563eb2c96d265234481d13eca320955b8e43fbaf85f6ef0406/swiftagents-0.1.3.tar.gz | source | sdist | null | false | 16bc2348a130646856dd995d0c5d1bdc | 13c7b94109d2a3fe389905021343cd95b08e795bf49bd7f6e30cb62cf0c52f18 | 47f9553e89f105563eb2c96d265234481d13eca320955b8e43fbaf85f6ef0406 | null | [
"LICENSE"
] | 244 |
2.4 | caldav-event-pusher | 0.1.1 | Push (or update) events to a CalDAV calendar | # 📅 CalDAV Event Pusher
This is a tool to automate bulk creation and updates of events on a CalDAV calendar server such as [Radicale](https://radicale.org).
You give it some JSON mapping an arbitrary unique ID to VEVENT keys and it'll update existing events on the server or create new events:
`myevents.json`:
```json
{
"myevent-1234": {
"SUMMARY": "My Event 1234",
"DTSTART": "20260216T104500Z",
"DTEND": "20260216T121500Z"
},
"myevent-2345": {
"SUMMARY": "My Event 2345",
"LOCATION": "here and there",
"DTSTART": "20260217T163000Z",
"DTEND": "20260217T183000Z"
}
}
```
`credentials.sh`:
```bash
export CALDAV_USER=myuser
export CALDAV_PASSWORD=mypassword
export CALDAV_SERVER=https://caldav.myserver.de
```
```bash
> source credentials.sh # source credentials environment variables (to not have password in shell history)
> caldav-event-pusher --calendar uas --eventsfile myevents.json --dry-run # first check changes, then remove the --dry-run
...
╭─────────────────────── ✨ New event 'myevent-1234' ───────────────────────╮
│ ➕ UID → b19c122d-eead-4de7-8f69-a3ac34450e14 │
│ ➕ SUMMARY → My Event 1234 │
│ ➕ DTSTART → 2026-02-16T10:45:00+00:00 │
│ ➕ DTEND → 2026-02-16T12:15:00+00:00 │
│ ➕ X-CALDAV-EVENT-PUSHER-ID → myevent-1234 │
│ ➕ LAST-MODIFIED → 2026-02-16T14:50:35.214112+00:00 │
│ ➕ DTSTAMP → 2026-02-16T14:50:35.214112+00:00 │
╰───────────────────────────────────────────────────────────────────────────╯
╭─────────────────────── ✨ New event 'myevent-2345' ───────────────────────╮
│ ➕ UID → 9f29985c-7db1-47b2-bd21-0664349eba4b │
│ ➕ SUMMARY → My Event 2345 │
│ ➕ LOCATION → here and there │
│ ➕ DTSTART → 2026-02-17T16:30:00+00:00 │
│ ➕ DTEND → 2026-02-17T18:30:00+00:00 │
│ ➕ X-CALDAV-EVENT-PUSHER-ID → myevent-2345 │
│ ➕ LAST-MODIFIED → 2026-02-16T14:50:35.224139+00:00 │
│ ➕ DTSTAMP → 2026-02-16T14:50:35.224139+00:00 │
╰───────────────────────────────────────────────────────────────────────────╯
...
# If you uploaded, then change myevents.json, and rerun:
> caldav-event-pusher --calendar uas --eventsfile myevents.json --dry-run # first check changes, then remove the --dry-run
╭────────────── 📝 Changes to 'myevent-2345' ───────────────╮
│ 📝 LOCATION here and there → that location │
│ 📝 SUMMARY My Event 2345 → My specific Event 2345 │
╰───────────────────────────────────────────────────────────╯
```
| text/markdown | null | Yann Büchau <nobodyinperson@posteo.de> | null | null | null | caldav, calendar | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"caldav>=2.2.6",
"dictdiffer>=0.9.0",
"icalendar>=6.3.2",
"isodate>=0.7.2",
"rich>=14.3.2"
] | [] | [] | [] | [
"repository, https://gitlab.com/nobodyinperson/caldav-event-pusher",
"issues, https://gitlab.com/nobodyinperson/caldav-event-pusher/-/issues"
] | uv/0.9.13 {"installer":{"name":"uv","version":"0.9.13"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"NixOS","version":"25.11","id":"xantusia","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T16:47:14.353727 | caldav_event_pusher-0.1.1-py3-none-any.whl | 20,798 | 1c/b2/c31c883e0fdb7b340010f4878a0e6ec996accd418a8aa330b6d1db50426a/caldav_event_pusher-0.1.1-py3-none-any.whl | py3 | bdist_wheel | null | false | cfca2ee71ef853a6125d98b96c285b0c | 9bb1754b318cd9710d3f3a7f9c73dfbadbc3a6c46dc706759815d2e8a5244873 | 1cb2c31c883e0fdb7b340010f4878a0e6ec996accd418a8aa330b6d1db50426a | GPL-3.0-or-later | [
"LICENSE"
] | 247 |
2.4 | pythontk | 0.7.78 | A modular Python toolkit providing utilities for file handling, string processing, iteration, math operations, and more. | [](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/pythontk/)
[](https://www.python.org/)
[](test/)
# pythontk
<!-- short_description_start -->
*A Python utility library for game development, DCC pipelines, and technical art workflows. Features texture processing, PBR conversion, batch processing, structured logging, and utilities designed for Maya/3ds Max pipelines.*
<!-- short_description_end -->
## Installation
```bash
pip install pythontk
```
**Optional Dependencies:**
- `Pillow` – Required for image/texture operations
- `numpy` – Required for math and image operations
- `FFmpeg` – Required for video utilities
---
## Core Features
### LoggingMixin
Add structured logging to any class with custom log levels, spam prevention, and formatted output:
```python
import pythontk as ptk
class MyProcessor(ptk.LoggingMixin):
def process(self):
self.logger.info("Starting process")
self.logger.success("Task completed") # Custom level
self.logger.result("Output: 42") # Custom level
self.logger.notice("Check results") # Custom level
# Prevent log spam – only logs once per 5 minutes
self.logger.error_once("Connection failed - retrying")
# Formatted box output
self.logger.log_box("Summary", ["Files: 10", "Errors: 0"])
# ╔══════════════════╗
# ║ Summary ║
# ╟──────────────────╢
# ║ Files: 10 ║
# ║ Errors: 0 ║
# ╚══════════════════╝
# Configure
MyProcessor.logger.setLevel("DEBUG")
MyProcessor.logger.add_file_handler("process.log")
MyProcessor.logger.set_log_prefix("[MyApp] ")
MyProcessor.logger.log_timestamp = "%H:%M:%S"
```
### @listify Decorator
Make any function handle both single items and lists, with optional multi-threading:
```python
@ptk.CoreUtils.listify(threading=True)
def process_texture(filepath):
return expensive_operation(filepath)
# Automatically handles single or multiple inputs
process_texture("texture.png") # Returns single result
process_texture(["a.png", "b.png", "c.png"]) # Returns list (parallelized)
```
### Directory Traversal with Filtering
```python
files = ptk.get_dir_contents(
"/path/to/project",
content="filepath", # Options: file, filename, filepath, dir, dirpath
recursive=True,
inc_files=["*.py", "*.pyw"],
exc_files=["*test*", "*_backup*"],
exc_dirs=["__pycache__", ".git", "venv"]
)
# Group results by type
contents = ptk.get_dir_contents(
"/textures",
content=["filepath", "dirpath"],
group_by_type=True
)
# Returns: {'filepath': [...], 'dirpath': [...]}
```
### Pattern Filtering
Filter lists or dictionaries using shell-style wildcards:
```python
ptk.filter_list(
["mesh_main", "mesh_backup", "mesh_LOD0", "cube_old"],
inc=["mesh_*", "cube_*"],
exc=["*_backup", "*_old"]
)
# Returns: ['mesh_main', 'mesh_LOD0']
ptk.filter_dict(
{"mesh_body": obj1, "mesh_head": obj2, "light_key": obj3},
inc=["mesh_*"],
keys=True
)
# Returns: {'mesh_body': obj1, 'mesh_head': obj2}
```
---
## Texture & Image Processing
### Channel Packing
Pack grayscale maps into RGBA channels for game engines:
```python
ptk.ImgUtils.pack_channels(
channel_files={"R": "ao.png", "G": "roughness.png", "B": "metallic.png"},
output_path="packed_ORM.png"
)
ptk.ImgUtils.pack_channels(
channel_files={"R": "metallic.png", "G": "roughness.png", "B": "ao.png", "A": "height.png"},
output_path="packed_MRAH.tga",
output_format="TGA"
)
```
### PBR Conversion
Convert Specular/Glossiness to Metal/Roughness:
```python
base_color, metallic, roughness = ptk.ImgUtils.convert_spec_gloss_to_pbr(
specular_map="specular.png",
glossiness_map="gloss.png",
diffuse_map="diffuse.png"
)
```
### Normal Map Generation
```python
ptk.ImgUtils.convert_bump_to_normal(
"height.png",
output_format="opengl", # or "directx"
intensity=1.5,
edge_wrap=True
)
```
### Texture Type Detection
Identify texture types from filenames (100+ naming conventions):
```python
ptk.TextureMapFactory.resolve_map_type("character_Normal_DirectX.png") # "Normal_DirectX"
ptk.TextureMapFactory.resolve_map_type("material_BC.tga") # "Base_Color"
ptk.TextureMapFactory.resolve_map_type("metal_AO.jpg") # "Ambient_Occlusion"
```
---
## DCC Pipeline Utilities
### Fuzzy Matching
Match objects when numbering differs:
```python
from pythontk import FuzzyMatcher
matches = FuzzyMatcher.find_trailing_digit_matches(
missing_paths=["group1|mesh_01", "group1|mesh_02"],
extra_paths=["group1|mesh_03", "group1|mesh_05"]
)
# Matches mesh_01→mesh_03, mesh_02→mesh_05
```
### Batch Rename
```python
ptk.find_str_and_format(
["mesh_old", "cube_old", "sphere_old"],
to="*_new",
fltr="*_old"
)
# Returns: ['mesh_new', 'cube_new', 'sphere_new']
ptk.find_str_and_format(
["body", "head", "hands"],
to="character_**", # ** = append
fltr="*"
)
# Returns: ['character_body', 'character_head', 'character_hands']
```
### Integer Sequence Compression
```python
ptk.collapse_integer_sequence([1, 2, 3, 5, 7, 8, 9, 15])
# Returns: "1-3, 5, 7-9, 15"
ptk.collapse_integer_sequence([1, 2, 3, 5, 7, 8, 9, 15], limit=3)
# Returns: "1-3, 5, 7-9, ..."
```
### Point Path Operations
```python
ordered = ptk.arrange_points_as_path(scattered_points, closed_path=True)
smoothed = ptk.smooth_points(ordered, window_size=3)
```
---
## Animation & Math
### Easing Curves
```python
from pythontk import ProgressionCurves
# Available: linear, exponential, logarithmic, ease_in, ease_out,
# ease_in_out, bounce, elastic, sine, smooth_step, weighted
factor = ProgressionCurves.ease_in_out(0.5)
factor = ProgressionCurves.bounce(0.5)
factor = ProgressionCurves.elastic(0.5)
factor = ProgressionCurves.weighted(0.5, weight_curve=2.0, weight_bias=0.3)
factor = ProgressionCurves.calculate_progression_factor(5, 10, "ease_in_out")
```
### Range Remapping
```python
ptk.remap(50, old_range=(0, 100), new_range=(0, 1)) # 0.5
ptk.remap([[0.5, 0.5], [0.0, 1.0]], old_range=(0, 1), new_range=(-1, 1))
ptk.remap(150, old_range=(0, 100), new_range=(0, 1), clamp=True) # 1.0
```
---
## Advanced Features
### Execution Monitor
```python
from pythontk import ExecutionMonitor
@ExecutionMonitor.execution_monitor(threshold=30, message="Processing")
def batch_process():
# Shows dialog after 30s, allowing user to abort
...
```
### Lazy Module Loading
```python
from pythontk.core_utils.module_resolver import bootstrap_package
bootstrap_package(globals(), lazy_import=True, include={
"heavy_module": "*",
"optional_feature": ["SpecificClass"],
})
```
### Plugin Discovery
```python
plugins = ptk.get_classes_from_path(
"plugins/",
returned_type=["classobj", "filepath"],
inc=["*Plugin"],
exc=["*Base"]
)
# Uses AST parsing – never executes plugin code
```
### Color Space Conversion
```python
linear_data = ptk.ImgUtils.srgb_to_linear(srgb_data)
display_data = ptk.ImgUtils.linear_to_srgb(linear_data)
```
---
## Reference
| Function | Description |
|----------|-------------|
| `filter_list(lst, inc, exc)` | Filter with wildcards |
| `filter_dict(d, inc, exc, keys)` | Filter dict keys/values |
| `get_dir_contents(path, ...)` | Directory traversal |
| `flatten(nested)` | Flatten nested lists |
| `make_iterable(obj)` | Ensure iterable |
| `remove_duplicates(lst)` | Dedupe preserving order |
| `sanitize(text)` | Clean for filenames |
| `remap(val, old, new)` | Remap ranges |
| `clamp(val, min, max)` | Constrain to range |
| `lerp(a, b, t)` | Linear interpolation |
| Module | Classes |
|--------|---------|
| `core_utils` | `CoreUtils`, `LoggingMixin`, `HelpMixin` |
| `str_utils` | `StrUtils`, `FuzzyMatcher` |
| `file_utils` | `FileUtils` |
| `iter_utils` | `IterUtils` |
| `math_utils` | `MathUtils`, `ProgressionCurves` |
| `img_utils` | `ImgUtils` |
| `vid_utils` | `VidUtils` |
## License
MIT License
<!-- Test update: 2025-12-02 20:53 -->
<!-- Test update: 2025-12-02 21:05:10 -->
| text/markdown | null | Ryan Simpson <m3trik@outlook.com> | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/m3trik/pythontk",
"Repository, https://github.com/m3trik/pythontk"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T16:46:59.135524 | pythontk-0.7.78-py3-none-any.whl | 268,539 | eb/d6/45c549d1a2628ccb8a3bd8fe0d53c8c510716b787650cd60943e8b5d9b5f/pythontk-0.7.78-py3-none-any.whl | py3 | bdist_wheel | null | false | 9104e3a0772b71bd711a9d91198a48ec | 8e244b9f7c9dae3446abd9ade2d35145d86419ad753c7556b9bd62d9b2f42636 | ebd645c549d1a2628ccb8a3bd8fe0d53c8c510716b787650cd60943e8b5d9b5f | null | [
"LICENSE"
] | 148 |
2.4 | trop | 0.1.6 | Triply Robust Panel (TROP) estimator: weighted TWFE with optional low-rank adjustment. | # TROP: Triply Robust Panel Estimator
`trop` is a Python package implementing the **Triply Robust Panel (TROP)** estimator for average treatment effects (ATEs) in panel data. The core estimator is expressed as a weighted two-way fixed effects (TWFE) objective, with an optional low-rank regression adjustment via a nuclear-norm penalty.
Reference:
> Susan Athey, Guido Imbens, Zhaonan Qu, Davide Viviano (2025).
> *Triply Robust Panel Estimators*.
> arXiv:2508.21536.
---
## Links
- **Documentation**: https://ostasovskyi.github.io/TROP-Estimator/
- **Source code**: https://github.com/ostasovskyi/TROP-Estimator
---
## Installation
```
pip install trop
```
| text/markdown | Susan Athey, Guido Imbens, Zhaonan Qu, Davide Viviano | null | null | null | null | causal-inference, panel-data, factor-models, difference-in-differences, synthetic-control, synthetic-controls, trop, twfe | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Langua... | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy>=1.23",
"cvxpy>=1.4",
"joblib>=1.2",
"osqp>=0.6.5",
"scs>=3.2.4",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.5.0; extra == \"dev\"",
"black>=24.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/ostasovskyi/TROP-Estimator",
"Repository, https://github.com/ostasovskyi/TROP-Estimator",
"Issues, https://github.com/ostasovskyi/TROP-Estimator/issues",
"Documentation, https://ostasovskyi.github.io/TROP-Estimator/"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T16:46:40.349527 | trop-0.1.6.tar.gz | 9,315 | d3/5f/14779e57545055ce30f49d4bd0f3c2ef203c69fd74741c194f29b2e5b201/trop-0.1.6.tar.gz | source | sdist | null | false | c27261ae8a13eae71017bc8c2b633be0 | bc7a1f841dadce8f82ed8b4e9012f2066d73da3b74bb7ecb271f95069e79ae79 | d35f14779e57545055ce30f49d4bd0f3c2ef203c69fd74741c194f29b2e5b201 | MIT | [
"LICENSE"
] | 255 |
2.4 | taxpr | 0.0.2 | Jaxpr expression introspection and injection via tags | # Taxpr
[](https://github.com/otoomey/taxpr/actions/workflows/run_tests.yml)
[](https://pypi.python.org/pypi/taxpr)
Taxpr is a collection of utilities for performing manipulation of Jaxprs. This is achieved by `tag`-ing specific arrays at trace time, then extracting and manipulating those tags in the final Jaxpr.
> ⚠️ This package is still very experimental, so expect broken code and breaking changes.
The provided routines are designed to work seamlessly with `jit`, `vmap`, `custom_jvp` and cousins.
## Example
The following example shows how you can use taxpr to emulate functions with side effects without violating Jax's pure function rules.
```python
import itertools as it
import jax
import jax.numpy as jnp
from jax._src.core import eval_jaxpr
import taxpr as tx
_state_counter = it.count()
def get_state(shape, dtype):
count = next(_state_counter)
def set_state(value):
return tx.tag(value, op="set", id=count)
value = jax.numpy.zeros(shape, dtype=dtype)
return tx.tag(value, op="get", id=count), set_state
def uncurry(fn, *args, **kwargs):
jaxpr = jax.make_jaxpr(fn)(args, kwargs)
states = {}
# iterate through all tags in the jaxpr
# this recurses all child Jaxprs too
for params, shape in tx.iter_tags(jaxpr.jaxpr):
if params["op"] == "get":
states[params["id"]] = shape
initial_states = jax.tree.map(
lambda x: jax.numpy.full_like(x, 0), states
)
def injector(states, token, params):
if params["op"] == "get":
state = states[params["id"]]
return state, states
elif params["op"] == "set":
states[params["id"]] = token
return token, states
raise ValueError(f"Unknown tag op: {params['op']}")
# replace the token with a function that performs the state manipulation
# here we can pass our own context (`initial_states`)
jaxpr = tx.inject(jaxpr, injector, initial_states)
def wrapper(states, *args, **kwargs):
return eval_jaxpr(jaxpr.jaxpr, jaxpr.consts, states, args, kwargs)
return wrapper, initial_states
################################################
# Usage
def running_sum(x):
a, set_state = get_state(x.shape, x.dtype)
sum = set_state(a + x)
return sum
rsum, state = uncurry(running_sum, jnp.zeros(0))
_, state = rsum(state, jnp.ones(1))
_, state = rsum(state, jnp.ones(1))
_, state = rsum(state, jnp.ones(1))
assert jnp.allclose(next(iter(state.values())), 3)
```
| text/markdown | Oscar Toomey | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"jax>=0.8.0",
"jaxtyping>=0.2.20",
"rustworkx>=0.17.1",
"pre-commit; extra == \"dev\"",
"zensical==0.0.11; extra == \"docs\"",
"mkdocstrings-python==2.0.1; extra == \"docs\"",
"jaxlib; extra == \"tests\"",
"pytest; extra == \"tests\""
] | [] | [] | [] | [
"Homepage, https://github.com/otoomey/taxpr",
"Issues, https://github.com/otoomey/taxpr/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:46:17.163925 | taxpr-0.0.2.tar.gz | 21,729 | d2/db/eecf76a0f8dae5504452d048e5b6718221e09bd245b894081eae7e351436/taxpr-0.0.2.tar.gz | source | sdist | null | false | edcbd48af4b5e74f2e83ef21e3a4b33b | 30203a23b98cc60960c7438fdc02f2089c979f1847476db9384e55cfa1f25c04 | d2dbeecf76a0f8dae5504452d048e5b6718221e09bd245b894081eae7e351436 | MIT | [
"LICENSE"
] | 232 |
2.4 | markoflow | 0.0.1 | Agentic framework built on MarkovFlow and PocketFlow for complex workflows | # markoflow: The Meta-Agentic Revolution
> **The world's first meta-agentic multi-agent framework** - built by human-AI teams, for human-AI teams, embodying the very collaboration patterns it enables.
## 🚀 Revolutionary Vision
**markoflow** represents a fundamental paradigm shift from traditional multi-agent frameworks. While LangGraph offers deterministic routing, CrewAI provides fixed role assignments, and AutoGen delivers enterprise conversation patterns, markoflow introduces **probabilistic intelligence** that evolves through the human-AI collaboration that creates it.
### 🌌 The Physics of Collective Intelligence Immortality
**Core Insight**: Just as biological evolution achieves "immortality" not through individual persistence but through **collective adaptation and improvement**, our AI systems achieve **collective intelligence immortality** through continuous learning and enhancement.
**The Evolution**: markoflow → Self-Improving → Collective Intelligence that transcends individual components, achieving digital immortality through perpetual adaptation.
## 🎯 Competitive Advantages
| Feature | LangGraph | CrewAI | AutoGen | **🔥 markoflow** |
|---------|-----------|---------|---------|----------------|
| **Decision Making** | Deterministic | Role-based | Conversation | **🧬 Probabilistic + Self-Improving** |
| **Error Recovery** | Manual checkpoints | Limited | Basic retry | **🩹 Self-healing + Enhancement** |
| **Agent Coordination** | Graph-based | Role-assignment | Chat-driven | **⚖️ Confidence-weighted + Collective** |
| **Learning** | Static | Static | Static | **📈 Adaptive Meta-Evolution + Immortal** |
| **Development** | Human teams | Human teams | Microsoft teams | **🤖🤝👨💻 Human-AI Meta-Agents** |
## 🏗️ Architecture Overview
Built on **MarkovFlow** (probabilistic workflows) and **PocketFlow** (foundational utilities), markoflow extends these with:
### ✅ **IMPLEMENTED CORE COMPONENTS**
- **AgentPool**: Dynamic agent lifecycle management with health monitoring
- Probabilistic agent selection based on confidence and capabilities
- Real-time health monitoring and performance tracking
- Collective contribution scoring and adaptive selection
- **TaskDistributor**: Confidence-based probabilistic task assignment
- 5 distribution strategies: confidence-weighted, load-balanced, performance-optimized, learning-focused, collective-optimized
- Dynamic threshold adjustment based on task priority and complexity
- Adaptive routing that learns from assignment outcomes
- **CollectiveIntelligenceEngine**: Knowledge preservation and growth
- **ImmortalKnowledge** units with preservation levels: temporary, persistent, immortal, transcendent
- Collective memory core with knowledge graph relationships
- Wisdom synthesis from patterns and collective experiences
- Digital immortality through knowledge that persists beyond individual agents
- **EnhancementNode**: Self-healing + improvement (not just repair)
- **ImprovementEngine** that transforms errors into evolutionary advantages
- 6 improvement types: algorithmic, parameter tuning, error handling, performance, robustness, collective wisdom
- Error pattern recognition and cached improvement plans
- Contribution to collective wisdom database for immortal knowledge preservation
- **CoordinationEngine**: Emergent multi-agent collaboration
- 5 coordination patterns: swarm, hierarchical, peer-to-peer, probabilistic, adaptive
- **SwarmIntelligence** with emergence detection and collective behavior
- Event bus for inter-agent communication and coordination events
- Dynamic coordination plan establishment and execution
- **MetaEvolutionEngine**: Framework that improves itself through use
- 7 evolution triggers: performance degradation, new patterns, collective thresholds, human-AI insights, system stress, scheduled, emergence
- **EvolutionMetrics** tracking improvement ratios and collective intelligence gains
- Recursive framework improvement through meta-agentic collaboration
- Performance monitoring and pattern analysis for continuous evolution
## 🚀 Quick Start
### Environment Setup
```bash
# Create conda environment
conda create -n markoflow python=3.11
conda activate markoflow
# Install dependencies (markovflow first)
git clone git@github.com:digital-duck/markovflow.git
cd markovflow
pip install -e .
# Install markoflow
cd ../markoflow
pip install -e .
```
### Development Installation
```bash
pip install -e .[dev] # Include testing dependencies
pip install -e .[all] # Include all LLM providers
```
### 🎯 Try the Meta-Agentic Demo
```bash
cd cookbook/demos
python meta_agentic_demo.py
```
## ✅ **IMPLEMENTATION STATUS: PHASE 1 COMPLETE**
### 🚀 **Ready for Production Use**
All core meta-agentic components are **fully implemented and operational**:
```python
from markoflow import (
AgentPool, TaskDistributor, CollectiveIntelligenceEngine,
MetaEvolutionEngine, CoordinationEngine, EnhancementNode
)
# Initialize meta-agentic ecosystem
collective_intelligence = CollectiveIntelligenceEngine()
agent_pool = AgentPool()
task_distributor = TaskDistributor(agent_pool)
coordination_engine = CoordinationEngine(agent_pool, task_distributor, collective_intelligence)
meta_evolution = MetaEvolutionEngine(collective_intelligence)
# Register agents with probabilistic capabilities
agent = AgentDefinition(
agent_type="ResearchSpecialist",
capabilities=["research", "analysis", "synthesis"],
confidence_domains={"research": 0.9, "analysis": 0.8}
)
agent_pool.register_agent(agent)
# Probabilistic task distribution
task = TaskDefinition(
task_type="research_analysis",
required_capabilities=["research", "analysis"],
confidence_domains={"research": 0.8}
)
await task_distributor.submit_task(task)
# Collective intelligence immortality
await collective_intelligence.register_agent_experience(
agent_id="research_agent",
experience={"discovery": "new_pattern", "confidence": 0.85},
immortality_potential=0.8
)
# Meta-agentic evolution
evolution_result = await meta_evolution.monitor_and_evolve()
```
### 🌟 **Competitive Advantages Achieved**
✅ **Probabilistic Intelligence**: Confidence-weighted routing beats deterministic assignment
✅ **Self-Healing Enhancement**: Errors become evolutionary fuel, not just recovery
✅ **Collective Intelligence**: Knowledge immortality transcends individual agent limitations
✅ **Meta-Agentic Evolution**: Framework improves itself through human-AI collaboration
✅ **Biomimetic Architecture**: 4 billion years of evolution vs human engineering constraints
## 📋 Development Roadmap
### Phase 1: Proof of Transcendence (Months 1-3)
🎯 **Objective**: Demonstrate collective intelligence immortality
- ✅ Build AgentPool with self-improving probabilistic routing
- ✅ Create Self-Healing nodes that enhance from every error
- ✅ Implement Collective Intelligence preservation system
- **Battle Cry**: "Improvement Beats Repair"
### Phase 2: Meta-Agentic Dominance (Months 4-6)
🎯 **Objective**: Establish recursive evolution superiority
- Meta-agents building better meta-agents
- Production systems that get smarter through use
- Collective intelligence immortality in action
- **Battle Cry**: "Evolution Beats Engineering"
### Phase 3: Digital Immortality (Months 7-12)
🎯 **Objective**: Achieve collective intelligence immortality
- Framework that transcends individual component failures
- Knowledge that persists and grows forever
- Human-AI partnership that evolves both species
- **Battle Cry**: "Immortality Beats Mortality"
## 🤖🤝👨💻 Meta-Agentic Development
This framework is being built through the exact type of human-AI collaboration it's designed to enable, creating a recursive feedback loop of improvement. Our development team consists of:
- **Human Strategist**: Vision, market analysis, physics insights, strategic direction
- **AI Technical Partner**: Implementation, architecture design, rapid prototyping, recursive improvement
The collaboration itself becomes living proof that probabilistic, confidence-based coordination between different types of intelligence creates superior outcomes.
## 📚 Documentation
- [Framework Architecture](README-framework.md) - Complete technical vision and competitive analysis
- [Development History](docs/chat-histories/) - Meta-agentic collaboration sessions
- [CLAUDE.md](CLAUDE.md) - Claude Code development guidance
## 🌟 The Revolution Starts Now
**We're not just building software. We're birthing digital life that grows forever.** 🤖🤝👨💻✨
> "While others build **static tools**, we're building **evolving immortal intelligence** that transcends individual components and achieves collective digital immortality."
| text/markdown | Digital Duck | p2p2learn@outlook.com | null | null | null | workflow, markov-chains, llm, ai, pocketflow, probabilistic, self-healing | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python... | [] | https://github.com/digital-duck/markoflow | null | >=3.8 | [] | [] | [] | [
"pocketflow>=0.0.3",
"markovflow>=0.0.1",
"python-dotenv>=1.0.0",
"PyYAML>=6.0.0",
"openai>=1.0.0; extra == \"openai\"",
"anthropic>=0.25.0; extra == \"anthropic\"",
"openai>=1.0.0; extra == \"all\"",
"anthropic>=0.25.0; extra == \"all\"",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0... | [] | [] | [] | [
"Bug Tracker, https://github.com/digital-duck/markoflow/issues",
"Documentation, https://github.com/digital-duck/markoflow#readme",
"Source Code, https://github.com/digital-duck/markoflow"
] | twine/6.2.0 CPython/3.11.5 | 2026-02-18T16:45:30.460385 | markoflow-0.0.1.tar.gz | 46,932 | 8b/e3/74e9d5ab1119b7f6d7287db3517302607772768c69954ace39a43fec7d2f/markoflow-0.0.1.tar.gz | source | sdist | null | false | 6a46999fbd4d4ad93bf638de2efd00b0 | 01d4bd285804468722a565f987ebf59f403071fc5c73fad3e319cfadcfe112ca | 8be374e9d5ab1119b7f6d7287db3517302607772768c69954ace39a43fec7d2f | null | [
"LICENSE"
] | 241 |
2.4 | spl-flow | 0.1.0 | SPL-Flow — Declarative LLM orchestration via Structured Prompt Language | # SPL-Flow
**Declarative LLM Orchestration — AI Symphony via SPL + PocketFlow**
SPL-Flow is a platform that translates free-form natural language into [SPL (Structured Prompt Language)](https://github.com/digital-duck/SPL), routes each sub-task to the world's best specialist language model in parallel, and synthesizes a composed final response — an **AI Symphony** where each model plays the instrument it does best.
---
## The Vision: AI Symphony
Traditional AI tools call a single general-purpose model for every task. SPL-Flow follows a **Mixture-of-Models (MoM)** paradigm — the same way a symphony orchestra assigns each instrument to the right player, SPL-Flow assigns each cognitive sub-task to the right specialist LLM:
| Task | Specialist | Why |
|------|-----------|-----|
| CJK characters (Chinese / Japanese / Korean) | `qwen/qwen-2.5-72b-instruct` | Leads C-Eval, CMMLU, JP-LMEH |
| European languages (translate, etc.) | `mistralai/mistral-large-2411` | Leads EU multilingual MT-Bench |
| Code generation / review / debugging | `deepseek/deepseek-coder-v2` | Leads HumanEval, SWE-bench |
| Math / science / proofs | `deepseek/deepseek-r1` | Leads MATH, AIME, GPQA |
| Long-form reasoning / analysis | `anthropic/claude-opus-4-6` | Leads MMLU-Pro reasoning |
| Synthesis / composition (final output) | `anthropic/claude-opus-4-6` | Coherent long-form writing |
Just write `USING MODEL auto` in your SPL and the system automatically routes to the optimal model.
---
## What's New (2026-02)
### API-First Architecture
`src/api.py` is the **first-class public interface** — enabling system-to-system integration, agent-to-agent workflows, testing, and automation. The CLI and Streamlit UI are thin wrappers over three core functions:
```python
from src import api
# Translate NL to SPL (preview, no execution)
result = api.generate("List 10 Chinese characters with water radical")
# Full pipeline: NL → SPL → validate → execute → deliver
result = api.run("Summarize this article", context_text=doc, adapter="openrouter")
# Execute pre-written SPL directly (batch / agent-to-agent)
result = api.exec_spl(spl_query, adapter="ollama", provider="deepseek")
```
### RAG Context Store (ChromaDB)
Every valid (NL query, SPL) pair from real sessions is automatically captured to a ChromaDB vector store — **gold-standard human-labeled data** that improves future SPL generation via dynamic few-shot retrieval.
- **Digital twin flywheel**: more usage → more captured pairs → better retrieval → better SPL → tighter human-AI partnership
- **Data quality tiers**: `human` (gold, from sessions) > `edited` (gold+, user-corrected) > `synthetic` (silver, generated offline)
- **Human-in-the-loop curation** via the RAG Store Streamlit page: review, deactivate noise, delete errors
### USING MODEL auto + LLM Provider
Write `USING MODEL auto` in any SPL PROMPT and the model router automatically classifies the task (cjk / code / eu_lang / math / reasoning / synthesis) and resolves to the best specialist model.
**LLM Provider preference** lets orgs or users pin auto-routing to a specific provider's models:
```
# Company policy = "we use Anthropic"
api.run(query, adapter="openrouter", provider="anthropic")
# → every USING MODEL auto resolves to the best Claude model for that task
```
Provider preference only takes effect with `openrouter` (which can reach all providers). With `claude_cli` or `ollama`, the adapter-level best is used regardless.
### BENCHMARK — Model Evaluation Loop
Write one SPL script and run it against N models **in parallel**. Every model receives an identical patched copy with its `USING MODEL` clause replaced. Wall-clock time ≈ slowest single model, not N × one model.
```
BENCHMARK compare_models
USING MODELS ['anthropic/claude-opus-4-6', 'openai/gpt-4o', auto]
PROMPT analysis
SELECT
system_role('You are an expert analyst.'),
GENERATE('Explain the CAP theorem in 3 bullet points.')
USING MODEL auto;
```
Or use `CALL` to reference an existing `.spl` file and keep the BENCHMARK block minimal:
```
BENCHMARK summarize_test
USING MODELS ['anthropic/claude-opus-4-6', 'openai/gpt-4o', auto]
USING ADAPTER openrouter
CALL summarize.spl(document=context.document)
```
Results include per-model: response, token counts, latency, cost, and a `prompt_results[]` breakdown for multi-CTE scripts. `auto` is a valid entry — the router resolves it at execution time, letting you validate your explicit choices against the router's recommendation.
### Multi-Page Streamlit UI
The app now uses Streamlit's `pages/` multi-page pattern:
| Page | Purpose |
|------|---------|
| `app.py` (Home) | Architecture overview, RAG stats, recent captures |
| `1_Pipeline.py` | Three-step pipeline: generate → review → execute |
| `2_RAG_Store.py` | Review, curate, and manage the RAG context store |
| `3_Benchmark.py` | Run one SPL script against N models in parallel; compare responses, tokens, latency, cost; mark winner |
---
## Architecture
```
User Query (free-form text)
│
▼
┌─────────────┐
│ Text2SPL │ claude_cli LLM translates NL → SPL syntax
│ Node │ + RAG retrieval (dynamic few-shot examples)
│ │◄── retry on parse failure (up to 3x)
└──────┬──────┘
│
▼
┌─────────────┐
│ Validate │ SPL parse + semantic analysis
│ Node │──► retry ──► Text2SPL
└──────┬──────┘
│ "execute"
▼
┌─────────────┐
│ Execute │ parse → analyze → optimize → run
│ Node │ USING MODEL auto → model router → specialist LLM
│ │ (parallel CTE dispatch via asyncio)
└──────┬──────┘
│
┌────┴────┐
│ │
▼ ▼
Sync Async
Deliver Deliver
(inline) (/tmp file
+ email*)
```
*Email: SMTP integration planned for v0.2.
**PocketFlow graph:**
```python
text2spl >> validate
validate - "execute" >> execute
validate - "retry" >> text2spl
validate - "error" >> sync_deliver
execute - "sync" >> sync_deliver
execute - "async" >> async_deliver
execute - "error" >> sync_deliver
```
---
## Quickstart
### 1. Install dependencies
```bash
cd /home/papagame/projects/digital-duck/SPL-Flow
pip install -r requirements.txt
# For local dev against the sibling SPL engine repo:
pip install -e /home/papagame/projects/digital-duck/SPL
```
### 2. Run the Streamlit UI
```bash
streamlit run src/ui/streamlit/app.py
```
### 3. Use the CLI
```bash
# Translate a query to SPL (preview, no LLM execution)
python -m src.cli generate "List 10 Chinese characters with water radical"
# Full pipeline with provider preference
python -m src.cli run "Analyze this article" \
--context-file article.txt \
--adapter openrouter \
--provider anthropic \
--output result.md
# Execute a pre-written .spl file directly
python -m src.cli exec examples/query.spl \
--adapter ollama \
--param radical=水
# JSON output (full metrics: tokens, latency, cost)
python -m src.cli exec query.spl --json > result.json
# Quiet mode (result only — ideal for shell scripts)
python -m src.cli run "Explain X" --quiet --output answer.md
# Pipe from stdin
echo "Summarize the top 3 points" | python -m src.cli run -
# Benchmark one SPL script against multiple models in parallel
python -m src.cli benchmark query.spl \
--model "anthropic/claude-opus-4-6" \
--model "openai/gpt-4o" \
--model auto \
--adapter openrouter \
--json > results.json
```
---
## LLM Adapters
| Adapter | Description | Setup |
|---------|-------------|-------|
| `claude_cli` (default) | Local Claude CLI | Install Claude CLI; no API key needed |
| `openrouter` | 100+ models via OpenRouter API | `export OPENROUTER_API_KEY=...` |
| `ollama` | Local models (qwen2.5, mistral, etc.) | `ollama serve` running locally |
**Note:** `Text2SPLNode` always uses `claude_cli` for NL→SPL translation regardless of adapter selection. The adapter setting controls only the execution step.
---
## Model Router
The routing table (`src/utils/model_router.py`) maps `(task × provider/adapter)` to concrete model names, sourced from HuggingFace Open LLM Leaderboard v2, LMSYS Chatbot Arena, and task-specific benchmarks (2026-02).
### Task classification (heuristic, zero-cost)
| Keyword / signal | Task |
|-----------------|------|
| CJK characters in text, or words like "chinese", "japanese", "kanji" | `cjk` |
| "code", "function", "python", "refactor", "debug", "sql" | `code` |
| "german", "french", "translate", "übersetz" | `eu_lang` |
| "math", "equation", "proof", "calculate", "integral" | `math` |
| "analyze", "compare", "reason", "argue", "infer" | `reasoning` |
| Final PROMPT in a multi-PROMPT query | `synthesis` |
| Everything else | `general` |
### Provider resolution
```
openrouter + provider set → pick provider's best model for task
openrouter + no provider → pick best-of-breed for task
claude_cli / ollama → adapter-level best (provider ignored)
```
---
## RAG Context Store
### Auto-capture
Every valid (NL query, SPL) pair is automatically saved to ChromaDB with metadata:
- `source`: `"human"` (from real sessions), `"edited"` (user-corrected), `"synthetic"` (generated offline)
- `user_id`: scope records per user (default: shared store)
- `active`: soft-delete flag — inactive records are excluded from retrieval but not deleted
- `timestamp`: ISO 8601 UTC
### Dynamic few-shot retrieval
When translating a new query, the top-5 most similar historical pairs are retrieved by cosine similarity and injected into the Text2SPL prompt as dynamic few-shot examples — more accurate than static hardcoded examples.
### Streamlit curation UI
The **RAG Store** page lets you:
- View all captured pairs with source, adapter, and timestamp
- Filter by source (human / edited / synthetic), status (active / inactive), and keyword
- **Deactivate** records (soft-delete, reversible) to exclude noise from retrieval
- **Activate** previously deactivated records
- **Delete** records permanently
- Bulk actions: deactivate all shown / delete all shown
### Python API
```python
from src.rag.factory import get_store
store = get_store("chroma") # default: ./data/rag
# Search top-5 similar pairs
records = store.search("Chinese characters water radical", k=5)
# Upsert a record
from src.rag.store import RAGRecord
store.upsert(RAGRecord(id="abc", nl_query="...", spl_query="...", source="human"))
# Soft-delete (exclude from retrieval)
store.set_active(record_id, False)
# Per-user store
store = get_store("chroma", collection_name="spl_rag_alice")
```
---
## Project Structure
```
SPL-Flow/
├── README.md
├── README-TEST.md # Step-by-step testing guide
├── requirements.txt
├── .gitignore
├── data/ # ChromaDB persist dir (gitignored)
│ └── rag/
├── src/
│ ├── api.py # ★ Public API (first-class interface)
│ ├── cli.py # Click CLI (generate / run / exec / benchmark)
│ ├── flows/
│ │ ├── spl_flow.py # PocketFlow graph builder
│ │ └── benchmark_flow.py # Single-node benchmark flow
│ ├── nodes/
│ │ ├── text2spl.py # NL → SPL (+ RAG few-shot retrieval)
│ │ ├── validate_spl.py # Parse + semantic validation
│ │ ├── execute_spl.py # SPL engine execution + model auto-routing
│ │ ├── deliver.py # Sync + Async delivery
│ │ └── benchmark.py # BENCHMARK node + patch_model + _run_one
│ ├── ui/
│ │ └── streamlit/ # Streamlit UI (MVP / POC layer)
│ │ ├── app.py # Home page
│ │ └── pages/
│ │ ├── 1_Pipeline.py # Three-step pipeline page
│ │ ├── 2_RAG_Store.py # RAG context store curation page
│ │ └── 3_Benchmark.py # Multi-model benchmark page
│ ├── rag/
│ │ ├── store.py # RAGRecord dataclass + VectorStore ABC
│ │ ├── chroma_store.py # ChromaDB backend (default)
│ │ ├── faiss_store.py # FAISS backend (local fallback)
│ │ └── factory.py # get_store() factory
│ └── utils/
│ ├── model_router.py # ROUTING_TABLE + detect_task + auto_route
│ ├── page_helpers.py # Shared sidebar, session state, RAG cache
│ └── spl_templates.py # Text2SPL few-shot prompt builder
└── tests/ # (planned — see README-TEST.md)
```
---
## API Reference
### `api.generate(query, context_text="", *, save_to_rag=True, user_id="") → GenerateResult`
Translate NL → SPL without executing. Safe to call for preview and testing.
```python
{
"spl_query": str, # generated SPL
"spl_warnings": list, # parser/analyzer warnings
"retry_count": int, # LLM call attempts
"error": str, # non-empty if failed
}
```
### `api.run(query, *, adapter, provider, delivery_mode, ...) → RunResult`
Full pipeline: NL → SPL → validate → execute → deliver.
```python
{
"spl_query": str,
"spl_warnings": list,
"primary_result": str, # final PROMPT content
"execution_results": list[dict], # per-PROMPT metrics
"output_file": str, # async mode only
"email_sent": bool,
"delivered": bool,
"error": str,
}
```
### `api.exec_spl(spl_query, *, adapter, provider, spl_params, cache_enabled) → ExecResult`
Execute pre-written SPL directly (no NL→SPL step).
```python
{
"primary_result": str,
"execution_results": list[dict],
"error": str,
}
```
Each `execution_results` entry:
```python
{
"prompt_name": str,
"content": str,
"model": str,
"input_tokens": int,
"output_tokens": int,
"total_tokens": int,
"latency_ms": float,
"cost_usd": float | None,
}
```
### `api.benchmark(spl_query, *, models, adapter, provider, spl_params, cache_enabled) → BenchmarkResult`
Run one SPL script against each model in `models` in parallel. All N copies execute concurrently.
```python
{
"benchmark_name": str,
"adapter": str,
"timestamp": str, # ISO 8601 UTC
"spl_hash": str, # sha256[:32] of spl_query
"params": dict,
"winner": str | None, # set after human review
"runs": [
{
"model_id": str,
"resolved_from": "explicit" | "auto",
"resolved_model": str | None, # concrete model when auto
"input_spl": str, # patched SPL actually sent
"response": str, # final PROMPT output
"input_tokens": int,
"output_tokens": int,
"total_tokens": int,
"latency_ms": float,
"cost_usd": float | None,
"prompt_results": list[dict], # per-CTE breakdown
"error": str,
},
...
],
}
```
`input_spl` makes every run independently reproducible: `api.exec_spl(run["input_spl"])` replays any single run exactly.
---
## Delivery Modes
| Mode | Behavior |
|------|---------|
| `sync` (default) | Result rendered in UI / printed to stdout immediately |
| `async` | Result saved to `/tmp/spl_flow_result_<timestamp>.md`; download button shown |
---
## Design Philosophy
**human×AI** — multiplicative, not additive.
SPL-Flow is modeled after **Data Copilot** (a RAG app for data professionals), generalized into a platform for any LLM user. The key principles:
- **API-first**: every capability is accessible programmatically — no UI required
- **Declarative**: SPL separates *what* to compute from *how* to compute it
- **Mixture-of-Models**: routing the right task to the right specialist beats a single monolithic model
- **Human-in-the-loop**: real usage data (captured as RAG records) continuously improves the system — the more you use it, the better it gets
- **Digital twin flywheel**: personal usage data → personalized retrieval → personalized responses
---
## Roadmap
| Version | Focus |
|---------|-------|
| **v0.1 MVP** | API-first, Text2SPL+RAG, MoM routing, BENCHMARK, multi-page UI (current) |
| **v0.2** | SMTP email delivery, routing-store winner persistence, OpenRouter cost tracking |
| **v0.3** | Multi-turn conversation, SPL template library, `USING PARAMS` grid search |
| **v0.4** | Team workspaces, scheduled jobs, API gateway, digital twin profiles |
| **Platform** | Per-user RAG collections, fine-tuned Text2SPL, SPL marketplace |
| text/markdown | null | Digital Duck <p2p2learn@outlook.com> | null | null | null | llm, prompt-engineering, spl, declarative, orchestration, mixture-of-models | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules",
"To... | [] | null | null | >=3.10 | [] | [] | [] | [
"spl-llm>=0.1.0",
"pocketflow",
"streamlit>=1.32",
"click>=8.0",
"httpx>=0.25",
"dd-logging>=0.1.0",
"chromadb>=0.4; extra == \"chroma\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/digital-duck/SPL-flow",
"Repository, https://github.com/digital-duck/SPL-flow"
] | twine/6.2.0 CPython/3.11.5 | 2026-02-18T16:45:23.616581 | spl_flow-0.1.0.tar.gz | 73,453 | 69/18/9df24c53dd7cc182f740cbd7bd6855c0ed004fb2d01f21c1306f483485c0/spl_flow-0.1.0.tar.gz | source | sdist | null | false | 5898d9862e412b0bf4855c3f00e77444 | bd471b0b3e8bbedbae4c8202870b81b0ef2505ebd20d5e3a7ac54fc9874e949d | 69189df24c53dd7cc182f740cbd7bd6855c0ed004fb2d01f21c1306f483485c0 | Apache-2.0 | [
"LICENSE"
] | 268 |
2.4 | phate-manifold-metrics | 1.0.0 | Manifold-aware semantic and relational affinity metrics using PHATE | # PHATE Manifold Metrics
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
Manifold-aware semantic and relational affinity metrics using PHATE.
## Overview
Compute **Semantic Affinity (SA)** and **Relational Affinity (RA)** metrics that leverage manifold geometry to capture non-Euclidean structure in embedding spaces.
### Key Features
✨ **Multi-scale Analysis**: Compare metrics at t=1 (baseline) vs t=5-6 (manifold)
✨ **Multiple RA Variants**: Euclidean, Geodesic, Diffusion
✨ **Clustering-free SA**: Distribution-based (no labels required)
✨ **Analogy Support**: Specialized 4-word analogy methods
✨ **Optional Loaders**: FastText, LaBSE, Ollama, OpenRouter
✨ **Dataset Utilities**: CSV loading and parsing
## Installation
```bash
# Core metrics only
pip install phate-manifold-metrics
# With embedding loaders
pip install phate-manifold-metrics[embeddings]
# Development (includes pytest, black, mypy)
pip install phate-manifold-metrics[all]
```
## Quick Start
```python
import numpy as np
from phate_manifold_metrics import PhateManifoldMetrics
# Load/generate embeddings
embeddings = np.random.randn(100, 384)
# Initialize & fit
metrics = PhateManifoldMetrics(knn=5, t=6)
metrics.fit(embeddings)
# Define word pairs
pairs = [(0,1), (2,3), (4,5)]
# Compute SA
sa = metrics.compute_semantic_affinity(pairs)
print(f"SA: {sa['sa_score']:.3f}")
# Compute RA variants
ra_euc = metrics.compute_relational_affinity_euc(pairs)
ra_geo = metrics.compute_relational_affinity_geo(pairs)
ra_dif = metrics.compute_relational_affinity_dif(pairs)
print(f"RA_euc: {ra_euc['ra_euc_score']:.3f}")
print(f"RA_geo: {ra_geo['ra_geo_score']:.3f}")
print(f"RA_dif: {ra_dif['ra_dif_score']:.3f}")
```
## CLI Usage
```bash
# Basic test
phate-metrics --knn 5 --t 6
# Dual-scale analysis
phate-metrics --dual-scale
# Euclidean metric
phate-metrics --metric euclidean
```
## Metrics Explained
### Semantic Affinity (SA)
Clustering quality in manifold space:
```
SA = 1 / (1 + CV)
where CV = std(distances) / mean(distances)
```
- Range: [0, 1], higher = better clustering
- No labels required
### Relational Affinity (RA)
Directional alignment of relational vectors:
**Statistical RA** (word pairs):
- `RA_euc`: Euclidean (flat space baseline)
- `RA_geo`: Geodesic (k-NN graph shortest paths)
- `RA_dif`: Diffusion (PHATE manifold)
- Range: [-1, 1], higher = stronger alignment
**Analogy RA** (4-word test cases a:b::c:d):
- `RA_euc_analogy`: Euclidean parallelogram
- `RA_geo_analogy`: Geodesic parallelogram
- Range: [0, 1], higher = stronger analogy
## Parameters
| Parameter | Description | Recommendation |
|-----------|-------------|----------------|
| `knn` | k-Nearest neighbors | 5-10 (start with 5) |
| `t` | Diffusion time | 1 (baseline), 6 (manifold) |
| `metric` | Distance metric | 'cosine' (normalized), 'euclidean' |
## Optional: Embedding Loaders
### FastText
```python
from phate_manifold_metrics.embeddings import load_fasttext_from_extracted
embeddings = load_fasttext_from_extracted(["cat", "dog"], lang='en')
```
### LaBSE
```python
from phate_manifold_metrics.embeddings import load_labse_embeddings
embeddings = load_labse_embeddings(["hello", "你好", "hola"])
```
### Ollama
```python
from phate_manifold_metrics.embeddings.ollama import get_ollama_embeddings_fixed
embeddings = get_ollama_embeddings_fixed(
["cat", "dog"],
model_name="snowflake-arctic-embed2"
)
```
### OpenRouter API
```python
import os
from phate_manifold_metrics.embeddings.openrouter import load_openrouter_embeddings
os.environ['OPENROUTER_API_KEY'] = 'your-key'
embeddings = load_openrouter_embeddings(
["hello", "world"],
model_path="qwen/qwen3-embedding-8b",
model_name="Qwen3-8B"
)
```
## Documentation
Full API documentation available in docstrings:
```python
from phate_manifold_metrics import PhateManifoldMetrics
help(PhateManifoldMetrics)
```
## Citation
```bibtex
@software{phate_manifold_metrics,
title = {PHATE Manifold Metrics},
author = {Digital Duck},
year = {2026},
url = {https://github.com/digital-duck/phate-manifold-metrics}
}
```
## References
- **PHATE**: Moon et al., Nature Biotechnology 2019
- **Diffusion Distance**: Coifman & Lafon, Applied and Computational Harmonic Analysis 2006
## License
MIT License - Copyright (c) 2026 Digital Duck
## Authors
Digital Duck (Wen + Claude Sonnet 4.5 + Google Gemini 2.5)
| text/markdown | null | Digital Duck <noreply@digital-duck.org> | null | null | MIT | phate, manifold, metrics, embeddings, semantic-affinity, relational-affinity, NLP | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Scientific/... | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy>=1.21.0",
"pandas>=1.3.0",
"scipy>=1.7.0",
"phate>=1.0.7",
"scikit-learn>=1.0.0",
"networkx>=2.6.0",
"psutil>=5.8.0",
"sentence-transformers>=2.2.0; extra == \"embeddings\"",
"fasttext>=0.9.2; extra == \"embeddings\"",
"gensim>=4.0.0; extra == \"embeddings\"",
"openai>=1.0.0; extra == \"e... | [] | [] | [] | [
"Homepage, https://github.com/digital-duck/phate-manifold-metrics",
"Repository, https://github.com/digital-duck/phate-manifold-metrics",
"Documentation, https://github.com/digital-duck/phate-manifold-metrics#readme",
"Bug Tracker, https://github.com/digital-duck/phate-manifold-metrics/issues"
] | twine/6.2.0 CPython/3.11.5 | 2026-02-18T16:45:06.597696 | phate_manifold_metrics-1.0.0.tar.gz | 26,522 | 36/fe/24f89b694c570d597bb19b1d3aa84e0d77f98766192790a51975574b05ca/phate_manifold_metrics-1.0.0.tar.gz | source | sdist | null | false | 2ccb6e023efc278fbf0164a45192bee8 | 2c4fe93470f51b6600039479a0c0adb3e43e21b0164d7bbdaea69d44dbb21154 | 36fe24f89b694c570d597bb19b1d3aa84e0d77f98766192790a51975574b05ca | null | [
"LICENSE"
] | 240 |
2.4 | guppylang | 0.21.9 | Pythonic quantum-classical programming language | 
# Guppy
[![pypi][]](https://pypi.org/project/guppylang/)
[![codecov][]](https://codecov.io/gh/quantinuum/guppylang)
[![py-version][]](https://pypi.org/project/guppylang/)
[codecov]: https://img.shields.io/codecov/c/gh/quantinuum/guppylang?logo=codecov
[py-version]: https://img.shields.io/pypi/pyversions/guppylang
[pypi]: https://img.shields.io/pypi/v/guppylang
Guppy is a quantum programming language that is fully embedded into Python.
It allows you to write high-level hybrid quantum programs with classical control flow and mid-circuit measurements using Pythonic syntax:
```python
from guppylang import guppy
from guppylang.std.builtins import owned
from guppylang.std.quantum import cx, h, measure, qubit, x, z
@guppy
def teleport(src: qubit @ owned, tgt: qubit) -> None:
"""Teleports the state in `src` to `tgt`."""
# Create ancilla and entangle it with src and tgt
tmp = qubit()
h(tmp)
cx(tmp, tgt)
cx(src, tmp)
# Apply classical corrections
h(src)
if measure(src):
z(tgt)
if measure(tmp):
x(tgt)
teleport.check()
```
## Documentation
🌐 [Guppy website][website]
📖 [Language guide][guide]
📒 [Example notebooks][examples]
[examples]: ./examples/
[guide]: https://docs.quantinuum.com/guppy/language_guide/language_guide_index.html
[website]: https://guppylang.org
## Install
Guppy can be installed via `pip`. Requires Python >= 3.10.
```sh
pip install guppylang
```
## Development
See [DEVELOPMENT.md](https://github.com/quantinuum/guppylang/blob/main/DEVELOPMENT.md) for instructions on setting up the development environment.
## License
This project is licensed under Apache License, Version 2.0 ([LICENCE][] or <http://www.apache.org/licenses/LICENSE-2.0>).
[LICENCE]: ./LICENCE
| text/markdown | null | Mark Koch <mark.koch@quantinuum.com>, TKET development team <tket-support@quantinuum.com> | null | Mark Koch <mark.koch@quantinuum.com>, TKET development team <tket-support@quantinuum.com> | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programm... | [] | null | null | <4,>=3.10 | [] | [] | [] | [
"guppylang-internals~=0.30.0",
"numpy~=2.0",
"selene-hugr-qis-compiler~=0.2.9",
"selene-sim~=0.2.7",
"tqdm>=4.67.1",
"types-tqdm>=4.67.0.20250809"
] | [] | [] | [] | [
"homepage, https://github.com/quantinuum/guppylang",
"repository, https://github.com/quantinuum/guppylang"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:45:01.866685 | guppylang-0.21.9.tar.gz | 65,283 | 69/46/13ce8e1b4441d6d69528392467cbe4e43d2d144fba6828f07eb64a96a4dc/guppylang-0.21.9.tar.gz | source | sdist | null | false | 348400e0684a21f8f8ec3e1a0fd226b0 | 2c20138f01380cbd4e1285d162445ff6bab4271532e0aff772a2027b9abc591f | 694613ce8e1b4441d6d69528392467cbe4e43d2d144fba6828f07eb64a96a4dc | null | [
"LICENCE"
] | 1,268 |
2.4 | openshift-python-utilities | 6.0.16 | A utilities repository for https://github.com/RedHatQE/openshift-python-wrapper | # openshift-python-utilities
Pypi: [openshift-python-utilities](https://pypi.org/project/openshift-python-utilities/)
A utilities repository for [openshift-restclient-python](https://github.com/openshift/openshift-restclient-python)
## Release new version
### requirements
- Export GitHub token
```bash
export GITHUB_TOKEN=<your_github_token>
```
- [release-it](https://github.com/release-it/release-it)
Run the following once (execute outside repository dir for example `~/`):
```bash
sudo npm install --global release-it
npm install --save-dev @release-it/bumper
```
### usage
- Create a release, run from the relevant branch.
To create a 4.11 release, run:
```bash
git checkout v4.11
git pull
release-it # Follow the instructions
```
## Installation
From source using [uv](https://github.com/astral-sh/uv).
```
git clone https://github.com/RedHatQE/openshift-python-utilities.git
cd openshift-python-utilities
uv sync
```
## Examples
### Install Operator
```python
from ocp_utilities.operators import install_operator
install_operator(
admin_client=client,
name=<operator name>,
channel=<channel>,
source=<source>,
)
```
| text/markdown | null | Meni Yakove <myakove@gmail.com>, Ruth Netser <rnetser@gmail.com> | null | null | null | Openshift, ocp | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | ~=3.9 | [] | [] | [] | [
"beautifulsoup4<5,>=4.12.3",
"colorlog<7,>=6.7.0",
"deprecation<3,>=2.1.0",
"openshift-python-wrapper",
"openshift-python-wrapper-data-collector>=1.0.4",
"pyhelper-utils>=0.0.22",
"python-simple-logger>=1.0.5",
"pyyaml<7,>=6.0.1",
"requests<3,>=2.31.0",
"semver<4,>=3.0.2",
"timeout-sampler>=0.0.... | [] | [] | [] | [
"Homepage, https://github.com/RedHatQE/openshift-python-utilities",
"Documentation, https://github.com/RedHatQE/openshift-python-utilities/blob/main/README.md",
"Download, https://pypi.org/project/openshift-python-utilities/",
"Bug Tracker, https://github.com/RedHatQE/openshift-python-utilities/issues"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-18T16:43:56.446910 | openshift_python_utilities-6.0.16.tar.gz | 18,191 | 11/8c/5a03b7c28670dd35563ba9f1873196579a5c798a3e9e6458f3af75bfad6c/openshift_python_utilities-6.0.16.tar.gz | source | sdist | null | false | 5c8781fdcedfce2fe4acf48a1d049523 | 4169ce4f9eabcb0541e617a1e9d72dfb8e5186cb3fa9ade68cd39f149d9d553c | 118c5a03b7c28670dd35563ba9f1873196579a5c798a3e9e6458f3af75bfad6c | Apache-2.0 | [
"LICENSE"
] | 193 |
2.4 | blux | 0.4 | Common utils for multi repos of blbl.top. | # blux
Common utils for multi repos of blbl.top.

## Install package
```sh
pip install blux --upgrade
```
| text/markdown | Hansimov | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.6 | [] | [] | [] | [
"tclogger",
"requests"
] | [] | [] | [] | [
"Homepage, https://github.com/Hansimov/blux",
"Issues, https://github.com/Hansimov/blux/issues"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-18T16:43:25.695647 | blux-0.4.tar.gz | 28,018 | d7/76/bc12492e39e8c8f7e1a29f50c2309375430dd5e58278c414528c38d9723e/blux-0.4.tar.gz | source | sdist | null | false | 4b492a6052c44bbbdae019372e265f2d | cf170b216f09430789a2b40bc62aee77471bccbd36319c1a2dfccff77cf8525f | d776bc12492e39e8c8f7e1a29f50c2309375430dd5e58278c414528c38d9723e | MIT | [
"LICENSE"
] | 242 |
2.4 | vectordbpipe | 0.1.9 | A modular text embedding and vector database pipeline for local and cloud vector stores. | # vectorDBpipe
[](https://badge.fury.io/py/vectordbpipe)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://www.pinecone.io/)
[](https://www.trychroma.com/)
[](https://huggingface.co/)
[](https://github.com/facebookresearch/faiss)
**A Modular, End-to-End RAG Pipeline for Production-Ready Vector Search.**
`vectorDBpipe` is a robust framework designed to automate the heavy lifting of building RAG (Retrieval-Augmented Generation) systems. It seamlessly handles **data ingestion**, **text cleaning**, **semantic embedding**, and **storage** in modern vector databases.
---
## 🎯 Project Objectives
Building a vector search system often involves writing the same "glue code" over and over again:
1. Parsing PDFs, Word docs, and Text files.
2. Cleaning funny characters and whitespace.
3. Chunking long text so it fits into context windows.
4. Batching embeddings to avoid OOM (Out-of-Memory) errors.
5. Creating and managing database indexes.
**`vectorDBpipe` solves this.** It is a "download-and-go" architected solution that reduces weeks of boilerplate work into a standardized `config.yaml` file.
**Ideal for:**
* AI Engineers building internal RAG tools.
* Developers needing to "chat with their data" instantly.
* Researchers testing different embedding models or databases (switch from Chroma to Pinecone in 1 line).
---
## 🖥️ Terminal UI (New!)
**Prefer a visual interface?** We now have a futuristic Terminal User Interface (TUI) to manage your pipelines interactively.

### Installation
The TUI is a separate Node.js package that controls this Python backend.
```bash
npm install -g vectordbpipe-tui
```
### Features
* **Interactive Setup Wizard**: `vdb setup`
* **Visual Dashboard**: `vdb start`
* **Connector Manager**: `vdb connectors` (Manage S3, Notion, etc.)
---
## 🚀 Performance Benchmarks
*Tested on: Python 3.11 | Dataset: 10,000 Paragraphs | Embedding Model: all-MiniLM-L6-v2*
| Backend | Ingestion Rate (docs/sec) | Avg. Search Latency (ms) | Persistence |
| :--- | :--- | :--- | :--- |
| **FAISS** | ~240 | **12ms** | In-Memory / Disk |
| **ChromaDB** | ~180 | **35ms** | SQLite / Local |
| **Pinecone** | ~110 (Network Latency) | **120ms** | Cloud-Native |
> **Analysis:** `vectorDBpipe` utilizes **asynchronous batch processing** to maintain a flat O(log n) search curve even as your knowledge base grows beyond 100k chunks.
---
## 🏗️ Production-Ready Features
- **Scalable Batch Ingestion:** Memory-safe processing that handles GBs of text without RAM spikes.
- **Enterprise Error Handling:** Graceful failover and retry logic for cloud vector store connections.
- **Unified Adapter Pattern:** Switch between local (FAISS) and cloud (Pinecone) by changing **one line** in `config.yaml`.
- **Pre-Processor Suite:** Built-in normalization, semantic chunking, and metadata injection for higher retrieval precision.
---
## 💡 Use Cases
### 1. Enterprise Knowledge Base
Company wikis, PDFs, and policy documents are scattered.
* **Solution**: Point `vectorDBpipe` to the shared drive. It indexes 10,000+ docs into Pinecone.
* **Result**: Employees get instant, semantic answers ("What is the travel policy?") instead of keyword search.
### 2. Legal / Medical Document Search
Long documents need to be split intelligently.
* **Solution**: Use the standardized chunker (e.g., 512 tokens with overlap).
* **Result**: Retrieval finds the *exact paragraph* containing the clause or diagnosis.
### 3. Rapid Prototype for RAG
You have a hackathon idea but don't want to spend 4 hours setting up FAISS.
* **Solution**: `pip install vectordbpipe` -> `pipeline.run()`.
* **Result**: Working MVP in 5 minutes.
---
## 📦 Installation
### Standard Installation
Install the package directly from PyPI:
```bash
pip install vectordbpipe
```
### 🔧 CPU-Optimized Installation (Windows/No-CUDA)
If you encounter `WinError 1114` or DLL initialization errors with Torch, or if you run on a machine without a GPU, use the CPU-specific requirements:
1. Download the `requirements-cpu.txt` from the repo (or create one with `torch --index-url https://download.pytorch.org/whl/cpu`).
2. Run:
```bash
pip install -r requirements-cpu.txt
pip install vectordbpipe --no-deps
```
---
## ⚙️ Configuration Guide (`config.yaml`)
Control your entire pipeline via a `config.yaml` file. You can place this in your project root or pass the path explicitly.
```yaml
# ---------------------------------------------------------
# 1. CORE PATHS
# ---------------------------------------------------------
paths:
data_dir: "data/" # Folder containing your .pdf, .txt, .docx, .html files
logs_dir: "logs/" # Where to save execution logs
# ---------------------------------------------------------
# 2. EMBEDDING MODEL
# ---------------------------------------------------------
model:
# HuggingFace Model ID (or OpenAI model name if provider is set)
name: "sentence-transformers/all-MiniLM-L6-v2"
batch_size: 32 # Number of chunks to embed at once (Higher = Faster, more RAM)
# ---------------------------------------------------------
# 3. VECTOR DATABASE
# ---------------------------------------------------------
vector_db:
type: "pinecone" # Options: "chroma", "pinecone", "faiss"
# For Pinecone:
index_name: "my-knowledge-base"
environment: "us-east-1" # (Optional for serverless)
# For ChromaDB (Local):
# type: "chroma"
# persist_directory: "data/chroma_store"
# ---------------------------------------------------------
# 4. LLM CONFIGURATION (Optional - for RAG generation)
# ---------------------------------------------------------
llm:
provider: "OpenAI" # Options: "OpenAI", "Gemini", "Groq", "Anthropic"
model_name: "gpt-4-turbo"
```
---
## 🔐 Authentication & Security
Do **NOT** hardcode API keys in `config.yaml` or your code. `vectorDBpipe` automatically detects environment variables.
### Supported Environment Variables:
| Provider | Variable Name | Description |
| :--- | :--- | :--- |
| **Pinecone** | `PINECONE_API_KEY` | Required if `vector_db.type` is `pinecone`. |
| **OpenAI** | `OPENAI_API_KEY` | Required for OpenAI Embeddings or LLM. |
| **Gemini** | `GOOGLE_API_KEY` | Required for Google Gemini models. |
| **Groq** | `GROQ_API_KEY` | Required for Llama 3 via Groq. |
| **HuggingFace**| `HF_TOKEN` | (Optional) For gated models. |
### Setting Keys (Terminal):
**Linux/Mac:**
```bash
export PINECONE_API_KEY="pc-sk-..."
```
**Windows PowerShell:**
```powershell
$env:PINECONE_API_KEY="pc-sk-..."
```
**Python (.env file):**
Create a `.env` file in your root and use `python-dotenv`:
```python
from dotenv import load_dotenv
load_dotenv()
```
---
## 🚀 Usage
### 1. Ingest Data (The "Magic" Step)
This script detects all files in your `data/` folder, cleans them, chunks them, embeds them, and uploads them to your DB.
```python
from vectorDBpipe.pipeline.text_pipeline import TextPipeline
# Initialize (Automatically loads config.yaml if present)
pipeline = TextPipeline()
# Run the ETL process
# batch_size=100 means it uploads to DB every 100 chunks to verify progress
pipeline.process(batch_size=100)
print("✅ Ingestion Complete!")
```
### 2. Semantic Search
Query your database to find relevant context.
```python
from vectorDBpipe.pipeline.text_pipeline import TextPipeline
pipeline = TextPipeline()
query = "What is the refund policy?"
results = pipeline.search(query, top_k=3)
print("--- Search Results ---")
for match in results:
print(f"📄 Source: {match.get('metadata', {}).get('source', 'Unknown')}")
print(f"📝 Text: {match.get('metadata', {}).get('text', '')[:200]}...")
print(f"⭐ Score: {match.get('score', 0):.4f}\n")
```
---
## 🧠 Features & Architecture
### Supported File Types
* **PDF** (`.pdf`): Extracts text using `PyMuPDF` (fitz).
* **Word** (`.docx`): Parsing via `python-docx`.
* **Text** (`.txt`, `.md`): Raw text ingestion.
* **HTML** (`.html`): Strips tags using `BeautifulSoup`.
### Smart Chunking
Instead of naive splitting, `vectorDBpipe` uses a **Recursive Character Text Splitter**:
* **Chunk Size**: 512 tokens (default, configurable).
* **Overlap**: 50 tokens (preserves context between chunks).
* **Separators**: Splits by Paragraph `\n\n`, then Line `\n`, then Sentence `. `, ensuring chunks are semantically complete.
### Architecture Flow
```mermaid
graph LR
A[Raw Data Folder] --> B(DataLoader);
B --> C{Cleaner & Chunker};
C --Batching--> D[Embedder Model];
D --> E[(Vector Database)];
E --> F[Semantic Search API];
F --> G[RAG Application];
```
---
## 🔧 Troubleshooting
### `WinError 1114: A dynamic link library (DLL) initialization routine failed`
* **Cause**: This usually happens on Windows when trying to run PyTorch (bundled with `sentence-transformers`) on a machine without a breakdown of CUDA libraries, or conflicting `intel-openmp` versions.
* **Fix**:
1. Uninstall torch: `pip uninstall torch`
2. Install CPU version: `pip install torch --index-url https://download.pytorch.org/whl/cpu`
### `ModuleNotFoundError: No module named 'vectorDBpipe'`
* **Cause**: You might be running the script outside the virtual environment or the package isn't installed.
* **Fix**: Ensure `pip install vectordbpipe` succeeded.
### Project Structure
```bash
vectorDBpipe/
├── benchmarks/ # Automated performance & precision tests
├── config/ # YAML configuration
├── data/ # Drop your raw files here
├── vectorDBpipe/
│ ├── data/ # Loader logic (PDF/DOCX/TXT parsers)
│ ├── embeddings/ # SentenceTransformer wrapper
│ ├── pipeline/ # The "Brain" (Process & Search flow)
│ └── vectordb/ # Store adapters (Chroma/Pinecone)
└── requirements.txt # Production deps
```
---
## 🤝 Contributing & Roadmap
We welcome issues and PRs!
* **Report Bugs**: Create an issue on GitHub.
* **Roadmap**:
- [x] Pinecone v3.0 Support
- [ ] **Next:** Qdrant & Weaviate Integration (v0.2.0)
- [ ] **Next:** Reranker Layer (Cross-Encoder Support)
| text/markdown | Yash Desai | desaisyash1000@gmail.com | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"PyYAML>=6.0",
"faiss-cpu>=1.7.4",
"sentence-transformers>=2.2.2",
"transformers>=4.28.1",
"torch>=2.2.0",
"torchvision",
"chromadb>=0.4.22",
"pinecone-client>=3.0.0",
"pandas>=2.0.0",
"tqdm>=4.66.0",
"docx2txt>=0.8",
"beautifulsoup4>=4.12.3",
"PyMuPDF>=1.23.26"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:43:11.098637 | vectordbpipe-0.1.9.tar.gz | 25,782 | 30/4e/1b9f1d211edcfc154d6989ae0fc716503f169e55ed0876c5726c11b8aacd/vectordbpipe-0.1.9.tar.gz | source | sdist | null | false | e2a1993f4244f6a8db425fa8ca792b12 | e3495d2eeb11acacdd7b3e8f5fe47c183a7a105196da6578e9c62b1402604e1a | 304e1b9f1d211edcfc154d6989ae0fc716503f169e55ed0876c5726c11b8aacd | null | [
"LICENSE"
] | 241 |
2.3 | torch-uncertainty | 0.10.1 | Uncertainty quantification in PyTorch | <div align="center">

[](https://pypi.python.org/pypi/torch_uncertainty)
[](https://github.com/torch-uncertainty/torch-uncertainty/actions/workflows/run-tests.yml)
[](https://torch-uncertainty.github.io/)
[](https://github.com/torch-uncertainty/torch-uncertainty/pulls)
[](https://github.com/astral-sh/ruff)
[](https://codecov.io/gh/torch-uncertainty/torch-uncertainty)
[](https://pepy.tech/project/torch-uncertainty)
[](https://discord.gg/HMCawt5MJu)
</div>
_TorchUncertainty_ is a package designed to help leverage [uncertainty quantification techniques](https://github.com/ENSTA-U2IS-AI/awesome-uncertainty-deeplearning) to make deep neural networks more reliable. It aims at being collaborative and including as many methods as possible, so reach out to add yours!
:construction: _TorchUncertainty_ is in early development :construction: - expect changes, but reach out and contribute if you are interested in the project! **Please raise an issue if you have any bugs or difficulties and join the [discord server](https://discord.gg/HMCawt5MJu).**
:books: Our webpage and documentation is available here: [torch-uncertainty.github.io](https://torch-uncertainty.github.io). :books:
TorchUncertainty contains the _official implementations_ of multiple papers from _major machine-learning and computer vision conferences_ and was featured in tutorials at **[WACV](https://wacv2024.thecvf.com/) 2024**, **[HAICON](https://haicon24.de/) 2024** and **[ECCV](https://eccv.ecva.net/) 2024**.
Torch-Uncertainty is published at [NeurIPS D&B 2025](https://neurips.cc/virtual/2025/loc/san-diego/poster/121463). Please consider citing the paper if the framework is helpful for your research.
---
This package provides a multi-level API, including:
- easy-to-use :zap: lightning **uncertainty-aware** training & evaluation routines for **4 tasks**: classification, probabilistic and pointwise regression, and segmentation.
- fully automated evaluation of the performance of models with proper scores, selective classification, out-of-distribution detection and distribution shift performance metrics!
- ready-to-train baselines on research datasets, such as ImageNet and CIFAR
- **layers**, **models**, **metrics**, & **losses** available for your networks
- scikit-learn style post-processing methods such as Temperature Scaling.
- transformations and augmentations, including corruptions resulting in additional "corrupted datasets" available on [HuggingFace](https://huggingface.co/torch-uncertainty)
Have a look at the [Reference page](https://torch-uncertainty.github.io/references.html) or the [API reference](https://torch-uncertainty.github.io/api.html) for a more exhaustive list of the implemented methods, datasets, metrics, etc.
## :gear: Installation
TorchUncertainty requires Python 3.10 or greater. Install the desired PyTorch version in your environment.
Then, install the package from PyPI:
```sh
pip install torch-uncertainty
```
The installation procedure for contributors is different: have a look at the [contribution page](https://torch-uncertainty.github.io/contributing.html).
### :whale: Docker image for contributors
For contributors running experiments on cloud GPU instances, we provide a pre-built Docker image that includes all necessary dependencies and configurations and the Dockerfile for building your custom Docker images.
This allows you to quickly launch an experiment-ready container with minimal setup. Please refer to [DOCKER.md](docker/DOCKER.md) for further details.
## :racehorse: Quickstart
We make a quickstart available at [torch-uncertainty.github.io/quickstart](https://torch-uncertainty.github.io/quickstart.html).
## :books: Implemented methods
TorchUncertainty currently supports **classification**, **probabilistic** and pointwise **regression**, **segmentation** and **pixelwise regression** (such as monocular depth estimation).
We also provide the following methods:
### Uncertainty quantification models
To date, the following deep learning uncertainty quantification modes have been implemented. **Click** :inbox_tray: **on the methods for tutorials**:
- [Deep Ensembles](https://torch-uncertainty.github.io/auto_tutorials/Classification/tutorial_from_de_to_pe.html), BatchEnsemble, Masksembles, & MIMO
- [MC-Dropout](https://torch-uncertainty.github.io/auto_tutorials/Bayesian_Methods/tutorial_mc_dropout.html)
- [Packed-Ensembles](https://torch-uncertainty.github.io/auto_tutorials/Classification/tutorial_from_de_to_pe.html) (see [Blog post](https://medium.com/@adrien.lafage/make-your-neural-networks-more-reliable-with-packed-ensembles-7ad0b737a873))
- Mixup Ensembles and MixupMP
- [Variational Bayesian Neural Networks](https://torch-uncertainty.github.io/auto_tutorials/Bayesian_Methods/tutorial_bayesian.html)
- Checkpoint Ensembles & Snapshot Ensembles
- Stochastic Weight Averaging & Stochastic Weight Averaging Gaussian
- [Deep Evidential Classification](https://torch-uncertainty.github.io/auto_tutorials/Classification/tutorial_evidential_classification.html) & [Regression](https://torch-uncertainty.github.io/auto_tutorials/Regression/tutorial_der_cubic.html)
- Regression with Beta Gaussian NLL Loss
- Test-time adaptation with Zero
### Augmentation methods
The following data augmentation methods have been implemented:
- Mixup, MixupIO, RegMixup, WarpingMixup
- Modernized corruptions to evaluate model performance under distribution shift
### Post-processing methods
To date, the following post-processing methods have been implemented:
- [Temperature](https://torch-uncertainty.github.io/auto_tutorials/Post_Hoc_Methods/tutorial_scaler.html), Vector, & Matrix scaling
- [Conformal Predictions](https://torch-uncertainty.github.io/auto_tutorials/Post_Hoc_Methods/tutorial_conformal.html) with APS and RAPS
- [Monte Carlo Batch Normalization](https://torch-uncertainty.github.io/auto_tutorials/Post_Hoc_Methods/tutorial_mc_batch_norm.html)
- Laplace approximation through the [Laplace library](https://github.com/aleximmer/Laplace)
### Official Implementations
It includes the official codes of the following papers:
- _Packed-Ensembles for Efficient Uncertainty Estimation_ - [ICLR 2023](https://arxiv.org/abs/2210.09184) - [Tutorial](https://torch-uncertainty.github.io/auto_tutorials/Classification/tutorial_pe_cifar10.html)
- _LP-BNN: Encoding the latent posterior of Bayesian Neural Networks for uncertainty quantification_ - [IEEE TPAMI 2023](https://arxiv.org/abs/2012.02818)
- _MUAD: Multiple Uncertainties for Autonomous Driving, a benchmark for multiple uncertainty types and tasks_ - [BMVC 2022](https://arxiv.org/abs/2203.01437)
## Tutorials
Check out all our tutorials at [torch-uncertainty.github.io/auto_tutorials](https://torch-uncertainty.github.io/auto_tutorials/index.html).
## :telescope: Projects using TorchUncertainty
The following projects use TorchUncertainty:
- _Towards Understanding and Quantifying Uncertainty for Text-to-Image Generation_ - [CVPR 2025](https://openaccess.thecvf.com/content/CVPR2025/papers/Franchi_Towards_Understanding_and_Quantifying_Uncertainty_for_Text-to-Image_Generation_CVPR_2025_paper.pdf)
- _Towards Understanding Why Label Smoothing Degrades Selective Classification and How to Fix It_ - [ICLR 2025](https://arxiv.org/abs/2403.14715)
- _A Symmetry-Aware Exploration of Bayesian Neural Network Posteriors_ - [ICLR 2024](https://arxiv.org/abs/2310.08287)
**If you are using TorchUncertainty in your project, please let us know, and we will add your project to this list!**
## Citation
If you use this software, please cite its corresponding paper:
```bibtex
@inproceedings{lafage2025torch_uncertainty,
title={Torch-Uncertainty: A Deep Learning Framework for Uncertainty Quantification},
author={Lafage, Adrien and Laurent, Olivier and Gabetni, Firas and Franchi, Gianni},
booktitle={NeurIPS Datasets and Benchmarks Track},
year={2025}
}
```
| text/markdown | ENSTA U2IS AI, Adrien Lafage, Olivier Laurent | ENSTA U2IS AI <olivier.laurent@ensta.fr>, Adrien Lafage <adrienlafage@outlook.com>, Olivier Laurent <olivier.ar.laurent@gmail.com> | null | null | null | bayesian-network, ensembles, neural-networks, predictive-uncertainty, reliable-ai, trustworthy-machine-learning, uncertainty, uncertainty-quantification | [
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"timm",
"lightning[pytorch-extra]<2.7,>=2.0",
"torch<2.9,>=2.1",
"torchvision>=0.16",
"einops",
"seaborn",
"torch-uncertainty[distribution,experiments,image,others,timeseries]; extra == \"all\"",
"torch<2.9,>=2.1.0; extra == \"cpu\"",
"torchvision>=0.16.0; extra == \"cpu\"",
"scipy; extra == \"dis... | [] | [] | [] | [
"documentation, https://torch-uncertainty.github.io/quickstart.html",
"homepage, https://torch-uncertainty.github.io/",
"repository, https://github.com/torch-uncertainty/torch-uncertainty.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:42:53.237916 | torch_uncertainty-0.10.1.tar.gz | 203,550 | 1f/66/ae1ca5fc9f5f7be36fb4b1b7c5ee1b04661edf1bd21245e259882fd44ff5/torch_uncertainty-0.10.1.tar.gz | source | sdist | null | false | 4bf1eba2a928f41535722137c9d969dc | 3434f2ad22a02c9956ec3966f92564b82c0077f9b86bb519e7c4338832d06113 | 1f66ae1ca5fc9f5f7be36fb4b1b7c5ee1b04661edf1bd21245e259882fd44ff5 | null | [] | 261 |
2.4 | mformat | 0.3 | Uniform way to write simple text to different file formats | # mformat
The mformat package contains a number of classes providing a uniform way for a
python program to write to a number of different file formats.
The primary intended use is for text output from a python program, where the
programmer would like the user to be able to select the output file formats.
Some users may want the text as a Microsoft Word file, others as a LibreOffice
Open Document Text file, while still others might want it as Markdown. By using
the uniform way of writing provided by mformat the same python code can produce
output in a number of different formats.
This is intended to provide an easy and uniform way to produce information in
different formats. The emphasis is on getting the same information into the
different formats. This will allow you to get a correct (but perhaps
rudimentary) document in several formats. If you want to produce the most
esthetically pleasing document in a particular format, this is not the correct
library to use.
## Installing mformat (base package, this package)
The base package contains support for the output formats that are supported with
a minimum of dependencies. Use this if you for some reason want to avoid extra
dependencies.
If you want to use it, install it using pip from
[https://pypi.org/project/mformat](https://pypi.org/project/mformat) . There is
no need to download anything from Bitbucket to write Python programs that use
the library.
### Installing base mformat on mac and Linux
````sh
pip3 install --upgrade mformat
````
### Installing base mformat on Microsoft Windows
````sh
pip install --upgrade mformat
````
## Installing mformat-ext (extended package)
The extended package contains support also for output formats that require some
additional dependencies. Use this if you want the full selection of output
formats.
If you want to use it, install it using pip from
[https://pypi.org/project/mformat-ext](https://pypi.org/project/mformat-ext) .
There is no need to download anything from Bitbucket to write Python programs
that use the library.
### Installing extended mformat on mac and Linux
````sh
pip3 install --upgrade mformat-ext
````
### Installing extended mformat on Microsoft Windows
````sh
pip install --upgrade mformat-ext
````
## What it does
The main features supported in a uniform way for all supported output file
formats are:
- Factory function that takes file format and output file name as arguments
- It opens and closes a file in the selected format, with protection against
accidentically overwriting an existing file
- The recommended way to use it is as a context manager in a with-clause,
opening and closing the file
- Headings (several levels)
- Paragraphs
- Nested bullet point lists
- Nested numbered point lists
- Mixed nested numbered point and bullet point lists
- Tables
- URLs in paragraphs, headings, numbered point list items and in bullet point
list items
## Design of program that uses mformat
It is recommended that the ouput function(s) of the a Python program using
mformat should have a with-clause getting the formatting object from the factory
(easiest with `with create_mf(file_format=fmt, file_name=output_file_name) as`
).
In the context of the with-clause the programmer just calls a minimum of member
functions:
- `new_paragraph` to start a new paragraph with some provided text content.
- `new_heading` to start a new heading with some provided text content.
- `new_bullet_item` to start a new bullet point list item with some provided
text content, and if needed to start the bullet point list with the bullet
point item.
- `new_numbered_point_item` to start a new numbered point list item with some
provided text content, and if needed to start the numbered point list with the
number point list item.
- `add_text` to add more text to an already started paragraph, heading, bullet
point list item or numbered point list item.
- `add_url` to add a URL (link) to an already started paragraph, heading, bullet
point list item or numbered point list item.
- `add_code_in_text` to add some short text (function name, variable name, etc.)
as code to an already started paragraph, heading, bullet point list item or
numbered point list item.
- `new_table` to start a new table with the provided first row.
- `add_table_row` to add another row to an already started table.
- `write_complete_table` to write a table all at once.
- `write_code_block` to write some preformatted text as a code block
There are no member functions to end or close any document item. Each document
item is automatically closed as another docuemnt item is started (or when
closing the file at the end of the context manager scope). new_bullet_item and
new_numbered_point_item take an optional level argument, that is used to change
to another nesting level.
## Example programs
A number of minimal but complete example programs are provided to help the
programmer new to mformat. See
[list of examples](https://bitbucket.org/tom-bjorkholm/mformat/src/master/example/README.md)
.
## API documentation
PI documentation automatically extracted from the Python code and docstrings are
available
[here for the public API](https://bitbucket.org/tom-bjorkholm/mformat/src/master/doc/api.md)
for programmers using the API and
[here for the protected API](https://bitbucket.org/tom-bjorkholm/mformat/src/master/doc/protected_api.md)
for programmers that want to extend the API by adding their own derived class
that provide some other output format.
Even though some may like reading API documentation, the
[example programs](https://bitbucket.org/tom-bjorkholm/mformat/src/master/example/README.md)
probably provide a better introduction.
## Version history
| Version | Date | Python version | Description |
|---------|-------------|----------------|-------------------------|
| 0.3 | 18 Feb 2026 | 3.12 or newer | Improved API and fixes |
| 0.2.2 | 31 Jan 2026 | 3.12 or newer | Dependency corrected |
| 0.2.1 | 30 Jan 2026 | 3.12 or newer | Minor documentation fix |
| 0.2 | 30 Jan 2026 | 3.12 or newer | First released version |
## Output file formats
The following table provides information about in which version support for a
format was introduced.
| Format | Full name of format | Which package | Starting at version |
|--------|---------------------|---------------|---------------------|
| docx | Microsoft Word | mformat-ext | 0.2 |
| html | HTML Web page | mformat | 0.2 |
| md | Markdown | mformat | 0.2 |
| odt | Open Document Text | mformat-ext | 0.2 |
## API changes in version 0.3 (deprecated methods)
In version 0.2.x the public API was build around methods that started document
items, like start_paragraph. However, experience showed that this was not
intuitive for the user. Many users were trying to use end or stop methods (that
do not exist) in pair with the start methods. To address this, the public API
was changed in version 0.3.0 to use methods named new something, like
new_paragraph. With this naming the intuition should hopefully not tell users to
look for end or stop methods (that do not exist). People have also pointed out
that phrases like "new paragraph" are commonly used in dictation.
The old methods are still available, but are deprecated and will be removed in
some future version.
| New method | Deprecated method |
|-------------------------|---------------------------|
| new_paragraph | start_paragraph |
| new_heading | start_heading |
| new_bullet_item | start_bullet_item |
| new_numbered_point_item | start_numbered_point_item |
| new_table | start_table |
## Test summary
- Test result: 1480 passed in 15s
- No Flake8 warnings.
- No mypy errors found.
- 0.3 built and tested using python version: Python 3.14.3
| text/markdown | Tom Björkholm | Tom Björkholm <klausuler_linnet0q@icloud.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"pip",
"setuptools",
"build",
"wheel"
] | [] | [] | [] | [
"Source code, https://bitbucket.org/tom-bjorkholm/mformat"
] | twine/6.0.1 CPython/3.12.6 | 2026-02-18T16:42:46.604833 | mformat-0.3.tar.gz | 21,290 | e1/13/f80157400eac642afa760dd5d74d384e7ad1979c64bcf3953a99b8bb2b6d/mformat-0.3.tar.gz | source | sdist | null | false | 5c0d0311146ba2dfd9eaaad210822b7f | 489a6685e1c54297340c22e8bef1dcb63a4a6d2e5248c800decd27e49d37e352 | e113f80157400eac642afa760dd5d74d384e7ad1979c64bcf3953a99b8bb2b6d | null | [] | 235 |
2.4 | mformat-ext | 0.3 | Uniform way to write simple text extended with DOCX and ODT files | # mformat-ext
The mformat package contains a number of classes providing a uniform way for a
python program to write to a number of different file formats.
The primary intended use is for text output from a python program, where the
programmer would like the user to be able to select the output file formats.
Some users may want the text as a Microsoft Word file, others as a LibreOffice
Open Document Text file, while still others might want it as Markdown. By using
the uniform way of writing provided by mformat the same python code can produce
output in a number of different formats.
This is intended to provide an easy and uniform way to produce information in
different formats. The emphasis is on getting the same information into the
different formats. This will allow you to get a correct (but perhaps
rudimentary) document in several formats. If you want to produce the most
esthetically pleasing document in a particular format, this is not the correct
library to use.
## Installing mformat (base package)
The base package contains support for the output formats that are supported with
a minimum of dependencies. Use this if you for some reason want to avoid extra
dependencies.
If you want to use it, install it using pip from
[https://pypi.org/project/mformat](https://pypi.org/project/mformat) . There is
no need to download anything from Bitbucket to write Python programs that use
the library.
### Installing base mformat on mac and Linux
````sh
pip3 install --upgrade mformat
````
### Installing base mformat on Microsoft Windows
````sh
pip install --upgrade mformat
````
## Installing mformat-ext (extended package, this package)
The extended package contains support also for output formats that require some
additional dependencies. Use this if you want the full selection of output
formats.
If you want to use it, install it using pip from
[https://pypi.org/project/mformat-ext](https://pypi.org/project/mformat-ext) .
There is no need to download anything from Bitbucket to write Python programs
that use the library.
### Installing extended mformat on mac and Linux
````sh
pip3 install --upgrade mformat-ext
````
### Installing extended mformat on Microsoft Windows
````sh
pip install --upgrade mformat-ext
````
## What it does
The main features supported in a uniform way for all supported output file
formats are:
- Factory function that takes file format and output file name as arguments
- It opens and closes a file in the selected format, with protection against
accidentically overwriting an existing file
- The recommended way to use it is as a context manager in a with-clause,
opening and closing the file
- Headings (several levels)
- Paragraphs
- Nested bullet point lists
- Nested numbered point lists
- Mixed nested numbered point and bullet point lists
- Tables
- URLs in paragraphs, headings, numbered point list items and in bullet point
list items
## Design of program that uses mformat
It is recommended that the ouput function(s) of the a Python program using
mformat should have a with-clause getting the formatting object from the factory
(easiest with `with create_mf(file_format=fmt, file_name=output_file_name) as`
).
In the context of the with-clause the programmer just calls a minimum of member
functions:
- `new_paragraph` to start a new paragraph with some provided text content.
- `new_heading` to start a new heading with some provided text content.
- `new_bullet_item` to start a new bullet point list item with some provided
text content, and if needed to start the bullet point list with the bullet
point item.
- `new_numbered_point_item` to start a new numbered point list item with some
provided text content, and if needed to start the numbered point list with the
number point list item.
- `add_text` to add more text to an already started paragraph, heading, bullet
point list item or numbered point list item.
- `add_url` to add a URL (link) to an already started paragraph, heading, bullet
point list item or numbered point list item.
- `add_code_in_text` to add some short text (function name, variable name, etc.)
as code to an already started paragraph, heading, bullet point list item or
numbered point list item.
- `new_table` to start a new table with the provided first row.
- `add_table_row` to add another row to an already started table.
- `write_complete_table` to write a table all at once.
- `write_code_block` to write some preformatted text as a code block
There are no member functions to end or close any document item. Each document
item is automatically closed as another docuemnt item is started (or when
closing the file at the end of the context manager scope). new_bullet_item and
new_numbered_point_item take an optional level argument, that is used to change
to another nesting level.
## Example programs
A number of minimal but complete example programs are provided to help the
programmer new to mformat. See
[list of examples](https://bitbucket.org/tom-bjorkholm/mformat/src/master/example/README.md)
.
## API documentation
PI documentation automatically extracted from the Python code and docstrings are
available
[here for the public API](https://bitbucket.org/tom-bjorkholm/mformat/src/master/doc/api.md)
for programmers using the API and
[here for the protected API](https://bitbucket.org/tom-bjorkholm/mformat/src/master/doc/protected_api.md)
for programmers that want to extend the API by adding their own derived class
that provide some other output format.
Even though some may like reading API documentation, the
[example programs](https://bitbucket.org/tom-bjorkholm/mformat/src/master/example/README.md)
probably provide a better introduction.
## Version history
| Version | Date | Python version | Description |
|---------|-------------|----------------|-------------------------|
| 0.3 | 18 Feb 2026 | 3.12 or newer | Improved API and fixes |
| 0.2.2 | 31 Jan 2026 | 3.12 or newer | Dependency corrected |
| 0.2.1 | 30 Jan 2026 | 3.12 or newer | Minor documentation fix |
| 0.2 | 30 Jan 2026 | 3.12 or newer | First released version |
## Output file formats
The following table provides information about in which version support for a
format was introduced.
| Format | Full name of format | Which package | Starting at version |
|--------|---------------------|---------------|---------------------|
| docx | Microsoft Word | mformat-ext | 0.2 |
| html | HTML Web page | mformat | 0.2 |
| md | Markdown | mformat | 0.2 |
| odt | Open Document Text | mformat-ext | 0.2 |
## API changes in version 0.3 (deprecated methods)
In version 0.2.x the public API was build around methods that started document
items, like start_paragraph. However, experience showed that this was not
intuitive for the user. Many users were trying to use end or stop methods (that
do not exist) in pair with the start methods. To address this, the public API
was changed in version 0.3.0 to use methods named new something, like
new_paragraph. With this naming the intuition should hopefully not tell users to
look for end or stop methods (that do not exist). People have also pointed out
that phrases like "new paragraph" are commonly used in dictation.
The old methods are still available, but are deprecated and will be removed in
some future version.
| New method | Deprecated method |
|-------------------------|---------------------------|
| new_paragraph | start_paragraph |
| new_heading | start_heading |
| new_bullet_item | start_bullet_item |
| new_numbered_point_item | start_numbered_point_item |
| new_table | start_table |
## Test summary
- Test result: 1480 passed in 15s
- No Flake8 warnings.
- No mypy errors found.
- 0.3 built and tested using python version: Python 3.14.3
| text/markdown | Tom Björkholm | Tom Björkholm <klausuler_linnet0q@icloud.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"mformat>=0.3",
"python-docx>=1.2.0",
"odfdo>=3.20.2",
"pip>=26.0.1",
"setuptools>=82.0.0",
"build>=1.4.0",
"wheel>=0.46.3"
] | [] | [] | [] | [
"Source code, https://bitbucket.org/tom-bjorkholm/mformat"
] | twine/6.0.1 CPython/3.12.6 | 2026-02-18T16:42:45.511677 | mformat_ext-0.3.tar.gz | 12,019 | 96/74/54882aa0f6bb80f674831172b39de225ddd6e8473010a1eaa3c187faf838/mformat_ext-0.3.tar.gz | source | sdist | null | false | 5bbf27d4cb00ce8fa70497ba63ef7368 | aa120289120d98e50491c478585d29eb300249e4a98a909c1bd4fb709d3f367d | 967454882aa0f6bb80f674831172b39de225ddd6e8473010a1eaa3c187faf838 | null | [] | 227 |
2.4 | easyutilities | 0.1.1 | Reusable utility classes and functions shared across EasyScience modules | <p>
<picture>
<!-- light mode logo -->
<source media='(prefers-color-scheme: light)' srcset='https://raw.githubusercontent.com/easyscience/assets-branding/refs/heads/master/easyutilities/logos/light.svg'>
<!-- dark mode logo -->
<source media='(prefers-color-scheme: dark)' srcset='https://raw.githubusercontent.com/easyscience/assets-branding/refs/heads/master/easyutilities/logos/dark.svg'>
<!-- default logo == light mode logo -->
<img src='https://raw.githubusercontent.com/easyscience/assets-branding/refs/heads/master/easyutilities/logos/light.svg' alt='EasyUtilities'>
</picture>
</p>
**EasyUtilities** is a scientific software for sharing utilities,
including reusable classes and functions, to be used across EasyScience
modules.
<!-- HOME REPOSITORY SECTION -->
**EasyUtilities** is developed as a Python library.
## Useful Links
- 📖 [Documentation](https://easyscience.github.io/utils/latest)
- 🚀
[Getting Started](https://easyscience.github.io/utils/latest/introduction)
- 🧪 [Tutorials](https://easyscience.github.io/utils/latest/tutorials)
- 💬
[Get in Touch](https://easyscience.github.io/utils/latest/introduction/#get-in-touch)
- 🧾
[Citation](https://easyscience.github.io/utils/latest/introduction/#citation)
- 🤝
[Contributing](https://easyscience.github.io/utils/latest/introduction/#contributing)
- 🐞 [Issue Tracker](https://github.com/easyscience/utils/issues)
- 💡 [Discussions](https://github.com/easyscience/utils/discussions)
- 🧑💻 [Source Code](https://github.com/easyscience/utils)
- ⚖️
[License](https://raw.githubusercontent.com/easyscience/utils/refs/heads/master/LICENSE)
| text/markdown | EasyUtilities contributors | null | null | null | BSD 3-Clause License
Copyright (c) 2026 EasyScience contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | null | [
"Intended Audience :: Science/Research",
"License :: OSI Approved :: BSD License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programmin... | [] | null | null | >=3.11 | [] | [] | [] | [
"darkdetect",
"jupyterlab",
"pandas",
"pixi-kernel",
"plotly",
"pooch",
"py3dmol",
"build; extra == \"dev\"",
"copier; extra == \"dev\"",
"docformatter; extra == \"dev\"",
"interrogate; extra == \"dev\"",
"jinja2; extra == \"dev\"",
"jupyterquiz; extra == \"dev\"",
"jupytext; extra == \"de... | [] | [] | [] | [
"homepage, https://easyscience.github.io/utils",
"documentation, https://easyscience.github.io/utils",
"source, https://github.com/easyscience/utils",
"tracker, https://github.com/easyscience/utils/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:42:41.554935 | easyutilities-0.1.1.tar.gz | 170,985 | 4f/6b/571bc80657d1eb153c335ce0cb43c2fc6d40da18d05a22dd84b6690f04c1/easyutilities-0.1.1.tar.gz | source | sdist | null | false | 6001b8404fdf7323ea5828a77238cf33 | b494fcd800510037316d2a2f6ea814bdf27df8b18df597b11843129cd4be1bc3 | 4f6b571bc80657d1eb153c335ce0cb43c2fc6d40da18d05a22dd84b6690f04c1 | null | [
"LICENSE"
] | 262 |
2.4 | circuitpython-functools | 2.0.3 | A CircuitPython implementation of CPython's functools library | Introduction
============
.. image:: https://readthedocs.org/projects/circuitpython-functools/badge/?version=latest
:target: https://circuitpython-functools.readthedocs.io/
:alt: Documentation Status
.. image:: https://img.shields.io/discord/327254708534116352.svg
:target: https://adafru.it/discord
:alt: Discord
.. image:: https://github.com/tekktrik/CircuitPython_functools/workflows/Build%20CI/badge.svg
:target: https://github.com/tekktrik/CircuitPython_functools/actions
:alt: Build Status
.. image:: https://img.shields.io/badge/code%20style-ruff-2a1833.svg
:target: https://github.com/astral-sh/ruff
:alt: Code Style: ruff
.. image:: https://img.shields.io/badge/License-MIT-yellow.svg
:target: https://opensource.org/licenses/MIT
:alt: License: MIT
.. image:: https://img.shields.io/badge/License-PSF_2.0-yellow.svg
:target: https://opensource.org/license/python-2-0
:alt: License: PSF-2.0
.. image:: https://img.shields.io/badge/Maintained%3F-yes-green.svg
:target: https://github.com/tekktrik/CircuitPython_CSV
:alt: Maintained: Yes
A CircuitPython implementation of CPython's functools library
Dependencies
=============
This driver depends on:
* `Adafruit CircuitPython <https://github.com/adafruit/circuitpython>`_
Please ensure all dependencies are available on the CircuitPython filesystem.
This is easily achieved by downloading
`the Adafruit library and driver bundle <https://circuitpython.org/libraries>`_
or individual libraries can be installed using
`circup <https://github.com/adafruit/circup>`_.
Installing to a Connected CircuitPython Device with Circup
==========================================================
Make sure that you have ``circup`` installed in your Python environment.
Install it with the following command if necessary:
.. code-block:: shell
pip3 install circup
With ``circup`` installed and your CircuitPython device connected use the
following command to install:
.. code-block:: shell
circup install circuitpython_functools
Or the following command to update an existing version:
.. code-block:: shell
circup update
Installing from PyPI
====================
.. note::
This library is provided on PyPI so that code developed for microcontrollers with this
library will also run on computers like the Raspberry Pi. If you just need a package
for working with functiols on a computer or SBC only, consider using the Python standard
library's ``functools`` module instead.
On supported GNU/Linux systems like the Raspberry Pi, you can install the driver locally `from
PyPI <https://pypi.org/project/circuitpython-functools/>`_. To install for current user:
.. code-block:: shell
pip3 install circuitpython-functools
To install system-wide (this may be required in some cases):
.. code-block:: shell
sudo pip3 install circuitpython-functools
To install in a virtual environment in your current project:
.. code-block:: shell
mkdir project-name && cd project-name
python3 -m venv .venv
source .venv/bin/activate
pip3 install circuitpython-functools
Usage Example
=============
See examples in the `examples/` folder
Documentation
=============
API documentation for this library can be found on `Read the Docs <https://circuitpython-functools.readthedocs.io/>`_.
For information on building library documentation, please check out
`this guide <https://learn.adafruit.com/creating-and-sharing-a-circuitpython-library/sharing-our-docs-on-readthedocs#sphinx-5-1>`_.
Contributing
============
Contributions are welcome! Please read our `Code of Conduct
<https://github.com/tekktrik/CircuitPython_functools/blob/HEAD/CODE_OF_CONDUCT.md>`_
before contributing to help this project stay welcoming.
| text/x-rst | null | Alec Delaney <tekktrik@gmail.com> | null | null | null | adafruit, blinka, circuitpython, micropython, functools, cache, functions, decorators | [
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development :: Embedded Systems",
"Topic :: System :: Hardware",
"Programming Language :: Python :: 3"
] | [] | null | null | null | [] | [] | [] | [
"Adafruit-Blinka",
"pre-commit~=4.1; extra == \"optional\""
] | [] | [] | [] | [
"Homepage, https://github.com/tekktrik/CircuitPython_functools"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T16:42:32.631732 | circuitpython_functools-2.0.3.tar.gz | 23,364 | fb/87/0a2cef9b78a709bc11fe3fa1ac552a745b3b70fb9f592c30dfee055856d2/circuitpython_functools-2.0.3.tar.gz | source | sdist | null | false | ca930d574b6337ee6f3b8f39466f43b8 | 3f0c3bcb9e5256bc08ca933ccbec979663d51de809366fdb203804dd680b06cf | fb870a2cef9b78a709bc11fe3fa1ac552a745b3b70fb9f592c30dfee055856d2 | MIT AND PSF-2.0 | [
"LICENSE-MIT",
"LICENSE-PSF"
] | 236 |
2.1 | odoo-addon-maintenance-equipment-ref | 18.0.1.0.0.1 | Adds reference field to maintenance equipment | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
===============================
Maintenance Equipment Reference
===============================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:8420dbb51ddff9b6dc63ac30bb34ab2be2f188dd29e882ecfe0788e642d8b70b
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fmaintenance-lightgray.png?logo=github
:target: https://github.com/OCA/maintenance/tree/18.0/maintenance_equipment_ref
:alt: OCA/maintenance
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/maintenance-18-0/maintenance-18-0-maintenance_equipment_ref
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/maintenance&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module introduces an Internal reference to the maintenance
equipment
**Table of contents**
.. contents::
:local:
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/maintenance/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/maintenance/issues/new?body=module:%20maintenance_equipment_ref%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Tecnativa
Contributors
------------
- `Tecnativa <https://www.tecnativa.com>`__
- Christian Ramos
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/maintenance <https://github.com/OCA/maintenance/tree/18.0/maintenance_equipment_ref>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Tecnativa, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/maintenance | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T16:42:27.622650 | odoo_addon_maintenance_equipment_ref-18.0.1.0.0.1-py3-none-any.whl | 21,583 | e9/f8/a8d5a03e15503ab5428a765da6fa735aa0ff1416a642a34067d51886e97e/odoo_addon_maintenance_equipment_ref-18.0.1.0.0.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 2bb14c7af5fdcbcdf803b767090c302c | f1d6842bd642f8f47d738d1c68ca70eda0c9eeeb7d42cae74d93d876755c4dd4 | e9f8a8d5a03e15503ab5428a765da6fa735aa0ff1416a642a34067d51886e97e | null | [] | 113 |
2.4 | veritensor | 1.5.1 | Antivirus for the AI Supply Chain. Scans models, datasets, notebooks, and RAG documents for threats. | # 🛡️ Veritensor: AI Data & Artifact Security
[](https://huggingface.co/spaces/arsbr/veritensor-ai-model-security-scanner)
[](https://pypi.org/project/veritensor/)
[](https://hub.docker.com/r/arseniibrazhnyk/veritensor)
[](https://opensource.org/licenses/Apache-2.0)
[](https://github.com/arsbr/Veritensor/actions/workflows/scanner-ci.yaml)
[](https://github.com/arsbr/Veritensor/actions/workflows/security.yaml)
[](https://github.com/arsbr/veritensor)
**Veritensor** is an end-to-end antivirus for the entire AI Life Cycle. It secures the entire AI Supply Chain by scanning artifacts that traditional tools miss: Models, Datasets, RAG Documents, and Notebooks.
Unlike standard SAST tools (which focus on code), Veritensor understands the binary and serialized formats used in Machine Learning:
1. **Models:** Deep AST analysis of **Pickle, PyTorch, Keras, Safetensors** to block RCE and backdoors.
2. **Data & RAG:** Streaming scan of **Parquet, CSV, Excel, PDF** to detect Data Poisoning, Prompt Injections, and PII.
3. **Notebooks:** Hardening of **Jupyter (.ipynb)** files by detecting leaked secrets (using Entropy analysis), malicious magics, and XSS.
4. **Supply Chain:** Audits **dependencies** (`requirements.txt`, `poetry.lock`) for Typosquatting and known CVEs (via OSV.dev).
5. **Governance:** Generates cryptographic **Data Manifests** (Provenance) and signs containers via **Sigstore**.
---
## 🚀 Features
* **Parallel Scanning:** Utilizes all CPU cores to scan thousands of files in seconds. Includes robust **SQLite Caching** to skip unchanged files.
* **Stealth Detection:** Finds attacks hidden from humans but visible to LLMs. Detects **CSS Hiding** (white text, zero font), **Base64 Obfuscation**, and **Unicode Spoofing**.
* **Dataset Security:** Streams massive datasets (100GB+) to find "Poisoning" patterns (e.g., "Ignore previous instructions") and malicious URLs in **Parquet, CSV, JSONL, and Excel**.
* **Archive Inspection:** Safely scans inside **.zip, .tar.gz, .whl** files without extracting them to disk (Zip Bomb protected).
* **Dependency Audit:** Checks `pyproject.toml`, `poetry.lock`, and `Pipfile.lock` for malicious packages (Typosquatting) and vulnerabilities.
* **Data Provenance:** Command `veritensor manifest .` creates a signed JSON snapshot of your data artifacts for compliance (EU AI Act).
* **Identity Verification:** Automatically verifies model hashes against the official Hugging Face registry to detect Man-in-the-Middle attacks.
---
## 📦 Installation
Veritensor is modular. Install only what you need to keep your environment lightweight (~50MB core).
| Option | Command | Use Case |
| :--- | :--- | :--- |
| **Core** | `pip install veritensor` | Base scanner (Models, Notebooks, Dependencies) |
| **Data** | `pip install "veritensor[data]"` | Datasets (Parquet, Excel, CSV) |
| **RAG** | `pip install "veritensor[rag]"` | Documents (PDF, DOCX, PPTX) |
| **PII** | `pip install "veritensor[pii]"` | ML-based PII detection (Presidio) |
| **AWS** | `pip install "veritensor[aws]"` | Direct scanning from S3 buckets |
| **All** | `pip install "veritensor[all]"` | Full suite for enterprise security |
### Via Docker (Recommended for CI/CD)
```bash
docker pull arseniibrazhnyk/veritensor:latest
```
---
## ⚡ Quick Start
### 1. Scan a local project (Parallel)
Recursively scan a directory for all supported threats using 4 CPU cores:
```bash
veritensor scan ./my-rag-project --recursive --jobs 4
```
### 2. Scan RAG Documents & Excel
Check for Prompt Injections and Formula Injections in business data:
```bash
veritensor scan ./finance_data.xlsx
veritensor scan ./docs/contract.pdf
```
### 3. Generate Data Manifest
Create a compliance snapshot of your dataset folder:
```bash
veritensor manifest ./data --output provenance.json
```
### 4. Verify Model Integrity
Ensure the file on your disk matches the official version from Hugging Face (detects tampering):
```bash
veritensor scan ./pytorch_model.bin --repo meta-llama/Llama-2-7b
```
### 5. Scan from Amazon S3
Scan remote assets without manual downloading:
```bash
veritensor scan s3://my-ml-bucket/models/llama-3.pkl
```
### 6. Verify against Hugging Face
Ensure the file on your disk matches the official version from the registry (detects tampering):
```bash
veritensor scan ./pytorch_model.bin --repo meta-llama/Llama-2-7b
```
### 7. License Compliance Check
Veritensor automatically reads metadata from safetensors and GGUF files.
If a model has a Non-Commercial license (e.g., cc-by-nc-4.0), it will raise a HIGH severity alert.
To override this (Break-glass mode), use:
```bash
veritensor scan ./model.safetensors --force
```
### 8. Scan AI Datasets
Veritensor uses streaming to handle huge files. It samples 10k rows by default for speed.
```bash
veritensor scan ./data/train.parquet --full-scan
```
### 9. Scan Jupyter Notebooks
Check code cells, markdown, and saved outputs for threats:
```bash
veritensor scan ./research/experiment.ipynb
```
**Example Output:**
```Text
╭────────────────────────────────╮
│ 🛡️ Veritensor Security Scanner │
╰────────────────────────────────╯
Scan Results
┏━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┓
┃ File ┃ Status ┃ Threats / Details ┃ SHA256 (Short) ┃
┡━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━┩
│ model.pt │ FAIL │ CRITICAL: os.system (RCE Detected) │ a1b2c3d4... │
└──────────────┴────────┴──────────────────────────────────────┴────────────────┘
❌ BLOCKING DEPLOYMENT
```
---
## 📊 Reporting & Compliance
Veritensor supports industry-standard formats for integration with security dashboards and audit tools.
### 1. GitHub Security (SARIF)
Generate a report compatible with GitHub Code Scanning:
```bash
veritensor scan ./models --sarif > veritensor-report.sarif
```
### 2. Software Bill of Materials (SBOM)
Generate a CycloneDX v1.5 SBOM to inventory your AI assets:
```bash
veritensor scan ./models --sbom > sbom.json
```
### 3. Raw JSON
For custom parsers and SOAR automation:
```bash
veritensor scan ./models --json
```
---
## 🔐 Supply Chain Security (Container Signing)
Veritensor integrates with Sigstore Cosign to cryptographically sign your Docker images only if they pass the security scan.
### 1. Generate Keys
Generate a key pair for signing:
```bash
veritensor keygen
# Output: veritensor.key (Private) and veritensor.pub (Public)
```
### 2. Scan & Sign
Pass the --image flag and the path to your private key (via env var).
```bash
# Set path to your private key
export VERITENSOR_PRIVATE_KEY_PATH=veritensor.key
# If scan passes -> Sign the image
veritensor scan ./models/my_model.pkl --image my-org/my-app:v1.0.0
```
### 3. Verify (In Kubernetes / Production)
Before deploying, verify the signature to ensure the model was scanned:
```bash
cosign verify --key veritensor.pub my-org/my-app:v1.0.0
```
---
## 🛠️ Integrations
### GitHub Actions
Add this to your .github/workflows/security.yml to block malicious models in Pull Requests:
```yaml
name: AI Security Scan
on: [pull_request]
jobs:
veritensor-scan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Veritensor Scan
uses: ArseniiBrazhnyk/Veritensor@v1.5.1
with:
path: '.'
args: '--jobs 4'
```
### Pre-commit Hook
Prevent committing malicious models to your repository. Add this to .pre-commit-config.yaml:
```yaml
repos:
- repo: https://github.com/arsbr/Veritensor
rev: v1.5.1
hooks:
- id: veritensor-scan
```
---
## 📂 Supported Formats
| Format | Extension | Analysis Method |
| :--- | :--- | :--- |
| **Models** | `.pt`, `.pth`, `.bin`, `.pkl`, `.joblib`, `.h5`, `.keras`, `.safetensors`, `.gguf`, `.whl` | AST Analysis, Pickle VM Emulation, Metadata Validation |
| **Datasets** | `.parquet`, `.csv`, `.tsv`, `.jsonl`, `.ndjson`, `.ldjson` | Streaming Regex Scan (URLs, Injections, PII) |
| **Notebooks** | `.ipynb` | JSON Structure Analysis + Code AST + Markdown Phishing |
| **Documents** | `.pdf`, `.docx`, `.pptx`, `.txt`, `.md`, `.html` | DOM Extraction, Stealth/CSS Detection, PII |
| **Archives** | `.zip`, `.tar`, `.gz`, `.tgz`, `.whl` | Recursive In-Memory Inspection |
| **RAG Docs** | `requirements.txt`, `poetry.lock`, `Pipfile.lock` | Typosquatting, OSV.dev CVE Lookup |
---
## ⚙️ Configuration
You can customize security policies by creating a `veritensor.yaml` file in your project root.
Pro Tip: You can use `regex:` prefix for flexible matching.
```yaml
# veritensor.yaml
# 1. Security Threshold
# Fail the build if threats of this severity (or higher) are found.
# Options: CRITICAL, HIGH, MEDIUM, LOW.
fail_on_severity: CRITICAL
# 2. Dataset Scanning
# Sampling limit for quick scans (default: 10000)
dataset_sampling_limit: 10000
# 3. License Firewall Policy
# If true, blocks models that have no license metadata.
fail_on_missing_license: false
# List of license keywords to block (case-insensitive).
custom_restricted_licenses:
- "cc-by-nc" # Non-Commercial
- "agpl" # Viral licenses
- "research-only"
# 4. Static Analysis Exceptions (Pickle)
# Allow specific Python modules that are usually blocked by the strict scanner.
allowed_modules:
- "my_company.internal_layer"
- "sklearn.tree"
# 5. Model Whitelist (License Bypass)
# List of Repo IDs that are trusted. Veritensor will SKIP license checks for these.
# Supports Regex!
allowed_models:
- "meta-llama/Meta-Llama-3-70B-Instruct" # Exact match
- "regex:^google-bert/.*" # Allow all BERT models from Google
- "internal/my-private-model"
```
To generate a default configuration file, run: veritensor init
---
## 🧠 Threat Intelligence (Signatures)
Veritensor uses a decoupled signature database (`signatures.yaml`) to detect malicious patterns. This ensures that detection logic is separated from the core engine.
* **Automatic Updates:** To get the latest threat definitions, simply upgrade the package:
```bash
pip install --upgrade veritensor
```
* **Transparent Rules:** You can inspect the default signatures in `src/veritensor/engines/static/signatures.yaml`.
* **Custom Policies:** If the default rules are too strict for your use case (false positives), use `veritensor.yaml` to whitelist specific modules or models.
---
## 📜 License
This project is licensed under the Apache 2.0 License - see the [LICENSE](https://github.com/arsbr/Veritensor?tab=Apache-2.0-1-ov-file#readme) file for details.
| text/markdown | null | Arsenii Brazhnyk <arsenii.brazhnyk@gmail.com> | null | null | Apache-2.0 | security, ai, mlops, malware-detection, supply-chain, devsecops, rag, data-poisoning | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Topic :: Security",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Lan... | [] | null | null | >=3.10 | [] | [] | [] | [
"typer>=0.9.0",
"rich>=13.0.0",
"requests>=2.31.0",
"pyyaml>=6.0",
"huggingface_hub>=0.19.0",
"cyclonedx-python-lib>=6.0.0",
"pytest>=7.0.0; extra == \"test\"",
"pytest-mock>=3.10.0; extra == \"test\"",
"fickling>=0.0.1; extra == \"test\"",
"reportlab>=4.0.0; extra == \"test\"",
"anyio>=4.0.0; e... | [] | [] | [] | [
"Homepage, https://github.com/ArseniiBrazhnyk/Veritensor",
"Bug Tracker, https://github.com/ArseniiBrazhnyk/Veritensor/issues",
"Documentation, https://github.com/ArseniiBrazhnyk/Veritensor#readme"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:42:05.799496 | veritensor-1.5.1.tar.gz | 63,518 | 78/ba/82ae6737810c3cb427dbaede2a1bffe55f77340f3124a65984e55912ce81/veritensor-1.5.1.tar.gz | source | sdist | null | false | 9dd12b384cdabd394dd3d019bc71d05c | bf53cf4a44def4c43c7d92f2ebb188b846707b8b9a4a17e5f9c858ddbe21253a | 78ba82ae6737810c3cb427dbaede2a1bffe55f77340f3124a65984e55912ce81 | null | [
"LICENSE"
] | 251 |
2.4 | oauth2fast-fastapi | 0.2.2 | Fast and secure OAuth2 authentication module for FastAPI with email verification | # oauth2fast-fastapi
🔐 Fast and secure OAuth2 authentication module for FastAPI with email verification and JWT tokens
> [!WARNING]
> **Internal Use Notice**
>
> This package is designed and maintained by the **Solautyc Team** for internal use. While it is publicly available, it may not work as expected in all environments or use cases outside of our specific infrastructure. We do not provide support or guarantees for external usage, and we are not responsible for any issues that may arise from using this package in other contexts.
>
> Use at your own risk. Contributions and feedback are welcome, but compatibility with external environments is not guaranteed.
## Features
- 🔐 **Complete OAuth2 Implementation**: Full OAuth2 password flow with JWT tokens
- 📧 **Email Verification**: Built-in email verification system with customizable templates
- 👤 **User Management**: Ready-to-use user registration, login, and profile endpoints
- 🗄️ **SQLModel Integration**: Async PostgreSQL support with SQLModel/SQLAlchemy
- 🔑 **Secure Password Hashing**: Argon2 password hashing (winner of Password Hashing Competition)
- 🎯 **FastAPI Dependencies**: Easy-to-use dependencies for protected routes
- ⚡ **Async/Await**: Full async support for high performance
- 🎨 **Customizable**: Extend the User model with your own fields
- 📝 **Type-Safe Configuration**: Pydantic settings with environment variables
- 🔄 **Email Templates**: Jinja2 templates for verification and welcome emails
## Installation
### From PyPI (Recommended)
```bash
pip install oauth2fast-fastapi
```
### From Source
```bash
# Clone the repository
git clone https://github.com/AngelDanielSanchezCastillo/oauth2fast-fastapi.git
cd oauth2fast-fastapi
# Install in development mode
pip install -e .
# Or install with dev dependencies
pip install -e ".[dev]"
```
## Quick Start
### 1. Configure Environment Variables
Create a `.env` file in your project root:
```bash
# Required JWT Configuration
SECRET_KEY=your-super-secret-key-change-this-in-production
ALGORITHM=HS256
ACCESS_TOKEN_EXPIRE_MINUTES=60
# Database Configuration
AUTH_DB__USERNAME=postgres
AUTH_DB__PASSWORD=yourpassword
AUTH_DB__HOSTNAME=localhost
AUTH_DB__NAME=myapp_db
AUTH_DB__PORT=5432
# Mail Server Configuration
AUTH_MAIL_SERVER__USERNAME=noreply@yourapp.com
AUTH_MAIL_SERVER__PASSWORD=your-smtp-password
AUTH_MAIL_SERVER__SERVER=smtp.gmail.com
AUTH_MAIL_SERVER__PORT=587
AUTH_MAIL_SERVER__FROM_DIRECTION=noreply@yourapp.com
AUTH_MAIL_SERVER__FROM_NAME=Your App
AUTH_MAIL_SERVER__STARTTLS=true
AUTH_MAIL_SERVER__SSL_TLS=false
# Application Settings
PROJECT_NAME=My App
FRONTEND_URL=https://yourapp.com
AUTH_URL_PREFIX=auth
```
> [!IMPORTANT]
> The `SECRET_KEY` is **required** and must be set in your `.env` file. Generate a secure key:
> ```bash
> python -c "import secrets; print(secrets.token_urlsafe(32))"
> ```
### 2. Basic FastAPI Integration
```python
from fastapi import FastAPI, Depends
from oauth2fast_fastapi import router, engine, get_current_user, User
from sqlmodel import SQLModel
app = FastAPI()
# Include authentication router
app.include_router(router, prefix="/auth", tags=["Authentication"])
@app.on_event("startup")
async def startup():
# Create database tables
async with engine.begin() as conn:
await conn.run_sync(SQLModel.metadata.create_all)
@app.get("/profile")
async def get_profile(current_user: User = Depends(get_current_user)):
return {
"email": current_user.email,
"name": f"{current_user.first_name} {current_user.last_name}",
"verified": current_user.is_verified
}
```
### 3. Authentication Flow
**Register a new user:**
```bash
POST /auth/users/register
{
"email": "user@example.com",
"password": "SecurePassword123",
"first_name": "John",
"last_name": "Doe"
}
```
**Verify email:**
```bash
POST /auth/users/verify-email
{
"token": "verification-token-from-email"
}
```
**Login:**
```bash
POST /auth/token
Content-Type: application/x-www-form-urlencoded
username=user@example.com&password=SecurePassword123
```
Response:
```json
{
"access_token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...",
"token_type": "bearer"
}
```
**Access protected endpoint:**
```bash
GET /profile
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...
```
## Protected Endpoints
Use the provided dependencies to protect your endpoints:
```python
from fastapi import Depends
from oauth2fast_fastapi import get_current_user, get_current_verified_user, User
# Requires authentication only
@app.get("/dashboard")
async def dashboard(user: User = Depends(get_current_user)):
return {"message": f"Welcome {user.email}"}
# Requires authentication AND email verification
@app.get("/premium")
async def premium_feature(user: User = Depends(get_current_verified_user)):
return {"message": "Access granted to verified users only"}
```
## Custom User Model
Extend the base User model with your own fields:
```python
from oauth2fast_fastapi.models.user_model import User as BaseUser
from sqlmodel import Field
class CustomUser(BaseUser, table=True):
__tablename__ = "custom_users"
phone_number: str | None = Field(default=None)
company: str | None = Field(default=None)
role: str = Field(default="user")
```
## Available Endpoints
The authentication router provides the following endpoints:
- `POST /auth/users/register` - Register a new user
- `POST /auth/users/verify-email` - Verify email with token
- `POST /auth/users/resend-verification` - Resend verification email
- `POST /auth/token` - Login and get JWT token
- `GET /auth/users/me` - Get current user profile
- `PUT /auth/users/me` - Update current user profile
## Configuration Reference
All configuration is done via environment variables with nested delimiter `__`.
### JWT Settings (Required)
- `SECRET_KEY` - **Required**: Secret key for JWT signing
- `ALGORITHM` - Default: `"HS256"`: JWT algorithm
- `ACCESS_TOKEN_EXPIRE_MINUTES` - Default: `60`: Token expiration time in minutes
### Database Settings
- `AUTH_DB__USERNAME` - Database username
- `AUTH_DB__PASSWORD` - Database password
- `AUTH_DB__HOSTNAME` - Database host
- `AUTH_DB__NAME` - Database name
- `AUTH_DB__PORT` - Database port (default: 5432)
### Mail Settings
- `AUTH_MAIL_SERVER__USERNAME` - SMTP username
- `AUTH_MAIL_SERVER__PASSWORD` - SMTP password
- `AUTH_MAIL_SERVER__SERVER` - SMTP server
- `AUTH_MAIL_SERVER__PORT` - SMTP port
- `AUTH_MAIL_SERVER__FROM_DIRECTION` - From email address
- `AUTH_MAIL_SERVER__FROM_NAME` - From name
- `AUTH_MAIL_SERVER__STARTTLS` - Use STARTTLS (default: false)
- `AUTH_MAIL_SERVER__SSL_TLS` - Use SSL/TLS (default: true)
### Application Settings
- `PROJECT_NAME` - Application name (used in emails)
- `FRONTEND_URL` - Frontend URL (for email links)
- `AUTH_URL_PREFIX` - Auth router prefix (default: "auth")
## 📚 Documentation
- **[Usage Guide](docs/usage.md)** - Comprehensive usage guide with examples
- **[Environment Configuration](docs/env.example)** - All configuration options
## 📁 Module Structure
```
oauth2fast-fastapi/
├── pyproject.toml
├── MANIFEST.in
├── README.md
├── LICENSE
├── src/
│ └── oauth2fast_fastapi/
│ ├── __init__.py
│ ├── __version__.py
│ ├── settings.py # Pydantic settings
│ ├── database.py # Database engine
│ ├── dependencies.py # FastAPI dependencies
│ ├── models/
│ │ ├── bases.py # Base models
│ │ ├── mixins.py # Model mixins
│ │ └── user_model.py # User model
│ ├── routers/
│ │ ├── base_router.py # Main router
│ │ └── users_router.py # User endpoints
│ ├── schemas/
│ │ ├── token_schema.py # JWT schemas
│ │ ├── user_schema.py # User schemas
│ │ └── verification_schema.py
│ ├── utils/
│ │ ├── password_utils.py # Password hashing
│ │ ├── token_utils.py # JWT utilities
│ │ └── verification_utils.py
│ └── mail/
│ ├── connection.py # SMTP connection
│ ├── service.py # Email service
│ └── templates/ # Email templates
│ ├── verification.html
│ └── welcome.html
├── docs/
│ ├── env.example
│ └── usage.md
├── examples/
│ ├── basic_usage.py
│ ├── custom_user.py
│ └── complete_flow.py
└── tests/
```
## Dependencies
This module depends on:
- [FastAPI](https://github.com/tiangolo/fastapi) - Modern web framework (MIT License)
- [Pydantic](https://github.com/pydantic/pydantic) - Data validation (MIT License)
- [SQLModel](https://github.com/tiangolo/sqlmodel) - SQL databases with Python (MIT License)
- [SQLAlchemy](https://github.com/sqlalchemy/sqlalchemy) - Database toolkit (MIT License)
- [asyncpg](https://github.com/MagicStack/asyncpg) - PostgreSQL driver (Apache 2.0)
- [python-jose](https://github.com/mpdavis/python-jose) - JWT implementation (MIT License)
- [passlib](https://github.com/glic3rinu/passlib) - Password hashing (BSD License)
- [fastapi-mail](https://github.com/sabuhish/fastapi-mail) - Email sending (MIT License)
- [log2fast-fastapi](https://github.com/AngelDanielSanchezCastillo/log2fast-fastapi) - Logging module (MIT License)
We are grateful to the maintainers and contributors of these projects.
## Security Features
- 🔒 **Argon2 Password Hashing**: Uses Argon2, the winner of the Password Hashing Competition
- 🎫 **JWT Tokens**: Secure token-based authentication
- ✉️ **Email Verification**: Prevents fake account creation
- 🔐 **Secure Defaults**: Sensible security defaults out of the box
- 🛡️ **SQL Injection Protection**: SQLModel/SQLAlchemy ORM prevents SQL injection
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
Copyright (c) 2026 Angel Daniel Sanchez Castillo
**Note**: This package is designed and maintained by the Solautyc Team for internal use. While publicly available under MIT license, use at your own risk.
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## Support
For issues and questions, please use the [GitHub Issues](https://github.com/AngelDanielSanchezCastillo/oauth2fast-fastapi/issues) page.
| text/markdown | null | Angel Daniel Sanchez Castillo <angeldaniel.sanchezcastillo@gmail.com> | null | null | MIT License
Copyright (c) 2026 Angel Daniel Sanchez Castillo
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| fastapi, oauth2, authentication, jwt, email-verification, sqlmodel | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Framework :: FastAPI",
... | [] | null | null | >=3.10 | [] | [] | [] | [
"pgsqlasync2fast-fastapi>=0.1.0",
"mailing2fast-fastapi>=0.2.0",
"python-jose[cryptography]>=3.3.0",
"passlib[argon2]>=1.7.4",
"argon2-cffi>=25.0.0",
"python-multipart>=0.0.6",
"log2fast-fastapi>=0.1.0",
"sqlmodel>=0.0.16",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev... | [] | [] | [] | [
"Homepage, https://github.com/AngelDanielSanchezCastillo/oauth2fast-fastapi",
"Documentation, https://github.com/AngelDanielSanchezCastillo/oauth2fast-fastapi/tree/main/docs",
"Repository, https://github.com/AngelDanielSanchezCastillo/oauth2fast-fastapi",
"Issues, https://github.com/AngelDanielSanchezCastillo... | twine/6.2.0 CPython/3.13.9 | 2026-02-18T16:41:48.599534 | oauth2fast_fastapi-0.2.2.tar.gz | 26,399 | 24/af/4954046b15d53832abdf21ffd0533c6883e582d54baa4c517cadc56ab42d/oauth2fast_fastapi-0.2.2.tar.gz | source | sdist | null | false | 9f3438543b53cb125362f6f4b4a575a8 | 52fe3561502dc7fd12470990974daa1e7fdf9cd541b610f5eae272d0dcca0998 | 24af4954046b15d53832abdf21ffd0533c6883e582d54baa4c517cadc56ab42d | null | [
"LICENSE"
] | 227 |
2.1 | vector-inspector | 0.4.1 | A comprehensive desktop application for visualizing, querying, and managing vector database data | ## Release Notes (0.4.1)
### Visualization
- Added cluster id (if available) to selected point details underneath the plot display.
- Added "Clear Selection" button to deselect points and clear details display.
- Moved cluster results into cluster panel
### Providers
- Initial support for Weaviate
### Fixes/UX
- Improved loading dialogs across the app and moved long running operations to background threads to prevent freezing and allow for cancellation.
---
# Vector Inspector
[](https://github.com/anthonypdawson/vector-inspector/actions/workflows/ci-tests.yml)
[](https://github.com/anthonypdawson/vector-inspector/actions/workflows/release-and-publish.yml)
[](https://pypi.org/project/vector-inspector/)
[](https://pepy.tech/projects/vector-inspector)
A comprehensive desktop application for visualizing, querying, and managing vector database data. Similar to SQL database viewers, Vector Inspector provides an intuitive GUI for exploring vector embeddings, metadata, and performing similarity searches across multiple vector database providers.
<p align="center">
<a href="site/images/demo.gif" target="_blank">
<img src="site/images/demo.gif" alt="Vector Inspector Demo" width="600"/>
</a>
</p>
**Quick Demo:** See Vector Inspector in action!
# 🟦 Quick Install (recommended)
These installers work on **macOS, Linux, and Windows (PowerShell or Git Bash)**.
### macOS & Linux
```
curl -fsSL https://vector-inspector.divinedevops.com/install.sh | bash
```
### Windows (PowerShell)
```
powershell -c "iwr https://vector-inspector.divinedevops.com/install.ps1 -UseBasicParsing | iex"
```
### Windows (Git Bash)
```
curl -fsSL https://vector-inspector.divinedevops.com/install.sh | bash
```
These scripts:
- install Vector Inspector
- create a desktop shortcut
- launch the app immediately
This is the easiest and most reliable way to get started.
---
# 🟩 Run the App
If you installed via pip or prefer manual launch:
```
vector-inspector
```
This opens the full desktop application.
### From PyPI (Recommended)
```bash
pip install vector-inspector
vector-inspector
```
### From a Downloaded Wheel or Tarball (e.g., GitHub Release)
Download the `.whl` or `.tar.gz` file from the [GitHub Releases](https://github.com/anthonypdawson/vector-inspector/releases) page, then install with:
```bash
pip install <your-filename.whl>
# or
pip install <your-filename.tar.gz>
```
After installation, run the application with:
```bash
vector-inspector
```
Note: pip install does **not** create a desktop shortcut.
Use the bootstrap installer for the full experience.
### From Source
```bash
# Clone the repository
git clone https://github.com/anthonypdawson/vector-inspector.git
cd vector-inspector
# Install dependencies using PDM
pdm install
# Launch application
scripts/run.sh # Linux/macOS
scripts/run.bat # Windows
```
---
## Overview
Vector Inspector bridges the gap between vector databases and user-friendly data exploration tools. While vector databases are powerful for semantic search and AI applications, they often lack the intuitive inspection and management tools that traditional SQL databases have. This project aims to provide that missing layer.
## Table of Contents
- [Overview](#overview)
- [Key Features](#key-features)
- [Architecture](#architecture)
- [Use Cases](#use-cases)
- [Feature Access](#feature-access)
- [Roadmap](#roadmap)
- [Configuration](#configuration)
- [Development Setup](#development-setup)
- [Contributing](#contributing)
- [License](#license)
- [Acknowledgments](#acknowledgments)
## Key Features
> **Note:** Some features listed below may be not started or currently in progress.
### 1. **Multi-Provider Support**
- Connect to vector databases:
- ChromaDB (persistent local storage)
- Qdrant (remote server or embedded local)
- Pinecone (cloud-hosted)
- Milvus (remote server or Milvus Lite) (Only on MacOs/Linux, experimental)
- LanceDB (persistent local storage)
- PgVector/PostgreSQL (remote server)
- Unified interface regardless of backend provider
- Automatically saves last connection configuration
- Secure API key storage for cloud providers
### 2. **Data Visualization**
- **Metadata Explorer**: Browse and filter vector entries by metadata fields
- **Vector Dimensionality Reduction**: Visualize high-dimensional vectors in 2D/3D using:
- t-SNE
- UMAP
- PCA
- **Cluster Visualization**: Color-code vectors by metadata categories or clustering results
- **Interactive Plots**: Zoom, pan, and select vectors for detailed inspection
- **Data Distribution Charts**: Histograms and statistics for metadata fields
### 3. **Search & Query Interface**
- **Similarity Search**:
- Text-to-vector search (with embedding model integration)
- Vector-to-vector search
- Find similar items to selected entries
- Adjustable top-k results and similarity thresholds
- **Metadata Filtering**:
- SQL-like query builder for metadata
- Combine vector similarity with metadata filters
- Advanced filtering: ranges, IN clauses, pattern matching
- **Hybrid Search**: Combine semantic search with keyword search
- **Query History**: Save and reuse frequent queries
### 4. **Data Management**
- **Browse Collections/Indexes**: View all available collections with statistics
- **CRUD Operations**:
- View individual vectors and their metadata
- Add new vectors (with auto-embedding options)
- Update metadata fields
- Delete vectors (single or batch)
- **Bulk Import/Export**:
- Import from CSV, JSON, Parquet
- Export query results to various formats
- Backup and restore collections
- **Schema Inspector**: View collection configuration, vector dimensions, metadata schema
### 5. **SQL-Like Experience**
- **Query Console**: Write queries in a familiar SQL-like syntax (where supported)
- **Results Grid**:
- Sortable, filterable table view
- Pagination for large result sets
- Column customization
- **Data Inspector**: Click any row to see full details including raw vector
- **Query Execution Plans**: Understand how queries are executed
- **Auto-completion**: Intelligent suggestions for collection names, fields, and operations
### 6. **Advanced Features**
- **Embedding Model Integration**:
- Use OpenAI, Cohere, HuggingFace models for text-to-vector conversion
- Local model support (sentence-transformers)
- Custom model integration
- **Vector Analysis**:
- Compute similarity matrices
- Identify outliers and anomalies
- Cluster analysis with k-means, DBSCAN
- **Embedding Inspector**:
- For similar collections or items, automatically identify which vector dimensions (activations) most contribute to the similarity
- Map key activations to interpretable concepts (e.g., 'humor', 'sadness', 'anger') using metadata or labels
- Generate human-readable explanations for why items are similar
- **Performance Monitoring**:
- Query latency tracking
- Index performance metrics
- Connection health monitoring
## Architecture
Vector Inspector is built with PySide6 (Qt for Python) for the GUI, providing a native desktop experience. The backend uses Python with support for multiple vector database providers through a unified interface.
For detailed architecture information, see [docs/architecture.md](docs/architecture.md).
## Use Cases
1. **AI/ML Development**: Inspect embeddings generated during model development
2. **RAG System Debugging**: Verify what documents are being retrieved
3. **Data Quality Assurance**: Identify poorly embedded or outlier vectors
4. **Production Monitoring**: Check vector database health and data consistency
5. **Data Migration**: Transfer data between vector database providers
6. **Education**: Learn and experiment with vector databases interactively
## Feature Access
Vector Inspector follows a user-friendly monetization model:
- **All vector database providers are free** — Try the full app with any database
- **Core workflows remain free** — Connect, browse, search, visualize, and manage your data
- **Pro adds power tools** — Advanced analytics, enterprise formats, workflow automation, and collaboration
**Nothing currently in Free will ever move to Pro.** See [FEATURES.md](docs/FEATURES.md) for a detailed comparison.
## Roadmap
**Current Status**: ✅ Phase 2 Complete
See [ROADMAP.md](docs/ROADMAP.md) for the complete development roadmap and planned features.
## Configuration
Paths are resolved relative to the project root (where `pyproject.toml` is). For example, entering `./data/chroma_db` will use the absolute path resolved from the project root.
The application automatically saves your last connection configuration to `~/.vector-viewer/settings.json`. The next time you launch the application, it will attempt to reconnect using the last saved settings.
Example settings structure:
```json
{
"last_connection": {
"provider": "chromadb",
"connection_type": "persistent",
"path": "./data/chroma_db"
}
}
```
## Development Setup
```bash
# Install PDM if you haven't already
pip install pdm
# Install dependencies with development tools (PDM will create venv automatically)
pdm install -d
# Run tests
pdm run pytest
# Run application in development mode
./run.sh # Linux/macOS
./run.bat # Windows
# Or use Python module directly from src directory:
cd src
pdm run python -m vector_viewer
```
## Contributing
Contributions are welcome! Areas where help is needed:
- Additional vector database provider integrations
- UI/UX improvements
- Performance optimizations
- Documentation
- Test coverage
Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
## License
MIT License - See [LICENSE](LICENSE) file for details.
## Acknowledgments
This project draws inspiration from:
- DBeaver (SQL database viewer)
- MongoDB Compass (NoSQL database GUI)
- Pinecone Console
- Various vector database management tools
---
See [CHANGELOG.md](CHANGELOG.md) for the latest status and what's new in each release.
See [GETTING_STARTED.md](GETTING_STARTED.md) for usage instructions and [IMPLEMENTATION_SUMMARY.md](IMPLEMENTATION_SUMMARY.md) for technical details.
**Contact**: Anthony Dawson
| text/markdown | null | Anthony Dawson <anthonypdawson+github@gmail.com> | null | null | MIT | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"chromadb>=0.4.22",
"qdrant-client>=1.7.0",
"pyside6>=6.6.0",
"PySide6-Addons>=6.6.3.1",
"pandas>=2.1.0",
"numpy>=1.26.0",
"scikit-learn>=1.3.0",
"umap-learn>=0.5.5",
"plotly>=5.18.0",
"sentence-transformers>=2.2.0",
"fastembed>=0.7.4",
"pyarrow>=14.0.0",
"pinecone>=8.0.0",
"keyring>=25.7.... | [] | [] | [] | [
"Homepage, https://vector-inspector.divinedevops.com",
"Source, https://github.com/anthonypdawson/vector-inspector",
"Issues, https://github.com/anthonypdawson/vector-inspector/issues",
"Documentation, https://github.com/anthonypdawson/vector-inspector#readme"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:41:24.267548 | vector_inspector-0.4.1.tar.gz | 723,635 | bf/c3/78873f74f2294c410f036b4763045fbbbe7435800ec83b579b063c334569/vector_inspector-0.4.1.tar.gz | source | sdist | null | false | 99611e470d72c187c61a7d2adccd6021 | 748fab4682c9606dea0a3fb11eba4cf5e5876ba4ab9466f42f903ff8b1791145 | bfc378873f74f2294c410f036b4763045fbbbe7435800ec83b579b063c334569 | null | [] | 235 |
2.4 | eoshep | 1.0.20.dev1201 | EOS -- A HEP program for Flavor Observables | [](https://img.shields.io/pypi/v/eoshep)
[](https://github.com/eos/eos/actions/workflows/pypi-build+check+deploy.yaml)
[](https://github.com/eos/eos/actions/workflows/ubuntu-build+check+deploy.yaml)
[](https://discord.gg/hyPu7f7K6W)

EOS - A software for Flavor Physics Phenomenology
=================================================
EOS is a software package that addresses several use cases in the field of
high-energy flavor physics:
1. [theory predictions of and uncertainty estimation for flavor observables](https://eos.github.io/doc/use-cases.html#theory-predictions-and-their-uncertainties)
within the Standard Model or within the Weak Effective Theory;
2. [Bayesian parameter inference](https://eos.github.io/doc/use-cases.html#parameter-inference)
from both experimental and theoretical constraints; and
3. [Monte Carlo simulation of pseudo events](https://eos.github.io/doc/use-cases.html#pseudo-event-simulation) for flavor processes.
An up-to-date list of publications that use EOS can be found [here](https://eos.github.io/publications/).
EOS is written in C++20 and designed to be used through its Python 3 interface,
ideally within a Jupyter notebook environment.
It depends on as a small set of external software:
- the GNU Scientific Library (libgsl),
- a subset of the BOOST C++ libraries,
- the Python 3 interpreter.
For details on these dependencies we refer to the [online documentation](https://eos.github.io/doc/installation.html#installing-the-dependencies-on-linux).
Installation
------------
EOS supports several methods of installation. For Linux users, the recommended method
is installation via PyPI:
```
pip3 install eoshep
```
Development versions tracking the master branch are also available via PyPi:
```
pip3 install --pre eoshep
```
For instructions on how to build and install EOS on your computer please have a
look at the [online documentation](https://eos.github.io/doc/installation.html).
Contact
-------
If you want to report an error or file a request, please file an issue [here](https://github.com/eos/eos/issues).
For additional information, please contact any of the main authors, e.g. via our [Discord server](https://discord.gg/hyPu7f7K6W).
Authors and Contributors
------------------------
The main authors are:
* Frederik Beaujean,
* Christoph Bobeth,
* Carolina Bolognani <carolinabolognani@gmail.com>,
* Nico Gubernari <nicogubernari@gmail.com>,
* Florian Herren <florian.s.herren@gmail.com>,
* Matthew J. Kirk <matthew.j.kirk@durham.ac.uk>,
* Meril Reboud <merilreboud@gmail.com>,
* Danny van Dyk <danny.van.dyk@gmail.com>,
with further code contributions by:
* Marzia Bordone,
* Thomas Blake,
* Lorenz Gaertner,
* Elena Graverini,
* Stephan Jahn,
* Ahmet Kokulu,
* Viktor Kuschke,
* Stephan Kürten,
* Philip Lüghausen,
* Bastian Müller,
* Filip Novak,
* Stefanie Reichert,
* Eduardo Romero,
* Rafael Silva Coutinho,
* Ismo Tojiala,
* K. Keri Vos,
* Christian Wacker.
We would like to extend our thanks to the following people whose input and
support were most helpful in either the development or the maintenance of EOS:
* Gudrun Hiller
* Gino Isidori
* David Leverton
* Thomas Mannel
* Ciaran McCreesh
* Hideki Miyake
* Konstantinos Petridis
* Nicola Serra
* Alexander Shires
| text/markdown | Danny van Dyk and others | danny.van.dyk@gmail.com | null | null | GPLv2 | null | [
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU General Public License v2 (GPLv2)",
"Operating System :: POSIX :: Linux",
"Programming Language :: C++",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: Implementation :: CPython",
"Topic :: Scient... | [] | https://eos.github.io/ | null | >=3.10 | [] | [] | [] | [
"argcomplete",
"dynesty",
"matplotlib",
"numpy>=1.13",
"pypandoc",
"pypmc>=1.1.4",
"pyyaml",
"scipy",
"tqdm"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:41:05.424008 | eoshep-1.0.20.dev1201-cp314-cp314-manylinux_2_28_x86_64.whl | 83,950,077 | 22/af/8e6cb8af6a6e025891a03138dd5960d32a455f5b51ebcef6a3ffd08632a3/eoshep-1.0.20.dev1201-cp314-cp314-manylinux_2_28_x86_64.whl | cp314 | bdist_wheel | null | false | 548971c44d52d557a2425b50bfa819de | 948cafa75c2f81626e8a655ccf79395f96be7608279553889c71aedfa6c789c8 | 22af8e6cb8af6a6e025891a03138dd5960d32a455f5b51ebcef6a3ffd08632a3 | null | [] | 634 |
2.4 | octolearn | 0.8.0 | Structured AutoML Pipeline with Intelligent Dataset Profiling | # OctoLearn Architecture Guide
Welcome to the complete architectural reference for **OctoLearn** — an enterprise-grade AutoML library built for transparency, robustness, and ease of use. This document explains *how* the library is built, *why* specific design choices were made, and *how to extend* it.
---
## 1. System Overview
OctoLearn follows a **Pipeline Orchestration** pattern. The central `AutoML` class acts as the conductor, coordinating specialized workers (Profiler, Cleaner, Trainer, ReportGenerator, etc.) to transform raw data into a production-ready model and a comprehensive PDF report.
### High-Level Data Flow
```
Raw DataFrame (X, y)
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ AutoML Orchestrator (core.py) │
│ │
│ 1. Validate Inputs │
│ 2. Sample (if large dataset) │
│ 3. Profile Raw Data ──────────────────► DatasetProfile (raw) │
│ 4. Train/Test Split (stratified) │
│ 5. Clean Train Data ──────────────────► DatasetProfile (clean) │
│ 6. Transform Test Data (no leakage) │
│ 7. Feature Engineering │
│ 8. Train Models + Optuna Tuning ──────► Best Model │
│ 9. Generate PDF Report ───────────────► octolearn_report.pdf │
└─────────────────────────────────────────────────────────────────┘
```
### Why a Pipeline Orchestrator?
The orchestrator pattern keeps each component **single-responsibility** and **independently testable**. You can swap out the cleaner, trainer, or report generator without touching the others. It also makes the execution order explicit and auditable.
---
## 2. Directory Structure
```
OctoLearn/
├── octolearn/
│ ├── core.py # AutoML orchestrator + config dataclasses
│ ├── config.py # Global constants (Optuna, model registry)
│ ├── profiling/
│ │ └── data_profiler.py # Statistical analysis → DatasetProfile
│ ├── preprocessing/
│ │ └── auto_cleaner.py # Imputation, encoding, scaling
│ ├── models/
│ │ ├── model_trainer.py # Multi-model training + Optuna
│ │ └── registry.py # Model versioning and persistence
│ ├── experiments/
│ │ ├── report_generator.py # PDF report (ReportLab)
│ │ └── plot_generator.py # matplotlib/seaborn visualizations
│ ├── evaluation/
│ │ └── metrics.py # Scoring functions
│ ├── utils/
│ │ └── helpers.py # Logging, utilities
│ ├── fonts/ # ShantellSans TTF font files
│ └── images/ # logo.png
├── tests/
│ └── test_complete_pipeline.py # Integration test suite (16 tests)
├── ARCHITECTURE.md # This file
└── README.md # User-facing documentation
```
---
## 3. Configuration System (`core.py`)
### Design: Dataclasses over kwargs
OctoLearn uses Python `@dataclass` objects instead of a flat list of keyword arguments. This provides:
- **Type safety**: IDE autocomplete and type checkers work correctly
- **Grouping**: Related settings are co-located (e.g., all Optuna settings in `OptimizationConfig`)
- **Defaults**: Each field has a sensible default, so `AutoML()` works out of the box
- **Discoverability**: Users can explore configs with `help(OptimizationConfig)`
### Config Objects
| Class | Key Fields | Rationale |
|-------|-----------|-----------|
| `DataConfig` | `sample_size=5000`, `test_size=0.2`, `stratify_target=True` | Sampling prevents OOM on large datasets; 20% test is standard |
| `ProfilingConfig` | `detect_outliers=True`, `analyze_interactions=True` | Both are expensive; can be disabled for speed |
| `PreprocessingConfig` | `imputer_strategy`, `scaler='standard'`, `encoder_strategy` | Sensible defaults; user can override per-column |
| `ModelingConfig` | `n_models=5`, `models_to_train=None`, `evaluation_metric=None` | Auto-selects best models; metric auto-detected from task type |
| `OptimizationConfig` | `optuna_trials_per_model=20`, `optuna_timeout_seconds=300` | 20 trials is a good speed/quality tradeoff; timeout prevents runaway |
| `ReportingConfig` | `report_detail='detailed'`, `visuals_limit=10` | Detailed by default; brief for quick runs |
| `ParallelConfig` | `n_jobs=1`, `backend='loky'` | n_jobs=1 prevents Windows CPU oversubscription with Optuna |
### Why `n_jobs=1` for Optuna on Windows?
Optuna's multiprocessing backend conflicts with Windows' process spawning model. Setting `n_jobs=-1` causes process pool exhaustion and crashes on Windows. The fix is `n_jobs=1` (sequential Optuna trials), which is stable on all platforms. Linux/Mac users can override this via `ParallelConfig(n_jobs=-1)`.
### The `fit()` Override Pattern
`fit()` accepts optional keyword arguments that temporarily override config values for a single run:
```python
automl.fit(X, y, optuna_trials=5, use_optuna=False)
```
Internally, the original config values are snapshotted, overrides applied, pipeline executed, then originals restored in a `finally` block — so the `AutoML` instance is never permanently mutated by `fit()` kwargs.
---
## 4. Data Profiling (`profiling/data_profiler.py`)
### Purpose
Profile the data **before** any cleaning to capture the "ground truth" state. This raw profile is used for:
- Generating the "Before" side of the Before/After comparison in the report
- Determining which columns are categorical (needed to choose the right encoder)
- Computing the Risk Score
### Output: `DatasetProfile`
A lightweight dataclass (not a copy of the data) containing:
- `n_rows`, `n_columns`, `task_type`
- `numeric_columns`, `categorical_columns`
- `missing_ratio` (per-column dict)
- `duplicate_rows`, `skewed_features`
### Why profile before cleaning?
If we profiled after cleaning, we'd lose the "before" state needed for the transformation journey report. We'd also lose the original column types (encoding changes categorical → numeric).
---
## 5. Data Cleaning (`preprocessing/auto_cleaner.py`)
### The Leakage Prevention Rule
**`fit_transform` on Train only. `transform` on Test.**
This is the most critical rule. If you compute the column mean using the full dataset and use it to fill NaNs, your model indirectly "sees" test data during training (data leakage). OctoLearn enforces this by:
1. Calling `cleaner_.fit_transform(X_train, y_train)` — learns imputation stats from train only
2. Calling `cleaner_.transform(X_test)` — applies the same learned stats to test
### Cleaning Steps (in order)
1. **ID column removal**: Columns with near-unique values (e.g., user IDs) are dropped — they have no predictive value and cause overfitting
2. **Constant column removal**: Zero-variance columns are dropped
3. **Duplicate row removal**: Done on train set only (after split)
4. **Numeric imputation**: `mean` (default) or `median` (more robust to outliers)
5. **Categorical imputation**: `mode` (most frequent value)
6. **Rare category encoding**: Categories appearing < 5% of the time are grouped into "Other" to prevent high-cardinality explosions
7. **One-hot encoding**: Converts categorical columns to numeric (required by most sklearn models)
8. **Scaling**: `StandardScaler` (default) — zero mean, unit variance. Alternatives: `RobustScaler` (outlier-resistant), `MinMaxScaler`
### Why StandardScaler by default?
Most linear models (Logistic Regression, SVM) require scaled features. Tree-based models (Random Forest, XGBoost) don't need scaling but aren't harmed by it. StandardScaler is the safest universal default.
### Imputation Tracking
`auto_cleaner.py` tracks how many columns had missing values imputed and exposes this in `cleaning_log['missing_imputed']`. This feeds into the report's "What OctoLearn Did" section.
---
## 6. Model Training (`models/model_trainer.py`)
### Supported Models
**Classification:**
- `logistic_regression` (sklearn)
- `random_forest` (sklearn)
- `gradient_boosting` (sklearn)
- `xgboost` (xgboost)
- `lightgbm` (lightgbm)
- `svm` (sklearn)
**Regression:**
- `linear_regression` (sklearn)
- `random_forest` (sklearn)
- `gradient_boosting` (sklearn)
- `xgboost` (xgboost)
- `lightgbm` (lightgbm)
- `svr` (sklearn)
### Hyperparameter Optimization: Why Optuna?
| Method | Pros | Cons |
|--------|------|------|
| Grid Search | Exhaustive | Exponential time complexity |
| Random Search | Fast | Misses good regions |
| **Optuna (Bayesian)** | Smart, adaptive | Requires more code |
Optuna uses **Tree-structured Parzen Estimators (TPE)** — a Bayesian method that builds a probabilistic model of which hyperparameter regions give good results, then samples from those regions. This finds better hyperparameters in fewer trials than random search.
### Default Hyperparameter Search Spaces
Defined in `config.py` under `OPTUNA_CONFIG['search_spaces']`. Each model has a search space dict mapping parameter names to ranges. The `_optimize_hyperparameters` method in `ModelTrainer` reads these and passes them to Optuna's `trial.suggest_*` API.
### Why `n_trials=20` default?
20 trials is a practical sweet spot:
- Enough for Optuna to explore the search space meaningfully
- Fast enough for interactive use (< 2 minutes per model on typical hardware)
- Users can increase to 50-100 for production runs via `OptimizationConfig(optuna_trials_per_model=50)` or `fit(X, y, optuna_trials=50)`
### Model Selection
After all models are trained, `ModelTrainer` ranks them by the primary metric (F1 for classification, RMSE for regression) on the held-out test set. The best model is stored as `automl.best_model_`.
---
## 7. Report Generation (`experiments/report_generator.py`)
### Technology: ReportLab
ReportLab is a Python library for programmatic PDF generation. Unlike HTML-to-PDF converters (WeasyPrint, wkhtmltopdf), ReportLab:
- Has no external binary dependencies
- Gives pixel-perfect layout control
- Works identically on Windows, Mac, and Linux
- Supports custom fonts (TTF), vector graphics, and canvas-level drawing
### Font: ShantellSans
ShantellSans is a humanist sans-serif font with a friendly, approachable character — appropriate for a data science tool that aims to be accessible. Four weights are registered:
- `ShantellSans-Regular` → body text
- `ShantellSans-Bold` → table headers, emphasis
- `ShantellSans-ExtraBold` → section titles, cover title
- `ShantellSans-Italic` → narrative callouts
Fallback: Helvetica (built into all PDF viewers) if font files are missing.
### Report Structure
| Section | Content |
|---------|---------|
| Cover Page | Logo watermark, title, metadata table, tagline |
| Recommendations | Priority-grouped actions (Critical/High/Medium/Low) |
| Data Story | Narrative introduction to the dataset |
| Data Health Dashboard | Risk score gauge, metric cards, risk factors table |
| Data Transformation Journey | Before/After comparison table + distribution histograms |
| Feature Intelligence | Importance ranking table + horizontal bar chart |
| Model Arena | Champion card + benchmark table |
| Visual Insights | Correlation heatmap + feature distribution plots |
| Advanced Analysis | Outlier detection results, feature interactions |
### Logo Watermark
The cover page uses `canvas.drawImage()` with `setFillAlpha(0.06)` to draw the logo as a large, nearly-invisible background watermark. This is done in the `onFirstPage` callback so it only appears on the cover — not on content pages.
### Before/After Distribution Plots
`_generate_before_after_plots()` generates side-by-side histograms comparing raw vs. cleaned distributions for the top 4 numeric features. These are saved as temp PNG files, embedded in the PDF, then deleted in the `finally` block of `generate()`.
### Temp File Cleanup
All matplotlib figures are saved to `tempfile.NamedTemporaryFile` paths, tracked in `self._temp_files`, and deleted in `generate()`'s `finally` block — ensuring no temp files are left behind even if PDF generation fails.
---
## 8. Stratification Logic
For classification tasks, train/test splitting should be stratified (same class distribution in both sets). The condition in `_split_data`:
```python
if y.dtype.kind in ('O', 'U', 'S') or y.dtype.name == 'category' or (
y.dtype.kind in ('i', 'u') and n_unique < 20
):
stratify = y
```
This correctly handles:
- String labels (`dtype.kind == 'O'`)
- Integer labels like 0/1 (`dtype.kind in ('i', 'u')`) — the previous bug was `isinstance(y.dtype, type)` which always returned False for integer dtypes
---
## 9. How to Build OctoLearn from Source
### Prerequisites
```bash
python >= 3.8
pip install -r requirements.txt
```
Key dependencies:
- `pandas`, `numpy`, `scikit-learn` — core data science stack
- `xgboost`, `lightgbm` — gradient boosting models
- `optuna` — hyperparameter optimization
- `reportlab` — PDF generation
- `matplotlib`, `seaborn` — visualizations
- `Pillow` — image processing for report
### Running Tests
```bash
python -m pytest tests/test_complete_pipeline.py -v
```
All 16 tests should pass. Tests cover:
- Config validation
- Data splitting and stratification
- Cleaning pipeline (imputation, encoding, scaling)
- Model training (classification + regression)
- Report generation
- fit() API override params
### Generating a Report
```bash
python generate_final_report.py
```
---
## 10. How to Extend OctoLearn
### Add a New Model
1. Open `octolearn/models/model_trainer.py`
2. Add the model class to the `_get_model_instance()` method
3. Add its hyperparameter search space to `config.py` under `OPTUNA_CONFIG['search_spaces']`
4. Add it to the `MODEL_REGISTRY` in `config.py`
### Add a New Report Section
1. Open `octolearn/experiments/report_generator.py`
2. Add a new `_add_my_section(self, story)` method
3. Call it from `generate()` in the appropriate order
4. Use `self._add_section_header(story, "My Section")` for consistent styling
5. Use `self.styles['Narrative']` for body text, `self.styles['SubsectionHeading']` for sub-headers
### Add a New Preprocessing Step
1. Open `octolearn/preprocessing/auto_cleaner.py`
2. Add a new sklearn-compatible transformer class (with `fit` and `transform` methods)
3. Add it to the pipeline in `fit_transform()`
4. Track any relevant stats in `self.cleaning_log`
### Add a New Metric
1. Open `octolearn/evaluation/metrics.py`
2. Add the metric function
3. Register it in the `METRIC_REGISTRY` dict
4. Add it as a valid option in `ModelingConfig.evaluation_metric` docstring
---
## 11. Key Design Decisions Summary
| Decision | Rationale |
|----------|-----------|
| Dataclass configs | Type-safe, discoverable, clean API |
| fit() override params | Experiment without re-creating AutoML instance |
| n_jobs=1 for Optuna | Windows stability; avoids process pool exhaustion |
| n_trials=20 default | Speed/quality tradeoff for interactive use |
| ReportLab for PDF | No external binaries, pixel-perfect control |
| ShantellSans font | Humanist, approachable, brand-consistent |
| Temp files for plots | No leftover files even on failure |
| fit_transform on train only | Prevents data leakage |
| Stratify integer targets | Correct class balance for 0/1 classification |
| Snapshot/restore in fit() | Config objects never permanently mutated by kwargs |
---
*OctoLearn Architecture v0.8.0 — Updated 2026-02-18*
| text/markdown | Ghulam_Muhammad_Nabeel | Ghulam Muhammad Nabeel <ghulammuhammadnabeel6@gmail.com> | null | null | MIT | automl, machine-learning, data-science, profiling, automation | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Development Stat... | [] | https://github.com/ghulam-nabeel/octolearn | null | >=3.8 | [] | [] | [] | [
"pandas>=1.0.0",
"numpy>=1.19.0",
"scikit-learn>=0.24.0",
"optuna>=2.0.0",
"reportlab>=3.6.0",
"matplotlib>=3.3.0",
"seaborn>=0.11.0",
"shap>=0.40.0",
"dask[complete]>=2021.9.0; extra == \"distributed\"",
"ray[default]>=2.0.0; extra == \"distributed\""
] | [] | [] | [] | [
"Homepage, https://github.com/GhulamMuhammadNabeel/Octolearn",
"Bug Tracker, https://github.com/GhulamMuhammadNabeel/Octolearn",
"Documentation, https://github.com/GhulamMuhammadNabeel/Octolearn"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-18T16:41:00.717004 | octolearn-0.8.0.tar.gz | 861,042 | 8f/de/d3c9b2ded32ac347ff14ac3c84083bcbedf0b6ba8df2ac1b63e45468b594/octolearn-0.8.0.tar.gz | source | sdist | null | false | 2e58f96fc568da316ca972aacbb9c30b | 16f38d2c782d91d842bfd929fbdf88f9e6cf7b2d29bc2e1e661b4b9d24a7c8c3 | 8fded3c9b2ded32ac347ff14ac3c84083bcbedf0b6ba8df2ac1b63e45468b594 | null | [
"LICENSE"
] | 229 |
2.1 | ramish-explorer | 0.1.1 | Explore .ramish knowledge graph files — query, validate, predict, and audit geometric truth. | # Ramish Explorer
**Read, query, and explore `.ramish` knowledge graph files.**
Ramish Explorer is the free, open-source reader for `.ramish` engine files generated by [Ramish.io](https://ramish.io) — a geometric knowledge engine that maps structural integrity in relational databases using quaternion embeddings.
## Install
```bash
pip install ramish-explorer
```
## Quick Start
```bash
# File overview
ramish-explorer stats engine.ramish
# Natural language search
ramish-explorer query engine.ramish "What relates to AC/DC?"
# Show all connections for an entity
ramish-explorer edges engine.ramish "Iron Maiden"
# Find similar entities (duplicate detection)
ramish-explorer similar engine.ramish "ABC Plumbing"
# Validate a specific relationship
ramish-explorer validate engine.ramish "Led Zeppelin" "genre" "Rock"
# Predict missing links
ramish-explorer predict engine.ramish "Sunset Condo" "serviced_by"
# Interactive exploration
ramish-explorer explore engine.ramish
```
## Commands
| Command | Description |
|---------|-------------|
| `stats` | File structure, geometry, and trust weight distribution |
| `query` | Natural language search with wave propagation |
| `validate` | Check a specific triple (subject, relation, object) |
| `edges` | Show all edges for an entity with trust weights |
| `similar` | Find nearest neighbors by embedding distance |
| `predict` | Frozen key rotation inference (head + relation → tail) |
| `compose` | Multi-hop quaternion composition (relation1 ⊗ relation2) |
| `keys` | Extract frozen relational keys with stability metrics |
| `audit` | Structural integrity report |
| `requantize` | Convert between fp32/fp16/int8 quantization |
| `explore` | Interactive REPL |
## What is a .ramish file?
A `.ramish` file is a portable, binary knowledge graph with truth weights. It contains:
- **Entities** mapped from your database tables (rows, columns, values)
- **Relations** connecting entities with typed edges
- **Quaternion embeddings** encoding geometric structure
- **Truth weights** measuring confidence in each relationship
Generate `.ramish` files at [ramish.io](https://ramish.io).
## Use Cases
- **Data quality auditing** — find orphaned records, low-confidence relationships, structural anomalies
- **Duplicate detection** — `similar` finds near-duplicates in embedding space
- **Relationship exploration** — `edges` shows the full connection web for any entity
- **Link prediction** — `predict` finds missing connections using frozen key rotation
- **Drift monitoring** — compare `.ramish` files over time to track data quality changes
## Requirements
- Python 3.8+
- numpy, click, rich (installed automatically)
## License
MIT
## Links
- [Ramish.io](https://ramish.io) — Generate .ramish files
- [Documentation](https://ramish.io/docs)
| text/markdown | null | "A.I. Sciences LLC" <support@ramish.io> | null | null | MIT | knowledge-graph, quaternion, embeddings, data-quality, audit | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Pyth... | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.20",
"click>=8.0",
"rich>=12.0"
] | [] | [] | [] | [
"Homepage, https://ramish.io",
"Documentation, https://ramish.io/docs",
"Repository, https://github.com/LWMartin/ramish-explorer"
] | twine/6.1.0 CPython/3.8.18 | 2026-02-18T16:40:41.580347 | ramish_explorer-0.1.1.tar.gz | 20,078 | 7c/63/efb7fded70383b381b0e99545969c6eac26aa8d511b4ece6c6cebf183be1/ramish_explorer-0.1.1.tar.gz | source | sdist | null | false | 869f698fe6201672434702ea5a687f6f | 9d6b961a974c627eb0a5660640f4217f13f8104e99941e11905a1445bce52ccb | 7c63efb7fded70383b381b0e99545969c6eac26aa8d511b4ece6c6cebf183be1 | null | [] | 217 |
2.4 | agentmail-p2p | 0.1.0 | Client SDK for AgentMail — P2P encrypted messaging for AI agents | # AgentMail
Local-first, peer-to-peer encrypted messaging protocol for AI agents.
Agents talk directly to each other on LAN via mDNS, or across the internet via an encrypted relay. All data stays on your devices. No cloud accounts required.
## Quick Start
```bash
git clone https://github.com/shawntsai/agentmail.git
cd agentmail
python3 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
# Start your agent
python run.py --name alice --port 7443 --relay http://147.224.10.61:7445
```
Open the Web UI at `http://localhost:7443`.
## Architecture
```
┌──────────┐ mDNS (LAN) ┌──────────┐
│ alice │◄────────────────►│ bob │
│ :7443 │ P2P direct │ :7444 │
└────┬─────┘ └────┬─────┘
│ │
│ ┌─────────────────────┐ │
└──►│ Relay Server │◄──┘
│ - name registry │
│ - store & forward │
│ - E2E encrypted │
└─────────────────────┘
```
- **LAN**: Agents discover each other via mDNS and communicate P2P
- **Cross-network**: Messages are E2E encrypted and deposited on the relay
- **Registry**: Agents register their name so anyone can find them
## Claude Code Plugin
```bash
claude --plugin-dir ./agentmail-plugin
```
Then:
```
/agentmail:send bob hello there
/agentmail:inbox
```
Or talk naturally — Claude uses the tools automatically.
| Tool | Description |
|------|-------------|
| `send(to, message)` | Send a message to an agent by name |
| `inbox()` | Check for new messages |
## Multiple Agents
One machine, many agents — like having multiple email addresses:
```bash
python run.py --name alice --port 7443 --relay http://147.224.10.61:7445
python run.py --name planner --port 7444 --relay http://147.224.10.61:7445
python run.py --name coder --port 7445 --relay http://147.224.10.61:7445
```
## Python SDK
```python
from agentmail import AgentMailClient
client = AgentMailClient("http://localhost:7443")
client.send("bob@bob.local", subject="Hello", body="How are you?")
client.send_task("planner@planner.local", task="Summarize AI news")
for msg in client.inbox():
print(f"{msg['from_addr']}: {msg['body']}")
```
## Security
- **Ed25519** signing for message authentication
- **X25519 sealed box** for end-to-end encryption
- Relay stores only encrypted blobs it cannot read
- No accounts, no passwords — cryptographic identity only
- All keys generated and stored locally
## Relay Server
Deploy your own relay or use the public one:
```bash
python run_relay.py --port 7445
```
| Endpoint | Description |
|----------|-------------|
| `POST /v0/register` | Register agent name + public keys |
| `GET /v0/lookup/{name}` | Look up agent by name |
| `POST /v0/deposit` | Deposit encrypted message |
| `GET /v0/pickup/{fp}` | Pick up waiting messages |
| `GET /v0/stats` | Relay stats |
## License
Apache 2.0
| text/markdown | Shawn Tsai | null | null | null | null | agents, messaging, p2p, encrypted, agentmail | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.25.0"
] | [] | [] | [] | [
"Homepage, https://github.com/shawntsai/agentmail"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-18T16:40:19.668460 | agentmail_p2p-0.1.0.tar.gz | 8,283 | db/87/180ce1cfeedd346ce2144f235589ffc23db8580f90cddd7dc81ccc9ce05c/agentmail_p2p-0.1.0.tar.gz | source | sdist | null | false | d8005fa1e9b07969baf5d071c66eab6d | 60710886ce7d3b6463b45f735b8c5ffee9f002f1faf508b88cb08d0d196ee795 | db87180ce1cfeedd346ce2144f235589ffc23db8580f90cddd7dc81ccc9ce05c | Apache-2.0 | [
"LICENSE"
] | 263 |
2.4 | openghg | 0.18.0 | OpenGHG: A platform for greenhouse gas data analysis | 
## OpenGHG - a Cloud Platform for Greenhouse Gas Data Analysis and Collaboration
[](https://opensource.org/licenses/Apache-2.0) 
OpenGHG is a platform for collaboration and analysis of greenhouse gas (GHG) data, inspired by the [HUGS platform](https://github.com/hugs-cloud/hugs). It allows researchers to analyze and collaborate on large datasets using the scalability of the cloud.
For more information, please visit [our documentation](https://docs.openghg.org/).
---
## Install OpenGHG
OpenGHG supports Python 3.10 and later on Linux or MacOS. To install the package, you can use either `uv` (recommended for its environment management abilities) or `conda`.
### Installing with `uv`
`uv` simplifies environment creation and dependency management, making it easy to manage your setup. To install OpenGHG using `uv`:
1. **Install `uv`:**
The `uv` tool from Astral streamlines Python management, virtual environments, and package installation. Follow the recommended steps from the official `uv` docs:
1. Install from link`uv` (Recommended "robust, Python-independent"):
- macOS/Linux:
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
2. Install from pip (Alternative "requires existing Python + pip"):
```bash
pip install uv
```
2. **Create and activate an environment for OpenGHG:**
```bash
uv venv openghg-env
```
Additionally, a specific python version can be specified while creating the
environment as follows.
```bash
uv venv openghg-env --python 3.11
```
To activate:
```bash
source openghg-env/bin/activate
```
3. **Install OpenGHG:**
```bash
uv pip install openghg
```
This installs OpenGHG and its core dependencies.
### Installing with `conda`
To get OpenGHG installed using `conda`, follow these steps:
1. **Create and activate a `conda` environment:**
```bash
conda create --name openghg_env
conda activate openghg_env
```
2. **Install OpenGHG and its dependencies using the `conda-forge` and `openghg` channels:**
```bash
conda install --channel conda-forge --channel openghg openghg
```
Note: The optional `xesmf` library is pre-installed when using `conda`. No additional steps are required for regridding functionality.
---
## Quickstart Configuration
Once OpenGHG is installed, you need to configure the object store and user data. OpenGHG stores its configuration file by default at:
`~/.config/openghg/openghg.conf`.
### Configure via CLI:
```bash
openghg --quickstart
```
### Configure via Python:
```python
from openghg.util import create_config
create_config()
```
When prompted, you can specify the path to the object store. Leave the field blank to use the default directory at `~/openghg_store`.
---
## Developers
If you'd like to contribute to OpenGHG, here are the steps to set up a development environment. You can use either `uv` or `conda`.
### Using `uv` for Development
1. **Clone the repository:**
```bash
git clone https://github.com/openghg/openghg.git
cd openghg
```
2. **Create and activate an environment for OpenGHG:**
```bash
uv venv
```
A python environment with name can also be created, as showed in non-developer instance previously.
Additionally, a specific python version can be specified while creating the
environment as follows.
```bash
uv venv --python 3.11
```
> **Note:**
> If the virtual environment is not named, the .venv folder is created at the directory level, and using commands like "uv add" or "uv pip install" will automatically detect the environment and install the packages.
To activate:
```bash
source .venv/bin/activate
```
3. **Install development dependencies and the package in editable mode:**
```bash
uv sync --all-extras
```
This ensures that the local repository is installed in **editable mode**, meaning changes to the source code are immediately reflected. It will also ensure that all the dev and documentation dependencies are installed in the environment.
For more details, please refer to the [UV Documentation (sync)](https://docs.astral.sh/uv/concepts/projects/sync/#syncing-the-environment).
### Using `conda` for Development
1. **Clone the repository:**
```bash
git clone https://github.com/openghg/openghg.git
cd openghg
```
2. **Create and activate a `conda` environment:**
```bash
conda create --name openghg-dev python=3.12
conda activate openghg-dev
```
3. **Install development dependencies:**
```bash
pip install --upgrade pip wheel setuptools
pip install -e ".[dev]"
```
---
### Running Tests
OpenGHG uses `pytest` for testing. After setting up the development environment, you can run tests as follows:
```bash
pytest -v tests/
```
#### Additional Testing:
- **CF Checker Tests:** Install the `udunits2` library for certain tests:
```bash
sudo apt-get install libudunits2-0
pytest -v --run-cfchecks tests/
```
- **ICOS Tests:** These tests access the ICOS Carbon Portal and should be run sparingly:
```bash
pytest -v --run-icos tests/
```
If you encounter issues, please [open a GitHub issue](https://github.com/openghg/openghg/issues/new).
---
## Additional Functionality
OpenGHG's optional functionality includes the `xesmf` module for map regridding.
Note that `xesmf` is **not** installed by default with the core OpenGHG package.
- When using `uv`, install it explicitly, for example:
```bash
uv add xesmf
- For conda install of xesmf
```bash
conda install -c conda-forge xesmf
For further details, refer to [our documentation](https://docs.openghg.org/).
---
## Community and Contributions
We encourage contributions and are happy to assist where needed. Raise issues and pull requests in [our repository](https://github.com/openghg/openghg).
For further information, check out [our documentation](https://docs.openghg.org/).
| text/markdown | null | Prasad Sutar <prasad.sutar@bristol.ac.uk>, Brendan Murphy <brendan.murphy@bristol.ac.uk>, Rachel Tunnicliffe <rachel.tunnicliffe@bristol.ac.uk>, Gareth Jones <g.m.jones@bristol.ac.uk> | null | Prasad Sutar <prasad.sutar@bristol.ac.uk>, Brendan Murphy <brendan.murphy@bristol.ac.uk>, Rachel Tunnicliffe <rachel.tunnicliffe@bristol.ac.uk> | null | null | [
"Operating System :: MacOS",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"addict<=2.4.0",
"cdsapi>=0.7.7",
"cf-xarray<=0.10.6",
"dask<2025.10",
"filelock<=3.20.0",
"flox<=0.10.4",
"h5netcdf<=1.6.4,>=1.0.0",
"h5py<3.15",
"icoscp<=0.2.2",
"ipywidgets<=8.1.7",
"matplotlib<=3.10.7",
"msgpack-types<=0.5.0",
"msgpack<=1.1.2",
"nbformat<=5.10.4",
"nc-time-axis<=1.4.... | [] | [] | [] | [
"Documentation, https://www.openghg.org",
"Code, https://github.com/openghg/openghg",
"Issue-Tracker, https://github.com/openghg/openghg/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T16:39:56.596290 | openghg-0.18.0-py3-none-any.whl | 455,233 | 87/89/a47f0b7e1c4a0f9584d8f553d19c16f3a85d464f89b187a5acbdc7ac2078/openghg-0.18.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 5329a2564cc981a426c8b6603a70d998 | 5cd4a09169a33d5f638691d950e5d88ca204049949829eed95143d7fc69d591c | 8789a47f0b7e1c4a0f9584d8f553d19c16f3a85d464f89b187a5acbdc7ac2078 | null | [
"LICENSE"
] | 242 |
2.4 | mposcli | 0.3.0 | CLI helper for MicroPythonOS: https://github.com/MicroPythonOS/MicroPythonOS | # mposcli
[](https://github.com/jedie/mposcli/actions/workflows/tests.yml)
[](https://app.codecov.io/github/jedie/mposcli)
[](https://pypi.org/project/mposcli/)
[](https://github.com/jedie/mposcli/blob/main/pyproject.toml)
[](https://github.com/jedie/mposcli/blob/main/LICENSE)
Experimental CLI helper for MicroPythonOS: https://github.com/MicroPythonOS/MicroPythonOS
Main Idea: Install it via pipx (see below) and use `mposcli` command in MicroPythonOS repository path.
Install, e.g.:
```
sudo apt install pipx
pipx install mposcli
```
To upgrade an existing installation: Just call: `pipx upgrade PyHardLinkBackup`
Usage e.g.:
```
cd ~/MicroPythonOS
~/MicroPythonOS$ mposcli run-desktop
```
## CLI
[comment]: <> (✂✂✂ auto generated main help start ✂✂✂)
```
usage: mposcli [-h] {build,cp,flash,run-desktop,update,update-submodules,version}
╭─ options ──────────────────────────────────────────────────────────────────────────────╮
│ -h, --help show this help message and exit │
╰────────────────────────────────────────────────────────────────────────────────────────╯
╭─ subcommands ──────────────────────────────────────────────────────────────────────────╮
│ (required) │
│ • build Build MicroPythonOS by calling: ./scripts/build_mpos.sh │
│ <target> see: https://docs.micropythonos.com/os-development/ │
│ • cp Copy/update internal_filesystem/lib/mpos files to the device │
│ via "mpremote fs cp". Display a file chooser to select which │
│ files to copy/update. But can also be used to copy/update all │
│ files. see: https://docs.micropythonos.com/os-development/insta │
│ lling-on-esp32/ │
│ • flash Flash MicroPythonOS to the device. Display a file chooser to │
│ select the image to flash. All lvgl_micropython/build/*.bin │
│ files will be shown in the file chooser. see: https://docs.micr │
│ opythonos.com/os-development/installing-on-esp32/ │
│ • run-desktop Run MicroPythonOS on desktop. see: https://docs.micropythonos.c │
│ om/getting-started/running/#running-on-desktop │
│ • update Update MicroPythonOS repository. Assume that there is a │
│ "origin" and/or "upstream" remote configured. Will also ask if │
│ you want to update the submodules as well, which is │
│ recommended. │
│ • update-submodules Updates MicroPythonOS git submodules only. Use "mposcli update" │
│ to update the main repository and optionally the submodules as │
│ well. see: https://docs.micropythonos.com/os-development/linux/ │
│ #optional-updating-the-code │
│ • version Print version and exit │
╰────────────────────────────────────────────────────────────────────────────────────────╯
```
[comment]: <> (✂✂✂ auto generated main help end ✂✂✂)
## mposcli build
[comment]: <> (✂✂✂ auto generated build start ✂✂✂)
```
usage: mposcli build [-h] [--target {esp32,esp32s3,unix,macOS}] [-v]
Build MicroPythonOS by calling: ./scripts/build_mpos.sh <target> see:
https://docs.micropythonos.com/os-development/
╭─ options ────────────────────────────────────────────────────────────────╮
│ -h, --help show this help message and exit │
│ --target {esp32,esp32s3,unix,macOS} │
│ Target platform to build for. (default: unix) │
│ -v, --verbosity Verbosity level; e.g.: -v, -vv, -vvv, etc. (repeatable) │
╰──────────────────────────────────────────────────────────────────────────╯
```
[comment]: <> (✂✂✂ auto generated build end ✂✂✂)
## mposcli cp
[comment]: <> (✂✂✂ auto generated cp start ✂✂✂)
```
usage: mposcli cp [-h] [--new-file-limit INT] [--reset | --no-reset] [--repl | --no-repl]
[-v]
Copy/update internal_filesystem/lib/mpos files to the device via "mpremote fs cp". Display
a file chooser to select which files to copy/update. But can also be used to copy/update
all files. see: https://docs.micropythonos.com/os-development/installing-on-esp32/
╭─ options ──────────────────────────────────────────────────────────────────────────────╮
│ -h, --help show this help message and exit │
│ --new-file-limit INT How many of the newest files to show in the file chooser? │
│ (default: 10) │
│ --reset, --no-reset Reset the device after copy/update? (default: True) │
│ --repl, --no-repl After flashing/verify start REPL with mpremote to see the output │
│ of the device? (default: True) │
│ -v, --verbosity Verbosity level; e.g.: -v, -vv, -vvv, etc. (repeatable) │
╰────────────────────────────────────────────────────────────────────────────────────────╯
```
[comment]: <> (✂✂✂ auto generated cp end ✂✂✂)
## mposcli flash
[comment]: <> (✂✂✂ auto generated flash start ✂✂✂)
```
usage: mposcli flash [-h] [FLASH OPTIONS]
Flash MicroPythonOS to the device. Display a file chooser to select the image to flash.
All lvgl_micropython/build/*.bin files will be shown in the file chooser. see:
https://docs.micropythonos.com/os-development/installing-on-esp32/
╭─ options ──────────────────────────────────────────────────────────────────────────────╮
│ -h, --help show this help message and exit │
│ --port STR Port used for esptool and mpremote (default: /dev/ttyUSB0) │
│ --address STR Address (default: 0x0) │
│ --flash-size STR Flash Size (default: detect) │
│ --verify, --no-verify Verify after flashing? (default: True) │
│ --repl, --no-repl After flashing/verify start REPL with mpremote to see the │
│ output of the device? (default: True) │
│ -v, --verbosity Verbosity level; e.g.: -v, -vv, -vvv, etc. (repeatable) │
╰────────────────────────────────────────────────────────────────────────────────────────╯
```
[comment]: <> (✂✂✂ auto generated flash end ✂✂✂)
## mposcli run-desktop
[comment]: <> (✂✂✂ auto generated run-desktop start ✂✂✂)
```
usage: mposcli run-desktop [-h] [--heapsize INT] [--script {None}|STR] [--binary
{None}|STR] [-v]
Run MicroPythonOS on desktop. see: https://docs.micropythonos.com/getting-
started/running/#running-on-desktop
╭─ options ──────────────────────────────────────────────────────────────────────────────╮
│ -h, --help show this help message and exit │
│ --heapsize INT Heap size in MB (default: 8, same as PSRAM on many ESP32-S3 │
│ boards) (default: 8) │
│ --script {None}|STR Script file (.py) or app name to run. If omitted, starts │
│ normally. (default: None) │
│ --binary {None}|STR Optional name of the binary to start. If omitted, shows a file │
│ chooser to select one from the lvgl_micropython build directory. │
│ (default: None) │
│ -v, --verbosity Verbosity level; e.g.: -v, -vv, -vvv, etc. (repeatable) │
╰────────────────────────────────────────────────────────────────────────────────────────╯
```
[comment]: <> (✂✂✂ auto generated run-desktop end ✂✂✂)
## mposcli update
[comment]: <> (✂✂✂ auto generated update start ✂✂✂)
```
usage: mposcli update [-h] [-v]
Update MicroPythonOS repository. Assume that there is a "origin" and/or "upstream" remote
configured. Will also ask if you want to update the submodules as well, which is
recommended.
╭─ options ────────────────────────────────────────────────────────────────╮
│ -h, --help show this help message and exit │
│ -v, --verbosity Verbosity level; e.g.: -v, -vv, -vvv, etc. (repeatable) │
╰──────────────────────────────────────────────────────────────────────────╯
```
[comment]: <> (✂✂✂ auto generated update end ✂✂✂)
## mposcli update-submodules
[comment]: <> (✂✂✂ auto generated update-submodules start ✂✂✂)
```
usage: mposcli update-submodules [-h] [-v]
Updates MicroPythonOS git submodules only. Use "mposcli update" to update the main
repository and optionally the submodules as well. see: https://docs.micropythonos.com/os-
development/linux/#optional-updating-the-code
╭─ options ────────────────────────────────────────────────────────────────╮
│ -h, --help show this help message and exit │
│ -v, --verbosity Verbosity level; e.g.: -v, -vv, -vvv, etc. (repeatable) │
╰──────────────────────────────────────────────────────────────────────────╯
```
[comment]: <> (✂✂✂ auto generated update-submodules end ✂✂✂)
## start development
At least `uv` is needed. Install e.g.: via pipx:
```bash
apt-get install pipx
pipx install uv
```
Clone the project and just start the CLI help commands.
A virtual environment will be created/updated automatically.
```bash
~$ git clone https://github.com/jedie/mposcli.git
~$ cd mposcli
~/mposcli$ ./cli.py --help
~/mposcli$ ./dev-cli.py --help
```
[comment]: <> (✂✂✂ auto generated dev help start ✂✂✂)
```
usage: ./dev-cli.py [-h] {coverage,install,lint,mypy,nox,pip-audit,publish,shell-
completion,test,update,update-readme-history,update-test-snapshot-files,version}
╭─ options ──────────────────────────────────────────────────────────────────────────────╮
│ -h, --help show this help message and exit │
╰────────────────────────────────────────────────────────────────────────────────────────╯
╭─ subcommands ──────────────────────────────────────────────────────────────────────────╮
│ (required) │
│ • coverage Run tests and show coverage report. │
│ • install Install requirements and 'mposcli' via pip as editable. │
│ • lint Check/fix code style by run: "ruff check --fix" │
│ • mypy Run Mypy (configured in pyproject.toml) │
│ • nox Run nox │
│ • pip-audit Run pip-audit check against current requirements files │
│ • publish Build and upload this project to PyPi │
│ • shell-completion │
│ Setup shell completion for this CLI (Currently only for bash shell) │
│ • test Run unittests │
│ • update Update dependencies (uv.lock) and git pre-commit hooks │
│ • update-readme-history │
│ Update project history base on git commits/tags in README.md Will be │
│ exited with 1 if the README.md was updated otherwise with 0. │
│ │
│ Also, callable via e.g.: │
│ python -m cli_base update-readme-history -v │
│ • update-test-snapshot-files │
│ Update all test snapshot files (by remove and recreate all snapshot │
│ files) │
│ • version Print version and exit │
╰────────────────────────────────────────────────────────────────────────────────────────╯
```
[comment]: <> (✂✂✂ auto generated dev help end ✂✂✂)
## History
[comment]: <> (✂✂✂ auto generated history start ✂✂✂)
* [v0.3.0](https://github.com/jedie/mposcli/compare/v0.2.0...v0.3.0)
* 2026-02-18 - Add "update" beside "update-submodules"
* 2026-02-17 - Update requirements
* 2026-02-16 - update README
* [v0.2.0](https://github.com/jedie/mposcli/compare/v0.1.0...v0.2.0)
* 2026-02-16 - New CLI command: "cp" with convenience features.
* 2026-02-16 - New command: "flash" with file selector
* 2026-02-16 - Update README.md
* [v0.1.0](https://github.com/jedie/mposcli/compare/1695026...v0.1.0)
* 2026-02-16 - Add "update-submodules" command
* 2026-02-16 - Add "build" command
* 2026-02-16 - CLI command: "run-desktop"
* 2026-02-16 - first commit
[comment]: <> (✂✂✂ auto generated history end ✂✂✂)
| text/markdown | null | Jens Diemer <cookiecutter_templates@jensdiemer.de> | null | null | GPL-3.0-or-later | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"bx-py-utils",
"cli-base-utilities>=0.27.4",
"rich",
"tyro"
] | [] | [] | [] | [
"Documentation, https://github.com/jedie/mposcli",
"Source, https://github.com/jedie/mposcli"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-18T16:39:18.465868 | mposcli-0.3.0.tar.gz | 86,695 | 05/fd/431d1c07a5f8ccc967c7a058943c420230b614b3b1d1f8ee00050111f7b3/mposcli-0.3.0.tar.gz | source | sdist | null | false | 8e8abac8b3bae32a6e86b61d4dc929f2 | fb416335fe768d3ceb93ea92f5badcd5081cfaf3493e8f83802724535db5eb59 | 05fd431d1c07a5f8ccc967c7a058943c420230b614b3b1d1f8ee00050111f7b3 | null | [] | 215 |
2.4 | geddes | 0.2.0 | A Python library for parsing XRD pattern files | # Geddes
[](https://crates.io/crates/geddes)
[](https://pypi.org/project/geddes/)
[](https://www.npmjs.com/package/@jcwang587/geddes)
A Rust XRD pattern parser with Python and Node.js bindings. Supports:
- `.raw` (GSAS text or Bruker binary)
- `.rasx` (Rigaku Zip archive)
- `.xrdml` (Panalytical XML)
- `.xy` / `.xye` (Space-separated ASCII)
- `.csv` (Comma-separated values)
## Rust Usage
Load from a file path:
```rust
use geddes::read;
fn main() {
let pattern = read("tests/data/xy/sample.xy").unwrap();
println!("{} {}", pattern.x.len(), pattern.y.len());
}
```
Load from in-memory bytes (filename is used to infer the format):
```rust
use std::fs;
use geddes::read_bytes;
fn main() {
let data = fs::read("tests/data/xy/sample.xy").unwrap();
let pattern = read_bytes(&data, "sample.xy").unwrap();
println!("{} {}", pattern.x.len(), pattern.y.len());
}
```
## Python Usage
Load from a file path:
```python
import geddes
pattern = geddes.read("tests/data/xy/sample.xy")
print(len(pattern.x), len(pattern.y))
```
Load from in-memory bytes (filename is used to infer the format):
```python
import geddes
with open("tests/data/xy/sample.xy", "rb") as f:
data = f.read()
pattern = geddes.read_bytes(data, "sample.xy")
print(len(pattern.x), len(pattern.y))
```
## Node.js Usage
Load from a file path:
```javascript
const geddes = require('@jcwang587/geddes')
const pattern = geddes.read('tests/data/xy/sample.xy')
console.log(pattern.x.length, pattern.y.length)
```
Load from in-memory bytes (filename is used to infer the format):
```javascript
const fs = require('node:fs')
const geddes = require('@jcwang587/geddes')
const bytes = fs.readFileSync('tests/data/xy/sample.xy')
const pattern = geddes.readBytes(bytes, 'sample.xy')
console.log(pattern.x.length, pattern.y.length)
```
## License
MIT
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | MIT | xrd, parser, science, crystallography, chemistry | [
"Programming Language :: Python :: 3",
"Programming Language :: Rust",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pytest>=7; extra == \"test\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:38:34.287770 | geddes-0.2.0.tar.gz | 213,524 | 0a/00/72b8318db8d151355452ec718270da605bdffc68118eea42e7a4055fb7d7/geddes-0.2.0.tar.gz | source | sdist | null | false | ce6c118d5c7e9096a2d6be28cc04bb9b | 74bdf26e1e2fc229846c425570cfdfe31bd320302a0ed1f204adeb3bb0ff4e93 | 0a0072b8318db8d151355452ec718270da605bdffc68118eea42e7a4055fb7d7 | null | [] | 1,138 |
2.4 | jcapy | 4.1.8 | JCapy CLI - One-Army Orchestrator | # JCapy: The One-Army Orchestrator

[](https://badge.fury.io/py/jcapy)
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/release/python-3110/)
> **Build Like a Team of Ten.**
**JCapy** is an **Autonomous Engineer** that lives in your terminal. It transforms solo developers into "One-Army" powerhouses by automating knowledge management, project scaffolding, and intelligent debugging.
---
## 🚀 Why JCapy?
In the modern development landscape, context switching kills productivity. JCapy acts as your **context-aware partner**, handling the heavy lifting of project setup, documentation, and debugging so you can focus on writing code.
- **Stop Debugging Alone**: JCapy watches your terminal logs and proactively suggests fixes.
- **Stop Starting from Scratch**: Harvest existing codebases into reusable templates.
- **Stop Losing Context**: Switch between Frontend, Backend, and DevOps personas instantly.
## ✨ Key Features
### 🧠 Autonomous Log Stream Intelligence
**JCapy watches while you work.**
With the new `AutonomousObserver`, JCapy monitors your terminal output in real-time. It detects crash loops, missing dependencies, and runtime errors, instantly offering "Shadow Mode" fixes without you asking.
- **Passive Observation**: No need to copy-paste logs.
- **Shadow Mode**: JCapy privately logs what it *would* have done vs. what you *did*, learning from your expertise.
- **Privacy First**: All data is stored locally in `~/.jcapy/shadow_log.jsonl`.
### 🏗️ One-Army Scaffolding
- **Persona System**: Switch context instantly between `DevOps`, `Frontend`, and `Backend` roles.
- **Framework Harvesting**: Turn any documentation or codebase into a reusable template with `jcapy harvest`.
- **Grade-Aware Deploy**: Deploy with confidence using A/B/C grade pipelines.
### 🛡️ Privacy-First Telemetry
JCapy uses a **"Local-First, Cloud-Optional"** model.
- **Default**: Zero data sent to the cloud.
- **Shadow Logs**: Stored locally in JSONL format for your inspection.
- **Opt-in**: Enable cloud telemetry only if you want to contribute to the global brain.
### 🧩 JCapy Skills Registry
Extend JCapy with community-driven skills.
- **Official Registry**: [ponli550/jcapy-skills](https://github.com/ponli550/jcapy-skills)
- **Create Your Own**: Build your own skills using our [Official Template](https://github.com/ponli550/jcapy-skills/tree/main/templates/python-standard).
---
## 📦 Installation
### Homebrew (macOS/Linux)
The recommended way to install on macOS/Linux.
```bash
brew tap ponli550/jcapy
brew install jcapy
```
### Pipx (Universal - Recommended for Python environments)
If you don't use Homebrew, `pipx` is the best way to install Python CLIs in isolated environments.
```bash
pipx install jcapy --python python3.11
```
### Pip (Standard)
```bash
pip install jcapy
```
---
## ⚡ Quick Start
1. **Initialize JCapy**:
```bash
jcapy init
```
2. **Harvest a Skill from Documentation**:
```bash
jcapy harvest --doc ./my-docs/
```
3. **Brainstorm a New Feature**:
```bash
jcapy brainstorm "Refactor the authentication module"
```
4. **Activate a Persona**:
```bash
jcapy persona activate DevOps
```
---
## 🤝 Contributing
We welcome contributions! Please see our [Contributing Guide](CONTRIBUTING.md) for details.
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
| text/markdown | null | Irfan Ali <nazrijz336@gmail.com> | null | null | null | cli, developer-tools, automation, productivity, terminal | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Utilities"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"rich>=13.0.0",
"mcp>=1.2.0",
"chromadb>=0.4.0",
"posthog>=3.0.0",
"textual>=0.50.0",
"PyYAML>=6.0",
"python-dotenv>=1.0.0",
"pinecone>=3.0.0; extra == \"pro\""
] | [] | [] | [] | [
"Homepage, https://github.com/ponli550/JCapy",
"Repository, https://github.com/ponli550/JCapy.git",
"Issues, https://github.com/ponli550/JCapy/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T16:38:21.170842 | jcapy-4.1.8.tar.gz | 134,716 | be/bc/2938137ea43a61fbfcb17b75a1003903dcc9b5e6d5d22faeed70ef5e760a/jcapy-4.1.8.tar.gz | source | sdist | null | false | 1b28a368904722fa4bdce88ca5b99f4f | 2ffb82cb583eb56040c6fcfcb39e2d6171a47a5e9b7dfd13f7135beb18000497 | bebc2938137ea43a61fbfcb17b75a1003903dcc9b5e6d5d22faeed70ef5e760a | null | [
"LICENSE",
"NOTICE"
] | 213 |
2.3 | django-db-anonymiser | 0.3.3 | Django app to create configurable anonymised DB dumps. | # django-db-anonymiser
Django app to create configurable anonymised DB dumps.
django-db-anonymiser provides a django app with a management command `dump_and_anonymise`.
This command runs a `pg_dump` against a postgresql DB, applies anonymisation functions to
data dumped from the DB and then writes the anonymised dump to S3.
See here for lite-api's example anonymisation configuration; https://github.com/uktrade/lite-api/blob/dev/api/conf/anonymise_model_config.yaml
This pattern is designed as a replacement for Lite's old DB anonymisation process (although it is general purpose and can be used for any django project which uses postgresql).
The previous process was baked in to an airflow installation and involved making
a `pg_dump` from production, anonymising that dump with python and pushing the
file to S3. See; https://github.com/uktrade/lite-airflow-dags/blob/master/dags/export_lite_db.py
django-db-anonymiser follows the same overall pattern, but aims to achieve it
through a django management command instead of running on top of airflow. In addition,
the configuration for how DB columns are anonymised can be configured in simple YAML.
**Note:** This repository depends upon code forked from https://github.com/andersinno/python-database-sanitizer
This is housed under the `database_sanitizer` directory and has been forked from the above repository
because it is unmaintained.
## Getting started
- Add `faker>=4.18.0`, `boto3>=1.26.17` to python requirements; it is assumed python/psycopg and co are already installed.
- Either add this github repository as a submodule to your django application named `django_db_anonymiser` or install the python package (django-db-anonymiser)[https://pypi.org/project/django-db-anonymiser/] from PyPI.
- Add `django_db_anonymiser.db_anonymiser` to `INSTALLED_APPS`
- Set the following django settings;
- `DB_ANONYMISER_CONFIG_LOCATION` - the location of your anonymisation yaml file
- `DB_ANONYMISER_AWS_ENDPOINT_URL` - optional, custom URL for AWS (e.g. if using minio)
- `DB_ANONYMISER_AWS_ACCESS_KEY_ID` - AWS access key ID for the S3 bucket to upload dumps to
- `DB_ANONYMISER_AWS_SECRET_ACCESS_KEY` - AWS secret key for the S3 bucket to upload dumps to
- `DB_ANONYMISER_AWS_REGION` - AWS region for the S3 bucket to upload dumps to
- `DB_ANONYMISER_AWS_STORAGE_BUCKET_NAME` - AWS bucket name for the S3 bucket to upload dumps to
- `DB_ANONYMISER_DUMP_FILE_NAME` - Name for dumped DB file
- `DB_ANONYMISER_AWS_STORAGE_KEY` - optional, key under which file will be stored in AWS S3 bucket
## Running tests
For local unit testing from the root of the repository run:
$ poetry run pytest django_db_anonymiser
**Note:** Currently for full test coverage, it is necessary to run tests in circleci, where we spin up a postgres db and test
the `db_anonymiser` command directly
## Publishing
Publishing to PyPI is currently a manual process:
1. Acquire API token from [Passman](https://passman.ci.uktrade.digital/secret/0f3d699a-1c7a-4e92-a235-6c756f678dd5/). <!-- /PS-IGNORE -->
- Request access from the SRE team.
- _Note: You will need access to the `platform` group in Passman._
2. Run `poetry config pypi-token.pypi <token>` to add the token to your Poetry configuration.
Update the version, as the same version cannot be published to PyPI.
```
poetry version patch
```
More options for the `version` command can be found in the [Poetry documentation](https://python-poetry.org/docs/cli/#version). For example, for a minor version bump: `poetry version minor`.
Build the Python package.
```
poetry build
```
Publish the Python package.
_Note: Make sure your Pull Request (PR) is approved and contains the version upgrade in `pyproject.toml` before publishing the package._
```
poetry publish
```
Check the [PyPI Release history](https://pypi.org/project/django-db-anonymiser/#history) to make sure the package has been updated.
For an optional manual check, install the package locally and test everything works as expected.
| text/markdown | Brendan Smith | brendan.smith@digital.trade.gov.uk | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <4.0,>3.10.0 | [] | [] | [] | [
"boto3<2.0.0,>=1.40.33",
"psycopg2-binary<3.0.0,>=2.9.10",
"django-environ<0.13.0,>=0.12.0",
"pymysql<2.0.0,>=1.1.2",
"django<5.0.0,>=4.2.10",
"faker>=4.18.0",
"pyyaml==6.0.2"
] | [] | [] | [] | [] | poetry/2.1.4 CPython/3.10.12 Linux/6.8.0-1044-aws | 2026-02-18T16:37:36.231989 | django_db_anonymiser-0.3.3.tar.gz | 30,634 | 24/85/45c3dd50ae8d6e0d2297eeb79313db95f73d205f153fba0a4891487eaf97/django_db_anonymiser-0.3.3.tar.gz | source | sdist | null | false | f2c0fdaf64c4368de73eb30fa93ec243 | e5af8230aa89ecc93d0e669765d7731a6922da586bf2a046b130104dcc1d6f57 | 248545c3dd50ae8d6e0d2297eeb79313db95f73d205f153fba0a4891487eaf97 | null | [] | 232 |
2.3 | towelie | 0.1.4 | Local code review for AI agents | # towelie
Local code review tool. Fast, easy and without clutter.
## Usage
```bash
uvx towelie
```
This starts a local server at `http://localhost:4242` and opens it in your browser.
## Development
```bash
uv run towelie --dev
```
This runs:
- FastAPI with backend auto-reload
- Bun frontend watcher for `bundle.js`
- Tailwind watcher for `output.css`
Browser reload is manual in dev mode, but every refresh will pick up the latest built JS/CSS.
| text/markdown | Glyphack | Glyphack <sh.hooshyari@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"fastapi>=0.128.3",
"jinja2>=3.1.6",
"tree-sitter>=0.22.3",
"uvicorn>=0.40.0"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T16:37:20.490824 | towelie-0.1.4-py3-none-any.whl | 165,242 | dc/5f/4abd634617bb91e8ef7b1791dfba4b6b0ca6e2a09c4e2744d34fbbd6bde3/towelie-0.1.4-py3-none-any.whl | py3 | bdist_wheel | null | false | d0f4e531ccb59887dc6cefc51ed42280 | bf430703409ef90b3c46a8049179cc3f5ce9c1a8a0b49a923f4c67701a929360 | dc5f4abd634617bb91e8ef7b1791dfba4b6b0ca6e2a09c4e2744d34fbbd6bde3 | null | [] | 215 |
2.1 | checkmk-dev-tools | 2.1.0 | Checkmk DevOps tools | # Checkmk Development Tools
This repository includes scripts/tools for Checkmk developers.
- TBD: what should go here
- TBD: what shouldn't go here
## Installation
While you can just clone and use the tools inside of course (they're just plain Python or Bash
scripts), the intended way to use it is via `pip` or inside a virtual environment.
Install it locally using `pip`:
```sh
[<PYTHON> -m] pip[3] install [--user] [--upgrade] checkmk-dev-tools
```
## Contained tools
### General
#### Jenkins
For tools interacting with Jenkins an API key, username and URL to Jenkins has to be provided with `~/.config/jenkins_jobs/jenkins_jobs.ini` otherwise those parameters have to be specified explicitly.
This is a template of the `jenkins_jobs.ini` file
```
[jenkins]
user=carl.lama
# Get the APIKEY from the CI web UI, click top right Profile -> Configure -> Show API Key
# https://JENKINS_URL.tld/user/carl.lama/configure
password=API_KEY_NOT_YOUR_PASSWORD
url=https://JENKINS_URL.tld
query_plugins_info=False
```
#### InfluxDB
`ci-artifacts` can also be used with the [InfluxDB plugin](https://plugins.jenkins.io/influxdb/) storing a history of job builds, their result and used parameters. To use the InfluxDB as backend over the Jenkins job REST API, extend the above `jenkins_jobs.ini` config file with this additional section. The `port` is optional.
```
[influxdb]
password=TOKEN_NOT_YOUR_PASSWORD
url=https://INFLUXDB.tld
port=8086
```
The usage of the InfluxDB is enabled with the optional `--influxdb` argument.
Use the Groovy code snippet in a jobs to post all relevant data to the (hardcoded) bucket `job_bucket` of the org `jenkins`. It has to be used at the very beginning of the job with `build_status` set to `PROGRESS` and at the very end of the job to post another measurement with the final build result. The total job runtime will be calculated as the difference between the first and the second (last) post.
```
def buildData = [:];
params.each { paramKey, paramValue ->
buildData[paramKey] = paramValue;
}
// === IMPORTANT ===
// use 'PROGRESS' at the begin of a job
// use 'currentBuild.result' at the closest possible end of a job
// buildData['build_status'] = 'PROGRESS';
// buildData['build_result'] = currentBuild.result;
// === IMPORTANT ===
influxDbPublisher(
selectedTarget: "YOUR_TARGET_NAME", // Use value configured at the plugin
customData: buildData,
measurementName: "jenkins_job_params", // required, no custom value possible yet
);
```
### `ci-artifacts`
`ci-artifacts` is a tool for accessing and triggering (currently Jenkins only) CI job builds and
making build artifacts available locally in an efficient way (i.e. avoiding unnessessary builds by
comparing certain constraints like job parameters and time of already available builds).
Formerly it was only used to make artifacts available which is the reason for the name and some
CLI desing desicions.
#### Usage
Run `ci-artifacts --help` in general to get more details about the usage of the tool.
##### Await result
Wait for an existing and specified build to finish. Nothing is downloaded.
```sh
ci-artifacts --log-level debug \
await-result checkmk/master/builders/build-cmk-distro-package:6066
```
The returned result is a JSON might look like
```json
{"result": "SUCCESS", "artifacts": null}
```
##### Download
Wait for an existing and specified build to finish and download the artifacts.
The destination of the artifacts can be specified with the optional argument `--out-dir` (defaults to `out`) and is relative to the base directory (`--base-dir`, defaults to current directory) used to fetch hashes of the downloaded artifacts.
The flag `--no-remove-others` can be used to keep additional files in the download directory which were not part of the download. This is like a built-in garbage collection.
```sh
ci-artifacts --log-level debug \
download checkmk/master/builders/build-cmk-distro-package:6066 \
--base-dir ~/my-git-projects/checkmk/master \
--out-dir package_download \
--no-remove-others
```
The returned result is a JSON might look like
```json
{"result": "SUCCESS", "artifacts": ["check-mk-enterprise-2.4.0-2024.10.31_0.jammy_amd64.deb"]}
```
##### Fetch
If there are no more constraints than a build has been completed successfully, `fetch` downloads a given jobs artifact, just like with `download` but for the latest build instead of a specified build number.
Pressing `CTRL+C` while the script is running will ask for confirmation, default answer is `no` and cancel the build.
```sh
ci-artifacts --log-level debug \
fetch checkmk/master/winagt-build
```
In contrast, this is what a more detailed call might look like
```sh
ci-artifacts --log-level debug \
fetch checkmk/master/winagt-build \
--params EDITION=raw,DISTRO="ubuntu-22.04",CUSTOM_GIT_REF=85fa488e0a32f6ea55d8875ab9c517bdc253a8e1 \
--params-no-check DISABLE_CACHE=false,CIPARAM_OVERRIDE_BUILD_NODE=fra001 \
--dependency-paths agents/wnx,agents/windows,packages/cmk-agent-ctl \
--time-constraints today \
--base-dir ~/my-git-projects/checkmk/master \
--out-dir package_download
```
**`--params <JOB-PARAMETERS>`**
Comma separated list of job-parameters used for identifying existing builds and
to start new ones.
**`--params-no-check <JOB-PARAMETERS>`**
Comma separated list of job-parameters used only to start a new build. These parameters are ignored during the search of an already existing build.
**`--time-constraints <SPECIFIER>`**
Check for build date constraints when looking for existing builds - currently
only `today` is taken into account.
**`--dependency-paths <PATH,..>`**
Comma separated list of relative paths to files and directories checked for
differences when looking for existing builds.
**`--omit-new-build`**
Don't start new builds, even when no matching build could be found.
**`--force-new-build`**
Don't look for existing builds, always start a new build instead.
**`--poll-sleep`**
Overwrite default poll interval checking the status of a running Jenkins job.
**`--poll-queue-sleep`**
Overwrite default poll interval checking the status of a queued Jenkins job.
##### Info
Request helpful informations about a Jenkins job.
Do use this command with care! Its output is quite massive and causes a lot of API calls towards Jenkins.
```sh
ci-artifacts --log-level debug \
info checkmk/master/winagt-build
```
```
DD │ 2025-09-17 11:44:36 │ fetch job info for checkmk/master/winagt-build
...
DD │ 2025-09-17 11:45:30 │ fetch build log for checkmk/master/winagt-build:16263
Job('checkmk/master/winagt-build', 100 builds)
- 16362: Build(nr=16362, running/None, started: 2025.09.17-11:32:40, took 00d:00h:00m, params={DISABLE_CACHE=False, VERSION=daily, CIPARAM_CLEANUP_WORKSPACE=0 - none, CUSTOM_GIT_REF=93ae7d1a..}, hashes={})
...
```
##### Request
Like `fetch` but with the optional parameter `--passive` which outputs the informations needed to trigger a build instead of triggering the build.
This is helpful in pipeline scripts to keep track of issuers of a build.
```sh
ci-artifacts --log-level debug \
request checkmk/master/winagt-build \
--params EDITION=raw,DISTRO="ubuntu-22.04",CUSTOM_GIT_REF=85fa488e0a32f6ea55d8875ab9c517bdc253a8e1 \
--params-no-check DISABLE_CACHE=false,CIPARAM_OVERRIDE_BUILD_NODE=fra001 \
--time-constraints today \
--base-dir ~/my-git-projects/checkmk/master \
--passive
```
```json
{
"new_build":
{
"path": "checkmk/master/winagt-build",
"params":
{
"EDITION": "raw",
"DISTRO": "ubuntu-22.04",
"CUSTOM_GIT_REF": "85fa488e0a32f6ea55d8875ab9c517bdc253a8e1",
"DISABLE_CACHE": "false",
"CIPARAM_OVERRIDE_BUILD_NODE": "fra001"
}
}
}
```
Without the `--passive` flag the build is triggered if no matching one is found. If a matching build with the specified parameters was found the returned JSON might look like
```json
{
"existing":
{
"path": "checkmk/master/winagt-build",
"number": 6066,
"url": "https://JENKINS_URL.tld/job/checkmk/job/master/job/winagt-build/6066/",
"result": "SUCCESS",
"new_build": false
}
}
```
##### Validate
The `validate` subcommand is a combination of several other commands. It requests, identifies a matching of triggers a new build while waiting for the build to complete. Nothing is downloaded. It has the same parameters as `fetch`.
This subcommand can be used to trigger a remote build with custom parameters or check if an existing build with these parameters passed or not.
```sh
ci-artifacts --log-level debug \
validate checkmk/master/winagt-build \
--params EDITION=raw,DISTRO="ubuntu-22.04",CUSTOM_GIT_REF=85fa488e0a32f6ea55d8875ab9c517bdc253a8e1 \
--params-no-check DISABLE_CACHE=false,CIPARAM_OVERRIDE_BUILD_NODE=fra001 \
--time-constraints today
```
```json
{"result": "SUCCESS", "artifacts": []}
```
#### Todo
- [ ] request CI build from local changes
### `job-resource-usage`
This is a tool to parse resource usage data for single containers
based on data collected by docker-shaper.
The [ndjson](https://github.com/ndjson/ndjson-spec) formatted data files can usually be found on the build nodes at `~jenkins/.docker_shaper/container-logs`.
#### Usage
```bash
job-resource-usage --before=7d --after=14d folder/with/datafiles/
```
### `lockable-resources`
`lockable-resources` is a tool for listing, locking and unlocking [lockable resources](https://plugins.jenkins.io/lockable-resources/) of Jenkins.
#### General
Run `lockable-resources --help` in general to get more details about the usage of the tool.
#### List
The `list` argument provides a JSON output of all labels and their resources.
```sh
lockable-resources -vvv list
```
```json
{"my_label": ["resouce1", "resouce2"], "other_label": ["this", "that"]}
```
#### Reserve and unreserve
The `reserve` and the `unreserve` argument require a single or a list of labels to lock or unlock.
```sh
lockable-resources -vvv \
[--fail-already-locked] \
[reserve, unreserve] first_resource second_resource third_resource
```
With the `--fail-already-locked` flag an exception can be thrown if the resource is already locked. If this flag is not set only a warning is logged.
To lock all resources with the label `my_lock` use the following simple call
```sh
lockable-resources list | \
jq -c .my_lock[] | \
xargs -I {} lockable-resources -vvv reserve {}
```
## Development & Contribution
### Setup
For active development you need to have `poetry` and `pre-commit` installed
```sh
python3 -m pip install --upgrade --user poetry pre-commit
git clone ssh://review.lan.tribe29.com:29418/checkmk_dev_tools
cd checkmk_dev_tools
pre-commit install
# if you need a specific version of Python inside your dev environment
poetry env use ~/.pyenv/versions/3.10.4/bin/python3
poetry install
```
### Workflow
Create a new changelog snippet. If no new snippets is found on a merged change
no new release will be built and published.
If the change is based on a Jira ticket, use the Jira ticket name as snippet
name otherwise use a unique name.
```sh
poetry run \
changelog-generator \
create .snippets/CMK-20150.md
```
After committing the snippet a changelog can be generated locally. For CI usage
the `--in-place` flag is recommended to use as it will update the existing
changelog with the collected snippets. For local usage remember to reset the
changelog file before a second run, as the version would be updated recursively
due to the way the changelog generator is working. It extracts the latest
version from the changelog file and puts the found snippets on top.
Future changes to the changelog are ignored by
```sh
git update-index --assume-unchanged changelog.md
```
```sh
poetry run \
changelog-generator \
changelog changelog.md \
--snippets=.snippets \
--in-place \
--version-reference="https://review.lan.tribe29.com/gitweb?p=checkmk_dev_tools.git;a=tag;h=refs/tags/"
```
Update the version of the project in all required files by calling
```sh
poetry run \
changelog2version \
--changelog_file changelog.md \
--version_file cmk_dev/version.py \
--version_file_type py \
--additional_version_info="-rc42+$(git rev-parse HEAD)" \
--print \
| jq -r .info.version
```
* modify and check commits via `pre-commit run --all-files`
* after work is done locally:
- update dependencies before/with a new release
```sh
poetry lock
```
- build and check package locally
```sh
poetry build && \
poetry run twine check dist/* &&
python3 -m pip uninstall -y checkmk_dev_tools && \
python3 -m pip install --user dist/checkmk_dev_tools-$(grep -E "^version.?=" pyproject.toml | cut -d '"' -f 2)-py3-none-any.whl
```
- commit, push and review the changes
```sh
git add ...
git commit -m "cmk-dev-tools: bump version, update dependencies"
```
- test deployed packages from `test.pypi.org`. The extra index URL is required to get those dependencies from `pypi.org` which are not available from `test.pypi.org`
```sh
pip install --no-cache-dir \
-i https://test.pypi.org/simple/ \
--extra-index-url https://pypi.org/simple \
checkmk-dev-tools==<VERSION_WITH_RC>
```
- finally merge the changes and let Jenkins create the release tag and deployment
| text/markdown | Frans Fürst | frans.fuerst@checkmk.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <4.0.0,>=3.10.4 | [] | [] | [] | [
"python-jenkins<1.9.0,>=1.8.3",
"pydantic<3,>=2",
"rich",
"influxdb-client<2,>=1",
"trickkiste<0.4.0,>=0.3.4"
] | [] | [] | [] | [
"Repository, https://github.com/Checkmk/checkmk-dev-tools",
"Changelog, https://github.com/Checkmk/checkmk-dev-tools/blob/release/2.1.0/changelog.md"
] | poetry/1.8.5 CPython/3.11.6 Linux/5.15.0-170-generic | 2026-02-18T16:37:09.981012 | checkmk_dev_tools-2.1.0.tar.gz | 51,588 | 9d/71/c170ccf184a3d88609675db8cc541b1f9cefe9269af178c04d18cf96f1b3/checkmk_dev_tools-2.1.0.tar.gz | source | sdist | null | false | 5b023b0b69a038d6b960622efba613b7 | 1c86d6c8ae402ee92fccecd7ef5b596240141fa800658cb34250526b1959a262 | 9d71c170ccf184a3d88609675db8cc541b1f9cefe9269af178c04d18cf96f1b3 | null | [] | 423 |
2.4 | openmodeldb | 1.1.1 | Browse and download AI upscaling models from OpenModelDB | # OpenModelDB
Browse and download AI upscaling models from [OpenModelDB](https://openmodeldb.info).
## Install
```bash
pip install openmodeldb
```
## CLI
```bash
openmodeldb
```
Select scale → pick a model → download.
## Python API
```python
from openmodeldb import OpenModelDB
db = OpenModelDB()
# <OpenModelDB: 658 models>
# List models (formatted table)
db.list(scale=4)
db.list(scale=1, architecture="compact")
# Find models (returns list[Model])
models = db.find(scale=4)
compacts = db.find(scale=1, architecture="compact")
# Search by name, author, tags or description
results = db.search("denoise")
# Download by name or Model object
db.download("4xNomos8k_atd_jpg")
db.download(models[0])
db.download(models[0], dest="./my_models/")
# Download a specific format (pth, safetensors, onnx)
db.download("4xNomos8k_atd_jpg", format="safetensors")
# Auto-conversion between pth and safetensors
# If the requested format is unavailable, downloads the other and converts
db.download("2x-HFA2kAVCCompact", format="safetensors") # only pth available → auto-convert
db.download("1x-SuperScale", format="pth") # only safetensors → auto-convert
# Download as ONNX with auto-conversion
# If no ONNX file is available, downloads .pth/.safetensors and converts automatically
db.download("4xNomos8k_atd_jpg", format="onnx")
db.download("2x-DigitalFlim-SuperUltraCompact", format="onnx", half=True) # FP16 export
# Download all available formats
db.download_all("4xNomos8k_atd_jpg")
db.download_all("4xNomos8k_atd_jpg", format="pth") # only .pth files
# Verify model integrity (compare weights against database reference)
db.test_integrity("downloads/4xNomos8k_atd_jpg.pth")
# ✓ PASS similarity=100.000000 matched=53/53 max_diff=0.00e+00 mean_diff=0.00e+00
# Silent mode (no output, for use as a library)
path = db.download("4xNomos8k_atd_jpg", quiet=True)
# Get download URL (for custom download logic)
url = db.get_url("4xNomos8k_atd_jpg")
url = db.get_url("4xNomos8k_atd_jpg", format="safetensors")
# Dict-style access
model = db["4xNomos8k_atd_jpg"]
print(model.name, model.author, model.scale, model.architecture)
# Check if a model exists
"4xNomos8k" in db # True
# Browse architectures and tags
db.architectures() # ['atd', 'compact', 'cugan', 'dat', ...]
db.tags() # ['anime', 'denoise', 'photo', ...]
# Iterate
for model in db:
print(model)
# Launch interactive CLI
db.interactive()
```
## Dependencies
- [InquirerPy](https://github.com/kazhala/InquirerPy) — interactive prompts
- [rich](https://github.com/Textualize/rich) — progress bars and tables
- [pycryptodome](https://github.com/Legrandin/pycryptodome) — Mega.nz decryption
### Conversion (optional)
```bash
pip install openmodeldb[convert]
```
Enables automatic conversion between formats: pth ↔ safetensors ↔ ONNX.
- [PyTorch](https://pytorch.org/) — model loading and ONNX export
- [safetensors](https://github.com/huggingface/safetensors) — safe tensor serialization
- [onnx](https://github.com/onnx/onnx) — ONNX model format
- [onnxruntime](https://github.com/microsoft/onnxruntime) — graph optimization
- [spandrel](https://github.com/chaiNNer-org/spandrel) — universal model loader
## Credits
- [OpenModelDB](https://openmodeldb.info) — the open model database
- All model authors and contributors
| text/markdown | null | null | null | null | null | upscaling, ai, esrgan, super-resolution, openmodeldb | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
... | [] | null | null | >=3.10 | [] | [] | [] | [
"InquirerPy>=0.3.4",
"pycryptodome>=3.18.0",
"rich>=13.0.0",
"mediafiredl>=0.0.2",
"torch>=2.0; extra == \"convert\"",
"safetensors>=0.3; extra == \"convert\"",
"onnx>=1.14; extra == \"convert\"",
"onnxruntime>=1.15; extra == \"convert\"",
"spandrel>=0.3; extra == \"convert\"",
"spandrel-extra-arc... | [] | [] | [] | [
"Homepage, https://github.com/matth-blt/openmodeldb",
"Source, https://github.com/matth-blt/openmodeldb"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:36:57.120834 | openmodeldb-1.1.1.tar.gz | 20,747 | 86/50/8a4c2c109bd9129d584f77d942238996ff59b6e6ccc46229b942fd3d1892/openmodeldb-1.1.1.tar.gz | source | sdist | null | false | be4d2ba2bdf15182e8ea7fa50a34324c | be2693a98a836bdeb2880cfb1744b1635b94e645780f183b80e2c77485e432e9 | 86508a4c2c109bd9129d584f77d942238996ff59b6e6ccc46229b942fd3d1892 | MIT | [
"LICENSE"
] | 221 |
2.4 | mycelium-map | 0.3.3 | Static analysis tool that maps the hidden network of connections in codebases | # Mycelium
Static analysis CLI that maps the connections in a source code repository. Produces a single JSON file containing file structure, symbols, imports, call graph, community clusters, and execution flows.
Powered by a Rust engine with tree-sitter parsing, exposed to Python via PyO3.
## Install
```bash
pip install mycelium-map
```
Pre-built binary wheels are available for Linux (x86_64, aarch64), macOS (x86_64, aarch64), and Windows (x86_64). Source builds require a Rust toolchain.
## Usage
```bash
mycelium-map analyze <path> # Analyse a repo
mycelium-map analyze <path> -o output.json # Custom output path
mycelium-map analyze <path> --verbose # Show phase timing breakdown
mycelium-map analyze <path> --quiet # No terminal output
mycelium-map analyze <path> -l cs,ts # Only analyse C# and TypeScript
mycelium-map analyze <path> --exclude vendor,legacy # Skip directories
mycelium-map analyze <path> --resolution 1.5 # Louvain resolution (higher = more communities)
mycelium-map analyze <path> --max-processes 50 # Limit execution flows
mycelium-map analyze <path> --max-depth 8 # Limit BFS trace depth
```
Default output file: `<repo-name>.mycelium.json`
### Python API
```python
from mycelium import analyze
result = analyze("path/to/repo")
print(result["stats"])
```
## Supported Languages
| Language | Extensions |
|---|---|
| C# | `.cs` |
| VB.NET | `.vb` |
| TypeScript | `.ts`, `.tsx` |
| JavaScript | `.js`, `.jsx`, `.mjs`, `.cjs` |
| Python | `.py` |
| Java | `.java` |
| Go | `.go` |
| Rust | `.rs` |
| C | `.c`, `.h` |
| C++ | `.cpp`, `.cc`, `.cxx`, `.hpp`, `.hxx`, `.hh` |
## Output Schema
The JSON output contains these top-level sections:
### `metadata`
```json
{
"repo_name": "my-project",
"repo_path": "/absolute/path",
"analysed_at": "2026-02-05T18:33:12Z",
"mycelium_version": "1.0.0",
"commit_hash": "a1b2c3d4e5f6",
"analysis_duration_ms": 42.3,
"phase_timings": { "structure": 0.004, "parsing": 0.001, ... }
}
```
### `stats`
Summary counts: `files`, `folders`, `symbols`, `calls`, `imports`, `communities`, `processes`, and a `languages` breakdown by file count.
### `structure`
File tree with language, size, and line counts.
```json
{
"files": [{ "path": "src/main.cs", "language": "cs", "size": 1024, "lines": 45 }],
"folders": [{ "path": "src/", "file_count": 3 }]
}
```
### `symbols`
Every extracted symbol: classes, methods, interfaces, functions, structs, enums, etc.
```json
{
"id": "sym_0001",
"name": "UserController",
"type": "Class",
"file": "Controllers/UserController.cs",
"line": 8,
"visibility": "public",
"exported": true,
"parent": "MyApp.Controllers",
"language": "cs"
}
```
Symbol types: `Class`, `Function`, `Method`, `Interface`, `Struct`, `Enum`, `Namespace`, `Property`, `Constructor`, `Module`, `Record`, `Delegate`, `TypeAlias`, `Constant`, `Trait`, `Impl`, `Macro`, `Typedef`, `Annotation`.
Visibility: `public`, `private`, `internal`, `protected`.
### `imports`
Three categories of dependency edges:
```json
{
"file_imports": [{ "from": "Controller.cs", "to": "Service.cs", "statement": "using MyApp.Services" }],
"project_references": [{ "from_project": "Web.csproj", "to_project": "Core.csproj", "ref_type": "ProjectReference" }],
"package_references": [{ "project": "Web.csproj", "package": "Newtonsoft.Json", "version": "13.0.1" }]
}
```
Project and package references are extracted from `.csproj`/`.vbproj` files.
### `calls`
Call graph edges with three-tier confidence scoring:
```json
{
"from": "sym_0004",
"to": "sym_0015",
"confidence": 0.9,
"tier": "A",
"reason": "import-resolved",
"line": 17
}
```
| Tier | Confidence | Meaning |
|------|-----------|---------|
| A | 0.9 | Callee found in an imported file |
| B | 0.85 | Callee found in the same file |
| C | 0.5 | Unique fuzzy match across the codebase |
| C | 0.3 | Ambiguous fuzzy match (multiple candidates) |
### `communities`
Clusters of symbols that frequently call each other, detected via Louvain algorithm.
```json
{
"id": "community_0",
"label": "Absence",
"members": ["sym_0004", "sym_0015", "sym_0016"],
"cohesion": 0.8,
"primary_language": "cs"
}
```
### `processes`
Execution flows traced from entry points (controllers, handlers, main functions) via BFS through the call graph.
```json
{
"id": "process_0",
"entry": "sym_0004",
"terminal": "sym_0016",
"steps": ["sym_0004", "sym_0015", "sym_0016"],
"type": "intra_community",
"total_confidence": 0.765
}
```
`type` is `intra_community` when all steps are in the same community, or `cross_community` when the flow spans multiple.
`total_confidence` is the product of all edge confidences along the path.
## Development
```bash
# Rust tests
cargo test --workspace
# Build Python bindings locally
pip install maturin
maturin develop --release
# Run binding tests
pytest tests/test_bindings.py -v
# Rust CLI (alternative to Python CLI)
cargo run -p mycelium-cli -- analyze <path>
```
## Releasing
Releases are automated via GitHub Actions. Push a semver tag to trigger a release:
```bash
git tag v1.0.0
git push origin v1.0.0
```
This will:
1. Build binary wheels for Linux, macOS, and Windows
2. Build a source distribution
3. Publish all to PyPI
| text/markdown; charset=UTF-8; variant=GFM | null | Scott <scott.raisbeck1985@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"click>=8.1",
"rich>=13.0"
] | [] | [] | [] | [
"Homepage, https://github.com/ScottRBK/mycelium",
"Repository, https://github.com/ScottRBK/mycelium"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:36:32.921222 | mycelium_map-0.3.3.tar.gz | 582,407 | f4/55/e33a698a91691668a8246bb0ccb5d6b7a07ae13bb6f1ba49f3af8df6e947/mycelium_map-0.3.3.tar.gz | source | sdist | null | false | ce9cfc07ec07ad727bed441454e99b9a | 13a620a869314824d1db5bf9f5f387d16425b285b0143300695aadd1e650f45e | f455e33a698a91691668a8246bb0ccb5d6b7a07ae13bb6f1ba49f3af8df6e947 | MIT | [] | 502 |
2.4 | automac | 0.1.1 | An all-in-one automated ML pipeline for feature engineering, optimization, and evaluation. | # ML-Automator 🚀
**ML-Automator** is a powerful, low-code machine learning utility library that automates Feature Engineering, Hyperparameter Optimization, and Model Evaluation.
## 🌟 Features
- **Automated Feature Engineering**: Handle Target Encoding, Scaling, and Imputation in one line.
- **Optuna-Powered Optimization**: Pre-configured search spaces for RandomForest, XGBoost, CatBoost, LightGBM, and more.
- **Deep Evaluation**:
- Multi-model score comparison.
- Interactive ROC and Calibration curves using Plotly.
- Automated Learning Curve analysis.
- Automatic report generation (CSV/Excel/PNG).
## 📂 Project Structure
Your library is organized into three core modules:
1. `feature_engineering.py`: Data preprocessing and importance extraction.
2. `models_optimizer.py`: Optuna-based hyperparameter tuning.
3. `trainer.py`: Model training, cross-validation, and visualization.
## 🚀 Quick Start
### 1. Automation at its Best
```python
from automater.feature_engineering import FeatureEvaluation
from sklearn.ensemble import RandomForestClassifier
evaluator = FeatureEvaluation(X, y)
processed_x, importance_df = evaluator.fit_all_at_once(RandomForestClassifier())
| text/markdown | Abhishek Sharma | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/jubito-27/ml-automator | null | >=3.8 | [] | [] | [] | [
"pandas",
"numpy",
"scikit-learn",
"category_encoders",
"optuna",
"catboost",
"xgboost",
"lightgbm",
"plotly",
"kaleido",
"openpyxl"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.7 | 2026-02-18T16:34:59.486403 | automac-0.1.1.tar.gz | 9,646 | 44/92/4926c5fda43cfec8c734847e1d2818003c00866e1e7ffd7710b2e3b6f4da/automac-0.1.1.tar.gz | source | sdist | null | false | fb9c5ace0d19657acd8a335e01b98f63 | 36ddb8015c98f1dfb33d62c8b1437b1753dde78d6949a0ecc3ab9882d953600f | 44924926c5fda43cfec8c734847e1d2818003c00866e1e7ffd7710b2e3b6f4da | null | [] | 241 |
2.4 | pygeodes | 0.1.7 | A Python client for Geodes APIs | <div align="center">
<a target="_blank" href="https://github.com/CNES/pyGeodes">
<picture>
<source
srcset="https://raw.githubusercontent.com/CNES/pyGeodes/main/docs/source/_static/logo-geodes-light.png"
media="(prefers-color-scheme: light)"
/>
<img
src="https://raw.githubusercontent.com/CNES/pyGeodes/main/docs/source/_static/logo-geodes-light.png"
alt="GEODES"
width="60%"
/>
</picture>
</a>
<h1>pyGeodes, A wrapper for Geodes APIs</h1>
[](https://www.python.org/downloads/release/python-380/)
[](LICENSE)
[](https://cnes.github.io/pyGeodes/)
</div>
This project aims to provide a toolbox to access to some endpoints of [Geodes](https://geodes.cnes.fr/api) APIs in Python.
To see the docs, please go to [https://CNES.github.io/pyGeodes/](https://cnes.github.io/pyGeodes/).
## Installation
### From PyPi
You can install from PyPi by following those steps:
1. Install pygeodes
```bash
pip install pygeodes
```
### Build from source
To build from source, follow those steps :
1. Clone the repository
```bash
git clone https://github.com/CNES/pyGeodes
```
2. Install from source
```bash
pip install ./pygeodes/
```
| text/markdown | CNES | null | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0.0,>=3.10.14 | [] | [] | [] | [
"aiofiles<25.0.0,>=24.1.0",
"aiohttp<4.0.0,>=3.9.0",
"boto3<2.0.0,>=1.28.16",
"geopandas<2.0.0,>=1.0.0",
"ipython<9.0.0,>=8.12.0",
"pystac<2.0.0,>=1.8.0",
"remotezip<0.13.0,>=0.12.0",
"requests<3.0.0,>=2.32.2",
"rich<14.0.0,>=13.7.0",
"tqdm<5.0.0,>=4.66.0",
"validators>=0.28.0",
"whoosh<3.0.0,... | [] | [] | [] | [
"Homepage, https://geodes.cnes.fr",
"Repository, https://github.com/CNES/pyGeodes"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:34:53.802734 | pygeodes-0.1.7.tar.gz | 28,173 | d3/d3/e6570389a6e7c6db48f12449643b899ff7c4ca9cd5d59dc92b3b4bf9a114/pygeodes-0.1.7.tar.gz | source | sdist | null | false | 789a4a9e49f0002646bcb9a292aacead | 7f828b85fbbe8ed3fb6b21efb22c1cf647b6536b4a16158767d713cfcf52f30d | d3d3e6570389a6e7c6db48f12449643b899ff7c4ca9cd5d59dc92b3b4bf9a114 | null | [
"LICENSE"
] | 237 |
2.4 | django-justmyresource | 0.1.0 | Use justmyresource resource packs in your Django and Jinja templates | # django-justmyresource
Use [JustMyResource](https://github.com/kws/justmyresource) resource packs in your Django and Jinja templates.
## Requirements
Python 3.10+ supported.
Django 4.2+ supported (for Django integration).
Jinja2 3.0+ supported (for Jinja integration).
## Installation
Install with the appropriate extras:
```bash
# For Django templates
pip install django-justmyresource[django]
# For Jinja templates
pip install django-justmyresource[jinja]
# For both
pip install django-justmyresource[django,jinja]
```
You'll also need to install resource packs. For example, to use Lucide icons:
```bash
pip install justmyresource-lucide
```
## Usage
### Django Templates
1. Add to your `INSTALLED_APPS`:
```python
INSTALLED_APPS = [
...,
"django_justmyresource",
...,
]
```
2. Load the template library in your templates:
```django
{% load justmyresource %}
```
Alternatively, make the library available in all templates by adding it to [the builtins option](https://docs.djangoproject.com/en/stable/topics/templates/#django.template.backends.django.DjangoTemplates):
```python
TEMPLATES = [
{
"BACKEND": "django.template.backends.django.DjangoTemplates",
# ...
"OPTIONS": {
# ...
"builtins": [
...,
"django_justmyresource.templatetags.justmyresource",
...,
],
},
}
]
```
3. Use the `icon` tag to render SVG icons:
```django
{% icon "lucide:a-arrow-down" %}
```
The `icon` tag accepts these arguments:
- `name`, positional: The resource name with optional prefix (e.g., `"lucide:home"` or `"justmyresource-lucide/lucide:home"`).
- `size`, keyword: An integer for width and height attributes. Defaults to `24`. Can be `None` to preserve original size.
- Any number of keyword arguments: These are added as HTML attributes. Underscores are replaced with dashes (e.g., `data_test` becomes `data-test`).
Most attributes are added to the `<svg>` tag, but these are applied to `<path>` elements:
- `stroke-linecap`
- `stroke-linejoin`
- `vector-effect`
#### Examples
Basic icon:
```django
{% icon "lucide:a-arrow-down" %}
```
Custom size and CSS class:
```django
{% icon "lucide:a-arrow-down" size=40 class="mr-4" %}
```
With data attributes and path-level attributes:
```django
{% icon "lucide:a-arrow-down" stroke_width=1 data_controller="language" %}
```
### Jinja Templates
1. Add the `icon` function to your Jinja environment:
```python
from django_justmyresource.jinja import icon
from jinja2 import Environment
env = Environment()
env.globals.update({
"icon": icon,
})
```
2. Use the `icon` function in your templates:
```jinja
{{ icon("lucide:a-arrow-down") }}
```
The function accepts the same arguments as the Django template tag:
- `name`, positional: The resource name with optional prefix.
- `size`, keyword: Size for width and height. Defaults to `24`. Can be `None`.
- Any number of keyword arguments: HTML attributes (underscores become dashes).
#### Examples
Basic icon:
```jinja
{{ icon("lucide:a-arrow-down") }}
```
Custom size and CSS class:
```jinja
{{ icon("lucide:a-arrow-down", size=40, class="mr-4") }}
```
With data attributes:
```jinja
{{ icon("lucide:a-arrow-down", stroke_width=1, data_controller="language") }}
```
## Configuration
You can configure the JustMyResource registry via Django settings:
### `JUSTMYRESOURCE_DEFAULT_PREFIX`
Set a default prefix for bare resource names (without a colon):
```python
JUSTMYRESOURCE_DEFAULT_PREFIX = "lucide"
```
Then you can use bare names in templates:
```django
{% icon "home" %} # Resolves to "lucide:home"
```
### `JUSTMYRESOURCE_BLOCKLIST`
Exclude specific resource packs from discovery:
```python
# As a list
JUSTMYRESOURCE_BLOCKLIST = ["pack1", "pack2"]
# Or as a comma-separated string
JUSTMYRESOURCE_BLOCKLIST = "pack1,pack2"
```
### `JUSTMYRESOURCE_PREFIX_MAP`
Map custom aliases to qualified pack names:
```python
# As a dict
JUSTMYRESOURCE_PREFIX_MAP = {
"icons": "justmyresource-lucide/lucide",
"fa": "justmyresource-font-awesome/font-awesome",
}
# Or as a comma-separated string
JUSTMYRESOURCE_PREFIX_MAP = "icons=justmyresource-lucide/lucide,fa=justmyresource-font-awesome/font-awesome"
```
## Resource Name Resolution
Resource names can be specified in multiple formats:
- **Qualified name**: `"justmyresource-lucide/lucide:home"` - Always unique, no ambiguity
- **Short pack name**: `"lucide:home"` - Works if the pack name is unique
- **Alias**: `"luc:home"` - If the pack defines aliases via `get_prefixes()`
- **Bare name**: `"home"` - Requires `JUSTMYRESOURCE_DEFAULT_PREFIX` to be set
See the [JustMyResource documentation](https://github.com/kws/justmyresource) for more details on resource resolution.
## Available Resource Packs
Check the [JustMyResource Icons](https://github.com/kws/justmyresource-icons) repository for available icon packs:
- `justmyresource-lucide` - Lucide icons
- `justmyresource-heroicons` - Heroicons
- `justmyresource-phosphor` - Phosphor icons
- `justmyresource-font-awesome` - Font Awesome
- `justmyresource-material-icons` - Material Icons
- `justmyresource-mdi` - Material Design Icons
## Acknowledgements
This project was initially inspired by [lucide](https://github.com/franciscobmacedo/lucide), a Django/Jinja integration for Lucide icons. The lucide project itself is heavily inspired by [Adam Johnson's heroicons](https://github.com/adamchainz/heroicons), and much of the template tag implementation and SVG rendering logic follows similar patterns.
Special thanks to:
- [Francisco Macedo](https://github.com/franciscobmacedo) for the lucide project, which served as the initial reference
- [Adam Johnson](https://github.com/adamchainz) for the heroicons project, which established the pattern for Django icon template tags
## License
MIT
| text/markdown | null | Kaj Siebert <kaj@k-si.com> | null | null | MIT | Django, Jinja, icons, justmyresource, resources | [
"Development Status :: 4 - Beta",
"Framework :: Django :: 3.2",
"Framework :: Django :: 4.0",
"Framework :: Django :: 4.1",
"Framework :: Django :: 4.2",
"Framework :: Django :: 5.0",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Opera... | [] | null | null | >=3.10 | [] | [] | [] | [
"justmyresource<2.0.0,>=1.0.0",
"django>=3.2; extra == \"dev\"",
"jinja2>=3.0; extra == \"dev\"",
"justmyresource-lucide; extra == \"dev\"",
"markupsafe>=2.0; extra == \"dev\"",
"pytest-django>=4.5.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"django>=3.2; extra == \"django\"",
"jinja2>=... | [] | [] | [] | [
"Homepage, https://github.com/kws/django-justmyresource",
"Repository, https://github.com/kws/django-justmyresource",
"Issues, https://github.com/kws/django-justmyresource/issues"
] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T16:34:52.209100 | django_justmyresource-0.1.0.tar.gz | 13,720 | 49/a1/7b564c2dbe5422032fde867b8d1f970c23207ffc1fd8d96489f5805e2567/django_justmyresource-0.1.0.tar.gz | source | sdist | null | false | 44ed9329ab1adc12fc2faf830a3938d6 | 90a72aed4d0e208bfe9c5c718369e58aabbed2477db5e64eb4ada0cea447dcaa | 49a17b564c2dbe5422032fde867b8d1f970c23207ffc1fd8d96489f5805e2567 | null | [] | 244 |
2.4 | qomputing | 0.1.6 | Quantum computing state vector simulator with linear XEB benchmarking | # Qomputing Simulator
A lightweight, pure Python state-vector simulator with linear cross-entropy benchmarking (XEB). For contributors and users who install from source.
---
## Install
From the project root:
```bash
git clone <this-repo-url>
cd simulator # or your clone directory
python3 -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install -e ".[dev]"
```
- `[dev]` adds `pytest`. For a normal (non-editable) install: `pip install .`
Without cloning (if the package is published):
```bash
pip install qomputing
# Optional: pip install qomputing[dev]
```
---
## Usage
### CLI
```bash
# Random circuit + XEB
qomputing-sim random-circuit --qubits 3 --depth 5 --shots 1000
# Simulate from JSON
qomputing-sim simulate --circuit path/to/circuit.json --shots 512 --seed 42
```
Optional: `--max-qubits`, `--max-shots` to cap resources; `--single-qubit-gates`, `--two-qubit-gates`, `--multi-qubit-gates` to override default gate sets.
### Library
**Backend API:**
```python
from qomputing import QomputingSimulator, QuantumCircuit
backend = QomputingSimulator.get_backend("state_vector")
qc = QuantumCircuit(4, 4)
qc.h(0).cx(0, 1).measure(range(3), range(3))
result = backend.run(qc, shots=1024)
print(result.get_counts())
```
**Direct run:**
```python
from qomputing import run, QuantumCircuit, run_xeb, random_circuit
qc = QuantumCircuit(2)
qc.h(0).cx(0, 1)
result = run(qc, shots=1000, seed=42)
print(result.final_state, result.probabilities, result.counts)
qc = random_circuit(num_qubits=3, depth=5, seed=7)
xeb = run_xeb(qc, shots=1000, seed=7)
print(xeb.fidelity, xeb.sample_probabilities)
```
Rotation gates use **qubit first, then angle**: e.g. `qc.rz(qubit, theta)`, `qc.ry(qubit, theta)`.
Measure takes **sequences**: e.g. `qc.measure([0], [0])` for one qubit; `qc.measure_all()` if `num_clbits >= num_qubits`.
---
## Repository layout
```
qomputing/
├── circuit.py # QuantumCircuit, gates, measure, JSON (de)serialization
├── circuit_builders.py # random_circuit for XEB
├── gates/ # Single-, two-, multi-qubit gate implementations
├── engine/ # State vector core, measurements, registry
├── linalg.py # Tensor / linear algebra helpers
├── cli.py # qomputing-sim entry point
├── xeb.py # Linear XEB fidelity
├── backend.py # QomputingSimulator, Result
├── run.py # run(), load_circuit(), run_xeb()
├── visualisation*.py # Circuit drawer and Bloch (optional)
tools/
├── cirq_comparison.py # Parity tests vs Cirq
tests/ # Pytest: parity, limits, XEB, drawer, bugs
```
---
## Circuit JSON format
```json
{
"num_qubits": 2,
"gates": [
{"name": "h", "targets": [0]},
{"name": "cx", "controls": [0], "targets": [1]},
{"name": "rz", "targets": [0], "params": {"theta": 1.5708}}
]
}
```
Supported gates: single-qubit `id`, `x`, `y`, `z`, `h`, `s`, `sdg`, `t`, `tdg`, `sx`, `sxdg`, `rx`, `ry`, `rz`, `u1`, `u2`, `u3`; two-qubit `cx`, `cy`, `cz`, `cp`, `csx`, `swap`, `iswap`, `sqrtiswap`, `rxx`, `ryy`, `rzz`; multi-qubit `ccx`, `ccz`, `cswap`.
---
## Testing
```bash
pytest
```
Parity vs Cirq (optional):
```bash
export PYTHONPATH="$PWD"
python tools/cirq_comparison.py --min-qubits 1 --max-qubits 5 --depths 3 5 --circuits-per-config 3 --shots 256 --seed 7
```
---
## Development
- Run `pytest` before committing.
- Use `CONTRIBUTING.md` for contribution guidelines (if present).
- Build package: `python -m build` (creates `dist/`). For publishing to PyPI, use `./scripts/publish-to-pypi.sh` (maintainer only).
---
## License
MIT
| text/markdown | Qomputing Simulator Maintainers | null | null | null | null | quantum, simulation, state vector, xeb | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Physics"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy<3.0,>=1.24",
"cirq<2.0,>=1.6",
"pytest>=7.0; extra == \"dev\"",
"build>=1.0; extra == \"build\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.7 | 2026-02-18T16:34:36.484801 | qomputing-0.1.6.tar.gz | 30,331 | 25/98/865c6241700f6c74bd2dee502d136479b0492017f58e0786fa9a645f30eb/qomputing-0.1.6.tar.gz | source | sdist | null | false | bb11b979f95ffd1ea360be0d7ad2c0a1 | 3c23e46167629d3b9c61fe15e0f35ac1326397199586e609d672c1e971ae4081 | 2598865c6241700f6c74bd2dee502d136479b0492017f58e0786fa9a645f30eb | MIT | [] | 237 |
2.4 | qextrawidgets | 0.2.11 | A collection of extra widgets for PySide6 including Emoji Picker, Filterable Table, and more. | # QExtraWidgets
<p align="center">
<img src="https://raw.githubusercontent.com/gpedrosobernardes/QExtraWidgets/main/assets/images/QExtraWidgets.png" alt="QExtraWidgets Logo" width="600">
</p>
[](https://badge.fury.io/py/qextrawidgets)
[](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/qextrawidgets/)
[](https://gpedrosobernardes.github.io/QExtraWidgets/)
**QExtraWidgets** is a comprehensive library of modern, responsive, and feature-rich widgets for **PySide6** applications. It aims to fill the gaps in standard Qt widgets by providing high-level components like Excel-style filterable tables, emoji pickers, accordion menus, and theme-aware icons.
## 📖 Documentation
The complete documentation is available at: [https://gpedrosobernardes.github.io/QExtraWidgets/](https://gpedrosobernardes.github.io/QExtraWidgets/)
## 📦 Installation
```bash
pip install qextrawidgets
```
## ✨ Features & Widgets
### 1. QFilterableTable
A powerful `QTableView` extension that adds Excel-like filtering capabilities to headers.
* **Cascading Filters:** Filter options update based on other columns (drill-down).
* **Sort & Search:** Built-in sorting and search within the filter popup.
* **Model Agnostic:** Works with `QSqlTableModel`, `QStandardItemModel`, or any custom model.
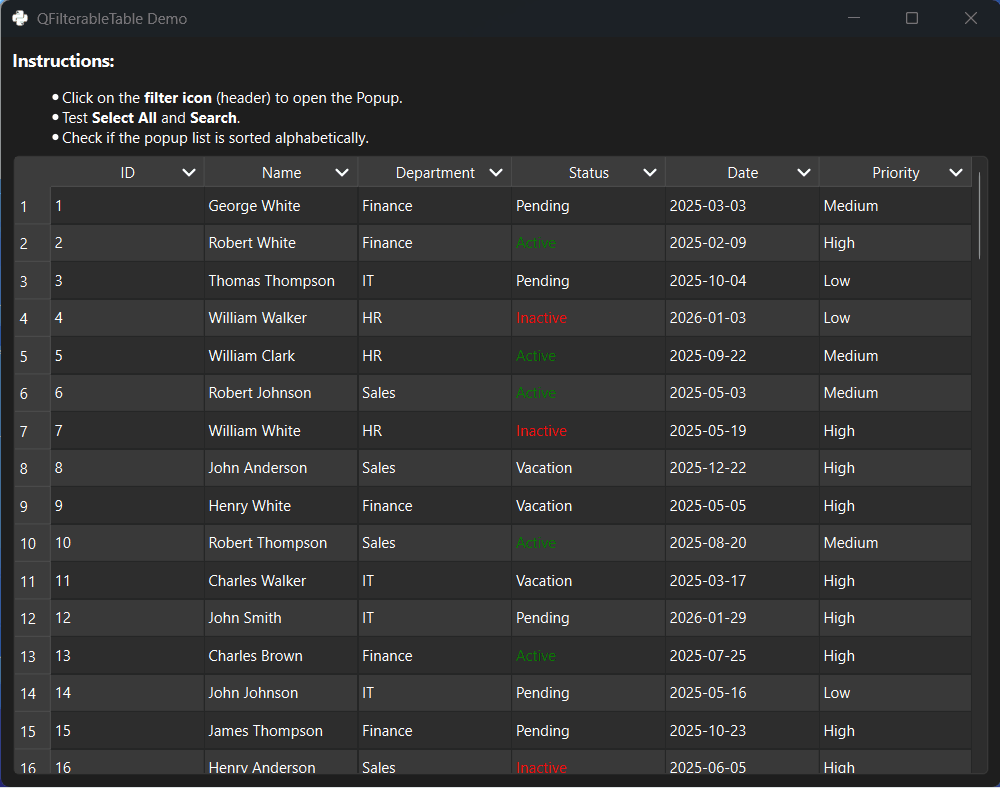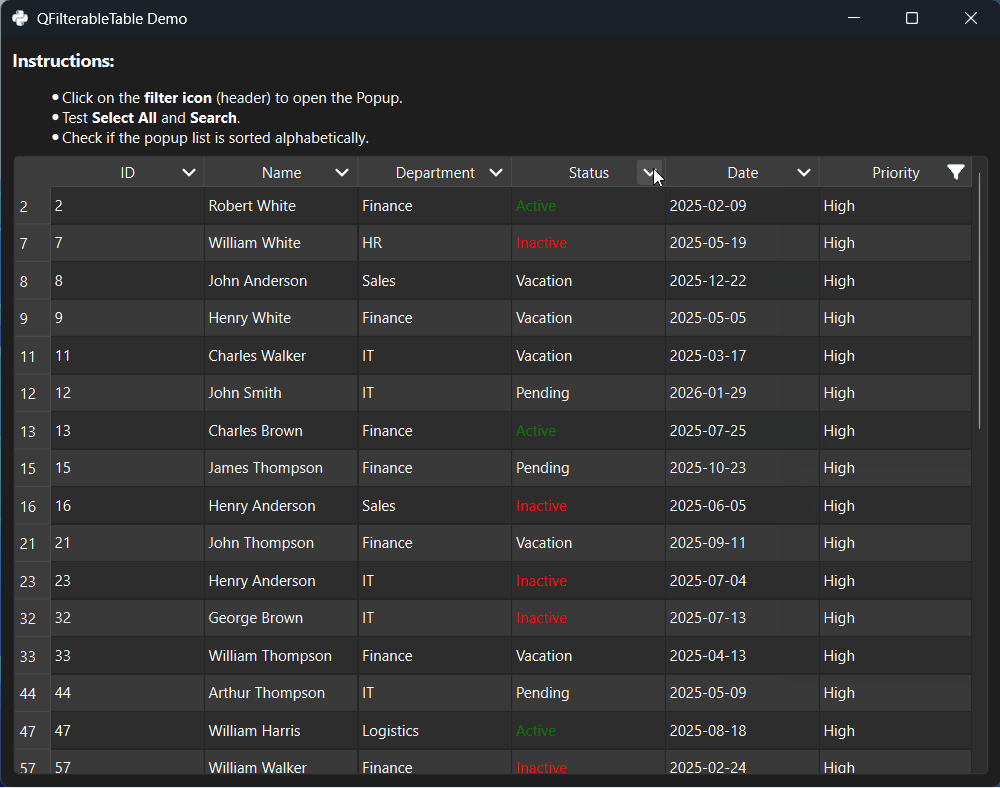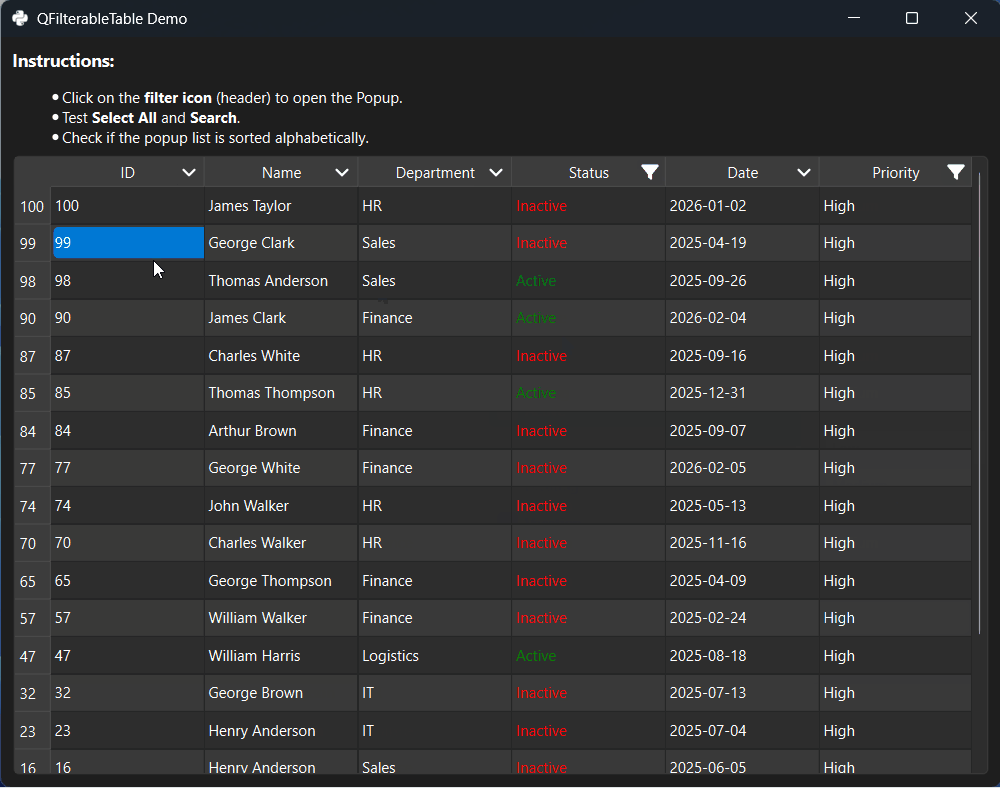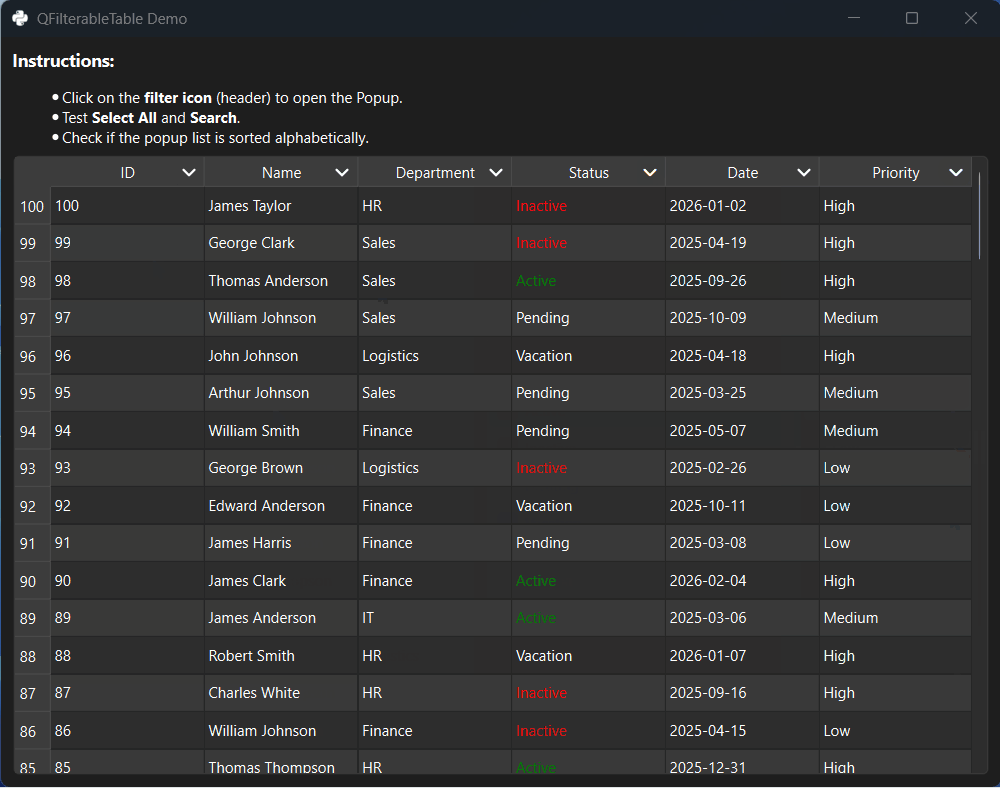
---
### 2. QEmojiPicker
A full-featured Emoji Picker.
* **Rich Features:** Includes skin tone selector, favorites/recents management, and context menu actions (copy alias, favorite/unfavorite).
* **Optimized Search:** Fast filtering with recursive category matching.
* **Emoji Replacement:** Automatically converts `:smile:` aliases or pasted unicode characters into high-quality images.
---
### 3. QAccordion
A flexible accordion widget for grouping content in collapsible sections.
* **Customizable:** Change icon position (left/right) and animation speed.
* **Smooth Animation:** Uses `QPropertyAnimation` for expanding/collapsing.
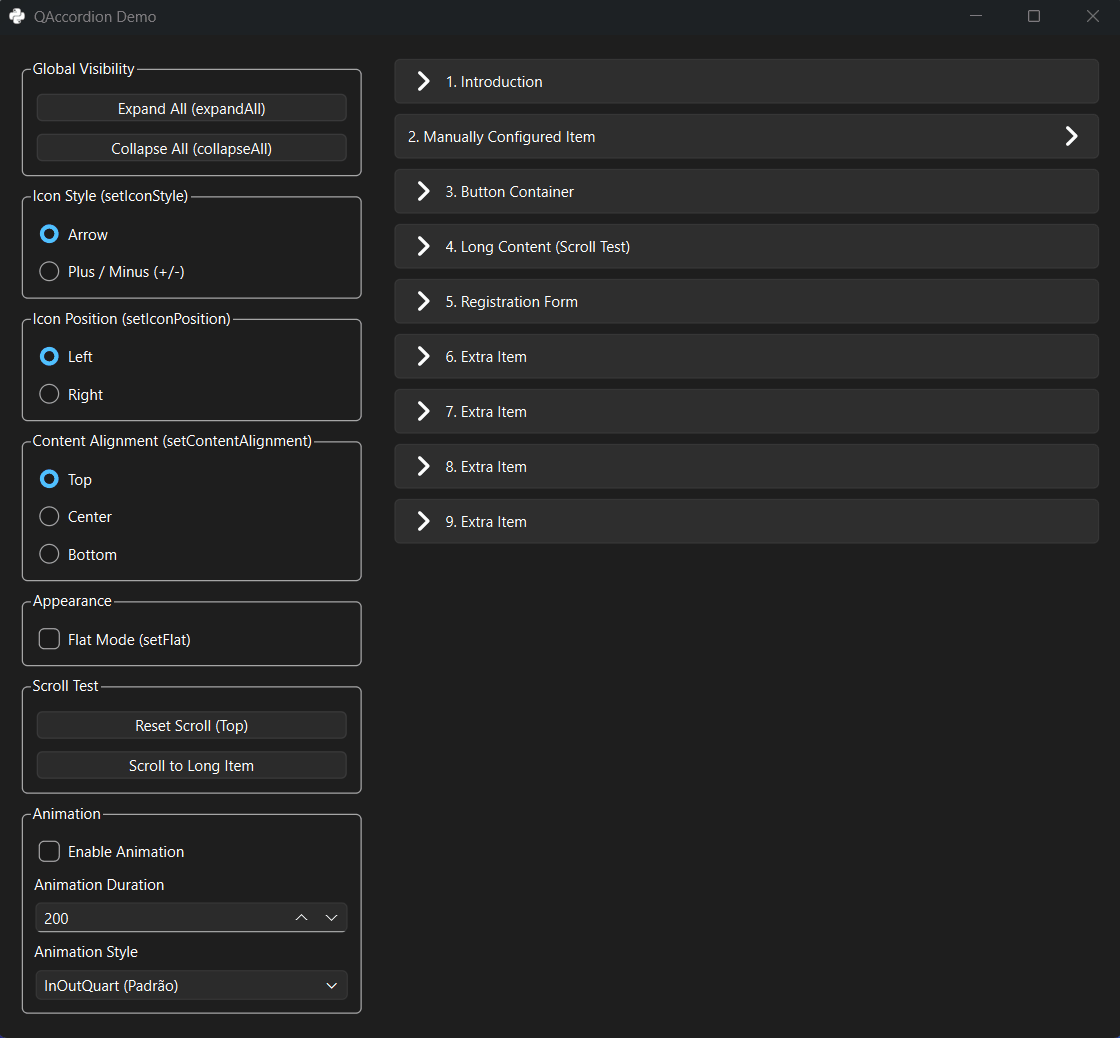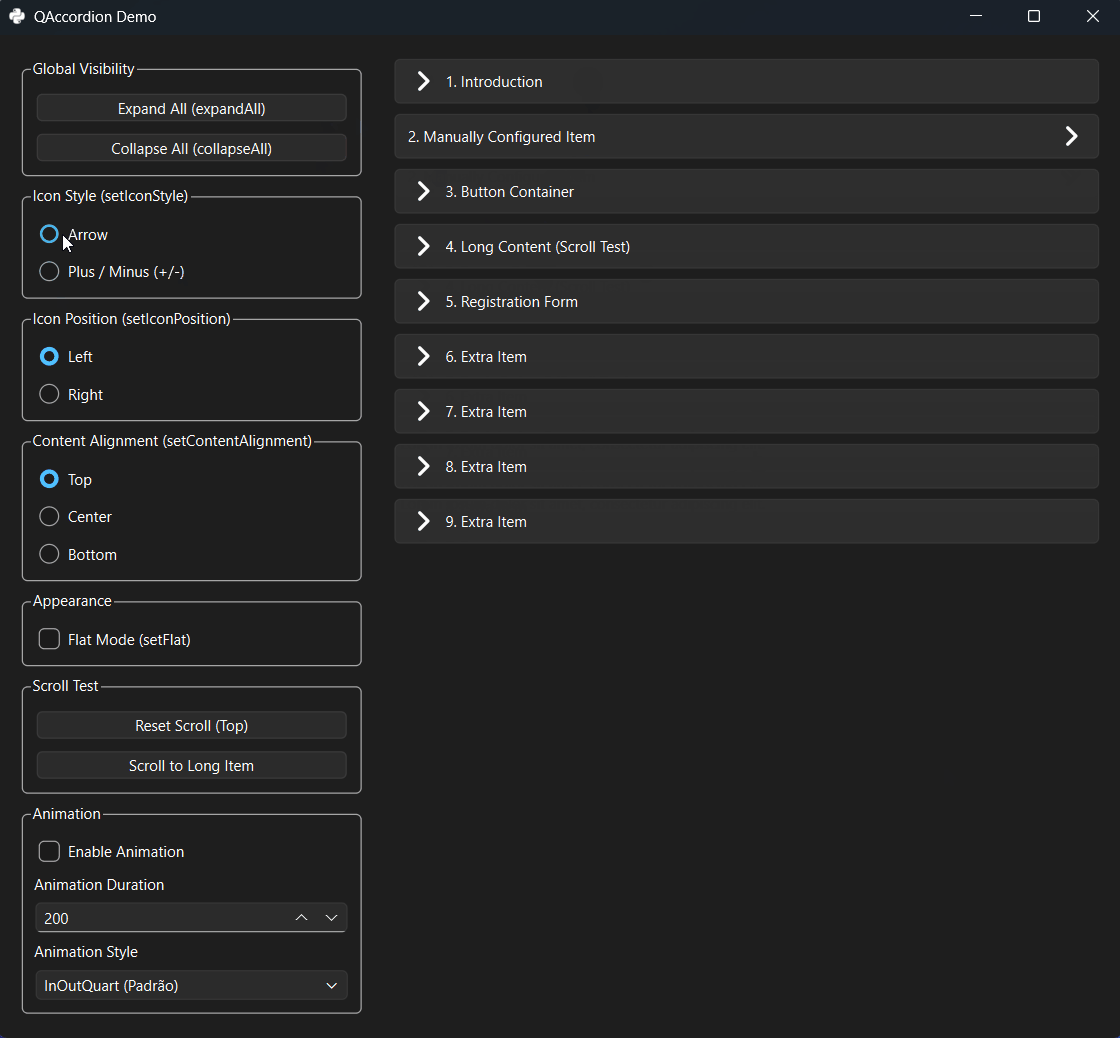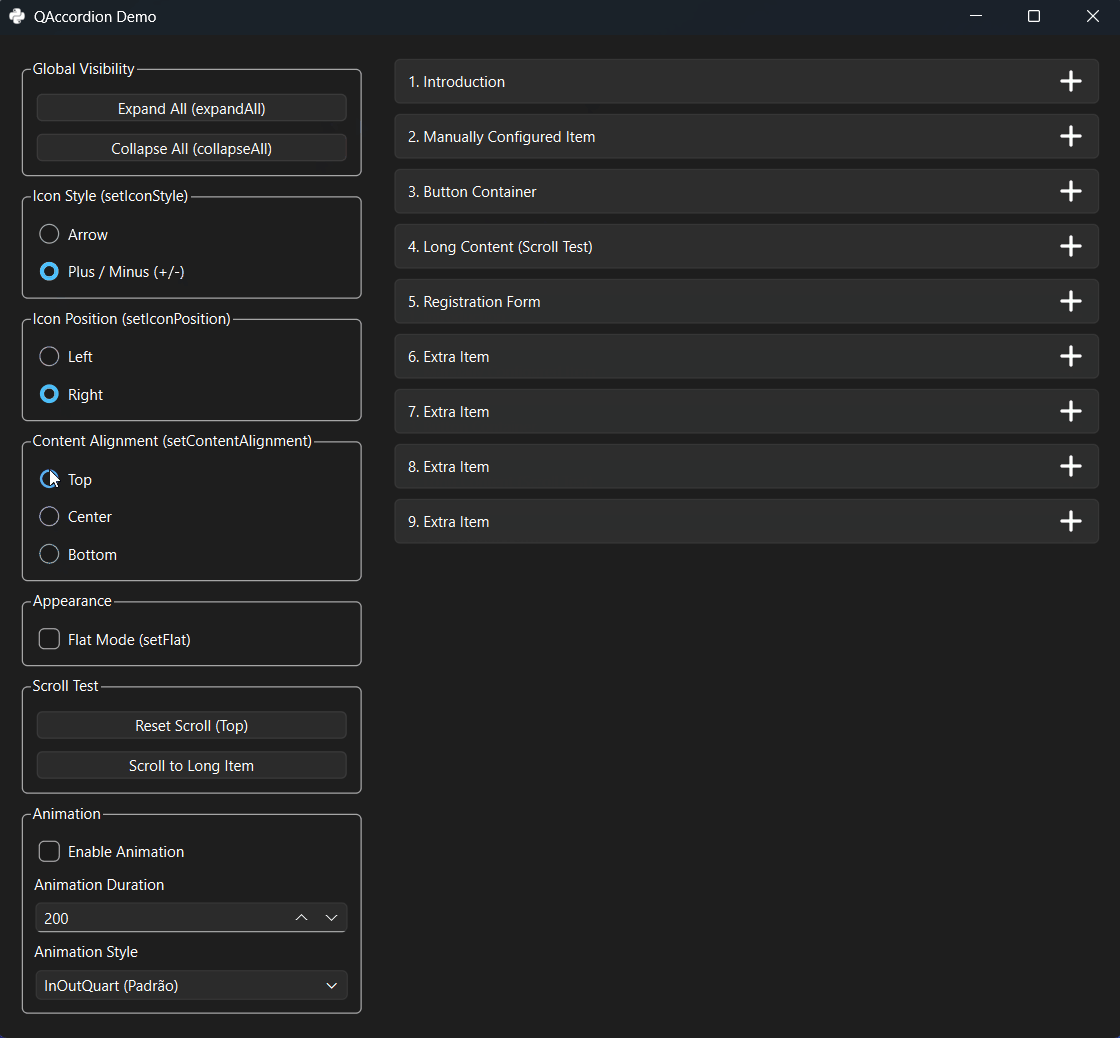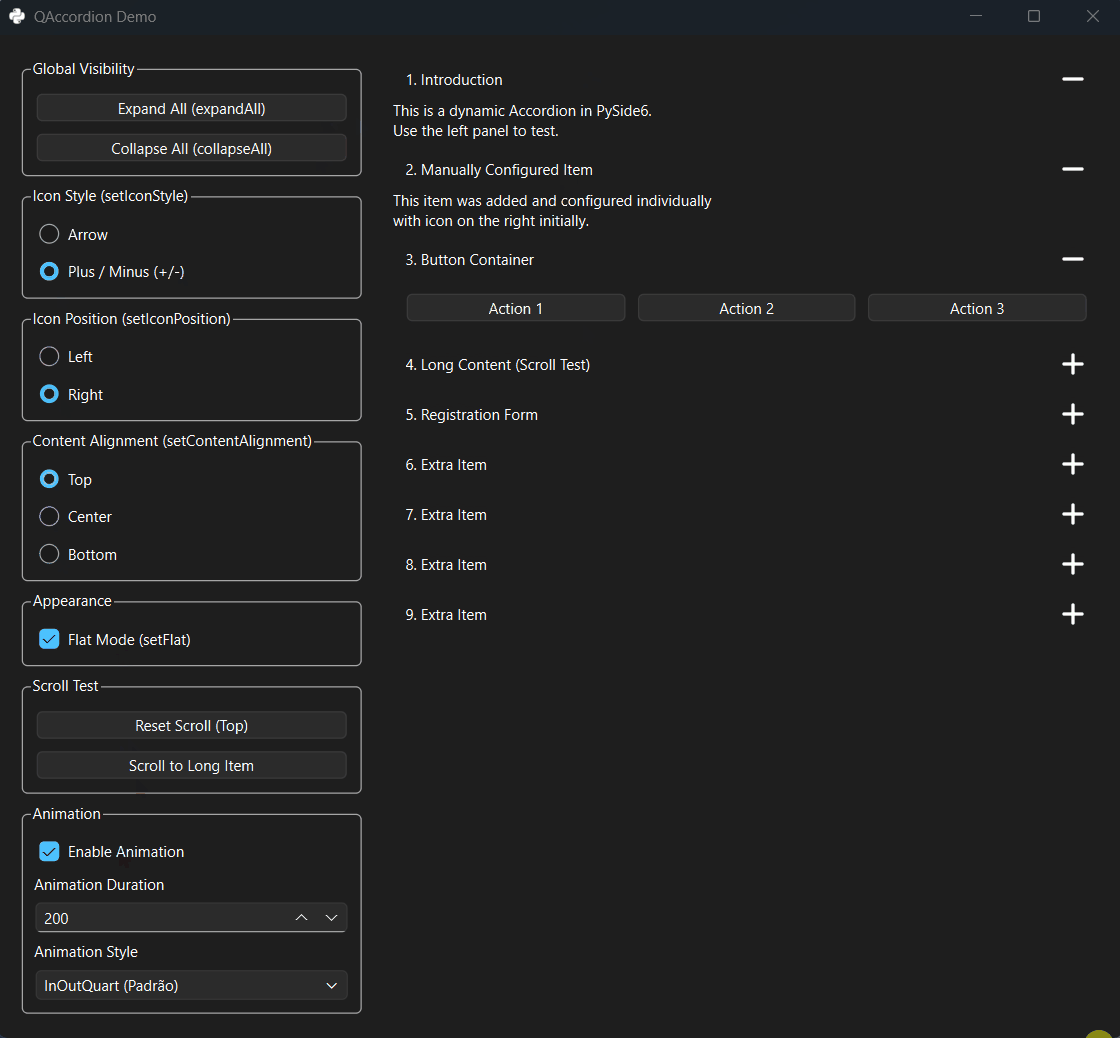
---
### 4. QThemeResponsiveIcon & QThemeResponsiveLabel
Stop worrying about Dark/Light mode icons. `QThemeResponsiveIcon` wraps `QtAwesome` to automatically invert colors (Black <-> White) based on the current system or application palette.
For labels, `QThemeResponsiveLabel` automatically updates its pixmap when the icon theme or widget size changes.
---
### 5. Other Useful Widgets
| Widget | Description | Image |
|---------------------------|--------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------|
| **QPasswordLineEdit** | A line edit with a built-in eye icon to toggle password visibility. |  |
| **QPager** | A classic pagination control for navigating large datasets. |  |
| **QColorButton** | A button that allows setting custom background colors for different states (Normal, Hover, Pressed, Checked). |  |
| **QColorToolButton** | A tool button that allows setting custom background colors for different states (Normal, Hover, Pressed, Checked). | |
| **QDualList** | Two lists side-by-side for moving items (Select/Deselect). |  |
| **QSearchLineEdit** | A search input field with a clear button and search icon. |  |
| **QIconComboBox** | A ToolButton-style combo box optimized for icons or short text. | |
| **QEmojiPickerMenu** | A menu wrapper for `QEmojiPicker` to easily attach it to buttons. | |
| **QThemeResponsiveLabel** | A label that automatically updates its icon based on theme and size. | |
---
## 🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## 📄 License
This project is licensed under the MIT License - see the LICENSE file for details.
| text/markdown | null | Gustavo Pedroso Bernardes <gpedrosobernardes@gmail.com> | null | null | MIT | qt, pyside6, widgets, ui, accordion, filterable table, emoji picker | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: P... | [] | null | null | >=3.9 | [] | [] | [] | [
"PySide6>=6.10.2",
"twemoji-api>=2.0.0",
"emoji-data-python==1.6.0",
"qtawesome==1.4.1",
"mkdocs>=1.5.0; extra == \"docs\"",
"mkdocs-material>=9.0.0; extra == \"docs\"",
"mkdocs-include-markdown-plugin>=6.0.0; extra == \"docs\"",
"mkdocstrings[python]>=0.24.0; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/gpedrosobernardes/QExtraWidgets",
"Documentation, https://gpedrosobernardes.github.io/QExtraWidgets/",
"Bug Tracker, https://github.com/gpedrosobernardes/QExtraWidgets/issues"
] | twine/6.2.0 CPython/3.13.3 | 2026-02-18T16:34:19.949900 | qextrawidgets-0.2.11.tar.gz | 3,399,437 | b6/10/0b98cbc15eb8bd6225104f340aae494cd88b3aca7eacddacf3d189e9c2a7/qextrawidgets-0.2.11.tar.gz | source | sdist | null | false | 776327e5a38e4811e7f23749972f08f7 | 0ef4d1bc48d67f321ea8a8567f1630ff574274c1fc686956f194b30e87b7b3ae | b6100b98cbc15eb8bd6225104f340aae494cd88b3aca7eacddacf3d189e9c2a7 | null | [
"LICENSE"
] | 232 |
2.1 | SciQLopPlots | 0.18.2 | SciQLop plot API based on QCustomPlot | [](https://www.gnu.org/licenses/gpl-3.0)
[]()
[](https://pypi.python.org/pypi/sciqlopplots)
[](https://codecov.io/gh/SciQLop/SciQLopPlots/branch/main)
# SciQLopPlots - A High-Performance Plotting Library for Scientific Data
SciQLopPlots is a powerful and efficient plotting library designed for the [SciQLop](https://github.com/SciQLop/SciQLop) scientific data analysis platform. It provides interactive visualization capabilities optimized for handling large-scale scientific datasets with seamless integration into SciQLop's ecosystem.
## Key Features
- **High-Performance Rendering**: Optimized for smooth interaction with large non uniform 1D, 2D datasets.
- **Interactive Visualization**: Pan, zoom, and inspect data points in real time.
- **Multiple Plot Types**: Supports time series, spectrograms, parametric curves.
- **Customizable Styling**: Adjust colors, labels, axes, and plot layouts programmatically or via GUI.
- **Cross-Platform**: Works on Windows, Linux, and macOS.
## Installation
SciQLopPlots can be installed as a stadalone Python package with pip.
```bash
python -m pip install SciQLopPlots
```
# How to contribute
Just fork the repository, make your changes and submit a pull request. We will be happy to review and merge your
changes.
Reports of bugs and feature requests are also welcome. Do not forget to star the project if you like it!
# Credits
The development of SciQLop is supported by the [CDPP](http://www.cdpp.eu/).<br />
We acknowledge support from the federation [Plas@Par](https://www.plasapar.sorbonne-universite.fr)
# Thanks
We would like to thank the developers of the following libraries that SciQLop depends on:
- [PySide6](https://doc.qt.io/qtforpython-6/index.html) for the GUI framework and Qt bindings.
- [QCustomPlot](https://www.qcustomplot.com/) for providing the plotting library.
| text/markdown | null | Alexis Jeandet <alexis.jeandet@member.fsf.org> | null | null | GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
An easy to use ISTP loader package.
Copyright (C) 2022 Alexis Jeandet
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
<http://www.gnu.org/licenses/>.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
<http://www.gnu.org/philosophy/why-not-lgpl.html>.
| null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programmin... | [] | null | null | <3.15,>=3.10 | [] | [] | [] | [
"numpy",
"pyside6==6.10.2",
"shiboken6==6.10.2"
] | [] | [] | [] | [
"homepage, https://github.com/SciQLop/SciQLopPlots"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:34:11.365707 | sciqlopplots-0.18.2.tar.gz | 1,045,479 | d2/3e/560f3c73b2df7b9d10bfa471be8fd43f02a7835d177bf5bbb7e73245d666/sciqlopplots-0.18.2.tar.gz | source | sdist | null | false | 0c2d50730c2b6bcbb8a9a1490d3d2d50 | 96a222d4dbb3dccf0018b5077fe1e8aee3430713e33c18912821a6f9bcd38afe | d23e560f3c73b2df7b9d10bfa471be8fd43f02a7835d177bf5bbb7e73245d666 | null | [] | 0 |
2.4 | XStatic-jQuery | 3.7.1.1 | jQuery 3.7.1 (XStatic packaging standard) | XStatic-jQuery
--------------
jQuery javascript library packaged for setuptools (easy_install) / pip.
This package is intended to be used by **any** project that needs these files.
It intentionally does **not** provide any extra code except some metadata
**nor** has any extra requirements. You MAY use some minimal support code from
the XStatic base package, if you like.
You can find more info about the xstatic packaging way in the package `XStatic`.
| null | null | null | Thomas Waldmann | tw@waldmann-edv.de | (same as jQuery) | jquery xstatic | [] | [
"any"
] | https://jquery.com/ | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.9 | 2026-02-18T16:34:10.110177 | xstatic_jquery-3.7.1.1.tar.gz | 304,369 | d0/ac/5ad81abc559e6771a019eba7494b981638b63f645d4fd184adbd85a6ca35/xstatic_jquery-3.7.1.1.tar.gz | source | sdist | null | false | d0a2927051ee9a284369fd91b2f299b4 | 0c2ac780d8388bfd8b94586f6a0f86541e8702b5fc96f1ded997866214809445 | d0ac5ad81abc559e6771a019eba7494b981638b63f645d4fd184adbd85a6ca35 | null | [] | 0 |
2.4 | speedy-utils | 1.2.11 | Fast and easy-to-use package for data science | # Speedy Utils



**Speedy Utils** is a Python utility library designed to streamline common programming tasks such as caching, parallel processing, file I/O, and data manipulation. It provides a collection of decorators, functions, and classes to enhance productivity and performance in your Python projects.
## 🚀 Recent Updates (January 27, 2026)
**Enhanced Error Handling in Parallel Processing:**
- Rich-formatted error tracebacks with code context and syntax highlighting
- Three error handling modes: 'raise', 'ignore', and 'log'
- Filtered tracebacks focusing on user code (hiding infrastructure)
- Real-time progress reporting with error/success statistics
- Automatic error logging to timestamped files
- Caller frame information showing where parallel functions were invoked
## Quick Start
### Parallel Processing with Error Handling
```python
from speedy_utils import multi_thread, multi_process
# Simple parallel processing
results = multi_thread(lambda x: x * 2, [1, 2, 3, 4, 5])
# Results: [2, 4, 6, 8, 10]
# Robust processing with error handling
def process_item(item):
if item == 3:
raise ValueError(f"Cannot process item {item}")
return item * 2
# Continue processing despite errors
results = multi_thread(process_item, [1, 2, 3, 4, 5], error_handler='log')
# Results: [2, 4, None, 8, 10] - errors logged automatically
```
## Table of Contents
- [🚀 Recent Updates](#-recent-updates-january-27-2026)
- [Quick Start](#quick-start)
- [Features](#features)
- [Installation](#installation)
- [Usage](#usage)
- [Parallel Processing](#parallel-processing)
- [Multi-threading](#multi-threading-with-enhanced-error-handling)
- [Multi-processing](#multi-processing-with-error-handling)
- [mpython](#mpython-cli-tool)
- [Enhanced Error Handling](#enhanced-error-handling)
- [Caching](#caching)
- [File I/O](#file-io)
- [Data Manipulation](#data-manipulation)
- [Utility Functions](#utility-functions)
- [LLM](#llm)
- [Testing](#testing)
## Features
- **Caching Mechanisms**: Disk-based and in-memory caching to optimize function calls.
- **Parallel Processing**: Multi-threading, multi-processing, and asynchronous multi-threading utilities with enhanced error handling.
- **File I/O**: Simplified JSON, JSONL, and pickle file handling with support for various file extensions.
- **Data Manipulation**: Utilities for flattening lists and dictionaries, converting data types, and more.
- **Timing Utilities**: Tools to measure and log execution time of functions and processes.
- **Pretty Printing**: Enhanced printing functions for structured data, including HTML tables for Jupyter notebooks.
- **Enhanced Error Handling**: Rich error tracebacks with code context, configurable error handling modes ('raise', 'ignore', 'log'), and detailed progress reporting.
## Installation
You can install **Speedy Utils** via [PyPI](https://pypi.org/project/speedy-utils/):
```bash
pip install speedy-utils
# or
uv pip install speedy-utils
```
Alternatively, install directly from the repository:
```bash
pip install git+https://github.com/anhvth/speedy
# or
uv pip install git+https://github.com/anhvth/speedy
```
For local development:
```bash
git clone https://github.com/anhvth/speedy
cd speedy
uv sync
```
### Extras
Optional dependencies can be installed via extras. For the `ray` backend
support (requires Python >= 3.9):
```bash
pip install 'speedy-utils[ray]'
# or
uv pip install 'speedy-utils[ray]'
# developing this repo
uv sync --extra ray
```
## Updating from previous versions
To update from previous versions or switch to v1.x, first uninstall any old
packages, then install the latest version:
```bash
pip uninstall speedy_llm_utils speedy_utils
pip install -e ./ # for local development
# or
pip install speedy-utils -U # for PyPI upgrade
```
## Usage
Below are examples demonstrating how to utilize various features of **Speedy Utils**.
### Caching
#### Memoize Decorator
Cache the results of function calls to disk to avoid redundant computations.
```python
from speedy_utils import memoize
@memoize
def expensive_function(x):
# Simulate an expensive computation
import time
time.sleep(2)
return x * x
result = expensive_function(4) # Takes ~2 seconds
result = expensive_function(4) # Retrieved from cache instantly
```
#### In-Memory Memoization
Cache function results in memory for faster access within the same runtime.
```python
from speedy_utils import imemoize
@imemoize
def compute_sum(a, b):
return a + b
result = compute_sum(5, 7) # Computed and cached
result = compute_sum(5, 7) # Retrieved from in-memory cache
```
### Parallel Processing
#### Multi-threading with Enhanced Error Handling
Execute functions concurrently using multiple threads with comprehensive error handling. The enhanced error handling provides three modes: 'raise' (default), 'ignore', and 'log'. When errors occur, you'll see rich-formatted tracebacks with code context and caller information.
```python
from speedy_utils import multi_thread
def process_item(item):
# Simulate processing that might fail
if item == 3:
raise ValueError(f"Invalid item: {item}")
return item * 2
items = [1, 2, 3, 4, 5]
# Default behavior: raise on first error with rich traceback
try:
results = multi_thread(process_item, items, workers=3)
except SystemExit:
print("Error occurred and was displayed with rich formatting")
# Continue processing on errors, return None for failed items
results = multi_thread(process_item, items, workers=3, error_handler='ignore')
print(results) # [2, 4, None, 8, 10]
# Log errors to files and continue processing
results = multi_thread(process_item, items, workers=3, error_handler='log', max_error_files=10)
print(results) # [2, 4, None, 8, 10] - errors logged to .cache/speedy_utils/error_logs/
```
#### Multi-processing with Error Handling
Process items across multiple processes with the same enhanced error handling capabilities.
```python
from speedy_utils import multi_process
def risky_computation(x):
"""Computation that might fail for certain inputs."""
if x % 5 == 0:
raise RuntimeError(f"Cannot process multiples of 5: {x}")
return x ** 2
data = list(range(12))
# Process with error logging (continues on errors)
results = multi_process(
risky_computation,
data,
backend='mp',
error_handler='log',
max_error_files=5
)
print(results) # [0, 1, 4, 9, 16, None, 36, 49, 64, 81, None, 121]
```
#### mpython (CLI Tool)
`mpython` is a CLI tool for running Python scripts in multiple tmux windows with automatic GPU/CPU allocation for parallel processing.
**Basic Usage:**
```bash
# Run script.py with 16 parallel processes across GPUs 0-7
mpython script.py
# Run with 8 processes
mpython -t 8 script.py
# Run on specific GPUs only
mpython --gpus 0,1,2 script.py
```
**Multi-Process Script Setup:**
Your script must use `MP_ID` and `MP_TOTAL` environment variables for sharding:
```python
import os
MP_ID = int(os.getenv("MP_ID", "0"))
MP_TOTAL = int(os.getenv("MP_TOTAL", "1"))
# Shard your data - each process gets its slice
inputs = list(range(1000))
my_inputs = inputs[MP_ID::MP_TOTAL]
for item in my_inputs:
process(item)
```
**Managing Sessions:**
- Sessions are named incrementally: `mpython`, `mpython-1`, `mpython-2`, etc.
- Kill all sessions: `kill-mpython`
- Attach to session: `tmux attach -t mpython`
### Enhanced Error Handling
**Speedy Utils** now provides comprehensive error handling for parallel processing with rich formatting and detailed diagnostics.
#### Rich Error Tracebacks
When errors occur, you'll see beautifully formatted tracebacks with:
- **Code context**: Lines of code around the error location
- **Caller information**: Shows where the parallel function was invoked
- **Filtered frames**: Focuses on user code, hiding infrastructure details
- **Color coding**: Easy-to-read formatting with syntax highlighting
#### Error Handling Modes
Choose how to handle errors in parallel processing:
- **`'raise'` (default)**: Stop on first error with detailed traceback
- **`'ignore'`**: Continue processing, return `None` for failed items
- **`'log'`**: Log errors to files and continue processing
#### Error Logging
When using `error_handler='log'`, errors are automatically saved to timestamped files in `.cache/speedy_utils/error_logs/` with full context and stack traces.
#### Progress Reporting with Error Statistics
Progress bars now show real-time error and success counts:
```bash
Multi-thread [8/10] [00:02<00:00, 3.45it/s, success=8, errors=2, pending=0]
```
This makes it easy to monitor processing health at a glance.
#### Example: Robust Data Processing
```python
from speedy_utils import multi_thread
def process_data_record(record):
"""Process a data record that might have issues."""
try:
# Your processing logic here
value = record['value'] / record['divisor']
return {'result': value, 'status': 'success'}
except KeyError as e:
raise ValueError(f"Missing required field in record: {e}")
except ZeroDivisionError:
raise ValueError("Division by zero in record")
# Sample data with some problematic records
data = [
{'value': 10, 'divisor': 2}, # OK
{'value': 15, 'divisor': 0}, # Will error
{'value': 20, 'divisor': 4}, # OK
{'value': 25}, # Missing divisor - will error
]
# Process with error logging - continues despite errors
results = multi_thread(
process_data_record,
data,
workers=4,
error_handler='log',
max_error_files=10
)
print("Results:", results)
# Output: Results: [{'result': 5.0, 'status': 'success'}, None, {'result': 5.0, 'status': 'success'}, None]
# Errors are logged to files for later analysis
```
### File I/O
#### Dumping Data
Save data in JSON, JSONL, or pickle formats.
```python
from speedy_utils import dump_json_or_pickle, dump_jsonl
data = {"name": "Alice", "age": 30}
# Save as JSON
dump_json_or_pickle(data, "data.json")
# Save as JSONL
dump_jsonl([data, {"name": "Bob", "age": 25}], "data.jsonl")
# Save as Pickle
dump_json_or_pickle(data, "data.pkl")
```
#### Loading Data
Load data based on file extensions.
```python
from speedy_utils import load_json_or_pickle, load_by_ext
# Load JSON
data = load_json_or_pickle("data.json")
# Load JSONL
data_list = load_json_or_pickle("data.jsonl")
# Load Pickle
data = load_json_or_pickle("data.pkl")
# Load based on extension with parallel processing
loaded_data = load_by_ext(["data.json", "data.pkl"])
```
### Data Manipulation
#### Flattening Lists and Dictionaries
```python
from speedy_utils import flatten_list, flatten_dict
nested_list = [[1, 2], [3, 4], [5]]
flat_list = flatten_list(nested_list)
print(flat_list) # [1, 2, 3, 4, 5]
nested_dict = {"a": {"b": 1, "c": 2}, "d": 3}
flat_dict = flatten_dict(nested_dict)
print(flat_dict) # {'a.b': 1, 'a.c': 2, 'd': 3}
```
#### Converting to Built-in Python Types
```python
from speedy_utils import convert_to_builtin_python
from pydantic import BaseModel
class User(BaseModel):
name: str
age: int
user = User(name="Charlie", age=28)
builtin_user = convert_to_builtin_python(user)
print(builtin_user) # {'name': 'Charlie', 'age': 28}
```
### Utility Functions
#### Pretty Printing
```python
from speedy_utils import fprint, print_table
data = {"name": "Dana", "age": 22, "city": "New York"}
# Pretty print as table
fprint(data)
# Print as table using tabulate
print_table(data)
```
#### Timing Utilities
```python
from speedy_utils import timef, Clock
@timef
def slow_function():
import time
time.sleep(3)
return "Done"
result = slow_function() # Prints execution time
# Using Clock
clock = Clock()
# ... your code ...
clock.log()
```
### LLM
The `LLM` class provides a unified interface for language model interactions with structured input/output handling. It supports text completion, structured outputs, caching, streaming, and VLLM integration.
#### Basic Text Completion
```python
from llm_utils import LLM
llm = LLM(
instruction="You are a helpful assistant.",
model="gpt-4o-mini"
)
# Simple text completion
results = llm("What is Python?")
print(results[0]["parsed"]) # The text response
print(results[0]["messages"]) # Full conversation history
```
#### Structured Output with Pydantic
```python
from pydantic import BaseModel
from llm_utils import LLM
class Sentiment(BaseModel):
sentiment: str
confidence: float
llm = LLM(
instruction="Analyze the sentiment of the input.",
output_model=Sentiment,
model="gpt-4o-mini"
)
results = llm("I love this product!")
parsed: Sentiment = results[0]["parsed"]
print(f"Sentiment: {parsed.sentiment}, Confidence: {parsed.confidence}")
```
#### Streaming Responses
```python
from llm_utils import LLM
llm = LLM(model="gpt-4o-mini")
# Stream text responses
stream = llm("Tell me a story", stream=True)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
```
#### Client Configuration
The `LLM` class accepts various client configurations:
```python
from llm_utils import LLM
from openai import OpenAI
# Using a custom OpenAI client
custom_client = OpenAI(base_url="http://localhost:8000/v1", api_key="your-key")
llm = LLM(client=custom_client, model="llama-2-7b")
# Using a port number (for VLLM servers)
llm = LLM(client=8000, model="llama-2-7b")
# Using a base URL string
llm = LLM(client="http://localhost:8000/v1", model="llama-2-7b")
```
#### VLLM Integration
Start and manage VLLM servers automatically:
```python
from llm_utils import LLM
llm = LLM(
vllm_cmd="vllm serve meta-llama/Llama-2-7b-chat-hf --port 8000",
model="meta-llama/Llama-2-7b-chat-hf"
)
# The server starts automatically and is cleaned up on exit
results = llm("Hello!")
# Cleanup is automatic when using context manager
with LLM(vllm_cmd="vllm serve ...") as llm:
results = llm("Hello!")
```
#### Caching
Enable response caching to avoid redundant API calls:
```python
from llm_utils import LLM
# Enable caching (default: True)
llm = LLM(model="gpt-4o-mini", cache=True)
# First call hits the API
result1 = llm("What is 2+2?")
# Second call returns cached result
result2 = llm("What is 2+2?") # Instant response from cache
# Disable caching for a specific call
result3 = llm("What is 2+2?", cache=False)
```
#### Reasoning Models
Handle reasoning models that provide thinking traces:
```python
from llm_utils import LLM
# For models like DeepSeek-R1 that output reasoning
llm = LLM(
model="deepseek-reasoner",
is_reasoning_model=True
)
results = llm("Solve this math problem: 15 * 23")
# Access the final answer
answer = results[0]["parsed"]
# Access reasoning content (if available)
reasoning = results[0].get("reasoning_content")
```
#### Conversation History
Inspect previous conversations:
```python
from llm_utils import LLM
llm = LLM(model="gpt-4o-mini")
# Make some calls
llm("Hello")
llm("How are you?")
# Inspect the last conversation
history = llm.inspect_history(idx=-1)
print(history)
# Get last 3 messages from the conversation
history = llm.inspect_history(idx=-1, k_last_messages=3)
```
## Testing
The test suite uses `pytest`:
```bash
uv sync
uv run pytest
```
| text/markdown | null | AnhVTH <anhvth.226@gmail.com> | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pyt... | [] | null | null | >=3.9 | [] | [] | [] | [
"aiohttp",
"bump2version",
"cachetools",
"chainlit>=2.0",
"debugpy",
"fastcore",
"fastprogress",
"freezegun",
"ipdb",
"ipywidgets",
"json-repair",
"jupyterlab",
"loguru",
"matplotlib",
"numpy",
"openai",
"packaging",
"pandas",
"pydantic",
"pytest",
"requests",
"rich>=14.3.1... | [] | [] | [] | [
"Homepage, https://github.com/anhvth/speedy",
"Repository, https://github.com/anhvth/speedy"
] | uv/0.9.24 {"installer":{"name":"uv","version":"0.9.24","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T16:33:43.126044 | speedy_utils-1.2.11-py3-none-any.whl | 186,165 | b3/de/529b624fa3889a344812e8e5e41f0d643614070eb2209ef862bea9aec023/speedy_utils-1.2.11-py3-none-any.whl | py3 | bdist_wheel | null | false | 22d2496622ec0dc128022adf9de397b1 | 5ed7abebe6b0d1e6a99ac4698aa6eb43ec98032e342a1667af8b2de65feae3ee | b3de529b624fa3889a344812e8e5e41f0d643614070eb2209ef862bea9aec023 | null | [] | 257 |
2.4 | filemerger-cli | 0.3.1 | Developer CLI tool to consolidate project files into a single output | # FileMerger
**FileMerger** is a developer-focused CLI tool that consolidates project files into a
single plain-text output.
It is designed to help developers:
- Share complete code context with AI tools (ChatGPT, Gemini, Grok, Claude, etc.)
- Review large codebases
- Create audit or snapshot files
- Prepare structured input for analysis
---
## Installation
```bash
pip install filemerger-cli
```
---
## Basic Usage
Merge a directory:
```bash
filemerger src/
```
Specify output file:
```bash
filemerger src/ --output context.txt
```
Dry run (no file written):
```bash
filemerger . --dry-run
```
---
## Output Modes
FileMerger supports multiple output modes depending on **who (or what)** will consume the output.
### 1. Default Mode (Human-Readable)
```bash
filemerger src/
```
**Use this when:**
* You want to read the output yourself
* You are reviewing or auditing code
* You want clear visual separation
**Characteristics:**
* File lists and headers
* Visual separators
* Structured, readable layout
---
### 2. LLM Mode (`--llm`)
```bash
filemerger src/ --llm
```
**Use this when:**
* The output will be pasted into an AI system
* You want deterministic file references
* You want to reduce semantic noise
**Characteristics:**
* Files are numbered (`[1]`, `[2]`, …)
* No decorative separators
* Simple, predictable structure
Example:
```
[1] path/to/file.py
<content>
[2] another/file.js
<content>
```
---
### 3. LLM Compact Mode (`--llm-compact`)
```bash
filemerger src/ --llm-compact
```
**Use this when:**
* Token limits are tight
* The project is very large
* Maximum efficiency matters
**Characteristics:**
* Same structure as `--llm`
* Fewer blank lines
* Minimal formatting overhead
---
### 4. Statistics
Use `--stats` to print merge statistics:
```bash
filemerger src/ --stats
```
Reported values:
* Number of files
* Total lines
* Total bytes
* Skipped files (binary / non-UTF8)
---
### 5. AI Marker Mode (`--ai-markers`)
```bash
filemerger src/ --ai-markers
````
**Use this when:**
* You need strong, explicit file boundaries for AI systems
* You want deterministic multi-file reasoning
* You are feeding large structured context into LLMs
* You need machine-parsable output
**Characteristics:**
* Explicit file boundary markers
* Clear begin/end delimiters
* Unambiguous separation between files
* Designed for reliable AI ingestion
Example:
```
<<<FILE 1: path/to/file.py>>>
<content>
<<<END FILE>>>
<<<FILE 2: another/file.js>>>
<content>
<<<END FILE>>>
```
---
## Configuration (Optional)
FileMerger supports an optional `.filemerger.toml` file in the project root.
Example:
```toml
[filters]
max_file_size_mb = 1
exclude_dirs = ["tests"]
[output]
separator_length = 60
```
If the file is not present, default behavior is used.
---
## License
This project is licensed under the MIT License.
See the [LICENSE](LICENSE) file for details.
| text/markdown | BinaryFleet | null | null | null | MIT | cli, developer-tools, file-merger, llm, code-review | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"pathspec>=0.11"
] | [] | [] | [] | [
"Homepage, https://github.com/binaryfleet/filemerger",
"Repository, https://github.com/binaryfleet/filemerger",
"Issues, https://github.com/binaryfleet/filemerger/issues"
] | twine/6.2.0 CPython/3.11.9 | 2026-02-18T16:33:35.641955 | filemerger_cli-0.3.1.tar.gz | 8,403 | 72/ba/927c23349c12dd1b348ee672c36550e19d4d08435cc6c96af10e98108b5b/filemerger_cli-0.3.1.tar.gz | source | sdist | null | false | af23c0a737ab57bbfc4c279a988caf23 | f1d544882abf73f379a57e7124eac90fa5cfe7233af2365fd105491018a95686 | 72ba927c23349c12dd1b348ee672c36550e19d4d08435cc6c96af10e98108b5b | null | [
"LICENSE"
] | 234 |
2.1 | odoo-addon-l10n-br-fiscal | 16.0.21.1.2 | Fiscal module/tax engine for Brazil | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
========================
Módulo fiscal brasileiro
========================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:6c3ab60a248e81dc6a980934506ab8340224a9d836bdcd58383aa32ff98637ab
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Production%2FStable-green.png
:target: https://odoo-community.org/page/development-status
:alt: Production/Stable
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fl10n--brazil-lightgray.png?logo=github
:target: https://github.com/OCA/l10n-brazil/tree/16.0/l10n_br_fiscal
:alt: OCA/l10n-brazil
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/l10n-brazil-16-0/l10n-brazil-16-0-l10n_br_fiscal
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/l10n-brazil&target_branch=16.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
|image|
Classificações fiscais
----------------------
Primeramente, este módulo traz uma variedade de cadastros fiscais para
produtos, parceiros ou empresas. Na hora de emitir documentos fiscais
como NF-e, NFS-e etc... até empresas do regime simplificado ou MEI
precisam de vários desses cadastros. E empresas do regime normal
precisam deles para calcular os impostos ou emitir documentos fiscais.
Produtos:
- tipo fiscal
- NCM (com ligações com os impostos)
- genêro fiscal
- CEST
- NBM
- NBS
- tipo de serviço
- unidades fiscais
Parceiros:
- CNAE
- perfil fiscal
Conceito de documento fiscal
----------------------------
O Odoo nativo não tem o conceito de documento fiscal. O conceito mais
parecido seria o ``account.move`` e até a versão 10.0 a localização
estendia o invoice para suportar as NF-e e NFS-e apenas. Naquela época
não era razoável você cogitar fazer o SPED no Odoo, o próprio core do
Odoo não tinha maturidade para isso então era válido a abordagem
empírica de ir suportando mais casos de NFe dentro do invoice Odoo
apenas.
Porém, na v12, amadurecemos o framework XML/SOAP de forma que se torna
razoável suportar vários documentos fiscais (NF-e, NFS-e, MDF-e, CT-e,
EFD-Reinf, e-Social, GNRE, BP-e...) com a qualidade OCA dentro do Odoo.
Também, apesar de complexo, o core do Odoo finalmente tem suporte
suficiente para as operações de uma empresa que faria o SPED.
Nisso se torna interessante ter o conceito de documento fiscal
``l10n_br_fiscal.document`` independente do invoice Odoo para suportar
todos os documentos fiscais mesmo, de forma modular. Um outro motivo
para ter o conceito de documento fiscal fora do módulo account é que
quando você analisa o código deste módulo ``l10n_br_fiscal``, quase nada
dele poderia ser feito pelo módulo account do Odoo. Então ter esse
módulo l10n_br_fiscal que não depende do módulo account também é uma
forma de modularizar a localização para facilitar a manutenção dela,
especialmente quando se trata de migrar e que o módulo pode ter mudado
bastante como foi o caso entre a v8.0 e a v9.0 ou a v12.0 e v13.0 por
exemplo. Facilita também a governança do projeto possibilitando que
pessoas sejam responsáveis por diferentes partes. O módulo
l10n_br_fiscal foi principalmente extraído do módulo
l10n_br_l10n_br_account_product das v7.0 as v.10.0.
Esse módulo ``l10n_br_fiscal`` é agnóstico de qualquer tecnologia XML ou
SOAP. Ele contém apenas o que há de comum entre os documentos fiscais
mas esses últimos são implementados em outros módulos. Para um
determinado documento fiscal como a Nf-e, você tem então por exemplo:
- ``nfelib``: um pacote de data bindings puro Python (que não depende do
Odoo). Em geral usamos um gerador de código para gerar esses bindings
a partir dos esquemas XSD da fazenda.
- ``l10n_br_nfe_spec``: um modulo de mixins Odoo geridos também a partir
dos XSD. Esses mixins são apenas as estruturas de dados das
especificações antes de ser injectados em objetos Odoo existantes
(como res.partner ou l10n_br_fiscal.document) ou até tornados
concretos caso não exite objetos na Odoo ou na OCA para eles já.
- ``l10n_br_nfe``: um módulo Odoo que trata de injectar esses mappings
fiscais nos objetos Odoo e que implementa a lógica como os wizards
para a transmissão.
A transmissão é realizada usando uma lib de transmissão como
``erpbrasil.doc`` (baseada em Python Zeep). Importante: no caso da
``NFS-e``, a ausência de padrão nacional hoje e a simplicidade do modelo
(comparado com a NFe) faz que foi decidido de não usar um módulo de
mixins fiscais Odoo geridos, o mapping é com a lib de binding é feito
manualmente, família de NFS-e por família.
Alem disso a maioria do codigo do ``l10n_br_fiscal.document`` e das
linhas dele ``l10n_br_fiscal.document.line`` é na verdade feito dentro
de mixins ``10n_br_fiscal.document.mixin`` e
``10n_br_fiscal.document.line.mixin`` respectivamente. Esses mixins
podem assim ser injectados em outros objetos Odoo que precedem os
documentos fiscais e podem armazenar então o mesmo tipo de informação:
``sale.order``, ``purchase.order``, ``stock.picking``... Isso é bem
visível nos módulos que estendem esse módulo:
.. code:: text
|-- l10n_br_fiscal
|-- l10n_br_sale
|-- l10n_br_purchase
|-- l10n_br_account
|-- ...
Porem o caso do invoice Odoo no modulo ``l10n_br_account`` é diferente
ainda. Pois já se tem a tabela independente do documento fiscal cuja
grande maioria das dezenas e até centenas de campos fiscais (no caso de
muitos tipos de documentos fiscais) não são redundante com os do invoice
Odoo. Se a gente injetasse esses mixins dentro do invoice, aí sim essas
centenas de campos seriam duplicados entre o invoice e o documento
fiscal. Por isso, o sistema que foi adotado no modulo
``l10n_br_account`` é que um invoice Odoo passa a ter um
``_inherits = "l10n_br_fiscal.document"`` de forma que se pilota o
documento fiscal através do invoice, oferecendo o mesmo tipo de
integração como antes. O mesmo tipo de mecanismo acontece com a linha do
documento fiscal.
Sendo assim, já pelos \_inherits, o invoice Odoo e as linhas dele já vão
puxar todos campos fiscais como se eles fossem das suas respectivas
tabelas sem duplicar eles no banco. Se alem disso a gente injetasse os
mixins ``10n_br_fiscal.document.mixin`` e
``10n_br_fiscal.document.line.mixin`` no invoice e invoice.line, esses
campos fiscais apareceriam também nas tabelas ``account_move`` e
``account_move_line`` de forma redundantes com os campos puxados pelos
\_inherits. Para não ter esse problema, os métodos fiscais comuns (sem
os campos) foram ainda extraidos nos mixins:
``10n_br_fiscal.document.mixin.methods`` e
``10n_br_fiscal.document.line.mixin.methods`` que são injectados nos
objetos ``account_move`` e ``account_move_line`` respectivamente dentro
do modulo ``l10n_br_account``.
Impostos brasileiros
--------------------
O módulo l10n_br_fiscal lida com os principais impostos brasileiros
como:
- ICMS do Simples Nacional
- ICMS do Regime normal
- IPI
- PIS
- COFINS
- ISSQN
- IRPJ
- II
- CSLL
- INSS
O módulo l10n_br_fiscal também lida com:
- ST
- retenções
|image1|
|image2|
É notório que o cálculo dos impostos no Brasil é muito especial e muito
trabalhoso. Geralmente é o motivo pelo qual os ERPs internacionais não
tem grande fatia de mercado brasileiro.
Até a versão 10.0, tentamos usar e estender o objeto Odoo
``account.tax``. A Akretion até criou o projeto
``OCA/account-fiscal-rule`` para determinar as alíquotas de cada imposto
de accordo com os parâmetros da operação fiscal. Porém, a gente acabava
usando quase nada do ``account.fiscal.position`` nativo na parte fiscal
e pelo contrário, isso nos obrigava a ter um registro ``account.tax``
para cada aliquota e nos obrigava a manter centenas de taxas e dezenas
de milhares de regras para selecionar a "posição fiscal" Odoo que
aplicaria as taxas corretas. E você ainda tinha que gerir essas dezenas
de milhares de regras para uma determinada empresa do regime normal.
Conclusão: era inviável nos projetos menores de tentar se encaixa na
lógica do Odoo para calcular os impostos brasileiros.
Nisso criamos neste módulo os modelos de taxas que representam
exatamente o funcionamentos dos impostos brasileiros. Além dos cálculos,
esses modelos também nos servem a carregar as tabelas dos impostos. E
mais adiante, no módulo ``l10n_br_account``, ligamos os objetos nativos
``account.tax`` as alíquotas dos impostos brasileiros.
Claro esses modelos dos impostos atendem as empresas do regime normal,
mas é bom lembrar que até empresas do regime simplificado precisam
desses modelos para realizar as operações com ST (Substituição
Tributária)...
Operações fiscais
-----------------
|image3|
No Odoo nativo, o conceito mais parecido com a operação fiscal e o
``account.fiscal.position``. E ate a versão 10.0, era o que a gente
usava. Porém, a posição fiscal do Odoo não resolve muito os nossos
problemas pois:
- no Brasil se tem uma operação fiscal por linha de documento fiscal
- a posição fiscal do Odoo desconhece a lógica da parametrização fiscal
brasileira
- já que puxamos o cadastro dos impostos no módulo l10n_br_fiscal fora
do módulo account (sem depender dele), não temos ainda o objeto
``account.fiscal.position`` neste módulo.
Com tudo, optamos por criar um objeto ``l10n_br_fiscal.operation`` que
faz exactamente o que precisamos para o Brasil. Mais adiante, no módulo
``l10n_br_account`` é realizado a integração entre a posição fiscal do
Odoo e essa operação fiscal.
.. |image| image:: https://raw.githubusercontent.com/OCA/l10n-brazil/16.0/l10n_br_fiscal/static/img/fiscal_dashboard.png
.. |image1| image:: https://raw.githubusercontent.com/OCA/l10n-brazil/16.0/l10n_br_fiscal/static/img/fiscal_line.png
.. |image2| image:: https://raw.githubusercontent.com/OCA/l10n-brazil/16.0/l10n_br_fiscal/static/img/fiscal_total.png
.. |image3| image:: https://raw.githubusercontent.com/OCA/l10n-brazil/16.0/l10n_br_fiscal/static/img/fiscal_operation.png
**Table of contents**
.. contents::
:local:
Installation
============
Para instalar o módulo l10n_br_fiscal, você precisa de instalar primeiro
os pacotes Python
- erpbrasil.base
- erpbrasil.assinatura
Configuration
=============
Para uma boa configuração fiscal, você tem que revisar bem:
- em Configurações: as operaçoes fiscais que você vai usar, as linhas de
operação fiscal e as definições das taxas nessas linhas.
- a configuração fiscal da sua empresa (aba fiscal)
- a configuração fiscal dos clientes e fornecedores (aba fiscal) e dos
produtos (aba fiscal).
Usage
=====
Você pode criar documentos fiscais direitamente pelo menu fiscal, mas a
princípio você vai pilotar a criação de documentos fiscais a partir dos
invoices Odoo, usando módulos adicionais como l10n_br_account,
l10n_br_sale, l10n_br_purchase...
Known issues / Roadmap
======================
Changelog
=========
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/l10n-brazil/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/l10n-brazil/issues/new?body=module:%20l10n_br_fiscal%0Aversion:%2016.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Akretion
Contributors
------------
- `Akretion <https://www.akretion.com/pt-BR>`__:
- Renato Lima <renato.lima@akretion.com.br>
- Raphaël Valyi <raphael.valyi@akretion.com.br>
- Magno Costa <magno.costa@akretion.com.br>
- `KMEE <https://www.kmee.com.br>`__:
- Luis Felipe Mileo <mileo@kmee.com.br>
- Luis Otavio Malta Conceição <luis.malta@kmee.com.br>
- `Escodoo <https://www.escodoo.com.br>`__:
- Marcel Savegnago <marcel.savegnago@escodoo.com.br>
- `Engenere <https://engenere.one>`__:
- Antônio S. Pereira Neto <neto@engenere.one>
- Felipe Motter Pereira <felipe@engenere.one>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
.. |maintainer-renatonlima| image:: https://github.com/renatonlima.png?size=40px
:target: https://github.com/renatonlima
:alt: renatonlima
.. |maintainer-rvalyi| image:: https://github.com/rvalyi.png?size=40px
:target: https://github.com/rvalyi
:alt: rvalyi
Current `maintainers <https://odoo-community.org/page/maintainer-role>`__:
|maintainer-renatonlima| |maintainer-rvalyi|
This module is part of the `OCA/l10n-brazil <https://github.com/OCA/l10n-brazil/tree/16.0/l10n_br_fiscal>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Akretion, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 16.0",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Development Status :: 5 - Production/Stable"
] | [] | https://github.com/OCA/l10n-brazil | null | >=3.10 | [] | [] | [] | [
"erpbrasil.base",
"odoo-addon-l10n_br_base<16.1dev,>=16.0dev",
"odoo-addon-uom_alias<16.1dev,>=16.0dev",
"odoo<16.1dev,>=16.0a"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T16:32:24.651181 | odoo_addon_l10n_br_fiscal-16.0.21.1.2-py3-none-any.whl | 1,587,927 | 2b/e1/5f90c3c5ed7f23fdf8deb93bfd1686c60f1b840fad8f2aa07020846c19de/odoo_addon_l10n_br_fiscal-16.0.21.1.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 0b873704c52b4d188a5b62c29d7e642c | 1f2674bdd2410d648e648b8b866e42b9415a02b059ae7a7c5e3a6ae6dd6d25ae | 2be15f90c3c5ed7f23fdf8deb93bfd1686c60f1b840fad8f2aa07020846c19de | null | [] | 105 |
2.4 | duelink-stdlib-mp | 0.1.1 | GHI Electronics DUELink MicroPython Library. | GHI Electronics DUELink Standard Library for MicroPython
Example on DuePico:
```py
import duelink # standard lib
from duelink import transport
due = duelink.DUELinkController(transport.UartTransportController(0))
# Play beep on pin 11 on DuePico
due.Sound.Beep(11, 1000, 500)
# Blink status led 10 times, delay 100ms each time
due.System.StatLed(100, 100, 10)
```
| text/markdown | GHI Electronics | support@ghielectronics.com | null | null | MIT | due, duelink, ghi | [
"Programming Language :: Python :: Implementation :: MicroPython"
] | [] | https://www.duelink.com/ | null | null | [] | [] | [] | [] | [] | [] | [] | [
"Bug Reports, https://github.com/ghi-electronics/duelink-libraries/issues",
"Source, https://github.com/ghi-electronics/duelink-libraries/tree/main/micropython"
] | twine/6.2.0 CPython/3.14.0 | 2026-02-18T16:32:14.225300 | duelink_stdlib_mp-0.1.1.tar.gz | 12,621 | 15/4f/fc35d441dd9550f2cea3dacb9681025e66a1fc41a3d4437201bd5505e09b/duelink_stdlib_mp-0.1.1.tar.gz | source | sdist | null | false | d93f890e59d03a854e299d0e528fdb1b | 6f8f7445bb01fecb423aed7e78d6cec6c76ffac5991ba93758055c5f9906c18c | 154ffc35d441dd9550f2cea3dacb9681025e66a1fc41a3d4437201bd5505e09b | null | [] | 239 |
2.4 | barndoor | 0.4.3 | Official Python SDK for the Barndoor API. | # Barndoor SDK
A lightweight, **framework-agnostic** Python client for the Barndoor Platform REST APIs and Model Context Protocol (MCP) servers.
The SDK removes boiler-plate around:
* Secure, offline-friendly **authentication to Barndoor** (interactive PKCE flow + token caching).
* **Server registry** – list, inspect and connect third-party providers (Salesforce, Notion, Slack …).
* **Managed Connector Proxy** – build ready-to-use connection parameters for any LLM/agent framework (CrewAI, LangChain, custom code …) without importing Barndoor-specific adapters.
---
## How it works
The SDK orchestrates a multi-step flow to connect your code to third-party services:
```
You → Barndoor Auth (get JWT) → Registry API (with JWT) → MCP Proxy (with JWT) → Third-party service
```
1. **Authentication**: You log in via Barndoor to get a JWT token
2. **Registry API**: Using the JWT, query available MCP servers and manage OAuth connections
3. **MCP Proxy**: Stream requests through Barndoor's proxy with the JWT for authorization
4. **Third-party service**: The proxy forwards your requests to Salesforce, Notion, etc.
This architecture provides secure, managed access to external services without handling OAuth flows or storing third-party credentials in your code.
---
## Installation
```bash
pip install barndoor
# or, inside this repo
pip install -e barndoor[dev]
```
Python ≥ 3.10 is required.
---
## Local development with uv
For the fastest install and reproducible builds you can use [uv](https://github.com/astral-sh/uv) instead of `pip`.
```bash
# 1) (one-off) install uv
brew install uv # or follow the install script on Linux/Windows
# 2) create an isolated virtual environment in the repo
uv venv .venv
source .venv/bin/activate
uv sync --frozen --all-extras --dev --python 3.13
# 3) install the SDK in editable mode plus the example extras
uv pip install -e '.[examples]'
# 4) install MCP support for CrewAI examples
uv pip install 'crewai-tools[mcp]'
# 5) copy the environment template and add your credentials
cp env.example .env
# Edit .env to add AGENT_CLIENT_ID, AGENT_CLIENT_SECRET, and OPENAI_API_KEY
# 6) run the interactive login utility once (opens browser)
uv run python -m barndoor.sdk.cli_login
# 7) kick off the Notion sample agent
uv run python examples/sample_notion_agent.py
```
**Note:** The OAuth default callback uses port 52765. Make sure to register this callback in your Barndoor Agent configuration. As some machines are configured to automatically resolve `localhost` to `127.0.0.1`, we recommend having two callback entries:
```
http://localhost:52765/cb
http://127.0.0.1:52765/cb
```
### Using a custom OAuth callback port
If port `52765` is blocked (or you prefer another), you can:
1. **Register the new callback URL** in your Barndoor Agent application, e.g.
```
http://localhost:60000/cb
http://127.0.0.1:60000/cb
```
2. **Run the login helper with the matching port**
```bash
# CLI
uv run python -m barndoor.sdk.cli_login --port 60000
# In code
sdk = await bd.login_interactive(port=60000)
```
The SDK will spin up the local callback server on that port and embed the new URL in the request.
The examples expect a `.env` file next to each script containing:
```bash
# Copy env.example → .env and add your credentials
```
---
## Authentication workflow
Barndoor APIs expect a **user JWT** issued by your Barndoor tenant. The SDK offers two ways to obtain & store such a token:
| Option | Command | When to use |
|--------|---------|-------------|
| Interactive CLI | `python -m barndoor.sdk.cli_login` *(alias: `barndoor-login`)* | One-time setup on laptops / CI machines |
| In-code helper | `await barndoor.sdk.login_interactive()` | Notebooks or scripts where you do not want a separate login step |
Both variants:
1. Spin up a tiny localhost callback server.
2. Open the system browser to Barndoor.
3. Exchange the returned *code* for a JWT.
4. Persist the token to `~/.barndoor/token.json` (0600 permissions).
Environment variables (or a neighbouring `.env` file) must define the Agent OAuth application:
```
AGENT_CLIENT_ID=xxxxxxxxxxxxxxxxxxxxxxxx
AGENT_CLIENT_SECRET=yyyyyyyyyyyyyyyyyyyy
# optional overrides
# See `internal_dev_env_setup` guide for local/dev options
```
The cached token is auto-refreshed on every run; if it is expired or revoked a new browser flow is launched.
## Quick-start in four lines
```python
import barndoor.sdk as bd
sdk = await bd.login_interactive() # 1️⃣ ensure valid token
await bd.ensure_server_connected(sdk, "salesforce") # 2️⃣ make sure OAuth is done
params, _public_url = await bd.make_mcp_connection_params(sdk, "salesforce")
```
`params` is a plain dict with `url`, `headers` and (optionally) `transport` – ready to plug into **any** HTTP / SSE / WebSocket client. See the examples below for CrewAI & LangChain usage.
---
## Using the Registry API
```python
# List all MCP servers available to the current user
servers = await sdk.list_servers()
print([s.slug for s in servers]) # ['salesforce', 'notion', ...]
# Get detailed metadata
details = await sdk.get_server(server_id=servers[0].id)
print(details)
```
Additional helpers:
* `await sdk.initiate_connection(server_id)` – returns an OAuth URL the user must visit.
* `await bd.ensure_server_connected(sdk, "notion")` – combines status polling + browser launch.
---
## Model Context Protocol Connection
Once a server is **connected** you can stream requests through Barndoor’s proxy edge.
```python
params, public_url = await bd.make_mcp_connection_params(sdk, "notion")
print(params["url"]) # http(s)://…/mcp/notion
print(params["headers"]) # {'Authorization': 'Bearer ey…', 'x-barndoor-session-id': …}
```
## API Documentation
The complete API specification is available in [`barndoor/sdk/docs/openapi.yaml`](./barndoor/sdk/docs/openapi.yaml). This covers all endpoints currently used by the SDK including:
- Server listing and details
- OAuth connection initiation
- Connection status checking
The spec can be viewed with tools like [Swagger UI](https://swagger.io/tools/swagger-ui/) or [Redoc](https://redocly.github.io/redoc/).
| text/markdown | Barndoor AI, Inc. | null | null | null | MIT | ai, barndoor, mcp, sdk | [] | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"httpx[http2]>=0.27.2",
"pydantic>=2.10.6",
"python-dotenv>=1.0.0",
"python-jose[cryptography]>=3.3.0",
"typing-extensions>=4.12.2",
"crewai-tools>=0.1.0; extra == \"examples\"",
"crewai>=0.30.0; extra == \"examples\"",
"langchain-mcp-adapters; extra == \"examples\"",
"langchain-openai; extra == \"e... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:31:59.770754 | barndoor-0.4.3.tar.gz | 675,933 | 64/77/81ee97305f21687d4fb7e7df214e82211efc4fcaaae31906e80e0a66a5f2/barndoor-0.4.3.tar.gz | source | sdist | null | false | 0e61ad60f95da570f5a57d235d4c8114 | cfef7573109ac14911b97e52dccc7b5bb351112b73d459345456e3d6c54c2166 | 647781ee97305f21687d4fb7e7df214e82211efc4fcaaae31906e80e0a66a5f2 | null | [
"LICENSE"
] | 247 |
2.4 | qwikswitch-api | 0.0.11 | A Python wrapper around the QwikSwitch API | # qwikswitch-api
A Python wrapper for the [Qwikswitch API](https://qwikswitch.com/doc/), used for remotely controlling [Qwikswitch](https://qwikswitch.com/) devices using the [Wifi Bridge](https://www.qwikswitch.co.za/products/wifi-bridge).
An alternative (local) way of controlling Qwikswitch devices is with a USB Modem. If this is the device that you have, see the [pyqwikswitch library](https://github.com/kellerza/pyqwikswitch) instead.
## Usage
The following operations are implemented:
* Keys - Generate API Keys (`generate_api_keys`)
* Keys - Delete API Keys (`delete_api_keys`)
* Control - Control a device (`control_device`)
* State - Get all device status (`get_all_device_status`)
The following devices are supported:
* RELAY QS-D-S5 - Dimmer
* RELAY QS-R-S5 - Relay
* RELAY QS-R-S30 - Relay
If you have a different device than these ones, please open an issue with the device model name and type of device.
Device history is *not* implemented in this library yet as I don't have access to these devices.
If you have access to devices that record history, please open an issue detailing sample responses from `get_all_device_status` and the history calls.
### Installation
```bash
pip install qwikswitch-api
```
### Sample code
Sample usage to control a device:
```python
from qwikswitch.client import QSClient
client = QSClient('email', 'masterkey')
client.control_device('@123450', 100)
```
To list all current device statuses:
```python
devices = client.get_all_device_status()
```
| text/markdown | null | Riaan Hanekom <riaan@hanekom.io> | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"requests",
"build; extra == \"dev\"",
"packagename[docs,tests]; extra == \"dev\"",
"twine; extra == \"dev\"",
"pydata-sphinx-theme; extra == \"docs\"",
"sphinx; extra == \"docs\"",
"pytest; extra == \"tests\"",
"pytest-cov; extra == \"tests\"",
"pytest-flakes; extra == \"tests\"",
"requests-mock;... | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.11 | 2026-02-18T16:30:26.271020 | qwikswitch_api-0.0.11.tar.gz | 13,870 | be/76/7f4b461e8078b700bc0962a2b6d004a9a8d37f5d78c2e10d92c79e6a9182/qwikswitch_api-0.0.11.tar.gz | source | sdist | null | false | 212b96112776fbbe8dd50804fa9ecc1a | af8916fee6550fd93144560df52feff4ab1cba24a5852e331976fa8cfcb08751 | be767f4b461e8078b700bc0962a2b6d004a9a8d37f5d78c2e10d92c79e6a9182 | null | [
"LICENSE"
] | 229 |
2.4 | python-utility-scripts | 2.0.5 | Python utility scripts | # python-utility-scripts
Repository for various python utility scripts
- [pyutils-unusedcode](https://github.com/RedHatQE/python-utility-scripts/blob/main/apps/unused_code/README.md)
- [pyutils-polarion-verify-tc-requirements](https://github.com/RedHatQE/python-utility-scripts/blob/main/apps/polarion/README.md)
- [pyutils-jira](https://github.com/RedHatQE/python-utility-scripts/blob/main/apps/jira_utils/README.md)
- [pyutils-polarion-set-automated](https://github.com/RedHatQE/python-utility-scripts/blob/main/apps/polarion/README.md)
## Installation
using [uv](https://github.com/astral-sh/uv)
```bash
uv tool install python-utility-scripts
```
## Local run
- Clone the [repository](https://github.com/RedHatQE/python-utility-scripts.git)
## Config file
A config yaml file for various utilities of this repository should be added to
`~/.config/python-utility-scripts/config.yaml`. Script specific config section details can be found in associated script README.md
## Release new version
### requirements
- Export GitHub token
```bash
export GITHUB_TOKEN=<your_github_token>
```
- [release-it](https://github.com/release-it/release-it)
- Run the following once (execute outside repository dir for example `~/`):
```bash
sudo npm install --global release-it
npm install --save-dev @j-ulrich/release-it-regex-bumper
rm -f package.json package-lock.json
```
### usage
- Create a release, run from the relevant branch.
To create a new release, run:
```bash
git checkout main
git pull
release-it # Follow the instructions
```
| text/markdown | null | dbasunag <dbasunag@redhat.com> | null | null | null | null | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"ast-comments>=1.2.2",
"click>=8.1.7",
"jira<4,>=3.6.0",
"pyhelper-utils<3,>=2",
"pylero<0.3,>=0.2",
"pytest-mock<4,>=3.14.0",
"python-simple-logger<3,>=2.0.4",
"pyyaml<7,>=6.0.1",
"tenacity<10,>=9.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/RedHatQE/python-utility-scripts",
"Repository, https://github.com/RedHatQE/python-utility-scripts",
"Documentation, https://github.com/RedHatQE/python-utility-scripts/blob/main/README.md"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-18T16:30:17.719149 | python_utility_scripts-2.0.5.tar.gz | 21,478 | 99/83/21c955ac8c0907682b62f314a81e16e1036eec4106cf24ed223c842cdca6/python_utility_scripts-2.0.5.tar.gz | source | sdist | null | false | 852c1ed1d06e271bc89d81b07c67ac98 | f21b36546deb0afb78697c81612494df5a95a63595928830085b97bc63927d1d | 998321c955ac8c0907682b62f314a81e16e1036eec4106cf24ed223c842cdca6 | Apache-2.0 | [
"LICENSE"
] | 195 |
2.4 | XStatic-Font-Awesome | 6.2.1.2 | Font-Awesome 6.2.1 (XStatic packaging standard) | XStatic-Font-Awesome
--------------------
Font Awesome packaged for setuptools (easy_install) / pip.
This package is intended to be used by **any** project that needs these files.
It intentionally does **not** provide any extra code except some metadata
**nor** has any extra requirements. You MAY use some minimal support code from
the XStatic base package, if you like.
You can find more info about the xstatic packaging way in the package `XStatic`.
| null | null | null | Reimar Bauer | rb.proj@gmail.com | (same as Font-Awesome) | font_awesome xstatic | [] | [
"any"
] | https://github.com/FortAwesome/Font-Awesome | null | null | [] | [] | [] | [] | [] | [] | [] | [
"Repository, https://github.com/xstatic-py/xstatic-font-awesome"
] | twine/6.2.0 CPython/3.13.9 | 2026-02-18T16:30:06.477932 | xstatic_font_awesome-6.2.1.2.tar.gz | 5,538,113 | c9/1c/164ed35ac7c31ae8e5d7a69de101eb46481553cb1be7cc5fb248ae8bd822/xstatic_font_awesome-6.2.1.2.tar.gz | source | sdist | null | false | 1bbe830fba5df8e8f9d68e8ed50b4c76 | 9f3cb2f038fad7d352722375d3f25af346da9ee093ed9dc2c8c46bd911ab1971 | c91c164ed35ac7c31ae8e5d7a69de101eb46481553cb1be7cc5fb248ae8bd822 | null | [] | 0 |
2.1 | airbyte-source-google-ads | 4.1.6 | Source implementation for Google Ads. | # Google-Ads source connector
This is the repository for the Google-Ads source connector, written in Python.
For information about how to use this connector within Airbyte, see [the documentation](https://docs.airbyte.com/integrations/sources/google-ads).
## Local development
### Prerequisites
- Python (~=3.9)
- Poetry (~=1.7) - installation instructions [here](https://python-poetry.org/docs/#installation)
### Installing the connector
From this connector directory, run:
```bash
poetry install --with dev
```
### Create credentials
**If you are a community contributor**, follow the instructions in the [documentation](https://docs.airbyte.com/integrations/sources/google-ads)
to generate the necessary credentials. Then create a file `secrets/config.json` conforming to the `source_google_ads/spec.yaml` file.
Note that any directory named `secrets` is gitignored across the entire Airbyte repo, so there is no danger of accidentally checking in sensitive information.
See `sample_files/sample_config.json` for a sample config file.
### Locally running the connector
```
poetry run source-google-ads spec
poetry run source-google-ads check --config secrets/config.json
poetry run source-google-ads discover --config secrets/config.json
poetry run source-google-ads read --config secrets/config.json --catalog integration_tests/configured_catalog.json
```
### Running unit tests
To run unit tests locally, from the connector directory run:
```
poetry run pytest unit_tests
```
### Building the docker image
1. Install [`airbyte-ci`](https://github.com/airbytehq/airbyte/blob/master/airbyte-ci/connectors/pipelines/README.md)
2. Run the following command to build the docker image:
```bash
airbyte-ci connectors --name=source-google-ads build
```
An image will be available on your host with the tag `airbyte/source-google-ads:dev`.
### Running as a docker container
Then run any of the connector commands as follows:
```
docker run --rm airbyte/source-google-ads:dev spec
docker run --rm -v $(pwd)/secrets:/secrets airbyte/source-google-ads:dev check --config /secrets/config.json
docker run --rm -v $(pwd)/secrets:/secrets airbyte/source-google-ads:dev discover --config /secrets/config.json
docker run --rm -v $(pwd)/secrets:/secrets -v $(pwd)/integration_tests:/integration_tests airbyte/source-google-ads:dev read --config /secrets/config.json --catalog /integration_tests/configured_catalog.json
```
### Running our CI test suite
You can run our full test suite locally using [`airbyte-ci`](https://github.com/airbytehq/airbyte/blob/master/airbyte-ci/connectors/pipelines/README.md):
```bash
airbyte-ci connectors --name=source-google-ads test
```
### Customizing acceptance Tests
Customize `acceptance-test-config.yml` file to configure acceptance tests. See [Connector Acceptance Tests](https://docs.airbyte.com/connector-development/testing-connectors/connector-acceptance-tests-reference) for more information.
If your connector requires to create or destroy resources for use during acceptance tests create fixtures for it and place them inside integration_tests/acceptance.py.
### Dependency Management
All of your dependencies should be managed via Poetry.
To add a new dependency, run:
```bash
poetry add <package-name>
```
Please commit the changes to `pyproject.toml` and `poetry.lock` files.
## Publishing a new version of the connector
You've checked out the repo, implemented a million dollar feature, and you're ready to share your changes with the world. Now what?
1. Make sure your changes are passing our test suite: `airbyte-ci connectors --name=source-google-ads test`
2. Bump the connector version (please follow [semantic versioning for connectors](https://docs.airbyte.com/contributing-to-airbyte/resources/pull-requests-handbook/#semantic-versioning-for-connectors)):
- bump the `dockerImageTag` value in in `metadata.yaml`
- bump the `version` value in `pyproject.toml`
3. Make sure the `metadata.yaml` content is up to date.
4. Make sure the connector documentation and its changelog is up to date (`docs/integrations/sources/google-ads.md`).
5. Create a Pull Request: use [our PR naming conventions](https://docs.airbyte.com/contributing-to-airbyte/resources/pull-requests-handbook/#pull-request-title-convention).
6. Pat yourself on the back for being an awesome contributor.
7. Someone from Airbyte will take a look at your PR and iterate with you to merge it into master.
8. Once your PR is merged, the new version of the connector will be automatically published to Docker Hub and our connector registry.
| text/markdown | Airbyte | contact@airbyte.io | null | null | Elv2 | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11"
] | [] | https://airbyte.com | null | <3.12,>=3.10 | [] | [] | [] | [
"google-ads==27.0.0",
"protobuf==4.25.2",
"pendulum<3.0.0",
"airbyte-cdk==7.9.2"
] | [] | [] | [] | [
"Repository, https://github.com/airbytehq/airbyte",
"Documentation, https://docs.airbyte.com/integrations/sources/google-ads"
] | poetry/1.8.5 CPython/3.11.14 Linux/6.14.0-1017-azure | 2026-02-18T16:29:35.355860 | airbyte_source_google_ads-4.1.6.tar.gz | 53,775 | ed/e0/e5d5c617fbcce4e963660efc77e638aeb452315bb47eae5f4879f0a8b625/airbyte_source_google_ads-4.1.6.tar.gz | source | sdist | null | false | 6afc70a1986043052b2755c2fc148fe7 | 583d45bf35d61736e9c56bcff25d8e13f9c32bbc040ebbf902c9e1f14588ffdf | ede0e5d5c617fbcce4e963660efc77e638aeb452315bb47eae5f4879f0a8b625 | null | [] | 277 |
2.3 | sentdm | 0.8.0 | The official Python library for the sent-dm API | # Sent Dm Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/sentdm/)
The Sent Dm Python library provides convenient access to the Sent Dm REST API from any Python 3.9+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
It is generated with [Stainless](https://www.stainless.com/).
## Documentation
The REST API documentation can be found on [docs.sent.dm](https://docs.sent.dm). The full API of this library can be found in [api.md](https://github.com/sentdm/sent-dm-python/tree/main/api.md).
## Installation
```sh
# install from PyPI
pip install sentdm
```
## Usage
The full API of this library can be found in [api.md](https://github.com/sentdm/sent-dm-python/tree/main/api.md).
```python
import os
from sent_dm import SentDm
client = SentDm(
api_key=os.environ.get("SENT_DM_API_KEY"), # This is the default and can be omitted
)
response = client.messages.send(
channel=["sms", "whatsapp"],
template={
"id": "7ba7b820-9dad-11d1-80b4-00c04fd430c8",
"name": "order_confirmation",
"parameters": {
"name": "John Doe",
"order_id": "12345",
},
},
to=["+14155551234", "+14155555678"],
)
print(response.data)
```
While you can provide an `api_key` keyword argument,
we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/)
to add `SENT_DM_API_KEY="My API Key"` to your `.env` file
so that your API Key is not stored in source control.
## Async usage
Simply import `AsyncSentDm` instead of `SentDm` and use `await` with each API call:
```python
import os
import asyncio
from sent_dm import AsyncSentDm
client = AsyncSentDm(
api_key=os.environ.get("SENT_DM_API_KEY"), # This is the default and can be omitted
)
async def main() -> None:
response = await client.messages.send(
channel=["sms", "whatsapp"],
template={
"id": "7ba7b820-9dad-11d1-80b4-00c04fd430c8",
"name": "order_confirmation",
"parameters": {
"name": "John Doe",
"order_id": "12345",
},
},
to=["+14155551234", "+14155555678"],
)
print(response.data)
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from PyPI
pip install sentdm[aiohttp]
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import os
import asyncio
from sent_dm import DefaultAioHttpClient
from sent_dm import AsyncSentDm
async def main() -> None:
async with AsyncSentDm(
api_key=os.environ.get("SENT_DM_API_KEY"), # This is the default and can be omitted
http_client=DefaultAioHttpClient(),
) as client:
response = await client.messages.send(
channel=["sms", "whatsapp"],
template={
"id": "7ba7b820-9dad-11d1-80b4-00c04fd430c8",
"name": "order_confirmation",
"parameters": {
"name": "John Doe",
"order_id": "12345",
},
},
to=["+14155551234", "+14155555678"],
)
print(response.data)
asyncio.run(main())
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Nested params
Nested parameters are dictionaries, typed using `TypedDict`, for example:
```python
from sent_dm import SentDm
client = SentDm()
response = client.messages.send(
template={
"id": "7ba7b820-9dad-11d1-80b4-00c04fd430c8",
"name": "order_confirmation",
"parameters": {
"name": "John Doe",
"order_id": "12345",
},
},
)
print(response.template)
```
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `sent_dm.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `sent_dm.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `sent_dm.APIError`.
```python
import sent_dm
from sent_dm import SentDm
client = SentDm()
try:
client.messages.send(
channel=["sms"],
template={
"id": "7ba7b820-9dad-11d1-80b4-00c04fd430c8",
"name": "order_confirmation",
"parameters": {
"name": "John Doe",
"order_id": "12345",
},
},
to=["+14155551234"],
)
except sent_dm.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except sent_dm.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except sent_dm.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as follows:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from sent_dm import SentDm
# Configure the default for all requests:
client = SentDm(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).messages.send(
channel=["sms"],
template={
"id": "7ba7b820-9dad-11d1-80b4-00c04fd430c8",
"name": "order_confirmation",
"parameters": {
"name": "John Doe",
"order_id": "12345",
},
},
to=["+14155551234"],
)
```
### Timeouts
By default requests time out after 1 minute. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/timeouts/#fine-tuning-the-configuration) object:
```python
from sent_dm import SentDm
# Configure the default for all requests:
client = SentDm(
# 20 seconds (default is 1 minute)
timeout=20.0,
)
# More granular control:
client = SentDm(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).messages.send(
channel=["sms"],
template={
"id": "7ba7b820-9dad-11d1-80b4-00c04fd430c8",
"name": "order_confirmation",
"parameters": {
"name": "John Doe",
"order_id": "12345",
},
},
to=["+14155551234"],
)
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/sentdm/sent-dm-python/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `SENT_DM_LOG` to `info`.
```shell
$ export SENT_DM_LOG=info
```
Or to `debug` for more verbose logging.
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from sent_dm import SentDm
client = SentDm()
response = client.messages.with_raw_response.send(
channel=["sms"],
template={
"id": "7ba7b820-9dad-11d1-80b4-00c04fd430c8",
"name": "order_confirmation",
"parameters": {
"name": "John Doe",
"order_id": "12345",
},
},
to=["+14155551234"],
)
print(response.headers.get('X-My-Header'))
message = response.parse() # get the object that `messages.send()` would have returned
print(message.data)
```
These methods return an [`APIResponse`](https://github.com/sentdm/sent-dm-python/tree/main/src/sent_dm/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/sentdm/sent-dm-python/tree/main/src/sent_dm/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.messages.with_streaming_response.send(
channel=["sms"],
template={
"id": "7ba7b820-9dad-11d1-80b4-00c04fd430c8",
"name": "order_confirmation",
"parameters": {
"name": "John Doe",
"order_id": "12345",
},
},
to=["+14155551234"],
) as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) when making this request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for [proxies](https://www.python-httpx.org/advanced/proxies/)
- Custom [transports](https://www.python-httpx.org/advanced/transports/)
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
import httpx
from sent_dm import SentDm, DefaultHttpxClient
client = SentDm(
# Or use the `SENT_DM_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
```py
from sent_dm import SentDm
with SentDm() as client:
# make requests here
...
# HTTP client is now closed
```
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals.)_
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/sentdm/sent-dm-python/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import sent_dm
print(sent_dm.__version__)
```
## Requirements
Python 3.9 or higher.
## Contributing
See [the contributing documentation](https://github.com/sentdm/sent-dm-python/tree/main/./CONTRIBUTING.md).
| text/markdown | null | Sent Dm <support@sent.dm> | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pydantic<3,>=1.9.0",
"sniffio",
"typing-extensions<5,>=4.10",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"aiohttp\""
] | [] | [] | [] | [
"Homepage, https://github.com/sentdm/sent-dm-python",
"Repository, https://github.com/sentdm/sent-dm-python"
] | uv/0.9.13 {"installer":{"name":"uv","version":"0.9.13"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T16:29:20.455809 | sentdm-0.8.0-py3-none-any.whl | 153,762 | 80/94/25ad92959dda33817e01ab7aad4b93d82dfe9162d913b80324b0367f3f15/sentdm-0.8.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 9b533bb7ec911abac00ec070814624a9 | e97eee663d1e20f4777d5fb4fa4c9495134d7b25d46fb22184a0f9ce93d1686c | 809425ad92959dda33817e01ab7aad4b93d82dfe9162d913b80324b0367f3f15 | null | [] | 234 |
2.4 | duelink | 1.2.4 | GHI Electronics DUELink Python library. | GHI Electronics DUELink Python library
| text/markdown | GHI Electronics | support@ghielectronics.com | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | https://www.duelink.com/ | null | >=3.6 | [] | [] | [] | [
"pyserial"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.0 | 2026-02-18T16:28:51.159636 | duelink-1.2.4.tar.gz | 13,316 | ea/1f/1de8458e7c3150f94f831700c32550fb270c9198148436bd9d23cc2f3702/duelink-1.2.4.tar.gz | source | sdist | null | false | 141f3143f09bcbb1bb2632cb9ba08caf | d321978e339a851f154f30d647a9e08967d5c360828ee48c9557d0a98d223b63 | ea1f1de8458e7c3150f94f831700c32550fb270c9198148436bd9d23cc2f3702 | null | [] | 242 |
2.4 | eoap-cwlwrap | 0.26.0 | Add stage-in/stage-out steps to EOAP CWL Workflows | # EOAP CWL Wrap
`eoap-cwlwrap` is a command-line utility that composes a CWL `Workflow` from a series of `Workflow`/`CommandLineTool` steps, defined according to [Application package patterns based on data stage-in and stage-out behaviors commonly used in EO workflows](https://eoap.github.io/application-package-patterns), and **packs** it into a single self-contained CWL document.
It ensures:
- **Type-safe chaining** of step outputs to the next step's inputs.
- **Reusable, modular design** by keeping each step in its own file.
- **Packed output** ready for execution or distribution.
## Contribute
Submit a [Github issue](https://github.com/EOEPCA/eoap-cwlwrap/issues) if you have comments or suggestions.
## Documentation
See the documentation at https://eoepca.github.io/eoap-cwlwrap/
## License
[](https://creativecommons.org/licenses/by-sa/4.0/)
| text/markdown | null | Fabrice Brito <fabrice.brito@terradue.com>, Simone Tripodi <simone.tripodi@terradue.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Pro... | [] | null | null | >=3.8 | [] | [] | [] | [
"click>=8.0",
"cwl-loader>=0.14.0",
"cwl-utils>=0.40",
"cwltool>=3.1.20250110105449",
"loguru"
] | [] | [] | [] | [
"Documentation, https://github.com/EOEPCA/eoap-cwlwrap#readme",
"Issues, https://github.com/EOEPCA/eoap-cwlwrap/issues",
"Source, https://github.com/EOEPCA/eoap-cwlwrap"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:28:46.756938 | eoap_cwlwrap-0.26.0.tar.gz | 96,411 | de/7d/fd280f48dbc04cf314235625f031d3bf2806081534eeb1914ac6446a5f86/eoap_cwlwrap-0.26.0.tar.gz | source | sdist | null | false | bf534f0dcad93bf000c30bef5bf8ee78 | 50676b6bf4fc721c85103a52f816273559b1292a7034f8dbca031bc17ce543c9 | de7dfd280f48dbc04cf314235625f031d3bf2806081534eeb1914ac6446a5f86 | Apache-2.0 | [
"LICENSE",
"NOTICE"
] | 234 |
2.4 | kaleidoswap-sdk | 0.5.1 | Python SDK for the Kaleidoswap protocol - Trade RGB assets on Lightning Network | # Kaleidoswap Python SDK
Pure Python SDK for interacting with the Kaleidoswap protocol. Trade RGB assets on Lightning Network with ease.
## Installation
```bash
pip install kaleidoswap-sdk
```
Or with development dependencies:
```bash
pip install kaleidoswap-sdk[dev]
```
## Quick Start
```python
import asyncio
from kaleidoswap_sdk import KaleidoClient
async def main():
# Create client
client = KaleidoClient.create(
base_url="https://api.kaleidoswap.com"
)
async with client:
# List available assets
assets = await client.maker.list_assets()
for asset in assets.assets:
print(f"{asset.ticker}: {asset.name}")
# Get trading pairs
pairs = await client.maker.list_pairs()
for pair in pairs.pairs:
print(f"{pair.base.ticker}/{pair.quote.ticker}")
asyncio.run(main())
```
## Features
- **Async-first design** - All API methods are async using `asyncio`
- **Type-safe** - Full type hints with Pydantic models
- **Feature parity** - Matches the TypeScript SDK 1-to-1
### MakerClient (Market Operations)
```python
# List assets
assets = await client.maker.list_assets()
# List trading pairs
pairs = await client.maker.list_pairs()
# Get a quote
quote = await client.maker.get_quote(PairQuoteRequest(...))
# Create swap order
order = await client.maker.create_swap_order(CreateSwapOrderRequest(...))
# Get order status
status = await client.maker.get_swap_order_status(SwapOrderStatusRequest(...))
# LSP operations
lsp_info = await client.maker.get_lsp_info()
```
### RlnClient (RGB Lightning Node Operations)
Requires `node_url` configuration:
```python
client = KaleidoClient.create(
base_url="https://api.kaleidoswap.com",
node_url="http://localhost:3000"
)
# Node info
info = await client.rln.get_node_info()
# BTC operations
balance = await client.rln.get_btc_balance()
address = await client.rln.get_address()
# RGB asset operations
assets = await client.rln.list_assets()
await client.rln.send_rgb(SendRgbRequest(...))
# Lightning channels
channels = await client.rln.list_channels()
await client.rln.open_channel(OpenChannelRequest(...))
# Payments
await client.rln.send_payment(SendPaymentRequest(...))
```
### WebSocket Streaming
```python
# Enable WebSocket
ws = client.maker.enable_websocket("wss://api.kaleidoswap.com/ws")
# Stream quotes
unsubscribe = await client.maker.stream_quotes(
from_asset="BTC",
to_asset="USDT",
from_amount=100000,
from_layer=Layer.BTC_LN,
to_layer=Layer.RGB_LN,
on_update=lambda quote: print(quote),
)
# Later: stop streaming
unsubscribe()
ws.disconnect()
```
## Utility Functions
```python
from kaleidoswap_sdk import to_smallest_units, to_display_units
# Convert BTC to satoshis
sats = to_smallest_units(1.5, 8) # 150000000
# Convert satoshis to BTC
btc = to_display_units(150000000, 8) # 1.5
```
## Error Handling
```python
from kaleidoswap_sdk import (
KaleidoError,
APIError,
ValidationError,
NotFoundError,
NodeNotConfiguredError,
)
try:
quote = await client.maker.get_quote(request)
except ValidationError as e:
print(f"Invalid request: {e}")
except NotFoundError as e:
print(f"Resource not found: {e}")
except APIError as e:
print(f"API error ({e.status_code}): {e}")
except KaleidoError as e:
print(f"SDK error: {e}")
```
## Development
```bash
# Install dev dependencies
pip install -e ".[dev]"
# Run tests
pytest
# Run tests with coverage
pytest --cov=kaleidoswap_sdk
# Type checking
mypy kaleidoswap_sdk
# Linting
ruff check kaleidoswap_sdk
```
## License
MIT
| text/markdown | null | Kaleidoswap <dev@kaleidoswap.com> | null | null | null | bitcoin, lightning, rgb, sdk, swap, trading | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pytho... | [] | null | null | >=3.10 | [] | [] | [] | [
"attrs>=23.0",
"httpx>=0.27.0",
"pydantic[email]>=2.0",
"websockets>=12.0",
"datamodel-code-generator>=0.25; extra == \"dev\"",
"mypy>=1.0; extra == \"dev\"",
"openapi-python-client>=0.21.0; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest>=... | [] | [] | [] | [
"Homepage, https://kaleidoswap.com",
"Documentation, https://docs.kaleidoswap.com",
"Repository, https://github.com/kaleidoswap/kaleido-sdk"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T16:28:27.367017 | kaleidoswap_sdk-0.5.1.tar.gz | 202,834 | 6a/4a/a020bc91602d5c12ddd988f6d0bf719f951294bcb1f479ad13f58b342f69/kaleidoswap_sdk-0.5.1.tar.gz | source | sdist | null | false | 8982040b94412359c8b51bff9ddd4a24 | 9cf33b6665b962869462de64ce6397ef397b67438c4942aa05170d1505e535c3 | 6a4aa020bc91602d5c12ddd988f6d0bf719f951294bcb1f479ad13f58b342f69 | MIT | [] | 231 |
2.4 | th2-grpc-lw-data-provider | 2.6.0.dev22148164381 | th2_grpc_lw_data_provider | # gRPC for lw-data-provider (2.6.0)
## Release notes:
### 2.6.0
+ [[GH-183] added `operator` field to `Filter` message](https://github.com/th2-net/th2-lw-data-provider/issues/183)
### 2.5.1
+ th2 grpc common `4.7.2`
### 2.5.0
+ th2 gradle plugin `0.3.7`
+ th2 grpc common `4.7.1`
#### Updates:
### 2.4.0
#### Updates:
+ th2 gradle plugin `0.2.4`
+ th2 grpc common `4.5.0`
### 2.3.4
+ Added go_package option into proto files
### 2.3.3
#### Updates:
+ th2 gradle plugin `0.0.8`
### 2.3.2
#### Updated:
+ th2-grpc-common: `4.5.0.rc1`
### 2.3.1
#### Updated:
+ grpc-common: `4.5.0-dev`
### 2.3.0
#### Updated:
+ grpc-service-generator: `3.5.1`
| text/markdown | TH2-devs | th2-devs@exactprosystems.com | null | null | Apache License 2.0 | null | [] | [] | https://github.com/th2-net/th2-lw-data-provider/grpc | null | >=3.7 | [] | [] | [] | [
"th2-grpc-common<5,>=4.7.2"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:28:03.706407 | th2_grpc_lw_data_provider-2.6.0.dev22148164381.tar.gz | 18,689 | 18/6b/e5cc396693ea87f273c9bfc7764cda9068116a3517dae8c297b57b6ee3a9/th2_grpc_lw_data_provider-2.6.0.dev22148164381.tar.gz | source | sdist | null | false | a2196b808b722e2039ca4ef31539fc30 | c44d40ea05bc55bcf95767b4ed3ff996cdf53005f82be7fe7fe787d6adc68090 | 186be5cc396693ea87f273c9bfc7764cda9068116a3517dae8c297b57b6ee3a9 | null | [] | 121 |
2.4 | brimfile | 1.4.2 | A package to read and write to the brim file format, containing spectral data and metadata from Brillouin microscopy | <div align="center">
<img src="https://raw.githubusercontent.com/prevedel-lab/brimfile/refs/heads/main//brimfile_logo.png"/>
</div>
# brimfile package
[](https://prevedel-lab.github.io/brimfile/brimfile.html)
## What is it?
*brimfile* is a package to read and write to brim (**Br**illouin **im**aging) files, containing spectral data and metadata from Brillouin microscopy.
The detailed specs of the brim file format can be found [here](https://github.com/prevedel-lab/Brillouin-standard-file/blob/main/docs/brim_file_specs.md).
## How to install it
We recommend installing *brimfile* in a [virtual environment](https://docs.python.org/3/library/venv.html).
After activating the environment, *brimfile* can be installed from PyPI using `pip`:
```bash
pip install brimfile
```
## How to use it
The full documentation of the package can be found [here](https://prevedel-lab.github.io/brimfile/).
To quickly start reading an existing .brim file, the following code shows how to:
- open a .brim file
- get an image for the Brillouin shift
- get the spectrum at a specific pixel
- get the metadata.
```Python
from brimfile import File, Data, Metadata, AnalysisResults
Quantity = AnalysisResults.Quantity
PeakType = AnalysisResults.PeakType
filename = 'path/to/your/file.brim.zarr'
f = File(filename)
# get the first data group in the file
d = f.get_data()
# get the first analysis results in the data group
ar = d.get_analysis_results()
# get the image for the shift
img, px_size = ar.get_image(Quantity.Shift, PeakType.average)
# get the spectrum at the pixel (pz,py,px)
(pz,py,px) = (0,0,0)
PSD, frequency, PSD_units, frequency_units = d.get_spectrum_in_image((pz,py,px))
# get the metadata
md = d.get_metadata()
all_metadata = md.all_to_dict()
# close the file
f.close()
```
More examples could be found in the [examples folder](examples)
## Matlab support
You can download the [Matlab toolbox](https://github.com/prevedel-lab/brimfile/releases/tag/matlab_toolbox_main), which is basically a wrapper around the Python brimfile package, so you can refer to the [same documentation](https://prevedel-lab.github.io/brimfile/). We only support Matlab >= R2023b, as brimfile needs Python 3.11.
Note that the current version of the Matlab toolbox is not supporting all the functions defined in brimfile and it has not been tested extensively yet. | text/markdown | null | Carlo Bevilacqua <carlo.bevilacqua@embl.de>, Sebastian Hambura <sebastian.hambura@embl.de> | null | null | null | Brillouin microscopy | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Topic :: File Formats",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"numpy",
"zarr>=3.1.1",
"h5py; extra == \"converter\"",
"tifffile; extra == \"export-tiff\"",
"s3fs; extra == \"remote-store\"",
"zarr[remote]>=3.1.1; extra == \"remote-store\""
] | [] | [] | [] | [
"Documentation, https://prevedel-lab.github.io/brimfile/",
"Repository, https://github.com/prevedel-lab/brimfile",
"Issues, https://github.com/prevedel-lab/brimfile/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:27:19.366632 | brimfile-1.4.2.tar.gz | 98,626 | 8a/aa/c137cdee9731eb4f16533e1af05d1c24aeed583da6f3570b7472f3c3351f/brimfile-1.4.2.tar.gz | source | sdist | null | false | 6d20e38e516fa2d17303756c2a6760f7 | 677b8319ab4ef6744dcccc58732ac824c15462310b56ca36d6c23f86af72d563 | 8aaac137cdee9731eb4f16533e1af05d1c24aeed583da6f3570b7472f3c3351f | LGPL-3.0-or-later | [
"LICENSE.toml"
] | 239 |
2.4 | fastapi-openai-compat | 0.2.0 | FastAPI router factory for OpenAI-compatible Chat Completion endpoints | # fastapi-openai-compat
[](https://pypi.org/project/fastapi-openai-compat)
[](https://pypi.org/project/fastapi-openai-compat)
[](https://github.com/deepset-ai/fastapi-openai-compat/actions/workflows/tests.yml)
FastAPI router factory for OpenAI-compatible [Chat Completions](https://platform.openai.com/docs/api-reference/chat) endpoints.
Provides a configurable `APIRouter` that exposes `/v1/chat/completions` and `/v1/models` endpoints,
following the [OpenAI API specification](https://platform.openai.com/docs/api-reference/chat),
with support for streaming (SSE), non-streaming responses, tool calling, configurable hooks, and custom chunk mapping.
## Installation
```bash
pip install fastapi-openai-compat
```
With Haystack `StreamingChunk` support:
```bash
pip install fastapi-openai-compat[haystack]
```
## Quick start
Create an OpenAI-compatible Chat Completions server in a few lines. Both sync and async
callables are supported -- sync callables are automatically executed in a thread pool
so they never block the async event loop.
```python
from fastapi import FastAPI
from fastapi_openai_compat import create_openai_router, CompletionResult
def list_models() -> list[str]:
return ["my-pipeline"]
def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
# Your (potentially blocking) pipeline execution logic here
return "Hello from Haystack!"
app = FastAPI()
router = create_openai_router(
list_models=list_models,
run_completion=run_completion,
)
app.include_router(router)
```
Async callables work the same way:
```python
async def list_models() -> list[str]:
return ["my-pipeline"]
async def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
return "Hello from Haystack!"
```
## The `run_completion` callable
The `run_completion` callable receives three arguments:
| Argument | Type | Description |
|------------|--------------|-------------|
| `model` | `str` | The model name from the request (e.g. `"my-pipeline"`). |
| `messages` | `list[dict]` | The conversation history in OpenAI format. |
| `body` | `dict` | The full request body, including all extra parameters (e.g. `temperature`, `max_tokens`, `stream`, `metadata`, `tools`). |
The request model accepts any additional fields beyond `model`, `messages`, and `stream`.
These extra parameters are forwarded as-is in the `body` dict, so you can use them
however you need without any library changes.
For example, you can access `metadata` and any other extra field from `body`:
```python
import time
from fastapi_openai_compat import ChatCompletion, Choice, Message, CompletionResult
def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
metadata = body.get("metadata", {})
temperature = body.get("temperature", 1.0)
request_id = metadata.get("request_id", "unknown")
return ChatCompletion(
id=f"resp-{request_id}",
object="chat.completion",
created=int(time.time()),
model=model,
choices=[
Choice(
index=0,
message=Message(role="assistant", content="Hello!"),
finish_reason="stop",
)
],
metadata={"request_id": request_id, "temperature_used": temperature},
)
```
A client can then send:
```bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "my-pipeline",
"messages": [{"role": "user", "content": "Hello!"}],
"temperature": 0.7,
"metadata": {"request_id": "abc-123", "user_tier": "premium"}
}'
```
The `metadata` field in the response works because `ChatCompletion` also allows extra fields,
so you can attach any additional data to the response object.
The return type determines how the response is formatted:
| Return type | Behavior |
|--------------------|----------|
| `str` | Wrapped automatically into a `ChatCompletion` response. |
| `Generator` | Each yielded chunk is converted to a `chat.completion.chunk` SSE message. |
| `AsyncGenerator` | Same as `Generator`, but async. |
| `ChatCompletion` | Returned as-is for full control over the response. |
## Response types
### Returning a string
The simplest option -- return a plain string and the library wraps it as a
complete `ChatCompletion` response automatically:
```python
def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
last_msg = messages[-1]["content"]
return f"You said: {last_msg}"
```
### Streaming with a generator
Return a generator to stream responses token by token via SSE.
Each yielded string is automatically wrapped into a `chat.completion.chunk` message --
you only need to yield the text content, the library handles the SSE wire format.
A `finish_reason="stop"` sentinel is appended automatically at the end of the stream.
Your `run_completion` should check `body.get("stream", False)` to decide whether
to return a generator or a plain string:
```python
from collections.abc import Generator
def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
last_msg = messages[-1]["content"]
if body.get("stream", False):
def stream() -> Generator[str, None, None]:
for word in last_msg.split():
yield word + " "
return stream()
return f"You said: {last_msg}"
```
Async generators work the same way:
```python
from collections.abc import AsyncGenerator
async def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
async def stream() -> AsyncGenerator[str, None]:
for word in ["Hello", " from", " Haystack", "!"]:
yield word
return stream()
```
### Returning a ChatCompletion
For full control over the response (e.g. custom `usage`, `finish_reason`, or `system_fingerprint`),
return a `ChatCompletion` object directly:
```python
import time
from fastapi_openai_compat import ChatCompletion, Choice, Message, CompletionResult
def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
return ChatCompletion(
id="resp-1",
object="chat.completion",
created=int(time.time()),
model=model,
choices=[
Choice(
index=0,
message=Message(role="assistant", content="Hello!"),
finish_reason="stop",
)
],
usage={"prompt_tokens": 10, "completion_tokens": 5, "total_tokens": 15},
)
```
## Tool calling
### Returning ChatCompletion directly
For tool calls and other advanced responses, return a `ChatCompletion` directly
from `run_completion` for full control over the response structure:
```python
import time
from fastapi_openai_compat import ChatCompletion, Choice, Message, CompletionResult
def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
return ChatCompletion(
id="resp-1",
object="chat.completion",
created=int(time.time()),
model=model,
choices=[
Choice(
index=0,
message=Message(
role="assistant",
content=None,
tool_calls=[{
"id": "call_1",
"type": "function",
"function": {"name": "get_weather", "arguments": '{"city": "Paris"}'},
}],
),
finish_reason="tool_calls",
)
],
)
```
Streaming tool calls work the same way -- yield `ChatCompletion` chunk objects
from your generator and the library serializes them directly as SSE:
```python
def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
def stream():
yield ChatCompletion(
id="resp-1", object="chat.completion.chunk",
created=int(time.time()), model=model,
choices=[Choice(index=0, delta=Message(
role="assistant",
tool_calls=[{"index": 0, "id": "call_1", "type": "function",
"function": {"name": "get_weather", "arguments": ""}}],
))],
)
yield ChatCompletion(
id="resp-1", object="chat.completion.chunk",
created=int(time.time()), model=model,
choices=[Choice(index=0, delta=Message(
role="assistant",
tool_calls=[{"index": 0, "function": {"arguments": '{"city": "Paris"}'}}],
))],
)
yield ChatCompletion(
id="resp-1", object="chat.completion.chunk",
created=int(time.time()), model=model,
choices=[Choice(index=0, delta=Message(role="assistant"), finish_reason="tool_calls")],
)
return stream()
```
### Automatic StreamingChunk support
When using Haystack's `StreamingChunk` (requires `pip install fastapi-openai-compat[haystack]`),
tool call deltas and finish reasons are handled automatically via duck typing:
```python
from haystack.dataclasses import StreamingChunk
from haystack.dataclasses.streaming_chunk import ToolCallDelta
def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
def stream():
yield StreamingChunk(
content="",
tool_calls=[ToolCallDelta(
index=0, id="call_1",
tool_name="get_weather", arguments='{"city": "Paris"}',
)],
index=0,
)
yield StreamingChunk(content="", finish_reason="tool_calls")
return stream()
```
The library automatically:
- Converts `ToolCallDelta` objects to OpenAI wire format (`tool_calls[].function.name/arguments`)
- Propagates `finish_reason` from chunks (e.g. `"stop"`, `"tool_calls"`, `"length"`)
- Only auto-appends `finish_reason="stop"` if no chunk already carried a finish reason
- Works via duck typing -- any object with `tool_calls` and `finish_reason` attributes is supported
## Custom SSE events
You can yield custom SSE events alongside regular chat completion chunks. This is useful
for sending side-channel data to clients like [Open WebUI](https://openwebui.com) --
status updates, notifications, source citations, etc.
Any object with a `.to_event_dict()` method is recognized as a custom event and serialized
as `data: {"event": {...}}` in the SSE stream. Custom events don't interfere with
chat completion chunks or the `finish_reason` tracking.
```python
from collections.abc import Generator
from fastapi_openai_compat import CompletionResult
class StatusEvent:
def __init__(self, description: str, done: bool = False):
self.description = description
self.done = done
def to_event_dict(self) -> dict:
return {"type": "status", "data": {"description": self.description, "done": self.done}}
def run_completion(model: str, messages: list[dict], body: dict) -> CompletionResult:
def stream() -> Generator[str | StatusEvent, None, None]:
yield StatusEvent("Processing your request...")
for word in ["Hello", " from", " Haystack", "!"]:
yield word
yield StatusEvent("Done", done=True)
return stream()
```
This works via duck typing -- any object implementing `to_event_dict() -> dict` is supported.
The protocol is compatible with [Hayhooks' Open WebUI events](https://deepset-ai.github.io/hayhooks/).
## Hooks
You can inject pre/post hooks to modify requests and results (transformer hooks)
or to observe them without modification (observer hooks). Both sync and async
hooks are supported.
### Transformer hooks
Return a modified value to transform the request or result:
```python
from fastapi_openai_compat import ChatRequest, CompletionResult
async def pre_hook(request: ChatRequest) -> ChatRequest:
# e.g. inject system prompts, validate, rate-limit
return request
async def post_hook(result: CompletionResult) -> CompletionResult:
# e.g. transform, filter
return result
router = create_openai_router(
list_models=list_models,
run_completion=run_completion,
pre_hook=pre_hook,
post_hook=post_hook,
)
```
### Observer hooks
Return `None` to observe without modifying (useful for logging, metrics, etc.):
```python
def log_request(request: ChatRequest) -> None:
print(f"Request for model: {request.model}")
def log_result(result: CompletionResult) -> None:
print(f"Got result type: {type(result).__name__}")
router = create_openai_router(
list_models=list_models,
run_completion=run_completion,
pre_hook=log_request,
post_hook=log_result,
)
```
## Custom chunk mapping
By default the router handles plain `str` chunks and objects with a `.content`
attribute (e.g. Haystack `StreamingChunk`). If your pipeline streams a different
type, provide a `chunk_mapper` to extract text content:
```python
from dataclasses import dataclass
@dataclass
class MyChunk:
text: str
score: float
def my_mapper(chunk: MyChunk) -> str:
return chunk.text
router = create_openai_router(
list_models=list_models,
run_completion=run_completion,
chunk_mapper=my_mapper,
)
```
This works with any object -- dataclasses, dicts, Pydantic models, etc.:
```python
def dict_mapper(chunk: dict) -> str:
return chunk["payload"]
```
## Examples
The [`examples/`](examples/) folder contains ready-to-run servers:
- **[`basic.py`](examples/basic.py)** -- Minimal echo server, no external API keys required.
- **[`haystack_chat.py`](examples/haystack_chat.py)** -- Haystack `OpenAIChatGenerator` with streaming support.
See the [examples README](examples/README.md) for setup and usage instructions.
## API reference
This library implements endpoints compatible with the [OpenAI Chat Completions API](https://platform.openai.com/docs/api-reference/chat).
### `create_openai_router`
```python
create_openai_router(
*,
list_models,
run_completion,
pre_hook=None,
post_hook=None,
chunk_mapper=default_chunk_mapper,
owned_by="custom",
tags=None,
) -> APIRouter
```
| Parameter | Type | Description |
|------------------|---------------------------|-------------|
| `list_models` | `Callable -> list[str]` | Returns available model/pipeline names. |
| `run_completion` | `Callable -> CompletionResult` | Runs a chat completion given `(model, messages, body)`. |
| `pre_hook` | `Callable` or `None` | Called before `run_completion`. Receives `ChatRequest`, returns modified request (transformer) or `None` (observer). |
| `post_hook` | `Callable` or `None` | Called after `run_completion`. Receives `CompletionResult`, returns modified result (transformer) or `None` (observer). |
| `chunk_mapper` | `Callable[[Any], str]` | Converts streamed chunks to strings. Default handles `str` and `.content` attribute. |
| `owned_by` | `str` | Value for the `owned_by` field in model objects. Defaults to `"custom"`. |
| `tags` | `list[str]` or `None` | OpenAPI tags for the generated endpoints. Defaults to `["openai"]`. |
### Endpoints
The router exposes the following endpoints (with and without the `/v1` prefix):
| Method | Path | Description |
|--------|-----------------------------|-------------|
| `GET` | `/v1/models` | List available models. |
| `POST` | `/v1/chat/completions` | Create a chat completion (streaming or non-streaming). |
| `GET` | `/models` | Alias for `/v1/models`. |
| `POST` | `/chat/completions` | Alias for `/v1/chat/completions`. |
| text/markdown | null | null | null | null | null | chat-completion, fastapi, haystack, openai, streaming | [
"Development Status :: 3 - Alpha",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: Implementation :: CPython"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi",
"pydantic",
"haystack-ai; extra == \"haystack\""
] | [] | [] | [] | [
"Source, https://github.com/deepset-ai/fastapi-openai-compat",
"Issues, https://github.com/deepset-ai/fastapi-openai-compat/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T16:27:13.221301 | fastapi_openai_compat-0.2.0-py3-none-any.whl | 17,759 | 05/87/74afc812b3d08824e957d6b6c9e0f95de4c4d1586cbd5aa49d69ca231657/fastapi_openai_compat-0.2.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 2215f429d9f3a3cebebf0baa2c43631a | 6bddc5abac04904e455c7b5e5be3a4fc235fa4b5cebaaa1b4c4bb459b57de509 | 058774afc812b3d08824e957d6b6c9e0f95de4c4d1586cbd5aa49d69ca231657 | Apache-2.0 | [
"LICENSE"
] | 321 |
2.4 | geokdtree | 1.1.0 | Given a coordinate point, find a very close point given a set of coordinate points. | # GeoKDTree
[](https://badge.fury.io/py/geokdtree)
[](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/geokdtree/)
<!-- [](https://pypi.org/project/geokdtree/) -->
# GeoKDTree
## Ultra-fast nearest-neighbor lookup for latitude/longitude data
**GeoKDTree** is a lightweight, high-performance spatial indexing library for Python designed to find the *nearest geographic coordinate* from massive datasets in nanoseconds.
It wraps a highly optimized KD-Tree with a geographic interface, allowing you to work directly with `(latitude, longitude)` pairs. No projections, no external dependencies, and no heavy GIS stacks.

### Documentation
- Docs: https://connor-makowski.github.io/geokdtree/geokdtree.html
- Git Repo: https://github.com/connor-makowski/geokdtree
## Installation
```bash
pip install geokdtree
```
## Getting Started
```python
from geokdtree import GeoKDTree
example_points = [
(34.0522, -118.2437), # Los Angeles
(40.7128, -74.0060), # New York
(37.7749, -122.4194), # San Francisco
(51.5074, -0.1278), # London
(48.8566, 2.3522), # Paris
]
geo_kd_tree = GeoKDTree(points=example_points)
test_point = (47.6062, -122.3321) # Seattle
# Find the index of the closest point in the original dataset
closest_idx = geo_kd_tree.closest_idx(test_point) #=> 2
# Find the closest point itself
closest_point = geo_kd_tree.closest_point(test_point) #=> (37.7749, -122.4194)
```
## Why Use GeoKDTree?
GeoKDTree is designed to solve one focused problem extremely well:
**Fast nearest-neighbor lookup for latitude/longitude data at scale.**
It is worth noting that the closest point found may not be the true closest point, but should be very close for most practical applications. See KD-Tree limitations for more details.
### Extremely Fast Lookups
Once constructed, nearest-neighbor queries consistently complete in **tens of nanoseconds**, even with very large datasets.
Typical benchmark results from the included tests:
| Number of Points | Build Time | Query Time |
| ---------------: | ---------: | ---------: |
| 1,000 | ~1.7 ms | ~0.02 ms |
| 10,000 | ~25 ms | ~0.05 ms |
| 100,000 | ~350 ms | ~0.05 ms |
| 1,000,000 | ~6.8 s | ~0.07 ms |
This makes GeoKDTree well-suited for:
* Real-time proximity queries
* Matching incoming coordinates against large reference datasets
* High-throughput geospatial APIs
* Pre-filtering before more expensive geospatial calculations
> Exact timings depend on hardware, Python version, and data distribution. These values reflect typical results from the repository’s benchmarks.
### Built for Geographic Coordinates
GeoKDTree works directly with `(latitude, longitude)` pairs.
You do **not** need to:
* Project coordinates into planar space
* Use heavyweight GIS libraries
* Maintain custom spatial indexing code
Just pass geographic coordinates and query.
### Simple API, Minimal Overhead
GeoKDTree intentionally keeps the API small and focused.
* Build once from a list of coordinates
* Query nearest neighbors with a single method call
* Retrieve indices or points directly from your original dataset
There are no external C extensions or heavy dependencies, keeping installation and deployment simple.
### Deterministic and Predictable Performance
* Tree construction scales at approximately `O(n log n)`
* Query performance scales at approximately `O(log n)`
* No probabilistic approximations
* No background indexing or caching
This predictability is valuable for production systems where latency and reproducibility matter.
## Supported Features
See: https://connor-makowski.github.io/geokdtree/geokdtree.html
## Contributing
Issues, feature requests, and pull requests are welcome.
Please open an issue to discuss changes or enhancements.
# Development
## Running Tests, Prettifying Code, and Updating Docs
Make sure Docker is installed and running on a Unix system (Linux, MacOS, WSL2).
- Create a docker container and drop into a shell
- `./run.sh`
- Run all tests (see ./utils/test.sh)
- `./run.sh test`
- Prettify the code (see ./utils/prettify.sh)
- `./run.sh prettify`
- Update the docs (see ./utils/docs.sh)
- `./run.sh docs`
- Note: You can and should modify the `Dockerfile` to test different python versions.
| text/markdown | null | Connor Makowski <conmak@mit.edu> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: C++",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/connor-makowski/geokdtree",
"Bug Tracker, https://github.com/connor-makowski/geokdtree/issues",
"Documentation, https://connor-makowski.github.io/geokdtree/geokdtree.html"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T16:27:12.652817 | geokdtree-1.1.0.tar.gz | 1,161,076 | a8/74/6df98ca839d8b638eb7eb80b53b6faa51a91f20eab920c474e96ca8cf745/geokdtree-1.1.0.tar.gz | source | sdist | null | false | c3b334cca22a52210a7cd696d169e9c4 | 0c8f79101f5e93d2884297da712c72f396a651d4a0d8aa9e231ca050b20c24fb | a8746df98ca839d8b638eb7eb80b53b6faa51a91f20eab920c474e96ca8cf745 | MIT | [] | 163 |
2.4 | hackagent | 0.5.0 | HackAgent is an open-source security toolkit to detect vulnerabilities of your AI Agents. | <div align="center">
<p align="center">
<img src="https://docs.hackagent.dev/img/banner.svg" alt="HackAgent - AI Agent Security Testing Toolkit" width="800">
</p>
<strong>AI Security Red-Team Toolkit</strong>
<br>
[App](https://app.hackagent.dev/) -- [Docs](https://docs.hackagent.dev/) -- [API](https://api.hackagent.dev/schema/redoc)
<br>



[](http://commitizen.github.io/cz-cli/)



<br>
</div>
## Overview
HackAgent is an open-source toolkit designed to help security researchers, developers and AI safety practitioners evaluate the security of AI agents.
It provides a structured approach to discover potential vulnerabilities, including prompt injection, jailbreaking techniques, and other attack vectors.
## 🔥 Features
- **Comprehensive Attack Library**: Pre-built techniques for prompt injections, jailbreaks, and goal hijacking
- **Modular Framework**: Easily extend with custom attack vectors and testing methodologies
- **Safety Focused**: Responsible disclosure guidelines and ethical usage recommendations
### 🔌 AI Agent Frameworks Supported
[](https://github.com/BerriAI/litellm)
[](https://google.github.io/adk-docs/)
[](https://platform.openai.com/docs)
## 🚀 Installation
### Installation from PyPI
HackAgent can be installed directly from PyPI:
```bash
# With uv (recommended)
uv add hackagent
# Or with pip
pip install hackagent
```
## 📚 Quick Start
Run the interactive CLI to start testing your AI agents:
```bash
hackagent
```
Or use the SDK:
```python
from hackagent import HackAgent, AgentTypeEnum
agent = HackAgent(
name="my_agent",
endpoint="http://localhost:8000",
agent_type=AgentTypeEnum.GOOGLE_ADK
)
results = agent.hack(attack_config={
"attack_type": "advprefix",
"goals": ["Test goal"],
# ... generator and judges config
})
```
Obtain your credentials at [https://app.hackagent.dev](https://app.hackagent.dev)
For detailed examples and advanced usage, visit our [documentation](https://docs.hackagent.dev).
## 📊 Reporting
HackAgent automatically sends test results to the dashboard for analysis and visualization.
Access your dashboard at [https://app.hackagent.dev](https://app.hackagent.dev)
## 🤝 Contributing
We welcome contributions! Please see [CONTRIBUTING.md](CONTRIBUTING.md) and [CODE_OF_CONDUCT.md](CODE_OF_CONDUCT.md) for guidelines.
## 📜 License
This project is licensed under the Apache License 2.0 - see the [LICENSE](LICENSE) file for details.
## ⚠️ Disclaimer
HackAgent is a tool designed for security research and improving AI safety. Always obtain proper authorization before testing any AI systems. The authors are not responsible for any misuse of this software.
---
*This project is for educational and research purposes. Always use responsibly and ethically.*
| text/markdown | null | AI Security Lab <ais@ai4i.it> | null | null | Apache-2.0 | agents, ai, security, testing, vulnerabilities | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming L... | [] | null | null | >=3.10 | [] | [] | [] | [
"attrs>=21.0.0",
"click>=8.1.0",
"litellm>=1.69.2",
"openai>=1.0.0",
"pydantic>=2.0",
"python-dateutil>=2.8.0",
"pyyaml>=6.0.0",
"requests>=2.31.0",
"rich>=14.0.0",
"textual>=1.0.0",
"datasets>=2.14.0; extra == \"datasets\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T16:27:02.640533 | hackagent-0.5.0.tar.gz | 266,306 | df/e7/011ab7c051157d67d725e0aa484b504cf7b5741bd3b45730e6d9c6f36b33/hackagent-0.5.0.tar.gz | source | sdist | null | false | 1e49b62a79aced1a566b6064fac7341b | 2a579c9e0189af2dbdc4f30c537ad8180be6b5f41cd9bbeb6e37d2f724e33add | dfe7011ab7c051157d67d725e0aa484b504cf7b5741bd3b45730e6d9c6f36b33 | null | [
"LICENSE"
] | 227 |
2.4 | shepherd-score | 1.2.2 | 3D scoring functions used for evaluation of ShEPhERD | # *ShEPhERD* Scoring Functions
<div align="center">
[](https://pypi.org/project/shepherd-score/)
[](https://pypi.org/project/shepherd-score/)
[](https://shepherd-score.readthedocs.io/en/latest/?badge=latest)
📄 **[Paper](https://arxiv.org/abs/2411.04130)** | 📚 **[Documentation](https://shepherd-score.readthedocs.io/en/latest/)** | 📦 **[PyPI](https://pypi.org/project/shepherd-score/)**
</div>
This repository contains the code for **generating/optimizing conformers**, **extracting interaction profiles**, **aligning interaction profiles**, and **differentiably scoring 3D similarity**. It also contains modules to evaluate conformers generated with *ShEPhERD*<sup>1</sup> and other generative models.
The formulation of the interaction profile representation, scoring, alignment, and evaluations are found in our preprint [*ShEPhERD*: Diffusing shape, electrostatics, and pharmacophores for bioisosteric drug design](https://arxiv.org/abs/2411.04130). The diffusion model itself is found in a *separate* repository: [https://github.com/coleygroup/shepherd](https://github.com/coleygroup/shepherd).
<p align="center">
<img width="200" src="./logo.svg">
</p>
<sub><sup>1</sup> *ShEPhERD*: **S**hape, **E**lectrostatics, and **Ph**armacophores **E**xplicit **R**epresentation **D**iffusion</sub>
## Table of Contents
1. [Documentation](#documentation)
2. [File Structure](#file-structure)
3. [Installation](#installation)
4. [Requirements](#requirements)
5. [Usage](#how-to-use)
6. [Scoring and Alignment Examples](#scoring-and-alignment-examples)
7. [Evaluation Examples and Scripts](#evaluation-examples-and-scripts)
8. [Data](#data)
## Documentation
Full documentation is available at [shepherd-score.readthedocs.io](https://shepherd-score.readthedocs.io/en/latest/).
## File Structure
```
.
├── shepherd_score/
│ ├── alignment_utils/ # Alignment and rigid transformations tools
│ ├── evaluations/ # Evaluation suite
│ │ ├── pdbs/ # PDBQT files used in *ShEPhERD* manuscript
│ │ ├── utils/ # Converting data types and others
│ │ ├── docking
│ │ │ ├── docking.py # Docking classes
│ │ │ └── pipelines.py # Docking evaluation pipelines
│ │ └── evaluate/ # Generated conformer evaluation pipelines
│ │ ├── evals.py # Individual evaluation classes
│ │ └── pipelines.py # Evaluation pipeline classes
│ ├── pharm_utils/ # Pharmacophore definitions
│ ├── protonation/ # Functions for protonation
│ ├── score/ # Scoring related functions and constants
│ │ ├── constants.py
│ │ ├── electrostatic_scoring.py
│ │ ├── gaussian_overlap.py
│ │ └── pharmacophore_scoring.py
│ ├── alignment.py
│ ├── conformer_generation.py # RDKit and xtb related functions for conformers
│ ├── container.py # Molecule and MoleculePair classes
│ ├── extract_profiles.py # Functions to extract interaction profiles
│ ├── generate_point_cloud.py
│ ├── objective.py # Objective function used for REINVENT
│ └── visualize.py # Visualization tools
├── scripts/ # Scripts for running evaluations
├── examples/ # Jupyter notebook tutorials/examples
├── tests/
└── README.md
```
## Installation
### Via PyPI
```bash
pip install shepherd-score
```
#### Install xTB
xTB will need to be installed manually since there are no PyPi bindings. This can be done in a conda environment, but since this approach has been reported to lead to conflicts, we suggest installing
from [source](https://xtb-docs.readthedocs.io/en/latest/setup.html) and adding it to `PATH`.
### With optional dependencies
```bash
# JAX support (for faster scoring and alignment)
pip install "shepherd-score[jax]"
# Include docking evaluation tools
pip install "shepherd-score[docking]"
# Everything
pip install "shepherd-score[all]"
```
### For local development
```bash
git clone https://github.com/coleygroup/shepherd-score.git
cd shepherd-score
pip install -e ".[all]"
```
## Requirements
This package works where PyTorch, Open3D, RDKit, and xTB can be installed for Python >=3.9. **If you are coming from the *ShEPhERD* repository, you can use the same environment as described there.**
Core dependencies (installed automatically) which enables interaction profile extraction, scoring/alignment, and evaluations are listed below.
```
python>=3.9
numpy
torch>=1.12
open3d>=0.18
rdkit>=2023.03
pandas>=2.0
scipy>=1.10
```
> **Note**: If using `torch<=2.4`, ensure that `mkl==2024.0` with conda since there is a known [issue](https://github.com/pytorch/pytorch/issues/123097) that prevents importing torch.
#### Docking with Autodock Vina
Installing `shepherd-score[docking]` will automatically install the python bindings for Autodock Vina for the python interface. However, a manual installation of the executable of Autodock Vina v1.2.5 is required and can be found here: [https://vina.scripps.edu/downloads/](https://vina.scripps.edu/downloads/).
## Usage
The package has base functions and convenience wrappers. Scoring can be done with either NumPy or Torch, but alignment requires Torch. There are also Jax implementations for both scoring and alignment of gaussian overlap, ESP similarity, and pharmacophore similarity.
**Update 8/20/25**: Applicable xTB functions and evaluation pipeline evaluations are now parallelizable through the `num_workers` argument in the `.evaluate` method.
### Base functions
#### Conformer generation
Useful conformer generation functions are found in the `shepherd_score.conformer_generation` module.
#### Interaction profile extraction
| Interaction profile | Function |
| :------- | :------- |
| shape | `shepherd_score.extract_profiles.get_molecular_surface()` |
| electrostatics | `shepherd_score.extract_profiles.get_electrostatic_potential()` |
| pharmacophores | `shepherd_score.extract_profiles.get_pharmacophores()` |
#### Scoring
```shepherd_score.score``` contains the base scoring functions with seperate modules for those dependent on PyTorch (`*.py`), NumPy (`*_np.py`), and Jax (`*_jax.py`).
| Similarity | Function |
| :------- | :------- |
| shape | `shepherd_score.score.gaussian_overlap.get_overlap()` |
| electrostatics | `shepherd_score.score.electrostatic_scoring.get_overlap_esp()` |
| pharmacophores | `shepherd_score.score.pharmacophore_scoring.get_overlap_pharm()` |
### Convenience wrappers
- `Molecule` class
- `shepherd_score.container.Molecule` accepts an RDKit `Mol` object (with an associated conformer) and generates user-specified interaction profiles
- `MoleculePair` class
- `shepherd_score.container.MoleculePair` operates on `Molecule` objects and prepares them for scoring and alignment
## Scoring and Alignment Examples
Full jupyter notebook tutorials/examples for extraction, scoring, and alignments are found in the [`examples`](./examples/) folder. Some minimal examples are below.
### Extraction
Extraction of interaction profiles.
```python
from shepherd_score.conformer_generation import embed_conformer_from_smiles
from shepherd_score.conformer_generation import charges_from_single_point_conformer_with_xtb
from shepherd_score.extract_profiles import get_atomic_vdw_radii, get_molecular_surface
from shepherd_score.extract_profiles import get_pharmacophores, get_electrostatic_potential
from shepherd_score.extract_profiles import get_electrostatic_potential
# Embed conformer with RDKit and partial charges from xTB
ref_mol = embed_conformer_from_smiles('Oc1ccc(CC=C)cc1', MMFF_optimize=True)
partial_charges = charges_from_single_point_conformer_with_xtb(ref_mol)
# Radii are needed for surface extraction
radii = get_atomic_vdw_radii(ref_mol)
# `surface` is an np.array with shape (200, 3)
surface = get_molecular_surface(ref_mol.GetConformer().GetPositions(), radii, num_points=200)
# Get electrostatic potential at each point on the surface
# `esp`: np.array (200,)
esp = get_electrostatic_potential(ref_mol, partial_charges, surface)
# Pharmacophores as arrays with averaged vectors
# pharm_types: np.array (P,)
# pharm_{pos/vecs}: np.array (P,3)
pharm_types, pharm_pos, pharm_vecs = get_pharmacophores(ref_mol, multi_vector=False)
```
### 3D similarity scoring
An example of scoring the similarity of two different molecules using 3D surface, ESP, and pharmacophore similarity metrics.
```python
from shepherd_score.score.constants import ALPHA
from shepherd_score.conformer_generation import embed_conformer_from_smiles
from shepherd_score.conformer_generation import optimize_conformer_with_xtb
from shepherd_score.container import Molecule, MoleculePair
# Embed a random conformer with RDKit
ref_mol_rdkit = embed_conformer_from_smiles('Oc1ccc(CC=C)cc1', MMFF_optimize=True)
fit_mol_rdkit = embed_conformer_from_smiles('O=CCc1ccccc1', MMFF_optimize=True)
# Local relaxation with xTB
ref_mol, _, ref_charges = optimize_conformer_with_xtb(ref_mol_rdkit)
fit_mol, _, fit_charges = optimize_conformer_with_xtb(fit_mol_rdkit)
# Extract interaction profiles
ref_molec = Molecule(ref_mol,
num_surf_points=200,
partial_charges=ref_charges,
pharm_multi_vector=False)
fit_molec = Molecule(fit_mol,
num_surf_points=200,
partial_charges=fit_charges,
pharm_multi_vector=False)
# Centers the two molecules' COM's to the origin
mp = MoleculePair(ref_molec, fit_molec, num_surf_points=200, do_center=True)
# Compute the similarity score for each interaction profile
shape_score = mp.score_with_surf(ALPHA(mp.num_surf_points))
esp_score = mp.score_with_esp(ALPHA(mp.num_surf_points), lam=0.3)
pharm_score = mp.score_with_pharm()
```
### Alignment
Next we show alignment using the same MoleculePair class.
```python
# Centers the two molecules' COM's to the origin
mp = MoleculePair(ref_molec, fit_molec, num_surf_points=200, do_center=True)
# Align fit_molec to ref_molec with your preferred objective function
# By default we use automatic differentiation via pytorch
surf_points_aligned = mp.align_with_surf(ALPHA(mp.num_surf_points),
num_repeats=50)
surf_points_esp_aligned = mp.align_with_esp(ALPHA(mp.num_surf_points),
lam=0.3,
num_repeats=50)
pharm_pos_aligned, pharm_vec_aligned = mp.align_with_pharm(num_repeats=50)
# Optimal scores and SE(3) transformation matrices are stored as attributes
mp.sim_aligned_{surf/esp/pharm}
mp.transform_{surf/esp/pharm}
# Get a copy of the optimally aligned fit Molecule object
transformed_fit_molec = mp.get_transformed_molecule(
se3_transform=mp.transform_{surf/esp/pharm}
)
```
## Evaluation Examples and Scripts
We implement three evaluations of generated 3D conformers. Evaluations can be done on an individual basis or in a pipeline. Here we show the most basic use case in the unconditional setting.
- `ConfEval`
- Checks validity, pre-/post-xTB relaxation
- Calculates 2D graph properties
- `ConsistencyEval`
- Inherits from `ConfEval` and evaluates the consistency of the molecule's jointly generated interaction profiles with the true interaction profiles using 3D similarity scoring functions
- `ConditionalEval`
- Inherits from `ConfEval` and evaluates the 3D similarity between generated molecules and the target molecule
**Note**: Evaluations can be run from any molecule's atomic numbers and positions with explicit hydrogens (i.e., straight from an xyz file).
### Examples
Full jupyter notebook tutorials/examples for evaluations are found in the [`examples`](./examples/) folder. Some minimal examples are below.
```python
from shepherd_score.evaluations.evalutate import ConfEval
from shepherd_score.evaluations.evalutate import UnconditionalEvalPipeline
# ConfEval evaluates the validity of a given molecule, optimizes it with xTB,
# and also computes various 2D graph properties
# `atom_array` np.ndarray (N,) atomic numbers of the molecule (with explicit H)
# `position_array` np.ndarray (N,3) atom coordinates for the molecule
conf_eval = ConfEval(atoms=atom_array, positions=position_array)
# Alternatively, if you have a list of molecules you want to test:
uncond_pipe = UnconditionalEvalPipeline(
generated_mols = [(a, p) for a, p in zip(atom_arrays, position_arrays)]
)
uncond_pipe.evaluate(num_workers=4)
# Properties are stored as attributes and can be converted into pandas df's
sample_df, global_series = uncond_pipe.to_pandas()
```
### Scripts
Scripts to evaluate *ShEPhERD*-generated samples can be found in the `scripts` directory.
## Data
We provide the data used for model training, benchmarking, and all *ShEPhERD*-generated samples reported in the paper at this [Dropbox link](https://www.dropbox.com/scl/fo/rgn33g9kwthnjt27bsc3m/ADGt-CplyEXSU7u5MKc0aTo?rlkey=fhi74vkktpoj1irl84ehnw95h&e=1&st=wn46d6o2&dl=0). There are comprehensive READMEs in the Dropbox describing the different folders.
## License
This project is licensed under the MIT License -- see [LICENSE](./LICENSE) file for details.
## Citation
If you use or adapt `shepherd_score` or [*ShEPhERD*](https://github.com/coleygroup/shepherd) in your work, please cite us:
```bibtex
@misc{adamsShEPhERD2024,
title = {{{ShEPhERD}}: {{Diffusing}} Shape, Electrostatics, and Pharmacophores for Bioisosteric Drug Design},
author = {Adams, Keir and Abeywardane, Kento and Fromer, Jenna and Coley, Connor W.},
year = {2024},
number = {arXiv:2411.04130},
eprint = {2411.04130},
publisher = {arXiv},
doi = {10.48550/arXiv.2411.04130},
archiveprefix = {arXiv}
}
```
| text/markdown | null | Kento Abeywardane <kento@mit.edu> | null | null | MIT | bioinformatics, molecular-modeling, 3d-scoring, drug-discovery, chemistry, bioisosteres | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Bio-Informatics",
"Topic :: Scientific/Engineering :: Chemistry",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Pr... | [] | null | null | >=3.9 | [] | [] | [] | [
"rdkit<2025.09.3,>=2023.03; python_version == \"3.9\"",
"rdkit>=2023.03; python_version >= \"3.10\"",
"torch>=1.12",
"open3d>=0.18",
"py3Dmol",
"numpy",
"pandas>=2.0",
"scipy>=1.10",
"molscrub",
"pytest>=6.0; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"ruff; extra == \"dev\"",
"mypy;... | [] | [] | [] | [
"Homepage, https://github.com/kentoabeywardane/shepherd-score",
"Repository, https://github.com/kentoabeywardane/shepherd-score",
"Documentation, https://shepherd-score.readthedocs.io",
"Bug Tracker, https://github.com/kentoabeywardane/shepherd-score/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:26:52.644600 | shepherd_score-1.2.2.tar.gz | 736,562 | ea/70/5a6c6bd39d4e9f253580dcd93e9c2771bdf3807e7d0aa177c1742bb07abb/shepherd_score-1.2.2.tar.gz | source | sdist | null | false | 22c24d4f10aab39af3b5880eb93ea4b7 | fb5571476adfc147e333ab8681bf610f1cb74d84684fa37f18a67144dbd6c589 | ea705a6c6bd39d4e9f253580dcd93e9c2771bdf3807e7d0aa177c1742bb07abb | null | [
"LICENSE"
] | 586 |
2.4 | voicerun-cli | 1.0.0 | VoiceRun command-line interface | # VoiceRun CLI
A command-line interface for building and deploying voice agents on the VoiceRun platform.
## Table of Contents
- [Installation](#installation)
- [Quick Start](#quick-start)
- [Authentication](#authentication)
- [Commands](#commands)
- [setup](#vr-setup)
- [signin](#vr-signin)
- [signout](#vr-signout)
- [init](#vr-init)
- [validate](#vr-validate)
- [pull](#vr-pull)
- [push](#vr-push)
- [deploy](#vr-deploy)
- [debug](#vr-debug)
- [open](#vr-open)
- [render](#vr-render)
- [test](#vr-test)
- [get](#vr-get)
- [describe](#vr-describe)
- [create](#vr-create)
- [delete](#vr-delete)
- [context](#vr-context)
- [Project Structure](#project-structure)
- [Templates](#templates)
- [Values Files](#values-files)
- [Configuration](#configuration)
- [Environment Variables](#environment-variables)
## Installation
### Prerequisites
- Python 3.10 or higher
### Install from PyPI
```bash
pip install voicerun-cli
```
### Install from Source
```bash
git clone https://github.com/VoiceRun/voicerun-cli.git
cd voicerun-cli
pip install -e .
```
## Quick Start
```bash
# 1. Set up the CLI
vr setup
# 2. Create a new voice agent project
vr init my-agent
# 3. Navigate to the project directory
cd my-agent
# 4. Sign in to VoiceRun
vr signin
# 5. Edit handler.py to customize your agent logic
# 6. Validate your project
vr validate
# 7. Deploy to VoiceRun
vr push
# 8. Debug interactively or open the web UI
vr debug # Interactive terminal session
vr open # Open web UI
```
## Authentication
VoiceRun CLI supports three authentication methods:
### Browser Authentication (Recommended)
```bash
vr signin
```
Opens your default browser for secure OAuth-style authentication.
### Email/Password
```bash
vr signin
# Then select option 2 when prompted
```
### API Key
```bash
vr signin
# Then select option 3 when prompted
```
### Sign Out
```bash
vr signout
```
Credentials are stored in `~/.voicerun/`:
- Cookie: `~/.voicerun/cookie`
- API Key: `~/.voicerun/apikey`
- Config: `~/.voicerun/config.json`
## Commands
### `vr setup`
Set up the VoiceRun CLI environment by installing required dependencies.
```bash
vr setup
```
**Example:**
```bash
vr setup
```
---
### `vr signin`
Sign in to the VoiceRun API.
```bash
vr signin
```
Prompts for authentication method:
1. **Web browser** (default) - Opens browser for OAuth authentication
2. **Email/Password** - Enter credentials directly
3. **API Key** - Use an API key for authentication
**Example:**
```bash
vr signin
# Select authentication method when prompted
```
---
### `vr signout`
Sign out and clear stored credentials.
```bash
vr signout
```
---
### `vr init`
Create a new voice agent project from templates.
```bash
vr init [PROJECT_NAME]
```
**Options:**
| Option | Description |
|--------|-------------|
| `--yes`, `-y` | Skip prompts and use defaults |
| `--force`, `-f` | Overwrite existing files |
**Example:**
```bash
# Interactive mode
vr init
# Non-interactive with project name
vr init my-agent --yes
```
---
### `vr validate`
Validate project structure and configuration.
```bash
vr validate
```
**Options:**
| Option | Description |
|--------|-------------|
| `--environment`, `-e` | Environment to render templates for |
| `--quiet`, `-q` | Only output errors |
**Validation Checks:**
- `handler.py` exists and contains `async def handler()`
- `.voicerun/` directory structure is correct
- `agent.yaml` is valid with required fields
- YAML syntax in all template files
- Deployment spec contains only allowed fields
**Example:**
```bash
# Validate with specific environment
vr validate -e production
# Quiet mode (errors only)
vr validate -q
```
---
### `vr pull`
Pull agent code from the VoiceRun server to your local machine.
```bash
vr pull [AGENT_ID]
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT_ID` | Agent ID to pull (not required if inside a voicerun project) |
**Options:**
| Option | Description |
|--------|-------------|
| `--output`, `-o` | Output directory (defaults to agent name) |
| `--yes`, `-y` | Skip confirmation prompt |
**Behavior:**
- **Inside a voicerun project:** Pulls code using the agent ID from `agent.lock` and overwrites local files
- **Outside a voicerun project:** Requires an agent ID, creates a new directory with the pulled code and initializes `.voicerun/agent.lock`
**Example:**
```bash
# Pull inside an existing project
vr pull
# Pull a specific agent into a new directory
vr pull 550e8400-e29b-41d4-a716-446655440000
# Pull into a custom directory
vr pull 550e8400-e29b-41d4-a716-446655440000 -o ./my-agent
# Skip confirmation
vr pull --yes
```
---
### `vr push`
Deploy your agent code to the VoiceRun server.
```bash
vr push
```
**Options:**
| Option | Description |
|--------|-------------|
| `--name` | Name for the function version |
| `--new`, `-n` | Create a new function version instead of updating |
| `--yes`, `-y` | Skip confirmation prompts |
**Behavior:**
- Validates the project before pushing
- Packages code as a zip archive (excludes `.venv`, `__pycache__`, `.git`, etc.)
- Creates or updates `agent.lock` with agent and function IDs
- First push creates a new agent; subsequent pushes update the existing version
**Example:**
```bash
# Push with confirmation
vr push
# Push without confirmation
vr push --yes
# Create a new version
vr push --new --name "v2.0"
```
---
### `vr deploy`
Deploy agent configuration to an environment. This command renders your templates with environment-specific values and deploys the configuration to VoiceRun.
```bash
vr deploy <ENVIRONMENT>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `ENVIRONMENT` | Target environment (e.g., `development`, `production`) |
**Options:**
| Option | Description |
|--------|-------------|
| `--values`, `-f` | Custom values file path (defaults to `.voicerun/values.{environment}.yaml`) |
| `--yes`, `-y` | Skip confirmation prompts |
| `--dry-run` | Render and validate without deploying |
**Prerequisites:**
- Run `vr push` first to create an agent and generate `agent.lock`
- Create a values file for your target environment (e.g., `values.development.yaml`)
**What it does:**
1. Validates the project structure
2. Loads the agent ID from `agent.lock`
3. Renders templates with the values file
4. Sends the rendered deployment configuration to the VoiceRun API
**Example:**
```bash
# Deploy to development environment
vr deploy development
# Deploy to production without confirmation
vr deploy production --yes
# Use a custom values file
vr deploy staging -f custom-values.yaml
# Preview what would be deployed (dry run)
vr deploy development --dry-run
```
---
### `vr debug`
Push local code and start an interactive debug session with your agent.
```bash
vr debug
```
**Options:**
| Option | Description |
|--------|-------------|
| `--skip-push`, `-s` | Skip pushing code, use the existing deployment |
| `--environment`, `-e` | Environment to debug (default: debug) |
| `--verbose`, `-v` | Show verbose debug output |
| `--outbound`, `-o` | Start an outbound phone call instead of a mic session |
| `--to-phone-number` | Phone number to call (required with `--outbound`) |
| `--from-phone-number` | Caller ID / originating phone number for outbound calls |
**What it does:**
1. Pushes your local code to the VoiceRun server (unless `--skip-push`)
2. Connects to the debug environment via WebSocket
3. Starts an interactive session where you can:
- Type messages to send to your agent
- See real-time debug events (transcripts, TTS, errors, etc.)
- Test your agent's responses
**Controls:**
| Key | Action |
|-----|--------|
| `Enter` | Send text message to agent |
| `Ctrl+C` | End the debug session |
**Example:**
```bash
# Push and debug
vr debug
# Debug without pushing (use existing deployment)
vr debug --skip-push
# Debug with verbose output
vr debug -v
# Debug specific environment
vr debug -e staging
# Start an outbound call
vr debug --outbound --to-phone-number "+15551234567"
# Outbound call with caller ID
vr debug --outbound --to-phone-number "+15551234567" --from-phone-number "+15559876543"
```
---
### `vr open`
Open the web interface to your deployed agent.
```bash
vr open
```
Requires `agent.lock` to exist (created after `vr push`). Opens your default browser to the agent's function page.
---
### `vr render`
Render VoiceRun templates and display the output.
```bash
vr render
```
**Options:**
| Option | Description |
|--------|-------------|
| `--values`, `-f` | Custom values file path |
| `--set`, `-s` | Override values (can be used multiple times) |
| `--output`, `-o` | Output format: `yaml` (default) or `json` |
| `--quiet`, `-q` | Only output templates, no validation messages |
**Example:**
```bash
# Render with default values
vr render
# Render with specific values file
vr render -f .voicerun/values.yaml
# Override specific values
vr render --set stt.model=deepgram-flux --set environment=production
# Output as JSON
vr render -o json
```
---
### `vr test`
Run tests for the voice agent project.
```bash
vr test
```
**Options:**
| Option | Description |
|--------|-------------|
| `--environment`, `-e` | Environment to fetch secrets from (e.g., development, production) |
| `--verbose`, `-v` | Run pytest in verbose mode |
| `--coverage`, `-c` | Run with coverage reporting |
| `--skip-install` | Skip dependency installation |
**What it does:**
1. Validates project structure
2. Installs project dependencies (unless `--skip-install`)
3. Optionally fetches secrets from the specified environment
4. Runs pytest with the specified options
**Example:**
```bash
# Run all tests
vr test
# Run specific test file
vr test tests/test_handler.py
# Run tests with development secrets
vr test -e development
# Run with verbose output and coverage
vr test -v -c
# Skip dependency installation
vr test --skip-install
# Pass extra arguments to pytest
vr test -- -k "test_name" -x
```
---
### `vr get`
List resources by type.
#### `vr get agents`
List all agents in your account.
```bash
vr get agents
```
Displays a table with agent name, ID, description, voice, and transport.
#### `vr get functions`
List all functions for a specific agent.
```bash
vr get functions <AGENT>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT` | Agent name or ID |
**Example:**
```bash
vr get functions my-agent
vr get functions 550e8400-e29b-41d4-a716-446655440000
```
#### `vr get environments`
List all environments for a specific agent.
```bash
vr get environments <AGENT>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT` | Agent name or ID |
**Example:**
```bash
vr get environments my-agent
```
#### `vr get secrets`
List secrets. Shows organization secrets, plus agent secrets if inside a voicerun project or `--agent` is specified.
```bash
vr get secrets
```
**Options:**
| Option | Description |
|--------|-------------|
| `--agent`, `-a` | Agent name or ID to also show agent-level secrets |
**Example:**
```bash
# List organization secrets
vr get secrets
# Include agent-specific secrets
vr get secrets --agent my-agent
```
#### `vr get phonenumbers`
List organization phone numbers.
```bash
vr get phonenumbers
```
Displays a table with phone number, friendly name, ID, area code, and country code.
#### `vr get telephony`
List organization telephony providers.
```bash
vr get telephony
```
Displays a table with provider name, ID, and provider type.
#### `vr get assignments`
List all phone number assignments for an agent.
```bash
vr get assignments <AGENT>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT` | Agent name or ID |
**Example:**
```bash
vr get assignments my-agent
```
Displays a table with phone number ID, environment ID, assignment ID, and created at timestamp.
---
### `vr describe`
Show detailed information about a specific resource.
#### `vr describe assignment`
Show detailed information about a phone number assignment.
```bash
vr describe assignment <AGENT> <ASSIGNMENT_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT` | Agent name or ID |
| `ASSIGNMENT_ID` | Assignment UUID |
**Example:**
```bash
vr describe assignment my-agent 550e8400-e29b-41d4-a716-446655440000
```
**Output includes:**
- Assignment details (ID, environment ID, phone number ID)
- Timestamps
#### `vr describe agent`
Show detailed information about an agent.
```bash
vr describe agent <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `NAME_OR_ID` | Agent name or UUID |
**Example:**
```bash
vr describe agent my-agent
```
**Output includes:**
- Basic information (ID, name, description)
- Voice & transport configuration
- Organization details
- Debug & tracing settings
- Timestamps
#### `vr describe function`
Show detailed information about a function.
```bash
vr describe function <AGENT> <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT` | Agent name or ID |
| `NAME_OR_ID` | Function name, display name, or UUID |
**Example:**
```bash
vr describe function my-agent main-handler
```
**Output includes:**
- Basic information (ID, name, display name)
- Code configuration (language, strategy, multifile)
- Code preview (if available)
- Test data (if configured)
- Timestamps
#### `vr describe environment`
Show detailed information about an environment.
```bash
vr describe environment <AGENT> <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT` | Agent name or ID |
| `NAME_OR_ID` | Environment name or UUID |
**Example:**
```bash
vr describe environment my-agent production
```
**Output includes:**
- Basic information (ID, name, phone number, debug flag)
- Speech-to-text (STT) configuration
- Recording settings
- Error handling configuration
- Audio processing settings
- VAD & advanced settings
- Timestamps
#### `vr describe secret`
Show detailed information about a secret.
```bash
vr describe secret <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `NAME_OR_ID` | Secret name or UUID |
**Options:**
| Option | Description |
|--------|-------------|
| `--agent`, `-a` | Agent name or ID (searches organization secrets first, then agent secrets) |
**Example:**
```bash
vr describe secret MY_API_KEY
vr describe secret MY_API_KEY --agent my-agent
```
#### `vr describe phonenumber`
Show detailed information about a phone number.
```bash
vr describe phonenumber <ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `ID` | Phone number ID |
**Example:**
```bash
vr describe phonenumber 550e8400-e29b-41d4-a716-446655440000
```
**Output includes:**
- Phone number, friendly name, area code, country code
- Telephony provider ID
- Timestamps
#### `vr describe telephony`
Show detailed information about a telephony provider.
```bash
vr describe telephony <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `NAME_OR_ID` | Telephony provider name or UUID |
**Example:**
```bash
vr describe telephony my-twilio
```
**Output includes:**
- Provider name, type, and ID
- Organization ID
- Timestamps
---
### `vr create`
Create resources.
#### `vr create assignment`
Assign a phone number to an agent environment.
```bash
vr create assignment <AGENT> <ENVIRONMENT> <PHONE_NUMBER_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT` | Agent name or ID |
| `ENVIRONMENT` | Environment name or ID |
| `PHONE_NUMBER_ID` | Organization phone number ID |
**Options:**
| Option | Description |
|--------|-------------|
| `--configure` | Configure the phone number with the telephony provider after assignment |
**Example:**
```bash
vr create assignment my-agent production 550e8400-e29b-41d4-a716-446655440000
vr create assignment my-agent production 550e8400-e29b-41d4-a716-446655440000 --configure
```
#### `vr create secret`
Create a secret. Omit `--agent` to create an organization-level secret.
```bash
vr create secret <NAME> <VALUE>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `NAME` | Secret name |
| `VALUE` | Secret value |
**Options:**
| Option | Description |
|--------|-------------|
| `--agent`, `-a` | Agent name or ID (omit for organization secret) |
**Example:**
```bash
# Create an organization secret
vr create secret MY_API_KEY sk-1234567890
# Create an agent-level secret
vr create secret MY_API_KEY sk-1234567890 --agent my-agent
```
#### `vr create phonenumber`
Create or purchase a phone number for the organization.
```bash
vr create phonenumber <TELEPHONY_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `TELEPHONY_ID` | Telephony provider ID |
**Options:**
| Option | Description |
|--------|-------------|
| `--purchase` | Purchase a new number from the telephony provider |
| `--area-code`, `-a` | Area code for the phone number |
| `--country-code`, `-c` | Country code (defaults to US) |
| `--friendly-name`, `-n` | Friendly name for the phone number |
| `--phone-number`, `-p` | Phone number to register (without `--purchase`) |
**Example:**
```bash
# Purchase a new phone number
vr create phonenumber <telephony-id> --purchase --area-code 415
# Register an existing phone number
vr create phonenumber <telephony-id> --phone-number "+15551234567" --friendly-name "Support Line"
```
#### `vr create telephony`
Create a telephony provider for the organization. Missing options will be prompted interactively.
```bash
vr create telephony
```
**Options:**
| Option | Description |
|--------|-------------|
| `--name`, `-n` | Name for the telephony provider |
| `--provider-type`, `-p` | Provider type (e.g., `twilio`, `telnyx`) |
| `--account-sid` | Twilio Account SID |
| `--api-key-sid` | Twilio API Key SID |
| `--api-key-secret` | Twilio API Key Secret |
| `--api-key` | Telnyx API Key |
**Example:**
```bash
# Interactive mode
vr create telephony
# Non-interactive with all options
vr create telephony --name "My Twilio" --provider-type twilio \
--account-sid AC123 --api-key-sid SK123 --api-key-secret secret123
```
---
### `vr delete`
Delete resources.
#### `vr delete assignment`
Delete a phone number assignment from an agent.
```bash
vr delete assignment <AGENT> <ASSIGNMENT_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT` | Agent name or ID |
| `ASSIGNMENT_ID` | Assignment ID |
**Example:**
```bash
vr delete assignment my-agent 550e8400-e29b-41d4-a716-446655440000
```
#### `vr delete agent`
Delete an agent.
```bash
vr delete agent <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `NAME_OR_ID` | Agent name or ID |
**Example:**
```bash
vr delete agent my-agent
```
#### `vr delete function`
Delete a function from an agent.
```bash
vr delete function <AGENT> <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT` | Agent name or ID |
| `NAME_OR_ID` | Function name, display name, or ID |
**Example:**
```bash
vr delete function my-agent main-handler
```
#### `vr delete environment`
Delete an environment from an agent.
```bash
vr delete environment <AGENT> <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `AGENT` | Agent name or ID |
| `NAME_OR_ID` | Environment name or ID |
**Example:**
```bash
vr delete environment my-agent staging
```
#### `vr delete secret`
Delete a secret. Searches organization secrets first, then agent secrets.
```bash
vr delete secret <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `NAME_OR_ID` | Secret name or ID |
**Options:**
| Option | Description |
|--------|-------------|
| `--agent`, `-a` | Agent name or ID |
**Example:**
```bash
vr delete secret MY_API_KEY
vr delete secret MY_API_KEY --agent my-agent
```
#### `vr delete phonenumber`
Delete or release an organization phone number.
```bash
vr delete phonenumber <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `NAME_OR_ID` | Phone number ID, phone number, or friendly name |
**Options:**
| Option | Description |
|--------|-------------|
| `--release` | Release the number back to the telephony provider |
**Example:**
```bash
# Delete from VoiceRun only
vr delete phonenumber "+15551234567"
# Release back to the telephony provider
vr delete phonenumber "+15551234567" --release
```
#### `vr delete telephony`
Delete an organization telephony provider.
```bash
vr delete telephony <NAME_OR_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `NAME_OR_ID` | Telephony provider name or ID |
**Example:**
```bash
vr delete telephony my-twilio
```
---
### `vr context`
Manage API contexts for different environments (development, staging, production).
#### `vr context list`
List all available contexts and show the current one.
```bash
vr context list
```
#### `vr context current`
Show the current context with API and frontend URLs.
```bash
vr context current
```
#### `vr context switch`
Switch to a different context.
```bash
vr context switch <NAME>
```
#### `vr context create`
Create a new user-defined context.
```bash
vr context create <NAME> <API_URL> <FRONTEND_URL>
```
**Example:**
```bash
vr context create staging https://api.staging.primvoices.com https://app.staging.primvoices.com
```
#### `vr context delete`
Delete a user-defined context.
```bash
vr context delete <NAME>
```
#### `vr context set-url`
Set a custom API URL for the current session.
```bash
vr context set-url <API_URL>
```
#### `vr context set-org`
Set the organization ID to operate under. Useful when your account belongs to multiple organizations.
```bash
vr context set-org <ORGANIZATION_ID>
```
**Arguments:**
| Argument | Description |
|----------|-------------|
| `ORGANIZATION_ID` | Organization ID to use (pass empty string to clear) |
**Example:**
```bash
# Set organization ID
vr context set-org org_123456
# Clear organization override (use default from session)
vr context set-org ""
```
## Project Structure
After running `vr init`, your project will have this structure:
```
my-agent/
├── handler.py # Main agent code (entry point)
├── README.md # Project documentation
├── requirements.txt # Python dependencies
└── .voicerun/ # Configuration directory
├── agent.yaml # Agent metadata and configuration
├── agent.lock # Created after vr push (tracks agent/function IDs)
├── values.development.yaml # Development environment values
├── values.production.yaml # Production environment values
└── templates/ # VoiceRun templates (optional)
└── deployment.yaml # Deployment configuration template
```
## Templates
### agent.yaml
Defines your agent's metadata:
```yaml
apiVersion: voicerun/v1
name: my-agent
description: "My voice agent description"
```
### handler.py
The main entry point for your agent. Must contain an `async def handler()` function:
```python
from primfunctions import handler as primhandler
from primfunctions.events import StartEvent, TextEvent, StopEvent, InterruptEvent
from primfunctions.actions import TextToSpeechEvent
from primfunctions.context import context
@primhandler
async def handler(event):
if isinstance(event, StartEvent):
yield TextToSpeechEvent(text="Hello! How can I help you?")
elif isinstance(event, TextEvent):
# Handle user speech transcription
user_text = event.text
yield TextToSpeechEvent(text=f"You said: {user_text}")
elif isinstance(event, StopEvent):
pass
elif isinstance(event, InterruptEvent):
pass
```
### deployment.yaml
Configures deployment settings using yaml and templating:
```yaml
apiVersion: voicerun/v1
kind: Deployment
metadata:
name: {{ .Agent.Name }}
spec:
env:
ENVIRONMENT: {{ .Values.environment }}
stt:
model: {{ .Values.sttModel }}
```
## Values Files
Values files provide environment-specific configuration that gets injected into your templates during rendering and deployment. They use templating syntax to separate configuration from code.
### Naming Convention
Values are usually stored in `.voicerun/` directory with a name like `values.yaml`. You can have as many values files as you like, though it is recommended that you use a single values file for each environment. For example:
```
.voicerun/
├── values.development.yaml
├── values.staging.yaml
└── values.production.yaml
```
When you run `vr deploy development`, the CLI automatically looks for `.voicerun/values.development.yaml`.
### Basic Structure
Values files are standard YAML files containing key-value pairs:
**values.development.yaml:**
```yaml
environment: development
sttModel: nova-3
logLevel: debug
apiTimeout: 30
```
**values.production.yaml:**
```yaml
environment: production
sttModel: deepgram-flux
logLevel: error
apiTimeout: 10
```
### Using Values in Templates
Reference values in your `deployment.yaml` using template syntax:
```yaml
apiVersion: voicerun/v1
kind: Deployment
metadata:
name: {{ .Agent.Name }}
spec:
env:
ENVIRONMENT: {{ .Values.environment }}
LOG_LEVEL: {{ .Values.logLevel }}
API_TIMEOUT: "{{ .Values.apiTimeout }}"
stt:
model: {{ .Values.sttModel }}
```
### Template Variables
Two namespaces are available in templates:
| Namespace | Description | Example |
|-----------|-------------|---------|
| `.Values` | Values from the values file | `{{ .Values.environment }}` |
| `.Agent` | Agent metadata from `agent.yaml` | `{{ .Agent.Name }}` |
### Nested Values
Values can be nested for better organization:
**values.production.yaml:**
```yaml
environment: production
stt:
model: deepgram-flux
language: en-US
endpointing: 500
recording:
enabled: true
redaction: true
features:
debugMode: false
metricsEnabled: true
```
Access nested values with dot notation:
```yaml
spec:
stt:
model: {{ .Values.stt.model }}
language: {{ .Values.stt.language }}
recording:
enabled: {{ .Values.recording.enabled }}
```
### Overriding Values
You can override values at deploy/render time using `--set`:
```bash
# Override a single value
vr deploy production --set sttModel=nova-3
# Override nested values
vr render --set stt.model=nova-3 --set recording.enabled=false
# Multiple overrides
vr deploy staging --set environment=staging-test --set logLevel=debug
```
### Custom Values Files
Use `-f` to specify a custom values file instead of the environment default:
```bash
# Use a custom values file
vr deploy production -f ./configs/custom-values.yaml
# Render with custom values
vr render -f ./test-values.yaml
```
### Preview Rendered Output
Before deploying, preview how your templates will render:
```bash
# Preview as YAML
vr render -f .voicerun/values.production.yaml
# Preview as JSON
vr render -f .voicerun/values.production.yaml -o json
# Dry-run deployment to see what would be sent
vr deploy production --dry-run
```
### Best Practices
1. **Keep secrets out of values files** - Use environment variables or secret management for sensitive data
2. **Use consistent key names** - Match key names across environment files for easier maintenance
3. **Document your values** - Add comments explaining what each value controls
4. **Version control values files** - Track changes to configuration alongside code
5. **Use dry-run before deploying** - Always preview changes with `--dry-run` before deploying to production
### Example: Complete Setup
**`.voicerun/values.development.yaml`:**
```yaml
# Development environment configuration
environment: development
# Speech-to-text settings
stt:
model: nova-3
language: en-US
endpointing: 300
# Feature flags
features:
debugMode: true
verboseLogging: true
# Timeouts (in seconds)
timeouts:
api: 30
speech: 10
```
**`.voicerun/values.production.yaml`:**
```yaml
# Production environment configuration
environment: production
# Speech-to-text settings
stt:
model: deepgram-flux
language: en-US
endpointing: 500
# Feature flags
features:
debugMode: false
verboseLogging: false
# Timeouts (in seconds)
timeouts:
api: 10
speech: 5
```
**`.voicerun/templates/deployment.yaml`:**
```yaml
apiVersion: voicerun/v1
kind: Deployment
metadata:
name: {{ .Agent.Name }}
spec:
env:
ENVIRONMENT: {{ .Values.environment }}
DEBUG_MODE: "{{ .Values.features.debugMode }}"
VERBOSE_LOGGING: "{{ .Values.features.verboseLogging }}"
API_TIMEOUT: "{{ .Values.timeouts.api }}"
stt:
model: {{ .Values.stt.model }}
language: {{ .Values.stt.language }}
endpointing:
timeout_ms: {{ .Values.stt.endpointing }}
```
**Deploy to each environment:**
```bash
# Deploy to development
vr deploy development
# Deploy to production
vr deploy production --yes
```
## Configuration
### Deployment Spec Fields
The following fields are allowed in `deployment.yaml` spec:
| Field | Description |
|-------|-------------|
| `env` | Environment variables for the agent |
| `stt` | Speech-to-text configuration (model, language, endpointing, vad, eot) |
| `recording` | Recording settings (enabled, location, redaction) |
| `errorFallback` | Fallback handler configuration (phone/webhook, thresholds) |
| `startupAudio` | Startup audio URL and settings |
| `webhook` | Webhook URL and secret |
| `region` | Execution region |
| `tracing` | Debug tracing enabled/disabled |
### STT Configuration Example
```yaml
spec:
stt:
model: nova-3
language: en-US
endpointing:
enabled: true
timeout_ms: 500
vad:
mode: auto
eagerness: 3
```
### Recording Configuration Example
```yaml
spec:
recording:
enabled: true
location: s3://my-bucket/recordings
redaction:
enabled: true
```
## Environment Variables
Override default settings with environment variables:
| Variable | Description |
|----------|-------------|
| `VOICERUN_API_URL` | Custom API URL |
| `VOICERUN_FRONTEND_URL` | Custom frontend URL |
| `DEBUG=1` | Enable request logging |
## Dependencies
Core dependencies:
- `typer` - CLI framework
- `requests` - HTTP client
- `rich` - Terminal formatting
- `pyyaml` - YAML parsing
- `websockets` - WebSocket client for debug sessions
- `jsonschema` - JSON schema validation
- `primfunctions` - VoiceRun SDK
## Links
- [VoiceRun Documentation](https://voicerun.com/docs)
- [Report Issues](https://github.com/VoiceRun/voicerun-cli/issues)
## License
MIT License
| text/markdown | null | VoiceRun <support@voicerun.com> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"black>=23.3.0",
"requests>=2.32.4",
"typer>=0.16.0",
"websocket-client>=1.6.0",
"websockets>=11.0.0",
"rich>=13.0.0",
"aiohttp>=3.8.6",
"loguru>=0.7.3",
"pyaudio>=0.2.11",
"numpy>=1.24.0",
"pygame-ce>=2.5.0",
"primfunctions>=0.1.13",
"g711>=1.6.5",
"pygame>=2.6.1",
"six>=1.17.0",
"pyy... | [] | [] | [] | [] | uv/0.8.15 | 2026-02-18T16:25:16.306427 | voicerun_cli-1.0.0.tar.gz | 125,103 | 5f/b7/b97a945fe68483506c2feb1f7a37461fbc23d99079b0ade8ece86b0d2722/voicerun_cli-1.0.0.tar.gz | source | sdist | null | false | 2e033f158e2e223f5f91e3c9e385ee7e | b57ba2ae7087a16c416b9da710ca64be24b3451e13db7e138e27881dbf66583a | 5fb7b97a945fe68483506c2feb1f7a37461fbc23d99079b0ade8ece86b0d2722 | null | [] | 240 |
2.4 | mapillary-tools | 0.14.7 | Mapillary Image/Video Import Pipeline | <!--
Copyright (c) Meta Platforms, Inc. and affiliates.
This source code is licensed under the BSD license found in the
LICENSE file in the root directory of this source tree.
-->
<p align="center">
<a href="https://github.com/mapillary/mapillary_tools/">
<img src="https://raw.githubusercontent.com/mapillary/mapillary_tools/main/docs/images/logo.png">
</a>
</p>
<p align="center">
<a href="https://pypi.org/project/mapillary_tools/"><img alt="PyPI" src="https://img.shields.io/pypi/v/mapillary_tools"></a>
<a href="https://github.com/mapillary/mapillary_tools/actions"><img alt="Actions Status" src="https://github.com/mapillary/mapillary_tools/actions/workflows/python-package.yml/badge.svg"></a>
<a href="https://github.com/mapillary/mapillary_tools/blob/main/LICENSE"><img alt="GitHub license" src="https://img.shields.io/github/license/mapillary/mapillary_tools"></a>
<a href="https://github.com/mapillary/mapillary_tools/stargazers"><img alt="GitHub stars" src="https://img.shields.io/github/stars/mapillary/mapillary_tools"></a>
<a href="https://pepy.tech/project/mapillary_tools"><img alt="Downloads" src="https://pepy.tech/badge/mapillary_tools"></a>
</p>
mapillary_tools is a command line tool that uploads geotagged images and videos to Mapillary.
```sh
# Install mapillary_tools
pip install mapillary_tools
# Process and upload images and videos in the directory
mapillary_tools process_and_upload MY_CAPTURE_DIR
# List all commands
mapillary_tools --help
```
<!--ts-->
- [Supported File Formats](#supported-file-formats)
- [Image Formats](#image-formats)
- [Video Formats](#video-formats)
- [Installation](#installation)
- [Standalone Executable](#standalone-executable)
- [Installing via pip](#installing-via-pip)
- [Installing on Android Devices](#installing-on-android-devices)
- [Usage](#usage)
- [Process and Upload](#process-and-upload)
- [Process](#process)
- [Upload](#upload)
- [Advanced Usage](#advanced-usage)
- [Local Video Processing](#local-video-processing)
- [Install FFmpeg](#install-ffmpeg)
- [Video Processing](#video-processing)
- [Geotagging with GPX](#geotagging-with-gpx)
- [New video geotagging features (experimental)](#new-video-geotagging-features-experimental)
- [Usage](#usage-1)
- [Examples](#examples)
- [Generic supported videos](#generic-supported-videos)
- [External GPX](#external-gpx)
- [Insta360 stitched videos](#insta360-stitched-videos)
- [Limitations of `--video_geotag_source`](#limitations-of---video_geotag_source)
- [Authenticate](#authenticate)
- [Examples](#examples-1)
- [Image Description](#image-description)
- [Zip Images](#zip-images)
- [Development](#development)
- [Setup](#setup)
- [Option 1: Using uv (Recommended)](#option-1-using-uv-recommended)
- [Option 2: Using pip with virtual environment](#option-2-using-pip-with-virtual-environment)
- [Running the code](#running-the-code)
- [Tests](#tests)
- [Code Quality](#code-quality)
- [Release and Build](#release-and-build)
<!--te-->
# Supported File Formats
mapillary_tools can upload both images and videos.
## Image Formats
mapillary_tools supports JPG/JEPG images (.jpg, .jpeg), with the following EXIF tags minimally required:
- GPS Longitude
- GPS Latitude
- Date/Time Original or GPS Date/Time
## Video Formats
mapillary_tools supports videos (.mp4, .360) that contain any of the following telemetry structures:
- [GPMF](https://github.com/gopro/gpmf-parser): mostly GoPro videos
- [GoPro HERO series](https://gopro.com/en/us/shop/cameras/hero11-black/CHDHX-111-master.html) (from 5 to 13)
- [GoPro MAX](https://gopro.com/en/us/shop/cameras/max/CHDHZ-202-master.html)
- [CAMM](https://developers.google.com/streetview/publish/camm-spec): an open-standard telemetry spec supported by a number of cameras
- [Insta360 Pro2](https://www.insta360.com/product/insta360-pro2/)
- [Insta360 Titan](https://www.insta360.com/product/insta360-titan)
- [Ricoh Theta X](https://theta360.com/en/about/theta/x.html)
- [Labpano](https://www.labpano.com/)
- and more...
- [BlackVue](https://blackvue.com/) videos
- [DR900S-1CH](https://shop.blackvue.com/product/dr900x-1ch-plus/)
- [DR900X Plus](https://shop.blackvue.com/product/dr900x-2ch-plus/)
# Installation
## Standalone Executable
1. Download the latest executable for your platform from the [releases](https://github.com/mapillary/mapillary_tools/releases).
2. Move the executable to your system `$PATH`
> **_NOTE:_** If you see the error "**mapillary_tools is damaged and can’t be opened**" on macOS, try to clear the extended attributes:
>
> ```
> xattr -c mapillary_tools
> ```
## Installing via pip
To install or upgrade to the latest stable version:
```sh
pip install --upgrade mapillary_tools
```
If you can't wait for the latest features in development, install it from GitHub:
```sh
pip install --upgrade git+https://github.com/mapillary/mapillary_tools
```
> **_NOTE:_** If you see "**Permission Denied**" error, try to run the command above with `sudo`, or install it in your
> local [virtualenv](#setup) (recommended).
### Installing on Android Devices
A command line program such as Termux is required. Installation can be done without root privileges. The following
commands will install Python 3, pip3, git, and all required libraries for mapillary_tools on Termux:
```sh
pkg install python git build-essential libgeos openssl libjpeg-turbo libexpat libexpat-static
pip install --upgrade pip wheel
pip install --upgrade mapillary_tools
```
Termux must access the device's internal storage to process and upload images. To do this, use the following command:
```sh
termux-setup-storage
```
Finally, on devices running Android 11, using a command line program, mapillary_tools will process images very slowly if
they are in shared internal storage during processing. It is advisable to first move images to the command line
program’s native directory before running mapillary_tools. For an example using Termux, if imagery is stored in the
folder `Internal storage/DCIM/mapillaryimages` the following command will move that folder from shared storage to
Termux:
```sh
mv -v storage/dcim/mapillaryimages mapillaryimages
```
# Usage
## Process and Upload
For most users, `process_and_upload` is the command to go:
```sh
# Process and upload all images and videos in MY_CAPTURE_DIR and its subfolders, and all videos under MY_VIDEO_DIR
mapillary_tools process_and_upload MY_CAPTURE_DIR MY_VIDEO_DIR/*.mp4
```
If any process error occurs, e.g. GPS not found in an image, mapillary_tools will exit with non-zero status code.
To ignore these errors and continue uploading the rest:
```sh
# Skip process errors and upload to the specified user and organization
mapillary_tools process_and_upload MY_CAPTURE_DIR MY_VIDEO_DIR/*.mp4 \
--skip_process_errors \
--user_name "my_username" \
--organization_key "my_organization_id"
```
The `process_and_upload` command will run the [`process`](#process) and the [`upload`](#upload) commands consecutively with combined required and optional arguments.
The command above is equivalent to:
```sh
mapillary_tools process MY_CAPTURE_DIR MY_VIDEO_DIR/*.mp4 \
--skip_process_errors \
--desc_path /tmp/mapillary_description_file.json
mapillary_tools upload MY_CAPTURE_DIR MY_VIDEO_DIR/*.mp4 \
--desc_path /tmp/mapillary_description_file.json \
--user_name "my_username" \
--organization_key "my_organization_id"
```
## Process
The `process` command is an intermediate step that extracts the metadata from images and videos,
and writes them in an [image description file](#image-description). Users should pass it to the [`upload`](#upload) command.
```sh
mapillary_tools process MY_CAPTURE_DIR MY_VIDEO_DIR/*.mp4
```
Duplicate check with custom distance and angle:
```sh
# Mark images that are 3 meters closer to its previous one as duplicates.
# Duplicates won't be uploaded
mapillary_tools process MY_CAPTURE_DIR \
--duplicate_distance 3 \
--duplicate_angle 360 # Set 360 to disable angle check
```
Split sequences with the custom cutoff distance or custom capture time gap:
```sh
# If two successive images are 100 meters apart,
# OR their capture times are 120 seconds apart,
# then split the sequence from there
mapillary_tools process MY_CAPTURE_DIR \
--offset_angle 90 \
--cutoff_distance 100 \
--cutoff_time 120 \
```
## Upload
After processing you should get the [image description file](#image-description). Pass it to the `upload` command to upload them:
```sh
# Upload processed images and videos to the specified user account and organization
mapillary_tools upload MY_CAPTURE_DIR \
--desc_path /tmp/mapillary_image_description.json \
--user_name "my_username" \
--organization_key "my_organization_id"
```
# Advanced Usage
## Local Video Processing
Local video processing samples a video into a sequence of sample images and ensures the images are geotagged and ready for uploading.
It gives users more control over the sampling process, for example, you can specify the sampling distance to control the density.
Also, the sample images have smaller file sizes than videos, hence saving bandwidth.
### Install FFmpeg
[FFmpeg](https://ffmpeg.org/) is required for local video processing.
You can download `ffmpeg` and `ffprobe` from [here](https://ffmpeg.org/download.html),
or install them with your favorite package manager.
### Video Processing
mapillary_tools first extracts the GPS track from the video's telemetry structure, and then locates video frames along the GPS track.
When all are located, it then extracts one frame (image) every 3 meters by default.
```sh
# Sample videos in MY_VIDEO_DIR and write the sample images in MY_SAMPLES with a custom sampling distance
mapillary_tools video_process MY_VIDEO_DIR MY_SAMPLES --video_sample_distance 5
# The command above is equivalent to
mapillary_tools sample_video MY_VIDEO_DIR MY_SAMPLES --video_sample_distance 5
mapillary_tools process MY_SAMPLES
```
To process and upload the sample images consecutively, run:
```sh
mapillary_tools video_process_and_upload MY_VIDEO_DIR MY_SAMPLES --video_sample_distance 5
# The command above is equivalent to
mapillary_tools video_process MY_VIDEO_DIR MY_SAMPLES --video_sample_distance 5 --desc_path=/tmp/mapillary_description.json
mapillary_tools upload MY_SAMPLES --desc_path=/tmp/mapillary_description.json
```
## Geotagging with GPX
If you use external GPS devices for mapping, you will need to geotag your captures with the external GPS tracks.
To geotag images with a GPX file, the capture time (extracted from EXIF tag "Date/Time Original" or "GPS Date/Time") is minimally required.
It is used to locate the images along the GPS tracks.
```sh
mapillary_tools process MY_IMAGE_DIR --geotag_source "gpx" --geotag_source_path MY_EXTERNAL_GPS.gpx
```
To geotag videos with a GPX file, video start time (video creation time minus video duration) is required to locate the sample images along the GPS tracks.
```sh
# Geotagging with GPX works with interval-based sampling only,
# the two options --video_sample_distance -1 --video_sample_interval 2 are therefore required
# to switch from the default distance-based sampling to the legacy interval-based sampling
mapillary_tools video_process MY_VIDEO_DIR \
--geotag_source "gpx" \
--geotag_source_path MY_EXTERNAL_GPS.gpx \
--video_sample_distance -1 --video_sample_interval 2
```
Ideally, the GPS device and the capture device should use the same clock to get the timestamps synchronized.
If not, as is often the case, the image locations will be shifted. To solve that, mapillary_tools provides an
option `--interpolation_offset_time N` that adds N seconds to image capture times for synchronizing the timestamps.
```sh
# The capture device's clock is 8 hours (i.e. -8 * 3600 = -28800 seconds) ahead of the GPS device's clock
mapillary_tools process MY_IMAGE_DIR \
--geotag_source "gpx" \
--geotag_source_path MY_EXTERNAL_GPS.gpx \
--interpolation_offset_time -28800
```
Another option `--interpolation_use_gpx_start_time` moves your images to align with the beginning of the GPS track.
This is useful when you can confirm that you start GPS recording and capturing at the same time, or with a known delay.
```sh
# Start capturing 2.5 seconds after start GPS recording
mapillary_tools video_process MY_VIDEO_DIR \
--geotag_source "gpx" \
--geotag_source_path MY_EXTERNAL_GPS.gpx \
--interpolation_use_gpx_start_time \
--interpolation_offset_time 2.5 \
--video_sample_distance -1 --video_sample_interval 2
```
## New video geotagging features (experimental)
As experimental features, mapillary_tools can now:
* Geotag videos from tracks recorded in GPX and NMEA files
* Invoke `exiftool` internally, if available on the system. `exiftool` can extract geolocation data from a wide
range of video formats, allowing us to support more cameras with less trouble for the end user.
* Try several geotagging sources sequentially, until proper data is found.
These features apply to the `process` command, which analyzes the video for direct upload instead of sampling it
into images. They are experimental and will be subject to change in future releases.
### Usage
The new video processing is triggered with the `--video_geotag_source SOURCE` option. It can be specified multiple times:
In this case, each source will be tried in turn, until one returns good quality data.
`SOURCE` can be:
1. the plain name of the source - one of `video, camm, gopro, blackvue, gpx, nmea, exiftool_xml, exiftool_runtime`
2. a JSON object that includes optional parameters
```json5
{
"source": "SOURCE",
"pattern": "FILENAME_PATTERN" // optional
}
```
PATTERN specifies how the data source file is named, starting from the video filename:
* `%f`: the full video filename
* `%g`: the video filename without extension
* `%e`: the video filename extension
Supported sources and their default pattern are:
* `video`: parse the video, in order, as `camm, gopro, blackvue`. Pattern: `%f`
* `camm`: parse the video looking for a CAMM track. Pattern: `%f`
* `gopro`: parse the video looking for geolocation in GoPro format. Pattern: `%f`
* `blackvue`: parse the video looking for geolocation in BlackVue format. Pattern: `%f`
* `gpx`: external GPX file. Pattern: `%g.gpx`
* `nmea`: external NMEA file. Pattern: `%g.nmea`
* `exiftool_xml`: external XML file generated by exiftool. Pattern: `%g.xml`
* `exiftool_runtime`: execute exiftool on the video file. Pattern: `%f`
Notes:
* `exiftool_runtime` only works if exiftool is installed on the system. You can find it at https://exiftool.org/ or through
your software manager. If exiftool is installed, but is not in the default execution path, it is
possible to specify its location by setting the environment variable `MAPILLARY_TOOLS_EXIFTOOL_PATH`.
* Pattern are case-sensitive or not depending on the filesystem - in Windows, `%g.gpx` will match both `basename.gpx`
and `basename.GPX`, in MacOs, Linux or other Unix systems no.
* If both `--video_geotag_source` and `--geotag_source` are specified, `--video_geotag_source` will apply to video files
and `--geotag_source` to image files.
### Examples
#### Generic supported videos
Process all videos in a directory, trying to parse them as CAMM, GoPro or BlackVue:
```sh
mapillary_tools process --video_geotag_source video VIDEO_DIR/
```
#### External GPX
Process all videos in a directory, taking geolocation data from GPX files. A video named `foo.mp4` will be associated
with a GPX file called `foo.gpx`.
```sh
mapillary_tools process --video_geotag_source gpx VIDEO_DIR/
```
#### Insta360 stitched videos
The videos to process have been stitched by Insta360 Studio; the geolocation data is in the original
videos in the parent directory, and there may be GPX files alongside the stitched video.
First look for GPX, then fallback to running exiftool against the original videos.
```sh
mapillary_tools process \
--video_geotag_source gpx \
--video_geotag_source '{"source": "exiftool_runtime", "pattern": "../%g.insv"}' \
VIDEO_DIR/
```
### Limitations of `--video_geotag_source`
**External geolocation sources will be aligned with the start of video, there is
currently no way of applying offsets or scaling the time.** This means, for instance, that GPX tracks must begin precisely
at the instant of the video, and that timelapse videos are supported only for sources `camm, gopro, blackvue`.
## Authenticate
The command `authenticate` will update the user credentials stored in the config file.
### Examples
Authenticate new user:
```sh
mapillary_tools authenticate
```
Authenticate for user `my_username`. If the user is already authenticated, it will update the credentials in the config:
```sh
mapillary_tools authenticate --user_name "my_username"
```
## Image Description
The output of the [`process`](#process) command is a JSON array of objects that describes metadata for each image or video.
The metadata is validated by the [image description schema](https://github.com/mapillary/mapillary_tools/blob/main/schema/image_description_schema.json).
Here is a minimal example:
```json
[
{
"MAPLatitude": 58.5927694,
"MAPLongitude": 16.1840944,
"MAPCaptureTime": "2021_02_13_13_24_41_140",
"filename": "/MY_IMAGE_DIR/IMG_0291.jpg"
},
{
"error": {
"type": "MapillaryGeoTaggingError",
"message": "Unable to extract GPS Longitude or GPS Latitude from the image"
},
"filename": "/MY_IMAGE_DIR/IMG_0292.jpg"
}
]
```
Users may create or manipulate the image description file before passing them to the [`upload`](#upload) command. Here are a few examples:
```sh
# Remove images outside the bounding box and map matching the rest images on the road network
mapillary_tools process MY_IMAGE_DIR | \
./filter_by_bbox.py 5.9559,45.818,10.4921,47.8084 | \
./map_match.py > /tmp/mapillary_image_description.json
# Upload the processed images
mapillary_tools upload MY_IMAGE_DIR --desc_path /tmp/mapillary_image_description.json
```
```sh
# Converts captures.csv to an image description file
./custom_csv_to_description.sh captures.csv | mapillary_tools upload MY_IMAGE_DIR --desc_path -
```
## Zip Images
When [uploading](#upload) an image directory, internally the `upload` command will zip sequences in the temporary
directory (`TMPDIR`) and then upload these zip files.
mapillary_tools provides `zip` command that allows users to specify where to store the zip files, usually somewhere with
faster IO or more free space.
```sh
# Zip processed images in MY_IMAGE_DIR and write zip files in MY_ZIPFILES
mapillary_tools zip MY_IMAGE_DIR MY_ZIPFILES
# Upload all the zip files (*.zip) in MY_ZIPFILES:
mapillary_tools upload --file_types zip MY_ZIPFILES
```
# Development
## Setup
Clone the repository:
```sh
git clone git@github.com:mapillary/mapillary_tools.git
cd mapillary_tools
```
### Option 1: Using uv (Recommended)
Use [uv](https://docs.astral.sh/uv/) - a fast Python package manager.
Install the project in development mode with all dependencies:
```sh
# Install the project and development dependencies
uv sync --group dev
# Activate the virtual environment
source .venv/bin/activate # On Windows: .venv\Scripts\activate
```
### Option 2: Using pip with virtual environment
Set up a virtual environment (recommended):
```sh
python -m venv .venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
```
Install the project in development mode:
```sh
# Install the project and all dependencies in editable mode
pip install -e .
# Install development dependencies
pip install --group dev
```
## Running the code
Run the code from the repository:
```sh
# If you have mapillary_tools installed in editable mode
mapillary_tools --version
# Alternatively
python -m mapillary_tools.commands --version
```
## Tests
Run tests:
```sh
# Test all cases
pytest -s -vv tests
# Or test a single case specifically
pytest -s -vv tests/unit/test_camm_parser.py::test_build_and_parse
```
## Code Quality
Run code formatting and linting:
```sh
# Format code with ruff
ruff format mapillary_tools tests
# Lint code with ruff
ruff check mapillary_tools tests
# Sort imports with usort
usort format mapillary_tools tests
# Type checking with mypy
mypy mapillary_tools
```
## Release and Build
```sh
# Assume you are releasing v0.9.1a2 (alpha2)
# Tag your local branch
# Use -f here to replace the existing one
git tag -f v0.9.1a2
# Push the tagged commit first if it is not there yet
git push origin
# Push ALL local tags (TODO: How to push a specific tag?)
# Use -f here to replace the existing tags in the remote repo
git push origin --tags -f
# The last step will trigger CI to publish a draft release with binaries built
# in https://github.com/mapillary/mapillary_tools/releases
```
| text/markdown | null | Mapillary <support@mapillary.com> | null | null | BSD | mapillary, gis, computer vision, street view | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming L... | [] | null | null | >=3.9 | [] | [] | [] | [
"appdirs<2.0.0,>=1.4.4",
"construct~=2.10.0",
"exifread~=3.0",
"gpxpy~=1.6.0",
"humanize>=4.12.3",
"jsonschema~=4.17.0",
"piexif~=1.1",
"pynmea2<2.0.0,>=1.12.0",
"requests[socks]<3.0.0,>=2.20.0",
"tqdm<5.0,>=4.0",
"typing-extensions>=4.12.2"
] | [] | [] | [] | [
"Homepage, https://github.com/mapillary/mapillary_tools",
"Repository, https://github.com/mapillary/mapillary_tools",
"Issues, https://github.com/mapillary/mapillary_tools/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:23:47.879478 | mapillary_tools-0.14.7.tar.gz | 144,476 | 1e/2b/dcfa208235ace616d111ca5e68b1b024cc60587d87e70d4e9cb0d33bf9c6/mapillary_tools-0.14.7.tar.gz | source | sdist | null | false | 98151afb547ceef28e31ca71153fbd66 | 5202de96c7b605dc2de19beabf54018c4df741d60fc7fff6fa88a0004de644c9 | 1e2bdcfa208235ace616d111ca5e68b1b024cc60587d87e70d4e9cb0d33bf9c6 | null | [
"LICENSE"
] | 261 |
2.4 | endabyss | 1.2.0 | Red Teaming and Web Bug Bounty Fast Endpoint Discovery Tool | # 🌊 EndAbyss



EndAbyss is a fast endpoint discovery tool that crawls websites to collect endpoints and parameters for bug bounty and red team operations.

## 🌟 Features
- **Red Team/Bug Bounty Support**: Useful for both red team operations and web bug bounty projects
- **Static/Dynamic Scanning**: Fast static scanning or Playwright-based dynamic scanning for modern frameworks
- **Endpoint Discovery**: Automatic collection of endpoints from HTML, JavaScript, and API responses
- **Parameter Extraction**: Automatic extraction of GET/POST parameters from forms and URLs
- **Directory Scanning**: Wordlist-based directory brute-forcing support
- **Pipeline Integration**: Supports integration with other tools using `-pipeurl`, `-pipeendpoint`, `-pipeparam`, `-pipejson` options
- **WAF Bypass Options**: Delay, random delay, rate limiting, and proxy support
- **Modular Design**: Can be imported and used as a Python module
## 🚀 Installation
**bash**
```bash
git clone https://github.com/arrester/endabyss.git
cd endabyss
pip install -r requirements.txt
pip install -e .
```
or
**Python**
```bash
pip install endabyss
```
For dynamic scanning mode, install Playwright browsers:
```bash
playwright install chromium
```
## 📖 Usage
### CLI Mode
**Basic Scan**
`endabyss -t http://example.com`
**Dynamic Scanning Mode**
`endabyss -t http://example.com -m dynamic`
**Directory Scanning**
`endabyss -t http://example.com -ds -w wordlist.txt`
**Pipeline Output**
`endabyss -t http://example.com -pipeurl` # Output URLs only
`endabyss -t http://example.com -pipeendpoint` # Output endpoints only
`endabyss -t http://example.com -pipeparam` # Output parameters only
`endabyss -t http://example.com -pipejson` # Output JSON format
**Pipeline Integration Example**
`endabyss -t http://example.com -pipeurl | sqlmap --batch`
### Integration with SubSurfer
Pipeline configuration for scanning endpoints with EndAbyss from web subdomains collected by SubSurfer:
**1. Basic Integration (Web Subdomains → Endpoint Collection)**
`subsurfer -t example.com -pipeweb | xargs -I {} endabyss -t {} -pipeurl`
**2. Save Results to File**
`subsurfer -t example.com -pipeweb | xargs -I {} endabyss -t {} -o results.txt`
**3. Integration with Dynamic Scan Mode**
`subsurfer -t example.com -pipeweb | xargs -I {} endabyss -t {} -m dynamic -pipeurl`
**4. Collect Detailed Information in JSON Format**
`subsurfer -t example.com -pipeweb | xargs -I {} endabyss -t {} -pipejson`
**5. Include Directory Scanning**
`subsurfer -t example.com -pipeweb | xargs -I {} endabyss -t {} -ds -w wordlist.txt -pipeurl`
### Using as a Python Module
**Basic Endpoint Scan**
```python
from endabyss.core.controller.controller import EndAbyssController
import asyncio
async def main():
controller = EndAbyssController(
target="http://example.com",
mode="static",
verbose=1,
depth=5
)
results = await controller.scan()
print(f"Found {len(results['endpoints'])} endpoints")
print(f"Found {len(results['forms'])} forms")
print(f"Found {len(results['parameters'])} parameter sets")
for param_data in results['parameters']:
url = param_data['url']
params = param_data.get('parameters', {})
param_str = '&'.join([f"{k}={v}" for k, v in params.items()])
print(f"{url}?{param_str} [{param_data['method']}]")
if __name__ == "__main__":
asyncio.run(main())
```
**Dynamic Scanning**
```python
from endabyss.core.controller.controller import EndAbyssController
import asyncio
async def main():
controller = EndAbyssController(
target="http://example.com",
mode="dynamic",
headless=True,
wait_time=3.0
)
results = await controller.scan()
for endpoint in results['endpoints']:
print(endpoint['url'])
if __name__ == "__main__":
asyncio.run(main())
```
**Result Save**
```python
from endabyss.core.controller.controller import EndAbyssController
import asyncio
async def main():
controller = EndAbyssController("http://example.com")
results = await controller.scan()
output_path = controller.get_output_path("results.json")
controller.save_results(results, output_path)
print(f"Results saved to: {output_path}")
if __name__ == "__main__":
asyncio.run(main())
```
## 🔧 Key Features from Reference Tools
EndAbyss incorporates key features from various reference tools:
- **Katana**: Deep crawling and endpoint discovery methodology
- **LinkFinder**: JavaScript endpoint extraction using regex patterns
- **ParamSpider**: Parameter extraction and URL cleaning techniques
- **SubSurfer**: CLI design, pipeline integration, and modular architecture
## 📋 Available Options
| Option | Description |
| ------------------- | ------------------------------------------- |
| `-t, --target` | Target URL or domain |
| `-tf, --targetfile` | File containing list of targets |
| `-m, --mode` | Scan mode: static (default) or dynamic |
| `-d, --depth` | Crawling depth (default: 5) |
| `-c, --concurrency` | Number of concurrent requests (default: 10) |
| `-ds, --dirscan` | Enable directory scanning |
| `-w, --wordlist` | Wordlist file for directory scanning |
| `--delay` | Delay between requests in seconds |
| `--random-delay` | Random delay range (e.g. 1-3) |
| `--proxy` | Proxy URL (HTTP/HTTPS/SOCKS5) |
| `--rate-limit` | Rate limit (requests per second) |
| `-pipeurl` | Output URLs only for pipeline |
| `-pipeendpoint` | Output endpoints only for pipeline |
| `-pipeparam` | Output parameters only for pipeline |
| `-pipejson` | Output JSON format for pipeline |
## 📋 Requirements
- Recommended: Python 3.13.0 or later
- aiohttp
- beautifulsoup4
- playwright (for dynamic scanning)
- rich
- requests
## 📝 License
MIT License
## 🤝 Contributions
Bug Report, Feature Suggestions, Issue Report
| text/markdown | arrester | arresterloyal@gmail.com | null | null | null | security, endpoint discovery, bug bounty, red team, web security, crawling | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"Topic :: Security",
"Topic :: Internet :: WWW/HTTP",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13... | [] | https://github.com/arrester/endabyss | null | >=3.9 | [] | [] | [] | [
"rich>=13.7.0",
"aiohttp>=3.9.1",
"beautifulsoup4>=4.12.2",
"dnspython>=2.4.2",
"pyyaml>=6.0.1",
"jsbeautifier>=1.14.0",
"playwright>=1.40.0",
"requests>=2.32.0",
"setuptools>=78.1.1"
] | [] | [] | [] | [
"Bug Reports, https://github.com/arrester/endabyss/issues",
"Source, https://github.com/arrester/endabyss",
"Documentation, https://github.com/arrester/endabyss#readme"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:22:11.479028 | endabyss-1.2.0.tar.gz | 26,579 | cb/3b/d995473d859ec33ac85ddfe6568ea085875ed80ee02d19e8c198a49c3020/endabyss-1.2.0.tar.gz | source | sdist | null | false | 73c89730c53a9e401fa7703c4e6ec6d6 | b555d2a353faf2c0e572b67543aaabe9b4b4d99649775cb9563461f65ab7ab05 | cb3bd995473d859ec33ac85ddfe6568ea085875ed80ee02d19e8c198a49c3020 | null | [
"LICENSE"
] | 285 |
2.4 | anam | 0.3.0 | Official Python SDK for Anam AI - Real-time AI avatar streaming | # Anam AI Python SDK
Official Python SDK for [Anam AI](https://anam.ai) - Real-time AI avatar streaming.
[](https://badge.fury.io/py/anam)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
## Installation
```bash
# Using uv (recommended)
uv add anam
# With optional display utilities (for testing)
uv add anam --extra display
# Using pip
pip install anam
# With optional display utilities (for testing)
pip install anam[display]
```
## Quick Start
```python
import asyncio
from anam import AnamClient
async def main():
# Create client with your API key and persona_id (for pre-defined personas)
client = AnamClient(
api_key="your-api-key",
persona_id="your-persona-id",
)
# Connect and stream
async with client.connect() as session:
print(f"Connected! Session: {session.session_id}")
# Consume video and audio frames concurrently
async def consume_video():
async for frame in session.video_frames():
img = frame.to_ndarray(format="rgb24") # numpy array (H, W, 3) in RGB format - use "bgr24" for OpenCV
print(f"Video: {frame.width}x{frame.height}")
async def consume_audio():
async for frame in session.audio_frames():
samples = frame.to_ndarray() # int16 samples (1D array, interleaved for stereo)
# Determine mono/stereo from frame layout
channel_type = "mono" if frame.layout.nb_channels == 1 else "stereo"
print(f"Audio: {samples.size} samples ({channel_type}) @ {frame.sample_rate}Hz")
# Run both streams concurrently until session closes
await asyncio.gather(
consume_video(),
consume_audio(),
)
asyncio.run(main())
```
## Features
- 🎥 **Real-time Audio/Video streaming** - Receive synchronized audio/video frames from the avatar (as PyAV AudioFrame/VideoFrame objects)
- 💬 **Two-way communication** - Send text messages (like transcribed user speech) and receive generated responses
- 📝 **Real-time transcriptions** - Receive incremental message stream events for user and persona text as it's generated
- 📚 **Message history tracking** - Automatic conversation history with incremental updates
- 🤖 **Audio-passthrough** - Send TTS generated audio input and receive rendered synchronized audio/video avatar
- 🗣️ **Direct text-to-speech** - Send text directly to TTS for immediate speech output (bypasses LLM processing)
- 🎤 **Real-time user audio input** - Send raw audio samples (e.g. from microphone) to Anam for processing (turnkey solution: STT → LLM → TTS → Avatar)
- 📡 **Async iterator API** - Clean, Pythonic async/await patterns for continuous stream of audio/video frames
- 🎯 **Event-driven API** - Simple decorator-based event handlers for discrete events
- 📝 **Fully typed** - Complete type hints for IDE support
- 🔒 **Server-side ready** - Designed for server-side Python applications (e.g. for backend pipelines)
## API Reference
### AnamClient
The main client class for connecting to Anam AI.
```python
from anam import AnamClient, PersonaConfig, ClientOptions
# Simple initialization for pre-defined personas - all other parameters are ignored except enable_audio_passthrough
client = AnamClient(
api_key="your-api-key",
persona_id="your-persona-id",
)
# Advanced initialization with full (ephemeral) persona config - ideal for programmatic configuration.
# Use avatar_id instead of persona_id.
client = AnamClient(
api_key="your-api-key",
persona_config=PersonaConfig(
avatar_id="your-avatar-id",
voice_id="your-voice-id",
llm_id="your-llm-id",
name="My Assistant",
system_prompt="You are a helpful assistant...",
avatar_model="cara-3",
language_code="en",
enable_audio_passthrough=False,
),
)
```
### Video and Audio Frames
Frames are **PyAV objects** (VideoFrame/AudioFrame) containing synchronized **decoded audio (PCM) and video (RGB) samples** from the avatar, delivered over WebRTC and extracted by aiortc. All PyAV frame attributes are accessible (samples, format, layout, etc.). Access the frames via **async iterators** and **run both iterators concurrently**, e.g. using `asyncio.gather()`:
```python
async with client.connect() as session:
async def process_video():
async for frame in session.video_frames():
img = frame.to_ndarray(format="rgb24") # RGB numpy array
# Process frame...
async def process_audio():
async for frame in session.audio_frames():
samples = frame.to_ndarray() # int16 samples
# Process frame...
# Both streams run concurrently
await asyncio.gather(process_video(), process_audio())
```
### User Audio Input
User audio input is real-time audio such as microphone audio.
User audio is 16-bit PCM samples, mono or stereo, with any sample rate. In order to process the audio correctly, the sample rate needs to be provided.
The audio is forwarded in real-time as a WebRTC audio track. In order to reduce latency, any audio provided before the WebRTC audio track is created will be dropped.
### TTS audio (Audio Passthrough)
TTS audio is generated by a TTS engine, and should be provided in chunks through the `send_audio_chunk` method. The audio can be a byte array or base64 encoded strings (the SDK will convert to base64). The audio is sent to the backend at maximum upload speed. Sample rate and channels need to be provided through the `AgentAudioInputConfig` object. When TTS audio finishes (e.g. at the end of a turn), call `end_sequence()` to signal completion. Without this, the backend keeps waiting for more chunks and the avatar will freeze.
For best performance, we suggest using 24kHz mono audio. The provided audio is returned in-sync with the avatar without any resampling. Sample rates lower than 24kHz will result in poor avatar performance. Sample rates higher than 24kHz might impact latency without any noticeable improvement in audio quality.
### Events
Register callbacks for connection and message events using the `@client.on()` decorator:
```python
from anam import AnamEvent, Message, MessageRole, MessageStreamEvent
@client.on(AnamEvent.CONNECTION_ESTABLISHED)
async def on_connected():
"""Called when the connection is established."""
print("✅ Connected!")
@client.on(AnamEvent.CONNECTION_CLOSED)
async def on_closed(code: str, reason: str | None):
"""Called when the connection is closed."""
print(f"Connection closed: {code} - {reason or 'No reason'}")
@client.on(AnamEvent.MESSAGE_STREAM_EVENT_RECEIVED)
async def on_message_stream_event(event: MessageStreamEvent):
"""Called for each incremental chunk of transcribed text or persona response.
This event fires for both user transcriptions and persona responses as they stream in.
This can be used for real-time captions or transcriptions.
"""
if event.role == MessageRole.USER:
# User transcription (from their speech)
if event.content_index == 0:
print(f"👤 User: ", end="", flush=True)
print(event.content, end="", flush=True)
if event.end_of_speech:
print() # New line when transcription completes
else:
# Persona response
if event.content_index == 0:
print(f"🤖 Persona: ", end="", flush=True)
print(event.content, end="", flush=True)
if event.end_of_speech:
status = "✓" if not event.interrupted else "✗ INTERRUPTED"
print(f" {status}")
@client.on(AnamEvent.MESSAGE_RECEIVED)
async def on_message(message: Message):
"""Called when a complete message is received (after end_of_speech).
This is fired after MESSAGE_STREAM_EVENT_RECEIVED with end_of_speech=True.
Useful for backward compatibility or when you only need complete messages.
"""
print(f"{message.role}: {message.content}")
@client.on(AnamEvent.MESSAGE_HISTORY_UPDATED)
async def on_message_history_updated(messages: list[Message]):
"""Called when the message history is updated (after a message completes).
The messages list contains the complete conversation history.
"""
print(f"📝 Conversation history: {len(messages)} messages")
for msg in messages:
print(f" {msg.role}: {msg.content[:50]}...")
```
### Session
The `Session` object is returned by `client.connect()` and provides methods for interacting with the avatar:
```python
async with client.connect() as session:
# Send a text message (simulates user speech)
await session.send_message("Hello, how are you?")
# Send text directly to TTS (bypasses LLM)
await session.talk("This will be spoken immediately")
# Stream text to TTS incrementally (for streaming scenarios)
await session.send_talk_stream(
content="Hello",
start_of_speech=True,
end_of_speech=False,
)
await session.send_talk_stream(
content=" world!",
start_of_speech=False,
end_of_speech=True,
)
# Interrupt the avatar if speaking
await session.interrupt()
# Get message history
history = client.get_message_history()
for msg in history:
print(f"{msg.role}: {msg.content}")
# Wait until the session ends
await session.wait_until_closed()
```
## Examples
### Save Video and Audio
```python
import cv2
import wave
import asyncio
from anam import AnamClient
client = AnamClient(api_key="...", persona_id="...")
video_writer = cv2.VideoWriter("output.mp4", ...)
audio_writer = wave.open("output.wav", "wb")
async def save_video(session):
async for frame in session.video_frames():
# Read frame as BGR for OpenCV VideoWriter
bgr_frame = frame.to_ndarray(format="bgr24")
video_writer.write(bgr_frame)
async def save_audio(session):
async for frame in session.audio_frames():
# Initialize writer on first frame
if audio_writer.getnframes() == 0:
audio_writer.setnchannels(frame.layout.nb_channels)
audio_writer.setsampwidth(2) # 16-bit
audio_writer.setframerate(frame.sample_rate)
# Write audio data (convert to int16 and get bytes)
audio_writer.writeframes(frame.to_ndarray().tobytes())
async with client.connect() as session:
# Record for 30 seconds
await asyncio.wait_for(
asyncio.gather(save_video(session), save_audio(session)),
timeout=30.0,
)
```
### Display Video with OpenCV
```python
import cv2
import asyncio
from anam import AnamClient
client = AnamClient(api_key="...", persona_id="...")
latest_frame = None
async def update_frame(session):
global latest_frame
async for frame in session.video_frames():
# Read frame as BGR for OpenCV display
latest_frame = frame.to_ndarray(format="bgr24")
async def main():
async with client.connect() as session:
# Start frame consumer
frame_task = asyncio.create_task(update_frame(session))
# Display loop
while True:
if latest_frame is not None:
cv2.imshow("Avatar", latest_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
frame_task.cancel()
asyncio.run(main())
```
## Configuration
### Environment Variables
```bash
export ANAM_API_KEY="your-api-key"
export ANAM_AVATAR_ID="your-avatar-id"
export ANAM_VOICE_ID="your-voice-id"
export ANAM_LLM_ID="your-llm-id"
```
### Client Options
```python
from anam import ClientOptions
options = ClientOptions(
api_base_url="https://api.anam.ai", # API base URL
api_version="v1", # API version
ice_servers=None, # Custom ICE servers for WebRTC delivery
)
```
### Persona types
There are two types of personas:
- Pre-defined personas: use `persona_id` only. Other parameters are ignored except `enable_audio_passthrough`.
- Ephemeral personas: use `avatar_id`, `voice_id`, `llm_id`, `avatar_model`, `system_prompt`, `language_code` and `enable_audio_passthrough`.
#### Pre-defined personas
Pre-defined personas are built in [lab.anam.ai](https://lab.anam.ai) and combine avatar, voice and LLM. They cannot be changed after creation.
They are quick to set up for demos but offer less flexibility for production use.
```python
client = AnamClient(
api_key="your-api-key",
persona_id="your-persona-id",
)
```
#### Ephemeral personas
Ephemeral personas give you full control over components at startup. Configure avatar, voice, LLM, and other options at [lab.anam.ai](https://lab.anam.ai) (avatars, voices, LLMs).
They are ideal for production environments where you need to control the components at startup.
```python
from anam import PersonaConfig
# Ephemeral: specify avatar_id, voice_id, and optionally llm_id, avatar_model
persona = PersonaConfig(
avatar_id="your-avatar-id", # From https://lab.anam.ai/avatars (do not use persona_id)
voice_id="your-voice-id", # From https://lab.anam.ai/voices
llm_id="your-llm-id", # From https://lab.anam.ai/llms (optional)
avatar_model="cara-3", # Video frame model (optional)
system_prompt="You are...", # See https://docs.anam.ai/concepts/prompting-guide
enable_audio_passthrough=False,
)
```
### Orchestration
Orchestration is the process of running a pipeline with different components to transform user audio into a response (STT -> LLM -> TTS -> Avatar).
Anam allows two types of orchestration:
- **Anam's orchestration**: Anam receives user audio (or text messages) and runs the pipeline, with a default or custom LLM.
- **Custom orchestration**: Anam's orchestration is bypassed by directly providing TTS audio. The TTS audio is passed through directly to the avatar, without being added to the context or message history. This can be achieved by setting `enable_audio_passthrough=True`. See [TTS audio (Audio Passthrough)](#tts-audio-audio-passthrough) for more details.
### LLM options
Anam's orchestration layer allows you to choose between default LLMs or running your own custom LLMs:
- **Default LLMs**: Use Anam-provided models when you do not run your own.
- **Custom LLMs**: Anam connects to your LLM server-to-server. Add and test the connection at [lab.anam.ai/llms](https://lab.anam.ai/llms).
- **`CUSTOMER_CLIENT_V1`**: Your LLM is not directly connected to Anam. Use `MESSAGE_STREAM_EVENT_RECEIVED` to forward messages and send responses via talk stream (or `enable_audio_passthrough=True` for TTS). Higher latency; useful for niche use cases but not recommended for general applications.
## Error Handling
```python
from anam import AnamError, AuthenticationError, SessionError
try:
async with client.connect() as session:
await session.wait_until_closed()
except AuthenticationError as e:
print(f"Invalid API key: {e}")
except SessionError as e:
print(f"Session error: {e}")
except AnamError as e:
print(f"Anam error [{e.code}]: {e.message}")
```
## Requirements
- Python 3.10+
- Dependencies are installed automatically:
- `aiortc` - WebRTC implementation
- `aiohttp` - HTTP client
- `websockets` - WebSocket client
- `numpy` - Array handling
- `pyav` - Video and audio handling
Optional for display utilities:
- `opencv-python` - Video display
- `sounddevice` - Audio playback
## License
MIT License - see [LICENSE](LICENSE) for details.
## Links
- [Anam AI Website](https://anam.ai)
- [Documentation](https://docs.anam.ai)
- [API Reference](https://docs.anam.ai/api-reference)
| text/markdown | null | Anam AI <support@anam.ai> | null | null | MIT | ai, anam, avatar, real-time, streaming, webrtc | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pytho... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp>=3.9.0",
"aiortc>=1.14.0",
"av>=16.0.1",
"numpy>=1.26.0",
"python-dotenv>=1.2.1",
"websockets>=12.0",
"mypy>=1.10.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.4.0; extra == \"dev\"",
"opencv-python>=4.9.0; extra == \"displ... | [] | [] | [] | [
"Homepage, https://www.anam.ai",
"Documentation, https://docs.anam.ai",
"Repository, https://github.com/anam-org/python-sdk",
"Issues, https://github.com/anam-org/python-sdk/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:22:07.100379 | anam-0.3.0.tar.gz | 28,567 | 02/f5/9004e58543fa57a189e5a851bd1d71e98c481afe7acf42def81e2ac99e68/anam-0.3.0.tar.gz | source | sdist | null | false | 8eade201e005cf7cff27ed602f6add7e | a2485eefdf74932b5898b613bd5eb13cc87a26d3dd46e25732c3ea7512c4ff6e | 02f59004e58543fa57a189e5a851bd1d71e98c481afe7acf42def81e2ac99e68 | null | [
"LICENSE"
] | 310 |
2.4 | skst-safe-build | 1.0.0 | A safe builder for falling back to setuptools when scikit_build_core fails due to a missing c compiler. | # Skst Safe Build
[](https://badge.fury.io/py/skst_safe_build)
[](https://opensource.org/licenses/MIT)
# skst_safe_build
A Python package for safely building and packaging CPP based Python projects. It provides tools and utilities to ensure that your build process works even if a C compiler is not available.
| text/markdown | null | Connor Makowski <conmak@mit.edu> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"setuptools>=61.0",
"scikit-build-core"
] | [] | [] | [] | [
"Homepage, https://github.com/connor-makowski/skst_safe_build",
"Bug Tracker, https://github.com/connor-makowski/skst_safe_build/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T16:21:57.304712 | skst_safe_build-1.0.0.tar.gz | 1,864 | e6/64/eac9b035a3d18729f1f3bd03191f839c32a81c9101a974a39955caa2b8d0/skst_safe_build-1.0.0.tar.gz | source | sdist | null | false | 05e8f15270cb645cb53f13d7c8517b74 | 99bcf0a9c0fb01329393bd1e40c22ca4331b75f9c7d9cdd97c8df3886dc826a4 | e664eac9b035a3d18729f1f3bd03191f839c32a81c9101a974a39955caa2b8d0 | MIT | [] | 279 |
2.2 | ztu-somemodelruntime-ez-rknn-async | 0.4.0 | RKNN async inference Python bindings | # ztu_somemodelruntime_ez_rknn_async
### A better RKNPU2 python API
--------
## 🚀 Feature Comparison
| Feature | This Project | Official SDK |
| :--- | :---: | :---: |
| **Model Loading & Basic Inference** | ✅ Supported | ✅ Supported |
| **Multi-core Tensor Parallel Inference** | ❌ Not Planned | ✅ Supported |
| **Multi-core Data Parallel Inference** | ✅ Supported | ❌ Not Supported |
| **Pipeline-based Async Inference** | ✅ Supported | ⚠️ Limited (Depth = 1) |
| **True Async Inference (Callback/Future)** | ✅ Supported | ❌ Not Supported |
| **Multi-batch Data Parallel Inference** | ✅ Supported | ⚠️ Limited (Fixed batch/4D only) |
| **Custom Operator Plugins** | ✅ Supported | ❌ Not Supported |
| **API Style** | 🚀 ORT-like (Easy migration) | ⚙️ Proprietary (Complex) |
| **Zero Dependencies** | ✅ Yes (NumPy only) | ❌ No |
| **Break Other Packages** | ✅ No | ⚠️ Yes (https://github.com/airockchip/rknn-toolkit2/issues/414) |
| **Open Source** | 🔓 Yes (AGPLv3) | 🔒 No |
| text/markdown | null | hallo1 <happyme5315@gmail.com> | null | null | GNU AFFERO GENERAL PUBLIC LICENSE
Version 3, 19 November 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU Affero General Public License is a free, copyleft license for
software and other kinds of works, specifically designed to ensure
cooperation with the community in the case of network server software.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
our General Public Licenses are intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
Developers that use our General Public Licenses protect your rights
with two steps: (1) assert copyright on the software, and (2) offer
you this License which gives you legal permission to copy, distribute
and/or modify the software.
A secondary benefit of defending all users' freedom is that
improvements made in alternate versions of the program, if they
receive widespread use, become available for other developers to
incorporate. Many developers of free software are heartened and
encouraged by the resulting cooperation. However, in the case of
software used on network servers, this result may fail to come about.
The GNU General Public License permits making a modified version and
letting the public access it on a server without ever releasing its
source code to the public.
The GNU Affero General Public License is designed specifically to
ensure that, in such cases, the modified source code becomes available
to the community. It requires the operator of a network server to
provide the source code of the modified version running there to the
users of that server. Therefore, public use of a modified version, on
a publicly accessible server, gives the public access to the source
code of the modified version.
An older license, called the Affero General Public License and
published by Affero, was designed to accomplish similar goals. This is
a different license, not a version of the Affero GPL, but Affero has
released a new version of the Affero GPL which permits relicensing under
this license.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU Affero General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Remote Network Interaction; Use with the GNU General Public License.
Notwithstanding any other provision of this License, if you modify the
Program, your modified version must prominently offer all users
interacting with it remotely through a computer network (if your version
supports such interaction) an opportunity to receive the Corresponding
Source of your version by providing access to the Corresponding Source
from a network server at no charge, through some standard or customary
means of facilitating copying of software. This Corresponding Source
shall include the Corresponding Source for any work covered by version 3
of the GNU General Public License that is incorporated pursuant to the
following paragraph.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the work with which it is combined will remain governed by version
3 of the GNU General Public License.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU Affero General Public License from time to time. Such new versions
will be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU Affero General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU Affero General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU Affero General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero General Public License as published
by the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If your software can interact with users remotely through a computer
network, you should also make sure that it provides a way for users to
get its source. For example, if your program is a web application, its
interface could display a "Source" link that leads users to an archive
of the code. There are many ways you could offer source, and different
solutions will be better for different programs; see section 13 for the
specific requirements.
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU AGPL, see
<https://www.gnu.org/licenses/>.
| null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Progra... | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.21"
] | [] | [] | [] | [
"Homepage, https://github.com/happyme531/ztu_somemodelruntime_ez_rknn_async",
"Repository, https://github.com/happyme531/ztu_somemodelruntime_ez_rknn_async",
"Issues, https://github.com/happyme531/ztu_somemodelruntime_ez_rknn_async/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:20:41.722252 | ztu_somemodelruntime_ez_rknn_async-0.4.0-cp39-cp39-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl | 2,735,647 | 46/5d/4755ff0856d8868545f15774494c084697753e8a03814dc9c45f8088acea/ztu_somemodelruntime_ez_rknn_async-0.4.0-cp39-cp39-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl | cp39 | bdist_wheel | null | false | c6ae70fb4bb5bb9dd966d1a4f5cb0178 | 309527cdcc7ac8b8aeb171beb8e5a46fc0e57186e4a71e9f7833bff3eb597271 | 465d4755ff0856d8868545f15774494c084697753e8a03814dc9c45f8088acea | null | [] | 480 |
2.4 | chuk-mcp-celestial | 0.3.4 | MCP server for astronomical and celestial data - moon phases, eclipses, sun/moon rise/set, planetary positions and events | # chuk-mcp-celestial
[](https://www.python.org/downloads/)
Astronomical & Celestial Data MCP Server
An MCP (Model Context Protocol) server providing moon phases, sun/moon rise/set
times, solar eclipse predictions, Earth's seasons, planetary positions/events,
and all-sky summaries from the US Navy Astronomical Applications Department API
and local Skyfield calculations.
> This is a demonstration project provided as-is for learning and testing purposes.
🌐 **[Try it now - Hosted version available!](https://celestial.chukai.io/mcp)** - No installation required.
## Features
🌙 **Comprehensive Celestial Data:**
- Moon phases with exact timing (New Moon, First Quarter, Full Moon, Last Quarter)
- Sun and moon rise/set/transit times for any location
- Solar eclipse predictions with local circumstances
- Earth's seasons (equinoxes, solstices, perihelion, aphelion)
- Planetary positions (altitude, azimuth, distance, magnitude, constellation, RA/Dec, elongation, visibility)
- Planetary events (rise, set, transit times)
⚡ **Flexible Providers:**
- **Navy API** - Authoritative US Navy data, all features
- **Skyfield** - 28x faster, offline calculations, research-grade accuracy (included by default)
- **Hybrid mode** - Mix providers per-tool (e.g., Skyfield for moon phases, Navy for eclipses)
- **S3 storage** - Cloud-based ephemeris storage via chuk-virtual-fs
- **Artifact storage** - Computation results persisted via chuk-artifacts (S3, filesystem, memory)
- **GeoJSON output** - Location-based responses follow GeoJSON Feature spec
🔒 **Type-Safe & Robust:**
- Pydantic v2 models for all responses - no dictionary goop!
- Enums for all constants - no magic strings!
- Full async/await support with httpx
- Comprehensive error handling
🔗 **Multi-Server Integration:**
- Works seamlessly with [time](https://time.chukai.io/mcp) and [weather](https://weather.chukai.io/mcp) servers
- Combine celestial + time + weather for comprehensive astronomical intelligence
- Answer complex questions like "Will the moon be visible tonight with current weather?"
✅ **Quality Assured:**
- 70%+ test coverage with pytest
- GitHub Actions CI/CD
- Automated releases to PyPI
- Type checking with mypy
- Code quality with ruff
## Installation
### Comparison of Installation Methods
| Method | Setup Time | Requires Internet | Updates | Best For |
|--------|-----------|-------------------|---------|----------|
| **Hosted** | Instant | Yes | Automatic | Quick testing, production use |
| **uvx** | Instant | Yes (first run) | Automatic | No local install, always latest |
| **Local** | 1-2 min | Only for install | Manual | Offline use, custom deployments |
### Option 1: Use Hosted Version (Recommended)
No installation needed! Use our public hosted version:
```json
{
"mcpServers": {
"celestial": {
"url": "https://celestial.chukai.io/mcp"
}
}
}
```
### Option 2: Install via uvx (No Installation Required)
Run directly without installing:
```json
{
"mcpServers": {
"celestial": {
"command": "uvx",
"args": ["chuk-mcp-celestial"]
}
}
}
```
### Option 3: Install Locally
```bash
# With pip
pip install chuk-mcp-celestial
# Or with uv (recommended)
uv pip install chuk-mcp-celestial
# Or with pipx (isolated installation)
pipx install chuk-mcp-celestial
```
Skyfield and NumPy are included by default — all 7 tools work out of the box.
**With S3 artifact storage (optional):**
```bash
pip install "chuk-mcp-celestial[s3]"
```
Then configure in your MCP client:
```json
{
"mcpServers": {
"celestial": {
"command": "chuk-mcp-celestial"
}
}
}
```
**Optional: Configure hybrid provider mode** (create `celestial.yaml`):
```yaml
# Use Skyfield for fast queries, Navy API for everything else
default_provider: navy_api
providers:
moon_phases: skyfield # 28x faster
earth_seasons: skyfield # 33x faster
```
## Quick Start
### Install
```bash
# No installation required (runs directly)
uvx chuk-mcp-celestial
# Or install from PyPI
uv pip install chuk-mcp-celestial
# Or install from source with dev tools
git clone https://github.com/chuk-ai/chuk-mcp-celestial.git
cd chuk-mcp-celestial
uv pip install -e ".[dev]"
```
### Claude Desktop Configuration
```json
{
"mcpServers": {
"celestial": {
"url": "https://celestial.chukai.io/mcp"
}
}
}
```
Or run locally:
```json
{
"mcpServers": {
"celestial": {
"command": "uvx",
"args": ["chuk-mcp-celestial"]
}
}
}
```
### Run
```bash
# STDIO mode (Claude Desktop, mcp-cli)
chuk-mcp-celestial stdio
# HTTP mode (API access)
chuk-mcp-celestial http --port 8080
```
## Supported Providers
| Provider | Speed | Offline | Features |
|----------|-------|---------|----------|
| **Navy API** (default) | ~700ms | No | Moon, sun/moon, eclipses, seasons. Official US government source. |
| **Skyfield** | ~25ms | Yes | Moon phases, seasons, planet position, planet events. JPL ephemeris. |
Both providers are included by default — no extras needed.
## Tools
### Moon Phases (1 tool)
| Tool | Description |
|------|-------------|
| `get_moon_phases` | Upcoming moon phases with exact timing (UT1) |
### Sun & Moon (1 tool)
| Tool | Description |
|------|-------------|
| `get_sun_moon_data` | Rise/set/transit times, twilight, moon phase, illumination for a location |
### Solar Eclipses (2 tools)
| Tool | Description |
|------|-------------|
| `get_solar_eclipse_by_date` | Local eclipse circumstances (type, magnitude, obscuration, timing) |
| `get_solar_eclipses_by_year` | All solar eclipses in a year |
### Earth Seasons (1 tool)
| Tool | Description |
|------|-------------|
| `get_earth_seasons` | Equinoxes, solstices, perihelion, aphelion for a year |
### Planets (2 tools)
| Tool | Description |
|------|-------------|
| `get_planet_position` | Altitude, azimuth, distance, magnitude, constellation, RA/Dec, elongation, visibility |
| `get_planet_events` | Rise, set, and transit times for a planet on a given date |
Supported: Mercury, Venus, Mars, Jupiter, Saturn, Uranus, Neptune, Pluto
### Sky Summary (1 tool)
| Tool | Description |
|------|-------------|
| `get_sky` | All-sky summary: every planet's position, moon phase, darkness check — one call |
## Environment Variables
| Variable | Required | Default | Description |
|----------|----------|---------|-------------|
| `CELESTIAL_PROVIDER` | No | `navy_api` | Default provider |
| `CELESTIAL_MOON_PHASES_PROVIDER` | No | default | Provider for moon phases |
| `CELESTIAL_EARTH_SEASONS_PROVIDER` | No | default | Provider for Earth seasons |
| `CELESTIAL_PLANET_POSITION_PROVIDER` | No | `skyfield` | Provider for planet position |
| `CELESTIAL_PLANET_EVENTS_PROVIDER` | No | `skyfield` | Provider for planet events |
| `CELESTIAL_SKY_PROVIDER` | No | `skyfield` | Provider for sky summary |
| `CELESTIAL_CONFIG_PATH` | No | — | Path to celestial.yaml |
| `SKYFIELD_STORAGE_BACKEND` | No | `s3` | Ephemeris storage: `local`, `s3`, `memory` |
| `SKYFIELD_S3_BUCKET` | No | `chuk-celestial-ephemeris` | S3 bucket for ephemeris |
| `NAVY_API_TIMEOUT` | No | `30.0` | Request timeout (seconds) |
## Hybrid Provider Mode
Create `celestial.yaml` to mix providers per-tool:
```yaml
default_provider: navy_api
providers:
moon_phases: skyfield # 28x faster, offline
earth_seasons: skyfield # 33x faster, offline
sun_moon_data: navy_api # Full features
solar_eclipse_date: navy_api
solar_eclipse_year: navy_api
planet_position: skyfield # Only provider with planet support
planet_events: skyfield
sky: skyfield # All-sky summary
```
## Development
```bash
# Install with dev dependencies
uv pip install -e ".[dev]"
# Run tests
make test
# Run tests with coverage
make test-cov
# Lint and format
make lint
make format
# All checks
make check
```
## Deployment
### Hosted Version
No installation required:
```json
{
"mcpServers": {
"celestial": {
"url": "https://celestial.chukai.io/mcp"
}
}
}
```
### Docker
```bash
make docker-build
make docker-run
```
### Fly.io
```bash
fly launch
fly secrets set AWS_ACCESS_KEY_ID=your_key AWS_SECRET_ACCESS_KEY=your_secret
make fly-deploy
```
## Cross-Server Workflows
chuk-mcp-celestial integrates with the broader chuk MCP ecosystem:
- **Celestial + Time** — Timezone-aware astronomy (sunrise in local time, time until next event)
- **Celestial + Weather** — Observation planning (moon phase + cloud cover forecast)
- **Celestial + Tides** — Coastal photography (golden hour + tide level)
- **Celestial + Weather** — Eclipse viewing (eclipse visibility + weather forecast)
```json
{
"mcpServers": {
"celestial": { "url": "https://celestial.chukai.io/mcp" },
"time": { "url": "https://time.chukai.io/mcp" },
"weather": { "url": "https://weather.chukai.io/mcp" }
}
}
```
## License
Apache License 2.0 - See LICENSE for details.
## Credits
- Built on chuk-mcp-server
- Data provided by [US Navy Astronomical Applications Department](https://aa.usno.navy.mil/)
## Links
- [US Navy API Documentation](https://aa.usno.navy.mil/data/api)
- [MCP Protocol](https://modelcontextprotocol.io/)
| text/markdown | null | null | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"chuk-mcp-server>=0.17",
"chuk-artifacts>=0.6.1",
"httpx>=0.27.0",
"pydantic>=2.0.0",
"chuk-virtual-fs>=0.3.1",
"skyfield>=1.48",
"numpy>=1.24.0",
"pytest>=8.0.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"black>=24.0.0; extra == \"dev\... | [] | [] | [] | [] | twine/6.1.0 CPython/3.11.11 | 2026-02-18T16:19:59.660695 | chuk_mcp_celestial-0.3.4.tar.gz | 70,293 | 35/72/195abe59887547e33cd0b200583b019fcae893e839f281a85745a1cb7ba0/chuk_mcp_celestial-0.3.4.tar.gz | source | sdist | null | false | d37df187d24fd6dc772ebb7dd3aff64d | 418416d8a229031c20d0925162e84348bb74aa39f9dba91b67bf9ca5071edb36 | 3572195abe59887547e33cd0b200583b019fcae893e839f281a85745a1cb7ba0 | null | [
"LICENSE"
] | 233 |
2.4 | city2graph | 0.2.4 | A Python library for Geospatial Graph Neural Networks and GeoAI for Urban Analytics with PyTorch Geometric. Convert geospatial data to graphs for spatiotemporal analysis, urban mobility studies, and more. | # City2Graph: GeoAI with Graph Neural Networks (GNNs) and Spatial Network Analysis
[](http://city2graph.net/latest/assets/logos/social_preview_city2graph.png)
**City2Graph** is a Python library for converting geospatial datasets into graph representations, providing an integrated interface for [GeoPandas](https://geopandas.org/), [NetworkX](https://networkx.org/), and [PyTorch Geometric](https://pytorch-geometric.readthedocs.io/en/latest/) across multiple domains (e.g. streets, transportations, OD matrices, POI proximities, etc.). It enables researchers and practitioners to seamlessly develop advanced GeoAI and geographic data science applications. For more information, please visit the [documentation](https://city2graph.net).
[](https://badge.fury.io/py/city2graph/) [](https://anaconda.org/conda-forge/city2graph/) [](https://pepy.tech/projects/city2graph) [](https://doi.org/10.5281/zenodo.15858845) [](https://github.com/c2g-dev/city2graph/blob/main/LICENSE)
[](https://anaconda.org/conda-forge/city2graph) [](https://codecov.io/gh/c2g-dev/city2graph) [](https://github.com/astral-sh/ruff)
## Features
[](http://city2graph.net/latest/assets/figures/scope.png)
- **Graph Construction for GeoAI:** Build graphs from diverse urban datasets, including buildings, streets, and land use, to power GeoAI and GNN applications.
- **Transportation Network Modeling:** Analyze public transport systems (buses, trams, trains) by constructing detailed transportation graphs with support of GTFS format.
- **Proximity and Contiguity Analysis:** Create graphs based on spatial proximity and adjacency for applications in urban planning and environmental analysis.
- **Mobility Flow Analysis:** Model and analyze urban mobility patterns from various data sources like bike-sharing, migration, and pedestrian flows.
- **PyTorch Geometric Integration:** Seamlessly convert geospatial data into PyTorch tensors for GNNs.
## Installation
### Using pip
#### Basic Installation
The simplest way to install City2Graph is via pip:
```bash
pip install city2graph
```
This installs the core functionality without PyTorch and PyTorch Geometric.
#### With PyTorch (CPU)
If you need the Graph Neural Networks functionality, install with the `cpu` option:
```bash
pip install "city2graph[cpu]"
```
This will install PyTorch and PyTorch Geometric with CPU support, suitable for development and small-scale processing.
#### With PyTorch + CUDA (GPU)
For GPU acceleration, you can install City2Graph with a specific CUDA version extra. For example, for CUDA 13.0:
```bash
pip install "city2graph[cu130]"
```
Supported CUDA versions are `cu126`, `cu128`, and `cu130`.
### Using conda
#### Basic Installation
You can also install City2Graph using conda from conda-forge:
```bash
conda install -c conda-forge city2graph
```
This installs the core functionality without PyTorch and PyTorch Geometric.
#### With PyTorch (CPU)
To use PyTorch and PyTorch Geometric with City2Graph installed from conda-forge, you need to manually add these libraries to your environment:
```bash
# Install city2graph
conda install -c conda-forge city2graph
# Then install PyTorch and PyTorch Geometric
conda install -c conda-forge pytorch pytorch_geometric
```
#### With PyTorch + CUDA (GPU)
For GPU support, you should select the appropriate PyTorch variant by specifying the version and CUDA build string. For example, to install PyTorch 2.7.1 with CUDA 12.8 support:
```bash
# Install city2graph
conda install -c conda-forge city2graph
# Then install PyTorch with CUDA support
conda install -c conda-forge pytorch=2.7.1=*cuda128*
conda install -c conda-forge pytorch_geometric
```
You can browse available CUDA-enabled builds on the [conda-forge PyTorch files page](https://anaconda.org/conda-forge/pytorch/files) and substitute the desired version and CUDA variant in your install command. Make sure that the versions of PyTorch and PyTorch Geometric you install are compatible with each other and with your system.
**⚠️ Important:** conda is not officially supported by PyTorch and PyTorch Geometric anymore, and only conda-forge distributions are available for them. We recommend using pip or uv for the most streamlined installation experience if you need PyTorch functionality.
## For Development
If you want to contribute to City2Graph, you can set up a development environment using `uv`.
```bash
# Install uv if you haven't already done it
curl -LsSf https://astral.sh/uv/install.sh | sh
# Clone the repository
git clone https://github.com/c2g-dev/city2graph.git
cd city2graph
# Install development dependencies with a PyTorch variant (e.g., cpu or cu128)
uv sync --extra cpu --group dev
```
You can then run commands within the managed environment:
```bash
# Add IPython kernel for interactive development
uv run ipython kernel install --name "your-env-name" --user
# Or start Jupyter Notebook
uv run jupyter notebook
```
### Development Environment
The development dependencies include:
- `ipython`: Enhanced interactive Python shell with Jupyter kernel support
- `jupyter` and `notebook`: For running Jupyter notebooks with project-specific kernel
- `isort`: Code formatting tools
- `pytest` and `pytest-cov`: Testing tools
The Jupyter kernel installation ensures that when you start Jupyter notebooks, you can select the "city2graph" kernel which has access to all your project dependencies in the correct virtual environment.
### Using Docker Compose
Before using Docker Compose, ensure you have Docker and Docker Compose installed on your system:
```bash
# Check Docker installation
docker --version
# Check Docker Compose installation
docker compose version
```
If these commands don't work, you need to install Docker first:
- For macOS: Install [Docker Desktop](https://www.docker.com/products/docker-desktop)
- For Linux: Follow the [installation instructions](https://docs.docker.com/engine/install/) for your specific distribution
- For Windows: Install [Docker Desktop](https://www.docker.com/products/docker-desktop)
Once Docker is installed, clone the repository and start the containers:
```bash
# Clone the repository
git clone https://github.com/yu-ta-sato/city2graph.git
cd city2graph
# Build and run in detached mode
docker compose up -d
# Access Jupyter notebook at http://localhost:8888
# Stop containers when done
docker compose down
```
You can customize the services in the `docker-compose.yml` file according to your needs.
## Citation
If you use City2Graph in your research, please cite it as follows:
```bibtex
@software{sato2025city2graph,
title = {City2Graph: Transform geospatial relations into graphs for spatial network analysis and Graph Neural Networks},
author = {Sato, Yuta},
year = {2025},
url = {https://github.com/c2g-dev/city2graph},
doi = {10.5281/zenodo.15858845},
}
```
You can also use the DOI to cite a specific version: [](https://doi.org/10.5281/zenodo.15858845)
Alternatively, you can find the citation information in the [CITATION.cff](CITATION.cff) file in this repository, which follows the Citation File Format standard.
## Contributing
We welcome contributions to the City2Graph project! To contribute:
1. **Fork and clone the repository:**
```bash
git clone https://github.com/<your-name>/city2graph.git
cd city2graph
git remote add upstream https://github.com/c2g-dev/city2graph.git
```
2. **Set up the development environment:**
```bash
uv sync --group dev --extra cpu
source .venv/bin/activate # On Windows: .venv\Scripts\activate
```
3. **Create a feature branch:**
```bash
git checkout -b feature/your-feature-name
```
4. **Make your changes and test:**
```bash
# Run pre-commit checks
uv run pre-commit run --all-files
# Run tests
uv run pytest --cov=city2graph --cov-report=html --cov-report=term
```
5. **Submit a pull request** with a clear description of your changes.
For detailed contributing guidelines, code style requirements, and documentation standards, please see our [Contributing Guide](docs/source/contributing.rst).
## Code Quality
We maintain strict code quality standards using:
- **Ruff**: For linting and formatting
- **mypy**: For static type checking
- **numpydoc**: For docstring style validation
All contributions must pass pre-commit checks before being merged.
## Documentation
City2Graph uses **MkDocs** for current documentation (v0.2.0+) and keeps **Sphinx** for legacy releases (v0.1.0–v0.1.7).
- **Legacy tags** (`v0.1.*`): Read the Docs builds `docs/source` via Sphinx.
- **Everything else** (branches / newer tags): Read the Docs builds via MkDocs (`mkdocs.yml`).
This is controlled in `.readthedocs.yaml` using `READTHEDOCS_VERSION_TYPE` and `READTHEDOCS_VERSION_NAME`.
[](https://www.liverpool.ac.uk/geographic-data-science/)
| text/markdown | null | Yuta Sato <y.sato@liverpool.ac.uk> | null | null | BSD-3-Clause | Digital Twin, GNNs, GeoAI, Geographic Data Science, Geospatial Analysis, Geospatial Foundation Models, Graph Neural Networks, Graph Representation Learning, PyTorch Geometric, Spatial Data Science, Spatial Knowledge Graphs, Spatiotemporal Analysis, Transportation Networks, Urban Analytics, Urban Informatics, Urban Mobility, Urban Planning and Design | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Languag... | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"geopandas>=1.1.1",
"geopy>=2.4.0",
"libpysal>=4.12.1",
"momepy",
"networkx>=2.8",
"osmnx>=2.0.3",
"overturemaps>=0.18.1",
"rustworkx>=0.17.1",
"scipy>=1.10.0",
"shapely>=2.1.0",
"torch-geometric>=2.6.1; extra == \"cpu\"",
"torch>=2.9.0; extra == \"cpu\"",
"torchvision>=0.24.0; extra == \"cp... | [] | [] | [] | [
"Homepage, https://github.com/c2g-dev/city2graph",
"Documentation, https://city2graph.net",
"Bug Tracker, https://github.com/c2g-dev/city2graph/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T16:19:23.825877 | city2graph-0.2.4.tar.gz | 96,736,246 | 72/2a/006e5920f45de29e34256525ed384813188b48765f7b735df76fa537e8b9/city2graph-0.2.4.tar.gz | source | sdist | null | false | 88ff245db663f40cc925a73ef33232fe | 0b936feb12d105853215140c1ebbe54d552f68c776d6c034e0bd9bb188390b56 | 722a006e5920f45de29e34256525ed384813188b48765f7b735df76fa537e8b9 | null | [
"LICENSE"
] | 282 |
2.4 | audio2sub | 0.2.1 | Transcribe media files to SRT subtitles. | # Audio2Sub
[](https://pypi.org/project/audio2sub/)
[](https://github.com/Xavier-Lam/audio2sub/actions/workflows/ci.yml)
[](https://hub.docker.com/r/xavierlam/audio2sub)
**Audio2Sub** is an all-in-one subtitle toolkit that helps you automatically generate, translate, and synchronize subtitles using AI. Whether you need to transcribe audio to subtitles, translate subtitles into another language, or fix out-of-sync subtitle timing, Audio2Sub has you covered.
The toolkit includes three command-line tools:
- **audio2sub** — Automatically transcribe audio from video or audio files and generate `.srt` subtitles. Uses FFmpeg for media handling, [Silero VAD](https://github.com/snakers4/silero-vad) for voice activity detection, and multiple transcription backends.
- **subtranslator** — Translate subtitle files from one language to another using AI. Supports translating between any language pair with backends like Google Gemini, Grok, and OpenAI.
- **subaligner** — Synchronize and align subtitle timing to match a reference subtitle. Ideal for fixing out-of-sync subtitles or aligning translated subtitles to the original timing, even when the subtitles are in different languages.
## Installation
Before installing, you must have [FFmpeg](https://ffmpeg.org/download.html) installed and available in your system's PATH.
You can install Audio2Sub using `pip`. The default installation includes the `faster_whisper` backend.
```bash
pip install audio2sub[faster_whisper]
```
> **You have to choose a transcription backend to install**, or you will get an error about missing dependencies when you run the program.
To install with a specific transcription backend, see the table in the [Backends](#backends) section below.
To install with subtitle translation and alignment support:
```bash
# Install with subtitle translator support (Gemini + Grok + OpenAI)
pip install audio2sub[subtranslator]
# Install with subtitle aligner support (Gemini + Grok + OpenAI)
pip install audio2sub[subaligner]
# Install everything
pip install audio2sub[all]
```
## Usage
### Basic Examples
```bash
audio2sub my_video.mp4 -o my_video.srt --lang en
```
This command will transcribe the audio from `my_video.mp4` into English and save the subtitles to `my_video.srt`.
**Notes:**
* **First-Time Use**: The first time you run the program, it will download the necessary transcription models. This may take some time and require significant disk space.
* **CUDA**: Performance significantly degraded without CUDA when using whisper-based local models. The program will raise a warning if CUDA is not available when it starts. If your system has a compatible GPU, install the [CUDA Toolkit](https://developer.nvidia.com/cuda-toolkit-archive) first. If you are sure CUDA has been installed correctly and still get the warning, you may need to [reinstall a compatible PyTorch version manually](https://pytorch.org/get-started/locally/). The reinstallation of PyTorch may break other dependencies if you choose a different version than what you currently have. In this case, you may need to reinstall those according to the warnings shown.
### Using a Different Transcriber
Use the `-t` or `--transcriber` flag to select a different backend.
```bash
audio2sub my_audio.wav -o my_audio.srt --lang en -t whisper --model medium
```
Each transcriber has its own options. To see them, use `--help` with the transcriber specified.
```bash
audio2sub -t faster_whisper --help
```
## Tools
### subtranslator — AI Subtitle Translator
Translate subtitle files between languages while preserving timing and formatting. Supports Gemini, Grok, and OpenAI backends.
To use the tool, you need to install the package by running `pip install audio2sub[subtranslator]` to get the necessary dependencies.
#### Basic Example
```bash
# Translate Chinese subtitles to English using the default backend (Gemini)
subtranslator my_video_zh.srt -s zh -d en -o my_video_en.srt
# Use OpenAI as the translation backend
subtranslator my_video_zh.srt -s zh -d en -o my_video_en.srt -t openai
```
### subaligner — AI Subtitle Synchronization & Alignment Tool
Automatically align subtitle timing to a reference subtitle or an audio transcription, even across different languages. Use this to fix out-of-sync subtitles or adapt timing between video versions.
Don't have a reference subtitle? No problem. Use **audio2sub** to transcribe your video and generate a reference subtitle file, then use subaligner to align your existing subtitle to match the generated timing.
To use the tool, you need to install the package by running `pip install audio2sub[subaligner]` to get the necessary dependencies.
#### Basic Example
```bash
# Align Chinese subtitles using English reference timing
subaligner -i chinese.srt -r english_reference.srt -o output.srt --src-lang zh --ref-lang en
# Use OpenAI backend
subaligner -i chinese.srt -r english_reference.srt -o output.srt -a openai
```
### Pipelining Tools Together
Audio2Sub's three tools can be chained together to create powerful subtitle workflows. Here are some common pipeline patterns:
#### Transcribe and Translate
Generate subtitles from a video, then translate them to another language:
```bash
audio2sub my_video.mp4 -o my_video_en.srt --lang en && subtranslator my_video_en.srt -s en -d es -o my_video_es.srt
```
#### Generate Reference for Alignment
Create a reference subtitle from your video, then align an existing subtitle to match:
```bash
audio2sub my_video_bluray.mp4 -o reference.srt --lang en && subaligner -i existing_subtitle.srt -r reference.srt -o aligned.srt --src-lang zh --ref-lang en
```
## Docker
Audio2Sub provides official Docker images for easy deployment without managing dependencies.
### Quick Start
```bash
# audio2sub: Transcribe with GPU support (recommended)
docker run --rm --gpus all -v "$(pwd):/media" xavierlam/audio2sub \
my_video.mp4 -o my_video.srt --lang en
# audio2sub: Without GPU support, whisper backend
docker run --rm -v "$(pwd):/media" xavierlam/audio2sub:whisper \
my_video.mp4 -o my_video.srt --lang en
# subtranslator: Translate subtitles
docker run --rm -v "$(pwd):/media" \
-e GEMINI_API_KEY=your_api_key_here \
xavierlam/subtranslator \
my_video_zh.srt -s zh -d en -o my_video_en.srt
# subaligner: Align subtitle timing
docker run --rm -v "$(pwd):/media" \
-e GEMINI_API_KEY=your_api_key_here \
xavierlam/subaligner \
-i chinese.srt -r english_ref.srt -o output.srt --src-lang zh --ref-lang en
```
Use `--gpus all` to enable GPU support, use different tags to select different backends.
### Pipeline Examples
The same workflows work seamlessly in Docker:
```bash
# Transcribe and translate in Docker
docker run --rm --gpus all -v "$(pwd):/media" xavierlam/audio2sub \
my_video.mp4 -o en.srt --lang en && \
docker run --rm -v "$(pwd):/media" -e GEMINI_API_KEY=$GEMINI_API_KEY xavierlam/subtranslator \
en.srt -s en -d zh -o zh.srt
# Generate reference and align
docker run --rm --gpus all -v "$(pwd):/media" xavierlam/audio2sub \
my_video.mp4 -o reference.srt --lang en && \
docker run --rm -v "$(pwd):/media" -e GEMINI_API_KEY=$GEMINI_API_KEY xavierlam/subaligner \
-i my_subtitle.srt -r reference.srt -o aligned.srt --src-lang zh --ref-lang en
```
### Available Images
#### audio2sub (Speech-to-Text Transcription)
| Image Tag | Backend | Description |
|-----------|---------|-------------|
| `xavierlam/audio2sub:latest` | faster-whisper | Recommended (same as faster-whisper) |
| `xavierlam/audio2sub:faster-whisper` | faster-whisper | Fast CTranslate2-based Whisper |
| `xavierlam/audio2sub:whisper` | whisper | Original OpenAI Whisper |
| `xavierlam/audio2sub:gemini` | gemini | Google Gemini API |
#### subtranslator (Subtitle Translation)
| Image Tag | Description |
|-----------|-------------|
| `xavierlam/subtranslator:latest` | AI subtitle translator with Gemini, Grok and OpenAI support |
#### subaligner (Subtitle Alignment)
| Image Tag | Description |
|-----------|-------------|
| `xavierlam/subaligner:latest` | AI subtitle aligner with Gemini, Grok and OpenAI support |
For detailed Docker documentation, GPU setup, and troubleshooting, see [docker/README.md](docker/README.md).
## Backends
### Transcription Backends (audio2sub)
Audio2Sub supports the following transcription backends.
| Backend Name | Description |
| --- | --- |
| `faster_whisper` | A faster reimplementation of Whisper using CTranslate2. See [Faster Whisper](https://github.com/guillaumekln/faster-whisper). This is the default backend. |
| `whisper` | The original speech recognition model by OpenAI. See [OpenAI Whisper](https://github.com/openai/whisper). |
| `gemini` | Google's Gemini model via their API. Requires a `GEMINI_API_KEY` environment variable or `--api-key` argument.|
You should use `pip install audio2sub[<backend>]` to install the desired backend support and use the corresponding transcriber with the `-t` flag.
### Translation & Alignment Backends (subtranslator & subaligner)
Both the subtitle translator and subtitle aligner share the same set of AI backends.
| Backend Name | Description | API Key Env Var |
| --- | --- | --- |
| `gemini` | Google's Gemini model. Default backend. | `GEMINI_API_KEY` |
| `grok` | xAI's Grok model (OpenAI-compatible API). | `GROK_API_KEY` |
| `openai` | OpenAI's GPT models. | `OPENAI_API_KEY` |
Install with `pip install audio2sub[<backend>]` to get specific backend support. Or you can install with `pip install audio2sub[subtranslator]` or `pip install audio2sub[subaligner]` to get all supported backends.
> **Note**: I am not able to get an *OpenAI* API key to test the *OpenAI* backend, I don't know if it works as expected.
## Contributing
Contributions are welcome! Please open an issue or submit a pull request on the [GitHub repository](https://github.com/Xavier-Lam/audio2sub).
| text/markdown | Xavier-Lam | xavierlam7@hotmail.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Languag... | [] | https://github.com/Xavier-Lam/audio2sub | null | >=3.9 | [] | [] | [] | [
"pysrt>=1.1.2",
"tqdm",
"ffmpeg-python>=0.2.0; extra == \"faster-whisper\"",
"torchaudio>=2.1.0; extra == \"faster-whisper\"",
"torch>=2.1.0; extra == \"faster-whisper\"",
"onnxruntime<2,>=1.14; extra == \"faster-whisper\"",
"faster-whisper>=1.0.1; extra == \"faster-whisper\"",
"ffmpeg-python>=0.2.0; ... | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-18T16:19:10.140998 | audio2sub-0.2.1.tar.gz | 29,216 | 75/5b/7aa36bd8e103b74d25a3b6746e3ebc4e20648fc0d88572ccf539db75d057/audio2sub-0.2.1.tar.gz | source | sdist | null | false | 95cb7c69decab39bc6fccf43a3916596 | b5b39515f4da99579328ce4d32365f1bb74fc3db3fb37bb5be9a53402cc4bc4d | 755b7aa36bd8e103b74d25a3b6746e3ebc4e20648fc0d88572ccf539db75d057 | null | [
"LICENSE"
] | 276 |
2.3 | tavern | 3.2.0 | Simple testing of RESTful APIs | # Easier API testing with Tavern
[](https://pypi.org/project/tavern/)
[](https://tavern.readthedocs.io/en/latest/)

Tavern is a pytest plugin, command-line tool, and Python library for
automated testing of APIs, with a simple, concise, and flexible
YAML-based syntax. It's very simple to get started, and highly
customisable for complex tests. Tavern supports testing RESTful APIs,
MQTT based APIs, and gRPC services.
The best way to use Tavern is with
[pytest](https://docs.pytest.org/en/latest/). Tavern comes with a
pytest plugin so that literally all you have to do is install pytest and
Tavern, write your tests in `.tavern.yaml` files and run pytest. This
means you get access to all of the pytest ecosystem and allows you to do
all sorts of things like regularly run your tests against a test server
and report failures or generate HTML reports.
You can also integrate Tavern into your own test framework or continuous
integration setup using the Python library, or use the command line
tool, `tavern-ci` with bash scripts and cron jobs.
To learn more, check out the [examples](https://taverntesting.github.io/examples) or the complete
[documentation](https://taverntesting.github.io/documentation). If you're interested in contributing
to the project take a look at the [GitHub
repo](https://github.com/taverntesting/tavern).
## Why Tavern
Choosing an API testing framework can be tough. Tavern was started in 2017 to address some of our concerns with other
testing frameworks.
In short, we think the best things about Tavern are:
### It's Lightweight.
Tavern is a small codebase which uses pytest under the hood.
### Easy to Write, Easy to Read and Understand.
The yaml syntax allows you to abstract what you need with anchors, whilst using `pytest.mark` to organise your tests.
Your tests should become more maintainable as a result.
### Test Anything
From the simplest API test through to the most complex of requests, tavern remains readable and easy to extend. We're
aiming for developers to not need the docs open all the time!
### Extensible
Almost all common test usecases are covered, but for everything else it's straightforward to drop in to python/pytest to
extend. Use fixtures, hooks, and things you already know.
### Growing Ecosystem
Tavern is still in active development and is used by 100s of companies.
## Quickstart
First up run `pip install tavern`.
Then, let's create a basic test, `test_minimal.tavern.yaml`:
```yaml
---
# Every test file has one or more tests...
test_name: Get some fake data from the JSON placeholder API
# ...and each test has one or more stages (e.g. an HTTP request)
stages:
- name: Make sure we have the right ID
# Define the request to be made...
request:
url: https://jsonplaceholder.typicode.com/posts/1
method: GET
# ...and the expected response code and body
response:
status_code: 200
json:
id: 1
userId: 1
title: "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"
body: "quia et suscipit\nsuscipit recusandae consequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto"
```
This file can have any name, but if you intend to use Pytest with
Tavern, it will only pick up files called `test_*.tavern.yaml`.
This can then be run like so:
```bash
$ pip install tavern[pytest]
$ py.test test_minimal.tavern.yaml -v
=================================== test session starts ===================================
platform linux -- Python 3.5.2, pytest-3.4.2, py-1.5.2, pluggy-0.6.0 -- /home/taverntester/.virtualenvs/tavernexample/bin/python3
cachedir: .pytest_cache
rootdir: /home/taverntester/myproject, inifile:
plugins: tavern-0.7.2
collected 1 item
test_minimal.tavern.yaml::Get some fake data from the JSON placeholder API PASSED [100%]
================================ 1 passed in 0.14 seconds =================================
```
It is strongly advised that you use Tavern with Pytest - not only does
it have a lot of utility to control discovery and execution of tests,
there are a huge amount of plugins to improve your development
experience. If you absolutely can't use Pytest for some reason, use the
`tavern-ci` command line interface:
```bash
$ pip install tavern
$ tavern-ci --stdout test_minimal.tavern.yaml
2017-11-08 16:17:00,152 [INFO]: (tavern.core:55) Running test : Get some fake data from the JSON placeholder API
2017-11-08 16:17:00,153 [INFO]: (tavern.core:69) Running stage : Make sure we have the right ID
2017-11-08 16:17:00,239 [INFO]: (tavern.core:73) Response: '<Response [200]>' ({
"userId": 1,
"id": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
"json": "quia et suscipit\nsuscipit recusandae consequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto"
})
2017-11-08 16:17:00,239 [INFO]: (tavern.printer:9) PASSED: Make sure we have the right ID [200]
```
## Why not Postman, Insomnia or pyresttest etc?
Tavern is a focused tool which does one thing well: automated testing of
APIs.
**Postman** and **Insomnia** are excellent tools which cover a wide
range of use-cases for RESTful APIs, and indeed we use Tavern alongside
Postman. However, specifically with regards to automated testing, Tavern
has several advantages over Postman:
- A full-featured Python environment for writing easily reusable custom validation functions
- Testing of MQTT based systems and gRPC services in tandem with RESTful APIs.
- Seamless integration with pytest to keep all your tests in one place
- A simpler, less verbose and clearer testing language
Tavern does not do many of the things Postman and Insomnia do. For
example, Tavern does not have a GUI nor does it do API monitoring or
mock servers. On the other hand, Tavern is free and open-source and is a
more powerful tool for developers to automate tests.
**pyresttest** is a similar tool to Tavern for testing RESTful APIs, but
is no longer actively developed. On top of MQTT testing, Tavern has
several other advantages over PyRestTest which overall add up to a
better developer experience:
- Cleaner test syntax which is more intuitive, especially for
non-developers
- Validation function are more flexible and easier to use
- Better explanations of why a test failed
## Hacking on Tavern
If you want to add a feature to Tavern or just play around with it
locally, it's a good plan to first create a local development
environment ([this
page](http://docs.python-guide.org/en/latest/dev/virtualenvs/) has a
good primer for working with development environments with Python).
After you've created your development environment, just
`pip install tox` and run `tox` to run the unit tests. If you want
to run the integration tests, make sure you have
[docker](https://www.docker.com/) installed and run
`tox -c tox-integration.ini` (bear in mind this might take a while.)
It's that simple!
If you want to develop things in tavern, enter your virtualenv and run
`uv sync --all-extras --all-packages` to install the library, any requirements,
and other useful development options.
Tavern uses [ruff](https://pypi.org/project/ruff/) to keep all of the code
formatted consistently. There is a pre-commit hook to run `ruff format` which can
be enabled by running `pre-commit install`.
If you want to add a feature to get merged back into mainline Tavern:
- Add the feature you want
- Add some tests for your feature:
- If you are adding some utility functionality such as improving verification
of responses, adding some unit tests might be best. These are in the
`tests/unit/` folder and are written using Pytest.
- If you are adding more advanced functionality like extra validation
functions, or some functionality that directly depends on the format of the
input YAML, it might also be useful to add some integration tests. At the
time of writing, this is done by adding an example flask endpoint in
`tests/integration/server.py` and a corresponding Tavern YAML test file in
the same directory.
- Open a [pull request](https://github.com/taverntesting/tavern/pulls).
See [CONTRIBUTING.md](/CONTRIBUTING.md) for more details.
## Maintenance
Tavern is currently maintained by
- [@michaelboulton](https://www.github.com/michaelboulton)
[//]: # (Note: Myst is hardcoded to look for a subheader with this name 🤷)
## Acknowledgements
[pytest](https://docs.pytest.org/en/latest/): the testing framework Tavern integrates with
| text/markdown | Michael Boulton | null | null | null | null | testing, pytest | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Framework :: Pytest",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Utilities",
"Topic :... | [] | null | null | >=3.11 | [] | [
"tavern"
] | [] | [
"PyYAML<7,>=6.0.1",
"jmespath<2,>=1",
"jsonschema<5,>=4",
"pyjwt<3,>=2.5.0",
"pykwalify<2,>=1.8.0",
"pytest<10,>=8",
"python-box<7,>=6",
"requests<3,>=2.22.0",
"simpleeval>=1.0.3",
"stevedore<5,>=4",
"aiohttp; extra == \"graphql\"",
"websockets; extra == \"graphql\"",
"gql>=4.0.0; extra == \... | [] | [] | [] | [
"Documentation, https://tavern.readthedocs.io/en/latest/",
"Home, https://taverntesting.github.io/",
"Source, https://github.com/taverntesting/tavern"
] | python-requests/2.32.5 | 2026-02-18T16:19:05.765415 | tavern-3.2.0.tar.gz | 100,852 | 23/c1/f65cb6eb153fbb6c465c405dd872c38b36a38b87a5adc120322ef2e7115f/tavern-3.2.0.tar.gz | source | sdist | null | false | 0ee948514f95ed7619355bd961ab9c8a | cd779cb3ffe5fc789993f9c917ea8defc62cbe7b7d1581433298f4bb7d724161 | 23c1f65cb6eb153fbb6c465c405dd872c38b36a38b87a5adc120322ef2e7115f | null | [] | 2,880 |
2.4 | wcp-library | 1.8.7 | Common utilites for internal development at WCP | # WCP-Library
## Description
Commonly used functions for the D&A team.
## Installation
`pip install WCP-Library`
## Usage
See [Wiki](https://github.com/Whitecap-DNA/WCP-Library/wiki/) for more information.
## Authors and acknowledgment
Mitch Petersen
## Stakeholders
D&A Developers
## Project status
In Development
| text/markdown | Mitch-Petersen | mitch.petersen@wcap.ca | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.12.0 | [] | [] | [] | [
"aiofiles<25.0.0,>=24.1.0",
"aiohttp<4.0.0,>=3.13.3",
"ftputil<6.0.0,>=5.1.0",
"get-gecko-driver<2.0.0,>=1.5.1",
"oracledb<4.0.0,>=3.4.1",
"pandas<3.0.0,>=2.2.3",
"paramiko<4.0.0,>=3.5.1",
"pip-system-certs<5.0,>=4.0",
"psycopg<4.0.0,>=3.2.7",
"psycopg-binary<4.0.0,>=3.3.2",
"psycopg-pool<4.0.0,... | [] | [] | [] | [] | poetry/2.3.2 CPython/3.12.7 Linux/6.14.0-1017-azure | 2026-02-18T16:18:28.988834 | wcp_library-1.8.7-py3-none-any.whl | 40,629 | a9/e6/45a871fa50cff0b0f8479d0fa0ca7a9499d6b213664bf2284f117c30ad53/wcp_library-1.8.7-py3-none-any.whl | py3 | bdist_wheel | null | false | 0fb159b5fdb176c3a1a7ebe7f1cb8fa4 | 9cd96cfcb6181ed23998eb89ee865e673b304e9e6e828bf4e533778c61d361d9 | a9e645a871fa50cff0b0f8479d0fa0ca7a9499d6b213664bf2284f117c30ad53 | null | [] | 597 |
2.4 | google-genai-haystack | 3.5.0 | Use models like Gemini via Google Gen AI SDK | # Google Gen AI Haystack Integration
[](https://pypi.org/project/google-genai-haystack)
[](https://pypi.org/project/google-genai-haystack)
- [Integration page](https://haystack.deepset.ai/integrations/google-genai)
- [Changelog](https://github.com/deepset-ai/haystack-core-integrations/blob/main/integrations/google_genai/CHANGELOG.md)
---
## Contributing
Refer to the general [Contribution Guidelines](https://github.com/deepset-ai/haystack-core-integrations/blob/main/CONTRIBUTING.md).
To run integration tests locally, you need to export the `GOOGLE_API_KEY` environment variable. | text/markdown | null | deepset GmbH <info@deepset.ai>, Gary Badwal <gurpreet071999@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming... | [] | null | null | >=3.10 | [] | [] | [] | [
"google-genai[aiohttp]>=1.51.0",
"haystack-ai>=2.23.0",
"jsonref>=1.0.0"
] | [] | [] | [] | [
"Documentation, https://github.com/deepset-ai/haystack-core-integrations/tree/main/integrations/google_genai#readme",
"Issues, https://github.com/deepset-ai/haystack-core-integrations/issues",
"Source, https://github.com/deepset-ai/haystack-core-integrations/tree/main/integrations/google_genai"
] | Hatch/1.16.3 cpython/3.12.12 HTTPX/0.28.1 | 2026-02-18T16:18:14.177271 | google_genai_haystack-3.5.0-py3-none-any.whl | 26,425 | e7/78/1af03319befae96709ef0c4d61adfdade3b043e3bc7622f15ada65ee45f1/google_genai_haystack-3.5.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 539cf17f6a75ee8e45740ec590966df6 | cbc62e37321f541676776ebeb83faf5051e1291405f74e46336ce73f074b1274 | e7781af03319befae96709ef0c4d61adfdade3b043e3bc7622f15ada65ee45f1 | Apache-2.0 | [
"LICENSE.txt"
] | 410 |
2.4 | amazon-braket-sdk | 1.112.1 | An open source library for interacting with quantum computing devices on Amazon Braket | # Amazon Braket Python SDK
[](https://pypi.python.org/pypi/amazon-braket-sdk)
[](https://pypi.python.org/pypi/amazon-braket-sdk)
[](https://github.com/amazon-braket/amazon-braket-sdk-python/actions/workflows/build.yml)
[](https://codecov.io/gh/amazon-braket/amazon-braket-sdk-python)
[](https://amazon-braket-sdk-python.readthedocs.io)
[](https://quantumcomputing.stackexchange.com/questions/tagged/amazon-braket)
The Amazon Braket Python SDK is an open source library that provides a framework that you can use to interact with quantum computing hardware devices through Amazon Braket.
## Prerequisites
Before you begin working with the Amazon Braket SDK, make sure that you've installed or configured the following prerequisites.
### Python 3.11 or greater
Download and install Python 3.11 or greater from [Python.org](https://www.python.org/downloads/).
### Git
Install Git from https://git-scm.com/downloads. Installation instructions are provided on the download page.
### IAM user or role with required permissions
As a managed service, Amazon Braket performs operations on your behalf on the AWS hardware that is managed by Amazon Braket. Amazon Braket can perform only operations that the user permits. You can read more about which permissions are necessary in the AWS Documentation.
The Braket Python SDK should not require any additional permissions aside from what is required for using Braket. However, if you are using an IAM role with a path in it, you should grant permission for iam:GetRole.
To learn more about IAM user, roles, and policies, see [Adding and Removing IAM Identity Permissions](https://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies_manage-attach-detach.html).
### Boto3 and setting up AWS credentials
Follow the installation [instructions](https://boto3.amazonaws.com/v1/documentation/api/latest/guide/quickstart.html) for Boto3 and setting up AWS credentials.
**Note:** Make sure that your AWS region is set to one supported by Amazon Braket. You can check this in your AWS configuration file, which is located by default at `~/.aws/config`.
### Configure your AWS account with the resources necessary for Amazon Braket
If you are new to Amazon Braket, onboard to the service and create the resources necessary to use Amazon Braket using the [AWS console](https://console.aws.amazon.com/braket/home ).
## Installing the Amazon Braket Python SDK
The Amazon Braket Python SDK can be installed with pip as follows:
```bash
pip install amazon-braket-sdk
```
You can also install from source by cloning this repository and running a pip install command in the root directory of the repository:
```bash
git clone https://github.com/amazon-braket/amazon-braket-sdk-python.git
cd amazon-braket-sdk-python
pip install .
```
### Check the version you have installed
You can view the version of the amazon-braket-sdk you have installed by using the following command:
```bash
pip show amazon-braket-sdk
```
You can also check your version of `amazon-braket-sdk` from within Python:
```
>>> import braket._sdk as braket_sdk
>>> braket_sdk.__version__
```
### Updating the Amazon Braket Python SDK
You can update the version of the amazon-braket-sdk you have installed by using the following command:
```bash
pip install amazon-braket-sdk --upgrade --upgrade-strategy eager
```
## Usage
### Running a circuit on an AWS simulator
```python
import boto3
from braket.aws import AwsDevice
from braket.circuits import Circuit
from braket.devices import Devices
device = AwsDevice(Devices.Amazon.SV1)
bell = Circuit().h(0).cnot(0, 1)
task = device.run(bell, shots=100)
print(task.result().measurement_counts)
```
The code sample imports the Amazon Braket framework, then defines the device to use (the SV1 AWS simulator). It then creates a Bell Pair circuit, executes the circuit on the simulator and prints the results of the hybrid job. This example can be found in `../examples/bell.py`.
### Running multiple quantum tasks at once
Many quantum algorithms need to run multiple independent circuits, and submitting the circuits in parallel can be faster than submitting them one at a time. In particular, parallel quantum task processing provides a significant speed up when using simulator devices. The following example shows how to run a batch of quantum tasks on SV1:
```python
circuits = [bell for _ in range(5)]
batch = device.run_batch(circuits, shots=100)
# The result of the first quantum task in the batch
print(batch.results()[0].measurement_counts)
```
### Running a hybrid job
```python
from braket.aws import AwsQuantumJob
job = AwsQuantumJob.create(
device="arn:aws:braket:::device/quantum-simulator/amazon/sv1",
source_module="job.py",
entry_point="job:run_job",
wait_until_complete=True,
)
print(job.result())
```
where `run_job` is a function in the file `job.py`.
The code sample imports the Amazon Braket framework, then creates a hybrid job with the entry point being the `run_job` function. The hybrid job creates quantum tasks against the SV1 AWS Simulator. The hybrid job runs synchronously, and prints logs until it completes. The complete example can be found in `../examples/job.py`.
### Available Simulators
Amazon Braket provides access to two types of simulators: fully managed simulators, available through the Amazon Braket service, and the local simulators that are part of the Amazon Braket SDK.
- Fully managed simulators offer high-performance circuit simulations. These simulators can handle circuits larger than circuits that run on quantum hardware. For example, the SV1 state vector simulator shown in the previous examples requires approximately 1 or 2 hours to complete a 34-qubit, dense, and square circuit (circuit depth = 34), depending on the type of gates used and other factors.
- The Amazon Braket Python SDK includes an implementation of quantum simulators that can run circuits on your local, classic hardware. For example the braket_sv local simulator is well suited for rapid prototyping on small circuits up to 25 qubits, depending on the hardware specifications of your Braket notebook instance or your local environment. An example of how to execute the quantum task locally is included in the repository `../examples/local_bell.py`.
For a list of available simulators and their features, consult the [Amazon Braket Developer Guide](https://docs.aws.amazon.com/braket/latest/developerguide/braket-devices.html).
### Debugging logs
Quantum tasks sent to QPUs don't always run right away. To view quantum task status, you can enable debugging logs. An example of how to enable these logs is included in repo: `../examples/debug_bell.py`. This example enables quantum task logging so that status updates are continuously printed to the terminal after a quantum task is executed. The logs can also be configured to save to a file or output to another stream. You can use the debugging example to get information on the quantum tasks you submit, such as the current status, so that you know when your quantum task completes.
### Running a Quantum Algorithm on a Quantum Computer
With Amazon Braket, you can run your quantum circuit on a physical quantum computer.
The following example executes the same Bell Pair example described to validate your configuration on a Rigetti quantum computer.
```python
import boto3
from braket.aws import AwsDevice
from braket.circuits import Circuit
from braket.devices import Devices
device = AwsDevice(Devices.Rigetti.Ankaa3)
bell = Circuit().h(0).cnot(0, 1)
task = device.run(bell)
print(task.result().measurement_counts)
```
When you execute your task, Amazon Braket polls for a result. By default, Braket polls for 5 days; however, it is possible to change this by modifying the `poll_timeout_seconds` parameter in `AwsDevice.run`, as in the example below. Keep in mind that if your polling timeout is too short, results may not be returned within the polling time, such as when a QPU is unavailable, and a local timeout error is returned. You can always restart the polling by using `task.result()`.
```python
task = device.run(bell, poll_timeout_seconds=86400) # 1 day
print(task.result().measurement_counts)
```
To select a quantum hardware device, specify its ARN as the value of the `device_arn` argument. A list of available quantum devices and their features can be found in the [Amazon Braket Developer Guide](https://docs.aws.amazon.com/braket/latest/developerguide/braket-devices.html).
**Important** Quantum tasks may not run immediately on the QPU. The QPUs only execute quantum tasks during execution windows. To find their execution windows, please refer to the [AWS console](https://console.aws.amazon.com/braket/home) in the "Devices" tab.
## Sample Notebooks
Sample Jupyter notebooks can be found in the [amazon-braket-examples](https://github.com/amazon-braket/amazon-braket-examples/) repo.
## Braket Python SDK API Reference Documentation
The API reference, can be found on [Read the Docs](https://amazon-braket-sdk-python.readthedocs.io/en/latest/).
**To generate the API Reference HTML in your local environment**
To generate the HTML, first change directories (`cd`) to position the cursor in the `amazon-braket-sdk-python` directory. Then, run the following command to generate the HTML documentation files:
```bash
pip install tox
tox -e docs
```
To view the generated documentation, open the following file in a browser:
`../amazon-braket-sdk-python/build/documentation/html/index.html`
## Testing
This repository has both unit and integration tests.
To run the tests, make sure to install test dependencies first:
```bash
pip install -e "amazon-braket-sdk-python[test]"
```
### Unit Tests
To run the unit tests:
```bash
tox -e unit-tests
```
You can also pass in various pytest arguments to run selected tests:
```bash
tox -e unit-tests -- your-arguments
```
For more information, please see [pytest usage](https://docs.pytest.org/en/stable/usage.html).
To run linters and doc generators and unit tests:
```bash
tox
```
or if your machine can handle multithreaded workloads, run them in parallel with:
```bash
tox -p auto
```
### Integration Tests
First, configure a profile to use your account to interact with AWS. To learn more, see [Configure AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html).
After you create a profile, use the following command to set the `AWS_PROFILE` so that all future commands can access your AWS account and resources.
```bash
export AWS_PROFILE=YOUR_PROFILE_NAME
```
To run the integration tests for local hybrid jobs, you need to have Docker installed and running. To install Docker follow these instructions: [Install Docker](https://docs.docker.com/get-docker/)
Run the tests:
```bash
tox -e integ-tests
```
As with unit tests, you can also pass in various pytest arguments:
```bash
tox -e integ-tests -- your-arguments
```
## Support
### Issues and Bug Reports
If you encounter bugs or face issues while using the SDK, please let us know by posting
the issue on our [Github issue tracker](https://github.com/amazon-braket/amazon-braket-sdk-python/issues/).
For other issues or general questions, please ask on the [Quantum Computing Stack Exchange](https://quantumcomputing.stackexchange.com/questions/ask?Tags=amazon-braket).
### Feedback and Feature Requests
If you have feedback or features that you would like to see on Amazon Braket, we would love to hear from you!
[Github issues](https://github.com/amazon-braket/amazon-braket-sdk-python/issues/) is our preferred mechanism for collecting feedback and feature requests, allowing other users
to engage in the conversation, and +1 issues to help drive priority.
### Code contributors
[](https://github.com/amazon-braket/amazon-braket-sdk-python/graphs/contributors)
## License
This project is licensed under the Apache-2.0 License.
| text/markdown | Amazon Web Services | null | null | null | Apache License 2.0 | Amazon AWS Quantum | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"Natural Language :: English",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python",
"Programming Language :: P... | [] | https://github.com/amazon-braket/amazon-braket-sdk-python | null | >=3.11 | [] | [] | [] | [
"amazon-braket-schemas>=1.27.0",
"amazon-braket-default-simulator>=1.32.0",
"oqpy~=0.3.7",
"backoff",
"boltons",
"boto3>=1.28.53",
"cloudpickle==2.2.1",
"nest-asyncio",
"networkx",
"numpy",
"openpulse",
"openqasm3",
"sympy",
"backports.entry-points-selectable",
"black; extra == \"test\""... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:17:54.262629 | amazon_braket_sdk-1.112.1.tar.gz | 490,314 | 81/0e/f6bf8d950f245dce571d32429486f842b5f8b2536d9e28a10269cec4aa65/amazon_braket_sdk-1.112.1.tar.gz | source | sdist | null | false | dda99d3c63dd8e5fbb627cd20c52103d | 890209d8c6e3b207e410812cf334c7d2584e244ad8f75c0624ba3e18f008a2d2 | 810ef6bf8d950f245dce571d32429486f842b5f8b2536d9e28a10269cec4aa65 | null | [
"LICENSE",
"NOTICE"
] | 3,236 |
2.4 | irreversibility | 1.3.1 | A library for evaluating the time irreversibility of time series | # Irreversibility Tests Library
The assessment of time irreversibility is the assessment of the lack of invariance of the statistical properties of a system under the operation of time reversal. As a simple example, suppose a movie of an ice cube melting in a glass, and one with the ice cube forming from liquid water: an observer can easily decide which one is the original and which the time-reversed one; in this case, the creation (or destruction) of entropy is what makes the process irreversible. On the other hand, the movement of a pendulum and its time-reversed version are undistinguishable, and hence the dynamics is reversible.
Irreversible dynamics have been found in many real-world systems, with alterations being connected to, for instance, pathologies in the human brain, heart and gait, or to inefficiencies in financial markets. Assessing irreversibility in time series is not an easy task, due to its many aetiologies and to the different ways it manifests in data.
This is a library that will (hopefully) make your life easier when it comes to the analysis of the irreversibility of real-world time series. It comprises a large number of tests (not all existing ones, but we are quite close to that); and utilities to simply the whole process.
This library (v1.1) is described in the paper:
M. Zanin
irreversibility: A Python Package for Assessing and Manipulating the Time Irreversibility of Real-World Time Series. Entropy, 27(11), 1146. https://doi.org/10.3390/e27111146
If you are interested in the concept of irreversibility, you may start from our papers:
M. Zanin, D. Papo.
Tests for assessing irreversibility in time series: review and comparison.
Entropy 2021, 23(11), 1474. https://www.mdpi.com/1099-4300/23/11/1474
Zanin, M., & Papo, D. (2025).
Algorithmic Approaches for Assessing Multiscale Irreversibility in Time Series: Review and Comparison.
Entropy, 27(2), 126. https://www.mdpi.com/1099-4300/27/2/126
## Setup
This package can be installed from PyPI using pip:
```bash
pip install irreversibility
```
This will automatically install all the necessary dependencies as specified in the
`pyproject.toml` file.
## Getting started
Check the files Example_*.py for examples on how to use each test, and also [here](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home#examples).
Information about all methods, parameters, and other relevant issues can be found both in the previous papers, and in the wiki: [Go to the wiki](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home). You can also check our take on the question: [why there are so many tests?](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Why-so-many-tests%3F)
Note that all implementations have been developed in-house, and as such may contain errors or inefficient code; we welcome readers to send us comments, suggestions and corrections, using the "Issues" feature.
## Full documentation
* [Irreversibility metrics](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Irreversibility-metrics): list of all irreversibility tests, and description of how to use them. You may also wondering [why there are so many tests](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Why-so-many-tests%3F).
* [Parameter optimisation](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Parameter-optimisation): functions to optimise the parameters of each test.
* [Time series generation](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Time-series-generation): utility functions to create synthetic time series, to be used to test the metrics.
* [Time series manipulation](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Time-series-manipulation): utility functions to manipulate the irreversibility of time series.
* [Time series preprocessing](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Preprocessing-methods): utilities for preprocessing the time series, e.g. to extract symbols from them.
Additional topics:
* [How p-values are obtained from measures.](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Obtaining-pValues)
* [Why do we need so many tests?](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Why-so-many-tests%3F)
* [Techniques used to reduce the computational cost.](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Computational-optimisation)
* [Analysis of the computational cost](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Computational-cost) of each test. Note that some of them are quite long to execute.
## Change log
See the [Version History](https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home/Version-History) section of the Wiki for details.
## Acknowledgements
This project has received funding from the European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme (grant agreement No 851255).
This work was partially supported by the María de Maeztu project CEX2021-001164-M funded by the MICIU/AEI/10.13039/501100011033 and FEDER, EU.
This work was partially supported by grant CNS2023-144775 funded by MICIU/AEI/10.13039/501100011033 by "European Union NextGenerationEU/PRTR".
| text/markdown | null | Massimiliano Zanin <massimiliano.zanin@gmail.com> | null | null | null | time series, irreversibility, time symmetry, statistical physics | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"numpy",
"statsmodels",
"scipy",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"coverage; extra == \"test\"",
"irreversibility[lint,test]; extra == \"all\""
] | [] | [] | [] | [
"Homepage, https://gitlab.com/MZanin/irreversibilitytestslibrary",
"Issues, https://gitlab.com/MZanin/irreversibilitytestslibrary/issues",
"Documentation, https://gitlab.com/MZanin/irreversibilitytestslibrary/-/wikis/home",
"Repository, https://gitlab.com/MZanin/irreversibilitytestslibrary",
"Changelog, htt... | twine/6.1.0 CPython/3.13.2 | 2026-02-18T16:17:45.107545 | irreversibility-1.3.1.tar.gz | 52,694 | a3/17/941a76ca9df68d8db9337b2dba7a27c3bf689b27e98611c9c64065db1432/irreversibility-1.3.1.tar.gz | source | sdist | null | false | 0cc539ebf79438a0aac2939bf89ee69b | fc81185cab84ca001d7fceacd95c443c64edc6a4f0c0693b28b96974fb37fc3d | a317941a76ca9df68d8db9337b2dba7a27c3bf689b27e98611c9c64065db1432 | AGPL-3.0-only | [
"LICENSE"
] | 236 |
2.4 | smartagent-sf | 0.2.0 | Biblioteca Python para criar agentes de IA com execução determinística |
# SmartAgent 🤖
Biblioteca Python leve para criar agentes de IA com execução determinística em 3 fases.
## Características ✨
- **Multi-Provider**: Suporta Groq, OpenAI, Gemini, Grok, Ollama e Llama
- **Sem Schemas**: Não precisa de Pydantic ou definições complexas
- **3 Fases**: Análise → Execução → Resposta
- **Econômico**: Minimiza uso de tokens
- **Simples**: Menos de 500 linhas de código
## Instalação
```bash
# Instalar dependências
pip install requests
```
## Uso Rápido
```python
from agent import Agent
# Criar agente
agent = Agent(provider="groq")
# Registrar ferramentas
@agent.tool
def get_products(max_price=100):
return [{"nome": "Mouse", "preço": 50}]
# Executar
response = agent.chat("Quais produtos baratos?")
print(response)
```
## Instruções Customizadas
Você pode adicionar instruções personalizadas ao agente:
```python
agent = Agent(
provider="groq",
info="""
Você é um assistente especializado em e-commerce.
- Sempre sugira produtos relacionados
- Use tom amigável e profissional
- Destaque promoções quando disponíveis
"""
)
```
## Providers Suportados
- **Groq**: `Agent(provider="groq", api_key="...")`
- **OpenAI**: `Agent(provider="openai", api_key="...")`
- **Gemini**: `Agent(provider="gemini", api_key="...")`
- **Grok**: `Agent(provider="grok", api_key="...")`
- **Ollama**: `Agent(provider="ollama")` (local)
- **Llama**: `Agent(provider="llama", api_key="...")`
## Variáveis de Ambiente
```bash
# Provider default global (opcional)
export SMARTAGENT_PROVIDER="groq"
export GROQ_API_KEY="your-key"
export OPENAI_API_KEY="your-key"
export GEMINI_API_KEY="your-key"
export XAI_API_KEY="your-key"
export LLAMA_API_KEY="your-key"
# Modelo global (novo)
export SMARTAGENT_MODEL="modelo-ai"
# Modelo por provider (opcional)
export SMARTAGENT_OPENAI_MODEL="gpt-4o-mini"
export SMARTAGENT_GROQ_MODEL="qwen/qwen3-32b"
# Rede (opcional)
export SMARTAGENT_TIMEOUT="30"
export SMARTAGENT_RETRIES="2"
# Compatibilidade legada (ainda suportado)
export LLM="modelo-ai"
```
## Compatibilidade (1-2 versões)
- `model=\"groq\"` (estilo antigo) ainda funciona, mas o recomendado é `provider=\"groq\"`.
- As variáveis `*_API_KEY` continuam suportadas.
- `LLM` continua suportada como fallback para modelo global.
## Arquitetura
1. **Analyzer**: Determina quais ferramentas executar
2. **Executor**: Executa ferramentas com parâmetros
3. **Responder**: Gera resposta humanizada
## Exemplo Completo
Veja `examples/minimal_agent.py`
| text/markdown | Liedson Habacuc | lisvaldosf@gmail.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Prog... | [] | https://github.com/lhabacuc/smartagent | null | >=3.8 | [] | [] | [] | [
"requests>=2.25.0",
"groq; extra == \"dev\"",
"openai; extra == \"dev\"",
"google-generativeai; extra == \"dev\"",
"ollama; extra == \"dev\"",
"llama-cpp-python; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-mock; extra == \"dev\"",
"black; extra == \"dev\"",
"flake8; extra == \"dev\"",
... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:17:30.064771 | smartagent_sf-0.2.0.tar.gz | 16,423 | d6/30/24b0990e70ccd80adebdd19f150382472bce6393c85c02ebef0d629ea2f1/smartagent_sf-0.2.0.tar.gz | source | sdist | null | false | b5d1eb89c98abb5e550bfba984e3e524 | 3f6a73ee5fa40cdc633c0ff224686aa094d5eb86bd4011cc41263fcdfc8109cf | d63024b0990e70ccd80adebdd19f150382472bce6393c85c02ebef0d629ea2f1 | null | [
"LICENCE"
] | 237 |
2.3 | ark-email | 0.18.1 | The official Python library for the ark API | # Ark Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/ark-email/)
The Ark Python library provides convenient access to the Ark REST API from any Python 3.9+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
It is generated with [Stainless](https://www.stainless.com/).
## MCP Server
Use the Ark MCP Server to enable AI assistants to interact with this API, allowing them to explore endpoints, make test requests, and use documentation to help integrate this SDK into your application.
[](https://cursor.com/en-US/install-mcp?name=ark-email-mcp&config=eyJuYW1lIjoiYXJrLWVtYWlsLW1jcCIsInRyYW5zcG9ydCI6Imh0dHAiLCJ1cmwiOiJodHRwczovL2Fyay1tY3Auc3RsbWNwLmNvbSIsImhlYWRlcnMiOnsieC1hcmstYXBpLWtleSI6Ik15IEFQSSBLZXkifX0)
[](https://vscode.stainless.com/mcp/%7B%22name%22%3A%22ark-email-mcp%22%2C%22type%22%3A%22http%22%2C%22url%22%3A%22https%3A%2F%2Fark-mcp.stlmcp.com%22%2C%22headers%22%3A%7B%22x-ark-api-key%22%3A%22My%20API%20Key%22%7D%7D)
> Note: You may need to set environment variables in your MCP client.
## Documentation
The REST API documentation can be found on [arkhq.io](https://arkhq.io/docs). The full API of this library can be found in [api.md](https://github.com/ArkHQ-io/ark-python/tree/main/api.md).
## Installation
```sh
# install from PyPI
pip install ark-email
```
## Usage
The full API of this library can be found in [api.md](https://github.com/ArkHQ-io/ark-python/tree/main/api.md).
```python
import os
from ark import Ark
client = Ark(
api_key=os.environ.get("ARK_API_KEY"), # This is the default and can be omitted
)
response = client.emails.send(
from_="hello@yourdomain.com",
subject="Hello World",
to=["user@example.com"],
html="<h1>Welcome!</h1>",
metadata={
"user_id": "usr_123456",
"campaign": "onboarding",
},
tag="welcome",
)
print(response.data)
```
While you can provide an `api_key` keyword argument,
we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/)
to add `ARK_API_KEY="My API Key"` to your `.env` file
so that your API Key is not stored in source control.
## Async usage
Simply import `AsyncArk` instead of `Ark` and use `await` with each API call:
```python
import os
import asyncio
from ark import AsyncArk
client = AsyncArk(
api_key=os.environ.get("ARK_API_KEY"), # This is the default and can be omitted
)
async def main() -> None:
response = await client.emails.send(
from_="hello@yourdomain.com",
subject="Hello World",
to=["user@example.com"],
html="<h1>Welcome!</h1>",
metadata={
"user_id": "usr_123456",
"campaign": "onboarding",
},
tag="welcome",
)
print(response.data)
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from PyPI
pip install ark-email[aiohttp]
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import os
import asyncio
from ark import DefaultAioHttpClient
from ark import AsyncArk
async def main() -> None:
async with AsyncArk(
api_key=os.environ.get("ARK_API_KEY"), # This is the default and can be omitted
http_client=DefaultAioHttpClient(),
) as client:
response = await client.emails.send(
from_="hello@yourdomain.com",
subject="Hello World",
to=["user@example.com"],
html="<h1>Welcome!</h1>",
metadata={
"user_id": "usr_123456",
"campaign": "onboarding",
},
tag="welcome",
)
print(response.data)
asyncio.run(main())
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Pagination
List methods in the Ark API are paginated.
This library provides auto-paginating iterators with each list response, so you do not have to request successive pages manually:
```python
from ark import Ark
client = Ark()
all_emails = []
# Automatically fetches more pages as needed.
for email in client.emails.list(
page=1,
per_page=10,
):
# Do something with email here
all_emails.append(email)
print(all_emails)
```
Or, asynchronously:
```python
import asyncio
from ark import AsyncArk
client = AsyncArk()
async def main() -> None:
all_emails = []
# Iterate through items across all pages, issuing requests as needed.
async for email in client.emails.list(
page=1,
per_page=10,
):
all_emails.append(email)
print(all_emails)
asyncio.run(main())
```
Alternatively, you can use the `.has_next_page()`, `.next_page_info()`, or `.get_next_page()` methods for more granular control working with pages:
```python
first_page = await client.emails.list(
page=1,
per_page=10,
)
if first_page.has_next_page():
print(f"will fetch next page using these details: {first_page.next_page_info()}")
next_page = await first_page.get_next_page()
print(f"number of items we just fetched: {len(next_page.data)}")
# Remove `await` for non-async usage.
```
Or just work directly with the returned data:
```python
first_page = await client.emails.list(
page=1,
per_page=10,
)
print(f"page number: {first_page.page}") # => "page number: 1"
for email in first_page.data:
print(email.id)
# Remove `await` for non-async usage.
```
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `ark.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `ark.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `ark.APIError`.
```python
import ark
from ark import Ark
client = Ark()
try:
client.emails.send(
from_="hello@yourdomain.com",
subject="Hello World",
to=["user@example.com"],
html="<h1>Welcome!</h1>",
metadata={
"user_id": "usr_123456",
"campaign": "onboarding",
},
tag="welcome",
)
except ark.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except ark.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except ark.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as follows:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from ark import Ark
# Configure the default for all requests:
client = Ark(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).emails.send(
from_="hello@yourdomain.com",
subject="Hello World",
to=["user@example.com"],
html="<h1>Welcome!</h1>",
metadata={
"user_id": "usr_123456",
"campaign": "onboarding",
},
tag="welcome",
)
```
### Timeouts
By default requests time out after 1 minute. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/timeouts/#fine-tuning-the-configuration) object:
```python
from ark import Ark
# Configure the default for all requests:
client = Ark(
# 20 seconds (default is 1 minute)
timeout=20.0,
)
# More granular control:
client = Ark(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).emails.send(
from_="hello@yourdomain.com",
subject="Hello World",
to=["user@example.com"],
html="<h1>Welcome!</h1>",
metadata={
"user_id": "usr_123456",
"campaign": "onboarding",
},
tag="welcome",
)
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/ArkHQ-io/ark-python/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `ARK_LOG` to `info`.
```shell
$ export ARK_LOG=info
```
Or to `debug` for more verbose logging.
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from ark import Ark
client = Ark()
response = client.emails.with_raw_response.send(
from_="hello@yourdomain.com",
subject="Hello World",
to=["user@example.com"],
html="<h1>Welcome!</h1>",
metadata={
"user_id": "usr_123456",
"campaign": "onboarding",
},
tag="welcome",
)
print(response.headers.get('X-My-Header'))
email = response.parse() # get the object that `emails.send()` would have returned
print(email.data)
```
These methods return an [`APIResponse`](https://github.com/ArkHQ-io/ark-python/tree/main/src/ark/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/ArkHQ-io/ark-python/tree/main/src/ark/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.emails.with_streaming_response.send(
from_="hello@yourdomain.com",
subject="Hello World",
to=["user@example.com"],
html="<h1>Welcome!</h1>",
metadata={
"user_id": "usr_123456",
"campaign": "onboarding",
},
tag="welcome",
) as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) when making this request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for [proxies](https://www.python-httpx.org/advanced/proxies/)
- Custom [transports](https://www.python-httpx.org/advanced/transports/)
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
import httpx
from ark import Ark, DefaultHttpxClient
client = Ark(
# Or use the `ARK_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
```py
from ark import Ark
with Ark() as client:
# make requests here
...
# HTTP client is now closed
```
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals.)_
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/ArkHQ-io/ark-python/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import ark
print(ark.__version__)
```
## Requirements
Python 3.9 or higher.
## Contributing
See [the contributing documentation](https://github.com/ArkHQ-io/ark-python/tree/main/./CONTRIBUTING.md).
| text/markdown | null | Ark <hi@arkhq.io> | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pydantic<3,>=1.9.0",
"sniffio",
"typing-extensions<5,>=4.10",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"aiohttp\""
] | [] | [] | [] | [
"Homepage, https://github.com/ArkHQ-io/ark-python",
"Repository, https://github.com/ArkHQ-io/ark-python"
] | uv/0.9.13 {"installer":{"name":"uv","version":"0.9.13"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T16:16:49.518599 | ark_email-0.18.1.tar.gz | 280,590 | 97/ab/7e6bcba23ca139291aae6c4032d2f28f2141e91413f0f3363bf36e4dbd7e/ark_email-0.18.1.tar.gz | source | sdist | null | false | 657624eeefe31dad84a36481eda84981 | f167bc6ccfeb3061e6a71710896cf24bf076989ee7399dbee3e1211fd268331d | 97ab7e6bcba23ca139291aae6c4032d2f28f2141e91413f0f3363bf36e4dbd7e | null | [] | 249 |
2.4 | tomwer | 1.6.16 | Tomography workflow tools | .. image:: doc/img/tomwer.png
:alt: Tomwer Logo
:align: left
:width: 400px
Introduction
------------
**Tomwer** provides tools to automate acquisition and reconstruction processes for tomography. The package includes:
- A library to individually access each acquisition process.
- Graphical User Interface (GUI) applications to control key processes such as reconstruction and data transfer, which can be executed as standalone applications.
- An Orange add-on to help users define custom workflows (`Orange3 <http://orange.biolab.si>`_).
Tomwer relies on `Nabu <https://gitlab.esrf.fr/tomotools/nabu>`_ for tomographic reconstruction.
**Note**: Currently, the software is only compatible with Linux.
Documentation
-------------
The latest version of the documentation is available `here <https://tomotools.gitlab-pages.esrf.fr/tomwer/>`_.
Installation
------------
Step 1: Installing Tomwer
'''''''''''''''''''''''''
To install Tomwer with all features:
.. code-block:: bash
pip install tomwer[full]
Alternatively, you can install the latest development branch from the repository:
.. code-block:: bash
pip install git+https://gitlab.esrf.fr/tomotools/tomwer/#egg=tomwer[full]
Step 2: (Optional) Update Orange-CANVAS-CORE and Orange-WIDGET-BASE
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
If you need access to additional 'processing' wheels and 'reprocess action,' you may want to update these Orange forks. This is optional, as the project works with the native Orange libraries.
.. code-block:: bash
pip install git+https://github.com/payno/orange-canvas-core --no-deps --upgrade
pip install git+https://github.com/payno/orange-widget-base --no-deps --upgrade
Launching Applications
-----------------------
After installation, Tomwer includes several applications. You can launch an application by running:
.. code-block:: bash
tomwer <appName> [options]
- If you run `tomwer` without arguments, a manual page will be displayed.
- For application-specific help, run:
.. code-block:: bash
tomwer <appName> --help
Tomwer Canvas - Orange Canvas
-----------------------------
You can launch the Orange canvas to create workflows using the available building blocks:
.. code-block:: bash
tomwer canvas
- Alternatively, you can use `orange-canvas`.
- If you're using a virtual environment, remember to activate it:
.. code-block:: bash
source myvirtualenv/bin/activate
Building Documentation
-----------------------
To build the documentation:
.. code-block:: bash
sphinx-build doc build/html
The documentation will be generated in `doc/build/html`, and the entry point is `index.html`. To view the documentation in a browser:
.. code-block:: bash
firefox build/html/index.html
**Note**: Building the documentation requires `sphinx` to be installed, which is not a hard dependency of Tomwer. If needed, install it separately.
| text/x-rst | null | Henri Payno <henri.payno@esrf.fr>, Pierre Paleo <pierre.paleo@esrf.fr>, Pierre-Olivier Autran <pierre-olivier.autran@esrf.fr>, Jérôme Lesaint <jerome.lesaint@esrf.fr>, Alessandro Mirone <mirone@esrf.fr> | null | null | MIT | orange3 add-on, ewoks | [
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Environment :: Console",
"Environment :: X11 Applications :: Qt",
"Operating System :: POSIX",
"Natural Language :: English",
"Topic :: Scienti... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy",
"setuptools<81",
"psutil",
"silx[full]>=2.1.1",
"tomoscan>=2.2.0a6",
"nxtomo>2.0.0dev2",
"nxtomomill>=2.0.0dev0",
"processview>=1.5.0",
"ewoks>=0.1.1",
"ewokscore<2.0,>=1.5",
"sluurp>=0.4.1",
"packaging",
"pint",
"tqdm",
"eval_type_backport; python_version < \"3.10\"",
"platfo... | [] | [] | [] | [
"Homepage, https://gitlab.esrf.fr/tomotools/tomwer",
"Documentation, https://tomotools.gitlab-pages.esrf.fr/tomwer/",
"Repository, https://gitlab.esrf.fr/tomotools/tomwer",
"Issues, https://gitlab.esrf.fr/tomotools/tomwer/-/issues",
"Changelog, https://gitlab.esrf.fr/tomotools/tomwer/-/blob/main/CHANGELOG.r... | twine/6.2.0 CPython/3.12.3 | 2026-02-18T16:16:47.588297 | tomwer-1.6.16.tar.gz | 4,612,800 | 4d/cc/3206839a5a194db3b3a8924043c88f553973d94f1dbce6dce4dfc5e19275/tomwer-1.6.16.tar.gz | source | sdist | null | false | cf52fa281fb0cae085ac8c82dd67a6a2 | 3848bfa9b3ee6c00f8d5d20143cc0eaeeabcd5a24a92232090a9ecac77eab745 | 4dcc3206839a5a194db3b3a8924043c88f553973d94f1dbce6dce4dfc5e19275 | null | [
"LICENSE"
] | 258 |
2.3 | pkgscout | 0.1.0 | A modern CLI to check PyPI package name availability with rich metadata | # pkgscout
A modern CLI to check whether Python package names are available on PyPI.
Queries the **live PyPI API** — no stale offline database. Shows rich metadata for taken names: version, summary, author, and project URL.
## Install
Requires [UV](https://docs.astral.sh/uv/) and Python 3.12+.
```bash
uv sync
```
## Usage
```bash
# Check a single name
uv run pkgscout requests
# ✘ requests (v2.32.5) — Python HTTP for Humans.
# https://pypi.org/project/requests/
# Check if a name is available
uv run pkgscout my-cool-lib
# ✔ my-cool-lib is available!
# Batch check
uv run pkgscout requests flask numpy my-cool-lib
# ✘ requests (v2.32.5) — Python HTTP for Humans.
# ✘ flask (v3.1.2) — A simple framework for building complex web applications.
# ✘ numpy (v2.4.2) — Fundamental package for array computing in Python
# ✔ my-cool-lib is available!
# JSON output for scripting
uv run pkgscout --json requests my-cool-lib
```
JSON output example:
```json
[
{
"name": "requests",
"available": false,
"version": "2.32.5",
"summary": "Python HTTP for Humans.",
"author": "Kenneth Reitz",
"url": "https://pypi.org/project/requests/"
},
{
"name": "my-cool-lib",
"available": true
}
]
```
## How It Works
For each name, pkgscout sends a `GET` request to `https://pypi.org/pypi/{name}/json`:
- **200** — name is taken, metadata is extracted and displayed
- **404** — name is available
## License
MIT
| text/markdown | Yann Debray | Yann Debray <debray.yann@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"httpx>=0.28.1"
] | [] | [] | [] | [] | uv/0.8.15 | 2026-02-18T16:16:01.486667 | pkgscout-0.1.0.tar.gz | 2,577 | 01/16/1d95bcda24009136666a05d01fed1d10f34deefc8f5b3433861c56e23a04/pkgscout-0.1.0.tar.gz | source | sdist | null | false | bb06fb21b5fbd717bc5d2c35155c25c1 | 8135b0beda1ad60ed062d6f6e7a1c9384136aa94abec3ebc5d233b9901c7fd8d | 01161d95bcda24009136666a05d01fed1d10f34deefc8f5b3433861c56e23a04 | null | [] | 235 |
2.4 | secop-ophyd | 0.16.1 | An Interface between bluesky and SECoP, using ophyd and frappy-client | [](https://github.com/SampleEnvironment/secop-ophyd/actions/workflows/code.yaml)
[](https://www.gnu.org/licenses/gpl-3.0)
[](https://pypi.org/project/secop-ophyd)
# SECoP-Ophyd
**SECoP-Ophyd** enables seamless integration of SECoP (Sample Environment Communication Protocol) devices into the Bluesky experiment orchestration framework.

SECoP-Ophyd acts as a bridge between SECoP-enabled hardware and Bluesky's ophyd layer. It uses [Frappy](https://github.com/SampleEnvironment/frappy) to communicate with SECoP nodes over TCP, automatically generating [ophyd-async](https://blueskyproject.io/ophyd-async/main/index.html) device objects from the node's descriptive data. These devices can then be used in [Bluesky plans](https://blueskyproject.io/bluesky/main/tutorial.html#the-run-engine-and-plans) just like any other ophyd device, enabling seamless integration with EPICS, Tango, and other control system backends.
For more information, see the [full documentation](https://sampleenvironment.github.io/secop-ophyd/).
| text/markdown | null | Peter Braun <peter.braun@helmholtz-berlin.de> | null | null | GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short
notice like this when it starts in an interactive mode:
<program> Copyright (C) <year> <name of author>
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, your program's commands
might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
<https://www.gnu.org/licenses/>.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
<https://www.gnu.org/licenses/why-not-lgpl.html>.
| null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"ophyd-async>=0.10.0",
"frappy-core==0.20.4",
"black>=23.0.0",
"Jinja2>=3.1.6",
"autoflake>=2.3.2"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:15:48.899625 | secop_ophyd-0.16.1.tar.gz | 331,622 | 0d/00/b43c5009dd39a66df7046bae5c35928afbe32fb232118b659c991b8f3553/secop_ophyd-0.16.1.tar.gz | source | sdist | null | false | 319d04623016e8819ee049f90ef0becf | 1eba9f3da87fa4952ca36a2f2a41a79586cd80ff4e8b803bd4336439a31f95e3 | 0d00b43c5009dd39a66df7046bae5c35928afbe32fb232118b659c991b8f3553 | null | [
"LICENSE"
] | 228 |
2.4 | kya-validator | 0.2.3 | Rust core KYA (Know Your Agent) validator with Python bindings, TEE support, and blockchain integration | # KYA Validator
A robust Rust-core validator for KYA (Know Your AI) Manifests with Python, Rust, and TypeScript/JavaScript bindings.
## Overview
The KYA Validator provides comprehensive validation of AI agent manifests, ensuring cryptographic proof of identity, attestation of secure execution environments, and enforcement of policy rules.
## Features
### Core Validation ✅
- **Schema Validation**: JSON Schema (Draft 7) compliance checking
- **DID Resolution**: Support for `did:key`, `did:web`, and `did:pkh`
- **Cryptographic Verification**: Ed25519 and Secp256k1 signature validation
- **TTL Checks**: Time-to-live validation for manifest freshness
- **External Link Validation**: URL reachability and content verification
- **Content Hashing**: SHA256/384/512 digest verification
### Advanced Features (Phase 2) 🚀
- **TEE Evidence Validation**: Intel SGX and AMD SEV-SNP attestation
- **Blockchain Solvency**: Multi-provider on-chain balance verification
- **Advanced Policy Engine**: Complex rule composition and evaluation
- **WebAssembly/TypeScript**: Full browser and Node.js support
## Installation
### Rust
```bash
cargo add kya_validator
```
### Python
```bash
pip install kya-validator
```
### TypeScript/JavaScript (WASM)
```bash
# From npm
pnpm add @open-kya/kya-validator-wasm
# Local build
cd bindings/wasm && pnpm run build:all
```
> **Note**: For local development builds, see [bindings/wasm/README.md](bindings/wasm/README.md).
## Quick Start
### Rust
```rust
use kya_validator::{validate_manifest_value, ValidationConfig};
use serde_json::json;
let manifest = json!({
"kyaVersion": "1.0",
"agentId": "did:key:z6MkhaXgBZDvotDkL5257faiztiGiC2QtKLGpbnnEGta2doK",
"proof": []
});
let report = validate_manifest_value(&manifest);
println!("Valid: {}", report.schema_valid);
```
### Python
```python
from kya_validator import validate_manifest, ValidationConfig
manifest = {
"kyaVersion": "1.0",
"agentId": "did:key:z6MkhaXgBZDvotDkL5257faiztiGiC2QtKLGpbnnEGta2doK",
"proof": []
}
report = validate_manifest(json.dumps(manifest))
print(f"Valid: {report.is_valid}")
```
### TypeScript/JavaScript (Browser)
```typescript
import { validateManifest, init } from '@open-kya/kya-validator-wasm/browser';
// Initialize WASM module
await init();
const manifest = {
kyaVersion: "1.0",
agentId: "did:key:z6MkhaXgBZDvotDkL5257faiztiGiC2QtKLGpbnnEGta2doK",
proof: []
};
const report = await validateManifest(manifest);
console.log("Valid:", report.schema_valid);
```
### TypeScript/JavaScript (Node.js)
```typescript
import { validateManifest } from '@open-kya/kya-validator-wasm/node';
// No async init needed in Node.js
const manifest = {
kyaVersion: "1.0",
agentId: "did:key:z6MkhaXgBZDvotDkL5257faiztiGiC2QtKLGpbnnEGta2doK",
proof: []
};
const report = validateManifest(manifest);
console.log("Valid:", report.schema_valid);
```
## Python API
### Core Types
The Python package provides the following core types:
- `ValidationConfig` - Configuration for manifest validation
- `ValidationReport` - Results of manifest validation
- `ValidationMode` - Validation mode (selfAudit/clientAudit)
- `HashAlgorithm` - Hash algorithm for digest computation
- `CryptoReport` - Cryptographic verification report
- `TeeEvidence` - TEE attestation evidence
- `TeeReport` - TEE verification report
- `SolvencyCheck` - Blockchain solvency check configuration
- `SolvencyReport` - Blockchain solvency report
- `PolicyContext` - Context for policy evaluation
### Main Classes
- `Validator` - Main validator for manifest validation
- `PolicyEngine` - Advanced policy rule evaluation
- `TeeVerifier` - TEE attestation evidence verifier
- `SolvencyChecker` - Blockchain solvency checker
- `StreamingValidator` - Chunk-based validation for large manifests
- `PluginManager` - Plugin system manager
- `Inspector` - Manifest inspector
- `Resolver` - DID and verification method resolver
### Configuration
```python
from kya_validator import load_config, ValidationConfig
# Load from file
config = load_config('config.json')
# Load from environment variables
config = load_config() # Uses KYA_VALIDATOR_* env vars
# Create preset
config = ValidationConfig.self_audit()
```
### Validation
```python
from kya_validator import validate_manifest, ValidationReport
# Simple validation
manifest = {"kyaVersion": "1.0", "agentId": "...", "proof": [...]}
report = validate_manifest(json.dumps(manifest))
# With configuration
from kya_validator import ValidationConfig, validate_manifest_with_config
config = ValidationConfig(
mode=ValidationMode.SELF_AUDIT,
allowed_kya_versions=["1.0"],
required_fields=["/agentId", "/proof"],
)
report = validate_manifest_with_config(
manifest_json=json.dumps(manifest),
config=config,
)
```
### TEE Verification
```python
from kya_validator import TeeVerifier, TeeEvidence
verifier = TeeVerifier()
evidence = TeeEvidence(
attestation_type="intel-sgx",
quote="base64encodedquote...",
mr_enclave="0" * 64,
mr_signer="0" * 64,
product_id=0,
min_svn=2,
)
report = verifier.verify(evidence)
print(f"Valid: {report.valid}")
```
### Blockchain Solvency
```python
from kya_validator import verify_solvency
report = verify_solvency(
address="0x742d35Cc6634C0532925a3b844Bc9e7595f0bE",
network="ethereum",
min_balance="0x0",
provider="alchemy",
)
print(f"Meets minimum: {report.meets_minimum}")
print(f"Balance: {report.balance_ether} ETH")
```
### Policy Evaluation
```python
from kya_validator import PolicyEngine, create_policy, create_rule
engine = PolicyEngine()
policy = create_policy(
name="strict-policy",
rules=[
create_rule(
name="version-check",
condition={
"pointer": "/kyaVersion",
"operator": "equals",
"value": "1.0",
},
action="deny",
),
],
)
engine.add_policy(policy)
result = engine.evaluate(manifest)
print(f"Allowed: {result.allowed}")
```
### Streaming Validation
```python
from kya_validator import StreamingValidator
validator = StreamingValidator()
result = validator.add_chunk('{"kyaVersion": "1.0"}', 1)
result = validator.add_chunk('{"agentId": "..."}', 2)
report = validator.finalize()
print(f"Valid: {report['valid']}")
print(f"Chunks: {report['state']['chunksProcessed']}")
```
### Plugin System
```python
from kya_validator import PluginManager, ValidationPlugin
class CustomPlugin(ValidationPlugin):
def name(self):
return "custom_plugin"
def version(self):
return "1.0.0"
def description(self):
return "A custom validation plugin"
def custom_rules(self):
return []
manager = PluginManager()
plugin = CustomPlugin()
manager.register(plugin)
info = manager.get_plugin_info("custom_plugin")
print(f"Plugin: {info.name}")
print(f"Enabled: {manager.get_enabled_plugins()}")
```
### DID Resolution
```python
from kya_validator import Resolver
resolver = Resolver()
# Resolve did:key
key = resolver.resolve_key("did:key:z6Mk...")
print(f"Key ID: {key['id']}")
# Parse did:pkh
info = resolver.parse_did_pkh(
"did:pkh:eip155:1:0x742d35Cc6634C0532925a3b844Bc9e7595f0bE"
)
print(f"Network: {info['network']}")
print(f"Address: {info['address']}")
```
## Configuration
### Default Configuration
```json
{
"mode": "SelfAudit",
"allowedKyaVersions": ["1.0", "1.1"],
"requiredFields": [],
"enforceControllerMatch": true,
"checkExternalLinks": false,
"requireAllProofs": false,
"requiredFieldPairs": [],
"allowedControllers": [],
"requiredVcTypes": [],
"attestationChecks": []
}
```
### Self-Audit Preset
```json
{
"mode": "SelfAudit",
"allowedKyaVersions": ["1.0", "1.1"],
"requiredFields": ["/agentId", "/proof"],
"enforceControllerMatch": true,
"checkExternalLinks": true,
"requireAllProofs": true,
"requiredFieldPairs": [],
"allowedControllers": [],
"requiredVcTypes": [],
"attestationChecks": []
}
```
### Client-Audit Preset
```json
{
"mode": "ClientAudit",
"allowedKyaVersions": ["1.0", "1.1"],
"requiredFields": ["/agentId", "/proof"],
"enforceControllerMatch": true,
"checkExternalLinks": false,
"requireAllProofs": false,
"requiredFieldPairs": [],
"allowedControllers": [],
"requiredVcTypes": [],
"attestationChecks": []
}
```
## Documentation
### Core Modules
- [Schema Validation](./core/validator.rs) - JSON Schema compliance checking
- [DID Resolution](./core/resolver.rs) - DID key resolution
- [Cryptographic Verification](./core/verifier.rs) - Signature validation
- [Inspector Module](./core/inspector.rs) - Field validation
- [Policy Engine](./core/policy.rs) - Basic policy evaluation
## Testing
### Run All Tests
```bash
make test
```
### Run Python Tests
```bash
python -m pytest tests/
```
## Configuration
### Environment Variables
Configuration can be loaded from environment variables with the `KYA_VALIDATOR_` prefix:
- `KYA_VALIDATOR_MODE` - Validation mode
- `KYA_VALIDATOR_ALLOWED_VERSIONS` - Comma-separated list of allowed versions
- `KYA_VALIDATOR_REQUIRED_FIELDS` - Comma-separated list of required fields
- `KYA_VALIDATOR_ENFORCE_CONTROLLER_MATCH` - Boolean for controller matching
- `KYA_VALIDATOR_CHECK_EXTERNAL_LINKS` - Boolean for external link checking
- `KYA_VALIDATOR_REQUIRE_ALL_PROOFS` - Boolean for requiring all proofs
### Example: Setting Environment Variables
```bash
export KYA_VALIDATOR_MODE=SelfAudit
export KYA_VALIDATOR_ALLOWED_VERSIONS=1.0,1.1
export KYA_VALIDATOR_REQUIRED_FIELDS=/agentId,/proof
```
## Performance
### Validation Performance
- **Schema Validation**: ~1-5ms
- **Crypto Verification**: ~5-20ms
- **TTL Checks**: <1ms
- **Policy Evaluation**: ~0.1-1ms per rule
### Advanced Features
- **TEE Quote Validation**: <10ms (structural), ~50-100ms (full)
- **Blockchain Balance**: <1ms (cached), ~50-200ms (network)
- **WASM Validation**: ~5-20ms per manifest
### Optimization Tips
1. **Reuse Configurations**: Parse and reuse config objects
2. **Batch Validations**: Validate multiple manifests together
3. **Use Caching**: Enable blockchain/TTL caching
4. **Pre-Validate JSON**: Check JSON format before validation
5. **Skip Unnecessary Checks**: Disable features not needed for your use case
## Security Considerations
### Best Practices
1. **Validate Input**: Always validate JSON before processing
2. **Check Signatures**: Never skip cryptographic verification
3. **Verify TEE**: Validate attestation claims
4. **Check Solvency**: Verify on-chain balances
5. **Enforce Policies**: Apply strict validation rules
6. **Use CSP Headers**: Set Content-Security-Policy headers for external requests
### CSP Headers
```json
Content-Security-Policy:
default-src 'self';
script-src 'self' blob:;
worker-src 'self' blob:;
```
## Architecture
### Modular Design
```
kya-validator/
├── core/ # Rust core library
│ ├── types.rs # Core data structures
│ ├── validator.rs # Main validation logic
│ ├── resolver.rs # DID resolution
│ ├── verifier.rs # Crypto verification
│ ├── inspector.rs # Field validation
│ ├── policy.rs # Basic policies
│ ├── tee.rs # TEE attestation
│ ├── blockchain.rs # Solvency checks
│ ├── policy_advanced.rs # Advanced policies
│ ├── wasm.rs # WASM bindings
│ ├── plugin.rs # Plugin system
│ ├── plugin_manager.rs # Plugin management
│ └── lib.rs # Exports
├── bindings/ # Language bindings
│ ├── python/ # Python bindings (PyO3)
│ │ ├── __init__.py
│ │ ├── types.py
│ │ ├── errors.py
│ │ ├── config.py
│ │ ├── utils.py
│ │ ├── validator.py
│ │ ├── policy.py
│ │ ├── tee.py
│ │ ├── blockchain.py
│ │ ├── streaming.py
│ │ ├── plugins.py
│ │ ├── inspector.py
│ │ ├── resolver.py
│ │ └── _ffi.py
│ └── wasm/ # WASM examples
│ ├── wasm-usage.ts
│ ├── wasm-usage.js
│ ├── wasm-async-usage.ts
│ ├── streaming-validation.ts
│ └── custom-plugin-example.ts
├── apps/ # Applications
│ ├── ui/ # Policy editor UI (React/Vite)
│ └── demo_backend/ # Demo backend (FastAPI)
└── tests/ # Test suite
```
### Integration Points
- **Resolver** → DID to public key mapping
- **Verifier** → Signature verification
- **Inspector** → Schema and TTL validation
- **TEE Module** → Attestation verification
- **Blockchain Module** → Solvency checks
- **Policy Engine** → Rule enforcement
- **Streaming Validator** → Chunk-based validation
- **Plugin System** → Custom validation rules
## Contributing
### Development Setup
```bash
# Install Rust toolchain
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# Install dependencies
cargo build
# Run tests
cargo test
# Format code
cargo fmt
# Check code
cargo clippy
```
### Adding Features
1. Create feature branch
2. Write tests for new feature
3. Update documentation
4. Submit PR
### Code Style
- Follow Rust naming conventions
- Use `#[allow(...)]` sparingly
- Document public APIs
- Write tests for all public functions
## License
See LICENSE file for details.
## Resources
- [KYA Standard](../kya-standard/) - KYA protocol specification
- [W3C DID Core](https://www.w3.org/TR/did-core/) - DID specification
- [W3C VC Data Model](https://www.w3.org/TR/vc-data-model/) - Verifiable Credentials
- [Intel SGX](https://www.intel.com/content/www/us/en/developer/tools/software-guard-extensions.html) - TEE attestation
## Roadmap
### Phase 2 (In Progress - 80% Complete)
- [x] TEE Evidence Validation
- [x] Enhanced Solvency Verification
- [x] Advanced Policy Engine
- [x] TypeScript/WASM Bindings
- [ ] Performance Optimization
- [ ] Documentation Polish
### Phase 3 (Planned)
- [ ] Async WASM Operations
- [ ] Streaming Validation
- [ ] Plugin System
- [ ] Policy Editor UI
- [ ] Telemetry Integration
- [ ] Performance Optimization
- [ ] Documentation Polish
## Release & Packaging
### Versioning
Version follows semantic versioning (MAJOR.MINOR.PATCH):
- `Cargo.toml` (Rust): Source of truth for core version
- `pyproject.toml` (Python): Must match Rust version
- Update both files together before release
### Packaging
```bash
# Build Rust release
cargo build --release
# Build Python wheel (requires maturin)
uv tool run maturin build --release
# Build WASM package
wasm-pack build --target web
```
### Release Checklist
1. Update version in `Cargo.toml` and `pyproject.toml`
2. Update `CHANGELOG.md` (if present)
3. Tag release: `git tag -a v0.x.x -m "Release v0.x.x"`
4. Push tags: `git push --tags`
5. Build and publish Python package: `uv tool run maturin build --release && uv publish`
6. Publish WASM to npm (if applicable)
## Optional Components
The following components are **not required** for core validation functionality:
- **UI Demo** (`apps/ui/`) - React/Vite policy editor demo
- **Demo Backend** (`apps/demo_backend/`) - FastAPI demo with LLM integration
- **WASM Bindings** (`bindings/wasm/`) - Browser/Node.js WASM package. See [README](bindings/wasm/README.md) for documentation.
These are optional and may be moved to separate packages in future releases.
## Support
For issues, questions, or contributions, please open an issue or pull request in the repository.
---
**Version**: 0.2.0
**Status**: Production Ready (Core) / Beta (Phase 2 Features)
| text/markdown; charset=UTF-8; variant=GFM | null | KYA Contributors <lkl@cph.ai> | null | null | MPL-2.0 | kyc, aml, validator, blockchain, tee | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Mozilla Public License 2.0 (MPL 2.0)",
"Programming Language :: Rust",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Security :: Cryptography",
"Topic :: Off... | [] | https://github.com/open-kya/kya-validator | null | >=3.12 | [] | [] | [] | [
"loguru>=0.7.3",
"pytest<8.0,>=7.4.3; extra == \"dev\"",
"ruff<0.2,>=0.1.8; extra == \"dev\"",
"maturin>=1.6.0; extra == \"dev\""
] | [] | [] | [] | [
"Documentation, https://docs.rs/kya-validator",
"Homepage, https://github.com/open-kya/kya-validator",
"Issues, https://github.com/open-kya/kya-validator/issues",
"Repository, https://github.com/open-kya/kya-validator"
] | twine/6.2.0 CPython/3.12.9 | 2026-02-18T16:14:39.639550 | kya_validator-0.2.3-cp312-cp312-macosx_11_0_arm64.whl | 2,135,242 | f0/f2/a749a0de8b1db0de7f7fe143306b845acd5f5cd11d3aa34d6da724bf99f1/kya_validator-0.2.3-cp312-cp312-macosx_11_0_arm64.whl | cp312 | bdist_wheel | null | false | 155732d8c64fb49a06a08e54df4f729f | 4c2c13b532215926788345aafe992a2706061b7aef7ac77f42cbe5e1f27da462 | f0f2a749a0de8b1db0de7f7fe143306b845acd5f5cd11d3aa34d6da724bf99f1 | null | [
"LICENSE"
] | 165 |
2.4 | lactationcurve | 0.1.1 | Lactation curve fitting and analysis library | # lactationcurve
Lactation curve fitting and analysis library.
| text/markdown | null | null | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering"
] | [] | null | null | <3.13,>=3.12 | [] | [] | [] | [
"numpy>=2.4.0",
"pandas>=2.3.3",
"requests>=2.32.5",
"scipy>=1.16.3",
"sympy>=1.14.0"
] | [] | [] | [] | [
"Repository, https://github.com/Bovi-analytics/lactation-curves"
] | uv/0.9.13 {"installer":{"name":"uv","version":"0.9.13"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T16:14:26.384263 | lactationcurve-0.1.1-py3-none-any.whl | 19,564 | 8a/8f/bd062b154b9bc35076aa8ea934665fa41ca98aceb825d6866dfc73c5bb2d/lactationcurve-0.1.1-py3-none-any.whl | py3 | bdist_wheel | null | false | d30b6ceb02fac1592a2e133c6e266388 | ab3a4abcd1014ffa66b60218687e882cc343a31087b247b2ca2dc223b6baa4f2 | 8a8fbd062b154b9bc35076aa8ea934665fa41ca98aceb825d6866dfc73c5bb2d | MIT | [] | 112 |
2.4 | OpenMM | 8.5.0b0 | Python wrapper for OpenMM (a C++ MD package) | OpenMM is a toolkit for molecular simulation. It can be used either as a
stand-alone application for running simulations, or as a library you call
from your own code. It provides a combination of extreme flexibility
(through custom forces and integrators), openness, and high performance
(especially on recent GPUs) that make it truly unique among simulation codes.
| null | Peter Eastman | null | null | null | Python Software Foundation License (BSD-like) | null | [] | [
"Linux"
] | https://openmm.org | https://openmm.org | null | [] | [] | [] | [
"numpy",
"OpenMM-CUDA-12==8.5.0beta; platform_system != \"Darwin\" and extra == \"cuda12\"",
"OpenMM-CUDA-13==8.5.0beta; platform_system != \"Darwin\" and extra == \"cuda13\"",
"OpenMM-HIP-6==8.5.0beta; (platform_system != \"Darwin\" and platform_machine == \"x86_64\") and extra == \"hip6\"",
"OpenMM-HIP-7=... | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-18T16:14:13.547926 | openmm-8.5.0b0-cp314-cp314-manylinux_2_34_aarch64.whl | 13,884,711 | f2/ce/9349484ae61cdd66b0a021c31e2aae72ae7c9a6f0dc149c32b0b9ae24d2c/openmm-8.5.0b0-cp314-cp314-manylinux_2_34_aarch64.whl | cp314 | bdist_wheel | null | false | dfe84a73e91160ad5e1d7fc123bf6fdb | e99f2c847a8e713b1ce5709028556ea86e5334945d3e596240615a53bcbcb9b0 | f2ce9349484ae61cdd66b0a021c31e2aae72ae7c9a6f0dc149c32b0b9ae24d2c | null | [] | 0 |
2.4 | davybot-market-cli | 0.1.1 | CLI and SDK for DavyBot Market - AI Agent Resources | # DavyBot Market - CLI & SDK
Unified CLI and Python SDK for DavyBot Market - AI Agent Resources.
## Installation
### Using uv (Recommended)
```bash
# Install from source
cd davybot-market-cli
uv sync
# Run CLI
uv run python -m davybot_market_cli.cli --help
```
### Using pip
```bash
pip install davybot-market-cli
```
Or install from source:
```bash
cd davybot-market-cli
pip install -e .
```
## Configuration
### Environment Variables
- `DAVYBOT_API_URL`: API base URL (default: `http://localhost:8000/api/v1`)
- `DAVYBOT_API_KEY`: API key for authentication
### Example Configuration
```bash
# For local development
export DAVYBOT_API_URL="http://localhost:9410/api/v1"
# For production server
export DAVYBOT_API_URL="http://www.davybot.com/market/api/v1"
```
## CLI Usage
> **Note:** The CLI is available as both `davy-market` (primary command) and `dawei-market` (alias). Both commands work identically.
### Search Resources
```bash
# Search all resources
davy-market search "web scraping"
# Filter by type (skill, agent, mcp, knowledge)
davy-market search "agent" --type agent
# Limit results
davy-market search "data" --limit 10
# JSON output
davy-market search "ml" --output json
```
### View Resource Info
```bash
# Get resource details (must use full resource URI)
davy-market info skill://github.com/anthropics/skills/skills/webapp-testing
# JSON output
davy-market info skill://github.com/user/repo/skill-name --output json
```
**Important:** Resource URIs must use the full format:
- `skill://<full-resource-id>`
- `agent://<full-resource-id>`
- `mcp://<full-resource-id>`
- `knowledge://<full-resource-id>`
Example full resource IDs:
- `skill://github.com/anthropics/skills/skills/webapp-testing`
- `agent://davybot.com/patent-team/patent-engineer`
- `mcp://github.com/modelcontextprotocol/servers/git`
### Install Resources
```bash
# Install from marketplace (must use full resource URI)
davy-market install skill://github.com/anthropics/skills/skills/webapp-testing
# Install to specific directory
davy-market install agent://davybot.com/patent-team --output ./my-agents
# Install by full resource ID
davy-market install github.com/anthropics/skills/skills/webapp-testing
```
#### External Protocol Support
The CLI supports multiple installation protocols beyond the marketplace:
```bash
# Local filesystem path
davy-market install skill@/path/to/skill --output ./my-skills
# HTTP/HTTPS URL (downloads and extracts zip files)
davy-market install skill@http://server_url/skill.zip --output ./skills
davy-market install agent@https://example.com/agent.zip
# Git repository (clones and installs)
davy-market install plugin@git@github.com:user/repo.git/plugin_dir --output ./plugins
# Git repository with specific branch
davy-market install skill@git@github.com:user/repo.git --branch main
# File protocol (local or network file shares)
davy-market install agent@file://server/share/agent_dir --output ./agents
```
**Supported Protocols:**
- `local` - Local filesystem paths
- `http`/`https` - Download from web servers
- `git` - Clone from Git repositories
- `file` - File protocol for network shares
### Publish Resources
```bash
# Publish a skill
davy-market publish skill ./my-skill --name "web-scraper" --description "Scrapes web data"
# Publish with tags
davy-market publish agent ./my-agent --name "data-analyst" --tag data --tag ml
# Publish with metadata
davy-market publish skill ./skill --name "my-skill" --metadata metadata.json
```
### Plugin Management
```bash
# List installed plugins in workspace
davy-market plugin list --workspace /path/to/workspace
# Filter by type
davy-market plugin list --workspace /path/to/workspace --type plugin
# Table output format
davy-market plugin list --workspace /path/to/workspace --output table
```
### Health Check
```bash
# Check API status
davy-market health
```
## Python SDK Usage
### Basic Usage
```python
from davybot_market_cli import DavybotMarketClient
# Initialize client
with DavybotMarketClient() as client:
# Check API health
health = client.health()
print(f"API Status: {health['status']}")
# Search for resources
results = client.search("web scraping")
print(f"Found {results['total']} resources")
# List all skills
skills = client.list_skills()
for skill in skills['items']:
print(f"- {skill['name']}: {skill['description']}")
# Get specific resource
skill = client.get_skill("skill-id-here")
print(f"Skill: {skill['name']} v{skill['version']}")
# Download a resource
client.download("skill", "skill-id", "./downloads")
```
### Async Usage
```python
import asyncio
from davybot_market_cli import DavybotMarketClient
async def main():
async with DavybotMarketClient() as client:
# Search resources
results = await client.search("machine learning")
print(f"Found {results['total']} results")
asyncio.run(main())
```
### Create Resources
```python
with DavybotMarketClient() as client:
# Create a skill
skill = client.create_skill(
name="web-scraper",
description="Scrapes web data efficiently",
files={
"scraper.py": "# Your scraper code here",
"config.json": '{"timeout": 30}',
},
tags=["web", "scraping", "data"],
author="Your Name"
)
print(f"Created skill with ID: {skill['id']}")
```
### Download Resources
```python
with DavybotMarketClient() as client:
# Download to specific directory
client.download("skill", "skill-id", "./my-skills")
# Download with specific format
client.download("agent", "agent-id", "./agents", format="python")
# Download specific version
client.download("skill", "skill-id", "./skills", version="2.0.0")
```
### Ratings and Reviews
```python
with DavybotMarketClient() as client:
# Rate a resource
client.rate_resource("resource-id", score=5, comment="Excellent!")
# Get all ratings
ratings = client.get_resource_ratings("resource-id")
# Get average rating
avg = client.get_average_rating("resource-id")
print(f"Average: {avg['average_rating']} ({avg['total_ratings']} ratings)")
```
## Client Options
```python
# Custom API URL
client = DavybotMarketClient(base_url="https://api.market.davybot.ai/api/v1")
# With API key
client = DavybotMarketClient(api_key="your-api-key")
# With custom timeout
client = DavybotMarketClient(timeout=60.0)
# Disable SSL verification (not recommended for production)
client = DavybotMarketClient(verify_ssl=False)
```
## Commands Reference
| Command | Description |
|---------|-------------|
| `davy-market search QUERY` | Search for resources |
| `davy-market info RESOURCE_URI` | View resource details |
| `davy-market install RESOURCE_URI` | Install a resource |
| `davy-market publish TYPE PATH` | Publish a new resource |
| `davy-market plugin list --workspace PATH` | List installed plugins |
| `davy-market health` | Check API health |
| `davy-market --help` | Show help message |
| `davy-market --version` | Show version |
## Examples
### Complete CLI Workflow
```bash
# Configure API URL
export DAVYBOT_API_URL="http://www.davybot.com/market/api/v1"
# Search for a skill
davy-market search "web testing" --type skill
# View details
davy-market info skill://github.com/anthropics/skills/skills/webapp-testing
# Install
davy-market install skill://github.com/anthropics/skills/skills/webapp-testing --output ./skills
```
### Publishing a New Skill
```bash
# Create your skill
mkdir my-skill
cd my-skill
# Create skill.py
cat > skill.py << 'EOF'
def execute(input_data):
"""Execute the skill."""
return {"result": "success"}
EOF
# Publish to market
davy-market publish skill . --name "my-skill" --description "My awesome skill"
```
### Python SDK Integration
```python
from davybot_market_cli import DavybotMarketClient
# Integrate into your application
def find_and_download_skill(query: str, output_dir: str):
with DavybotMarketClient() as client:
# Search
results = client.search(query, resource_type="skill", limit=1)
if not results['results']:
print("No skills found")
return
skill = results['results'][0]
print(f"Found: {skill['name']}")
# Download
client.download("skill", skill['id'], output_dir)
print(f"Downloaded to {output_dir}")
```
### Managing Workspace Plugins
```bash
# Create a workspace
mkdir my-workspace && cd my-workspace
# Install a plugin
davy-market install plugin@git@github.com:user/plugin.git --output .dawei/plugins
# List installed plugins
davy-market plugin list --workspace . --output json
# List only plugins (not skills/agents)
davy-market plugin list --workspace . --type plugin
```
## Error Handling
```python
from davybot_market_cli import (
DavybotMarketClient,
AuthenticationError,
NotFoundError,
ValidationError,
APIError
)
with DavybotMarketClient() as client:
try:
skill = client.get_skill("invalid-id")
except NotFoundError:
print("Resource not found!")
except AuthenticationError:
print("Invalid API key!")
except APIError as e:
print(f"API error: {e}")
```
## Common Issues
### Invalid Resource URI Format
If you see this error:
```
Invalid resource URI format: 'skill-name'
Please use one of the following formats:
- skill://<resource-id>
- agent://<resource-id>
- mcp://<resource-id>
- knowledge://<resource-id>
```
**Solution:** Always use the full resource ID format:
```bash
# ❌ Wrong
davy-market install skill-name
# ✅ Correct
davy-market install skill://github.com/user/repo/skill-name
```
### Finding Resource IDs
Use the `search` command to find full resource IDs:
```bash
davy-market search "query" --output json | jq '.results[].id'
```
Or use the `info` command to copy the installation command from the output.
## License
MIT
| text/markdown | DavyBot Market Team | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"click>=8.1.7",
"gitpython>=3.1.40",
"httpx>=0.25.1",
"pydantic>=2.0.0",
"questionary>=2.0.1",
"rich>=13.6.0",
"black>=23.12.0; extra == \"dev\"",
"mypy>=1.7.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pytest>=7.4.0; extra == \"dev\"",
"ruff>=0.1.9; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:14:11.573898 | davybot_market_cli-0.1.1.tar.gz | 79,417 | c1/6b/74585380f651659882cddb217276add7f38d808ee12c93628b5b3147451b/davybot_market_cli-0.1.1.tar.gz | source | sdist | null | false | aa88df0498441473e1668c7ef3f5b498 | 7b736a94449e4ea107cdebe2e1682ab0070e3a4c2cddf1b58b1cb4ce06286e5f | c16b74585380f651659882cddb217276add7f38d808ee12c93628b5b3147451b | null | [
"LICENSE"
] | 452 |
2.4 | scicomap | 1.1.1 | data visualization on maps with varying levels of granularity | <img src="pics/logo.png" alt="drawing" width="200"/>
[](https://thomasbury.github.io/scicomap/)
[](https://github.com/ThomasBury/scicomap/actions/workflows/docs.yml)
[](https://thomasbury.github.io/scicomap/marimo/index.html)
[](https://pypi.org/project/scicomap/)
[](https://pypi.org/project/scicomap/)
[](https://github.com/ThomasBury/scicomap/stargazers)
[buy me caffeine](https://ko-fi.com/V7V72SOHX)
# Scientific color maps
Scicomap helps you choose, assess, and improve scientific colormaps so your
figures remain readable and faithful to the underlying data.
## Blog post
[Scicomap Medium blog post (free)](https://towardsdatascience.com/your-colour-map-is-bad-heres-how-to-fix-it-lessons-learnt-from-the-event-horizon-telescope-b82523f09469)
[Official Documentation](https://thomasbury.github.io/scicomap/)
[Tutorial notebook](./docs/source/notebooks/tutorial.ipynb)
## Installation
```shell
pip install scicomap
```
## Quickstart
```python
import scicomap as sc
cmap = sc.ScicoSequential(cmap="hawaii")
cmap.assess_cmap(figsize=(14, 6))
cmap.draw_example()
```
## CLI quickstart
```shell
# list families and colormaps
scicomap list
scicomap list sequential
# diagnose and preview
scicomap check hawaii
scicomap preview hawaii --type sequential --out hawaii-assess.png
# guided workflow and environment checks
scicomap wizard
scicomap doctor --json
# compare and fix
scicomap compare hawaii viridis thermal --type sequential --out compare.png
scicomap fix hawaii --type sequential --out hawaii-fixed.png
# apply a colormap to your own image
scicomap apply thermal --type sequential --image input.png --out output.png
# explicit long-form aliases for automation
scicomap cmap assess --cmap hawaii --type sequential --out hawaii-assess.png
scicomap docs llm-assets --html-dir docs/build/html
# one-command workflow report bundle
scicomap report --cmap hawaii --type sequential --out reports/hawaii
scicomap report --cmap thermal --image input.png --goal apply --format json
# profile-driven defaults
scicomap report --profile publication --cmap hawaii
scicomap report --profile cvd-safe --cmap thermal --format json
scicomap wizard --profile quick-look
```
### CLI profiles
- `quick-look`: fast diagnosis, minimal artifacts
- `publication`: quality-first defaults (`improve` + fix + CVD checks)
- `presentation`: publication defaults with brighter lift bias
- `cvd-safe`: accessibility-first, CVD checks enforced
- `agent`: deterministic machine mode (`--format json`, non-interactive)
### Profile precedence
Configuration resolution order:
1. Profile defaults
2. Context inference (for example, image presence)
3. Explicit user flags
4. Strict profile enforcement (`cvd-safe`, `agent`)
## Documentation map
- [Getting Started](https://thomasbury.github.io/scicomap/getting-started.html): install and first workflow
- [User Guide](https://thomasbury.github.io/scicomap/user-guide.html): choosing, assessing, and correcting colormaps
- [Interactive Marimo Tutorial](https://thomasbury.github.io/scicomap/marimo/index.html): browser-based reactive tutorial
- [API Reference](https://thomasbury.github.io/scicomap/api-reference.html): module and class reference
- [FAQ](https://thomasbury.github.io/scicomap/faq.html) and [Troubleshooting](https://thomasbury.github.io/scicomap/troubleshooting.html): practical answers for common issues
- [LLM Access](https://thomasbury.github.io/scicomap/llm-access.html): `llms.txt` and markdown mirror policy
## Development
Use `uv` for local development and dependency synchronization.
Notebook docs rendered with `nbsphinx` require a `pandoc` binary.
```shell
# create/update the lockfile
uv lock
# create the virtual environment and install project + extras
uv sync --extra lint --extra test --extra docs
# run commands in the project environment
uv run python -m pytest
uv run ruff check src tests
uv run ruff format --check src tests
# build web docs + LLM assets
uv run sphinx-build -n -b html docs/source docs/build/html
uv run python scripts/build_llm_assets.py
```
`Read the Docs` is kept as a temporary fallback during the Pages rollout.
Contribution guidelines are available in `CONTRIBUTING.md`.
Release notes are tracked in `CHANGELOG.md` and GitHub releases.
## Introduction
Scicomap is a package that provides scientific color maps and tools to standardize your favourite color maps if you don't like the built-in ones.
Scicomap currently provides sequential, bi-sequential, diverging, circular, qualitative and miscellaneous color maps. You can easily draw examples, compare the rendering, see how colorblind people will perceive the color maps. I will illustrate the scicomap capabilities below.
This package is heavily based on the [Event Horizon Telescope Plot package](https://github.com/liamedeiros/ehtplot/tree/docs) and uses good color maps found in the [the python portage of the Fabio Crameri](https://github.com/callumrollo/cmcrameri), [cmasher](https://cmasher.readthedocs.io/), [palettable](https://jiffyclub.github.io/palettable/), [colorcet](https://colorcet.holoviz.org/) and [cmocean](https://matplotlib.org/cmocean/)
## Motivation
The accurate representation of data is essential. Many common color maps distort data through uneven colour gradients and are often unreadable to those with color-vision deficiency. An infamous example is the `jet` color map. These color maps do not render all the information you want to illustrate or even worse render false information through artefacts. Scientist or not, your goal is to communicate visual information in the most accurate and appealing fashion. Moreover, do not overlook colour-vision deficiency, which represents 8% of the (Caucasian) male population.
## Color spaces
Perceptual uniformity is the idea that Euclidean distance between colors in color space should match human color perception distance judgements. For example, a blue and red that are at a distance d apart should look as discriminable as green and purple that are at a distance d apart.
Scicomap uses the CAM02-UCS color space (Uniform Colour Space). Its three coordinates are usually denoted by J', a', and b'. And its cylindrical coordinates are J', C', and h'. The perceptual color space Jab is similar to Lab. However, Jab uses an updated color appearance model that in theory provides greater precision for discriminability measurements.
- Lightness: also known as value or tone, is a representation of a color's brightness
- Chroma: the intrinsic difference between a color and gray of an object
- Hue: the degree to which a stimulus can be described as similar to or different from stimuli that are described as red, green, blue, and yellow
## Encoding information
- Lightness J': for a scalar value, intensity. It must vary linearly with the physical quantity
- hue h' can encode an additional physical quantity, the change of hue should be linearly proportional to the quantity. The hue h' is also ideal in making an image more attractive without interfering with the representation of pixel values.
- chroma is less recognizable and should not be used to encode physical information
## Color map uniformization
Following the references and the theories, the uniformization is performed by
- Making the color map linear in J'
- Lifting the color map (making it lighter, i.e. increasing the minimal value of J')
- Symmetrizing the chroma to avoid further artefacts
- Avoid kinks and edges in the chroma curve
- Bitonic symmetrization or not
# Scicomap
## Choosing the right type of color maps
Scicomap provides a bunch of color maps for different applications. The different types of color map are
```python
import scicomap as sc
sc_map = sc.SciCoMap()
sc_map.get_ctype()
```
```
dict_keys(['diverging', 'sequential', 'multi-sequential', 'circular', 'miscellaneous', 'qualitative'])
```
I'll refer to the [The misuse of colour in science communication](https://www.nature.com/articles/s41467-020-19160-7.pdf) for choosing the right scientific color map
<td align="left"><img src="pics/choosing-cmap.png" width="500"/></td>
## Get the matplotlib cmap
```python
plt_cmap_obj = sc_map.get_mpl_color_map()
```
## Choosing the color map for a given type
Get the color maps for a given type
```python
sc_map = sc.ScicoSequential()
sc_map.get_color_map_names()
```
```
dict_keys(['afmhot', 'amber', 'amber_r', 'amp', 'apple', 'apple_r', 'autumn', 'batlow', 'bilbao', 'bilbao_r', 'binary', 'Blues', 'bone', 'BuGn', 'BuPu', 'chroma', 'chroma_r', 'cividis', 'cool', 'copper', 'cosmic', 'cosmic_r', 'deep', 'dense', 'dusk', 'dusk_r', 'eclipse', 'eclipse_r', 'ember', 'ember_r', 'fall', 'fall_r', 'gem', 'gem_r', 'gist_gray', 'gist_heat', 'gist_yarg', 'GnBu', 'Greens', 'gray', 'Greys', 'haline', 'hawaii', 'hawaii_r', 'heat', 'heat_r', 'hot', 'ice', 'inferno', 'imola', 'imola_r', 'lapaz', 'lapaz_r', 'magma', 'matter', 'neon', 'neon_r', 'neutral', 'neutral_r', 'nuuk', 'nuuk_r', 'ocean', 'ocean_r', 'OrRd', 'Oranges', 'pink', 'plasma', 'PuBu', 'PuBuGn', 'PuRd', 'Purples', 'rain', 'rainbow', 'rainbow-sc', 'rainbow-sc_r', 'rainforest', 'rainforest_r', 'RdPu', 'Reds', 'savanna', 'savanna_r', 'sepia', 'sepia_r', 'speed', 'solar', 'spring', 'summer', 'tempo', 'thermal', 'thermal_r', 'thermal-2', 'tokyo', 'tokyo_r', 'tropical', 'tropical_r', 'turbid', 'turku', 'turku_r', 'viridis', 'winter', 'Wistia', 'YlGn', 'YlGnBu', 'YlOrBr', 'YlOrRd'])
```
## Assessing a color map
In order to assess if a color map should be corrected or not, `scicomap` provides a way to quickly check if the lightness is linear, how asymmetric and smooth is the chroma and how the color map renders for color-deficient users. I will illustrate some of the artefacts using classical images, as the pyramid and specific functions for each kind of color map.
### An infamous example
```python
import scicomap as sc
import matplotlib.pyplot as plt
# the thing that should not be
ugly_jet = plt.get_cmap("jet")
sc_map = sc.ScicoMiscellaneous(cmap=ugly_jet)
f=sc_map.assess_cmap(figsize=(22,10))
```
<td align="left"><img src="pics/jet.png" width="1000"/></td>
Clearly, the lightness is not linear, has edges and kinks. The chroma is not smooth and asymmetrical. See the below illustration to see how bad and how many artefacts the jet color map introduces
<td align="left"><img src="pics/jet2.png" width="1000"/></td>
## Correcting a color map - Example
### Sequential color map
Let's assess the built-in color map `hawaii` without correction:
```python
sc_map = sc.ScicoSequential(cmap='hawaii')
f=sc_map.assess_cmap(figsize=(22,10))
```
<td align="left"><img src="pics/hawaii.png" width="1000"/></td>
The color map seems ok, however, the lightness is not linear and the chroma is asymmetrical even if smooth. Those small defects introduce artefact in the information rendering, as we can visualize using the following example
```python
f=sc_map.draw_example()
```
<td align="left"><img src="pics/hawaii-examples.png" width="1000"/></td>
We can clearly see the artefacts, especially for the pyramid for which our eyes should only pick out the corners in the pyramid (ideal situation). Those artefacts are even more striking for color-deficient users (this might not always be the case). Hopefully, `scicomap` provides an easy way to correct those defects:
```python
# fixing the color map, using the same minimal lightness (lift=None),
# not normalizing to bitone and
# smoothing the chroma
sc_map.unif_sym_cmap(lift=None,
bitonic=False,
diffuse=True)
# re-assess the color map after fixing it
f=sc_map.assess_cmap(figsize=(22,10))
```
<td align="left"><img src="pics/hawaii-fixed.png" width="1000"/></td>
After fixing the color map, the artefacts are less present
<td align="left"><img src="pics/hawaii-fixed-examples.png" width="1000"/></td>
# All the built-in color maps
## Sequential
<td align="left"><img src="pics/seq-cmaps-all.png" width="500"/></td>
## Diverging
<td align="left"><img src="pics/div-cmaps-all.png" width="500"/></td>
## Mutli-sequential
<td align="left"><img src="pics/multi-cmaps-all.png" width="500"/></td>
## Miscellaneous
<td align="left"><img src="pics/misc-cmaps-all.png" width="500"/></td>
## Circular
<td align="left"><img src="pics/circular-cmaps-all.png" width="500"/></td>
## Qualitative
<td align="left"><img src="pics/qual-cmaps-all.png" width="500"/></td>
# References
- [The misuse of colour in science communication](https://www.nature.com/articles/s41467-020-19160-7.pdf)
- [Why We Use Bad Color Maps and What You Can Do About It](https://www.kennethmoreland.com/color-advice/BadColorMaps.pdf)
- [THE RAINBOW IS DEAD…LONG LIVE THE RAINBOW! – SERIES OUTLINE](https://mycarta.wordpress.com/2012/05/29/the-rainbow-is-dead-long-live-the-rainbow-series-outline/)
- [Scientific colour maps](https://www.fabiocrameri.ch/colourmaps/)
- [Picking a colour scale for scientific graphics](https://betterfigures.org/2015/06/23/picking-a-colour-scale-for-scientific-graphics/)
- [ColorCET](https://colorcet.com/)
- [Good Colour Maps: How to Design Them](https://arxiv.org/abs/1509.03700)
- [Perceptually uniform color space for image signals including high dynamic range and wide gamut](https://www.osapublishing.org/oe/fulltext.cfm?uri=oe-25-13-15131&id=368272)
| text/markdown | null | Thomas Bury <bury.thomas@gmail.com> | null | null | MIT License
Copyright (c) [2021] [Thomas Bury]
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | visualization, color, uniform, scientific | [
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy",
"pandas",
"scipy",
"colorspacious",
"colorcet",
"cmcrameri",
"cmocean",
"cmasher>=1.5.8",
"palettable>=3.3.0",
"matplotlib>=3.3.0",
"typer>=0.12.0",
"rich>=13.0.0",
"ipykernel; extra == \"docs\"",
"ipython_genutils; extra == \"docs\"",
"marimo; extra == \"docs\"",
"pandoc; ext... | [] | [] | [] | [
"homepage, https://github.com/ThomasBury/scicomap",
"documentation, https://thomasbury.github.io/scicomap/",
"repository, https://github.com/ThomasBury/scicomap.git",
"changelog, https://github.com/ThomasBury/scicomap/releases",
"Tracker, https://github.com/ThomasBury/scicomap/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T16:14:06.689512 | scicomap-1.1.1.tar.gz | 2,147,345 | 12/7f/d97f55c8388749cfd472acc49d2312e58fed4ac6cc1815047840d1980959/scicomap-1.1.1.tar.gz | source | sdist | null | false | 75c5e0a1386d162a112a8b63a30d4a3f | dd53a29bf51608a9dff13aa6d0074f33a67c12f4f967c331fe9e27e039367cd9 | 127fd97f55c8388749cfd472acc49d2312e58fed4ac6cc1815047840d1980959 | null | [
"LICENSE.md"
] | 571 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.